This research has been built using the disent framework
The version of disent included in this repo is frozen at v0.4.0


Please use the following citation if you use this research in your own work:
@article{michlo2022data,
title={Data Overlap: A Prerequisite For Disentanglement},
author={Michlo, Nathan and James, Steven and Klein, Richard},
journal={arXiv preprint arXiv:2202.13341},
year={2022}
}Please use the following citation if you use disent in your own research:
@Misc{Michlo2021Disent,
author = {Nathan Juraj Michlo},
title = {Disent - A modular disentangled representation learning framework for pytorch},
howpublished = {Github},
year = {2021},
url = {https://github.com/nmichlo/disent}
}My MSc research includes creation of the (disent)[https://github.com/nmichlo/disent] framework which implements models, metrics and datasets from various papers relating to disentanglement. The framework itself is highly configurable and customizable.
We contribute the following "🧵" frameworks, metrics and datasets as part of my research.
We contribute four new synthetic datasets, each with various settings that can be adjusted. Each dataset is designed to highlight key issues with learning disentangled representations with VAEs:
-
VAEs learn distances over the data according to the reconstruction loss measured between raw datapoints. We call these distances the perceived distances of VAEs. XYSquares highlights this issue as the distance between each observation is constant in terms of a pixel-wise loss function! A VAE cannot order elements in the latent space because of this and disentanglement does not occur!
-
🧵 XYSquares: Three non-overlapping squares that can move around a grid. This dataset is adversarial for disentanglement when pixel-wise reconstruction losses are used for VAEs.

FIX: A simple way to remedy this problem and improve disentanglement is by changing to a reconstruction loss that can re-capture the distances between observations such ground-truth distances are captured, OR by changing the spacing between grid-points such that squares once again overlap and the pixel-wise loss can now capture the ground-truth distances. In the case of this XYSquares dataset, a loss function that would introduce overlap is for example augmenting the observations passed to a pixel-wise loss function with some type of blurring operation.
-
Example! Changing Spacing: Adjusting the spacing of gridpoints for this dataset affects overlap and improves disentanglement.
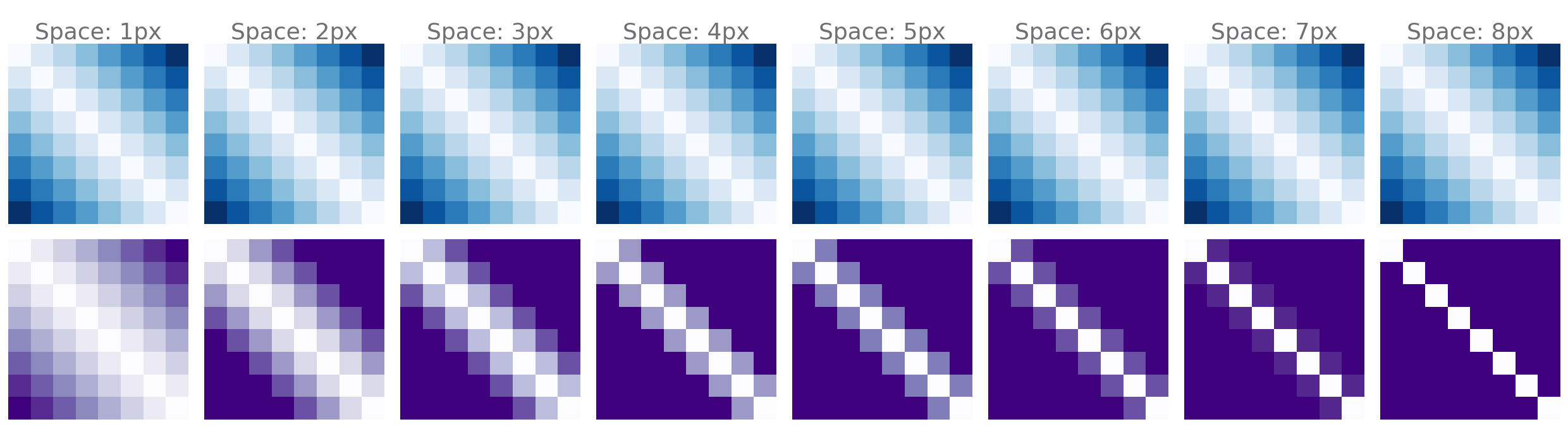
Blue represents the average matrix of ground-truth distances over factor traversals measured using the L1 distance (Just for reference). Purple represents the perceived distance matrix along the same ground-truth factor traversals when changing the spacing between gridpoints as measured using the pixel-wise MSE.
-
-
Disentanglement is subjective. Different representations of ground-truth factors can be chosen for the same task, eg. RGB versus HSV colour spaces in images. If the ground-truth distances between observations do not correspond to the perceived distances between observations (according to the reconstruction loss of the VAE), then disentanglement performance suffers. Different choices of ground-truth factors can make disentanglement tasks easier.
-
🧵 XYObject: A simplistic version of dSprites with a single square.
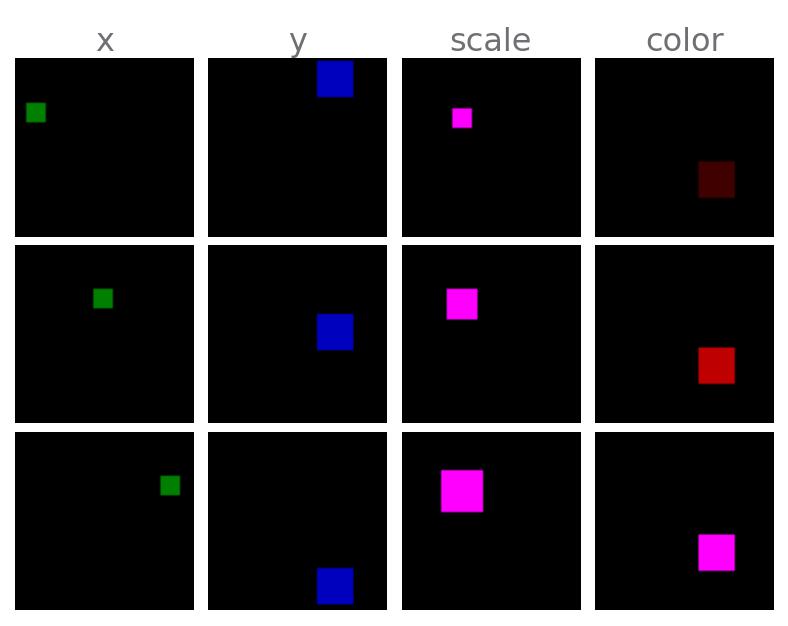
-
🧵 XYObjectShaded: Exact same dataset as XYObject, but ground truth factors have a different representation. Disentanglement is subjective: If ground-truth factors do not align with distances in the dataspace, disentanglement performance suffers!
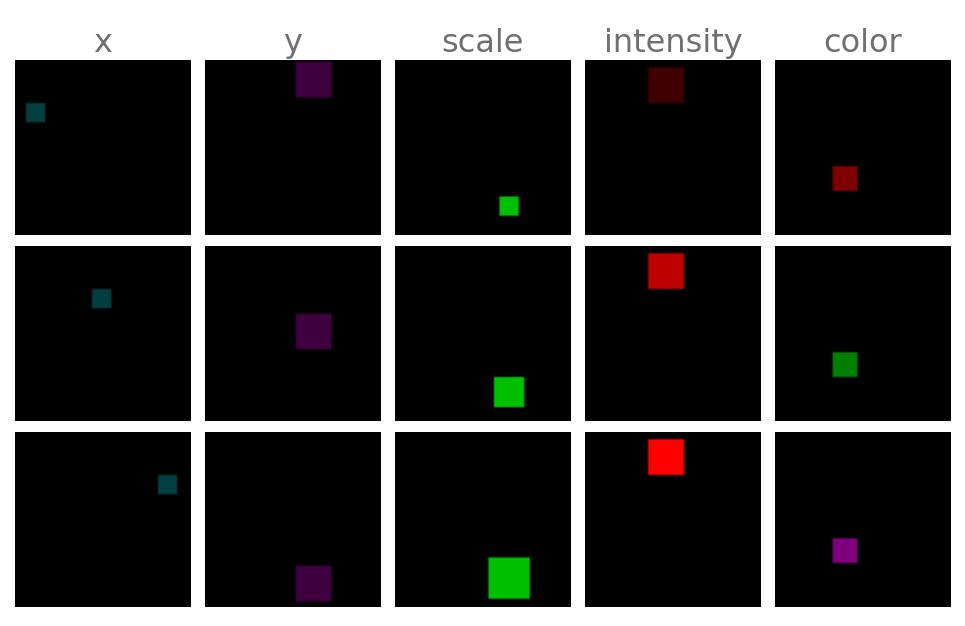
-
-
The desired ground-truth factors can be masked by external ground-truth factors that we do not care about. These factors affect the distances learnt by VAEs. Simply incorporating real world noise into an existing synthetic dataset can drastically hinder disentanglement performance. Adjusting the strength of this noise can improve or hinder disentanglement performance too.
-
🧵 dSpritesImagenet: Version of DSprite with foreground or background deterministically masked out with tiny-imagenet data. External factors can mask desired ground-truth factors!

-




We contribute the following supervised and unsupervised VAE frameworks.
Supervised:
- Ada-TVAE a supervised disentanglement framework that can learn disentangled representations from a distance function used as a supervision signal. Combining metric learning, specifically triplet loss, and using ideas from the Ada-GVAE, which estimates which variables are shared between two different representations.
Unsupervised:
- Ada-TVAE (unsupervised): The same as the Ada-TVAE, but the supervision signal is replaced with some distance function between raw datapoints. Using this approach, there is an upper bound on how disentangled representations can be. Some datasets are more conducive to this than others depending on how well the ground-truth distances between observations aligns with the distances between datapoints.
We propose multiple metrics for measuring how well a VAE has learnt disentangled/factored representations by learning distances over the data. These metrics measure three properties. To obtain disentangled/factored representations all three properties need to be satisfied. VAEs usually only satisfy the first two properties, but only accidentally satisfy the third if unsupervised.
-
Ground-Truth Correlation: between Ground-Truth and Latent Distances
- Perceived distances over the data according to the chosen reconstruction loss of the VAE should correspond to distances between ground-truth factors of the observations themselves. This metric measures the Spearman rank correlation coefficient between these corresponding distances.
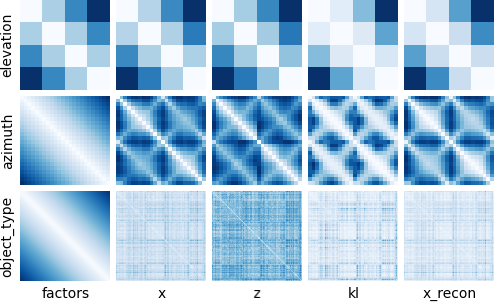
VAEs learn distances in the latent space (z) that correspond to distances in the data space (x) as measured by the reconstruction loss. The distances between ground-truth factors of the factor traversals used to computed these average distance matrices are given on the left (factors). These average distance matrices for each ground-truth factor are computed over the Cars3D dataset. See README_DISENT.md. Some factors naturally correlate more with ground-truth distances. This implies datasets are accidentally disentangled!
-
Linearity ratio: of representations in the latent space
- If we encode a series of observations that correspond to a single ground-truth factor traversal, where only the target factor is changed, but the rest remain fixed. Then corresponding representations encoded by the VAE should lie along some arbitrary n-dimensional line in the latent space. This metric measures how well these encoded points correspond to a single n-dimensional line by performing PCA over the encoded values and taking the max eigenvalue over the sum of eigenvalues. This can be seen as taking the variance along the n-dimensional line which best describes the points over the sum of the variances of all the perpendicular lines that are additionally needed to represent the points. A score of 1 is good, all the points can be represented by a single n-dimensional line. A score of 0 is bad and the encodings need many axes to represent them.
-
Axis-alignment ratio: of representations in the latent space
- Like the linearity ratio, this metric encodes observations that lie along the same factor traversals. The variance of each latent unit of the resulting encodings are then computed. The max variance is taken over the sum of all variances. This metric makes sure that the factor traversal is encoded by a single latent unit indicating the resulting representations are factored. But not necessarily ordered according to the correlation above. Note that the axis-alignment ratio is bounded above by the linearity ratio. If a good linearity ratio is obtained, the latent space just needs to be rotated to obtain a good axis-alignment ratio.
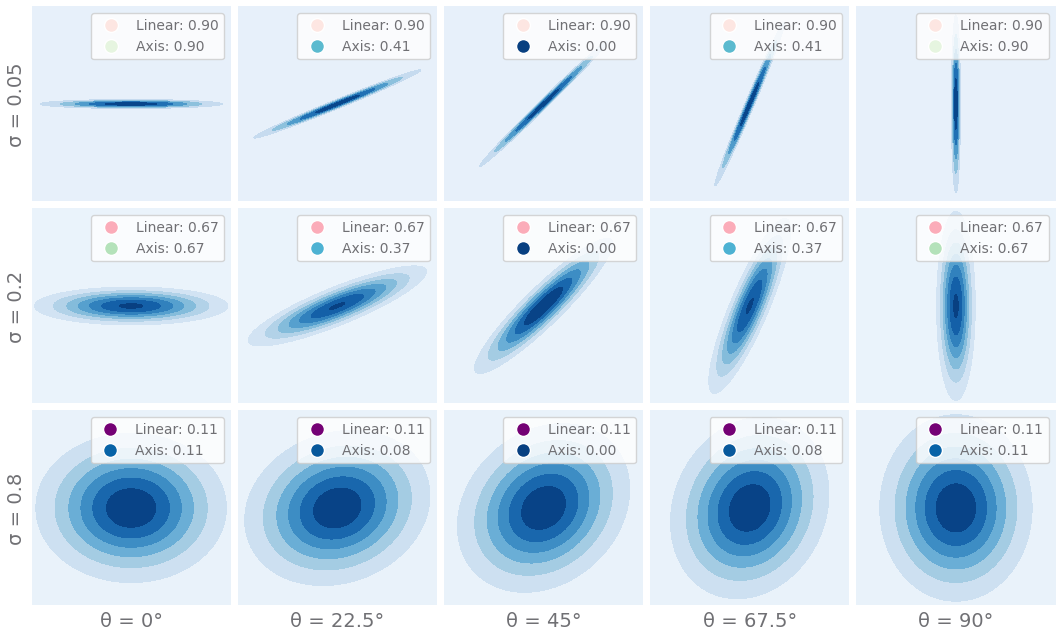
A comparison of the linearity and axis-alignment ratios for samples of points in a 2D space. With differing widths and rotations for the distributions that the points are sampled from.


This repo is the uncleaned frozen version of disent v0.4.0.
- Originally, to generate the disent versions, we used the script
prepare_release.shto remove all research related code from thexdevbranch before being merged into thedevbranch. - This repo has simply not performed this cleaning process before merging the
xdevbranch intodevandmain.
Disent Structure: Please see the architecture for disent under the Architecture section.
/disent: See the architecture for disent/experiment: See the architecture for disent/tests: See the architecture for disent/docs: See the architecture for disent
Research Structure: All research related files are contained in /research
research.code- contains the experimental additions to the disent framework. The package structure mirrors that of disent.research.code.dataset: Additional ground-truth datasetsresearch.code.frameworks: Additional experimental frameworksresearch.code.metrics: Additional disentanglement metricsresearch.code.util: Additional helper code
research/config: Hydra config files that override or complement those fromexperiment/configresearch/part*: Collections of scripts for running experiments and generating plotsresearch/scriptsHelper scripts for running experiments in a generic way on the University of the Witwatersrand's computing cluster. These can be adapted for custom use.