CN111275784B - Method and device for generating image - Google Patents
Method and device for generating image Download PDFInfo
- Publication number
- CN111275784B CN111275784B CN202010065575.7A CN202010065575A CN111275784B CN 111275784 B CN111275784 B CN 111275784B CN 202010065575 A CN202010065575 A CN 202010065575A CN 111275784 B CN111275784 B CN 111275784B
- Authority
- CN
- China
- Prior art keywords
- image
- countermeasure network
- face
- generating
- input
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T11/00—2D [Two Dimensional] image generation
- G06T11/001—Texturing; Colouring; Generation of texture or colour
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/088—Non-supervised learning, e.g. competitive learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/168—Feature extraction; Face representation
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- General Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Mathematical Physics (AREA)
- Evolutionary Computation (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Human Computer Interaction (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Multimedia (AREA)
- Image Analysis (AREA)
Abstract
The embodiment of the disclosure discloses a method and a device for generating an image. The method comprises the following steps: acquiring a first image comprising a first face; inputting the first image into a pre-trained generation type countermeasure network to obtain a second image which is output by the generation type countermeasure network and comprises a second face; wherein the generated countermeasure network takes face attribute information generated based on the input image as a constraint. The method can improve the accuracy and efficiency of the generation type countermeasure network for generating the second image based on the input first image, reduce the probability of generating the image by mistake, and reduce the constraint that the input image can only be the image in the preset area.
Description
Technical Field
The present disclosure relates to the field of computer technology, and in particular, to the field of image conversion technology, and in particular, to a method and apparatus for generating an image.
Background
At present, a plurality of self-timer special effect playing methods such as children changing, faces changing and the like are available in the market, so that the self-timer special effect playing method has great interest, and a plurality of users like playing, and even a night-time fire-explosion phenomenon level Application (APP) appears.
The prior art scheme has two kinds: one is a photo cartoon method (carton gan) based on a generative challenge network, which, like adding a cartoon filter to the input image, is substantially incapable of generating a usable cartoon character. Another is the recently published paper-unsupervised generation attention network (UGATIT) algorithm, but in practical use it is found that cartoon characters are generated at a low rate, many bad examples (bad cases) such as eyes on clothes, many textures on faces or not at all, and there are strict limitations on the input image (square, only frontal face image can be input), and the existing method can only generate girls.
Disclosure of Invention
The embodiment of the disclosure provides a method and a device for generating an image.
In a first aspect, embodiments of the present disclosure provide a method of generating an image, including: acquiring a first image comprising a first face; inputting the first image into a pre-trained generation type countermeasure network to obtain a second image which is output by the generation type countermeasure network and comprises a second face; wherein the generated countermeasure network takes face attribute information generated based on the input image as a constraint.
In some embodiments, inputting the first image into the pre-trained generated countermeasure network includes: carrying out Gaussian blur on the first image in different degrees, and inputting the first image with the Gaussian blur in different degrees into a pre-trained generation type countermeasure network; or detecting whether the texture characteristic parameter value of the first image is larger than a texture threshold value, if so, carrying out Gaussian blur on the first image to different degrees, and inputting the first image with different degrees of Gaussian blur into a pre-trained generation type countermeasure network.
In some embodiments, the generating the face attribute information generated based on the input image by the countermeasure network includes: the generated countermeasure network takes the key points of the human face and/or the semantic segmentation result of the human face generated based on the input image as constraints.
In some embodiments, the generating an countermeasure network includes, as constraints, face keypoints and/or face semantic segmentation results generated based on the input image: the generating type countermeasure network takes a multichannel face image generated based on the input image as input; wherein the multichannel face image comprises RGB three channels of the input image and at least one of the following of the input image: a binary image one-channel or RGB three-channel of the key points of the human face; a binary image one-channel or RGB three-channel of a human face semantic segmentation result; and binary image of hair-a channel.
In some embodiments, the pre-trained image samples of the input for training of the generated countermeasure network include: and carrying out data enhancement on the initial image sample to obtain an image sample.
In some embodiments, data enhancement of the initial image sample includes: performing at least one of the following operations on the initial image sample: rotation, flipping, scaling, and varying degrees of gaussian blur.
In some embodiments, the generated countermeasure network includes at least any one of: the method comprises the steps of generating a countermeasure network GAN, circularly consistent generating the countermeasure network CycleGan, generating a face high-precision attribute editing model AttGAN, generating a star-shaped countermeasure network StarGAN and generating the countermeasure network STGAN by a space transformer.
In some embodiments, the first image is a real face image; the second image is a cartoon image.
In a second aspect, embodiments of the present disclosure provide an apparatus for generating an image, including: an acquisition unit configured to acquire a first image including a first face; a generating unit configured to input the first image into a pre-trained generation type countermeasure network, and obtain a second image including a second face output by the generation type countermeasure network; wherein the generated countermeasure network takes face attribute information generated based on the input image as a constraint.
In some embodiments, the generating unit is further configured to: carrying out Gaussian blur on the first image in different degrees, and inputting the first image with the Gaussian blur in different degrees into a pre-trained generation type countermeasure network; or detecting whether the texture characteristic parameter value of the first image is larger than a texture threshold value, if so, carrying out Gaussian blur on the first image to different degrees, and inputting the first image with different degrees of Gaussian blur into a pre-trained generation type countermeasure network.
In some embodiments, the generation countermeasure network employed in the generation unit includes, as a constraint, face attribute information generated based on the input image: the generated countermeasure network adopted in the generating unit takes the key points of the human face and/or the semantic segmentation result of the human face generated based on the input image as constraints.
In some embodiments, the generation-type countermeasure network employed in the generation unit includes, as constraints, face keypoints and/or face semantic segmentation results generated based on the input image: the generation type countermeasure network adopted in the generation unit takes a multichannel face image generated based on the input image as input; wherein the multichannel face image comprises RGB three channels of the input image and at least one of the following of the input image: a binary image one-channel or RGB three-channel of the key points of the human face; a binary image one-channel or RGB three-channel of a human face semantic segmentation result; and binary image of hair-a channel.
In some embodiments, the pre-trained generated countermeasure network employed in the generating unit for training the input image samples comprises: and carrying out data enhancement on the initial image sample to obtain an image sample.
