JP5561622B2 - 多重化システム、データ通信カード、状態異常検出方法、及びプログラム - Google Patents
多重化システム、データ通信カード、状態異常検出方法、及びプログラム Download PDFInfo
- Publication number
- JP5561622B2 JP5561622B2 JP2011210049A JP2011210049A JP5561622B2 JP 5561622 B2 JP5561622 B2 JP 5561622B2 JP 2011210049 A JP2011210049 A JP 2011210049A JP 2011210049 A JP2011210049 A JP 2011210049A JP 5561622 B2 JP5561622 B2 JP 5561622B2
- Authority
- JP
- Japan
- Prior art keywords
- physical machine
- state
- data communication
- communication card
- power supply
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000006854 communication Effects 0.000 title claims description 167
- 238000004891 communication Methods 0.000 title claims description 167
- 238000001514 detection method Methods 0.000 title claims description 31
- 230000005856 abnormality Effects 0.000 title claims description 21
- 238000012544 monitoring process Methods 0.000 claims description 56
- 239000000758 substrate Substances 0.000 claims description 13
- 230000004044 response Effects 0.000 claims description 9
- 230000002159 abnormal effect Effects 0.000 claims description 5
- 230000006870 function Effects 0.000 description 20
- 238000000034 method Methods 0.000 description 12
- 238000012545 processing Methods 0.000 description 9
- 238000010586 diagram Methods 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 5
- 230000008859 change Effects 0.000 description 4
- 230000002093 peripheral effect Effects 0.000 description 4
- 239000004065 semiconductor Substances 0.000 description 3
- 230000008901 benefit Effects 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 241000699670 Mus sp. Species 0.000 description 1
- 230000007175 bidirectional communication Effects 0.000 description 1
- 230000002457 bidirectional effect Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000001816 cooling Methods 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/3003—Monitoring arrangements specially adapted to the computing system or computing system component being monitored
- G06F11/3006—Monitoring arrangements specially adapted to the computing system or computing system component being monitored where the computing system is distributed, e.g. networked systems, clusters, multiprocessor systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/3055—Monitoring arrangements for monitoring the status of the computing system or of the computing system component, e.g. monitoring if the computing system is on, off, available, not available
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/3058—Monitoring arrangements for monitoring environmental properties or parameters of the computing system or of the computing system component, e.g. monitoring of power, currents, temperature, humidity, position, vibrations
- G06F11/3062—Monitoring arrangements for monitoring environmental properties or parameters of the computing system or of the computing system component, e.g. monitoring of power, currents, temperature, humidity, position, vibrations where the monitored property is the power consumption
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computing Systems (AREA)
- Physics & Mathematics (AREA)
- Quality & Reliability (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Hardware Redundancy (AREA)
- Power Sources (AREA)
- Debugging And Monitoring (AREA)
Description
以下に、本発明の実施形態について添付図面を参照して説明する。
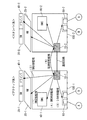
図1に示すように、本発明に係る多重化システムは、複数の物理マシン100(100−i,i=1〜n:nは台数)を含む。
図2を参照して、物理マシン100(100−i,i=1〜n)の各々の内部構成の詳細について説明する。
図3を参照して、データ通信カード10の詳細について説明する。
図4を参照して、FPGA11及びCPLD12の詳細について説明する。
以下に、ハードウェア(HW)状態監視の動作の詳細について説明する。
以下に、ソフトウェア(SW)状態監視の動作の詳細について説明する。
以下に、I/Oチップ状態監視機能の動作の詳細について説明する。
以下に、BMC状態監視の動作の詳細について説明する。
以下に、自機の電源状態監視の動作の詳細について説明する。
電源監視部121は、自機の物理マシンのメイン電源がON状態であることを検出する。また、電源監視部121は、通信制御部124を介して、リモート接続先の物理マシンのメイン電源がON状態であることを検出する。
電源監視部121は、自機の物理マシンのメイン電源がOFF状態であることを検出する。また、電源監視部121は、通信制御部124を介して、リモート接続先の物理マシンのメイン電源がOFF状態であることを検出する。
以下に、リモート接続先の電源状態監視の動作の詳細について説明する。
電源監視部121は、通信制御部124を介して、リモート接続先の物理マシンのメイン電源がON状態であることを検出する。また、電源監視部121は、自機の物理マシンのメイン電源がON状態であることを検出する。
電源監視部121は、通信制御部124を介して、リモート接続先の物理マシンのメイン電源がOFF状態であることを検出する。また、電源監視部121は、自機の物理マシンのメイン電源がOFF状態であることを検出する。
以下に、自律制御によりメイン電源をOFF状態にする動作の詳細について説明する。
以下に、自律制御によりメイン電源をON状態にする動作の詳細について説明する。
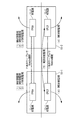
図5を参照して、データ通信カード10が、物理マシン100(100−i,i=1〜n)の基板から独立して存在している「システム構成1」について説明する。
図6を参照して、データ通信カード10が、物理マシン100(100−i,i=1〜n)の基板と一体化している「システム構成2」について説明する。
以上のように、本発明は、一般的なIAサーバでソフトウェア方式のフォールトトレラントシステムやクラスターシステムを構築するために利用されるデータ通信カードに、スタンバイ電源から動作可能な装置の状態監視機能、他系装置への状態通知機能及び電源制御機能を追加することで、早期の故障検出とフェイルオーバ(failover)及びコールドスタンバイ(cold standby)を実現する。
以上、本発明の実施形態を詳述してきたが、実際には、上記の実施形態に限られるものではなく、本発明の要旨を逸脱しない範囲の変更があっても本発明に含まれる。
11… FPGA(Field Programmable Gate Array)
111… プロセッサ
112… SW(software)状態取得部
113… PCI(Peripheral Components Interconnect bus)制御部
114… 通信制御部
12… CPLD(Complex Programmable Logic Device)
121… 電源監視部
122… 電源制御部
123… SMBus(System Management Bus)制御部
124… 通信制御部
20… ハードウェア(HW:hardware)
30… ソフトウェア(SW:software)
40… ドライバ
50… I/O(Input/Output)チップ
60… BMC(Baseboard Management Controller)
100(−i,i=1〜n)… 物理マシン
Claims (11)
- 複数の物理マシンと、
前記複数の物理マシンの各々に搭載され、通信回線を介して自系の物理マシンと他系の物理マシンとを接続し、相互にデータの送受信を行うためのデータ通信カードと
を含み、
前記データ通信カードは、
メイン電源の給電により駆動し、前記自系の物理マシン及び前記他系の物理マシンの内部状態を監視し、状態異常を検出する第1のLSI
を具備し、
前記第1のLSIは、
前記メイン電源がONの状態で、監視及び検出対象の物理マシンのメモリに対してデータの読み出し要求を定期的に発行し、前記読み出し要求に対する応答を確認することで、前記監視及び検出対象の物理マシンの状態異常を検出する
多重化システム。 - 請求項1に記載の多重化システムであって、
前記データ通信カードは、
搭載された物理マシンの基板上にチップとして搭載され、前記基板上にそれぞれ配置されているCPUとI/Oチップとの間に設けられており、
前記第1のLSIは、
前記メイン電源がONの状態で、監視及び検出対象の物理マシンの前記I/Oチップに対して設定情報の読み出し要求を定期的に発行し、前記読み出し要求に対する応答を確認することで、前記監視及び検出対象の物理マシンの状態異常を検出する
多重化システム。 - 請求項1または2に記載の多重化システムであって、
前記データ通信カードは、
スタンバイ電源の給電により駆動し、前記メイン電源がOFFの状態の時でも、前記自系の物理マシン及び前記他系の物理マシンの電源状態を監視し、電源の異常を検出する第2のLSI
を更に具備する
多重化システム。 - 請求項3に記載の多重化システムであって、
前記第1のLSIは、
前記データ通信カード内部を制御するプロセッサと、
前記自系の物理マシン上で動作するソフトウェア(SW)の状態を取得するSW状態取得部と、
PCI Expressバスを介して、前記自系の物理マシン内部のハードウェア及びI/Oチップと接続し、前記ハードウェア及び前記I/Oチップの状態を監視するPCI制御部と、
前記第2のLSI側とデータの送受信を行い、通信回線を介して前記他系の物理マシン側とデータの送受信を行う通信制御部と
を更に具備し、
前記第2のLSIは、
前記自系の物理マシン及び前記他系の物理マシンの電源状態を監視する電源監視部と、
前記自系の物理マシン及び前記他系の物理マシンの電源状態を制御する電源制御部と、
SMBusを介して、前記自系の物理マシン内部のBMC(Baseboard Management Controller)と接続し、前記BMCから監視結果を取得するSMBus制御部と、
前記第1のLSI側とデータの送受信を行い、通信回線を介して前記他系の物理マシン側とデータの送受信を行い、前記自系の物理マシンから電源の給電を受けられない場合、前記他系の物理マシンから電源の給電を受ける通信制御部と
を更に具備する
多重化システム。 - 請求項1に記載の多重化システムであって、
前記データ通信カードは、
前記自系の物理マシンの基板上にチップとして搭載され、前記自系の物理マシン内部の前記基板上にそれぞれ配置されているCPUとI/Oチップとの間に設けられている
多重化システム。 - 複数の物理マシンの各々に搭載されたデータ通信カードであって、
通信回線を介して自系の物理マシンと他系の物理マシンとを接続し、相互にデータの送受信を行う手段と、
メイン電源の給電により駆動し、前記自系の物理マシン及び前記他系の物理マシンの内部状態を監視し、状態異常を検出する第1のLSIと
を具備し、
前記第1のLSIは、
前記メイン電源がONの状態で、監視及び検出対象の物理マシンのメモリに対してデータの読み出し要求を定期的に発行し、前記読み出し要求に対する応答を確認することで、前記監視及び検出対象の物理マシンの状態異常を検出する
データ通信カード。 - 請求項6に記載のデータ通信カードであって、
前記データ通信カードは、
搭載された物理マシンの基板上にチップとして搭載され、前記基板上にそれぞれ配置されているCPUとI/Oチップとの間に設けられており、
前記第1のLSIは、
前記メイン電源がONの状態で、前記監視及び検出対象の物理マシンの前記I/Oチップに対して設定情報の読み出し要求を定期的に発行し、前記読み出し要求に対する応答を確認することで、前記監視及び検出対象の物理マシンの状態異常を検出する
データ通信カード。 - 請求項6または7に記載のデータ通信カードであって、
スタンバイ電源の給電により駆動し、前記メイン電源がOFFの状態の時でも、前記自系の物理マシン及び前記他系の物理マシンの電源状態を監視し、電源の異常を検出する第2のLSIと
を更に具備する
データ通信カード。 - 請求項8に記載のデータ通信カードであって、
前記第1のLSIは、
前記データ通信カード内部を制御するプロセッサと、
前記自系の物理マシン上で動作するソフトウェア(SW)の状態を取得するSW状態取得部と、
PCI Expressバスを介して、前記自系の物理マシン内部のハードウェア及びI/Oチップと接続し、前記ハードウェア及び前記I/Oチップの状態を監視するPCI制御部と、
前記第2のLSI側とデータの送受信を行い、通信回線を介して前記他系の物理マシン側とデータの送受信を行う通信制御部と
を更に具備し、
前記第2のLSIは、
前記自系の物理マシン及び前記他系の物理マシンの電源状態を監視する電源監視部と、
前記自系の物理マシン及び前記他系の物理マシンの電源状態を制御する電源制御部と、
SMBusを介して、前記自系の物理マシン内部のBMC(Baseboard Management Controller)と接続し、前記BMCから監視結果を取得するSMBus制御部と、
前記第1のLSI側とデータの送受信を行い、通信回線を介して前記他系の物理マシン側とデータの送受信を行い、前記自系の物理マシンから電源の給電を受けられない場合、前記他系の物理マシンから電源の給電を受ける通信制御部と
を更に具備する
データ通信カード。 - 複数の物理マシンの各々に搭載されたデータ通信カードにより実施される状態異常検出方法であって、
前記データ通信カードは、
通信手段と、
メイン電源の給電により駆動する第1のLSIと
を具備しており、
前記状態異常検出方法は、
前記通信手段が、通信回線を介して自系の物理マシンと他系の物理マシンとを接続し、相互にデータの送受信を行うステップと、
前記第1のLSIが、前記自系の物理マシン及び前記他系の物理マシンの内部状態を監視し、状態異常を検出するステップと
を含み、
前記状態異常を検出するステップでは、
前記第1のLSIが、前記メイン電源がONの状態で、監視及び検出対象の物理マシンのメモリに対してデータの読み出し要求を定期的に発行し、前記読み出し要求に対する応答を確認することで、前記監視及び検出対象の物理マシンの状態異常を検出する
状態異常検出方法。 - 複数の物理マシンの各々に搭載されたデータ通信カードにより実行されるプログラムであって、
前記データ通信カードは、
通信手段と、
メイン電源の給電により駆動する第1のLSIと
を具備しており、
前記プログラムは、
前記通信手段が、通信回線を介して自系の物理マシンと他系の物理マシンとを接続し、相互にデータの送受信を行うステップと、
前記第1のLSIが、前記自系の物理マシン及び前記他系の物理マシンの内部状態を監視し、状態異常を検出するステップと
を含み
前記状態異常を検出するステップでは、
前記第1のLSIが、前記メイン電源がONの状態で、監視及び検出対象の物理マシンのメモリに対してデータの読み出し要求を定期的に発行し、前記読み出し要求に対する応答を確認することで、前記監視及び検出対象の物理マシンの状態異常を検出すること
をデータ通信カードに実行させるためのプログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011210049A JP5561622B2 (ja) | 2011-09-27 | 2011-09-27 | 多重化システム、データ通信カード、状態異常検出方法、及びプログラム |
| US13/609,556 US8990632B2 (en) | 2011-09-27 | 2012-09-11 | System for monitoring state information in a multiplex system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011210049A JP5561622B2 (ja) | 2011-09-27 | 2011-09-27 | 多重化システム、データ通信カード、状態異常検出方法、及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2013073289A JP2013073289A (ja) | 2013-04-22 |
| JP5561622B2 true JP5561622B2 (ja) | 2014-07-30 |
Family
ID=47912617
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011210049A Active JP5561622B2 (ja) | 2011-09-27 | 2011-09-27 | 多重化システム、データ通信カード、状態異常検出方法、及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US8990632B2 (ja) |
| JP (1) | JP5561622B2 (ja) |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9087005B2 (en) * | 2013-05-31 | 2015-07-21 | International Business Machines Corporation | Increasing resiliency of a distributed computing system through lifeboat monitoring |
| CN104008037A (zh) * | 2014-03-13 | 2014-08-27 | 英业达科技有限公司 | 监控模块的监控方法 |
| WO2015163084A1 (ja) * | 2014-04-22 | 2015-10-29 | オリンパス株式会社 | データ処理システム及びデータ処理方法 |
| US9804937B2 (en) * | 2014-09-08 | 2017-10-31 | Quanta Computer Inc. | Backup backplane management control in a server rack system |
| US9130559B1 (en) * | 2014-09-24 | 2015-09-08 | Xilinx, Inc. | Programmable IC with safety sub-system |
| CN105808407B (zh) * | 2014-12-31 | 2019-09-13 | 华为技术有限公司 | 管理设备的方法、设备和设备管理控制器 |
| WO2016157328A1 (ja) * | 2015-03-27 | 2016-10-06 | 三菱電機株式会社 | 制御システム、及び通信ゲートウェイ装置 |
| US10846160B2 (en) * | 2018-01-12 | 2020-11-24 | Quanta Computer Inc. | System and method for remote system recovery |
| CN109067707A (zh) * | 2018-06-29 | 2018-12-21 | 国家电网公司信息通信分公司 | 一种电力企业ims通信方法、装置以及ims通信系统 |
| CN109634397A (zh) * | 2018-12-07 | 2019-04-16 | 郑州云海信息技术有限公司 | 一种实现智能网卡上下电功能的系统及方法 |
| TWI776427B (zh) * | 2021-03-17 | 2022-09-01 | 英業達股份有限公司 | 切換式供電系統及其方法 |
| WO2024121952A1 (ja) * | 2022-12-06 | 2024-06-13 | 日本電信電話株式会社 | 故障復旧高速化システム、故障復旧高速化方法及び故障復旧高速化プログラム |
Family Cites Families (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH08251814A (ja) * | 1995-03-15 | 1996-09-27 | Hitachi Ltd | 電源二重化運転方式 |
| JPH10150479A (ja) * | 1996-11-19 | 1998-06-02 | Fujitsu Ltd | 二重化装置の障害時における誤動作防止装置 |
| JP2001060160A (ja) * | 1999-08-23 | 2001-03-06 | Mitsubishi Heavy Ind Ltd | 制御装置のcpu二重化システム |
| US6738930B1 (en) * | 2000-12-22 | 2004-05-18 | Crystal Group Inc. | Method and system for extending the functionality of an environmental monitor for an industrial personal computer |
| US6895285B2 (en) * | 2002-05-23 | 2005-05-17 | American Megatrends, Inc. | Computer system status monitoring |
| US6721907B2 (en) * | 2002-06-12 | 2004-04-13 | Zambeel, Inc. | System and method for monitoring the state and operability of components in distributed computing systems |
| US7219254B2 (en) * | 2003-03-19 | 2007-05-15 | Lucent Technologies Inc. | Method and apparatus for high availability distributed processing across independent networked computer fault groups |
| US7428655B2 (en) * | 2004-09-08 | 2008-09-23 | Hewlett-Packard Development Company, L.P. | Smart card for high-availability clustering |
| JP2006172050A (ja) * | 2004-12-15 | 2006-06-29 | Yaskawa Information Systems Co Ltd | ホットスタンバイ式2重化システム |
| US7809992B2 (en) * | 2005-07-27 | 2010-10-05 | Ati Technologies Ulc | Device and method for malfunction monitoring and control |
| JP2008033483A (ja) * | 2006-07-27 | 2008-02-14 | Nec Corp | 計算機システム、計算機および計算機動作環境の移動方法 |
| JP5068056B2 (ja) * | 2006-10-11 | 2012-11-07 | 株式会社日立製作所 | 障害回復方法、計算機システム及び管理サーバ |
| JP2008225567A (ja) * | 2007-03-08 | 2008-09-25 | Nec Computertechno Ltd | 情報処理システム |
| JP4468426B2 (ja) * | 2007-09-26 | 2010-05-26 | 株式会社東芝 | 高可用システム及び実行状態制御方法 |
| JP2009080692A (ja) * | 2007-09-26 | 2009-04-16 | Toshiba Corp | 仮想計算機システム及び同システムにおけるサービス引き継ぎ制御方法 |
| JP2009205334A (ja) * | 2008-02-27 | 2009-09-10 | Hitachi Ltd | 性能モニタ回路及び性能モニタ方法 |
| JP5377898B2 (ja) * | 2008-07-10 | 2013-12-25 | 株式会社日立製作所 | クラスタリングを構成する計算機システムの系切替方法、及びシステム |
| JP5204603B2 (ja) * | 2008-09-29 | 2013-06-05 | 株式会社日立製作所 | 4重化コンピュータシステムおよび2重化リングネットワーク |
| JP5605672B2 (ja) * | 2009-07-21 | 2014-10-15 | 日本電気株式会社 | 電圧監視システムおよび電圧監視方法 |
| US8117494B2 (en) * | 2009-12-22 | 2012-02-14 | Intel Corporation | DMI redundancy in multiple processor computer systems |
-
2011
- 2011-09-27 JP JP2011210049A patent/JP5561622B2/ja active Active
-
2012
- 2012-09-11 US US13/609,556 patent/US8990632B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2013073289A (ja) | 2013-04-22 |
| US20130080840A1 (en) | 2013-03-28 |
| US8990632B2 (en) | 2015-03-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5561622B2 (ja) | 多重化システム、データ通信カード、状態異常検出方法、及びプログラム | |
| US8948000B2 (en) | Switch fabric management | |
| US7802127B2 (en) | Method and computer system for failover | |
| KR100952553B1 (ko) | 가상 계산기 시스템 및 그 제어 방법 | |
| US8745438B2 (en) | Reducing impact of a switch failure in a switch fabric via switch cards | |
| US8677175B2 (en) | Reducing impact of repair actions following a switch failure in a switch fabric | |
| US11573737B2 (en) | Method and apparatus for performing disk management of all flash array server | |
| JP2014170394A (ja) | クラスタシステム | |
| WO2012176278A1 (ja) | 情報処理装置、仮想マシン制御方法およびプログラム | |
| JP2006107080A (ja) | ストレージ装置システム | |
| US11836100B1 (en) | Redundant baseboard management controller (BMC) system and method | |
| JP5549733B2 (ja) | 計算機管理装置、計算機管理システム及び計算機システム | |
| JP2019121338A (ja) | 機器ラック及び機器ラックからの状態報告を保証する方法 | |
| JP5422705B2 (ja) | 仮想計算機システム | |
| CN113535472A (zh) | 集群服务器 | |
| CN113535471A (zh) | 集群服务器 | |
| CN112912848A (zh) | 一种丛集作业过程中的电源请求管理方法 | |
| JP4779948B2 (ja) | サーバシステム | |
| JP5422706B2 (ja) | 管理システム | |
| JP5147955B2 (ja) | 仮想計算機システム | |
| KR20150049349A (ko) | 펌웨어 관리 장치 및 방법 | |
| JPWO2012176278A1 (ja) | 情報処理装置、仮想マシン制御方法およびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20130206 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20130802 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130807 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20131007 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20140304 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140423 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20140516 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20140529 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5561622 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |