CN111382232A - 问答信息处理方法、装置及计算机设备 - Google Patents
问答信息处理方法、装置及计算机设备 Download PDFInfo
- Publication number
- CN111382232A CN111382232A CN202010159784.8A CN202010159784A CN111382232A CN 111382232 A CN111382232 A CN 111382232A CN 202010159784 A CN202010159784 A CN 202010159784A CN 111382232 A CN111382232 A CN 111382232A
- Authority
- CN
- China
- Prior art keywords
- information
- reply
- vectors
- word
- pending
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/332—Query formulation
- G06F16/3329—Natural language query formulation or dialogue systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3344—Query execution using natural language analysis
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Human Computer Interaction (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本申请提出一种问答信息处理方法、装置及计算机设备,在用户提出的询问信息同时触发多个答复场景的情况下,即获取与询问信息关联的多个不同答复场景下的待定答复信息,本申请可以获取这多个待定答复信息之间的逻辑关系,并获取多个待定答复信息各自的第一词向量,及表征该逻辑关系的第二词向量作为模型输入,输入预先训练的答复融合模型进行处理,从而得到一个包含语义逻辑的复杂的目标答复信息,使得答复更加自然和连贯,进一步提升了用户体验,同时相对于现有技术采用人工标注方式提供目标答复信息的方式,本实施例这种处理方式极大减少了人工答案标注带来的人力和物力。
Description
技术领域
本申请主要涉及通信技术领域,更具体地说是涉及一种问答信息处理方法、装置及计算机设备。
背景技术
随着人工智能技术发展,越来越多的企业使用了智能客服系统,通过自助服务代替人工,能够实时响应客户问询,极大提高了客户的沟通和交流效率,降低了人工成本。
在实际应用中,智能客服系统获得询问信息,从多个预设答复信息中查询相匹配的目标答复信息过程中,可能会查询到多个目标答复信息,并将这多个目标答复信息依次反馈至用户,再由用户自己理解这多个目标答复信息共同所表达的含义,过程繁琐,降低了智能客服系统反馈答复信息的准确性。
发明内容
有鉴于此,本申请提供了一种问答信息处理方法,所述方法包括:
获取询问信息;
获得与所述询问信息关联的多个不同答复场景下的待定答复信息,以及多个所述待定答复信息之间的逻辑关系;
获取多个所述待定答复信息各自的第一词向量,以及相应的所述逻辑关系对应的关联词的第二词向量;
将获取的多个第一词向量及相应的所述第二词向量输入答复融合模型,得到针对所述询问信息的目标答复信息;
输出所述目标答复信息。
可选的,所述获得多个所述待定答复信息之间的逻辑关系,包括:
查询答复关系图,得到多个所述待定答复信息之间的逻辑关系,所述答复关系图包含不同答复场景下的答复信息之间的逻辑关系。
可选的,所述答复关系图的获取过程包括:
获取不同答复场景对应的候选答复信息,以及不同候选答复信息之间的逻辑关系;
将所述不同答复场景对应的候选答复信息作为节点,按照所述逻辑关系,构建所述答复关系图。
可选的,所述将获取的多个第一词向量及相应的所述第二词向量输入答复融合模型,得到针对所述询问信息的目标答复信息,包括:
将获取的多个第一词向量输入答复融合模型的编码网络进行编码处理,得到相应的第一编码向量;
通过注意力机制,对得到的多个第一编码向量及相应的所述第二词向量进行处理,得到多个所述待定答复信息的语境向量;
将得到的语境向量输入所述答复融合模型的解码网络进行解码处理,得到针对所述询问信息的目标答复信息。
可选的,所述编码网络和所述解码网络均为循环神经网络。
可选的,所述通过注意力机制,对得到的多个第一编码向量及相应的所述第二词向量进行处理,得到多个所述待定答复信息的语境向量,包括:
对不同的所述第一编码向量包含的元素进行相似度计算,得到相应待定答复信息的字词权重,所述字词权重表明相应字词相对于具有逻辑关系的另一所述待定答复信息的重要程度;
利用得到的所述字词权重,对得到的多个第一编码向量进行加权运算,得到多个所述待定答复信息的语境向量。
可选的,所述获取与所述询问信息关联的多个不同答复场景下的待定答复信息,包括:
对所述询问信息进行语义分析,依据语义分析结果,从候选答复信息集合中,筛选与所述询问信息关联的待定答复信息;
如果所述待定答复信息包括多个不同答复场景下的待定答复信息,执行步骤所述获得多个所述待定答复信息之间的逻辑关系。
本申请还提出了一种问答信息处理装置,所述装置包括:
信息获取模块,用于获取产品的询问信息;
获得模块,用于获得与所述询问信息关联的多个不同答复场景下的待定答复信息,以及多个所述待定答复信息之间的逻辑关系;
词向量获取模块,用于获取多个所述待定答复信息各自的第一词向量,以及相应的所述逻辑关系对应的关联词的第二词向量;
目标答复信息得到模块,用于将获取的多个第一词向量及相应的所述第二词向量输入答复融合模型,得到针对所述询问信息的目标答复信息;
信息输出模块,用于输出所述目标答复信息。
可选的,所述目标答复信息得到模块包括:
编码处理单元,用于将获取的多个第一词向量输入答复融合模型的编码网络进行编码处理,得到相应的第一编码向量;
语境向量得到单元,用于通过注意力机制,对得到的多个第一编码向量及相应的所述第二词向量进行处理,得到多个所述待定答复信息的语境向量;
解码处理单元,用于将得到的语境向量输入所述答复融合模型的解码网络进行解码处理,得到针对所述询问信息的目标答复信息。
本申请还提供了一种计算机设备,所述计算机设备包括:
通信接口;
存储器,用于存储实现如上所述的问答信息处理方法的程序;
处理器,用于加载并执行所述存储器存储的程序,实现如上所述的问答信息处理方法的各个步骤。
由此可见,与现有技术相比,本申请提供了一种问答信息处理方法、装置及计算机设备,在用户提出的询问信息同时触发多个答复场景的情况下,也就是说,计算机设备针对该询问信息,查询到与其关联的多个不同答复场景下的待定答复信息的情况下,本实施例可以获取这多个待定答复信息之间的逻辑关系,之后,将多个待定答复信息各自的第一词向量,以及表征该逻辑关系的第二词向量作为模型输入,输入预先训练的答复融合模型进行处理,从而得到一个包含语义逻辑的复杂的目标答复信息,使得答复更加自然和连贯,进一步提升了用户体验,同时相对于现有技术采用人工标注方式提供目标答复信息的方式,本实施例这种处理方式极大减少了人工答案标注带来的人力和物力。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1示出了实现本申请提出的问答信息处理方法的系统架构图;
图2示出了本申请提出的计算机设备的一可选示例的硬件结构示意图;
图3示出了本申请提出了问答信息处理方法的一可选示例的流程示意图;
图4示出了本申请提出的问答信息处理方法的又一可选实例的流程示意图;
图5示出了本申请提出的问答信息处理方法中,构建答复关系图的一可选实例的流程示意图;
图6示出了本申请提出的问答信息处理方法的又一可选实例的场景流程示意图;
图7示出了本申请提出了问答信息处理装置的一可选示例的结构示意图;
图8示出了本申请提出了问答信息处理装置的又一可选示例的结构示意图;
图9示出了本申请提出了问答信息处理装置的又一可选示例的结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
应当理解,本申请中使用的“系统”、“装置”、“单元”和/或“模块”是用于区分不同级别的不同组件、元件、部件、部分或装配的一种方法。然而,如果其他词语可实现相同的目的,则可通过其他表达来替换该词语。
如本申请和权利要求书中所示,除非上下文明确提示例外情形,“一”、“一个”、“一种”和/或“该”等词并非特指单数,也可包括复数。一般说来,术语“包括”与“包含”仅提示包括已明确标识的步骤和元素,而这些步骤和元素不构成一个排它性的罗列,方法或者设备也可能包含其它的步骤或元素。由语句“包括一个……”限定的要素,并不排除在包括要素的过程、方法、商品或者设备中还存在另外的相同要素。
其中,在本申请实施例的描述中,除非另有说明,“/”表示或的意思,例如,A/B可以表示A或B;本文中的“和/或”仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。另外,在本申请实施例的描述中,“多个”是指两个或多于两个。以下术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。
另外,本申请中使用了流程图用来说明根据本申请的实施例的系统所执行的操作。应当理解的是,前面或后面操作不一定按照顺序来精确地执行。相反,可以按照倒序或同时处理各个步骤。同时,也可以将其他操作添加到这些过程中,或从这些过程移除某一步或数步操作。
针对背景技术部分描述的现有技术方案,针对用户提出的询问信息,系统可能会从预先设定的大量预设答复信息(其可以是人工标注的)中,查询到与该询问信息关联的多个待定答复信息,由于目前的系统是直接将这多个待定答复信息反馈至用户的客户端输出,需要用户自己分析理解这多个待定答复信息之间的关系,以得到目标答复信息,比较繁琐,影响了系统反馈答复信息的准确性。
为了改善上述问题,本申请希望系统能够直接给出更加直观,用户不需要分析理解的目标答复信息,也就是说,对于上文描述的情况,希望系统可以对查询到的多个待定答复信息进行处理,得到自然、连贯的一个目标答复信息,反馈至用户,不需要用户再凭借自身知识储备分析理解,减少了用户工作量,而且,极大提高了系统反馈答复信息的准确性。
在上文描述的发明构思下,本申请提出了一种新的问答信息处理方法,具体实现过程可以参照但并不局限于下文实施例相应部分的描述,本实施例在此不做详述。
参照图1,示出了实现本申请提出的问答信息处理方法的系统架构图,该系统可以包括智能客服系统,本申请对系统的具体应用场景不做限定,如图1所示,该系统可以包括终端11和计算机设备12,其中:
终端11可以是智能手机、平板电脑、可穿戴设备、超级移动个人计算机(ultra-mobile personal computer,UMPC)、上网本、个人数字助理(personal digitalassistant,PDA)、电子书阅读器、台式计算机等电子设备,用户可以启动终端11中的客户端,访问智能客服系统,输入询问信息,以获取该智能客服系统针对该询问信息反馈的目标答复信息,关于该智能客服系统如何获得该目标答复信息的过程,可以参照下文相应实施例的描述。
其中,上述客户端可以是终端11安装的专用应用程序,如某些购物应用程序、某些社交应用程序、某些咨询应用程序等等,当然,客户端也可以是终端11中的浏览器,这种情况下,用户可以通过在浏览器中输入相应的网址,接入智能客服系统,本申请对上述终端11的类型,及其访问计算机设备12的实现方式均不作限定,可以依据具体应用场景确定。
计算机设备12可以是支持智能客服系统的服务业务的服务设备,具体可以是一个或多个服务器构成,也可以是具有较强数据处理及计算能力的终端,本申请对该计算机设备12的产品类型不做限定。
通常情况下,若发送询问信息的客户端是终端11安装的专业应用程序,该计算机设备可以是与该客户端匹配的服务设备,如为该客户端提供服务的服务器;若发送询问信息的客户端是浏览器,即通过网页方式访问智能客服系统,上述系统还可以包括与该客户端匹配的服务器13,客户端可以将询问信息发送至该服务器13,再由该服务器13转发至相应的计算机设备12,这种情况下的计算机设备12可以是服务器,也可以是具有一定数据处理能力的电子设备。
应该理解,实现问答信息处理方法的系统组成,并不局限于上文终端11和计算机设备12,还可以包括能够与计算机设备通信连接的数据存储设备,用来存储预设答复信息等信内容,当然,该数据存储设备也可以部署在计算机设备12中,本申请对实现答信息处理方法的系统组成结构不作限定。
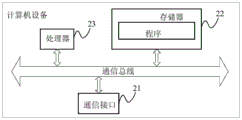
参照图2,示出了本申请提出的计算机设备的一可选示例的硬件结构示意图,该计算机设备可以是如上述实施例描述的服务器,或具有一定数据处理和计算能力的电子设备,本申请对该计算机设备的产品类型不做限定,如图2所示,该计算机设备可以包括:通信接口21、存储器22及处理器23,其中:
通信接口21、存储器22及处理器23各自的数量可以是至少一个,且通信接口21、存储器22及处理器23之间可以通过通信总线进行通信。
通信接口21可以是无线通信模块和/或有线通信模块的接口,如WIFI模块、GPRS模块、GSM模块等等通信模块的接口,还可以包括如USB接口、串/并口等接口,用于实现计算机设备内部组成部件之间的数据交互,具体可以依据具体网络通信需求配置计算机设备的通信接口,本申请对该通信接口21的类型及数量不做限定。
在实际应用中,可以通过通信接口获取询问信息、预设答复信息、候选答复信息等,还可以用来实现该计算机设备各组成部件之间的数据传输等,可以根据问答信息处理方法的具体通信需求确定,本实施例在此不做详述。
存储器22可以存储实现本申请实施例提出的问答信息处理方法的程序。
本实施例实际应用中,该存储器22还可以用来存储问答信息处理过程中,产生的各种中间数据、获取数据及输出数据等等,如不同答复场景下的待定答复信息、不同待定答复信息之间的逻辑关系,候选答复信息等等。
可选的,该存储器可以存储实现上述虚拟装置包含的各功能模块的程序代码,具体可以是高速RAM存储器,或者是非易失性存储器(non-volatile memory),例如至少一个磁盘存储器等。
处理器23可以是中央处理器(Central Processing Unit,CPU)、或者是特定集成电路ASIC(Application Specific Integrated Circuit)、数字信号处理器(DSP)、专用集成电路(ASIC)、现成可编程门阵列(FPGA)或者其他可编程逻辑器件等。
在本申请中,处理器23可以用于加载并执行存储器22存储的程序,实现本申请提出的问答信息处理方法的各个步骤,关于该问答信息处理方法的各个步骤,可以参照下文方法实施例相应部分的描述,本实施例在此不做详述。
应该理解的是,图2所示的计算机设备的结构并不构成对本申请实施例中计算机设备的限定,在实际应用中,计算机设备可以包括比图2所示的更多或更少的部件,或者组合某些部件,本申请在此不做一一列举。
参照图3,示出了本申请提出了问答信息处理方法的一可选示例的流程示意图,该方法可以适用于计算机设备,该计算机设备的组成结构及其产品类型,可以参照但并不局限于上述计算机设备实施例的描述,可以根据实际需求确定。如图3所示,本实施例提出的问答信息处理方法可以包括但并不局限于以下步骤:
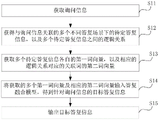
步骤S11,获取询问信息;
其中,询问信息可以是用户输入的针对任意疑问的提问内容,本申请对该询问信息所包含的具体询问内容不做限定,可以依据具体应用场景确定。
在一种可能的实现方式中,用户可以使用终端登录所要提问的智能客服系统所在的应用平台,在该应用平台的询问输入框中,直接输入想要了解的询问信息,如用户可以输入“选择哪个按钮拍照?我想和客服A聊天”这一内容的询问信息,终端可以检测针对询问输入框输入的询问信息,并将其发送至计算机设备,当前,计算机设备也可以实时或周期性检测,是否存在针对该询问输入框输入的询问信息,以获得询问信息等等。可见,本申请对计算机设备获取询问信息的具体实现方式不做限定,并不局限于上文列举的两种实现方式。
而且,对于上述询问信息的输入,用户可以借助如键盘、触摸屏等输入设备输入,也可以通过语音输入方式,实现向询问输入框输入询问信息等,本申请对上述询问信息的输入方式不做限定。
当然,在某些实施例中,对于上述询问信息,也可能不是用户直接在询问输入框中直接输入得到的,也可能是用户在应用平台上进行操作,该应用平台基于该操作自动生成的询问信息,如应用平台可以基于用户浏览历史、用户兴趣、当前浏览对象的热点问题等信息,向用户推送其可能感兴趣的问题信息,并在当前界面输出,这样,用户可以从中选择一问题信息作为询问信息,发送至计算机设备。但并不局限于本实施例描述的这种询问信息生成方式。
步骤S12,获得与询问信息关联的多个不同答复场景下的待定答复信息,以及多个待定答复信息之间的逻辑关系;
为了提高问答效率,降低人工成本,通常会统计大量用户可能会提出的问题(即询问信息),并针对每一个问题,配置至少一个答复信息,以便在用户提出某一询问信息后,系统能够快速且相对准确地给出答复信息。
然而,在实际应用中,往往会存在针对一个询问信息,系统查询到多个预先配置的答复信息的情况,本申请为了使系统最终反馈至用户的答复信息自然连贯,提出先对这多个答复信息进行分析处理,得到一个目标答复信息。对此,本申请经过研究发现,对于预先配置的大量答复信息,往往属于不同的答复场景,且不同答复场景下的答复信息之间,可能存在一定的逻辑关系,如转折关系、递进关系、并列关系等等。所以,为了得到自然连贯的目标答复信息,本申请可以依据不同答复场景下的答复信息之间的逻辑关系,对这些答复信息进行分析,来获得目标答复信息。
具体的,本申请为了提高获取目标答复信息的效率,可以对预先配置的大量的答复信息进行答复场景分类,即确定预先配置的大量答复信息所属的答复场景,使得每一种答复场景可能具有至少一个预设答复信息,再通过对不同答复场景的答复信息内容进行分析,确定不同答复场景的答复信息之间的逻辑关系,具体分析过程不做详述。
为了方便后续描述,可以将不同答复场景s的集合记为S,将每一个答复场景中的预设答复信息r构成的答复集合记为R。可见,S={s1,s2,…,sn},其中的每一个元素可以表示智能客服系统中预设答复信息的一种答复场景;R={r1,r2,…,rm}该集合R中的每一个元素可以表示一个答复场景下的一个预设答复信息,本申请对n、m的具体数值不做限定。
结合上述分析,应该理解,对于预先配置的预设答复信息,通常都是针对用户可能提出的询问信息确定的,也就是说,各预设答复信息与预设的各询问信息具有一定的关联关系,所以,计算机设备获取当前用户输入的询问信息后,可以利用这些关联关系,查询与该询问信息关联的预设答复信息,为了区别其他预设答复信息,本申请将于该询问信息关联的预设答复信息记为待定答复信息。
应该理解,若计算机设备查询到与询问信息关联的待定答复信息的数量为一个,即一种答复场景下的待定答复信息,本申请可以直接将其确定为目标答复信息输出;若计算机设备查询到的待定答复信息的数量为多个,且属于不同的答复场景,也就是说,计算机设备获得与该询问信息关联的多个答复场景下的待定答复信息,需要对其作进一步分析处理,以得到一个目标答复信息。这种情况下,本申请可以获取这多个待定答复信息之间的逻辑关系。
其中,不同答复场景下的预设答复信息之间的逻辑关系,可以按照上文相应部分的描述,通过对预设答复信息的内容分析确定,也可以由人工分析确定等,本申请对该逻辑关系的确定方式不做限定。
需要说明,对于答复场景A和答复场景B中不同的预设答复信息之间的逻辑关系可以相同,也可能不同,可以依据预设答复信息具体内容确定。本申请可以将不同答复场景的各预设答复信息之间的逻辑关系构成的集合记为G,该G={g1:di.j;g2…;gm…}(i,j<n),di,j可以表示第i个答复场景中的预设答复信息与第j个答复场景中的预设答复信息融合后的句子,m可以表示所有不同答复场景的预设答复信息之间共有m种逻辑关系,每一种逻辑关系对应有一个融合后的句子包含的关联词gk(k<m)。
可见,对于不同答复场景的逻辑关系(即语义逻辑关系),可以采用能够表征该逻辑关系的关联词gk表示,通过将关联词融入多个待定答复信息构成的复合语句(即目标答复信息)中,使其不仅能够表明这多个待定答复信息的内容,还能够表明这多个待定答复信息的内容之间的逻辑关系,进而使得所得复合语句更加自然连贯。
其中,对于不同的逻辑关系通常可以由至少一个关联词表征,即每一种逻辑关系可以对应有至少一个关联词,本申请可以根据实际情况,来确定各逻辑关系所应用的关联词gk并存储,以供实际使用时调用。如转折关系对应的关联词可以为“虽然…但是…”、“…然而…”、“…但是/却…”等,并列关系对应的关联词可以为“既…又…”“一面…一面”等;递进关系对应的关联词可以为“不但…而且…”、“不仅…还…”、“不但不…反而…”等;选择关系对应的关联词可以为“是…还是…”、“与其…不如…”、“要么…要么”等,对于如因果关系、假设关系、承接关系、条件关系等其他逻辑关系对应的关联词,可以根据语义语法确定,本申请不做一一详述。
步骤S13,获取多个待定答复信息各自的第一词向量,以及相应的逻辑关系对应的关联词的第二词向量;
继上述分析,本实施例主要是对用户提问存在多个答复场景共存的问题的情况下,如何针对多个答复场景之间的逻辑关系,生成一个包含逻辑关系(其可以由相应的关联词表示)的复合句回复给用户,更好地表达各个答复场景对应的答复信息之间的逻辑关系。
基于此,本实施例可以利用预先构建的模型,实现对所得多个待定答复信息和相应的关联词的融合处理,因此,本实施例在得到多个待定答复信息,以及表征相应的逻辑关系的关联词后,可以通过向量转换方式,将各待定答复信息包含的字词转换得到词向量,并将关联词包含的字词转换得到词向量,为了方便描述,本实施例将各待定答复信息的词向量记为第一词向量,将关联词的词向量记为第二词向量。
其中,词向量(Word embedding),又叫Word嵌入式自然语言处理(NLP)中的一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。从概念上讲,它涉及从每个单词一维的空间到具有更低维度的连续向量空间的数学嵌入。本申请可以利用神经网络等算法,对待定答复信息包含的字词进行处理,得到相应的第一词向量,同理,对得到的关联词进行处理,得到相应的第二词向量,具体实现过程不做详述。
步骤S14,将获取的多个第一词向量及相应的第二词向量输入答复融合模型,得到针对询问信息的目标答复信息;
本实施例中,答复融合模型即为上述用于实现对多个待定答复信息和关联词的融合,以得到目标答复信息的模型,可以基于机器学习算法,对样本答复信息及其对应的关联词进行训练得到,本申请对该答复融合模型的具体训练过程不做限定。
在一些实施例中,可以按照上述方式,预先定义由多个答复场景构成的答复场景集合S,对应于每一个答复场景下的多个预设答复信息构成的结合R,还可以利用这些不同答复场景对应的预设答复信息,对不同答复场景之间的关系归类,定义不同答复场景之间的逻辑关系;并根据不同答复场景之间的逻辑关系,由相应的预设答复信息融合得到复合语句,从而由此定义构成不同答复场景下的融合答复数据集合D,D={di.j}(i,j<n),di,j可以表示第i个答复场景中的预设答复信息与第j个答复场景中的预设答复信息融合后的复合语句,以便在模型训练过程中,作为标准答复信息用以矫正训练所得模型,提高模型输出准确性,也就是说,本申请可以采用有监督方式实现上述答复融合模型的训练。
其中,对于上述集合D中的复合语句,可以通过分析,,得到相应逻辑关系的句子模板,用以辅助实现对该逻辑关系对应的多个预设答复信息的融合处理,本申请对不同逻辑关系对应的句子模板的内容及其获取方式不做限定。
另外,对于上述不同答复场景之间存在的逻辑关系,具体可以由上述集合D包含的句子中的关联词gk,构成逻辑关系集合G。关于这些集合的具体定义过程,及其定义表示形式,可以参照但并不局限于上文描述的方式
基于上述预处理,可以从上述不同答复场景对应的预设答复数据集合R中,选择简单的预设答复信息作为样本答复信息,通过向量转换处理得到各自的词向量,并从结合G中查询表征与该答复场景对应的逻辑关系的关联词,将其作为样本关联词,转换得到相应的词向量,之后,可以利用如神经网络等机器学习算法,对样本答复信息的词向量及相应样本关联词的词向量进行训练,得到包含该样本关联词且能够表明该样本答复信息内容的复合语句,将其与上述即可D中相应预设答复场景对应的复合语句进行语义比对,若比对结果的不符合约束条件,可以按照上述方式继续进行模型训练,直至比较结果符合约束条件,本申请对该约束条件的内容不做限定,如语义相似度小于阈值等。
其中,为了提高模型输出的准确性,本申请在模型训练过程中,可以结合注意力机制实现模型的训练。在计算能力有限情况下,注意力机制是解决信息超载问题的主要手段的一种资源分配方案,将计算资源分配给更重要的任务,可以将其看做是一种仿生,是机器通过对人类阅读、听说中的注意力行为进行模拟,通过注意力机制教会计算机选择遗忘和关联上下文。
基于此,本申请可以在神经网络的隐藏层,增加注意力机制的加权,使不符合注意力模型的内容弱化或者遗忘。如对于不同答复场景的预设答复信息包含的各字词,利用注意力机制,可以从中确定出对所表达语义更加重要且准确的字词,增加这些字词的权重,以便后续训练过程中,提高这类字词被选为目标答复信息(即复合语句)的字词的概率,进而提高模型输出准确性。本申请对如何利用神经网络和注意力机制,实现上述答复融合模型的训练的具体实现过程不做一一详述。
结合上文对答复融合模型的分析可知,其在对多个待定答复信息各自的第一词向量,以及表征这多个待定答复信息之间的逻辑关系的关联词的第二词向量进行处理过程中,不仅考虑到多个待定答复信息各自的语义,而且还考虑到不同待定答复信息之间的语义逻辑关系,并将该逻辑关系融合到模型处理所得的目标答复信息中,相对于简单地将多个待定答复信息叠加输出,本申请所得目标答复信息更加自然连贯,所表达含义更加直接且准确,不需要用户再自己理解输出的多个待定答复信息之间的关系,确定其所表达的含义。
需要说明,本实施例所得目标答复信息,可以添加至上述集合D中,用以实现对本申请所使用的答复融合模型的优化,进一步提高模型输出准确性,本申请对该答复融合模型的优化过程不做详述。
步骤S15,输出目标答复信息。
本实施例中,计算机设备按照上述方式,得到用户所提出的询问信息的目标答复信息后,可以将其发送至用户提出询问信息的客户端界面,供用户查看,也可以将该目标答复信息发送至预设绑定的终端输出等,本申请对步骤S15的具体实现过程不做详述。
综上,在用户提出的询问信息同时触发多个答复场景的情况下,也就是说,计算机设备针对该询问信息,查询到与其关联的多个不同答复场景下的待定答复信息的情况下,本实施例可以获取这多个待定答复信息之间的逻辑关系,之后,将多个待定答复信息各自的第一词向量,以及表征该逻辑关系的第二词向量作为模型输入,输入预先训练的答复融合模型进行处理,从而得到一个包含语义逻辑的复杂的目标答复信息,使得答复更加自然和连贯,进一步提升了用户体验,同时相对于现有技术采用人工标注方式提供目标答复信息的方式,本实施例这种处理方式极大减少了人工答案标注带来的人力和物力。
参照图4,示出了本申请提出的问答信息处理方法的又一可选实例的流程示意图,本实施例可以是对上述实施例提出的问答信息处理方法的一可选细化实现方式,如图4所示,该方法可以包括:
步骤S21,获取询问信息;
步骤S22,获得与该询问信息关联的多个不同答复场景下的待定答复信息;
关于步骤S21和步骤S22的具体实现过程,可以参照上述实施例相应部分的描述,本实施例不再赘述。且本实施例主要对用户提出的询问信息触发多个答复场景的情况下,计算机设备如何获得目标答复信息并反馈给用户的方案进行描述,但应该理解,在某一些实施例中,用户提出的询问信息可能进触发一个答复场景,这种情况下,可以直接将于该询问信息关联的待定答复信息反馈至用户。
因此,计算机设备获取询问信息后,可以对该询问信息进行语义分析,依据语义分析结果,从后续答复信息集合中,筛选与询问信息关联的待定答复信息,若查询到的待定答复信息的数量为多个,且是多个不同答复场景对应的待定答复信息,可以按照本实施例给出的问答信息处理方式,获得相应的目标答复信息;若查询到一个待定答复信息,可以直接将其作为目标答复信息输出。
步骤S23,查询答复关系图,得到多个待定答复信息之间的逻辑关系;
结合上述分析,由于在实际应用中,用户提问存在多个答复场景共存的情况,即用户提出的询问信息可能触发多个答复场景的情况,若分别针对每个答复场景进行独立答复,将得到不同答复场景的待定答复信息放在一起进行回复,还需要用户自己理解多个待定答复信息之间的关系及其所表达的含义。为了改善上述问题,本实施例将考虑不同答复场景之间的逻辑关系,以便结合该逻辑关系,实现对上述不同答复场景下的待定答复信息的语句重构,得到更加连贯、更有逻辑的答复信息。
所以,本申请可以依据语义语法等规则,定义不同答复场景之间的逻辑关系,以构建答复关系图,因此,该答复关系图可以包含不同答复场景下的答复信息之间的逻辑关系,本实施例对该答复关系图的具体构建过程不做限定。
在一种可能的实现方式中,参照图5示出了的一种构建答复关系图的可选示例的流程图,该构建方法可以包括:
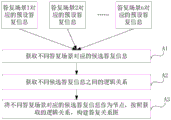
步骤A1,获取不同答复场景对应的候选答复信息;
结合上述分析,本申请可以对预先答复信息进行答复场景分类,将属于每一种答复场景的预设答复信息作为该答复场景的候选答复信息,也可以从每一种答复场景对应的预设答复信息中,选择部分预设答复信息确定为候选答复信息,如选择使用率较高或用户反馈较好的预设答复信息为候选答复信息等等,本实施例对不同答复场景对应的候选答复信息的内容及其确定方式不做限定。
步骤A2,获取不同候选答复信息之间的逻辑关系;
关于不同候选答复信息之间的逻辑关系的获取方式,可以参照上文对不同答复场景下的答复信息的逻辑关系的获取过程的描述,本实施例不再赘述。
步骤A3,将不同答复场景对应的候选答复信息作为节点,按照获取的逻辑关系,构建答复关系图。
本实施例的答复关系图可以是一种有向图,即一种表示物件与物件之间的关系的方法,可以由一些小圆点(称为顶点或节点)和连结这些圆点的直线或曲线(称为边)组成的。如果给图的每条边规定一个方向,那么得到的图称为有向图,其边也称为有向边。
基于此,本实施例可以将不同答复场景对应的候选答复信息作为有向图的节点,按照不同候选答复信息之间的逻辑关系,确定该有向图的节点之间的有向边,从而得到答复关系图,这样,在后续查询待定答复信息之间的逻辑关系时,可以直接从答复关系图中确定出多个待定答复信息,并将这多个待定答复信息之间的有向边对应的逻辑关系,确定为这多个待定答复信息之间的逻辑关系,其中,按照该有向边的方向表明了所连接的两个节点之间的逻辑先后顺序。
在一些实施例中,对于上述答复关系图,也可以按照上述方式,对预先确定的不同答复场景,构建相应的答复关系图,这种情况下,该答复关系图可以由不同答复场景作为节点,由不同答复场景之间的逻辑关系确定相应节点之间的有向边。在这种构建方式中,可以通过查询多个待定答复信息所属答复场景之间的逻辑关系,得到相应待定答复信息之间的逻辑关系。
需要说明,若增加新的答复场景,可以据此更新答复关系图,以提高后续问答信息处理的准确性。本申请对该答复关系图的存储方式及其更新方式不做限定。
步骤S24,获取所得到的逻辑关系对应的关联词;
关于表征不同逻辑关系的关联词,可以参照上文实施例相应部分的描述,本实施例不再赘述。
步骤S25,获取多个待定答复信息各自的第一词向量,以及相应关联词对应的第二词向量;
步骤S26,将获取的多个第一词向量输入答复融合模型的编码网络进行编码处理,得到相应的第一编码向量;
关于答复融合模型的训练过程,可以参照上述实施例的描述,不再赘述。在一些实施例中,答复融合模型的编码网络可以是循环神经网络,如双向长短时记忆网络(Bi-directional Long Short-Term Memory,Bi-LSTM),利用这种网络结构提供给输出层输入向量中每个点完整的过去和未来的上下文信息,本申请对第一词向量的具体编码过程不做详述。
仍以上述Bi-LSTM编码网络为例进行说明,答复场景i下的待定答复信息ri,以及答复场景j下的待定答复信息rj,转换得到相应的第一词向量输入Bi-LSTM编码,得到句子隐藏层向量表示,即得到不同待定答复信息对应的第一编码向量,记为hi和hj。以对ri的第一词向量进行编码处理,得到第一编码向量hi为例进行说明,可以按照但并不局限于以下公式进行编码处理:

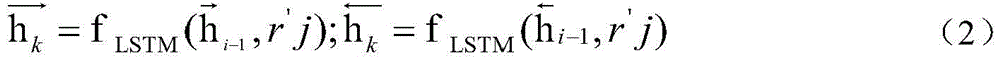
上述公式中,fLSTM()可以表示基于LSTM的编码函数,即上述编码网络,本申请对这种编码网络的编码计算过程不做详述。 表示异或逻辑运算符。由于本实施例采用Bi-LSTM这种双向长短时记忆网络,是利用两个LSTM网络分别向前和向后进行运算,上述公式中
表示异或逻辑运算符。由于本实施例采用Bi-LSTM这种双向长短时记忆网络,是利用两个LSTM网络分别向前和向后进行运算,上述公式中 可以表示向前的运算,
可以表示向前的运算, 可以表示向后的运算,本申请对基于LSTM的向前和向后的具体运算过程不做详述。
可以表示向后的运算,本申请对基于LSTM的向前和向后的具体运算过程不做详述。
步骤S27,通过注意力机制,对得到的多个第一编码向量及相应的第二词向量进行处理,得到多个待定答复信息的语境向量;
关于注意力机制的分析,可以参照上文相应部分的描述,本实施例对其运算原理不做详述。
另外,结合上文对本申请发明构思的描述,本申请在对多个待定答复信息对应的第一编码向量进行处理时,结合了这多个待定答复信息之间的逻辑关系对应的第二词向量,以使处理所得语境向量能够表征这多个待定答复信息的语义,还能够表征这多个待定答复信息之间的语义逻辑。
而且,为了提高所得语境向量的准确性,本申请将结合注意力机制对多个第一编码向量及相应的第二词向量进行处理,具体处理方式不做限定。在一些实施例中,可以利用如下公式,计算各第一编码向量的各组成元素的权重,以确定构成语境向量的元素。


上述公式中,v、W均可以表示模型中预设的参数,可以根据实际需求确定,本申请对两者数值不做限定,ψ(t)可以表示关联词g1中所有字词的第二词向量,hit可以表示hi最后一层的隐层状态,如上述神经网络中隐藏层的最后一层的输出,具体计算方式不做详述。
基于上述分析,在一些可能的实现方式中,上述步骤S27可以包括:
步骤B1,对不同的第一编码向量包含的元素进行相似度计算,得到相应待定答复信息的字词权重;
其中,字词权重可以表明相应字词相对于具有逻辑关系的另一待定答复信息的重要程度,通常情况下,该字词权重越大,表明相应字词相对于该另一待定答复信息越重要,能够更加准确体现待定答复信息的语义。
需要说明,本申请对步骤B1涉及到的相似度计算方法不做限定。
步骤B2,利用得到的字词权重,对得到的多个第一编码向量进行加权运算,得到多个待定答复信息的语境向量。
如上述公式(3)和公式(4)的记载,
步骤S28,将得到的语境向量输入答复融合模型的解码网络进行解码处理,得到针对询问信息的目标答复信息;
本实施例中,答复融合模型的解码网络与上述编码网络的网络结构可以相同,均可以为循环神经网络,具体可以为上述Bi-LSTM网络,按照上述方式得到该网络隐藏层状态后,可以继续计算所得语境向量中各字词的生成概率,从而据此选择生成概率较高的字词构成目标答复信息,具体运算方法不做限定。
继上述答复融合模型的网络结构的示例,本实施例可以利用如下公式的计算结果,得到目标答复信息,但并不局限于本申请给出的计算公式
h't=fLSTM(h't-1,di,jt-1) (5)

上述公式中,softmax()可以表示归一化函数,本申请对其运算原理不做限定,Wp、bp可以表示答复融合模型中预设的参数,本申请对其具体数值不做限定,h、t可以表示解码网络中t时刻生产的隐藏层的隐藏状态,此处的fLSTM()可以表示基于LSTM的解码函数,di,jt可以表示答复融合模型对答复场景i和答复场景j分别对应的待定答复信息进行处理,t时刻输出的融合处理得到的复合语句。
需要说明,关于答复融合模型的解码网络的网络结构,及其对语境向量的解码处理过程,并不局限于上文描述的实现方式。
步骤S29,输出该目标答复信息。
综上,本实施例中,结合图6所示的场景示意图,针对获取的询问信息,在得到与其关联的多个待定答复信息属于不同答复场景的情况下,可以获取表征这多个待定答复信息之间的逻辑关系的关联词,之后,获取各待定答复信息的第一词向量及相应关联词的第二词向量,将各第一词向量和第二词向量作为模型输入,输入至预先训练得到的答复融合模型进行处理,如通过对不同答复场景的待定答复信息对应的第一词向量进行编码,得到隐藏层输出的相应的第一编码向量,再结合表征逻辑关系的第二词向量的处理,得到同时表达各待定答复信息的语义及之间的逻辑关系的语境向量,再对该语境向量进行解码处理,得到同时表达各待定答复信息的语义及之间的逻辑关系的目标答复信息,相对于直接对多个待定答复信息进行罗列输出的方式,提高了答复准确性及可靠性,且因不需要用户再对输出的多个待定答复信息进行语义分析,减少了人力和物力。
参照图7,示出了本申请提出的问答信息处理装置的一可选实例的结构示意图,该装置可以适用于计算机设备,如图7所示,该装置可以包括:
信息获取模块31,用于获取询问信息;
获得模块32,用于获得与所述询问信息关联的多个不同答复场景下的待定答复信息,以及多个所述待定答复信息之间的逻辑关系;
在一些实施例中,如图8所示,该获得模块32可以包括:
语义分析单元321,用于对所述询问信息进行语义分析;
筛选单元322,用于依据语义分析结果,从候选答复信息集合中,筛选与所述询问信息关联的待定答复信息;
查询单元323,用于在待定答复信息包括多个不同答复场景下的待定答复信息的情况下,查询答复关系图,得到多个所述待定答复信息之间的逻辑关系。
其中,答复关系图包含不同答复场景下的答复信息之间的逻辑关系,在一些实施例中,为了实现对答复关系图的构建,本申请提出的问答信息处理装置还可以包括:
候选答复信息获取模块,用于获取不同答复场景对应的候选答复信息;
逻辑关系获取模块,用于获取不同候选答复信息之间的逻辑关系;
构建模块,用于将所述不同答复场景对应的候选答复信息作为节点,按照所述逻辑关系,构建所述答复关系图。
需要说明,关于该答复关系图的具体构建过程可以参照上述方法实施例相应部分的描述,不再赘述。
词向量获取模块33,用于获取多个所述待定答复信息各自的第一词向量,以及相应的所述逻辑关系对应的关联词的第二词向量;
目标答复信息得到模块34,用于将获取的多个第一词向量及相应的所述第二词向量输入答复融合模型,得到针对所述询问信息的目标答复信息;
在一些实施例中,如图9所示,目标答复信息得到模块34可以包括:
编码处理单元341,用于将获取的多个第一词向量输入答复融合模型的编码网络进行编码处理,得到相应的第一编码向量;
语境向量得到单元342,用于通过注意力机制,对得到的多个第一编码向量及相应的所述第二词向量进行处理,得到多个所述待定答复信息的语境向量;
在一种可能的实现方式中,上述语境向量得到单元342可以包括:
相似度计算单元,用于对不同的所述第一编码向量包含的元素进行相似度计算,得到相应待定答复信息的字词权重,所述字词权重表明相应字词相对于具有逻辑关系的另一所述待定答复信息的重要程度;
加权运算单元,用于利用得到的所述字词权重,对得到的多个第一编码向量进行加权运算,得到多个所述待定答复信息的语境向量。
解码处理单元343,用于将得到的语境向量输入所述答复融合模型的解码网络进行解码处理,得到针对所述询问信息的目标答复信息。
本实施例中,上述编码网络和所述解码网络均为循环神经网络,具体可以是BiLSTM网络,关于如何利用这种网络结构实现上述编码和解码过程,可以参照上述实施例以及这种双向循环神经网络的运算原理确定,本实施例不做详述。
信息输出模块35,用于输出所述目标答复信息。
需要说明的是,关于上述各装置实施例中的各种模块、单元等,均可以作为程序模块存储在存储器中,由处理器执行存储在存储器中的上述程序模块,以实现相应的功能,关于各程序模块及其组合所实现的功能,以及达到的技术效果,可以参照上述方法实施例相应部分的描述,本实施例不再赘述。
本申请还提供了一种存储介质,其上可以存储计算机程序,该计算机程序可以被处理器调用并加载,以实现上述实施例描述的问答信息处理方法的各个步骤。
本申请实施例还提出了一种计算机设备,如上图2所示,,该计算机设备可以包括但并不局限于:信接口21、存储器22及处理器23等,关于计算机设备的组成结构及其功能,可以参照上述实施例相应部分的描述,本实施例不再赘述。
最后,需要说明,本说明书中各个实施例采用递进或并列的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置和计算机设备而言,由于其与实施例公开的方法对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
Claims (10)
1.一种问答信息处理方法,所述方法包括:
获取询问信息;
获得与所述询问信息关联的多个不同答复场景下的待定答复信息,以及多个所述待定答复信息之间的逻辑关系;
获取多个所述待定答复信息各自的第一词向量,以及相应的所述逻辑关系对应的关联词的第二词向量;
将获取的多个第一词向量及相应的所述第二词向量输入答复融合模型,得到针对所述询问信息的目标答复信息;
输出所述目标答复信息。
2.根据权利要求1所述的方法,所述获得多个所述待定答复信息之间的逻辑关系,包括:
查询答复关系图,得到多个所述待定答复信息之间的逻辑关系,所述答复关系图包含不同答复场景下的答复信息之间的逻辑关系。
3.根据权利要求2所述的方法,所述答复关系图的获取过程包括:
获取不同答复场景对应的候选答复信息,以及不同候选答复信息之间的逻辑关系;
将所述不同答复场景对应的候选答复信息作为节点,按照所述逻辑关系,构建所述答复关系图。
4.根据权利要求1所述的方法,所述将获取的多个第一词向量及相应的所述第二词向量输入答复融合模型,得到针对所述询问信息的目标答复信息,包括:
将获取的多个第一词向量输入答复融合模型的编码网络进行编码处理,得到相应的第一编码向量;
通过注意力机制,对得到的多个第一编码向量及相应的所述第二词向量进行处理,得到多个所述待定答复信息的语境向量;
将得到的语境向量输入所述答复融合模型的解码网络进行解码处理,得到针对所述询问信息的目标答复信息。
5.根据权利要求4所述的方法,所述编码网络和所述解码网络均为循环神经网络。
6.根据权利要求4所述的方法,所述通过注意力机制,,对得到的多个第一编码向量及相应的所述第二词向量进行处理,得到多个所述待定答复信息的语境向量,包括:
对不同的所述第一编码向量包含的元素进行相似度计算,得到相应待定答复信息的字词权重,所述字词权重表明相应字词相对于具有逻辑关系的另一所述待定答复信息的重要程度;
利用得到的所述字词权重,对得到的多个第一编码向量进行加权运算,得到多个所述待定答复信息的语境向量。
7.根据权利要求1所述的方法,所述获取与所述询问信息关联的多个不同答复场景下的待定答复信息,包括:
对所述询问信息进行语义分析,依据语义分析结果,从候选答复信息集合中,筛选与所述询问信息关联的待定答复信息;
如果所述待定答复信息包括多个不同答复场景下的待定答复信息,执行步骤所述获得多个所述待定答复信息之间的逻辑关系。
8.一种问答信息处理装置,所述装置包括:
信息获取模块,用于获取询问信息;
获得模块,用于获得与所述询问信息关联的多个不同答复场景下的待定答复信息,以及多个所述待定答复信息之间的逻辑关系;
词向量获取模块,用于获取多个所述待定答复信息各自的第一词向量,以及相应的所述逻辑关系对应的关联词的第二词向量;
目标答复信息得到模块,用于将获取的多个第一词向量及相应的所述第二词向量输入答复融合模型,得到针对所述询问信息的目标答复信息;
信息输出模块,用于输出所述目标答复信息。
9.根据权利要求8所述的装置,所述目标答复信息得到模块包括:
编码处理单元,用于将获取的多个第一词向量输入答复融合模型的编码网络进行编码处理,得到相应的第一编码向量;
语境向量得到单元,用于通过注意力机制,对得到的多个第一编码向量及相应的所述第二词向量进行处理,得到多个所述待定答复信息的语境向量;
解码处理单元,用于将得到的语境向量输入所述答复融合模型的解码网络进行解码处理,得到针对所述询问信息的目标答复信息。
10.一种计算机设备,所述计算机设备包括:
通信接口;
存储器,用于存储实现如权利要求1~7任一项所述的问答信息处理方法的程序;
处理器,用于加载并执行所述存储器存储的程序,实现如权利要求1~7任一项所述的问答信息处理方法的各个步骤。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010159784.8A CN111382232A (zh) | 2020-03-09 | 2020-03-09 | 问答信息处理方法、装置及计算机设备 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010159784.8A CN111382232A (zh) | 2020-03-09 | 2020-03-09 | 问答信息处理方法、装置及计算机设备 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN111382232A true CN111382232A (zh) | 2020-07-07 |
Family
ID=71221521
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010159784.8A Pending CN111382232A (zh) | 2020-03-09 | 2020-03-09 | 问答信息处理方法、装置及计算机设备 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111382232A (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111949791A (zh) * | 2020-07-28 | 2020-11-17 | 中国工商银行股份有限公司 | 一种文本分类方法、装置及设备 |
| CN113035200A (zh) * | 2021-03-03 | 2021-06-25 | 科大讯飞股份有限公司 | 基于人机交互场景的语音识别纠错方法、装置以及设备 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103853842A (zh) * | 2014-03-20 | 2014-06-11 | 百度在线网络技术(北京)有限公司 | 一种自动问答方法和系统 |
| CN107870964A (zh) * | 2017-07-28 | 2018-04-03 | 北京中科汇联科技股份有限公司 | 一种应用于答案融合系统的语句排序方法及系统 |
| CN109829040A (zh) * | 2018-12-21 | 2019-05-31 | 深圳市元征科技股份有限公司 | 一种智能对话方法及装置 |
| US20190228098A1 (en) * | 2018-01-19 | 2019-07-25 | International Business Machines Corporation | Facilitating answering questions involving reasoning over quantitative information |
| CN110297897A (zh) * | 2019-06-21 | 2019-10-01 | 科大讯飞(苏州)科技有限公司 | 问答处理方法及相关产品 |
| CN110704591A (zh) * | 2019-09-27 | 2020-01-17 | 联想(北京)有限公司 | 一种信息处理方法及计算机设备 |
-
2020
- 2020-03-09 CN CN202010159784.8A patent/CN111382232A/zh active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103853842A (zh) * | 2014-03-20 | 2014-06-11 | 百度在线网络技术(北京)有限公司 | 一种自动问答方法和系统 |
| CN107870964A (zh) * | 2017-07-28 | 2018-04-03 | 北京中科汇联科技股份有限公司 | 一种应用于答案融合系统的语句排序方法及系统 |
| US20190228098A1 (en) * | 2018-01-19 | 2019-07-25 | International Business Machines Corporation | Facilitating answering questions involving reasoning over quantitative information |
| CN109829040A (zh) * | 2018-12-21 | 2019-05-31 | 深圳市元征科技股份有限公司 | 一种智能对话方法及装置 |
| CN110297897A (zh) * | 2019-06-21 | 2019-10-01 | 科大讯飞(苏州)科技有限公司 | 问答处理方法及相关产品 |
| CN110704591A (zh) * | 2019-09-27 | 2020-01-17 | 联想(北京)有限公司 | 一种信息处理方法及计算机设备 |
Non-Patent Citations (2)
| Title |
|---|
| 栾克鑫;杜新凯;孙承杰;刘秉权;王晓龙;: "基于注意力机制的句子排序方法", 中文信息学报 * |
| 田文洪;高印权;黄厚文;黎在万;张朝阳;: "基于多任务双向长短时记忆网络的隐式句间关系分析", 中文信息学报 * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111949791A (zh) * | 2020-07-28 | 2020-11-17 | 中国工商银行股份有限公司 | 一种文本分类方法、装置及设备 |
| CN111949791B (zh) * | 2020-07-28 | 2024-01-30 | 中国工商银行股份有限公司 | 一种文本分类方法、装置及设备 |
| CN113035200A (zh) * | 2021-03-03 | 2021-06-25 | 科大讯飞股份有限公司 | 基于人机交互场景的语音识别纠错方法、装置以及设备 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111061946B (zh) | 场景化内容推荐方法、装置、电子设备及存储介质 | |
| US9811765B2 (en) | Image captioning with weak supervision | |
| US9792534B2 (en) | Semantic natural language vector space | |
| CN110555469B (zh) | 处理交互序列数据的方法及装置 | |
| US20210182680A1 (en) | Processing sequential interaction data | |
| CN112308650B (zh) | 推荐理由生成方法、装置、设备及存储介质 | |
| GB2547068A (en) | Semantic natural language vector space | |
| CN111680159A (zh) | 数据处理方法、装置及电子设备 | |
| CN106447066A (zh) | 一种大数据的特征提取方法和装置 | |
| CN109145245A (zh) | 预测点击率的方法、装置、计算机设备及存储介质 | |
| CN106445988A (zh) | 一种大数据的智能处理方法和系统 | |
| CN111680147A (zh) | 一种数据处理方法、装置、设备以及可读存储介质 | |
| CN113191154B (zh) | 基于多模态图神经网络的语义分析方法、系统和存储介质 | |
| CN113254711B (zh) | 一种互动图像的显示方法、装置、计算机设备和存储介质 | |
| CN115455171B (zh) | 文本视频的互检索以及模型训练方法、装置、设备及介质 | |
| CN113656699B (zh) | 用户特征向量确定方法、相关设备及介质 | |
| CN115659995B (zh) | 一种文本情感分析方法和装置 | |
| Ermakova et al. | Commercial sentiment analysis solutions: a comparative study | |
| CN111382232A (zh) | 问答信息处理方法、装置及计算机设备 | |
| Ermakova et al. | A Comparison of Commercial Sentiment Analysis Services | |
| CN114169418B (zh) | 标签推荐模型训练方法及装置、标签获取方法及装置 | |
| CN111401922A (zh) | 问答信息处理方法、装置及计算机设备 | |
| CN117235264A (zh) | 文本处理方法、装置、设备和计算机可读存储介质 | |
| CN117725220A (zh) | 文档表征和文档检索的方法、服务器及存储介质 | |
| CN116956183A (zh) | 多媒体资源推荐方法、模型训练方法、装置及存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |