CN112035675A - Medical text labeling method, device, equipment and storage medium - Google Patents
Medical text labeling method, device, equipment and storage medium Download PDFInfo
- Publication number
- CN112035675A CN112035675A CN202010897823.4A CN202010897823A CN112035675A CN 112035675 A CN112035675 A CN 112035675A CN 202010897823 A CN202010897823 A CN 202010897823A CN 112035675 A CN112035675 A CN 112035675A
- Authority
- CN
- China
- Prior art keywords
- labeling
- entity
- medical
- text
- knowledge
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000002372 labelling Methods 0.000 title claims abstract description 236
- 238000000034 method Methods 0.000 claims abstract description 51
- 238000005516 engineering process Methods 0.000 claims abstract description 14
- 238000012986 modification Methods 0.000 claims description 36
- 230000004048 modification Effects 0.000 claims description 36
- 238000012549 training Methods 0.000 claims description 32
- 238000004422 calculation algorithm Methods 0.000 claims description 18
- 238000003058 natural language processing Methods 0.000 claims description 12
- 238000012937 correction Methods 0.000 claims description 9
- 238000005457 optimization Methods 0.000 claims description 7
- 238000004590 computer program Methods 0.000 claims description 2
- 238000013473 artificial intelligence Methods 0.000 abstract description 2
- 239000013598 vector Substances 0.000 description 26
- 238000010586 diagram Methods 0.000 description 11
- 239000003814 drug Substances 0.000 description 9
- 230000004927 fusion Effects 0.000 description 9
- 239000003086 colorant Substances 0.000 description 7
- 229940079593 drug Drugs 0.000 description 6
- 238000012545 processing Methods 0.000 description 5
- 238000007781 pre-processing Methods 0.000 description 3
- 238000004458 analytical method Methods 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 238000013136 deep learning model Methods 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 230000014509 gene expression Effects 0.000 description 2
- 238000003062 neural network model Methods 0.000 description 2
- 230000000007 visual effect Effects 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000013145 classification model Methods 0.000 description 1
- 238000013500 data storage Methods 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 235000019580 granularity Nutrition 0.000 description 1
- 230000008676 import Effects 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000002085 persistent effect Effects 0.000 description 1
- 230000011218 segmentation Effects 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- G06F16/367—Ontology
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
- G06F40/295—Named entity recognition
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Evolutionary Computation (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Biophysics (AREA)
- Animal Behavior & Ethology (AREA)
- Medical Treatment And Welfare Office Work (AREA)
Abstract
The invention relates to the technical field of artificial intelligence and discloses a medical text labeling method, a medical text labeling device, medical text labeling equipment and a storage medium. The method comprises the steps of setting a marking configuration table, calling marking parameters configured in the marking configuration table according to the data type requested in a request to mark the knowledge entities in the medical text to be marked in batches after receiving a marking request, and identifying the medical knowledge entities by using a medical knowledge map in the marking process, wherein the knowledge entities which are similar or identical exist in the knowledge map, and the system can be helped to carry out quick identification and quick marking based on comparison. In addition, the invention also relates to a block chain technology, and medical texts and entities can be stored in the block chain.
Description
Technical Field
The application relates to the technical field of artificial intelligence, in particular to a medical text labeling method, device, equipment and storage medium.
Background
With the popularization of mobile internet and social network, a great amount of User Generated Content (UGC) is Generated, and people often use different words and expressions to express similar contents due to different cultural backgrounds and expression habits. Particularly in the medical field, the naming of the medicine name is not a standard semantic naming mode, so that the difficulty of identification is increased.
The current implementation mode mainly adopts natural language processing technology to realize automatic marking identification. The natural language processing technology or the semantic mode is used for calculating and identifying, so that labeling is performed, and the error identification of a computer is corrected after labeling, so that the calculation amount required for completing one-time identification is overlarge, the semantics of the medicine name cannot be identified by conventional semantic analysis, a large amount of training and learning is required, development is not facilitated, the cost is high, and the efficiency and the accuracy are low during use.
Disclosure of Invention
The invention mainly aims to solve the technical problem that the existing medical text labeling efficiency and accuracy are low.
The invention provides a medical text labeling method in a first aspect, which comprises the following steps:
acquiring a medical text to be labeled and a labeling request;
extracting the data type of the data which is requested to be labeled in the labeling request;
according to the data type, querying a marking parameter corresponding to the data type from a preset marking configuration table;
identifying the knowledge entities of the medical texts to be labeled by using a medical knowledge map, and classifying the identified knowledge entities according to data types to obtain an entity set;
and inquiring the knowledge entity corresponding to the data type in the labeling request in the entity set, and labeling according to the labeling parameters to obtain a labeling text.
Optionally, in a first implementation manner of the first aspect of the present invention, the method further includes:
acquiring a modification request of a text modification user;
extracting configuration items and specific configuration parameters in the modification request, wherein the configuration item information comprises a labeled data type, a labeled tag number, a tag name, a tag color and a shortcut called by a tag;
and adding corresponding header names in a preset labeling configuration table template based on the configuration items, and setting display data under the header names according to the specific configuration parameters to form the labeling configuration table.
Optionally, in a second implementation manner of the first aspect of the present invention, after the adding, based on the configuration item, a corresponding header name to a preset tagging configuration table template, and setting display data under the header name according to the specific configuration parameter to form the tagging configuration table, the method further includes:
acquiring a historical medical entity, and calling a natural language processing technology to learn the historical medical entity to obtain an entity identification model;
and performing labeling training on the entity recognition model by using the labeling parameters in the labeling configuration table to obtain a labeling model, wherein the labeling model is used for recognizing and pre-labeling the knowledge entity in the medical text to be labeled.
Optionally, in a third implementation manner of the first aspect of the present invention, the recognizing, by using a medical knowledge graph, a knowledge entity of the medical text to be labeled, and classifying the recognized knowledge entity according to an entity of a data type to obtain an entity set includes:
extracting sentences in the medical texts to be labeled by utilizing a natural language processing technology to obtain a medical sentence set;
extracting entity names in the medical knowledge graph, matching words of each sentence in the medical sentence set one by one based on the entity names, and determining words meeting matching conditions in the sentences to obtain a word set;
analyzing entity semantics of each word in the word set according to a semantic recognition algorithm, and classifying the word set based on a corresponding relation between the entity semantics and the data types to obtain a plurality of knowledge entity groups;
outputting the plurality of knowledge entity groups as an entity set.
Optionally, in a fourth implementation manner of the first aspect of the present invention, the querying a knowledge entity in the entity set corresponding to the data type in the annotation request, and performing annotation according to the annotation parameter to obtain an annotation text includes:
inquiring a knowledge entity group corresponding to the data type in the entity set according to the data type of the labeling request;
marking each word in the knowledge entity group as the label color corresponding to the data type according to the label color corresponding to the data type, and displaying the corresponding label name and modifying the name of a user on the word to obtain pre-marking data;
and replacing the words corresponding to the knowledge entity group in the medical text to be labeled with the pre-marking data to generate a labeled text.
Optionally, in a fifth implementation manner of the first aspect of the present invention, after querying the knowledge entity corresponding to the data type in the annotation request in the entity set, and performing annotation according to the annotation parameter to obtain an annotation text, the method further includes:
calling an entity naming error correction algorithm to identify whether the name of the tagged knowledge entity is correct;
if not, inquiring an internet dictionary, and selecting an entity name similar to the knowledge entity for replacement to obtain a new labeling text; alternatively, the modification user is notified to make the manual modification.
Optionally, in a sixth implementation manner of the first aspect of the present invention, after querying an internet dictionary, selecting an entity name similar to the knowledge entity for replacement, and obtaining a new annotation text, the method further includes:
and obtaining the replaced entity name as a training set, and performing model optimization and training on the labeling model to obtain an optimized labeling model.
A second aspect of the present invention provides a medical text labeling apparatus, including:
the receiving module is used for acquiring the medical text to be labeled and the labeling request;
the extracting module is used for extracting the data type of the data which is requested to be labeled in the labeling request;
the query module is used for querying the marking parameters corresponding to the data types from a preset marking configuration table according to the data types;
the identification module is used for identifying the knowledge entities of the medical texts to be labeled by utilizing the medical knowledge map and classifying the identified knowledge entities according to the entities of the data types to obtain an entity set;
and the marking module is used for inquiring the knowledge entity corresponding to the data type in the marking request in the entity set and marking according to the marking parameters to obtain a marking text.
Optionally, in a first implementation manner of the second aspect of the present invention, the medical text labeling apparatus further includes a setting module, which is specifically configured to:
acquiring a modification request of a text modification user;
extracting configuration items and specific configuration parameters in the modification request, wherein the configuration item information comprises a labeled data type, a labeled tag number, a tag name, a tag color and a shortcut called by a tag;
and adding corresponding header names in a preset labeling configuration table template based on the configuration items, and setting display data under the header names according to the specific configuration parameters to form the labeling configuration table.
Optionally, in a second implementation manner of the second aspect of the present invention, the medical text labeling apparatus further includes a training module, which is specifically configured to:
acquiring a historical medical entity, and calling a natural language processing technology to learn the historical medical entity to obtain an entity identification model;
and performing labeling training on the entity recognition model by using the labeling parameters in the labeling configuration table to obtain a labeling model, wherein the labeling model is used for recognizing and pre-labeling the knowledge entity in the medical text to be labeled.
Optionally, in a third implementation manner of the second aspect of the present invention, the identification module includes:
the sentence dividing unit is used for extracting sentences in the medical text to be labeled by utilizing a natural language processing technology to obtain a medical sentence set;
the matching unit is used for extracting entity names in the medical knowledge graph, matching words of each sentence in the medical sentence set one by one based on the entity names, and determining words meeting matching conditions in the sentences to obtain a word set;
the recognition unit is used for analyzing the entity semantics of each word in the word set according to a semantic recognition algorithm and classifying the word set based on the corresponding relation between the entity semantics and the data types to obtain a plurality of knowledge entity groups; outputting the plurality of knowledge entity groups as an entity set.
Optionally, in a fourth implementation manner of the second aspect of the present invention, the labeling module includes:
the query unit is used for querying a knowledge entity group corresponding to the data type in the entity set according to the data type of the annotation request;
the preprocessing unit is used for labeling each word in the knowledge entity group as the label color corresponding to the data type according to the label color corresponding to the data type, and displaying the corresponding label name and modifying the name of a user on the word to obtain pre-marking data;
and the labeling unit is used for replacing words corresponding to the knowledge entity group in the medical text to be labeled with the pre-labeling data to generate a labeling text.
Optionally, in a fifth implementation manner of the second aspect of the present invention, the medical text labeling apparatus further includes an error correction module, which is specifically configured to:
calling an entity naming error correction algorithm to identify whether the name of the tagged knowledge entity is correct;
if not, inquiring an internet dictionary, and selecting an entity name similar to the knowledge entity for replacement to obtain a new labeling text; alternatively, the modification user is notified to make the manual modification.
Optionally, in a sixth implementation manner of the second aspect of the present invention, the training module is further specifically configured to:
and obtaining the replaced entity name as a training set, and performing model optimization and training on the labeling model to obtain an optimized labeling model.
A third aspect of the present invention provides a medical text labeling apparatus comprising: a memory having instructions stored therein and at least one processor, the memory and the at least one processor interconnected by a line;
the at least one processor invokes the instructions in the memory to cause the medical text labeling apparatus to perform the medical text labeling method described above.
A fourth aspect of the present invention provides a computer-readable storage medium having stored therein a computer program which, when run on a computer, causes the computer to execute the above-mentioned medical text labeling method.
According to the technical scheme provided by the invention, the annotation configuration table is set, after an annotation request is received, the annotation parameters configured in the annotation configuration table are called according to the data type requested in the request to carry out batch annotation on the knowledge entities in the medical text to be annotated, in addition, in the annotation process, the medical knowledge graph is also used for carrying out medical knowledge entity identification, similar or identical entities exist in the knowledge graph, and the system can be helped to carry out quick identification and quick annotation based on comparison.
Drawings
FIG. 1 is a schematic diagram of a first embodiment of a medical text annotation method in an embodiment of the invention;
FIG. 2 is a diagram of a second embodiment of a medical text annotation method according to an embodiment of the invention;
FIG. 3 is a flowchart illustrating a detailed process of step 203 in an embodiment of the present invention;
FIG. 4 is a diagram of a medical text annotation method according to a third embodiment of the present invention;
FIG. 5 is a diagram illustrating a tag configuration table according to an embodiment of the present invention;
FIG. 6 is a diagram illustrating an embodiment of a markup text;
FIG. 7 is another diagram illustrating annotation text in an embodiment of the present invention;
FIG. 8 is a diagram of a fourth embodiment of a medical text annotation method in an embodiment of the invention;
FIG. 9 is a schematic diagram of an embodiment of a medical text labeling apparatus according to an embodiment of the present invention;
FIG. 10 is a schematic diagram of another embodiment of a medical text labeling apparatus according to an embodiment of the present invention;
FIG. 11 is a diagram of an embodiment of a medical text labeling apparatus according to an embodiment of the present invention.
Detailed Description
Aiming at the problem that the accuracy and the processing efficiency are low when a user marks and modifies a medical text by the existing medical text labeling method, the modification identification of the medical text is improved by setting a semi-automatic labeling method, firstly, different labeling modes are set according to different users, labeling contents of different users are distributed, then, entity identification is carried out on the medical text based on a medical knowledge graph, so that pre-labeling information is generated and displayed in the medical text, the user can select and modify according to the labeling condition, the efficiency of labeling modification is improved, the accuracy of modification is also ensured, meanwhile, simultaneous labeling modification by multiple people is realized, and the processing efficiency is greatly improved.
The terms "first," "second," "third," "fourth," and the like in the description and in the claims, as well as in the drawings, if any, are used for distinguishing between similar elements and not necessarily for describing a particular sequential or chronological order. It will be appreciated that the data so used may be interchanged under appropriate circumstances such that the embodiments described herein may be practiced otherwise than as specifically illustrated or described herein. Furthermore, the terms "comprises," "comprising," or "having," and any variations thereof, are intended to cover non-exclusive inclusions, such that a process, method, system, article, or apparatus that comprises a list of steps or elements is not necessarily limited to those steps or elements expressly listed, but may include other steps or elements not expressly listed or inherent to such process, method, article, or apparatus.
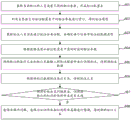
For convenience of understanding, a detailed flow of an embodiment of the present invention is described below, and referring to fig. 1, a first embodiment of a medical text labeling method according to an embodiment of the present invention includes:
101. acquiring a medical text to be labeled and a labeling request;
in this step, the medical text to be annotated can be medical books, internet forum knowledge and medical records, and even can be diagnosis reports.
In practical application, when a medical terminal receives a marking operation triggered by a user on the terminal, the medical terminal generates a marking request according to the marking operation, wherein the marking request comprises a data type to be marked and a name of a medical text to be marked.
Furthermore, the data type of the annotation request is determined according to words selected by the user in the text, the type information is connected in series to the trigger instruction, and meanwhile, the name of the corresponding text is also connected in series to the trigger instruction, so that the annotation request is generated.
102. Extracting the data type of the data which is requested to be labeled in the labeling request;
in this embodiment, after receiving the annotation request, the server or the background of the medical system parses the request, where the parsing is mainly performed according to a generation format of the request, for example, the generation format is trigger instruction + data type + text name, the trigger instruction, the data type, and the text name are separately divided based on the format, then a text annotation process is started according to the trigger instruction, and then a medical text corresponding to the text name is loaded and displayed on the display interface.
In practical application, the steps further comprise: and displaying the information of the data type in the medical text, or determining a labeling shortcut key according to the data type and displaying the labeling shortcut key at the edge position of the medical text.
103. According to the data type, querying a marking parameter corresponding to the data type from a preset marking configuration table;
in this step, whether a configuration record of a corresponding type exists in the annotation configuration table is queried according to the data type, and if so, the corresponding annotation parameter is read, for example: the type is seq, the tag ID is 101, the name is drug, the shortcut key is d, and the color is green.
In practical application, if there is no configuration record of a corresponding type in the tag configuration table, a parameter configuration program may be started, a corresponding configuration interface is scheduled based on the configured program, parameters such as a type name, a tag name and ID, a shortcut key, a display color of a tag, and the like are set according to a current annotation requirement of a user, and specifically, if there is a special font or a phrase name in the tag, an identification rule of the special font or the phrase name may be set.
104. Identifying the knowledge entities of the medical text to be annotated by using the medical knowledge map, and classifying the identified knowledge entities according to the entities of the data types to obtain an entity set;
in this step, the medical knowledge graph is an entity tree graph obtained by training and learning through a model algorithm in advance, a plurality of nodes are arranged on the tree graph, and each node corresponds to an entity name and a class of entity voice analysis corresponding to the entity.
Specifically, the training process comprises: acquiring entity data which is labeled and classified by medical experts in a manual labeling mode from a medical database, and training a model based on the entity data, optionally, when the medical knowledge graph is constructed according to graph construction data, inputting the graph construction data into a preset graph tree to construct the medical knowledge graph, wherein the graph tree refers to a tree structure graph containing a plurality of father nodes and child nodes, so as to form the medical knowledge graph.
The medical knowledge graph is used for identifying the medical text to be labeled, extracting various types of entities in the medical text, classifying the entities by using a classification model, or classifying the entities by using a clustering algorithm, wherein the clustering algorithm is used for clustering based on the semantics or ontology by calculating the semantics or ontology of each entity so as to obtain a plurality of entity classes, thereby obtaining an entity set.
Further, the method also comprises the steps of identifying the data type of each entity category in the entity set, establishing the corresponding relation between the entity category and the data type, and forming a table.
105. And inquiring the knowledge entity corresponding to the data type in the labeling request in the entity set, and labeling according to the labeling parameters to obtain a labeling text.
In the step, the entity set is identified and classified by the medical knowledge graph and comprises a set of at least two groups of entity categories, the data types are matched with the data types in the entity set, the entity categories are extracted according to the matching result, all entities in the entity categories are labeled by the labeling parameters inquired in the step to form labeling data, and the labeling data are mapped to the medical text to be labeled, so that a labeling text is obtained.
By setting the marking parameters, selecting the corresponding data types to mark according to the marking requests of specific users, specifically calling the marking parameters configured in the marking configuration table according to the data types requested in the requests to mark the knowledge entities in the medical texts to be marked in batches, and because the different marking parameters selected by the requests are different, the method can also be distinguished when multiple users request simultaneously, thereby realizing the multi-user cooperation and the marking task distribution, only needing to select and mark the text spans, and supporting the shortcut key, so that the text spans can be marked quickly, one judgment of invalid labels and doubt labels on the data is supported in the marking process, the marking operation is updated in real time, page turning is stored automatically, the model pre-marking and the manual marking are combined, and the manual marking is assisted by the result of model run out, different colors are generated by different entity label configurations, whether the labeling result is correct or not is manually checked, and only the model pre-judgment error needs to be modified, so that the consistency and the efficiency of labeling are improved.
Referring to fig. 2, a second embodiment of the method for labeling medical texts according to the embodiment of the present invention includes:
201. acquiring a medical text to be labeled and a labeling request;
202. extracting the data type of the data which is requested to be labeled in the labeling request;
203. according to the data type, querying a marking parameter corresponding to the data type from a preset marking configuration table;
in practical applications, the specific implementation of step 201-: the type is seq, the tag ID is 101, the name is drug, the shortcut key is d, and the color is green.
In practical application, if there is no configuration record of a corresponding type in the tag configuration table, a parameter configuration program may be started, a corresponding configuration interface is scheduled based on the configured program, parameters such as a type name, a tag name and ID, a shortcut key, a display color of a tag, and the like are set according to a current annotation requirement of a user, and specifically, if there is a special font or a phrase name in the tag, an identification rule of the special font or the phrase name may be set.
204. Extracting sentences in the medical texts to be labeled by utilizing a natural language processing technology to obtain a medical sentence set;
205. extracting entity names in the medical knowledge graph, matching words of each sentence in the medical sentence set one by one based on the entity names, and determining words in the sentences which meet matching conditions to obtain a word set;
206. analyzing the entity semantics of each word in the word set according to a semantic recognition algorithm, and classifying the word set based on the corresponding relation between the entity semantics and the data types to obtain a plurality of knowledge entity groups;
207. outputting a plurality of knowledge entity groups as an entity set;
specifically, the step 204-207 substantially implements accurate recognition of the entity of each sentence in the medical text, and in practical applications, when recognizing the knowledge entity in the medical text to be labeled, the method can be implemented in the following manner, as shown in fig. 3:
301. inputting a Chinese medical text to be identified, and preprocessing the Chinese medical text;
specifically, each sentence S in the chinese medical text data to be recognized is first segmented and labeled according to a labeling dictionary, where S is (w1, w2, … wi, … wn), and wi represents the ith word in the sentence after S is segmented;
then, dividing the word of each sentence, wherein S is (c1, c2 … ci … cm), wherein ci represents the ith character after dividing the word of the sentence S;
302. for each sentence S, extracting the characteristics of three granularities of characters, words and radicals which form the sentence S respectively;
specifically, firstly, extracting word characteristics and expressing vectors;
for each word wi in each sentence after word segmentation and labeling, the first character of the word is represented by 1, the last character is represented by 3, and the characters appearing in the middle position are uniformly coded into 2; if the length of a word is less than 2, the corresponding vector is uniformly filled with 0 after the termination position; for words which are only independently formed by single Chinese characters, the words are used in a unified way;
a 20-dimensional vector of 0, resulting in a vector of words
Further, extracting character features and expressing vectors;
training each character in the text by using a Skip-Gram algorithm in the existing Word2Vec model, and expressing each character by using a 100-dimensional numerical vector to obtain a Word vector;
then, extracting and vector representing the characteristics of the radicals;
dividing the radicals of each single character in the text, setting the ideogram corresponding to the radicals as P, obtaining the 100-dimensional character vector corresponding to the ideogram by searching the character vector dictionary, regarding the 100-dimensional vector as the radical vector of the character, and recording as the radical vector
303. And performing feature fusion on the extracted three features to obtain joint vector representation of the features for entity identification and classification.
In practical application, this step can be implemented by first fusing the word vector and the radical vector;
feature fusion is performed on the two vectors by using a point-by-point addition method, corresponding components of the two vectors are added one by one, the component after the addition is used as a component of a new feature vector after the fusion, and the feature vector after the fusion of the word vector and the radical vector is expressed as x (x1, x2, … xl), and the process can be expressed by the following formula:
x=(x1,x2,…xl)=(μ1+θ1,μ2+θ2,…μt+xl);
then, fusing the word characteristics;
for the fusion of the feature vector of the word + the radical and the feature vector of the word, because the two dimensions are different, the feature fusion is performed by using a dimension splicing method, and it is noted that the final feature vector after the fusion is Y ═ Y1 … yd, where d represents the dimension of the feature after the fusion, and then the dimension splicing process is represented by the following formula:

as can be seen from the foregoing conditions, d is 120, that is, the feature vector after the final fusion is 120-dimensional.
According to the embodiment of the method, only data needs to be imported into the system platform, the platform rapidly marks the data type appointed by the user according to the preset marking parameters, and the marking mode can realize simultaneous marking of multiple persons and different person operations, and the setting of the marking parameters can be different, so that the marking efficiency is greatly improved.
Furthermore, in the marking process, the medical knowledge graph is used for identifying the medical knowledge entity, so that the system is helped to quickly identify and quickly mark, the realization mode not only improves the quick marking of the entity name of the medical text by the user, but also ensures the accuracy of marking the entity, and greatly improves the marking efficiency and the use experience of the user.
208. And inquiring the knowledge entity corresponding to the data type in the labeling request in the entity set, and labeling according to the labeling parameters to obtain a labeling text.
In the embodiment, the marking colors selected according to different requests are different, so that when multiple users request simultaneously, the multiple users can be distinguished, cooperation of multiple users is realized, a marking task is distributed, only text spans need to be selected and marked, shortcut keys are supported, so that the text spans can be marked quickly, invalid labels and doubt labels are supported in the marking process to judge data, the marking operation is updated in real time, page turning is automatically stored, model pre-marking and manual marking are combined, manual marking is assisted by using a model run-out result, different entity label configurations generate different colors, whether the marking result is correct is checked manually, only the model pre-judging error needs to be modified, and the marking consistency and efficiency are improved.
Referring to fig. 4, a third embodiment of the method for labeling a medical text according to the embodiment of the present invention includes:
401. acquiring a modification request of a text modification user;
402. extracting configuration items and specific configuration parameters in the modification request;
in this step, the configuration item information includes a labeled data type, a labeled tag number, a tag name, a tag color, and a shortcut for tag calling.
403. Adding corresponding header names in a preset labeling configuration table template based on configuration items, and setting display data under the header names according to specific configuration parameters to form a labeling configuration table;
in practical application, the configuration is mainly set in the form of a tag, and the configurable item parameter design of the tag includes, but is not limited to, the following: data type, label name and label color;
specifically, the type of the labeling data, the tag ID, the associated batch, the tag name, the tag shortcut key and the tag color may be set; setting related parameters according to different data annotation types, such as: and label marking, wherein a label is set through page operation, the type is seq, the label ID is 101, the name is drug, the shortcut key is d, and the color is gree, so that a label parameter is successfully configured, and visual operation can be additionally, indirectly and visually checked on an interface.
404. Acquiring a medical text to be labeled and a labeling request;
405. extracting the data type of the data which is requested to be labeled in the labeling request;
406. according to the data type, querying a marking parameter corresponding to the data type from a preset marking configuration table;
in practical applications, the specific implementation of the steps 404-406 is the same as the specific implementation of the steps 101-103 in the embodiment, and the detailed description thereof is omitted here.
407. Inquiring a knowledge entity corresponding to the data type in the labeling request in the entity set, and labeling according to the labeling parameters to obtain a labeling text;
in the step, when inquiring the knowledge entity, specifically, inquiring a knowledge entity group corresponding to the data type in the entity set according to the data type requested by the marking request;
marking each word in the knowledge entity group as the label color corresponding to the data type according to the label color corresponding to the data type, and displaying the corresponding label name and modifying the name of a user on the word to obtain pre-marking data;
and replacing the words corresponding to the knowledge entity group in the medical text to be labeled with the pre-marking data to generate a labeled text.
In practical application, a label parameter is generally set by page operation to be a label, the type is seq, the tag ID is 101, the name is drug, the shortcut key is d, and the color is green, so that a label parameter is successfully configured.
As shown in fig. 5-7, when labeling is performed according to the set labeling parameters, labeling data can be imported into a labeling interface of a medical text entity, and meanwhile, labeling task allocation can be performed according to provided labeling personnel information, labeling data can be queried according to import batches and initialized search conditions, the labeling data can be set by self according to pages and display quantity of each page, labeling personnel perform labeling work on the interface according to allocated data, primarily loaded data is model pre-labeling data, and the data is displayed on the interface according to pre-labeling data results and configured medical entity labels, for example: the entity labels are displayed in different colors of matching medicines and diseases in a distinguishing mode, manual marking is assisted by results run out of the models, whether the marking results are correct or not is checked manually, only the model is required to be corrected in a prejudgment mode, a span interval is generated on a data text needing to be corrected through mouse sliding and is matched with keyboard shortcut key operation, meanwhile, the marking judgment processing of invalid data and doubt data is supported, and the marking efficiency is improved.
408. And inquiring the knowledge entity corresponding to the data type in the labeling request in the entity set, and labeling according to the labeling parameters to obtain a labeling text.
In order to further improve the efficiency of labeling, in this embodiment, the labeling model may also be implemented by using a labeling model, and the labeling model is obtained by training based on the specific setting parameters in the preset labeling configuration table, as shown in fig. 8, the implementation steps of performing fast labeling based on the labeling model are as follows:
501. acquiring different marking parameters set by a currently marked person to form a marking configuration table;
specifically, a modification request of a text modification user is obtained, a configuration item and specific configuration parameters in the modification request are extracted, wherein the configuration item information comprises a labeled data type, a labeled label number, a label name and a label color, and a label calling shortcut, a corresponding header name is added to a preset labeled configuration table template based on the configuration item, and display data under the header name is set according to the specific configuration parameters to form a labeled configuration table.
In practical application, the configuration is mainly set in the form of a tag, and the configurable item parameter design of the tag includes, but is not limited to, the following: data type, label name and label color;
specifically, the type of the labeling data, the tag ID, the associated batch, the tag name, the tag shortcut key and the tag color may be set; setting related parameters according to different data annotation types, such as: and label marking, wherein a label is set through page operation, the type is seq, the label ID is 101, the name is drug, the shortcut key is d, and the color is gree, so that a label parameter is successfully configured, and visual operation can be additionally, indirectly and visually checked on an interface.
502. Learning the labeling parameters in the labeling configuration table by using natural language to obtain a labeling model;
in this step, the labeling model is used to identify and pre-label the knowledge entities in the medical text to be labeled. The specific training process comprises the following steps: firstly, acquiring a historical medical entity, and calling a natural language processing technology to learn the historical medical entity to obtain an entity identification model;
and then, carrying out labeling training on the entity recognition model by using the labeling parameters in the labeling configuration table to obtain a labeling model, wherein the labeling model is used for recognizing and pre-labeling the knowledge entity in the medical text to be labeled.
In practical application, specifically, a first word sequence composed of a plurality of words included in the labeled text is input into a pre-trained neural network model, so as to obtain a recognition result of the first word sequence output by the neural network model, and parameters of the model are adjusted based on the recognition result, wherein the labeled text is a text classified in advance through manual labeling; the identification result is the identification result of the medical entity of the first word sequence; and further, comparing the recognition result with the labeled result, judging whether the recognition is accurate or not based on the comparison result, if the comparison result is lower than the preset probability value, adjusting the parameters of the model for retraining, otherwise, continuing to train the next text, and entering the test for getting on-line after all the texts are trained.
In this embodiment, when labeling a medical text to be labeled by using a trained labeling model, the implementation steps are as follows:
firstly, determining corresponding marking parameters according to the data type in the request in the same way;
and then, inputting the medical text to be annotated into an annotation model, identifying entities according to data types to obtain entity groups, reading the inquired parameters into the annotation model, annotating each entity in the entity groups by the annotation model to obtain annotation data, and replacing the corresponding entity in the medical text to be annotated by using the annotation data as a replacement text to obtain the annotation text.
503. Acquiring information of a labeling person to perform labeling task allocation, and determining the data type labeled in each task;
504. inquiring corresponding marking parameters from a marking configuration table according to the data types;
specifically, the labeling parameters are data type, tag ID, associated batch, tag name, tag shortcut key and tag color.
505. Inputting the medical text to be labeled and the labeling parameters into a labeling model for identification and labeling to obtain pre-labeling data;
506. marking the medical text according to the pre-marked data to obtain a marked text;
507. calling an entity naming error correction algorithm to identify whether the name of the tagged knowledge entity is correct;
508. and if not, inquiring the Internet dictionary, and selecting an entity name similar to the knowledge entity for replacement to obtain a new labeling text.
In this embodiment, after the labeling is performed by using the model or the technical algorithm, a certain error may exist, that is, the entity name in the text of the user may have a problem.
In practical application, the modification adjustment can be manual modification or automatic machine modification, and for automatic machine modification, an error correction model is required to be called, the error correction model is also obtained by training, and training is carried out by acquiring medical nouns which are frequently known in medicine or have different names with different tones to form a training set.
Further, in order to improve the accuracy of the labeling model, after the labeling result is modified, the modified entity name and the entity name before modification are recorded, and when the collection number reaches a certain order of magnitude, the data in the records are used as a new training set and input into the labeling model for optimization training, specifically: and obtaining the replaced entity name as a training set, and performing model optimization and training on the labeling model to obtain an optimized labeling model.
In practical application, the actual labeling work result of the text data is beneficial to learning of a deep learning sequence labeling model algorithm, large-scale unsupervised data are subjected to pre-standard reaching through the existing deep learning model algorithm, data with high confidence coefficient is selected to be combined with manual labeling, a labeling platform system automatically records the text result labeled by a medical entity, quality inspection is carried out on the result labeled by the second time, finally, the labeled data is subjected to model optimization and training, the accuracy of a deep learning model is improved, and the task of automatic entity extraction is favorably completed.
In this embodiment, when receiving the tagging request, the method further includes detecting the number of tagging users in the tag request, and if there are a plurality of tagging users, sorting the tagging users according to priority, and sequentially performing tagging processing.
By implementing the scheme, the data can be imported to a system platform according to needs, multiple languages are labeled, RESTful style calling is supported, multi-person cooperation can be carried out, a labeling task is distributed, only text spans need to be selected and labeled, and shortcut keys are supported, so that the text spans can be labeled quickly, invalid labels and doubt labels are supported in the labeling process to judge the data, the labeling operation is updated in real time, page turning is automatically stored, model pre-labeling and manual labeling are combined, manual labeling is assisted by results of model running out, different entity labels are configured to generate different colors, whether the labeling result is correct or not is manually checked, only the model pre-judgment error needs to be modified, and the labeling consistency and efficiency are improved.
In the above description of the method for labeling a medical text in the embodiment of the present invention, referring to fig. 9, a medical text labeling apparatus in the embodiment of the present invention is described below, where a first embodiment of the medical text labeling apparatus in the embodiment of the present invention includes:
a receiving module 901, configured to obtain a medical text to be annotated and an annotation request;
an extracting module 902, configured to extract a data type of the data requested to be annotated in the annotation request;
a query module 903, configured to query, according to the data type, a label parameter corresponding to the data type from a preset label configuration table;
the identification module 904 is configured to identify the knowledge entity of the medical text to be labeled by using a medical knowledge map, and classify the identified knowledge entity according to the entity of the data type to obtain an entity set;
and the marking module 905 is configured to query the knowledge entities in the entity set corresponding to the data types in the marking request, and mark according to the marking parameters to obtain a marking text.
