Note: All code and demonstrations are used for our INFOCOM demo paper:
Ruyu Luo, Wanli Ni, and Hui Tian, "Visualizing Multi-Agent Reinforcement Learning for Robotic Communication in Industrial IoT Networks," in Proc. IEEE INFOCOM Demos, virtual, May 2022.
Abstract:
| With its mobility and flexibility, autonomous robots have received extensive attention in industrial Internet of Things (IoT). In this paper, we adopt non-orthogonal multiple access and multi-antenna technology to enhance the connectivity of sensors and the throughput of data collection through taking advantage of the power and spatial domains. For average sum rate maximization, we optimize the transmit power of sensors and the trajectories of robots jointly. To deal with uncertainty and dynamics in the industrial environment, we propose a multi-agent reinforcement learning (MARL) algorithm with experience exchange. Next, we present the visualization of robotic communication and mobility to analyze the learning behavior intuitively. From the software implementation results, we observe that the proposed MARL algorithm can effectively adjust the communication strategies of sensors and control the trajectories of robots in a fully distributed manner. |
|---|
| Keywords: Multi-agent reinforcement learning, robotic communication, industrial Internet of Things. |
In this paper, we present the simulation and visualization of multi-agent reinforcement learning (MARL) with upper-confidence bound (UCB) exploration.
- Here are four demonstrations for different stages in the MARL training process.
- the beginning of training

- 800 rounds of training

- 1600 rounds of training

- the end of training
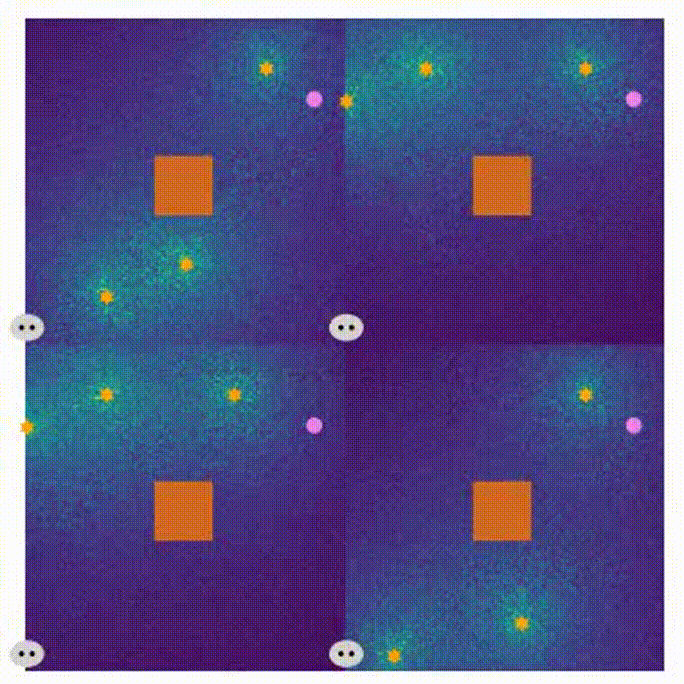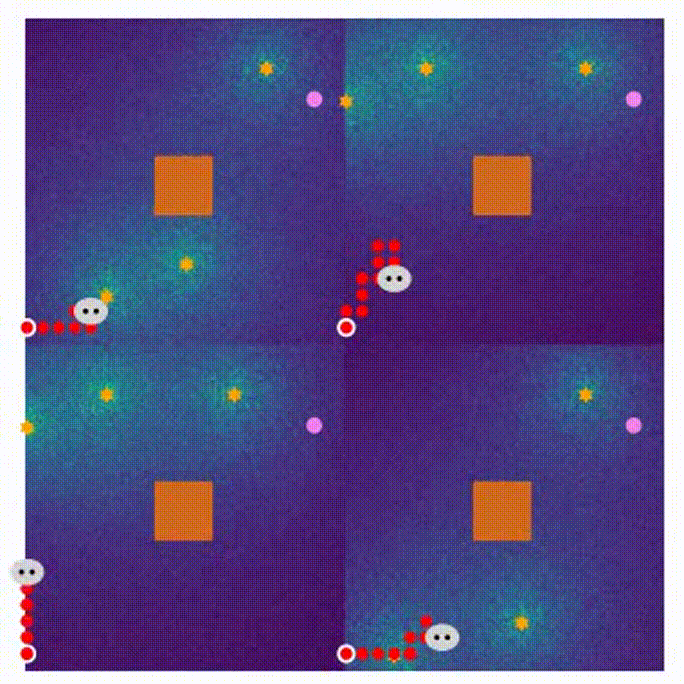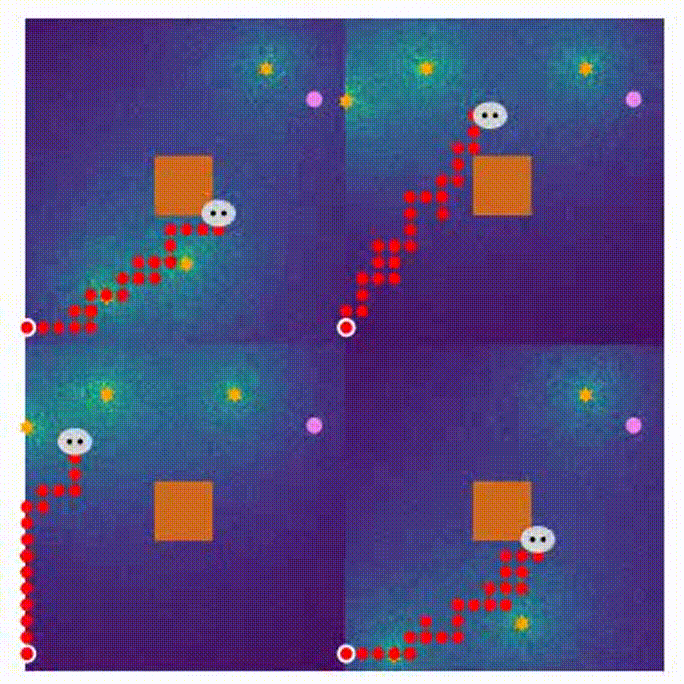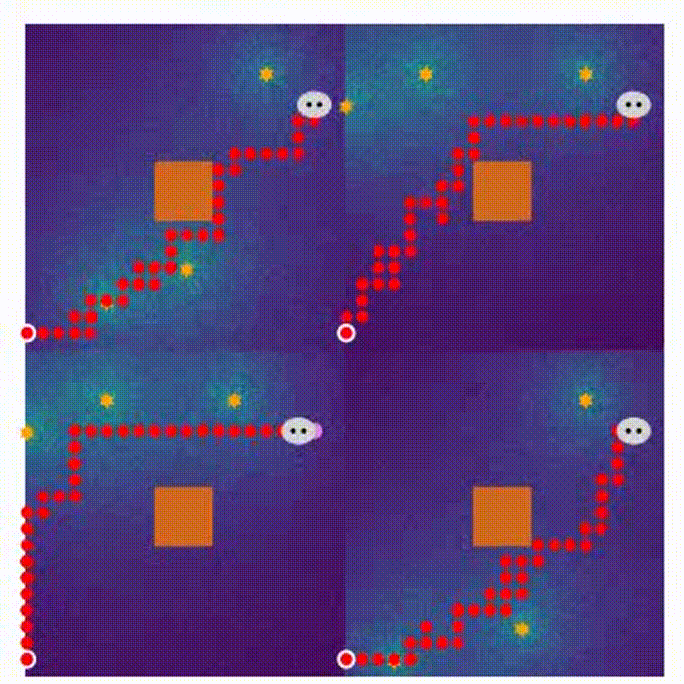
- the beginning of training




- Here is a simple introduction to the code used in our paper.
-
- visualization tool.py: Mian code of four robots, connections between the environment and learning agents
- RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
- plot_figure.py: Reward convergence figure
-
- MARL convergence.py: Mian code of six robots with experience exchange, connections between the environment and learning agents & the visualization of real-time system status
- RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
-
- robot_trajectory.py: Mian code of two robots, connections between the environment and learning agents
- RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
- plot_figure.py: The trajectories with different reward policy
-
[1] D. C. Nguyen et al., “6G Internet of Things: A Comprehensive Survey,” IEEE Internet of Things J., vol. 9, no. 1, pp. 359-383, Jan. 2022.
[2] R. Luo, H. Tian and W. Ni, “Communication-Aware Path Design for Indoor Robots Exploiting Federated Deep Reinforcement Learning,” in Proc. IEEE PIMRC, Helsinki, Finland, Sept. 2021, pp. 1197-1202.
[3] C. Jin et al., “Is Q-learning Provably Efficient?” in Proc. NeurIPS, Montr´eal, Canada, Dec. 2018, pp. 4868-4878.