In some embodiments, the pre-trained generated countermeasure network employed in the generating unit for training the input image samples comprises: performing at least one of the following operations on the initial image sample: rotation, flipping, scaling, and varying degrees of gaussian blur.
In some embodiments, the generated countermeasure network includes at least any one of: the method comprises the steps of generating a countermeasure network GAN, circularly consistent generating the countermeasure network CycleGan, generating a face high-precision attribute editing model AttGAN, generating a star-shaped countermeasure network StarGAN and generating the countermeasure network STGAN by a space transformer.
In some embodiments, the first image is a real face image; the second image is a cartoon image.
In a third aspect, an embodiment of the present disclosure provides an electronic device/terminal/server, including: one or more processors; a storage means for storing one or more programs; the one or more programs, when executed by the one or more processors, cause the one or more processors to implement the method of generating an image as described in any of the above.
In a fourth aspect, embodiments of the present disclosure provide a computer readable medium having stored thereon a computer program which, when executed by a processor, implements a method of generating an image as described in any of the above.
The method and the device for generating the image provided by the embodiment of the disclosure firstly acquire a first image comprising a first face; inputting the first image into a pre-trained generation type countermeasure network to obtain a second image which is output by the generation type countermeasure network and comprises a second face; wherein the generated countermeasure network takes face attribute information generated based on the input image as a constraint. In this process, the accuracy and efficiency of the generation-type countermeasure network for generating the second image based on the input first image can be improved, the probability of erroneously generating the image is reduced, and the constraint that the input image can only be an image in a predetermined area is reduced.
Drawings
Other features, objects and advantages of the present disclosure will become more apparent upon reading of the detailed description of non-limiting embodiments, made with reference to the following drawings in which:
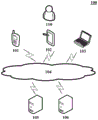
FIG. 1 is an exemplary system architecture diagram to which the present disclosure may be applied;
FIG. 2 is a flow diagram of one embodiment of a method of generating an image according to an embodiment of the present disclosure;
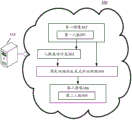
FIG. 3 is one exemplary application scenario of a method of generating an image according to an embodiment of the present disclosure;
FIG. 4 is a flow diagram of yet another embodiment of a method of generating an image according to an embodiment of the present disclosure;
FIG. 5a is an example diagram of a first image of a cyclic consistent generation type countermeasure network input pre-trained in yet another embodiment of a method of generating images in accordance with an embodiment of the present disclosure;
FIG. 5b is a face keypoint image represented in RGB three channels based on the first image extraction in FIG. 5a according to an embodiment of the present disclosure;
FIG. 5c is a segmentation result image of hair represented using a binary image one-pass extraction based on the first image of FIG. 5a, in accordance with an embodiment of the present disclosure;
FIG. 5d is a face semantic segmentation result image represented in RGB three channels based on the first image extraction in FIG. 5a according to an embodiment of the present disclosure;
FIG. 6 is a schematic structural diagram of a pre-trained cyclically consistent generating type countermeasure network for a method of generating images according to an embodiment of the present disclosure;
FIG. 7 is an exemplary block diagram of one embodiment of an apparatus of the present disclosure for generating an image;
fig. 8 is a schematic diagram of a computer system suitable for use in implementing embodiments of the present disclosure.
Detailed Description
The present disclosure is described in further detail below with reference to the drawings and examples. It is to be understood that the specific embodiments described herein are merely illustrative of the invention and are not limiting of the invention. It should be noted that, for convenience of description, only the portions related to the present invention are shown in the drawings.
It should be noted that, without conflict, the embodiments of the present disclosure and features of the embodiments may be combined with each other. The present disclosure will be described in detail below with reference to the accompanying drawings in conjunction with embodiments. Those skilled in the art will also appreciate that, although the terms "first," "second," etc. may be used herein to describe various faces, images, etc., these faces, images should not be limited by these terms. These terms are only used to distinguish one face, image from other faces, images.
Fig. 1 illustrates an exemplary system architecture 100 to which embodiments of the methods of generating an image or apparatus of generating an image of the present disclosure may be applied.
As shown in fig. 1, a system architecture 100 may include terminal devices 101, 102, 103, a network 104, and a server 105. The network 104 is used as a medium to provide communication links between the terminal devices 101, 102, 103 and the server 105. The network 104 may include various connection types, such as wired, wireless communication links, or fiber optic cables, among others.
The user may interact with the server 105 via the network 104 using the terminal devices 101, 102, 103 to receive or send messages or the like. Various communication client applications, such as a browser application, a shopping class application, a search class application, an instant messaging tool, a mailbox client, social platform software, etc., may be installed on the terminal devices 101, 102, 103.
The terminal devices 101, 102, 103 may be hardware or software. When the terminal devices 101, 102, 103 are hardware, they may be various electronic devices supporting browser applications, including but not limited to tablet computers, laptop and desktop computers, and the like. When the terminal devices 101, 102, 103 are software, they can be installed in the above-listed electronic devices. It may be implemented as a plurality of software or software modules, for example, for providing distributed services, or as a single software or software module. The present invention is not particularly limited herein.
The server 105 may be a server providing various services, such as a background server providing support for browser applications running on the terminal devices 101, 102, 103. The background server can analyze and process the received data such as the request and the like, and feed back the processing result to the terminal equipment.
The server may be hardware or software. When the server is hardware, the server may be implemented as a distributed server cluster formed by a plurality of servers, or may be implemented as a single server. When the server is software, it may be implemented as a plurality of software or software modules, for example, for providing distributed services, or as a single software or software module. The present invention is not particularly limited herein.
In practice, the method of generating an image provided by the embodiments of the present disclosure may be performed by the terminal device 101, 102, 103 and/or the server 105, 106, and the apparatus for generating an image may also be provided in the terminal device 101, 102, 103 and/or the server 105, 106.
It should be understood that the number of terminal devices, networks and servers in fig. 1 is merely illustrative. There may be any number of terminal devices, networks, and servers, as desired for implementation.
With continued reference to fig. 2, fig. 2 illustrates a flow 200 of one embodiment of a method of generating an image according to the present disclosure. The method for generating the image comprises the following steps:
in step 201, a first image is acquired comprising a first face.
In this embodiment, the execution subject (e.g., the terminal or the server shown in fig. 1) of the method for generating an image may acquire the first image including the first face from a local or remote album or database, or may acquire the first image including the first face via a local or remote photographing service.
In the present embodiment, the pre-trained generation type countermeasure network refers to a deep learning model developed based on the generation type countermeasure network (GAN, generative Adversarial Networks). For example, the generation type countermeasure network GAN, the cyclic coincidence generation type countermeasure network CycleGan, the face high precision attribute editing model AttGAN, the star generation type countermeasure network StarGAN, the space transformer generation type countermeasure network STGAN, the generation countermeasure network DualGAN, discoGAN of the dual learning, and the like.
The pre-trained generative antagonism network generally includes a generator G (generator) and a Discriminator (Discriminator). There are two data fields, X, Y, respectively. G is responsible for mimicking data in the X domain into real data and hiding them in real data, while D is responsible for separating the spurious data from the real data. After the two games, the counterfeiting technology of G is more and more serious, and the discrimination technology of D is more and more serious. The process of countermeasure reaches a dynamic balance until D no longer separates whether the data is real or G generated.
Training a generated challenge network requires two penalty functions: the reconstruction loss function of the generator and the discrimination loss function of the discriminator. The reconstruction loss function is used for determining whether the generated picture is similar to the original picture as far as possible; the discrimination loss function is used for inputting the generated false picture and the original true picture into the discriminator to obtain the two-class loss with the formula of 0 and 1.
The generator is composed of an encoder, a converter and a decoder. The encoder uses convolutional neural networks to extract features from the input image. For example, an image is compressed into 256 feature vectors of 64 x 64. The converter converts feature vectors of the image in the DA domain into feature vectors in the DB domain by combining non-similar features of the image. For example, a 6-layer Reset module may be used, each of which is a neural network layer consisting of two convolutional layers, to achieve the goal of preserving the original image features at the time of conversion. The decoder uses deconvolution layer (deconvolution) to restore low-level features from the feature vectors, and finally obtains the generated image.
The discriminator takes as input an image and tries to predict it as the original image or as the output image of the generator. The discriminator itself belongs to a convolutional network and features need to be extracted from the image, and then whether the extracted features belong to a specific class is determined by adding a convolutional layer which generates one-dimensional output.
The pre-trained generated countermeasure network generates face attribute information based on an input image as a constraint. The human face attribute information is a series of biological characteristic information for representing human face characteristics, has strong self stability and individual difference, and identifies the identity of a person. Including gender, skin tone, age, expression, etc.
The generated countermeasure network may be implemented by using a method for machine learning constraints in the prior art or a future developed technology, when face attribute information generated based on an input image (for example, a first image input when the generated countermeasure network is applied or a first image sample input when the generated countermeasure network is trained) is used as constraints, which is not limited in this application.
In a specific example of the present application, the face attribute information generated based on the input image may be used as an input of any one or more layers of the generator network in the generating type countermeasure network, and combined with an input of the original layer network to be used as an input, so as to improve the relevance between the output image of the generator network introducing the constraint and the face attribute information in the machine learning.
In another specific example of the present application, the facial attribute information generated based on the input image described above employs facial marker features to define a consistency penalty, guiding training of the discriminator in the generated countermeasure network. First, the generator generates a rough second image based on the input first image. The generating countermeasure network then generates a pre-training regression (regressor) based on the generated second image to predict a facial landmark land mark and mark key points of the face. Finally, the face features corresponding to the first image in the second image are refined through the local discriminator and the global discriminator. At this stage, the consistency of the landmark is emphasized, so that the final result is realistic and recognizable.
As will be appreciated by those skilled in the art, the generated countermeasure network takes as constraints face attribute information generated based on the input image. Wherein the input image may be the first image sample of the input while training the generated countermeasure network. The generating type countermeasure network extracts face attribute information of the input first image sample, and takes the face attribute information as constraint of the generating type countermeasure network to obtain an output generated image. In applying the generated countermeasure network, the input image may be an input first image including a first face. The generating type countermeasure network extracts the face attribute information of the input first image comprising the first face, takes the face attribute information of the first image as the constraint of the generating type countermeasure network, and obtains the output second image comprising the second face.
The first image input to the generated type countermeasure network may be an image including a face. The second image output by the countermeasure network may be an image which is different in style or sex from the first image and includes a face.
In some optional implementations of the present embodiment, the generating the face attribute information generated based on the input image by the countermeasure network includes: the generated countermeasure network takes the key points of the human face and/or the semantic segmentation result of the human face generated based on the input image as constraints.
In this implementation manner, the executing body may use a face key point extraction technology to extract face key points of the input image, and use the face key points as constraints when the generating type countermeasure network generates the output image. Alternatively or additionally, the executing body may employ a face semantic segmentation technique, and use a face semantic segmentation result as a constraint when the generating type countermeasure network generates the output image.
The generated type countermeasure network in the implementation mode adopts the key points of the human face generated based on the input image and/or the semantic segmentation result of the human face as constraints, so that the generator can link the five sense organs of the input image with those of the output image, thereby avoiding false generation of the human face features at other parts, enabling the input image to be a larger image comprising the human face, not being limited to only the input human face image, and improving the accuracy and quality of the output image.
In some alternative implementations of the present embodiment, inputting the first image into the pre-trained generated countermeasure network includes: and (3) carrying out different degrees of Gaussian blur on the first image, and inputting the first image with different degrees of Gaussian blur into a pre-trained generation type countermeasure network.
In this implementation, gaussian Blur (Gaussian blue), also called Gaussian smoothing, can reduce image noise and reduce the level of detail, enhancing the image effect of the image at different scale sizes (see scale space representation and scale space implementation). From a mathematical point of view, the gaussian blur process of an image is the convolution of the image with a normal distribution. Since the normal distribution is also called gaussian distribution, this technique is also called gaussian blur.
By adopting the first images with different degrees of Gaussian blur as the input of the generation type countermeasure network, the second images with different definition can be obtained, so that the needed second images with different definition can be determined on the basis of the second images with different definition.
Alternatively or additionally, inputting the first image into the pre-trained generated countermeasure network includes: and detecting whether the texture feature parameter value of the first image is larger than a texture threshold value, if so, carrying out Gaussian blur on the first image to different degrees, and inputting the first image with different degrees of Gaussian blur into a pre-trained generation type countermeasure network.
Here, the texture feature parameter value of the image refers to a parameter value for characterizing the texture feature of the image. Such as the thickness, density, and directionality of the texture. When the texture feature parameter value of the first image is detected to be greater than the texture threshold value, the texture of the first image is indicated to be complex. In general, image content generated based on an image with complex texture is disordered. Therefore, the first image can be subjected to different degrees of Gaussian blur, so that the second image is respectively generated for the first image subjected to different degrees of Gaussian blur, and the second image with different definition is obtained. Then, the second image with the required definition can be determined on the basis of the second images with different resolutions, so that the quality of the generated image is improved.
The pre-trained generated countermeasure network can adopt a crawler to crawl image samples from the network or directly acquire an image sample data set, and each image in the images comprises a human face; then, the crawled or acquired image sample can be directly used as the image sample of the training generation type countermeasure network; or taking the crawled image comprising the human face as an initial image sample, further processing data of the initial image sample to obtain a screened image meeting the requirement of the image sample, and taking the screened image as an image sample of the training generation type countermeasure network.
In some alternative implementations of the present embodiment, the pre-trained generated image samples of the input for training of the countermeasure network include: and carrying out data enhancement on the initial image sample to obtain an image sample.
In this implementation, the data enhancement may include operations such as rotation, translation, turnover, and the like. The training data needs to be uniform in style and contain image samples with different sexes, angles and face sizes, so that the initial image samples can be subjected to data enhancement, the training data volume is increased, the generalization capability of the generating type countermeasure network is improved, noise data is increased, and the robustness of the generating type countermeasure network is improved.
In some optional implementations of the present embodiment, data enhancement of the initial image sample includes: performing at least one of the following operations on the initial image sample: rotation, flipping, scaling, and varying degrees of gaussian blur.
In the implementation manner, the generalization capability and the robustness of the training-completed generating type countermeasure network can be improved by performing one or more operations of rotation, turnover, scaling and Gaussian blur of different degrees on the initial image sample.
According to the method for generating the image, in the process of generating the second image by the generation type countermeasure network based on the first image, the face attribute information of the first image is adopted as the constraint of the generation type countermeasure network, so that the quality, accuracy and efficiency of generating the second image by the generation type countermeasure network based on the input first image can be improved, the probability of generating the image by mistake is reduced, and the constraint that the input image can only be the image in the preset area is reduced.
An exemplary application scenario of the method of generating an image of the present disclosure is described below in conjunction with fig. 3.
As shown in fig. 3, fig. 3 illustrates one exemplary application scenario of a method of generating an image according to the present disclosure.
As shown in fig. 3, a method 300 of generating an image, operating in an electronic device 310, may include:
first, a first image 302 including a first face 301 is acquired;
then, face attribute information 303 is generated based on the face 301 in the first image 302;
finally, the first image 302 is input into a pre-trained generative countermeasure network 304, and the face attribute information 303 is used as a constraint of the generative countermeasure network 304, so as to obtain a second image 306 including a second face 305 output by the generative countermeasure network 304.
It should be understood that the above application scenario of the method of generating an image shown in fig. 3 is merely an exemplary description of the method of generating an image, and does not represent a limitation of the method. For example, the steps illustrated in fig. 3 above may be further implemented in greater detail. Other steps for generating images can be further added on the basis of the above-mentioned fig. 3.
With further reference to fig. 4, fig. 4 shows a schematic flow chart of one embodiment of a method of uploading a file in a method of generating an image according to the present disclosure.
As shown in fig. 4, the method 400 for uploading a file in the method for generating an image of the present embodiment may include the following steps:
In this embodiment, the execution subject (e.g., the terminal or the server shown in fig. 1) of the method for generating an image may acquire the first image including the first face from a local or remote album or database, or may acquire the first image including the first face via a local or remote photographing service.
In this embodiment, a technology of extracting a face key point in the prior art or a technology developed in the future may be used to obtain a face key point image of the first image based on the first image, which is not limited in this application. For example, face keypoint extraction may be performed using an active shape model (ASM, active Shape Model), an active appearance model (AMM, active Appearance Model), a cascade shape regression model Cascaded Shape Regression (CSR), or a face alignment algorithm (DAN, deep Alignment Network), or the like.
In this embodiment, the technique of the hair segmentation technique in the prior art or the future developed technique may be used to obtain the binary image of the hair of the first image based on the first image, which is not limited in this application. For example, a technique of segmenting hair may be employed to obtain a hair segmentation result and then convert the hair segmentation result into a binary image of hair.
In this embodiment, the multi-channel face image is a face image including RGB three channels of the first image and the following of the first image: three channels of the key points RGB of the human face and one channel of the binary image of the hair.
Wherein, three channels of RGB of the image are that each pixel point is represented by three RGB values, and the three channels are respectively: red channel R (red), green channel G (green), blue channel B (blue).
The three channels of the face key points RGB of the first image refer to extracting the face key points from the first image, and each pixel point of the face key point feature map is represented by three channels RGB. In a specific example, the first image input is fig. 5a, and the face key points represented by RGB three channels as shown in fig. 5b may be extracted.
The binary image-channel of the hair of the input image is that a binary image of the hair is obtained by adopting a hair segmentation technology, and each pixel point of the hair segmentation result is represented by the binary image-channel. The binary image means that in the image, the gray level is only two, that is, the gray value of any pixel point in the image is 0 or 255, which respectively represents black and white. In a specific example, the input image is shown in fig. 5a, and the result of dividing the hair using the binary image one-channel representation shown in fig. 5c can be obtained.
And step 405, inputting the multichannel face image into a pre-trained cyclic consistent generation type countermeasure network, and obtaining a second image which is output by the pre-trained cyclic consistent generation type countermeasure network and comprises a second face.
In this embodiment, the multi-channel face image may be input into a pre-trained cyclic coincidence generation type countermeasure network (CycleGan), so as to obtain a second image output by the cyclic coincidence generation type countermeasure network.
In a specific example, the first image is a real face image; the second image is a cartoon image. The cartoon image can be sketch and bottom of wall painting, oil painting, carpet, etc., or cartoon image, irony painting, humour painting, etc.
As will be appreciated by those skilled in the art, the multi-channel face image samples employed in pre-training the cyclically-congruent generated countermeasure network are adapted to the multi-channel face images input in the application of the cyclically-congruent generated countermeasure network to obtain a trained cyclically-congruent generated countermeasure network suitable for the multi-channel face images input in the application.
In one specific example, the structure of a pre-trained recurring consistent generation type countermeasure network is shown in fig. 6, including two generators g_a B, G _b2a and two discriminators d_a and d_b. The generator G_A2B is used for generating cartoon based on the input real person image, and the generator G_B2A is used for generating real person based on the cartoon image. The discriminator D_A is used for judging whether the image is a real face image or not according to the output result (0, 1), and the discriminator D_B is used for judging whether the image is a real cartoon image or not according to the output result (0, 1).
During training, the combined network of the two groups of generators and the discriminator is used for training alternately, and after training is completed, a real person is used for coming to the cartoon G_A2B generator to be on line.
It will be appreciated by those skilled in the art that the embodiment shown in fig. 4 described above is merely an exemplary embodiment of the present application and is not meant to be limiting.
For example, the pre-trained recurring consistent generation type countermeasure network described above may be other generation type countermeasure networks based on GAN improvement.
For another example, the multi-channel face image in fig. 4 may further include three channels of the face semantic segmentation result RGB of the first image on the basis of the three channels of RGB of the first image.
The face semantic segmentation result RGB three channels of the first image refer to that the face semantic segmentation result is extracted from an input image, and each pixel point of the face semantic segmentation result is represented by three channels of RGB. In a specific example, the input image is fig. 5a, and the face semantic segmentation result represented by RGB three channels as shown in fig. 5d can be extracted.
The semantic segmentation of the face semantic segmentation result image of the first image is an extension of target detection, the output of the semantic segmentation result image is a color mask of the target, which is distinguished by types, and the target can be positioned more accurately and is not influenced by the complex shape of the target.
When the face semantic segmentation is performed, the face semantic segmentation result of the first image can be obtained based on the first image by adopting the face semantic segmentation technology in the prior art or the technology developed in the future, which is not limited in the application. In some specific examples, techniques to segment facial semantics may employ a full convolution neural network FCN (Fully Convolutional Networks forSemantic Segmentation), a semantic segmentation network (SegNet, semantic Segmentation), a hole convolution (Dilated Convolutions), semantic segmentation (deeplat (V1, V2, V3, etc)), an image segmentation model (refinnenet), a pyramid scene parsing network (PSPNet), etc., to obtain a facial semantic segmentation result of the first image based on the first image.
For another example, the multi-channel face image in fig. 4 may further include a binary image first channel of the face semantic segmentation result on the basis of the RGB three channels including the first image. Alternatively, the multi-channel face image in fig. 4 may further include a binary image first channel of the face key points of the first image and a binary image first channel of the hair on the basis of the RGB three channels including the first image. Alternatively, the multi-channel face image in fig. 4 may further include a face key point RGB three-channel of the first image and a binary image one-channel of the face semantic segmentation result on the basis of the RGB three-channel of the first image. And will not be described in detail herein.
The method for generating an image in the embodiment shown in fig. 4 of the present disclosure further discloses that, based on the method for generating an image shown in fig. 2, a multichannel face image is input into a pre-trained cyclic consistent generation type countermeasure network, and a second image including a second face output by the pre-trained cyclic consistent generation type countermeasure network is obtained. In the process, the multichannel face image is used as a reference for generating the second image, so that the accuracy and quality of the generated second image are improved.
As an implementation of the method shown in the above figures, the embodiment of the disclosure provides an embodiment of an apparatus for generating an image, where the embodiment of the apparatus corresponds to the embodiment of the method shown in fig. 2 to 6, and the apparatus is specifically applicable to the terminal or the server shown in fig. 1.
As shown in fig. 7, the apparatus 700 for generating an image of the present embodiment may include: an acquisition unit 710 configured to acquire a first image including a first face; a generating unit 720 configured to input the first image into a pre-trained generation type countermeasure network, and obtain a second image including a second face output by the generation type countermeasure network; wherein the generated countermeasure network takes face attribute information generated based on the input image as a constraint.
In some embodiments, the generating unit 720 is further configured to: carrying out Gaussian blur on the first image in different degrees, and inputting the first image with the Gaussian blur in different degrees into a pre-trained generation type countermeasure network; or detecting whether the texture characteristic parameter value of the first image is larger than a texture threshold value, if so, carrying out Gaussian blur on the first image to different degrees, and inputting the first image with different degrees of Gaussian blur into a pre-trained generation type countermeasure network.
In some embodiments, the generation type countermeasure network employed in the generation unit 720 includes, as constraints, face attribute information generated based on the input image: the generated countermeasure network adopted in the generating unit takes the key points of the human face and/or the semantic segmentation result of the human face generated based on the input image as constraints.
In some embodiments, the generation type countermeasure network employed in the generation unit 720 includes, as constraints, face keypoints and/or face semantic segmentation results generated based on the input image: the generation type countermeasure network adopted in the generation unit takes a multichannel face image generated based on the input image as input; wherein the multichannel face image comprises RGB three channels of the input image and at least one of the following of the input image: a binary image one-channel or RGB three-channel of the key points of the human face; a binary image one-channel or RGB three-channel of a human face semantic segmentation result; and binary image of hair-a channel.
In some embodiments, the image samples of the input employed in the generation unit 720 for training by the pre-trained generated countermeasure network include: and carrying out data enhancement on the initial image sample to obtain an image sample.
In some embodiments, the image samples of the input employed in the generation unit 720 for training by the pre-trained generated countermeasure network include: performing at least one of the following operations on the initial image sample: rotation, flipping, scaling, and varying degrees of gaussian blur.
In some embodiments, the generated countermeasure network includes at least any one of: the method comprises the steps of generating a countermeasure network GAN, circularly consistent generating the countermeasure network CycleGan, generating a face high-precision attribute editing model AttGAN, generating a star-shaped countermeasure network StarGAN and generating the countermeasure network STGAN by a space transformer.
In some embodiments, the first image is a real face image; the second image is a cartoon image.
It should be understood that the various elements recited in apparatus 700 correspond to the various steps recited in the methods described with reference to fig. 2-5. Thus, the operations and features described above with respect to the method are equally applicable to the apparatus 700 and the various units contained therein, and are not described in detail herein.
Referring now to fig. 8, a schematic diagram of an electronic device (e.g., server or terminal device of fig. 1) 800 suitable for use in implementing embodiments of the present disclosure is shown. Terminal devices in embodiments of the present disclosure may include, but are not limited to, devices such as notebook computers, desktop computers, and the like. The terminal device/server illustrated in fig. 8 is merely an example, and should not impose any limitation on the functionality and scope of use of embodiments of the present disclosure.
As shown in fig. 8, the electronic device 800 may include a processing means (e.g., a central processor, a graphics processor, etc.) 801, which may perform various appropriate actions and processes according to a program stored in a Read Only Memory (ROM) 802 or a program loaded from a storage means 808 into a Random Access Memory (RAM) 803. In the RAM803, various programs and data required for the operation of the electronic device 800 are also stored. The processing device 801, the ROM 802, and the RAM803 are connected to each other by a bus 804. An input/output (I/O) interface 805 is also connected to the bus 804.
In general, the following devices may be connected to the I/O interface 805: input devices 806 including, for example, a touch screen, touchpad, keyboard, mouse, camera, microphone, accelerometer, gyroscope, and the like; an output device 807 including, for example, a Liquid Crystal Display (LCD), speakers, vibrators, etc.; storage 808 including, for example, magnetic tape, hard disk, etc.; communication means 809. The communication means 809 may allow the electronic device 800 to communicate wirelessly or by wire with other devices to exchange data. While fig. 8 shows an electronic device 800 having various means, it is to be understood that not all of the illustrated means are required to be implemented or provided. More or fewer devices may be implemented or provided instead. Each block shown in fig. 8 may represent one device or a plurality of devices as needed.
In particular, according to embodiments of the present disclosure, the processes described above with reference to flowcharts may be implemented as computer software programs. For example, embodiments of the present disclosure include a computer program product comprising a computer program embodied on a computer readable medium, the computer program comprising program code for performing the method shown in the flowcharts. In such an embodiment, the computer program may be downloaded and installed from a network via communication device 809, or installed from storage device 808, or installed from ROM 802. The above-described functions defined in the methods of the embodiments of the present disclosure are performed when the computer program is executed by the processing device 801. It should be noted that, the computer readable medium according to the embodiments of the present disclosure may be a computer readable signal medium or a computer readable storage medium, or any combination of the two. The computer readable storage medium can be, for example, but not limited to, an electronic, magnetic, optical, electromagnetic, infrared, or semiconductor system, apparatus, or device, or a combination of any of the foregoing. More specific examples of the computer-readable storage medium may include, but are not limited to: an electrical connection having one or more wires, a portable computer diskette, a hard disk, a Random Access Memory (RAM), a read-only memory (ROM), an erasable programmable read-only memory (EPROM or flash memory), an optical fiber, a portable compact disc read-only memory (CD-ROM), an optical storage device, a magnetic storage device, or any suitable combination of the foregoing. In an embodiment of the present disclosure, a computer readable storage medium may be any tangible medium that can contain, or store a program for use by or in connection with an instruction execution system, apparatus, or device. Whereas in embodiments of the present disclosure, the computer-readable signal medium may comprise a data signal propagated in baseband or as part of a carrier wave, with computer-readable program code embodied therein. Such a propagated data signal may take any of a variety of forms, including, but not limited to, electro-magnetic, optical, or any suitable combination of the foregoing. A computer readable signal medium may also be any computer readable medium that is not a computer readable storage medium and that can communicate, propagate, or transport a program for use by or in connection with an instruction execution system, apparatus, or device. Program code embodied on a computer readable medium may be transmitted using any appropriate medium, including but not limited to: electrical wires, fiber optic cables, RF (radio frequency), and the like, or any suitable combination of the foregoing.
The computer readable medium may be contained in the electronic device; or may exist alone without being incorporated into the electronic device. The computer readable medium carries one or more programs which, when executed by the electronic device, cause the electronic device to: acquiring a first image comprising a first face; inputting the first image into a pre-trained generation type countermeasure network to obtain a second image which is output by the generation type countermeasure network and comprises a second face; wherein the generated countermeasure network takes face attribute information generated based on the input image as a constraint.
Computer program code for carrying out operations of embodiments of the present disclosure may be written in one or more programming languages, including an object oriented programming language such as Java, smalltalk, C ++ and conventional procedural programming languages, such as the "C" programming language or similar programming languages. The program code may execute entirely on the user's computer, partly on the user's computer, as a stand-alone software package, partly on the user's computer and partly on a remote computer or entirely on the remote computer or server. In the case of a remote computer, the remote computer may be connected to the user's computer through any kind of network, including a Local Area Network (LAN) or a Wide Area Network (WAN), or may be connected to an external computer (for example, through the Internet using an Internet service provider).
The flowcharts and block diagrams in the figures illustrate the architecture, functionality, and operation of possible implementations of systems, methods and computer program products according to various embodiments of the present disclosure. In this regard, each block in the flowchart or block diagrams may represent a module, segment, or portion of code, which comprises one or more executable instructions for implementing the specified logical function(s). It should also be noted that, in some alternative implementations, the functions noted in the block may occur out of the order noted in the figures. For example, two blocks shown in succession may, in fact, be executed substantially concurrently, or the blocks may sometimes be executed in the reverse order, depending upon the functionality involved. It will also be noted that each block of the block diagrams and/or flowchart illustration, and combinations of blocks in the block diagrams and/or flowchart illustration, can be implemented by special purpose hardware-based systems which perform the specified functions or acts, or combinations of special purpose hardware and computer instructions.
The units involved in the embodiments of the present disclosure may be implemented by means of software, or may be implemented by means of hardware. The described units may also be provided in a processor, for example, described as: a processor includes an acquisition unit and a generation unit. The names of these units do not constitute a limitation on the unit itself in some cases, and for example, the acquisition unit may also be described as "a unit that acquires a first image including a first face".
The foregoing description is only of the preferred embodiments of the present disclosure and description of the principles of the technology being employed. It will be appreciated by those skilled in the art that the scope of the invention referred to in this disclosure is not limited to the specific combination of features described above, but encompasses other embodiments in which features described above or their equivalents may be combined in any way without departing from the spirit of the invention. Such as those described above, are mutually substituted with the technical features having similar functions disclosed in the present disclosure (but not limited thereto).
Claims (16)
1. A method of generating an image, comprising:
acquiring a first image comprising a first face;
inputting the first image into a pre-trained generation type countermeasure network to obtain a second image which is output by the generation type countermeasure network and comprises a second face; the generated type countermeasure network takes face attribute information generated based on an input image as constraint;
wherein said inputting said first image into a pre-trained generated countermeasure network comprises:
carrying out Gaussian blur on the first image in different degrees, and inputting the first image with the Gaussian blur in different degrees into a pre-trained generation type countermeasure network; or (b)
And detecting whether the texture characteristic parameter value of the first image is larger than a texture threshold value, if so, carrying out Gaussian blur on the first image to different degrees, and inputting the first image with different degrees of Gaussian blur into a pre-trained generation type countermeasure network.
2. The method of claim 1, wherein the generating an countermeasure network having face attribute information generated based on the input image as constraints comprises: the generated countermeasure network takes the key points of the human face and/or the semantic segmentation result of the human face generated based on the input image as constraints.
3. The method of claim 2, wherein the generating an countermeasure network to constrain face keypoints and/or face semantic segmentation results generated based on the input image comprises:
the generating type countermeasure network takes a multichannel face image generated based on an input image as input; wherein the multichannel face image comprises RGB three channels of the input image and at least one of the following of the input image:
a binary image one-channel or RGB three-channel of the key points of the human face;
a binary image one-channel or RGB three-channel of a human face semantic segmentation result; and
binary image of hair-a channel.
4. The method of claim 1, wherein the pre-trained generated countermeasure network for training input image samples comprises:
and carrying out data enhancement on the initial image sample to obtain an image sample.
5. The method of claim 4, wherein the data enhancing the initial image sample comprises:
performing at least one of the following operations on the initial image sample: rotation, flipping, scaling, and varying degrees of gaussian blur.
6. The method of claim 1, wherein the generated countermeasure network includes at least any one of: the method comprises the steps of generating a countermeasure network GAN, circularly consistent generating the countermeasure network CycleGan, generating a face high-precision attribute editing model AttGAN, generating a star-shaped countermeasure network StarGAN and generating the countermeasure network STGAN by a space transformer.
7. The method of any of claims 1-6, wherein the first image is a real face image; the second image is a cartoon image.
8. An apparatus for generating an image, comprising:
an acquisition unit configured to acquire a first image including a first face;
a generating unit configured to input the first image into a pre-trained generation type countermeasure network, and obtain a second image including a second face output by the generation type countermeasure network; the generated type countermeasure network takes face attribute information generated based on an input image as constraint;
The generation unit is further configured to:
carrying out Gaussian blur on the first image in different degrees, and inputting the first image with the Gaussian blur in different degrees into a pre-trained generation type countermeasure network; or (b)
And detecting whether the texture characteristic parameter value of the first image is larger than a texture threshold value, if so, carrying out Gaussian blur on the first image to different degrees, and inputting the first image with different degrees of Gaussian blur into a pre-trained generation type countermeasure network.
9. The apparatus according to claim 8, wherein the generation countermeasure network employed in the generation unit regards face attribute information generated based on the input image as a constraint, includes: the generated countermeasure network adopted in the generating unit takes the key points of the human face and/or the semantic segmentation result of the human face generated based on the input image as constraints.
10. The apparatus according to claim 9, wherein the generation-type countermeasure network employed in the generation unit includes, as a constraint, face keypoints and/or face semantic segmentation results generated based on the input image:
the generation type countermeasure network adopted in the generation unit takes a multichannel face image generated based on the input image as input; wherein the multichannel face image comprises RGB three channels of the input image and at least one of the following of the input image:
A binary image one-channel or RGB three-channel of the key points of the human face;
a binary image one-channel or RGB three-channel of a human face semantic segmentation result; and
binary image of hair-a channel.
11. The apparatus of claim 8, wherein the pre-trained generated countermeasure network employed in the generating unit includes an image sample of an input for training:
and carrying out data enhancement on the initial image sample to obtain an image sample.
12. The apparatus of claim 11, wherein the pre-trained generated countermeasure network employed in the generating unit includes an image sample of an input for training:
performing at least one of the following operations on the initial image sample: rotation, flipping, scaling, and varying degrees of gaussian blur.
13. The apparatus of claim 8, wherein the generated countermeasure network includes at least any one of: the method comprises the steps of generating a countermeasure network GAN, circularly consistent generating the countermeasure network CycleGan, generating a face high-precision attribute editing model AttGAN, generating a star-shaped countermeasure network StarGAN and generating the countermeasure network STGAN by a space transformer.
14. The apparatus of any of claims 8-13, wherein the first image is a real face image; the second image is a cartoon image.
15. An electronic device, comprising:
one or more processors;
a storage means for storing one or more programs;
when executed by the one or more processors, causes the one or more processors to implement the method of any of claims 1-7.
16. A computer readable medium having stored thereon a computer program which, when executed by a processor, implements the method of any of claims 1-7.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010065575.7A CN111275784B (en) | 2020-01-20 | 2020-01-20 | Method and device for generating image |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010065575.7A CN111275784B (en) | 2020-01-20 | 2020-01-20 | Method and device for generating image |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111275784A CN111275784A (en) | 2020-06-12 |
| CN111275784B true CN111275784B (en) | 2023-06-13 |
Family
ID=70999026
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010065575.7A Active CN111275784B (en) | 2020-01-20 | 2020-01-20 | Method and device for generating image |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111275784B (en) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111709875B (en) * | 2020-06-16 | 2023-11-14 | 北京百度网讯科技有限公司 | Image processing method, device, electronic equipment and storage medium |
| CN111709878B (en) * | 2020-06-17 | 2023-06-23 | 北京百度网讯科技有限公司 | Face super-resolution implementation method and device, electronic equipment and storage medium |
| CN111754596B (en) * | 2020-06-19 | 2023-09-19 | 北京灵汐科技有限公司 | Editing model generation method, device, equipment and medium for editing face image |
| CN112819715B (en) * | 2021-01-29 | 2024-04-05 | 北京百度网讯科技有限公司 | Data recovery method, network training method, related device and electronic equipment |
| CN112991150A (en) * | 2021-02-08 | 2021-06-18 | 北京字跳网络技术有限公司 | Style image generation method, model training method, device and equipment |
| CN113255807B (en) * | 2021-06-03 | 2022-03-25 | 北京的卢深视科技有限公司 | Face analysis model training method, electronic device and storage medium |
| CN113822798B (en) * | 2021-11-25 | 2022-02-18 | 北京市商汤科技开发有限公司 | Method and device for training generation countermeasure network, electronic equipment and storage medium |
| CN114091662B (en) * | 2021-11-26 | 2024-05-14 | 广东伊莱特生活电器有限公司 | Text image generation method and device and electronic equipment |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109858445A (en) * | 2019-01-31 | 2019-06-07 | 北京字节跳动网络技术有限公司 | Method and apparatus for generating model |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5060233B2 (en) * | 2007-09-25 | 2012-10-31 | 富士フイルム株式会社 | Imaging apparatus and automatic photographing method thereof |
| US8457367B1 (en) * | 2012-06-26 | 2013-06-04 | Google Inc. | Facial recognition |
| CN106951867B (en) * | 2017-03-22 | 2019-08-23 | 成都擎天树科技有限公司 | Face identification method, device, system and equipment based on convolutional neural networks |
| CN107577985B (en) * | 2017-07-18 | 2019-10-15 | 南京邮电大学 | The implementation method of the face head portrait cartooning of confrontation network is generated based on circulation |
| AU2017101166A4 (en) * | 2017-08-25 | 2017-11-02 | Lai, Haodong MR | A Method For Real-Time Image Style Transfer Based On Conditional Generative Adversarial Networks |
| US10482337B2 (en) * | 2017-09-29 | 2019-11-19 | Infineon Technologies Ag | Accelerating convolutional neural network computation throughput |
| CN108537152B (en) * | 2018-03-27 | 2022-01-25 | 百度在线网络技术(北京)有限公司 | Method and apparatus for detecting living body |
| CN108564127B (en) * | 2018-04-19 | 2022-02-18 | 腾讯科技(深圳)有限公司 | Image conversion method, image conversion device, computer equipment and storage medium |
| CN108550176A (en) * | 2018-04-19 | 2018-09-18 | 咪咕动漫有限公司 | Image processing method, equipment and storage medium |
| US10607065B2 (en) * | 2018-05-03 | 2020-03-31 | Adobe Inc. | Generation of parameterized avatars |
| JP7010774B2 (en) * | 2018-06-26 | 2022-01-26 | トヨタ自動車株式会社 | Intermediate process state estimation method |
| CN109376582B (en) * | 2018-09-04 | 2022-07-29 | 电子科技大学 | Interactive face cartoon method based on generation of confrontation network |
| CN109800732B (en) * | 2019-01-30 | 2021-01-15 | 北京字节跳动网络技术有限公司 | Method and device for generating cartoon head portrait generation model |
| CN110070483B (en) * | 2019-03-26 | 2023-10-20 | 中山大学 | Portrait cartoon method based on generation type countermeasure network |
| CN110503601A (en) * | 2019-08-28 | 2019-11-26 | 上海交通大学 | Face based on confrontation network generates picture replacement method and system |
| CN110648294B (en) * | 2019-09-19 | 2022-08-30 | 北京百度网讯科技有限公司 | Image restoration method and device and electronic equipment |
| CN111047509B (en) * | 2019-12-17 | 2024-07-05 | 中国科学院深圳先进技术研究院 | Image special effect processing method, device and terminal |
-
2020
- 2020-01-20 CN CN202010065575.7A patent/CN111275784B/en active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109858445A (en) * | 2019-01-31 | 2019-06-07 | 北京字节跳动网络技术有限公司 | Method and apparatus for generating model |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111275784A (en) | 2020-06-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111275784B (en) | Method and device for generating image | |
| CN111260545B (en) | Method and device for generating image | |
| US20230081645A1 (en) | Detecting forged facial images using frequency domain information and local correlation | |
| CN108898186B (en) | Method and device for extracting image | |
| CN108509915B (en) | Method and device for generating face recognition model | |
| CN111368685B (en) | Method and device for identifying key points, readable medium and electronic equipment | |
| CN111476871B (en) | Method and device for generating video | |
| WO2022105125A1 (en) | Image segmentation method and apparatus, computer device, and storage medium | |
| CN111553267B (en) | Image processing method, image processing model training method and device | |
| CN111898696A (en) | Method, device, medium and equipment for generating pseudo label and label prediction model | |
| CN116824278B (en) | Image content analysis method, device, equipment and medium | |
| CN111402143A (en) | Image processing method, device, equipment and computer readable storage medium | |
| CN113792871B (en) | Neural network training method, target identification device and electronic equipment | |
| CN113704531A (en) | Image processing method, image processing device, electronic equipment and computer readable storage medium | |
| CN112215171B (en) | Target detection method, device, equipment and computer readable storage medium | |
| TWI803243B (en) | Method for expanding images, computer device and storage medium | |
| JP7282474B2 (en) | Encryption mask determination method, encryption mask determination device, electronic device, storage medium, and computer program | |
| CN114298997B (en) | Fake picture detection method, fake picture detection device and storage medium | |
| US20240320807A1 (en) | Image processing method and apparatus, device, and storage medium | |
| CN115131698A (en) | Video attribute determination method, device, equipment and storage medium | |
| CN114972016A (en) | Image processing method, image processing apparatus, computer device, storage medium, and program product | |
| CN113569740A (en) | Video recognition model training method and device and video recognition method and device | |
| CN108921138B (en) | Method and apparatus for generating information | |
| CN113822521A (en) | Method and device for detecting quality of question library questions and storage medium | |
| CN118135058A (en) | Image generation method and device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |