By Mohit Goenka, Gnanavel Shanmugam, and Lance Welsh
At Yahoo Mail, we’re constantly striving to upgrade our product experience. We do this not only by adding new features based on our members’ feedback, but also by providing the best technical solutions to power the most engaging experiences. As such, we’ve recently introduced a number of novel and unique revisions to the way in which we use Redux that have resulted in significant stability and performance improvements. Developers may find our methods useful in achieving similar results in their apps.
Improvements to product metrics
Last year Yahoo Mail implemented a brand new architecture using Redux. Since then, we have transformed the overall architecture to reduce latencies in various operations, reduce JavaScript exceptions, and better synchronized states. As a result, the product is much faster and more stable.
Stability improvements:
when checking for new emails – 20%
when reading emails – 30%
when sending emails – 20%
Performance improvements:
10% improvement in page load performance
40% improvement in frame rendering time
We have also reduced API calls by approximately 20%.
How we use Redux in Yahoo Mail
Redux architecture is reliant on one large store that represents the application state. In a Redux cycle, action creators dispatch actions to change the state of the store. React Components then respond to those state changes. We’ve made some modifications on top of this architecture that are atypical in the React-Redux community.
For instance, when fetching data over the network, the traditional methodology is to use Thunk middleware. Yahoo Mail fetches data over the network from our API. Thunks would create an unnecessary and undesirable dependency between the action creators and our API. If and when the API changes, the action creators must then also change. To keep these concerns separate we dispatch the action payload from the action creator to store them in the Redux state for later processing by “action syncers”. Action syncers use the payload information from the store to make requests to the API and process responses. In other words, the action syncers form an API layer by interacting with the store. An additional benefit to keeping the concerns separate is that the API layer can change as the backend changes, thereby preventing such changes from bubbling back up into the action creators and components. This also allowed us to optimize the API calls by batching, deduping, and processing the requests only when the network is available. We applied similar strategies for handling other side effects like route handling and instrumentation. Overall, action syncers helped us to reduce our API calls by ~20% and bring down API errors by 20-30%.
Another change to the normal Redux architecture was made to avoid unnecessary props. The React-Redux community has learned to avoid passing unnecessary props from high-level components through multiple layers down to lower-level components (prop drilling) for rendering. We have introduced action enhancers middleware to avoid passing additional unnecessary props that are purely used when dispatching actions. Action enhancers add data to the action payload so that data does not have to come from the component when dispatching the action. This avoids the component from having to receive that data through props and has improved frame rendering by ~40%. The use of action enhancers also avoids writing utility functions to add commonly-used data to each action from action creators.
In our new architecture, the store reducers accept the dispatched action via action enhancers to update the state. The store then updates the UI, completing the action cycle. Action syncers then initiate the call to the backend APIs to synchronize local changes.
Conclusion
Our novel use of Redux in Yahoo Mail has led to significant user-facing benefits through a more performant application. It has also reduced development cycles for new features due to its simplified architecture. We’re excited to share our work with the community and would love to hear from anyone interested in learning more.
When it comes to performance and reliability, there is perhaps no application where this matters more than with email. Today, we announced a new Yahoo Mail experience for desktop based on a completely rewritten tech stack that embodies these fundamental considerations and more.
We built the new Yahoo Mail experience using a best-in-class front-end tech stack with open source technologies including React, Redux, Node.js, react-intl (open-sourced by Yahoo), and others. A high-level architectural diagram of our stack is below.
New Yahoo Mail Tech Stack
In building our new tech stack, we made use of the most modern tools available in the industry to come up with the best experience for our users by optimizing the following fundamentals:
Performance
A key feature of the new Yahoo Mail architecture is blazing-fast initial loading (aka, launch).
We introduced new network routing which sends users to their nearest geo-located email servers (proximity-based routing). This has resulted in a significant reduction in time to first byte and should be immediately noticeable to our international users in particular.
We now do server-side rendering to allow our users to see their mail sooner. This change will be immediately noticeable to our low-bandwidth users. Our application is isomorphic, meaning that the same code runs on the server (using Node.js) and the client. Prior versions of Yahoo Mail had programming logic duplicated on the server and the client because we used PHP on the server and JavaScript on the client.
Using efficient bundling strategies (JavaScript code is separated into application, vendor, and lazy loaded bundles) and pushing only the changed bundles during production pushes, we keep the cache hit ratio high. By using react-atomic-css, our homegrown solution for writing modular and scoped CSS in React, we get much better CSS reuse.
In prior versions of Yahoo Mail, the need to run various experiments in parallel resulted in additional branching and bloating of our JavaScript and CSS code. While rewriting all of our code, we solved this issue using Mendel, our homegrown solution for bucket testing isomorphic web apps, which we have open sourced.
Rather than using custom libraries, we use native HTML5 APIs and ES6 heavily and use PolyesterJS, our homegrown polyfill solution, to fill the gaps. These factors have further helped us to keep payload size minimal.
With all the above optimizations, we have been able to reduce our JavaScript and CSS footprint by approximately 50% compared to the previous desktop version of Yahoo Mail, helping us achieve a blazing-fast launch.
In addition to initial launch improvements, key features like search and message read (when a user opens an email to read it) have also benefited from the above optimizations and are considerably faster in the latest version of Yahoo Mail.
We also significantly reduced the memory consumed by Yahoo Mail on the browser. This is especially noticeable during a long running session.
Reliability
With this new version of Yahoo Mail, we have a 99.99% success rate on core flows: launch, message read, compose, search, and actions that affect messages. Accomplishing this over several billion user actions a day is a significant feat. Client-side errors (JavaScript exceptions) are reduced significantly when compared to prior Yahoo Mail versions.
Product agility and launch velocity
We focused on independently deployable components. As part of the re-architecture of Yahoo Mail, we invested in a robust continuous integration and delivery flow. Our new pipeline allows for daily (or more) pushes to all Mail users, and we push only the bundles that are modified, which keeps the cache hit ratio high.
Developer effectiveness and satisfaction
In developing our tech stack for the new Yahoo Mail experience, we heavily leveraged open source technologies, which allowed us to ensure a shorter learning curve for new engineers. We were able to implement a consistent and intuitive onboarding program for 30+ developers and are now using our program for all new hires. During the development process, we emphasise predictable flows and easy debugging.
Accessibility
The accessibility of this new version of Yahoo Mail is state of the art and delivers outstanding usability (efficiency) in addition to accessibility. It features six enhanced visual themes that can provide accommodation for people with low vision and has been optimized for use with Assistive Technology including alternate input devices, magnifiers, and popular screen readers such as NVDA and VoiceOver. These features have been rigorously evaluated and incorporate feedback from users with disabilities. It sets a new standard for the accessibility of web-based mail and is our most-accessible Mail experience yet.
Open source
We have open sourced some key components of our new Mail stack, like Mendel, our solution for bucket testing isomorphic web applications. We invite the community to use and build upon our code. Going forward, we plan on also open sourcing additional components like react-atomic-css, our solution for writing modular and scoped CSS in React, and lazy-component, our solution for on-demand loading of resources.
Many of our company’s best technical minds came together to write a brand new tech stack and enable a delightful new Yahoo Mail experience for our users.
We encourage our users and engineering peers in the industry to test the limits of our application, and to provide feedback by clicking on the Give Feedback call out in the lower left corner of the new version of Yahoo Mail.
Front-end web development is evolving fast; a lot of new tools and libraries are published which challenge best practices everyday. It’s exciting, but also overwhelming. One of those new tools that can make a developer’s life easier is Redux, a popular open source state container. This past year, our team at Yahoo Search has been using Redux to refresh a legacy tool used for data analytics. We paired Redux with another popular library for building front-end components called React. Due to the scale of Yahoo Search, we measure and store thousands of metrics on the data grid every second. Our data analytics tool allows internal users from our Search team to query stored data, analyze traffic, and compare A/B testing results. The biggest goal of creating the new tool was to deliver ease of use and speed. When we started, we knew our application would grow complex and we would have a lot of state living inside it. During the course of development we got hit by unforeseen performance bottlenecks. It took us some digging and refactoring to achieve the performance we expected from our technology stack. We want to share our experience and encourage developers who use Redux, that by reasoning about your React components and your state structure, you will make your application performant and easy to scale.
Redux wants your application state changes to be more predictable and easier to debug. It achieves this by extending the ideas of the Flux pattern by making your application’s state live in a single store. You can use reducers to split the state logically and manage responsibility. Your React components subscribe to changes from the Redux store. For front-end developers this is very appealing and you can imagine the cool debugging tools that can be paired with Redux (see Time Travel).
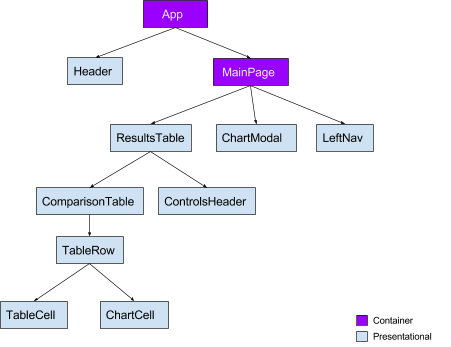
With React it is easier to reason and create components into two different categories, Container vs Presentational. You can read more about it (here). The gist is that your Container components will usually subscribe to state and manage flow, while Presentational are concerned with rendering markup using the properties passed to them. Taking guidance from early Redux documentation, we started by adding container components at the top of our component tree. The most critical part of our application is the interactive ResultsTable component; for the sake of brevity, this will be the focus for the rest of the post.
React Component Tree
To achieve optimal performance from our API, we make a lot of simple calls to the backend and combine and filter data in the reducers. This means we dispatch a lot of async actions to fetch bits and pieces of the data and use redux-thunk to manage the control flow. However, with any change in user selections it invalidates most of the things we have fetched in the state, and we need to then re-fetch. Overall this works great, but it also means we are mutating state many times as responses come in.
The Problem
While we were getting great performance from our API, the browser flame graphs started revealing performance bottlenecks on the client. Our MainPage component sitting high up in the component tree triggered re-renders against every dispatch. While your component render should not be a costly operation, on a number of occasions we had a huge amount of data rows to be rendered. The delta time for re-render in such cases was in seconds.
So how could we make render more performant? A well-advertized method is the shouldComponentUpdate lifecycle method, and that is where we started. This is a common method used to increase performance that should be implemented carefully across your component tree. We were able to filter out access re-renders where our desired props to a component had not changed.
Despite the shouldComponentUpdate improvement, our whole UI still seemed clogged. User actions got delayed responses, our loading indicators would show up after a delay, autocomplete lists would take time to close, and small user interactions with the application were slow and heavy. At this point it was not about React render performance anymore.
In order to determine bottlenecks, we used two tools: React Performance Tools and React Render Visualizer. The experiment was to study users performing different actions and then creating a table of the count of renders and instances created for the key components.
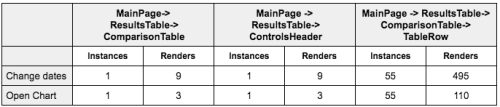
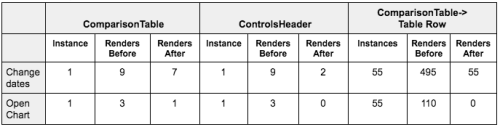
Below is one such table that we created. We analyzed two frequently-used actions. For this table we are looking at how many renders were triggered for our main table components.
Change Dates: Users can change dates to fetch historical data. To fetch data, we make parallel API calls for all metrics and merge everything in the Reducers.Open Chart: Users can select a metric to see a daily breakdown plotted on a line chart. This is opened in a modal dialog.
Experiments revealed that state needed to travel through the tree and recompute a lot of things repeatedly along the way before affecting the relevant component. This was costly and CPU intensive. While switching products from the UI, React spent 1080ms on table and row components. It was important to realize this was more of a problem of shared state which made our thread busy. While React’s virtual DOM is performant, you should still strive to minimize virtual DOM creation. Which means minimizing renders.
Performance Refactor
The idea was to look at container components and try and distribute the state changes more evenly in the tree. We also wanted to put more thought into the state, make it less shared, and more derived. We wanted to store the most essential items in the state while computing state for the components as many times as we wanted.
We executed the refactor in two steps:
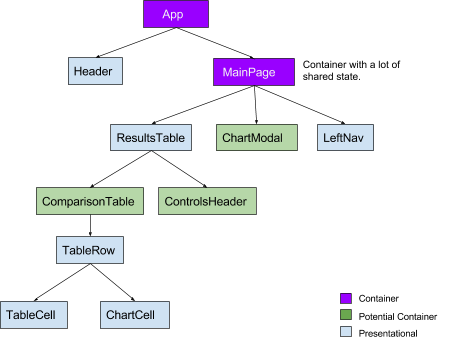
Step 1. We added more container components subscribing to the state across the component hierarchy. Components consuming exclusive state did not need a container component at the top threading props to it; they can subscribe to the state and become a container component. This dramatically reduces the amount of work React has to do against Redux actions.
React Component Tree with potential container components
We identified how the state was being utilized across the tree. The important question was, “How could we make sure there are more container components with exclusive states?” For this we had to split a few key components and wrap them in containers or make them containers themselves.
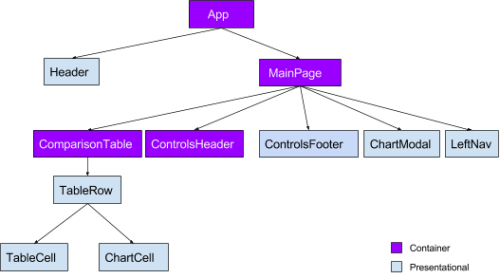
React Component Tree after refactor
In the tree above, notice how the MainPage container is no longer responsible for any Table renders. We extracted another component ControlsFooter out of ResultsTable which has its own exclusive state. Our focus was to reduce re-renders on all table-related components.
Step 2. Derived state and should component update.
It is critical to make sure your state is well defined and flat in nature. It is easier if you think of Redux state as a database and start to normalize it. We have a lot of entities like products, metrics, results, chart data, user selections, UI state, etc. For most of them we store them as Key/Value pairs and avoid nesting. Each container component queries the state object and de-normalizes data. For example, our navigation menu component needs a list of metrics for the product which we can easily extract from the metrics state by filtering the list of metrics with the product ID.
The whole process of deriving state and querying it repeatedly can be optimized. Enter Redux Reselect. Reselect allows you to define selectors to compute derived state. They are memoized for efficiency and can also be cascaded. So a function like the one below can be defined as a selector, and if there is no change in metrics or productId in state, it will return a memoized copy.
getMetrics(productId, metrics) {
metrics.find(m => m.productId === productId)
}
We wanted to make sure all our async actions resolved and our state had everything we needed before triggering a re-render. We created selectors to define such behaviours for shouldComponentUpdate in our container components (e.g our table will only render if metrics and results were all loaded). While you can still do all of this directly in shouldComponentUpdate, we felt that using selectors allowed you to think differently. It makes your containers predict state and wait on it before rendering while the state that it needs to render can be a subset of it. Not to mention, it is more performant.
The Results
Once we finished refactoring we ran our experiment again to compare the impact from all our tweaks. We were expecting some improvement and better flow of state mutations across the component tree.
A quick glance at the table above tells you how the refactor has clearly come into effect. In the new results, observe how changing dates distributes the render count between comparisonTable (7) and controlsHeader (2). It still adds up to 9. Such logical refactors have allowed us to to speed up our application rendering up to 4 times. It has also allowed us to optimize time wasted by React easily. This has been a significant improvement for us and a step in the right direction.
What’s Next
Redux is a great pattern for front-end applications. It has allowed us to reason about our application state better, and as the app grows more complex, the single store makes it much easier to scale and debug.
Going forward we want to explore Immutability for Redux State. We want to enforce the discipline for Redux state mutations and also make a case for faster shallow comparison props in shouldComponentUpdate.
react-i13n is provided for all React.js users to have a performant and scalable approach to instrumentation.
Typically, you have to manually add instrumentation code throughout your application, e.g., hooking up onClick handlers to the links you want to track. react-i13n provides a simplified approach by letting you define the data model you want to track and handling the beaconing for you.
react-i13n is made to be pluggable, it does this by building its own eventing system so you can define your own plugin for your preferred instrumentation libraries.
Moreover, by using react-i13n, you can define your instrumentation data with an inherit architecture, it does this by building an instrumentation tree that mirrors your applications React component hierarchy. With the instrumentation tree built with react life cycle events, we can get all the information we need in memory instead of DOM manipulation, which is efficient and fast.
react-i13n is simple, flexible and performant. Please try it, add your own plugins and provide us feedback at github.
By Kaeson Ho, Seth Bertalotto, Rafael Martins, Irae Carvalho
We blogged about the evolution of Yahoo Mail to React + Flux and Node.js. It is important to focus on building a strong foundation when you are building a new platform and having a robust test infrastructure is a big part of the foundation. Yahoo Mail today relies on automated testing on our Continuous Integration pipeline before we deploy changes to production. We run Cucumber and Waitr-Webdriver based functional tests run across IE, Chrome and Firefox using selenium to certify our builds. Building this infrastructure gave us a lot of insight into the challenges of doing automated testing at the scale of Yahoo Mail.
Our requirements for a robust automated test infrastructure are as follows
Comprehensive
Fast and consistent
Easy to maintain
Shorter learning curve
All engineers are accountable for quality of the product and maintaining the infrastructure. So the infrastructure should be easy to understand. We want to make sure that the tests are comprehensive enough so that it gives us the confidence to push the code everyday without human intervention and we should have the ability to run the tests multiple times a day.
There are different levels and capabilities of tests we could have invested in. Based on the above requirements, we chose to focus on the following types of tests
We have used multiple unit testing infrastructures in Mail in the past. So going by our experience, we arrived fairly quickly at our decision to use Mocha as our test framework, Karma as our test runner and Chai for assertion. We also decided to use Sinon to stub out external methods.
Functional Tests:
Now comes the interesting part. We knew that we needed to test UI thoroughly since there are chances of things breaking when code components start interacting with each other. No one can just rely on unit tests to determine whether the code will work as expected.
On the other hand, we had to be careful about what we actually end up testing as part of the functional test suite. In an application like mail, executing our tests on actual mail data could mean that the functional tests are actually executing as integration tests. It was important for us to call out this difference that functional tests should just test the functionality of the code written agnostic to the actual data. Working with actual data brings in dependencies to setup the account to a given initial state and also go over network to all our sub-systems every time. This can be time consuming and can potentially trigger false alarms.
We divided our functional tests into two categories
Tests at Component Level
Tests at App Level
Component level tests focused on functionally testing a component in isolation. We would pass different props and see if the component behaved as expected. React TestUtils with Karma and PhantomJS seemed like the way to go as it was fast and easy to write. We earlier blogged about our experience with using React TestUtils for this.
App level tests focused on launching the entire app in the browser and testing real user scenarios. For example, Marking a mail as read. The Mail backend and APIs have their own robust automated tests, so our focus was to test the functionality of the client. So we decided to stub our data request layer using Sinon and return responses that can execute all the code paths for the given functionality. This means our test runs are very fast, the tests are reliable and predictable.
Now for the choice of framework, we narrowed down to two options. First option was to use the already familiar Waitr Webdriver with Cucumber. We loved this because we can write true BDD styles tests with Cucumber. We had well integrated tooling around this like support for screen capture for failing tests and running tests in parallel. On the down side, not everyone was comfortable with the relaxed syntax of Ruby, there were plenty of hacks done to make sure the tests run consistently on Chrome, Firefox and IE.
The second option was to use Protractor. The biggest advantage Protractor brought to the table was that we would be doing development and tests in the same language, Javascript. This would eliminate learning curve for writing and debugging tests. Protractor also speeds up tests by avoiding the need for a lot of “sleeps” and “waits” in tests. We used chai-as-promised for asserting promises returned by Protractor. Even though Protractor was built for testing AngularJS applications, in reality it can be used for testing any web application. It had everything that you would expect from UI testing framework.
Based on the benefits we saw and the fact that other teams in Yahoo were also going with Protractor, we chose the second option. Since we had good experience with BDD, it was easy to set this up with Protractor in the future if needed.
Organizing Protractor tests:
A typical protractor test starts to get messy very soon with promise chains. We wanted our code to be readable and maintainable. So we started creating Page Objects for the different components of our app that eliminated duplication of code and made our test files to read more like business-like expressions. With page objects and support for adding stubs for API, our protractor test started looking like this
it('marks a conversation as read', function() {
var conversation;
testHelper.stub('ReadConversations', 'read_success');
conversation = page.conversationList.getConversation(1);
expect(conversation.isRead()).to.eventually.equal(false);
conversation.read();
expect(conversation.isRead()).to.eventually.equal(true);
});
Smoke and Integration Tests:
We chose to use the Protractor setup for writing smoke and integration tests as well. The only difference is that with Smoke and Integration tests we interact with actual mail data instead of using stubs. Smoke tests comprise of a collection of tests just to make sure application is able to launch and the core flows work. A core flow could be something as simple as whether clicking on compose and sending a message works.
Integration tests are the meanest, most intensive tests we want to run on actual data before the code goes to production. Using protractor for functional, smoke and integration tests meant reusing the same infrastructure and same code for running all the tests (e.g. page objects and specs)
Running tests in the pipeline
Having a clear separation between the various tests meant we can now configure the various stages in the automation pipeline to run the test suites. The unit tests are the lowest level tests we want to run to make sure the code units are all working as expected. We want these to be completed within 5 minutes. The functional tests make sure that the components work well together. Smoke is a quick sanity check that nothing major is broken and the Integration tests are the true gate keepers for end to end quality.
On every pull request, we would run all unit tests, functional tests and smoke tests. That gave us high confidence whenever any code is merged to master, we are keeping the quality bar high and at the same time having them finished really quickly.
Every 3 hours, we build a production candidate from master. We put this build through all the tests including integration tests to make sure that the package is completely certified end to end.
The setup also allows for deploying individual components separately because we can now pick and choose the test suite we want to run, either the entire functional test suite or just the functional tests for the given component. We also have strict code coverage thresholds, application metric checks, payload size checks, code style ( lint ) checks etc on every build before its deployed to production.
We are overall excited to see things fall into place. We have many more challenges we need to overcome. We will do a separate blog post for a deep dive into our protractor setup where we will talk about page objects, writing synchronous code, stubbing and failing the test on js exceptions
 Engineering
Engineering