KR102336311B1 - 딥러닝을 이용한 암의 예후 예측 모델 - Google Patents
딥러닝을 이용한 암의 예후 예측 모델 Download PDFInfo
- Publication number
- KR102336311B1 KR102336311B1 KR1020190146627A KR20190146627A KR102336311B1 KR 102336311 B1 KR102336311 B1 KR 102336311B1 KR 1020190146627 A KR1020190146627 A KR 1020190146627A KR 20190146627 A KR20190146627 A KR 20190146627A KR 102336311 B1 KR102336311 B1 KR 102336311B1
- Authority
- KR
- South Korea
- Prior art keywords
- prognosis
- cancer
- learning
- predicting
- data
- Prior art date
Links
Images





Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H50/00—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics
- G16H50/50—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics for simulation or modelling of medical disorders
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H10/00—ICT specially adapted for the handling or processing of patient-related medical or healthcare data
- G16H10/60—ICT specially adapted for the handling or processing of patient-related medical or healthcare data for patient-specific data, e.g. for electronic patient records
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H20/00—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H50/00—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics
- G16H50/30—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics for calculating health indices; for individual health risk assessment
Landscapes
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Medical Informatics (AREA)
- Public Health (AREA)
- Epidemiology (AREA)
- General Health & Medical Sciences (AREA)
- Primary Health Care (AREA)
- Biomedical Technology (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Pathology (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
본 발명은 암 환자의 오믹스 데이터로부터 암의 예후를 예측할 수 있는 예후 예측 시스템에 관한 것으로, 상기 시스템에 따르면 복수의 오믹스 데이터를 사용함으로써 분자생물학적 다양성을 통합적으로 고려하여 암 환자의 예후를 예측할 수 있고, 단일 유전자가 암의 예후 예측에 미치는 중요도를 판단할 수 있다.
Description
본 발명은 암 환자의 멀티 오믹스 데이터를 이용하여 딥러닝 기반으로 암의 예후에 영향을 미치는 요인을 파악함으로써 효과적으로 암의 예후를 예측하는 시스템에 관한 것이다.
암의 예후를 예측하는 것, 즉 암 환자의 수술 후 생존기간을 예측하는 것은 암 환자들에게 매우 중요한 요소이다. 과거의 예후 예측 모델은 환자의 나이, 암의 단계(stage), 성별 등 임상정보만을 이용하여 오직 선형적인 관계로 예후를 예측하였다. 그러나 이러한 방법은 같은 암이라도 개별 환자마다 암의 특성이 다르다는 점을 반영하지 못하므로 예측 성능이 떨어지는 한계점이 있었다.
이러한 문제를 해결하기 위해 최근 암의 다양성에 대한 연구가 진행되고 있다. 2018년 종결된 암 유전체 지도(The Cancer Genome Atlas, TCGA) 프로젝트는 개별 환자의 암 특성을 확인할 수 있는 다양한 오믹스(omics) 데이터를 생산하였다. 최근에는 이런 오믹스 데이터를 암의 예후 예측에 적용함으로써 기존 예후 예측 모델의 한계점을 극복하려는 연구가 진행되고 있다.
그러나 지금까지 연구된 암의 예후 예측 모델은 일부 한계점이 있다. 첫째는 현재 가장 많이 사용하는 예후 예측 방법은 선형적인 방식이라는 점이다. 이 방법은 직관적으로 예후에 미치는 영향을 확인할 수 있다는 장점이 있지만 생물학적 복잡성을 단순한 선형 모델로 설명하기 어렵다는 한계점이 있고 그로 인해 예후 예측 성능이 조금 떨어진다는 단점이 있다.
둘째로 대부분의 암 예후 예측은 단일 오믹스만을 사용한다는 점이다. 최근까지 암의 특징을 확인할 수 있는 다양한 오믹스 방법들이 많이 개발되어 분석에 사용되고 있지만 예후 예측에는 RNA 서열분석과 같이 대부분 유전자의 발현을 확인하는 오믹스 방법만이 사용되고 있다. 하지만 암은 유전자의 발현뿐만 아니라 유전자의 변이 등 복잡한 원인으로 인해 발생하고 예후에 영향을 미친다. 따라서 단일 오믹스만으로는 암의 다양성을 설명하기 힘든 문제가 있다.
셋째는 선행 기술에서는 단일 유전자당 예후에 미치는 중요도 확인을 통해 최종 마커 유전자를 선별하기 어렵다는 것이다. 선행 기술에서는 하나의 유전자당 여러 멀티 오믹스 특징들에 대해 독립적으로 할당한다. 하지만 이 방식으로는 각 오믹스 특징마다 중요한 유전자가 서로 다르기 때문에 최종적으로 어떤 유전자가 예후 예측의 마커로 사용될 수 있을지 선별하기 어렵다는 단점이 존재한다.
본 발명자들은 상기 한계점을 해결하기 위해 비선형모델로 생물학적 다양성을 학습하고, 멀티 오믹스를 이용해 암의 분자생물학적 다양성을 통합적으로 고려하며, 단일 유전자당 중요도를 판단할 수 있는 암의 예후 예측용 시스템을 개발하여 본 발명을 완성하였다.
1. SCIENTIFIC REPORTS | 7: 16954
2. Clin Cancer Res; 24(6) March 15, 2018
본 발명의 목적은 멀티 오믹스 데이터에 기반하여 암의 분자생물학적 다양성을 통합적으로 고려함으로써 암의 예후를 효과적으로 예측할 수 있는 암의 예후 예측용 시스템을 제공하는 것이다.
상기 목적을 달성하기 위하여, 본 발명의 일 양상은 하기 단계를 포함하는 딥러닝을 이용한 암의 예후 예측용 시스템을 제공한다:
(1) 암 환자로부터 수집된 오믹스 데이터와 암의 예후와의 상관관계를 학습하는 학습 모듈;
(2) 상기 학습 모듈에서 학습된 암의 예후 예측 알고리즘을 저장하는 저장 모듈; 및
(3) 분석 정보를 수신하고, 상기 저장 모듈에 저장된 암의 예후 예측 알고리즘을 사용하여 예후를 모르는 암 환자의 예후를 산출하는 예측 모듈.
본 발명의 일 구체예에 있어서, 상기 암의 예후 예측용 시스템은 암 환자의 치료 후 생존 기간, 또는 외과적 수술 후 생존 기간 예측에 사용될 수 있다.
본 명세서에 사용된 용어, "오믹스(omics)"는 유전체, 전사체, 단백체, 대사체 등 다양한 분자 수준에서 생성된 여러 데이터들을 의미하며, 초고속, 대량분석이 가능한 분자생물학적 기술의 발전, 컴퓨터 산업의 발전에 따른 정보 처리 능력의 비약적 발달에 따라 멀티 오믹스 데이터가 생성되고 있다.
본 발명의 일 구체예에 있어서, 상기 오믹스 데이터는 유전체(genome), 전사체(transcriptome), 단백체(proteome), 대사체(metabolome), 후성유전체 (epigenome), 지질체(lipodome) 및 메틸체(methylome)로 이루어진 군에서 선택될 수 있으나, 이에 제한되지 않는다. 본 발명에서, 상기 오믹스 데이터는 복수개가 사용될 수 있고, 바람직하게는 최소 3개의 오믹스 데이터가 사용될 수 있으며, 예를 들어 유전체, 전사체 및 메틸체 데이터가 사용될 수 있다.
본 발명의 일 구체예에 있어서, 상기 학습 모듈은 하기 단계를 포함할 수 있다.
(a) 예후를 알고 있는 암 환자의 오믹스 데이터로부터 딥러닝용 학습 데이터를 생성하는 학습 데이터 생성부;
(b) 생성된 학습 데이터로부터 오믹스 데이터와 암의 예후와의 상관 관계를 학습하는 딥러닝 수행부; 및
(c) 상기 딥러닝 수행부의 결과로부터 암의 예후를 예측하는 알고리즘을 생성하는 알고리즘 생성부.
본 명세서에 사용된 용어, "딥러닝(deep learning)"은 심층 학습으로도 불리우며, 최근 기계학습 분야에서 대두되고 있는 기술 중 하나로 복수개의 은닉 계층(hidden layer)와 이들에 포함되는 복수 개의 유닛(hidden unit)으로 구성되는 신경망(neural network)이다.
딥러닝 모델에 기본 특성(low level feature)들을 입력하는 경우, 이러한 기본 특성들이 복수 개의 은닉 계층을 통과하면서 예측하고자 하는 문제를 보다 잘 설명할 수 있는 상위 레벨 특성(high level feature)로 변형된다. 이러한 과정에서 전문가의 사전 지식 또는 직관이 요구되지 않기 때문에 특성 추출에서의 주관적 요인을 제거할 수 있으며, 보다 높은 일반화 능력을 갖는 모델을 개발할 수 있게 된다.
또한, 딥러닝의 경우 특징 추출과 모델 구축이 하나의 세트로 구성되어 있기 때문에 기존의 기계학습 이론 대비 보다 단순한 과정을 통하여 최종 모델을 형성할 수 있는 장점이 있다.
본 발명에서, 상기 딥러닝은 심층 신경망(Deep Neural Network, DNN)에 기반하여 수행될 수 있으며, 예를 들어 구글 오픈소스인 텐서플로우(TensorFlow)로 수행될 수 있다.
본 발명에서, 상기 학습 데이터 생성부는 예후를 알고 있는 암 환자의 오믹스 데이터를 개별 유전자에 대해 매트릭스 형태로 정렬할 수 있다. 매트릭스 형태로 정렬함으로써 개별 유전자, 단일 오믹스에 대한 정보만으로 암의 예후를 예측하는 것이 아니라, 개별 유전자에 대한 오믹스 데이터들의 공통 특징을 학습하여 비선형적인 방법으로 암의 예후를 예측할 수 있다. 사용되는 유전자는 따로 선별하는 것이 아니라, 오믹스 데이터에 포함된 전체 유전자를 사용할 수 있다.
