> Will Intel share specific manufacturing dates and serial number ranges for the oxidized processors so mission-critical businesses can selectively rip and replace?
> Intel will continue working with its customers on Via Oxidation-related reports and ensure that they are fully supported in the exchange process.
Intel is refusing to disclose serial number ranges of the fundamentally defective processors?
Followup question: How do owners of that series of CPU, who suspect theirs is one of the defective units, exchange it for a non-defective CPU before it fails?
Something similar happened a few years back with the Atom CPUs. The downside is that these were typically found soldered on expensive devices like Cisco routers, firewalls, etc. The company I was working at the time had to RMA a ton of devices that could be faulty. I thought for sure that this would result in earnings hits and lawsuits but none of that seemed to happen.
I had high hopes for Pat Gelsinger too. I suspect most management expects the consequences of short-sighted corporate culture to manifest in products as maybe a 1% failure rate within 90 days of sale, not a 25%+ failure rate slowly manifesting over more than a year. The former is the cost of doing business, the latter is an existential problem. I suspect Gelsinger didn't know about it and lower management buried it thinking it was a <1% problem, and he's only found out about it as it's become clear what a massive problem it is.
When Gelsinger promised (in 2021) zettaflop systems by 2027, although there is still time, it seemed so absurdly optimistic that it is hard to trust anything he says.
However, I think people really want to give him a chance on his long term plans to make Intel competitive again.
Interesting. I bought a 13900 (non-k) in mid April this year for a new server build. It ran fine for a couple of weeks and then started randomly crashing. Having never had a cpu go bad on me before and not having another one laying around to test with, it took me a long time to figure out what the issue was. Finally, by the end of May, I had ruled everything else out and RMA’d it. The system has been running fine ever since.
I assumed I had just got a bad unit. Now I’m wondering if this might have been the cause.
Prediction: Intel is stalling the recall until after the earnings report to avoid tanking the stock.
Glad I switched to using AMD. Although some RUMINT indicating quality assurance troubles in 9000 series though. They were supposed to push out new product by end of July. But delayed to mid August.
> Glad I switched to using AMD. Although some RUMINT indicating quality assurance troubles in 9000 series though. They were supposed to push out new product by end of July. But delayed to mid August.
I had a theory that the "quality issues" are a marketing ploy (see? we don't send customers bad products, unlike those other guys) combined with an excuse to delay the release date (and thus the review embargo date) until after the proposed Intel microcode release, since the updated microcode was expected to negatively impact Intel in the performance comparison.
Is there any RUMINT about specifically why it's delayed? The delay itself is not RUMINT, and it's obviously some QA issue, but beyond that?
The only rumors I've seen are generic guesses: something AMD wasn't screening for, maybe coincidence, or maybe detected after the Intel mess sent AMD's QA teams scurrying to make sure they don't have any similar issues.
It could even be a combined issue with 3rd-party motherboards with AMD's new chipsets, the combination of which they wouldn't have been able to thoroughly test much earlier.
Isn't RUMINT on the Intel problem that, even though it's nominally a chip problem, it may occur primarily due to motherboards not following guidance? For instance, if a spec says the chip and mobo should lower max voltage by 100mV under certain conditions, but the chip still sometimes requests the full original voltage under those conditions, and the mobo provides it, whose fault is that? Maybe not exclusively Intel's, depending on how the specs are documented (a classic should vs must issue).
It seems likely that small process sizes and pushing the limits of performance are going to cause more problems like this Intel one. Notice Intel didn't have this problem before they had to push their chips to compete against the high-end Ryzens.
There hasn't been anything official but there were rumors about some reviewers got unexpectedly bad performance that AMD narrowed down to bad packaging for the SOC die.
If it is the SOC it doesn't have anything to do with pushing nodes as it's on a larger node and the soc itself should be a mature architecture because it's reused from zen 4
AMD has its issues too, from time to time. I even replaced a processor through them once. As chip complexity increases, both companies are going to have these issues more often. The solution is to let other people be guinea pigs for a year.
The headline isn't clear, but the claim so far is that the microcode update will fix any CPUs that haven't begun exhibiting instability. Nothing can fix the ones that are already broken. For those that are somewhere in between, hope it fails within the warranty period I guess.
The way I understand it, they had a bug that will run the CPU on higher voltage than the hardware can tolerate.
Those who pushed the limits physically damaged their CPU and these are now cooked. The microcode update will limit the voltage, which will result in degraded performance but will prevent damage under load.
You mean everyone who owns a motherboard from a manufacturer that was given unclear guidance on power delivery from Intel, but also encouraged to make sure their boards benchmarked competitively (by providing enough voltage for clock boosts)? That's pretty much every enthusiast.
Right, so maybe a better phrasing would be: They had a design flaw and the voltage they run the CPU would actually be over the limits of what the hardware can tolerate.
Those who pushed their CPU to its maximum loads damaged their CPU physically and these are now cooked. The microcode update will limit the voltage, which will result in degraded performance but will prevent damage under load.
Level One Techs' Wendell was saying the same thing after asking companies running server farms independently. Both got some sketchily-high numbers, in the 25-50% range. This is only looking worse for Intel as days go by.
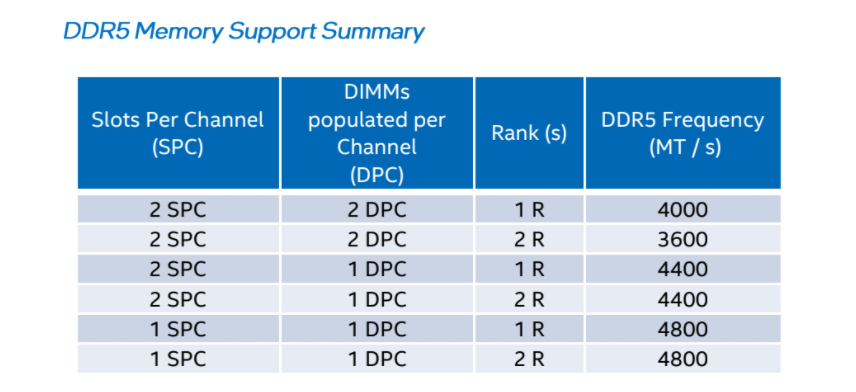
Server boards don’t mean it’s being run in-spec. The workstation boards will let you configure many parameters out-of-spec and in fact some vendors will configure them out-of-spec by default. For example W680 is definitely capable of configuring memory speeds higher than the official spec (which is only 4400 for any quad-slot board even if not fully populated!). But also things like disabling the current limiting or setting an increased or unlimited power limit.
Insofar as GN was saying that, it was because Steve was out of his depth and Wendell has had to go out of his way to correct this in subsequent interviews like the one with Ian Cutress. Not the first or the last time GN makes an innocent (or overtly malicious, in some cases) journalistic boo-boo. Not even the first problem with their coverage of this topic, in fact.
People are letting the outrage way overtake the facts here. And this includes the tech media themselves. No, it’s not in-spec just because it’s a server board with w680. Actually asus in particular was shipping with very out-of-spec defaults.
People don’t like it when IHVs keep the partners on a short leash. People literally whined about nvidia capping the voltage on Turing, for example. And then things happen (like this, or like AMD’s problems last year with chips physically exploding and deforming from over voltage) and people indignantly ask why the IHVs were allowed to do these things.
At the time people said this was utter crap, everyone knows electromigration isn’t really a big deal and takes years to even slightly affect anything, assuming it ever does at all. Like you have to really cook a modern processor, like 4.7 GHz sandy bridge for a couple years.
2-3 prompt-electromigration disasters later, it appears that maybe “the community” doesn’t actually have a particularly firm grasp of silicon aging mechanics. Or gpu costs/economics, for that matter ;)
That's a legitimate strategy for some Amazon trinkets but CPUs are a major purchase for most people such that they won't likely let them sit in a closet beyond the warranty period.
I was similarly peeved with AMD a few years ago. There was a window of time where an AMD chip would not work with many deployed motherboards. AMD would ship you a loaner, outdated chip so you could boot the motherboard and apply the latest compatible BIOS.
Knowing this, I felt confident to purchase a certain configuration. Parts arrive and I reached out to AMD support for my loaner chip. They gave me the third degree. Insisted I provided documentation of previous attempts to reach out to the motherboard manufacturer before they would lift a finger. So, reach out to the manufacturer and say I am an idiot who cannot read the compatibility warning slathered all over their product material? I was furious at what was an obvious roadblock to not deliver on their support promise.
I feel like the language is intentionally vague and intended to link the voltage issue with the oxidization issue. However, I would not feel comfortable knowing my chip may randomly become unstable way before the expected end of life.
What a mess. Intel should be out in front of this, but they are going to kick the can down the road and hope some of the problem goes away.
No system integrator has the infrastructure to handle replacing vast numbers of CPU's and entire systems where the CPU is soldered to the mainboard and cannot be replaced.
Also, there's no way this problem suddenly snuck up on them without warning. They had customers returning massive numbers of them, but Intel kept selling defective units instead of stopping production. They absolutely knew about this as soon as problems started popping up.
A microcode patch may make it stable, but if you have a dud, you have a dud. There's no way to patch around defects in manufacturing of this nature. Microcode can reduce frequencies, but a defective part is still defective.
Unless they have specific evidence to delineate heat damage from excessive voltages and "oxidation" from a manufacturing process, then they're just playing coy at admitting their chips are burning out.
Try to avoid using it until the microcode fix in a week or two. If you bought it last week, you probably haven't used it enough to permanently damage anything from the voltage issue yet.
Keep careful watch of problems in the future: the oxidation issue for the 13th gen is a physical defect not fixable by the microcode update, but we don't know how widespread it is yet (and Intel is keeping mum). If possible, it might well be worth returning and getting a 14th gen chip, which doesn't suffer from the latter problem and the former will be fixed by microcode.
No known safety issue. Both issues (the overvoltage in both 13 and 14 gen chips, and the oxidation that's limited to 13th gen) lead to system instability. How quickly these occur is unknown from the Intel reports. Claims are as little as a few weeks, but independent verification is needed on that one.
Good question, if you set any obvious power limit in the BIOS to say 10-20% below the advertised TDP*, would that bring the actual voltages down or would it just underclock the CPU but still use the same dangerous voltages?
Or do you need to go through every obscure voltage setting and bring it down? Will even that be obeyed?
* which has no connection to the real TDP but at least it will tell the CPU ... something ...
The microcode update will probably be automatic but it might also be distributed as a bios update.
Realistically there’s no way to tell if you have an affected unit or not (Intel hasn't provided any information that would help). Nor is there any guarantee that the microcode update will prevent future issues. It appears that there is both microcode and manufacturing issues at play here.
I've seen multiple rumor-style explanations to this issue, including:
- it may have to do with oxidation of metallic copper deposited inside through-sillicon via(TSV)
- it may have to do with improper connection between die and substrate(that hard green plate) causing higher resistance and temperature somewhere, which is by the way the true limiting factor for socket Tjmax
- it could have to do with VCORE values used to meet the performance target being too high for the on-die ring bus logic including L1
- it is possibly related to big-little heterogeneous configuration and how voltages for big-core and little-core/uncore/IO are generated
- I've heard they had an HVAC outage in one of US fabs and it ruined some dies
- Yeah they just flew too close to the Sun, frankly
- ...
I have absolutely no skin in this game, and my question is: are there any more plausible technobabbly stories around? It all sounds intriguing to me. Some of it could be correct or relevant.
Tell that to my 2950x, the thing is a heap of garbage...
80% of the time it won't boot at xmp memory speeds...
If it does, it trashes the pcie bus during boot...
Either way, I also had to turn off ASPM, because my nvme drives will crash during boot, or shortly afterwards...
Then there's all the random amdgpu errors it also throws, it's better with everything turned off, but the machine is basically on life support until I can build a new PC.
Maybe off topic but I am old enough that I remember when AMD were inferior and should be avoided. It is one point in the famous "Is your son a computer hacker [1]
> If your son has requested a new "processor" from a company called "AMD", this is genuine cause for alarm. AMD is a third-world based company who make inferior, "knock-off" copies of American processor chips
Other than the chips that are significantly damaged prior to the updated microcode, why should this be treated differently from the meltdown saga? Fixes for that required significant slowdowns, except in niche applications with trustworthy code or air-gapped systems such that the vulnerability could be ignored. No Recall. Class actions ongoing, but everyone's mostly forgotten about them.
More conservative voltages will only lead to small (low single-digit) performance decreases, right? Isn't that less significant a performance hit than meltdown countermeasures? The only way I can imagine performance really tanking would be if Intel has to severely down-rate supported memory speeds as well, if the ring bus can't handle higher memory speeds at slightly reduced voltages.
{kind=link}
> Intel will continue working with its customers on Via Oxidation-related reports and ensure that they are fully supported in the exchange process.
Intel is refusing to disclose serial number ranges of the fundamentally defective processors?
Followup question: How do owners of that series of CPU, who suspect theirs is one of the defective units, exchange it for a non-defective CPU before it fails?
reply