CN113254659A - File studying and judging method and system based on knowledge graph technology - Google Patents
File studying and judging method and system based on knowledge graph technology Download PDFInfo
- Publication number
- CN113254659A CN113254659A CN202110153678.3A CN202110153678A CN113254659A CN 113254659 A CN113254659 A CN 113254659A CN 202110153678 A CN202110153678 A CN 202110153678A CN 113254659 A CN113254659 A CN 113254659A
- Authority
- CN
- China
- Prior art keywords
- file
- archive
- knowledge
- studying
- judging
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000034 method Methods 0.000 title claims abstract description 41
- 238000005516 engineering process Methods 0.000 title claims abstract description 27
- 230000004927 fusion Effects 0.000 claims abstract description 18
- 238000004458 analytical method Methods 0.000 claims description 36
- 238000000605 extraction Methods 0.000 claims description 29
- 239000013598 vector Substances 0.000 claims description 21
- 238000002372 labelling Methods 0.000 claims description 12
- 230000007246 mechanism Effects 0.000 claims description 10
- 230000002457 bidirectional effect Effects 0.000 claims description 8
- 238000003058 natural language processing Methods 0.000 claims description 7
- 230000008520 organization Effects 0.000 claims description 6
- 238000013135 deep learning Methods 0.000 claims description 5
- 238000012098 association analyses Methods 0.000 claims description 4
- 230000008030 elimination Effects 0.000 claims description 3
- 238000003379 elimination reaction Methods 0.000 claims description 3
- 230000002159 abnormal effect Effects 0.000 claims description 2
- 238000010801 machine learning Methods 0.000 abstract description 10
- 230000006870 function Effects 0.000 description 7
- 238000013145 classification model Methods 0.000 description 6
- 239000011159 matrix material Substances 0.000 description 6
- 238000012549 training Methods 0.000 description 5
- 238000013527 convolutional neural network Methods 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 230000018109 developmental process Effects 0.000 description 4
- 238000010586 diagram Methods 0.000 description 4
- 238000011156 evaluation Methods 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 238000004422 calculation algorithm Methods 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 238000013528 artificial neural network Methods 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 238000005065 mining Methods 0.000 description 2
- 210000002569 neuron Anatomy 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 230000011218 segmentation Effects 0.000 description 2
- 230000004913 activation Effects 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 210000004027 cell Anatomy 0.000 description 1
- 238000007596 consolidation process Methods 0.000 description 1
- 238000010219 correlation analysis Methods 0.000 description 1
- 230000001186 cumulative effect Effects 0.000 description 1
- 238000013016 damping Methods 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 238000007418 data mining Methods 0.000 description 1
- 230000009849 deactivation Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000007499 fusion processing Methods 0.000 description 1
- 230000007787 long-term memory Effects 0.000 description 1
- 238000003062 neural network model Methods 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 238000007639 printing Methods 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 238000012706 support-vector machine Methods 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- G06F16/367—Ontology
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/31—Indexing; Data structures therefor; Storage structures
- G06F16/313—Selection or weighting of terms for indexing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3344—Query execution using natural language analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/335—Filtering based on additional data, e.g. user or group profiles
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- G06F16/353—Clustering; Classification into predefined classes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
- G06F40/295—Named entity recognition
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Animal Behavior & Ethology (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
The invention provides a file studying and judging method and a system based on a knowledge graph technology, wherein the file studying and judging method comprises the following steps: uploading the file; and (3) extracting file entities: extracting names of people, places, organizations, colleges and universities, works, events, buildings and data entities; and (3) extracting a file relation: extracting the incidence relation between the two entities and constructing the edge of the archive knowledge graph; and (3) archive knowledge fusion: fusing the extracted file entities from different sources to generate a unique file entity with comprehensive attributes; and (3) archive knowledge storage: storing the extracted archive entity and the relation data, wherein the archive entity and the relation data can be stored in a graph database; analyzing and judging the file: and intelligently retrieving files. Under the support of knowledge maps and machine learning technologies, the established file knowledge maps are fully utilized, the association recommendation of various related file entities and the accurate recommendation of related files are realized, the file studying and judging personnel are helped to expand reading, and the depth and the breadth of file studying and judging are expanded.
Description
Technical Field
The invention belongs to the technical field of file management and study and judgment, and particularly relates to a file study and judgment method and system based on a knowledge graph technology.
Background
The archives are the place where the national development history is collected, the archives are the records of past work and history situations, and are the real evidence of history, and along with the development of informatization, the digital archives are the necessary building objects of all levels of archives. However, with the development of the national and social economy, the traditional file informatization service can not meet the increasing practical requirements of the files, and the great promotion of the intelligent file construction becomes the inevitable requirement of the current social development.
In the past, the analysis of a data statistical analysis layer is mainly performed through a multidimensional data analysis tool, a data mining tool and the like, but the intelligent file construction needs to be capable of mining deeper meanings of files, such as the relationship between a certain person and other persons, the relationship between a relevant organization and certain events, so as to realize the correlation analysis and recommendation of related persons, cities, events, writings and the like of file study and judgment objects.
Therefore, a knowledge graph technology-based file study and judgment method and system are needed, which combine with a deep learning technology to construct a file knowledge graph, assist a user in performing file association analysis and intelligent retrieval, and provide data support for file study and judgment decisions.
Disclosure of Invention
In order to solve the above technical problems, the present invention provides a method and a system for studying and judging files based on the knowledge graph technology, wherein the method for studying and judging files comprises the following steps:
step 1, uploading files;
step 2: and (3) extracting file entities: extracting names of people, places, organizations, colleges and universities, works, events, buildings and data entities;
and step 3: and (3) extracting a file relation: extracting the incidence relation between the two entities and constructing the edge of the archive knowledge graph;
and 4, step 4: and (3) archive knowledge fusion: fusing the extracted file entities from different sources to generate a unique file entity with comprehensive attributes;
and 5: and (3) archive knowledge storage: storing the extracted archive entity and the relation data, wherein the archive entity and the relation data can be stored in a graph database;
step 6: analyzing and judging the file: the method comprises file hot word analysis, file sensitive word analysis, file special word identification, file automatic classification and file clustering, and is based on the utilization of a natural language processing technology and a deep learning technology to assist file analysis and study personnel to efficiently study and analyze file data.
And 7: intelligent retrieval of archives: the intelligent retrieval of the file comprises the steps of retrieving semantic keyword recommendation, related person recommendation, related organization recommendation, related event recommendation, related work recommendation and related policy recommendation, helping a user to expand reading through semantic related recommendation, improving the depth and the breadth of information search and analysis, and carrying out weighted average on the similarity according to the weight of each chapter to obtain the overall similarity of the document.
Preferably, the step 2 comprises the following steps:
step 21, vectorizing the corpus and inputting the corpus into a network;
step 22, automatically extracting input features by using the bidirectional LSTM;
and 23, performing sentence-level sequence labeling on the upper-layer result by using a CRF layer.
Preferably, the step 3 comprises the following steps:
step 31, analyzing sentence contents of the input file text, vectorizing the file text, and inputting the file text into a next layer of network;
step 32, using bidirectional LSTM to learn context information in forward and backward directions;
step 33, selecting a group of abnormal candidate sets by using an Attention mechanism for analysis, generating a weight vector, and combining the vocabulary-level characteristics in each iteration into sentence-level characteristics by multiplying the weight vector;
and 34, sending the vector generated by the Attention layer into a softmax classifier to predict a label value, and selecting the label with the maximum probability as a prediction label.
Preferably, the step 6 comprises the following steps:
step 61: analyzing the file hot words;
step 62: extracting file keywords: extracting a group of words identifying the input file;
and step 63: automatic file classification: automatically classifying the position compiling and researching files;
step 64: and (3) carrying out association analysis on the file characters: producing events and mechanisms associated with the character;
preferably, the file studying and judging system includes: the system comprises a file uploading module, a file entity extraction module, a file relation extraction module, a file knowledge fusion module, a file knowledge storage module and a file studying and judging analysis module.
Preferably, the archive uploading module is used for uploading and collecting archive documents, and automatically indexing metadata such as titles, authors, keywords, classifications and abstracts of the archive documents by using a natural language processing technology; the archive entity extraction module is used for automatically extracting archive entities such as names of people, place names, organization names, events, buildings and data from archives; the archive relation extraction module is used for extracting the association relation between archive entities from the archive so as to form an archive knowledge graph; the archive knowledge fusion module is used for performing ambiguity elimination and reference resolution on archive entity attributes extracted from all archive documents to realize the combination and fusion of the archive entity attributes; the archive knowledge storage module is used for storing the extracted and constructed archive knowledge graph and providing data query of the archive knowledge graph; the file studying and judging analysis module is used for providing intelligent tools for file studying and judging analysis personnel, such as file hot word analysis, file sensitive word analysis, file special word identification, file automatic classification, file clustering, file character relation extraction and the like, and simultaneously providing file intelligent retrieval, integrating file knowledge maps and file full-text retrieval, and realizing accurate recommendation of file retrieval keywords, file entities and related files.
Compared with the prior art, the invention has the beneficial effects that:
1. under the support of knowledge maps and machine learning technology, the established archive knowledge maps are fully utilized in archive search to realize the associated recommendation of various related archive entities and the accurate recommendation of related archives, so that archive studying and judging personnel are helped to expand reading, and the depth and breadth of archive studying and judging are expanded.
2. The invention provides an intelligent file compiling and researching method which comprises a plurality of automatic methods of file hot word analysis, file sensitive word analysis, file special word identification, automatic file classification, file clustering and file entity association analysis, and assists a compiling and researching staff to extract high-quality file information, thereby greatly improving the working efficiency of file compiling and researching.
Drawings
FIG. 1 is a general flow diagram of the present invention;
FIG. 2 is a BILSTM-CRF architecture diagram of the present invention;
FIG. 3 is a diagram of the bidirectional LSTM architecture based on the Attention mechanism of the present invention;
FIG. 4 is a flow chart of the intellectual search based on knowledge-graph of the present invention;
FIG. 5 is a schematic diagram of an overall structure of the archive compiling and researching system according to the present invention.
Detailed Description
The invention is further described below with reference to the accompanying drawings:
example (b):
as shown in fig. 1, a method for compiling and researching archives based on knowledge graph technology comprises the following steps:
step 1, uploading files:
the archive data mainly comprises archive catalogue data, archive full-text data, archive photo data, archive multimedia data, archive professional archive data, archive historical literature data and archive management data.