본 발명의 일 구체예에 있어서, 상기 딥러닝 수행부는 하기 단계를 포함할 수 있다:
(b-1) 정렬된 오믹스 데이터로부터 개별 유전자에 대한 오믹스 데이터의 공통 특징을 학습하는 단계;
(b-2) 학습된 개별 유전자에 대한 오믹스 데이터의 공통 특징에서 중요하지 않은 정보를 제거하는 단계;
(b-3) 상기 (b-2)의 결과로부터 개별 유전자당 가장 높은 값을 암의 예후 예측을 위한 대푯값으로 선별하는 단계;
(b-4) 상기 (b-3)에서 선별한 개별 유전자당 대푯값을 조합하여 암의 예후 예측의 정확도를 확인하는 단계; 및
(b-5) 상기 (b-4)의 결과에서 정확도가 가장 높은 대푯값의 조합을 선별하는 단계.
본 발명의 일 구체예에 있어서, 상기 (b-1) 단계는 정렬된 오믹스 데이터로 컨볼루션(convolution)을 진행하여 수행될 수 있으며, (b-2) 단계는 학습된 개별 유전자에 대한 오믹스 데이터의 공통 특징에 ReLU (rectified linear unit) 함수를 적용하여 수행될 수 있다.
본 발명의 일 구체예에 있어서, 상기 (b-4) 단계는 콕스 비례 위험 모델(Cox proportional hazards model)을 사용하여 개별 유전자당 대푯값과 암 환자의 예후와의 음의 로그 부분 유도(negative log partial likelihood)를 계산하는 것일 수 있다.
본 발명의 다른 양상은 상기 암의 예후 예측 시스템을 사용한 암의 예후 예측 방법을 제공한다. 상기 암의 예후 예측 시스템을 사용하면 예후를 모르는 암 환자에서 수집된 멀티 오믹스 데이터로부터 암의 예후에 가장 큰 영향을 미치는 개별 유전자를 선별할 수 있으므로 예후가 불분명한 암 환자의 예후를 효과적으로 예측할 수 있다. 또한, 암의 예후를 예측함으로써 예후가 나쁠 것으로 예상되면 공격적 치료를 수행한다는 등의 방식으로 개인별 맞춤 의료를 제공할 수 있다.
본 발명의 암의 예후 예측용 시스템에 따르면 복수의 오믹스 데이터를 사용함으로써 암의 분자생물학적 다양성을 통합적으로 고려하여 암 환자의 예후를 예측할 수 있고, 단일 유전자가 암의 예후 예측에 미치는 중요도를 판단할 수 있다.
도 1은 본 발명에 따른 암의 예후 예측 시스템의 구성을 설명하기 위한 블록도이다.
도 2는 본 발명에 따른 암의 예후 예측 시스템에서 학습 모듈의 학습 데이터 생성부의 일 예를 나타낸다.
도 3은 본 발명에 따른 암의 예후 예측 시스템에서 학습 모듈의 딥러닝 수행부의 일 예를 나타낸다.
도 4는 본 발명의 일 실시예에 따른 암의 예후 예측 시스템과 기존의 암 예후 예측 모델의 예후 예측 성능을 비교한 결과를 나타낸다.
도 5는 본 발명의 일 실시예에 따른 암의 예후 예측 시스템과 암의 예후 예측 마커로 알려진 유전자의 예후 예측 성능을 비교한 결과를 나타낸다.
도 2는 본 발명에 따른 암의 예후 예측 시스템에서 학습 모듈의 학습 데이터 생성부의 일 예를 나타낸다.
도 3은 본 발명에 따른 암의 예후 예측 시스템에서 학습 모듈의 딥러닝 수행부의 일 예를 나타낸다.
도 4는 본 발명의 일 실시예에 따른 암의 예후 예측 시스템과 기존의 암 예후 예측 모델의 예후 예측 성능을 비교한 결과를 나타낸다.
도 5는 본 발명의 일 실시예에 따른 암의 예후 예측 시스템과 암의 예후 예측 마커로 알려진 유전자의 예후 예측 성능을 비교한 결과를 나타낸다.
이하에서는 첨부한 도면을 참조하여 본 발명을 설명하기로 한다. 그러나 본 발명은 여러 가지 상이한 형태로 구현될 수 있으며, 따라서 여기에서 설명하는 실시예로 한정되는 것은 아니다. 그리고 도면에서 본 발명을 명확하게 설명하기 위해서 설명과 관계없는 부분은 생략하였으며, 명세서 전체를 통하여 유사한 부분에 대해서는 유사한 도면 부호를 붙였다.
어떤 부분이 어떤 구성요소를 "포함"한다고 할 때, 이는 특별히 반대되는 기재가 없는 한 다른 구성요소를 제외하는 것이 아니라 다른 구성요소를 추가로 구비할 수 있다는 것을 의미한다.
이하, 첨부된 도면을 참고하여 본 발명을 더욱 상세히 설명한다.
도 1은 본 발명의 암의 예후 예측 시스템의 구성을 예시적으로 나타낸다.
상기 암의 예후 예측 시스템은
(a) 암 환자로부터 수집된 오믹스 데이터와 암의 예후와의 상관관계를 학습하는 학습 모듈(100);
(b) 상기 학습 모듈에서 학습된 암의 예후 예측 알고리즘을 저장하는 저장 모듈(200); 및
(c) 분석 정보를 수신하고, 상기 저장 모듈에 저장된 암의 예후 예측 알고리즘을 사용하여 예후를 모르는 암 환자의 예후를 산출하는 예측 모듈(300)을 포함한다.
상기 (a)의 학습 모듈(100)은 암의 예후, 즉 치료 후 생존 기간을 이미 알고 있는 암 환자의 오믹스 데이터와 암의 예후와의 상관관계를 딥러닝에 의해 학습하는 부분이며, 학습 데이터 생성부(110), 딥러닝 수행부(120) 및 알고리즘 생성부(130)를 포함한다.
상기 오믹스 데이터는 암 유전체 지도(The Cancer Genome Atlas, TCGA)와 같은 공개 데이터베이스로부터 수집할 수 있으며, 이외에 NCBI (National Center for Biotechnology Information) 등으로부터도 수집할 수 있다. 상기 오믹스 데이터는 암의 분자생물학적 다양성을 통합적으로 위해 복수개가 사용될 수 있으며, 바람직하게는 3개 이상의 오믹스 데이터가 사용될 수 있다.
상기 학습 데이터 생성부(110)는 암 환자의 오믹스 데이터를 딥러닝용 학습 데이터로 가공하는 부분이며, 도 2에 도시된 바와 같이 각각의 오믹스 데이터를 개별 유전자에 대해 매트릭스 형태로 정렬한다. 매트릭스 형태로 정렬하는 것은 유전자 발현 데이터만을 이용해 암의 예후를 예측했던 기존의 방법과는 달리 유전자의 발현, 유전자 변이 등 암의 다양성을 통합적으로 고려하는 예후 예측 시스템을 구축하기 위함이다.
상기 딥러닝 수행부(120)는 학습 데이터로부터 서로 다른 딥러닝 함수를 사용하여 개별 유전자에 대해 정렬된 오믹스 데이터와 암의 예후와의 상관 관계를 학습하는 부분이며, 도 3에 도시된 바와 같이 하기 단계를 포함할 수 있다:
(b-1) 정렬된 오믹스 데이터로부터 개별 유전자에 대한 오믹스 데이터의 공통 특징을 학습하는 단계;
(b-2) 학습된 개별 유전자에 대한 오믹스 데이터의 공통 특징에서 중요하지 않은 정보를 제거하는 단계;
(b-3) 상기 (b-2)의 결과로부터 개별 유전자당 가장 높은 값을 암의 예후 예측을 위한 대푯값으로 선별하는 단계;
(b-4) 상기 (b-3)에서 선별한 개별 유전자당 대푯값을 조합하여 암의 예후 예측의 정확도를 확인하는 단계; 및
(b-5) 상기 (b-4)의 결과에서 정확도가 가장 높은 대푯값의 조합을 암의 예후 예측용 마커로 선별하는 단계.
상기 (b-1) 단계는 매트릭스 형태로 정렬된 오믹스 데이터로 컨볼루션 (convolution)을 진행하여 수행될 수 있다. 구체적으로 하기 수학식 1에 따라 n개의 유전자에 대해 k개의 커널로 컨볼루션(convolution)을 진행하며, 예를 들어 k=3이라면 k=1, 2, 3 각각에 대해 컨볼루션을 진행하게 된다. 이 과정을 통해 각 커널마다 개별 유전자에 대한 오믹스 데이터들의 공통 특징이 학습된다. 딥러닝이 완료된 후 하기 수학식 1에서 w의 크기는 해당 오믹스 데이터의 예후 예측에 있어서의 중요도를 나타내며, k는 하이퍼파라미터(hyperperparameter) 튜닝(최적화) 과정에서 높은 성능을 나타내는 값을 사용한다. 하이퍼파라미터는 딥러닝을 수행하기 위해 사전에 설정해야 하는 값을 의미한다.
[수학식 1]

(m=오믹스, n=유전자, Xmn=유전자와 오믹스 특징들로 이루어진 매트릭스, w= 개별 유전자의 멀티 오믹스 데이터와 곱해지는 웨이트(weight), k=컨볼루션을 진행하는 커널(kernel), 및 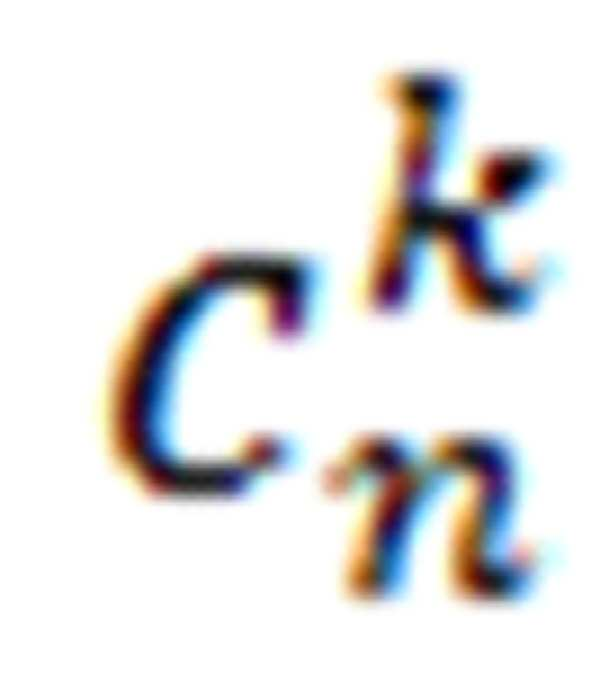 는 커널 k로 컨볼루션을 진행한 유전자 n에 대한 값을 의미함)
는 커널 k로 컨볼루션을 진행한 유전자 n에 대한 값을 의미함)
상기 (b-2) 단계는 학습된 개별 유전자에 대한 오믹스 데이터들의 공통 특징에 하기 수학식 2를 적용하여 중요하지 않은 정보를 제거하는 단계이며, 이 과정에서 중요도가 높은 유전자에 대한 결괏값(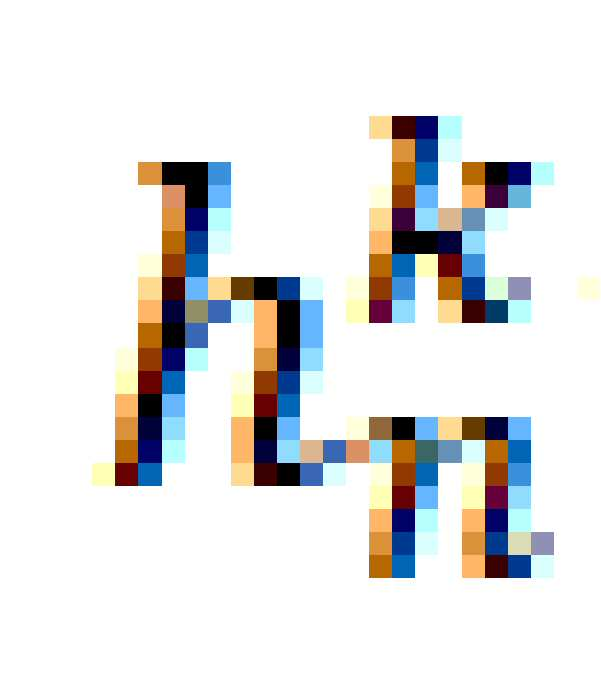 )만 남게 된다.
)만 남게 된다.
[수학식 2]

상기 수학식 2에 사용된 ReLU(rectified linear unit) 함수는 딥러닝 과정에서 사용되는 활성화 함수(activation fuction)로 상기 수학식 2에 기재된 바와 같이 x가 0보다 작은 값일 때는 0을 사용하고, 반대로 0보다 큰 값일 때는 해당 값을 그대로 사용하는 함수이다. 또한, 상기 b는 바이어스(bias)를 의미하며, 딥러닝 과정에서 자동적으로 정해진다.
상기 (b-3) 단계는 상기 (b-2)에서 나온 중요도가 높은 유전자에 대한 결괏값에 대하여 수학식 3에 따른 맥스 풀링(max pooling)을 진행하여 개별 유전자당 가장 높은 값을 암의 예후 예측을 위한 대푯값(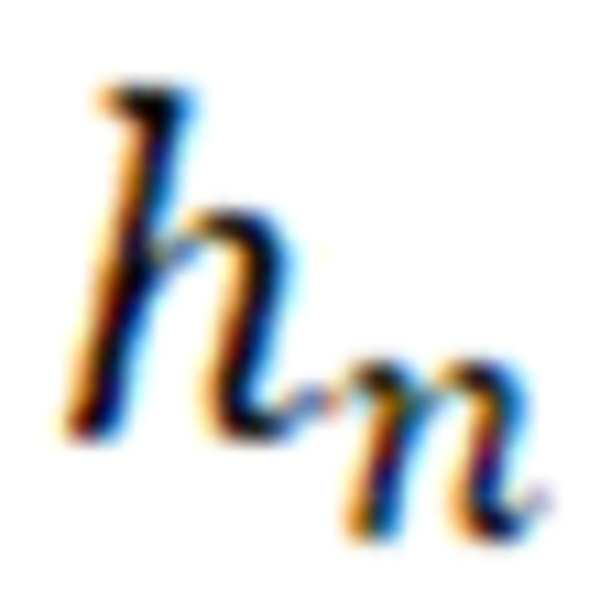 )으로 선별하는 단계이다.
)으로 선별하는 단계이다.
[수학식 3]
상기 (b-4) 단계는 (b-3)에서 선별한 개별 유전자당 대푯값을 조합하여 암의 예후 예측의 정확도를 확인하는 단계이며, 구체적으로 개별 유전자당 대푯값의 조합으로 예측된 암의 예후와 이미 알고 있는 예후를 비교하여 정확도를 확인한다. 이때 하기 수학식 4에 따른 콕스 비례 위험 모델(Cox proportional hazards model)을 사용하여 개별 유전자당 대푯값과 암 환자의 예후와의 음의 로그 부분 유도(negative log partial likelihood)를 계산하여 학습을 진행하였다.
[수학식 4]
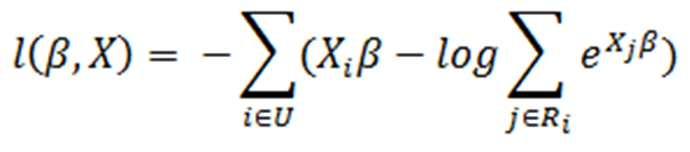
( =매트릭스,
=매트릭스,  =콕스 비례 위험 모델의 파라미터,
=콕스 비례 위험 모델의 파라미터,  =검열이 안된 샘플들(uncensored samples) 집단,
=검열이 안된 샘플들(uncensored samples) 집단,  =검열된 샘플들(at-risk samples) 및
=검열된 샘플들(at-risk samples) 및  =생존 추적(follow up) 기간으로
=생존 추적(follow up) 기간으로  보다 더 길 때를 의미함)
보다 더 길 때를 의미함)
상기 (b-5) 단계는 상기 (b-4)의 결과에서 정확도가 가장 높은 대푯값의 조합을 암의 예후 예측용 마커로 선별하는 단계이며, 이 과정에서 암의 예후 예측에 중요한 영향을 미치는 유전자 또는 유전자들의 조합이 선별된다.
상기 저장 모듈(200)은 상기 학습모듈에 의해 학습된 암의 예후 예측 알고리즘을 저장하는 부분으로, 암의 예후 예측 알고리즘 데이터베이스(database, DB)(220)를 포함하여 구성되고, 학습된 개별 유전자당 오믹스 데이터와 암의 예후와의 관련성을 저장하기 위한 오믹스 데이터-예후 관련 DB(210)를 더 포함하여 구성될 수도 있다.
상기 예측 모듈(300)은 분석할 정보를 수신하는 분석 정보 수신부(310) 및 저장 모듈에 저장된 예후 예측 알고리즘을 사용하여 분석 정보로부터 산출한 예후를 출력하는 예후 결과 출력부(320)를 포함한다.
상기 분석 정보는 예후가 불확실한 암 환자의 오믹스 데이터일 수 있으며, 상기 예후 결과는 암 치료 후 생존 기간일 수 있다.
이하, 실시예를 통해 본 발명을 더욱 상세히 기술한다.
실시예: 암의 예후 예측 시스템 검증
본 발명의 암의 예후 예측 시스템(이하, 예후 예측 시스템으로 기재함)은 TCGA 간암 환자 데이터 중에서 유전제, 전사체 및 메틸체 데이터를 학습에 사용하였다. 구체적으로 TCGA 간암 환자 데이터의 80%는 예후 예측 시스템의 학습, 검증 및 하이퍼파라미터 최적화에 사용하였고, 나머지 20%는 예후 예측 시스템의 테스트에 사용하였다.
본 발명의 예후 예측 시스템이 학습에 사용된 데이터에 과적합(overfitting)된 것이 아니라 완전히 다른 데이터셋에서도 작동하는 것을 확인하기 위하여 TCGA 데이터뿐만 아니라 완전히 독립적인 데이터셋인 한국인 간암 샘플 데이터에서 성능 확인을 진행했다.
구체적으로 TCGA 간암 환자 211명과 한국인 간암 환자 144명에 대해 유전자 발현, DNA 체세포 변이(somatic mutation), DNA 생식선 변이(germline mutation), 복수체 변이(copy number variation), 발현 조절(DNA methylation)에 해당하는 오믹스 특징들을 사용해 본 발명의 예후 예측 시스템으로 간암 환자의 예후를 예측하고, 선행기술인 Glmnet, RSF(random survival forest) 모델과 성능을 비교하였다.
그 결과, 도 4에 나타낸 바와 같이 선형모델을 사용하는 Glmnet 모델은 두 데이터셋 모두에서 성능(concordance index, C-index)이 0.5 근처로 나타나 제일 낮았다. 상기 C-index는 0.0 내지 1.0 사이의 값을 가지며, 0.5에 가까울수록 무작위로 예측하는 것으로 평가하고, 1.0에 가까울수록 정확히 예측한다고 평가한다. 비선형 모델을 사용하는 RSF 모델은 학습에 사용되는 TCGA 간암 샘플에서는 높은 성능을 보였으나, 한국인 간암 샘플에서는 성능이 낮은 것으로 나타나 학습에 사용되는 데이터셋에 과적합되어 있는 현상을 확인할 수 있다. 반면 본 발명의 예후 예측 시스템은 모든 데이터셋에서 다른 모델들에 비해 높은 성능을 나타내었다.
또한, 논문에서 간암의 예후를 예측하는 것으로 알려진 3개 유전자 (UPB1, SOCS2 및 RTN3), 11개 유전자 (ACSM3, CXCL14, INTS8, LCAT, MARCO, PAMR1, CRHBP, DNASE1L3, FCN2, MT1X 및 VIPR1) 및 종양 관련 섬유아세포(cancer associated fibroblasts, CAF)와 관련된 12종의 유전자(ACSM3, CXCL14, INTS8, LCAT, MARCO, PAMR1, CRHBP, DNASE1L3, FCN2, MT1X 및 VIPR1)를 확인하고, 상기 유전자들의 간암 예후 예측 성능을 평가하였다. 그 결과, 도 5에 나타낸 바와 같이 논문에서 제시하는 간암의 예후 예측 유전자들은 학습에 사용되는 TCGA 샘플에 과적합되어 있는 현상을 확인할 수 있었다.
본 결과를 통해 본 발명의 예후 예측 시스템은 다양한 오믹스 데이터를 활용한 유전자 단위의 통합적인 학습으로 인해 다른 예후 예측 모델과 비교하여 간암의 예후 예측에 현저히 우수한 성능을 보이는 것을 확인할 수 있었다.
100: 학습 모듈
110: 학습 데이터 생성부
120: 딥러닝 수행부
130: 알고리즘 생성부
200: 저장 모듈
210: 오믹스 데이터-예후 관련 DB
220: 예후 예측 알고리즘 DB
300: 예측 모듈
310: 분석 정보 수신부
320: 예후 결과 출력부
110: 학습 데이터 생성부
120: 딥러닝 수행부
130: 알고리즘 생성부
200: 저장 모듈
210: 오믹스 데이터-예후 관련 DB
220: 예후 예측 알고리즘 DB
300: 예측 모듈
310: 분석 정보 수신부
320: 예후 결과 출력부
Claims (9)
- (1) 암 환자로부터 수집된 3개 이상의 오믹스 데이터와 암의 예후와의 상관관계를 학습하는 학습 모듈;
(2) 상기 학습 모듈에서 생성된 암의 예후 예측 알고리즘을 저장하는 저장 모듈; 및
(3) 분석 정보를 수신하고, 상기 저장 모듈에 저장된 암의 예후 예측 알고리즘을 사용하여 예후를 모르는 암 환자의 예후를 산출하는 예측 모듈;을 포함하고,
상기 학습 모듈은
(a) 예후를 알고 있는 암 환자의 오믹스 데이터를 개별 유전자에 대해 매트릭스 형태로 정렬하여 딥러닝용 학습 데이터를 생성하는 학습 데이터 생성부;
(b) 생성된 학습 데이터로부터 오믹스 데이터와 암의 예후와의 상관 관계를 학습하는 딥러닝 수행부; 및
(c) 상기 딥러닝 수행부의 결과로부터 암의 예후를 예측하는 알고리즘을 생성하는 알고리즘 생성부;를 포함하는 것인, 암의 예후 예측용 시스템. - 제1항에 있어서, 상기 암의 예후는 암 치료 후 생존 기간인 것인, 암의 예후 예측용 시스템.
- 제1항에 있어서, 상기 오믹스 데이터는 유전체, 전사체, 단백체, 대사체, 후성유전체, 지질체 및 메틸체로 이루어진 군에서 선택되는 것인, 암의 예후 예측용 시스템.
- 삭제
- 삭제
- 삭제
- 제1항에 있어서, 상기 딥러닝 수행부는
(b-1) 정렬된 오믹스 데이터로부터 개별 유전자에 대한 오믹스 데이터의 공통 특징을 학습하는 단계;
(b-2) 학습된 개별 유전자에 대한 오믹스 데이터의 공통 특징에서 중요하지 않은 정보를 제거하는 단계;
(b-3) 상기 (b-2)의 결과로부터 개별 유전자당 가장 높은 값을 암의 예후 예측을 위한 대푯값으로 선별하는 단계;
(b-4) 상기 (b-3)에서 선별한 개별 유전자당 대푯값을 조합하여 암의 예후 예측의 정확도를 확인하는 단계; 및
(b-5) 상기 (b-4)의 결과에서 정확도가 가장 높은 대푯값의 조합을 암의 예후 예측용 마커로 선별하는 단계;를 포함하는 암의 예후 예측용 시스템. - 제7항에 있어서, 상기 (b-4) 단계는 콕스 비례 위험 모델(Cox proportional hazards model)을 사용하여 개별 유전자당 대푯값과 암 환자의 예후와의 음의 로그 부분 유도(negative log partial likelihood)를 계산하는 것인, 암의 예후 예측용 시스템.
- 제1항 내지 제3항, 제7항 및 제8항 중 어느 한 항에 따른 암의 예후 예측용 시스템을 사용한 암의 예후 예측 방법.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020190146627A KR102336311B1 (ko) | 2019-11-15 | 2019-11-15 | 딥러닝을 이용한 암의 예후 예측 모델 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020190146627A KR102336311B1 (ko) | 2019-11-15 | 2019-11-15 | 딥러닝을 이용한 암의 예후 예측 모델 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20210059325A KR20210059325A (ko) | 2021-05-25 |
| KR102336311B1 true KR102336311B1 (ko) | 2021-12-08 |
Family
ID=76145766
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020190146627A KR102336311B1 (ko) | 2019-11-15 | 2019-11-15 | 딥러닝을 이용한 암의 예후 예측 모델 |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102336311B1 (ko) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102706355B1 (ko) * | 2021-12-01 | 2024-09-19 | 부산대학교 산학협력단 | 유전체 기능별 딥러닝을 이용한 암종 분류를 위한 장치 및 방법 |
| CN117334325B (zh) * | 2023-09-26 | 2024-04-16 | 中山大学肿瘤防治中心(中山大学附属肿瘤医院、中山大学肿瘤研究所) | 一种lcat在肝细胞癌诊断、治疗和预测复发的应用 |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014059036A1 (en) * | 2012-10-09 | 2014-04-17 | Five3 Genomics, Llc | Systems and methods for learning and identification of regulatory interactions in biological pathways |
| KR102190299B1 (ko) * | 2017-02-02 | 2020-12-11 | 사회복지법인 삼성생명공익재단 | 인공신경망을 이용한 위암의 예후 예측 방법, 장치 및 프로그램 |
-
2019
- 2019-11-15 KR KR1020190146627A patent/KR102336311B1/ko active IP Right Grant
Also Published As
| Publication number | Publication date |
|---|---|
| KR20210059325A (ko) | 2021-05-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Boulesteix et al. | IPF‐LASSO: integrative L1‐penalized regression with penalty factors for prediction based on multi‐omics data | |
| US10339464B2 (en) | Systems and methods for generating biomarker signatures with integrated bias correction and class prediction | |
| KR102190299B1 (ko) | 인공신경망을 이용한 위암의 예후 예측 방법, 장치 및 프로그램 | |
| CA2877430C (en) | Systems and methods for generating biomarker signatures with integrated dual ensemble and generalized simulated annealing techniques | |
| Le et al. | Statistical inference relief (STIR) feature selection | |
| Boulesteix et al. | Microarray-based classification and clinical predictors: on combined classifiers and additional predictive value | |
| Meinicke | UProC: tools for ultra-fast protein domain classification | |
| CN111933212B (zh) | 一种基于机器学习的临床组学数据处理方法及装置 | |
| US20160364522A1 (en) | Systems and methods for classifying, prioritizing and interpreting genetic variants and therapies using a deep neural network | |
| US20020095260A1 (en) | Methods for efficiently mining broad data sets for biological markers | |
| US20180166170A1 (en) | Generalized computational framework and system for integrative prediction of biomarkers | |
| CN110993113B (zh) | 基于MF-SDAE的lncRNA-疾病关系预测方法及系统 | |
| Zararsiz et al. | voomDDA: discovery of diagnostic biomarkers and classification of RNA-seq data | |
| CN115997255A (zh) | 从基因组预测细菌表型性状的分子技术 | |
| KR102336311B1 (ko) | 딥러닝을 이용한 암의 예후 예측 모델 | |
| Yu et al. | SANPolyA: a deep learning method for identifying Poly (A) signals | |
| CN115280415A (zh) | 致病性模型的应用和其训练 | |
| CN108427865B (zh) | 一种预测LncRNA和环境因素关联关系的方法 | |
| Shibahara et al. | Deep learning generates custom-made logistic regression models for explaining how breast cancer subtypes are classified | |
| Lagani et al. | Structure-based variable selection for survival data | |
| Wu et al. | Stacked autoencoder based multi-omics data integration for cancer survival prediction | |
| Gross et al. | A selective approach to internal inference | |
| CN115565610A (zh) | 基于多组学数据的复发转移分析模型建立方法及系统 | |
| US11107555B2 (en) | Methods and systems for identifying a causal link | |
| JP2023547571A (ja) | アクティブラーニングによる薬剤の最適化 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal | ||
| E701 | Decision to grant or registration of patent right |