 Engineering
EngineeringRefactoring Components for Redux Performance
By Shahzad Aziz
Front-end web development is evolving fast; a lot of new tools and libraries are published which challenge best practices everyday. It’s exciting, but also overwhelming. One of those new tools that can make a developer’s life easier is Redux, a popular open source state container. This past year, our team at Yahoo Search has been using Redux to refresh a legacy tool used for data analytics. We paired Redux with another popular library for building front-end components called React. Due to the scale of Yahoo Search, we measure and store thousands of metrics on the data grid every second. Our data analytics tool allows internal users from our Search team to query stored data, analyze traffic, and compare A/B testing results. The biggest goal of creating the new tool was to deliver ease of use and speed. When we started, we knew our application would grow complex and we would have a lot of state living inside it. During the course of development we got hit by unforeseen performance bottlenecks. It took us some digging and refactoring to achieve the performance we expected from our technology stack. We want to share our experience and encourage developers who use Redux, that by reasoning about your React components and your state structure, you will make your application performant and easy to scale.
Redux wants your application state changes to be more predictable and easier to debug. It achieves this by extending the ideas of the Flux pattern by making your application’s state live in a single store. You can use reducers to split the state logically and manage responsibility. Your React components subscribe to changes from the Redux store. For front-end developers this is very appealing and you can imagine the cool debugging tools that can be paired with Redux (see Time Travel).
With React it is easier to reason and create components into two different categories, Container vs Presentational. You can read more about it (here). The gist is that your Container components will usually subscribe to state and manage flow, while Presentational are concerned with rendering markup using the properties passed to them. Taking guidance from early Redux documentation, we started by adding container components at the top of our component tree. The most critical part of our application is the interactive ResultsTable component; for the sake of brevity, this will be the focus for the rest of the post.
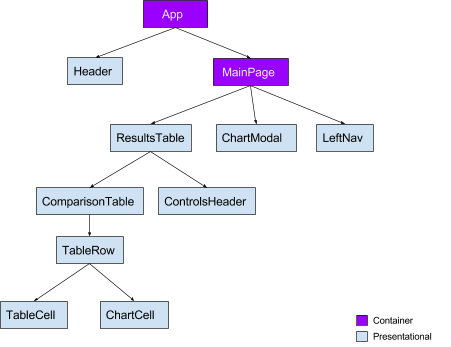
To achieve optimal performance from our API, we make a lot of simple calls to the backend and combine and filter data in the reducers. This means we dispatch a lot of async actions to fetch bits and pieces of the data and use redux-thunk to manage the control flow. However, with any change in user selections it invalidates most of the things we have fetched in the state, and we need to then re-fetch. Overall this works great, but it also means we are mutating state many times as responses come in.
The Problem
While we were getting great performance from our API, the browser flame graphs started revealing performance bottlenecks on the client. Our MainPage component sitting high up in the component tree triggered re-renders against every dispatch. While your component render should not be a costly operation, on a number of occasions we had a huge amount of data rows to be rendered. The delta time for re-render in such cases was in seconds.
So how could we make render more performant? A well-advertized method is the shouldComponentUpdate lifecycle method, and that is where we started. This is a common method used to increase performance that should be implemented carefully across your component tree. We were able to filter out access re-renders where our desired props to a component had not changed.
Despite the shouldComponentUpdate improvement, our whole UI still seemed clogged. User actions got delayed responses, our loading indicators would show up after a delay, autocomplete lists would take time to close, and small user interactions with the application were slow and heavy. At this point it was not about React render performance anymore.
In order to determine bottlenecks, we used two tools: React Performance Tools and React Render Visualizer. The experiment was to study users performing different actions and then creating a table of the count of renders and instances created for the key components.
Below is one such table that we created. We analyzed two frequently-used actions. For this table we are looking at how many renders were triggered for our main table components.
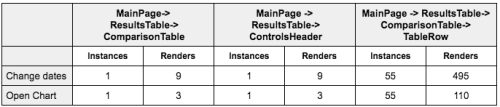
Experiments revealed that state needed to travel through the tree and recompute a lot of things repeatedly along the way before affecting the relevant component. This was costly and CPU intensive. While switching products from the UI, React spent 1080ms on table and row components. It was important to realize this was more of a problem of shared state which made our thread busy. While React’s virtual DOM is performant, you should still strive to minimize virtual DOM creation. Which means minimizing renders.
Performance Refactor
The idea was to look at container components and try and distribute the state changes more evenly in the tree. We also wanted to put more thought into the state, make it less shared, and more derived. We wanted to store the most essential items in the state while computing state for the components as many times as we wanted.
We executed the refactor in two steps:
Step 1. We added more container components subscribing to the state across the component hierarchy. Components consuming exclusive state did not need a container component at the top threading props to it; they can subscribe to the state and become a container component. This dramatically reduces the amount of work React has to do against Redux actions.
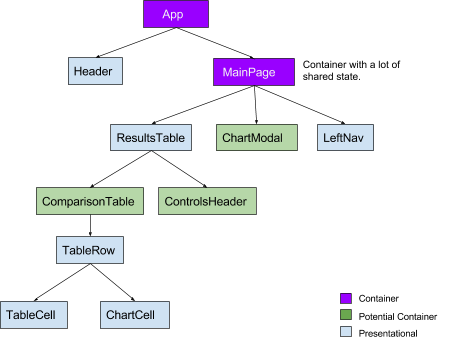
React Component Tree with potential container components
We identified how the state was being utilized across the tree. The important question was, “How could we make sure there are more container components with exclusive states?” For this we had to split a few key components and wrap them in containers or make them containers themselves.
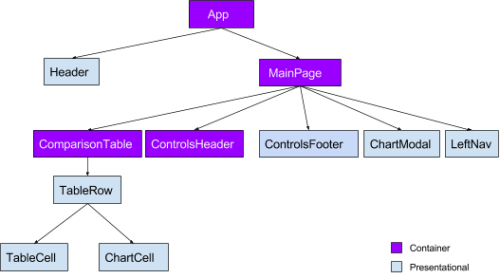
In the tree above, notice how the MainPage container is no longer responsible for any Table renders. We extracted another component ControlsFooter out of ResultsTable which has its own exclusive state. Our focus was to reduce re-renders on all table-related components.
Step 2. Derived state and should component update.
It is critical to make sure your state is well defined and flat in nature. It is easier if you think of Redux state as a database and start to normalize it. We have a lot of entities like products, metrics, results, chart data, user selections, UI state, etc. For most of them we store them as Key/Value pairs and avoid nesting. Each container component queries the state object and de-normalizes data. For example, our navigation menu component needs a list of metrics for the product which we can easily extract from the metrics state by filtering the list of metrics with the product ID.
The whole process of deriving state and querying it repeatedly can be optimized. Enter Redux Reselect. Reselect allows you to define selectors to compute derived state. They are memoized for efficiency and can also be cascaded. So a function like the one below can be defined as a selector, and if there is no change in metrics or productId in state, it will return a memoized copy.
getMetrics(productId, metrics) {
metrics.find(m => m.productId === productId)
}
We wanted to make sure all our async actions resolved and our state had everything we needed before triggering a re-render. We created selectors to define such behaviours for shouldComponentUpdate in our container components (e.g our table will only render if metrics and results were all loaded). While you can still do all of this directly in shouldComponentUpdate, we felt that using selectors allowed you to think differently. It makes your containers predict state and wait on it before rendering while the state that it needs to render can be a subset of it. Not to mention, it is more performant.
The Results
Once we finished refactoring we ran our experiment again to compare the impact from all our tweaks. We were expecting some improvement and better flow of state mutations across the component tree.
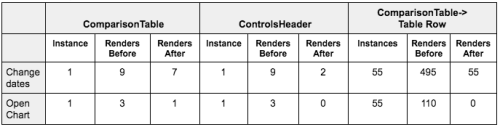
A quick glance at the table above tells you how the refactor has clearly come into effect. In the new results, observe how changing dates distributes the render count between comparisonTable (7) and controlsHeader (2). It still adds up to 9. Such logical refactors have allowed us to to speed up our application rendering up to 4 times. It has also allowed us to optimize time wasted by React easily. This has been a significant improvement for us and a step in the right direction.
What’s Next
Redux is a great pattern for front-end applications. It has allowed us to reason about our application state better, and as the app grows more complex, the single store makes it much easier to scale and debug.
Going forward we want to explore Immutability for Redux State. We want to enforce the discipline for Redux state mutations and also make a case for faster shallow comparison props in shouldComponentUpdate.