US20070134715A1 - Systematic evolution of ligands by exponential enrichment: blended selex - Google Patents
Systematic evolution of ligands by exponential enrichment: blended selex Download PDFInfo
- Publication number
- US20070134715A1 US20070134715A1 US11/668,337 US66833707A US2007134715A1 US 20070134715 A1 US20070134715 A1 US 20070134715A1 US 66833707 A US66833707 A US 66833707A US 2007134715 A1 US2007134715 A1 US 2007134715A1
- Authority
- US
- United States
- Prior art keywords
- nucleic acid
- blended
- selex
- ligands
- ligand
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Abandoned
Links
- 239000003446 ligand Substances 0.000 title claims abstract description 168
- 230000009897 systematic effect Effects 0.000 title description 10
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 185
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 161
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 161
- 238000000034 method Methods 0.000 claims abstract description 69
- 239000000203 mixture Substances 0.000 claims description 60
- 108091034117 Oligonucleotide Proteins 0.000 claims description 30
- 238000000638 solvent extraction Methods 0.000 claims description 19
- 150000001875 compounds Chemical class 0.000 claims description 15
- 239000003153 chemical reaction reagent Substances 0.000 claims description 6
- 239000002253 acid Substances 0.000 claims 1
- 102000016387 Pancreatic elastase Human genes 0.000 abstract description 37
- 108010067372 Pancreatic elastase Proteins 0.000 abstract description 37
- 108020004414 DNA Proteins 0.000 abstract description 23
- 102000006495 integrins Human genes 0.000 abstract description 16
- 108010044426 integrins Proteins 0.000 abstract description 16
- 108010000421 fibronectin attachment peptide Proteins 0.000 abstract description 8
- 102000053602 DNA Human genes 0.000 abstract description 6
- 108020004682 Single-Stranded DNA Proteins 0.000 abstract description 4
- 230000004071 biological effect Effects 0.000 abstract 2
- 229950010342 uridine triphosphate Drugs 0.000 description 59
- 108090000765 processed proteins & peptides Proteins 0.000 description 39
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 34
- 238000009739 binding Methods 0.000 description 28
- 230000027455 binding Effects 0.000 description 27
- IYMAXBFPHPZYIK-BQBZGAKWSA-N Arg-Gly-Asp Chemical group NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O IYMAXBFPHPZYIK-BQBZGAKWSA-N 0.000 description 17
- 239000003112 inhibitor Substances 0.000 description 17
- 230000005764 inhibitory process Effects 0.000 description 16
- 238000006243 chemical reaction Methods 0.000 description 15
- 125000003729 nucleotide group Chemical group 0.000 description 15
- 239000000758 substrate Substances 0.000 description 15
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 14
- 101000851058 Homo sapiens Neutrophil elastase Proteins 0.000 description 12
- 230000000694 effects Effects 0.000 description 12
- 102000052502 human ELANE Human genes 0.000 description 12
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 11
- PGAVKCOVUIYSFO-XVFCMESISA-N UTP Chemical compound O[C@@H]1[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O[C@H]1N1C(=O)NC(=O)C=C1 PGAVKCOVUIYSFO-XVFCMESISA-N 0.000 description 10
- 230000003321 amplification Effects 0.000 description 10
- 238000005859 coupling reaction Methods 0.000 description 10
- 238000003199 nucleic acid amplification method Methods 0.000 description 10
- 230000008569 process Effects 0.000 description 10
- 235000018102 proteins Nutrition 0.000 description 10
- 102000004169 proteins and genes Human genes 0.000 description 10
- 108090000623 proteins and genes Proteins 0.000 description 10
- PGAVKCOVUIYSFO-UHFFFAOYSA-N uridine-triphosphate Natural products OC1C(O)C(COP(O)(=O)OP(O)(=O)OP(O)(O)=O)OC1N1C(=O)NC(=O)C=C1 PGAVKCOVUIYSFO-UHFFFAOYSA-N 0.000 description 10
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 9
- 239000002773 nucleotide Substances 0.000 description 9
- 108091028043 Nucleic acid sequence Proteins 0.000 description 8
- 238000005349 anion exchange Methods 0.000 description 8
- 230000008878 coupling Effects 0.000 description 8
- 238000010168 coupling process Methods 0.000 description 8
- 238000004809 thin layer chromatography Methods 0.000 description 8
- 230000003993 interaction Effects 0.000 description 7
- -1 peptide motifs Chemical class 0.000 description 7
- 239000011780 sodium chloride Substances 0.000 description 7
- 238000013518 transcription Methods 0.000 description 7
- 102000004190 Enzymes Human genes 0.000 description 6
- 108090000790 Enzymes Proteins 0.000 description 6
- TWRXJAOTZQYOKJ-UHFFFAOYSA-L Magnesium chloride Chemical compound [Mg+2].[Cl-].[Cl-] TWRXJAOTZQYOKJ-UHFFFAOYSA-L 0.000 description 6
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Chemical group O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 description 6
- 108010072041 arginyl-glycyl-aspartic acid Proteins 0.000 description 6
- 229940088598 enzyme Drugs 0.000 description 6
- 230000006870 function Effects 0.000 description 6
- AFQIYTIJXGTIEY-UHFFFAOYSA-N hydrogen carbonate;triethylazanium Chemical compound OC(O)=O.CCN(CC)CC AFQIYTIJXGTIEY-UHFFFAOYSA-N 0.000 description 6
- 229950003188 isovaleryl diethylamide Drugs 0.000 description 6
- 230000035897 transcription Effects 0.000 description 6
- FPQQSJJWHUJYPU-UHFFFAOYSA-N 3-(dimethylamino)propyliminomethylidene-ethylazanium;chloride Chemical compound Cl.CCN=C=NCCCN(C)C FPQQSJJWHUJYPU-UHFFFAOYSA-N 0.000 description 5
- 108090000190 Thrombin Proteins 0.000 description 5
- 239000000872 buffer Substances 0.000 description 5
- BULLHNJGPPOUOX-UHFFFAOYSA-N chloroacetone Chemical compound CC(=O)CCl BULLHNJGPPOUOX-UHFFFAOYSA-N 0.000 description 5
- 238000010828 elution Methods 0.000 description 5
- 238000004949 mass spectrometry Methods 0.000 description 5
- 238000002360 preparation method Methods 0.000 description 5
- 241000894007 species Species 0.000 description 5
- 229960004072 thrombin Drugs 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 4
- 101000781681 Protobothrops flavoviridis Disintegrin triflavin Proteins 0.000 description 4
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 4
- 238000003556 assay Methods 0.000 description 4
- 239000003602 elastase inhibitor Substances 0.000 description 4
- 238000010348 incorporation Methods 0.000 description 4
- 230000002401 inhibitory effect Effects 0.000 description 4
- 230000004048 modification Effects 0.000 description 4
- 238000012986 modification Methods 0.000 description 4
- 238000005192 partition Methods 0.000 description 4
- 239000011541 reaction mixture Substances 0.000 description 4
- 238000001179 sorption measurement Methods 0.000 description 4
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- 108010067306 Fibronectins Proteins 0.000 description 3
- 102000016359 Fibronectins Human genes 0.000 description 3
- 101710163270 Nuclease Proteins 0.000 description 3
- 102000012479 Serine Proteases Human genes 0.000 description 3
- 108010022999 Serine Proteases Proteins 0.000 description 3
- 239000012505 Superdex™ Substances 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 230000003197 catalytic effect Effects 0.000 description 3
- 238000010265 fast atom bombardment Methods 0.000 description 3
- 125000000524 functional group Chemical group 0.000 description 3
- 238000001502 gel electrophoresis Methods 0.000 description 3
- 230000002779 inactivation Effects 0.000 description 3
- 238000002955 isolation Methods 0.000 description 3
- 229910001629 magnesium chloride Inorganic materials 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- 102000044158 nucleic acid binding protein Human genes 0.000 description 3
- 108700020942 nucleic acid binding protein Proteins 0.000 description 3
- 102000004196 processed proteins & peptides Human genes 0.000 description 3
- 238000000746 purification Methods 0.000 description 3
- 238000000926 separation method Methods 0.000 description 3
- 229910000162 sodium phosphate Inorganic materials 0.000 description 3
- 239000000243 solution Substances 0.000 description 3
- 238000001228 spectrum Methods 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 230000001225 therapeutic effect Effects 0.000 description 3
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 description 3
- 229940045145 uridine Drugs 0.000 description 3
- 229960005356 urokinase Drugs 0.000 description 3
- UMZVBZDHGKJFGQ-LLLAAFKUSA-N (2s)-1-[(2s,3r)-2-[[(2s)-2-[[2-[[(2s)-2-[(2-aminoacetyl)amino]-5-(diaminomethylideneamino)pentanoyl]amino]acetyl]amino]-3-carboxypropanoyl]amino]-3-hydroxybutanoyl]pyrrolidine-2-carboxylic acid Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@H](O)C)C(=O)N1CCC[C@H]1C(O)=O UMZVBZDHGKJFGQ-LLLAAFKUSA-N 0.000 description 2
- SUNMBRGCANLOEG-UHFFFAOYSA-N 1,3-dichloroacetone Chemical class ClCC(=O)CCl SUNMBRGCANLOEG-UHFFFAOYSA-N 0.000 description 2
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 2
- XSYKVGBBBLUSAQ-UHFFFAOYSA-N 2-[[1-[2-[2-[(4-methoxy-4-oxobutanoyl)amino]propanoylamino]propanoyl]pyrrolidine-2-carbonyl]amino]-3-methylbutanoic acid Chemical compound COC(=O)CCC(=O)NC(C)C(=O)NC(C)C(=O)N1CCCC1C(=O)NC(C(C)C)C(O)=O XSYKVGBBBLUSAQ-UHFFFAOYSA-N 0.000 description 2
- 206010001052 Acute respiratory distress syndrome Diseases 0.000 description 2
- 229920000936 Agarose Polymers 0.000 description 2
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 2
- HEDRZPFGACZZDS-UHFFFAOYSA-N Chloroform Chemical compound ClC(Cl)Cl HEDRZPFGACZZDS-UHFFFAOYSA-N 0.000 description 2
- 238000007445 Chromatographic isolation Methods 0.000 description 2
- 102100023795 Elafin Human genes 0.000 description 2
- 229940122858 Elastase inhibitor Drugs 0.000 description 2
- 239000007995 HEPES buffer Substances 0.000 description 2
- 101001048718 Homo sapiens Elafin Proteins 0.000 description 2
- 108010085895 Laminin Proteins 0.000 description 2
- 102000007547 Laminin Human genes 0.000 description 2
- 229910019142 PO4 Chemical group 0.000 description 2
- 102000035195 Peptidases Human genes 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 208000013616 Respiratory Distress Syndrome Diseases 0.000 description 2
- 102000003990 Urokinase-type plasminogen activator Human genes 0.000 description 2
- 108090000435 Urokinase-type plasminogen activator Proteins 0.000 description 2
- 108010031318 Vitronectin Proteins 0.000 description 2
- 102100035140 Vitronectin Human genes 0.000 description 2
- 238000002835 absorbance Methods 0.000 description 2
- 102000019997 adhesion receptor Human genes 0.000 description 2
- 108010013985 adhesion receptor Proteins 0.000 description 2
- 208000011341 adult acute respiratory distress syndrome Diseases 0.000 description 2
- 201000000028 adult respiratory distress syndrome Diseases 0.000 description 2
- 150000001450 anions Chemical class 0.000 description 2
- 239000012148 binding buffer Substances 0.000 description 2
- 102000023732 binding proteins Human genes 0.000 description 2
- 108091008324 binding proteins Proteins 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- RYYVLZVUVIJVGH-UHFFFAOYSA-N caffeine Chemical compound CN1C(=O)N(C)C(=O)C2=C1N=CN2C RYYVLZVUVIJVGH-UHFFFAOYSA-N 0.000 description 2
- 239000001110 calcium chloride Substances 0.000 description 2
- 229910001628 calcium chloride Inorganic materials 0.000 description 2
- 239000004202 carbamide Substances 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 230000021164 cell adhesion Effects 0.000 description 2
- 238000004440 column chromatography Methods 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 210000002808 connective tissue Anatomy 0.000 description 2
- 108091036078 conserved sequence Proteins 0.000 description 2
- 239000003599 detergent Substances 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 201000010099 disease Diseases 0.000 description 2
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 2
- 238000001962 electrophoresis Methods 0.000 description 2
- 230000002349 favourable effect Effects 0.000 description 2
- 239000008187 granular material Substances 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 239000013038 irreversible inhibitor Substances 0.000 description 2
- 150000002632 lipids Chemical class 0.000 description 2
- 230000001404 mediated effect Effects 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical group [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 2
- 239000010452 phosphate Chemical group 0.000 description 2
- 108091033319 polynucleotide Proteins 0.000 description 2
- 102000040430 polynucleotide Human genes 0.000 description 2
- 238000010839 reverse transcription Methods 0.000 description 2
- 238000001542 size-exclusion chromatography Methods 0.000 description 2
- 239000001488 sodium phosphate Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 238000010613 succinylation reaction Methods 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- ZFXYFBGIUFBOJW-UHFFFAOYSA-N theophylline Chemical compound O=C1N(C)C(=O)N(C)C2=C1NC=N2 ZFXYFBGIUFBOJW-UHFFFAOYSA-N 0.000 description 2
- 239000001226 triphosphate Substances 0.000 description 2
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 2
- UMZVBZDHGKJFGQ-UHFFFAOYSA-N 1-[2-[[2-[[2-[[2-[(2-aminoacetyl)amino]-5-(diaminomethylideneamino)pentanoyl]amino]acetyl]amino]-3-carboxypropanoyl]amino]-3-hydroxybutanoyl]pyrrolidine-2-carboxylic acid Chemical compound NC(N)=NCCCC(NC(=O)CN)C(=O)NCC(=O)NC(CC(O)=O)C(=O)NC(C(O)C)C(=O)N1CCCC1C(O)=O UMZVBZDHGKJFGQ-UHFFFAOYSA-N 0.000 description 1
- RNAMYOYQYRYFQY-UHFFFAOYSA-N 2-(4,4-difluoropiperidin-1-yl)-6-methoxy-n-(1-propan-2-ylpiperidin-4-yl)-7-(3-pyrrolidin-1-ylpropoxy)quinazolin-4-amine Chemical compound N1=C(N2CCC(F)(F)CC2)N=C2C=C(OCCCN3CCCC3)C(OC)=CC2=C1NC1CCN(C(C)C)CC1 RNAMYOYQYRYFQY-UHFFFAOYSA-N 0.000 description 1
- FALRKNHUBBKYCC-UHFFFAOYSA-N 2-(chloromethyl)pyridine-3-carbonitrile Chemical compound ClCC1=NC=CC=C1C#N FALRKNHUBBKYCC-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- VKIGAWAEXPTIOL-UHFFFAOYSA-N 2-hydroxyhexanenitrile Chemical compound CCCCC(O)C#N VKIGAWAEXPTIOL-UHFFFAOYSA-N 0.000 description 1
- 125000003974 3-carbamimidamidopropyl group Chemical group C(N)(=N)NCCC* 0.000 description 1
- 108010039209 Blood Coagulation Factors Proteins 0.000 description 1
- 102000015081 Blood Coagulation Factors Human genes 0.000 description 1
- 102000004506 Blood Proteins Human genes 0.000 description 1
- 108010017384 Blood Proteins Proteins 0.000 description 1
- 206010006458 Bronchitis chronic Diseases 0.000 description 1
- 108010035532 Collagen Proteins 0.000 description 1
- 102000008186 Collagen Human genes 0.000 description 1
- 102000001187 Collagen Type III Human genes 0.000 description 1
- 108010069502 Collagen Type III Proteins 0.000 description 1
- 102000004266 Collagen Type IV Human genes 0.000 description 1
- 108010042086 Collagen Type IV Proteins 0.000 description 1
- 108010069112 Complement System Proteins Proteins 0.000 description 1
- 102000000989 Complement System Proteins Human genes 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 201000003883 Cystic fibrosis Diseases 0.000 description 1
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical group OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 108010014258 Elastin Proteins 0.000 description 1
- 102000016942 Elastin Human genes 0.000 description 1
- 206010014561 Emphysema Diseases 0.000 description 1
- 108010073385 Fibrin Proteins 0.000 description 1
- 102000009123 Fibrin Human genes 0.000 description 1
- BWGVNKXGVNDBDI-UHFFFAOYSA-N Fibrin monomer Chemical compound CNC(=O)CNC(=O)CN BWGVNKXGVNDBDI-UHFFFAOYSA-N 0.000 description 1
- 108010049003 Fibrinogen Proteins 0.000 description 1
- 102000008946 Fibrinogen Human genes 0.000 description 1
- 108060003393 Granulin Proteins 0.000 description 1
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- LPHGQDQBBGAPDZ-UHFFFAOYSA-N Isocaffeine Natural products CN1C(=O)N(C)C(=O)C2=C1N(C)C=N2 LPHGQDQBBGAPDZ-UHFFFAOYSA-N 0.000 description 1
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- NQTADLQHYWFPDB-UHFFFAOYSA-N N-Hydroxysuccinimide Chemical compound ON1C(=O)CCC1=O NQTADLQHYWFPDB-UHFFFAOYSA-N 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 101710137500 T7 RNA polymerase Proteins 0.000 description 1
- 239000013504 Triton X-100 Substances 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- 108090000631 Trypsin Proteins 0.000 description 1
- 102000004142 Trypsin Human genes 0.000 description 1
- 239000008351 acetate buffer Substances 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 125000001931 aliphatic group Chemical group 0.000 description 1
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 235000001014 amino acid Nutrition 0.000 description 1
- 150000001413 amino acids Chemical class 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000002399 angioplasty Methods 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 125000000637 arginyl group Chemical group N[C@@H](CCCNC(N)=N)C(=O)* 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N aspartic acid group Chemical group N[C@@H](CC(=O)O)C(=O)O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- 125000004429 atom Chemical group 0.000 description 1
- HNYOPLTXPVRDBG-UHFFFAOYSA-N barbituric acid Chemical compound O=C1CC(=O)NC(=O)N1 HNYOPLTXPVRDBG-UHFFFAOYSA-N 0.000 description 1
- 230000002051 biphasic effect Effects 0.000 description 1
- 239000003114 blood coagulation factor Substances 0.000 description 1
- 229910021538 borax Inorganic materials 0.000 description 1
- 206010006451 bronchitis Diseases 0.000 description 1
- 206010006475 bronchopulmonary dysplasia Diseases 0.000 description 1
- 238000010804 cDNA synthesis Methods 0.000 description 1
- 229960001948 caffeine Drugs 0.000 description 1
- VJEONQKOZGKCAK-UHFFFAOYSA-N caffeine Natural products CN1C(=O)N(C)C(=O)C2=C1C=CN2C VJEONQKOZGKCAK-UHFFFAOYSA-N 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 238000006555 catalytic reaction Methods 0.000 description 1
- 210000004027 cell Anatomy 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 125000003636 chemical group Chemical group 0.000 description 1
- 239000013626 chemical specie Substances 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 125000004218 chloromethyl group Chemical group [H]C([H])(Cl)* 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 208000007451 chronic bronchitis Diseases 0.000 description 1
- 230000035602 clotting Effects 0.000 description 1
- 229920001436 collagen Polymers 0.000 description 1
- 230000006957 competitive inhibition Effects 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 238000009833 condensation Methods 0.000 description 1
- 230000005494 condensation Effects 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 230000000875 corresponding effect Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 230000030609 dephosphorylation Effects 0.000 description 1
- 238000006209 dephosphorylation reaction Methods 0.000 description 1
- 238000010511 deprotection reaction Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 238000007865 diluting Methods 0.000 description 1
- 238000010494 dissociation reaction Methods 0.000 description 1
- 230000005593 dissociations Effects 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 229920002549 elastin Polymers 0.000 description 1
- 239000002532 enzyme inhibitor Substances 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 229950003499 fibrin Drugs 0.000 description 1
- 229940012952 fibrinogen Drugs 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 210000003714 granulocyte Anatomy 0.000 description 1
- 229960002897 heparin Drugs 0.000 description 1
- 229920000669 heparin Polymers 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 230000000415 inactivating effect Effects 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000002757 inflammatory effect Effects 0.000 description 1
- 229940125798 integrin inhibitor Drugs 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 230000002427 irreversible effect Effects 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 125000003473 lipid group Chemical group 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- 208000010125 myocardial infarction Diseases 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 230000008506 pathogenesis Effects 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 238000005897 peptide coupling reaction Methods 0.000 description 1
- 230000035699 permeability Effects 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- 150000003904 phospholipids Chemical class 0.000 description 1
- 238000006303 photolysis reaction Methods 0.000 description 1
- 230000015843 photosynthesis, light reaction Effects 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 230000002028 premature Effects 0.000 description 1
- 125000000561 purinyl group Chemical group N1=C(N=C2N=CNC2=C1)* 0.000 description 1
- 150000003230 pyrimidines Chemical group 0.000 description 1
- 239000000376 reactant Substances 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 238000004007 reversed phase HPLC Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 206010039073 rheumatoid arthritis Diseases 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 238000007086 side reaction Methods 0.000 description 1
- AJPJDKMHJJGVTQ-UHFFFAOYSA-M sodium dihydrogen phosphate Chemical compound [Na+].OP(O)([O-])=O AJPJDKMHJJGVTQ-UHFFFAOYSA-M 0.000 description 1
- 159000000000 sodium salts Chemical class 0.000 description 1
- 235000010339 sodium tetraborate Nutrition 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 238000004611 spectroscopical analysis Methods 0.000 description 1
- 208000010110 spontaneous platelet aggregation Diseases 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 239000007858 starting material Substances 0.000 description 1
- 229940014800 succinic anhydride Drugs 0.000 description 1
- 230000035322 succinylation Effects 0.000 description 1
- 229960000278 theophylline Drugs 0.000 description 1
- 229940124597 therapeutic agent Drugs 0.000 description 1
- 125000003396 thiol group Chemical group [H]S* 0.000 description 1
- 230000036964 tight binding Effects 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 108700012359 toxins Proteins 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- UNXRWKVEANCORM-UHFFFAOYSA-N triphosphoric acid Chemical compound OP(O)(=O)OP(O)(=O)OP(O)(O)=O UNXRWKVEANCORM-UHFFFAOYSA-N 0.000 description 1
- BSVBQGMMJUBVOD-UHFFFAOYSA-N trisodium borate Chemical compound [Na+].[Na+].[Na+].[O-]B([O-])[O-] BSVBQGMMJUBVOD-UHFFFAOYSA-N 0.000 description 1
- 239000012588 trypsin Substances 0.000 description 1
- 238000007039 two-step reaction Methods 0.000 description 1
- 238000002211 ultraviolet spectrum Methods 0.000 description 1
- 208000019553 vascular disease Diseases 0.000 description 1
- 239000011800 void material Substances 0.000 description 1
Images


















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P19/00—Preparation of compounds containing saccharide radicals
- C12P19/26—Preparation of nitrogen-containing carbohydrates
- C12P19/28—N-glycosides
- C12P19/30—Nucleotides
- C12P19/34—Polynucleotides, e.g. nucleic acids, oligoribonucleotides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/62—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being a protein, peptide or polyamino acid
- A61K47/64—Drug-peptide, drug-protein or drug-polyamino acid conjugates, i.e. the modifying agent being a peptide, protein or polyamino acid which is covalently bonded or complexed to a therapeutically active agent
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K5/00—Peptides containing up to four amino acids in a fully defined sequence; Derivatives thereof
- C07K5/04—Peptides containing up to four amino acids in a fully defined sequence; Derivatives thereof containing only normal peptide links
- C07K5/10—Tetrapeptides
- C07K5/1002—Tetrapeptides with the first amino acid being neutral
- C07K5/1005—Tetrapeptides with the first amino acid being neutral and aliphatic
- C07K5/1008—Tetrapeptides with the first amino acid being neutral and aliphatic the side chain containing 0 or 1 carbon atoms, i.e. Gly, Ala
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1048—SELEX
Definitions
- Described herein is a method of combining nucleic acids with other functional units for generation of high affinity ligands.
- the method of this invention takes advantage of the method for identifying nucleic acid ligands referred to as SELEX.
- SELEX is an acronym for Systematic Evolution of Ligands by EXponential enrichment.
- the method presented herein is termed blended SELEX.
- Examples of functional units that may be coupled to nucleic acids include proteins, peptides, photoreactive groups, chemically-reactive groups, active site directed compounds, lipids, biotin, and fluorescent compounds.
- the blended nucleic acid ligands of the present invention consist of at least one nucleic acid ligand unit and at least one functional unit.
- the nucleic acid ligand unit(s) of the blended nucleic acid ligand serve in whole or in part as ligands to a given target.
- the functional unit(s) can be designed to serve in a large variety of functions.
- the functional unit may independently or in combination with the nucleic acid ligand have specific affinity for the target, and in some cases may be a ligand to a different site of interaction with the target than the nucleic acid ligand.
- SELEX The SELEX method (hereinafter termed SELEX), was first described in U.S. application Ser. No. 07/536,428, filed Jun. 11, 1990, entitled “Systematic Evolution of Ligands By Exponential Enrichment,” now abandoned.
- U.S. Pat. No. 5,270,163, entitled “Methods for Identifying Nucleic Acid Ligands” further disclose the basic SELEX process.
- Each of these applications are herein specifically incorporated by reference.
- the SELEX process provides a class of products which are referred to as nucleic acid ligands, such ligands having a unique sequence, and which have the property of binding specifically to a desired target compound or molecule.
- Each SELEX-identified nucleic acid ligand is a specific ligand of a given target compound or molecule.
- SELEX is based on the unique insight that nucleic acids have sufficient capacity for forming a variety of two- and three-dimensional structures and sufficient chemical versatility available within their monomers to act as ligands (form specific binding pairs) with virtually any chemical compound, whether monomeric or polymeric. Molecules of any size can serve as targets.
- the SELEX method involves selection from a mixture of candidates and step-wise iterations of binding, partitioning, and amplification, using the same general selection theme, to achieve virtually any desired criterion of binding affinity and selectivity.
- the method includes steps of contacting the mixture with the target under conditions favorable for binding, partitioning unbound nucleic acids from those nucleic acids which have bound to target molecules, dissociating the nucleic acid-target pairs, amplifying the nucleic acids dissociated from the nucleic acid-target pairs to yield a ligand-enriched mixture of nucleic acids, then reiterating the steps of binding, partitioning, dissociating and amplifying through as many cycles as desired.
- a variety of techniques can be used to partition members in the pool of nucleic acids that have a higher affinity to the target than the bulk of the nucleic acids in the mixture.
- SELEX is based on the inventors' insight that within a nucleic acid mixture containing a large number of possible sequences and structures there is a wide range of binding affinities for a given target.
- a nucleic acid mixture comprising, for example, a 20 nucleotide randomized segment, can have 4 20 candidate possibilities. Those which have the higher affinity constants for the target are most likely to bind to the target.
- a second nucleic acid mixture is generated, enriched for the higher binding affinity candidates. Additional rounds of selection progressively favor the best ligands until the resulting nucleic acid mixture is predominantly composed of only one or a few sequences. These can then be cloned, sequenced and individually tested for binding affinity as pure ligands.
- the method may be used to sample as many as about 10 18 different nucleic acid species.
- the nucleic acids of the test mixture preferably include a randomized sequence portion as well as conserved sequences necessary for efficient amplification.
- Nucleic acid sequence variants can be produced in a number of ways including synthesis of randomized nucleic acid sequences and size selection from randomly cleaved cellular nucleic acids.
- the variable sequence portion may contain fully or partially random sequence; it may also contain subportions of conserved sequence incorporated with randomized sequence. Sequence variation in test nucleic acids can be introduced or increased by mutagenesis before or during the selection/partition/amplification iterations.
- evolved SELEX ligands may be homologous to the natural ligand since the nucleic acid binding protein target has evolved naturally to present side-chain and/or main-chain atoms with the correct geometry to interact with nucleic acids.
- Non-nucleic acid binding proteins which have evolved to bind poly-anions such as sulfated glycans (e.g., heparin), or to bind phospholipids or phosphosugars, also have sites into which nucleic acids can fit and make contacts analogous with the natural ligands and/or substrates.
- the basic SELEX method may be modified to achieve specific objectives.
- the SELEX method encompasses the identification of high-affinity nucleic acid ligands containing modified nucleotides conferring improved characteristics on the ligand, such as improved in vivo stability or delivery. Examples of such modifications include chemical substitutions at the ribose and/or phosphate and/or base positions. Specific SELEX-identified nucleic acid ligands containing modified nucleotides are described in U.S. patent application Ser. No. 08/117,991, filed Sep. 8, 1993, entitled “High Affinity Nucleic Acid Ligands Containing Modified Nucleotides,” now abandoned (See U.S. Pat. No.
- Integrin gpIIbIIIa is a protein expressed on activated platelets which mediates platelet adhesion to fibrinogen and fibrin clots (Phillips et al. (1988) Blood 71:831; Frojmovic et al. (1991) Blood 78:369). When gpIIbIIIa binds a RGD-containing ligand, a signal is generated which triggers platelet granule release, shape change, aggregation and adhesion (Loftus et al.
- Inhibitors of gpIIbIIIa-mediated platelet clot formation may have therapeutic potential in a variety of vascular diseases including reducing the occurrence of heart attacks following angioplasty.
- HNE Human neutrophil elastase
- elastase Human neutrophil elastase
- elastase is a major protein stored in the azurophilic granules of human polymorphonuclear granulocytes (Dewald et al. (1975) J. Exp. Med. 141:709) and secreted upon inflammatory stimuli (Bonney et al. (1989) J. Cell. Biochem. 39:47).
- Elastase is a serine protease with a broad substrate specificity able to digest many of the macromolecules found in connective tissue such as elastin, type III and type IV collagen, and fibronectin.
- connective tissue components many plasma proteins such as immunoglobulins, clotting factors, and complement proteins can also be hydrolyzed by elastase.
- blended nucleic acid ligands comprised of functional unit(s) added to provide a nucleic acid ligand with additional functions.
- the functional unit provides additional affinity or a desired effect such as inhibition or induction between the blended nucleic acid ligand and the target molecule.
- This method for combining nucleic acids with other functional groups to use in molecular evolution is herein referred to as blended SELEX.
- the method of this invention provides novel means for generating nucleic acid ligands with specifically selected functionalities. For example, high affinity ligands are generated by the method of this invention which are highly specific inhibitors of a target enzyme.
- the present invention encompasses nucleic acid ligands coupled to a non-nucleic acid functional unit.
- a peptide-conjugated nucleotide was produced by coupling the peptide Gly-Arg-Gly-Asp-Thr-Pro (SEQ ID NO:1) to the derivatized base 5-(3-aminoallyl)-uridine triphosphate (RGD-UTP).
- RGD-UTP containing oligonucleotides were generated by the method of this invention and shown to bind the RGD-binding protein integrin gpIIbIIIa. It is expected that RGD-RNA is a highly specific inhibitor of gpIIbIIIa.
- blended nucleic acid ligands produced by the method of this invention, a blended nucleic acid ligand to elastase with the ability to specifically inhibit elastase activity was generated.
- An inhibitory peptide was coupled to a single-stranded DNA ligand to elastase and the blended nucleic acid ligand shown to specifically inhibit elastase activity.
- FIG. 1 illustrates the structure of 5-(3-aminoallyl)-uridine triphosphate (AA-UTP) and the synthetic scheme for production of Arg-Gly-Asp-UTP (RGD-UTP). Details of the reaction conditions are as described in Example 1.
- FIG. 2A shows the isolation of succinyl-UTP by Mono Q anion exchange column chromatography.
- FIG. 2B shows the fractions versus the optical density at 290 nm. As described in Example 1, succinyl-UTP eluted in fractions 43-49.
- FIG. 3A shows the isolation of RGD-UTP by Mono Q anion exchange column chromatography.
- FIG. 3B shows the fractions versus the optical density at 290 nm. As described in Example 1, RGD-UTP eluted in fractions 35-38.
- FIG. 4 shows the results of thin layer chromatography of aminoallyl-UTP, succinyl-UTP, and RGD-UTP.
- FIG. 5 shows the results of RGD-UTP RNA transcript purification by anion exchange chromatography. The elution of RGD-UTP RNA ( ⁇ ) and RNA ( ⁇ ) from a Mono Q anion exchange column is shown.
- FIG. 6 shows the separation of RGD-30n7 RNA and gpIIbIIIa by size exclusion chromatography on Superdex 200 (Pharmacia). The elution profiles of RGD-30n7 bound to gpIIbIIIa ( ⁇ ) and RGD-30n7 ( ⁇ ) are shown.
- FIG. 8 shows the inactivation of 1.95 mM N-methoxysuccinyl Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2) by 50 mM DTT.
- FIG. 9 shows the inhibition of the blended nucleic acid ligand in the presence of 20 mM DTT.
- FIG. 10 shows the inhibition of elastase by DNA-17 conjugated at the 5′ end with chloromethyl ketone ( ⁇ ), and DNA-17 conjugated at the 3′ end with chloromethyl ketone ( ⁇ ).
- FIG. 11 is a Lineweaver-Burk plot of the inhibition of elastase by N-methoxysuccinyl Ala-Ala-Pro-Val (SEQ ID NO:5) ( ⁇ ), peptide-conjugated oligonucleotide ( ⁇ ) and substrate alone ( ⁇ ).
- FIGS. 12A-12C show the inhibition of elastase by DNA ligands with and without the inhibitors conjugated at the 3′ end compared with the effect of conjugated and non-conjugated ligands on (A) HNE Activity, (B) Urokinase Activity and (C) Thrombin Activity.
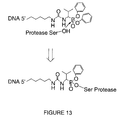
- FIG. 13 depicts the valyl phosphonate moiety attached to a nucleic acid segment as used in Example 4 below, and the reaction of the species with human neutrophil elastase.
- FIG. 14 depicts the first order rate constant of a pool of splint blended SELEX nucleic acid ligands after five rounds of SELEX measured by gel electrophoresis; TBE pH 8 ( ⁇ ) and MAE pH 6 ( ⁇ ).
- This application describes methods for generating blended nucleic acid ligand molecules. Examples of blended nucleic acid libraries and molecules generated by these methods are provided. The methods herein described are based on the SELEX method. SELEX is described in U.S. patent application Ser. No. 07/536,428, entitled “Systematic Evolution of Ligands by EXponential Enrichment,” now abandoned, U.S. Pat. No. 5,475,096, entitled “Nucleic Acid Ligands,” U.S. Pat. No. 5,270,163, entitled “Methods for Identifying Nucleic Acid Ligands,” (see also WO 91/19813). These applications, each specifically incorporated herein by reference, are collectively called the SELEX Patent Applications.
- a candidate mixture of nucleic acids of differing sequence is prepared.
- the candidate mixture generally includes regions of fixed sequences (i.e., each of the members of the candidate mixture contains the same sequences in the same location) and regions of randomized sequences.
- the fixed sequence regions are selected either: a) to assist in the amplification steps described below; b) to mimic a sequence known to bind to the target; or c) to enhance the concentration of a given structural arrangement of the nucleic acids in the candidate mixture.
- the randomized sequences can be totally randomized (i.e., the probability of finding a base at any position being one in four) or only partially randomized (e.g., the probability of finding a base at any location can be selected at any level between 0 and 100 percent).
- the candidate mixture is contacted with the selected target under conditions favorable for binding between the target and members of the candidate mixture. Under these circumstances, the interaction between the target and the nucleic acids of the candidate mixture can be considered as forming nucleic acid-target pairs between the target and those nucleic acids having the strongest affinity for the target.
- nucleic acids with the highest affinity for the target are partitioned from those nucleic acids with lesser affinity to the target. Because only an extremely small number of sequences (and possibly only one molecule of nucleic acid) corresponding to the highest affinity nucleic acids exist in the candidate mixture, it is generally desirable to set the partitioning criteria so that a significant amount of the nucleic acids in the candidate mixture (approximately 5-50%) are retained during partitioning.
- nucleic acids selected during partitioning as having the relatively higher affinity to the target are then amplified to create a new candidate mixture that is enriched in nucleic acids having a relatively higher affinity for the target.
- the newly formed candidate mixture contains fewer and fewer unique sequences, and the average degree of affinity of the nucleic acids to the target will generally increase.
- the SELEX process will yield a candidate mixture containing one or a small number of unique nucleic acids representing those nucleic acids from the original candidate mixture having the highest affinity to the target molecule.
- the SELEX Patent Applications describe and elaborate on this process in great detail. Included are targets that can be used in the process; methods for the preparation of the initial candidate mixture; methods for partitioning nucleic acids within a candidate mixture; and methods for amplifying partitioned nucleic acids to generate enriched candidate mixtures.
- the SELEX Patent Applications also describe ligand solutions obtained to a number of target species, including both protein targets wherein the protein is and is not a nucleic acid binding protein.
- the present invention includes a method for generating high affinity blended nucleic acid ligands to specific target molecules.
- the method generates blended nucleic acid molecules comprised of at least one functional unit.
- Functional units that can be coupled to nucleotides or oligonucleotides include peptides, amino acids, aliphatic groups and lipid chains, or larger compounds such as peptide motifs, recognizable by the target molecule. These non-nucleic acid components of oligonucleotides may fit into specific binding pockets to form a tight binding via appropriate hydrogen bonds, salt bridges, or van der Waals interactions.
- the blended nucleic acid ligands generated by the method of this invention may guide SELEX-generated ligands to specific sites of the target molecule.
- Further blended nucleic acid ligands may be prepared after the SELEX process for post-SELEX modification to add functionality to the ligand, for example, to increase RNA hydrophobicity and enhance binding, membrane partitioning and/or permeability, or to add reporter molecules, such as biotin- or fluorescence-tagged reporter oligonucleotides, for use as diagnostics.
- Blended nucleic acid ligands may be generated by the addition of chemical groups which covalently react and couple the SELEX ligand to the target molecule; in addition, catalytic groups can be added to nucleic acids to aid in the selection of SELEX ligands with protease or nuclease activity.
- the functional units may also serve as toxins or radiochemicals that are delivered to specific locations in the body determined by the specificity of the SELEX devised nucleic acid ligand.
- Blended nucleic acid ligands are defined herein as comprising at least one nucleic acid ligand and at least one functional unit.
- a nucleic acid ligand is defined as any nucleic acid identified generally according to the SELEX process as described in the SELEX Patent Applications.
- the functional unit may be any chemical species not naturally associated with nucleic acids, and may have any number of functions as enumerated herein.
- the blended nucleic acid ligand is prepared by performing the SELEX method utilizing an initial candidate mixture wherein each nucleic acid sequence of the candidate mixture contains at least one function unit, or a “blended candidate mixture”. This may be accomplished using a candidate mixture wherein each nucleic acid sequence of the candidate mixture has 1) a single functional unit attached at either the 5′ or 3′ end of nucleic acid sequence, 2) functional units at both the 5′ and 3′ ends of the nucleic acid sequence, 3) functional units added to individual nucleic acid residues, 4) functional units attached to all or a portion of all pyrimidine or purine residues, or functional units attached to all or a portion of all nucleotides of a given type.
- the functional units may also be attached only to the fixed or to the randomized regions of each nucleic acid sequence of the candidate mixture.
- one or more functional units may be attached to a nucleic acid ligand identified according to the SELEX method wherein a blended candidate mixture is not used. Again the points of attachment of the functional unit(s) to the nucleic acid ligand may vary depending on the ultimate requirements for the blended nucleic acid ligands.
- nucleotides and oligonucleotides containing a new functional unit are useful in generating blended nucleic acid ligands to specific sites of a target molecule.
- peptide molecules Two examples are described for coupling peptide molecules to SELEX nucleic acid ligands in order to target specific peptide binding pockets.
- a peptide containing the sequence arginine-glycine-aspartic acid (RGD) is coupled to a nucleotide and enzymatically incorporated into unselected polyribonucleotide.
- the RGD-containing peptide is recognized and bound by the gpIIbIIIa integrin protein, causing gpIIbIIIa-mediated platelet aggregation.
- a SELEX RGD-nucleic acid ligand may be generated with high specificity for gpIIbIIIa that would not crossreact with other integrins such as receptors for fibronectin, vitronectin, collagen, or laminin.
- SELEX blended nucleic acid ligands containing the RGD peptide could bind at or near the gpIIbIIIa ligand site and specifically inhibit gpIIbIIIa activity.
- Example 1 describes the generation of a peptide-conjugated RNA.
- the peptide Gly-Arg-Gly-Asp-Thr-Pro (SEQ ID NO:1) was coupled to the derivatized base, 5-(3-aminoallyl)-uridine triphosphate to produce the peptide-conjugated UTP (RGD-UTP), as shown in FIG. 1 .
- RGD-UTP may be used in SELEX T7-catalyzed template-dependent transcription to produce an RNA oligonucleotide containing the RGD peptide at every uridine position.
- the Gly-Arg-Gly-Asp-Thr-Pro (SEQ ID NO:1) peptide was chosen because the Arg-Gly-Asp (RGD) motif in matrix proteins is recognized and bound specifically by proteins of the integrin superfamily of cell adhesion receptors. Integrins bind to such proteins as fibronectin, laminin and vitronectin, at sites containing the RGD sequence. This binding is inhibited by short RGD-containing peptides which bind integrin proteins with a Kd of approximately 10 ⁇ 5 M.
- an RGD-containing peptide conjugated to an oligonucleotide may facilitate selection of high-affinity ligands to a RGD-binding target molecule.
- peptide-conjugated oligonucleotides must also be compatible with the SELEX method: the peptide-conjugated nucleotide must be incorporated with reasonable efficiency into transcribed RNA; partitioned RNA in turn must be reasonably efficiently transcribed into complementary DNA for amplification and additional rounds of SELEX.
- the Examples below demonstrate that all of the conditions required for successful SELEX identification of nucleic acid ligands containing new functional groups are met by the method of this invention.
- the peptide-UTP derivative was enzymatically incorporated into a blended RNA oligonucleotide as shown by increased size and altered charge compared with the native or unmodified oligonucleotide and by the UV shoulder at 310 nm.
- Example 2 describes the binding of RGD-RNA to RGD-binding integrin gpIIbIIIa. After separation, the bound RGD-RNA was reversed transcribed into DNA using normal SELEX protocols. The efficient transcription, partitioning, and reverse transcription shows that the site-directed blended nucleic acid ligands of this invention are compatible with the basic SELEX procedure.
- a second example of the method of the present invention describes a DNA SELEX ligand coupled to a peptide inhibitor known to bind elastase.
- Example 3 describes the generation of a highly specific elastase inhibitor by the method of the present invention.
- a SELEX-identified single stranded DNA ligand to elastase was produced and coupled to inhibitory substrate peptide chloromethyl ketone.
- a description of the isolation of DNA ligands to elastase and specific ligands to elastase are provided in U.S. Pat. No. 5,472,841, entitled, “Methods for Identifying Nucleic Acid Ligands of Human Neutrophil Elastase,” incorporated specifically herein by reference.
- the resulting blended nucleic acid ligand was shown to specifically inhibit elastase.
- the methods described herein do not include all of the schemes for introducing non-nucleic acid functional units, such as peptides, into an oligonucleotide. However, such methods would be well within the skill of those ordinarily practicing in the art.
- Putting a peptide on every uridine, as done in Example 1 has several advantages as compared with other labelling methods for use in the SELEX procedure.
- Second, distributing the peptide at multiple sites does not restrict the geometry of RNA and does not interfere with SELEX identification of the optimal peptide position.
- Non-nucleic acid functional units may be used to yield evolved ligands with a non-overlapping spectrum of binding sites. For instance, a peptide could be placed at the 5′ or 3′ end of SELEX identified RNA ligands.
- Another embodiment of this invention for introducing a non-nucleic acid functional unit at random positions and amounts is by use of a template-directed reaction with non-traditional base pairs. This method uses molecular evolution to select the best placement of the non-nucleic acid group on the SELEX identified ligand.
- a X-dY base pair could be used, where X is a derivatizable ribonucleotide and the deoxynucleotide dY would pair only with X.
- the X-RNA would contain the non-nucleic acid functional unit only at positions opposite dY in the dY-DNA template; the derivatized X base could be positioned in either the fixed or random regions or both, and the amount of X at each position could vary between 0-100%.
- the sequence space of non-evolved SELEX ligands would be increased from N 4 to N 5 by substituting this fifth base without requiring changes in the SELEX protocol.
- This embodiment may be used with photo-SELEX (U.S. Pat. No. 5,736,177, specifically incorporated herein by reference), where photo-active bases are placed at random sites, and these blended ligands partitioned after photolysis, then high affinity ligands are selected with the minimum number of substituted bases needed to crosslink with the target.
- functional units that react covalently at enzyme active sites such as chloromethylketones, may be incorporated to produce irreversible enzyme inhibitors.
- Use of directed incorporation could be used also for post-SELEX incorporation of fluorescence tags, biotin, radiolabel, lipid groups, or to cap the oligonucleotide with a uniquely modified base for protection against nuclease digestion.
- incorporación of non-nucleic acid functional units to produce blended SELEX ligands increases the repertoire of structures and interactions available to produce high affinity binding ligands.
- Various types of functional units can be incorporated to produce a spectrum of molecular structures. At one end of this structural spectrum are normal polynucleic acids where the ligand interactions involve only nucleic acid functional units. At the other, are fully substituted nucleic acid ligands where ligand interactions involve only non-nucleic acid functional units. Since the nucleic acid topology is determined by the sequence, and sequence partitioning and amplification are the basic SELEX steps, the best ligand topology is selected by nucleic acid evolution.
- Example 3 describes the preparation of a blended nucleic acid ligand to elastase to act as an elastase inhibitor.
- N-methoxysuccinyl-Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2) is an effective irreversible inhibitor for elastase.
- SEQ ID NO:2 N-methoxysuccinyl-Ala-Ala-Pro-Val-chloromethyl ketone
- the nonspecific high reactive nature of chloromethyl ketone functionality in conjunction with mM range Kd of the tetrapeptide makes the inhibitor molecule unsuitable as a therapeutic agent.
- the enzyme inhibition of nucleic acid ligands to elastase may be improved by coupling such ligands to the substrate tetrapeptide in a nonhydrolyzable manner such that the blended nucleic acid will inhibit the enzyme by occupying the substrate binding pocket.
- a blended nucleic acid affinity and specificity is provided by the SELEX-derived nucleic acid ligand, whereas inhibition is provided by the peptide.
- the functional unit of the blended nucleic acid ligand is attached to the SELEX derived nucleic acid ligand via the attachment of the functional unit to a nucleic acid that hybridizes to a region of the nucleic acid sequence of the ligand.
- the functional unit oligonucleotide is DNA, and hybridizes to the fixed region of the nucleic acid ligand or at least a region of the nucleic acid ligand that is not involved in the binding reaction to the target.
- the SELEX process is accomplished by the preparation of a candidate mixture of nucleic acid sequences comprised of fixed and randomized regions.
- the candidate mixture also contains an oligonucleotide attached to a selected functional group.
- the oligonucleotide is complementary to the fixed region of the nucleic acid candidate mixture, and is able to hybridize under the conditions employed in SELEX for the partitioning of high affinity ligands from the bulk of the candidate mixture. Following partitioning, the conditions can be adjusted so that the oligo-functional unit dissociates from the nucleic acid sequences.
- Advantages to this embodiment include the following: 1) it places a single functional unit, such as a peptide analog, at a site where it is available for interaction with the random region of nucleic acid sequences of the candidate mixture; 2) because the functional unit is coupled to a separate molecule, the coupling reaction must only be performed once, whereas when the functional unit is coupled directly to the SELEX ligand, the coupling reaction must be performed at every SELEX cycle.
- a single functional unit such as a peptide analog
- 5-(3-aminoallyl)UTP (5 mg) was dissolved in 250 ⁇ l of 0.2 M sodium borate, pH 8.5. The solution was mixed with 750 ⁇ l succinic anhydride (97 mg/1.14 ml DMF) and reacted for 2 h at 4° C. An equal volume of 0.1 M triethylammonium bicarbonate, pH 7.6, was added, filtered and purified on Mono Q 5 ⁇ 5 anion exchange FPLC (Pharmacia). The sample was applied in 0.1 M triethylammonium bicarbonate, and eluted with a linear gradient to 1.0 M triethylammonium bicarbonate. The column was eluted at 1.0 ml/min over 20 min.
- the major peak was pooled, lyophilized, and taken up in dry DMF for the next reaction.
- the sample was analyzed by TLC by spotting on PEI-F chromatography plates (J.T. Baker) and developing with 0.2 M sodium phosphate, pH 3.5.
- succinyl-UTP Chromatographic isolation of succinyl-UTP.
- the succinylation reaction mixture was diluted 1:1 with 0.1 M triethylammonium-bicarbonate, pH 7.6 (Buffer A), filtered and applied to a 0.5 cm ⁇ 5 cm Mono Q anion exchange column which was equilibrated with the same buffer.
- the column was eluted with a gradient to 1.0 M triethylammonium-bicarbonate (Buffer B) at a flow rate of 0.5 ml/ml (1 min/fraction) ( FIG. 2 ).
- Succinyl-UTP was easily separated by ion exchange from the starting material.
- the activated nucleotide was added to 14 mg of lyophilized GRGDTP and the mixture reacted for 2 h at 4° C.
- the reaction mixture was diluted 1:1 with 0.1 M triethylammonium bicarbonate, purified on a Mono Q column as above, and analyzed by TLC and Fast Atom Bombardment (FAB) Mass Spectrometry (University of Colorado Structural Division).
- RGD-UTP Chromatographic isolation of RGD-UTP.
- RGD-UTP was purified by ion exchange chromatography. The peptide coupling reaction mixture was diluted with Buffer A, filtered and purified on the Mono Q column described above. RGD-UTP eluted from the Mono Q column similar to AA-UTP, but ahead of succinyl-UTP, suggesting the arginine side chain also interacts with the phosphate charge. The major peak eluted at approximately 70% of Buffer B, ahead of the peak of residual succinyl-UPT (which eluted at approximately 90% of Buffer B) ( FIG. 3 ). Only trace amounts of other peaks were detected, except for the EDC which eluted earlier. Fractions 35-38 were pooled and lyophilized. The sample was dissolved in dry DMF for thin layer chromatography (TLC) and FAB mass spectroscopy. The sample had a maximum adsorption at 290 nm.
- TLC thin layer chromat
- Mass spectrometry analysis RGD-UTP analyzed by FAB mass spectroscopy yielded a mass of 1223, remarkably close to the calculated formula weight (FW) of 1222.
- the precision of the mass spectrometry result shows that RGD was coupled in the predicted manner, and that no side reactions occurred introducing alternative or additional derivatives. Further, there were no smaller peaks present which would indicate degradation or dephosphorylation of the triphosphate.
- RNA transcription reaction mixture was phenol:chloroform extracted, ethanol precipitated and washed, and dissolved in 50 mM sodium phosphate, 0.2 M NaCl, 6 M urea, 50% formamide (Fisher, Ultrapore, low-UV absorbance), pH 6.0. Following sample application, the column was developed with a linear gradient to 1 M NaCl.
- RNA peak was precipitated by addition of 2:1 v/v ethanol, the pellet was washed with 80% ethanol and dried in a speed-vac, then dissolved in SELEX binding buffer (150 mM NaCl, 10 nM HEPES, 2 mM CaCl 2 , 1 mM MgCl 2 , 0.1% Tween, pH 7.4).
- SELEX binding buffer 150 mM NaCl, 10 nM HEPES, 2 mM CaCl 2 , 1 mM MgCl 2 , 0.1% Tween, pH 7.4
- RNA and RNA-gpIIbIIIa (Enzyme Research) complexes were prepared by incubation at 37° C. for 10 min, and separated by size exclusion chromatography on a 16 ⁇ 100 Superdex 200 column (Pharmacia) which was equilibrated and run in the binding buffer. Concentration and removal of detergent from the samples collected from the Superdex column was achieved by adsorption onto a Resource Q
- RGD-UPT transcription and purification RGD-UTP was used in a T7 RNA polymerase reaction by direct substitution for normal UTP, and gave yields that were at least 50% of those obtainable with UTP.
- the concentration of RGD-UTP and other NTPs was 1 mM; the DNA template contained 5′ and 3′ fixed regions flanking a 30 base pair random sequence.
- the RNA transcript was purified by adsorption onto an anion exchange column (Mono Q) in a phosphate buffer containing 6 M urea and 50% formamide, and eluted with a gradient to 1 M NaCl ( FIG. 5 ).
- RGD-RNA eluted as one major peak from the column at a position in the gradient slightly ahead of the elution position of an equivalent RNA transcript made with normal UTP, consistent with the altered charge and perhaps altered conformation of the derivatized RNA.
- the amount of truncated RNA material was only slightly increased compared to normal RNA transcription.
- Binding of RGD-30n7 RNA to gpIIbIIIa is a method for identifying high affinity RNA ligands to gpIIbIIIa (Kd ⁇ 10 ⁇ 8 ).
- RGD-RNA was incubated with gpIIbIIIa (2 mg/ml) in 0.15 M NaCl, 2 mM CaCl 2 , 1 mM MgCl 2 , 20 mM HEPES, 0.1% Tween 20, pH 7.4.
- ssDNA ligand 17 (DNA-17) (from U.S. Pat. No.
- 5,472,841 entitled, “Methods for Identifying Nucleic Acid Ligands of Human Neutrophil Elastase,” having the sequence TAGCGATACTGCGTGGGTTGGGGCGGGTAGGGCCAGCAGTCTCGTGCGGTACTTGA GCA (SEQ ID NO:3)) has a Kd for elastase of 15 nM. Because it was not known which end of DNA-17 is in close proximity to the active site of elastase, blended nucleic acid molecules were prepared in which the substrate peptide was attached to both the 3′ and 5′ ends of the DNA.
- FIG. 7 An oligonucleotide with four 18-atom ethylene glycol moieties (synthesized by using spacer phosphoramidite, Clonetech) and a thiol group at the 3′ end was synthesized by automated DNA synthesis, deprotected by standard methods, and gel purified.
- the oligonucleotide was passed through a Sephadex-G50 spin column equilibrated in 0.5 M triethylammonium acetate buffer (pH 7.5) to remove excess DTT, and then mixed with N-methoxysuccinyl Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2) (25 mg/200 V ⁇ l of DMF). The mixture was incubated at 37° C. overnight.
- Elastase inhibition assay The assay for elastase inhibition is based on the use of a chromogenic tetrapeptide substrate.
- the assay was conducted in a buffer containing 10 nM elastase, 0.5 mM N-methoxysuccinyl-Ala-Ala-Pro-Val-p-nitroanilide (SEQ ID NO:4), 150 mM NaCl, 26 mM KCl, 2 mM MgCl 2 , 0.02% HSA, 0.05% DMSO, 0.01% Triton X-100, and 100 mM Tris-HCl, at 25° C.
- the assay measured the generation of elastase-induced release of p-nitroanilide as a function of time by spectroscopy (OD 405 nm). The rate of p-nitroanilide generation in the absence of inhibitor was used as the control. Positive control was established in the presence of the irreversible inhibitor N-methoxysuccinyl-Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2).
- FIG. 8 shows the inactivation of N-methoxysuccinyl Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2) by DTT.
- Incubation of 1.95 M N-methoxysuccinyl Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2) with 50 mM DTT destroyed the inhibition.
- the partial inhibition seen with the inactivated inhibitor may be due to competitive inhibition due to the high peptide concentration.
- FIG. 9 shows the inhibition of the blended nucleic acid ligand in the presence of 20 mM DTT.
- the inhibition of elastase by the 5′ end blended nucleic acid ligand and the 3′ end blended nucleic acid ligand is shown in FIG. 10 .
- a Lineweaver-Burk plot of elastase inhibition by N-methoxysuccinyl Ala-Ala-Pro-Val (SEQ ID NO:5) or the blended nucleic acid ligand is shown in FIG. 11 .
- the resulting Km of 0.16 mM for the substrate is in good agreement with published values.
- the Ki of the blended nucleic acid ligands was 30 nM versus 920 ⁇ M for the inhibitor peptide alone, or a 30,000 fold improvement.
- the splint blended SELEX process was performed by preparing a standard SELEX candidate mixture and a single compound containing a valyl phosphonate attached to a nucleic acid sequence that hybridizes to a portion of the fixed region of the candidate mixture of nucleic acid sequences as shown in FIG. 13 .
- FIG. 13 also shows the chemical reaction that occurs between the valyl phosphonate and human neutrophil elastase (HNE).
- valyl phosphonate was activated via an NHS ester.
- This compound was coupled to the 5′ hexyl amine linker of a 19-mer DNA oligo complementary to the 5′-fixed region of 40N7.1.
- a candidate mixture composed of pyrimidine 2′NH 2 -substituted RNA was hybridized to the splint, and reacted with HNE at subsaturating protein concentrations. Covalent complexes were enriched by diluting the reaction 100-fold, then filtering through nitrocellulose.
- the reported rate constant for the valyl phosphonate alone is 10 3 -10 4 M ⁇ 1 min ⁇ 1 (Oleksyszyn et al. (1989) Biophys. Biochem. Res. Comm. 161: 143-149).
- the splint blended nucleic acid mixture increases the reaction rate of the species by at least 10 3 fold.
- the reaction of the selected pool is also highly specific. No reaction of the pool with thrombin, another serine protease, is detectable.
- the second-order rate constant for the thrombin reaction is estimated to be ⁇ 200 M ⁇ 1 min ⁇ 1 , 10 4 fold lower than the reaction rate with elastase.
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Biochemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Biotechnology (AREA)
- Medicinal Chemistry (AREA)
- Biophysics (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- Plant Pathology (AREA)
- Epidemiology (AREA)
- Crystallography & Structural Chemistry (AREA)
- Physics & Mathematics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Pharmacology & Pharmacy (AREA)
- Bioinformatics & Computational Biology (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
Description
- This application is a continuation of U.S. patent application Ser. No. 10/263,456, filed Oct. 2, 2002, entitled “Systematic Evolution of Ligands by Exponential Enrichment: Blended SELEX,” which is a continuation of U.S. patent application Ser. No. 09/606,477, now U.S. Pat. No. 6,465,189, filed Jun. 30, 2000, entitled “Systematic Evolution of Ligands by Exponential Enrichment: Blended SELEX,” which is a continuation of U.S. patent application Ser. No. 08/956,699, filed Oct. 23, 1997, now U.S. Pat. No. 6,083,696, entitled “Systematic Evolution of Ligands by Exponential Enrichment: Blended SELEX,” which is a continuation of U.S. patent application Ser. No. 08/234,997, filed Apr. 28, 1994, now U.S. Pat. No. 5,683,867, entitled “Systematic Evolution of Ligands by Exponential Enrichment: Blended SELEX,” which is a continuation-in-part of U.S. patent application Ser. No. 08/199,507, filed Feb. 22, 1994, entitled “Methods for Identifying Nucleic Acid Ligands of Human Neutrophil Elastase,” now U.S. Pat. No. 5,472,841, which is a continuation-in-part of U.S. patent application Ser. No. 08/123,935, filed Sep. 17, 1993, entitled “Photoselection of Nucleic Acid Ligands,” now abandoned, which is a continuation-in-part of U.S. patent application Ser. No. 08/117,991, filed Sep. 8, 1993, entitled “High Affinity Nucleic Acid Ligands Containing Modified Nucleotides,” now abandoned, which is a continuation-in-part of U.S. patent application Ser. No. 07/714,131, filed Jun. 10, 1991, entitled “Nucleic Acid Ligands,” now U.S. Pat. No. 5,475,096, which was filed as a continuation-in-part of U.S. patent application Ser. No. 07/536,428, filed Jun. 11, 1990, entitled “Systematic Evolution of Ligands by Exponential Enrichment,” now abandoned.
- Described herein is a method of combining nucleic acids with other functional units for generation of high affinity ligands. The method of this invention takes advantage of the method for identifying nucleic acid ligands referred to as SELEX. SELEX is an acronym for Systematic Evolution of Ligands by EXponential enrichment. The method presented herein is termed blended SELEX. Examples of functional units that may be coupled to nucleic acids include proteins, peptides, photoreactive groups, chemically-reactive groups, active site directed compounds, lipids, biotin, and fluorescent compounds. The blended nucleic acid ligands of the present invention consist of at least one nucleic acid ligand unit and at least one functional unit. The nucleic acid ligand unit(s) of the blended nucleic acid ligand serve in whole or in part as ligands to a given target. The functional unit(s) can be designed to serve in a large variety of functions. For example, the functional unit may independently or in combination with the nucleic acid ligand have specific affinity for the target, and in some cases may be a ligand to a different site of interaction with the target than the nucleic acid ligand. The functional unit(s) may be added which covalently react and couple the ligand to the target molecule, catalytic groups may be added to aid in the selection of protease or nuclease activity, and reporter molecules such as biotin- or fluorescence-tagged oligonucleotides may be added for use as diagnostic reagents.
- The SELEX method (hereinafter termed SELEX), was first described in U.S. application Ser. No. 07/536,428, filed Jun. 11, 1990, entitled “Systematic Evolution of Ligands By Exponential Enrichment,” now abandoned. U.S. Pat. No. 5,475,096, entitled “Nucleic Acid Ligands,” and U.S. Pat. No. 5,270,163, entitled “Methods for Identifying Nucleic Acid Ligands,” further disclose the basic SELEX process. Each of these applications are herein specifically incorporated by reference. The SELEX process provides a class of products which are referred to as nucleic acid ligands, such ligands having a unique sequence, and which have the property of binding specifically to a desired target compound or molecule. Each SELEX-identified nucleic acid ligand is a specific ligand of a given target compound or molecule. SELEX is based on the unique insight that nucleic acids have sufficient capacity for forming a variety of two- and three-dimensional structures and sufficient chemical versatility available within their monomers to act as ligands (form specific binding pairs) with virtually any chemical compound, whether monomeric or polymeric. Molecules of any size can serve as targets.
- The SELEX method involves selection from a mixture of candidates and step-wise iterations of binding, partitioning, and amplification, using the same general selection theme, to achieve virtually any desired criterion of binding affinity and selectivity. Starting from a mixture of nucleic acids, preferably comprising a segment of randomized sequence, the method includes steps of contacting the mixture with the target under conditions favorable for binding, partitioning unbound nucleic acids from those nucleic acids which have bound to target molecules, dissociating the nucleic acid-target pairs, amplifying the nucleic acids dissociated from the nucleic acid-target pairs to yield a ligand-enriched mixture of nucleic acids, then reiterating the steps of binding, partitioning, dissociating and amplifying through as many cycles as desired. A variety of techniques can be used to partition members in the pool of nucleic acids that have a higher affinity to the target than the bulk of the nucleic acids in the mixture.
- While not bound by theory, SELEX is based on the inventors' insight that within a nucleic acid mixture containing a large number of possible sequences and structures there is a wide range of binding affinities for a given target. A nucleic acid mixture comprising, for example, a 20 nucleotide randomized segment, can have 420 candidate possibilities. Those which have the higher affinity constants for the target are most likely to bind to the target. After partitioning, dissociation and amplification, a second nucleic acid mixture is generated, enriched for the higher binding affinity candidates. Additional rounds of selection progressively favor the best ligands until the resulting nucleic acid mixture is predominantly composed of only one or a few sequences. These can then be cloned, sequenced and individually tested for binding affinity as pure ligands.
- Cycles of selection, partition and amplification are repeated until a desired goal is achieved. In the most general case, selection/partition/amplification is continued until no significant improvement in binding strength is achieved on repetition of the cycle. The method may be used to sample as many as about 1018 different nucleic acid species. The nucleic acids of the test mixture preferably include a randomized sequence portion as well as conserved sequences necessary for efficient amplification. Nucleic acid sequence variants can be produced in a number of ways including synthesis of randomized nucleic acid sequences and size selection from randomly cleaved cellular nucleic acids. The variable sequence portion may contain fully or partially random sequence; it may also contain subportions of conserved sequence incorporated with randomized sequence. Sequence variation in test nucleic acids can be introduced or increased by mutagenesis before or during the selection/partition/amplification iterations.
- For target molecules which are nucleic acid binding proteins, evolved SELEX ligands may be homologous to the natural ligand since the nucleic acid binding protein target has evolved naturally to present side-chain and/or main-chain atoms with the correct geometry to interact with nucleic acids. Non-nucleic acid binding proteins which have evolved to bind poly-anions such as sulfated glycans (e.g., heparin), or to bind phospholipids or phosphosugars, also have sites into which nucleic acids can fit and make contacts analogous with the natural ligands and/or substrates.
- For certain target molecules where the natural ligand is not a poly-anion, it can be more difficult (but still likely with relatively more rounds of SELEX) to identify oligonucleotides that fit into the substrate or ligand site. For instance, the binding pocket of trypsin contains a carboxyl group which interacts during catalysis with a lysine or arginine residue on the substrate. An oligonucleotide may not fit into this specific catalytic site because it would not contain a positively charged counter ion. Basic SELEX evolution of oligonucleotide ligands to such a target molecule may result in ligands to a site(s) distant from the substrate site, since the probability of recovering ligands to the substrate site may be low.
- The basic SELEX method may be modified to achieve specific objectives. For example, U.S. Pat. No. 5,707,796, entitled “Method for Selecting Nucleic Acids on the Basis of Structure,” describes the use of SELEX in conjunction with gel electrophoresis to select nucleic acid molecules with specific structural characteristics, such as bent DNA. U.S. Pat. No. 5,763,177, entitled “Photoselection of Nucleic Acid Ligands,” describes a SELEX based method for selecting nucleic acid ligands containing photoreactive groups capable of binding and/or photocrosslinking to and/or photoinactivating a target molecule. U.S. Pat. No. 5,580,737, entitled “High-Affinity Nucleic Acid Ligands That Discriminate Between Theophylline and Caffeine,” describes a method for identifying highly specific nucleic acid ligands able to discriminate between closely related molecules, termed “counter-SELEX”. U.S. patent application Ser. No. 08/143,564, filed Oct. 25, 1993, entitled “Systematic Evolution of Ligands by EXponential Enrichment: Solution SELEX,” now abandoned (See U.S. Pat. No. 5,567,588), describes a SELEX-based method which achieves highly efficient partitioning between oligonucleotides having high and low affinity for a target molecule.
- The SELEX method encompasses the identification of high-affinity nucleic acid ligands containing modified nucleotides conferring improved characteristics on the ligand, such as improved in vivo stability or delivery. Examples of such modifications include chemical substitutions at the ribose and/or phosphate and/or base positions. Specific SELEX-identified nucleic acid ligands containing modified nucleotides are described in U.S. patent application Ser. No. 08/117,991, filed Sep. 8, 1993, entitled “High Affinity Nucleic Acid Ligands Containing Modified Nucleotides,” now abandoned (See U.S. Pat. No. 5,660,985), that describes oligonucleotides containing nucleotide derivatives chemically modified at the 5- and 2′-positions of pyrimidines, as well as specific RNA ligands to thrombin containing 2′-amino modifications. U.S. patent application Ser. No. 08/117,911, supra, describes highly specific nucleic acid ligands containing one or more nucleotides modified with 2′-amino (2′-NH2), 2′-fluoro (2′-F), and/or 2′-O-methyl (2′-OMe).
- Members of the integrin superfamily of cell adhesion receptors are known to recognize the peptide arginine-glycine-aspartic acid sequence (RGD). Integrin gpIIbIIIa is a protein expressed on activated platelets which mediates platelet adhesion to fibrinogen and fibrin clots (Phillips et al. (1988) Blood 71:831; Frojmovic et al. (1991) Blood 78:369). When gpIIbIIIa binds a RGD-containing ligand, a signal is generated which triggers platelet granule release, shape change, aggregation and adhesion (Loftus et al. (1990) Science 249:915; Ware et al. (1993) N. Eng. J. Med. 328:628). Inhibitors of gpIIbIIIa-mediated platelet clot formation may have therapeutic potential in a variety of vascular diseases including reducing the occurrence of heart attacks following angioplasty.
- Currently known integrin inhibitors are limited by a lack of specificity. The development of a high specificity integrin inhibitor which does not crossreact with other integrin proteins would have significant therapeutic potential.
- Human neutrophil elastase (HNE or elastase) is a major protein stored in the azurophilic granules of human polymorphonuclear granulocytes (Dewald et al. (1975) J. Exp. Med. 141:709) and secreted upon inflammatory stimuli (Bonney et al. (1989) J. Cell. Biochem. 39:47). Elastase is a serine protease with a broad substrate specificity able to digest many of the macromolecules found in connective tissue such as elastin, type III and type IV collagen, and fibronectin. In addition to connective tissue components, many plasma proteins such as immunoglobulins, clotting factors, and complement proteins can also be hydrolyzed by elastase.
- An excess of elastase activity has been implicated in various disease states, such as pulmonary emphysema (Kaplan et al. (1973) J. Lab. Clin. Med. 82:349; Sanders and Moore (1983) Am. Rev. Respir. Dis. 127:554), cystic fibrosis, rheumatoid arthritis (Barrett (1978) Agents and Actions 8:11), chronic bronchitis, bronchopulmonary dysplasia in premature infants, and adult respiratory distress syndrome (ARDS) (Weiland et al. (1986) Am. Rev. Respir. Dis. 133:218). In most cases, the pathogenesis of these diseases has been correlated with the inactivation or the insufficiency of natural inhibitors of elastase, which have the primary role of keeping excess elastase activity under control.
- The development of an elastase-specific inhibitor has been a major therapeutic goal of the pharmaceutical industry for some time. While different types of elastase inhibitors have been developed, most of them appear to be nonspecific inhibitors of other serine proteases as well (Hemmi et al. (1985) Biochem. 24:1841). A method for developing an elastase-specific inhibitor and such an inhibitor would be highly desirable.
- Herein described is a method for generating blended nucleic acid ligands comprised of functional unit(s) added to provide a nucleic acid ligand with additional functions. In the preferred embodiment, the functional unit provides additional affinity or a desired effect such as inhibition or induction between the blended nucleic acid ligand and the target molecule. This method for combining nucleic acids with other functional groups to use in molecular evolution is herein referred to as blended SELEX.
- The method of this invention provides novel means for generating nucleic acid ligands with specifically selected functionalities. For example, high affinity ligands are generated by the method of this invention which are highly specific inhibitors of a target enzyme.
- The present invention encompasses nucleic acid ligands coupled to a non-nucleic acid functional unit. In one example of the blended nucleic acid ligand generated by the method of this invention, a peptide-conjugated nucleotide was produced by coupling the peptide Gly-Arg-Gly-Asp-Thr-Pro (SEQ ID NO:1) to the derivatized base 5-(3-aminoallyl)-uridine triphosphate (RGD-UTP). RGD-UTP containing oligonucleotides (RGD-RNA) were generated by the method of this invention and shown to bind the RGD-binding protein integrin gpIIbIIIa. It is expected that RGD-RNA is a highly specific inhibitor of gpIIbIIIa.
- In another example of the blended nucleic acid ligands produced by the method of this invention, a blended nucleic acid ligand to elastase with the ability to specifically inhibit elastase activity was generated. An inhibitory peptide was coupled to a single-stranded DNA ligand to elastase and the blended nucleic acid ligand shown to specifically inhibit elastase activity.
-
FIG. 1 illustrates the structure of 5-(3-aminoallyl)-uridine triphosphate (AA-UTP) and the synthetic scheme for production of Arg-Gly-Asp-UTP (RGD-UTP). Details of the reaction conditions are as described in Example 1. -
FIG. 2A shows the isolation of succinyl-UTP by Mono Q anion exchange column chromatography.FIG. 2B shows the fractions versus the optical density at 290 nm. As described in Example 1, succinyl-UTP eluted in fractions 43-49. -
FIG. 3A shows the isolation of RGD-UTP by Mono Q anion exchange column chromatography.FIG. 3B shows the fractions versus the optical density at 290 nm. As described in Example 1, RGD-UTP eluted in fractions 35-38. -
FIG. 4 shows the results of thin layer chromatography of aminoallyl-UTP, succinyl-UTP, and RGD-UTP. -
FIG. 5 shows the results of RGD-UTP RNA transcript purification by anion exchange chromatography. The elution of RGD-UTP RNA (□) and RNA (●) from a Mono Q anion exchange column is shown. -
FIG. 6 shows the separation of RGD-30n7 RNA and gpIIbIIIa by size exclusion chromatography on Superdex 200 (Pharmacia). The elution profiles of RGD-30n7 bound to gpIIbIIIa (□) and RGD-30n7 (●) are shown. -
FIG. 7 shows the chemistry of the attachment of the inhibitory substrate peptide N-methoxysuccinyl Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2) to a high affinity single-stranded DNA (DNA-17). -
FIG. 8 shows the inactivation of 1.95 mM N-methoxysuccinyl Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2) by 50 mM DTT. -
FIG. 9 shows the inhibition of the blended nucleic acid ligand in the presence of 20 mM DTT. -
FIG. 10 shows the inhibition of elastase by DNA-17 conjugated at the 5′ end with chloromethyl ketone (◯), and DNA-17 conjugated at the 3′ end with chloromethyl ketone (●). -
FIG. 11 is a Lineweaver-Burk plot of the inhibition of elastase by N-methoxysuccinyl Ala-Ala-Pro-Val (SEQ ID NO:5) (●), peptide-conjugated oligonucleotide (□) and substrate alone (◯). -
FIGS. 12A-12C show the inhibition of elastase by DNA ligands with and without the inhibitors conjugated at the 3′ end compared with the effect of conjugated and non-conjugated ligands on (A) HNE Activity, (B) Urokinase Activity and (C) Thrombin Activity. -
FIG. 13 depicts the valyl phosphonate moiety attached to a nucleic acid segment as used in Example 4 below, and the reaction of the species with human neutrophil elastase. -
FIG. 14 depicts the first order rate constant of a pool of splint blended SELEX nucleic acid ligands after five rounds of SELEX measured by gel electrophoresis; TBE pH 8 (▪) and MAE pH 6 (●). - This application describes methods for generating blended nucleic acid ligand molecules. Examples of blended nucleic acid libraries and molecules generated by these methods are provided. The methods herein described are based on the SELEX method. SELEX is described in U.S. patent application Ser. No. 07/536,428, entitled “Systematic Evolution of Ligands by EXponential Enrichment,” now abandoned, U.S. Pat. No. 5,475,096, entitled “Nucleic Acid Ligands,” U.S. Pat. No. 5,270,163, entitled “Methods for Identifying Nucleic Acid Ligands,” (see also WO 91/19813). These applications, each specifically incorporated herein by reference, are collectively called the SELEX Patent Applications.
- In its most basic form, the SELEX process may be defined by the following series of steps:
- 1) A candidate mixture of nucleic acids of differing sequence is prepared. The candidate mixture generally includes regions of fixed sequences (i.e., each of the members of the candidate mixture contains the same sequences in the same location) and regions of randomized sequences. The fixed sequence regions are selected either: a) to assist in the amplification steps described below; b) to mimic a sequence known to bind to the target; or c) to enhance the concentration of a given structural arrangement of the nucleic acids in the candidate mixture. The randomized sequences can be totally randomized (i.e., the probability of finding a base at any position being one in four) or only partially randomized (e.g., the probability of finding a base at any location can be selected at any level between 0 and 100 percent).
- 2) The candidate mixture is contacted with the selected target under conditions favorable for binding between the target and members of the candidate mixture. Under these circumstances, the interaction between the target and the nucleic acids of the candidate mixture can be considered as forming nucleic acid-target pairs between the target and those nucleic acids having the strongest affinity for the target.
- 3) The nucleic acids with the highest affinity for the target are partitioned from those nucleic acids with lesser affinity to the target. Because only an extremely small number of sequences (and possibly only one molecule of nucleic acid) corresponding to the highest affinity nucleic acids exist in the candidate mixture, it is generally desirable to set the partitioning criteria so that a significant amount of the nucleic acids in the candidate mixture (approximately 5-50%) are retained during partitioning.
- 4) Those nucleic acids selected during partitioning as having the relatively higher affinity to the target are then amplified to create a new candidate mixture that is enriched in nucleic acids having a relatively higher affinity for the target.
- 5) By repeating the partitioning and amplifying steps above, the newly formed candidate mixture contains fewer and fewer unique sequences, and the average degree of affinity of the nucleic acids to the target will generally increase. Taken to its extreme, the SELEX process will yield a candidate mixture containing one or a small number of unique nucleic acids representing those nucleic acids from the original candidate mixture having the highest affinity to the target molecule.
- The SELEX Patent Applications describe and elaborate on this process in great detail. Included are targets that can be used in the process; methods for the preparation of the initial candidate mixture; methods for partitioning nucleic acids within a candidate mixture; and methods for amplifying partitioned nucleic acids to generate enriched candidate mixtures. The SELEX Patent Applications also describe ligand solutions obtained to a number of target species, including both protein targets wherein the protein is and is not a nucleic acid binding protein.
- The present invention includes a method for generating high affinity blended nucleic acid ligands to specific target molecules. The method generates blended nucleic acid molecules comprised of at least one functional unit.
- Functional units that can be coupled to nucleotides or oligonucleotides include peptides, amino acids, aliphatic groups and lipid chains, or larger compounds such as peptide motifs, recognizable by the target molecule. These non-nucleic acid components of oligonucleotides may fit into specific binding pockets to form a tight binding via appropriate hydrogen bonds, salt bridges, or van der Waals interactions.
- In certain embodiments of this invention, the blended nucleic acid ligands generated by the method of this invention may guide SELEX-generated ligands to specific sites of the target molecule. Further blended nucleic acid ligands may be prepared after the SELEX process for post-SELEX modification to add functionality to the ligand, for example, to increase RNA hydrophobicity and enhance binding, membrane partitioning and/or permeability, or to add reporter molecules, such as biotin- or fluorescence-tagged reporter oligonucleotides, for use as diagnostics. Blended nucleic acid ligands may be generated by the addition of chemical groups which covalently react and couple the SELEX ligand to the target molecule; in addition, catalytic groups can be added to nucleic acids to aid in the selection of SELEX ligands with protease or nuclease activity. The functional units may also serve as toxins or radiochemicals that are delivered to specific locations in the body determined by the specificity of the SELEX devised nucleic acid ligand.
- Blended nucleic acid ligands are defined herein as comprising at least one nucleic acid ligand and at least one functional unit. A nucleic acid ligand is defined as any nucleic acid identified generally according to the SELEX process as described in the SELEX Patent Applications. The functional unit may be any chemical species not naturally associated with nucleic acids, and may have any number of functions as enumerated herein.
- In one preferred embodiment of the invention, the blended nucleic acid ligand is prepared by performing the SELEX method utilizing an initial candidate mixture wherein each nucleic acid sequence of the candidate mixture contains at least one function unit, or a “blended candidate mixture”. This may be accomplished using a candidate mixture wherein each nucleic acid sequence of the candidate mixture has 1) a single functional unit attached at either the 5′ or 3′ end of nucleic acid sequence, 2) functional units at both the 5′ and 3′ ends of the nucleic acid sequence, 3) functional units added to individual nucleic acid residues, 4) functional units attached to all or a portion of all pyrimidine or purine residues, or functional units attached to all or a portion of all nucleotides of a given type. The functional units may also be attached only to the fixed or to the randomized regions of each nucleic acid sequence of the candidate mixture.
- In an alternate preferred embodiment of the invention, one or more functional units may be attached to a nucleic acid ligand identified according to the SELEX method wherein a blended candidate mixture is not used. Again the points of attachment of the functional unit(s) to the nucleic acid ligand may vary depending on the ultimate requirements for the blended nucleic acid ligands.
- The examples below describe methods for generating the blended nucleic acid ligands of the present invention. As these examples establish, nucleotides and oligonucleotides containing a new functional unit are useful in generating blended nucleic acid ligands to specific sites of a target molecule.
- Two examples are described for coupling peptide molecules to SELEX nucleic acid ligands in order to target specific peptide binding pockets. In the first example, a peptide containing the sequence arginine-glycine-aspartic acid (RGD) is coupled to a nucleotide and enzymatically incorporated into unselected polyribonucleotide. The RGD-containing peptide is recognized and bound by the gpIIbIIIa integrin protein, causing gpIIbIIIa-mediated platelet aggregation. A SELEX RGD-nucleic acid ligand may be generated with high specificity for gpIIbIIIa that would not crossreact with other integrins such as receptors for fibronectin, vitronectin, collagen, or laminin. SELEX blended nucleic acid ligands containing the RGD peptide could bind at or near the gpIIbIIIa ligand site and specifically inhibit gpIIbIIIa activity.
- Example 1 describes the generation of a peptide-conjugated RNA. The peptide Gly-Arg-Gly-Asp-Thr-Pro (SEQ ID NO:1) was coupled to the derivatized base, 5-(3-aminoallyl)-uridine triphosphate to produce the peptide-conjugated UTP (RGD-UTP), as shown in
FIG. 1 . RGD-UTP may be used in SELEX T7-catalyzed template-dependent transcription to produce an RNA oligonucleotide containing the RGD peptide at every uridine position. The Gly-Arg-Gly-Asp-Thr-Pro (SEQ ID NO:1) peptide was chosen because the Arg-Gly-Asp (RGD) motif in matrix proteins is recognized and bound specifically by proteins of the integrin superfamily of cell adhesion receptors. Integrins bind to such proteins as fibronectin, laminin and vitronectin, at sites containing the RGD sequence. This binding is inhibited by short RGD-containing peptides which bind integrin proteins with a Kd of approximately 10−5 M. - Because of the specificity of RGD-containing peptides for integrins, the inventors of this application concluded that an RGD-containing peptide conjugated to an oligonucleotide may facilitate selection of high-affinity ligands to a RGD-binding target molecule. However, according to this embodiment of the invention utilizing a blended candidate mixture, peptide-conjugated oligonucleotides must also be compatible with the SELEX method: the peptide-conjugated nucleotide must be incorporated with reasonable efficiency into transcribed RNA; partitioned RNA in turn must be reasonably efficiently transcribed into complementary DNA for amplification and additional rounds of SELEX. The Examples below demonstrate that all of the conditions required for successful SELEX identification of nucleic acid ligands containing new functional groups are met by the method of this invention. The peptide-UTP derivative was enzymatically incorporated into a blended RNA oligonucleotide as shown by increased size and altered charge compared with the native or unmodified oligonucleotide and by the UV shoulder at 310 nm.
- Example 2 describes the binding of RGD-RNA to RGD-binding integrin gpIIbIIIa. After separation, the bound RGD-RNA was reversed transcribed into DNA using normal SELEX protocols. The efficient transcription, partitioning, and reverse transcription shows that the site-directed blended nucleic acid ligands of this invention are compatible with the basic SELEX procedure.
- A second example of the method of the present invention describes a DNA SELEX ligand coupled to a peptide inhibitor known to bind elastase.
- Example 3 describes the generation of a highly specific elastase inhibitor by the method of the present invention. A SELEX-identified single stranded DNA ligand to elastase was produced and coupled to inhibitory substrate peptide chloromethyl ketone. A description of the isolation of DNA ligands to elastase and specific ligands to elastase are provided in U.S. Pat. No. 5,472,841, entitled, “Methods for Identifying Nucleic Acid Ligands of Human Neutrophil Elastase,” incorporated specifically herein by reference. The resulting blended nucleic acid ligand was shown to specifically inhibit elastase.
- The methods described herein do not include all of the schemes for introducing non-nucleic acid functional units, such as peptides, into an oligonucleotide. However, such methods would be well within the skill of those ordinarily practicing in the art. Putting a peptide on every uridine, as done in Example 1, has several advantages as compared with other labelling methods for use in the SELEX procedure. First, the peptide is introduced throughout both the random and fixed regions, so that evolved RNA ligands could bind close to the peptide binding site. Second, distributing the peptide at multiple sites does not restrict the geometry of RNA and does not interfere with SELEX identification of the optimal peptide position. Third, one can use pre-derivatized nucleotides with SELEX. Post-transcription modification may require additional time and expertise and introduces the additional variable of coupling efficiency.
- Other methods for coupling non-nucleic acid functional units to nucleic acids may be used to yield evolved ligands with a non-overlapping spectrum of binding sites. For instance, a peptide could be placed at the 5′ or 3′ end of SELEX identified RNA ligands. Another embodiment of this invention for introducing a non-nucleic acid functional unit at random positions and amounts is by use of a template-directed reaction with non-traditional base pairs. This method uses molecular evolution to select the best placement of the non-nucleic acid group on the SELEX identified ligand. For example, a X-dY base pair could be used, where X is a derivatizable ribonucleotide and the deoxynucleotide dY would pair only with X. The X-RNA would contain the non-nucleic acid functional unit only at positions opposite dY in the dY-DNA template; the derivatized X base could be positioned in either the fixed or random regions or both, and the amount of X at each position could vary between 0-100%. The sequence space of non-evolved SELEX ligands would be increased from N4 to N5 by substituting this fifth base without requiring changes in the SELEX protocol.
- This embodiment may be used with photo-SELEX (U.S. Pat. No. 5,736,177, specifically incorporated herein by reference), where photo-active bases are placed at random sites, and these blended ligands partitioned after photolysis, then high affinity ligands are selected with the minimum number of substituted bases needed to crosslink with the target. In the same way, functional units that react covalently at enzyme active sites, such as chloromethylketones, may be incorporated to produce irreversible enzyme inhibitors. Use of directed incorporation could be used also for post-SELEX incorporation of fluorescence tags, biotin, radiolabel, lipid groups, or to cap the oligonucleotide with a uniquely modified base for protection against nuclease digestion.
- Incorporation of non-nucleic acid functional units to produce blended SELEX ligands increases the repertoire of structures and interactions available to produce high affinity binding ligands. Various types of functional units can be incorporated to produce a spectrum of molecular structures. At one end of this structural spectrum are normal polynucleic acids where the ligand interactions involve only nucleic acid functional units. At the other, are fully substituted nucleic acid ligands where ligand interactions involve only non-nucleic acid functional units. Since the nucleic acid topology is determined by the sequence, and sequence partitioning and amplification are the basic SELEX steps, the best ligand topology is selected by nucleic acid evolution.
- Example 3 below describes the preparation of a blended nucleic acid ligand to elastase to act as an elastase inhibitor. N-methoxysuccinyl-Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2) is an effective irreversible inhibitor for elastase. However, the nonspecific high reactive nature of chloromethyl ketone functionality in conjunction with mM range Kd of the tetrapeptide makes the inhibitor molecule unsuitable as a therapeutic agent. The enzyme inhibition of nucleic acid ligands to elastase may be improved by coupling such ligands to the substrate tetrapeptide in a nonhydrolyzable manner such that the blended nucleic acid will inhibit the enzyme by occupying the substrate binding pocket. In such a blended nucleic acid affinity and specificity is provided by the SELEX-derived nucleic acid ligand, whereas inhibition is provided by the peptide.
- In one embodiment of the invention, referred to as splint blended SELEX, the functional unit of the blended nucleic acid ligand is attached to the SELEX derived nucleic acid ligand via the attachment of the functional unit to a nucleic acid that hybridizes to a region of the nucleic acid sequence of the ligand. In the preferred embodiment, the functional unit oligonucleotide is DNA, and hybridizes to the fixed region of the nucleic acid ligand or at least a region of the nucleic acid ligand that is not involved in the binding reaction to the target.
- In one variation of this embodiment, the SELEX process is accomplished by the preparation of a candidate mixture of nucleic acid sequences comprised of fixed and randomized regions. The candidate mixture also contains an oligonucleotide attached to a selected functional group. The oligonucleotide is complementary to the fixed region of the nucleic acid candidate mixture, and is able to hybridize under the conditions employed in SELEX for the partitioning of high affinity ligands from the bulk of the candidate mixture. Following partitioning, the conditions can be adjusted so that the oligo-functional unit dissociates from the nucleic acid sequences.
- Advantages to this embodiment include the following: 1) it places a single functional unit, such as a peptide analog, at a site where it is available for interaction with the random region of nucleic acid sequences of the candidate mixture; 2) because the functional unit is coupled to a separate molecule, the coupling reaction must only be performed once, whereas when the functional unit is coupled directly to the SELEX ligand, the coupling reaction must be performed at every SELEX cycle. (aliquots from this reaction can be withdrawn for use at every cycle of SELEX); 3) the coupling chemistry between the functional unit and the oligonucleotide need not be compatible with RNA integrity or solubility—thus simplifying the task of coupling; 4) in cases where the functional unit forms a covalent complex with the target, the SELEX derived nucleic acid ligand portion of the selected members of the candidate mixture can be released from the target for amplification or identification; and 5) following the successful identification of a blended nucleic ligand, the tethered portion of nucleic acid can be made into a hairpin loop to covalently attach the two portions of the blended nucleic acid ligand. An example of splint blended nucleic acid ligand for human neutrophil elastase is shown in Example 4 below.
- The following examples are provided for illustrative purposes only and are not intended to limit the scope of the invention.
- Synthesis of Peptide Conjugated UTP.
- Reagents. 5-(3-aminoallyl)-
uridine 5′-triphosphate, sodium salt, was obtained from Sigma Chem. Co. (St. Louis, Mo.). Gly-Arg-Gly-Asp-Thr-Pro (SEQ ID NO:1) was obtained from GIBCO-BRL (Gaithersburg, Md.). 1-ethyl-3-(dimethylaminopropyl) carbodiimide hydrochloride (EDC) was obtained from Pierce Chemical Co. (Rockford, Ill.). Other chemicals were of highest quality available from Aldrich Chem. Co. (Milwaukee, Wis.). - Succinylation of AA-UTP. The peptide Gly-Arg-Gly-Asp-Thr-Pro (SEQ ID NO:1) was coupled to UTP via a two-step reaction through the N-terminal α-amino group of the peptide. This α-amino group is the only reactive amine in the peptide and is not required for integrin binding. Condensation with peptide carboxyl groups could function to block the aspartic acid residue, thus preventing integrin binding.
- 5-(3-aminoallyl)UTP (5 mg) was dissolved in 250 μl of 0.2 M sodium borate, pH 8.5. The solution was mixed with 750 μl succinic anhydride (97 mg/1.14 ml DMF) and reacted for 2 h at 4° C. An equal volume of 0.1 M triethylammonium bicarbonate, pH 7.6, was added, filtered and purified on
Mono Q 5×5 anion exchange FPLC (Pharmacia). The sample was applied in 0.1 M triethylammonium bicarbonate, and eluted with a linear gradient to 1.0 M triethylammonium bicarbonate. The column was eluted at 1.0 ml/min over 20 min. The major peak was pooled, lyophilized, and taken up in dry DMF for the next reaction. The sample was analyzed by TLC by spotting on PEI-F chromatography plates (J.T. Baker) and developing with 0.2 M sodium phosphate, pH 3.5. - Chromatographic isolation of succinyl-UTP. The succinylation reaction mixture was diluted 1:1 with 0.1 M triethylammonium-bicarbonate, pH 7.6 (Buffer A), filtered and applied to a 0.5 cm×5 cm Mono Q anion exchange column which was equilibrated with the same buffer. The column was eluted with a gradient to 1.0 M triethylammonium-bicarbonate (Buffer B) at a flow rate of 0.5 ml/ml (1 min/fraction) (
FIG. 2 ). Succinyl-UTP was easily separated by ion exchange from the starting material. This separation is achieved because succinyl-UTP elutes from Mono Q similar to UTP, whereas AA-UTP partially neutralizes the 5′-triphosphate and elutes earlier in the salt gradient. Succinyl-UTP eluted late in the gradient from the Mono Q column (92% of Buffer B), well separated from reactants and from the AA-UTP (which eluted at approximated 68% of Buffer B). The majority of UV adsorbing material eluted in the major peak, although several other peaks were present. Succinyl-UTP pooled from fractions 43-49 was lyophilized to remove the volatile buffer in preparation for the next step. The yield of this step was 80-95%. The dried sample was dissolved in dry DMF and its UV spectrum determined. This peak had the expected maximum at 290 nm. - Coupling of GRGDTP peptide to 5′(3-succinyl-aminoallyl)
uridine 5′-triphosphate. The RGD peptide was condensed with succinyl-UTP using the water soluble carbodiimide. Succinyl-UTP in 58 μl of DMF was cooled to 4° C. 117 μl of N-hydroxy-succinimide (24 mg/1.4 ml DMF) was added and the mixture was reacted for 30 min at 4° C. 175 μl of EDC (0.1 M, pH 4.8) was added and the mixture reacted for 2 h at 4° C. The activated nucleotide was added to 14 mg of lyophilized GRGDTP and the mixture reacted for 2 h at 4° C. The reaction mixture was diluted 1:1 with 0.1 M triethylammonium bicarbonate, purified on a Mono Q column as above, and analyzed by TLC and Fast Atom Bombardment (FAB) Mass Spectrometry (University of Colorado Structural Division). - Chromatographic isolation of RGD-UTP. RGD-UTP was purified by ion exchange chromatography. The peptide coupling reaction mixture was diluted with Buffer A, filtered and purified on the Mono Q column described above. RGD-UTP eluted from the Mono Q column similar to AA-UTP, but ahead of succinyl-UTP, suggesting the arginine side chain also interacts with the phosphate charge. The major peak eluted at approximately 70% of Buffer B, ahead of the peak of residual succinyl-UPT (which eluted at approximately 90% of Buffer B) (
FIG. 3 ). Only trace amounts of other peaks were detected, except for the EDC which eluted earlier. Fractions 35-38 were pooled and lyophilized. The sample was dissolved in dry DMF for thin layer chromatography (TLC) and FAB mass spectroscopy. The sample had a maximum adsorption at 290 nm. - Thin layer chromatography of AA-UTP, succinyl-UTP, and RGD-UTP. As shown in
FIG. 4 , RGD-UTP is cleanly separated from both AA-UTP and succinyl-UTP. AA-UTP, succinyl-UTP, and RGD-UTP were spotted onto cellulose PEI-F TLC plates (J. T. Baker, Inc.) and developed with 0.75 M NaH2PO4, pH 3.5. AA-UTP migrated near the solvent front, succinyl-UTP migrated with an Rf of 0.42, and RGD-UTP remained at the origin. This TLC system is an ideal method for monitoring product formation. - Mass spectrometry analysis. RGD-UTP analyzed by FAB mass spectroscopy yielded a mass of 1223, remarkably close to the calculated formula weight (FW) of 1222. The precision of the mass spectrometry result shows that RGD was coupled in the predicted manner, and that no side reactions occurred introducing alternative or additional derivatives. Further, there were no smaller peaks present which would indicate degradation or dephosphorylation of the triphosphate.
- Binding of RGD-RNA to gpIIbIIIa.
- Molecular biology techniques. Agarose electrophoresis, T7 RNA transcription, and AMV reverse transcription were performed generally as described in the SELEX Patent Applications. FPLC purification of RNA oligonucleotides was achieved using a 5×5 Mono Q anion exchange column. The RNA transcription reaction mixture was phenol:chloroform extracted, ethanol precipitated and washed, and dissolved in 50 mM sodium phosphate, 0.2 M NaCl, 6 M urea, 50% formamide (Fisher, Ultrapore, low-UV absorbance), pH 6.0. Following sample application, the column was developed with a linear gradient to 1 M NaCl. The RNA peak was precipitated by addition of 2:1 v/v ethanol, the pellet was washed with 80% ethanol and dried in a speed-vac, then dissolved in SELEX binding buffer (150 mM NaCl, 10 nM HEPES, 2 mM CaCl2, 1 mM MgCl2, 0.1% Tween, pH 7.4). RNA and RNA-gpIIbIIIa (Enzyme Research) complexes were prepared by incubation at 37° C. for 10 min, and separated by size exclusion chromatography on a 16×100
Superdex 200 column (Pharmacia) which was equilibrated and run in the binding buffer. Concentration and removal of detergent from the samples collected from the Superdex column was achieved by adsorption onto a Resource Q column (Pharmacia) and elution with 1 M NaCl. - RGD-UPT transcription and purification. RGD-UTP was used in a T7 RNA polymerase reaction by direct substitution for normal UTP, and gave yields that were at least 50% of those obtainable with UTP. The concentration of RGD-UTP and other NTPs was 1 mM; the DNA template contained 5′ and 3′ fixed regions flanking a 30 base pair random sequence. The RNA transcript was purified by adsorption onto an anion exchange column (Mono Q) in a phosphate buffer containing 6 M urea and 50% formamide, and eluted with a gradient to 1 M NaCl (
FIG. 5 ). RGD-RNA eluted as one major peak from the column at a position in the gradient slightly ahead of the elution position of an equivalent RNA transcript made with normal UTP, consistent with the altered charge and perhaps altered conformation of the derivatized RNA. The amount of truncated RNA material was only slightly increased compared to normal RNA transcription. - Binding of RGD-30n7 RNA to gpIIbIIIa. Size-based partitioning, used to separate RGD-RNA bound to gpIIbIIIa integrin from unbound RGD-RNA, is a method for identifying high affinity RNA ligands to gpIIbIIIa (Kd<10−8). RGD-RNA was incubated with gpIIbIIIa (2 mg/ml) in 0.15 M NaCl, 2 mM CaCl2, 1 mM MgCl2, 20 mM HEPES, 0.1
% Tween 20, pH 7.4. The results showed that RGD-RNA incubated with gpIIbIIIa yielded a higher molecular weight RNA peak than obtained for samples not incubated with gpIIbIIIa. Normal RNA made with UTP and partitioned in the same manner did not have the high molecular weight peak, indicating that binding to gpIIbIIIa of RNA not coupled to the RGD peptide was weaker than that of the blended molecule. The estimated molecular mass is consistent with the addition of the RGD peptide at each uridine position (FIG. 6 ). Perhaps more conclusively, chromatographically purified RGD-RNA had an absorbance shoulder, compared to normal RNA, at 310 nm resulting from incorporation of AA-UTP. A small peak of early eluting material was detected in the column void volume which was not present in samples of RGD-RNA chromatographed without protein. The high molecular weight RGD-RNA-gpIIbIIIa peak was concentrated and detergent removed by adsorption and elution from an anion exchange column. The RNA was reversed transcribed and PCR amplified. The DNA obtained yielded a single band of expected size on agarose electrophoresis, indicating that RGD-RNA is reverse transcribed with acceptable efficiency even with the low amounts of RNA extracted during SELEX partitioning. - Substrate-Coupled SELEX-Derived Blended Ligands as Elastase Inhibitors.
- To demonstrate that a high affinity, high specificity nucleic acid ligand coupled to an inhibitor peptide is a viable method of producing a high affinity inhibitor to elastase, a ssDNA ligand to elastase was coupled to the inhibitory substrate peptide chloromethyl ketone such that the chloromethyl functionality is inactivated by creating a non-hydrolyzable linkage. ssDNA ligand 17 (DNA-17) (from U.S. Pat. No. 5,472,841, entitled, “Methods for Identifying Nucleic Acid Ligands of Human Neutrophil Elastase,” having the sequence TAGCGATACTGCGTGGGTTGGGGCGGGTAGGGCCAGCAGTCTCGTGCGGTACTTGA GCA (SEQ ID NO:3)) has a Kd for elastase of 15 nM. Because it was not known which end of DNA-17 is in close proximity to the active site of elastase, blended nucleic acid molecules were prepared in which the substrate peptide was attached to both the 3′ and 5′ ends of the DNA.
- Peptide conjugation. The chemistry of the attachment is shown in
FIG. 7 . An oligonucleotide with four 18-atom ethylene glycol moieties (synthesized by using spacer phosphoramidite, Clonetech) and a thiol group at the 3′ end was synthesized by automated DNA synthesis, deprotected by standard methods, and gel purified. Immediately after the deprotection of the 3′-SH group, the oligonucleotide was passed through a Sephadex-G50 spin column equilibrated in 0.5 M triethylammonium acetate buffer (pH 7.5) to remove excess DTT, and then mixed with N-methoxysuccinyl Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2) (25 mg/200 Vμl of DMF). The mixture was incubated at 37° C. overnight. - 20 μl of 1 M DTT was added to inactivate the unreacted chloromethyl ketone inhibitor. The peptide conjugated DNA was finally purified from the unconjugated peptide either by three successive Sephadex-G50 spin columns or by reverse phase HPLC.
- Elastase inhibition assay. The assay for elastase inhibition is based on the use of a chromogenic tetrapeptide substrate. The assay was conducted in a buffer containing 10 nM elastase, 0.5 mM N-methoxysuccinyl-Ala-Ala-Pro-Val-p-nitroanilide (SEQ ID NO:4), 150 mM NaCl, 26 mM KCl, 2 mM MgCl2, 0.02% HSA, 0.05% DMSO, 0.01% Triton X-100, and 100 mM Tris-HCl, at 25° C. The assay measured the generation of elastase-induced release of p-nitroanilide as a function of time by spectroscopy (
OD 405 nm). The rate of p-nitroanilide generation in the absence of inhibitor was used as the control. Positive control was established in the presence of the irreversible inhibitor N-methoxysuccinyl-Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2). - The presence of trace amounts of unreacted N-methoxysuccinyl Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2) in the final blended nucleic acid ligand preparation will inhibit the enzyme. However, this possibility will be eliminated by inactivating the inhibitor with DTT.
FIG. 8 shows the inactivation of N-methoxysuccinyl Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2) by DTT. Incubation of 1.95 M N-methoxysuccinyl Ala-Ala-Pro-Val-chloromethyl ketone (SEQ ID NO:2) with 50 mM DTT destroyed the inhibition. The partial inhibition seen with the inactivated inhibitor may be due to competitive inhibition due to the high peptide concentration. -
FIG. 9 shows the inhibition of the blended nucleic acid ligand in the presence of 20 mM DTT. The inhibition of elastase by the 5′ end blended nucleic acid ligand and the 3′ end blended nucleic acid ligand is shown inFIG. 10 . A Lineweaver-Burk plot of elastase inhibition by N-methoxysuccinyl Ala-Ala-Pro-Val (SEQ ID NO:5) or the blended nucleic acid ligand is shown inFIG. 11 . The resulting Km of 0.16 mM for the substrate is in good agreement with published values. The Ki of the blended nucleic acid ligands was 30 nM versus 920 μM for the inhibitor peptide alone, or a 30,000 fold improvement. - The inhibition of two other human serine proteases—urokinase and thrombin—by the 3′ end blended nucleic acid DNA-17 was also examined, and shown in
FIG. 12 . At 70 nm concentration the 3′ end blended nucleic acid has greater than 50% inhibition of elastase, whereas even at 650 nm concentration neither urokinase nor thrombin were inhibited to any detectable extent. These results demonstrate the specificity of the blended nucleic acid ligand for elastase. - Splint Blended SELEX.
- The splint blended SELEX process was performed by preparing a standard SELEX candidate mixture and a single compound containing a valyl phosphonate attached to a nucleic acid sequence that hybridizes to a portion of the fixed region of the candidate mixture of nucleic acid sequences as shown in
FIG. 13 .FIG. 13 also shows the chemical reaction that occurs between the valyl phosphonate and human neutrophil elastase (HNE). - The valyl phosphonate was activated via an NHS ester. This compound was coupled to the 5′ hexyl amine linker of a 19-mer DNA oligo complementary to the 5′-fixed region of 40N7.1. A candidate mixture composed of
pyrimidine 2′NH2-substituted RNA was hybridized to the splint, and reacted with HNE at subsaturating protein concentrations. Covalent complexes were enriched by diluting the reaction 100-fold, then filtering through nitrocellulose. - After five rounds of selection for species that reacted with the HNE, the reactivity of the pool was assayed by gel electrophoresis (5% polyacrylamide/TBE pH 8 or
MAE pH 6/0.25% SDS). The results are shown inFIG. 14 . The analysis of reaction rates indicates biphasic kinetics, with k1obs≅0.1 min−1, and k2obs≅0.01 min−1. The reaction plateaus at 30%, presumably because the valyl phosphonate is a racemic mixture and the theoretical limit is 50%. A k1obs of 0.1 min−1 at a protein concentration of 50 nM indicates a second order rate constant >2×106 M−1min−1. The reported rate constant for the valyl phosphonate alone is 103-104 M−1min−1 (Oleksyszyn et al. (1989) Biophys. Biochem. Res. Comm. 161: 143-149). Thus, the splint blended nucleic acid mixture increases the reaction rate of the species by at least 103 fold. The reaction of the selected pool is also highly specific. No reaction of the pool with thrombin, another serine protease, is detectable. The second-order rate constant for the thrombin reaction is estimated to be <200 M−1min−1, 104 fold lower than the reaction rate with elastase.
Claims (4)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US11/668,337 US20070134715A1 (en) | 1990-06-11 | 2007-01-29 | Systematic evolution of ligands by exponential enrichment: blended selex |
Applications Claiming Priority (10)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US53642890A | 1990-06-11 | 1990-06-11 | |
| US07/714,131 US5475096A (en) | 1990-06-11 | 1991-06-10 | Nucleic acid ligands |
| US11799193A | 1993-09-08 | 1993-09-08 | |
| US12393593A | 1993-09-17 | 1993-09-17 | |
| US08/199,507 US5472841A (en) | 1990-06-11 | 1994-02-22 | Methods for identifying nucleic acid ligands of human neutrophil elastase |
| US08/234,997 US5683867A (en) | 1990-06-11 | 1994-04-28 | Systematic evolution of ligands by exponential enrichment: blended SELEX |
| US08/956,699 US6083696A (en) | 1990-06-11 | 1997-10-23 | Systematic evolution of ligands exponential enrichment: blended selex |
| US09/606,477 US6465189B1 (en) | 1990-06-11 | 2000-06-29 | Systematic evolution of ligands by exponential enrichment: blended selex |
| US10/263,456 US7176295B2 (en) | 1990-06-11 | 2002-10-02 | Systematic evolution of ligands by exponential enrichment: blended SELEX |
| US11/668,337 US20070134715A1 (en) | 1990-06-11 | 2007-01-29 | Systematic evolution of ligands by exponential enrichment: blended selex |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US10/263,456 Continuation US7176295B2 (en) | 1990-06-11 | 2002-10-02 | Systematic evolution of ligands by exponential enrichment: blended SELEX |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| US20070134715A1 true US20070134715A1 (en) | 2007-06-14 |
Family
ID=27568758
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US09/606,477 Expired - Fee Related US6465189B1 (en) | 1990-06-11 | 2000-06-29 | Systematic evolution of ligands by exponential enrichment: blended selex |
| US10/263,456 Expired - Fee Related US7176295B2 (en) | 1990-06-11 | 2002-10-02 | Systematic evolution of ligands by exponential enrichment: blended SELEX |
| US11/668,337 Abandoned US20070134715A1 (en) | 1990-06-11 | 2007-01-29 | Systematic evolution of ligands by exponential enrichment: blended selex |
Family Applications Before (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US09/606,477 Expired - Fee Related US6465189B1 (en) | 1990-06-11 | 2000-06-29 | Systematic evolution of ligands by exponential enrichment: blended selex |
| US10/263,456 Expired - Fee Related US7176295B2 (en) | 1990-06-11 | 2002-10-02 | Systematic evolution of ligands by exponential enrichment: blended SELEX |
Country Status (1)
| Country | Link |
|---|---|
| US (3) | US6465189B1 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8236570B2 (en) | 2009-11-03 | 2012-08-07 | Infoscitex | Methods for identifying nucleic acid ligands |
| US8841429B2 (en) | 2009-11-03 | 2014-09-23 | Vivonics, Inc. | Nucleic acid ligands against infectious prions |
Families Citing this family (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5962219A (en) * | 1990-06-11 | 1999-10-05 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: chemi-selex |
| US6465189B1 (en) * | 1990-06-11 | 2002-10-15 | Gilead Sciences, Inc. | Systematic evolution of ligands by exponential enrichment: blended selex |
| US6465188B1 (en) * | 1990-06-11 | 2002-10-15 | Gilead Sciences, Inc. | Nucleic acid ligand complexes |
| US8071737B2 (en) * | 1995-05-04 | 2011-12-06 | Glead Sciences, Inc. | Nucleic acid ligand complexes |
| ATE516366T1 (en) * | 2002-07-25 | 2011-07-15 | Archemix Corp | REGULATED APTAMER THERAPEUTICS |
| US7727969B2 (en) | 2003-06-06 | 2010-06-01 | Massachusetts Institute Of Technology | Controlled release nanoparticle having bound oligonucleotide for targeted delivery |
| WO2005051174A2 (en) * | 2003-11-21 | 2005-06-09 | The Trustees Of Columbia University In The City Of New York | Nucleic acid aptamer-based compositions and methods |
| EP2048246B1 (en) * | 2006-08-03 | 2011-09-14 | NEC Soft, Ltd. | Method for obtaining oligonucleotide |
| US9725713B1 (en) | 2007-01-22 | 2017-08-08 | Steven A Benner | In vitro selection with expanded genetic alphabets |
| US8586303B1 (en) | 2007-01-22 | 2013-11-19 | Steven Albert Benner | In vitro selection with expanded genetic alphabets |
| US20080248958A1 (en) * | 2007-04-05 | 2008-10-09 | Hollenbach Andrew D | System for pulling out regulatory elements in vitro |
| WO2009114325A2 (en) | 2008-03-03 | 2009-09-17 | Tosk, Incorporated | Methotrexate adjuvants to reduce toxicity and methods for using the same |
| CN112587671A (en) | 2012-07-18 | 2021-04-02 | 博笛生物科技有限公司 | Targeted immunotherapy for cancer |
| AU2015205756A1 (en) | 2014-01-10 | 2016-07-21 | Birdie Biopharmaceuticals Inc. | Compounds and compositions for treating EGFR expressing tumors |
| EP3166976B1 (en) | 2014-07-09 | 2022-02-23 | Birdie Biopharmaceuticals Inc. | Anti-pd-l1 combinations for treating tumors |
| CN112546231A (en) | 2014-07-09 | 2021-03-26 | 博笛生物科技有限公司 | Combination therapeutic compositions and combination therapeutic methods for treating cancer |
| CN112587672A (en) | 2014-09-01 | 2021-04-02 | 博笛生物科技有限公司 | anti-PD-L1 conjugates for the treatment of tumors |
| US20180153884A1 (en) | 2015-05-31 | 2018-06-07 | Curegenix Corporation | Combination compositions for immunotherapy |
Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5270163A (en) * | 1990-06-11 | 1993-12-14 | University Research Corporation | Methods for identifying nucleic acid ligands |
| US5472840A (en) * | 1988-09-30 | 1995-12-05 | Amoco Corporation | Nucleic acid structures with catalytic and autocatalytic replicating features and methods of use |
| US5683867A (en) * | 1990-06-11 | 1997-11-04 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: blended SELEX |
| US5705337A (en) * | 1990-06-11 | 1998-01-06 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: chemi-SELEX |
| US5723323A (en) * | 1985-03-30 | 1998-03-03 | Kauffman; Stuart Alan | Method of identifying a stochastically-generated peptide, polypeptide, or protein having ligand binding property and compositions thereof |
| US5998142A (en) * | 1993-09-08 | 1999-12-07 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: chemi-SELEX |
| US6011020A (en) * | 1990-06-11 | 2000-01-04 | Nexstar Pharmaceuticals, Inc. | Nucleic acid ligand complexes |
| US6083696A (en) * | 1990-06-11 | 2000-07-04 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands exponential enrichment: blended selex |
| US6147204A (en) * | 1990-06-11 | 2000-11-14 | Nexstar Pharmaceuticals, Inc. | Nucleic acid ligand complexes |
| US6465189B1 (en) * | 1990-06-11 | 2002-10-15 | Gilead Sciences, Inc. | Systematic evolution of ligands by exponential enrichment: blended selex |
| US6465188B1 (en) * | 1990-06-11 | 2002-10-15 | Gilead Sciences, Inc. | Nucleic acid ligand complexes |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3755295A (en) | 1969-10-24 | 1973-08-28 | Syntex Corp | 1-(2-amino-2-deoxy-{62 -d-ribofuranosyl) pyrimidines and derivatives thereof |
| WO1989006694A1 (en) | 1988-01-15 | 1989-07-27 | Trustees Of The University Of Pennsylvania | Process for selection of proteinaceous substances which mimic growth-inducing molecules |
| US5118672A (en) | 1989-07-10 | 1992-06-02 | University Of Georgia Research Foundation | 5'-diphosphohexose nucleoside pharmaceutical compositions |
| AU7759291A (en) | 1990-03-29 | 1991-10-21 | Gilead Sciences, Inc. | Oligonucleotide-transport agent disulfide conjugates |
| ATE318832T1 (en) | 1990-06-11 | 2006-03-15 | Gilead Sciences Inc | METHOD FOR USING NUCLEIC ACID LIGANDS |
| US5962219A (en) | 1990-06-11 | 1999-10-05 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: chemi-selex |
| AU1435492A (en) | 1991-02-21 | 1992-09-15 | Gilead Sciences, Inc. | Aptamer specific for biomolecules and method of making |
| US5672472A (en) | 1991-08-23 | 1997-09-30 | Isis Pharmaceuticals, Inc. | Synthetic unrandomization of oligomer fragments |
| CA2145761C (en) | 1992-09-29 | 2009-12-22 | Larry M. Gold | Nucleic acid ligands and methods for producing the same |
| CA2179315A1 (en) | 1993-12-17 | 1995-06-22 | Roger S. Cubicciotti | Nucleotide-directed assembly of bimolecular and multimolecular drugs and devices |
| EP2168973A1 (en) | 1995-05-04 | 2010-03-31 | Gilead Sciences, Inc. | Nucleic acid ligand complexes |
-
2000
- 2000-06-29 US US09/606,477 patent/US6465189B1/en not_active Expired - Fee Related
-
2002
- 2002-10-02 US US10/263,456 patent/US7176295B2/en not_active Expired - Fee Related
-
2007
- 2007-01-29 US US11/668,337 patent/US20070134715A1/en not_active Abandoned
Patent Citations (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5723323A (en) * | 1985-03-30 | 1998-03-03 | Kauffman; Stuart Alan | Method of identifying a stochastically-generated peptide, polypeptide, or protein having ligand binding property and compositions thereof |
| US5472840A (en) * | 1988-09-30 | 1995-12-05 | Amoco Corporation | Nucleic acid structures with catalytic and autocatalytic replicating features and methods of use |
| US6011020A (en) * | 1990-06-11 | 2000-01-04 | Nexstar Pharmaceuticals, Inc. | Nucleic acid ligand complexes |
| US5705337A (en) * | 1990-06-11 | 1998-01-06 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: chemi-SELEX |
| US5683867A (en) * | 1990-06-11 | 1997-11-04 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: blended SELEX |
| US5270163A (en) * | 1990-06-11 | 1993-12-14 | University Research Corporation | Methods for identifying nucleic acid ligands |
| US6083696A (en) * | 1990-06-11 | 2000-07-04 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands exponential enrichment: blended selex |
| US6147204A (en) * | 1990-06-11 | 2000-11-14 | Nexstar Pharmaceuticals, Inc. | Nucleic acid ligand complexes |
| US6465189B1 (en) * | 1990-06-11 | 2002-10-15 | Gilead Sciences, Inc. | Systematic evolution of ligands by exponential enrichment: blended selex |
| US6465188B1 (en) * | 1990-06-11 | 2002-10-15 | Gilead Sciences, Inc. | Nucleic acid ligand complexes |
| US20030125263A1 (en) * | 1990-06-11 | 2003-07-03 | Gilead Sciences, Inc. | Nucleic acid ligand complexes |
| US20050164974A1 (en) * | 1990-06-11 | 2005-07-28 | Larry Gold | Nucleic acid ligand complexes |
| US7176295B2 (en) * | 1990-06-11 | 2007-02-13 | Gilead Sciences, Inc. | Systematic evolution of ligands by exponential enrichment: blended SELEX |
| US5998142A (en) * | 1993-09-08 | 1999-12-07 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: chemi-SELEX |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8236570B2 (en) | 2009-11-03 | 2012-08-07 | Infoscitex | Methods for identifying nucleic acid ligands |
| US8841429B2 (en) | 2009-11-03 | 2014-09-23 | Vivonics, Inc. | Nucleic acid ligands against infectious prions |
| US9085773B2 (en) | 2009-11-03 | 2015-07-21 | Vivonics, Inc. | Methods for identifying nucleic acid ligands |
Also Published As
| Publication number | Publication date |
|---|---|
| US7176295B2 (en) | 2007-02-13 |
| US20030077646A1 (en) | 2003-04-24 |
| US6465189B1 (en) | 2002-10-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US5683867A (en) | Systematic evolution of ligands by exponential enrichment: blended SELEX | |
| US6083696A (en) | Systematic evolution of ligands exponential enrichment: blended selex | |
| US20070134715A1 (en) | Systematic evolution of ligands by exponential enrichment: blended selex | |
| AU692469B2 (en) | Nucleic acid ligands and improved methods for producing the same | |
| AU714469B2 (en) | Parallel selex | |
| KR970002255B1 (en) | Nucleic acid ligands | |
| US9873879B2 (en) | Nucleic acid fragment binding to target protein | |
| US5472841A (en) | Methods for identifying nucleic acid ligands of human neutrophil elastase | |
| US5962219A (en) | Systematic evolution of ligands by exponential enrichment: chemi-selex | |
| US6030776A (en) | Parallel SELEX | |
| US6184364B1 (en) | High affinity nucleic acid ligands containing modified nucleotides | |
| US5763595A (en) | Systematic evolution of ligands by exponential enrichment: Chemi-SELEX | |
| US5773598A (en) | Systematic evolution of ligands by exponential enrichment: chimeric selex | |
| US5476766A (en) | Ligands of thrombin | |
| IE920561A1 (en) | Aptamer specific for thrombin and methods of use | |
| AU2006292524A1 (en) | Focused libraries, functional profiling, laser selex and deselex | |
| JPH09216895A (en) | Cathepsin g-inhibiting aptamer | |
| US6177557B1 (en) | High affinity ligands of basic fibroblast growth factor and thrombin | |
| Jensen | Systematic Evolution Of Ligands By Exponential Enrichment: Chemi-selex |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AS | Assignment |
Owner name: NEXAGEN, INC., COLORADO Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:BIESECKER, GREG;JAYASENA, SUMEDHA;GOLD, LARRY;AND OTHERS;REEL/FRAME:018831/0519;SIGNING DATES FROM 19940613 TO 19940620 Owner name: NEXSTAR PHARMACEUTICALS, INC., COLORADO Free format text: CHANGE OF NAME;ASSIGNOR:NEXAGEN, INC.;REEL/FRAME:018831/0465 Effective date: 19950221 Owner name: GILEAD SCIENCES, INC., CALIFORNIA Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:NEXSTAR PHARMACEUTICALS, INC.;REEL/FRAME:018831/0575 Effective date: 20010123 |
|
| STCB | Information on status: application discontinuation |
Free format text: ABANDONED -- FAILURE TO RESPOND TO AN OFFICE ACTION |