Note: All code and demonstrations are used for our submitted papers:
Ruyu Luo, Wanli Ni, and Hui Tian, "Visualizing Multi-Agent Reinforcement Learning for Robotic Communication in Industrial IoT Networks," IEEE INFOCOM Demo, May. 2022.
In this paper, we present the simulation and visualization of multi-agent reinforcement learning (MARL).
- Here are four demonstrations for different stages in the MARL training process.
- the beginning of training

- 800 rounds of training

- 1600 rounds of training

- the end of training
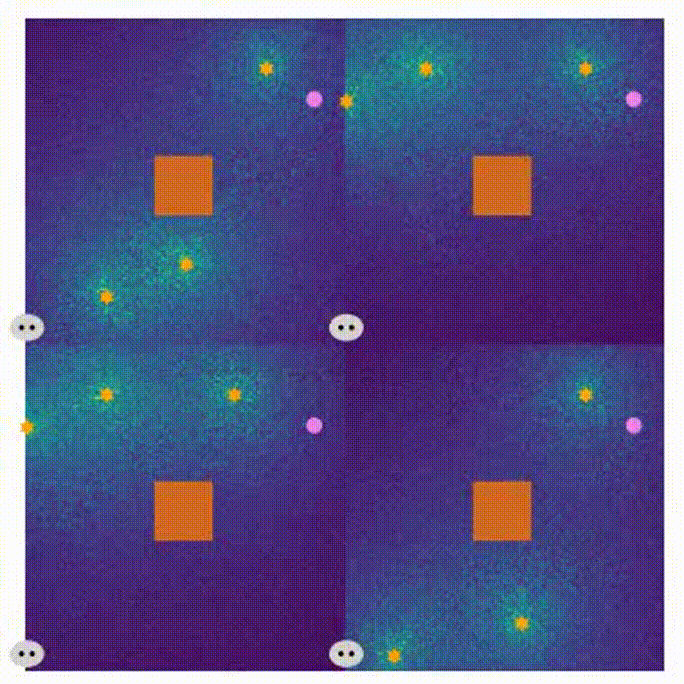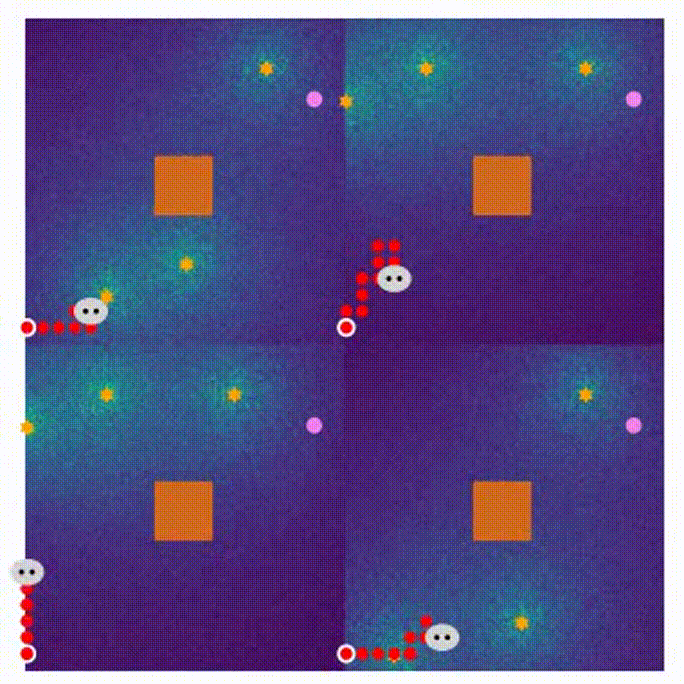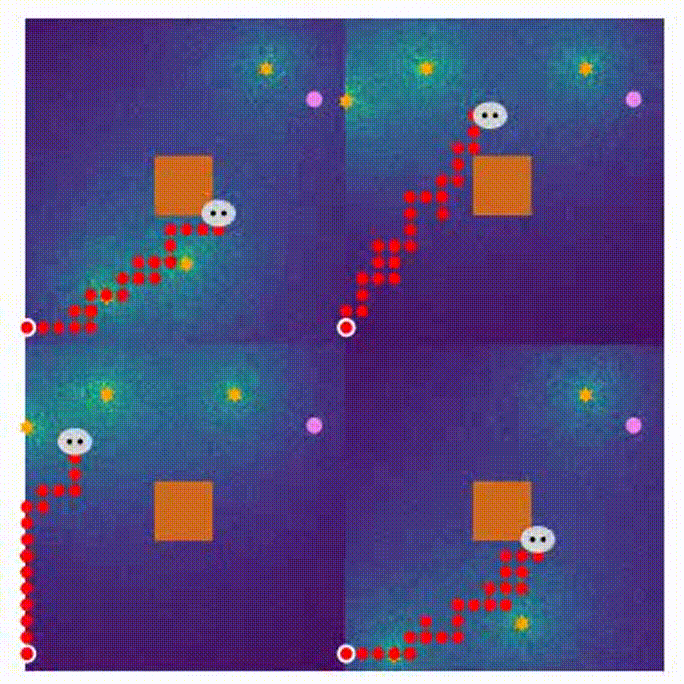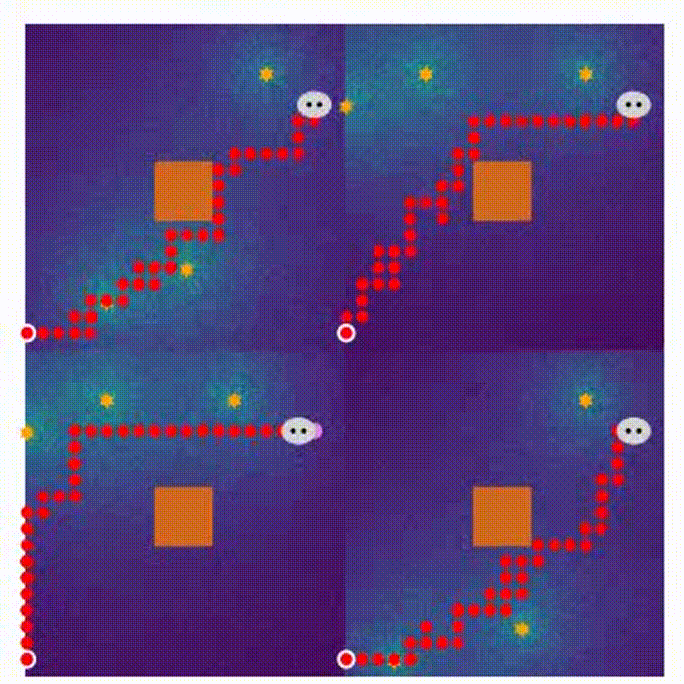
- the beginning of training




- Here is a simple introduction to the code used in our paper.
-
- visualization tool.py: Main code of four robots, connections between the environment and learning agents
- RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
- plot_figure.py: Reward convergence figure
-
- MARL convergence.py: Main code of six robots with experience exchange, connections between the environment and learning agents & the visualization of real-time system status
- RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
-
- robot_trajectory.py: Main code of two robots, connections between the environment and learning agents
- RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
- plot_figure.py: The trajectories with different reward policy
-
[1] D. C. Nguyen et al., “6G Internet of Things: A Comprehensive Survey,” IEEE Internet of Things J., vol. 9, no. 1, pp. 359-383, Jan. 2022.
[2] R. Luo, H. Tian and W. Ni, “Communication-Aware Path Design for Indoor Robots Exploiting Federated Deep Reinforcement Learning,” in Proc. IEEE PIMRC, Helsinki, Finland, Sept. 2021, pp. 1197-1202.
[3] C. Jin et al., “Is Q-learning Provably Efficient?” in Proc. NeurIPS, Montr´eal, Canada, Dec. 2018, pp. 4868-4878.