KR20220101631A - 간 질환 치료를 위한 조성물 및 방법 - Google Patents
간 질환 치료를 위한 조성물 및 방법 Download PDFInfo
- Publication number
- KR20220101631A KR20220101631A KR1020227016178A KR20227016178A KR20220101631A KR 20220101631 A KR20220101631 A KR 20220101631A KR 1020227016178 A KR1020227016178 A KR 1020227016178A KR 20227016178 A KR20227016178 A KR 20227016178A KR 20220101631 A KR20220101631 A KR 20220101631A
- Authority
- KR
- South Korea
- Prior art keywords
- ser
- pro
- leu
- ala
- gln
- Prior art date
Links
- 239000000203 mixture Substances 0.000 title claims abstract description 118
- 238000000034 method Methods 0.000 title claims abstract description 102
- 208000019423 liver disease Diseases 0.000 title claims abstract description 95
- 210000003494 hepatocyte Anatomy 0.000 claims abstract description 189
- 102000040945 Transcription factor Human genes 0.000 claims abstract description 81
- 108091023040 Transcription factor Proteins 0.000 claims abstract description 81
- 101001069749 Homo sapiens Prospero homeobox protein 1 Proteins 0.000 claims abstract description 68
- 102100033880 Prospero homeobox protein 1 Human genes 0.000 claims abstract description 68
- 102100029721 DnaJ homolog subfamily B member 1 Human genes 0.000 claims abstract description 63
- 102100023172 Nuclear receptor subfamily 0 group B member 2 Human genes 0.000 claims abstract description 58
- 101000978937 Homo sapiens Nuclear receptor subfamily 0 group B member 2 Proteins 0.000 claims abstract description 55
- 102100025815 Nuclear envelope pore membrane protein POM 121C Human genes 0.000 claims abstract description 52
- 101001121610 Homo sapiens Nuclear envelope pore membrane protein POM 121C Proteins 0.000 claims abstract description 51
- 102100038885 Histone acetyltransferase p300 Human genes 0.000 claims abstract description 49
- 101000882390 Homo sapiens Histone acetyltransferase p300 Proteins 0.000 claims abstract description 49
- 239000012634 fragment Substances 0.000 claims abstract description 37
- 101000905751 Homo sapiens Cyclic AMP-dependent transcription factor ATF-6 alpha Proteins 0.000 claims abstract description 36
- 101000905743 Homo sapiens Cyclic AMP-dependent transcription factor ATF-4 Proteins 0.000 claims abstract description 34
- 102100023580 Cyclic AMP-dependent transcription factor ATF-4 Human genes 0.000 claims abstract description 33
- 101000866018 Homo sapiens DnaJ homolog subfamily B member 1 Proteins 0.000 claims abstract description 33
- 102100023583 Cyclic AMP-dependent transcription factor ATF-6 alpha Human genes 0.000 claims abstract description 30
- 108010042283 HSP40 Heat-Shock Proteins Proteins 0.000 claims abstract description 30
- 102100026839 Sterol regulatory element-binding protein 1 Human genes 0.000 claims abstract description 11
- 108010074436 Sterol Regulatory Element Binding Protein 1 Proteins 0.000 claims abstract description 6
- 102100022669 Nuclear receptor subfamily 5 group A member 2 Human genes 0.000 claims abstract description 5
- 102100034174 Eukaryotic translation initiation factor 2-alpha kinase 3 Human genes 0.000 claims abstract description 3
- 101150068639 Hnf4a gene Proteins 0.000 claims abstract 18
- 101000798109 Homo sapiens Melanotransferrin Proteins 0.000 claims abstract 4
- 101000967073 Homo sapiens Metal regulatory transcription factor 1 Proteins 0.000 claims abstract 4
- 101001030197 Homo sapiens Myelin transcription factor 1 Proteins 0.000 claims abstract 4
- 101001109685 Homo sapiens Nuclear receptor subfamily 5 group A member 2 Proteins 0.000 claims abstract 4
- 102100032239 Melanotransferrin Human genes 0.000 claims abstract 4
- 108091008010 PERKs Proteins 0.000 claims abstract 2
- 239000013598 vector Substances 0.000 claims description 120
- 241000282414 Homo sapiens Species 0.000 claims description 94
- 150000007523 nucleic acids Chemical class 0.000 claims description 90
- 102000039446 nucleic acids Human genes 0.000 claims description 81
- 108020004707 nucleic acids Proteins 0.000 claims description 81
- 206010016654 Fibrosis Diseases 0.000 claims description 48
- 208000019425 cirrhosis of liver Diseases 0.000 claims description 47
- 230000007882 cirrhosis Effects 0.000 claims description 42
- 108010029485 Protein Isoforms Proteins 0.000 claims description 26
- 102000001708 Protein Isoforms Human genes 0.000 claims description 26
- 108020004414 DNA Proteins 0.000 claims description 20
- 208000010334 End Stage Liver Disease Diseases 0.000 claims description 15
- 208000011444 chronic liver failure Diseases 0.000 claims description 15
- 201000007270 liver cancer Diseases 0.000 claims description 15
- 208000014018 liver neoplasm Diseases 0.000 claims description 15
- 206010057573 Chronic hepatic failure Diseases 0.000 claims description 14
- 230000014509 gene expression Effects 0.000 abstract description 151
- 230000001965 increasing effect Effects 0.000 abstract description 22
- 230000014759 maintenance of location Effects 0.000 abstract description 12
- 230000002222 downregulating effect Effects 0.000 abstract description 4
- 108090000765 processed proteins & peptides Proteins 0.000 description 93
- 229920001184 polypeptide Polymers 0.000 description 92
- 102000004196 processed proteins & peptides Human genes 0.000 description 92
- 108090000623 proteins and genes Proteins 0.000 description 90
- 210000004185 liver Anatomy 0.000 description 87
- -1 NR5A2 Proteins 0.000 description 70
- 210000004027 cell Anatomy 0.000 description 65
- 230000006870 function Effects 0.000 description 64
- 102100033810 RAC-alpha serine/threonine-protein kinase Human genes 0.000 description 58
- 108091008611 Protein Kinase B Proteins 0.000 description 57
- 108010018012 transcription factor MTF-1 Proteins 0.000 description 55
- 239000002105 nanoparticle Substances 0.000 description 47
- 102000040430 polynucleotide Human genes 0.000 description 41
- 108091033319 polynucleotide Proteins 0.000 description 41
- 239000002157 polynucleotide Substances 0.000 description 41
- 102000004169 proteins and genes Human genes 0.000 description 40
- 208000008338 non-alcoholic fatty liver disease Diseases 0.000 description 36
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 35
- 210000004940 nucleus Anatomy 0.000 description 33
- 206010053219 non-alcoholic steatohepatitis Diseases 0.000 description 32
- 231100000835 liver failure Toxicity 0.000 description 30
- 206010019663 Hepatic failure Diseases 0.000 description 29
- 208000007903 liver failure Diseases 0.000 description 29
- 108010026333 seryl-proline Proteins 0.000 description 28
- 239000002245 particle Substances 0.000 description 27
- 108010057821 leucylproline Proteins 0.000 description 24
- 238000001262 western blot Methods 0.000 description 24
- 230000009368 gene silencing by RNA Effects 0.000 description 23
- 108091030071 RNAI Proteins 0.000 description 22
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 22
- 108010050848 glycylleucine Proteins 0.000 description 22
- 230000001105 regulatory effect Effects 0.000 description 22
- 238000001994 activation Methods 0.000 description 20
- 241000282412 Homo Species 0.000 description 19
- 230000004913 activation Effects 0.000 description 19
- 108010087924 alanylproline Proteins 0.000 description 19
- 238000004458 analytical method Methods 0.000 description 19
- 108020004999 messenger RNA Proteins 0.000 description 19
- 238000012360 testing method Methods 0.000 description 19
- 150000002632 lipids Chemical class 0.000 description 18
- 108010031719 prolyl-serine Proteins 0.000 description 18
- 235000018102 proteins Nutrition 0.000 description 18
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 17
- 230000030648 nucleus localization Effects 0.000 description 17
- 230000003612 virological effect Effects 0.000 description 17
- 241000713666 Lentivirus Species 0.000 description 16
- 241000700605 Viruses Species 0.000 description 16
- 230000021736 acetylation Effects 0.000 description 16
- 238000006640 acetylation reaction Methods 0.000 description 16
- 230000002596 correlated effect Effects 0.000 description 16
- 230000000694 effects Effects 0.000 description 16
- KDXKERNSBIXSRK-UHFFFAOYSA-N lysine Chemical compound NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 16
- 230000001404 mediated effect Effects 0.000 description 16
- 230000007423 decrease Effects 0.000 description 15
- 238000012417 linear regression Methods 0.000 description 15
- 230000004807 localization Effects 0.000 description 15
- 102000005962 receptors Human genes 0.000 description 15
- 108020003175 receptors Proteins 0.000 description 15
- 239000000243 solution Substances 0.000 description 15
- 239000013603 viral vector Substances 0.000 description 15
- 241000880493 Leptailurus serval Species 0.000 description 14
- 239000012124 Opti-MEM Substances 0.000 description 14
- 241000283973 Oryctolagus cuniculus Species 0.000 description 14
- 230000001086 cytosolic effect Effects 0.000 description 14
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 14
- 108010051242 phenylalanylserine Proteins 0.000 description 14
- 208000002267 Anti-neutrophil cytoplasmic antibody-associated vasculitis Diseases 0.000 description 13
- 230000037361 pathway Effects 0.000 description 13
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 12
- 210000001808 exosome Anatomy 0.000 description 12
- 230000003908 liver function Effects 0.000 description 12
- 108010029020 prolylglycine Proteins 0.000 description 12
- 238000012546 transfer Methods 0.000 description 12
- 238000002054 transplantation Methods 0.000 description 12
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 11
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 11
- 108010044940 alanylglutamine Proteins 0.000 description 11
- 230000005754 cellular signaling Effects 0.000 description 11
- 235000012000 cholesterol Nutrition 0.000 description 11
- 108010078144 glutaminyl-glycine Proteins 0.000 description 11
- 210000005229 liver cell Anatomy 0.000 description 11
- 230000004481 post-translational protein modification Effects 0.000 description 11
- 230000002829 reductive effect Effects 0.000 description 11
- 206010009208 Cirrhosis alcoholic Diseases 0.000 description 10
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 10
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 10
- 108010005233 alanylglutamic acid Proteins 0.000 description 10
- 208000010002 alcoholic liver cirrhosis Diseases 0.000 description 10
- 108010093581 aspartyl-proline Proteins 0.000 description 10
- 239000005090 green fluorescent protein Substances 0.000 description 10
- 239000002207 metabolite Substances 0.000 description 10
- 239000002953 phosphate buffered saline Substances 0.000 description 10
- 230000026731 phosphorylation Effects 0.000 description 10
- 238000006366 phosphorylation reaction Methods 0.000 description 10
- 238000013518 transcription Methods 0.000 description 10
- 230000035897 transcription Effects 0.000 description 10
- 108010065920 Insulin Lispro Proteins 0.000 description 9
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 9
- 238000003559 RNA-seq method Methods 0.000 description 9
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 9
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 9
- 238000000540 analysis of variance Methods 0.000 description 9
- 108010077245 asparaginyl-proline Proteins 0.000 description 9
- 239000000872 buffer Substances 0.000 description 9
- 210000000805 cytoplasm Anatomy 0.000 description 9
- 201000010099 disease Diseases 0.000 description 9
- 230000004761 fibrosis Effects 0.000 description 9
- 108010010147 glycylglutamine Proteins 0.000 description 9
- 239000003446 ligand Substances 0.000 description 9
- 238000001543 one-way ANOVA Methods 0.000 description 9
- 229920001223 polyethylene glycol Polymers 0.000 description 9
- 230000011664 signaling Effects 0.000 description 9
- 241000702421 Dependoparvovirus Species 0.000 description 8
- 206010061218 Inflammation Diseases 0.000 description 8
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 8
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 8
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 8
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 8
- 239000002202 Polyethylene glycol Substances 0.000 description 8
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 8
- 108010013835 arginine glutamate Proteins 0.000 description 8
- 108010062796 arginyllysine Proteins 0.000 description 8
- 230000003247 decreasing effect Effects 0.000 description 8
- 208000035475 disorder Diseases 0.000 description 8
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 8
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 8
- 108010089804 glycyl-threonine Proteins 0.000 description 8
- 208000027700 hepatic dysfunction Diseases 0.000 description 8
- 108010025306 histidylleucine Proteins 0.000 description 8
- 230000004054 inflammatory process Effects 0.000 description 8
- 210000004698 lymphocyte Anatomy 0.000 description 8
- 238000004519 manufacturing process Methods 0.000 description 8
- 239000002609 medium Substances 0.000 description 8
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 8
- 238000003068 pathway analysis Methods 0.000 description 8
- 108010077112 prolyl-proline Proteins 0.000 description 8
- 231100000240 steatosis hepatitis Toxicity 0.000 description 8
- 108010061238 threonyl-glycine Proteins 0.000 description 8
- KWVJHCQQUFDPLU-YEUCEMRASA-N 2,3-bis[[(z)-octadec-9-enoyl]oxy]propyl-trimethylazanium Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC(C[N+](C)(C)C)OC(=O)CCCCCCC\C=C/CCCCCCCC KWVJHCQQUFDPLU-YEUCEMRASA-N 0.000 description 7
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 7
- IVCOYUURLWQDJQ-LPEHRKFASA-N Gln-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O IVCOYUURLWQDJQ-LPEHRKFASA-N 0.000 description 7
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 7
- 206010019728 Hepatitis alcoholic Diseases 0.000 description 7
- 108091028043 Nucleic acid sequence Proteins 0.000 description 7
- SNGZLPOXVRTNMB-LPEHRKFASA-N Pro-Ser-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N2CCC[C@@H]2C(=O)O SNGZLPOXVRTNMB-LPEHRKFASA-N 0.000 description 7
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 7
- 108010008355 arginyl-glutamine Proteins 0.000 description 7
- 108010068380 arginylarginine Proteins 0.000 description 7
- 108010060199 cysteinylproline Proteins 0.000 description 7
- 239000003814 drug Substances 0.000 description 7
- 108010077515 glycylproline Proteins 0.000 description 7
- 108010034529 leucyl-lysine Proteins 0.000 description 7
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 7
- 108010009298 lysylglutamic acid Proteins 0.000 description 7
- 229920001427 mPEG Polymers 0.000 description 7
- 108010005942 methionylglycine Proteins 0.000 description 7
- 239000003607 modifier Substances 0.000 description 7
- 238000000513 principal component analysis Methods 0.000 description 7
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 7
- 108010071207 serylmethionine Proteins 0.000 description 7
- 238000010186 staining Methods 0.000 description 7
- 230000001225 therapeutic effect Effects 0.000 description 7
- 238000010361 transduction Methods 0.000 description 7
- 238000001890 transfection Methods 0.000 description 7
- 230000032258 transport Effects 0.000 description 7
- 238000011144 upstream manufacturing Methods 0.000 description 7
- 210000002845 virion Anatomy 0.000 description 7
- MWRBNPKJOOWZPW-NYVOMTAGSA-N 1,2-dioleoyl-sn-glycero-3-phosphoethanolamine zwitterion Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OC[C@H](COP(O)(=O)OCCN)OC(=O)CCCCCCC\C=C/CCCCCCCC MWRBNPKJOOWZPW-NYVOMTAGSA-N 0.000 description 6
- 102100036009 5'-AMP-activated protein kinase catalytic subunit alpha-2 Human genes 0.000 description 6
- 102000008186 Collagen Human genes 0.000 description 6
- 108010035532 Collagen Proteins 0.000 description 6
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 6
- 101000783681 Homo sapiens 5'-AMP-activated protein kinase catalytic subunit alpha-2 Proteins 0.000 description 6
- 101000629597 Homo sapiens Sterol regulatory element-binding protein 1 Proteins 0.000 description 6
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 6
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 6
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 6
- 108010079364 N-glycylalanine Proteins 0.000 description 6
- XQLBWXHVZVBNJM-FXQIFTODSA-N Pro-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 XQLBWXHVZVBNJM-FXQIFTODSA-N 0.000 description 6
- SKICPQLTOXGWGO-GARJFASQSA-N Pro-Gln-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O SKICPQLTOXGWGO-GARJFASQSA-N 0.000 description 6
- FKLSMYYLJHYPHH-UWVGGRQHSA-N Pro-Gly-Leu Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O FKLSMYYLJHYPHH-UWVGGRQHSA-N 0.000 description 6
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 6
- KCGIREHVWRXNDH-GARJFASQSA-N Ser-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N KCGIREHVWRXNDH-GARJFASQSA-N 0.000 description 6
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 6
- 108010047495 alanylglycine Proteins 0.000 description 6
- 208000002353 alcoholic hepatitis Diseases 0.000 description 6
- 108010047857 aspartylglycine Proteins 0.000 description 6
- 230000000903 blocking effect Effects 0.000 description 6
- 229920001436 collagen Polymers 0.000 description 6
- 239000003636 conditioned culture medium Substances 0.000 description 6
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 6
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 6
- 238000003364 immunohistochemistry Methods 0.000 description 6
- 238000001727 in vivo Methods 0.000 description 6
- 210000005228 liver tissue Anatomy 0.000 description 6
- 230000001323 posttranslational effect Effects 0.000 description 6
- 108010093296 prolyl-prolyl-alanine Proteins 0.000 description 6
- 108010004914 prolylarginine Proteins 0.000 description 6
- 238000011002 quantification Methods 0.000 description 6
- 238000002271 resection Methods 0.000 description 6
- 230000007863 steatosis Effects 0.000 description 6
- 230000035882 stress Effects 0.000 description 6
- 239000006228 supernatant Substances 0.000 description 6
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 6
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 5
- KTXKIYXZQFWJKB-VZFHVOOUSA-N Ala-Thr-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O KTXKIYXZQFWJKB-VZFHVOOUSA-N 0.000 description 5
- 108010040163 CREB-Binding Protein Proteins 0.000 description 5
- 102100021975 CREB-binding protein Human genes 0.000 description 5
- 108091033409 CRISPR Proteins 0.000 description 5
- 208000004930 Fatty Liver Diseases 0.000 description 5
- YJIUYQKQBBQYHZ-ACZMJKKPSA-N Gln-Ala-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YJIUYQKQBBQYHZ-ACZMJKKPSA-N 0.000 description 5
- KVXVVDFOZNYYKZ-DCAQKATOSA-N Gln-Gln-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KVXVVDFOZNYYKZ-DCAQKATOSA-N 0.000 description 5
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 5
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 5
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 5
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 5
- JNDYEOUZBLOVOF-AVGNSLFASA-N Leu-Leu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JNDYEOUZBLOVOF-AVGNSLFASA-N 0.000 description 5
- PHURAEXVWLDIGT-LPEHRKFASA-N Met-Ser-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N PHURAEXVWLDIGT-LPEHRKFASA-N 0.000 description 5
- 241000699666 Mus <mouse, genus> Species 0.000 description 5
- 241000699670 Mus sp. Species 0.000 description 5
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 5
- 206010028980 Neoplasm Diseases 0.000 description 5
- 102000007999 Nuclear Proteins Human genes 0.000 description 5
- 108010089610 Nuclear Proteins Proteins 0.000 description 5
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 5
- FDMCIBSQRKFSTJ-RHYQMDGZSA-N Pro-Thr-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O FDMCIBSQRKFSTJ-RHYQMDGZSA-N 0.000 description 5
- AIOWVDNPESPXRB-YTWAJWBKSA-N Pro-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2)O AIOWVDNPESPXRB-YTWAJWBKSA-N 0.000 description 5
- BQWCDDAISCPDQV-XHNCKOQMSA-N Ser-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N)C(=O)O BQWCDDAISCPDQV-XHNCKOQMSA-N 0.000 description 5
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 5
- 102000007562 Serum Albumin Human genes 0.000 description 5
- 108010071390 Serum Albumin Proteins 0.000 description 5
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 5
- 108010060035 arginylproline Proteins 0.000 description 5
- 201000011510 cancer Diseases 0.000 description 5
- 230000034994 death Effects 0.000 description 5
- 231100000517 death Toxicity 0.000 description 5
- 239000003623 enhancer Substances 0.000 description 5
- 238000001415 gene therapy Methods 0.000 description 5
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 5
- 108010040030 histidinoalanine Proteins 0.000 description 5
- 108010018006 histidylserine Proteins 0.000 description 5
- 230000005976 liver dysfunction Effects 0.000 description 5
- 230000004048 modification Effects 0.000 description 5
- 238000012986 modification Methods 0.000 description 5
- 239000012071 phase Substances 0.000 description 5
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 5
- 229920000642 polymer Polymers 0.000 description 5
- 108010070643 prolylglutamic acid Proteins 0.000 description 5
- 210000002966 serum Anatomy 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 208000024891 symptom Diseases 0.000 description 5
- 230000026683 transduction Effects 0.000 description 5
- 241000701161 unidentified adenovirus Species 0.000 description 5
- 108010073969 valyllysine Proteins 0.000 description 5
- HSINOMROUCMIEA-FGVHQWLLSA-N (2s,4r)-4-[(3r,5s,6r,7r,8s,9s,10s,13r,14s,17r)-6-ethyl-3,7-dihydroxy-10,13-dimethyl-2,3,4,5,6,7,8,9,11,12,14,15,16,17-tetradecahydro-1h-cyclopenta[a]phenanthren-17-yl]-2-methylpentanoic acid Chemical compound C([C@@]12C)C[C@@H](O)C[C@H]1[C@@H](CC)[C@@H](O)[C@@H]1[C@@H]2CC[C@]2(C)[C@@H]([C@H](C)C[C@H](C)C(O)=O)CC[C@H]21 HSINOMROUCMIEA-FGVHQWLLSA-N 0.000 description 4
- BYWPQQOQVPVCTC-UHFFFAOYSA-N 2-[3-[2-[2-[2-[2-[bis[3-[2-(2-methyl-3-octylsulfanylpropanoyl)oxyethoxy]-3-oxopropyl]amino]ethylamino]ethyl-[3-[2-(2-methyl-3-octylsulfanylpropanoyl)oxyethoxy]-3-oxopropyl]amino]ethylamino]ethyl-[3-[2-(2-methyl-3-octylsulfanylpropanoyl)oxyethoxy]-3-oxopropyl]amino]propanoyloxy]ethyl 2-methyl-3-octylsulfanylpropanoate Chemical compound CCCCCCCCSCC(C)C(=O)OCCOC(=O)CCN(CCNCCN(CCC(=O)OCCOC(=O)C(C)CSCCCCCCCC)CCC(=O)OCCOC(=O)C(C)CSCCCCCCCC)CCNCCN(CCC(=O)OCCOC(=O)C(C)CSCCCCCCCC)CCC(=O)OCCOC(=O)C(C)CSCCCCCCCC BYWPQQOQVPVCTC-UHFFFAOYSA-N 0.000 description 4
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 4
- NHLAEBFGWPXFGI-WHFBIAKZSA-N Ala-Gly-Asn Chemical compound C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N NHLAEBFGWPXFGI-WHFBIAKZSA-N 0.000 description 4
- PCIFXPRIFWKWLK-YUMQZZPRSA-N Ala-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N PCIFXPRIFWKWLK-YUMQZZPRSA-N 0.000 description 4
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 4
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 4
- IPZQNYYAYVRKKK-FXQIFTODSA-N Ala-Pro-Ala Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IPZQNYYAYVRKKK-FXQIFTODSA-N 0.000 description 4
- KUFVXLQLDHJVOG-SHGPDSBTSA-N Ala-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C)N)O KUFVXLQLDHJVOG-SHGPDSBTSA-N 0.000 description 4
- QGZKDVFQNNGYKY-UHFFFAOYSA-N Ammonia Chemical compound N QGZKDVFQNNGYKY-UHFFFAOYSA-N 0.000 description 4
- 102000003952 Caspase 3 Human genes 0.000 description 4
- 108090000397 Caspase 3 Proteins 0.000 description 4
- HEDRZPFGACZZDS-UHFFFAOYSA-N Chloroform Chemical compound ClC(Cl)Cl HEDRZPFGACZZDS-UHFFFAOYSA-N 0.000 description 4
- 108091026890 Coding region Proteins 0.000 description 4
- PKVWNYGXMNWJSI-CIUDSAMLSA-N Gln-Gln-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKVWNYGXMNWJSI-CIUDSAMLSA-N 0.000 description 4
- FNAJNWPDTIXYJN-CIUDSAMLSA-N Gln-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O FNAJNWPDTIXYJN-CIUDSAMLSA-N 0.000 description 4
- PBYFVIQRFLNQCO-GUBZILKMSA-N Gln-Pro-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O PBYFVIQRFLNQCO-GUBZILKMSA-N 0.000 description 4
- UWMDGPFFTKDUIY-HJGDQZAQSA-N Gln-Pro-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O UWMDGPFFTKDUIY-HJGDQZAQSA-N 0.000 description 4
- ILWHFUZZCFYSKT-AVGNSLFASA-N Glu-Lys-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O ILWHFUZZCFYSKT-AVGNSLFASA-N 0.000 description 4
- CCBIBMKQNXHNIN-ZETCQYMHSA-N Gly-Leu-Gly Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CCBIBMKQNXHNIN-ZETCQYMHSA-N 0.000 description 4
- GGLIDLCEPDHEJO-BQBZGAKWSA-N Gly-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)CN GGLIDLCEPDHEJO-BQBZGAKWSA-N 0.000 description 4
- FGPLUIQCSKGLTI-WDSKDSINSA-N Gly-Ser-Glu Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O FGPLUIQCSKGLTI-WDSKDSINSA-N 0.000 description 4
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 4
- 102100022054 Hepatocyte nuclear factor 4-alpha Human genes 0.000 description 4
- LJHGALIOHLRRQN-DCAQKATOSA-N Leu-Ala-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LJHGALIOHLRRQN-DCAQKATOSA-N 0.000 description 4
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 4
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 4
- XWEVVRRSIOBJOO-SRVKXCTJSA-N Leu-Pro-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O XWEVVRRSIOBJOO-SRVKXCTJSA-N 0.000 description 4
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 4
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 4
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 4
- BIYWZVCPZIFGPY-QWRGUYRKSA-N Phe-Gly-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CO)C(O)=O BIYWZVCPZIFGPY-QWRGUYRKSA-N 0.000 description 4
- DZZCICYRSZASNF-FXQIFTODSA-N Pro-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 DZZCICYRSZASNF-FXQIFTODSA-N 0.000 description 4
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 4
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 4
- SUENWIFTSTWUKD-AVGNSLFASA-N Pro-Leu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SUENWIFTSTWUKD-AVGNSLFASA-N 0.000 description 4
- LEIKGVHQTKHOLM-IUCAKERBSA-N Pro-Pro-Gly Chemical compound OC(=O)CNC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 LEIKGVHQTKHOLM-IUCAKERBSA-N 0.000 description 4
- SBVPYBFMIGDIDX-SRVKXCTJSA-N Pro-Pro-Pro Chemical compound OC(=O)[C@@H]1CCCN1C(=O)[C@H]1N(C(=O)[C@H]2NCCC2)CCC1 SBVPYBFMIGDIDX-SRVKXCTJSA-N 0.000 description 4
- LNICFEXCAHIJOR-DCAQKATOSA-N Pro-Ser-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LNICFEXCAHIJOR-DCAQKATOSA-N 0.000 description 4
- QKDIHFHGHBYTKB-IHRRRGAJSA-N Pro-Ser-Phe Chemical compound N([C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C(=O)[C@@H]1CCCN1 QKDIHFHGHBYTKB-IHRRRGAJSA-N 0.000 description 4
- 102100027378 Prothrombin Human genes 0.000 description 4
- 108010094028 Prothrombin Proteins 0.000 description 4
- 108010038912 Retinoid X Receptors Proteins 0.000 description 4
- 102000034527 Retinoid X Receptors Human genes 0.000 description 4
- OJPHFSOMBZKQKQ-GUBZILKMSA-N Ser-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CO OJPHFSOMBZKQKQ-GUBZILKMSA-N 0.000 description 4
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 4
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 4
- MQUZANJDFOQOBX-SRVKXCTJSA-N Ser-Phe-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O MQUZANJDFOQOBX-SRVKXCTJSA-N 0.000 description 4
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 4
- QUGRFWPMPVIAPW-IHRRRGAJSA-N Ser-Pro-Phe Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QUGRFWPMPVIAPW-IHRRRGAJSA-N 0.000 description 4
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 4
- JCLAFVNDBJMLBC-JBDRJPRFSA-N Ser-Ser-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JCLAFVNDBJMLBC-JBDRJPRFSA-N 0.000 description 4
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 4
- ZSDXEKUKQAKZFE-XAVMHZPKSA-N Ser-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N)O ZSDXEKUKQAKZFE-XAVMHZPKSA-N 0.000 description 4
- 238000008050 Total Bilirubin Reagent Methods 0.000 description 4
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 4
- 230000003213 activating effect Effects 0.000 description 4
- 239000000556 agonist Substances 0.000 description 4
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 4
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 4
- 230000006907 apoptotic process Effects 0.000 description 4
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 4
- 108010092854 aspartyllysine Proteins 0.000 description 4
- 108010068265 aspartyltyrosine Proteins 0.000 description 4
- 239000003613 bile acid Substances 0.000 description 4
- 230000027455 binding Effects 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 4
- 239000013592 cell lysate Substances 0.000 description 4
- 239000003795 chemical substances by application Substances 0.000 description 4
- 108010016616 cysteinylglycine Proteins 0.000 description 4
- 230000001419 dependent effect Effects 0.000 description 4
- 238000010790 dilution Methods 0.000 description 4
- 239000012895 dilution Substances 0.000 description 4
- 238000009826 distribution Methods 0.000 description 4
- 239000003937 drug carrier Substances 0.000 description 4
- 230000004064 dysfunction Effects 0.000 description 4
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 4
- 238000004817 gas chromatography Methods 0.000 description 4
- 238000002290 gas chromatography-mass spectrometry Methods 0.000 description 4
- 108010079547 glutamylmethionine Proteins 0.000 description 4
- 230000002440 hepatic effect Effects 0.000 description 4
- 108010028295 histidylhistidine Proteins 0.000 description 4
- 238000010166 immunofluorescence Methods 0.000 description 4
- 238000012405 in silico analysis Methods 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 239000002502 liposome Substances 0.000 description 4
- 239000006166 lysate Substances 0.000 description 4
- 108010054155 lysyllysine Proteins 0.000 description 4
- 239000000463 material Substances 0.000 description 4
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 4
- YBYRMVIVWMBXKQ-UHFFFAOYSA-N phenylmethanesulfonyl fluoride Chemical compound FS(=O)(=O)CC1=CC=CC=C1 YBYRMVIVWMBXKQ-UHFFFAOYSA-N 0.000 description 4
- 150000003904 phospholipids Chemical class 0.000 description 4
- 239000013612 plasmid Substances 0.000 description 4
- 108010090894 prolylleucine Proteins 0.000 description 4
- 229940039716 prothrombin Drugs 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 108010048818 seryl-histidine Proteins 0.000 description 4
- 239000011780 sodium chloride Substances 0.000 description 4
- 238000007619 statistical method Methods 0.000 description 4
- 210000001519 tissue Anatomy 0.000 description 4
- 108091008023 transcriptional regulators Proteins 0.000 description 4
- 108010020532 tyrosyl-proline Proteins 0.000 description 4
- GJLXVWOMRRWCIB-MERZOTPQSA-N (2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanamide Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=C(O)C=C1 GJLXVWOMRRWCIB-MERZOTPQSA-N 0.000 description 3
- NRJAVPSFFCBXDT-HUESYALOSA-N 1,2-distearoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCCCCCCCC NRJAVPSFFCBXDT-HUESYALOSA-N 0.000 description 3
- 239000013607 AAV vector Substances 0.000 description 3
- BUANFPRKJKJSRR-ACZMJKKPSA-N Ala-Ala-Gln Chemical compound C[C@H]([NH3+])C(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CCC(N)=O BUANFPRKJKJSRR-ACZMJKKPSA-N 0.000 description 3
- YLTKNGYYPIWKHZ-ACZMJKKPSA-N Ala-Ala-Glu Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O YLTKNGYYPIWKHZ-ACZMJKKPSA-N 0.000 description 3
- HXNNRBHASOSVPG-GUBZILKMSA-N Ala-Glu-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O HXNNRBHASOSVPG-GUBZILKMSA-N 0.000 description 3
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 3
- YHKANGMVQWRMAP-DCAQKATOSA-N Ala-Leu-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YHKANGMVQWRMAP-DCAQKATOSA-N 0.000 description 3
- HHRAXZAYZFFRAM-CIUDSAMLSA-N Ala-Leu-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O HHRAXZAYZFFRAM-CIUDSAMLSA-N 0.000 description 3
- NOGFDULFCFXBHB-CIUDSAMLSA-N Ala-Leu-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)O)N NOGFDULFCFXBHB-CIUDSAMLSA-N 0.000 description 3
- AWZKCUCQJNTBAD-SRVKXCTJSA-N Ala-Leu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN AWZKCUCQJNTBAD-SRVKXCTJSA-N 0.000 description 3
- LDLSENBXQNDTPB-DCAQKATOSA-N Ala-Lys-Arg Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LDLSENBXQNDTPB-DCAQKATOSA-N 0.000 description 3
- MFMDKJIPHSWSBM-GUBZILKMSA-N Ala-Lys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFMDKJIPHSWSBM-GUBZILKMSA-N 0.000 description 3
- OLVCTPPSXNRGKV-GUBZILKMSA-N Ala-Pro-Pro Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OLVCTPPSXNRGKV-GUBZILKMSA-N 0.000 description 3
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 3
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 3
- NZGRHTKZFSVPAN-BIIVOSGPSA-N Ala-Ser-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N NZGRHTKZFSVPAN-BIIVOSGPSA-N 0.000 description 3
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 3
- MUXONAMCEUBVGA-DCAQKATOSA-N Arg-Arg-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O MUXONAMCEUBVGA-DCAQKATOSA-N 0.000 description 3
- WOPFJPHVBWKZJH-SRVKXCTJSA-N Arg-Arg-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O WOPFJPHVBWKZJH-SRVKXCTJSA-N 0.000 description 3
- FSNVAJOPUDVQAR-AVGNSLFASA-N Arg-Lys-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FSNVAJOPUDVQAR-AVGNSLFASA-N 0.000 description 3
- NGYHSXDNNOFHNE-AVGNSLFASA-N Arg-Pro-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O NGYHSXDNNOFHNE-AVGNSLFASA-N 0.000 description 3
- RYQSYXFGFOTJDJ-RHYQMDGZSA-N Arg-Thr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O RYQSYXFGFOTJDJ-RHYQMDGZSA-N 0.000 description 3
- APHUDFFMXFYRKP-CIUDSAMLSA-N Asn-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N APHUDFFMXFYRKP-CIUDSAMLSA-N 0.000 description 3
- DJIMLSXHXKWADV-CIUDSAMLSA-N Asn-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(N)=O DJIMLSXHXKWADV-CIUDSAMLSA-N 0.000 description 3
- UMHUHHJMEXNSIV-CIUDSAMLSA-N Asp-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UMHUHHJMEXNSIV-CIUDSAMLSA-N 0.000 description 3
- GIKOVDMXBAFXDF-NHCYSSNCSA-N Asp-Val-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GIKOVDMXBAFXDF-NHCYSSNCSA-N 0.000 description 3
- 102100038495 Bile acid receptor Human genes 0.000 description 3
- YDNKGFDKKRUKPY-JHOUSYSJSA-N C16 ceramide Natural products CCCCCCCCCCCCCCCC(=O)N[C@@H](CO)[C@H](O)C=CCCCCCCCCCCCCC YDNKGFDKKRUKPY-JHOUSYSJSA-N 0.000 description 3
- 238000010354 CRISPR gene editing Methods 0.000 description 3
- 102000053602 DNA Human genes 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 3
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 3
- PRBLYKYHAJEABA-SRVKXCTJSA-N Gln-Arg-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O PRBLYKYHAJEABA-SRVKXCTJSA-N 0.000 description 3
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 3
- JXBZEDIQFFCHPZ-PEFMBERDSA-N Gln-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N JXBZEDIQFFCHPZ-PEFMBERDSA-N 0.000 description 3
- OREPWMPAUWIIAM-ZPFDUUQYSA-N Gln-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N OREPWMPAUWIIAM-ZPFDUUQYSA-N 0.000 description 3
- YPFFHGRJCUBXPX-NHCYSSNCSA-N Gln-Pro-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O)C(O)=O YPFFHGRJCUBXPX-NHCYSSNCSA-N 0.000 description 3
- VLOLPWWCNKWRNB-LOKLDPHHSA-N Gln-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O VLOLPWWCNKWRNB-LOKLDPHHSA-N 0.000 description 3
- ARYKRXHBIPLULY-XKBZYTNZSA-N Gln-Thr-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ARYKRXHBIPLULY-XKBZYTNZSA-N 0.000 description 3
- RUFHOVYUYSNDNY-ACZMJKKPSA-N Glu-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O RUFHOVYUYSNDNY-ACZMJKKPSA-N 0.000 description 3
- RJONUNZIMUXUOI-GUBZILKMSA-N Glu-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N RJONUNZIMUXUOI-GUBZILKMSA-N 0.000 description 3
- JRCUFCXYZLPSDZ-ACZMJKKPSA-N Glu-Asp-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O JRCUFCXYZLPSDZ-ACZMJKKPSA-N 0.000 description 3
- XHUCVVHRLNPZSZ-CIUDSAMLSA-N Glu-Gln-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XHUCVVHRLNPZSZ-CIUDSAMLSA-N 0.000 description 3
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 3
- HRBYTAIBKPNZKQ-AVGNSLFASA-N Glu-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O HRBYTAIBKPNZKQ-AVGNSLFASA-N 0.000 description 3
- IDEODOAVGCMUQV-GUBZILKMSA-N Glu-Ser-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IDEODOAVGCMUQV-GUBZILKMSA-N 0.000 description 3
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 3
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 3
- KKBWDNZXYLGJEY-UHFFFAOYSA-N Gly-Arg-Pro Natural products NCC(=O)NC(CCNC(=N)N)C(=O)N1CCCC1C(=O)O KKBWDNZXYLGJEY-UHFFFAOYSA-N 0.000 description 3
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 3
- ABPRMMYHROQBLY-NKWVEPMBSA-N Gly-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)CN)C(=O)O ABPRMMYHROQBLY-NKWVEPMBSA-N 0.000 description 3
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 3
- 206010019708 Hepatic steatosis Diseases 0.000 description 3
- 208000005176 Hepatitis C Diseases 0.000 description 3
- YAALVYQFVJNXIV-KKUMJFAQSA-N His-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 YAALVYQFVJNXIV-KKUMJFAQSA-N 0.000 description 3
- 101000603876 Homo sapiens Bile acid receptor Proteins 0.000 description 3
- 101000926508 Homo sapiens Eukaryotic translation initiation factor 2-alpha kinase 3 Proteins 0.000 description 3
- 101001045740 Homo sapiens Hepatocyte nuclear factor 4-alpha Proteins 0.000 description 3
- LRAUKBMYHHNADU-DKIMLUQUSA-N Ile-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)CC)CC1=CC=CC=C1 LRAUKBMYHHNADU-DKIMLUQUSA-N 0.000 description 3
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 3
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 3
- GRZSCTXVCDUIPO-SRVKXCTJSA-N Leu-Arg-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRZSCTXVCDUIPO-SRVKXCTJSA-N 0.000 description 3
- ILJREDZFPHTUIE-GUBZILKMSA-N Leu-Asp-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ILJREDZFPHTUIE-GUBZILKMSA-N 0.000 description 3
- CQGSYZCULZMEDE-SRVKXCTJSA-N Leu-Gln-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CQGSYZCULZMEDE-SRVKXCTJSA-N 0.000 description 3
- WIDZHJTYKYBLSR-DCAQKATOSA-N Leu-Glu-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WIDZHJTYKYBLSR-DCAQKATOSA-N 0.000 description 3
- HGFGEMSVBMCFKK-MNXVOIDGSA-N Leu-Ile-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O HGFGEMSVBMCFKK-MNXVOIDGSA-N 0.000 description 3
- DSFYPIUSAMSERP-IHRRRGAJSA-N Leu-Leu-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DSFYPIUSAMSERP-IHRRRGAJSA-N 0.000 description 3
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 3
- MVHXGBZUJLWZOH-BJDJZHNGSA-N Leu-Ser-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MVHXGBZUJLWZOH-BJDJZHNGSA-N 0.000 description 3
- PPGBXYKMUMHFBF-KATARQTJSA-N Leu-Ser-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PPGBXYKMUMHFBF-KATARQTJSA-N 0.000 description 3
- IRNSXVOWSXSULE-DCAQKATOSA-N Lys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN IRNSXVOWSXSULE-DCAQKATOSA-N 0.000 description 3
- WRODMZBHNNPRLN-SRVKXCTJSA-N Lys-Leu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O WRODMZBHNNPRLN-SRVKXCTJSA-N 0.000 description 3
- IHITVQKJXQQGLJ-LPEHRKFASA-N Met-Asn-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N IHITVQKJXQQGLJ-LPEHRKFASA-N 0.000 description 3
- YCUSPBPZVJDMII-YUMQZZPRSA-N Met-Gly-Glu Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O YCUSPBPZVJDMII-YUMQZZPRSA-N 0.000 description 3
- LRALLISKBZNSKN-BQBZGAKWSA-N Met-Gly-Ser Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LRALLISKBZNSKN-BQBZGAKWSA-N 0.000 description 3
- 241001465754 Metazoa Species 0.000 description 3
- CRJGESKKUOMBCT-VQTJNVASSA-N N-acetylsphinganine Chemical compound CCCCCCCCCCCCCCC[C@@H](O)[C@H](CO)NC(C)=O CRJGESKKUOMBCT-VQTJNVASSA-N 0.000 description 3
- DRVIASBABBMZTF-GUBZILKMSA-N Pro-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@@H]1CCCN1 DRVIASBABBMZTF-GUBZILKMSA-N 0.000 description 3
- WPQKSRHDTMRSJM-CIUDSAMLSA-N Pro-Asp-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 WPQKSRHDTMRSJM-CIUDSAMLSA-N 0.000 description 3
- YFNOUBWUIIJQHF-LPEHRKFASA-N Pro-Asp-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O YFNOUBWUIIJQHF-LPEHRKFASA-N 0.000 description 3
- FISHYTLIMUYTQY-GUBZILKMSA-N Pro-Gln-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 FISHYTLIMUYTQY-GUBZILKMSA-N 0.000 description 3
- LXVLKXPFIDDHJG-CIUDSAMLSA-N Pro-Glu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O LXVLKXPFIDDHJG-CIUDSAMLSA-N 0.000 description 3
- FEVDNIBDCRKMER-IUCAKERBSA-N Pro-Gly-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEVDNIBDCRKMER-IUCAKERBSA-N 0.000 description 3
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 3
- XYSXOCIWCPFOCG-IHRRRGAJSA-N Pro-Leu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XYSXOCIWCPFOCG-IHRRRGAJSA-N 0.000 description 3
- FKYKZHOKDOPHSA-DCAQKATOSA-N Pro-Leu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FKYKZHOKDOPHSA-DCAQKATOSA-N 0.000 description 3
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 3
- KIDXAAQVMNLJFQ-KZVJFYERSA-N Pro-Thr-Ala Chemical compound C[C@@H](O)[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](C)C(O)=O KIDXAAQVMNLJFQ-KZVJFYERSA-N 0.000 description 3
- GZNYIXWOIUFLGO-ZJDVBMNYSA-N Pro-Thr-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZNYIXWOIUFLGO-ZJDVBMNYSA-N 0.000 description 3
- ZMLRZBWCXPQADC-TUAOUCFPSA-N Pro-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 ZMLRZBWCXPQADC-TUAOUCFPSA-N 0.000 description 3
- 238000002123 RNA extraction Methods 0.000 description 3
- WTUJZHKANPDPIN-CIUDSAMLSA-N Ser-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N WTUJZHKANPDPIN-CIUDSAMLSA-N 0.000 description 3
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 3
- XWCYBVBLJRWOFR-WDSKDSINSA-N Ser-Gln-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O XWCYBVBLJRWOFR-WDSKDSINSA-N 0.000 description 3
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 3
- XKFJENWJGHMDLI-QWRGUYRKSA-N Ser-Phe-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O XKFJENWJGHMDLI-QWRGUYRKSA-N 0.000 description 3
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 3
- JLKWJWPDXPKKHI-FXQIFTODSA-N Ser-Pro-Asn Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CO)N)C(=O)N[C@@H](CC(=O)N)C(=O)O JLKWJWPDXPKKHI-FXQIFTODSA-N 0.000 description 3
- DINQYZRMXGWWTG-GUBZILKMSA-N Ser-Pro-Pro Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DINQYZRMXGWWTG-GUBZILKMSA-N 0.000 description 3
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 3
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 3
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 3
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 3
- AABIBDJHSKIMJK-FXQIFTODSA-N Ser-Ser-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O AABIBDJHSKIMJK-FXQIFTODSA-N 0.000 description 3
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 3
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 3
- WUXCHQZLUHBSDJ-LKXGYXEUSA-N Ser-Thr-Asp Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WUXCHQZLUHBSDJ-LKXGYXEUSA-N 0.000 description 3
- 108020004459 Small interfering RNA Proteins 0.000 description 3
- 229930182558 Sterol Natural products 0.000 description 3
- 108091027544 Subgenomic mRNA Proteins 0.000 description 3
- VGYBYGQXZJDZJU-XQXXSGGOSA-N Thr-Glu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VGYBYGQXZJDZJU-XQXXSGGOSA-N 0.000 description 3
- UDQBCBUXAQIZAK-GLLZPBPUSA-N Thr-Glu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UDQBCBUXAQIZAK-GLLZPBPUSA-N 0.000 description 3
- ONNSECRQFSTMCC-XKBZYTNZSA-N Thr-Glu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ONNSECRQFSTMCC-XKBZYTNZSA-N 0.000 description 3
- VYEHBMMAJFVTOI-JHEQGTHGSA-N Thr-Gly-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O VYEHBMMAJFVTOI-JHEQGTHGSA-N 0.000 description 3
- UBDDORVPVLEECX-FJXKBIBVSA-N Thr-Gly-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O UBDDORVPVLEECX-FJXKBIBVSA-N 0.000 description 3
- NCXVJIQMWSGRHY-KXNHARMFSA-N Thr-Leu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O NCXVJIQMWSGRHY-KXNHARMFSA-N 0.000 description 3
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 3
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 3
- MFMGPEKYBXFIRF-SUSMZKCASA-N Thr-Thr-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MFMGPEKYBXFIRF-SUSMZKCASA-N 0.000 description 3
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 3
- CXPJPTFWKXNDKV-NUTKFTJISA-N Trp-Leu-Ala Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 CXPJPTFWKXNDKV-NUTKFTJISA-N 0.000 description 3
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 3
- DEGUERSKQBRZMZ-FXQIFTODSA-N Val-Ser-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DEGUERSKQBRZMZ-FXQIFTODSA-N 0.000 description 3
- KSFXWENSJABBFI-ZKWXMUAHSA-N Val-Ser-Asn Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KSFXWENSJABBFI-ZKWXMUAHSA-N 0.000 description 3
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 3
- OFTXTCGQJXTNQS-XGEHTFHBSA-N Val-Thr-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N)O OFTXTCGQJXTNQS-XGEHTFHBSA-N 0.000 description 3
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 3
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 3
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 3
- 230000001476 alcoholic effect Effects 0.000 description 3
- 238000003556 assay Methods 0.000 description 3
- 230000009286 beneficial effect Effects 0.000 description 3
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 3
- 229920002988 biodegradable polymer Polymers 0.000 description 3
- 239000004621 biodegradable polymer Substances 0.000 description 3
- 239000000969 carrier Substances 0.000 description 3
- 125000002091 cationic group Chemical group 0.000 description 3
- 230000001364 causal effect Effects 0.000 description 3
- 229940106189 ceramide Drugs 0.000 description 3
- ZVEQCJWYRWKARO-UHFFFAOYSA-N ceramide Natural products CCCCCCCCCCCCCCC(O)C(=O)NC(CO)C(O)C=CCCC=C(C)CCCCCCCCC ZVEQCJWYRWKARO-UHFFFAOYSA-N 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- 150000001875 compounds Chemical class 0.000 description 3
- 229920001577 copolymer Polymers 0.000 description 3
- 230000002950 deficient Effects 0.000 description 3
- 238000009472 formulation Methods 0.000 description 3
- 239000008103 glucose Substances 0.000 description 3
- 230000004153 glucose metabolism Effects 0.000 description 3
- 108010049041 glutamylalanine Proteins 0.000 description 3
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 3
- 108010015792 glycyllysine Proteins 0.000 description 3
- 108010037850 glycylvaline Proteins 0.000 description 3
- 208000006454 hepatitis Diseases 0.000 description 3
- 231100000283 hepatitis Toxicity 0.000 description 3
- 208000002672 hepatitis B Diseases 0.000 description 3
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 3
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 3
- 108010085325 histidylproline Proteins 0.000 description 3
- 230000013632 homeostatic process Effects 0.000 description 3
- 238000011534 incubation Methods 0.000 description 3
- 208000015181 infectious disease Diseases 0.000 description 3
- 230000002401 inhibitory effect Effects 0.000 description 3
- 238000001990 intravenous administration Methods 0.000 description 3
- 108010000761 leucylarginine Proteins 0.000 description 3
- 108010025153 lysyl-alanyl-alanine Proteins 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 108010003814 member 2 group B nuclear receptor subfamily 0 Proteins 0.000 description 3
- 239000012528 membrane Substances 0.000 description 3
- VVGIYYKRAMHVLU-UHFFFAOYSA-N newbouldiamide Natural products CCCCCCCCCCCCCCCCCCCC(O)C(O)C(O)C(CO)NC(=O)CCCCCCCCCCCCCCCCC VVGIYYKRAMHVLU-UHFFFAOYSA-N 0.000 description 3
- 230000025308 nuclear transport Effects 0.000 description 3
- 239000002773 nucleotide Substances 0.000 description 3
- 125000003729 nucleotide group Chemical group 0.000 description 3
- 238000004806 packaging method and process Methods 0.000 description 3
- 108010064486 phenylalanyl-leucyl-valine Proteins 0.000 description 3
- 108010084525 phenylalanyl-phenylalanyl-glycine Proteins 0.000 description 3
- 108010084572 phenylalanyl-valine Proteins 0.000 description 3
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 3
- 229920000136 polysorbate Polymers 0.000 description 3
- 108010014614 prolyl-glycyl-proline Proteins 0.000 description 3
- 230000008672 reprogramming Effects 0.000 description 3
- 238000012552 review Methods 0.000 description 3
- 150000003839 salts Chemical class 0.000 description 3
- 150000003432 sterols Chemical class 0.000 description 3
- 235000003702 sterols Nutrition 0.000 description 3
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 3
- 230000002103 transcriptional effect Effects 0.000 description 3
- 108010080629 tryptophan-leucine Proteins 0.000 description 3
- 230000004906 unfolded protein response Effects 0.000 description 3
- 108010015385 valyl-prolyl-proline Proteins 0.000 description 3
- 239000003981 vehicle Substances 0.000 description 3
- 239000011534 wash buffer Substances 0.000 description 3
- OZFAFGSSMRRTDW-UHFFFAOYSA-N (2,4-dichlorophenyl) benzenesulfonate Chemical compound ClC1=CC(Cl)=CC=C1OS(=O)(=O)C1=CC=CC=C1 OZFAFGSSMRRTDW-UHFFFAOYSA-N 0.000 description 2
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 2
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- 108010036211 5-HT-moduline Proteins 0.000 description 2
- 229940126638 Akt inhibitor Drugs 0.000 description 2
- 230000007730 Akt signaling Effects 0.000 description 2
- SBGXWWCLHIOABR-UHFFFAOYSA-N Ala Ala Gly Ala Chemical compound CC(N)C(=O)NC(C)C(=O)NCC(=O)NC(C)C(O)=O SBGXWWCLHIOABR-UHFFFAOYSA-N 0.000 description 2
- HHGYNJRJIINWAK-FXQIFTODSA-N Ala-Ala-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N HHGYNJRJIINWAK-FXQIFTODSA-N 0.000 description 2
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 2
- FJVAQLJNTSUQPY-CIUDSAMLSA-N Ala-Ala-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN FJVAQLJNTSUQPY-CIUDSAMLSA-N 0.000 description 2
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 2
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 2
- FXKNPWNXPQZLES-ZLUOBGJFSA-N Ala-Asn-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O FXKNPWNXPQZLES-ZLUOBGJFSA-N 0.000 description 2
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 2
- CRWFEKLFPVRPBV-CIUDSAMLSA-N Ala-Gln-Met Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O CRWFEKLFPVRPBV-CIUDSAMLSA-N 0.000 description 2
- CZPAHAKGPDUIPJ-CIUDSAMLSA-N Ala-Gln-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CZPAHAKGPDUIPJ-CIUDSAMLSA-N 0.000 description 2
- FUSPCLTUKXQREV-ACZMJKKPSA-N Ala-Glu-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O FUSPCLTUKXQREV-ACZMJKKPSA-N 0.000 description 2
- PUBLUECXJRHTBK-ACZMJKKPSA-N Ala-Glu-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O PUBLUECXJRHTBK-ACZMJKKPSA-N 0.000 description 2
- XYTNPQNAZREREP-XQXXSGGOSA-N Ala-Glu-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XYTNPQNAZREREP-XQXXSGGOSA-N 0.000 description 2
- CCDFBRZVTDDJNM-GUBZILKMSA-N Ala-Leu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CCDFBRZVTDDJNM-GUBZILKMSA-N 0.000 description 2
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 2
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 2
- DEWWPUNXRNGMQN-LPEHRKFASA-N Ala-Met-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N DEWWPUNXRNGMQN-LPEHRKFASA-N 0.000 description 2
- ZBLQIYPCUWZSRZ-QEJZJMRPSA-N Ala-Phe-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=CC=C1 ZBLQIYPCUWZSRZ-QEJZJMRPSA-N 0.000 description 2
- ADSGHMXEAZJJNF-DCAQKATOSA-N Ala-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N ADSGHMXEAZJJNF-DCAQKATOSA-N 0.000 description 2
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 2
- YHBDGLZYNIARKJ-GUBZILKMSA-N Ala-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N YHBDGLZYNIARKJ-GUBZILKMSA-N 0.000 description 2
- KLALXKYLOMZDQT-ZLUOBGJFSA-N Ala-Ser-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(N)=O KLALXKYLOMZDQT-ZLUOBGJFSA-N 0.000 description 2
- PEEYDECOOVQKRZ-DLOVCJGASA-N Ala-Ser-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PEEYDECOOVQKRZ-DLOVCJGASA-N 0.000 description 2
- HIIJOGIBQXHFKE-HHKYUTTNSA-N Ala-Thr-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O HIIJOGIBQXHFKE-HHKYUTTNSA-N 0.000 description 2
- QOIGKCBMXUCDQU-KDXUFGMBSA-N Ala-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C)N)O QOIGKCBMXUCDQU-KDXUFGMBSA-N 0.000 description 2
- IETUUAHKCHOQHP-KZVJFYERSA-N Ala-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)[C@@H](C)O)C(O)=O IETUUAHKCHOQHP-KZVJFYERSA-N 0.000 description 2
- ZCUFMRIQCPNOHZ-NRPADANISA-N Ala-Val-Gln Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N ZCUFMRIQCPNOHZ-NRPADANISA-N 0.000 description 2
- 208000022309 Alcoholic Liver disease Diseases 0.000 description 2
- KWKQGHSSNHPGOW-BQBZGAKWSA-N Arg-Ala-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)NCC(O)=O KWKQGHSSNHPGOW-BQBZGAKWSA-N 0.000 description 2
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 2
- OVVUNXXROOFSIM-SDDRHHMPSA-N Arg-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O OVVUNXXROOFSIM-SDDRHHMPSA-N 0.000 description 2
- KMSHNDWHPWXPEC-BQBZGAKWSA-N Arg-Asp-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KMSHNDWHPWXPEC-BQBZGAKWSA-N 0.000 description 2
- BGDILZXXDJCKPF-CIUDSAMLSA-N Arg-Gln-Cys Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CS)C(O)=O BGDILZXXDJCKPF-CIUDSAMLSA-N 0.000 description 2
- HQIZDMIGUJOSNI-IUCAKERBSA-N Arg-Gly-Arg Chemical compound N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQIZDMIGUJOSNI-IUCAKERBSA-N 0.000 description 2
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 2
- UZGFHWIJWPUPOH-IHRRRGAJSA-N Arg-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UZGFHWIJWPUPOH-IHRRRGAJSA-N 0.000 description 2
- RIIVUOJDDQXHRV-SRVKXCTJSA-N Arg-Lys-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O RIIVUOJDDQXHRV-SRVKXCTJSA-N 0.000 description 2
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 2
- DNBMCNQKNOKOSD-DCAQKATOSA-N Arg-Pro-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O DNBMCNQKNOKOSD-DCAQKATOSA-N 0.000 description 2
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 2
- FVBZXNSRIDVYJS-AVGNSLFASA-N Arg-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N FVBZXNSRIDVYJS-AVGNSLFASA-N 0.000 description 2
- VENMDXUVHSKEIN-GUBZILKMSA-N Arg-Ser-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VENMDXUVHSKEIN-GUBZILKMSA-N 0.000 description 2
- KMFPQTITXUKJOV-DCAQKATOSA-N Arg-Ser-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O KMFPQTITXUKJOV-DCAQKATOSA-N 0.000 description 2
- ICRHGPYYXMWHIE-LPEHRKFASA-N Arg-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ICRHGPYYXMWHIE-LPEHRKFASA-N 0.000 description 2
- CPTXATAOUQJQRO-GUBZILKMSA-N Arg-Val-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O CPTXATAOUQJQRO-GUBZILKMSA-N 0.000 description 2
- 206010003445 Ascites Diseases 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- 102000005427 Asialoglycoprotein Receptor Human genes 0.000 description 2
- NUHQMYUWLUSRJX-BIIVOSGPSA-N Asn-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N NUHQMYUWLUSRJX-BIIVOSGPSA-N 0.000 description 2
- DAPLJWATMAXPPZ-CIUDSAMLSA-N Asn-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O DAPLJWATMAXPPZ-CIUDSAMLSA-N 0.000 description 2
- FAEFJTCTNZTPHX-ACZMJKKPSA-N Asn-Gln-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FAEFJTCTNZTPHX-ACZMJKKPSA-N 0.000 description 2
- PQAIOUVVZCOLJK-FXQIFTODSA-N Asn-Gln-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N PQAIOUVVZCOLJK-FXQIFTODSA-N 0.000 description 2
- SRUUBQBAVNQZGJ-LAEOZQHASA-N Asn-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N SRUUBQBAVNQZGJ-LAEOZQHASA-N 0.000 description 2
- PPMTUXJSQDNUDE-CIUDSAMLSA-N Asn-Glu-Arg Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PPMTUXJSQDNUDE-CIUDSAMLSA-N 0.000 description 2
- HYQYLOSCICEYTR-YUMQZZPRSA-N Asn-Gly-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O HYQYLOSCICEYTR-YUMQZZPRSA-N 0.000 description 2
- GJFYPBDMUGGLFR-NKWVEPMBSA-N Asn-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CC(=O)N)N)C(=O)O GJFYPBDMUGGLFR-NKWVEPMBSA-N 0.000 description 2
- FTCGGKNCJZOPNB-WHFBIAKZSA-N Asn-Gly-Ser Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FTCGGKNCJZOPNB-WHFBIAKZSA-N 0.000 description 2
- MYVBTYXSWILFCG-BQBZGAKWSA-N Asn-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC(=O)N)N MYVBTYXSWILFCG-BQBZGAKWSA-N 0.000 description 2
- GKKUBLFXKRDMFC-BQBZGAKWSA-N Asn-Pro-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O GKKUBLFXKRDMFC-BQBZGAKWSA-N 0.000 description 2
- UWFOMGUWGPRVBW-GUBZILKMSA-N Asn-Pro-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)N)N UWFOMGUWGPRVBW-GUBZILKMSA-N 0.000 description 2
- REQUGIWGOGSOEZ-ZLUOBGJFSA-N Asn-Ser-Asn Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)C(=O)N REQUGIWGOGSOEZ-ZLUOBGJFSA-N 0.000 description 2
- JWQWPRCDYWNVNM-ACZMJKKPSA-N Asn-Ser-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N JWQWPRCDYWNVNM-ACZMJKKPSA-N 0.000 description 2
- HPNDKUOLNRVRAY-BIIVOSGPSA-N Asn-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N)C(=O)O HPNDKUOLNRVRAY-BIIVOSGPSA-N 0.000 description 2
- RGKKALNPOYURGE-ZKWXMUAHSA-N Asp-Ala-Val Chemical compound N[C@@H](CC(=O)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O RGKKALNPOYURGE-ZKWXMUAHSA-N 0.000 description 2
- KVPHTGVUMJGMCX-BIIVOSGPSA-N Asp-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N)C(=O)O KVPHTGVUMJGMCX-BIIVOSGPSA-N 0.000 description 2
- PDECQIHABNQRHN-GUBZILKMSA-N Asp-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(O)=O PDECQIHABNQRHN-GUBZILKMSA-N 0.000 description 2
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 2
- ZBYLEBZCVKLPCY-FXQIFTODSA-N Asp-Ser-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ZBYLEBZCVKLPCY-FXQIFTODSA-N 0.000 description 2
- KGHLGJAXYSVNJP-WHFBIAKZSA-N Asp-Ser-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O KGHLGJAXYSVNJP-WHFBIAKZSA-N 0.000 description 2
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 2
- JSNWZMFSLIWAHS-HJGDQZAQSA-N Asp-Thr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O JSNWZMFSLIWAHS-HJGDQZAQSA-N 0.000 description 2
- PDIYGFYAMZZFCW-JIOCBJNQSA-N Asp-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N)O PDIYGFYAMZZFCW-JIOCBJNQSA-N 0.000 description 2
- GCACQYDBDHRVGE-LKXGYXEUSA-N Asp-Thr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC(O)=O GCACQYDBDHRVGE-LKXGYXEUSA-N 0.000 description 2
- 208000014644 Brain disease Diseases 0.000 description 2
- 101710186200 CCAAT/enhancer-binding protein Proteins 0.000 description 2
- 102000000844 Cell Surface Receptors Human genes 0.000 description 2
- 108010001857 Cell Surface Receptors Proteins 0.000 description 2
- SFRQEQGPRTVDPO-NRPADANISA-N Cys-Gln-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O SFRQEQGPRTVDPO-NRPADANISA-N 0.000 description 2
- MUZAUPFGPMMZSS-GUBZILKMSA-N Cys-Glu-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N MUZAUPFGPMMZSS-GUBZILKMSA-N 0.000 description 2
- ZEXHDOQQYZKOIB-ACZMJKKPSA-N Cys-Glu-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZEXHDOQQYZKOIB-ACZMJKKPSA-N 0.000 description 2
- DZSICRGTVPDCRN-YUMQZZPRSA-N Cys-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CS)N DZSICRGTVPDCRN-YUMQZZPRSA-N 0.000 description 2
- XTHUKRLJRUVVBF-WHFBIAKZSA-N Cys-Gly-Ser Chemical compound SC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O XTHUKRLJRUVVBF-WHFBIAKZSA-N 0.000 description 2
- SRIRHERUAMYIOQ-CIUDSAMLSA-N Cys-Leu-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SRIRHERUAMYIOQ-CIUDSAMLSA-N 0.000 description 2
- LBSKYJOZIIOZIO-DCAQKATOSA-N Cys-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N LBSKYJOZIIOZIO-DCAQKATOSA-N 0.000 description 2
- XBELMDARIGXDKY-GUBZILKMSA-N Cys-Pro-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CS)N XBELMDARIGXDKY-GUBZILKMSA-N 0.000 description 2
- GGRDJANMZPGMNS-CIUDSAMLSA-N Cys-Ser-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O GGRDJANMZPGMNS-CIUDSAMLSA-N 0.000 description 2
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 2
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 2
- 229920002491 Diethylaminoethyl-dextran Polymers 0.000 description 2
- 102100035966 DnaJ homolog subfamily A member 2 Human genes 0.000 description 2
- 239000012591 Dulbecco’s Phosphate Buffered Saline Substances 0.000 description 2
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 2
- 238000002965 ELISA Methods 0.000 description 2
- 208000032274 Encephalopathy Diseases 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- 108090000790 Enzymes Proteins 0.000 description 2
- 241000283074 Equus asinus Species 0.000 description 2
- WUAYFMZULZDSLB-ACZMJKKPSA-N Gln-Ala-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O WUAYFMZULZDSLB-ACZMJKKPSA-N 0.000 description 2
- LKUWAWGNJYJODH-KBIXCLLPSA-N Gln-Ala-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LKUWAWGNJYJODH-KBIXCLLPSA-N 0.000 description 2
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 2
- SHERTACNJPYHAR-ACZMJKKPSA-N Gln-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O SHERTACNJPYHAR-ACZMJKKPSA-N 0.000 description 2
- WLODHVXYKYHLJD-ACZMJKKPSA-N Gln-Asp-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N WLODHVXYKYHLJD-ACZMJKKPSA-N 0.000 description 2
- AJDMYLOISOCHHC-YVNDNENWSA-N Gln-Gln-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AJDMYLOISOCHHC-YVNDNENWSA-N 0.000 description 2
- RBWKVOSARCFSQQ-FXQIFTODSA-N Gln-Gln-Ser Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O RBWKVOSARCFSQQ-FXQIFTODSA-N 0.000 description 2
- UFNSPPFJOHNXRE-AUTRQRHGSA-N Gln-Gln-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UFNSPPFJOHNXRE-AUTRQRHGSA-N 0.000 description 2
- ZQPOVSJFBBETHQ-CIUDSAMLSA-N Gln-Glu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZQPOVSJFBBETHQ-CIUDSAMLSA-N 0.000 description 2
- SNLOOPZHAQDMJG-CIUDSAMLSA-N Gln-Glu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SNLOOPZHAQDMJG-CIUDSAMLSA-N 0.000 description 2
- ORYMMTRPKVTGSJ-XVKPBYJWSA-N Gln-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O ORYMMTRPKVTGSJ-XVKPBYJWSA-N 0.000 description 2
- GQZDDFRXSDGUNG-YVNDNENWSA-N Gln-Ile-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O GQZDDFRXSDGUNG-YVNDNENWSA-N 0.000 description 2
- UWKPRVKWEKEMSY-DCAQKATOSA-N Gln-Lys-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O UWKPRVKWEKEMSY-DCAQKATOSA-N 0.000 description 2
- YGNPTRVNRUKVLA-DCAQKATOSA-N Gln-Met-Met Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCC(=O)N)N YGNPTRVNRUKVLA-DCAQKATOSA-N 0.000 description 2
- SWDSRANUCKNBLA-AVGNSLFASA-N Gln-Phe-Asp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N SWDSRANUCKNBLA-AVGNSLFASA-N 0.000 description 2
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 2
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 2
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 2
- JILRMFFFCHUUTJ-ACZMJKKPSA-N Gln-Ser-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O JILRMFFFCHUUTJ-ACZMJKKPSA-N 0.000 description 2
- BYKZWDGMJLNFJY-XKBZYTNZSA-N Gln-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)O BYKZWDGMJLNFJY-XKBZYTNZSA-N 0.000 description 2
- UXXIVIQGOODKQC-NUMRIWBASA-N Gln-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UXXIVIQGOODKQC-NUMRIWBASA-N 0.000 description 2
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 2
- SOEXCCGNHQBFPV-DLOVCJGASA-N Gln-Val-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SOEXCCGNHQBFPV-DLOVCJGASA-N 0.000 description 2
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 2
- FYBSCGZLICNOBA-XQXXSGGOSA-N Glu-Ala-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FYBSCGZLICNOBA-XQXXSGGOSA-N 0.000 description 2
- AVZHGSCDKIQZPQ-CIUDSAMLSA-N Glu-Arg-Ala Chemical compound C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AVZHGSCDKIQZPQ-CIUDSAMLSA-N 0.000 description 2
- RDPOETHPAQEGDP-ACZMJKKPSA-N Glu-Asp-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RDPOETHPAQEGDP-ACZMJKKPSA-N 0.000 description 2
- VAIWPXWHWAPYDF-FXQIFTODSA-N Glu-Asp-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O VAIWPXWHWAPYDF-FXQIFTODSA-N 0.000 description 2
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 2
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 2
- HJIFPJUEOGZWRI-GUBZILKMSA-N Glu-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N HJIFPJUEOGZWRI-GUBZILKMSA-N 0.000 description 2
- PVBBEKPHARMPHX-DCAQKATOSA-N Glu-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCC(O)=O PVBBEKPHARMPHX-DCAQKATOSA-N 0.000 description 2
- ILGFBUGLBSAQQB-GUBZILKMSA-N Glu-Glu-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ILGFBUGLBSAQQB-GUBZILKMSA-N 0.000 description 2
- LYCDZGLXQBPNQU-WDSKDSINSA-N Glu-Gly-Cys Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CS)C(O)=O LYCDZGLXQBPNQU-WDSKDSINSA-N 0.000 description 2
- WRNAXCVRSBBKGS-BQBZGAKWSA-N Glu-Gly-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O WRNAXCVRSBBKGS-BQBZGAKWSA-N 0.000 description 2
- WVYJNPCWJYBHJG-YVNDNENWSA-N Glu-Ile-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O WVYJNPCWJYBHJG-YVNDNENWSA-N 0.000 description 2
- LZMQSTPFYJLVJB-GUBZILKMSA-N Glu-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N LZMQSTPFYJLVJB-GUBZILKMSA-N 0.000 description 2
- SJJHXJDSNQJMMW-SRVKXCTJSA-N Glu-Lys-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O SJJHXJDSNQJMMW-SRVKXCTJSA-N 0.000 description 2
- ZGEJRLJEAMPEDV-SRVKXCTJSA-N Glu-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)O)N ZGEJRLJEAMPEDV-SRVKXCTJSA-N 0.000 description 2
- CQAHWYDHKUWYIX-YUMQZZPRSA-N Glu-Pro-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O CQAHWYDHKUWYIX-YUMQZZPRSA-N 0.000 description 2
- BIYNPVYAZOUVFQ-CIUDSAMLSA-N Glu-Pro-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O BIYNPVYAZOUVFQ-CIUDSAMLSA-N 0.000 description 2
- BPLNJYHNAJVLRT-ACZMJKKPSA-N Glu-Ser-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O BPLNJYHNAJVLRT-ACZMJKKPSA-N 0.000 description 2
- QOXDAWODGSIDDI-GUBZILKMSA-N Glu-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N QOXDAWODGSIDDI-GUBZILKMSA-N 0.000 description 2
- GUOWMVFLAJNPDY-CIUDSAMLSA-N Glu-Ser-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O GUOWMVFLAJNPDY-CIUDSAMLSA-N 0.000 description 2
- BXSZPACYCMNKLS-AVGNSLFASA-N Glu-Ser-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O BXSZPACYCMNKLS-AVGNSLFASA-N 0.000 description 2
- MFVQGXGQRIXBPK-WDSKDSINSA-N Gly-Ala-Glu Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFVQGXGQRIXBPK-WDSKDSINSA-N 0.000 description 2
- UGVQELHRNUDMAA-BYPYZUCNSA-N Gly-Ala-Gly Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)NCC([O-])=O UGVQELHRNUDMAA-BYPYZUCNSA-N 0.000 description 2
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 2
- MHHUEAIBJZWDBH-YUMQZZPRSA-N Gly-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN MHHUEAIBJZWDBH-YUMQZZPRSA-N 0.000 description 2
- VNBNZUAPOYGRDB-ZDLURKLDSA-N Gly-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)CN)O VNBNZUAPOYGRDB-ZDLURKLDSA-N 0.000 description 2
- XLFHCWHXKSFVIB-BQBZGAKWSA-N Gly-Gln-Gln Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O XLFHCWHXKSFVIB-BQBZGAKWSA-N 0.000 description 2
- LXXANCRPFBSSKS-IUCAKERBSA-N Gly-Gln-Leu Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LXXANCRPFBSSKS-IUCAKERBSA-N 0.000 description 2
- JUGQPPOVWXSPKJ-RYUDHWBXSA-N Gly-Gln-Phe Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JUGQPPOVWXSPKJ-RYUDHWBXSA-N 0.000 description 2
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 2
- GNPVTZJUUBPZKW-WDSKDSINSA-N Gly-Gln-Ser Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GNPVTZJUUBPZKW-WDSKDSINSA-N 0.000 description 2
- DHDOADIPGZTAHT-YUMQZZPRSA-N Gly-Glu-Arg Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DHDOADIPGZTAHT-YUMQZZPRSA-N 0.000 description 2
- SOEATRRYCIPEHA-BQBZGAKWSA-N Gly-Glu-Glu Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SOEATRRYCIPEHA-BQBZGAKWSA-N 0.000 description 2
- JUBDONGMHASUCN-IUCAKERBSA-N Gly-Glu-His Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O JUBDONGMHASUCN-IUCAKERBSA-N 0.000 description 2
- KAJAOGBVWCYGHZ-JTQLQIEISA-N Gly-Gly-Phe Chemical compound [NH3+]CC(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KAJAOGBVWCYGHZ-JTQLQIEISA-N 0.000 description 2
- FSPVILZGHUJOHS-QWRGUYRKSA-N Gly-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CNC=N1 FSPVILZGHUJOHS-QWRGUYRKSA-N 0.000 description 2
- UUYBFNKHOCJCHT-VHSXEESVSA-N Gly-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN UUYBFNKHOCJCHT-VHSXEESVSA-N 0.000 description 2
- LHYJCVCQPWRMKZ-WEDXCCLWSA-N Gly-Leu-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LHYJCVCQPWRMKZ-WEDXCCLWSA-N 0.000 description 2
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 2
- LOEANKRDMMVOGZ-YUMQZZPRSA-N Gly-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O LOEANKRDMMVOGZ-YUMQZZPRSA-N 0.000 description 2
- NTBOEZICHOSJEE-YUMQZZPRSA-N Gly-Lys-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O NTBOEZICHOSJEE-YUMQZZPRSA-N 0.000 description 2
- ICUTTWWCDIIIEE-BQBZGAKWSA-N Gly-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN ICUTTWWCDIIIEE-BQBZGAKWSA-N 0.000 description 2
- HFPVRZWORNJRRC-UWVGGRQHSA-N Gly-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN HFPVRZWORNJRRC-UWVGGRQHSA-N 0.000 description 2
- OOCFXNOVSLSHAB-IUCAKERBSA-N Gly-Pro-Pro Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OOCFXNOVSLSHAB-IUCAKERBSA-N 0.000 description 2
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 2
- OHUKZZYSJBKFRR-WHFBIAKZSA-N Gly-Ser-Asp Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O OHUKZZYSJBKFRR-WHFBIAKZSA-N 0.000 description 2
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 2
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 2
- LYZYGGWCBLBDMC-QWHCGFSZSA-N Gly-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)CN)C(=O)O LYZYGGWCBLBDMC-QWHCGFSZSA-N 0.000 description 2
- RYAOJUMWLWUGNW-QMMMGPOBSA-N Gly-Val-Gly Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O RYAOJUMWLWUGNW-QMMMGPOBSA-N 0.000 description 2
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 2
- JZNWSCPGTDBMEW-UHFFFAOYSA-N Glycerophosphorylethanolamin Natural products NCCOP(O)(=O)OCC(O)CO JZNWSCPGTDBMEW-UHFFFAOYSA-N 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 239000007995 HEPES buffer Substances 0.000 description 2
- WZUVPPKBWHMQCE-UHFFFAOYSA-N Haematoxylin Chemical compound C12=CC(O)=C(O)C=C2CC2(O)C1C1=CC=C(O)C(O)=C1OC2 WZUVPPKBWHMQCE-UHFFFAOYSA-N 0.000 description 2
- 108010086524 Hepatocyte Nuclear Factor 4 Proteins 0.000 description 2
- IDQKGZWUPVOGPZ-GUBZILKMSA-N His-Cys-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N IDQKGZWUPVOGPZ-GUBZILKMSA-N 0.000 description 2
- CWSZWFILCNSNEX-CIUDSAMLSA-N His-Ser-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CWSZWFILCNSNEX-CIUDSAMLSA-N 0.000 description 2
- GIRSNERMXCMDBO-GARJFASQSA-N His-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O GIRSNERMXCMDBO-GARJFASQSA-N 0.000 description 2
- MDOBWSFNSNPENN-PMVVWTBXSA-N His-Thr-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O MDOBWSFNSNPENN-PMVVWTBXSA-N 0.000 description 2
- PZUZIHRPOVVHOT-KBPBESRZSA-N His-Tyr-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)NCC(O)=O)C1=CN=CN1 PZUZIHRPOVVHOT-KBPBESRZSA-N 0.000 description 2
- 102000006947 Histones Human genes 0.000 description 2
- 108010033040 Histones Proteins 0.000 description 2
- 101000870166 Homo sapiens DnaJ homolog subfamily C member 14 Proteins 0.000 description 2
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical compound OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 description 2
- TZCGZYWNIDZZMR-NAKRPEOUSA-N Ile-Arg-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C)C(=O)O)N TZCGZYWNIDZZMR-NAKRPEOUSA-N 0.000 description 2
- TZCGZYWNIDZZMR-UHFFFAOYSA-N Ile-Arg-Ala Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(C)C(O)=O)CCCN=C(N)N TZCGZYWNIDZZMR-UHFFFAOYSA-N 0.000 description 2
- OVPYIUNCVSOVNF-ZPFDUUQYSA-N Ile-Gln-Pro Natural products CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O OVPYIUNCVSOVNF-ZPFDUUQYSA-N 0.000 description 2
- NZOCIWKZUVUNDW-ZKWXMUAHSA-N Ile-Gly-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O NZOCIWKZUVUNDW-ZKWXMUAHSA-N 0.000 description 2
- SJLVSMMIFYTSGY-GRLWGSQLSA-N Ile-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N SJLVSMMIFYTSGY-GRLWGSQLSA-N 0.000 description 2
- DMSVBUWGDLYNLC-IAVJCBSLSA-N Ile-Ile-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 DMSVBUWGDLYNLC-IAVJCBSLSA-N 0.000 description 2
- PHRWFSFCNJPWRO-PPCPHDFISA-N Ile-Leu-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N PHRWFSFCNJPWRO-PPCPHDFISA-N 0.000 description 2
- NZGTYCMLUGYMCV-XUXIUFHCSA-N Ile-Lys-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N NZGTYCMLUGYMCV-XUXIUFHCSA-N 0.000 description 2
- AKOYRLRUFBZOSP-BJDJZHNGSA-N Ile-Lys-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N AKOYRLRUFBZOSP-BJDJZHNGSA-N 0.000 description 2
- FTUZWJVSNZMLPI-RVMXOQNASA-N Ile-Met-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N FTUZWJVSNZMLPI-RVMXOQNASA-N 0.000 description 2
- XLXPYSDGMXTTNQ-UHFFFAOYSA-N Ile-Phe-Leu Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(CC(C)C)C(O)=O)CC1=CC=CC=C1 XLXPYSDGMXTTNQ-UHFFFAOYSA-N 0.000 description 2
- XHBYEMIUENPZLY-GMOBBJLQSA-N Ile-Pro-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O XHBYEMIUENPZLY-GMOBBJLQSA-N 0.000 description 2
- JNLSTRPWUXOORL-MMWGEVLESA-N Ile-Ser-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N JNLSTRPWUXOORL-MMWGEVLESA-N 0.000 description 2
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 2
- RQZFWBLDTBDEOF-RNJOBUHISA-N Ile-Val-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N RQZFWBLDTBDEOF-RNJOBUHISA-N 0.000 description 2
- SNDPXSYFESPGGJ-BYPYZUCNSA-N L-2-aminopentanoic acid Chemical compound CCC[C@H](N)C(O)=O SNDPXSYFESPGGJ-BYPYZUCNSA-N 0.000 description 2
- HGCNKOLVKRAVHD-UHFFFAOYSA-N L-Met-L-Phe Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 HGCNKOLVKRAVHD-UHFFFAOYSA-N 0.000 description 2
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 2
- 150000008575 L-amino acids Chemical class 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 2
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 2
- SNDPXSYFESPGGJ-UHFFFAOYSA-N L-norVal-OH Natural products CCCC(N)C(O)=O SNDPXSYFESPGGJ-UHFFFAOYSA-N 0.000 description 2
- 102000007330 LDL Lipoproteins Human genes 0.000 description 2
- 108010007622 LDL Lipoproteins Proteins 0.000 description 2
- MJOZZTKJZQFKDK-GUBZILKMSA-N Leu-Ala-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(N)=O MJOZZTKJZQFKDK-GUBZILKMSA-N 0.000 description 2
- HASRFYOMVPJRPU-SRVKXCTJSA-N Leu-Arg-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O HASRFYOMVPJRPU-SRVKXCTJSA-N 0.000 description 2
- WGNOPSQMIQERPK-UHFFFAOYSA-N Leu-Asn-Pro Natural products CC(C)CC(N)C(=O)NC(CC(=O)N)C(=O)N1CCCC1C(=O)O WGNOPSQMIQERPK-UHFFFAOYSA-N 0.000 description 2
- RRSLQOLASISYTB-CIUDSAMLSA-N Leu-Cys-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O RRSLQOLASISYTB-CIUDSAMLSA-N 0.000 description 2
- VQPPIMUZCZCOIL-GUBZILKMSA-N Leu-Gln-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O VQPPIMUZCZCOIL-GUBZILKMSA-N 0.000 description 2
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 2
- ZTLGVASZOIKNIX-DCAQKATOSA-N Leu-Gln-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZTLGVASZOIKNIX-DCAQKATOSA-N 0.000 description 2
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 2
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 2
- LAGPXKYZCCTSGQ-JYJNAYRXSA-N Leu-Glu-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LAGPXKYZCCTSGQ-JYJNAYRXSA-N 0.000 description 2
- OXRLYTYUXAQTHP-YUMQZZPRSA-N Leu-Gly-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(O)=O OXRLYTYUXAQTHP-YUMQZZPRSA-N 0.000 description 2
- CCQLQKZTXZBXTN-NHCYSSNCSA-N Leu-Gly-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CCQLQKZTXZBXTN-NHCYSSNCSA-N 0.000 description 2
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 2
- AVEGDIAXTDVBJS-XUXIUFHCSA-N Leu-Ile-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AVEGDIAXTDVBJS-XUXIUFHCSA-N 0.000 description 2
- OMHLATXVNQSALM-FQUUOJAGSA-N Leu-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(C)C)N OMHLATXVNQSALM-FQUUOJAGSA-N 0.000 description 2
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 2
- PDQDCFBVYXEFSD-SRVKXCTJSA-N Leu-Leu-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O PDQDCFBVYXEFSD-SRVKXCTJSA-N 0.000 description 2
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 2
- RXGLHDWAZQECBI-SRVKXCTJSA-N Leu-Leu-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O RXGLHDWAZQECBI-SRVKXCTJSA-N 0.000 description 2
- JLWZLIQRYCTYBD-IHRRRGAJSA-N Leu-Lys-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JLWZLIQRYCTYBD-IHRRRGAJSA-N 0.000 description 2
- WXUOJXIGOPMDJM-SRVKXCTJSA-N Leu-Lys-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O WXUOJXIGOPMDJM-SRVKXCTJSA-N 0.000 description 2
- RZXLZBIUTDQHJQ-SRVKXCTJSA-N Leu-Lys-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O RZXLZBIUTDQHJQ-SRVKXCTJSA-N 0.000 description 2
- KPYAOIVPJKPIOU-KKUMJFAQSA-N Leu-Lys-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O KPYAOIVPJKPIOU-KKUMJFAQSA-N 0.000 description 2
- LZHJZLHSRGWBBE-IHRRRGAJSA-N Leu-Lys-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O LZHJZLHSRGWBBE-IHRRRGAJSA-N 0.000 description 2
- ZDBMWELMUCLUPL-QEJZJMRPSA-N Leu-Phe-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 ZDBMWELMUCLUPL-QEJZJMRPSA-N 0.000 description 2
- PTRKPHUGYULXPU-KKUMJFAQSA-N Leu-Phe-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O PTRKPHUGYULXPU-KKUMJFAQSA-N 0.000 description 2
- UCBPDSYUVAAHCD-UWVGGRQHSA-N Leu-Pro-Gly Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UCBPDSYUVAAHCD-UWVGGRQHSA-N 0.000 description 2
- CHJKEDSZNSONPS-DCAQKATOSA-N Leu-Pro-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O CHJKEDSZNSONPS-DCAQKATOSA-N 0.000 description 2
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 2
- IDGZVZJLYFTXSL-DCAQKATOSA-N Leu-Ser-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-DCAQKATOSA-N 0.000 description 2
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 2
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 2
- AAKRWBIIGKPOKQ-ONGXEEELSA-N Leu-Val-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AAKRWBIIGKPOKQ-ONGXEEELSA-N 0.000 description 2
- FZIJIFCXUCZHOL-CIUDSAMLSA-N Lys-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN FZIJIFCXUCZHOL-CIUDSAMLSA-N 0.000 description 2
- RVOMPSJXSRPFJT-DCAQKATOSA-N Lys-Ala-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVOMPSJXSRPFJT-DCAQKATOSA-N 0.000 description 2
- NFLFJGGKOHYZJF-BJDJZHNGSA-N Lys-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN NFLFJGGKOHYZJF-BJDJZHNGSA-N 0.000 description 2
- KCXUCYYZNZFGLL-SRVKXCTJSA-N Lys-Ala-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O KCXUCYYZNZFGLL-SRVKXCTJSA-N 0.000 description 2
- CLBGMWIYPYAZPR-AVGNSLFASA-N Lys-Arg-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O CLBGMWIYPYAZPR-AVGNSLFASA-N 0.000 description 2
- GQUDMNDPQTXZRV-DCAQKATOSA-N Lys-Arg-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O GQUDMNDPQTXZRV-DCAQKATOSA-N 0.000 description 2
- GGAPIOORBXHMNY-ULQDDVLXSA-N Lys-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N)O GGAPIOORBXHMNY-ULQDDVLXSA-N 0.000 description 2
- DGWXCIORNLWGGG-CIUDSAMLSA-N Lys-Asn-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O DGWXCIORNLWGGG-CIUDSAMLSA-N 0.000 description 2
- RZHLIPMZXOEJTL-AVGNSLFASA-N Lys-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N RZHLIPMZXOEJTL-AVGNSLFASA-N 0.000 description 2
- MQMIRLVJXQNTRJ-SDDRHHMPSA-N Lys-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N)C(=O)O MQMIRLVJXQNTRJ-SDDRHHMPSA-N 0.000 description 2
- PBIPLDMFHAICIP-DCAQKATOSA-N Lys-Glu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PBIPLDMFHAICIP-DCAQKATOSA-N 0.000 description 2
- GCMWRRQAKQXDED-IUCAKERBSA-N Lys-Glu-Gly Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)N[C@@H](CCC([O-])=O)C(=O)NCC([O-])=O GCMWRRQAKQXDED-IUCAKERBSA-N 0.000 description 2
- ZJWIXBZTAAJERF-IHRRRGAJSA-N Lys-Lys-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N ZJWIXBZTAAJERF-IHRRRGAJSA-N 0.000 description 2
- PYFNONMJYNJENN-AVGNSLFASA-N Lys-Lys-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PYFNONMJYNJENN-AVGNSLFASA-N 0.000 description 2
- WBSCNDJQPKSPII-KKUMJFAQSA-N Lys-Lys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O WBSCNDJQPKSPII-KKUMJFAQSA-N 0.000 description 2
- KJIXWRWPOCKYLD-IHRRRGAJSA-N Lys-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N KJIXWRWPOCKYLD-IHRRRGAJSA-N 0.000 description 2
- BOJYMMBYBNOOGG-DCAQKATOSA-N Lys-Pro-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O BOJYMMBYBNOOGG-DCAQKATOSA-N 0.000 description 2
- MSSABBQOBUZFKZ-IHRRRGAJSA-N Lys-Pro-His Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCCCN)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O MSSABBQOBUZFKZ-IHRRRGAJSA-N 0.000 description 2
- LUTDBHBIHHREDC-IHRRRGAJSA-N Lys-Pro-Lys Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O LUTDBHBIHHREDC-IHRRRGAJSA-N 0.000 description 2
- VHTOGMKQXXJOHG-RHYQMDGZSA-N Lys-Thr-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O VHTOGMKQXXJOHG-RHYQMDGZSA-N 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- 108010052285 Membrane Proteins Proteins 0.000 description 2
- DJDFBVNNDAUPRW-GUBZILKMSA-N Met-Glu-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O DJDFBVNNDAUPRW-GUBZILKMSA-N 0.000 description 2
- VZBXCMCHIHEPBL-SRVKXCTJSA-N Met-Glu-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN VZBXCMCHIHEPBL-SRVKXCTJSA-N 0.000 description 2
- BCRQJDMZQUHQSV-STQMWFEESA-N Met-Gly-Tyr Chemical compound [H]N[C@@H](CCSC)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BCRQJDMZQUHQSV-STQMWFEESA-N 0.000 description 2
- AFFKUNVPPLQUGA-DCAQKATOSA-N Met-Leu-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O AFFKUNVPPLQUGA-DCAQKATOSA-N 0.000 description 2
- JYPITOUIQVSCKM-IHRRRGAJSA-N Met-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCSC)N JYPITOUIQVSCKM-IHRRRGAJSA-N 0.000 description 2
- AWGBEIYZPAXXSX-RWMBFGLXSA-N Met-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N AWGBEIYZPAXXSX-RWMBFGLXSA-N 0.000 description 2
- HSJIGJRZYUADSS-IHRRRGAJSA-N Met-Lys-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HSJIGJRZYUADSS-IHRRRGAJSA-N 0.000 description 2
- 108700011259 MicroRNAs Proteins 0.000 description 2
- 102000005431 Molecular Chaperones Human genes 0.000 description 2
- 108010006519 Molecular Chaperones Proteins 0.000 description 2
- WYBVBIHNJWOLCJ-UHFFFAOYSA-N N-L-arginyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCCN=C(N)N WYBVBIHNJWOLCJ-UHFFFAOYSA-N 0.000 description 2
- 108010034522 NNQQ peptide Proteins 0.000 description 2
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 2
- 108020005497 Nuclear hormone receptor Proteins 0.000 description 2
- SUHOOTKUPISOBE-UHFFFAOYSA-N O-phosphoethanolamine Chemical compound NCCOP(O)(O)=O SUHOOTKUPISOBE-UHFFFAOYSA-N 0.000 description 2
- 102000035195 Peptidases Human genes 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- 208000037581 Persistent Infection Diseases 0.000 description 2
- OPEVYHFJXLCCRT-AVGNSLFASA-N Phe-Gln-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O OPEVYHFJXLCCRT-AVGNSLFASA-N 0.000 description 2
- WPTYDQPGBMDUBI-QWRGUYRKSA-N Phe-Gly-Asn Chemical compound N[C@@H](Cc1ccccc1)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O WPTYDQPGBMDUBI-QWRGUYRKSA-N 0.000 description 2
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 2
- AFNJAQVMTIQTCB-DLOVCJGASA-N Phe-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 AFNJAQVMTIQTCB-DLOVCJGASA-N 0.000 description 2
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 2
- BSKMOCNNLNDIMU-CDMKHQONSA-N Phe-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O BSKMOCNNLNDIMU-CDMKHQONSA-N 0.000 description 2
- DXWNFNOPBYAFRM-IHRRRGAJSA-N Phe-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N DXWNFNOPBYAFRM-IHRRRGAJSA-N 0.000 description 2
- 102000004160 Phosphoric Monoester Hydrolases Human genes 0.000 description 2
- 108090000608 Phosphoric Monoester Hydrolases Proteins 0.000 description 2
- 108091000080 Phosphotransferase Proteins 0.000 description 2
- 229920002873 Polyethylenimine Polymers 0.000 description 2
- VXCHGLYSIOOZIS-GUBZILKMSA-N Pro-Ala-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 VXCHGLYSIOOZIS-GUBZILKMSA-N 0.000 description 2
- APKRGYLBSCWJJP-FXQIFTODSA-N Pro-Ala-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O APKRGYLBSCWJJP-FXQIFTODSA-N 0.000 description 2
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 2
- FYQSMXKJYTZYRP-DCAQKATOSA-N Pro-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 FYQSMXKJYTZYRP-DCAQKATOSA-N 0.000 description 2
- HFZNNDWPHBRNPV-KZVJFYERSA-N Pro-Ala-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HFZNNDWPHBRNPV-KZVJFYERSA-N 0.000 description 2
- OCSACVPBMIYNJE-GUBZILKMSA-N Pro-Arg-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O OCSACVPBMIYNJE-GUBZILKMSA-N 0.000 description 2
- BNBBNGZZKQUWCD-IUCAKERBSA-N Pro-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 BNBBNGZZKQUWCD-IUCAKERBSA-N 0.000 description 2
- XZGWNSIRZIUHHP-SRVKXCTJSA-N Pro-Arg-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 XZGWNSIRZIUHHP-SRVKXCTJSA-N 0.000 description 2
- ICTZKEXYDDZZFP-SRVKXCTJSA-N Pro-Arg-Pro Chemical compound N([C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(O)=O)C(=O)[C@@H]1CCCN1 ICTZKEXYDDZZFP-SRVKXCTJSA-N 0.000 description 2
- ZSKJPKFTPQCPIH-RCWTZXSCSA-N Pro-Arg-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZSKJPKFTPQCPIH-RCWTZXSCSA-N 0.000 description 2
- TXPUNZXZDVJUJQ-LPEHRKFASA-N Pro-Asn-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O TXPUNZXZDVJUJQ-LPEHRKFASA-N 0.000 description 2
- JFNPBBOGGNMSRX-CIUDSAMLSA-N Pro-Gln-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O JFNPBBOGGNMSRX-CIUDSAMLSA-N 0.000 description 2
- ZPPVJIJMIKTERM-YUMQZZPRSA-N Pro-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)N)NC(=O)[C@@H]1CCCN1 ZPPVJIJMIKTERM-YUMQZZPRSA-N 0.000 description 2
- HJSCRFZVGXAGNG-SRVKXCTJSA-N Pro-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 HJSCRFZVGXAGNG-SRVKXCTJSA-N 0.000 description 2
- XZONQWUEBAFQPO-HJGDQZAQSA-N Pro-Gln-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XZONQWUEBAFQPO-HJGDQZAQSA-N 0.000 description 2
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 2
- YTWNSIDWAFSEEI-RWMBFGLXSA-N Pro-His-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)N3CCC[C@@H]3C(=O)O YTWNSIDWAFSEEI-RWMBFGLXSA-N 0.000 description 2
- CLJLVCYFABNTHP-DCAQKATOSA-N Pro-Leu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O CLJLVCYFABNTHP-DCAQKATOSA-N 0.000 description 2
- MRYUJHGPZQNOAD-IHRRRGAJSA-N Pro-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 MRYUJHGPZQNOAD-IHRRRGAJSA-N 0.000 description 2
- MCWHYUWXVNRXFV-RWMBFGLXSA-N Pro-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 MCWHYUWXVNRXFV-RWMBFGLXSA-N 0.000 description 2
- WFIVLLFYUZZWOD-RHYQMDGZSA-N Pro-Lys-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WFIVLLFYUZZWOD-RHYQMDGZSA-N 0.000 description 2
- GFHXZNVJIKMAGO-IHRRRGAJSA-N Pro-Phe-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O GFHXZNVJIKMAGO-IHRRRGAJSA-N 0.000 description 2
- POQFNPILEQEODH-FXQIFTODSA-N Pro-Ser-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O POQFNPILEQEODH-FXQIFTODSA-N 0.000 description 2
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 2
- SEZGGSHLMROBFX-CIUDSAMLSA-N Pro-Ser-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O SEZGGSHLMROBFX-CIUDSAMLSA-N 0.000 description 2
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 2
- KWMZPPWYBVZIER-XGEHTFHBSA-N Pro-Ser-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWMZPPWYBVZIER-XGEHTFHBSA-N 0.000 description 2
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 2
- RMJZWERKFFNNNS-XGEHTFHBSA-N Pro-Thr-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O RMJZWERKFFNNNS-XGEHTFHBSA-N 0.000 description 2
- XDKKMRPRRCOELJ-GUBZILKMSA-N Pro-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 XDKKMRPRRCOELJ-GUBZILKMSA-N 0.000 description 2
- OOZJHTXCLJUODH-QXEWZRGKSA-N Pro-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 OOZJHTXCLJUODH-QXEWZRGKSA-N 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 101710115195 Protease inhibitor 2 Proteins 0.000 description 2
- 241000125945 Protoparvovirus Species 0.000 description 2
- 108091028664 Ribonucleotide Proteins 0.000 description 2
- 108091029810 SaRNA Proteins 0.000 description 2
- LVVBAKCGXXUHFO-ZLUOBGJFSA-N Ser-Ala-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O LVVBAKCGXXUHFO-ZLUOBGJFSA-N 0.000 description 2
- IDQFQFVEWMWRQQ-DLOVCJGASA-N Ser-Ala-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O IDQFQFVEWMWRQQ-DLOVCJGASA-N 0.000 description 2
- BRKHVZNDAOMAHX-BIIVOSGPSA-N Ser-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N BRKHVZNDAOMAHX-BIIVOSGPSA-N 0.000 description 2
- JPIDMRXXNMIVKY-VZFHVOOUSA-N Ser-Ala-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPIDMRXXNMIVKY-VZFHVOOUSA-N 0.000 description 2
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 2
- KNZQGAUEYZJUSQ-ZLUOBGJFSA-N Ser-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N KNZQGAUEYZJUSQ-ZLUOBGJFSA-N 0.000 description 2
- OHKLFYXEOGGGCK-ZLUOBGJFSA-N Ser-Asp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OHKLFYXEOGGGCK-ZLUOBGJFSA-N 0.000 description 2
- BGOWRLSWJCVYAQ-CIUDSAMLSA-N Ser-Asp-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BGOWRLSWJCVYAQ-CIUDSAMLSA-N 0.000 description 2
- GHPQVUYZQQGEDA-BIIVOSGPSA-N Ser-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N)C(=O)O GHPQVUYZQQGEDA-BIIVOSGPSA-N 0.000 description 2
- MMAPOBOTRUVNKJ-ZLUOBGJFSA-N Ser-Asp-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CO)N)C(=O)O MMAPOBOTRUVNKJ-ZLUOBGJFSA-N 0.000 description 2
- CRZRTKAVUUGKEQ-ACZMJKKPSA-N Ser-Gln-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O CRZRTKAVUUGKEQ-ACZMJKKPSA-N 0.000 description 2
- IXUGADGDCQDLSA-FXQIFTODSA-N Ser-Gln-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N IXUGADGDCQDLSA-FXQIFTODSA-N 0.000 description 2
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 2
- SQBLRDDJTUJDMV-ACZMJKKPSA-N Ser-Glu-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O SQBLRDDJTUJDMV-ACZMJKKPSA-N 0.000 description 2
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 2
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 2
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 2
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 2
- IXZHZUGGKLRHJD-DCAQKATOSA-N Ser-Leu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IXZHZUGGKLRHJD-DCAQKATOSA-N 0.000 description 2
- LRZLZIUXQBIWTB-KATARQTJSA-N Ser-Lys-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LRZLZIUXQBIWTB-KATARQTJSA-N 0.000 description 2
- JAWGSPUJAXYXJA-IHRRRGAJSA-N Ser-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)N)CC1=CC=CC=C1 JAWGSPUJAXYXJA-IHRRRGAJSA-N 0.000 description 2
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 2
- WNDUPCKKKGSKIQ-CIUDSAMLSA-N Ser-Pro-Gln Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O WNDUPCKKKGSKIQ-CIUDSAMLSA-N 0.000 description 2
- FKYWFUYPVKLJLP-DCAQKATOSA-N Ser-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FKYWFUYPVKLJLP-DCAQKATOSA-N 0.000 description 2
- FLONGDPORFIVQW-XGEHTFHBSA-N Ser-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FLONGDPORFIVQW-XGEHTFHBSA-N 0.000 description 2
- JURQXQBJKUHGJS-UHFFFAOYSA-N Ser-Ser-Ser-Ser Chemical compound OCC(N)C(=O)NC(CO)C(=O)NC(CO)C(=O)NC(CO)C(O)=O JURQXQBJKUHGJS-UHFFFAOYSA-N 0.000 description 2
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 2
- RXUOAOOZIWABBW-XGEHTFHBSA-N Ser-Thr-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RXUOAOOZIWABBW-XGEHTFHBSA-N 0.000 description 2
- SZRNDHWMVSFPSP-XKBZYTNZSA-N Ser-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N)O SZRNDHWMVSFPSP-XKBZYTNZSA-N 0.000 description 2
- VLMIUSLQONKLDV-HEIBUPTGSA-N Ser-Thr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VLMIUSLQONKLDV-HEIBUPTGSA-N 0.000 description 2
