Note: All code and demonstrations are used for the submitted paper:
Ruyu Luo, Wanli Ni, Hui Tian, Julian Cheng, and Kwang-Cheng Chen, "Joint Trajectory and Radio Resource Optimization by Multi-Agent Reinforcement Learning for Autonomous Mobile Robots in Industrial Internet of Things", submitted to IEEE TCom, Dec. 2022.
In this paper, we present the simulation codes of multi-agent reinforcement learning (MARL) with upper-confidence bound (UCB) exploration.
Here are the setting of our simulations.
| Notation | Simulation Value | Physical Meaning |
|---|---|---|
| the number of SNs in each group | ||
| the maximal x-axis size of the moving area | ||
| the maximal y-axis size of the moving area | ||
| the antenna height of robots | ||
| the antenna height of SNs | ||
| the power of the AWGN | ||
| the maximum transmit power | ||
| the large-scale channel power gain at the reference distance |
||
| the path loss exponent | ||
| the Rician factor | ||
| the grid size |
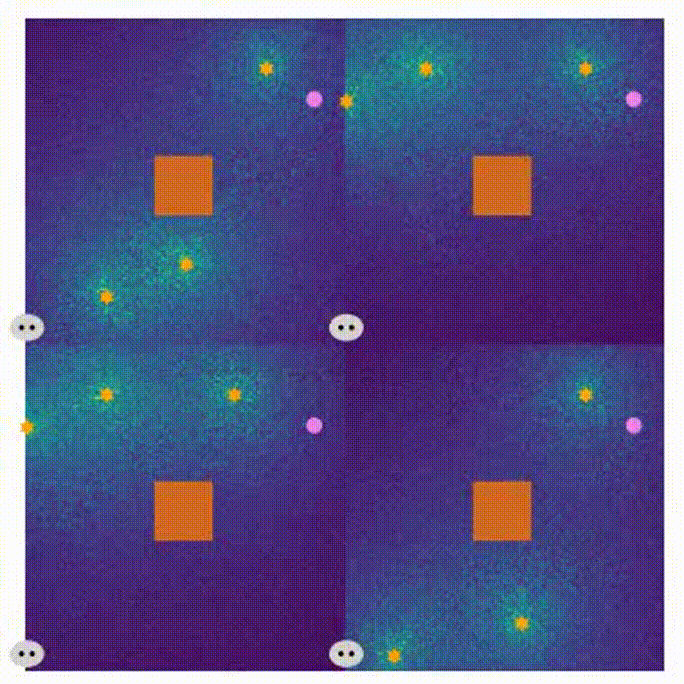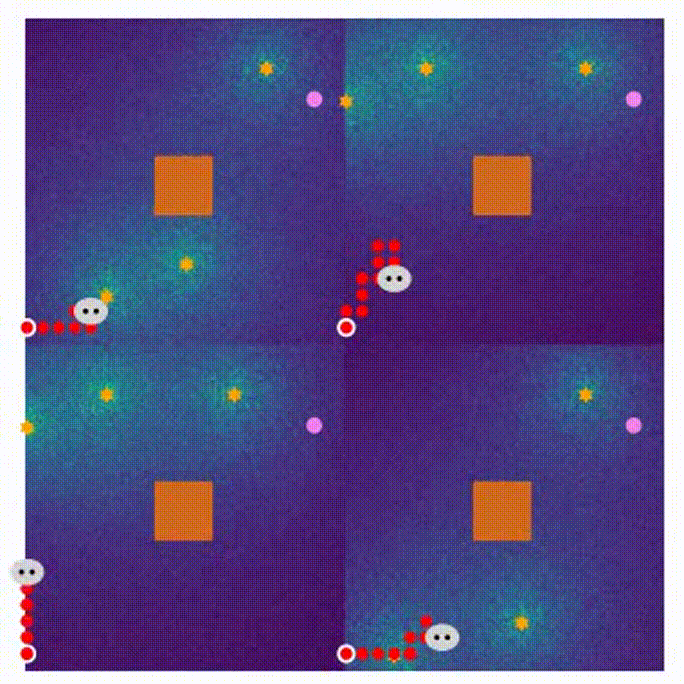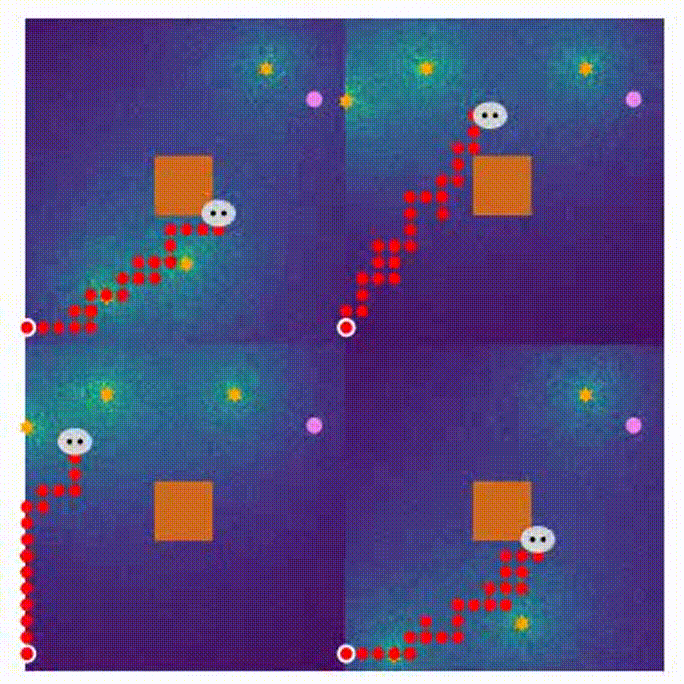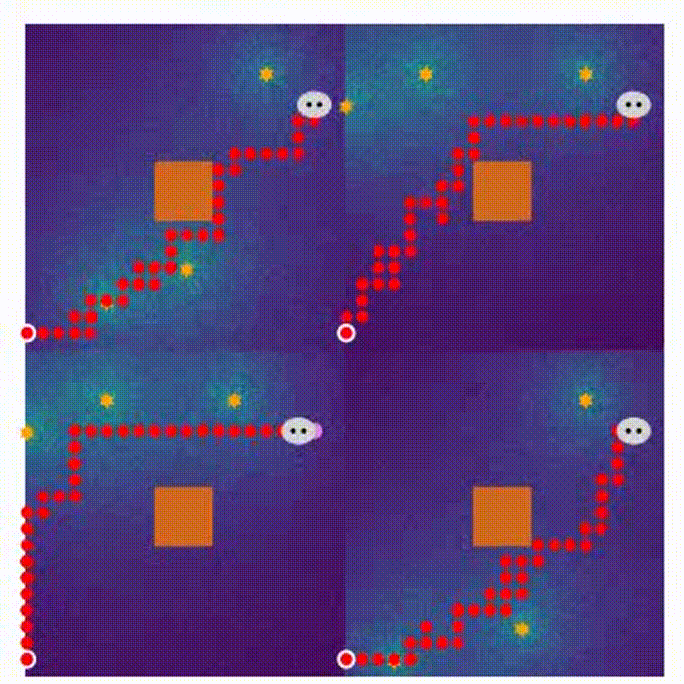
The visualization of the proposed MARL can be seen in Visual_MARL.
- Here are four demonstrations for different stages in the MARL training process.
- the beginning of training

- 800 rounds of training

- 1600 rounds of training

- the end of training
- the beginning of training




Here is a simple introduction to the code used in our paper.
-
Figure_1_reward_comparison (Reward comparison between different algorithms)
-
Centralized_QL
- RL_brain.py: Centralized tabular Q-learning agent with e-greedy exploration
- main.py: Main code of two robots that train with global information, connections between the environment and learning agents without experience exchange
-
UCB_MARL_environment1
- RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
- main.py: Main code of four robots, connections between the environment and learning agents, where two robots without interference at the strictly same environment exchange experience.
-
UCB_MARL_environment2
-
RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
-
main.py: Main code of four robots, connections between the environment and learning agents, where two nearby robots with interference at the same SN deployment exchange experience.
-
-
-
Figure_2_convergence_comparison (Convergence comparison between different
$H$ )-
UCB_MARL
- RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
- main.py: Main code of six robots, connections between the environment and learning agents
-
e-greedy_MARL
-
RL_brain.py: Tabular Q-learning agent with e-greedy exploration
-
main.py: Main code of two robots that train locally without experience exchange, connections between the environment and learning agents
-
-
-
Figure_3_robot_trajectory (Robot trajectory under different
$\kappa$ )-
RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
-
plot_figure.py: The trajectories with different reward policy
-
[robot trajectory.py](https://github.com/lry-bupt/UCB_MARL/blob/main/Figure_3_robot_trajectory/robot trajectory.py): Main code of four robots with experience exchange, connections between the environment and learning agents
-
-
Figure_4_relation_between_R_T (Relation between average sum rate and arrival time)
-
RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
-
main.py: Main code of two robots with experience exchange, connections between the environment and learning agents
-
-
Figure_5_R_versus_P (Convergence comparison between different
$H$ )-
NOMA
- RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
- main.py: Main code of robots with experience exchange, connections between the environment and learning agents that communicate with non-orthogonal multiple access (NOMA)
-
OMA
-
RL_brain.py: One learning agent with upper-confidence bound (UCB) exploration
-
main.py: Main code of robots with experience exchange, connections between the environment and learning agents that communicate with orthogonal multiple access (OMA)
-
-
[1] R. Luo, W. Ni and H. Tian, "Visualizing Multi-Agent Reinforcement Learning for Robotic Communication in Industrial IoT Networks," admitted by IEEE INFOCOM Demo, Mar. 2022.
[2] R. Luo, H. Tian and W. Ni, “Communication-Aware Path Design for Indoor Robots Exploiting Federated Deep Reinforcement Learning,” in Proc. IEEE PIMRC, Helsinki, Finland, Sept. 2021, pp. 1197-1202.
[3] C. Jin et al., “Is Q-learning Provably Efficient?” in Proc. NeurIPS, Montr´eal, Canada, Dec. 2018, pp. 4868-4878.