CN1241170C - 语音编解码器中用于线频谱频率矢量量化的方法和系统 - Google Patents
语音编解码器中用于线频谱频率矢量量化的方法和系统 Download PDFInfo
- Publication number
- CN1241170C CN1241170C CNB028098293A CN02809829A CN1241170C CN 1241170 C CN1241170 C CN 1241170C CN B028098293 A CNB028098293 A CN B028098293A CN 02809829 A CN02809829 A CN 02809829A CN 1241170 C CN1241170 C CN 1241170C
- Authority
- CN
- China
- Prior art keywords
- frequency spectrum
- coefficient
- parameter
- quantification
- distortion
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
- 239000013598 vector Substances 0.000 title claims abstract description 126
- 238000000034 method Methods 0.000 title claims abstract description 55
- 230000003595 spectral effect Effects 0.000 title claims abstract description 17
- 238000013139 quantization Methods 0.000 title description 24
- 238000001228 spectrum Methods 0.000 claims description 191
- 238000011002 quantification Methods 0.000 claims description 76
- 230000014509 gene expression Effects 0.000 claims description 39
- 230000005540 biological transmission Effects 0.000 claims description 16
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 7
- 230000005284 excitation Effects 0.000 claims description 7
- 238000004458 analytical method Methods 0.000 claims description 5
- 238000012546 transfer Methods 0.000 claims description 5
- 238000004891 communication Methods 0.000 claims description 3
- 238000005457 optimization Methods 0.000 claims description 3
- 238000010586 diagram Methods 0.000 description 19
- 230000001174 ascending effect Effects 0.000 description 9
- 230000006870 function Effects 0.000 description 6
- 238000012163 sequencing technique Methods 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 239000002131 composite material Substances 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 101100455531 Arabidopsis thaliana LSF1 gene Proteins 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 230000008676 import Effects 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 238000012805 post-processing Methods 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 238000005086 pumping Methods 0.000 description 1
- 238000013442 quality metrics Methods 0.000 description 1
- 230000005236 sound signal Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 230000009452 underexpressoin Effects 0.000 description 1
Images
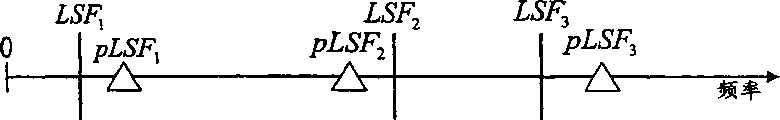
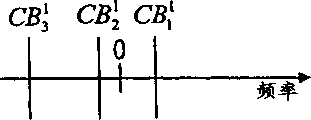
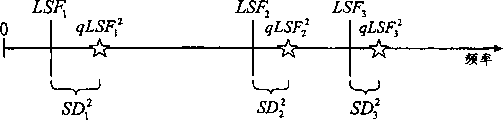


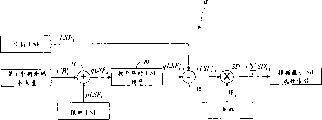

Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/06—Determination or coding of the spectral characteristics, e.g. of the short-term prediction coefficients
- G10L19/07—Line spectrum pair [LSP] vocoders
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/032—Quantisation or dequantisation of spectral components
- G10L19/038—Vector quantisation, e.g. TwinVQ audio
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
一种在语音编码器中用于量化LSF矢量的方法,其中将基于先前解码输出值的预测LSF值连同剩余编码本矢量和LSF系数用于估算频谱失真。此方法包括如下步骤:从相应预测LSF值和剩余编码本矢量中得到多个量化LSF系数;以有序的方式对频域中的量化LSF系数重新排列;根据重新排列的量化LSF系数和相应的LSF系数得到频谱失真;并基于频谱失真选择最优码矢量。
Description
技术领域
本发明主要涉及语音音频信号的编码,尤其涉及线频谱频域中线性预测系数的量化。
背景技术
语音音频编码算法在通信、多媒体和存储器系统中具有广泛地应用。在节省传输和存储容量的同时又能维持合成信号的高质量,正是这种需求推动了编码算法的发展。编码器的复杂程度受应用平台的处理能力的限制。在一些应用如语音存储应用中,编码器可以非常复杂而解码器则应尽可能地简单。
在典型的语音编码器中,按段对输入语音信号进行处理,这些段称为帧。通常帧的长度为10-30毫秒,后续帧中5-15毫秒的导前段也是可用的。帧还可进一步分为许多子帧。对于每一帧,解码器确定输入信号的参数表示。可将参数量化并通过通信信道传输或以数字形式存储在存储媒体中。在接收端,解码器基于所接收的参数来解释合成信号。
目前多个的语音编码器包括线性预测(LP)滤波器用于产生激励信号。L滤波器一般具有如下式给出的全极点结构:
其中A(z)为具有非量化LP系数a1、a2、…、ap的逆滤波器,且p是的预测器的阶,通常为8-12。
输入语音信号按帧进行处理。对于每个语音帧,编码器利用例如Levinson-Durbin算法(参见“AMR语音编解码器;代码转换功能”3G TS 26.090 v3.1.0(1999-12))确定LP系数。由于线频谱频率(LSF)表示或其它类似的的表示如线频谱对(LSP)、导抗频谱频率(ISF)和导抗频谱对(ISP)等(其中所得的稳定滤波器用阶矢量表示(ordervector)表示)具备良好的量化性能,因此被用于对系数进行量化。对于中间的子帧,可采用LSF表示对系数作线性内插。
为定义LSF,用逆LP滤波器A(z)多项式来构造如下两个多项式:
P(z)=A(z)+z-(p+1)A(z-1),
=(1-z-1)κ(1-2z-1cosωi+z-2),.i=2,4,...,p (2)
和
Q(z)=A(z)-z-(p+1)A(z-1)
=(1-z-1)κ(1-2z-1cosωi+z-2),i=1,3,...,p-1.(3)
多项式P(z)和Q(z)的根称为LSF系数。这些多项式的所有根均在单位圆ejωi上(其中i=1,2,...p)。多项式P(z)和Q(z)有以下特性:1)多项式的所有零点(根)均在单位圆上;2)多项式P(z)和Q(z)的零点彼此交织。更具体地说,总满足以下关系:
0=ω0<ω1<ω2<...<ωp-1<ωp<ωp+1=π (4)
升序排列确保了语音编码应用中通常要求的滤波稳定性。应当注意,第一个和最后一个参数总是分别为0和π,并且只需传输p的值。
当语言编码器中需要高效的表示法用于存储LSF信息,采用矢量量化(VQ)通常再加上预测(参见图1)来将LSF量化。通常,基于先前解码输出值(AR(自回归)-预测器)或先前的量化值(MA(移动平均)-预测器)来估计预测值。
其中,Aj和Bi为预测矩阵,m和n为预测器的阶。pLSFk、qLSFk和CBk分别为预测LSF、量化LSF和第k帧的码本矢量。mLSK为LSF矢量的均值。
在计算预测值之后,可以得到量化的LSF值:
qLSFk=pLSFk+CBk, (6)
其中,CBk为第k帧的最优码本项。
实际上,当使用预测量化或约束VQ时,所得的qLSFk在转化为LP系数前必须检查其稳定性。只有在直接VQ(非预测、单级、未分裂)的情况下,才可以设计码本以使所得的量化矢量总是顺序的。
在现有技术的解决方案中,滤波器的稳定性是在经量化和码本选择后通过对LSF矢量排序而得以保证的。
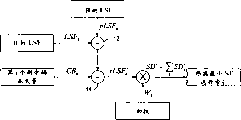
当搜索最优码本矢量时,通常要尝试所有矢量(全搜索)并对每种情况计算一些感觉上重要的质量度量。通常使用的搜索过程的方框图示于图1a。
选择最好基于如下的频谱失真SDi:
其中,S(ω)和S(ω)分别是经量化和未经量化的语音帧频谱。因为计算量非常大,所以可使用更简单的方法来替代。
通常使用的方法是用(Wk)对LSF误差(rLSFi k)加权。例如,使用如下的加权方法(参见“AMR语音编解码器;代码转换功能”3G TS26.090 v3.1.0(1999-12)):
对于dk<450Hz,
否则,
其中,dk=LSFk+1-LSFk-1,其中LSF0=0Hz和LSF11=4000Hz。
这种失真测量基本上取决于LSF频率间的距离。LSF彼此间越接近,它们所得的权重就越大。感觉上,这意味着对共振峰区域的量化更为精确。
根据失真值,将对应最小失真值的码本矢量选作最佳码本索引。通常,判据为:
正如从图1a中可看到,首先在求和部件12中确定目标LSF的系数LSFk和相应的预测LSF系数pLSFk之差,进而在另一个求和部件14中用第j个码本项的相应的剩余码本矢量CBj 1k来调整该差值。式9可简化为:
进而可简化为:
在如图1b所示的解码器中可较容易地看出式10和11所示的简化步骤。如图1b所示,求和部件16用于计算量化的LSF系数。随后,由求和部件18根据量化的LSF系数和目标LSF系数来计算LSF误差。
如果量化的LSF系数qLSFi k没有关于k按升序排列,那么现有技术的解决方案不一定能找到最佳码本索引。图2a-2e说明这种问题。为简单起见,仅显示了前3个LSF系数(k=1,2,3)。但是,简化的示范足以表示分裂矢量量化(split VQ)情况下相当常见的第一分裂(split)。目标LSF矢量用LSF1...LSF3来标记,并且还显示了基于先前帧的LSF的预测值(pLSF1...pLSF3)。如图2a所示,一些预测值大于相应的目标矢量,而一些则较小。在矢量量化器剩余码本中的第一个码本项看起来像码本矢量,如图2b所示。利用qLSF1 1-3=pLSF1-3+CB1 1-3,计算量化LSF系数并将其示于图2c中。为简单起见,未使用加权,即Wk=1,这样,频谱失真直接与目标值和量化值(量化的LSF系数)之间距离的平方或绝对值成比例。目标值和量化值之间的距离为qLSFi k,因此第一分裂的总失真为:
第二码本项(未示出)可以生成如图2d所示的量化LSF矢量(qLSF2 1-3)和频谱失真(SD2 1-3)。当将图2d与图2c相比时,所得的qLSF矢量大不相同,但是总的失真几乎相同,即(SD1≈SD2)。对于前两个码本项,所得的量化LSF矢量是有序的。
为说明有关现有技术量化方法的问题,假设由第三码本项(未示出)得到的量化LSF系数(qLSF3 1-3)和相应的频谱失真(SD3 1-3)如图2e所示那样分布。如图2e所示,根据频谱失真,总的失真
的值非常大。这意味着,按照现有技术方法,由第一分裂得到的最佳码本索引对应SD1和SD2中较小的一个。然而,稍后图4a将说明,选定的“最优”码本索引不能生成最优码矢量。这是因为对应第三码本项的所得的量化LSF矢量不是有序的。
一般而言,语音编码器要求其中所用的线性预测(LP)滤波器是稳定的。例如,如图1a中所示的现有技术的码本搜索例程可能导致所得的量化LSF矢量无序从而变得不稳定。在现有技术中,矢量的稳定性是通过量化后将LSF矢量排序而取得的。但是,所得的编码矢量可能不是最优的。
应当注意,频谱(对)参数矢量(如表示线性预测系数的线性频谱对(LSP)矢量、导抗频谱频率(LSF)矢量和导抗频谱对(ISP)矢量)也必须是有序的以便稳定。
希望提供一种用于量化频谱参数(或表示)的方法和系统,这是有利的,其中,所得编码矢量是最优的。
发明内容
本发明的主要目的是提供一种用于频谱参数量化的方法和装置,其中,在保持原来的位分配的同时,选择最优的编码矢量以在频谱失真方面提高频谱参数量化性能。此目的可以这样达到:在根据频谱失真选择编码矢量之前,在频域内以有序方式重新排列所量化的频谱参数矢量。
因此,根据本发明的第一方面,提供了一种在语音编码器中量化频谱参数矢量的方法,其中,线性预测滤波器用于计算频域中的多个频谱参数系数,并且将多个基于先前解码输出值的预测频谱参数值和多个剩余码本矢量连同所述的多个频谱参数系数用于估算频谱失真,并根据频谱失真选定最优码矢量,所述方法的特征在于:
从相应的预测频谱参数值和剩余码本矢量中得到多个量化的频谱参数系数;
在频域中以有序方式对所量化的频谱参数系数重新排列;以及
从重新排列的量化频谱参数系数和相应的线频谱频率系数中得到频谱失真。
最好按照表示每个所述重新排列的量化频谱参数系数和相应的频谱参数系数之间差异的误差来计算频谱失真,其中,在根据频谱参数系数计算频谱失真之前先对所述误差加权。
根据本发明,当所量化的频谱参数系数的重新排列是在单分裂中进行时,适用所述方法。
根据本发明,当所量化的频谱参数系数的重新排列是在多分裂中进行时,也适用所述方法。在这种情况下,根据每一分裂中的频谱失真选择最优码矢量。
根据本发明,当所量化的频谱参数系数的重新排列是在多级量化下的一级或多级中进行时,也适用所述方法。在这种情况下,根据每级中的频谱失真选择最优码矢量。各级或排序或不排序。最好提前作出哪级排序哪级不排序的选择。否则,排序信息必须作为边信息(side information)传送给接收器。
根据本发明,当量化频谱参数系数的重新排列作为针对一定数量的预选矢量的优化级进行时,也适用所述方法。对推荐矢量排序并且利用所公开的方法从该预选矢量集中选择最终的索引。
根据本发明,所述方法还适用于如下情形:其中,对量化频谱参数系数的重新排列是作为优化级执行的,以及不经重新排列就可选择(各级或各分裂的)码本初始索引并采用所公开的排序方法仅根据选定的最佳预选矢量来作出最终的选择。
频谱参数可以是线频谱频率、线频谱对、导抗频谱频率、导抗频谱对等。
根据本发明的第二方面,提供了一种在语音编码器中量化频谱参数矢量的装置,其中,线性预测滤波器用于计算频域中的多个频谱参数系数,并将多个基于先前解码输出值的预测频谱参数值、多个剩余码本矢量连同所述多个频谱参数系数用于估算频谱失真以便基于频谱失真选择最优码矢量。所述装置的特征在于:
用于从相应的预测频谱参数值和剩余码本矢量得到多个量化频谱参数系数以便提供表示量化频谱参数系数的第一信号序列的部件;
用于响应所述第一信号而在频域中以有序方式将量化频谱参数系数重新排列以便提供表示重新排列的量化频谱参数系数的第二信号序列的部件;以及
用于响应所述第二信号而从所述重新排列的量化频谱参数系数和相应的频谱参数系数得到频谱失真的部件。
频谱参数可以是线频谱频率、线频谱对、导抗频谱频率、导抗频谱对等。
根据本发明的第三方面,提供了一种可为解码器提供比特流的语音编码器,其中,比特流包含表示编码参数、增益参数和音调参数的第一传输信号以及表示频谱表示参数的第二传输信号,其中,激励搜索模块用于提供编码参数、增益参数和音调参数,线性预测分析模块用于提供多个频域中的频谱表示系数、多个基于先前解码输出值的预测频谱表示值和多个剩余码本矢量,此编码器的特征在于:
用于根据相应的预测频谱表示值和剩余码本矢量得到多个量化频谱表示系数以便提供表示量化频谱表示系数的第一信号序列的部件;
用于响应所述第一信号而在频域中以有序方式将量化频谱表示系数重新排列以便提供表示重新排列的量化频谱表示系数的第二信号序列的部件;以及
用于响应所述第二信号而从所述重新排列的量化频谱表示系数和相应的频谱表示系数中得到频谱失真以便提供第三信号序列的部件;
用于响应所述第三信号而根据所述频谱失真选择多个表示频谱表示参数的最优码矢量并提供表示最优码矢量的第二传输信号的部件。
根据本发明的第四方面,提供了一种能够接收输入语音并对其预处理以便提供比特流至电信网络中的至少一个基站的移动台,其中比特流包含表示编码参数、增益参数和音调参数的第一传输信号以及表示频谱表示参数的第二传输信号,其中,激励搜索模块根据预处理输入信号来提供第一传输信号,而线性预测分析模块根据预处理输入信号来提供频域中的多个频谱表示系数、多个基于先前解码输出值的预测频谱表示值和多个剩余码本矢量。所述移动台的特征在于:
用于从相应的预测频谱表示值和剩余码本矢量中得到多个量化频谱表示系数以便提供表示量化频谱表示系数的第一信号序列的部件;
用于响应所述第一信号序列而在频域中以有序方式将所述量化频谱表示系数重新排列以便提供表示所述重新排列的量化频谱表示系数的第二信号序列的部件;
用于响应所述第二信号序列而从所述重新排列的量化频谱表示系数和相应的频谱表示系数中得到频谱失真以便提供第三信号序列的部件;
用于根据所述频谱失真选择多个表示频谱表示参数的最优码矢量以便提供第二传输信号的部件。
在结合图3至图6阅读了本说明书之后,就可以明白本发明。
附图说明
图1a是说明现有技术的LSF量化系统的框图。
图1b是说明具有不同系统部件配置的现有技术的LSF量化系统的框图。
图2a是说明目标LSF矢量和预测LSF值在频域中的分布的示意图。
图2b是说明矢量量化器剩余码本中第一码本项的示意图。
图2c是说明对应第一码本项的与目标LSF矢量相比较的量化LSF系数以及所得频谱失真的示意图。
图2d是说明对应第二码本项的量化LSF系数以及所得频谱失真的示意图。
图2e是说明对应第三码本项的量化LSF系数以及所得频谱失真的示意图。
图2f是说明对应第四码本项的量化LSF系数以及所得频谱失真的示意图。
图2g是说明对应不同于图2c所示第一码本项的量化LSF系数以及所得频谱失真的示意图。
图2h是说明对应不同于图2d所示第二码本项的量化LSF系数以及所得频谱失真的示意图。
图3是说明根据本发明的LSF量化系统的框图。
图4a是说明图2e所示的对应第三码本项的量化LSF系数以及所得频谱失真在经过根据本发明的LSF量化系统重新排列之后的示意图。
图4b是说明图2f所示的对应第四码本项的量化LSF系数以及所得频谱失真在经根据本发明的LSF量化系统重新排列之后的示意图。
图5是说明包括根据本发明的用于语音编码的编码器和解码器的语音编解码器的框图。
图6是说明根据本发明的用于移动电信网络中的移动台的示意图。
具体实施方式
频谱(对)参数矢量是表示线性预测系数的矢量,以便稳定的频谱(对)矢量总是有序的。这种表示包括线频谱频率(LSF)、线频谱对(LSP)、导抗频谱频率(ISF)、导抗频谱对(ISP)等。为简单起见,就以LSF表示为例来对本发明进行描述。
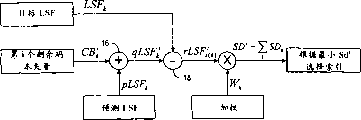
图3显示了根据本发明的LSF量化系统40。除图1a所示的系统部件外,在求和部件16和求和部件18之间设置了排序部件20。排序部件20用于对量化LSF系数qLSFi k重新排列以使其对频率按升序分布。例如,如图2a以及2b所示,量化LSF系数qLSF1 k和qLSF2 k已经按升序排列,即qLSFi 1<qLSFi 2<qLSFi 3,故排序部件20的功能并不影响这些量化LSF系数的分布。在这种情况下,量化LSF矢量qLSFi被说成是顺序正确的。但是,如图2e所示,量化LSF矢量qLSF3顺序错了,这是因为qLSF3 1<qLSF3 2<qLSF3 3。如图4a所示,在经过排序之后,这些量化LSF系数按升序分布。
在矢量定序后,总的频谱失真SD3(图4a)比SD1或SD2都小。因此,包含待选的前三个帧的第一分裂的最佳码本索引为i=3。由于进行了排序,故在解码器中自动找到解码码本的正确顺序(132),而不需要额外的信息。
排序部件20所完成的排序功能可表示如下:
13式还可进一步简化为:
其中,s(k)是给出当前第k个LSF分量的正确顺序的置换函数,以便在计算SDi前使所有的LSFi k按升序排列。根据本发明,在将量化矢量排好序之后计算频谱失真值,而不是进行有可能导致无效的有序LSF矢量的剩余矢量比较。
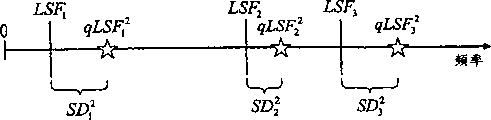
应当注意,在某些情况下,使用现有技术搜索方法来从未按升序排列的量化LSF系数中得到最小频谱失真SDI是有可能的。例如,如图2f和2g中所示,第一和第二码本项生成两组不同的量化LSF系数qLSF1 k和qLSF2 k,而第三量化LSF系数qLSF3 k与图2e中显示的相同。在这种情况下,虽然量化LSF系数qLSF3 k未按升序排列,但还是由第三码本项生成了最小频谱失真。因此,基于最小总频谱失真而选择的量化LSF矢量是不稳定的。在现有技术的编码器中,在码本选择后可通过对量化LSF系数排序从而使不稳定的量化LSF矢量稳定。在此特定情况下,现有技术的语音编解码器和根据本发明的语音编解码器所得的结果是相同的。
一般而言,根据现有技术的方法所得的结果可能不是最优的,因为还可能存在另一个顺序错误的量化矢量。例如,如果第四码本项生成一组如图2h所示的量化LSF系数qLSF4 k,那么此量化LSF矢量在如图2e、2f、2g以及2h所示的量化矢量中具有最大的频谱失真。在现有技术码本搜索例程中,最小的总频谱失真是由第三码本项得到的(图2g)。
根据本发明的LSF量化方法,由排序部件20对图2g和2h中的量化LSF系数重新排列。在对图2h所示的量化LSF系数qLSF4 k重新排列以使量化LSF系数按升序排列后,所得结果在图4b中显示。与图2f、2g以及4a所示的量化LSF矢量相比,图4b所示的量化LSF矢量具有最小频谱失真。
上述例子已经表明,根据现有技术的码本搜索例程,量化之后执行矢量稳定操作(通过对LSF矢量排序)并不总是可以得到在频谱失真方面最优的矢量。
采用根据本发明的LSF量化方法,在选择用于传输的LSF矢量之前将它们排好序。此方法总能找到最优矢量。如果对矢量量化器码本只进行单分裂且在单级中完成对最优矢量的选择,则找到的矢量是全局最优的。这意味着总可找到帧的提供全局最小误差的索引i。如果采用约束矢量量化器,则不一定能找到全局最优索引。但是,即使只在单分裂或单级内使用本方法,仍旧提高了性能。为了能找到分裂矢量量化的更佳的全局最优值,可采用如下方法:
1)采用根据本发明的预排序方法找到第一分裂的最佳码本索引,和
2)以相同的方式分别找到第二分裂、第三分裂等的最佳码本索引。
然而,为找出更佳的解决方案,则不保存每一分裂的最优分裂矢量量化器索引而要保存多个较好的索引。然后基于已保存的索引尝试各分裂的所有索引组合,以及生成相应的已排序量化LSF矢量(qLSF1...qLSFp)并计算SDi。最后,选择码本索引的最佳组合。
类似的方法可如下应用于多级向量量化器:用所谓的M-best搜索法选择若干最佳第一级量化器,再在这些量化器之后增加后续各级量化器。如果需要,则在各级对所得的qLSF排序,并计算SDi。再将码本索引的最佳组合送到接收器中。排序可用于一个或多个内部级。在这种情况下,解码器必须在同一级中进行排序以便正确地进行解码(可在设计阶段确定要进行排序的级)。
对于分裂矢量量化器,可采用如下程序:
1)对第一分裂进行最优码本搜索;
2)对最后一个系数的误差的加权稍小于通常所做的加权;
3)存储多个较佳的索引以供下一阶段使用;
4)转到下一分裂而不是在本分裂内计算误差,计算包括第一分裂的值和当前矢量(在经过定序过程之后)的所有组合的误差;以及
5)重复相同的过程直到计算完所有的分裂。这种方法连续执行,以包括所选择的一些量化值,这些量化值是目前找到的最优值。在增加新的分裂后,所得的较长矢量是有序的,并且可根据失真度确定之前分裂的索引。这样就在一定程度上将对各分裂排序的限制效应纳入考虑。最后的系数的加权较低意味着最终的系数在定序完成之后可由后续分裂的值代替。
图5是说明根据本发明的语音编解码器1的框图。语音编解码器1包括编码器4和解码器6。编码器4包括预处理单元22以对输入语音信号进行高通滤波。线性预测系数(LPC)分析单元26根据经过预处理的输入信号估计LP滤波器系数。LP系数由LPC量化单元28量化。激励搜索单元30亦基于经预处理的输入信号为解码器6提供编码参数、增益参数以及音调参数。预处理单元22、LPC分析单元26、LPC量化单元28和激励搜索单元30及其功能是本领域中已知的。本发明的编码器4的独有特征在于排序部件20,排序部件20用于在将LSF参数发送给解码器6之前,对量化LSF系数重新排列以便用于频谱失真估计。类似地,解码器6中的LPC去量化单元40具有排序部件42,用于在由LPC内插单元44进行LPC内插之前对接收的LSF系数重新排列。LPC内插单元44、激励产生单元46、LPC合成单元48以及后处理单元50也是本领域中已知的。
图6是说明本发明的移动电话2的示意图。如图6所示,移动电话具有麦克风60,用于接收输入语音并将输入语音传送给编码器4。编码器4具有将编码参数、增益参数、音调参数以及LSF参数(图5)转换成可通过天线80传输的比特流82的装置。移动电话2具有排序部件20,用于对量化矢量排序。
概括地说,本发明提出了一种用于提供始终稳定的量化LSF矢量的方法和装置。根据本发明的方法和装置在频谱失真方面提高了LSF量化性能,而不需要改变位分配。所述方法和装置可推广用于预测和非预测分裂(分区)矢量量化器以及多级矢量量化器。当使用更高阶的LPC模型(p>10)时,根据本发明的方法和装置在改善语音编码器的性能上效果更明显,因为在这些情况下,LSF彼此更加接近,无效排序越有可能发生。但是,同样的方法和装置也可用在基于低阶LPC模型(p<=10)的语音编码器中。
应当注意,如根据LSF所述的量化方法/装置还适用于线性预测系数的其它表现形式,例如LSP、ISF、ISP以及其它类似的频谱参数和频谱表示。
因此,虽然参照本发明的最佳实施例对本发明作了说明,但本领域的技术人员应理解,在不脱离本发明的精神和范围的前提下,可在形式上和细节上对本发明进行上述和各种其它的变化、省略以及修改。
Claims (20)
1.一种在语音编码器中用于量化频谱参数矢量的方法,其中,线性预测滤波器用于计算频域中的多个频谱参数系数,其中,将多个基于先前解码输出值的预测频谱参数值和多个剩余码本矢量以及所述多个频谱参数系数用于估算频谱失真,以便基于所述频谱失真选择最优码矢量,所述方法的特征在于包括以下步骤:
从所述相应预测频谱参数值和所述剩余码本矢量中得到多个量化频谱参数系数;
对所述频域中的量化频谱参数系数按有序方式重新排列;和
从所述重新排列的量化频谱参数系数和相应的频谱参数系数中得到频谱失真。
2.如权利要求1所述的方法,其特征在于,根据表示每个所述重新排列的量化频谱参数系数和所述相应的频谱参数系数之差的误差来计算所述频谱失真。
3.如权利要求2所述的方法,其特征还在于,在根据所述频谱参数系数得到所述频谱失真之前对所述误差加权。
4.如权利要求1所述的方法,其特征在于,对所述量化频谱参数系数的重新排列是在单分裂中进行的。
5.如权利要求1所述的方法,其特征在于,对所述量化频谱参数系数的重新排列是在多分裂中进行的,并且根据每一分裂中的所述频谱失真选择最优码矢量。
6.如权利要求1所述的方法,其特征在于,所述频谱参数包括线频谱参数。
7.如权利要求1所述的方法,其特征在于,所述频谱参数包括线频谱对。
8.如权利要求1所述的方法,其特征在于,所述频谱参数包括导抗频谱频率。
9.如权利要求1所述的方法,其特征在于,所述频谱参数包括导抗频谱对。
10.如权利要求1所述的方法,其特征在于,所述重新排列的步骤是在单级中进行的。
11.如权利要求1所述的方法,其特征在于,对所述量化频谱参数系数的重新排列是在最优码矢量选择的多级之一中完成的,所述一个级是预先确定的并且所述最优码矢量选择基于所述一个级中的所述频谱失真。
12.如权利要求1所述的方法,其特征在于,所述量化频谱参数系数的重新排列是在最优码矢量选择的多级中的某些级中进行的,其中,所述某些级是预先确定的并且所述最优码矢量选择基于所述某些级中的所述频谱失真。
13.如权利要求1所述的方法,其特征在于,所述量化频谱参数系数的重新排列是在最优码矢量选择的多级中进行的,所述多级是预先确定的并且所述最优码矢量选择基于所述多级中的所述频谱失真。
14.如权利要求1所述的方法,其特征在于,所述量化频谱参数系数的重新排列是作为针对最优矢量选择所用的一定数量的预选矢量的优化级来进行的,所述最优矢量选择基于所述预选矢量。
15.一种在语音编码器中用于量化频谱参数矢量的装置,其中,将线性预测滤波器用于计算频域中的多个频谱参数系数,并且将基于先前解码输出值的多个预测频谱参数值、多个剩余码本矢量和所述多个频谱参数系数用于估算频谱失真并根据所述频谱失真选择最优码矢量,所述装置的特征在于包括:
用于从所述相应的预测频谱参数值和所述剩余码本矢量得到多个量化频谱参数系数、以便提供表示所述量化频谱参数系数的第一信号序列的部件;
用于响应所述第一信号而在频域中以有序方式将所述量化频谱参数系数重新排列、以便提供表示所述重新排列的量化频谱参数系数的第二信号序列的部件;以及
用于响应所述第二信号而从所述重新排列的量化频谱参数系数和所述相应的频谱参数系数获得频谱失真的部件。
16.如权利要求15所述的装置,其特征在于,基于表示各所述重新排列的量化频谱参数系数之间差异的误差来计算所述频谱失真,并且,所述频谱失真获得部件在得到所述频谱失真之前根据所述频谱参数系数对所述误差加权。
17.如权利要求15所述的装置,其特征在于,所述量化频谱参数系数的重新排列是在单分裂中进行的。
18.如权利要求15所述的装置,其特征在于,所述量化频谱参数系数的重新排列是在多分裂中进行的,并且根据每一分裂中的所述频谱失真选择最优码矢量。
19.一种用于为解码器提供比特流的语音编码器,所述比特流包含表示编码参数、增益参数和音调参数的第一传输信号和表示频谱表示参数的第二传输信号,其中,激励搜索模块用于提供所述编码参数、所述增益参数以及所述音调参数,线性预测分析模块用于提供频域中的多个频谱表示系数、多个基于先前解码输出值的预测频谱表示值以及多个剩余码本矢量,所述编码器包括:
用于根据所述相应的预测频谱表示值和所述剩余码本矢量得到多个量化频谱表示系数、以便提供表示所述量化频谱表示系数的第一信号序列的部件;
用于响应所述第一信号而在所述频域中以有序方式将所述量化频谱表示系数重新排列、以便提供表示所述重新排列的量化频谱表示系数的第二信号序列的部件;以及
用于响应所述第二信号而从所述重新排列的量化频谱表示系数和所述相应的频谱表示系数中得到频谱失真以便提供表示所述频谱失真的第三信号序列的部件;
用于响应所述第三信号而根据所述频谱失真选择多个表示所述频谱表示参数的最优码矢量并提供表示最优码矢量的第二传输信号的部件。
20.一种能够接收输入和预处理语音以便提供比特流至电信网络中至少一个基站的移动台,其中,所述比特流包括表示编码参数、增益参数和音调参数的第一传输信号以及表示频谱表示参数的第二传输信号,其中,激励检索模块用于根据所述预处理输入信号提供所述第一传输信号,而线性预测分析模块用于根据所述预处理输入信号提供频域中的多个频谱表示系数、多个基于先前解码输出值的预测频谱表示值和多个剩余码本矢量,所述移动台的特征在于:
用于从所述相应的预测频谱表示值和所述剩余码本矢量中得到多个量化频谱表示系数、以便提供表示所述量化频谱表示系数的第一信号序列的部件;
用于响应所述第一信号而在所述频域中以有序方式将所述量化频谱表示系数重新排列、以便提供表示所述重新排列的量化频谱表示系数的第二信号序列的部件;
用于响应所述第二信号而从所述重新排列的量化频谱表示系数和所述相应的频谱表示系数中得到频谱失真、以便提供表示所述频谱失真的第三信号序列的部件;
用于响应所述第三信号而选择多个表示频谱表示参数的最优码矢量、以便提供表示所述最优码矢量的第二传输信号的部件。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/859,225 | 2001-05-16 | ||
| US09/859,225 US7003454B2 (en) | 2001-05-16 | 2001-05-16 | Method and system for line spectral frequency vector quantization in speech codec |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN1509469A CN1509469A (zh) | 2004-06-30 |
| CN1241170C true CN1241170C (zh) | 2006-02-08 |
Family
ID=25330384
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB028098293A Expired - Lifetime CN1241170C (zh) | 2001-05-16 | 2002-05-10 | 语音编解码器中用于线频谱频率矢量量化的方法和系统 |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US7003454B2 (zh) |
| EP (1) | EP1388144B1 (zh) |
| JP (1) | JP2004526213A (zh) |
| KR (1) | KR20040028750A (zh) |
| CN (1) | CN1241170C (zh) |
| AU (1) | AU2002302874A1 (zh) |
| BR (1) | BR0208635A (zh) |
| CA (1) | CA2443443C (zh) |
| ES (1) | ES2649237T3 (zh) |
| PT (1) | PT1388144T (zh) |
| WO (1) | WO2002093551A2 (zh) |
Families Citing this family (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004502204A (ja) * | 2000-07-05 | 2004-01-22 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | ラインスペクトル周波数をフィルタ係数に変換する方法 |
| EP1771841B1 (en) * | 2004-07-23 | 2010-04-14 | Telecom Italia S.p.A. | Method for generating and using a vector codebook, method and device for compressing data, and distributed speech recognition system |
| KR100647290B1 (ko) * | 2004-09-22 | 2006-11-23 | 삼성전자주식회사 | 합성된 음성의 특성을 이용하여 양자화/역양자화를선택하는 음성 부호화/복호화 장치 및 그 방법 |
| KR100612889B1 (ko) * | 2005-02-05 | 2006-08-14 | 삼성전자주식회사 | 선스펙트럼 쌍 파라미터 복원 방법 및 장치와 그 음성복호화 장치 |
| US8510105B2 (en) * | 2005-10-21 | 2013-08-13 | Nokia Corporation | Compression and decompression of data vectors |
| CN100421370C (zh) * | 2005-10-31 | 2008-09-24 | 连展科技(天津)有限公司 | 一种amr语音编码的源控制速率中降低sid帧传输速率的方法 |
| WO2007114290A1 (ja) * | 2006-03-31 | 2007-10-11 | Matsushita Electric Industrial Co., Ltd. | ベクトル量子化装置、ベクトル逆量子化装置、ベクトル量子化方法及びベクトル逆量子化方法 |
| US8392176B2 (en) * | 2006-04-10 | 2013-03-05 | Qualcomm Incorporated | Processing of excitation in audio coding and decoding |
| US7805292B2 (en) * | 2006-04-21 | 2010-09-28 | Dilithium Holdings, Inc. | Method and apparatus for audio transcoding |
| US9454974B2 (en) * | 2006-07-31 | 2016-09-27 | Qualcomm Incorporated | Systems, methods, and apparatus for gain factor limiting |
| US20110004469A1 (en) * | 2006-10-17 | 2011-01-06 | Panasonic Corporation | Vector quantization device, vector inverse quantization device, and method thereof |
| US7813922B2 (en) * | 2007-01-30 | 2010-10-12 | Nokia Corporation | Audio quantization |
| US20090192742A1 (en) * | 2008-01-30 | 2009-07-30 | Mensur Omerbashich | Procedure for increasing spectrum accuracy |
| MX2011000363A (es) * | 2008-07-10 | 2011-06-16 | Voiceage Corp | Dispositivo y sistema para cuantificar y cuantificar inversamente filtros lpc en un supermarco. |
| EP2304722B1 (en) * | 2008-07-17 | 2018-03-14 | Nokia Technologies Oy | Method and apparatus for fast nearest-neighbor search for vector quantizers |
| CN101630510B (zh) * | 2008-07-18 | 2012-03-28 | 上海摩波彼克半导体有限公司 | Amr语音编码中lsp系数量化的快速码本搜索的方法 |
| EP2398149B1 (en) * | 2009-02-13 | 2014-05-07 | Panasonic Corporation | Vector quantization device, vector inverse-quantization device, and associated methods |
| CN102656629B (zh) | 2009-12-10 | 2014-11-26 | Lg电子株式会社 | 编码语音信号的方法和设备 |
| CN102222505B (zh) * | 2010-04-13 | 2012-12-19 | 中兴通讯股份有限公司 | 可分层音频编解码方法系统及瞬态信号可分层编解码方法 |
| KR101747917B1 (ko) | 2010-10-18 | 2017-06-15 | 삼성전자주식회사 | 선형 예측 계수를 양자화하기 위한 저복잡도를 가지는 가중치 함수 결정 장치 및 방법 |
| WO2014009775A1 (en) * | 2012-07-12 | 2014-01-16 | Nokia Corporation | Vector quantization |
| CN102867516B (zh) * | 2012-09-10 | 2014-08-27 | 大连理工大学 | 一种采用高阶线性预测系数分组矢量量化的语音编解方法 |
| CN102903365B (zh) * | 2012-10-30 | 2014-05-14 | 山东省计算中心 | 一种在解码端细化窄带声码器参数的方法 |
| CN108172239B (zh) * | 2013-09-26 | 2021-01-12 | 华为技术有限公司 | 频带扩展的方法及装置 |
| US9892742B2 (en) * | 2013-12-17 | 2018-02-13 | Nokia Technologies Oy | Audio signal lattice vector quantizer |
| EP4095854B1 (en) * | 2014-01-15 | 2024-08-07 | Samsung Electronics Co., Ltd. | Weight function determination device and method for quantizing linear prediction coding coefficient |
| EP3648103B1 (en) * | 2014-04-24 | 2021-10-20 | Nippon Telegraph And Telephone Corporation | Decoding method, decoding apparatus, corresponding program and recording medium |
| CN104269176B (zh) * | 2014-09-30 | 2017-11-24 | 武汉大学深圳研究院 | 一种isf系数矢量量化的方法与装置 |
| EP3429230A1 (en) * | 2017-07-13 | 2019-01-16 | GN Hearing A/S | Hearing device and method with non-intrusive speech intelligibility prediction |
| CN110660400B (zh) * | 2018-06-29 | 2022-07-12 | 华为技术有限公司 | 立体声信号的编码、解码方法、编码装置和解码装置 |
| CN115831130A (zh) * | 2018-06-29 | 2023-03-21 | 华为技术有限公司 | 立体声信号的编码方法、解码方法、编码装置和解码装置 |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5651026A (en) * | 1992-06-01 | 1997-07-22 | Hughes Electronics | Robust vector quantization of line spectral frequencies |
| DE4236315C1 (de) * | 1992-10-28 | 1994-02-10 | Ant Nachrichtentech | Verfahren zur Sprachcodierung |
| DE4492048C2 (de) * | 1993-03-26 | 1997-01-02 | Motorola Inc | Vektorquantisierungs-Verfahren |
| US5704001A (en) | 1994-08-04 | 1997-12-30 | Qualcomm Incorporated | Sensitivity weighted vector quantization of line spectral pair frequencies |
| US5675701A (en) | 1995-04-28 | 1997-10-07 | Lucent Technologies Inc. | Speech coding parameter smoothing method |
| US5754733A (en) * | 1995-08-01 | 1998-05-19 | Qualcomm Incorporated | Method and apparatus for generating and encoding line spectral square roots |
| KR100322706B1 (ko) * | 1995-09-25 | 2002-06-20 | 윤종용 | 선형예측부호화계수의부호화및복호화방법 |
| KR100198476B1 (ko) * | 1997-04-23 | 1999-06-15 | 윤종용 | 노이즈에 견고한 스펙트럼 포락선 양자화기 및 양자화 방법 |
| TW408298B (en) | 1997-08-28 | 2000-10-11 | Texas Instruments Inc | Improved method for switched-predictive quantization |
| US6141640A (en) | 1998-02-20 | 2000-10-31 | General Electric Company | Multistage positive product vector quantization for line spectral frequencies in low rate speech coding |
| US6148283A (en) * | 1998-09-23 | 2000-11-14 | Qualcomm Inc. | Method and apparatus using multi-path multi-stage vector quantizer |
-
2001
- 2001-05-16 US US09/859,225 patent/US7003454B2/en not_active Expired - Lifetime
-
2002
- 2002-05-10 BR BR0208635-2A patent/BR0208635A/pt not_active Application Discontinuation
- 2002-05-10 CA CA2443443A patent/CA2443443C/en not_active Expired - Lifetime
- 2002-05-10 CN CNB028098293A patent/CN1241170C/zh not_active Expired - Lifetime
- 2002-05-10 WO PCT/IB2002/001608 patent/WO2002093551A2/en active Application Filing
- 2002-05-10 AU AU2002302874A patent/AU2002302874A1/en not_active Abandoned
- 2002-05-10 KR KR10-2003-7014370A patent/KR20040028750A/ko not_active Application Discontinuation
- 2002-05-10 ES ES02730559.8T patent/ES2649237T3/es not_active Expired - Lifetime
- 2002-05-10 EP EP02730559.8A patent/EP1388144B1/en not_active Expired - Lifetime
- 2002-05-10 PT PT2730559T patent/PT1388144T/pt unknown
- 2002-05-10 JP JP2002590143A patent/JP2004526213A/ja not_active Withdrawn
Also Published As
| Publication number | Publication date |
|---|---|
| EP1388144B1 (en) | 2017-10-18 |
| US20030014249A1 (en) | 2003-01-16 |
| KR20040028750A (ko) | 2004-04-03 |
| CN1509469A (zh) | 2004-06-30 |
| EP1388144A2 (en) | 2004-02-11 |
| CA2443443C (en) | 2012-10-02 |
| WO2002093551A3 (en) | 2003-05-01 |
| PT1388144T (pt) | 2017-12-01 |
| ES2649237T3 (es) | 2018-01-11 |
| BR0208635A (pt) | 2004-03-30 |
| CA2443443A1 (en) | 2002-11-21 |
| US7003454B2 (en) | 2006-02-21 |
| EP1388144A4 (en) | 2007-08-08 |
| WO2002093551A2 (en) | 2002-11-21 |
| AU2002302874A1 (en) | 2002-11-25 |
| JP2004526213A (ja) | 2004-08-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1241170C (zh) | 语音编解码器中用于线频谱频率矢量量化的方法和系统 | |
| CN1154086C (zh) | Celp转发 | |
| CN1795495A (zh) | 音频编码设备、音频解码设备、音频编码方法和音频解码方法 | |
| CN1192356C (zh) | 解码方法和包括自适应后置滤波器的系统 | |
| CN1121683C (zh) | 语音编码 | |
| CN1273663A (zh) | 具有改进的语音编码器的传输系统 | |
| CN1235190C (zh) | 改善音频信号编码效率的方法 | |
| CN1739142A (zh) | 用于可变比特率语音编码中的线性预测参数的稳健预测向量量化的方法和设备 | |
| CN1167048C (zh) | 语音编码设备和语音解码设备 | |
| CN1167046C (zh) | 矢量编码方法及其利用该方法的编码器和解码器 | |
| CN1109697A (zh) | 矢量量化器方法和设备 | |
| CN1410970A (zh) | 用于语音快速编码的被选信号脉冲幅度的代数码本 | |
| CN1159691A (zh) | 用于声频信号线性预测分析的方法 | |
| CN1820306A (zh) | 可变比特率宽带语音编码中增益量化的方法和装置 | |
| CN1126869A (zh) | 语音编码和解码设备及其方法 | |
| CN1152164A (zh) | 码激励线性预测编码装置 | |
| CN101030377A (zh) | 提高声码器基音周期参数量化精度的方法 | |
| CN1174457A (zh) | 语音信号传输方法及语音编码和解码系统 | |
| CN1486486A (zh) | 用于编码和解码声学参数的方法、设备和程序及用于编码和解码语音的方法、设备和程序 | |
| EP1450352B1 (en) | Block-constrained TCQ method, and method and apparatus for quantizing LSF parameters employing the same in a speech coding system | |
| CN1192357C (zh) | 用于语音编码的自适应规则 | |
| CN1145925C (zh) | 具有改进语音编码器和解码器的发射机 | |
| CN101044554A (zh) | 可扩展性编码装置、可扩展性解码装置以及可扩展性编码方法 | |
| KR20070029754A (ko) | 음성 부호화 장치 및 그 방법과, 음성 복호화 장치 및 그방법 | |
| CN1218296C (zh) | 音调周期搜索范围设置装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| C41 | Transfer of patent application or patent right or utility model | ||
| TR01 | Transfer of patent right |
Effective date of registration: 20160125 Address after: Espoo, Finland Patentee after: Technology Co., Ltd. of Nokia Address before: Espoo, Finland Patentee before: Nokia Oyj |
|
| CX01 | Expiry of patent term |
Granted publication date: 20060208 |
|
| CX01 | Expiry of patent term |