The user can upload the archives through modes such as uploading button or dragging, and the archives metadata are automatically formed by utilizing technologies such as natural language processing, such as archives names, archives authors, archives time, archives classification, archives keywords, archives abstract, archives security level and the like, and meanwhile, the operation records of uploading, inquiring, modifying and deleting of the data are recorded, and the efficiency of archives metadata entry is greatly improved.
Step 2, file entity extraction:
the archive entity mainly comprises entities of names of people, places, organizations, colleges and universities, works, events, buildings and data.
The archive entity extraction method mainly adopts an archive relation extraction method based on a mode or a rule, an archive relation extraction method based on a sequence labeling supervised learning technology and an archive relation extraction method based on text classification supervised learning, and takes the archive relation extraction method based on text classification supervised learning as an example:
a document relation extraction method based on text classification supervised learning includes the steps of firstly, carrying out entity labeling on a part of document data by using a BIO labeling method, and then, utilizing machine learning and deep learning methods such as BILSTM-CRF, SVM, Bayes and the like to construct a model.
Taking the BILSTM-CRF method as an example, the input of the file named entity recognition is the word sequence s ═ w corresponding to one sentence in the file1,w2…wn>When the supervised learning method is used, the NER problem is a sequence labeling problem, and the file corpora are processed by using a BIO labeling method, wherein B represents the initial position of the file entity, I represents the middle or end position of the file entity, and O represents that the file entity is not; if the name of the PERSON is marked, the name of the PERSON is marked with a starting mark B-PERSON, the I-PERSON represents the middle or the end position of the name entity of the PERSON, the starting mark B-LOC of the place name represents the middle or the end position of the name entity of the placeThe position is ended.
In the NER identification task, common deep networks comprise a CNN convolutional neural network and an RNN cyclic neural network, wherein the CNN convolutional neural network is used for vector feature learning, the RNN cyclic neural network simultaneously learns vector features and sequence labels, and a long-term memory network LSTM of RNN is used as an example for modeling:
the BILSTM-CRF is a NER identification method based on deep learning, and as shown in figure 2, mainly comprises an input layer, a BILSTM layer, a CRF layer and an output layer.
The function of each layer is as follows:
step 21: an input layer:
the first layer is an input layer, a group of words are generated after the document text is input and word segmentation is carried out, each word is expressed into a vector, the vector of each word is inquired from the model by using a pre-trained word2vec model, and the vector is transmitted to the next layer.
Step 22: BILSTM layer:
the second layer is a bidirectional LSTM layer, automatically extracts input features, and comprises two LSTMs, a forward input sequence and a reverse input sequence, so that the model can simultaneously consider the features extracted in the forward process and the features extracted in the backward process, namely the past features and the future features, an input word vector sequence (w0, w1, w2 and … wn) is used as the input of each time step of the bidirectional LSTM, and the hidden state sequences (h1, h2, h3 and … hn) output by the forward LSTM and the hidden state sequences (r1, r2 and r3 ….. rn) output by the reverse LSTM at each position are spliced in sequence to obtain a complete hidden state sequence;
and accessing a linear layer, reducing the dimension of the implicit state sequence vector to the dimension k, wherein the dimension k is the label number of the file corpus set, and further obtaining the automatically extracted sentence characteristics which are marked as C (C1, C2 and C3 … ck). Each item is a score value of a j label classified by a word, if softmax is carried out later, the k classification is carried out independently on each position, so that the labeled information cannot be utilized by labeling each position, and the result is input to a CRF layer for labeling;
step 23: CRF layer
The third layer is a CRF layer, sentence-level sequence labeling is carried out on the results of the upper layer, context information is learned through a BILSTM layer, the results are output to the CRF layer through a hidden layer, scoring values of each class of each word belonging to each word are input into the CRF layer, and the sequence with the highest predicted score is selected as the best answer through sequence labeling;
the parameter of the CRF layer is a matrix of (k +2) × (k +2), each entry of the matrix representing the transition score from the ith tag to the jth tag, k +2 meaning that a start state is added at the beginning of the sentence and an end state is added at the end of the sentence, if the tag sequence of a sentence is y ═ y (y +2)1,y2,....,yn) The label scoring result of model prediction is

The scoring result of the whole sequence is the accumulated sum of the scoring results of all positions, and the probability of normalization by using softmax is as follows:

in model prediction, the optimal path is solved by using a Viterbi (Viterbi) algorithm of dynamic programming

After the optimal solution, the model predicts the result as < word, label >, such as
King B-PERSON
Greeting I-PERSON
Bio O
Industry O
In O
Same as B-ORG
Ji I-ORG
Large I-ORG
Study I-ORG
And step 3: extracting a file relation;
the archive relation extraction is to extract the incidence relation between two entities and construct the edges of an archive knowledge graph, wherein generally, a triple < subject, predicate, object >, namely an SPO structure;
the archive relation extraction method mainly adopts an extraction method based on a mode or a rule, a supervised learning method based on sequence labeling and a supervised learning method based on text classification, and takes the supervised learning method based on text classification as an example;
the two-way LSTM neural network model based on the Attention mechanism is used for extracting the archival relationship, and the Attention mechanism can automatically discover the words which are important for the classification of the archival relationship, so that the model can capture the most important semantic information from sentences.
As shown in fig. 3, the system mainly includes four parts, namely an input layer, a blstm layer, an Attention layer and an output layer, and the function of each layer is as follows:
step 31: input layer
The first layer is an input layer, sentence content analysis is carried out on input archive texts, a group of words are generated, words are embedded, vectors are generated, and the vectors are transmitted to the next layer of the model.
Step 32: BILSTM layer:
the bidirectional LSTM comprises two LSTM networks, context information can be learned in a forward direction and a reverse direction, the finally output current hidden state is composed of the current cell state and an output gate weight matrix, and the output of the ith word is as follows;
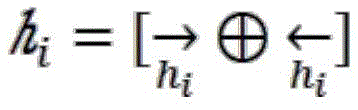
summing the forward and reverse results to produce an output for the layer;
step 33: attention layer
A weight vector is generated and the vocabulary-level features in each iteration are combined into sentence-level features by multiplication with this weight vector.
Representing the input vector of the LSTM layer as The weight matrix of the Attention layer is obtained by the following formula:
The weight matrix of the Attention layer is obtained by the following formula:
M=tanh(H)
a=softmax(wNM)
r=HaN
wherein, dw,dwis the dimension of the word vector, w is the variable matrix in the training process, wNIs the transpose matrix of the learned parameter vectors, we calculate the final classification of the sentence by the following formula.
dw,dwis the dimension of the word vector, w is the variable matrix in the training process, wNIs the transpose matrix of the learned parameter vectors, we calculate the final classification of the sentence by the following formula.
h*=tanh(r)
By using an attention mechanism, each step of output of the encoder layer is calculated in parallel with the current output, and then a probability value is generated by using a softmx function. These inputs are selectively learned by retaining intermediate output results of the LSTM encoder on the input sequence, and then training the model and associating the output sequence with the model as it is output.
Step 34: output layer
Sending the vector generated by the Attenttion layer into a softmax classifier to predict a tag value, selecting the tag with the maximum probability as a prediction tag, and finally generating a triple;
to avoid overfitting, we use dropout in the network forward computation. Droupout refers to the fact that when forward propagation calculation is carried out, the activation value of a certain neuron stops working with a certain probability p, so that two neurons do not necessarily appear in a dropout network each time, updating of weight values does not depend on implicit nodes of inherent relations any more, network learning is forced to be more robust, and model generalization capability is stronger.
And 4, step 4: archival knowledge fusion
Fusing the extracted file entities from different sources to generate a unique file entity with comprehensive attributes;
the method comprises the following steps of (1) archive knowledge fusion, wherein the archive knowledge fusion is mainly divided into two types, one type is based on the fusion of a plurality of archive knowledge maps, each group of archive data sources independently constructs one archive knowledge map, and then the plurality of archive knowledge maps are fused; the second category is based on the fusion of multiple different data sources, and archive knowledge is obtained by analyzing each data source and then combining all archive knowledge into a knowledge graph.
Taking the fusion of a plurality of different data sources as an example, the archive knowledge fusion process is divided into two parts, namely archive entity linking and archive knowledge merging. When the archive entities are linked, the extracted archive entities are linked to the existing archive entity objects, and archive knowledge merging is to blend the newly linked archive entities into the existing archive entities.
Step 41: file physical linking
The archive entity link is to extract an archive entity object from an archive text and link the archive entity object to an existing archive entity object in an archive knowledge base, and the processing flow is as follows:
extracting a file entity object from a file text;
performing the operations of reference resolution and entity disambiguation, and judging whether the meanings of the file entities with the same name in the file knowledge base and the currently extracted file entities are consistent;
if the selected archive entity is consistent with the archive entity in the archive repository, the extracted archive entity is linked to the archive entity in the archive repository.
And the index resolution is used for solving the problem that a plurality of names correspond to the same archive entity object, and the index resolution can be related to the correct archive entity.
The entity disambiguation is to solve the ambiguity problem of the same name file entity. Assuming that the attributes of the two archive entities are recorded as x and y, the value on the ith attribute is xiAnd yiThen the similarity of the archival entities can be obtained by calculating the similarity of the accumulated single attributes.
[sim(x1,y1),sim(x2,y2),…,sim(xn,yn)]
We use cosine clip similarity to calculate attribute similarity.

The larger the cosine value of the generated included angle is, the higher the similarity of the two file entities is;
if we extract a file character entity containing name, ID card number, mobile phone number and age information, firstly, go to the file knowledge base to search the file entity list consistent with the name, calculate the similarity by using the cosine of the included angle, select the file entity with the largest similarity value and larger than the threshold value, and link it to the file entity, otherwise, it is a new file entity.
Step 42: archival knowledge consolidation
Combining the newly extracted archive entity linked together with the archive entity in the archive knowledge base, constructing the archive knowledge graph into a more complete graph, for example, fusing the entity attributes of the archive character entities linked together, and adding the extracted new attribute and the attribute with more complete description into the archive entity attributes of the archive knowledge base.
And 5: storing archive knowledge;
and storing the extracted archive entity and relationship data, wherein the archive knowledge map data is stored by adopting two modes: the knowledge data is stored in a graph database by taking the storage mode based on the graph model as an example.
Taking the example of using Neo4j graph database to store the extracted archival entities and relationship data, Neo4j is a native graph database engine, which has a unique storage structure and an index-free neighbor node storage method, and has a corresponding graph traversal algorithm, thereby having very high query performance; the nature of the graph data structure and its unstructured data format allow the database design of Neo4j to have great flexibility and flexibility.
Step 6: analyzing the file;
by means of a machine learning technology, a natural language processing technology and a constructed file knowledge graph, massive file data are mined, file text key information is automatically extracted by means of intelligent analysis technologies such as text information extraction, text classification, text clustering, automatic abstract extraction, file character relation and intelligent retrieval aiming at information requirements of different research users, high-value file information is generated, work efficiency of research personnel is effectively improved, and data and tool support are provided for the research personnel to compile high-quality research reports.
Step 61: archival hotword analysis
A method for analyzing file hot words is based on the text document data of the file, and by mining and analyzing the full-text data of the file, a hot word list corresponding to the currently input file data is generated and displayed in a list or word cloud form.
Archival hotword analysis is implemented using the tf-idf method.
the tf formula is shown below.

Wherein, the numerator represents the number of times of a certain word in the input file text, and the denominator represents the number of all words in the input file text.
The idf formula is shown below.

Where the numerator represents the total number of documents in the input archive text and the denominator represents the number of documents containing a word, if the word is not in the archive text, this will result in the denominator being zero, so we add 1 to the denominator.
The formula for calculating the product of tf and idf is shown below.
tfidfi,j=tfi,j×idfi
If the word frequency of one word is very high and the word rarely appears in other documents, the word is a word with high distinguishing degree, each word is calculated in sequence, and finally a hot word list of topN is generated and can be presented to a user by using a word cloud;
step 62: archive keyword extraction
For an input file text, a group of words capable of identifying the file text is extracted and widely used in file keyword indexing and file information retrieval.
Tf-idf method
tf-idf is a commonly used method of scoring words in a sentence, and the tf-idf value of a word depends on two factors: the word frequency and the importance of the word. And generating top words through calculation to form a keyword set.
Textrank method
the textrank method is derived from page-rank, and considers that the importance of adjacent words in a document or a sentence is mutually influenced, and introduces the sequence information of the words.

Wherein, ViIdentifying the words for which weights are to be calculated, S (V)j) Weight of the word, d is the damping coefficient, In (V)i) Represents and ViWord sets in the same window, Out (V)j) Is represented by the formula VjAdding absolute values to the word sets in the same window to represent the number of the word sets;
textrank initializes the weight of each word, and then updates according to the formula until convergence, and the screened word set can reflect the whole file or sentence most.
And step 63: automatic file classification
The automatic file classification function is provided, the automatic classification of the compiled and researched files of unknown classification can be realized, and two methods of automatic classification based on rules and automatic classification based on machine learning are provided.
1. Rule-based automatic classification
According to the actual analysis scenario, rules are provided by the user in the form: the system automatically classifies unknown classified archives according to rules set by a user, a rule file comprises classification categories, word lists and weights corresponding to the classification categories, after word segmentation processing and word deactivation are carried out on input archive data, position association and cumulative weighting calculation are carried out on the word lists under each category of the rule file in sequence, finally, the category and the probability of the whole section of input data are given, and the user can designate the category and the probability with the highest topN category probability to return.
2. Automatic classification based on machine learning
The user provides training corpora, the system automatically learns the classification rules in the corpora by using a machine learning algorithm, establishes an automatic file classification model, realizes the automatic classification of unknown classification files, provides a series of machine learning file classification methods, such as Bayesian classification, and calculates the probability after the exchange of two files based on the probability under a certain known condition; bayesian classification is classification of a generated model under the condition of adopting attribute condition independence assumption; support vector machines are methods that map low-order space linearly indivisible samples to high-dimensional linearly separable space through a kernel function.
And providing a machine learning classification model training function, inputting a specified archive theme data set, making a classification label, and performing classification model training.
And providing a machine learning classification model evaluation function, inputting a specified theme data set (printing classification labels) and generating a model evaluation result.
Effect evaluation use accuracy, recall and F of classification model1-score,As follows:



wherein, tp: predicting a correct positive sample; fp: the prediction is the wrong positive sample; fn: negative samples for which the prediction is wrong;
after the effect evaluation of the classification model reaches the standard, automatic classification labels can be marked on the archive texts, and label distribution statistics is supported;
step 64: archival character relationship analysis
In the extraction of the archive entity, the archive entity information such as people, mechanisms, events and the like is extracted, in the analysis of the relationship of the archive characters, target characters to be analyzed are input, the events and the mechanisms related to the people are inquired from an archive knowledge graph and are shown to a user in a semantic network mode.
And 7: and intelligently retrieving files.
The search is a behavior of information search initiated by a user, the user submits a query request, matched contents are searched after the system receives the query request, query results are returned to the user after being sorted, and the archive intelligent search based on the knowledge graph can help the user to expand reading and improve the depth and the breadth of information search and analysis through semantic association recommendation on the basis of the traditional full-text search.
As shown in fig. 4, the intelligent search based on the archival knowledge graph mainly comprises the following steps:
1. analyzing the intention of the user: identifying a target entity of a user from a query submitted by the user, and generating a query condition of the target entity for searching;
2. target query: searching the target entity and related content related to the target entity in the knowledge graph by using a query statement for the query condition of the target entity;
3. the results show that: if the target entity is not unique, the results need to be sorted;
4. target entity exploration: and after the target entity is produced, displaying the related entities having the incidence relation with the target entity to the expanded search result.
Specifically, as shown in fig. 5, the file studying and judging system includes: the system comprises a file uploading module, a file entity extraction module, a file relation extraction module, a file knowledge fusion module, a file knowledge storage module and a file studying and judging analysis module, wherein the file uploading module is used for uploading and collecting file documents and automatically indexing metadata such as file document titles, authors, keywords, classifications and abstracts by using a natural language processing technology; the archive entity extraction module is used for automatically extracting archive entities such as names of people, place names, organization names, events, buildings and data from archives; the archive relation extraction module is used for extracting the association relation between archive entities from the archive so as to form an archive knowledge graph; the archive knowledge fusion module is used for performing ambiguity elimination and reference resolution on archive entity attributes extracted from all archive documents to realize the combination and fusion of the archive entity attributes; the archive knowledge storage module is used for storing the extracted and constructed archive knowledge graph and providing data query of the archive knowledge graph; the file studying and judging analysis module is used for providing intelligent tools for file studying and judging analysis personnel, such as file hot word analysis, file sensitive word analysis, file special word identification, file automatic classification, file clustering, file character relation extraction and the like, and simultaneously providing file intelligent retrieval, integrating file knowledge maps and file full-text retrieval, and realizing accurate recommendation of file retrieval keywords, file entities and related files.
The technical solutions of the present invention or similar technical solutions designed by those skilled in the art based on the teachings of the technical solutions of the present invention are all within the scope of the present invention.
Claims (6)
1. A file studying and judging method and a system based on knowledge graph technology are characterized in that the file studying and judging method comprises the following steps:
step 1, uploading files;
step 2: and (3) extracting file entities: extracting names of people, places, organizations, colleges and universities, works, events, buildings and data entities;
and step 3: and (3) extracting a file relation: extracting the incidence relation between the two entities and constructing the edge of the archive knowledge graph;
and 4, step 4: and (3) archive knowledge fusion: fusing the extracted file entities from different sources to generate a unique file entity with comprehensive attributes;
and 5: and (3) archive knowledge storage: storing the extracted archive entity and the relation data, wherein the archive entity and the relation data can be stored in a graph database;
step 6: analyzing and judging the file: the method comprises the steps of file hot word analysis, file sensitive word analysis, file special word identification, automatic file classification and file clustering, and is used for assisting file analysis and judgment personnel to efficiently judge and analyze file data based on a natural language processing technology and a deep learning technology;
and 7: intelligent retrieval of archives: the intelligent retrieval of the file comprises the steps of retrieving semantic keyword recommendation, related person recommendation, related organization recommendation, related event recommendation, related work recommendation and related policy recommendation, helping a user to expand reading through semantic related recommendation, improving the depth and the breadth of information search and analysis, and carrying out weighted average on the similarity according to the weight of each chapter to obtain the overall similarity of the document.
2. The method and system for studying and judging archives based on knowledge-graph technology as claimed in claim 1, wherein said step 2 comprises the steps of:
step 21, vectorizing the corpus and inputting the corpus into a network;
step 22, automatically extracting input features by using the bidirectional LSTM;
and 23, performing sentence-level sequence labeling on the upper-layer result by using a CRF layer.
3. The method and system for studying and judging archives based on knowledge-graph technology as claimed in claim 1, wherein said step 3 comprises the steps of:
step 31, analyzing sentence contents of the input file text, vectorizing the file text, and inputting the file text into a next layer of network;
step 32, using bidirectional LSTM to learn context information in forward and backward directions;
step 33, selecting a group of abnormal candidate sets by using an Attention mechanism for analysis, generating a weight vector, and combining the vocabulary-level characteristics in each iteration into sentence-level characteristics by multiplying the weight vector;
and 34, sending the vector generated by the Attention layer into a softmax classifier to predict a label value, and selecting the label with the maximum probability as a prediction label.
4. The method and system for studying and judging archives based on the knowledge-graph technology as claimed in claim 1, wherein said step 6 comprises the steps of:
step 41: analyzing the file hot words;
step 42: extracting file keywords: extracting a group of words identifying the input file;
step 43: automatic file classification: automatically classifying the position compiling and researching files;
step 44: and (3) carrying out association analysis on the file characters: and producing the events and mechanisms associated with the character.
5. The system and method of claim 1, wherein the system comprises: the system comprises a file uploading module, a file entity extraction module, a file relation extraction module, a file knowledge fusion module, a file knowledge storage module and a file studying and judging analysis module.
6. The method and system for studying and judging archives based on the knowledge-graph technology as claimed in claim 5, wherein the archive uploading module is used for uploading and collecting archive documents and automatically indexing metadata such as titles, authors, keywords, classifications and abstracts of the archive documents by using a natural language processing technology; the archive entity extraction module is used for automatically extracting archive entities such as names of people, place names, organization names, events, buildings and data from archives; the archive relation extraction module is used for extracting the association relation between archive entities from the archive so as to form an archive knowledge graph; the archive knowledge fusion module is used for performing ambiguity elimination and reference resolution on archive entity attributes extracted from all archive documents to realize the combination and fusion of the archive entity attributes; the archive knowledge storage module is used for storing the extracted and constructed archive knowledge graph and providing data query of the archive knowledge graph; the file studying and judging analysis module is used for providing intelligent tools for file studying and judging analysis personnel, such as file hot word analysis, file sensitive word analysis, file special word identification, file automatic classification, file clustering, file character relation extraction and the like, and simultaneously providing file intelligent retrieval, integrating file knowledge maps and file full-text retrieval, and realizing accurate recommendation of file retrieval keywords, file entities and related files.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110153678.3A CN113254659A (en) | 2021-02-04 | 2021-02-04 | File studying and judging method and system based on knowledge graph technology |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110153678.3A CN113254659A (en) | 2021-02-04 | 2021-02-04 | File studying and judging method and system based on knowledge graph technology |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN113254659A true CN113254659A (en) | 2021-08-13 |
Family
ID=77180868
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110153678.3A Pending CN113254659A (en) | 2021-02-04 | 2021-02-04 | File studying and judging method and system based on knowledge graph technology |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113254659A (en) |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113610194A (en) * | 2021-09-09 | 2021-11-05 | 重庆数字城市科技有限公司 | Automatic classification method for digital files |
| CN113761033A (en) * | 2021-09-13 | 2021-12-07 | 江苏楚风信息科技有限公司 | Information arrangement method and system based on file digital management |
| CN113836940A (en) * | 2021-09-26 | 2021-12-24 | 中国南方电网有限责任公司 | Knowledge fusion method and device in electric power metering field and computer equipment |
| CN114003553A (en) * | 2021-09-27 | 2022-02-01 | 上海金慧软件有限公司 | Intelligent counting display method and device for drawing management |
| CN114090789A (en) * | 2021-11-12 | 2022-02-25 | 复旦大学 | Intelligent multi-round interaction system for traditional Chinese medicine health maintenance based on knowledge graph |
| CN114238526A (en) * | 2022-02-23 | 2022-03-25 | 浙江大华技术股份有限公司 | Image gathering method, electronic equipment and storage medium |
| CN115455169A (en) * | 2022-10-31 | 2022-12-09 | 杭州远传新业科技股份有限公司 | Knowledge graph question-answering method and system based on vocabulary knowledge and semantic dependence |
| WO2023130837A1 (en) * | 2022-01-10 | 2023-07-13 | 华南理工大学 | Automatic machine learning implementation method, platform and apparatus for scientific research application |
| CN116756088A (en) * | 2023-08-21 | 2023-09-15 | 湖南云档信息科技有限公司 | Method for analyzing character relationship in file and related equipment |
| CN117828082A (en) * | 2024-01-03 | 2024-04-05 | 文华智典(武汉)科技有限公司 | File security identification method and system based on semantic learning |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109062939A (en) * | 2018-06-20 | 2018-12-21 | 广东外语外贸大学 | A kind of intelligence towards Chinese international education leads method |
| CN110188346A (en) * | 2019-04-29 | 2019-08-30 | 浙江工业大学 | A kind of network security bill part intelligence analysis method based on information extraction |
| CN110413795A (en) * | 2019-06-21 | 2019-11-05 | 厦门美域中央信息科技有限公司 | A kind of professional knowledge map construction method of data-driven |
| CN111191012A (en) * | 2018-10-25 | 2020-05-22 | 财团法人资讯工业策进会 | Knowledge graph generation apparatus, method and computer program product thereof |
| CN111241305A (en) * | 2020-01-16 | 2020-06-05 | 北京明略软件系统有限公司 | Data processing method and device, electronic equipment and computer readable storage medium |
| CN111475629A (en) * | 2020-03-31 | 2020-07-31 | 渤海大学 | Knowledge graph construction method and system for math tutoring question-answering system |
| CN111737471A (en) * | 2020-06-28 | 2020-10-02 | 中国农业科学院农业信息研究所 | Archive management model construction method and system based on knowledge graph |
| CN111753099A (en) * | 2020-06-28 | 2020-10-09 | 中国农业科学院农业信息研究所 | Method and system for enhancing file entity association degree based on knowledge graph |
| CN113254634A (en) * | 2021-02-04 | 2021-08-13 | 天津德尔塔科技有限公司 | File classification method and system based on phase space |
-
2021
- 2021-02-04 CN CN202110153678.3A patent/CN113254659A/en active Pending
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109062939A (en) * | 2018-06-20 | 2018-12-21 | 广东外语外贸大学 | A kind of intelligence towards Chinese international education leads method |
| CN111191012A (en) * | 2018-10-25 | 2020-05-22 | 财团法人资讯工业策进会 | Knowledge graph generation apparatus, method and computer program product thereof |
| CN110188346A (en) * | 2019-04-29 | 2019-08-30 | 浙江工业大学 | A kind of network security bill part intelligence analysis method based on information extraction |
| CN110413795A (en) * | 2019-06-21 | 2019-11-05 | 厦门美域中央信息科技有限公司 | A kind of professional knowledge map construction method of data-driven |
| CN111241305A (en) * | 2020-01-16 | 2020-06-05 | 北京明略软件系统有限公司 | Data processing method and device, electronic equipment and computer readable storage medium |
| CN111475629A (en) * | 2020-03-31 | 2020-07-31 | 渤海大学 | Knowledge graph construction method and system for math tutoring question-answering system |
| CN111737471A (en) * | 2020-06-28 | 2020-10-02 | 中国农业科学院农业信息研究所 | Archive management model construction method and system based on knowledge graph |
| CN111753099A (en) * | 2020-06-28 | 2020-10-09 | 中国农业科学院农业信息研究所 | Method and system for enhancing file entity association degree based on knowledge graph |
| CN113254634A (en) * | 2021-02-04 | 2021-08-13 | 天津德尔塔科技有限公司 | File classification method and system based on phase space |
Non-Patent Citations (2)
| Title |
|---|
| 雷洁: "基于知识图谱的科研档案管理研究", 《中国优秀博士学位论文全文数据库 信息科技辑》 * |
| 雷洁: "基于知识图谱的科研档案管理研究", 《中国优秀博士学位论文全文数据库 信息科技辑》, 15 January 2021 (2021-01-15), pages 5 - 2 * |
Cited By (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113610194A (en) * | 2021-09-09 | 2021-11-05 | 重庆数字城市科技有限公司 | Automatic classification method for digital files |
| CN113610194B (en) * | 2021-09-09 | 2023-08-11 | 重庆数字城市科技有限公司 | Automatic classification method for digital files |
| CN113761033B (en) * | 2021-09-13 | 2022-03-25 | 江苏楚风信息科技有限公司 | Information arrangement method and system based on file digital management |
| CN113761033A (en) * | 2021-09-13 | 2021-12-07 | 江苏楚风信息科技有限公司 | Information arrangement method and system based on file digital management |
| CN113836940A (en) * | 2021-09-26 | 2021-12-24 | 中国南方电网有限责任公司 | Knowledge fusion method and device in electric power metering field and computer equipment |
| CN113836940B (en) * | 2021-09-26 | 2024-04-12 | 南方电网数字电网研究院股份有限公司 | Knowledge fusion method and device in electric power metering field and computer equipment |
| CN114003553A (en) * | 2021-09-27 | 2022-02-01 | 上海金慧软件有限公司 | Intelligent counting display method and device for drawing management |
| CN114003553B (en) * | 2021-09-27 | 2023-12-15 | 上海金慧软件有限公司 | Intelligent counting display method and device for drawing management |
| CN114090789A (en) * | 2021-11-12 | 2022-02-25 | 复旦大学 | Intelligent multi-round interaction system for traditional Chinese medicine health maintenance based on knowledge graph |
| WO2023130837A1 (en) * | 2022-01-10 | 2023-07-13 | 华南理工大学 | Automatic machine learning implementation method, platform and apparatus for scientific research application |
| CN114238526A (en) * | 2022-02-23 | 2022-03-25 | 浙江大华技术股份有限公司 | Image gathering method, electronic equipment and storage medium |
| CN115455169A (en) * | 2022-10-31 | 2022-12-09 | 杭州远传新业科技股份有限公司 | Knowledge graph question-answering method and system based on vocabulary knowledge and semantic dependence |
| CN115455169B (en) * | 2022-10-31 | 2023-04-18 | 杭州远传新业科技股份有限公司 | Knowledge graph question-answering method and system based on vocabulary knowledge and semantic dependence |
| CN116756088A (en) * | 2023-08-21 | 2023-09-15 | 湖南云档信息科技有限公司 | Method for analyzing character relationship in file and related equipment |
| CN117828082A (en) * | 2024-01-03 | 2024-04-05 | 文华智典(武汉)科技有限公司 | File security identification method and system based on semantic learning |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113254659A (en) | File studying and judging method and system based on knowledge graph technology | |
| CN110633409B (en) | Automobile news event extraction method integrating rules and deep learning | |
| CN116909991B (en) | NLP-based scientific research archive management method and system | |
| Abello et al. | Computational folkloristics | |
| CN117171333B (en) | Electric power file question-answering type intelligent retrieval method and system | |
| CN109829104A (en) | Pseudo-linear filter model information search method and system based on semantic similarity | |
| Jotheeswaran et al. | OPINION MINING USING DECISION TREE BASED FEATURE SELECTION THROUGH MANHATTAN HIERARCHICAL CLUSTER MEASURE. | |
| CN105393265A (en) | Active featuring in computer-human interactive learning | |
| CN116127084A (en) | Knowledge graph-based micro-grid scheduling strategy intelligent retrieval system and method | |
| CN113064999B (en) | Knowledge graph construction algorithm, system, equipment and medium based on IT equipment operation and maintenance | |
| CN118132719A (en) | Intelligent dialogue method and system based on natural language processing | |
| Reddy et al. | Convolutional recurrent neural network with template based representation for complex question answering | |
| Mustafa et al. | Optimizing document classification: Unleashing the power of genetic algorithms | |
| Wang et al. | Content-based hybrid deep neural network citation recommendation method | |
| CN111428502A (en) | Named entity labeling method for military corpus | |
| Wang et al. | Automatic dialogue system of marriage law based on the parallel C4. 5 decision tree | |
| CN117235253A (en) | Truck user implicit demand mining method based on natural language processing technology | |
| Lamba et al. | Predictive Modeling | |
| Li et al. | Deep learning for semantic matching: A survey | |
| Utami | Sentiment Analysis of Hotel User Review using RNN Algorithm | |
| CN114417885A (en) | Network table column type detection method based on probability graph model | |
| CN113849639A (en) | Method and system for constructing theme model categories of urban data warehouse | |
| Zhang et al. | A deep recommendation framework for completely new users in mashup creation | |
| Rabby et al. | Establishing a formal benchmarking process for sentiment analysis for the bangla language | |
| CN114936277B (en) | Similarity problem matching method and user similarity problem matching system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication | ||
| RJ01 | Rejection of invention patent application after publication |
Application publication date: 20210813 |