WO2020077357A1 - Compositions and methods for increasing transposition frequency - Google Patents
Compositions and methods for increasing transposition frequency Download PDFInfo
- Publication number
- WO2020077357A1 WO2020077357A1 PCT/US2019/056272 US2019056272W WO2020077357A1 WO 2020077357 A1 WO2020077357 A1 WO 2020077357A1 US 2019056272 W US2019056272 W US 2019056272W WO 2020077357 A1 WO2020077357 A1 WO 2020077357A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- piggybac
- seq
- culture media
- transposon
- inhibitor
- Prior art date
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/065—Modulators of histone acetylation
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/90—Vectors containing a transposable element
Definitions
- the disclosure is directed to molecular biology, and more, specifically, to compositions and methods for increasing transposition frequency.
- compositions and methods for increasing transposition frequency that may be used, for example, for integrating an exogenous sequence into a genome.
- the present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a histone deacetylase (HD AC) inhibitor, a histone methyltransferase (HMT) inhibitor or a combination thereof, thereby increasing the frequency of transposition in a population of cells.
- Step a) can occur prior to step b), step b) can occur prior to the step a) or step a) and step b) can occur concurrently.
- the culture media in step b) can comprise a combination of the HD AC inhibitor and the HMT inhibitor.
- the plurality of modified cells in step b) can be cultured in a culture media comprising the combination of the HD AC inhibitor and the HMT inhibitor for at least 12 hours.
- the plurality of modified cells in step b) can be cultured in a culture media comprising the combination of the HD AC inhibitor and the HMT inhibitor for at least 24 hours.
- the plurality of modified cells in step b) can be cultured in a culture media comprising the combination of the HD AC inhibitor and the HMT inhibitor for about 3 hours to about 30 hours.
- the present disclosure provides method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture culture conditions sufficient for cell proliferation and for transposition media comprising a HD AC inhibitor and a HMT inhibitor; c) removing the HD AC inhibitor from the culture media; and d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor following step c, thereby increasing the frequency of transposition in a population of cells.
- Step a) can occur prior to step b), step b) can occur prior to the step a) or step a) and step b) can occur concurrently.
- the plurality of modified cells in step b) can be cultured in a culture media comprising the HD AC inhibitor and the HMT inhibitor for at least 12 hours.
- the plurality of modified cells in step b) can be cultured in a culture media comprising the HD AC inhibitor and the HMT inhibitor for at least 24 hours.
- the plurality of modified cells in step b) can be cultured in a culture media comprising the HD AC inhibitor and the HMT inhibitor for about 3 hours to about 30 hours.
- the plurality of modified cells in step d) can be cultured in a culture media comprising a HMT inhibitor for at least 48 hours following step c.
- the plurality of modified cells in step d) can be cultured in a culture media comprising a HMT inhibitor for at least 3 days following step c.
- the plurality of modified cells in step d) can be cultured in a culture media comprising a HMT inhibitor for about 1 day to about 5 days following step c.
- the HMT inhibitor in step b) and the HMT inhibitor in step d) can be the same or different.
- the HMT inhibitor in step b) can comprise UNC0638.
- the HMT inhibitor in step d) can comprise UNC0638.
- the HMT inhibitor in step b) and step d) can comprise UNC0638.
- the culture media can comprise about 0.5 mM to about 2 mM of UNC0638 in step b), in step d) or in both step b) and step d).
- the culture media can comprise about 1 mM of UNC0638 in step b), in step d) or in both step b) and step d).
- the HD AC inhibitor can comprise valproic acid or sodium phenylbutyrate.
- the HD AC inhibitor is valproic acid.
- the culture media can comprise about 0.25 mM to about 1.25 mM of valproic acid.
- the culture media can comprise about 0.5 mM or about 0.75 mM of valproic acid.
- the culture media can comprise about 0.5 mM to about 2 mM of sodium phenylbutyrate.
- the culture media can comprise about 1.5 mM of sodium
- the culture media in step b) comprising the combination of the HD AC inhibitor and the HMT inhibitor can further comprise a second HD AC inhibitor, a second HMT inhibitor, StemRegenin 1 (SR1), UM171, or a combination thereof.
- SR1 StemRegenin 1
- the culture conditions in steps b) - d) result in an increase in frequency of transposition and at least a one-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions sufficient for cell proliferation and for transposition wherein said conditions do not comprise a HD AC inhibitor and a HMT inhibitor.
- the culture conditions in steps b) - d) result in an increase in frequency of transposition and at least a two-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions sufficient for cell proliferation and for transposition wherein said conditions do not comprise a HD AC inhibitor and a HMT inhibitor.
- the culture conditions in steps b) - d) result in an increase in frequency of transposition and about one-fold to about a four-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions sufficient for cell proliferation and for transposition wherein said conditions do not comprise a HD AC inhibitor and a HMT inhibitor.
- the present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for at least 24 hours; c) removing the valproic acid from the culture media; and d) culturing the plurality of modified cells in a culture media comprising UNC0638 for at least 3 days following step c, thereby increasing the frequency of transposition in a population of cells.
- Step a) can occur prior to step b), step b) can occur prior to the step a) or step a) and step b) can occur concurrently.
- the disclosed method of increasing the frequency of transposition can further comprise a method of expanding the population of cells comprise e) removing the HMT inhibitor from the culture media following step d); and f) culturing the plurality of modified cells in a culture media comprising an expansion agent following step e, wherein the expansion agent comprises an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative.
- the expansion agent can comprise at least two of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative.
- the expansion agent can comprise each of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative.
- the plurality of modified cells in step f) can be cultured in a culture media comprising the expansion agent for at least 5 days following step e.
- the plurality of modified cells in step f) can be cultured in a culture media comprising the expansion agent for at least 7 days following step e.
- the plurality of modified cells in step f) can be cultured in a culture media comprising the expansion agent for about 4 days to about 9 days following step e.
- the HMT inhibitor in step f) can comprise UNC0638.
- the culture media in step f) can comprise about 0.5 mM to about 2 mM of UNC0638.
- the culture media in step f) can comprise about 1 mM of UNC0638.
- the aryl hydrocarbon receptor inhibitor in step f) can comprise
- the culture media in step f) can comprise about 0.5 mM to about 2 mM of SR1.
- the culture media in step f) can comprise about 1 mM of SR1.
- the aryl hydrocarbon receptor inhibitor in step f) can comprise UM171.
- the culture media in step f) can comprise about 25 nM to about 50 nM of UM171.
- the culture media in step f) can comprise about 35 nM of UM171.
- the expansion agent can further comprise valproic acid.
- the culture media in step f) can comprise about 0.25 mM to about 1.25 mM of valproic acid.
- the culture media in step f) can comprise about 1 mM of valproic acid.
- the expansion agent can further comprise nicotinamide.
- the culture media in step f) can comprise about 2.5 mM to about 10 mM of nicotinamide.
- the culture media in step f) can comprise about 5 mM of nicotinamide.
- the expansion agent can further comprise garcinol.
- the culture media in step f) can comprise about 5 mM to about 15 mM of garcinol.
- the culture media in step f) can comprise about 10 mM of garcinol.
- the expansion agent can further comprise sodium phenylbutyrate.
- the culture media in step f) can comprise about 1 mM to about 2 mM of sodium phenylbutyrate.
- the culture media in step f) can comprise about 1.5 mM of sodium phenylbutyrate.
- the disclosed method of increasing the frequency of transposition and expanding the population of cells can further comprise a method of selecting the population of cells comprising wherein the transposon in step a) comprises a selection gene and step f) further comprises a selection agent.
- the transposon can comprise a dihydrofolate reductase (DHFR) resistance gene or the transposon can comprise a sequence encoding a DHFR mutein enzyme and step f) can further comprise a selection agent, wherein the selection agent can comprise methotrexate or pralatrexate.
- the culture media in step f) can comprise about 100 nM to about 500 nM of methotrexate.
- the culture media in step f) can comprise about 250 nM of
- the culture media in step f) can comprise about 50 nM to about 250 nM of pralatrexate.
- the culture media in step f) can comprise about 125 nM of pralatrexate.
- the selection agent can comprise pralatrexate and dipyridimole.
- the culture media in step f) can comprise about 50 nM to about 250 nM of pralatrexate and about 1 mM to about 10 mM of dipyridimole.
- the culture media in step f) can comprise about 125 nM of pralatrexate and about 5 mM of dipyridimole.
- Culturing the plurality of modified cells with an expansion agent can occur prior to culturing the plurality of modified cells with a selection agent, culturing the plurality of modified cells with a selection agent can occur prior to culturing the plurality of modified cells with an expansion agent, or culturing the plurality of modified cells with an expansion agent and culturing the plurality of modified cells with a selection agent can occur concurrently.
- the culture conditions in steps e) - f) result in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions sufficient for cell proliferation and for transposition wherein said conditions do not comprise a selection agent and expansion agent.
- the culture conditions in steps e) - f) result in at least five-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions sufficient for cell proliferation and for transposition wherein said conditions do not comprise a selection agent and expansion agent.
- the culture conditions in steps e) - f) result in about two-fold to about five-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions sufficient for cell proliferation and for transposition wherein said conditions do not comprise a selection agent and expansion agent.
- the transposon can comprise a sequence encoding for a selection marker.
- the selection marker can be a nucleic acid molecule or a protein.
- the transposon can comprise a sequence for a DHFR resistance gene.
- the transposon can comprise a sequence encoding a DHFR mutein enzyme.
- the transposon can comprise a sequence encoding for a therapeutic agent.
- the therapeutic agent can be a therapeutic protein or a therapeutic RNA.
- the therapeutic agent can be human beta-globin (HBB), T87Q human beta- globin (HBB T87Q), BAF chromatin remodeling complex subunit (BCL11A) shRNA, insulin like growth factor 2 binding protein 1 (IGF2BP1), interleukin 2 receptor gamma (IL2RG), alpha galactosidase A (GLA), alpha-L-idurondase (IDUA), iduronate 2-sulfatase (IDS), cystinosin lysosomal cysteine transporter (CTNS).
- the transposon can comprise a sequence encoding a chimeric antigen receptor (CAR).
- the transposon can comprise a sequence encoding a non- naturally occurring chimeric stimulatory receptor (CSR) comprising: (a) an ectodomain comprising a activation component, wherein the activation component is isolated or derived from a first protein; (b) a transmembrane domain; and (c) an endodomain comprising at least one signal transduction domain, wherein the at least one signal transduction domain is isolated or derived from a second protein; wherein the first protein and the second protein are not identical.
- the transposon can comprise a sequence for a CAR and a sequence for a CSR.
- the transposon can comprise a sequence encoding for an inducible proapoptotic polypeptide comprising (a) a ligand binding region, (b) a linker, and (c) a caspase polypeptide, wherein the inducible proapoptotic polypeptide does not comprise a non-human sequence.
- the transposon can be integrated into the genome of the cell by the transposase. The integration can be stable or transient.
- the sequence encoding the transposase can comprise an amino acid or a nucleic acid sequence encoding a transposase protein.
- the nucleic acid sequence encoding a transposase protein can comprise an RNA sequence or comprise a DNA sequence.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for at least 24 hours; c) removing the valproic acid from the culture media; d) culturing the plurality of modified cells in a culture media comprising UNC0638 for at least 3 days following step c; e) removing the UNC0638 from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least 7 days following step e, wherein the selection agent comprises methotrexate or
- the present invention provides a plurality of modified cells produced by any of the methods disclosed herein.
- the present invention provides compositions comprising a plurality of modified cells produced by any of the methods disclosed herein.
- the present invention provides pharmaceutical compositions comprising a plurality of modified cells produced by any of the methods disclosed herein and and a pharmaceutically-acceptable carrier.
- the present invention provides a modified cell population wherein at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, at least 99.5%, at least 99.9%, or 100% of the plurality of modified cells in the population comprise a genome-integrated transposon.
- the present invention provides compositions comprising a modified cell population wherein at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, at least 99.5%, at least 99.9%, or 100% of the plurality of modified cells in the population comprise a genome- integrated transposon.
- the present invention provides pharmaceutical compositions comprising a modified cell population wherein at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, at least 99.5%, at least 99.9%, or 100% of the plurality of modified cells in the population comprise a genome-integrated transposonand a and a pharmaceutically-acceptable carrier.
- the present invention provides a method of treating a disease or disorder in a subject in need thereof, comprising administering to the subject a therapeutically-effective amount of compositions or pharmaceutical compositions disclosed herein.
- the present invention also provides compositions or pharmaceutical compositions for use in treating a disease or disorder.
- the pharmaceutical composition comprises a plurality of autologous cells.
- the pharmaceutical composition comprises a plurality of allogeneic cells.
- the patent or application file contains at least one drawing executed in color.
- Fig. 1 A is a schematic diagram depicting a piggyBac (PB) transposon vector construct (nanoV5 EFla GFP-T2A-DHFR vector) used for delivering the GFP reporter transgene as well as for enabling HSC selection.
- PB piggyBac
- Fig. 1B is a linear illustration depicting a piggyBac (PB) transposon vector construct (nanoV5 EFla GFP-T2A-DHFR vector) used for delivering the GFP reporter transgene as well as for enabling HSC selection.
- PB piggyBac
- FIG. 2A is a schematic diagram depicting a construct for erythroid-specific expression of the human therapeutic T87Q beta-globin and the constitutive expression of GFP and DHFR (PB -HBB -PGK-GFP- T2 A-DHFR) .
- Fig. 2B is a schematic diagram depicting a construct for erythroid-specific expression of the human therapeutic T87Q beta-globin and the constitutive expression of GFP and DHFR (PB- HBB-PGK-GFP-T2A-DHFR).
- Fig. 3A is a graph depicting the relative increase in total GFP+ cells between a control cytokine treatment (lOOng/ml each of hrSCF, hrTPO and hrFLT3L) and 0.5mM VPA 24hr washout, as assessed by flow cytometry at Day 7.
- Fig. 3B is a graph depicting a negative correlation between the frequency of GFP+ cells in a control nucleofection and the fold increase in GFP+ cells achieved by adding 0.5mM VPA for 24hrs post nucleofection.
- Fig. 3C is a graph depicting a cumulative summary of the transposition efficiency achieved with the nanoV5 EFla GFP-T2A-DHFR vector +sPB RNA.
- Fig. 4 is a schematic diagram depicting an experimental design to assess the effects of several modifiers on transposition yield.
- Fig. 5 is a series of flow cytometry plots showing the frequency of GFP+ cells in each condition for each donor as assessed at Day 7.
- Fig. 6A is a graph showing the frequency of GFP+ under various experimental conditions.
- Fig. 6B is a graph showing the absolute number of GFP+ cells under various experimental conditions normalized to the cytokine control condition.
- Fig. 7 is a schematic diagram depicting an experimental design to assess the effects of several modifiers on transposition yield and expansion.
- Fig. 8A is a plot depicting GFP+ frequency of each condition as assayed by flow cytometry at day 4 before the initiation of MTX selection and expansion.
- Fig. 8B is a plot depicting GFP+ frequency of each condition as assayed by flow cytometry at day 11 after 7 days of selection in 250nM MTX and expansion with
- Fig. 8C is a graph depicting absolute numbers of GFP+ cells for each condition at Day 4 before selection/expansion and Day 11 after selection/expansion.
- Fig. 9A is a graph comparing the relative number of bulk GFP+ cells in each condition at Day 11 post selection.
- Fig. 9B a graph comparing the relative number of GFP+ phenotypic HSCs
- the present disclosure provides a method of increasing the frequency of transposition in a cell comprising a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into the cell to produce a modified cell and b) culturing the modified cell in a culture media comprising a histone deacetylase (HD AC) inhibitor, a histone methyltransferase (HMT) inhibitor, or a combination thereof, thereby increasing the frequency of transposition in the cell.
- HD AC histone deacetylase
- HMT histone methyltransferase
- the present disclosure provides a method of increasing the frequency of transposition in a population of cells comprising a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells and b) culturing the plurality of modified cells in a culture media comprising a histone deacetylase (HD AC) inhibitor, a histone methyltransferase (HMT) inhibitor, or a combination thereof, thereby increasing the frequency of transposition in a population of cells.
- HD AC histone deacetylase
- HMT histone methyltransferase
- the cell or plurality of cells can be cultured in a culture media comprising the HD AC inhibitor, the HMT inhibitor, or a combination thereof, before, after or concurrently with introducing the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into the cell or plurality of cells to produce the modified cell or plurality of modified cells.
- a modified cell comprises a genome-integrated transposon.
- a plurality of modified cells comprise a plurality of cells comprising a genome-integrated transposon.
- the integration can be stable or transient.
- the HD AC inhibitor, the HMT inhibitor, or a combination thereof can be present in the culture media (e.g ., in contact with the cell or plurality of cells) for at least about 1 minute, at least about 2 minutes, at least about 5 minutes, at least about 10 minutes, at least about 15 minutes, at least about 20 minutes, at least about 25 minutes, at least about 30 minutes, at least about 35 minutes, at least about 40 minutes, at least about 45 minutes, at least about 50 minutes, at least about 55 minutes, at least about 60 minutes, or any number of minutes in between.
- the culture media e.g ., in contact with the cell or plurality of cells
- the HD AC inhibitor, the HMT inhibitor, or a combination thereof can be present in the culture media (e.g., in contact with the cell or plurality of cells) for at least about 1 hour, at least about 2 hours, at least about 4 hours, at least about 6 hours, at least about 8 hours, at least about 10 hours, at least about 12 hours, at least about 14 hours, at least about 16 hours, at least about
- the HD AC inhibitor, the HMT inhibitor, or a combination thereof can be present in the culture media (e.g., in contact with the cell or plurality of cells) for at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 7 days, at least about 8 days, at least about 9 days, at least about 10 days, at least about 11 days, at least about 12 days, at least about 13 days, or at least about 14 days.
- the HD AC inhibitor can be present in the culture media (e.g., in contact with the cell or plurality of cells) for at least about 1 hour, at least about 2 hours, at least about 4 hours, at least about 6 hours, at least about 8 hours, at least about 10 hours, at least about 12 hours, at least about 14 hours, at least about 16 hours, at least about 18 hours, at least about 20 hours, at least about 22 hours, at least about 24 hours, at least about 26 hours, at least about 28 hours, at least about 30 hours, or any number of hours in between.
- the HMT inhibitor can be present in the culture media (e.g., in contact with the cell or plurality of cells) in the presence of the HD AC inhibitor for at least about 3 hours, at least about 6 hours, at least about 12 hours, at least about 18 hours, at least about 1 day, at least about 2 days, at least about 3 days, or at least about 4 days.
- the HMT inhibitor can be present in the culture media (e.g., in contact with the cell or plurality of cells) in the absence of the HD AC inhibitor for at least about 3 hours, at least about 6 hours, at least about 12 hours, at least about 18 hours, at least about 1 day, at least about 2 days, at least about 3 days, or at least about 4 days.
- the combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g., in contact with the cell or plurality of cells) for at least one hour; at least about 3 hours, at least about 6 hours, about 12 hours, about 18 hours, at least about 24 hours.
- the combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g., in contact with the cell or plurality of cells) for at least one hour; at least about 3 hours, at least about 6 hours, about 12 hours, about 18 hours, at least about 24 hours following the introduction of the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell or a plurality of cells to produce the modified cell or the plurality of modified cells.
- the culture media e.g., in contact with the cell or plurality of cells
- the methods of increasing the frequency of transposition can further comprise a recovery period following the introducing step, wherein the modified cell or plurality of modified cells and the HD AC inhibitor, HMT inhibitor, or combination thereof are not in contact. That is, the modified cell or plurality of modified cells can be cultured in a culture media not comprising the HD AC inhibitor, HMT inhibitor, or combination thereof as part of the recovery period following the introduction of the transposon or sequence encoding the transposon.
- the recovery period can have a duration of at least 1 minute, at least 2 minutes, at least 5 minutes, at least 10 minutes, at least 15 minutes, at least 20 minutes, at least 25 minutes, at least 30 minutes, at least 35 minutes, at least 40 minutes, at least 45 minutes, at least 50 minutes, at least 55 minutes, at least 60 minutes, or any number of minutes in between.
- the recovery period can have a duration of least about 1 hour, at least about 2 hours, at least about 4 hours, at least about 6 hours, at least about 8 hours, at least about 10 hours, at least about 12 hours, at least about 14 hours, at least about 16 hours, at least about 18 hours, at least about 20 hours, at least about 22 hours, at least about 24 hours, at least about 26 hours, at least about 28 hours, at least about 30 hours, or any number of hours in between.
- the combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g ., in contact with the cell or plurality of cells) for at least one hour; at least about 3 hours, at least about 6 hours, about 12 hours, about 18 hours, at least about 24 hours following the introduction of the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell or a plurality of cells to produce the modified cell or plurality of modified cells and then the HD AC inhibitor is removed from the cell culture media.
- the HD AC inhibitor can be removed by any means known in the art (e.g., washing the cells and adding culture media not comprising an HD AC inhibitor).
- the combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (and in contact with the plurality of cells) for at least one hour; at least about 3 hours, at least about 6 hours, about 12 hours, about 18 hours, at least about 24 hours following the introduction of the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce the plurality of modified cells and then the HD AC inhibitor is removed from the cell culture media.
- the HD AC inhibitor can be removed by any means known in the art (e.g., washing the cells and adding culture media not comprising an HD AC inhibitor).
- the modified cell or plurality of modified cells are cultured in a culture media comprising an HMT inhibitor (e.g., without an HD AC inhibitor present) for at least about 3 hours, at least about 6 hours, about 12 hours, about 18 hours, at least about 1 day, at least about 2 days, at least about 3 days, or at least about 4 days.
- the HMT inhibitor is removed from the cell culture media at the same time as removal of the HD AC inhibitor (e.g., washing the cells) and new culture media is added comprising an HMT inhibitor and not comprising an HD AC inhibitor.
- the HD AC inhibitor, the HMT inhibitor, or a combination thereof can be present in the culture media (e.g., in contact with the cell or plurality of cells) for about 30 minutes to about 36 hours; about 1 hour to about 34 hours; about 2 hours to about 32 hours; about 3 hours to about 30 hours; about 4 hours to about 28 hours; about 6 hours to about 26 hours; about 6 hours to about 24 hours; about 8 hours to about 24 hours; about 10 hours to about 24 hours; about 12 hours to about 24 hours; about 14 hours to about 24 hours; about 16 hours to about 24 hours; about 18 hours to about 24 hours; or about 18 hours to about 24 hours.
- the HD AC inhibitor, the HMT inhibitor, or a combination thereof can be present in the culture media (e.g ., in contact with the cell or plurality of cells) for about 1 day to about 2 days; about 1 day to about 3 days, about 1 day to about 4 days, about 1 day to about 5 days, about 1 day to about 6 days, about 1 day to about 7 days, about 1 day to about 8 days, about 1 day to about 9 days, about 1 day to about 10 days, about 1 day to about 11 days, about 1 day to about 12 days, about 1 day to about 13 days, about 1 day to about 14 days.
- the combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g., in contact with the cell or plurality of cells) for about 30 minutes to about 36 hours; about 1 hour to about 34 hours; about 2 hours to about 32 hours; about 3 hours to about 30 hours; about 4 hours to about 28 hours; about 6 hours to about 26 hours; about 6 hours to about 24 hours; about 8 hours to about 24 hours; about 10 hours to about 24 hours; about 12 hours to about 24 hours; about 14 hours to about 24 hours; about 16 hours to about 24 hours; about 18 hours to about 24 hours; or about 18 hours to about 24 hours.
- the combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g., in contact with the cell or plurality of cells) for about 1 hour to about 24 hours; about 2 hours to about 24 hours; about 3 hours to about 24 hours; about 4 hours to about 24 hours; about 5 hours to about 24 hours; about 6 hours to about 24 hours; about 8 hours to about 24 hours; about 10 hours to about 24 hours; about 12 hours to about 24 hours; about 14 hours to about 24 hours; about 16 hours to about 24 hours; about 18 hours to about 24 hours; or about 18 hours to about 24 hours.
- the combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g., in contact with the cell or plurality of cells) for about 1 hour to about 24 hours; about 2 hours to about 24 hours; about 3 hours to about 24 hours; about 4 hours to about 24 hours; about 5 hours to about 24 hours; about 6 hours to about 24 hours; about 8 hours to about 24 hours; about 10 hours to about 24 hours; about 12 hours to about 24 hours; about 14 hours to about 24 hours; about 16 hours to about 24 hours; about 18 hours to about 24 hours; or about 18 hours to about 24 hours following the introduction of the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell or a plurality of cells to produce the modified cell or plurality of modified cells.
- the combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g ., in contact with the cell or plurality of cells) for about 1 hour to about 24 hours; about 2 hours to about 24 hours; about 3 hours to about 24 hours; about 4 hours to about 24 hours; about 5 hours to about 24 hours; about 6 hours to about 24 hours; about 8 hours to about 24 hours; about 10 hours to about 24 hours; about 12 hours to about 24 hours; about 14 hours to about 24 hours; about 16 hours to about 24 hours; about 18 hours to about 24 hours; or about 18 hours to about 24 hours following the introduction of the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell or a plurality of cells to produce the modified cell or plurality of modified cells and then the HD AC inhibitor is removed from the cell culture media.
- the HD AC inhibitor can be removed by any means known in the art (e.g., washing
- the combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g., in contact with the cell or plurality of cells) for about 1 hour to about 24 hours; about 2 hours to about 24 hours; about 3 hours to about 24 hours; about 4 hours to about 24 hours; about 5 hours to about 24 hours; about 6 hours to about 24 hours; about 8 hours to about 24 hours; about 10 hours to about 24 hours; about 12 hours to about 24 hours; about 14 hours to about 24 hours; about 16 hours to about 24 hours; about 18 hours to about 24 hours; or about 18 hours to about 24 hours following the introduction of the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell or a plurality of cells to produce the modified cell or the plurality of modified cells and then the HD AC inhibitor is removed from the cell culture media.
- the HD AC inhibitor can be removed by any means known in the art (e.g., washing the cells and adding culture media not comprising an HD AC inhibitor). Following removal of the HD AC inhibitor the modified cell or the plurality of modified cells are cultured in a culture media comprising an HMT inhibitor (e.g., without an HD AC inhibitor present) for about one day to about 7 days; about one day to about 6 days; about one day to about 5 days; about one day to about 4 days.
- the HMT inhibitor is removed from the cell culture media at the same time as removal of the HD AC inhibitor (e.g ., washing the cells) and new culture media is added comprising an HMT inhibitor and not comprising an HD AC inhibitor.
- the present disclosure provides a method of increasing the frequency of transposition in a cell or a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell to produce a modified cell or into a plurality of cells to produce a plurality of modified cells; b) culturing the modified cell or the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 24 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the modified cell or the plurality of modified cells in a culture media comprising a HMT inhibitor for about 3 days following step c; thereby increasing the frequency of transposition in a cell or a population of cells.
- the present disclosure provides a method of increasing the frequency of transposition in a cell or a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell to produce a modified cell or a plurality of cells to produce a plurality of modified cells; b) culturing the modified cell or the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 3 hours to about 30 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the modified cell or the plurality of modified cells in a culture media comprising a HMT inhibitor for about 1 day to about 5 days following step c; thereby increasing the frequency of transposition in a cell or a population of cells.
- the disclosed culture methods for increasing the frequency of transposition can be compared to culture methods utilizing culture media not comprising a HD AC inhibitor, a HMT inhibitor, or a combination thereof.
- the disclosed culture methods for increasing the frequency of transposition can be compared to identical culture conditions sufficient for cell proliferation and for transposition into a cell but utilizing culture media not comprising a HD AC inhibitor, a HMT inhibitor, or a combination thereof.
- the culture methods comprising a culture media comprising a HD AC inhibitor, a HMT inhibitor, or a combination thereof result in an increase in frequency of transposition and at least a one-fold; at least a two-fold; at least a three-fold; at least a four-fold increase in the yield of transposed cells in the plurality of modified cells when compared to culture conditions sufficient for cell proliferation and for transposition into the cell utilizing culture media not comprising a HD AC inhibitor, a HMT inhibitor, or a combination thereof.
- Culture conditions sufficient for cell proliferation and transposition comprise culture in the presence of one or more cytokines.
- the one or more cytokines can comprise, consist essential of, or consist of human recombinant stem cell factor (hrSCF), human recombinant thrombopoietin (hrTPO), human recombinant FMS-like tyrosine kinase 3 ligand (hrFLT3L).
- the culture conditions sufficient for cell proliferation comprise culture in the presence of each of hrSCF, hrTPO and hrFLT3L.
- the culture media can comprise about 50 ng/ml to about 200 ng/ml of hrSCF.
- the culture media can comprise about lOOng/ml of hrSCF.
- the culture media can comprise about 50 ng/ml to about 200 ng/ ml of hrTPO.
- the culture media can comprise about lOOng/ml of hrTPO.
- the culture media can comprise about 50 ng/ml to about 200 ng/ ml of hrFLT3L.
- the culture media can comprise lOOng/ml of hrFLT3L.
- the present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 24 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 3 days following step c; wherein said culturing results in an increase in frequency of transposition and at least a one-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a HD AC inhibitor and HMT inhibitor.
- the present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 3 hours to about 30 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 1 day to about 5 days following step c; wherein said culturing results in an increase in frequency of transposition and at least a one-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a HD AC inhibitor and HMT
- the present methods can be used to increase the frequency of transposition in a naturally poor transposer cell.
- a naturally poor transposer cell means a cell that has a transposition frequency of less than or equal to about 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, or 15% when utilizing standard transposon in a standard nucleofection or electroporation assay and without the addition of any transposition enhancing or boosting agents.
- a naturally high transposer cell means a cell that has a transposition frequency of equal to or greater than about 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, 15%, 16%, 17%, 18%, 19%, 20%, 21%, 22%, 23%, 24%, 25%, 26%, 27%, 28%, 29%, or 30% when utilizing standard transposon in a standard nucleofection or electroporation assay and without the addition of any transposition enhancing or boosting agents.
- the present methods increase the frequency of transposition from less than or equal to about 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, or 15% to equal to greater than about 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, 15%, 16%, 17%, 18%, 19%, 20%, 21%, 22%, 23%, 24%, 25%, 26%, 27%, 28%, 29%, or 30%.
- a cell transposed with a vector comprising a transposon comprising an EFIalpha promoter expressing GFP and DHFR is“a naturally poor transposer cell” with a transposition frequency less than or equal to about 10% when utilizing standard transposon in a standard nucleofection or electroporation assay and without the addition of any transposition enhancing or boosting agents.
- a cell transposed with a vector comprising a transposon comprising an EFIalpha promoter expressing GFP and DHFR is“a naturally high transposer cell” with a transposition frequency of equal to greater than about 15%.
- the present methods increase the frequency of transposition of the transposon comprising an EFIalpha promoter expressing GFP and DHFR from less than or equal to about 10% to equal to or greater than about 15%.
- the HD AC inhibitor, the HMT inhibitor, or a combination thereof can open the chromatin of a cell or cells in a plurality of cells and/or increase access of the transposon and transpose as to the genomic DNA of a cell or cells in a plurality of cells.
- the HD AC inhibitor, the HMT inhibitor, or a combination thereof can be present in the culture media in an amount from about 0.5 mM to about 2 mM; about 1.0 mM to about 1 mM; about 2.0 mM to about 1.0 mM; or about 5.0 mM to about 1.0 mM.
- the HD AC inhibitor can be a pan-HD AC inhibitor, a class I HD AC inhibitor, a class II
- HD AC inhibitor or a class I and class II inhibitor include Trichostatin A (TSA), Vorinostat, CAY10433 (targets class I and II), or sodium phenylbutyrate (targets class I and Ila).
- TSA Trichostatin A
- Vorinostat CAY10433
- sodium phenylbutyrate targets class I and Ila
- class I HD AC inhibitors targeting HDAC 1, 2, 3, and 8
- MS-275 MS-275, CAY10398, or Entinostat.
- class II HDAC inhibitors include MC-1568, Scriptaid, or CAY10603.
- Valproic acid (VP A) can inhibits multiple histone deacetylases from both Class I and Class II (but not HDAC6 or HDAC 10) and has high potency for Class I HDACs.
- the HDAC inhibitor can be valproic acid, sodium phenylbutyrate (NaPB), trichostatin A, vorinostat, CAY10433, MS-275, CAY10398, entinostat, MC-1568, scriptaid, or CAY10603.
- the HDAC inhibitor is valproic acid.
- VPA can be present in the culture media in an amount from about 0.1 mM to about 2 mM; about 0.25 mM to about 1 mM; about 0.25 to about 0.75 mM; about 0.25 to about 0.5 mM or about 0.5 mM to about 0.75 mM.
- VPA is present in the culture media at about 0.25 mM; about 0.5 mM; about 0.75 mM or about 1 mM. In a preferred aspect, VPA is present in the culture media at about 0.5 mM or about 0.75 mM. In another preferred aspect, VPA is present in the culture media at about 0.5 mM for about 24 hours. In another preferred aspect, VPA is present in the culture media at about 0.75 mM for about 24 hours.
- NaPB can be present in the culture media in an amount from about 0.5 mM to about 3 mM; about 1.0 mM to about 2.0 mM; or about 1.0 mM to about 1.5 mM. In a one aspect, NaPB is present in the culture media at about 1.5 mM. In another aspect, NaPB is present in the culture media at about 1.5 mM for about 1 day to about 7 days.
- the HMT inhibitor can be a selective inhibitor of G9a/GLP histone methyltransferases, which methylate lysine 9 of histone 3 (H3K9).
- G9a/GLP inhibitors include BIX01294, UNC0642, A-366, UNC0224, UNC0631, UNC0646, BRD4770, or
- Non-limiting examples of histone lysine methyltransferases include chaetocin, EPZ005687, EPZ6438, GSK126, GKS343, Ell, UNC199, EPZ004777, EPZ5676, LLY-507, AZ505, or A-893.
- the HMT inhibitor can be 2-Cyclohexyl-N-(l-isopropylpiperidin-4-yl)-6-methoxy-7- (3-(pyrrolidin-l-yl)propoxy) quinazolin-4-amine (ETNC0638), BIX01294, ETNC0642, A-366, UNC0224, UNC0631, UNC0646, BRD4770, UNC0631, chaetocin, EPZ005687, EPZ6438, GSK126, GKS343, Ell, UNC199, EPZ004777, EPZ5676, LLY-507, AZ505 or A-893.
- the HMT inhibitor is UNC0638.
- the term UNC0638 also includes UNC0638 hydrate.
- UNC0638 can be present in the culture media in an amount from about 0.5 mM to about
- the culture media for increasing the frequency of transposition comprising a HD AC inhibitor, HMT inhibitor, or a combination thereof, can further comprise a DNA
- methyltransferase inhibitor aryl hydrocarbon receptor inhibitor, a pyrimido-indole derivative, a second HD AC inhibitor, a second HMT inhibitor, or a combination thereof.
- the DNA methyltransferase inhibitor can be 5-azacytidine.
- the 5-azacytidine can be present in the culture media in an amount from about 0.1 mM to about 1 mM or about 0.5 mM to about 1 mM. In a one aspect, the 5-azacytidine is present in the culture media at about 0.1 mM, about 0.5 mM or about 1 mM for about 24 hours.
- the aryl hydrocarbon receptor inhibitor can be StemRegenin 1 (SR1), alpha- naphthoflavone, beta-naphthoflavone, brevifolincarboxylic acid, 6,2',4'-Trimethoxyflavone, D,L- Sulforaphane, 2,3,7,8-tetrachlorodibenzo-p-dioxin (TCDD), PDM2, salicylamide, l,3-dichloro- 5-[(lE)-2-(4-methoxyphenyl)ethenyl]-benzene, CH 223191, methylindoles, methoxyindoles, indole-3-carbinol, mexiletine, hydroxytamoxifen, raloxifene, 2,3,7,8-tetrachlorodibenzo-p- dioxin, laquinimod, aminoflavone (NSC686288), CB7993
- the aryl hydrocarbon receptor inhibitor is SR1.
- SR1 can be present in the culture media in an amount from about 0.5 mM to about 2 mM; about 0.5 mM to about 1.5 mM; about 0.5 mM to about 1 mM; or about 0.75 mM to about 1.25 mM. In some aspects, SR1 is present in the culture media at about 0.75 mM; about 1 mM or about 1.25 mM. In a preferred aspect, SR1 is present in the culture media at about 1.0 mM.
- the pyrimido-indole derivative can be a pyrimido-[4,5-b]-indole derivative.
- the pyrimido-indole derivative inhibitor is UM171 and has the following
- UM171 can be present in the culture media in an amount from about 25 nM to about 75 nM; or about 25 nM to about 50 nM.
- UM171 is present in the culture media at about 35 nM.
- the culture media for increasing the frequency of transposition in a cell or plurality of cells as disclosed herein can include the non-limiting agents: valproic acid;
- the culture media for increasing the frequency of transposition in a cell or plurality of cells as disclosed herein comprises a combination of VP A and UNC0638.
- the culture media comprises a combination VPA and UNC0638
- the VPA is present from about 0.1 mM to about 2 mM; about 0.25 mM to about 1 mM; about 0.25 to about 0.75 mM; about 0.25 to about 0.5 mM or about 0.5 mM to about 0.75 mM
- the UNC0638 is present from about 0.5 mM to about 2 mM; about 0.5 mM to about 1.5 mM; about 0.5 mM to about 1 mM; or about 0.75 mM to about 1.25 mM.
- the VPA is present in the culture media at about 0.5 mM or about 0.75 mM and UNC0638 is present in the culture media at about 0.75 mM; about 1 mM or about 1.25 mM. In a preferred aspect, the VPA is present in the culture media at about 0.5 mM or about 0.75 mM and UNC0638 is present in the culture media at about 1.0 mM for about 4 days to about 11 days.
- the present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 24 hours; c) removing the valproic acid from the culture media; and d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 3 days following step c, thereby increasing the frequency of transposition in a population of cells.
- the present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 3 hours to about 30 hours; c) removing the valproic acid from the culture media; and d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 1 day to about 5 days following step c, thereby increasing the frequency of transposition in a population of cells.
- the present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 24 hours; c) removing the valproic acid from the culture media; and d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 3 days following step c, wherein said culturing results in an increase in frequency of transposition and at least a one-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising valproic acid and UNC0638.
- the present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 3 hours to about 30 hours; c) removing the valproic acid from the culture media; and d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 1 day to about 5 days following step c, wherein said culturing results in an increase in frequency of transposition and at least a one-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising valproic acid and UN
- the present disclosure also provides methods for selecting a population of cells.
- the selection of a population of cells includes the selection of a plurality of modified cells comprising a selection marker.
- the present disclosure also provides methods for expansion and selection of a population of cells.
- the expansion and selection of a population of cells includes the expansion of a plurality of modified cells.
- the selection of a population of cells includes the selection of a plurality of modified cells comprising a selection marker.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least about 3 days, wherein the expansion agent comprises at least two of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido- indole derivative, thereby expanding a population of modified cells.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least about 3 days, wherein the expansion agent comprises each of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor and a pyrimido- indole derivative, thereby expanding a population of modified cells.
- the HMT inhibitor, aryl hydrocarbon receptor inhibitor, pyrimido-indole derivative, or a combination thereof can be present in the culture media (e.g in contact with the cell or plurality of cells) for at least about 4 days, at least about 5 days, at least about 6 days, at least about 7 days, at least about 8 days, at least about 9 days, at least about 10 days, at least about 11 days, at least about 12 days, at least about 13 days, or at least about 14 days. In a preferred aspect, at least 7 days.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the expansion agent comprises at least two of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative, thereby expanding a population of modified cells.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the expansion agent comprises each of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor and a pyrimido- indole derivative, thereby expanding a population of modified cells.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a dihydrofolate reductase (DHFR) resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises at least two of SR1, UM171 or UNC0638, thereby expanding a population of modified cells.
- DHFR dihydrofolate reductase
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises each of SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
- the HMT inhibitor, aryl hydrocarbon receptor inhibitor, pyrimido-indole derivative, or a combination thereof can be present in the culture media (e.g in contact with the cell or plurality of cells) for about 3 days to about 14 days; about 3 days to about 13 days; about 3 days to about 12 days; about 3 days to about 12 days; about 3 days to about 11 days; about 3 days to about 10 days; about 3 days to about 9 days; about 3 days to about 8 days; about 3 days to about 7 days; about 4 days to about 9 days; about 4 days to about 8 days; about 4 days to about 7 days; or about 5 days to about 7 days. In a preferred aspect, about 5 days to about 7 days.
- HMT inhibitor can be UNC0638, BIX01294, UNC0642, A-366, UNC0224, UNC0631, UNC0646, BRD4770, UNC0631, chaetocm, EPZ005687, EPZ6438, GSK126, GKS343, Ell, UNC199, EPZ004777, EPZ5676, LLY-507, AZ505 or A-893.
- the HMT inhibitor is ETNC0638.
- UNC0638 also includes UNC0638 hydrate.
- UNC0638 can be present in the culture media in an amount from about 0.5 mM to about
- UNC0638 is present in the culture media at about 0.75 mM; about 1 mM or about 1.25 mM. In a preferred aspect, UNC0638 is present in the culture media at about 1.0 mM. In another preferred aspect, UNC0638 is present in the culture media at about 1.0 mM for about 4 days to about 11 days. In another preferred aspect, UNC0638 is present in the culture media at about 1.0 mM for at least 7 days.
- the aryl hydrocarbon receptor inhibitor can be StemRegenin 1 (SR1), alpha- naphthoflavone, beta-naphthoflavone, brevifolincarboxybc acid, 6,2',4'-Trimethoxyflavone, D,L- Sulforaphane, 2,3,7,8-tetrachlorodibenzo-p-dioxin (TCDD), PDM2, salicylamide, l,3-dichloro- 5-[(lE)-2-(4-methoxyphenyl)ethenyl]-benzene, CH 223191, methylindoles, methoxyindoles, indole-3-carbinol, mexiletine, hydroxytamoxifen, raloxifene, 2,3,7,8-tetrachlorodibenzo-p- dioxin, laquinimod, aminoflavone (NSC686288), CB79
- SR1 can be present in the culture media in an amount from about 0.5 mM to about 2 mM; about 0.5 mM to about 1.5 mM; about 0.5 mM to about 1 mM; or about 0.75 mM to about 1.25 mM. In some aspects, SR1 is present in the culture media at about 0.75 mM; about 1 mM or about 1.25 mM. In a preferred aspect, SR1 is present in the culture media at about 1.0 mM. In another preferred aspect, SR1 is present in the culture media at about 1.0 mM for about 4 days to about 11 days. In another preferred aspect, SR1 is present in the culture media at about 1.0 mM for at least 7 days.
- the pyrimido-indole derivative can be a pyrimido-[4,5-b]-indole derivative.
- the pyrimido-indole derivative inhibitor is UM171 and has the following
- UM171 can be present in the culture media in an amount from about 25 nM to about 75 nM; or about 25 nM to about 50 nM. In a preferred aspect, UM171 is present in the culture media at about 35 nM. In another preferred aspect, UM171 is present in the culture media at about 35 nM for about 4 days to about 11 days. In another preferred aspect, UM171 is present in the culture media at about 35 nM for at least 7 days.
- the culture media comprises a combination of SR1, UM171 and UNC0638 (termed SUU herein)
- the SR1 is present from about 0.75 mM; about 1 mM or about 1.25 mM; the UM171 is present from about 25 nM to about 50 nM; the UNC0638 is present from about 0.75 mM; about 1 mM or about 1.25 mM.
- the SR1 is present in the culture media at about 1 mM
- the UM171 is present in the culture media at about 35 nM
- UNC0638 is present in the culture media at about 1.0 mM for about 4 days to about 11 days.
- the SR1 is present in the culture media at about 1 mM
- the UM171 is present in the culture media at about 35 nM
- UNC0638 is present in the culture media at least 7 days.
- Hematopoietic stem cells or a plurality of HSCs cultured in a culture media comprising SR1 and UM171 demonstrate phentotypic expansion from about 2 fold to about 10 fold, about 4 fold to about 10 fold, about 6 fold to about 10 fold, or about 8 fold to about 10 fold.
- the SUU combination demonstrates phentotypic expansion from 2 fold to about 15 fold, about 4 fold to about 15 fold, about 6 fold to about 15 fold, or about 8 fold to about 15 fold or about 10 fold to about 15 fold, with an average phentotypic expansion of about 12 fold.
- the SUU combination significantly expands (more than about 2 fold, about 4 fold, about 6 fold, about 8 fold, or about 10 fold) cobblestone forming cells compared to cytokine culture only.
- the expansion agent can comprise valproic acid.
- the culture media can comprise about 0.25 mM to about 1.25 mM of VPA.
- the culture media can comprise about 1 mM of VPA.
- HSCs or a plurality of HSCs cultured in a culture media comprising valproic acid demonstrate phentotypic expansion from about 300 fold to about 350 fold with an average phenotypic expansion of about 335 fold but does not have a significant expansion effect on cobblestone forming cells compared to culture in the presence of cytokines alone.
- HSCs or a plurality of HSCs cultured in valproic acid demonstrate engraftment, either alone or in combination with UNC0638 and/or UM171.
- the expansion agent can further comprise nicotinamide.
- the culture media can comprise about 2.5 mM to about 10 mM of nicotinamide.
- the culture media can comprise about 5 mM of nicotinamide.
- HSCs or a plurality of HSCs cultured in a culture media comprising SUU and nicotinamide show at least a one-fold, at least a two-fold or at least a three-fold increase in phentotypic expansion when compared to culturing in a culture media comprising SUU alone.
- HSCs or a plurality of HSCs cultured in a culture media comprising SUU and nicotinamide show about a one-fold to about a four-fold increase, about a two-fold to about a 4 fold increase or about a one-fold to about a three-fold increase in phentotypic expansion when compared to culturing in a culture media comprising SUU alone.
- the expansion agent can further comprise garcinol.
- the culture media can comprise about 5 mM to about 15 mM of garcinol.
- the culture media can comprise about 10 mM of garcinol.
- HSCs or a plurality of HSCs cultured in a culture media comprising SUU and garcinol show at least a 0.5 fold, at least a 1 fold, at least a 1.5 fold or at least a 2 fold increase in phentotypic expansion when compared to culturing in a culture media comprising SUU alone.
- the addition of garcinol didn’t improve function over SUU alone.
- the expansion agent can further comprise NaPB.
- the culture media can comprise about 1 mM to about 2 mM of NaPB.
- the culture media can comprise about 1.5 mM of NaPB.
- HSCs or a plurality of HSCs cultured in a culture media comprising NaPB demonstrate phentotypic expansion.
- Additional expansion agents may comprise dmPGE2, 5-azacytidine, 4-HPR, hlGFBP2, hANGPTL5, PCI-34051, GW9662 and N-acetylcysteme.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least about 3 days, wherein the expansion agent comprises at least two of SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least about 3 days, wherein the expansion agent comprises each of SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
- the selection gene is a dihydrofolate reductase (DHFR) resistance gene.
- the selection agent is methotrexate, pralatrexate, pyrimethamine, dapsone, raltitrexed, trimetrexate, metoprine, iclaprim, aminopterin, lometrexol, nolatrexed, brodimoprim, trimethoprim, pemetrexed, proguanil, piritrexim, or cycloguanil.
- the selection agent when the selection gene is DHFR or a sequence encoding a DHFR mutein enzyme, the selection agent is methotrexate, pralatrexate, pyrimethamine, dapsone, raltitrexed, trimetrexate, metoprine, iclaprim, aminopterin, lometrexol, nolatrexed, brodimoprim, trimethoprim, pemetrexed, proguanil, piritrexim, or cycloguanil. In one aspect, when the selection gene is DHFR or a sequence encoding a DHFR mutein enzyme, the selection agent is methotrexate (MTX) or pralatrexate (PTX).
- MTX methotrexate
- PTX pralatrexate
- the DHFR mutein enzyme can comprise, consist essentially of, or consist of the amino acid sequence of SEQ ID NO: 14677.
- the DHFR mutein enzyme is encoded by a nucleic acid sequence comprising, consisting essentially of, or consisting of the nucleic acid sequence of SEQ ID NO: 14678.
- the amino acid sequence of the DHFR mutein enzyme can further comprises a mutation at one or more of positions 80, 113, or 153.
- the amino acid sequence of the DHFR mutein enzyme comprises one or more of a substitution of a Phenylalanine (F) or a Leucine (L) at position 80, a substitution of a Leucine (L) or a Valine (V) at position 113, and a substitution of a Valine (V) or an Aspartic Acid (D) at position 153.
- the transposon comprises a sequence encoding a DHFR mutein enzyme the selection agent is methotrexate or pralatrexate.
- the methotrexate can be present in the culture media in an amount from about 100 nM to about 500 nM. In a preferred aspect, the culture media can comprise about 250 nM of methotrexate.
- the pralatrexate can be present in the culture media in an amount from about 50 nM to about 250 nM. In a preferred aspect, the culture media can comprise about 125 nM of pralatrexate.
- the selection agent is pralatrexate and dipyridamole (DP).
- the culture media can comprise about 50 nM to about 250 nM of pralatrexate and about 1 mM to about 10 mM of dipyridamole. In a preferred aspect, the culture media can comprise about 125 nM of pralatrexate and about 5 mM of dipyridimole.
- culturing the plurality of modified cells with an expansion agent occurs prior to culturing the plurality of modified cells with a selection agent. In some aspects, culturing the plurality of modified cells with a selection agent occurs prior to culturing the plurality of modified cells with an expansion agent. In some aspects, culturing the plurality of modified cells with an expansion agent and culturing the plurality of modified cells with a selection agent occur concurrently.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least about 3 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises at least two of SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least about 3 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises each of SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
- the disclosed culture methods for expanding a population of modified cells can be compared to culture methods utilizing culture media not comprising a selection agent, an expansion agent, or a combination thereof.
- the culture methods comprising a culture media comprising a selection agent, an expansion agent, or a combination thereof result in at least a one-fold, at least a two-fold, at least a three-fold, at least a four-fold, at least a five-fold; at least a six-fold; at least a seven-fold; at least an eight-fold; at least a nine-fold or at least a ten-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent, an expansion agent, or a combination thereof.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days, wherein the expansion agent comprises at least two of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days, wherein the expansion agent comprises each of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor and a pyrimido-indole derivative, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises at least two of SR1, UM171 or UNC0638, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises each of SR1, UM171 and UNC0638, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the expansion agent comprises at least two of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the expansion agent comprises each of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor and a pyrimido- indole derivative, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises at least two of SR1, UM171 or UNC0638, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises each of SR1, UM171 and UNC0638, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
- the present disclosure provides methods for increasing the frequency of transposition in a cell or population of cells and further comprises expanding that population of cells.
- the method of increasing the frequency of transposition in a cell or plurality of cells and expansion of a population of cells includes the expansion of a plurality of modified cells.
- the present disclosure also provides methods for increasing the frequency of transposition in a cell or plurality of cells and further comprises expanding and selecting that population of cells.
- the method of increasing the frequency of transposition in a cell or plurality of cells and expansion of a population of cells includes the expansion and selection of a plurality of modified cells.
- the selection of a population of cells includes the selection of a plurality of modified cells comprising a selection marker.
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 24 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 3 days following step c; e) removing the HMT inhibitor from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days following step e, wherein the expansion agent comprises an HMT inhibitor, a aryl hydrocarbon receptor inhibitor
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 24 hours; c) removing the valproic acid from the culture media; d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 3 days following step c; e) removing the UNC0638 from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 3 hours to about 30 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 1 day to about 5 days following step c; e) removing the HMT inhibitor from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days following step e, wherein the expansion agent comprises an H
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 3 hours to about 30 hours; c) removing the valproic acid from the culture media; d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 1 day to about 5 days following step c; e) removing the UNC0638 from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 24 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 3 days following step c; e) removing the HMT inhibitor from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days following step e, wherein the expansion agent comprises an HMT inhibitor, a aryl hydrocarbon receptor inhibitor
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 24 hours; c) removing the valproic acid from the culture media; d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 3 days following step c; e) removing the UNC0638 from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 3 hours to about 30 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 1 day to about 5 days following step c; e) removing the HMT inhibitor from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days following step e, wherein the expansion agent comprises an H
- the present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 3 hours to about 30 hours; c) removing the valproic acid from the culture media; d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 1 day to about 5 days following step c; e) removing the UNC0638 from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a
- the transposon can be integrated into the genome of the cell by the transposase.
- the integration can be transient or stable.
- the transposon or the sequence encoding the transposon can be comprised within a composition; the transposase or a sequence encoding a transposase can be comprised within a composition; or the transposon or the sequence encoding the transposon and the transposase or a sequence encoding a transposase can be comprised within a composition.
- the sequence encoding the transposase can comprise an amino acid or a nucleic acid sequence encoding a transposase protein.
- the nucleic acid sequence encoding a transposase protein can comprise an RNA sequence.
- the nucleic acid sequence encoding a transposase protein can comprise a DNA sequence.
- the transposon can be a piggyBac ® (PB) transposon, a piggy-Bac ® like transposon, a piggyBat transposon, a Sleeping Beauty transposon, a Helraiser transposon, a Tol2 transposon or a TcBuster transposon.
- PB piggyBac ®
- the transposase can be a piggyBac ® transposase, a piggy-Bac ® like transposase, a Super piggyBac ® (SPB) transposase, a piggyBat transposase, a Sleeping Beauty transposase, a hyperactive Sleeping Beauty (SB100X) transposase, Helitron transposase, a Tol2 transposase, a TcBuster transposase or a hyperactive TcBuster transposase.
- the Helitron transposase can be a Helibatl transposase.
- the transposase can be a piggyBac ® transposase or a Super piggyBac ® transposase.
- the transposase can be a piggy-Bac ® like transposase.
- the transposase can be a Sleeping Beauty transposase.
- the transposase can be a Helitron transposase.
- the transposase can be a Tol2 transposase.
- the transposase can be a TcBuster transposase or a hyperactive TcBuster transposase.
- the piggyBac ® transposase comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14487.
- the piggyBac ® transposase comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14487.
- the piggyBac ® transposase comprises an amino acid substitution at one or more of positions 30, 165, 282 or 538 of SEQ ID NO: 14487.
- the piggyBac ® transposase comprises an amino acid substitution at two or more of positions 30, 165, 282 or 538 of SEQ ID NO: 14487.
- the piggyBac ® transposase comprises an amino acid substitution at three or more of positions 30, 165, 282 or 538 of SEQ ID NO: 14487.
- the piggyBac ® transposase comprises an amino acid substitution at each of positions 30, 165, 282 or 538 of SEQ ID NO: 14487.
- the amino acid substitution at position 30 of SEQ ID NO: 14487 is a substitution of a valine (V) for an isoleucine (I) (130V).
- the amino acid substitution at position 165 of SEQ ID NO: 14487 is a substitution of a serine (S) for a glycine (G) (G165S).
- the amino acid substitution at position 282 of SEQ ID NO: 14487 is a substitution of a valine (V) for a methionine (M) (M282V).
- the amino acid substitution at position 538 of SEQ ID NO: 14487 is a substitution of a lysine (K) for an asparagine (N) (N538K).
- the piggyBac ® transposase comprises, consists essential of, or consists of an amino acid substitution at each of positions 30, 165, 282 or 538 of SEQ ID NO: 14487.
- the Super piggyBac ® transposase comprises, consists essential of, or consists of an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14484.
- the Super piggyBac ® transposase comprises, consists essential of, or consists of, the amino acid sequence SEQ ID NO: 14484.
- the TcBuster transposase comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14735.
- the TcBuster transposase comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14735.
- the piggyBat transposase comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14965.
- the piggyBat transposase comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14967.
- the piggyBat transposase comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14968.
- the nucleic acid encoding the piggyBat transposase comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14966.
- the nucleic acid encoding the piggyBat transposon comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14963.
- the nucleic acid encoding the piggyBat transposon comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14964.
- the transposon can comprise, consist essential of, or consist of at least one exogenous sequence (transgene sequence).
- the transposon can comprise, consist essential of, or consist of at least two exogenous sequences (transgene sequences).
- the transposon can comprise, consist essential of, or consist of at least three exogenous sequences (transgene sequences).
- the transposon can comprise, consist essential of, or consist of at least four exogenous sequences (transgene sequences).
- the transposon can comprise, consist essential of, or consist of at least five exogenous sequences (transgene sequences).
- the exogenous sequence can comprise, consist essential of, or consist of a sequence encoding a chimeric antigen receptor (CAR).
- CAR chimeric antigen receptor
- the exogenous sequence can comprise, consist essential of, or consist of a sequence encoding a therapeutic agent.
- the therapeutic agent can be a therapeutic protein.
- the therapeutic agent can be a therapeutic RNA.
- the therapeutic RNA can be iRNA, siRNA, or shRNA.
- the therapeutic agent can be human beta-globin (HBB), human beta-globin comprising a T87Q mutation (HBB T87Q), BAF chromatin remodeling complex subunit (BCL11A) shRNA, insulin like growth factor 2 binding protein 1 (IGF2BP1), interleukin 2 receptor gamma
- HBB human beta-globin
- HBB T87Q human beta-globin comprising a T87Q mutation
- BCL11A BAF chromatin remodeling complex subunit
- IGF2BP1 insulin like growth factor 2 binding protein 1
- IGF2BP1 interleukin 2 receptor gamma
- IL2RG alpha galactosidase A
- IDETA alpha-L-idurondase
- IDDS iduronate 2-sulfatase
- CNS cystinosin lysosomal cysteine transporter
- the HBB comprises the amino acid sequence of SEQ ID NO: 14724.
- the sequence encoding the HBB comprises the nucleic acid sequence of SEQ ID NO: 14969.
- the HBB T87Q comprises the amino acid sequence of SEQ ID NO: 14477.
- the sequence encoding HBB T87Q comprises the nucleic acid sequence of SEQ ID NO: 14478.
- the BCL11 A shRNA comprises the nucleic acid sequence of SEQ ID NO: 14713.
- the IGF2BP1 comprises the amino acid sequence of SEQ ID NO: 14722.
- the nucleic acid encoding the IGF2BP1 comprises the nucleic acid sequence of SEQ ID NO: 14721.
- the IL2RG comprises the amino acid sequence of SEQ ID NO: 14723.
- the nucleic acid encoding the IL2RG comprises the nucleic acid sequence of SEQ ID NO: 14718.
- the GLA comprises the amino acid sequence of SEQ ID NO: 5974 or SEQ ID NO: 5975.
- the nucleic acid encoding the GLA comprises the nucleic acid sequence of SEQ ID NO: 14970.
- the IDETA comprises the amino acid sequence of any one of SEQ ID NO: 6715 - SEQ ID NO: 6720.
- the nucleic acid encoding the IDETA comprises the nucleic acid sequence of SEQ ID NO: 14971.
- the IDS comprises the amino acid sequence of any of SEQ ID NO: 6709 - SEQ ID NO: 6714.
- the nucleic acid encoding the IDS comprises the nucleic acid sequence of SEQ ID NO: 14972.
- the CTNS comprises the amino acid sequence of any of SEQ ID NO: 3672 - SEQ ID NO: 3679.
- the nucleic acid encoding the CTNS comprises the nucleic acid sequence of SEQ ID NO: 14973.
- the nucleic acid encoding the selectable marker comprises a nucleic acid sequence encoding a DHFR enzyme or a nucleic acid sequence encoding a DHFR mutein enzyme.
- the nucleic acid encoding the DHFR enzyme comprises the nucleic acid sequence of SEQ ID NO: 14976.
- the DHFR enzyme comprises the amino acid sequence of SEQ ID NO: 14476.
- the amino acid sequence of the DHFR enzyme further comprises a mutation at one or more of positions 80, 113, or 153.
- the amino acid sequence of the DHFR enzyme comprises a substitution of a Phenylalanine (F) or a Leucine (L) at position 80.
- the amino acid sequence of the DHFR enzyme comprises a substitution of a Leucine (L) or a Valine (V) at position 113.
- the amino acid sequence of the DHFR enzyme comprises a substitution of a Valine (V) or an Aspartic Acid (D) at position 153.
- the DHFR mutein enzyme comprises the amino acid sequence of SEQ ID NO: 14725.
- the sequence encoding the DHFR mutein enzyme comprises the nucleic acid sequence of SEQ ID NO: 14709 or SEQ ID NO: 14901.
- the exogenous sequence can comprise, consist essential of, or consist of a sequence encoding a selection marker.
- a selection marker is a gene introduced into a cell, especially a cell in culture, that confers a trait suitable for artificial selection. They are a type of reporter gene used to indicate the success of a transposition, transduction, transfection or other procedure meant to introduce exogenous or foreign DNA into a cell.
- a non-limiting example of a selectable marker is an antibiotic resistance gene (an antibiotic resistance marker is a gene that produces a protein that provides cells expressing this protein with resistance to an antibiotic).
- the selection marker can be a DHFR resistance gene.
- the selection marker can be a sequence encoding a DHFR mutein enzyme.
- the DHFR mutein enzyme can comprise, consist essentially of, or consist of the amino acid sequence of SEQ ID NO: 14677.
- the DHFR mutein enzyme is encoded by a nucleic acid sequence comprising, consisting essentially of, or consisting of the nucleic acid sequence of SEQ ID NO: 14678.
- the amino acid sequence of the DHFR mutein enzyme can further comprises a mutation at one or more of positions 80, 113, or 153.
- the amino acid sequence of the DHFR mutein enzyme comprises one or more of a substitution of a Phenylalanine (F) or a Leucine (L) at position 80, a substitution of a Leucine (L) or a Valine (V) at position 113, and a substitution of a Valine (V) or an Aspartic Acid (D) at position 153.
- the exogenous sequence can comprise, consist essential of, or consist of a sequence encoding an inducible proapoptotic polypeptide.
- the inducible proapoptotic polypeptide can be a inducible caspase polypeptide.
- the inducible proapoptotic polypeptide can comprise, consist essential of, or consist of (a) a ligand binding region, (b) a linker, and (c) a truncated caspase 9 polypeptide, wherein the inducible caspase polypeptide does not comprise a non-human sequence.
- the non-human sequence is a restriction site.
- the ligand binding region inducible caspase polypeptide comprises a FK506 binding protein 12 (FKBP12) polypeptide.
- the amino acid sequence of the FK506 binding protein 12 (FKBP12) polypeptide can comprise, consist essential of, or consist of a modification at position 36 of the sequence.
- the modification can be a substitution of valine (V) for phenylalanine (F) at position 36 (F36V).
- the FKBP12 polypeptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14494.
- the FKBP12 polypeptide can be encoded by a nucleic acid sequence comprising, consisting essential of, or consisting of, the nucleic acid sequence of SEQ ID NO: 14495.
- the linker region of the inducible proapoptotic polypeptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14496.
- the linker region of the inducible proapoptotic polypeptide can be encoded by a nucleic acid sequence comprising, consisting essential of, or consisting of, the nucleic acid sequence of SEQ ID NO: 14497.
- the truncated caspase 9 polypeptide of the inducible proapoptotic polypeptide is encoded by an amino acid sequence that does not comprise an arginine (R) at position 87 of the sequence.
- the truncated caspase 9 polypeptide of the inducible proapoptotic polypeptide is encoded by an amino acid sequence that does not comprise an alanine (A) at position 282 of the sequence.
- the truncated caspase 9 polypeptide of the inducible proapoptotic polypeptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14498.
- the truncated caspase 9 polypeptide of the inducible proapoptotic polypeptide can be encoded by a nucleic acid sequence comprising, consisting essential of, or consisting of, the nucleic acid sequence of SEQ ID NO: 14499.
- the inducible proapoptotic polypeptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14503.
- the inducible proapoptotic polypeptide can be encoded by a nucleic acid sequence comprising, consisting essential of, or consisting of, the nucleic acid sequence of SEQ ID NO: 14636.
- the transposon or the exogenous sequence can further comprise, consist essential of, or consist of at least one sequence encoding a self-cleaving peptide.
- the at least one self-cleaving peptide can comprise, consist essential of, or consist of T2A peptide, GSG-T2A peptide, an E2A peptide, a GSG-E2A peptide, an F2A peptide, a GSG-F2A peptide, a P2A peptide, or a GSG- P2A peptide.
- the GSG-T2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14638.
- the T2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14637.
- the E2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14639.
- the GSG- E2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14640.
- the F2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14641.
- the GSG-F2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14642.
- the P2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14643.
- the GSG- P2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14644.
- the miRE sh49 BCL11 A of the disclosure is encoded by a sequence comprising SEQ ID NO: 14713.
- the HBB T87Q of the disclosure comprises an amino acid sequence comprising SEQ ID NO: 14934.
- the GLA of the disclosure comprises an amino acid sequence comprising any one of SEQ ID NO: 5974 - SEQ ID NO: 5975.
- the IDETA of the disclosure comprises an amino acid sequence comprising any one of SEQ ID NO: 6715 - SEQ ID NO: 6720.
- the IDS of the disclosure comprises an amino acid sequence comprising any one of SEQ ID NO: 6709 - SEQ ID NO: 6714.
- the CTNS of the disclosure comprises an amino acid sequence comprising any one of SEQ ID NO: 3672 - SEQ ID NO: 3679.
- the IGF2BP1 of the disclosure is encoded by a nucleic acid sequence sequence comprising SEQ ID NO: 14721.
- the IGF2BP1 of the disclosure comprises an amino acid sequence sequence comprising SEQ ID NO: 14722.
- the IL2RG of the disclosure is encoded by a nucleic acid sequence sequence comprising SEQ ID NO: 14718.
- the IL2RG of the disclosure comprises an amino acid sequence sequence comprising: SEQ ID NO: 14723.
- the present disclosure provides a population of modified cells produced by any of the methods disclosed herein.
- the present disclosure also provides a composition comprising, consisting essential of, or consisting of a population of modified cells produced by any of the methods disclosed herein.
- the present disclosure also provides a pharmaceutical composition comprising, consisting essential of, or consisting of a population of modified cells produced by any of the methods disclosed herein and a pharmaceutically-acceptable carrier.
- the present disclosure provides a modified cell population wherein at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, at least 99.5%, at least 99.9% or 100% of the plurality of modified cells in the population comprise a genome-integrated transposon.
- the present disclosure also provides a composition comprising, consisting essential of, or consisting of a modified cell population wherein at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, at least 99.5%, at least 99.9% or 100% of the plurality of modified cells in the population comprise a genome-integrated transposon.
- the present disclosure also provides a pharmaceutical composition
- a pharmaceutical composition comprising, consisting essential of, or consisting of a modified cell population wherein at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, at least 99.5%, at least 99.9% or 100% of the plurality of modified cells in the population comprise a genome-integrated transposon and a pharmaceutically-acceptable carrier.
- the genome- integrated transposon can comprise at least one of, at least two of, at least three of, at least four of, at least five of a sequence comprising a selection marker, a sequence encoding a chimeric antigen receptor (CAR), a sequence encoding a therapeutic agent, a sequence encoding an inducible proapoptotic polypeptide or a sequence encoding a self-cleaving peptide.
- CAR chimeric antigen receptor
- the population of cells or plurality of cells can comprise, consist essential of, or consist of somatic cells, germline cells, stem cells, or a combination thereof.
- a cell in the population of cells or plurality of cells can be a somatic cell, a germline cell or a stem cell.
- the stem cells within the population of stem cells or plurality of stem cells can be induced pluripotent stem cells (iPSCs), hematopoietic stem cells (HSCs), embryonic stem cells, adult tissue stem cells, or a combination thereof.
- a stem cell within the population of stem cells or plurality of stem cells can be an induced pluripotent stem cell (iPSC), a hematopoietic stem cell (HSC), an embryonic stem cell or an adult tissue stem cell.
- the population of cells or plurality of cells can comprise, consist essential of, or consist of mammalian cells.
- a cell in the population of cells or plurality of cells can be a mammalian cell.
- the population of cells or plurality of cells can comprise, consist essential of, or consist of human cells, non-human cells, or a combination thereof.
- a cell in the population of cells or plurality of cells can be a human cell.
- a cell in the population of cells or plurality of cells can be a non-human cell (not a human cell).
- the population of cells or plurality of cells can comprise, consist essential of, or consist of human cells.
- a cell in the population of cells or plurality of cells is a human cell.
- the population of cells or plurality of cells can comprise, consist essential of, or consist of autologous cells.
- a cell in the population of cells or plurality of cells can be an autologous cell.
- the population of cells or plurality of cells can comprise, consist essential of, or consist of allogeneic cells.
- a cell in the population of cells or plurality of cells can be an allogeneic cell.
- the population of cells or plurality of cells can be in vivo, ex vivo, in vitro or in situ.
- a cell in the population of cells or plurality of cells can be in vivo, ex vivo, in vitro or in situ.
- the population of cells or plurality of cells can comprise, consist essential of, or consist of immune cells, neural cells, endothelial cells, epithelial cells, muscle cells, bone cells, hematopoeitic cells, or any combination thereof.
- a cell in the population of cells or plurality of cells can be an immune cell.
- a cell in the population of cells or plurality of cells can be a neural cell.
- a cell in the population of cells or plurality of cells can be an endothelial cell.
- a cell in the population of cells or plurality of cells can be an epithelial cell.
- a cell in the population of cells or plurality of cells can be a muscle cell.
- a cell in the population of cells or plurality of cells can be a bone cell.
- a cell in the population of cells or plurality of cells can be hematopoetic cell.
- the immune cells within the population of immune cells or plurality of immune cells can be T-cells, Natural Killer (NK) cells, Natural Killer (NK)-like cells, hematopoeitic progenitor cells, or B-cells.
- An immune cell in the population of immune cells or plurality of immune cells can be a T-cell, a Natural Killer (NK) cell, a Natural Killer (NK)-like cell, a hematopoeitic progenitor cell, or a B-cell.
- the T-cell can be a stem memory T-cell (TSCM), a TscM-like cell, a peripheral blood (PB) derived T cell, an umbilical cord blood (UBC) derived T- cell, a helper T-cell, a cytotoxic T-cell, a regulatory T-cell or a gd T-cell.
- TSCM stem memory T-cell
- PB peripheral blood
- UBC umbilical cord blood
- helper T-cell a cytotoxic T-cell
- regulatory T-cell a regulatory T-cell or a gd T-cell.
- a hematopoeitic stem cell (HSC) or HSC descendent cell can be isolated, derived or obtained from the peripheral blood, the umbilical cord blood, the bone marrow, a peritoneal dialysis effluent, an adult stem cell, or an induced pluripotent stem cell (iPSC) of a subject.
- the peripheral blood can comprise mobilized peripheral blood of a subject.
- the cells in a population of cells or a plurality of cells can be isolated from, derived from or obtained from a healthy subject.
- the cells in a population of cells or a plurality of cells cannot be isolated from, derived from or obtained from a healthy subject.
- the cells in a population of cells or a plurality of cells cannot be isolated from, derived from or obtained from a non-healthy subject.
- the cells in a population of cells or a plurality of cells cannot be isolated from, derived from or obtained from a subject with a disease or disorder.
- the disease or disorder is a proliferation disorder.
- the proliferation disorder is cancer.
- the cells in a population of cells or a plurality of cells isolated from, derived from or obtained from a non-healthy subject can be tumor cells or cancer cells.
- the cells in a population of cells or a plurality of cells isolated from, derived from or obtained from a non-healthy subject can comprise, consist essential of, or consist of a genetic or epigenetic marker of a disease or disorder.
- the genetic or epigenetic marker causes the disease or disorder.
- the genetic or epigenetic marker predicts a risk of occurrence, a severity, or a prognosis of the disease or disorder.
- the disease or disorder is a proliferation disorder.
- the proliferation disorder is cancer.
- the transposon can be introduced to the cell or the plurality of cells by any means known in the art.
- the transposon can be introduced to the cell or the plurality of cells via nucleofection or electroporation. Conditions sufficient for transposition comprise a
- the nucleofection or the electroporation can comprise at least one of an application of one or more pulses of electricity at a specified voltage, a buffer, and one or more supplemental factor(s).
- the buffer can comprise PBS, HBSS, OptiMEM, BTXpress, Amaxa Nucleofector, Human T cell nucleofection buffer or any combination thereof.
- the one or more supplemental factor(s) comprise: (a) a recombinant human cytokine, a chemokine, an interleukin or any combination thereof; (b) a salt, a mineral, a metabolite or any combination thereof; (c) a cell medium; (d) an inhibitor of cellular DNA sensing, metabolism, differentiation, signal transduction, one or more apoptotic pathway(s) or combinations thereof; and/or (e) a reagent that modifies or stabilizes one or more nucleic acids.
- the recombinant human cytokine, the chemokine, the interleukin or any combination thereof can comprise, consist essential of, or consist of IL2, IL7, IL12, IL15, IL21, IL1, IL3, IL4, IL5, IL6, IL8, CXCL8, IL9, IL10, IL11, IL13, IL14, IL16, IL17, IL18, IL19, IL20, IL22, IL23, IL25, IL26, IL27, IL28, IL29, IL30, IL31, IL32, IL33, IL35, IL36, GM-CSF, IFN-gamma, IF-l alpha/IF-lFl, IF-l beta/IF-lF2, IF-12 p70, IF-12/IF-35 p35, IF-13, IF-17/IF-17A, IF-17A/F Heterodimer,
- the salt, the mineral, the metabolite or any combination thereof can comprise, consist essential of, or consist of HEPES, Nicotinamide, Heparin, Sodium Pyruvate, L-Glutamine, MEM Non-Essential Amino Acid Solution, Ascorbic Acid, Nucleosides, FBS/FCS, Human serum, serum-substitute, anti-biotics, pH adjusters, Earle’s Salts, 2-Mercaptoethanol, Human transferrin, Recombinant human insulin, Human serum albumin, Nucleofector PLUS Supplement, KCL, MgCI 2 , Na2HP0 4 , NAH2PO4, Sodium lactobionate, Manitol, Sodium succinate, Sodium
- Chloride CINa, Glucose, Ca(NO 3 )2, Tris/HCl, K2HPO4, KH2PO4, Polyethylenimine, Poly- ethylene-glycol, Poloxamer 188, Poloxamer 181, Poloxamer 407, Poly-vinylpyrrolidone,
- the cell medium can comprise, consist essential of, or consist of PBS, HBSS,
- OptiMEM DMEM, RPMI 1640, AIM-V, X-VIVO 15, CellGro DC Medium, CTS OpTimizer T Cell Expansion SFM, TexMACS Medium, PRIME-XV T Cell Expansion Medium,
- the inhibitor of cellular DNA sensing, metabolism, differentiation, signal transduction, one or more apoptotic pathway(s) or combinations thereof can comprise, consist essential of, or consist of inhibitors of TLR9, MyD88, IRAK, TRAF6, TRAF3, IRF-7, NF-KB, Type 1
- Interferons pro-inflammatory cytokines, cGAS, STING, Sec5, TBK1, IRF-3, RNA pol III, RIG- 1, IPS-l, FADD, RIP1, TRAF3, AIM2, ASC, Caspasel, Pro-ILlB, PI3K, Akt, Wnt3A, glycogen synthase kinase-3P (GSK-3 b), TWS119, Bafilomycin, Chloroquine, Quinacrine, AC-YVAD- CMK, Z-VAD-FMK, Z-IETD-FMK or any combination thereof.
- the reagent that modifies or stabilizes one or more nucleic acids can comprise, consist essential of, or consist of a pH modifier, a DNA-binding protein, a lipid, a phospholipid, CaPOr, a net neutral charge DNA binding peptide with or without a NLS sequence, a TREX1 enzyme or any combination thereof.
- the disclosure provides methods of transplantation comprising transplanting a therapeutically effective amount of a population of cells of the disclosure, a composition comprising a population of cells of the disclosure or a pharmaceutical composition comprising a population of cells of the disclosure to a subject in need thereof.
- the disclosure provides a population of cells of the disclosure or a pharmaceutical composition comprising a population of cells of the disclosure for use in transplantation.
- the disclosure provides methods of treating a subject for a disease or disorder, comprising administering to the subject a therapeutically effective amount of a population of cells of the disclosure, a composition comprising a population of cells of the disclosure or a pharmaceutical composition comprising a population of cells of the disclosure.
- the disclosure provides a population of cells of the disclosure or a pharmaceutical composition comprising a population of cells of the disclosure for use in treating a disease or disorder.
- the disclosure provides methods of treating a subject for a disease or disorder, comprising administering to the subject a therapeutically effective amount of a population of modified cells of the disclosure, a composition comprising a population of modified cells of the disclosure or a pharmaceutical composition comprising a population of modified cells of the disclosure.
- the disclosure provides a population of modified cells of the disclosure or a pharmaceutical composition comprising a population of modified cells of the disclosure for use in treating a disease or disorder.
- the population of cells of the disclosure, the composition comprising the population of cells of the disclosure or the pharmaceutical composition comprising the population of cells of the disclosure comprise a plurality of autologous cells.
- the population of cells of the disclosure, the composition comprising the population of cells of the disclosure or the pharmaceutical composition comprising the population of cells of the disclosure comprise a plurality of allogeneic cells.
- the methods of treating a disease or disorder, methods of transplantation or methods of adoptive immunotherapy described herein can further comprise, consist essentially of or consist of administering a myeloablative agent.
- the myeloablative agent comprises low dose and/or local irradiation.
- the myeloablative agent comprises busulphan, treosulphan, melphalan, thiotepa or a combination thereof.
- the myeloablative agent can be administered prior to, after or concurrently with administration with the pharmaceutical compositions comprising the modified HSCs of the present invention.
- the methods of treating a disease or disorder, methods of transplantation or methods of adoptive immunotherapy described herein can further comprise, consist essentially of or consist of administering an activating composition to induce or increase proliferation of the plurality modified HSCs in vivo.
- the activating composition can be administered prior to, after or concurrently with administration with the pharmaceutical compositions comprising the modified HSCs of the present invention.
- a therapeutically-effective amount can be a single dose.
- the therapeutically-effective amount can be a single dose over a lifetime of the subject.
- compositions of the disclosure can be used to treat a disease or disorder including, but not limited to: Osteopetrosis, Parkinson’s Disease, Hunter Syndrome, Sickle Cell Disease, Severe Combined Immunodeficiency, Alpha-mannosidosis, Sideroblastic anemia, Autosomal Recessive Hyper IgE Syndrome, Primary Myelofibrosis, Cutaneous vasculitis, X-linked protoporphyria, Fucosidosis, Maroteaux Lamy syndrome, WAS Related Disorders, Chronic Granulomatous, Thalassemia Major, Hereditary Angioedema, Hereditary Lymphedemia, Hyper IgM Syndrome, Friedrich’s Ataxia, Charcot Marie Tooth Disease, Phenylketonuria,
- Methylmalonic Acidemia Adrenoleukodystrophy, Kugelberg Welander Syndrome, Retinitis Pigmentosa, Hydrocephalus, Hereditary Sensory and Autonomic Neuropathy Type IV,
- Mucopolysaccharidosis Type III Corneal Dystrophies, Erythropoietic Protoporphyria, Fabry Disease, Werdnig-Hoffman Disease, Hypoposphatasia, Coats Disease, Fanconi Anemia, Niemann Pick Disease, Crigler-Najjar Syndrome, Hemophilia A, Hemophilia B,
- compositions of the disclosure may be used to treat a disease or disorder by use of a therapeutic transgene encoding for an exogenous nucleic acid sequence or exogenous amino acid sequence.
- the therapeutic transgene can include [Disease (therapeutic transge): Beta-Thalassemia (HBB T87Q, BCL11 A shRNA, IGF2BP1), Sickle Cell Disease (HBB T87Q, BCL11 A shRNA, IGF2BP1), Hemophilia A (Factor VIII), Hemophilia B (Factor IX), X-linked Severe Combined Immunodeficiency (Interleukin 2 receptor gamma (IL2RG)), Hypophosphatasia (Tissue Non-specific Alkaline Phosphatase (TNAP)),
- GAA Alpha-Galactosidase A Deficiency
- GLA Alpha-galactosidase A
- MPS I Mucopolysaccharidosis Type I
- IDUA Alpha-L-iduronidase
- Mucopolysaccharidosis Type II (MPS II) (Iduronate 2-sulfatase (IDS)), Mucopolysaccharidosis Type IIIA (MPS IIIA) (sulfoglycosamine-sulfohydrolase (SGSH)), Mucopolysaccharidosis Type IIIB (MPS IIIB) (N-alpha-acetylglucosaminidase (NAGLU)), Mucopolysaccharidosis Type IV A (MPS IV A) (Morquio) (N-acetylgalactosamine-6-sulfate sulfatase (GALNS)),
- Administration of the population of cells can be systemic.
- Administration of the population of cells can be intravenous, local, intra-tumoral, intraspinal, intracerebroventricular, intraocular or intraosseous.
- the administration is direct to the cerebral spinal fluid (CSF).
- CSF cerebral spinal fluid
- Transposons of the disclosure may be episomally maintained or integrated into the genome of the recombinant/modified cell.
- transposon/transposase systems of the disclosure include, but are not limited to, piggyBac and piggyBac-like transposons and transposases, Sleeping Beauty transposons and transposases, Helraiser transposons and transposases and Tol2 transposons and transposases.
- the piggyBac transposase recognizes transposon-specific inverted terminal repeat sequences (ITRs) on the ends of the transposon, and moves the contents between the ITRs into TTAA chromosomal sites.
- ITRs inverted terminal repeat sequences
- the piggyBac transposon system has no payload limit for the genes of interest that can be included between the ITRs.
- the transposase is a piggyBacTM or a Super piggyBacTM (SPB) transposase.
- the sequence encoding the transposase is an mRNA sequence.
- the transposase enzyme is a piggyBacTM (PB) transposase enzyme.
- PB piggyBac
- the piggyBac (PB) transposase enzyme may comprise or consist of an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:
- the transposase enzyme is a piggyBacTM (PB) transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at one or more of positions 30, 165, 282, or 538 of the sequence:
- PB piggyBacTM
- the transposase enzyme is a piggyBacTM (PB) transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at two or more of positions 30, 165, 282, or 538 of the sequence of SEQ ID NO: 14487.
- the transposase enzyme is a piggyBacTM (PB) transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at three or more of positions 30, 165, 282, or 538 of the sequence of SEQ ID NO: 14487.
- the transposase enzyme is a piggyBacTM (PB) transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at each of the following positions 30, 165, 282, and 538 of the sequence of SEQ ID NO: 14487.
- the amino acid substitution at position 30 of the sequence of SEQ ID NO: 14487 is a substitution of a valine (V) for an isoleucine (I).
- the amino acid substitution at position 165 of the sequence of SEQ ID NO: 14487 is a substitution of a serine (S) for a glycine (G).
- the amino acid substitution at position 282 of the sequence of SEQ ID NO: 14487 is a substitution of a valine (V) for a methionine (M).
- the amino acid substitution at position 538 of the sequence of SEQ ID NO: 14487 is a substitution of a lysine (K) for an asparagine (N).
- the transposase enzyme is a Super piggyBacTM (SPB) transposase enzyme.
- the Super piggyBacTM (SPB) transposase enzymes of the disclosure may comprise or consist of the amino acid sequence of the sequence of SEQ ID NO: 14487 wherein the amino acid substitution at position 30 is a substitution of a valine (V) for an isoleucine (I), the amino acid substitution at position 165 is a substitution of a serine (S) for a glycine (G), the amino acid substitution at position 282 is a substitution of a valine (V) for a methionine (M), and the amino acid substitution at position 538 is a substitution of a lysine (K) for an asparagine (N).
- the Super piggyBacTM (SPB) transposase enzyme may comprise or consist of an amino acid sequence at least 75%, 80%,
- the piggyBacTM or Super piggyBacTM transposase enzyme may further comprise an amino acid substitution at one or more of positions 3, 46, 82, 103, 119, 125, 177, 180, 185, 187,
- the piggyBacTM or Super piggyBacTM transposase enzyme may further comprise an amino acid substitution at one or more of positions 46, 119, 125, 177, 180, 185, 187, 200, 207, 209, 226, 235, 240, 241, 243, 296, 298, 311, 315, 319, 327, 328, 340, 421, 436, 456, 470, 485, 503, 552 and 570.
- positions 46, 119, 125, 177, 180, 185, 187, 200, 207, 209, 226, 235, 240, 241, 243, 296, 298, 311, 315, 319, 327, 328, 340, 421, 436, 456, 470, 485, 503, 552 and 570 may further comprise an amino acid substitution at one or more of positions 46, 119, 125, 177, 180, 185, 187, 200, 207, 209, 226, 235, 240, 241, 243, 296, 29
- the amino acid substitution at position 3 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an asparagine (N) for a serine (S).
- the amino acid substitution at position 46 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a serine (S) for an alanine (A).
- the amino acid substitution at position 46 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a threonine (T) for an alanine (A).
- the amino acid substitution at position 82 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tryptophan (W) for an isoleucine (I).
- the amino acid substitution at position 103 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a serine (S).
- the amino acid substitution at position 119 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for an arginine (R).
- the amino acid substitution at position 125 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) a cysteine (C). In certain embodiments, the amino acid substitution at position 125 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a cysteine (C). In certain
- the amino acid substitution at position 177 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a tyrosine (Y).
- the amino acid substitution at position 177 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a histidine (H) for a tyrosine (Y).
- the amino acid substitution at position 180 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a phenylalanine (F).
- the amino acid substitution at position 180 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a phenylalanine (F).
- the amino acid substitution at position 180 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a phenylalanine (F).
- the amino acid substitution at position 185 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a methionine (M).
- the amino acid substitution at position 187 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for an alanine (A).
- the amino acid substitution at position 200 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tryptophan (W) for a phenylalanine (F).
- the amino acid substitution at position 207 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a valine (V).
- the amino acid substitution at position 209 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a valine (V).
- the amino acid substitution at position 226 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a methionine (M).
- the amino acid substitution at position 235 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an arginine (R) for a leucine (L).
- the amino acid substitution at position 240 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a valine (V).
- the amino acid substitution at position 241 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a phenylalanine (F).
- the amino acid substitution at position 243 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a proline (P).
- the amino acid substitution at position 258 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a serine (S) for an asparagine (N).
- the amino acid substitution at position 296 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tryptophan (W) for a leucine (L).
- the amino acid substitution at position 296 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tyrosine (Y) for a leucine (L).
- the amino acid substitution at position 296 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a leucine (L).
- the amino acid substitution at position 298 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a methionine (M).
- the amino acid substitution at position 298 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) for a methionine (M).
- the amino acid substitution at position 298 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a methionine (M).
- the amino acid substitution at position 311 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a proline (P).
- the amino acid substitution at position 311 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine for a proline (P).
- the amino acid substitution at position 315 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for an arginine (R).
- the amino acid substitution at position 319 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for a threonine (T).
- the amino acid substitution at position 327 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an arginine (R) for a tyrosine (Y).
- the amino acid substitution at position 328 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a tyrosine (Y).
- the amino acid substitution at position 340 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for a cysteine (C).
- the amino acid substitution at position 340 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a cysteine (C).
- the amino acid substitution at position 421 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a histidine (H) for the aspartic acid (D).
- the amino acid substitution at position 436 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a valine (V).
- the amino acid substitution at position 456 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tyrosine (Y) for a methionine (M).
- the amino acid substitution at position 470 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a leucine (L).
- the amino acid substitution at position 485 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a serine (S).
- the amino acid substitution at position 503 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a methionine (M).
- the amino acid substitution at position 503 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a methionine (M).
- the amino acid substitution at position 552 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a valine (V).
- the amino acid substitution at position 570 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a threonine (T) for an alanine (A).
- the amino acid substitution at position 591 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a glutamine (Q). In certain embodiments, the amino acid substitution at position 591 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an arginine (R) for a glutamine (Q).
- the piggyBacTM transposase enzyme may comprise or the Super piggyBacTM transposase enzyme may further comprise an amino acid substitution at one or more of positions 103, 194, 372, 375, 450, 509 and 570 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484.
- the piggyBacTM transposase enzyme may comprise or the Super piggyBacTM transposase enzyme may further comprise an amino acid substitution at two, three, four, five, six or more of positions 103, 194, 372, 375, 450, 509 and 570 of the sequence of SEQ ID NO:
- the piggyBacTM transposase enzyme may comprise or the Super piggyBacTM transposase enzyme may further comprise an amino acid substitution at positions 103, 194, 372, 375, 450, 509 and 570 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484.
- the amino acid substitution at position 103 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a serine (S).
- the amino acid substitution at position 194 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a methionine (M).
- the amino acid substitution at position 372 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) for an arginine (R).
- the amino acid substitution at position 375 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) for a lysine (K).
- the amino acid substitution at position 450 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an asparagine (N) for an aspartic acid (D).
- the amino acid substitution at position 509 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for a serine (S).
- the amino acid substitution at position 570 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a serine (S) for an asparagine (N).
- the piggyBacTM transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487.
- the piggyBacTM transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487
- the piggyBacTM transposase enzyme may further comprise an amino acid substitution at positions 372, 375 and 450 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484.
- the piggyBacTM transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487, a substitution of an alanine (A) for an arginine (R) at position 372 of SEQ ID NO: 14487, and a substitution of an alanine (A) for a lysine (K) at position 375 of SEQ ID NO: 14487.
- the piggyBacTM transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487, a substitution of an alanine (A) for an arginine (R) at position 372 of SEQ ID NO: 14487, a substitution of an alanine (A) for a lysine (K) at position 375 of SEQ ID NO: 14487 and a substitution of an asparagine (N) for an aspartic acid (D) at position 450 of SEQ ID NO: 14487.
- the sleeping beauty transposon is transposed into the target genome by the Sleeping Beauty transposase that recognizes ITRs, and moves the contents between the ITRs into TA chromosomal sites.
- SB transposon-mediated gene transfer, or gene transfer using any of a number of similar transposons may be used in the compositions and methods of the disclosure.
- the transposase is a Sleeping Beauty transposase or a hyperactive Sleeping Beauty transposase (SB100X).
- the Sleeping Beauty transposase enzyme comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:
- the hyperactive Sleeping Beauty (SB100X) transposase enzyme comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:
- the Helraiser transposon is transposed by the Helitron transposase.
- An exemplary Helraiser transposon of the disclosure includes Helibatl, which comprises a nucleic acid sequence comprising:
- the Helitron transposase does not contain an RNase-H like catalytic domain, but instead comprises a RepHel motif made up of a replication initiator domain
- Rep domain is a nuclease domain of the HUH superfamily of nucleases.
- An exemplary Helitron transposase of the disclosure comprises an amino acid sequence comprising:
- a hairpin close to the 3’ end of the transposon functions as a terminator.
- this hairpin can be bypassed by the transposase, resulting in the transduction of flanking sequences.
- Helraiser transposition generates covalently closed circular intermediates.
- Helitron transpositions can lack target site duplications.
- the transposase is flanked by 5’ and 3’ terminal sequences termed LTS and RTS. These sequences terminate with a conserved 5’-TC/CTAG-3’ motif.
- a 19 bp palindromic sequence with the potential to form the hairpin termination structure is located 11 nucleotides upstream of the RTS and consists of the sequence
- GTGCACGAATTTCGTGCACCGGGCCACTAG SEQ ID NO: 14500.
- Tol2 transposons may be isolated or derived from the genome of the medaka fish, and may be similar to transposons of the hAT family.
- Exemplary Tol2 transposons of the disclosure are encoded by a sequence comprising about 4.7 kilobases and contain a gene encoding the Tol2 transposase, which contains four exons.
- An exemplary Tol2 transposase of the disclosure comprises an amino acid sequence comprising the following:
- An exemplary Tol2 transposon of the disclosure including inverted repeats, subterminal sequences and the Tol2 transposase, is encoded by a nucleic acid sequence comprising the following:
- transposon/transposase systems of the disclosure include, but are not limited to, piggyBac and piggyBac-like transposons and transposases.
- PiggyBac and piggyBac-like transposases recognizes transposon-specific inverted terminal repeat sequences (ITRs) on the ends of the transposon, and moves the contents between the ITRs into TTAA or TTAT chromosomal sites.
- ITRs inverted terminal repeat sequences
- the piggyBac or piggyBac-like transposon system has no payload limit for the genes of interest that can be included between the ITRs.
- the transposase is a piggyBacTM, Super piggyBacTM (SPB) transposase.
- the sequence encoding the transposase is an mRNA sequence.
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the transposase enzyme is a piggyBac or a piggyBac-like transposase enzyme.
- the piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at one or more of positions 30, 165, 282, or 538 of the sequence:
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at two or more of positions 30, 165, 282, or 538 of the sequence of SEQ ID NO: 14487.
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at three or more of positions 30, 165, 282, or 538 of the sequence of SEQ ID NO: 14487.
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at each of the following positions 30, 165, 282, and 538 of the sequence of SEQ ID NO: 14487.
- the amino acid substitution at position 30 of the sequence of SEQ ID NO: 14487 is a substitution of a valine (V) for an isoleucine (I).
- the amino acid substitution at position 165 of the sequence of SEQ ID NO: 14487 is a substitution of a serine (S) for a glycine (G).
- the amino acid substitution at position 282 of the sequence of SEQ ID NO: 14487 is a substitution of a valine (V) for a methionine (M).
- the amino acid substitution at position 538 of the sequence of SEQ ID NO: 14487 is a substitution of a lysine (K) for an asparagine (N).
- the transposase enzyme is a Super piggyBacTM (SPB) or piggyBac-like transposase enzyme.
- the Super piggyBacTM (SPB) or piggyBac-like transposase enzyme of the disclosure may comprise or consist of the amino acid sequence of the sequence of SEQ ID NO: 14487 wherein the amino acid substitution at position 30 is a substitution of a valine (V) for an isoleucine (I), the amino acid substitution at position 165 is a substitution of a serine (S) for a glycine (G), the amino acid substitution at position 282 is a substitution of a valine (V) for a methionine (M), and the amino acid substitution at position 538 is a substitution of a lysine (K) for an asparagine (N).
- the Super piggyBacTM (SPB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:
- the piggyBacTM, Super piggyBacTM or piggyBac-like transposase enzyme may further comprise an amino acid substitution at one or more of positions 3, 46, 82, 103, 119, 125, 177, 180, 185, 187, 200, 207, 209, 226, 235, 240, 241, 243, 258, 296, 298, 311, 315, 319, 327,
- the piggyBacTM, Super piggyBacTM or piggyBac-like transposase enzyme may further comprise an amino acid substitution at one or more of positions 46, 119, 125, 177, 180, 185, 187, 200, 207,
- the amino acid substitution at position 3 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an asparagine (N) for a serine (S).
- the amino acid substitution at position 46 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a serine (S) for an alanine (A).
- the amino acid substitution at position 46 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a threonine (T) for an alanine (A).
- the amino acid substitution at position 82 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tryptophan (W) for an isoleucine (I).
- the amino acid substitution at position 103 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a serine (S).
- the amino acid substitution at position 119 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for an arginine (R).
- the amino acid substitution at position 125 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) a cysteine (C).
- the amino acid substitution at position 125 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a cysteine (C).
- the amino acid substitution at position 177 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a tyrosine (Y).
- the amino acid substitution at position 177 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a histidine (H) for a tyrosine (Y).
- the amino acid substitution at position 180 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a phenylalanine (F).
- the amino acid substitution at position 180 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a phenylalanine (F).
- the amino acid substitution at position 180 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a phenylalanine (F).
- the amino acid substitution at position 185 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a methionine (M).
- the amino acid substitution at position 187 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for an alanine (A).
- the amino acid substitution at position 200 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tryptophan (W) for a phenylalanine (F).
- the amino acid substitution at position 207 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a valine (V).
- the amino acid substitution at position 209 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a valine (V).
- the amino acid substitution at position 226 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a methionine (M).
- the amino acid substitution at position 235 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an arginine (R) for a leucine (L).
- the amino acid substitution at position 240 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a valine (V).
- the amino acid substitution at position 241 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a phenylalanine (F).
- the amino acid substitution at position 243 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a proline (P).
- the amino acid substitution at position 258 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a serine (S) for an asparagine (N).
- the amino acid substitution at position 296 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tryptophan (W) for a leucine (L).
- the amino acid substitution at position 296 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tyrosine (Y) for a leucine (L).
- the amino acid substitution at position 296 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a leucine (L).
- the amino acid substitution at position 298 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a methionine (M).
- the amino acid substitution at position 298 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) for a methionine (M).
- the amino acid substitution at position 298 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a methionine (M).
- the amino acid substitution at position 311 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a proline (P).
- the amino acid substitution at position 311 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine for a proline (P).
- the amino acid substitution at position 315 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for an arginine (R).
- the amino acid substitution at position 319 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for a threonine (T).
- the amino acid substitution at position 327 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an arginine (R) for a tyrosine (Y).
- the amino acid substitution at position 328 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a tyrosine (Y).
- the amino acid substitution at position 340 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for a cysteine (C).
- the amino acid substitution at position 340 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a cysteine (C).
- the amino acid substitution at position 421 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a histidine (H) for the aspartic acid (D).
- the amino acid substitution at position 436 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a valine (V).
- the amino acid substitution at position 456 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tyrosine (Y) for a methionine (M).
- the amino acid substitution at position 470 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a leucine (L).
- the amino acid substitution at position 485 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a serine (S).
- the amino acid substitution at position 503 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a methionine (M). In certain embodiments, the amino acid substitution at position 503 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a methionine (M). In certain embodiments, the amino acid substitution at position 552 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a valine (V).
- the amino acid substitution at position 570 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a threonine (T) for an alanine (A).
- the amino acid substitution at position 591 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a glutamine (Q).
- the amino acid substitution at position 591 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an arginine (R) for a glutamine (Q).
- the piggyBacTM or piggyBac-like transposase enzyme or may comprise or the Super piggyBacTM transposase enzyme may further comprise an amino acid substitution at one or more of positions 103, 194, 372, 375, 450, 509 and 570 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484.
- the piggyBacTM or piggyBac-like transposase enzyme may comprise or the Super piggyBacTM transposase enzyme may further comprise an amino acid substitution at two, three, four, five, six or more of positions 103, 194, 372, 375, 450, 509 and 570 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484.
- the piggyBacTM or piggyBac-like transposase enzyme may comprise or the Super piggyBacTM transposase enzyme may further comprise an amino acid substitution at positions 103, 194, 372, 375, 450, 509 and 570 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484.
- the amino acid substitution at position 103 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a serine (S).
- the amino acid substitution at position 194 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a methionine (M).
- the amino acid substitution at position 372 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) for an arginine (R).
- the amino acid substitution at position 375 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) for a lysine (K).
- the amino acid substitution at position 450 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an asparagine (N) for an aspartic acid (D).
- the amino acid substitution at position 509 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for a serine (S).
- the amino acid substitution at position 570 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a serine (S) for an asparagine (N).
- the piggyBacTM or piggyBac-like transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487. In certain embodiments, including those
- the piggyBacTM or piggyBac-like transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487
- the piggyBacTM or piggyBac-like transposase enzyme may further comprise an amino acid substitution at positions 372, 375 and 450 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484.
- the piggyBacTM or piggyBac-like transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487, a substitution of an alanine (A) for an arginine (R) at position 372 of SEQ ID NO: 14487, and a substitution of an alanine (A) for a lysine (K) at position 375 of SEQ ID NO: 14487.
- the piggyBacTM or piggyBac-like transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487, a substitution of an alanine (A) for an arginine (R) at position 372 of SEQ ID NO: 14487, a substitution of an alanine (A) for a lysine (K) at position 375 of SEQ ID NO: 14487 and a substitution of an asparagine (N) for an aspartic acid (D) at position 450 of SEQ ID NO: 14487.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from an insect.
- the insect is Trichoplusia ni (GenBank
- Argyrogramma agnata Messour bouvieri, Megachile rotundata, Bombus impatiens, Mamestra brassicae, Mayetiola destructor or A pis mellifera.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from an insect.
- the insect is Trichoplusia ni (AAA87375).
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from an insect.
- the insect is Bombyx mori (BAD11135).
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from a crustacean.
- the crustacean is Daphnia pulicaria
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from a vertebrate.
- the vertebrate is Xenopus tropicalis
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from a urochordate.
- the urochordate is Ciona intestinalis (GenBank Accession No. XP_002l23602; SEQ ID NO: 14670).
- the piggyBac or piggyBac-like transposase inserts a transposon at the sequence 5’-TTAT-3’ within a chromosomal site (a TTAT target sequence).
- the piggyBac or piggyBac-like transposase inserts a transposon at the sequence 5’-TTAA-3’ within a chromosomal site (a TTAA target sequence).
- the target sequence of the piggyBac or piggyBac-like transposon comprises or consists of 5’-CTAA-3’, 5’-TTAG-3’, 5’-ATAA-3’, 5’-TCAA-3’, 5’AGTT-3’, 5’- ATTA-3’, 5’-GTTA-3’, 5’-TTGA-3’, 5’-TTTA-3’, 5’-TTAC-3’, 5’-ACTA-3’, 5’-AGGG-3’, 5’- CTAG-3’, 5’-TGAA-3’, 5’-AGGT-3’, 5’-ATCA-3’, 5’-CTCC-3’, 5’-TAAA-3’, 5’-TCTC-3’, 5’TGAA-3’, 5’-AAAT-3’, 5’-AATC-3’, 5’-ACAA-3’, 5’-ACAT-3’, 5’-ACTC-3’, 5’-AGTG-3’,
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Bombyx mori.
- the piggyBac or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%,
- the piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%,
- the piggyBac or piggyBac-like transposase is fused to a nuclear localization signal.
- the amino acid sequence of the piggyBac or piggyBac-like transposase fused to a nuclear localization signal is encoded by a polynucleotide sequence comprising:
- the piggyBac or piggyBac-like transposase is hyperactive.
- a hyperactive piggyBac or piggyBac-like transposase is a transposase that is more active than the naturally occurring variant from which it is derived.
- the hyperactive piggyBac or piggyBac-like transposase enzyme is isolated or derived from Bombyx mori.
- the piggyBac or piggyBac-like transposase is a hyperactive variant of SEQ ID NO: 14505.
- the hyperactive piggyBac or piggyBac-like transposase comprises a sequence that is at least 90% identical to:
- the hyperactive piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14576. In certain embodiments, the hyperactive piggyBac or piggyBac- like transposase comprises a sequence of:
- the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:
- the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:
- the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:
- the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:
- the hyperactive piggyBac or piggyBac-like transposase is more active than the transposase of SEQ ID NO: 14505. In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase is at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% or any percentage in between identical to SEQ ID NO: 14505.
- the hyperactive piggyBac or piggyBac-like transposase comprises an amino acid substitution at a position selected from 92, 93, 96, 97, 165, 178, 189, 196, 200, 201, 211, 215, 235, 238, 246, 253, 258, 261, 263, 271, 303, 321, 324, 330, 373, 389, 399, 402, 403, 404, 448, 473, 484, 507,5 23, 527, 528, 543, 549, 550, 557,6 01, 605, 607, 609, 610 or a combination thereof (relative to SEQ ID NO: 14505).
- the hyperactive piggyBac or piggyBac-like transposase comprises an amino acid substitution of Q92A, V93L, V93M, P96G, F97H, F97C, H165E, H165W, E178S, E178H, C189P, A196G, F200I, A201Q, F211A, W215Y, G219S, Q235Y, Q235G, Q238F, K246I, K253V, M258V, F261F, S263K, C271S, N303R, F321W, F321D, V324K, V324H, A330V, F373C, F373V, V389F, S399N, R402K, T403F, D404Q, D404S, D404M, N441R, G448W, E449A, V469T, C473Q, R484K T507C, G523A, I
- the hyperactive piggyBac or piggyBac-like transposase comprises an amino acid substitution of Q92A, V93F, V93M, P96G, F97H, F97C, H165E, H165W, E178S, E178H, C189P, A196G, F200I, A201Q, F211A, W215Y, G219S, Q235Y, Q235G, Q238F, K246I, K253V, M258V, F261F, S263K, C271S, N303R, F321W, F321D, V324K, V324H, A330V, F373C, F373V, V389F, S399N, R402K, T403F, D404Q, D404S, D404M, N441R, G448W, E449A, V469T, C473Q, R484K T507C, G523A, I
- the hyperactive piggyBac or piggyBac-like transposase comprises one or more substitutions of an amino acid that is not wild type, wherein the one or more substitutions a for wild type amino acid comprises a substitution of E4X, A12X,
- the piggyBac or piggyBac-like transposase is integration deficient.
- an integration deficient piggyBac or piggyBac-like transposase is a transposase that can excise its corresponding transposon, but that integrates the excised transposon at a lower frequency than a corresponding wild type transposase.
- the piggyBac or piggyBac-like transposase is an integration deficient variant of SEQ ID NO: 14505.
- the excision competent, integration deficient piggyBac or piggyBac-like transposase comprises one or more substitutions of an amino acid that is not wild type, wherein the one or more substitutions a for wild type amino acid comprises a substitution of R9X, A12X, M13X, D20X, Y21K, D23X, E24X, S25X, S26X, S27X, E28X, E30X, D32X, H33X, E36X, H37X, A39X, Y41X, D42X, T43X, E44X, E45X, E46X, R47X, D49X, S50X, S55X, A62X, N63X, A64X, I66X, A67X, N68X, E69X, D70X, D71X, S72X, D73X, P74X, D75X, D76X, D77X,I78X, S8lX,V83X, R
- the integration deficient piggyBac or piggyBac-like transposase comprises a sequence of:
- the integration deficient piggyBac or piggyBac-like transposase comprises a sequence of:
- the piggyBac or piggyBac-like transposase that is is integration deficient comprises a sequence of:
- the integration deficient transposase comprises a sequence that is at least 90% identical to SEQ ID NO: 14608.
- the piggyBac or piggyBac-like transposon is isolated or derived from Bombyx mori. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBacTM (PB) or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a 5’ sequence corresponding to SEQ ID NO: 14506 and a 3’ sequence corresponding to SEQ ID NO: 14507.
- one piggyBac or piggyBac-like transposon end is at least 85%, at least 90%, at least 95%, at least 98%, at least 99% identical or any percentage in between identical to SEQ ID NO: 14506 and the other piggyBac or piggyBac-like transposon end is at least 85%, at least 90%, at least 95%, at least 98%, at least 99% or any percentage in between identical to SEQ ID NO: 14507.
- the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14506 and SEQ ID NO: 14507 or SEQ ID NO: 14509. In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14508 and SEQ ID NO: 14507 or SEQ ID NO: 14509. In certain embodiments, the 5’ and 3’ transposon ends share a 16 bp repeat sequence at their ends of CCCGGCGAGCATGAGG (SEQ ID NO: 14510) immediately adjacent to the 5'-TTAT-3 target insertion site, which is inverted in the orientation in the two ends.
- 5’ transposon end begins with a sequence comprising 5'-TTATCCCGGCGAGCATGAGG-3 (SEQ ID NO: 14511), and the 3’ transposon ends with a sequence comprising the reverse complement of this sequence: 5'- [0279]
- the piggyBac or piggyBac-like transposon comprises one end comprising at least 14, 16, 18, 20, 30 or 40 contiguous nucleotides of SEQ ID NO: 14506 or SEQ ID NO: 14508.
- the piggyBac or piggyBac-like transposon comprises one end comprising at least 14, 16, 18, 20, 30 or 40 contiguous nucleotides of SEQ ID NO: 14507 or SEQ ID NO: 14509. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end with at least 90% identity to SEQ ID NO: 14506 or SEQ ID NO: 14508. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end with at least 90% identity to SEQ ID NO: 14507 or SEQ ID NO: 14509.
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of CCCGGCGAGCATGAGG (SEQ ID NO: 14510). In certain embodiments, the piggyBac or piggyBac-like transposon comprises an ITR sequence of SEQ ID NO: 14510. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of TTATCCCGGCGAGCATGAGG (SEQ ID NO: 14511). In certain embodiments, the piggyBac or piggyBac-like transposon comprises at least 16 contiguous nucleotides from SEQ ID NO: 14511.
- the piggyBac or piggyBac-like transposon comprises a sequence of CCTCATGCTCGCCGGGTTAT (SEQ ID NO: 14512). In certain embodiments, the piggyBac or piggyBac-like transposon comprises at least 16 contiguous nucleotides from SEQ ID NO: 14512. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end comprising at least 16 contiguous nucleotides from SEQ ID NO: 14511 and one end comprising at least 16 contiguous nucleotides from SEQ ID NO: 14512.
- the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14511 and SEQ ID NO: 14512. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of TTAACCCGGCGAGCATGAGG (SEQ ID NO: 14513). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of
- the piggyBac or piggyBac-like transposon may have ends comprising SEQ ID NO: 14506 and SEQ ID NO: 14507, or a variant of either or both of these having at least 90% sequence identity to SEQ ID NO: 14506 or SEQ ID NO: 14507, and the piggyBac or piggyBac-like transposase has the sequence of SEQ ID NO: 14504 or SEQ ID NO: 14505, or a sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%,
- the piggyBac or piggyBac-like transposon comprises a heterologous polynucleotide inserted between a pair of inverted repeats, where the transposon is capable of transposition by a piggyBac or piggyBac-like transposase having at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identity to SEQ ID NO: 14504 or SEQ ID NO: 14505.
- the transposon comprises two transposon ends, each of which comprises SEQ ID NO: 14510 in inverted orientations in the two transposon ends.
- each inverted terminal repeat (ITR) is at least 90% identical to SEQ ID NO: 14510.
- the piggyBac or piggyBac-like transposon is capable of insertion by a piggyBac or piggyBac-like transposase at the sequence 5'-TTAT-3 within a target nucleic acid.
- one end of the piggyBac or piggyBac-like transposon comprises at least 16 contiguous nucleotides from SEQ ID NO: 14506 and the other transposon end comprises at least 16 contiguous nucleotides from SEQ ID NO: 14507.
- one end of the piggyBac or piggyBac-like transposon comprises at least 17, at least 18, at least 19, at least 20, at least 22, at least 25, at least 30 contiguous nucleotides from SEQ ID NO: 14506 and the other transposon end comprises at least 17, at least 18, at least 19, at least 20, at least 22, at least 25, at least 30 contiguous nucleotides from SEQ ID NO: 14507.
- the piggyBac or piggyBac-like transposon comprises transposon ends (each end comprising an ITR) corresponding to SEQ ID NO: 14506 and SEQ ID NO: 14507, and has a target sequence corresponding to 5'-TTAT3'.
- the piggyBac or piggyBac-like transposon also comprises a sequence encoding a transposase (e.g. SEQ ID NO: 14505).
- the piggyBac or piggyBac-like transposon comprises one transposon end corresponding to SEQ ID NO: 14506 and a second transposon end corresponding to SEQ ID NO: 14516.
- SEQ ID NO: 14516 is very similar to SEQ ID NO: 14507, but has a large insertion shortly before the ITR.
- the ITR sequences for the two transposon ends are identical (they are both identical to SEQ ID NO: 14510), they have different target sequences: the second transposon has a target sequence corresponding to 5'-TTAA-3', providing evidence that no change in ITR sequence is necessary to modify the target sequence specificity.
- the piggyBac or piggyBac-like transposase (SEQ ID NO: 14504), which is associated with the 5'-TTAA-3’ target site differs from the 5'-TTAT-3'-associated transposase (SEQ ID NO: 14505) by only 4 ammo acid changes (D322Y, S473C, A507T, H582R).
- the piggyBac or piggyBac-like transposase (SEQ ID NO: 14504), which is associated with the 5'-TTAA-3’ target site is less active than the 5'-TTAT-3'-associated piggyBac or piggyBac-like transposase (SEQ ID NO: 14505) on the transposon with 5'-TTAT-3' ends.
- piggyBac or piggyBac-like transposons with 5'-TTAA-3’ target sites can be converted to piggyBac or piggyBac-like transposases with 5'-TTAT-3 target sites by replacing 5'-TTAA-3’ target sites with 5'-TTAT-3'.
- Such transposons can be used either with a piggyBac or piggyBac-like transposase such as SEQ ID NO: 14504 which recognizes the 5'- TTAT-3’ target sequence, or with a variant of a transposase originally associated with the 5'- TTAA-3' transposon.
- the high similarity between the 5'-TTAA-3' and 5'-TTAT-3' piggyBac or piggyBac-like transposases demonstrates that very few changes to the amino acid sequence of a piggyBac or piggyBac-like transposase alter target sequence specificity.
- modification of any piggyBac or piggyBac-like transposon- transposase gene transfer system in which 5'-TTAA-3’ target sequences are replaced with 5'- TTAT-3'-target sequences, the ITRs remain the same, and the transposase is the original piggyBac or piggyBac-like transposase or a variant thereof resulting from using a low-level mutagenesis to introduce mutations into the transposase.
- piggyBac or piggyBac-like transposon transposase transfer systems can be formed by the modification of a 5'- TTAT-3'-active piggyBac or piggyBac-like transposon-transposase gene transfer systems in which 5'-TTAT-3’ target sequences are replaced with 5'-TTAA-3'-target sequences, the ITRs remain the same, and the piggyBac or piggyBac-like transposase is the original transposase or a variant thereof.
- the piggyBac or piggyBac-like transposon is isolated or derived from Bombyx mori.
- the piggyBac or piggyBac-like transposon comprises a sequence of: g ggg g g g g g ( Q )
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the transposon comprises at least 16 contiguous bases from SEQ ID NO: 14577 and at least 16 contiguous bases from SEQ ID NO: 14578, and inverted terminal repeats that are at least 87% identical to CCCGGCGAGCATGAGG (SEQ ID NO: 14510).
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14595 and SEQ ID NO: 14596, and is transposed by the piggyBac or piggyBac-like transposase of SEQ ID NO: 14505.
- the ITRs of SEQ ID NO: 14595 and SEQ ID: 14596 are not flanked by a 5’-TTAA-3’ sequence.
- the ITRs of SEQ ID NO: 14595 and SEQ ID: 14596 are flanked by a 5’-TTAT-3’ sequence.
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the 5’ end of the piggyBac or piggyBac-like transposon comprises a sequence of SEQ ID NO: 14577, SEQ ID NO: 14595, or SEQ ID NOs: 14597- 14599. In certain embodiments, the 5’ end of the piggyBac or piggyBac-like transposon is preceded by a 5’ target sequence.
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the 3’ end of the piggyBac or piggyBac-like transposon comprises a sequence of SEQ ID NO: 14578, SEQ ID NO: 14596, or SEQ ID NOs: 14600- 14601.
- the 3’ end of the piggyBac or piggyBac-like transposon is followed by a 3’ target sequence.
- the transposon is transposed by the transposase of SEQ ID NO: 14505.
- the 5’ and 3’ ends of the piggyBac or piggyBac-like transposon share a 16 bp repeat sequence of SEQ ID NO: 14510 in inverted orientation and immediately adjacent to the target sequence.
- the 5’ transposon end begins with SEQ ID NO: 14510
- the 3’ transposon end ends with the reverse complement of SEQ ID NO: 14510, 5’- CCTCATGCTCGCCGGG-3’ (SEQ ID NO: 14603).
- the piggyBac or piggyBac-like transposon comprises an ITR with at least 93%, at least 87%, or at least 81% or any percentage in between identity to SEQ ID NO: 14510 or SEQ ID NO: 14603.
- the piggyBac or piggyBac-like transposon comprises a target sequence followed by a 5’ transposon end comprising a sequence selected from SEQ ID NOs: 14577, 14595 or 14597 and a 3’ transposon end comprising SEQ ID NO: 14578 or 14596 followed by a target sequence
- the piggyBac or piggyBac like transposon comprises one end that comprises a sequence that is at least 90%, at least 95% or at least 99% or any percentage in between identical to SEQ ID NO: 14577 and one end that comprises a sequence that is at least 90%, at least 95% or at least 99% or any percentage in between identical to SEQ ID NO: 14578.
- one transposon end comprises at least 14, at least 16, at least 18 or at least 20 contiguous bases from SEQ ID NO: 14577 and one transposon end comprises at least 14, at least 16, at least 18 or at least 20 contiguous bases from SEQ ID NO: 14578.
- the piggyBac or piggyBac-like transposon comprises two transposon ends wherein each transposon ends comprises a sequence that is at least 81% identical, at least 87% identical or at least 93% identical or any percentage in between identical to SEQ ID NO: 14510 in inverted orientation in the two transposon ends.
- One end may further comprise at least 14, at least 16, at least 18 or at least 20 contiguous bases from SEQ ID NO: 14599, and the other end may further comprise at least 14, at least 16, at least 18 or at least 20 contiguous bases from SEQ ID NO: 14601.
- the piggyBac or piggyBac-like transposon may be transposed by the transposase of SEQ ID NO: 14505, and the transposase may optionally be fused to a nuclear localization signal.
- the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14595 and SEQ ID NO: 14596 and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14504 or SEQ ID NO: 14505.
- the piggyBac or piggyBac- like transposon comprises SEQ ID NO: 14597 and SEQ ID NO: 14596 and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14504 or SEQ ID NO: 14505.
- the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14595 and SEQ ID NO: 14578 and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14504 or SEQ ID NO: 14505.
- the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14602 and SEQ ID NO: 14600 and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14504 or SEQ ID NO: 14505.
- the piggyBac or piggyBac-like transposon comprises a 5’ end comprising 1, 2, 3, 4, 5, 6, or 7 sequences selected from ATGAGGCAGGGTAT (SEQ ID NO: 14614), ATACCCTGCCTCAT (SEQ ID NO: 14615), GGCAGGGTAT (SEQ ID NO: 14616), ATACCCTGCC (SEQ ID NO: 14617), TAAAATTTTA (SEQ ID NO: 14618),
- the piggyBac or piggyBac-like transposon comprises a 3’ end comprising 1 , 2 or 3 sequences selected from SEQ ID NO: 14617, SEQ ID NO: 14620 and SEQ ID NO: 14621.
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Xenopus tropicalis.
- the piggyBac or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%,
- the piggyBac or piggyBac-like transposase is a hyperactive variant of SEQ ID NO: 14517.
- the piggyBac or piggyBac-like transposase is an integration defective variant of SEQ ID NO: 14517.
- the piggyBac or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%,
- the piggyBac or piggyBac-like transposase is isolated or derived from Xenopus tropicalis. In certain embodiments, the piggyBac or piggyBac-like transposase is a hyperactive piggyBac or piggyBac-like transposase. In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence at least 90% identical to:
- piggyBac or piggyBac-like transposase is a hyperactive piggyBac or piggyBac-like transposase.
- a hyperactive piggyBac or piggyBac-like transposase is a transposase that is more active than the naturally occurring variant from which it is derived.
- a hyperactive piggyBac or piggyBac-like transposase is more active than the transposase of SEQ ID NO: 14517.
- the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:
- the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:
- the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:
- the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:
- the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:
- the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:
- the hyperactive piggyBac or piggyBac-like transposase comprises an amino acid substitution at a position selected from amino acid 6, 7, 16, 19, 20, 21,
- the hyperactive piggyBac or piggyBac-like transposase comprises an amino acid substitution of Y6C, S7G, M16S, S19G, S20Q, S20G, S20D, E21D, E22Q, F23T, F23P, S24Y, S26V, S28Q, V31K, A34E, L67A, G73H, A76V, D77N, P88A, N91D, Y141Q, Y141A, N145E, N145V, P146T, P146V, P146K, P148T, P148H, Y150G, Y150S, Y150C, H157Y, A162C, A179K, L182I, L182V, T189G, L192H, S193N, S193K, V196I, S198G, T200W, L210H, F212N, N218E, A248N, L263M, Q270L, S
- the hyperactive piggyBac or piggyBac-like transposase comprises one or more substitutions of an amino acid that is not wild type, wherein the one or more substitutions a for wild type amino acid comprises a substitution of A2X, K3X, R4X, F5X, Y6X, S7X, A11X, A13X, C15X, M16X, A17X, S18X, S19X, S20X, E21X, E22X, F23X, S24X, G25X, 26X, D27X, S28X, E29X, E42X, E43X, S44X, C46X, S47X, S48X, S49X, T50X, V51X, S52X, A53X, L54X, E55X, E56X, P57X, M58X, E59X, E62X, D63X, V64X, D65X, D66X, L67X, E68X, D
- the piggyBac or piggyBac-like transposase is integration deficient.
- an integration deficient piggyBac or piggyBac-like transposase is a transposase that can excise its corresponding transposon, but that integrates the excised transposon at a lower frequency than a corresponding naturally occurring transposase.
- the piggyBac or piggyBac-like transposase is an integration deficient variant of SEQ ID NO: 14517.
- the integration deficient piggyBac or piggyBac-like transposase is deficient relative to SEQ ID NO: 14517.
- the piggyBac or piggyBac-like transposase is active for excision but deficient in integration.
- the integration deficient piggyBac or piggyBac-like transposase comprises a sequence that is at least 90% identical to a sequence of
- the integration deficient piggyBac or piggyBac-like transposase comprises a sequence that is at least 90% identical to a sequence of:
- the integration deficient piggyBac or piggyBac-like transposase comprises a sequence that is at least 90% identical to a sequence of:
- the integration deficient piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14611. In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase comprises a sequence that is at least 90% identical to a sequence of:
- the integration deficient piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14612. In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase comprises a sequence that is at least 90% identical to a sequence of:
- the integration deficient piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14613. In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase comprises an amino acid substitution wherein the Asn at position 218 is replaced by a Glu or an Asp (N218D or N218E) (relative to SEQ ID NO: 14517).
- the excision competent, integration deficient piggyBac or piggyBac-like transposase comprises one or more substitutions of an amino acid that is not wild type, wherein the one or more substitutions a for wild type amino acid comprises a substitution of A2X, K3X, R4X, F5X, Y6X, S7X, A8X, E9X, E10X, Al IX, A12X, A13X, H14X, C15X, M16X, A17X, S18X, S19X, S20X, E21X, E22X, F23X, S24X, G25X, 26X, D27X, S28X, E29X, V31X, P32X, P33X, A34X, S35X, E36X, S37X, D38X, S39X, S40X, T41X, E42X, E43X, S44X, W45X, C46X, S47X, S48X,
- the piggyBac or piggyBac-like transposase is fused to a nuclear localization signal.
- SEQ ID NO: 14517 or SEQ ID NO: 14518 is fused to a nuclear localization signal.
- the amino acid sequence of the piggyBac or piggyBac like transposase fused to a nuclear localization signal is encoded by a polynucleotide sequence comprising:
- the piggyBac or piggyBac-like transposon is isolated or derived from Xenopus tropicalis. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14519 and SEQ ID NO: 14520. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises SEQ ID NO:
- the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14522 and
- the piggyBac or piggyBac-like transposon comprises one end comprising at least 14, 16, 18, 20, 30 or 40 contiguous nucleotides from SEQ ID NO: 14519, SEQ ID NO: 14521 or SEQ ID NO:
- the piggyBac or piggyBac-like transposon comprises one end comprising at least 14, 16, 18, 20, 30 or 40 contiguous nucleotides from SEQ ID NO: 14520 or
- the piggyBac or piggyBac-like transposon comprises one end with at least 90% identity to SEQ ID NO: 14519, SEQ ID NO: 14521 or SEQ ID NO: 14523. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end with at least 90% identity to SEQ ID NO: 14520 or SEQ ID NO: 14522. In one embodiment, one transposon end is at least 90% identical to SEQ ID NO: 14519 and the other transposon end is at least 90% identical to SEQ ID NO: 14520.
- the piggyBac or piggyBac-like transposon comprises a sequence of TTAACCTTTTTACTGCCA (SEQ ID NO: 14524). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of TTAACCCTTTGCCTGCCA (SEQ ID NO: 14526). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of TTAACCYTTTTACTGCCA (SEQ ID NO: 14527). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of
- the piggyBac or piggyBac-like transposon comprises a sequence of TGGCAGTGAAAGGGTTAA (SEQ ID NO: 14531). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of TTAACCYTTTKMCTGCCA (SEQ ID NO: 14533). In certain embodiments, one end of the piggyBac or piggyBac-like transposon comprises a sequence selected from SEQ ID NO: 14524, SEQ ID NO: 14526 and SEQ ID NO: 14527.
- one end of the piggyBacTM (PB) or piggyBac-like transposon comprises a sequence selected from SEQ ID NO: 14529 and SEQ ID NO: 14531.
- each inverted terminal repeat of the piggyBac or piggyBac-like transposon comprises a sequence of ITR sequence of
- each end of the piggyBacTM (PB) or piggyBac-like transposon comprises SEQ ID NO: 14563 in inverted orientations.
- one ITR of the piggyBac or piggyBac-like transposon comprises a sequence selected from SEQ ID NO: 14524, SEQ ID NO: 14526 and SEQ ID NO: 14527.
- one ITR of the piggyBac or piggyBac-like transposon comprises a sequence selected from SEQ ID NO: 14529 and SEQ ID NO: 14531.
- the piggyBac or piggyBac like transposon comprises SEQ ID NO: 14533 in inverted orientation in the two transposon ends.
- the piggyBac or piggyBac-like transposon may have ends comprising SEQ ID NO: 14519 and SEQ ID NO: 14520 or a variant of either or both of these having at least 90% sequence identity to SEQ ID NO: 14519 or SEQ ID NO: 14520, and the piggyBac or piggyBac-like transposase has the sequence of SEQ ID NO: 14517 or a variant showing at least %, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between sequence identity to SEQ ID NO: 14517 or SEQ ID NO: 14518.
- one piggyBac or piggyBac-like transposon end comprises at least 14 contiguous nucleotides from SEQ ID NO: 14519, SEQ ID NO: 14521 or SEQ ID NO: 14523, and the other transposon end comprises at least 14 contiguous nucleotides from SEQ ID NO: 14520 or SEQ ID NO: 14522.
- one transposon end comprises at least 15, at least 16, at least 17, at least 18, at least 19, at least 20, at least 22, at least 25, at least 30 contiguous nucleotides from SEQ ID NO: 14519, SEQ ID NO: 14521 or SEQ ID NO: 14523, and the other transposon end comprises at least 15, at least 16, at least 17, at least 18, at least 19, at least 20, at least 22, at least 25 or at least 30 contiguous nucleotides from SEQ ID NO: 14520 or SEQ ID NO: 14522.
- the piggyBac or piggyBac-like transposase recognizes a transposon end with a 5’ sequence corresponding to SEQ ID NO: 14519, and a 3’ sequence corresponding to SEQ ID NO: 14520. It will excise the transposon from one DNA molecule by cutting the DNA at the 5'-TTAA-3' sequence at the 5’ end of one transposon end to the 5'- TTAA-3' at the 3’ end of the second transposon end, including any heterologous DNA that is placed between them, and insert the excised sequence into a second DNA molecule.
- truncated and modified versions of the 5’ and 3’ transposon ends will also function as part of a transposon that can be transposed by the piggyBac or piggyBac-like transposase.
- the 5’ transposon end can be replaced by a sequence corresponding to SEQ ID NO: 14521 or SEQ ID NO: 14523
- the 3’ transposon end can be replaced by a shorter sequence corresponding to SEQ ID NO: 14522.
- the 5’ and 3’ transposon ends share an 18 bp almost perfectly repeated sequence at their ends (5'- TTAACCYTTTKMCTGCCA: SEQ ID NO: 14533) that includes the 5'-TTAA-3' insertion site, which sequence is inverted in the orientation in the two ends.
- the 5’ transposon end begins with the sequence 5'- TTAACCTTTTTACTGCCA-3' (SEQ ID NO: 14524), or in SEQ ID NO: 14521 the 5’ transposon end begins with the sequence 5'-TTAACCCTTTGCCTGCCA-3' (SEQ ID NO: 14526); the 3’ transposon ends with approximately the reverse complement of this sequence: in SEQ ID NO: 14520 it ends 5' TGGCAGTAAAAGGGTTAA-3' (SEQ ID NO: 14529), in SEQ ID NO: 14522 it ends 5'-TGGCAGTGAAAGGGTTAA-3' (SEQ ID NO: 14531.)
- One embodiment of the invention is a transposon that comprises a heterologous polynucleotide inserted between two transposon ends each comprising SEQ ID NO: 14533 in inverted orientations in the two transposon ends.
- one transposon end comprises a sequence selected from SEQ ID NOS: 14524, SEQ ID NO: 14526 and SEQ ID NO: 14527. In some embodiments, one transposon end comprises a sequence selected from SEQ ID NO: 14529 and SEQ ID NO: 14531.
- the piggyBacTM (PB) or piggyBac-like transposon is isolated or derived from Xenopus tropicalis.
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises at least 16 contiguous bases from SEQ ID NO: 14573 or SEQ ID NO: 14574, and inverted terminal repeat of CC YTTTBMCT GCC A (SEQ ID NO: 14575).
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises a 5’ transposon end sequence selected from SEQ ID NO: 14573 and SEQ ID NOs: 14579-14585. In certain embodiments, the 5’ transposon end sequence is preceded by a 5’ target sequence. In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises at a sequence of:
- the piggyBac or piggyBac-like transposon comprises a 3’ transposon end sequence selected from SEQ ID NO: 14574 and SEQ ID NOs: 14587-14590.
- the 3’ transposon end sequence is followed by a 3’ target sequence.
- the 5’ and 3’ transposon ends share a 14 repeated sequence inverted in orientation in the two ends (SEQ ID NO: 14575) adjacent to the target sequence.
- the piggyBac or piggyBac-like transposon comprises a 5’ transposon end comprising a target sequence and a sequence that is selected from SEQ ID NOs: 14582-14584 and 14573, and a 3’ transposon end comprising a sequence selected from SEQ ID NOs: 14588- 14590 and 14574 followed by a 3’ target sequence.
- the 5’ transposon end of the piggyBac or piggyBac-like transposon comprises
- the 5’ transposon end comprises
- the 3’ transposon end of the piggyBac or piggyBac-like transposon comprises
- the 3’ transposon end comprises
- one transposon end comprises a sequence that is at least 90%, at least 95%, at least 99% or any percentage in between identical to SEQ ID NO: 14573 and the other transposon end comprises a sequence that is at least 90%, at least 95%, at least 99% or any percentage in between identical to SEQ ID NO: 14574.
- one transposon end comprises at least 14, at least 16, at least 18, at least 20 or at least 25 contiguous nucleotides from SEQ ID NO: 14573 and one transposon end comprises at least 14, at least 16, at least 18, at least 20 or at least 25 contiguous nucleotides from SEQ ID NO: 14574.
- one transposon end comprises at least 14, at least 16, at least 18, at least 20 from SEQ ID NO: 14591, and the other end comprises at least 14, at least 16, at least 18, at least 20 from SEQ ID NO: 14593.
- each transposon end comprises SEQ ID NO: 14575 in inverted orientations.
- the piggyBac or piggyBac-like transposon comprises a sequence selected from of SEQ ID NO: 14573, SEQ ID NO: 14579, SEQ ID NO: 14581, SEQ ID NO: 14582, SEQ ID NO: 14583, and SEQ ID NO: 14588, and a sequence selected from SEQ ID NO: 14587, SEQ ID NO: 14588, SEQ ID NO: 14589 and SEQ ID NO: 14586 and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14517 or SEQ ID NO: 14518.
- the piggyBac or piggyBac-like transposon comprises ITRs of CCCTTTGCCTGCCA (SEQ ID NO: 14622) (left ITR or 5’ ITR) and T GGC AGT GAAAGGG (SEQ ID NO: 14623) (3’ ITR or 3’ ITR) adjacent to the target sequences.
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Helicoverpa armigera.
- the piggyBac or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%,
- the piggyBac or piggyBac-like transposon is isolated or derived from Helicoverpa armigera. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Pectinophora gossypiella.
- the piggyBac or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%,
- the piggyBac or piggyBac-like transposon is isolated or derived from Pectinophora gossypiella. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Ctenoplusia agnata.
- the piggyBac or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%,
- the piggyBac or piggyBac-like transposon is isolated or derived from Ctenoplusia agnata. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises an ITR sequence of CCCTAGAAGCCCAATC (SEQ ID NO: 14564).
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from A gratis ipsilon.
- the piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:
- the piggyBac or piggyBac-like transposon is isolated or derived from Agroiis ipsilon. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- piggyBac or piggyBac-like transposon comprises a sequence of:
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Megachile rotundata.
- the piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%,
- the piggyBac or piggyBac-like transposon is isolated or derived from Megachile rotundata. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Bombus impatiens.
- the piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:
- the piggyBac or piggyBac-like transposon is isolated or derived from Bombus impatiens. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Mamestra brassicae.
- the piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:
- the piggyBac or piggyBac-like transposon is isolated or derived from Mamestra brassicae. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Mayetiola destructor.
- the piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to: 14549) .
- the piggyBac or piggyBac-like transposon is isolated or derived from Mayetiola destructor. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Apis mellifera.
- the piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:
- the piggyBac or piggyBac-like transposon is isolated or derived from Apis mellifera. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Messor bouvieri.
- the piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:
- the piggyBac or piggyBac-like transposon is isolated or derived from Messor bouvieri. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
- the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Trichoplusia ni.
- the piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:
- the piggyBac or piggyBac-like transposon is isolated or derived from Trichoplusia ni. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises a sequence of:
- the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14561 and SEQ ID NO: 14562, and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14558.
- the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14609 and SEQ ID NO: 14610, and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14558.
- the piggyBac or piggyBac-like transposon is isolated or derived from Aphis gossypii.
- the piggyBac or piggyBac-like transposon comprises an ITR sequence of CCTTCCAGCGGGCGCGC (SEQ ID NO: 14565).
- the piggyBac or piggyBac-like transposon is isolated or derived from Chilo suppressalis.
- the piggyBac or piggyBac-like transposon comprises an ITR sequence of CCCAGATTAGCCT (SEQ ID NO: 14566).
- the piggyBac or piggyBac-like transposon is isolated or derived from Heliothis virescens.
- the piggyBac or piggyBac-like transposon comprises an ITR sequence of CCCTTAATTACTCGCG (SEQ ID NO: 14567).
- the piggyBac or piggyBac-like transposon is isolated or derived from Pectinophora gossypiella.
- the piggyBac or piggyBac-like transposon comprises an ITR sequence of CCCTAGATAACTAAAC (SEQ ID NO: 14568).
- the piggyBac or piggyBac-like transposon is isolated or derived from Anopheles stephensi.
- the piggyBac or piggyBac-like transposon comprises an ITR sequence of CCCTAGAAAGATA (SEQ ID NO: 14569).
- DNA transposons in the hAT family are widespread in plants and animals.
- a number of active hAT transposon systems have been identified and found to be functional, including but not limited to, the Hermes transposon, Ac transposon, hobo transposon, and the Tol2 transposon.
- the hAT family is composed of two families that have been classified as the AC subfamily and the Buster subfamily, based on the primary sequence of their transposases.
- Members of the hAT family belong to Class II transposable elements. Class II mobile elements use a cut and paste mechanism of transposition.
- hAT elements share similar transposases, short terminal inverted repeats, and an eight base-pairs duplication of genomic target.
- compositions and methods of the disclosure may comprise a TcBuster transposon and/or a TcBuster transposase.
- compositions and methods of the disclosure may comprise a TcBuster transposon and/or a hyperactive TcBuster transposase.
- a hyperactive TcBuster transposase demonstrates an increased excision and/or increased insertion frequency when compared to an excision and/or insertion frequency of a wild type TcBuster transposase.
- a hyperactive TcBuster transposase demonstrates an increased transposition frequency when compared to a transposition frequency of a wild type TcBuster transposase.
- a wild type TcBuster transposase comprises or consists of the amino acid sequence of:
- a TcBuster Transposase comprises or consists of a sequence having at least 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 97%, 99% or any percentage identity in between to a wild type TcBuster transposase comprising or consisting of the amino acid sequence of:
- compositions and methods of the disclosure a wild type
- TcBuster transposase is encoded by a nucleic acid sequence comprising or consisting of:
- a TcBuster Transposase comprises or consists of a sequence having at least 20%, 25%, 30%, 35%, 40%,
- a TcBuster Transposase comprises or consists of a naturally occurring amino acid sequence.
- a TcBuster Transposase comprises or consists of a non-naturally occurring amino acid sequence.
- a TcBuster Transposase is encoded by a sequence comprising or consisting of a naturally occurring nucleic acid sequence.
- a TcBuster Transposase is encoded by a sequence comprising or consisting of a non-naturally occurring nucleic acid sequence.
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the wild type TcBuster Transposase comprises or consists of the amino acid sequence of SEQ ID NO: 14735.
- the wild type TcBuster Transposase is encoded by a sequence comprising or consisting of the nucleic acid sequence of SEQ ID NO: 14688.
- the one or more sequence variations comprises one or more of a substitution, inversion, insertion, deletion, transposition, and frameshift.
- the one or more sequence variations comprises a modified, synthetic, artificial or non-naturally occurring amino acid.
- the one or more sequence variations comprises a modified, synthetic, artificial or non-naturally occurring nucleic acid.
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises an amino acid substitution in one or more of a DNA Binding and Oligomerization domain, an insertion domain and a Zn-BED domain.
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises an amino acid substitution that increases a net charge a neutral pH when compared to a wild type TcBuster Transposase.
- the wild type TcBuster Transposase comprises or consists of the amino acid sequence of SEQ ID NO: 14735.
- the wild type TcBuster Transposase is encoded by a sequence comprising or consisting of the nucleic acid sequence of SEQ ID NO: 14688.
- the one or more sequence variations comprises an amino acid substitution of the aspartic acid (D) at position 223 (D223), the aspartic acid (D) at position 289 (D289) and the aspartic acid (E) at position 589 (E289) of SEQ ID NO: 14735.
- the one or more sequence variations comprises an amino acid substitution within 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 or any number of amino acids in between of position 223, 289 and/or 289 of SEQ ID NO: 14735.
- the one or more sequence variations comprises an amino acid substitution within 70 amino acids of position 223, 289 and/or 289 of SEQ ID NO: 14735. In some embodiments, the one or more sequence variations comprises an amino acid substitution within 80 amino acids of position 223, 289 and/or 289 of SEQ ID NO: 14735. In some embodiments, the one or more sequence variations comprises an amino acid substitution of an aspartic acid (D) or a aspartic acid (E) to a neutral amino acid, a lysine (L) or an arginine (R) (e.g. D223L,
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises one or more of Q82E, N85S,D99A, D132A, Q151S, Q151A, E153K, E153R, A154P, Y155H, E159A, T171K, T171R, K177E, D183K, D183R, D189A, T191E, S193K, S193R, Y201A, F202D, F202K, C203I, C203V, Q221T, M222L, I223Q, E224G, S225W, D227A, R239H, E243A, E247K, P257K, P257R, Q258T, E263A, E263K, E263R, E274K, E27
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises one or more of E247K, V297K, A358K, S278K, E247R, E274R, V297R, A358R, S278R, T171R, D183R, S193R, P257K, E263R, L282K, T618K, D622R, E153K, N450K, T171K, D183K, S193K, P257R, E263K, L282R, T618R, D622K, E153R and N450R of SEQ ID NO: 14735.
- the one or more sequence variations comprises an amino acid substitution within 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 or any number of amino acids in between of position 153, 171, 183, 193, 247, 257, 263, 274, 278, 282, 297, 358, 450, 618, 622 of SEQ ID NO: 14735.
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises one or more of V377T/E469K, V377T/E469K/R536S, A332S, V553S/P554T, E517R, K299S, Q615A/T618K, S278K, A303T, P510D, P510N, N281S, N281E, K590T, Q258T, E247K, S447E, N85S, V297K, A358K, I452F, V377T/E469K/D189A, K573E/E578L,
- K573E/E578L/V377T/E469K/D189A T171R, D183R, S193R, P257K, E263R, L282K, T618K, D622R, E153K, N450K, T171K, D183K, S193K, P257R, E263K, L282R, T618R, D622K, E153R, N450R, E247K/E274K/V297K/A358K of SEQ ID NO: 14735.
- the one or more sequence variations comprises an amino acid substitution within 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 or any number of amino acids in between of position 85, 153, 171, 189, 193, 247, 257, 258, 263, 274, 278, 281, 282, 297, 299, 303, 332, 358, 377, 450, 469, 447, 452, 469, 510, 517, 536, 553, 554, 573, 578, 590, 615, 618, 622 of SEQ ID NO: 14735.
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises one or more of V377T/E469K, V377T/E469K/R536S, V553S/P554T, Q615A/T618K, S278K, A303T, P510D, P510N, N281S, N281E, K590T, Q258T, E247K, S447E, N85S, V297K, A358K, I452F, V377T/E469K/D189A and K573E/E578L.
- the one or more sequence variations comprises an amino acid substitution within 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 or any number of amino acids in between of position 85, 189, 247, 258, 278, 281, 297, 303, 358, 377, 447, 452, 469, 510, 536, 553, 554, 573, 578, 590, 615, 618 of SEQ ID NO: 1687.
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises one or more of Q151S, Q151A, A154P, Q615A, V553S, Y155H, Y201A, F202D, F202K,
- the one or more sequence variations comprises an amino acid substitution within 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95,
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises one or more of V377T, E469K, and D189A, when numbered in accordance with SEQ ID NO: 14735.
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises one or more of K573E and E578L, when numbered in accordance with SEQ ID NO: 14735.
- the mutant TcBuster transposase comprises amino acid substitution I452K, when numbered in accordance with SEQ ID NO: 14735.
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of A358K, when numbered in accordance with SEQ ID NO: 14735. [0407] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of V297K, when numbered in accordance with SEQ ID NO: 14735.
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises one or more of N85S, when numbered in accordance with SEQ ID NO: 14735.
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises one or more of I452F, V377T, E469K, and D189A, when numbered in accordance with SEQ ID NO: 14735.
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises one or more of A358K, V377T, E469K, and D189A, when numbered in accordance with SEQ ID NO: 14735.
- a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase.
- the one or more sequence variations comprises one or more of V377T, E469K, D189A, K573E and E578L, when numbered in accordance with SEQ ID NO: 14735.
- a TcBuster Transposase recognizes a 5’ inverted repeat comprising or consisting of the sequence of:
- a TcBuster Transposase recognizes a 3’ inverted repeat comprising or consisting of the sequence of:
- a TcBuster Transposase recognizes a 5’ inverted repeat comprising or consisting of the sequence of SEQ ID NO: 14689 and a 3’ inverted repeat comprising or consisting of the sequence of SEQ ID NO: 14690.
- a TcBuster Transposase recognizes a 5’ inverted repeat comprising or consisting of the sequence of:
- a TcBuster Transposase recognizes a 3’ inverted repeat comprising or consisting of the sequence of:
- a TcBuster Transposase recognizes a 5’ inverted repeat comprising or consisting of the sequence of SEQ ID NO: 14691 and a 3’ inverted repeat comprising or consisting of the sequence of SEQ ID NO: 14692.
- a TcBuster Transposase recognizes an inverted repeat comprising or consisting of a sequence having at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95,% 97%, 99% or any percentage identify in between to one or more of SEQ ID NO: 14689, 14690, 14691 or 14692.
- a TcBuster Transposase recognizes an inverted repeat comprising or consisting of a sequence having at least In some embodiments of the compositions and methods of the disclosure, a TcBuster
- Transposase recognizes an inverted repeat comprising or consisting of a sequence having at least 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 97, 99 or any number of contiguous nucleotides in between having between 90 and 100% identity to SEQ ID NO: 14689, 14690, 14691 or 14692 or any portion thereof.
- a TcBuster Transposase recognizes an inverted repeat comprising or consisting of a sequence having at least 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 97, 99 or any number of discontinuous nucleotides in between having between 90 and 100% identity to SEQ ID NO: 14689, 14690, 14691 or 14692 or any portion thereof.
- a TcBuster transposon comprises a 3’ inverted repeat and a 5’ inverted repeat.
- a TcBuster Transposase recognizes a TcBuster transposon comprising a 3’ inverted repeat and a 5’ inverted repeat comprising or consisting of a sequence having at least 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80 85, 90, 95, 97, 99 or any number of discontinuous nucleotides in between having between 90 and 100% identity to SEQ ID NO: 14689, 14690, 14691 or 14692 or any portion thereof.
- compositions and methods of the disclosure a piggyBat
- a piggyBat transposase of the disclosure is encoded by an amino acid sequence comprising:
- a piggyBat transposase of the disclosure is encoded by an amino acid sequence comprising:
- a piggyBat transposon of the disclosure is encoded by an amino acid sequence comprising:
- a piggyBat transposon of the disclosure is encoded by an amino acid sequence comprising:
- the disclosure provides a nanotransposon comprising: (a) a sequence encoding a transposon insert, comprising a sequence encoding a first inverted terminal repeat (ITR), a sequence encoding a second inverted terminal repeat (ITR), and an intra-ITR sequence; (b) a sequence encoding a backbone, wherein the sequence encoding the backbone comprises a sequence encoding an origin of replication having between 1 and 450 nucleotides, inclusive of the endpoints, and a sequence encoding a selectable marker having between 1 and 200 nucleotides, inclusive of the endpoints, and (c) an inter-ITR sequence.
- the inter-ITR sequence of (c) comprises the sequence of (b).
- the intra-ITR sequence of (a) comprises the sequence of (b).
- the sequence encoding the backbone comprises between 1 and 600 nucleotides, inclusive of the endpoints. In some embodiments, the sequence encoding the backbone consists of between 1 and 50 nucleotides, between 50 and 100 nucleotides, between 100 and 150 nucleotides, between 150 and 200 nucleotides, between 200 and 250 nucleotides, between 250 and 300 nucleotides, between 300 and 350 nucleotides, between 350 and 400 nucleotides, between 400 and 450 nucleotides, between 450 and 500 nucleotides, between 500 and 550 nucleotides, between 550 and 600 nucleotides, each range inclusive of the endpoints.
- the inter-ITR sequence comprises between 1 and 1000 nucleotides, inclusive of the endpoints. In some embodiments, the inter-ITR sequence consists of between 1 and 50 nucleotides, between 50 and 100 nucleotides, between 100 and 150 nucleotides, between 150 and 200 nucleotides, between 200 and 250 nucleotides, between 250 and 300 nucleotides, between 300 and 350 nucleotides, between 350 and 400 nucleotides, between 400 and 450 nucleotides, between 450 and 500 nucleotides, between 500 and 550 nucleotides, between 550 and 600 nucleotides, between 600 and 650 nucleotides, between 650 and 700 nucleotides, between 700 and 750 nucleotides, between 750 and 800 nucleotides, between 800 and 850 nucleotides, between 850 and 900 nucleotides, between 900 and 950 nucleo
- the inter-ITR sequence comprises between 1 and 200 nucleotides, inclusive of the endpoints.
- the inter-ITR sequence consists of between 1 and 10 nucleotides, between 10 and 20 nucleotides, between 20 and 30 nucleotides, between 30 and 40 nucleotides, between 40 and 50 nucleotides, between 50 and 60 nucleotides, between 60 and 70 nucleotides, between 70 and 80 nucleotides, between 80 and 90 nucleotides, or between 90 and 100 nucleotides, each range inclusive of the endpoints.
- the selectable marker having between 1 and 200 nucleotides, inclusive of the endpoints comprises a sequence encoding a sucrose-selectable marker.
- the sequence encoding a sucrose- selectable marker comprises a sequence encoding an RNA-OUT sequence.
- the sequence encoding an RNA-OUT sequence comprises or consists of 137 base pairs (bp).
- the selectable marker having between 1 and 200 nucleotides, inclusive of the endpoints comprises a sequence encoding a fluorescent marker.
- the selectable marker having between 1 and 200 nucleotides, inclusive of the endpoints comprises a sequence encoding a cell surface marker.
- the sequence encoding an origin of replication having between 1 and 450 nucleotides, inclusive of the endpoints comprises a sequence encoding a mini origin of replication.
- the sequence encoding an origin of replication having between 1 and 450 nucleotides, inclusive of the endpoints comprises a sequence encoding an R6K origin of replication.
- the R6K origin of replication comprises an R6K gamma origin of replication.
- the R6K origin of replication comprises an R6K mini origin of replication.
- the R6K origin of replication comprises an R6K gamma mini origin of replication.
- the R6K gamma mini origin of replication comprises or consists of 281 base pairs (bp).
- the sequence encoding the backbone does not comprise a recombination site, an excision site, a ligation site or a combination thereof.
- neither the nanotransposon nor the sequence encoding the backbone comprises a product of a recombination site, an excision site, a ligation site or a combination thereof.
- neither the nanotransposon nor the sequence encoding the backbone is derived from a recombination site, an excision site, a ligation site or a combination thereof.
- a recombination site comprises a sequence resulting from a recombination event.
- a recombination site comprises a sequence that is a product of a recombination event.
- the recombination event comprises an activity of a recombinase (e.g., a recombinase site).
- the sequence encoding the backbone does not further comprise a sequence encoding foreign DNA.
- the inter-ITR sequence does not comprise a recombination site, an excision site, a ligation site or a combination thereof. In some embodiments, the inter-ITR sequence does not comprise a product of a recombination event, an excision event, a ligation event or a combination thereof. In some embodiments, the inter-ITR sequence is not derived from a recombination event, an excision event, a ligation event or a combination thereof.
- the inter-ITR sequence comprises a sequence encoding foreign DNA.
- the intra-ITR sequence comprises at least one sequence encoding an insulator and a sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell.
- the mammalian cell is a human cell.
- the intra-ITR sequence comprises a first sequence encoding an insulator, a sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell and a second sequence encoding an insulator.
- the intra-ITR sequence comprises a first sequence encoding an insulator, a sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell, a polyadenosine (poly A) sequence and a second sequence encoding an insulator.
- the intra-ITR sequence comprises a first sequence encoding an insulator, a sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell, at least one exogenous sequence, a polyadenosine (poly A) sequence and a second sequence encoding an insulator.
- the sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell is capable of expressing an exogenous sequence in a human cell.
- the sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell comprises a sequence encoding a constitutive promoter.
- the sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell comprises a sequence encoding an inducible promoter.
- the intra-ITR sequence comprises a first sequence encoding a first promoter capable of expressing an exogenous sequence in a mammalian cell and a second sequence encoding a second promoter capable of expressing an exogenous sequence in mammalian cell, wherein the first promoter is a constitutive promoter, wherein the second promoter is an inducible promoter, and wherein the first sequence encoding the first promoter and the second sequence encoding the second promoter are oriented in opposite directions.
- the sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell comprises a sequence encoding a cell-type or tissue-type specific promoter.
- the sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell comprises a sequence encoding an elongation factor- 1 alpha (EF1 alpha) promoter, a sequence encoding a cytomegalovirus (CMV) promoter, a sequence encoding an MND promoter, a sequence encoding an simian vacuolating virus 40 (SV40) promoter, a sequence encoding a phosphoglycerate kinase 1 (PGK1) promoter, a sequence encoding a human phosphoglycerate kinase l(hPGK) promoter, a sequence encoding a ubiquitin c (Ubc) promoter, a sequence encoding an SPTA1 promoter, a sequence encoding an ankryin-l (Ank-l) promoter, a sequence encoding a Gly-A promoter, a sequence encoding a CAG
- the polyadenosine (poly A) sequence is isolated or derived from a viral polyA sequence. In some embodiments, the polyadenosine (polyA) sequence is isolated or derived from an (SV40) polyA sequence.
- sequence encoding the hPGK promoter comprises or consists of the nucleic acid sequence:
- sequence encoding the EFla promoter comprises or consists of the nucleic acid sequence:
- sequence encoding the EFla promoter comprises or consists of the nucleic acid sequence:
- sequence encoding the MND promoter comprises or consists of the nucleic acid sequence:
- sequence encoding the SPTA1 promoter comprises or consists of the nucleic acid sequence:
- sequence encoding the Ank-l promoter comprises or consists of the nucleic acid sequence:
- sequence encoding the Gly-A promoter comprises or consists of the nucleic acid sequence:
- the at least one exogenous sequence comprises an inducible proapoptotic polypeptide.
- the inducible caspase polypeptide comprises (a) a ligand binding region, (b) a linker, and (c) a caspase polypeptide, wherein the inducible proapoptotic polypeptide does not comprise a non human sequence.
- the inducible caspase polypeptide comprises (a) a ligand binding region, (b) a linker, and (c) a truncated caspase 9 polypeptide, wherein the inducible proapoptotic polypeptide does not comprise a non-human sequence.
- the ligand binding region comprises a FK506 binding protein 12 (FKBP12) polypeptide.
- the amino acid sequence of the ligand binding region comprises a FK506 binding protein 12 (FKBP12) polypeptide.
- the FK506 binding protein 12 (FKBP12) polypeptide comprises a modification at position 36 of the sequence.
- the modification comprises a substitution of valine (V) for phenylalanine (F) at position 36 (F36V).
- the FKBP12 polypeptide is encoded by an amino acid sequence comprising
- the FKBP12 polypeptide is encoded by a nucleic acid sequence comprising
- the linker region is encoded by an amino acid comprising GGGGS (SEQ ID NO: 14496) or a nucleic acid sequence comprising GGAGGAGGAGGATCC (SEQ ID NO: 14497).
- the nucleic acid sequence encoding the linker does not comprise a restriction site.
- the truncated caspase 9 polypeptide is encoded by an amino acid sequence that does not comprise an arginine (R) at position 87 of the sequence. In some embodiments, the truncated caspase 9 polypeptide is encoded by an amino acid sequence that does not comprise an alanine (A) at position 282 the sequence. In some embodiments, the truncated caspase 9 polypeptide is encoded by an amino acid comprising
- the truncated caspase 9 polypeptide is encoded by a nucleic acid sequence comprising
- the at least one exogenous sequence comprises an inducible proapoptotic polypeptide
- the inducible proapoptotic polypeptide is encoded by an amino acid sequence comprising
- the inducible proapoptotic polypeptide is encoded by a nucleic acid sequence comprising
- the exogenous sequence further comprises a sequence encoding a selectable marker.
- the sequence encoding the selectable marker comprises a sequence encoding a detectable marker.
- the detectable marker comprises a fluorescent marker or a cell-surface marker.
- the sequence encoding the selectable marker comprises a sequence encoding a protein that is active in dividing cells and not active in non dividing cells.
- the sequence encoding the selectable marker comprises a sequence encoding a metabolic marker.
- the sequence encoding the selectable marker comprises a sequence encoding a dihydrofolate reductase (DHFR) mutein enzyme.
- the DHFR mutein enzyme comprises or consists of the amino acid sequence of:
- exogenous sequence comprises a sequence encoding a selectable marker, the exogenous sequence further comprises a sequence encoding a non-naturally occurring antigen receptor, and/or a sequence encoding a therapeutic polypeptide.
- the non-naturally occurring antigen receptor comprises a T cell Receptor (TCR).
- TCR T cell Receptor
- a sequence encoding the TCR comprises one or more of an insertion, a deletion, a substitution, an invertion, a transposition or a frameshift compared to a corresponding wild type sequence.
- a sequence encoding the TCR comprises a chimeric or recombinant sequence.
- the non-naturally occurring antigen receptor comprises a chimeric antigen receptor (CAR).
- the CAR comprises: (a) an ectodomain comprising an antigen recognition region, (b) a transmembrane domain, and (c) an endodomain comprising at least one costimulatory domain.
- the ectodomain of (a) of the CAR further comprises a signal peptide.
- the ectodomain of (a) of the CAR further comprises a hinge between the antigen recognition region and the transmembrane domain.
- the endodomain comprises a human CD3z endodomain.
- the at least one costimulatory domain comprises a human 4-1BB, CD28, CD40, ICOS, MyD88, OX-40 intracellular segment, or any combination thereof. In some embodiments, the at least one costimulatory domain comprises a human CD28 and/or a 4-1BB costimulatory domain. In some embodiments, the antigen recognition region comprises one or more of a scFv, a VHH, a VH, and a Centyrin.
- the exogenous sequence comprises an inducible proapoptotic polypeptide and/or the exogenous sequence comprises a sequence encoding a selectable marker
- the exogenous sequence further comprises a sequence encoding a transposase.
- the intra-ITR sequence comprises a sequence encoding a selectable marker, an exogenous sequence, a sequence encoding an inducible caspase polypeptide, and at least one sequence encoding a self-cleaving peptide.
- the at least one sequence encoding a self-cleaving peptide is positioned between one or more of: (a) the sequence encoding a selectable marker and the exogenous sequence, (b) the sequence encoding a selectable marker and the inducible caspase polypeptide, and (c) the exogenous sequence and the inducible caspase polypeptide.
- a first sequence encoding a self-cleaving peptide is positioned between the sequence encoding a selectable marker and the exogenous sequence and a second sequence encoding a self-cleaving peptide is positioned between the exogenous sequence and the inducible caspase polypeptide.
- the at least one self-cleaving peptide comprises T2A peptide, GSG-T2A peptide, an E2A peptide, a GSG-E2A peptide, an F2A peptide, a GSG-F2A peptide, a P2A peptide, or a GSG-P2A peptide.
- the T2A peptide comprises an amino acid sequence comprising EGRGSLLTCGDVEENPGP (SEQ ID NO: 14637). In some embodiments, the GSG-T2A peptide comprises an amino acid sequence comprising GS GEGRGSLLT CGD VEENPGP (SEQ ID NO: 14638). In some embodiments, the E2A peptide comprises an amino acid sequence comprising
- the GSG-E2A peptide comprises an amino acid sequence comprising GSGQCTNYALLKLAGDVESNPGP (SEQ ID NO: 14640).
- the F2A peptide comprises an amino acid sequence comprising VKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 14641).
- the GSG-F2A peptide comprises an amino acid sequence comprising
- the P2A peptide comprises an amino acid sequence comprising ATNFSLLKQAGD VEENPGP (SEQ ID NO: 14643). In some embodiments, the GSG-P2A peptide comprises an amino acid sequence comprising GSGATNFSLLKQAGD VEENPGP (SEQ ID NO: 14644).
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a piggyBac transposase or a piggyBac-like transposase.
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a piggyBac transposase.
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a piggyBac-like transposase.
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprise a TTAA, a TTAT or a TTAX recognition sequence.
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprise a TTAA, a TTAT or a TTAX recognition sequence and a sequence having at least 50% identity to a sequence isolated or derived from a piggyBac transposase or a piggyBac-like transposase.
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprise at least 2 nucleotides (nts), 3 nts, 4 nts, 5 nts, 6 nts, 7 nts, 8 nts, 9 nts, 10 nts, 11 nts, 12 nts, 13 nts, 14 nts, 15 nts, 16 nts, 17 nts, 18 nts, 19 nts, or 20 nts.
- nts nucleotides
- the at least one exogenous sequence comprises one or more of an inducible proapoptotic polypeptide, a sequence encoding a selectable marker, and an exogenous sequence
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a piggyBac transposase or a piggyBac-like transposase.
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprises the sequence of CCCTAGAAAGAT AGT CT GCGT AAAATT GACGC AT G (SEQ ID NO: 14679) or a sequence having at least 70% identity to the sequence of
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprises the sequence of
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprises the sequence of CCCTAGAAAGATAGTCTGCGTAAAATTGACGCATG (SEQ ID NO: 14679) and comprises the sequence of
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprises the sequence of CCCTAGAAAGATAGTCTGCGTAAAATTGACGCATG (SEQ ID NO: 14679) and comprises the sequence of
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprises the sequence of CCCTAGAAAGATAGTCTGCGTAAAATTGACGCATG (SEQ ID NO: 14679) and comprises the sequence of
- the at least one exogenous sequence comprises one or more of an inducible proapoptotic polypeptide, a sequence encoding a selectable marker, and an exogenous sequence
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a piggyBac transposase or a piggyBac-like transposase.
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) is recognized by a piggyBac transposase having an amino acid sequence of at least 20% identity to the amino acid sequence of
- ITR inverted terminal repeat
- ITR inverted terminal repeat
- a piggyBac transposase having an amino acid sequence of at least 20% identity to the amino acid sequence of
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) is recognized by a piggyBac transposase having the amino acid sequence of
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a Sleeping Beauty transposase.
- the Sleeping Beauty transposase is a hyperactive Sleeping Beauty transposase (SB100X).
- the at least one exogenous sequence comprises one or more of an inducible proapoptotic polypeptide, a sequence encoding a selectable marker, and an exogenous sequence
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a Helitron transposase.
- the at least one exogenous sequence comprises one or more of an inducible proapoptotic polypeptide, a sequence encoding a selectable marker, and an exogenous sequence
- the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a Tol2 transposase.
- the disclosure provides a cell comprising a nanotransposon of the disclosure.
- the cell further comprises a transposase composition.
- the transposase composition comprises a transposase or a sequence encoding the transposase that is capable of recognizing the first ITR or the second ITR of the nanotransposon.
- the transposase composition comprises a nanotransposon comprising the sequence encoding the transposase.
- the cell comprises a first
- the cell is an allogeneic cell.
- the disclosure provides a composition comprising the nanotransposon of the disclosure.
- the disclosure provides a composition comprising the cell of the disclosure.
- the cell comprises a nanotransposon of the disclosure.
- the cell is not further modified.
- the cell is allogeneic.
- the disclosure provides a composition comprising the cell of the disclosure.
- the cell comprises a nanotransposon of the disclosure.
- the cell is not further modified.
- the cell is autologous.
- the disclosure provides a composition comprising a plurality of cells of the disclosure.
- at least one cell of the plurality of cells comprises a nanotransposon of the disclosure.
- a portion of the plurality of cells comprises a
- the portion comprises at least 1%, 2%, 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 97%, 99% or any percentage in between of the plurality of cells.
- each cell of the plurality of cells comprises a nanotransposon of the disclosure.
- the plurality of cells does not comprise a modified cell of the disclosure.
- at least one cell of the plurality of cells is not further modified.
- none of the plurality of cells is not further modified.
- plurality of cells is allogeneic.
- an allogeneic plurality of cells are produced according to the methods of the disclosure.
- plurality of cells is autologous.
- an autologous plurality of cells are produced according to the methods of the disclosure.
- the disclosure provides a modified cell comprising: (a) a nanotransposon of the disclosure; (b) a sequence encoding an inducible proapoptotic polypeptide; and wherein the cell is a T cell, (c) a modification of an endogenous sequence encoding a T cell Receptor (TCR), wherein the modification reduces or eliminates a level of expression or activity of the TCR.
- a modified cell comprising: (a) a nanotransposon of the disclosure; (b) a sequence encoding an inducible proapoptotic polypeptide; and wherein the cell is a T cell, (c) a modification of an endogenous sequence encoding a T cell Receptor (TCR), wherein the modification reduces or eliminates a level of expression or activity of the TCR.
- TCR T cell Receptor
- the cell further comprises: (d) a non-naturally occurring sequence comprising an HLA class I histocompatibility antigen, alpha chain E (HLA-E), and (e) a modification of an endogenous sequence encoding Beta-2-Microglobulin (B2M), wherein the modification reduces or eliminates a level of expression or activity of a major
- HLA-E alpha chain E
- B2M Beta-2-Microglobulin
- the disclosure provides a modified cell comprising: (a) a nanotransposon of the disclosure; (b) a sequence encoding an inducible proapoptotic polypeptide; (c) a non-naturally occurring sequence comprising an HLA class I histocompatibility antigen, alpha chain E (HLA- E), and (e) a modification of an endogenous sequence encoding Beta-2-Microglobulin (B2M), wherein the modification reduces or eliminates a level of expression or activity of a major histocompatibility complex (MHC) class I (MHC-I).
- MHC major histocompatibility complex
- the non-naturally occurring sequence comprising a HLA-E further comprises a sequence encoding a B2M signal peptide.
- the non-naturally occurring sequence comprising an HLA-E further comprises a linker, wherein the linker is positioned between the sequence encoding the sequence encoding a B2M polypeptide and the sequence encoding the HLA-E.
- the non-naturally occurring sequence comprising an HLA-E further comprises a sequence encoding a peptide and a sequence encoding a B2M polypeptide.
- the non-naturally occurring sequence comprising an HLA-E further comprises a first linker positioned between the sequence encoding the B2M signal peptide and the sequence encoding the peptide, and a second linker positioned between the sequence encoding the B2M polypeptide and the sequence encoding the HLA-E.
- the cell is a mammalian cell.
- the cell is a human cell.
- the cell is a stem cell.
- the cell is a differentiated cell.
- the cell is a somatic cell.
- the cell is an immune cell or an immune cell precursor.
- the immune cell is a lymphoid progenitor cell, a natural killer (NK) cell, a cytokine induced killer (CIK) cell, a T lymphocyte (T cell), a B lymphocyte (B-cell) or an antigen presenting cell (APC).
- the immune cell is a T cell, an early memory T cell, a stem cell like T cell, a stem memory T cell (Tscm), or a central memory T cell (Tcm).
- the immune cell precursor is a hematopoietic stem cell (HSC).
- the cell is an antigen presenting cell (APC).
- the cell further comprises a gene editing composition.
- the gene editing composition comprises a sequence encoding a DNA binding domain and a sequence encoding a nuclease protein or a nuclease domain thereof.
- the gene editing composition comprises a sequence encoding a nuclease protein or a sequence encoding a nuclease domain thereof.
- the e sequence encoding a nuclease protein or the sequence encoding a nuclease domain thereof comprises a DNA sequence, an RNA sequence, or a combination thereof.
- the nuclease or the nuclease domain thereof comprises one or more of a CRISPR/Cas protein, a Transcription Activator- Like Effector Nuclease (TALEN), a Zinc Finger Nuclease (ZFN), and an endonuclease.
- the CRISPR/Cas protein comprises a nuclease-inactivated Cas (dCas) protein.
- the cell further comprises a gene editing composition.
- the gene editing composition comprises a sequence encoding a DNA binding domain and a sequence encoding a nuclease protein or a nuclease domain thereof.
- the nuclease or the nuclease domain thereof comprises a nuclease-inactivated Cas (dCas) protein and an endonuclease.
- the endonuclease comprises a Clo051 nuclease or a nuclease domain thereof.
- the gene editing composition comprises a fusion protein.
- the fusion protein comprises a nuclease- inactivated Cas9 (dCas9) protein and a Clo05l nuclease or a Clo05l nuclease domain.
- the gene editing composition further comprises a guide sequence.
- the guide sequence comprises an RNA sequence.
- the fusion protein comprises or consists of the amino acid sequence:
- nucleic acid comprising or consisting of the sequence:
- the fusion protein comprises or consists of the amino acid sequence:
- a nanotransposon comprises the gene editing composition comprising a guide sequence and a sequence encoding a fusion protein comprising a sequence encoding an inactivated Cas9 (dCas9) and a sequence encoding a Clo051 nuclease or a nuclease domain thereof.
- dCas9 inactivated Cas9
- the cell expresses the gene editing composition transiently.
- the cell is a T cell and the guide RNA comprises a sequence complementary to a target sequence encoding an endogenous TCR.
- the guide RNA comprises a sequence complementary to a target sequence encoding a B2M polypeptide.
- the guide RNA comprises a sequence complementary to a target sequence within a safe harbor site of a genomic DNA sequence.
- the Clo05l nuclease or a nuclease domain thereof induces a single or double strand break in a target sequence.
- the disclosure provides a composition comprising a modified cell according to the disclosure.
- the composition further comprises a pharmaceutically- acceptable carrier.
- the disclosure provides a composition comprising a plurality of modified cells according to the disclosure.
- the composition further comprises a pharmaceutically-acceptable carrier.
- the disclosure provides a composition of the disclosure for use in the treatment of a disease or disorder.
- compositions of the disclosure for the treatment of a disease or disorder.
- the disclosure provides a method of treating a disease or disorder comprising administering to a subject in need thereof a therapeutically-effective amount of a composition of the disclosure.
- the subject does not develop graft vs. host (GvH) and/or host vs. graft (HvG) following administration of the composition.
- the administration is systemic.
- the composition is administered by an intravenous route.
- the composition is administered by an intravenous injection or an intravenous infusion.
- the disclosure provides a method of treating a disease or disorder comprising administering to a subject in need thereof a therapeutically-effective amount of a composition of the disclosure.
- the subject does not develop graft vs. host (GvH) and/or host vs. graft (HvG) following administration of the composition.
- the administration is local.
- the composition is administered by an intra- tumoral route, an intraspinal route, an intracerebroventricular route, an intraocular route or an intraosseous route.
- the composition is administered by an intra-tumoral injection or infusion, an intraspinal injection or infusion, an intracerebroventricular injection or infusion, an intraocular injection or infusion or an intraosseous injection or infusion.
- the therapeutically effective dose is a single dose and wherein the allogeneic cells of the composition engraft and/or persist for a sufficient time to treat the disease or disorder.
- the single dose is one of at least 2, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 or any number of doses in between that are manufactured simultaneously.
- the therapeutically effective dose is a single dose and wherein the autologous cells of the composition engraft and/or persist for a sufficient time to treat the disease or disorder.
- the single dose is one of at least 2, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 or any number of doses in between that are manufactured
- DHFR (nano.PB.EFla.IL2RG-T2A-GFP-T2A-DHFR ) is encoded by a sequence comprising:
- the 3’ITR of the nano.PB.EFla.IL2RG-T2A-GFP-T2A-DHFR construct is encoded by a sequence comprising:
- the Insulator of the nano.PB.EFla.IL2RG-T2A-GFP-T2A-DHFR construct is encoded by a sequence comprising:
- the EFla Promoter of the nano.PB.EFla.IL2RG-T2A-GFP-T2A-DHFR construct is encoded by a sequence comprising:
- the IL2RG of the nano.PB.EF 1 a.IL2RG-T2A-GFP-T2A-DHFR construct is encoded by a sequence comprising:
- the EGFP of the nano.PB.EFla.IL2RG-T2A-GFP-T2A-DHFR construct is encoded by a sequence comprising:
- the DHFR of the nano.PB.EFla.IL2RG-T2A-GFP-T2A-DHFR construct is encoded by a sequence comprising:
- the SV40 Poly (A) of the nano . PB . EF 1 a . IL2RG- T2 A- GFP-T2A-DHFR construct is encoded by a sequence comprising:
- the 5'ITR of the nano . PB . EF 1 a . IL2RG- T2 A- GFP-T2A-DHFR construct is encoded by a sequence comprising:
- a vector for erythroid-specific expression of a BCL11 A targeted shRNA and the constitutive expression of GFP and DHFR is encoded by a sequence comprising:
- GFP-T2A-DHFR construct is encoded by a sequence comprising:
- Ank-BCL 11 ashRNA.MND.
- GFP-T2A-DHFR construct is encoded by a sequence comprising:
- a vector for erythroid-specific expression of a BCL11 A targeted shRNA and the expression of an iC9 safety switch (nanoPB.Ank-BCLl lashRNA.MND.iC9-T2A-DHFR ) is encoded by a sequence comprising:
- the 3’ITR of the nanoPB.Ank-BCLl 1 ashRNA.MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:
- the Insulator 1 of the nanoPB.Ank-BCLl 1 ashRNA.MND. iC9-T2A-DHER construct is encoded by a sequence comprising:
- Th eAnkyrin-1 Promoter of the nanoPB.Ank-BCLl lashRNA.MND.iC9-T2A-DHFR construct is encoded by a sequence comprising:
- the miRE sh49 BCL11A of the nanoPB.Ank-BCLl lashRNA.MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:
- the BBBMND PROMOTER of the nanoPB.Ank-BCLl lashRNA.MND. iC9-T2A- DHFR construct is encoded by a sequence comprising:
- iC9 of the nanoPB.Ank-BCLl lashRNA.MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:
- Ank-BCLl 1 ashRNA.MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:
- Ank-BCLl lashRNA.MND.iC9-T2A-DHFR construct is encoded by a sequence comprising:
- Ank-BCLl 1 ashRNA.MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:
- DHFR (nanoPB. MND.IL2RG-T2A-iC9-T2A-DHFR) is encoded by a sequence comprising:
- the 3 TTR of the nanoPB.MND.IL2RG-T2A-iC9-T2A-DHLR construct is encoded by a sequence comprising:
- Insulator 1 of the nanoPB.MND.IL2RG-T2A-iC9-T2A-DHLR construct is encoded by a sequence comprising:
- the iC9 of the nanoPB.MND.IL2RG-T2A-iC9-T2A-DHFR construct is encoded by a sequence comprising:
- the DHFR of the nanoPB.MND.IL2RG-T2A-iC9-T2A-DHFR construct is encoded by a sequence comprising:
- the SV40 Poly(A) of the nanoPB . MND . IL2RG- T2 A-iC9- T2 A-DHFR construct is encoded by a sequence comprising:
- the Insulator 1 of the nanoPB.MND.IL2RG-T2A-iC9-T2A-DHFR construct is encoded by a sequence comprising:
- the 5’ITR of the nanoPB.MND.IL2RG-T2A-iC9-T2A-DHFR construct is encoded by a sequence comprising:
- a vector for erythroid-specific expression of Insulin growth factor 2 binding protein 1 (IGF2BP1) and the expression of an iC9 safety switch (nanoPB.SPTA.IGF2BPl .MND.iC9- T2A-DHFR) is encoded by a sequence comprising:
- the 3’ITR of the nanoPB.SPTA.IGF2BPl .MND.iC9-T2A-DHFR construct is encoded by a sequence comprising:
- AAATTT C A AAATTT CTTCT AT AAAGT AAC AA AACTTTTA (ALL CAPS) (SEQ ID NO: 14704).
- the Insulator 1 of the nanoPB.SPTA.IGF2BPl .MND.iC9-T2A-DHFR construct is encoded by a sequence comprising:
- MND . iC9- T2 A-DHFR construct is encoded by a sequence comprising:
- SPT A IGF2BP 1.
- MND . iC9-T2 A-DHFR construct is encoded by a sequence comprising:
- MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:
- MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:
- MND . iC9-T2 A-DHFR construct is encoded by a sequence comprising:
- MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:
- the HBB cassette in opposite orientation of the PB.HBB.PGK. GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
- the hPGK promoter of the PB.HBB.PGK.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
- the GFP of the PB.HBB.PGK.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
- the DHFR of the PB.HBB.PGK.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
- the SV40 Poly(A) of the PB . HBB . PGK. GFP-T2 A-DHFR construct is encoded by a nucleic acid sequence comprising:
- the Insulator 2 of the PB.HBB.PGK.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
- the 5’ITR of the PB HBB.PGK.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
- PB.EFla.GFP-T2A-DHFR is encoded by a sequence comprising:
- the 3 TTR of the PB.EFla.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
Landscapes
- Genetics & Genomics (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Wood Science & Technology (AREA)
- Organic Chemistry (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Molecular Biology (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Mycology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
Disclosed are compositions and methods for increasing the transposition frequency of a transposon, including, but not limited to a piggyBac transposon.
Description
COMPOSITIONS AND METHODS FOR INCREASING TRANSPOSITION
FREQUENCY
CROSS-REFERENCE TO RELATED APPLICATIONS
[01] This application claims priority to, and the benefit of, U.S. Provisional Application No. 62/745,100 filed on October 12, 2018; U.S. Provisional Application No. 62/783,128 filed on December 20, 2018; and U.S. Provisional Application No. 62/815,333 filed on March 7, 2019. The contents of each of these applications are incorporated by reference herein, in their entirety and for all purposes.
INCORPORATION-BY-REFERENCE OF SEQUENCE LISTING
[02] The contents of the file named“POTH-045 001WO SeqListing_ST25.txt”, which was created on October 12, 2019, and is 45.0 MB in size are hereby incorporated by reference in their entirety.
FIELD OF THE DISCLOSURE
[03] The disclosure is directed to molecular biology, and more, specifically, to compositions and methods for increasing transposition frequency.
BACKGROUND OF THE INVENTION
[04] There has been a long-felt but unmet need in the art for a method of increasing transposition frequency, for example, to integrate exogenous sequences into a genome. The disclosure provides compositions and methods for increasing transposition frequency that may be used, for example, for integrating an exogenous sequence into a genome.
SUMMARY OF THE INVENTION
[05] The present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions
sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a histone deacetylase (HD AC) inhibitor, a histone methyltransferase (HMT) inhibitor or a combination thereof, thereby increasing the frequency of transposition in a population of cells. Step a) can occur prior to step b), step b) can occur prior to the step a) or step a) and step b) can occur concurrently.
[06] The culture media in step b) can comprise a combination of the HD AC inhibitor and the HMT inhibitor. The plurality of modified cells in step b) can be cultured in a culture media comprising the combination of the HD AC inhibitor and the HMT inhibitor for at least 12 hours. The plurality of modified cells in step b) can be cultured in a culture media comprising the combination of the HD AC inhibitor and the HMT inhibitor for at least 24 hours. The plurality of modified cells in step b) can be cultured in a culture media comprising the combination of the HD AC inhibitor and the HMT inhibitor for about 3 hours to about 30 hours.
[07] The present disclosure provides method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture culture conditions sufficient for cell proliferation and for transposition media comprising a HD AC inhibitor and a HMT inhibitor; c) removing the HD AC inhibitor from the culture media; and d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor following step c, thereby increasing the frequency of transposition in a population of cells. Step a) can occur prior to step b), step b) can occur prior to the step a) or step a) and step b) can occur concurrently.
[08] The plurality of modified cells in step b) can be cultured in a culture media comprising the HD AC inhibitor and the HMT inhibitor for at least 12 hours. The plurality of modified cells in step b) can be cultured in a culture media comprising the HD AC inhibitor and the HMT inhibitor for at least 24 hours. The plurality of modified cells in step b) can be cultured in a culture media comprising the HD AC inhibitor and the HMT inhibitor for about 3 hours to about 30 hours.
[09] The plurality of modified cells in step d) can be cultured in a culture media comprising a HMT inhibitor for at least 48 hours following step c. The plurality of modified cells in step d) can be cultured in a culture media comprising a HMT inhibitor for at least 3 days following step c. The plurality of modified cells in step d) can be cultured in a culture media comprising a HMT inhibitor for about 1 day to about 5 days following step c.
[010] The HMT inhibitor in step b) and the HMT inhibitor in step d) can be the same or different. The HMT inhibitor in step b) can comprise UNC0638. The HMT inhibitor in step d) can comprise UNC0638. The HMT inhibitor in step b) and step d) can comprise UNC0638. The culture media can comprise about 0.5 mM to about 2 mM of UNC0638 in step b), in step d) or in both step b) and step d). The culture media can comprise about 1 mM of UNC0638 in step b), in step d) or in both step b) and step d).
[Oil] The HD AC inhibitor can comprise valproic acid or sodium phenylbutyrate. In a preferred aspect, the HD AC inhibitor is valproic acid. The culture media can comprise about 0.25 mM to about 1.25 mM of valproic acid. The culture media can comprise about 0.5 mM or about 0.75 mM of valproic acid. The culture media can comprise about 0.5 mM to about 2 mM of sodium phenylbutyrate. The culture media can comprise about 1.5 mM of sodium
phenylbutyrate.
[012] The culture media in step b) comprising the combination of the HD AC inhibitor and the HMT inhibitor can further comprise a second HD AC inhibitor, a second HMT inhibitor, StemRegenin 1 (SR1), UM171, or a combination thereof.
[013] The culture conditions in steps b) - d) result in an increase in frequency of transposition and at least a one-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions sufficient for cell proliferation and for transposition wherein said conditions do not comprise a HD AC inhibitor and a HMT inhibitor. The culture conditions in steps b) - d) result in an increase in frequency of transposition and at least a two-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions sufficient for cell proliferation and for transposition wherein said conditions do not comprise a HD AC inhibitor and a HMT inhibitor. The culture conditions in steps b) - d) result in an increase in frequency of transposition and about one-fold to about a four-fold increase in the
yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions sufficient for cell proliferation and for transposition wherein said conditions do not comprise a HD AC inhibitor and a HMT inhibitor.
[014] The present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for at least 24 hours; c) removing the valproic acid from the culture media; and d) culturing the plurality of modified cells in a culture media comprising UNC0638 for at least 3 days following step c, thereby increasing the frequency of transposition in a population of cells. Step a) can occur prior to step b), step b) can occur prior to the step a) or step a) and step b) can occur concurrently.
[015] The disclosed method of increasing the frequency of transposition can further comprise a method of expanding the population of cells comprise e) removing the HMT inhibitor from the culture media following step d); and f) culturing the plurality of modified cells in a culture media comprising an expansion agent following step e, wherein the expansion agent comprises an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative. The expansion agent can comprise at least two of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative. The expansion agent can comprise each of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative.
[016] The plurality of modified cells in step f) can be cultured in a culture media comprising the expansion agent for at least 5 days following step e. The plurality of modified cells in step f) can be cultured in a culture media comprising the expansion agent for at least 7 days following step e. The plurality of modified cells in step f) can be cultured in a culture media comprising the expansion agent for about 4 days to about 9 days following step e.
[017] The HMT inhibitor in step f) can comprise UNC0638. The culture media in step f) can comprise about 0.5 mM to about 2 mM of UNC0638. The culture media in step f) can comprise about 1 mM of UNC0638. The aryl hydrocarbon receptor inhibitor in step f) can comprise
StemRegenin 1 (SR1). The culture media in step f) can comprise about 0.5 mM to about 2 mM of
SR1. The culture media in step f) can comprise about 1 mM of SR1. The aryl hydrocarbon receptor inhibitor in step f) can comprise UM171. The culture media in step f) can comprise about 25 nM to about 50 nM of UM171. The culture media in step f) can comprise about 35 nM of UM171.
[018] The expansion agent can further comprise valproic acid. The culture media in step f) can comprise about 0.25 mM to about 1.25 mM of valproic acid. The culture media in step f) can comprise about 1 mM of valproic acid. The expansion agent can further comprise nicotinamide. The culture media in step f) can comprise about 2.5 mM to about 10 mM of nicotinamide. The culture media in step f) can comprise about 5 mM of nicotinamide. The expansion agent can further comprise garcinol. The culture media in step f) can comprise about 5 mM to about 15 mM of garcinol. The culture media in step f) can comprise about 10 mM of garcinol. The expansion agent can further comprise sodium phenylbutyrate. The culture media in step f) can comprise about 1 mM to about 2 mM of sodium phenylbutyrate. The culture media in step f) can comprise about 1.5 mM of sodium phenylbutyrate.
[019] The disclosed method of increasing the frequency of transposition and expanding the population of cells can further comprise a method of selecting the population of cells comprising wherein the transposon in step a) comprises a selection gene and step f) further comprises a selection agent. In one aspect, the transposon can comprise a dihydrofolate reductase (DHFR) resistance gene or the transposon can comprise a sequence encoding a DHFR mutein enzyme and step f) can further comprise a selection agent, wherein the selection agent can comprise methotrexate or pralatrexate. The culture media in step f) can comprise about 100 nM to about 500 nM of methotrexate. The culture media in step f) can comprise about 250 nM of
methotrexate. The culture media in step f) can comprise about 50 nM to about 250 nM of pralatrexate. The culture media in step f) can comprise about 125 nM of pralatrexate. The selection agent can comprise pralatrexate and dipyridimole. The culture media in step f) can comprise about 50 nM to about 250 nM of pralatrexate and about 1 mM to about 10 mM of dipyridimole. The culture media in step f) can comprise about 125 nM of pralatrexate and about 5 mM of dipyridimole.
[020] Culturing the plurality of modified cells with an expansion agent can occur prior to culturing the plurality of modified cells with a selection agent, culturing the plurality of modified cells with a selection agent can occur prior to culturing the plurality of modified cells with an expansion agent, or culturing the plurality of modified cells with an expansion agent and culturing the plurality of modified cells with a selection agent can occur concurrently.
[021] The culture conditions in steps e) - f) result in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions sufficient for cell proliferation and for transposition wherein said conditions do not comprise a selection agent and expansion agent. The culture conditions in steps e) - f) result in at least five-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions sufficient for cell proliferation and for transposition wherein said conditions do not comprise a selection agent and expansion agent. The culture conditions in steps e) - f) result in about two-fold to about five-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions sufficient for cell proliferation and for transposition wherein said conditions do not comprise a selection agent and expansion agent.
[022] In the methods of the present disclosure, the transposon can comprise a sequence encoding for a selection marker. The selection marker can be a nucleic acid molecule or a protein. The transposon can comprise a sequence for a DHFR resistance gene. The transposon can comprise a sequence encoding a DHFR mutein enzyme. The transposon can comprise a sequence encoding for a therapeutic agent. The therapeutic agent can be a therapeutic protein or a therapeutic RNA. The therapeutic agent can be human beta-globin (HBB), T87Q human beta- globin (HBB T87Q), BAF chromatin remodeling complex subunit (BCL11A) shRNA, insulin like growth factor 2 binding protein 1 (IGF2BP1), interleukin 2 receptor gamma (IL2RG), alpha galactosidase A (GLA), alpha-L-idurondase (IDUA), iduronate 2-sulfatase (IDS), cystinosin lysosomal cysteine transporter (CTNS). The transposon can comprise a sequence encoding a chimeric antigen receptor (CAR). The transposon can comprise a sequence encoding a non- naturally occurring chimeric stimulatory receptor (CSR) comprising: (a) an ectodomain comprising a activation component, wherein the activation component is isolated or derived from a first protein; (b) a transmembrane domain; and (c) an endodomain comprising at least one
signal transduction domain, wherein the at least one signal transduction domain is isolated or derived from a second protein; wherein the first protein and the second protein are not identical. In one aspect, the transposon can comprise a sequence for a CAR and a sequence for a CSR. The transposon can comprise a sequence encoding for an inducible proapoptotic polypeptide comprising (a) a ligand binding region, (b) a linker, and (c) a caspase polypeptide, wherein the inducible proapoptotic polypeptide does not comprise a non-human sequence. The transposon can be integrated into the genome of the cell by the transposase. The integration can be stable or transient. The sequence encoding the transposase can comprise an amino acid or a nucleic acid sequence encoding a transposase protein. The nucleic acid sequence encoding a transposase protein can comprise an RNA sequence or comprise a DNA sequence.
[023] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for at least 24 hours; c) removing the valproic acid from the culture media; d) culturing the plurality of modified cells in a culture media comprising UNC0638 for at least 3 days following step c; e) removing the UNC0638 from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least 7 days following step e, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
[024] The present invention provides a plurality of modified cells produced by any of the methods disclosed herein. The present invention provides compositions comprising a plurality of modified cells produced by any of the methods disclosed herein. The present invention provides pharmaceutical compositions comprising a plurality of modified cells produced by any of the methods disclosed herein and and a pharmaceutically-acceptable carrier.
[025] The present invention provides a modified cell population wherein at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, at least 99.5%, at least 99.9%, or 100% of the plurality of modified cells in the population comprise a genome-integrated transposon.
[026] The present invention provides compositions comprising a modified cell population wherein at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, at least 99.5%, at least 99.9%, or 100% of the plurality of modified cells in the population comprise a genome- integrated transposon. The present invention provides pharmaceutical compositions comprising a modified cell population wherein at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, at least 99.5%, at least 99.9%, or 100% of the plurality of modified cells in the population comprise a genome-integrated transposonand a and a pharmaceutically-acceptable carrier.
[027] The present invention provides a method of treating a disease or disorder in a subject in need thereof, comprising administering to the subject a therapeutically-effective amount of compositions or pharmaceutical compositions disclosed herein. The present invention also provides compositions or pharmaceutical compositions for use in treating a disease or disorder. The pharmaceutical composition comprises a plurality of autologous cells. The pharmaceutical composition comprises a plurality of allogeneic cells.
BRIEF DESCRIPTION OF THE DRAWINGS
[028] The patent or application file contains at least one drawing executed in color.
Copies of this patent or patent application publication with color drawing(s) will be provided by the Office upon request and payment of the necessary fee.
[029] Fig. 1 A is a schematic diagram depicting a piggyBac (PB) transposon vector construct (nanoV5 EFla GFP-T2A-DHFR vector) used for delivering the GFP reporter transgene as well as for enabling HSC selection.
[030] Fig. 1B is a linear illustration depicting a piggyBac (PB) transposon vector construct (nanoV5 EFla GFP-T2A-DHFR vector) used for delivering the GFP reporter transgene as well as for enabling HSC selection.
[031] Fig. 2A is a schematic diagram depicting a construct for erythroid-specific expression of the human therapeutic T87Q beta-globin and the constitutive expression of GFP and DHFR (PB -HBB -PGK-GFP- T2 A-DHFR) .
[032] Fig. 2B is a schematic diagram depicting a construct for erythroid-specific expression of the human therapeutic T87Q beta-globin and the constitutive expression of GFP and DHFR (PB- HBB-PGK-GFP-T2A-DHFR).
[033] Fig. 3A is a graph depicting the relative increase in total GFP+ cells between a control cytokine treatment (lOOng/ml each of hrSCF, hrTPO and hrFLT3L) and 0.5mM VPA 24hr washout, as assessed by flow cytometry at Day 7.
[034] Fig. 3B is a graph depicting a negative correlation between the frequency of GFP+ cells in a control nucleofection and the fold increase in GFP+ cells achieved by adding 0.5mM VPA for 24hrs post nucleofection.
[035] Fig. 3C is a graph depicting a cumulative summary of the transposition efficiency achieved with the nanoV5 EFla GFP-T2A-DHFR vector +sPB RNA.
[036] Fig. 4 is a schematic diagram depicting an experimental design to assess the effects of several modifiers on transposition yield.
[037] Fig. 5 is a series of flow cytometry plots showing the frequency of GFP+ cells in each condition for each donor as assessed at Day 7.
[038] Fig. 6A is a graph showing the frequency of GFP+ under various experimental conditions.
[039] Fig. 6B is a graph showing the absolute number of GFP+ cells under various experimental conditions normalized to the cytokine control condition.
[040] Fig. 7 is a schematic diagram depicting an experimental design to assess the effects of several modifiers on transposition yield and expansion.
[041] Fig. 8A is a plot depicting GFP+ frequency of each condition as assayed by flow cytometry at day 4 before the initiation of MTX selection and expansion.
[042] Fig. 8B is a plot depicting GFP+ frequency of each condition as assayed by flow cytometry at day 11 after 7 days of selection in 250nM MTX and expansion with
SR1+UM171+UNC0638 (SUU).
[043] Fig. 8C is a graph depicting absolute numbers of GFP+ cells for each condition at Day 4 before selection/expansion and Day 11 after selection/expansion.
[044] Fig. 9A is a graph comparing the relative number of bulk GFP+ cells in each condition at Day 11 post selection.
[045] Fig. 9B a graph comparing the relative number of GFP+ phenotypic HSCs
(CD34+/CD38-/CD90+/CD45RA-/CD49f+/GFP+) in each condition at Day 11 post selection.
[046] All documents cited herein, including any cross referenced or related patent or application is hereby incorporated herein by reference in its entirety for all purposes, unless expressly excluded or otherwise limited. The citation of any document is not an admission that it is prior art with respect to any invention disclosed or claimed herein or that it alone, or in any combination with any other reference or references, teaches, suggests or discloses any such invention. Further, to the extent that any meaning or definition of a term in this document conflicts with any meaning or definition of the same term in a document incorporated by reference, the meaning or definition assigned to that term in this document shall govern.
DETAILED DESCRIPTION OF THE INVENTION
[047] The present disclosure provides a method of increasing the frequency of transposition in a cell comprising a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into the cell to produce a modified cell and b) culturing the modified cell in a culture media comprising a histone deacetylase (HD AC) inhibitor, a histone methyltransferase (HMT) inhibitor, or a combination thereof, thereby increasing the frequency of transposition in the cell.
[048] The present disclosure provides a method of increasing the frequency of transposition in a population of cells comprising a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells and b) culturing the plurality of modified cells in a culture media comprising a histone deacetylase (HD AC) inhibitor, a histone methyltransferase (HMT) inhibitor, or a combination thereof, thereby increasing the frequency of transposition in a population of cells.
[049] The cell or plurality of cells can be cultured in a culture media comprising the HD AC inhibitor, the HMT inhibitor, or a combination thereof, before, after or concurrently with introducing the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into the cell or plurality of cells to produce the modified cell or plurality of modified cells.
[050] A modified cell comprises a genome-integrated transposon. A plurality of modified cells comprise a plurality of cells comprising a genome-integrated transposon. The integration can be stable or transient.
[051] The HD AC inhibitor, the HMT inhibitor, or a combination thereof can be present in the culture media ( e.g ., in contact with the cell or plurality of cells) for at least about 1 minute, at least about 2 minutes, at least about 5 minutes, at least about 10 minutes, at least about 15 minutes, at least about 20 minutes, at least about 25 minutes, at least about 30 minutes, at least about 35 minutes, at least about 40 minutes, at least about 45 minutes, at least about 50 minutes, at least about 55 minutes, at least about 60 minutes, or any number of minutes in between.
[052] The HD AC inhibitor, the HMT inhibitor, or a combination thereof can be present in the culture media (e.g., in contact with the cell or plurality of cells) for at least about 1 hour, at least about 2 hours, at least about 4 hours, at least about 6 hours, at least about 8 hours, at least about 10 hours, at least about 12 hours, at least about 14 hours, at least about 16 hours, at least about
18 hours, at least about 20 hours, at least about 22 hours, at least about 24 hours, at least about
26 hours, at least about 28 hours, at least about 30 hours, at least about 32 hours, at least about
34 hours, at least about 36 hours, or any number of hours in between.
[053] The HD AC inhibitor, the HMT inhibitor, or a combination thereof can be present in the culture media (e.g., in contact with the cell or plurality of cells) for at least about 3 days, at least about 4 days, at least about 5 days, at least about 6 days, at least about 7 days, at least about 8 days, at least about 9 days, at least about 10 days, at least about 11 days, at least about 12 days, at least about 13 days, or at least about 14 days.
[054] The HD AC inhibitor can be present in the culture media (e.g., in contact with the cell or plurality of cells) for at least about 1 hour, at least about 2 hours, at least about 4 hours, at least about 6 hours, at least about 8 hours, at least about 10 hours, at least about 12 hours, at least about 14 hours, at least about 16 hours, at least about 18 hours, at least about 20 hours, at least about 22 hours, at least about 24 hours, at least about 26 hours, at least about 28 hours, at least about 30 hours, or any number of hours in between.
[055] The HMT inhibitor can be present in the culture media (e.g., in contact with the cell or plurality of cells) in the presence of the HD AC inhibitor for at least about 3 hours, at least about
6 hours, at least about 12 hours, at least about 18 hours, at least about 1 day, at least about 2 days, at least about 3 days, or at least about 4 days.
[056] The HMT inhibitor can be present in the culture media (e.g., in contact with the cell or plurality of cells) in the absence of the HD AC inhibitor for at least about 3 hours, at least about 6 hours, at least about 12 hours, at least about 18 hours, at least about 1 day, at least about 2 days, at least about 3 days, or at least about 4 days.
[057] The combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g., in contact with the cell or plurality of cells) for at least one hour; at least about 3 hours, at least about 6 hours, about 12 hours, about 18 hours, at least about 24 hours.
[058] The combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g., in contact with the cell or plurality of cells) for at least one hour; at least about 3 hours, at least about 6 hours, about 12 hours, about 18 hours, at least about 24 hours following the introduction of the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell or a plurality of cells to produce the modified cell or the plurality of modified cells.
[059] The methods of increasing the frequency of transposition can further comprise a recovery period following the introducing step, wherein the modified cell or plurality of modified cells and the HD AC inhibitor, HMT inhibitor, or combination thereof are not in contact. That is, the modified cell or plurality of modified cells can be cultured in a culture media not comprising the HD AC inhibitor, HMT inhibitor, or combination thereof as part of the recovery period following the introduction of the transposon or sequence encoding the transposon. The recovery period can have a duration of at least 1 minute, at least 2 minutes, at least 5 minutes, at least 10 minutes, at least 15 minutes, at least 20 minutes, at least 25 minutes, at least 30 minutes, at least 35 minutes, at least 40 minutes, at least 45 minutes, at least 50 minutes, at least 55 minutes, at least 60 minutes, or any number of minutes in between. The recovery period can have a duration of least about 1 hour, at least about 2 hours, at least about 4 hours, at least about 6 hours, at least about 8 hours, at least about 10 hours, at least about 12 hours, at least about 14 hours, at least about 16 hours, at least about 18 hours, at least about 20
hours, at least about 22 hours, at least about 24 hours, at least about 26 hours, at least about 28 hours, at least about 30 hours, or any number of hours in between.
[060] The combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media ( e.g ., in contact with the cell or plurality of cells) for at least one hour; at least about 3 hours, at least about 6 hours, about 12 hours, about 18 hours, at least about 24 hours following the introduction of the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell or a plurality of cells to produce the modified cell or plurality of modified cells and then the HD AC inhibitor is removed from the cell culture media. The HD AC inhibitor can be removed by any means known in the art (e.g., washing the cells and adding culture media not comprising an HD AC inhibitor).
[061] The combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (and in contact with the plurality of cells) for at least one hour; at least about 3 hours, at least about 6 hours, about 12 hours, about 18 hours, at least about 24 hours following the introduction of the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce the plurality of modified cells and then the HD AC inhibitor is removed from the cell culture media. The HD AC inhibitor can be removed by any means known in the art (e.g., washing the cells and adding culture media not comprising an HD AC inhibitor). Following removal of the HD AC inhibitor the modified cell or plurality of modified cells are cultured in a culture media comprising an HMT inhibitor (e.g., without an HD AC inhibitor present) for at least about 3 hours, at least about 6 hours, about 12 hours, about 18 hours, at least about 1 day, at least about 2 days, at least about 3 days, or at least about 4 days. In some aspects, the HMT inhibitor is removed from the cell culture media at the same time as removal of the HD AC inhibitor (e.g., washing the cells) and new culture media is added comprising an HMT inhibitor and not comprising an HD AC inhibitor.
[062] The HD AC inhibitor, the HMT inhibitor, or a combination thereof can be present in the culture media (e.g., in contact with the cell or plurality of cells) for about 30 minutes to about 36 hours; about 1 hour to about 34 hours; about 2 hours to about 32 hours; about 3 hours to about 30 hours; about 4 hours to about 28 hours; about 6 hours to about 26 hours; about 6 hours to about
24 hours; about 8 hours to about 24 hours; about 10 hours to about 24 hours; about 12 hours to about 24 hours; about 14 hours to about 24 hours; about 16 hours to about 24 hours; about 18 hours to about 24 hours; or about 18 hours to about 24 hours.
[063] The HD AC inhibitor, the HMT inhibitor, or a combination thereof can be present in the culture media ( e.g ., in contact with the cell or plurality of cells) for about 1 day to about 2 days; about 1 day to about 3 days, about 1 day to about 4 days, about 1 day to about 5 days, about 1 day to about 6 days, about 1 day to about 7 days, about 1 day to about 8 days, about 1 day to about 9 days, about 1 day to about 10 days, about 1 day to about 11 days, about 1 day to about 12 days, about 1 day to about 13 days, about 1 day to about 14 days.
[064] The combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g., in contact with the cell or plurality of cells) for about 30 minutes to about 36 hours; about 1 hour to about 34 hours; about 2 hours to about 32 hours; about 3 hours to about 30 hours; about 4 hours to about 28 hours; about 6 hours to about 26 hours; about 6 hours to about 24 hours; about 8 hours to about 24 hours; about 10 hours to about 24 hours; about 12 hours to about 24 hours; about 14 hours to about 24 hours; about 16 hours to about 24 hours; about 18 hours to about 24 hours; or about 18 hours to about 24 hours.
[065] The combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g., in contact with the cell or plurality of cells) for about 1 hour to about 24 hours; about 2 hours to about 24 hours; about 3 hours to about 24 hours; about 4 hours to about 24 hours; about 5 hours to about 24 hours; about 6 hours to about 24 hours; about 8 hours to about 24 hours; about 10 hours to about 24 hours; about 12 hours to about 24 hours; about 14 hours to about 24 hours; about 16 hours to about 24 hours; about 18 hours to about 24 hours; or about 18 hours to about 24 hours.
[066] The combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g., in contact with the cell or plurality of cells) for about 1 hour to about 24 hours; about 2 hours to about 24 hours; about 3 hours to about 24 hours; about 4 hours to about 24 hours; about 5 hours to about 24 hours; about 6 hours to about 24 hours; about 8 hours to about 24 hours; about 10 hours to about 24 hours; about 12 hours to about 24 hours; about 14 hours to about 24 hours; about 16 hours to about 24 hours; about 18 hours to about 24 hours; or about 18 hours to about 24 hours following the introduction of the transposon or a sequence
encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell or a plurality of cells to produce the modified cell or plurality of modified cells.
[067] The combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media ( e.g ., in contact with the cell or plurality of cells) for about 1 hour to about 24 hours; about 2 hours to about 24 hours; about 3 hours to about 24 hours; about 4 hours to about 24 hours; about 5 hours to about 24 hours; about 6 hours to about 24 hours; about 8 hours to about 24 hours; about 10 hours to about 24 hours; about 12 hours to about 24 hours; about 14 hours to about 24 hours; about 16 hours to about 24 hours; about 18 hours to about 24 hours; or about 18 hours to about 24 hours following the introduction of the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell or a plurality of cells to produce the modified cell or plurality of modified cells and then the HD AC inhibitor is removed from the cell culture media. The HD AC inhibitor can be removed by any means known in the art (e.g., washing the cells and adding culture media not comprising an HD AC inhibitor).
[068] The combination of the HD AC inhibitor and the HMT inhibitor can both be present in the culture media (e.g., in contact with the cell or plurality of cells) for about 1 hour to about 24 hours; about 2 hours to about 24 hours; about 3 hours to about 24 hours; about 4 hours to about 24 hours; about 5 hours to about 24 hours; about 6 hours to about 24 hours; about 8 hours to about 24 hours; about 10 hours to about 24 hours; about 12 hours to about 24 hours; about 14 hours to about 24 hours; about 16 hours to about 24 hours; about 18 hours to about 24 hours; or about 18 hours to about 24 hours following the introduction of the transposon or a sequence encoding the transposon and the transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell or a plurality of cells to produce the modified cell or the plurality of modified cells and then the HD AC inhibitor is removed from the cell culture media. The HD AC inhibitor can be removed by any means known in the art (e.g., washing the cells and adding culture media not comprising an HD AC inhibitor). Following removal of the HD AC inhibitor the modified cell or the plurality of modified cells are cultured in a culture media comprising an HMT inhibitor (e.g., without an
HD AC inhibitor present) for about one day to about 7 days; about one day to about 6 days; about one day to about 5 days; about one day to about 4 days. In some aspects, the HMT inhibitor is removed from the cell culture media at the same time as removal of the HD AC inhibitor ( e.g ., washing the cells) and new culture media is added comprising an HMT inhibitor and not comprising an HD AC inhibitor.
[069] The present disclosure provides a method of increasing the frequency of transposition in a cell or a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell to produce a modified cell or into a plurality of cells to produce a plurality of modified cells; b) culturing the modified cell or the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 24 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the modified cell or the plurality of modified cells in a culture media comprising a HMT inhibitor for about 3 days following step c; thereby increasing the frequency of transposition in a cell or a population of cells.
[070] The present disclosure provides a method of increasing the frequency of transposition in a cell or a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a cell to produce a modified cell or a plurality of cells to produce a plurality of modified cells; b) culturing the modified cell or the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 3 hours to about 30 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the modified cell or the plurality of modified cells in a culture media comprising a HMT inhibitor for about 1 day to about 5 days following step c; thereby increasing the frequency of transposition in a cell or a population of cells.
[071] The disclosed culture methods for increasing the frequency of transposition can be compared to culture methods utilizing culture media not comprising a HD AC inhibitor, a HMT inhibitor, or a combination thereof. The disclosed culture methods for increasing the frequency of transposition can be compared to identical culture conditions sufficient for cell proliferation
and for transposition into a cell but utilizing culture media not comprising a HD AC inhibitor, a HMT inhibitor, or a combination thereof.
[072] In preferred aspects; the culture methods comprising a culture media comprising a HD AC inhibitor, a HMT inhibitor, or a combination thereof result in an increase in frequency of transposition and at least a one-fold; at least a two-fold; at least a three-fold; at least a four-fold increase in the yield of transposed cells in the plurality of modified cells when compared to culture conditions sufficient for cell proliferation and for transposition into the cell utilizing culture media not comprising a HD AC inhibitor, a HMT inhibitor, or a combination thereof.
[073] Culture conditions sufficient for cell proliferation and transposition comprise culture in the presence of one or more cytokines. In one aspect, the one or more cytokines can comprise, consist essential of, or consist of human recombinant stem cell factor (hrSCF), human recombinant thrombopoietin (hrTPO), human recombinant FMS-like tyrosine kinase 3 ligand (hrFLT3L). In one aspect, the culture conditions sufficient for cell proliferation comprise culture in the presence of each of hrSCF, hrTPO and hrFLT3L. The culture media can comprise about 50 ng/ml to about 200 ng/ml of hrSCF. The culture media can comprise about lOOng/ml of hrSCF. The culture media can comprise about 50 ng/ml to about 200 ng/ ml of hrTPO. The culture media can comprise about lOOng/ml of hrTPO. The culture media can comprise about 50 ng/ml to about 200 ng/ ml of hrFLT3L. The culture media can comprise lOOng/ml of hrFLT3L.
[074] The present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 24 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 3 days following step c; wherein said culturing results in an increase in frequency of transposition and at least a one-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a HD AC inhibitor and HMT inhibitor. The culture conditions not
comprising a HD AC inhibitor and HMT inhibitor are sufficient for cell proliferation and for transposition.
[075] The present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 3 hours to about 30 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 1 day to about 5 days following step c; wherein said culturing results in an increase in frequency of transposition and at least a one-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a HD AC inhibitor and HMT inhibitor. The culture conditions not comprising a HD AC inhibitor and HMT inhibitor are sufficient for cell proliferation and for transposition.
[076] The present methods can be used to increase the frequency of transposition in a naturally poor transposer cell. The term“a naturally poor transposer cell” as used herein means a cell that has a transposition frequency of less than or equal to about 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, or 15% when utilizing standard transposon in a standard nucleofection or electroporation assay and without the addition of any transposition enhancing or boosting agents. The term“a naturally high transposer cell” as used herein means a cell that has a transposition frequency of equal to or greater than about 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, 15%, 16%, 17%, 18%, 19%, 20%, 21%, 22%, 23%, 24%, 25%, 26%, 27%, 28%, 29%, or 30% when utilizing standard transposon in a standard nucleofection or electroporation assay and without the addition of any transposition enhancing or boosting agents. In one aspect, the present methods increase the frequency of transposition from less than or equal to about 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, or 15% to equal to greater than about 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, 15%, 16%, 17%, 18%, 19%, 20%, 21%, 22%, 23%, 24%, 25%, 26%, 27%, 28%, 29%, or 30%.
[077] For example, a cell transposed with a vector comprising a transposon comprising an EFIalpha promoter expressing GFP and DHFR is“a naturally poor transposer cell” with a transposition frequency less than or equal to about 10% when utilizing standard transposon in a standard nucleofection or electroporation assay and without the addition of any transposition enhancing or boosting agents. A cell transposed with a vector comprising a transposon comprising an EFIalpha promoter expressing GFP and DHFR is“a naturally high transposer cell” with a transposition frequency of equal to greater than about 15%. In one aspect, the present methods increase the frequency of transposition of the transposon comprising an EFIalpha promoter expressing GFP and DHFR from less than or equal to about 10% to equal to or greater than about 15%.
[078] Without being bound by any theory, the HD AC inhibitor, the HMT inhibitor, or a combination thereof can open the chromatin of a cell or cells in a plurality of cells and/or increase access of the transposon and transpose as to the genomic DNA of a cell or cells in a plurality of cells.
[079] The HD AC inhibitor, the HMT inhibitor, or a combination thereof can be present in the culture media in an amount from about 0.5 mM to about 2 mM; about 1.0 mM to about 1 mM; about 2.0 mM to about 1.0 mM; or about 5.0 mM to about 1.0 mM.
[080] The HD AC inhibitor can be a pan-HD AC inhibitor, a class I HD AC inhibitor, a class II
HD AC inhibitor or a class I and class II inhibitor. Non-limiting examples of pan-HD AC inhibitors include Trichostatin A (TSA), Vorinostat, CAY10433 (targets class I and II), or sodium phenylbutyrate (targets class I and Ila). Non-limiting examples of class I HD AC inhibitors (targeting HDAC 1, 2, 3, and 8) include MS-275, CAY10398, or Entinostat. Non limiting examples of class II HDAC inhibitors (targeting HDAC 4, 5, 6, 7, 9, and 10) include MC-1568, Scriptaid, or CAY10603. Valproic acid (VP A) can inhibits multiple histone deacetylases from both Class I and Class II (but not HDAC6 or HDAC 10) and has high potency for Class I HDACs.
[081] The HDAC inhibitor can be valproic acid, sodium phenylbutyrate (NaPB), trichostatin A, vorinostat, CAY10433, MS-275, CAY10398, entinostat, MC-1568, scriptaid, or CAY10603. In a preferred aspect, the HDAC inhibitor is valproic acid.
[082] VPA can be present in the culture media in an amount from about 0.1 mM to about 2 mM; about 0.25 mM to about 1 mM; about 0.25 to about 0.75 mM; about 0.25 to about 0.5 mM or about 0.5 mM to about 0.75 mM. In some aspects, VPA is present in the culture media at about 0.25 mM; about 0.5 mM; about 0.75 mM or about 1 mM. In a preferred aspect, VPA is present in the culture media at about 0.5 mM or about 0.75 mM. In another preferred aspect, VPA is present in the culture media at about 0.5 mM for about 24 hours. In another preferred aspect, VPA is present in the culture media at about 0.75 mM for about 24 hours.
[083] NaPB can be present in the culture media in an amount from about 0.5 mM to about 3 mM; about 1.0 mM to about 2.0 mM; or about 1.0 mM to about 1.5 mM. In a one aspect, NaPB is present in the culture media at about 1.5 mM. In another aspect, NaPB is present in the culture media at about 1.5 mM for about 1 day to about 7 days.
[084] The HMT inhibitor can be a selective inhibitor of G9a/GLP histone methyltransferases, which methylate lysine 9 of histone 3 (H3K9). Non-limiting examples of G9a/GLP inhibitors include BIX01294, UNC0642, A-366, UNC0224, UNC0631, UNC0646, BRD4770, or
UNC0631. Non-limiting examples of histone lysine methyltransferases include chaetocin, EPZ005687, EPZ6438, GSK126, GKS343, Ell, UNC199, EPZ004777, EPZ5676, LLY-507, AZ505, or A-893.
[085] The HMT inhibitor can be 2-Cyclohexyl-N-(l-isopropylpiperidin-4-yl)-6-methoxy-7- (3-(pyrrolidin-l-yl)propoxy) quinazolin-4-amine (ETNC0638), BIX01294, ETNC0642, A-366, UNC0224, UNC0631, UNC0646, BRD4770, UNC0631, chaetocin, EPZ005687, EPZ6438, GSK126, GKS343, Ell, UNC199, EPZ004777, EPZ5676, LLY-507, AZ505 or A-893. In a preferred aspect, the HMT inhibitor is UNC0638. The term UNC0638 also includes UNC0638 hydrate.
[086] UNC0638 can be present in the culture media in an amount from about 0.5 mM to about
2 mM; about 0.5 mM to about 1.5 mM; about 0.5 mM to about 1 mM; or about 0.75 mM to about 1.25 mM. In some aspects, UNC0638 is present in the culture media at about 0.75 mM; about 1 mM or about 1.25 mM. In a preferred aspect, UNC0638 is present in the culture media at about 1.0 mM. In another preferred aspect, UNC0638 is present in the culture media at about 1.0 mM for about 4 days to about 11 days.
[087] The culture media for increasing the frequency of transposition comprising a HD AC inhibitor, HMT inhibitor, or a combination thereof, can further comprise a DNA
methyltransferase inhibitor, aryl hydrocarbon receptor inhibitor, a pyrimido-indole derivative, a second HD AC inhibitor, a second HMT inhibitor, or a combination thereof.
[088] The DNA methyltransferase inhibitor can be 5-azacytidine. The 5-azacytidine can be present in the culture media in an amount from about 0.1 mM to about 1 mM or about 0.5 mM to about 1 mM. In a one aspect, the 5-azacytidine is present in the culture media at about 0.1 mM, about 0.5 mM or about 1 mM for about 24 hours.
[089] The aryl hydrocarbon receptor inhibitor can be StemRegenin 1 (SR1), alpha- naphthoflavone, beta-naphthoflavone, brevifolincarboxylic acid, 6,2',4'-Trimethoxyflavone, D,L- Sulforaphane, 2,3,7,8-tetrachlorodibenzo-p-dioxin (TCDD), PDM2, salicylamide, l,3-dichloro- 5-[(lE)-2-(4-methoxyphenyl)ethenyl]-benzene, CH 223191, methylindoles, methoxyindoles, indole-3-carbinol, mexiletine, hydroxytamoxifen, raloxifene, 2,3,7,8-tetrachlorodibenzo-p- dioxin, laquinimod, aminoflavone (NSC686288), CB7993113, diindolylmethane (DIM), tranilast, flutamide or omeprazole. In a preferred aspect, the aryl hydrocarbon receptor inhibitor is SR1. SR1 can be present in the culture media in an amount from about 0.5 mM to about 2 mM; about 0.5 mM to about 1.5 mM; about 0.5 mM to about 1 mM; or about 0.75 mM to about 1.25 mM. In some aspects, SR1 is present in the culture media at about 0.75 mM; about 1 mM or about 1.25 mM. In a preferred aspect, SR1 is present in the culture media at about 1.0 mM.
[090] The pyrimido-indole derivative can be a pyrimido-[4,5-b]-indole derivative. In a preferred aspect, the pyrimido-indole derivative inhibitor is UM171 and has the following
chemical structure:
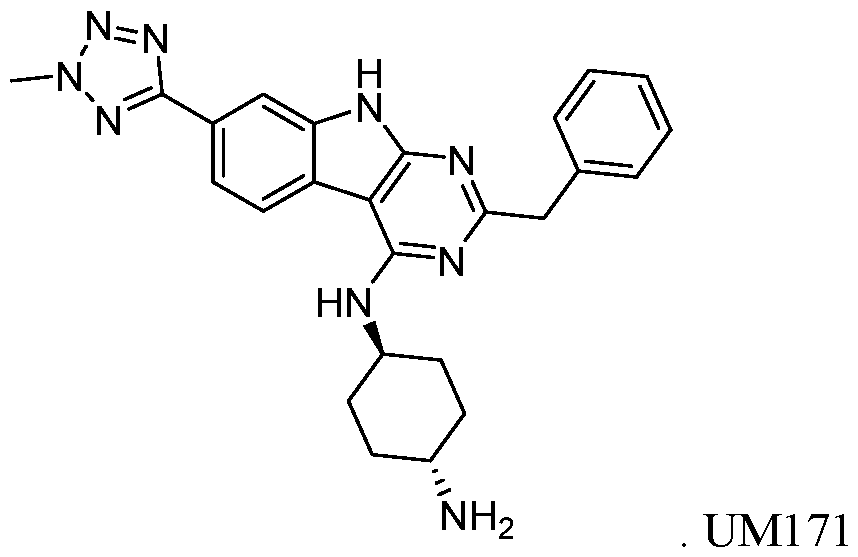 can be present in the culture
media in an amount from about 25 nM to about 75 nM; or about 25 nM to about 50 nM. In a preferred aspect, UM171 is present in the culture media at about 35 nM.
can be present in the culture
media in an amount from about 25 nM to about 75 nM; or about 25 nM to about 50 nM. In a preferred aspect, UM171 is present in the culture media at about 35 nM.
[091] In some aspects, the culture media for increasing the frequency of transposition in a cell or plurality of cells as disclosed herein can include the non-limiting agents: valproic acid;
UNC0638; SR1; UM171; valproic acid and UNC0638; valproic acid and SR1; valproic acid and UM171; UNC0638 and SR1; UNC0638 and UMl7l; SR1 and UM171 ; valproic acid, UNC0638 and SR1; valproic acid, UNC0638 and UM171 ; UNC0638, SR1 and UM171 ; valproic acid, SR1, UM171; or valproic acid, UNC0638, SR1 and UM171. In a preferred aspect, the culture media for increasing the frequency of transposition in a cell or plurality of cells as disclosed herein comprises a combination of VP A and UNC0638.
[092] When the culture media comprises a combination VPA and UNC0638, the VPA is present from about 0.1 mM to about 2 mM; about 0.25 mM to about 1 mM; about 0.25 to about 0.75 mM; about 0.25 to about 0.5 mM or about 0.5 mM to about 0.75 mM and the UNC0638 is present from about 0.5 mM to about 2 mM; about 0.5 mM to about 1.5 mM; about 0.5 mM to about 1 mM; or about 0.75 mM to about 1.25 mM. In one aspect, the VPA is present in the culture media at about 0.5 mM or about 0.75 mM and UNC0638 is present in the culture media at about 0.75 mM; about 1 mM or about 1.25 mM. In a preferred aspect, the VPA is present in the culture media at about 0.5 mM or about 0.75 mM and UNC0638 is present in the culture media at about 1.0 mM for about 4 days to about 11 days.
[093] The present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 24 hours; c) removing the valproic acid from the culture media; and d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 3 days following step c, thereby increasing the frequency of transposition in a population of cells.
[094] The present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the
transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 3 hours to about 30 hours; c) removing the valproic acid from the culture media; and d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 1 day to about 5 days following step c, thereby increasing the frequency of transposition in a population of cells.
[095] The present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 24 hours; c) removing the valproic acid from the culture media; and d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 3 days following step c, wherein said culturing results in an increase in frequency of transposition and at least a one-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising valproic acid and UNC0638.
[096] The present disclosure provides a method of increasing the frequency of transposition in a population of cells, comprising: a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 3 hours to about 30 hours; c) removing the valproic acid from the culture media; and d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 1 day to about 5 days following step c, wherein said culturing results in an increase in frequency of transposition and at least a one-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising valproic acid and UNC0638.
[097] The present disclosure provides methods for expansion of a population of cells. The expansion of a population of cells includes the expansion of a plurality of modified cells.
[098] The present disclosure also provides methods for selecting a population of cells. The selection of a population of cells includes the selection of a plurality of modified cells comprising a selection marker.
[099] The present disclosure also provides methods for expansion and selection of a population of cells. The expansion and selection of a population of cells includes the expansion of a plurality of modified cells. The selection of a population of cells includes the selection of a plurality of modified cells comprising a selection marker.
[0100] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least about 3 days, wherein the expansion agent comprises at least two of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido- indole derivative, thereby expanding a population of modified cells.
[0101] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least about 3 days, wherein the expansion agent comprises each of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor and a pyrimido- indole derivative, thereby expanding a population of modified cells.
[0102] The HMT inhibitor, aryl hydrocarbon receptor inhibitor, pyrimido-indole derivative, or a combination thereof, can be present in the culture media ( e.g in contact with the cell or plurality of cells) for at least about 4 days, at least about 5 days, at least about 6 days, at least about 7 days, at least about 8 days, at least about 9 days, at least about 10 days, at least about 11
days, at least about 12 days, at least about 13 days, or at least about 14 days. In a preferred aspect, at least 7 days.
[0103] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the expansion agent comprises at least two of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative, thereby expanding a population of modified cells.
[0104] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the expansion agent comprises each of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor and a pyrimido- indole derivative, thereby expanding a population of modified cells.
[0105] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a dihydrofolate reductase (DHFR) resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises at least two of SR1, UM171 or UNC0638, thereby expanding a population of modified cells.
[0106] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon
comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises each of SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
[0107] The HMT inhibitor, aryl hydrocarbon receptor inhibitor, pyrimido-indole derivative, or a combination thereof, can be present in the culture media ( e.g in contact with the cell or plurality of cells) for about 3 days to about 14 days; about 3 days to about 13 days; about 3 days to about 12 days; about 3 days to about 12 days; about 3 days to about 11 days; about 3 days to about 10 days; about 3 days to about 9 days; about 3 days to about 8 days; about 3 days to about 7 days; about 4 days to about 9 days; about 4 days to about 8 days; about 4 days to about 7 days; or about 5 days to about 7 days. In a preferred aspect, about 5 days to about 7 days.
[0108] HMT inhibitor can be UNC0638, BIX01294, UNC0642, A-366, UNC0224, UNC0631, UNC0646, BRD4770, UNC0631, chaetocm, EPZ005687, EPZ6438, GSK126, GKS343, Ell, UNC199, EPZ004777, EPZ5676, LLY-507, AZ505 or A-893. In a preferred aspect, the HMT inhibitor is ETNC0638. The term UNC0638 also includes UNC0638 hydrate.
[0109] UNC0638 can be present in the culture media in an amount from about 0.5 mM to about
2 mM; about 0.5 mM to about 1.5 mM; about 0.5 mM to about 1 mM; or about 0.75 mM to about 1.25 mM. In some aspects, UNC0638 is present in the culture media at about 0.75 mM; about 1 mM or about 1.25 mM. In a preferred aspect, UNC0638 is present in the culture media at about 1.0 mM. In another preferred aspect, UNC0638 is present in the culture media at about 1.0 mM for about 4 days to about 11 days. In another preferred aspect, UNC0638 is present in the culture media at about 1.0 mM for at least 7 days.
[0110] The aryl hydrocarbon receptor inhibitor can be StemRegenin 1 (SR1), alpha- naphthoflavone, beta-naphthoflavone, brevifolincarboxybc acid, 6,2',4'-Trimethoxyflavone, D,L- Sulforaphane, 2,3,7,8-tetrachlorodibenzo-p-dioxin (TCDD), PDM2, salicylamide, l,3-dichloro- 5-[(lE)-2-(4-methoxyphenyl)ethenyl]-benzene, CH 223191, methylindoles, methoxyindoles,
indole-3-carbinol, mexiletine, hydroxytamoxifen, raloxifene, 2,3,7,8-tetrachlorodibenzo-p- dioxin, laquinimod, aminoflavone (NSC686288), CB7993113, diindolylmethane (DIM), tranilast, flutamide or omeprazole. In a preferred aspect, the aryl hydrocarbon receptor inhibitor is SR1.
[0111] SR1 can be present in the culture media in an amount from about 0.5 mM to about 2 mM; about 0.5 mM to about 1.5 mM; about 0.5 mM to about 1 mM; or about 0.75 mM to about 1.25 mM. In some aspects, SR1 is present in the culture media at about 0.75 mM; about 1 mM or about 1.25 mM. In a preferred aspect, SR1 is present in the culture media at about 1.0 mM. In another preferred aspect, SR1 is present in the culture media at about 1.0 mM for about 4 days to about 11 days. In another preferred aspect, SR1 is present in the culture media at about 1.0 mM for at least 7 days.
[0112] The pyrimido-indole derivative can be a pyrimido-[4,5-b]-indole derivative. In a preferred aspect, the pyrimido-indole derivative inhibitor is UM171 and has the following
chemical structure:

[0113] UM171 can be present in the culture media in an amount from about 25 nM to about 75 nM; or about 25 nM to about 50 nM. In a preferred aspect, UM171 is present in the culture media at about 35 nM. In another preferred aspect, UM171 is present in the culture media at about 35 nM for about 4 days to about 11 days. In another preferred aspect, UM171 is present in the culture media at about 35 nM for at least 7 days.
[0114] When the culture media comprises a combination of SR1, UM171 and UNC0638 (termed SUU herein), the SR1 is present from about 0.75 mM; about 1 mM or about 1.25 mM; the UM171 is present from about 25 nM to about 50 nM; the UNC0638 is present from about 0.75 mM; about 1 mM or about 1.25 mM. In a preferred aspect, the SR1 is present in the culture media
at about 1 mM, the UM171 is present in the culture media at about 35 nM and UNC0638 is present in the culture media at about 1.0 mM for about 4 days to about 11 days. In a preferred aspect, the SR1 is present in the culture media at about 1 mM, the UM171 is present in the culture media at about 35 nM and UNC0638 is present in the culture media at least 7 days.
[0115] Hematopoietic stem cells (HSCs) or a plurality of HSCs cultured in a culture media comprising SR1 and UM171 demonstrate phentotypic expansion from about 2 fold to about 10 fold, about 4 fold to about 10 fold, about 6 fold to about 10 fold, or about 8 fold to about 10 fold. Addition of UNC0638 to SR1 and UM171 phentotypic expansion about 0.5 fold, about 1 fold, about 1.5 fold or about 2 fold. The SUU combination demonstrates phentotypic expansion from 2 fold to about 15 fold, about 4 fold to about 15 fold, about 6 fold to about 15 fold, or about 8 fold to about 15 fold or about 10 fold to about 15 fold, with an average phentotypic expansion of about 12 fold. The SUU combination significantly expands (more than about 2 fold, about 4 fold, about 6 fold, about 8 fold, or about 10 fold) cobblestone forming cells compared to cytokine culture only. HSCs cultured in SUU engraft well as demonstrated by in vivo engraftment assays.
[0116] The expansion agent can comprise valproic acid. The culture media can comprise about 0.25 mM to about 1.25 mM of VPA. The culture media can comprise about 1 mM of VPA.
HSCs or a plurality of HSCs cultured in a culture media comprising valproic acid demonstrate phentotypic expansion from about 300 fold to about 350 fold with an average phenotypic expansion of about 335 fold but does not have a significant expansion effect on cobblestone forming cells compared to culture in the presence of cytokines alone. HSCs or a plurality of HSCs cultured in valproic acid demonstrate engraftment, either alone or in combination with UNC0638 and/or UM171.
[0117] The expansion agent can further comprise nicotinamide. The culture media can comprise about 2.5 mM to about 10 mM of nicotinamide. The culture media can comprise about 5 mM of nicotinamide. HSCs or a plurality of HSCs cultured in a culture media comprising SUU and nicotinamide show at least a one-fold, at least a two-fold or at least a three-fold increase in phentotypic expansion when compared to culturing in a culture media comprising SUU alone. HSCs or a plurality of HSCs cultured in a culture media comprising SUU and nicotinamide show about a one-fold to about a four-fold increase, about a two-fold to about a 4
fold increase or about a one-fold to about a three-fold increase in phentotypic expansion when compared to culturing in a culture media comprising SUU alone.
[0118] The expansion agent can further comprise garcinol. The culture media can comprise about 5 mM to about 15 mM of garcinol. The culture media can comprise about 10 mM of garcinol. HSCs or a plurality of HSCs cultured in a culture media comprising SUU and garcinol show at least a 0.5 fold, at least a 1 fold, at least a 1.5 fold or at least a 2 fold increase in phentotypic expansion when compared to culturing in a culture media comprising SUU alone. However, the addition of garcinol didn’t improve function over SUU alone.
[0119] The expansion agent can further comprise NaPB. The culture media can comprise about 1 mM to about 2 mM of NaPB. The culture media can comprise about 1.5 mM of NaPB. HSCs or a plurality of HSCs cultured in a culture media comprising NaPB demonstrate phentotypic expansion.
[0120] Additional expansion agents may comprise dmPGE2, 5-azacytidine, 4-HPR, hlGFBP2, hANGPTL5, PCI-34051, GW9662 and N-acetylcysteme.
[0121] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least about 3 days, wherein the expansion agent comprises at least two of SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
[0122] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least about 3 days, wherein the expansion agent comprises each of SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
[0123] In one aspect, the selection gene is a dihydrofolate reductase (DHFR) resistance gene.
In one aspect, the selection agent is methotrexate, pralatrexate, pyrimethamine, dapsone, raltitrexed, trimetrexate, metoprine, iclaprim, aminopterin, lometrexol, nolatrexed, brodimoprim, trimethoprim, pemetrexed, proguanil, piritrexim, or cycloguanil. In one aspect, when the selection gene is DHFR or a sequence encoding a DHFR mutein enzyme, the selection agent is methotrexate, pralatrexate, pyrimethamine, dapsone, raltitrexed, trimetrexate, metoprine, iclaprim, aminopterin, lometrexol, nolatrexed, brodimoprim, trimethoprim, pemetrexed, proguanil, piritrexim, or cycloguanil. In one aspect, when the selection gene is DHFR or a sequence encoding a DHFR mutein enzyme, the selection agent is methotrexate (MTX) or pralatrexate (PTX). The DHFR mutein enzyme can comprise, consist essentially of, or consist of the amino acid sequence of SEQ ID NO: 14677. The DHFR mutein enzyme is encoded by a nucleic acid sequence comprising, consisting essentially of, or consisting of the nucleic acid sequence of SEQ ID NO: 14678. The amino acid sequence of the DHFR mutein enzyme can further comprises a mutation at one or more of positions 80, 113, or 153. In some embodiments, the amino acid sequence of the DHFR mutein enzyme comprises one or more of a substitution of a Phenylalanine (F) or a Leucine (L) at position 80, a substitution of a Leucine (L) or a Valine (V) at position 113, and a substitution of a Valine (V) or an Aspartic Acid (D) at position 153. In one aspect, when the transposon comprises a sequence encoding a DHFR mutein enzyme the selection agent is methotrexate or pralatrexate.
[0124] The methotrexate can be present in the culture media in an amount from about 100 nM to about 500 nM. In a preferred aspect, the culture media can comprise about 250 nM of methotrexate. The pralatrexate can be present in the culture media in an amount from about 50 nM to about 250 nM. In a preferred aspect, the culture media can comprise about 125 nM of pralatrexate.
[0125] In some aspects, the selection agent is pralatrexate and dipyridamole (DP). The culture media can comprise about 50 nM to about 250 nM of pralatrexate and about 1 mM to about 10 mM of dipyridamole. In a preferred aspect, the culture media can comprise about 125 nM of pralatrexate and about 5 mM of dipyridimole.
[0126] In some aspects, culturing the plurality of modified cells with an expansion agent occurs prior to culturing the plurality of modified cells with a selection agent. In some aspects, culturing
the plurality of modified cells with a selection agent occurs prior to culturing the plurality of modified cells with an expansion agent. In some aspects, culturing the plurality of modified cells with an expansion agent and culturing the plurality of modified cells with a selection agent occur concurrently.
[0127] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least about 3 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises at least two of SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
[0128] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least about 3 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises each of SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
[0129] The disclosed culture methods for expanding a population of modified cells can be compared to culture methods utilizing culture media not comprising a selection agent, an expansion agent, or a combination thereof.
[0130] In preferred aspects; the culture methods comprising a culture media comprising a selection agent, an expansion agent, or a combination thereof result in at least a one-fold, at least a two-fold, at least a three-fold, at least a four-fold, at least a five-fold; at least a six-fold; at least a seven-fold; at least an eight-fold; at least a nine-fold or at least a ten-fold expansion of the
plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent, an expansion agent, or a combination thereof.
[0131] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days, wherein the expansion agent comprises at least two of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
[0132] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days, wherein the expansion agent comprises each of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor and a pyrimido-indole derivative, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
[0133] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises at least two of SR1,
UM171 or UNC0638, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
[0134] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises each of SR1, UM171 and UNC0638, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
[0135] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the expansion agent comprises at least two of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
[0136] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the expansion
agent comprises each of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor and a pyrimido- indole derivative, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
[0137] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises at least two of SR1, UM171 or UNC0638, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
[0138] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and b) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises each of SR1, UM171 and UNC0638, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
[0139] The present disclosure provides methods for increasing the frequency of transposition in a cell or population of cells and further comprises expanding that population of cells. The method of increasing the frequency of transposition in a cell or plurality of cells and expansion of a population of cells includes the expansion of a plurality of modified cells.
[0140] The present disclosure also provides methods for increasing the frequency of transposition in a cell or plurality of cells and further comprises expanding and selecting that population of cells. The method of increasing the frequency of transposition in a cell or plurality of cells and expansion of a population of cells includes the expansion and selection of a plurality of modified cells. The selection of a population of cells includes the selection of a plurality of modified cells comprising a selection marker.
[0141] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 24 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 3 days following step c; e) removing the HMT inhibitor from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days following step e, wherein the expansion agent comprises an HMT inhibitor, a aryl hydrocarbon receptor inhibitor and a pyrimido-indole derivative, thereby expanding a population of modified cells.
[0142] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 24 hours; c) removing the valproic acid from the culture media; d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 3 days following step c; e) removing the UNC0638 from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days following step e, wherein the selection agent comprises methotrexate or
pralatrexate and wherein the expansion agent comprises SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
[0143] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 3 hours to about 30 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 1 day to about 5 days following step c; e) removing the HMT inhibitor from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days following step e, wherein the expansion agent comprises an HMT inhibitor, a aryl hydrocarbon receptor inhibitor and a pyrimido-indole derivative, thereby expanding a population of modified cells.
[0144] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 3 hours to about 30 hours; c) removing the valproic acid from the culture media; d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 1 day to about 5 days following step c; e) removing the UNC0638 from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days following step e, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises SR1, UM171 and UNC0638, thereby expanding a population of modified cells.
[0145] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the
transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 24 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 3 days following step c; e) removing the HMT inhibitor from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days following step e, wherein the expansion agent comprises an HMT inhibitor, a aryl hydrocarbon receptor inhibitor and a pyrimido-indole derivative, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
[0146] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 24 hours; c) removing the valproic acid from the culture media; d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 3 days following step c; e) removing the UNC0638 from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 7 days following step e, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises SR1, UM171 and UNC0638, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
[0147] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a selection gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions
sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor for about 3 hours to about 30 hours; c) removing the HD AC inhibitor from the culture media; d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 1 day to about 5 days following step c; e) removing the HMT inhibitor from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days following step e, wherein the expansion agent comprises an HMT inhibitor, a aryl hydrocarbon receptor inhibitor and a pyrimido-indole derivative, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
[0148] The present disclosure provides a method of expanding a population of modified cells, comprising: a) introducing a transposon comprising a DHFR resistance gene or a transposon comprising a sequence encoding a DHFR mutein enzyme or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for about 3 hours to about 30 hours; c) removing the valproic acid from the culture media; d) culturing the plurality of modified cells in a culture media comprising UNC0638 for about 1 day to about 5 days following step c; e) removing the UNC0638 from the culture media; and f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for about 4 days to about 9 days following step e, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises SR1, UM171 and UNC0638, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
[0149] In the methods of the disclosure, the transposon can be integrated into the genome of the cell by the transposase. The integration can be transient or stable. The transposon or the sequence encoding the transposon can be comprised within a composition; the transposase or a
sequence encoding a transposase can be comprised within a composition; or the transposon or the sequence encoding the transposon and the transposase or a sequence encoding a transposase can be comprised within a composition.
[0150] The sequence encoding the transposase can comprise an amino acid or a nucleic acid sequence encoding a transposase protein. The nucleic acid sequence encoding a transposase protein can comprise an RNA sequence. The nucleic acid sequence encoding a transposase protein can comprise a DNA sequence.
[0151] The transposon can be a piggyBac® (PB) transposon, a piggy-Bac® like transposon, a piggyBat transposon, a Sleeping Beauty transposon, a Helraiser transposon, a Tol2 transposon or a TcBuster transposon. The transposase can be a piggyBac® transposase, a piggy-Bac® like transposase, a Super piggyBac® (SPB) transposase, a piggyBat transposase, a Sleeping Beauty transposase, a hyperactive Sleeping Beauty (SB100X) transposase, Helitron transposase, a Tol2 transposase, a TcBuster transposase or a hyperactive TcBuster transposase. The Helitron transposase can be a Helibatl transposase.
[0152] When the transposon is a piggyBac® transposon, the transposase can be a piggyBac® transposase or a Super piggyBac® transposase. When the transposon is a piggy-Bac® like transposon, the transposase can be a piggy-Bac® like transposase. When the transposon is a Sleeping Beauty transposon, the transposase can be a Sleeping Beauty transposase. When the transposon is a Helraiser transposon, the transposase can be a Helitron transposase. When the transposon is a Tol2 transposon, the transposase can be a Tol2 transposase. When the transposon is a TcBuster transposon, the transposase can be a TcBuster transposase or a hyperactive TcBuster transposase.
[0153] The piggyBac® transposase comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14487. The piggyBac® transposase comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14487. The piggyBac® transposase comprises an amino acid substitution at one or more of positions 30, 165, 282 or 538 of SEQ ID NO: 14487. The piggyBac® transposase comprises an amino acid substitution at two or more of positions 30, 165, 282 or 538 of SEQ ID NO: 14487. The piggyBac® transposase comprises an amino acid substitution at three or more of positions 30,
165, 282 or 538 of SEQ ID NO: 14487. The piggyBac® transposase comprises an amino acid substitution at each of positions 30, 165, 282 or 538 of SEQ ID NO: 14487. The amino acid substitution at position 30 of SEQ ID NO: 14487 is a substitution of a valine (V) for an isoleucine (I) (130V). The amino acid substitution at position 165 of SEQ ID NO: 14487 is a substitution of a serine (S) for a glycine (G) (G165S). The amino acid substitution at position 282 of SEQ ID NO: 14487 is a substitution of a valine (V) for a methionine (M) (M282V). The amino acid substitution at position 538 of SEQ ID NO: 14487 is a substitution of a lysine (K) for an asparagine (N) (N538K).
[0154] The piggyBac® transposase comprises, consists essential of, or consists of an amino acid substitution at each of positions 30, 165, 282 or 538 of SEQ ID NO: 14487. The Super piggyBac® transposase comprises, consists essential of, or consists of an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14484. The Super piggyBac® transposase comprises, consists essential of, or consists of, the amino acid sequence SEQ ID NO: 14484.
[0155] The TcBuster transposase comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14735. The TcBuster transposase comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14735.
[0156] The piggyBat transposase comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14965. The piggyBat transposase comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14967. The piggyBat transposase comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14968.
[0157] The nucleic acid encoding the piggyBat transposase comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14966. The nucleic acid encoding the piggyBat transposon comprises, consists essential of, or consists of, an amino acid
sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14963. The nucleic acid encoding the piggyBat transposon comprises, consists essential of, or consists of, an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to the amino acid sequence of SEQ ID NO: 14964.
[0158] Transposons and transposes suitable for use in the compositions and methods of the present disclosure are described in more detail herein.
[0159] The transposon can comprise, consist essential of, or consist of at least one exogenous sequence (transgene sequence). The transposon can comprise, consist essential of, or consist of at least two exogenous sequences (transgene sequences). The transposon can comprise, consist essential of, or consist of at least three exogenous sequences (transgene sequences). The transposon can comprise, consist essential of, or consist of at least four exogenous sequences (transgene sequences). The transposon can comprise, consist essential of, or consist of at least five exogenous sequences (transgene sequences).
[0160] The exogenous sequence can comprise, consist essential of, or consist of a sequence encoding a chimeric antigen receptor (CAR).
[0161] The exogenous sequence can comprise, consist essential of, or consist of a sequence encoding a therapeutic agent. The therapeutic agent can be a therapeutic protein. The therapeutic agent can be a therapeutic RNA. The therapeutic RNA can be iRNA, siRNA, or shRNA.
[0162] The therapeutic agent can be human beta-globin (HBB), human beta-globin comprising a T87Q mutation (HBB T87Q), BAF chromatin remodeling complex subunit (BCL11A) shRNA, insulin like growth factor 2 binding protein 1 (IGF2BP1), interleukin 2 receptor gamma
(IL2RG), alpha galactosidase A (GLA), alpha-L-idurondase (IDETA), iduronate 2-sulfatase (IDS), cystinosin lysosomal cysteine transporter (CTNS).
[0163] The HBB comprises the amino acid sequence of SEQ ID NO: 14724. The sequence encoding the HBB comprises the nucleic acid sequence of SEQ ID NO: 14969. The HBB T87Q comprises the amino acid sequence of SEQ ID NO: 14477. The sequence encoding HBB T87Q comprises the nucleic acid sequence of SEQ ID NO: 14478. The BCL11 A shRNA comprises the nucleic acid sequence of SEQ ID NO: 14713. The IGF2BP1 comprises the amino acid sequence
of SEQ ID NO: 14722. The nucleic acid encoding the IGF2BP1 comprises the nucleic acid sequence of SEQ ID NO: 14721. The IL2RG comprises the amino acid sequence of SEQ ID NO: 14723. The nucleic acid encoding the IL2RG comprises the nucleic acid sequence of SEQ ID NO: 14718. The GLA comprises the amino acid sequence of SEQ ID NO: 5974 or SEQ ID NO: 5975. The nucleic acid encoding the GLA comprises the nucleic acid sequence of SEQ ID NO: 14970. The IDETA comprises the amino acid sequence of any one of SEQ ID NO: 6715 - SEQ ID NO: 6720. The nucleic acid encoding the IDETA comprises the nucleic acid sequence of SEQ ID NO: 14971. The IDS comprises the amino acid sequence of any of SEQ ID NO: 6709 - SEQ ID NO: 6714. The nucleic acid encoding the IDS comprises the nucleic acid sequence of SEQ ID NO: 14972. The CTNS comprises the amino acid sequence of any of SEQ ID NO: 3672 - SEQ ID NO: 3679. The nucleic acid encoding the CTNS comprises the nucleic acid sequence of SEQ ID NO: 14973. The nucleic acid encoding the selectable marker comprises a nucleic acid sequence encoding a DHFR enzyme or a nucleic acid sequence encoding a DHFR mutein enzyme. The nucleic acid encoding the DHFR enzyme comprises the nucleic acid sequence of SEQ ID NO: 14976. The DHFR enzyme comprises the amino acid sequence of SEQ ID NO: 14476. The amino acid sequence of the DHFR enzyme further comprises a mutation at one or more of positions 80, 113, or 153. The amino acid sequence of the DHFR enzyme comprises a substitution of a Phenylalanine (F) or a Leucine (L) at position 80. The amino acid sequence of the DHFR enzyme comprises a substitution of a Leucine (L) or a Valine (V) at position 113.
[0164] The amino acid sequence of the DHFR enzyme comprises a substitution of a Valine (V) or an Aspartic Acid (D) at position 153. The DHFR mutein enzyme comprises the amino acid sequence of SEQ ID NO: 14725. The sequence encoding the DHFR mutein enzyme comprises the nucleic acid sequence of SEQ ID NO: 14709 or SEQ ID NO: 14901.
[0165] The exogenous sequence can comprise, consist essential of, or consist of a sequence encoding a selection marker. A selection marker is a gene introduced into a cell, especially a cell in culture, that confers a trait suitable for artificial selection. They are a type of reporter gene used to indicate the success of a transposition, transduction, transfection or other procedure meant to introduce exogenous or foreign DNA into a cell. A non-limiting example of a selectable marker is an antibiotic resistance gene (an antibiotic resistance marker is a gene that produces a protein that provides cells expressing this protein with resistance to an antibiotic). The selection
marker can be a DHFR resistance gene. The selection marker can be a sequence encoding a DHFR mutein enzyme. The DHFR mutein enzyme can comprise, consist essentially of, or consist of the amino acid sequence of SEQ ID NO: 14677. The DHFR mutein enzyme is encoded by a nucleic acid sequence comprising, consisting essentially of, or consisting of the nucleic acid sequence of SEQ ID NO: 14678. The amino acid sequence of the DHFR mutein enzyme can further comprises a mutation at one or more of positions 80, 113, or 153. In some embodiments, the amino acid sequence of the DHFR mutein enzyme comprises one or more of a substitution of a Phenylalanine (F) or a Leucine (L) at position 80, a substitution of a Leucine (L) or a Valine (V) at position 113, and a substitution of a Valine (V) or an Aspartic Acid (D) at position 153.
[0166] The exogenous sequence can comprise, consist essential of, or consist of a sequence encoding an inducible proapoptotic polypeptide. The inducible proapoptotic polypeptide can be a inducible caspase polypeptide. The inducible proapoptotic polypeptide can comprise, consist essential of, or consist of (a) a ligand binding region, (b) a linker, and (c) a truncated caspase 9 polypeptide, wherein the inducible caspase polypeptide does not comprise a non-human sequence. In a one aspect, the non-human sequence is a restriction site.
[0167] In a one aspect, the ligand binding region inducible caspase polypeptide comprises a FK506 binding protein 12 (FKBP12) polypeptide. The amino acid sequence of the FK506 binding protein 12 (FKBP12) polypeptide can comprise, consist essential of, or consist of a modification at position 36 of the sequence. The modification can be a substitution of valine (V) for phenylalanine (F) at position 36 (F36V). The FKBP12 polypeptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14494. The FKBP12 polypeptide can be encoded by a nucleic acid sequence comprising, consisting essential of, or consisting of, the nucleic acid sequence of SEQ ID NO: 14495.
[0168] The linker region of the inducible proapoptotic polypeptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14496. The linker region of the inducible proapoptotic polypeptide can be encoded by a nucleic acid sequence comprising, consisting essential of, or consisting of, the nucleic acid sequence of SEQ ID NO: 14497.
[0169] The truncated caspase 9 polypeptide of the inducible proapoptotic polypeptide is encoded by an amino acid sequence that does not comprise an arginine (R) at position 87 of the
sequence. The truncated caspase 9 polypeptide of the inducible proapoptotic polypeptide is encoded by an amino acid sequence that does not comprise an alanine (A) at position 282 of the sequence. The truncated caspase 9 polypeptide of the inducible proapoptotic polypeptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14498. The truncated caspase 9 polypeptide of the inducible proapoptotic polypeptide can be encoded by a nucleic acid sequence comprising, consisting essential of, or consisting of, the nucleic acid sequence of SEQ ID NO: 14499.
[0170] The inducible proapoptotic polypeptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14503. The inducible proapoptotic polypeptide can be encoded by a nucleic acid sequence comprising, consisting essential of, or consisting of, the nucleic acid sequence of SEQ ID NO: 14636.
[0171] The transposon or the exogenous sequence can further comprise, consist essential of, or consist of at least one sequence encoding a self-cleaving peptide. The at least one self-cleaving peptide can comprise, consist essential of, or consist of T2A peptide, GSG-T2A peptide, an E2A peptide, a GSG-E2A peptide, an F2A peptide, a GSG-F2A peptide, a P2A peptide, or a GSG- P2A peptide. The GSG-T2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14638. The T2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14637. The E2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14639. The GSG- E2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14640. The F2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14641. The GSG-F2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14642. The P2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14643. The GSG- P2A peptide comprises, consists essential of, or consists of, the amino acid sequence of SEQ ID NO: 14644.
[0172] Exogenous sequences and transgenes suitable for use in the compositions and methods of the present disclosure are described in more detail herein.
[0173] The miRE sh49 BCL11 A of the disclosure is encoded by a sequence comprising SEQ ID NO: 14713.
[0174] The HBB T87Q of the disclosure comprises an amino acid sequence comprising SEQ ID NO: 14934. The GLA of the disclosure comprises an amino acid sequence comprising any one of SEQ ID NO: 5974 - SEQ ID NO: 5975. The IDETA of the disclosure comprises an amino acid sequence comprising any one of SEQ ID NO: 6715 - SEQ ID NO: 6720. The IDS of the disclosure comprises an amino acid sequence comprising any one of SEQ ID NO: 6709 - SEQ ID NO: 6714. The CTNS of the disclosure comprises an amino acid sequence comprising any one of SEQ ID NO: 3672 - SEQ ID NO: 3679.
[0175] The IGF2BP1 of the disclosure is encoded by a nucleic acid sequence sequence comprising SEQ ID NO: 14721.
[0176] The IGF2BP1 of the disclosure comprises an amino acid sequence sequence comprising SEQ ID NO: 14722.
[0177] The IL2RG of the disclosure is encoded by a nucleic acid sequence sequence comprising SEQ ID NO: 14718.
[0178] The IL2RG of the disclosure comprises an amino acid sequence sequence comprising: SEQ ID NO: 14723.
[0179] Exogenous sequences and transgenes suitable for use in the compositions and methods of the present disclosure are described in more detail herein
[0180] The present disclosure provides a population of modified cells produced by any of the methods disclosed herein. The present disclosure also provides a composition comprising, consisting essential of, or consisting of a population of modified cells produced by any of the methods disclosed herein. The present disclosure also provides a pharmaceutical composition comprising, consisting essential of, or consisting of a population of modified cells produced by any of the methods disclosed herein and a pharmaceutically-acceptable carrier.
[0181] The present disclosure provides a modified cell population wherein at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, at least 99.5%, at least 99.9% or 100% of the plurality of modified cells in the population comprise a genome-integrated transposon. The present disclosure also provides a composition comprising, consisting essential of, or consisting of a modified cell population wherein at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, at least 99.5%, at least 99.9% or 100% of the
plurality of modified cells in the population comprise a genome-integrated transposon. The present disclosure also provides a pharmaceutical composition comprising, consisting essential of, or consisting of a modified cell population wherein at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, at least 99.5%, at least 99.9% or 100% of the plurality of modified cells in the population comprise a genome-integrated transposon and a pharmaceutically-acceptable carrier. The genome- integrated transposon can comprise at least one of, at least two of, at least three of, at least four of, at least five of a sequence comprising a selection marker, a sequence encoding a chimeric antigen receptor (CAR), a sequence encoding a therapeutic agent, a sequence encoding an inducible proapoptotic polypeptide or a sequence encoding a self-cleaving peptide.
[0182] The population of cells or plurality of cells can comprise, consist essential of, or consist of somatic cells, germline cells, stem cells, or a combination thereof. A cell in the population of cells or plurality of cells can be a somatic cell, a germline cell or a stem cell.
[0183] The stem cells within the population of stem cells or plurality of stem cells can be induced pluripotent stem cells (iPSCs), hematopoietic stem cells (HSCs), embryonic stem cells, adult tissue stem cells, or a combination thereof. A stem cell within the population of stem cells or plurality of stem cells can be an induced pluripotent stem cell (iPSC), a hematopoietic stem cell (HSC), an embryonic stem cell or an adult tissue stem cell.
[0184] The population of cells or plurality of cells can comprise, consist essential of, or consist of mammalian cells. A cell in the population of cells or plurality of cells can be a mammalian cell. The population of cells or plurality of cells can comprise, consist essential of, or consist of human cells, non-human cells, or a combination thereof. A cell in the population of cells or plurality of cells can be a human cell. A cell in the population of cells or plurality of cells can be a non-human cell (not a human cell). Preferably, the population of cells or plurality of cells can comprise, consist essential of, or consist of human cells. Preferably, a cell in the population of cells or plurality of cells is a human cell.
[0185] The population of cells or plurality of cells can comprise, consist essential of, or consist of autologous cells. A cell in the population of cells or plurality of cells can be an autologous cell. The population of cells or plurality of cells can comprise, consist essential of, or consist of allogeneic cells. A cell in the population of cells or plurality of cells can be an allogeneic cell.
[0186] The population of cells or plurality of cells can be in vivo, ex vivo, in vitro or in situ. A cell in the population of cells or plurality of cells can be in vivo, ex vivo, in vitro or in situ.
[0187] The population of cells or plurality of cells can comprise, consist essential of, or consist of immune cells, neural cells, endothelial cells, epithelial cells, muscle cells, bone cells, hematopoeitic cells, or any combination thereof. A cell in the population of cells or plurality of cells can be an immune cell. A cell in the population of cells or plurality of cells can be a neural cell. A cell in the population of cells or plurality of cells can be an endothelial cell. A cell in the population of cells or plurality of cells can be an epithelial cell. A cell in the population of cells or plurality of cells can be a muscle cell. A cell in the population of cells or plurality of cells can be a bone cell. A cell in the population of cells or plurality of cells can be hematopoetic cell.
[0188] The immune cells within the population of immune cells or plurality of immune cells can be T-cells, Natural Killer (NK) cells, Natural Killer (NK)-like cells, hematopoeitic progenitor cells, or B-cells. An immune cell in the population of immune cells or plurality of immune cells can be a T-cell, a Natural Killer (NK) cell, a Natural Killer (NK)-like cell, a hematopoeitic progenitor cell, or a B-cell. The T-cell can be a stem memory T-cell (TSCM), a TscM-like cell, a peripheral blood (PB) derived T cell, an umbilical cord blood (UBC) derived T- cell, a helper T-cell, a cytotoxic T-cell, a regulatory T-cell or a gd T-cell.
[0189] A hematopoeitic stem cell (HSC) or HSC descendent cell can be isolated, derived or obtained from the peripheral blood, the umbilical cord blood, the bone marrow, a peritoneal dialysis effluent, an adult stem cell, or an induced pluripotent stem cell (iPSC) of a subject. The peripheral blood can comprise mobilized peripheral blood of a subject.
[0190] The cells in a population of cells or a plurality of cells can be isolated from, derived from or obtained from a healthy subject. The cells in a population of cells or a plurality of cells cannot be isolated from, derived from or obtained from a healthy subject. The cells in a population of cells or a plurality of cells cannot be isolated from, derived from or obtained from a non-healthy subject. The cells in a population of cells or a plurality of cells cannot be isolated from, derived from or obtained from a subject with a disease or disorder. In one aspect, the disease or disorder is a proliferation disorder. In one aspect, the proliferation disorder is cancer.
[0191] The cells in a population of cells or a plurality of cells isolated from, derived from or obtained from a non-healthy subject can be tumor cells or cancer cells. The cells in a population
of cells or a plurality of cells isolated from, derived from or obtained from a non-healthy subject can comprise, consist essential of, or consist of a genetic or epigenetic marker of a disease or disorder. In one aspect, the genetic or epigenetic marker causes the disease or disorder. In one aspect, the genetic or epigenetic marker predicts a risk of occurrence, a severity, or a prognosis of the disease or disorder. In one aspect, the disease or disorder is a proliferation disorder. In one aspect, the proliferation disorder is cancer.
[0192] Cells and/or populations of cells suitable for use in the compositions and methods of the present disclosure are described in more detail herein.
[0193] The transposon can be introduced to the cell or the plurality of cells by any means known in the art. The transposon can be introduced to the cell or the plurality of cells via nucleofection or electroporation. Conditions sufficient for transposition comprise a
nucleofection or an electroporation.
[0194] The nucleofection or the electroporation can comprise at least one of an application of one or more pulses of electricity at a specified voltage, a buffer, and one or more supplemental factor(s). The buffer can comprise PBS, HBSS, OptiMEM, BTXpress, Amaxa Nucleofector, Human T cell nucleofection buffer or any combination thereof. The one or more supplemental factor(s) comprise: (a) a recombinant human cytokine, a chemokine, an interleukin or any combination thereof; (b) a salt, a mineral, a metabolite or any combination thereof; (c) a cell medium; (d) an inhibitor of cellular DNA sensing, metabolism, differentiation, signal transduction, one or more apoptotic pathway(s) or combinations thereof; and/or (e) a reagent that modifies or stabilizes one or more nucleic acids.
[0195] The recombinant human cytokine, the chemokine, the interleukin or any combination thereof can comprise, consist essential of, or consist of IL2, IL7, IL12, IL15, IL21, IL1, IL3, IL4, IL5, IL6, IL8, CXCL8, IL9, IL10, IL11, IL13, IL14, IL16, IL17, IL18, IL19, IL20, IL22, IL23, IL25, IL26, IL27, IL28, IL29, IL30, IL31, IL32, IL33, IL35, IL36, GM-CSF, IFN-gamma, IF-l alpha/IF-lFl, IF-l beta/IF-lF2, IF-12 p70, IF-12/IF-35 p35, IF-13, IF-17/IF-17A, IF-17A/F Heterodimer, IF-17F, IF-18/IF-1F4, IF-23, IF-24, IF-32, IF-32 beta, IF-32 gamma, IF-33, FAP (TGF-beta 1), Fymphotoxin-alpha/TNF-beta, TGF-beta, TNF-alpha,
TRANCE/TNFSF1 l/RANK F, or any combination thereof.
[0196] The salt, the mineral, the metabolite or any combination thereof can comprise, consist essential of, or consist of HEPES, Nicotinamide, Heparin, Sodium Pyruvate, L-Glutamine, MEM Non-Essential Amino Acid Solution, Ascorbic Acid, Nucleosides, FBS/FCS, Human serum, serum-substitute, anti-biotics, pH adjusters, Earle’s Salts, 2-Mercaptoethanol, Human transferrin, Recombinant human insulin, Human serum albumin, Nucleofector PLUS Supplement, KCL, MgCI2, Na2HP04, NAH2PO4, Sodium lactobionate, Manitol, Sodium succinate, Sodium
Chloride, CINa, Glucose, Ca(NO3)2, Tris/HCl, K2HPO4, KH2PO4, Polyethylenimine, Poly- ethylene-glycol, Poloxamer 188, Poloxamer 181, Poloxamer 407, Poly-vinylpyrrolidone,
Pop3l3, Crown-5, or any combination thereof.
[0197] The cell medium can comprise, consist essential of, or consist of PBS, HBSS,
OptiMEM, DMEM, RPMI 1640, AIM-V, X-VIVO 15, CellGro DC Medium, CTS OpTimizer T Cell Expansion SFM, TexMACS Medium, PRIME-XV T Cell Expansion Medium,
ImmunoCult-XF T Cell Expansion Medium or any combination thereof.
[0198] The inhibitor of cellular DNA sensing, metabolism, differentiation, signal transduction, one or more apoptotic pathway(s) or combinations thereof can comprise, consist essential of, or consist of inhibitors of TLR9, MyD88, IRAK, TRAF6, TRAF3, IRF-7, NF-KB, Type 1
Interferons, pro- inflammatory cytokines, cGAS, STING, Sec5, TBK1, IRF-3, RNA pol III, RIG- 1, IPS-l, FADD, RIP1, TRAF3, AIM2, ASC, Caspasel, Pro-ILlB, PI3K, Akt, Wnt3A, glycogen synthase kinase-3P (GSK-3 b), TWS119, Bafilomycin, Chloroquine, Quinacrine, AC-YVAD- CMK, Z-VAD-FMK, Z-IETD-FMK or any combination thereof.
[0199] The reagent that modifies or stabilizes one or more nucleic acids can comprise, consist essential of, or consist of a pH modifier, a DNA-binding protein, a lipid, a phospholipid, CaPOr, a net neutral charge DNA binding peptide with or without a NLS sequence, a TREX1 enzyme or any combination thereof.
[0200] Methods of introducing exogenous sequences into cells and/or populations of cells, including nucleofection and electroporation, suitable for use in the compositions and methods of the present disclosure are described in more detail herein.
[0201] Methods of Use
[0202] The disclosure provides methods of transplantation comprising transplanting a therapeutically effective amount of a population of cells of the disclosure, a composition
comprising a population of cells of the disclosure or a pharmaceutical composition comprising a population of cells of the disclosure to a subject in need thereof. The disclosure provides a population of cells of the disclosure or a pharmaceutical composition comprising a population of cells of the disclosure for use in transplantation.
[0203] The disclosure provides methods of treating a subject for a disease or disorder, comprising administering to the subject a therapeutically effective amount of a population of cells of the disclosure, a composition comprising a population of cells of the disclosure or a pharmaceutical composition comprising a population of cells of the disclosure. The disclosure provides a population of cells of the disclosure or a pharmaceutical composition comprising a population of cells of the disclosure for use in treating a disease or disorder.
[0204] The disclosure provides methods of treating a subject for a disease or disorder, comprising administering to the subject a therapeutically effective amount of a population of modified cells of the disclosure, a composition comprising a population of modified cells of the disclosure or a pharmaceutical composition comprising a population of modified cells of the disclosure. The disclosure provides a population of modified cells of the disclosure or a pharmaceutical composition comprising a population of modified cells of the disclosure for use in treating a disease or disorder.
[0205] The population of cells of the disclosure, the composition comprising the population of cells of the disclosure or the pharmaceutical composition comprising the population of cells of the disclosure comprise a plurality of autologous cells. The population of cells of the disclosure, the composition comprising the population of cells of the disclosure or the pharmaceutical composition comprising the population of cells of the disclosure comprise a plurality of allogeneic cells.
[0206] The methods of treating a disease or disorder, methods of transplantation or methods of adoptive immunotherapy described herein can further comprise, consist essentially of or consist of administering a myeloablative agent. The myeloablative agent comprises low dose and/or local irradiation. The myeloablative agent comprises busulphan, treosulphan, melphalan, thiotepa or a combination thereof. The myeloablative agent can be administered prior to, after or concurrently with administration with the pharmaceutical compositions comprising the modified HSCs of the present invention.
[0207] The methods of treating a disease or disorder, methods of transplantation or methods of adoptive immunotherapy described herein can further comprise, consist essentially of or consist of administering an activating composition to induce or increase proliferation of the plurality modified HSCs in vivo. The activating composition can be administered prior to, after or concurrently with administration with the pharmaceutical compositions comprising the modified HSCs of the present invention.
[0208] A therapeutically-effective amount can be a single dose. The therapeutically-effective amount can be a single dose over a lifetime of the subject.
[0209] The compositions of the disclosure can be used to treat a disease or disorder including, but not limited to: Osteopetrosis, Parkinson’s Disease, Hunter Syndrome, Sickle Cell Disease, Severe Combined Immunodeficiency, Alpha-mannosidosis, Sideroblastic anemia, Autosomal Recessive Hyper IgE Syndrome, Primary Myelofibrosis, Cutaneous vasculitis, X-linked protoporphyria, Fucosidosis, Maroteaux Lamy syndrome, WAS Related Disorders, Chronic Granulomatous, Thalassemia Major, Hereditary Angioedema, Hereditary Lymphedemia, Hyper IgM Syndrome, Friedrich’s Ataxia, Charcot Marie Tooth Disease, Phenylketonuria,
Methylmalonic Acidemia, Adrenoleukodystrophy, Kugelberg Welander Syndrome, Retinitis Pigmentosa, Hydrocephalus, Hereditary Sensory and Autonomic Neuropathy Type IV,
Mucopolysaccharidosis Type III, Corneal Dystrophies, Erythropoietic Protoporphyria, Fabry Disease, Werdnig-Hoffman Disease, Hypoposphatasia, Coats Disease, Fanconi Anemia, Niemann Pick Disease, Crigler-Najjar Syndrome, Hemophilia A, Hemophilia B,
Feukodystrophy, Sandhoff Disease, Fisher Syndrome, Wolman Disease, Dupuytren’s
Contracture, Wolfram Syndrome, X-Finked Myotubular Myopathy, Canavan Disease, Ehler’s Danlos Syndrome, Epidermolysis Bullosa, Osteogenesis Imperfecta, Short Bowel Syndrome, Giant Axonal Neuropathy, Paroxysmal Nocturnal Hemoglobinuria, Phelan-McDermid
Syndrome, Retinoschisis, Beta-Thalassemia, Hypophosphatasia, Propionic Acidemia,
Cholesteryl Ester Storage Disease, Cystinosis, Glycogen Storage Disease Type II Pompe Disease, Mucopolysaccharidoses (MPS I H-S Hurler-Scheie), Mucopolysaccharidoses (Type II (Hunter syndrome)), and Mucopolysaccharidoses (Type IV (Morquio)).
[0210] The compositions of the disclosure may be used to treat a disease or disorder by use of a therapeutic transgene encoding for an exogenous nucleic acid sequence or exogenous amino acid
sequence. For certain diseases or disorders the therapeutic transgene can include [Disease (therapeutic transge): Beta-Thalassemia (HBB T87Q, BCL11 A shRNA, IGF2BP1), Sickle Cell Disease (HBB T87Q, BCL11 A shRNA, IGF2BP1), Hemophilia A (Factor VIII), Hemophilia B (Factor IX), X-linked Severe Combined Immunodeficiency (Interleukin 2 receptor gamma (IL2RG)), Hypophosphatasia (Tissue Non-specific Alkaline Phosphatase (TNAP)),
Osteopetrosis (TCIRG1), Glycogen Storage Disease Type II (Pompe Disease) (Alpha
Glucosidase (GAA)), Alpha-Galactosidase A Deficiency (Fabry disease) (Alpha-galactosidase A (GLA)), Mucopolysaccharidosis Type I (MPS I) (Alpha-L-iduronidase (IDUA)),
Mucopolysaccharidosis Type II (MPS II) (Iduronate 2-sulfatase (IDS)), Mucopolysaccharidosis Type IIIA (MPS IIIA) (sulfoglycosamine-sulfohydrolase (SGSH)), Mucopolysaccharidosis Type IIIB (MPS IIIB) (N-alpha-acetylglucosaminidase (NAGLU)), Mucopolysaccharidosis Type IV A (MPS IV A) (Morquio) (N-acetylgalactosamine-6-sulfate sulfatase (GALNS)),
Mucopolysaccharidosis Type IV B (MPS IVB) Beta-galactosidase (GLB1 (Beta-galactosidase (GLB1)), Cholesteryl Ester Storage Disease (CESD) (Lysosomal acid lipase (LIP A)), Cystinosis (Cystinosin lysosomal cystine transporter (CTNS)), X-linked chronic granulomatous disease (X- CGD) (CYBB), Wiskott-Aldrich Syndrome (WAS) (WAS), X-linked Adrenoleukodystrophy (X- ALD) (ABCD1), Metachromatic leukopdystrophy (MLD) (ARSA), Phenylketonuria (PAH), Methylmalonic academia (MMUT), Propionic Acidemia (PCCA, PCCB), Retinitis Pigmentosa (RPE65), Usher Syndrome (MY07A), and Gaucher Disease (GBA).
[0211] Administration of the population of cells can be systemic. Administration of the population of cells can be intravenous, local, intra-tumoral, intraspinal, intracerebroventricular, intraocular or intraosseous. In some aspects, the administration is direct to the cerebral spinal fluid (CSF).
[0212] Methods of using the compositions and methods of the present disclosure are described in more detail herein.
[0213] Transposons of the disclosure may be episomally maintained or integrated into the genome of the recombinant/modified cell.
[0214] Exemplary transposon/transposase systems of the disclosure include, but are not limited to, piggyBac and piggyBac-like transposons and transposases, Sleeping Beauty transposons and transposases, Helraiser transposons and transposases and Tol2 transposons and transposases.
[0215] The piggyBac transposase recognizes transposon-specific inverted terminal repeat sequences (ITRs) on the ends of the transposon, and moves the contents between the ITRs into TTAA chromosomal sites. The piggyBac transposon system has no payload limit for the genes of interest that can be included between the ITRs. In certain embodiments, and, in particular, those embodiments wherein the transposon is a piggyBac transposon, the transposase is a piggyBac™ or a Super piggyBac™ (SPB) transposase. In certain embodiments, and, in particular, those embodiments wherein the transposase is a Super piggyBac™ (SPB) transposase, the sequence encoding the transposase is an mRNA sequence.
[0216] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac™ (PB) transposase enzyme. The piggyBac (PB) transposase enzyme may comprise or consist of an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:

[0217] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac™ (PB) transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at one or more of positions 30, 165, 282, or 538 of the sequence:


[0218] In certain embodiments, the transposase enzyme is a piggyBac™ (PB) transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at two or more of positions 30, 165, 282, or 538 of the sequence of SEQ ID NO: 14487. In certain embodiments, the transposase enzyme is a piggyBac™ (PB) transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at three or more of positions 30, 165, 282, or 538 of the sequence of SEQ ID NO: 14487. In certain embodiments, the transposase enzyme is a piggyBac™ (PB) transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at each of the following positions 30, 165, 282, and 538 of the sequence of SEQ ID NO: 14487. In certain embodiments, the amino acid substitution at position 30 of the sequence of SEQ ID NO: 14487 is a substitution of a valine (V) for an isoleucine (I). In certain embodiments, the amino acid substitution at position 165 of the sequence of SEQ ID NO: 14487 is a substitution of a serine (S) for a glycine (G). In certain embodiments, the amino acid substitution at position 282 of the sequence of SEQ ID NO: 14487 is a substitution of a valine (V) for a methionine (M). In certain embodiments, the amino acid substitution at position 538 of the sequence of SEQ ID NO: 14487 is a substitution of a lysine (K) for an asparagine (N).
[0219] In certain embodiments of the methods of the disclosure, the transposase enzyme is a Super piggyBac™ (SPB) transposase enzyme. In certain embodiments, the Super piggyBac™ (SPB) transposase enzymes of the disclosure may comprise or consist of the amino acid sequence of the sequence of SEQ ID NO: 14487 wherein the amino acid substitution at position 30 is a substitution of a valine (V) for an isoleucine (I), the amino acid substitution at position 165 is a substitution of a serine (S) for a glycine (G), the amino acid substitution at position 282 is a substitution of a valine (V) for a methionine (M), and the amino acid substitution at position 538 is a substitution of a lysine (K) for an asparagine (N). In certain embodiments, the Super piggyBac™ (SPB) transposase enzyme may comprise or consist of an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:

[0220] In certain embodiments of the methods of the disclosure, including those embodiments wherein the transposase comprises the above-described mutations at positions 30, 165, 282 and/or 538, the piggyBac™ or Super piggyBac™ transposase enzyme may further comprise an amino acid substitution at one or more of positions 3, 46, 82, 103, 119, 125, 177, 180, 185, 187,
200, 207, 209, 226, 235, 240, 241, 243, 258, 296, 298, 311, 315, 319, 327, 328, 340, 421, 436, 456, 470, 486, 503, 552, 570 and 591 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484. In certain embodiments, including those embodiments wherein the transposase comprises the above-described mutations at positions 30, 165, 282 and/or 538, the piggyBac™ or Super piggyBac™ transposase enzyme may further comprise an amino acid substitution at one or more of positions 46, 119, 125, 177, 180, 185, 187, 200, 207, 209, 226, 235, 240, 241, 243, 296, 298, 311, 315, 319, 327, 328, 340, 421, 436, 456, 470, 485, 503, 552 and 570. In certain
embodiments, the amino acid substitution at position 3 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an asparagine (N) for a serine (S). In certain embodiments, the amino acid substitution at position 46 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a serine (S) for an alanine (A). In certain embodiments, the amino acid substitution at position 46 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a threonine (T) for an alanine (A). In certain embodiments, the amino acid substitution at position 82 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tryptophan (W) for an isoleucine (I). In certain embodiments, the amino acid substitution at position 103 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a serine (S). In certain embodiments, the amino acid substitution at position 119 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a
proline (P) for an arginine (R). In certain embodiments, the amino acid substitution at position 125 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) a cysteine (C). In certain embodiments, the amino acid substitution at position 125 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a cysteine (C). In certain
embodiments, the amino acid substitution at position 177 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a tyrosine (Y). In certain embodiments, the amino acid substitution at position 177 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a histidine (H) for a tyrosine (Y). In certain embodiments, the amino acid substitution at position 180 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a phenylalanine (F). In certain embodiments, the amino acid substitution at position 180 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a phenylalanine (F). In certain embodiments, the amino acid substitution at position 180 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a phenylalanine (F). In certain embodiments, the amino acid substitution at position 185 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a methionine (M). In certain embodiments, the amino acid substitution at position 187 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for an alanine (A). In certain embodiments, the amino acid substitution at position 200 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tryptophan (W) for a phenylalanine (F).In certain embodiments, the amino acid substitution at position 207 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a valine (V). In certain embodiments, the amino acid substitution at position 209 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a valine (V). In certain embodiments, the amino acid substitution at position 226 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a methionine (M). In certain embodiments, the amino acid substitution at position 235 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an arginine (R) for a leucine (L). In certain embodiments, the amino acid substitution at position 240 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a valine (V). In certain embodiments, the amino acid substitution at position 241 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a phenylalanine (F). In certain embodiments, the amino acid substitution at position 243 of SEQ ID NO: 14487 or SEQ ID NO:
14484 is a substitution of a lysine (K) for a proline (P). In certain embodiments, the amino acid substitution at position 258 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a serine (S) for an asparagine (N). In certain embodiments, the amino acid substitution at position 296 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tryptophan (W) for a leucine (L). In certain embodiments, the amino acid substitution at position 296 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tyrosine (Y) for a leucine (L). In certain embodiments, the amino acid substitution at position 296 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a leucine (L). In certain embodiments, the amino acid substitution at position 298 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a methionine (M). In certain embodiments, the amino acid substitution at position 298 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) for a methionine (M). In certain embodiments, the amino acid substitution at position 298 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a methionine (M). In certain embodiments, the amino acid substitution at position 311 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a proline (P). In certain embodiments, the amino acid substitution at position 311 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine for a proline (P). In certain embodiments, the amino acid substitution at position 315 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for an arginine (R).In certain embodiments, the amino acid substitution at position 319 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for a threonine (T). In certain embodiments, the amino acid substitution at position 327 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an arginine (R) for a tyrosine (Y). In certain embodiments, the amino acid substitution at position 328 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a tyrosine (Y). In certain embodiments, the amino acid substitution at position 340 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for a cysteine (C). In certain embodiments, the amino acid substitution at position 340 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a cysteine (C). In certain embodiments, the amino acid substitution at position 421 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a histidine (H) for the aspartic acid (D). In certain embodiments, the amino acid substitution at position 436 of SEQ ID
NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a valine (V). In certain embodiments, the amino acid substitution at position 456 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tyrosine (Y) for a methionine (M). In certain embodiments, the amino acid substitution at position 470 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a leucine (L). In certain embodiments, the amino acid substitution at position 485 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a serine (S). In certain embodiments, the amino acid substitution at position 503 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a methionine (M). In certain embodiments, the amino acid substitution at position 503 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a methionine (M). In certain embodiments, the amino acid substitution at position 552 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a valine (V). In certain embodiments, the amino acid substitution at position 570 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a threonine (T) for an alanine (A). In certain embodiments, the amino acid substitution at position 591 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a glutamine (Q). In certain embodiments, the amino acid substitution at position 591 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an arginine (R) for a glutamine (Q).
[0221] In certain embodiments of the methods of the disclosure, including those embodiments wherein the transposase comprises the above-described mutations at positions 30, 165, 282 and/or 538, the piggyBac™ transposase enzyme may comprise or the Super piggyBac™ transposase enzyme may further comprise an amino acid substitution at one or more of positions 103, 194, 372, 375, 450, 509 and 570 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484. In certain embodiments of the methods of the disclosure, including those embodiments wherein the transposase comprises the above-described mutations at positions 30, 165, 282 and/or 538, the piggyBac™ transposase enzyme may comprise or the Super piggyBac™ transposase enzyme may further comprise an amino acid substitution at two, three, four, five, six or more of positions 103, 194, 372, 375, 450, 509 and 570 of the sequence of SEQ ID NO:
14487 or SEQ ID NO: 14484. In certain embodiments, including those embodiments wherein the transposase comprises the above-described mutations at positions 30, 165, 282 and/or 538, the piggyBac™ transposase enzyme may comprise or the Super piggyBac™ transposase enzyme
may further comprise an amino acid substitution at positions 103, 194, 372, 375, 450, 509 and 570 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484. In certain embodiments, the amino acid substitution at position 103 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a serine (S). In certain embodiments, the amino acid substitution at position 194 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a methionine (M). In certain embodiments, the amino acid substitution at position 372 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) for an arginine (R). In certain embodiments, the amino acid substitution at position 375 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) for a lysine (K). In certain embodiments, the amino acid substitution at position 450 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an asparagine (N) for an aspartic acid (D). In certain embodiments, the amino acid substitution at position 509 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for a serine (S). In certain embodiments, the amino acid substitution at position 570 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a serine (S) for an asparagine (N). In certain embodiments, the piggyBac™ transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487. In certain
embodiments, including those embodiments wherein the piggyBac™ transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487, the piggyBac™ transposase enzyme may further comprise an amino acid substitution at positions 372, 375 and 450 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484. In certain embodiments, the piggyBac™ transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487, a substitution of an alanine (A) for an arginine (R) at position 372 of SEQ ID NO: 14487, and a substitution of an alanine (A) for a lysine (K) at position 375 of SEQ ID NO: 14487. In certain embodiments, the piggyBac™ transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487, a substitution of an alanine (A) for an arginine (R) at position 372 of SEQ ID NO: 14487, a substitution of an alanine (A) for a lysine (K) at position 375 of SEQ ID NO: 14487 and a substitution of an asparagine (N) for an aspartic acid (D) at position 450 of SEQ ID NO: 14487.
[0222] The sleeping beauty transposon is transposed into the target genome by the Sleeping Beauty transposase that recognizes ITRs, and moves the contents between the ITRs into TA chromosomal sites. In various embodiments, SB transposon-mediated gene transfer, or gene transfer using any of a number of similar transposons, may be used in the compositions and methods of the disclosure.
[0223] In certain embodiments, and, in particular, those embodiments wherein the transposon is a Sleeping Beauty transposon, the transposase is a Sleeping Beauty transposase or a hyperactive Sleeping Beauty transposase (SB100X).
[0224] In certain embodiments of the methods of the disclosure, the Sleeping Beauty transposase enzyme comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:

[0225] In certain embodiments of the methods of the disclosure, the hyperactive Sleeping Beauty (SB100X) transposase enzyme comprises an amino acid sequence at least 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:

[0226] The Helraiser transposon is transposed by the Helitron transposase. Helitron
transposases mobilize the Helraiser transposon, an ancient element from the bat genome that was active about 30 to 36 million years ago. An exemplary Helraiser transposon of the disclosure includes Helibatl, which comprises a nucleic acid sequence comprising:




[0227] Unlike other transposases, the Helitron transposase does not contain an RNase-H like catalytic domain, but instead comprises a RepHel motif made up of a replication initiator domain
(Rep) and a DNA helicase domain. The Rep domain is a nuclease domain of the HUH superfamily of nucleases.
[0228] An exemplary Helitron transposase of the disclosure comprises an amino acid sequence comprising:


[0229] In Helitron transpositions, a hairpin close to the 3’ end of the transposon functions as a terminator. However, this hairpin can be bypassed by the transposase, resulting in the transduction of flanking sequences. In addition, Helraiser transposition generates covalently closed circular intermediates. Furthermore, Helitron transpositions can lack target site duplications. In the Helraiser sequence, the transposase is flanked by 5’ and 3’ terminal sequences termed LTS and RTS. These sequences terminate with a conserved 5’-TC/CTAG-3’ motif. A 19 bp palindromic sequence with the potential to form the hairpin termination structure is located 11 nucleotides upstream of the RTS and consists of the sequence
GTGCACGAATTTCGTGCACCGGGCCACTAG (SEQ ID NO: 14500).
[0230] Tol2 transposons may be isolated or derived from the genome of the medaka fish, and may be similar to transposons of the hAT family. Exemplary Tol2 transposons of the disclosure are encoded by a sequence comprising about 4.7 kilobases and contain a gene encoding the Tol2 transposase, which contains four exons. An exemplary Tol2 transposase of the disclosure comprises an amino acid sequence comprising the following:


[0231] An exemplary Tol2 transposon of the disclosure, including inverted repeats, subterminal sequences and the Tol2 transposase, is encoded by a nucleic acid sequence comprising the following:



[0232] Exemplary transposon/transposase systems of the disclosure include, but are not limited to, piggyBac and piggyBac-like transposons and transposases.
[0233] PiggyBac and piggyBac-like transposases recognizes transposon-specific inverted terminal repeat sequences (ITRs) on the ends of the transposon, and moves the contents between the ITRs into TTAA or TTAT chromosomal sites. The piggyBac or piggyBac-like transposon system has no payload limit for the genes of interest that can be included between the ITRs.
[0234] In certain embodiments, and, in particular, those embodiments wherein the transposon is a piggyBac transposon, the transposase is a piggyBac™, Super piggyBac™ (SPB) transposase. In certain embodiments, and, in particular, those embodiments wherein the transposase is a piggyBac™, Super piggyBac™ (SPB), the sequence encoding the transposase is an mRNA sequence.
[0235] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme.
[0236] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or a piggyBac-like transposase enzyme. The piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%,
20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:

[0237] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at one or more of positions 30, 165, 282, or 538 of the sequence:

[0238] In certain embodiments, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at two or more of positions 30, 165, 282, or 538 of the sequence of SEQ ID NO: 14487. In certain embodiments, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at three or more of positions 30, 165, 282, or 538 of the sequence of SEQ ID NO:
14487. In certain embodiments, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme that comprises or consists of an amino acid sequence having an amino acid substitution at each of the following positions 30, 165, 282, and 538 of the sequence of SEQ ID NO: 14487. In certain embodiments, the amino acid substitution at position 30 of the sequence of SEQ ID NO: 14487 is a substitution of a valine (V) for an isoleucine (I). In certain embodiments, the amino acid substitution at position 165 of the sequence of SEQ ID NO: 14487 is a substitution of a serine (S) for a glycine (G). In certain embodiments, the amino acid substitution at position 282 of the sequence of SEQ ID NO: 14487 is a substitution of a valine (V) for a methionine (M). In certain embodiments, the amino acid substitution at position 538 of the sequence of SEQ ID NO: 14487 is a substitution of a lysine (K) for an asparagine (N).
[0239] In certain embodiments of the methods of the disclosure, the transposase enzyme is a Super piggyBac™ (SPB) or piggyBac-like transposase enzyme. In certain embodiments, the Super piggyBac™ (SPB) or piggyBac-like transposase enzyme of the disclosure may comprise or consist of the amino acid sequence of the sequence of SEQ ID NO: 14487 wherein the amino acid substitution at position 30 is a substitution of a valine (V) for an isoleucine (I), the amino acid substitution at position 165 is a substitution of a serine (S) for a glycine (G), the amino acid substitution at position 282 is a substitution of a valine (V) for a methionine (M), and the amino acid substitution at position 538 is a substitution of a lysine (K) for an asparagine (N). In certain embodiments, the Super piggyBac™ (SPB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:

[0240] In certain embodiments of the methods of the disclosure, including those embodiments wherein the transposase comprises the above-described mutations at positions 30, 165, 282 and/or 538, the piggyBac™, Super piggyBac™ or piggyBac-like transposase enzyme may further comprise an amino acid substitution at one or more of positions 3, 46, 82, 103, 119, 125, 177, 180, 185, 187, 200, 207, 209, 226, 235, 240, 241, 243, 258, 296, 298, 311, 315, 319, 327,
328, 340, 421, 436, 456, 470, 486, 503, 552, 570 and 591 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484. In certain embodiments, including those embodiments wherein the transposase comprises the above-described mutations at positions 30, 165, 282 and/or 538, the piggyBac™, Super piggyBac™ or piggyBac-like transposase enzyme may further comprise an amino acid substitution at one or more of positions 46, 119, 125, 177, 180, 185, 187, 200, 207,
209, 226, 235, 240, 241, 243, 296, 298, 311, 315, 319, 327, 328, 340, 421, 436, 456, 470, 485,
503, 552 and 570. In certain embodiments, the amino acid substitution at position 3 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an asparagine (N) for a serine (S). In certain embodiments, the amino acid substitution at position 46 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a serine (S) for an alanine (A). In certain embodiments, the amino acid substitution at position 46 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a threonine (T) for an alanine (A). In certain embodiments, the amino acid substitution at position 82 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tryptophan (W) for an isoleucine (I). In certain embodiments, the amino acid substitution at position 103 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a serine (S). In certain embodiments, the amino acid substitution at position 119 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for an arginine (R). In certain embodiments, the amino acid substitution at position 125 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) a cysteine (C). In certain embodiments, the amino acid substitution at position 125 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a cysteine (C). In certain embodiments, the amino acid substitution at position 177 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a tyrosine (Y). In certain embodiments, the amino acid substitution at position 177 of SEQ ID NO: 14487
or SEQ ID NO: 14484 is a substitution of a histidine (H) for a tyrosine (Y). In certain embodiments, the amino acid substitution at position 180 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a phenylalanine (F). In certain embodiments, the amino acid substitution at position 180 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a phenylalanine (F). In certain embodiments, the amino acid substitution at position 180 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a phenylalanine (F). In certain embodiments, the amino acid substitution at position 185 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a methionine (M). In certain embodiments, the amino acid substitution at position 187 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for an alanine (A). In certain embodiments, the amino acid substitution at position 200 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tryptophan (W) for a phenylalanine (F). In certain embodiments, the amino acid substitution at position 207 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a valine (V). In certain embodiments, the amino acid substitution at position 209 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a valine (V). In certain embodiments, the amino acid substitution at position 226 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a methionine (M). In certain embodiments, the amino acid substitution at position 235 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an arginine (R) for a leucine (L). In certain
embodiments, the amino acid substitution at position 240 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a valine (V). In certain embodiments, the amino acid substitution at position 241 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a phenylalanine (F). In certain embodiments, the amino acid substitution at position 243 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a proline (P). In certain embodiments, the amino acid substitution at position 258 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a serine (S) for an asparagine (N). In certain embodiments, the amino acid substitution at position 296 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tryptophan (W) for a leucine (L). In certain embodiments, the amino acid substitution at position 296 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tyrosine (Y) for a leucine (L). In certain embodiments, the amino acid substitution at position
296 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a leucine (L). In certain embodiments, the amino acid substitution at position 298 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a methionine (M). In certain embodiments, the amino acid substitution at position 298 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) for a methionine (M). In certain embodiments, the amino acid substitution at position 298 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a methionine (M). In certain embodiments, the amino acid substitution at position 311 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a proline (P). In certain embodiments, the amino acid substitution at position 311 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine for a proline (P).
In certain embodiments, the amino acid substitution at position 315 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for an arginine (R).In certain embodiments, the amino acid substitution at position 319 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for a threonine (T). In certain embodiments, the amino acid substitution at position 327 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an arginine (R) for a tyrosine (Y). In certain embodiments, the amino acid substitution at position 328 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a tyrosine (Y). In certain embodiments, the amino acid substitution at position 340 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for a cysteine (C). In certain
embodiments, the amino acid substitution at position 340 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a cysteine (C). In certain embodiments, the amino acid substitution at position 421 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a histidine (H) for the aspartic acid (D). In certain embodiments, the amino acid substitution at position 436 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a valine (V). In certain embodiments, the amino acid substitution at position 456 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a tyrosine (Y) for a methionine (M). In certain embodiments, the amino acid substitution at position 470 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a phenylalanine (F) for a leucine (L). In certain embodiments, the amino acid substitution at position 485 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a serine (S). In certain embodiments, the amino acid substitution
at position 503 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a leucine (L) for a methionine (M). In certain embodiments, the amino acid substitution at position 503 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an isoleucine (I) for a methionine (M). In certain embodiments, the amino acid substitution at position 552 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a lysine (K) for a valine (V). In certain embodiments, the amino acid substitution at position 570 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a threonine (T) for an alanine (A). In certain embodiments, the amino acid substitution at position 591 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a glutamine (Q). In certain embodiments, the amino acid substitution at position 591 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an arginine (R) for a glutamine (Q).
[0241] In certain embodiments of the methods of the disclosure, including those embodiments wherein the transposase comprises the above-described mutations at positions 30, 165, 282 and/or 538, the piggyBac™ or piggyBac-like transposase enzyme or may comprise or the Super piggyBac™ transposase enzyme may further comprise an amino acid substitution at one or more of positions 103, 194, 372, 375, 450, 509 and 570 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484. In certain embodiments of the methods of the disclosure, including those embodiments wherein the transposase comprises the above-described mutations at positions 30, 165, 282 and/or 538, the piggyBac™ or piggyBac-like transposase enzyme may comprise or the Super piggyBac™ transposase enzyme may further comprise an amino acid substitution at two, three, four, five, six or more of positions 103, 194, 372, 375, 450, 509 and 570 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484. In certain embodiments, including those embodiments wherein the transposase comprises the above-described mutations at positions 30, 165, 282 and/or 538, the piggyBac™ or piggyBac-like transposase enzyme may comprise or the Super piggyBac™ transposase enzyme may further comprise an amino acid substitution at positions 103, 194, 372, 375, 450, 509 and 570 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484. In certain embodiments, the amino acid substitution at position 103 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a proline (P) for a serine (S). In certain embodiments, the amino acid substitution at position 194 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a valine (V) for a methionine (M). In certain embodiments, the amino
acid substitution at position 372 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) for an arginine (R). In certain embodiments, the amino acid substitution at position 375 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an alanine (A) for a lysine (K). In certain embodiments, the amino acid substitution at position 450 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of an asparagine (N) for an aspartic acid (D). In certain embodiments, the amino acid substitution at position 509 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a glycine (G) for a serine (S). In certain embodiments, the amino acid substitution at position 570 of SEQ ID NO: 14487 or SEQ ID NO: 14484 is a substitution of a serine (S) for an asparagine (N). In certain embodiments, the piggyBac™ or piggyBac-like transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487. In certain embodiments, including those
embodiments wherein the piggyBac™ or piggyBac-like transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487, the piggyBac™ or piggyBac-like transposase enzyme may further comprise an amino acid substitution at positions 372, 375 and 450 of the sequence of SEQ ID NO: 14487 or SEQ ID NO: 14484. In certain embodiments, the piggyBac™ or piggyBac-like transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487, a substitution of an alanine (A) for an arginine (R) at position 372 of SEQ ID NO: 14487, and a substitution of an alanine (A) for a lysine (K) at position 375 of SEQ ID NO: 14487. In certain embodiments, the piggyBac™ or piggyBac-like transposase enzyme may comprise a substitution of a valine (V) for a methionine (M) at position 194 of SEQ ID NO: 14487, a substitution of an alanine (A) for an arginine (R) at position 372 of SEQ ID NO: 14487, a substitution of an alanine (A) for a lysine (K) at position 375 of SEQ ID NO: 14487 and a substitution of an asparagine (N) for an aspartic acid (D) at position 450 of SEQ ID NO: 14487.
[0242] In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from an insect. In certain embodiments, the insect is Trichoplusia ni (GenBank
Accession No. AAA87375; SEQ ID NO: 14647), Argyrogramma agnata (GenBank Accession No. GU477713; SEQ ID NO: 14534, SEQ ID NO: 14648), Anopheles gambiae (GenBank Accession No. CR_312615 (SEQ ID NO: 14772); GenBank Accession No. XP_3204l4 (SEQ ID NO: 14650); GenBank Accession No. XP_310729 (SEQ ID NO: 14651)), Aphis gossypii
(GenBank Accession No. GU329918; SEQ ID NO: 14652, SEQ ID NO: 14653), Acyrthosiphon pisum (GenBank Accession No. XP 001948139; SEQ ID NO: 14654), Agrotis ipsilon (GenBank Accession No. GU477714; SEQ ID NO: 14537, SEQ ID NO: 14655), Bombyx mori (GenBank Accession No. BAD11135; SEQ ID NO: 14505), Chilo suppressalis (GenBank Accession No. JX294476; SEQ ID NO: 14656, SEQ ID NO: 14657), Drosophila melanogaster (GenBank Accession No. AAL39784; SEQ ID NO: 14658), Helicoverpa armigera (GenBank Accession No. ABS18391; SEQ ID NO: 14525), Heliothis virescens (GenBank Accession No. ABD76335; SEQ ID NO: 14659), Macdunnoughia crassisigna (GenBank Accession No. EU287451 ; SEQ ID NO: 14660, SEQ ID NO: 14900), Pectinophora gossypiella (GenBank Accession No.
GU270322; SEQ ID NO: 14530, SEQ ID NO: 14735), Tribolium castaneum (GenBank
Accession No. XP 001814566; SEQ ID NO: 14663), Ctenoplusia agnata (also called
Argyrogramma agnata), Messour bouvieri, Megachile rotundata, Bombus impatiens, Mamestra brassicae, Mayetiola destructor or A pis mellifera.
[0243] In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from an insect. In certain embodiments, the insect is Trichoplusia ni (AAA87375).
[0244] In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from an insect. In certain embodiments, the insect is Bombyx mori (BAD11135).
[0245] In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from a crustacean. In certain embodiments, the crustacean is Daphnia pulicaria
(AAM76342, SEQ ID NO: 14664).
[0246] In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from a vertebrate. In certain embodiments, the vertebrate is Xenopus tropicalis
(GenBank Accession No. BAF82026; SEQ ID NO: 14518), Homo sapiens (GenBank Accession No. NP_689808; SEQ ID NO: 14665), Mus musculus (GenBank Accession No. NP_74l958; SEQ ID NO: 14666), Macaca fascicularis (GenBank Accession No. AB179012; SEQ ID NO: 14667, SEQ ID NO: 14668), Rattus norvegicus (GenBank Accession No. XP 220453; SEQ ID NO: 14669) or Myotis lucifugus.
[0247] In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from a urochordate. In certain embodiments, the urochordate is Ciona intestinalis (GenBank Accession No. XP_002l23602; SEQ ID NO: 14670).
[0248] In certain embodiments, the piggyBac or piggyBac-like transposase inserts a transposon at the sequence 5’-TTAT-3’ within a chromosomal site (a TTAT target sequence).
[0249] In certain embodiments, the piggyBac or piggyBac-like transposase inserts a transposon at the sequence 5’-TTAA-3’ within a chromosomal site (a TTAA target sequence).
[0250] In certain embodiments, the target sequence of the piggyBac or piggyBac-like transposon comprises or consists of 5’-CTAA-3’, 5’-TTAG-3’, 5’-ATAA-3’, 5’-TCAA-3’, 5’AGTT-3’, 5’- ATTA-3’, 5’-GTTA-3’, 5’-TTGA-3’, 5’-TTTA-3’, 5’-TTAC-3’, 5’-ACTA-3’, 5’-AGGG-3’, 5’- CTAG-3’, 5’-TGAA-3’, 5’-AGGT-3’, 5’-ATCA-3’, 5’-CTCC-3’, 5’-TAAA-3’, 5’-TCTC-3’, 5’TGAA-3’, 5’-AAAT-3’, 5’-AATC-3’, 5’-ACAA-3’, 5’-ACAT-3’, 5’-ACTC-3’, 5’-AGTG-3’,
5’-AT AG-3’, 5’-CAAA-3’, 5’-CACA-3’, 5’-CATA-3’, 5’-CCAG-3’, 5’-CCCA-3’, 5’-CGTA-3’, 5’-GTCC-3’, 5’-TAAG-3’, 5’-TCTA-3’, 5’-TGAG-3’, 5’-TGTT-3’, 5’-TTCA-3’5’-TTCT-3’ and 5’-TTTT-3’.
[0251] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme. In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Bombyx mori. The piggyBac or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%,
90%, 95%, 99% or any percentage in between identical to:

[0252] The piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%,
65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:


[0253] In certain embodiments, the piggyBac or piggyBac-like transposase is fused to a nuclear localization signal. In certain embodiments, the amino acid sequence of the piggyBac or piggyBac-like transposase fused to a nuclear localization signal is encoded by a polynucleotide sequence comprising:

[0254] In certain embodiments, the piggyBac or piggyBac-like transposase is hyperactive. A hyperactive piggyBac or piggyBac-like transposase is a transposase that is more active than the naturally occurring variant from which it is derived. In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase enzyme is isolated or derived from Bombyx mori. In
certain embodiments, the piggyBac or piggyBac-like transposase is a hyperactive variant of SEQ ID NO: 14505. In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence that is at least 90% identical to:

[0255] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14576. In certain embodiments, the hyperactive piggyBac or piggyBac- like transposase comprises a sequence of:

[0256] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:

[0257] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:


[0258] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:

[0259] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:

[0260] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase is more active than the transposase of SEQ ID NO: 14505. In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase is at least 90%, at least 95%, at least 96%, at least 97%, at least 98%, or at least 99% or any percentage in between identical to SEQ ID NO: 14505.
[0261] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises an amino acid substitution at a position selected from 92, 93, 96, 97, 165, 178, 189, 196, 200, 201, 211, 215, 235, 238, 246, 253, 258, 261, 263, 271, 303, 321, 324, 330, 373, 389, 399, 402, 403, 404, 448, 473, 484, 507,5 23, 527, 528, 543, 549, 550, 557,6 01, 605, 607, 609,
610 or a combination thereof (relative to SEQ ID NO: 14505). In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises an amino acid substitution of Q92A, V93L, V93M, P96G, F97H, F97C, H165E, H165W, E178S, E178H, C189P, A196G, F200I, A201Q, F211A, W215Y, G219S, Q235Y, Q235G, Q238F, K246I, K253V, M258V, F261F, S263K, C271S, N303R, F321W, F321D, V324K, V324H, A330V, F373C, F373V, V389F, S399N, R402K, T403F, D404Q, D404S, D404M, N441R, G448W, E449A, V469T, C473Q, R484K T507C, G523A, I527M, Y528K Y543I, E549A, K550M, P557S, E601V, E605H, E605W, D607H, S609H, F610I or any combination thereof. In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises an amino acid substitution of Q92A, V93F, V93M, P96G, F97H, F97C, H165E, H165W, E178S, E178H, C189P, A196G, F200I, A201Q, F211A, W215Y, G219S, Q235Y, Q235G, Q238F, K246I, K253V, M258V, F261F, S263K, C271S, N303R, F321W, F321D, V324K, V324H, A330V, F373C, F373V, V389F, S399N, R402K, T403F, D404Q, D404S, D404M, N441R, G448W, E449A, V469T, C473Q, R484K T507C, G523A, I527M, Y528K Y543I, E549A, K550M, P557S, E601V, E605H, E605W, D607H, S609H and F610I.
[0262] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises one or more substitutions of an amino acid that is not wild type, wherein the one or more substitutions a for wild type amino acid comprises a substitution of E4X, A12X,
M13C,E14C, E15X, D20X, E24X, S25X, S26X, S27X, D32X, H33X, E36X, E44X, E45X, E46X, I48X, D49X, R58X, A62X, N63X, A64X, I65X, I66X, N68X, E69X, D71X, S72X, D76X, P79X, R84X, Q85X, A87X, S88X, Q92X, V93X, S94X, G95X, P96X, F97X, Y98X, T99X, I145X, S149X, D150X, F152X, E154X, T157X, N160X, S161X, S162X, H165X, R166X, T168X, K169X, T170X, A171X, E173X, S175X, S176X, E178X, T179X, M183X, Q184X, T186X, T187X, F188X, C189X, F194X, I195X, A196X, F198X, F200X, A201X, F203X, I204X, K205X, A206X, N207X, Q209X, S210X, F211X, K212X, D213X, F214X, W215X, R216X, T217X, G219X, V222X, D223X, I224X, T227X, M229X, Q235X, F237X, Q238X, N239X, N240X, P302X, N303X, P305X, A306X, K307X, Y308X, I310X, K31 IX, I312X, F313X, A314X, F315X, V3l6X,D3 l7X, A318X, K319X, N320X, F321X, Y322X, V323X, V324X, F326X, E327X, V328X, A330X, Q333X, P334X, S335X, G336X, P337X, A339X, V340X, S341X, N342X, R343X, P344X, F345X, E346X, V347X, E349X, I352X,
Q353X, V355X, A356X, R357X, N361X, D365X, W367X, T369X, G370X, L373X, M374X, L375X, H376X, N379X, E380X, R382X, V386X, V389X, N392X, R394X, Q395X, S399X, F400X, 140 IX, R402XT403X, D404X, R405X, Q406X, P407X, N408X, S409X, S410X, V411X, F412X, F414X, Q415X, I418X, T419X, F420X, N428XV432X, M434X, D440X, N441X, S442X, I443X, D444X, E445X, G448X, E449X, Q451X, K452X, M455X, I456X, T457X, F458X, S461X, A464X, V466X, Q468X, V469X, E471X, F472X, C473X, A474X, K483X, W485X, T488X, F489X, Y491X, G492X, V493X, M496X, I499X, C502X, I503X, T507X, K509X, N510X, V511X, T512X, I513X, R515X, E517X, S521X, G523X, F524X, S525X, I527X, Y528X, E529X, H532X, S533X, N535X, K536X, K537X, N539X, I540X, T542X, Y543X, Q546X, E549X, K550X, Q551X, G553X, E554X, P555X, S556X, P557X, R558X, H559X, V560X, N561X, V562X, P563X, G564X, R565X, Y566X, V567X, Q570X, D571X, P573X, Y574X, K576X, K581X, S583X, A586X, A588X, E594X, F598X, F599X, E601X, N602X, C603X, A604X, E605X, F606X, D607X, S608X, S609X or F610X (relative to SEQ ID NO: 14505). A list of hyperactive amino acid substitutions can be found in ETS patent No. 10,041,077, the contents of which are incorporated herein by reference in their entirety.
[0263] In certain embodiments, the piggyBac or piggyBac-like transposase is integration deficient. In certain embodiments, an integration deficient piggyBac or piggyBac-like transposase is a transposase that can excise its corresponding transposon, but that integrates the excised transposon at a lower frequency than a corresponding wild type transposase. In certain embodiments, the piggyBac or piggyBac-like transposase is an integration deficient variant of SEQ ID NO: 14505.
[0264] In certain embodiments, the excision competent, integration deficient piggyBac or piggyBac-like transposase comprises one or more substitutions of an amino acid that is not wild type, wherein the one or more substitutions a for wild type amino acid comprises a substitution of R9X, A12X, M13X, D20X, Y21K, D23X, E24X, S25X, S26X, S27X, E28X, E30X, D32X, H33X, E36X, H37X, A39X, Y41X, D42X, T43X, E44X, E45X, E46X, R47X, D49X, S50X, S55X, A62X, N63X, A64X, I66X, A67X, N68X, E69X, D70X, D71X, S72X, D73X, P74X, D75X, D76X, D77X,I78X, S8lX,V83X, R84X, Q85X, A87X, S88X, A89X,S90X,R9lX, Q92X, V93X, S94X, G95X, P96X, F97X, Y98X, T99X, W012X, G103X, Y107X, K108X, L117X, I122X, Q128X, I312X, D135X, S137X, E139X, Y140X, I145X, S149X, D150X,
Q153X, E154X, T157X, S161X, S162X, R164X, H165X, R166X, Q167X, T168X, K169X, T170X, A171X, A172X, E173X, R174X, S175X, S176X, A177X, E178X, T179X,
S 180X, Y 182X, Q184X, E185X, T187X, L188X, C189X, L194X, I195X, A196X, L198X, L200X, A201X, L203X, I204X, K205X, N207X, Q209X, L211X, D213X, L214X, W215X, R216X, T217X, G219X, T220X, V222X, D223X, I224X, T227X, T228X, F234X, Q235X, L237X, Q238X, N239X, N240X, N303X, K304X, I310X, I312X, L313X, A314X, L315X, V3 l6X,D3 l7X, A318X, K319X, N320X, F321X, Y322X, V323X, V324X, N325X, L326X, E327X, V328X, A330X, G331X, K332X, Q333X, S335X, P337X, P344X, F345X, E349X, H359X, N361X, V362X, D365X, F368X, Y371X, E372X, L373X, H376X, E380X, R382X, R382X, V386X, G387X, T388X, V389X, K391X, N392X, R394X, Q395X, E398X, S399X, F400X, 140 IX, R402XT403X, D404X, R405X, Q406X, P407X, N408X, S409X, S410X, Q4l5X,K4l6X, A424X, K426X, N428X, V430X, V432X, V433X, M434X, D436X, D440X, N441X, S442X, I443X, D444X, E445X, S446X, T447X, G448X, E449X, K450X, Q451X, E454X, M455X, I456X, T457X, F458X, S461X, A464X, V466X, Q468X, V469X, C473X, A474X, N475X, N477X, K483X, R484X, P486X, T488X, L489X, G492X, V493X, M496X, I499X, I503X, Y505X, T507X, N510X, V511X, T512X, I513X, K514X, T516X, E517X, S521X, G523X, L524X, S525X, I527X, Y528X, L531X, H532X, S533X, N535X, I540X, T542X, Y543X, R545X, Q546X, E549X, L552X, G553X, E554X, P555X, S556X, P557X, R558X, H559X, V560X, N561X, V562X, P563X, G564X, V567X, Q570X, D571X, P573X, Y574X, K575X, K576X, N585X, A586X, M593X, K596X, E601X, N602X, A604X, E605X, L606X, D607X, S608X, S609X or L610X (relative to SEQ ID NO: 14505). A list of integration deficient amino acid substitutions can be found in ETS patent No. 10,041,077, the contents of which are incorporated by reference in their entirety.
[0265] In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase comprises a sequence of:


In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase comprises a sequence of:

In certain embodiments, the piggyBac or piggyBac-like transposase that is is integration deficient comprises a sequence of:

In certain embodiments, the integration deficient transposase comprises a sequence that is at least 90% identical to SEQ ID NO: 14608.
[0266] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Bombyx mori. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0275] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0276] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0277] In certain embodiments, the piggyBac™ (PB) or piggyBac-like transposon comprises a sequence of:

[0278] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a 5’ sequence corresponding to SEQ ID NO: 14506 and a 3’ sequence corresponding to SEQ ID NO: 14507. In certain embodiments, one piggyBac or piggyBac-like transposon end is at least 85%, at least 90%, at least 95%, at least 98%, at least 99% identical or any percentage in between identical to SEQ ID NO: 14506 and the other piggyBac or piggyBac-like transposon end is at least 85%, at least 90%, at least 95%, at least 98%, at least 99% or any percentage in between identical to SEQ ID NO: 14507. In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14506 and SEQ ID NO: 14507 or SEQ ID NO: 14509. In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14508 and SEQ ID NO: 14507 or SEQ ID NO: 14509. In certain embodiments, the 5’ and 3’ transposon ends share a 16 bp repeat sequence at their ends of CCCGGCGAGCATGAGG (SEQ ID NO: 14510) immediately adjacent to the 5'-TTAT-3 target insertion site, which is inverted in the orientation in the two ends. In certain embodiments, 5’ transposon end begins with a sequence comprising 5'-TTATCCCGGCGAGCATGAGG-3 (SEQ ID NO: 14511), and the 3’ transposon ends with a sequence comprising the reverse complement of this sequence: 5'-
 [0279] In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end comprising at least 14, 16, 18, 20, 30 or 40 contiguous nucleotides of SEQ ID NO: 14506 or SEQ ID NO: 14508. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end comprising at least 14, 16, 18, 20, 30 or 40 contiguous nucleotides of SEQ ID NO: 14507 or SEQ ID NO: 14509. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end with at least 90% identity to SEQ ID NO: 14506 or SEQ ID NO: 14508. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end with at least 90% identity to SEQ ID NO: 14507 or SEQ ID NO: 14509.
[0279] In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end comprising at least 14, 16, 18, 20, 30 or 40 contiguous nucleotides of SEQ ID NO: 14506 or SEQ ID NO: 14508. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end comprising at least 14, 16, 18, 20, 30 or 40 contiguous nucleotides of SEQ ID NO: 14507 or SEQ ID NO: 14509. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end with at least 90% identity to SEQ ID NO: 14506 or SEQ ID NO: 14508. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end with at least 90% identity to SEQ ID NO: 14507 or SEQ ID NO: 14509.
[0280] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0281] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0282] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of CCCGGCGAGCATGAGG (SEQ ID NO: 14510). In certain embodiments, the piggyBac or piggyBac-like transposon comprises an ITR sequence of SEQ ID NO: 14510. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of TTATCCCGGCGAGCATGAGG (SEQ ID NO: 14511). In certain embodiments, the piggyBac
or piggyBac-like transposon comprises at least 16 contiguous nucleotides from SEQ ID NO: 14511. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of CCTCATGCTCGCCGGGTTAT (SEQ ID NO: 14512). In certain embodiments, the piggyBac or piggyBac-like transposon comprises at least 16 contiguous nucleotides from SEQ ID NO: 14512. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end comprising at least 16 contiguous nucleotides from SEQ ID NO: 14511 and one end comprising at least 16 contiguous nucleotides from SEQ ID NO: 14512. In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14511 and SEQ ID NO: 14512. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of TTAACCCGGCGAGCATGAGG (SEQ ID NO: 14513). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of
CCTCATGCTCGCCGGGTTAA (SEQ ID NO: 14514).
[0283] In certain embodiments, the piggyBac or piggyBac-like transposon may have ends comprising SEQ ID NO: 14506 and SEQ ID NO: 14507, or a variant of either or both of these having at least 90% sequence identity to SEQ ID NO: 14506 or SEQ ID NO: 14507, and the piggyBac or piggyBac-like transposase has the sequence of SEQ ID NO: 14504 or SEQ ID NO: 14505, or a sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%,
60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identity to SEQ ID NO: 14504 or SEQ ID NO: 14505. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a heterologous polynucleotide inserted between a pair of inverted repeats, where the transposon is capable of transposition by a piggyBac or piggyBac-like transposase having at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identity to SEQ ID NO: 14504 or SEQ ID NO: 14505. In certain embodiments, the transposon comprises two transposon ends, each of which comprises SEQ ID NO: 14510 in inverted orientations in the two transposon ends. In certain embodiments, each inverted terminal repeat (ITR) is at least 90% identical to SEQ ID NO: 14510.
[0284] In certain embodiments, the piggyBac or piggyBac-like transposon is capable of insertion by a piggyBac or piggyBac-like transposase at the sequence 5'-TTAT-3 within a target nucleic acid. In certain embodiments, one end of the piggyBac or piggyBac-like transposon
comprises at least 16 contiguous nucleotides from SEQ ID NO: 14506 and the other transposon end comprises at least 16 contiguous nucleotides from SEQ ID NO: 14507. In certain embodiments, one end of the piggyBac or piggyBac-like transposon comprises at least 17, at least 18, at least 19, at least 20, at least 22, at least 25, at least 30 contiguous nucleotides from SEQ ID NO: 14506 and the other transposon end comprises at least 17, at least 18, at least 19, at least 20, at least 22, at least 25, at least 30 contiguous nucleotides from SEQ ID NO: 14507.
[0285] In certain embodiments, the piggyBac or piggyBac-like transposon comprises transposon ends (each end comprising an ITR) corresponding to SEQ ID NO: 14506 and SEQ ID NO: 14507, and has a target sequence corresponding to 5'-TTAT3'. In certain embodiments, the piggyBac or piggyBac-like transposon also comprises a sequence encoding a transposase (e.g. SEQ ID NO: 14505). In certain embodiments, the piggyBac or piggyBac-like transposon comprises one transposon end corresponding to SEQ ID NO: 14506 and a second transposon end corresponding to SEQ ID NO: 14516. SEQ ID NO: 14516 is very similar to SEQ ID NO: 14507, but has a large insertion shortly before the ITR. Although the ITR sequences for the two transposon ends are identical (they are both identical to SEQ ID NO: 14510), they have different target sequences: the second transposon has a target sequence corresponding to 5'-TTAA-3', providing evidence that no change in ITR sequence is necessary to modify the target sequence specificity. The piggyBac or piggyBac-like transposase (SEQ ID NO: 14504), which is associated with the 5'-TTAA-3’ target site differs from the 5'-TTAT-3'-associated transposase (SEQ ID NO: 14505) by only 4 ammo acid changes (D322Y, S473C, A507T, H582R). In certain embodiments, the piggyBac or piggyBac-like transposase (SEQ ID NO: 14504), which is associated with the 5'-TTAA-3’ target site is less active than the 5'-TTAT-3'-associated piggyBac or piggyBac-like transposase (SEQ ID NO: 14505) on the transposon with 5'-TTAT-3' ends. In certain embodiments, piggyBac or piggyBac-like transposons with 5'-TTAA-3’ target sites can be converted to piggyBac or piggyBac-like transposases with 5'-TTAT-3 target sites by replacing 5'-TTAA-3’ target sites with 5'-TTAT-3'. Such transposons can be used either with a piggyBac or piggyBac-like transposase such as SEQ ID NO: 14504 which recognizes the 5'- TTAT-3’ target sequence, or with a variant of a transposase originally associated with the 5'- TTAA-3' transposon. In certain embodiments, the high similarity between the 5'-TTAA-3' and 5'-TTAT-3' piggyBac or piggyBac-like transposases demonstrates that very few changes to the
amino acid sequence of a piggyBac or piggyBac-like transposase alter target sequence specificity. In certain embodiments, modification of any piggyBac or piggyBac-like transposon- transposase gene transfer system, in which 5'-TTAA-3’ target sequences are replaced with 5'- TTAT-3'-target sequences, the ITRs remain the same, and the transposase is the original piggyBac or piggyBac-like transposase or a variant thereof resulting from using a low-level mutagenesis to introduce mutations into the transposase. In certain embodiments, piggyBac or piggyBac-like transposon transposase transfer systems can be formed by the modification of a 5'- TTAT-3'-active piggyBac or piggyBac-like transposon-transposase gene transfer systems in which 5'-TTAT-3’ target sequences are replaced with 5'-TTAA-3'-target sequences, the ITRs remain the same, and the piggyBac or piggyBac-like transposase is the original transposase or a variant thereof.
[0286] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Bombyx mori. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
 g ggg g g g g g ( Q )
g ggg g g g g g ( Q )
[0287] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0288] In certain embodiments, the transposon comprises at least 16 contiguous bases from SEQ ID NO: 14577 and at least 16 contiguous bases from SEQ ID NO: 14578, and inverted terminal repeats that are at least 87% identical to CCCGGCGAGCATGAGG (SEQ ID NO: 14510).
[0289] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:


[0278] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0290] In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14595 and SEQ ID NO: 14596, and is transposed by the piggyBac or piggyBac-like transposase of SEQ ID NO: 14505. In certain embodiments, the ITRs of SEQ ID NO: 14595 and SEQ ID: 14596 are not flanked by a 5’-TTAA-3’ sequence. In certain embodiments, the ITRs of SEQ ID NO: 14595 and SEQ ID: 14596 are flanked by a 5’-TTAT-3’ sequence.
[0291] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0292] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
1 cagggtatct cataccctgg taaaatttta aagttgtgta ttttataaaa ttttcgtctg
61 acaacactag cgcgctcagt agctggaggc aggagcgtgc gggaggggat agtggcgtga
121 tcgcagtgtg gcacgggaca ccggcgagat attcgtgtgc aaacctgttt cgggtatgtt
181 ataccctgcc tcattgttga cgtatttttt ttatgtaatt tttccgatta ttaatttcaa
241 ctgttttatt ggtattttta tgttatccat tgttcttttt ttatg (SEQ ID NO: 14598).
[0293] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
1 cagggtatct cataccctgg taaaatttta aagttgtgta ttttataaaa ttttcgtctg
61 acaacactag cgcgctcagt agctggaggc aggagcgtgc gggaggggat agtggcgtga
121 tcgcagtgtg gcacgggaca ccggcgagat attcgtgtgc aaacctgttt cgggtatgtt 181 ataccctgcc tcattgttga cgtat (SEQ ID NO: 14599).
[0294] In certain embodiments, the 5’ end of the piggyBac or piggyBac-like transposon comprises a sequence of SEQ ID NO: 14577, SEQ ID NO: 14595, or SEQ ID NOs: 14597- 14599. In certain embodiments, the 5’ end of the piggyBac or piggyBac-like transposon is preceded by a 5’ target sequence.
[0295] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
1 tcatattttt agtttaaaaa aataattata tgttttataa tgaaaagaat ctcattatct
61 ttcagtatta ggttgattta tattccaaag aataatattt ttgttaaatt gttgattttt
121 gtaaacctct aaatgtttgt tgctaaaatt actgtgttta agaaaaagat taataaataa
181 taataatttc ataattaaaa acttctttca ttgaatgcca ttaaataaac cattatttta
241 caaaataaga tcaacataat tgagtaaata ataataagaa caatattata gtacaacaaa
301 atatgggtat gtcataccct gccacattct tgatgtaact ttttttcacc tcatgctcgc
361 cggg (SEQ ID NO: 14600).
[0296] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
1 tttaagaaaa agattaataa ataataataa tttcataatt aaaaacttct ttcattgaat
61 gccattaaat aaaccattat tttacaaaat aagatcaaca taattgagta aataataata
121 agaacaatat tatagtacaa caaaatatgg gtatgtcata ccctgccaca ttcttgatgt
181 aacttttttt ca (SEQ ID NO: 14601).
[0297] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
1 cccggcgagc atgaggcagg gtatctcata ccctggtaaa attttaaagt tgtgtatttt
61 ataaaatttt cgtctgacaa cactagcgcg ctcagtagct ggaggcagga gcgtgcggga
121 ggggatagtg gcgtgatcgc agtgtggcac gggacaccgg cgagatattc gtgtgcaaac
181 ctgtttcggg tatgttatac cctgcctcat tgttgacgta ttttttttat gtaatttttc
241 cgattattaa tttcaactgt tttattggta tttttatgtt atccattgtt ctttttttat
301 gatttactgt atcggttgtc tttcgttcct ttagttgagt ttttttttat tattttcagt
361 ttttgatcaa a (SEQ ID NO: 14602).
[0298] In certain embodiments, the 3’ end of the piggyBac or piggyBac-like transposon comprises a sequence of SEQ ID NO: 14578, SEQ ID NO: 14596, or SEQ ID NOs: 14600- 14601. In certain embodiments, the 3’ end of the piggyBac or piggyBac-like transposon is followed by a 3’ target sequence. In certain embodiments, the transposon is transposed by the transposase of SEQ ID NO: 14505. In certain embodiments, the 5’ and 3’ ends of the piggyBac or piggyBac-like transposon share a 16 bp repeat sequence of SEQ ID NO: 14510 in inverted orientation and immediately adjacent to the target sequence. In certain embodiments, the 5’ transposon end begins with SEQ ID NO: 14510, and the 3’ transposon end ends with the reverse complement of SEQ ID NO: 14510, 5’- CCTCATGCTCGCCGGG-3’ (SEQ ID NO: 14603). In certain embodiments, the piggyBac or piggyBac-like transposon comprises an ITR with at least 93%, at least 87%, or at least 81% or any percentage in between identity to SEQ ID NO: 14510 or SEQ ID NO: 14603. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a target sequence followed by a 5’ transposon end comprising a sequence selected from SEQ ID NOs: 14577, 14595 or 14597 and a 3’ transposon end comprising SEQ ID NO: 14578 or 14596 followed by a target sequence in certain embodiments, the piggyBac or piggyBac like transposon comprises one end that comprises a sequence that is at least 90%, at least 95% or at least 99% or any percentage in between identical to SEQ ID NO: 14577 and one end that comprises a sequence that is at least 90%, at least 95% or at least 99% or any percentage in between identical to SEQ ID NO: 14578. In certain embodiments, one transposon end comprises at least 14, at least 16, at least 18 or at least 20 contiguous bases from SEQ ID NO: 14577 and one transposon end comprises at least 14, at least 16, at least 18 or at least 20 contiguous bases from SEQ ID NO: 14578.
[0299] In certain embodiments, the piggyBac or piggyBac-like transposon comprises two transposon ends wherein each transposon ends comprises a sequence that is at least 81% identical, at least 87% identical or at least 93% identical or any percentage in between identical to SEQ ID NO: 14510 in inverted orientation in the two transposon ends. One end may further comprise at least 14, at least 16, at least 18 or at least 20 contiguous bases from SEQ ID NO: 14599, and the other end may further comprise at least 14, at least 16, at least 18 or at least 20 contiguous bases from SEQ ID NO: 14601. The piggyBac or piggyBac-like transposon may be
transposed by the transposase of SEQ ID NO: 14505, and the transposase may optionally be fused to a nuclear localization signal.
[0300] In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14595 and SEQ ID NO: 14596 and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14504 or SEQ ID NO: 14505. In certain embodiments, the piggyBac or piggyBac- like transposon comprises SEQ ID NO: 14597 and SEQ ID NO: 14596 and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14504 or SEQ ID NO: 14505. In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14595 and SEQ ID NO: 14578 and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14504 or SEQ ID NO: 14505. In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14602 and SEQ ID NO: 14600 and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14504 or SEQ ID NO: 14505.
[0301] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a 5’ end comprising 1, 2, 3, 4, 5, 6, or 7 sequences selected from ATGAGGCAGGGTAT (SEQ ID NO: 14614), ATACCCTGCCTCAT (SEQ ID NO: 14615), GGCAGGGTAT (SEQ ID NO: 14616), ATACCCTGCC (SEQ ID NO: 14617), TAAAATTTTA (SEQ ID NO: 14618),
ATTTT AT AAAAT (SEQ ID NO: 14619), TCATACCCTG (SEQ ID NO: 14620) and
TAAATAATAATAA (SEQ ID NO: 14621). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a 3’ end comprising 1 , 2 or 3 sequences selected from SEQ ID NO: 14617, SEQ ID NO: 14620 and SEQ ID NO: 14621.
[0302] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme. In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Xenopus tropicalis. The piggyBac or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%,
90%, 95%, 99% or any percentage in between identical to:
1 MAKRFYSAEE AAAHCMASSS EEFSGSDSEY VPPASESDSS TEESWCSSST VSALEEPMEV
61 DEDVDDLEDQ EAGDRADAAA GGEPAWGPPC NFPPEIPPFT TVPGVKVDTS NFEPINFFQL
121 FMTEAI LQDM VLYTNVYAEQ YLTQNPLPRY ARAHAWHPTD IAEMKRFVGL TLAMGLIKAN
18 1 SLESYWDTTT VLSIPVFSAT MSRNRYQLLL RFLHFNNNAT AVPPDQPGHD RLHKLRPLID
24 1 SLSERFAAVY TPCQNICIDE SLLLFKGRLQ FRQYIPSKRA RYGIKFYKLC ESSSGYTSYF
301 LIYEGKDSKL DPPGCPPDLT VSGKIVWELI SPLLGQGFHL YVDNFYSSI P LFTALYCLDT
361 PACGTINRNR KGLPRALLDK KLNRGETYAL RKNELLAIKF FDKKNVFMLT SIHDESVI RE

[0303] In some embodiments, the piggyBac or piggyBac-like transposase is a hyperactive variant of SEQ ID NO: 14517. In certain embodiments, the piggyBac or piggyBac-like transposase is an integration defective variant of SEQ ID NO: 14517. The piggyBac or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%,
90%, 95%, 99% or any percentage in between identical to:

[0304] In certain embodiments, the piggyBac or piggyBac-like transposase is isolated or derived from Xenopus tropicalis. In certain embodiments, the piggyBac or piggyBac-like transposase is a hyperactive piggyBac or piggyBac-like transposase. In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence at least 90% identical to:

[0305] In certain embodiments, piggyBac or piggyBac-like transposase is a hyperactive piggyBac or piggyBac-like transposase. A hyperactive piggyBac or piggyBac-like transposase is a transposase that is more active than the naturally occurring variant from which it is derived. In certain embodiments, a hyperactive piggyBac or piggyBac-like transposase is more active than
the transposase of SEQ ID NO: 14517. In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:

14572).
[0306] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:

[0307] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:
1

[0308] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:


[0309] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:

[0310] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises a sequence of:

[0311] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises an amino acid substitution at a position selected from amino acid 6, 7, 16, 19, 20, 21,
22, 23, 24, 26, 28, 31, 34, 67, 73, 76, 77, 88, 91, 141, 145, 146, 148, 150, 157, 162, 179, 182.
189, 192, 193, 196, 198, 200, 210, 212, 218, 248, 263, 270, 294, 297, 308, 310, 333, 336, 354,
357, 358, 359, 377, 423, 426, 428, 438, 447, 450, 462, 469, 472, 498, 502, 517, 520, 523, 533, 534, 576, 577, 582, 583 or 587 (relative to SEQ ID NO: 14517). In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises an amino acid substitution of Y6C, S7G, M16S, S19G, S20Q, S20G, S20D, E21D, E22Q, F23T, F23P, S24Y, S26V, S28Q, V31K, A34E, L67A, G73H, A76V, D77N, P88A, N91D, Y141Q, Y141A, N145E, N145V, P146T, P146V, P146K, P148T, P148H, Y150G, Y150S, Y150C, H157Y, A162C, A179K, L182I, L182V, T189G, L192H, S193N, S193K, V196I, S198G, T200W, L210H, F212N,
N218E, A248N, L263M, Q270L, S294T, T297M, S308R, L310R, L333M, Q336M, A354H, C357V, L358F, D359N, L377I, V 423H, P426K, K428R, S438A, T447G, T447A, L450V, A462H, A462Q, I469V, I472L, Q498M, L502V, E5171, P520D, P520G, N523S, I533E, D534A, F576R, F576E, K577I, I582R, Y583F, L587Y or L587W, or any combination thereof including at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 or all of these mutations (relative to SEQ ID NO: 14517).
[0312] In certain embodiments, the hyperactive piggyBac or piggyBac-like transposase comprises one or more substitutions of an amino acid that is not wild type, wherein the one or more substitutions a for wild type amino acid comprises a substitution of A2X, K3X, R4X, F5X, Y6X, S7X, A11X, A13X, C15X, M16X, A17X, S18X, S19X, S20X, E21X, E22X, F23X, S24X, G25X, 26X, D27X, S28X, E29X, E42X, E43X, S44X, C46X, S47X, S48X, S49X, T50X, V51X, S52X, A53X, L54X, E55X, E56X, P57X, M58X, E59X, E62X, D63X, V64X, D65X, D66X, L67X, E68X, D69X, Q70X, E71X, A72X, G73X, D74X, R75X, A76X, D77X, A78X, A79X, A80X, G81X, G82X, E83X, P84X, A85X, W86X, G87X, P88X, P89X, C90X, N91X, F92X, P93X, E95X, I96X, P97X, P98X, F99X, T100X, T101X, P103X, G104X, V105X, K106X, V107X, D108X, T109X, N111X, P114X, I115X, N116X, F117X, F118X, Q119X, M122X, T123X, E124X, A125X, I126X, L127X, Q128X, D129X, M130X, L132X, Y133X, V126X, Y127X, A138X, E139X, Q140X, Y141X, L142X, Q144X, N145X, P146X, L147X, P148X, Y150X, A151X, A155X, H157X, P158X , I161X, A162X, V168X, T171X, L172X, A173X, M174X, I177X, A179X, L182X, D187X, T188X, T189X, T190X, L192X, S193X, I194X, P195X, V196X, S198X, A199X, T200X, S202X, L208X, L209X, L210X, R211X, F212X, F215X, N217X, N218X, A219X, T220X, A221X, V222X, P224X, D225X, Q226X, P227X, H229X, R231X, H233X, L235X, P237X, I239X, D240X, L242X, S243X, E244X, R244X, F246X, A247X, A248X, V249X, Y250X, T251X, P252X, C253X, Q254X, I256X, C257X, I258X, D259X, E260X, S261X, L262X, L263X, L264X, F265X, K266X, G267X, R268X, L269X, Q270X, F271X, R272X, Q273X, Y274X, I275X, P276X, S277X, K278X, R279X, A280X, R281X, Y282X, G283X, I284X, K285X, F286X, Y287X, K288X, L289X, C290X, E291X, S292X, S293XS294X, G295X, Y296X, T297X, S298X, Y299X, F300X, E304X, L310X, P313X, G314X, P316X, P317X, D318X, L319X, T320X, V321X, K324X, E328X,
133 OX, S331X, P332X, L333X, L334X, G335X, Q336X, F338X, L340X, D343X, N344X, F345X, Y346X, S347X, L351X, F352X, A354X, L355X, Y356X, C357X, L358X, D359X,
T360X, R422X, Y423X, G424X, P426X, K428X, N429X, K430X, P431X, L432X, S434X, K435X, E436X, S438X, K439X, Y440X, G443X, R446X, T447X, L450X, Q451X, N455X, T460X, R461X, A462X, K465X, V467X, G468X, I469X, Y470X, L471X, I472X, M474X, A475X, L476X, R477X, S479X, Y480X, V482XY483X, K484X, A485X, A486X, V487X, P488X, P490X, K491X, S493X, Y494X, Y495X, K496X, Y497T, Q498X, L499X, Q500X, I501X, L502X, P503X, A504X, L505X, L506X, F507X, G508X, G509X, V510X, E511X, E512X, Q513X, T514X, V515X, E517X, M518X, P519X, P520X, S521X, D522X, N523X, V524X, A525X, L527X, I528X, K530X, H531X, F532X, I533X, D534X, T535X, L536X, T539X, P540X,Q546X, K550X, R553X, K554X, R555X, G556X, I557X, R558X, R559X, D560X, T561X, Y564X, P566X, K567X, P569X, R570X, N571X, L574X, C575X, F576X, K577X, P578X, F580X, E581X, I582X, Y583X, T585X, Q586X, L587X, H588X or Y589X (relative to SEQ ID NO: 14517). A list of hyperactive amino acid substitutions can be found in ETS patent No. 10,041,077, the contents of which are incorporated by reference in their entirety.
[0313] In certain embodiments, the piggyBac or piggyBac-like transposase is integration deficient. In certain embodiments, an integration deficient piggyBac or piggyBac-like transposase is a transposase that can excise its corresponding transposon, but that integrates the excised transposon at a lower frequency than a corresponding naturally occurring transposase. In certain embodiments, the piggyBac or piggyBac-like transposase is an integration deficient variant of SEQ ID NO: 14517. In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase is deficient relative to SEQ ID NO: 14517.
[0314] In certain embodiments, the piggyBac or piggyBac-like transposase is active for excision but deficient in integration. In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase comprises a sequence that is at least 90% identical to a sequence of

[0315] In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase comprises a sequence that is at least 90% identical to a sequence of:

14604 ) .
[0316] In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase comprises a sequence that is at least 90% identical to a sequence of:

NO : 14611) .
[0317] In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14611. In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase comprises a sequence that is at least 90% identical to a sequence of:
NO :


[0319] In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14613. In certain embodiments, the integration deficient piggyBac or piggyBac-like transposase comprises an amino acid substitution wherein the Asn at position 218 is replaced by a Glu or an Asp (N218D or N218E) (relative to SEQ ID NO: 14517).
[0320] In certain embodiments, the excision competent, integration deficient piggyBac or piggyBac-like transposase comprises one or more substitutions of an amino acid that is not wild type, wherein the one or more substitutions a for wild type amino acid comprises a substitution of A2X, K3X, R4X, F5X, Y6X, S7X, A8X, E9X, E10X, Al IX, A12X, A13X, H14X, C15X, M16X, A17X, S18X, S19X, S20X, E21X, E22X, F23X, S24X, G25X, 26X, D27X, S28X, E29X, V31X, P32X, P33X, A34X, S35X, E36X, S37X, D38X, S39X, S40X, T41X, E42X, E43X, S44X, W45X, C46X, S47X, S48X, S49X, T50X, V51X, S52X, A53X, L54X, E55X, E56X, P57X, M58X, E59X, V60X, M122X, T123X, E124X, A125X, L127X, Q128X, D129X, L132X, Y133X, V126X, Y127X, E139X, Q140X, Y141X, L142X, T143X, Q144X, N145X, P146X, L147X, P148X, R149X, Y150X, A151X, H154X, H157X, P158X, T159X, D160X, I161X, A162X, E163X, M164X, K165X, R166X, F167X, V168X, G169X, L170X, T171X, L172X, A173X, M174X, G175X, L176X, I177X, K178X, A179X, N180X, S181X, L182X, S184X, Y185X, D187X, T188X, T189X, T190X, V191X, L192X, S193X, I194X, P195X, V196X, F197X, S198X, A199X, T200X, M201X, S202X, R203X, N204X, R205X, Y206X, Q207X, L208X, L209X, L210X, R21 IX, F212X, L213X, H241X, F215X, N216X, N217X,
N218X, A219X, T220X, A221X, V222X, P223X, P224X, D225X, Q226X, P227X, G228X, H229X, D230X, R231X, H233X, K234X, L235X, R236X, L238X, I239X, D240X, L242X, S243X, E244X, R244X, F246X, A247X, A248X, V249X, Y250X, T251X, P252X, C253X, Q254X, N255X, I256X, C257X, I258X, D259X, E260X, S261X, L262X, L263X, L264X, F265X, K266X, G267X, R268X, L269X, Q270X, F271X, R272X, Q273X, Y274X, I275X, P276X, S277X, K278X, R279X, A280X, R281X, Y282X, G283X, I284X, K285X, F286X, Y287X, K288X, L289X, C290X, E291X, S292X, S293X, S294X, G295X, Y296X, T297X, S298X, Y299X, F300X, I302X, E304X, G305X,K306X, D307X, S308X, K309X, L310X, D311X, P312X, P313X, G314X, C315X, P316X, P317X, D318X, L319X, T320X, V321X, S322X, G323X, K324X, I325X, V326X, W327X, E328X, L329X, I330X, S331X, P332X, L333X, L334X, G335X, Q336X, F338X, H339X, L340X, V342X, N344X, F345X, Y346X, S347X, S348X, I349X, L351X, T353X, A354X, Y356X, C357X, L358X, D359X, T360X, P361X, A362X, C363X, G364X, I366X, N367X, R368X, D369X, K371X, G372X, L373X, R375X, A376X, L377X, L378X, D379X, K380X, K381X, L382X, N383X, R384XG385X, T387X, Y388X, A389X, L390X, K392X, N393X, E394X, A397X, K399X, F400X, F401X, D402X, N405X, L406X, L409X, R422X, Y423X, G424X, E425X, P426X, K428X, N429X, K430X, P431X, L432X, S434X, K435X, E436X, S438X, K439X, Y440X, G442X, G443X, V444X, R446X, T447X, L450X, Q451X, H452X, N455X, T457X, R458X, T460X, R461X, A462X, Y464X, K465X, V467X, G468X, I469X, L471X, I472X, Q473X, M474X, L476X, R477X, N478X, S479X, Y480X, V482XY483X, K484X, A485X, A486X, V487X, P488X, G489X, P490X, K491X, L492X, S493X, Y494X, Y495X, K496X, Q498X, L499X, Q500X, I501X, L502X, P503X, A504X, L505X, L506X, F507X, G508X, G509X, V510X, E511X, E512X, Q513X, T514X, V515X, E517X, M518X, P519X, P520X, S521X, D522X, N523X, V524X, A525X, L527X, I528X, G529X, K530X, F532X, I533X, D534X, T535X, L536X, P537X, P538X, T539X, P540X, G541X, F542X, Q543X, R544X, P545X, Q546X, K547X, G548X, C549X, K550X, V551X, C552X, R553X, K554X, R555X, G556X, I557X, R558X, R559X, D560X, T561X, R562X, Y563X, Y564X, C565X, P566X, K567X, C568X, P569X, R570X, N571X, P572X, G573X, L574X, C575X, F576X, K577X, P578X, C579X, F580X, E581X, I582X, Y583X, H584X, T585X, Q586X, L587X, H588X or Y589X (relative to SEQ ID NO: 14517). A list of excision competent, integration deficient amino acid substitutions can be
found in US patent No. 10,041,077, the contents of which are incorporated by reference in their entirety.
[0321] In certain embodiments, the piggyBac or piggyBac-like transposase is fused to a nuclear localization signal. In certain embodiments, SEQ ID NO: 14517 or SEQ ID NO: 14518 is fused to a nuclear localization signal. In certain embodiments, the amino acid sequence of the piggyBac or piggyBac like transposase fused to a nuclear localization signal is encoded by a polynucleotide sequence comprising:

[0322] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Xenopus tropicalis. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:


[0324] In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14519 and SEQ ID NO: 14520. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0325] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0326] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0327] In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID
NO: 14520 and SEQ ID NO: 14519, SEQ ID NO: 14521 or SEQ ID NO: 14523. In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14522 and
SEQ ID NO: 14519, SEQ ID NO: 14521 or SEQ ID NO: 14523. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end comprising at least 14, 16, 18, 20, 30 or 40 contiguous nucleotides from SEQ ID NO: 14519, SEQ ID NO: 14521 or SEQ ID NO:
14523. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end comprising at least 14, 16, 18, 20, 30 or 40 contiguous nucleotides from SEQ ID NO: 14520 or
SEQ ID NO: 14522. In certain embodiments, the piggyBac or piggyBac-like transposon
comprises one end with at least 90% identity to SEQ ID NO: 14519, SEQ ID NO: 14521 or SEQ ID NO: 14523. In certain embodiments, the piggyBac or piggyBac-like transposon comprises one end with at least 90% identity to SEQ ID NO: 14520 or SEQ ID NO: 14522. In one embodiment, one transposon end is at least 90% identical to SEQ ID NO: 14519 and the other transposon end is at least 90% identical to SEQ ID NO: 14520.
[0328] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of TTAACCTTTTTACTGCCA (SEQ ID NO: 14524). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of TTAACCCTTTGCCTGCCA (SEQ ID NO: 14526). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of TTAACCYTTTTACTGCCA (SEQ ID NO: 14527). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of
TGGCAGTAAAAGGGTTAA (SEQ ID NO: 14529). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of TGGCAGTGAAAGGGTTAA (SEQ ID NO: 14531). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of TTAACCYTTTKMCTGCCA (SEQ ID NO: 14533). In certain embodiments, one end of the piggyBac or piggyBac-like transposon comprises a sequence selected from SEQ ID NO: 14524, SEQ ID NO: 14526 and SEQ ID NO: 14527. In certain embodiments, one end of the piggyBac™ (PB) or piggyBac-like transposon comprises a sequence selected from SEQ ID NO: 14529 and SEQ ID NO: 14531. In certain embodiments, each inverted terminal repeat of the piggyBac or piggyBac-like transposon comprises a sequence of ITR sequence of
CCYTTTKMCTGCCA (SEQ ID NO: 14563). In certain embodiments, each end of the piggyBac™ (PB) or piggyBac-like transposon comprises SEQ ID NO: 14563 in inverted orientations. In certain embodiments, one ITR of the piggyBac or piggyBac-like transposon comprises a sequence selected from SEQ ID NO: 14524, SEQ ID NO: 14526 and SEQ ID NO: 14527. In certain embodiments, one ITR of the piggyBac or piggyBac-like transposon comprises a sequence selected from SEQ ID NO: 14529 and SEQ ID NO: 14531. In certain embodiments, the piggyBac or piggyBac like transposon comprises SEQ ID NO: 14533 in inverted orientation in the two transposon ends.
[0329] In certain embodiments, The piggyBac or piggyBac-like transposon may have ends comprising SEQ ID NO: 14519 and SEQ ID NO: 14520 or a variant of either or both of these
having at least 90% sequence identity to SEQ ID NO: 14519 or SEQ ID NO: 14520, and the piggyBac or piggyBac-like transposase has the sequence of SEQ ID NO: 14517 or a variant showing at least %, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between sequence identity to SEQ ID NO: 14517 or SEQ ID NO: 14518. In certain embodiments, one piggyBac or piggyBac-like transposon end comprises at least 14 contiguous nucleotides from SEQ ID NO: 14519, SEQ ID NO: 14521 or SEQ ID NO: 14523, and the other transposon end comprises at least 14 contiguous nucleotides from SEQ ID NO: 14520 or SEQ ID NO: 14522. In certain
embodiments, one transposon end comprises at least 15, at least 16, at least 17, at least 18, at least 19, at least 20, at least 22, at least 25, at least 30 contiguous nucleotides from SEQ ID NO: 14519, SEQ ID NO: 14521 or SEQ ID NO: 14523, and the other transposon end comprises at least 15, at least 16, at least 17, at least 18, at least 19, at least 20, at least 22, at least 25 or at least 30 contiguous nucleotides from SEQ ID NO: 14520 or SEQ ID NO: 14522.
[0330] In certain embodiments, the piggyBac or piggyBac-like transposase recognizes a transposon end with a 5’ sequence corresponding to SEQ ID NO: 14519, and a 3’ sequence corresponding to SEQ ID NO: 14520. It will excise the transposon from one DNA molecule by cutting the DNA at the 5'-TTAA-3' sequence at the 5’ end of one transposon end to the 5'- TTAA-3' at the 3’ end of the second transposon end, including any heterologous DNA that is placed between them, and insert the excised sequence into a second DNA molecule. In certain embodiments, truncated and modified versions of the 5’ and 3’ transposon ends will also function as part of a transposon that can be transposed by the piggyBac or piggyBac-like transposase. For example, the 5’ transposon end can be replaced by a sequence corresponding to SEQ ID NO: 14521 or SEQ ID NO: 14523, the 3’ transposon end can be replaced by a shorter sequence corresponding to SEQ ID NO: 14522. In certain embodiments, the 5’ and 3’ transposon ends share an 18 bp almost perfectly repeated sequence at their ends (5'- TTAACCYTTTKMCTGCCA: SEQ ID NO: 14533) that includes the 5'-TTAA-3' insertion site, which sequence is inverted in the orientation in the two ends. That is in SEQ ID NO: 14519 and SEQ ID NO: 14523 the 5’ transposon end begins with the sequence 5'- TTAACCTTTTTACTGCCA-3' (SEQ ID NO: 14524), or in SEQ ID NO: 14521 the 5’ transposon end begins with the sequence 5'-TTAACCCTTTGCCTGCCA-3' (SEQ ID NO:
14526); the 3’ transposon ends with approximately the reverse complement of this sequence: in SEQ ID NO: 14520 it ends 5' TGGCAGTAAAAGGGTTAA-3' (SEQ ID NO: 14529), in SEQ ID NO: 14522 it ends 5'-TGGCAGTGAAAGGGTTAA-3' (SEQ ID NO: 14531.) One embodiment of the invention is a transposon that comprises a heterologous polynucleotide inserted between two transposon ends each comprising SEQ ID NO: 14533 in inverted orientations in the two transposon ends. In certain embodiments, one transposon end comprises a sequence selected from SEQ ID NOS: 14524, SEQ ID NO: 14526 and SEQ ID NO: 14527. In some embodiments, one transposon end comprises a sequence selected from SEQ ID NO: 14529 and SEQ ID NO: 14531.
[0331] In certain embodiments, the piggyBac™ (PB) or piggyBac-like transposon is isolated or derived from Xenopus tropicalis. In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:

[0332] In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:

(SEQ ID NO: 14574).
[0333] In certain embodiments, the piggyBac or piggyBac-like transposon comprises at least 16 contiguous bases from SEQ ID NO: 14573 or SEQ ID NO: 14574, and inverted terminal repeat of CC YTTTBMCT GCC A (SEQ ID NO: 14575).
[0334] In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:

[0335] In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:


[0337] In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:

[0338] In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:

[0339] In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:

[0340] In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:

[0341] In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:

[0342] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a 5’ transposon end sequence selected from SEQ ID NO: 14573 and SEQ ID NOs: 14579-14585. In
certain embodiments, the 5’ transposon end sequence is preceded by a 5’ target sequence. In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:

[0343] In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:

[0344] In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:

[0345] In certain embodiments, the piggyBac or piggyBac-like transposon comprises at a sequence of:

[0346] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a 3’ transposon end sequence selected from SEQ ID NO: 14574 and SEQ ID NOs: 14587-14590. In certain embodiments, the 3’ transposon end sequence is followed by a 3’ target sequence. In certain embodiments, the 5’ and 3’ transposon ends share a 14 repeated sequence inverted in orientation in the two ends (SEQ ID NO: 14575) adjacent to the target sequence. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a 5’ transposon end comprising a target sequence and a sequence that is selected from SEQ ID NOs: 14582-14584 and 14573, and a 3’ transposon end comprising a sequence selected from SEQ ID NOs: 14588- 14590 and 14574 followed by a 3’ target sequence.
[0347] In certain embodiments, the 5’ transposon end of the piggyBac or piggyBac-like transposon comprises

(SEQ ID NO: 14591), and an ITR. In certain embodiments, the 5’ transposon end comprises

(SEQ ID NO: 14592) and an ITR. In certain embodiments, the 3’ transposon end of the piggyBac or piggyBac-like transposon comprises

(SEQ ID NO: 14593) and an ITR. In certain embodiments, the 3’ transposon end comprises

(SEQ ID NO: 14594) and an ITR.
[0348] In certain embodiments, one transposon end comprises a sequence that is at least 90%, at least 95%, at least 99% or any percentage in between identical to SEQ ID NO: 14573 and the other transposon end comprises a sequence that is at least 90%, at least 95%, at least 99% or any percentage in between identical to SEQ ID NO: 14574. In certain embodiments, one transposon end comprises at least 14, at least 16, at least 18, at least 20 or at least 25 contiguous nucleotides from SEQ ID NO: 14573 and one transposon end comprises at least 14, at least 16, at least 18, at least 20 or at least 25 contiguous nucleotides from SEQ ID NO: 14574. In certain embodiments, one transposon end comprises at least 14, at least 16, at least 18, at least 20 from SEQ ID NO: 14591, and the other end comprises at least 14, at least 16, at least 18, at least 20 from SEQ ID NO: 14593. In certain embodiments, each transposon end comprises SEQ ID NO: 14575 in inverted orientations.
[0349] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence selected from of SEQ ID NO: 14573, SEQ ID NO: 14579, SEQ ID NO: 14581, SEQ ID NO: 14582, SEQ ID NO: 14583, and SEQ ID NO: 14588, and a sequence selected from SEQ ID NO: 14587, SEQ ID NO: 14588, SEQ ID NO: 14589 and SEQ ID NO: 14586 and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14517 or SEQ ID NO: 14518.
[0350] In certain embodiments, the piggyBac or piggyBac-like transposon comprises ITRs of CCCTTTGCCTGCCA (SEQ ID NO: 14622) (left ITR or 5’ ITR) and T GGC AGT GAAAGGG (SEQ ID NO: 14623) (3’ ITR or 3’ ITR) adjacent to the target sequences.
[0351] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme. In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Helicoverpa armigera. The piggyBac or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%,
75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:

[0352] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Helicoverpa armigera. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

14570 ) . In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:

[0354] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Pectinophora gossypiella. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

14532). In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0355] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme. In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Ctenoplusia agnata. The piggyBac or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least
5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%,
90%, 95%, 99% or any percentage in between identical to:

[0356] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Ctenoplusia agnata. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

In certain embodiments, the piggyBac or piggyBac-like transposon comprises an ITR sequence of CCCTAGAAGCCCAATC (SEQ ID NO: 14564).
[0357] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme. In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from A gratis ipsilon. The piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:


[0358] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Agroiis ipsilon. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

piggyBac or piggyBac-like transposon comprises a sequence of:

[0359] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme. In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Megachile rotundata. The piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%,
75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:


In certain embodiments, the the piggyBac or piggyBac-like transposon comprises a sequence of:

[0361] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme. In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Bombus impatiens. The piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:
1 MNEKNGIGEF YLDDLSDCPD SYSRSNSGDE SDGSDTI IRK RGSVLPPRYS DSEDDEINNV

[0362] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Bombus impatiens. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:


[0363] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme. In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Mamestra brassicae. The piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:

[0364] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Mamestra brassicae. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:
1 atgatttttt ctttttaaac caattttaat tagttaattg atataaaaat ccgcaattac 61 tttttgggca acccaataa (SEQ ID NO: 14548).
[0365] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme. In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Mayetiola destructor. The piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:

 14549) .
14549) .
[0366] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Mayetiola destructor. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0367] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme. In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Apis mellifera. The piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:

[0368] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Apis mellifera. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:


[0370] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Messor bouvieri. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0371] In certain embodiments of the methods of the disclosure, the transposase enzyme is a piggyBac or piggyBac-like transposase enzyme. In certain embodiments, the piggyBac or piggyBac-like transposase enzyme is isolated or derived from Trichoplusia ni. The piggyBac (PB) or piggyBac-like transposase enzyme may comprise or consist of an amino acid sequence at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 99% or any percentage in between identical to:


[0372] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Trichoplusia ni. In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0373] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0374] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0375] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0376] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a
 sequence of:
sequence of:

[0377] In certain embodiments, the piggyBac or piggyBac-like transposon comprises a sequence of:

[0378] In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14561 and SEQ ID NO: 14562, and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14558. In certain embodiments, the piggyBac or piggyBac-like transposon comprises SEQ ID NO: 14609 and SEQ ID NO: 14610, and the piggyBac or piggyBac-like transposase comprises SEQ ID NO: 14558.
[0379] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Aphis gossypii. In certain embodiments, the piggyBac or piggyBac-like transposon comprises an ITR sequence of CCTTCCAGCGGGCGCGC (SEQ ID NO: 14565).
[0380] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Chilo suppressalis. In certain embodiments, the piggyBac or piggyBac-like transposon comprises an ITR sequence of CCCAGATTAGCCT (SEQ ID NO: 14566).
[0381] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Heliothis virescens. In certain embodiments, the piggyBac or piggyBac-like transposon comprises an ITR sequence of CCCTTAATTACTCGCG (SEQ ID NO: 14567).
[0382] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Pectinophora gossypiella. In certain embodiments, the piggyBac or piggyBac-like transposon comprises an ITR sequence of CCCTAGATAACTAAAC (SEQ ID NO: 14568).
[0383] In certain embodiments, the piggyBac or piggyBac-like transposon is isolated or derived from Anopheles stephensi. In certain embodiments, the piggyBac or piggyBac-like transposon comprises an ITR sequence of CCCTAGAAAGATA (SEQ ID NO: 14569).
[0384] DNA transposons in the hAT family are widespread in plants and animals. A number of active hAT transposon systems have been identified and found to be functional, including but not limited to, the Hermes transposon, Ac transposon, hobo transposon, and the Tol2 transposon.
The hAT family is composed of two families that have been classified as the AC subfamily and the Buster subfamily, based on the primary sequence of their transposases. Members of the hAT family belong to Class II transposable elements. Class II mobile elements use a cut and paste mechanism of transposition. hAT elements share similar transposases, short terminal inverted repeats, and an eight base-pairs duplication of genomic target.
[0385] Compositions and methods of the disclosure may comprise a TcBuster transposon and/or a TcBuster transposase.
[0386] Compositions and methods of the disclosure may comprise a TcBuster transposon and/or a hyperactive TcBuster transposase. A hyperactive TcBuster transposase demonstrates an increased excision and/or increased insertion frequency when compared to an excision and/or insertion frequency of a wild type TcBuster transposase. A hyperactive TcBuster transposase demonstrates an increased transposition frequency when compared to a transposition frequency of a wild type TcBuster transposase.
[0387] In some embodiments of the compositions and methods of the disclosure, a wild type TcBuster transposase comprises or consists of the amino acid sequence of:

[0388] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase comprises or consists of a sequence having at least 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 97%, 99% or any percentage identity in between to a wild type TcBuster transposase comprising or consisting of the amino acid sequence of:

(GenBank Accession No. ABF20545 and SEQ ID NO: 14735) .
[0389] In some embodiments of the compositions and methods of the disclosure, a wild type
TcBuster transposase is encoded by a nucleic acid sequence comprising or consisting of:

[0390] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase comprises or consists of a sequence having at least 20%, 25%, 30%, 35%, 40%,
45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 97%, 99% or any percentage identity in between to a wild type TcBuster transposase encoded by a nucleic acid sequence comprising or consisting of:

[0391] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase comprises or consists of a naturally occurring amino acid sequence.
[0392] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase comprises or consists of a non-naturally occurring amino acid sequence.
[0393] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase is encoded by a sequence comprising or consisting of a naturally occurring nucleic acid sequence.
[0394] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase is encoded by a sequence comprising or consisting of a non-naturally occurring nucleic acid sequence.
[0395] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the wild type TcBuster Transposase comprises or consists of the amino acid sequence of SEQ ID NO: 14735. In some embodiments, the wild type TcBuster Transposase is encoded by a sequence comprising or consisting of the nucleic acid sequence of SEQ ID NO: 14688. In some embodiments, the one or more sequence variations comprises one or more of a substitution, inversion, insertion, deletion, transposition, and frameshift. In some embodiments, the one or more sequence variations comprises a modified, synthetic, artificial or non-naturally occurring amino acid. In some embodiments, the one or more sequence variations comprises a modified, synthetic, artificial or non-naturally occurring nucleic acid.
[0396] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises an amino acid substitution in one or more of a DNA Binding and Oligomerization domain, an insertion domain and a Zn-BED domain.
[0397] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises an amino acid substitution that increases a net charge a neutral pH when compared to a wild type TcBuster Transposase. In some embodiments, the wild type TcBuster Transposase comprises or consists of the amino acid sequence of SEQ ID NO: 14735. In some embodiments, the wild type TcBuster Transposase is encoded by a sequence comprising or consisting of the nucleic acid sequence of SEQ ID NO: 14688. In some embodiments, the one or more sequence variations
comprises an amino acid substitution of the aspartic acid (D) at position 223 (D223), the aspartic acid (D) at position 289 (D289) and the aspartic acid (E) at position 589 (E289) of SEQ ID NO: 14735. In some embodiments, the one or more sequence variations comprises an amino acid substitution within 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 or any number of amino acids in between of position 223, 289 and/or 289 of SEQ ID NO: 14735. In some embodiments, the one or more sequence variations comprises an amino acid substitution within 70 amino acids of position 223, 289 and/or 289 of SEQ ID NO: 14735. In some embodiments, the one or more sequence variations comprises an amino acid substitution within 80 amino acids of position 223, 289 and/or 289 of SEQ ID NO: 14735. In some embodiments, the one or more sequence variations comprises an amino acid substitution of an aspartic acid (D) or a aspartic acid (E) to a neutral amino acid, a lysine (L) or an arginine (R) (e.g. D223L,
D223R, D289L, D289R, E289L, E289R of SEQ ID NO: 14735).
[0398] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of Q82E, N85S,D99A, D132A, Q151S, Q151A, E153K, E153R, A154P, Y155H, E159A, T171K, T171R, K177E, D183K, D183R, D189A, T191E, S193K, S193R, Y201A, F202D, F202K, C203I, C203V, Q221T, M222L, I223Q, E224G, S225W, D227A, R239H, E243A, E247K, P257K, P257R, Q258T, E263A, E263K, E263R, E274K, E274R, S278K, N281E, L282K, L282R, K292P, V297K, K299S, A303T, H322E, A332S, A358E, A358K, A358S, D376A, V377T, L380N, I398D, I398S, I398K, F400L, V431L, S447E, N450K, N450R, I452F, E469K, K469K, P510D, P510N, E517R, R536S, V553S, P554T, P559D, P559S, P559K, K573E, E578L, K590T, Y595L, V596A, T598I, K599A, Q615A, T618K, T618K, T618R, D622K and D622R of SEQ ID NO: 14735. In some embodiments, the one or more sequence variations comprises an amino acid substitution within 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 or any number of amino acids in between of position
154, 155, 159, 171, 177, 183, 189, 191, 193, 201, 202, 203, 221, 223, 224, 225, 227, 239, 243,
247, 257, 258, 263, 274, 278, 281, 282, 292, 297, 299, 303, 322, 332, 358, 376, 377, 380, 398,
400, 431, 447, 450, 452, 469, 510, 517, 536, 553, 554, 559, 573, 578, 590, 595, 596, 598, 599,
615, 618, and 622 of SEQ ID NO: 14735.
[0399] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of E247K, V297K, A358K, S278K, E247R, E274R, V297R, A358R, S278R, T171R, D183R, S193R, P257K, E263R, L282K, T618K, D622R, E153K, N450K, T171K, D183K, S193K, P257R, E263K, L282R, T618R, D622K, E153R and N450R of SEQ ID NO: 14735. In some embodiments, the one or more sequence variations comprises an amino acid substitution within 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 or any number of amino acids in between of position 153, 171, 183, 193, 247, 257, 263, 274, 278, 282, 297, 358, 450, 618, 622 of SEQ ID NO: 14735.
[0400] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of V377T/E469K, V377T/E469K/R536S, A332S, V553S/P554T, E517R, K299S, Q615A/T618K, S278K, A303T, P510D, P510N, N281S, N281E, K590T, Q258T, E247K, S447E, N85S, V297K, A358K, I452F, V377T/E469K/D189A, K573E/E578L,
I452F/V377T/E469K/D 189A, A358K/V377T/E469K/D 189 A,
K573E/E578L/V377T/E469K/D189A, T171R, D183R, S193R, P257K, E263R, L282K, T618K, D622R, E153K, N450K, T171K, D183K, S193K, P257R, E263K, L282R, T618R, D622K, E153R, N450R, E247K/E274K/V297K/A358K of SEQ ID NO: 14735. In some embodiments, the one or more sequence variations comprises an amino acid substitution within 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 or any number of amino acids in between of position 85, 153, 171, 189, 193, 247, 257, 258, 263, 274, 278, 281, 282, 297, 299, 303, 332, 358, 377, 450, 469, 447, 452, 469, 510, 517, 536, 553, 554, 573, 578, 590, 615, 618, 622 of SEQ ID NO: 14735.
[0401] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of V377T/E469K, V377T/E469K/R536S, V553S/P554T, Q615A/T618K, S278K, A303T, P510D, P510N, N281S, N281E, K590T, Q258T, E247K, S447E, N85S, V297K,
A358K, I452F, V377T/E469K/D189A and K573E/E578L. In some embodiments, the one or more sequence variations comprises an amino acid substitution within 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 or any number of amino acids in between of position 85, 189, 247, 258, 278, 281, 297, 303, 358, 377, 447, 452, 469, 510, 536, 553, 554, 573, 578, 590, 615, 618 of SEQ ID NO: 1687.
[0402] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of Q151S, Q151A, A154P, Q615A, V553S, Y155H, Y201A, F202D, F202K,
C203I, C203V, F400L, I398D, I398S, I398K, V431L, P559D, P559S, P559K, M222L of SEQ ID NO: 14735. In some embodiments, the one or more sequence variations comprises an amino acid substitution within 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95,
100 or any number of amino acids in between of position 151, 154, 615, 553, 155, 201, 202, 203, 400, 398, 431, 559, 222 of SEQ ID NO: 14735.
[0403] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of V377T, E469K, and D189A, when numbered in accordance with SEQ ID NO: 14735.
[0404] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of K573E and E578L, when numbered in accordance with SEQ ID NO: 14735.
[0405] In some embodiments, the mutant TcBuster transposase comprises amino acid substitution I452K, when numbered in accordance with SEQ ID NO: 14735.
[0406] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of A358K, when numbered in accordance with SEQ ID NO: 14735.
[0407] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of V297K, when numbered in accordance with SEQ ID NO: 14735.
[0408] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of N85S, when numbered in accordance with SEQ ID NO: 14735.
[0409] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of I452F, V377T, E469K, and D189A, when numbered in accordance with SEQ ID NO: 14735.
[0410] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of A358K, V377T, E469K, and D189A, when numbered in accordance with SEQ ID NO: 14735.
[0411] In some embodiments of the compositions and methods of the disclosure, a mutant TcBuster Transposase comprises one or more sequence variations when compared to a wild type TcBuster Transposase. In some embodiments, the one or more sequence variations comprises one or more of V377T, E469K, D189A, K573E and E578L, when numbered in accordance with SEQ ID NO: 14735.
[0412] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase recognizes a 5’ inverted repeat comprising or consisting of the sequence of:

[0413] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase recognizes a 3’ inverted repeat comprising or consisting of the sequence of:

[0414] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase recognizes a 5’ inverted repeat comprising or consisting of the sequence of SEQ ID NO: 14689 and a 3’ inverted repeat comprising or consisting of the sequence of SEQ ID NO: 14690.
[0415] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase recognizes a 5’ inverted repeat comprising or consisting of the sequence of:

[0416] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase recognizes a 3’ inverted repeat comprising or consisting of the sequence of:

[0417] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase recognizes a 5’ inverted repeat comprising or consisting of the sequence of SEQ ID NO: 14691 and a 3’ inverted repeat comprising or consisting of the sequence of SEQ ID NO: 14692.
[0418] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase recognizes an inverted repeat comprising or consisting of a sequence having at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95,% 97%, 99% or any percentage identify in between to one or more of SEQ ID NO: 14689, 14690, 14691 or 14692.
[0419] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase recognizes an inverted repeat comprising or consisting of a sequence having at least In some embodiments of the compositions and methods of the disclosure, a TcBuster
Transposase recognizes an inverted repeat comprising or consisting of a sequence having at least 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 97, 99 or any number of contiguous nucleotides in between having between 90 and 100% identity to SEQ ID NO: 14689, 14690, 14691 or 14692 or any portion thereof.
[0420] In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase recognizes an inverted repeat comprising or consisting of a sequence having at least 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 97, 99 or any number of discontinuous nucleotides in between having between 90 and 100% identity to SEQ ID NO: 14689, 14690, 14691 or 14692 or any portion thereof.
[0421] In some embodiments of the compositions and methods of the disclosure, a TcBuster transposon comprises a 3’ inverted repeat and a 5’ inverted repeat. In some embodiments of the compositions and methods of the disclosure, a TcBuster Transposase recognizes a TcBuster transposon comprising a 3’ inverted repeat and a 5’ inverted repeat comprising or consisting of a sequence having at least 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80 85, 90, 95, 97, 99 or any number of discontinuous nucleotides in between having between 90 and 100% identity to SEQ ID NO: 14689, 14690, 14691 or 14692 or any portion thereof.
[0422] In some embodiments of the compositions and methods of the disclosure, a piggyBat


[0424] In some embodiments of the compositions and methods of the disclosure, a piggyBat transposase of the disclosure is encoded by an amino acid sequence comprising:


[0425] In some embodiments of the compositions and methods of the disclosure, a piggyBat transposase of the disclosure is encoded by an amino acid sequence comprising:


[0426] In some embodiments of the compositions and methods of the disclosure, a piggyBat transposon of the disclosure is encoded by an amino acid sequence comprising:


[0427] In some embodiments of the compositions and methods of the disclosure, a piggyBat transposon of the disclosure is encoded by an amino acid sequence comprising:
C AC ATT GCGT ACCGCT C ACGAGTTTT CTCGTGTTT CGCGCGCC AT CT GTTAAGGACC
GCTCACGAGTGTTCTCGTTTTTCACGCGCCATCTGTTATGGACCTTAGATGTCAACAC
ACTGTCTTGTCCACTGTGGGGCGCGGTTACAGTGTTTTGGCCAGGTTCAAGCCTCGG
ACTAATGAAAGGACAGGGTCCTCTCACTGCCACGTGCAAGTCCCAGCTGGAGGGCA
GGGCCCTCCCAGCACAATCATAGCCAACGGCTGTGGTTGTAAGCTTGAACCTATGGT
CCGAACACGTAGCCCCACGTGCCTTGTGATAGAGTTCGGGTGCATGTAGTTGAGTAG
GGTTGAGACTCACGAGAATGCTGTAAACAACGTGATCACGCCCCTACTTTGCCTCGT
GGCATCTGCTATAAAATAAAGACACGGCTTGTGGGCGCTGGCGTTGTCTCCTCTTCA
GGGAGCAGCGTCCCACCGAGACCCAGCTATTATTCTCTTGTCTGTCTTTCCTTAATCC
TTTCACCCCCCCACTCAGAGACACCCTTGGCCGTGCTGGCGCGGCACAGTCCACATC
GAAT GAAGCGAT CT C ATT GGT GGAAACCGT GC AGGT C AAT CT ACGAAAAACT AT AT
AATTGCACGAACCCATAAAGCATTGCAGTTACATTGTATTTTGGTCATTCGAATAGT
CTT CGTCTT C AAGTT CCTGGCGCTTTT AGAAAT GCCCT CTCT C AGAAAAAGGAAGGA
AACCAACGAAACTGATACACTTCCGGAAGTATTTAACGATAATTTATCAGATATTCC
TAGTGAGATCGAAGATGCGGATGACTGTTTTGACGATTCCGGAGACGATTCTACTGA
TTCTACTGACAGTGAAATTATTAGACCTGTAAGGAAGCGCAAGGTGGCGGTGCTTTC
AAGTGATTCCGACACTGACGAAGCTACTGATAATTGTTGGTCTGAAATTGACACACC
ACCACGCTTACAAATGTTTGAAGGTCATGCTGGGGTCACTACATTTCCGTCTCAGTG
TGACTCTGTACCCTCTGTGACCAATCTCTTTTTTGGTGATGAATTGTTTGAGATGTTG
T GC AAAGAGCT GT CCA ACT AT C ACGAT C AAACCGC AATGA AACGC AAAAC ACC AT C
T AGAAC ACT AAAGT GGT CT CCGGTT AC AC AGAAGGAC AT C AAGAAATTCCTT GGCC
T AATT ATTCTGAT GGGT C AAAC AAGAAA AGAT AGCTT GAAAGACTATT GGT C AAC A
GATCCTTTGATATGTACCCCTATATTTCCACAGACAATGAGTCGCCATAGATTTGAG
CAAATATGGACATTCTGGCATTTCAATGATAACGCCAAAATGGACAGTCGCTCGGG
GAGACTTTTCAAGATCCAACCTGTGCTGGATTATTTCCTGCATAAATTTCGAACAAT

[0428] The disclosure provides a nanotransposon comprising: (a) a sequence encoding a transposon insert, comprising a sequence encoding a first inverted terminal repeat (ITR), a sequence encoding a second inverted terminal repeat (ITR), and an intra-ITR sequence; (b) a sequence encoding a backbone, wherein the sequence encoding the backbone comprises a sequence encoding an origin of replication having between 1 and 450 nucleotides, inclusive of the endpoints, and a sequence encoding a selectable marker having between 1 and 200 nucleotides, inclusive of the endpoints, and (c) an inter-ITR sequence. In some embodiments, the
inter-ITR sequence of (c) comprises the sequence of (b). In some embodiments, the intra-ITR sequence of (a) comprises the sequence of (b).
[0429] In some embodiments of the nanotransposons of the disclosure, the sequence encoding the backbone comprises between 1 and 600 nucleotides, inclusive of the endpoints. In some embodiments, the sequence encoding the backbone consists of between 1 and 50 nucleotides, between 50 and 100 nucleotides, between 100 and 150 nucleotides, between 150 and 200 nucleotides, between 200 and 250 nucleotides, between 250 and 300 nucleotides, between 300 and 350 nucleotides, between 350 and 400 nucleotides, between 400 and 450 nucleotides, between 450 and 500 nucleotides, between 500 and 550 nucleotides, between 550 and 600 nucleotides, each range inclusive of the endpoints.
[0430] In some embodiments of the nanotransposons of the disclosure, the inter-ITR sequence comprises between 1 and 1000 nucleotides, inclusive of the endpoints. In some embodiments, the inter-ITR sequence consists of between 1 and 50 nucleotides, between 50 and 100 nucleotides, between 100 and 150 nucleotides, between 150 and 200 nucleotides, between 200 and 250 nucleotides, between 250 and 300 nucleotides, between 300 and 350 nucleotides, between 350 and 400 nucleotides, between 400 and 450 nucleotides, between 450 and 500 nucleotides, between 500 and 550 nucleotides, between 550 and 600 nucleotides, between 600 and 650 nucleotides, between 650 and 700 nucleotides, between 700 and 750 nucleotides, between 750 and 800 nucleotides, between 800 and 850 nucleotides, between 850 and 900 nucleotides, between 900 and 950 nucleotides, or between 950 and 1000 nucleotides, each range inclusive of the endpoints.
[0431] In some embodiments of the nanotransposons of the disclosure, including the short nanotransposons (SNTs) of the disclosure, the inter-ITR sequence comprises between 1 and 200 nucleotides, inclusive of the endpoints. In some embodiments, the inter-ITR sequence consists of between 1 and 10 nucleotides, between 10 and 20 nucleotides, between 20 and 30 nucleotides, between 30 and 40 nucleotides, between 40 and 50 nucleotides, between 50 and 60 nucleotides, between 60 and 70 nucleotides, between 70 and 80 nucleotides, between 80 and 90 nucleotides, or between 90 and 100 nucleotides, each range inclusive of the endpoints.
[0432] In some embodiments of the nanotransposons of the disclosure, the selectable marker having between 1 and 200 nucleotides, inclusive of the endpoints, comprises a sequence
encoding a sucrose-selectable marker. In some embodiments, the sequence encoding a sucrose- selectable marker comprises a sequence encoding an RNA-OUT sequence. In some
embodiments, the sequence encoding an RNA-OUT sequence comprises or consists of 137 base pairs (bp). In some embodiments, the selectable marker having between 1 and 200 nucleotides, inclusive of the endpoints, comprises a sequence encoding a fluorescent marker. In some embodiments, the selectable marker having between 1 and 200 nucleotides, inclusive of the endpoints, comprises a sequence encoding a cell surface marker.
[0433] In some embodiments of the nanotransposons of the disclosure, the sequence encoding an origin of replication having between 1 and 450 nucleotides, inclusive of the endpoints, comprises a sequence encoding a mini origin of replication. In some embodiments, the sequence encoding an origin of replication having between 1 and 450 nucleotides, inclusive of the endpoints, comprises a sequence encoding an R6K origin of replication. In some embodiments, the R6K origin of replication comprises an R6K gamma origin of replication. In some embodiments, the R6K origin of replication comprises an R6K mini origin of replication. In some embodiments, the R6K origin of replication comprises an R6K gamma mini origin of replication. In some embodiments, the R6K gamma mini origin of replication comprises or consists of 281 base pairs (bp).
[0434] In some embodiments of the nanotransposons of the disclosure, the sequence encoding the backbone does not comprise a recombination site, an excision site, a ligation site or a combination thereof. In some embodiments, neither the nanotransposon nor the sequence encoding the backbone comprises a product of a recombination site, an excision site, a ligation site or a combination thereof. In some embodiments, neither the nanotransposon nor the sequence encoding the backbone is derived from a recombination site, an excision site, a ligation site or a combination thereof.
[0435] In some embodiments of the nanotransposons of the disclosure, a recombination site comprises a sequence resulting from a recombination event. In some embodiments, a recombination site comprises a sequence that is a product of a recombination event. In some embodiments, the recombination event comprises an activity of a recombinase (e.g., a recombinase site).
[0436] In some embodiments of the nanotransposons of the disclosure, the sequence encoding the backbone does not further comprise a sequence encoding foreign DNA.
[0437] In some embodiments of the nanotransposons of the disclosure, the inter-ITR sequence does not comprise a recombination site, an excision site, a ligation site or a combination thereof. In some embodiments, the inter-ITR sequence does not comprise a product of a recombination event, an excision event, a ligation event or a combination thereof. In some embodiments, the inter-ITR sequence is not derived from a recombination event, an excision event, a ligation event or a combination thereof.
[0438] In some embodiments of the nanotransposons of the disclosure, the inter-ITR sequence comprises a sequence encoding foreign DNA.
[0439] In some embodiments of the nanotransposons of the disclosure, the intra-ITR sequence comprises at least one sequence encoding an insulator and a sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell. In some embodiments, the mammalian cell is a human cell.
[0440] In some embodiments of the nanotransposons of the disclosure, the intra-ITR sequence comprises a first sequence encoding an insulator, a sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell and a second sequence encoding an insulator.
[0441] In some embodiments of the nanotransposons of the disclosure, the intra-ITR sequence comprises a first sequence encoding an insulator, a sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell, a polyadenosine (poly A) sequence and a second sequence encoding an insulator.
[0442] In some embodiments of the nanotransposons of the disclosure, the intra-ITR sequence comprises a first sequence encoding an insulator, a sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell, at least one exogenous sequence, a polyadenosine (poly A) sequence and a second sequence encoding an insulator.
[0443] In some embodiments of the nanotransposons of the disclosure, the sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell is capable of expressing an exogenous sequence in a human cell. In some embodiments, the sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell
comprises a sequence encoding a constitutive promoter. In some embodiments, the sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell comprises a sequence encoding an inducible promoter. In some embodiments, the intra-ITR sequence comprises a first sequence encoding a first promoter capable of expressing an exogenous sequence in a mammalian cell and a second sequence encoding a second promoter capable of expressing an exogenous sequence in mammalian cell, wherein the first promoter is a constitutive promoter, wherein the second promoter is an inducible promoter, and wherein the first sequence encoding the first promoter and the second sequence encoding the second promoter are oriented in opposite directions. In some embodiments, the sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell comprises a sequence encoding a cell-type or tissue-type specific promoter. In some embodiments, the sequence encoding a promoter capable of expressing an exogenous sequence in a mammalian cell comprises a sequence encoding an elongation factor- 1 alpha (EF1 alpha) promoter, a sequence encoding a cytomegalovirus (CMV) promoter, a sequence encoding an MND promoter, a sequence encoding an simian vacuolating virus 40 (SV40) promoter, a sequence encoding a phosphoglycerate kinase 1 (PGK1) promoter, a sequence encoding a human phosphoglycerate kinase l(hPGK) promoter, a sequence encoding a ubiquitin c (Ubc) promoter, a sequence encoding an SPTA1 promoter, a sequence encoding an ankryin-l (Ank-l) promoter, a sequence encoding a Gly-A promoter, a sequence encoding a CAG promoter, a sequence encoding an Hl promoter, or a sequence encoding a U6 promoter.
[0444] In some embodiments of the nanotransposons of the disclosure, the polyadenosine (poly A) sequence is isolated or derived from a viral polyA sequence. In some embodiments, the polyadenosine (polyA) sequence is isolated or derived from an (SV40) polyA sequence.
[0445] In some embodiments, the sequence encoding the hPGK promoter comprises or consists of the nucleic acid sequence:
[0446] Ttgcgccttttccaaggcagccctgggtttgcgcagggacgcggctgctctgggcgtggttccgggaaacgcagcggcgcc gaccctgggtctcgcacattcttcacgtccgttcgcagcgtcacccggatcttcgccgctacccttgtgggccccccggcgacgcttcctgct ccgcccctaagtcgggaaggttccttgcggttcgcggcgtgccggacgtgacaaacggaagccgcacgtctcactagtaccctcgcaga cggacagcgccagggagcaatggcagcgcgccgaccgcgatgggctgtggccaatagcggctgctcagcagggcgcgccgagagc

[0447] In some embodiments, the sequence encoding the EFla promoter comprises or consists of the nucleic acid sequence:

[0449] In some embodiments, the sequence encoding the EFla promoter comprises or consists of the nucleic acid sequence:

[0451] In some embodiments, the sequence encoding the MND promoter comprises or consists of the nucleic acid sequence:


[0453] In some embodiments, the sequence encoding the SPTA1 promoter comprises or consists of the nucleic acid sequence:

[0455] In some embodiments, the sequence encoding the Ank-l promoter comprises or consists of the nucleic acid sequence:

[0457] In some embodiments, the sequence encoding the Gly-A promoter comprises or consists of the nucleic acid sequence:

[0460] In some embodiments of the nanotransposons of the disclosure, including those wherein the at least one exogenous sequence comprises an inducible proapoptotic polypeptide, the ligand binding region comprises a FK506 binding protein 12 (FKBP12) polypeptide. In some embodiments, the amino acid sequence of the ligand binding region comprises a FK506 binding protein 12 (FKBP12) polypeptide. In some embodiments, the FK506 binding protein 12 (FKBP12) polypeptide comprises a modification at position 36 of the sequence. In some embodiments, the modification comprises a substitution of valine (V) for phenylalanine (F) at position 36 (F36V). In some embodiments, the FKBP12 polypeptide is encoded by an amino acid sequence comprising

14494). In some embodiments, the FKBP12 polypeptide is encoded by a nucleic acid sequence comprising

[0461] In some embodiments of the nanotransposons of the disclosure, including those wherein the at least one exogenous sequence comprises an inducible proapoptotic polypeptide, the linker region is encoded by an amino acid comprising GGGGS (SEQ ID NO: 14496) or a nucleic acid
sequence comprising GGAGGAGGAGGATCC (SEQ ID NO: 14497). In some embodiments, the nucleic acid sequence encoding the linker does not comprise a restriction site.
[0462] In some embodiments of the nanotransposons of the disclosure, including those wherein the at least one exogenous sequence comprises an inducible proapoptotic polypeptide, the truncated caspase 9 polypeptide is encoded by an amino acid sequence that does not comprise an arginine (R) at position 87 of the sequence. In some embodiments, the truncated caspase 9 polypeptide is encoded by an amino acid sequence that does not comprise an alanine (A) at position 282 the sequence. In some embodiments, the truncated caspase 9 polypeptide is encoded by an amino acid comprising

some embodiments, the truncated caspase 9 polypeptide is encoded by a nucleic acid sequence comprising


[0463] In some embodiments of the nanotransposons of the disclosure, including those wherein the at least one exogenous sequence comprises an inducible proapoptotic polypeptide, the inducible proapoptotic polypeptide is encoded by an amino acid sequence comprising

embodiments, the inducible proapoptotic polypeptide is encoded by a nucleic acid sequence comprising

[0464] In some embodiments of the nanotransposons of the disclosure, including those wherein the at least one exogenous sequence comprises an inducible proapoptotic polypeptide, the
exogenous sequence further comprises a sequence encoding a selectable marker. In some embodiments, the sequence encoding the selectable marker comprises a sequence encoding a detectable marker. In some embodiments, the detectable marker comprises a fluorescent marker or a cell-surface marker. In some embodiments, the sequence encoding the selectable marker comprises a sequence encoding a protein that is active in dividing cells and not active in non dividing cells. In some embodiments, the sequence encoding the selectable marker comprises a sequence encoding a metabolic marker. In some embodiments, the sequence encoding the selectable marker comprises a sequence encoding a dihydrofolate reductase (DHFR) mutein enzyme. In some embodiments, the DHFR mutein enzyme comprises or consists of the amino acid sequence of:

[0466] In some embodiments of the nanotransposons of the disclosure, including those wherein the at least one exogenous sequence comprises an inducible proapoptotic polypeptide and/or the exogenous sequence comprises a sequence encoding a selectable marker, the exogenous sequence further comprises a sequence encoding a transposase.
[0467] In some embodiments of the nanotransposons of the disclosure, the intra-ITR sequence comprises a sequence encoding a selectable marker, an exogenous sequence, a sequence encoding an inducible caspase polypeptide, and at least one sequence encoding a self-cleaving peptide. In some embodiments, the at least one sequence encoding a self-cleaving peptide is positioned between one or more of: (a) the sequence encoding a selectable marker and the exogenous sequence, (b) the sequence encoding a selectable marker and the inducible caspase polypeptide, and (c) the exogenous sequence and the inducible caspase polypeptide. In some
embodiments, a first sequence encoding a self-cleaving peptide is positioned between the sequence encoding a selectable marker and the exogenous sequence and a second sequence encoding a self-cleaving peptide is positioned between the exogenous sequence and the inducible caspase polypeptide. In some embodiments, the at least one self-cleaving peptide comprises T2A peptide, GSG-T2A peptide, an E2A peptide, a GSG-E2A peptide, an F2A peptide, a GSG-F2A peptide, a P2A peptide, or a GSG-P2A peptide. In some embodiments, the T2A peptide comprises an amino acid sequence comprising EGRGSLLTCGDVEENPGP (SEQ ID NO: 14637). In some embodiments, the GSG-T2A peptide comprises an amino acid sequence comprising GS GEGRGSLLT CGD VEENPGP (SEQ ID NO: 14638). In some embodiments, the E2A peptide comprises an amino acid sequence comprising
QCTNYALLKLAGDVESNPGP (SEQ ID NO: 14639). In some embodiments, the GSG-E2A peptide comprises an amino acid sequence comprising GSGQCTNYALLKLAGDVESNPGP (SEQ ID NO: 14640). In some embodiments, the F2A peptide comprises an amino acid sequence comprising VKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 14641). In some embodiments, the GSG-F2A peptide comprises an amino acid sequence comprising
GSGVKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 14642). In some embodiments, the P2A peptide comprises an amino acid sequence comprising ATNFSLLKQAGD VEENPGP (SEQ ID NO: 14643). In some embodiments, the GSG-P2A peptide comprises an amino acid sequence comprising GSGATNFSLLKQAGD VEENPGP (SEQ ID NO: 14644).
[0468] In some embodiments of the nanotransposons of the disclosure, including those wherein the at least one exogenous sequence comprises one or more of an inducible proapoptotic polypeptide, a sequence encoding a selectable marker, and an exogenous sequence, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a piggyBac transposase or a piggyBac-like transposase. In some embodiments, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a piggyBac transposase. In some embodiments, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a piggyBac-like transposase. In some embodiments, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR)
comprise a TTAA, a TTAT or a TTAX recognition sequence. In some embodiments, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprise a TTAA, a TTAT or a TTAX recognition sequence and a sequence having at least 50% identity to a sequence isolated or derived from a piggyBac transposase or a piggyBac-like transposase. In some embodiments, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprise at least 2 nucleotides (nts), 3 nts, 4 nts, 5 nts, 6 nts, 7 nts, 8 nts, 9 nts, 10 nts, 11 nts, 12 nts, 13 nts, 14 nts, 15 nts, 16 nts, 17 nts, 18 nts, 19 nts, or 20 nts.
[0469] In some embodiments of the nanotransposons of the disclosure, including those wherein the at least one exogenous sequence comprises one or more of an inducible proapoptotic polypeptide, a sequence encoding a selectable marker, and an exogenous sequence, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a piggyBac transposase or a piggyBac-like transposase. In some embodiments, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprises the sequence of CCCTAGAAAGAT AGT CT GCGT AAAATT GACGC AT G (SEQ ID NO: 14679) or a sequence having at least 70% identity to the sequence of
CCCTAGAAAGATAGTCTGCGTAAAATTGACGCATG (SEQ ID NO: 14679). In some embodiments, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprises the sequence of
CCCTAGAAAGATAATCATATTGTGACGTACGTTAAAGATAATCATGCGTAAAATTG ACGCATG (SEQ ID NO: 14680). In some embodiments, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprises the sequence of CCCTAGAAAGATAGTCTGCGTAAAATTGACGCATG (SEQ ID NO: 14679) and comprises the sequence of
CCCTAGAAAGATAATCATATTGTGACGTACGTTAAAGATAATCATGCGTAAAATTG ACGCATG (SEQ ID NO: 14680). In some embodiments, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprises the sequence of CCCTAGAAAGATAGTCTGCGTAAAATTGACGCATG (SEQ ID NO: 14679) and comprises the sequence of

ACGCATG (SEQ ID NO: 14681). In some embodiments, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) comprises the sequence of CCCTAGAAAGATAGTCTGCGTAAAATTGACGCATG (SEQ ID NO: 14679) and comprises the sequence of

[0470] In some embodiments of the nanotransposons of the disclosure, including those wherein the at least one exogenous sequence comprises one or more of an inducible proapoptotic polypeptide, a sequence encoding a selectable marker, and an exogenous sequence, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a piggyBac transposase or a piggyBac-like transposase. In some embodiments, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) is recognized by a piggyBac transposase having an amino acid sequence of at least 20% identity to the amino acid sequence of

NO: 14487) . In some embodiments, the sequence encoding a first inverted terminal repeat
(ITR) or the sequence encoding a second inverted terminal repeat (ITR) is recognized by a piggyBac transposase having the amino acid sequence of

NO: 14487) . In some embodiments, the sequence encoding a first inverted terminal repeat
(ITR) or the sequence encoding a second inverted terminal repeat (ITR) is recognized by a piggyBac transposase having an amino acid sequence of at least 20% identity to the amino acid sequence of

14484 ) . In some embodiments, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) is recognized by a piggyBac transposase having the amino acid sequence of

541 PGTSDDSTEE PVMKKRTYCT YCPSKIRRKA NASCKKCKKV I CREHNI DMC QSCF (SEQ ID NO: 14484) .
[0471] In some embodiments of the nanotransposons of the disclosure, including those wherein the at least one exogenous sequence comprises one or more of an inducible proapoptotic polypeptide, a sequence encoding a selectable marker, and an exogenous sequence, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a Sleeping Beauty transposase. In some embodiments, the Sleeping Beauty transposase is a hyperactive Sleeping Beauty transposase (SB100X).
[0472] In some embodiments of the nanotransposons of the disclosure, including those wherein the at least one exogenous sequence comprises one or more of an inducible proapoptotic polypeptide, a sequence encoding a selectable marker, and an exogenous sequence, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a Helitron transposase.
[0473] In some embodiments of the nanotransposons of the disclosure, including those wherein the at least one exogenous sequence comprises one or more of an inducible proapoptotic polypeptide, a sequence encoding a selectable marker, and an exogenous sequence, the sequence encoding a first inverted terminal repeat (ITR) or the sequence encoding a second inverted terminal repeat (ITR) are recognized by a Tol2 transposase.
[0474] The disclosure provides a cell comprising a nanotransposon of the disclosure. In some embodiments, the cell further comprises a transposase composition. In some embodiments, the transposase composition comprises a transposase or a sequence encoding the transposase that is capable of recognizing the first ITR or the second ITR of the nanotransposon. In some embodiments, the transposase composition comprises a nanotransposon comprising the sequence encoding the transposase. In some embodiments, the cell comprises a first
nanotransposon comprising an exogenous sequence and a second nanotransposon comprising a sequence encoding a transposase. In some embodiments, the cell is an allogeneic cell.
[0475] The disclosure provides a composition comprising the nanotransposon of the disclosure.
[0476] The disclosure provides a composition comprising the cell of the disclosure. In some embodiments, the cell comprises a nanotransposon of the disclosure. In some embodiments, the cell is not further modified. In some embodiments, the cell is allogeneic.
[0477] The disclosure provides a composition comprising the cell of the disclosure. In some embodiments, the cell comprises a nanotransposon of the disclosure. In some embodiments, the cell is not further modified. In some embodiments, the cell is autologous.
[0478] The disclosure provides a composition comprising a plurality of cells of the disclosure. In some embodiments, at least one cell of the plurality of cells comprises a nanotransposon of the disclosure. In some embodiments, a portion of the plurality of cells comprises a
nanotransposon of the disclosure. In some embodiments, the portion comprises at least 1%, 2%, 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 97%, 99% or any percentage in between of the plurality of cells. In some embodiments, each cell of the plurality of cells comprises a nanotransposon of the disclosure. In some embodiments, the plurality of cells does not comprise a modified cell of the disclosure. In some embodiments, at least one cell of the plurality of cells is not further modified. In some embodiments, none of the plurality of cells is not further modified. In some embodiments, plurality of cells is allogeneic. In some embodiments, an allogeneic plurality of cells are produced according to the methods of the disclosure. In some embodiments, plurality of cells is autologous. In some embodiments, an autologous plurality of cells are produced according to the methods of the disclosure.
[0479] The disclosure provides a modified cell comprising: (a) a nanotransposon of the disclosure; (b) a sequence encoding an inducible proapoptotic polypeptide; and wherein the cell is a T cell, (c) a modification of an endogenous sequence encoding a T cell Receptor (TCR), wherein the modification reduces or eliminates a level of expression or activity of the TCR. In some embodiments, the cell further comprises: (d) a non-naturally occurring sequence comprising an HLA class I histocompatibility antigen, alpha chain E (HLA-E), and (e) a modification of an endogenous sequence encoding Beta-2-Microglobulin (B2M), wherein the modification reduces or eliminates a level of expression or activity of a major
histocompatibility complex (MHC) class I (MHC-I).
[0480] The disclosure provides a modified cell comprising: (a) a nanotransposon of the disclosure; (b) a sequence encoding an inducible proapoptotic polypeptide; (c) a non-naturally occurring sequence comprising an HLA class I histocompatibility antigen, alpha chain E (HLA- E), and (e) a modification of an endogenous sequence encoding Beta-2-Microglobulin (B2M), wherein the modification reduces or eliminates a level of expression or activity of a major histocompatibility complex (MHC) class I (MHC-I).
[0481] In some embodiments of the modified cells of the disclosure, the non-naturally occurring sequence comprising a HLA-E further comprises a sequence encoding a B2M signal peptide. In some embodiments, the non-naturally occurring sequence comprising an HLA-E further comprises a linker, wherein the linker is positioned between the sequence encoding the sequence encoding a B2M polypeptide and the sequence encoding the HLA-E. In some embodiments, the non-naturally occurring sequence comprising an HLA-E further comprises a sequence encoding a peptide and a sequence encoding a B2M polypeptide. In some
embodiments, the non-naturally occurring sequence comprising an HLA-E further comprises a first linker positioned between the sequence encoding the B2M signal peptide and the sequence encoding the peptide, and a second linker positioned between the sequence encoding the B2M polypeptide and the sequence encoding the HLA-E.
[0482] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, the cell is a mammalian cell.
[0483] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, the cell is a human cell.
[0484] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, the cell is a stem cell.
[0485] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, the cell is a differentiated cell.
[0486] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, the cell is a somatic cell.
[0487] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, the cell is an immune cell or an immune cell precursor. In some embodiments, the immune cell is a lymphoid progenitor cell, a natural killer (NK) cell, a cytokine induced killer
(CIK) cell, a T lymphocyte (T cell), a B lymphocyte (B-cell) or an antigen presenting cell (APC). In some embodiments, the immune cell is a T cell, an early memory T cell, a stem cell like T cell, a stem memory T cell (Tscm), or a central memory T cell (Tcm). In some embodiments, the immune cell precursor is a hematopoietic stem cell (HSC). In some embodiments, the cell is an antigen presenting cell (APC).
[0488] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, the cell further comprises a gene editing composition. In some embodiments, the gene editing composition comprises a sequence encoding a DNA binding domain and a sequence encoding a nuclease protein or a nuclease domain thereof. In some embodiments, the gene editing composition comprises a sequence encoding a nuclease protein or a sequence encoding a nuclease domain thereof. In some embodiments, the e sequence encoding a nuclease protein or the sequence encoding a nuclease domain thereof comprises a DNA sequence, an RNA sequence, or a combination thereof. In some embodiments, the nuclease or the nuclease domain thereof comprises one or more of a CRISPR/Cas protein, a Transcription Activator- Like Effector Nuclease (TALEN), a Zinc Finger Nuclease (ZFN), and an endonuclease. In some embodiments, the CRISPR/Cas protein comprises a nuclease-inactivated Cas (dCas) protein.
[0489] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, the cell further comprises a gene editing composition. In some embodiments, the gene editing composition comprises a sequence encoding a DNA binding domain and a sequence encoding a nuclease protein or a nuclease domain thereof. In some embodiments, the nuclease or the nuclease domain thereof comprises a nuclease-inactivated Cas (dCas) protein and an endonuclease. In some embodiments, the endonuclease comprises a Clo051 nuclease or a nuclease domain thereof. In some embodiments, the gene editing composition comprises a fusion protein. In some embodiments, the fusion protein comprises a nuclease- inactivated Cas9 (dCas9) protein and a Clo05l nuclease or a Clo05l nuclease domain. In some embodiments, the gene editing composition further comprises a guide sequence. In some embodiments, the guide sequence comprises an RNA sequence. In some embodiments, the fusion protein comprises or consists of the amino acid sequence:


nucleic acid comprising or consisting of the sequence:



embodiments, the fusion protein comprises or consists of the amino acid sequence:

comprising or consisting of the sequence:



[0490] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, a nanotransposon comprises the gene editing composition comprising a guide sequence and a sequence encoding a fusion protein comprising a sequence encoding an inactivated Cas9 (dCas9) and a sequence encoding a Clo051 nuclease or a nuclease domain thereof.
[0491] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, the cell expresses the gene editing composition transiently.
[0492] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, the cell is a T cell and the guide RNA comprises a sequence complementary to a target sequence encoding an endogenous TCR. In some embodiments, the guide RNA comprises a sequence complementary to a target sequence encoding a B2M polypeptide.
[0493] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, the guide RNA comprises a sequence complementary to a target sequence within a safe harbor site of a genomic DNA sequence.
[0494] In some embodiments of the cells, unmodified cells and modified cells of the disclosure, the Clo05l nuclease or a nuclease domain thereof induces a single or double strand break in a target sequence. In some embodiments, a donor sequence, a donor plasmid, or a donor nanotransposon intra-ITR sequence integrated at a position of single or double strand break and/or at a position of cellular repair within a target sequence.
[0495] The disclosure provides a composition comprising a modified cell according to the disclosure. In some embodiments, the composition further comprises a pharmaceutically- acceptable carrier.
[0496] The disclosure provides a composition comprising a plurality of modified cells according to the disclosure. In some embodiments, the composition further comprises a pharmaceutically-acceptable carrier.
[0497] The disclosure provides a composition of the disclosure for use in the treatment of a disease or disorder.
[0498] The disclosure provides the use of a composition of the disclosure for the treatment of a disease or disorder.
[0499] The disclosure provides a method of treating a disease or disorder comprising administering to a subject in need thereof a therapeutically-effective amount of a composition of the disclosure. In some embodiments, the subject does not develop graft vs. host (GvH) and/or host vs. graft (HvG) following administration of the composition. In some embodiments, the administration is systemic. In some embodiments, the composition is administered by an intravenous route. In some embodiments, the composition is administered by an intravenous injection or an intravenous infusion.
[0500] The disclosure provides a method of treating a disease or disorder comprising administering to a subject in need thereof a therapeutically-effective amount of a composition of the disclosure. In some embodiments, the subject does not develop graft vs. host (GvH) and/or host vs. graft (HvG) following administration of the composition. In some embodiments, the administration is local. In some embodiments, the composition is administered by an intra- tumoral route, an intraspinal route, an intracerebroventricular route, an intraocular route or an intraosseous route. In some embodiments, the composition is administered by an intra-tumoral injection or infusion, an intraspinal injection or infusion, an intracerebroventricular injection or infusion, an intraocular injection or infusion or an intraosseous injection or infusion.
[0501] In some embodiments of the methods of treating a disease or disorder of the disclosure, the therapeutically effective dose is a single dose and wherein the allogeneic cells of the composition engraft and/or persist for a sufficient time to treat the disease or disorder. In some embodiments, the single dose is one of at least 2, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65,
70, 75, 80, 85, 90, 95, 100 or any number of doses in between that are manufactured simultaneously.
[0502] In some embodiments of the methods of treating a disease or disorder of the disclosure, the therapeutically effective dose is a single dose and wherein the autologous cells of the composition engraft and/or persist for a sufficient time to treat the disease or disorder. In some embodiments, the single dose is one of at least 2, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100 or any number of doses in between that are manufactured
simultaneously.
[0503] A vector for constitutive expression of Interleukin 2 Receptor subunit gamma, GFP, and
DHFR (nano.PB.EFla.IL2RG-T2A-GFP-T2A-DHFR ) is encoded by a sequence comprising:



[0504] The 3’ITR of the nano.PB.EFla.IL2RG-T2A-GFP-T2A-DHFR construct is encoded by a sequence comprising:

[0505] The Insulator of the nano.PB.EFla.IL2RG-T2A-GFP-T2A-DHFR construct is encoded by a sequence comprising:

agctttgcaaagatggataaagttttaaacagagaggaatctttgcagctaatggaccttctaggtcttgaaaggagtgggaattggctc cggtgcccgtcagtgggcagagcgcacatcgcccacagtccccgagaagttggggggaggggtcggcaattgaaccggtgcctag agaaggtggcgcggggtaaactgggaaagtgatgtcgtgtactggctccgcctttttcccgagggtgggggagaaccgtatataagtg cagtagtcgccgtgaacgttctttttcgcaacgggtttgccgccagaacacaggtaagtgccgtgtgtggttcccgcgggcctggcctctt tacgggttatggcccttgcgtgccttgaattacttccacctggctgcagtacgtgattcttgatcccgagcttcgggttggaagtgggtggg agagttcgaggccttgcgcttaaggagccccttcgcctcgtgcttgagttgaggcctggcctgggcgctggggccgccgcgtgcgaatc tggtggcaccttcgcgcctgtctcgctgctttcgataagtctctagccatttaaaatttttgatgacctgctgcgacgctttttttctggcaagat agtcttgtaaatgcgggccaagatctgcacactggtatttcggtttttggggccgcgggcggcgacggggcccgtgcgtcccagcgcac atgttcggcgaggcggggcctgcgagcgcggccaccgagaatcggacgggggtagtctcaagctggccggcctgctctggtgcctg gcctcgcgccgccgtgtatcgccccgccctgggcggcaaggctggcccggtcggcaccagttgcgtgagcggaaagatggccgcttc ccggccctgctgcagggagctcaaaatggaggacgcggcgctcgggagagcgggcgggtgagtcacccacacaaaggaaaagg gcctttccgtcctcagccgtcgcttcatgtgactccacggagtaccgggcgccgtccaggcacctcgattagttctcgagcttttggagtac gtcgtctttaggttggggggaggggttttatgcgatggagtttccccacactgagtgggtggagactgaagttaggccagcttggcacttg atgtaattctccttggaatttgccctttttgagtttggatcttggttcattctcaagcctcagacagtggttcaaagtttttttcttccatttcaggtg tcgtga (italicized) (SEQ ID NO: 14706).
[0507] The IL2RG of the nano.PB.EF 1 a.IL2RG-T2A-GFP-T2A-DHFR construct is encoded by a sequence comprising:
atgctgaagcccagcctgccttttaccagcctgctgttcctgcagctgcctctgcttggcgtgggcctgaataccaccatcctgacac ctaacggcaacgaggatacaaccgccgacttcttcctgaccaccatgcctaccgatagcctgagcgtgtccacactgccactgcct gaggtgcagtgcttcgtgttcaacgtcgagtacatgaactgcacctggaacagctccagcgagccccagcctaccaatctgacact gcactattggtacaagaacagcgacaacgacaaggtgcagaagtgcagccactacctgttcagcgaggaaatcaccagcggctg ccagctgcagaagaaagagatccacctgtaccagaccttcgtggtgcagctccaggatcctagagagcctagaaggcaggccac acagatgctgaaactgcagaacctcgtgatcccctgggctcccgaaaacctgactctgcacaagctgagcgagagccagctggaa ctgaactggaacaaccggttcctgaatcactgcctggaacatctggtgcagtaccggaccgactgggatcactcttggacagagca gagcgtggactaccggcacaagttcagcctgccatctgtggacggccagaagcggtacacctttagagtgcggagccggttcaac cctctgtgtggatctgctcagcattggagcgagtggtcacacccaatccactggggcagcaacaccagcaaagagaaccccttcct gttcgccctggaagccgtggttatcagcgtgggctctatgggcctgatcatctccctgctgtgcgtgtacttctggctggaaagaacc atgcctcggatccccactctgaagaacctggaagatctcgtgaccgagtaccacggcaacttcagtgcttggagcggcgtgtcaaa

[0508] The EGFP of the nano.PB.EFla.IL2RG-T2A-GFP-T2A-DHFR construct is encoded by a sequence comprising:

[0509] The DHFR of the nano.PB.EFla.IL2RG-T2A-GFP-T2A-DHFR construct is encoded by a sequence comprising:

[0510] The SV40 Poly (A) of the nano . PB . EF 1 a . IL2RG- T2 A- GFP-T2A-DHFR construct is encoded by a sequence comprising:
taagatacattgatgagtttggacaaaccacaactagaatgcagtgaaaaaaatgctttatttgtgaaatttgtgatgctattgctttatttgt aaccattataagctgcaataaacaagtt (bold italicized) (SEQ ID NO: 14710).
[0511] The 5'ITR of the nano . PB . EF 1 a . IL2RG- T2 A- GFP-T2A-DHFR construct is encoded by a sequence comprising:


[0512] A vector for erythroid-specific expression of a BCL11 A targeted shRNA and the constitutive expression of GFP and DHFR (nano.PB-Ank-BCFl lashRNA-MND.GFP-T2A- DHFR construct) is encoded by a sequence comprising:




[0520] The EGFP of the nanoPB . Ank-BCL 11 ashRNA.MND. GFP-T2A-DHFR construct is encoded by a sequence comprising:

[0521] The DHFR of the nanoPB. Ank-BCL 11 ashRNA.MND. GFP-T2A-DHFR construct is encoded by a sequence comprising:


[0522] The SV40 Poly(A) of the nanoPB . Ank-B CL 11 ashRNA. MND . GFP-T2 A-DHFR construct is encoded by a sequence comprising:

[0523] The 5'ITR of the nanoPB. Ank-BCLl lashRNA.MND.GFP-T2A-DHFR construct is encoded by a sequence comprising:

[0524] A vector for erythroid-specific expression of a BCL11 A targeted shRNA and the expression of an iC9 safety switch (nanoPB.Ank-BCLl lashRNA.MND.iC9-T2A-DHFR ) is encoded by a sequence comprising:



[0526] The 3’ITR of the nanoPB.Ank-BCLl 1 ashRNA.MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:

[0527] The Insulator 1 of the nanoPB.Ank-BCLl 1 ashRNA.MND. iC9-T2A-DHER construct is encoded by a sequence comprising:


[0529] The miRE sh49 BCL11A of the nanoPB.Ank-BCLl lashRNA.MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:
gtacaagtaatagggccctacgagcttgctgtttgaatgaggcttcagtactttacagaatcgttgcctgcacatcttggaaacactt gctgggattacttcgacttcttaacccaacagaaggctcgagaaggtatattgctgttgacagtgagcgccgcacagaacactcat ggatttagtgaagccacagatgtaaatccatgagtgttctgtgcgttgcctactgcctcggacttcaaggggctacaattggagcaa ttatcttgtttactaaaactgaataccttgctatctctttgatacatttttacaaagctgaattaaaatggtataaattaaatcactgc
(bold) (SEQ ID NO: 14713).
[0530] The BBBMND PROMOTER of the nanoPB.Ank-BCLl lashRNA.MND. iC9-T2A- DHFR construct is encoded by a sequence comprising:

[0531] The iC9 of the nanoPB.Ank-BCLl lashRNA.MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:


[0532] The DHFR of the nanoPB. Ank-BCLl 1 ashRNA.MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:

[0533] The SV40 Poly(A) of the nanoPB. Ank-BCLl lashRNA.MND.iC9-T2A-DHFR construct is encoded by a sequence comprising:

[0534] The Insulator 2 of the nanoPB. Ank-BCLl 1 ashRNA.MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:


[0535] The 5'ITR of the nanoPB. Ank-BCLl 1 ashRNA.MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:

[0536] A vector for constitutive expression of Interleukin 2 Receptor subunit gamma, iC9 and
DHFR (nanoPB. MND.IL2RG-T2A-iC9-T2A-DHFR) is encoded by a sequence comprising:



[0538] The 3 TTR of the nanoPB.MND.IL2RG-T2A-iC9-T2A-DHLR construct is encoded by a sequence comprising:

[0539] The Insulator 1 of the nanoPB.MND.IL2RG-T2A-iC9-T2A-DHLR construct is encoded by a sequence comprising:



[0542] The iC9 of the nanoPB.MND.IL2RG-T2A-iC9-T2A-DHFR construct is encoded by a sequence comprising:

[0543] The DHFR of the nanoPB.MND.IL2RG-T2A-iC9-T2A-DHFR construct is encoded by a sequence comprising:

[0544] The SV40 Poly(A) of the nanoPB . MND . IL2RG- T2 A-iC9- T2 A-DHFR construct is encoded by a sequence comprising:

[0545] The Insulator 1 of the nanoPB.MND.IL2RG-T2A-iC9-T2A-DHFR construct is encoded by a sequence comprising:

[0546] The 5’ITR of the nanoPB.MND.IL2RG-T2A-iC9-T2A-DHFR construct is encoded by a sequence comprising:

[0547] A vector for erythroid-specific expression of Insulin growth factor 2 binding protein 1 (IGF2BP1) and the expression of an iC9 safety switch (nanoPB.SPTA.IGF2BPl .MND.iC9- T2A-DHFR) is encoded by a sequence comprising:



NO: 14720).
[0549] The 3’ITR of the nanoPB.SPTA.IGF2BPl .MND.iC9-T2A-DHFR construct is encoded by a sequence comprising:
CCCTAGAAAGATAATCATATTGTGACGTACGTTAAAGATAATCATGCGTAAAATTGA CGCATGTGTTTTATCGGTCTGTATATCGAGGTTTATTTATTAATTTGAATAGATATTA AGTTTTATTATATTTACACTTACATACTAATAATAAATTCAACAAACAATTTATTTAT GTTTATTT ATTT ATTAAAA AAAAAC A AAAACT C A AAATTT CTTCT AT AAAGT AAC AA AACTTTTA (ALL CAPS) (SEQ ID NO: 14704).
[0550] The Insulator 1 of the nanoPB.SPTA.IGF2BPl .MND.iC9-T2A-DHFR construct is encoded by a sequence comprising:
gagggacagcccccccccaaagcccccagggatgtaattacgtccctcccccgctagggggcagcagcgagccgcccggggctccgc tccggtccggcgctccccccgcatccccgagccggcagcgtgcggggacagcccgggcacggggaaggtggcacgggatcgctttcc tctgaacgcttctcgctgctctttgagcctgcagacacctggggggatacggggaaaa (underlined) (SEQ ID NO: 14705).
[0551] The SPTAlPromoter of the nanoPB . SPT A. IGF2BP 1. MND . iC9- T2 A-DHFR construct is encoded by a sequence comprising:
ccagactttcaagaagagaatgtaaaggactctcagtttttctatgtgagatccaagaacaggggaaaccacaaatgtagaatcaaaa tcttctcttgtagatcatggaagttagattattcaagctgcatttacactggaatgaagtttggcatggatagccccactggcttgtagaaag gtctaagagcatcccactattttctttttgcttgtttgtttcatttttgtaagttagtctaaaataactatgcctatggaaaaagtctacctctttttg ttctccattaaaattaatacatacagtaggatgatttataccatatatatcagaagtcagccatattttcaacttttttgtgacatcattggtttg
tcaaataaggtatcctaatttttgttttacaaaatattaatgaacacatcatataactttttttgttccttccatttaaatgattaagagtacaact aaatcagatttttaaagaccaaattgttgaggttaggaataaaatcttattttgtgaaagactctctagaaaaagccaggataattcgttg acttaaagactgtgaaaaatctgcagttgagttggatgaagttgttgagctgtatttcctataaatatatggggttttttttctaatttttcatcc aaaaaccttactttcattttttaagtcttattgagtaactttgaaagccagagcctcccaaaactgctgagtcacccagtatctgtaaaactt agcagttgcctcagctgagtatgtcttctaaagataatgtcgattgtgtatggctgatgggattctaggaccaagcaagaggtttttttttttc ccccacatacttaacgtttctatatttctatttgaattcgactggacagttccatttgaattatttctctctctctctctctctctctgacacattttat cttgccaggttctaaaccc (italicized) (SEQ ID NO: 14700).
[0552] The IGF2BP1 of the nanoPB . SPT A. IGF2BP 1. MND . iC9-T2 A-DHFR construct is encoded by a sequence comprising:
atgaacaagctttacatcggcaacctcaacgagagcgtgacccccgcggacttggagaaagtgtttgcggagcacaagatctcct acagcggccagttcttggtcaaatccggctacgccttcgtggactgcccggacgagcactgggcgatgaaggccatcgaaactttc tccgggaaagtagaattacaaggaaaacgcttagagattgaacattcggtgcccaaaaaacaaaggagccggaaaattcaaatc cgaaatattccaccccagctccgatgggaagtactggacagcctgctggctcagtatggtacagtagagaactgtgagcaagtga acaccgagagtgagacggcagtggtgaatgtcacctattccaaccgggagcagaccaggcaagccatcatgaagctgaatggcc accagttggagaaccatgccctgaaggtctcctacatccccgatgagcagatagcacagggacctgagaatgggcgccgagggg gctttggctctcggggtcagccccgccagggctcacctgtggcagcgggggccccagccaagcagcagcaagtggacatccccct tcggctcctggtgcccacccagtatgtgggtgccattattggcaaggagggggccaccatccgcaacatcacaaaacagacccag tccaagatagacgtgcataggaaggagaacgcaggtgcagctgaaaaagccatcagtgtgcactccacccctgagggctgctcct ccgcttgtaagatgatcttggagattatgcataaagaggctaaggacaccaaaacggctgacgaggttcccctgaagatcctggcc cataataactttgtagggcgtctcattggcaaggaaggacggaacctgaagaaggtagagcaagataccgagacaaaaatcacc atctcctcgttgcaagaccttaccctttacaaccctgagaggaccatcactgtgaagggggccatcgagaattgttgcagggccga gcaggaaataatgaagaaagttcgggaggcctatgagaatgatgtggctgccatgagcctgcagtctcacctgatccctggcctga acctggctgctgtaggtcttttcccagcttcatccagcgcagtcccgccgcctcccagcagcgttactggggctgctccctatagctcc tttatgcaggctcccgagcaggagatggtgcaggtgtttatccccgcccaggcagtgggcgccatcatcggcaagaaggggcagc acatcaaacagctctcccggtttgccagcgcctccatcaagattgcaccacccgaaacacctgactccaaagttcgtatggttatca tcactggaccgccagaggcccaattcaaggctcagggaagaatctatggcaaactcaaggaggagaacttctttggtcccaagga ggaagtgaagctggagacccacatacgtgtgccagcatcagcagctggccgggtcattggcaaaggtggaaaaacggtgaacg agttgcagaatttgacggcagctgaggtggtagtaccaagagaccagacccctgatgagaacgaccaggtcatcgtgaaaatcat cggacatttctatgccagtcagatggctcaacggaagatccgagacatcctggcccaggttaagcagcagcatcagaagggacag agtaaccaggcccaggcacggaggaagtga (bold) (SEQ ID NO: 14721).
[0553] The bbbMND PROMOTER of the nanoPB . SPT A. IGF2BP 1. MND . iC9-T2 A-DHFR construct is encoded by a sequence comprising:

[0554] The iC9 of the nanoPB. SPTA.IGF2BP1. MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:

[0555] The DHFR of the nanoPB. SPTA.IGF2BP1. MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:


[0556] The SV40 Poly(A) of the nanoPB . SPT A. IGF2BP 1. MND . iC9-T2 A-DHFR construct is encoded by a sequence comprising:
cagacatgataagatacattgatgagtttggacaaaccacaactagaatgcagtgaaaaaaatgctttatttgtgaaatttgtgatgctat tgctttatttgtaaccattataagctgcaataaacaagttaacaacaacaattgcattcattttatgtttcaggttcagggggaggtgtggga ggttt (bold italicized) (SEQ ID NO: 14710).
[0557] The Insulator 2 of the nanoPB. SPTA.IGF2BP1. MND. iC9-T2A-DHFR construct is encoded by a sequence comprising:

[0558] The 5'ITR of the nanoPB . SPT A. IGF2BP 1. MND . iC9- T2 A-DHFR construct is encoded by a sequence comprising:





[0563] The HBB cassette in opposite orientation of the PB.HBB.PGK. GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:

(SEQ ID NO: 14935).
[0564] The hPGK promoter of the PB.HBB.PGK.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
ttgcgccttttccaaggcagccctgggtttgcgcagggacgcggctgctctgggcgtggttccgggaaacgcagcggcgccgaccctg ggtctcgcacattcttcacgtccgttcgcagcgtcacccggatcttcgccgctacccttgtgggccccccggcgacgcttcctgctccgcc cctaagtcgggaaggttccttgcggttcgcggcgtgccggacgtgacaaacggaagccgcacgtctcactagtaccctcgcagacgg acagcgccagggagcaatggcagcgcgccgaccgcgatgggctgtggccaatagcggctgctcagcagggcgcgccgagagca gcggccgggaaggggcggtgcgggaggcggggtgtggggcggtagtgtgggccctgttcctgcccgcgcggtgttccgcattctgca
agcctccggagcgcacgtcggcagtcggctccctcgttgaccgaatcaccgacctctctccccag (italicized) (SEQ ID NO: 14696).
[0565] The GFP of the PB.HBB.PGK.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:

[0566] The DHFR of the PB.HBB.PGK.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:

[0567] The SV40 Poly(A) of the PB . HBB . PGK. GFP-T2 A-DHFR construct is encoded by a nucleic acid sequence comprising:
taagatacattgatgagtttggacaaaccacaactagaatgcagtgaaaaaaatgctttatttgtgaaatttgtgatgctattgctttatttgt aaccattataagctgcaataaacaagtt (bold italicized) (SEQ ID NO: 14710).
[0568] The Insulator 2 of the PB.HBB.PGK.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:


[0569] The 5’ITR of the PB HBB.PGK.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:

[0570] A piggyBac transposon vector construct for expression of GFP and DHFR
(PB.EFla.GFP-T2A-DHFR) is encoded by a sequence comprising:


[0571] The 3 TTR of the PB.EFla.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
CCCTAGAAAGATAATCATATTGTGACGTACGTTAAAGATAATCATGCGTAAAATTGA CGCATGTGTTTTATCGGTCTGTATATCGAGGTTTATTTATTAATTTGAATAGATATTA AGTTTT ATTATATTTAC ACTT AC AT ACT AAT AAT AAATTC AAC AAAC AATTT ATTT AT GTTTATTT ATTT ATTAAAA AAAAAC A AAAACT C A AAATTT CTTCT AT AAAGT AAC AA AACTTTTA (ALL CAPS) (SEQ ID NO: 14704).
[0572] The Insulator of the PB.EFla.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
gagggacagcccccccccaaagcccccagggatgtaattacgtccctcccccgctagggggcagcagcgagccgcccggggctccgc tccggtccggcgctccccccgcatccccgagccggcagcgtgcggggacagcccgggcacggggaaggtggcacgggatcgctttcc tctgaacgcttctcgctgctctttgagcctgcagacacctggggggatacggggaaaa (underlined) (SEQ ID NO: 14705).
[0573] The EFla Promoter of the PB.EFla.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
agctttgcaaagatggataaagttttaaacagagaggaatctttgcagctaatggaccttctaggtcttgaaaggagtgggaattggctc cggtgcccgtcagtgggcagagcgcacatcgcccacagtccccgagaagttggggggaggggtcggcaattgaaccggtgcctag agaaggtggcgcggggtaaactgggaaagtgatgtcgtgtactggctccgcctttttcccgagggtgggggagaaccgtatataagtg cagtagtcgccgtgaacgttctttttcgcaacgggtttgccgccagaacacaggtaagtgccgtgtgtggttcccgcgggcctggcctctt tacgggttatggcccttgcgtgccttgaattacttccacctggctgcagtacgtgattcttgatcccgagcttcgggttggaagtgggtggg agagttcgaggccttgcgcttaaggagccccttcgcctcgtgcttgagttgaggcctggcctgggcgctggggccgccgcgtgcgaatc tggtggcaccttcgcgcctgtctcgctgctttcgataagtctctagccatttaaaatttttgatgacctgctgcgacgctttttttctggcaagat agtcttgtaaatgcgggccaagatctgcacactggtatttcggtttttggggccgcgggcggcgacggggcccgtgcgtcccagcgcac atgttcggcgaggcggggcctgcgagcgcggccaccgagaatcggacgggggtagtctcaagctggccggcctgctctggtgcctg gcctcgcgccgccgtgtatcgccccgccctgggcggcaaggctggcccggtcggcaccagttgcgtgagcggaaagatggccgcttc ccggccctgctgcagggagctcaaaatggaggacgcggcgctcgggagagcgggcgggtgagtcacccacacaaaggaaaagg gcctttccgtcctcagccgtcgcttcatgtgactccacggagtaccgggcgccgtccaggcacctcgattagttctcgagcttttggagtac

[0574] The GFP of the PB.EFla.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:

[0575] The DHFR of the PB.EFla.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:

[0576] The SV40 Poly(A) of the PB.EFla.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:

[0577] The 5’ITR of the PB.EFla.GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:

[0578] A vector for the expression of HBB T87Q, iCasp9, and DHFR (PB-HBB-PGK-iCasp9- T2A-DHFR construct) is encoded by a sequence comprising:




[0580] The 3 TTR of the PB-HBB-PGK-iCasp9-T2A-DHFR construct is encoded by a sequence comprising:


NO: 14705).
[0584] The T87Q beta-globm cassette with LCR of the PB-HBB-PGK-iCasp9-T2A-DHFR construct is encoded by a sequence comprising:



sequence comprising:

[0591] The SV40Poly(A) of the PB-HBB-PGK-iCasp9-T2A-DHFR construct is encoded by a sequence comprising:

[0593] The Insulator 2 of the PB-HBB-PGK-iCasp9-T2A-DHFR construct is encoded by a sequence comprising:

[0595] The 5’ITR of the PB-HBB-PGK-iCasp9-T2A-DHFR construct is encoded by a sequence comprising:

[0597] A construct for constitutive expression of Interleukin 2 Receptor subunit gamma, GFP, and DHFR (Nano-PB - V5 - J ctR- Ank-miRE-sh49-B CL 11 A-EF 1 a- GFP-T2 A-DHFR) is encoded by a sequence comprising:



[0599] The 3’ITR of the Nano-PB-V5-JctR-Ank-miRE-sh49-BCLl 1 A-EF 1 a-GFP-T2A-DHFR construct is encoded by a sequence comprising:

[0601] The Ank promoter of the Nano-PB-V5-JctR-Ank-miRE-sh49-BCLl 1 A-EFla-GFP- T2A-DHFR construct is encoded by a sequence comprising:
cgcgttcgaaggggcaaccaggggtccgcgcgccgaggcctggggagcggggcctcctggggttgggggaggaggtgctcttgtaa tctgcggtggtccccaggcgggcgccacccctccgcccgcccgtgccgggagcgcccggcccgacagcaagcgcctctggggccg ataaggccctcgggggcctggcccgcacgtcacaggccccgcagaggctgcggtgagtccgccagccccagctgctcctcctcaag cccccaaggcccttcggcggcaattcccaccgg (italicized) (SEQ ID NO: 14701).
[0602] The miR-E sh49 BCL11 A of the Nano-PB -V 5 - JctR- Ank-miRE-sh49-B CL 11 A-EF 1 a- GFP-T2A-DHFR construct is encoded by a sequence comprising:
gtacaagtaatagggccctacgagcttgctgtttgaatgaggcttcagtactttacagaatcgttgcctgcacatcttggaaacactt gctgggattacttcgacttcttaacccaacagaaggctcgagaaggtatattgctgttgacagtgagcgccgcacagaacactcat ggatttagtgaagccacagatgtaaatccatgagtgttctgtgcgttgcctactgcctcggacttcaaggggctacaattggagcaa ttatcttgtttactaaaactgaataccttgctatctctttgatacatttttacaaagctgaattaaaatggtataaattaaatcactgc
(bold) (SEQ ID NO: 14713).
[0603] The EFlalpha of the Nano-PB-V5-JctR-Ank-miRE-sh49-BCLl 1 A-EF 1 a-GFP-T2A- DHFR construct is encoded by a sequence comprising:
A GC TTTGCAAA GATGGA TAAAGTTTTAAA CA GA GA GGAA TC TTTGCA GC TAA TGGACCTTC
TAGGTCTTGAAAGGAGTGGGAATTGGCTCCGGTGCCCGTCAGTGGGCAGAGCGCACATC
GCCCACAGTCCCCGAGAAGTTGGGGGGAGGGGTCGGCAATTGAACCGGTGCCTAGAGA
AGGTGGCGCGGGGTAAACTGGGAAAGTGATGTCGTGTACTGGCTCCGCCTTTTTCCCGA
GGGTGGGGGAGAACCGTATATAAGTGCAGTAGTCGCCGTGAACGTTCTTTTTCGCAACGG
GTTTGCCGCCAGAACACAGGTAAGTGCCGTGTGTGGTTCCCGCGGGCCTGGCCTCTTTA
CGGGTTATGGCCCTTGCGTGCCTTGAATTACTTCCACCTGGCTGCAGTACGTGATTCTTGA
TCCCGAGCTTCGGGTTGGAAGTGGGTGGGAGAGTTCGAGGCCTTGCGCTTAAGGAGCCC
CTTCGCCTCGTGCTTGAGTTGAGGCCTGGCCTGGGCGCTGGGGCCGCCGCGTGCGAAT
CTGGTGGCACCTTCGCGCCTGTCTCGCTGCTTTCGATAAGTCTCTAGCCATTTAAAATTTTT
GATGACCTGCTGCGACGCTTTTTTTCTGGCAAGATAGTCTTGTAAATGCGGGCCAAGATCT
GCACACTGGTATTTCGGTTTTTGGGGCCGCGGGCGGCGACGGGGCCCGTGCGTCCCAG
CGCACATGTTCGGCGAGGCGGGGCCTGCGAGCGCGGCCACCGAGAATCGGACGGGGG
TAGTCTCAAGCTGGCCGGCCTGCTCTGGTGCCTGGCCTCGCGCCGCCGTGTATCGCCCC
GCCCTGGGCGGCAAGGCTGGCCCGGTCGGCACCAGTTGCGTGAGCGGAAAGATGGCCG
CTTCCCGGCCCTGCTGCAGGGAGCTCAAAATGGAGGACGCGGCGCTCGGGAGAGCGGG
CGGGTGAGTCACCCACACAAAGGAAAAGGGCCTTTCCGTCCTCAGCCGTCGCTTCATGTG
ACTCCACGGAGTACCGGGCGCCGTCCAGGCACCTCGATTAGTTCTCGAGCTTTTGGAGTA
CGTCGTCTTTAGGTTGGGGGGAGGGGTTTTATGCGATGGAGTTTCCCCACACTGAGTGGG
TGGAGACTGAAGTTAGGCCAGCTTGGCACTTGATGTAATTCTCCTTGGAATTTGCCCTTTT

[0604] The eGFP of the Nano-PB-V5-JctR-Ank-miRE-sh49-BCLl 1 A-EF 1 a-GFP-T2A-DHFR construct is encoded by a sequence comprising:

[0605] The DHFR of the Nano-PB-V5-JctR-Ank-miRE-sh49-BCFl 1 A-EF 1 a-GFP-T2A-DHFR construct is encoded by a sequence comprising:

[0606] The SV40 polyA signal of the Nano-PB-V5-JctR-Ank-miRE-sh49-BCLl 1 A-EFla- GFP-T2A-DHFR construct is encoded by a sequence comprising:
taagatacattgatgagtttggacaaaccacaactagaatgcagtgaaaaaaatgctttatttgtgaaatttgtgatgctattgctttatttgt aaccattataagctgcaataaacaagtt (bold italicized) (SEQ ID NO: 14710).
[0607] The Insulator 2 of the Nano-PB-V5-JctR-Ank-miRE-sh49-BCLl 1 A-EFla-GFP-T2A- DHFR construct is encoded by a sequence comprising:


[0608] The 5’-ITR of the Nano-PB - V5 - J ctR- Ank-miRE-sh49-B CL 11 A-EF 1 a- GFP-T2 A- DHFR construct is encoded by a sequence comprising:

[0609] A vector for the expression of IGF2BP1, GFP, and DHFR (PB-V5-JctR-SPTAl - IGF2BPl -EFla-GFP-T2A-DHFR) is encoded by a sequence comprising:




[0611] The 3’ITR of the PB-V5-JctR-SPTAl-IGF2BPl -EFla-GFP-T2A-DHFR construct is encoded by a sequence comprising:

[0613] The Insulator 1 of the PB-V5-JctR-SPTAl-IGF2BPl-EFla-GFP-T2A-DHFR construct is encoded by a sequence comprising:

[0615] The SPTAlPromoter of the PB-V5-JctR-SPTAl -IGF2BPl-EFla-GFP-T2A-DHFR construct is encoded by a sequence comprising:


[0617] The IGF2BP1 of the PB-V 5-JctR-SPTAl -IGF2BP1 -EF1 a-GFP-T2A-DHFR construct is encoded by a sequence comprising:


[0621] The GFP of the PB-V 5-JctR-SPTAl -IGF2BP1 -EF1 a-GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
c ct g c g g g t
 )
)
[0623] The DHFR of the PB-V5- JctR-SPTAl -IGF2BP 1 -EF 1 a-GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:

[0625] The SV40 Poly(A) of the PB-V5-JctR-SPTAl-IGF2BPl-EFla-GFP-T2A-DHFR construct is encoded by a nucleic acid sequence comprising:
T

14710).
[0627] The 5'ITR of the PB - V5 - J ctR- SPT A 1 -IGF2BP 1 -EF 1 a- GFP-T2 A-DHFR construct is encoded by a nucleic acid sequence comprising:

[0629] In some embodiments of the methods of the disclosure, a cell of the disclosure may be produced by introducing a transgene into a cell of the disclosure. The introducing step may comprise delivery of a nucleic acid sequence and/or a genomic editing construct via a non transposition delivery system.
[0630] In some embodiments of the methods of the disclosure, introducing a nucleic acid sequence and/or a genomic editing construct into a cell ex vivo, in vivo, in vitro or in situ comprises one or more of topical delivery, adsorption, absorption, electroporation, spin-fection, co-culture, transfection, mechanical delivery, sonic delivery, vibrational delivery,
magnetofection or by nanoparticle-mediated delivery. In some embodiments of the methods of the disclosure, introducing a nucleic acid sequence and/or a genomic editing construct into a cell ex vivo, in vivo, in vitro or in situ comprises liposomal transfection, calcium phosphate transfection, fugene transfection, and dendrimer-mediated transfection. In some embodiments of the methods of the disclosure, introducing a nucleic acid sequence and/or a genomic editing construct into a cell ex vivo, in vivo, in vitro or in situ by mechanical transfection comprises cell squeezing, cell bombardment, or gene gun techniques. In some embodiments of the methods of the disclosure, introducing a nucleic acid sequence and/or a genomic editing construct into a cell ex vivo, in vivo, in vitro or in situ by nanoparticle-mediated transfection comprises liposomal delivery, delivery by micelles, and delivery by polymerosomes.
[0631] In some embodiments of the methods of the disclosure, introducing a nucleic acid sequence and/or a genomic editing construct into a cell ex vivo, in vivo, in vitro or in situ comprises a non-viral vector. In some embodiments, the non-viral vector comprises a nucleic acid. In some embodiments, the non-viral vector comprises plasmid DNA, linear double- stranded DNA (dsDNA), linear single-stranded DNA (ssDNA), DoggyBone™ DNA, nanoplasmids, minicircle DNA, single-stranded oligodeoxynucleotides (ssODN), DDNA oligonucleotides, single-stranded mRNA (ssRNA), and double-stranded mRNA (dsRNA). In some embodiments, the non-viral vector comprises a transposon of the disclosure.
[0632] In some embodiments of the methods of the disclosure, introducing a nucleic acid sequence and/or a genomic editing construct into a cell ex vivo, in vivo, in vitro or in situ comprises a viral vector. In some embodiments, the viral vector is a non- integrating non- chromosomal vector. Exemplary non-integrating non-chromosomal vectors include, but are not limited to, adeno-associated virus (AAV), adenovirus, and herpes viruses. In some embodiments, the viral vector is an integrating chromosomal vector. Integrating chromosomal vectors include, but are not limited to, adeno-associated vectors (AAV), Lentiviruses, and gamma-retroviruses.
[0633] In some embodiments of the methods of the disclosure, introducing a nucleic acid sequence and/or a genomic editing construct into a cell ex vivo, in vivo, in vitro or in situ comprises a combination of vectors. Exemplary, non-limiting vector combinations include: viral and non-viral vectors, a plurality of non-viral vectors, or a plurality of viral vectors. Exemplary but non-limiting vectors combinations include: a combination of a DNA-derived and an RNA-
derived vector, a combination of an RNA and a reverse transcriptase, a combination of a transposon and a transposase, a combination of a non-viral vector and an endonuclease, and a combination of a viral vector and an endonuclease.
[0634] In some embodiments of the methods of the disclosure, genome modification comprising introducing a nucleic acid sequence and/or a genomic editing construct into a cell ex vivo, in vivo, in vitro or in situ stably integrates a nucleic acid sequence, transiently integrates a nucleic acid sequence, produces site-specific integration a nucleic acid sequence, or produces a biased integration of a nucleic acid sequence. In some embodiments, the nucleic acid sequence is a transgene.
[0635] In some embodiments of the methods of the disclosure, genome modification comprising introducing a nucleic acid sequence and/or a genomic editing construct into a cell ex vivo, in vivo, in vitro or in situ stably integrates a nucleic acid sequence. In some embodiments, the stable chromosomal integration can be a random integration, a site-specific integration, or a biased integration. In some embodiments, the site-specific integration can be non-assisted or assisted. In some embodiments, the assisted site-specific integration is co-delivered with a site- directed nuclease. In some embodiments, the site-directed nuclease comprises a transgene with 5’ and 3’ nucleotide sequence extensions that contain a percentage homology to upstream and downstream regions of the site of genomic integration. In some embodiments, the transgene with homologous nucleotide extensions enable genomic integration by homologous recombination, microhomology-mediated end joining, or nonhomologous end-joining. In some embodiments the site-specific integration occurs at a safe harbor site. Genomic safe harbor sites are able to accommodate the integration of new genetic material in a manner that ensures that the newly inserted genetic elements function reliably (for example, are expressed at a therapeutically effective level of expression) and do not cause deleterious alterations to the host genome that cause a risk to the host organism. Potential genomic safe harbors include, but are not limited to, intronic sequences of the human albumin gene, the adeno-associated virus site 1 (AAVS1), a naturally occurring site of integration of AAV virus on chromosome 19, the site of the chemokine (C-C motif) receptor 5 (CCR5) gene and the site of the human ortholog of the mouse Rosa26 locus.
[0636] In some embodiments, the site-specific transgene integration occurs at a site that disrupts expression of a target gene. In some embodiments, disruption of target gene expression occurs by site-specific integration at introns, exons, promoters, genetic elements, enhancers, suppressors, start codons, stop codons, and response elements. In some embodiments, exemplary target genes targeted by site-specific integration include but are not limited to TRAC, TRAB, PDI, any immunosuppressive gene, and genes involved in allo-rejection.
[0637] In some embodiments, the site-specific transgene integration occurs at a site that results in enhanced expression of a target gene. In some embodiments, enhancement of target gene expression occurs by site-specific integration at introns, exons, promoters, genetic elements, enhancers, suppressors, start codons, stop codons, and response elements.
[0638] In some embodiments of the methods of the disclosure, enzymes may be used to create strand breaks in the host genome to facilitate delivery or integration of the transgene. In some embodiments, enzymes create single-strand breaks. In some embodiments, enzymes create double-strand breaks. In some embodiments, examples of break-inducing enzymes include but are not limited to: transposases, integrases, endonucleases, CRISPR-Cas9, transcription activator-like effector nucleases (TALEN), zinc finger nucleases (ZFN), Cas-CLOVER™, and CPF1. In some embodiments, break-inducing enzymes can be delivered to the cell encoded in DNA, encoded in mRNA, as a protein, as a nucleoprotein complex with a guide RNA (gRNA).
[0639] In some embodiments of the methods of the disclosure, the site-specific transgene integration is controlled by a vector-mediated integration site bias. In some embodiments vector- mediated integration site bias is controlled by the chosen lentiviral vector. In some embodiments vector-mediated integration site bias is controlled by the chosen gamma-retroviral vector.
[0640] In some embodiments of the methods of the disclosure, the site-specific transgene integration site is a non-stable chromosomal insertion. In some embodiments, the integrated transgene may become silenced, removed, excised, or further modified.
[0641] In some embodiments of the methods of the disclosure, the genome modification is a non-stable integration of a transgene. In some embodiments, the non-stable integration can be a transient non-chromosomal integration, a semi-stable non chromosomal integration, a semi- persistent non-chromosomal insertion, or a non-stable chromosomal insertion. In some embodiments, the transient non-chromosomal insertion can be epi-chromosomal or cytoplasmic.
[0642] In some embodiments, the transient non-chromosomal insertion of a transgene does not integrate into a chromosome and the modified genetic material is not replicated during cell division.
[0643] In some embodiments of the methods of the disclosure, the genome modification is a semi-stable or persistent non-chromosomal integration of a transgene. In some embodiments, a DNA vector encodes a Scaffold/matrix attachment region (S-MAR) module that binds to nuclear matrix proteins for episomal retention of a non-viral vector allowing for autonomous replication in the nucleus of dividing cells.
[0644] In some embodiments of the methods of the disclosure, the genome modification is a non-stable chromosomal integration of a transgene. In some embodiments, the integrated transgene may become silenced, removed, excised, or further modified.
[0645] In some embodiments of the methods of the disclosure, the modification to the genome by transgene insertion can occur via host cell-directed double-strand breakage repair (homology- directed repair) by homologous recombination (HR), microhomology-mediated end joining (MMEJ), nonhomologous end joining (NHEJ), transposase enzyme-mediated modification, integrase enzyme-mediated modification, endonuclease enzyme-mediated modification, or recombinant enzyme-mediated modification. In some embodiments, the modification to the genome by transgene insertion can occur via CRISPR-Cas9, TALEN, ZFNs, Cas-CLOVER, and cpfl .
[0646] Poly(histidine) (i.e., poly(L- histidine)), is a pH-sensitive polymer due to the imidazole ring providing an electron lone pair on the unsaturated nitrogen. That is, poly(histidine) has amphoteric properties through protonation-deprotonation. The various embodiments enable intracellular delivery of gene editing tools by complexing with poly(histidine)-based micelles. In particular, the various embodiments provide triblock copolymers made of a hydrophilic block, a hydrophobic block, and a charged block. In some embodiments, the hydrophilic block may be poly (ethylene oxide) (PEO), and the charged block may be poly(L-histidine). An example tri block copolymer that may be used in various embodiments is a PEO-b-PLA-b-PHIS, with variable numbers of repeating units in each block varying by design. The gene editing tools may be various molecules that are recognized as capable of modifying, repairing, adding and/or silencing genes in various cells. The correct and efficient repair of double-strand breaks (DSBs)
in DNA is critical to maintaining genome stability in cells. Structural damage to DNA may occur randomly and unpredictably in the genome due to any of a number of intracellular factors (e.g., nucleases, reactive oxygen species, etc.) as well as external forces (e.g., ionizing radiation, ultraviolet (UV) radiation, etc.). In particular, correct and efficient repair of double-strand breaks (DSBs) in DNA is critical to maintaining genome stability. Accordingly, cells naturally possess a number of DNA repair mechanisms, which can be leveraged to alter DNA sequences through controlled DSBs at specific sites. Genetic modification tools may therefore be composed of programmable, sequence-specific DNA-binding modules associated with a nonspecific DNA nuclease, introducing DSBs into the genome. For example CRISPR, mostly found in bacteria, are loci containing short direct repeats, and are part of the acquired prokaryotic immune system, conferring resistance to exogenous sequences such as plasmids and phages. RNA-guided endonucleases are programmable genetic engineering tools that are adapted from the
CRISPR/CRISPR-associated protein 9 (Cas9) system, which is a component of prokaryotic innate immunity.
[0647] Diblock copolymers that may be used as intermediates for making triblock copolymers of the embodiment micelles may have hydrophilic biocompatible poly(ethylene oxide) (PEO), which is chemically synonymous with PEG, coupled to various hydrophobic aliphatic poly(anhydrides), poly(nucleic acids), poly(esters), poly(ortho esters), poly(peptides), poly(phosphazenes) and poly(saccharides), including but not limited by poly(lactide) (PLA), poly(glycolide) (PLGA), poly(lactic-co-glycolic acid) (PLGA), poly(s-caprolactone) (PCL), and poly (trimethylene carbonate) (PTMC). Polymeric micelles comprised of 100% PEGylated surfaces possess improved in vitro chemical stability, augmented in vivo bioavailablity, and prolonged blood circulatory half-lives. For example, aliphatic polyesters, constituting the polymeric micelle's membrane portions, are degraded by hydrolysis of their ester linkages in physiological conditions such as in the human body. Because of their biodegradable nature, aliphatic polyesters have received a great deal of attention for use as implantable biomaterials in drug delivery devices, bioresorbable sutures, adhesion barriers, and as scaffolds for injury repair via tissue engineering.
[0648] In various embodiments, molecules required for gene editing (i.e., gene editing tools) may be delivered to cells using one or more micelle formed from self-assembled triblock
copolymers containing poly (histidine). The term "gene editing" as used herein refers to the insertion, deletion or replacement of nucleic acids in genomic DNA so as to add, disrupt or modify the function of the product that is encoded by a gene. Various gene editing systems require, at a minimum, the introduction of a cutting enzyme (e.g., a nuclease or recombinase) that cuts genomic DNA to disrupt or activate gene function.
[0649] Further, in gene editing systems that involve inserting new or existing nucleotides/nucleic acids, insertion tools (e.g. DNA template vectors, transposable elements (transposons or retrotransposons) must be delivered to the cell in addition to the cutting enzyme (e.g. a nuclease, recombinase, integrase or transposase). Examples of such insertion tools for a recombinase may include a DNA vector. Other gene editing systems require the delivery of an integrase along with an insertion vector, a transposase along with a transposon/retrotransposon, etc. In some embodiments, an example recombinase that may be used as a cutting enzyme is the CRE recombinase. In various embodiments, example integrases that may be used in insertion tools include viral based enzymes taken from any of a number of viruses including, but not limited to, AAV, gamma retrovirus, and lentivirus. Example transposons/retrotransposons that may be used in insertion tools include, but are not limited to, the piggyBac transposon, Sleeping Beauty transposon, and the Ll retrotransposon.
[0650] In certain embodiments of the methods of the disclosure, the transgene is delivered in vivo. In certain embodiments of the methods of the disclosure, in vivo transgene delivery can occur by: topical delivery, adsorption, absorption, electroporation, spin-fection, co-culture, transfection, mechanical delivery, sonic delivery, vibrational delivery, magnetofection or by nanoparticle-mediated delivery. In certain embodiments of the methods of the disclosure, in vivo transgene delivery by transfection can occur by liposomal transfection, calcium phosphate transfection, fugene transfection, and dendrimer-mediated transfection. In certain embodiments of the methods of the disclosure, in vivo mechanical transgene delivery can occur by cell squeezing, bombardment, and gene gun. In certain embodiments of the methods of the disclosure, in vivo nanoparticle-mediated transgene delivery can occur by liposomal delivery, delivery by micelles, and delivery by polymerosomes. In various embodiments, nucleases that may be used as cutting enzymes include, but are not limited to, Cas9, transcription activator-like effector nucleases (TALENs) and zinc finger nucleases.
[0651] In various embodiments, the gene editing systems described herein, particularly proteins and/or nucleic acids, may be complexed with nanoparticles that are poly(histidine)-based micelles. In particular, at certain pHs, poly(histidine)-containing triblock copolymers may assemble into a micelle with positively charged poly(histidine) units on the surface, thereby enabling complexing with the negatively-charged gene editing molecule(s). Using these nanoparticles to bind and release proteins and/or nucleic acids in a pH-dependent manner may provide an efficient and selective mechanism to perform a desired gene modification. In particular, this micelle-based delivery system provides substantial flexibility with respect to the charged materials, as well as a large payload capacity, and targeted release of the nanoparticle payload. In one example, site-specific cleavage of the double stranded DNA may be enabled by delivery of a nuclease using the poly(histidine)-based micelles.
[0652] The various embodiments enable intracellular delivery of gene editing tools by complexing with poly(histidine)-based micelles. In particular, the various embodiments provide triblock copolymers made of a hydrophilic block, a hydrophobic block, and a charged block. In some embodiments, the hydrophilic block may be poly(ethylene oxide) (PEO), and the charged block may be poly(L-histidine). An example tri-block copolymer that may be used in various embodiments is a PEO-b-PLA-b-PHIS, with variable numbers of repeating units in each block varying by design. Without wishing to be bound by a particular theory, it is believed that believed that in the micelles that are formed by the various embodiment triblock copolymers, the hydrophobic blocks aggregate to form a core, leaving the hydrophilic blocks and poly(histidine) blocks on the ends to form one or more surrounding layer.
[0653] In certain embodiments of the methods of the disclosure, non-viral vectors are used for transgene delivery. In certain embodiments, the non-viral vector is a nucleic acid. In certain embodiments, the nucleic acid non-viral vector is plasmid DNA, linear double-stranded DNA (dsDNA), linear single-stranded DNA (ssDNA), DoggyBone™ DNA, nanoplasmids, minicircle DNA, single-stranded oligodeoxynucleotides (ssODN), DDNA oligonucleotides, single-stranded mRNA (ssRNA), and double-stranded mRNA (dsRNA). In certain embodiments, the non-viral vector is a transposon. In certain embodiments, the transposon is piggyBac™.
[0654] In certain embodiments of the methods of the disclosure, transgene delivery can occur via viral vector. In certain embodiments, the viral vector is a non-integrating non-chromosomal
vectors. Non-integrating non-chromosomal vectors can include adeno-associated virus (AAV), adenovirus, and herpes viruses. In certain embodiments, the viral vector is an integrating chromosomal vectors. Integrating chromosomal vectors can include adeno-associated vectors (AAV), Lentiviruses, and gamma-retroviruses.
[0655] In certain embodiments of the methods of the disclosure, transgene delivery can occur by a combination of vectors. Exemplary but non-limiting vector combinations can include: viral plus non-viral vectors, more than one non-viral vector, or more than one viral vector. Exemplary but non-limiting vectors combinations can include: DNA-derived plus RNA-derived vectors, RNA plus reverse transcriptase, a transposon and a transposase, a non-viral vectors plus an endonuclease, and a viral vector plus an endonuclease.
[0656] In certain embodiments of the methods of the disclosure, the genome modification can be a stable integration of a transgene, a transient integration of a transgene, a site-specific integration of a transgene, or a biased integration of a transgene.
[0657] In certain embodiments of the methods of the disclosure, the genome modification can be a stable chromosomal integration of a transgene. In certain embodiments, the stable chromosomal integration can be a random integration, a site-specific integration, or a biased integration. In certain embodiments, the site-specific integration can be non-assisted or assisted. In certain embodiments, the assisted site-specific integration is co-debvered with a site-directed nuclease. In certain embodiments, the site-directed nuclease comprises a transgene with 5’ and 3’ nucleotide sequence extensions that contain homology to upstream and downstream regions of the site of genomic integration. In certain embodiments, the transgene with homologous nucleotide extensions enable genomic integration by homologous recombination,
microhomology-mediated end joining, or nonhomologous end-joining. In certain embodiments the site-specific integration occurs at a safe harbor site. Genomic safe harbor sites are able to accommodate the integration of new genetic material in a manner that ensures that the newly inserted genetic elements function reliably (for example, are expressed at a therapeutically effective level of expression) and do not cause deleterious alterations to the host genome that cause a risk to the host organism. Potential genomic safe harbors include, but are not limited to, intronic sequences of the human albumin gene, the adeno-associated virus site 1 (AAVS1), a naturally occurring site of integration of AAV virus on chromosome 19, the site of the
chemokine (C-C motif) receptor 5 (CCR5) gene and the site of the human ortholog of the mouse Rosa26 locus.
[0658] In certain embodiments, the site-specific transgene integration occurs at a site that disrupts expression of a target gene. In certain embodiments, disruption of target gene expression occurs by site-specific integration at introns, exons, promoters, genetic elements, enhancers, suppressors, start codons, stop codons, and response elements. In certain embodiments, exemplary target genes targeted by site-specific integration include but are not limited to TRAC, TRAB, PDI, any immunosuppressive gene, and genes involved in allo-rejection.
[0659] In certain embodiments, the site-specific transgene integration occurs at a site that results in enhanced expression of a target gene. In certain embodiments, enhancement of target gene expression occurs by site-specific integration at introns, exons, promoters, genetic elements, enhancers, suppressors, start codons, stop codons, and response elements.
[0660] In certain embodiments of the methods of the disclosure, enzymes may be used to create strand breaks in the host genome to facilitate delivery or integration of the transgene. In certain embodiments, enzymes create single-strand breaks. In certain embodiments, enzymes create double-strand breaks. In certain embodiments, examples of break- inducing enzymes include but are not limited to: transposases, integrases, endonucleases, CRISPR-Cas9, transcription activator-like effector nucleases (TALEN), zinc finger nucleases (ZFN), Cas-CLOVER™, and cpfl . In certain embodiments, break-inducing enzymes can be delivered to the cell encoded in DNA, encoded in mRNA, as a protein, as a nucleoprotein complex with a guide RNA (gRNA).
[0661] In certain embodiments of the methods of the disclosure, the site-specific transgene integration is controlled by a vector-mediated integration site bias. In certain embodiments vector-mediated integration site bias is controlled by the chosen lentiviral vector. In certain embodiments vector-mediated integration site bias is controlled by the chosen gamma-retroviral vector.
[0662] In certain embodiments of the methods of the disclosure, the site-specific transgene integration site is a non-stable chromosomal insertion. In certain embodiments, the integrated transgene may become silenced, removed, excised, or further modified. In certain embodiments of the methods of the disclosure, the genome modification is a non-stable integration of a transgene. In certain embodiments, the non-stable integration can be a transient non-
chromosomal integration, a semi-stable non chromosomal integration, a semi-persistent non- chromosomal insertion, or a non-stable chromosomal insertion. In certain embodiments, the transient non-chromosomal insertion can be epi-chromosomal or cytoplasmic. In certain embodiments, the transient non-chromosomal insertion of a transgene does not integrate into a chromosome and the modified genetic material is not replicated during cell division.
[0663] In certain embodiments of the methods of the disclosure, the genome modification is a semi-stable or persistent non-chromosomal integration of a transgene. In certain embodiments, a DNA vector encodes a Scaffold/matrix attachment region (S-MAR) module that binds to nuclear matrix proteins for episomal retention of a non-viral vector allowing for autonomous replication in the nucleus of dividing cells.
[0664] In certain embodiments of the methods of the disclosure, the genome modification is a non-stable chromosomal integration of a transgene. In certain embodiments, the integrated transgene may become silenced, removed, excised, or further modified.
[0665] In certain embodiments of the methods of the disclosure, the modification to the genome by transgene insertion can occur via host cell-directed double-strand breakage repair (homology- directed repair) by homologous recombination (HR), microhomology-mediated end joining (MMEJ), nonhomologous end joining (NHEJ), transposase enzyme-mediated modification, integrase enzyme-mediated modification, endonuclease enzyme-mediated modification, or recombinant enzyme-mediated modification. In certain embodiments, the modification to the genome by transgene insertion can occur via CRISPR-Cas9, TALEN, ZFNs, Cas-CLOVER, and cpfl .
[0666] In certain embodiments of the methods of the disclosure, a cell with an in vivo or ex vivo genomic modification can be a germline cell or a somatic cell. In certain embodiments the modified cell can be a human, non-human, mammalian, rat, mouse, or dog cell. In certain embodiments, the modified cell can be differentiated, undifferentiated, or immortalized. In certain embodiments, the modified undifferentiated cell can be a stem cell. In certain
embodiments, the modified cell can be differentiated, undifferentiated, or immortalized. In certain embodiments, the modified undifferentiated cell can be an induced pluripotent stem cell. In certain embodiments, the modified cell can be a T cell, a hematopoietic stem cell, a natural killer cell, a macrophage, a dendritic cell, a monocyte, a megakaryocyte, or an osteoclast. In
certain embodiments, the modified cell can be modified while the cell is quiescent, in an activated state, resting, in interphase, in prophase, in metaphase, in anaphase, or in telophase. . In certain embodiments, the modified cell can be fresh, cryopreserved, bulk, sorted into sub populations, from whole blood, from leukapheresis, or from an immortalized cell line.
[0667] The disclosure provides chimeric antigen receptors comprising at least one Centyrin. Chimeric antigen receptors of the disclosure may comprise more than one Centyrin. For example, a bi-specific CAR may comprise two Centyrins that specifically bind two distinct antigens. As used herein a CAR comprising a Centyrin of the disclosure is referred to as a CARTyrin.
[0668] Centyrins of the disclosure specifically bind to an antigen. Chimeric antigen receptors of the disclosure comprising one or more Centyrins that specifically bind an antigen may be used to direct the specificity of a cell, (e.g. a cytotoxic immune cell) towards the specific antigen.
[0669] Centyrins of the disclosure may comprise a consensus sequence comprising
MLPAPKNLWSRITEDSARLSWTAPDAAFDSFPIRYIETLIWGEAIWLDVPGSERSYDLT GLKPGTE Y A WIT GVKGGRF S SPL V ASFTT (anti-BCMA Centyrin) (SEQ ID NO: 14672), [0670] The disclosure provides chimeric antigen receptors comprising at least one Single Chain antibody (ScFv), camelid domain antibody (VHH), single domain antibody (VH), or antibody mimetic. Chimeric antigen receptors of the disclosure may comprise more than one Single Chain antibody (ScFv), camelid domain antibody (VHH), single domain antibody (VH), or antibody mimetic. For example, a bi-specific CAR may comprise two Single Chain antibodies (ScFvx), camelid domain antibodies (VHHs), single domain antibodies (VHs), or antibody mimetics that specifically bind two distinct antigens. As used herein a CAR comprising a camelid domain antibody (VHH) or a single domain antibody (VH) of the disclosure is referred to as a VCAR.
[0671] The disclosure provides chimeric antigen receptors comprising at least one protein scaffold of the disclosure, wherein the scaffold is capable of specifically binding an antigen. A protein scaffold may comprise a consensus sequence of at least one fibronectin type III (FN3) domain, wherein the scaffold is capable of specifically binding an antigen. The at least one fibronectin type III (FN3) domain may be derived from a human protein. The human protein may be Tenascin-C. The consensus sequence may comprise

sequence may be encoded by a nucleic acid sequence comprising
atgctgcctgcaccaaagaacctggtggtgtctcatgtgacagaggatagtgccagactgtcatggactgctcccgacgcagccttcgata gttttatcatcgtgtaccgggagaacatcgaaaccggcgaggccattgtcctgacagtgccagggtccgaacgctcttatgacctgacagat ctgaagcccggaactgagtactatgtgcagatcgccggcgtcaaaggaggcaatatcagcttccctctgtccgcaatcttcaccaca (SEQ ID NO: 14635). The consensus sequence may be modified at one or more positions within (a) a A-B loop comprising or consisting of the amino acid residues TEDS (SEQ ID NO: 14675) at positions 13-16 of the consensus sequence; (b) a B-C loop comprising or consisting of the amino acid residues TAPDAAF (SEQ ID NO: 14475) at positions 22-28 of the consensus sequence; (c) a C-D loop comprising or consisting of the amino acid residues SEKVGE (SEQ ID NO: 14476) at positions 38-43 of the consensus sequence; (d) a D-E loop comprising or consisting of the amino acid residues GSER (SEQ ID NO: 14477) at positions 51-54 of the consensus sequence; (e) a E-F loop comprising or consisting of the amino acid residues GLKPG (SEQ ID NO: 14478) at positions 60-64 of the consensus sequence; (f) a F-G loop comprising or consisting of the amino acid residues KGGHRSN (SEQ ID NO: 14479) at positions 75-81 of the consensus sequence; or (g) any combination of (a)-(f). Protein scaffolds of the disclosure may comprise a consensus sequence of at least 5 fibronectin type III (FN3) domains, at least 10 fibronectin type III (FN3) domains or at least 15 fibronectin type III (FN3) domains. The scaffold may bind an antigen with at least one affinity selected from a KD of less than or equal to l0_9M, less than or equal to lCT10M, less than or equal to 10_11M, less than or equal to l0_12M, less than or equal to l0_13M, less than or equal to lO_14M, and less than or equal to l0_15M. The KD may be determined by surface plasmon resonance.
[0672] Scaffolds of the disclosure may comprise an antibody mimetic.
[0673] The term“antibody mimetic” is intended to describe an organic compound that specifically binds a target sequence and has a structure distinct from a naturally-occurring antibody. Antibody mimetics may comprise a protein, a nucleic acid, or a small molecule. The target sequence to which an antibody mimetic of the disclosure specifically binds may be an
antigen. Antibody mimetics may provide superior properties over antibodies including, but not limited to, superior solubility, tissue penetration, stability towards heat and enzymes (e.g.
resistance to enzymatic degradation), and lower production costs. Exemplary antibody mimetics include, but are not limited to, an affibody, an afflilin, an affimer, an affitin, an alphabody, an anticalin, and avimer (also known as avidity multimer), a DARPin (Designed Ankyrin Repeat Protein), a Fynomer, a Kunitz domain peptide, and a monobody.
[0674] Affibody molecules of the disclosure comprise a protein scaffold comprising or consisting of one or more alpha helix without any disulfide bridges. Preferably, affibody molecules of the disclosure comprise or consist of three alpha helices. For example, an affibody molecule of the disclosure may comprise an immunoglobulin binding domain. An affibody molecule of the disclosure may comprise the Z domain of protein A.
[0675] Affilin molecules of the disclosure comprise a protein scaffold produced by
modification of exposed amino acids of, for example, either gamma-B crystallin or ubiquitin. Affilin molecules functionally mimic an antibody’s affinity to antigen, but do not structurally mimic an antibody. In any protein scaffold used to make an affilin, those amino acids that are accessible to solvent or possible binding partners in a properly-folded protein molecule are considered exposed amino acids. Any one or more of these exposed amino acids may be modified to specifically bind to a target sequence or antigen.
[0676] Affimer molecules of the disclosure comprise a protein scaffold comprising a highly stable protein engineered to display peptide loops that provide a high affinity binding site for a specific target sequence. Exemplary affimer molecules of the disclosure comprise a protein scaffold based upon a cystatin protein or tertiary structure thereof. Exemplary affimer molecules of the disclosure may share a common tertiary structure of comprising an alpha-helix lying on top of an anti-parallel beta-sheet.
[0677] Affitin molecules of the disclosure comprise an artificial protein scaffold, the structure of which may be derived, for example, from a DNA binding protein (e.g. the DNA binding protein Sac7d). Affitins of the disclosure selectively bind a target sequence, which may be the entirety or part of an antigen. Exemplary affitins of the disclosure are manufactured by randomizing one or more amino acid sequences on the binding surface of a DNA binding protein and subjecting the resultant protein to ribosome display and selection. Target sequences of
affitins of the disclosure may be found, for example, in the genome or on the surface of a peptide, protein, virus, or bacteria. In certain embodiments of the disclosure, an affitin molecule may be used as a specific inhibitor of an enzyme. Affitin molecules of the disclosure may include heat-resistant proteins or derivatives thereof.
[0678] Alphabody molecules of the disclosure may also be referred to as Cell-Penetrating Alphabodies (CPAB). Alphabody molecules of the disclosure comprise small proteins (typically of less than 10 kDa) that bind to a variety of target sequences (including antigens). Alphabody molecules are capable of reaching and binding to intracellular target sequences. Structurally, alphabody molecules of the disclosure comprise an artificial sequence forming single chain alpha helix (similar to naturally occurring coiled-coil structures). Alphabody molecules of the disclosure may comprise a protein scaffold comprising one or more amino acids that are modified to specifically bind target proteins. Regardless of the binding specificity of the molecule, alphabody molecules of the disclosure maintain correct folding and thermostability.
[0679] Anticalin molecules of the disclosure comprise artificial proteins that bind to target sequences or sites in either proteins or small molecules. Anticalin molecules of the disclosure may comprise an artificial protein derived from a human lipocalin. Anticalin molecules of the disclosure may be used in place of, for example, monoclonal antibodies or fragments thereof. Anticalin molecules may demonstrate superior tissue penetration and thermostability than monoclonal antibodies or fragments thereof. Exemplary anticalin molecules of the disclosure may comprise about 180 amino acids, having a mass of approximately 20 kDa. Structurally, anticalin molecules of the disclosure comprise a barrel structure comprising antiparallel beta- strands pairwise connected by loops and an attached alpha helix. In preferred embodiments, anticalin molecules of the disclosure comprise a barrel structure comprising eight antiparallel beta-strands pairwise connected by loops and an attached alpha helix.
[0680] Avimer molecules of the disclosure comprise an artificial protein that specifically binds to a target sequence (which may also be an antigen). Avimers of the disclosure may recognize multiple binding sites within the same target or within distinct targets. When an avimer of the disclosure recognize more than one target, the avimer mimics function of a bi-specific antibody. The artificial protein avimer may comprise two or more peptide sequences of approximately 30- 35 amino acids each. These peptides may be connected via one or more linker peptides. Amino
acid sequences of one or more of the peptides of the avimer may be derived from an A domain of a membrane receptor. Avimers have a rigid structure that may optionally comprise disulfide bonds and/or calcium. Avimers of the disclosure may demonstrate greater heat stability compared to an antibody.
[0681] DARPins (Designed Ankyrin Repeat Proteins) of the disclosure comprise genetically- engineered, recombinant, or chimeric proteins having high specificity and high affinity for a target sequence. In certain embodiments, DARPins of the disclosure are derived from ankyrin proteins and, optionally, comprise at least three repeat motifs (also referred to as repetitive structural units) of the ankyrin protein. Ankyrin proteins mediate high-affinity protein-protein interactions. DARPins of the disclosure comprise a large target interaction surface.
[0682] Fynomers of the disclosure comprise small binding proteins (about 7 kDa) derived from the human Fyn SH3 domain and engineered to bind to target sequences and molecules with equal affinity and equal specificity as an antibody.
[0683] Kunitz domain peptides of the disclosure comprise a protein scaffold comprising a Kunitz domain. Kunitz domains comprise an active site for inhibiting protease activity.
Structurally, Kunitz domains of the disclosure comprise a disulfide-rich alpha+beta fold. This structure is exemplified by the bovine pancreatic trypsin inhibitor. Kunitz domain peptides recognize specific protein structures and serve as competitive protease inhibitors. Kunitz domains of the disclosure may comprise Ecallantide (derived from a human lipoprotein- associated coagulation inhibitor (LACI)).
[0684] Monobodies of the disclosure are small proteins (comprising about 94 amino acids and having a mass of about 10 kDa) comparable in size to a single chain antibody. These genetically engineered proteins specifically bind target sequences including antigens. Monobodies of the disclosure may specifically target one or more distinct proteins or target sequences. In preferred embodiments, monobodies of the disclosure comprise a protein scaffold mimicking the structure of human fibronectin, and more preferably, mimicking the structure of the tenth extracellular type III domain of fibronectin. The tenth extracellular type III domain of fibronectin, as well as a monobody mimetic thereof, contains seven beta sheets forming a barrel and three exposed loops on each side corresponding to the three complementarity determining regions (CDRs) of an antibody. In contrast to the structure of the variable domain of an antibody, a monobody lacks
any binding site for metal ions as well as a central disulfide bond. Multispecific monobodies may be optimized by modifying the loops BC and FG. Monobodies of the disclosure may comprise an adnectin.
[0685] Chimeric antigen receptors of the disclosure may comprise a signal peptide of human CD2, CD35, CD3e, CD3y, Oϋ3z, CD4, CD8a, CD19, CD28, 4-lBBor GM-CSFR. A hinge/spacer domain of the disclosure may comprise a hinge/spacer/stalk of human CD8a, IgG4, and/or CD4. An intracellular domain or endodomain of the disclosure may comprise an intracellular signaling domain of human Oϋ3z and may further comprise human 4-1BB, CD28, CD40, ICOS, MyD88, OX-40 intracellular segment, or any combination thereof. Exemplary transmembrane domains include, but are not limited to a human CD2, CD35, CD3e, CD3y,
Oϋ3z, CD4, CD8a, CD19, CD28, 4-lBBor GM-CSFR transmembrane domain.
[0686] In certain embodiments of the CARs of the disclosure, the signal peptide may comprise a sequence encoding a human CD2, CD35, CD3e, CD3y, 0 ϋ3z, CD4, CD8a, CD19, CD28, 4-1BB or GM-CSFR signal peptide. In certain embodiments of the CARs of the disclosure, the signal peptide may comprise a sequence encoding a human CD8a signal peptide. The human CD8a signal peptide may comprise an amino acid sequence comprising
MALP VT ALLLPL ALLLH A ARP (SEQ ID NO: 14480). The human CD8a signal peptide may comprise an amino acid sequence comprising MALP VT ALLLPL ALLLH A ARP (SEQ ID NO:
3) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to an amino acid sequence comprising MALPVTALLLPLALLLHAARP (SEQ ID NO: 14480). The human CD8a signal peptide may be encoded by a nucleic acid sequence comprising
atggcactgccagtcaccgccctgctgctgcctctggctctgctgctgcacgcagctagacca (SEQ ID NO: 14481).
[0687] In certain embodiments of the CARs of the disclosure, the transmembrane domain may comprise a sequence encoding a human CD2, CD35, CD3e, CD3y, CD3z, CD4, CD8a, CD19, CD28, 4-1BB or GM-CSFR transmembrane domain. In certain embodiments of the CARs of the disclosure, the transmembrane domain may comprise a sequence encoding a human CD8a transmembrane domain. The CD8a transmembrane domain may comprise an amino acid sequence comprising IYIWAPLAGTCGVLLLSLVITLY C (SEQ ID NO: 14482) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising IYIWAPLAGTCGVLLLSLVITLY C (SEQ ID NO: 14482). The CD8a transmembrane domain
may be encoded by the nucleic acid sequence comprising
atctacatttgggcaccactggccgggacctgtggagtgctgctgctgagcctggtcatcacactgtactgc (SEQ ID NO:
14483).
[0688] In certain embodiments of the CARs of the disclosure, the endodomain may comprise a human Oϋ3z endodomain.
[0689] In certain embodiments of the CARs of the disclosure, the at least one costimulatory domain may comprise a human 4-1BB, CD28, CD40, ICOS, MyD88, OX-40 intracellular segment, or any combination thereof. In certain embodiments of the CARs of the disclosure, the at least one costimulatory domain may comprise a CD28 and/or a 4-1BB costimulatory domain. The CD28 costimulatory domain may comprise an amino acid sequence comprising
RVKFSRS DAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGL YNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
(SEQ ID NO: 14488) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising

TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACD (SEQ ID NO: 14492) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACD (SEQ ID NO: 14492). The human CD8a hinge amino acid sequence may be encoded by the nucleic acid sequence comprising
actaccacaccagcacctagaccaccaactccagctccaaccatcgcgagtcagcccctgagtctgagacctgaggcctgcaggccagc tgcaggaggagctgtgcacaccaggggcctggacttcgcctgcgac (SEQ ID NO: 14493).
[0691] The disclosure provides modified cells, such as T cells, NK cells, hematopoietic progenitor cells, peripheral blood (PB) derived T cells (including T cells from G-CSF-mobilized peripheral blood), umbilical cord blood (ETCB) derived T cells rendered specific for one or more antigens by introducing to these cells a CAR, VCAR and/or CARTyrin of the disclosure. Cells of the disclosure may be modified by electrotransfer of a transposon encoding a CAR, VCAR or CARTyrin of the disclosure and a plasmid comprising a sequence encoding a transposase of the disclosure (preferably, the sequence encoding a transposase of the disclosure is an mRNA sequence).
[0692] Therapeutic cells of the disclosure may be modified to express a therapeutic protein. Therapeutic cells of the disclosure may be modified to express a secreted therapeutic protein, including secreted human proteins. In some embodiments, the therapeutic protein is not secreted, but rather functions intracellularly (e.g. hemoglobin for hemoglobinopathies). In some embodiments, the therapeutic protein is not secreted, but rather directs a modified cell of the disclosure to a cell niche of a subject’s body (e.g. expression of CXCR4 to increase homing of modified cells of the disclosure to the bone marrow of a subject).
[0693] In some embodiments, the therapeutic protein is a human hemoglobin. In some embodiments, the therapeutic protein comprises a human beta-globin. In some embodiments, the human beta-globin comprises a substitution of Glutamine (Q) for Threonine at position 87
(T87Q). In some embodiments, the human beta globin is encoded by the amino acid sequence comprising:
MVHLTPEEKS AVTALWGKVN VDEVGGEALG RLLWYPWTQ RFFES FGDLS TPDAVMGNPK 60 VKAHGKKVLG AFSDGLAHLD NLKGTFAQLS ELHCDKLHVD PENFRLLGNV LVCVLAHHFG 120 KEFTPPVQAA YQKWAGVAN ALAHKYH (SEQ ID NO: 14934)
147
[0694] In some embodiments, the human beta-globin is encoded by a nucleic acid sequence comprising:



[0695] In certain embodiments of the methods of the disclosure, at least one cell of the plurality of therapeutic cells is genetically modified. In certain embodiments, each cell of the plurality of therapeutic cells is genetically modified.
[0696] In certain embodiments of the methods of the disclosure, the subject has a disease or disorder and the plurality of therapeutic cells improves a sign or symptom of the disease or disorder, optionally by providing (e.g. secreting) a therapeutic protein systemically or locally within the subject that acts upon the therapeutic cell or upon a second cell in the subject.
[0697] In certain embodiments of the methods of the disclosure, the subject has an immune disease or disorder and wherein the plurality of therapeutic cells improves a sign or symptom of the immune disease or disorder. In certain embodiments, at least one cell of the plurality of
therapeutic cells is genetically modified to improve a sign or symptom of the immune disease or disorder of the subject. In certain embodiments, each cell of the plurality of therapeutic cells is genetically modified to improve a sign or symptom of the immune disease or disorder of the subject. Exemplary immune disorders include, but are not limited to, inflammation and autoimmune conditions.
[0698] In certain embodiments of the methods of the disclosure, the subject has a genetic or epigenetic marker for a disease or disorder that manifests in a blood cell, an immune cell circulating in the blood, a bone marrow cell or a precursor cell thereof and the plurality of therapeutic cells improves a sign or symptom of the disease or disorder. In certain embodiments, the disease or disorder is a clotting disorder. In certain embodiments, at least one cell of the plurality of therapeutic cells has been modified to secrete a protein that improves a sign or symptom of the clotting disorder. In certain embodiments, a majority of cells of the plurality of therapeutic cells have been modified to secrete a protein that improves a sign or symptom of the clotting disorder. In certain embodiments, each cell of the plurality of therapeutic cells has been modified to secrete a protein that improves a sign or symptom of the clotting disorder. In certain embodiments, the at least one cell, the majority of cells or each cell of the plurality of therapeutic cells are modified to secrete a protein that improves a sign or symptom of the clotting disorder.
In certain embodiments, the at least one cell, the majority of cells or each cell of the plurality of therapeutic cells are modified to secrete one or more clotting factors.
[0699] In certain embodiments of the methods of the disclosure, the subject has a genetic or epigenetic marker for a glycogen storage disease or disorder and the plurality of therapeutic cells improves a sign or symptom of the glycogen storage disease or disorder. In certain embodiments, the glycogen storage disease or disorder is glycogen storage disease (GSD) type 0, GSD type I, GSD type II, GSD type III, GSD type IV, GSD type V, GSD type VI, GSD type VII, GSD type IX, GSD type X, GSD type XI, GSD type XII or GSD type XIII. In certain embodiments, at least one cell, a majority of cells or each cell of the plurality of therapeutic cells are modified to secrete one or more of glycogen synthase, glucose-6-phosphatase, acid alpha-glucosidase, glycogen debranching enzyme, glycogen branching enzyme, muscle glycogen phosphorylase, liver glycogen phosphorylase, muscle phosphofructokinase, phosphorylase kinase, glucose transporter GLUT2, Aldolase A or b-enolase and wherein the plurality of therapeutic cells
improves a sign or symptom of GSD type 0, GSD type I, GSD type II, GSD type III, GSD type IV, GSD type V, GSD type VI, GSD type VII, GSD type IX, GSD type X, GSD type XI, GSD type XII or GSD type XIII, respectively.
[0700] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject is human.
[0701] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has an immune system disease or disorder or the subject is at risk of developing an immune system disease or disorder.
[0702] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has an autoimmune disease or disorder. In certain embodiments, the autoimmune disease or disorder is acute disseminated encephalomyelitis (ADEM), acute necrotizing hemorrhagic leukoencephalitis, Addison’s disease, agammaglobulinemia, alopecia areata, amyloidosis, ankylosing spondylitis, anti-GBM/anti-TBM nephritis, antiphospholipid syndrome (APS), autoimmune angioedema, autoimmune aplastic anemia, autoimmune dysautonomia, autoimmune hepatitis, autoimmune hyperlipidemia, autoimmune immunodeficiency, autoimmune inner ear disease (AIED), autoimmune myocarditis, autoimmune oophoritis, autoimmune pancreatitis, autoimmune retinopathy, autoimmune thrombocytopenic purpura (ATP), autoimmune thyroid disease, autoimmune urticaria, axonal & neuronal neuropathies, Balo disease, Behcet’s disease, bullous pemphigoid, cardiomyopathy, Castleman disease, Celiac disease, Chagas disease, chronic inflammatory demyelinating polyneuropathy (CIDP), chronic recurrent multifocal ostomyelitis (CRMO), Churg-Strauss syndrome, cicatricial
pemphigoid/benign mucosal pemphigoid, Crohn’s disease, Cogans syndrome, cold agglutinin disease, congenital heart block, coxsackie myocarditis, CREST disease, essential mixed cryoglobulinemia, demyelinating neuropathies, dermatitis herpetiformis, dermatomyositis, Devic’s disease (neuromyelitis optica), discoid lupus, Dressler’s syndrome, endometriosis, eosinophilic esophagitis, eosinophilic fasciitis, erythema nodosum, experimental allergic encephalomyelitis, Evans syndrome, fibrosing alveolitis, giant cell arteritis (temporal arteritis), giant cell myocarditis, glomerulonephritis, Goodpasture’s syndrome, Granulomatosis with Polyangiitis (GPA), Graves’ disease, Guillain-Barre syndrome, Hashimoto’s encephalitis, Hashimoto’s thyroiditis, hemolytic anemia, Henoch- Schonlein purpura, herpes gestationis,
hypogammaglobulinemia, idiopathic thrombocytopenic purpura (ITP), IgA nephropathy, IgG4- related sclerosing disease, immunoregulatory lipoproteins, inclusion body myositis, interstitial cystitis, juvenile arthritis, juvenile diabetes (Type 1 diabetes), juvenile myositis, Kawasaki syndrome, Lambert-Eaton syndrome, leukocytoclastic vasculitis, lichen planus, lichen sclerosus, ligneous conjunctivitis, linear IgA disease (LAD), Lupus (SLE, Lyme disease, chronic Meniere’s disease, microscopic polyangiitis, mixed connective tissue disease (MCTD), Mooren’s ulcer, Mucha-Habermann disease, multiple sclerosis, myasthenia gravis, myositis, narcolepsy, neuromyelitis optica (Devic’s), neutropenia, ocular cicatricial pemphigoid, optic neuritis, palindromic rheumatism, PANDAS (Pediatric Autoimmune Neuropsychiatric Disorders Associated with Streptococcus), paraneoplastic cerebellar degeneration, paroxysmal nocturnal hemoglobinuria (PNH) Parry Romberg syndrome, Parsonnage-Turner syndrome, pars planitis (peripheral uveitis), pemphigus, peripheral neuropathy, perivenous encephalomyelitis, pernicious anemia, POEMS syndrome, polyarteritis nodosa, type I autoimmune polyglandular syndrome, type II autoimmune polyglandular syndrome, type III autoimmune polyglandular syndrome, polymyalgia rheumatica, polymyositis, postmyocardial infarction syndrome, postpericardiotomy syndrome, progesterone dermatitis, primary biliary cirrhosis, primary sclerosing cholangitis, psoriasis, psoriatic arthritis, idiopathic pulmonary fibrosis, pyoderma gangrenosum, pure red cell aplasia, Raynauds phenomenon, reactive arthritis, reflex sympathetic dystrophy, Reiter’s syndrome, relapsing polychondritis, restless legs syndrome, retroperitoneal fibrosis, rheumatic fever, rheumatoid arthritis, sarcoidosis, Schmidt syndrome, scleritis, scleroderma, Sjogren’s syndrome, sperm & testicular autoimmunity, stiff person syndrome, subacute bacterial endocarditis (SBE), susac’s syndrome, sympathetic ophthalmia, Takayasu’s arteritis, temporal arteritis/Giant cell arteritis, thrombocytopenic purpura (TTP), Tolosa-Hunt syndrome, transverse myelitis, type 1 diabetes, ulcerative colitis, undifferentiated connective tissue disease (UCTD), uveitis, vasculitis, vesiculobullous dermatosis or vitiligo.
[0703] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject is immunocompromised.
[0704] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has an inflammatory disorder.
[0705] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has an immune system disease or disorder or the subject is at risk of developing an immune system disease or disorder. In certain embodiments, the subject has a genetic or epigenetic marker for the immune system disease or disorder. In certain embodiments, the immune system disease or disorder is induced a medical intervention.
[0706] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has a genetic or epigenetic marker for the immune system disease or disorder.
[0707] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has a genetic or epigenetic marker for a disease or disorder that manifests in a blood cell, an immune cell circulating in the blood, a bone marrow cell or a precursor cell thereof. In certain embodiments, the precursor cell is a hematopoietic stem cell (HSC).
[0708] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has a genetic or epigenetic marker for a disease or disorder that manifests in a blood cell, an immune cell circulating in the blood, a bone marrow cell or a precursor cell thereof. In certain embodiments, the precursor cell is a hematopoietic stem cell (HSC). In some
embodiments of the methods of treating a disease or disorder of the disclosure, the disease or disorder is cancer. In certain embodiments, the cancer is a lymphoma, a leukemia, a myeloma or a malignant immunoproliferative disease. In certain embodiments, the lymphoma is Hodgkin lymphoma, Non-Hodgkin lymphoma, anaplastic large cell lymphoma, angioimmunoblastic T- cell lymphoma (AILT), hepatosplenic T-cell lymphoma, B-cell lymphoma, reticuloendotheliosis, reticulosis, microglioma, diffuse large B-cell lymphoma, follicular lymphoma, mucosa- associated lymphatic tissue lymphoma, B-cell chronic lymphocytic leukemia, mantle cell lymphoma (MCL), Burkitt lymphoma, mediastinal large B cell lymphoma, Waldenstrom's macroglobulinemia, nodal marginal zone B cell lymphoma, splenic marginal zone lymphoma (SMZL), intravascular large B-cell lymphoma, primary effusion lymphoma, lymphomatoid granulomatosis or nodular lymphocyte predominant Hodgkin's lymphoma.
[0709] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has a genetic or epigenetic marker for a disease or disorder that manifests in a blood cell, an immune cell circulating in the blood, a bone marrow cell or a precursor cell thereof. In certain embodiments, the precursor cell is a hematopoietic stem cell (HSC). In certain
embodiments, the disease or disorder is cancer. In certain embodiments, the cancer is a lymphoma, a leukemia, a myeloma or a malignant immunoproliferative disease. In certain embodiments, the leukemia is plasma cell leukemia (PCL), acute erythraemia and
erythroleukaemia, acute erythremic myelosis, acute erythroid leukemia, Heilmeyer-Schoner disease, acute megakaryoblastic leukemia (AMKL), mast cell leukemia, panmyelosis, acute panmyelosis with myelofibrosis (APMF), lymphosarcoma cell leukemia, blastic phase chronic myelogenous leukemia, stem cell leukemia, accelerated phase chronic myelogenous leukemia, acute myeloid leukemia (AML), polycythemia vera, acute promyelocytic leukemia, acute basophilic leukemia, acute eosinophilic leukemia, acute lymphoblastic leukemia, acute monocytic leukemia, acute myeloblastic leukemia with maturation, acute myeloid dendritic cell leukemia, adult T-cell leukemia/lymphoma, aggressive NK-cell leukemia, B-cell prolymphocytic leukemia, B-cell chronic lymphocytic leukemia, B-cell leukemia, chronic myelogenous leukemia, chronic myelomonocytic leukemia, chronic neutrophilic leukemia, chronic lymphocytic leukemia, hairy cell leukemia or chronic idiopathic myelofibrosis.
[0710] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has a genetic or epigenetic marker for a disease or disorder that manifests in a blood cell, an immune cell circulating in the blood, a bone marrow cell or a precursor cell thereof. In certain embodiments, the precursor cell is a hematopoietic stem cell (HSC). In certain embodiments, the disease or disorder is cancer. In certain embodiments, the cancer is a lymphoma, a leukemia, a myeloma or a malignant immunoproliferative disease. In certain embodiments, the myeloma is multiple myeloma, Kahler's disease, myelomatosis, solitary myeloma, plasma cell leukemia, extramedullary plasmacytoma, malignant plasma cell tumour or plasmacytoma.
[0711] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has a genetic or epigenetic marker for a disease or disorder that manifests in a blood cell, an immune cell circulating in the blood, a bone marrow cell or a precursor cell thereof. In certain embodiments, the precursor cell is a hematopoietic stem cell (HSC). In certain embodiments, the disease or disorder is cancer. In certain embodiments, the cancer is a lymphoma, a leukemia, a myeloma or a malignant immunoproliferative disease. In certain
embodiments, the malignant immunoproliferative disease is alpha heavy chain disease or gamma heavy chain disease.
[0712] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has a genetic or epigenetic marker for a disease or disorder that manifests in a blood cell, an immune cell circulating in the blood, a bone marrow cell or a precursor cell thereof. In certain embodiments, the precursor cell is a hematopoietic stem cell (HSC). In certain embodiments, the disease or disorder is an anemia. In certain embodiments, the anemia is a hemolytic anemia, an autoimmune hemolytic anemia, a congenital hemolytic anemia, an aplastic anemia, a b-thalassemia, a congenital erythroid aplasia, a congenital dyserythropoietic anemia, a glucose-6-phosphate dehydrogenase deficiency, a Fanconi anemia, a hereditary spherocytosis, a hereditary elliptocytosis, a hereditary pyropoikilocytosis, a hereditary persistence of fetal hemoglobin, a hereditary stomatocytosis, a hexokinase deficiency, a hyperanaemia, a hypochromic anemia, an ineffective erythropoiesis, a macrocytic anemia, a megaloblastic anemia, a myelophthisic anemia, a neuroacanthocytosis, a chorea-acanthocytosis, a paroxysmal nocturnal hemoglobinuria, a pyruvate kinase deficiency, a Rh deficiency syndrome, a sickle-cell disease, a sideroblastic anemia, a stomatocytic ovalocytosis, a thalassemia, a triosephosphate isomerase (TPI) deficiency or a warm autoimmune hemolytic anemia.
[0713] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has a genetic or epigenetic marker for a disease or disorder that manifests in a blood cell, an immune cell circulating in the blood, a bone marrow cell or a precursor cell thereof. In certain embodiments, the precursor cell is a hematopoietic stem cell (HSC). In certain embodiments, the disease or disorder is a clotting disorder or a hemorrhagic condition. In certain embodiments, the disease or disorder is a clotting disorder. In certain embodiments, the clotting disorder is a defibrination syndrome, a protein C deficiency, a protein S deficiency, Factor V Leiden, thrombocytosis, thrombosis, recurrent thrombosis, antiphospholipid syndrome, primary antiphospholipid syndrome or thrombotic thrombocytopenic purpura (TTP).
[0714] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has a genetic or epigenetic marker for a disease or disorder that manifests in a blood cell, an immune cell circulating in the blood, a bone marrow cell or a precursor cell thereof. In certain embodiments, the precursor cell is a hematopoietic stem cell (HSC). In certain
embodiments, the disease or disorder is a clotting disorder or a hemorrhagic condition. In certain embodiments, the disease or disorder is a hemorrhagic condition. In certain
embodiments, the hemorrhagic condition is thrombocytopenia, hemophilia, hemophilia A, hemophilia B, hemophilia C, Von Willebrand disease (vWD), hereditary Von Willebrand disease (vWD), vWD type 1, vWD type 2, vWD type 3, Glanzmann's thrombasthenia or Wiskott- Aldrich syndrome (WAS).
[0715] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has a genetic or epigenetic marker for a disease or disorder that manifests in a secondary target cell that may be contacted by the composition comprising a plurality of modified cells. In certain embodiments, the secondary target cell is a stem cell or a progenitor cell. In certain embodiments, the stem cell is a somatic stem cell. In certain embodiments, the stem cell is a target HSC, a mesenchymal stem cell, an epidermal stem cell, an epithelial stem cell, a neural stem cell. In certain embodiments, the secondary target cell is a differentiated cell. In certain embodiments, the differentiated cell is a red blood cell, a white blood cell, a monocyte, a granulocyte, a platelet, or a dendritic cell.
[0716] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has a genetic or epigenetic marker for a disease or disorder that manifests in a secondary target cell that may be contacted by the composition comprising a plurality of modified cells. In certain embodiments, the secondary target cell is a stem cell or a progenitor cell. In certain embodiments, the progenitor cell is an osteoblast. In certain embodiments, the at least one cell of the composition comprising a plurality of modified cells is modified to secrete a ligand, peptide or protein that enhances an activity of an osteoblast. In certain embodiments, the composition comprising a plurality of modified cells treats or prevents a disease or disorder associated with aberrant osteoblast function. In certain embodiments, the subject has one or more genetic or epigenetic markers for the disease or disorder associated with aberrant osteoblast function. In certain embodiments, the disease or disorder associated with aberrant osteoblast function is Paget’s disease, hypophosphatasia or ostesopetrosis.
[0717] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has a genetic or epigenetic marker for a disease or disorder that manifests in a secondary target cell that may be contacted by the composition comprising a plurality of
modified cells. In certain embodiments, the secondary target cell is a differentiated cell. In certain embodiments, the differentiated cell is a red blood cell, a white blood cell, a monocyte, a granulocyte, a platelet, or a dendritic cell. In certain embodiments, the at least one cell of the composition comprising a plurality of modified cells is modified to secrete a ligand, peptide or protein that enhances an activity of a granulocyte. In certain embodiments, the composition comprising a plurality of modified cells treats or prevents a disease or disorder associated with aberrant granulocyte function. In certain embodiments, the subject has one or more genetic or epigenetic markers for the disease or disorder associated with aberrant granulocyte function. In certain embodiments, the disease or disorder associated with aberrant granulocyte function is Chronic Granulomatous Disease.
[0718] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has an immune system disease or disorder or the subject is at risk of developing an immune system disease or disorder. In certain embodiments, the immune system disease or disorder is induced a medical intervention. In certain embodiments, the subject is at risk of developing an immune system disease or disorder due to a past, present or future medical intervention.
[0719] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject has an immune system disease or disorder or the subject is at risk of developing an immune system disease or disorder. In certain embodiments, the immune system disease or disorder was induced by an infection. In certain embodiments, the subject is at risk of developing an immune system disease or disorder due to a past, present or potential infection. In certain embodiments, the infection is viral, bacterial and/or microbial. In certain embodiments, the infection is viral. In certain embodiments, the infection is viral and the subject becomes immunocompromised as a result of the infection. In certain embodiments, the subject was exposed to or infected with HIV. In certain embodiments, the subject has developed AIDS. In certain embodiments, the infection is viral. In certain embodiments, the infection is viral and the subject develops cancer.
[0720] In some embodiments of the methods of treating a disease or disorder of the disclosure, the subject’s endogenous HSCs have been eliminated prior to administering a composition of the disclosure.
[0721] Exemplary therapeutic secreted proteins may be used as a monotherapy or in combination with another therapy in the treatment or prevention of any disease or disorder. These secreted proteins may be used as a monotherapy or in combination with another therapy for enzyme replacement and/or administration of biologic therapeutics. A database of human secreted proteins can be found at
proteinatlas.org/search/protein_class:Predicted%20secreted%20proteins, the contents of which are incorporated herein by reference. Exemplary human secreted proteins can be found, but are not limited to the human secreted proteins in Table 1.
[0722] Table 1 Human Therapeutic Proteins



































































































Further Modifications of Cell Compositions
[0723] Allogeneic cells of the disclosure are engineered to prevent adverse reactions to engraftment following administration to a subject. Allogeneic cells may be any type of cell.
[0724] In some embodiments of the composition and methods of the disclosure, allogeneic cells are stem cells. In some embodiments, allogeneic cells are derived from stem cells.
Exemplary stem cells include, but are not limited to, embryonic stem cells, adult stem cells, induced pluripotent stem cells (iPSCs), multipotent stem cells, pluripotent stem cells, and hematopoetic stem cells (HSCs).
[0725] In some embodiments of the composition and methods of the disclosure, allogeneic cells are differentiated somatic cells.
[0726] In some embodiments of the composition and methods of the disclosure, allogeneic cells are immune cells. In some embodiments, allogeneic cells are T lymphocytes (T cells). In some embodiments, allogeneic cells are T cells that do not express one or more components of a naturally-occurring T-cell Receptor (TCR). In some embodiments, allogeneic cells are T cells that express a non-naturally occurring antigen receptor. Alternatively, or in addition, in some embodiments, allogeneic cells are T cells that express a non-naturally occurring Chimeric Stimulatory Receptor (CSR). In some embodiments, the non-naturally occurring CSR comprises or consists of a switch receptor. In some embodiments, the switch receptor comprises an extracellular domain, a transmembrane domain, and an intracellular domain. In some
embodiments, the extracellular domain of the switch receptor binds to a TCR co-stimulatory molecule and transduces a signal to the intracellular space of the allogeneic cell that recapitulates TCR signaling or TCR co-stimulatory signaling.
[0727] Adoptive cell compositions that are“universally” safe for administration to any patient requires a significant reduction or elimination of alloreactivity.
[0728] Towards this end, allogeneic cells of the disclosure are modified to interrupt expression or function of a T-cell Receptor (TCR) and/or a class of Major Histocompatibility Complex (MHC). The TCR mediates graft vs host (GvH) reactions whereas the MHC mediates host vs graft (HvG) reactions. In preferred embodiments, any expression and/or function of the TCR is eliminated in allogeneic cells of the disclosure to prevent T-cell mediated GvH that could cause death to the subject. Thus, in particularly preferred embodiments, the disclosure provides a pure TCR-negative allogeneic T-cell composition (e.g. each cell of the composition expresses at a level so low as to either be undetectable or non-existent).
[0729] In preferred embodiments, expression and/or function of MHC class I (MHC -I, specifically, HLA-A, HLA-B, and HLA-C) is reduced or eliminated in allogeneic cells of the disclosure to prevent HvG and, consequently, to improve engraftment of allogeneic cells of the disclosure in a subject. Improved engraftment of the allogeneic cells of the disclosure results in longer persistence of the cells, and, therefore, a larger therapeutic window for the subject.
Specifically, in the allogeneic cells of the disclosure, expression and/or function of a structural element of MHC-I, Beta-2-Microglobulin (B2M), is reduced or eliminated in allogeneic cells of the disclosure.
[0730] The above strategies for generating an allogeneic cell of the disclosure induce further challenges. T Cell Receptor (TCR) knockout (KO) in T cells results in loss of expression of CD3-zeta (CD3z or CD3V), which is part of the TCR complex. The loss of CD3z in TCR-KO T- cells dramatically reduces the ability of optimally activating and expanding these cells using standard stimulation/activation reagents, including, but not limited to, agonist anti-CD3 mAb. When the expression or function of any one component of the TCR complex is interrupted, all components of the complex are lost, including TCR-alpha (TCRa), TCR-beta (TCRP), CD3- gamma (CD3y), CD3-epsilon (CD3e), CD3-delta (CD35), and CD3-zeta (CD3V). Both CD3e and CD3z are required for T cell activation and expansion. Agonist anti-CD3 mAbs typically
recognize CD3e and possibly another protein within the complex which, in turn, signals to CD3V. CD3V provides the primary stimulus for T cell activation (along with a secondary co stimulatory signal) for optimal activation and expansion. Under normal conditions, full T-cell activation depends on the engagement of the TCR in conjunction with a second signal mediated by one or more co-stimulatory receptors (e.g. CD28, CD2, 4-1BBL, etc... ) that boost the immune response. However, when the TCR is not present, T cell expansion is severely reduced when stimulated using standard activation/stimulation reagents, including agonist anti-CD3 mAb. In fact, T cell expansion is reduced to only 20-40% of the normal level of expansion when stimulated using standard activation/stimulation reagents, including agonist anti-CD3 mAb.
[0731] The disclosure provides a transposon comprising a sequence encoding a non-naturally occurring chimeric stimulatory receptor (CSR) comprising: (a) an ectodomain comprising a activation component, wherein the activation component is isolated or derived from a first protein; (b) a transmembrane domain; and (c) an endodomain comprising at least one signal transduction domain, wherein the at least one signal transduction domain is isolated or derived from a second protein; wherein the first protein and the second protein are not identical. In one aspect, the CSR activation component comprises a CD2 extracellular domain or a portion thereof to which an agonist binds and the signal transduction domain comprises a CD3 protein or a portion thereof. In a one aspect, the CD3 protein comprises a CD3z protein or a portion thereof. In one aspect, the transposon comprises a sequence for a CAR and a sequence for a CSR.
[0732] The disclosure provides a Chimeric Stimulatory Receptor (CSR) to deliver CD3z primary stimulation to allogeneic T cells in the absence of an endogenous TCR (and, consequently, an endogenous CD3V) when stimulated using standard activation/stimulation reagents, including agonist anti-CD3 mAb.
[0733] In the absence of an endogenous TCR, Chimeric Stimulatory Receptors (CSRs) of the disclosure provide a CD3V stimulus to enhance activation and expansion of allogeneic T cells. In other words, in the absence of an endogenous TCR, Chimeric Stimulatory Receptors (CSRs) of the disclosure rescue the allogeneic cell from an activation-based disadvantage when compared to non-allogeneic T-cells that express an endogenous TCR. In some embodiments, CSRs of the disclosure comprise an agonist mAb epitope extracellularly and a CD3z stimulatory domain intracellularly and, functionally, convert an anti-CD28 or anti-CD2 binding event on the surface
into a CD3z signaling event in an allogeneic T cell modified to express the CSR. In some embodiments, a CSR comprises a wild type CD28 or CD2 protein and a CD3z intracellular stimulation domain, to produce CD28z CSR and CD2z CSR, respectively. In preferred embodiments, CD28z CSR and/or CD2z CSR further express a non-naturally occurring antigen receptor and/or a therapeutic protein. In preferred embodiments, the non-naturally occurring antigen receptor comprises a Chimeric Antigen Receptor.
[0734] The data provided herein demonstrate that modified allogeneic T cells of the disclosure comprising/expressing a CSR of the disclosure improve or rescue, the expansion of allogeneic T cells that no longer express endogenous TCR when compared to those cells that do not comprise/express a CSR of the disclosure.
[0735] The disclosure provides a chimeric stimulatory receptor (CSR) comprising: (a) an ectodomain comprising an activation component and (b) a transmembrane domain or a cell- membrane attachment region, wherein the combination of (a) and (b) is non-naturally occurring. In some embodiments, this CSR binds a component of the environment and changes the cellular consequence of that signaling by competing with full-length or transmembrane versions of the receptor to reduce the intracellular signal resulting from binding of the component of the environment to the activation component.
[0736] The disclosure provides a chimeric stimulatory receptor (CSR) comprising: (a) an ectodomain comprising a activation component; (b) a transmembrane domain; and (c) an endodomain comprising at least one signal transduction domain; wherein the combination of (a),
(b) and (c) is non-naturally occurring.
[0737] In some embodiments of the CSRs of the disclosure, the activation component of (a) is isolated or derived from a first protein. In some embodiments, the signal transduction domain of
(c) is isolated or derived from a second protein. In some embodiments, the first protein and the second protein are not identical.
[0738] In some embodiments of the CSRs of the disclosure, the CSR is a switch receptor that translates binding of the activation component extracellularly with either suppressing a signal or transducing a qualitatively different signal than would be transduced by a wild type, full-length or transmembrane version of the first protein. Because a CSR switch receptor is chimeric with respect to the extracellular and intracellular domains, the CSR can switch the consequence of
binding the extracellular activation component from the naturally-occurring scenario to an engineered, non-naturally occurring, scenario.
[0739] In some embodiments of the CSRs of the disclosure, the activation component comprises one or more of a component of a human transmembrane receptor, a human cell- surface receptor, a T-cell Receptor (TCR), a component of a TCR complex, a component of a TCR co-receptor, a component of a TCR co-stimulatory protein, a component of a TCR inhibitory protein, a cytokine receptor, and a chemokine receptor. In some embodiments, the Activation component comprises a portion of one or more of a component of a human transmembrane receptor, a human cell-surface receptor, a T-cell Receptor (TCR), a component of a TCR complex, a component of a TCR co-receptor, a component of a TCR co-stimulatory protein, a component of a TCR inhibitory protein, a cytokine receptor, and a chemokine receptor to which an agonist of the activation component binds.
[0740] In some embodiments of the CSRs of the disclosure, the agonist comprises one or more of a small organic or inorganic molecule, a nucleic acid, an amino acid, an antibody or a fragment thereof, an antibody mimetic, an aptamer, a scaffold protein, a ligand, a receptor, a naturally occurring biomolecule, and a non-naturally occurring molecule (organic or inorganic).
[0741] In some embodiments of the CSRs of the disclosure, the Activation component comprises a CD2 protein or a portion thereof to which an agonist binds.
[0742] In some embodiments of the CSRs of the disclosure, the signal transduction domain comprises one or more of a component of human signal transduction domain, a T-cell Receptor (TCR), a component of a TCR complex, a component of a TCR co-receptor, a component of a TCR co-stimulatory protein, a component of a TCR inhibitory protein, a cytokine receptor, and a chemokine receptor. In some embodiments, the signal transduction domain comprises a CD3 protein. In some embodiments, the CD3 protein comprises a CD3z protein.
[0743] In some embodiments of the CSRs of the disclosure, the endodomain further comprises a cytoplasmic domain. In some embodiments, the sequence encoding the cytoplasmic domain comprises a sequence encoding a co-stimulatory protein. In some embodiments, the cytoplasmic domain is isolated or derived from a third protein. In some embodiments, the first protein and the third protein are identical.
[0744] In some embodiments of the CSRs of the disclosure, the ectodomain further comprises a signal peptide. In some embodiments, the signal peptide is derived from a fourth protein. In some embodiments, the first protein and the fourth protein are identical.
[0745] In some embodiments of the CSRs of the disclosure, the transmembrane domain is isolated or derived from a fifth protein. In some embodiments, the first protein and the fifth protein are identical.
[0746] In some embodiments of the CSRs of the disclosure, the CSR comprises an ectodomain comprising a signal peptide having a sequence isolated or derived from a CD2 protein and a Activation component comprising a sequence isolated or derived from a CD2 protein or a portion thereof to which an agonist binds, a transmembrane domain comprising a sequence isolated or derived from a CD2 protein, and an endodomain comprising a cytoplasmic domain comprising a sequence isolated or derived from a CD2 protein and a signal transduction domain comprising a sequence isolated or derived form a CD3z protein.
[0747] In some embodiments of the CSRs of the disclosure, the Activation component does not bind a naturally-occurring molecule.
[0748] In some embodiments of the CSRs of the disclosure, the CSR does not transduce a signal upon binding of the Activation component to a naturally-occurring molecule. In some embodiments, the ectodomain comprises a modification. In some embodiments, the modification comprises a mutation or a truncation of a sequence encoding the Activation component when compared to a wild type sequence of the first protein.
[0749] In some embodiments of the CSRs of the disclosure, the Activation component binds to a non-naturally occurring molecule. In some embodiments of the CSRs of the disclosure, the CSR selectively transduces a signal upon binding of the Activation component to a non-naturally occurring molecule.
[0750] The disclosure provides a nucleic acid sequence encoding the CSR of the disclosure.
The disclosure provides a vector comprising the nucleic acid sequence encoding the CSR of the disclosure. The disclosure provides a transposon comprising the nucleic acid sequence encoding the CSR of the disclosure.
[0751] The disclosure provides a cell comprising the CSR of the disclosure. The disclosure provides a cell comprising the nucleic acid encoding the CSR of the disclosure. The disclosure
provides a cell comprising the vector comprising the nucleic acid sequence encoding the CSR of the disclosure. The disclosure provides a cell comprising the transposon comprising the nucleic acid sequence encoding the CSR of the disclosure. In some embodiments of the cells of the disclosure, including those comprising a CSR of the disclosure, the cell is an allogeneic cell.
[0752] The disclosure provides a composition comprising the CSR of the disclosure. The disclosure provides a composition comprising the nucleic acid encoding the CSR of the disclosure. The disclosure provides a composition comprising the vector comprising the nucleic acid sequence encoding the CSR of the disclosure. The disclosure provides a composition comprising the transposon comprising the nucleic acid sequence encoding the CSR of the disclosure. The disclosure provides a composition comprising a cell of the disclosure, including those comprising a sequence encoding a CSR and/or expressing a CSR of the disclosure. The disclosure provides a composition comprising a plurality of cells of the disclosure, including those comprising a sequence encoding a CSR and/or expressing a CSR of the disclosure.
[0753] The disclosure provides a modified cell comprising: (a) a sequence encoding a CSR of the disclosure; (b) a sequence encoding an inducible proapoptotic polypeptide; and wherein the cell is a T-cell, (c) a modification of an endogenous sequence encoding a T-cell Receptor (TCR), wherein the modification reduces or eliminates a level of expression or activity of the TCR. In some embodiments, the cell further comprises: (d) a non- naturally occurring sequence comprising an HLA class I histocompatibility antigen, alpha chain E (HLA-E), and (e) a modification of an endogenous sequence encoding Beta-2-Microglobulin (B2M), wherein the modification reduces or eliminates a level of expression or activity of a major histocompatibility complex (MHC) class I (MHC-I).
[0754] The disclosure provides a modified cell comprising: (a) a sequence encoding a CSR of the disclosure; (b) a sequence encoding an inducible proapoptotic polypeptide; (c) a non- naturally occurring sequence comprising an HLA class I histocompatibility antigen, alpha chain E (HLA-E), and (e) a modification of an endogenous sequence encoding Beta-2-Microglobulin (B2M), wherein the modification reduces or eliminates a level of expression or activity of a major histocompatibility complex (MHC) class I (MHC-I).
[0755] In some embodiments of the modified cells of the disclosure, including those comprising a non-naturally occurring sequence comprising a HLA-E, the non-naturally
occurring sequence comprising a HLA-E further comprises a sequence encoding a B2M signal peptide. In some embodiments, the non-naturally occurring sequence comprising an HLA-E further comprises a sequence encoding a B2M polypeptide. In some embodiments, the non- naturally occurring sequence comprising an HLA-E further comprises a linker, wherein the linker is positioned between the sequence encoding the sequence encoding a B2M polypeptide and the sequence encoding the HLA-E.
[0756] In some embodiments of the modified cells of the disclosure, including those comprising a non-naturally occurring sequence comprising a HLA-E, the non-naturally occurring sequence comprising a HLA-E further comprises a sequence encoding a B2M signal peptide. In some embodiments, the non-naturally occurring sequence comprising an HLA-E further comprises a sequence encoding a peptide and a sequence encoding a B2M polypeptide.
In some embodiments, the non-naturally occurring sequence comprising an HLA-E further comprises a first linker positioned between the sequence encoding the B2M signal peptide and the sequence encoding the peptide, and a second linker positioned between the sequence encoding the B2M polypeptide and the sequence encoding the HLA-E.
[0757] In some embodiments of the transposons of the disclosure, including those comprising a CAR of the disclosure, the transposon further comprises a sequence encoding a chimeric stimulatory receptor (CSR). In some embodiments, the CSR comprises: (a) an ectodomain comprising an activation component; (b) a transmembrane domain; and (c) an endodomain comprising at least one signal transduction domain; wherein the combination of (a), (b) and (c) is non-naturally occurring. In some embodiments, the activation component of (a) is isolated or derived from a first protein. In some embodiments, the at least one signal transduction domain of (c) is isolated or derived from a second protein. In some embodiments, the first protein and the second protein are not identical. In some embodiments, the Activation component comprises one or more of a component of a human transmembrane receptor, a human cell-surface receptor, a T- cell Receptor (TCR), a component of a TCR complex, a component of a TCR co-receptor, a component of a TCR co-stimulatory protein, a component of a TCR inhibitory protein, a cytokine receptor, and a chemokine receptor. In some embodiments, the activation component comprises a portion of one or more of a component of a T-cell Receptor (TCR), a component of a TCR complex, a component of a TCR co-receptor, a component of a TCR co-stimulatory
protein, a component of a TCR inhibitory protein, a cytokine receptor, and a chemokine receptor to which an agonist of the Activation component binds. In some embodiments, the activation component comprises a CD2 protein or a portion thereof to which an agonist binds. In some embodiments, the signal transduction domain comprises one or more of a component of a human signal transduction domain, T-cell Receptor (TCR), a component of a TCR complex, a component of a TCR co-receptor, a component of a TCR co-stimulatory protein, a component of a TCR inhibitory protein, a cytokine receptor, and a chemokine receptor. In some embodiments, the signal transduction domain comprises a CD3 protein. In some embodiments, the CD3 protein comprises a CD3V protein. In some embodiments, the endodomain further comprises a cytoplasmic domain. In some embodiments, the cytoplasmic domain is isolated or derived from a third protein. In some embodiments, the first protein and the third protein are identical. In some embodiments, the ectodomain further comprises a signal peptide. In some embodiments, the signal peptide is derived from a fourth protein. In some embodiments, the first protein and the fourth protein are identical. In some embodiments, the transmembrane domain is isolated or derived from a fifth protein. In some embodiments, the first protein and the fifth protein are identical. In some embodiments, the Activation component does not bind a naturally-occurring molecule. In some embodiments, the CSR does not transduce a signal upon binding of the activation component to a naturally-occurring molecule. In some embodiments, the ectodomain comprises a modification. In some embodiments, the modification comprises a mutation or a truncation of a sequence encoding the activation component when compared to a wild type sequence of the first protein. In some embodiments, the Activation component binds to a non- naturally occurring molecule. In some embodiments, the CSR selectively transduces a signal upon binding of the Activation component to a non-naturally occurring molecule.
[0758] The disclosure provides a composition comprising a CAR of the disclosure. In some embodiments, the composition further comprises a CSR of the disclosure or a sequence encoding the CSR. In some embodiments, the sequence encoding the CSR comprises DNA. In some embodiments, the sequence encoding the CSR comprises RNA. In some embodiments, the sequence encoding the CSR comprises messenger RNA (mRNA). In some embodiments, upon introduction to a cell of the disclosure, the CSR or the sequence encoding the CSR is stably integrated by the cell. In some embodiments, upon introduction to a cell of the disclosure, the
CSR or the sequence encoding the CSR is not stably integrated by the cell. In some embodiments, upon introduction to a cell of the disclosure, the CSR or the sequence encoding the CSR is stably expressed by the cell. In some embodiments, upon introduction to a cell of the disclosure, the CSR or the sequence encoding the CSR is transiently expressed by the cell. In some embodiments, upon introduction to a cell of the disclosure, the CSR or the sequence encoding the CSR comprises an RNA or an mRNA and the CSR or the sequence encoding the CSR is transiently expressed by the cell.
[0759] The disclosure provides a cell comprising a CAR of the disclosure. In some
embodiments, the cell further comprises a CSR of the disclosure or a sequence encoding the CSR. In some embodiments, the sequence encoding the CSR comprises DNA. In some embodiments, the sequence encoding the CSR comprises RNA. In some embodiments, the sequence encoding the CSR comprises messenger RNA (mRNA). In some embodiments, the CSR or the sequence encoding the CSR is stably integrated into a genomic locus or loci of the cell. In some embodiments, the CSR or the sequence encoding the CSR is not stably integrated into a genomic locus or loci of the cell. In some embodiments, the CSR or the sequence encoding the CSR is stably expressed by the cell. In some embodiments, the CSR or the sequence encoding the CSR is transiently expressed by the cell. In some embodiments, the CSR or the sequence encoding the CSR comprises an RNA or an mRNA and the CSR or the sequence encoding the CSR is transiently expressed by the cell.
[0760] A wildtype/natural human CD28 protein (NCBI: CD28 HUMAN; UniProt/Swiss-Prot: P 10747.1) comprises or consists of the amino acid sequence of:

[0761] A nucleotide sequence encoding wildtype/natural CD28 protein (NCBI: CCDS2361.1) comprises or consists of the nucleotide sequence of:


[0762] An exemplary CSR CD28z protein of the disclosure comprises or consists of the amino acid sequence of (CD28 Signal peptide, CD28 Extracellular Domain, CD28 Transmembrane domain. CD28 Cytoplasmic Domain, CD3z Intracellular Domain):


[0763] An exemplary nucleotide sequence encoding a CSR CD28z protein of the disclosure comprises or consists of the nucleotide sequence of (CD28 Signal peptide, CD28 Extracellular Domain, CD28 Transmembrane domain. CD28 Cytoplasmic Domain , CD3z Intracellular Domain):


[0764] A wildtype/natural human CD2 protein (NCBI: CD2_HUMAN; UniProt/Swiss-Prot: P06729.2) comprises or consists of the amino acid sequence of:

[0765] A nucleotide sequence encoding wildtype/natural CD2 protein (NCBI: CCDS889.1) comprises or consists of the nucleotide sequence of:

[0766] An exemplary CSR CD2z protein of the disclosure comprises or consists of the amino acid sequence of (CD2 Signal peptide, CD2 Extracellular Domain, CD2 Transmembrane domain. CD2 Cytoplasmic Domain, CD3z Intracellular Domain):


[0767] The present disclosure provides a non-naturally occurring CSR CD2 protein
comprising, consisting essential of, or consisting of an amino acid sequence at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99% or 100% identical to SEQ ID NO: 14756. The present disclosure provides a CD2 signal peptide comprising, consisting essential of, or consisting of an amino acid sequence at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99% or 100% identical to SEQ ID NO: 14758. The present disclosure provides a CD2 extracellular domain comprising, consisting essential of, or consisting of an amino acid sequence at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99% or 100% identical to SEQ ID NO: 14759. The present disclosure provides a CD2 transmembrande domain comprising, consisting essential of, or consisting of an amino acid sequence at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at
least 97%, at least 98%, at least 99% or 100% identical to SEQ ID NO: 14760. The present disclosure provides a CD2 cytoplasmic domain comprising, consisting essential of, or consisting of an amino acid sequence at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99% or 100% identical to SEQ ID NO: 14761. The present disclosure provides a CD3z intracellular domain comprising, consisting essential of, or consisting of an amino acid sequence at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99% or 100% identical to SEQ ID NO: 14748.
[0768] An exemplary nucleotide sequence encoding a CSR CD2z protein of the disclosure comprises or consists of the amino acid sequence of (CD2 Signal peptide, CD2 Extracellular
Domain, CD2 Transmembrane domain. CD2 Cytoplasmic Domain, CD3z Intracellular Domain):



[0769] An exemplary mutant CSR CD2z-Dl 11H protein of the disclosure comprises or consists of the amino acid sequence of (CD2 Signal peptide, CD2 Extracellular domain with


[0770] The present disclosure provides a non-naturally occurring CSR CD2 protein
comprising, consisting essential of, or consisting of an amino acid sequence at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99% or 100% identical to SEQ ID NO: 14768. The present disclosure provides a CD2 extracellular domain comprising, consisting essential of, or consisting of an amino acid sequence at least 80%, at least 85%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99% or 100% identical to SEQ ID NO: 14769.
[0771] An exemplary nucleotide sequence encoding a mutant CSR CD2z-Dl 11H protein of the disclosure comprises or consists of the amino acid sequence of (CD2 Signal peptide, CD2



[0773] Gene editing compositions of the disclosure, including but not limited to, RNA-guided fusion proteins comprising dCas9-Clo05l, may be used to target and decrease or eliminate expression of an endogenous T-cell receptor of an allogeneic cell of the disclosure. In preferred embodiments, the gene editing compositions of the disclosure target and delete a gene, a portion of a gene, or a regulatory element of a gene (such as a promoter) encoding an endogenous T-cell receptor of an allogeneic cell of the disclosure.
[0774] Nonlimiting examples of primers (including a T7 promoter, genome target sequence, and gRNA scaffold) for the generation of guide RNA (gRNA) templates for targeting and deleting TCR-alpha (TCR-a) are provided in Table 2
[0775] Table 2. Target sequences underlined



[0776] Nonlimiting examples of primers for the generation of guide RNA (gRNA) templates for targeting and deleting TCR-beta (TCR-b) are provided in Table 3.
[0777] Table 3. Target sequences underlined


[0778] Nonlimiting examples of primers for the generation of guide RNA (gRNA) templates for targeting and deleting beta-2-microglobulin (b2M) are provided in Table 4.
[0779] Table 4. Target sequences underlined


[0780] Gene editing compositions of the disclosure, including but not limited to, RNA-guided fusion proteins comprising dCas9-Clo05l, may be used to target and decrease or eliminate expression of an endogenous MHCI, MHCII, or MHC activator of an allogeneic cell of the disclosure. In preferred embodiments, the gene editing compositions of the disclosure target and delete a gene, a portion of a gene, or a regulatory element of a gene (such as a promoter) encoding one or more components of an endogenous MHCI, MHCII, or MHC activator of an allogeneic cell of the disclosure.
[0781] Nonlimiting examples of guide RNAs (gRNAs) for targeting and deleting MHC activators are provided in Tables 5 and 6.
[0782] Table 5.





[0785] Two strategies are contemplated by the disclosure for engineering allo (MHCI-neg) T cells (including CAR-T cells) more resistant to NK cell-mediated cytotoxicity. In some embodiments, a sequence encoding a molecule (such as single-chain HLA-E) that reduces or prevents NK killing is introduced or delivered to an allogeneic cell. Alternatively, or in addition, gene editing methods of the disclosure retain certain endogenous HLA molecules (such as endogenous HLA-E). Lor example, the first approach involves piggyBac (PB) delivery of a single-chain (sc)HLA-E molecule to B2M KO T cells.
[0786] The second approach uses a gene editing composition with guide RNAs selective for HLA-A, HLA-B and HLA-C, but not, for example, HLA-E or other molecules that are protective against natural-killer cell mediated cytotoxicity for MHCI KO cells.
[0787] Alternative or additional molecules to HLA-E that are protective against NK cell- mediated cytotoxicity include, but are not limited to, CD47, interferon alpha/beta receptor 1 (ILNAR1), human IPNAR1, interferon alpha/beta receptor 2 (ILNAR2), human ILNAR2, HLA- Gl, HLA-G2, HLA-G3, HLA-G4, HLA-G5, HLA-G6, HLA-G7, human carcino embryonic antigen-related cell adhesion molecule 1 (CEACAM1), viral hemoagglutinins, CD48, LLT1
(also referred to as C-type lectin domain family 2 member (CLC2D)), ULBP2, ULBP3, and sMICA or a variant thereof.
[0788] An exemplary CD47 protein of the disclosure comprises or consists of the amino acid sequence of (Signal peptide. Extracellular, TM, Cytoplasmic ):

[0789] An exemplary INFAR1 protein of the disclosure comprises or consists of the amino acid sequence of (Signal peptide. Extracellular, TM, Cytoplasmic ):

[0790] An exemplary INFAR2 protein of the disclosure comprises or consists of the amino acid sequence of (Signal peptide. Extracellular, TM, Cytoplasmic ):

[0791] An exemplary HLA-G1 protein of the disclosure comprises or consists of the amino acid sequence of (Alpha chain 1 , Alpha chain 2, Alpha chain 3):


[0792] An exemplary HLA-G2 protein of the disclosure comprises or consists of the amino acid sequence of (Alpha chain 1, Alpha chain 2, Alpha chain 3):

[0793] An exemplary HLA-G3 protein of the disclosure comprises or consists of the amino acid sequence of (Alpha chain 1, Alpha chain 2, Alpha chain 3h

[0794] An exemplary HLA-G4 protein of the disclosure comprises or consists of the amino acid sequence of (Alpha chain 1, Alpha chain 2, Alpha chain 3):

[0795] An exemplary HLA-G5 protein of the disclosure comprises or consists of the amino acid sequence of (Alpha chain 1, Alpha chain 2, Alpha chain 3. intron 4)

[0796] An exemplary HLA-G5 protein of the disclosure comprises or consists of the amino acid sequence of (Alpha chain 1, Alpha chain 2, Alpha chain 3. intron 4)

[0797] An exemplary HLA-G5 protein of the disclosure comprises or consists of the amino acid sequence of (Alpha chain 1, Alpha chain 2, Alpha chain 3. intron 2):

[0798] An exemplary CEACAM1 protein of the disclosure comprises or consists of the amino acid sequence of (Extracellular, TM, Cytoplasmic]:

[0799] An exemplary viral hemagglutinin protein of the disclosure comprises or consists of the amino acid sequence of (HAforInfluenzaAvirus(A/NewCaledonia/20/l999(HlNl); TM):

[0800] An exemplary CD48 protein of the disclosure comprises or consists of the amino acid sequence of (Signal peptide. Chain, Pro peptide removed in mature form):


[0801] An exemplary LLT1 protein of the disclosure comprises or consists of the amino acid sequence of (Cytoplasmic, TM, Extracellular]:

[0802] An exemplary ULBP2 protein of the disclosure comprises or consists of the amino acid sequence of (also known as NKG2D ligand; Genbank ACCESSION No. AAQ89028):

[0803] An exemplary ULBP3 protein of the disclosure comprises or consists of the amino acid sequence of (also known as NKG2D ligand; Genbank ACCESSION No. NP_078794):

[0804] An exemplary sMICA protein of the disclosure comprises or consists of the amino acid sequence of (Signal Peptide. Portion of Extracellular domain, TM and cytoplasmic domain) (Genbank Accession No. Q29983):

[0805] An exemplary sMICA protein of the disclosure comprises or consists of the amino acid sequence of (Alpha- 1. Alpha-2, Alpha- 3):


[0806] An exemplary sMICA protein of the disclosure comprises or consists of the amino acid sequence of ( Signal peptide ; Alpha- 1. Alpha-2, Alpha- 3) :

[0807] An exemplary sMICA protein of the disclosure comprises or consists of the amino acid sequence of ( Signal peptide) .

[0808] An exemplary bGBE Trimer (270G and 484S) protein of the disclosure comprises or consists of the amino acid sequence of:

[0809] An exemplary bGBE Trimer (270G and 484S) protein of the disclosure comprises or consists of the nucleic acid sequence of:


[0810] An exemplary bGBE Trimer (270R and 484S) protein of the disclosure comprises or consists of the amino acid sequence of:

[0811] An exemplary bGBE Trimer (270R and 484S) protein of the disclosure comprises or consists of the nucleic acid sequence of:


[0812] An exemplary gBE Dimer (R and A) protein of the disclosure comprises or consists of the amino acid sequence of:

[0813] An exemplary gBE Dimer (R and A) protein of the disclosure comprises or consists of the nucleic acid sequence of:


[0814] An exemplary gBE Dimer (G andS) protein of the disclosure comprises or consists of the amino acid sequence of:

[0815] An exemplary gBE Dimer (G andS) protein of the disclosure comprises or consists of the amino acid sequence of:


[0816] An exemplary WT HLA-E Monomer (R andS) protein of the disclosure comprises or consists of the amino acid sequence of:

[0817] An exemplary WT HLA-E Monomer (R andS) protein of the disclosure comprises or consists of the nucleic acid sequence of:

[0818] An exemplary WT HLA-E Monomer (G and A) protein of the disclosure comprises or consists of the nucleic acid sequence of:

[0819] An exemplary WT HLA-E Monomer (G and S) protein of the disclosure comprises or consists of the nucleic acid sequence of:

[0820] Inducible proapoptotic polypeptides of the disclosure are superior to existing inducible polypeptides because the inducible proapoptotic polypeptides of the disclosure are far less immunogenic. While inducible proapoptotic polypeptides of the disclosure are recombinant polypeptides, and, therefore, non-naturally occurring, the sequences that are recombined to produce the inducible proapoptotic polypeptides of the disclosure do not comprise non-human sequences that the host human immune system could recognize as“non-self’ and, consequently, induce an immune response in the subject receiving an inducible proapoptotic polypeptide of the disclosure, a cell comprising the inducible proapoptotic polypeptide or a composition comprising
the inducible proapoptotic polypeptide or the cell comprising the inducible proapoptotic polypeptide.
[0821] Transposons of the disclosure may comprise an inducible proapoptotic polypeptide comprising (a) a ligand binding region, (b) a linker, and (c) a proapoptotic polypeptide, wherein the inducible proapoptotic polypeptide does not comprise a non-human sequence. In certain embodiments, the non-human sequence comprises a restriction site. In certain embodiments, the ligand binding region may be a multimeric ligand binding region. Inducible proapoptotic polypeptides of the disclosure may also be referred to as an“iC9 safety switch”. In certain embodiments, transposons of the disclosure may comprise an inducible caspase polypeptide comprising (a) a ligand binding region, (b) a linker, and (c) a caspase polypeptide, wherein the inducible proapoptotic polypeptide does not comprise a non-human sequence. In certain embodiments, transposons of the disclosure may comprise an inducible caspase polypeptide comprising (a) a ligand binding region, (b) a linker, and (c) a caspase polypeptide, wherein the inducible proapoptotic polypeptide does not comprise a non-human sequence. In certain embodiments, transposons of the disclosure may comprise an inducible caspase polypeptide comprising (a) a ligand binding region, (b) a linker, and (c) a truncated caspase 9 polypeptide, wherein the inducible proapoptotic polypeptide does not comprise a non-human sequence. In certain embodiments of the inducible proapoptotic polypeptides, inducible caspase polypeptides or truncated caspase 9 polypeptides of the disclosure, the ligand binding region may comprise a FK506 binding protein 12 (FKBP12) polypeptide. In certain embodiments, the amino acid sequence of the ligand binding region that comprise a FK506 binding protein 12 (FKBP12) polypeptide may comprise a modification at position 36 of the sequence. The modification may be a substitution of valine (V) for phenylalanine (F) at position 36 (F36V).
[0822] In certain embodiments, the FKBP12 polypeptide is encoded by an amino acid sequence comprising
GVQVETISPGDGRTFPKRGQTCWHYTGMLEDGKKVDSSRDRNKPFKFMLGKQEVIRG WEEGV AQMS V GQRAKLTISPD Y AY GAT GHPGIIPPHATLVFD VELLKLE (SEQ ID NO: 14494).
[0823] In certain embodiments, the FKBP12 polypeptide is encoded by a nucleic acid sequence comprising

certain embodiments, the induction agent specific for the ligand binding region may comprise a FK506 binding protein 12 (FKBP12) polypeptide having a substitution of valine (V) for phenylalanine (F) at position 36 (F36V) comprises AP20187 and/or AP1903, both synthetic drugs.
[0824] In certain embodiments of the inducible proapoptotic polypeptides, inducible caspase polypeptides or truncated caspase 9 polypeptides of the disclosure, the linker region is encoded by an amino acid comprising GGGGS (SEQ ID NO: 14496) or a nucleic acid sequence comprising GGAGGAGGAGGATCC (SEQ ID NO: 14497). In certain embodiments, the nucleic acid sequence encoding the linker does not comprise a restriction site.
[0825] In certain embodiments of the truncated caspase 9 polypeptides of the disclosure, the truncated caspase 9 polypeptide is encoded by an amino acid sequence that does not comprise an arginine (R) at position 87 of the sequence. Alternatively, or in addition, in certain embodiments of the inducible proapoptotic polypeptides, inducible caspase polypeptides or truncated caspase 9 polypeptides of the disclosure, the truncated caspase 9 polypeptide is encoded by an amino acid sequence that does not comprise an alanine (A) at position 282 the sequence. In certain embodiments of the inducible proapoptotic polypeptides, inducible caspase polypeptides or truncated caspase 9 polypeptides of the disclosure, the truncated caspase 9 polypeptide is encoded by an amino acid comprising


[0826] In certain embodiments of the inducible proapoptotic polypeptides, wherein the polypeptide comprises a truncated caspase 9 polypeptide, the inducible proapoptotic polypeptide is encoded by an amino acid sequence comprising

[0827] Transposons of the disclosure may comprise at least one self-cleaving peptide(s) located, for example, between one or more of a sequence encoding an inducible proapoptotic polypeptide of the disclosure, a sequence encoding a therapeutic protein of the disclosure and a selection gene of the disclosure.
[0828] Transposons of the disclosure may comprise at least two self-cleaving peptide(s), a first self-cleaving peptide located, for example, upstream or immediately upstream of an inducible proapoptotic polypeptide of the disclosure of the disclosure and a second first self-cleaving peptide located, for example, downstream or immediately upstream of an inducible proapoptotic polypeptide of the disclosure.
[0829] The at least one self-cleaving peptide may comprise, for example, a T2A peptide, GSG- T2A peptide, an E2A peptide, a GSG-E2A peptide, an F2A peptide, a GSG-F2A peptide, a P2A peptide, or a GSG-P2A peptide. A T2A peptide may comprise an amino acid sequence comprising EGRGSLLTCGDVEENPGP (SEQ ID NO: 14637) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising
EGRGSLLTCGDVEENPGP (SEQ ID NO: 14638). A GSG-T2A peptide may comprise an amino acid sequence comprising GSGEGRGSLLTCGDVEENPGP (SEQ ID NO: 14638) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising GSGEGRGSLLTCGDVEENPGP (SEQ ID NO: 14638) . A GSG-T2A peptide may comprise a nucleic acid sequence comprising
ggatctggagagggaaggggaagcctgctgacctgtggagacgtggaggaaaacccaggacca (SEQ ID NO: 14676). An E2A peptide may comprise an amino acid sequence comprising
QCTNY ALLKLAGDVESNPGP (SEQ ID NO: 14639) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising
QCTNY ALLKLAGDVESNPGP (SEQ ID NO: 14639) . A GSG-E2A peptide may comprise an amino acid sequence comprising GSGQCTNY ALLKLAGDVESNPGP (SEQ ID NO: 14640) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising GSGQCTNY ALLKLAGDVESNPGP (SEQ ID NO: 14640). An L2A peptide may comprise an amino acid sequence comprising VKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 14641) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising VKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 14641) . A GSG-F2A peptide may comprise an amino acid sequence comprising
GSGVKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 14642) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising
GSGVKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 14642). A P2A peptide may comprise an amino acid sequence comprising ATNFSLLKQAGDVEENPGP (SEQ ID NO: 14643) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising ATNFSLLKQAGDVEENPGP (SEQ ID NO: 14643) . A GSG-P2A peptide may comprise an amino acid sequence comprising GSGATNFSLLKQAGDVEENPGP (SEQ ID NO: 14644) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising GSGATNFSLLKQAGDVEENPGP (SEQ ID NO: 14644).
[0830] Transposons of the disclosure may comprise a first and a second self-cleaving peptide, the first self-cleaving peptide located, for example, upstream of one or more of a sequence encoding a therapeutic protein of the disclosure the second self-cleaving peptide located, for example, downstream of a sequence encoding a therapeutic protein of the disclosure. The first and/or the second self-cleaving peptide may comprise, for example, a T2A peptide, GSG-T2A peptide, an E2A peptide, a GSG-E2A peptide, an F2A peptide, a GSG-F2A peptide, a P2A peptide, or a GSG-P2A peptide. A T2A peptide may comprise an amino acid sequence comprising EGRGSLLTCGDVEENPGP (SEQ ID NO: 14637) or a sequence having at least
70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising
EGRGSLLTCGDVEENPGP (SEQ ID NO: 14638). A GSG-T2A peptide may comprise an amino acid sequence comprising GSGEGRGSLLTCGDVEENPGP (SEQ ID NO: 14638) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising GSGEGRGSLLTCGDVEENPGP (SEQ ID NO: 14638) . A GSG-T2A peptide may comprise a nucleic acid sequence comprising
ggatctggagagggaaggggaagcctgctgacctgtggagacgtggaggaaaacccaggacca (SEQ ID NO: 14676). An E2A peptide may comprise an amino acid sequence comprising
QCTNY ALLKLAGDVESNPGP (SEQ ID NO: 14639) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising
QCTNY ALLKLAGDVESNPGP (SEQ ID NO: 14639) . A GSG-E2A peptide may comprise an amino acid sequence comprising GSGQCTNY ALLKLAGDVESNPGP (SEQ ID NO: 14640) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising GSGQCTNY ALLKLAGDVESNPGP (SEQ ID NO: 14640). An F2A peptide may comprise an amino acid sequence comprising VKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 14641) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising VKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 14641) . A GSG-F2A peptide may comprise an amino acid sequence comprising
GSGVKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 14642) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising
GSGVKQTLNFDLLKLAGDVESNPGP (SEQ ID NO: 14642). A P2A peptide may comprise an amino acid sequence comprising ATNFSLLKQAGDVEENPGP (SEQ ID NO: 14643) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising ATNFSLLKQAGDVEENPGP (SEQ ID NO: 14643) . A GSG-P2A peptide may comprise an amino acid sequence comprising GSGATNFSLLKQAGDVEENPGP (SEQ ID NO: 14644) or a sequence having at least 70%, 80%, 90%, 95%, or 99% identity to the amino acid sequence comprising GSGATNFSLLKQAGDVEENPGP (SEQ ID NO: 14644).
[0831] Transposons of the disclosure may comprise a selection gene for identification, enrichment and/or isolation of cells that express the transposon. Exemplary selection genes encode any gene product (e.g. transcript, protein, and enzyme) essential for cell viability and survival. Exemplary selection genes encode any gene product (e.g. transcript, protein, enzyme)
essential for conferring resistance to a drug challenge against which the cell is sensitive (or which could be lethal to the cell) in the absence of the gene product encoded by the selection gene. Exemplary selection genes encode any gene product (e.g. transcript, protein, and enzyme) essential for viability and/or survival in a cell media lacking one or more nutrients essential for cell viability and/or survival in the absence of the selection gene. Exemplary selection genes include, but are not limited to, neo (conferring resistance to neomycin), DHFR (encoding Dihydrofolate Reductase and conferring resistance to Methotrexate), TYMS (encoding
Thymidylate Synthetase), MGMT ( encoding 0(6)-methylguanine-DNA methyltransferase), multi drug resistance gene (MDR1), ALDH1 (encoding Aldehyde dehydrogenase 1 family, member Al), FRANCF, RAD51C (encoding RAD51 Paralog C), GCS (encoding
glucosylceramide synthase), Nerve growth factor receptor (NGFR), and NKX2.2 (encoding NK2 Homeobox 2).
[0832] The disclosure provides a vector comprising a transposon of the disclosure. In certain embodiments, the vector is a viral vector. The vector may be an isolated and/or a recombinant vector. The vector may be a self-complementary vector. In preferred embodiments, the viral vector is replication-deficient.
[0833] Viral vectors of the disclosure may comprise a sequence isolated or derived from a retrovirus, a lentivirus, an adenovirus, an adeno-associated virus or any combination thereof. The viral vector may comprise a sequence isolated or derived from an adeno-associated virus (AAV). The viral vector may comprise a recombinant AAV (rAAV). Exemplary adeno-associated viruses and recombinant adeno-associated viruses of the disclosure comprise two or more inverted terminal repeat (ITR) sequences located in cis next to a sequence encoding an inducible proapoptotic polypeptide, a sequence encoding a therapeutic protein, and/or a sequence encoding a selection marker of the disclosure. Exemplary adeno-associated viruses and recombinant adeno-associated viruses of the disclosure include, but are not limited to all serotypes (e.g.
AAV1, AAV2, AAV3, AAV4, AAV5, AAV6, AAV7, AAV8, and AAV9). Exemplary adeno- associated viruses and recombinant adeno-associated viruses of the disclosure include, but are not limited to, self-complementary AAV (scAAV) and AAV hybrids containing the genome of one serotype and the capsid of another serotype (e.g. AAV2/5, AAV-DJ and AAV-DJ8).
Exemplary adeno-associated viruses and recombinant adeno-associated viruses of the disclosure include, but are not limited to, rAAV-LK03.
[0834] The disclosure provides a vector comprising a transposon of the disclosure. In certain embodiments, the vector is a nanoparticle. Exemplary nanoparticle vectors of the disclosure include, but are not limited to, nucleic acids (e.g. RNA, DNA, synthetic nucleotides, modified nucleotides or any combination thereof ), amino acids (L-amino acids, D-amino acids, synthetic amino acids, modified amino acids, or any combination thereof), polymers (e.g. polymersomes), micelles, lipids (e.g. liposomes), organic molecules (e.g. carbon atoms, sheets, fibers, tubes), inorganic molecules (e.g. calcium phosphate or gold) or any combination thereof. A nanoparticle vector may be passively or actively transported across a cell membrane.
[0835] Vectors of the disclosure may comprise a selection gene. Exemplary selection genes encode any gene product (e.g. transcript, protein, and enzyme) essential for cell viability and survival. Exemplary selection genes encode any gene product (e.g. transcript, protein, enzyme) essential for conferring resistance to a drug challenge against which the cell is sensitive (or which could be lethal to the cell) in the absence of the gene product encoded by the selection gene. Exemplary selection genes encode any gene product (e.g. transcript, protein, and enzyme) essential for viability and/or survival in a cell media lacking one or more nutrients essential for cell viability and/or survival in the absence of the selection gene. Exemplary selection genes include, but are not limited to, neo (conferring resistance to neomycin), DHFR (encoding Dihydrofolate Reductase and conferring resistance to Methotrexate), TYMS (encoding
Thymidylate Synthetase), MGMT ( encoding 0(6)-methylguanine-DNA methyltransferase), multi drug resistance gene (MDR1), ALDH1 (encoding Aldehyde dehydrogenase 1 family, member Al), FRANCF, RAD51C (encoding RAD51 Paralog C), GCS (encoding
glucosylceramide synthase), Nerve growth factor receptor (NGFR), and NKX2.2 (encoding NK2 Homeobox 2).
[0836] Vectors of the disclosure may comprise an inducible proapoptotic polypeptide comprising (a) a ligand binding region, (b) a linker, and (c) a proapoptotic polypeptide, wherein the inducible proapoptotic polypeptide does not comprise a non-human sequence. In certain embodiments, the non-human sequence comprises a restriction site. In certain embodiments, the
ligand binding region may be a multimeric ligand binding region. Inducible proapoptotic polypeptides of the disclosure may also be referred to as an“iC9 safety switch”.
[0837] The disclosure provides a composition comprising a vector of the disclosure.
[0838] Nucleic acid molecules of the disclosure can be in the form of RNA, such as mRNA, hnRNA, tRNA or any other form, or in the form of DNA, including, but not limited to, cDNA and genomic DNA obtained by cloning or produced synthetically, or any combinations thereof. The DNA can be triple-stranded, double-stranded or single-stranded, or any combination thereof. Any portion of at least one strand of the DNA or RNA can be the coding strand, also known as the sense strand, or it can be the non-coding strand, also referred to as the anti-sense strand.
[0839] Isolated nucleic acid molecules of the disclosure can include nucleic acid molecules comprising an open reading frame (ORF), optionally, with one or more introns, e.g., but not limited to, nucleic acid molecules comprising the coding sequence for a protein, an inducible proapoptotic polypeptide, a selection gene product, a transposase, a gene editing composition or effector domain thereof, an HD AC inhibitor, an HMT inhibitor and nucleic acid molecules which comprise a nucleotide sequence substantially different from those described above but which, due to the degeneracy of the genetic code, still encode the proteins of the disclosure as described herein and/or as known in the art. Of course, the genetic code is well known in the art. Thus, it would be routine for one skilled in the art to generate such degenerate nucleic acid variants that code for specific protein scaffolds of the present invention. See, e.g., Ausubel, et al, supra, and such nucleic acid variants are included in the present invention.
[0840] As indicated herein, nucleic acid molecules of the disclosure include, but are not limited to, those encoding the amino acid sequence of a protein of the disclosure, by itself; the coding sequence for the entire protein or a portion thereof; the coding sequence for a protein, fragment or portion, as well as additional sequences, such as the coding sequence of at least one signal leader or fusion peptide, with or without the aforementioned additional coding sequences, such as at least one intron, together with additional, non-coding sequences, including but not limited to, non-coding 5' and 3' sequences, such as the transcribed, non-translated sequences that play a role in transcription, mRNA processing, including splicing and polyadenylation signals (for example, ribosome binding and stability of mRNA); an additional coding sequence that codes for additional amino acids, such as those that provide additional functionalities. Thus, the sequence
encoding a protein can be fused to a marker sequence, such as a sequence encoding a peptide that facilitates purification of the fused protein scaffold comprising a protein scaffold fragment or portion.
[0841] The amino acids that make up protein scaffolds of the disclosure are often abbreviated. The amino acid designations can be indicated by designating the amino acid by its single letter code, its three letter code, name, or three nucleotide codon(s) as is well understood in the art (see Alberts, B., et al, Molecular Biology of The Cell, Third Ed., Garland Publishing, Inc., New York, 1994). A protein scaffold of the disclosure can include one or more amino acid
substitutions, deletions or additions, either from natural mutations or human manipulation, as specified herein. Amino acids in a protein scaffold of the disclosure that are essential for function can be identified by methods known in the art, such as site-directed mutagenesis or alanine-scanning mutagenesis (e.g., Ausubel, supra, Chapters 8, 15; Cunningham and Wells, Science 244: 1081-1085 (1989)). The latter procedure introduces single alanine mutations at every residue in the molecule. The resulting mutant molecules are then tested for biological activity, such as, but not limited to, at least one neutralizing activity. Sites that are critical for protein scaffold binding can also be identified by structural analysis, such as crystallization, nuclear magnetic resonance or photoaffinity labeling (Smith, et al., J. Mol. Biol. 224:899-904 (1992) and de Vos, et al., Science 255:306-312 (1992)).
[0842] Cell compositions or any portion thereof may be genetically modified using, for example, a nucleofection strategy such as electroporation. The total number of cells to be nucleofected, the total volume of the nucleofection reaction, and the precise timing of the preparation of the sample may be optimized to yield cells that have greater viability, nucleofect with higher efficiency, exhibit greater viability post-nucleofection, display a more desirable cell phenotype, and/or greater/faster expansion upon addition of expansion technologies.
[0843] Nucleofection and/or electroporation may be accomplished using, for example, Lonza Amaxa, MaxCyte PulseAgile, Harvard Apparatus BTX, and/or Invitrogen Neon. Non-metal electrode systems, including, but not limited to, plastic polymer electrodes, may be preferred for nucleofection.
[0844] Prior to genetic modification by nucleofection, Cell compositions or any portion thereof may be resuspended in a nucleofection buffer. Nucleofection buffers of the disclosure include
commercially-available nucleofection buffers. Nucleofection buffers of the disclosure may be optimized to yield cells that have greater viability, nucleofect with higher efficiency, exhibit greater viability post-nucleofection, display a more desirable cell phenotype, and/or
greater/faster expansion upon addition of expansion technologies. Nucleofection buffers of the disclosure may include, but are not limited to, PBS, HBSS, OptiMEM, BTXpress, Amaxa Nucleofector, HyClone Electroporation buffer and any combination thereof. Nucleofection buffers of the disclosure may comprise one or more supplemental factors to yield cells that have greater viability, nucleofect with higher efficiency, exhibit greater viability post-nucleofection, display a more desirable cell phenotype, and/or greater/faster expansion upon addition of expansion technologies. Exemplary supplemental factors include, but are not limited to, salts, minerals, metabolites or any combination thereof. Nucleofection buffers of the disclosure may include, an HD AC inhibitor composition or an HMT inhibitor composition of the disclosure.
[0845] Transposition reagents, including a transposon and a transposase, may be added to a nucleofection reaction of the disclosure prior to, simultaneously with, or after an addition of cells to a nucleofection buffer (optionally, contained within a nucleofection reaction vial or cuvette). Transposons of the disclosure may comprise plasmid DNA, linearized plasmid DNA, a PCR product, DOGGYBONE™ DNA, an mRNA template, a single or double-stranded DNA, a protein-nucleic acid combination or any combination thereof. Transposons of the disclosure may comprised one or more sequences that encode one or more TTAA site(s), one or more inverted terminal repeat(s) (ITRs), one or more long terminal repeat(s) (LTRs), one or more insulator(s), one or more promotor(s), one or more full-length or truncated gene(s), one or more polyA signal(s), one or more self-cleaving 2A peptide cleavage site(s), one or more internal ribosome entry site(s) (IRES), one or more enhancer(s), one or more regulator(s), one or more replication origin(s), and any combination thereof.
[0846] Transposons of the disclosure may comprise one or more sequences that encode one or more full-length or truncated gene(s). Full-length and/or truncated gene(s) introduced by transposons of the disclosure may encode one or more of a signal peptide, a therapeutic protein, a drug resistance gene, or any combination thereof.
[0847] Transposons of the disclosure may be prepared in water, TAE, TBE, PBS, HBSS, media, a supplemental factor of the disclosure or any combination thereof.
[0848] Transposons of the disclosure may be designed to optimize clinical safety and/or improve manufacturability. As a non-limiting example, transposons of the disclosure may be designed to optimize clinical safety and/or improve manufacturability by eliminating unnecessary sequences or regions. Transposons of the disclosure may or may not be GMP grade.
[0849] Transposase enzymes of the disclosure may be encoded by one or more sequences of plasmid DNA, mRNA, protein, protein-nucleic acid combination or any combination thereof.
[0850] Transposase enzymes of the disclosure may be prepared in water, TAE, TBE, PBS, HBSS, media, a supplemental factor of the disclosure or any combination thereof. Transposase enzymes of the disclosure or the sequences/constructs encoding or delivering them may or may not be GMP grade.
[0851] Transposons and transposase enzymes of the disclosure may be delivered to a cell by any means.
[0852] Although compositions and methods of the disclosure include delivery of a transposon and/or transposase of the disclosure to a cell by plasmid DNA (pDNA), the use of a plasmid for delivery may allow the transposon and/or transposase to be integrated into the chromosomal DNA of the cell, which may lead to continued transposase expression. Accordingly, transposon and/or transposase enzymes of the disclosure may be delivered to a cell as either mRNA or protein to remove any possibility for chromosomal integration.
[0853] Transposons and transposases of the disclosure may be pre-incubated alone or in combination with one another prior to the introduction of the transposon and/or transposase into a nucleofection reaction. The absolute amounts of each of the transposon and the transposase, as well as the relative amounts, e.g., a ratio of transposon to transposase may be optimized.
[0854] Following preparation of nucleofection reaction, optionally, in a vial or cuvette, the reaction may be loaded into a nucleofector apparatus and activated for delivery of an electric pulse according to the manufacturer’s protocol. Electric pulse conditions used for delivery of a transposon and/or a transposase of the disclosure (or a sequence encoding a transposon and/or a transposase of the disclosure) to a cell may be optimized for yielding cells with enhanced viability, higher nucleofection efficiency, greater viability post-nucleofection, desirable cell phenotype, and/or greater/faster expansion upon addition of expansion technologies. When using
Amaxa nucleofector technology, each of the various nucleofection programs for the Amaxa 2B or 4D nucleofector are contemplated.
[0855] Following a nucleofection reaction of the disclosure, cells may be gently added to a cell medium. Post-nucleofection cell media of the disclosure may comprise any one or more commercially-available media. Post-nucleofection cell media of the disclosure may be optimized to yield cells with greater viability, higher nucleofection efficiency, exhibit greater viability post- nucleofection, display a more desirable cell phenotype, and/or greater/faster expansion upon addition of expansion technologies. Post-nucleofection cell media of the disclosure may comprise an HD AC inhibitor composition or an HMT inhibitor composition of the disclosure.
[0856] Post-nucleofection cell media of the disclosure may be used at room temperature or pre warmed to, for example to between 32°C to 37°C, inclusive of the endpoints. Post-nucleofection cell media of the disclosure may be pre-warmed to any temperature that maintains or enhances cell viability and/or expression of a transposon or portion thereof of the disclosure.
[0857] Post-nucleofection cell media of the disclosure may be contained in tissue culture flasks or dishes, G-Rex flasks, Bioreactor or cell culture bags, or any other standard receptacle. Post- nucleofection cell cultures of the disclosure may be may be kept still, or, alternatively, they may be perturbed (e.g. rocked, swirled, or shaken).
[0858] Post-nucleofection cell cultures may comprise genetically-modified cells. Post- nucleofection cell cultures may comprise genetically-modified cells. Genetically modified cells of the disclosure may be either rested for a defined period of time or stimulated for expansion by, for example, the addition of an HD AC inhibitor composition or an HMT inhibitor composition. In certain embodiments, genetically modified cells of the disclosure may be either rested for a defined period of time or immediately stimulated for expansion by, for example, the addition of an HD AC inhibitor composition or an HMT inhibitor composition. Genetically modified cells of the disclosure may be rested to allow them sufficient time to acclimate, time for transposition to occur, and/or time for positive or negative selection, resulting in cells with enhanced viability, higher nucleofection efficiency, greater viability post-nucleofection, desirable cell phenotype, and/or greater/faster expansion upon addition of expansion technologies. Genetically modified cells of the disclosure may be rested, for example, for 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or more hours. In certain embodiments, genetically
modified cells of the disclosure may be rested, for example, for an overnight. In certain aspects, an overnight is about 12 hours. Genetically modified cells of the disclosure may be rested, for example, for 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 or more days.
[0859] Genetically modified cells of the disclosure may be selected following a nucleofection reaction and prior to addition of an expander technology.
[0860] Genetically modified cells of the disclosure may be simultaneously selected and expanded following a nucleofection reaction.
[0861] As early as 24-hours post-nucleofection, expression of a selection marker of the disclosure may be detectable in modified cells upon successful nucleofection of a transposon of the disclosure. Due to epi-chromosomal expression of the transposon, expression of a selection marker alone may not distinguish modified cells (those cells in which the transposon has been successfully integrated) from unmodified cells (those cells in which the transposon was not successfully integrated). When epi-chromosomal expression of the transposon obscures the detection of modified cells by the selection marker, the nucleofected cells (both modified and unmodified cells) may be rested for a period of time (e.g. 2-14 days) to allow the cells to cease expression or lose all epi-chromosomal transposon expression. Following this extended resting period, only modified cells should remain positive for expression of selection marker. The length of this extended resting period may be optimized for each nucleofection reaction and selection process. When epi-chromosomal expression of the transposon obscures the detection of modified cells by the selection marker, selection may be performed without this extended resting period, however, an additional selection step may be included at a later time point (e.g. either during or after the expansion stage).
[0862] The disclosure provides modified cells for administration to a subject in need thereof. Modified cells of the disclosure may be formulated for storage at any temperature including room temperature and body temperature. Modified cells of the disclosure may be formulated for cryopreservation and subsequent thawing. Modified cells of the disclosure may be formulated in a pharmaceutically acceptable carrier for direct administration to a subject from sterile packaging. Modified cells of the disclosure may be formulated in a pharmaceutically acceptable carrier with an indicator of cell viability. Modified cells of the disclosure may be formulated in a
pharmaceutically acceptable carrier at a prescribed density with one or more reagents to inhibit further expansion and/or prevent cell death.
[0863] In certain embodiments of the disclosure, modified cells of the disclosure are delivered to a patient via injection or intravenous infusion.
[0864] In certain embodiments, a therapeutically effective dose of a composition of the disclosure or of compositions comprising modified cells of the disclosure comprises between lxl 03 and lxl 010 cells per kg of body weight of the subject per administration, or any range, value or fraction thereof.
[0865] In certain embodiments of the disclosure, modified cells of the disclosure are delivered to a patient via injection or intravenous infusion. In certain embodiments, a therapeutically effective dose of a composition of the disclosure or of compositions comprising modified cells of the disclosure comprises a single or multiple doses. In certain embodiments, a therapeutically effective dose of a composition of the disclosure or of compositions comprising modified cells of the disclosure comprises a single dose.
[0866] While particular embodiments of the disclosure have been illustrated and described, various other changes and modifications can be made without departing from the spirit and scope of the disclosure. The scope of the appended claims includes all such changes and modifications that are within the scope of this disclosure.
EXAMPLES
[0867] Constructs
[0868] Fig. 1A is a schematic diagram and Fig. 1B is a linear illustration of a piggyBac (PB) transposon vector construct (nanoV5 EFla GFP-T2A-DHFR vector) used for delivering the GFP reporter transgene as well as for enabling HSC selection. The elongation factor- 1 alpha (EFla) is used as a constitutive promoter to drive the bi-cistronic cassette consisting of the enhanced green fluorescence (GFP) reporter and the dihydrofolate reductase resistance (DHFR) genes. The SV40 polyA signal and the 250 bp cHS4 chromatin insulator are indicated. During transposition, the co-delivered PB transposase recognizes the transposon-specific inverted terminal repeat sequence (ITR) located on both ends of the transposon vector and efficiently moves the contents
from the original sites in the delivered DNA plasmid and efficiently integrates them into TTAA chromosomal sites.
[0869] Fig. 2A is a schematic diagram depicting a construct for erythroid-specific expression of the human therapeutic T87Q beta-globin and the constitutive expression of GFP and DHFR (PB-HBB-PGK-GFP-T2A-DHFR). Fig. 2B is a schematic diagram depicting a construct for erythroid-specific expression of the human therapeutic T87Q beta-globin and the constitutive expression of GFP and DHFR (PB -HBB -PGK-GFP- T2 A-DHFR) .
[0870] Example 1 : Effect of valproic acid on transposition
[0871] Fig. 3A, Fig. 3B and Fig. 3C is a series of graphs assessing the effect of VP A post treatment on transposition. Fig. 3 A depicts the relative increase in total GFP+ cells between a control cytokine treatment (lOOng/ml each of hrSCF, hrTPO and hrFLT3L) and 0.5mM VP A 24hr washout, as assessed by flow cytometry at Day 7. Three different donors were tested. Fig. 3B depicts a negative correlation between the frequency of GFP+ cells in a control nucleofection and the fold increase in GFP+ cells achieved by adding 0.5mM VPA for 24hrs post
nucleofection. These results show that VPA treatment can be used to‘rescue’ poor transposers but has minimal impact upon a donor that transposes highly (-20%). Fig. 3C provides a cumulative summary of the transposition efficiency achieved with the nanoV5 EFla GFP-T2A- DHFR vector +sPB RNA (as illustrated in Fig. 1 A and Fig. 1B). Different colors/symbols represent distinct donors. Transposition efficiency is assessed in liquid culture 7 days after nucleofection. The data points within the green box represent‘strong’ transposers that would be minimally impacted by a 0.5mM VPA 24hr post treatment, while the red box encompasses ‘poor’ transposers that could be rescued with the 0.5mM VPA 24hr post treatment.
[0872] Example 2: Epigenetic modifiers impact on transposition yield
[0873] Human CD34+ cells were provided frozen or provided fresh then frozen after CD34+ isolation. Cells were stimulated in SFEM II media (StemCell Technologies) containing the following cytokines at a concentration of lOOng/ml: hSCF, hTPO. hFLT3L (all purchased from StemCell Technologies) for 24hrs at a concentration of le6 cell/ml. After a 24 hour stimulation with cytokines, CD34+ cells were nucleofected with 5pg nanoPB.HBB.PGK.GFP-T2A-DHFR DNA and 5pg sPB RNA. One bulk nucleofection was performed per donor. Ten minutes post nucleofection, cells were spun down, resuspended and separated into four distinct treatment
groups: 1) cytokine treatment alone, 2) 0.5mM VP A, 3) 1 mM UNC0638, 4) 0.5mM VPA + 1 mM UNC0638. After 24 hours, all conditions were spun again and resuspended. Conditions 1 and 2 were resuspended in cytokine media alone. Conditions 3 and 4 were resuspended in 1 mM
UNC0638. Culture media did not change again through the end of the experiment. Conditions were counted every 2-3 days and supplemented with additional media to maintain a cell concentration of 5e5 cell/ml. 7 days post nucleofection, flow cytometry was performed to determine the frequency of GFP+ cells. Fig. 4 is schematic illustration of the experimental protocol described above.
[0874] Fig. 5 shows the frequency of GFP+ cells in each condition for each donor was assessed by flow cytometry at Day 7. In each donor, the cytokine alone condition has the lowest frequency of GFP+ cells and the 0.5mM VPA+ 1 mM UNC0638 condition has the highest frequency of GFP+ cells.
[0875] Fig. 6A is a graphical representation of the GFP+ flow cytometry plots from Fig. 5. Fig. 6B is a graph depicting the fold increase in GFP+ cells at Day 7 normalized to the cytokine control condition. Both donors showed the strongest increase in transposed cell yield with 0.5mM VPA 24 washout + I mM UNC0638 treatment. Other treatment conditions tested showed more modest increases in transposed cell yield over cytokine control.
[0876] Example 3: Transposition efficiency in CD34+ cells using transposition boosting agents and expansion boosting agents
[0877] Frozen human CD34+ cells were used. Cells were stimulated in SFEM II media (StemCell Technologies) containing the following cytokines at a concentration of lOOng/ml: hSCF, hTPO. hFLT3L (all purchased from StemCell Technologies) for 24hrs at a concentration of le6 cell/ml. After a 24-hour stimulation with cytokines, CD34+ cells were nucleofected with 5pg nanoPB.HBB.PGK.GFP-T2A-DHFR DNA and 5pg sPB RNA. One bulk nucleofection was performed. Ten minutes post nucleofection, cells were spun down, resuspended and separated into 2 treatment groups: 1) cytokine treatment alone, 2) 0.5mM VPA + 1 mM UNC0638. After 24 hours, all conditions were spun again and resuspended. Condition 1 was resuspended in cytokine media alone. Condition 2 was resuspended in 1 mM UNC0638. At Day 4, cells were transferred to a selection/expansion media containing SFEM II + cytokines + 1 mM SR1 + 35nM UM 171 +
1 mM E1NC0638 (SUU) + 250nM MTX and plated at a cell density of le6 cell/ml. Before
selection at Day 4, conditions were assayed for GFP+ content using flow cytometry. Conditions were fed with additional media every 1-2 days. At Day 11, conditions were assayed for GFP+ content using flow cytometry to determine the efficiency of MTX selection. Fig. 7 is schematic illustration of the experimental protocol described above.
[0878] The frequency of GFP+ cells in each condition for each donor was assessed by flow cytometry depicting MTX selection of HSC cells comprising PB-HBB. Fig. 8A is a plot depicting GFP+ frequency of each condition as assayed by flow cytometry at day 4 before the initiation of MTX selection and expansion. 0.5mM VPA + 1 mM UNC0638 condition has a slightly higher frequency of GFP+ cells. Fig. 8B is a plot depicting GFP+ frequency of each condition as assayed by flow cytometry at day 11 after 7 days of selection in 250 nM MTX and expansion with SR1+UM171+UNC0638 (SUU). 0.5mM VPA + 1 mM UNC0638 condition has selected to have a higher frequency of GFP+ cells than the control condition. Fig. 8C is a graph depicting absolute numbers of GFP+ cells for each condition at Day 4 before selection/expansion and Day 11 after selection/expansion. At Day 4, 0.5mM VPA+l pM UNC0638 yielded a 1.55- fold increase in GFP+ cells over a cytokine control. At Day 11, this treatment yielded a 1.84-fold increase in GFP+ cells over a cytokine control.
[0879] Additionally, CD34+ cells were delivered a PB-EFla-GFP-T2A-DHFR piggyBac transposon, and then cultured in either cytokine control conditions or 0.5mM VPA and I mM UNC0638 as described previously. At 4 days after delivery, cells were selected and expanded in culture with 250nM Methotrexate (MTX) and SR1/UM171/UNC0638. This data set
encompasses 3 separate experiments and 2 different donor samples. Fig. 9A and Fig. 9B show the impact of treatment with 0.5mM VPA for 24 hours post nucleofection and luM UNC0638 for 4 days post nucleofection upon the yield of modified CD34+ cells at the end of cell production. Fig. 9 A is a graph showing the relative number of bulk GFP+ cells in each condition at Day 11 post selection. Treatment of CD34+ cells with VPA and UNC0638 resulted in a significant increase in transposed GFP+ cells at Day 11. Fig. 9B is a graph comparing the relative number of GFP+ phenotypic HSCs (CD34+/CD38-/CD90+/CD45RA-/CD49f+/GFP+) in each condition at Day 11 post selection. Treatment of CD34+ cells with VPA and UNC0638 resulted in a significant increase in transposed GFP+ HSCs at Day 11.
Claims
What is claimed:
1 A method of increasing the frequency of transposition in a population of cells, comprising:
a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells; and
b) culturing the plurality of modified cells in a culture media comprising a histone deacetylase (HD AC) inhibitor, a histone methyltransferase (HMT) inhibitor or a combination thereof,
thereby increasing the frequency of transposition in a population of cells.
2. The method of claim 1 , wherein the culture media in step b) comprises a combination of the HD AC inhibitor and the HMT inhibitor.
3. The method of claim 2, comprising in step b) culturing the plurality of modified cells in a culture media comprising the combination of the HD AC inhibitor and the HMT inhibitor for at least 12 hours.
4. The method of claim 2, comprising in step b) culturing the plurality of modified cells in a culture media comprising the combination of the HD AC inhibitor and the HMT inhibitor for at least 24 hours.
5. The method of claim 2, comprising in step b) culturing the plurality of modified cells in a culture media comprising the combination of the HD AC inhibitor and the HMT inhibitor for about 3 hours to about 30 hours.
6. A method of increasing the frequency of transposition in a population of cells, comprising:
a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells;
b) culturing the plurality of modified cells in a culture media comprising a HD AC inhibitor and a HMT inhibitor;
c) removing the HD AC inhibitor from the culture media; and
d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor following step c;
thereby increasing the frequency of transposition in a population of cells.
7. The method of claim 6, comprising in step b) culturing the plurality of modified cells in a culture media comprising the combination of the HD AC inhibitor and the HMT inhibitor for at least 12 hours.
8. The method of claim 6, comprising in step b) culturing the plurality of modified cells in a culture media comprising the combination of the HD AC inhibitor and the HMT inhibitor for at least 24 hours.
9. The method of claim 6, comprising in step b) culturing the plurality of modified cells in a culture media comprising the combination of the HD AC inhibitor and the HMT inhibitor for at least about 3 hours to about 30 hours.
10. The method of claim 6, comprising in step d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for at least 48 hours following step c.
11. The method of claim 6, comprising in step d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for at least 3 days following step c.
12. The method of claim 6, comprising in step d) culturing the plurality of modified cells in a culture media comprising a HMT inhibitor for about 1 day to about 5 days.
13. The method of claim 6, wherein the HMT inhibitor in step b) and the HMT inhibitor in step d) are the same.
14. The method of claim 6, wherein the HMT inhibitor in step b) and the HMT inhibitor in step d) are different.
15. The method of claim 6, wherein the HD AC inhibitor comprises valproic acid.
16. The method of claim 15, wherein the culture media comprises about 0.25 mM to about 1.25 mM of valproic acid.
17. The method of claim 15, wherein the culture media comprises about 0.5 mM of valproic acid.
18. The method of claim 15, wherein the culture media comprises about 0.75 mM of valproic acid.
19. The method of claim 6, wherein the HD AC inhibitor comprises sodium phenylbutyrate.
20. The method of claim 19, wherein the culture media comprises about 0.5 mM to about 2 mM of sodium phenylbutyrate.
21. The method of claim 19, wherein the culture media comprises about 1.5 mM of sodium phenylbutyrate.
22. The method of claim 6, wherein the HMT inhibitor in step b) comprises UNC0638.
23. The method of claim 6, wherein the HMT inhibitor in step d) comprises UNC0638.
24. The method of claim 6, wherein the HMT inhibitor in step b) and step d) comprise
UNC0638.
25. The method of claims 22-24, wherein the culture media comprises about 0.5 mM to about 2 mM of UNC0638.
26. The method of claims 22-24, wherein the culture media comprises about 1 mM of UNC0638.
27. The method of claim 6, wherein the culture media in step b) comprising the combination of the HD AC inhibitor and the HMT inhibitor further comprises a second HD AC inhibitor, a second HMT inhibitor, StemRegenin 1 (SR1), UM171 or a combination thereof.
28. The method of claim 6, wherein said culturing results in an increase in frequency of transposition and at least a one-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a HD AC inhibitor and HMT inhibitor.
29. The method of claim 6, wherein said culturing results in an increase in frequency of transposition and at least a two-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a HD AC inhibitor and HMT inhibitor.
30. The method of claim 6, wherein said culturing results in an increase in frequency of transposition and about a one-fold to about a four-fold increase in the yield of transposed cells in the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a HD AC inhibitor and HMT inhibitor.
31. The method of claim 6, wherein step a) occurs prior to step b).
32. The method of claim 6, wherein step b) occurs prior to the step a).
33. The method of claim 6, wherein step a) and step b) occur concurrently.
34. A method of increasing the frequency of transposition in a population of cells, comprising:
a) introducing a transposon or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells;
b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for at least 24 hours;
c) removing the valproic acid from the culture media; and
d) culturing the plurality of modified cells in a culture media comprising UNC0638 for at least 3 days following step c,
thereby increasing the frequency of transposition in a population of cells.
35. The method of claim 34, further comprising e) removing the HMT inhibitor from the culture media following step d); and f) culturing the plurality of modified cells in a culture media comprising an expansion agent following step e, wherein the expansion agent comprises an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative.
36. The method of claim 34, further comprising e) removing the HMT inhibitor from the culture media following step d); and f) culturing the plurality of modified cells in a culture media comprising an expansion agent following step e, wherein the expansion agent comprises at least two of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative.
37. The method of claim 34, further comprising e) removing the HMT inhibitor from the culture media following step d); and f) culturing the plurality of modified cells in a culture media
comprising an expansion agent following step e), wherein the expansion agent comprises each of an HMT inhibitor, a aryl hydrocarbon receptor inhibitor or a pyrimido-indole derivative.
38. The method of claims 35-37, comprising in step f) culturing the plurality of modified cells in a culture media comprising the expansion agent following step e) for at least 5 days.
39. The method of claims 35-37, comprising in step f) culturing the plurality of modified cells in a culture media comprising the expansion agent following step e) for at least 7 days.
40. The method of claims 35-37, comprising in step f) culturing the plurality of modified cells in a culture media comprising the expansion agent following step e) for about 4 days to about 9 days.
41. The method of claims 35-37, wherein the HMT inhibitor in step f) comprises UNC0638.
42. The method of claim 41, wherein the culture media comprises about 0.5 mM to about 2 mM of UNC0638.
43. The method of claim 41, wherein the culture media comprises about 1 mM of UNC0638.
44. The method of claims 35-37, wherein the aryl hydrocarbon receptor inhibitor in step f) comprises StemRegenin 1 (SR1).
45. The method of claim 44, wherein the culture media comprises about 0.5 mM to about 2 pM of SRl.
46. The method of claim 44, wherein the culture media comprises about 1 mM of SR1.
47. The method of claims 35-37, wherein the pyrimido-indole derivative in step f) comprises UM171.
48. The method of claim 47, wherein the culture media comprises about 25 nM to about 50 nM of UM171.
49. The method of claim 47, wherein the culture media comprises about 35 nM of UM171.
51. The method of claims 35-37, wherein the expansion agent further comprises valproic acid.
52. The method of claim 51, wherein the culture media comprises about 0.25 mM to about 1.25 mM of valproic acid.
53. The method of claim 51, wherein the culture media comprises about 1 mM of valproic acid.
54. The method of claims 35-37, wherein the expansion agent further comprises
nicotinamide.
55. The method of claim 54, wherein the culture media comprises about 2.5 mM to about 10 mM of nicotinamide.
56. The method of claim 54, wherein the culture media comprises about 5 mM of nicotinamide.
57. The method of claims 35-37, wherein the expansion agent further comprises garcinol.
58. The method of claim 57, wherein the culture media comprises about 5 mM to about 15 mM of garcinol.
59. The method of claim 57, wherein the culture media comprises about 10 mM of garcinol.
60. The method of claims 35-37, wherein the expansion agent further comprises sodium phenylbutyrate.
61. The method of claim 60, wherein the culture media comprises about 1 mM to about 2 mM of sodium phenylbutyrate.
62. The method of claim 60, wherein the culture media comprises about 1.5 mM of sodium phenylbutyrate.
63. The method of claims 35-37, wherein the transposon comprises a selection gene and step f) further comprises a selection agent.
64. The method of claim 63, wherein the transposon comprises a dihydrofolate reductase (DHFR) resistance gene and step f) further comprises a selection agent, wherein the selection agent comprises methotrexate or pralatrexate.
65. The method of claim 64, wherein the culture media comprises about 100 nM to about 500 nM of methotrexate.
66. The method of claim 64, wherein the culture media comprises about 250 nM of methotrexate.
67. The method of claim 64, wherein the culture media comprises about 50 nM to about 250 nM of pralatrexate.
68. The method of claim 64, wherein the culture media comprises about 125 nM of pralatrexate.
69. The method of claim 64, wherein the selection agent comprises pralatrexate and dipyridimole.
70. The method of claim 69, wherein the culture media comprises about 50 nM to about 250 nM of pralatrexate and about 1 mM to about 10 mM of dipyridimole
71. The method of claim 69, wherein the culture media comprises about 125 nM of pralatrexate and about 5 mM of dipyridimole.
72. The method of claim 63, wherein culturing the plurality of modified cells with an expansion agent occurs prior to culturing the plurality of modified cells with a selection agent.
73. The method of claim 63, wherein culturing the plurality of modified cells with a selection agent occurs prior to culturing the plurality of modified cells with an expansion agent.
74. The method of claim 63, wherein culturing the plurality of modified cells with an expansion agent and culturing the plurality of modified cells with a selection agent occur concurrently.
75. The method of claim 63, wherein said culturing results in at least two-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
76. The method of claim 63, wherein said culturing results in at least five-fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
77. The method of claim 63, wherein said culturing results in about two-fold to about five fold expansion of the plurality of modified cells compared to a plurality of modified cells cultured under culture conditions not comprising a selection agent and expansion agent.
78. The method of claims 1, 6, or 34, wherein the transposon comprises a sequence encoding for a selection marker protein.
79. The method of claims 1, 6, or 34, wherein the transposon comprises a DHFR resistance gene.
80. The method of claims 1, 6, or 34, wherein the transposon comprises a sequence encoding a DHFR mutein enzyme.
81. The method of claims 1, 6, or 34, wherein the transposon comprises a sequence encoding for a therapeutic agent.
82. The method of claims 1, 6, or 34, wherein the transposon comprises a sequence encoding a chimeric antigen receptor (CAR).
83. The method of claim 82, wherein the transposon further comprises a sequence encoding a non-naturally occurring chimeric stimulatory receptor (CSR) comprising: (a) an ectodomain comprising a activation component, wherein the activation component is isolated or derived from a first protein; (b) a transmembrane domain; and (c) an endodomain comprising at least one signal transduction domain, wherein the at least one signal transduction domain is isolated or derived from a second protein; wherein the first protein and the second protein are not identical.
84. The method of claims 1, 6, or 34, wherein the transposon comprises a sequence encoding for an inducible proapoptotic polypeptide comprising (a) a ligand binding region, (b) a linker,
and (c) a caspase polypeptide, wherein the inducible proapoptotic polypeptide does not comprise a non-human sequence.
85. The method of claims 1, 6, or 34, wherein the transposon is integrated into the genome of the cell by the transposase.
86. The method of claims 1, 6, or 34, wherein the sequence encoding the transposase comprises an amino acid or a nucleic acid sequence encoding a transposase protein.
87. The method of claim 86, wherein the nucleic acid sequence encoding a transposase protein comprises an RNA sequence.
88. The method of claim 86, wherein the nucleic acid sequence encoding a transposase protein comprises a DNA sequence.
89. A method of expanding a population of modified cells, comprising:
a) introducing a transposon comprising a DHFR resistance gene or a sequence encoding the transposon and a transposase or a sequence encoding the transposase under culture conditions sufficient for cell proliferation and for transposition into a plurality of cells to produce a plurality of modified cells;
b) culturing the plurality of modified cells in a culture media comprising valproic acid and UNC0638 for at least 24 hours;
c) removing the valproic acid from the culture media;
d) culturing the plurality of modified cells in a culture media comprising UNC0638 for at least 3 days following step c;
e) removing the UNC0638 from the culture media; and
f) culturing the plurality of modified cells in a culture media comprising a selection agent and an expansion agent for at least 7 days following step e, wherein the selection agent comprises methotrexate or pralatrexate and wherein the expansion agent comprises SR1, UM171 and UNC0638,
thereby expanding a population of modified cells.
90. A plurality of modified cells produced by the method of claim claims 1, 6, 34 or 89.
91 A modified cell population wherein at least 98% of the plurality of modified cells in the population comprise a genome-integrated transposon.
92 The modified cell population of claim 93, wherein at least 99% of the plurality of modified cells in the population comprise a genome-integrated transposon.
93. A composition comprising the plurality of modified cells of claims 90, 91 or 92.
94. A pharmaceutical composition comprising the composition of claim 93 and a pharmaceutically-acceptable carrier.
95. The pharmaceutical composition of claim 94 for use in treating a disease or disorder.
96. The use of claim 95, wherein the pharmaceutical composition comprises a plurality of autologous cells.
97. The use of claim 95, wherein the pharmaceutical composition comprises a plurality of allogeneic cells.
Applications Claiming Priority (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862745100P | 2018-10-12 | 2018-10-12 | |
| US62/745,100 | 2018-10-12 | ||
| US201862783125P | 2018-12-20 | 2018-12-20 | |
| US62/783,125 | 2018-12-20 | ||
| US201962815333P | 2019-03-07 | 2019-03-07 | |
| US62/815,333 | 2019-03-07 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020077357A1 true WO2020077357A1 (en) | 2020-04-16 |
Family
ID=68470616
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2019/056272 WO2020077357A1 (en) | 2018-10-12 | 2019-10-15 | Compositions and methods for increasing transposition frequency |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2020077357A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021226141A1 (en) * | 2020-05-04 | 2021-11-11 | Saliogen Therapeutics, Inc. | Transposition-based therapies |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2011123572A1 (en) * | 2010-03-31 | 2011-10-06 | The Scripps Research Institute | Reprogramming cells |
| WO2015003643A1 (en) * | 2013-07-12 | 2015-01-15 | Hong Guan Ltd. | Compositions and methods for reprograming non- pluripotent cells into pluripotent stem cells |
| US10041077B2 (en) | 2014-04-09 | 2018-08-07 | Dna2.0, Inc. | DNA vectors, transposons and transposases for eukaryotic genome modification |
-
2019
- 2019-10-15 WO PCT/US2019/056272 patent/WO2020077357A1/en active Application Filing
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2011123572A1 (en) * | 2010-03-31 | 2011-10-06 | The Scripps Research Institute | Reprogramming cells |
| WO2015003643A1 (en) * | 2013-07-12 | 2015-01-15 | Hong Guan Ltd. | Compositions and methods for reprograming non- pluripotent cells into pluripotent stem cells |
| US10041077B2 (en) | 2014-04-09 | 2018-08-07 | Dna2.0, Inc. | DNA vectors, transposons and transposases for eukaryotic genome modification |
Non-Patent Citations (3)
| Title |
|---|
| "GenBank", Database accession no. XP_002123602 |
| MALI PRASHANT ET AL: "Butyrate greatly enhances derivation of human induced pluripotent stem cells by promoting epigenetic remodeling and the expression of pluripotency-associated genes", STEM CELLS (MIAMISBURG),, vol. 28, no. 4, 1 April 2010 (2010-04-01), pages 713 - 720, XP002621303, ISSN: 1066-5099, [retrieved on 20100303], DOI: 10.1002/STEM.402 * |
| NINA D. TIMBERLAKE ET AL.: "Non-viral engineered human CAR T cells for stem cell transplant conditioning", 2 September 2018 (2018-09-02), XP055656101, Retrieved from the Internet <URL:https://poseida.com/wp-content/uploads/ASGCT2018-Poster-FINAL.pdf> [retrieved on 20200109] * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021226141A1 (en) * | 2020-05-04 | 2021-11-11 | Saliogen Therapeutics, Inc. | Transposition-based therapies |
| US11542528B2 (en) | 2020-05-04 | 2023-01-03 | Saliogen Therapeutics, Inc. | Transposition-based therapies |
| US11993784B2 (en) | 2020-05-04 | 2024-05-28 | Saliogen Therapeutics, Inc. | Transposition-based therapies |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7399866B2 (en) | CARTyrin composition and its use | |
| CN113383018B (en) | Allogeneic cell compositions and methods of use | |
| AU2018393110B2 (en) | VCAR compositions and methods for use | |
| US20200299661A1 (en) | Cpf1-related methods and compositions for gene editing | |
| US20240117352A1 (en) | Expression of foxp3 in edited cd34+ cells | |
| US20190136230A1 (en) | Genetically engineered cells and methods of making the same | |
| CN111727256A (en) | Compositions and methods for Chimeric Ligand Receptor (CLR) -mediated conditional gene expression | |
| WO2020077360A1 (en) | Hematopoietic stem cell compositions, methods of making and method of use | |
| EP3701028B1 (en) | Systems and methods for treating hyper-igm syndrome | |
| WO2020077357A1 (en) | Compositions and methods for increasing transposition frequency | |
| WO2022256448A2 (en) | Compositions and methods for targeting, editing, or modifying genes | |
| WO2024178069A1 (en) | Compositions and methods for genome editing |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19798774 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19798774 Country of ref document: EP Kind code of ref document: A1 |