In this embodiment, the medical text labeling device operates the medical text labeling method, and the method comprises the steps of setting a label configuration table, calling label parameters configured in the label configuration table according to the data type requested in the request to label the knowledge entities in the medical text to be labeled in batches after receiving a label request, and identifying the medical knowledge entities by using a medical knowledge graph in the labeling process, wherein similar or same entities exist in the knowledge graph, so that the system can be helped to quickly identify and quickly label the entities based on comparison.
Referring to fig. 10, a medical text labeling apparatus according to a second embodiment of the present invention specifically includes:
a receiving module 901, configured to obtain a medical text to be annotated and an annotation request;
an extracting module 902, configured to extract a data type of the data requested to be annotated in the annotation request;
a query module 903, configured to query, according to the data type, a label parameter corresponding to the data type from a preset label configuration table;
the identification module 904 is configured to identify the knowledge entity of the medical text to be labeled by using a medical knowledge map, and classify the identified knowledge entity according to the entity of the data type to obtain an entity set;
and the marking module 905 is configured to query the knowledge entities in the entity set corresponding to the data types in the marking request, and mark according to the marking parameters to obtain a marking text.
Wherein, the medical text labeling apparatus further comprises a setting module 906, which is specifically configured to:
acquiring a modification request of a text modification user;
extracting configuration items and specific configuration parameters in the modification request, wherein the configuration item information comprises a labeled data type, a labeled tag number, a tag name, a tag color and a shortcut called by a tag;
and adding corresponding header names in a preset labeling configuration table template based on the configuration items, and setting display data under the header names according to the specific configuration parameters to form the labeling configuration table.
Wherein, the medical text labeling apparatus further comprises a training module 907, which is specifically configured to:
acquiring a historical medical entity, and calling a natural language processing technology to learn the historical medical entity to obtain an entity identification model;
and performing labeling training on the entity recognition model by using the labeling parameters in the labeling configuration table to obtain a labeling model, wherein the labeling model is used for recognizing and pre-labeling the knowledge entity in the medical text to be labeled.
Optionally, the identifying module 904 comprises:
a sentence dividing unit 9041, configured to extract a sentence in the medical text to be labeled by using a natural language processing technology, so as to obtain a medical sentence set;
a matching unit 9042, configured to extract entity names in the medical knowledge graph, match words of each sentence in the medical sentence set one by one based on the entity names, and determine words in the sentences that meet matching conditions, to obtain a word set;
the recognition unit 9043 is configured to analyze an entity semantic of each word in the word set according to a semantic recognition algorithm, and classify the word set based on a correspondence between the entity semantic and the data type to obtain a plurality of knowledge entity groups; outputting the plurality of knowledge entity groups as an entity set.
Wherein the labeling module 905 comprises:
a query unit 9051, configured to query, according to the data type of the annotation request, a knowledge entity group corresponding to the data type in the entity set;
a preprocessing unit 9052, configured to label each word in the knowledge entity group as a label color corresponding to the data type according to the label color corresponding to the data type, and display a corresponding label name on the word and modify a name of a user to obtain pre-marking data;
and the labeling unit 9053 is configured to replace the word in the medical text to be labeled, which corresponds to the knowledge entity group, with the pre-labeling data, so as to generate a labeled text.
The medical text labeling apparatus further includes an error correction module 908, which is specifically configured to:
calling an entity naming error correction algorithm to identify whether the name of the tagged knowledge entity is correct;
if not, inquiring an internet dictionary, and selecting an entity name similar to the knowledge entity for replacement to obtain a new labeling text; alternatively, the modification user is notified to make the manual modification.
Optionally, the training module 906 is further specifically configured to:
and obtaining the replaced entity name as a training set, and performing model optimization and training on the labeling model to obtain an optimized labeling model.
In conclusion, the marking colors selected based on different requests are different, so that when a plurality of users request simultaneously, the users can also distinguish, cooperation of the users can be realized, a marking task is distributed, only the text span needs to be selected and marked, and a shortcut key is supported, so that the text span can be quickly marked, in the marking process, one judgment of an invalid label and a suspicion label on data is supported, the marking operation is updated in real time, page turning is automatically stored, model pre-marking and manual marking are combined, the manual marking is assisted by using the result of model run-out, different entity labels are configured to generate different colors, whether the marking result is correct or not is manually checked, only the error of model pre-judging is needed to be modified, and the consistency and the efficiency of marking are improved.
The above fig. 9 and fig. 10 describe the medical text labeling apparatus in the embodiment of the present invention in detail from the perspective of the modular functional entity, and the following describes the medical text labeling device in the embodiment of the present invention in detail from the perspective of the hardware processing, and the medical text labeling apparatus can set the identification of the implementation of the dialogues with the medical text labeling device in the form of a plug-in.
Fig. 11 is a schematic structural diagram of a medical text labeling apparatus 600 according to an embodiment of the present invention, which may have a relatively large difference due to different configurations or performances, and may include one or more processors (CPUs) 610 (e.g., one or more processors) and a memory 620, one or more storage media 630 (e.g., one or more mass storage devices) for storing applications 633 or data 632. Memory 620 and storage medium 630 may be, among other things, transient or persistent storage. The program stored on the storage medium 630 may include one or more modules (not shown), each of which may include a series of instructions operating on the medical text annotation device 600. Still further, the processor 610 may be configured to communicate with the storage medium 630 and execute a series of instruction operations in the storage medium 630 on the medical text labeling device 600 to implement the steps of the medical text labeling method described above.
The medical text labeling device 600 may also include one or more power supplies 640, one or more wired or wireless network interfaces 650, one or more input-output interfaces 660, and/or one or more operating systems 631, such as Windows Server, Mac OS X, Unix, Linux, FreeBSD, and the like. Those skilled in the art will appreciate that the medical text annotation device configuration illustrated in FIG. 11 does not constitute a limitation of the medical text annotation devices provided herein, and may include more or less components than those illustrated, or some components in combination, or a different arrangement of components.
The block chain is a novel application mode of computer technologies such as distributed data storage, point-to-point transmission, a consensus mechanism, an encryption algorithm and the like. A block chain (Blockchain), which is essentially a decentralized database, is a series of data blocks associated by using a cryptographic method, and each data block contains information of a batch of network transactions, so as to verify the validity (anti-counterfeiting) of the information and generate a next block. The blockchain may include a blockchain underlying platform, a platform product service layer, an application service layer, and the like.
The present invention also provides a computer-readable storage medium, which may be a non-volatile computer-readable storage medium, and may also be a volatile computer-readable storage medium, where instructions are stored in the computer-readable storage medium, and when the instructions are executed on a computer, the instructions cause the computer to perform the steps of the medical text labeling method provided in each of the above embodiments.
It is clear to those skilled in the art that, for convenience and brevity of description, the specific working processes of the above-described systems, apparatuses and units may refer to the corresponding processes in the foregoing method embodiments, and are not described herein again.
The integrated unit, if implemented in the form of a software functional unit and sold or used as a stand-alone product, may be stored in a computer readable storage medium. Based on such understanding, the technical solution of the present invention may be embodied in the form of a software product, which is stored in a storage medium and includes instructions for causing a computer device (which may be a personal computer, a server, or a network device) to execute all or part of the steps of the method according to the embodiments of the present invention. And the aforementioned storage medium includes: various media capable of storing program codes, such as a usb disk, a removable hard disk, a read-only memory (ROM), a Random Access Memory (RAM), a magnetic disk, or an optical disk.
The above-mentioned embodiments are only used for illustrating the technical solutions of the present invention, and not for limiting the same; although the present invention has been described in detail with reference to the foregoing embodiments, it will be understood by those of ordinary skill in the art that: the technical solutions described in the foregoing embodiments may still be modified, or some technical features may be equivalently replaced; and such modifications or substitutions do not depart from the spirit and scope of the corresponding technical solutions of the embodiments of the present invention.
Claims (10)
1. A medical text labeling method is characterized by comprising the following steps:
acquiring a medical text to be labeled and a labeling request;
extracting the data type of the data which is requested to be labeled in the labeling request;
according to the data type, querying a marking parameter corresponding to the data type from a preset marking configuration table;
identifying the knowledge entities of the medical texts to be labeled by using a medical knowledge map, and classifying the identified knowledge entities according to data types to obtain an entity set;
and inquiring the knowledge entity corresponding to the data type in the labeling request in the entity set, and labeling according to the labeling parameters to obtain a labeling text.
2. The medical text labeling method of claim 1, further comprising:
acquiring a modification request of a text modification user;
extracting configuration items and specific configuration parameters in the modification request, wherein the configuration item information comprises a labeled data type, a labeled tag number, a tag name, a tag color and a shortcut called by a tag;
and adding corresponding header names in a preset labeling configuration table template based on the configuration items, and setting display data under the header names according to the specific configuration parameters to form the labeling configuration table.
3. The method for labeling medical texts according to claim 2, wherein after the corresponding header name is added to a preset labeling configuration table template based on the configuration item, and the display data under the header name is set according to the specific configuration parameter to form the labeling configuration table, the method further comprises:
acquiring a historical medical entity, and calling a natural language processing technology to learn the historical medical entity to obtain an entity identification model;
and performing labeling training on the entity recognition model by using the labeling parameters in the labeling configuration table to obtain a labeling model, wherein the labeling model is used for recognizing and pre-labeling the knowledge entity in the medical text to be labeled.
4. The method for labeling medical texts according to claim 3, wherein the identifying knowledge entities of the medical texts to be labeled by using the medical knowledge graph, and classifying the identified knowledge entities according to data type entities to obtain an entity set comprises:
extracting sentences in the medical texts to be labeled by utilizing a natural language processing technology to obtain a medical sentence set;
extracting entity names in the medical knowledge graph, matching words of each sentence in the medical sentence set one by one based on the entity names, and determining words meeting matching conditions in the sentences to obtain a word set;
analyzing entity semantics of each word in the word set according to a semantic recognition algorithm, and classifying the word set based on a corresponding relation between the entity semantics and the data types to obtain a plurality of knowledge entity groups;
outputting the plurality of knowledge entity groups as an entity set.
5. The medical text labeling method according to claim 4, wherein the querying knowledge entities in the entity set corresponding to the data types in the labeling request, and labeling according to the labeling parameters to obtain a labeling text comprises:
inquiring a knowledge entity group corresponding to the data type in the entity set according to the data type of the labeling request;
marking each word in the knowledge entity group as the label color corresponding to the data type according to the label color corresponding to the data type, and displaying the corresponding label name and modifying the name of a user on the word to obtain pre-marking data;
and replacing the words corresponding to the knowledge entity group in the medical text to be labeled with the pre-marking data to generate a labeled text.
6. The medical text labeling method according to claim 5, wherein after querying the knowledge entity corresponding to the data type in the labeling request in the entity set and labeling according to the labeling parameters to obtain a labeling text, the method further comprises:
calling an entity naming error correction algorithm to identify whether the name of the tagged knowledge entity is correct;
if not, inquiring an internet dictionary, and selecting an entity name similar to the knowledge entity for replacement to obtain a new labeling text; alternatively, the modification user is notified to make the manual modification.
7. The method of claim 6, wherein after querying an internet dictionary and selecting an entity name similar to the knowledge entity for replacement to obtain a new tagged text, the method further comprises:
and obtaining the replaced entity name as a training set, and performing model optimization and training on the labeling model to obtain an optimized labeling model.
8. A medical text labeling apparatus, characterized in that the medical text labeling apparatus comprises:
the receiving module is used for acquiring the medical text to be labeled and the labeling request;
the extracting module is used for extracting the data type of the data which is requested to be labeled in the labeling request;
the query module is used for querying the marking parameters corresponding to the data types from a preset marking configuration table according to the data types;
the identification module is used for identifying the knowledge entities of the medical texts to be labeled by utilizing the medical knowledge map and classifying the identified knowledge entities according to the entities of the data types to obtain an entity set;
and the marking module is used for inquiring the knowledge entity corresponding to the data type in the marking request in the entity set and marking according to the marking parameters to obtain a marking text.
9. A medical text labeling apparatus, characterized in that the medical text labeling apparatus comprises: a memory having instructions stored therein and at least one processor, the memory and the at least one processor interconnected by a line;
the at least one processor invokes the instructions in the memory to cause the medical text annotation device to perform the medical text annotation process of any one of claims 1-7.
10. A computer-readable storage medium, on which a computer program is stored which, when being executed by a processor, carries out a medical text annotation method according to any one of claims 1 to 7.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010897823.4A CN112035675A (en) | 2020-08-31 | 2020-08-31 | Medical text labeling method, device, equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010897823.4A CN112035675A (en) | 2020-08-31 | 2020-08-31 | Medical text labeling method, device, equipment and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112035675A true CN112035675A (en) | 2020-12-04 |
Family
ID=73586036
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010897823.4A Pending CN112035675A (en) | 2020-08-31 | 2020-08-31 | Medical text labeling method, device, equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112035675A (en) |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112836019A (en) * | 2021-02-19 | 2021-05-25 | 中国科学院新疆理化技术研究所 | Public health and public health named entity identification and entity linking method and device, electronic equipment and storage medium |
| CN112906375A (en) * | 2021-03-24 | 2021-06-04 | 平安科技(深圳)有限公司 | Text data labeling method, device, equipment and storage medium |
| CN113298112A (en) * | 2021-04-01 | 2021-08-24 | 安徽继远软件有限公司 | Integrated data intelligent labeling method and system |
| CN113408290A (en) * | 2021-06-29 | 2021-09-17 | 山东亿云信息技术有限公司 | Intelligent marking method and system for Chinese text |
| CN113742444A (en) * | 2021-07-08 | 2021-12-03 | 平安科技(深圳)有限公司 | Text labeling method and device, storage medium and computer equipment |
| CN113918713A (en) * | 2021-09-22 | 2022-01-11 | 南京复保科技有限公司 | Data annotation method and device, computer equipment and storage medium |
| CN114548057A (en) * | 2022-02-21 | 2022-05-27 | 上海市精神卫生中心(上海市心理咨询培训中心) | Method, system, device, processor and storage medium for realizing interview text automatic labeling processing based on depression diagnosis and treatment standard |
| CN114661900A (en) * | 2022-02-25 | 2022-06-24 | 安阳师范学院 | Text annotation recommendation method, device, equipment and storage medium |
| CN117034864A (en) * | 2023-09-07 | 2023-11-10 | 广州市新谷电子科技有限公司 | Visual labeling method, visual labeling device, computer equipment and storage medium |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106776711A (en) * | 2016-11-14 | 2017-05-31 | 浙江大学 | A kind of Chinese medical knowledge mapping construction method based on deep learning |
| CN109686423A (en) * | 2018-11-06 | 2019-04-26 | 众安信息技术服务有限公司 | A kind of medical imaging mask method and system |
| CN111079377A (en) * | 2019-12-03 | 2020-04-28 | 哈尔滨工程大学 | Method for recognizing named entities oriented to Chinese medical texts |
| CN111128323A (en) * | 2019-12-18 | 2020-05-08 | 中电云脑(天津)科技有限公司 | Medical electronic case labeling method, device, equipment and storage medium |
| CN111177309A (en) * | 2019-12-05 | 2020-05-19 | 宁波紫冬认知信息科技有限公司 | Medical record data processing method and device |
| CN111553161A (en) * | 2020-04-28 | 2020-08-18 | 郑州大学 | Entity and relation labeling system for medical texts |
-
2020
- 2020-08-31 CN CN202010897823.4A patent/CN112035675A/en active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106776711A (en) * | 2016-11-14 | 2017-05-31 | 浙江大学 | A kind of Chinese medical knowledge mapping construction method based on deep learning |
| CN109686423A (en) * | 2018-11-06 | 2019-04-26 | 众安信息技术服务有限公司 | A kind of medical imaging mask method and system |
| CN111079377A (en) * | 2019-12-03 | 2020-04-28 | 哈尔滨工程大学 | Method for recognizing named entities oriented to Chinese medical texts |
| CN111177309A (en) * | 2019-12-05 | 2020-05-19 | 宁波紫冬认知信息科技有限公司 | Medical record data processing method and device |
| CN111128323A (en) * | 2019-12-18 | 2020-05-08 | 中电云脑(天津)科技有限公司 | Medical electronic case labeling method, device, equipment and storage medium |
| CN111553161A (en) * | 2020-04-28 | 2020-08-18 | 郑州大学 | Entity and relation labeling system for medical texts |
Cited By (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112836019A (en) * | 2021-02-19 | 2021-05-25 | 中国科学院新疆理化技术研究所 | Public health and public health named entity identification and entity linking method and device, electronic equipment and storage medium |
| CN112836019B (en) * | 2021-02-19 | 2023-04-25 | 中国科学院新疆理化技术研究所 | Public medical health named entity identification and entity linking method and device, electronic equipment and storage medium |
| CN112906375B (en) * | 2021-03-24 | 2024-05-14 | 平安科技(深圳)有限公司 | Text data labeling method, device, equipment and storage medium |
| CN112906375A (en) * | 2021-03-24 | 2021-06-04 | 平安科技(深圳)有限公司 | Text data labeling method, device, equipment and storage medium |
| CN113298112A (en) * | 2021-04-01 | 2021-08-24 | 安徽继远软件有限公司 | Integrated data intelligent labeling method and system |
| CN113408290A (en) * | 2021-06-29 | 2021-09-17 | 山东亿云信息技术有限公司 | Intelligent marking method and system for Chinese text |
| CN113742444A (en) * | 2021-07-08 | 2021-12-03 | 平安科技(深圳)有限公司 | Text labeling method and device, storage medium and computer equipment |
| CN113742444B (en) * | 2021-07-08 | 2024-05-28 | 平安科技(深圳)有限公司 | Text labeling method, text labeling device, storage medium and computer equipment |
| CN113918713A (en) * | 2021-09-22 | 2022-01-11 | 南京复保科技有限公司 | Data annotation method and device, computer equipment and storage medium |
| CN114548057A (en) * | 2022-02-21 | 2022-05-27 | 上海市精神卫生中心(上海市心理咨询培训中心) | Method, system, device, processor and storage medium for realizing interview text automatic labeling processing based on depression diagnosis and treatment standard |
| CN114661900A (en) * | 2022-02-25 | 2022-06-24 | 安阳师范学院 | Text annotation recommendation method, device, equipment and storage medium |
| CN117034864B (en) * | 2023-09-07 | 2024-05-10 | 广州市新谷电子科技有限公司 | Visual labeling method, visual labeling device, computer equipment and storage medium |
| CN117034864A (en) * | 2023-09-07 | 2023-11-10 | 广州市新谷电子科技有限公司 | Visual labeling method, visual labeling device, computer equipment and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112035675A (en) | Medical text labeling method, device, equipment and storage medium | |
| JP5356197B2 (en) | Word semantic relation extraction device | |
| CN114616572A (en) | Cross-document intelligent writing and processing assistant | |
| CN104199871B (en) | A kind of high speed examination question introduction method for wisdom teaching | |
| CN106934069B (en) | Data retrieval method and system | |
| CN112632989B (en) | Method, device and equipment for prompting risk information in contract text | |
| KR20200139008A (en) | User intention-analysis based contract recommendation and autocomplete service using deep learning | |
| CN111143531A (en) | Question-answer pair construction method, system, device and computer readable storage medium | |
| CN116244410B (en) | Index data analysis method and system based on knowledge graph and natural language | |
| CN113742493A (en) | Method and device for constructing pathological knowledge map | |
| CN117474507A (en) | Intelligent recruitment matching method and system based on big data application technology | |
| CN111597789A (en) | Electronic medical record text evaluation method and equipment | |
| CN111859934A (en) | Chinese sentence metaphor recognition system | |
| CN116976321A (en) | Text processing method, apparatus, computer device, storage medium, and program product | |
| KR102185733B1 (en) | Server and method for automatically generating profile | |
| CN110738050A (en) | Text recombination method, device and medium based on word segmentation and named entity recognition | |
| KR101565367B1 (en) | Method for calculating plagiarism rate of documents by number normalization | |
| CN110610003A (en) | Method and system for assisting text annotation | |
| CN116882414B (en) | Automatic comment generation method and related device based on large-scale language model | |
| KR101506757B1 (en) | Method for the formation of an unambiguous model of a text in a natural language | |
| CN115017271B (en) | Method and system for intelligently generating RPA flow component block | |
| CN112053760B (en) | Medication guide method, medication guide device, and computer-readable storage medium | |
| CN116069946A (en) | Biomedical knowledge graph construction method based on deep learning | |
| CN111949781B (en) | Intelligent interaction method and device based on natural sentence syntactic analysis | |
| CN114661900A (en) | Text annotation recommendation method, device, equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication | ||
| RJ01 | Rejection of invention patent application after publication |
Application publication date: 20201204 |