CN110738050A - Text recombination method, device and medium based on word segmentation and named entity recognition - Google Patents
Text recombination method, device and medium based on word segmentation and named entity recognition Download PDFInfo
- Publication number
- CN110738050A CN110738050A CN201910984742.5A CN201910984742A CN110738050A CN 110738050 A CN110738050 A CN 110738050A CN 201910984742 A CN201910984742 A CN 201910984742A CN 110738050 A CN110738050 A CN 110738050A
- Authority
- CN
- China
- Prior art keywords
- text
- attribute information
- named entity
- character
- result set
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Landscapes
- Machine Translation (AREA)
Abstract
text recombination methods based on word segmentation and named entity recognition comprise the steps of determining attribute information of each character in a text according to attribute information of each word in the text and attribute information of each named entity in the text after the text to be processed is received, determining association relation between each character and characters at adjacent positions of each character according to the attribute information of each character, recombining the text according to the association relation to obtain a recombination result set, and recombining and rendering the recombination result set to comprise the attribute information of all words and/or named entities forming the text.
Description
Technical Field
The present disclosure relates to the field of natural language processing, and in particular, to text recombination methods, apparatuses, and media based on word segmentation and named entity recognition.
Background
Named Entity Recognition (NER) can extract entities such as a person name, a place name, an organization name, and the like from natural language, thereby facilitating understanding of a user. Currently, methods for implementing NER are broadly classified into three categories:
, rule-based approach this approach primarily utilizes manually written rules to match text to rules to identify named entities.
And secondly, a method based on the characteristic template. The method mainly treats NER as a sequence labeling task through a statistical machine learning method, and utilizes large-scale linguistic data to learn a labeling model, so that each position of a sentence is labeled, and a named entity is identified.
And thirdly, a method based on a neural network. The method mainly utilizes a Neural network as a model for effectively processing NER tasks, tokens are mapped into dense embedding in a low-dimensional space from a discrete one-hot representation, then an embedding sequence of a sentence is input into a Recurrent Neural Network (RNN), features are automatically extracted by the Neural network, and Softmax is used for predicting the label of each token, so that a named entity is identified.
Based on the above three methods, there are many tools for named entity recognition in the related art, which provide multiple ways for human to obtain entities, however, the labeling set of each tool is different, and the labeling result is not , i.e., the named entities recognized by the tools are slightly different.
Disclosure of Invention
To overcome the problems in the related art, the present disclosure provides text reorganization methods, apparatuses, and media based on segmentation and named entity recognition.
According to aspect of the disclosed embodiment, methods for text reorganization based on segmentation and named entity recognition are provided, which include:
after receiving a text to be processed, determining attribute information of each character in the text according to attribute information of each word in a word segmentation result set obtained by the text through word segmentation operation and attribute information of each named entity in a named entity result set obtained by the text through named entity identification operation;
determining the incidence relation between each character in the text and the character at the adjacent position according to the attribute information of each character in the text, and recombining the text according to the determined incidence relation to obtain a recombination result set, wherein the recombination result set comprises the attribute information of all words and/or named entities forming the text;
the attribute information of each word or named entity obtained by recombination is obtained by combining the attribute information of all characters forming the word or named entity.
Optionally, in the above method, the attribute information of each word in the word segmentation result set, the attribute information of each named entity in the named entity result set, and the attribute information of each character in the text at least include any types or several types of the content, the start position, the end position, the type, the identifier, and the weight.
Optionally, in the above method, a weight in the attribute information of the character is smaller than a weight in the attribute information of the term and the named entity;
the weight in the attribute information of the term is less than or equal to the weight in the attribute information of the named entity.
Optionally, in the foregoing method, the determining, according to the attribute information of each word in the word segmentation result set obtained by the text through the word segmentation operation and the attribute information of each named entity in the named entity result set obtained by the text through the named entity identification operation, the attribute information of each character in the text includes:
setting attribute information of each character in the text based on the attribute information of each named entity in the named entity result set and the position relation between each character in the text and each named entity in the named entity result set in the text;
setting attribute information of each character in the text based on the attribute information of each word in the word segmentation result set and the position relation between each character in the text and each word in the word segmentation result set in the text;
and determining the attribute information with the maximum weight value in the plurality of different attribute information as the attribute information of the character when the plurality of different attribute information are set for the same character based on the named entity result set and the word segmentation result set.
Optionally, in the above method, the determining, according to the attribute information of each character in the text, an association relationship between each character in the text and a character at an adjacent position thereof, and recombining the text according to the determined association relationship to obtain a recombination result set includes:
comparing all characters in the text with the attribute information of the upper characters in sequence;
when the comparison result shows that intersection exists, the current character and the upper character are divided into the same words or named entities;
when the comparison result shows that no intersection exists, determining that the words or the named entities are completely divided, and determining that the current character belongs to a new word or a new named entity;
and traversing all characters of the text according to the mode to obtain a recombination result set of the text.
Optionally, the method further includes:
after receiving the text, performing word segmentation operation on the text to obtain or more word segmentation result sets, wherein each word segmentation result set comprises attribute information of all words forming the text.
Optionally, in the above method, the performing a word segmentation operation on the text includes:
performing word segmentation operation on the text by using a word segmentation tool;
wherein, a plurality of word segmentation result sets are obtained by utilizing different word segmentation tools.
Optionally, the method further includes:
after receiving the text, carrying out named entity identification operation on the text to obtain or more named entity result sets;
wherein each named entity result set includes attribute information of all named entities constituting the text.
Optionally, in the foregoing method, performing a named entity recognition operation on the text includes:
carrying out named entity recognition operation on the text by using a named entity recognition tool;
wherein, a plurality of word segmentation result sets are obtained by utilizing different named entity recognition tools.
According to a second aspect of the embodiments of the present disclosure, there are provided kinds of text reorganization apparatuses based on segmentation and named entity recognition, including:
the character segmentation and entity feature setting module is used for determining the attribute information of each character in the text according to the attribute information of each word in a segmentation result set obtained by the text through the segmentation operation and the attribute information of each named entity in a named entity result set obtained by the text through the named entity identification operation after receiving the text to be processed;
and the attribute merging module of the text characters is used for determining the association relationship between each character in the text and the character at the adjacent position of the character according to the attribute information of each character in the text, recombining the text according to the determined association relationship to obtain a recombination result set, wherein the recombination result set comprises the attribute information of all words and/or named entities forming the text, and the attribute information of each word or named entity obtained by recombination is obtained by merging the attribute information of all characters forming the word or named entity.
Optionally, in the above apparatus, the attribute information of each word in the word segmentation result set, the attribute information of each named entity in the named entity result set, and the attribute information of each character in the text at least include any one of or more of the following types:
content, start location, end location, type, identity, weight.
Optionally, in the above apparatus, a weight in the attribute information of the character is smaller than a weight in the attribute information of the term and the named entity;
the weight in the attribute information of the term is less than or equal to the weight in the attribute information of the named entity.
Optionally, in the above apparatus, the determining, by the character segmentation and entity feature setting module, attribute information of each character in the text according to attribute information of each word in a segmentation result set obtained by performing a segmentation operation on the text and attribute information of each named entity in a named entity result set obtained by performing a named entity recognition operation on the text includes:
setting attribute information of each character in the text based on the attribute information of each named entity in the named entity result set and the position relation between each character in the text and each named entity in the named entity result set in the text;
setting attribute information of each character in the text based on the attribute information of each word in the word segmentation result set and the position relation between each character in the text and each word in the word segmentation result set in the text;
and determining the attribute information with the maximum weight value in the plurality of different attribute information as the attribute information of the character when the plurality of different attribute information are set for the same character based on the named entity result set and the word segmentation result set.
Optionally, in the above apparatus, the attribute merging module of the text character determines, according to the attribute information of each character in the text, an association relationship between each character in the input text and a character at an adjacent position thereof, and reconstructs the text according to the determined association relationship to obtain an reconstruction result set, including:
comparing all characters in the text with the attribute information of the upper characters in sequence;
when the comparison result shows that intersection exists, the current character and the upper character are divided into the same words or named entities;
when the comparison result shows that no intersection exists, determining that the words or the named entities are completely divided, and determining that the current character belongs to a new word or a new named entity;
and traversing all characters of the text according to the mode to obtain a recombination result set of the text.
Optionally, the apparatus further comprises:
and the word segmentation module is used for performing word segmentation operation on the text after receiving the text to obtain or more word segmentation result sets, wherein each word segmentation result set comprises attribute information of all words forming the text.
Optionally, in the above apparatus, the word segmentation module performs word segmentation on the text by using a word segmentation tool;
wherein, a plurality of word segmentation result sets are obtained by utilizing different word segmentation tools.
Optionally, the apparatus further comprises:
and the named entity identification module is used for carrying out named entity identification operation on the text after receiving the text to obtain or more named entity result sets, wherein each named entity result set comprises attribute information of all named entities forming the text.
Optionally, in the above apparatus, the named entity recognition module performs a named entity recognition operation on the text by using a named entity recognition tool;
wherein a plurality of named entity result sets are obtained using different named entity recognition tools.
According to a third aspect of the embodiments of the present disclosure, there are provided text reorganization apparatuses based on segmentation and named entity recognition, including:
a processor;
a memory for storing processor-executable instructions;
wherein the processor is configured to:
after receiving a text to be processed, determining attribute information of each character in the text according to attribute information of each word in a word segmentation result set obtained by the text through word segmentation operation and attribute information of each named entity in a named entity result set obtained by the text through named entity identification operation;
determining the association relationship between each character in the text and the character at the adjacent position according to the attribute information of each character in the text, and recombining the text according to the determined association relationship to obtain a recombination result set, wherein the recombination result set comprises the attribute information of all words and/or named entities forming the text, and the attribute information of each word or named entity obtained by recombination is obtained by combining the attribute information of all characters forming the word or named entity.
According to a fourth aspect of embodiments of the present disclosure, there are provided non-transitory computer-readable storage media having instructions thereon which, when executed by a processor of a mobile terminal, enable the mobile terminal to perform text re-composition methods based on segmentation and named entity recognition, the methods comprising:
after receiving a text to be processed, determining attribute information of each character in the text according to attribute information of each word in a word segmentation result set obtained by the text through word segmentation operation and attribute information of each named entity in a named entity result set obtained by the text through named entity identification operation;
determining the association relationship between each character in the text and the character at the adjacent position according to the attribute information of each character in the text, and recombining the text according to the determined association relationship to obtain a recombination result set, wherein the recombination result set comprises the attribute information of all words and/or named entities forming the text, and the attribute information of each word or named entity obtained by recombination is obtained by combining the attribute information of all characters forming the word or named entity.
The technical scheme provided by the embodiment of the disclosure can have the following beneficial effects:
the technical scheme disclosed by the invention is based on word segmentation and named entity recognition technology, the text to be processed is recombined and rendered, the output of diversity labels is realized, and then the reading rendering mode convenient for the user to get used is realized by establishing the weight in the attribute information of the characters.
It is to be understood that both the foregoing -general description and the following detailed description are exemplary and explanatory only and are not restrictive of the disclosure.
Drawings
The accompanying drawings, which are incorporated in and constitute a part of this specification , illustrate embodiments consistent with the invention and together with the description , serve to explain the principles of the invention.
FIG. 1 is a flowchart illustrating implementations of text reassembly methods based on segmentation and named entity recognition, according to an exemplary embodiment of .
Fig. 2 is a flow diagram illustrating another implementation of another text reorganization method based on segmentation and named entity recognition, according to an exemplary embodiment of .
Fig. 3 is a flowchart illustrating a method of determining attribute information for each character in text to be processed according to an exemplary embodiment .
FIG. 4 is a flowchart illustrating methods of implementation of the method of reformulating text according to determined associations to result in a reformulation result set, according to .
FIG. 5 is a schematic diagram illustrating implementations of rendering text from a reformulation result set according to an exemplary embodiment .
Fig. 6 is a block diagram illustrating the structure of text reorganization apparatuses based on segmentation and named entity recognition according to an exemplary embodiment of .
Detailed Description
The embodiments described in the exemplary embodiments below do not represent all embodiments consistent with the invention's , rather, they are merely examples consistent with the invention's aspects , as detailed in the appended claims.
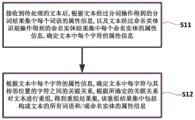
FIG. 1 is a flowchart illustrating implementations of text re-composition methods based on segmentation and named entity recognition according to an exemplary embodiment of . As shown in FIG. 1, the method includes the steps of:
step S11, after receiving the text to be processed, determining attribute information of each character in the text according to the attribute information of each word in the word segmentation result set obtained by the word segmentation operation of the text and the attribute information of each named entity in the named entity result set obtained by the named entity recognition operation of the text.
In this embodiment, the attribute information of each word in the word segmentation result set, the attribute information of each named entity in the named entity result set, and the attribute information of each character in the text may be represented in a multidimensional form, that is, the attribute information at least includes types or more of content, start position, end position, type, identifier, and weight.
The content refers to specific content of any words obtained through word segmentation, or specific content of any named entities obtained through named entity recognition, or specific content of any characters.
The start position refers to a position mark where the above-mentioned contents start in the whole text to be processed.
The end position refers to a position mark where the above contents end in the entire text to be processed.
The manner of marking the position of the entire text is not limited and may include various manners. For example, the initial position marker of the entire text may be set to start with 0, or may start with an arbitrary integer. The difference of the position marks between every two adjacent characters in the whole text can be set to be 1, and the difference of the position marks between every two adjacent characters in the whole text can also be set to be 5. It is only necessary that the difference of the position marks between two adjacent characters in the whole text is the same value. Therefore, in the embodiment, the position of the content in the whole text is determined according to the position mark corresponding to the starting position and the position mark of the ending position.
Type refers to text type, which can be types of characters, words or named entities.
Identification means -only identification of text in the whole system, that is, characters or words or named entities can be determined only by through the identification, and the identification can be set in the form of UUID (universal Unique Identifier).
For example, the weight of the text of the character type is set to be minimum, the weight of the text of the named entity type is set to be minimum, and the weight of the text of the word type is set to be maximum, and the weight of the text of the same type as is set to be different according to the weight of the tool used, so that the weight of the named entity type is set to be maximum by using a plurality of tools, wherein the weight of the named entity type is maximum by using a tool, the weight of the second tool is minimum by using a third tool, the weight of the named entity obtained by using a tool is maximum by using a second tool, the weight of the named entity obtained by using a second tool is maximum by using a third tool, the weight of the named entity is minimum by using a tool, the weight of the named entity obtained by using a third tool, the weight of the named entity is set to be maximum by using a tool, the weight of the named entity obtained by using a second tool, the weight of the named entity obtained by using a third tool, the weight of the named entity type is set to be closer to the user, and the result of the named entity recognition by the user can be set to be closer to the default weight of the user.
In step S11, a word segmentation operation may be performed by using an existing word segmentation tool. The named entity recognition operation can also be performed by utilizing the existing named entity recognition tool.
Step S12, determining the association relationship between each character in the text and the character at the adjacent position according to the attribute information of each character in the text, and recombining the text according to the determined association relationship to obtain a recombination result set, wherein the recombination result set comprises the attribute information of all words and/or named entities forming the text.
The attribute information of each word or named entity obtained by recombination is obtained by combining the attribute information of all characters forming the word or named entity.
In the above step S12, the process of obtaining the recombination result set may refer to the following operations:
comparing all characters in the text with the attribute information of the upper characters in sequence;
when the comparison result shows that intersection exists, the current character and the upper character are divided into the same words or named entities;
when the comparison result shows that no intersection exists, determining that the words or the named entities are completely divided, and determining that the current character belongs to a new word or a new named entity;
and traversing all characters of the text according to the mode to obtain a recombination result set of the text to be processed.
After the step S12, the following steps may be further included: and rendering and displaying the text according to the recombination result set.
It can be seen from the above embodiments that the technical solution of the present disclosure utilizes word segmentation tools, named entity recognition tools, and the like, and based on the difference in labeling methods adopted among these tools, various recognition results can be obtained, and the various recognition results are recombined after being comprehensively considered, so that the accuracy and reliability of recombination can be improved.
FIG. 2 is a flow diagram of another implementation of a text reorganization method based on segmentation and named entity recognition according to , which is an exemplary embodiment, assuming that the text to be processed is sentences, "CEO of future technologies is Zhang three", and text reorganization is performed by using segmentation tool and two different named entity recognition tools at the same time, as shown in FIG. 2, the text reorganization process includes the following steps:
in step S21, after receiving the text to be processed, performing a word segmentation operation on the text to be processed to obtain word segmentation result sets, where each word segmentation result set includes attribute information of all words constituting the text to be processed.
In the step S21, the number of the obtained word segmentation result sets may be or more, and each word segmentation result set may include attribute information of all words constituting the text to be processed.
In the word segmentation result set, attribute information of each word may be stored in a multidimensional form, for example, each word includes attribute information of each item as shown below:
{ content, start position, end position, type ═ seg ", UUID, priority ═ 0 }.
In this embodiment, taking word segmentation result sets as an example for explanation, the step S21 may be subdivided into the following two steps:
in step S21a, a segmentation tool publicly used in the art may be used to perform a segmentation operation to segment the sentence of the text to be processed into a plurality of words.
Step S21b, sets attribute information of each word obtained by the word segmentation operation.
In this embodiment, the start position and the end position are subscripts of th characters and the last th characters of the word obtained by the word segmentation operation in the original character string (i.e., the text to be processed).
The UUID is an -only identification of the word within the system, and this UUID needs to be guaranteed not to be repeated.
priority is the weight of a word, generally requires only to be set during the entire system.
In this example, the segmentation result set obtained after performing the segmentation operation on the text to be processed is shown in table 1,
table 1 is a list of attribute information of all words in the word segmentation result set.
| Content providing method and apparatus | Starting position | End position | Type (B) | UUID | Priority |
| Future of the day | 0 | 1 | SEG | uuid0 | 0 |
| Science and technology | 2 | 3 | SEG | uuid1 | 0 |
| Company(s) | 4 | 5 | SEG | uuid2 | 0 |
| Is/are as follows | 6 | 6 | SEG | uuid3 | 0 |
| CEO | 7 | 9 | SEG | uuid4 | 0 |
| Is that | 10 | 10 | SEG | uuid5 | 0 |
| Is not provided with | 11 | 12 | SEG | uuid6 | 0 |
| Zhang three | 13 | 14 | SEG | uuid7 | 0 |
As can be seen from Table 1, in the present embodiment, the initial position marks of the entire text to be processed are marked from 0, i.e., the subscript of the th character in the entire text to be processed is marked from 0, the difference of the position marks between every two adjacent characters in the entire text is 1, i.e., the subscript of each character in the entire text to be processed is the subscript number of the first characters plus 1.
For example, in the word segmentation result set of the text to be processed, the starting position of the "science and technology" word is 2, namely the position where the "science and technology" word starts in the whole text to be processed is marked as 2, the ending position is 3, namely the position where the "science and technology" word ends in the whole text to be processed is marked as 3, and the UUID of the "science and technology" word is "UUID 1".
In step S22, after receiving the text to be processed, conducting named entity recognition on the text to be processed to obtain named entity result sets, where each named entity result set includes attribute information of all named entities constituting the text to be processed.
In step S22, the number of the obtained named entity result sets may be or more, and each named entity result set may include attribute information of all named entities constituting the text to be processed.
In the named entity result set, attribute information of each named entity may be saved in a multidimensional form, for example, each named entity includes the following items of attribute information:
{ Contents, Start position, end position, type, UUID, priorityy=#pri};
In the embodiment, two named entity result sets are taken as an example for illustration, and the step S22 can be subdivided into the following two steps:
step S22a, extracting attribute information of the corresponding named entity from the text to be processed, including but not limited to the value and attribute of the named entity, by using a named entity recognition tool disclosed in the art;
step S22b, setting attribute information of the recognition result of each named entity, wherein the starting position and the ending position are subscripts of th character and the last th character of the recognition result in the original character string, the UUID is a mark number which needs to ensure no duplication, and the # pri is a weight value aiming at the recognized named entity.
, the value of # pri of the named entity is set to be greater than the value of the weight of the word in the segmentation result set, that is, the result of the named entity recognition in this embodiment is more important than the segmentation result.
For example, the results obtained after the text to be processed according to the named entity recognition tool is identified are shown in table 2.
Table 2 is a list of attribute information for all named entities in the result set identified by the th named entity identification tool.
| Content providing method and apparatus | Starting position | End position | Type (B) | UUID | Priority |
| Future science and technology company | 0 | 5 | COMPANY | uuid10 | 1 |
| Is/are as follows | 6 | 6 | \ | uuid11 | |
| CEO | 7 | 9 | TITLE | uuid12 | 1 |
| Is that | 10 | 10 | \ | uuid13 | |
| Is not provided with | 11 | 12 | \ | uuid14 | |
| Zhang three | 13 | 14 | PERSON | uuid15 | 1 |
As can be seen from table 2, the th named entity result set of the text to be processed, "future technology company" is named entities, the starting position of which is 0, i.e., the position where the named entity "future technology company" starts in the entire text to be processed is marked as 0, the ending position of which is 5, i.e., the position where the named entity "future technology company" ends in the entire text to be processed is marked as 5, i.e., the UUID of the named entity "future technology company" is "UUID 10".
For another example, the results obtained after the text to be processed is identified by the second named entity identifying tool are shown in table 3.
Table 3 is a list of attribute information of all named entities in the result set identified by the second named entity identification tool.
| Content providing method and apparatus | Starting position | End position | Type (B) | UUID | Priority |
| Future science and technology company | 0 | 5 | COMPANY | uuid20 | 1 |
| Is/are as follows | 6 | 6 | \ | uuid21 | |
| CEO | 7 | 9 | \ | uuid22 | |
| Is that | 10 | 10 | \ | uuid23 | |
| Is not provided with | 11 | 12 | \ | uuid24 | |
| Zhang three | 13 | 14 | PERSON | uuid25 | 1 |
As can be seen from Table 3, the term "CEO" is not recognized as "TITLE" when named entity recognition is performed using the second named entity recognition tool. As can be seen herein, the results of different named entity recognition tools may not be identical, and thus, in order to increase the reliability and accuracy of the reformulation results, a variety of different named entity recognition tools may be utilized to identify the named entities.
In addition, as can be seen from the descriptions of the above steps S21 and S22, the starting position counting of the participle and named entity recognition in the present embodiment starts from 0, but in other application scenarios, other counting starting positions (for example, the position counting starts from 1) or other steps (for example, the distance between every two characters can be set to 2) can be included, and as long as the position uniqueness and the character localizability can be ensured, the same way as that used in the present example can be considered.
In other application scenarios, the order of the above steps S21 and S22 may be changed, as long as the word segmentation result set and the named entity result set are obtained.
In step S23, the attribute information of each character in the text to be processed is determined according to the attribute information of each word in the segmentation result set obtained by the text to be processed through the segmentation operation and the attribute information of each named entity in the named entity result set obtained by the text to be processed through the named entity recognition operation.
To facilitate understanding of the technical solution of the present embodiment, the operation of the step S23 may be divided into several steps for description, where fig. 3 is a flowchart of a method for determining attribute information of each character in a text to be processed in the present exemplary embodiment, and as shown in fig. 3, the method includes the following steps:
in step S23a, attribute information of each character of the text to be processed is initialized;
in this embodiment, the initialized attribute information of each character may include the following items:
{ content, start location, end location, type, UUID, priority };
in this embodiment, the weight (priority) in the attribute information of the character is smaller than the weight in the attribute information of the term and the named entity; the weight in the attribute information of the term is less than or equal to the weight in the attribute information of the named entity.
It can be seen that, in this embodiment, the weight of the character is the smallest, the weight of the word is the smallest, and the weight of the named entity is the largest.
Taking the text to be processed of the present exemplary embodiment as an example, the initialized attribute information for the th character "not" in the text to be processed is { "not", 0,0, [ ], [ ], "-1" }, i.e., for the character "not", its start position is 0, end position is 0, type is null, UUID is null, priority is-1.
In step S23b, setting attribute information of each character in the text to be processed based on the attribute information of each named entity in the named entity result set and the position relationship between each character in the text to be processed and each named entity in the named entity result set in the text to be processed;
the implementation manner of the step S23b can be various, and in the present embodiment, the following manner is taken as an example to illustrate the specific operation thereof:
the method comprises the steps of sequentially traversing all characters of a text to be processed in an NER result set, and setting attribute information of each character, wherein for any named entities N in the NER result set, if the subscript relation of char (characters) meets the requirement (char, start position > -N, start position & & char, end position < N. end position), adding the UUID of the named entity N and the UUID of the characters, adding the type of the named entity and the type of the characters, and assigning the priority of the named entity N to char.
Taking the text to be processed in this embodiment as an example, after the text to be processed is processed according to the above operation, for the th character "not" of the text to be processed, the attribute information set in the result set of the NER of the named entity recognition tool is:
{ "not", 0,0, [ "COMANY" ], [ "UUID 10" ],1 }.
Because two different named entity recognition tools are used in this embodiment, there are two NER result sets in this embodiment, each character needs to traverse the two NER result sets, at this time, according to the operation of step S23b, for the th character "no" of the text to be processed, the result set of the NER passing through the second named entity recognition tool sets the attribute information as:
{ "not", 0,0, [ "COMANY" ], [ "UUID 20" ],1 }.
In step S23c, attribute information of each character in the text to be processed is set based on the attribute information of each word in the word segmentation result set and the position relationship between each character in the text to be processed and each word in the word segmentation result set in the text to be processed, where when multiple pieces of different attribute information are set for the same character based on the named entity result set and the word segmentation result set, the attribute information with the largest weight value in the multiple pieces of different attribute information is determined as the attribute information of the character.
There are various embodiments of the step S23c, and in this embodiment, the following is taken as an example to illustrate the specific operation thereof:
traversing all the characters operated in the step S23b in the segmentation result set, for a word S in any segmentation result set, if the subscript satisfies the relationship (char. start position > -S. start position & & char. end position < ═ S. end position), and if s.priority > char. priority is satisfied, appending the UUID of the word S and the UUID of the character, appending the type of the word S and the type of the character, and assigning the priority of the word S to the priority, that is, setting char priority to 0, and finally setting the attribute information of char as follows:
{ content, start position, end position, S type, UUID of S, priority ═ 0 }.
Still taking the th character "not" in the text to be processed as an example, according to the operation of the above step S23b, there are two pieces of attribute information of the character "not", which are { "not", 0,0, [ "communication" ], [ "UUID 10" ],1}, { "not", 0,0, [ "communication" ], [ "UUID 20" ],1 }. in this embodiment, since the priority of a word in the segmentation result set is 0 and the current value of the priority of the character is 1, that is, the weight of the word is smaller than that of the character that has been set, the weight is not assigned to the character, that is, after the operation according to the step S23c, there are two pieces of attribute information of the character "not", that is { "not", 0,0, [ "communication" ], [ "UUID 10" ],1}, { "not", 0, [ "communication" ], 20.
For another example, for the character "no" in the text to be processed, it does not belong to any named entity result, and therefore, after the operation of the above step S23b, the attribute information of the character "no" is { "no", 11, 11, [ ], [ ], 0 }. At this time, according to the operation of step S23c, since the character "no" belongs to the word in the segmentation result set, and the priority of the word is 0 and is greater than the current value-1 of the priority of the character, the weight of the word is assigned to the character. That is, after the operation according to step S23c, the attribute information of the character "no" is { "no", 11, 11, [ "SEG" ], [ "UUID 6" ], 0 }.
As can be seen from the above, two named entity recognition tools are used in the present embodiment, so after the operation of step S23c, there may be two records of character attribute information, and at this time, pieces of attribute information may be finally determined to be reserved for the character according to the weights of the two named entity recognition tools, for example, there are two pieces of attribute information of character "not" as described above, which are { "not", 0,0, [ "company" ], [ "UUID 10" ],1}, { "not", 0,0, [ "company" ], [ "UUID 20" ],1}, respectively, wherein the piece of attribute information is obtained by using type named entity recognition tools, the second piece of attribute information is obtained by using the second type named entity recognition tools, it is assumed that the weight of type named entity recognition tool is greater than that of the second type named entity recognition tools, the character "not" attribute information is finally determined as { "0", uuy ", 10 }.
In step S24, according to the attribute information of each character in the text to be processed, an association relationship between each character in the text to be processed and a character at an adjacent position thereof is determined, and the text to be processed is recombined according to the determined association relationship, so as to obtain a recombination result set.
Fig. 4 is a flowchart of implementation methods for recombining texts to be processed according to the determined association relationship in the exemplary embodiment to obtain a recombination result set, and as shown in fig. 4, the method includes the following steps:
in step S24a, structure temp are defined, and the initial information of this structure is empty, that is, the initial information of the structure temp is as follows:
{[],0,0,[],[“UUID0”],0}。
in step S24b, all characters of the text to be processed are sorted from small to large according to the starting positions, the characters of the text to be processed are sequentially compared with temp according to the sorted order, whether the intersection of the UUID of the character and the UUID of the temp is empty is determined, if the intersection of the UUID of the character and the UUID of the temp is empty, step S24c is executed, and if the intersection of the UUID of the character and the UUID of the temp is not empty, step S24d is executed.
In step S24c, if the intersection of the UUID of the character and the UUID of the temp is empty, it indicates that the current character and the top character stored in the temp do not belong to the same words or the same named entities, that is, it is determined that the top word or named entity is divided completely, and the current character belongs to a new word or named entity, at this time, the content already stored in the temp is moved to the recombination result set list, the temp is set empty, and then the current character is added to the temp, and step S24e is performed.
In step S24d, if the intersection of the UUID of the character and the UUID of the temp is not empty, it indicates that the current character and the top character stored in the temp belong to the same words or the same named entities, at this time, the content of the character is added into the temp, and the attribute information of the character and the attribute information of the temp are merged, and the process advances to step S24 e.
In step S24e, it is checked whether the current character is the last characters of the text to be processed, if the current character is the last characters, it indicates that all characters have been traversed, step S24f is entered, if the current character is not the last characters, it indicates that all characters have not been traversed, step S24b is returned, and it is checked whether the intersection of the UUID of the next characters and the UUID of temp is empty until all characters have been traversed.
In step S24f, a recombination result set of the text to be processed is obtained.
In step S25, the text to be processed is rendered and displayed according to the recombination result set.
FIG. 5 is a schematic diagram illustrating implementations of rendering and presenting the text to be processed according to the recomposing result set in the exemplary embodiment.
And setting color matching corresponding to each character according to the type through cs rendering in html, wherein the larger the weight is, the lower the transparency is, and the named entity results obtained by different named entity tools can be set to be different color matching.
And outputting the recombination result from the small to large starting position of the recombination result list obtained in the step S24, and outputting the recombination result according to the color matching corresponding to each character when outputting the recombination result.
As can be seen from FIG. 5, the technical scheme of the present disclosure provides a visualization presentation manner of hierarchical overlapping, which facilitates presentation of a plurality of recognition results.
FIG. 6 is a block diagram illustrating the structure of a text reorganization device based on segmentation and named entity recognition according to an exemplary embodiment of , as shown in FIG. 6, the device at least comprises a character segmentation and entity feature setting module 601 and a text character attribute merging module 602.
The character segmentation and entity feature setting module 601 is configured to, after receiving a text to be processed, determine attribute information of each character in the text to be processed according to attribute information of each word in a segmentation result set obtained by performing a segmentation operation on the text to be processed and attribute information of each named entity in a named entity result set obtained by performing a named entity recognition operation on the text to be processed;
in this embodiment, the attribute information of each word in the word segmentation result set, the attribute information of each named entity in the named entity result set, and the attribute information of each character in the text to be processed may all be represented by multidimensional information, that is, the attribute information may include any or more kinds of information as follows:
content, start location, end location, type, identity, weight.
In this embodiment, the content refers to specific content of any words obtained through word segmentation, or specific content of any named entities obtained through named entity recognition, or specific content of any characters
The start position refers to a position mark where the above-mentioned contents start in the whole text to be processed.
The end position refers to a position mark where the above contents end in the entire text to be processed.
The present embodiment may determine the position of the content in the whole text to be processed according to the position mark corresponding to the start position and the position mark corresponding to the end position.
Type refers to text type, which can be types of characters, words or named entities.
Identification refers to -only identification of text in the whole system, namely characters or words or named entities and the like can be determined only by through the identification, and the identification can be set in the form of UUID.
The weight of the named entity identified by the named entity identification tool with preference of the user to different named entity identification tools can be set to be a numerical value different from that of the named entity identified by other named entity identification tools according to the user's preference.
In practical applications, the character segmentation and entity feature setting module 601 may adopt various ways to determine attribute information of each character in a text to be processed, and this embodiment illustrates implementation formulas as follows:
the character word segmentation and entity feature setting module sets attribute information of each character in the text to be processed based on attribute information of each named entity in the named entity result set and the position relation between each character in the text to be processed and each named entity in the named entity result set in the text to be processed;
setting attribute information of each character in the text to be processed based on the attribute information of each word in the word segmentation result set and the position relation between each character in the text to be processed and each word in the word segmentation result set in the text to be processed;
when attribute information is set for each character in the text to be processed in the above manner, if there are a plurality of pieces of attribute information of a certain character, the attribute information with the highest weight among the plurality of pieces of attribute information is determined as the attribute information of the character.
The attribute merging module 602 of the text characters is configured to determine, according to the attribute information of each character in the text to be processed, an association relationship between each character in the text to be processed and a character at an adjacent position thereof, and recombine the text to be processed according to the determined association relationship to obtain a recombination result set, where the recombination result set includes attribute information of all words and/or named entities constituting the text to be processed, and the attribute information of each word or named entity obtained through recombination is obtained by merging the attribute information of all characters constituting the word or named entity.
In practical applications, there are various ways for the attribute merging module 602 of the text character to obtain the recombined result set, and the present embodiment takes implementation manners as an example.
Comparing all characters in the text to be processed with the attribute information of the upper characters in sequence;
when the comparison result shows that intersection exists, the current character and the upper character are divided into the same words or named entities;
when the comparison result shows that no intersection exists, determining that the words or the named entities are completely divided, and determining that the current character belongs to a new word or a new named entity;
and traversing all characters of the text to be processed according to the mode to obtain a recombination result set of the text to be processed.
In addition, the structure of the device is a basic structure, and a word segmentation module and a named entity recognition module can be added.
The method comprises the steps of adding a word segmentation module, obtaining or more word segmentation result sets by performing word segmentation operation on a text to be processed, wherein each word segmentation result set comprises attribute information of all words forming the text to be processed.
The added named entity recognition module is used for carrying out named entity recognition operation on a text to be processed to obtain or a plurality of named entity result sets, wherein each named entity result set comprises attribute information of all named entities forming the text to be processed.
Besides the word segmentation module and the named entity recognition module, in scenes, a result rendering output module can be added, and the module renders and displays the text to be processed according to the recombination result set.
With regard to the apparatus in the above-described embodiment, the specific manner in which each module performs the operation has been described in detail in the embodiment related to the method, and will not be elaborated here.
an exemplary embodiment provides text reorganization apparatuses based on segmentation and named entity recognition, including a processor, and a memory for storing processor-executable instructions;
wherein the processor is configured to:
after receiving a text to be processed, determining attribute information of each character in the text to be processed according to attribute information of each word in a word segmentation result set obtained by the word segmentation operation of the text to be processed and attribute information of each named entity in a named entity result set obtained by the recognition operation of the named entity of the text to be processed;
determining the association relationship between each character in the text to be processed and the character at the adjacent position according to the attribute information of each character in the text to be processed, recombining the text to be processed according to the determined association relationship to obtain a recombination result set, wherein the recombination result set comprises the attribute information of all words and/or named entities forming the text to be processed, and the attribute information of each word or named entity obtained by recombination is obtained by combining the attribute information of all characters forming the word or named entity.
With regard to the apparatus in the above-described embodiment, the specific manner in which the processor is configured to perform the operations has been described in detail in the embodiment related to the text reorganization method based on the word segmentation and named entity recognition, and will not be elaborated herein.
exemplary embodiments provide non-transitory computer readable storage media that when executed by a processor of a mobile terminal enable the mobile terminal to perform text reorganization methods based on segmentation and named entity recognition, the method comprising:
after receiving a text to be processed, determining attribute information of each character in the text to be processed according to attribute information of each word in a word segmentation result set obtained by the word segmentation operation of the text to be processed and attribute information of each named entity in a named entity result set obtained by the recognition operation of the named entity of the text to be processed;
determining the association relationship between each character in the text to be processed and the character at the adjacent position according to the attribute information of each character in the text to be processed, recombining the text to be processed according to the determined association relationship to obtain a recombination result set, wherein the recombination result set comprises the attribute information of all words and/or named entities forming the text to be processed, and the attribute information of each word or named entity obtained by recombination is obtained by combining the attribute information of all characters forming the word or named entity.
With regard to the non-transitory computer-readable storage medium in the above-mentioned embodiment, the specific manner in which the mobile terminal performs text reorganization methods based on segmentation and named entity recognition has been described in detail in the embodiment of the text reorganization method based on segmentation and named entity recognition, and will not be described in detail herein.
This application is intended to cover any variations, uses, or adaptations of the invention following, in general, the -like principles of the invention and including such departures from the present disclosure as come within known or customary practice within the art to which the invention pertains and as may be applied to the essential features hereinbefore set forth, the specification and examples are to be considered as illustrative, the true scope and spirit of the invention being indicated by the following claims.
It will be understood that the invention is not limited to the precise arrangements described above and shown in the drawings and that various modifications and changes may be made without departing from the scope thereof. The scope of the invention is limited only by the appended claims.
Claims (20)
1, text recombination method based on word segmentation and named entity recognition, which comprises:
after receiving a text to be processed, determining attribute information of each character in the text according to attribute information of each word in a word segmentation result set obtained by the text through word segmentation operation and attribute information of each named entity in a named entity result set obtained by the text through named entity identification operation;
determining the incidence relation between each character in the text and the character at the adjacent position according to the attribute information of each character in the text, and recombining the text according to the determined incidence relation to obtain a recombination result set, wherein the recombination result set comprises the attribute information of all words and/or named entities forming the text;
the attribute information of each word or named entity obtained by recombination is obtained by combining the attribute information of all characters forming the word or named entity.
2. The method of claim 1, wherein the attribute information of each word in the word segmentation result set, the attribute information of each named entity in the named entity result set, and the attribute information of each character in the text at least comprise or more of content, starting position, ending position, type, identification, and weight.
3. The method of claim 2,
the weight in the attribute information of the characters is smaller than the weight in the attribute information of the words and the named entities;
the weight in the attribute information of the term is less than or equal to the weight in the attribute information of the named entity.
4. The method according to claim 2 or 3, wherein the determining attribute information of each character in the text according to the attribute information of each word in the word segmentation result set obtained by the text through the word segmentation operation and the attribute information of each named entity in the named entity result set obtained by the text through the named entity recognition operation comprises:
setting attribute information of each character in the text based on the attribute information of each named entity in the named entity result set and the position relation between each character in the text and each named entity in the named entity result set in the text;
setting attribute information of each character in the text based on the attribute information of each word in the word segmentation result set and the position relation between each character in the text and each word in the word segmentation result set in the text;
and determining the attribute information with the maximum weight value in the plurality of different attribute information as the attribute information of the character when the plurality of different attribute information are set for the same character based on the named entity result set and the word segmentation result set.
5. The method according to claim 1, wherein the determining an association relationship between each character in the text and a character at an adjacent position thereof according to the attribute information of each character in the text, and recombining the text according to the determined association relationship to obtain a recombination result set comprises:
comparing all characters in the text with the attribute information of the upper characters in sequence;
when the comparison result shows that intersection exists, the current character and the upper character are divided into the same words or named entities;
when the comparison result shows that no intersection exists, determining that the words or the named entities are completely divided, and determining that the current character belongs to a new word or a new named entity;
and traversing all characters of the text according to the mode to obtain a recombination result set of the text.
6. The method according to claim 1 or 5, characterized in that the method further comprises:
after receiving the text, performing word segmentation operation on the text to obtain or more word segmentation result sets, wherein each word segmentation result set comprises attribute information of all words forming the text.
7. The method of claim 6, wherein the performing a word segmentation operation on the text comprises:
performing word segmentation operation on the text by using a word segmentation tool;
wherein, a plurality of word segmentation result sets are obtained by utilizing different word segmentation tools.
8. The method of claim 6, further comprising:
after receiving the text, carrying out named entity identification operation on the text to obtain or more named entity result sets;
wherein each named entity result set includes attribute information of all named entities constituting the text.
9. The method of claim 8, wherein performing a named entity recognition operation on the text comprises:
carrying out named entity recognition operation on the text by using a named entity recognition tool;
wherein, a plurality of word segmentation result sets are obtained by utilizing different named entity recognition tools.
10, A text reorganization device based on word segmentation and named entity recognition, comprising:
the character segmentation and entity feature setting module is used for determining the attribute information of each character in the text according to the attribute information of each word in a segmentation result set obtained by the text through the segmentation operation and the attribute information of each named entity in a named entity result set obtained by the text through the named entity identification operation after receiving the text to be processed;
and the attribute merging module of the text characters is used for determining the association relationship between each character in the text and the character at the adjacent position of the character according to the attribute information of each character in the text, recombining the text according to the determined association relationship to obtain a recombination result set, wherein the recombination result set comprises the attribute information of all words and/or named entities forming the text, and the attribute information of each word or named entity obtained by recombination is obtained by merging the attribute information of all characters forming the word or named entity.
11. The apparatus according to claim 10, wherein the attribute information of each word in the word segmentation result set, the attribute information of each named entity in the named entity result set, and the attribute information of each character in the text at least include any or more of the following items:
content, start location, end location, type, identity, weight.
12. The apparatus of claim 11,
the weight in the attribute information of the characters is smaller than the weight in the attribute information of the words and the named entities;
the weight in the attribute information of the term is less than or equal to the weight in the attribute information of the named entity.
13. The apparatus according to claim 11 or 12, wherein the character segmentation and entity feature setting module determines the attribute information of each character in the text according to the attribute information of each word in the segmentation result set obtained by the text through the segmentation operation and the attribute information of each named entity in the named entity result set obtained by the text through the named entity recognition operation, and includes:
setting attribute information of each character in the text based on the attribute information of each named entity in the named entity result set and the position relation between each character in the text and each named entity in the named entity result set in the text;
setting attribute information of each character in the text based on the attribute information of each word in the word segmentation result set and the position relation between each character in the text and each word in the word segmentation result set in the text;
and determining the attribute information with the maximum weight value in the plurality of different attribute information as the attribute information of the character when the plurality of different attribute information are set for the same character based on the named entity result set and the word segmentation result set.
14. The apparatus according to claim 10, wherein the attribute merging module of the text characters determines, according to attribute information of each character in the text, an association relationship between each character in the input text and a character at an adjacent position thereof, and reconstructs the text according to the determined association relationship to obtain an reconstruction result set, includes:
comparing all characters in the text with the attribute information of the upper characters in sequence;
when the comparison result shows that intersection exists, the current character and the upper character are divided into the same words or named entities;
when the comparison result shows that no intersection exists, determining that the words or the named entities are completely divided, and determining that the current character belongs to a new word or a new named entity;
and traversing all characters of the text according to the mode to obtain a recombination result set of the text.
15. The apparatus of claim 10 or 14, further comprising:
and the word segmentation module is used for performing word segmentation operation on the text after receiving the text to obtain or more word segmentation result sets, wherein each word segmentation result set comprises attribute information of all words forming the text.
16. The apparatus of claim 15,
the word segmentation module is used for performing word segmentation operation on the text by using a word segmentation tool;
wherein, a plurality of word segmentation result sets are obtained by utilizing different word segmentation tools.
17. The apparatus of claim 15, further comprising:
and the named entity identification module is used for carrying out named entity identification operation on the text after receiving the text to obtain or more named entity result sets, wherein each named entity result set comprises attribute information of all named entities forming the text.
18. The apparatus of claim 17,
the named entity recognition module is used for carrying out named entity recognition operation on the text by using a named entity recognition tool;
wherein a plurality of named entity result sets are obtained using different named entity recognition tools.
19, A text reorganization device based on word segmentation and named entity recognition, comprising:
a processor;
a memory for storing processor-executable instructions;
wherein the processor is configured to:
after receiving a text to be processed, determining attribute information of each character in the text according to attribute information of each word in a word segmentation result set obtained by the text through word segmentation operation and attribute information of each named entity in a named entity result set obtained by the text through named entity identification operation;
determining the association relationship between each character in the text and the character at the adjacent position according to the attribute information of each character in the text, and recombining the text according to the determined association relationship to obtain a recombination result set, wherein the recombination result set comprises the attribute information of all words and/or named entities forming the text, and the attribute information of each word or named entity obtained by recombination is obtained by combining the attribute information of all characters forming the word or named entity.
20, non-transitory computer readable storage media having instructions thereon that, when executed by a processor of a mobile terminal, enable the mobile terminal to perform text re-composition methods based on segmentation and named entity recognition, the method comprising:
after receiving a text to be processed, determining attribute information of each character in the text according to attribute information of each word in a word segmentation result set obtained by the text through word segmentation operation and attribute information of each named entity in a named entity result set obtained by the text through named entity identification operation;
determining the association relationship between each character in the text and the character at the adjacent position according to the attribute information of each character in the text, and recombining the text according to the determined association relationship to obtain a recombination result set, wherein the recombination result set comprises the attribute information of all words and/or named entities forming the text, and the attribute information of each word or named entity obtained by recombination is obtained by combining the attribute information of all characters forming the word or named entity.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910984742.5A CN110738050B (en) | 2019-10-16 | 2019-10-16 | Text reorganization method, device and medium based on word segmentation and named entity recognition |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910984742.5A CN110738050B (en) | 2019-10-16 | 2019-10-16 | Text reorganization method, device and medium based on word segmentation and named entity recognition |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110738050A true CN110738050A (en) | 2020-01-31 |
| CN110738050B CN110738050B (en) | 2023-08-04 |
Family
ID=69270096
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910984742.5A Active CN110738050B (en) | 2019-10-16 | 2019-10-16 | Text reorganization method, device and medium based on word segmentation and named entity recognition |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110738050B (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111612157A (en) * | 2020-05-22 | 2020-09-01 | 四川无声信息技术有限公司 | Training method, character recognition method, device, storage medium and electronic equipment |
| CN114442897A (en) * | 2021-12-24 | 2022-05-06 | 北京幻想纵横网络技术有限公司 | Text processing method and device, electronic equipment and storage medium |
| CN114742029A (en) * | 2022-04-20 | 2022-07-12 | 中国传媒大学 | Chinese text comparison method, storage medium and device |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090204596A1 (en) * | 2008-02-08 | 2009-08-13 | Xerox Corporation | Semantic compatibility checking for automatic correction and discovery of named entities |
| CN101510221A (en) * | 2009-02-17 | 2009-08-19 | 北京大学 | Enquiry statement analytical method and system for information retrieval |
| CN110209812A (en) * | 2019-05-07 | 2019-09-06 | 北京地平线机器人技术研发有限公司 | File classification method and device |
-
2019
- 2019-10-16 CN CN201910984742.5A patent/CN110738050B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20090204596A1 (en) * | 2008-02-08 | 2009-08-13 | Xerox Corporation | Semantic compatibility checking for automatic correction and discovery of named entities |
| CN101510221A (en) * | 2009-02-17 | 2009-08-19 | 北京大学 | Enquiry statement analytical method and system for information retrieval |
| CN110209812A (en) * | 2019-05-07 | 2019-09-06 | 北京地平线机器人技术研发有限公司 | File classification method and device |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111612157A (en) * | 2020-05-22 | 2020-09-01 | 四川无声信息技术有限公司 | Training method, character recognition method, device, storage medium and electronic equipment |
| CN111612157B (en) * | 2020-05-22 | 2023-06-30 | 四川无声信息技术有限公司 | Training method, character recognition device, storage medium and electronic equipment |
| CN114442897A (en) * | 2021-12-24 | 2022-05-06 | 北京幻想纵横网络技术有限公司 | Text processing method and device, electronic equipment and storage medium |
| CN114442897B (en) * | 2021-12-24 | 2023-12-15 | 北京幻想纵横网络技术有限公司 | Text processing method and device, electronic equipment and storage medium |
| CN114742029A (en) * | 2022-04-20 | 2022-07-12 | 中国传媒大学 | Chinese text comparison method, storage medium and device |
| CN114742029B (en) * | 2022-04-20 | 2022-12-16 | 中国传媒大学 | Chinese text comparison method, storage medium and device |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110738050B (en) | 2023-08-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109885692B (en) | Knowledge data storage method, apparatus, computer device and storage medium | |
| US9384389B1 (en) | Detecting errors in recognized text | |
| CN109165384A (en) | A kind of name entity recognition method and device | |
| CN110598203A (en) | Military imagination document entity information extraction method and device combined with dictionary | |
| CN106778878B (en) | Character relation classification method and device | |
| CN112035675A (en) | Medical text labeling method, device, equipment and storage medium | |
| CN109446521B (en) | Named entity recognition method, named entity recognition device, electronic equipment and machine-readable storage medium | |
| CN106815194A (en) | Model training method and device and keyword recognition method and device | |
| CN112487149A (en) | Text auditing method, model, equipment and storage medium | |
| CN111753120B (en) | Question searching method and device, electronic equipment and storage medium | |
| CN113360654B (en) | Text classification method, apparatus, electronic device and readable storage medium | |
| CN112100384B (en) | Data viewpoint extraction method, device, equipment and storage medium | |
| CN109948518B (en) | Neural network-based PDF document content text paragraph aggregation method | |
| CN110738050A (en) | Text recombination method, device and medium based on word segmentation and named entity recognition | |
| CN114610892A (en) | Knowledge point annotation method and device, electronic equipment and computer storage medium | |
| CN109857912A (en) | A kind of font recognition methods, electronic equipment and storage medium | |
| EP4336379A1 (en) | Tracking concepts within content in content management systems and adaptive learning systems | |
| CN111680506A (en) | External key mapping method and device of database table, electronic equipment and storage medium | |
| CN112328655A (en) | Text label mining method, device, equipment and storage medium | |
| US11520835B2 (en) | Learning system, learning method, and program | |
| CN112015907A (en) | Method and device for quickly constructing discipline knowledge graph and storage medium | |
| CN115577095B (en) | Electric power standard information recommendation method based on graph theory | |
| CN104077288B (en) | Web page contents recommend method and web page contents recommendation apparatus | |
| CN107783958B (en) | Target statement identification method and device | |
| CN107797981B (en) | Target text recognition method and device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |