JP3691538B2 - Vector data addition method and vector data multiplication method - Google Patents
Vector data addition method and vector data multiplication method Download PDFInfo
- Publication number
- JP3691538B2 JP3691538B2 JP04676395A JP4676395A JP3691538B2 JP 3691538 B2 JP3691538 B2 JP 3691538B2 JP 04676395 A JP04676395 A JP 04676395A JP 4676395 A JP4676395 A JP 4676395A JP 3691538 B2 JP3691538 B2 JP 3691538B2
- Authority
- JP
- Japan
- Prior art keywords
- vector
- instruction
- register
- multiplication
- addition
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images
















Landscapes
- Complex Calculations (AREA)
Description
【0001】
【産業上の利用分野】
本発明は、ベクトル加算処理を高速に実行できるようにするベクトルデータ加算方法と、そのベクトルデータ加算方法を使って、ベクトル乗算処理を高速に実行できるようにするベクトルデータ乗算方法とに関する。
【0002】
ベクトル処理装置では、ベクトル加算処理やベクトル乗算処理を実行する。このようなベクトル演算処理は高速に実行できるようにする必要がある。
【0003】
【従来の技術】
従来のベクトル処理装置では、ベクトル加算処理を実行するときには、桁上げの発生を考慮して、ベクトルシフト命令を実行しながらベクトル加算命令を実行していくという構成を採っていた。
【0004】
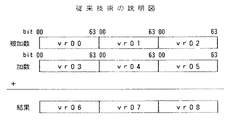
次に、160ビットの被加数と160ビットの加数との加算処理を例にとって、この従来技術を詳細に説明する。
加算器が64ビット同士の加算処理を実行する場合には、従来では、図13に示すように、64ビットの3つのレジスタ(vr00,vr01,vr02)からなる被加数用のレジスタと、64ビットの3つのレジスタ(vr03,vr04,vr05)からなる加数用のレジスタとを用意して、例えば、図14に示す形式、すなわち、図15に図式化する形式に従って、その被加数用のレジスタに160ビットの被加数を格納するとともに、加数用のレジスタに160ビットの加数を格納する。
【0005】
そして、図16に示すベクトル命令列を発行することで、160ビットの被加数と160ビットの加数との加算処理を実行する。ここで、
「VA vr1,vr2,vr3」
は、ベクトルレジスタvr1とベクトルレジスタvr2との加算結果をベクトルレジスタvr3に格納しろというベクトル加算命令であり、
「VSR vr1,SC,vr3」
は、ベクトルレジスタvr1のデータをSCビット右シフトしてベクトルレジスタvr3に格納しろというベクトルシフト命令であり、
「VSL vr1,SC,vr3」
は、ベクトルレジスタvr1のデータをSCビット左シフトしてベクトルレジスタvr3に格納しろというベクトルシフト命令である。
【0006】
すなわち、図16に示すベクトル命令列に従い、先ず最初に、(1) のベクトル加算命令VAに従って、ベクトルレジスタvr02の被加数部分と、ベクトルレジスタvr05の加数部分とを加算してベクトルレジスタvr10に格納する。このとき、桁上げが発生する可能性があるので、続いて、(2) のベクトルシフト命令VSRに従って、ベクトルレジスタ10の格納データを60ビット右シフトすることでその桁上げ値(キャリーアウトデータ)を取り出して、それをベクトルレジスタ15に格納する。
【0007】
続いて、(3) のベクトル加算命令VAに従って、ベクトルレジスタvr01の被加数部分と、ベクトルレジスタvr04の加数部分とを加算してベクトルレジスタvr20に格納する。
【0008】
続いて、(4) のベクトル加算命令VAに従って、下位部分の加算処理により発生したキャリーアウトデータを加算すべく、ベクトルレジスタvr15の格納するキャリーアウトデータと、ベクトルレジスタvr20の格納データとを加算してベクトルレジスタvr20に格納する。このとき、桁上げが発生する可能性があるので、続いて、(5) のベクトルシフト命令VSRに従って、ベクトルレジスタ20の格納データを60ビット右シフトすることでそのキャリーアウトデータを取り出して、それをベクトルレジスタvr25に格納する。
【0009】
続いて、(6) のベクトル加算命令VAに従って、ベクトルレジスタvr00の被加数部分と、ベクトルレジスタvr03の加数部分とを加算してベクトルレジスタvr30に格納する。
【0010】
続いて、(7) のベクトル加算命令VAに従って、下位部分の加算処理により発生したキャリーアウトデータを加算すべく、ベクトルレジスタvr25の格納するキャリーアウトデータと、ベクトルレジスタvr30の格納データとを加算してベクトルレジスタvr6 に格納する。
【0011】
続いて、ベクトルレジスタvr10に格納される60ビットの有効データを取り出すべく、(8) のベクトルシフト命令VSLに従って、ベクトルレジスタ10の格納データを4ビット左シフトして、それをベクトルレジスタvr10に格納し、(9) のベクトルシフト命令VSRに従って、そのベクトルレジスタvr10の格納データを4ビット右シフトしてベクトルレジスタvr8 に格納することで、上位4ビットにゼロ値を持つその60ビットの有効データをベクトルレジスタvr8 に格納する。
【0012】
続いて、ベクトルレジスタvr20に格納される60ビットの有効データを取り出すべく、(10)のベクトルシフト命令VSLに従って、ベクトルレジスタ20の格納データを4ビット左シフトして、それをベクトルレジスタvr20に格納し、(11)のベクトルシフト命令VSRに従って、そのベクトルレジスタvr20の格納データを4ビット右シフトしてベクトルレジスタvr7 に格納することで、上位4ビットにゼロ値を持つその60ビットの有効データをベクトルレジスタvr7 に格納する。
【0013】
このように、従来のベクトル処理装置では、ベクトル加算処理を実行するときには、桁上げの発生を考慮して、ベクトルシフト命令を実行しながらベクトル加算命令を実行していくという構成を採っていたのである。
【0014】
一方、従来のベクトル処理装置の備える乗算器では、64ビット×64ビットのような入力仕様を持つ場合にあっても、ハードウェア量の削減を図るために、64ビット×16ビットのような少ないビット数の乗算機能を持つ構成を採っていた。
【0015】
そして、入力仕様の64ビット同士の乗算処理を実現するために、乗数を16ビット単位に4分割し、64ビット×16ビット乗算機能を使って、それらの16ビットの乗数部分と64ビットの被乗数とを乗算することで部分積を求め、それらの部分積を16ビットシフトしつつ加算して、その加算結果の示す64ビット部分を乗算結果として出力するという構成を採っていた。
【0016】
