phd placeholder: IPFS crawl experience, metadata, and semantic gap awareness #7290
Comments
|
Ideas...
|
|
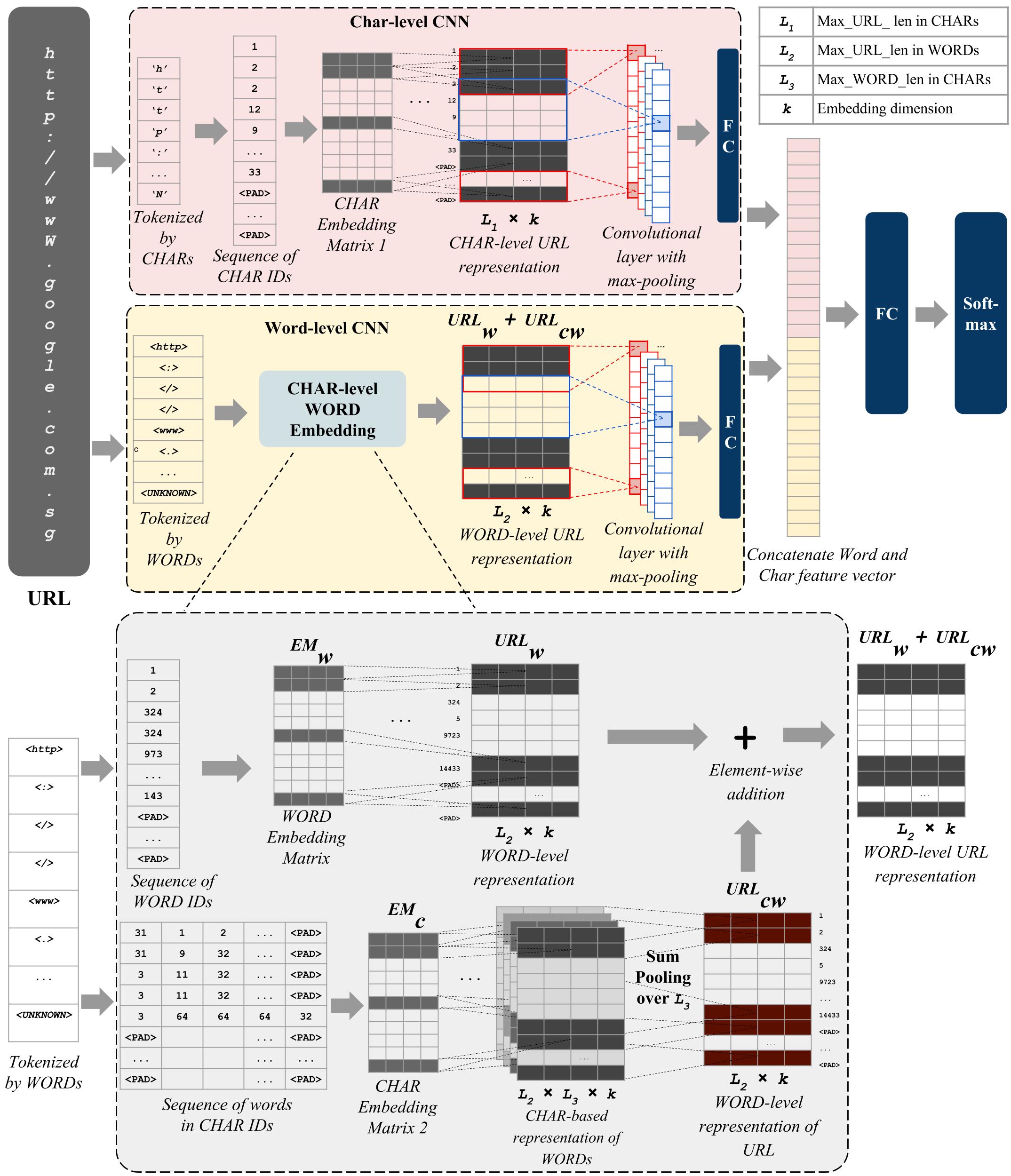
Brainstorm: We present a decentralised search engine, based on deep learning of URLs, URIs, magnet links, and IPFS links. Deep learning has been successfully used in the past to identify trusted and malicious websites. We go beyond this prior work and present an experimental search engine based on fully decentralised unsupervised learning. Our fuzzy search algorithm is based on unsupervised online learning-to-rank (OL2R). Literature, Dataset and code:
|
|
Spent the last week doing basic courses on neural networks again. Trying to get a linear regression model running to predict a sine function (using SGD). As basic as this is, implementing it is not as easy as I would have expected 🥲 I will continue to try to get it to work. I need to learn it at some point, I think. However, I'm inclined to first-publication ideas that do not directly employ NN/learning, as kind of a soft start. Talked to @kozlovsky again about semantic search based on simple embeddings. We could use the crowdsourced information and metadata to compute embeddings for every torrent and build a distributed (dec.) search algorithm based on vector distance to have a YouTube-like search experience.
Use this as a basis for semantic search and improve through OL2R in the next step? This week's ToDos:
|
|
Please chat to all people in the lab, understand their speciality. btw documenting your lesson learned; ML blogs make it look easy, none of them worked. Please review the Meerkat system Github repo from RedPajama.
Suggested sprint: you successfully encoded |
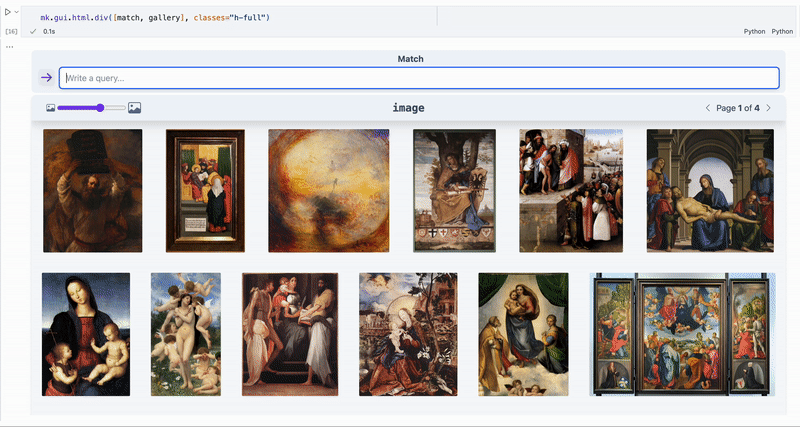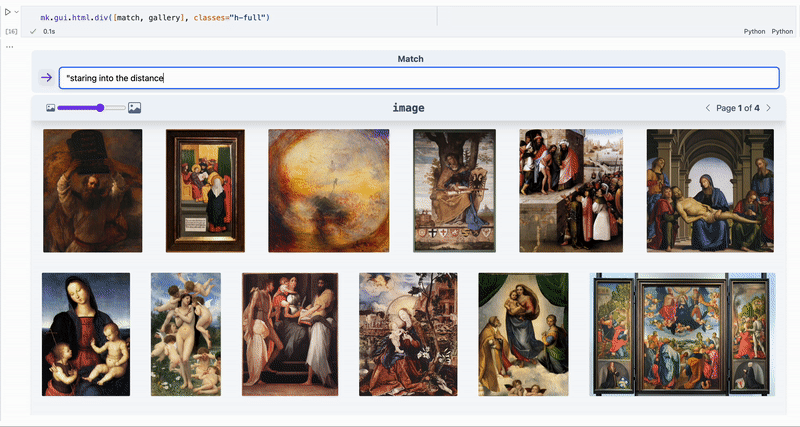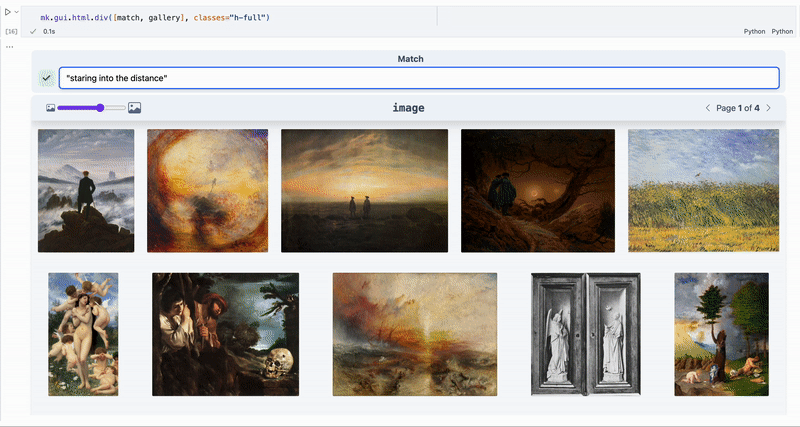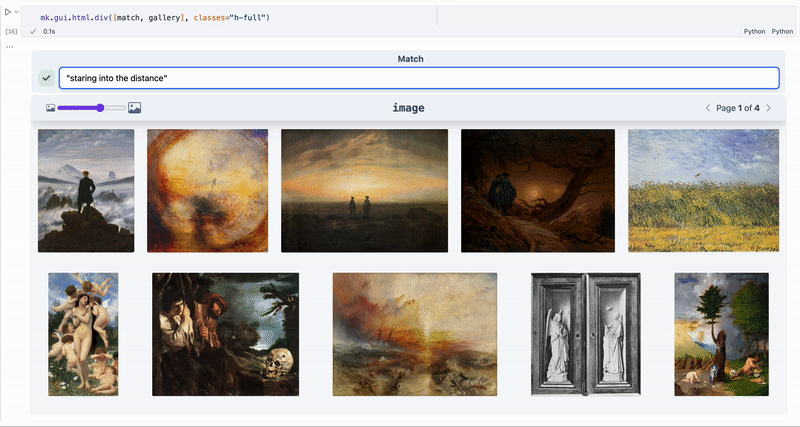
|
Got a sine function prediction working using a NN regression model. It's not much... but feels good to have succeeded at this task. Learned about activation functions, and the challenge of parametrization in ML. Also did some reading on tagging, recommender systems, and collaborative filtering, which opens another broad area of research, e.g., the issue of trust in collaborative tagging (see research topic 4 in science#42) - which I do find interesting. This (and perhaps also the next) week, I want to play around with Meerkat, learn about Autoencoder, and see if I can get something up and running, i.e., another ML model. I hope to further evolve my understanding of AI/ML and learn about yet new concepts. |

|
Rich metadata embedding of "artist passport" Cullah. |

|
Update on Autoencoder: The hardships of the last weeks seem to start paying off. I was able to create some functional autoencoders within just one day. I trained a model on eight pictures displaying tulips (dimensions: 240x180px), i.e., an input layer of 3x240x180=130k neurons, reduced that to 1000 neurons in a single hidden layer (encoding). If I'm not mistaken, this equates to a data reduction from 130 to 4 KB (the original JPEGs had 50-80 KB). Example decoded output: This might not be impressive, and with the right parametrization, we might be able to get more out of it. But for now, I'm just happy that it works in principle. |

|
Motivated by my recent success with autoencoders, I spent the last week trying again to get a pairwise LTR model for a sample of test data running. By doing that, I learned a lot more about the details of this approach. However, I had to pause this project because I would like to move this outside of a notebook and run it locally. I'm waiting for my work MacBook for that (my machine has difficulties) - it should arrive next week. So now I turned to the idea of NN-based file compression which apparently is not only successful with the task of lossless compression but can actually compete with traditional algorithms like GZIP or 7Z (see, e.g., DZIP or its successor DeepZIP). |
|
Using LLM for ranking. Background https://blog.vespa.ai/improving-text-ranking-with-few-shot-prompting/ and also https://blog.reachsumit.com/posts/2023/03/llm-for-text-ranking/ Did a silly OpenAI experiment, might be useful building block, but small part: Found this dataset with 7000+ pet images (+ code) for scientific research, so it sort of works 🐶 |
|
So I ended up not learning about RNNs, NN-compression, etc. last week. Instead, I investigated an idea proposed by @grimadas, which is to leverage ML as a means to classify nodes as Sybil or not-Sybil and use the resulting score as a weight-factor in the reputation algorithms of MeritRank. Back to LTRGot my new MacBook yesterday 🔥 so I was able to continue my work on the OL2R project. My goal was to just get anything working, and I specifically sticked with the pairwise LTR approach for this. To this end, I was only following the basic idea, which is to train a model based on query-document-pair triples, and followed my intuition for the rest. Algorithm
Demo Remarks
|

Sprint: get a solid production-level metadata dataset (Creative Commons, https://github.com/MTG/mtg-jamendo-dataset ?) |
|
Update:
Love this roadmap!! ❤️ I have started getting my hands on the Tribler code and gain a better understanding of its inner workings. Will try to move forward with the practical preparatory work for the next thesis chapter, such as getting a dataset. |
|
Over the last month, I was mainly focused on my first thesis chapter. That involved writing, but also running experiments, fixing bugs in our code, and figuring out the best way to present our data. For example, visualising the chunk size distribution was a challenge because of the amount of experiments and amount of algorithms we evaluate. Furthermore, the variance in behavior made it difficult to fit everything into a single plot while preserving readability. 
Apart from this, I was reading some papers, talking to my peers in the lab, trying to understand what they're doing, and also continuing to explore AI/ML, e.g., learning about transformers. |
|
Please write 3 next paper ideas around topic of "Web3 crowdsourcing". 6-page for DICG 4th workshop would be indeed a great learning. One of 3: crowdsourcing of metadata using MeritRank; everybody can tag, describe work done of Great news, hoping chapter to be ready for final reading & submission aug/sep. As a starting point for new lab people a short history and essential reading. |

|
New ACM Journal on Collective Intelligence seems like a solid venue to target. Your second chapter could then simply be decentralised collective intelligence. Using Tribler to share info, use tagging, and trust. You can re-publish a lot of the Tribler work done by others in the past 18 years and 3 months. |
|
To give a little update...
|
|
I'm focusing on the DICG'23 now. @grimadas MovieLens DatasetI was able to find a really nice dataset. MovieLens is a non-commercial project run by people from U. Minnesota since 1995. It's a database of movies that users are allowed to rate and tag. Any user can add new tags, and existing tags can be up- and downvoted in a way (see screenshot). 
Tags also have the attribute of being positive, neutral, or negative. I am not sure how complete their dataset is about that, but they are responsive to my emails and seem highly cooperative with the provision of data. We can use this dataset to get an idea of the quantity and quality when it comes to crowdsourcing of tags, and base our simulations on it. Quick plots... IdeaPerhaps, for this workshop, I could come up with some subjective tag scoring algorithm, a bit related to the "Justin Bieber is gay" problem. Playing with the idea that for a group of similar users, a tag might be agreed upon, but for another group of users the same might not, etc. Approach
Will further investigate this idea and the dataset and make updates here. Comments welcome. |


|
Just noticed this line of work, very interesting! I worked on something similar (trust, tags + MovieLens dataset) more than a year ago, see this issue (note that this is a private repo with many of our research ideas so you might have to request access). The overall goal of that issue was to work on the foundation of tag-centric crowdsourcing in Tribler. I tried out a few algorithms/approaches and I remember I identified some shortcomings of Credence, which is related to what you're trying to achieve. but as reputation/trust was not really my domain, I decided to focus on the fundamental data structures instead (using Skip Graphs and Knowledge Graphs for Web3 data management). The paper with these ideas is currently under review. Nonetheless, extending that work with a trust layer would be a valuable contribution! |
|
Hi Martijn :) thanks for your input! I was knocked out by COVID over the last two weeks, and still am a bit, but here is the continuation of what I was trying to do: I have calculated user similarity based on the Pearson correlation of common sets of rated movies (as suggested here), and based on that, subjective tags on movies (indeed similar to Credence in that I weigh based on peer correlation). I based this solely on the interactions of the 200 most active users (perf reasons). Example of a sample of users and their subjective tags on the movie "The Shawshank Redemption"From there on, I tried to find extreme results, i.e., movie tags for users of "opposite" groups. To this end, I looked up controversial movies and their tags for users with minimum/negative correlation, hoping for something like a clear political or a gender split. And it wasn't easy, perhaps due to the lack of data. But I still found an interesting disparity for Disney's Star Wars remake. While one user has funny, good action, and great action among his top tags, Full list of tags for two negatively correlated users on "Star Wars: The Last Jedi"That was fun to explore but it still lacks a scientific methodology in order to really evaluate the effectiveness of the subjective tags I computed. Previously, I proposed that
Maybe that gives us something. Maybe for all tags that have been up- and down-voted, I can compare the subjective with the objective reality and derive a success metric. And this would allow me to experiment with more sophisticated scoring algorithms and see their effect on this metric.
Good stuff. I don't know if trust should be my scope either. I'll talk to Johan today, will know more then. Status update on
After almost half a year, I still don't have a grasp of the field enough to come up with own ideas for publications. |
|
No worries about your progress in 6 months of a 48 months phd. Getting into the field of distributed system and doing something novel is hard. Having a draft publication within the first 12 months is already a solid achievement. Goal: April 2024 == 1 thesis chapter under review + 1 finished draft thesis chapter. Non-linear productivity 📈 Task for September 2023: come up with ideas for a scientific paper and select one (or get inspiration) SwarmLLM: collective LLM intelligence (with new AI phd expert??)We present the first proof-of-principle of collective intelligence for transformers. Intelligence emerges from the interaction between numerous elements [REFS]. We use a transformer as the basic building block for a interconnected network of connected unique transformers. Instead of the classical transformer approach with billions of parameters, we connect thousands of specialised transformers into a network. This is a generalisation of the mixture of experts approach with the highly desired new property of unbounded scalability. There is a cost to pay in our approach. In a typical divide and conquer style, the challenge of finding the correct expert becomes harder. LLM as a key/value storekey: any youtube URL in Youtube-8M dataset. Rich metadata inside an LLMTulip picture embedding in generic form. Tribler: a public semantic search engineWe shamelessly claim to have a proof-of-principle for public Internet infrastructure after 20 years of effort. We argue that critical societal infrastructure should be developed as a non-profit endeavour. Similar to Bittorrent and Bitcoin we present a self-organising system for semantic search. Our work is based on learn-to-rank and clicklog gossip with privacy-enhancing technology using a Tor-derived protocol. Web3Search: Online Pairwise Learning to Rank by Divide-and-Conquer with full decentralisationEmbedding nodes using algorithms like node2vec. Embedding of any item using 50-ish dimensional vector. Foundations of Trust and Tags.Use the @grimadas work with theoretical grounding: emergence of trust networks with repeated successful interactions. Use tags based on crowdsourcing if you have successfully collaborated. Next steps: learn-by-doing methodology. Work for 2 weeks further on the Tulip stuff. Autoencoder of 1000-ish Youtube-8M thumbnails. Work for 2 weeks on another of above brainfarts. Commit to best chapter idea. |
|
Seeing how far I can get autoencoding YouTube thumbnails. Time for some quick coding. Using YouTube's API I got the thumbnails of 577 search results with "starship" as the query. Note Using YouTube's search API instead of its 8M dataset (can't run that on my machine!) is different in that I collect the thumbnails of videos which match the search query, and in the 8M dataset they sort of match the query (selected set of visual entities) with what they actually found displayed in the video. I still went with it, trained the network on 576 thumbnails, and then ran the 577th search result's thumbnail through the autoencoder.
What might do is the labeling we get on frame-level (or ~1-second-interval video segments). We have that in the 8M dataset. Getting an actual image entails downloading the original YouTube video and then extracting the corresponding frame. That's costly but doable on a small to mid scale. We have been thinking about doing text-to-image basically, using auto-encoders? I think that was the plan... |


|
wow, as impressive as I hoped it would be!! 4k! |
|
There was an error in my code, and a bit in the approach. What I did was training only on 50 thumbnails, and then use a thumbnail that was part of the training data for testing. I updated my last comment; the result is very different. Click here to see previous (misleading) result
Actually, PyTorch does not support CUDA (GPU acceleration) on Mac :( Google Colab with GPU runs faster for me. |

|
I'll share my notes on three of the suggested topics SwarmLLM: collective LLM intelligence (with new AI phd expert??)
Web3Search: Online Pairwise Learning to Rank by Divide-and-Conquer with full decentralisation
Tribler: a public semantic search engineSo, LTR through clicklog gossip. That's G-Rank! Crowdsourcing experiment that discovers user-perceived dimensions of semantic similarity among near duplicates Vliegendhart et al. (2011) Researching these topics over the last few days, I feel inspired and more confident to develop ideas for publications! |

|
I'm really interested in designing my own holistic search system. Either using a simple algorithm like done in G-Rank or we actually dare to implement something like a decentralized LTR where each peer trains their own model. I like the aspect of personalized search by the metric of peer similarity. I would do something privacy-preserving: Private Set Intersection (Protocol II). This could be implemented with both approaches, i.e., even with NN-based LTR we could still maintain local ClickLog databases in addition to the model. So that's about the privacy aspect. Apart from that, Sybil-resistance was a weak spot in G-Rank, we could mix MeritRank-computed reputation weights in the algorithm. I'm trying to build a prototype. ✨ 1st paper idea ✨ Update 5 days later I implemented Protocol II from Zeilemaker et al. (2013) (my code in gist) and noticed what I would have understood if I just read a bit further in the paper: High item values and large sets of items become computationally very heavy, very fast. It's impractical for what I planned on doing. Variance Reduction in Gradient Exploration for Online Learning to Rank TODO
|
|
Field: https://scholar.google.com/scholar?hl=en&q=adversarial+information+retrieval Also: https://scholar.google.com/scholar?hl=en&q=dark+patterns+~youtube
Great stuff, metadata authorship is actually fundamentally broken on Youtube. Incentives are due to The Algorithm of ranking are obsessively geared towards clickbait. Related: Justin Bieber tag spam: https://musicbrainz.org/artist/e0140a67-e4d1-4f13-8a01-364355bee46e/tags also conflicting versions of content: https://musicbrainz.org/artist/c7d0d6f4-4eb2-4d36-8f61-fe7e2ce4af0d Scientific related work: https://www.kaggle.com/datasets/thelazyaz/youtube-clickbait-classification See clickbait example: https://www.youtube.com/watch?v=CuyOr7WThug |
May the Best Metadata Win: Authorship for Perfect Metadata CurationI gotta say I understand my field (IR in DS) much better now. The problem can and must be attacked from two sides:
(2) -> I thought about the metadata issue, and tried to take a few steps back... The web is essentially decentralized, YouTube in a way is decentralized. Not with regards to (1) but (2). I am also intrigued by the following intuition: If YouTube believed that crowdsourcing worked, if it would help describing the content truthfully and therefore help users find the content they’re looking for (which they care about), they would do it!! They might do so in many implicit ways (likes/dislikes, watch time, …) and they might have automatic annotations (nowadays a lot of ML probably), but not in the way of crowdsourcing tags. So what am I advocating for? Authorship! I feel like if you really want solid metadata, authorship is the way to go. ✨ 2nd paper idea ✨ People don't put up with clickbait and will react by the means of reporting, dislikes, comments. |

Notes on ✨ 1st paper idea ✨The goal of this paper would be to propose a system for personalized search (at best, learning-to-rank) with an emphasis on privacy. I continue thinking about this issue. It is difficult. Very challenging. I can think of an online protocol doing secure multi-party computation, k-anonymity, ..., a lot of things become imaginable in this scenario. Designing such a protocol becomes a fun thought-experiment, but its application is impracticable: dependence on similar peers being online, and expensive network operations with every search. We need something that works offline! Peers could apply their set of queries and selected results on Bloom filters and gossip that around the network. Much more space- and network-efficient than what G-Rank did. This, however, would still only serve for a "If you know, you know" privacy... which is also better than what G-Rank did. Edit/ spontaneous idea: What if we use distance-sensitive Bloom filters. Not only can we then respect for query or document similarity, but we could also add noise to the data (differential privacy?) I also thought about learning-to-rank (LTR) and how and if this should be combined with search personalization.
In the latter case, could we couple that with Maybe from this question we can derive the ✨ 3rd paper idea ✨, which would deal with decentralized LTR, its risks and challenges. ToDo for this week: |
✨ 1st paper idea ✨ Towards Privacy in Personalized Ranking Models in Decentralized SearchI spent a whole lot of time in the last two weeks thinking about a solution to this problem. My conclusion, in the end, was to use Bloom filters with calibrated parameters for plausible deniability in addition. Either that, for an "offline" protocol, or do SMPC. I'm a bit disappointed by the simplicity of this solution and if something truly paper-worthy could grow out of it. So I've set that on hold. ✨ 2nd paper idea ✨ May the Best Metadata Win: Authorship for Perfect Metadata CurationStill interested in that as good metadata lays the foundation for every IR algorithm I could develop later. I was too distracted by other ideas to really focus on that. But in the back of my head, I kept thinking of ways to approach this paper. How could I possibly evaluate this idea, what dataset could I use... it does not seem obvious to me at all. ✨ 3rd paper idea ✨ Decentralized OL2R: Risks and ChallengesGossip learning works so why not go and try implementing OL2R on it, nobody has done it. ✨ 4th paper idea ✨ Decentralized LLMEverything would be easier if we just had a semantic understanding of the documents. Maybe then I could use the distance-sensitive Bloom filters I have encountered earlier, researching my 1st idea. |
update after your 1 months sprint you could join the "Blockchain for Trust" team for another 1 month sprint. Today this team has been formed by @grimadas joining @InvictusRMC for #7517 |
Tada🙆🏻♂️🙆🏼♂️ Source code: https://github.com/mg98/p2p-ol2r We learned that gossiping an entire model is expensive due to its size. In our prototype, this corresponds to a payload of 2.7MB (multitude of that to be expected in real-world applications, of course). The literature suggests various compression techniques (e.g., only gossiping a subset of the model parameters). Furthermore, there are ways to decrease the total number of messages sent. While we have a solid base implementation of OL2R in P2P, many improvements are required or desirable to make it practical. These include
Perhaps those are all general to gossip learning. We wonder what is the specific challenge with the application of LTR. One might be the size of the model: How much space would it need, and would it still fit on a single device, or would we have to think about distributing the intelligence? |

|
Great news! Please focus fully on practical deployment. Nobody has done this yet in a fully decentralised manner, all prior work is just unproven theory 🙃 (credits to MIT: "On-Device Training Under 256KB Memory) This payload of 2.7MB for a single pairwise sync is a lot. Ideally it fits inside a single UDP message of 1472 Bytes. So, just a few compressed parameters or something would be awesome. |
|
Quick update:
Sparse weight updates seem like a good idea. See our following experiment: Training alters only a subset of parameters (30-80% and possibly less)However, those require proper annotation which would blow up the size. I doubt it's worth pruning only the 0-delta params. |
|
ToDo: Determine an effective deployment plan. Grand idea: quick to production and iterate fast - ELON style.
Reason for pushing strong on simple gossip exchange of human readable data versus model exchange with pure magic numbers. stability, ease of debugging, correctness, convergence, expertise of team, bloat in ML libraries, and lack of machine learning maturity. Really everything is in favour of doing gossip learning with data exchange, only true AI expert would do maximal AI. Easy low hanging fruit for a scientific in-depth 2nd paper: Distributed artificial intelligence: empirical proof for the model exchange versus data exchange paradigm (thesis chapter @pneague or @mg98). silly idea: learning aggragation and compression. Locality of learning to guard horizontal scalability, instead of global broadcast of 1 day of node-learning. |
Update on my experiments with QuantizationIt's not as trivial as I thought, and I'm not sure if I fully understood it, but I'll try to give an explanation for those interested: Quantization: Introduction & OverviewQuantization is a technique that is used to shrink a model's size by basically discretizing its parameters. This makes computations on the model faster and more memory-efficient. Typically, weights and activations are quantized from Quantization relies on a phase of calibration in which it learns the typical range (scale) and zero-point of individual tensors, thereby optimizing the quantization parameters. There exist three ways to do quantization. We are interested in Quantization-Aware Training. In this mode, there is no separate calibration stage (which wouldn't work in our use case). Instead, the model is in a quantization-prepared mode, constantly fine-tuning its parameters, but never actually quantized until conversion. If you are interested in learning more, I found this source the easiest to follow. However, I think the full process behind PyTorch's quantization is more sophisticated and, frankly, still a little mysterious to me. It also took me a while to implement it. Aggregating a quantized model with an unquantized-but-prepared-to-quantize model is, again, not a trivial task. In the end, I got it to work. Below I show a demo without and then with quantization. (By the way, the UI evolved Demo.mp4Demo.Quantization.mp4Observations:
I think I'll pause it at this point, and switch my focus to the dataset, maybe do some empirical analysis. |
|
I discovered that our ranking model does not perform nearly as well as I thought. Reasons being a small set of results (length 5), which inherently resulted in minor ranking errors, as well as my own confirmation bias which gave undue credit to the occasional successes. Above all, our testing lacked a rigorous analytical approach. Thus, the last two weeks have been an intense period of debugging, refactoring, and testing. I increased the number of results to around 10 and introduced an evaluation metric (nDCG) to gauge the model's performance--it was about random😑. This led me to experiment with new loss functions, new optimizers, even new model designs, in addition to all the other hyperparameters like model size, epochs, learning rate, ... I learned that those little things can often have a dramatic impact on the performance. Furthermore, I learned about overfitting and dropout regularization. I made everything configurable! And played around with the options running against my automated tests. Tweaking around, I managed to get near-optimal performance with 10 results (according to my simulation of 5,500 user signals). To further optimize my parameters, I plan to adopt a systematic approach to parameter search. I know that there exist some tools (e.g., RayTune) that can do this intelligently... will read into that... in any case, being able to control everything from my Another major concern that arose was the effect of the number of epochs on the model accuracy. In an online (= continuous learning) environment, the number of epochs is not only arbitrary but also ever-increasing. Therefore, with static parameters the model will always continue to overfit. We'll have to dig the OL2R papers to see how they dealt with it... My guess is the solution will involve something like adaptive learning rates. |
|
On a hybrid work/vacation until mid-December. Trying to recap and orient myself in my research: Broader Goal: Better information retrieval in decentralized systems Explored Methods:
Roadmap:
|
|
Continual learning Quick-fix for the overfitting problem of continuous LTR (= indefinitely growing number of epochs). I applied an exp learning rate decay and found parameters which converge to optimal ranking. How I think LTR relates to the DSI approach
Another thought:
In a future work, it would be interesting to test this out in a first-DSI-then-LTR architecture and evaluate if and how far LTR's re-ranking capabilities change the ranking of search results, and finally improve the accuracy of search results. The latter could be measured by metrics like clicks @ 1st result, for example. Empiric dataset required. |

|
Possible next paper: DSI-then-LTR two-stage IR system. Another key issue for real-world usability is the bundeling and filtering of |

|
Queries Is All You NeedWhen Google presented DSI, they had the luxury of knowing complete document texts. These were used as the foundation in training their LLM to map queries to (arbitrary) docids. They further state:
Petru, lacking any document contents or metadata, trained solely on query-docid pairs. Astoninglishly, this model became able to output the correct docid to unseen queries (i.e., generalize to new inputs). This is a discovery that deserves more attention for its implications in search, especially in systems where metadata is scarce. Can we really describe documents by (and solely by) the queries people used to find it? Can we maybe by collecting enough diverse queries to a popular document, have a model learn the document's rich semantic profile? Those, I think, are ideas worth an examination in another short-formed paper. </Pitch> Time for a first figure. I designed a simple experiment using a small subset of the ORCAS dataset.
Experiment setup might have some flaws, but I hope with my first figure to give a general idea, which should be: the majority of queries can be processed successfully given only very few (according to experiment at least 2) prior queries to the sought document. 
(y = success rate on unseen queries) I wanna try again with 1000 (instead of 100) of distinct documents. Will update here. Live update: (1, 10%), (2, 23%), (3, 27%), (4, 32%), ... so it definitely has the capacity to decrease sharply as the output space grows, but still fair results |
|
|
It's time for another update. I have been conducting more and more experiments, as I was trying to better understand what's going on. Here is one very interesting finding: 💡 More popular documents have a more diverse semantic range of queries than more niche documents.For example, people who looked for Gmail got successful querying "google login online" but also "create a new account". We can also visualize that by clustering the embeddings for queries of low popularity (40-50 queries), and queries of high popularity (1000+ queries) on a 2D semantic space. (Dots represent queries, color-coded by their associated document)
As we can see, the queries of popular documents are semantically more dispersed, which makes them more difficult to group them together just by looking at their position. In other words, if you let k-means do the clustering (intuitively what our model would do), the mismatch rate would be higher with the high-pop docs than with the low-pop docs. There are also metrics to quantify that. In the following figure, I have plotted the Adjusted Rand Index (ARI) of the clustering and increasing document popularity. ARI values range from -1 to 1. A score of 1 indicates a perfect match between the clustering results and the ground truth, while a score of 0 indicates random clustering, and a negative score suggests less agreement than expected by chance. 
I have plotted this for 20 docs and for 40 docs, to show that of course the more documents share the same semantic space, the more crowded the queries get, and the more unreliable the clustering. Finally, this is of course reflected in the accuracy the model can attain, as shows the following example (here with 100 docs trained on 10 queries). 
💡 Second finding is that the model often hallucinates, and beam search sometimes duplicates results.I call a result a hallucination (or invalid) if it outputs a string that was not part of the outputs it got trained on. This means that if you have a system where you are aware of the existing documents, you can instead take the first valid docid output by beam search, and therefore bump the accuracy. On the lowest range of our experiments (100 docs and 1 query fed) this made a difference of +3%. However, on the upper end it is rather negligible. The following shows an excerpt of the results.
|

|
I have been digging into some papers in the context of the upcoming Queries-Is-All-You-Need chapter and potential future work. Dumping my learnings here.
|

update : (more paper ideas then finished chapter, simply documenting) |
"learn to tokenize documents"I got the script to work (GenRet). However, I was rethinking this idea and I don't see how we could sell it. Learning semantic docids from the queries themselves obviously requires you to have the queries beforehand, and even then it implies some fluidity (cannot just "improve" the ID in the continuum). I'm dropping this! roadmap on life-long decentralised learning [...] what is the first realistic next step?Yeah as you listed: overfitting, pollution, spam, those are also things that come to my mind. While there are some ideas how it could work conceptually (e.g., DSI++, IncDSI), the datasets they use to validate them are a bit weak (in those papers, NQ and MS MARCO). For a real evaluation, we (1) need real search queries, including spam, but also (2) we should care about the chronological order that the queries come in, and that the model learns on. Waiting for the Tribler Clicklog. Would it be possible to filter hallucination of our magnet link generative AI (Queries Is All You Need)?Not in the way that is described in this body of research (referring to your survey link), I think. What we can do in the next step is to assume knowledge of, let's say, healthy torrents. Using this knowledge, the model will be configured to predict the most likely token, with which the resulting output continues to match a prefix found within the set of healthy torrents. Will do! |
Representation of Targets MatterIn our last paper, we saw significant differences in performance when representing our targets as ORCAS docids (e.g., D1234567) vs. as magnet links (40 character hex string). The model would generally have a harder time predicting magnet links. We blamed this on their length; more tokens to generate, more chances to trip along the way. When thinking about how to optimize the performance of our model, I therefore thought the number of tokens on a docid should be minimized. Why not use the entire ASCII space for example? Or hell, the T5-small has 32k tokens, why not encode docids as, for instance, "car 2001": two tokens, 1 billion possible combinations. It turns out this confuses the model more than it helps 😅. This beeeeeegs the question.... 🤔 Using an LLM to predict arbitrary identifiers, what kind of identifiers come natural to it?Is it a question of length? Or consistency? Or the employed vocabulary? What tokens should you use? How many? I ran a lot of experiments to get closer to an answer about all these things. In order to enhance the performance of our model, I initially thought that the number of tokens used to represent a docid should be minimized. My rationale was _less tokens, less chances to mispredict. And while that might be true, or maybe only true to some extent, it definitely seems to be case that the employed vocabulary matters too! I have been experimenting with different representations (or rather encodings) of the targets (i.e., the docids) -- and, spoiler, the results are actually quite impressive. Here is exactly what I did
I repeat this experiment with different encodings. A full list, including some result metrics, is shown below.
Boxplot of token lengths with each encoding
🚀 In this experiment, we made a 7% performance increase over our original results just by choosing a different encoding for the docids It seems to have an easier time with numbers. Maybe it is because there exist many tokens for compounded digits (69, 420, 2001, 1944), thus reducing in less tokens needed to represent a docid. Another theory I have is that having predicted a number token, based on this context it is more likely to predict another number token, and that this might help performance a little. It is perhaps also interesting to acknowledge that number tokens are semantically very similar to each other. That goes to say the tokens for We might already be very close to what the perfect (or perfectly-enough) representation is. But it might be interesting, not just for this application, but also for the broader ML community, to investigate what representations an LLM works best with. @pneague and me were thinking of using ML (genetic algorithms in particular) to learn an optimal vocabulary for representing arbitrary string identifiers. 🌈 Edit: Looking at the results again, it might just be that the model favors a low but consistent token length. But more experiments need to be conducted. |

< Placeholder >
timeline: April 2023 - April 2027.
ToDo: 6 weeks hands-on Python onboarding project. Learn a lot and plan to throw it away. Next step is then to start working on your first scientific article. You need 4 thesis chapters and you then completed your phd.
One idea: towards trustworthy and perfect metadata for search (e.g. perfect memory retrieval for the global brain #7064 ).
Another idea: Gradient decent model takes any keyword search query as input. Output is a limited set of vectors. Only valid content is recommended. Learning goal is to provide semantic matching between input query and output vector.
General background and Spotity linkage possible dataset sharing
Max. usage of expertise: product/market fit thinking
Background reading:
pointwise approach, broadly speaking, each historic impression with a click is a positive training example, and each impression without a click is a negative training example.https://towardsdatascience.com/learning-to-rank-a-primer-40d2ff9960afWe will implement a character-level sequence-to-sequence model, processing the input character-by-character and generating the output character-by-character. Another option would be a word-level model, which tends to be more common for machine translation., https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.htmlVenues:
note no prior msc courses on machine learning. We are a systems lab and might know how to apply machine learning in permissionless, byzantine, unsupervised, decentralised, adversarial, continuous learning context.
Possible scientific storyline: SearchZero a decentralised, self-supervised search engine with continuous learning
The text was updated successfully, but these errors were encountered: