데이터 모델
Data model데이터 모델은 데이터의 요소를 구성하고 그것들이 서로 및 실제 실체의 속성과 어떻게 관련되어 있는지를 표준화하는 추상 모델입니다.예를 들어, 데이터 모델은 자동차를 나타내는 데이터 요소가 차량의 색상과 크기를 나타내는 다른 여러 요소로 구성되도록 지정하고 소유자를 정의할 수 있다.
데이터 모델이라는 용어는 구별되지만 밀접하게 관련된 두 가지 개념을 나타낼 수 있습니다.특정 애플리케이션 도메인(예: 제조 조직에서 발견된 고객, 제품 및 주문)에서 발견된 개체와 관계를 추상적으로 공식화하는 것을 의미할 수 있습니다.또한 엔티티, 속성, 관계 또는 표와 같은 개념을 정의하는 데 사용되는 일련의 개념을 가리킵니다.따라서 은행 애플리케이션의 "데이터 모델"은 기업-관계 "데이터 모델"을 사용하여 정의할 수 있다.이 글은 두 가지 의미로 그 용어를 사용한다.

데이터 모델은 데이터의 구조를 명시적으로 결정한다.데이터 모델은 일반적으로 데이터 전문가, 데이터 라이브러리 관리자 또는 디지털 인문학 학자에 의해 데이터 모델링 표기법으로 지정됩니다.이러한 표기는 그래픽 형식으로 [7]표시되는 경우가 많습니다.
데이터 모델은 특히 프로그래밍 언어의 맥락에서 데이터 구조라고 할 수 있습니다.데이터 모델은 특히 엔터프라이즈 모델의 맥락에서 기능 모델로 보완되는 경우가 많습니다.
개요
대량의 정형 및 비정형 데이터를 관리하는 것은 정보 시스템의 주요 기능입니다.데이터 모델은 관계형 데이터베이스와 같은 데이터 관리 시스템에 저장된 데이터의 구조, 조작 및 무결성 측면을 설명합니다.또한 워드프로세서 문서, 이메일메시지, 사진, 디지털오디오, 비디오 등 보다 느슨한 구조로 데이터를 기술할 수도 있습니다.예를 들어 XDM은 XML 문서의 데이터 모델을 제공합니다.
데이터 모델의 역할

데이터 모델의 주된 목적은 데이터의 정의와 형식을 제공함으로써 정보 시스템의 개발을 지원하는 것이다.West and Fowler(1999)에 따르면 "이것이 시스템 전체에서 일관되게 수행된다면 데이터의 호환성이 달성될 수 있다.데이터를 저장 및 액세스하는 데 동일한 데이터 구조가 사용되는 경우 서로 다른 응용 프로그램이 데이터를 공유할 수 있습니다.이 결과는 위에 나와 있습니다.그러나 시스템과 인터페이스는 구축, 운영 및 유지 보수에 필요한 비용보다 더 많이 듭니다.또한 비즈니스를 지원하기보다는 제약할 수도 있습니다.주요 원인은 시스템과 인터페이스에 구현된 데이터 모델의 품질이 떨어진다는 것입니다."[8]
- "특정 장소에서 작업을 수행하는 방법에 대한 비즈니스 규칙은 종종 데이터 모델의 구조에서 고정됩니다.즉, 비즈니스 수행 방식의 작은 변화가 컴퓨터 시스템과 인터페이스의 큰 변화를 가져온다는 것입니다."[8]
- 엔티티 유형이 식별되지 않거나 잘못 식별되는 경우가 많습니다.이로 인해 데이터, 데이터 구조 및 기능의 복제와 함께 개발 및 유지보수에 따른 비용이 발생할 수 있습니다."[8]
- 「시스템 마다 데이터 모델이 임의로 다릅니다.그 결과 데이터를 공유하는 시스템 간에 복잡한 인터페이스가 필요합니다.이러한 인터페이스는 현재 시스템 비용의 25~70%를 차지할 수 있습니다."[8]
- 데이터의 구조와 의미가 표준화되지 않았기 때문에 고객 및 공급업체와 데이터를 전자적으로 공유할 수 없습니다.예를 들어, 프로세스 플랜트의 엔지니어링 설계 데이터와 도면이 여전히 서류로 교환되는 경우가 있습니다."[8]
이러한 문제가 발생하는 이유는 데이터 모델이 비즈니스 요구를 충족하고 [8]일관성을 유지할 수 있는 표준이 부족하기 때문입니다.
데이터 모델은 데이터의 구조를 명시적으로 결정한다.데이터 모델의 일반적인 응용 프로그램에는 데이터베이스 모델, 정보 시스템 설계 및 데이터 교환이 포함됩니다.일반적으로 데이터 모델은 데이터 모델링 언어로 지정됩니다.[3]
3가지 관점

데이터 모델인스턴스는 1975년 [9]ANSI에 따라 다음 세 가지 종류 중 하나입니다.
- 개념 데이터 모델: 모델의 범위인 도메인의 의미론을 설명합니다.예를 들어, 조직이나 산업의 관심 분야 모형일 수 있습니다.이것은 도메인에서 중요한 종류의 것을 나타내는 엔티티 클래스와 엔티티 클래스 쌍 간의 연관성에 대한 관계 어설션으로 구성됩니다.개념 스키마는 모델을 사용하여 표현할 수 있는 사실 또는 명제의 종류를 지정합니다.그런 의미에서 모델의 범위에 의해 제한된 범위를 가진 인위적인 '언어'에서 허용되는 표현을 정의합니다.
- 논리 데이터 모델: 특정 데이터 조작 기술로 표현되는 의미론을 설명합니다.이것은 테이블과 컬럼, 객체 지향 클래스 및 XML 태그 등의 설명으로 구성됩니다.
- 물리적 데이터 모델: 데이터를 저장하는 물리적 방법을 설명합니다.이는 파티션, CPU, 테이블스페이스 등과 관련이 있습니다.
ANSI에 따르면, 이 접근법의 중요성은 세 가지 관점이 서로 상대적으로 독립적일 수 있다는 것이다.스토리지 테크놀로지는 논리 모델이나 개념 모델에 영향을 주지 않고 변경할 수 있습니다.테이블/열 구조는 (필요한) 개념 모델에 영향을 주지 않고 변경될 수 있습니다.물론 각각의 경우 구조물은 다른 모델과 일관성을 유지해야 합니다.표/열 구조는 엔티티 클래스 및 속성의 직접 변환과는 다를 수 있지만, 궁극적으로 개념 엔티티 클래스 구조의 목적을 수행해야 합니다.많은 소프트웨어 개발 프로젝트의 초기 단계에서는 개념 데이터 모델의 설계가 강조됩니다.이러한 설계는 논리 데이터 모델로 상세하게 설명할 수 있습니다.이후 단계에서는 이 모델을 물리적 데이터 모델로 변환할 수 있습니다.그러나 개념 모델을 직접 구현할 수도 있습니다.
역사
정보 시스템을 모델링하는 최초의 선구적 연구 중 하나는 "데이터 처리 문제의 정보 및 시간 특성을 지정하는 정확하고 추상적인 방법"을 주장한 영과 켄트(1958)[10][11]에 의해 이루어졌다.이들은 "분석가가 모든 하드웨어에 대해 문제를 정리할 수 있는 표기법"을 만들고 싶었습니다.이들의 작업은 추상적인 규격을 만들고 서로 다른 하드웨어 컴포넌트를 사용하여 서로 다른 대체 구현을 설계하기 위한 불변적인 기반을 만들기 위한 첫 번째 노력이었다.IS 모델링의 다음 단계는 1959년에 결성된 IT 산업 컨소시엄 CODASYL에 의해 이루어졌습니다.CODASYL은 기본적으로 Young 및 Kent와 동일한 것을 목표로 했습니다.이 컨소시엄은 "데이터 처리 시스템 수준에서 기계에 의존하지 않는 문제 정의 언어를 위한 적절한 구조"를 개발하는 것입니다.이것은 특정 IS 정보 [11]대수의 개발로 이어졌다.
1960년대에 데이터 모델링은 관리 정보 시스템(MIS) 개념이 시작되면서 더욱 중요해졌다.Leondes(2002)에 따르면, "그동안 정보 시스템은 관리 목적으로 데이터와 정보를 제공했습니다.통합 데이터 스토어(IDS)라고 불리는 1세대 데이터베이스 시스템은 제너럴 일렉트릭의 찰스 바크만이 설계했다.이 기간 동안 네트워크 데이터 모델과 계층 데이터 모델의 두 가지 유명한 데이터베이스 모델이 제안되었습니다."[12]1960년대 말, 에드거 F. Codd는 데이터 배치 이론을 제시하고 1차 술어 [13]논리에 기초한 데이터베이스 관리를 위한 관계형 모델을 제안했습니다.
1970년대에 엔티티 관계 모델링은 1976년 Peter Chen에 의해 공식화된 새로운 유형의 개념 데이터 모델링으로 등장했습니다.요구사항 분석 중 정보 시스템 설계의 첫 번째 단계에서 정보 요구 또는 데이터베이스에 저장해야 할 정보의 유형을 설명하기 위해 개체 관계 모델을 사용했다.이 기술은 특정 관심 영역에 대한 개념과 그 관계에 대한 개요와 분류와 같은 모든 온톨로지를 설명할 수 있습니다.
1970년대에 G.M. Nijssen은 Natural Language Information Analysis Method(NIAM;자연언어정보분석방법)을 개발하였고, 1980년대에 Terry Halpin과 협력하여 Object-Role Modeling(ORM; 객체역할모델링)으로 개발하였다. 그러나 Role-Modelation에 관한 공식 논문을 만든 것은 Terry Halpin의 1989년 논문이었다.
빌 켄트는 1978년 저서 '데이터와 현실'[14]에서 데이터 모델을 영토 지도와 비교하면서 현실에서는 "고속도로는 빨간색으로 칠해져 있지 않고, 강은 중앙을 따라 흐르는 군 경계선이 없으며, 산에서는 윤곽선을 볼 수 없다"고 강조했다.수학적으로 깨끗하고 우아한 모델을 만들려고 했던 다른 연구자들과는 대조적으로, 켄트는 현실 세계의 본질적인 혼란과 지나치게 진실을 왜곡하지 않고 혼돈에서 질서를 만드는 데이터 모델러의 임무를 강조했다.
1980년대, Jan L. Harrington(2000)에 따르면, "객체 지향 패러다임의 발달은 데이터에 대한 우리의 시각과 데이터 운용 절차에 근본적인 변화를 가져왔다.기존에는 데이터와 프로시저가 별도로 저장되었습니다.데이터와 그 관계, 어플리케이션 프로그램의 프로시저입니다.그러나 객체 방향은 기업의 절차와 데이터를 [15]결합했습니다."
1990년대 초, 세 명의 네덜란드 수학자 귀도 베이크마, 하르트 반 데 레크, 얀 피터 즈워트는 G.M. 니센의 연구를 계속 발전시켰다.그들은 의미론의 의사소통 부분에 더 초점을 맞췄다.1997년에 Fully Communication Oriented Information Modeling FCO-IM 방법을 공식화했습니다.
종류들
데이터베이스 모델
데이터베이스 모델은 데이터베이스의 구조화 및 사용 방법을 설명하는 사양입니다.
그러한 모델이 몇 가지 제안되었다.일반적인 모델은 다음과 같습니다.
- 플랫 모델
- 이것은 데이터 모델로서 엄밀하게는 적합하지 않을 수 있습니다.평면(또는 표) 모델은 단일 2차원 데이터 요소 배열로 구성되며, 여기서 주어진 열의 모든 구성원은 유사한 값으로 간주되고 행의 모든 구성원은 서로 관련이 있는 것으로 간주됩니다.
- 계층 모형
- 계층 모델은 계층 모델의 링크가 트리 구조를 형성하는 반면 네트워크 모델은 임의 그래프를 허용하는 점을 제외하고는 네트워크 모델과 유사합니다.
- 네트워크 모델
- 이 모델은 레코드와 세트라고 불리는 두 가지 기본 구조를 사용하여 데이터를 구성합니다.레코드에는 필드가 포함되어 있으며 세트에는 레코드 간의 일대다 관계(소유자 1명, 멤버 다수)가 정의되어 있습니다.네트워크 데이터 모델은 데이터베이스 구현에 사용되는 설계 개념을 추상화한 것입니다.
- 관계형 모델
- 는 1차 술어 논리에 기초한 데이터베이스 모델입니다.이것의 핵심 아이디어는 데이터베이스를 유한한 술어 변수 집합의 술어 집합으로 기술하고 가능한 값과 값의 조합에 대한 제약 조건을 기술하는 것입니다.관계형 데이터 모델의 힘은 수학적 기초와 단순한 사용자 수준의 패러다임에 있습니다.
- 객체 관계 모델
- 관계형 데이터베이스 모델과 비슷하지만 개체, 클래스 및 상속은 데이터베이스 스키마 및 쿼리 언어로 직접 지원됩니다.
- 객체 역할 모델링
- "속성 없음" 및 "사실 기반"으로 정의된 데이터 모델링 방법입니다.그 결과 ERD, UML 및 의미론 모델과 같은 다른 일반적인 아티팩트가 도출될 수 있는 검증 가능한 올바른 시스템이 된다.데이터 객체 간의 연관성은 데이터베이스 설계 절차 중에 설명되므로 정규화는 프로세스의 불가피한 결과입니다.
- 스타 스키마
- 데이터 웨어하우스 스키마의 가장 단순한 스타일입니다.스타 스키마는 임의의 수의 "차원 테이블"을 참조하는 몇 개의 "팩트 테이블"(아마도 한 개만 해당)로 구성됩니다.스타 스키마는 눈꽃 스키마의 중요한 특수한 경우로 여겨진다.

개념 지향 모델






data 구조도

데이터 구조도(DSD)는 엔티티와 그 관계를 문서화하는 그래픽 표시를 제공하여 개념 데이터 모델을 기술하는 데 사용되는 다이어그램 및 데이터 모델입니다.DSD의 기본 그래픽 요소는 실체를 나타내는 상자 및 관계를 나타내는 화살표로 구성됩니다.데이터 구조 다이어그램은 복잡한 데이터 엔티티를 문서화하는 데 가장 유용합니다.
데이터 구조 다이어그램은 개체 관계 모델(ER 모델)의 확장입니다.DSD에서는 속성은 엔티티 상자 바깥이 아닌 엔티티 상자 안에 지정되며 관계는 엔티티를 결합하는 구속조건을 지정하는 속성으로 구성된 상자로 그려집니다.DSD는 ER 모델이 서로 다른 엔티티 간의 관계에 초점을 맞춘다는 점에서 ER 모델과 다른 반면, DSD는 엔티티 내 요소의 관계에 초점을 맞추고 사용자가 각 엔티티 간의 링크와 관계를 완전히 볼 수 있도록 한다.
데이터 구조 다이어그램에는 몇 가지 스타일이 있으며 카디널리티를 정의하는 방식에 현저한 차이가 있습니다.화살촉, 반전 화살촉(군중 발) 또는 카디널리티의 숫자 표현 중 하나를 선택할 수 있습니다.

엔티티-관계 모델
때로는 엔티티 관계도(ERM)라고 불리는 엔티티 관계 모델(ERM)은 구조화된 데이터를 나타내기 위해 소프트웨어 공학에서 사용되는 추상 개념 데이터 모델(또는 의미 데이터 모델 또는 물리적 데이터 모델)을 나타내기 위해 사용될 수 있다.ERM에는 몇 가지 표기가 사용됩니다.DSD와 마찬가지로 속성은 엔티티 상자 밖이 아닌 내부에서 지정되며 관계는 선으로 그려지며 관계 제약 조건은 선의 설명으로 표시됩니다.E-R 모델은 견고하지만 여러 속성을 가진 엔터티를 나타낼 때 시각적으로 복잡해질 수 있습니다.
데이터 구조 다이어그램에는 몇 가지 스타일이 있으며 카디널리티를 정의하는 방식에 현저한 차이가 있습니다.화살촉, 반전 화살촉(군중 발) 또는 카디널리티의 숫자 표현 중 하나를 선택할 수 있습니다.
지리적 데이터 모델
지리 정보 시스템의 데이터 모델은 지리 객체 또는 표면을 데이터로 표현하기 위한 수학적 구성입니다.예를들면,
- 벡터 데이터 모델은 지리를 점, 선 및 다각형으로 나타낸다
- 래스터 데이터 모델은 지리를 숫자 값을 저장하는 셀 매트릭스로 나타냅니다.
- TIN(Triangulated Orgular Network) 데이터 모델은 지리를 겹치지 않는 연속 [17]삼각형의 집합으로 나타냅니다.
![Groups relate to process of making a map[18]](https://yoda.wiki/wiki/File:Groups_relate_to_the_process_of_making_a_map.jpg)
![NGMDB data model applications[18]](https://yoda.wiki/wiki/File:NGMDB_data_model_application.jpg)
![NGMDB databases linked together[18]](https://yoda.wiki/wiki/File:NGMDB_databases_linked_together.jpg)
![Representing 3D map information[18]](https://yoda.wiki/wiki/File:Representing_three-dimensional_map_information.jpg)
범용 데이터 모델
일반 데이터 모델은 기존 데이터 모델의 일반화입니다.이들은 표준화된 일반 관계 유형과 이러한 관계 유형에 의해 관련될 수 있는 종류의 것들을 정의한다.범용 데이터 모델은 기존 데이터 모델의 몇 가지 단점을 해결하기 위한 접근 방식으로 개발되었습니다.예를 들어, 서로 다른 모델러는 일반적으로 동일한 영역의 서로 다른 재래식 데이터 모델을 생성합니다.이로 인해 서로 다른 사람의 모델을 통합하는 것이 어려워질 수 있으며 데이터 교환 및 데이터 통합에 장애가 될 수 있습니다.그러나, 변함없이, 이 차이는 모델의 다른 추상화 수준과 인스턴스화될 수 있는 사실의 종류(모델의 의미적 표현 능력)의 차이 때문이다.모델러들은 차이를 덜 중요하게 만들기 위해 보다 구체적으로 렌더링해야 할 특정 요소를 전달하고 합의해야 합니다.
의미 데이터 모델

소프트웨어 공학에서 의미 데이터 모델은 다른 데이터와의 상호 관계 내에서 데이터의 의미를 정의하는 기술입니다.의미 데이터 모델은 저장된 기호가 실제 [16]세계와 어떻게 관련되어 있는지를 정의하는 추상화입니다.의미 데이터 모델을 개념 데이터 모델이라고 부르기도 합니다.
Database Management System(DBMS; 데이터베이스 관리 시스템)의 논리적 데이터 구조는 계층형, 네트워크형, 관계형 등 데이터 개념 정의 요건을 완전히 충족할 수 없습니다.데이터는 범위가 한정되어 있고 DBMS가 채택하는 구현 전략에 치우쳐 있기 때문입니다.따라서 개념 뷰에서 데이터를 정의할 필요가 있습니다.의미 데이터 모델링 기술의 개발로 이어졌다.즉, 다른 데이터와의 상호 관계에서 데이터의 의미를 정의하는 기법이다.그림과 같이.실제 세계는 리소스, 아이디어, 이벤트 등의 측면에서 물리적 데이터 저장소 내에서 상징적으로 정의됩니다.의미 데이터 모델은 저장된 기호가 실제 세계와 어떻게 관련되어 있는지를 정의하는 추상화입니다.따라서, 모델은 [16]실제 세계를 실제로 나타낸 것이어야 합니다.
토픽
데이터 아키텍처
데이터 아키텍처는 목표 상태를 정의하고 목표 상태에 도달하기 위해 필요한 후속 계획을 정의하는 데 사용할 데이터의 설계입니다.일반적으로 엔터프라이즈 아키텍처 또는 솔루션 아키텍처의 기둥을 구성하는 여러 아키텍처 도메인 중 하나입니다.
데이터 아키텍처는 비즈니스 및/또는 애플리케이션에서 사용되는 데이터 구조를 설명합니다.스토리지 내의 데이터와 이동 중인 데이터에 대한 설명, 데이터 저장소, 데이터 그룹 및 데이터 항목에 대한 설명, 그리고 이러한 데이터 아티팩트의 데이터 품질, 애플리케이션, 위치 등에 대한 매핑 등이 있습니다.
목표 상태를 실현하는 데 필수적인 데이터 아키텍처는 주어진 시스템에서 데이터가 처리, 저장 및 사용되는 방법을 설명합니다.데이터 플로우를 설계할 수 있고 시스템 내 데이터 플로우를 제어할 수 있는 데이터 처리 작업의 기준을 제공합니다.
데이터 모델링

소프트웨어 엔지니어링에서 데이터 모델링은 데이터 모델링 기술을 사용하여 공식적인 데이터 모델 설명을 적용하여 데이터 모델을 생성하는 프로세스입니다.데이터 모델링은 데이터베이스에 대한 비즈니스 요구사항을 정의하는 기술입니다.데이터 모델이 최종적으로 데이터베이스에 [19]구현되기 때문에 데이터베이스 모델링이라고도 합니다.
이 그림은 오늘날 데이터 모델이 개발 및 사용되는 방식을 보여 줍니다.개념 데이터 모델은 개발 중인 애플리케이션에 대한 데이터 요건에 기초하여 개발되며, 아마도 활동 모델의 맥락에서 개발될 수 있습니다.데이터 모델은 일반적으로 엔티티 유형, 속성, 관계, 무결성 규칙 및 이러한 개체의 정의로 구성됩니다.다음으로 인터페이스 또는 데이터베이스 [8]설계의 시작점으로 사용됩니다.
데이터 속성

요건을 충족해야 하는 데이터의 중요한 속성은 다음과 같습니다.
- 정의 관련 속성[8]
- 관련성: 비즈니스 환경에서 데이터의 유용성.
- 명확성: 데이터에 대한 명확하고 공유된 정의를 사용할 수 있습니다.
- 일관성: 다른 소스로부터의 동일한 유형의 데이터 호환성.
- 콘텐츠 관련 속성
- 적시성: 필요한 시간에 데이터를 사용할 수 있는지, 그리고 해당 데이터가 얼마나 최신 상태인지.
- 정확도: 데이터가 얼마나 진실에 가까운가.
- 정의와 내용 모두에 관련된 속성
- 완전성: 필요한 데이터 중 어느 정도 사용 가능한가.
- 접근성: 데이터를 이용할 수 있는 장소, 방법 및 사용자(보안 등)
- 비용: 데이터를 입수하여 사용할 수 있도록 하는 데 드는 비용입니다.
data 구성
다른 종류의 데이터 모델은 데이터베이스 관리 시스템 또는 기타 데이터 관리 기술을 사용하여 데이터를 구성하는 방법을 설명합니다.예를 들어 관계형 테이블 및 열이나 객체 지향 클래스 및 속성을 설명합니다.이러한 데이터 모델을 물리 데이터 모델이라고 부르기도 하지만, 원래의 ANSI 3 스키마 아키텍처에서는 "논리"라고 부릅니다.이 아키텍처에서 실제 모델은 스토리지 미디어(실린더, 트랙 및 테이블 영역)를 설명합니다.이상적으로는 이 모델은 위에서 설명한 보다 개념적인 데이터 모델에서 파생됩니다.다만, 처리 능력이나 사용 패턴등의 제약 조건을 고려하는 것은 다를 수 있습니다.
데이터 분석은 데이터 모델링의 일반적인 용어이지만, 실제로 이 활동은 분석(더 일반적인 개념에서 구성 요소 개념을 식별하는 것)보다 합성 아이디어 및 방법과 더 많은 공통점을 가지고 있습니다(특정 인스턴스에서 일반적인 개념을 추론).{시스템 신시사이저를 말할 수 있는 사람은 아무도 없기 때문에 시스템 분석가라고 부릅니다.} 데이터 모델링은 불필요한 데이터 중복을 제거하고 데이터 구조를 관계와 연관시킴으로써 관심 있는 데이터 구조를 하나의 응집력 있고 분리할 수 없는 전체로 통합하기 위해 노력합니다.
다른 접근법은 데이터의 암묵적 모델을 자율적으로 생성할 수 있는 인공 신경망과 같은 적응 시스템을 사용하는 것이다.
data 구조

데이터 구조는 데이터를 효율적으로 사용할 수 있도록 컴퓨터에 저장하는 방법입니다.데이터의 수학적, 논리적 개념의 조직입니다.대부분의 경우 신중하게 선택된 데이터 구조를 사용하면 가장 효율적인 알고리즘을 사용할 수 있습니다.데이터 구조의 선택은 종종 추상 데이터 유형의 선택에서 시작됩니다.
데이터 모델은 특정 도메인 내의 데이터 구조와 그 도메인 자체의 기본 구조를 암시적으로 기술합니다.즉, 실제로 데이터 모델은 해당 도메인에 대한 전용 인공 언어에 대한 전용 문법을 지정합니다.데이터 모델은 기업이 정보를 보유하고자 하는 실체(종류)의 종류, 해당 정보의 속성, 이들 실체 간의 관계 및 이들 속성 간의 (종종 암묵적인) 관계를 나타낸다.이 모델은 컴퓨터 시스템에서 데이터가 어떻게 표현될 수 있는지에 관계없이 데이터의 구성을 어느 정도 설명합니다.
데이터 모형으로 표현되는 실체는 유형실체가 될 수 있지만, 그러한 구체적인 실체 분류를 포함하는 모형은 시간이 지남에 따라 변화하는 경향이 있다.견고한 데이터 모델은 종종 그러한 엔티티의 추상화를 식별한다.예를 들어, 데이터 모델에는 조직과 상호작용하는 모든 사용자를 나타내는 "개인"이라는 엔티티 클래스가 포함될 수 있습니다.이러한 추상적인 엔티티 클래스는 일반적으로 이러한 사람들이 수행하는 특정 역할을 식별하는 "벤더" 또는 "직원"이라고 불리는 클래스보다 더 적합합니다.
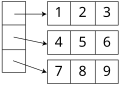
어레이



데이터 모델 이론
데이터 모델이라는 용어는 두 가지 의미를 [20]가질 수 있습니다.
- 데이터 모델 이론, 즉 데이터를 구조화하고 액세스하는 방법에 대한 공식적인 설명입니다.
- 데이터 모델 인스턴스, 즉 데이터 모델 이론을 적용하여 일부 특정 애플리케이션을 위한 실용적인 데이터 모델 인스턴스를 만듭니다.
데이터 모델 이론에는 [20]세 가지 주요 구성요소가 있습니다.
- 구조 부분: 데이터베이스에 의해 모델링된 엔티티 또는 개체를 나타내는 데이터베이스를 만드는 데 사용되는 데이터 구조의 집합입니다.
- 무결성 부분: 구조 무결성을 보장하기 위해 이러한 데이터 구조에 부과된 제약을 지배하는 규칙의 집합.
- 조작부: 데이터 구조에 적용할 수 있는 연산자의 집합으로 데이터베이스에 포함된 데이터를 갱신 및 조회한다.
예를 들어 관계모델에서 구조부분은 수학적 관계의 수정개념에 기초하고, 무결성부분은 1차 논리로 표현되며, 조작부분은 관계대수, 태플 미적분 및 영역 미적분을 사용하여 표현된다.
데이터 모델 인스턴스를 데이터 모델 이론을 적용하여 작성한다.이것은, 통상, 기업의 몇개의 요건을 해결하기 위해서입니다.비즈니스 요건은 일반적으로 의미 논리 데이터 모델에 의해 파악됩니다.이 인스턴스는 물리적 데이터베이스를 생성하는 물리적 데이터 모델 인스턴스로 변환됩니다.예를 들어, 데이터 모형 작성자는 데이터 모형 작성 도구를 사용하여 일부 기업의 기업 데이터 저장소의 실체 관계 모형을 작성할 수 있다.이 모델은 관계형 모델로 변환되어 관계형 데이터베이스가 생성됩니다.
패턴
패턴은[21] 많은 데이터 모델에서 발생하는 일반적인 데이터 모델링 구조입니다.
관련 모델
데이터 흐름도

데이터 흐름도(DFD)는 정보 시스템을 통한 데이터 흐름을 그래픽으로 표현한 것입니다.프로그램의 제어 흐름 대신 데이터 흐름을 보여 주기 때문에 흐름도와 다릅니다.데이터 플로우 다이어그램은 데이터 처리(구조화 설계)의 시각화에도 사용할 수 있습니다.데이터 흐름도는 구조화 [23]설계의 원조 개발자인 Larry Constantine이 마틴과 에스트린의 "데이터 흐름 그래프" 계산 모델을 기반으로 발명했습니다.
시스템과 외부 엔티티 간의 상호작용을 나타내는 컨텍스트 수준의 데이터 흐름도를 먼저 그리는 것이 일반적입니다.DFD는 시스템이 어떻게 더 작은 부분으로 분할되어 있는지 보여주고 이러한 부분 간의 데이터 흐름을 강조하기 위해 설계되었습니다.이 컨텍스트 레벨의 데이터 플로우 다이어그램은 모델링 대상 시스템의 상세 내용을 나타내기 위해 "폭발"됩니다.
정보 모델

정보 모델은 데이터 모델의 유형이 아니라 대체 모델입니다.소프트웨어 엔지니어링 분야에서는 데이터 모델과 정보 모델 모두 그 속성, 관계 및 이에 대해 수행할 수 있는 작업을 포함하는 엔티티 유형의 추상적이고 형식적인 표현일 수 있습니다.모델 내의 엔티티 유형은 네트워크 내의 디바이스와 같은 실제 객체의 종류이거나 과금 시스템에서 사용되는 엔티티와 같이 추상적일 수 있습니다.일반적으로 이들은 엔티티 유형, 속성, 관계 및 연산의 닫힌 집합으로 설명할 수 있는 제약된 도메인을 모델링하는 데 사용됩니다.
Lee(1999)[24]에 따르면, 정보 모델은 개념, 관계, 제약, 규칙 및 선택된 담화 영역에 대한 데이터 의미를 규정하기 위한 연산의 표현이다.도메인 [24]컨텍스트에 대한 정보 요건의 공유 가능하고 안정적이며 체계적인 구조를 제공할 수 있습니다.일반적으로 정보 모델이라는 용어는 설비, 건물, 프로세스 플랜트 등 개별적인 것의 모델에 사용됩니다.이 경우 이 개념은 설비정보모델, 건물정보모델, 플랜트정보모델 등에 특화되어 있다.이러한 정보 모델은 시설의 모델과 시설에 관한 데이터 및 문서를 통합한 것이다.
정보모델은 문제영역의 기술이 소프트웨어의 실제 구현에 어떻게 매핑되는지를 제약하지 않고 형식주의를 제공한다.정보 모델에는 많은 매핑이 있을 수 있습니다.이러한 매핑은 객체 모델(예: UML 사용), 엔티티 관계 모델 또는 XML 스키마 여부에 관계없이 데이터 모델이라고 불립니다.

오브젝트 모델
컴퓨터 과학에서 객체 모델은 프로그램이 세계의 특정 부분을 조사하고 조작할 수 있는 객체 또는 클래스의 집합입니다.즉, 어떤 서비스 또는 시스템에 대한 객체 지향 인터페이스입니다.이러한 인터페이스는 제시된 서비스 또는 시스템의 객체 모델이라고 불립니다.예를 들어, 문서 객체 모델(DOM) [1]은 웹 브라우저의 페이지를 나타내는 오브젝트 모음으로, 스크립트 프로그램에서 페이지를 검사하고 동적으로 변경하는 데 사용됩니다.다른 프로그램에서 Microsoft Excel을 제어하는 Microsoft Excel 객체[25] 모델이 있으며, ASCOM Telescope[26] Driver는 천체 망원경을 제어하는 객체 모델입니다.
오브젝트 모델이라는 용어는 그것들을 사용하는 특정 컴퓨터 프로그래밍 언어, 기술, 표기법 또는 방법론에서 오브젝트의 일반적인 속성에 대한 명확한 두 번째 의미를 갖는다.예를 들어 Java 개체 모델, COM 개체 모델 또는 OMT 개체 모델입니다. 이러한 개체 모델은 일반적으로 클래스, 메시지, 상속, 다형성 및 캡슐화 등의 개념을 사용하여 정의됩니다.프로그래밍 언어의 형식적 의미론의 하위 집합으로서 형식화된 객체 모델에 대한 광범위한 문헌이 있습니다.
오브젝트 롤모델

Object-Role Modeling(ORM; 객체 역할 모델링)은 개념 모델링을 위한 방법으로 정보 및 규칙 [28]분석 도구로 사용할 수 있습니다.
객체 역할 모델링은 개념 수준에서 시스템 분석을 수행하기 위한 사실 지향적인 방법입니다.데이터베이스 응용프로그램의 품질은 설계에 따라 결정적으로 달라집니다.정확성, 명확성, 적응성 및 생산성을 보장하기 위해 정보 시스템은 먼저 개념 수준에서 사람들이 쉽게 이해할 수 있는 개념과 언어를 사용하여 가장 잘 지정됩니다.
개념 설계에는 데이터, 프로세스 및 행동 관점이 포함될 수 있으며, 설계를 구현하기 위해 사용되는 실제 DBMS는 여러 논리 데이터 모델(관계형, 계층형, 네트워크, 객체 지향 등)[29] 중 하나에 기반할 수 있습니다.
통합 모델링 언어 모델
Unified Modeling Language(UML)는 소프트웨어 엔지니어링 분야의 표준화된 범용 모델링 언어입니다.소프트웨어 집약적인 시스템의 아티팩트를 시각화, 지정, 구성 및 문서화하기 위한 그래픽 언어입니다.Unified Modeling Language는 다음과 [30]같은 시스템 Blueprint를 작성하는 표준 방법을 제공합니다.
UML은 기능 모델, 데이터 모델 및 데이터베이스 모델을 혼합하여 제공합니다.
「 」를 참조해 주세요.
- 비즈니스 프로세스 모델
- 핵심 아키텍처 데이터 모델
- 공통 데이터 모델, 표준화된 데이터 모델
- 데이터 수집 시스템
- 데이터 사전
- 데이터 포맷 기술 언어(DFDL)
- 분포-관계 데이터베이스
- JC3IEDM
- 프로세스 모델
레퍼런스
- ^ "UML Domain Modeling - Stack Overflow". Stack Overflow. Stack Exchange Inc. Retrieved 4 February 2017.
- ^ "XQuery and XPath Data Model 3.1". World Wide Web Consortium (W3C). W3C. Retrieved 4 February 2017.
- ^ "DataModel". npm. npm, Inc. Retrieved 4 February 2017.
- ^ "DataModel (Java EE 6)". Java Documentation. Oracle. Retrieved 4 February 2017.
- ^ Ostrovskiy, Stan. "iOS: Three ways to pass data from Model to Controller". Medium. A Medium Corporation. Retrieved 4 February 2017.
- ^ Paul R. Smith & Richard Sarfaty Publications, LLC 2009
- ^ 마이클 R.McCaleb(1999년)."데이터 시스템의 개념 데이터 모델" 2008-09-21을 웨이백 머신에 아카이브했습니다.미국 국립 표준 기술 연구소1999년 8월
- ^ a b c d e f g h i j k 매튜 웨스트와 줄리안 파울러(1999년).고품질 데이터 모델 개발European Process Industries STEP 기술연락책임자(EPISTLE).
- ^ 미국 국립 표준 협회.1975. 데이터베이스 관리 시스템에 관한 ANSI/X3/SPARC 연구 그룹; 중간 보고서.FDT(ACM SIGMOD의 Bulletin) 7:2.
- ^ 영, J. W., 켄트 H. K. (1958)"데이터 처리 문제의 추상화"인: 산업 공학 저널.1958년 11월 - 12월 9일(6), 471-479페이지
- ^ a b 재니스 A. Bubenko jr(2007) "정보 대수에서 엔터프라이즈 모델링 및 온톨로지까지 - 정보 시스템의 모델링에 대한 역사적 관점"In: 정보 시스템 엔지니어링의 개념 모델링.존 크록스티 외 에디트 페이지 1-18
- ^ 코넬리우스 T.Leondes(2002년).데이터베이스 및 데이터 통신 네트워크 시스템: 기술과 응용 프로그램.7페이지.
- ^ "대규모 데이터 뱅크에 저장된 관계의 파생성, 중복성 및 일관성", E.F. Codd, IBM Research Report, 1969
- ^ Data and Reality
- ^ Jan L. Harrington(2000).객체 지향 데이터베이스 설계에 대해 명확하게 설명합니다.4 페이지
- ^ a b c d FIPS 간행물 184 국립표준기술연구소(NIST)의 컴퓨터 시스템 연구소에 의해 IDEF1X가 공개된 웨이백 머신에서 2013-12-03년 아카이브. 1993년 12월 21일(2008년 도면).
- ^ 웨이드, T.와 소머, S. ed.A to Z GIS
- ^ a b c d 데이비드 R.솔러1과 토마스 M.버그(2003)국가 지질 지도 데이터베이스 프로젝트: 개요 및 진행 미국 지질조사 공개 파일 보고서 03-471.
- ^ 휘튼, 제프리 L.; 로니 D. 벤틀리, 케빈 C 디트먼.(2004).시스템 분석 및 설계 방법.제6판ISBN 0-256-19906-X.
- ^ a b Beynon-Davies P. (2004년)Database Systems 제3판영국, 베이싱스토크 팰그레이브ISBN 1-4039-1601-2
- ^ "데이터 모델 리소스 북:데이터 모델링의 유니버설 패턴" Len Silverstone & Paul Agnew (2008).
- ^ 존 아졸리니(2000).시스템 엔지니어링 프랙티스 소개2000년 7월
- ^ W. Stevens, G. Myers, L. Constantine, "구조화 설계", IBM Systems Journal, 13(2), 115-139, 1974.
- ^ a b Y. Tina Lee(1999년)."설계에서 구현까지 정보 모델링" 국립 표준 기술 연구소.
- ^ Excel 객체 모델의 개요
- ^ "ASCOM General Requirements". 2011-05-13. Retrieved 2014-09-25.
- ^ 스티븐 M.리처드(1999년).지질학적 개념 모델링.미국 지질조사국 공개 파일 보고서 99-386
- ^ 요아힘 로스버그와 리카드 레들러(2005).Pro 스케일러블NET 2.0 어플리케이션 설계..페이지 27
- ^ 오브젝트 역할 모델링: A Overview(msdn.microsoft.com).2008년 9월 19일 취득.
- ^ Grady Boch, Ivar Jacobson & Jim Rumbaugh (2005) OMG 통합 모델링 언어 사양
추가 정보
- 데이비드 C.헤이(1996년).데이터 모델 패턴: 생각의 규칙.뉴욕:도싯 하우스 퍼블리셔스
- Len Silverston(2001년).데이터 모델 리소스 북 볼륨 1/2.John Wiley & Sons.
- Len Silverston & Paul Agnew (2008).데이터 모델 리소스 북: 데이터 모델링의 유니버설 패턴 제3권.John Wiley & Sons.
- 매튜 웨스트와 줄리안 파울러(1999년).고품질 데이터 모델 개발European Process Industries STEP 기술연락책임자(EPISTLE).
- Matthew West(2011) 고품질 데이터 모델 Morgan Kaufmann 개발
| 필드 | |||||||
|---|---|---|---|---|---|---|---|
| 개념 | |||||||
| 오리엔테이션 | |||||||
| 모델 |
| ||||||
| 관련 필드 | |||||||

