CN111428502A - Named entity labeling method for military corpus - Google Patents
Named entity labeling method for military corpus Download PDFInfo
- Publication number
- CN111428502A CN111428502A CN202010102664.4A CN202010102664A CN111428502A CN 111428502 A CN111428502 A CN 111428502A CN 202010102664 A CN202010102664 A CN 202010102664A CN 111428502 A CN111428502 A CN 111428502A
- Authority
- CN
- China
- Prior art keywords
- military
- entity
- samples
- labeling
- entry
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000002372 labelling Methods 0.000 title claims abstract description 46
- 238000000034 method Methods 0.000 claims abstract description 23
- 238000003062 neural network model Methods 0.000 claims abstract description 15
- 230000002457 bidirectional effect Effects 0.000 claims abstract description 10
- 238000012549 training Methods 0.000 claims abstract description 9
- 238000004422 calculation algorithm Methods 0.000 claims abstract description 8
- 238000013528 artificial neural network Methods 0.000 claims abstract description 6
- 230000006870 function Effects 0.000 claims description 21
- 239000012634 fragment Substances 0.000 claims description 15
- 230000004913 activation Effects 0.000 claims description 4
- 238000004364 calculation method Methods 0.000 claims description 4
- 230000020411 cell activation Effects 0.000 claims description 3
- 230000008569 process Effects 0.000 description 6
- 238000000605 extraction Methods 0.000 description 5
- 238000010586 diagram Methods 0.000 description 4
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 230000008901 benefit Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 238000007636 ensemble learning method Methods 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 230000008676 import Effects 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000005065 mining Methods 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 238000007781 pre-processing Methods 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000000306 recurrent effect Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000011218 segmentation Effects 0.000 description 1
- 238000005728 strengthening Methods 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/049—Temporal neural networks, e.g. delay elements, oscillating neurons or pulsed inputs
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Machine Translation (AREA)
Abstract
The invention discloses a military corpus-oriented named entity labeling method which comprises the steps of respectively using three deep neural networks based on bidirectional L STM and CRF combined neural network models, L attece L STM neural network models and BERT pre-training neural network models to automatically label named entities of machines, using an XGboost method to integrally learn results obtained by three algorithms of S1 to obtain samples with successful labeling and samples with failed labeling, wherein the successful samples are defined as samples with any two consistent recognition results in three types of machine entity recognition, the failed samples are defined as samples with three different machine entity recognition results, using a manual labeling mode to label the failed samples, and storing all sample labeling results in a data base management mode in a json mode.
Description
Technical Field
The invention relates to the field of natural language data processing, in particular to a method for labeling military entities in a military corpus by using an ensemble learning method to provide training corpuses for application of named entity recognition in the military field, and the recognition accuracy of the military entities is improved.
Background
Named Entity recognition (Named Entity recognition) is an important task in information extraction and information retrieval, and aims to recognize and classify components in text representing Named entities, and is sometimes referred to as Named Entity recognition and classification. With the advent of the big data age, the internet has become an important source for military intelligence acquisition. The method is characterized in that a large amount of military text information can be obtained through ways such as news lines, news magazines, military reports, operation schemes, exercise reports, military magazines, dictionaries, government documents, military comments and the like, and military entities facing the military field, such as military officials, military equipment names, military facility names and military organization names, need to be extracted in order to realize text semantic understanding, semantic representation and knowledge management. In order to achieve the purpose that a computer automatically identifies military entities, a large amount of high-quality military entity labeling corpora are needed, however, in the current era with extremely high labor cost, on one hand, a large amount of labeling corpora consume a small amount of manpower, material resources and financial resources, and on the other hand, the labeling quality from non-professionals may be lower than that from experts, so that the generated low-quality corpora cannot guarantee the accuracy of named entity identification. Therefore, the establishment of the efficient military corpus-oriented named entity labeling method has important value and significance for mining the potential value of the military corpus.
At present, there are 3 common modes of corpus tagging, which are a traditional tagging mode, a crowd-sourced tagging mode and a group tagging mode. The three labeling modes are all used for labeling the corpora in a manual labeling mode, the traditional labeling mode is characterized in that labeling personnel label the corpora under the guidance of labeling standards, the crowdsourcing labeling mode utilizes a network, the same corpora are labeled on line through the labeling personnel, high-quality labeling corpora are obtained through vote arbitration, and group labeling is realized by utilizing a large-scale labeling group to label and obtain the corpora. The method is based on the fact that the labeled linguistic data are obtained through labeling work of labeling personnel. Even the social annotation and the group-based intelligent corpus annotation method with efficient information resource indexing, organizing and retrieving modes still cannot get rid of the defect. Some software platforms or networks are utilized, and the marking personnel are still required to spend a large amount of time for arbitration comparison besides unifying marking specifications to finally adopt the optimal linguistic data.
Xgboost, used in the invention, is currently the most popular integrated learning method. The ensemble learning refers to that a plurality of weak supervision models are utilized to obtain a better and more comprehensive strong supervision model, and the potential idea of the ensemble learning is that even if a certain weak classifier obtains wrong prediction, other weak classifiers can correct the errors. Xgboost is an efficient algorithm proposed by Chentianqi of Washington university in 2016, with a linear scale solver and tree learning. The method is an improvement on the traditional integrated learning GBDT algorithm and is more efficient. The traditional GBDT method only utilizes first-order derivative information, Xgboost is Taylor expansion of a loss function in second order, a regular term is added outside an objective function, an optimal solution is integrally solved for balancing the reduction of the objective function and the complexity of a model, overfitting is avoided, and the solving efficiency of the model is improved, and the method comprises the following steps:
(1) given a dataset D { (xi, yi): i ═ 1, 2, …, n, xi ∈ Rp, yi ∈ R }, where n is the number of samples, each sample having P features.

(2) The objective function is defined as follows:

in the formula, yi is a predicted value, yi is a true value, in order to prevent overfitting, a regularization item is defined, T and omega are the number of tree leaf nodes and leaf weight values respectively, gamma is a leaf tree punishment coefficient, and lambda is a leaf weight punishment coefficient.
(3) Xgboost uses a gradient lifting strategy, an existing model is reserved, a new regression tree is added to the model at one time, and assuming that the prediction result of the ith sample in the t iteration is yi (t), ft (xi) is the added new regression tree, the following derivation process can be obtained:

(4) by substituting the result of formula (8) into formula (7), it is possible to obtain:

(5) performing second-order Taylor expansion on the target function, and introducing a regular term:
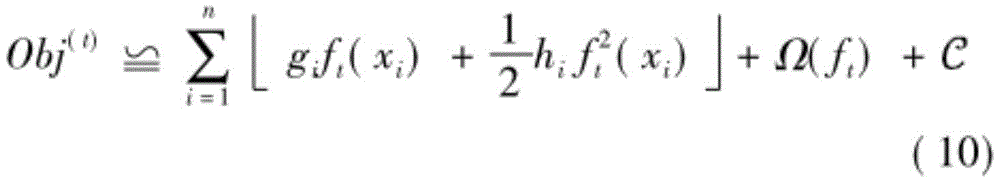
in the formula:
the XGboost integrated learning has good performance on data sets of various scales, and is one of the most stable methods for improving the accuracy rate of the algorithm and the best effect at present.
Disclosure of Invention
The invention aims to provide a named entity labeling method facing military corpora, which aims to solve the problem of military entity identification contained in massive Internet texts and provides a basis for discovery and extraction of open source information.
In order to realize the purpose, the following technical scheme is adopted: the method comprises the following steps:
s1, performing automatic labeling of machine named entity recognition by using three deep neural networks, namely a neural network model based on bidirectional L STM and CRF combination, a neural network model based on L attice L STM and a neural network model based on BERT pre-training;
s2, performing ensemble learning on results obtained by the three algorithms of S1 by using an XGboost method, and obtaining samples with successful labeling and samples with failed labeling, wherein the successful samples are defined as samples with consistent results of any two of the three machine entity identifications, and the failed samples are defined as samples with inconsistent results of the three machine entity identifications;
s3, marking failed samples in a manual marking mode;
and S4, storing all sample labeling results into a database for management in a json mode.
Further, the military entity labels are divided into 7 types, including a person name entity, a time entity, a place name entity, a personnel military affairs and military rank entity, a military equipment entity, a military facility entity, and a military institution entity, which are respectively labeled as person _ entry, time _ entry, location _ entry, position _ entry, weather _ entry, facility _ entry, and location _ org _ entry, and each element is labeled as "X-B", "X-I", or "O". Wherein "X-B" indicates that the fragment in which the element is located belongs to X type and the element is at the beginning of the fragment, "X-I" indicates that the fragment in which the element is located belongs to X type and the element is in the middle position of the fragment, and "O" indicates that the fragment does not belong to any type. For example, "the F-16 aircraft landed at Anderson air force base 23 points at 15, day 4", labeled "Webon _ entry _ B _ Webon _ entry _ I _ Webon _ entry _ Iwebon _ entry _ I _ Webon _ entry _ I _ time _ entry _ I _ entry _ I _ O location _ entry _ location _ I _ location _ entry _ I _ location _ I _ entry _ I".
Further, the calculation process of the long-time and short-time memory module in the L STM model is as follows:
(1) the Input word Xt enters the network through an Input Gate (Input Gate) at the time t, and comprises the Input at the time t and the output of a hidden layer and a cell update (cell) at the time t-1 connected with the Input at the time t, and the function calculation is activated;
(2) information forgetting is realized through a forgetting Gate (Forget Gate), and an activation function is obtained in the same way as in the step (1);
(3) the cell activation function comprises an input at the time t and an output of a hidden layer at the time t-1;
(4) the final information unit output includes the vector output through the output gate Ot and the cell unit output, i.e., the result of the forward estimation.
In theory, backward estimation is the inverse derivative based on forward estimation, with a process similar to forward, bidirectional L STM performs L STM-specific training twice forward and backward against known training sequences, thereby ensuring the globality and completeness of feature extraction.
Compared with the prior art, the invention has the following advantages: the method can obviously improve the labeling accuracy of military entities in the military corpora, and simultaneously achieves the best labeling effect with the minimum labor cost.
Drawings
Table 1 shows the military entity labeling specifications provided by the present invention.
FIG. 1 is a basic flow diagram of the present invention.
Fig. 2 is a diagram of a bidirectional L STM neural network model structure.
FIG. 3 is a diagram of a model architecture of an STM neural network based on L attice L.
FIG. 4 is a diagram of a BERT-based pre-trained neural network model architecture.
Detailed Description
The invention is further described below with reference to the accompanying drawings:
with reference to fig. 1-4, the method of the present invention comprises the following steps:
s1, performing automatic labeling of machine named entity recognition by using three deep neural networks, namely a neural network model based on bidirectional L STM and CRF combination, a neural network model based on L attice L STM and a neural network model based on BERT pre-training;
s2, performing ensemble learning on results obtained by the three algorithms of S1 by using an XGboost method, and obtaining samples with successful labeling and samples with failed labeling, wherein the successful samples are defined as samples with consistent results of any two of the three machine entity identifications, and the failed samples are defined as samples with inconsistent results of the three machine entity identifications;
s3, marking failed samples in a manual marking mode;
and S4, storing all sample labeling results into a database for management in a json mode.
TABLE 1 military entity Mark Specifications in the present invention


As shown in table 1, the military entity labels are divided into 7 types, including a person name entity, a time entity, a place name entity, a personnel military affairs and military rank entity, a military equipment entity, a military facility entity, and a military institution entity, which are respectively labeled as person _ entry, time _ entry, location _ entry, position _ entry, weather _ entry, facility _ entry, and location _ org _ entry, and each element is labeled as "X-B", "X-I", or "O". Wherein "X-B" indicates that the fragment in which the element is located belongs to X type and the element is at the beginning of the fragment, "X-I" indicates that the fragment in which the element is located belongs to X type and the element is in the middle position of the fragment, and "O" indicates that the fragment does not belong to any type. For example, "the F-16 aircraft landed at Anderson air force base 23 points at 15, day 4", labeled "Webon _ entry _ B Webon _ entry _ I Webon _ entry _ Iwebon _ entry _ I webon _ entry _ I time _ entry _ I O location _ entry _ I location _ entry _ I location _ entry _ I location _ entry _ I location _ entry _ I location.
Further explanation is as follows:
1. military named entity part-of-speech tagging specification formulation
2. Military text import and preprocessing
For a corpus annotation platform, a large number of raw corpora need to be annotated to form a corpus with complete annotation. The raw corpus is obtained by the existing text data or crawlers on the network, so that the most basic functional requirements of the text loading part are that the text data is imported, the network crawlers and other loading modes are added with the function of manual input, and the loss that some file contents which cannot be imported cannot be marked is avoided. On the basis of the prior art, if the platform is to be improved and strengthened, the functions of loading texts and adding picture and character recognition input and the like can be considered, and with the development of networks and technical equipment, texts are not only recorded in text files, but also a large amount of character information actually exists in pictures, audios and videos. Certainly, the audio and video are not required to be analyzed by making corpus labeling, but some texts can be recorded on pictures, so that the function can be considered to be added by the platform for later-stage strengthening.
3. Military text named entity recognition
The neural network model combining bidirectional L STM (Bi-L STM) with CRF is a more common extraction algorithm in named entity recognition, the bidirectional L STM is a subclass of a recurrent neural network, which is firstly proposed by HOCHREITER and the like, and is also a complex nonlinear unit in nature, and the bidirectional L STM has the remarkable characteristics of stronger memory capacity and fitting capacity to nonlinear relation, and the long-time and short-time memory module in the L STM model has the following calculation process:
(1) the Input word Xt enters the network at the time t through an Input Gate (Input Gate), and comprises an Input at the time t and an output of a cell update (cell) and a hidden layer at the time t-1 connected with the Input, and the activation function is calculated as follows:
(2) the information forgetting is realized through a forgetting Gate (Forget Gate), and an activation function is obtained in the same way as in (1):
(3) the cell activation function includes an input at time t and an output of the hidden layer at time t-1:
(4) the final information unit output includes the vector output and cell unit output through the output gate Ot, i.e. the result of forward estimation:
in theory, backward estimation is the inverse derivative based on forward estimation, with a process similar to forward, bidirectional L STM performs L STM-specific training twice forward and backward against known training sequences, thereby ensuring the globality and completeness of feature extraction.
The Conditional Random Field (CRF) is essentially a discriminant undirected graph, and the theoretical basis is a hidden Markov model and a maximum entropy model, and an observable symbol X belonging to the whole observable vector is mainly used for part-of-speech tagging and segmentation of ordered data. The application and development of the conditional random field still reserve part of the characteristics of a hidden Markov model, variables in the practical application process obey the Markov assumption, and the transition probability of each state depends on the instantaneous state of the adjacent variables. Taking a linear chain random field as an example, assuming a random variable sequence, if the two satisfy markov property, i.e., p (Y X) is called a linear chain element random field, where X is an input observation sequence and Y represents an output tag sequence (or state sequence) corresponding thereto. The feature function of the conditional random field comprises a transfer feature and a state feature, the transfer feature function defines the part of speech of the front word and the rear word, and the state feature function calculates the probability of each state of each word.
4. Standard labeled corpus warehousing
After a worker utilizes a corpus labeling platform to identify entities and add attributes to a text, a corpus can be generated through a corpus generation function of software, the corpus can be automatically generated through a corpus generation scheme which is designed to meet the corpus specification, a corpus editing frame of an XM L view is formed, the frame is used for adjustment and modification, and after the situation that the corpus is correct is confirmed, the corpus can be generated by clicking XM L, and the corpus is finally incorporated into a corpus database with complete labeling.
The above-mentioned embodiments are merely illustrative of the preferred embodiments of the present invention, and do not limit the scope of the present invention, and various modifications and improvements of the technical solution of the present invention by those skilled in the art should fall within the protection scope defined by the claims of the present invention without departing from the spirit of the present invention.
Claims (3)
1. A named entity labeling method for military corpora is characterized by comprising the following steps:
s1, performing automatic labeling of machine named entity recognition by using three deep neural networks, namely a neural network model based on bidirectional L STM and CRF combination, a neural network model based on L attice L STM and a neural network model based on BERT pre-training;
s2, performing ensemble learning on results obtained by the three algorithms of S1 by using an XGboost method, and obtaining samples with successful labeling and samples with failed labeling, wherein the successful samples are defined as samples with consistent results of any two of the three machine entity identifications, and the failed samples are defined as samples with inconsistent results of the three machine entity identifications;
s3, marking failed samples in a manual marking mode;
and S4, storing all sample labeling results into a database for management in a json mode.
2. The military corpus-oriented named entity tagging method of claim 1, characterized in that: the military entity labels are divided into 7 types, including a person name entity, a time entity, a place name entity, a personnel military affairs and military rank entity, a military equipment entity, a military facility entity and a military institution entity which are respectively marked as person _ entry, time _ entry, location _ entry, position _ entry, weather _ entry, facility _ entry and location _ org _ entry, and each element is labeled as 'B-X', 'I-X' or 'O'. Wherein "B-X" indicates that the fragment in which the element is located belongs to X type and the element is at the beginning of the fragment, "I-X" indicates that the fragment in which the element is located belongs to X type and the element is in the middle position of the fragment, and "O" indicates that the fragment does not belong to any type.
3. The military corpus-oriented named entity labeling method according to claim 1, wherein a long-time and short-time memory module in an L STM model is calculated as follows:
(1) the Input word Xt enters the network through an Input Gate (Input Gate) at the time t, and comprises the Input at the time t and the output of a hidden layer and a cell update (cell) at the time t-1 connected with the Input at the time t, and the function calculation is activated;
(2) the information forgetting is realized through a forgetting Gate (Forget Gate), and an activation function is obtained in the same way as in (1):
(3) the cell activation function comprises an input at the time t and an output of a hidden layer at the time t-1;
(4) the final information unit output includes the vector output through the output gate Ot and the cell unit output, i.e., the result of the forward estimation.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010102664.4A CN111428502A (en) | 2020-02-19 | 2020-02-19 | Named entity labeling method for military corpus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010102664.4A CN111428502A (en) | 2020-02-19 | 2020-02-19 | Named entity labeling method for military corpus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN111428502A true CN111428502A (en) | 2020-07-17 |
Family
ID=71547206
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010102664.4A Pending CN111428502A (en) | 2020-02-19 | 2020-02-19 | Named entity labeling method for military corpus |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111428502A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112151183A (en) * | 2020-09-23 | 2020-12-29 | 上海海事大学 | Entity identification method of Chinese electronic medical record based on Lattice LSTM model |
| CN112765985A (en) * | 2021-01-13 | 2021-05-07 | 中国科学技术信息研究所 | Named entity identification method for specific field patent embodiment |
| CN112966510A (en) * | 2021-02-05 | 2021-06-15 | 武汉工程大学 | Weapon equipment entity extraction method, system and storage medium based on ALBERT |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106202054A (en) * | 2016-07-25 | 2016-12-07 | 哈尔滨工业大学 | A kind of name entity recognition method learnt based on the degree of depth towards medical field |
| CN107133220A (en) * | 2017-06-07 | 2017-09-05 | 东南大学 | Name entity recognition method in a kind of Geography field |
| US20190005020A1 (en) * | 2017-06-30 | 2019-01-03 | Elsevier, Inc. | Systems and methods for extracting funder information from text |
| CN109255119A (en) * | 2018-07-18 | 2019-01-22 | 五邑大学 | A kind of sentence trunk analysis method and system based on the multitask deep neural network for segmenting and naming Entity recognition |
| CN109359293A (en) * | 2018-09-13 | 2019-02-19 | 内蒙古大学 | Mongolian name entity recognition method neural network based and its identifying system |
| CN109918647A (en) * | 2019-01-30 | 2019-06-21 | 中国科学院信息工程研究所 | A kind of security fields name entity recognition method and neural network model |
| CN110162772A (en) * | 2018-12-13 | 2019-08-23 | 北京三快在线科技有限公司 | Name entity recognition method and device |
| CN110705293A (en) * | 2019-08-23 | 2020-01-17 | 中国科学院苏州生物医学工程技术研究所 | Electronic medical record text named entity recognition method based on pre-training language model |
-
2020
- 2020-02-19 CN CN202010102664.4A patent/CN111428502A/en active Pending
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106202054A (en) * | 2016-07-25 | 2016-12-07 | 哈尔滨工业大学 | A kind of name entity recognition method learnt based on the degree of depth towards medical field |
| CN107133220A (en) * | 2017-06-07 | 2017-09-05 | 东南大学 | Name entity recognition method in a kind of Geography field |
| US20190005020A1 (en) * | 2017-06-30 | 2019-01-03 | Elsevier, Inc. | Systems and methods for extracting funder information from text |
| CN109255119A (en) * | 2018-07-18 | 2019-01-22 | 五邑大学 | A kind of sentence trunk analysis method and system based on the multitask deep neural network for segmenting and naming Entity recognition |
| CN109359293A (en) * | 2018-09-13 | 2019-02-19 | 内蒙古大学 | Mongolian name entity recognition method neural network based and its identifying system |
| CN110162772A (en) * | 2018-12-13 | 2019-08-23 | 北京三快在线科技有限公司 | Name entity recognition method and device |
| CN109918647A (en) * | 2019-01-30 | 2019-06-21 | 中国科学院信息工程研究所 | A kind of security fields name entity recognition method and neural network model |
| CN110705293A (en) * | 2019-08-23 | 2020-01-17 | 中国科学院苏州生物医学工程技术研究所 | Electronic medical record text named entity recognition method based on pre-training language model |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112151183A (en) * | 2020-09-23 | 2020-12-29 | 上海海事大学 | Entity identification method of Chinese electronic medical record based on Lattice LSTM model |
| CN112765985A (en) * | 2021-01-13 | 2021-05-07 | 中国科学技术信息研究所 | Named entity identification method for specific field patent embodiment |
| CN112765985B (en) * | 2021-01-13 | 2023-10-27 | 中国科学技术信息研究所 | Named entity identification method for patent embodiments in specific fields |
| CN112966510A (en) * | 2021-02-05 | 2021-06-15 | 武汉工程大学 | Weapon equipment entity extraction method, system and storage medium based on ALBERT |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111914558B (en) | Course knowledge relation extraction method and system based on sentence bag attention remote supervision | |
| CN108897857B (en) | Chinese text subject sentence generating method facing field | |
| CN104318340B (en) | Information visualization methods and intelligent visible analysis system based on text resume information | |
| CN110609897A (en) | Multi-category Chinese text classification method fusing global and local features | |
| CN112819023B (en) | Sample set acquisition method, device, computer equipment and storage medium | |
| CN111325029B (en) | Text similarity calculation method based on deep learning integrated model | |
| CN117171333B (en) | Electric power file question-answering type intelligent retrieval method and system | |
| CN113254659A (en) | File studying and judging method and system based on knowledge graph technology | |
| CN116127090B (en) | Aviation system knowledge graph construction method based on fusion and semi-supervision information extraction | |
| CN110457585B (en) | Negative text pushing method, device and system and computer equipment | |
| CN111274790A (en) | Chapter-level event embedding method and device based on syntactic dependency graph | |
| CN111222318A (en) | Trigger word recognition method based on two-channel bidirectional LSTM-CRF network | |
| CN111428502A (en) | Named entity labeling method for military corpus | |
| CN112836051A (en) | Online self-learning court electronic file text classification method | |
| CN113434688B (en) | Data processing method and device for public opinion classification model training | |
| CN113516198A (en) | Cultural resource text classification method based on memory network and graph neural network | |
| CN113011161A (en) | Method for extracting human and pattern association relation based on deep learning and pattern matching | |
| CN111507093A (en) | Text attack method and device based on similar dictionary and storage medium | |
| CN114840685A (en) | Emergency plan knowledge graph construction method | |
| CN114329181A (en) | Question recommendation method and device and electronic equipment | |
| CN117474010A (en) | Power grid language model-oriented power transmission and transformation equipment defect corpus construction method | |
| CN111783464A (en) | Electric power-oriented domain entity identification method, system and storage medium | |
| CN114238524B (en) | Satellite frequency-orbit data information extraction method based on enhanced sample model | |
| CN115392254A (en) | Interpretable cognitive prediction and discrimination method and system based on target task | |
| CN114911893A (en) | Method and system for automatically constructing knowledge base based on knowledge graph |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication |
Application publication date: 20200717 |