Home
This repository contains documentation and implementation guidelines for a proof-of-concept linked data infrastructure for describing, relating, and exposing information about diverse information resources relevant to UN SDGs: SDG entities, data series, documents, reference taxonomies and identifiers.
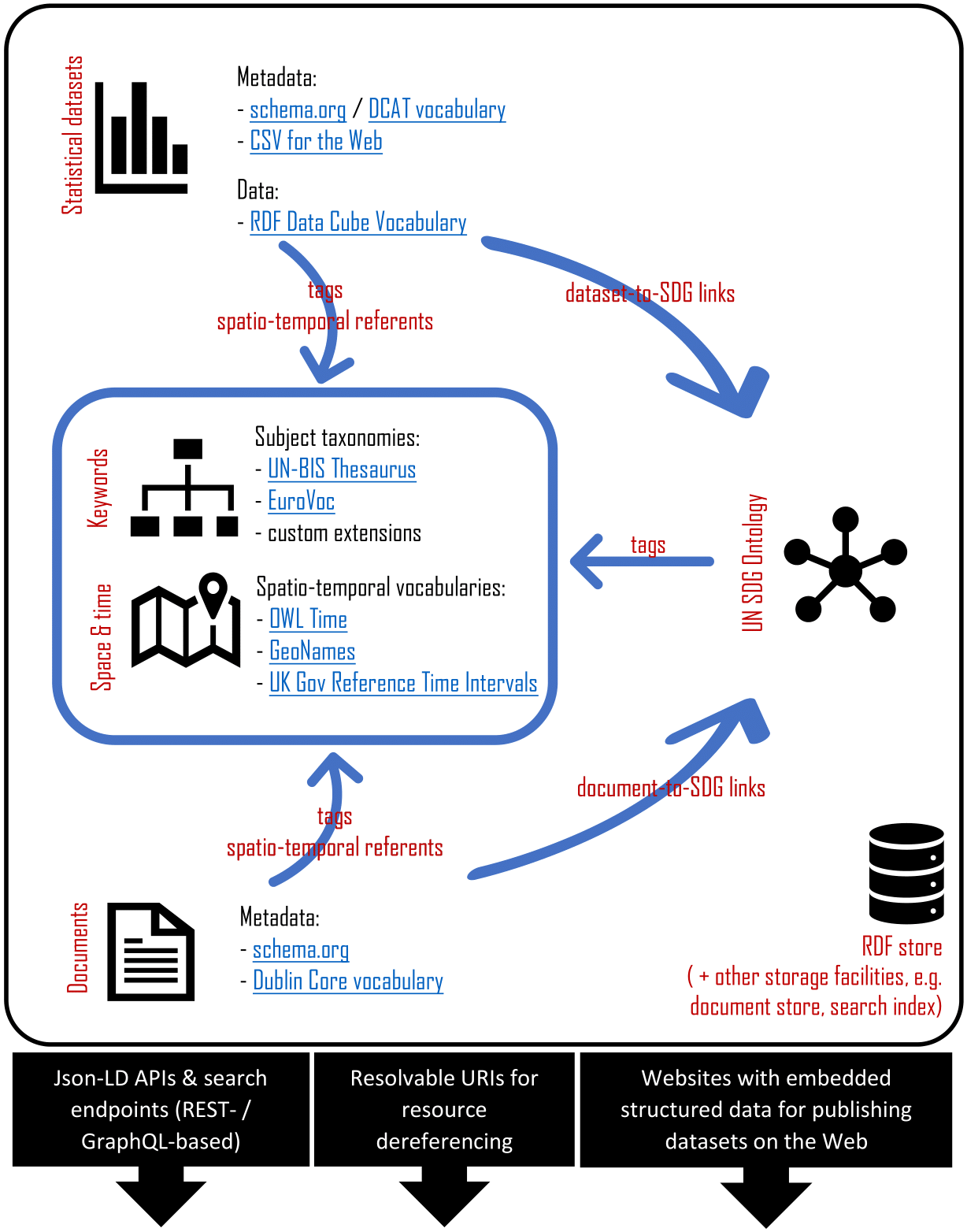
Building on the principles of linked data, the proposed infrastructure employs a selection of broadly supported, machine-accessible vocabularies, identifiers, and service types for representing and sharing the meaning of the information resources over the Web. It covers aspects described in an accompanying concept note and illustrated in the following diagram:
The three major themes and more specific aspects and use-cases associated with them that have been generally considered in scoping this PoC have been as follows:
I. DATASET DESCRIPTION
This theme is concerned with expressing and utilizing metadata over a dataset in order to enable discoverability of that dataset and facilitating interpretation of its content / provenance / scope, etc, in external or internal search and integration services.
- using schema.org or DCAT annotations tailored towards Google Dataset Search, as described in Google's guidelines.
- using CSV for the Web (CSVW) (a semantic approach to describing CSV tables)
- tagging datasets with concepts from relevant taxonomies (UN-BIS + EuroVoc) for describing the general content and context of the dataset
- facilitating registration of datasets and their description using interactive tools publishing static websites with structured data embedding for the registered datasets, in ordered to be crawled and indexed by major search engines.
II. DATA DESCRIPTION
This theme is concerned with representing and serving/consuming statistical data in a fully-fledged linked data-compliant formats and environments.
- using RDF Data Cube Vocabulary, SCOVO vocabulary, and general good practice recommendations, building up on current and previous experiences of several National Statistics Offices
- determining a set of reference identifiers for representing specific (and shared across different datasets) dimensions of data (e.g., temporal, spatial, conceptual, etc.); setting up a service and relevant vocabularies to serve and reference such identifiers form RDF Cube datasets
- aiming to serve the disaggrergated data as valid JSON-LD objects.
- serving statistical data (as RDF in JSON-LD) using GraphQL.
III. CONTENT LINKING
This theme is about effectively linking different types of content in a meaningful and useful manner, based on semantic annotations provided on different levels.
- determining similarity/relatedness of different content items based on their semantic annotations, e.g.:
- finding out which datasets are relevant to which SDG indicators based on the taxonomy tags
- linking unstructured documents (e.g. in the legal domain) to statistical datasets and SDG indicators based on the (semi-) automatically extracted concepts
- facilitating semantic search over the existing resources combining different techniques exploiting features of semantic (structured) and unstructured data (e.g., text, keyword frequencies, etc) understanding and exploring the complementary role of other AI technologies in supporting those tasks (e.g., NLP & concept extraction, data mining, etc)