- VEVYMLNYMULSMS-AVGNSLFASA-N Ser-Tyr-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VEVYMLNYMULSMS-AVGNSLFASA-N 0.000 description 2
- PMTWIUBUQRGCSB-FXQIFTODSA-N Ser-Val-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O PMTWIUBUQRGCSB-FXQIFTODSA-N 0.000 description 2
- 108091027967 Small hairpin RNA Proteins 0.000 description 2
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 2
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 2
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 2
- JNQZPAWOPBZGIX-RCWTZXSCSA-N Thr-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)O)CCCN=C(N)N JNQZPAWOPBZGIX-RCWTZXSCSA-N 0.000 description 2
- LIXBDERDAGNVAV-XKBZYTNZSA-N Thr-Gln-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O LIXBDERDAGNVAV-XKBZYTNZSA-N 0.000 description 2
- MPUMPERGHHJGRP-WEDXCCLWSA-N Thr-Gly-Lys Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)O)N)O MPUMPERGHHJGRP-WEDXCCLWSA-N 0.000 description 2
- PAXANSWUSVPFNK-IUKAMOBKSA-N Thr-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N PAXANSWUSVPFNK-IUKAMOBKSA-N 0.000 description 2
- GMXIJHCBTZDAPD-QPHKQPEJSA-N Thr-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N GMXIJHCBTZDAPD-QPHKQPEJSA-N 0.000 description 2
- YJCVECXVYHZOBK-KNZXXDILSA-N Thr-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H]([C@@H](C)O)N YJCVECXVYHZOBK-KNZXXDILSA-N 0.000 description 2
- VTVVYQOXJCZVEB-WDCWCFNPSA-N Thr-Leu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O VTVVYQOXJCZVEB-WDCWCFNPSA-N 0.000 description 2
- KRDSCBLRHORMRK-JXUBOQSCSA-N Thr-Lys-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O KRDSCBLRHORMRK-JXUBOQSCSA-N 0.000 description 2
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 2
- SIEZEMFJLYRUMK-YTWAJWBKSA-N Thr-Met-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N)O SIEZEMFJLYRUMK-YTWAJWBKSA-N 0.000 description 2
- VEIKMWOMUYMMMK-FCLVOEFKSA-N Thr-Phe-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 VEIKMWOMUYMMMK-FCLVOEFKSA-N 0.000 description 2
- WTMPKZWHRCMMMT-KZVJFYERSA-N Thr-Pro-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WTMPKZWHRCMMMT-KZVJFYERSA-N 0.000 description 2
- DEGCBBCMYWNJNA-RHYQMDGZSA-N Thr-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O DEGCBBCMYWNJNA-RHYQMDGZSA-N 0.000 description 2
- GVMXJJAJLIEASL-ZJDVBMNYSA-N Thr-Pro-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O GVMXJJAJLIEASL-ZJDVBMNYSA-N 0.000 description 2
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 2
- NDZYTIMDOZMECO-SHGPDSBTSA-N Thr-Thr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O NDZYTIMDOZMECO-SHGPDSBTSA-N 0.000 description 2
- COYHRQWNJDJCNA-NUJDXYNKSA-N Thr-Thr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O COYHRQWNJDJCNA-NUJDXYNKSA-N 0.000 description 2
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- GLNADSQYFUSGOU-GPTZEZBUSA-J Trypan blue Chemical compound [Na+].[Na+].[Na+].[Na+].C1=C(S([O-])(=O)=O)C=C2C=C(S([O-])(=O)=O)C(/N=N/C3=CC=C(C=C3C)C=3C=C(C(=CC=3)\N=N\C=3C(=CC4=CC(=CC(N)=C4C=3O)S([O-])(=O)=O)S([O-])(=O)=O)C)=C(O)C2=C1N GLNADSQYFUSGOU-GPTZEZBUSA-J 0.000 description 2
- OHOVFPKXPZODHS-SJWGOKEGSA-N Tyr-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N OHOVFPKXPZODHS-SJWGOKEGSA-N 0.000 description 2
- NKUGCYDFQKFVOJ-JYJNAYRXSA-N Tyr-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NKUGCYDFQKFVOJ-JYJNAYRXSA-N 0.000 description 2
- QPOUERMDWKKZEG-HJPIBITLSA-N Tyr-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 QPOUERMDWKKZEG-HJPIBITLSA-N 0.000 description 2
- 108010064997 VPY tripeptide Proteins 0.000 description 2
- ASQFIHTXXMFENG-XPUUQOCRSA-N Val-Ala-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O ASQFIHTXXMFENG-XPUUQOCRSA-N 0.000 description 2
- ZLFHAAGHGQBQQN-AEJSXWLSSA-N Val-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZLFHAAGHGQBQQN-AEJSXWLSSA-N 0.000 description 2
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 2
- UDNYEPLJTRDMEJ-RCOVLWMOSA-N Val-Asn-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)NCC(=O)O)N UDNYEPLJTRDMEJ-RCOVLWMOSA-N 0.000 description 2
- DBOXBUDEAJVKRE-LSJOCFKGSA-N Val-Asn-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N DBOXBUDEAJVKRE-LSJOCFKGSA-N 0.000 description 2
- ISERLACIZUGCDX-ZKWXMUAHSA-N Val-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N ISERLACIZUGCDX-ZKWXMUAHSA-N 0.000 description 2
- XLDYBRXERHITNH-QSFUFRPTSA-N Val-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)C(C)C XLDYBRXERHITNH-QSFUFRPTSA-N 0.000 description 2
- BMGOFDMKDVVGJG-NHCYSSNCSA-N Val-Asp-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BMGOFDMKDVVGJG-NHCYSSNCSA-N 0.000 description 2
- LHADRQBREKTRLR-DCAQKATOSA-N Val-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N LHADRQBREKTRLR-DCAQKATOSA-N 0.000 description 2
- NYTKXWLZSNRILS-IFFSRLJSSA-N Val-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N)O NYTKXWLZSNRILS-IFFSRLJSSA-N 0.000 description 2
- JTWIMNMUYLQNPI-WPRPVWTQSA-N Val-Gly-Arg Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N JTWIMNMUYLQNPI-WPRPVWTQSA-N 0.000 description 2
- OTJMMKPMLUNTQT-AVGNSLFASA-N Val-Leu-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N OTJMMKPMLUNTQT-AVGNSLFASA-N 0.000 description 2
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 2
- ZHQWPWQNVRCXAX-XQQFMLRXSA-N Val-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZHQWPWQNVRCXAX-XQQFMLRXSA-N 0.000 description 2
- JAKHAONCJJZVHT-DCAQKATOSA-N Val-Lys-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N JAKHAONCJJZVHT-DCAQKATOSA-N 0.000 description 2
- XPKCFQZDQGVJCX-RHYQMDGZSA-N Val-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N)O XPKCFQZDQGVJCX-RHYQMDGZSA-N 0.000 description 2
- MHHAWNPHDLCPLF-ULQDDVLXSA-N Val-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=CC=C1 MHHAWNPHDLCPLF-ULQDDVLXSA-N 0.000 description 2
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 2
- DOFAQXCYFQKSHT-SRVKXCTJSA-N Val-Pro-Pro Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DOFAQXCYFQKSHT-SRVKXCTJSA-N 0.000 description 2
- RYHUIHUOYRNNIE-NRPADANISA-N Val-Ser-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RYHUIHUOYRNNIE-NRPADANISA-N 0.000 description 2
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 2
- UQMPYVLTQCGRSK-IFFSRLJSSA-N Val-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N)O UQMPYVLTQCGRSK-IFFSRLJSSA-N 0.000 description 2
- RTJPAGFXOWEBAI-SRVKXCTJSA-N Val-Val-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RTJPAGFXOWEBAI-SRVKXCTJSA-N 0.000 description 2
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 2
- NRLNQCOGCKAESA-KWXKLSQISA-N [(6z,9z,28z,31z)-heptatriaconta-6,9,28,31-tetraen-19-yl] 4-(dimethylamino)butanoate Chemical compound CCCCC\C=C/C\C=C/CCCCCCCCC(OC(=O)CCCN(C)C)CCCCCCCC\C=C/C\C=C/CCCCC NRLNQCOGCKAESA-KWXKLSQISA-N 0.000 description 2
- 238000009825 accumulation Methods 0.000 description 2
- 108010045350 alanyl-tyrosyl-alanine Proteins 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 150000001408 amides Chemical class 0.000 description 2
- 229940024606 amino acid Drugs 0.000 description 2
- 235000001014 amino acid Nutrition 0.000 description 2
- 150000001413 amino acids Chemical class 0.000 description 2
- 229910021529 ammonia Inorganic materials 0.000 description 2
- 125000000129 anionic group Chemical group 0.000 description 2
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 2
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 2
- 108010091092 arginyl-glycyl-proline Proteins 0.000 description 2
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 2
- 108010043240 arginyl-leucyl-glycine Proteins 0.000 description 2
- 108010006523 asialoglycoprotein receptor Proteins 0.000 description 2
- 108010038633 aspartylglutamate Proteins 0.000 description 2
- 230000002238 attenuated effect Effects 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 230000033228 biological regulation Effects 0.000 description 2
- 210000000234 capsid Anatomy 0.000 description 2
- 230000003915 cell function Effects 0.000 description 2
- 239000008004 cell lysis buffer Substances 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 210000000349 chromosome Anatomy 0.000 description 2
- 210000001072 colon Anatomy 0.000 description 2
- 230000009089 cytolysis Effects 0.000 description 2
- 230000007711 cytoplasmic localization Effects 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- 238000012217 deletion Methods 0.000 description 2
- 230000037430 deletion Effects 0.000 description 2
- 239000005547 deoxyribonucleotide Substances 0.000 description 2
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 2
- 230000006866 deterioration Effects 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 239000010432 diamond Substances 0.000 description 2
- 230000029087 digestion Effects 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 2
- 108010054813 diprotin B Proteins 0.000 description 2
- 230000005750 disease progression Effects 0.000 description 2
- 238000004090 dissolution Methods 0.000 description 2
- 230000003828 downregulation Effects 0.000 description 2
- 229920001971 elastomer Polymers 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 229940088598 enzyme Drugs 0.000 description 2
- 150000002148 esters Chemical class 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 230000005284 excitation Effects 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 208000010706 fatty liver disease Diseases 0.000 description 2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 2
- 108010080575 glutamyl-aspartyl-alanine Proteins 0.000 description 2
- 108010037389 glutamyl-cysteinyl-lysine Proteins 0.000 description 2
- HPAIKDPJURGQLN-UHFFFAOYSA-N glycyl-L-histidyl-L-phenylalanine Natural products C=1C=CC=CC=1CC(C(O)=O)NC(=O)C(NC(=O)CN)CC1=CN=CN1 HPAIKDPJURGQLN-UHFFFAOYSA-N 0.000 description 2
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 2
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 2
- 108010074027 glycyl-seryl-phenylalanine Proteins 0.000 description 2
- 108010081551 glycylphenylalanine Proteins 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 208000007386 hepatic encephalopathy Diseases 0.000 description 2
- 108010036413 histidylglycine Proteins 0.000 description 2
- 108010092114 histidylphenylalanine Proteins 0.000 description 2
- 238000000126 in silico method Methods 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 230000002452 interceptive effect Effects 0.000 description 2
- 208000028867 ischemia Diseases 0.000 description 2
- 230000000302 ischemic effect Effects 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 238000003064 k means clustering Methods 0.000 description 2
- 108010053037 kyotorphin Proteins 0.000 description 2
- 108010083708 leucyl-aspartyl-valine Proteins 0.000 description 2
- 108010030617 leucyl-phenylalanyl-valine Proteins 0.000 description 2
- 108010012058 leucyltyrosine Proteins 0.000 description 2
- 230000037356 lipid metabolism Effects 0.000 description 2
- 230000007762 localization of cell Effects 0.000 description 2
- 108010003700 lysyl aspartic acid Proteins 0.000 description 2
- 108010064235 lysylglycine Proteins 0.000 description 2
- 108010038320 lysylphenylalanine Proteins 0.000 description 2
- 108010017391 lysylvaline Proteins 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- 108010016686 methionyl-alanyl-serine Proteins 0.000 description 2
- 108010056582 methionylglutamic acid Proteins 0.000 description 2
- 108010085203 methionylmethionine Proteins 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- 102000006255 nuclear receptors Human genes 0.000 description 2
- 108020004017 nuclear receptors Proteins 0.000 description 2
- 230000005305 organ development Effects 0.000 description 2
- 230000036542 oxidative stress Effects 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 239000008188 pellet Substances 0.000 description 2
- 230000010412 perfusion Effects 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- 108010012581 phenylalanylglutamate Proteins 0.000 description 2
- WTJKGGKOPKCXLL-RRHRGVEJSA-N phosphatidylcholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCC=CCCCCCCCC WTJKGGKOPKCXLL-RRHRGVEJSA-N 0.000 description 2
- 102000020233 phosphotransferase Human genes 0.000 description 2
- 230000004962 physiological condition Effects 0.000 description 2
- 229920000747 poly(lactic acid) Polymers 0.000 description 2
- 229920001606 poly(lactic acid-co-glycolic acid) Polymers 0.000 description 2
- 229920000070 poly-3-hydroxybutyrate Polymers 0.000 description 2
- 229920002791 poly-4-hydroxybutyrate Polymers 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 108010015796 prolylisoleucine Proteins 0.000 description 2
- 108010053725 prolylvaline Proteins 0.000 description 2
- 230000000069 prophylactic effect Effects 0.000 description 2
- 238000000751 protein extraction Methods 0.000 description 2
- 238000000164 protein isolation Methods 0.000 description 2
- 239000003197 protein kinase B inhibitor Substances 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 239000002336 ribonucleotide Substances 0.000 description 2
- 125000002652 ribonucleotide group Chemical group 0.000 description 2
- 229940078677 sarna Drugs 0.000 description 2
- 239000013049 sediment Substances 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 239000004055 small Interfering RNA Substances 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- ATHGHQPFGPMSJY-UHFFFAOYSA-N spermidine Chemical compound NCCCCNCCCN ATHGHQPFGPMSJY-UHFFFAOYSA-N 0.000 description 2
- 108010005652 splenotritin Proteins 0.000 description 2
- 239000003381 stabilizer Substances 0.000 description 2
- 238000010561 standard procedure Methods 0.000 description 2
- 238000001356 surgical procedure Methods 0.000 description 2
- 108010084932 tryptophyl-proline Proteins 0.000 description 2
- 241001515965 unidentified phage Species 0.000 description 2
- 238000003260 vortexing Methods 0.000 description 2
- JNTMAZFVYNDPLB-PEDHHIEDSA-N (2S,3S)-2-[[[(2S)-1-[(2S,3S)-2-amino-3-methyl-1-oxopentyl]-2-pyrrolidinyl]-oxomethyl]amino]-3-methylpentanoic acid Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JNTMAZFVYNDPLB-PEDHHIEDSA-N 0.000 description 1
- JSPNNZKWADNWHI-PNANGNLXSA-N (2r)-2-hydroxy-n-[(2s,3r,4e,8e)-3-hydroxy-9-methyl-1-[(2r,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoctadeca-4,8-dien-2-yl]heptadecanamide Chemical compound CCCCCCCCCCCCCCC[C@@H](O)C(=O)N[C@H]([C@H](O)\C=C\CC\C=C(/C)CCCCCCCCC)CO[C@@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@H]1O JSPNNZKWADNWHI-PNANGNLXSA-N 0.000 description 1
- XVZCXCTYGHPNEM-IHRRRGAJSA-N (2s)-1-[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(O)=O XVZCXCTYGHPNEM-IHRRRGAJSA-N 0.000 description 1
- BRPMXFSTKXXNHF-IUCAKERBSA-N (2s)-1-[2-[[(2s)-pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound OC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H]1NCCC1 BRPMXFSTKXXNHF-IUCAKERBSA-N 0.000 description 1
- AXFMEGAFCUULFV-BLFANLJRSA-N (2s)-2-[[(2s)-1-[(2s,3r)-2-amino-3-methylpentanoyl]pyrrolidine-2-carbonyl]amino]pentanedioic acid Chemical compound CC[C@@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AXFMEGAFCUULFV-BLFANLJRSA-N 0.000 description 1
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 1
- JFBCSFJKETUREV-UHFFFAOYSA-N 1,2 ditetradecanoylglycerol Chemical compound CCCCCCCCCCCCCC(=O)OCC(CO)OC(=O)CCCCCCCCCCCCC JFBCSFJKETUREV-UHFFFAOYSA-N 0.000 description 1
- CITHEXJVPOWHKC-UUWRZZSWSA-N 1,2-di-O-myristoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCCCC CITHEXJVPOWHKC-UUWRZZSWSA-N 0.000 description 1
- KILNVBDSWZSGLL-KXQOOQHDSA-N 1,2-dihexadecanoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCCCCCC KILNVBDSWZSGLL-KXQOOQHDSA-N 0.000 description 1
- PORPENFLTBBHSG-MGBGTMOVSA-N 1,2-dihexadecanoyl-sn-glycerol-3-phosphate Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(O)=O)OC(=O)CCCCCCCCCCCCCCC PORPENFLTBBHSG-MGBGTMOVSA-N 0.000 description 1
- IJFVSSZAOYLHEE-SSEXGKCCSA-N 1,2-dilauroyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCC IJFVSSZAOYLHEE-SSEXGKCCSA-N 0.000 description 1
- TZCPCKNHXULUIY-RGULYWFUSA-N 1,2-distearoyl-sn-glycero-3-phosphoserine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@H](N)C(O)=O)OC(=O)CCCCCCCCCCCCCCCCC TZCPCKNHXULUIY-RGULYWFUSA-N 0.000 description 1
- PIDRBUDUWHBYSR-UHFFFAOYSA-N 1-[2-[[2-[(2-amino-4-methylpentanoyl)amino]-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O PIDRBUDUWHBYSR-UHFFFAOYSA-N 0.000 description 1
- RYCNUMLMNKHWPZ-SNVBAGLBSA-N 1-acetyl-sn-glycero-3-phosphocholine Chemical compound CC(=O)OC[C@@H](O)COP([O-])(=O)OCC[N+](C)(C)C RYCNUMLMNKHWPZ-SNVBAGLBSA-N 0.000 description 1
- JLPULHDHAOZNQI-ZTIMHPMXSA-N 1-hexadecanoyl-2-(9Z,12Z-octadecadienoyl)-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCC\C=C/C\C=C/CCCCC JLPULHDHAOZNQI-ZTIMHPMXSA-N 0.000 description 1
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 1
- PRDFBSVERLRRMY-UHFFFAOYSA-N 2'-(4-ethoxyphenyl)-5-(4-methylpiperazin-1-yl)-2,5'-bibenzimidazole Chemical compound C1=CC(OCC)=CC=C1C1=NC2=CC=C(C=3NC4=CC(=CC=C4N=3)N3CCN(C)CC3)C=C2N1 PRDFBSVERLRRMY-UHFFFAOYSA-N 0.000 description 1
- QVOBNSFUVPLVPE-ROUUACIJSA-N 2-[[(2s)-2-[[2-[[(2s)-2-amino-3-phenylpropanoyl]amino]acetyl]amino]-3-phenylpropanoyl]amino]acetic acid Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(O)=O)C1=CC=CC=C1 QVOBNSFUVPLVPE-ROUUACIJSA-N 0.000 description 1
- ZFDBLGBZACCLMH-UHFFFAOYSA-N 2-[[2-[2-[2-[(2-aminoacetyl)amino]propanoylamino]propanoylamino]-4-methylpentanoyl]amino]-4-methylpentanoic acid Chemical compound CC(C)CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(C)NC(=O)CN ZFDBLGBZACCLMH-UHFFFAOYSA-N 0.000 description 1
- BOCWTHDHJPOLAY-UHFFFAOYSA-N 2-[[2-[[2-[(2-amino-4-methylsulfanylbutanoyl)amino]acetyl]amino]-4-methylsulfanylbutanoyl]amino]-4-methylsulfanylbutanoic acid Chemical compound CSCCC(N)C(=O)NCC(=O)NC(CCSC)C(=O)NC(CCSC)C(O)=O BOCWTHDHJPOLAY-UHFFFAOYSA-N 0.000 description 1
- XWTNPSHCJMZAHQ-QMMMGPOBSA-N 2-[[2-[[2-[[(2s)-2-amino-4-methylpentanoyl]amino]acetyl]amino]acetyl]amino]acetic acid Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(=O)NCC(O)=O XWTNPSHCJMZAHQ-QMMMGPOBSA-N 0.000 description 1
- DQPMXYDFWRYWQV-UHFFFAOYSA-N 2-[[6-amino-2-[[2-[(2-amino-3-methylbutanoyl)amino]-3-hydroxybutanoyl]amino]hexanoyl]amino]acetic acid Chemical compound CC(C)C(N)C(=O)NC(C(C)O)C(=O)NC(CCCCN)C(=O)NCC(O)=O DQPMXYDFWRYWQV-UHFFFAOYSA-N 0.000 description 1
- HSTOKWSFWGCZMH-UHFFFAOYSA-N 3,3'-diaminobenzidine Chemical compound C1=C(N)C(N)=CC=C1C1=CC=C(N)C(N)=C1 HSTOKWSFWGCZMH-UHFFFAOYSA-N 0.000 description 1
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 1
- IMIZPWSVYADSCN-UHFFFAOYSA-N 4-methyl-2-[[4-methyl-2-[[4-methyl-2-(pyrrolidine-2-carbonylamino)pentanoyl]amino]pentanoyl]amino]pentanoic acid Chemical compound CC(C)CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(CC(C)C)NC(=O)C1CCCN1 IMIZPWSVYADSCN-UHFFFAOYSA-N 0.000 description 1
- 101150009360 ATF4 gene Proteins 0.000 description 1
- ZKHQWZAMYRWXGA-KQYNXXCUSA-J ATP(4-) Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](COP([O-])(=O)OP([O-])(=O)OP([O-])([O-])=O)[C@@H](O)[C@H]1O ZKHQWZAMYRWXGA-KQYNXXCUSA-J 0.000 description 1
- 102100022900 Actin, cytoplasmic 1 Human genes 0.000 description 1
- 108010085238 Actins Proteins 0.000 description 1
- ZKHQWZAMYRWXGA-UHFFFAOYSA-N Adenosine triphosphate Natural products C1=NC=2C(N)=NC=NC=2N1C1OC(COP(O)(=O)OP(O)(=O)OP(O)(O)=O)C(O)C1O ZKHQWZAMYRWXGA-UHFFFAOYSA-N 0.000 description 1
- PIPTUBPKYFRLCP-NHCYSSNCSA-N Ala-Ala-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PIPTUBPKYFRLCP-NHCYSSNCSA-N 0.000 description 1
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 1
- ODWSTKXGQGYHSH-FXQIFTODSA-N Ala-Arg-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O ODWSTKXGQGYHSH-FXQIFTODSA-N 0.000 description 1
- SSSROGPPPVTHLX-FXQIFTODSA-N Ala-Arg-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSROGPPPVTHLX-FXQIFTODSA-N 0.000 description 1
- LWUWMHIOBPTZBA-DCAQKATOSA-N Ala-Arg-Lys Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O LWUWMHIOBPTZBA-DCAQKATOSA-N 0.000 description 1
- YWWATNIVMOCSAV-UBHSHLNASA-N Ala-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 YWWATNIVMOCSAV-UBHSHLNASA-N 0.000 description 1
- PJNSIUPOXFBHDM-GUBZILKMSA-N Ala-Arg-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O PJNSIUPOXFBHDM-GUBZILKMSA-N 0.000 description 1
- PXKLCFFSVLKOJM-ACZMJKKPSA-N Ala-Asn-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PXKLCFFSVLKOJM-ACZMJKKPSA-N 0.000 description 1
- CVGNCMIULZNYES-WHFBIAKZSA-N Ala-Asn-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CVGNCMIULZNYES-WHFBIAKZSA-N 0.000 description 1
- HGRBNYQIMKTUNT-XVYDVKMFSA-N Ala-Asn-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N HGRBNYQIMKTUNT-XVYDVKMFSA-N 0.000 description 1
- NXSFUECZFORGOG-CIUDSAMLSA-N Ala-Asn-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXSFUECZFORGOG-CIUDSAMLSA-N 0.000 description 1
- XCVRVWZTXPCYJT-BIIVOSGPSA-N Ala-Asn-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N XCVRVWZTXPCYJT-BIIVOSGPSA-N 0.000 description 1
- MCKSLROAGSDNFC-ACZMJKKPSA-N Ala-Asp-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MCKSLROAGSDNFC-ACZMJKKPSA-N 0.000 description 1
- ZIWWTZWAKYBUOB-CIUDSAMLSA-N Ala-Asp-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O ZIWWTZWAKYBUOB-CIUDSAMLSA-N 0.000 description 1
- LSLIRHLIUDVNBN-CIUDSAMLSA-N Ala-Asp-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN LSLIRHLIUDVNBN-CIUDSAMLSA-N 0.000 description 1
- MKZCBYZBCINNJN-DLOVCJGASA-N Ala-Asp-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MKZCBYZBCINNJN-DLOVCJGASA-N 0.000 description 1
- YSMPVONNIWLJML-FXQIFTODSA-N Ala-Asp-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(O)=O YSMPVONNIWLJML-FXQIFTODSA-N 0.000 description 1
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 1
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 1
- WJRXVTCKASUIFF-FXQIFTODSA-N Ala-Cys-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WJRXVTCKASUIFF-FXQIFTODSA-N 0.000 description 1
- FRFDXQWNDZMREB-ACZMJKKPSA-N Ala-Cys-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O FRFDXQWNDZMREB-ACZMJKKPSA-N 0.000 description 1
- CXZFXHGJJPVUJE-CIUDSAMLSA-N Ala-Cys-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)O)N CXZFXHGJJPVUJE-CIUDSAMLSA-N 0.000 description 1
- NKJBKNVQHBZUIX-ACZMJKKPSA-N Ala-Gln-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKJBKNVQHBZUIX-ACZMJKKPSA-N 0.000 description 1
- ZODMADSIQZZBSQ-FXQIFTODSA-N Ala-Gln-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZODMADSIQZZBSQ-FXQIFTODSA-N 0.000 description 1
- FVSOUJZKYWEFOB-KBIXCLLPSA-N Ala-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)N FVSOUJZKYWEFOB-KBIXCLLPSA-N 0.000 description 1
- MVBWLRJESQOQTM-ACZMJKKPSA-N Ala-Gln-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O MVBWLRJESQOQTM-ACZMJKKPSA-N 0.000 description 1
- PWYFCPCBOYMOGB-LKTVYLICSA-N Ala-Gln-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N PWYFCPCBOYMOGB-LKTVYLICSA-N 0.000 description 1
- NJPMYXWVWQWCSR-ACZMJKKPSA-N Ala-Glu-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O NJPMYXWVWQWCSR-ACZMJKKPSA-N 0.000 description 1
- BGNLUHXLSAQYRQ-FXQIFTODSA-N Ala-Glu-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O BGNLUHXLSAQYRQ-FXQIFTODSA-N 0.000 description 1
- WKOBSJOZRJJVRZ-FXQIFTODSA-N Ala-Glu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WKOBSJOZRJJVRZ-FXQIFTODSA-N 0.000 description 1
- HMRWQTHUDVXMGH-GUBZILKMSA-N Ala-Glu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HMRWQTHUDVXMGH-GUBZILKMSA-N 0.000 description 1
- VBRDBGCROKWTPV-XHNCKOQMSA-N Ala-Glu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N VBRDBGCROKWTPV-XHNCKOQMSA-N 0.000 description 1
- OMMDTNGURYRDAC-NRPADANISA-N Ala-Glu-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OMMDTNGURYRDAC-NRPADANISA-N 0.000 description 1
- WGDNWOMKBUXFHR-BQBZGAKWSA-N Ala-Gly-Arg Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N WGDNWOMKBUXFHR-BQBZGAKWSA-N 0.000 description 1
- MPLOSMWGDNJSEV-WHFBIAKZSA-N Ala-Gly-Asp Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MPLOSMWGDNJSEV-WHFBIAKZSA-N 0.000 description 1
- WMYJZJRILUVVRG-WDSKDSINSA-N Ala-Gly-Gln Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O WMYJZJRILUVVRG-WDSKDSINSA-N 0.000 description 1
- BLIMFWGRQKRCGT-YUMQZZPRSA-N Ala-Gly-Lys Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN BLIMFWGRQKRCGT-YUMQZZPRSA-N 0.000 description 1
- MQIGTEQXYCRLGK-BQBZGAKWSA-N Ala-Gly-Pro Chemical compound C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O MQIGTEQXYCRLGK-BQBZGAKWSA-N 0.000 description 1
- NBTGEURICRTMGL-WHFBIAKZSA-N Ala-Gly-Ser Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O NBTGEURICRTMGL-WHFBIAKZSA-N 0.000 description 1
- JDIQCVUDDFENPU-ZKWXMUAHSA-N Ala-His-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CNC=N1 JDIQCVUDDFENPU-ZKWXMUAHSA-N 0.000 description 1
- IVKWMMGFLAMMKJ-XVYDVKMFSA-N Ala-His-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N IVKWMMGFLAMMKJ-XVYDVKMFSA-N 0.000 description 1
- ANGAOPNEPIDLPO-XVYDVKMFSA-N Ala-His-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CS)C(=O)O)N ANGAOPNEPIDLPO-XVYDVKMFSA-N 0.000 description 1
- 108010076441 Ala-His-His Proteins 0.000 description 1
- ATAKEVCGTRZKLI-UWJYBYFXSA-N Ala-His-His Chemical compound C([C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 ATAKEVCGTRZKLI-UWJYBYFXSA-N 0.000 description 1
- SHKGHIFSEAGTNL-DLOVCJGASA-N Ala-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CN=CN1 SHKGHIFSEAGTNL-DLOVCJGASA-N 0.000 description 1
- HUUOZYZWNCXTFK-INTQDDNPSA-N Ala-His-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N2CCC[C@@H]2C(=O)O)N HUUOZYZWNCXTFK-INTQDDNPSA-N 0.000 description 1
- NJWJSLCQEDMGNC-MBLNEYKQSA-N Ala-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C)N)O NJWJSLCQEDMGNC-MBLNEYKQSA-N 0.000 description 1
- HJGZVLLLBJLXFC-LSJOCFKGSA-N Ala-His-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O HJGZVLLLBJLXFC-LSJOCFKGSA-N 0.000 description 1
- FOHXUHGZZKETFI-JBDRJPRFSA-N Ala-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C)N FOHXUHGZZKETFI-JBDRJPRFSA-N 0.000 description 1
- GSHKMNKPMLXSQW-KBIXCLLPSA-N Ala-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C)N GSHKMNKPMLXSQW-KBIXCLLPSA-N 0.000 description 1
- CKLDHDOIYBVUNP-KBIXCLLPSA-N Ala-Ile-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O CKLDHDOIYBVUNP-KBIXCLLPSA-N 0.000 description 1
- CFPQUJZTLUQUTJ-HTFCKZLJSA-N Ala-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@H](C)N CFPQUJZTLUQUTJ-HTFCKZLJSA-N 0.000 description 1
- OKIKVSXTXVVFDV-MMWGEVLESA-N Ala-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C)N OKIKVSXTXVVFDV-MMWGEVLESA-N 0.000 description 1
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 1
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 1
- ZKEHTYWGPMMGBC-XUXIUFHCSA-N Ala-Leu-Leu-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O ZKEHTYWGPMMGBC-XUXIUFHCSA-N 0.000 description 1
- QPBSRMDNJOTFAL-AICCOOGYSA-N Ala-Leu-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QPBSRMDNJOTFAL-AICCOOGYSA-N 0.000 description 1
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 1
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 1
- PIXQDIGKDNNOOV-GUBZILKMSA-N Ala-Lys-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O PIXQDIGKDNNOOV-GUBZILKMSA-N 0.000 description 1
- PMQXMXAASGFUDX-SRVKXCTJSA-N Ala-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CCCCN PMQXMXAASGFUDX-SRVKXCTJSA-N 0.000 description 1
- VCSABYLVNWQYQE-SRVKXCTJSA-N Ala-Lys-Lys Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O VCSABYLVNWQYQE-SRVKXCTJSA-N 0.000 description 1
- FUKFQILQFQKHLE-DCAQKATOSA-N Ala-Lys-Met Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(O)=O FUKFQILQFQKHLE-DCAQKATOSA-N 0.000 description 1
- VHEVVUZDDUCAKU-FXQIFTODSA-N Ala-Met-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O VHEVVUZDDUCAKU-FXQIFTODSA-N 0.000 description 1
- PVQLRJRPUTXFFX-CIUDSAMLSA-N Ala-Met-Gln Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O PVQLRJRPUTXFFX-CIUDSAMLSA-N 0.000 description 1
- IHRGVZXPTIQNIP-NAKRPEOUSA-N Ala-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C)N IHRGVZXPTIQNIP-NAKRPEOUSA-N 0.000 description 1
- GKAZXNDATBWNBI-DCAQKATOSA-N Ala-Met-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)O)N GKAZXNDATBWNBI-DCAQKATOSA-N 0.000 description 1
- VEAPAYQQLSEKEM-GUBZILKMSA-N Ala-Met-Met Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCSC)C(O)=O VEAPAYQQLSEKEM-GUBZILKMSA-N 0.000 description 1
- AWNAEZICPNGAJK-FXQIFTODSA-N Ala-Met-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O AWNAEZICPNGAJK-FXQIFTODSA-N 0.000 description 1
- 108010011667 Ala-Phe-Ala Proteins 0.000 description 1
- XRUJOVRWNMBAAA-NHCYSSNCSA-N Ala-Phe-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 XRUJOVRWNMBAAA-NHCYSSNCSA-N 0.000 description 1
- DHBKYZYFEXXUAK-ONGXEEELSA-N Ala-Phe-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 DHBKYZYFEXXUAK-ONGXEEELSA-N 0.000 description 1
- BHTBAVZSZCQZPT-GUBZILKMSA-N Ala-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N BHTBAVZSZCQZPT-GUBZILKMSA-N 0.000 description 1
- GMGWOTQMUKYZIE-UBHSHLNASA-N Ala-Pro-Phe Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 GMGWOTQMUKYZIE-UBHSHLNASA-N 0.000 description 1
- FFZJHQODAYHGPO-KZVJFYERSA-N Ala-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N FFZJHQODAYHGPO-KZVJFYERSA-N 0.000 description 1
- DCVYRWFAMZFSDA-ZLUOBGJFSA-N Ala-Ser-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DCVYRWFAMZFSDA-ZLUOBGJFSA-N 0.000 description 1
- RMAWDDRDTRSZIR-ZLUOBGJFSA-N Ala-Ser-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RMAWDDRDTRSZIR-ZLUOBGJFSA-N 0.000 description 1
- YYAVDNKUWLAFCV-ACZMJKKPSA-N Ala-Ser-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O YYAVDNKUWLAFCV-ACZMJKKPSA-N 0.000 description 1
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 1
- OEVCHROQUIVQFZ-YTLHQDLWSA-N Ala-Thr-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O OEVCHROQUIVQFZ-YTLHQDLWSA-N 0.000 description 1
- VRTOMXFZHGWHIJ-KZVJFYERSA-N Ala-Thr-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VRTOMXFZHGWHIJ-KZVJFYERSA-N 0.000 description 1
- XQNRANMFRPCFFW-GCJQMDKQSA-N Ala-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C)N)O XQNRANMFRPCFFW-GCJQMDKQSA-N 0.000 description 1
- YNOCMHZSWJMGBB-GCJQMDKQSA-N Ala-Thr-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O YNOCMHZSWJMGBB-GCJQMDKQSA-N 0.000 description 1
- HCBKAOZYACJUEF-XQXXSGGOSA-N Ala-Thr-Gln Chemical compound N[C@@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCC(N)=O)C(=O)O HCBKAOZYACJUEF-XQXXSGGOSA-N 0.000 description 1
- AAWLEICNDUHIJM-MBLNEYKQSA-N Ala-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C)N)O AAWLEICNDUHIJM-MBLNEYKQSA-N 0.000 description 1
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 1
- SAHQGRZIQVEJPF-JXUBOQSCSA-N Ala-Thr-Lys Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN SAHQGRZIQVEJPF-JXUBOQSCSA-N 0.000 description 1
- JJHBEVZAZXZREW-LFSVMHDDSA-N Ala-Thr-Phe Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](Cc1ccccc1)C(O)=O JJHBEVZAZXZREW-LFSVMHDDSA-N 0.000 description 1
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 1
- CKIBTNMWVMKAHB-RWGOJESNSA-N Ala-Trp-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](N)C)C(O)=O)=CNC2=C1 CKIBTNMWVMKAHB-RWGOJESNSA-N 0.000 description 1
- ZJLORAAXDAJLDC-CQDKDKBSSA-N Ala-Tyr-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O ZJLORAAXDAJLDC-CQDKDKBSSA-N 0.000 description 1
- ZXKNLCPUNZPFGY-LEWSCRJBSA-N Ala-Tyr-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N ZXKNLCPUNZPFGY-LEWSCRJBSA-N 0.000 description 1
- JPOQZCHGOTWRTM-FQPOAREZSA-N Ala-Tyr-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPOQZCHGOTWRTM-FQPOAREZSA-N 0.000 description 1
- YEBZNKPPOHFZJM-BPNCWPANSA-N Ala-Tyr-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O YEBZNKPPOHFZJM-BPNCWPANSA-N 0.000 description 1
- XSLGWYYNOSUMRM-ZKWXMUAHSA-N Ala-Val-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XSLGWYYNOSUMRM-ZKWXMUAHSA-N 0.000 description 1
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 1
- VHAQSYHSDKERBS-XPUUQOCRSA-N Ala-Val-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O VHAQSYHSDKERBS-XPUUQOCRSA-N 0.000 description 1
- REWSWYIDQIELBE-FXQIFTODSA-N Ala-Val-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O REWSWYIDQIELBE-FXQIFTODSA-N 0.000 description 1
- MCYJBCKCAPERSE-FXQIFTODSA-N Arg-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N MCYJBCKCAPERSE-FXQIFTODSA-N 0.000 description 1
- GXCSUJQOECMKPV-CIUDSAMLSA-N Arg-Ala-Gln Chemical compound C[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GXCSUJQOECMKPV-CIUDSAMLSA-N 0.000 description 1
- VBFJESQBIWCWRL-DCAQKATOSA-N Arg-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCNC(N)=N VBFJESQBIWCWRL-DCAQKATOSA-N 0.000 description 1
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 1
- XPSGESXVBSQZPL-SRVKXCTJSA-N Arg-Arg-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XPSGESXVBSQZPL-SRVKXCTJSA-N 0.000 description 1
- UXJCMQFPDWCHKX-DCAQKATOSA-N Arg-Arg-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O UXJCMQFPDWCHKX-DCAQKATOSA-N 0.000 description 1
- HJVGMOYJDDXLMI-AVGNSLFASA-N Arg-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCCNC(N)=N HJVGMOYJDDXLMI-AVGNSLFASA-N 0.000 description 1
- HJWQFFYRVFEWRM-SRVKXCTJSA-N Arg-Arg-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(O)=O HJWQFFYRVFEWRM-SRVKXCTJSA-N 0.000 description 1
- UISQLSIBJKEJSS-GUBZILKMSA-N Arg-Arg-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(O)=O UISQLSIBJKEJSS-GUBZILKMSA-N 0.000 description 1
- NUBPTCMEOCKWDO-DCAQKATOSA-N Arg-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N NUBPTCMEOCKWDO-DCAQKATOSA-N 0.000 description 1
- QPOARHANPULOTM-GMOBBJLQSA-N Arg-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N QPOARHANPULOTM-GMOBBJLQSA-N 0.000 description 1
- BVBKBQRPOJFCQM-DCAQKATOSA-N Arg-Asn-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BVBKBQRPOJFCQM-DCAQKATOSA-N 0.000 description 1
- ITVINTQUZMQWJR-QXEWZRGKSA-N Arg-Asn-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O ITVINTQUZMQWJR-QXEWZRGKSA-N 0.000 description 1
- RWCLSUOSKWTXLA-FXQIFTODSA-N Arg-Asp-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RWCLSUOSKWTXLA-FXQIFTODSA-N 0.000 description 1
- RCAUJZASOAFTAJ-FXQIFTODSA-N Arg-Asp-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N)CN=C(N)N RCAUJZASOAFTAJ-FXQIFTODSA-N 0.000 description 1
- DXQIQUIQYAGRCC-CIUDSAMLSA-N Arg-Asp-Gln Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)CN=C(N)N DXQIQUIQYAGRCC-CIUDSAMLSA-N 0.000 description 1
- OZNSCVPYWZRQPY-CIUDSAMLSA-N Arg-Asp-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O OZNSCVPYWZRQPY-CIUDSAMLSA-N 0.000 description 1
- YFBGNGASPGRWEM-DCAQKATOSA-N Arg-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N YFBGNGASPGRWEM-DCAQKATOSA-N 0.000 description 1
- YSUVMPICYVWRBX-VEVYYDQMSA-N Arg-Asp-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YSUVMPICYVWRBX-VEVYYDQMSA-N 0.000 description 1
- JTWOBPNAVBESFW-FXQIFTODSA-N Arg-Cys-Asp Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)CN=C(N)N JTWOBPNAVBESFW-FXQIFTODSA-N 0.000 description 1
- FEZJJKXNPSEYEV-CIUDSAMLSA-N Arg-Gln-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FEZJJKXNPSEYEV-CIUDSAMLSA-N 0.000 description 1
- GIVWETPOBCRTND-DCAQKATOSA-N Arg-Gln-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O GIVWETPOBCRTND-DCAQKATOSA-N 0.000 description 1
- SNBHMYQRNCJSOJ-CIUDSAMLSA-N Arg-Gln-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O SNBHMYQRNCJSOJ-CIUDSAMLSA-N 0.000 description 1
- KBBKCNHWCDJPGN-GUBZILKMSA-N Arg-Gln-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KBBKCNHWCDJPGN-GUBZILKMSA-N 0.000 description 1
- RYRQZJVFDVWURI-SRVKXCTJSA-N Arg-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N RYRQZJVFDVWURI-SRVKXCTJSA-N 0.000 description 1
- JCAISGGAOQXEHJ-ZPFDUUQYSA-N Arg-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N JCAISGGAOQXEHJ-ZPFDUUQYSA-N 0.000 description 1
- VNFWDYWTSHFRRG-SRVKXCTJSA-N Arg-Gln-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O VNFWDYWTSHFRRG-SRVKXCTJSA-N 0.000 description 1
- RKRSYHCNPFGMTA-CIUDSAMLSA-N Arg-Glu-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O RKRSYHCNPFGMTA-CIUDSAMLSA-N 0.000 description 1
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 1
- PBSOQGZLPFVXPU-YUMQZZPRSA-N Arg-Glu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PBSOQGZLPFVXPU-YUMQZZPRSA-N 0.000 description 1
- QAXCZGMLVICQKS-SRVKXCTJSA-N Arg-Glu-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N QAXCZGMLVICQKS-SRVKXCTJSA-N 0.000 description 1
- SKTGPBFTMNLIHQ-KKUMJFAQSA-N Arg-Glu-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SKTGPBFTMNLIHQ-KKUMJFAQSA-N 0.000 description 1
- HPSVTWMFWCHKFN-GARJFASQSA-N Arg-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O HPSVTWMFWCHKFN-GARJFASQSA-N 0.000 description 1
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 1
- HAVKMRGWNXMCDR-STQMWFEESA-N Arg-Gly-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HAVKMRGWNXMCDR-STQMWFEESA-N 0.000 description 1
- ZATRYQNPUHGXCU-DTWKUNHWSA-N Arg-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ZATRYQNPUHGXCU-DTWKUNHWSA-N 0.000 description 1
- VRZDJJWOFXMFRO-ZFWWWQNUSA-N Arg-Gly-Trp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O VRZDJJWOFXMFRO-ZFWWWQNUSA-N 0.000 description 1
- YBIAYFFIVAZXPK-AVGNSLFASA-N Arg-His-Arg Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O YBIAYFFIVAZXPK-AVGNSLFASA-N 0.000 description 1
- PZVMBNFTBWQWQL-DCAQKATOSA-N Arg-His-Cys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N PZVMBNFTBWQWQL-DCAQKATOSA-N 0.000 description 1
- UPKMBGAAEZGHOC-RWMBFGLXSA-N Arg-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O UPKMBGAAEZGHOC-RWMBFGLXSA-N 0.000 description 1
- GNYUVVJYGJFKHN-RVMXOQNASA-N Arg-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N GNYUVVJYGJFKHN-RVMXOQNASA-N 0.000 description 1
- GXXWTNKNFFKTJB-NAKRPEOUSA-N Arg-Ile-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O GXXWTNKNFFKTJB-NAKRPEOUSA-N 0.000 description 1
- HJDNZFIYILEIKR-OSUNSFLBSA-N Arg-Ile-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HJDNZFIYILEIKR-OSUNSFLBSA-N 0.000 description 1
- UHFUZWSZQKMDSX-DCAQKATOSA-N Arg-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UHFUZWSZQKMDSX-DCAQKATOSA-N 0.000 description 1
- GMFAGHNRXPSSJS-SRVKXCTJSA-N Arg-Leu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GMFAGHNRXPSSJS-SRVKXCTJSA-N 0.000 description 1
- YBZMTKUDWXZLIX-UWVGGRQHSA-N Arg-Leu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YBZMTKUDWXZLIX-UWVGGRQHSA-N 0.000 description 1
- NOZYDJOPOGKUSR-AVGNSLFASA-N Arg-Leu-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O NOZYDJOPOGKUSR-AVGNSLFASA-N 0.000 description 1
- COXMUHNBYCVVRG-DCAQKATOSA-N Arg-Leu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O COXMUHNBYCVVRG-DCAQKATOSA-N 0.000 description 1
- SSZGOKWBHLOCHK-DCAQKATOSA-N Arg-Lys-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCN=C(N)N SSZGOKWBHLOCHK-DCAQKATOSA-N 0.000 description 1
- CVXXSWQORBZAAA-SRVKXCTJSA-N Arg-Lys-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCN=C(N)N CVXXSWQORBZAAA-SRVKXCTJSA-N 0.000 description 1
- NGTYEHIRESTSRX-UWVGGRQHSA-N Arg-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N NGTYEHIRESTSRX-UWVGGRQHSA-N 0.000 description 1
- DIIGDGJKTMLQQW-IHRRRGAJSA-N Arg-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCN=C(N)N)N DIIGDGJKTMLQQW-IHRRRGAJSA-N 0.000 description 1
- CLICCYPMVFGUOF-IHRRRGAJSA-N Arg-Lys-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O CLICCYPMVFGUOF-IHRRRGAJSA-N 0.000 description 1
- BTJVOUQWFXABOI-IHRRRGAJSA-N Arg-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCNC(N)=N BTJVOUQWFXABOI-IHRRRGAJSA-N 0.000 description 1
- MTYLORHAQXVQOW-AVGNSLFASA-N Arg-Lys-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(O)=O MTYLORHAQXVQOW-AVGNSLFASA-N 0.000 description 1
- GRRXPUAICOGISM-RWMBFGLXSA-N Arg-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O GRRXPUAICOGISM-RWMBFGLXSA-N 0.000 description 1
- PYZPXCZNQSEHDT-GUBZILKMSA-N Arg-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N PYZPXCZNQSEHDT-GUBZILKMSA-N 0.000 description 1
- JBIRFLWXWDSDTR-CYDGBPFRSA-N Arg-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCCN=C(N)N)N JBIRFLWXWDSDTR-CYDGBPFRSA-N 0.000 description 1
- GSUFZRURORXYTM-STQMWFEESA-N Arg-Phe-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 GSUFZRURORXYTM-STQMWFEESA-N 0.000 description 1
- SLQQPJBDBVPVQV-JYJNAYRXSA-N Arg-Phe-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O SLQQPJBDBVPVQV-JYJNAYRXSA-N 0.000 description 1
- BSYKSCBTTQKOJG-GUBZILKMSA-N Arg-Pro-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O BSYKSCBTTQKOJG-GUBZILKMSA-N 0.000 description 1
- ATABBWFGOHKROJ-GUBZILKMSA-N Arg-Pro-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O ATABBWFGOHKROJ-GUBZILKMSA-N 0.000 description 1
- VUGWHBXPMAHEGZ-SRVKXCTJSA-N Arg-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N VUGWHBXPMAHEGZ-SRVKXCTJSA-N 0.000 description 1
- KXOPYFNQLVUOAQ-FXQIFTODSA-N Arg-Ser-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KXOPYFNQLVUOAQ-FXQIFTODSA-N 0.000 description 1
- JOTRDIXZHNQYGP-DCAQKATOSA-N Arg-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JOTRDIXZHNQYGP-DCAQKATOSA-N 0.000 description 1
- JQHASVQBAKRJKD-GUBZILKMSA-N Arg-Ser-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JQHASVQBAKRJKD-GUBZILKMSA-N 0.000 description 1
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 1
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 1
- OQPAZKMGCWPERI-GUBZILKMSA-N Arg-Ser-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OQPAZKMGCWPERI-GUBZILKMSA-N 0.000 description 1
- ASQKVGRCKOFKIU-KZVJFYERSA-N Arg-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ASQKVGRCKOFKIU-KZVJFYERSA-N 0.000 description 1
- LYJXHXGPWDTLKW-HJGDQZAQSA-N Arg-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O LYJXHXGPWDTLKW-HJGDQZAQSA-N 0.000 description 1
- UZSQXCMNUPKLCC-FJXKBIBVSA-N Arg-Thr-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UZSQXCMNUPKLCC-FJXKBIBVSA-N 0.000 description 1
- DDBMKOCQWNFDBH-RHYQMDGZSA-N Arg-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O DDBMKOCQWNFDBH-RHYQMDGZSA-N 0.000 description 1
- XRNXPIGJPQHCPC-RCWTZXSCSA-N Arg-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCCNC(N)=N)[C@@H](C)O)C(O)=O XRNXPIGJPQHCPC-RCWTZXSCSA-N 0.000 description 1
- BFDDUDQCPJWQRQ-IHRRRGAJSA-N Arg-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O BFDDUDQCPJWQRQ-IHRRRGAJSA-N 0.000 description 1
- VLIJAPRTSXSGFY-STQMWFEESA-N Arg-Tyr-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 VLIJAPRTSXSGFY-STQMWFEESA-N 0.000 description 1
- XRLOBFSLPCHYLQ-ULQDDVLXSA-N Arg-Tyr-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O XRLOBFSLPCHYLQ-ULQDDVLXSA-N 0.000 description 1
- QCTOLCVIGRLMQS-HRCADAONSA-N Arg-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O QCTOLCVIGRLMQS-HRCADAONSA-N 0.000 description 1
- IZSMEUDYADKZTJ-KJEVXHAQSA-N Arg-Tyr-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IZSMEUDYADKZTJ-KJEVXHAQSA-N 0.000 description 1
- VYZBPPBKFCHCIS-WPRPVWTQSA-N Arg-Val-Gly Chemical compound OC(=O)CNC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N VYZBPPBKFCHCIS-WPRPVWTQSA-N 0.000 description 1
- XEOXPCNONWHHSW-AVGNSLFASA-N Arg-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N XEOXPCNONWHHSW-AVGNSLFASA-N 0.000 description 1
- SUMJNGAMIQSNGX-TUAOUCFPSA-N Arg-Val-Pro Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N1CCC[C@@H]1C(O)=O SUMJNGAMIQSNGX-TUAOUCFPSA-N 0.000 description 1
- ANAHQDPQQBDOBM-UHFFFAOYSA-N Arg-Val-Tyr Natural products CC(C)C(NC(=O)C(N)CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O ANAHQDPQQBDOBM-UHFFFAOYSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- YNDLOUMBVDVALC-ZLUOBGJFSA-N Asn-Ala-Ala Chemical compound C[C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CC(=O)N)N YNDLOUMBVDVALC-ZLUOBGJFSA-N 0.000 description 1
- SWLOHUMCUDRTCL-ZLUOBGJFSA-N Asn-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N SWLOHUMCUDRTCL-ZLUOBGJFSA-N 0.000 description 1
- HZPSDHRYYIORKR-WHFBIAKZSA-N Asn-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC(N)=O HZPSDHRYYIORKR-WHFBIAKZSA-N 0.000 description 1
- CMLGVVWQQHUXOZ-GHCJXIJMSA-N Asn-Ala-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CMLGVVWQQHUXOZ-GHCJXIJMSA-N 0.000 description 1
- XYOVHPDDWCEUDY-CIUDSAMLSA-N Asn-Ala-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O XYOVHPDDWCEUDY-CIUDSAMLSA-N 0.000 description 1
- VDCIPFYVCICPEC-FXQIFTODSA-N Asn-Arg-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O VDCIPFYVCICPEC-FXQIFTODSA-N 0.000 description 1
- DQTIWTULBGLJBL-DCAQKATOSA-N Asn-Arg-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)N)N DQTIWTULBGLJBL-DCAQKATOSA-N 0.000 description 1
- ZZXMOQIUIJJOKZ-ZLUOBGJFSA-N Asn-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O ZZXMOQIUIJJOKZ-ZLUOBGJFSA-N 0.000 description 1
- RCENDENBBJFJHZ-ACZMJKKPSA-N Asn-Asn-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RCENDENBBJFJHZ-ACZMJKKPSA-N 0.000 description 1
- IOTKDTZEEBZNCM-UGYAYLCHSA-N Asn-Asn-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOTKDTZEEBZNCM-UGYAYLCHSA-N 0.000 description 1
- NVGWESORMHFISY-SRVKXCTJSA-N Asn-Asn-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O NVGWESORMHFISY-SRVKXCTJSA-N 0.000 description 1
- NLCDVZJDEXIDDL-BIIVOSGPSA-N Asn-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N)C(=O)O NLCDVZJDEXIDDL-BIIVOSGPSA-N 0.000 description 1
- WVCJSDCHTUTONA-FXQIFTODSA-N Asn-Asp-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WVCJSDCHTUTONA-FXQIFTODSA-N 0.000 description 1
- XSGBIBGAMKTHMY-WHFBIAKZSA-N Asn-Asp-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O XSGBIBGAMKTHMY-WHFBIAKZSA-N 0.000 description 1
- QISZHYWZHJRDAO-CIUDSAMLSA-N Asn-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N QISZHYWZHJRDAO-CIUDSAMLSA-N 0.000 description 1
- JZRLLSOWDYUKOK-SRVKXCTJSA-N Asn-Asp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N JZRLLSOWDYUKOK-SRVKXCTJSA-N 0.000 description 1
- PAXHINASXXXILC-SRVKXCTJSA-N Asn-Asp-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N)O PAXHINASXXXILC-SRVKXCTJSA-N 0.000 description 1
- XWFPGQVLOVGSLU-CIUDSAMLSA-N Asn-Gln-Arg Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N XWFPGQVLOVGSLU-CIUDSAMLSA-N 0.000 description 1
- AYKKKGFJXIDYLX-ACZMJKKPSA-N Asn-Gln-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O AYKKKGFJXIDYLX-ACZMJKKPSA-N 0.000 description 1
- QGNXYDHVERJIAY-ACZMJKKPSA-N Asn-Gln-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)N)N QGNXYDHVERJIAY-ACZMJKKPSA-N 0.000 description 1
- NNMUHYLAYUSTTN-FXQIFTODSA-N Asn-Gln-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O NNMUHYLAYUSTTN-FXQIFTODSA-N 0.000 description 1
- QPTAGIPWARILES-AVGNSLFASA-N Asn-Gln-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QPTAGIPWARILES-AVGNSLFASA-N 0.000 description 1
- ULRPXVNMIIYDDJ-ACZMJKKPSA-N Asn-Glu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)N)N ULRPXVNMIIYDDJ-ACZMJKKPSA-N 0.000 description 1
- CTQIOCMSIJATNX-WHFBIAKZSA-N Asn-Gly-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O CTQIOCMSIJATNX-WHFBIAKZSA-N 0.000 description 1
- DXVMJJNAOVECBA-WHFBIAKZSA-N Asn-Gly-Asn Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O DXVMJJNAOVECBA-WHFBIAKZSA-N 0.000 description 1
- IICZCLFBILYRCU-WHFBIAKZSA-N Asn-Gly-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O IICZCLFBILYRCU-WHFBIAKZSA-N 0.000 description 1
- OPEPUCYIGFEGSW-WDSKDSINSA-N Asn-Gly-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OPEPUCYIGFEGSW-WDSKDSINSA-N 0.000 description 1
- UDSVWSUXKYXSTR-QWRGUYRKSA-N Asn-Gly-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UDSVWSUXKYXSTR-QWRGUYRKSA-N 0.000 description 1
- ODBSSLHUFPJRED-CIUDSAMLSA-N Asn-His-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N ODBSSLHUFPJRED-CIUDSAMLSA-N 0.000 description 1
- MOHUTCNYQLMARY-GUBZILKMSA-N Asn-His-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N MOHUTCNYQLMARY-GUBZILKMSA-N 0.000 description 1
- IKLAUGBIDCDFOY-SRVKXCTJSA-N Asn-His-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O IKLAUGBIDCDFOY-SRVKXCTJSA-N 0.000 description 1
- SXNJBDYEBOUYOJ-DCAQKATOSA-N Asn-His-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC(=O)N)N SXNJBDYEBOUYOJ-DCAQKATOSA-N 0.000 description 1
- SGAUXNZEFIEAAI-GARJFASQSA-N Asn-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)N)N)C(=O)O SGAUXNZEFIEAAI-GARJFASQSA-N 0.000 description 1
- AITGTTNYKAWKDR-CIUDSAMLSA-N Asn-His-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O AITGTTNYKAWKDR-CIUDSAMLSA-N 0.000 description 1
- UYXXMIZGHYKYAT-NHCYSSNCSA-N Asn-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC(=O)N)N UYXXMIZGHYKYAT-NHCYSSNCSA-N 0.000 description 1
- PTSDPWIHOYMRGR-UGYAYLCHSA-N Asn-Ile-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O PTSDPWIHOYMRGR-UGYAYLCHSA-N 0.000 description 1
- KMCRKVOLRCOMBG-DJFWLOJKSA-N Asn-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KMCRKVOLRCOMBG-DJFWLOJKSA-N 0.000 description 1
- XLZCLJRGGMBKLR-PCBIJLKTSA-N Asn-Ile-Phe Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XLZCLJRGGMBKLR-PCBIJLKTSA-N 0.000 description 1
- GLWFAWNYGWBMOC-SRVKXCTJSA-N Asn-Leu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GLWFAWNYGWBMOC-SRVKXCTJSA-N 0.000 description 1
- UBGGJTMETLEXJD-DCAQKATOSA-N Asn-Leu-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O UBGGJTMETLEXJD-DCAQKATOSA-N 0.000 description 1
- JLNFZLNDHONLND-GARJFASQSA-N Asn-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N JLNFZLNDHONLND-GARJFASQSA-N 0.000 description 1
- RCFGLXMZDYNRSC-CIUDSAMLSA-N Asn-Lys-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O RCFGLXMZDYNRSC-CIUDSAMLSA-N 0.000 description 1
- ZYPWIUFLYMQZBS-SRVKXCTJSA-N Asn-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N ZYPWIUFLYMQZBS-SRVKXCTJSA-N 0.000 description 1
- QDXQWFBLUVTOFL-FXQIFTODSA-N Asn-Met-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CC(=O)N)N QDXQWFBLUVTOFL-FXQIFTODSA-N 0.000 description 1
- KNENKKKUYGEZIO-FXQIFTODSA-N Asn-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N KNENKKKUYGEZIO-FXQIFTODSA-N 0.000 description 1
- UYRPHDGXHKBZHJ-CIUDSAMLSA-N Asn-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N UYRPHDGXHKBZHJ-CIUDSAMLSA-N 0.000 description 1
- BKZFBJYIVSBXCO-KKUMJFAQSA-N Asn-Phe-His Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC=N1)C(O)=O BKZFBJYIVSBXCO-KKUMJFAQSA-N 0.000 description 1
- XMHFCUKJRCQXGI-CIUDSAMLSA-N Asn-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O XMHFCUKJRCQXGI-CIUDSAMLSA-N 0.000 description 1
- SZNGQSBRHFMZLT-IHRRRGAJSA-N Asn-Pro-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SZNGQSBRHFMZLT-IHRRRGAJSA-N 0.000 description 1
- VCJCPARXDBEGNE-GUBZILKMSA-N Asn-Pro-Pro Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 VCJCPARXDBEGNE-GUBZILKMSA-N 0.000 description 1
- IIQIOFVDFOLCHP-UHFFFAOYSA-N Asn-Pro-Ser-Ser Chemical compound NC(=O)CC(N)C(=O)N1CCCC1C(=O)NC(CO)C(=O)NC(CO)C(O)=O IIQIOFVDFOLCHP-UHFFFAOYSA-N 0.000 description 1
- SUIJFTJDTJKSRK-IHRRRGAJSA-N Asn-Pro-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SUIJFTJDTJKSRK-IHRRRGAJSA-N 0.000 description 1
- VWADICJNCPFKJS-ZLUOBGJFSA-N Asn-Ser-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O VWADICJNCPFKJS-ZLUOBGJFSA-N 0.000 description 1
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 1
- ZNYKKCADEQAZKA-FXQIFTODSA-N Asn-Ser-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O ZNYKKCADEQAZKA-FXQIFTODSA-N 0.000 description 1
- SNYCNNPOFYBCEK-ZLUOBGJFSA-N Asn-Ser-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O SNYCNNPOFYBCEK-ZLUOBGJFSA-N 0.000 description 1
- HNXWVVHIGTZTBO-LKXGYXEUSA-N Asn-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O HNXWVVHIGTZTBO-LKXGYXEUSA-N 0.000 description 1
- NCXTYSVDWLAQGZ-ZKWXMUAHSA-N Asn-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O NCXTYSVDWLAQGZ-ZKWXMUAHSA-N 0.000 description 1
- WLVLIYYBPPONRJ-GCJQMDKQSA-N Asn-Thr-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O WLVLIYYBPPONRJ-GCJQMDKQSA-N 0.000 description 1
- QUMKPKWYDVMGNT-NUMRIWBASA-N Asn-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QUMKPKWYDVMGNT-NUMRIWBASA-N 0.000 description 1
- JBDLMLZNDRLDIX-HJGDQZAQSA-N Asn-Thr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O JBDLMLZNDRLDIX-HJGDQZAQSA-N 0.000 description 1
- AMGQTNHANMRPOE-LKXGYXEUSA-N Asn-Thr-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O AMGQTNHANMRPOE-LKXGYXEUSA-N 0.000 description 1
- YSYTWUMRHSFODC-QWRGUYRKSA-N Asn-Tyr-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O YSYTWUMRHSFODC-QWRGUYRKSA-N 0.000 description 1
- LTDGPJKGJDIBQD-LAEOZQHASA-N Asn-Val-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LTDGPJKGJDIBQD-LAEOZQHASA-N 0.000 description 1
- ZAESWDKAMDVHLL-RCOVLWMOSA-N Asn-Val-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O ZAESWDKAMDVHLL-RCOVLWMOSA-N 0.000 description 1
- JNCRAQVYJZGIOW-QSFUFRPTSA-N Asn-Val-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JNCRAQVYJZGIOW-QSFUFRPTSA-N 0.000 description 1
- CBHVAFXKOYAHOY-NHCYSSNCSA-N Asn-Val-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O CBHVAFXKOYAHOY-NHCYSSNCSA-N 0.000 description 1
- WQAOZCVOOYUWKG-LSJOCFKGSA-N Asn-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CC(=O)N)N WQAOZCVOOYUWKG-LSJOCFKGSA-N 0.000 description 1
- UWMIZBCTVWVMFI-FXQIFTODSA-N Asp-Ala-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UWMIZBCTVWVMFI-FXQIFTODSA-N 0.000 description 1
- PBVLJOIPOGUQQP-CIUDSAMLSA-N Asp-Ala-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O PBVLJOIPOGUQQP-CIUDSAMLSA-N 0.000 description 1
- VPPXTHJNTYDNFJ-CIUDSAMLSA-N Asp-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N VPPXTHJNTYDNFJ-CIUDSAMLSA-N 0.000 description 1
- NECWUSYTYSIFNC-DLOVCJGASA-N Asp-Ala-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 NECWUSYTYSIFNC-DLOVCJGASA-N 0.000 description 1
- XPGVTUBABLRGHY-BIIVOSGPSA-N Asp-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N XPGVTUBABLRGHY-BIIVOSGPSA-N 0.000 description 1
- OERMIMJQPQUIPK-FXQIFTODSA-N Asp-Arg-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O OERMIMJQPQUIPK-FXQIFTODSA-N 0.000 description 1
- GVPSCJQLUGIKAM-GUBZILKMSA-N Asp-Arg-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O GVPSCJQLUGIKAM-GUBZILKMSA-N 0.000 description 1
- AXXCUABIFZPKPM-BQBZGAKWSA-N Asp-Arg-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O AXXCUABIFZPKPM-BQBZGAKWSA-N 0.000 description 1
- HMQDRBKQMLRCCG-GMOBBJLQSA-N Asp-Arg-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HMQDRBKQMLRCCG-GMOBBJLQSA-N 0.000 description 1
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 1
- FAEIQWHBRBWUBN-FXQIFTODSA-N Asp-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N)CN=C(N)N FAEIQWHBRBWUBN-FXQIFTODSA-N 0.000 description 1
- NYLBGYLHBDFRHL-VEVYYDQMSA-N Asp-Arg-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NYLBGYLHBDFRHL-VEVYYDQMSA-N 0.000 description 1
- UQBGYPFHWFZMCD-ZLUOBGJFSA-N Asp-Asn-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O UQBGYPFHWFZMCD-ZLUOBGJFSA-N 0.000 description 1
- UGKZHCBLMLSANF-CIUDSAMLSA-N Asp-Asn-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O UGKZHCBLMLSANF-CIUDSAMLSA-N 0.000 description 1
- JDHOJQJMWBKHDB-CIUDSAMLSA-N Asp-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N JDHOJQJMWBKHDB-CIUDSAMLSA-N 0.000 description 1
- KNMRXHIAVXHCLW-ZLUOBGJFSA-N Asp-Asn-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)C(=O)O KNMRXHIAVXHCLW-ZLUOBGJFSA-N 0.000 description 1
- QOVWVLLHMMCFFY-ZLUOBGJFSA-N Asp-Asp-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QOVWVLLHMMCFFY-ZLUOBGJFSA-N 0.000 description 1
- VPSHHQXIWLGVDD-ZLUOBGJFSA-N Asp-Asp-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O VPSHHQXIWLGVDD-ZLUOBGJFSA-N 0.000 description 1
- FRSGNOZCTWDVFZ-ACZMJKKPSA-N Asp-Asp-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O FRSGNOZCTWDVFZ-ACZMJKKPSA-N 0.000 description 1
- ZCKYZTGLXIEOKS-CIUDSAMLSA-N Asp-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N ZCKYZTGLXIEOKS-CIUDSAMLSA-N 0.000 description 1
- SBHUBSDEZQFJHJ-CIUDSAMLSA-N Asp-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O SBHUBSDEZQFJHJ-CIUDSAMLSA-N 0.000 description 1
- CELPEWWLSXMVPH-CIUDSAMLSA-N Asp-Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O CELPEWWLSXMVPH-CIUDSAMLSA-N 0.000 description 1
- VZNOVQKGJQJOCS-SRVKXCTJSA-N Asp-Asp-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VZNOVQKGJQJOCS-SRVKXCTJSA-N 0.000 description 1
- WLKVEEODTPQPLI-ACZMJKKPSA-N Asp-Gln-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O WLKVEEODTPQPLI-ACZMJKKPSA-N 0.000 description 1
- DXQOQMCLWWADMU-ACZMJKKPSA-N Asp-Gln-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O DXQOQMCLWWADMU-ACZMJKKPSA-N 0.000 description 1
- ZSJFGGSPCCHMNE-LAEOZQHASA-N Asp-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N ZSJFGGSPCCHMNE-LAEOZQHASA-N 0.000 description 1
- XAJRHVUUVUPFQL-ACZMJKKPSA-N Asp-Glu-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O XAJRHVUUVUPFQL-ACZMJKKPSA-N 0.000 description 1
- ZEDBMCPXPIYJLW-XHNCKOQMSA-N Asp-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)O)N)C(=O)O ZEDBMCPXPIYJLW-XHNCKOQMSA-N 0.000 description 1
- DGKCOYGQLNWNCJ-ACZMJKKPSA-N Asp-Glu-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O DGKCOYGQLNWNCJ-ACZMJKKPSA-N 0.000 description 1
- YNCHFVRXEQFPBY-BQBZGAKWSA-N Asp-Gly-Arg Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N YNCHFVRXEQFPBY-BQBZGAKWSA-N 0.000 description 1
- BIVYLQMZPHDUIH-WHFBIAKZSA-N Asp-Gly-Cys Chemical compound C([C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N)C(=O)O BIVYLQMZPHDUIH-WHFBIAKZSA-N 0.000 description 1
- HAFCJCDJGIOYPW-WDSKDSINSA-N Asp-Gly-Gln Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O HAFCJCDJGIOYPW-WDSKDSINSA-N 0.000 description 1
- QCVXMEHGFUMKCO-YUMQZZPRSA-N Asp-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O QCVXMEHGFUMKCO-YUMQZZPRSA-N 0.000 description 1
- SVABRQFIHCSNCI-FOHZUACHSA-N Asp-Gly-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O SVABRQFIHCSNCI-FOHZUACHSA-N 0.000 description 1
- ODNWIBOCFGMRTP-SRVKXCTJSA-N Asp-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CN=CN1 ODNWIBOCFGMRTP-SRVKXCTJSA-N 0.000 description 1
- ICZWAZVKLACMKR-CIUDSAMLSA-N Asp-His-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CN=CN1 ICZWAZVKLACMKR-CIUDSAMLSA-N 0.000 description 1
- TZOZNVLBTAFJRW-UGYAYLCHSA-N Asp-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N TZOZNVLBTAFJRW-UGYAYLCHSA-N 0.000 description 1
- KQBVNNAPIURMPD-PEFMBERDSA-N Asp-Ile-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O KQBVNNAPIURMPD-PEFMBERDSA-N 0.000 description 1
- SEMWSADZTMJELF-BYULHYEWSA-N Asp-Ile-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O SEMWSADZTMJELF-BYULHYEWSA-N 0.000 description 1
- KLYPOCBLKMPBIQ-GHCJXIJMSA-N Asp-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N KLYPOCBLKMPBIQ-GHCJXIJMSA-N 0.000 description 1
- UZNSWMFLKVKJLI-VHWLVUOQSA-N Asp-Ile-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O UZNSWMFLKVKJLI-VHWLVUOQSA-N 0.000 description 1
- CLUMZOKVGUWUFD-CIUDSAMLSA-N Asp-Leu-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O CLUMZOKVGUWUFD-CIUDSAMLSA-N 0.000 description 1
- PAYPSKIBMDHZPI-CIUDSAMLSA-N Asp-Leu-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O PAYPSKIBMDHZPI-CIUDSAMLSA-N 0.000 description 1
- AITKTFCQOBRJTG-CIUDSAMLSA-N Asp-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)O)N AITKTFCQOBRJTG-CIUDSAMLSA-N 0.000 description 1
- XLILXFRAKOYEJX-GUBZILKMSA-N Asp-Leu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O XLILXFRAKOYEJX-GUBZILKMSA-N 0.000 description 1
- DWOGMPWRQQWPPF-GUBZILKMSA-N Asp-Leu-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O DWOGMPWRQQWPPF-GUBZILKMSA-N 0.000 description 1
- AYFVRYXNDHBECD-YUMQZZPRSA-N Asp-Leu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AYFVRYXNDHBECD-YUMQZZPRSA-N 0.000 description 1
- CJUKAWUWBZCTDQ-SRVKXCTJSA-N Asp-Leu-Lys Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O CJUKAWUWBZCTDQ-SRVKXCTJSA-N 0.000 description 1
- KFAFUJMGHVVYRC-DCAQKATOSA-N Asp-Leu-Met Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O KFAFUJMGHVVYRC-DCAQKATOSA-N 0.000 description 1
- HKEZZWQWXWGASX-KKUMJFAQSA-N Asp-Leu-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 HKEZZWQWXWGASX-KKUMJFAQSA-N 0.000 description 1
- IVPNEDNYYYFAGI-GARJFASQSA-N Asp-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N IVPNEDNYYYFAGI-GARJFASQSA-N 0.000 description 1
- ORRJQLIATJDMQM-HJGDQZAQSA-N Asp-Leu-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O ORRJQLIATJDMQM-HJGDQZAQSA-N 0.000 description 1
- LIVXPXUVXFRWNY-CIUDSAMLSA-N Asp-Lys-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O LIVXPXUVXFRWNY-CIUDSAMLSA-N 0.000 description 1
- UZFHNLYQWMGUHU-DCAQKATOSA-N Asp-Lys-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UZFHNLYQWMGUHU-DCAQKATOSA-N 0.000 description 1
- XWSIYTYNLKCLJB-CIUDSAMLSA-N Asp-Lys-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O XWSIYTYNLKCLJB-CIUDSAMLSA-N 0.000 description 1
- AKKUDRZKFZWPBH-SRVKXCTJSA-N Asp-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N AKKUDRZKFZWPBH-SRVKXCTJSA-N 0.000 description 1
- NVFSJIXJZCDICF-SRVKXCTJSA-N Asp-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N NVFSJIXJZCDICF-SRVKXCTJSA-N 0.000 description 1
- NZWDWXSWUQCNMG-GARJFASQSA-N Asp-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)C(=O)O NZWDWXSWUQCNMG-GARJFASQSA-N 0.000 description 1
- IOXWDLNHXZOXQP-FXQIFTODSA-N Asp-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N IOXWDLNHXZOXQP-FXQIFTODSA-N 0.000 description 1
- WQSXAPPYLGNMQL-IHRRRGAJSA-N Asp-Met-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N WQSXAPPYLGNMQL-IHRRRGAJSA-N 0.000 description 1
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 1
- WOPJVEMFXYHZEE-SRVKXCTJSA-N Asp-Phe-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O WOPJVEMFXYHZEE-SRVKXCTJSA-N 0.000 description 1
- UCHSVZYJKJLPHF-BZSNNMDCSA-N Asp-Phe-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O UCHSVZYJKJLPHF-BZSNNMDCSA-N 0.000 description 1
- PWAIZUBWHRHYKS-MELADBBJSA-N Asp-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)O)N)C(=O)O PWAIZUBWHRHYKS-MELADBBJSA-N 0.000 description 1
- KOWYNSKRPUWSFG-IHPCNDPISA-N Asp-Phe-Trp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)NC(=O)[C@H](CC(=O)O)N KOWYNSKRPUWSFG-IHPCNDPISA-N 0.000 description 1
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 1
- DWOSGXZMLQNDBN-FXQIFTODSA-N Asp-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CS)C(=O)O DWOSGXZMLQNDBN-FXQIFTODSA-N 0.000 description 1
- QSFHZPQUAAQHAQ-CIUDSAMLSA-N Asp-Ser-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O QSFHZPQUAAQHAQ-CIUDSAMLSA-N 0.000 description 1
- HRVQDZOWMLFAOD-BIIVOSGPSA-N Asp-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N)C(=O)O HRVQDZOWMLFAOD-BIIVOSGPSA-N 0.000 description 1
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 1
- XYPJXLLXNSAWHZ-SRVKXCTJSA-N Asp-Ser-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XYPJXLLXNSAWHZ-SRVKXCTJSA-N 0.000 description 1
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 1
- GXHDGYOXPNQCKM-XVSYOHENSA-N Asp-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O GXHDGYOXPNQCKM-XVSYOHENSA-N 0.000 description 1
- ITGFVUYOLWBPQW-KKHAAJSZSA-N Asp-Thr-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O ITGFVUYOLWBPQW-KKHAAJSZSA-N 0.000 description 1
- DKQCWCQRAMAFLN-UBHSHLNASA-N Asp-Trp-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(O)=O)C(O)=O DKQCWCQRAMAFLN-UBHSHLNASA-N 0.000 description 1
- KNDCWFXCFKSEBM-AVGNSLFASA-N Asp-Tyr-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O KNDCWFXCFKSEBM-AVGNSLFASA-N 0.000 description 1
- OTKUAVXGMREHRX-CFMVVWHZSA-N Asp-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CC=C(O)C=C1 OTKUAVXGMREHRX-CFMVVWHZSA-N 0.000 description 1
- NWAHPBGBDIFUFD-KKUMJFAQSA-N Asp-Tyr-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O NWAHPBGBDIFUFD-KKUMJFAQSA-N 0.000 description 1
- BPAUXFVCSYQDQX-JRQIVUDYSA-N Asp-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC(=O)O)N)O BPAUXFVCSYQDQX-JRQIVUDYSA-N 0.000 description 1
- WAEDSQFVZJUHLI-BYULHYEWSA-N Asp-Val-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WAEDSQFVZJUHLI-BYULHYEWSA-N 0.000 description 1
- OQMGSMNZVHYDTQ-ZKWXMUAHSA-N Asp-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)O)N OQMGSMNZVHYDTQ-ZKWXMUAHSA-N 0.000 description 1
- UXRVDHVARNBOIO-QSFUFRPTSA-N Asp-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC(=O)O)N UXRVDHVARNBOIO-QSFUFRPTSA-N 0.000 description 1
- GGBQDSHTXKQSLP-NHCYSSNCSA-N Asp-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N GGBQDSHTXKQSLP-NHCYSSNCSA-N 0.000 description 1
- QPDUWAUSSWGJSB-NGZCFLSTSA-N Asp-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N QPDUWAUSSWGJSB-NGZCFLSTSA-N 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 102100021277 Beta-secretase 2 Human genes 0.000 description 1
- 101710150190 Beta-secretase 2 Proteins 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 102000009122 CCAAT-Enhancer-Binding Proteins Human genes 0.000 description 1
- 108010048401 CCAAT-Enhancer-Binding Proteins Proteins 0.000 description 1
- 108091079001 CRISPR RNA Proteins 0.000 description 1
- 241000220450 Cajanus cajan Species 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 102000011727 Caspases Human genes 0.000 description 1
- 108010076667 Caspases Proteins 0.000 description 1
- YBSQGNFRWZKFMJ-UHFFFAOYSA-N Cerebroside B Natural products CCCCCCCCCCCCCCC(O)C(=O)NC(C(O)C=CCCC=C(C)CCCCCCCCC)COC1OC(CO)C(O)C(O)C1O YBSQGNFRWZKFMJ-UHFFFAOYSA-N 0.000 description 1
- 208000017667 Chronic Disease Diseases 0.000 description 1
- 102000029816 Collagenase Human genes 0.000 description 1
- 108020004394 Complementary RNA Proteins 0.000 description 1
- 208000011231 Crohn disease Diseases 0.000 description 1
- AEJSNWMRPXAKCW-WHFBIAKZSA-N Cys-Ala-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O AEJSNWMRPXAKCW-WHFBIAKZSA-N 0.000 description 1
- DCJNIJAWIRPPBB-CIUDSAMLSA-N Cys-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CS)N DCJNIJAWIRPPBB-CIUDSAMLSA-N 0.000 description 1
- JTNKVWLMDHIUOG-IHRRRGAJSA-N Cys-Arg-Phe Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JTNKVWLMDHIUOG-IHRRRGAJSA-N 0.000 description 1
- BYALSSDCQYHKMY-XGEHTFHBSA-N Cys-Arg-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CS)N)O BYALSSDCQYHKMY-XGEHTFHBSA-N 0.000 description 1
- SBMGKDLRJLYZCU-BIIVOSGPSA-N Cys-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CS)N)C(=O)O SBMGKDLRJLYZCU-BIIVOSGPSA-N 0.000 description 1
- UUERSUCTHOZPMG-SRVKXCTJSA-N Cys-Asn-Tyr Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UUERSUCTHOZPMG-SRVKXCTJSA-N 0.000 description 1
- VZKXOWRNJDEGLZ-WHFBIAKZSA-N Cys-Asp-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O VZKXOWRNJDEGLZ-WHFBIAKZSA-N 0.000 description 1
- XABFFGOGKOORCG-CIUDSAMLSA-N Cys-Asp-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XABFFGOGKOORCG-CIUDSAMLSA-N 0.000 description 1
- WXKWQSDHEXKKNC-ZKWXMUAHSA-N Cys-Asp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N WXKWQSDHEXKKNC-ZKWXMUAHSA-N 0.000 description 1
- ZIKWRNJXFIQECJ-CIUDSAMLSA-N Cys-Cys-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O ZIKWRNJXFIQECJ-CIUDSAMLSA-N 0.000 description 1
- GHUVBPIYQYXXEF-SRVKXCTJSA-N Cys-Cys-Tyr Chemical compound SC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 GHUVBPIYQYXXEF-SRVKXCTJSA-N 0.000 description 1
- YRKJQKATZOTUEN-ACZMJKKPSA-N Cys-Gln-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N YRKJQKATZOTUEN-ACZMJKKPSA-N 0.000 description 1
- HHABWQIFXZPZCK-ACZMJKKPSA-N Cys-Gln-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N HHABWQIFXZPZCK-ACZMJKKPSA-N 0.000 description 1
- DZIGZIIJIGGANI-FXQIFTODSA-N Cys-Glu-Gln Chemical compound SC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O DZIGZIIJIGGANI-FXQIFTODSA-N 0.000 description 1
- KABHAOSDMIYXTR-GUBZILKMSA-N Cys-Glu-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N KABHAOSDMIYXTR-GUBZILKMSA-N 0.000 description 1
- SBORMUFGKSCGEN-XHNCKOQMSA-N Cys-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N)C(=O)O SBORMUFGKSCGEN-XHNCKOQMSA-N 0.000 description 1
- WTNLLMQAFPOCTJ-GARJFASQSA-N Cys-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CS)N)C(=O)O WTNLLMQAFPOCTJ-GARJFASQSA-N 0.000 description 1
- ZLHPWFSAUJEEAN-KBIXCLLPSA-N Cys-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N ZLHPWFSAUJEEAN-KBIXCLLPSA-N 0.000 description 1
- OTXLNICGSXPGQF-KBIXCLLPSA-N Cys-Ile-Glu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTXLNICGSXPGQF-KBIXCLLPSA-N 0.000 description 1
- MRVSLWQRNWEROS-SVSWQMSJSA-N Cys-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CS)N MRVSLWQRNWEROS-SVSWQMSJSA-N 0.000 description 1
- KXUKWRVYDYIPSQ-CIUDSAMLSA-N Cys-Leu-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O KXUKWRVYDYIPSQ-CIUDSAMLSA-N 0.000 description 1
- ABLJDBFJPUWQQB-DCAQKATOSA-N Cys-Leu-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CS)N ABLJDBFJPUWQQB-DCAQKATOSA-N 0.000 description 1
- DYBIDOHFRRUMLW-CIUDSAMLSA-N Cys-Leu-Cys Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CS)C(=O)N[C@@H](CS)C(O)=O DYBIDOHFRRUMLW-CIUDSAMLSA-N 0.000 description 1
- HKALUUKHYNEDRS-GUBZILKMSA-N Cys-Leu-Gln Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HKALUUKHYNEDRS-GUBZILKMSA-N 0.000 description 1
- MKMKILWCRQLDFJ-DCAQKATOSA-N Cys-Lys-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MKMKILWCRQLDFJ-DCAQKATOSA-N 0.000 description 1
- CIVXDCMSSFGWAL-YUMQZZPRSA-N Cys-Lys-Gly Chemical compound C(CCN)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N CIVXDCMSSFGWAL-YUMQZZPRSA-N 0.000 description 1
- WTEACWBAULENKE-SRVKXCTJSA-N Cys-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CS)N WTEACWBAULENKE-SRVKXCTJSA-N 0.000 description 1
- BQWNEMPMDFSLCY-FHWLQOOXSA-N Cys-Phe-Phe-Gly Chemical compound C([C@H](NC(=O)[C@H](CS)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(O)=O)C1=CC=CC=C1 BQWNEMPMDFSLCY-FHWLQOOXSA-N 0.000 description 1
- MBRWOKXNHTUJMB-CIUDSAMLSA-N Cys-Pro-Glu Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O MBRWOKXNHTUJMB-CIUDSAMLSA-N 0.000 description 1
- NITLUESFANGEIW-BQBZGAKWSA-N Cys-Pro-Gly Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O NITLUESFANGEIW-BQBZGAKWSA-N 0.000 description 1
- KSMSFCBQBQPFAD-GUBZILKMSA-N Cys-Pro-Pro Chemical compound SC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 KSMSFCBQBQPFAD-GUBZILKMSA-N 0.000 description 1
- JUNZLDGUJZIUCO-IHRRRGAJSA-N Cys-Pro-Tyr Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CS)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O JUNZLDGUJZIUCO-IHRRRGAJSA-N 0.000 description 1
- KVCJEMHFLGVINV-ZLUOBGJFSA-N Cys-Ser-Asn Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(N)=O KVCJEMHFLGVINV-ZLUOBGJFSA-N 0.000 description 1
- ABLQPNMKLMFDQU-BIIVOSGPSA-N Cys-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CS)N)C(=O)O ABLQPNMKLMFDQU-BIIVOSGPSA-N 0.000 description 1
- YNJBLTDKTMKEET-ZLUOBGJFSA-N Cys-Ser-Ser Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O YNJBLTDKTMKEET-ZLUOBGJFSA-N 0.000 description 1
- JAHCWGSVNZXHRR-SVSWQMSJSA-N Cys-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CS)N JAHCWGSVNZXHRR-SVSWQMSJSA-N 0.000 description 1
- KFYPRIGJTICABD-XGEHTFHBSA-N Cys-Thr-Val Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N)O KFYPRIGJTICABD-XGEHTFHBSA-N 0.000 description 1
- SPJRFUJMDJGDRO-UBHSHLNASA-N Cys-Trp-Ser Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CS)N)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 SPJRFUJMDJGDRO-UBHSHLNASA-N 0.000 description 1
- BOMGEMDZTNZESV-QWRGUYRKSA-N Cys-Tyr-Gly Chemical compound SC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 BOMGEMDZTNZESV-QWRGUYRKSA-N 0.000 description 1
- UGPCUUWZXRMCIJ-KKUMJFAQSA-N Cys-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CS)N UGPCUUWZXRMCIJ-KKUMJFAQSA-N 0.000 description 1
- KZZYVYWSXMFYEC-DCAQKATOSA-N Cys-Val-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KZZYVYWSXMFYEC-DCAQKATOSA-N 0.000 description 1
- 102000004328 Cytochrome P-450 CYP3A Human genes 0.000 description 1
- 108010081668 Cytochrome P-450 CYP3A Proteins 0.000 description 1
- 108010015742 Cytochrome P-450 Enzyme System Proteins 0.000 description 1
- 102000003849 Cytochrome P450 Human genes 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- 239000004375 Dextrin Substances 0.000 description 1
- 229920001353 Dextrin Polymers 0.000 description 1
- 101150007095 Dnajb1 gene Proteins 0.000 description 1
- 101150068427 EP300 gene Proteins 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 101150106966 FOXO1 gene Proteins 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- NNQHEEQNPQYPGL-FXQIFTODSA-N Gln-Ala-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O NNQHEEQNPQYPGL-FXQIFTODSA-N 0.000 description 1
- RZSLYUUFFVHFRQ-FXQIFTODSA-N Gln-Ala-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O RZSLYUUFFVHFRQ-FXQIFTODSA-N 0.000 description 1
- HHWQMFIGMMOVFK-WDSKDSINSA-N Gln-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O HHWQMFIGMMOVFK-WDSKDSINSA-N 0.000 description 1
- MLZRSFQRBDNJON-GUBZILKMSA-N Gln-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MLZRSFQRBDNJON-GUBZILKMSA-N 0.000 description 1
- XXLBHPPXDUWYAG-XQXXSGGOSA-N Gln-Ala-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XXLBHPPXDUWYAG-XQXXSGGOSA-N 0.000 description 1
- KWUSGAIFNHQCBY-DCAQKATOSA-N Gln-Arg-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O KWUSGAIFNHQCBY-DCAQKATOSA-N 0.000 description 1
- DLOHWQXXGMEZDW-CIUDSAMLSA-N Gln-Arg-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O DLOHWQXXGMEZDW-CIUDSAMLSA-N 0.000 description 1
- YNNXQZDEOCYJJL-CIUDSAMLSA-N Gln-Arg-Asp Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)CN=C(N)N YNNXQZDEOCYJJL-CIUDSAMLSA-N 0.000 description 1
- WOACHWLUOFZLGJ-GUBZILKMSA-N Gln-Arg-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O WOACHWLUOFZLGJ-GUBZILKMSA-N 0.000 description 1
- LZRMPXRYLLTAJX-GUBZILKMSA-N Gln-Arg-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O LZRMPXRYLLTAJX-GUBZILKMSA-N 0.000 description 1
- INFBPLSHYFALDE-ACZMJKKPSA-N Gln-Asn-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O INFBPLSHYFALDE-ACZMJKKPSA-N 0.000 description 1
- OETQLUYCMBARHJ-CIUDSAMLSA-N Gln-Asn-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OETQLUYCMBARHJ-CIUDSAMLSA-N 0.000 description 1
- AAOBFSKXAVIORT-GUBZILKMSA-N Gln-Asn-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O AAOBFSKXAVIORT-GUBZILKMSA-N 0.000 description 1
- KWLMLNHADZIJIS-CIUDSAMLSA-N Gln-Asn-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)N)N KWLMLNHADZIJIS-CIUDSAMLSA-N 0.000 description 1
- RMOCFPBLHAOTDU-ACZMJKKPSA-N Gln-Asn-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RMOCFPBLHAOTDU-ACZMJKKPSA-N 0.000 description 1
- GMGKDVVBSVVKCT-NUMRIWBASA-N Gln-Asn-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GMGKDVVBSVVKCT-NUMRIWBASA-N 0.000 description 1
- BTSPOOHJBYJRKO-CIUDSAMLSA-N Gln-Asp-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O BTSPOOHJBYJRKO-CIUDSAMLSA-N 0.000 description 1
- XEYMBRRKIFYQMF-GUBZILKMSA-N Gln-Asp-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XEYMBRRKIFYQMF-GUBZILKMSA-N 0.000 description 1
- JFSNBQJNDMXMQF-XHNCKOQMSA-N Gln-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O JFSNBQJNDMXMQF-XHNCKOQMSA-N 0.000 description 1
- IXFVOPOHSRKJNG-LAEOZQHASA-N Gln-Asp-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O IXFVOPOHSRKJNG-LAEOZQHASA-N 0.000 description 1
- PCKOTDPDHIBGRW-CIUDSAMLSA-N Gln-Cys-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCC(=O)N)N)CN=C(N)N PCKOTDPDHIBGRW-CIUDSAMLSA-N 0.000 description 1
- LPJVZYMINRLCQA-AVGNSLFASA-N Gln-Cys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCC(=O)N)N LPJVZYMINRLCQA-AVGNSLFASA-N 0.000 description 1
- COYGBRTZEVWZBW-XKBZYTNZSA-N Gln-Cys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCC(N)=O COYGBRTZEVWZBW-XKBZYTNZSA-N 0.000 description 1
- NKCZYEDZTKOFBG-GUBZILKMSA-N Gln-Gln-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NKCZYEDZTKOFBG-GUBZILKMSA-N 0.000 description 1
- QYKBTDOAMKORGL-FXQIFTODSA-N Gln-Gln-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N QYKBTDOAMKORGL-FXQIFTODSA-N 0.000 description 1
- XFKUFUJECJUQTQ-CIUDSAMLSA-N Gln-Gln-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XFKUFUJECJUQTQ-CIUDSAMLSA-N 0.000 description 1
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 1
- GPISLLFQNHELLK-DCAQKATOSA-N Gln-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N GPISLLFQNHELLK-DCAQKATOSA-N 0.000 description 1
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 1
- GHYJGDCPHMSFEJ-GUBZILKMSA-N Gln-Gln-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N GHYJGDCPHMSFEJ-GUBZILKMSA-N 0.000 description 1
- NPTGGVQJYRSMCM-GLLZPBPUSA-N Gln-Gln-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NPTGGVQJYRSMCM-GLLZPBPUSA-N 0.000 description 1
- MCAVASRGVBVPMX-FXQIFTODSA-N Gln-Glu-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MCAVASRGVBVPMX-FXQIFTODSA-N 0.000 description 1
- LWDGZZGWDMHBOF-FXQIFTODSA-N Gln-Glu-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O LWDGZZGWDMHBOF-FXQIFTODSA-N 0.000 description 1
- KCJJFESQRXGTGC-BQBZGAKWSA-N Gln-Glu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O KCJJFESQRXGTGC-BQBZGAKWSA-N 0.000 description 1
- JHPFPROFOAJRFN-IHRRRGAJSA-N Gln-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O JHPFPROFOAJRFN-IHRRRGAJSA-N 0.000 description 1
- XJKAKYXMFHUIHT-AUTRQRHGSA-N Gln-Glu-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N XJKAKYXMFHUIHT-AUTRQRHGSA-N 0.000 description 1
- JEFZIKRIDLHOIF-BYPYZUCNSA-N Gln-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(O)=O JEFZIKRIDLHOIF-BYPYZUCNSA-N 0.000 description 1
- XKBASPWPBXNVLQ-WDSKDSINSA-N Gln-Gly-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XKBASPWPBXNVLQ-WDSKDSINSA-N 0.000 description 1
- HVQCEQTUSWWFOS-WDSKDSINSA-N Gln-Gly-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N HVQCEQTUSWWFOS-WDSKDSINSA-N 0.000 description 1
- QQAPDATZKKTBIY-YUMQZZPRSA-N Gln-Gly-Met Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O QQAPDATZKKTBIY-YUMQZZPRSA-N 0.000 description 1
- VGTDBGYFVWOQTI-RYUDHWBXSA-N Gln-Gly-Phe Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VGTDBGYFVWOQTI-RYUDHWBXSA-N 0.000 description 1
- NSORZJXKUQFEKL-JGVFFNPUSA-N Gln-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCC(=O)N)N)C(=O)O NSORZJXKUQFEKL-JGVFFNPUSA-N 0.000 description 1
- DWDBJWAXPXXYLP-SRVKXCTJSA-N Gln-His-Arg Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N DWDBJWAXPXXYLP-SRVKXCTJSA-N 0.000 description 1
- NROSLUJMIQGFKS-IUCAKERBSA-N Gln-His-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N NROSLUJMIQGFKS-IUCAKERBSA-N 0.000 description 1
- RGAOLBZBLOJUTP-GRLWGSQLSA-N Gln-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H](CCC(=O)N)N RGAOLBZBLOJUTP-GRLWGSQLSA-N 0.000 description 1
- ZNTDJIMJKNNSLR-RWRJDSDZSA-N Gln-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZNTDJIMJKNNSLR-RWRJDSDZSA-N 0.000 description 1
- LGIKBBLQVSWUGK-DCAQKATOSA-N Gln-Leu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGIKBBLQVSWUGK-DCAQKATOSA-N 0.000 description 1
- QKCZZAZNMMVICF-DCAQKATOSA-N Gln-Leu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O QKCZZAZNMMVICF-DCAQKATOSA-N 0.000 description 1
- CAXXTYYGFYTBPV-IUCAKERBSA-N Gln-Leu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CAXXTYYGFYTBPV-IUCAKERBSA-N 0.000 description 1
- XFAUJGNLHIGXET-AVGNSLFASA-N Gln-Leu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XFAUJGNLHIGXET-AVGNSLFASA-N 0.000 description 1
- IULKWYSYZSURJK-AVGNSLFASA-N Gln-Leu-Lys Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O IULKWYSYZSURJK-AVGNSLFASA-N 0.000 description 1
- SHAUZYVSXAMYAZ-JYJNAYRXSA-N Gln-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N SHAUZYVSXAMYAZ-JYJNAYRXSA-N 0.000 description 1
- ZBKUIQNCRIYVGH-SDDRHHMPSA-N Gln-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZBKUIQNCRIYVGH-SDDRHHMPSA-N 0.000 description 1
- IOFDDSNZJDIGPB-GVXVVHGQSA-N Gln-Leu-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IOFDDSNZJDIGPB-GVXVVHGQSA-N 0.000 description 1
- IHSGESFHTMFHRB-GUBZILKMSA-N Gln-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(N)=O IHSGESFHTMFHRB-GUBZILKMSA-N 0.000 description 1
- GURIQZQSTBBHRV-SRVKXCTJSA-N Gln-Lys-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GURIQZQSTBBHRV-SRVKXCTJSA-N 0.000 description 1
- HPCOBEHVEHWREJ-DCAQKATOSA-N Gln-Lys-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HPCOBEHVEHWREJ-DCAQKATOSA-N 0.000 description 1
- FKXCBKCOSVIGCT-AVGNSLFASA-N Gln-Lys-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O FKXCBKCOSVIGCT-AVGNSLFASA-N 0.000 description 1
- WEAVZFWWIPIANL-SRVKXCTJSA-N Gln-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N WEAVZFWWIPIANL-SRVKXCTJSA-N 0.000 description 1
- CELXWPDNIGWCJN-WDCWCFNPSA-N Gln-Lys-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CELXWPDNIGWCJN-WDCWCFNPSA-N 0.000 description 1
- MSHXWFKYXJTLEZ-CIUDSAMLSA-N Gln-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MSHXWFKYXJTLEZ-CIUDSAMLSA-N 0.000 description 1
- NMYFPKCIGUJMIK-GUBZILKMSA-N Gln-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N NMYFPKCIGUJMIK-GUBZILKMSA-N 0.000 description 1
- QMVCEWKHIUHTSD-GUBZILKMSA-N Gln-Met-Glu Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N QMVCEWKHIUHTSD-GUBZILKMSA-N 0.000 description 1
- LVRKAFPPFJRIOF-GARJFASQSA-N Gln-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N LVRKAFPPFJRIOF-GARJFASQSA-N 0.000 description 1
- LHMWTCWZARHLPV-CIUDSAMLSA-N Gln-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N LHMWTCWZARHLPV-CIUDSAMLSA-N 0.000 description 1
- JNVGVECJCOZHCN-DRZSPHRISA-N Gln-Phe-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O JNVGVECJCOZHCN-DRZSPHRISA-N 0.000 description 1
- QBEWLBKBGXVVPD-RYUDHWBXSA-N Gln-Phe-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N QBEWLBKBGXVVPD-RYUDHWBXSA-N 0.000 description 1
- WHVLABLIJYGVEK-QEWYBTABSA-N Gln-Phe-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WHVLABLIJYGVEK-QEWYBTABSA-N 0.000 description 1
- OZEQPCDLCDRCGY-SOUVJXGZSA-N Gln-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCC(=O)N)N)C(=O)O OZEQPCDLCDRCGY-SOUVJXGZSA-N 0.000 description 1
- XUMFMAVDHQDATI-DCAQKATOSA-N Gln-Pro-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XUMFMAVDHQDATI-DCAQKATOSA-N 0.000 description 1
- NPMFDZGLKBNFOO-SRVKXCTJSA-N Gln-Pro-His Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NPMFDZGLKBNFOO-SRVKXCTJSA-N 0.000 description 1
- MFORDNZDKAVNSR-SRVKXCTJSA-N Gln-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O MFORDNZDKAVNSR-SRVKXCTJSA-N 0.000 description 1
- VNTGPISAOMAXRK-CIUDSAMLSA-N Gln-Pro-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O VNTGPISAOMAXRK-CIUDSAMLSA-N 0.000 description 1
- LGWNISYVKDNJRP-FXQIFTODSA-N Gln-Ser-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGWNISYVKDNJRP-FXQIFTODSA-N 0.000 description 1
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 1
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 1
- ZGHMRONFHDVXEF-AVGNSLFASA-N Gln-Ser-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ZGHMRONFHDVXEF-AVGNSLFASA-N 0.000 description 1
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 1
- OTQSTOXRUBVWAP-NRPADANISA-N Gln-Ser-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O OTQSTOXRUBVWAP-NRPADANISA-N 0.000 description 1
- PAOHIZNRJNIXQY-XQXXSGGOSA-N Gln-Thr-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O PAOHIZNRJNIXQY-XQXXSGGOSA-N 0.000 description 1
- DUGYCMAIAKAQPB-GLLZPBPUSA-N Gln-Thr-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O DUGYCMAIAKAQPB-GLLZPBPUSA-N 0.000 description 1
- OUBUHIODTNUUTC-WDCWCFNPSA-N Gln-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O OUBUHIODTNUUTC-WDCWCFNPSA-N 0.000 description 1
- RONJIBWTGKVKFY-HTUGSXCWSA-N Gln-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O RONJIBWTGKVKFY-HTUGSXCWSA-N 0.000 description 1
- HLRLXVPRJJITSK-IFFSRLJSSA-N Gln-Thr-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HLRLXVPRJJITSK-IFFSRLJSSA-N 0.000 description 1
- FVEMBYKESRUFBG-SZMVWBNQSA-N Gln-Trp-His Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)NC(=O)[C@H](CCC(=O)N)N FVEMBYKESRUFBG-SZMVWBNQSA-N 0.000 description 1
- YMCPEHDGTRUOHO-SXNHZJKMSA-N Gln-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)N)N YMCPEHDGTRUOHO-SXNHZJKMSA-N 0.000 description 1
- WBBVTGIFQIZBHP-JBACZVJFSA-N Gln-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CCC(=O)N)N WBBVTGIFQIZBHP-JBACZVJFSA-N 0.000 description 1
- OACQOWPRWGNKTP-AVGNSLFASA-N Gln-Tyr-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O OACQOWPRWGNKTP-AVGNSLFASA-N 0.000 description 1
- UBRQJXFDVZNYJP-AVGNSLFASA-N Gln-Tyr-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UBRQJXFDVZNYJP-AVGNSLFASA-N 0.000 description 1
- VDMABHYXBULDGN-LAEOZQHASA-N Gln-Val-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O VDMABHYXBULDGN-LAEOZQHASA-N 0.000 description 1
- QGWXAMDECCKGRU-XVKPBYJWSA-N Gln-Val-Gly Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(N)=O)C(=O)NCC(O)=O QGWXAMDECCKGRU-XVKPBYJWSA-N 0.000 description 1
- ZMXZGYLINVNTKH-DZKIICNBSA-N Gln-Val-Phe Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZMXZGYLINVNTKH-DZKIICNBSA-N 0.000 description 1
- VYOILACOFPPNQH-UMNHJUIQSA-N Gln-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N VYOILACOFPPNQH-UMNHJUIQSA-N 0.000 description 1
- RLZBLVSJDFHDBL-KBIXCLLPSA-N Glu-Ala-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RLZBLVSJDFHDBL-KBIXCLLPSA-N 0.000 description 1
- HUWSBFYAGXCXKC-CIUDSAMLSA-N Glu-Ala-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O HUWSBFYAGXCXKC-CIUDSAMLSA-N 0.000 description 1
- ATRHMOJQJWPVBQ-DRZSPHRISA-N Glu-Ala-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ATRHMOJQJWPVBQ-DRZSPHRISA-N 0.000 description 1
- KBKGRMNVKPSQIF-XDTLVQLUSA-N Glu-Ala-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KBKGRMNVKPSQIF-XDTLVQLUSA-N 0.000 description 1
- NCWOMXABNYEPLY-NRPADANISA-N Glu-Ala-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O NCWOMXABNYEPLY-NRPADANISA-N 0.000 description 1
- DIXKFOPPGWKZLY-CIUDSAMLSA-N Glu-Arg-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O DIXKFOPPGWKZLY-CIUDSAMLSA-N 0.000 description 1
- VTTSANCGJWLPNC-ZPFDUUQYSA-N Glu-Arg-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VTTSANCGJWLPNC-ZPFDUUQYSA-N 0.000 description 1
- LTUVYLVIZHJCOQ-KKUMJFAQSA-N Glu-Arg-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LTUVYLVIZHJCOQ-KKUMJFAQSA-N 0.000 description 1
- VPKBCVUDBNINAH-GARJFASQSA-N Glu-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O VPKBCVUDBNINAH-GARJFASQSA-N 0.000 description 1
- SRZLHYPAOXBBSB-HJGDQZAQSA-N Glu-Arg-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SRZLHYPAOXBBSB-HJGDQZAQSA-N 0.000 description 1
- FLLRAEJOLZPSMN-CIUDSAMLSA-N Glu-Asn-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FLLRAEJOLZPSMN-CIUDSAMLSA-N 0.000 description 1
- MLCPTRRNICEKIS-FXQIFTODSA-N Glu-Asn-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MLCPTRRNICEKIS-FXQIFTODSA-N 0.000 description 1
- YYOBUPFZLKQUAX-FXQIFTODSA-N Glu-Asn-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O YYOBUPFZLKQUAX-FXQIFTODSA-N 0.000 description 1
- AFODTOLGSZQDSL-PEFMBERDSA-N Glu-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N AFODTOLGSZQDSL-PEFMBERDSA-N 0.000 description 1
- SBYVDRJAXWSXQL-AVGNSLFASA-N Glu-Asn-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SBYVDRJAXWSXQL-AVGNSLFASA-N 0.000 description 1
- VAZZOGXDUQSVQF-NUMRIWBASA-N Glu-Asn-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N)O VAZZOGXDUQSVQF-NUMRIWBASA-N 0.000 description 1
- PCBBLFVHTYNQGG-LAEOZQHASA-N Glu-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N PCBBLFVHTYNQGG-LAEOZQHASA-N 0.000 description 1
- QPRZKNOOOBWXSU-CIUDSAMLSA-N Glu-Asp-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N QPRZKNOOOBWXSU-CIUDSAMLSA-N 0.000 description 1
- GZWOBWMOMPFPCD-CIUDSAMLSA-N Glu-Asp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N GZWOBWMOMPFPCD-CIUDSAMLSA-N 0.000 description 1
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 1
- SBCYJMOOHUDWDA-NUMRIWBASA-N Glu-Asp-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SBCYJMOOHUDWDA-NUMRIWBASA-N 0.000 description 1
- CYHBMLHCQXXCCT-AVGNSLFASA-N Glu-Asp-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CYHBMLHCQXXCCT-AVGNSLFASA-N 0.000 description 1
- ZZIFPJZQHRJERU-WDSKDSINSA-N Glu-Cys-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)NCC(O)=O ZZIFPJZQHRJERU-WDSKDSINSA-N 0.000 description 1
- ISXJHXGYMJKXOI-GUBZILKMSA-N Glu-Cys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCC(O)=O ISXJHXGYMJKXOI-GUBZILKMSA-N 0.000 description 1
- UENPHLAAKDPZQY-XKBZYTNZSA-N Glu-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCC(=O)O)N)O UENPHLAAKDPZQY-XKBZYTNZSA-N 0.000 description 1
- PXHABOCPJVTGEK-BQBZGAKWSA-N Glu-Gln-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O PXHABOCPJVTGEK-BQBZGAKWSA-N 0.000 description 1
- UMIRPYLZFKOEOH-YVNDNENWSA-N Glu-Gln-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UMIRPYLZFKOEOH-YVNDNENWSA-N 0.000 description 1
- SJPMNHCEWPTRBR-BQBZGAKWSA-N Glu-Glu-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SJPMNHCEWPTRBR-BQBZGAKWSA-N 0.000 description 1
- AUTNXSQEVVHSJK-YVNDNENWSA-N Glu-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O AUTNXSQEVVHSJK-YVNDNENWSA-N 0.000 description 1
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 1
- AIGROOHQXCACHL-WDSKDSINSA-N Glu-Gly-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O AIGROOHQXCACHL-WDSKDSINSA-N 0.000 description 1
- VOORMNJKNBGYGK-YUMQZZPRSA-N Glu-Gly-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)O)N VOORMNJKNBGYGK-YUMQZZPRSA-N 0.000 description 1
- HILMIYALTUQTRC-XVKPBYJWSA-N Glu-Gly-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HILMIYALTUQTRC-XVKPBYJWSA-N 0.000 description 1
- DVLZZEPUNFEUBW-AVGNSLFASA-N Glu-His-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)O)N DVLZZEPUNFEUBW-AVGNSLFASA-N 0.000 description 1
- QXDXIXFSFHUYAX-MNXVOIDGSA-N Glu-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O QXDXIXFSFHUYAX-MNXVOIDGSA-N 0.000 description 1
- WTMZXOPHTIVFCP-QEWYBTABSA-N Glu-Ile-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 WTMZXOPHTIVFCP-QEWYBTABSA-N 0.000 description 1
- ZHNHJYYFCGUZNQ-KBIXCLLPSA-N Glu-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O ZHNHJYYFCGUZNQ-KBIXCLLPSA-N 0.000 description 1
- KRRFFAHEAOCBCQ-SIUGBPQLSA-N Glu-Ile-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KRRFFAHEAOCBCQ-SIUGBPQLSA-N 0.000 description 1
- HVYWQYLBVXMXSV-GUBZILKMSA-N Glu-Leu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HVYWQYLBVXMXSV-GUBZILKMSA-N 0.000 description 1
- VSRCAOIHMGCIJK-SRVKXCTJSA-N Glu-Leu-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VSRCAOIHMGCIJK-SRVKXCTJSA-N 0.000 description 1
- PJBVXVBTTFZPHJ-GUBZILKMSA-N Glu-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N PJBVXVBTTFZPHJ-GUBZILKMSA-N 0.000 description 1
- DNPCBMNFQVTHMA-DCAQKATOSA-N Glu-Leu-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DNPCBMNFQVTHMA-DCAQKATOSA-N 0.000 description 1
- IRXNJYPKBVERCW-DCAQKATOSA-N Glu-Leu-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IRXNJYPKBVERCW-DCAQKATOSA-N 0.000 description 1
- ATVYZJGOZLVXDK-IUCAKERBSA-N Glu-Leu-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O ATVYZJGOZLVXDK-IUCAKERBSA-N 0.000 description 1
- NWOUBJNMZDDGDT-AVGNSLFASA-N Glu-Leu-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NWOUBJNMZDDGDT-AVGNSLFASA-N 0.000 description 1
- MWMJCGBSIORNCD-AVGNSLFASA-N Glu-Leu-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O MWMJCGBSIORNCD-AVGNSLFASA-N 0.000 description 1
- IVGJYOOGJLFKQE-AVGNSLFASA-N Glu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N IVGJYOOGJLFKQE-AVGNSLFASA-N 0.000 description 1
- IOUQWHIEQYQVFD-JYJNAYRXSA-N Glu-Leu-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IOUQWHIEQYQVFD-JYJNAYRXSA-N 0.000 description 1
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 1
- MFNUFCFRAZPJFW-JYJNAYRXSA-N Glu-Lys-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFNUFCFRAZPJFW-JYJNAYRXSA-N 0.000 description 1
- RBXSZQRSEGYDFG-GUBZILKMSA-N Glu-Lys-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O RBXSZQRSEGYDFG-GUBZILKMSA-N 0.000 description 1
- SUIAHERNFYRBDZ-GVXVVHGQSA-N Glu-Lys-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O SUIAHERNFYRBDZ-GVXVVHGQSA-N 0.000 description 1
- ZQYZDDXTNQXUJH-CIUDSAMLSA-N Glu-Met-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(=O)O)N ZQYZDDXTNQXUJH-CIUDSAMLSA-N 0.000 description 1
- LGWUJBCIFGVBSJ-CIUDSAMLSA-N Glu-Met-Cys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N LGWUJBCIFGVBSJ-CIUDSAMLSA-N 0.000 description 1
- QMOSCLNJVKSHHU-YUMQZZPRSA-N Glu-Met-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O QMOSCLNJVKSHHU-YUMQZZPRSA-N 0.000 description 1
- CBEUFCJRFNZMCU-SRVKXCTJSA-N Glu-Met-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O CBEUFCJRFNZMCU-SRVKXCTJSA-N 0.000 description 1
- HQOGXFLBAKJUMH-CIUDSAMLSA-N Glu-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N HQOGXFLBAKJUMH-CIUDSAMLSA-N 0.000 description 1
- LHIPZASLKPYDPI-AVGNSLFASA-N Glu-Phe-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O LHIPZASLKPYDPI-AVGNSLFASA-N 0.000 description 1
- QNJNPKSWAHPYGI-JYJNAYRXSA-N Glu-Phe-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=CC=C1 QNJNPKSWAHPYGI-JYJNAYRXSA-N 0.000 description 1
- YTRBQAQSUDSIQE-FHWLQOOXSA-N Glu-Phe-Phe Chemical compound C([C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 YTRBQAQSUDSIQE-FHWLQOOXSA-N 0.000 description 1
- TWYFJOHWGCCRIR-DCAQKATOSA-N Glu-Pro-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O TWYFJOHWGCCRIR-DCAQKATOSA-N 0.000 description 1
- UDEPRBFQTWGLCW-CIUDSAMLSA-N Glu-Pro-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O UDEPRBFQTWGLCW-CIUDSAMLSA-N 0.000 description 1
- HLYCMRDRWGSTPZ-CIUDSAMLSA-N Glu-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CS)C(=O)O HLYCMRDRWGSTPZ-CIUDSAMLSA-N 0.000 description 1
- SYWCGQOIIARSIX-SRVKXCTJSA-N Glu-Pro-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O SYWCGQOIIARSIX-SRVKXCTJSA-N 0.000 description 1
- DCBSZJJHOTXMHY-DCAQKATOSA-N Glu-Pro-Pro Chemical compound OC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DCBSZJJHOTXMHY-DCAQKATOSA-N 0.000 description 1
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 1
- GMVCSRBOSIUTFC-FXQIFTODSA-N Glu-Ser-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMVCSRBOSIUTFC-FXQIFTODSA-N 0.000 description 1
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 1
- SYAYROHMAIHWFB-KBIXCLLPSA-N Glu-Ser-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SYAYROHMAIHWFB-KBIXCLLPSA-N 0.000 description 1
- WXONSNSSBYQGNN-AVGNSLFASA-N Glu-Ser-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O WXONSNSSBYQGNN-AVGNSLFASA-N 0.000 description 1
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 1
- TWYSSILQABLLME-HJGDQZAQSA-N Glu-Thr-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O TWYSSILQABLLME-HJGDQZAQSA-N 0.000 description 1
- JVYNYWXHZWVJEF-NUMRIWBASA-N Glu-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O JVYNYWXHZWVJEF-NUMRIWBASA-N 0.000 description 1
- ZGXGVBYEJGVJMV-HJGDQZAQSA-N Glu-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O ZGXGVBYEJGVJMV-HJGDQZAQSA-N 0.000 description 1
- UMZHHILWZBFPGL-LOKLDPHHSA-N Glu-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O UMZHHILWZBFPGL-LOKLDPHHSA-N 0.000 description 1
- CAQXJMUDOLSBPF-SUSMZKCASA-N Glu-Thr-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAQXJMUDOLSBPF-SUSMZKCASA-N 0.000 description 1
- CGWHAXBNGYQBBK-JBACZVJFSA-N Glu-Trp-Tyr Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CCC(O)=O)N)C(O)=O)C1=CC=C(O)C=C1 CGWHAXBNGYQBBK-JBACZVJFSA-N 0.000 description 1
- HVKAAUOFFTUSAA-XDTLVQLUSA-N Glu-Tyr-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O HVKAAUOFFTUSAA-XDTLVQLUSA-N 0.000 description 1
- VXEFAWJTFAUDJK-AVGNSLFASA-N Glu-Tyr-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O VXEFAWJTFAUDJK-AVGNSLFASA-N 0.000 description 1
- BKMOHWJHXQLFEX-IRIUXVKKSA-N Glu-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCC(=O)O)N)O BKMOHWJHXQLFEX-IRIUXVKKSA-N 0.000 description 1
- LSYFGBRDBIQYAQ-FHWLQOOXSA-N Glu-Tyr-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LSYFGBRDBIQYAQ-FHWLQOOXSA-N 0.000 description 1
- HBMRTXJZQDVRFT-DZKIICNBSA-N Glu-Tyr-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O HBMRTXJZQDVRFT-DZKIICNBSA-N 0.000 description 1
- KIEICAOUSNYOLM-NRPADANISA-N Glu-Val-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O KIEICAOUSNYOLM-NRPADANISA-N 0.000 description 1
- MLILEEIVMRUYBX-NHCYSSNCSA-N Glu-Val-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O MLILEEIVMRUYBX-NHCYSSNCSA-N 0.000 description 1
- UZWUBBRJWFTHTD-LAEOZQHASA-N Glu-Val-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O UZWUBBRJWFTHTD-LAEOZQHASA-N 0.000 description 1
- YPHPEHMXOYTEQG-LAEOZQHASA-N Glu-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O YPHPEHMXOYTEQG-LAEOZQHASA-N 0.000 description 1
- LZEUDRYSAZAJIO-AUTRQRHGSA-N Glu-Val-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LZEUDRYSAZAJIO-AUTRQRHGSA-N 0.000 description 1
- VIPDPMHGICREIS-GVXVVHGQSA-N Glu-Val-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VIPDPMHGICREIS-GVXVVHGQSA-N 0.000 description 1
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 1
- FVGOGEGGQLNZGH-DZKIICNBSA-N Glu-Val-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FVGOGEGGQLNZGH-DZKIICNBSA-N 0.000 description 1
- RMWAOBGCZZSJHE-UMNHJUIQSA-N Glu-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N RMWAOBGCZZSJHE-UMNHJUIQSA-N 0.000 description 1
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 1
- PYTZFYUXZZHOAD-WHFBIAKZSA-N Gly-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)CN PYTZFYUXZZHOAD-WHFBIAKZSA-N 0.000 description 1
- GQGAFTPXAPKSCF-WHFBIAKZSA-N Gly-Ala-Cys Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(=O)O GQGAFTPXAPKSCF-WHFBIAKZSA-N 0.000 description 1
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 1
- MZZSCEANQDPJER-ONGXEEELSA-N Gly-Ala-Phe Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MZZSCEANQDPJER-ONGXEEELSA-N 0.000 description 1
- QSDKBRMVXSWAQE-BFHQHQDPSA-N Gly-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN QSDKBRMVXSWAQE-BFHQHQDPSA-N 0.000 description 1
- JRDYDYXZKFNNRQ-XPUUQOCRSA-N Gly-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN JRDYDYXZKFNNRQ-XPUUQOCRSA-N 0.000 description 1
- JXYMPBCYRKWJEE-BQBZGAKWSA-N Gly-Arg-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O JXYMPBCYRKWJEE-BQBZGAKWSA-N 0.000 description 1
- XUDLUKYPXQDCRX-BQBZGAKWSA-N Gly-Arg-Asn Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O XUDLUKYPXQDCRX-BQBZGAKWSA-N 0.000 description 1
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 1
- OVSKVOOUFAKODB-UWVGGRQHSA-N Gly-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N OVSKVOOUFAKODB-UWVGGRQHSA-N 0.000 description 1
- KFMBRBPXHVMDFN-UWVGGRQHSA-N Gly-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCNC(N)=N KFMBRBPXHVMDFN-UWVGGRQHSA-N 0.000 description 1
- VXKCPBPQEKKERH-IUCAKERBSA-N Gly-Arg-Pro Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N1CCC[C@H]1C(O)=O VXKCPBPQEKKERH-IUCAKERBSA-N 0.000 description 1
- NZAFOTBEULLEQB-WDSKDSINSA-N Gly-Asn-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN NZAFOTBEULLEQB-WDSKDSINSA-N 0.000 description 1
- IWAXHBCACVWNHT-BQBZGAKWSA-N Gly-Asp-Arg Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IWAXHBCACVWNHT-BQBZGAKWSA-N 0.000 description 1
- FUTAPPOITCCWTH-WHFBIAKZSA-N Gly-Asp-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FUTAPPOITCCWTH-WHFBIAKZSA-N 0.000 description 1
- FZQLXNIMCPJVJE-YUMQZZPRSA-N Gly-Asp-Leu Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O FZQLXNIMCPJVJE-YUMQZZPRSA-N 0.000 description 1
- JPWIMMUNWUKOAD-STQMWFEESA-N Gly-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN JPWIMMUNWUKOAD-STQMWFEESA-N 0.000 description 1
- TZOVVRJYUDETQG-RCOVLWMOSA-N Gly-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN TZOVVRJYUDETQG-RCOVLWMOSA-N 0.000 description 1
- XXGQRGQPGFYECI-WDSKDSINSA-N Gly-Cys-Glu Chemical compound NCC(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCC(O)=O XXGQRGQPGFYECI-WDSKDSINSA-N 0.000 description 1
- CEXINUGNTZFNRY-BYPYZUCNSA-N Gly-Cys-Gly Chemical compound [NH3+]CC(=O)N[C@@H](CS)C(=O)NCC([O-])=O CEXINUGNTZFNRY-BYPYZUCNSA-N 0.000 description 1
- GHHAMXVMWXMGSV-STQMWFEESA-N Gly-Cys-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CS)NC(=O)CN)C(O)=O)=CNC2=C1 GHHAMXVMWXMGSV-STQMWFEESA-N 0.000 description 1
- PNMUAGGSDZXTHX-BYPYZUCNSA-N Gly-Gln Chemical compound NCC(=O)N[C@H](C(O)=O)CCC(N)=O PNMUAGGSDZXTHX-BYPYZUCNSA-N 0.000 description 1
- DTRUBYPMMVPQPD-YUMQZZPRSA-N Gly-Gln-Arg Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DTRUBYPMMVPQPD-YUMQZZPRSA-N 0.000 description 1
- JMQFHZWESBGPFC-WDSKDSINSA-N Gly-Gln-Asp Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JMQFHZWESBGPFC-WDSKDSINSA-N 0.000 description 1
- VUUOMYFPWDYETE-WDSKDSINSA-N Gly-Gln-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN VUUOMYFPWDYETE-WDSKDSINSA-N 0.000 description 1
- QPDUVFSVVAOUHE-XVKPBYJWSA-N Gly-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)CN)C(O)=O QPDUVFSVVAOUHE-XVKPBYJWSA-N 0.000 description 1
- HDNXXTBKOJKWNN-WDSKDSINSA-N Gly-Glu-Asn Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O HDNXXTBKOJKWNN-WDSKDSINSA-N 0.000 description 1
- BIRKKBCSAIHDDF-WDSKDSINSA-N Gly-Glu-Cys Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O BIRKKBCSAIHDDF-WDSKDSINSA-N 0.000 description 1
- ZQIMMEYPEXIYBB-IUCAKERBSA-N Gly-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)CN ZQIMMEYPEXIYBB-IUCAKERBSA-N 0.000 description 1
- QSVCIFZPGLOZGH-WDSKDSINSA-N Gly-Glu-Ser Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QSVCIFZPGLOZGH-WDSKDSINSA-N 0.000 description 1
- JSNNHGHYGYMVCK-XVKPBYJWSA-N Gly-Glu-Val Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O JSNNHGHYGYMVCK-XVKPBYJWSA-N 0.000 description 1
- HQRHFUYMGCHHJS-LURJTMIESA-N Gly-Gly-Arg Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N HQRHFUYMGCHHJS-LURJTMIESA-N 0.000 description 1
- KMSGYZQRXPUKGI-BYPYZUCNSA-N Gly-Gly-Asn Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(N)=O KMSGYZQRXPUKGI-BYPYZUCNSA-N 0.000 description 1
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 1
- IDOGEHIWMJMAHT-BYPYZUCNSA-N Gly-Gly-Cys Chemical compound NCC(=O)NCC(=O)N[C@@H](CS)C(O)=O IDOGEHIWMJMAHT-BYPYZUCNSA-N 0.000 description 1
- QPTNELDXWKRIFX-YFKPBYRVSA-N Gly-Gly-Gln Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O QPTNELDXWKRIFX-YFKPBYRVSA-N 0.000 description 1
- PDAWDNVHMUKWJR-ZETCQYMHSA-N Gly-Gly-His Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC1=CNC=N1 PDAWDNVHMUKWJR-ZETCQYMHSA-N 0.000 description 1
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 1
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 1
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 1
- HPAIKDPJURGQLN-KBPBESRZSA-N Gly-His-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CNC=N1 HPAIKDPJURGQLN-KBPBESRZSA-N 0.000 description 1
- LPCKHUXOGVNZRS-YUMQZZPRSA-N Gly-His-Ser Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O LPCKHUXOGVNZRS-YUMQZZPRSA-N 0.000 description 1
- HMHRTKOWRUPPNU-RCOVLWMOSA-N Gly-Ile-Gly Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O HMHRTKOWRUPPNU-RCOVLWMOSA-N 0.000 description 1
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 1
- IUZGUFAJDBHQQV-YUMQZZPRSA-N Gly-Leu-Asn Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IUZGUFAJDBHQQV-YUMQZZPRSA-N 0.000 description 1
- YTSVAIMKVLZUDU-YUMQZZPRSA-N Gly-Leu-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YTSVAIMKVLZUDU-YUMQZZPRSA-N 0.000 description 1
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 1
- LRQXRHGQEVWGPV-NHCYSSNCSA-N Gly-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN LRQXRHGQEVWGPV-NHCYSSNCSA-N 0.000 description 1
- UHPAZODVFFYEEL-QWRGUYRKSA-N Gly-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN UHPAZODVFFYEEL-QWRGUYRKSA-N 0.000 description 1
- LLZXNUUIBOALNY-QWRGUYRKSA-N Gly-Leu-Lys Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN LLZXNUUIBOALNY-QWRGUYRKSA-N 0.000 description 1
- YSDLIYZLOTZZNP-UWVGGRQHSA-N Gly-Leu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN YSDLIYZLOTZZNP-UWVGGRQHSA-N 0.000 description 1
- TVUWMSBGMVAHSJ-KBPBESRZSA-N Gly-Leu-Phe Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 TVUWMSBGMVAHSJ-KBPBESRZSA-N 0.000 description 1
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 1
- VEPBEGNDJYANCF-QWRGUYRKSA-N Gly-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN VEPBEGNDJYANCF-QWRGUYRKSA-N 0.000 description 1
- WDEHMRNSGHVNOH-VHSXEESVSA-N Gly-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)CN)C(=O)O WDEHMRNSGHVNOH-VHSXEESVSA-N 0.000 description 1
- DBJYVKDPGIFXFO-BQBZGAKWSA-N Gly-Met-Ala Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O DBJYVKDPGIFXFO-BQBZGAKWSA-N 0.000 description 1
- YHYDTTUSJXGTQK-UWVGGRQHSA-N Gly-Met-Leu Chemical compound CSCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(C)C)C(O)=O YHYDTTUSJXGTQK-UWVGGRQHSA-N 0.000 description 1
- LXTRSHQLGYINON-DTWKUNHWSA-N Gly-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN LXTRSHQLGYINON-DTWKUNHWSA-N 0.000 description 1
- FJWSJWACLMTDMI-WPRPVWTQSA-N Gly-Met-Val Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O FJWSJWACLMTDMI-WPRPVWTQSA-N 0.000 description 1
- JBCLFWXMTIKCCB-VIFPVBQESA-N Gly-Phe Chemical compound NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-VIFPVBQESA-N 0.000 description 1
- IEGFSKKANYKBDU-QWHCGFSZSA-N Gly-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)CN)C(=O)O IEGFSKKANYKBDU-QWHCGFSZSA-N 0.000 description 1
- GGAPHLIUUTVYMX-QWRGUYRKSA-N Gly-Phe-Ser Chemical compound OC[C@@H](C([O-])=O)NC(=O)[C@@H](NC(=O)C[NH3+])CC1=CC=CC=C1 GGAPHLIUUTVYMX-QWRGUYRKSA-N 0.000 description 1
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 1
- SCJJPCQUJYPHRZ-BQBZGAKWSA-N Gly-Pro-Asn Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O SCJJPCQUJYPHRZ-BQBZGAKWSA-N 0.000 description 1
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 1
- OCPPBNKYGYSLOE-IUCAKERBSA-N Gly-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN OCPPBNKYGYSLOE-IUCAKERBSA-N 0.000 description 1
- IXHQLZIWBCQBLQ-STQMWFEESA-N Gly-Pro-Phe Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IXHQLZIWBCQBLQ-STQMWFEESA-N 0.000 description 1
- BMWFDYIYBAFROD-WPRPVWTQSA-N Gly-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN BMWFDYIYBAFROD-WPRPVWTQSA-N 0.000 description 1
- CSMYMGFCEJWALV-WDSKDSINSA-N Gly-Ser-Gln Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O CSMYMGFCEJWALV-WDSKDSINSA-N 0.000 description 1
- VNNRLUNBJSWZPF-ZKWXMUAHSA-N Gly-Ser-Ile Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNNRLUNBJSWZPF-ZKWXMUAHSA-N 0.000 description 1
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 1
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 1
- FKESCSGWBPUTPN-FOHZUACHSA-N Gly-Thr-Asn Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O FKESCSGWBPUTPN-FOHZUACHSA-N 0.000 description 1
- DBUNZBWUWCIELX-JHEQGTHGSA-N Gly-Thr-Glu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O DBUNZBWUWCIELX-JHEQGTHGSA-N 0.000 description 1
- FFALDIDGPLUDKV-ZDLURKLDSA-N Gly-Thr-Ser Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O FFALDIDGPLUDKV-ZDLURKLDSA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- CUVBTVWFVIIDOC-YEPSODPASA-N Gly-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)CN CUVBTVWFVIIDOC-YEPSODPASA-N 0.000 description 1
- NWOSHVVPKDQKKT-RYUDHWBXSA-N Gly-Tyr-Gln Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O NWOSHVVPKDQKKT-RYUDHWBXSA-N 0.000 description 1
- RIYIFUFFFBIOEU-KBPBESRZSA-N Gly-Tyr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 RIYIFUFFFBIOEU-KBPBESRZSA-N 0.000 description 1
- OCRQUYDOYKCOQG-IRXDYDNUSA-N Gly-Tyr-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 OCRQUYDOYKCOQG-IRXDYDNUSA-N 0.000 description 1
- GBYYQVBXFVDJPJ-WLTAIBSBSA-N Gly-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)CN)O GBYYQVBXFVDJPJ-WLTAIBSBSA-N 0.000 description 1
- DNVDEMWIYLVIQU-RCOVLWMOSA-N Gly-Val-Asp Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O DNVDEMWIYLVIQU-RCOVLWMOSA-N 0.000 description 1
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 1
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 1
- AFMOTCMSEBITOE-YEPSODPASA-N Gly-Val-Thr Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O AFMOTCMSEBITOE-YEPSODPASA-N 0.000 description 1
- ZWZWYGMENQVNFU-UHFFFAOYSA-N Glycerophosphorylserin Natural products OC(=O)C(N)COP(O)(=O)OCC(O)CO ZWZWYGMENQVNFU-UHFFFAOYSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 229930186217 Glycolipid Natural products 0.000 description 1
- 102000010818 Hepatocyte Nuclear Factor 3-alpha Human genes 0.000 description 1
- 108010038661 Hepatocyte Nuclear Factor 3-alpha Proteins 0.000 description 1
- 102000008088 Hepatocyte Nuclear Factors Human genes 0.000 description 1
- 108010049606 Hepatocyte Nuclear Factors Proteins 0.000 description 1
- KZTLOHBDLMIFSH-XVYDVKMFSA-N His-Ala-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O KZTLOHBDLMIFSH-XVYDVKMFSA-N 0.000 description 1
- YXBRCTXAEYSCHS-XVYDVKMFSA-N His-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N YXBRCTXAEYSCHS-XVYDVKMFSA-N 0.000 description 1
- VCDNHBNNPCDBKV-DLOVCJGASA-N His-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N VCDNHBNNPCDBKV-DLOVCJGASA-N 0.000 description 1
- ZIMTWPHIKZEHSE-UWVGGRQHSA-N His-Arg-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O ZIMTWPHIKZEHSE-UWVGGRQHSA-N 0.000 description 1
- CJGDTAHEMXLRMB-ULQDDVLXSA-N His-Arg-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O CJGDTAHEMXLRMB-ULQDDVLXSA-N 0.000 description 1
- LYSVCKOXIDKEEL-SRVKXCTJSA-N His-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CN=CN1 LYSVCKOXIDKEEL-SRVKXCTJSA-N 0.000 description 1
- QQQHYJFKDLDUNK-CIUDSAMLSA-N His-Asp-Cys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N QQQHYJFKDLDUNK-CIUDSAMLSA-N 0.000 description 1
- LSQHWKPPOFDHHZ-YUMQZZPRSA-N His-Asp-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N LSQHWKPPOFDHHZ-YUMQZZPRSA-N 0.000 description 1
- ZZLWLWSUIBSMNP-CIUDSAMLSA-N His-Asp-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZZLWLWSUIBSMNP-CIUDSAMLSA-N 0.000 description 1
- NNBWMLHQXBTIIT-HVTMNAMFSA-N His-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N NNBWMLHQXBTIIT-HVTMNAMFSA-N 0.000 description 1
- VHHYJBSXXMPQGZ-AVGNSLFASA-N His-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N VHHYJBSXXMPQGZ-AVGNSLFASA-N 0.000 description 1
- LPZUKJALYGXBIE-SRVKXCTJSA-N His-Gln-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N LPZUKJALYGXBIE-SRVKXCTJSA-N 0.000 description 1
- NELVFWFDOKRTOR-SDDRHHMPSA-N His-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O NELVFWFDOKRTOR-SDDRHHMPSA-N 0.000 description 1
- DVHGLDYMGWTYKW-GUBZILKMSA-N His-Gln-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O DVHGLDYMGWTYKW-GUBZILKMSA-N 0.000 description 1
- JWLWNCVBBSBCEM-NKIYYHGXSA-N His-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N)O JWLWNCVBBSBCEM-NKIYYHGXSA-N 0.000 description 1
- FIMNVXRZGUAGBI-AVGNSLFASA-N His-Glu-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O FIMNVXRZGUAGBI-AVGNSLFASA-N 0.000 description 1
- STWGDDDFLUFCCA-GVXVVHGQSA-N His-Glu-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O STWGDDDFLUFCCA-GVXVVHGQSA-N 0.000 description 1
- YADRBUZBKHHDAO-XPUUQOCRSA-N His-Gly-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](C)C(O)=O YADRBUZBKHHDAO-XPUUQOCRSA-N 0.000 description 1
- NQKRILCJYCASDV-QWRGUYRKSA-N His-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CN=CN1 NQKRILCJYCASDV-QWRGUYRKSA-N 0.000 description 1
- FYTCLUIYTYFGPT-YUMQZZPRSA-N His-Gly-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FYTCLUIYTYFGPT-YUMQZZPRSA-N 0.000 description 1
- JBSLJUPMTYLLFH-MELADBBJSA-N His-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC3=CN=CN3)N)C(=O)O JBSLJUPMTYLLFH-MELADBBJSA-N 0.000 description 1
- BZKDJRSZWLPJNI-SRVKXCTJSA-N His-His-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O BZKDJRSZWLPJNI-SRVKXCTJSA-N 0.000 description 1
- ORZGPQXISSXQGW-IHRRRGAJSA-N His-His-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O ORZGPQXISSXQGW-IHRRRGAJSA-N 0.000 description 1
- SKYULSWNBYAQMG-IHRRRGAJSA-N His-Leu-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SKYULSWNBYAQMG-IHRRRGAJSA-N 0.000 description 1
- VFBZWZXKCVBTJR-SRVKXCTJSA-N His-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N VFBZWZXKCVBTJR-SRVKXCTJSA-N 0.000 description 1
- UROVZOUMHNXPLZ-AVGNSLFASA-N His-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 UROVZOUMHNXPLZ-AVGNSLFASA-N 0.000 description 1
- SKOKHBGDXGTDDP-MELADBBJSA-N His-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N SKOKHBGDXGTDDP-MELADBBJSA-N 0.000 description 1
- LVXFNTIIGOQBMD-SRVKXCTJSA-N His-Leu-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O LVXFNTIIGOQBMD-SRVKXCTJSA-N 0.000 description 1
- LVWIJITYHRZHBO-IXOXFDKPSA-N His-Leu-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LVWIJITYHRZHBO-IXOXFDKPSA-N 0.000 description 1
- GJMHMDKCJPQJOI-IHRRRGAJSA-N His-Lys-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CN=CN1 GJMHMDKCJPQJOI-IHRRRGAJSA-N 0.000 description 1
- JUIOPCXACJLRJK-AVGNSLFASA-N His-Lys-Glu Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N JUIOPCXACJLRJK-AVGNSLFASA-N 0.000 description 1
- UMBKDWGQESDCTO-KKUMJFAQSA-N His-Lys-Lys Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O UMBKDWGQESDCTO-KKUMJFAQSA-N 0.000 description 1
- NKRWVZQTPXPNRZ-SRVKXCTJSA-N His-Met-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC1=CN=CN1 NKRWVZQTPXPNRZ-SRVKXCTJSA-N 0.000 description 1
- YXASFUBDSDAXQD-UWVGGRQHSA-N His-Met-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O YXASFUBDSDAXQD-UWVGGRQHSA-N 0.000 description 1
- WSEITRHJRVDTRX-QTKMDUPCSA-N His-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CC1=CN=CN1)N)O WSEITRHJRVDTRX-QTKMDUPCSA-N 0.000 description 1
- SGLXGEDPYJPGIQ-ACRUOGEOSA-N His-Phe-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)NC(=O)[C@H](CC3=CN=CN3)N SGLXGEDPYJPGIQ-ACRUOGEOSA-N 0.000 description 1
- ULRFSEJGSHYLQI-YESZJQIVSA-N His-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CN=CN3)N)C(=O)O ULRFSEJGSHYLQI-YESZJQIVSA-N 0.000 description 1
- WHKLDLQHSYAVGU-ACRUOGEOSA-N His-Phe-Tyr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O WHKLDLQHSYAVGU-ACRUOGEOSA-N 0.000 description 1
- FLXCRBXJRJSDHX-AVGNSLFASA-N His-Pro-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O FLXCRBXJRJSDHX-AVGNSLFASA-N 0.000 description 1
- KAXZXLSXFWSNNZ-XVYDVKMFSA-N His-Ser-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KAXZXLSXFWSNNZ-XVYDVKMFSA-N 0.000 description 1
- ILUVWFTXAUYOBW-CUJWVEQBSA-N His-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CN=CN1)N)O ILUVWFTXAUYOBW-CUJWVEQBSA-N 0.000 description 1
- FCPSGEVYIVXPPO-QTKMDUPCSA-N His-Thr-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FCPSGEVYIVXPPO-QTKMDUPCSA-N 0.000 description 1
- PFOUFRJYHWZJKW-NKIYYHGXSA-N His-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O PFOUFRJYHWZJKW-NKIYYHGXSA-N 0.000 description 1
- ZNTSGDNUITWTRA-WDSOQIARSA-N His-Trp-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(O)=O ZNTSGDNUITWTRA-WDSOQIARSA-N 0.000 description 1
- WYKXJGWSJUULSL-AVGNSLFASA-N His-Val-Arg Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)Cc1cnc[nH]1)C(=O)N[C@@H](CCCNC(=N)N)C(=O)O WYKXJGWSJUULSL-AVGNSLFASA-N 0.000 description 1
- FBOMZVOKCZMDIG-XQQFMLRXSA-N His-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N FBOMZVOKCZMDIG-XQQFMLRXSA-N 0.000 description 1
- XGBVLRJLHUVCNK-DCAQKATOSA-N His-Val-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O XGBVLRJLHUVCNK-DCAQKATOSA-N 0.000 description 1
- DRKZDEFADVYTLU-AVGNSLFASA-N His-Val-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O DRKZDEFADVYTLU-AVGNSLFASA-N 0.000 description 1
- 101710155878 Histone acetyltransferase p300 Proteins 0.000 description 1
- 102100039996 Histone deacetylase 1 Human genes 0.000 description 1
- 108010048671 Homeodomain Proteins Proteins 0.000 description 1
- 102000009331 Homeodomain Proteins Human genes 0.000 description 1
- 101100389547 Homo sapiens EP300 gene Proteins 0.000 description 1
- 101001035024 Homo sapiens Histone deacetylase 1 Proteins 0.000 description 1
- 101000779418 Homo sapiens RAC-alpha serine/threonine-protein kinase Proteins 0.000 description 1
- 229920002153 Hydroxypropyl cellulose Polymers 0.000 description 1
- JRHFQUPIZOYKQP-KBIXCLLPSA-N Ile-Ala-Glu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O JRHFQUPIZOYKQP-KBIXCLLPSA-N 0.000 description 1
- VAXBXNPRXPHGHG-BJDJZHNGSA-N Ile-Ala-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)O)N VAXBXNPRXPHGHG-BJDJZHNGSA-N 0.000 description 1
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 1
- BOTVMTSMOUSDRW-GMOBBJLQSA-N Ile-Arg-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(N)=O)C(O)=O BOTVMTSMOUSDRW-GMOBBJLQSA-N 0.000 description 1
- QLRMMMQNCWBNPQ-QXEWZRGKSA-N Ile-Arg-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(=O)O)N QLRMMMQNCWBNPQ-QXEWZRGKSA-N 0.000 description 1
- ATXGFMOBVKSOMK-PEDHHIEDSA-N Ile-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N ATXGFMOBVKSOMK-PEDHHIEDSA-N 0.000 description 1
- YOTNPRLPIPHQSB-XUXIUFHCSA-N Ile-Arg-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N YOTNPRLPIPHQSB-XUXIUFHCSA-N 0.000 description 1
- QTUSJASXLGLJSR-OSUNSFLBSA-N Ile-Arg-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N QTUSJASXLGLJSR-OSUNSFLBSA-N 0.000 description 1
- YKRIXHPEIZUDDY-GMOBBJLQSA-N Ile-Asn-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YKRIXHPEIZUDDY-GMOBBJLQSA-N 0.000 description 1
- QYZYJFXHXYUZMZ-UGYAYLCHSA-N Ile-Asn-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N QYZYJFXHXYUZMZ-UGYAYLCHSA-N 0.000 description 1
- PJLLMGWWINYQPB-PEFMBERDSA-N Ile-Asn-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PJLLMGWWINYQPB-PEFMBERDSA-N 0.000 description 1
- HDODQNPMSHDXJT-GHCJXIJMSA-N Ile-Asn-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O HDODQNPMSHDXJT-GHCJXIJMSA-N 0.000 description 1
- NCSIQAFSIPHVAN-IUKAMOBKSA-N Ile-Asn-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N NCSIQAFSIPHVAN-IUKAMOBKSA-N 0.000 description 1
- QIHJTGSVGIPHIW-QSFUFRPTSA-N Ile-Asn-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N QIHJTGSVGIPHIW-QSFUFRPTSA-N 0.000 description 1
- UMYZBHKAVTXWIW-GMOBBJLQSA-N Ile-Asp-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UMYZBHKAVTXWIW-GMOBBJLQSA-N 0.000 description 1
- NKRJALPCDNXULF-BYULHYEWSA-N Ile-Asp-Gly Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O NKRJALPCDNXULF-BYULHYEWSA-N 0.000 description 1
- JQLFYZMEXFNRFS-DJFWLOJKSA-N Ile-Asp-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N JQLFYZMEXFNRFS-DJFWLOJKSA-N 0.000 description 1
- NPROWIBAWYMPAZ-GUDRVLHUSA-N Ile-Asp-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N NPROWIBAWYMPAZ-GUDRVLHUSA-N 0.000 description 1
- AWTDTFXPVCTHAK-BJDJZHNGSA-N Ile-Cys-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N AWTDTFXPVCTHAK-BJDJZHNGSA-N 0.000 description 1
- SRGRINJFBHKHAC-NAKRPEOUSA-N Ile-Cys-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCSC)C(=O)O)N SRGRINJFBHKHAC-NAKRPEOUSA-N 0.000 description 1
- BSWLQVGEVFYGIM-ZPFDUUQYSA-N Ile-Gln-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N BSWLQVGEVFYGIM-ZPFDUUQYSA-N 0.000 description 1
- LJKDGRWXYUTRSH-YVNDNENWSA-N Ile-Gln-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N LJKDGRWXYUTRSH-YVNDNENWSA-N 0.000 description 1
- OVPYIUNCVSOVNF-KQXIARHKSA-N Ile-Gln-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N OVPYIUNCVSOVNF-KQXIARHKSA-N 0.000 description 1
- JRYQSFOFUFXPTB-RWRJDSDZSA-N Ile-Gln-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N JRYQSFOFUFXPTB-RWRJDSDZSA-N 0.000 description 1
- WUKLZPHVWAMZQV-UKJIMTQDSA-N Ile-Glu-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N WUKLZPHVWAMZQV-UKJIMTQDSA-N 0.000 description 1
- KFVUBLZRFSVDGO-BYULHYEWSA-N Ile-Gly-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O KFVUBLZRFSVDGO-BYULHYEWSA-N 0.000 description 1
- IGJWJGIHUFQANP-LAEOZQHASA-N Ile-Gly-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N IGJWJGIHUFQANP-LAEOZQHASA-N 0.000 description 1
- KIAOPHMUNPPGEN-PEXQALLHSA-N Ile-Gly-His Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KIAOPHMUNPPGEN-PEXQALLHSA-N 0.000 description 1
- JNDYZNJRRNFYIR-VGDYDELISA-N Ile-His-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CS)C(=O)O)N JNDYZNJRRNFYIR-VGDYDELISA-N 0.000 description 1
- CMNMPCTVCWWYHY-MXAVVETBSA-N Ile-His-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(C)C)C(=O)O)N CMNMPCTVCWWYHY-MXAVVETBSA-N 0.000 description 1
- APDIECQNNDGFPD-PYJNHQTQSA-N Ile-His-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C(C)C)C(=O)O)N APDIECQNNDGFPD-PYJNHQTQSA-N 0.000 description 1
- RIVKTKFVWXRNSJ-GRLWGSQLSA-N Ile-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RIVKTKFVWXRNSJ-GRLWGSQLSA-N 0.000 description 1
- TWPSALMCEHCIOY-YTFOTSKYSA-N Ile-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(=O)O)N TWPSALMCEHCIOY-YTFOTSKYSA-N 0.000 description 1
- CSQNHSGHAPRGPQ-YTFOTSKYSA-N Ile-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(=O)O)N CSQNHSGHAPRGPQ-YTFOTSKYSA-N 0.000 description 1
- PFPUFNLHBXKPHY-HTFCKZLJSA-N Ile-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)O)N PFPUFNLHBXKPHY-HTFCKZLJSA-N 0.000 description 1
- GLLAUPMJCGKPFY-BLMTYFJBSA-N Ile-Ile-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 GLLAUPMJCGKPFY-BLMTYFJBSA-N 0.000 description 1
- KBAPKNDWAGVGTH-IGISWZIWSA-N Ile-Ile-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KBAPKNDWAGVGTH-IGISWZIWSA-N 0.000 description 1
- YGDWPQCLFJNMOL-MNXVOIDGSA-N Ile-Leu-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YGDWPQCLFJNMOL-MNXVOIDGSA-N 0.000 description 1
- HUORUFRRJHELPD-MNXVOIDGSA-N Ile-Leu-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N HUORUFRRJHELPD-MNXVOIDGSA-N 0.000 description 1
- DBXXASNNDTXOLU-MXAVVETBSA-N Ile-Leu-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DBXXASNNDTXOLU-MXAVVETBSA-N 0.000 description 1
- GAZGFPOZOLEYAJ-YTFOTSKYSA-N Ile-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N GAZGFPOZOLEYAJ-YTFOTSKYSA-N 0.000 description 1
- IOVUXUSIGXCREV-DKIMLUQUSA-N Ile-Leu-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IOVUXUSIGXCREV-DKIMLUQUSA-N 0.000 description 1
- PWUMCBLVWPCKNO-MGHWNKPDSA-N Ile-Leu-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PWUMCBLVWPCKNO-MGHWNKPDSA-N 0.000 description 1
- PNTWNAXGBOZMBO-MNXVOIDGSA-N Ile-Lys-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PNTWNAXGBOZMBO-MNXVOIDGSA-N 0.000 description 1
- ADDYYRVQQZFIMW-MNXVOIDGSA-N Ile-Lys-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ADDYYRVQQZFIMW-MNXVOIDGSA-N 0.000 description 1
- CEPIAEUVRKGPGP-DSYPUSFNSA-N Ile-Lys-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 CEPIAEUVRKGPGP-DSYPUSFNSA-N 0.000 description 1
- VOCZPDONPURUHV-QEWYBTABSA-N Ile-Phe-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N VOCZPDONPURUHV-QEWYBTABSA-N 0.000 description 1
- USXAYNCLFSUSBA-MGHWNKPDSA-N Ile-Phe-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N USXAYNCLFSUSBA-MGHWNKPDSA-N 0.000 description 1
- XLXPYSDGMXTTNQ-DKIMLUQUSA-N Ile-Phe-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CC(C)C)C(O)=O XLXPYSDGMXTTNQ-DKIMLUQUSA-N 0.000 description 1
- VEPIBPGLTLPBDW-URLPEUOOSA-N Ile-Phe-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N VEPIBPGLTLPBDW-URLPEUOOSA-N 0.000 description 1
- IITVUURPOYGCTD-NAKRPEOUSA-N Ile-Pro-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IITVUURPOYGCTD-NAKRPEOUSA-N 0.000 description 1
- BATWGBRIZANGPN-ZPFDUUQYSA-N Ile-Pro-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BATWGBRIZANGPN-ZPFDUUQYSA-N 0.000 description 1
- BJECXJHLUJXPJQ-PYJNHQTQSA-N Ile-Pro-His Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N BJECXJHLUJXPJQ-PYJNHQTQSA-N 0.000 description 1
- PELCGFMHLZXWBQ-BJDJZHNGSA-N Ile-Ser-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)O)N PELCGFMHLZXWBQ-BJDJZHNGSA-N 0.000 description 1
- QQVXERGIFIRCGW-NAKRPEOUSA-N Ile-Ser-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)O)N QQVXERGIFIRCGW-NAKRPEOUSA-N 0.000 description 1
- RKQAYOWLSFLJEE-SVSWQMSJSA-N Ile-Thr-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N RKQAYOWLSFLJEE-SVSWQMSJSA-N 0.000 description 1
- QGXQHJQPAPMACW-PPCPHDFISA-N Ile-Thr-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)O)N QGXQHJQPAPMACW-PPCPHDFISA-N 0.000 description 1
- WCNWGAUZWWSYDG-SVSWQMSJSA-N Ile-Thr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)O)N WCNWGAUZWWSYDG-SVSWQMSJSA-N 0.000 description 1
- JTBFQNHKNRZJDS-SYWGBEHUSA-N Ile-Trp-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](C)C(=O)O)N JTBFQNHKNRZJDS-SYWGBEHUSA-N 0.000 description 1
- HQLSBZFLOUHQJK-STECZYCISA-N Ile-Tyr-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HQLSBZFLOUHQJK-STECZYCISA-N 0.000 description 1
- OMDWJWGZGMCQND-CFMVVWHZSA-N Ile-Tyr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OMDWJWGZGMCQND-CFMVVWHZSA-N 0.000 description 1
- ZUWSVOYKBCHLRR-MGHWNKPDSA-N Ile-Tyr-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCCN)C(=O)O)N ZUWSVOYKBCHLRR-MGHWNKPDSA-N 0.000 description 1
- ZGKVPOSSTGHJAF-HJPIBITLSA-N Ile-Tyr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CO)C(=O)O)N ZGKVPOSSTGHJAF-HJPIBITLSA-N 0.000 description 1
- BCISUQVFDGYZBO-QSFUFRPTSA-N Ile-Val-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O BCISUQVFDGYZBO-QSFUFRPTSA-N 0.000 description 1
- YWCJXQKATPNPOE-UKJIMTQDSA-N Ile-Val-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YWCJXQKATPNPOE-UKJIMTQDSA-N 0.000 description 1
- UYODHPPSCXBNCS-XUXIUFHCSA-N Ile-Val-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(C)C UYODHPPSCXBNCS-XUXIUFHCSA-N 0.000 description 1
- NJGXXYLPDMMFJB-XUXIUFHCSA-N Ile-Val-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N NJGXXYLPDMMFJB-XUXIUFHCSA-N 0.000 description 1
- WIYDLTIBHZSPKY-HJWJTTGWSA-N Ile-Val-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 WIYDLTIBHZSPKY-HJWJTTGWSA-N 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- PWWVAXIEGOYWEE-UHFFFAOYSA-N Isophenergan Chemical compound C1=CC=C2N(CC(C)N(C)C)C3=CC=CC=C3SC2=C1 PWWVAXIEGOYWEE-UHFFFAOYSA-N 0.000 description 1
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 1
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 1
- CQQGCWPXDHTTNF-GUBZILKMSA-N Leu-Ala-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O CQQGCWPXDHTTNF-GUBZILKMSA-N 0.000 description 1
- KWTVLKBOQATPHJ-SRVKXCTJSA-N Leu-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N KWTVLKBOQATPHJ-SRVKXCTJSA-N 0.000 description 1
- XIRYQRLFHWWWTC-QEJZJMRPSA-N Leu-Ala-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XIRYQRLFHWWWTC-QEJZJMRPSA-N 0.000 description 1
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 1
- XBBKIIGCUMBKCO-JXUBOQSCSA-N Leu-Ala-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XBBKIIGCUMBKCO-JXUBOQSCSA-N 0.000 description 1
- HXWALXSAVBLTPK-NUTKFTJISA-N Leu-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(C)C)N HXWALXSAVBLTPK-NUTKFTJISA-N 0.000 description 1
- HBJZFCIVFIBNSV-DCAQKATOSA-N Leu-Arg-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(N)=O)C(O)=O HBJZFCIVFIBNSV-DCAQKATOSA-N 0.000 description 1
- VKOAHIRLIUESLU-ULQDDVLXSA-N Leu-Arg-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O VKOAHIRLIUESLU-ULQDDVLXSA-N 0.000 description 1
- IBMVEYRWAWIOTN-RWMBFGLXSA-N Leu-Arg-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(O)=O IBMVEYRWAWIOTN-RWMBFGLXSA-N 0.000 description 1
- UCOCBWDBHCUPQP-DCAQKATOSA-N Leu-Arg-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O UCOCBWDBHCUPQP-DCAQKATOSA-N 0.000 description 1
- STAVRDQLZOTNKJ-RHYQMDGZSA-N Leu-Arg-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STAVRDQLZOTNKJ-RHYQMDGZSA-N 0.000 description 1
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 1
- VIWUBXKCYJGNCL-SRVKXCTJSA-N Leu-Asn-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 VIWUBXKCYJGNCL-SRVKXCTJSA-N 0.000 description 1
- OXKYZSRZKBTVEY-ZPFDUUQYSA-N Leu-Asn-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OXKYZSRZKBTVEY-ZPFDUUQYSA-N 0.000 description 1
- POJPZSMTTMLSTG-SRVKXCTJSA-N Leu-Asn-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N POJPZSMTTMLSTG-SRVKXCTJSA-N 0.000 description 1
- RIMMMMYKGIBOSN-DCAQKATOSA-N Leu-Asn-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O RIMMMMYKGIBOSN-DCAQKATOSA-N 0.000 description 1
- WGNOPSQMIQERPK-GARJFASQSA-N Leu-Asn-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N WGNOPSQMIQERPK-GARJFASQSA-N 0.000 description 1
- OGCQGUIWMSBHRZ-CIUDSAMLSA-N Leu-Asn-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OGCQGUIWMSBHRZ-CIUDSAMLSA-N 0.000 description 1
- FIJMQLGQLBLBOL-HJGDQZAQSA-N Leu-Asn-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FIJMQLGQLBLBOL-HJGDQZAQSA-N 0.000 description 1
- YKNBJXOJTURHCU-DCAQKATOSA-N Leu-Asp-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YKNBJXOJTURHCU-DCAQKATOSA-N 0.000 description 1
- DLFAACQHIRSQGG-CIUDSAMLSA-N Leu-Asp-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O DLFAACQHIRSQGG-CIUDSAMLSA-N 0.000 description 1
- ZDSNOSQHMJBRQN-SRVKXCTJSA-N Leu-Asp-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N ZDSNOSQHMJBRQN-SRVKXCTJSA-N 0.000 description 1
- KTFHTMHHKXUYPW-ZPFDUUQYSA-N Leu-Asp-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KTFHTMHHKXUYPW-ZPFDUUQYSA-N 0.000 description 1
- DLCOFDAHNMMQPP-SRVKXCTJSA-N Leu-Asp-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DLCOFDAHNMMQPP-SRVKXCTJSA-N 0.000 description 1
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 1
- MMEDVBWCMGRKKC-GARJFASQSA-N Leu-Asp-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N MMEDVBWCMGRKKC-GARJFASQSA-N 0.000 description 1
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 1
- QCSFMCFHVGTLFF-NHCYSSNCSA-N Leu-Asp-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O QCSFMCFHVGTLFF-NHCYSSNCSA-N 0.000 description 1
- IIKJNQWOQIWWMR-CIUDSAMLSA-N Leu-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(C)C)N IIKJNQWOQIWWMR-CIUDSAMLSA-N 0.000 description 1
- KWURTLAFFDOTEQ-GUBZILKMSA-N Leu-Cys-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N KWURTLAFFDOTEQ-GUBZILKMSA-N 0.000 description 1
- HUEBCHPSXSQUGN-GARJFASQSA-N Leu-Cys-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N HUEBCHPSXSQUGN-GARJFASQSA-N 0.000 description 1
- DLCXCECTCPKKCD-GUBZILKMSA-N Leu-Gln-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O DLCXCECTCPKKCD-GUBZILKMSA-N 0.000 description 1
- BOFAFKVZQUMTID-AVGNSLFASA-N Leu-Gln-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N BOFAFKVZQUMTID-AVGNSLFASA-N 0.000 description 1
- RSFGIMMPWAXNML-MNXVOIDGSA-N Leu-Gln-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RSFGIMMPWAXNML-MNXVOIDGSA-N 0.000 description 1
- LOLUPZNNADDTAA-AVGNSLFASA-N Leu-Gln-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LOLUPZNNADDTAA-AVGNSLFASA-N 0.000 description 1
- CIVKXGPFXDIQBV-WDCWCFNPSA-N Leu-Gln-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CIVKXGPFXDIQBV-WDCWCFNPSA-N 0.000 description 1
- DZQMXBALGUHGJT-GUBZILKMSA-N Leu-Glu-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O DZQMXBALGUHGJT-GUBZILKMSA-N 0.000 description 1
- RVVBWTWPNFDYBE-SRVKXCTJSA-N Leu-Glu-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVVBWTWPNFDYBE-SRVKXCTJSA-N 0.000 description 1
- KVMULWOHPPMHHE-DCAQKATOSA-N Leu-Glu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KVMULWOHPPMHHE-DCAQKATOSA-N 0.000 description 1
- NEEOBPIXKWSBRF-IUCAKERBSA-N Leu-Glu-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O NEEOBPIXKWSBRF-IUCAKERBSA-N 0.000 description 1
- IWTBYNQNAPECCS-AVGNSLFASA-N Leu-Glu-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IWTBYNQNAPECCS-AVGNSLFASA-N 0.000 description 1
- HVJVUYQWFYMGJS-GVXVVHGQSA-N Leu-Glu-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVJVUYQWFYMGJS-GVXVVHGQSA-N 0.000 description 1
- LAPSXOAUPNOINL-YUMQZZPRSA-N Leu-Gly-Asp Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O LAPSXOAUPNOINL-YUMQZZPRSA-N 0.000 description 1
- VWHGTYCRDRBSFI-ZETCQYMHSA-N Leu-Gly-Gly Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(O)=O VWHGTYCRDRBSFI-ZETCQYMHSA-N 0.000 description 1
- QPXBPQUGXHURGP-UWVGGRQHSA-N Leu-Gly-Met Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CCSC)C(=O)O)N QPXBPQUGXHURGP-UWVGGRQHSA-N 0.000 description 1
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 1
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 1
- POZULHZYLPGXMR-ONGXEEELSA-N Leu-Gly-Val Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O POZULHZYLPGXMR-ONGXEEELSA-N 0.000 description 1
- PBGDOSARRIJMEV-DLOVCJGASA-N Leu-His-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(O)=O PBGDOSARRIJMEV-DLOVCJGASA-N 0.000 description 1
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 1
- OYQUOLRTJHWVSQ-SRVKXCTJSA-N Leu-His-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O OYQUOLRTJHWVSQ-SRVKXCTJSA-N 0.000 description 1
- OHZIZVWQXJPBJS-IXOXFDKPSA-N Leu-His-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OHZIZVWQXJPBJS-IXOXFDKPSA-N 0.000 description 1
- DBSLVQBXKVKDKJ-BJDJZHNGSA-N Leu-Ile-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O DBSLVQBXKVKDKJ-BJDJZHNGSA-N 0.000 description 1
- AUBMZAMQCOYSIC-MNXVOIDGSA-N Leu-Ile-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O AUBMZAMQCOYSIC-MNXVOIDGSA-N 0.000 description 1
- HNDWYLYAYNBWMP-AJNGGQMLSA-N Leu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N HNDWYLYAYNBWMP-AJNGGQMLSA-N 0.000 description 1
- KYIIALJHAOIAHF-KKUMJFAQSA-N Leu-Leu-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 KYIIALJHAOIAHF-KKUMJFAQSA-N 0.000 description 1
- FAELBUXXFQLUAX-AJNGGQMLSA-N Leu-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C FAELBUXXFQLUAX-AJNGGQMLSA-N 0.000 description 1
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 1
- UBZGNBKMIJHOHL-BZSNNMDCSA-N Leu-Leu-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 UBZGNBKMIJHOHL-BZSNNMDCSA-N 0.000 description 1
- UCNNZELZXFXXJQ-BZSNNMDCSA-N Leu-Leu-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCNNZELZXFXXJQ-BZSNNMDCSA-N 0.000 description 1
- ZRHDPZAAWLXXIR-SRVKXCTJSA-N Leu-Lys-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O ZRHDPZAAWLXXIR-SRVKXCTJSA-N 0.000 description 1
- HVHRPWQEQHIQJF-AVGNSLFASA-N Leu-Lys-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HVHRPWQEQHIQJF-AVGNSLFASA-N 0.000 description 1
- LVTJJOJKDCVZGP-QWRGUYRKSA-N Leu-Lys-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LVTJJOJKDCVZGP-QWRGUYRKSA-N 0.000 description 1
- RTIRBWJPYJYTLO-MELADBBJSA-N Leu-Lys-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N RTIRBWJPYJYTLO-MELADBBJSA-N 0.000 description 1
- OVZLLFONXILPDZ-VOAKCMCISA-N Leu-Lys-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OVZLLFONXILPDZ-VOAKCMCISA-N 0.000 description 1
- CPONGMJGVIAWEH-DCAQKATOSA-N Leu-Met-Ala Chemical compound CSCC[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](C)C(O)=O CPONGMJGVIAWEH-DCAQKATOSA-N 0.000 description 1
- PKKMDPNFGULLNQ-AVGNSLFASA-N Leu-Met-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O PKKMDPNFGULLNQ-AVGNSLFASA-N 0.000 description 1
- BJWKOATWNQJPSK-SRVKXCTJSA-N Leu-Met-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N BJWKOATWNQJPSK-SRVKXCTJSA-N 0.000 description 1
- FLNPJLDPGMLWAU-UWVGGRQHSA-N Leu-Met-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC(C)C FLNPJLDPGMLWAU-UWVGGRQHSA-N 0.000 description 1
- MJTOYIHCKVQICL-ULQDDVLXSA-N Leu-Met-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N MJTOYIHCKVQICL-ULQDDVLXSA-N 0.000 description 1
- GNRPTBRHRRZCMA-RWMBFGLXSA-N Leu-Met-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N GNRPTBRHRRZCMA-RWMBFGLXSA-N 0.000 description 1
- GCXGCIYIHXSKAY-ULQDDVLXSA-N Leu-Phe-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GCXGCIYIHXSKAY-ULQDDVLXSA-N 0.000 description 1
- ZAVCJRJOQKIOJW-KKUMJFAQSA-N Leu-Phe-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(O)=O)C(O)=O)CC1=CC=CC=C1 ZAVCJRJOQKIOJW-KKUMJFAQSA-N 0.000 description 1
- INCJJHQRZGQLFC-KBPBESRZSA-N Leu-Phe-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O INCJJHQRZGQLFC-KBPBESRZSA-N 0.000 description 1
- FYPWFNKQVVEELI-ULQDDVLXSA-N Leu-Phe-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 FYPWFNKQVVEELI-ULQDDVLXSA-N 0.000 description 1
- BMVFXOQHDQZAQU-DCAQKATOSA-N Leu-Pro-Asp Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N BMVFXOQHDQZAQU-DCAQKATOSA-N 0.000 description 1
- VULJUQZPSOASBZ-SRVKXCTJSA-N Leu-Pro-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O VULJUQZPSOASBZ-SRVKXCTJSA-N 0.000 description 1
- YUTNOGOMBNYPFH-XUXIUFHCSA-N Leu-Pro-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YUTNOGOMBNYPFH-XUXIUFHCSA-N 0.000 description 1
- KWLWZYMNUZJKMZ-IHRRRGAJSA-N Leu-Pro-Leu Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O KWLWZYMNUZJKMZ-IHRRRGAJSA-N 0.000 description 1
- YRRCOJOXAJNSAX-IHRRRGAJSA-N Leu-Pro-Lys Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N YRRCOJOXAJNSAX-IHRRRGAJSA-N 0.000 description 1
- XXXXOVFBXRERQL-ULQDDVLXSA-N Leu-Pro-Phe Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XXXXOVFBXRERQL-ULQDDVLXSA-N 0.000 description 1
- PWPBLZXWFXJFHE-RHYQMDGZSA-N Leu-Pro-Thr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O PWPBLZXWFXJFHE-RHYQMDGZSA-N 0.000 description 1
- UCXQIIIFOOGYEM-ULQDDVLXSA-N Leu-Pro-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCXQIIIFOOGYEM-ULQDDVLXSA-N 0.000 description 1
- RGUXWMDNCPMQFB-YUMQZZPRSA-N Leu-Ser-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RGUXWMDNCPMQFB-YUMQZZPRSA-N 0.000 description 1
- ZDJQVSIPFLMNOX-RHYQMDGZSA-N Leu-Thr-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N ZDJQVSIPFLMNOX-RHYQMDGZSA-N 0.000 description 1
- AEDWWMMHUGYIFD-HJGDQZAQSA-N Leu-Thr-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O AEDWWMMHUGYIFD-HJGDQZAQSA-N 0.000 description 1
- DAYQSYGBCUKVKT-VOAKCMCISA-N Leu-Thr-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O DAYQSYGBCUKVKT-VOAKCMCISA-N 0.000 description 1
- KLSUAWUZBMAZCL-RHYQMDGZSA-N Leu-Thr-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(O)=O KLSUAWUZBMAZCL-RHYQMDGZSA-N 0.000 description 1
- GZRABTMNWJXFMH-UVOCVTCTSA-N Leu-Thr-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZRABTMNWJXFMH-UVOCVTCTSA-N 0.000 description 1
- YWFZWQKWNDOWPA-XIRDDKMYSA-N Leu-Trp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O YWFZWQKWNDOWPA-XIRDDKMYSA-N 0.000 description 1
- UCRJTSIIAYHOHE-ULQDDVLXSA-N Leu-Tyr-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UCRJTSIIAYHOHE-ULQDDVLXSA-N 0.000 description 1
- FBNPMTNBFFAMMH-AVGNSLFASA-N Leu-Val-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-AVGNSLFASA-N 0.000 description 1
- FBNPMTNBFFAMMH-UHFFFAOYSA-N Leu-Val-Arg Natural products CC(C)CC(N)C(=O)NC(C(C)C)C(=O)NC(C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-UHFFFAOYSA-N 0.000 description 1
- CGHXMODRYJISSK-NHCYSSNCSA-N Leu-Val-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O CGHXMODRYJISSK-NHCYSSNCSA-N 0.000 description 1
- LMDVGHQPPPLYAR-IHRRRGAJSA-N Leu-Val-His Chemical compound N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O LMDVGHQPPPLYAR-IHRRRGAJSA-N 0.000 description 1
- QQXJROOJCMIHIV-AVGNSLFASA-N Leu-Val-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O QQXJROOJCMIHIV-AVGNSLFASA-N 0.000 description 1
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 1
- 239000000232 Lipid Bilayer Substances 0.000 description 1
- 108010071324 Livagen Proteins 0.000 description 1
- 206010067125 Liver injury Diseases 0.000 description 1
- PNPYKQFJGRFYJE-GUBZILKMSA-N Lys-Ala-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNPYKQFJGRFYJE-GUBZILKMSA-N 0.000 description 1
- XFIHDSBIPWEYJJ-YUMQZZPRSA-N Lys-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN XFIHDSBIPWEYJJ-YUMQZZPRSA-N 0.000 description 1
- BTSXLXFPMZXVPR-DLOVCJGASA-N Lys-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCCN)N BTSXLXFPMZXVPR-DLOVCJGASA-N 0.000 description 1
- WSXTWLJHTLRFLW-SRVKXCTJSA-N Lys-Ala-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O WSXTWLJHTLRFLW-SRVKXCTJSA-N 0.000 description 1
- YIBOAHAOAWACDK-QEJZJMRPSA-N Lys-Ala-Phe Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 YIBOAHAOAWACDK-QEJZJMRPSA-N 0.000 description 1
- WXJKFRMKJORORD-DCAQKATOSA-N Lys-Arg-Ala Chemical compound NC(=N)NCCC[C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CCCCN WXJKFRMKJORORD-DCAQKATOSA-N 0.000 description 1
- ALSRJRIWBNENFY-DCAQKATOSA-N Lys-Arg-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O ALSRJRIWBNENFY-DCAQKATOSA-N 0.000 description 1
- NTEVEUCLFMWSND-SRVKXCTJSA-N Lys-Arg-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O NTEVEUCLFMWSND-SRVKXCTJSA-N 0.000 description 1
- JGAMUXDWYSXYLM-SRVKXCTJSA-N Lys-Arg-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O JGAMUXDWYSXYLM-SRVKXCTJSA-N 0.000 description 1
- YNNPKXBBRZVIRX-IHRRRGAJSA-N Lys-Arg-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O YNNPKXBBRZVIRX-IHRRRGAJSA-N 0.000 description 1
- SWWCDAGDQHTKIE-RHYQMDGZSA-N Lys-Arg-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SWWCDAGDQHTKIE-RHYQMDGZSA-N 0.000 description 1
- NTSPQIONFJUMJV-AVGNSLFASA-N Lys-Arg-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O NTSPQIONFJUMJV-AVGNSLFASA-N 0.000 description 1
- DNEJSAIMVANNPA-DCAQKATOSA-N Lys-Asn-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DNEJSAIMVANNPA-DCAQKATOSA-N 0.000 description 1
- WLCYCADOWRMSAJ-CIUDSAMLSA-N Lys-Asn-Cys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(O)=O WLCYCADOWRMSAJ-CIUDSAMLSA-N 0.000 description 1
- HQVDJTYKCMIWJP-YUMQZZPRSA-N Lys-Asn-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O HQVDJTYKCMIWJP-YUMQZZPRSA-N 0.000 description 1
- MKBIVWXCFINCLE-SRVKXCTJSA-N Lys-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N MKBIVWXCFINCLE-SRVKXCTJSA-N 0.000 description 1
- FACUGMGEFUEBTI-SRVKXCTJSA-N Lys-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCCCN FACUGMGEFUEBTI-SRVKXCTJSA-N 0.000 description 1
- ZQCVMVCVPFYXHZ-SRVKXCTJSA-N Lys-Asn-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCCN ZQCVMVCVPFYXHZ-SRVKXCTJSA-N 0.000 description 1
- WGCKDDHUFPQSMZ-ZPFDUUQYSA-N Lys-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCCCN WGCKDDHUFPQSMZ-ZPFDUUQYSA-N 0.000 description 1
- SSYOBDBNBQBSQE-SRVKXCTJSA-N Lys-Cys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O SSYOBDBNBQBSQE-SRVKXCTJSA-N 0.000 description 1
- AIPHUKOBUXJNKM-KKUMJFAQSA-N Lys-Cys-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O AIPHUKOBUXJNKM-KKUMJFAQSA-N 0.000 description 1
- HWMZUBUEOYAQSC-DCAQKATOSA-N Lys-Gln-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O HWMZUBUEOYAQSC-DCAQKATOSA-N 0.000 description 1
- QQUJSUFWEDZQQY-AVGNSLFASA-N Lys-Gln-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCCN QQUJSUFWEDZQQY-AVGNSLFASA-N 0.000 description 1
- HEWWNLVEWBJBKA-WDCWCFNPSA-N Lys-Gln-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCCCN HEWWNLVEWBJBKA-WDCWCFNPSA-N 0.000 description 1
- DRCILAJNUJKAHC-SRVKXCTJSA-N Lys-Glu-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DRCILAJNUJKAHC-SRVKXCTJSA-N 0.000 description 1
- ZXEUFAVXODIPHC-GUBZILKMSA-N Lys-Glu-Asn Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZXEUFAVXODIPHC-GUBZILKMSA-N 0.000 description 1
- GRADYHMSAUIKPS-DCAQKATOSA-N Lys-Glu-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRADYHMSAUIKPS-DCAQKATOSA-N 0.000 description 1
- LPAJOCKCPRZEAG-MNXVOIDGSA-N Lys-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCCCN LPAJOCKCPRZEAG-MNXVOIDGSA-N 0.000 description 1
- DCRWPTBMWMGADO-AVGNSLFASA-N Lys-Glu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DCRWPTBMWMGADO-AVGNSLFASA-N 0.000 description 1
- IMAKMJCBYCSMHM-AVGNSLFASA-N Lys-Glu-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN IMAKMJCBYCSMHM-AVGNSLFASA-N 0.000 description 1
- PAMDBWYMLWOELY-SDDRHHMPSA-N Lys-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)C(=O)O PAMDBWYMLWOELY-SDDRHHMPSA-N 0.000 description 1
- ODUQLUADRKMHOZ-JYJNAYRXSA-N Lys-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)O ODUQLUADRKMHOZ-JYJNAYRXSA-N 0.000 description 1
- ULUQBUKAPDUKOC-GVXVVHGQSA-N Lys-Glu-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ULUQBUKAPDUKOC-GVXVVHGQSA-N 0.000 description 1
- UETQMSASAVBGJY-QWRGUYRKSA-N Lys-Gly-His Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CNC=N1 UETQMSASAVBGJY-QWRGUYRKSA-N 0.000 description 1
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 1
- PBLLTSKBTAHDNA-KBPBESRZSA-N Lys-Gly-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PBLLTSKBTAHDNA-KBPBESRZSA-N 0.000 description 1
- CANPXOLVTMKURR-WEDXCCLWSA-N Lys-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN CANPXOLVTMKURR-WEDXCCLWSA-N 0.000 description 1
- ZASPELYMPSACER-HOCLYGCPSA-N Lys-Gly-Trp Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O ZASPELYMPSACER-HOCLYGCPSA-N 0.000 description 1
- OWRUUFUVXFREBD-KKUMJFAQSA-N Lys-His-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O OWRUUFUVXFREBD-KKUMJFAQSA-N 0.000 description 1
- FGMHXLULNHTPID-KKUMJFAQSA-N Lys-His-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CN=CN1 FGMHXLULNHTPID-KKUMJFAQSA-N 0.000 description 1
- ZMMDPRTXLAEMOD-BZSNNMDCSA-N Lys-His-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ZMMDPRTXLAEMOD-BZSNNMDCSA-N 0.000 description 1
- SLQJJFAVWSZLBL-BJDJZHNGSA-N Lys-Ile-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN SLQJJFAVWSZLBL-BJDJZHNGSA-N 0.000 description 1
- IUWMQCZOTYRXPL-ZPFDUUQYSA-N Lys-Ile-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O IUWMQCZOTYRXPL-ZPFDUUQYSA-N 0.000 description 1
- OJDFAABAHBPVTH-MNXVOIDGSA-N Lys-Ile-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O OJDFAABAHBPVTH-MNXVOIDGSA-N 0.000 description 1
- CBNMHRCLYBJIIZ-XUXIUFHCSA-N Lys-Ile-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCCCN)N CBNMHRCLYBJIIZ-XUXIUFHCSA-N 0.000 description 1
- IZJGPPIGYTVXLB-FQUUOJAGSA-N Lys-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IZJGPPIGYTVXLB-FQUUOJAGSA-N 0.000 description 1
- PRSBSVAVOQOAMI-BJDJZHNGSA-N Lys-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN PRSBSVAVOQOAMI-BJDJZHNGSA-N 0.000 description 1
- NJNRBRKHOWSGMN-SRVKXCTJSA-N Lys-Leu-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O NJNRBRKHOWSGMN-SRVKXCTJSA-N 0.000 description 1
- MUXNCRWTWBMNHX-SRVKXCTJSA-N Lys-Leu-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O MUXNCRWTWBMNHX-SRVKXCTJSA-N 0.000 description 1
- RBEATVHTWHTHTJ-KKUMJFAQSA-N Lys-Leu-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O RBEATVHTWHTHTJ-KKUMJFAQSA-N 0.000 description 1
- ORVFEGYUJITPGI-IHRRRGAJSA-N Lys-Leu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCCN ORVFEGYUJITPGI-IHRRRGAJSA-N 0.000 description 1
- XIZQPFCRXLUNMK-BZSNNMDCSA-N Lys-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCCCN)N XIZQPFCRXLUNMK-BZSNNMDCSA-N 0.000 description 1
- YPLVCBKEPJPBDQ-MELADBBJSA-N Lys-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N YPLVCBKEPJPBDQ-MELADBBJSA-N 0.000 description 1
- LJADEBULDNKJNK-IHRRRGAJSA-N Lys-Leu-Val Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O LJADEBULDNKJNK-IHRRRGAJSA-N 0.000 description 1
- XOQMURBBIXRRCR-SRVKXCTJSA-N Lys-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN XOQMURBBIXRRCR-SRVKXCTJSA-N 0.000 description 1
- UQRZFMQQXXJTTF-AVGNSLFASA-N Lys-Lys-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O UQRZFMQQXXJTTF-AVGNSLFASA-N 0.000 description 1
- GAHJXEMYXKLZRQ-AJNGGQMLSA-N Lys-Lys-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GAHJXEMYXKLZRQ-AJNGGQMLSA-N 0.000 description 1
- HVAUKHLDSDDROB-KKUMJFAQSA-N Lys-Lys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HVAUKHLDSDDROB-KKUMJFAQSA-N 0.000 description 1
- WKUXWMWQTOYTFI-SRVKXCTJSA-N Lys-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N WKUXWMWQTOYTFI-SRVKXCTJSA-N 0.000 description 1
- ZCWWVXAXWUAEPZ-SRVKXCTJSA-N Lys-Met-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZCWWVXAXWUAEPZ-SRVKXCTJSA-N 0.000 description 1
- MSSJJDVQTFTLIF-KBPBESRZSA-N Lys-Phe-Gly Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](Cc1ccccc1)C(=O)NCC(O)=O MSSJJDVQTFTLIF-KBPBESRZSA-N 0.000 description 1
- LNMKRJJLEFASGA-BZSNNMDCSA-N Lys-Phe-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O LNMKRJJLEFASGA-BZSNNMDCSA-N 0.000 description 1
- SVSQSPICRKBMSZ-SRVKXCTJSA-N Lys-Pro-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O SVSQSPICRKBMSZ-SRVKXCTJSA-N 0.000 description 1
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 1
- LECIJRIRMVOFMH-ULQDDVLXSA-N Lys-Pro-Phe Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 LECIJRIRMVOFMH-ULQDDVLXSA-N 0.000 description 1
- HKXSZKJMDBHOTG-CIUDSAMLSA-N Lys-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN HKXSZKJMDBHOTG-CIUDSAMLSA-N 0.000 description 1
- JOSAKOKSPXROGQ-BJDJZHNGSA-N Lys-Ser-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JOSAKOKSPXROGQ-BJDJZHNGSA-N 0.000 description 1
- PLOUVAYOMTYJRG-JXUBOQSCSA-N Lys-Thr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O PLOUVAYOMTYJRG-JXUBOQSCSA-N 0.000 description 1
- TVHCDSBMFQYPNA-RHYQMDGZSA-N Lys-Thr-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O TVHCDSBMFQYPNA-RHYQMDGZSA-N 0.000 description 1
- CUHGAUZONORRIC-HJGDQZAQSA-N Lys-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N)O CUHGAUZONORRIC-HJGDQZAQSA-N 0.000 description 1
- UWHCKWNPWKTMBM-WDCWCFNPSA-N Lys-Thr-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O UWHCKWNPWKTMBM-WDCWCFNPSA-N 0.000 description 1
- YCJCEMKOZOYBEF-OEAJRASXSA-N Lys-Thr-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O YCJCEMKOZOYBEF-OEAJRASXSA-N 0.000 description 1
- BDFHWFUAQLIMJO-KXNHARMFSA-N Lys-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N)O BDFHWFUAQLIMJO-KXNHARMFSA-N 0.000 description 1
- RMOKGALPSPOYKE-KATARQTJSA-N Lys-Thr-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O RMOKGALPSPOYKE-KATARQTJSA-N 0.000 description 1
- OPJRECCCQSDDCZ-TUSQITKMSA-N Lys-Trp-Trp Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O OPJRECCCQSDDCZ-TUSQITKMSA-N 0.000 description 1
- SUZVLFWOCKHWET-CQDKDKBSSA-N Lys-Tyr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O SUZVLFWOCKHWET-CQDKDKBSSA-N 0.000 description 1
- XABXVVSWUVCZST-GVXVVHGQSA-N Lys-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN XABXVVSWUVCZST-GVXVVHGQSA-N 0.000 description 1
- TXTZMVNJIRZABH-ULQDDVLXSA-N Lys-Val-Phe Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 TXTZMVNJIRZABH-ULQDDVLXSA-N 0.000 description 1
- 101150029199 MTF1 gene Proteins 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- ONGCSGVHCSAATF-CIUDSAMLSA-N Met-Ala-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O ONGCSGVHCSAATF-CIUDSAMLSA-N 0.000 description 1
- MUYQDMBLDFEVRJ-LSJOCFKGSA-N Met-Ala-His Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CNC=N1 MUYQDMBLDFEVRJ-LSJOCFKGSA-N 0.000 description 1
- VTKPSXWRUGCOAC-GUBZILKMSA-N Met-Ala-Met Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCSC VTKPSXWRUGCOAC-GUBZILKMSA-N 0.000 description 1
- ULNXMMYXQKGNPG-LPEHRKFASA-N Met-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N ULNXMMYXQKGNPG-LPEHRKFASA-N 0.000 description 1
- WXHHTBVYQOSYSL-FXQIFTODSA-N Met-Ala-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O WXHHTBVYQOSYSL-FXQIFTODSA-N 0.000 description 1
- DSWOTZCVCBEPOU-IUCAKERBSA-N Met-Arg-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCNC(N)=N DSWOTZCVCBEPOU-IUCAKERBSA-N 0.000 description 1
- WDTLNWHPIPCMMP-AVGNSLFASA-N Met-Arg-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O WDTLNWHPIPCMMP-AVGNSLFASA-N 0.000 description 1
- ZAJNRWKGHWGPDQ-SDDRHHMPSA-N Met-Arg-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N ZAJNRWKGHWGPDQ-SDDRHHMPSA-N 0.000 description 1
- AHZNUGRZHMZGFL-GUBZILKMSA-N Met-Arg-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CCCNC(N)=N AHZNUGRZHMZGFL-GUBZILKMSA-N 0.000 description 1
- CAODKDAPYGUMLK-FXQIFTODSA-N Met-Asn-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CAODKDAPYGUMLK-FXQIFTODSA-N 0.000 description 1
- OHMKUHXCDSCOMT-QXEWZRGKSA-N Met-Asn-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O OHMKUHXCDSCOMT-QXEWZRGKSA-N 0.000 description 1
- SQUTUWHAAWJYES-GUBZILKMSA-N Met-Asp-Arg Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SQUTUWHAAWJYES-GUBZILKMSA-N 0.000 description 1
- GODBLDDYHFTUAH-CIUDSAMLSA-N Met-Asp-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(O)=O GODBLDDYHFTUAH-CIUDSAMLSA-N 0.000 description 1
- FJVJLMZUIGMFFU-BQBZGAKWSA-N Met-Asp-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O FJVJLMZUIGMFFU-BQBZGAKWSA-N 0.000 description 1
- WGBMNLCRYKSWAR-DCAQKATOSA-N Met-Asp-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN WGBMNLCRYKSWAR-DCAQKATOSA-N 0.000 description 1
- FBQMBZLJHOQAIH-GUBZILKMSA-N Met-Asp-Met Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O FBQMBZLJHOQAIH-GUBZILKMSA-N 0.000 description 1
- MCNGIXXCMJAURZ-VEVYYDQMSA-N Met-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCSC)N)O MCNGIXXCMJAURZ-VEVYYDQMSA-N 0.000 description 1
- CNUPMMXDISGXMU-CIUDSAMLSA-N Met-Cys-Glu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O CNUPMMXDISGXMU-CIUDSAMLSA-N 0.000 description 1
- FWTBMGAKKPSTBT-GUBZILKMSA-N Met-Gln-Glu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FWTBMGAKKPSTBT-GUBZILKMSA-N 0.000 description 1
- GXYYFDKJHLRNSI-SRVKXCTJSA-N Met-Gln-His Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(O)=O GXYYFDKJHLRNSI-SRVKXCTJSA-N 0.000 description 1
- QMIXOTQHYHOUJP-KKUMJFAQSA-N Met-Gln-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N QMIXOTQHYHOUJP-KKUMJFAQSA-N 0.000 description 1
- KQBJYJXPZBNEIK-DCAQKATOSA-N Met-Glu-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQBJYJXPZBNEIK-DCAQKATOSA-N 0.000 description 1
- AETNZPKUUYYYEK-CIUDSAMLSA-N Met-Glu-Asn Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O AETNZPKUUYYYEK-CIUDSAMLSA-N 0.000 description 1
- WWWGMQHQSAUXBU-BQBZGAKWSA-N Met-Gly-Asn Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(N)=O WWWGMQHQSAUXBU-BQBZGAKWSA-N 0.000 description 1
- GVIVXNFKJQFTCE-YUMQZZPRSA-N Met-Gly-Gln Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O GVIVXNFKJQFTCE-YUMQZZPRSA-N 0.000 description 1
- UZWMJZSOXGOVIN-LURJTMIESA-N Met-Gly-Gly Chemical compound CSCC[C@H](N)C(=O)NCC(=O)NCC(O)=O UZWMJZSOXGOVIN-LURJTMIESA-N 0.000 description 1
- JACAKCWAOHKQBV-UWVGGRQHSA-N Met-Gly-Lys Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN JACAKCWAOHKQBV-UWVGGRQHSA-N 0.000 description 1
- UZVKFARGHHMQGX-IUCAKERBSA-N Met-Gly-Met Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCSC UZVKFARGHHMQGX-IUCAKERBSA-N 0.000 description 1
- MVBZBRKNZVJEKK-DTWKUNHWSA-N Met-Gly-Pro Chemical compound CSCC[C@@H](C(=O)NCC(=O)N1CCC[C@@H]1C(=O)O)N MVBZBRKNZVJEKK-DTWKUNHWSA-N 0.000 description 1
- SXWQMBGNFXAGAT-FJXKBIBVSA-N Met-Gly-Thr Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O SXWQMBGNFXAGAT-FJXKBIBVSA-N 0.000 description 1
- MXEASDMFHUKOGE-ULQDDVLXSA-N Met-His-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N MXEASDMFHUKOGE-ULQDDVLXSA-N 0.000 description 1
- XMQZLGBUJMMODC-AVGNSLFASA-N Met-His-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O XMQZLGBUJMMODC-AVGNSLFASA-N 0.000 description 1
- HGAJNEWOUHDUMZ-SRVKXCTJSA-N Met-Leu-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O HGAJNEWOUHDUMZ-SRVKXCTJSA-N 0.000 description 1
- SODXFJOPSCXOHE-IHRRRGAJSA-N Met-Leu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O SODXFJOPSCXOHE-IHRRRGAJSA-N 0.000 description 1
- KMSMNUFBNCHMII-IHRRRGAJSA-N Met-Leu-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN KMSMNUFBNCHMII-IHRRRGAJSA-N 0.000 description 1
- USBFEVBHEQBWDD-AVGNSLFASA-N Met-Leu-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O USBFEVBHEQBWDD-AVGNSLFASA-N 0.000 description 1
- UNPGTBHYKJOCCZ-DCAQKATOSA-N Met-Lys-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O UNPGTBHYKJOCCZ-DCAQKATOSA-N 0.000 description 1
- JCMMNFZUKMMECJ-DCAQKATOSA-N Met-Lys-Asn Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O JCMMNFZUKMMECJ-DCAQKATOSA-N 0.000 description 1
- HAQLBBVZAGMESV-IHRRRGAJSA-N Met-Lys-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O HAQLBBVZAGMESV-IHRRRGAJSA-N 0.000 description 1
- OBPCXINRFKHSRY-SDDRHHMPSA-N Met-Met-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N OBPCXINRFKHSRY-SDDRHHMPSA-N 0.000 description 1
- MIAZEQZXAFTCCG-UBHSHLNASA-N Met-Phe-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 MIAZEQZXAFTCCG-UBHSHLNASA-N 0.000 description 1
- VQILILSLEFDECU-GUBZILKMSA-N Met-Pro-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O VQILILSLEFDECU-GUBZILKMSA-N 0.000 description 1
- MPCKIRSXNKACRF-GUBZILKMSA-N Met-Pro-Asn Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O MPCKIRSXNKACRF-GUBZILKMSA-N 0.000 description 1
- WYDFQSJOARJAMM-GUBZILKMSA-N Met-Pro-Asp Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O WYDFQSJOARJAMM-GUBZILKMSA-N 0.000 description 1
- YLDSJJOGQNEQJK-AVGNSLFASA-N Met-Pro-Leu Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O YLDSJJOGQNEQJK-AVGNSLFASA-N 0.000 description 1
- CIDICGYKRUTYLE-FXQIFTODSA-N Met-Ser-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O CIDICGYKRUTYLE-FXQIFTODSA-N 0.000 description 1
- PCTFVQATEGYHJU-FXQIFTODSA-N Met-Ser-Asn Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O PCTFVQATEGYHJU-FXQIFTODSA-N 0.000 description 1
- ZDJICAUBMUKVEJ-CIUDSAMLSA-N Met-Ser-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O ZDJICAUBMUKVEJ-CIUDSAMLSA-N 0.000 description 1
- FIZZULTXMVEIAA-IHRRRGAJSA-N Met-Ser-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FIZZULTXMVEIAA-IHRRRGAJSA-N 0.000 description 1
- MIXPUVSPPOWTCR-FXQIFTODSA-N Met-Ser-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MIXPUVSPPOWTCR-FXQIFTODSA-N 0.000 description 1
- DBMLDOWSVHMQQN-XGEHTFHBSA-N Met-Ser-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DBMLDOWSVHMQQN-XGEHTFHBSA-N 0.000 description 1
- KSIPKXNIQOWMIC-RCWTZXSCSA-N Met-Thr-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KSIPKXNIQOWMIC-RCWTZXSCSA-N 0.000 description 1
- RIIFMEBFDDXGCV-VEVYYDQMSA-N Met-Thr-Asn Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O RIIFMEBFDDXGCV-VEVYYDQMSA-N 0.000 description 1
- FXBKQTOGURNXSL-HJGDQZAQSA-N Met-Thr-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(O)=O FXBKQTOGURNXSL-HJGDQZAQSA-N 0.000 description 1
- KYJHWKAMFISDJE-RCWTZXSCSA-N Met-Thr-Met Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCSC KYJHWKAMFISDJE-RCWTZXSCSA-N 0.000 description 1
- GWADARYJIJDYRC-XGEHTFHBSA-N Met-Thr-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GWADARYJIJDYRC-XGEHTFHBSA-N 0.000 description 1
- VYXIKLFLGRTANT-HRCADAONSA-N Met-Tyr-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N VYXIKLFLGRTANT-HRCADAONSA-N 0.000 description 1
- CNFMPVYIVQUJOO-NHCYSSNCSA-N Met-Val-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(N)=O CNFMPVYIVQUJOO-NHCYSSNCSA-N 0.000 description 1
- QAVZUKIPOMBLMC-AVGNSLFASA-N Met-Val-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(C)C QAVZUKIPOMBLMC-AVGNSLFASA-N 0.000 description 1
- VYDLZDRMOFYOGV-TUAOUCFPSA-N Met-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N VYDLZDRMOFYOGV-TUAOUCFPSA-N 0.000 description 1
- 208000001145 Metabolic Syndrome Diseases 0.000 description 1
- 108090000157 Metallothionein Proteins 0.000 description 1
- 229920000168 Microcrystalline cellulose Polymers 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- HSHXDCVZWHOWCS-UHFFFAOYSA-N N'-hexadecylthiophene-2-carbohydrazide Chemical compound CCCCCCCCCCCCCCCCNNC(=O)c1cccs1 HSHXDCVZWHOWCS-UHFFFAOYSA-N 0.000 description 1
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 1
- 101150004229 NR0B2 gene Proteins 0.000 description 1
- 101150072008 NR5A2 gene Proteins 0.000 description 1
- 101710167899 Nuclear envelope pore membrane protein POM 121C Proteins 0.000 description 1
- 101710105538 Nuclear receptor subfamily 5 group A member 2 Proteins 0.000 description 1
- 108010047956 Nucleosomes Proteins 0.000 description 1
- CTQNGGLPUBDAKN-UHFFFAOYSA-N O-Xylene Chemical compound CC1=CC=CC=C1C CTQNGGLPUBDAKN-UHFFFAOYSA-N 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 238000010222 PCR analysis Methods 0.000 description 1
- 101150092014 POM121C gene Proteins 0.000 description 1
- 101150074172 PROX1 gene Proteins 0.000 description 1
- 229930040373 Paraformaldehyde Natural products 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- LBSARGIQACMGDF-WBAXXEDZSA-N Phe-Ala-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 LBSARGIQACMGDF-WBAXXEDZSA-N 0.000 description 1
- UHRNIXJAGGLKHP-DLOVCJGASA-N Phe-Ala-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O UHRNIXJAGGLKHP-DLOVCJGASA-N 0.000 description 1
- VHWOBXIWBDWZHK-IHRRRGAJSA-N Phe-Arg-Asp Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](CC(O)=O)C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 VHWOBXIWBDWZHK-IHRRRGAJSA-N 0.000 description 1
- XWBJLKDCHJVKAK-KKUMJFAQSA-N Phe-Arg-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N XWBJLKDCHJVKAK-KKUMJFAQSA-N 0.000 description 1
- BRDYYVQTEJVRQT-HRCADAONSA-N Phe-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O BRDYYVQTEJVRQT-HRCADAONSA-N 0.000 description 1
- HXSUFWQYLPKEHF-IHRRRGAJSA-N Phe-Asn-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HXSUFWQYLPKEHF-IHRRRGAJSA-N 0.000 description 1
- HHOOEUSPFGPZFP-QWRGUYRKSA-N Phe-Asn-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O HHOOEUSPFGPZFP-QWRGUYRKSA-N 0.000 description 1
- KIEPQOIQHFKQLK-PCBIJLKTSA-N Phe-Asn-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KIEPQOIQHFKQLK-PCBIJLKTSA-N 0.000 description 1
- UEEVBGHEGJMDDV-AVGNSLFASA-N Phe-Asp-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 UEEVBGHEGJMDDV-AVGNSLFASA-N 0.000 description 1
- IUVYJBMTHARMIP-PCBIJLKTSA-N Phe-Asp-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O IUVYJBMTHARMIP-PCBIJLKTSA-N 0.000 description 1
- MQVFHOPCKNTHGT-MELADBBJSA-N Phe-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O MQVFHOPCKNTHGT-MELADBBJSA-N 0.000 description 1
- KOUUGTKGEQZRHV-KKUMJFAQSA-N Phe-Gln-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O KOUUGTKGEQZRHV-KKUMJFAQSA-N 0.000 description 1
- UMKYAYXCMYYNHI-AVGNSLFASA-N Phe-Gln-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N UMKYAYXCMYYNHI-AVGNSLFASA-N 0.000 description 1
- IILUKIJNFMUBNF-IHRRRGAJSA-N Phe-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O IILUKIJNFMUBNF-IHRRRGAJSA-N 0.000 description 1
- UNLYPPYNDXHGDG-IHRRRGAJSA-N Phe-Gln-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 UNLYPPYNDXHGDG-IHRRRGAJSA-N 0.000 description 1
- MGBRZXXGQBAULP-DRZSPHRISA-N Phe-Glu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 MGBRZXXGQBAULP-DRZSPHRISA-N 0.000 description 1
- FMMIYCMOVGXZIP-AVGNSLFASA-N Phe-Glu-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O FMMIYCMOVGXZIP-AVGNSLFASA-N 0.000 description 1
- KYYMILWEGJYPQZ-IHRRRGAJSA-N Phe-Glu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 KYYMILWEGJYPQZ-IHRRRGAJSA-N 0.000 description 1
- FIRWJEJVFFGXSH-RYUDHWBXSA-N Phe-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 FIRWJEJVFFGXSH-RYUDHWBXSA-N 0.000 description 1
- CSDMCMITJLKBAH-SOUVJXGZSA-N Phe-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O CSDMCMITJLKBAH-SOUVJXGZSA-N 0.000 description 1
- LWPMGKSZPKFKJD-DZKIICNBSA-N Phe-Glu-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O LWPMGKSZPKFKJD-DZKIICNBSA-N 0.000 description 1
- JJHVFCUWLSKADD-ONGXEEELSA-N Phe-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O JJHVFCUWLSKADD-ONGXEEELSA-N 0.000 description 1
- RFEXGCASCQGGHZ-STQMWFEESA-N Phe-Gly-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O RFEXGCASCQGGHZ-STQMWFEESA-N 0.000 description 1
- APJPXSFJBMMOLW-KBPBESRZSA-N Phe-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 APJPXSFJBMMOLW-KBPBESRZSA-N 0.000 description 1
- HBGFEEQFVBWYJQ-KBPBESRZSA-N Phe-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HBGFEEQFVBWYJQ-KBPBESRZSA-N 0.000 description 1
- SWCOXQLDICUYOL-ULQDDVLXSA-N Phe-His-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SWCOXQLDICUYOL-ULQDDVLXSA-N 0.000 description 1
- SFKOEHXABNPLRT-KBPBESRZSA-N Phe-His-Gly Chemical compound N[C@@H](Cc1ccccc1)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)NCC(O)=O SFKOEHXABNPLRT-KBPBESRZSA-N 0.000 description 1
- VADLTGVIOIOKGM-BZSNNMDCSA-N Phe-His-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CN=CN1 VADLTGVIOIOKGM-BZSNNMDCSA-N 0.000 description 1
- WEMYTDDMDBLPMI-DKIMLUQUSA-N Phe-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N WEMYTDDMDBLPMI-DKIMLUQUSA-N 0.000 description 1
- RSPUIENXSJYZQO-JYJNAYRXSA-N Phe-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RSPUIENXSJYZQO-JYJNAYRXSA-N 0.000 description 1
- METZZBCMDXHFMK-BZSNNMDCSA-N Phe-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N METZZBCMDXHFMK-BZSNNMDCSA-N 0.000 description 1
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 1
- CMHTUJQZQXFNTQ-OEAJRASXSA-N Phe-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC1=CC=CC=C1)N)O CMHTUJQZQXFNTQ-OEAJRASXSA-N 0.000 description 1
- INHMISZWLJZQGH-ULQDDVLXSA-N Phe-Leu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 INHMISZWLJZQGH-ULQDDVLXSA-N 0.000 description 1
- PHJUFDQVVKVOPU-ULQDDVLXSA-N Phe-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CC=CC=C1)N PHJUFDQVVKVOPU-ULQDDVLXSA-N 0.000 description 1
- BNRFQGLWLQESBG-YESZJQIVSA-N Phe-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O BNRFQGLWLQESBG-YESZJQIVSA-N 0.000 description 1
- JKJSIYKSGIDHPM-WBAXXEDZSA-N Phe-Phe-Ala Chemical compound C[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@@H](N)Cc1ccccc1)C(O)=O JKJSIYKSGIDHPM-WBAXXEDZSA-N 0.000 description 1
- OXKJSGGTHFMGDT-UFYCRDLUSA-N Phe-Phe-Arg Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C1=CC=CC=C1 OXKJSGGTHFMGDT-UFYCRDLUSA-N 0.000 description 1
- OWSLLRKCHLTUND-BZSNNMDCSA-N Phe-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OWSLLRKCHLTUND-BZSNNMDCSA-N 0.000 description 1
- PBWNICYZGJQKJV-BZSNNMDCSA-N Phe-Phe-Cys Chemical compound N[C@@H](Cc1ccccc1)C(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CS)C(O)=O PBWNICYZGJQKJV-BZSNNMDCSA-N 0.000 description 1
- AXIOGMQCDYVTNY-ACRUOGEOSA-N Phe-Phe-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 AXIOGMQCDYVTNY-ACRUOGEOSA-N 0.000 description 1
- RBRNEFJTEHPDSL-ACRUOGEOSA-N Phe-Phe-Lys Chemical compound C([C@@H](C(=O)N[C@@H](CCCCN)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 RBRNEFJTEHPDSL-ACRUOGEOSA-N 0.000 description 1
- MGLBSROLWAWCKN-FCLVOEFKSA-N Phe-Phe-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MGLBSROLWAWCKN-FCLVOEFKSA-N 0.000 description 1
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 1
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 1
- XDMMOISUAHXXFD-SRVKXCTJSA-N Phe-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O XDMMOISUAHXXFD-SRVKXCTJSA-N 0.000 description 1
- JXQVYPWVGUOIDV-MXAVVETBSA-N Phe-Ser-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JXQVYPWVGUOIDV-MXAVVETBSA-N 0.000 description 1
- IPFXYNKCXYGSSV-KKUMJFAQSA-N Phe-Ser-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N IPFXYNKCXYGSSV-KKUMJFAQSA-N 0.000 description 1
- QSWKNJAPHQDAAS-MELADBBJSA-N Phe-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O QSWKNJAPHQDAAS-MELADBBJSA-N 0.000 description 1
- BPIMVBKDLSBKIJ-FCLVOEFKSA-N Phe-Thr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BPIMVBKDLSBKIJ-FCLVOEFKSA-N 0.000 description 1
- QUUCAHIYARMNBL-FHWLQOOXSA-N Phe-Tyr-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N QUUCAHIYARMNBL-FHWLQOOXSA-N 0.000 description 1
- MHNBYYFXWDUGBW-RPTUDFQQSA-N Phe-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CC=CC=C2)N)O MHNBYYFXWDUGBW-RPTUDFQQSA-N 0.000 description 1
- JSGWNFKWZNPDAV-YDHLFZDLSA-N Phe-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 JSGWNFKWZNPDAV-YDHLFZDLSA-N 0.000 description 1
- GAMLAXHLYGLQBJ-UFYCRDLUSA-N Phe-Val-Tyr Chemical compound N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)O)CC1=CC=C(C=C1)O)C(C)C)CC1=CC=CC=C1 GAMLAXHLYGLQBJ-UFYCRDLUSA-N 0.000 description 1
- 108010089430 Phosphoproteins Proteins 0.000 description 1
- 102000007982 Phosphoproteins Human genes 0.000 description 1
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 1
- 229920002732 Polyanhydride Polymers 0.000 description 1
- 229920001273 Polyhydroxy acid Polymers 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- FZHBZMDRDASUHN-NAKRPEOUSA-N Pro-Ala-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1)C(O)=O FZHBZMDRDASUHN-NAKRPEOUSA-N 0.000 description 1
- IFMDQWDAJUMMJC-DCAQKATOSA-N Pro-Ala-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O IFMDQWDAJUMMJC-DCAQKATOSA-N 0.000 description 1
- LCRSGSIRKLXZMZ-BPNCWPANSA-N Pro-Ala-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LCRSGSIRKLXZMZ-BPNCWPANSA-N 0.000 description 1
- NHDVNAKDACFHPX-GUBZILKMSA-N Pro-Arg-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O NHDVNAKDACFHPX-GUBZILKMSA-N 0.000 description 1
- LNLNHXIQPGKRJQ-SRVKXCTJSA-N Pro-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 LNLNHXIQPGKRJQ-SRVKXCTJSA-N 0.000 description 1
- SSSFPISOZOLQNP-GUBZILKMSA-N Pro-Arg-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSFPISOZOLQNP-GUBZILKMSA-N 0.000 description 1
- HPXVFFIIGOAQRV-DCAQKATOSA-N Pro-Arg-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O HPXVFFIIGOAQRV-DCAQKATOSA-N 0.000 description 1
- INXAPZFIOVGHSV-CIUDSAMLSA-N Pro-Asn-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1 INXAPZFIOVGHSV-CIUDSAMLSA-N 0.000 description 1
- KQCCDMFIALWGTL-GUBZILKMSA-N Pro-Asn-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1 KQCCDMFIALWGTL-GUBZILKMSA-N 0.000 description 1
- AHXPYZRZRMQOAU-QXEWZRGKSA-N Pro-Asn-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1)C(O)=O AHXPYZRZRMQOAU-QXEWZRGKSA-N 0.000 description 1
- JARJPEMLQAWNBR-GUBZILKMSA-N Pro-Asp-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JARJPEMLQAWNBR-GUBZILKMSA-N 0.000 description 1
- ILMLVTGTUJPQFP-FXQIFTODSA-N Pro-Asp-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ILMLVTGTUJPQFP-FXQIFTODSA-N 0.000 description 1
- SGCZFWSQERRKBD-BQBZGAKWSA-N Pro-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 SGCZFWSQERRKBD-BQBZGAKWSA-N 0.000 description 1
- DEDANIDYQAPTFI-IHRRRGAJSA-N Pro-Asp-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O DEDANIDYQAPTFI-IHRRRGAJSA-N 0.000 description 1
- XUSDDSLCRPUKLP-QXEWZRGKSA-N Pro-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 XUSDDSLCRPUKLP-QXEWZRGKSA-N 0.000 description 1
- DIZLUAZLNDFDPR-CIUDSAMLSA-N Pro-Cys-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H]1CCCN1 DIZLUAZLNDFDPR-CIUDSAMLSA-N 0.000 description 1
- TUYWCHPXKQTISF-LPEHRKFASA-N Pro-Cys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N2CCC[C@@H]2C(=O)O TUYWCHPXKQTISF-LPEHRKFASA-N 0.000 description 1
- ODPIUQVTULPQEP-CIUDSAMLSA-N Pro-Gln-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@@H]1CCCN1 ODPIUQVTULPQEP-CIUDSAMLSA-N 0.000 description 1
- PZSCUPVOJGKHEP-CIUDSAMLSA-N Pro-Gln-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PZSCUPVOJGKHEP-CIUDSAMLSA-N 0.000 description 1
- SNIPWBQKOPCJRG-CIUDSAMLSA-N Pro-Gln-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O SNIPWBQKOPCJRG-CIUDSAMLSA-N 0.000 description 1
- CMOIIANLNNYUTP-SRVKXCTJSA-N Pro-Gln-His Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O CMOIIANLNNYUTP-SRVKXCTJSA-N 0.000 description 1
- DRIJZWBRGMJCDD-DCAQKATOSA-N Pro-Gln-Met Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O DRIJZWBRGMJCDD-DCAQKATOSA-N 0.000 description 1
- DIFXZGPHVCIVSQ-CIUDSAMLSA-N Pro-Gln-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O DIFXZGPHVCIVSQ-CIUDSAMLSA-N 0.000 description 1
- QCARZLHECSFOGG-CIUDSAMLSA-N Pro-Glu-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O QCARZLHECSFOGG-CIUDSAMLSA-N 0.000 description 1
- VDGTVWFMRXVQCT-GUBZILKMSA-N Pro-Glu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 VDGTVWFMRXVQCT-GUBZILKMSA-N 0.000 description 1
- FRKBNXCFJBPJOL-GUBZILKMSA-N Pro-Glu-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FRKBNXCFJBPJOL-GUBZILKMSA-N 0.000 description 1
- NMELOOXSGDRBRU-YUMQZZPRSA-N Pro-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 NMELOOXSGDRBRU-YUMQZZPRSA-N 0.000 description 1
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 1
- DMKWYMWNEKIPFC-IUCAKERBSA-N Pro-Gly-Arg Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O DMKWYMWNEKIPFC-IUCAKERBSA-N 0.000 description 1
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 1
- XQSREVQDGCPFRJ-STQMWFEESA-N Pro-Gly-Phe Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XQSREVQDGCPFRJ-STQMWFEESA-N 0.000 description 1
- FFSLAIOXRMOFIZ-GJZGRUSLSA-N Pro-Gly-Trp Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)O)C(=O)CNC(=O)[C@@H]1CCCN1 FFSLAIOXRMOFIZ-GJZGRUSLSA-N 0.000 description 1
- HAEGAELAYWSUNC-WPRPVWTQSA-N Pro-Gly-Val Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAEGAELAYWSUNC-WPRPVWTQSA-N 0.000 description 1
- PEYNRYREGPAOAK-LSJOCFKGSA-N Pro-His-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C([O-])=O)NC(=O)[C@H]1[NH2+]CCC1)C1=CN=CN1 PEYNRYREGPAOAK-LSJOCFKGSA-N 0.000 description 1
- LCUOTSLIVGSGAU-AVGNSLFASA-N Pro-His-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O LCUOTSLIVGSGAU-AVGNSLFASA-N 0.000 description 1
- JUJGNDZIKKQMDJ-IHRRRGAJSA-N Pro-His-His Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC=N1)C(O)=O JUJGNDZIKKQMDJ-IHRRRGAJSA-N 0.000 description 1
- STASJMBVVHNWCG-IHRRRGAJSA-N Pro-His-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)NC(=O)[C@H]1[NH2+]CCC1)C1=CN=CN1 STASJMBVVHNWCG-IHRRRGAJSA-N 0.000 description 1
- AQSMZTIEJMZQEC-DCAQKATOSA-N Pro-His-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CO)C(=O)O AQSMZTIEJMZQEC-DCAQKATOSA-N 0.000 description 1
- TYMBHHITTMGGPI-NAKRPEOUSA-N Pro-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@@H]1CCCN1 TYMBHHITTMGGPI-NAKRPEOUSA-N 0.000 description 1
- BWCZJGJKOFUUCN-ZPFDUUQYSA-N Pro-Ile-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O BWCZJGJKOFUUCN-ZPFDUUQYSA-N 0.000 description 1
- XYHMFGGWNOFUOU-QXEWZRGKSA-N Pro-Ile-Gly Chemical compound OC(=O)CNC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 XYHMFGGWNOFUOU-QXEWZRGKSA-N 0.000 description 1
- UREQLMJCKFLLHM-NAKRPEOUSA-N Pro-Ile-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UREQLMJCKFLLHM-NAKRPEOUSA-N 0.000 description 1
- AUQGUYPHJSMAKI-CYDGBPFRSA-N Pro-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 AUQGUYPHJSMAKI-CYDGBPFRSA-N 0.000 description 1
- GURGCNUWVSDYTP-SRVKXCTJSA-N Pro-Leu-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GURGCNUWVSDYTP-SRVKXCTJSA-N 0.000 description 1
- FYPGHGXAOZTOBO-IHRRRGAJSA-N Pro-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@@H]2CCCN2 FYPGHGXAOZTOBO-IHRRRGAJSA-N 0.000 description 1
- HATVCTYBNCNMAA-AVGNSLFASA-N Pro-Leu-Met Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O HATVCTYBNCNMAA-AVGNSLFASA-N 0.000 description 1
- DWGFLKQSGRUQTI-IHRRRGAJSA-N Pro-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 DWGFLKQSGRUQTI-IHRRRGAJSA-N 0.000 description 1
- PUQRDHNIOONJJN-AVGNSLFASA-N Pro-Lys-Met Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(O)=O PUQRDHNIOONJJN-AVGNSLFASA-N 0.000 description 1
- NTXFLJULRHQMDC-GUBZILKMSA-N Pro-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 NTXFLJULRHQMDC-GUBZILKMSA-N 0.000 description 1
- WIPAMEKBSHNFQE-IUCAKERBSA-N Pro-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@@H]1CCCN1 WIPAMEKBSHNFQE-IUCAKERBSA-N 0.000 description 1
- ANESFYPBAJPYNJ-SDDRHHMPSA-N Pro-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 ANESFYPBAJPYNJ-SDDRHHMPSA-N 0.000 description 1
- WLJYLAQSUSIQNH-GUBZILKMSA-N Pro-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@@H]1CCCN1 WLJYLAQSUSIQNH-GUBZILKMSA-N 0.000 description 1
- QGLFRQCECIWXFA-RCWTZXSCSA-N Pro-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@@H]1CCCN1)O QGLFRQCECIWXFA-RCWTZXSCSA-N 0.000 description 1
- JFBJPBZSTMXGKL-JYJNAYRXSA-N Pro-Met-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JFBJPBZSTMXGKL-JYJNAYRXSA-N 0.000 description 1
- DYMPSOABVJIFBS-IHRRRGAJSA-N Pro-Phe-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N[C@@H](CS)C(=O)O DYMPSOABVJIFBS-IHRRRGAJSA-N 0.000 description 1
- JIWJRKNYLSHONY-KKUMJFAQSA-N Pro-Phe-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O JIWJRKNYLSHONY-KKUMJFAQSA-N 0.000 description 1
- KDBHVPXBQADZKY-GUBZILKMSA-N Pro-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KDBHVPXBQADZKY-GUBZILKMSA-N 0.000 description 1
- JLMZKEQFMVORMA-SRVKXCTJSA-N Pro-Pro-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 JLMZKEQFMVORMA-SRVKXCTJSA-N 0.000 description 1
- GFHOSBYCLACKEK-GUBZILKMSA-N Pro-Pro-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O GFHOSBYCLACKEK-GUBZILKMSA-N 0.000 description 1
- HWLKHNDRXWTFTN-GUBZILKMSA-N Pro-Pro-Cys Chemical compound C1C[C@H](NC1)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CS)C(=O)O HWLKHNDRXWTFTN-GUBZILKMSA-N 0.000 description 1
- FYKUEXMZYFIZKA-DCAQKATOSA-N Pro-Pro-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FYKUEXMZYFIZKA-DCAQKATOSA-N 0.000 description 1
- SVXXJYJCRNKDDE-AVGNSLFASA-N Pro-Pro-His Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1NCCC1)C1=CN=CN1 SVXXJYJCRNKDDE-AVGNSLFASA-N 0.000 description 1
- CGSOWZUPLOKYOR-AVGNSLFASA-N Pro-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 CGSOWZUPLOKYOR-AVGNSLFASA-N 0.000 description 1
- QAAYIXYLEMRULP-SRVKXCTJSA-N Pro-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 QAAYIXYLEMRULP-SRVKXCTJSA-N 0.000 description 1
- NAIPAPCKKRCMBL-JYJNAYRXSA-N Pro-Pro-Phe Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1NCCC1)C1=CC=CC=C1 NAIPAPCKKRCMBL-JYJNAYRXSA-N 0.000 description 1
- RTQKBZIRDWZLDF-BZSNNMDCSA-N Pro-Pro-Trp Chemical compound C([C@H]1C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)O)CCN1C(=O)[C@@H]1CCCN1 RTQKBZIRDWZLDF-BZSNNMDCSA-N 0.000 description 1
- AJNGQVUFQUVRQT-JYJNAYRXSA-N Pro-Pro-Tyr Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1NCCC1)C1=CC=C(O)C=C1 AJNGQVUFQUVRQT-JYJNAYRXSA-N 0.000 description 1
- KBUAPZAZPWNYSW-SRVKXCTJSA-N Pro-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KBUAPZAZPWNYSW-SRVKXCTJSA-N 0.000 description 1
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 1
- CZCCVJUUWBMISW-FXQIFTODSA-N Pro-Ser-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O CZCCVJUUWBMISW-FXQIFTODSA-N 0.000 description 1
- FNGOXVQBBCMFKV-CIUDSAMLSA-N Pro-Ser-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O FNGOXVQBBCMFKV-CIUDSAMLSA-N 0.000 description 1
- BGWKULMLUIUPKY-BQBZGAKWSA-N Pro-Ser-Gly Chemical compound OC(=O)CNC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 BGWKULMLUIUPKY-BQBZGAKWSA-N 0.000 description 1
- ITUDDXVFGFEKPD-NAKRPEOUSA-N Pro-Ser-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ITUDDXVFGFEKPD-NAKRPEOUSA-N 0.000 description 1
- UGDMQJSXSSZUKL-IHRRRGAJSA-N Pro-Ser-Tyr Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O UGDMQJSXSSZUKL-IHRRRGAJSA-N 0.000 description 1
- PKHDJFHFMGQMPS-RCWTZXSCSA-N Pro-Thr-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PKHDJFHFMGQMPS-RCWTZXSCSA-N 0.000 description 1
- QUBVFEANYYWBTM-VEVYYDQMSA-N Pro-Thr-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O QUBVFEANYYWBTM-VEVYYDQMSA-N 0.000 description 1
- HRIXMVRZRGFKNQ-HJGDQZAQSA-N Pro-Thr-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HRIXMVRZRGFKNQ-HJGDQZAQSA-N 0.000 description 1
- DCHQYSOGURGJST-FJXKBIBVSA-N Pro-Thr-Gly Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O DCHQYSOGURGJST-FJXKBIBVSA-N 0.000 description 1
- GBUNEGKQPSAMNK-QTKMDUPCSA-N Pro-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@@H]2CCCN2)O GBUNEGKQPSAMNK-QTKMDUPCSA-N 0.000 description 1
- CHYAYDLYYIJCKY-OSUNSFLBSA-N Pro-Thr-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CHYAYDLYYIJCKY-OSUNSFLBSA-N 0.000 description 1
- JDJMFMVVJHLWDP-UNQGMJICSA-N Pro-Thr-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JDJMFMVVJHLWDP-UNQGMJICSA-N 0.000 description 1
- JRBWMRUPXWPEID-JYJNAYRXSA-N Pro-Trp-Cys Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CS)C(=O)O)C(=O)[C@@H]1CCCN1 JRBWMRUPXWPEID-JYJNAYRXSA-N 0.000 description 1
- GNFHQWNCSSPOBT-ULQDDVLXSA-N Pro-Trp-Gln Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CCC(=O)N)C(=O)O GNFHQWNCSSPOBT-ULQDDVLXSA-N 0.000 description 1
- VGFFUEVZKRNRHT-ULQDDVLXSA-N Pro-Trp-Glu Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CCC(=O)O)C(=O)O VGFFUEVZKRNRHT-ULQDDVLXSA-N 0.000 description 1
- ZYJMLBCDFPIGNL-JYJNAYRXSA-N Pro-Tyr-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)[C@H](Cc1ccc(O)cc1)NC(=O)[C@@H]1CCCN1)C(O)=O ZYJMLBCDFPIGNL-JYJNAYRXSA-N 0.000 description 1
- CWZUFLWPEFHWEI-IHRRRGAJSA-N Pro-Tyr-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O CWZUFLWPEFHWEI-IHRRRGAJSA-N 0.000 description 1
- BVRBCQBUNGAWFP-KKUMJFAQSA-N Pro-Tyr-Gln Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O BVRBCQBUNGAWFP-KKUMJFAQSA-N 0.000 description 1
- YHUBAXGAAYULJY-ULQDDVLXSA-N Pro-Tyr-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O YHUBAXGAAYULJY-ULQDDVLXSA-N 0.000 description 1
- UIUWGMRJTWHIJZ-ULQDDVLXSA-N Pro-Tyr-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCCCN)C(=O)O UIUWGMRJTWHIJZ-ULQDDVLXSA-N 0.000 description 1
- VEUACYMXJKXALX-IHRRRGAJSA-N Pro-Tyr-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VEUACYMXJKXALX-IHRRRGAJSA-N 0.000 description 1
- QKWYXRPICJEQAJ-KJEVXHAQSA-N Pro-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@@H]2CCCN2)O QKWYXRPICJEQAJ-KJEVXHAQSA-N 0.000 description 1
- ZAUHSLVPDLNTRZ-QXEWZRGKSA-N Pro-Val-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O ZAUHSLVPDLNTRZ-QXEWZRGKSA-N 0.000 description 1
- STGVYUTZKGPRCI-GUBZILKMSA-N Pro-Val-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 STGVYUTZKGPRCI-GUBZILKMSA-N 0.000 description 1
- JXVXYRZQIUPYSA-NHCYSSNCSA-N Pro-Val-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JXVXYRZQIUPYSA-NHCYSSNCSA-N 0.000 description 1
- KHRLUIPIMIQFGT-AVGNSLFASA-N Pro-Val-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHRLUIPIMIQFGT-AVGNSLFASA-N 0.000 description 1
- VDHGTOHMHHQSKG-JYJNAYRXSA-N Pro-Val-Phe Chemical compound CC(C)[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O VDHGTOHMHHQSKG-JYJNAYRXSA-N 0.000 description 1
- FIODMZKLZFLYQP-GUBZILKMSA-N Pro-Val-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FIODMZKLZFLYQP-GUBZILKMSA-N 0.000 description 1
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 1
- 102000001253 Protein Kinase Human genes 0.000 description 1
- 102000009516 Protein Serine-Threonine Kinases Human genes 0.000 description 1
- 108010009341 Protein Serine-Threonine Kinases Proteins 0.000 description 1
- 241001112090 Pseudovirus Species 0.000 description 1
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 1
- 230000004570 RNA-binding Effects 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 108091027981 Response element Proteins 0.000 description 1
- ZUGXSSFMTXKHJS-ZLUOBGJFSA-N Ser-Ala-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O ZUGXSSFMTXKHJS-ZLUOBGJFSA-N 0.000 description 1
- FIXILCYTSAUERA-FXQIFTODSA-N Ser-Ala-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FIXILCYTSAUERA-FXQIFTODSA-N 0.000 description 1
- BTKUIVBNGBFTTP-WHFBIAKZSA-N Ser-Ala-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)NCC(O)=O BTKUIVBNGBFTTP-WHFBIAKZSA-N 0.000 description 1
- WTWGOQRNRFHFQD-JBDRJPRFSA-N Ser-Ala-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WTWGOQRNRFHFQD-JBDRJPRFSA-N 0.000 description 1
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 1
- GXXTUIUYTWGPMV-FXQIFTODSA-N Ser-Arg-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O GXXTUIUYTWGPMV-FXQIFTODSA-N 0.000 description 1
- NLQUOHDCLSFABG-GUBZILKMSA-N Ser-Arg-Arg Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NLQUOHDCLSFABG-GUBZILKMSA-N 0.000 description 1
- FCRMLGJMPXCAHD-FXQIFTODSA-N Ser-Arg-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O FCRMLGJMPXCAHD-FXQIFTODSA-N 0.000 description 1
- QWZIOCFPXMAXET-CIUDSAMLSA-N Ser-Arg-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O QWZIOCFPXMAXET-CIUDSAMLSA-N 0.000 description 1
- RZUOXAKGNHXZTB-GUBZILKMSA-N Ser-Arg-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(O)=O RZUOXAKGNHXZTB-GUBZILKMSA-N 0.000 description 1
- NRCJWSGXMAPYQX-LPEHRKFASA-N Ser-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CO)N)C(=O)O NRCJWSGXMAPYQX-LPEHRKFASA-N 0.000 description 1
- OOKCGAYXSNJBGQ-ZLUOBGJFSA-N Ser-Asn-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OOKCGAYXSNJBGQ-ZLUOBGJFSA-N 0.000 description 1
- BCKYYTVFBXHPOG-ACZMJKKPSA-N Ser-Asn-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N BCKYYTVFBXHPOG-ACZMJKKPSA-N 0.000 description 1
- ZXLUWXWISXIFIX-ACZMJKKPSA-N Ser-Asn-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZXLUWXWISXIFIX-ACZMJKKPSA-N 0.000 description 1
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 1
- FIDMVVBUOCMMJG-CIUDSAMLSA-N Ser-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO FIDMVVBUOCMMJG-CIUDSAMLSA-N 0.000 description 1
- KAAPNMOKUUPKOE-SRVKXCTJSA-N Ser-Asn-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KAAPNMOKUUPKOE-SRVKXCTJSA-N 0.000 description 1
- DKKGAAJTDKHWOD-BIIVOSGPSA-N Ser-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)C(=O)O DKKGAAJTDKHWOD-BIIVOSGPSA-N 0.000 description 1
- MESDJCNHLZBMEP-ZLUOBGJFSA-N Ser-Asp-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MESDJCNHLZBMEP-ZLUOBGJFSA-N 0.000 description 1
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 1
- BTPAWKABYQMKKN-LKXGYXEUSA-N Ser-Asp-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BTPAWKABYQMKKN-LKXGYXEUSA-N 0.000 description 1
- MOVJSUIKUNCVMG-ZLUOBGJFSA-N Ser-Cys-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N)O MOVJSUIKUNCVMG-ZLUOBGJFSA-N 0.000 description 1
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 1
- YPUSXTWURJANKF-KBIXCLLPSA-N Ser-Gln-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YPUSXTWURJANKF-KBIXCLLPSA-N 0.000 description 1
- SMIDBHKWSYUBRZ-ACZMJKKPSA-N Ser-Glu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O SMIDBHKWSYUBRZ-ACZMJKKPSA-N 0.000 description 1
- GYXVUTAOICLGKJ-ACZMJKKPSA-N Ser-Glu-Cys Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N GYXVUTAOICLGKJ-ACZMJKKPSA-N 0.000 description 1
- YRBGKVIWMNEVCZ-WDSKDSINSA-N Ser-Glu-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YRBGKVIWMNEVCZ-WDSKDSINSA-N 0.000 description 1
- QKQDTEYDEIJPNK-GUBZILKMSA-N Ser-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CO QKQDTEYDEIJPNK-GUBZILKMSA-N 0.000 description 1
- AEGUWTFAQQWVLC-BQBZGAKWSA-N Ser-Gly-Arg Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O AEGUWTFAQQWVLC-BQBZGAKWSA-N 0.000 description 1
- SNVIOQXAHVORQM-WDSKDSINSA-N Ser-Gly-Gln Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O SNVIOQXAHVORQM-WDSKDSINSA-N 0.000 description 1
- IOVHBRCQOGWAQH-ZKWXMUAHSA-N Ser-Gly-Ile Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOVHBRCQOGWAQH-ZKWXMUAHSA-N 0.000 description 1
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 1
- UAJAYRMZGNQILN-BQBZGAKWSA-N Ser-Gly-Met Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O UAJAYRMZGNQILN-BQBZGAKWSA-N 0.000 description 1
- FYUIFUJFNCLUIX-XVYDVKMFSA-N Ser-His-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(O)=O FYUIFUJFNCLUIX-XVYDVKMFSA-N 0.000 description 1
- QGAHMVHBORDHDC-YUMQZZPRSA-N Ser-His-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CN=CN1 QGAHMVHBORDHDC-YUMQZZPRSA-N 0.000 description 1
- IOVBCLGAJJXOHK-SRVKXCTJSA-N Ser-His-His Chemical compound C([C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 IOVBCLGAJJXOHK-SRVKXCTJSA-N 0.000 description 1
- UGHCUDLCCVVIJR-VGDYDELISA-N Ser-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CO)N UGHCUDLCCVVIJR-VGDYDELISA-N 0.000 description 1
- HZNFKPJCGZXKIC-DCAQKATOSA-N Ser-His-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CO)N HZNFKPJCGZXKIC-DCAQKATOSA-N 0.000 description 1
- CAOYHZOWXFFAIR-CIUDSAMLSA-N Ser-His-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O CAOYHZOWXFFAIR-CIUDSAMLSA-N 0.000 description 1
- NBUKGEFVZJMSIS-XIRDDKMYSA-N Ser-His-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC3=CN=CN3)NC(=O)[C@H](CO)N NBUKGEFVZJMSIS-XIRDDKMYSA-N 0.000 description 1
- SFTZTYBXIXLRGQ-JBDRJPRFSA-N Ser-Ile-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SFTZTYBXIXLRGQ-JBDRJPRFSA-N 0.000 description 1
- LQESNKGTTNHZPZ-GHCJXIJMSA-N Ser-Ile-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O LQESNKGTTNHZPZ-GHCJXIJMSA-N 0.000 description 1
- BKZYBLLIBOBOOW-GHCJXIJMSA-N Ser-Ile-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O BKZYBLLIBOBOOW-GHCJXIJMSA-N 0.000 description 1
- RIAKPZVSNBBNRE-BJDJZHNGSA-N Ser-Ile-Leu Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O RIAKPZVSNBBNRE-BJDJZHNGSA-N 0.000 description 1
- JIPVNVNKXJLFJF-BJDJZHNGSA-N Ser-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N JIPVNVNKXJLFJF-BJDJZHNGSA-N 0.000 description 1
- ZOPISOXXPQNOCO-SVSWQMSJSA-N Ser-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CO)N ZOPISOXXPQNOCO-SVSWQMSJSA-N 0.000 description 1
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 1
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 1
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 1
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 1
- GVMUJUPXFQFBBZ-GUBZILKMSA-N Ser-Lys-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GVMUJUPXFQFBBZ-GUBZILKMSA-N 0.000 description 1
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 1
- QJKPECIAWNNKIT-KKUMJFAQSA-N Ser-Lys-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QJKPECIAWNNKIT-KKUMJFAQSA-N 0.000 description 1
- PMCMLDNPAZUYGI-DCAQKATOSA-N Ser-Lys-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O PMCMLDNPAZUYGI-DCAQKATOSA-N 0.000 description 1
- ZGFRMNZZTOVBOU-CIUDSAMLSA-N Ser-Met-Gln Chemical compound N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)O ZGFRMNZZTOVBOU-CIUDSAMLSA-N 0.000 description 1
- JUTGONBTALQWMK-NAKRPEOUSA-N Ser-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CO)N JUTGONBTALQWMK-NAKRPEOUSA-N 0.000 description 1
- XNXRTQZTFVMJIJ-DCAQKATOSA-N Ser-Met-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O XNXRTQZTFVMJIJ-DCAQKATOSA-N 0.000 description 1
- ZSLFCBHEINFXRS-LPEHRKFASA-N Ser-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N ZSLFCBHEINFXRS-LPEHRKFASA-N 0.000 description 1
- XVWDJUROVRQKAE-KKUMJFAQSA-N Ser-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC1=CC=CC=C1 XVWDJUROVRQKAE-KKUMJFAQSA-N 0.000 description 1
- RWDVVSKYZBNDCO-MELADBBJSA-N Ser-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CO)N)C(=O)O RWDVVSKYZBNDCO-MELADBBJSA-N 0.000 description 1
- FBLNYDYPCLFTSP-IXOXFDKPSA-N Ser-Phe-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FBLNYDYPCLFTSP-IXOXFDKPSA-N 0.000 description 1
- QMCDMHWAKMUGJE-IHRRRGAJSA-N Ser-Phe-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O QMCDMHWAKMUGJE-IHRRRGAJSA-N 0.000 description 1
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 1
- FZXOPYUEQGDGMS-ACZMJKKPSA-N Ser-Ser-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZXOPYUEQGDGMS-ACZMJKKPSA-N 0.000 description 1
- GYDFRTRSSXOZCR-ACZMJKKPSA-N Ser-Ser-Glu Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GYDFRTRSSXOZCR-ACZMJKKPSA-N 0.000 description 1
- NVNPWELENFJOHH-CIUDSAMLSA-N Ser-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)N NVNPWELENFJOHH-CIUDSAMLSA-N 0.000 description 1
- SQHKXWODKJDZRC-LKXGYXEUSA-N Ser-Thr-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O SQHKXWODKJDZRC-LKXGYXEUSA-N 0.000 description 1
- KKKVOZNCLALMPV-XKBZYTNZSA-N Ser-Thr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KKKVOZNCLALMPV-XKBZYTNZSA-N 0.000 description 1
- PURRNJBBXDDWLX-ZDLURKLDSA-N Ser-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CO)N)O PURRNJBBXDDWLX-ZDLURKLDSA-N 0.000 description 1
- FLMYSKVSDVHLEW-SVSWQMSJSA-N Ser-Thr-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FLMYSKVSDVHLEW-SVSWQMSJSA-N 0.000 description 1
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 1
- UYLKOSODXYSWMQ-XGEHTFHBSA-N Ser-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CO)N)O UYLKOSODXYSWMQ-XGEHTFHBSA-N 0.000 description 1
- DYEGLQRVMBWQLD-IXOXFDKPSA-N Ser-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CO)N)O DYEGLQRVMBWQLD-IXOXFDKPSA-N 0.000 description 1
- XPVIVVLLLOFBRH-XIRDDKMYSA-N Ser-Trp-Lys Chemical compound NCCCC[C@H](NC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)[C@@H](N)CO)C(O)=O XPVIVVLLLOFBRH-XIRDDKMYSA-N 0.000 description 1
- GSCVDSBEYVGMJQ-SRVKXCTJSA-N Ser-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)O GSCVDSBEYVGMJQ-SRVKXCTJSA-N 0.000 description 1
- PLQWGQUNUPMNOD-KKUMJFAQSA-N Ser-Tyr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O PLQWGQUNUPMNOD-KKUMJFAQSA-N 0.000 description 1
- OQSQCUWQOIHECT-YJRXYDGGSA-N Ser-Tyr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OQSQCUWQOIHECT-YJRXYDGGSA-N 0.000 description 1
- JZRYFUGREMECBH-XPUUQOCRSA-N Ser-Val-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O JZRYFUGREMECBH-XPUUQOCRSA-N 0.000 description 1
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 1
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 1
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- 101150044214 Srebf1 gene Proteins 0.000 description 1
- 102000008078 Sterol Regulatory Element Binding Protein 1 Human genes 0.000 description 1
- DFTCYYILCSQGIZ-GCJQMDKQSA-N Thr-Ala-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DFTCYYILCSQGIZ-GCJQMDKQSA-N 0.000 description 1
- FQPQPTHMHZKGFM-XQXXSGGOSA-N Thr-Ala-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O FQPQPTHMHZKGFM-XQXXSGGOSA-N 0.000 description 1
- PXQUBKWZENPDGE-CIQUZCHMSA-N Thr-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H]([C@@H](C)O)N PXQUBKWZENPDGE-CIQUZCHMSA-N 0.000 description 1
- BSNZTJXVDOINSR-JXUBOQSCSA-N Thr-Ala-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BSNZTJXVDOINSR-JXUBOQSCSA-N 0.000 description 1
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 1
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 1
- PKXHGEXFMIZSER-QTKMDUPCSA-N Thr-Arg-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N)O PKXHGEXFMIZSER-QTKMDUPCSA-N 0.000 description 1
- VFEHSAJCWWHDBH-RHYQMDGZSA-N Thr-Arg-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VFEHSAJCWWHDBH-RHYQMDGZSA-N 0.000 description 1
- NAXBBCLCEOTAIG-RHYQMDGZSA-N Thr-Arg-Lys Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CCCCN)C(O)=O NAXBBCLCEOTAIG-RHYQMDGZSA-N 0.000 description 1
- GZYNMZQXFRWDFH-YTWAJWBKSA-N Thr-Arg-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O GZYNMZQXFRWDFH-YTWAJWBKSA-N 0.000 description 1
- VIBXMCZWVUOZLA-OLHMAJIHSA-N Thr-Asn-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O VIBXMCZWVUOZLA-OLHMAJIHSA-N 0.000 description 1
- CTONFVDJYCAMQM-IUKAMOBKSA-N Thr-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H]([C@@H](C)O)N CTONFVDJYCAMQM-IUKAMOBKSA-N 0.000 description 1
- PZVGOVRNGKEFCB-KKHAAJSZSA-N Thr-Asn-Val Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N)O PZVGOVRNGKEFCB-KKHAAJSZSA-N 0.000 description 1
- DCCGCVLVVSAJFK-NUMRIWBASA-N Thr-Asp-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O DCCGCVLVVSAJFK-NUMRIWBASA-N 0.000 description 1
- JEDIEMIJYSRUBB-FOHZUACHSA-N Thr-Asp-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O JEDIEMIJYSRUBB-FOHZUACHSA-N 0.000 description 1
- OHAJHDJOCKKJLV-LKXGYXEUSA-N Thr-Asp-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O OHAJHDJOCKKJLV-LKXGYXEUSA-N 0.000 description 1
- XDARBNMYXKUFOJ-GSSVUCPTSA-N Thr-Asp-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XDARBNMYXKUFOJ-GSSVUCPTSA-N 0.000 description 1
- ZUUDNCOCILSYAM-KKHAAJSZSA-N Thr-Asp-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ZUUDNCOCILSYAM-KKHAAJSZSA-N 0.000 description 1
- NRUPKQSXTJNQGD-XGEHTFHBSA-N Thr-Cys-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NRUPKQSXTJNQGD-XGEHTFHBSA-N 0.000 description 1
- ODSAPYVQSLDRSR-LKXGYXEUSA-N Thr-Cys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(O)=O ODSAPYVQSLDRSR-LKXGYXEUSA-N 0.000 description 1
- KZUJCMPVNXOBAF-LKXGYXEUSA-N Thr-Cys-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O KZUJCMPVNXOBAF-LKXGYXEUSA-N 0.000 description 1
- GCXFWAZRHBRYEM-NUMRIWBASA-N Thr-Gln-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O GCXFWAZRHBRYEM-NUMRIWBASA-N 0.000 description 1
- KGKWKSSSQGGYAU-SUSMZKCASA-N Thr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KGKWKSSSQGGYAU-SUSMZKCASA-N 0.000 description 1
- CQNFRKAKGDSJFR-NUMRIWBASA-N Thr-Glu-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O CQNFRKAKGDSJFR-NUMRIWBASA-N 0.000 description 1
- SHOMROOOQBDGRL-JHEQGTHGSA-N Thr-Glu-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SHOMROOOQBDGRL-JHEQGTHGSA-N 0.000 description 1
- JMGJDTNUMAZNLX-RWRJDSDZSA-N Thr-Glu-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JMGJDTNUMAZNLX-RWRJDSDZSA-N 0.000 description 1
- HJOSVGCWOTYJFG-WDCWCFNPSA-N Thr-Glu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N)O HJOSVGCWOTYJFG-WDCWCFNPSA-N 0.000 description 1
- KBLYJPQSNGTDIU-LOKLDPHHSA-N Thr-Glu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O KBLYJPQSNGTDIU-LOKLDPHHSA-N 0.000 description 1
- SLUWOCTZVGMURC-BFHQHQDPSA-N Thr-Gly-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O SLUWOCTZVGMURC-BFHQHQDPSA-N 0.000 description 1
- XFTYVCHLARBHBQ-FOHZUACHSA-N Thr-Gly-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XFTYVCHLARBHBQ-FOHZUACHSA-N 0.000 description 1
- NIEWSKWFURSECR-FOHZUACHSA-N Thr-Gly-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NIEWSKWFURSECR-FOHZUACHSA-N 0.000 description 1
- YZUWGFXVVZQJEI-PMVVWTBXSA-N Thr-Gly-His Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N)O YZUWGFXVVZQJEI-PMVVWTBXSA-N 0.000 description 1
- QQWNRERCGGZOKG-WEDXCCLWSA-N Thr-Gly-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O QQWNRERCGGZOKG-WEDXCCLWSA-N 0.000 description 1
- IGGFFPOIFHZYKC-PBCZWWQYSA-N Thr-His-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O IGGFFPOIFHZYKC-PBCZWWQYSA-N 0.000 description 1
- AYCQVUUPIJHJTA-IXOXFDKPSA-N Thr-His-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O AYCQVUUPIJHJTA-IXOXFDKPSA-N 0.000 description 1
- SXAGUVRFGJSFKC-ZEILLAHLSA-N Thr-His-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SXAGUVRFGJSFKC-ZEILLAHLSA-N 0.000 description 1
- ADPHPKGWVDHWML-PPCPHDFISA-N Thr-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N ADPHPKGWVDHWML-PPCPHDFISA-N 0.000 description 1
- AHOLTQCAVBSUDP-PPCPHDFISA-N Thr-Ile-Lys Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)[C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O AHOLTQCAVBSUDP-PPCPHDFISA-N 0.000 description 1
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 1
- BVOVIGCHYNFJBZ-JXUBOQSCSA-N Thr-Leu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O BVOVIGCHYNFJBZ-JXUBOQSCSA-N 0.000 description 1
- IMDMLDSVUSMAEJ-HJGDQZAQSA-N Thr-Leu-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IMDMLDSVUSMAEJ-HJGDQZAQSA-N 0.000 description 1
- ODXKUIGEPAGKKV-KATARQTJSA-N Thr-Leu-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)O)N)O ODXKUIGEPAGKKV-KATARQTJSA-N 0.000 description 1
- HOVLHEKTGVIKAP-WDCWCFNPSA-N Thr-Leu-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HOVLHEKTGVIKAP-WDCWCFNPSA-N 0.000 description 1
- RFKVQLIXNVEOMB-WEDXCCLWSA-N Thr-Leu-Gly Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)O)N)O RFKVQLIXNVEOMB-WEDXCCLWSA-N 0.000 description 1
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 1
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 1
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 1
- TZJSEJOXAIWOST-RHYQMDGZSA-N Thr-Lys-Arg Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N TZJSEJOXAIWOST-RHYQMDGZSA-N 0.000 description 1
- UUSQVWOVUYMLJA-PPCPHDFISA-N Thr-Lys-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UUSQVWOVUYMLJA-PPCPHDFISA-N 0.000 description 1
- WFAUDCSNCWJJAA-KXNHARMFSA-N Thr-Lys-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(O)=O WFAUDCSNCWJJAA-KXNHARMFSA-N 0.000 description 1
- JWQNAFHCXKVZKZ-UVOCVTCTSA-N Thr-Lys-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JWQNAFHCXKVZKZ-UVOCVTCTSA-N 0.000 description 1
- MCDVZTRGHNXTGK-HJGDQZAQSA-N Thr-Met-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O MCDVZTRGHNXTGK-HJGDQZAQSA-N 0.000 description 1
- WRUWXBBEFUTJOU-XGEHTFHBSA-N Thr-Met-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)O)N)O WRUWXBBEFUTJOU-XGEHTFHBSA-N 0.000 description 1
- KZURUCDWKDEAFZ-XVSYOHENSA-N Thr-Phe-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O KZURUCDWKDEAFZ-XVSYOHENSA-N 0.000 description 1
- NZRUWPIYECBYRK-HTUGSXCWSA-N Thr-Phe-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O NZRUWPIYECBYRK-HTUGSXCWSA-N 0.000 description 1
- WNQJTLATMXYSEL-OEAJRASXSA-N Thr-Phe-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O WNQJTLATMXYSEL-OEAJRASXSA-N 0.000 description 1
- JMBRNXUOLJFURW-BEAPCOKYSA-N Thr-Phe-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N)O JMBRNXUOLJFURW-BEAPCOKYSA-N 0.000 description 1
- ABWNZPOIUJMNKT-IXOXFDKPSA-N Thr-Phe-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O ABWNZPOIUJMNKT-IXOXFDKPSA-N 0.000 description 1
- MXNAOGFNFNKUPD-JHYOHUSXSA-N Thr-Phe-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MXNAOGFNFNKUPD-JHYOHUSXSA-N 0.000 description 1
- MUAFDCVOHYAFNG-RCWTZXSCSA-N Thr-Pro-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MUAFDCVOHYAFNG-RCWTZXSCSA-N 0.000 description 1
- NDXSOKGYKCGYKT-VEVYYDQMSA-N Thr-Pro-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O NDXSOKGYKCGYKT-VEVYYDQMSA-N 0.000 description 1
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 1
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 1
- BDENGIGFTNYZSJ-RCWTZXSCSA-N Thr-Pro-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(O)=O BDENGIGFTNYZSJ-RCWTZXSCSA-N 0.000 description 1
- KERCOYANYUPLHJ-XGEHTFHBSA-N Thr-Pro-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O KERCOYANYUPLHJ-XGEHTFHBSA-N 0.000 description 1
- YGCDFAJJCRVQKU-RCWTZXSCSA-N Thr-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O YGCDFAJJCRVQKU-RCWTZXSCSA-N 0.000 description 1
- FWTFAZKJORVTIR-VZFHVOOUSA-N Thr-Ser-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O FWTFAZKJORVTIR-VZFHVOOUSA-N 0.000 description 1
- PRTHQBSMXILLPC-XGEHTFHBSA-N Thr-Ser-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PRTHQBSMXILLPC-XGEHTFHBSA-N 0.000 description 1
- IVDFVBVIVLJJHR-LKXGYXEUSA-N Thr-Ser-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O IVDFVBVIVLJJHR-LKXGYXEUSA-N 0.000 description 1
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 1
- WKGAAMOJPMBBMC-IXOXFDKPSA-N Thr-Ser-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WKGAAMOJPMBBMC-IXOXFDKPSA-N 0.000 description 1
- VUXIQSUQQYNLJP-XAVMHZPKSA-N Thr-Ser-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N)O VUXIQSUQQYNLJP-XAVMHZPKSA-N 0.000 description 1
- HUPLKEHTTQBXSC-YJRXYDGGSA-N Thr-Ser-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUPLKEHTTQBXSC-YJRXYDGGSA-N 0.000 description 1
- IEZVHOULSUULHD-XGEHTFHBSA-N Thr-Ser-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O IEZVHOULSUULHD-XGEHTFHBSA-N 0.000 description 1
- QYDKSNXSBXZPFK-ZJDVBMNYSA-N Thr-Thr-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYDKSNXSBXZPFK-ZJDVBMNYSA-N 0.000 description 1
- UQCNIMDPYICBTR-KYNKHSRBSA-N Thr-Thr-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UQCNIMDPYICBTR-KYNKHSRBSA-N 0.000 description 1
- BBPCSGKKPJUYRB-UVOCVTCTSA-N Thr-Thr-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O BBPCSGKKPJUYRB-UVOCVTCTSA-N 0.000 description 1
- QJIODPFLAASXJC-JHYOHUSXSA-N Thr-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O QJIODPFLAASXJC-JHYOHUSXSA-N 0.000 description 1
- ZMYCLHFLHRVOEA-HEIBUPTGSA-N Thr-Thr-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ZMYCLHFLHRVOEA-HEIBUPTGSA-N 0.000 description 1
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 1
- REJRKTOJTCPDPO-IRIUXVKKSA-N Thr-Tyr-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O REJRKTOJTCPDPO-IRIUXVKKSA-N 0.000 description 1
- PELIQFPESHBTMA-WLTAIBSBSA-N Thr-Tyr-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 PELIQFPESHBTMA-WLTAIBSBSA-N 0.000 description 1
- XVHAUVJXBFGUPC-RPTUDFQQSA-N Thr-Tyr-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XVHAUVJXBFGUPC-RPTUDFQQSA-N 0.000 description 1
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 1
- AXEJRUGTOJPZKG-XGEHTFHBSA-N Thr-Val-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(=O)O)N)O AXEJRUGTOJPZKG-XGEHTFHBSA-N 0.000 description 1
- QGVBFDIREUUSHX-IFFSRLJSSA-N Thr-Val-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O QGVBFDIREUUSHX-IFFSRLJSSA-N 0.000 description 1
- KPMIQCXJDVKWKO-IFFSRLJSSA-N Thr-Val-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O KPMIQCXJDVKWKO-IFFSRLJSSA-N 0.000 description 1
- AKHDFZHUPGVFEJ-YEPSODPASA-N Thr-Val-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AKHDFZHUPGVFEJ-YEPSODPASA-N 0.000 description 1
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 1
- BPGDJSUFQKWUBK-KJEVXHAQSA-N Thr-Val-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BPGDJSUFQKWUBK-KJEVXHAQSA-N 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- 239000013504 Triton X-100 Substances 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- QAXCHNZDPLSFPC-PJODQICGSA-N Trp-Ala-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 QAXCHNZDPLSFPC-PJODQICGSA-N 0.000 description 1
- HYVLNORXQGKONN-NUTKFTJISA-N Trp-Ala-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 HYVLNORXQGKONN-NUTKFTJISA-N 0.000 description 1
- RSUXQZNWAOTBQF-XIRDDKMYSA-N Trp-Arg-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RSUXQZNWAOTBQF-XIRDDKMYSA-N 0.000 description 1
- KZIQDVNORJKTMO-WDSOQIARSA-N Trp-Arg-His Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)N KZIQDVNORJKTMO-WDSOQIARSA-N 0.000 description 1
- DVAAUUVLDFKTAQ-VHWLVUOQSA-N Trp-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N DVAAUUVLDFKTAQ-VHWLVUOQSA-N 0.000 description 1
- MDDYTWOFHZFABW-SZMVWBNQSA-N Trp-Gln-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 MDDYTWOFHZFABW-SZMVWBNQSA-N 0.000 description 1
- BORCDLUWGBGTKL-XIRDDKMYSA-N Trp-Gln-Met Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O)=CNC2=C1 BORCDLUWGBGTKL-XIRDDKMYSA-N 0.000 description 1
- YRSOERSDNRSCBC-XIRDDKMYSA-N Trp-His-Cys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CN=CN3)C(=O)N[C@@H](CS)C(=O)O)N YRSOERSDNRSCBC-XIRDDKMYSA-N 0.000 description 1
- AIISTODACBDQLW-WDSOQIARSA-N Trp-Leu-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 AIISTODACBDQLW-WDSOQIARSA-N 0.000 description 1
- CMXACOZDEJYZSK-XIRDDKMYSA-N Trp-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N CMXACOZDEJYZSK-XIRDDKMYSA-N 0.000 description 1
- YVXIAOOYAKBAAI-SZMVWBNQSA-N Trp-Leu-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 YVXIAOOYAKBAAI-SZMVWBNQSA-N 0.000 description 1
- MEZCXKYMMQJRDE-PMVMPFDFSA-N Trp-Leu-Tyr Chemical compound C([C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)CC(C)C)C(O)=O)C1=CC=C(O)C=C1 MEZCXKYMMQJRDE-PMVMPFDFSA-N 0.000 description 1
- ZHZLQVLQBDBQCQ-WDSOQIARSA-N Trp-Lys-Arg Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N ZHZLQVLQBDBQCQ-WDSOQIARSA-N 0.000 description 1
- RQLNEFOBQAVGSY-WDSOQIARSA-N Trp-Met-Leu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O RQLNEFOBQAVGSY-WDSOQIARSA-N 0.000 description 1
- UHXOYRWHIQZAKV-SZMVWBNQSA-N Trp-Pro-Arg Chemical compound O=C([C@H](CC=1C2=CC=CC=C2NC=1)N)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O UHXOYRWHIQZAKV-SZMVWBNQSA-N 0.000 description 1
- BOBZBMOTRORUPT-XIRDDKMYSA-N Trp-Ser-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 BOBZBMOTRORUPT-XIRDDKMYSA-N 0.000 description 1
- GSCPHMSPGQSZJT-JYBASQMISA-N Trp-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O GSCPHMSPGQSZJT-JYBASQMISA-N 0.000 description 1
- 108010040002 Tumor Suppressor Proteins Proteins 0.000 description 1
- 102000001742 Tumor Suppressor Proteins Human genes 0.000 description 1
- VCXWRWYFJLXITF-AUTRQRHGSA-N Tyr-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 VCXWRWYFJLXITF-AUTRQRHGSA-N 0.000 description 1
- JONPRIHUYSPIMA-UWJYBYFXSA-N Tyr-Ala-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JONPRIHUYSPIMA-UWJYBYFXSA-N 0.000 description 1
- NOXKHHXSHQFSGJ-FQPOAREZSA-N Tyr-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NOXKHHXSHQFSGJ-FQPOAREZSA-N 0.000 description 1
- WTXQBCCKXIKKHB-JYJNAYRXSA-N Tyr-Arg-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WTXQBCCKXIKKHB-JYJNAYRXSA-N 0.000 description 1
- HKIUVWMZYFBIHG-KKUMJFAQSA-N Tyr-Arg-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O HKIUVWMZYFBIHG-KKUMJFAQSA-N 0.000 description 1
- ADBDQGBDNUTRDB-ULQDDVLXSA-N Tyr-Arg-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O ADBDQGBDNUTRDB-ULQDDVLXSA-N 0.000 description 1
- DYEGCOJHFNJBKB-UFYCRDLUSA-N Tyr-Arg-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 DYEGCOJHFNJBKB-UFYCRDLUSA-N 0.000 description 1
- ZNFPUOSTMUMUDR-JRQIVUDYSA-N Tyr-Asn-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZNFPUOSTMUMUDR-JRQIVUDYSA-N 0.000 description 1
- BARBHMSSVWPKPZ-IHRRRGAJSA-N Tyr-Asp-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O BARBHMSSVWPKPZ-IHRRRGAJSA-N 0.000 description 1
- CGDZGRLRXPNCOC-SRVKXCTJSA-N Tyr-Cys-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 CGDZGRLRXPNCOC-SRVKXCTJSA-N 0.000 description 1
- ZAGPDPNPWYPEIR-SRVKXCTJSA-N Tyr-Cys-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O ZAGPDPNPWYPEIR-SRVKXCTJSA-N 0.000 description 1
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 1
- IYHNBRUWVBIVJR-IHRRRGAJSA-N Tyr-Gln-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 IYHNBRUWVBIVJR-IHRRRGAJSA-N 0.000 description 1
- GIOBXJSONRQHKQ-RYUDHWBXSA-N Tyr-Gly-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O GIOBXJSONRQHKQ-RYUDHWBXSA-N 0.000 description 1
- GFJXBLSZOFWHAW-JYJNAYRXSA-N Tyr-His-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O GFJXBLSZOFWHAW-JYJNAYRXSA-N 0.000 description 1
- WVGKPKDWYQXWLU-BZSNNMDCSA-N Tyr-His-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CCCCN)C(=O)O)N)O WVGKPKDWYQXWLU-BZSNNMDCSA-N 0.000 description 1
- ARSHSYUZHSIYKR-ACRUOGEOSA-N Tyr-His-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ARSHSYUZHSIYKR-ACRUOGEOSA-N 0.000 description 1
- JHORGUYURUBVOM-KKUMJFAQSA-N Tyr-His-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O JHORGUYURUBVOM-KKUMJFAQSA-N 0.000 description 1
- PJWCWGXAVIVXQC-STECZYCISA-N Tyr-Ile-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 PJWCWGXAVIVXQC-STECZYCISA-N 0.000 description 1
- QARCDOCCDOLJSF-HJPIBITLSA-N Tyr-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QARCDOCCDOLJSF-HJPIBITLSA-N 0.000 description 1
- DWAMXBFJNZIHMC-KBPBESRZSA-N Tyr-Leu-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O DWAMXBFJNZIHMC-KBPBESRZSA-N 0.000 description 1
- PRONOHBTMLNXCZ-BZSNNMDCSA-N Tyr-Leu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 PRONOHBTMLNXCZ-BZSNNMDCSA-N 0.000 description 1
- ARJASMXQBRNAGI-YESZJQIVSA-N Tyr-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N ARJASMXQBRNAGI-YESZJQIVSA-N 0.000 description 1
- OLYXUGBVBGSZDN-ACRUOGEOSA-N Tyr-Leu-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 OLYXUGBVBGSZDN-ACRUOGEOSA-N 0.000 description 1
- HSBZWINKRYZCSQ-KKUMJFAQSA-N Tyr-Lys-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O HSBZWINKRYZCSQ-KKUMJFAQSA-N 0.000 description 1
- MXFPBNFKVBHIRW-BZSNNMDCSA-N Tyr-Lys-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O MXFPBNFKVBHIRW-BZSNNMDCSA-N 0.000 description 1
- PMHLLBKTDHQMCY-ULQDDVLXSA-N Tyr-Lys-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O PMHLLBKTDHQMCY-ULQDDVLXSA-N 0.000 description 1
- YSGAPESOXHFTQY-IHRRRGAJSA-N Tyr-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N YSGAPESOXHFTQY-IHRRRGAJSA-N 0.000 description 1
- OFHKXNKJXURPSY-ULQDDVLXSA-N Tyr-Met-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O OFHKXNKJXURPSY-ULQDDVLXSA-N 0.000 description 1
- XJPXTYLVMUZGNW-IHRRRGAJSA-N Tyr-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O XJPXTYLVMUZGNW-IHRRRGAJSA-N 0.000 description 1
- SOEGLGLDSUHWTI-STECZYCISA-N Tyr-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=C(O)C=C1 SOEGLGLDSUHWTI-STECZYCISA-N 0.000 description 1
- KWKJGBHDYJOVCR-SRVKXCTJSA-N Tyr-Ser-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N)O KWKJGBHDYJOVCR-SRVKXCTJSA-N 0.000 description 1
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 1
- UMSZZGTXGKHTFJ-SRVKXCTJSA-N Tyr-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 UMSZZGTXGKHTFJ-SRVKXCTJSA-N 0.000 description 1
- LUMQYLVYUIRHHU-YJRXYDGGSA-N Tyr-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUMQYLVYUIRHHU-YJRXYDGGSA-N 0.000 description 1
- MDXLPNRXCFOBTL-BZSNNMDCSA-N Tyr-Ser-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MDXLPNRXCFOBTL-BZSNNMDCSA-N 0.000 description 1
- TYFLVOUZHQUBGM-IHRRRGAJSA-N Tyr-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 TYFLVOUZHQUBGM-IHRRRGAJSA-N 0.000 description 1
- RIVVDNTUSRVTQT-IRIUXVKKSA-N Tyr-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O RIVVDNTUSRVTQT-IRIUXVKKSA-N 0.000 description 1
- XFEMMSGONWQACR-KJEVXHAQSA-N Tyr-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O XFEMMSGONWQACR-KJEVXHAQSA-N 0.000 description 1
- WQOHKVRQDLNDIL-YJRXYDGGSA-N Tyr-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O WQOHKVRQDLNDIL-YJRXYDGGSA-N 0.000 description 1
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 1
- DJSYPCWZPNHQQE-FHWLQOOXSA-N Tyr-Tyr-Gln Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCC(N)=O)C(O)=O)C1=CC=C(O)C=C1 DJSYPCWZPNHQQE-FHWLQOOXSA-N 0.000 description 1
- KRXFXDCNKLANCP-CXTHYWKRSA-N Tyr-Tyr-Ile Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 KRXFXDCNKLANCP-CXTHYWKRSA-N 0.000 description 1
- SQUMHUZLJDUROQ-YDHLFZDLSA-N Tyr-Val-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O SQUMHUZLJDUROQ-YDHLFZDLSA-N 0.000 description 1
- KLOZTPOXVVRVAQ-DZKIICNBSA-N Tyr-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 KLOZTPOXVVRVAQ-DZKIICNBSA-N 0.000 description 1
- DJIJBQYBDKGDIS-JYJNAYRXSA-N Tyr-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(C)C)C(O)=O DJIJBQYBDKGDIS-JYJNAYRXSA-N 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- UEOOXDLMQZBPFR-ZKWXMUAHSA-N Val-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N UEOOXDLMQZBPFR-ZKWXMUAHSA-N 0.000 description 1
- YFOCMOVJBQDBCE-NRPADANISA-N Val-Ala-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N YFOCMOVJBQDBCE-NRPADANISA-N 0.000 description 1
- AZSHAZJLOZQYAY-FXQIFTODSA-N Val-Ala-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O AZSHAZJLOZQYAY-FXQIFTODSA-N 0.000 description 1
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 1
- LABUITCFCAABSV-BPNCWPANSA-N Val-Ala-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 LABUITCFCAABSV-BPNCWPANSA-N 0.000 description 1
- LABUITCFCAABSV-UHFFFAOYSA-N Val-Ala-Tyr Natural products CC(C)C(N)C(=O)NC(C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LABUITCFCAABSV-UHFFFAOYSA-N 0.000 description 1
- PFNZJEPSCBAVGX-CYDGBPFRSA-N Val-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](C(C)C)N PFNZJEPSCBAVGX-CYDGBPFRSA-N 0.000 description 1
- PAPWZOJOLKZEFR-AVGNSLFASA-N Val-Arg-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N PAPWZOJOLKZEFR-AVGNSLFASA-N 0.000 description 1
- QPZMOUMNTGTEFR-ZKWXMUAHSA-N Val-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N QPZMOUMNTGTEFR-ZKWXMUAHSA-N 0.000 description 1
- AUMNPAUHKUNHHN-BYULHYEWSA-N Val-Asn-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N AUMNPAUHKUNHHN-BYULHYEWSA-N 0.000 description 1
- GXAZTLJYINLMJL-LAEOZQHASA-N Val-Asn-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N GXAZTLJYINLMJL-LAEOZQHASA-N 0.000 description 1
- IDKGBVZGNTYYCC-QXEWZRGKSA-N Val-Asn-Pro Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(O)=O IDKGBVZGNTYYCC-QXEWZRGKSA-N 0.000 description 1
- JLFKWDAZBRYCGX-ZKWXMUAHSA-N Val-Asn-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N JLFKWDAZBRYCGX-ZKWXMUAHSA-N 0.000 description 1
- IQQYYFPCWKWUHW-YDHLFZDLSA-N Val-Asn-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N IQQYYFPCWKWUHW-YDHLFZDLSA-N 0.000 description 1
- TZVUSFMQWPWHON-NHCYSSNCSA-N Val-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N TZVUSFMQWPWHON-NHCYSSNCSA-N 0.000 description 1
- HIZMLPKDJAXDRG-FXQIFTODSA-N Val-Cys-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N HIZMLPKDJAXDRG-FXQIFTODSA-N 0.000 description 1
- DBMMKEHYWIZTPN-JYJNAYRXSA-N Val-Cys-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N DBMMKEHYWIZTPN-JYJNAYRXSA-N 0.000 description 1
- XTAUQCGQFJQGEJ-NHCYSSNCSA-N Val-Gln-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N XTAUQCGQFJQGEJ-NHCYSSNCSA-N 0.000 description 1
- YCMXFKWYJFZFKS-LAEOZQHASA-N Val-Gln-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCMXFKWYJFZFKS-LAEOZQHASA-N 0.000 description 1
- IWZYXFRGWKEKBJ-GVXVVHGQSA-N Val-Gln-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N IWZYXFRGWKEKBJ-GVXVVHGQSA-N 0.000 description 1
- CPTQYHDSVGVGDZ-UKJIMTQDSA-N Val-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N CPTQYHDSVGVGDZ-UKJIMTQDSA-N 0.000 description 1
- VFOHXOLPLACADK-GVXVVHGQSA-N Val-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N VFOHXOLPLACADK-GVXVVHGQSA-N 0.000 description 1
- AGKDVLSDNSTLFA-UMNHJUIQSA-N Val-Gln-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N AGKDVLSDNSTLFA-UMNHJUIQSA-N 0.000 description 1
- PWRITNSESKQTPW-NRPADANISA-N Val-Gln-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N PWRITNSESKQTPW-NRPADANISA-N 0.000 description 1
- AAOPYWQQBXHINJ-DZKIICNBSA-N Val-Gln-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N AAOPYWQQBXHINJ-DZKIICNBSA-N 0.000 description 1
- GBESYURLQOYWLU-LAEOZQHASA-N Val-Glu-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N GBESYURLQOYWLU-LAEOZQHASA-N 0.000 description 1
- VVZDBPBZHLQPPB-XVKPBYJWSA-N Val-Glu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O VVZDBPBZHLQPPB-XVKPBYJWSA-N 0.000 description 1
- XWYUBUYQMOUFRQ-IFFSRLJSSA-N Val-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N)O XWYUBUYQMOUFRQ-IFFSRLJSSA-N 0.000 description 1
- DJEVQCWNMQOABE-RCOVLWMOSA-N Val-Gly-Asp Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)O)C(=O)O)N DJEVQCWNMQOABE-RCOVLWMOSA-N 0.000 description 1
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 1
- XXROXFHCMVXETG-UWVGGRQHSA-N Val-Gly-Val Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXROXFHCMVXETG-UWVGGRQHSA-N 0.000 description 1
- OPGWZDIYEYJVRX-AVGNSLFASA-N Val-His-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N OPGWZDIYEYJVRX-AVGNSLFASA-N 0.000 description 1
- WJVLTYSHNXRCLT-NHCYSSNCSA-N Val-His-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(=O)O)C(=O)O)N WJVLTYSHNXRCLT-NHCYSSNCSA-N 0.000 description 1
- SDSCOOZQQGUQFC-GVXVVHGQSA-N Val-His-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N SDSCOOZQQGUQFC-GVXVVHGQSA-N 0.000 description 1
- CHWRZUGUMAMTFC-IHRRRGAJSA-N Val-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CNC=N1 CHWRZUGUMAMTFC-IHRRRGAJSA-N 0.000 description 1
- ZIGZPYJXIWLQFC-QTKMDUPCSA-N Val-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N)O ZIGZPYJXIWLQFC-QTKMDUPCSA-N 0.000 description 1
- KDKLLPMFFGYQJD-CYDGBPFRSA-N Val-Ile-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N KDKLLPMFFGYQJD-CYDGBPFRSA-N 0.000 description 1
- WNZSAUMKZQXHNC-UKJIMTQDSA-N Val-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N WNZSAUMKZQXHNC-UKJIMTQDSA-N 0.000 description 1
- KNYHAWKHFQRYOX-PYJNHQTQSA-N Val-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N KNYHAWKHFQRYOX-PYJNHQTQSA-N 0.000 description 1
- APQIVBCUIUDSMB-OSUNSFLBSA-N Val-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C(C)C)N APQIVBCUIUDSMB-OSUNSFLBSA-N 0.000 description 1
- BZWUSZGQOILYEU-STECZYCISA-N Val-Ile-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BZWUSZGQOILYEU-STECZYCISA-N 0.000 description 1
- FEXILLGKGGTLRI-NHCYSSNCSA-N Val-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N FEXILLGKGGTLRI-NHCYSSNCSA-N 0.000 description 1
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 1
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 1
- AEMPCGRFEZTWIF-IHRRRGAJSA-N Val-Leu-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O AEMPCGRFEZTWIF-IHRRRGAJSA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- GVJUTBOZZBTBIG-AVGNSLFASA-N Val-Lys-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N GVJUTBOZZBTBIG-AVGNSLFASA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- MBGFDZDWMDLXHQ-GUBZILKMSA-N Val-Met-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N MBGFDZDWMDLXHQ-GUBZILKMSA-N 0.000 description 1
- OFQGGTGZTOTLGH-NHCYSSNCSA-N Val-Met-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N OFQGGTGZTOTLGH-NHCYSSNCSA-N 0.000 description 1
- MGVYZTPLGXPVQB-CYDGBPFRSA-N Val-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N MGVYZTPLGXPVQB-CYDGBPFRSA-N 0.000 description 1
- WHVSJHJTMUHYBT-SRVKXCTJSA-N Val-Met-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCSC)C(=O)O)N WHVSJHJTMUHYBT-SRVKXCTJSA-N 0.000 description 1
- BCBFMJYTNKDALA-UFYCRDLUSA-N Val-Phe-Phe Chemical compound N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O BCBFMJYTNKDALA-UFYCRDLUSA-N 0.000 description 1
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 1
- LGXUZJIQCGXKGZ-QXEWZRGKSA-N Val-Pro-Asn Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)N)C(=O)O)N LGXUZJIQCGXKGZ-QXEWZRGKSA-N 0.000 description 1
- GQMNEJMFMCJJTD-NHCYSSNCSA-N Val-Pro-Gln Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O GQMNEJMFMCJJTD-NHCYSSNCSA-N 0.000 description 1
- RYQUMYBMOJYYDK-NHCYSSNCSA-N Val-Pro-Glu Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RYQUMYBMOJYYDK-NHCYSSNCSA-N 0.000 description 1
- SJRUJQFQVLMZFW-WPRPVWTQSA-N Val-Pro-Gly Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SJRUJQFQVLMZFW-WPRPVWTQSA-N 0.000 description 1
- BGXVHVMJZCSOCA-AVGNSLFASA-N Val-Pro-Lys Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N BGXVHVMJZCSOCA-AVGNSLFASA-N 0.000 description 1
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 1
- MIKHIIQMRFYVOR-RCWTZXSCSA-N Val-Pro-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C(C)C)N)O MIKHIIQMRFYVOR-RCWTZXSCSA-N 0.000 description 1
- QSPOLEBZTMESFY-SRVKXCTJSA-N Val-Pro-Val Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O QSPOLEBZTMESFY-SRVKXCTJSA-N 0.000 description 1
- LTTQCQRTSHJPPL-ZKWXMUAHSA-N Val-Ser-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N LTTQCQRTSHJPPL-ZKWXMUAHSA-N 0.000 description 1
- VIKZGAUAKQZDOF-NRPADANISA-N Val-Ser-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O VIKZGAUAKQZDOF-NRPADANISA-N 0.000 description 1
- PGQUDQYHWICSAB-NAKRPEOUSA-N Val-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N PGQUDQYHWICSAB-NAKRPEOUSA-N 0.000 description 1
- GBIUHAYJGWVNLN-AEJSXWLSSA-N Val-Ser-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N GBIUHAYJGWVNLN-AEJSXWLSSA-N 0.000 description 1
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 1
- YQYFYUSYEDNLSD-YEPSODPASA-N Val-Thr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O YQYFYUSYEDNLSD-YEPSODPASA-N 0.000 description 1
- JAIZPWVHPQRYOU-ZJDVBMNYSA-N Val-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O JAIZPWVHPQRYOU-ZJDVBMNYSA-N 0.000 description 1
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 1
- GUIYPEKUEMQBIK-JSGCOSHPSA-N Val-Tyr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)NCC(O)=O GUIYPEKUEMQBIK-JSGCOSHPSA-N 0.000 description 1
- RLVTVHSDKHBFQP-ULQDDVLXSA-N Val-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=C(O)C=C1 RLVTVHSDKHBFQP-ULQDDVLXSA-N 0.000 description 1
- PGBMPFKFKXYROZ-UFYCRDLUSA-N Val-Tyr-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N PGBMPFKFKXYROZ-UFYCRDLUSA-N 0.000 description 1
- ZHWZDZFWBXWPDW-GUBZILKMSA-N Val-Val-Cys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O ZHWZDZFWBXWPDW-GUBZILKMSA-N 0.000 description 1
- VVIZITNVZUAEMI-DLOVCJGASA-N Val-Val-Gln Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(N)=O VVIZITNVZUAEMI-DLOVCJGASA-N 0.000 description 1
- SSKKGOWRPNIVDW-AVGNSLFASA-N Val-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SSKKGOWRPNIVDW-AVGNSLFASA-N 0.000 description 1
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 1
- WHNSHJJNWNSTSU-BZSNNMDCSA-N Val-Val-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 WHNSHJJNWNSTSU-BZSNNMDCSA-N 0.000 description 1
- 208000027418 Wounds and injury Diseases 0.000 description 1
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 1
- 101710159548 Zinc transporter 1 Proteins 0.000 description 1
- 102100034993 Zinc transporter 1 Human genes 0.000 description 1
- CWRILEGKIAOYKP-SSDOTTSWSA-M [(2r)-3-acetyloxy-2-hydroxypropyl] 2-aminoethyl phosphate Chemical compound CC(=O)OC[C@@H](O)COP([O-])(=O)OCCN CWRILEGKIAOYKP-SSDOTTSWSA-M 0.000 description 1
- ATBOMIWRCZXYSZ-XZBBILGWSA-N [1-[2,3-dihydroxypropoxy(hydroxy)phosphoryl]oxy-3-hexadecanoyloxypropan-2-yl] (9e,12e)-octadeca-9,12-dienoate Chemical compound CCCCCCCCCCCCCCCC(=O)OCC(COP(O)(=O)OCC(O)CO)OC(=O)CCCCCCC\C=C\C\C=C\CCCCC ATBOMIWRCZXYSZ-XZBBILGWSA-N 0.000 description 1
- 201000000690 abdominal obesity-metabolic syndrome Diseases 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 125000002252 acyl group Chemical group 0.000 description 1
- 230000002730 additional effect Effects 0.000 description 1
- TTWYZDPBDWHJOR-IDIVVRGQSA-L adenosine triphosphate disodium Chemical compound [Na+].[Na+].C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP([O-])([O-])=O)[C@@H](O)[C@H]1O TTWYZDPBDWHJOR-IDIVVRGQSA-L 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 238000013019 agitation Methods 0.000 description 1
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 1
- 108010041407 alanylaspartic acid Proteins 0.000 description 1
- 108010011559 alanylphenylalanine Proteins 0.000 description 1
- 230000003281 allosteric effect Effects 0.000 description 1
- AWUCVROLDVIAJX-UHFFFAOYSA-N alpha-glycerophosphate Natural products OCC(O)COP(O)(O)=O AWUCVROLDVIAJX-UHFFFAOYSA-N 0.000 description 1
- 125000000539 amino acid group Chemical group 0.000 description 1
- 230000037354 amino acid metabolism Effects 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 239000000427 antigen Substances 0.000 description 1
- 108091007433 antigens Proteins 0.000 description 1
- 102000036639 antigens Human genes 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 235000006708 antioxidants Nutrition 0.000 description 1
- 239000008346 aqueous phase Substances 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 108010072041 arginyl-glycyl-aspartic acid Proteins 0.000 description 1
- 108010057412 arginyl-glycyl-aspartyl-phenylalanine Proteins 0.000 description 1
- 108010018691 arginyl-threonyl-arginine Proteins 0.000 description 1
- 108010084758 arginyl-tyrosyl-aspartic acid Proteins 0.000 description 1
- 229960005070 ascorbic acid Drugs 0.000 description 1
- 235000010323 ascorbic acid Nutrition 0.000 description 1
- 239000011668 ascorbic acid Substances 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 108010010430 asparagine-proline-alanine Proteins 0.000 description 1
- 230000004900 autophagic degradation Effects 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 238000003236 bicinchoninic acid assay Methods 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 230000000975 bioactive effect Effects 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 229920000249 biocompatible polymer Polymers 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 239000000090 biomarker Substances 0.000 description 1
- 229920001400 block copolymer Polymers 0.000 description 1
- 238000009835 boiling Methods 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 230000003833 cell viability Effects 0.000 description 1
- 230000007960 cellular response to stress Effects 0.000 description 1
- 210000003169 central nervous system Anatomy 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 229930183167 cerebroside Natural products 0.000 description 1
- RIZIAUKTHDLMQX-UHFFFAOYSA-N cerebroside D Natural products CCCCCCCCCCCCCCCCC(O)C(=O)NC(C(O)C=CCCC=C(C)CCCCCCCCC)COC1OC(CO)C(O)C(O)C1O RIZIAUKTHDLMQX-UHFFFAOYSA-N 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- 231100000012 chronic liver injury Toxicity 0.000 description 1
- 239000007979 citrate buffer Substances 0.000 description 1
- 239000000512 collagen gel Substances 0.000 description 1
- 229960002424 collagenase Drugs 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000000875 corresponding effect Effects 0.000 description 1
- 108010004073 cysteinylcysteine Proteins 0.000 description 1
- 108010069495 cysteinyltyrosine Proteins 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 230000032459 dedifferentiation Effects 0.000 description 1
- 230000006735 deficit Effects 0.000 description 1
- 238000011257 definitive treatment Methods 0.000 description 1
- 230000003412 degenerative effect Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 238000002716 delivery method Methods 0.000 description 1
- 108010060455 des-Tyr- beta-casomorphin Proteins 0.000 description 1
- 235000019425 dextrin Nutrition 0.000 description 1
- WQZGKKKJIJFFOK-UKLRSMCWSA-N dextrose-2-13c Chemical compound OC[C@H]1OC(O)[13C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-UKLRSMCWSA-N 0.000 description 1
- 206010012601 diabetes mellitus Diseases 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 235000014113 dietary fatty acids Nutrition 0.000 description 1
- 229960003724 dimyristoylphosphatidylcholine Drugs 0.000 description 1
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 1
- 108010054812 diprotin A Proteins 0.000 description 1
- 150000002016 disaccharides Chemical class 0.000 description 1
- ZGSPNIOCEDOHGS-UHFFFAOYSA-L disodium [3-[2,3-di(octadeca-9,12-dienoyloxy)propoxy-oxidophosphoryl]oxy-2-hydroxypropyl] 2,3-di(octadeca-9,12-dienoyloxy)propyl phosphate Chemical compound [Na+].[Na+].CCCCCC=CCC=CCCCCCCCC(=O)OCC(OC(=O)CCCCCCCC=CCC=CCCCCC)COP([O-])(=O)OCC(O)COP([O-])(=O)OCC(OC(=O)CCCCCCCC=CCC=CCCCCC)COC(=O)CCCCCCCC=CCC=CCCCCC ZGSPNIOCEDOHGS-UHFFFAOYSA-L 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 230000036267 drug metabolism Effects 0.000 description 1
- 230000013020 embryo development Effects 0.000 description 1
- 210000004039 endoderm cell Anatomy 0.000 description 1
- 210000003989 endothelium vascular Anatomy 0.000 description 1
- 230000019439 energy homeostasis Effects 0.000 description 1
- 230000037149 energy metabolism Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 210000000981 epithelium Anatomy 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 238000010195 expression analysis Methods 0.000 description 1
- 239000000194 fatty acid Substances 0.000 description 1
- 229930195729 fatty acid Natural products 0.000 description 1
- 230000004129 fatty acid metabolism Effects 0.000 description 1
- 150000004665 fatty acids Chemical class 0.000 description 1
- 230000003176 fibrotic effect Effects 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 238000007667 floating Methods 0.000 description 1
- 238000007710 freezing Methods 0.000 description 1
- 108020001507 fusion proteins Proteins 0.000 description 1
- 102000037865 fusion proteins Human genes 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 238000001476 gene delivery Methods 0.000 description 1
- 235000013531 gin Nutrition 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 108010085059 glutamyl-arginyl-proline Proteins 0.000 description 1
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 1
- 108010073628 glutamyl-valyl-phenylalanine Proteins 0.000 description 1
- 150000002327 glycerophospholipids Chemical class 0.000 description 1
- 150000002339 glycosphingolipids Chemical class 0.000 description 1
- 229930004094 glycosylphosphatidylinositol Natural products 0.000 description 1
- JYPCXBJRLBHWME-UHFFFAOYSA-N glycyl-L-prolyl-L-arginine Natural products NCC(=O)N1CCCC1C(=O)NC(CCCN=C(N)N)C(O)=O JYPCXBJRLBHWME-UHFFFAOYSA-N 0.000 description 1
- 108010062266 glycyl-glycyl-argininal Proteins 0.000 description 1
- 108010084264 glycyl-glycyl-cysteine Proteins 0.000 description 1
- 108010051307 glycyl-glycyl-proline Proteins 0.000 description 1
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 1
- 108010028188 glycyl-histidyl-serine Proteins 0.000 description 1
- 108010079413 glycyl-prolyl-glutamic acid Proteins 0.000 description 1
- 108010087823 glycyltyrosine Proteins 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 229940093915 gynecological organic acid Drugs 0.000 description 1
- 208000019622 heart disease Diseases 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 229910001385 heavy metal Inorganic materials 0.000 description 1
- 208000005252 hepatitis A Diseases 0.000 description 1
- 229920001519 homopolymer Polymers 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- XNXVOSBNFZWHBV-UHFFFAOYSA-N hydron;o-methylhydroxylamine;chloride Chemical compound Cl.CON XNXVOSBNFZWHBV-UHFFFAOYSA-N 0.000 description 1
- 229920001477 hydrophilic polymer Polymers 0.000 description 1
- 239000001863 hydroxypropyl cellulose Substances 0.000 description 1
- 235000010977 hydroxypropyl cellulose Nutrition 0.000 description 1
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 1
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 1
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000006882 induction of apoptosis Effects 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 230000002458 infectious effect Effects 0.000 description 1
- 230000002757 inflammatory effect Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 208000014674 injury Diseases 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 238000007917 intracranial administration Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000007919 intrasynovial administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 108010031424 isoleucyl-prolyl-proline Proteins 0.000 description 1
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 1
- 108010027338 isoleucylcysteine Proteins 0.000 description 1
- 108010078274 isoleucylvaline Proteins 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 239000000787 lecithin Substances 0.000 description 1
- 235000010445 lecithin Nutrition 0.000 description 1
- 229940067606 lecithin Drugs 0.000 description 1
- 108010076756 leucyl-alanyl-phenylalanine Proteins 0.000 description 1
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 1
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 1
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 1
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 1
- 108010087810 leucyl-seryl-glutamyl-leucine Proteins 0.000 description 1
- 108010091871 leucylmethionine Proteins 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 108010056787 lysyl-arginyl-glutamyl-glutamic acid Proteins 0.000 description 1
- 108010044348 lysyl-glutamyl-aspartic acid Proteins 0.000 description 1
- 108010057952 lysyl-phenylalanyl-lysine Proteins 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 230000037353 metabolic pathway Effects 0.000 description 1
- 108010063431 methionyl-aspartyl-glycine Proteins 0.000 description 1
- 108010090114 methionyl-tyrosyl-lysine Proteins 0.000 description 1
- 230000011987 methylation Effects 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- 108091070501 miRNA Proteins 0.000 description 1
- 239000002679 microRNA Substances 0.000 description 1
- 239000008108 microcrystalline cellulose Substances 0.000 description 1
- 235000019813 microcrystalline cellulose Nutrition 0.000 description 1
- 229940016286 microcrystalline cellulose Drugs 0.000 description 1
- 239000011859 microparticle Substances 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 230000004065 mitochondrial dysfunction Effects 0.000 description 1
- 230000004898 mitochondrial function Effects 0.000 description 1
- 230000006705 mitochondrial oxidative phosphorylation Effects 0.000 description 1
- 230000000897 modulatory effect Effects 0.000 description 1
- 230000003990 molecular pathway Effects 0.000 description 1
- 150000002772 monosaccharides Chemical class 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- 208000015122 neurodegenerative disease Diseases 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- 230000008689 nuclear function Effects 0.000 description 1
- 210000004492 nuclear pore Anatomy 0.000 description 1
- 210000001623 nucleosome Anatomy 0.000 description 1
- 238000006384 oligomerization reaction Methods 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 210000003463 organelle Anatomy 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 230000026792 palmitoylation Effects 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 229920002866 paraformaldehyde Polymers 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 231100000915 pathological change Toxicity 0.000 description 1
- 230000036285 pathological change Effects 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- 230000008823 permeabilization Effects 0.000 description 1
- 102000013415 peroxidase activity proteins Human genes 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 239000008194 pharmaceutical composition Substances 0.000 description 1
- 108010082795 phenylalanyl-arginyl-arginine Proteins 0.000 description 1
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 1
- 108010024607 phenylalanylalanine Proteins 0.000 description 1
- 108010018625 phenylalanylarginine Proteins 0.000 description 1
- 108010073101 phenylalanylleucine Proteins 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- 239000007981 phosphate-citrate buffer Substances 0.000 description 1
- 150000008104 phosphatidylethanolamines Chemical class 0.000 description 1
- 150000003908 phosphatidylinositol bisphosphates Chemical class 0.000 description 1
- 150000003907 phosphatidylinositol monophosphates Chemical class 0.000 description 1
- 150000003905 phosphatidylinositols Chemical class 0.000 description 1
- 229950004354 phosphorylcholine Drugs 0.000 description 1
- PYJNAPOPMIJKJZ-UHFFFAOYSA-N phosphorylcholine chloride Chemical compound [Cl-].C[N+](C)(C)CCOP(O)(O)=O PYJNAPOPMIJKJZ-UHFFFAOYSA-N 0.000 description 1
- 108010025488 pinealon Proteins 0.000 description 1
- 229920001983 poloxamer Polymers 0.000 description 1
- 229920000233 poly(alkylene oxides) Polymers 0.000 description 1
- 229920001610 polycaprolactone Polymers 0.000 description 1
- 239000004632 polycaprolactone Substances 0.000 description 1
- 229920002643 polyglutamic acid Polymers 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 230000004911 positive regulation of CREB transcription factor activity Effects 0.000 description 1
- 230000029279 positive regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 230000013823 prenylation Effects 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 230000000750 progressive effect Effects 0.000 description 1
- 230000002062 proliferating effect Effects 0.000 description 1
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 1
- 108010020432 prolyl-prolylisoleucine Proteins 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000012846 protein folding Effects 0.000 description 1
- 108060006633 protein kinase Proteins 0.000 description 1
- 230000007398 protein translocation Effects 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 239000002096 quantum dot Substances 0.000 description 1
- 230000010837 receptor-mediated endocytosis Effects 0.000 description 1
- 230000007115 recruitment Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000001172 regenerating effect Effects 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 230000001718 repressive effect Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 229920002477 rna polymer Polymers 0.000 description 1
- 238000007480 sanger sequencing Methods 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 210000000813 small intestine Anatomy 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 229940083466 soybean lecithin Drugs 0.000 description 1
- 229940063673 spermidine Drugs 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 150000005846 sugar alcohols Chemical class 0.000 description 1
- 230000010741 sumoylation Effects 0.000 description 1
- 230000000153 supplemental effect Effects 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 230000031068 symbiosis, encompassing mutualism through parasitism Effects 0.000 description 1
- 208000011580 syndromic disease Diseases 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- BCNZYOJHNLTNEZ-UHFFFAOYSA-N tert-butyldimethylsilyl chloride Chemical compound CC(C)(C)[Si](C)(C)Cl BCNZYOJHNLTNEZ-UHFFFAOYSA-N 0.000 description 1
- 230000008719 thickening Effects 0.000 description 1
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 1
- 108010031491 threonyl-lysyl-glutamic acid Proteins 0.000 description 1
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 108091006106 transcriptional activators Proteins 0.000 description 1
- 230000037426 transcriptional repression Effects 0.000 description 1
- 238000011222 transcriptome analysis Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 150000003626 triacylglycerols Chemical class 0.000 description 1
- UFTFJSFQGQCHQW-UHFFFAOYSA-N triformin Chemical compound O=COCC(OC=O)COC=O UFTFJSFQGQCHQW-UHFFFAOYSA-N 0.000 description 1
- 108700004896 tripeptide FEG Proteins 0.000 description 1
- 239000001226 triphosphate Substances 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 108010038745 tryptophylglycine Proteins 0.000 description 1
- 108010079202 tyrosyl-alanyl-cysteine Proteins 0.000 description 1
- 108010005834 tyrosyl-alanyl-glycine Proteins 0.000 description 1
- 108010051110 tyrosyl-lysine Proteins 0.000 description 1
- 108010003137 tyrosyltyrosine Proteins 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 230000003827 upregulation Effects 0.000 description 1
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 description 1
- 108010003885 valyl-prolyl-glycyl-glycine Proteins 0.000 description 1
- 210000005166 vasculature Anatomy 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 108010027345 wheylin-1 peptide Proteins 0.000 description 1
- 108010000998 wheylin-2 peptide Proteins 0.000 description 1
- 239000002676 xenobiotic agent Substances 0.000 description 1
- 230000022814 xenobiotic metabolic process Effects 0.000 description 1
- 239000008096 xylene Substances 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
Images




















































Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/005—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'active' part of the composition delivered, i.e. the nucleic acid delivered
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/1703—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- A61K38/1709—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/16—Drugs for disorders of the alimentary tract or the digestive system for liver or gallbladder disorders, e.g. hepatoprotective agents, cholagogues, litholytics
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4702—Regulators; Modulating activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPRs]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/16011—Human Immunodeficiency Virus, HIV
- C12N2740/16041—Use of virus, viral particle or viral elements as a vector
- C12N2740/16043—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14141—Use of virus, viral particle or viral elements as a vector
- C12N2750/14143—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Genetics & Genomics (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Gastroenterology & Hepatology (AREA)
- Molecular Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Zoology (AREA)
- Epidemiology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biotechnology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Toxicology (AREA)
- Immunology (AREA)
- Marine Sciences & Fisheries (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Virology (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Microbiology (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
대상체에서 간세포의 핵으로 전사 인자인 HNF4α의 수송 또는 보유를 증가시켜 대상체에서 간 질환을 치료하기 위한 조성물 및 방법이 개시된다. 일부 구현예에서, 방법은 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택된 하나 이상의 전사 인자 및 그의 기능적 단편의 발현 또는 기능을 상향 조절하고/하거나 하나 이상의 전사 인자 DNAJB1/HSP40, ATF6, ATF4, 및 PERK 및 그의 기능적 단편의 발현 또는 기능을 하향 조절하는 것을 포함한다.
Description
관련 출원에 대한 상호-참조
본 출원은 2019년 10월 16일자 출원된 미국 가출원 번호 62/915,765의 우선권을 주장하며, 전체로서 본원에 참조로 도입된다.
연방 지원 연구 또는 개발에 대한 진술
본 발명은 국립 보건원 (National Institutes of Health)이 부여한 승인 번호 DK099257에 따른 정부 지원으로 이루어졌다. 정부는 발명에 대해 특정 권리를 갖는다.
본 개시는 예를 들어 간 질환 및/또는 간 장애를 치료하기 위한 HNF4α 발현 또는 활성의 조절과 관련이 있다.
진행성 간경변(advanced liver cirrhosis)으로 인한 말기 간기능 부전(TLF)은 2015년 전 세계적으로 인구 100,000명당 15.8명이 사망하는 12번째 주요 사망 원인으로 나타났다 (Tsochatzis EA et al., 2014). 미국에서 2015년 만성 간 질환과 간경변으로 인한 사망 등록 건수는 40,326명이었고 사망률은 인구 100,000명당 12.5명으로 연간 3.8% 증가했다 (Murphy SL et al., 2017; Goldman L, et al., 2016). 가장 영향을 받는 연령대는 45세에서 64세 사이이며, 사망률은 인구 100,000명당 26.4명으로, 만성 간 질환 및 간경변이 이 연령대에서 암, 심장 질환, 및 의도치않은 부상에 이어 네 번째 주요 사망 원인이다 (Murphy SL et al., 2017). TLF에 대한 유일한 결정적인 치료법은 간 이식이 필요한 환자의 수와 사용 가능한 장기의 불충분한 수를 고려할 때 TLF를 근본적으로 치료할 수 없는 질병으로 만드는 치환 간 이식(orthotopic liver transplantation)이다 (Lopez PM et al., 2006).
간염 바이러스에 의한 만성 감염, 알코올-매개 간경변, 및 비-알코올성 지방간염(NASH)을 포함하여 만성 간 질환의 원인은 다양하며 (Archambeaud I et al., 2015; Donato F et al,. 2006; Gelatti U et al., 2005; Kuper H et al., 2000), 각각은 간세포 부전을 일으킬 수 있다 (Guzman-Lepe J et al., 2018; Hernaez R et al., 2017; Lee YA et al., 2015; Pessayre D et al., 1978). 인간의 간세포 기능의 악화와 궁극적으로 간 부전의 원인이 되는 메커니즘은 잘 알려져 있지 않다.
만성 간질환, 간경변, 및 최근 TLF의 주요 원인은 B형 및 C형 간염 바이러스에 의한 감염, 알코올 매개 Laennec's 간경변, 비알코올성 지방간염(NASH)/대사 증후군과 관련이 있다 (Archambeaud et al., 2015; Donato F et al., 2006; Gelatti et al., 2005; Kuper et al., 2000). 이러한 병인(etiologic agent)은 혈관 구조의 변경으로 정상적인 소엽 구조(lobular architecture)를 방해하는 섬유증을 유발한다 (Goldman L, et al., 2016). 이러한 병리학적 변화는 간세포 부전 및 간세포가 정상적인 기능을 수행하지 못하는 것과 관련이 있으나 (Guzman-Lepe J et al., 2018; Hernaez R et al., 2007; Lee Ya et al., 2015; Pessayre D et al., 1978), 간세포 기능의 악화와 궁극적으로 간 부전에 대한 메커니즘은 인간에게 알려져 있지 않다. 만성 간 손상은 세포 사멸을 유도하는 (Cichoz-Lach H et al., 2014; Malhi H et al., 2011; Zhang XQ et al., 2014; Wang K et al., 2014; Seki E et al., 2015) 산화 스트레스 (Cichoz-Lach H et al., 2014; Simoes ICM et al., 2018) 및 소포체 스트레스 (Malhi H et al., 2011; Zhang XQ et al., 2014)를 생성하며, 궁극적으로 간세포의 증식 능력을 감소시킨다 (Zhang BH et al., 1999; Michalopoulos GK et al., 2015; Dubuquoy L et al., 2015).
말기 간경변이 있는 쥐의 간세포에서 간-강화 전사 인자는 안정적으로 하향조절되고 (Nishikawa T et al., 2014; Guzman-Lepe J et al., 2019), 그 중 하나인 간세포 핵 인자 4 알파 (hepatocyte nuclear factor 4 alpha, HNF4α)의 강제 재발현은 기능 장애 간세포를 재프로그래밍하여 배양 및 생체 내 모두에서 기능을 회복하는 것으로 확인되었다 (Nishikawa T et al., 2014). 진행성 간 질환 환자의 대규모 코호트 연구는, 병든 간에서 HNF4α mRNA 발현 수준이 간 기능 장애의 정도 (Childs-Pug 분류)와 상관관계가 있으며, HNF4α 발현이 핵에 국한되지 않음을 보여준다 (Guzman-Lepe J et al., 2019). 간세포 핵 인자 4 알파 (HNF4α)의 강제 재발현은 새로운 간세포 또는 줄기 세포의 확장 없이도 말기 간경변 간에서 기능 장애 간세포를 재프로그래밍하여 배양 및 생체 내에서 다시 기능하도록 할 수 있다 (Nishikawa T et al., 2014). HNF4α 핵 국소화 및 mRNA 발현의 상당한 감소를 포함한 LETF의 하향 조절은 TLF가 있는 인간 간의 대규모 코호트에서 간 기능 장애 정도와 관련이 있다 (Guzman-Lepe J et al., 2018).
HNF4α는 성인 간에서 간 기관 형성 및 간세포 기능에 중요한 역할을 하는 전사 인자이다 (Nishikawa T et al., 2014; Babeu JP et al., 2014). 주요 HNF4α 작용은 지질, 포도당, 생체이물(xenobiotic), 및 약물 대사와 관련된 특정 표적 유전자의 조절이다 (Nishikawa T et al., 2014; Babeu JP et al., 2014). 단일 유전자는 인간에서 HNF4α를 암호화하며 (Kritis AA et al., 1999), 이는 두 개의 다른 프로모터에 의해 조절된다. 이러한 프로모터는 P1 및 P2의 두 가지 이소형 부류를 생성한다 (Babeu JP et al., 2014). P1 이소형은 주로 성인 간에서 발현되는 반면, P2 이소형은 배아 발달 및 암과 같은 병리학적 조건 하에서 간에서 검출되었다 (Babeu JP et al., 2014; Walesky C et al., 2015; Tanaka T et al., 2006). HNF4α의 발현과 기능은 여러 수준에서 조절된다 (Chellappa K et al., 2012; Guo H et al., 2014; Hong YH et al., 2003; Lu H et al., 2016, Song Y et al., 2015; Soutoglou E et al., 2000; Sun K et al., 2007; Xu Z et al., 2007; Yokoyama A et al., 2011; Zhou W et al., 2012).
따라서, HNF4α 발현을 조절하고/하거나 간 질환 및/또는 간 장애를 치료하기 위한 조성물 및 방법이 필요하다. 본원에 개시된 조성물 및 방법은 이러한 요구 및 기타 요구를 다룬다.
본원에 개시된 조성물 및 방법은 간 질환 치료에서 충족되지 않은 특정 요구를 다룬다. 일부 측면에서, 간 질환 및/또는 간 장애의 치료용 약제를 위한 조성물 및 이의 용도가 본원에 개시되며, 여기서 상기 조성물은 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및/또는 POM121C로 이루어진 군으로부터 선택된 하나 이상의 전사 인자의 양 또는 기능을 증가시키거나 DNAJB1/HSP40, ATF6, ATF4, 및 PERK으로 이루어진 군으로부터 선택된 하나 이상의 전사 인자의 양을 감소시키거나 기능을 억제한다. 일부 구현예에서, 상기 조성물은 벡터이고, 상기 벡터는 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및/또는 POM121C 중 하나 이상을 암호화하는 하나 이상의 핵산을 포함한다. 일부 구현예에서, 상기 조성물은 HNF4α (예를 들어, HNF4α 이소형 2)를 암호화하는 핵산을 포함하는 벡터이다. 본원에 개시된 조성물 및 방법은 간세포에서 HNF4α의 양의 놀라운 증가를 초래하여 (예를 들어, 간세포에서 HNF4α 총량의 증가, 및/또는 간세포의 핵에서 HNF4α의 양의 증가), 간 질환의 효과적인 치료를 초래한다 (예를 들어, 말기 간 질환).
일부 측면에서, 본 발명은 대상체에게 조성물을 투여하는 것을 포함하는, 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하는 방법을 개시하며, 여기서 상기 조성물은 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자의 양 또는 기능을 증가시킨다.
일부 측면에서, 본 발명은 대상체에게 조성물을 투여하는 것을 포함하는, 간 질환의 치료를 필요로 하는 대상체에서 간 질환 치료용 약제의 제조를 위한 조성물의 용도를 개시하며, 여기서 상기 조성물은 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자의 양 또는 기능을 증가시킨다.
일부 구현예에서, 상기 조성물은 벡터이고, 여기서 벡터는 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C 중 하나 이상을 암호화하는 하나 이상의 핵산을 포함한다. 일부 구현예에서, 상기 벡터는 PROX1 및/또는 SREBP1를 암호화하는 하나 이상의 핵산을 포함한다. 상기 하나 이상의 핵산은 DNA 또는 mRNA일 수 있다.
일부 측면에서, 본 발명은 대상체에게 조성물을 투여하는 것을 포함하는, 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하는 방법을 개시하며, 여기서 상기 조성물은 DNAJB1/HSP40, ATF6, ATF4, 및 PERK로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자의 양을 감소시키거나 기능을 억제한다.
일부 측면에서, 본 발명은 대상체에게 조성물을 투여하는 것을 포함하는, 간 질환의 치료를 필요로 하는 대상체에서 간 질환 치료용 약제의 제조를 위한 조성물의 용도를 개시하며, 여기서 상기 조성물은 DNAJB1/HSP40, ATF6, ATF4, 및 PERK로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자의 양 또는 기능을 감소시킨다.
일부 구현예에서, 상기 조성물의 투여는 대상체의 간세포 핵에서 HNF4α의 양을 증가시킨다. 일부 구현예에서, 상기 조성물의 투여는 간세포에서 HNF4α의 총량을 증가시키지 않는다. 일부 구현예에서, 상기 조성물의 투여는 간세포에서 HNF4α의 총량을 증가시킨다.
일부 구현예에서, 상기 벡터는 HNF4α을 암호화하는 핵산을 더 포함한다. 일부 구현예에서, 상기 방법은 HNF4α를 암호화하는 핵산을 포함하는 벡터를 대상체에게 투여하는 것을 더 포함한다. 일 예시에서, 상기 핵산은 HNF4α 이소형 2를 암호화한다.
일부 측면에서, 본 발명은 벡터를 포함하는 조성물을 개시하며, 여기서 상기 벡터는 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자, 및 이의 기능적 단편을 암호화하는 하나 이상의 핵산을 포함한다.
일부 측면에서, 본 발명은 대상체에게 HNF4α 이소형 2를 암호화하는 핵산을 포함하는 벡터를 투여하는 것을 포함하는, 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하는 방법을 개시한다.
일부 측면에서, 본 발명은 간 질환의 치료용 약제의 제조를 위한 벡터의 용도를 개시하며, 여기서 상기 벡터는 HNF4α 이소형 2를 암호화하는 핵산을 포함한다.
도 1A-1C는 정상 및 간경변 간의 간세포에서 HNF4α 위치를 나타낸다. 도 1A는 NASH 비대상 간에서 분리된 간세포 및 정상 인간 간세포의 HNF4α 면역형광의 대표 사진을 나타낸다. 기능적으로 비대상된 간 (NASH 및 알코올-매개 Laennec's 간경변)(n=6)에서 분리된 간세포 및 정상 간 대조군(n=2)에서 분리된 간세포에서 베타-액틴으로 정규화된 HNF4α의 웨스턴 블롯 분석 및 정량화. 도 1A는 총 HNF4α를 나타낸다; 정상 인간 간세포 vs 비대상 인간 간세포, P = 0.166. 도 1B는 세포질 HNF4α를 나타낸다; 정상 인간 간세포 vs 비대상 인간 간세포, P = 0.023. 도 1C는 핵 HNF4α를 나타낸다; 정상 인간 간세포 vs 비대상 인간 간세포, P = 0.023). A에서 C까지의 그래프는 평균±SD로 표시된다. 통계적 유의미(P < 0.05). 다이아몬드는 Child-Pugh "B"를 나타내고 사각형은 Child-Pugh "C"를 나타낸다.
도 2A-2C는 HNF4α 번역 후 변형자의 단백질 발현 및 스피어만 순위 상관 테스트를 보여준다. 도 2A 및 2B는 비대상 NASH(n=4) 및 알코올 매개 Laennec's 간경변 간세포(n=2) 및 정상 대조군 간세포(n=2)에서 EGFR(P=0.904), cMET(P=0.023), 총 AMPKα(P > 0.999), p-AMPKα(Thr172)(P=0.547), 총 AKT(P=0.047), p-AKT(Ser473)(P=0.547), p-AKT(Thr308)(P=0.024), p-AMPKα(Thr172)/AMPKα 비율(P=0.5476), p- AKT(Ser473)/AKT 비율(P=0.1667) 및 p-AKT(Thr308)/총 AKT 비율(P=0.0238)의 웨스턴 블롯 분석(2A) 및 정량화(2B)를 보여준다. 도 2B에서 채워진 사각형은 Child-Pugh "B"를 나타내고 채워진 다이아몬드는 Child-Pugh "C"를 나타낸다. 도 2C는 스피어만 순위 상관 테스트가 표시되고 핵 HNF4α가 cMET (r=0.71; P=0.037), 총 AKT (r=0.71; P=0.037), 포스포-AKT(Thr308) (r=0.82; P=0.011), 및 포스포-AKT(Thr308)/총 AKT 비율 (r=0.73; P=0.031)과 유의한 상관관계가 있음을 보여준다. 세포질 HNF4α는 cMET (r=-0.80; P=0.014), 총 AKT (r=-0.73; P=0.031), 포스포-AKT(Thr308) (r=-0.77; P=0.021, 및 포스포-AKT(Thr308)/총 AKT 비율 (r=- 0.72; P=0.037)과 유의한 상관관계를 나타낸다. 도 2B의 막대 그래프는 평균 ± SD로 표시된다. 통계적 유의미(P < 0.05).
도 3A-3D는 번역 후 변형자와 HNF4α 세포 국소화의 관계를 보여준다. 도 3A는 경로 분석이 cMET(0.56; P=0.004), 포스포AKT(Thr308)/총 AKT 비율(0.05; P=0.006) 및 총 HNF4α 수준(0.60; P=0.042)과 HNF4α 국소화 사이에 유의한 직접적 관계가 있음을 보여준다. 경로 분석은 cMET과 총 HNF4α(-0.37; P=0.024) 사이에 음의 유의한 관계가 있음을 보여준다. 도 3B는 선형 회귀 분석이 핵 HNF4α 발현과 간 기능 장애의 정도(Child-Pugh 점수)의 유의한 관계를 보여줌(R2=0.80, P=0.007)을 도시한다. 도 3C는 주성분 분석(PCA)이 HNF4α 발현과 상관관계가 있는 단백질 프로파일을 보여주며 정상 인간 간세포(n=2)의 특성을 명확히 설명하는 반면, 세포질 HNF4α, 활성 카스파제 3, p-AKT(Ser473)/총 AKT 비율 및 p-AMPK(Ser172)/AMPK는 NASH(n=4) 및 알코올 매개 Laennec's 간경변 간(n=2)의 비대상된 인간 간세포의 특성을 설명한다. 도 3D의 그래프는 정상 인간 간세포와 비교하여 비대상 인간 간세포(차일드-퍼 분류 B 및 C)에서 전체, 핵 또는 세포질 HNF4α(상단 행의 세 그래프), cMET, p-AMPK(Ser172)/AMPK, p-AKT(Ser473)/총 AKT 및 포스포AKT(Thr308)/총 AKT 비율, p-H3(Ser10) 및 활성화된 카스파제 (두 번째 및 맨 아래 행의 그래프)의 PCA 분석에 사용된 단백질 발현 배수 변화를 보여준다. 그래프는 평균 ± SD로 표시된다. 통계적 유의미(P < 0.05).
도 4A-4C는 핵 HNF4α의 아세틸화가 NASH 및 알코올 매개 Laennec's 간경변 외식 간(explanted liver)의 인간 비대상 간세포에서 변화됨을 나타낸다. 도 4A 및 4B는 비대상 NASH(n=4) 및 알코올 매개 Laennec's 간경변(n=4) 외식간(P=0.024)에서 인간 간세포의 핵 분획에서 HNF4α(Lys106)의 아세틸화된 형태의 웨스턴 블롯 및 정량화를 보여준다. 도 4C의 선형 회귀 분석은 감소된 아세틸화 형태의 HNF4α(Lys106)와 간 기능 장애(R2=0.71, P=0.004)의 유의한 상관 관계를 보여준다. 막대 그래프는 평균 ± SD로 표시된다. 통계적 유의미(P < 0.05).
도 5는 HNF4α 번역 후 변형(PTM)의 인 실리코 분석을 보여준다. 도 5는 HNF4α-PTM의 목록을 제공한다.
도 6A-6B는 활성화된 AKT 경로와 HNF4α 번역 후 변형자와 NASH 및 알코올 매개 Laennec's 간경변 외식간에서 인간 비대상 간세포의 p-EGFR 발현과의 관계를 보여준다. 도 6A는 포스포-AKT(Thr308)/AKT에 대한 스피어만 상관관계를 보여준다. 도 6B는 포스포-AKT(Ser473)/AKT에 대한 스피어만 상관관계를 보여준다.
도 7A-7C는 갓 분리된 정상 인간 간세포와 비교하여 mRNA 수준(도 7A)에서, 및 알코올 간염 간세포의 약 40%만이 약한 강도로 핵에서 HNF4α를 발현하고 세포의 약 10%가 HNF4α 세포질 발현을 갖는다는 것을 면역조직화학에 의해 입증하여 단백질 수준(도 7B)에서 알코올성 간염 환자의 외식된 간에서 분리한 인간 간세포에서 간-강화 전사 인자 HNF4α의 발현 수준을 보여준다. 도 7C의 경우, 갓 분리된 인간 알코올 간염 간세포를 HNF4α를 암호화하는 렌티바이러스(Systems Bioscience, Cat#CS970S-1; CD511B-1의 HNF4α)로 처리했다. 이 도면은 72시간 후에, HNF4α 발현이 핵에서 HNF4α를 발현하는 간세포의 백분율을 변경하지 않았음을 보여준다. 그러나 HNF4α 발현 강도는 기존 세포에서 급격히 증가하였다. 전체적으로 이 데이터는 핵으로의 HNF4α 수송이 알코올성 간염에 걸린 인간에서 간세포가 기능을 회복하는 데 중요한 역할을 할 수 있음을 보여준다.
도 8A-8F는 1차 인간 간세포에서 MTF1 발현을 보여준다. 도 8A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 MTF1(MA5-26738 1:1000) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여준다. 도 8B 및 8C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 HNF4α(도 8B 및 8C) 및 MTF1(도 8D 및 8E)의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. HNF4α 및 MTF1의 발현은 차일드 B 간세포에 비해 차일드 C 간세포에서 더 낮았다. 도 8B 및 8D, *p<0.003, **p<0.01, ***p<0.0001, n=25. 도 8C R2=0.019, p=0.06, n=19. 도 8E R2=0.015, p=0.1, n=19. 도 8F는 차일드-퍼 점수, HNF4α의 단백질 발현 및 MTF1과의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 어두운 회색 원은 차일드 C를 나타낸다. HNF4α의 단백질 발현은 MTF1의 단백질 발현과 상관관계가 있다(R2=0.28, p=0.007, n=25).
도 9A-9D는 1차 인간 간세포에서 NR0B2 발현을 보여준다. 도 9A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 NR0B2(Abclonal A1836 1:500) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여준다. 도 9B 및 9C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 NR0B2의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. 도 9B *p<0.05, **p<0.01, ***p<0.001, n=25. 도 9C R2=0.19, p=0.06, n=19. NR0B2의 발현은 차일드 C, 차일드 B 및 대조군 간세포에서 다르다. 도 9D 차일드-퍼 점수, HNF4α의 단백질 발현 및 NR0B2와의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 짙은 회색 원은 차일드 C를 나타낸다(R2=0.12, p=0.1, n=25).
도 10A-10D는 1차 인간 간세포에서 NR5A2 발현을 보여준다. 도 10A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 NR5A2(Novus NBP2-27196 1:500) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여준다. 도 10B 및 10C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 NR5A2의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. 도 10B *p<0.05, n=25. 도 10C R2=0.17, p=0.07, n=19. NR5A2의 발현은 차일드 B, 차일드 C 및 대조군 간세포에서 다르다. 도 10B는 차일드-퍼 점수, HNF4α의 단백질 발현 및 NR0B2와의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. NR5A2의 단백질 발현은 HNF4α의 발현과 상관관계가 있다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 짙은 회색 원은 차일드 C를 나타낸다(R2=0.17, p<0.05, n=25).
도 11A-11D는 1차 인간 간세포에서 Prox1 발현을 보여준다. 도 11A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 PROX1(R&D AF2727 1:500) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여준다. 도 11B 및 11C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 PROX1의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. 도 11B *p<0.02, n=25. 도 11C R2=0.02, p=0.6, n=19. PROX1의 발현은 차일드 C 및 대조군 간세포에서 다르다. 도 11D는 차일드-퍼 점수, HNF4α의 단백질 발현 및 PROX1과의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 짙은 회색 원은 차일드 C를 나타낸다(R2=0.02, p=0.46, n=25).
도 12A-12D는 1차 인간 간세포에서 POM121C 발현을 보여준다. 도 12A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 POM121C(PA5-85161 1:500) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여준다. 도 12B 및 12C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 POM121C의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. 도 12B n=25. 도 12C R2=0.08, p=0.24, n=25. 도 12D는 차일드-퍼 점수, HNF4α의 단백질 발현 및 POM121C와의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 짙은 회색 원은 차일드 C를 나타낸다(R2=0.06, p=0.23, n=25).
도 13A-13D는 1차 인간 간세포에서 SREBP1 발현을 보여준다. 도 13A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 SREBP1(Abcam ab28481 1:500) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여준다. 도 13B 및 13C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 SREBP1의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. 도 13B n=25. 도 13C R2=0.02, p=0.54, n=19. 도 13D는 차일드-퍼 점수, HNF4α의 단백질 발현 및 SREBP1과의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 짙은 회색 원은 차일드 C를 나타낸다(R2=0.01, p=0.86, n=25).
도 14A-14D는 1차 인간 간세포에서 EP300 발현을 보여준다. 도 14A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 EP300(Novus NB100-616 1:500) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여줍니다. 도 14B 및 14C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 EP300의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. 도 14B n=25. 도 14C R2=0.32, p=0.01, n=19. 도 14D는 차일드-퍼 점수, HNF4α의 단백질 발현 및 EP300과의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 짙은 회색 원은 차일드 C를 나타낸다(R2=0.01, p=0.69, n=25).
도 15A 및 B는 HepG2 세포에서 EP300, MTF1, NR0B2, NR5A2, POM121C, PROX1 또는 SREBP1의 CRISPR/Cas9 녹아웃이 수행되었고 세포 HNF4α 위치가 면역형광에서 분석되었음을 보여준다(ab41898 1:500). DAPI 및 HNF4α에서 양성인 핵의 총 수(도 15A) 및 세포질에서 HNF4α에 대해 양성인 세포(도 15B)를 카운팅하였다. 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)을 사용하여 통계 분석을 수행했다. EP300, MTF1, NR0B2, NR5A2, POM121C, PROX1 및 SREBP1의 녹아웃은 HNF4α의 핵 위치 감소와 HNF4α의 세포질 위치 증가를 보여주었다. *p<0.05.
도 16은 간 이식을 겪은 NASH 환자로부터 분리된 1차 인간 간세포가 105의 MOI를 갖는 AAV-MTF1, NR0B2, NR5A2, POM121C, PROX1, SREBP1 또는 GFP 및 AAV-HNF4α로 형질도입되었음을 나타낸다. HNF4α에 대해 양성인 핵의 백분율을 계산했다. 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)을 사용하여 통계 분석을 수행했다. HNF4α, MTF1, NR0B2, POM121C, PROX1 및 SREBP1과의 동시 형질도입은 GFPHNF4α 동시 형질도입 그룹에 비해 증가된 양성 핵의 수를 갖는다 (****p<0.0001, ***p<0.0005, **p<0.001, *p<0.05).
도 2A-2C는 HNF4α 번역 후 변형자의 단백질 발현 및 스피어만 순위 상관 테스트를 보여준다. 도 2A 및 2B는 비대상 NASH(n=4) 및 알코올 매개 Laennec's 간경변 간세포(n=2) 및 정상 대조군 간세포(n=2)에서 EGFR(P=0.904), cMET(P=0.023), 총 AMPKα(P > 0.999), p-AMPKα(Thr172)(P=0.547), 총 AKT(P=0.047), p-AKT(Ser473)(P=0.547), p-AKT(Thr308)(P=0.024), p-AMPKα(Thr172)/AMPKα 비율(P=0.5476), p- AKT(Ser473)/AKT 비율(P=0.1667) 및 p-AKT(Thr308)/총 AKT 비율(P=0.0238)의 웨스턴 블롯 분석(2A) 및 정량화(2B)를 보여준다. 도 2B에서 채워진 사각형은 Child-Pugh "B"를 나타내고 채워진 다이아몬드는 Child-Pugh "C"를 나타낸다. 도 2C는 스피어만 순위 상관 테스트가 표시되고 핵 HNF4α가 cMET (r=0.71; P=0.037), 총 AKT (r=0.71; P=0.037), 포스포-AKT(Thr308) (r=0.82; P=0.011), 및 포스포-AKT(Thr308)/총 AKT 비율 (r=0.73; P=0.031)과 유의한 상관관계가 있음을 보여준다. 세포질 HNF4α는 cMET (r=-0.80; P=0.014), 총 AKT (r=-0.73; P=0.031), 포스포-AKT(Thr308) (r=-0.77; P=0.021, 및 포스포-AKT(Thr308)/총 AKT 비율 (r=- 0.72; P=0.037)과 유의한 상관관계를 나타낸다. 도 2B의 막대 그래프는 평균 ± SD로 표시된다. 통계적 유의미(P < 0.05).
도 3A-3D는 번역 후 변형자와 HNF4α 세포 국소화의 관계를 보여준다. 도 3A는 경로 분석이 cMET(0.56; P=0.004), 포스포AKT(Thr308)/총 AKT 비율(0.05; P=0.006) 및 총 HNF4α 수준(0.60; P=0.042)과 HNF4α 국소화 사이에 유의한 직접적 관계가 있음을 보여준다. 경로 분석은 cMET과 총 HNF4α(-0.37; P=0.024) 사이에 음의 유의한 관계가 있음을 보여준다. 도 3B는 선형 회귀 분석이 핵 HNF4α 발현과 간 기능 장애의 정도(Child-Pugh 점수)의 유의한 관계를 보여줌(R2=0.80, P=0.007)을 도시한다. 도 3C는 주성분 분석(PCA)이 HNF4α 발현과 상관관계가 있는 단백질 프로파일을 보여주며 정상 인간 간세포(n=2)의 특성을 명확히 설명하는 반면, 세포질 HNF4α, 활성 카스파제 3, p-AKT(Ser473)/총 AKT 비율 및 p-AMPK(Ser172)/AMPK는 NASH(n=4) 및 알코올 매개 Laennec's 간경변 간(n=2)의 비대상된 인간 간세포의 특성을 설명한다. 도 3D의 그래프는 정상 인간 간세포와 비교하여 비대상 인간 간세포(차일드-퍼 분류 B 및 C)에서 전체, 핵 또는 세포질 HNF4α(상단 행의 세 그래프), cMET, p-AMPK(Ser172)/AMPK, p-AKT(Ser473)/총 AKT 및 포스포AKT(Thr308)/총 AKT 비율, p-H3(Ser10) 및 활성화된 카스파제 (두 번째 및 맨 아래 행의 그래프)의 PCA 분석에 사용된 단백질 발현 배수 변화를 보여준다. 그래프는 평균 ± SD로 표시된다. 통계적 유의미(P < 0.05).
도 4A-4C는 핵 HNF4α의 아세틸화가 NASH 및 알코올 매개 Laennec's 간경변 외식 간(explanted liver)의 인간 비대상 간세포에서 변화됨을 나타낸다. 도 4A 및 4B는 비대상 NASH(n=4) 및 알코올 매개 Laennec's 간경변(n=4) 외식간(P=0.024)에서 인간 간세포의 핵 분획에서 HNF4α(Lys106)의 아세틸화된 형태의 웨스턴 블롯 및 정량화를 보여준다. 도 4C의 선형 회귀 분석은 감소된 아세틸화 형태의 HNF4α(Lys106)와 간 기능 장애(R2=0.71, P=0.004)의 유의한 상관 관계를 보여준다. 막대 그래프는 평균 ± SD로 표시된다. 통계적 유의미(P < 0.05).
도 5는 HNF4α 번역 후 변형(PTM)의 인 실리코 분석을 보여준다. 도 5는 HNF4α-PTM의 목록을 제공한다.
도 6A-6B는 활성화된 AKT 경로와 HNF4α 번역 후 변형자와 NASH 및 알코올 매개 Laennec's 간경변 외식간에서 인간 비대상 간세포의 p-EGFR 발현과의 관계를 보여준다. 도 6A는 포스포-AKT(Thr308)/AKT에 대한 스피어만 상관관계를 보여준다. 도 6B는 포스포-AKT(Ser473)/AKT에 대한 스피어만 상관관계를 보여준다.
도 7A-7C는 갓 분리된 정상 인간 간세포와 비교하여 mRNA 수준(도 7A)에서, 및 알코올 간염 간세포의 약 40%만이 약한 강도로 핵에서 HNF4α를 발현하고 세포의 약 10%가 HNF4α 세포질 발현을 갖는다는 것을 면역조직화학에 의해 입증하여 단백질 수준(도 7B)에서 알코올성 간염 환자의 외식된 간에서 분리한 인간 간세포에서 간-강화 전사 인자 HNF4α의 발현 수준을 보여준다. 도 7C의 경우, 갓 분리된 인간 알코올 간염 간세포를 HNF4α를 암호화하는 렌티바이러스(Systems Bioscience, Cat#CS970S-1; CD511B-1의 HNF4α)로 처리했다. 이 도면은 72시간 후에, HNF4α 발현이 핵에서 HNF4α를 발현하는 간세포의 백분율을 변경하지 않았음을 보여준다. 그러나 HNF4α 발현 강도는 기존 세포에서 급격히 증가하였다. 전체적으로 이 데이터는 핵으로의 HNF4α 수송이 알코올성 간염에 걸린 인간에서 간세포가 기능을 회복하는 데 중요한 역할을 할 수 있음을 보여준다.
도 8A-8F는 1차 인간 간세포에서 MTF1 발현을 보여준다. 도 8A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 MTF1(MA5-26738 1:1000) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여준다. 도 8B 및 8C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 HNF4α(도 8B 및 8C) 및 MTF1(도 8D 및 8E)의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. HNF4α 및 MTF1의 발현은 차일드 B 간세포에 비해 차일드 C 간세포에서 더 낮았다. 도 8B 및 8D, *p<0.003, **p<0.01, ***p<0.0001, n=25. 도 8C R2=0.019, p=0.06, n=19. 도 8E R2=0.015, p=0.1, n=19. 도 8F는 차일드-퍼 점수, HNF4α의 단백질 발현 및 MTF1과의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 어두운 회색 원은 차일드 C를 나타낸다. HNF4α의 단백질 발현은 MTF1의 단백질 발현과 상관관계가 있다(R2=0.28, p=0.007, n=25).
도 9A-9D는 1차 인간 간세포에서 NR0B2 발현을 보여준다. 도 9A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 NR0B2(Abclonal A1836 1:500) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여준다. 도 9B 및 9C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 NR0B2의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. 도 9B *p<0.05, **p<0.01, ***p<0.001, n=25. 도 9C R2=0.19, p=0.06, n=19. NR0B2의 발현은 차일드 C, 차일드 B 및 대조군 간세포에서 다르다. 도 9D 차일드-퍼 점수, HNF4α의 단백질 발현 및 NR0B2와의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 짙은 회색 원은 차일드 C를 나타낸다(R2=0.12, p=0.1, n=25).
도 10A-10D는 1차 인간 간세포에서 NR5A2 발현을 보여준다. 도 10A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 NR5A2(Novus NBP2-27196 1:500) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여준다. 도 10B 및 10C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 NR5A2의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. 도 10B *p<0.05, n=25. 도 10C R2=0.17, p=0.07, n=19. NR5A2의 발현은 차일드 B, 차일드 C 및 대조군 간세포에서 다르다. 도 10B는 차일드-퍼 점수, HNF4α의 단백질 발현 및 NR0B2와의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. NR5A2의 단백질 발현은 HNF4α의 발현과 상관관계가 있다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 짙은 회색 원은 차일드 C를 나타낸다(R2=0.17, p<0.05, n=25).
도 11A-11D는 1차 인간 간세포에서 Prox1 발현을 보여준다. 도 11A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 PROX1(R&D AF2727 1:500) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여준다. 도 11B 및 11C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 PROX1의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. 도 11B *p<0.02, n=25. 도 11C R2=0.02, p=0.6, n=19. PROX1의 발현은 차일드 C 및 대조군 간세포에서 다르다. 도 11D는 차일드-퍼 점수, HNF4α의 단백질 발현 및 PROX1과의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 짙은 회색 원은 차일드 C를 나타낸다(R2=0.02, p=0.46, n=25).
도 12A-12D는 1차 인간 간세포에서 POM121C 발현을 보여준다. 도 12A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 POM121C(PA5-85161 1:500) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여준다. 도 12B 및 12C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 POM121C의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. 도 12B n=25. 도 12C R2=0.08, p=0.24, n=25. 도 12D는 차일드-퍼 점수, HNF4α의 단백질 발현 및 POM121C와의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 짙은 회색 원은 차일드 C를 나타낸다(R2=0.06, p=0.23, n=25).
도 13A-13D는 1차 인간 간세포에서 SREBP1 발현을 보여준다. 도 13A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 SREBP1(Abcam ab28481 1:500) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여준다. 도 13B 및 13C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 SREBP1의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. 도 13B n=25. 도 13C R2=0.02, p=0.54, n=19. 도 13D는 차일드-퍼 점수, HNF4α의 단백질 발현 및 SREBP1과의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 짙은 회색 원은 차일드 C를 나타낸다(R2=0.01, p=0.86, n=25).
도 14A-14D는 1차 인간 간세포에서 EP300 발현을 보여준다. 도 14A는 NASH 또는 알코올 유발 간경변증으로 간 이식을 받은 환자의 간에서 분리된 1차 인간 간세포가 웨스턴 블롯에 의해 EP300(Novus NB100-616 1:500) 및 HNF4α(ab41898 1:1000)의 발현에 대해 분석되었음을 보여줍니다. 도 14B 및 14C는 대조군 간세포, 차일드 B 간세포 및 차일드 C 간세포 중 EP300의 상대 강도가 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)에 의해 비교되었음을 보여준다. 도 14B n=25. 도 14C R2=0.32, p=0.01, n=19. 도 14D는 차일드-퍼 점수, HNF4α의 단백질 발현 및 EP300과의 상관 관계 연구가 단순 선형 회귀를 사용하여 수행되었음을 보여준다. 검은색 원은 대조군, 밝은 회색 원은 차일드 B, 짙은 회색 원은 차일드 C를 나타낸다(R2=0.01, p=0.69, n=25).
도 15A 및 B는 HepG2 세포에서 EP300, MTF1, NR0B2, NR5A2, POM121C, PROX1 또는 SREBP1의 CRISPR/Cas9 녹아웃이 수행되었고 세포 HNF4α 위치가 면역형광에서 분석되었음을 보여준다(ab41898 1:500). DAPI 및 HNF4α에서 양성인 핵의 총 수(도 15A) 및 세포질에서 HNF4α에 대해 양성인 세포(도 15B)를 카운팅하였다. 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)을 사용하여 통계 분석을 수행했다. EP300, MTF1, NR0B2, NR5A2, POM121C, PROX1 및 SREBP1의 녹아웃은 HNF4α의 핵 위치 감소와 HNF4α의 세포질 위치 증가를 보여주었다. *p<0.05.
도 16은 간 이식을 겪은 NASH 환자로부터 분리된 1차 인간 간세포가 105의 MOI를 갖는 AAV-MTF1, NR0B2, NR5A2, POM121C, PROX1, SREBP1 또는 GFP 및 AAV-HNF4α로 형질도입되었음을 나타낸다. HNF4α에 대해 양성인 핵의 백분율을 계산했다. 다중 비교를 위해 Brown-Forsythe 및 Welch ANOVA 테스트와 함께 일원 분산 분석(One-Way ANOVA)을 사용하여 통계 분석을 수행했다. HNF4α, MTF1, NR0B2, POM121C, PROX1 및 SREBP1과의 동시 형질도입은 GFPHNF4α 동시 형질도입 그룹에 비해 증가된 양성 핵의 수를 갖는다 (****p<0.0001, ***p<0.0005, **p<0.001, *p<0.05).
본원은 대상체에서 간세포의 핵으로 전사 인자인 HNF4α의 발현 및/또는 수송 또는 보유를 증가시켜 대상체에서 간 질환을 치료하기 위한 조성물 및 방법을 개시한다. 일부 구현예에서, 상기 방법은 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자 및 그의 기능적 단편의 발현 또는 기능을 상향 조절하고/하거나 하나 이상의 전사 인자 DNAJB1/HSP40, ATF6, ATF4, 및 PERK 및 그의 기능적 단편의 발현 또는 기능을 하향 조절하는 것을 포함한다. 이러한 전사 인자가 HNF4α의 발현 및/또는 국소화를 조절하여 간 질환 치료에 사용될 수 있다는 것은 놀라운 발견이다.
일부 구현예에서, 상기 방법은 벡터를 투여하는 단계를 포함하며, 여기서 상기 벡터는 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택된 하나 이상의 전사 인자, 및 그의 기능적 단편을 암호화하는 핵산 (예를 들어, DNA, ceDNA, 또는 mRNA)을 포함한다. 일부 측면에서, 상기 방법은 HNF4α(예를 들어, HNF4α 이소형 2)를 암호화하는 핵산(예를 들어, DNA, ceDNA 또는 mRNA)을 포함하는 벡터를 투여하는 단계를 포함한다. 다른 또는 추가 구현예에서, 상기 방법은 조성물을 투여하는 단계를 포함하며, 여기서 상기 조성물은 DNAJB1/HSP40, ATF6, ATF4, 및 PERK로 이루어진 군으로부터 선택된 하나 이상의 전사 인자, 및 그의 기능적 단편의 양을 감소시키거나 기능을 억제한다. 다른 구현예에서, 상기 방법은 Lys106에서 HNF4α의 아세틸화를 증가시키는 단계, cMET의 발현을 증가시키는 단계, 및/또는 Thr308에서 인산화를 통해 AKT의 활성화를 증가시키는 단계를 포함한다. 본원에 개시된 방법은 간세포의 핵에서 HNF4α의 양을 놀랍게도 증가시키는 것으로 나타났다. HNF4α의 이러한 조작은 간 질환 환자의 간세포 기능을 향상시킨다.
본 출원 전반에 걸쳐 사용된 용어는 당업자에게 통상적이고 일반적인 의미로 해석되어야 한다. 그러나 출원인은 다음과 같은 용어에 아래 제공된 특정 정의가 부여되기를 바란다.
용어
명세서 및 청구범위에서 사용된 단수 형태 "a", "an" 및 "the"는 문맥상 다르게 지시하지 않는 한 복수의 인용을 포함한다. 예를 들어, 용어 "a cell"은 이의 혼합물을 포함하는 복수의 cells을 포함한다.
양, 백분율 등과 같은 측정 가능한 값을 언급할 때, 본원에서 사용된 용어 "약"은 측정 가능한 값으로부터 ±20%, ±10%, ±5%, 또는 ±1%의 변동을 포함하는 것을 의미한다.
대상체에 대한 "투여" 또는 "투여하는"은 대상체에게 제제를 도입하거나 전달하는 모든 경로를 포함한다. 투여는 임의의 적합한 경로에 의해 수행될 수 있으며, 정맥내, 복강내 등을 포함한다. 투여는 자가-투여 및 타인에 의한 투여를 포함한다.
본원에서 사용된 용어 "포함하는(comprising)" 및 그의 변형은 용어 "포함하는(including)" 및 그의 변형과 동의어로 사용되며 개방적, 비제한적인 용어이다. 용어 "포함하는(comprising)" 및 "포함하는(including)"이 다양한 구현예를 설명하기 위해 본원에서 사용되었지만, 용어 "~로 필수적으로 구성되는(consisting essentially of)" 및 "~로 구성되는(consisting of)"는 "포함하는(comprising)" 및 "포함하는(including)" 대신에 보다 구체적인 구현예를 제공하기 위해 사용될 수 있고 또한 개시되어 있다.
"조성물"은 유익한 생물학적 효과가 있는 임의의 제제를 의미한다. 유익한 생물학적 효과는 치료적 효과 (예: 장애 또는 기타 바람직하지 않은 생리학적 상태의 치료)와 예방 효과 (예: 장애 또는 기타 바람직하지 않은 생리학적 상태 (예: 간 질환)의 예방)를 모두 포함한다. 상기 용어는 또한 본원에 구체적으로 언급된 유익한 제제의 약학적으로 허용가능한, 약리학적 활성 유도체를 포함하며, 벡터, 폴리뉴클레오타이드, 세포, 염, 에스테르, 아마이드, 촉진제(proagent), 활성 대사물, 이성질체, 단편, 유사체 등을 포함하나 이에 제한되는 것은 아니다. "조성물"이라는 용어가 사용되는 경우, 또는 특정 조성물이 구체적으로 확인되는 경우, 그 용어는 조성물 그 자체뿐만 아니라 약학적으로 허용가능한 약리학적 활성 벡터, 폴리뉴클레오타이드, 염, 에스테르, 아마이드, 촉진제, 접합체, 활성 대사물, 이성질체, 단편, 유사체 등을 포함하는 것으로 이해되어야 한다. 일부 측면에서, 본원에 개시된 조성물은 벡터를 포함하며, 여기서 상기 벡터는 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자, 및 이의 기능적 단편을 암호화하는 핵산을 포함한다. 일부 측면에서, 본원에 개시된 조성물은 DNAJB1/HSP40, ATF6, ATF4, 및 PERK로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자, 및 이의 기능적 단편의 양을 감소시키거나 기능을 억제하는 핵산을 포함한다. 일부 측면에서, 본원에 개시된 조성물은 벡터를 포함하며, 여기서 상기 벡터는 HNFα를 암호화하는 핵산을 포함한다.
"유효량"은 의학적 상태 EH는 장애 (예: 간 질환)의 증상 또는 징후를 개선, 전환, 완화, 예방 또는 진단할 수 있는 양을 제한 없이 포함한다. 달리 명시되지 않는 한, 명시적으로 또는 문맥에 따라 "유효량"은 상태를 개선하기에 충분한 최소량으로 제한되지 않는다. 질병 또는 장애의 중증도, 및 질병 또는 장애를 예방, 치료 또는 완화하는 치료 능력은 제한 없이 바이오마커 또는 임상 파라미터에 의해 측정될 수 있다. 용어 "벡터의 유효량" 또는 "조성물의 유효량"은 간 질환의 일부 완화 또는 간 기능의 회복을 야기하기에 충분한 벡터 또는 조성물의 양을 지칭한다.
"단편"은 다른 서열에 부착되었는지 여부에 관계없이, 특정 영역 또는 특정 아미노산 잔기의 삽입, 결실, 치환 또는 기타 선택된 변형을 포함할 수 있다 (단, 단편의 활성이 비변형된 펩타이드 또는 단백질과 비교하여 크게 변경되거나 손상되지 않는다). 이러한 변형은 이황화 결합이 가능한 아미노산의 제거 또는 추가, 생체 수명(bio-longevity) 증가, 분비 특성 변경 등과 같은 일부 추가 속성을 제공할 수 있다. 어떠한 경우든 단편은 표적 유전자의 전사를 조절하는 것과 같은 생리활성 특성을 가져야 한다.
용어 "유전자" 또는 "유전자 서열"은 암호화 서열 또는 제어 서열, 또는 이의 단편을 지칭한다. 유전자는 암호화 서열과 조절 서열, 또는 이의 단편의 임의의 조합을 포함할 수 있다. 따라서, 본원에서 언급되는 "유전자"는 천연 유전자의 전부 또는 일부일 수 있다. 본원에서 언급된 폴리뉴클레오타이드 서열은 용어 "유전자"와 상호교환적으로 사용될 수 있거나, 임의의 암호화 서열, 비-암호화 서열 또는 조절 서열, 이의 단편, 및 이의 조합을 포함할 수 있다. 용어 "유전자" 또는 "유전자 서열"은, 예를 들어 암호화 서열의 상류에 있는 제어 서열(예를 들어, 리보솜 결합 부위)을 포함한다.
본원에 사용된 "간 질환"은 일반적으로 간에 영향을 미치는 질환, 장애 및 상태를 나타내며, 예를 들어 간세포에 지방의 단순 축적(지방증), 비알코올성 지방간염(NASH), 비알코올성 지방간 질환(NAFLD), 알코올 간 질환(ALD), 알코올-관련 간 질환(지방간, 알코올성 간염, 알코올-관련 간경변을 포함하나 이에 제한되지 않음), 거대수포성 지방증, 문맥주위 및 소엽 염증(지방간염), 간경변, 섬유증, 간 허혈, 간세포 암종을 포함한 간암, A형 간염, B형 간염, C형 간염, 특발성 간 질환, 말기 간 질환 및 간부전을 포함하는 광범위한 중증도를 가질 수 있다. "간경변"은 간 조직 및/또는 재생 결절의 섬유성 비후를 특징으로 하는 간의 만성 질환으로 본원에서 정의된다. "간경변"의 정도 또는 중증도는 차일드-퍼 점수(Child-Pugh score)에 의해 지정될 수 있으며, 여기서 5가지 임상 측정값인 총 빌리루빈(bilirubin) 수준, 혈청 알부민, 프로트롬빈 시간 연장, 복수(ascite) 및 간성 뇌병증이 1점, 2점, 및 3점 값의 점수 시스템을 사용하여 각 임상 측정값의 다양한 수준에 대해 채점되며 3점 값은 각 측정의 가장 심각한 수준에 할당된다. 차일드-퍼 점수 및 분류에 도달하기 위해 5개 측정값 모두에 대한 총점이 추가된다. 5-6점은 차일드-퍼 분류 A, 7-9점은 차일드-퍼 분류 B, 10-15점은 차일드-퍼 분류 C이다. 일반적으로 차일드-퍼 분류 A는 가장 덜 심각한 간 질환을 나타내며, 차일드-퍼 분류 C는 가장 심각한 간 질환을 나타낸다. 따라서, 일부 구현예에서, 본원에 개시된 방법은 차일드-퍼 분류 B 또는 차일드-퍼 분류 C 간 질환을 갖는 대상체를 치료하는 데 사용될 수 있다. 일부 구현예에서, 본원에 개시된 방법은 차일드-퍼 분류 A 간 질환을 갖는 대상체를 치료하는 데 사용될 수 있다. 다양한 측면에서, 상기 방법은 대상체의 차일드-퍼 점수를 개선한다. 일부 구현예에서, 상기 간 질환은 알코올성 간염이다. 일부 구현예에서, 본원에 개시된 방법은 생체외 관류를 위해 허혈성 공여자 간을 치료하는 데 사용될 수 있다. 본 발명은 간 절제 전 또는 후를 포함하는 암 치료 전 또는 후에 간암을 치료하는데 사용될 수 있다.
본원에 사용된 용어 "핵산"은 뉴클레오타이드로 구성된 중합체 (예: 데옥시리보뉴클레오타이드(DNA) 또는 리보뉴클레오타이드(RNA))를 의미한다. 본원에서 사용된 용어 "리보핵산" 및 "RNA"는 리보뉴클레오타이드로 구성된 중합체를 의미한다. 본원에서 사용된 용어 "데옥시리보핵산" 및 "DNA"는 데옥시리보뉴클레오타이드로 구성된 중합체를 의미한다. 일부 구현예에서, 상기 핵산은 DNA(예: ceDNA 또는 cDNA)이다. 일부 구현예에서, 상기 핵산은 mRNA이다.
용어 "폴리뉴클레오타이드"는 뉴클레오타이드 단량체로 구성된 단일 또는 이중 가닥 중합체를 지칭한다.
용어 "폴리펩타이드"는 D- 또는 L-아미노산의 단일 사슬 또는 펩타이드 결합으로 연결된 D- 및 L-아미노산의 혼합물로 구성된 화합물을 지칭한다.
용어 "프로모터" 또는 "조절 요소"는 전사의 시작으로부터 상류 또는 하류에 위치하고 전사를 개시하기 위한 RNA 폴리머레이스 및 기타 단백질의 인식 및 결합에 관여하는 영역 또는 서열 결정자를 지칭한다. 프로모터는 박테리아 기원일 필요는 없으며, 예를 들어 바이러스 또는 다른 유기체로부터 유래된 프로모터는 본원에 기재된 조성물, 시스템 또는 방법에서 사용될 수 있다.
"약학적으로 허용가능한 담체"(때때로 "담체"라고도 함)는 일반적으로 안전하고 무독성인 약학적 또는 치료적 조성물을 제조하는 데 유용한 담체 또는 부형제를 의미하며, 수의학적 및/또는 또는 인간의 약학적 또는 치료적 용도에 허용되는 담체를 포함한다. 용어 "담체" 또는 "약학적으로 허용가능한 담체"는 인산염 완충 식염수 용액, 물, 에멀젼(예: 오일/물 또는 물/오일 에멀젼) 및/또는 다양한 유형의 습윤제를 포함할 수 있으나 이에 제한되는 것은 아니다.
본원에 사용된 용어 "담체"는 임의의 부형제, 희석제, 충전제, 염, 완충제, 안정화제, 가용화제, 지질, 안정화제, 또는 약학적 제형에 사용하기 위해 당업계에 널리 공지된 기타 물질을 포함한다. 조성물에 사용하기 위한 담체의 선택은 조성물의 의도된 투여 경로에 따라 달라질 것이다. 이러한 물질을 함유하는 약학적으로 허용가능한 담체 및 제형의 제조는 예를 들어 Remington's Pharmaceutical Sciences, 21st Edition, ed. University of the Sciences in Philadelphia, Lippincott, Williams & Wilkins, Philadelphia, PA, 2005에 기재되어 있다. 생리학적으로 허용가능한 담체의 예로는 식염수, 글리세롤, DMSO, 완충액 (예: 인산염 완충액, 시트르산염 완충액, 및 기타 유기산을 포함하는 완충액); 아스코르브산을 포함하는 항산화제; 저분자량(약 10개 미만의 잔기) 폴리펩타이드; 혈청 알부민, 젤라틴 또는 면역글로불린과 같은 단백질; 폴리비닐피롤리돈과 같은 친수성 고분자; 글리신, 글루타민, 아스파라긴, 아르기닌 또는 리신과 같은 아미노산; 단당류, 이당류, 및 포도당, 만노오스 또는 덱스트린을 포함하는 기타 탄수화물; EDTA와 같은 킬레이트제; 만니톨 또는 소르비톨과 같은 당 알코올; 나트륨과 같은 염-형성 반대이온; 및/또는 TWEENTM(ICI, Inc.; Bridgewater, New Jersey), 폴리에틸렌 글리콜(PEG) 및 PLURONICSTM(BASF; Florham Park, NJ)와 같은 비이온성 계면활성제를 포함한다. 원하는 치료적 치료를 위한 이러한 투여량의 투여를 제공하기 위해, 본원에 개시된 조성물은 유리하게는 담체 또는 희석제를 포함하는 총 조성물의 중량을 기준으로 하나 이상의 대상 화합물의 총 중량의 약 0.1% 내지 99%를 포함할 수 있다.
용어 "대상체"는 영장류(예를 들어, 인간), 소, 양, 염소, 말, 개, 고양이, 토끼, 쥐, 마우스 등을 포함하나 이에 제한되지 않는 포유동물과 같은 동물을 포함하는 것으로 본원에서 정의된다. 일부 구현예에서, 상기 대상체는 인간이다.
본 명세서에서 용어 "전사 인자"는 DNA를 RNA로 전사하는 과정에 관여하는 단백질을 지칭한다. 일반적으로, 전사 인자는 특정 유전자의 프로모터 또는 인핸서 영역에 결합하는 영역(domain)을 보유한다. 전사 인자는 또한 RNA 중합효소 및/또는 일부 다른 전사 인자와 상호작용하는 영역을 가질 수 있으며, 이러한 상호작용은 결과적으로 DNA에서 전사된 RNA의 양을 조절한다. 전사 인자는 세포질에 존재하고 활성화 시 핵으로 이동할 수 있다.
본원에서 사용된 용어 "치료하다", "치료하는", "치료" 및 이들의 문법적 변형은 장애 또는 상태의 하나 이상의 수반되는 증상의 강도를 부분적으로 또는 완전히 지연, 경감, 완화 또는 감소시키는 것 및/또는 장애 또는 상태의 하나 이상의 원인을 경감, 완화 또는 방해하는 것을 포함한다. 본 발명에 따른 치료는 예방적으로, 완화적으로 또는 치료적으로 적용될 수 있다. 치료는 발병 전(예: 간 질환의 명백한 징후 전), 조기 발병 동안(예: 간 질환의 초기 징후 및 증상 시), 간 질환의 확립 후, 또는 말기 간부전의 단계에 대상체에게 투여될 수 있다. 예방적 투여는 간 질환의 증상이 나타나기 이전 몇 일에서 몇 년 동안 발생할 수 있다.
일부 예에서, 용어 "치료하다", "치료하는", "치료" 및 이들의 문법적 변형은 대상체의 치료 전과 비교하거나 또는 일반 또는 연구 집단에서 이러한 증상의 발생률과 비교하여 간 질환 완화, 간 기능 회복 및/또는 대상체의 간세포 핵에서 HNFα 양의 증가를 포함한다.
본원에 사용된 "벡터"는 분리된 핵산을 포함하고 분리된 핵산을 세포 내부로 전달하는 데 사용될 수 있는 물질의 조성물이다. 벡터는 자가-복제, 염색체외 벡터 또는 숙주 게놈에 통합되는 벡터일 수 있다. 또는, 벡터는 또한 전술한 핵산 서열을 포함하는 비히클일 수 있다. 벡터는 플라스미드, 박테리오파지, 바이러스 벡터(분리, 약독화, 재조합, 바이러스 입자로 캡슐화 등), 리포솜, 엑소좀, 세포외 소포, 마이크로입자 및/또는 나노입자일 수 있다. 벡터는 이중-가닥 또는 단일-가닥 DNA, RNA, 또는 이중-가닥 및/또는 단일-가닥 뉴클레오타이드를 포함하는 하이브리드 DNA/RNA 서열을 포함할 수 있다. 일부 구현예에서, 상기 벡터는 하나 또는 복수의 폴리펩타이드를 암호화하는 하나 또는 복수의 핵산 서열을 패키징하는 역할을 하는 바이러스 패키징 서열인 핵산 서열을 포함하는 바이러스 벡터이다. 일부 구현예에서, 벡터는 상기 플라스미드이다. 일부 구현예에서 상기 벡터는 엑소좀이다. 일부 구현예에서, 상기 벡터는 바이러스 입자이다. 일부 구현예에서, 상기 바이러스 입자는 렌티바이러스 입자이다. 일부 구현예에서, 상기 벡터는 천연 및/또는 조작된 캡시드를 갖는 바이러스 벡터이다. 일부 구현예에서, 상기 벡터는 조절 서열에 작동 가능하게 연결된 핵산 서열을 포함하는 바이러스 입자를 포함하고, 여기서 상기 핵산 서열은 하나 또는 복수의 AAV 바이러스 입자 폴리펩타이드 또는 그의 단편을 포함하는 융합 단백질을 암호화한다. 일부 구현예에서, 상기 벡터는 핵산 또는 폴리펩타이드를 포함하는 나노입자이다. 다양한 구현예에서, 상기 벡터는 지질계 나노입자이다.
조성물
상기 언급된 바와 같이, 본원에서는 대상체에서 간세포의 핵으로 전사 인자인 HNF4α의 발현 및/또는 수송 및/또는 보유를 증가시켜 간 질환을 치료하는 방법을 개시한다. 일부 구현예에서, 상기 방법은 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자의 발현 또는 기능을 상향 조절하고/하거나 DNAJB1/HSP40, ATF6, ATF4 및 PERK로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자의 발현 또는 기능을 하향 조절하는 단계를 포함한다. 일부 구현예에서, 상기 방법은 선택적으로 내인성 HNFα의 발현을 증가시키거나 외인성 HNFα를 도입하여 세포 (예를 들어, 간 세포) 내부, 바람직하게는 세포의 핵 내부에 HNF4α의 발현 또는 기능을 상향 조절하는 단계를 더 포함한다. PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300 및 POM121C의 상향 조절 및/또는 DNAJB1/HSP40, ATF6, ATF4 및 PERK의 하향 조절이 간세포의 핵에서 HNF4α의 수준을 증가시켜 간 기능의 회복 및 간 질환 완화를 유도한다는 것이 본원에 설명되어 있다. 다른 구현예에서, 상기 방법은 Lys106에서 HNF4α의 아세틸화를 증가시키는 단계, cMET의 발현을 증가시키는 단계, 및/또는 Thr308에서 인산화를 통해 AKT의 활성화를 증가시키는 단계를 포함한다. 이들 방법은 전체로서 참조로 도입되는 미국 특허 출원 공개 2014/0249209에 기재된 방법과 함께 사용될 수 있다.
일부 구현예에서, 상기 방법은 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택된 하나 이상의 전사 인자와 함께 HNF4α의 발현 또는 기능을 상향 조절하는 단계를 추가로 포함한다. 일부 구현예에서, 상기 조성물은 HNF4α 및 PROX1의 발현 또는 기능을 상향 조절하는 것을 추가로 포함한다. 일부 구현예에서, 상기 방법은 HNF4α 및 SREBP1의 발현 또는 기능을 상향 조절하는 단계를 추가로 포함한다. 일부 구현예에서, 상기 방법은 HNF4α, PROX1 및 SREBP1의 발현 또는 기능을 상향 조절하는 단계를 추가로 포함한다.
따라서, PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300 및 POM121C로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자의 발현 또는 기능을 증가시키고/시키거나 DNAJB1/HSP40, ATF6, ATF4 및 PERK로 이루어진 군에서 선택되는 하나 이상의 전사 인자의 발현 또는 기능을 감소시키는 조성물이 본원에 포함된다. 일부 구현예에서, 상기 조성물은 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택된 하나 이상의 전사 인자와 함께 HNF4α의 발현 또는 기능을 상향 조절한다. 일부 구현예에서, 상기 조성물은 HNF4α 및 PROX1의 발현 또는 기능을 상향 조절한다. 일부 구현예에서, 상기 조성물은 HNF4α 및 SREBP1의 발현 또는 기능을 상향조절한다. 일부 구현예에서, 상기 조성물은 HNF4α, PROX1 및 SREBP1의 발현 또는 기능을 상향조절한다.
벡터를 포함하는 조성물이 본원에 개시되며, 여기서 상기 벡터는 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및/또는 POM121C로 이루어진 군으로부터 선택된 하나 이상의 전사 인자, 및 그의 기능적 단편을 암호화하는 핵산을 포함한다. 일부 구현예에서, 상기 벡터는 PROX1 또는 그의 기능적 단편을 암호화하는 핵산을 포함한다. 다른 구현예에서, 상기 벡터는 NR5A2 또는 그의 기능적 단편을 암호화하는 핵산을 포함한다. 다른 구현예에서, 상기 벡터는 NR0B2 또는 그의 기능적 단편을 암호화하는 핵산을 포함한다. 다른 구현예에서, 상기 벡터는 MTF1 또는 그의 기능적 단편을 암호화하는 핵산을 포함한다. 다른 구현예에서, 상기 벡터는 SREBP1 또는 그의 기능적 단편을 암호화하는 핵산을 포함한다. 다른 구현예에서, 상기 벡터는 EP300 또는 그의 기능적 단편을 암호화하는 핵산을 포함한다. 다른 구현예에서, 상기 벡터는 POM121C 또는 그의 기능적 단편을 암호화하는 핵산을 포함한다. 일부 구현예에서, 상기 벡터는 HNF4α를 암호화하는 핵산을 추가로 포함한다. 일부 구현예에서, 상기 벡터는 PROX1 및 SREBP1을 암호화하는 핵산을 포함한다. 일부 구현예에서, 상기 벡터는 HNF4α, PROX1, 및 SREBP1을 암호화하는 핵산을 포함한다. 일부 구현예에서, 상기 벡터는 HNF4α 및 PROX1을 암호화하는 핵산을 포함한다. 일부 구현예에서, 상기 벡터는 HNF4α 및 SREBP1을 암호화하는 핵산을 포함한다.
HNF4α는 간 외에도 신장, 소장, 결장 및 췌장에서도 많이 발현되며, 중요한 역할을 한다. HNF4α 유전자의 다형성 돌연변이는 성숙기발병당뇨병 (MODY), 크론병 및 염증성 장 증후군을 포함하는 광범위한 질병과 관련이 있다. 대체 스플라이싱과 결합된 P1 또는 P2 프로모터의 전사는 12개의 다른 전사체를 생성할 수 있다. 상대적인 이소형 발현은 조직에 따라 다르다. 12개의 이소형은 각각 전사 활성화 및 억제를 담당하는 N 및 C 말단에서만 상이하다 (Ko et al., Cell Rep. 2019 Mar 5;26(10):2549-2557.e3 참조, 전체로서 본원에 참조로 도입됨). 각 이소형이 조직- 의존적 방식으로 유전자의 특정 하위 집합을 조절하는 별개의 기능을 수행한다는 것이 점점 인식되고 있다. 예를 들어, HNF4α 이소형 2는 보고된 바에 따르면 간에서 풍부하고 본 출원에 기재된 바와 같이 손실이 간암(hepatocarcinoma) 또는 간부전과 관련된 종양 억제인자로 작용하는 반면, HNF4α 이소형 8은 결장에서 고도로 발현되고 성장-촉진 유전자의 발현을 조절한다.
따라서, 일부 구현예에서, 본원에 개시된 벡터는 HNF4α 이소형 2 폴리펩타이드를 암호화하는 핵산을 추가로 포함한다. 일부 구현예에서, HNF4α 이소형 2 폴리펩타이드는 서열번호 1 또는 그의 단편과 적어도 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 상동성인 서열을 포함한다. 일부 구현예에서, 상기 핵산은 서열번호 31 또는 그의 단편과 적어도 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 상동성이 있다. 일부 측면에서, HNF4α 이소형 2 폴리펩타이드는 프로모터 1(P1)에 의해 구동되거나, 다시 말해서 이의 발현은 HNF4α의 P1 프로모터에 의해 구동된다. 이는 본원에서 HNF4α 이소형 2(P1)로 지정된다. 따라서, 일부 구현예에서, HNF4α 이소형 2 폴리뉴클레오타이드 또는 핵산은 P1 프로모터에 작동 가능하게 연결된다.
벡터는 발현 가능한 유전자의 복제를 제어하는 조절 핵산 서열을 포함하는 핵산 서열일 수 있다. 일부 구현예에서, 제2 핵산에 작동 가능하게 연결된 프로모터(예를 들어, 전사 인자를 암호화하는 폴리뉴클레오타이드)를 포함하는 벡터는 인간 조작(예: Sambrook et al., Molecular Cloning―A Laboratory Manual, Cold Spring Harbor Laboratory, Cold Spring Harbor, N.Y., (1989) or Current Protocols in Molecular Biology Volumes 1-3, John Wiley & Sons, Inc. (1994-1998)에 기재된 방법에 의한) 의 결과로서 제2 핵산(예를 들어, 전사 인자를 암호화하는 폴리뉴클레오타이드)과 이종인 프로모터를 포함할 수 있다. 본원에 기재된 임의의 측면의 벡터는 프로모터, 인핸서, 항생제 내성 유전자 및/또는 원점을 추가로 포함할 수 있으며, 이는 상기 언급된 전사 인자 중 하나 이상에 작동 가능하게 연결될 수 있음을 이해해야 한다.
일부 구현예에서, 상기 벡터는 바이러스 벡터일 수 있다. 본원에 개시된 "바이러스 벡터"는 비히클과 관련하여, 바이러스, 바이러스-유사 입자, 비리온, 바이러스 입자. 또는 유사형 바이러스(pseudotyped virus) 내 핵산 서열의 패키징을 지시하는 핵산 서열을 포함하는 임의의 바이러스, 바이러스-유사 입자, 비리온, 바이러스 입자, 또는 유사형 바이러스를 의미한다. 일부 구현예에서, 상기 바이러스, 바이러스-유사 입자, 비리온, 바이러스 입자 또는 유사형 바이러스는 벡터(예: 핵산 벡터)를 숙주 세포 내로 및/또는 숙주 세포 간에 전달할 수 있다. 일부 구현예에서, 상기 바이러스, 바이러스-유사 입자, 비리온, 바이러스 입자, 또는 유사형 바이러스는 벡터(예: 핵산 벡터)를 대상체의 간 내 간세포와 같은 표적 세포 내로 및/또는 표적 세포 간에 전달할 수 있다. 중요하게는, 일부 구현예에서, 상기 바이러스, 바이러스-유사 입자, 비리온, 바이러스 입자 또는 유사형 바이러스는 표적 세포(예를 들어, 간세포)의 핵 내로 수송될 수 있다. 용어 "바이러스 벡터"는 또한 모든 목적을 위해 본원에 참조로 도입된 미국 특허 출원 공개 U.S. 2018/0057839에 보다 완전하게 기술된 형태를 지칭하는 것을 의미한다. 적합한 바이러스 벡터는 예를 들어, 아데노바이러스, 아데노연관바이러스(AAV), 백시니아 바이러스, 헤르페스바이러스, 배큘로바이러스 및 레트로바이러스, 파보바이러스, 및 렌티바이러스를 포함한다. 일부 구현예에서, 상기 바이러스 벡터는 렌티바이러스 벡터 또는 아데노연관바이러스 벡터이다.
복제-결함 아데노바이러스(replication-defective adenoviruse)의 구성이 (Berkner et al., J. Virology 61:1213-1220 (1987); Massie et al., Mol. Cell. Biol. 6:2872-2883 (1986); Haj-Ahmad et al., J. Virology 57:267-274 (1986); Davidson et al., J. Virology 61:1226-1239 (1987); Zhang "Generation and identification of recombinant adenovirus by liposome-mediated transfection and PCR analysis" BioTechniques 15:868-872 (1993))에 기재되어 있다. 이러한 바이러스를 벡터로 사용하는 이점은 초기 감염된 세포 내에서 복제할 수 있지만 새로운 감염성 바이러스 입자를 형성할 수 없기 때문에 다른 세포 유형으로 퍼질 수 있는 범위가 제한된다는 것이다. 재조합 아데노바이러스는 기도 상피, 간세포, 혈관 내피, CNS 실질(parenchyma) 및 다수의 기타 조직 부위로 직접 생체내 전달된 후 고효율 유전자 전달을 달성하는 것으로 나타났다 (Morsy, J. Clin. Invest. 92:1580-1586 (1993); Kirshenbaum, J. Clin. Invest. 92:381-387 (1993); Roessler, J. Clin. Invest. 92:1085-1092 (1993); Moullier, Nature Genetics 4:154-159 (1993); La Salle, Science 259:988-990 (1993); Gomez-Foix, J. Biol. Chem. 267:25129-25134 (1992); Rich, Human Gene Therapy 4:461-476 (1993); Zabner, Nature Genetics 6:75-83 (1994); Guzman, Circulation Research 73:1201-1207 (1993); Bout, Human Gene Therapy 5:3-10 (1994); Zabner, Cell 75:207-216 (1993); Caillaud, Eur. J. Neuroscience 5:1287-1291 (1993); and Ragot, J. Gen. Virology 74:501-507 (1993)). 재조합 아데노바이러스는 특정 세포 표면 수용체에 결합하여 유전자 도입(transduction)을 달성하고, 그 후 바이러스는 야생형 또는 복제-결함 아데노바이러스와 동일한 방식으로 수용체-매개 내포작용(endocytosis)에 의해 내재화된다 (Chardonnet and Dales, Virology 40:462-477 (1970); Brown and Burlingham, J. Virology 12:386-396 (1973); Svensson and Persson, J. Virology 55:442-449 (1985); Seth, et al., J. Virol. 51:650-655 (1984); Seth, et al., Mol. Cell. Biol. 4:1528-1533 (1984); Varga et al., J. Virology 65:6061-6070 (1991); Wickham et al., Cell 73:309-319 (1993)).
다른 유형의 바이러스 벡터는 아데노연관바이러스(AAV)를 기반으로 한다. 이 결손(defective) 파보바이러스는 많은 세포 유형을 감염시킬 수 있으며 인간에게는 비병원성이다. AAV 유형 벡터는 약 4 내지 5kb를 수송할 수 있고 야생형 AAV는 19번 염색체에 안정적으로 삽입되는 것으로 알려져 있다. AAV 역 말단 반복부(ITR) 또는 이의 변형은 감염성 및 부위 특이적 도입을 부여하지만, 세포 독성은 부여하지 않으며, 프로모터는 세포 특이적 발현을 지시한다. 미국 특허 번호 6,261,834는 AAV 벡터와 관련된 물질에 대해 참조로 본원에 도입된다. 생체내에서 간 세포를 형질도입하기 위해 AAV 벡터를 사용하는 방법은 당업계에 공지되어 있다. 전체로서 본원에 참조로 도입된 미국 특허 번호 9,981,048 참조.
바이러스 벡터, 특히 아데노바이러스 벡터는 양이온성 지질, 폴리L-리신(PLL) 및 디에틸아미노에틸덱스트란(DELAE-덱스트란)과 같은 양이온성 양친매성 물질과 복합될 수 있으며, 이는 표적 세포의 바이러스 감염 효율을 증가시킨다 (예: Nov. 20, 1997 출원된 PCT/US97/21496 참조, 본원에 참조로 도입됨). 예를 들어 본원에 도입된 Zhong et al., J. Genet Syndr Gene Therapy 2012 Jan. 10; S1. pii: 008, U.S. Pat. Nos. 5,139,941, 5,252,479 및 5,753,500 및 PCT 공보 WO 97/09441에 개시된 AAV 벡터는, 또한 이러한 벡터가 벡터의 반복 투여에 대한 최소한의 필요로 숙주 염색체에 도입되기 때문에 유용하다. 유전자 요법에서 바이러스 벡터에 대한 리뷰는 McConnell et al., 2004, Hum Gene Ther. 15(11):1022-33; Mccarty et al., 2004, Annu Rev Genet. 38:819-45; Mah et al., 2002, Clin. Pharmacokinet. 41(12):901-11; Scott et al., 2002, Neuromuscul. Disord. 12(Suppl 1):S23-9를 참고할 수 있다.
일부 구현예에서, 상기 벡터는 나노입자이다. 본원에서 사용되는 나노입자는 핵산의 전달에 유용한 임의의 나노입자일 수 있다. 본원에 사용된 용어 "나노입자"는 생체적합성이 있고 그러한 사용 환경에 의한 화학적 및/또는 물리적 파괴에 충분히 내성이 있어 충분한 수의 나노입자가 적용 또는 치료 부위에 전달된 후 실질적으로 손상되지 않은 상태로 유지되고, 크기가 나노미터 범위에 있는 입자 또는 구조를 지칭한다. 일부 구현예에서, 상기 나노입자는 지질-유사 나노입자를 포함한다. 예를 들어, 본원에 참조로 도입된 WO WO/2016/187531A1, WO/2017/176974, WO/2019/027999, 또는 Li, B et al., An Orthogonal array optimization of lipid-like nanoparticles for mRNA delivery in vivo. Nano Lett. 2015, 15, 8099-8107를 참조할 수 있다. 일부 구현예에서, 상기 나노입자는 지질 이중층 또는 리포솜을 포함할 수 있다. 일부 구현예에서, 상기 벡터는 mRNA 지질 나노입자이다.
일부 구현예에서, 개시된 나노입자는 생물학적 개체, 예를 들어 표적 세포 상의 특정 막 성분 또는 세포 표면 수용체(예: 간 세포로의 전달을 촉진하는 수용체 또는 간 세포 상의 수용체)에 효율적으로 결합하거나 회합될 수 있다. 예를 들어, 개시된 나노입자는 정상 또는 병든 간 세포 상에서 발현되는 수용체 (예: 간 아시알로당단백질 수용체(ASGPR) 또는 저밀도 지단백질(LDLR) 수용체) 에 결합하는 리간드를 포함하도록 조작될 수 있다.
일부 측면에서, 본원에 개시된 나노입자는 간 세포 내로 핵산의 전달을 촉진하는 보충 성분을 포함할 수 있다. 상기 나노입자는 양이온성 지질, 보조 지질, 콜레스테롤, 및 폴리에틸렌 글리콜 (PEG)을 포함할 수 있다. 일부 구현예에서, 상기 나노입자는 5A2-SC8, 1,2-디올레오일-sn-글리세로-3-포스포에탄올아민 (DOPE), 콜레스테롤, 및/또는 1,2-디미리스토일-rac-글리세롤-메톡시(폴리(에틸렌 글리콜)), 또는 이들의 임의의 조합을 포함한다. 일부 구현예에서, 상기 나노입자는 5A2-SC8, 1,2-디올레오일-sn-글리세로-3-포스포에탄올아민 (DOPE), 콜레스테롤, 및 1,2-디미리스토일-rac-글리세롤-메톡시(폴리(에틸렌 글리콜))을 더 포함한다. 일부 구현예에서, 상기 나노입자는 1,2-디올레오일-3-트리메틸암모늄-프로판 (DOTAP)을 더 포함한다. 일부 구현예에서, 상기 나노입자 5A2-SC8, 1,2-디올레오일-sn-글리세로-3-포스포에탄올아민 (DOPE), 콜레스테롤, 및 1,2-디미리스토일-rac-글리세롤-메톡시(폴리(에틸렌 글리콜))의 몰비(molar ratio)는 약 15/15/30/3이다.
일부 구현예에서, 상기 나노입자는 DLin-MC3-DMA, 1,2-디스테아로일-sn-글리세로-3-포스포콜린 (DSPC), 콜레스테롤, 및 1,2-디미리스토일-rac-글리세롤-메톡시(폴리(에틸렌 글리콜))을 포함한다. 일부 구현예에서, DLin-MC3-DMA, 1,2-디스테아로일-sn-글리세로-3-포스포콜린 (DSPC), 콜레스테롤, 및 1,2-디미리스토일-rac-글리세롤-메톡시(폴리(에틸렌 글리콜))의 몰비는 약 50/10/38.5/1.5이다.
일부 구현예에서, 상기 나노입자는 C12-200, 1,2-디올레오일-sn-글리세로-3-포스포에탄올아민 (DOPE), 콜레스테롤, 및 1,2-디미리스토일-rac-글리세롤-메톡시(폴리(에틸렌 글리콜))을 포함한다. 일부 구현예에서, C12-200, 1,2-디올레오일-sn-글리세로-3-포스포에탄올아민 (DOPE), 콜레스테롤, 및 1,2-디미리스토일-rac-글리세롤-메톡시(폴리(에틸렌 글리콜))의 몰비는 약 35/16/46.5/2.5이다.
일부 구현예에서, 본원에 개시된 상기 나노입자는 5A2-SC8, 1,2-디올레오일-sn-글리세로-3-포스포에탄올아민 (DOPE), 콜레스테롤, 1,2-디미리스토일-rac-글리세롤-메톡시(폴리(에틸렌 글리콜)), 및 1,2-디올레오일-3-트리메틸암모늄-프로판 (DOTAP)을 포함한다. 상기 나노입자는 DOTAP을 약 0.1% 내지 약 30% 몰/몰(mol/mol)을 포함할 수 있다. 예를 들어, 나노입자에 존재하는 DOTAP의 양은 나노입자의 약 0.1%, 약 0.2%, 약 0.3%, 약 0.4%, 약 0.5%, 약 0.6% 몰/몰, 약 0.7% 몰/몰, 약 0.8% 몰/몰, 약 0.9% 몰/몰, 약 1% 몰/몰, 약 2% 몰/몰, 약 2.5% 몰/몰, 약 3% 몰/몰, 약 3.5% 몰/몰, 약 4% 몰/몰, 약 4.5% 몰/몰, 약 5% 몰/몰, 약 5.5% 몰/몰, 약 6% 몰/몰, 약 6.5% 몰/몰, 약 7% 몰/몰, 약 7.5% 몰/몰, 약 8% 몰/몰, 약 8.5% 몰/몰, 약 9% 몰/몰, 약 9.5% 몰/몰, 약 10% 몰/몰, 약 10.5% 몰/몰, 약 11% 몰/몰, 약 11.5% 몰/몰, 약 12% 몰/몰, 약 12.5% 몰/몰, 약 13% 몰/몰, 약 13.5% 몰/몰, 약 14% 몰/몰, 약 15% 몰/몰, 약 16% 몰/몰, 약 17% 몰/몰, 약 18% 몰/몰, 약 19% 몰/몰, 약 20% 몰/몰, 약 22% 몰/몰, 약 24% 몰/몰, 약 26% 몰/몰, 약 28% 몰/몰, 약 30% 몰/몰 일 수 있다. 일부 구현예에서, 나노입자에 존재하는 DOTAP의 양은 나노입자의 약 20% 몰/몰 이다.
일부 구현예에서, 본원에 개시된 나노입자 및 간-특이적 전달 방법은 당업계, 예를 들어 Cheng et al., Nat Nanotechnol. 2020 Apr;15(4):313-320. Epub 2020 Apr 6; Trepotec et al., Mol Ther. 2019 Apr 10;27(4):794-802. Epub 2018 Dec 22; Truong, et al., Proc Natl Acad Sci USA. 2019 Oct 15;116(42):21150-21159. Epub 2019 Sep 9;에 기재되어 있으며, 전체로서 본원에 참조로 도입된다.
추가 구현예에서, 본원에 개시된 벡터는 폴리(아미도-아민), 폴리-베타 아미노-에스터 (PBAEs), 및/또는 폴리에틸렌이민 (PEI)을 포함한다. 일부 구현예에서, 상기 벡터는 폴리아크리딘 PEG를 포함한다. 일부 구현예에서, 본원에 개시된 벡터는 외부 PEG 쉘 및 나노입자-기반 코어를 포함한다.
지질-기반 나노 입자는 간으로 치료용 페이로드를 성공적으로 전달한다. 예를 들어, Witzigmann et al., Adv Drug Deliv Rev. 2020 Jul, doi: 10.1016/j.addr.2020.06.026 참고. 리포솜은 여러 유형의 지질로부터 만들어질 수 있지만, 인지질은 약물 운반체로 지질-기반 나노 입자를 생성하는 데 가장 일반적으로 사용된다. 본 발명에서 사용하기 위한 지질 입자는 리포솜-형성 지질 및 인지질, 및 막 활성 스테롤(예: 콜레스테롤)을 포함하도록 제조될 수 있다. 리포솜은 리포솜 형성 지질이 아닌 다른 지질 및 인지질을 포함할 수 있다.
인지질은 예를 들어 레시틴(예: 계란 또는 대두 레시틴); 포스파티딜콜린(예: 계란 포스파티딜콜린); 수소화된 포스포티딜콜린; 리소포스파티딜 콜린; 디팔미토일포스파티딜콜린; 디스테아로일 포스파티딜콜린; 디미리스토일 포스파티딜콜린; 디라우로일포스파티딜콜린; 글리세로인지질(예: 포스파티딜글리세롤, 포스파티딜세린, 포스파티딜에탄올아민, 리소포스파티딜에탄올아민, 포스파티딜이노시톨, 포스파티딜이노시톨 포스페이트, 포스파티딜이노시톨 비스포스페이트 및 포스파티딜이노시톨 트리포스페이트); 스핑고미엘린; 카디오리핀; 포스파티드산; 플라스마로겐; 또는 이들의 혼합물로부터 선택될 수 있다. 각 경우는 본 발명의 각각의 구현예를 나타낸다. 사용될 수 있는 다른 지질의 예는 당지질(예를 들어, 글리세로당지질(예: 갈락토리피드 및 설포리피드), 글리코스핑고리피드(예: 세레브로사이드, 글루코세레브로사이드 및 갈락토세레브로사이드), 및 글리코실포스파티딜이노시톨); 포스포스핑고리피드(예: 세라마이드 포스포릴콜린, 세라마이드 포스포릴에탄올아민, 및 세라마이드 포스포릴글리세롤 등); 또는 이들의 혼합물을 포함한다. 각 경우는 본 발명의 각각의 구현예를 나타낸다. 음전하 또는 양전하를 띤 지질 나노입자는 예를 들어 음이온성 또는 양이온성 인지질 또는 지질을 사용하여 얻을 수 있다. 이러한 음이온성/양이온성 인지질 또는 지질은 일반적으로 스테롤, 아실 또는 디아실 사슬과 같은 친유성 모이어티를 가지며, 여기서 지질은 전체 알짜 음전하/양전하를 갖는다.
일부 구현예에서, 본원에 개시된 나노입자는 1개, 2개, 3개 또는 그 이상의 생체적합성 및/또는 생분해성 중합체를 포함한다. 예를 들어, 고려되는 나노입자는 생분해성 중합체 및 폴리에틸렌 글리콜을 포함하는 하나 이상의 블록 공중합체를 약 10 내지 약 99 중량%로 포함할 수 있으며, 생분해성 단독중합체를 약 0 내지 약 50 중량%로 포함할 수 있다. 중합체는 예를 들어 미세결정질 셀룰로오스, 히드록시프로필 셀룰로오스, 히드록시프로필 메틸셀룰로오스, 폴리알킬렌 옥사이드, 예를 들어 폴리에틸렌 옥사이드(PEG)), 폴리무수물, 폴리(에스테르 무수물), 폴리하이드록시산, 예를 들어 폴리락타이드(PLA), 폴리글리콜라이드(PGA), 폴리(락타이드-코-글리콜라이드)(PLGA), 폴리-3-하이드록시부티레이트(PHB) 및 이들의 공중합체, 폴리-4-하이드록시부티레이트(P4HB) 및 이들의 공중합체, 폴리카프로락톤 및 이들의 공중합체, 및 이들의 조합과 같은 생안정성 및 생분해성 중합체 모두를 포함할 수 있다.
일부 구현예에서, 상기 나노입자는 약 1 nm 내지 약 1000 nm의 직경을 갖는다. 일부 구현예에서, 상기 나노입자는 예를 들어 약 1000 nm, 약 950 nm, 약 900 nm, 약 850 nm, 약 800 nm, 약 750 nm, 약 700 nm, 약 650 nm, 약 600 nm, 약 550 nm, 약 500 nm, 약 450 nm, 약 400 nm, 약 350 nm, 약 300 nm, 약 290 nm, 약 280 nm, 약 270 nm, 약 260 nm, 약 250 nm, 약 240 nm, 약 230 nm, 약 220 nm, 약 210 nm, 약 200 nm, 약 190 nm, 약 180 nm, 약 170 nm, 약 160 nm, 약 150 nm, 약 140 nm, 약 130 nm, 약 120 nm, 약 110 nm, 약 100 nm, 약 90 nm, 약 80 nm, 약 70 nm, 약 60 nm, 약 50 nm, 약 40 nm, 약 30 nm, 약 20 nm, 또는 약 10 nm 미만의 직경을 갖는다. 일부 구현예에서, 상기 나노입자는 예를 들어 약 20 nm 내지 약 1000 nm, 약 20 nm 내지 약 800 nm, 약 20 nm 내지 약 700 nm, 약 30 nm 내지 약 600 nm, 약 30 nm 내지 약 500 nm, 약 40 nm 내지 약 400 nm, 약 40 nm 내지 약 300 nm, 약 40 nm 내지 약 250 nm, 약 50 nm 내지 약 250 nm, 약 50 nm 내지 약 200 nm, 약 50 nm 내지 약 150 nm, 약 60 nm 내지 약 150 nm, 약 70 nm 내지 약 150 nm, 약 80 nm 내지 약 150 nm, 약 90 nm 내지 약 150 nm, 약 100 nm 내지 약 150 nm, 약 110 nm 내지 약 150 nm, 약 120 nm 내지 약 150 nm, 약 90 nm 내지 약 140 nm, 약 90 nm 내지 약 130 nm, 약 90 nm 내지 약 120 nm, from 100 nm 내지 약 140 nm, 약 100 nm 내지 약 130 nm, 약 100 nm 내지 약 120 nm, 약 100 nm 내지 약 110 nm, 약 110 nm 내지 약 120 nm, 약 110 nm 내지 약 130 nm, 약 110 nm 내지 약 140 nm, 약 90 nm 내지 약 200 nm, 약 100 nm 내지 약 195 nm, 약 110 nm 내지 약 190 nm, 약 120 nm 내지 약 185 nm, 약 130 nm 내지 약 180 nm, 약 140 nm 내지 약 175 nm, from 150 nm 내지 175nm, 또는 약 150 nm 내지 약 170 nm의 직경을 갖는다. 일부 구현예에서, 상기 나노입자는 약 100 nm 내지 약 250 nm의 직경을 갖는다. 일부 구현예에서, 상기 나노입자는 약 150 nm 내지 약 175 nm의 직경을 갖는다. 일부 구현예에서, 상기 나노입자는 약 135 nm 내지 약 175 nm의 직경을 갖는다. 상기 입자는 임의의 모양을 가질 수 있으나, 일반적으로 구형이다.
일부 구현예에서, 본원에 사용된 벡터는 엑소좀이다. 본원에 사용된 용어 "미세소포(microvesicle)" 및 "엑소좀"은 약 10 nm 내지 약 5000 nm, 보다 일반적으로 30 nm 내지 1000 nm의, 및 가장 일반적으로 약 50 nm 내지 750 nm의 직경을 갖는 막형 입자를 지칭하고 (또는 입자가 회전 타원체(spheroid)가 아닌 경우 최대 치수), 여기서 엑소좀 막의 적어도 일부는 세포로부터 직접 수득된다. 가장 일반적으로 엑소좀은 도너 세포 크기의 최대 5%인 크기(평균 직경)를 갖는다. 따라서, 특히 고려되는 엑소좀은 세포로부터 배출된 엑소좀을 포함한다. 엑소좀의 제조 방법은 당업계에 공지되어 있다. 예를 들어, 전체로서 본원에 참조로 도입된 미국 공개 번호 2018/0177727을 참조할 수 있다. 폴리뉴클레오타이드 및 폴리펩타이드를 전달하기 위한 엑소좀 및 이의 용도는 당업계에 공지되어 있다. 본원에 참조로 도입된 미국 특허 번호 10,577,630을 참조할 수 있다.
또한 RNA 활성화(RNAa)를 통해 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택된 하나 이상의 전사 인자의 발현 또는 기능을 증가시키는 조성물이 본원에 포함된다. 따라서, 일부 구현예에서, 상기 조성물은 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C 중 하나 이상을 활성화하는 짧은 헤어핀 RNA(shRNA)를 포함한다.
본원에서 "HNF4α"는 인간에서 HNF4A 유전자에 의해 암호화되는 폴리펩타이드를 지칭한다. 일부 구현예에서, HNF4α 폴리펩타이드는 HGNC: 5024, Entrez Gene: 3172, Ensembl: ENSG00000101076, OMIM: 600281, UniProtKB: P41235와 같이 하나 이상의 공개적으로 이용가능한 데이터베이스에서 확인된 것이다. 일부 구현예에서, HNF4α 폴리펩타이드는 서열번호 1의 서열(HNF4α 이소형 2), 또는 서열번호 1과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리펩타이드 서열, 또는 서열번호 1의 부분을 포함하는 폴리펩타이드를 포함한다. 서열번호 1의 HNF4α 폴리펩타이드는 성숙한 HNF4α의 미성숙 또는 전처리된 형태를 나타낼 수 있고, 이에 따라 본원에 포함되는 것은 서열번호 1의 HNF4α 폴리펩타이드의 성숙 또는 가공된 부분이다. 일부 구현예에서, 상기 HNF4α 폴리펩타이드는 모든 목적을 위해 본원에 참고로 포함된 미국 특허 출원 공개 US 2014/0249209에 기재된 것이다. 일부 구현예에서, 상기 HNF4α 폴리뉴클레오타이드는 서열번호 31, 서열번호 32, 서열번호 33, 또는 서열번호 34의 서열, 또는 서열번호 31, 서열번호 32, 서열번호 33, 또는 서열번호 34의 서열과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리뉴클레오타이드 서열, 또는 서열번호 31, 서열번호 32, 서열번호 33, 또는 서열번호 34의 부분을 포함하는 폴리뉴클레오타이드를 포함한다.
PROX1(Prospero-related homeobox 1)은 보통 간 기관 형성 동안 생쥐의 내배엽 세포에서 배아 8.5일(E8.5)에 처음 발현된다. 성인 간에서, PROX1의 역할은 간세포의 에너지 대사를 제어할 수 있다. 더 중요하게는 Prox1이 특정 DNA 요소에 대한 호메오도메인의 직접 결합에 의해 유전자 전사의 활성제로 기능할 수 있다고 보고되었다. 본원에서 "PROX1"은 인간에서 PROX1 유전자에 의해 암호되는 폴리펩타이드를 지칭한다. 일부 구현예에서, PROX1 폴리펩타이드는 HGNC: 9459, Entrez Gene: 5629, Ensembl: ENSG00000117707, OMIM: 601546, UniProtKB: Q92786와 같이 하나 이상의 공개적으로 이용가능한 데이터베이스에서 확인된 것이다. 일부 구현예에서, PROX1 폴리펩타이드는 서열번호 2의 서열, 또는 서열번호 2와 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리펩타이드 서열, 또는 서열번호 2의 부분을 포함하는 폴리펩타이드를 포함한다. 서열번호 2의 PROX1 폴리펩타이드는 성숙한 PROX1의 미성숙 또는 전처리된 형태를 나타낼 수 있고, 이에 따라 본원에 포함되는 것은 서열번호 2의 PROX1 폴리펩타이드의 성숙 또는 가공된 부분이다. 일부 구현예에서, 상기 PROX1 폴리뉴클레오타이드는 서열번호 13의 서열, 또는 서열번호 13의 서열과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리뉴클레오타이드 서열, 또는 서열번호 13의 부분을 포함하는 폴리뉴클레오타이드를 포함한다.
NR5A2(Nuclear receptor 5A2; Liver receptor homologue-1; LRH-1)는 표적 유전자의 프로모터 및 조절 영역 내의 특정 반응 요소에 단량체로 결합하는 핵 수용체이다. NR5A2는 또한 담즙산 생산 효소, 지방산 대사 및 미토콘드리아 기능을 암호화하는 유전자를 양성 조절할 수 있다. 본원에서 "NR5A2"는 인간에서 NR5A2 유전자에 의해 암호화되는 폴리펩타이드를 지칭한다. 일부 구현예에서, NR5A2 폴리펩타이드는 HGNC: 7984, Entrez Gene: 2494, Ensembl: ENSG00000116833, OMIM: 604453, UniProtKB: O00482와 같은 하나 이상의 공개적으로 이용가능한 데이터베이스에서 확인된 것이다. 일부 구현예에서, NR5A2 폴리펩타이드는 서열번호 3의 서열, 또는 서열번호 3과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리펩타이드 서열, 또는 서열번호 3의 부분을 포함하는 폴리펩타이드를 포함한다. 서열번호 3의 NR5A2 폴리펩타이드는 성숙한 NR5A2의 미성숙 또는 전처리된 형태를 나타낼 수 있고, 이에 따라 본원에 포함되는 것은 서열번호 3의 NR5A2 폴리펩타이드의 성숙 또는 가공된 부분이다. 일부 구현예에서, 상기 NR5A2 폴리뉴클레오타이드는 서열번호 14, 서열번호 15, 또는 서열번호 16의 서열, 또는 서열번호 14, 서열번호 15, 또는 서열번호 16의 서열과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리뉴클레오타이드 서열, 또는 서열번호 14, 서열번호 15, 또는 서열번호 16의 부분을 포함하는 폴리뉴클레오타이드를 포함한다.
NR0B2(Nuclear receptor small heterodimer partner; SHP)는 보통 정상 간세포에서 높게 발현되며 담즙산, 포도당 및 지질 대사에 대한 중요한 전사 조절자 역할을 한다. NR0B2의 수모일화(SUMOylation)는 핵 수송 및 담즙산 항상성을 유지하고 간 독성으로부터 보호하는 데 중요한 담즙산 생합성의 피드백 억제에서 SHP의 유전자 억제 기능에 필요할 수 있다. (Kim DH et al., 2016). 본원에서 "NR0B2"는 인간에서 NR0B2 유전자에 의해 암호화되는 폴리펩타이드를 지칭한다. 일부 구현예에서, NR0B2 폴리펩타이드는 HGNC: 7961, Entrez Gene: 8431, Ensembl: ENSG00000131910, OMIM: 604630, UniProtKB: Q15466과 같이 하나 이상의 공개적으로 이용가능한 데이터베이스에서 확인된 것이다. 일부 구현예에서, NR0B2 폴리펩타이드는 서열번호 4의 서열, 또는 서열번호 4와 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리펩타이드 서열, 또는 서열번호 4의 부분을 포함하는 폴리펩타이드를 포함한다. 서열 번호 4의 NR0B2 폴리펩타이드는 성숙한 NR0B2의 미성숙 또는 전처리된 형태를 나타낼 수 있고, 이에 따라 본원에 포함되는 것은 서열번호 4의 NR0B2 폴리펩타이드의 성숙 또는 가공된 부분이다. 일부 구현예에서, 상기 NR0B2 폴리뉴클레오타이드는 서열번호 17의 서열, 또는 서열번호 17의 서열과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리뉴클레오타이드 서열, 또는 서열번호 17의 부분을 포함하는 폴리뉴클레오타이드를 포함한다.
MTF1(Metal-responsive transcription factor 1)은 메탈로티오네인(metallothionein) 유전자의 기초 및 중금속 유도 전사를 매개할 수 있으며 또한 세포 스트레스 반응 및 금속 항상성에 관련된 다른 유전자를 조절할 수 있다. MTF1은 또한 아연 수송체 1과 같은 다른 금속 반응성 유전자의 전사 조절에 관여할 수 있다. MTF1은 간세포의 아연 수준을 조절할 수 있다. 본원에서 "MTF1"은 신호전달 림프구 활성화 분자 패밀리의 자가-리간드 수용체인 폴리펩타이드를 지칭하며, 인간에서 MTF1 유전자에 의해 암호화된다. 일부 구현예에서, MTF1 폴리펩타이드는 HGNC: 7428, Entrez Gene: 4520, Ensembl: ENSG00000188786, OMIM: 600172, UniProtKB: Q14872와 같이 하나 이상의 공개적으로 이용가능한 데이터베이스에서 확인된 것이다. 일부 구현예에서, MTF1 폴리펩타이드는 서열번호 5의 서열, 또는 서열번호 5와 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리펩타이드 서열, 또는 서열번호 5의 부분을 포함하는 폴리펩타이드를 포함한다. 서열번호 5의 MTF1 폴리펩타이드는 성숙한 MTF1의 미성숙 또는 전처리된 형태를 나타낼 수 있고, 이에 따라 본원에 포함되는 것은 서열번호 5의 MTF1 폴리펩타이드의 성숙 또는 가공된 부분이다. 일부 구현예에서, 상기 MTF1 폴리뉴클레오타이드는 서열번호 18의 서열, 또는 서열번호 18의 서열과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리뉴클레오타이드 서열, 또는 서열번호 18의 부분을 포함하는 폴리뉴클레오타이드를 포함한다.
SREBP1(Sterol regulator element binding proteins 1)은 콜레스테롤, 지방산 및 트리글리세리드의 생합성에 관여하는 전사 인자이다. SREBP1은 AKT/PI3K 신호전달 경로의 발현과 활성을 제어할 수 있으며 그 반대의 경우도 마찬가지이다 (Shi Q et al., 2016; Porstmann T et al., 2008). 본원에서 "SREBF1"은 신호전달 림프구 활성화 분자 패밀리의 자가-리간드 수용체인 폴리펩타이드를 지칭하며, 인간에서 SREBF1 유전자에 의해 암호화된다. 일부 구현예에서, SREBF1 폴리펩타이드는 HGNC: 11289, Entrez Gene: 6720, Ensembl: ENSG00000072310, OMIM: 184756, UniProtKB: P36956과 같이 하나 이상의 공개적으로 이용가능한 데이터베이스에서 확인된 것이다. 일부 구현예에서, SREBF1 폴리펩타이드는 서열번호 6의 서열, 또는 서열번호 6과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리펩타이드 서열, 또는 서열번호 6의 부분을 포함하는 폴리펩타이드를 포함한다. 서열번호 6의 SREBF1 폴리펩타이드는 성숙한 SREBF1의 미성숙 또는 전처리된 형태를 나타낼 수 있고, 이에 따라 본원에 포함되는 것은 서열번호 6의 SREBF1 폴리펩타이드의 성숙 또는 가공된 부분이다. 일부 구현예에서, 상기 SREBP1 폴리뉴클레오타이드는 서열번호 19, 서열번호 20, 또는 서열번호 21의 서열, 또는 서열번호 19, 서열번호 20, 또는 서열번호 21의 서열과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리뉴클레오타이드 서열, 또는 서열번호 19, 서열번호 20, 또는 서열번호 21의 부분을 포함하는 폴리뉴클레오타이드를 포함한다.
EP300(The histone acetyltransferase p300) 은 C/EBP 단백질과 복합체를 형성할 수 있고, 간 지방증 발달, 포도당 대사 및 간에서 높게 발현되는 Foxo1 및 파네소이드 X 수용체(farnesoid X receptor, FXR)와 같은 여러 전사 인자의 조절 동안 트리글리세리드 합성에 관여하는 유전자의 프로모터를 활성화할 수 있다. 본원에서 "EP300"은 신호전달 림프구 활성화 분자 패밀리의 자가-리간드 수용체인 폴리펩타이드를 나타내며, 인간에서 EP300 유전자에 의해 암호화된다. 일부 구현예에서, EP300 폴리펩타이드는 HGNC: 3373, Entrez Gene: 2033, Ensembl: ENSG00000100393, OMIM: 602700, UniProtKB: Q09472와 같이 하나 이상의 공개적으로 이용가능한 데이터베이스에서 확인된 것이다. 일부 구현예에서, EP300 폴리펩타이드는 서열번호 7의 서열, 또는 서열번호 7과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리펩타이드 서열, 또는 서열번호 7의 부분을 포함하는 폴리펩타이드를 포함한다. 서열번호 7의 EP300 폴리펩타이드는 성숙한 EP300의 미성숙 또는 전처리된 형태를 나타낼 수 있고, 이에 따라 본원에 포함되는 것은 서열번호 7의 EP300 폴리펩타이드의 성숙 또는 가공된 부분이다. 일부 구현예에서, 상기 EP300 폴리뉴클레오타이드는 서열번호 22 또는 서열번호 23의 서열, 또는 서열번호 22 또는 서열번호 23의 서열과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리뉴클레오타이드 서열, 또는 서열번호 22 또는 서열번호 23의 부분을 포함하는 폴리뉴클레오타이드를 포함한다.
POM121C(Nuclear envelope pore membrane protein POM 121)는 핵공 생합성에 관여하는 것으로 여겨지는 공극막 단백질이라고 하는 단백질 그룹의 구성원인 막 단백질이다. 본원에서 "POM121C"는 신호전달 림프구 활성화 분자 패밀리의 자가-리간드 수용체인 폴리펩타이드를 나타내며, 인간에서 POM121C 유전자에 의해 암호화된다. 일부 구현예에서, POM121C 폴리펩타이드는 HGNC: 34005, Entrez Gene: 100101267, Ensembl: ENSG00000272391, OMIM: 615754, UniProtKB: A8CG34와 같이 하나 이상의 공개적으로 이용가능한 데이터베이스에서 확인된 것이다. 일부 구현예에서, POM121C 폴리펩타이드는 서열번호 8의 서열, 또는 서열번호 8과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리펩타이드 서열, 또는 서열번호 8의 부분을 포함하는 폴리펩타이드를 포함한다. 서열번호 8의 POM121C 폴리펩타이드는 성숙한 POM121C의 미성숙 또는 전처리된 형태를 나타낼 수 있고, 이에 따라 본원에 포함되는 것은 서열번호 8의 성숙 또는 가공된 부분이다. 일부 구현예에서, 상기 POM121C 폴리뉴클레오타이드는 서열번호 24의 서열, 또는 서열번호 24의 서열과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리뉴클레오타이드 서열, 또는 서열번호 24의 부분을 포함하는 폴리뉴클레오타이드를 포함한다.
또한 DNAJB1/HSP40, ATF6, ATF4, 및 PERK로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자의 양을 감소시키거나 기능을 억제하는 조성물이 본원에 개시된다. 따라서, DNAJB1/HSP40, ATF6, ATF4, 및 PERK 폴리뉴클레오타이드에 상관되고/되거나 이에 작용하는 작은 간섭 RNA(siRNA) 및 마이크로RNA(miRNA)와 같은 작은 활성화 RNA(saRNA), 또는 crisgRNA 또는 tracr/mate RNA와 같은 CRISPR RNA를 포함하는 조성물이 본원에 포함된다. 단백질의 기능을 감소 또는 억제하기 위해 saRNA를 사용하는 방법은 당업계에 공지되어 있다. 예를 들어, 전체로서 본원에 참조로 도입된 국제 공개 번호 WO2019/048632를 참고할 수 있다. 따라서, DNAJB1/HSP40, ATF6, ATF4 및 PERK로 이루어진 군으로부터 선택된 하나 이상의 전사 인자의 양을 감소시키거나 기능을 억제하기 위해 saRNA를 사용하여 HNF4α의 발현을 증가시키는 방법이 본원에 포함된다. 일부 구현예에서, 상기 조성물은 DNAJB1/HSP40의 양을 감소시키거나 기능을 억제하는 핵산을 포함한다. 일부 구현예에서, 상기 조성물은 ATF6의 양을 감소시키거나 기능을 억제하는 핵산을 포함한다. 일부 구현예에서, 상기 조성물은 ATF4의 양을 감소시키거나 기능을 억제하는 핵산을 포함한다. 일부 구현예에서, 상기 조성물은 PERK의 양을 감소시키거나 기능을 억제하는 핵산을 포함한다. 일부 구현예에서, 상기 조성물은 HNF4α를 암호화하는 핵산을 추가로 포함한다.
DNAJB1/HSP40(Heat shock protein 40)은 유전자 발현 및 번역 개시, 접힘 및 비-접힘, 및 단백질의 전위 및 분해에 필수적인 역할을 할 수 있는 분자 샤페론 단백질이다. DNAJ/HSP40의 활성은 여러 번역 후 변형에 의해 조절된다. 많은 경우에, DNAJ/HSP40은 인단백질(예: DnaJA1, DnaJB4, DnaJC1, DnaJC29)이며, 그 발현과 기능은 각각 아세틸화(예: DnaJA1, DnaJB2, DnaJB12, DnaJC5, DnaJC8, DnaJC13), 당화(DnaJB11, DnaJC10, DnaJC16), 팔미토일화(DnaJC5, DnaJC5B, DnaJC5G), 메틸화(DnaJA1-4), 프레닐화(DnaJA1, DnaJA2, DnaJA4), 및 분자내 이황화 결합(DnaJB11, DnaJC3, DnaJC10)에 의해 번역 동시 및 번역 후 추가로 조절될 수 있다. 본원에서 "DNAJB1/HSP40"은 신호전달 림프구 활성화 분자 패밀리의 자가-리간드 수용체인 폴리펩타이드를 지칭하며, 인간에서 DNAJB1 유전자에 의해 암호화된다. 일부 구현예에서, DNAJB1 폴리펩타이드는 HGNC: 5270, Entrez Gene: 3337, Ensembl: ENSG00000132002, OMIM: 604572, UniProtKB: P25685와 같이 하나 이상의 공개적으로 이용가능한 데이터베이스에서 확인된 것이다. 일부 구현예에서, DNAJB1 폴리펩타이드는 서열번호 9의 서열, 또는 서열번호 9와 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리펩타이드 서열, 또는 서열번호 9의 부분을 포함하는 폴리펩타이드를 포함한다. 서열번호 9의 DNAJB1 폴리펩타이드는 성숙한 DNAJB1의 미성숙 또는 전처리된 형태를 나타낼 수 있고, 이에 따라 본원에 포함되는 것은 서열번호 9의 DNAJB1 폴리펩타이드의 성숙 또는 가공된 부분이다. 일부 구현예에서, 상기 DNAJB1 폴리뉴클레오타이드는 서열번호 25 또는 서열번호 26의 서열, 또는 서열번호 25 또는 서열번호 26의 서열과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리뉴클레오타이드 서열, 또는 서열번호 25 또는 서열번호 26의 부분을 포함하는 폴리뉴클레오타이드를 포함한다.
ATF6은 비-접힘 단백질 반응(UPR)의 센서일 수 있고 전사 발현을 조절하는 기능을 할 수 있다. 어떤 경우에는 ER 스트레스 시 ATF6이 ER에서 골지로 이동하여 단백질 분해로 절단되어 단백질의 접힘 및 이동에 관여하는 유전자의 전사 인자인 N-말단 ATF6 조각을 방출하는 것으로 나타났다. 본원에서 "ATF6"은 신호전달 림프구 활성화 분자 패밀리의 자가-리간드 수용체인 폴리펩타이드를 나타내며, 인간에서 ATF6 유전자에 의해 암호화된다. 일부 구현예에서, ATF6 폴리펩타이드는 HGNC: 791, Entrez Gene: 22926, Ensembl: ENSG00000118217, OMIM: 605537, UniProtKB: P18850와 같이 하나 이상의 공개적으로 이용가능한 데이터베이스에서 확인된 것이다. 일부 구현예에서, ATF6 폴리펩타이드는 서열번호 10의 서열, 또는 서열번호 10과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리펩타이드 서열, 또는 서열번호 10의 부분을 포함하는 폴리펩타이드를 포함한다. 서열번호 10의 ATF6 폴리펩타이드는 성숙한 ATF6의 미성숙 또는 전처리된 형태를 나타낼 수 있고, 이에 따라 본원에 포함되는 것은 서열번호 10의 ATF6 폴리펩타이드의 성숙 또는 가공된 부분이다. 일부 구현예에서, 상기 ATF6 폴리뉴클레오타이드는 서열번호 27의 서열, 또는 서열번호 27의 서열과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리뉴클레오타이드 서열, 또는 서열번호 27의 부분을 포함하는 폴리뉴클레오타이드를 포함한다.
ATF4는 UPR 표적 유전자의 전사 활성제로, 아미노산 대사 및 산화 스트레스에 대한 내성에 관여하는 유전자의 전사 발현을 향상시키는 역할을 할 수 있다. (Fusakio ME et al., 2016) 본원에서 "ATF4"는 신호전달 림프구 활성화 분자 패밀리의 자가-리간드 수용체인 폴리펩타이드를 나타내며, 인간에서 ATF4 유전자에 의해 암호화된다. 일부 구현예에서, ATF4 폴리펩타이드는 HGNC: 786, Entrez Gene: 468, Ensembl: ENSG00000128272, OMIM: 604064, UniProtKB: P18848과 같은 하나 이상의 공개적으로 이용가능한 데이터베이스에서 확인된 것이다. 일부 구현예에서, ATF4 폴리펩타이드는 서열번호 11의 서열, 또는 서열번호 11과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리펩타이드 서열, 또는 서열번호 11의 부분을 포함하는 폴리펩타이드를 포함한다. 서열번호 11의 ATF4 폴리펩타이드는 성숙한 ATF4의 미성숙 또는 전처리된 형태를 나타낼 수 있고, 이에 따라 본원에 포함되는 것은 서열번호 11의 ATF4 폴리펩타이드의 성숙 또는 가공된 부분이다. 일부 구현예에서, 상기 ATF4 폴리뉴클레오타이드는 서열번호 28의 서열, 또는 서열번호 28의 서열과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리뉴클레오타이드 서열, 또는 서열번호 28의 부분을 포함하는 폴리뉴클레오타이드를 포함한다.
PERK(protein kinase RNA-like endoplasmic reticulum kinase)는 PERK에서 떨어진 샤페론 모집(recruitment)을 통해 일반적으로 활성화되어 세포질 키나아제 도메인의 올리고머화 및 활성화를 유도하는 유형 1 막횡단 단백질이다. PERK 및 ATF4의 하류에서 세포자멸사 신호 전달을 매개하는 중요한 단백질은 간 질환의 진행과 관련된 CCAAT 인핸서-결합 단백질(C/EBP) 상동 단백질(CHOP)이다. (Malhi H et al., 2011) "EIF2AK3"으로도 알려진 "PERK"는 본원에서 신호전달 림프구 활성화 분자 패밀리의 자가-리간드 수용체인 폴리펩타이드를 지칭하며, 인간에서 EIF2AK3 유전자에 의해 암호화된다. 일부 구현예에서, PERK 폴리펩타이드는 NC: 3255, Entrez Gene: 9451, Ensembl: ENSG00000172071, OMIM: 604032, UniProtKB: Q9NZJ5와 같이 하나 이상의 공개적으로 이용가능한 데이터베이스에서 확인된 것이다. 일부 구현예에서, PERK 폴리펩타이드는 서열번호 12의 서열, 또는 서열번호 12와 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리펩타이드 서열, 또는 서열번호 12의 부분을 포함하는 폴리펩타이드를 포함한다. 서열번호 12의 PERK 폴리펩타이드는 성숙한 PERK의 미성숙 또는 전처리된 형태를 나타낼 수 있고, 이에 따라 본원에 포함되는 것은 서열번호 12의 PERK 폴리펩타이드의 성숙 또는 가공된 부분이다. 일부 구현예에서, 상기 PERK 또는 EIF2AK3 폴리펩타이드는 서열번호 29 또는 서열번호 30의 서열, 또는 서열번호 29 또는 서열번호 30의 서열과 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98% 이상의 상동성을 갖는 폴리뉴클레오타이드 서열, 또는 서열번호 29 또는 서열번호 30의 부분을 포함하는 폴리뉴클레오타이드를 포함한다.
임의의 전술한 측면의 조성물은 HNF4α 작용제를 추가로 포함할 수 있고, 여기서 HNF4α 작용제는 모든 목적을 위해 본원에 참고로 도입되는 미국 특허 출원 공개 US2014/0249209에 보다 완전히 기재된 조성물을 지칭하는 것을 의미한다.
일부 구현예에서, 임의의 전술한 측면의 조성물 및/또는 벡터는 생물학적으로 허용되는 담체와 함께 제제화될 수 있다. 일부 구현예에서, 생물학적으로 허용되는 담체는 조성물 및/또는 벡터를 숙주 세포 내로 및/또는 숙주 세포 간에 전달할 수 있다. 일부 구현예에서, 상기 생물학적으로 허용되는 담체는 대상체의 간에 있는 간세포와 같은 표적 세포 내로 및/또는 표적 세포 사이에서 조성물 및/또는 벡터를 전달할 수 있다. 중요하게도, 일부 구현예에서, 생물학적으로 허용되는 담체와 함께 조성물 및/또는 벡터는 DNA 및 RNA와 같은 기능적 거대분자를 표적 세포(예를 들어, 간세포)의 핵으로 수송할 수 있다.
치료 방법
본원에서는 대상체에서 간세포의 핵으로 전사 인자인 HNF4α의 발현 및/또는 수송 및/또는 보유를 증가시켜 간 질환을 치료하는 방법을 제공한다. 일부 구현예에서, 상기 방법은 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자의 발현 또는 기능을 상향 조절하고/하거나 DNAJB1/HSP40, ATF6, ATF4, 및 PERK로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자의 발현 또는 기능을 하향 조절하는 것을 포함한다. 일부 측면에서, 본원은 벡터를 대상체에게 투여하는 것을 포함하는, 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하는 방법이 개시하며, 여기서 상기 벡터는 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및/또는 POM121C로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자 및 그의 기능적 단편을 암호화하는 핵산을 포함한다. 일부 측면에서, 본원은 DNAJB1/HSP40, ATF6, ATF4 및 PERK로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자의 발현 또는 기능을 하향 조절하는 조성물을 대상체에게 투여하는 것을 포함하는, 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하는 방법이 개시한다. 일부 측면에서, 상기 조성물은 siRNA, miRNA, sgRNA 또는 tracr/mate RNA를 포함한다. 다른 구현예에서, 상기 방법은 Lys106에서 HNF4α의 아세틸화를 증가시키는 단계, cMET의 발현을 증가시키는 단계, 및/또는 Thr308에서 인산화를 통해 AKT의 활성화를 증가시키는 단계를 포함한다.
일부 구현예에서, 본원은 PROX1을 암호화하는 핵산을 포함하는 벡터를 대상체에게 투여하는 것을 포함하는 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하는 방법을 개시한다. 일부 구현예에서, SREBP1을 암호화하는 핵산을 포함하는 벡터를 대상체에게 투여하는 것을 포함하는, 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하는 방법이 개시된다. 일부 구현예에서, 상기 벡터는 HNF4α를 암호화하는 핵산을 추가로 포함한다. 일부 구현예에서, 상기 벡터는 HNF4α, PROX1, 및 SREBP1을 암호화하는 하나 이상의 핵산을 포함한다. 일부 구현예에서, 상기 방법은 HNF4α를 암호화하는 핵산을 포함하는 벡터를 투여하는 단계를 추가로 포함한다.
앞서 언급한 바와 같이, PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300 및 POM121C는 모두 예를 들어 HNF4α의 아세틸화, 세포 대사 경로, 또는 핵공 복합체의 형성을 포함하는 직접 EH는 간접 메커니즘을 통해 HNF4α 핵 수송을 조절하는 전사 인자 및/또는 조절자이다. HNF4α에 대한 이러한 효과는 간 질환이 있는 환자의 간 세포 기능을 회복시킬 수 있다.
따라서, 일부 구현예에서, 벡터 또는 벡터들의 투여는 대상체의 간세포의 핵에서 HNF4α의 양을 증가시킨다. 일부 구현예에서, 벡터(들)의 투여는 간세포에서 HNF4α의 총량을 증가시키지 않는다. 일부 구현예에서, 벡터(들)의 투여는 간세포에서 HNF4α의 총량을 증가시킨다. 일부 구현예에서, 임의의 선행하는 측면의 벡터는 HNF4α를 암호화하는 핵산을 추가로 포함한다. 일부 구현예에서, 본원에 개시된 벡터는 HNF4α 이소형 2 폴리펩타이드를 암호화하는 핵산을 추가로 포함한다. 일부 구현예에서, HNF4α 이소형 2 폴리펩타이드는 서열번호 1 또는 그의 단편과 적어도 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98%의 상동성을 갖는 서열을 포함한다. 일부 구현예에서, 핵산은 서열번호 31 또는 그의 단편과 적어도 약 80%, 약 85%, 약 90%, 약 95%, 또는 약 98%의 상동성을 갖는다.
따라서, 일부 측면에서, 본원은 HNF4α 이소형 2를 암호화하는 핵산을 포함하는 벡터를 대상체에게 투여하는 것을 포함하는, 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하는 방법을 개시한다. 또한 본원은 HNF4α 이소형 2를 암호화하는 핵산을 포함하는 조성물을 대상체에게 투여하는 것을 포함하는 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하기 위한 약제의 제조를 위한 조성물의 용도를 포함한다.
상기 방법에 사용된 벡터는 플라스미드, 박테리오파지, 바이로스 입자(분리, 약독화, 재조합 등), 엑소좀, 세포외 소포 및/또는 나노입자를 포함하는 본원에 기재된 임의의 것일 수 있다. 일부 구현예에서, 상기 벡터는 플라스미드이다. 일부 구현예에서, 상기 벡터는 바이러스 입자이다. 일부 구현예에서, 상기 벡터는 천연 및/또는 조작된 캡시드를 갖는 바이러스 벡터이다. 일부 구현예에서, 상기 벡터는 엑소솜이다. 일부 구현예에서 상기 벡터는 나노입자이다. 일부 구현예에서, 상기 벡터는 mRNA 지질 나노입자이다. 일부 구현예에서, 상기 핵산은 DNA(예를 들어, 폐쇄형 DNA(ceDNA)) 또는 RNA이다. ceDNA 및 ceDNA의 제조 및 사용 방법은 당업계에 공지되어 있다. 예를 들어, 전체로서 본원에 참조로 도입된 국제 공개 번호 WO2019/169233 및 WO2017152149를 참조할 수 있다. 방법, 재료, 나노 입자의 전달 및 이의 제조 및 사용을 포함하는(양 및 제형 포함) 나노 입자, 이의 구성요소 및 이러한 구성요소의 전달과 관련하여, 모두 본 발명의 실시에 유용하며, Wu et al., J. Biol. Chem. 262, 4429, 1987, U.S. 특허 출원 공개 2011/0274706, 및 WO2018/170405는 모든 목적을 위해 본원에 참조로 도입된다.
일부 측면에서, 본원에 대상체에게 조성물을 투여하는 것을 포함하는 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하는 방법이 개시되며, 여기서 상기 조성물은 DNAJB1/HSP40, ATF6, ATF4, 및 PERK로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자의 양을 감소시키거나 기능을 억제한다.
앞서 언급한 바와 같이, DNAJB1/HSP40, ATF6, ATF4 및 PERK는 모두 소포체(ER) 스트레스의 전사 조절자이다. ER은 단백질의 적절한 접힘, 변형 및 수송에 중요한 진핵 세포의 일종의 막성 소기관이다. 단백질을 접는 ER의 능력이 포화될 때 발생하는 ER 스트레스는 세포 사멸 및/또는 염증과 같은 반응으로 이어질 수 있다. 이러한 전사 조절자는 ER 스트레스와 관련된 경로를 통해 HNF4α 핵 수송을 조절한다. 이러한 전사 조절제 중 하나 이상의 양의 감소 또는 기능의 억제가 간 질환이 있는 환자에서 간 세포 기능을 회복시킬 수 있음이 본원에서 제시된다. 따라서, 일부 구현예에서, 조성물의 투여는 대상체의 간세포의 핵에서 HNF4α의 양을 증가시킨다. 일부 구현예에서, 조성물의 투여는 간세포에서 HNF4α의 총량을 증가시키지 않는다. 일부 구현예에서, 조성물의 투여는 간세포에서 HNF4α의 총량을 증가시킨다. 일부 구현예에서, 조성물은 HNF4α를 암호화하는 핵산을 추가로 포함한다.
일부 구현예에서, 조성물은 이들 유전자의 녹다운에 의해 DNAJB1/HSP40, ATF6, ATF4, 및/또는 PERK로 이루어진 군으로부터 선택된 하나 이상의 전사 인자의 양을 감소시킨다. DNAJB1/HSP40, ATF6, ATF4 및/또는 PERK의 녹다운은 상보적 RNA 분자에 의한 DNAJB1/HSP40, ATF6, ATF4 및/또는 PERK를 암호화하는 mRNA 또는 DNAJB1/HSP40, ATF6, ATF4 및/또는 PERK의 활성에 필요한 효소와 같은 관련 mRNA의 인식에 의해 야기될 수 있으며, RNA 간섭에 의해 매개될 수 있다. 예를 들어, 간섭 RNA(RNAi)를 암호화하는 분자는 형질감염(transfection) 또는 형질도입(transduction)과 같은 방법을 통해 렌티바이러스, 레트로바이러스 벡터 또는 나노입자와 같은 적합한 벡터에 의해 간세포 또는 간세포 전구체에 도입될 수 있다.
일부 구현예에서, DNAJB1/HSP40, ATF6, ATF4 및/또는 PERK로 이루어진 군으로부터 선택된 하나 이상의 전사 인자를 녹아웃시키기 위한 임의의 하나 또는 복수의 CRISPR 복합체 성분은 본원에 개시된 바이러스 입자, 비리온(virion), 또는 바이러스 벡터와 함께 또는 그 안에 투여될 수 있다. 일부 구현예에서, sgRNA 또는 tracr/mate RNA는 하나 이상의 재프로그래밍 인자와 함께 패키징될 수 있다. 일부 구현예에서, 바이러스 입자, 비리온 또는 바이러스 벡터에 의해 캡슐화된 sgRNA 분자는 하나 이상의 재프로그래밍 인자와 함께 패키징될 수 있다. CRISPRCas 시스템에 관한 일반 정보, 그의 구성 요소 및 방법, 재료, 전달 비히클, 벡터, 입자, AAV를 포함하는 이러한 구성 요소의 전달 및 양 및 제형을 포함하여 이의 제조 및 사용과 관련하여, 본 발명의 실시에 유용한 모든 목적을 위해 본 명세서에 참고로 도입된 미국 공개 2018/0057839를 참조한다.
상기 언급한 바와 같이, 본원에서 사용된 "간 질환"은 일반적으로 간에 영향을 미치는 질환, 장애 및 상태를 지칭하며, 예를 들어 간세포에 단순 지방 축적(지방증), 거대낭포성 지방증, 문맥주위 및 소엽 염증(지방간염), 간경변, 섬유증, 간 허혈, 간세포 암종을 포함하는 간암, 초기 질환 단계의 간 질환, 말기 간 질환, 및 간 부전을 포함하는 광범위한 중증도를 가질 수 있다. 따라서, 지방증, 거대낭포성 지방증, 지방간염, 간경변, 섬유증, 간암, 간세포 암종, 말기 간 질환, 만성 간 질환, 및 간 부전은 각각 "간 질환"의 정의에 포함된다. "간 경변"의 정도 또는 중증도는 차일드-퍼 점수에 의해 지정될 수 있으며, 여기서 5가지 임상 측정값인 총 빌리루빈(bilirubin) 수준, 혈청 알부민, 프로트롬빈 시간 연장, 복수(ascite) 및 간성 뇌병증이 1점, 2점, 및 3점 값의 점수 시스템을 사용하여 각 임상 측정값의 다양한 수준에 대해 채점되며 3점 값은 각 측정의 가장 심각한 수준에 할당된다. 차일드-퍼 점수 및 분류에 도달하기 위해 5개 측정값 모두에 대한 총점이 추가된다. 5-6점은 차일드-퍼 분류 A, 7-9점은 차일드-퍼 분류 B, 10-15점은 차일드-퍼 분류 C이다. 일반적으로 차일드-퍼 분류 A는 가장 덜 심각한 간 질환을 나타내며, 차일드-퍼 분류 C는 가장 심각한 간 질환을 나타낸다. 일부 구현예에서, 본원에 개시된 방법은 차일드-퍼 분류 B 또는 차일드-퍼 분류 C 간 질환을 갖는 대상체를 치료하는 데 사용될 수 있다. 일부 구현예에서, 본원에 개시된 방법은 차일드-퍼 분류 A 간 질환을 갖는 대상체를 치료하는 데 사용될 수 있다. 일부 구현예에서, 상기 간 질환은 알코올성 간염이다. 일부 구현예에서, 본원에 개시된 방법은 생체외 관류를 갖는 허혈성 공여자 간을 치료하는 데 사용될 수 있다. 본 발명은 간 절제 전 또는 후를 포함하는 암 치료 전 또는 후에 간암을 치료하는데 사용될 수 있다. 초기 질환 단계의 간 질환은 비알코올성 지방간 질환(NAFLD), 비알코올성 지방간염(NASH), 알코올-관련 간 질환(지방간, 알코올성 간염 및 알코올-관련 간경변을 포함하나 이에 제한되지 않음)일 수 있음을 이해하고 본원에서 고려한다. 본원에 개시된 말기 간 질환은 예를 들어 바이러스성, 알코올성, 비-알코올성 및 잠복성을 포함하여 당업계에 공지된 모든 원인에 기인할 수 있음을 또한 이해해야 한다.
따라서, 본원에 개시된 방법은 임의의 상기 측면의 간 질환을 갖는 대상체에서 간 기능을 개선하는데 사용될 수 있다. 이러한 간 기능의 개선은 예를 들어 혈청 알부민의 증가, 혈청 암모니아 수준의 감소, 총 빌리루빈의 감소, 뇌병증 점수의 증가 및/또는 프로트롬빈 시간 연장의 감소로 나타날 수 있다. 따라서, 본원에 개시된 방법은 혈청 알부민 수준을 증가시키고, 혈청 암모니아 수준을 감소시키고, 총 빌리루빈 수준을 감소시키고, 뇌병증 점수를 증가시키고 및/또는 프로트롬빈 시간 연장을 감소시키는데 사용될 수 있다.
간 질환은 염증, 섬유증, 간경변, 말기 간 질환, 및 간암을 포함하는 여러 단계로 진행될 수 있다. 간염 바이러스에 의한 만성 감염, 알코올-매개 간경변, 및/또는 비알코올성 지방간염(NASH)을 포함하여 만성 간 질환의 다양한 원인이 있음을 알아야 한다. 간 질환의 시기를 예측할 수 없는 경우가 많기 때문에, 간 질환을 치료, 예방, 감소 및/또는 억제하는 개시된 방법은 염증, 섬유증, 간경변, 말기 간 질환, 및/또는 간암의 발병 전 또는 후에, 심지어 간염 바이러스 감염, 알코올 매개 간경변, 및/또는 비알코올성 지방간염의 전 또는 도중에 간 질환의 임의의 단계를 치료, 예방, 억제 및/또는 완화하기 위해 사용될 수 있음을 이해해야 한다. 개시된 방법은 염증, 섬유증, 간경변, 말기 간 질환 및/또는 간암이 발병하기 전에 언제든지 수행할 수 있다. 한 측면에서, 개시된 방법은 염증, 섬유증, 간경변, 말기 간 질환, 및/또는 간암의 발병 60, 59, 58, 57, 56, 55, 54, 53, 52, 51, 50, 49, 48, 47, 46, 45, 44, 43, 42, 41, 40, 39, 38, 37, 36, 35, 34, 33, 32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 또는 1년; 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 또는 1개월; 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 또는 3일; 60, 48, 36, 30, 24, 18, 15, 12, 10, 9, 8, 7, 6, 5, 4, 3, 또는 2시간 전; 또는 염증, 섬유증, 간경변, 말기 간 질환, 및/또는 간암의 발병 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 75, 90, 105, 120분; 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 15, 18, 24, 30, 36, 48, 60시간; 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 45, 60, 90일 또는 그 이상; 4, 5, 6, 7, 8, 9, 10, 11, 12개월 또는 그 이상; 60, 59, 58, 57, 56, 55, 54, 53, 52, 51, 50, 49, 48, 47, 46, 45, 44, 43, 42, 41, 40, 39, 38, 37, 36, 35, 34, 33, 32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1년 후에 사용될 수 있다.
간 절제는 간 질환(예: 간경변, 말기 간 질환, 및/또는 간암)이 있는 대상체의 간 전체 또는 일부를 외과적으로 제거하는 것이다. 개시된 방법은 간 절제 전 또는 후에 언제든지 대상체에게 수행될 수 있다. 한 측면에서, 개시된 방법은 간 절제 수술 5, 4, 3, 2, 또는 1년; 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 또는 1개월; 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 또는 3일; 60, 48, 36, 30, 24, 18, 15, 12, 10, 9, 8, 7, 6, 5, 4, 3, 또는 2시간 전; 또는 간 절제 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 75, 90, 105, 120분; 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 15, 18, 24, 30, 36, 48, 60시간; 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 45, 60, 90일 또는 그 이상; 4, 5, 6, 7, 8, 9, 10, 11, 12개월 또는 그 이상; 60, 59, 58, 57, 56, 55, 54, 53, 52, 51, 50, 49, 48, 47, 46, 45, 44, 43, 42, 41, 40, 39, 38, 37, 36, 35, 34, 33, 32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1년 후에 사용될 수 있다.
본원에 기재된 벡터 또는 조성물은 경구, 국소, 정맥내, 피하, 경피, 경피, 근육내, 관절내, 비경구, 동맥내, 피내, 뇌실내, 두개내, 복강내, 병변내, 비강내, 직장, 질, 흡입 또는 이식된 저장소를 통하는 것을 포함하는 임의의 경로를 통해 대상체에게 투여될 수 있다. 용어 "비경구"는 피하, 정맥내, 근육내, 관절내, 활막내, 흉골내, 척추강내, 간내, 병변내, 및 두개내 주사 또는 주입 기술을 포함한다. 일부 구현예에서, 벡터 또는 조성물의 투여는 정맥내이다.
본 개시의 또 다른 측면은 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및/또는 POM121C로 이루어진 군으로부터 선택되는 하나 이상의 전사 인자, 및 이의 기능적 단편의 양 또는 기능을 증가시키는 상기 기재된 조성물 및 DNAJB1/HSP40, ATF6, ATF4 및 PERK로 이루어진 군으로부터 선택된 하나 이상의 전사 인자의 양을 감소시키거나 기능을 억제하는 조성물 모두를 투여하는 것에 관한 것이다. 일부 구현예에서, 두 조성물은 동시에 투여된다. 다른 구현예에서, 하나의 조성물은 다른 것보다 먼저 투여된다. 일부 구현예에서, 임의의 전술한 측면의 방법은 HNF4α의 발현 또는 기능을 상향조절하는 것을 추가로 포함한다. 일부 구현예에서, 임의의 전술한 측면의 방법은 HNF4α 작용제를 추가로 투여하는 것을 포함하며, 용어 작용제는 모든 목적을 위해 본원에 참조로 포함된 미국 특허 출원 공개 US2014/0249209에 보다 완전히 기재된 조성물을 지칭한다.
벡터 또는 임의의 전술한 측면의 조성물에 대한 투여 빈도는 적어도 1년에 1회, 2년에 1회, 3년에 1회, 4년에 1회, 5년에 1회, 6년에 1회, 7년에 1회, 8년에 1회, 9년에 1회, 10년에 1회, 적어도 2개월에 1회, 3개월에 1회, 4개월에 1회, 5개월에 1회, 6개월에 1회, 7개월에 1회, 8개월에 1회, 9개월에 1회, 10개월에 1회, 11개월에 1회, 적어도 1개월에 1회, 3주에 1회, 2주에 1회, 1주에 1회, 1주에 2회, 1주에 3회, 1주에 4회, 1주에 5회, 1주에 6회, 또는 매일을 포함하나 이에 제한되는 것은 아니다. 투여는 또한 연속적일 수 있고 임의의 원하는 특정 범위 내에서 화합물의 수준을 유지하도록 조정될 수 있다. 임의의 전술한 측면의 벡터 및/또는 조성물을 사용하여 간 질환을 치료하기 위해 본원에 사용된 용어 "투여" 또는 "투여하는"은 모든 목적을 위해 본원에 참조로 도입된 미국 특허 출원 공개 2018/0057839에 보다 완전히 기재된 투여 형태를 포함한다.
실시예
하기 실시예는 개시된 주제에 따른 조성물, 방법 및 결과를 예시하기 위해 아래에 제시된다. 이들 예는 본원에 개시된 주제의 모든 측면을 포함하는 것으로 의도되지 않고, 오히려 대표적인 방법 및 결과를 예시하기 위한 것이다. 이들 실시예는 당업자에게 자명한 본 발명의 균등물 및 변형을 배제하도록 의도되지 않는다.
실시예 1: 방법 및 재료
인간 샘플 및 간세포 분리. 비식별화된 정상 인간 간 조직 및/또는 세포는 NIH 계약 번호 HSN276201200017C 하에 지원된 피츠버그 대학의 인간 연구 검토 위원회(Human Research Review Committee)에서 승인한 프로토콜에 의해 서면 동의를 얻은 후 간 조직 세포 분배 시스템(Liver Tissue Cell Distribution System)(Pittsburgh, PA)을 통해 얻었다. 성인 인간 간 조직 및/또는 세포는 또한 피츠버그 대학의 인간 연구 검토 위원회 및 기관 검토 위원회(Institutional Review Board)(식별자가 제거된 면제; IRB#: PRO12090466)에서 승인한 프로토콜에 따라 UPMC 아동 병원의 Ira J Fox 연구소에서 얻었다 (표 1). 간세포는 이전에 설명한 대로 3단계 콜라게나제 소화 기술을 사용하여 분리되었다(Gramignoli R et al., 2012). 트리판 블루 배제를 사용하여 이전에 설명한 대로 분리 후 세포 생존율을 평가했으며 생존율이 >80%인 세포 제제만 분석에 사용했다.

인 실리코 HNF4α 번역 후 변형(PTM) 분석. HNF4α 세포 국소화를 조절하는 PTM을 식별하기 위해 데이터베이스 및 간행물에서 컴퓨터 검색을 통해 인 실리코 분석을 수행했다(도 5). 프로세스는 식별(identification), 선별(screening) 및 선택(selection)의 세 단계로 나뉜다. 처음에는 51개의 PTM이 식별되었다. 다음으로 선별 단계에서 두 가지 제거 기준을 적용하여 23개의 PTM을 선택했다(도 5). 2개의 인산화 및 1개의 아세틸화 변형이 평가할 수 있는 HNF4α 국소화와 관련된 가장 그럴듯한 PTM으로 선택 단계에서 확인되었다.
기체 크로마토그래피-질량 분석법을 사용한 안정 동위원소 분석. 100만개의 인간 간세포를 13-C6-표지 글루코스 및 글루타민 동위원소 추적자의 존재 하에 DMEM(Dulbecco's Modified Eagle's Medium) F12에서 96시간 동안 배양하였다(Thermo Fisher Scientific, San Jose, CA). 배지를 제거하고 세포를 얼음처럼 차가운 인산완충생리식염수로 세척하였다. 다음으로, 세포를 400μL 메탄올 및 1 μL 노르발린을 함유하는 400μL 물에 켄칭하고, 긁어내고, 800μL 얼음처럼 차가운 클로로포름으로 세척하고, 4℃에서 30분간 볼텍싱하고, 4℃에서 7,300 rpm으로 10분간 원심분리하였다. 대사 산물(metabolite) 분석을 위해 상부 수상(aqueous phase)을 수집했다. 대사 산물 추출물을 14,000g에서 10분간 원심분리하여 극성상, 단백질 간상, 클로로포름상을 분리하였다. 물/메탄올 상을 포함하는 극성 대사 산물을 새로운 미세원심분리 튜브로 옮기고 SpeedVac에서 건조시키고 기체 크로마토그래피-질량 분석(GC-MS) 분석까지 -80℃에서 보관하였다. 그런 다음, 30 μL의 메톡시아민 하이드로클로라이드(Thermo Scientific)를 건조된 샘플에 첨가하고 간헐적으로 볼텍싱하면서 30℃에서 2시간 동안 인큐베이션하였다. 샘플에 총 45μL의 MMBTSTFA + 1% 털트-부틸디메틸클로로실란을 첨가하고 55℃에서 1시간 동안 인큐베이션하였다. 유도체화된 샘플을 유리 삽입물이 있는 가스 크로마토그래피(GC) 바이알로 옮기고 GC-MS 자동샘플러에 추가했다. GC-MS 분석은 Agilent 5977B 질량 분석기에 연결된 30-m HP-5MSUI 모세관 컬럼이 장착된 Agilent 7890 GC(Santa Clara, CA)를 사용하여 수행되었다. 극성 대사 산물의 경우 GC 오븐에 대해 다음 가열 사이클이 사용되었다: 3분 동안 100℃, 이어서 300℃까지 5℃/분의 램프 및 48분의 총 실행 시간 동안 300℃에서 유지하였다. 스캔 모드에서 데이터를 수집했다. 대사 산물의 상대적 풍부함은 각 대사 산물 단편에 대한 잠재적으로 표지된 모든 이온의 통합 신호로부터 계산되었다. 질량 동위원소 분포는 모델로 분석하기 전에 IsoCorrectoR을 사용하여 본래 풍부도에 대해 수정되었다. 대사 산물 수준은 내부 표준 노르발린의 신호로 정규화되었다. 부분 농축 계산은 기질에서 중간 대사 산물에 대한 13C의 부분 기여도를 나타낸다. 이는 다음과 같이 계산된다:
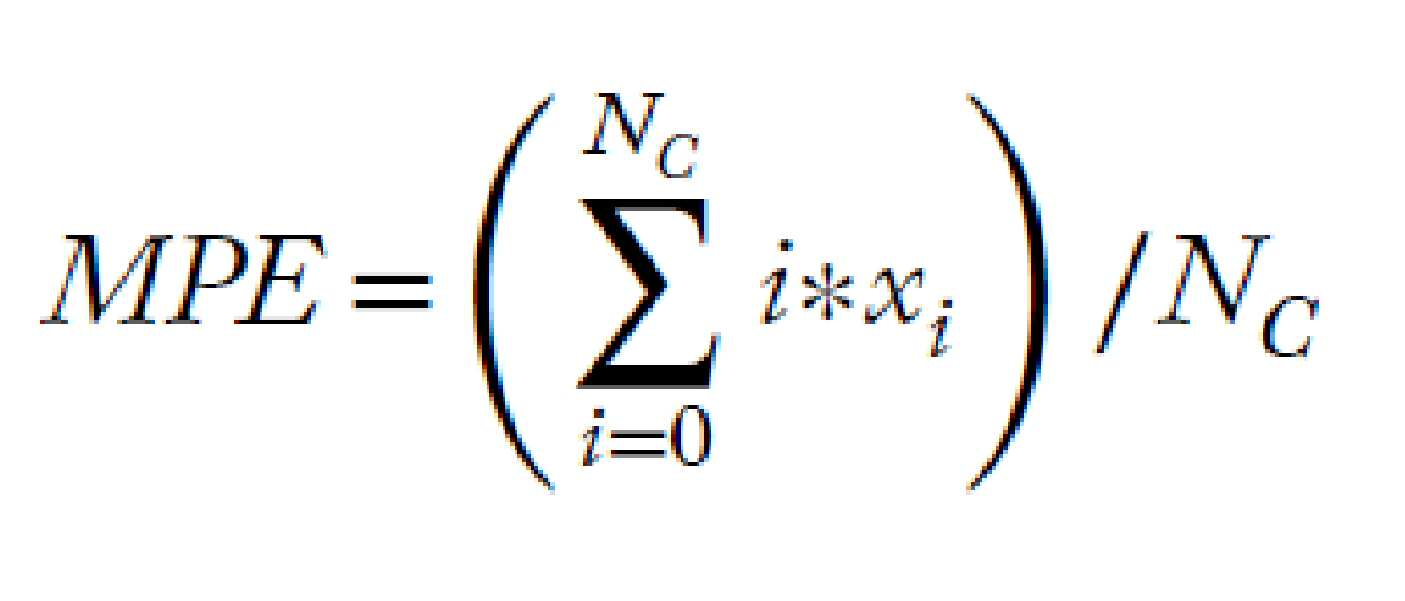
여기서 NC는 13C로 표지할 수 있는 탄소의 수이고, xi는 (M + i)번째 동위 원소의 비율이다.
면역조직화학 및 HNF4α 정량화. 파라핀이 포매된 간 조직을 자일렌으로 탈파라핀화하고 에탄올로 탈수하였다. 항원 언마스킹(unmasking)은 pH 6.0의 시트르산 완충액에서 끓임으로써 수행되었다. 그런 다음 슬라이드를 3% 과산화수소에서 인큐베이션하고 정상 동물 혈청으로 차단한 다음, 1차 항체와 함께 4℃에서 밤새 인큐베이션했다. 사용된 1차 항체는 표 2에 나열되어 있다. 그런 다음 조직 섹션을 1차 항체의 동물 종에 해당하는 비오틴화된 2차 항체와 함께 인큐베이션하고(BA-1000; Vector Laboratories, Burlingame, CA), 3,3'-디아미노벤지딘에 노출시켜서(SK-4105; Vector Laboratories) 퍼옥시다제 활성을 시각화했다. 대조염색은 Richard-Allan Scientific Signature Series Hematoxylin(Thermo Scientific, Waltham, MA)으로 수행되었다. 정량화를 위해 2명의 간 병리학자가 핵 및 세포질 HNF4α의 면역 반응성을 독립적으로 등급을 매겼으며, 샘플당 3개의 고-전력 필드에서 1,000개의 간세포를 계산했다. 정상 간(n = 2), 차일드-퍼 B(n = 4) 및 차일드-퍼 C(n = 2)가 이러한 분석에 포함되었다. 차일드-퍼 B 및 C는 간경변 인간 간으로 그룹화되고 결과는 계산된 총 세포 수에 대한 백분율로 표시된다.
| 항체/표적 | 종 | 면역조직화학 희석배율 |
웨스턴 블롯 희석배율 |
회사/카탈로그 번호 |
| HNF4α | 생쥐 | 1:200 | 1:1000 | Abcam/Ab41898 |
| 아세틸-HNF4α(Lys106) | 토끼 | - | 1:500 | Cusabio/CSB-PA727840 |
| cMET | 토끼 | 1:200 | 1:1000 | Cell Signaling/8198T |
| 총 AKT | 토끼 | - | 1:1000 | Cell Signaling/ 4691S |
| 포스포-AKT(Ser473) | 토끼 | 1:50 | 1:1000 | Cell Signaling/4060S |
| 포스포-AKT(Thr308) | 토끼 | 1:100 | 1:1000 | Cell Signaling/9275S |
| 총 AMPKα | 토끼 | - | 1:1000 | Cell Signaling/5831S |
| 포스포-AMPKα(Thr172) | 토끼 | 1:100 | 1:1000 | Cell Signaling/2535S |
| 총 EGFR | 토끼 | - | 1:1000 | Cell Signaling/ 4267S |
| 포스포-EGFR(Y1086) | 토끼 | - | 1:1000 | Cell Signaling/2220S |
| 포스포-H3(Ser10) | 토끼 | 1:200 | 1:1000 | Cell Signaling/9701S |
| 카스파제 3 활성 | 토끼 | 1:100 | 1:500 | Abcam/Ab32042 |
| HDAC1 | 토끼 | - | 1:100 | Cell Signaling/2062 |
| 히스톤 H3 | 생쥐 | - | 1:100 | Santa Cruz/SC517576 |
| B-액틴 | 토끼 | - | 1:2000 | Cell Signaling/4970S |
단백질 추출 및 웨스턴 블로팅. 단백질 발현 분석을 수행하기 위해, 분리된 간세포를 두 부분으로 나누었다; 한 분획은 이전에 설명한 표준 절차(Bell AW et al., 2006)에 따라 총 단백질 추출에 사용되었고, 다른 분획은 핵 단백질 분리에 사용되었다. 핵 단백질 분리를 위해, 환자당 1 x 107 에서 5 x 107 사이의 분리된 간세포를 세척하고 40mmol/L Tris(pH 7.6), 14mmol/L NaCl 및 1mmol/L EDTA에서 수거한 다음 원심분리(5분, 100g)하였다. 세포 펠렛을 2mL의 저장성 완충액[10mmol/L HEPES (pH 7.9), 10mmol/L NaH2PO4, 1.5mmol/L MgCl2, 1mmol/L DTT, 0.5mmol/L 스퍼미딘, 및 프로테아제 및 포스파타제 억제제 칵테일을 포함하는 1mol/L NaF (Sigma, St. Louis, MO)]에 현탁시켰다. 얼음 위에서 10분간 인큐베이션한 후, 샘플을 Dounce 균질화기에서 균질화한 다음 원심분리했다(5분, 800g). 트리판 블루 염색으로 세포 용해를 모니터링했다. 상층액은 세포질 추출물로 저장되었다. 핵 펠렛을 동일한 완충액에서 추가로 2회 세척하였다.
핵 단백질은 연속 교반과 함께 4℃에서 45분 동안 고장성 완충액[30mmol/L HEPES (pH 7.9), 25% 글리세롤, 450mmol/L NaCl, 12mmol/L MgCl2, 1mmol/L DTT, 및 프로테아제 및 포스파타제 억제제 칵테일을 포함하는 0.1mmol/L EDTA (Sigma, St. Louis, MO)] 50-100μL에서 추출되었다. 추출물을 30,000g에서 원심분리하고, 상층액을 수집하고 150mmol/L NaCl을 함유하지만 동일한 용액에 대해 2시간 동안 투석하였다. 단백질 농도는 Bicinchoninic Acid assay(Sigma, St. Louis, MO)에 의해 결정되었다.
표준 절차에 따라 웨스턴 블롯 분석을 수행했다(Natarajan A et al., 2007). 각 단백질 밴드의 강도는 National Institutes of Health Image J 소프트웨어를 사용하여 정량화되었다. 1차 항체 및 그 희석액은 상기 표 2에 나와 있다.
RNA 시퀀싱 및 분석. 전체 게놈 가닥 특이적 RNA-seq를 사용하여 인간 분리된 1차 간세포로부터 RNA 발현 수준을 프로파일링했다. RNA-Seq 라이브러리는 이전(Hainer SJ et al., Genes Dev. 2015) 및 문헌(Kumar R et al., 2012)에 설명된 대로 준비되었다. TRIzol을 사용하여 장 세포에서 RNA를 추출한 후 제조업체의 지침에 따라 컬럼 정제(Zymo RNA clean and concentrator column)를 수행했다. 총 RNA는 풀링된 안티센스 올리고 혼성화를 사용하여 rRNA를 고갈시켰고, 이전에 설명한 대로 RNaseH 소화를 통해 고갈되었다 (Morlan JD et al., 2012; Adiconis X et al., 2013). Zymo RNA clean and concentrator column을 통한 정제 후, 첫 번째 가닥 cDNA가 합성되었다. 이어서, 두 번째 가닥 cDNA를 합성, 정제 및 단편화하였다. Illumina 기술을 사용하여 RNA-seq 라이브러리를 준비했다. 간단히 말해서, 말단 수선, A-테일링(A-tailing) 및 바코드 어댑터 결찰 후 PCR 증폭 및 크기 선택을 수행했다. 라이브러리의 완전성은 quBit 정량화, 단편 분석기 크기 분포 평가 및 각 라이브러리에서 ~10개 단편의 생어(Sanger) 시퀀싱으로 확인되었다. 라이브러리는 페어드엔드(paired-end) Illumina 시퀀싱을 사용하여 시퀀싱되었다.
페어드 엔드 리드(Paired-end read)는 QIAGEN의 CLC Genomics 워크벤치를 사용하여 hg38에 정렬되었고 TPM(transcript per million)으로 평가되었다. 데이터를 정렬하기 위해, Cluster 3.0(De Hoon MJ et al., 2004)을 사용하여 K-평균 클러스터링을 수행하고 Java TreeView(Saldanha AJ, 2004)를 사용하여 히트맵을 생성했다. 미스매치(Murphy SL et al., 2015)에 대한 기본 설정으로 삽입 비용(Goldman L et al., 2016)과 결실 비용(Goldman L et al., 2016)이 사용되었다. IPA (Ingenuity Pathway Analysis)는 차등적으로 발현된 유전자를 식별하고, 다운스트림 효과를 예측하고, 표적을 식별하는 데 사용되었다(QIAGEN Bioinformatics; www.qiagen.com/ingenuity). IPA 내의 조절 효과 분석은 상류 조절자와 생물학적 기능 간의 관계를 식별하는 데 사용되었다. 기본 설정이 분석에 사용되었다(즉, 상류 조절자는 유전자, RNA 및 단백질로 제한됨). RNA-seq 데이터는 Gene Expression Omnibus(등록 번호 www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE134422)에서 사용할 수 있다.
정상 인간 간세포에서 AKT 억제. 정상 인간 간세포(1백만 세포/웰)를 콜라겐 코팅된 웰에서 배양하였다. 세포를 성장 인자 또는 혈청 없이 6시간 동안 배양하였다. 그런 다음 세포를 AKT 억제제인 5μM의 MK-2206(Cayman Chemical, Ann Arbor, Michigan)으로 24시간 동안 처리하였다. 총, 세포질 및 핵 단백질은 앞에서 설명한 대로 웨스턴 블로팅을 위해 추출되었다.
통계 분석. 데이터는 평균 ± SD로 표현되었다. 2개의 통계 그룹에 대한 웨스턴 블롯 결과는 Mann-Whitney 비모수 검정에 의해 평가되었고 3개의 통계 그룹에 대해서는 Kruskal Wallis 비모수 검정에 의해 평가되었다. 그룹 간의 비교는 Dunn 다중 비교 테스트에 의해 수행되었다. 분석된 단백질 간의 연관성은 스피어만 순위 상관계수 테스트를 사용하여 평가되었다. 차일드-퍼 점수와 MELD 점수로 측정된 임상 상태와 단백질 발현 사이의 관계를 설명하기 위해 선형 회귀가 사용되었다. 통계는 Prism 4.0(GraphPad Software Inc., San Diego, California, USA)을 사용하여 수행되었다. 차이는 P < 0.05일 때 유의한 것으로 간주되었다.
웨스턴 블롯으로 분석한 단백질 간의 직접적인 의존성을 확인하기 위해, 경로분석(구조방정식모델)을 이용하였다. 경로 분석 모델은 종속 변수와 다중 독립 변수 간의 관찰된 상관관계 사이의 가능한 인과 관계를 설명하는 것을 목표로 한다. 경로 모델은 연구 프레임워크와 회귀 가중치 및 모델 적합도 결과를 기반으로 경로를 추가 및 제거하여 테스트 및 수정되었다. 결과는 연구 시스템에 대한 변수의 직접 및 간접 효과를 보여주는 다이어그램으로 표시되었다. 변수 간의 상관관계와 선형 관계는 P < 0.05와 중요도를 나타내는 임의의 계수(숫자가 클수록 큰 관계를 나타냄)에 의해 결정된다. 경로 분석은 InfoStat 버전 2013(Grupo InfoStat, FCA, Universidad Nacional de Cordoba, Cordoba, Argentina)을 사용하여 수행되었다.
샘플의 임상 상태를 구별하는 단백질 그룹을 밝히기 위해 자율(Unsupervised) 다변량 주성분 분석(PCA)이 웨스턴 블롯 데이터에 적용되었다. 대부분의 분산을 설명하는 주성분(PC)의 산점도(Scatter plot)가 그려졌다. PCA 분석에는 통계 소프트웨어 JMP 버전 14(SAS Institute, Cary, NC, USA)가 사용되었다.
실시예 2. 말기 간부전이 있는 인간 간에서 HNF4α 핵 국소화는 감소하지만 세포질 국소화는 증가된다.
HNF4α는 전사 인자로 기능하며 활성을 위해서는 핵 국소화가 필요하다 (Babeu JP et al., 2014; Chellappa K et al., 2012; Guo H, 2014; Hong YH et al., 2003; Lu H et al., 2016, Song Y et al., 2015; Soutoglou E et al., 2000; Sun K et al., 2007; Yokoyama A et al., 2011; Zhou W et al., 2012; Bell AW et al., 2006; Kritis AA et al., 1996; Tanaka T et al., 2006; Walesky C et al., 2015). 따라서, HNF4α의 위치를 결정하고 발현을 간 대상부전(decompensation)과 연관시키기 위해 병든 간 표본의 간세포에 대한 면역 조직 화학(immunohistochemistry) 및 웨스턴 블롯을 수행했다. 말기 간부전이 있는 간의 간세포의 약 78%는 HNF4α의 세포질 발현 또는 세포질 및 약한 핵 발현을 모두 나타내는 반면, 정상 인간 간은 75%의 간세포가 HNF4α의 강한 핵 국소화를 나타냈다. 웨스턴 블롯에 의해 평가된 분리된 간세포로부터의 총 HNF4α 단백질 발현은 말기 간과 정상 대조군 사이에 통계적 차이를 나타내지 않았다(P = 0.166; 도 1A). 퇴행성 질환이 있는 환자와 기능적 대상부전 정도에 따른 대조군의 간에서 HNF4α 발현의 차이를 식별하는 능력은 대규모 환자 코호트에 대한 연구가 필요했기 때문에 이 결과는 놀라운 일이 아니다(Guzman-Lepe J et al., 2018). 그러나 본 연구에서는, HNF4α 위치에 따라 통계적으로 유의한 차이가 관찰되었다. HNF4α는 정상 대조군에서 분리된 간세포와 비교할 때, 기능적으로 보상되지 않은 간에서 분리된 간세포의 세포질에서 높은 수준(P = 0.023; 도 1B) 및 핵에서 낮은 수준(P = 0.023; 도 1C)으로 검출되었다.
HNF4α의 기능과 안정성은 많은 번역-후 변형자에 의해 조절되기 때문에(Chellappa K et al., 2012; Guo H, 2014; Hong YH et al., 2003; Lu H et al., 2016, Song Y et al., 2015; Soutoglou E et al., 2000; Sun K et al., 2007; Yokoyama A et al., 2011; Zhou W et al., 2012), 그리고 핵 국소화가 활성에 중요하기 때문에, HNF4α 국소화를 조절하는 변형자를 평가하기 위한 인 실리코 분석을 수행했다. AMPKα 활성화가 HNF4α 전사를 조절하는 것으로 밝혀졌다(Hong YH et al., 2003). 또한, AKT 경로에 의해 매개될 수 있는 HNF4α의 아세틸화는 분자를 안정화시켜 핵에서의 유지를 촉진한다(Soutoglou E et al., 2000)(도 5).
실시예 3: HNF4α는 진행성 간 질환에서 인간 간세포 기능의 주요 조절자이다.
다음 평가는 정상 대조군(n=4)의 인간 간세포와 간경변 및 말기 간부전 환자로부터 회복된 간세포(n=4)(차일드-퍼 C) 간의 유전자 발현 차이를 비교하기 위해 수행되었으며, 연구를 NASH 및 알코올 매개 Laennec's 간경변 환자로 제한했다. RNA-seq 데이터의 계층적 클러스터링은 K-평균 클러스터링의 히트맵에서 계산된 간경변 및 간 기능 장애와 관련된 세 가지 주요 동적 패턴을 나타냈다(대조군에 대한 log2 FC; K=3). 클러스터 I(3478개 유전자) 및 III(1669개 유전자)는 대조군 인간 간세포에 비해 말기 간부전 환자의 간세포에서 중간 내지 고도로 상향 조절된 유전자를 나타낸다. 이 클러스터의 대부분의 유전자는 자가포식(authphagy) 및 세포자살 신호 전달과 관련이 있다(데이터는 표시되지 않음).
그러나 클러스터 II는, 말기 간세포에서 유의하게 하향 조절된 1669개의 유전자로 구성되었으며, 세린-트레오닌 단백질 키나아제(AKT1), 사이토크롬 P450(cytochrome P450 [CYP]c8, CYP2c9, CYP2e1, CYP3A4) 및 간세포 핵 인자(HNF4α, forkhead box a1[FOXa1])을 암호화하는 유전자를 포함했다. 이 클러스터에 표시된 상위 경로에는 파르네소이드 X 수용체/레티노이드 X 수용체(RXR) 및 간 X 수용체/RXR 활성화, 미토콘드리아 기능 장애, 산화적 인산화 및 RXR 기능 억제가 포함된다. 이러한 하향 조절된 유전자에 대한 경로 분석은 HNF4α가 중심 상류 조절자임을 보여주었으며, 히트맵은 NASH 및 알코올 매개 Laennec's 간경변 환자의 간세포의 유전자 발현 프로필에서 많은 유사성을 확인했다(데이터는 표시되지 않음). 이러한 결과는 말기 부전이 있는 간경변성 간에서 회수된 쥐 간세포의 유전자 발현 프로필과 거의 동일했다(Liu L et al., 2012).
실시예 4: cMET 및 AKT 인산화는 말기 간부전 환자의 인간 간세포에서 HNF4α 핵 국소화와 상관관계가 있다.
EGFR 및 cMET은 인 실리코 및 RNAseq 분석에서 확인된 AMPK 및 AKT 경로(Komposch K et al., 2015; Paranjpe S et al., 2016; Tsagianni A et al., 2018)를 조절하는 것으로 나타났기 때문에, 간 표본에서 이러한 분자에 대한 HNF4α 항체-기반 분석의 중요한 조절자로 수행되었다. 비대상 간 표본에서 cMET 발현은 면역조직화학 및 웨스턴 블롯(P = 0.023; 도 2A 및 2B) 모두에 의해 측정될 때 분리된 대조군 인간 간세포와 비교할 때 현저히 감소되었다. 정상 및 병든 간 표본 간에 EGFR 발현에는 유의한 차이가 없었다(도 2A 및 2B). 그러나 EGFR의 활성 형태인 포스포-EGFR(Y1086)은 정상 인간 간세포와 비교할 때 비대상 질환 환자의 병든 간에서 유래한 간세포에서 높게 발현되었다(도 6A 및 6B). 또한, 세포 사멸과 간세포 복제의 연속적인 주기가 간경변의 특징이므로(Tsochatzis EA et al., 2014), 환자의 간세포에서 이러한 관찰은 면역조직화학 및 웨스턴 블롯을 사용하여 말기 간세포에서 복제 [포스포-H3(Ser10)] 및 세포 사멸(활성 카스파제 3) 마커의 발현을 입증하는 말기 간부전으로 확증되었다.
cMET는 AMPKα 및 AKT를 제어할 수 있고 cMET는 기능적으로 비대상된 간의 간세포에서 유의하게 하향조절되므로, AMPKα 및 AKT의 활성화 과정을 분석했다. 총 AMPKα, 활성화된 AMPKα(Thr172) 및 그 기능 비대상 간세포와 정상 인간 간세포 간에 통계적으로 차이가 없었다(도 2A 및 2B). 그러나, 총 AKT, 활성화된 AKT(Thr308) 및 그 비율은 간 표본 및 간 기능 비대상 환자의 분리된 간세포에서 유의하게 감소했다(도 2A 및 2B). 또 다른 AKT 인산화 부위(Ser473)는 간 표본이나 정상 대조군 또는 비대상 표본에서 분리된 간세포에서 변하지 않았다(도 2A 및 B).
HNF4α의 핵 국소화와 번역 후 변형 간의 관계를 추가로 분석하기 위해 스피어만 순위 상관 테스트를 수행했다. cMET 발현은 총 HNF4α(r = 0.76; P = 0.021; 도 2C) 및 핵 HNF4α(r = 0.71; P = 0.037; 도 2C)와 통계적으로 양의 유의한 상관관계를 보였다. 활성화된 AKT(Thr308)는 또한 총 HNF4α(r = 0.73; P = 0.031; 도 2C) 및 핵 HNF4α(r = 0.82; P = 0.011; 도 2C)와 통계적으로 양의 유의한 상관관계를 보인 반면, 세포질 HNF4α는 cMET(r = -0.80; P = 0.014; 도 2C) 및 활성화된 AKT(Thr308)(r = -0.77; P = 0.021; 도 2C)와 음의 상관관계를 보였다. 또한, 포스포-AKT(Thr308)/총 AKT의 비율은 cMET(r = 0.80; P = 0.014; 도 6A) 및 총 AKT(r = 0.71; P = 0.037; 도 6A)와 양의 상관관계가 있다. 따라서, 감소된 cMET은 AKT 경로의 감소된 활성화, 핵에서 감소된 HNF4α 및 세포질에서 HNF4α의 더 많은 발현과 관련이 있었다.
실시예 5: HNF4α의 핵 국소화는 cMET/AKT 축에 의해 영향을 받고 간 기능 장애의 정도와 상관관계가 있다.
도 3A에서 볼 수 있듯이, 경로 분석은 cMET 발현과 핵 HNF4α 발현(0.56; P = 0.004) 사이의 유의한 인과 관계와 핵 HNF4α 수준과 활성화된 AKT(Thr308)/총 AKT 비율(0.05; P = 0.006) 사이의 직접적인 관계를 보였다. 모델링은 또한 총 HNF4α 발현 수준이 핵 국소화에 기여한다는 것을 보여주었다(0.60; P = 0.042). 그러나, cMET 발현은 총 HNF4α 발현(-0.37; P = 0.024)(도 3A)과 음의 관계를 가져서, cMET 발현이 총 HNF4α 발현에 직접적인 영향을 미치지 않고 핵 국소화에만 영향을 미친다는 것을 나타낸다. 핵 발현 수준이 간 기능 장애의 정도(차일드-퍼 점수)와 상관관계가 있는지 여부를 평가하기 위해, 선형 회귀 분석을 수행했는데, 핵 HNF4α 발현 수준이 차일드-퍼 점수(R2 = 0.80; P = 0.007)(도 3B)와 유의한 역 관계가 있음을 보여주었다. 함께, 이러한 경로 및 단백질 발현의 선형 회귀 통계 분석은 HNF4α 국소화가 간 질환 진행과 연관되고, cMET 발현 및 AKT 인산화가 간세포 HNF4α 핵 국소화 및 기능을 유지하는 데 중심적 역할을 한다는 것을 보여준다.
다음으로, 주성분 분석(PCA)을 수행하여 HNF4α 번역 후 변형자 관련 분자를 평가하고, 분자 패턴이 말기 간세포에서 간 기능과 상관관계가 있는지(차일드-퍼 점수) 묘사했다(도 3C 및 3D). 도 3C에 도시된 바와 같이, PC1(69.9%) 및 PC2(30.1%)는 연구된 분리된 간세포에서 간 기능 수준(차일드-퍼 점수)의 가변성을 100% 구별한다. 정상 인간 간세포를 특징으로 하는 벡터는 cMET 및 활성화된 AKT(Thr308)/총 AKT 비율, 총 HNF4α 및 핵 HNF4α인 반면, 인간 간세포 부전을 특징으로 하는 음성 특성은 세포질 HNF4α 및 활성 카스파제 3 발현이다(도 3C 및 3D). 이와 함께, 이 통계 분석은 말기 간부전이 있는 인간 간세포의 분자 프로파일링을 확증하고 cMET, 활성화된 AKT(Thr308), 및 전체 및 핵 HNF4α의 발현 사이의 인과 관계를 확립한다.
실시예 6: 아세틸화 감소를 통해 말기 간부전 환자에서 핵에서의 HNF4α 보유가 감소한다.
AKT의 표적 중 하나는 CREB 결합 단백질의 활성화이다(Dekker FJ et al., 2009). CREB 결합 단백질은 뉴클레오솜 DNA에 대한 전사 인자의 접근을 증가시켜 핵 내 전사 인자의 전사 및 보유를 활성화시키는 뉴클레오솜 히스톤에 대한 고유 아세틸화 활성을 갖는 것으로 잘 알려져 있다. 따라서 이 축은 HNF4α 핵 보유와 관련될 수 있다(Soutoglou E et al., 2000). 게놈 전체 전사체 분석 및 인 실리코 분석에서 cMET/AKT 키나아제 축 경로가 CREB 결합 단백질의 활성화를 통해 HNF4α의 국소화 및 안정성을 제어할 수 있음을 나타내므로(Kumar R et al., 2012), 아세틸화된 HNF4α의 핵 발현을 측정했고(도 4A-4C), 정상 대조군과 비교할 때 말기 간부전 환자의 간세포에서 핵의 HNF4α 아세틸화가 유의하게 감소되었음을 발견했다(P = 0.024; 도 4A). 그리고 HNF4α의 아세틸화가 간 기능 장애의 정도(차일드-퍼 점수)와 관련이 있음을 확인하기 위해, 선형 회귀 분석을 수행했으며, 아세틸화된 HNF4α의 감소가 간 기능 장애와 직접적으로 유의한 상관관계가 있음을 보였다(R2 = 0.71; P = 0.004; 도 4C). 원리의 증명으로, HNF4α 핵 국소화에서 활성화된 AKT(Thr308)의 역할을 확증하기 위해 AKT 신호 전달을 억제하여 갓 분리된 정상 인간 간세포에서 예비 실험을 수행했다. 갓 분리된 정상 인간 간세포를 강력한 알로스테릭 범-AKT 억제제(allosteric pan-AKT inhibitor)인 MK-2206으로 처리했다. AKT 억제 처리 24시간 후, 비처리 대조군과 비교하여 활성화된 AKT(Thr308)의 80%, 핵 HNF4α의 25% 및 아세틸화된 핵 HNF4α 발현의 14%가 감소되었다.
실시예 7: 핵에서 HNF4α의 보유는 여러 신호 분자에 의해 조절되며, 이는 말기 간부전과 유의하게 음의 연관성을 나타낸다.
HNF4α는 간 기능의 마스터 조절자이다(Babeu JP et al., 2014; Chellappa K et al., 2012; Guo H et al., 2014; Lu H et al., 2016, Song Y et al., 2015; Soutoglou E et al., 2000; Sun K et al., 2007; Xu Z et al., 2007; Zhou W et al., 2012; Bell AW et al., 2006). HNF4α 발현의 변화는 암, B형 및 C형 간염, 알코올 매개 간경변, NASH와 같은 여러 병인을 가진 간 질환과 관련이 있다(Babeu JP et al., 2014; Chellappa K et al., 2012; Guo H et al., 2014; Lu H et al., 2016, Song Y et al., 2015; Soutoglou E et al., 2000; Sun K et al., 2007; Xu Z et al., 2007; Zhou W et al., 2012; Bell AW et al., 2006). TLF가 있는 동물 모델에서 HNF4α 발현의 강력한 감소가 확인되었으며, 유전자 요법을 사용하여 HNF4α 생산을 복원함으로써 간 세포를 정상 기능으로 재부팅한다(Nishikawa T et al., 2014). 이러한 관찰이 인간에게 적용되는지 여부를 평가하기 위해, 간 기능이 비대상된 대규모 환자 코호트의 간에서 간-강화 전사 인자 발현에 대한 연구가 수행되었다(Guzman-Lepe J et al., 2018). HNF4α mRNA 수준이 하향 조절되고 차일드-퍼 분류에 기초한 간 기능 장애의 정도와 상관관계가 있는 것으로 밝혀졌다. 이러한 연구에서 HNF4α의 핵 국소화는 균일하지 않았다(Guzman-Lepe J et al., 2018).
인간 간세포는 NASH 및 알코올 매개 Laennec's 간경변으로 인한 간경변 및 말기(차일드-퍼 B, C) 간부전 환자의 외식된 간에서 분리되었다. 이러한 분리된 간세포에서 대조군 정상 간세포에서 볼 수 있는 것과 비교하여 세포질에 위치한 HNF4α의 증가와 핵의 HNF4α의 감소가 있었다. 또한, 인간 부전 간경변성 간세포에서 세포질 또는 핵으로의 HNF4α의 국소화는 간세포 기능 장애의 정도와 상관관계가 있었다. 이러한 데이터는 HNF4α 핵 수송 또는 보유를 조절하는 경로가 말기 간부전 치료의 표적이 될 수 있음을 나타낸다.
AMPK 및 AKT 키나아제는 HNF4α 국소화를 조절할 수 있는 주요 구성요소ㅇ이(Hong YH et al., 2003; Song Y et al., 2015; Soutoglou E et al., 2000). AMPK는 에너지 항상성을 유지하고, ATP(아데노신 삼인산) 생산 경로를 촉진하며, ATP 소비를 줄이는 데 중심 역할을 하는 반면(Woods A et al., 2017), AKT 활성화는 세포 증식, 생존 및 성장을 촉진한다(Manning BD et al., 2017, Morales-Ruiz M et al., 2017). AKT 활성화는 트레오닌 308 및/또는 세린 473에서의 인산화에 의해 매개된다(Praveen P et al., 2016; Inoue J et al., 2017). 본원에 개시된 것은 활성화된 AKT(Thr308) 수준이 말기 인간 간세포에서 유의하게 감소되었기 때문에 활성화된 AKT(Thr308)와 HNF4α 국소화 사이의 유의한 상관관계를 보여준다. 이러한 발견은 Thr308에서의 AKT 인산화가 간 질환의 말기 단계에서 간세포 부전에 중요한 역할을 할 수 있음을 나타낸다.
분석은 AKT와 AMPK의 상류 조절자이며 간 기능 및 재생과 관련된 두 가지 중심 수용체인 cMET 및 EGFR에 대해 수행되었다(Natarajan A et al., 2007; Komposch K et al., 2015; Paranjpe S et al., 2016; Tsagianni A et al., 2018; Alam A et al., 2017). 생쥐(mouse)에서 cMET와 EGFR의 결합된 파괴(disruption)는 간 항상성을 변경하고 말기 간부전으로 이어진다(Tsagianni A et al., 2018). 인간 부전 간경변 간세포에서, cMET의 발현 감소가 있었고 발현 감소는 HNF4α 국소화와 직접적으로 상관관계가 있었다. 대조적으로, 인간 부전 간경변 간세포 또는 대조군 인간 간세포에서 총 EGFR 발현에는 차이가 없었다. 따라서, 인간 간에서 cMET는 AKT 경로 활성화와 HNF4α 국소화 및 기능을 조절하는 데 중요한 역할을 할 수 있다. 또한, 다양한 통계 분석(스피어만 순위 상관 테스트, 경로 분석, 선형 회귀 분석 및 주성분 분석)을 사용하여 인간 부전 간경변 및 정상 간세포에서 분석된 번역 후 변형자 간의 연관성을 설정할 수 있다. 이러한 통계적 분석은 cMET과 활성화된 AKT(Thr308)가 핵 HNF4α의 발현 수준과 직접적인 관련이 있음을 보여주었다. cMET 단백질 발현과 총 HNF4α 사이에서 발견된 음의 연관성은 cMET 발현이 총 HNF4α 발현에 직접적인 영향을 미치지 않고 핵 국소화에만 영향을 미친다는 것을 나타낸다.
HNF4α의 아세틸화는 인간 부전 간경변 간세포에서 활성화된 AKT(Thr308)의 낮은 발현 수준과, 뉴클레오솜 DNA에 대한 전사 인자 결합을 증가시키는 고유 아세틸화 활성을 갖는 분자인 CREB 결합 단백질에 대한 AKT의 직접적인 효과에 기초하여, 간경변 부전 간세포에서 영향을 받을 수 있다. 실제로, 핵 HNF4α 아세틸화는 간경변성 간의 인간 간세포에서 현저하게 감소되었으며 그 수준은 간 기능 장애의 정도와 관련이 있었다. 이러한 관찰은 트레오닌 308에서의 AKT 인산화가 CREB 결합 단백질을 조절함으로써 아세틸화를 통해 HNF4α 핵 보유를 매개한다는 것을 나타낸다(Soutoglou E et al., 2000).
요약하면, 세포질에서 HNF4α의 국소화는 간 질환의 진행 단계 동안 핵에서 HNF4α를 유지하는 분자 경로의 변경으로 인해 발생한다. cMET 및 활성화된 AKT(Thr308)는 하향 조절되고 HNF4α의 아세틸화 및 핵 보유에 영향을 미친다. 이러한 데이터는 HNF4α를 핵에 국소화하는 것을 통해 만성 간 질환에서 간세포 기능의 회복을 보여준다.
실시예 8: 전사 인자 렌티바이러스(LV) 구축물(construct)을 사용한 1차 인간 간세포의 형질도입.
전사 인자 LV를 사용한 1차 인간 간세포의 형질도입. 간세포는 이중 콜라겐(두꺼운 층) 시스템에서 배양되어 간세포의 역분화를 방지한다. 콜라겐 샌드위치 프로토콜은 이후에 사용된다. 다음을 준비한다:
WARM: dPBS, HMM(기본+SingleQuots), HCM(HBM 기본 + HCM SingleQuots); ON ICE: 녹색 형광 단백질(GFP) LV*, 전사 인자(TF) LV*, Max Enhancer, TransDux; 기타: 1.5mL 튜브, 50mL 튜브, 팁, 피펫.
1. 두꺼운 층의 콜라겐에 웰당 5e5 간세포를 플레이팅하고 4시간 동안 세포를 부착시킨다.
2. 따뜻한 dPBS 2X로 웰을 세척하여 죽은 세포를 제거하고 배지를 500uL HMM(FBS 없음)으로 교체한다.
3. 5개의 튜브를 준비하고 다음과 같이 라벨을 붙인다: a. GFPLV-2; b. GFPLV-10; c. TFLV-0; d. TFLV-2; e. TFLV-10.
4. 50mL 튜브에 HMM/Max Enhancer/TransDux(HMT) 용액을 준비한다: 12.323mL HMM + 3.100mL Max Enhancer + 77.5uL TransDux.
5. 미리 라벨이 붙은 튜브에 LV 용액을 준비한다: a. GFPLV-2: 618.3uL HMM + 1.7uL GFP LV; b. GFPLV-10: 611.6uL HMM + 8.4uL GFP LV; c. TFLV-0: 620uL HMM; d. TFLV-2: 618.6uL HMM + 1.44uL TF4 LV; e. TFLV-10: 612.82uL HMM + 7.18uL TF4 LV.
6. 웰의 HMM 배지를 500μL HMT 용액으로 교체한다.
7. 각 LV 용액 100uL를 웰에 분배한다. 혼합할 접시를 흔들어준다.
8. 다음날 따뜻한 dPBS 2X로 웰을 세척하여 죽은 세포와 남아 있는 LV 용액을 제거한다.
9. 두꺼운 콜라겐으로 세포를 덮고 콜라겐이 겔화되도록 2시간 동안 둔다.
10. 500uL HCM을 웰에 추가하고 매일 신선한 HCM으로 교체한다.
11. 형질도입 후 72시간 및 96시간에 샘플을 얻는다(72시간 프로토콜 참조).
12. 96시간에 얻은 샘플의 경우 따뜻한 dPBS로 세포를 세척하고 배지를 500uL HCM(FBS 없음)으로 교체한다.
참고: *37℃의 수조에서 LV를 빠르게 해동한다. 후드로 옮겨 회전, 반전 또는 부드럽게 볼텍싱하여 혼합하고 얼음 위에 보관한다. 사용하지 않은 LV는 분취하여 -80℃에서 재냉동할 수 있으며 각 재냉동 시 바이러스 활성이 10-20% 손실된다.
전사 인자(TF) LV 구축물.
TF LV 구축물은 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, POM121C 또는 HNF4α를 암호화하는 폴리뉴클레오타이드 또는 DNAJB1/HSP40, ATF6, ATF4 또는 PERK에 해당하는 RNAi를 함유하는 렌티바이러스 벡터(Systems Bioscience, Cat#CS970S-1)이다.
ELISA(72 및 96시간)에 대해 조정 배지(conditioned medium) 수집. 각 그룹에 대해 2개의 웰에서 1200uL의 조정 배지를 수집하고 1.5mL 튜브로 옮긴다. 수집된 배지를 따뜻한 HMM으로 교체한다. 조정 배지를 2분 동안 20,000xg에서 원심분리 한다. 상층액을 새 튜브에 옮기고 -20℃에서 보관한다.
GFP 발현 및 브라이트필드(Brightfield)의 사진을 찍어 형질감염 효율을 결정한다(72 및 96시간). 따뜻한 dPBS로 부유(floating) 세포를 세척한다. 따뜻한 HCM으로 교체한다. GFP 발현에는 필터 2(녹색 여기(excitation))를 사용하고 브라이트필드에는 필터 6을 사용하여 사진을 찍는다.
RNA 추출을 위해 Qiazol에서 세포 용해물을 수집한다(72 및 96시간). 따뜻한 dPBS 2X로 세포를 세척한다. 600uL Qiazol로 웰을 코팅하고 1분 동안 인큐베이션한다. P1000을 사용하여 플레이트에서 세포를 긁어내고 1.5mL 튜브로 옮긴다. RNA가 분리될 때까지 -20℃에서 보관한다.
IF로 대한 웰을 고정한다(72시간). 따뜻한 dPBS 2X로 세포를 세척한다. 750uL 4% PFA 용액으로 웰을 코팅하고 40분 동안 인큐베이션한다. 1mL dPBS 3X로, 세척당 10분간 웰을 세척한다. dPBS 1mL를 추가한다. HNF4A가 염색될 때까지 4C에서 보관한다.
웨스턴 블롯에 대한 세포 용해물을 수집한다(72 및 96시간). 다음을 함유하는 얼음처럼 차가운 용해 용액을 준비한다:
| 1mL | 2mL | 3mL | |
| a. NP40 세포 용해 완충액 - 90% | 900uL | 1800uL | 2700uL |
| b. Complete (1 tab/1.5mL) - 6% | 60uL | 120uL | 180uL |
| c. Halt protease inhibitor - 2% | 20uL | 40uL | 60uL |
| d. 0.1M PMSF in ethanol - 2% | 20uL | 40uL | 60uL |
따뜻한 dPBS 2X로 세포를 세척한다. 200uL의 얼음처럼 차가운 용해 용액으로 웰을 코팅하고 워크인 냉장고에서 흔들면서 30분 동안 인큐베이션한다. 고무 청소기(rubber policeman)를 사용하여 세포를 분리하고 침전물 및 고체를 포함하는 용해물을 미리 라벨이 붙은 튜브에 수집하고 옮긴다. 4℃에서 10분 동안 20,000xg에서 회전시킨다. 상층액을 미리 라벨이 붙은 깨끗한 1.5mL 튜브에 옮긴다. -80℃ 냉동고에 용해물을 보관한다.
TF 면역형광 공동 염색(두꺼운 콜라겐 샌드위치 층이 있는 12-웰 플레이트용). 세포의 분리를 방지하기 위해 부드럽게 샘플을 흡인한다. 샘플을 건조시키지 않는다. * 최대 속도에서 5분 동안 회전을 줄인다. * 2차 항체는 실험에 따라 적절한 다른 항체로 대체될 수 있다.
고정(세포가 이미 고정된 경우 차단 및 투과 단계로 이동). 실온에서 40분 동안 PBS pH 7.4에서 4% 파라포름알데히드로 샘플을 고정한다. 샘플을 얼음처럼 차가운 PBS로 각 세척당 10분간 3X 세척한다. 염색을 진행하거나 염색이 될 때까지 4℃에서 보관한다(최대 2주).
차단 및 투과. 샘플을 1mL PBS로 2X 세척한다. 샘플을 1mL 세척 완충액(PBS, 0.1% BSA 및 0.1% Tween)으로 각 세척당 10분간 3X 세척한다. 1mL 차단 완충액(PBS, 10% 정상 당나귀 혈청, 1% BSA, 0.1% Tween 및 0.1% Triton X-100)에서 샘플을 2시간 동안 인큐베이션하여 차단하고 투과시킵니다.
항체 인큐베이션: *마우스 항-TF stock 1°Ab를 볼텍싱 및 스핀다운. 차단 완충액에서 1:500 마우스 항-TF 1°Ab 희석을 준비한다. 600uL의 희석된 1°Ab로 샘플을 코팅하고 가습 챔버에서 실온에서 6시간 동안 또는 4℃에서 밤새 인큐베이션한다. 1°Ab 용액을 흡인하고 세척 완충액으로 세포를 각 세척당 10분간 3X 세척한다. *당나귀 항-마우스IgG-AF594(Invitrogen A21203)를 볼텍싱 및 스핀다운한다. 차단 완충액에 1:250으로 희석된 2°Ab를 준비한다. 600μL의 희석된 2°Ab로 샘플을 코팅하고 실온에서 2시간 동안 가습 챔버에서 인큐베이션한다. 2°Ab 용액을 흡인하고 세척 완충액으로 세포를 각 세척당 10분간 3X 세척한다.
카운터염색 및 마운팅: PBS 3X로 샘플을 세척한다. 암실의 PBS에서 1ug/ml Hoechst 33342의 1 mL에서 2분 동안 세포를 인큐베이션한다. PBS로 샘플을 3X 세척한다. 샘플은 4℃의 암실에서 보관될 수 있다. RED 채널을 사용하여 TF를 테스트한다.
실시예 9: 전사 인자(TF) mRNA(50, 100, 500ng)를 사용한 1차 인간 간세포의 형질감염.
1차 인간 간세포의 형질감염. 다음을 준비한다:
WARM: DPBS, HMM(HMM 기본 배지 + HMM SingleQuots), Opti-MEM → RT; ON ICE: Lipofectamine Messenger Max → RT, mRNA → RT; 기타: 1.5mL 튜브, 50mL 튜브, 팁, 피펫.
1. 따뜻한 DPBS로 세포를 세척하고 배지를 500uL HMM(FBS 없음)으로 교체한다.
2. 다음과 같이 라벨이 붙은 두 세트의 튜브를 준비한다: a. GFP-50. b. GFP-100. c. GFP-500. d. TF-0. e. TF-50. f. TF-100. g. TF-500. TF는 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, POM121C 및 HNF4α에서 선택된다.
3. Opti-MEM에서 두 번 희석된 mRNA를 준비한다: a. DilGFP: 32.5uL OptiMEM + 3.61uL GFP mRNA. b. DilHNF: 40.3uL OptiMEM + 4.47uL TF mRNA.
4. 미리 라벨이 붙은 튜브의 첫 번째 세트에서 mRNA-OptiMEM 혼합물을 준비한다: a. GFP-50: 312.2uL Opti-MEM + 2.8uL DilGFP. b. GFP-100: 309.4uL Opti-MEM + 5.6uL DilGFP. c. GFP-500: 287.3uL Opti-MEM + 27.7uL DilGFP. d. HNF-0: 315uL Opti-MEM. e. TF-50: 311.5uL Opti-MEM + 3.5uL DilTF. f. TF-100: 308.1uL Opti-MEM + 6.9uL DilTF. g. TF-500: 280.7uL Opti-MEM + 34.3uL DilTF.
5. 희석된 Lipo 혼합물을 준비한다: a. 2,220.75uL Opti-MEM + 141.75uL Lipo.
6. 2-3초 동안 희석된 Lipo 혼합물을 볼텍싱하고 미리 라벨이 붙은 두 번째 세트의 튜브에 310uL를 분배한다. 실온에서 10분 동안 인큐베이션한다.
7. 각 mRNA-OptiMEM 혼합물의 310uL를 희석된 Lipo 혼합물이 함유된 튜브에 옮긴다. 실온에서 5분 동안 인큐베이션한다.
8. 각 웰에 각 혼합물 100uL를 분배한다.
9. 인큐베이션하고 다음날 아침, 따뜻한 dPBS로 세척하고 500uL HMM(FBS 없음)으로 교체한다.
10. 형질감염 후 24* 및 48*시간에 샘플을 얻는다(언제 간세포가 플레이팅 되는지에 따라 다름).
ELISA(24 및 48시간)에 대해 조정 배지(conditioned medium) 수집. 각 그룹에 대해 2개의 웰에서 1200uL의 조정 배지를 수집하고 1.5mL 튜브로 옮긴다. 수집된 배지를 따뜻한 HMM으로 교체한다. 조정 배지를 2분 동안 20,000xg에서 원심분리 한다. 상층액을 새 튜브에 옮기고 -20℃에서 보관한다.
GFP 발현 및 브라이트필드(Brightfield)의 사진을 찍어 형질감염 효율을 결정한다(24 및 48시간). 따뜻한 dPBS로 부유 세포를 세척한다. 따뜻한 HMM으로 교체한다. GFP 발현에는 필터 2(녹색 여기)를 사용하고 브라이트필드에는 필터 6을 사용하여 사진을 찍는다.
RNA 추출을 위해 Qiazol에서 세포 용해물을 수집한다(24 및 48시간). 따뜻한 dPBS 2X로 세포를 세척한다. 600uL Qiazol로 웰을 코팅하고 1분 동안 인큐베이션한다. P1000을 사용하여 플레이트에서 세포를 긁어내고 1.5mL 튜브로 옮긴다. RNA가 분리될 때까지 -20℃에서 보관한다.
IF로 웰을 고정한다(24시간). 따뜻한 dPBS 2X로 세포를 세척한다. 750uL 4% PFA 용액으로 웰을 코팅하고 20분 동안 인큐베이션한다. 1mL dPBS 3X로, 세척당 5분간 웰을 세척한다. dPBS 1mL를 추가한다. TF가 염색될 때까지 4C에서 보관한다.
웨스턴 블롯에 대한 세포 용해물을 수집한다(24 및 48시간). 다음을 함유하는 얼음처럼 차가운 용해 용액을 준비한다:
| 1mL | 2mL | 3mL | |
| a. NP40 세포 용해 완충액 - 90% | 900uL | 1800uL | 2700uL |
| b. Complete (1 tab/1.5mL) - 6% | 60uL | 120uL | 180uL |
| c. Halt protease inhibitor - 2% | 20uL | 40uL | 60uL |
| d. 0.1M PMSF in ethanol - 2% | 20uL | 40uL | 60uL |
따뜻한 dPBS 2X로 세포를 세척한다. 200uL의 얼음처럼 차가운 용해 용액으로 웰을 코팅하고 워크인 냉장고에서 흔들면서 30분 동안 인큐베이션한다. 고무 청소기(rubber policeman)를 사용하여 세포를 분리하고 침전물 및 고체를 포함하는 용해물을 미리 라벨이 붙은 튜브에 수집하고 옮긴다. 4℃에서 10분 동안 20,000xg에서 회전시킨다. 상층액을 미리 라벨이 붙은 깨끗한 1.5mL 튜브에 옮긴다. -80℃냉동고에 용해물을 보관한다.
면역형광 동시 염색(염색, 고정, 차단 및 투과, 항체 인큐베이션, 카운터염색 및 마운팅)은 상기 실시예 9에서 언급된 바와 동일하다.
실시예 10. 전사 인자 및 조절자 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300 및 POM121C는 말기 간부전이 있는 간경변성 간세포의 HNF4α 핵 발현을 개선한다.
간-강화 전사 인자는 말기 간경변이 있는 쥐의 간세포에서 안정적으로 하향 조절되며, 그 중 하나인 간세포 핵 인자 4 알파(HNF4α)의 강제 재발현이 기능을 회복하기 위해 기능 장애 간세포를 배양과 생체내 모두에서 재프로그래밍하는 것으로 밝혀졌다. 진행성 간 질환 환자의 대규모 코호트에서 병든 간에서 HNF4α mRNA 발현 수준이 간 기능 장애의 정도(차일드-퍼 분류)와 상관관계가 있으며 그 발현이 쥐 연구의 경우처럼 핵에 국한되지 않는 것으로 나타났다. 진행성 간경변 환자의 간에서는, 간 기능이 저하됨에 따라 HNF4α RNA 발현량이 감소하고, 세포질에서 단백질 발현이 발견된다. 이러한 발견은 퇴행성 간 질환 환자의 간 기능 손상을 설명할 수 있다. 더욱이, RNA-seq 분석은 HNF4α 및 핵 단백질 전위에 관여하는 기타 전사 인자/조절자-관련 경로가 말기 부전 환자의 간경변 세포에서 하향 조절되는 것으로 나타났으며, 여기서 HNF4α의 핵 수준은 유의하게 감소되었으며, HNF4α의 세포질 발현이 증가된 것으로 밝혀졌다. 또한, 소포체(ER) 스트레스의 4가지 주요 전사 조절자가 유의하게 상향 조절되는 것으로 밝혀졌다. 이 연구는 HNF4α 및 번역 후 변형과 관련된 경로의 조작이 말기 간부전 환자에서 간세포 기능을 회복시킬 수 있음을 나타낸다.
PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300 및 POM121C의 단백질 발현은 말기 간부전 환자의 간 기능 장애 정도와 상관관계가 있다. HNF4α가 제대로 기능하려면 핵에서 발현되어야 한다; 따라서 HNF4α의 핵 국소화와 관련된 신호 전달 경로는 기능이 비대상된 외식된 인간 간에서 분리된 간세포에서 분석되었다. 전사 인자 및 조절자 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300 및 POM121C가 RNA-seq 분석에서 HNF4α의 중요한 조절자로 확인되었기 때문에, NASH 또는 알코올 유발 간경변(차일드 퍼 "B" 및 "C")을 위해 간 이식을 겪은 환자의 간으로부터 분리한 1차 인간 간세포 또는 대조군 정상 간세포에서 이러한 분자에 대한 항체 기반 분석이 수행되었다. HNF4α 발현은 분리된 대조군 인간 간세포와 비교하면 웨스턴 블롯(도 8A)으로 측정할 때 비대상 간 표본에서 현저히 감소했다. 간부전이 진행됨에 따라 MTF1 발현에도 유의한 차이가 있었다. 또한, 단순 선형 회귀를 사용하여 차일드-퍼로 채점된 인간 간세포는 HNF4α 및 MTF1의 단백질 발현과 상관관계가 있었으며, HNF4α 및 MTF1 모두 간부전 정도와 유의하게 상관관계가 있음을 발견했다(p=0.007)(도 8B-8F). 또한, NR0B2(도 9A-D), NR5A2(도 10A-D), PROX1(도 11A-D)의 단백질 발현은 차일드 퍼 C 간세포에서 유의하게 낮았으며 이들의 발현은 간세포 기능 장애의 정도와 상관관계가 있었다.
HNF4α 핵 발현 및 위치에 대한 이러한 확인된 전사 인자 및 조절자의 역할을 더 이해하기 위해, 인간 간세포주를 CRISPR/Cas9를 사용하여 유전자 편집하여 PROX1 또는 NR5A2 또는 NR0B2 또는 MTF1 또는 SREBP1 또는 EP300 및 POM121C의 발현을 녹아웃(KO)시켰다(도 15A-B). PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300 또는 POM121C의 KO에 의해 HNF4α 핵 발현이 유의하게 감소하는 것으로 나타났다(도 15A). 특히 HNF4α의 높은 비-핵 발현은 PROX1 또는 SREBP1이 KO일 때 관찰되었다. 세포질에서 HNF4α의 발현은 말기 간부전이 있는 인간 간세포에 대한 이전 연구에서 유사하게 확인되었다. 또한 HNF4α 단독 또는 PROX1 또는 NR5A2 또는 NR0B2 또는 MTF1 또는 SREBP1 또는 POM121C와 조합하여 HNF4α의 핵 발현을 유도하는 효과를 테스트하기 위해, 간 이식을 겪는 NASH로 인한 말기 간부전 환자의 외식된 간에서 분리된 인간 간세포에서 치료를 수행했다(도 16). HNF4α-AAV 단독으로 처리한 지 96시간 후에 대조군(GFP-AAV)과 비교하여 HNF4α의 핵 발현이 약 1배 증가됨을 발견했다. 그러나 HNF4α-AAV 치료가 PROX1-AAV 또는 NR5A2-AAV 또는 NR0B2-AAV 또는 MTF1-AAV 또는 SREBP1-AAV 또는 POM121C-AAV와 조합되었을 때, 모든 조합은 HNF4α의 유의한 핵 발현을 유도했으며(도 16), 특히 조합이 HNF4α + PROX1 또는 SREBP1과 관련된 경우 유의한 핵 발현을 유도했다.
따라서, 이 연구는 전사 인자 및 조절자 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300 및 POM121C가 말기 간부전이 있는 간경변 간세포에서 HNF4α의 핵 발현을 개선함을 입증한다. 더욱이, 이 결과는 HNF4α와 하나 이상의 전사 인자 및 조절자(PROX1 또는 NR5A2 또는 NR0B2 또는 MTF1 또는 SREBP1 또는 EP300 및 POM121C)를 포함하는 모든 조합이 HNF4α의 핵 발현 및 말기 간 부전을 치료하는 HNF4α의 재프로그래밍 능력을 향상시킨다는 것을 보여준다.
참고문헌:
Tsochatzis EA, Bosch J, Burroughs AK. Liver cirrhosis. Lancet 2014; 383:1749-1761.
Murphy SL, Xu J, Kochanek KD, Curtin SC, Arias E. Deaths: Final Data for 2015. In: Prevention CfDCa, editor.: National Vital Statistics Reports; 2017.
Goldman L, Schafer AI. Goldman-Cecil medicine. 25th edition. ed. Philadelphia, PA: Elsevier/Saunders, 2016: 2 volumes (xl, 2722, I2108 pages).
Lopez PM, Martin P. Update on liver transplantation: indications, organ allocation, and long-term care. Mt Sinai J Med 2006;73:1056-1066.
Archambeaud I, Auble H, Nahon P, Planche L, Fallot G, Faroux R, Gournay J, et al. Risk factors for hepatocellular carcinoma in Caucasian patients with non-viral cirrhosis: the importance of prior obesity. Liver Int 2015;35:1872-1876.
Donato F, Gelatti U, Limina RM, Fattovich G. Southern Europe as an example of interaction between various environmental factors: a systematic review of the epidemiologic evidence, Oncogene 2006;25:3756-3770.
Gelatti U, Covolo L, Talamini R, Tagger A, Barbone F, Martelli C, Cremaschini F, et al. N-Acetyltransferase-2, glutathione S-transferase M1 and T1 genetic polymorphisms, cigarette smoking and hepatocellular carcinoma: a case-control study. Int J Cancer 2005;115:301-306.
Kuper H, Tzonou A, Kaklamani E, Hsieh CC, Lagiou P, Adami HO, Trichopoulos D, et al. Tobacco smoking, alcohol consumption and their interaction in the causation of hepatocellular carcinoma. Int J Cancer 2000;85:498-502.
Guzman-Lepe J, Cervantes-Alvarez E, Collin de l'Hortet A, Wang Y, Mars WM, Oda Y, Bekki Y, et al. Liver-enriched transcription factor expression relates to chronic hepatic failure in humans. Hepatol Commun 2018;2:582-594.
Hernaez R, Sola E, Moreau R, Gines P. Acute-on-chronic liver failure: an update. Gut 2017;66:541-553.
Lee YA, Wallace MC, Friedman SL. Pathobiology of liver fibrosis: a translational success story. Gut 2015;64:830-841.
Pessayre D, Lebrec D, Descatoire V, Peignoux M, Benhamou JP. Mechanism for reduced drug clearance in patients with cirrhosis. Gastroenterology 1978;74:566-571.
Cichoz-Lach H, Michalak A. Oxidative stress as a crucial factor in liver diseases. World J Gastroenterol 2014;20:8082-8091.
Simoes ICM, Fontes A, Pinton P, Zischka H, Wieckowski MR. Mitochondria in non-alcoholic fatty liver disease. Int J Biochem Cell Biol 2018;95:93-99.
Malhi H, Kaufman RJ. Endoplasmic reticulum stress in liver disease. J Hepatol 2011;54:795-809.
Zhang XQ, Xu CF, Yu CH, Chen WX, Li YM. Role of endoplasmic reticulum stress in the pathogenesis of nonalcoholic fatty liver disease. World J Gastroenterol 2014;20:1768-1776.
Wang K. Molecular mechanisms of hepatic apoptosis. Cell Death Dis 2014;5:e996.
Seki E, Schwabe RF. Hepatic inflammation and fibrosis: functional links and key pathways. Hepatology 2015;61:1066-1079.
Zhang BH, Weltman M, Farrell GC. Does steatohepatitis impair liver regeneration? A study in a dietary model of non-alcoholic steatohepatitis in rats. J Gastroenterol Hepatol 1999;14:133-137.
Michalopoulos GK, Khan Z. Liver Stem Cells: Experimental Findings and Implications for Human Liver Disease. Gastroenterology 2015;149:876-882.
Dubuquoy L, Louvet A, Lassailly G, Truant S, Boleslawski E, Artru F, Maggiotto F, et al. Progenitor cell expansion and impaired hepatocyte regeneration in explanted livers from alcoholic hepatitis. Gut 2015;64:1949-1960.
Nishikawa T, Bell A, Brooks JM, Setoyama K, Melis M, Han B, Fukumitsu K, et al. Resetting the transcription factor network reverses terminal chronic hepatic failure. J Clin Invest 2015;125:1533-1544.
Babeu JP, Boudreau F. Hepatocyte nuclear factor 4-alpha involvement in liver and intestinal inflammatory networks. World J Gastroenterol 2014;20:22-30.
Chellappa K, Jankova L, Schnabl JM, Pan S, Brelivet Y, Fung CL, Chan C, et al. Src tyrosine kinase phosphorylation of nuclear receptor HNF4alpha correlates with isoform-specific loss of HNF4alpha in human colon cancer. Proc Natl Acad Sci U S A 2012;109:2302-2307.
Guo H, Gao C, Mi Z, Wai PY, Kuo PC. Phosphorylation of Ser158 regulates inflammatory redox-dependent hepatocyte nuclear factor-4a transcriptional activity. Biochem J 2014;461:347.
Hong YH, Varanasi US, Yang W, Leff T. AMP-activated protein kinase regulates HNF4alpha transcriptional activity by inhibiting dimer formation and decreasing protein stability. J Biol Chem 2003;278:27495-27501.
Lu H. Crosstalk of HNF4alpha with extracellular and intracellular signaling pathways in the regulation of hepatic metabolism of drugs and lipids. Acta Pharm Sin B 2016;6:393-408.
Song Y, Zheng D, Zhao M, Qin Y, Wang T, Xing W, Gao L, et al. Thyroid-Stimulating Hormone Increases HNF-4alpha Phosphorylation via cAMP/PKA Pathway in the Liver. Sci Rep 2015;5:13409.
Soutoglou E, Katrakili N, Talianidis I. Acetylation regulates transcription factor activity at multiple levels. Mol Cell 2000;5:745-751.
Sun K, Montana V, Chellappa K, Brelivet Y, Moras D, Maeda Y, Parpura V, et al. Phosphorylation of a conserved serine in the deoxyribonucleic acid binding domain of nuclear receptors alters intracellular localization. Mol Endocrinol 2007;21:1297-1311.
Xu Z, Tavares-Sanchez OL, Li Q, Fernando J, Rodriguez CM, Studer EJ, Pandak WM, et al. Activation of bile acid biosynthesis by the p38 mitogen-activated protein kinase (MAPK): hepatocyte nuclear factor-4alpha phosphorylation by the p38 MAPK is required for cholesterol 7alpha-hydroxylase expression. J Biol Chem 2007;282:24607-24614.
Yokoyama A, Katsura S, Ito R, Hashiba W, Sekine H, Fujiki R, Kato S. Multiple post-translational modifications in hepatocyte nuclear factor 4alpha. Biochem Biophys Res Commun 2011;410:749-753.
Zhou W, Hannoun Z, Jaffray E, Medine CN, Black JR, Greenhough S, Zhu L, et al. SUMOylation of HNF4alpha regulates protein stability and hepatocyte function. J Cell Sci 2012;125:3630-3635.
Gramignoli R, Green ML, Tahan V, Dorko K, Skvorak KJ, Marongiu F, Zao W, et al. Development and application of purified tissue dissociation enzyme mixtures for human hepatocyte isolation. Cell Transplant 2012;21:1245-1260.
Bell AW, Michalopoulos GK. Phenobarbital regulates nuclear expression of HNF-4alpha in mouse and rat hepatocytes independent of CAR and PXR. Hepatology 2006;44:186-194.
Natarajan A, Wagner B, Sibilia M. The EGF receptor is required for efficient liver regeneration. Proc Natl Acad Sci U S A 2007;104:17081-17086.
Rasband WS. ImageJ, U. S. National Institutes of Health, Bethesda, Maryland, USA,. In.
Hainer SJ, Gu W, Carone BR, Landry BD, Rando OJ, Mello CC, Fazzio TG. Suppression of pervasive noncoding transcription in embryonic stem cells by esBAF. Genes Dev 2015;29:362-378.
Kumar R, Ichihashi Y, Kimura S, Chitwood DH, Headland LR, Peng J, Maloof JN, et al. A High-Throughput Method for Illumina RNA-Seq Library Preparation. Front Plant Sci 2012;3:202.
Morlan JD, Qu K, Sinicropi DV. Selective depletion of rRNA enables whole transcriptome profiling of archival fixed tissue. PLoS One 2012;7:e42882.
Adiconis X, Borges-Rivera D, Satija R, DeLuca DS, Busby MA, Berlin AM, Sivachenko A, et al. Comparative analysis of RNA sequencing methods for degraded or low-input samples. Nat Methods 2013;10:623-629.
de Hoon MJ, Imoto S, Nolan J, Miyano S. Open source clustering software. Bioinformatics 2004;20:1453-1454.
Saldanha AJ. Java Treeview--extensible visualization of microarray data. Bioinformatics 2004;20:3246-3248.
Kritis AA, Argyrokastritis A, Moschonas NK, Power S, Katrakili N, Zannis VI, Cereghini S, et al. Isolation and characterization of a third isoform of human hepatocyte nuclear factor4. Gene 1996;173:275-280.
Tanaka T, Jiang S, Hotta H, Takano K, Iwanari H, Sumi K, Daigo K, et al. Dysregulated expression of P1 and P2 promoter-driven hepatocyte nuclear factor-4alpha in the pathogenesis of human cancer. J Pathol 2006;208:662-672.
Walesky C, Apte U. Role of hepatocyte nuclear factor 4alpha (HNF4alpha) in cell proliferation and cancer. Gene Expr 2015;16:101-108.
Liu L, Yannam GR, Nishikawa T, Yamamoto T, Basma H, Ito R, Nagaya M, et al. The microenvironment in hepatocyte regeneration and function in rats with advanced cirrhosis. Hepatology 2012;55:1529-1539.
Komposch K, Sibilia M. EGFR Signaling in Liver Diseases. Int J Mol Sci 2015;17.
Paranjpe S, Bowen WC, Mars WM, Orr A, Haynes MM, DeFrances MC, Liu S, et al. Combined systemic elimination of MET and epidermal growth factor receptor signaling completely abolishes liver regeneration and leads to liver decompensation. Hepatology 2016;64:1711-1724.
Tsagianni A, Mars WM, Bhushan B, Bowen WC, Orr A, Stoops J, Paranjpe S, et al. Combined Systemic Disruption of MET and Epidermal Growth Factor Receptor Signaling Causes Liver Failure in Normal Mice. Am J Pathol 2018;188:2223-2235.
Dekker FJ, Haisma HJ. Histone acetyl transferases as emerging drug targets. Drug Discov Today 2009;14:942-948.
Argemi J, Latasa MU, Atkinson SR, Blokhin IO, Massey V, Gue JP, Cabezas J, et al. Defective HNF4alpha-dependent gene expression as a driver of hepatocellular failure in alcoholic hepatitis. Nat Commun 2019;10:3126.
Woods A, Williams JR, Muckett PJ, Mayer FV, Liljevald M, Bohlooly YM, Carling D. Liver-Specific Activation of AMPK Prevents Steatosis on a High-Fructose Diet. Cell Rep 2017;18:3043-3051.
Manning BD, Toker A. AKT/PKB Signaling: Navigating the Network. Cell 2017;169:381-405.
Morales-Ruiz M, Santel A, Ribera J, Jimenez W. The Role of Akt in Chronic Liver Disease and Liver Regeneration. Semin Liver Dis 2017;37:11-16.
Alam A, Chun Suen K, Ma D. Acute-on-chronic liver failure: recent update. J Biomed Res 2017;31:283-300.
B. Sosa-Pineda, J.T. Wigle, G. Oliver Hepatocyte migration during liver development requires Prox1 Nat. Genet., 25 (2000), pp. 254-255.
Song KH, Li T and Chiang JY (2006) A prospero-related homeodomain protein is a novel co-regulator of hepatocyte nuclear factor 4alpha that regulates the cholesterol 7alpha-hydroxylase gene. J Biol Chem 281, 10081-10088.
Xu SZ. Prox1 Facilitates Transfected CHO Cell Proliferation through Activation of the AKT Signaling Pathway. Int J Biomed Sci. 2010 Mar;6(1):49-59.
Rausa FM, Galarneau L, Belanger L, Costa RH. 1999. The nuclear receptor fetoprotein transcription factor is coexpressed with its target HNF-3b in the developing murine liver intestine and pancreas. Mech Dev 89: 185-188.
Labelle-Dumais C, Jacob-Wagner M, Pare JF, Belanger L, Dufort D. Nuclear receptor NR5A2 is required for proper primitive streak morphogenesis. Dev Dyn. 2006 Dec;235(12):3359-69.
Kim DH, Kwon S, Byun S, Xiao Z, Park S, Wu SY, Chiang CM, Kemper B, Kemper JK. Critical role of RanBP2-mediated SUMOylation of Small Heterodimer Partner in maintaining bile acid homeostasis. Nat Commun. 2016 Jul 14;7:12179.
Lindert U, Cramer M, Meuli M, Georgiev O, Schaffner W. Metal-responsive transcription factor 1 (MTF-1) activity is regulated by a nonconventional nuclear localization signal and a metal-responsive transactivation domain. Mol Cell Biol. 2009 Dec;29(23):6283-93. doi: 10.1128/MCB.00847-09.
Rutherford JC, Bird AJ. Metal-responsive transcription factors that regulate iron, zinc, and copper homeostasis in eukaryotic cells. Eukaryot Cell. 2004 Feb;3(1):1-13.
Shi Q, Hoffman B, Liu Q, PI3K-Akt signaling pathway upregulates hepatitis C virus RNA translation through the activation of SREBPs. Virology. 2016 Mar; 490():99-108.
Porstmann T, Santos CR, Griffiths B, Cully M, Wu M, Leevers S, Griffiths JR, Chung YL, Schulze A. SREBP activity is regulated by mTORC1 and contributes to Akt-dependent cell growth. Cell Metab. 2008 Sep;8(3):224-36.
Breaux M, Lewis K, Valanejad L, Iakova P, Chen F, Mo Q, Medrano E, Timchenko L, Timchenko N. p300 Regulates Liver Functions by Controlling p53 and C/EBP Family Proteins through Multiple Signaling Pathways. Mol Cell Biol. 2015 Sep 1;35(17):3005-16.
He L, Cao J, Meng S, Ma A, Radovick S, Wondisford FE, Activation of basal gluconeogenesis by coactivator p300 maintains hepatic glycogen storage. Mol Endocrinol. 2013 Aug; 27(8):1322-32.
Stavru F, Nautrup-Pedersen G, Cordes VC, Gφrlich D. Nuclear pore complex assembly and maintenance in POM121- and gp210-deficient cells. J Cell Biol. 2006 May 22;173(4):477-83.
Fusakio ME, Willy JA, Wang Y, Mirek ET, Al Baghdadi RJ, Adams CM, Anthony TG, Wek RC. Transcription factor ATF4 directs basal and stress-induced gene expression in the unfolded protein response and cholesterol metabolism in the liver. Mol Biol Cell. 2016 May 1;27(9):1536-51.
Malhi H, Kaufman RJ. Endoplasmic reticulum stress in liver disease. J Hepatol. 2011 Apr;54(4):795-809.
Florentino RM, Fraunhoffer NA, Morita K, Takeishi K, Ostrowska A, Achreja A, Animasahun O, Haep N, Arazov S, Agarwal N, Collin de l'Hortet A, Guzman-Lepe J, Tafaleng EN, Mukherjee A, Troy K, Banerjee S, Paranjpe S, Michalopoulos GK, Bell A, Nagrath D, Hainer SJ, Fox IJ, Soto-Gutierrez A. Cellular Location of HNF4α is Linked With Terminal Liver Failure in Humans. Hepatol Commun. 2020 Apr 21;4(6):859-875.
Guzman-Lepe J, Cervantes-Alvarez E, Collin de l'Hortet A, Wang Y, Mars WM, Oda Y, Bekki Y, Shimokawa M, Wang H, Yoshizumi T, Maehara Y, Bell A, Fox IJ, Takeishi K, Soto-Gutierrez A. Hepatol Commun. Liver-enriched transcription factor expression relates to chronic hepatic failure in humans. 2018 Mar 23;2(5):582-594.
Nishikawa T, Bellance N, Damm A, Bing H, Zhu Z, Handa K, Yovchev MI, Sehgal V, Moss TJ, Oertel M, Ram PT, Pipinos II, Soto-Gutierrez A, Fox IJ, Nagrath D. A switch in the source of ATP production and a loss in capacity to perform glycolysis are hallmarks of hepatocyte failure in advance liver disease. J Hepatol. 2014 Jun;60(6):1203-11.
Nishikawa T, Bell A, Brooks JM, Setoyama K, Melis M, Han B, Fukumitsu K, Handa K, Tian J, Kaestner KH, Vodovotz Y, Locker J, Soto-Gutierrez A, Fox IJ. Resetting the transcription factor network reverses terminal chronic hepatic failure. J Clin Invest. 2015 Apr;125(4):1533-44.
SEQUENCE LISTING
<110> UNIVERSITY OF PITTSBURGH-OF THE COMMONWEALTH SYSTEM OF
HIGHER EDUCATION
<120> COMPOSITIONS AND METHODS FOR TREATING LIVER DISEASE
<130> 10504-041WO1
<160> 34
<170> PatentIn version 3.5
<210> 1
<211> 474
<212> PRT
<213> Homo sapiens
<400> 1
Met Arg Leu Ser Lys Thr Leu Val Asp Met Asp Met Ala Asp Tyr Ser
1 5 10 15
Ala Ala Leu Asp Pro Ala Tyr Thr Thr Leu Glu Phe Glu Asn Val Gln
20 25 30
Val Leu Thr Met Gly Asn Asp Thr Ser Pro Ser Glu Gly Thr Asn Leu
35 40 45
Asn Ala Pro Asn Ser Leu Gly Val Ser Ala Leu Cys Ala Ile Cys Gly
50 55 60
Asp Arg Ala Thr Gly Lys His Tyr Gly Ala Ser Ser Cys Asp Gly Cys
65 70 75 80
Lys Gly Phe Phe Arg Arg Ser Val Arg Lys Asn His Met Tyr Ser Cys
85 90 95
Arg Phe Ser Arg Gln Cys Val Val Asp Lys Asp Lys Arg Asn Gln Cys
100 105 110
Arg Tyr Cys Arg Leu Lys Lys Cys Phe Arg Ala Gly Met Lys Lys Glu
115 120 125
Ala Val Gln Asn Glu Arg Asp Arg Ile Ser Thr Arg Arg Ser Ser Tyr
130 135 140
Glu Asp Ser Ser Leu Pro Ser Ile Asn Ala Leu Leu Gln Ala Glu Val
145 150 155 160
Leu Ser Arg Gln Ile Thr Ser Pro Val Ser Gly Ile Asn Gly Asp Ile
165 170 175
Arg Ala Lys Lys Ile Ala Ser Ile Ala Asp Val Cys Glu Ser Met Lys
180 185 190
Glu Gln Leu Leu Val Leu Val Glu Trp Ala Lys Tyr Ile Pro Ala Phe
195 200 205
Cys Glu Leu Pro Leu Asp Asp Gln Val Ala Leu Leu Arg Ala His Ala
210 215 220
Gly Glu His Leu Leu Leu Gly Ala Thr Lys Arg Ser Met Val Phe Lys
225 230 235 240
Asp Val Leu Leu Leu Gly Asn Asp Tyr Ile Val Pro Arg His Cys Pro
245 250 255
Glu Leu Ala Glu Met Ser Arg Val Ser Ile Arg Ile Leu Asp Glu Leu
260 265 270
Val Leu Pro Phe Gln Glu Leu Gln Ile Asp Asp Asn Glu Tyr Ala Tyr
275 280 285
Leu Lys Ala Ile Ile Phe Phe Asp Pro Asp Ala Lys Gly Leu Ser Asp
290 295 300
Pro Gly Lys Ile Lys Arg Leu Arg Ser Gln Val Gln Val Ser Leu Glu
305 310 315 320
Asp Tyr Ile Asn Asp Arg Gln Tyr Asp Ser Arg Gly Arg Phe Gly Glu
325 330 335
Leu Leu Leu Leu Leu Pro Thr Leu Gln Ser Ile Thr Trp Gln Met Ile
340 345 350
Glu Gln Ile Gln Phe Ile Lys Leu Phe Gly Met Ala Lys Ile Asp Asn
355 360 365
Leu Leu Gln Glu Met Leu Leu Gly Gly Ser Pro Ser Asp Ala Pro His
370 375 380
Ala His His Pro Leu His Pro His Leu Met Gln Glu His Met Gly Thr
385 390 395 400
Asn Val Ile Val Ala Asn Thr Met Pro Thr His Leu Ser Asn Gly Gln
405 410 415
Met Cys Glu Trp Pro Arg Pro Arg Gly Gln Ala Ala Thr Pro Glu Thr
420 425 430
Pro Gln Pro Ser Pro Pro Gly Gly Ser Gly Ser Glu Pro Tyr Lys Leu
435 440 445
Leu Pro Gly Ala Val Ala Thr Ile Val Lys Pro Leu Ser Ala Ile Pro
450 455 460
Gln Pro Thr Ile Thr Lys Gln Glu Val Ile
465 470
<210> 2
<211> 737
<212> PRT
<213> Homo sapiens
<400> 2
Met Pro Asp His Asp Ser Thr Ala Leu Leu Ser Arg Gln Thr Lys Arg
1 5 10 15
Arg Arg Val Asp Ile Gly Val Lys Arg Thr Val Gly Thr Ala Ser Ala
20 25 30
Phe Phe Ala Lys Ala Arg Ala Thr Phe Phe Ser Ala Met Asn Pro Gln
35 40 45
Gly Ser Glu Gln Asp Val Glu Tyr Ser Val Val Gln His Ala Asp Gly
50 55 60
Glu Lys Ser Asn Val Leu Arg Lys Leu Leu Lys Arg Ala Asn Ser Tyr
65 70 75 80
Glu Asp Ala Met Met Pro Phe Pro Gly Ala Thr Ile Ile Ser Gln Leu
85 90 95
Leu Lys Asn Asn Met Asn Lys Asn Gly Gly Thr Glu Pro Ser Phe Gln
100 105 110
Ala Ser Gly Leu Ser Ser Thr Gly Ser Glu Val His Gln Glu Asp Ile
115 120 125
Cys Ser Asn Ser Ser Arg Asp Ser Pro Pro Glu Cys Leu Ser Pro Phe
130 135 140
Gly Arg Pro Thr Met Ser Gln Phe Asp Met Asp Arg Leu Cys Asp Glu
145 150 155 160
His Leu Arg Ala Lys Arg Ala Arg Val Glu Asn Ile Ile Arg Gly Met
165 170 175
Ser His Ser Pro Ser Val Ala Leu Arg Gly Asn Glu Asn Glu Arg Glu
180 185 190
Met Ala Pro Gln Ser Val Ser Pro Arg Glu Ser Tyr Arg Glu Asn Lys
195 200 205
Arg Lys Gln Lys Leu Pro Gln Gln Gln Gln Gln Ser Phe Gln Gln Leu
210 215 220
Val Ser Ala Arg Lys Glu Gln Lys Arg Glu Glu Arg Arg Gln Leu Lys
225 230 235 240
Gln Gln Leu Glu Asp Met Gln Lys Gln Leu Arg Gln Leu Gln Glu Lys
245 250 255
Phe Tyr Gln Ile Tyr Asp Ser Thr Asp Ser Glu Asn Asp Glu Asp Gly
260 265 270
Asn Leu Ser Glu Asp Ser Met Arg Ser Glu Ile Leu Asp Ala Arg Ala
275 280 285
Gln Asp Ser Val Gly Arg Ser Asp Asn Glu Met Cys Glu Leu Asp Pro
290 295 300
Gly Gln Phe Ile Asp Arg Ala Arg Ala Leu Ile Arg Glu Gln Glu Met
305 310 315 320
Ala Glu Asn Lys Pro Lys Arg Glu Gly Asn Asn Lys Glu Arg Asp His
325 330 335
Gly Pro Asn Ser Leu Gln Pro Glu Gly Lys His Leu Ala Glu Thr Leu
340 345 350
Lys Gln Glu Leu Asn Thr Ala Met Ser Gln Val Val Asp Thr Val Val
355 360 365
Lys Val Phe Ser Ala Lys Pro Ser Arg Gln Val Pro Gln Val Phe Pro
370 375 380
Pro Leu Gln Ile Pro Gln Ala Arg Phe Ala Val Asn Gly Glu Asn His
385 390 395 400
Asn Phe His Thr Ala Asn Gln Arg Leu Gln Cys Phe Gly Asp Val Ile
405 410 415
Ile Pro Asn Pro Leu Asp Thr Phe Gly Asn Val Gln Met Ala Ser Ser
420 425 430
Thr Asp Gln Thr Glu Ala Leu Pro Leu Val Val Arg Lys Asn Ser Ser
435 440 445
Asp Gln Ser Ala Ser Gly Pro Ala Ala Gly Gly His His Gln Pro Leu
450 455 460
His Gln Ser Pro Leu Ser Ala Thr Thr Gly Phe Thr Thr Ser Thr Phe
465 470 475 480
Arg His Pro Phe Pro Leu Pro Leu Met Ala Tyr Pro Phe Gln Ser Pro
485 490 495
Leu Gly Ala Pro Ser Gly Ser Phe Ser Gly Lys Asp Arg Ala Ser Pro
500 505 510
Glu Ser Leu Asp Leu Thr Arg Asp Thr Thr Ser Leu Arg Thr Lys Met
515 520 525
Ser Ser His His Leu Ser His His Pro Cys Ser Pro Ala His Pro Pro
530 535 540
Ser Thr Ala Glu Gly Leu Ser Leu Ser Leu Ile Lys Ser Glu Cys Gly
545 550 555 560
Asp Leu Gln Asp Met Ser Glu Ile Ser Pro Tyr Ser Gly Ser Ala Met
565 570 575
Gln Glu Gly Leu Ser Pro Asn His Leu Lys Lys Ala Lys Leu Met Phe
580 585 590
Phe Tyr Thr Arg Tyr Pro Ser Ser Asn Met Leu Lys Thr Tyr Phe Ser
595 600 605
Asp Val Lys Phe Asn Arg Cys Ile Thr Ser Gln Leu Ile Lys Trp Phe
610 615 620
Ser Asn Phe Arg Glu Phe Tyr Tyr Ile Gln Met Glu Lys Tyr Ala Arg
625 630 635 640
Gln Ala Ile Asn Asp Gly Val Thr Ser Thr Glu Glu Leu Ser Ile Thr
645 650 655
Arg Asp Cys Glu Leu Tyr Arg Ala Leu Asn Met His Tyr Asn Lys Ala
660 665 670
Asn Asp Phe Glu Val Pro Glu Arg Phe Leu Glu Val Ala Gln Ile Thr
675 680 685
Leu Arg Glu Phe Phe Asn Ala Ile Ile Ala Gly Lys Asp Val Asp Pro
690 695 700
Ser Trp Lys Lys Ala Ile Tyr Lys Val Ile Cys Lys Leu Asp Ser Glu
705 710 715 720
Val Pro Glu Ile Phe Lys Ser Pro Asn Cys Leu Gln Glu Leu Leu His
725 730 735
Glu
<210> 3
<211> 541
<212> PRT
<213> Homo sapiens
<400> 3
Met Ser Ser Asn Ser Asp Thr Gly Asp Leu Gln Glu Ser Leu Lys His
1 5 10 15
Gly Leu Thr Pro Ile Gly Ala Gly Leu Pro Asp Arg His Gly Ser Pro
20 25 30
Ile Pro Ala Arg Gly Arg Leu Val Met Leu Pro Lys Val Glu Thr Glu
35 40 45
Ala Leu Gly Leu Ala Arg Ser His Gly Glu Gln Gly Gln Met Pro Glu
50 55 60
Asn Met Gln Val Ser Gln Phe Lys Met Val Asn Tyr Ser Tyr Asp Glu
65 70 75 80
Asp Leu Glu Glu Leu Cys Pro Val Cys Gly Asp Lys Val Ser Gly Tyr
85 90 95
His Tyr Gly Leu Leu Thr Cys Glu Ser Cys Lys Gly Phe Phe Lys Arg
100 105 110
Thr Val Gln Asn Asn Lys Arg Tyr Thr Cys Ile Glu Asn Gln Asn Cys
115 120 125
Gln Ile Asp Lys Thr Gln Arg Lys Arg Cys Pro Tyr Cys Arg Phe Gln
130 135 140
Lys Cys Leu Ser Val Gly Met Lys Leu Glu Ala Val Arg Ala Asp Arg
145 150 155 160
Met Arg Gly Gly Arg Asn Lys Phe Gly Pro Met Tyr Lys Arg Asp Arg
165 170 175
Ala Leu Lys Gln Gln Lys Lys Ala Leu Ile Arg Ala Asn Gly Leu Lys
180 185 190
Leu Glu Ala Met Ser Gln Val Ile Gln Ala Met Pro Ser Asp Leu Thr
195 200 205
Ile Ser Ser Ala Ile Gln Asn Ile His Ser Ala Ser Lys Gly Leu Pro
210 215 220
Leu Asn His Ala Ala Leu Pro Pro Thr Asp Tyr Asp Arg Ser Pro Phe
225 230 235 240
Val Thr Ser Pro Ile Ser Met Thr Met Pro Pro His Gly Ser Leu Gln
245 250 255
Gly Tyr Gln Thr Tyr Gly His Phe Pro Ser Arg Ala Ile Lys Ser Glu
260 265 270
Tyr Pro Asp Pro Tyr Thr Ser Ser Pro Glu Ser Ile Met Gly Tyr Ser
275 280 285
Tyr Met Asp Ser Tyr Gln Thr Ser Ser Pro Ala Ser Ile Pro His Leu
290 295 300
Ile Leu Glu Leu Leu Lys Cys Glu Pro Asp Glu Pro Gln Val Gln Ala
305 310 315 320
Lys Ile Met Ala Tyr Leu Gln Gln Glu Gln Ala Asn Arg Ser Lys His
325 330 335
Glu Lys Leu Ser Thr Phe Gly Leu Met Cys Lys Met Ala Asp Gln Thr
340 345 350
Leu Phe Ser Ile Val Glu Trp Ala Arg Ser Ser Ile Phe Phe Arg Glu
355 360 365
Leu Lys Val Asp Asp Gln Met Lys Leu Leu Gln Asn Cys Trp Ser Glu
370 375 380
Leu Leu Ile Leu Asp His Ile Tyr Arg Gln Val Val His Gly Lys Glu
385 390 395 400
Gly Ser Ile Phe Leu Val Thr Gly Gln Gln Val Asp Tyr Ser Ile Ile
405 410 415
Ala Ser Gln Ala Gly Ala Thr Leu Asn Asn Leu Met Ser His Ala Gln
420 425 430
Glu Leu Val Ala Lys Leu Arg Ser Leu Gln Phe Asp Gln Arg Glu Phe
435 440 445
Val Cys Leu Lys Phe Leu Val Leu Phe Ser Leu Asp Val Lys Asn Leu
450 455 460
Glu Asn Phe Gln Leu Val Glu Gly Val Gln Glu Gln Val Asn Ala Ala
465 470 475 480
Leu Leu Asp Tyr Thr Met Cys Asn Tyr Pro Gln Gln Thr Glu Lys Phe
485 490 495
Gly Gln Leu Leu Leu Arg Leu Pro Glu Ile Arg Ala Ile Ser Met Gln
500 505 510
Ala Glu Glu Tyr Leu Tyr Tyr Lys His Leu Asn Gly Asp Val Pro Tyr
515 520 525
Asn Asn Leu Leu Ile Glu Met Leu His Ala Lys Arg Ala
530 535 540
<210> 4
<211> 257
<212> PRT
<213> Homo sapiens
<400> 4
Met Ser Thr Ser Gln Pro Gly Ala Cys Pro Cys Gln Gly Ala Ala Ser
1 5 10 15
Arg Pro Ala Ile Leu Tyr Ala Leu Leu Ser Ser Ser Leu Lys Ala Val
20 25 30
Pro Arg Pro Arg Ser Arg Cys Leu Cys Arg Gln His Arg Pro Val Gln
35 40 45
Leu Cys Ala Pro His Arg Thr Cys Arg Glu Ala Leu Asp Val Leu Ala
50 55 60
Lys Thr Val Ala Phe Leu Arg Asn Leu Pro Ser Phe Trp Gln Leu Pro
65 70 75 80
Pro Gln Asp Gln Arg Arg Leu Leu Gln Gly Cys Trp Gly Pro Leu Phe
85 90 95
Leu Leu Gly Leu Ala Gln Asp Ala Val Thr Phe Glu Val Ala Glu Ala
100 105 110
Pro Val Pro Ser Ile Leu Lys Lys Ile Leu Leu Glu Glu Pro Ser Ser
115 120 125
Ser Gly Gly Ser Gly Gln Leu Pro Asp Arg Pro Gln Pro Ser Leu Ala
130 135 140
Ala Val Gln Trp Leu Gln Cys Cys Leu Glu Ser Phe Trp Ser Leu Glu
145 150 155 160
Leu Ser Pro Lys Glu Tyr Ala Cys Leu Lys Gly Thr Ile Leu Phe Asn
165 170 175
Pro Asp Val Pro Gly Leu Gln Ala Ala Ser His Ile Gly His Leu Gln
180 185 190
Gln Glu Ala His Trp Val Leu Cys Glu Val Leu Glu Pro Trp Cys Pro
195 200 205
Ala Ala Gln Gly Arg Leu Thr Arg Val Leu Leu Thr Ala Ser Thr Leu
210 215 220
Lys Ser Ile Pro Thr Ser Leu Leu Gly Asp Leu Phe Phe Arg Pro Ile
225 230 235 240
Ile Gly Asp Val Asp Ile Ala Gly Leu Leu Gly Asp Met Leu Leu Leu
245 250 255
Arg
<210> 5
<211> 753
<212> PRT
<213> Homo sapiens
<400> 5
Met Gly Glu His Ser Pro Asp Asn Asn Ile Ile Tyr Phe Glu Ala Glu
1 5 10 15
Glu Asp Glu Leu Thr Pro Asp Asp Lys Met Leu Arg Phe Val Asp Lys
20 25 30
Asn Gly Leu Val Pro Ser Ser Ser Gly Thr Val Tyr Asp Arg Thr Thr
35 40 45
Val Leu Ile Glu Gln Asp Pro Gly Thr Leu Glu Asp Glu Asp Asp Asp
50 55 60
Gly Gln Cys Gly Glu His Leu Pro Phe Leu Val Gly Gly Glu Glu Gly
65 70 75 80
Phe His Leu Ile Asp His Glu Ala Met Ser Gln Gly Tyr Val Gln His
85 90 95
Ile Ile Ser Pro Asp Gln Ile His Leu Thr Ile Asn Pro Gly Ser Thr
100 105 110
Pro Met Pro Arg Asn Ile Glu Gly Ala Thr Leu Thr Leu Gln Ser Glu
115 120 125
Cys Pro Glu Thr Lys Arg Lys Glu Val Lys Arg Tyr Gln Cys Thr Phe
130 135 140
Glu Gly Cys Pro Arg Thr Tyr Ser Thr Ala Gly Asn Leu Arg Thr His
145 150 155 160
Gln Lys Thr His Arg Gly Glu Tyr Thr Phe Val Cys Asn Gln Glu Gly
165 170 175
Cys Gly Lys Ala Phe Leu Thr Ser Tyr Ser Leu Arg Ile His Val Arg
180 185 190
Val His Thr Lys Glu Lys Pro Phe Glu Cys Asp Val Gln Gly Cys Glu
195 200 205
Lys Ala Phe Asn Thr Leu Tyr Arg Leu Lys Ala His Gln Arg Leu His
210 215 220
Thr Gly Lys Thr Phe Asn Cys Glu Ser Glu Gly Cys Ser Lys Tyr Phe
225 230 235 240
Thr Thr Leu Ser Asp Leu Arg Lys His Ile Arg Thr His Thr Gly Glu
245 250 255
Lys Pro Phe Arg Cys Asp His Asp Gly Cys Gly Lys Ala Phe Ala Ala
260 265 270
Ser His His Leu Lys Thr His Val Arg Thr His Thr Gly Glu Arg Pro
275 280 285
Phe Phe Cys Pro Ser Asn Gly Cys Glu Lys Thr Phe Ser Thr Gln Tyr
290 295 300
Ser Leu Lys Ser His Met Lys Gly His Asp Asn Lys Gly His Ser Tyr
305 310 315 320
Asn Ala Leu Pro Gln His Asn Gly Ser Glu Asp Thr Asn His Ser Leu
325 330 335
Cys Leu Ser Asp Leu Ser Leu Leu Ser Thr Asp Ser Glu Leu Arg Glu
340 345 350
Asn Ser Ser Thr Thr Gln Gly Gln Asp Leu Ser Thr Ile Ser Pro Ala
355 360 365
Ile Ile Phe Glu Ser Met Phe Gln Asn Ser Asp Asp Thr Ala Ile Gln
370 375 380
Glu Asp Pro Gln Gln Thr Ala Ser Leu Thr Glu Ser Phe Asn Gly Asp
385 390 395 400
Ala Glu Ser Val Ser Asp Val Pro Pro Ser Thr Gly Asn Ser Ala Ser
405 410 415
Leu Ser Leu Pro Leu Val Leu Gln Pro Gly Leu Ser Glu Pro Pro Gln
420 425 430
Pro Leu Leu Pro Ala Ser Ala Pro Ser Ala Pro Pro Pro Ala Pro Ser
435 440 445
Leu Gly Pro Gly Ser Gln Gln Ala Ala Phe Gly Asn Pro Pro Ala Leu
450 455 460
Leu Gln Pro Pro Glu Val Pro Val Pro His Ser Thr Gln Phe Ala Ala
465 470 475 480
Asn His Gln Glu Phe Leu Pro His Pro Gln Ala Pro Gln Pro Ile Val
485 490 495
Pro Gly Leu Ser Val Val Ala Gly Ala Ser Ala Ser Ala Ala Ala Val
500 505 510
Ala Ser Ala Val Ala Ala Pro Ala Pro Pro Gln Ser Thr Thr Glu Pro
515 520 525
Leu Pro Ala Met Val Gln Thr Leu Pro Leu Gly Ala Asn Ser Val Leu
530 535 540
Thr Asn Asn Pro Thr Ile Thr Ile Thr Pro Thr Pro Asn Thr Ala Ile
545 550 555 560
Leu Gln Ser Ser Leu Val Met Gly Glu Gln Asn Leu Gln Trp Ile Leu
565 570 575
Asn Gly Ala Thr Ser Ser Pro Gln Asn Gln Glu Gln Ile Gln Gln Ala
580 585 590
Ser Lys Val Glu Lys Val Phe Phe Thr Thr Ala Val Pro Val Ala Ser
595 600 605
Ser Pro Gly Ser Ser Val Gln Gln Ile Gly Leu Ser Val Pro Val Ile
610 615 620
Ile Ile Lys Gln Glu Glu Ala Cys Gln Cys Gln Cys Ala Cys Arg Asp
625 630 635 640
Ser Ala Lys Glu Arg Ala Ser Ser Arg Arg Lys Gly Cys Ser Ser Pro
645 650 655
Pro Pro Pro Glu Pro Ser Pro Gln Ala Pro Asp Gly Pro Ser Leu Gln
660 665 670
Leu Pro Ala Gln Thr Phe Ser Ser Ala Pro Val Pro Gly Ser Ser Ser
675 680 685
Ser Thr Leu Pro Ser Ser Cys Glu Gln Ser Arg Gln Ala Glu Thr Pro
690 695 700
Ser Asp Pro Gln Thr Glu Thr Leu Ser Ala Met Asp Val Ser Glu Phe
705 710 715 720
Leu Ser Leu Gln Ser Leu Asp Thr Pro Ser Asn Leu Ile Pro Ile Glu
725 730 735
Ala Leu Leu Gln Gly Glu Glu Glu Met Gly Leu Thr Ser Ser Phe Ser
740 745 750
Lys
<210> 6
<211> 1147
<212> PRT
<213> Homo sapiens
<400> 6
Met Asp Glu Pro Pro Phe Ser Glu Ala Ala Leu Glu Gln Ala Leu Gly
1 5 10 15
Glu Pro Cys Asp Leu Asp Ala Ala Leu Leu Thr Asp Ile Glu Asp Met
20 25 30
Leu Gln Leu Ile Asn Asn Gln Asp Ser Asp Phe Pro Gly Leu Phe Asp
35 40 45
Pro Pro Tyr Ala Gly Ser Gly Ala Gly Gly Thr Asp Pro Ala Ser Pro
50 55 60
Asp Thr Ser Ser Pro Gly Ser Leu Ser Pro Pro Pro Ala Thr Leu Ser
65 70 75 80
Ser Ser Leu Glu Ala Phe Leu Ser Gly Pro Gln Ala Ala Pro Ser Pro
85 90 95
Leu Ser Pro Pro Gln Pro Ala Pro Thr Pro Leu Lys Met Tyr Pro Ser
100 105 110
Met Pro Ala Phe Ser Pro Gly Pro Gly Ile Lys Glu Glu Ser Val Pro
115 120 125
Leu Ser Ile Leu Gln Thr Pro Thr Pro Gln Pro Leu Pro Gly Ala Leu
130 135 140
Leu Pro Gln Ser Phe Pro Ala Pro Ala Pro Pro Gln Phe Ser Ser Thr
145 150 155 160
Pro Val Leu Gly Tyr Pro Ser Pro Pro Gly Gly Phe Ser Thr Gly Ser
165 170 175
Pro Pro Gly Asn Thr Gln Gln Pro Leu Pro Gly Leu Pro Leu Ala Ser
180 185 190
Pro Pro Gly Val Pro Pro Val Ser Leu His Thr Gln Val Gln Ser Val
195 200 205
Val Pro Gln Gln Leu Leu Thr Val Thr Ala Ala Pro Thr Ala Ala Pro
210 215 220
Val Thr Thr Thr Val Thr Ser Gln Ile Gln Gln Val Pro Val Leu Leu
225 230 235 240
Gln Pro His Phe Ile Lys Ala Asp Ser Leu Leu Leu Thr Ala Met Lys
245 250 255
Thr Asp Gly Ala Thr Val Lys Ala Ala Gly Leu Ser Pro Leu Val Ser
260 265 270
Gly Thr Thr Val Gln Thr Gly Pro Leu Pro Thr Leu Val Ser Gly Gly
275 280 285
Thr Ile Leu Ala Thr Val Pro Leu Val Val Asp Ala Glu Lys Leu Pro
290 295 300
Ile Asn Arg Leu Ala Ala Gly Ser Lys Ala Pro Ala Ser Ala Gln Ser
305 310 315 320
Arg Gly Glu Lys Arg Thr Ala His Asn Ala Ile Glu Lys Arg Tyr Arg
325 330 335
Ser Ser Ile Asn Asp Lys Ile Ile Glu Leu Lys Asp Leu Val Val Gly
340 345 350
Thr Glu Ala Lys Leu Asn Lys Ser Ala Val Leu Arg Lys Ala Ile Asp
355 360 365
Tyr Ile Arg Phe Leu Gln His Ser Asn Gln Lys Leu Lys Gln Glu Asn
370 375 380
Leu Ser Leu Arg Thr Ala Val His Lys Ser Lys Ser Leu Lys Asp Leu
385 390 395 400
Val Ser Ala Cys Gly Ser Gly Gly Asn Thr Asp Val Leu Met Glu Gly
405 410 415
Val Lys Thr Glu Val Glu Asp Thr Leu Thr Pro Pro Pro Ser Asp Ala
420 425 430
Gly Ser Pro Phe Gln Ser Ser Pro Leu Ser Leu Gly Ser Arg Gly Ser
435 440 445
Gly Ser Gly Gly Ser Gly Ser Asp Ser Glu Pro Asp Ser Pro Val Phe
450 455 460
Glu Asp Ser Lys Ala Lys Pro Glu Gln Arg Pro Ser Leu His Ser Arg
465 470 475 480
Gly Met Leu Asp Arg Ser Arg Leu Ala Leu Cys Thr Leu Val Phe Leu
485 490 495
Cys Leu Ser Cys Asn Pro Leu Ala Ser Leu Leu Gly Ala Arg Gly Leu
500 505 510
Pro Ser Pro Ser Asp Thr Thr Ser Val Tyr His Ser Pro Gly Arg Asn
515 520 525
Val Leu Gly Thr Glu Ser Arg Asp Gly Pro Gly Trp Ala Gln Trp Leu
530 535 540
Leu Pro Pro Val Val Trp Leu Leu Asn Gly Leu Leu Val Leu Val Ser
545 550 555 560
Leu Val Leu Leu Phe Val Tyr Gly Glu Pro Val Thr Arg Pro His Ser
565 570 575
Gly Pro Ala Val Tyr Phe Trp Arg His Arg Lys Gln Ala Asp Leu Asp
580 585 590
Leu Ala Arg Gly Asp Phe Ala Gln Ala Ala Gln Gln Leu Trp Leu Ala
595 600 605
Leu Arg Ala Leu Gly Arg Pro Leu Pro Thr Ser His Leu Asp Leu Ala
610 615 620
Cys Ser Leu Leu Trp Asn Leu Ile Arg His Leu Leu Gln Arg Leu Trp
625 630 635 640
Val Gly Arg Trp Leu Ala Gly Arg Ala Gly Gly Leu Gln Gln Asp Cys
645 650 655
Ala Leu Arg Val Asp Ala Ser Ala Ser Ala Arg Asp Ala Ala Leu Val
660 665 670
Tyr His Lys Leu His Gln Leu His Thr Met Gly Lys His Thr Gly Gly
675 680 685
His Leu Thr Ala Thr Asn Leu Ala Leu Ser Ala Leu Asn Leu Ala Glu
690 695 700
Cys Ala Gly Asp Ala Val Ser Val Ala Thr Leu Ala Glu Ile Tyr Val
705 710 715 720
Ala Ala Ala Leu Arg Val Lys Thr Ser Leu Pro Arg Ala Leu His Phe
725 730 735
Leu Thr Arg Phe Phe Leu Ser Ser Ala Arg Gln Ala Cys Leu Ala Gln
740 745 750
Ser Gly Ser Val Pro Pro Ala Met Gln Trp Leu Cys His Pro Val Gly
755 760 765
His Arg Phe Phe Val Asp Gly Asp Trp Ser Val Leu Ser Thr Pro Trp
770 775 780
Glu Ser Leu Tyr Ser Leu Ala Gly Asn Pro Val Asp Pro Leu Ala Gln
785 790 795 800
Val Thr Gln Leu Phe Arg Glu His Leu Leu Glu Arg Ala Leu Asn Cys
805 810 815
Val Thr Gln Pro Asn Pro Ser Pro Gly Ser Ala Asp Gly Asp Lys Glu
820 825 830
Phe Ser Asp Ala Leu Gly Tyr Leu Gln Leu Leu Asn Ser Cys Ser Asp
835 840 845
Ala Ala Gly Ala Pro Ala Tyr Ser Phe Ser Ile Ser Ser Ser Met Ala
850 855 860
Thr Thr Thr Gly Val Asp Pro Val Ala Lys Trp Trp Ala Ser Leu Thr
865 870 875 880
Ala Val Val Ile His Trp Leu Arg Arg Asp Glu Glu Ala Ala Glu Arg
885 890 895
Leu Cys Pro Leu Val Glu His Leu Pro Arg Val Leu Gln Glu Ser Glu
900 905 910
Arg Pro Leu Pro Arg Ala Ala Leu His Ser Phe Lys Ala Ala Arg Ala
915 920 925
Leu Leu Gly Cys Ala Lys Ala Glu Ser Gly Pro Ala Ser Leu Thr Ile
930 935 940
Cys Glu Lys Ala Ser Gly Tyr Leu Gln Asp Ser Leu Ala Thr Thr Pro
945 950 955 960
Ala Ser Ser Ser Ile Asp Lys Ala Val Gln Leu Phe Leu Cys Asp Leu
965 970 975
Leu Leu Val Val Arg Thr Ser Leu Trp Arg Gln Gln Gln Pro Pro Ala
980 985 990
Pro Ala Pro Ala Ala Gln Gly Thr Ser Ser Arg Pro Gln Ala Ser Ala
995 1000 1005
Leu Glu Leu Arg Gly Phe Gln Arg Asp Leu Ser Ser Leu Arg Arg
1010 1015 1020
Leu Ala Gln Ser Phe Arg Pro Ala Met Arg Arg Val Phe Leu His
1025 1030 1035
Glu Ala Thr Ala Arg Leu Met Ala Gly Ala Ser Pro Thr Arg Thr
1040 1045 1050
His Gln Leu Leu Asp Arg Ser Leu Arg Arg Arg Ala Gly Pro Gly
1055 1060 1065
Gly Lys Gly Gly Ala Val Ala Glu Leu Glu Pro Arg Pro Thr Arg
1070 1075 1080
Arg Glu His Ala Glu Ala Leu Leu Leu Ala Ser Cys Tyr Leu Pro
1085 1090 1095
Pro Gly Phe Leu Ser Ala Pro Gly Gln Arg Val Gly Met Leu Ala
1100 1105 1110
Glu Ala Ala Arg Thr Leu Glu Lys Leu Gly Asp Arg Arg Leu Leu
1115 1120 1125
His Asp Cys Gln Gln Met Leu Met Arg Leu Gly Gly Gly Thr Thr
1130 1135 1140
Val Thr Ser Ser
1145
<210> 7
<211> 2414
<212> PRT
<213> Homo sapiens
<400> 7
Met Ala Glu Asn Val Val Glu Pro Gly Pro Pro Ser Ala Lys Arg Pro
1 5 10 15
Lys Leu Ser Ser Pro Ala Leu Ser Ala Ser Ala Ser Asp Gly Thr Asp
20 25 30
Phe Gly Ser Leu Phe Asp Leu Glu His Asp Leu Pro Asp Glu Leu Ile
35 40 45
Asn Ser Thr Glu Leu Gly Leu Thr Asn Gly Gly Asp Ile Asn Gln Leu
50 55 60
Gln Thr Ser Leu Gly Met Val Gln Asp Ala Ala Ser Lys His Lys Gln
65 70 75 80
Leu Ser Glu Leu Leu Arg Ser Gly Ser Ser Pro Asn Leu Asn Met Gly
85 90 95
Val Gly Gly Pro Gly Gln Val Met Ala Ser Gln Ala Gln Gln Ser Ser
100 105 110
Pro Gly Leu Gly Leu Ile Asn Ser Met Val Lys Ser Pro Met Thr Gln
115 120 125
Ala Gly Leu Thr Ser Pro Asn Met Gly Met Gly Thr Ser Gly Pro Asn
130 135 140
Gln Gly Pro Thr Gln Ser Thr Gly Met Met Asn Ser Pro Val Asn Gln
145 150 155 160
Pro Ala Met Gly Met Asn Thr Gly Met Asn Ala Gly Met Asn Pro Gly
165 170 175
Met Leu Ala Ala Gly Asn Gly Gln Gly Ile Met Pro Asn Gln Val Met
180 185 190
Asn Gly Ser Ile Gly Ala Gly Arg Gly Arg Gln Asn Met Gln Tyr Pro
195 200 205
Asn Pro Gly Met Gly Ser Ala Gly Asn Leu Leu Thr Glu Pro Leu Gln
210 215 220
Gln Gly Ser Pro Gln Met Gly Gly Gln Thr Gly Leu Arg Gly Pro Gln
225 230 235 240
Pro Leu Lys Met Gly Met Met Asn Asn Pro Asn Pro Tyr Gly Ser Pro
245 250 255
Tyr Thr Gln Asn Pro Gly Gln Gln Ile Gly Ala Ser Gly Leu Gly Leu
260 265 270
Gln Ile Gln Thr Lys Thr Val Leu Ser Asn Asn Leu Ser Pro Phe Ala
275 280 285
Met Asp Lys Lys Ala Val Pro Gly Gly Gly Met Pro Asn Met Gly Gln
290 295 300
Gln Pro Ala Pro Gln Val Gln Gln Pro Gly Leu Val Thr Pro Val Ala
305 310 315 320
Gln Gly Met Gly Ser Gly Ala His Thr Ala Asp Pro Glu Lys Arg Lys
325 330 335
Leu Ile Gln Gln Gln Leu Val Leu Leu Leu His Ala His Lys Cys Gln
340 345 350
Arg Arg Glu Gln Ala Asn Gly Glu Val Arg Gln Cys Asn Leu Pro His
355 360 365
Cys Arg Thr Met Lys Asn Val Leu Asn His Met Thr His Cys Gln Ser
370 375 380
Gly Lys Ser Cys Gln Val Ala His Cys Ala Ser Ser Arg Gln Ile Ile
385 390 395 400
Ser His Trp Lys Asn Cys Thr Arg His Asp Cys Pro Val Cys Leu Pro
405 410 415
Leu Lys Asn Ala Gly Asp Lys Arg Asn Gln Gln Pro Ile Leu Thr Gly
420 425 430
Ala Pro Val Gly Leu Gly Asn Pro Ser Ser Leu Gly Val Gly Gln Gln
435 440 445
Ser Ala Pro Asn Leu Ser Thr Val Ser Gln Ile Asp Pro Ser Ser Ile
450 455 460
Glu Arg Ala Tyr Ala Ala Leu Gly Leu Pro Tyr Gln Val Asn Gln Met
465 470 475 480
Pro Thr Gln Pro Gln Val Gln Ala Lys Asn Gln Gln Asn Gln Gln Pro
485 490 495
Gly Gln Ser Pro Gln Gly Met Arg Pro Met Ser Asn Met Ser Ala Ser
500 505 510
Pro Met Gly Val Asn Gly Gly Val Gly Val Gln Thr Pro Ser Leu Leu
515 520 525
Ser Asp Ser Met Leu His Ser Ala Ile Asn Ser Gln Asn Pro Met Met
530 535 540
Ser Glu Asn Ala Ser Val Pro Ser Leu Gly Pro Met Pro Thr Ala Ala
545 550 555 560
Gln Pro Ser Thr Thr Gly Ile Arg Lys Gln Trp His Glu Asp Ile Thr
565 570 575
Gln Asp Leu Arg Asn His Leu Val His Lys Leu Val Gln Ala Ile Phe
580 585 590
Pro Thr Pro Asp Pro Ala Ala Leu Lys Asp Arg Arg Met Glu Asn Leu
595 600 605
Val Ala Tyr Ala Arg Lys Val Glu Gly Asp Met Tyr Glu Ser Ala Asn
610 615 620
Asn Arg Ala Glu Tyr Tyr His Leu Leu Ala Glu Lys Ile Tyr Lys Ile
625 630 635 640
Gln Lys Glu Leu Glu Glu Lys Arg Arg Thr Arg Leu Gln Lys Gln Asn
645 650 655
Met Leu Pro Asn Ala Ala Gly Met Val Pro Val Ser Met Asn Pro Gly
660 665 670
Pro Asn Met Gly Gln Pro Gln Pro Gly Met Thr Ser Asn Gly Pro Leu
675 680 685
Pro Asp Pro Ser Met Ile Arg Gly Ser Val Pro Asn Gln Met Met Pro
690 695 700
Arg Ile Thr Pro Gln Ser Gly Leu Asn Gln Phe Gly Gln Met Ser Met
705 710 715 720
Ala Gln Pro Pro Ile Val Pro Arg Gln Thr Pro Pro Leu Gln His His
725 730 735
Gly Gln Leu Ala Gln Pro Gly Ala Leu Asn Pro Pro Met Gly Tyr Gly
740 745 750
Pro Arg Met Gln Gln Pro Ser Asn Gln Gly Gln Phe Leu Pro Gln Thr
755 760 765
Gln Phe Pro Ser Gln Gly Met Asn Val Thr Asn Ile Pro Leu Ala Pro
770 775 780
Ser Ser Gly Gln Ala Pro Val Ser Gln Ala Gln Met Ser Ser Ser Ser
785 790 795 800
Cys Pro Val Asn Ser Pro Ile Met Pro Pro Gly Ser Gln Gly Ser His
805 810 815
Ile His Cys Pro Gln Leu Pro Gln Pro Ala Leu His Gln Asn Ser Pro
820 825 830
Ser Pro Val Pro Ser Arg Thr Pro Thr Pro His His Thr Pro Pro Ser
835 840 845
Ile Gly Ala Gln Gln Pro Pro Ala Thr Thr Ile Pro Ala Pro Val Pro
850 855 860
Thr Pro Pro Ala Met Pro Pro Gly Pro Gln Ser Gln Ala Leu His Pro
865 870 875 880
Pro Pro Arg Gln Thr Pro Thr Pro Pro Thr Thr Gln Leu Pro Gln Gln
885 890 895
Val Gln Pro Ser Leu Pro Ala Ala Pro Ser Ala Asp Gln Pro Gln Gln
900 905 910
Gln Pro Arg Ser Gln Gln Ser Thr Ala Ala Ser Val Pro Thr Pro Thr
915 920 925
Ala Pro Leu Leu Pro Pro Gln Pro Ala Thr Pro Leu Ser Gln Pro Ala
930 935 940
Val Ser Ile Glu Gly Gln Val Ser Asn Pro Pro Ser Thr Ser Ser Thr
945 950 955 960
Glu Val Asn Ser Gln Ala Ile Ala Glu Lys Gln Pro Ser Gln Glu Val
965 970 975
Lys Met Glu Ala Lys Met Glu Val Asp Gln Pro Glu Pro Ala Asp Thr
980 985 990
Gln Pro Glu Asp Ile Ser Glu Ser Lys Val Glu Asp Cys Lys Met Glu
995 1000 1005
Ser Thr Glu Thr Glu Glu Arg Ser Thr Glu Leu Lys Thr Glu Ile
1010 1015 1020
Lys Glu Glu Glu Asp Gln Pro Ser Thr Ser Ala Thr Gln Ser Ser
1025 1030 1035
Pro Ala Pro Gly Gln Ser Lys Lys Lys Ile Phe Lys Pro Glu Glu
1040 1045 1050
Leu Arg Gln Ala Leu Met Pro Thr Leu Glu Ala Leu Tyr Arg Gln
1055 1060 1065
Asp Pro Glu Ser Leu Pro Phe Arg Gln Pro Val Asp Pro Gln Leu
1070 1075 1080
Leu Gly Ile Pro Asp Tyr Phe Asp Ile Val Lys Ser Pro Met Asp
1085 1090 1095
Leu Ser Thr Ile Lys Arg Lys Leu Asp Thr Gly Gln Tyr Gln Glu
1100 1105 1110
Pro Trp Gln Tyr Val Asp Asp Ile Trp Leu Met Phe Asn Asn Ala
1115 1120 1125
Trp Leu Tyr Asn Arg Lys Thr Ser Arg Val Tyr Lys Tyr Cys Ser
1130 1135 1140
Lys Leu Ser Glu Val Phe Glu Gln Glu Ile Asp Pro Val Met Gln
1145 1150 1155
Ser Leu Gly Tyr Cys Cys Gly Arg Lys Leu Glu Phe Ser Pro Gln
1160 1165 1170
Thr Leu Cys Cys Tyr Gly Lys Gln Leu Cys Thr Ile Pro Arg Asp
1175 1180 1185
Ala Thr Tyr Tyr Ser Tyr Gln Asn Arg Tyr His Phe Cys Glu Lys
1190 1195 1200
Cys Phe Asn Glu Ile Gln Gly Glu Ser Val Ser Leu Gly Asp Asp
1205 1210 1215
Pro Ser Gln Pro Gln Thr Thr Ile Asn Lys Glu Gln Phe Ser Lys
1220 1225 1230
Arg Lys Asn Asp Thr Leu Asp Pro Glu Leu Phe Val Glu Cys Thr
1235 1240 1245
Glu Cys Gly Arg Lys Met His Gln Ile Cys Val Leu His His Glu
1250 1255 1260
Ile Ile Trp Pro Ala Gly Phe Val Cys Asp Gly Cys Leu Lys Lys
1265 1270 1275
Ser Ala Arg Thr Arg Lys Glu Asn Lys Phe Ser Ala Lys Arg Leu
1280 1285 1290
Pro Ser Thr Arg Leu Gly Thr Phe Leu Glu Asn Arg Val Asn Asp
1295 1300 1305
Phe Leu Arg Arg Gln Asn His Pro Glu Ser Gly Glu Val Thr Val
1310 1315 1320
Arg Val Val His Ala Ser Asp Lys Thr Val Glu Val Lys Pro Gly
1325 1330 1335
Met Lys Ala Arg Phe Val Asp Ser Gly Glu Met Ala Glu Ser Phe
1340 1345 1350
Pro Tyr Arg Thr Lys Ala Leu Phe Ala Phe Glu Glu Ile Asp Gly
1355 1360 1365
Val Asp Leu Cys Phe Phe Gly Met His Val Gln Glu Tyr Gly Ser
1370 1375 1380
Asp Cys Pro Pro Pro Asn Gln Arg Arg Val Tyr Ile Ser Tyr Leu
1385 1390 1395
Asp Ser Val His Phe Phe Arg Pro Lys Cys Leu Arg Thr Ala Val
1400 1405 1410
Tyr His Glu Ile Leu Ile Gly Tyr Leu Glu Tyr Val Lys Lys Leu
1415 1420 1425
Gly Tyr Thr Thr Gly His Ile Trp Ala Cys Pro Pro Ser Glu Gly
1430 1435 1440
Asp Asp Tyr Ile Phe His Cys His Pro Pro Asp Gln Lys Ile Pro
1445 1450 1455
Lys Pro Lys Arg Leu Gln Glu Trp Tyr Lys Lys Met Leu Asp Lys
1460 1465 1470
Ala Val Ser Glu Arg Ile Val His Asp Tyr Lys Asp Ile Phe Lys
1475 1480 1485
Gln Ala Thr Glu Asp Arg Leu Thr Ser Ala Lys Glu Leu Pro Tyr
1490 1495 1500
Phe Glu Gly Asp Phe Trp Pro Asn Val Leu Glu Glu Ser Ile Lys
1505 1510 1515
Glu Leu Glu Gln Glu Glu Glu Glu Arg Lys Arg Glu Glu Asn Thr
1520 1525 1530
Ser Asn Glu Ser Thr Asp Val Thr Lys Gly Asp Ser Lys Asn Ala
1535 1540 1545
Lys Lys Lys Asn Asn Lys Lys Thr Ser Lys Asn Lys Ser Ser Leu
1550 1555 1560
Ser Arg Gly Asn Lys Lys Lys Pro Gly Met Pro Asn Val Ser Asn
1565 1570 1575
Asp Leu Ser Gln Lys Leu Tyr Ala Thr Met Glu Lys His Lys Glu
1580 1585 1590
Val Phe Phe Val Ile Arg Leu Ile Ala Gly Pro Ala Ala Asn Ser
1595 1600 1605
Leu Pro Pro Ile Val Asp Pro Asp Pro Leu Ile Pro Cys Asp Leu
1610 1615 1620
Met Asp Gly Arg Asp Ala Phe Leu Thr Leu Ala Arg Asp Lys His
1625 1630 1635
Leu Glu Phe Ser Ser Leu Arg Arg Ala Gln Trp Ser Thr Met Cys
1640 1645 1650
Met Leu Val Glu Leu His Thr Gln Ser Gln Asp Arg Phe Val Tyr
1655 1660 1665
Thr Cys Asn Glu Cys Lys His His Val Glu Thr Arg Trp His Cys
1670 1675 1680
Thr Val Cys Glu Asp Tyr Asp Leu Cys Ile Thr Cys Tyr Asn Thr
1685 1690 1695
Lys Asn His Asp His Lys Met Glu Lys Leu Gly Leu Gly Leu Asp
1700 1705 1710
Asp Glu Ser Asn Asn Gln Gln Ala Ala Ala Thr Gln Ser Pro Gly
1715 1720 1725
Asp Ser Arg Arg Leu Ser Ile Gln Arg Cys Ile Gln Ser Leu Val
1730 1735 1740
His Ala Cys Gln Cys Arg Asn Ala Asn Cys Ser Leu Pro Ser Cys
1745 1750 1755
Gln Lys Met Lys Arg Val Val Gln His Thr Lys Gly Cys Lys Arg
1760 1765 1770
Lys Thr Asn Gly Gly Cys Pro Ile Cys Lys Gln Leu Ile Ala Leu
1775 1780 1785
Cys Cys Tyr His Ala Lys His Cys Gln Glu Asn Lys Cys Pro Val
1790 1795 1800
Pro Phe Cys Leu Asn Ile Lys Gln Lys Leu Arg Gln Gln Gln Leu
1805 1810 1815
Gln His Arg Leu Gln Gln Ala Gln Met Leu Arg Arg Arg Met Ala
1820 1825 1830
Ser Met Gln Arg Thr Gly Val Val Gly Gln Gln Gln Gly Leu Pro
1835 1840 1845
Ser Pro Thr Pro Ala Thr Pro Thr Thr Pro Thr Gly Gln Gln Pro
1850 1855 1860
Thr Thr Pro Gln Thr Pro Gln Pro Thr Ser Gln Pro Gln Pro Thr
1865 1870 1875
Pro Pro Asn Ser Met Pro Pro Tyr Leu Pro Arg Thr Gln Ala Ala
1880 1885 1890
Gly Pro Val Ser Gln Gly Lys Ala Ala Gly Gln Val Thr Pro Pro
1895 1900 1905
Thr Pro Pro Gln Thr Ala Gln Pro Pro Leu Pro Gly Pro Pro Pro
1910 1915 1920
Ala Ala Val Glu Met Ala Met Gln Ile Gln Arg Ala Ala Glu Thr
1925 1930 1935
Gln Arg Gln Met Ala His Val Gln Ile Phe Gln Arg Pro Ile Gln
1940 1945 1950
His Gln Met Pro Pro Met Thr Pro Met Ala Pro Met Gly Met Asn
1955 1960 1965
Pro Pro Pro Met Thr Arg Gly Pro Ser Gly His Leu Glu Pro Gly
1970 1975 1980
Met Gly Pro Thr Gly Met Gln Gln Gln Pro Pro Trp Ser Gln Gly
1985 1990 1995
Gly Leu Pro Gln Pro Gln Gln Leu Gln Ser Gly Met Pro Arg Pro
2000 2005 2010
Ala Met Met Ser Val Ala Gln His Gly Gln Pro Leu Asn Met Ala
2015 2020 2025
Pro Gln Pro Gly Leu Gly Gln Val Gly Ile Ser Pro Leu Lys Pro
2030 2035 2040
Gly Thr Val Ser Gln Gln Ala Leu Gln Asn Leu Leu Arg Thr Leu
2045 2050 2055
Arg Ser Pro Ser Ser Pro Leu Gln Gln Gln Gln Val Leu Ser Ile
2060 2065 2070
Leu His Ala Asn Pro Gln Leu Leu Ala Ala Phe Ile Lys Gln Arg
2075 2080 2085
Ala Ala Lys Tyr Ala Asn Ser Asn Pro Gln Pro Ile Pro Gly Gln
2090 2095 2100
Pro Gly Met Pro Gln Gly Gln Pro Gly Leu Gln Pro Pro Thr Met
2105 2110 2115
Pro Gly Gln Gln Gly Val His Ser Asn Pro Ala Met Gln Asn Met
2120 2125 2130
Asn Pro Met Gln Ala Gly Val Gln Arg Ala Gly Leu Pro Gln Gln
2135 2140 2145
Gln Pro Gln Gln Gln Leu Gln Pro Pro Met Gly Gly Met Ser Pro
2150 2155 2160
Gln Ala Gln Gln Met Asn Met Asn His Asn Thr Met Pro Ser Gln
2165 2170 2175
Phe Arg Asp Ile Leu Arg Arg Gln Gln Met Met Gln Gln Gln Gln
2180 2185 2190
Gln Gln Gly Ala Gly Pro Gly Ile Gly Pro Gly Met Ala Asn His
2195 2200 2205
Asn Gln Phe Gln Gln Pro Gln Gly Val Gly Tyr Pro Pro Gln Gln
2210 2215 2220
Gln Gln Arg Met Gln His His Met Gln Gln Met Gln Gln Gly Asn
2225 2230 2235
Met Gly Gln Ile Gly Gln Leu Pro Gln Ala Leu Gly Ala Glu Ala
2240 2245 2250
Gly Ala Ser Leu Gln Ala Tyr Gln Gln Arg Leu Leu Gln Gln Gln
2255 2260 2265
Met Gly Ser Pro Val Gln Pro Asn Pro Met Ser Pro Gln Gln His
2270 2275 2280
Met Leu Pro Asn Gln Ala Gln Ser Pro His Leu Gln Gly Gln Gln
2285 2290 2295
Ile Pro Asn Ser Leu Ser Asn Gln Val Arg Ser Pro Gln Pro Val
2300 2305 2310
Pro Ser Pro Arg Pro Gln Ser Gln Pro Pro His Ser Ser Pro Ser
2315 2320 2325
Pro Arg Met Gln Pro Gln Pro Ser Pro His His Val Ser Pro Gln
2330 2335 2340
Thr Ser Ser Pro His Pro Gly Leu Val Ala Ala Gln Ala Asn Pro
2345 2350 2355
Met Glu Gln Gly His Phe Ala Ser Pro Asp Gln Asn Ser Met Leu
2360 2365 2370
Ser Gln Leu Ala Ser Asn Pro Gly Met Ala Asn Leu His Gly Ala
2375 2380 2385
Ser Ala Thr Asp Leu Gly Leu Ser Thr Asp Asn Ser Asp Leu Asn
2390 2395 2400
Ser Asn Leu Ser Gln Ser Thr Leu Asp Ile His
2405 2410
<210> 8
<211> 1229
<212> PRT
<213> Homo sapiens
<400> 8
Met Ser Pro Ala Ala Ala Ala Ala Gly Ala Gly Glu Arg Arg Arg Pro
1 5 10 15
Ile Ala Ser Val Arg Asp Gly Arg Gly Arg Gly Cys Gly Gly Pro Ala
20 25 30
Gly Ala Ala Leu Leu Gly Leu Ser Leu Val Gly Leu Leu Leu Tyr Leu
35 40 45
Val Pro Ala Ala Ala Ala Leu Ala Trp Leu Ala Val Gly Thr Thr Ala
50 55 60
Ala Trp Trp Gly Leu Ser Arg Glu Pro Arg Gly Ser Arg Pro Leu Ser
65 70 75 80
Ser Phe Val Gln Lys Ala Arg His Arg Arg Thr Leu Phe Ala Ser Pro
85 90 95
Pro Ala Lys Ser Thr Ala Asn Gly Asn Leu Leu Glu Pro Arg Thr Leu
100 105 110
Leu Glu Gly Pro Asp Pro Ala Glu Leu Leu Leu Met Gly Ser Tyr Leu
115 120 125
Gly Lys Pro Gly Pro Pro Gln Pro Ala Pro Ala Pro Glu Gly Gln Asp
130 135 140
Leu Arg Asn Arg Pro Gly Arg Arg Pro Pro Ala Arg Pro Ala Pro Arg
145 150 155 160
Ser Thr Pro Pro Ser Gln Pro Thr His Arg Val His His Phe Tyr Pro
165 170 175
Ser Leu Pro Thr Pro Leu Leu Arg Pro Ser Gly Arg Pro Ser Pro Arg
180 185 190
Asp Arg Gly Thr Leu Pro Asp Arg Phe Val Ile Thr Pro Arg Arg Arg
195 200 205
Tyr Pro Ile His Gln Thr Gln Tyr Ser Cys Pro Gly Val Leu Pro Thr
210 215 220
Val Cys Trp Asn Gly Tyr His Lys Lys Ala Val Leu Ser Pro Arg Asn
225 230 235 240
Ser Arg Met Val Cys Ser Pro Val Thr Val Arg Ile Ala Pro Pro Asp
245 250 255
Arg Arg Phe Ser Arg Ser Ala Ile Pro Glu Gln Ile Ile Ser Ser Thr
260 265 270
Leu Ser Ser Pro Ser Ser Asn Ala Pro Asp Pro Cys Ala Lys Glu Thr
275 280 285
Val Leu Ser Ala Leu Lys Glu Lys Lys Lys Lys Arg Thr Val Glu Glu
290 295 300
Glu Asp Gln Ile Phe Leu Asp Gly Gln Glu Asn Lys Arg Arg Arg His
305 310 315 320
Asp Ser Ser Gly Ser Gly His Ser Ala Phe Glu Pro Leu Val Ala Ser
325 330 335
Gly Val Pro Ala Ser Phe Val Pro Lys Pro Gly Ser Leu Lys Arg Gly
340 345 350
Leu Asn Ser Gln Ser Ser Asp Asp His Leu Asn Lys Arg Ser Arg Ser
355 360 365
Ser Ser Met Ser Ser Leu Thr Gly Ala Tyr Thr Ser Gly Ile Pro Ser
370 375 380
Ser Ser Arg Asn Ala Ile Thr Ser Ser Tyr Ser Ser Thr Arg Gly Ile
385 390 395 400
Ser Gln Leu Trp Lys Arg Asn Gly Pro Ser Ser Ser Pro Phe Ser Ser
405 410 415
Pro Ala Ser Ser Arg Ser Gln Thr Pro Glu Arg Pro Ala Lys Lys Ile
420 425 430
Arg Glu Glu Glu Leu Cys His His Ser Ser Ser Ser Thr Pro Leu Ala
435 440 445
Ala Asp Lys Glu Ser Gln Gly Glu Lys Ala Ala Asp Thr Thr Pro Arg
450 455 460
Lys Lys Gln Asn Ser Asn Ser Gln Ser Thr Pro Gly Ser Ser Gly Gln
465 470 475 480
Arg Lys Arg Lys Val Gln Leu Leu Pro Ser Arg Arg Gly Glu Gln Leu
485 490 495
Thr Leu Pro Pro Pro Pro Gln Leu Gly Tyr Ser Ile Thr Ala Glu Asp
500 505 510
Leu Asp Leu Glu Lys Lys Ala Ser Leu Gln Trp Phe Asn Gln Ala Leu
515 520 525
Glu Asp Lys Ser Asp Ala Ala Ser Asn Ser Val Thr Glu Thr Pro Pro
530 535 540
Thr Thr Gln Pro Ser Phe Thr Phe Thr Leu Pro Ala Ala Ala Thr Ala
545 550 555 560
Ser Pro Pro Thr Ser Leu Leu Ala Pro Ser Thr Asn Pro Leu Leu Glu
565 570 575
Ser Leu Lys Lys Met Gln Thr Pro Pro Ser Leu Pro Pro Cys Pro Glu
580 585 590
Ser Ala Gly Ala Ala Thr Thr Glu Ala Leu Ser Pro Pro Lys Thr Pro
595 600 605
Ser Leu Leu Pro Pro Leu Gly Leu Ser Gln Ser Gly Pro Pro Gly Leu
610 615 620
Leu Pro Ser Pro Ser Phe Asp Ser Lys Pro Pro Thr Thr Leu Leu Gly
625 630 635 640
Leu Ile Pro Ala Pro Ser Met Val Pro Ala Thr Asp Thr Lys Ala Pro
645 650 655
Pro Thr Leu Gln Ala Glu Thr Ala Thr Lys Pro Gln Ala Thr Ser Ala
660 665 670
Pro Ser Pro Ala Pro Lys Gln Ser Phe Leu Phe Gly Thr Gln Asn Thr
675 680 685
Ser Pro Ser Ser Pro Ala Ala Pro Ala Ala Ser Ser Ala Ser Pro Met
690 695 700
Phe Lys Pro Ile Phe Thr Ala Pro Pro Lys Ser Glu Lys Glu Gly Leu
705 710 715 720
Thr Pro Pro Gly Pro Ser Val Ser Ala Thr Ala Pro Ser Ser Ser Ser
725 730 735
Leu Pro Thr Thr Thr Ser Thr Thr Ala Pro Thr Phe Gln Pro Val Phe
740 745 750
Ser Ser Met Gly Pro Pro Ala Ser Val Pro Leu Pro Ala Pro Phe Phe
755 760 765
Lys Gln Thr Thr Thr Pro Ala Thr Ala Pro Thr Thr Thr Ala Pro Leu
770 775 780
Phe Thr Gly Leu Ala Ser Ala Thr Ser Ala Val Ala Pro Ile Thr Ser
785 790 795 800
Ala Ser Pro Ser Thr Asp Ser Ala Ser Lys Pro Ala Phe Gly Phe Gly
805 810 815
Ile Asn Ser Val Ser Ser Ser Ser Val Ser Thr Thr Thr Ser Thr Ala
820 825 830
Thr Ala Ala Ser Gln Pro Phe Leu Phe Gly Ala Pro Gln Ala Ser Ala
835 840 845
Ala Ser Phe Thr Pro Ala Met Gly Ser Ile Phe Gln Phe Gly Lys Pro
850 855 860
Pro Ala Leu Pro Thr Thr Thr Thr Val Thr Thr Phe Ser Gln Ser Leu
865 870 875 880
Pro Thr Ala Val Pro Thr Ala Thr Ser Ser Ser Ala Ala Asp Phe Ser
885 890 895
Gly Phe Gly Ser Thr Leu Ala Thr Ser Ala Pro Ala Thr Ser Ser Gln
900 905 910
Pro Thr Leu Thr Phe Ser Asn Thr Ser Thr Pro Thr Phe Asn Ile Pro
915 920 925
Phe Gly Ser Ser Ala Lys Ser Pro Leu Pro Ser Tyr Pro Gly Ala Asn
930 935 940
Pro Gln Pro Ala Phe Gly Ala Ala Glu Gly Gln Pro Pro Gly Ala Ala
945 950 955 960
Lys Pro Ala Leu Thr Pro Ser Phe Gly Ser Ser Phe Thr Phe Gly Asn
965 970 975
Ser Ala Ala Pro Ala Pro Ala Thr Ala Pro Thr Pro Ala Pro Ala Ser
980 985 990
Thr Ile Lys Ile Val Pro Ala His Val Pro Thr Pro Ile Gln Pro Thr
995 1000 1005
Phe Gly Gly Ala Thr His Ser Ala Phe Gly Leu Lys Ala Thr Ala
1010 1015 1020
Ser Ala Phe Gly Ala Pro Ala Ser Ser Gln Pro Ala Phe Gly Gly
1025 1030 1035
Ser Thr Ala Val Phe Ser Phe Gly Ala Ala Thr Ser Ser Gly Phe
1040 1045 1050
Gly Ala Thr Thr Gln Thr Ala Ser Ser Gly Ser Ser Ser Ser Val
1055 1060 1065
Phe Gly Ser Thr Thr Pro Ser Pro Phe Thr Phe Gly Gly Ser Ala
1070 1075 1080
Ala Pro Ala Gly Ser Gly Ser Phe Gly Ile Asn Val Ala Thr Pro
1085 1090 1095
Gly Ser Ser Ala Thr Thr Gly Ala Phe Ser Phe Gly Ala Gly Gln
1100 1105 1110
Ser Gly Ser Thr Ala Thr Ser Thr Pro Phe Thr Gly Gly Leu Gly
1115 1120 1125
Gln Asn Ala Leu Gly Thr Thr Gly Gln Ser Thr Pro Phe Ala Phe
1130 1135 1140
Asn Val Gly Ser Thr Thr Glu Ser Lys Pro Val Phe Gly Gly Thr
1145 1150 1155
Ala Thr Pro Thr Phe Gly Gln Asn Thr Pro Ala Pro Gly Val Gly
1160 1165 1170
Thr Ser Gly Ser Ser Leu Ser Phe Gly Ala Ser Ser Ala Pro Ala
1175 1180 1185
Gln Gly Phe Val Gly Val Gly Pro Phe Gly Ser Ala Ala Pro Ser
1190 1195 1200
Phe Ser Ile Gly Ala Gly Ser Lys Thr Pro Gly Ala Arg Gln Arg
1205 1210 1215
Leu Gln Ala Arg Arg Gln His Thr Arg Lys Lys
1220 1225
<210> 9
<211> 339
<212> PRT
<213> Homo sapiens
<400> 9
Gly Lys Asp Tyr Tyr Gln Thr Leu Gly Leu Ala Arg Gly Ala Ser Asp
1 5 10 15
Glu Glu Ile Lys Arg Ala Tyr Arg Arg Gln Ala Leu Arg Tyr His Pro
20 25 30
Asp Lys Asn Lys Glu Pro Gly Ala Glu Glu Lys Phe Lys Glu Ile Ala
35 40 45
Glu Ala Tyr Asp Val Leu Ser Asp Pro Arg Lys Arg Glu Ile Phe Asp
50 55 60
Arg Tyr Gly Glu Glu Gly Leu Lys Gly Ser Gly Pro Ser Gly Gly Ser
65 70 75 80
Gly Gly Gly Ala Asn Gly Thr Ser Phe Ser Tyr Thr Phe His Gly Asp
85 90 95
Pro His Ala Met Phe Ala Glu Phe Phe Gly Gly Arg Asn Pro Phe Asp
100 105 110
Thr Phe Phe Gly Gln Arg Asn Gly Glu Glu Gly Met Asp Ile Asp Asp
115 120 125
Pro Phe Ser Gly Phe Pro Met Gly Met Gly Gly Phe Thr Asn Val Asn
130 135 140
Phe Gly Arg Ser Arg Ser Ala Gln Glu Pro Ala Arg Lys Lys Gln Asp
145 150 155 160
Pro Pro Val Thr His Asp Leu Arg Val Ser Leu Glu Glu Ile Tyr Ser
165 170 175
Gly Cys Thr Lys Lys Met Lys Ile Ser His Lys Arg Leu Asn Pro Asp
180 185 190
Gly Lys Ser Ile Arg Asn Glu Asp Lys Ile Leu Thr Ile Glu Val Lys
195 200 205
Lys Gly Trp Lys Glu Gly Thr Lys Ile Thr Phe Pro Lys Glu Gly Asp
210 215 220
Gln Thr Ser Asn Asn Ile Pro Ala Asp Ile Val Phe Val Leu Lys Asp
225 230 235 240
Lys Pro His Asn Ile Phe Lys Arg Asp Gly Ser Asp Val Ile Tyr Pro
245 250 255
Ala Arg Ile Ser Leu Arg Glu Ala Leu Cys Gly Cys Thr Val Asn Val
260 265 270
Pro Thr Leu Asp Gly Arg Thr Ile Pro Val Val Phe Lys Asp Val Ile
275 280 285
Arg Pro Gly Met Arg Arg Lys Val Pro Gly Glu Gly Leu Pro Leu Pro
290 295 300
Lys Thr Pro Glu Lys Arg Gly Asp Leu Ile Ile Glu Phe Glu Val Ile
305 310 315 320
Phe Pro Glu Arg Ile Pro Gln Thr Ser Arg Thr Val Leu Glu Gln Val
325 330 335
Leu Pro Ile
<210> 10
<211> 670
<212> PRT
<213> Homo sapiens
<400> 10
Met Gly Glu Pro Ala Gly Val Ala Gly Thr Met Glu Ser Pro Phe Ser
1 5 10 15
Pro Gly Leu Phe His Arg Leu Asp Glu Asp Trp Asp Ser Ala Leu Phe
20 25 30
Ala Glu Leu Gly Tyr Phe Thr Asp Thr Asp Glu Leu Gln Leu Glu Ala
35 40 45
Ala Asn Glu Thr Tyr Glu Asn Asn Phe Asp Asn Leu Asp Phe Asp Leu
50 55 60
Asp Leu Met Pro Trp Glu Ser Asp Ile Trp Asp Ile Asn Asn Gln Ile
65 70 75 80
Cys Thr Val Lys Asp Ile Lys Ala Glu Pro Gln Pro Leu Ser Pro Ala
85 90 95
Ser Ser Ser Tyr Ser Val Ser Ser Pro Arg Ser Val Asp Ser Tyr Ser
100 105 110
Ser Thr Gln His Val Pro Glu Glu Leu Asp Leu Ser Ser Ser Ser Gln
115 120 125
Met Ser Pro Leu Ser Leu Tyr Gly Glu Asn Ser Asn Ser Leu Ser Ser
130 135 140
Ala Glu Pro Leu Lys Glu Asp Lys Pro Val Thr Gly Pro Arg Asn Lys
145 150 155 160
Thr Glu Asn Gly Leu Thr Pro Lys Lys Lys Ile Gln Val Asn Ser Lys
165 170 175
Pro Ser Ile Gln Pro Lys Pro Leu Leu Leu Pro Ala Ala Pro Lys Thr
180 185 190
Gln Thr Asn Ser Ser Val Pro Ala Lys Thr Ile Ile Ile Gln Thr Val
195 200 205
Pro Thr Leu Met Pro Leu Ala Lys Gln Gln Pro Ile Ile Ser Leu Gln
210 215 220
Pro Ala Pro Thr Lys Gly Gln Thr Val Leu Leu Ser Gln Pro Thr Val
225 230 235 240
Val Gln Leu Gln Ala Pro Gly Val Leu Pro Ser Ala Gln Pro Val Leu
245 250 255
Ala Val Ala Gly Gly Val Thr Gln Leu Pro Asn His Val Val Asn Val
260 265 270
Val Pro Ala Pro Ser Ala Asn Ser Pro Val Asn Gly Lys Leu Ser Val
275 280 285
Thr Lys Pro Val Leu Gln Ser Thr Met Arg Asn Val Gly Ser Asp Ile
290 295 300
Ala Val Leu Arg Arg Gln Gln Arg Met Ile Lys Asn Arg Glu Ser Ala
305 310 315 320
Cys Gln Ser Arg Lys Lys Lys Lys Glu Tyr Met Leu Gly Leu Glu Ala
325 330 335
Arg Leu Lys Ala Ala Leu Ser Glu Asn Glu Gln Leu Lys Lys Glu Asn
340 345 350
Gly Thr Leu Lys Arg Gln Leu Asp Glu Val Val Ser Glu Asn Gln Arg
355 360 365
Leu Lys Val Pro Ser Pro Lys Arg Arg Val Val Cys Val Met Ile Val
370 375 380
Leu Ala Phe Ile Ile Leu Asn Tyr Gly Pro Met Ser Met Leu Glu Gln
385 390 395 400
Asp Ser Arg Arg Met Asn Pro Ser Val Ser Pro Ala Asn Gln Arg Arg
405 410 415
His Leu Leu Gly Phe Ser Ala Lys Glu Ala Gln Asp Thr Ser Asp Gly
420 425 430
Ile Ile Gln Lys Asn Ser Tyr Arg Tyr Asp His Ser Val Ser Asn Asp
435 440 445
Lys Ala Leu Met Val Leu Thr Glu Glu Pro Leu Leu Tyr Ile Pro Pro
450 455 460
Pro Pro Cys Gln Pro Leu Ile Asn Thr Thr Glu Ser Leu Arg Leu Asn
465 470 475 480
His Glu Leu Arg Gly Trp Val His Arg His Glu Val Glu Arg Thr Lys
485 490 495
Ser Arg Arg Met Thr Asn Asn Gln Gln Lys Thr Arg Ile Leu Gln Gly
500 505 510
Ala Leu Glu Gln Gly Ser Asn Ser Gln Leu Met Ala Val Gln Tyr Thr
515 520 525
Glu Thr Thr Ser Ser Ile Ser Arg Asn Ser Gly Ser Glu Leu Gln Val
530 535 540
Tyr Tyr Ala Ser Pro Arg Ser Tyr Gln Asp Phe Phe Glu Ala Ile Arg
545 550 555 560
Arg Arg Gly Asp Thr Phe Tyr Val Val Ser Phe Arg Arg Asp His Leu
565 570 575
Leu Leu Pro Ala Thr Thr His Asn Lys Thr Thr Arg Pro Lys Met Ser
580 585 590
Ile Val Leu Pro Ala Ile Asn Ile Asn Glu Asn Val Ile Asn Gly Gln
595 600 605
Asp Tyr Glu Val Met Met Gln Ile Asp Cys Gln Val Met Asp Thr Arg
610 615 620
Ile Leu His Ile Lys Ser Ser Ser Val Pro Pro Tyr Leu Arg Asp Gln
625 630 635 640
Gln Arg Asn Gln Thr Asn Thr Phe Phe Gly Ser Pro Pro Ala Ala Thr
645 650 655
Glu Ala Thr His Val Val Ser Thr Ile Pro Glu Ser Leu Gln
660 665 670
<210> 11
<211> 351
<212> PRT
<213> Homo sapiens
<400> 11
Met Thr Glu Met Ser Phe Leu Ser Ser Glu Val Leu Val Gly Asp Leu
1 5 10 15
Met Ser Pro Phe Asp Gln Ser Gly Leu Gly Ala Glu Glu Ser Leu Gly
20 25 30
Leu Leu Asp Asp Tyr Leu Glu Val Ala Lys His Phe Lys Pro His Gly
35 40 45
Phe Ser Ser Asp Lys Ala Lys Ala Gly Ser Ser Glu Trp Leu Ala Val
50 55 60
Asp Gly Leu Val Ser Pro Ser Asn Asn Ser Lys Glu Asp Ala Phe Ser
65 70 75 80
Gly Thr Asp Trp Met Leu Glu Lys Met Asp Leu Lys Glu Phe Asp Leu
85 90 95
Asp Ala Leu Leu Gly Ile Asp Asp Leu Glu Thr Met Pro Asp Asp Leu
100 105 110
Leu Thr Thr Leu Asp Asp Thr Cys Asp Leu Phe Ala Pro Leu Val Gln
115 120 125
Glu Thr Asn Lys Gln Pro Pro Gln Thr Val Asn Pro Ile Gly His Leu
130 135 140
Pro Glu Ser Leu Thr Lys Pro Asp Gln Val Ala Pro Phe Thr Phe Leu
145 150 155 160
Gln Pro Leu Pro Leu Ser Pro Gly Val Leu Ser Ser Thr Pro Asp His
165 170 175
Ser Phe Ser Leu Glu Leu Gly Ser Glu Val Asp Ile Thr Glu Gly Asp
180 185 190
Arg Lys Pro Asp Tyr Thr Ala Tyr Val Ala Met Ile Pro Gln Cys Ile
195 200 205
Lys Glu Glu Asp Thr Pro Ser Asp Asn Asp Ser Gly Ile Cys Met Ser
210 215 220
Pro Glu Ser Tyr Leu Gly Ser Pro Gln His Ser Pro Ser Thr Arg Gly
225 230 235 240
Ser Pro Asn Arg Ser Leu Pro Ser Pro Gly Val Leu Cys Gly Ser Ala
245 250 255
Arg Pro Lys Pro Tyr Asp Pro Pro Gly Glu Lys Met Val Ala Ala Lys
260 265 270
Val Lys Gly Glu Lys Leu Asp Lys Lys Leu Lys Lys Met Glu Gln Asn
275 280 285
Lys Thr Ala Ala Thr Arg Tyr Arg Gln Lys Lys Arg Ala Glu Gln Glu
290 295 300
Ala Leu Thr Gly Glu Cys Lys Glu Leu Glu Lys Lys Asn Glu Ala Leu
305 310 315 320
Lys Glu Arg Ala Asp Ser Leu Ala Lys Glu Ile Gln Tyr Leu Lys Asp
325 330 335
Leu Ile Glu Glu Val Arg Lys Ala Arg Gly Lys Lys Arg Val Pro
340 345 350
<210> 12
<211> 1116
<212> PRT
<213> Homo sapiens
<400> 12
Met Glu Arg Ala Ile Ser Pro Gly Leu Leu Val Arg Ala Leu Leu Leu
1 5 10 15
Leu Leu Leu Leu Leu Gly Leu Ala Ala Arg Thr Val Ala Ala Gly Arg
20 25 30
Ala Arg Gly Leu Pro Ala Pro Thr Ala Glu Ala Ala Phe Gly Leu Gly
35 40 45
Ala Ala Ala Ala Pro Thr Ser Ala Thr Arg Val Pro Ala Ala Gly Ala
50 55 60
Val Ala Ala Ala Glu Val Thr Val Glu Asp Ala Glu Ala Leu Pro Ala
65 70 75 80
Ala Ala Gly Glu Gln Glu Pro Arg Gly Pro Glu Pro Asp Asp Glu Thr
85 90 95
Glu Leu Arg Pro Arg Gly Arg Ser Leu Val Ile Ile Ser Thr Leu Asp
100 105 110
Gly Arg Ile Ala Ala Leu Asp Pro Glu Asn His Gly Lys Lys Gln Trp
115 120 125
Asp Leu Asp Val Gly Ser Gly Ser Leu Val Ser Ser Ser Leu Ser Lys
130 135 140
Pro Glu Val Phe Gly Asn Lys Met Ile Ile Pro Ser Leu Asp Gly Ala
145 150 155 160
Leu Phe Gln Trp Asp Gln Asp Arg Glu Ser Met Glu Thr Val Pro Phe
165 170 175
Thr Val Glu Ser Leu Leu Glu Ser Ser Tyr Lys Phe Gly Asp Asp Val
180 185 190
Val Leu Val Gly Gly Lys Ser Leu Thr Thr Tyr Gly Leu Ser Ala Tyr
195 200 205
Ser Gly Lys Val Arg Tyr Ile Cys Ser Ala Leu Gly Cys Arg Gln Trp
210 215 220
Asp Ser Asp Glu Met Glu Gln Glu Glu Asp Ile Leu Leu Leu Gln Arg
225 230 235 240
Thr Gln Lys Thr Val Arg Ala Val Gly Pro Arg Ser Gly Asn Glu Lys
245 250 255
Trp Asn Phe Ser Val Gly His Phe Glu Leu Arg Tyr Ile Pro Asp Met
260 265 270
Glu Thr Arg Ala Gly Phe Ile Glu Ser Thr Phe Lys Pro Asn Glu Asn
275 280 285
Thr Glu Glu Ser Lys Ile Ile Ser Asp Val Glu Glu Gln Glu Ala Ala
290 295 300
Ile Met Asp Ile Val Ile Lys Val Ser Val Ala Asp Trp Lys Val Met
305 310 315 320
Ala Phe Ser Lys Lys Gly Gly His Leu Glu Trp Glu Tyr Gln Phe Cys
325 330 335
Thr Pro Ile Ala Ser Ala Trp Leu Leu Lys Asp Gly Lys Val Ile Pro
340 345 350
Ile Ser Leu Phe Asp Asp Thr Ser Tyr Thr Ser Asn Asp Asp Val Leu
355 360 365
Glu Asp Glu Glu Asp Ile Val Glu Ala Ala Arg Gly Ala Thr Glu Asn
370 375 380
Ser Val Tyr Leu Gly Met Tyr Arg Gly Gln Leu Tyr Leu Gln Ser Ser
385 390 395 400
Val Arg Ile Ser Glu Lys Phe Pro Ser Ser Pro Lys Ala Leu Glu Ser
405 410 415
Val Thr Asn Glu Asn Ala Ile Ile Pro Leu Pro Thr Ile Lys Trp Lys
420 425 430
Pro Leu Ile His Ser Pro Ser Arg Thr Pro Val Leu Val Gly Ser Asp
435 440 445
Glu Phe Asp Lys Cys Leu Ser Asn Asp Lys Phe Ser His Glu Glu Tyr
450 455 460
Ser Asn Gly Ala Leu Ser Ile Leu Gln Tyr Pro Tyr Asp Asn Gly Tyr
465 470 475 480
Tyr Leu Pro Tyr Tyr Lys Arg Glu Arg Asn Lys Arg Ser Thr Gln Ile
485 490 495
Thr Val Arg Phe Leu Asp Asn Pro His Tyr Asn Lys Asn Ile Arg Lys
500 505 510
Lys Asp Pro Val Leu Leu Leu His Trp Trp Lys Glu Ile Val Ala Thr
515 520 525
Ile Leu Phe Cys Ile Ile Ala Thr Thr Phe Ile Val Arg Arg Leu Phe
530 535 540
His Pro His Pro His Arg Gln Arg Lys Glu Ser Glu Thr Gln Cys Gln
545 550 555 560
Thr Glu Asn Lys Tyr Asp Ser Val Ser Gly Glu Ala Asn Asp Ser Ser
565 570 575
Trp Asn Asp Ile Lys Asn Ser Gly Tyr Ile Ser Arg Tyr Leu Thr Asp
580 585 590
Phe Glu Pro Ile Gln Cys Leu Gly Arg Gly Gly Phe Gly Val Val Phe
595 600 605
Glu Ala Lys Asn Lys Val Asp Asp Cys Asn Tyr Ala Ile Lys Arg Ile
610 615 620
Arg Leu Pro Asn Arg Glu Leu Ala Arg Glu Lys Val Met Arg Glu Val
625 630 635 640
Lys Ala Leu Ala Lys Leu Glu His Pro Gly Ile Val Arg Tyr Phe Asn
645 650 655
Ala Trp Leu Glu Ala Pro Pro Glu Lys Trp Gln Glu Lys Met Asp Glu
660 665 670
Ile Trp Leu Lys Asp Glu Ser Thr Asp Trp Pro Leu Ser Ser Pro Ser
675 680 685
Pro Met Asp Ala Pro Ser Val Lys Ile Arg Arg Met Asp Pro Phe Ala
690 695 700
Thr Lys Glu His Ile Glu Ile Ile Ala Pro Ser Pro Gln Arg Ser Arg
705 710 715 720
Ser Phe Ser Val Gly Ile Ser Cys Asp Gln Thr Ser Ser Ser Glu Ser
725 730 735
Gln Phe Ser Pro Leu Glu Phe Ser Gly Met Asp His Glu Asp Ile Ser
740 745 750
Glu Ser Val Asp Ala Ala Tyr Asn Leu Gln Asp Ser Cys Leu Thr Asp
755 760 765
Cys Asp Val Glu Asp Gly Thr Met Asp Gly Asn Asp Glu Gly His Ser
770 775 780
Phe Glu Leu Cys Pro Ser Glu Ala Ser Pro Tyr Val Arg Ser Arg Glu
785 790 795 800
Arg Thr Ser Ser Ser Ile Val Phe Glu Asp Ser Gly Cys Asp Asn Ala
805 810 815
Ser Ser Lys Glu Glu Pro Lys Thr Asn Arg Leu His Ile Gly Asn His
820 825 830
Cys Ala Asn Lys Leu Thr Ala Phe Lys Pro Thr Ser Ser Lys Ser Ser
835 840 845
Ser Glu Ala Thr Leu Ser Ile Ser Pro Pro Arg Pro Thr Thr Leu Ser
850 855 860
Leu Asp Leu Thr Lys Asn Thr Thr Glu Lys Leu Gln Pro Ser Ser Pro
865 870 875 880
Lys Val Tyr Leu Tyr Ile Gln Met Gln Leu Cys Arg Lys Glu Asn Leu
885 890 895
Lys Asp Trp Met Asn Gly Arg Cys Thr Ile Glu Glu Arg Glu Arg Ser
900 905 910
Val Cys Leu His Ile Phe Leu Gln Ile Ala Glu Ala Val Glu Phe Leu
915 920 925
His Ser Lys Gly Leu Met His Arg Asp Leu Lys Pro Ser Asn Ile Phe
930 935 940
Phe Thr Met Asp Asp Val Val Lys Val Gly Asp Phe Gly Leu Val Thr
945 950 955 960
Ala Met Asp Gln Asp Glu Glu Glu Gln Thr Val Leu Thr Pro Met Pro
965 970 975
Ala Tyr Ala Arg His Thr Gly Gln Val Gly Thr Lys Leu Tyr Met Ser
980 985 990
Pro Glu Gln Ile His Gly Asn Ser Tyr Ser His Lys Val Asp Ile Phe
995 1000 1005
Ser Leu Gly Leu Ile Leu Phe Glu Leu Leu Tyr Pro Phe Ser Thr
1010 1015 1020
Gln Met Glu Arg Val Arg Thr Leu Thr Asp Val Arg Asn Leu Lys
1025 1030 1035
Phe Pro Pro Leu Phe Thr Gln Lys Tyr Pro Cys Glu Tyr Val Met
1040 1045 1050
Val Gln Asp Met Leu Ser Pro Ser Pro Met Glu Arg Pro Glu Ala
1055 1060 1065
Ile Asn Ile Ile Glu Asn Ala Val Phe Glu Asp Leu Asp Phe Pro
1070 1075 1080
Gly Lys Thr Val Leu Arg Gln Arg Ser Arg Ser Leu Ser Ser Ser
1085 1090 1095
Gly Thr Lys His Ser Arg Gln Ser Asn Asn Ser His Ser Pro Leu
1100 1105 1110
Pro Ser Asn
1115
<210> 13
<211> 8468
<212> DNA
<213> Homo sapiens
<400> 13
agctgaggga gcgctctgaa ataatacacc attgcagccg gggaaagcag agcggcgcaa 60
aagagctctc gccgggtccg cctgctccct ctccgcttcg ctcctcttct cttctttacc 120
cttctcctct ctcctcctct gctgctctct cctctcctcc cgctcttctc tctcctcctc 180
tcctgctctc tcctcttccc ttagctcctc ttcttttctt ctcctcttct tccctctcct 240
cgcctctccc ctgctcctct tctctcgtct cccctcccct cccgcctctc tctcccctct 300
ccctctccca ctcgccccgc tcgctcgctc gctgtcgcac agactcaccg tcccttgtcc 360
aattatcata ttcatcaccc gcaagatatc accgtgtgtg cactcgcgtg ttttcctctc 420
tctgccgggg gaaaaaaaag agagagagag agatagagag agagagagag agagagagag 480
agaggctcgg tcccactgct ccctgcaccg cggtcccggg attcttgagc tgtgcccagc 540
tgacgagctt ttgaagatgg cacaataacc gtccagtgat gcctgaccat gacagcacag 600
ccctcttaag ccggcaaacc aagaggagaa gagttgacat tggagtgaaa aggacggtag 660
ggacagcatc tgcatttttt gctaaggcaa gagcaacgtt ttttagtgcc atgaatcccc 720
aaggttctga gcaggatgtt gagtattcag tggtgcagca tgcagatggg gaaaagtcaa 780
atgtactccg caagctgctg aagagggcga actcgtatga agatgccatg atgccttttc 840
caggagcaac cataatttcc cagctgttga aaaataacat gaacaaaaat ggtggcacgg 900
agcccagttt ccaagccagc ggtctctcta gtacaggctc cgaagtacat caggaggata 960
tatgcagcaa ctcttcaaga gacagccccc cagagtgtct ttcccctttt ggcaggccta 1020
ctatgagcca gtttgatatg gatcgcttat gtgatgagca cctgagagca aagcgcgccc 1080
gggttgagaa tataattcgg ggtatgagcc attcccccag tgtggcatta aggggcaatg 1140
aaaatgaaag agagatggcc ccgcagtctg tgagtccccg agaaagttac agagaaaaca 1200
aacgcaagca aaagcttccc cagcagcagc aacagagttt ccagcagctg gtttcagccc 1260
gaaaagaaca gaagcgagag gagcgccgac agctgaaaca gcagctggag gacatgcaga 1320
aacagctgcg ccagctgcag gaaaagttct accaaatcta tgacagcact gattcggaaa 1380
atgatgaaga tggtaacctg tctgaagaca gcatgcgctc ggagatcctg gatgccaggg 1440
cccaggactc tgtcggaagg tcagataatg agatgtgcga gctagaccca ggacagttta 1500
ttgaccgagc tcgagccctg atcagagagc aggaaatggc tgaaaacaag ccgaagcgag 1560
aaggcaacaa caaagaaaga gaccatgggc caaactcctt acaaccggaa ggcaaacatt 1620
tggctgagac cttgaaacag gaactgaaca ctgccatgtc gcaagttgtg gacactgtgg 1680
tcaaagtctt ttcggccaag ccctcccgcc aggttcctca ggtcttccca cctctccaga 1740
tcccccaggc cagatttgca gtcaatgggg aaaaccacaa tttccacacc gccaaccagc 1800
gcctgcagtg ctttggcgac gtcatcattc cgaaccccct ggacaccttt ggcaatgtgc 1860
agatggccag ttccactgac cagacagaag cactgcccct ggttgtccgc aaaaactcct 1920
ctgaccagtc tgcctccggc cctgccgctg gcggccacca ccagcccctg caccagtcgc 1980
ctctctctgc caccacgggc ttcaccacgt ccaccttccg ccaccccttc ccccttccct 2040
tgatggccta tccatttcag agcccattag gtgctccctc cggctccttc tctggaaaag 2100
acagagcctc tcctgaatcc ttagacttaa ctagggatac cacgagtctg aggaccaaga 2160
tgtcatctca ccacctgagc caccaccctt gttcaccagc acacccgccc agcaccgccg 2220
aagggctctc cttgtcgctc ataaagtccg agtgcggcga tcttcaagat atgtctgaaa 2280
tatcacctta ttcgggaagt gcaatgcagg aaggattgtc acccaatcac ttgaaaaaag 2340
caaagctcat gtttttttat acccgttatc ccagctccaa tatgctgaag acctacttct 2400
ccgacgtaaa gttcaacaga tgcattacct ctcagctcat caagtggttt agcaatttcc 2460
gtgagtttta ctacattcag atggagaagt acgcacgtca agccatcaac gatggggtca 2520
ccagtactga agagctgtct ataaccagag actgtgagct gtacagggct ctgaacatgc 2580
actacaataa agcaaatgac tttgaggttc cagagagatt cctggaagtt gctcagatca 2640
cattacggga gtttttcaat gccattatcg caggcaaaga tgttgatcct tcctggaaga 2700
aggccatata caaggtcatc tgcaagctgg atagtgaagt ccctgagatt ttcaaatccc 2760
cgaactgcct acaagagctg cttcatgagt agaaatttca acaactcttt ttgaatgtat 2820
gaagagtagc agtccccttt ggatgtccaa gttatatgtg tctagatttt gatttcatat 2880
atatgtgtat gggaggcatg gatatgttat gaaatcagct ggtaattcct cctcatcacg 2940
tttctctcat tttcttttgt tttccattgc aaggggatgg ttgttttctt tctgccttta 3000
gtttgctttt gcccaaggcc cttaacattt ggacacttaa aatagggtta attttcaggg 3060
aaaaagaatg ttggcgtgtg taaagtctct attagcaatg aagggaattt gttaacgatg 3120
catccacttg attgatgact tattgcaaat ggcggttggc tgaggaaaac ccatgacaca 3180
gcacaactct acagacagtg atgtgtctct tgtttctact gctaagaagg tctgaaaatt 3240
taatgaaacc acttcataca tttaagtatt ttgtttggtt tgaactcaat cagtagcttt 3300
tccttacatg tttaaaaata attccaatga cagatgagca gctcactttt ccaaagtacc 3360
ccaaaaggcc aaattaaaaa agaaaaataa tcactctcaa gccttgtcta agaaaagagg 3420
caaactctga aagtcgtacc agtttcttct ggaggcaaag caattttgca caaaaccagc 3480
tctctcaaga tgagactaga aattcatacc tggtcttgta gccacctctc taaacttgaa 3540
aataggttct tcttcataag tgagcttaca tcattcttca taaagaaaaa tcctataact 3600
tgttatcatt tttgcttcag atactaaaag gcactaagtt tccaatttac gctgctcaac 3660
tttgtttata tgcttaaaag gattctgttt acttaacaat tttttcccct aaaatactat 3720
tttctgaata cttccttcca gtaaggaata aaggaaagcc caacttggcc ataaaattct 3780
tgcctacact agaagtttgt tgacagccat tagctgactt gatcgtcatc tcctaagagg 3840
aacacatata ttttcacaag caattccaca ctatcctgat gggtatgcaa agtggtgaca 3900
gtctaactca gtgtttcttc attttaggta taacatttta aagcaattga taatgcctct 3960
tccaattcag aagctagtat tgaccaaaat gtgagaagag tgtatagcat aggaaaattt 4020
ggggttaacc caaaagacac aattccagca cacataagaa agctagctgc tattttatgc 4080
tttcttccat ggttctcctc ttttttccct tttatttttc cctgtttttc aatgatgtac 4140
agtgttccct acttgcattg aaaaaactcg tatggcattc acactttttt tcttaggtgg 4200
gtttttgtgt ccagatgcag taagaattca ttgttcatcc taaaactgtt ttccagaccc 4260
ttccttcccc ttaggtaatt tgatatacac ctcctaaaat gacacagtaa caaatctggt 4320
atttagaaca tatagaacat aaatgccatt ttttaattca actttaataa gaattacatt 4380
tgactttgga gaatacaggt cttgacccat gtgactgact agctgacccg atcgctgtaa 4440
tttaacgtca tttataaatt ctgctgatgg acaggaatgt atgaactcaa ttattgtcag 4500
cacaaagcct taaaacctgc tgactttaaa ttaaatggtg cagtcctatg atgccctgca 4560
ccatccaggg gactaacagg gcctcgcagt gtagacagag ggtgcagcca cacgggcggg 4620
ggcaccagcc acctcactct gcacccgcgg cctcacacat ctcccagctc acactctact 4680
aatgcacaga gtcattagat ccaatttgtt atttttctca cttgctttaa aaaaaagcag 4740
tttggataat catgacattg gaataaagtg ggaaggaaaa attccatcag cacaaaatag 4800
ggaagtaatc ccaacttgta gtcacagttt tctgactggc tttgttttaa aagaggatgg 4860
cagtccttgt tcgtgtcagt gtgccactgg gtttttgctg ttccgtgtaa ttcatatcaa 4920
ctttgtgttg ccatttgcaa ggtaaaaggc aaagctgtag tgtattcacc tatgtagaca 4980
gattgctaga tatctttttg atctggggcg agttcaatat tgattccaga cttatttgga 5040
tttttttagt attattttcc cctccctttc taatttaaat agacaaatta agcaaaagtg 5100
tgtgttcaca accaaatgtt gatgccctta tctactgata atatcctctc aatgttcact 5160
gaggcataga aattatttca gagtagaaat tgcagcatga ggataaactc acctctttgt 5220
tctgaaaata gaactttatc actatgcttt ccggtggttt tcccttttac aatcgaaatc 5280
ttgtgcctcc caagtgcatt ggaaaatgac aaaagcctgt ctctccaaat tcctatttaa 5340
cagtttgatt tttttttttt aatcaccatc tttcaaatct tagctcaact ctcaccaagt 5400
gaaaattggc tacttgggag aaagttaact ttctatggtg ggatggtgaa ggatgaggga 5460
cagtttacat aggaaaagaa aaaaaaaagt ctaaagtcca tgttgaaaaa ccacactacc 5520
acttattttc tgctaaccct aaattatttt tgcgtatacg cttgaggtta tagtctgtgc 5580
ctagacctaa aatgcaccag cgggggggat tttaaaaaat ccttcaaaat accagttttt 5640
tcccaacaag tacaattgtt cttgtgcctt ctgtggcttt cgatttcatc tttttgactt 5700
tatttccaat tactacagct gcaataaaca ctagattttt tttctggctg tttgacataa 5760
cgttgatagc tatgcatatt ttgtgtcttt ttaaaacaaa gcgggagaat acgtttttga 5820
agaagagaat ttttagaaca gtttgatacc gcaaattatt ttttcctcaa ttgtttgagc 5880
agcattcgag ttttgaaaat tcttgtagaa gccaattttt tgtaactgtg gtgcaaatct 5940
tgtgttttct tagcctaatg aaaagtagta tagaagcaat atttcatacc atgtgctata 6000
tatgtgtgcg cagatgtgtg aacataaaat cacatacaca catatacaca catgtaaaaa 6060
tatacatata tatatatgcg tgtgaagtgg aaagcttacc ttttcctatc tagatttaag 6120
aacctatttt agacatttgt tatgttttgt gaaaagaatg ttctatttgc aacaaaacat 6180
ttaattctta ctgtatctct ggctgtttaa tgaggacgtt tcacattaaa tggtaaaaca 6240
catggaagat gttagaatgt agtaattatt taagtaaacg ttcacccaca tattcctgaa 6300
gtttgctttg tgcctccgag tattatttaa ttaaagaagt gttttatgtt tgcagaatct 6360
ttgtcactgt actagggatg tgggtgaata tcatttaaaa aaatttaaaa caacaaaaaa 6420
aaagcaaaac agaaacacta aagcaagagg ggaactttta taaagcaatg taaatattta 6480
acctcatggc tgtcattatg taagacatga gattttaata aataactaca ttctcacgac 6540
atctgttgaa tttactagga acactacagt gactgtatag acagttgaaa gcattcttga 6600
aaatcctgct ctctcctttt aaaagttaac aatctctttt atcagatgtc aagggcaagg 6660
gtaatgcagt ttctgtaaat ttatgaaatt tctttttcta tgtacatgaa gacatttagt 6720
aagtaacacc cccccttccc atgcgcacat gtgcgcatac acacacacac acacacacac 6780
acacacacaa acacacacac tgtcataaag ctaatgattt ggggacttta aaaaatagga 6840
tgtcctccag gaacaatcat aaatttatga aagaaagagt agtttacaga ctcccctgaa 6900
agaagcagtg tatatgtgaa gacagtgcaa aaatctcttt gccatgtata ttatagcgta 6960
ttcattggtg tgaatagtac aaatgtttcc ttctggtaca aactctgtgt ttgcaaattt 7020
acaagaagca ttgttttcaa aaagctcccc ttaaaaaatg taactggttt atatgagtaa 7080
gcagttaccg tattgcactt aaatgttatg ttgaaggaaa tgcagttttg ttttctgtag 7140
atctgttggt tgtaaaccat ctataaaact aaagctaaaa tgctcatatt cagagctggg 7200
atcaaaactg gtatttaacc tttgcatctt cttataatta tccttctaag aatataacag 7260
aatgtggaag tgtctggact ttgagtcttt tcaactgagc cttctctcaa atctgacacc 7320
ccctcagaat gcacaaacat aagcagaaaa ggcaaacaag cttaccttct tttgtgaaaa 7380
cgtattcatt ctgtattttt ttaaatattc aattccccta aaaatgggga gaaaatattt 7440
taaaattgta tattacgact tcaaatttag aactaagaaa aaaatgtatt tgggattggt 7500
ctcagcgcta cctagaagaa tcaaaggtca tggcttccct caatattgtc ccagccattt 7560
ctcatatgta tatagtataa accgtgacaa aacactgcct ttatattatt tagcaatatg 7620
ttgtaaatag cattattaag ctcttttttg taataaagac cctttgattt gaatatagta 7680
caataactga actgataaag tcaatttttg atttttgttt gtttttttta gctagaggca 7740
atttcaattg tgaatttttg ttgttgtcta ttgttctgaa gactttgcat aatttattgg 7800
tttaatttat cctaatttat ttgatgaagg tgtacaattt tgtattacca aggatgtact 7860
gtaatattaa ttgatatgat aaacacaatg agactccctg tccatattaa aaagaaaata 7920
aaaaggtgca gtagacaatt gattttaaag gaaaagttaa aaaaattagt ttggcagcta 7980
ctaaatttta aaacaggaaa aaaaaaagtt gttgtgggga gggtgggaaa ggggttttac 8040
tttgtgtgtt ttaagctttt gtatactctc caaactttta ccttttgctt tgtaccactt 8100
aaaggataca gtagtccaat tgccttgtgt gccttccatc tcctcttaaa ctgaatgtat 8160
gtgcagtata tatgcaagct tgtgcaaaat aaaatataca ttacaagctc agtgccgttt 8220
gattttctta aagaaagagt gacttttaat ttttggacct gtatccaatt gtaggacagt 8280
aggctagttg tgccagtaat gtcaagtatg gagattttct ttcactacaa ttcttcattc 8340
tgttagccta acgtgcagct cctagaaaca acctctttta ctttagatgc ttggaataat 8400
tgcttggatt tctctctctg aaacatcttt caggcttaac tttatttagc cctgaaactt 8460
aaaaaaaa 8468
<210> 14
<211> 4969
<212> DNA
<213> Homo sapiens
<400> 14
gctttttctt aactttcact aagggttact gtagtctgat gtgtccttcc caaggccacg 60
aaatttgaca agctgcactt ttcttttgct caatgatttc tgctttaagc caaagaactg 120
cctataattt cactaagaat gtcttctaat tcagatactg gggatttaca agagtcttta 180
aagcacggac ttacacctat tggtgctggg cttccggacc gacacggatc ccccatcccc 240
gcccgcggtc gccttgtcat gctgcccaaa gtggagacgg aagccctggg actggctcga 300
tcgcatgggg aacagggcca gatgccggaa aacatgcaag tgtctcaatt taaaatggtg 360
aattactcct atgatgaaga tctggaagag ctttgtcccg tgtgtggaga taaagtgtct 420
gggtaccatt atgggctcct cacctgtgaa agctgcaagg gattttttaa gcgaacagtc 480
caaaataata aaaggtacac atgtatagaa aaccagaact gccaaattga caaaacacag 540
agaaagcgtt gtccttactg tcgttttcaa aaatgtctaa gtgttggaat gaagctagaa 600
gctgtaaggg ccgaccgaat gcgtggagga aggaataagt ttgggccaat gtacaagaga 660
gacagggccc tgaagcaaca gaaaaaagcc ctcatccgag ccaatggact taagctagaa 720
gccatgtctc aggtgatcca agctatgccc tctgacctga ccatttcctc tgcaattcaa 780
aacatccact ctgcctccaa aggcctacct ctgaaccatg ctgccttgcc tcctacagac 840
tatgacagaa gtccctttgt aacatccccc attagcatga caatgccccc tcacggcagc 900
ctgcaaggtt accaaacata tggccacttt cctagccggg ccatcaagtc tgagtaccca 960
gacccctata ccagctcacc cgagtccata atgggctatt catatatgga tagttaccag 1020
acgagctctc cagcaagcat cccacatctg atactggaac ttttgaagtg tgagccagat 1080
gagcctcaag tccaggctaa aatcatggcc tatttgcagc aagagcaggc taaccgaagc 1140
aagcacgaaa agctgagcac ctttgggctt atgtgcaaaa tggcagatca aactctcttc 1200
tccattgtcg agtgggccag gagtagtatc ttcttcagag aacttaaggt tgatgaccaa 1260
atgaagctgc ttcagaactg ctggagtgag ctcttaatcc tcgaccacat ttaccgacaa 1320
gtggtacatg gaaaggaagg atccatcttc ctggttactg ggcaacaagt ggactattcc 1380
ataatagcat cacaagccgg agccaccctc aacaacctca tgagtcatgc acaggagtta 1440
gtggcaaaac ttcgttctct ccagtttgat caacgagagt tcgtatgtct gaaattcttg 1500
gtgctcttta gtttagatgt caaaaacctt gaaaacttcc agctggtaga aggtgtccag 1560
gaacaagtca atgccgccct gctggactac acaatgtgta actacccgca gcagacagag 1620
aaatttggac agctacttct tcgactaccc gaaatccggg ccatcagtat gcaggctgaa 1680
gaatacctct actacaagca cctgaacggg gatgtgccct ataataacct tctcattgaa 1740
atgttgcatg ccaaaagagc ataagttaca acccctagga gctctgcttt caaaacaaaa 1800
agagattggg ggagtgggga gggggaagaa gaacaggaag aaaaaaagta ctctgaactg 1860
ctccaagtaa cgctaattaa aaacttgctt taaagatatt gaatttaaaa aggcataata 1920
atcaaatact taatagcaaa taaatgatgt atcagggtat ttgtattgca aactgtgaat 1980
caaaggcttc acagccccag aggattccat ataaaagaca ttgtaatgga gtggattgaa 2040
ctcacagatg gataccaaca cggtcagaag aaaaacggac agaacggttc ttgtatattt 2100
aaactgatct ccactatgaa gaaatttagg aactaatctt attaattagg cttatacagc 2160
gggggatttg agcttacagg attcctccat ggtaaagctg aactgaaaca attctcaaga 2220
atgcatcagc tgtacctaca atagcccctc cctcttcctt tgaaggcccc agcacctctg 2280
ccctgtggtc accgaatctg tactaaggac ctgtgttcag ccacacccag tggtagctcc 2340
accaaatcat gaacagccta attttgagtg tctgtgtctt agacctgcaa acagctaata 2400
ggaaattcta ttaatatgtt agcttgccat tttaaatatg ttctgagggt tgttttgtct 2460
cgtgttcatg atgttaagaa aatgcaggca gtatccctca tcttatgtaa gtgttaatta 2520
atattaaggg aaatgactac aaactttcaa agcaaatgct ccatagctaa agcaacttag 2580
accttatttc tgctactgtt gctgaaatgt ggctttggca ttgttggatt tcataaaaaa 2640
tttctggcag gaagtcttgt tagtatacat cagtcttttt catcatccaa gtttgtagtt 2700
catttaaaaa tacaacatta aacacatttt gctaggatgt caaatagtca cagttctaag 2760
tagttggaaa caaaattgac gcatgttaat ctatgcaaag agaaaggaaa ggatgaggtg 2820
atgtattgac tcaaggttca ttcttgctgc aattgaacat cctcaagagt tgggatggaa 2880
atggtgattt ttacatgtgt cctggaaaga tattaaagta attcaaatct tccccaaagg 2940
ggaaaggaag agagtgatac tgaccttttt aagtcataga ccaaagtctg ctgtagaaca 3000
aatatgggag gacaaagaat cgcaaattct tcaaatgact attatcagta ttattaacat 3060
gcgatgccac aggtatgaaa gtcttgcctt atttcacaat tttaaaaggt agctgtgcag 3120
atgtggatca acatttgttt aaaataaagt attaatactt taaagtcaaa taagatatag 3180
tgtttacatt ctttaggtcc tgaggggcag ggggatctgt gatataacaa aatagcaaaa 3240
gcggtaattt ccttaatgtt atttttctga ttggtaatta tttttaacag tacttaatta 3300
ttctatgtcg tgagacacta aaatcaaaaa cgggaatctc atttagactt taattttttt 3360
gagattatcg gcggcacaat cactttgtag aaactgtaaa aaataaaagt atctcctagt 3420
cccttaattt tttcataaat atttctggct tttgagtagt gtatttatat tgtatatcat 3480
actttcaact gtagacaatt atgatgctaa tttattgttt cttggtttca cctttgtata 3540
agatatagcc aagactgaag aaaccaaata tatgtgttta ctgtagcatg tcttcaaatt 3600
agtggaactt agttcaggga catagaagag tcttaatgaa ttaaaatcat tcacttgatt 3660
aaatgtctgt aaatcttcat cattcctact gtagtttatt taatatctat tgtaaattat 3720
gtgacttgta gcttcctctg gttttcaagt aaactcaaca aggtggagtc ttacctggtt 3780
ttcctttcca agcattgtaa attgtatacc aaagatatta gttattactt ctgtgtgtac 3840
aaagaggatt attttattat gtttattaat cacctctaat actcatccac atgaagggta 3900
cacattaggt aagctgggcg ttgactcatg cgcagtctca gtcacccgtg ttatcttcgt 3960
ggctcaaagg acaatgcaaa atcgccgatc agagctcata cccaaagcat tacagagaac 4020
agcagcatca ttgccctccc cagctgaaaa acaagttggc tagaagatac atggagagga 4080
atggtgtggt caacagttaa tgaaacggtt ctatcatgca tgtgtaatgt ggatggagac 4140
aattataaga tttgactata actatttgga gggtctttaa cattgccaaa aaaacaaata 4200
tgttgatttt tattttattt tattttttat tttaagaggc gggatcttga tctcacatgt 4260
tgcccaggct ggccttgaac tcctgggctc aagcattcct cctgcctcag cctcccccat 4320
agctgggact aggggtgcat gccagcatac ctggctacgt tgactcttaa aatctatgtt 4380
ctcttatttt aaagatacag tgctccccac tgaaaattaa acctaaaaaa tgtcacatat 4440
tggtatgttg ttaacctggt agattaaatc atgagaatga ttagaaagac gggcaacaca 4500
gcgggttaca tccacactgc tgatcacacc aacgacagga gctgataagc aagaaagcgt 4560
cacagccagc gtctgttcac ccaaggttga caagtgaagt ttctctaatg ttgattgtta 4620
gccgatttgt aacctggcat ttacttagca actgccttat caattacagg atttgccggt 4680
aaaagcagac tcaaatataa aggtttttgg cttaacttgg tttattatag ttgctctatg 4740
tttgtaaaca gacaatctct aatgtctgat tatttgtatc acagatctgc agctgccttg 4800
gacttgaatc catgcaatgt ttagagtgtg aagtcagtta cttgttgatg ttttcttact 4860
gtatcaatga aatacatatt gtcatgtcag ttcttgccag gaacttctca acaaaatgga 4920
attttttttt tcagtatttc aataaatatt gatatgccca gcctgataa 4969
<210> 15
<211> 4831
<212> DNA
<213> Homo sapiens
<400> 15
gctttttctt aactttcact aagggttact gtagtctgat gtgtccttcc caaggccacg 60
aaatttgaca agctgcactt ttcttttgct caatgatttc tgctttaagc caaagaactg 120
cctataattt cactaagaat gtcttctaat tcagatactg gggatttaca agagtcttta 180
aagcacggac ttacacctat tgtgtctcaa tttaaaatgg tgaattactc ctatgatgaa 240
gatctggaag agctttgtcc cgtgtgtgga gataaagtgt ctgggtacca ttatgggctc 300
ctcacctgtg aaagctgcaa gggatttttt aagcgaacag tccaaaataa taaaaggtac 360
acatgtatag aaaaccagaa ctgccaaatt gacaaaacac agagaaagcg ttgtccttac 420
tgtcgttttc aaaaatgtct aagtgttgga atgaagctag aagctgtaag ggccgaccga 480
atgcgtggag gaaggaataa gtttgggcca atgtacaaga gagacagggc cctgaagcaa 540
cagaaaaaag ccctcatccg agccaatgga cttaagctag aagccatgtc tcaggtgatc 600
caagctatgc cctctgacct gaccatttcc tctgcaattc aaaacatcca ctctgcctcc 660
aaaggcctac ctctgaacca tgctgccttg cctcctacag actatgacag aagtcccttt 720
gtaacatccc ccattagcat gacaatgccc cctcacggca gcctgcaagg ttaccaaaca 780
tatggccact ttcctagccg ggccatcaag tctgagtacc cagaccccta taccagctca 840
cccgagtcca taatgggcta ttcatatatg gatagttacc agacgagctc tccagcaagc 900
atcccacatc tgatactgga acttttgaag tgtgagccag atgagcctca agtccaggct 960
aaaatcatgg cctatttgca gcaagagcag gctaaccgaa gcaagcacga aaagctgagc 1020
acctttgggc ttatgtgcaa aatggcagat caaactctct tctccattgt cgagtgggcc 1080
aggagtagta tcttcttcag agaacttaag gttgatgacc aaatgaagct gcttcagaac 1140
tgctggagtg agctcttaat cctcgaccac atttaccgac aagtggtaca tggaaaggaa 1200
ggatccatct tcctggttac tgggcaacaa gtggactatt ccataatagc atcacaagcc 1260
ggagccaccc tcaacaacct catgagtcat gcacaggagt tagtggcaaa acttcgttct 1320
ctccagtttg atcaacgaga gttcgtatgt ctgaaattct tggtgctctt tagtttagat 1380
gtcaaaaacc ttgaaaactt ccagctggta gaaggtgtcc aggaacaagt caatgccgcc 1440
ctgctggact acacaatgtg taactacccg cagcagacag agaaatttgg acagctactt 1500
cttcgactac ccgaaatccg ggccatcagt atgcaggctg aagaatacct ctactacaag 1560
cacctgaacg gggatgtgcc ctataataac cttctcattg aaatgttgca tgccaaaaga 1620
gcataagtta caacccctag gagctctgct ttcaaaacaa aaagagattg ggggagtggg 1680
gagggggaag aagaacagga agaaaaaaag tactctgaac tgctccaagt aacgctaatt 1740
aaaaacttgc tttaaagata ttgaatttaa aaaggcataa taatcaaata cttaatagca 1800
aataaatgat gtatcagggt atttgtattg caaactgtga atcaaaggct tcacagcccc 1860
agaggattcc atataaaaga cattgtaatg gagtggattg aactcacaga tggataccaa 1920
cacggtcaga agaaaaacgg acagaacggt tcttgtatat ttaaactgat ctccactatg 1980
aagaaattta ggaactaatc ttattaatta ggcttataca gcgggggatt tgagcttaca 2040
ggattcctcc atggtaaagc tgaactgaaa caattctcaa gaatgcatca gctgtaccta 2100
caatagcccc tccctcttcc tttgaaggcc ccagcacctc tgccctgtgg tcaccgaatc 2160
tgtactaagg acctgtgttc agccacaccc agtggtagct ccaccaaatc atgaacagcc 2220
taattttgag tgtctgtgtc ttagacctgc aaacagctaa taggaaattc tattaatatg 2280
ttagcttgcc attttaaata tgttctgagg gttgttttgt ctcgtgttca tgatgttaag 2340
aaaatgcagg cagtatccct catcttatgt aagtgttaat taatattaag ggaaatgact 2400
acaaactttc aaagcaaatg ctccatagct aaagcaactt agaccttatt tctgctactg 2460
ttgctgaaat gtggctttgg cattgttgga tttcataaaa aatttctggc aggaagtctt 2520
gttagtatac atcagtcttt ttcatcatcc aagtttgtag ttcatttaaa aatacaacat 2580
taaacacatt ttgctaggat gtcaaatagt cacagttcta agtagttgga aacaaaattg 2640
acgcatgtta atctatgcaa agagaaagga aaggatgagg tgatgtattg actcaaggtt 2700
cattcttgct gcaattgaac atcctcaaga gttgggatgg aaatggtgat ttttacatgt 2760
gtcctggaaa gatattaaag taattcaaat cttccccaaa ggggaaagga agagagtgat 2820
actgaccttt ttaagtcata gaccaaagtc tgctgtagaa caaatatggg aggacaaaga 2880
atcgcaaatt cttcaaatga ctattatcag tattattaac atgcgatgcc acaggtatga 2940
aagtcttgcc ttatttcaca attttaaaag gtagctgtgc agatgtggat caacatttgt 3000
ttaaaataaa gtattaatac tttaaagtca aataagatat agtgtttaca ttctttaggt 3060
cctgaggggc agggggatct gtgatataac aaaatagcaa aagcggtaat ttccttaatg 3120
ttatttttct gattggtaat tatttttaac agtacttaat tattctatgt cgtgagacac 3180
taaaatcaaa aacgggaatc tcatttagac tttaattttt ttgagattat cggcggcaca 3240
atcactttgt agaaactgta aaaaataaaa gtatctccta gtcccttaat tttttcataa 3300
atatttctgg cttttgagta gtgtatttat attgtatatc atactttcaa ctgtagacaa 3360
ttatgatgct aatttattgt ttcttggttt cacctttgta taagatatag ccaagactga 3420
agaaaccaaa tatatgtgtt tactgtagca tgtcttcaaa ttagtggaac ttagttcagg 3480
gacatagaag agtcttaatg aattaaaatc attcacttga ttaaatgtct gtaaatcttc 3540
atcattccta ctgtagttta tttaatatct attgtaaatt atgtgacttg tagcttcctc 3600
tggttttcaa gtaaactcaa caaggtggag tcttacctgg ttttcctttc caagcattgt 3660
aaattgtata ccaaagatat tagttattac ttctgtgtgt acaaagagga ttattttatt 3720
atgtttatta atcacctcta atactcatcc acatgaaggg tacacattag gtaagctggg 3780
cgttgactca tgcgcagtct cagtcacccg tgttatcttc gtggctcaaa ggacaatgca 3840
aaatcgccga tcagagctca tacccaaagc attacagaga acagcagcat cattgccctc 3900
cccagctgaa aaacaagttg gctagaagat acatggagag gaatggtgtg gtcaacagtt 3960
aatgaaacgg ttctatcatg catgtgtaat gtggatggag acaattataa gatttgacta 4020
taactatttg gagggtcttt aacattgcca aaaaaacaaa tatgttgatt tttattttat 4080
tttatttttt attttaagag gcgggatctt gatctcacat gttgcccagg ctggccttga 4140
actcctgggc tcaagcattc ctcctgcctc agcctccccc atagctggga ctaggggtgc 4200
atgccagcat acctggctac gttgactctt aaaatctatg ttctcttatt ttaaagatac 4260
agtgctcccc actgaaaatt aaacctaaaa aatgtcacat attggtatgt tgttaacctg 4320
gtagattaaa tcatgagaat gattagaaag acgggcaaca cagcgggtta catccacact 4380
gctgatcaca ccaacgacag gagctgataa gcaagaaagc gtcacagcca gcgtctgttc 4440
acccaaggtt gacaagtgaa gtttctctaa tgttgattgt tagccgattt gtaacctggc 4500
atttacttag caactgcctt atcaattaca ggatttgccg gtaaaagcag actcaaatat 4560
aaaggttttt ggcttaactt ggtttattat agttgctcta tgtttgtaaa cagacaatct 4620
ctaatgtctg attatttgta tcacagatct gcagctgcct tggacttgaa tccatgcaat 4680
gtttagagtg tgaagtcagt tacttgttga tgttttctta ctgtatcaat gaaatacata 4740
ttgtcatgtc agttcttgcc aggaacttct caacaaaatg gaattttttt tttcagtatt 4800
tcaataaata ttgatatgcc cagcctgata a 4831
<210> 16
<211> 4787
<212> DNA
<213> Homo sapiens
<400> 16
atagtttgtc atctttttag ctgcgaagac gccttcgtgg gtctgcgtcc ggagcaaggc 60
ggttacccga tcccggcagt gagccgcgcc gcgcgtcgtg gcggcctgat ttctgtttaa 120
ctttaatagg gcgatctcga gtgtctcaat ttaaaatggt gaattactcc tatgatgaag 180
atctggaaga gctttgtccc gtgtgtggag ataaagtgtc tgggtaccat tatgggctcc 240
tcacctgtga aagctgcaag ggatttttta agcgaacagt ccaaaataat aaaaggtaca 300
catgtataga aaaccagaac tgccaaattg acaaaacaca gagaaagcgt tgtccttact 360
gtcgttttca aaaatgtcta agtgttggaa tgaagctaga agctgtaagg gccgaccgaa 420
tgcgtggagg aaggaataag tttgggccaa tgtacaagag agacagggcc ctgaagcaac 480
agaaaaaagc cctcatccga gccaatggac ttaagctaga agccatgtct caggtgatcc 540
aagctatgcc ctctgacctg accatttcct ctgcaattca aaacatccac tctgcctcca 600
aaggcctacc tctgaaccat gctgccttgc ctcctacaga ctatgacaga agtccctttg 660
taacatcccc cattagcatg acaatgcccc ctcacggcag cctgcaaggt taccaaacat 720
atggccactt tcctagccgg gccatcaagt ctgagtaccc agacccctat accagctcac 780
ccgagtccat aatgggctat tcatatatgg atagttacca gacgagctct ccagcaagca 840
tcccacatct gatactggaa cttttgaagt gtgagccaga tgagcctcaa gtccaggcta 900
aaatcatggc ctatttgcag caagagcagg ctaaccgaag caagcacgaa aagctgagca 960
cctttgggct tatgtgcaaa atggcagatc aaactctctt ctccattgtc gagtgggcca 1020
ggagtagtat cttcttcaga gaacttaagg ttgatgacca aatgaagctg cttcagaact 1080
gctggagtga gctcttaatc ctcgaccaca tttaccgaca agtggtacat ggaaaggaag 1140
gatccatctt cctggttact gggcaacaag tggactattc cataatagca tcacaagccg 1200
gagccaccct caacaacctc atgagtcatg cacaggagtt agtggcaaaa cttcgttctc 1260
tccagtttga tcaacgagag ttcgtatgtc tgaaattctt ggtgctcttt agtttagatg 1320
tcaaaaacct tgaaaacttc cagctggtag aaggtgtcca ggaacaagtc aatgccgccc 1380
tgctggacta cacaatgtgt aactacccgc agcagacaga gaaatttgga cagctacttc 1440
ttcgactacc cgaaatccgg gccatcagta tgcaggctga agaatacctc tactacaagc 1500
acctgaacgg ggatgtgccc tataataacc ttctcattga aatgttgcat gccaaaagag 1560
cataagttac aacccctagg agctctgctt tcaaaacaaa aagagattgg gggagtgggg 1620
agggggaaga agaacaggaa gaaaaaaagt actctgaact gctccaagta acgctaatta 1680
aaaacttgct ttaaagatat tgaatttaaa aaggcataat aatcaaatac ttaatagcaa 1740
ataaatgatg tatcagggta tttgtattgc aaactgtgaa tcaaaggctt cacagcccca 1800
gaggattcca tataaaagac attgtaatgg agtggattga actcacagat ggataccaac 1860
acggtcagaa gaaaaacgga cagaacggtt cttgtatatt taaactgatc tccactatga 1920
agaaatttag gaactaatct tattaattag gcttatacag cgggggattt gagcttacag 1980
gattcctcca tggtaaagct gaactgaaac aattctcaag aatgcatcag ctgtacctac 2040
aatagcccct ccctcttcct ttgaaggccc cagcacctct gccctgtggt caccgaatct 2100
gtactaagga cctgtgttca gccacaccca gtggtagctc caccaaatca tgaacagcct 2160
aattttgagt gtctgtgtct tagacctgca aacagctaat aggaaattct attaatatgt 2220
tagcttgcca ttttaaatat gttctgaggg ttgttttgtc tcgtgttcat gatgttaaga 2280
aaatgcaggc agtatccctc atcttatgta agtgttaatt aatattaagg gaaatgacta 2340
caaactttca aagcaaatgc tccatagcta aagcaactta gaccttattt ctgctactgt 2400
tgctgaaatg tggctttggc attgttggat ttcataaaaa atttctggca ggaagtcttg 2460
ttagtataca tcagtctttt tcatcatcca agtttgtagt tcatttaaaa atacaacatt 2520
aaacacattt tgctaggatg tcaaatagtc acagttctaa gtagttggaa acaaaattga 2580
cgcatgttaa tctatgcaaa gagaaaggaa aggatgaggt gatgtattga ctcaaggttc 2640
attcttgctg caattgaaca tcctcaagag ttgggatgga aatggtgatt tttacatgtg 2700
tcctggaaag atattaaagt aattcaaatc ttccccaaag gggaaaggaa gagagtgata 2760
ctgacctttt taagtcatag accaaagtct gctgtagaac aaatatggga ggacaaagaa 2820
tcgcaaattc ttcaaatgac tattatcagt attattaaca tgcgatgcca caggtatgaa 2880
agtcttgcct tatttcacaa ttttaaaagg tagctgtgca gatgtggatc aacatttgtt 2940
taaaataaag tattaatact ttaaagtcaa ataagatata gtgtttacat tctttaggtc 3000
ctgaggggca gggggatctg tgatataaca aaatagcaaa agcggtaatt tccttaatgt 3060
tatttttctg attggtaatt atttttaaca gtacttaatt attctatgtc gtgagacact 3120
aaaatcaaaa acgggaatct catttagact ttaatttttt tgagattatc ggcggcacaa 3180
tcactttgta gaaactgtaa aaaataaaag tatctcctag tcccttaatt ttttcataaa 3240
tatttctggc ttttgagtag tgtatttata ttgtatatca tactttcaac tgtagacaat 3300
tatgatgcta atttattgtt tcttggtttc acctttgtat aagatatagc caagactgaa 3360
gaaaccaaat atatgtgttt actgtagcat gtcttcaaat tagtggaact tagttcaggg 3420
acatagaaga gtcttaatga attaaaatca ttcacttgat taaatgtctg taaatcttca 3480
tcattcctac tgtagtttat ttaatatcta ttgtaaatta tgtgacttgt agcttcctct 3540
ggttttcaag taaactcaac aaggtggagt cttacctggt tttcctttcc aagcattgta 3600
aattgtatac caaagatatt agttattact tctgtgtgta caaagaggat tattttatta 3660
tgtttattaa tcacctctaa tactcatcca catgaagggt acacattagg taagctgggc 3720
gttgactcat gcgcagtctc agtcacccgt gttatcttcg tggctcaaag gacaatgcaa 3780
aatcgccgat cagagctcat acccaaagca ttacagagaa cagcagcatc attgccctcc 3840
ccagctgaaa aacaagttgg ctagaagata catggagagg aatggtgtgg tcaacagtta 3900
atgaaacggt tctatcatgc atgtgtaatg tggatggaga caattataag atttgactat 3960
aactatttgg agggtcttta acattgccaa aaaaacaaat atgttgattt ttattttatt 4020
ttatttttta ttttaagagg cgggatcttg atctcacatg ttgcccaggc tggccttgaa 4080
ctcctgggct caagcattcc tcctgcctca gcctccccca tagctgggac taggggtgca 4140
tgccagcata cctggctacg ttgactctta aaatctatgt tctcttattt taaagataca 4200
gtgctcccca ctgaaaatta aacctaaaaa atgtcacata ttggtatgtt gttaacctgg 4260
tagattaaat catgagaatg attagaaaga cgggcaacac agcgggttac atccacactg 4320
ctgatcacac caacgacagg agctgataag caagaaagcg tcacagccag cgtctgttca 4380
cccaaggttg acaagtgaag tttctctaat gttgattgtt agccgatttg taacctggca 4440
tttacttagc aactgcctta tcaattacag gatttgccgg taaaagcaga ctcaaatata 4500
aaggtttttg gcttaacttg gtttattata gttgctctat gtttgtaaac agacaatctc 4560
taatgtctga ttatttgtat cacagatctg cagctgcctt ggacttgaat ccatgcaatg 4620
tttagagtgt gaagtcagtt acttgttgat gttttcttac tgtatcaatg aaatacatat 4680
tgtcatgtca gttcttgcca ggaacttctc aacaaaatgg aatttttttt ttcagtattt 4740
caataaatat tgatatgccc agcctgataa tttttaaaaa aaaaaaa 4787
<210> 17
<211> 1165
<212> DNA
<213> Homo sapiens
<400> 17
gccagagagc tggaagtgag agcagatccc taaccatgag caccagccaa ccaggggcct 60
gcccatgcca gggagctgca agccgccccg ccattctcta cgcacttctg agctccagcc 120
tcaaggctgt cccccgaccc cgtagccgct gcctatgtag gcagcaccgg cccgtccagc 180
tatgtgcacc tcatcgcacc tgccgggagg ccttggatgt tctggccaag acagtggcct 240
tcctcaggaa cctgccatcc ttctggcagc tgcctcccca ggaccagcgg cggctgctgc 300
agggttgctg gggccccctc ttcctgcttg ggttggccca agatgctgtg acctttgagg 360
tggctgaggc cccggtgccc agcatactca agaagattct gctggaggag cccagcagca 420
gtggaggcag tggccaactg ccagacagac cccagccctc cctggctgcg gtgcagtggc 480
ttcaatgctg tctggagtcc ttctggagcc tggagcttag ccccaaggaa tatgcctgcc 540
tgaaagggac catcctcttc aaccccgatg tgccaggcct ccaagccgcc tcccacattg 600
ggcacctgca gcaggaggct cactgggtgc tgtgtgaagt cctggaaccc tggtgcccag 660
cagcccaagg ccgcctgacc cgtgtcctcc tcacggcctc caccctcaag tccattccga 720
ccagcctgct tggggacctc ttctttcgcc ctatcattgg agatgttgac atcgctggcc 780
ttcttgggga catgcttttg ctcaggtgac ctgttccagc ccaggcagag atcaggtggg 840
cagaggctgg cagtgctgat tcagcctggc catccccaga ggtgacccaa tgctcctgga 900
gggggcaagc ctgtatagac agcacttggc tccttaggaa cagctcttca ctcagccaca 960
ccccacattg gacttccttg gtttggacac agtgttccag ctgcctggga ggcttttggt 1020
ggtccccaca gcctctgggc caagactcct gtcccttctt gggatgagaa tgaaagctta 1080
ggctgcttat tggaccagaa gtcctatcga ctttatacag aactgaatta agttattgat 1140
ttttgtaata aaaggtatga aacac 1165
<210> 18
<211> 7937
<212> DNA
<213> Homo sapiens
<400> 18
aatcatggtg ccgctgggga ggggagaagc tgctgctgcc gccgttgccg ggagccgcgg 60
agacaagtca ttacgttttc atttctcaca actgggctga gcacaactga accatggggg 120
aacacagtcc agacaacaac atcatctact ttgaggcaga ggaagatgag ctgacccccg 180
atgataaaat gctcaggttt gtggataaaa acggactggt gccttcctca tctggaactg 240
tttatgatag gaccactgtt cttattgagc aggaccctgg cactttggag gatgaagatg 300
acgacggaca gtgcggagaa cacttgcctt ttctagtagg gggtgaagag ggctttcacc 360
tgatagatca tgaagcaatg tcccagggtt atgtgcagca cattatctca ccagatcaga 420
ttcatttgac aataaaccct ggttccacac ccatgccaag aaatattgaa ggtgcaaccc 480
tcactctgca gtcggaatgt ccggaaacaa aacgtaaaga agtaaagcgg taccaatgta 540
cctttgaggg ctgtccccgc acctacagca cagcaggcaa cctgcgaacc caccagaaga 600
ctcaccgagg agagtacacc tttgtctgta atcaggaggg ctgtggcaaa gccttcctta 660
cctcttacag cctcaggatc cacgtgcgag tgcacacgaa ggagaagcca tttgagtgtg 720
acgtgcaggg ctgtgagaag gcattcaaca cactgtacag gctgaaagca catcagaggc 780
ttcacacagg gaaaacgttt aactgtgaat ctgaaggctg cagcaaatac ttcaccacac 840
tcagtgatct gaggaagcac attcgaactc atacagggga aaagccattt cggtgcgatc 900
acgatggctg tggaaaagca tttgcagcaa gccaccacct taaaactcac gttcgtacac 960
atactggtga aagacccttc ttctgcccca gtaatggctg tgagaaaaca ttcagcactc 1020
aatacagtct caaaagtcac atgaaaggtc atgataacaa aggacactca tacaatgcac 1080
ttccacaaca caatggatca gaggatacaa atcactcact ttgtctaagt gacttgagcc 1140
ttctgtccac agattctgaa ttgcgagaaa attccagtac gacccagggc caggacctca 1200
gcacaatttc accagcaatc atctttgaat caatgttcca gaattcagat gatacggcaa 1260
ttcaggaaga tcctcaacag acagcttcct tgactgaaag ttttaatggt gatgcagagt 1320
cagtcagtga tgttccgcca tccacaggaa attcagcatc tttatctctt ccacttgtac 1380
tgcaacctgg cctctccgag ccaccccagc ctctactacc tgcctcagct ccgtctgctc 1440
ctccgcctgc tccctcccta ggacctggct cccagcaagc tgcatttggc aacccccctg 1500
ctctcttaca acctccagaa gtgcctgttc cccacagcac acagtttgct gctaatcatc 1560
aagagtttct tccgcacccc caggcaccgc agcccattgt accaggactt tctgttgttg 1620
ctggggcttc tgcatcagca gcggcagtgg catcagctgt ggcagcacca gccccaccac 1680
aaagtactac tgagcccctg ccagccatgg tccagactct gcccctgggt gccaactctg 1740
tcctaactaa taatcccaca ataaccatca ccccaactcc caacacagct atcctgcagt 1800
ccagcctagt catgggagaa cagaacttac aatggatatt aaatggtgcc accagttctc 1860
cacaaaacca agaacaaatt cagcaagcat ctaaagttga gaaggtgttt tttaccactg 1920
cagtaccagt agccagtagc ccagggagct ctgtccagca gattggcctc agtgttcctg 1980
tgatcatcat caaacaagaa gaggcatgtc agtgtcagtg tgcatgccgg gactctgcaa 2040
aggagcgggc atccagcagg agaaagggct gctcctcccc accccctcca gagccgagcc 2100
cccaggctcc tgatgggccc agcctgcagc tcccagcgca gactttctct tcagcccctg 2160
ttcccgggtc atcatcctct accttgccct cctcctgtga gcaaagccga caagcagaga 2220
ctccttcaga ccctcagaca gaaacattaa gtgccatgga tgtgtcagag tttctatccc 2280
tccagagcct ggacaccccg tccaatctga ttcccattga agcactactg cagggggagg 2340
aggagatggg cctcaccagc agcttctcca agtgaagggc ccatgtgtgc tcacctctgg 2400
gaaaagcggg tgagcaggag gcatgaggta caatgcctgc catcatgggt cagaaatttg 2460
aaggatgaag aaatctactg tttgaaatcc tcacctttca gacgtatttt ctttattcac 2520
atcccaggag catccatttt aaggaactat tctttggaaa aaaacaaaaa acaaaaaaaa 2580
caacaaaaaa agctaagtta taagtgaact gtttggctgc actgtatgtc acttttgctt 2640
gttgtcatgt gaacttggaa actaaggtta ctcgtgtgca taaaaattct aaatgaaagg 2700
gtgtggtttc catcaatctg atgctgccca tcgcttgcac tggggtcttt gtggatcggg 2760
caggagtttt cagtgtgttg ggtgttgctc cttcctatgt gtcttttgaa tctgaggctg 2820
acatttgctt ggaaggccag acccttgctc catcagagag ggcagtggca aaggccagtg 2880
aggcagctgt gagttggaca gggttcaggt gagatggtgt tgtcatttgt gcttagtgtt 2940
ggtggtgctc agggtggata acacgggtcg ttctgcagcc cgcttcagca caaataggca 3000
gcttaaggcc tggctcacag gctgtggggt tgatctggct ctgcagaggc cctaggcagc 3060
ttgttgactg ctgtctgttg atgacgtgtg tgcaaagcag gctctagcaa catgatcact 3120
gtccttgcct tcctggttct ttctctcggt tggttgccag ggcttgcaga tcgcagtgaa 3180
ttttccttgg ggaacatcgc tgttttgtcc tagagtgaac ttgtggctta tggccagtgc 3240
tgtttggtgg tctgccttct ttttaatggt attttcttcc tcagagcaga agggctgcat 3300
tttgcttatc agaagaaggt gcagatttaa gggaattcat atgaggtggc atgtaattgg 3360
caggccaggt gtcctggttc caggttccag ccaggctttg ggttgccccc tccatctctg 3420
cccccctctg gattttgcat acagcctcat acagtgcaaa caaggatgtg acttgctcag 3480
cttagtcatg tgatttattt aaaaaaaaaa aaaaaagaaa cacaaaacga tgatcttcta 3540
ctcagggtat agcaaaacaa aaaaattccc tttccaccaa aaagcctgaa atgttgcaat 3600
aagttatctc atttggaatg tttcattaag ttgtgttata ggaaaaaatt gtgtgtgtgt 3660
gttatagaat tatatccata tgtctgcctt tggctccaag tcattgcctc ttaaaataaa 3720
agatacaatc catactagca tgaaaagttt ccctcaacag gctatattaa catagtcatg 3780
agtgctgacc aaactcaccg agctcagagg ccaggcatgg cctgaggtgc agaataggcc 3840
tctgcctccc aagagccctt tccttgccct gagcaaggag tggtgttcca caaacaaggc 3900
tgctcttcta agccaacagt gtcaggcagg aagcagccat aattttgcct tgcattttca 3960
ttccctaatg taaagggatc tgcattggtc actctcctgt tctctgagcc attgctcagg 4020
gccagccaag atattattga gaacagataa tttaccttgg agccagaggc cctccctgcc 4080
tttagcaagg atgttcaggg acagacaaag agggcagtgg tggtgaatgt tgttactgcc 4140
atgaggagaa atggcagtaa gaaatcttaa ctacaagcag ccaatttctc attccaggac 4200
cctagccaga ataattgact tctttttttt tttgagacag agttttgctt ttgttgccct 4260
ggctggagtg cagtggcgca atcttggctc accgcaacct ccacttccca ggttcaagca 4320
attctgcctc agcctcccga gtagctggga ttacaggcat gcgccaccac gcctggctaa 4380
ttttgtattt ttagtagaga cggggtttct ccatgttggt caggctggtc tcgaactccc 4440
aacgtcaggt gatcctcccg cctcagtctc ccaaagtgct gggattacag gtgtgagcca 4500
ccatgcctgg tctagggaat tgacttcttt ttgaccttct gcactccctt ccccaaaagg 4560
attgtggctt ctgttgacca ttgacctcag cagaagttga taaggcagga ggtttccagt 4620
cctcctggaa aaccaactgc tgagcatgag ttgtccttgg ctgtctctgg gcctcgcacc 4680
catgggaagt tttgaggtag ggcccttgct gtttacaact tctgagagag tagtgatggg 4740
accccaaagt aagcttgtat cagagggcag taatgacctt cccatatccc catcctgtgg 4800
tcacctggga tttgggttcc ctggggcgga agtgggaaat aggagcccag ggaaggacat 4860
ctgaagcacc cacagtttaa atagcgactc ttcttggtta gccagggctg tgctcatgtt 4920
gggccctacc caggtcagtg gccttttcac tctcaaagat cgggggtgac gaagcagcat 4980
cttaaacagt gtttaggctg acagattttt ccagttgaag aagctgaagt atctgccttt 5040
tgagggtgac tctagattac aagagagact atcagatcca atcagctttt gaaaaatcag 5100
gaatgtgctt aaaatgccag tgagtggttg tgaagatcag gtttatttcc caggataggc 5160
agtctttctt tccctccttt tccagttctc ttttcctacc tgtccttcca taagcctggt 5220
ctctagtgcc gaggaccttg gagaagagag ggcccctagc taagctggag ccagaaagaa 5280
ccttcatggt gagtgtggtt tcccaaactt gggaaatgaa cctagggtga ggttagggag 5340
gatttgtaga attctagcag gtaaaaatca agcctttttc ccctcccata gtaaacttaa 5400
ccattttcac cctgtacgtt atcttctagc tcctactaac atctccaatt agacaaccgc 5460
ttcaaagggt gcttagcacc agggattggg gttcatggac ttaggaggtg gtaaggaaac 5520
tggctggcac caccaaactg ccttagtgaa cttggccctt cccaggcagg taggttgggc 5580
attgagggaa ggtggcccag tctttgctgg cagggtctgg ccagtctcat gggggcacca 5640
ccagtttggt gacagaagtg gtgtcattta ttgaattcca cctccgttta gaaggagatc 5700
atggtacaaa gcccaggagg ggccttaaga tgtgaagatc tctctgagta aaaggcaagg 5760
ggcttctctt cttcacctct gggatagttg gtagatcgga gagttttatt ttcagggtca 5820
aggctgtgga ctgatgggga tattggaggg tgggtgggtt ttcctgagag actttgtata 5880
atgctgaatg tgtccagagg gacaagtttg cagaacctca tattggtata ttaaagaaat 5940
aataaaataa aaaagcactt taggttattt tatctttaac ccgattgctg caatttcttt 6000
tgtgtgtata tatacatata tatactttcc acaaagtttt attttttgct cagaataaaa 6060
agttaaattg aggtgtgaaa agaaaagcac ttaccttggt gcaatatgtg tagcttgatg 6120
gtcgttgtcc catgtggccc tggcctggca gcgtttttcc gctcaatcag ccctgtgctg 6180
tgagactgtc catagggaaa cactattatg cattctcagc aaccgctcaa tctatgcaag 6240
ccttccctgt gtgccccagg gcgccccctc aggctctctg aagaactgct gtgggtcctg 6300
ttttctgctg actgttgagg ccctttttca tcacttcttg gtctctcgcc atcttttccc 6360
tcttcaccat tacaaaatga tgcctgaaag gaaggaacag attgttccta ggtagaaacc 6420
tggcaccttc tagactttta tatttgtaat cacatccatt gtccttaaag acttttccag 6480
agtgattgaa accattgatt tgtggaactg caacaatatt tctcaagagt ttacaattgt 6540
cttacaccac caatcagaaa tatgtttggg gaggcatggg tggcaggggg caacatgagc 6600
catttccata ctgctcccca tactacctgt gttggttcct taagcaaaaa ggcctccagc 6660
cttcattaaa tcctataaac aaacattaca tcccatgaat cattatcaac tttcttcctt 6720
tactccacct cccccatttt atcttcaatt ctcaggctat agaatagaca agttttagaa 6780
tatacttcag ccaaagcaga aggattttca tagatccaat atgcaaatag ttctgctgtg 6840
acatagatca gaaattgtct gttccttaat atttgggggt ggaggcaaca aaactgaagc 6900
atatttctga ttggttagcc attttggcct gtttcctctt gcatgttttt tagggagaga 6960
gggaaacagt cctgtatttc ttctgatgcc ctttggggaa gccgacgacc actgggcatt 7020
tctcactgtt actcctgttc aagagagggc ttctcagtct gcactgaaaa atgcaaatta 7080
aactggatct ttatgtcaat gtgtacatag tacaagcttt tttactggaa ttgaggttta 7140
aaaccacaca ctgccctttt ggtggtgtgc ctgttgggcc aaaaattggg tgataatgta 7200
gtgtcacttt ctcagctcaa tgcagtttct actttttctt atgggaaaat ttttcataaa 7260
acctttttgc accaaaaccc aggggtgttt tttgcaatat ccttgttatc ctcgtagtgt 7320
gccaagtcag aggctttctc ttgccctttt cctgctgtgt tctcaggcct cccaagggct 7380
atttgactca acagtctaca tccttcgttg tgttttggag aatgtggggg tgggggtcag 7440
agttcaaggt gtctgttccc ttttcctgtg aactctttct agtccctatt tggggagggt 7500
ggctggaaac agatttttgc tgaatttctg gctcagatct tctagccagg aaaggcaaga 7560
gcccccaaga gccctttttt ttgacataca ctaatcattg gccggggtct tggtgacaac 7620
ttttaaaatc ccaaatagtt ttatttggat tatgtaaaag taagtgtgaa acatgggaac 7680
aacggacttc cactgagcga tgtgaaaacg ttacaggttc agtacttcca aaggaagaaa 7740
cctccaaacc caaaaaagaa taaatatgaa tttgtatttt tgaagaatgt gaaataatgg 7800
tgtttgctta attgctcatt ttgtataaac ttaatattgt actttaaaat atctgctaaa 7860
aagtgaaaat ttaacttttt ggaattgaaa aagcaatatt aaatactaat gaaatcctaa 7920
ttaaatgctt atttaaa 7937
<210> 19
<211> 4991
<212> DNA
<213> Homo sapiens
<400> 19
agtttccgag gaacttttcg ccggcgccgg gccgcctctg aggccagggc aggacacgaa 60
cgcgcggagc ggcggcggcg actgagagcc ggggccgcgg cggcgctccc taggaagggc 120
cgtacgaggc ggcgggcccg gcgggcctcc cggaggaggc ggctgcgcca tggacgagcc 180
acccttcagc gaggcggctt tggagcaggc gctgggcgag ccgtgcgatc tggacgcggc 240
gctgctgacc gacatcgaag gtgaagtcgg cgcggggagg ggtagggcca acggcctgga 300
cgccccaagg gcgggcgcag atcgcggagc catggattgc actttcgaag acatgcttca 360
gcttatcaac aaccaagaca gtgacttccc tggcctattt gacccaccct atgctgggag 420
tggggcaggg ggcacagacc ctgccagccc cgataccagc tccccaggca gcttgtctcc 480
acctcctgcc acattgagct cctctcttga agccttcctg agcgggccgc aggcagcgcc 540
ctcacccctg tcccctcccc agcctgcacc cactccattg aagatgtacc cgtccatgcc 600
cgctttctcc cctgggcctg gtatcaagga agagtcagtg ccactgagca tcctgcagac 660
ccccacccca cagcccctgc caggggccct cctgccacag agcttcccag ccccagcccc 720
accgcagttc agctccaccc ctgtgttagg ctaccccagc cctccgggag gcttctctac 780
aggaagccct cccgggaaca cccagcagcc gctgcctggc ctgccactgg cttccccgcc 840
aggggtcccg cccgtctcct tgcacaccca ggtccagagt gtggtccccc agcagctact 900
gacagtcaca gctgccccca cggcagcccc tgtaacgacc actgtgacct cgcagatcca 960
gcaggtcccg gtcctgctgc agccccactt catcaaggca gactcgctgc ttctgacagc 1020
catgaagaca gacggagcca ctgtgaaggc ggcaggtctc agtcccctgg tctctggcac 1080
cactgtgcag acagggcctt tgccgaccct ggtgagtggc ggaaccatct tggcaacagt 1140
cccactggtc gtagatgcgg agaagctgcc tatcaaccgg ctcgcagctg gcagcaaggc 1200
cccggcctct gcccagagcc gtggagagaa gcgcacagcc cacaacgcca ttgagaagcg 1260
ctaccgctcc tccatcaatg acaaaatcat tgagctcaag gatctggtgg tgggcactga 1320
ggcaaagctg aataaatctg ctgtcttgcg caaggccatc gactacattc gctttctgca 1380
acacagcaac cagaaactca agcaggagaa cctaagtctg cgcactgctg tccacaaaag 1440
caaatctctg aaggatctgg tgtcggcctg tggcagtgga gggaacacag acgtgctcat 1500
ggagggcgtg aagactgagg tggaggacac actgacccca cccccctcgg atgctggctc 1560
acctttccag agcagcccct tgtcccttgg cagcaggggc agtggcagcg gtggcagtgg 1620
cagtgactcg gagcctgaca gcccagtctt tgaggacagc aaggcaaagc cagagcagcg 1680
gccgtctctg cacagccggg gcatgctgga ccgctcccgc ctggccctgt gcacgctcgt 1740
cttcctctgc ctgtcctgca accccttggc ctccttgctg ggggcccggg ggcttcccag 1800
cccctcagat accaccagcg tctaccatag ccctgggcgc aacgtgctgg gcaccgagag 1860
cagagatggc cctggctggg cccagtggct gctgccccca gtggtctggc tgctcaatgg 1920
gctgttggtg ctcgtctcct tggtgcttct ctttgtctac ggtgagccag tcacacggcc 1980
ccactcaggc cccgccgtgt acttctggag gcatcgcaag caggctgacc tggacctggc 2040
ccggggagac tttgcccagg ctgcccagca gctgtggctg gccctgcggg cactgggccg 2100
gcccctgccc acctcccacc tggacctggc ttgtagcctc ctctggaacc tcatccgtca 2160
cctgctgcag cgtctctggg tgggccgctg gctggcaggc cgggcagggg gcctgcagca 2220
ggactgtgct ctgcgagtgg atgctagcgc cagcgcccga gacgcagccc tggtctacca 2280
taagctgcac cagctgcaca ccatggggaa gcacacaggc gggcacctca ctgccaccaa 2340
cctggcgctg agtgccctga acctggcaga gtgtgcaggg gatgccgtgt ctgtggcgac 2400
gctggccgag atctatgtgg cggctgcatt gagagtgaag accagtctcc cacgggcctt 2460
gcattttctg acacgcttct tcctgagcag tgcccgccag gcctgcctgg cacagagtgg 2520
ctcagtgcct cctgccatgc agtggctctg ccaccccgtg ggccaccgtt tcttcgtgga 2580
tggggactgg tccgtgctca gtaccccatg ggagagcctg tacagcttgg ccgggaaccc 2640
agtggacccc ctggcccagg tgactcagct attccgggaa catctcttag agcgagcact 2700
gaactgtgtg acccagccca accccagccc tgggtcagct gatggggaca aggaattctc 2760
ggatgccctc gggtacctgc agctgctgaa cagctgttct gatgctgcgg gggctcctgc 2820
ctacagcttc tccatcagtt ccagcatggc caccaccacc ggcgtagacc cggtggccaa 2880
gtggtgggcc tctctgacag ctgtggtgat ccactggctg cggcgggatg aggaggcggc 2940
tgagcggctg tgcccgctgg tggagcacct gccccgggtg ctgcaggagt ctgagagacc 3000
cctgcccagg gcagctctgc actccttcaa ggctgcccgg gccctgctgg gctgtgccaa 3060
ggcagagtct ggtccagcca gcctgaccat ctgtgagaag gccagtgggt acctgcagga 3120
cagcctggct accacaccag ccagcagctc cattgacaag gccgtgcagc tgttcctgtg 3180
tgacctgctt cttgtggtgc gcaccagcct gtggcggcag cagcagcccc cggccccggc 3240
cccagcagcc cagggcacca gcagcaggcc ccaggcttcc gcccttgagc tgcgtggctt 3300
ccaacgggac ctgagcagcc tgaggcggct ggcacagagc ttccggcccg ccatgcggag 3360
ggtgttccta catgaggcca cggcccggct gatggcgggg gccagcccca cacggacaca 3420
ccagctcctc gaccgcagtc tgaggcggcg ggcaggcccc ggtggcaaag gaggcgcggt 3480
ggcggagctg gagccgcggc ccacgcggcg ggagcacgcg gaggccttgc tgctggcctc 3540
ctgctacctg ccccccggct tcctgtcggc gcccgggcag cgcgtgggca tgctggctga 3600
ggcggcgcgc acactcgaga agcttggcga tcgccggctg ctgcacgact gtcagcagat 3660
gctcatgcgc ctgggcggtg ggaccactgt cacttccagc tagaccccgt gtccccggcc 3720
tcagcacccc tgtctctagc cactttggtc ccgtgcagct tctgtcctgc gtcgaagctt 3780
tgaaggccga aggcagtgca agagactctg gcctccacag ttcgacctgc ggctgctgtg 3840
tgccttcgcg gtggaaggcc cgaggggcgc gatcttgacc ctaagaccgg cggccatgat 3900
ggtgctgacc tctggtggcc gatcggggca ctgcaggggc cgagccattt tggggggccc 3960
ccctccttgc tctgcaggca ccttagtggc ttttttcctc ctgtgtacag ggaagagagg 4020
ggtacatttc cctgtgctga cggaagccaa cttggctttc ccggactgca agcagggctc 4080
tgccccagag gcctctctct ccgtcgtggg agagagacgt gtacatagtg taggtcagcg 4140
tgcttagcct cctgacctga ggctcctgtg ctactttgcc ttttgcaaac tttattttca 4200
tagattgaga agttttgtac agagaattaa aaatgaaatt atttataatc tgggttttgt 4260
gtcttcagct gatggatgtg ctgactagtg agagtgcttg ggccctcccc cagcacctag 4320
ggaaaggctt cccctccccc tccggccaca aggtacacaa cttttaactt agctcttccc 4380
gatgtttgtt tgttagtggg aggagtgggg agggctggct gtatggcctc cagcctacct 4440
gttccccctg ctcccagggc acatggttgg gctgtgtcaa cccttagggc ctccatgggg 4500
tcagttgtcc cttctcacct cccagctctg tccccatcag gtccctgggt ggcacgggag 4560
gatggactga cttccaggac ctgttgtgtg acaggagcta cagcttgggt ctccctgcaa 4620
gaagtctggc acgtctcacc tcccccatcc cggcccctgg tcatctcaca gcaaagaagc 4680
ctcctccctc ccgacctgcc gccacactgg agagggggca caggggcggg ggaggtttcc 4740
tgttctgtga aaggccgact ccctgactcc attcatgccc ccccccccag cccctccctt 4800
cattcccatt ccccaaccta aagcctggcc cggctcccag ctgaatctgg tcggaatcca 4860
cgggctgcag attttccaaa acaatcgttg tatctttatt gacttttttt tttttttttt 4920
tctgaatgca atgactgttt tttactctta aggaaaataa acatctttta gaaacagctc 4980
gatacacaca a 4991
<210> 20
<211> 4923
<212> DNA
<213> Homo sapiens
<400> 20
agcagagctg cggccggggg aacccagttt ccgaggaact tttcgccggc gccgggccgc 60
ctctgaggcc agggcaggac acgaacgcgc ggagcggcgg cggcgactga gagccggggc 120
cgcggcggcg ctccctagga agggccgtac gaggcggcgg gcccggcggg cctcccggag 180
gaggcggctg cgccatggac gagccaccct tcagcgaggc ggctttggag caggcgctgg 240
gcgagccgtg cgatctggac gcggcgctgc tgaccgacat cgaagacatg cttcagctta 300
tcaacaacca agacagtgac ttccctggcc tatttgaccc accctatgct gggagtgggg 360
cagggggcac agaccctgcc agccccgata ccagctcccc aggcagcttg tctccacctc 420
ctgccacatt gagctcctct cttgaagcct tcctgagcgg gccgcaggca gcgccctcac 480
ccctgtcccc tccccagcct gcacccactc cattgaagat gtacccgtcc atgcccgctt 540
tctcccctgg gcctggtatc aaggaagagt cagtgccact gagcatcctg cagaccccca 600
ccccacagcc cctgccaggg gccctcctgc cacagagctt cccagcccca gccccaccgc 660
agttcagctc cacccctgtg ttaggctacc ccagccctcc gggaggcttc tctacaggaa 720
gccctcccgg gaacacccag cagccgctgc ctggcctgcc actggcttcc ccgccagggg 780
tcccgcccgt ctccttgcac acccaggtcc agagtgtggt cccccagcag ctactgacag 840
tcacagctgc ccccacggca gcccctgtaa cgaccactgt gacctcgcag atccagcagg 900
tcccggtcct gctgcagccc cacttcatca aggcagactc gctgcttctg acagccatga 960
agacagacgg agccactgtg aaggcggcag gtctcagtcc cctggtctct ggcaccactg 1020
tgcagacagg gcctttgccg accctggtga gtggcggaac catcttggca acagtcccac 1080
tggtcgtaga tgcggagaag ctgcctatca accggctcgc agctggcagc aaggccccgg 1140
cctctgccca gagccgtgga gagaagcgca cagcccacaa cgccattgag aagcgctacc 1200
gctcctccat caatgacaaa atcattgagc tcaaggatct ggtggtgggc actgaggcaa 1260
agctgaataa atctgctgtc ttgcgcaagg ccatcgacta cattcgcttt ctgcaacaca 1320
gcaaccagaa actcaagcag gagaacctaa gtctgcgcac tgctgtccac aaaagcaaat 1380
ctctgaagga tctggtgtcg gcctgtggca gtggagggaa cacagacgtg ctcatggagg 1440
gcgtgaagac tgaggtggag gacacactga ccccaccccc ctcggatgct ggctcacctt 1500
tccagagcag ccccttgtcc cttggcagca ggggcagtgg cagcggtggc agtggcagtg 1560
actcggagcc tgacagccca gtctttgagg acagcaaggc aaagccagag cagcggccgt 1620
ctctgcacag ccggggcatg ctggaccgct cccgcctggc cctgtgcacg ctcgtcttcc 1680
tctgcctgtc ctgcaacccc ttggcctcct tgctgggggc ccgggggctt cccagcccct 1740
cagataccac cagcgtctac catagccctg ggcgcaacgt gctgggcacc gagagcagag 1800
atggccctgg ctgggcccag tggctgctgc ccccagtggt ctggctgctc aatgggctgt 1860
tggtgctcgt ctccttggtg cttctctttg tctacggtga gccagtcaca cggccccact 1920
caggccccgc cgtgtacttc tggaggcatc gcaagcaggc tgacctggac ctggcccggg 1980
gagactttgc ccaggctgcc cagcagctgt ggctggccct gcgggcactg ggccggcccc 2040
tgcccacctc ccacctggac ctggcttgta gcctcctctg gaacctcatc cgtcacctgc 2100
tgcagcgtct ctgggtgggc cgctggctgg caggccgggc agggggcctg cagcaggact 2160
gtgctctgcg agtggatgct agcgccagcg cccgagacgc agccctggtc taccataagc 2220
tgcaccagct gcacaccatg gggaagcaca caggcgggca cctcactgcc accaacctgg 2280
cgctgagtgc cctgaacctg gcagagtgtg caggggatgc cgtgtctgtg gcgacgctgg 2340
ccgagatcta tgtggcggct gcattgagag tgaagaccag tctcccacgg gccttgcatt 2400
ttctgacacg cttcttcctg agcagtgccc gccaggcctg cctggcacag agtggctcag 2460
tgcctcctgc catgcagtgg ctctgccacc ccgtgggcca ccgtttcttc gtggatgggg 2520
actggtccgt gctcagtacc ccatgggaga gcctgtacag cttggccggg aacccagtgg 2580
accccctggc ccaggtgact cagctattcc gggaacatct cttagagcga gcactgaact 2640
gtgtgaccca gcccaacccc agccctgggt cagctgatgg ggacaaggaa ttctcggatg 2700
ccctcgggta cctgcagctg ctgaacagct gttctgatgc tgcgggggct cctgcctaca 2760
gcttctccat cagttccagc atggccacca ccaccggcgt agacccggtg gccaagtggt 2820
gggcctctct gacagctgtg gtgatccact ggctgcggcg ggatgaggag gcggctgagc 2880
ggctgtgccc gctggtggag cacctgcccc gggtgctgca ggagtctgag agacccctgc 2940
ccagggcagc tctgcactcc ttcaaggctg cccgggccct gctgggctgt gccaaggcag 3000
agtctggtcc agccagcctg accatctgtg agaaggccag tgggtacctg caggacagcc 3060
tggctaccac accagccagc agctccattg acaaggccgt gcagctgttc ctgtgtgacc 3120
tgcttcttgt ggtgcgcacc agcctgtggc ggcagcagca gcccccggcc ccggccccag 3180
cagcccaggg caccagcagc aggccccagg cttccgccct tgagctgcgt ggcttccaac 3240
gggacctgag cagcctgagg cggctggcac agagcttccg gcccgccatg cggagggtgt 3300
tcctacatga ggccacggcc cggctgatgg cgggggccag ccccacacgg acacaccagc 3360
tcctcgaccg cagtctgagg cggcgggcag gccccggtgg caaaggaggc gcggtggcgg 3420
agctggagcc gcggcccacg cggcgggagc acgcggaggc cttgctgctg gcctcctgct 3480
acctgccccc cggcttcctg tcggcgcccg ggcsagcgcg tgggcatgct ggctgaggcg 3540
gcgcgcacac tcgagaagct tggcgatcgc cggctgctgc acgactgtca gcagatgctc 3600
atgcgcctgg gcggtgggac cactgtcact tccagctaga ccccgtgtcc ccggcctcag 3660
cacccctgtc tctagccact ttggtcccgt gcagcttctg tcctgcgtcg aagctttgaa 3720
ggccgaaggc agtgcaagag actctggcct ccacagttcg acctgcggct gctgtgtgcc 3780
ttcgcggtgg aaggcccgag gggcgcgatc ttgaccctaa gaccggcggc catgatggtg 3840
ctgacctctg gtggccgatc ggggcactgc aggggccgag ccattttggg gggcccccct 3900
ccttgctctg caggcacctt agtggctttt ttcctcctgt gtacagggaa gagaggggta 3960
catttccctg tgctgacgga agccaacttg gctttcccgg actgcaagca gggctctgcc 4020
ccagaggcct ctctctccgt cgtgggagag agacgtgtac atagtgtagg tcagcgtgct 4080
tagcctcctg acctgaggct cctgtgctac tttgcctttt gcaaacttta ttttcataga 4140
ttgagaagtt ttgtacagag aattaaaaat gaaattattt ataatctggg ttttgtgtct 4200
tcagctgatg gatgtgctga ctagtgagag tgcttgggcc ctcccccagc acctagggaa 4260
aggcttcccc tccccctccg gccacaaggt acacaacttt taacttagct cttcccgatg 4320
tttgtttgtt agtgggagga gtggggaggg ctggctgtat ggcctccagc ctacctgttc 4380
cccctgctcc cagggcacat ggttgggctg tgtcaaccct tagggcctcc atggggtcag 4440
ttgtcccttc tcacctccca gctctgtccc catcaggtcc ctgggtggca cgggaggatg 4500
gactgacttc caggacctgt tgtgtgacag gagctacagc ttgggtctcc ctgcaagaag 4560
tctggcacgt ctcacctccc ccatcccggc ccctggtcat ctcacagcaa agaagcctcc 4620
tccctcccga cctgccgcca cactggagag ggggcacagg ggcgggggag gtttcctgtt 4680
ctgtgaaagg ccgactccct gactccattc atgccccccc ccccagcccc tcccttcatt 4740
cccattcccc aacctaaagc ctggcccggc tcccagctga atctggtcgg aatccacggg 4800
ctgcagattt tccaaaacaa tcgttgtatc tttattgact tttttttttt tttttttctg 4860
aatgcaatga ctgtttttta ctcttaagga aaataaacat cttttagaaa caaaaaaaaa 4920
aaa 4923
<210> 21
<211> 4754
<212> DNA
<213> Homo sapiens
<400> 21
aaaaatccgc cgcgccttga caggtgaagt cggcgcgggg aggggtaggg ccaacggcct 60
ggacgcccca agggcgggcg cagatcgcgg agccatggat tgcactttcg aagacatgct 120
tcagcttatc aacaaccaag acagtgactt ccctggccta tttgacccac cctatgctgg 180
gagtggggca gggggcacag accctgccag ccccgatacc agctccccag gcagcttgtc 240
tccacctcct gccacattga gctcctctct tgaagccttc ctgagcgggc cgcaggcagc 300
gccctcaccc ctgtcccctc cccagcctgc acccactcca ttgaagatgt acccgtccat 360
gcccgctttc tcccctgggc ctggtatcaa ggaagagtca gtgccactga gcatcctgca 420
gacccccacc ccacagcccc tgccaggggc cctcctgcca cagagcttcc cagccccagc 480
cccaccgcag ttcagctcca cccctgtgtt aggctacccc agccctccgg gaggcttctc 540
tacaggaagc cctcccggga acacccagca gccgctgcct ggcctgccac tggcttcccc 600
gccaggggtc ccgcccgtct ccttgcacac ccaggtccag agtgtggtcc cccagcagct 660
actgacagtc acagctgccc ccacggcagc ccctgtaacg accactgtga cctcgcagat 720
ccagcaggtc ccggtcctgc tgcagcccca cttcatcaag gcagactcgc tgcttctgac 780
agccatgaag acagacggag ccactgtgaa ggcggcaggt ctcagtcccc tggtctctgg 840
caccactgtg cagacagggc ctttgccgac cctggtgagt ggcggaacca tcttggcaac 900
agtcccactg gtcgtagatg cggagaagct gcctatcaac cggctcgcag ctggcagcaa 960
ggccccggcc tctgcccaga gccgtggaga gaagcgcaca gcccacaacg ccattgagaa 1020
gcgctaccgc tcctccatca atgacaaaat cattgagctc aaggatctgg tggtgggcac 1080
tgaggcaaag ctgaataaat ctgctgtctt gcgcaaggcc atcgactaca ttcgctttct 1140
gcaacacagc aaccagaaac tcaagcagga gaacctaagt ctgcgcactg ctgtccacaa 1200
aagcaaatct ctgaaggatc tggtgtcggc ctgtggcagt ggagggaaca cagacgtgct 1260
catggagggc gtgaagactg aggtggagga cacactgacc ccacccccct cggatgctgg 1320
ctcacctttc cagagcagcc ccttgtccct tggcagcagg ggcagtggca gcggtggcag 1380
tggcagtgac tcggagcctg acagcccagt ctttgaggac agcaaggcaa agccagagca 1440
gcggccgtct ctgcacagcc ggggcatgct ggaccgctcc cgcctggccc tgtgcacgct 1500
cgtcttcctc tgcctgtcct gcaacccctt ggcctccttg ctgggggccc gggggcttcc 1560
cagcccctca gataccacca gcgtctacca tagccctggg cgcaacgtgc tgggcaccga 1620
gagcagagat ggccctggct gggcccagtg gctgctgccc ccagtggtct ggctgctcaa 1680
tgggctgttg gtgctcgtct ccttggtgct tctctttgtc tacggtgagc cagtcacacg 1740
gccccactca ggccccgccg tgtacttctg gaggcatcgc aagcaggctg acctggacct 1800
ggcccgggga gactttgccc aggctgccca gcagctgtgg ctggccctgc gggcactggg 1860
ccggcccctg cccacctccc acctggacct ggcttgtagc ctcctctgga acctcatccg 1920
tcacctgctg cagcgtctct gggtgggccg ctggctggca ggccgggcag ggggcctgca 1980
gcaggactgt gctctgcgag tggatgctag cgccagcgcc cgagacgcag ccctggtcta 2040
ccataagctg caccagctgc acaccatggg gaagcacaca ggcgggcacc tcactgccac 2100
caacctggcg ctgagtgccc tgaacctggc agagtgtgca ggggatgccg tgtctgtggc 2160
gacgctggcc gagatctatg tggcggctgc attgagagtg aagaccagtc tcccacgggc 2220
cttgcatttt ctgacacgct tcttcctgag cagtgcccgc caggcctgcc tggcacagag 2280
tggctcagtg cctcctgcca tgcagtggct ctgccacccc gtgggccacc gtttcttcgt 2340
ggatggggac tggtccgtgc tcagtacccc atgggagagc ctgtacagct tggccgggaa 2400
cccagtggac cccctggccc aggtgactca gctattccgg gaacatctct tagagcgagc 2460
actgaactgt gtgacccagc ccaaccccag ccctgggtca gctgatgggg acaaggaatt 2520
ctcggatgcc ctcgggtacc tgcagctgct gaacagctgt tctgatgctg cgggggctcc 2580
tgcctacagc ttctccatca gttccagcat ggccaccacc accggcgtag acccggtggc 2640
caagtggtgg gcctctctga cagctgtggt gatccactgg ctgcggcggg atgaggaggc 2700
ggctgagcgg ctgtgcccgc tggtggagca cctgccccgg gtgctgcagg agtctgagag 2760
acccctgccc agggcagctc tgcactcctt caaggctgcc cgggccctgc tgggctgtgc 2820
caaggcagag tctggtccag ccagcctgac catctgtgag aaggccagtg ggtacctgca 2880
ggacagcctg gctaccacac cagccagcag ctccattgac aaggccgtgc agctgttcct 2940
gtgtgacctg cttcttgtgg tgcgcaccag cctgtggcgg cagcagcagc ccccggcccc 3000
ggccccagca gcccagggca ccagcagcag gccccaggct tccgcccttg agctgcgtgg 3060
cttccaacgg gacctgagca gcctgaggcg gctggcacag agcttccggc ccgccatgcg 3120
gagggtgttc ctacatgagg ccacggcccg gctgatggcg ggggccagcc ccacacggac 3180
acaccagctc ctcgaccgca gtctgaggcg gcgggcaggc cccggtggca aaggaggcgc 3240
ggtggcggag ctggagccgc ggcccacgcg gcgggagcac gcggaggcct tgctgctggc 3300
ctcctgctac ctgccccccg gcttcctgtc ggcgcccggg cagcgcgtgg gcatgctggc 3360
tgaggcggcg cgcacactcg agaagcttgg cgatcgccgg ctgctgcacg actgtcagca 3420
gatgctcatg cgcctgggcg gtgggaccac tgtcacttcc agctagaccc cgtgtccccg 3480
gcctcagcac ccctgtctct agccactttg gtcccgtgca gcttctgtcc tgcgtcgaag 3540
ctttgaaggc cgaaggcagt gcaagagact ctggcctcca cagttcgacc tgcggctgct 3600
gtgtgccttc gcggtggaag gcccgagggg cgcgatcttg accctaagac cggcggccat 3660
gatggtgctg acctctggtg gccgatcggg gcactgcagg ggccgagcca ttttgggggg 3720
cccccctcct tgctctgcag gcaccttagt ggcttttttc ctcctgtgta cagggaagag 3780
aggggtacat ttccctgtgc tgacggaagc caacttggct ttcccggact gcaagcaggg 3840
ctctgcccca gaggcctctc tctccgtcgt gggagagaga cgtgtacata gtgtaggtca 3900
gcgtgcttag cctcctgacc tgaggctcct gtgctacttt gccttttgca aactttattt 3960
tcatagattg agaagttttg tacagagaat taaaaatgaa attatttata atctgggttt 4020
tgtgtcttca gctgatggat gtgctgacta gtgagagtgc ttgggccctc ccccagcacc 4080
tagggaaagg cttcccctcc ccctccggcc acaaggtaca caacttttaa cttagctctt 4140
cccgatgttt gtttgttagt gggaggagtg gggagggctg gctgtatggc ctccagccta 4200
cctgttcccc ctgctcccag ggcacatggt tgggctgtgt caacccttag ggcctccatg 4260
gggtcagttg tcccttctca cctcccagct ctgtccccat caggtccctg ggtggcacgg 4320
gaggatggac tgacttccag gacctgttgt gtgacaggag ctacagcttg ggtctccctg 4380
caagaagtct ggcacgtctc acctccccca tcccggcccc tggtcatctc acagcaaaga 4440
agcctcctcc ctcccgacct gccgccacac tggagagggg gcacaggggc gggggaggtt 4500
tcctgttctg tgaaaggccg actccctgac tccattcatg cccccccccc cagcccctcc 4560
cttcattccc attccccaac ctaaagcctg gcccggctcc cagctgaatc tggtcggaat 4620
ccacgggctg cagattttcc aaaacaatcg ttgtatcttt attgactttt tttttttttt 4680
ttttctgaat gcaatgactg ttttttactc ttaaggaaaa taaacatctt ttagaaacag 4740
ctcgatacac acaa 4754
<210> 22
<211> 8779
<212> DNA
<213> Homo sapiens
<400> 22
gagaaggagg aggacagcgc cgaggaggaa gaggttgatg gcggcggcgg agctccgaga 60
gacctcggct gggcaggggc cggccgtggc gggccgggga ctgcgcctct agagccgcga 120
gttctcggga attcgccgca gcggacgcgc tcggcgaatt tgtgctcttg tgccctcctc 180
cgggcttggg cccaggcccg gcccctcgca cttgccctta ccttttctat cgagtccgca 240
tccctctcca gccactgcga cccggcgaag agaaaaagga acttccccca ccccctcggg 300
tgccgtcgga gccccccagc ccacccctgg gtgcggcgcg gggaccccgg gccgaagaag 360
agatttcctg aggattctgg ttttcctcgc ttgtatctcc gaaagaatta aaaatggccg 420
agaatgtggt ggaaccgggg ccgccttcag ccaagcggcc taaactctca tctccggccc 480
tctcggcgtc cgccagcgat ggcacagatt ttggctctct atttgacttg gagcacgact 540
taccagatga attaatcaac tctacagaat tgggactaac caatggtggt gatattaatc 600
agcttcagac aagtcttggc atggtacaag atgcagcttc taaacataaa cagctgtcag 660
aattgctgcg atctggtagt tcccctaacc tcaatatggg agttggtggc ccaggtcaag 720
tcatggccag ccaggcccaa cagagcagtc ctggattagg tttgataaat agcatggtca 780
aaagcccaat gacacaggca ggcttgactt ctcccaacat ggggatgggc actagtggac 840
caaatcaggg tcctacgcag tcaacaggta tgatgaacag tccagtaaat cagcctgcca 900
tgggaatgaa cacagggatg aatgcgggca tgaatcctgg aatgttggct gcaggcaatg 960
gacaagggat aatgcctaat caagtcatga acggttcaat tggagcaggc cgagggcgac 1020
agaatatgca gtacccaaac ccaggcatgg gaagtgctgg caacttactg actgagcctc 1080
ttcagcaggg ctctccccag atgggaggac aaacaggatt gagaggcccc cagcctctta 1140
agatgggaat gatgaacaac cccaatcctt atggttcacc atatactcag aatcctggac 1200
agcagattgg agccagtggc cttggtctcc agattcagac aaaaactgta ctatcaaata 1260
acttatctcc atttgctatg gacaaaaagg cagttcctgg tggaggaatg cccaacatgg 1320
gtcaacagcc agccccgcag gtccagcagc caggcctggt gactccagtt gcccaaggga 1380
tgggttctgg agcacataca gctgatccag agaagcgcaa gctcatccag cagcagcttg 1440
ttctcctttt gcatgctcac aagtgccagc gccgggaaca ggccaatggg gaagtgaggc 1500
agtgcaacct tccccactgt cgcacaatga agaatgtcct aaaccacatg acacactgcc 1560
agtcaggcaa gtcttgccaa gtggcacact gtgcatcttc tcgacaaatc atttcacact 1620
ggaagaattg tacaagacat gattgtcctg tgtgtctccc cctcaaaaat gctggtgata 1680
agagaaatca acagccaatt ttgactggag cacccgttgg acttggaaat cctagctctc 1740
taggggtggg tcaacagtct gcccccaacc taagcactgt tagtcagatt gatcccagct 1800
ccatagaaag agcctatgca gctcttggac taccctatca agtaaatcag atgccgacac 1860
aaccccaggt gcaagcaaag aaccagcaga atcagcagcc tgggcagtct ccccaaggca 1920
tgcggcccat gagcaacatg agtgctagtc ctatgggagt aaatggaggt gtaggagttc 1980
aaacgccgag tcttctttct gactcaatgt tgcattcagc cataaattct caaaacccaa 2040
tgatgagtga aaatgccagt gtgccctccc tgggtcctat gccaacagca gctcaaccat 2100
ccactactgg aattcggaaa cagtggcacg aagatattac tcaggatctt cgaaatcatc 2160
ttgttcacaa actcgtccaa gccatatttc ctacgccgga tcctgctgct ttaaaagaca 2220
gacggatgga aaacctagtt gcatatgctc ggaaagttga aggggacatg tatgaatctg 2280
caaacaatcg agcggaatac taccaccttc tagctgagaa aatctataag atccagaaag 2340
aactagaaga aaaacgaagg accagactac agaagcagaa catgctacca aatgctgcag 2400
gcatggttcc agtttccatg aatccagggc ctaacatggg acagccgcaa ccaggaatga 2460
cttctaatgg ccctctacct gacccaagta tgatccgtgg cagtgtgcca aaccagatga 2520
tgcctcgaat aactccacaa tctggtttga atcaatttgg ccagatgagc atggcccagc 2580
cccctattgt accccggcaa acccctcctc ttcagcacca tggacagttg gctcaacctg 2640
gagctctcaa cccgcctatg ggctatgggc ctcgtatgca acagccttcc aaccagggcc 2700
agttccttcc tcagactcag ttcccatcac agggaatgaa tgtaacaaat atccctttgg 2760
ctccgtccag cggtcaagct ccagtgtctc aagcacaaat gtctagttct tcctgcccgg 2820
tgaactctcc tataatgcct ccagggtctc aggggagcca cattcactgt ccccagcttc 2880
ctcaaccagc tcttcatcag aattcaccct cgcctgtacc tagtcgtacc cccacccctc 2940
accatactcc cccaagcata ggggctcagc agccaccagc aacaacaatt ccagcccctg 3000
ttcctacacc tcctgccatg ccacctgggc cacagtccca ggctctacat ccccctccaa 3060
ggcagacacc tacaccacca acaacacaac ttccccaaca agtgcagcct tcacttcctg 3120
ctgcaccttc tgctgaccag ccccagcagc agcctcgctc acagcagagc acagcagcgt 3180
ctgttcctac cccaacagca ccgctgcttc ctccgcagcc tgcaactcca ctttcccagc 3240
cagctgtaag cattgaagga caggtatcaa atcctccatc tactagtagc acagaagtga 3300
attctcaggc cattgctgag aagcagcctt cccaggaagt gaagatggag gccaaaatgg 3360
aagtggatca accagaacca gcagatactc agccggagga tatttcagag tctaaagtgg 3420
aagactgtaa aatggaatct accgaaacag aagagagaag cactgagtta aaaactgaaa 3480
taaaagagga ggaagaccag ccaagtactt cagctaccca gtcatctccg gctccaggac 3540
agtcaaagaa aaagattttc aaaccagaag aactacgaca ggcactgatg ccaactttgg 3600
aggcacttta ccgtcaggat ccagaatccc ttccctttcg tcaacctgtg gaccctcagc 3660
ttttaggaat ccctgattac tttgatattg tgaagagccc catggatctt tctaccatta 3720
agaggaagtt agacactgga cagtatcagg agccctggca gtatgtcgat gatatttggc 3780
ttatgttcaa taatgcctgg ttatataacc ggaaaacatc acgggtatac aaatactgct 3840
ccaagctctc tgaggtcttt gaacaagaaa ttgacccagt gatgcaaagc cttggatact 3900
gttgtggcag aaagttggag ttctctccac agacactgtg ttgctacggc aaacagttgt 3960
gcacaatacc tcgtgatgcc acttattaca gttaccagaa caggtatcat ttctgtgaga 4020
agtgtttcaa tgagatccaa ggggagagcg tttctttggg ggatgaccct tcccagcctc 4080
aaactacaat aaataaagaa caattttcca agagaaaaaa tgacacactg gatcctgaac 4140
tgtttgttga atgtacagag tgcggaagaa agatgcatca gatctgtgtc cttcaccatg 4200
agatcatctg gcctgctgga ttcgtctgtg atggctgttt aaagaaaagt gcacgaacta 4260
ggaaagaaaa taagttttct gctaaaaggt tgccatctac cagacttggc acctttctag 4320
agaatcgtgt gaatgacttt ctgaggcgac agaatcaccc tgagtcagga gaggtcactg 4380
ttagagtagt tcatgcttct gacaaaaccg tggaagtaaa accaggcatg aaagcaaggt 4440
ttgtggacag tggagagatg gcagaatcct ttccataccg aaccaaagcc ctctttgcct 4500
ttgaagaaat tgatggtgtt gacctgtgct tctttggcat gcatgttcaa gagtatggct 4560
ctgactgccc tccacccaac cagaggagag tatacatatc ttacctcgat agtgttcatt 4620
tcttccgtcc taaatgcttg aggactgcag tctatcatga aatcctaatt ggatatttag 4680
aatatgtcaa gaaattaggt tacacaacag ggcatatttg ggcatgtcca ccaagtgagg 4740
gagatgatta tatcttccat tgccatcctc ctgaccagaa gatacccaag cccaagcgac 4800
tgcaggaatg gtacaaaaaa atgcttgaca aggctgtatc agagcgtatt gtccatgact 4860
acaaggatat ttttaaacaa gctactgaag atagattaac aagtgcaaag gaattgcctt 4920
atttcgaggg tgatttctgg cccaatgttc tggaagaaag cattaaggaa ctggaacagg 4980
aggaagaaga gagaaaacga gaggaaaaca ccagcaatga aagcacagat gtgaccaagg 5040
gagacagcaa aaatgctaaa aagaagaata ataagaaaac cagcaaaaat aagagcagcc 5100
tgagtagggg caacaagaag aaacccggga tgcccaatgt atctaacgac ctctcacaga 5160
aactatatgc caccatggag aagcataaag aggtcttctt tgtgatccgc ctcattgctg 5220
gccctgctgc caactccctg cctcccattg ttgatcctga tcctctcatc ccctgcgatc 5280
tgatggatgg tcgggatgcg tttctcacgc tggcaaggga caagcacctg gagttctctt 5340
cactccgaag agcccagtgg tccaccatgt gcatgctggt ggagctgcac acgcagagcc 5400
aggaccgctt tgtctacacc tgcaatgaat gcaagcacca tgtggagaca cgctggcact 5460
gtactgtctg tgaggattat gacttgtgta tcacctgcta taacactaaa aaccatgacc 5520
acaaaatgga gaaactaggc cttggcttag atgatgagag caacaaccag caggctgcag 5580
ccacccagag cccaggcgat tctcgccgcc tgagtatcca gcgctgcatc cagtctctgg 5640
tccatgcttg ccagtgtcgg aatgccaatt gctcactgcc atcctgccag aagatgaagc 5700
gggttgtgca gcataccaag ggttgcaaac ggaaaaccaa tggcgggtgc cccatctgca 5760
agcagctcat tgccctctgc tgctaccatg ccaagcactg ccaggagaac aaatgcccgg 5820
tgccgttctg cctaaacatc aagcagaagc tccggcagca acagctgcag caccgactac 5880
agcaggccca aatgcttcgc aggaggatgg ccagcatgca gcggactggt gtggttgggc 5940
agcaacaggg cctcccttcc cccactcctg ccactccaac gacaccaact ggccaacagc 6000
caaccacccc gcagacgccc cagcccactt ctcagcctca gcctacccct cccaatagca 6060
tgccacccta cttgcccagg actcaagctg ctggccctgt gtcccagggt aaggcagcag 6120
gccaggtgac ccctccaacc cctcctcaga ctgctcagcc accccttcca gggcccccac 6180
ctgcagcagt ggaaatggca atgcagattc agagagcagc ggagacgcag cgccagatgg 6240
cccacgtgca aatttttcaa aggccaatcc aacaccagat gcccccgatg actcccatgg 6300
cccccatggg tatgaaccca cctcccatga ccagaggtcc cagtgggcat ttggagccag 6360
ggatgggacc gacagggatg cagcaacagc caccctggag ccaaggagga ttgcctcagc 6420
cccagcaact acagtctggg atgccaaggc cagccatgat gtcagtggcc cagcatggtc 6480
aacctttgaa catggctcca caaccaggat tgggccaggt aggtatcagc ccactcaaac 6540
caggcactgt gtctcaacaa gccttacaaa accttttgcg gactctcagg tctcccagct 6600
ctcccctgca gcagcaacag gtgcttagta tccttcacgc caacccccag ctgttggctg 6660
cattcatcaa gcagcgggct gccaagtatg ccaactctaa tccacaaccc atccctgggc 6720
agcctggcat gccccagggg cagccagggc tacagccacc taccatgcca ggtcagcagg 6780
gggtccactc caatccagcc atgcagaaca tgaatccaat gcaggcgggc gttcagaggg 6840
ctggcctgcc ccagcagcaa ccacagcagc aactccagcc acccatggga gggatgagcc 6900
cccaggctca gcagatgaac atgaaccaca acaccatgcc ttcacaattc cgagacatct 6960
tgagacgaca gcaaatgatg caacagcagc agcaacaggg agcagggcca ggaataggcc 7020
ctggaatggc caaccataac cagttccagc aaccccaagg agttggctac ccaccacagc 7080
agcagcagcg gatgcagcat cacatgcaac agatgcaaca aggaaatatg ggacagatag 7140
gccagcttcc ccaggccttg ggagcagagg caggtgccag tctacaggcc tatcagcagc 7200
gactccttca gcaacagatg gggtcccctg ttcagcccaa ccccatgagc ccccagcagc 7260
atatgctccc aaatcaggcc cagtccccac acctacaagg ccagcagatc cctaattctc 7320
tctccaatca agtgcgctct ccccagcctg tcccttctcc acggccacag tcccagcccc 7380
cccactccag tccttcccca aggatgcagc ctcagccttc tccacaccac gtttccccac 7440
agacaagttc cccacatcct ggactggtag ctgcccaggc caaccccatg gaacaagggc 7500
attttgccag cccggaccag aattcaatgc tttctcagct tgctagcaat ccaggcatgg 7560
caaacctcca tggtgcaagc gccacggacc tgggactcag caccgataac tcagacttga 7620
attcaaacct ctcacagagt acactagaca tacactagag acaccttgta gtattttggg 7680
agcaaaaaaa ttattttctc ttaacaagac tttttgtact gaaaacaatt tttttgaatc 7740
tttcgtagcc taaaagacaa ttttccttgg aacacataag aactgtgcag tagccgtttg 7800
tggtttaaag caaacatgca agatgaacct gagggatgat agaatacaaa gaatatattt 7860
ttgttatggc tggttaccac cagcctttct tcccctttgt gtgtgtggtt caagtgtgca 7920
ctgggaggag gctgaggcct gtgaagccaa acaatatgct cctgccttgc acctccaata 7980
ggttttatta ttttttttaa attaatgaac atatgtaata ttaatagtta ttatttactg 8040
gtgcagatgg ttgacatttt tccctatttt cctcacttta tggaagagtt aaaacatttc 8100
taaaccagag gacaaaaggg gttaatgtta ctttaaaatt acattctata tatatataaa 8160
tatatataaa tatatattaa aataccagtt ttttttctct gggtgcaaag atgttcattc 8220
ttttaaaaaa tgtttaaaaa aaaaaaaaaa ctgcctttct tcccctcaag tcaacttttg 8280
tgctccagaa aattttctat tctgtaagtc tgagcgtaaa acttcaagta ttaaaataat 8340
ttgtacatgt agagagaaaa atgacttttt caaaaatata caggggcagc tgccaaattg 8400
atgtattata tattgtggtt tctgtttctt gaaagaattt ttttcgttat ttttacatct 8460
aacaaagtaa aaaaattaaa aagagggtaa gaaacgattc cggtgggatg attttaacat 8520
gcaaaatgtc cctgggggtt tcttctttgc ttgctttctt cctccttacc ctacccccca 8580
ctcacacaca cacacacaca cacacacaca cacacacaca cacactttct ataaaacttg 8640
aaaatagcaa aaaccctcaa ctgttgtaaa tcatgcaatt aaagttgatt acttataaat 8700
atgaactttg gatcactgta tagactgtta aatttgattt cttattacct attgttaaat 8760
aaactgtgtg agacagaca 8779
<210> 23
<211> 8701
<212> DNA
<213> Homo sapiens
<400> 23
gagaaggagg aggacagcgc cgaggaggaa gaggttgatg gcggcggcgg agctccgaga 60
gacctcggct gggcaggggc cggccgtggc gggccgggga ctgcgcctct agagccgcga 120
gttctcggga attcgccgca gcggacgcgc tcggcgaatt tgtgctcttg tgccctcctc 180
cgggcttggg cccaggcccg gcccctcgca cttgccctta ccttttctat cgagtccgca 240
tccctctcca gccactgcga cccggcgaag agaaaaagga acttccccca ccccctcggg 300
tgccgtcgga gccccccagc ccacccctgg gtgcggcgcg gggaccccgg gccgaagaag 360
agatttcctg aggattctgg ttttcctcgc ttgtatctcc gaaagaatta aaaatggccg 420
agaatgtggt ggaaccgggg ccgccttcag ccaagcggcc taaactctca tctccggccc 480
tctcggcgtc cgccagcgat ggcacagatt ttggctctct atttgacttg gagcacgact 540
taccagatga attaatcaac tctacagaat tgggactaac caatggtggt gatattaatc 600
agcttcagac aagtcttggc atggtacaag atgcagcttc taaacataaa cagctgtcag 660
aattgctgcg atctggtagt tcccctaacc tcaatatggg agttggtggc ccaggtcaag 720
tcatggccag ccaggcccaa cagagcagtc ctggattagg tttgataaat agcatggtca 780
aaagcccaat gacacaggca ggcttgactt ctcccaacat ggggatgggc actagtggac 840
caaatcaggg tcctacgcag tcaacaggta tgatgaacag tccagtaaat cagcctgcca 900
tgggaatgaa cacagggatg aatgcgggca tgaatcctgg aatgttggct gcaggcaatg 960
gacaagggat aatgcctaat caagtcatga acggttcaat tggagcaggc cgagggcgac 1020
agaatatgca gtacccaaac ccaggcatgg gaagtgctgg caacttactg actgagcctc 1080
ttcagcaggg ctctccccag atgggaggac aaacaggatt gagaggcccc cagcctctta 1140
agatgggaat gatgaacaac cccaatcctt atggttcacc atatactcag aatcctggac 1200
agcagattgg agccagtggc cttggtctcc agattcagac aaaaactgta ctatcaaata 1260
acttatctcc atttgctatg gacaaaaagg cagttcctgg tggaggaatg cccaacatgg 1320
gtcaacagcc agccccgcag gtccagcagc caggcctggt gactccagtt gcccaaggga 1380
tgggttctgg agcacataca gctgatccag agaagcgcaa gctcatccag cagcagcttg 1440
ttctcctttt gcatgctcac aagtgccagc gccgggaaca ggccaatggg gaagtgaggc 1500
agtgcaacct tccccactgt cgcacaatga agaatgtcct aaaccacatg acacactgcc 1560
agtcaggcaa gtcttgccaa gtggcacact gtgcatcttc tcgacaaatc atttcacact 1620
ggaagaattg tacaagacat gattgtcctg tgtgtctccc cctcaaaaat gctggtgata 1680
agagaaatca acagccaatt ttgactggag cacccgttgg acttggaaat cctagctctc 1740
taggggtggg tcaacagtct gcccccaacc taagcactgt tagtcagatt gatcccagct 1800
ccatagaaag agcctatgca gctcttggac taccctatca agtaaatcag atgccgacac 1860
aaccccaggt gcaagcaaag aaccagcaga atcagcagcc tgggcagtct ccccaaggca 1920
tgcggcccat gagcaacatg agtgctagtc ctatgggagt aaatggaggt gtaggagttc 1980
aaacgccgag tcttctttct gactcaatgt tgcattcagc cataaattct caaaacccaa 2040
tgatgagtga aaatgccagt gtgccctccc tgggtcctat gccaacagca gctcaaccat 2100
ccactactgg aattcggaaa cagtggcacg aagatattac tcaggatctt cgaaatcatc 2160
ttgttcacaa actcgtccaa gccatatttc ctacgccgga tcctgctgct ttaaaagaca 2220
gacggatgga aaacctagtt gcatatgctc ggaaagttga aggggacatg tatgaatctg 2280
caaacaatcg agcggaatac taccaccttc tagctgagaa aatctataag atccagaaag 2340
aactagaaga aaaacgaagg accagactac agaagcagaa catgctacca aatgctgcag 2400
gcatggttcc agtttccatg aatccagggc ctaacatggg acagccgcaa ccaggaatga 2460
cttctagttt gaatcaattt ggccagatga gcatggccca gccccctatt gtaccccggc 2520
aaacccctcc tcttcagcac catggacagt tggctcaacc tggagctctc aacccgccta 2580
tgggctatgg gcctcgtatg caacagcctt ccaaccaggg ccagttcctt cctcagactc 2640
agttcccatc acagggaatg aatgtaacaa atatcccttt ggctccgtcc agcggtcaag 2700
ctccagtgtc tcaagcacaa atgtctagtt cttcctgccc ggtgaactct cctataatgc 2760
ctccagggtc tcaggggagc cacattcact gtccccagct tcctcaacca gctcttcatc 2820
agaattcacc ctcgcctgta cctagtcgta cccccacccc tcaccatact cccccaagca 2880
taggggctca gcagccacca gcaacaacaa ttccagcccc tgttcctaca cctcctgcca 2940
tgccacctgg gccacagtcc caggctctac atccccctcc aaggcagaca cctacaccac 3000
caacaacaca acttccccaa caagtgcagc cttcacttcc tgctgcacct tctgctgacc 3060
agccccagca gcagcctcgc tcacagcaga gcacagcagc gtctgttcct accccaacag 3120
caccgctgct tcctccgcag cctgcaactc cactttccca gccagctgta agcattgaag 3180
gacaggtatc aaatcctcca tctactagta gcacagaagt gaattctcag gccattgctg 3240
agaagcagcc ttcccaggaa gtgaagatgg aggccaaaat ggaagtggat caaccagaac 3300
cagcagatac tcagccggag gatatttcag agtctaaagt ggaagactgt aaaatggaat 3360
ctaccgaaac agaagagaga agcactgagt taaaaactga aataaaagag gaggaagacc 3420
agccaagtac ttcagctacc cagtcatctc cggctccagg acagtcaaag aaaaagattt 3480
tcaaaccaga agaactacga caggcactga tgccaacttt ggaggcactt taccgtcagg 3540
atccagaatc ccttcccttt cgtcaacctg tggaccctca gcttttagga atccctgatt 3600
actttgatat tgtgaagagc cccatggatc tttctaccat taagaggaag ttagacactg 3660
gacagtatca ggagccctgg cagtatgtcg atgatatttg gcttatgttc aataatgcct 3720
ggttatataa ccggaaaaca tcacgggtat acaaatactg ctccaagctc tctgaggtct 3780
ttgaacaaga aattgaccca gtgatgcaaa gccttggata ctgttgtggc agaaagttgg 3840
agttctctcc acagacactg tgttgctacg gcaaacagtt gtgcacaata cctcgtgatg 3900
ccacttatta cagttaccag aacaggtatc atttctgtga gaagtgtttc aatgagatcc 3960
aaggggagag cgtttctttg ggggatgacc cttcccagcc tcaaactaca ataaataaag 4020
aacaattttc caagagaaaa aatgacacac tggatcctga actgtttgtt gaatgtacag 4080
agtgcggaag aaagatgcat cagatctgtg tccttcacca tgagatcatc tggcctgctg 4140
gattcgtctg tgatggctgt ttaaagaaaa gtgcacgaac taggaaagaa aataagtttt 4200
ctgctaaaag gttgccatct accagacttg gcacctttct agagaatcgt gtgaatgact 4260
ttctgaggcg acagaatcac cctgagtcag gagaggtcac tgttagagta gttcatgctt 4320
ctgacaaaac cgtggaagta aaaccaggca tgaaagcaag gtttgtggac agtggagaga 4380
tggcagaatc ctttccatac cgaaccaaag ccctctttgc ctttgaagaa attgatggtg 4440
ttgacctgtg cttctttggc atgcatgttc aagagtatgg ctctgactgc cctccaccca 4500
accagaggag agtatacata tcttacctcg atagtgttca tttcttccgt cctaaatgct 4560
tgaggactgc agtctatcat gaaatcctaa ttggatattt agaatatgtc aagaaattag 4620
gttacacaac agggcatatt tgggcatgtc caccaagtga gggagatgat tatatcttcc 4680
attgccatcc tcctgaccag aagataccca agcccaagcg actgcaggaa tggtacaaaa 4740
aaatgcttga caaggctgta tcagagcgta ttgtccatga ctacaaggat atttttaaac 4800
aagctactga agatagatta acaagtgcaa aggaattgcc ttatttcgag ggtgatttct 4860
ggcccaatgt tctggaagaa agcattaagg aactggaaca ggaggaagaa gagagaaaac 4920
gagaggaaaa caccagcaat gaaagcacag atgtgaccaa gggagacagc aaaaatgcta 4980
aaaagaagaa taataagaaa accagcaaaa ataagagcag cctgagtagg ggcaacaaga 5040
agaaacccgg gatgcccaat gtatctaacg acctctcaca gaaactatat gccaccatgg 5100
agaagcataa agaggtcttc tttgtgatcc gcctcattgc tggccctgct gccaactccc 5160
tgcctcccat tgttgatcct gatcctctca tcccctgcga tctgatggat ggtcgggatg 5220
cgtttctcac gctggcaagg gacaagcacc tggagttctc ttcactccga agagcccagt 5280
ggtccaccat gtgcatgctg gtggagctgc acacgcagag ccaggaccgc tttgtctaca 5340
cctgcaatga atgcaagcac catgtggaga cacgctggca ctgtactgtc tgtgaggatt 5400
atgacttgtg tatcacctgc tataacacta aaaaccatga ccacaaaatg gagaaactag 5460
gccttggctt agatgatgag agcaacaacc agcaggctgc agccacccag agcccaggcg 5520
attctcgccg cctgagtatc cagcgctgca tccagtctct ggtccatgct tgccagtgtc 5580
ggaatgccaa ttgctcactg ccatcctgcc agaagatgaa gcgggttgtg cagcatacca 5640
agggttgcaa acggaaaacc aatggcgggt gccccatctg caagcagctc attgccctct 5700
gctgctacca tgccaagcac tgccaggaga acaaatgccc ggtgccgttc tgcctaaaca 5760
tcaagcagaa gctccggcag caacagctgc agcaccgact acagcaggcc caaatgcttc 5820
gcaggaggat ggccagcatg cagcggactg gtgtggttgg gcagcaacag ggcctccctt 5880
cccccactcc tgccactcca acgacaccaa ctggccaaca gccaaccacc ccgcagacgc 5940
cccagcccac ttctcagcct cagcctaccc ctcccaatag catgccaccc tacttgccca 6000
ggactcaagc tgctggccct gtgtcccagg gtaaggcagc aggccaggtg acccctccaa 6060
cccctcctca gactgctcag ccaccccttc cagggccccc acctgcagca gtggaaatgg 6120
caatgcagat tcagagagca gcggagacgc agcgccagat ggcccacgtg caaatttttc 6180
aaaggccaat ccaacaccag atgcccccga tgactcccat ggcccccatg ggtatgaacc 6240
cacctcccat gaccagaggt cccagtgggc atttggagcc agggatggga ccgacaggga 6300
tgcagcaaca gccaccctgg agccaaggag gattgcctca gccccagcaa ctacagtctg 6360
ggatgccaag gccagccatg atgtcagtgg cccagcatgg tcaacctttg aacatggctc 6420
cacaaccagg attgggccag gtaggtatca gcccactcaa accaggcact gtgtctcaac 6480
aagccttaca aaaccttttg cggactctca ggtctcccag ctctcccctg cagcagcaac 6540
aggtgcttag tatccttcac gccaaccccc agctgttggc tgcattcatc aagcagcggg 6600
ctgccaagta tgccaactct aatccacaac ccatccctgg gcagcctggc atgccccagg 6660
ggcagccagg gctacagcca cctaccatgc caggtcagca gggggtccac tccaatccag 6720
ccatgcagaa catgaatcca atgcaggcgg gcgttcagag ggctggcctg ccccagcagc 6780
aaccacagca gcaactccag ccacccatgg gagggatgag cccccaggct cagcagatga 6840
acatgaacca caacaccatg ccttcacaat tccgagacat cttgagacga cagcaaatga 6900
tgcaacagca gcagcaacag ggagcagggc caggaatagg ccctggaatg gccaaccata 6960
accagttcca gcaaccccaa ggagttggct acccaccaca gcagcagcag cggatgcagc 7020
atcacatgca acagatgcaa caaggaaata tgggacagat aggccagctt ccccaggcct 7080
tgggagcaga ggcaggtgcc agtctacagg cctatcagca gcgactcctt cagcaacaga 7140
tggggtcccc tgttcagccc aaccccatga gcccccagca gcatatgctc ccaaatcagg 7200
cccagtcccc acacctacaa ggccagcaga tccctaattc tctctccaat caagtgcgct 7260
ctccccagcc tgtcccttct ccacggccac agtcccagcc cccccactcc agtccttccc 7320
caaggatgca gcctcagcct tctccacacc acgtttcccc acagacaagt tccccacatc 7380
ctggactggt agctgcccag gccaacccca tggaacaagg gcattttgcc agcccggacc 7440
agaattcaat gctttctcag cttgctagca atccaggcat ggcaaacctc catggtgcaa 7500
gcgccacgga cctgggactc agcaccgata actcagactt gaattcaaac ctctcacaga 7560
gtacactaga catacactag agacaccttg tagtattttg ggagcaaaaa aattattttc 7620
tcttaacaag actttttgta ctgaaaacaa tttttttgaa tctttcgtag cctaaaagac 7680
aattttcctt ggaacacata agaactgtgc agtagccgtt tgtggtttaa agcaaacatg 7740
caagatgaac ctgagggatg atagaataca aagaatatat ttttgttatg gctggttacc 7800
accagccttt cttccccttt gtgtgtgtgg ttcaagtgtg cactgggagg aggctgaggc 7860
ctgtgaagcc aaacaatatg ctcctgcctt gcacctccaa taggttttat tatttttttt 7920
aaattaatga acatatgtaa tattaatagt tattatttac tggtgcagat ggttgacatt 7980
tttccctatt ttcctcactt tatggaagag ttaaaacatt tctaaaccag aggacaaaag 8040
gggttaatgt tactttaaaa ttacattcta tatatatata aatatatata aatatatatt 8100
aaaataccag ttttttttct ctgggtgcaa agatgttcat tcttttaaaa aatgtttaaa 8160
aaaaaaaaaa aactgccttt cttcccctca agtcaacttt tgtgctccag aaaattttct 8220
attctgtaag tctgagcgta aaacttcaag tattaaaata atttgtacat gtagagagaa 8280
aaatgacttt ttcaaaaata tacaggggca gctgccaaat tgatgtatta tatattgtgg 8340
tttctgtttc ttgaaagaat ttttttcgtt atttttacat ctaacaaagt aaaaaaatta 8400
aaaagagggt aagaaacgat tccggtggga tgattttaac atgcaaaatg tccctggggg 8460
tttcttcttt gcttgctttc ttcctcctta ccctaccccc cactcacaca cacacacaca 8520
cacacacaca cacacacaca cacacacttt ctataaaact tgaaaatagc aaaaaccctc 8580
aactgttgta aatcatgcaa ttaaagttga ttacttataa atatgaactt tggatcactg 8640
tatagactgt taaatttgat ttcttattac ctattgttaa ataaactgtg tgagacagac 8700
a 8701
<210> 24
<211> 5867
<212> DNA
<213> Homo sapiens
<400> 24
actgccctcg cttcctgtgc ctcttcaggt catcgcttgc tctcgttccc aggctttggc 60
ttctagtgga cgagaatcac cgagtctgcg gggctggatg ctgaccgccc ggaccagcac 120
ctaggcgggc gggagctgtg cggcccaggg ttcgcgcggg ccgggtagag gctcgagctg 180
ggacccccga gcgtgaaccc cggagccggc ggcgctgggg ccagaggggc cgggagcccc 240
agggaggcgg atctgggccc cgagaaggac acccgcctgg atttgccccg taggcccggc 300
ccgggcccct cgggagcaga acagccttgg tgaggtggac aggaggggac ctcgcgagca 360
gacgcgcgcg ccagcgacag cagcccgccc cggcctctcg ggagccgtgg ggcagaggct 420
gcggagcccc aggagggggc cagtgtcatt caaagatgtg gctgtggatt tcacccagga 480
ggagtggcgg caactggacc ctgatgagaa gataacatac ggggatgtga tgttggagaa 540
ctacagccat ctagtttcct tggcttatga ggtggcaaca tcttgtactt cggagattct 600
gaagccgagc aacttgccca agtccttctt cttttcccat taacaagata tgatatcacc 660
aagccaaacg tcatcattaa gttggagcag ggagaggagc tgtggataac gggaggtgaa 720
tttccatgtc aacatagtcc tgggatcgtg ggactttacc agatcggttt gtaataacac 780
ctcgaagacg ctatccgatc catcagaccc agtattcctg tccgggggta cttcccacag 840
tgtgctggaa tggttatcac aagaaggctg tgctgtcccc tcgcaactcc aggatggtgt 900
gtagcccagt gactgtgagg atcgcccctc ctgacagaag attttcacgt tctgcgatac 960
cagagcagat aatcagctca acactgtcgt caccatcaag taatgcccca gacccatgtg 1020
caaaggagac tgtactgagt gccctcaaag agaagaagaa gaaaaggaca gtggaggaag 1080
aagaccaaat attccttgat ggccaggaaa ataaaagaag gcgccatgat agcagtggca 1140
gtggacattc agcatttgag cccctggtgg ccagtggagt ccccgcttct tttgtgccta 1200
agcctgggtc tctgaagaga ggcctcaatt ctcagagctc agatgaccac ttgaataaga 1260
gatcccgaag ctcttccatg agctccttga caggcgctta cacaagtggc atccctagct 1320
ccagccgcaa tgccattacc agttcctaca gctccactcg aggcatctca cagctgtgga 1380
agagaaatgg ccccagttca tcacccttct ctagcccagc ctcatcccgc tcccagacac 1440
cggagaggcc agcaaagaaa ataagagaag aagagctgtg tcatcattcc agttcttcaa 1500
ctccattggc agcagacaag gagtcccagg gagaaaaggc tgcagataca accccaagga 1560
agaaacaaaa ctcgaattct cagtctacac ctggcagctc tgggcagcgt aagcggaaag 1620
ttcagctgct gccttctcgg cgaggggaac agctgacctt gcctccacct ccccagcttg 1680
gctattcgat cactgccgag gacctagact tagagaagaa ggcttcatta cagtggttca 1740
accaggcctt ggaggacaag agtgatgctg cctcgaactc tgtcactgag accccaccta 1800
ccactcagcc ttcatttacc tttaccctgc ctgctgctgc aactgcctcc ccacccacct 1860
ccctcctggc cccaagcacc aacccactgt tagagagctt gaagaagatg cagactcccc 1920
cgagcctgcc accctgccca gaatctgctg gagcagcaac cactgaggcc ctctcacctc 1980
caaagacacc cagcctccta cccccgctgg gtttatcaca gtcagggccg ccagggctgc 2040
tccccagccc ctcctttgac tccaaacccc cgaccacttt gctggggctg atccctgctc 2100
catccatggt accagccact gacaccaagg cacctccaac ccttcaggca gagacggcta 2160
ccaaacccca agccacatct gccccgtccc ccgcccccaa gcaaagcttc ctgtttggaa 2220
cacagaacac ctcaccttcc agccctgccg cccctgctgc atcttcagca tctcccatgt 2280
tcaagcccat tttcacggct ccacccaaga gtgagaagga aggcctcaca ccgcctggcc 2340
cttcagtctc agccacagcg ccctccagct cctccctccc cacgaccacc agcaccacag 2400
ccccgacctt ccagcctgtc tttagcagca tggggccacc tgcatctgtg cccttgcctg 2460
ctcccttctt caagcagaca actactcccg ccactgctcc caccacaact gccccgctct 2520
tcactggcct ggccagcgcc acctctgctg tggctcccat cacctctgcc agtccatcca 2580
cagactctgc ttcgaagcct gcgtttggct ttggcataaa cagtgtgagc agcagcagtg 2640
tgagtaccac gaccagcacc gccactgccg cctcacagcc tttcctcttc ggggcgcccc 2700
aggcctctgc tgccagcttc accccggcca tgggctccat attccagttt ggcaaacctc 2760
ctgccttgcc cacaaccacc acagtcacca ccttcagcca gtccctgccc actgccgtgc 2820
caacggccac cagcagcagc gctgccgact ttagtggttt tggcagcacc ctcgccacct 2880
ccgccccggc caccagcagc cagcccactc tgacgttcag taacacgagc acccccacgt 2940
tcaacattcc ctttggctca agcgccaagt ccccgctccc atcatatccg ggagccaacc 3000
cccagcccgc atttggggcc gctgaggggc agccaccggg ggccgccaag ccagccctta 3060
cccccagctt tggcagctct ttcacttttg gaaactctgc agccccggcc ccggctactg 3120
cacccacacc tgcacctgcg tccacgatca agatcgtgcc tgcgcacgtg cctacgccca 3180
tccagcctac ctttggcggt gccacgcact cggcgtttgg attgaaagcc acggcttccg 3240
ccttcggcgc tcccgccagc tcacagcccg cctttggcgg ctccactgct gtcttctcct 3300
tcggtgcagc caccagctcc ggctttggag ccaccaccca gaccgccagc agcgggagca 3360
gcagctcggt gtttggcagc acaacaccat cacccttcac gtttgggggt tcggcagccc 3420
ccgctggcag tgggagcttt gggatcaacg tggccacccc aggctccagc gccaccaccg 3480
gagctttcag ctttggagca ggacagagtg ggagcacagc cacctccacc cccttcacag 3540
ggggcttagg tcagaacgcc ctgggcacca ccggccagag cacaccgttt gccttcaacg 3600
tgggcagcac aactgagagc aaacctgtgt ttggaggcac cgccaccccc acctttggtc 3660
agaacacccc tgcgcctgga gtgggcacat cgggcagcag cctctccttt ggggcatctt 3720
cagcacccgc ccaaggcttt gttggtgttg gaccgttcgg atcggcggcc ccttcatttt 3780
ccattggtgc gggatccaag accccagggg ctcgacagcg actgcaggcc cgaaggcagc 3840
acacccgcaa aaagtagcct ttgtcccctg tccctgttcc ccccacccct tccctaaatc 3900
tggaccttgg cacgtgctag aaagagcctt ggacccttcc agctgcgtaa agcaaaccta 3960
ccccggatct ctggcttcag ccgccagggg gcagtggcag ccctggggcc ctttcccttc 4020
tggaggaagc acaagcctca gggaagggga agcaggatgc ggagggccaa agcccgggac 4080
ctctacttga acagttccac tggggaggct ggagaactaa ggacctgtac atagtgtccg 4140
ctgccctgac tcccgcttag cgcaccctta ggcaggcgcc ccttccacct ttccccgaga 4200
gccgtcgtcg ctggaggggg cagggtccag cccgcctgga tcggtggtgt gcacctgatg 4260
ggatttggga aatgggttat ccctaaagct ttatcttgct tggcttagct gtgagaagtg 4320
gttctcttcc tctggtccct tctggggact ctgtttcccc atttcttgct gctgtgtccc 4380
tcaccggttc cttgcaggat tccctccttt ttaaatgccc ttgaatctag ctttgccttg 4440
gagaccccag tgggtgctgc tcctgccgtt ttcttcctgc caagcctgaa tcaatgtttc 4500
atctccaacc ctctgccagt ttggcccctc agagcttggt ggctcaagac tgttagcctg 4560
gcagagccag gggtgaaggg agaagctctt ggagcaggca ggatgcccac tgctgcttca 4620
gctgcctcct cgcccagcta ccctttggcc ccattgggcc ctcgtctgcc tctccaggat 4680
tgtatgtttc aagccttgtc ctgtgttcct ttgtctgacg ctctgtgtat tgctctttga 4740
atcgagtttg gaggaagagt tgagttgtat gagtggcggc atgttggtag tgccggactt 4800
cctgtttcaa gttttctggg gcctcgctaa ttgaatgtgg aaagtagcac cacttgacgg 4860
ctacaagtgc cgactcctga attttcccat ggtgttctga cttcaagggc tggcagccag 4920
ggagaatggg cccaggggaa gcaaagacct cttccctctg cggtttctgt cccacttaac 4980
tgacctcact ggaggctacg tcacccaaag tagatgttag aaaacctaaa ttaatgaacc 5040
atatttttaa aatcctattt ttcccaaaca gggccctctg cagcccatcc tttccttccg 5100
tccttctgaa accacatacc ccaggcccaa gcgccttgct gtcacgccca acctctttgg 5160
gagaagtatg aatgcgtgtg tctaaattaa aagaaaaaaa tatttaaacg ttttttaaca 5220
aaaatttatt tttgtattta agctaaattg ccttttaaat tccttcaagc ttggttcatt 5280
gaggtggtta agtataaatg ctattaacta ggaattagct gtatagttaa gttatgcctg 5340
tgcaaagaag aggctcaaat gctgtccccg gcagctttcc tgggggacta gagctccttc 5400
tggccatgtt atatgaaatg taattcttat tttataaata atgtgatgta gatgtaaccg 5460
gtgccccctc cccgttgtga ctgagggcga gtgttatacc tggctgcgtg tgcagctgag 5520
gagggagtga acctcaagcc taaatacctg ttaggattgg agggtctggg tgggcctggg 5580
cctagcaatc aagcttctac ctgtacctta tgtaaggtag accctcctag tgtcagtacc 5640
tgagcttgtt tacctcagtt ccgcaggcag gacagccggt ccgggaaccc tgagtgagag 5700
tgagtgtgga tgtgtacagt acacacactg gacggcagcg ggaggctggg actttccatt 5760
acaaatagag acttcattcc tgttgagtct agttggaatt tttagtatga atgtgagatt 5820
tttctcctgc ttgtgacatt aagaataaaa aactgtgatc tatcgta 5867
<210> 25
<211> 2242
<212> DNA
<213> Homo sapiens
<400> 25
ggagccgggg gacggcgaca gcgggtcggc gggccgcagg agggggtcat gggtaaagac 60
tactaccaga cgttgggcct ggcccgcggc gcgtcggacg aggagatcaa gcgggcctac 120
cgccgccagg cgctgcgcta ccacccggac aagaacaagg agcccggcgc cgaggagaag 180
ttcaaggaga tcgctgaggc ctacgacgtg ctcagcgacc cgcgcaagcg cgagatcttc 240
gaccgctacg gggaggaagg cctaaagggg agtggcccca gtggcggtag cggcggtggt 300
gccaatggta cctctttcag ctacacattc catggagacc ctcatgccat gtttgctgag 360
ttcttcggtg gcagaaatcc ctttgacacc ttttttgggc agcggaacgg ggaggaaggc 420
atggacattg atgacccatt ctctggcttc cctatgggca tgggtggctt caccaacgtg 480
aactttggcc gctcccgctc tgcccaagag cccgcccgaa agaagcaaga tcccccagtc 540
acccacgacc ttcgagtctc ccttgaagag atctacagcg gctgtaccaa gaagatgaaa 600
atctcccaca agcggctaaa ccccgacgga aagagcattc gaaacgaaga caaaatattg 660
accatcgaag tgaagaaggg gtggaaagaa ggaaccaaaa tcactttccc caaggaagga 720
gaccagacct ccaacaacat tccagctgat atcgtctttg ttttaaagga caagccccac 780
aatatcttta agagagatgg ctctgatgtc atttatcctg ccaggatcag cctccgggag 840
gctctgtgtg gctgcacagt gaacgtcccc actctggacg gcaggacgat acccgtcgta 900
ttcaaagatg ttatcaggcc tggcatgcgg cgaaaagttc ctggagaagg cctccccctc 960
cccaaaacac ccgagaaacg tggggacctc attattgagt ttgaagtgat cttccccgaa 1020
aggattcccc agacatcaag aaccgtactt gagcaggttc ttccaatata gctatctgag 1080
ctccccaagg actgaccagg gacctttcca gagctcaagg atttctggac ctttctacca 1140
gttgtggacc atgagagggt gggagggccc agggagggct ttcgtactgc tgaatgtttt 1200
ccagagcata tattacaatc tttcaaagtc gcacactaga cttcagtggt ttttcgagct 1260
atagggcatc aggtggtggg aacagcagga aaaggcattc cagtctgccc cactgggtct 1320
ggcagccctc ccgggatggg cccacatcca cctccagtcc ctggccaggg gtgagaggca 1380
gaccagcaga tggacttgat ccctctgtgt ctttttgctt ctggctggta gataatgtca 1440
acctgcagtc ttgattccca gaccctgtac actcctcctt ttctgttgtg tgatcagttt 1500
gtgctttatt ctgtatttgt ctcccatgtc ttgctcttct cctggagaat tctgtcttct 1560
ctttggccat ctcaaattga gaacctaaac tattcctgca gaactgcctg gttggcgtcc 1620
acaagcaata cctctcgttc cagcaggacc aagggagcca gcctccagtg agtgactcca 1680
gcaagtgcag ccacctctcc cttgatggtc tgggagcctg gcctcagcaa ggggccttcc 1740
tgacctctgg ctccagtgaa gctgaatgtc ctcactttgt gggtcacact ctttacattt 1800
ctgtaaggca atcttggcac acgtggggct taccagtggc ccaggtaatt ttttgtttca 1860
tggactatgg actctttcaa agggatctga tccttttgaa ttttgcacag ccctagatac 1920
aatccctttt gataaaaggg tctttgcttc tgattacagg agcactgtgg aacgtctgta 1980
aatatgtttt tataattcca tgtatagttg gtgtacactc aaaacctgtc cccggcagcc 2040
agtgctctct gtatagggcc ataatggaat tctgaagaaa tcttggggag ggaaggggag 2100
ttggaacaaa tgtctgttcc ctggaggcca gtccagtgct cagaccttta gactcattgt 2160
aagttgccac tgccaacatg agaccaaagt gtgtgactag tcaatgaagt gcgacagcat 2220
taaagactga tgctaaacct ca 2242
<210> 26
<211> 2270
<212> DNA
<213> Homo sapiens
<400> 26
gtgcatgggg gtgggggagc cgggggtgac gacggggacg gcgcggcgga gcccgctgcg 60
gacccgggct cacctgggct cggccgccgg ggtccgcggg gcggcgcctc cggctcagct 120
gcggggcgag gggttgtgaa tgcaggagcc gaccccgttc gtgggcttgg gggctgggtt 180
gggataattc ccgggaagtg atgacctggc cccggcaggg cacgcaggag gcagcggccg 240
cccaggtccg gagagcgggg ccgcctcgga gggcctaaag gggagtggcc ccagtggcgg 300
tagcggcggt ggtgccaatg gtacctcttt cagctacaca ttccatggag accctcatgc 360
catgtttgct gagttcttcg gtggcagaaa tccctttgac accttttttg ggcagcggaa 420
cggggaggaa ggcatggaca ttgatgaccc attctctggc ttccctatgg gcatgggtgg 480
cttcaccaac gtgaactttg gccgctcccg ctctgcccaa gagcccgccc gaaagaagca 540
agatccccca gtcacccacg accttcgagt ctcccttgaa gagatctaca gcggctgtac 600
caagaagatg aaaatctccc acaagcggct aaaccccgac ggaaagagca ttcgaaacga 660
agacaaaata ttgaccatcg aagtgaagaa ggggtggaaa gaaggaacca aaatcacttt 720
ccccaaggaa ggagaccaga cctccaacaa cattccagct gatatcgtct ttgttttaaa 780
ggacaagccc cacaatatct ttaagagaga tggctctgat gtcatttatc ctgccaggat 840
cagcctccgg gaggctctgt gtggctgcac agtgaacgtc cccactctgg acggcaggac 900
gatacccgtc gtattcaaag atgttatcag gcctggcatg cggcgaaaag ttcctggaga 960
aggcctcccc ctccccaaaa cacccgagaa acgtggggac ctcattattg agtttgaagt 1020
gatcttcccc gaaaggattc cccagacatc aagaaccgta cttgagcagg ttcttccaat 1080
atagctatct gagctcccca aggactgacc agggaccttt ccagagctca aggatttctg 1140
gacctttcta ccagttgtgg accatgagag ggtgggaggg cccagggagg gctttcgtac 1200
tgctgaatgt tttccagagc atatattaca atctttcaaa gtcgcacact agacttcagt 1260
ggtttttcga gctatagggc atcaggtggt gggaacagca ggaaaaggca ttccagtctg 1320
ccccactggg tctggcagcc ctcccgggat gggcccacat ccacctccag tccctggcca 1380
ggggtgagag gcagaccagc agatggactt gatccctctg tgtctttttg cttctggctg 1440
gtagataatg tcaacctgca gtcttgattc ccagaccctg tacactcctc cttttctgtt 1500
gtgtgatcag tttgtgcttt attctgtatt tgtctcccat gtcttgctct tctcctggag 1560
aattctgtct tctctttggc catctcaaat tgagaaccta aactattcct gcagaactgc 1620
ctggttggcg tccacaagca atacctctcg ttccagcagg accaagggag ccagcctcca 1680
gtgagtgact ccagcaagtg cagccacctc tcccttgatg gtctgggagc ctggcctcag 1740
caaggggcct tcctgacctc tggctccagt gaagctgaat gtcctcactt tgtgggtcac 1800
actctttaca tttctgtaag gcaatcttgg cacacgtggg gcttaccagt ggcccaggta 1860
attttttgtt tcatggacta tggactcttt caaagggatc tgatcctttt gaattttgca 1920
cagccctaga tacaatccct tttgataaaa gggtctttgc ttctgattac aggagcactg 1980
tggaacgtct gtaaatatgt ttttataatt ccatgtatag ttggtgtaca ctcaaaacct 2040
gtccccggca gccagtgctc tctgtatagg gccataatgg aattctgaag aaatcttggg 2100
gagggaaggg gagttggaac aaatgtctgt tccctggagg ccagtccagt gctcagacct 2160
ttagactcat tgtaagttgc cactgccaac atgagaccaa agtgtgtgac tagtcaatga 2220
agtgcgacag cattaaagac tgatgctaaa cctcagggga aaaaaaaaaa 2270
<210> 27
<211> 7470
<212> DNA
<213> Homo sapiens
<400> 27
agatattaat cacggagttc cagggagaag gaacttgtga aatgggggag ccggctgggg 60
ttgccggcac catggagtca ccttttagcc cgggactctt tcacaggctg gatgaagatt 120
gggattctgc tctctttgct gaactcggtt atttcacaga cactgatgag ctgcaattgg 180
aagcagcaaa tgagacgtat gaaaacaatt ttgataatct tgattttgat ttggatttga 240
tgccttggga gtcagacatt tgggacatca acaaccaaat ctgtacagtt aaagatatta 300
aggcagaacc tcagccactt tctccagcct cctcaagtta ttcagtctcg tctcctcggt 360
cagtggactc ttattcttca actcagcatg ttcctgagga gttggatttg tcttctagtt 420
ctcagatgtc tcccctttcc ttatatggtg aaaactctaa tagtctctct tcagcggagc 480
cactgaagga agataagcct gtcactggtc ctaggaacaa gactgaaaat ggactgactc 540
caaagaaaaa aattcaggtg aattcaaaac cttcaattca gcccaagcct ttattgcttc 600
cagcagcacc caagactcaa acaaactcca gtgttccagc aaaaaccatc attattcaga 660
cagtaccaac gcttatgcca ttggcaaagc agcaaccaat tatcagttta caacctgcac 720
ccactaaagg ccagacggtt ttgctgtctc agcctactgt ggtacaactt caagcacctg 780
gagttctgcc ctctgctcag ccagtccttg ctgttgctgg gggagtcaca cagctcccta 840
atcacgtggt gaatgtggta ccagcccctt cagcgaatag cccagtgaat ggaaaacttt 900
ccgtgactaa acctgtccta caaagtacca tgagaaatgt cggttcagat attgctgtgc 960
taaggagaca gcaacgtatg ataaaaaatc gagaatccgc ttgtcagtct cgcaagaaga 1020
agaaagaata tatgctaggg ttagaggcga gattaaaggc tgccctctca gaaaacgagc 1080
aactgaagaa agaaaatgga acactgaagc ggcagctgga tgaagttgtg tcagagaacc 1140
agaggcttaa agtccctagt ccaaagcgaa gagttgtctg tgtgatgata gtattggcat 1200
ttataatact gaactatgga cctatgagca tgttggaaca ggattccagg agaatgaacc 1260
ctagtgtgag ccctgcaaat caaaggaggc accttctagg attttctgct aaagaggcac 1320
aggacacatc agatggtatt atccagaaaa acagctacag atatgatcat tctgtttcaa 1380
atgacaaagc cctgatggtg ctaactgaag aaccattgct ttacattcct ccacctcctt 1440
gtcagcccct aattaacaca acagagtctc tcaggttaaa tcatgaactt cgaggatggg 1500
ttcatagaca tgaagtagaa aggaccaagt caagaagaat gacaaataat caacagaaaa 1560
cccgtattct tcagggtgct ctggaacagg gctcaaattc tcagctgatg gctgttcaat 1620
acacagaaac cactagtagt atcagcagga actcagggag tgagctacaa gtgtattatg 1680
cttcacccag aagttatcaa gacttttttg aagccatccg cagaagggga gacacatttt 1740
atgttgtgtc atttcgaagg gatcacctgc tgttaccagc taccacccat aacaagacca 1800
caagaccaaa aatgtcaatt gtgttaccag caataaacat aaatgagaat gtgatcaatg 1860
ggcaggacta cgaagtgatg atgcagattg actgtcaggt gatggacacc aggatcctcc 1920
atatcaaaag ttcgtcagtt cctccttacc tccgagatca gcagaggaat caaaccaaca 1980
ccttctttgg ctcccctccc gcagccacag aggcaaccca cgttgtcagc accatccctg 2040
agtcattaca atagcaccct gcagctatgc tggaaaactg agcgtgggac cctgccagac 2100
tgaagagcag gtgagcaaaa tgctgctttc tgccttggtg gcaggcagag aactgtctcg 2160
tactagaatt caaggaggaa agaagaagaa ataaaagaag ctgctccatt tttcatcatc 2220
tacccatcta tttggaaagc actggaattc agatgcaaga gaacaatgtt tcttcagtgg 2280
caaatgtagc cctgcatcct ccagtgttac ctggtgtaga tttttttttc tgtacctttc 2340
taaacctctc ttccctctgt gatggttttg tgtttaaaca gtcatcttct tttaaataat 2400
atccacctct cctttttgcc atttcactta ttgattcata aagtgaattt tatttaaagc 2460
tatgccacac atgcatgttc aaatggtttc cactgattcg atttttcatt catttaatgc 2520
aaacccattc tggatattgt gcttatttga gaaaacacat ttcaaaacca gaaaagccaa 2580
aaacactcca aaaacaagca aaacaatttg gagctttaga taaaaggaaa aactcccagt 2640
tggtaaagtt tatctttact taggatttgt ggctcacacc taaacaaagg gggtcaggga 2700
gtgggtacaa atttgagaaa atagaagggt aagggaaggg ccagtggtgg ggtttggaga 2760
gaggagatag ctccattaat acacatgttt aaaagatgga aagttcacgc ctgtaatccc 2820
agcactttgg gaggccgagg cgggtggatc acgaggtcag gagatcaaga ccatcccggc 2880
taaaacggtg aaaccccgtc tctactaaaa atacaaaaaa ttagccgggc gtagtgacgg 2940
gcgcctgtag tcccagctac ttgggaggct gaggcaggag aatggcgtga acccgggagg 3000
cggagcttgc agtgagccga gatcccgcca ctgcactcca gcctgggcga cagagcgaga 3060
ctccgtctca aaaaaaaaaa aaaaaaaaaa aaaagatgga aagttcgatg tgactgcagt 3120
atgagattaa agccacaact attgtttatt ttggggactc taggccacca agtattagca 3180
cacatactta tgttttctct actaatctgg tccaggtcct catggaccac aggacaaagc 3240
tttcattttc attcattctt ctattgaaat tataccaaat tcagctgagg aatatggaag 3300
taactttaga cttaaacaag acaaaagttt tttcactgaa gaattgacaa gtatttgctc 3360
cttaaaacaa cgcagattag tgaacgtgga ttcctgctga gggagtgcat cccataatat 3420
ggcaataatt ttcagtttct ccaacgaaaa gatagtgaag gaattaaatc ttttgtcctc 3480
ccatggttaa aaaaaaaaaa aaagctgtgt tcatttttac tgtactatgc ctcttttttc 3540
accatagtag acaattatgt ttcatttgat gaattcatag aactggatct catacagcga 3600
tgtcctctct aatgttctac ctttcagttt ctaaagtgag tcttcctccc tctcctacaa 3660
aacttttcaa ttttttgatg taactcatct acaaatactg tttcttaccc cagttgactt 3720
gcctttgtca gatttcttct tgttccacac tatagcaatc aatttctctt cttccttaca 3780
agaaagggaa cgagaaattg tagcaacctc tcaaggatta tatgcagcta gttagttttc 3840
tgcctgtgaa attaggtctg gctcctaaat aattttaaag aaccatcagc acttctaact 3900
ctctggacag gtgcctcttt gtccaagcta gttaaatgct ttccaaggaa atcagttcaa 3960
cttttgtgag cggggaaaag cagggcttta ttgttgtgtt acctgggagt ctggagtttg 4020
aaaagtgcta attaaccttc ctctttttcc acattacaaa cctttttaag cagcgcagca 4080
ctccccttag atttggctat cctgggtgat tttcagacaa gaaccatttt ctctggggac 4140
cattcttctg ctgggtgcca aggaatataa ggcaaatgcc cagaagacct tcaggtgact 4200
gggcagtctt atcatgggat atttcttctg gccctgcccc ttcccattct gtaatgtgaa 4260
ttagccacac cagaggctgt gaccatggct agtagacagt ggcaacatag tcatccccaa 4320
gatgctaatc ttctgctgga actgtcatac gttatcatgg tcaatgtaaa cctggtttgt 4380
gtggggtgat tataaataga gtttccctcc tctctgtgac agaatcacag gagaaggacc 4440
catctcgtgg ccttcttgtt cttagcgctt cacttttact tcatccctcg attcccagct 4500
ttttctatca tcattttgcc aactcctcag atgcaagact ttggttatgt catactcacc 4560
aacgttagtc cctctcttcc aggtgaaaag gtgggtagcg gttgggaggg agtctccact 4620
gaagagcagg aaggtggtag cagggccggc agctctgcca cagagctagg ggtgcctgta 4680
aggtgccgcc tagagcagcc tgggagcttt gccttctttt gtctctcact agcccttcta 4740
ctctttgtca ttgcctgttc ttgagtggat ctttgaaatg aggggacagg attctcctaa 4800
gggtagagtt tcaggaaatg agtgaaaggc aattgacaaa tgcaaagaag tagtcacttt 4860
ttaaattgct ggcaaagcta taattaatcc ctaggcacaa ttgtagtttt tattttaatg 4920
tttgtatgca caaggccctt taggaaatga gaagttgcca tgccagatta attttttttt 4980
ttttttttgg tgggattgcc ttttgggggt tgcagccaga aattgtgggt aatgtgtgta 5040
tttttttatt tattaaattt taaacaggat tgtgcaagct tatgagacaa ttagataaac 5100
tcatggagga ggcaggtcct cctgttatta gatgattttg tgctcttggg gctgacaata 5160
atacactctt gggaagtgat ggtagagact gatgggaata gtctttctgc ctggttgcaa 5220
gtcccaaatt tttaagggtt aatggaagta agtggatgtt tcctcatgtt aactactgaa 5280
tcagatgtta ggagcttgtc cctttggggt tgacttatgc ccagcagtac agggacacag 5340
cttcattaga gtgttagtgt aaactaactc caaagttagg agttaatgtg aaaggatcat 5400
ccttgaaaca aatctgctgt ttgccatgct tgtagtacag aaacttcaca tggagttttg 5460
ggtgggattt gtgttttcac aagtaaaaaa tccctcacga ttataaaact cagagcatca 5520
tctaattttt ttttttaatg actacaagtt ccagcacaaa actggcattt ctttgccatt 5580
tcttgccagt aagaagttga cacggaggta tttgaaagca atgttatgtg agtcattctt 5640
aagtgttcca agtaagttta gaaacagaaa aggaacttgg gattcaaatt gatttttcaa 5700
atcattttta aagagacatc atcctgacta aatcttagcc tgaaccttcc tcccctgtgt 5760
gtattccccg gtagtcaccg cagcgagatg ctggtgagac tgccgtggtg gcatttagca 5820
tcgttaaaac tggaaaactc tcaagctctt tgccactttc ctactatttt ttgattcttg 5880
ccattttacc aagcttaggt tgtgaaactt gacagaaatg tattacagga aaaacttata 5940
attgtatttg actttctaac acattgcaaa gtttcaaagt gactttcact ttcaacaaca 6000
tattagaagt aaccactttt gctttcacag cctgaagagt tagagcctga tctgatgccc 6060
cctttcactc tgaagtcatg ggaaattttc cagccatgaa agccctcttt ccactgcata 6120
ctgatgggct gactcagctt ccttcagccg actgagatct tttcatacta ttggctattt 6180
cataccaatt aacctcttaa ataagattgt gaattgccaa aattgataga cacttattac 6240
cacctgtgga ctccatattc cttaccacaa atgttatttt catcagtcct gagtcatttt 6300
aacttacaga aattaggatt gttgctgcta atatgaatac caattataac ttttagaaac 6360
aagaataaag cctaaaagag aatgaaatat aagaaatgtt cgttcccacc cctaataaca 6420
tttggaagtg aatattccca ttttcttcca cccacaggga ttgggattga tttttaattt 6480
cctaggaaac aatactagac tacccaaaaa gatgttgcca gaatccaaaa ggaactatgc 6540
tcgtaaaaga aatgcagttt tctcctacct aaaaaaaaga aagtaaagtg tgttctgttc 6600
ttatcttttt aatgactaag ctttaaacag tttattttgg gtaagactag aactttcggc 6660
catttgttct aatatgtgtg ttattagatg caatagaatt tatgaaaaga agaatgacaa 6720
aggtatctga ttagaaaatt tgatcttacg catgaatcca tgtcatggcc agccactgtc 6780
acatagtggg tgccattctc aacatattgg tttgctaact ttaagcatta gggatttagc 6840
acactaaaat acttttaatt atattaggtt tggtaactaa ggagtaaata aatcataatt 6900
tatcatttgc caaggccaac aaacaacact attgtgctgt ttgctctcaa tgaagttgaa 6960
taaaccagga ggcttggcat atccccttta tgttaatccc agctagagat tagtaggttg 7020
actttcacag caattgtata ttgatccatt ttaactcatc cttgccataa tttccaggcc 7080
agtcaccagg acagaggaga tgatggggaa acagagcttt agatgaaaac tactatgcac 7140
tactagcctt agaggcactg gtttcctgtt accactttgg caagtatgga tggtctaagt 7200
ccagtagggc ttcatccatg gagccattag aactgagggg ggagtgttag agatgccatt 7260
tcaccaggat ctttttgctc aggttgtacc catgccaatt gaagaacgtg ttaaagatga 7320
ggaggagaga tgtaccattc tctcccttaa taatgatgtt ggtttgcaaa acctaaagaa 7380
ataataacaa cagactattt catactttca agcaagtctt tatactacct gttatttctc 7440
taaaattcaa ataaagaatt tttaaactta 7470
<210> 28
<211> 2041
<212> DNA
<213> Homo sapiens
<400> 28
agccatttct actttgcccg cccacagatg tagttttctc tgcgcgtgtg cgttttccct 60
cctccccgcc ctcagggtcc acggccacca tggcgtatta ggggcagcag tgcctgcggc 120
agcattggcc tttgcagcgg cggcagcagc accaggctct gcagcggcaa cccccagcgg 180
cttaagccat ggcgtgagta ccggggcggg tcgtccagct gtgctcctgg ggccggcgcg 240
ggttttggat tggtggggtg cggcctgggg ccagggcggt gccgccaagg gggaagcgat 300
ttaacgagcg cccgggacgc gtggtctttg cttgggtgtc cccgagacgc tcgcgtgcct 360
gggatcggga aagcgtagtc gggtgcccgg actgcttccc caggagccct acagccctcg 420
gaccccgagc cccgcaaggg tcccaggggt cttggctgtt gccccacgaa acgtggcagg 480
aaccaagatg gcggcggcag ggcggcggcg cgggcgtgag tcaagggcgg gcggtgggcg 540
gggcgcggcc gccctggccg tatttggacg tggggacgga gcgctttcct cttggcggcc 600
ggtggaagaa tcccctggtc tccgtgagcg tccattttgt ggaacctgag ttgcaagcag 660
ggaggggcaa atacaactgc cctgttcccg attctctaga tggccgatct agagaagtcc 720
cgcctcataa gtggaaggat gaaattctca gaacagctaa cctctaatgg gagttggctt 780
ctgattctca ttcaggcttc tcacggcatt cagcagcagc gttgctgtaa ccgacaaaga 840
caccttcgaa ttaagcacat tcctcgattc cagcaaagca ccgcaacatg accgaaatga 900
gcttcctgag cagcgaggtg ttggtggggg acttgatgtc ccccttcgac cagtcgggtt 960
tgggggctga agaaagccta ggtctcttag atgattacct ggaggtggcc aagcacttca 1020
aacctcatgg gttctccagc gacaaggcta aggcgggctc ctccgaatgg ctggctgtgg 1080
atgggttggt cagtccctcc aacaacagca aggaggatgc cttctccggg acagattgga 1140
tgttggagaa aatggatttg aaggagttcg acttggatgc cctgttgggt atagatgacc 1200
tggaaaccat gccagatgac cttctgacca cgttggatga cacttgtgat ctctttgccc 1260
ccctagtcca ggagactaat aagcagcccc cccagacggt gaacccaatt ggccatctcc 1320
cagaaagttt aacaaaaccc gaccaggttg cccccttcac cttcttacaa cctcttcccc 1380
tttccccagg ggtcctgtcc tccactccag atcattcctt tagtttagag ctgggcagtg 1440
aagtggatat cactgaagga gataggaagc cagactacac tgcttacgtt gccatgatcc 1500
ctcagtgcat aaaggaggaa gacacccctt cagataatga tagtggcatc tgtatgagcc 1560
cagagtccta tctggggtct cctcagcaca gcccctctac caggggctct ccaaatagga 1620
gcctcccatc tccaggtgtt ctctgtgggt ctgcccgtcc caaaccttac gatcctcctg 1680
gagagaagat ggtagcagca aaagtaaagg gtgagaaact ggataagaag ctgaaaaaaa 1740
tggagcaaaa caagacagca gccactaggt accgccagaa gaagagggcg gagcaggagg 1800
ctcttactgg tgagtgcaaa gagctggaaa agaagaacga ggctctaaaa gagagggcgg 1860
attccctggc caaggagatc cagtacctga aagatttgat agaagaggtc cgcaaggcaa 1920
gggggaagaa aagggtcccc tagttgagga tagtcaggag cgtcaatgtg cttgtacata 1980
gagtgctgta gctgtgtgtt ccaataaatt attttgtagg gaaagtaaaa aaaaaaaaaa 2040
a 2041
<210> 29
<211> 4536
<212> DNA
<213> Homo sapiens
<400> 29
aggctgtcac tcaggtggca gcggcagagg ccgggctgag acgtggccag gggaacacgg 60
ctggctgtcc aggccgtcgg ggcggcagta gggtccctag cacgtccttg ccttcttggg 120
agctccaagc ggcgggagag gcaggcgtca gtggctgcgc ctccatgcct gcgcgcgggg 180
cgggacgctg atggagcgcg ccatcagccc ggggctgctg gtacgggcgc tgctgctgct 240
gctgctgctg ctggggctcg cggcaaggac ggtggccgcg gggcgcgccc gtggcctccc 300
agcgccgacg gcggaggcgg cgttcggcct cggggcggcc gctgctccca cctcagcgac 360
gcgagtaccg gcggcgggcg ccgtggctgc ggccgaggtg actgtggagg acgctgaggc 420
gctgccggca gccgcgggag agcaggagcc tcggggtccg gaaccagacg atgagacaga 480
gttgcgaccg cgcggcaggt cattagtaat tatcagcact ttagatggga gaattgctgc 540
cttggatcct gaaaatcatg gtaaaaagca gtgggatttg gatgtgggat ccggttcctt 600
ggtgtcatcc agccttagca aaccagaggt atttgggaat aagatgatca ttccttccct 660
ggatggagcc ctcttccagt gggaccaaga ccgtgaaagc atggaaacag ttcctttcac 720
agttgaatca cttcttgaat cttcttataa atttggagat gatgttgttt tggttggagg 780
aaaatctctg actacatatg gactcagtgc atatagtgga aaggtgaggt atatctgttc 840
agctctgggt tgtcgccaat gggatagtga cgaaatggaa caagaggaag acatcctgct 900
tctacagcgt acccaaaaaa ctgttagagc tgtcggacct cgcagtggca atgagaagtg 960
gaatttcagt gttggccact ttgaacttcg gtatattcca gacatggaaa cgagagccgg 1020
atttattgaa agcaccttta agcccaatga gaacacagaa gagtctaaaa ttatttcaga 1080
tgtggaagaa caggaagctg ccataatgga catagtgata aaggtttcgg ttgctgactg 1140
gaaagttatg gcattcagta agaagggagg acatctggaa tgggagtacc agttttgtac 1200
tccaattgca tctgcctggt tacttaagga tgggaaagtc attcccatca gtctttttga 1260
tgatacaagt tatacatcta atgatgatgt tttagaagat gaagaagaca ttgtagaagc 1320
tgccagagga gccacagaaa acagtgttta cttgggaatg tatagaggcc agctgtatct 1380
gcagtcatca gtcagaattt cagaaaagtt tccttcaagt cccaaggctt tggaatctgt 1440
cactaatgaa aacgcaatta ttcctttacc aacaatcaaa tggaaaccct taattcattc 1500
tccttccaga actcctgtct tggtaggatc tgatgaattt gacaaatgtc tcagtaatga 1560
taagttttct catgaagaat atagtaatgg tgcactttca atcttgcagt atccatatga 1620
taatggttat tatctaccat actacaagag ggagaggaac aaacgaagca cacagattac 1680
agtcagattc ctcgacaacc cacattacaa caagaatatc cgcaaaaagg atcctgttct 1740
tcttttacac tggtggaaag aaatagttgc aacgattttg ttttgtatca tagcaacaac 1800
gtttattgtg cgcaggcttt tccatcctca tcctcacagg caaaggaagg agtctgaaac 1860
tcagtgtcaa actgaaaata aatatgattc tgtaagtggt gaagccaatg acagtagctg 1920
gaatgacata aaaaactctg gatatatatc acgatatcta actgattttg agccaattca 1980
atgcctggga cgtggtggct ttggagttgt ttttgaagct aaaaacaaag tagatgactg 2040
caattatgct atcaagagga tccgtctccc caatagggaa ttggctcggg aaaaggtaat 2100
gcgagaagtt aaagccttag ccaagcttga acacccgggc attgttagat atttcaatgc 2160
ctggctcgaa gcaccaccag agaagtggca agaaaagatg gatgaaattt ggctgaaaga 2220
tgaaagcaca gactggccac tcagctctcc tagcccaatg gatgcaccat cagttaaaat 2280
acgcagaatg gatcctttcg ctacaaaaga acatattgaa atcatagctc cttcaccaca 2340
aagaagcagg tctttttcag tagggatttc ctgtgaccag acaagttcat ctgagagcca 2400
gttctcacca ctggaattct caggaatgga ccatgaggac atcagtgagt cagtggatgc 2460
agcatacaac ctccaggaca gttgccttac agactgtgat gtggaagatg ggactatgga 2520
tggcaatgat gaggggcact cctttgaact ttgtccttct gaagcttctc cttatgtaag 2580
gtcaagggag agaacctcct cttcaatagt atttgaagat tctggctgtg ataatgcttc 2640
cagtaaagaa gagccgaaaa ctaatcgatt gcatattggc aaccattgtg ctaataaact 2700
aactgctttc aagcccacca gtagcaaatc ttcttctgaa gctacattgt ctatttctcc 2760
tccaagacca accactttaa gtttagatct cactaaaaac accacagaaa aactccagcc 2820
cagttcacca aaggtgtatc tttacattca aatgcagctg tgcagaaaag aaaacctcaa 2880
agactggatg aatggacgat gtaccataga ggagagagag aggagcgtgt gtctgcacat 2940
cttcctgcag atcgcagagg cagtggagtt tcttcacagt aaaggactga tgcacaggga 3000
cctcaagcca tccaacatat tctttacaat ggatgatgtg gtcaaggttg gagactttgg 3060
gttagtgact gcaatggacc aggatgagga agagcagacg gttctgaccc caatgccagc 3120
ttatgccaga cacacaggac aagtagggac caaactgtat atgagcccag agcagattca 3180
tggaaacagc tattctcata aagtggacat cttttcttta ggcctgattc tatttgaatt 3240
gctgtatcca ttcagcactc agatggagag agtcaggacc ttaactgatg taagaaatct 3300
caaatttcca ccattattta ctcagaaata tccttgtgag tacgtgatgg ttcaagacat 3360
gctctctcca tcccccatgg aacgacctga agctataaac atcattgaaa atgctgtatt 3420
tgaggacttg gactttccag gaaaaacagt gctcagacag aggtctcgct ccttgagttc 3480
atcgggaaca aaacattcaa gacagtccaa caactcccat agccctttgc caagcaatta 3540
gccttaagtt gtgctagcaa ccctaatagg tgatgcagat aatagcctac ttcttagaat 3600
atgcctgtcc aaaattgcag acttgaaaag tttgttcttc gctcaatttt tttgtggact 3660
acttttttta tatcaaattt aagctggatt tgggggcata acctaatttg agccaactcc 3720
tgagttttgc tatacttaag gaaagggcta tctttgttct ttgttagtct cttgaaactg 3780
gctgctggcc aagctttata gccctcacca tttgcctaag gaggtagcag caatccctaa 3840
tatatatata tagtgagaac taaaatggat atatttttat aatgcagaag aaggaaagtc 3900
cccctgtgtg gtaactgtat tgttctagaa atatgctttc tagagatatg atgattttga 3960
aactgatttc tagaaaaagc tgactccatt tttgtccctg gcgggtaaat taggaatctg 4020
cactattttg gaggacaagt agcacaaact gtataacggt ttatgtccgt agttttatag 4080
tcctatttgt agcattcaat agctttattc cttagatggt tctagggtgg gtttacagct 4140
ttttgtactt ttacctccaa taaagggaaa atgaagcttt ttatgtaaat tggttgaaag 4200
gtctagtttt gggaggaaaa aagccgtagt aagaaatgga tcatatatat tacaactaac 4260
ttcttcaact atggactttt taagcctaat gaaatcttaa gtgtcttata tgtaatcctg 4320
taggttggta cttcccccaa actgattata ggtaacagtt taatcatctc acttgctaac 4380
atgtttttat ttttcactgt aaatatgttt atgttttatt tataaaaatt ctgaaatcaa 4440
tccatttggg ttggtggtgt acagaacaca cttaagtgtg ttaacttgtg acttctttca 4500
agtctaaatg atttaataaa acttttttta aattaa 4536
<210> 30
<211> 4233
<212> DNA
<213> Homo sapiens
<400> 30
agttcagatg agaggtttag tgtaaagtgg tataggacag aggggacaga gttgagatat 60
ttgatgcaaa atctaggttc ctggcaagtg aatgcattct tcctttcttg gtacccttgt 120
ccagagattg agactgcgtg gccagaagtt gacaaaagag gtttaaggga gcagggaaga 180
aaaggtcatt agtaattatc agcactttag atgggagaat tgctgccttg gatcctgaaa 240
atcatggtaa aaagcagtgg gatttggatg tgggatccgg ttccttggtg tcatccagcc 300
ttagcaaacc agaggtattt gggaataaga tgatcattcc ttccctggat ggagccctct 360
tccagtggga ccaagaccgt gaaagcatgg aaacagttcc tttcacagtt gaatcacttc 420
ttgaatcttc ttataaattt ggagatgatg ttgttttggt tggaggaaaa tctctgacta 480
catatggact cagtgcatat agtggaaagg tgaggtatat ctgttcagct ctgggttgtc 540
gccaatggga tagtgacgaa atggaacaag aggaagacat cctgcttcta cagcgtaccc 600
aaaaaactgt tagagctgtc ggacctcgca gtggcaatga gaagtggaat ttcagtgttg 660
gccactttga acttcggtat attccagaca tggaaacgag agccggattt attgaaagca 720
cctttaagcc caatgagaac acagaagagt ctaaaattat ttcagatgtg gaagaacagg 780
aagctgccat aatggacata gtgataaagg tttcggttgc tgactggaaa gttatggcat 840
tcagtaagaa gggaggacat ctggaatggg agtaccagtt ttgtactcca attgcatctg 900
cctggttact taaggatggg aaagtcattc ccatcagtct ttttgatgat acaagttata 960
catctaatga tgatgtttta gaagatgaag aagacattgt agaagctgcc agaggagcca 1020
cagaaaacag tgtttacttg ggaatgtata gaggccagct gtatctgcag tcatcagtca 1080
gaatttcaga aaagtttcct tcaagtccca aggctttgga atctgtcact aatgaaaacg 1140
caattattcc tttaccaaca atcaaatgga aacccttaat tcattctcct tccagaactc 1200
ctgtcttggt aggatctgat gaatttgaca aatgtctcag taatgataag ttttctcatg 1260
aagaatatag taatggtgca ctttcaatct tgcagtatcc atatgataat ggttattatc 1320
taccatacta caagagggag aggaacaaac gaagcacaca gattacagtc agattcctcg 1380
acaacccaca ttacaacaag aatatccgca aaaaggatcc tgttcttctt ttacactggt 1440
ggaaagaaat agttgcaacg attttgtttt gtatcatagc aacaacgttt attgtgcgca 1500
ggcttttcca tcctcatcct cacaggcaaa ggaaggagtc tgaaactcag tgtcaaactg 1560
aaaataaata tgattctgta agtggtgaag ccaatgacag tagctggaat gacataaaaa 1620
actctggata tatatcacga tatctaactg attttgagcc aattcaatgc ctgggacgtg 1680
gtggctttgg agttgttttt gaagctaaaa acaaagtaga tgactgcaat tatgctatca 1740
agaggatccg tctccccaat agggaattgg ctcgggaaaa ggtaatgcga gaagttaaag 1800
ccttagccaa gcttgaacac ccgggcattg ttagatattt caatgcctgg ctcgaagcac 1860
caccagagaa gtggcaagaa aagatggatg aaatttggct gaaagatgaa agcacagact 1920
ggccactcag ctctcctagc ccaatggatg caccatcagt taaaatacgc agaatggatc 1980
ctttcgctac aaaagaacat attgaaatca tagctccttc accacaaaga agcaggtctt 2040
tttcagtagg gatttcctgt gaccagacaa gttcatctga gagccagttc tcaccactgg 2100
aattctcagg aatggaccat gaggacatca gtgagtcagt ggatgcagca tacaacctcc 2160
aggacagttg ccttacagac tgtgatgtgg aagatgggac tatggatggc aatgatgagg 2220
ggcactcctt tgaactttgt ccttctgaag cttctcctta tgtaaggtca agggagagaa 2280
cctcctcttc aatagtattt gaagattctg gctgtgataa tgcttccagt aaagaagagc 2340
cgaaaactaa tcgattgcat attggcaacc attgtgctaa taaactaact gctttcaagc 2400
ccaccagtag caaatcttct tctgaagcta cattgtctat ttctcctcca agaccaacca 2460
ctttaagttt agatctcact aaaaacacca cagaaaaact ccagcccagt tcaccaaagg 2520
tgtatcttta cattcaaatg cagctgtgca gaaaagaaaa cctcaaagac tggatgaatg 2580
gacgatgtac catagaggag agagagagga gcgtgtgtct gcacatcttc ctgcagatcg 2640
cagaggcagt ggagtttctt cacagtaaag gactgatgca cagggacctc aagccatcca 2700
acatattctt tacaatggat gatgtggtca aggttggaga ctttgggtta gtgactgcaa 2760
tggaccagga tgaggaagag cagacggttc tgaccccaat gccagcttat gccagacaca 2820
caggacaagt agggaccaaa ctgtatatga gcccagagca gattcatgga aacagctatt 2880
ctcataaagt ggacatcttt tctttaggcc tgattctatt tgaattgctg tatccattca 2940
gcactcagat ggagagagtc aggaccttaa ctgatgtaag aaatctcaaa tttccaccat 3000
tatttactca gaaatatcct tgtgagtacg tgatggttca agacatgctc tctccatccc 3060
ccatggaacg acctgaagct ataaacatca ttgaaaatgc tgtatttgag gacttggact 3120
ttccaggaaa aacagtgctc agacagaggt ctcgctcctt gagttcatcg ggaacaaaac 3180
attcaagaca gtccaacaac tcccatagcc ctttgccaag caattagcct taagttgtgc 3240
tagcaaccct aataggtgat gcagataata gcctacttct tagaatatgc ctgtccaaaa 3300
ttgcagactt gaaaagtttg ttcttcgctc aatttttttg tggactactt tttttatatc 3360
aaatttaagc tggatttggg ggcataacct aatttgagcc aactcctgag ttttgctata 3420
cttaaggaaa gggctatctt tgttctttgt tagtctcttg aaactggctg ctggccaagc 3480
tttatagccc tcaccatttg cctaaggagg tagcagcaat ccctaatata tatatatagt 3540
gagaactaaa atggatatat ttttataatg cagaagaagg aaagtccccc tgtgtggtaa 3600
ctgtattgtt ctagaaatat gctttctaga gatatgatga ttttgaaact gatttctaga 3660
aaaagctgac tccatttttg tccctggcgg gtaaattagg aatctgcact attttggagg 3720
acaagtagca caaactgtat aacggtttat gtccgtagtt ttatagtcct atttgtagca 3780
ttcaatagct ttattcctta gatggttcta gggtgggttt acagcttttt gtacttttac 3840
ctccaataaa gggaaaatga agctttttat gtaaattggt tgaaaggtct agttttggga 3900
ggaaaaaagc cgtagtaaga aatggatcat atatattaca actaacttct tcaactatgg 3960
actttttaag cctaatgaaa tcttaagtgt cttatatgta atcctgtagg ttggtacttc 4020
ccccaaactg attataggta acagtttaat catctcactt gctaacatgt ttttattttt 4080
cactgtaaat atgtttatgt tttatttata aaaattctga aatcaatcca tttgggttgg 4140
tggtgtacag aacacactta agtgtgttaa cttgtgactt ctttcaagtc taaatgattt 4200
aataaaactt tttttaaatt aagaaaaaaa aaa 4233
<210> 31
<211> 4737
<212> DNA
<213> Homo sapiens
<400> 31
ggtttgaaag gaaggcagag agggcactgg gaggaggcag tgggagggcg gagggcgggg 60
gccttcgggg tgggcgccca gggtagggca ggtggccgcg gcgtggaggc agggagaatg 120
cgactctcca aaaccctcgt cgacatggac atggccgact acagtgctgc actggaccca 180
gcctacacca ccctggaatt tgagaatgtg caggtgttga cgatgggcaa tgacacgtcc 240
ccatcagaag gcaccaacct caacgcgccc aacagcctgg gtgtcagcgc cctgtgtgcc 300
atctgcgggg accgggccac gggcaaacac tacggtgcct cgagctgtga cggctgcaag 360
ggcttcttcc ggaggagcgt gcggaagaac cacatgtact cctgcagatt tagccggcag 420
tgcgtggtgg acaaagacaa gaggaaccag tgccgctact gcaggctcaa gaaatgcttc 480
cgggctggca tgaagaagga agccgtccag aatgagcggg accggatcag cactcgaagg 540
tcaagctatg aggacagcag cctgccctcc atcaatgcgc tcctgcaggc ggaggtcctg 600
tcccgacaga tcacctcccc cgtctccggg atcaacggcg acattcgggc gaagaagatt 660
gccagcatcg cagatgtgtg tgagtccatg aaggagcagc tgctggttct cgttgagtgg 720
gccaagtaca tcccagcttt ctgcgagctc cccctggacg accaggtggc cctgctcaga 780
gcccatgctg gcgagcacct gctgctcgga gccaccaaga gatccatggt gttcaaggac 840
gtgctgctcc taggcaatga ctacattgtc cctcggcact gcccggagct ggcggagatg 900
agccgggtgt ccatacgcat ccttgacgag ctggtgctgc ccttccagga gctgcagatc 960
gatgacaatg agtatgccta cctcaaagcc atcatcttct ttgacccaga tgccaagggg 1020
ctgagcgatc cagggaagat caagcggctg cgttcccagg tgcaggtgag cttggaggac 1080
tacatcaacg accgccagta tgactcgcgt ggccgctttg gagagctgct gctgctgctg 1140
cccaccttgc agagcatcac ctggcagatg atcgagcaga tccagttcat caagctcttc 1200
ggcatggcca agattgacaa cctgttgcag gagatgctgc tgggagggtc ccccagcgat 1260
gcaccccatg cccaccaccc cctgcaccct cacctgatgc aggaacatat gggaaccaac 1320
gtcatcgttg ccaacacaat gcccactcac ctcagcaacg gacagatgtg tgagtggccc 1380
cgacccaggg gacaggcagc cacccctgag accccacagc cctcaccgcc aggtggctca 1440
gggtctgagc cctataagct cctgccggga gccgtcgcca caatcgtcaa gcccctctct 1500
gccatccccc agccgaccat caccaagcag gaagttatct agcaagccgc tggggcttgg 1560
gggctccact ggctcccccc agccccctaa gagagcacct ggtgatcacg tggtcacggc 1620
aaaggaagac gtgatgccag gaccagtccc agagcaggaa tgggaaggat gaagggcccg 1680
agaacatggc ctaagggcca catcccactg ccacccttga cgccctgctc tggataacaa 1740
gactttgact tggggagacc tctactgcct tggacaactt ttctcatgtt gaagccactg 1800
ccttcacctt caccttcatc catgtccaac ccccgacttc atcccaaagg acagccgcct 1860
ggagatgact tgaggcctta cttaaaccca gctcccttct tccctagcct ggtgcttctc 1920
ctctcctagc ccctgtcatg gtgtccagac agagccctgt gaggctgggt ccaattgtgg 1980
cacttggggc accttgctcc tccttctgct gctgccccca cctctgctgc ctccctctgc 2040
tgtcaccttg ctcagccatc ccgtcttctc caacaccacc tctccagagg ccaaggaggc 2100
cttggaaacg attcccccag tcattctggg aacatgttgt aagcactgac tgggaccagg 2160
caccaggcag ggtctagaag gctgtggtga gggaagacgc ctttctcctc caacccaacc 2220
tcatcctcct tcttcaggga cttgggtggg tacttgggtg aggatccctg aaggccttca 2280
acccgagaaa acaaacccag gttggcgact gcaacaggaa cttggagtgg agaggaaaag 2340
catcagaaag aggcagacca tccaccaggc ctttgagaaa gggtagaatt ctggctggta 2400
gagcaggtga gatgggacat tccaaagaac agcctgagcc aaggcctagt ggtagtaaga 2460
atctagcaag aattgaggaa gaatggtgtg ggagagggat gatgaagaga gagagggcct 2520
gctggagagc atagggtctg gaacaccagg ctgaggtcct gatcagcttc aaggagtatg 2580
cagggagctg ggcttccaga aaatgaacac agcagttctg cagaggacgg gaggctggaa 2640
gctgggaggt caggtggggt ggatgatata atgcgggtga gagtaatgag gcttggggct 2700
ggagaggaca agatgggtaa accctcacat cagagtgaca tccaggagga ataagctccc 2760
agggcctgtc tcaagctctt ccttactccc aggcactgtc ttaaggcatc tgacatgcat 2820
catctcattt aatcctccct tcctccctat taacctagag attgtttttg ttttttattc 2880
tcctcctccc tccccgccct cacccgcccc actccctcct aacctagaga ttgttacaga 2940
agctgaaatt gcgttctaag aggtgaagtg attttttttc tgaaactcac acaactagga 3000
agtggctgag tcaggacttg aacccaggtc tccctggatc agaacaggag ctcttaacta 3060
cagtggctga atagcttctc caaaggctcc ctgtgttctc accgtgatca agttgagggg 3120
cttccggctc ccttctacag cctcagaaac cagactcgtt cttctgggaa ccctgcccac 3180
tcccaggacc aagattggcc tgaggctgca ctaaaattca cttagggtcg agcatcctgt 3240
ttgctgataa atattaagga gaattcatga ctcttgacag cttttctctc ttcactcccc 3300
aagtcaaggg gaggggtggc aggggtctgt ttcctggaag tcaggctcat ctggcctgtt 3360
ggcatggggg tgggacagtg tgcacagtgt gggggcaggg gagggctaag caggcctggg 3420
tttgagggct gctccggaga ccgtcactcc aggtgcattc tggaagcatt agaccccagg 3480
atggagcgac cagcatgtca tccatgtgga atcttggtgg ctttgaggac attctggaaa 3540
atgccactga ccagtgtgaa caaaagggat gtgttatggg gctggaggtg tgattaggta 3600
ggagggaaac tgttggaccg actcctgccc cctgctcaac actgacccct ctgagtggtt 3660
ggaggcagtg ccccagtgcc cagaaatccc accattagtg attgtttttt atgagaaaga 3720
ggcgtggaga agtattgggg caatgtgtca gggaggaatc accacatccc tacggcagtc 3780
ccagccaagc ccccaatccc agcggagact gtgccctgct cagagctccc aagccttccc 3840
ccaccacctc actcaagtgc ccctgaaatc cctgccagac ggctcagcct ggtctgcggt 3900
aaggcaggga ggctggaacc atttctgggc attgtggtca ttcccactgt gttcctccac 3960
ctcctccctc cagcgttgct cagacctctg tcttgggaga aaggttgaga taagaatgtc 4020
ccatggagtg ccgtgggcaa cagtggccct tcatgggaac aatctgttgg agcagggggt 4080
cagttctctg ctgggaatct acccctttct ggaggagaaa cccattccac cttaataact 4140
ttattgtaat gtgagaaaca caaaacaaag tttacttttt tgactctaag ctgacatgat 4200
attagaaaat ctctcgctct cttttttttt tttttttttt tttttggcta cttgagttgt 4260
ggtcctaaaa cataaaatct gatggacaaa cagagggttg ctggggggac aagcgtgggc 4320
acaatttccc caccaagaca ccctgatctt caggcgggtc tcaggagctt ctaaaaatcc 4380
gcatggctct cctgagagtg gacagaggag aggagagggt cagaaatgaa cgctcttcta 4440
tttcttgtca ttaccaagcc aattactttt gccaaatttt tctgtgatct gccctgatta 4500
agatgaattg tgaaatttac atcaagcaat tatcaaagcg ggctgggtcc catcagaacg 4560
acccacatct ttctgtgggt gtgaatgtca ttaggtcttg cgctgacccc tgagccccca 4620
tcactgccgc ctgatggggc aaagaaacaa aaaacatttc ttactcttct gtgttttaac 4680
aaaagtttat aaaacaaaat aaatggcgca tatgttttct aaaaaaaaaa aaaaaaa 4737
<210> 32
<211> 6460
<212> DNA
<213> Homo sapiens
<400> 32
agatcttccc agaggacggt ttgaaaggaa ggcagagagg gcactgggag gaggcagtgg 60
gagggcggag ggcgggggcc ttcggggtgg gcgcccaggg tagggcaggt ggccgcggcg 120
tggaggcagg gagaatgcga ctctccaaaa ccctcgtcga catggacatg gccgactaca 180
gtgctgcact ggacccagcc tacaccaccc tggaatttga gaatgtgcag gtgttgacga 240
tgggcaatga cacgtcccca tcagaaggca ccaacctcaa cgcgcccaac agcctgggtg 300
tcagcgccct gtgtgccatc tgcggggacc gggccacggg caaacactac ggtgcctcga 360
gctgtgacgg ctgcaagggc ttcttccgga ggagcgtgcg gaagaaccac atgtactcct 420
gcagatttag ccggcagtgc gtggtggaca aagacaagag gaaccagtgc cgctactgca 480
ggctcaagaa atgcttccgg gctggcatga agaaggaagc cgtccagaat gagcgggacc 540
ggatcagcac tcgaaggtca agctatgagg acagcagcct gccctccatc aatgcgctcc 600
tgcaggcgga ggtcctgtcc cgacagatca cctcccccgt ctccgggatc aacggcgaca 660
ttcgggcgaa gaagattgcc agcatcgcag atgtgtgtga gtccatgaag gagcagctgc 720
tggttctcgt tgagtgggcc aagtacatcc cagctttctg cgagctcccc ctggacgacc 780
aggtggccct gctcagagcc catgctggcg agcacctgct gctcggagcc accaagagat 840
ccatggtgtt caaggacgtg ctgctcctag gcaatgacta cattgtccct cggcactgcc 900
cggagctggc ggagatgagc cgggtgtcca tacgcatcct tgacgagctg gtgctgccct 960
tccaggagct gcagatcgat gacaatgagt atgcctacct caaagccatc atcttctttg 1020
acccagatgc caaggggctg agcgatccag ggaagatcaa gcggctgcgt tcccaggtgc 1080
aggtgagctt ggaggactac atcaacgacc gccagtatga ctcgcgtggc cgctttggag 1140
agctgctgct gctgctgccc accttgcaga gcatcacctg gcagatgatc gagcagatcc 1200
agttcatcaa gctcttcggc atggccaaga ttgacaacct gttgcaggag atgctgctgg 1260
gagggtcccc cagcgatgca ccccatgccc accaccccct gcaccctcac ctgatgcagg 1320
aacatatggg aaccaacgtc atcgttgcca acacaatgcc cactcacctc agcaacggac 1380
agatgtccac ccctgagacc ccacagccct caccgccagg tggctcaggg tctgagccct 1440
ataagctcct gccgggagcc gtcgccacaa tcgtcaagcc cctctctgcc atcccccagc 1500
cgaccatcac caagcaggaa gttatctagc aagccgctgg ggcttggggg ctccactggc 1560
tccccccagc cccctaagag agcacctggt gatcacgtgg tcacggcaaa ggaagacgtg 1620
atgccaggac cagtcccaga gcaggaatgg gaaggatgaa gggcccgaga acatggccta 1680
agggccacat cccactgcca cccttgacgc cctgctctgg ataacaagac tttgacttgg 1740
ggagacctct actgccttgg acaacttttc tcatgttgaa gccactgcct tcaccttcac 1800
cttcatccat gtccaacccc cgacttcatc ccaaaggaca gccgcctgga gatgacttga 1860
ggccttactt aaacccagct cccttcttcc ctagcctggt gcttctcctc tcctagcccc 1920
tgtcatggtg tccagacaga gccctgtgag gctgggtcca attgtggcac ttggggcacc 1980
ttgctcctcc ttctgctgct gcccccacct ctgctgcctc cctctgctgt caccttgctc 2040
agccatcccg tcttctccaa caccacctct ccagaggcca aggaggcctt ggaaacgatt 2100
cccccagtca ttctgggaac atgttgtaag cactgactgg gaccaggcac caggcagggt 2160
ctagaaggct gtggtgaggg aagacgcctt tctcctccaa cccaacctca tcctccttct 2220
tcagggactt gggtgggtac ttgggtgagg atccctgaag gccttcaacc cgagaaaaca 2280
aacccaggtt ggcgactgca acaggaactt ggagtggaga ggaaaagcat cagaaagagg 2340
cagaccatcc accaggcctt tgagaaaggg tagaattctg gctggtagag caggtgagat 2400
gggacattcc aaagaacagc ctgagccaag gcctagtggt agtaagaatc tagcaagaat 2460
tgaggaagaa tggtgtggga gagggatgat gaagagagag agggcctgct ggagagcata 2520
gggtctggaa caccaggctg aggtcctgat cagcttcaag gagtatgcag ggagctgggc 2580
ttccagaaaa tgaacacagc agttctgcag aggacgggag gctggaagct gggaggtcag 2640
gtggggtgga tgatataatg cgggtgagag taatgaggct tggggctgga gaggacaaga 2700
tgggtaaacc ctcacatcag agtgacatcc aggaggaata agctcccagg gcctgtctca 2760
agctcttcct tactcccagg cactgtctta aggcatctga catgcatcat ctcatttaat 2820
cctcccttcc tccctattaa cctagagatt gtttttgttt tttattctcc tcctccctcc 2880
ccgccctcac ccgccccact ccctcctaac ctagagattg ttacagaagc tgaaattgcg 2940
ttctaagagg tgaagtgatt ttttttctga aactcacaca actaggaagt ggctgagtca 3000
ggacttgaac ccaggtctcc ctggatcaga acaggagctc ttaactacag tggctgaata 3060
gcttctccaa aggctccctg tgttctcacc gtgatcaagt tgaggggctt ccggctccct 3120
tctacagcct cagaaaccag actcgttctt ctgggaaccc tgcccactcc caggaccaag 3180
attggcctga ggctgcacta aaattcactt agggtcgagc atcctgtttg ctgataaata 3240
ttaaggagaa ttcatgactc ttgacagctt ttctctcttc actccccaag tcaaggggag 3300
gggtggcagg ggtctgtttc ctggaagtca ggctcatctg gcctgttggc atgggggtgg 3360
gacagtgtgc acagtgtggg ggcaggggag ggctaagcag gcctgggttt gagggctgct 3420
ccggagaccg tcactccagg tgcattctgg aagcattaga ccccaggatg gagcgaccag 3480
catgtcatcc atgtggaatc ttggtggctt tgaggacatt ctggaaaatg ccactgacca 3540
gtgtgaacaa aagggatgtg ttatggggct ggaggtgtga ttaggtagga gggaaactgt 3600
tggaccgact cctgccccct gctcaacact gacccctctg agtggttgga ggcagtgccc 3660
cagtgcccag aaatcccacc attagtgatt gttttttatg agaaagaggc gtggagaagt 3720
attggggcaa tgtgtcaggg aggaatcacc acatccctac ggcagtccca gccaagcccc 3780
caatcccagc ggagactgtg ccctgctcag agctcccaag ccttccccca ccacctcact 3840
caagtgcccc tgaaatccct gccagacggc tcagcctggt ctgcggtaag gcagggaggc 3900
tggaaccatt tctgggcatt gtggtcattc ccactgtgtt cctccacctc ctccctccag 3960
cgttgctcag acctctgtct tgggagaaag gttgagataa gaatgtccca tggagtgccg 4020
tgggcaacag tggcccttca tgggaacaat ctgttggagc agggggtcag ttctctgctg 4080
ggaatctacc cctttctgga ggagaaaccc attccacctt aataacttta ttgtaatgtg 4140
agaaacacaa aacaaagttt acttttttga ctctaagctg acatgatatt agaaaatctc 4200
tcgctctctt tttttttttt tttttttttt ttggctactt gagttgtggt cctaaaacat 4260
aaaatctgat ggacaaacag agggttgctg gggggacaag cgtgggcaca atttccccac 4320
caagacaccc tgatcttcag gcgggtctca ggagcttcta aaaatccgca tggctctcct 4380
gagagtggac agaggagagg agagggtcag aaatgaacgc tcttctattt cttgtcatta 4440
ccaagccaat tacttttgcc aaatttttct gtgatctgcc ctgattaaga tgaattgtga 4500
aatttacatc aagcaattat caaagcgggc tgggtcccat cagaacgacc cacatctttc 4560
tgtgggtgtg aatgtcatta ggtcttgcgc tgacccctga gcccccatca ctgccgcctg 4620
atggggcaaa gaaacaaaaa acatttctta ctcttctgtg ttttaacaaa agtttataaa 4680
acaaaataaa tggcgcatat gttttctaag tccttggata agtatctttt ctttcaggta 4740
tcagaaataa gactgaatct tctggttcta cttgggggtt aaaaaatttt ttttaaagga 4800
agaatgagaa tagttttata gttctttgtg atgtgcagaa tgtttttgtg tccattataa 4860
tttttcagtc ttcacatcaa gaggtaagca gttagacatg attactccca ctttccagat 4920
gaggagactg aggcttgggg gaagtgactt ctcttggaag gcagaggtgg acatctaacc 4980
ctggtctctt gattccaagt acttagtata tcgagagagt gaaagttgat cccccttctt 5040
gaagagggga gtgatgaggg gagagtgcaa tggcaagatc tggaagaatg gcaagagggt 5100
ccaagggtct gtcatcctcc accaaggttc aagacagaac cttttgctgg gtcacctcaa 5160
tctgccagca atggaagatg agtagctgtg gggacatttc ataaaagcaa gtggtttttt 5220
tgttttgttt tgttttgttt tttgtttttt tttctagaac aaggctgtgc acagtggctc 5280
acctctgtaa tcccagcact ttgggaggct gaggcgggag gatcacttga gctcaggagt 5340
tcgagaccag ccagagcaat ataaggagac cccatctcta caaaaaattt aaaaattagc 5400
caggtatagt ggtgtgtgcc tatagtacca gctactctga aggctgaggt gggaagattg 5460
cttcagccca ggagttcgag gatgcagtga gctatgaatg caacactgca ctacagcctg 5520
gatgaaagaa caagactctg tctcaaaaca taaataataa gtaaaaagaa taaaagcaag 5580
agatgcactt gagaatctcc agccagatct gtagccactg ggcttctctc caaggctaaa 5640
ctattacagg agggtggcct tgtgtctcgg tcaccacaga ccacagcgtt ccattcactc 5700
ggggttgtgc tggagctggc ttgtgagaac tgactgttag cttctcttcc caactccatg 5760
tttgccagtg ccacactgat agcttgaaat tggttattgc cggagtgttt acaccacaag 5820
gactagcaaa ctctacaaat ccgggctttt gttcctggag agcccgttgt taacattcac 5880
cagcacacca cagcattcgg caatggctgg accatgggat gcctacatat ggggacatcc 5940
tccttgggga tgagggtaga gcagggcgat cctttcacct cttccttaag ggaggggaca 6000
aaagttctgg tctgggaagc acacgttttg ctgatcagcg taaccttggg caggtcactc 6060
caccactccg agcctcatct gtaaagtggg aatgatatct ccctccaggg cagatgtcag 6120
gattcaatgg aatgagatca cagtaactgt gagagctccc gttacatgag gagtacaagt 6180
gaactcttca tgcgcccctt tttagcgaga agttaaccat taaactctcc aggcttcaga 6240
gcacccattc gctgtctacc tgatccctag ggccgctccc gccttcccct gtgccttccc 6300
tccactagtc agcaccagga aatgttttcg ataacgttgc aacggaggcc ttgttcatgc 6360
tgccgccatc ggggacaagc gcgggggggg gggggtggag gccagaggag actatttcag 6420
tcctaaattg tgcttaataa acccatatca aaaccataaa 6460
<210> 33
<211> 6581
<212> DNA
<213> Homo sapiens
<400> 33
agatcttccc agaggacggt ttgaaaggaa ggcagagagg gcactgggag gaggcagtgg 60
gagggcggag ggcgggggcc ttcggggtgg gcgcccaggg tagggcaggt ggccgcggcg 120
tggaggcagg gagaatgcga ctctccaaaa ccctcgtcga catggacatg gccgactaca 180
gtgctgcact ggacccagcc tacaccaccc tggaatttga gaatgtgcag gtgttgacga 240
tgggcaatga ttttgttgcc gctgcgtctc gccagattga ggcatcccct ccgacatcac 300
tggagcatat ctggaggggt ggacagttct ccacagggag acacgtcccc atcagaaggc 360
accaacctca acgcgcccaa cagcctgggt gtcagcgccc tgtgtgccat ctgcggggac 420
cgggccacgg gcaaacacta cggtgcctcg agctgtgacg gctgcaaggg cttcttccgg 480
aggagcgtgc ggaagaacca catgtactcc tgcagattta gccggcagtg cgtggtggac 540
aaagacaaga ggaaccagtg ccgctactgc aggctcaaga aatgcttccg ggctggcatg 600
aagaaggaag ccgtccagaa tgagcgggac cggatcagca ctcgaaggtc aagctatgag 660
gacagcagcc tgccctccat caatgcgctc ctgcaggcgg aggtcctgtc ccgacagatc 720
acctcccccg tctccgggat caacggcgac attcgggcga agaagattgc cagcatcgca 780
gatgtgtgtg agtccatgaa ggagcagctg ctggttctcg ttgagtgggc caagtacatc 840
ccagctttct gcgagctccc cctggacgac caggtggccc tgctcagagc ccatgctggc 900
gagcacctgc tgctcggagc caccaagaga tccatggtgt tcaaggacgt gctgctccta 960
ggcaatgact acattgtccc tcggcactgc ccggagctgg cggagatgag ccgggtgtcc 1020
atacgcatcc ttgacgagct ggtgctgccc ttccaggagc tgcagatcga tgacaatgag 1080
tatgcctacc tcaaagccat catcttcttt gacccagatg ccaaggggct gagcgatcca 1140
gggaagatca agcggctgcg ttcccaggtg caggtgagct tggaggacta catcaacgac 1200
cgccagtatg actcgcgtgg ccgctttgga gagctgctgc tgctgctgcc caccttgcag 1260
agcatcacct ggcagatgat cgagcagatc cagttcatca agctcttcgg catggccaag 1320
attgacaacc tgttgcagga gatgctgctg ggagggtccc ccagcgatgc accccatgcc 1380
caccaccccc tgcaccctca cctgatgcag gaacatatgg gaaccaacgt catcgttgcc 1440
aacacaatgc ccactcacct cagcaacgga cagatgtgtg agtggccccg acccagggga 1500
caggcagcca cccctgagac cccacagccc tcaccgccag gtggctcagg gtctgagccc 1560
tataagctcc tgccgggagc cgtcgccaca atcgtcaagc ccctctctgc catcccccag 1620
ccgaccatca ccaagcagga agttatctag caagccgctg gggcttgggg gctccactgg 1680
ctccccccag ccccctaaga gagcacctgg tgatcacgtg gtcacggcaa aggaagacgt 1740
gatgccagga ccagtcccag agcaggaatg ggaaggatga agggcccgag aacatggcct 1800
aagggccaca tcccactgcc acccttgacg ccctgctctg gataacaaga ctttgacttg 1860
gggagacctc tactgccttg gacaactttt ctcatgttga agccactgcc ttcaccttca 1920
ccttcatcca tgtccaaccc ccgacttcat cccaaaggac agccgcctgg agatgacttg 1980
aggccttact taaacccagc tcccttcttc cctagcctgg tgcttctcct ctcctagccc 2040
ctgtcatggt gtccagacag agccctgtga ggctgggtcc aattgtggca cttggggcac 2100
cttgctcctc cttctgctgc tgcccccacc tctgctgcct ccctctgctg tcaccttgct 2160
cagccatccc gtcttctcca acaccacctc tccagaggcc aaggaggcct tggaaacgat 2220
tcccccagtc attctgggaa catgttgtaa gcactgactg ggaccaggca ccaggcaggg 2280
tctagaaggc tgtggtgagg gaagacgcct ttctcctcca acccaacctc atcctccttc 2340
ttcagggact tgggtgggta cttgggtgag gatccctgaa ggccttcaac ccgagaaaac 2400
aaacccaggt tggcgactgc aacaggaact tggagtggag aggaaaagca tcagaaagag 2460
gcagaccatc caccaggcct ttgagaaagg gtagaattct ggctggtaga gcaggtgaga 2520
tgggacattc caaagaacag cctgagccaa ggcctagtgg tagtaagaat ctagcaagaa 2580
ttgaggaaga atggtgtggg agagggatga tgaagagaga gagggcctgc tggagagcat 2640
agggtctgga acaccaggct gaggtcctga tcagcttcaa ggagtatgca gggagctggg 2700
cttccagaaa atgaacacag cagttctgca gaggacggga ggctggaagc tgggaggtca 2760
ggtggggtgg atgatataat gcgggtgaga gtaatgaggc ttggggctgg agaggacaag 2820
atgggtaaac cctcacatca gagtgacatc caggaggaat aagctcccag ggcctgtctc 2880
aagctcttcc ttactcccag gcactgtctt aaggcatctg acatgcatca tctcatttaa 2940
tcctcccttc ctccctatta acctagagat tgtttttgtt ttttattctc ctcctccctc 3000
cccgccctca cccgccccac tccctcctaa cctagagatt gttacagaag ctgaaattgc 3060
gttctaagag gtgaagtgat tttttttctg aaactcacac aactaggaag tggctgagtc 3120
aggacttgaa cccaggtctc cctggatcag aacaggagct cttaactaca gtggctgaat 3180
agcttctcca aaggctccct gtgttctcac cgtgatcaag ttgaggggct tccggctccc 3240
ttctacagcc tcagaaacca gactcgttct tctgggaacc ctgcccactc ccaggaccaa 3300
gattggcctg aggctgcact aaaattcact tagggtcgag catcctgttt gctgataaat 3360
attaaggaga attcatgact cttgacagct tttctctctt cactccccaa gtcaagggga 3420
ggggtggcag gggtctgttt cctggaagtc aggctcatct ggcctgttgg catgggggtg 3480
ggacagtgtg cacagtgtgg gggcagggga gggctaagca ggcctgggtt tgagggctgc 3540
tccggagacc gtcactccag gtgcattctg gaagcattag accccaggat ggagcgacca 3600
gcatgtcatc catgtggaat cttggtggct ttgaggacat tctggaaaat gccactgacc 3660
agtgtgaaca aaagggatgt gttatggggc tggaggtgtg attaggtagg agggaaactg 3720
ttggaccgac tcctgccccc tgctcaacac tgacccctct gagtggttgg aggcagtgcc 3780
ccagtgccca gaaatcccac cattagtgat tgttttttat gagaaagagg cgtggagaag 3840
tattggggca atgtgtcagg gaggaatcac cacatcccta cggcagtccc agccaagccc 3900
ccaatcccag cggagactgt gccctgctca gagctcccaa gccttccccc accacctcac 3960
tcaagtgccc ctgaaatccc tgccagacgg ctcagcctgg tctgcggtaa ggcagggagg 4020
ctggaaccat ttctgggcat tgtggtcatt cccactgtgt tcctccacct cctccctcca 4080
gcgttgctca gacctctgtc ttgggagaaa ggttgagata agaatgtccc atggagtgcc 4140
gtgggcaaca gtggcccttc atgggaacaa tctgttggag cagggggtca gttctctgct 4200
gggaatctac ccctttctgg aggagaaacc cattccacct taataacttt attgtaatgt 4260
gagaaacaca aaacaaagtt tacttttttg actctaagct gacatgatat tagaaaatct 4320
ctcgctctct tttttttttt tttttttttt tttggctact tgagttgtgg tcctaaaaca 4380
taaaatctga tggacaaaca gagggttgct ggggggacaa gcgtgggcac aatttcccca 4440
ccaagacacc ctgatcttca ggcgggtctc aggagcttct aaaaatccgc atggctctcc 4500
tgagagtgga cagaggagag gagagggtca gaaatgaacg ctcttctatt tcttgtcatt 4560
accaagccaa ttacttttgc caaatttttc tgtgatctgc cctgattaag atgaattgtg 4620
aaatttacat caagcaatta tcaaagcggg ctgggtccca tcagaacgac ccacatcttt 4680
ctgtgggtgt gaatgtcatt aggtcttgcg ctgacccctg agcccccatc actgccgcct 4740
gatggggcaa agaaacaaaa aacatttctt actcttctgt gttttaacaa aagtttataa 4800
aacaaaataa atggcgcata tgttttctaa gtccttggat aagtatcttt tctttcaggt 4860
atcagaaata agactgaatc ttctggttct acttgggggt taaaaaattt tttttaaagg 4920
aagaatgaga atagttttat agttctttgt gatgtgcaga atgtttttgt gtccattata 4980
atttttcagt cttcacatca agaggtaagc agttagacat gattactccc actttccaga 5040
tgaggagact gaggcttggg ggaagtgact tctcttggaa ggcagaggtg gacatctaac 5100
cctggtctct tgattccaag tacttagtat atcgagagag tgaaagttga tcccccttct 5160
tgaagagggg agtgatgagg ggagagtgca atggcaagat ctggaagaat ggcaagaggg 5220
tccaagggtc tgtcatcctc caccaaggtt caagacagaa ccttttgctg ggtcacctca 5280
atctgccagc aatggaagat gagtagctgt ggggacattt cataaaagca agtggttttt 5340
ttgttttgtt ttgttttgtt ttttgttttt ttttctagaa caaggctgtg cacagtggct 5400
cacctctgta atcccagcac tttgggaggc tgaggcggga ggatcacttg agctcaggag 5460
ttcgagacca gccagagcaa tataaggaga ccccatctct acaaaaaatt taaaaattag 5520
ccaggtatag tggtgtgtgc ctatagtacc agctactctg aaggctgagg tgggaagatt 5580
gcttcagccc aggagttcga ggatgcagtg agctatgaat gcaacactgc actacagcct 5640
ggatgaaaga acaagactct gtctcaaaac ataaataata agtaaaaaga ataaaagcaa 5700
gagatgcact tgagaatctc cagccagatc tgtagccact gggcttctct ccaaggctaa 5760
actattacag gagggtggcc ttgtgtctcg gtcaccacag accacagcgt tccattcact 5820
cggggttgtg ctggagctgg cttgtgagaa ctgactgtta gcttctcttc ccaactccat 5880
gtttgccagt gccacactga tagcttgaaa ttggttattg ccggagtgtt tacaccacaa 5940
ggactagcaa actctacaaa tccgggcttt tgttcctgga gagcccgttg ttaacattca 6000
ccagcacacc acagcattcg gcaatggctg gaccatggga tgcctacata tggggacatc 6060
ctccttgggg atgagggtag agcagggcga tcctttcacc tcttccttaa gggaggggac 6120
aaaagttctg gtctgggaag cacacgtttt gctgatcagc gtaaccttgg gcaggtcact 6180
ccaccactcc gagcctcatc tgtaaagtgg gaatgatatc tccctccagg gcagatgtca 6240
ggattcaatg gaatgagatc acagtaactg tgagagctcc cgttacatga ggagtacaag 6300
tgaactcttc atgcgcccct ttttagcgag aagttaacca ttaaactctc caggcttcag 6360
agcacccatt cgctgtctac ctgatcccta gggccgctcc cgccttcccc tgtgccttcc 6420
ctccactagt cagcaccagg aaatgttttc gataacgttg caacggaggc cttgttcatg 6480
ctgccgccat cggggacaag cgcggggggg ggggggtgga ggccagagga gactatttca 6540
gtcctaaatt gtgcttaata aacccatatc aaaaccataa a 6581
<210> 34
<211> 6588
<212> DNA
<213> Homo sapiens
<400> 34
gcactcaccg ccttcctggt ggacgggctc ctggtggctg tgctgctgct gtgagcgggc 60
ccctgctcct ccatgccccc agctctccgg ctgggtgggc ttggccatgg tcagcgtgaa 120
cgcgcccctc ggggctccag tggagagttc ttacggtctg cagtttccat ggagaccgcc 180
tcccaccatc cctgaaatct cattgtgacc agtattaagg gattaactct gcccagcggc 240
cctcgcaggg tctggggtgc tgagaggggc cagcaggagc tccctcaagg atgaagaggt 300
tgtgcactgt gcgggacccc atagcagcag gaggaggatg tcggactggg gccagggctt 360
cccccaggac ccaccagaca cgtccccatc agaaggcacc aacctcaacg cgcccaacag 420
cctgggtgtc agcgccctgt gtgccatctg cggggaccgg gccacgggca aacactacgg 480
tgcctcgagc tgtgacggct gcaagggctt cttccggagg agcgtgcgga agaaccacat 540
gtactcctgc agatttagcc ggcagtgcgt ggtggacaaa gacaagagga accagtgccg 600
ctactgcagg ctcaagaaat gcttccgggc tggcatgaag aaggaagccg tccagaatga 660
gcgggaccgg atcagcactc gaaggtcaag ctatgaggac agcagcctgc cctccatcaa 720
tgcgctcctg caggcggagg tcctgtcccg acagatcacc tcccccgtct ccgggatcaa 780
cggcgacatt cgggcgaaga agattgccag catcgcagat gtgtgtgagt ccatgaagga 840
gcagctgctg gttctcgttg agtgggccaa gtacatccca gctttctgcg agctccccct 900
ggacgaccag gtggccctgc tcagagccca tgctggcgag cacctgctgc tcggagccac 960
caagagatcc atggtgttca aggacgtgct gctcctaggc aatgactaca ttgtccctcg 1020
gcactgcccg gagctggcgg agatgagccg ggtgtccata cgcatccttg acgagctggt 1080
gctgcccttc caggagctgc agatcgatga caatgagtat gcctacctca aagccatcat 1140
cttctttgac ccagatgcca aggggctgag cgatccaggg aagatcaagc ggctgcgttc 1200
ccaggtgcag gtgagcttgg aggactacat caacgaccgc cagtatgact cgcgtggccg 1260
ctttggagag ctgctgctgc tgctgcccac cttgcagagc atcacctggc agatgatcga 1320
gcagatccag ttcatcaagc tcttcggcat ggccaagatt gacaacctgt tgcaggagat 1380
gctgctggga gggtccccca gcgatgcacc ccatgcccac caccccctgc accctcacct 1440
gatgcaggaa catatgggaa ccaacgtcat cgttgccaac acaatgccca ctcacctcag 1500
caacggacag atgtccaccc ctgagacccc acagccctca ccgccaggtg gctcagggtc 1560
tgagccctat aagctcctgc cgggagccgt cgccacaatc gtcaagcccc tctctgccat 1620
cccccagccg accatcacca agcaggaagt tatctagcaa gccgctgggg cttgggggct 1680
ccactggctc cccccagccc cctaagagag cacctggtga tcacgtggtc acggcaaagg 1740
aagacgtgat gccaggacca gtcccagagc aggaatggga aggatgaagg gcccgagaac 1800
atggcctaag ggccacatcc cactgccacc cttgacgccc tgctctggat aacaagactt 1860
tgacttgggg agacctctac tgccttggac aacttttctc atgttgaagc cactgccttc 1920
accttcacct tcatccatgt ccaacccccg acttcatccc aaaggacagc cgcctggaga 1980
tgacttgagg ccttacttaa acccagctcc cttcttccct agcctggtgc ttctcctctc 2040
ctagcccctg tcatggtgtc cagacagagc cctgtgaggc tgggtccaat tgtggcactt 2100
ggggcacctt gctcctcctt ctgctgctgc ccccacctct gctgcctccc tctgctgtca 2160
ccttgctcag ccatcccgtc ttctccaaca ccacctctcc agaggccaag gaggccttgg 2220
aaacgattcc cccagtcatt ctgggaacat gttgtaagca ctgactggga ccaggcacca 2280
ggcagggtct agaaggctgt ggtgagggaa gacgcctttc tcctccaacc caacctcatc 2340
ctccttcttc agggacttgg gtgggtactt gggtgaggat ccctgaaggc cttcaacccg 2400
agaaaacaaa cccaggttgg cgactgcaac aggaacttgg agtggagagg aaaagcatca 2460
gaaagaggca gaccatccac caggcctttg agaaagggta gaattctggc tggtagagca 2520
ggtgagatgg gacattccaa agaacagcct gagccaaggc ctagtggtag taagaatcta 2580
gcaagaattg aggaagaatg gtgtgggaga gggatgatga agagagagag ggcctgctgg 2640
agagcatagg gtctggaaca ccaggctgag gtcctgatca gcttcaagga gtatgcaggg 2700
agctgggctt ccagaaaatg aacacagcag ttctgcagag gacgggaggc tggaagctgg 2760
gaggtcaggt ggggtggatg atataatgcg ggtgagagta atgaggcttg gggctggaga 2820
ggacaagatg ggtaaaccct cacatcagag tgacatccag gaggaataag ctcccagggc 2880
ctgtctcaag ctcttcctta ctcccaggca ctgtcttaag gcatctgaca tgcatcatct 2940
catttaatcc tcccttcctc cctattaacc tagagattgt ttttgttttt tattctcctc 3000
ctccctcccc gccctcaccc gccccactcc ctcctaacct agagattgtt acagaagctg 3060
aaattgcgtt ctaagaggtg aagtgatttt ttttctgaaa ctcacacaac taggaagtgg 3120
ctgagtcagg acttgaaccc aggtctccct ggatcagaac aggagctctt aactacagtg 3180
gctgaatagc ttctccaaag gctccctgtg ttctcaccgt gatcaagttg aggggcttcc 3240
ggctcccttc tacagcctca gaaaccagac tcgttcttct gggaaccctg cccactccca 3300
ggaccaagat tggcctgagg ctgcactaaa attcacttag ggtcgagcat cctgtttgct 3360
gataaatatt aaggagaatt catgactctt gacagctttt ctctcttcac tccccaagtc 3420
aaggggaggg gtggcagggg tctgtttcct ggaagtcagg ctcatctggc ctgttggcat 3480
gggggtggga cagtgtgcac agtgtggggg caggggaggg ctaagcaggc ctgggtttga 3540
gggctgctcc ggagaccgtc actccaggtg cattctggaa gcattagacc ccaggatgga 3600
gcgaccagca tgtcatccat gtggaatctt ggtggctttg aggacattct ggaaaatgcc 3660
actgaccagt gtgaacaaaa gggatgtgtt atggggctgg aggtgtgatt aggtaggagg 3720
gaaactgttg gaccgactcc tgccccctgc tcaacactga cccctctgag tggttggagg 3780
cagtgcccca gtgcccagaa atcccaccat tagtgattgt tttttatgag aaagaggcgt 3840
ggagaagtat tggggcaatg tgtcagggag gaatcaccac atccctacgg cagtcccagc 3900
caagccccca atcccagcgg agactgtgcc ctgctcagag ctcccaagcc ttcccccacc 3960
acctcactca agtgcccctg aaatccctgc cagacggctc agcctggtct gcggtaaggc 4020
agggaggctg gaaccatttc tgggcattgt ggtcattccc actgtgttcc tccacctcct 4080
ccctccagcg ttgctcagac ctctgtcttg ggagaaaggt tgagataaga atgtcccatg 4140
gagtgccgtg ggcaacagtg gcccttcatg ggaacaatct gttggagcag ggggtcagtt 4200
ctctgctggg aatctacccc tttctggagg agaaacccat tccaccttaa taactttatt 4260
gtaatgtgag aaacacaaaa caaagtttac ttttttgact ctaagctgac atgatattag 4320
aaaatctctc gctctctttt tttttttttt tttttttttt ggctacttga gttgtggtcc 4380
taaaacataa aatctgatgg acaaacagag ggttgctggg gggacaagcg tgggcacaat 4440
ttccccacca agacaccctg atcttcaggc gggtctcagg agcttctaaa aatccgcatg 4500
gctctcctga gagtggacag aggagaggag agggtcagaa atgaacgctc ttctatttct 4560
tgtcattacc aagccaatta cttttgccaa atttttctgt gatctgccct gattaagatg 4620
aattgtgaaa tttacatcaa gcaattatca aagcgggctg ggtcccatca gaacgaccca 4680
catctttctg tgggtgtgaa tgtcattagg tcttgcgctg acccctgagc ccccatcact 4740
gccgcctgat ggggcaaaga aacaaaaaac atttcttact cttctgtgtt ttaacaaaag 4800
tttataaaac aaaataaatg gcgcatatgt tttctaagtc cttggataag tatcttttct 4860
ttcaggtatc agaaataaga ctgaatcttc tggttctact tgggggttaa aaaatttttt 4920
ttaaaggaag aatgagaata gttttatagt tctttgtgat gtgcagaatg tttttgtgtc 4980
cattataatt tttcagtctt cacatcaaga ggtaagcagt tagacatgat tactcccact 5040
ttccagatga ggagactgag gcttggggga agtgacttct cttggaaggc agaggtggac 5100
atctaaccct ggtctcttga ttccaagtac ttagtatatc gagagagtga aagttgatcc 5160
cccttcttga agaggggagt gatgagggga gagtgcaatg gcaagatctg gaagaatggc 5220
aagagggtcc aagggtctgt catcctccac caaggttcaa gacagaacct tttgctgggt 5280
cacctcaatc tgccagcaat ggaagatgag tagctgtggg gacatttcat aaaagcaagt 5340
ggtttttttg ttttgttttg ttttgttttt tgtttttttt tctagaacaa ggctgtgcac 5400
agtggctcac ctctgtaatc ccagcacttt gggaggctga ggcgggagga tcacttgagc 5460
tcaggagttc gagaccagcc agagcaatat aaggagaccc catctctaca aaaaatttaa 5520
aaattagcca ggtatagtgg tgtgtgccta tagtaccagc tactctgaag gctgaggtgg 5580
gaagattgct tcagcccagg agttcgagga tgcagtgagc tatgaatgca acactgcact 5640
acagcctgga tgaaagaaca agactctgtc tcaaaacata aataataagt aaaaagaata 5700
aaagcaagag atgcacttga gaatctccag ccagatctgt agccactggg cttctctcca 5760
aggctaaact attacaggag ggtggccttg tgtctcggtc accacagacc acagcgttcc 5820
attcactcgg ggttgtgctg gagctggctt gtgagaactg actgttagct tctcttccca 5880
actccatgtt tgccagtgcc acactgatag cttgaaattg gttattgccg gagtgtttac 5940
accacaagga ctagcaaact ctacaaatcc gggcttttgt tcctggagag cccgttgtta 6000
acattcacca gcacaccaca gcattcggca atggctggac catgggatgc ctacatatgg 6060
ggacatcctc cttggggatg agggtagagc agggcgatcc tttcacctct tccttaaggg 6120
aggggacaaa agttctggtc tgggaagcac acgttttgct gatcagcgta accttgggca 6180
ggtcactcca ccactccgag cctcatctgt aaagtgggaa tgatatctcc ctccagggca 6240
gatgtcagga ttcaatggaa tgagatcaca gtaactgtga gagctcccgt tacatgagga 6300
gtacaagtga actcttcatg cgcccctttt tagcgagaag ttaaccatta aactctccag 6360
gcttcagagc acccattcgc tgtctacctg atccctaggg ccgctcccgc cttcccctgt 6420
gccttccctc cactagtcag caccaggaaa tgttttcgat aacgttgcaa cggaggcctt 6480
gttcatgctg ccgccatcgg ggacaagcgc gggggggggg gggtggaggc cagaggagac 6540
tatttcagtc ctaaattgtg cttaataaac ccatatcaaa accataaa 6588
Claims (34)
- PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군에서 선택된 하나 이상의 전사 인자의 양 또는 기능을 증가시키는 조성물을 대상체에 투여하는 단계를 포함하는, 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하는 방법.
- 제1항에 있어서, 상기 조성물은 벡터이고, 상기 벡터는 PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C 중 하나 이상을 암호화하는 하나 이상의 핵산을 포함하는 것인, 방법.
- 제1항에 있어서, 상기 조성물은 벡터이고, 상기 벡터는 PROX1 및/또는 SREBP1을 암호화하는 하나 이상의 핵산을 포함하는 것인, 방법.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 상기 하나 이상의 핵산은 DNA 또는 RNA인, 방법.
- 제1항 내지 제4항 중 어느 한 항에 있어서, 상기 조성물의 투여가 대상체의 간세포의 핵에서 HNF4α의 양을 증가시키는 것인, 방법.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 조성물의 투여가 간세포에서 HNF4α의 총량을 증가시키지 않는 것인, 방법.
- 제1항 내지 제6항 중 어느 한 항에 있어서, 상기 조성물의 투여가 간세포에서 HNF4α의 총량을 증가시키는 것인, 방법.
- 제1항 내지 제7항 중 어느 한 항에 있어서, 상기 벡터가 HNF4α을 암호화하는 핵산을 더 포함하는 것인, 방법.
- 제1항 내지 제7항 중 어느 한 항에 있어서, HNF4α를 암호화하는 핵산을 포함하는 벡터를 대상체에게 투여하는 단계를 더 포함하는, 방법.
- 제8항 또는 제9항에 있어서, 상기 핵산은 HNF4α 이소형 2 (P1)을 암호화하는 것인, 방법.
- 제8항 또는 제9항에 있어서, 상기 HNF4α를 암호화하는 핵산은 서열번호 1을 포함하는 것인, 방법.
- 제1항 내지 제11항 중 어느 한 항에 있어서, 상기 간 질환은 간 섬유증, 간경변, 간암 또는 말기 간 질환인, 방법.
- 제1항 내지 제12항 중 어느 한 항에 있어서, 상기 간 질환은 간경변인, 방법.
- 제1항 내지 제13항 중 어느 한 항에 있어서, 상기 대상체는 인간인, 방법.
- DNAJB1/HSP40, ATF6, ATF4, 및 PERK으로 이루어진 군으로부터 선택된 하나 이상의 전사 인자의 양을 감소시키거나 기능을 억제시키는 조성물을 대상체에 투여하는 단계를 포함하는, 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하는 방법.
- 제15항에 있어서, 상기 조성물은 핵산인, 방법.
- 제16항에 있어서, 상기 핵산은 DNA 또는 RNA인, 방법.
- 제15항 내지 제17항 중 어느 한 항에 있어서, 상기 조성물의 투여가 대상체의 간세포의 핵에서 HNF4α의 양을 증가시키는 것인, 방법.
- 제15항 내지 제18항 중 어느 한 항에 있어서, 상기 조성물의 투여가 간세포에서 HNF4α의 총량을 증가시키지 않는 것인, 방법.
- 제15항 내지 제19항 중 어느 한 항에 있어서, 상기 조성물의 투여가 간세포에서 HNF4α의 총량을 증가시키는 것인, 방법.
- 제15항 내지 제20항 중 어느 한 항에 있어서, 상기 조성물은 HNF4α를 암호화하는 핵산을 더 포함하는 것인, 방법.
- 제15항 내지 제21항 중 어느 한 항에 있어서, HNF4α를 암호화하는 핵산을 포함하는 벡터를 대상체에게 투여하는 단계를 더 포함하는, 방법.
- 제21항 또는 제22항에 있어서, 상기 핵산은 HNF4α 이소형 2를 암호화하는 것인, 방법.
- 제21항 또는 제22항에 있어서, 상기 HNF4α를 암호화하는 핵산은 서열번호 1을 포함하는 것인, 방법.
- 제15항 내지 제24항 중 어느 한 항에 있어서, 상기 간 질환은 간 섬유증, 간경변, 간암 또는 말기 간 질환을 포함하는 것인, 방법.
- 제15항 내지 제25항 중 어느 한 항에 있어서, 상기 대상체는 인간인, 방법.
- PROX1, NR5A2, NR0B2, MTF1, SREBP1, EP300, 및 POM121C로 이루어진 군으로부터 선택된 하나 이상의 전사 인자, 및 그의 기능적 단편을 암호화하는 하나 이상의 핵산을 포함하는 벡터를 포함하는 조성물.
- 제27항에 있어서, HNF4α를 암호화하는 핵산을 포함하는 또 다른 벡터를 더 포함하는 조성물.
- 제28항에 있어서, 상기 HNF4α를 암호화하는 핵산은 서열번호 1을 포함하는 것인, 조성물.
- HNF4α 이소형 2를 암호화하는 핵산을 포함하는 벡터를 대상체에 투여하는 단계를 포함하는, 간 질환의 치료를 필요로 하는 대상체에서 간 질환을 치료하는 방법.
- 제30항에 있어서, 상기 핵산은 서열번호 1을 포함하는 것인, 방법.
- 제30항 또는 제31항에 있어서, 상기 간 질환은 간 섬유증, 간경변, 간암 또는 말기 간 질환인, 방법.
- 제32항에 있어서, 상기 간 질환은 간경변인, 방법.
- 제30항 내지 제33항 중 어느 한 항에 있어서, 상기 대상체는 인간인, 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201962915765P | 2019-10-16 | 2019-10-16 | |
| US62/915,765 | 2019-10-16 | ||
| PCT/US2020/055500 WO2021076566A1 (en) | 2019-10-16 | 2020-10-14 | Compositions and methods for treating liver disease |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220101631A true KR20220101631A (ko) | 2022-07-19 |
Family
ID=75538048
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227016178A KR20220101631A (ko) | 2019-10-16 | 2020-10-14 | 간 질환 치료를 위한 조성물 및 방법 |
Country Status (13)
| Country | Link |
|---|---|
| US (1) | US20220362405A1 (ko) |
| EP (1) | EP4045094A4 (ko) |
| JP (1) | JP2022551987A (ko) |
| KR (1) | KR20220101631A (ko) |
| CN (1) | CN115209923A (ko) |
| AU (1) | AU2020367770A1 (ko) |
| BR (1) | BR112022007252A2 (ko) |
| CA (1) | CA3154460A1 (ko) |
| CL (1) | CL2022000967A1 (ko) |
| IL (1) | IL292221A (ko) |
| MX (1) | MX2022004625A (ko) |
| WO (1) | WO2021076566A1 (ko) |
| ZA (1) | ZA202205289B (ko) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20230056669A (ko) | 2020-07-27 | 2023-04-27 | 안자리움 바이오사이언시스 아게 | Dna 분자의 조성물, 이의 제조 방법 및 이의 사용 방법 |
| EP4460336A1 (en) * | 2022-01-06 | 2024-11-13 | University of Pittsburgh - of The Commonwealth System of Higher Education | Transcriptional therapy based-lipid nanoparticles and mrna for the treatment of end-stage liver disease |
| WO2023214405A1 (en) * | 2022-05-01 | 2023-11-09 | Yeda Research And Development Co. Ltd. | Reexpression of hnf4a to alleviate cancer-associated cachexia |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9981048B2 (en) * | 2013-02-12 | 2018-05-29 | University of Pittsburgh—of the Commonwealth System of Higher Education | Methods for the treatment and prevention of liver disease |
| US9682123B2 (en) * | 2013-12-20 | 2017-06-20 | The Trustees Of Columbia University In The City Of New York | Methods of treating metabolic disease |
| WO2016086227A2 (en) * | 2014-11-26 | 2016-06-02 | The Regents Of The University Of California | Therapeutic compositions comprising transcription factors and methods of making and using the same |
| CN105521482B (zh) * | 2015-12-22 | 2020-07-14 | 中国人民解放军第二军医大学 | 联合应用HNF1α、HNF4α、FOXA3诱导分化治疗肝细胞癌 |
| WO2020198485A1 (en) * | 2019-03-26 | 2020-10-01 | The Penn State Research Foundation | Methods and materials for treating cancer |
-
2020
- 2020-10-14 WO PCT/US2020/055500 patent/WO2021076566A1/en unknown
- 2020-10-14 US US17/769,886 patent/US20220362405A1/en active Pending
- 2020-10-14 EP EP20877983.5A patent/EP4045094A4/en active Pending
- 2020-10-14 AU AU2020367770A patent/AU2020367770A1/en active Pending
- 2020-10-14 MX MX2022004625A patent/MX2022004625A/es unknown
- 2020-10-14 CA CA3154460A patent/CA3154460A1/en active Pending
- 2020-10-14 CN CN202080084749.2A patent/CN115209923A/zh active Pending
- 2020-10-14 BR BR112022007252A patent/BR112022007252A2/pt not_active Application Discontinuation
- 2020-10-14 JP JP2022522789A patent/JP2022551987A/ja active Pending
- 2020-10-14 KR KR1020227016178A patent/KR20220101631A/ko active Search and Examination
-
2022
- 2022-04-13 IL IL292221A patent/IL292221A/en unknown
- 2022-04-14 CL CL2022000967A patent/CL2022000967A1/es unknown
- 2022-05-12 ZA ZA2022/05289A patent/ZA202205289B/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| ZA202205289B (en) | 2024-09-25 |
| AU2020367770A1 (en) | 2022-05-19 |
| EP4045094A1 (en) | 2022-08-24 |
| IL292221A (en) | 2022-06-01 |
| CN115209923A (zh) | 2022-10-18 |
| CL2022000967A1 (es) | 2023-03-24 |
| BR112022007252A2 (pt) | 2022-08-23 |
| WO2021076566A1 (en) | 2021-04-22 |
| EP4045094A4 (en) | 2024-02-21 |
| JP2022551987A (ja) | 2022-12-14 |
| MX2022004625A (es) | 2022-07-11 |
| US20220362405A1 (en) | 2022-11-17 |
| CA3154460A1 (en) | 2021-04-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU2020270508B2 (en) | C/EBP alpha short activating RNA compositions and methods of use | |
| KR102301464B1 (ko) | 종양 세포에 의한 면역 억제를 감소시키기 위한 방법 및 조성물 | |
| AU2023274083A1 (en) | Compositions and methods for treating non-age-associated hearing impairment in a human subject | |
| CN113490850A (zh) | 用于治疗乳腺癌的诊断和治疗方法 | |
| AU2008286361B2 (en) | IVIG modulation of chemokines for treatment of multiple sclerosis, Alzheimer's disease, and Parkinson's disease | |
| KR20120082906A (ko) | 자가포식현상-향상 유전자 생성물의 조절을 통한 자가포식현상의 조절 방법 | |
| KR20160027968A (ko) | Foxp3 발현을 조절하기 위한 조성물 및 방법 | |
| KR20110036608A (ko) | 유방암 위험도 평가를 위한 유전적 변이 | |
| KR20220101631A (ko) | 간 질환 치료를 위한 조성물 및 방법 | |
| KR20230124915A (ko) | 세포 사멸 유도 dffa 유사 이펙터 b(cideb) 억제제를 이용한 간 질환의 치료 | |
| TW202309274A (zh) | 產生成熟角膜內皮細胞之方法 | |
| WO2021183218A1 (en) | Compositions and methods for modulating the interaction between ss18-ssx fusion oncoprotein and nucleosomes | |
| KR102195319B1 (ko) | 상처치료제 스크리닝용 조성물 및 이를 이용한 상처 치료제 스크리닝 방법 | |
| KR20190126812A (ko) | 질환 진단용 바이오마커 | |
| US20230035235A1 (en) | Swi/snf family chromatin remodeling complexes and uses thereof | |
| JP2022512921A (ja) | 有毛細胞の分化を誘導する組成物及び方法 | |
| US20220265798A1 (en) | Cancer vaccine compositions and methods for using same to prevent and/or treat cancer | |
| AU2013276992B2 (en) | IVIG Modulations of Chemokines for Treatment of Multiple Sclerosis, Alzheimer's Disease, and Parkinson's Disease | |
| KR101104105B1 (ko) | 대장암 진단용 조성물 및 그 용도 | |
| KR20110036559A (ko) | 대장암 진단용 조성물 및 그 용도 | |
| KR20110036560A (ko) | 대장암 진단용 조성물 및 그 용도 | |
| KR20110036561A (ko) | 대장암 진단용 조성물 및 그 용도 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination |