

Exploring memory allocation and strings
Edit on GitHubA while back, I wrote about making code allocate less memory (go read it now if you haven’t). In that post, we saw how the Garbage Collector works and how it decides to keep objects around in memory or reclaim them. There’s one specific type we never touched on in that post: strings. Why would we? They look like value types, so they aren’t subject to Garbage Collection, right? Well… Wrong.
Strings are objects like any other object and follow the same rules. In this post, we will look at how they behave in terms of memory allocation. Let’s see what that means.
In this series:
- Making .NET code less allocatey - Allocations and the Garbage Collector
- Exploring .NET managed heap with ClrMD
- Exploring memory allocation and strings
Strings are objects
When writing code in C#, sometimes it almost looks as if a string is a value type. They look immutable: re-assigning a string just replaces the value we are working with. We write code with string, we can compare strings using == knowing it compares the value of the string and not the reference, … But don’t be fooled! There’s quite some magic happening to make strings easy to work with, but they are in fact objects.
If we look at MSDN, we can read:
A string is an object of type String whose value is text. Internally, the text is stored as a sequential read-only collection of Char objects. (…) The Length property of a string represents the number of Char objects it contains, not the number of Unicode characters.
There we have it: strings are objects. They may hold an immutable array of Char and a length property that is a value type, but the bits of text we are passing around in memory are objects.
Quick note: If you want to learn more about strings in C#, I highly recommend the chapter on strings in "C# in depth" and this tutorial on strings.
When are strings allocated?
Let’s start at the beginning. In any .NET application, a string is allocated whenever we either new a string, which I haven’t seen happen too often, when we create one using quotes, e.g. "this is a new string", or when we load a string from somewhere else, for example a database or a remote HTTP API.
There are some other cases as well, but these are essentially the cases:
var a = new string('-', 25);
var b = "Hello, World!";
var c = httpClient.GetStringAsync("https://blog.maartenballiauw.be");
If we profile this, we can see that strings have indeed been allocated:
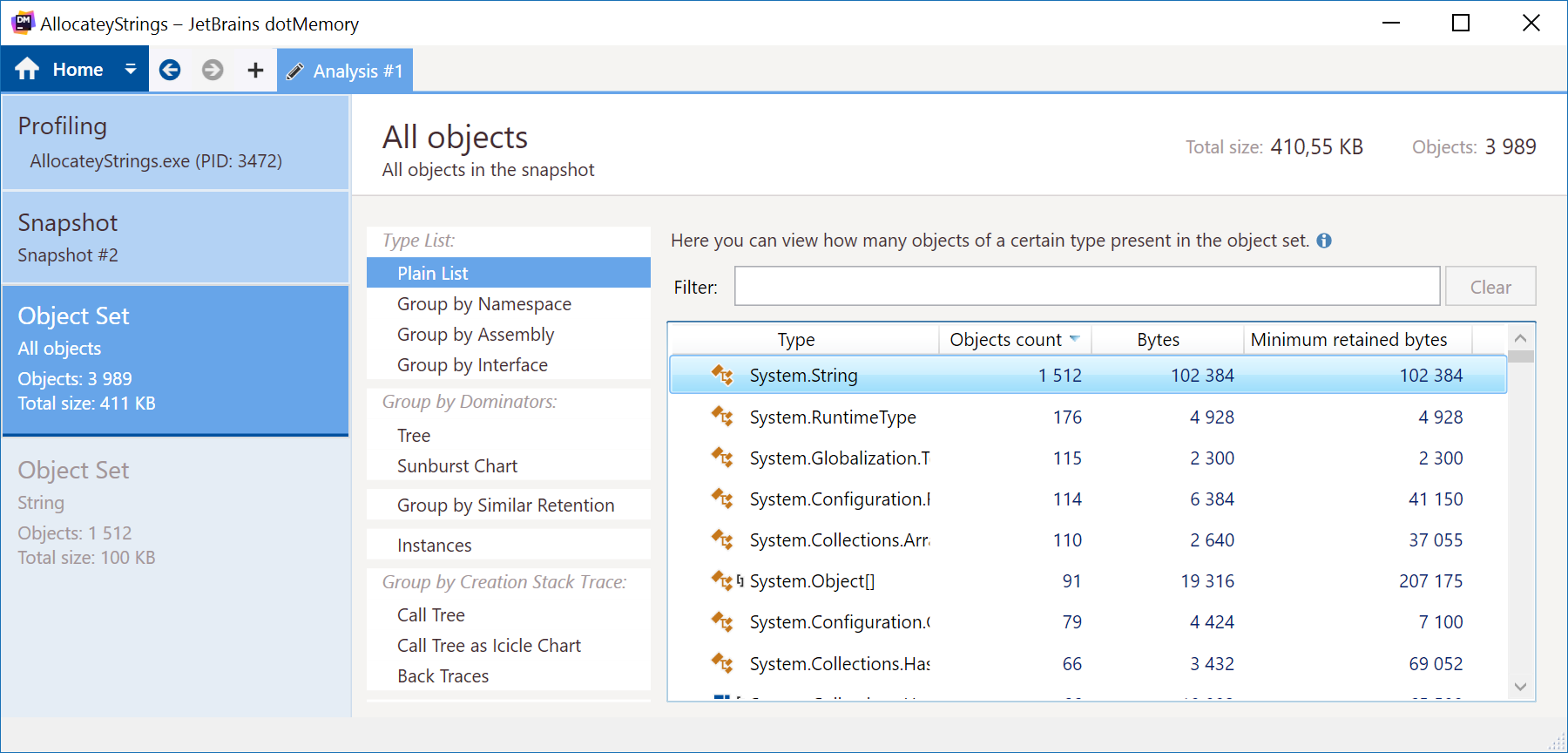
Whoa! That’s a lot of strings! As you can imagine, the .NET runtime also needs a couple of strings to do its thing, and objects such as the HttpClient used in the above code snippet obviously also need to store HTTP requests and responses.
What’s interesting though, is that it seems our application is duplicating string content. Here’s "https://blog.maartenballiauw.be". We can see that string is in memory 6 different times.

Just for fun: I also attached the profiler to a running devenv.exe (Visual Studio). If you ever wonder why it consumes so much memory, this is a good start of an explanation... Yes, that is the string "https://schemas.microsoft.com/winfx/2006/xaml/" duplicated 673 times.</code>

String duplication isn’t bad though. As we’ve seen previously, the .NET Garbage Collector (GC) is quite fast at cleaning up objects, especially when they are short-lived. But just as with any other object type, it may be bad to have lots of duplicate strings when they move to higher heap generatons like Gen 2 (or the large object heap if you have very large strings). We wouldn’t want our memory swallowed by a huge amount of unwanted string duplicates or (string) objects that aren’t being collected.
String literals
Are all strings allocated on the managed heap? No. The Common Language Runtime (CLR) does some optimization. Consider the following snippet of code:
var a = "Hello, World!";
var b = "Hello, World!";
If we run this piece of code, we will not see the string "Hello, World!" appear in the profiler. The reason for that is that the compiler optimizes this code and places the string "Hello, World!" in the assembly (or more correctly, the Portable Excecutable (PE)) #US metadata stream. When we run our application, the CLR reads these metadata values and loads them into a special place, called the intern pool. Every string literal in our code is placed in this pool, and duplicates simply reference the entry in the pool. If we’d run the following snippet, the result would be True, twice, because both the value and object reference of a and b are equal.
Console.WriteLine(a == b);
Console.WriteLine(Object.ReferenceEquals(a, b));
So in essence, "Hello, World!" is in memory only once - very optimized!
Quick note: What would be the better thing to use: "" or string.Empty? From what we learned so far, "" would be interned, which means it will only be stored in memory once, right? Right! There is one downside however: each time we use "", the intern pool is checked which spends some precious CPU time. If we use string.Empty, we're passing around the object reference instead which means no extra memory is allocated and no extra CPU cycles are wasted checking the intern pool.
Let’s geek out a little bit. We can double-check the string literals using dotPeek, exploring the Portable Executable (PE) metadata tree. The full list of unique strings is added in the #Strings and #US (for User Strings) metadata streams.
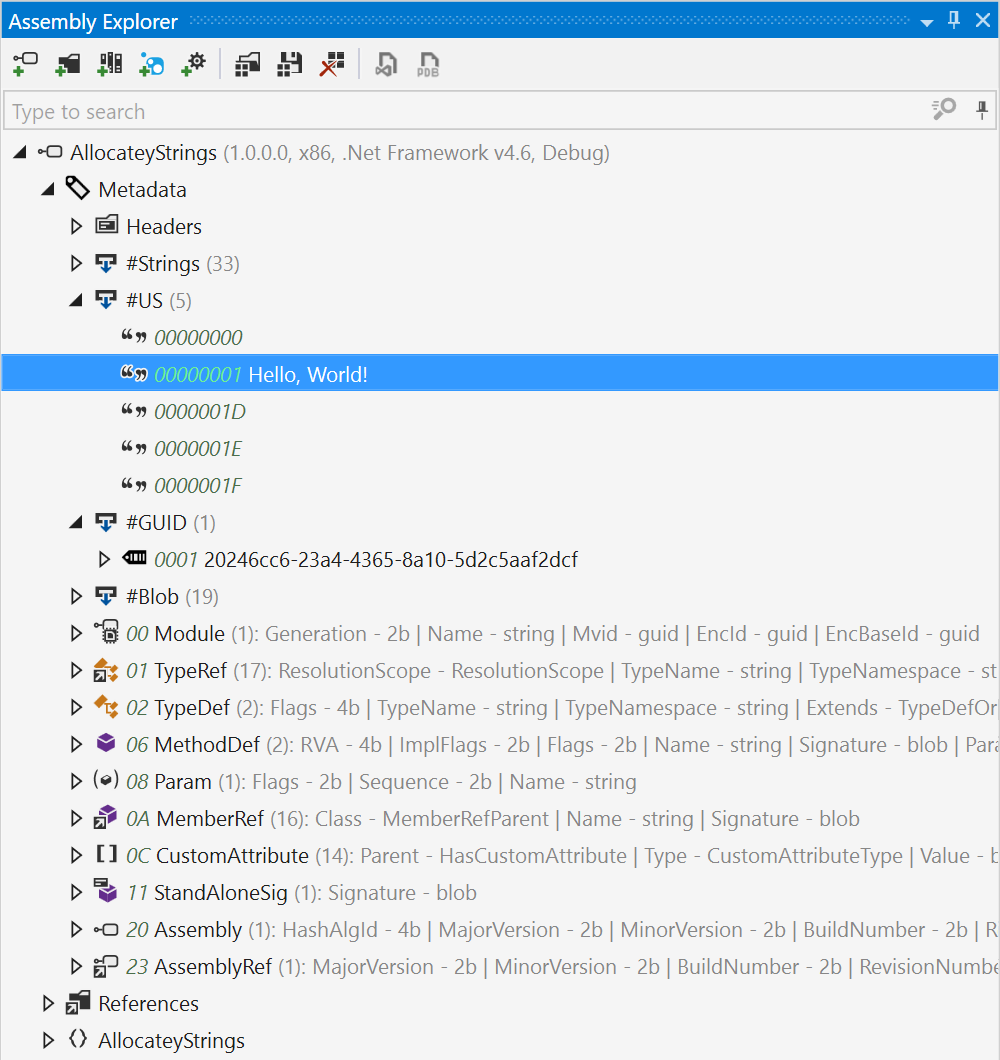
If you need some bed literature, the metadata streams are described in the ECMA-335 standard, section II.24.2.4. Under section III.4.16, we can see the Intermediate Language (IL) instruction ldstr loads a string literal from the metadata.
String interning
With string interning, we can store strings in the intern pool, a set of unique strings we can reference at runtime. We saw that the compiler optimizes string usage by storing string literals in the PE metadata and that the CLR adds those into the intern pool, making sure they are not duplicated.
Why aren’t all strings in our application interned then? There are several reasons for that… But before we answer that, let’s see how we can allocate strings on the intern pool ourselves.
We can intern strings manually by using the String.Intern method. We can check whether there is already an interned string with the same value (or the same “character sequence”, to be correct), using the String.IsInterned method.
For example, the following snippet will only keep two strings around:
var url = "https://blog.maartenballiauw.be";
var stringList = new List<string>();
for (int i = 0; i < 100; i++)
{
stringList.Add(string.Intern(url + "/"));
}
Which strings? "https://blog.maartenballiauw.be" - in the intern pool because it’s a literal - and "https://blog.maartenballiauw.be/" (with the trailing slash) because we’re interning the string. 100 calls? No problem, we’re just adding the reference to that same string into our list. Nice and optimized! Why aren’t all strings interned by default, then?
One reason is the classic “CPU vs. memory” debate. When using the intern pool, we’re increasing CPU usage as we’re checking if the string exists in there or not. When not using the intern pool, we’re just consuming memory.
While this is a valid argument, there is a better reason for not auto-interning all strings. Interned strings no longer appear on the heap and are allocated on the intern pool instead. There is no garbage collection on that pool: this means those strings will stay in memory forever (well, for the lifetime of the AppDomain), even if they are no longer being referenced. So use with caution!
With great power comes great responsibility
So what is it? Is string interning good? Or bad? It is fast and can be very good for optimizing memory.
War story! In the MyGet.org code base, we are using string interning for package id's. We did some profiling on our application and found that there are not that many different package id's around and in fact, since a package id can exist in multiple versions, we were seeing a lot of duplicate package id's in memory. We started interning package id's, and have seen a nice improvement in memory usage with virtually no impact on CPU usage.
As a rule of thumb, keep this in mind:
If an application has a lot of long-lived strings, but not a massive amount of unique strings, interning can improve memory efficiency.
If an application has a lot of long-lived strings, but these are almost all distinct values, string interning adds no benefit as the strings have to be stored anyway. Plus it may exhaust memory…
If an application has a lot of short-lived strings, trust the Garbage Collector to do its thing fast and efficiently.
When in doubt, measure. Use a memory profiler to detect string duplicates and analyze where they come from and how they can be optimized. Do watch out: you may see strings as a potential memory issue but they most probably are not.
Enjoy! And remember, don’t optimize what should not be optimized (but do optimize the rest).
P.S.: Thank you Wesley Cabus for reviewing!
13 responses