例えば、64ビット同士の乗算処理の上位64ビットが必要となる場合には、命令指示に従って、図17に示すように、4分割した乗数を下位側から順番に選択して部分積を求め、それらの部分積を16ビット左シフトしつつ加算していくことで乗算処理の上位64ビットを得て出力していた。また、64ビット同士の乗算処理の下位64ビットが必要となる場合には、命令指示に従って、4分割した乗数を上位側から順番に選択して部分積を求め、それらの部分積を16ビット右シフトしつつ加算していくことで乗算処理の下位64ビットを得て出力していた。
【0017】
【発明が解決しようとする課題】
しかしながら、従来技術のように、ベクトル加算処理を実行するときに、桁上げの発生を考慮して、ベクトルシフト命令を実行しながらベクトル加算命令を実行していくという構成を採っていると、命令数が多くなることから高速にベクトル加算処理を実行できないという問題点があった。
【0018】
また、従来技術の乗算器では、内部で実行する乗算回数が多くなるとともに、内部に、部分積をシフトし加算する機能(ループ構成を使用している)を持たなくてはならないという問題点があった。
【0019】
本発明はかかる事情に鑑みてなされたものであって、ベクトル加算処理を高速に実行できるようにするベクトルデータ加算方法の提供と、そのベクトルデータ加算方法を使って、ベクトル乗算処理を高速に実行できるようにするベクトルデータ乗算方法の提供とを目的とする。
【0020】
【課題を解決するための手段】
図1に本発明の原理構成を図示する。
図中、1は本発明を実行するベクトル処理装置であって、CPU10と、ベクトル命令制御機構11と、ベクトルレジスタ12と、マスクレジスタ13と、加算器14と、乗算器15とを備える。
【0021】
このCPU10は、ベクトル命令を発行する。ベクトル命令制御機構11は、ベクトル命令の実行を制御する。ベクトルレジスタ12は、ベクトルデータを格納する。マスクレジスタ13は、ベクトル処理で使用するマスクデータを格納する。加算器14は、ベクトル加算命令を実行する。乗算器15は、ベクトル乗算命令を実行する。
【0022】
本発明を実現するために、加算器14は、ベクトルオペランドの加数と被加数の他に、マスクレジスタ13に格納されるキャリーアウトデータを入力するとともに、算出結果のキャリーアウトデータをマスクレジスタ13へ出力する構成を採る。このとき、マスクオペランドの増加により命令で指定するレジスタ数が増える場合には、命令で指定するレジスタ数を抑えるべく、入力用のマスクレジスタと出力用のマスクレジスタとして同一のものを使用する構成を採ることが好ましい。
【0023】
一方、本発明を実現するために、乗算器15は、入力される2つのmビットデータの乗算値となる2mビットデータを算出する機能を有するとともに、命令に応答して、乗算値の上位mビットデータか下位mビットデータのいずれか一方を選択して出力するセレクタを持つ構成を採る。
【0026】
【作用】
本発明で用いる加算器14は、ベクトルオペランドの被加数と加数の他に、マスクレジスタ13に書き込まれるキャリーアウトデータを入力として加算処理を実行して、その加算結果により生ずるキャリーアウトデータをマスクレジスタ13に書き込んでいく。
【0027】
このように構成される加算器14を使い、本発明を実行するベクトル処理装置1では、
(i)ベクトルレジスタvr1に格納されるmビットデータとベクトルレジスタvr2に格納されるmビットデータとマスクレジスタmr1に格納されるキャリーアウトデータとの加算結果をベクトルレジスタvr3に格納するとともに、そのとき発生するキャリーアウトデータをマスクレジスタmr2に格納しろというベクトル加算命令を、
「VAC vr1,vr2,mr1,vr3,mr2」
と表すならば、このベクトル加算命令の命令列で表される被加数と加数との加算命令を受け取り、
( ii )上述の構成を採る加算器14を使って、この命令列のベクトル加算命令をその命令列の順番に従って実行することで、被加数と加数とを加算する。
このように、本発明によれば、キャリーアウトデータをマスクレジスタ13に格納していく構成を採ることから、従来技術のように、ベクトルシフト命令を実行しながらベクトル加算命令を実行していくという構成を採る必要がなくなり、少ない命令数でもって高速にベクトル加算命令を実行できるようになる。
【0028】
また、本発明で用いる乗算器15は、入力される2つのmビットデータの乗算値となる2mビットデータを算出する機能を有する。すなわち、従来の乗算器では、部分積を求め、それらをシフトしつつ加算することで、入力される2つのmビットデータの乗算値となるmビットデータを算出する構成を採っているのに対して、本発明で用いる乗算器15では、部分積を求めることなく、直接、乗算値となる2mビットデータを算出する構成を採っている。例えば、64ビットのデータと、64ビットのデータとを乗算して、128ビットの乗算結果のデータを算出するのである。
【0029】
これから、従来の乗算器では、内部で実行する乗算回数が多くなるとともに、内部に、部分積をシフトし加算する機能を持たなくてはならないという問題点があったが、本発明で用いる乗算器15では、これを解決できることになる。
【0030】
しかるに、乗算器15に入力されるデータがmビット構成であるときには、加算器14に入力されるデータもmビット構成を採るので、乗算器15が2mビットのデータを出力したのでは整合性を保てない。これから、本発明で用いる乗算器15では、命令に応答して、乗算値の上位mビットデータか下位mビットデータのいずれか一方を選択して出力するセレクタを持つ構成を採ることで、これに対処している。
このように構成される乗算器15及び加算器14を使い、本発明を実行するベクトル処理装置1では、
(i)ベクトルレジスタvr1に格納されるmビットデータとベクトルレジスタvr2に格納されるmビットデータとの乗算結果の下位mビットデータ部分をベクトルレジスタvr3に格納しろというベクトル乗算命令を、
「VML vr1,vr2,vr3」
と表し、ベクトルレジスタvr1に格納されるmビットデータとベクトルレジスタvr2に格納されるmビットデータとの乗算結果の上位mビットデータ部分をベクトルレジスタvr3に格納しろというベクトル乗算命令を、
「VMU vr1,vr2,vr3」
と表し、ベクトルレジスタvr1に格納されるmビットデータとベクトルレジスタvr2に格納されるmビットデータとマスクレジスタmr1に格納されるキャリーアウトデータとの加算結果をベクトルレジスタvr3に格納するとともに、そのとき発生するキャリーアウトデータをマスクレジスタmr2に格納しろというベクトル加算命令を、
「VAC vr1,vr2,mr1,vr3,mr2」
と表すならば、第1番目にVML命令、それに続いてVMU命令、それに続いてVML命令、それに続いてVAC命令、それに続いてVML命令、それに続いてVAC命令、それに続いてVMU命令、それに続いてVMU命令、それに続いてVAC命令、それに続いてVML命令、それに続いてVAC命令、それに続いてVMU命令、最後にVAC命令という命令列で表される被乗数と乗数との乗算命令を受け取り、
( ii )この命令列の乗算命令をその命令列の順番に従って実行するとともに、その実行にあたって、VML命令及びVMU命令を実行するときは、上述の構成を採る乗算器15を使ってその命令を実行し、VAC命令を実行するときは、上述の構成を採る加算器14を使ってその命令を実行する。
このように、本発明によれば、ベクトル乗算命令を実行するにあたって実行が要求されることになるベクトル加算命令の実行にあたって、キャリーアウトデータをマスクレジスタ13に格納していく構成を採ることから、従来技術のように、ベクトルシフト命令を実行しながらベクトル加算命令を実行していくという構成を採る必要がなくなることで、少ない命令数でもって高速にベクトル加算命令を実行できるようになり、これにより、少ない命令数でもって高速にベクトル乗算命令を実行できるようになる。
