A modular disentangled representation learning framework built with PyTorch Lightning
![]()
Visit the docs for more info, or browse the releases.
Contributions are welcome!
────────────────
NOTE: My MSc. research has moved here
Some of the contributions have been incorporated directly into disent
────────────────
Disent is a modular disentangled representation learning framework for auto-encoders, built upon PyTorch-Lightning. This framework consists of various composable components that can be used to build and benchmark various disentanglement vision tasks.
The name of the framework is derived from both disentanglement and scientific dissent.
Get started with disent by installing it with $pip install disent or cloning this repository.
Disent aims to fill the following criteria:
- Provide high quality, readable, consistent and easily comparable implementations of frameworks
- Highlight difference between framework implementations by overriding hooks and minimising duplicate code
- Use best practice eg.
torch.distributions - Be extremely flexible & configurable
- Support low memory systems
Please use the following citation if you use Disent in your own research:
@Misc{Michlo2021Disent,
author = {Nathan Juraj Michlo},
title = {Disent - A modular disentangled representation learning framework for pytorch},
howpublished = {Github},
year = {2021},
url = {https://github.com/nmichlo/disent}
}Disent includes implementations of modules, metrics and datasets from various papers.
Note that "🧵" means that the dataset, framework or metric was introduced by disent!
Various common datasets used in disentanglement research are included with disent. The dataset loaders provide various features including:
- automatic downloads & preperation
prepare=True - automatic hash verification
- automatic optimization of underlying hdf5 formats for low-memory disk-based access.
Data input and target dataset augmentations and transforms are supported, as well as augmentations on the GPU or CPU at different points in the pipeline.
-
Ground Truth:
-
🚗 Cars3D

-
◻️ dSprites

-
🔺 MPI3D

-
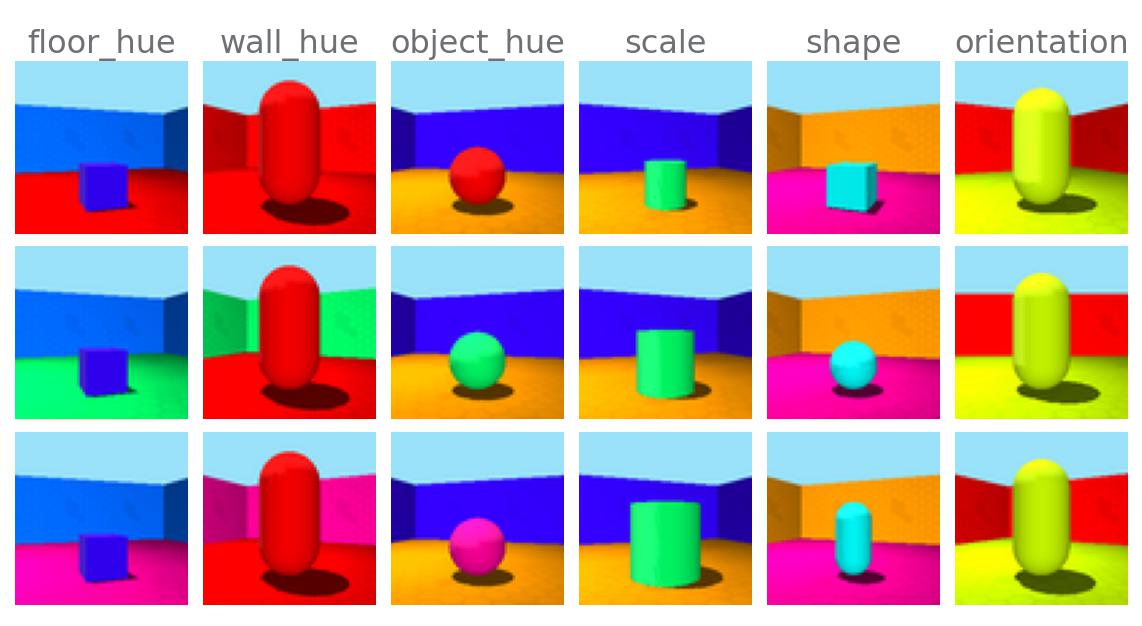
🌈 Shapes3D
-
🧵 dSpritesImagenet: Version of DSprite with foreground or background deterministically masked out with tiny-imagenet data.

-
-
Ground Truth Synthetic:
-
🧵 XYSquares: Three non-overlapping squares that can move around a grid. This dataset is adversarial to VAEs that use pixel-wise reconstruction losses.

-
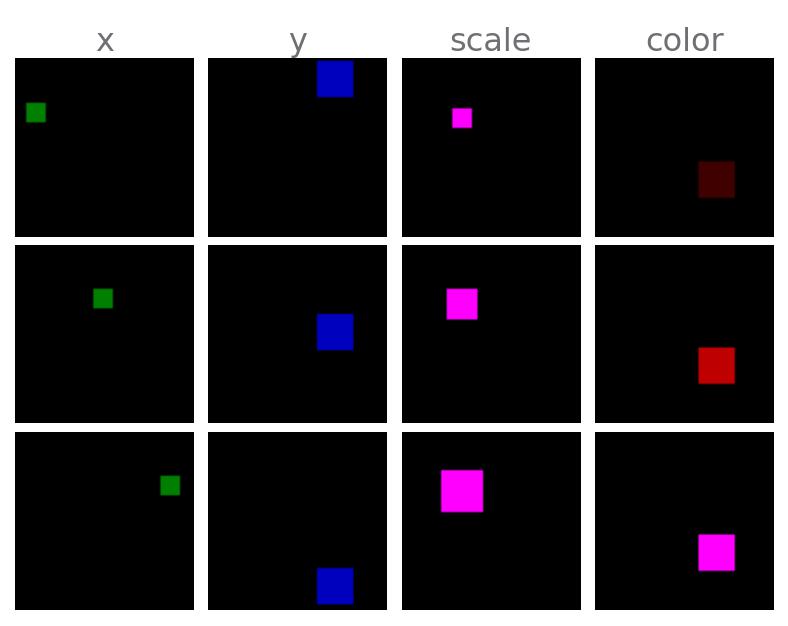
🧵 XYObject: A simplistic version of dSprites with a single square.
-
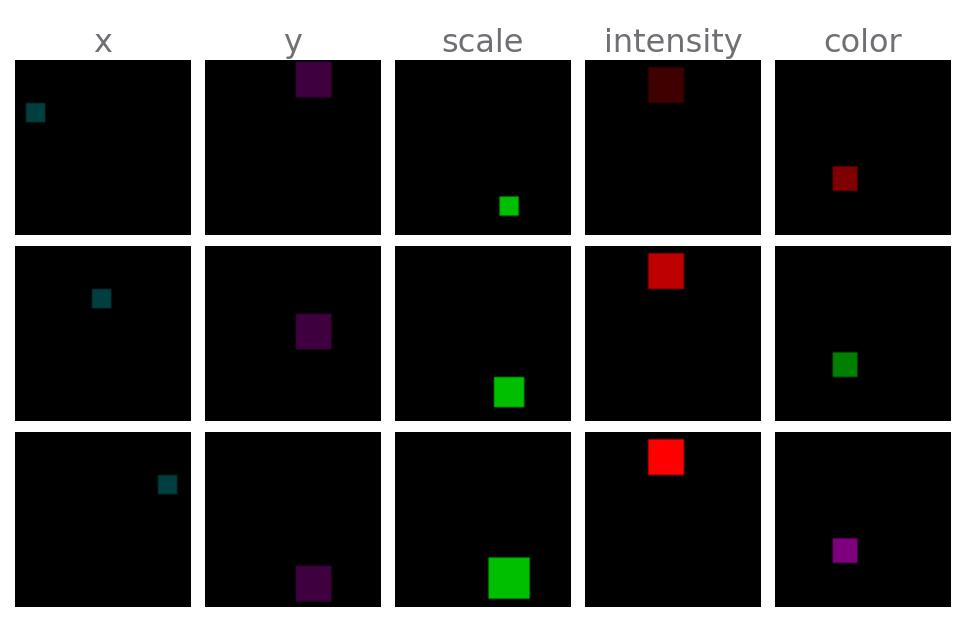
🧵 XYObjectShaded: Exact same dataset as XYObject, but ground truth factors have a different representation.
-







Disent provides the following Auto-Encoders and Variational Auto-Encoders!
- Unsupervised:
- Weakly Supervised:
- Ada-GVAE: Adaptive GVAE,
AdaVae.cfg(average_mode='gvae'), usually better than below! - Ada-ML-VAE: Adaptive ML-VAE,
AdaVae.cfg(average_mode='ml-vae')
- Ada-GVAE: Adaptive GVAE,
- Supervised:
- TAE: Triplet Auto-Encoder
- TVAE: Triplet Variational Auto-Encoder
Introduced in Disent
- Unsupervised:
- 🧵 Ada-TVAE-D: Adaptive Triplet VAE that uses data distances instead of ground-truth distances as the supervision signal.
- 🧵 Ada-TAE-D: Adaptive Triplet AE that uses data distances instead of ground-truth distances as the supervision signal.
- Weakly Supervised:
- 🧵 Ada-AE: Adaptive AE, the auto-encoder version of the Ada-GVAE
- Supervised:
- 🧵 Ada-TVAE: Adaptive Triplet VAE, disentangled version of the TVAE
- 🧵 Ada-TAE: Adaptive Triplet AE, disentangled version of the TAE
🏗 Todo: Many popular disentanglement frameworks still need to be added, please submit an issue if you have a request for an additional framework.
- FactorVAE
- GroupVAE
- MLVAE
Various metrics are provided by disent that can be used to evaluate the learnt representations of models that have been trained on ground-truth data.
- Disentanglement:
- FactorVAE Score
- DCI
- MIG
- SAP
- Unsupervised Scores
- 🧵 Flatness Components: Measures of the three components needed to learn factored representations from distances. VAEs often learn the first two (correlation & linearity), and the can happen accidentally (axis-alignment)!
- 🪡 Ground-Truth Correlation - The spearman rank correlation between latent distances and ground-truth distances.
- 🪡 Linearity Ratio - How well factor traversals lie along an n-dimensional arbitrarily rotated line in the latent space
- 🪡 Axis-Alignment Ratio - How well factor traversals are represented by a single latent variable, ie. an n-dimensional line that is axis-aligned.
- 🧵 Flatness Score - Measuring the max distance between factor traversal embeddings and the path length of their embeddings.
🏗 Todo: Some popular metrics still need to be added, please submit an issue if you wish to add your own, or you have a request.
Hyper-parameter annealing is supported through the use of schedules. The currently implemented schedules include:
- Linear Schedule
- Cyclic Schedule
- Cosine Wave Schedule
- Various other wrapper schedules
The disent module structure:
disent.dataset: dataset wrappers, datasets & sampling strategiesdisent.dataset.data: raw datasetsdisent.dataset.sampling: sampling strategies forDisentDatasetwhen multiple elements are required by frameworks, eg. for triplet lossdisent.dataset.transform: common data transforms and augmentationsdisent.dataset.wrapper: wrapped datasets are no longer ground-truth datasets, these may have some elements masked out. We can still unwrap these classes to obtain the original datasets for benchmarking.
disent.frameworks: frameworks, including Auto-Encoders and VAEsdisent.frameworks.ae: Auto-Encoder based frameworksdisent.frameworks.vae: Variational Auto-Encoder based frameworks
disent.metrics: metrics for evaluating disentanglement using ground truth datasetsdisent.model: common encoder and decoder models used for VAE researchdisent.nn: torch components for building models including layers, transforms, losses and general mathsdisent.schedule: annealing schedules that can be registered to a frameworkdisent.util: helper classes, functions, callbacks, anything unrelated to a pytorch system/model/framework.
Disent is still under development. Features and APIs are subject to change! However, I will try and minimise the impact of these.
A small suite of tests currently exist which will be expanded upon in time.
Hydra Experiment Directories
Easily run experiments with hydra config, these files
are not available from pip install.
experiment/run.py: entrypoint for running basic experiments with hydra configexperiment/config/config.yaml: main configuration file, this is probably what you want to edit!experiment/config: root folder for hydra config filesexperiment/util: various helper code for experiments
Extending The Default Configs
All configs in experiment/config can easily be extended or overridden
without modifying any files. We can add a new config folder to the hydra search path
by setting the environment variable DISENT_CONFIGS_PREPEND to point to a config folder
that should take priority over those contained in the default folder.
The advantage of this is that new frameworks and datasets can be used with experiments without cloning or modifying disent itself. You can separate your research code from the library!
- See the examples in the docs for more information!
The following is a basic working example of disent that trains a BetaVAE with a cyclic beta schedule and evaluates the trained model with various metrics.
💾 Basic Example
import lightning as L
import torch
from torch.utils.data import DataLoader
from disent.dataset import DisentDataset
from disent.dataset.data import XYObjectData
from disent.dataset.sampling import SingleSampler
from disent.dataset.transform import ToImgTensorF32
from disent.frameworks.vae import BetaVae
from disent.metrics import metric_dci
from disent.metrics import metric_mig
from disent.model import AutoEncoder
from disent.model.ae import DecoderConv64
from disent.model.ae import EncoderConv64
from disent.schedule import CyclicSchedule
# create the dataset & dataloaders
# - ToImgTensorF32 transforms images from numpy arrays to tensors and performs checks
# - if you use `num_workers != 0` in the DataLoader, the make sure to
# wrap `trainer.fit` with `if __name__ == '__main__': ...`
data = XYObjectData()
dataset = DisentDataset(dataset=data, sampler=SingleSampler(), transform=ToImgTensorF32())
dataloader = DataLoader(dataset=dataset, batch_size=128, shuffle=True, num_workers=0)
# create the BetaVAE model
# - adjusting the beta, learning rate, and representation size.
module = BetaVae(
model=AutoEncoder(
# z_multiplier is needed to output mu & logvar when parameterising normal distribution
encoder=EncoderConv64(x_shape=data.x_shape, z_size=10, z_multiplier=2),
decoder=DecoderConv64(x_shape=data.x_shape, z_size=10),
),
cfg=BetaVae.cfg(
optimizer='adam',
optimizer_kwargs=dict(lr=1e-3),
loss_reduction='mean_sum',
beta=4,
)
)
# cyclic schedule for target 'beta' in the config/cfg. The initial value from the
# config is saved and multiplied by the ratio from the schedule on each step.
# - based on: https://arxiv.org/abs/1903.10145
module.register_schedule(
'beta', CyclicSchedule(
period=1024, # repeat every: trainer.global_step % period
)
)
# train model
# - for 2048 batches/steps
trainer = L.Trainer(
max_steps=2048, gpus=1 if torch.cuda.is_available() else None, logger=False, enable_checkpointing=False
)
trainer.fit(module, dataloader)
# compute disentanglement metrics
# - we cannot guarantee which device the representation is on
# - this will take a while to run
get_repr = lambda x: module.encode(x.to(module.device))
metrics = {
**metric_dci(dataset, get_repr, num_train=1000, num_test=500, show_progress=True),
**metric_mig(dataset, get_repr, num_train=2000),
}
# evaluate
print('metrics:', metrics)Visit the docs for more examples!
The entrypoint for basic experiments is experiment/run.py.
Some configuration will be required, but basic experiments can
be adjusted by modifying the Hydra Config 1.1
files in experiment/config.
Modifying the main experiment/config/config.yaml is all you
need for most basic experiments. The main config file contains
a defaults list with entries corresponding to yaml configuration
files (config options) in the subfolders (config groups) in
experiment/config/<config_group>/<option>.yaml.
💾 Config Defaults Example
defaults:
# data
- sampling: default__bb
- dataset: xyobject
- augment: none
# system
- framework: adavae_os
- model: vae_conv64
# training
- optimizer: adam
- schedule: beta_cyclic
- metrics: fast
- run_length: short
# logs
- run_callbacks: vis
- run_logging: wandb
# runtime
- run_location: local
- run_launcher: local
- run_action: train
# <rest of config.yaml left out>
...Easily modify any of these values to adjust how the basic experiment
will be run. For example, change framework: adavae to framework: betavae, or
change the dataset from xyobject to shapes3d. Add new options by adding new
yaml files in the config group folders.
Weights and Biases is supported by changing run_logging: none to
run_logging: wandb. However, you will need to login from the command line. W&B logging supports
visualisations of latent traversals.
pip install disentOtherwise, to install from source we recommend using a conda virtual environment.
⤵️ Install from Source
# clone the repo
git clone https://github.com/nmichlo/disent
cd disent
# create and activate the conda environment [py38,py39,py310]
conda create -n disent-py310 python=3.10
conda activate disent-py310
# check that the correct python version is used
which python
which pip
# make sure to upgrade pip
pip install --upgrade pip
# install minimal requirements
pip install -r requirements.txt
# (optional) install extra requirements
# - first do the above because torch is required to compile torchsort while installing
pip install -r requirements-extra.txt
# (optional) install test requirements
pip install -r requirements-test.txt
Make sure to install pre-commit hooks to ensure code is automatically formatted
correctly when committing or pushing changes to disent.
# install git hooks
pip install pre-commit
pre-commit install
# manually trigger all pre-commit hooks
pre-commit run --all-filesTo run tests locally, make sure to install all the test and extra dependencies in your environment.
pip install -r requirements.txt
# torchsort first requires torch to be installed
pip install -r requirements-extra.txt -r requirements-test.txt- Created as part of my Computer Science MSc which ended early 2022.
- I needed custom high quality implementations of various VAE's.
- A pytorch version of disentanglement_lib.
- I didn't have time to wait for Weakly-Supervised Disentanglement Without Compromises to release their code as part of disentanglement_lib. (As of September 2020 it has been released, but has unresolved discrepencies).
- disentanglement_lib still uses outdated Tensorflow 1.0, and the flow of data is unintuitive because of its use of Gin Config.