【0031】
【実施例】
以下、実施例に従って本発明を詳細に説明する。
図1で説明したように、本発明で用いる加算器14は、ベクトルオペランドの被加数と加数の他に、マスクレジスタ13に書き込まれるキャリーアウトデータを入力として加算処理を実行して、その加算結果により生ずるキャリーアウトデータをマスクレジスタ13に書き込む構成を採っている。
【0032】
すなわち、図2に示すように、ベクトルレジスタ12から読み込む被加数と、ベクトルレジスタ12から読み込む加数と、マスクレジスタ13から読み込むキャリーアウトデータとを入力して加算処理を実行して、その加算値をベクトルレジスタ12に書き込むとともに、その加算処理により生じたキャリーアウトデータをマスクレジスタ13に書き込む構成を採るのである。
【0033】
マスクレジスタ13から読み込むキャリーアウトデータは、1ビットのデータであることから、この加算処理は簡単なハードウェア構成により実現できることになる。
【0034】
一方、図1で説明したように、本発明で用いる乗算器15は、入力される2つのmビットデータの乗算値となる2mビットデータを算出する機能を有するとともに、命令に応答して、乗算値の上位mビットデータか下位mビットデータのいずれか一方を選択して出力するセレクタを持つ構成を採る。
【0035】
すなわち、図3に示すように、ベクトルレジスタ12から読み込むmビットの被乗数と、ベクトルレジスタ12から読み込むmビットの乗数とを入力として乗算処理を実行して、その乗算値の2mビットのデータをラッチし、命令に応答して、その乗算値の上位mビットデータか下位mビットデータのいずれか一方を選択して出力するセレクタを持つ構成を採るのである。
【0036】
次に、上述の構成を採る加算器14を用いて実行される本発明によるベクトル加算処理について、160ビットの被加数と160ビットの加数との加算処理を例にして説明する。
加算器14が64ビット同士の加算処理を実行する場合には、図13で示したように、64ビットの3つのレジスタ(vr00,vr01,vr02)からなる被加数用のレジスタと、64ビットの3つのレジスタ(vr03,vr04,vr05)からなる加数用のレジスタとを用意して、図4に示す形式、すなわち、図5に図式化する形式に従って、その被加数用のレジスタに160ビットの被加数を格納するとともに、加数用のレジスタに160ビットの加数を格納する。
【0037】
そして、図6に示すベクトル命令列を発行することで、160ビットの被加数と160ビットの加数との加算処理を実行する。ここで、
「VAC vr1,vr2,mr1,vr3,mr2」
は、ベクトルレジスタvr1とベクトルレジスタvr2とマスクレジスタmr1との加算結果をベクトルレジスタvr3に格納するとともに、そのとき発生するキャリーアウトデータをマスクレジスタmr2に格納しろというベクトル加算命令である。
【0038】
すなわち、図6に示すベクトル命令列に従い、先ず最初に、(1) のベクトル加算命令VACに従って、ベクトルレジスタvr02の被加数部分と、ベクトルレジスタvr05の加数部分と、初期値としてゼロ値を格納するマスクレジスタmr00の格納データとを加算してベクトルレジスタvr08に格納するとともに、このとき発生する桁上げ値のキャリーアウトデータをマスクレジスタmr01に格納する。
【0039】
続いて、(2) のベクトル加算命令VACに従って、ベクトルレジスタvr01の被加数部分と、ベクトルレジスタvr04の加数部分と、マスクレジスタmr01に格納されるキャリーアウトデータとを加算してベクトルレジスタvr07に格納するとともに、このとき発生する桁上げ値のキャリーアウトデータをマスクレジスタmr02に格納する。
【0040】
最後に、(3) のベクトル加算命令VACに従って、ベクトルレジスタvr00の被加数部分と、ベクトルレジスタvr03の加数部分と、マスクレジスタmr02に格納されるキャリーアウトデータとを加算してベクトルレジスタvr06に格納するとともに、このとき発生する桁上げ値のキャリーアウトデータをマスクレジスタmr00に格納する。
【0041】
このように、上述の構成を採る加算器14を用いて実行される本発明によるベクトル加算処理では、図7に示すように、マスクレジスタmr00,01,02を使いつつ、3個のベクトル加算命令を発行することで、160ビットの被加数と160ビットの加数との加算値を算出できることになる。これに対して、従来技術に従っていると、図13で説明したように、11個のベクトル加算命令/ベクトルシフト命令を発行しなければならない。
【0042】
次に、上述の構成を採る乗算器15を用いて実行される本発明によるベクトル乗算処理について説明する。
図8に示すように、4倍精度データでは、112ビットの仮数を持っている。これから、4倍精度の乗算処理では、乗算結果の仮数を求めるために、図9に示すオペランドの乗算処理を実行する必要がある。
【0043】
これから、上述の構成を採る乗算器15を用いて実行される本発明によるベクトル乗算処理について、128ビットの被乗数と128ビットの乗数との乗算処理を例にして説明する。
【0044】
乗算器15が64ビット同士の乗算処理を実行する場合には、図10に示すように、128ビットの被乗数用のレジスタ(上位64ビット部分を“01”、下位64ビット部分を“02”で表してある)と、128ビットの乗数用のレジスタ(上位64ビット部分を“03”、下位64ビット部分を“04”で表してある)とを用意して、その被乗数レジスタに128ビットの被乗数(上位64ビット部分をA1、下位64ビット部分をA2で表してある)を格納するとともに、その乗数レジスタに128ビットの乗数(上位64ビット部分をB1、下位64ビット部分をB2で表してある)を格納する。
【0045】
そして、図11に示すベクトル命令列を発行することで、図12に図式化する乗算過程に従いつつ、128ビットの被乗数と128ビットの乗数との乗算処理を実行する。ここで、
「VML vr1,vr2,vr3」
は、ベクトルレジスタvr1とベクトルレジスタvr2との乗算結果の下位64ビットをベクトルレジスタvr3に格納しろというベクトル乗算命令であり、
「VMU vr1,vr2,vr3」
は、ベクトルレジスタvr1とベクトルレジスタvr2との乗算結果の上位64ビットをベクトルレジスタvr3に格納しろというベクトル乗算命令であり、
「VAC vr1,vr2,mr1,vr3,mr2」
は、ベクトルレジスタvr1とベクトルレジスタvr2とマスクレジスタmr1との加算結果をベクトルレジスタvr3に格納するとともに、そのとき発生するキャリーアウトデータをマスクレジスタmr2に格納しろというベクトル加算命令である。
【0046】
すなわち、図11に示すベクトル命令列に従い、先ず最初に、(1) のベクトル乗算命令VMLに従って、ベクトルレジスタvr02の被乗数部分A2と、ベクトルレジスタvr04の乗数部分B2とを乗算して、乗算器15のセレクタを制御することで出力されるその乗算結果の下位64ビットのA2B2Lをベクトルレジスタvr23に格納する。
【0047】
続いて、(2) のベクトル乗算命令VMUに従って、ベクトルレジスタvr02の被乗数部分A2と、ベクトルレジスタvr04の乗数部分B2とを乗算して、乗算器15のセレクタを制御することで出力されるその乗算結果の上位64ビットのA2B2Uをベクトルレジスタvr05に格納する。
【0048】
続いて、(3) のベクトル乗算命令VMLに従って、ベクトルレジスタvr01の被乗数部分A1と、ベクトルレジスタvr04の乗数部分B2とを乗算して、乗算器15のセレクタを制御することで出力されるその乗算結果の下位64ビットのA1B2Lをベクトルレジスタvr06に格納する。
【0049】
続いて、(4) のベクトル加算命令VACに従って、ベクトルレジスタvr05に格納されるA2B2Uと、ベクトルレジスタvr06に格納されるA1B2Lと、初期値としてゼロ値を格納するマスクレジスタmr00の格納データとを加算してベクトルレジスタvr07に格納するとともに、このとき発生する桁上げ値のキャリーアウトデータをマスクレジスタmr01に格納する。
【0050】
続いて、(5) のベクトル乗算命令VMLに従って、ベクトルレジスタvr02の被乗数部分A2と、ベクトルレジスタvr03の乗数部分B1とを乗算して、乗算器15のセレクタを制御することで出力されるその乗算結果の下位64ビットのA2B1Lをベクトルレジスタvr08に格納する。
【0051】
続いて、(6) のベクトル加算命令VACに従って、ベクトルレジスタvr07の格納データと、ベクトルレジスタvr08に格納されるA2B1Lと、初期値としてゼロ値を格納するマスクレジスタmr00の格納データとを加算してベクトルレジスタvr22に格納するとともに、このとき発生する桁上げ値のキャリーアウトデータをマスクレジスタmr02に格納する。
【0052】
続いて、(7) のベクトル乗算命令VMUに従って、ベクトルレジスタvr01の被乗数部分A1と、ベクトルレジスタvr04の乗数部分B2とを乗算して、乗算器15のセレクタを制御することで出力されるその乗算結果の上位64ビットのA1B2Uをベクトルレジスタvr10に格納する。
【0053】
続いて、(8) のベクトル乗算命令VMUに従って、ベクトルレジスタvr02の被乗数部分A2と、ベクトルレジスタvr03の乗数部分B1とを乗算して、乗算器15のセレクタを制御することで出力されるその乗算結果の上位64ビットのA2B1Uをベクトルレジスタvr11に格納する。
【0054】
続いて、(9) のベクトル加算命令VACに従って、ベクトルレジスタvr10に格納されるA1B2Uと、ベクトルレジスタvr11に格納されるA2B1Uと、マスクレジスタmr01に格納されるキャリーアウトデータとを加算してベクトルレジスタvr12に格納するとともに、このとき発生する桁上げ値のキャリーアウトデータをマスクレジスタmr00に格納する。
【0055】
続いて、(10)のベクトル乗算命令VMLに従って、ベクトルレジスタvr01の被乗数部分A1と、ベクトルレジスタvr03の乗数部分B1とを乗算して、乗算器15のセレクタを制御することで出力されるその乗算結果の下位64ビットのA1B1Lをベクトルレジスタvr13に格納する。
【0056】
続いて、(11)のベクトル加算命令VACに従って、ベクトルレジスタvr12の格納データと、ベクトルレジスタvr13に格納されるA1B1Lと、マスクレジスタmr02に格納されるキャリーアウトデータとを加算してベクトルレジスタvr21に格納するとともに、このとき発生する桁上げ値のキャリーアウトデータをマスクレジスタmr03に格納する。
【0057】
続いて、(12)のベクトル乗算命令VMUに従って、ベクトルレジスタvr01の被乗数部分A1と、ベクトルレジスタvr03の乗数部分B1とを乗算して、乗算器15のセレクタを制御することで出力されるその乗算結果の上位64ビットのA1B1Uをベクトルレジスタvr15に格納する。
【0058】
最後に、(13)のベクトル加算命令VACに従って、初期値としてゼロ値を格納するマスクレジスタvr00の格納データと、ベクトルレジスタvr15に格納されるA1B1Uと、マスクレジスタmr03に格納されるキャリーアウトデータとを加算してベクトルレジスタvr20に格納するとともに、このとき発生する桁上げ値のキャリーアウトデータをマスクレジスタmr00に格納する。
【0059】
このように、上述の構成を採る乗算器15を用いて実行される本発明によるベクトル乗算処理では、64ビット同士の乗算処理により求まる128ビットの乗算結果の上位64ビットか下位64ビットのいずれかを取り出しながら、上述の構成を採る加算器14を用いて実行される本発明によるベクトル加算処理を用いつつ、128ビットの被乗数と128ビットの乗数との乗算値を算出していくのである。
【0060】
なお、この構成にあって、マスクレジスタmr00やベクトルレジスタvr00には、ゼロ値を格納しておく必要はなく、そのようなレジスタ番号が指定されるときには、ゼロ値の入力指定があったと見なしていく構成を採ってもよい。また、mr00へ書き込むキャリーアウトデータは、実際には後で使用するものではない。これから、そのようなレジスタ番号が指定されるときには、実際の書込処理を行わないことで、元のデータを壊さないようにする構成を採ってもよい。また、ベクトル加算命令VACでは、5個のレジスタを指定しなければならないが、入力と出力とでマスクレジスタを共通にすれば、4個のレジスタの指定で済むことになる。
【0061】
【発明の効果】
以上説明したように、本発明のベクトルデータ加算方法によれば、キャリーアウトデータをマスクレジスタに格納していく構成を採ることから、従来技術のように、ベクトルシフト命令を実行しながらベクトル加算命令を実行していくという構成を採る必要がなくなり、少ない命令数でもって高速にベクトル加算命令を実行できるようになる。
【0062】
また、本発明のベクトルデータ乗算方法によれば、ベクトル乗算命令を実行するにあたって実行が要求されることになるベクトル加算命令の実行にあたって、キャリーアウトデータをマスクレジスタに格納していく構成を採ることから、従来技術のように、ベクトルシフト命令を実行しながらベクトル加算命令を実行していくという構成を採る必要がなくなることで、少ない命令数でもって高速にベクトル加算命令を実行できるようになり、これにより、少ない命令数でもって高速にベクトル乗算命令を実行できるようになる。
【図面の簡単な説明】
【図1】 本発明を実行するベクトル処理装置の装置構成図である。
【図2】 本発明で用いる加算器の説明図である。
【図3】 本発明で用いる乗算器の説明図である。
【図4】被加数及び加数の格納処理の説明図である。
【図5】被加数及び加数の格納処理の説明図である。
【図6】本発明で発行するベクトル加算命令の説明図である。
【図7】本発明の加算処理の説明図である。
【図8】4倍精度データのデータフォーマットの説明図である。
【図9】4倍精度乗算処理のオペランドの説明図である。
【図10】被乗数及び乗数の格納処理の説明図である。
【図11】本発明で発行するベクトル乗算命令の説明図である。
【図12】本発明の乗算処理の説明図である。
【図13】従来技術の説明図である。
【図14】従来技術の説明図である。
【図15】従来技術の説明図である。
【図16】従来技術の説明図である。
【図17】従来技術の説明図である。
【符号の説明】
1 ベクトル処理装置
10 CPU
11 ベクトル命令制御機構
12 ベクトルレジスタ
13 マスクレジスタ
14 加算器
15 乗算器[0001]
[Industrial application fields]
The present invention is a vector that enables vector addition processing to be executed at high speed.Data vector addition method, and vector data multiplication method that enables vector multiplication processing to be executed at high speed using the vector data addition method,About.
[0002]
The vector processing device executes vector addition processing and vector multiplication processing. Such vector operation processing needs to be executed at high speed.
[0003]
[Prior art]
In the conventional vector processing apparatus, when performing the vector addition process, the vector addition instruction is executed while executing the vector shift instruction in consideration of the occurrence of carry.
[0004]
Next, this prior art will be described in detail by taking an addition process of a 160-bit addend and a 160-bit addend as an example.
When the adder performs 64-bit addition processing, conventionally, as shown in FIG. 13, a 64-bit addend register composed of three 64-bit registers (vr00, vr01, vr02); A register for addends consisting of three registers (vr03, vr04, vr05) of bits is prepared, for example, for the addend in accordance with the format shown in FIG. 14, that is, the format illustrated in FIG. A 160-bit addend is stored in the register, and a 160-bit addend is stored in the addend register.
[0005]
Then, by issuing the vector instruction sequence shown in FIG. 16, the addition process of the 160-bit addend and the 160-bit addend is executed. here,
"VA vr1, vr2, vr3"
Is a vector addition instruction to store the addition result of the vector register vr1 and the vector register vr2 in the vector register vr3,
"VSR vr1, SC, vr3"
Is a vector shift instruction to shift the data in the vector register vr1 to the right by SC bits and store it in the vector register vr3.
"VSL vr1, SC, vr3"
Is a vector shift instruction to shift the data of the vector register vr1 to the left by SC bits and store it in the vector register vr3.
[0006]
That is, according to the vector instruction sequence shown in FIG. 16, first, according to the vector addition instruction VA of (1), the addend part of the vector register vr02 and the addend part of the vector register vr05 are added to obtain the vector register vr10. To store. At this time, there is a possibility that a carry may occur. Then, according to the vector shift instruction VSR of (2), the carry data (carry-out data) is shifted right by 60 bits to the data stored in the
[0007]
Subsequently, the addend part of the vector register vr01 and the addend part of the vector register vr04 are added according to the vector addition instruction VA of (3) and stored in the vector register vr20.
[0008]
Subsequently, according to the vector addition instruction VA of (4), the carry-out data stored in the vector register vr15 and the storage data in the vector register vr20 are added in order to add the carry-out data generated by the addition processing of the lower part. Is stored in the vector register vr20. At this time, there is a possibility that a carry may occur. Subsequently, according to the vector shift instruction VSR of (5), the stored data in the
[0009]
Subsequently, in accordance with the vector addition instruction VA of (6), the addend part of the vector register vr00 and the addend part of the vector register vr03 are added and stored in the vector register vr30.
[0010]
Subsequently, according to the vector addition instruction VA of (7), the carry-out data stored in the vector register vr25 and the storage data in the vector register vr30 are added in order to add the carry-out data generated by the addition processing of the lower part. Is stored in the vector register vr6.
[0011]
Subsequently, in order to extract the 60-bit valid data stored in the vector register vr10, the stored data in the
[0012]
Subsequently, in order to extract the 60-bit valid data stored in the vector register vr20, the stored data in the
[0013]
As described above, in the conventional vector processing apparatus, when the vector addition process is executed, the vector addition instruction is executed while executing the vector shift instruction in consideration of the occurrence of carry. is there.
[0014]
On the other hand, in the multiplier provided in the conventional vector processing apparatus, even if it has an input specification of 64 bits × 64 bits, in order to reduce the amount of hardware, the number is as small as 64 bits × 16 bits. It had a configuration with a bit number multiplication function.
[0015]
Then, in order to realize the 64-bit multiplication process of the input specification, the multiplier is divided into four 16-bit units, and the 16-bit multiplier part and 64-bit multiplicand using the 64-bit × 16-bit multiplication function. The partial products are obtained by multiplying and added while shifting the partial products by 16 bits, and the 64-bit portion indicated by the addition result is output as the multiplication result.
[0016]
For example, when the upper 64 bits of a 64-bit multiplication process are required, as shown in FIG. 17, in accordance with the instruction instruction, multipliers divided into four are selected in order from the lower side to obtain partial products. Are added while shifting the left 16 bits to the left, and the higher 64 bits of the multiplication process are obtained and output. Also, when the lower 64 bits of the 64-bit multiplication process are required, the partial product is obtained by selecting the multipliers divided into four in order from the upper side in accordance with the instruction, and those partial products are converted to the right 16 bits. By adding while shifting, the lower 64 bits of the multiplication process were obtained and output.
[0017]
[Problems to be solved by the invention]
However, when the vector addition processing is executed while executing the vector shift instruction in consideration of the occurrence of carry when the vector addition processing is executed as in the conventional technique, the instruction There is a problem that the vector addition processing cannot be executed at high speed because the number increases.
[0018]
In addition, the multiplier of the prior art has a problem that the number of multiplications to be executed internally increases, and a function for shifting and adding partial products (using a loop configuration) must be provided inside. there were.
[0019]
The present invention has been made in view of such circumstances, and is a vector that enables vector addition processing to be executed at high speed.Provides a vector data addition method and a vector data multiplication method that enables vector multiplication processing to be executed at high speed using the vector data addition method.For the purpose of providing.
[0020]
[Means for Solving the Problems]
FIG. 1 illustrates the principle configuration of the present invention.
In the figure, 1 is the present invention.RunThe vector processing apparatus includes a
[0021]
The
[0022]
In order to implement the present invention, the
[0023]
On the other hand, in order to implement the present invention, the
[0026]
[Action]
Main departureUsed in the lightThe
[0027]
In the
(I) The addition result of the m-bit data stored in the vector register vr1, the m-bit data stored in the vector register vr2, and the carry-out data stored in the mask register mr1 is stored in the vector register vr3. A vector addition instruction to store the generated carry-out data in the mask register mr2,
"VAC vr1, vr2, mr1, vr3, mr2"
If it represents, the addition instruction of the addend and the addend represented by the instruction sequence of this vector addition instruction is received,
( ii The
in this way,According to the present invention,Since the carry-out data is stored in the
[0028]
In addition, this departureThe power used in the
[0029]
As a result, the conventional multiplier has a problem that the number of multiplications to be executed internally is increased and a function for shifting and adding partial products must be provided internally.The power used in the
[0030]
However, when the data input to the
In the
(I) A vector multiplication instruction to store in the vector register vr3 the lower m-bit data part of the multiplication result of the m-bit data stored in the vector register vr1 and the m-bit data stored in the vector register vr2.
“VML vr1, vr2, vr3”
A vector multiplication instruction for storing the upper m-bit data portion of the multiplication result of the m-bit data stored in the vector register vr1 and the m-bit data stored in the vector register vr2 in the vector register vr3,
“VMU vr1, vr2, vr3”
The addition result of the m-bit data stored in the vector register vr1, the m-bit data stored in the vector register vr2, and the carry-out data stored in the mask register mr1 is stored in the vector register vr3. A vector addition instruction to store the generated carry-out data in the mask register mr2,
"VAC vr1, vr2, mr1, vr3, mr2"
The first VML instruction, followed by the VMU instruction, followed by the VML instruction, followed by the VAC instruction, followed by the VML instruction, followed by the VAC instruction, followed by the VMU instruction, followed by A VMU instruction, followed by a VAC instruction, followed by a VML instruction, followed by a VAC instruction, followed by a VMU instruction, and finally a multiplicand-multiplier instruction represented by an instruction sequence of VAC instruction,
( ii ) The multiplication instruction of this instruction sequence is executed according to the order of the instruction sequence, and when executing the VML instruction and the VMU instruction, the instruction is executed using the
As described above, according to the present invention, the carry-out data is stored in the
[0031]
【Example】
Hereinafter, the present invention will be described in detail according to examples.
As explained in FIG.Used in the lightThe
[0032]
That is, as shown in FIG. 2, an addend read from the
[0033]
Since the carry-out data read from the
[0034]
On the other hand, as described in FIG.The power used in the
[0035]
That is, as shown in FIG. 3, the multiplication process is executed with the m-bit multiplicand read from the
[0036]
NextIn addition to the above configurationPerformed using calculator 14According to the inventionThe vector addition process will be described using an example of an addition process of a 160-bit addend and a 160-bit addend.
When the
[0037]
Then, by issuing the vector instruction sequence shown in FIG. 6, the addition process of the 160-bit addend and the 160-bit addend is executed. here,
"VAC vr1, vr2, mr1, vr3, mr2"
Is a vector addition instruction to store the addition result of the vector register vr1, vector register vr2, and mask register mr1 in the vector register vr3 and store the carry-out data generated at that time in the mask register mr2.
[0038]
That is, according to the vector instruction sequence shown in FIG. 6, first, in accordance with the vector addition instruction VAC of (1), the addend part of the vector register vr02, the addend part of the vector register vr05, and a zero value as an initial value are set. The stored data of the mask register mr00 to be stored is added and stored in the vector register vr08, and the carry-out data of the carry value generated at this time is stored in the mask register mr01.
[0039]
Subsequently, the addend part of the vector register vr01, the addend part of the vector register vr04, and the carry-out data stored in the mask register mr01 are added according to the vector addition instruction VAC of (2) to obtain the vector register vr07. The carry-out data of the carry value generated at this time is stored in the mask register mr02.
[0040]
Finally, according to the vector addition instruction VAC of (3), the addend part of the vector register vr00, the addend part of the vector register vr03, and the carry-out data stored in the mask register mr02 are added to the vector register vr06. The carry-out data of the carry value generated at this time is stored in the mask register mr00.
[0041]
like thisIn addition to the above configurationUsing calculator 14In the vector addition process according to the present invention,7 calculates the addition value of the 160-bit addend and the 160-bit addend by issuing three vector addition instructions while using the mask registers mr00,01,02 as shown in FIG. It will be possible. On the other hand, according to the prior art, 11 vector addition instructions / vector shift instructions must be issued as described in FIG.
[0042]
NextIn the above-mentioned configurationPerformed using calculator 15According to the inventionThe vector multiplication process will be described.
As shown in FIG. 8, the quadruple precision data has a 112-bit mantissa. Thus, in quadruple precision multiplication processing, it is necessary to execute operand multiplication processing shown in FIG. 9 in order to obtain the mantissa of the multiplication result.
[0043]
ThisAnd the above-mentioned configurationPerformed using calculator 15According to the inventionVector multiplication processing will be described by taking multiplication processing of a 128-bit multiplicand and a 128-bit multiplier as an example.
[0044]
When the
[0045]
Then, by issuing the vector instruction sequence shown in FIG. 11, the multiplication process of the 128-bit multiplicand and the 128-bit multiplier is executed while following the multiplication process schematically shown in FIG. here,
“VML vr1, vr2, vr3”
Is a vector multiplication instruction to store the lower 64 bits of the multiplication result of the vector register vr1 and the vector register vr2 in the vector register vr3.
“VMU vr1, vr2, vr3”
Is a vector multiplication instruction for storing the upper 64 bits of the multiplication result of the vector register vr1 and the vector register vr2 in the vector register vr3.
"VAC vr1, vr2, mr1, vr3, mr2"
Is a vector addition instruction to store the addition result of the vector register vr1, vector register vr2, and mask register mr1 in the vector register vr3 and store the carry-out data generated at that time in the mask register mr2.
[0046]
That is, according to the vector instruction sequence shown in FIG. 11, first, according to the vector multiplication instruction VML of (1), the multiplicand part A2 of the vector register vr02 and the multiplier part B2 of the vector register vr04 are multiplied, and the
[0047]
Subsequently, in accordance with the vector multiplication instruction VMU of (2), the multiplicand part A2 of the vector register vr02 and the multiplier part B2 of the vector register vr04 are multiplied, and the multiplication output by controlling the selector of the
[0048]
Subsequently, in accordance with the vector multiplication instruction VML in (3), the multiplicand part A1 of the vector register vr01 and the multiplier part B2 of the vector register vr04 are multiplied, and the multiplication output by controlling the selector of the
[0049]
Subsequently, in accordance with the vector addition instruction VAC of (4), A2B2U stored in the vector register vr05, A1B2L stored in the vector register vr06, and the stored data of the mask register mr00 storing a zero value as an initial value are added. Then, the carry-out data of the carry value generated at this time is stored in the mask register mr01.
[0050]
Subsequently, in accordance with the vector multiplication instruction VML in (5), the multiplicand part A2 of the vector register vr02 and the multiplier part B1 of the vector register vr03 are multiplied, and the multiplication output by controlling the selector of the
[0051]
Subsequently, according to the vector addition instruction VAC of (6), the data stored in the vector register vr07, A2B1L stored in the vector register vr08, and the data stored in the mask register mr00 that stores a zero value as an initial value are added. The carry-out data of the carry value generated at this time is stored in the mask register mr02.
[0052]
Subsequently, in accordance with the vector multiplication instruction VMU in (7), the multiplicand part A1 of the vector register vr01 and the multiplier part B2 of the vector register vr04 are multiplied, and the multiplication output by controlling the selector of the
[0053]
Subsequently, in accordance with the vector multiplication instruction VMU of (8), the multiplicand part A2 of the vector register vr02 and the multiplier part B1 of the vector register vr03 are multiplied, and the multiplication output by controlling the selector of the
[0054]
Subsequently, according to the vector addition instruction VAC of (9), A1B2U stored in the vector register vr10, A2B1U stored in the vector register vr11, and carry-out data stored in the mask register mr01 are added to the vector register. The carry-out data of the carry value generated at this time is stored in the mask register mr00.
[0055]
Subsequently, in accordance with the vector multiplication instruction VML in (10), the multiplicand part A1 of the vector register vr01 and the multiplier part B1 of the vector register vr03 are multiplied, and the multiplication output by controlling the selector of the
[0056]
Subsequently, in accordance with the vector addition instruction VAC of (11), the data stored in the vector register vr12, A1B1L stored in the vector register vr13, and carry-out data stored in the mask register mr02 are added to the vector register vr21. The carry-out data of the carry value generated at this time is stored in the mask register mr03.
[0057]
Subsequently, in accordance with the vector multiplication instruction VMU of (12), the multiplicand part A1 of the vector register vr01 and the multiplier part B1 of the vector register vr03 are multiplied, and the multiplication output by controlling the selector of the
[0058]
Finally, in accordance with the vector addition instruction VAC of (13), the stored data of the mask register vr00 that stores a zero value as an initial value, the A1B1U stored in the vector register vr15, the carry-out data stored in the mask register mr03, And the carry-out data of the carry value generated at this time is stored in the mask register mr00.
[0059]
like thisIn the above-mentioned configurationUse calculator 15Executed by the vector multiplication processing according to the present invention.Does not extract either the upper 64 bits or the lower 64 bits of the 128-bit multiplication result obtained by the 64-bit multiplication process.Further, the vector addition processing according to the present invention executed using the
[0060]
In this configuration, it is not necessary to store a zero value in the mask register mr00 and the vector register vr00. When such a register number is designated, it is assumed that the zero value has been designated. Any configuration may be adopted. Also, the carry-out data written to mr00 is not actually used later. From now on, when such a register number is designated, a configuration may be adopted in which the original data is not destroyed by not performing the actual writing process. In addition, in the vector addition instruction VAC, five registers must be specified. However, if the mask register is shared between the input and the output, it is only necessary to specify four registers.
[0061]
【The invention's effect】
As explained above,For bright vector data addition methodAccordingly, since the configuration in which carry-out data is stored in the mask register is adopted, it is not necessary to adopt the configuration in which the vector addition instruction is executed while executing the vector shift instruction as in the prior art, and there is little The vector addition instruction can be executed at high speed by the number of instructions.
[0062]
In addition, the present inventionAccording to this vector data multiplication method, the carry-out data is stored in the mask register when executing the vector addition instruction that is required to be executed when executing the vector multiplication instruction. As described above, it is not necessary to adopt a configuration in which the vector addition instruction is executed while executing the vector shift instruction, so that the vector addition instruction can be executed at a high speed with a small number of instructions. The vector multiplication instruction can be executed at high speed with the number of instructions.
[Brief description of the drawings]
[Figure 1] Main departureThe structure of the vector processing deviceIt is a chart.
[Figure 2] Main departureIn the explanatory diagram of the adder used in the lightis there.
[Figure 3] Main departureIn the explanatory diagram of the multiplier used in Mingis there.
FIG. 4 is an explanatory diagram of processing for storing an addend and an addend.
FIG. 5 is an explanatory diagram of a processing for storing an addend and an addend.
FIG. 6 is an explanatory diagram of a vector addition instruction issued in the present invention.
FIG. 7 is an explanatory diagram of addition processing according to the present invention.
FIG. 8 is an explanatory diagram of a data format of quadruple precision data.
FIG. 9 is an explanatory diagram of operands of quadruple precision multiplication processing;
FIG. 10 is an explanatory diagram of multiplicand and multiplier storage processing;
FIG. 11 is an explanatory diagram of a vector multiply instruction issued in the present invention.
FIG. 12 is an explanatory diagram of multiplication processing according to the present invention.
FIG. 13 is an explanatory diagram of a conventional technique.
FIG. 14 is an explanatory diagram of the prior art.
FIG. 15 is an explanatory diagram of a prior art.
FIG. 16 is an explanatory diagram of a conventional technique.
FIG. 17 is an explanatory diagram of the prior art.
[Explanation of symbols]
1 Vector processing device
10 CPU
11 Vector instruction control mechanism
12 Vector register
13 Mask register
14 Adder
15 multiplier
Claims (2)
(i)ベクトルレジスタvr1に格納されるmビットデータとベクトルレジスタvr2に格納されるmビットデータとマスクレジスタmr1に格納されるキャリーアウトデータとの加算結果をベクトルレジスタvr3に格納するとともに、そのとき発生するキャリーアウトデータをマスクレジスタmr2に格納しろというベクトル加算命令を、(I) The addition result of the m-bit data stored in the vector register vr1, the m-bit data stored in the vector register vr2, and the carry-out data stored in the mask register mr1 is stored in the vector register vr3. A vector addition instruction to store the generated carry-out data in the mask register mr2,
「VAC vr1,vr2,mr1,vr3,mr2」"VAC vr1, vr2, mr1, vr3, mr2"
と表すならば、このベクトル加算命令の命令列で表される被加数と加数との加算命令を受け取り、If it represents, the addition instruction of the addend and the addend represented by the instruction sequence of this vector addition instruction is received,
(( iiii )上記加算器を使って、上記命令列のベクトル加算命令をその命令列の順番に従って実行することで、被加数と加数とを加算することを、) Using the adder to execute the vector addition instruction of the instruction sequence according to the order of the instruction sequence, to add the algend and the addend,
特徴とするベクトルデータ加算方法。A feature of vector data addition method.
(i)ベクトルレジスタvr1に格納されるmビットデータとベクトルレジスタvr2に格納されるmビットデータとの乗算結果の下位mビットデータ部分をベクトルレジスタvr3に格納しろというベクトル乗算命令を、(I) A vector multiplication instruction to store in the vector register vr3 the lower m-bit data part of the multiplication result of the m-bit data stored in the vector register vr1 and the m-bit data stored in the vector register vr2.
「VML vr1,vr2,vr3」“VML vr1, vr2, vr3”
と表し、ベクトルレジスタvr1に格納されるmビットデータとベクトルレジスタvr2に格納されるmビットデータとの乗算結果の上位mビットデータ部分をベクトルレジスタvr3に格納しろというベクトル乗算命令を、A vector multiplication instruction for storing the upper m-bit data portion of the multiplication result of the m-bit data stored in the vector register vr1 and the m-bit data stored in the vector register vr2 in the vector register vr3,
「VMU vr1,vr2,vr3」“VMU vr1, vr2, vr3”
と表し、ベクトルレジスタvr1に格納されるmビットデータとベクトルレジスタvr2に格納されるmビットデータとマスクレジスタmr1に格納されるキャリーアウトデータとの加算結果をベクトルレジスタvr3に格納するとともに、そのとき発生するキャリーアウトデータをマスクレジスタmr2に格納しろというベクトル加算命令を、The addition result of the m-bit data stored in the vector register vr1, the m-bit data stored in the vector register vr2, and the carry-out data stored in the mask register mr1 is stored in the vector register vr3. A vector addition instruction to store the generated carry-out data in the mask register mr2,
「VAC vr1,vr2,mr1,vr3,mr2」"VAC vr1, vr2, mr1, vr3, mr2"
と表すならば、第1番目にVML命令、それに続いてVMU命令、それに続いてVML命令、それに続いてVAC命令、それに続いてVML命令、それに続いてVAC命令、それに続いてVMU命令、それに続いてVMU命令、それに続いてVAC命令、それに続いてVML命令、それに続いてVAC命令、それに続いてVMU命令、最後にVAC命令という命令列で表される被乗数と乗数との乗算命令を受け取り、The first VML instruction, followed by the VMU instruction, followed by the VML instruction, followed by the VAC instruction, followed by the VML instruction, followed by the VAC instruction, followed by the VMU instruction, followed by A VMU instruction, followed by a VAC instruction, followed by a VML instruction, followed by a VAC instruction, followed by a VMU instruction, and finally a multiplicand-multiplier instruction represented by an instruction sequence of VAC instruction,
(( iiii )上記命令列の乗算命令をその命令列の順番に従って実行するとともに、その実行にあたって、上記VML命令及び上記VMU命令を実行するときは、上記乗算器を使ってその命令を実行し、上記VAC命令を実行するときは、上記加算器を使ってその命令を実行することを、) The multiplication instruction of the instruction sequence is executed according to the order of the instruction sequence, and when executing the VML instruction and the VMU instruction, the instruction is executed using the multiplier, and the VAC instruction is executed. To execute the instruction using the above adder,
特徴とするベクトルデータ乗算方法。A characteristic vector data multiplication method.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP04676395A JP3691538B2 (en) | 1995-03-07 | 1995-03-07 | Vector data addition method and vector data multiplication method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP04676395A JP3691538B2 (en) | 1995-03-07 | 1995-03-07 | Vector data addition method and vector data multiplication method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPH08241302A JPH08241302A (en) | 1996-09-17 |
| JP3691538B2 true JP3691538B2 (en) | 2005-09-07 |
Family
ID=12756384
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP04676395A Expired - Fee Related JP3691538B2 (en) | 1995-03-07 | 1995-03-07 | Vector data addition method and vector data multiplication method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP3691538B2 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB2497450B (en) * | 2010-09-24 | 2017-08-02 | Intel Corp | Functional unit for vector integer multiply add instruction |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3499362B1 (en) * | 2017-12-13 | 2022-11-30 | ARM Limited | Vector add-with-carry instruction |
-
1995
- 1995-03-07 JP JP04676395A patent/JP3691538B2/en not_active Expired - Fee Related
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB2497450B (en) * | 2010-09-24 | 2017-08-02 | Intel Corp | Functional unit for vector integer multiply add instruction |
Also Published As
| Publication number | Publication date |
|---|---|
| JPH08241302A (en) | 1996-09-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7724261B2 (en) | Processor having a compare extension of an instruction set architecture | |
| US6742012B2 (en) | Apparatus and method for performing multiplication operations | |
| JP5866128B2 (en) | Arithmetic processor | |
| JPH0749772A (en) | Floating-point arithmetic unit using corrected newton-raphson technique regarding division and computation of extraction of square root | |
| JPH0863353A (en) | Data processing using multiplication accumulation instruction | |
| US6295597B1 (en) | Apparatus and method for improved vector processing to support extended-length integer arithmetic | |
| JPH07168697A (en) | Circuit and method for double-precision division | |
| US20110276614A1 (en) | Data processing apparatus and method for performing a reciprocal operation on an input value to produce a result value | |
| JP3476960B2 (en) | Arithmetic logic operation device and control method | |
| US6732259B1 (en) | Processor having a conditional branch extension of an instruction set architecture | |
| JPH0477932B2 (en) | ||
| JP3691538B2 (en) | Vector data addition method and vector data multiplication method | |
| US7260711B2 (en) | Single instruction multiple data processing allowing the combination of portions of two data words with a single pack instruction | |
| EP1163591B1 (en) | Processor having a compare extension of an instruction set architecture | |
| JPS6115233A (en) | Multiplier | |
| JPH10333883A (en) | Multiplying method and circuit therefor | |
| JP2812365B2 (en) | Multiplication circuit | |
| JP2512801B2 (en) | Multiplier | |
| WO2000048080A9 (en) | Processor having a compare extension of an instruction set architecture | |
| JPH04205559A (en) | Vector arithmetic unit | |
| JPH0445860B2 (en) | ||
| JPH0683587A (en) | Multiplication processing unit | |
| JPH0317738A (en) | Arithmetic processor | |
| JP2654062B2 (en) | Information processing device | |
| JPS6120132A (en) | Processing unit |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20041026 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20041222 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20050614 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20050616 |
|
| R150 | Certificate of patent (=grant) or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (prs date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20090624 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (prs date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20100624 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (prs date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110624 Year of fee payment: 6 |
|
| FPAY | Renewal fee payment (prs date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120624 Year of fee payment: 7 |
|
| FPAY | Renewal fee payment (prs date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120624 Year of fee payment: 7 |
|
| FPAY | Renewal fee payment (prs date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130624 Year of fee payment: 8 |
|
| LAPS | Cancellation because of no payment of annual fees |