KR20240050408A - Method for correcting motion information and device therefor - Google Patents
Method for correcting motion information and device therefor Download PDFInfo
- Publication number
- KR20240050408A KR20240050408A KR1020247010188A KR20247010188A KR20240050408A KR 20240050408 A KR20240050408 A KR 20240050408A KR 1020247010188 A KR1020247010188 A KR 1020247010188A KR 20247010188 A KR20247010188 A KR 20247010188A KR 20240050408 A KR20240050408 A KR 20240050408A
- Authority
- KR
- South Korea
- Prior art keywords
- motion information
- motion
- block
- current block
- corrected
- Prior art date
Links
- 230000033001 locomotion Effects 0.000 title claims abstract description 1018
- 238000000034 method Methods 0.000 title claims description 260
- 238000012937 correction Methods 0.000 claims abstract description 91
- 239000013598 vector Substances 0.000 claims description 59
- 230000003287 optical effect Effects 0.000 claims description 26
- 230000002146 bilateral effect Effects 0.000 claims description 9
- 230000001174 ascending effect Effects 0.000 claims description 6
- 230000008569 process Effects 0.000 description 61
- 238000010586 diagram Methods 0.000 description 58
- 230000009466 transformation Effects 0.000 description 39
- 238000013139 quantization Methods 0.000 description 38
- 238000011156 evaluation Methods 0.000 description 24
- 238000012545 processing Methods 0.000 description 21
- 230000002457 bidirectional effect Effects 0.000 description 16
- 238000001914 filtration Methods 0.000 description 12
- 238000009826 distribution Methods 0.000 description 10
- 230000011664 signaling Effects 0.000 description 10
- 238000005516 engineering process Methods 0.000 description 9
- 239000000523 sample Substances 0.000 description 9
- 230000002123 temporal effect Effects 0.000 description 9
- 230000008859 change Effects 0.000 description 8
- 229910003460 diamond Inorganic materials 0.000 description 8
- 239000010432 diamond Substances 0.000 description 8
- 230000000694 effects Effects 0.000 description 8
- 208000037170 Delayed Emergence from Anesthesia Diseases 0.000 description 7
- 230000003044 adaptive effect Effects 0.000 description 7
- 238000006243 chemical reaction Methods 0.000 description 7
- 239000013074 reference sample Substances 0.000 description 6
- PXFBZOLANLWPMH-UHFFFAOYSA-N 16-Epiaffinine Natural products C1C(C2=CC=CC=C2N2)=C2C(=O)CC2C(=CC)CN(C)C1C2CO PXFBZOLANLWPMH-UHFFFAOYSA-N 0.000 description 5
- 230000006835 compression Effects 0.000 description 5
- 238000007906 compression Methods 0.000 description 5
- 241000023320 Luma <angiosperm> Species 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 239000011159 matrix material Substances 0.000 description 4
- OSWPMRLSEDHDFF-UHFFFAOYSA-N methyl salicylate Chemical compound COC(=O)C1=CC=CC=C1O OSWPMRLSEDHDFF-UHFFFAOYSA-N 0.000 description 4
- 238000004891 communication Methods 0.000 description 3
- 238000012790 confirmation Methods 0.000 description 3
- 230000001419 dependent effect Effects 0.000 description 3
- 238000009795 derivation Methods 0.000 description 3
- 238000005457 optimization Methods 0.000 description 3
- 238000003672 processing method Methods 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 238000000638 solvent extraction Methods 0.000 description 3
- 230000008901 benefit Effects 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 230000008570 general process Effects 0.000 description 2
- 238000005192 partition Methods 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 230000001131 transforming effect Effects 0.000 description 2
- 238000012935 Averaging Methods 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 238000005286 illumination Methods 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000001151 other effect Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 230000000750 progressive effect Effects 0.000 description 1
- 230000001902 propagating effect Effects 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 238000011426 transformation method Methods 0.000 description 1
Images






































Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/513—Processing of motion vectors
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/11—Selection of coding mode or of prediction mode among a plurality of spatial predictive coding modes
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/119—Adaptive subdivision aspects, e.g. subdivision of a picture into rectangular or non-rectangular coding blocks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/132—Sampling, masking or truncation of coding units, e.g. adaptive resampling, frame skipping, frame interpolation or high-frequency transform coefficient masking
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/189—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the adaptation method, adaptation tool or adaptation type used for the adaptive coding
- H04N19/192—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the adaptation method, adaptation tool or adaptation type used for the adaptive coding the adaptation method, adaptation tool or adaptation type being iterative or recursive
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/56—Motion estimation with initialisation of the vector search, e.g. estimating a good candidate to initiate a search
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/573—Motion compensation with multiple frame prediction using two or more reference frames in a given prediction direction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/577—Motion compensation with bidirectional frame interpolation, i.e. using B-pictures
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/593—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving spatial prediction techniques
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/70—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by syntax aspects related to video coding, e.g. related to compression standards
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/90—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using coding techniques not provided for in groups H04N19/10-H04N19/85, e.g. fractals
- H04N19/96—Tree coding, e.g. quad-tree coding
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
비디오 신호 디코딩 장치는 프로세서를 포함하고, 상기 프로세서는 현재 블록과 관련된 하나 이상의 제1 움직임 정보들을 포함하는 제1 움직임 정보 리스트를 획득하고, 상기 하나 이상의 제1 움직임 정보들을 보정하여 하나 이상의 제1 보정된 움직임 정보들을 획득하고, 상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대한 하나 이상의 제1 코스트 값들을 획득하고, 상기 하나 이상의 제1 보정된 움직임 정보들을 상기 제1 코스트 값들에 기초하여 재정렬하여 제2 움직임 정보 리스트를 획득하고, 상기 제2 움직임 정보 리스트에 포함되는 제1 움직임 정보에 기초하여 하나 이상의 제2 움직임 정보들을 획득하고, 상기 하나 이상의 제2 움직임 정보들을 보정하여 하나 이상의 제2 보정된 움직임 정보들을 획득하고, 상기 제2 보정된 움직임 정보들 각각에 대한 하나 이상의 제2 코스트 값들을 획득하고, 상기 제2 코스트 값들에 기초하여 결정되는 제2 움직임 정보에 기초하여 상기 현재 블록을 예측한다.A video signal decoding apparatus includes a processor, wherein the processor obtains a first motion information list including one or more first motion information related to a current block, corrects the one or more first motion information, and performs one or more first corrections. Obtaining motion information, obtaining one or more first cost values for each of the one or more first corrected motion information, and rearranging the one or more first corrected motion information based on the first cost values. Obtaining a second motion information list, obtaining one or more second motion information based on the first motion information included in the second motion information list, and correcting the one or more second motion information to perform one or more second corrections Obtaining motion information, obtaining one or more second cost values for each of the second corrected motion information, and predicting the current block based on second motion information determined based on the second cost values. do.
Description
본 발명은 비디오 신호의 처리 방법 및 장치에 관한 것으로, 보다 상세하게는 비디오 신호를 인코딩하거나 디코딩하는 비디오 신호 처리 방법 및 장치에 관한 것이다.The present invention relates to a method and device for processing video signals, and more particularly, to a method and device for processing video signals for encoding or decoding video signals.
압축 부호화란 디지털화한 정보를 통신 회선을 통해 전송하거나, 저장 매체에 적합한 형태로 저장하기 위한 일련의 신호 처리 기술을 의미한다. 압축 부호화의 대상에는 음성, 영상, 문자 등의 대상이 존재하며, 특히 영상을 대상으로 압축 부호화를 수행하는 기술을 비디오 영상 압축이라고 일컫는다. 비디오 신호에 대한 압축 부호화는 공간적인 상관관계, 시간적인 상관관계, 확률적인 상관관계 등을 고려하여 잉여 정보를 제거함으로써 이루어진다. 그러나 최근의 다양한 미디어 및 데이터 전송 매체의 발전으로 인해, 더욱 고효율의 비디오 신호 처리 방법 및 장치가 요구되고 있다.Compression encoding refers to a series of signal processing technologies for transmitting digitized information through communication lines or storing it in a form suitable for storage media. Targets of compression coding include audio, video, and text. In particular, the technology for performing compression coding on video is called video image compression. Compression coding for video signals is accomplished by removing redundant information by considering spatial correlation, temporal correlation, and probabilistic correlation. However, due to recent developments in various media and data transmission media, more highly efficient video signal processing methods and devices are required.
본 명세서는 비디오 신호 처리 방법 및 이를 위한 장치를 제공하여 비디오 신호의 코딩 효율을 높이기 위한 목적이 있다.The purpose of this specification is to increase the coding efficiency of video signals by providing a video signal processing method and apparatus for the same.
본 명세서는 비디오 신호 처리 방법 및 이를 위한 장치를 제공한다.This specification provides a video signal processing method and a device therefor.
본 명세서에 있어서, 비디오 신호 디코딩 장치는 프로세서를 포함하며, 상기 프로세서는, 현재 블록과 관련된 하나 이상의 제1 움직임 정보들을 포함하는 제1 움직임 정보 리스트를 획득하고, 상기 하나 이상의 제1 움직임 정보들을 보정하여 하나 이상의 제1 보정된 움직임 정보들을 획득하고, 상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대한 하나 이상의 제1 코스트 값들을 획득하고, 상기 하나 이상의 제1 보정된 움직임 정보들을 상기 제1 코스트 값들에 기초하여 재정렬하여 제2 움직임 정보 리스트를 획득하고, 상기 제2 움직임 정보 리스트에 포함되는 제1 움직임 정보에 기초하여 하나 이상의 제2 움직임 정보들을 획득하고, 상기 하나 이상의 제2 움직임 정보들을 보정하여 하나 이상의 제2 보정된 움직임 정보들을 획득하고, 상기 제2 보정된 움직임 정보들 각각에 대한 하나 이상의 제2 코스트 값들을 획득하고, 상기 제2 코스트 값들에 기초하여 결정되는 제2 움직임 정보에 기초하여 상기 현재 블록을 예측하는 것을 특징으로 한다.In this specification, a video signal decoding device includes a processor, wherein the processor obtains a first motion information list including one or more first motion information related to a current block, and corrects the one or more first motion information. Obtain one or more first corrected motion information, obtain one or more first cost values for each of the one or more first corrected motion information, and obtain the one or more first cost values for the one or more first corrected motion information. Obtaining a second motion information list by rearranging the values, obtaining one or more pieces of second motion information based on first motion information included in the second motion information list, and correcting the one or more pieces of second motion information. Obtain one or more pieces of second corrected motion information, obtain one or more second cost values for each of the second corrected motion information, and based on the second motion information determined based on the second cost values. It is characterized by predicting the current block.
본 명세서에 있어서, 비디오 신호 인코딩 장치는 프로세서를 포함하며 상기 프로세서는, 디코딩 방법에 의해 디코딩되는 비트스트림을 획득하고, 상기 디코딩 방법은, 현재 블록과 관련된 하나 이상의 제1 움직임 정보들을 포함하는 제1 움직임 정보 리스트를 획득하는 단계; 상기 하나 이상의 제1 움직임 정보들을 보정하여 하나 이상의 제1 보정된 움직임 정보들을 획득하는 단계; 상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대한 하나 이상의 제1 코스트 값들을 획득하는 단계; 상기 하나 이상의 제1 보정된 움직임 정보들을 상기 제1 코스트 값들에 기초하여 재정렬하여 제2 움직임 정보 리스트를 획득하는 단계; 상기 제2 움직임 정보 리스트에 포함되는 제1 움직임 정보에 기초하여 하나 이상의 제2 움직임 정보들을 획득하는 단계; 상기 하나 이상의 제2 움직임 정보들을 보정하여 하나 이상의 제2 보정된 움직임 정보들을 획득하는 단계; 상기 제2 보정된 움직임 정보들 각각에 대한 하나 이상의 제2 코스트 값들을 획득하는 단계; 및 상기 제2 코스트 값들에 기초하여 결정되는 제2 움직임 정보에 기초하여 상기 현재 블록을 예측하는 단계를 포함하는 것을 특징으로 한다.In this specification, a video signal encoding device includes a processor, and the processor obtains a bitstream to be decoded by a decoding method, and the decoding method includes first motion information including one or more first motion information related to the current block. Obtaining a motion information list; Correcting the one or more pieces of first motion information to obtain one or more pieces of first corrected motion information; Obtaining one or more first cost values for each of the one or more pieces of first corrected motion information; Obtaining a second motion information list by rearranging the one or more pieces of first corrected motion information based on the first cost values; Obtaining one or more pieces of second motion information based on first motion information included in the second motion information list; Correcting the one or more pieces of second motion information to obtain one or more pieces of second corrected motion information; Obtaining one or more second cost values for each of the second corrected motion information; and predicting the current block based on second motion information determined based on the second cost values.
본 명세서에 있어서, 비트스트림을 저장하는 컴퓨터 판독 가능한 비 일시적 저장 매체에 있어서, 상기 비트스트림은 디코딩 방법에 의해 디코딩되고, 상기 디코딩 방법은, 현재 블록과 관련된 하나 이상의 제1 움직임 정보들을 포함하는 제1 움직임 정보 리스트를 획득하는 단계; 상기 하나 이상의 제1 움직임 정보들을 보정하여 하나 이상의 제1 보정된 움직임 정보들을 획득하는 단계; 상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대한 하나 이상의 제1 코스트 값들을 획득하는 단계; 상기 하나 이상의 제1 보정된 움직임 정보들을 상기 제1 코스트 값들에 기초하여 재정렬하여 제2 움직임 정보 리스트를 획득하는 단계; 상기 제2 움직임 정보 리스트에 포함되는 제1 움직임 정보에 기초하여 하나 이상의 제2 움직임 정보들을 획득하는 단계; 상기 하나 이상의 제2 움직임 정보들을 보정하여 하나 이상의 제2 보정된 움직임 정보들을 획득하는 단계; 상기 제2 보정된 움직임 정보들 각각에 대한 하나 이상의 제2 코스트 값들을 획득하는 단계; 및 상기 제2 코스트 값들에 기초하여 결정되는 제2 움직임 정보에 기초하여 상기 현재 블록을 예측하는 단계를 포함하는 것을 특징으로 한다.In the present specification, in a computer-readable non-transitory storage medium storing a bitstream, the bitstream is decoded by a decoding method, wherein the decoding method includes one or more first motion information related to the current block. 1 Obtaining a motion information list; Correcting the one or more pieces of first motion information to obtain one or more pieces of first corrected motion information; Obtaining one or more first cost values for each of the one or more pieces of first corrected motion information; Obtaining a second motion information list by rearranging the one or more pieces of first corrected motion information based on the first cost values; Obtaining one or more pieces of second motion information based on first motion information included in the second motion information list; Correcting the one or more pieces of second motion information to obtain one or more pieces of second corrected motion information; Obtaining one or more second cost values for each of the second corrected motion information; and predicting the current block based on second motion information determined based on the second cost values.
상기 하나 이상의 제1 코스트 값들은 상기 현재 블록과 상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대응되는 참조 블록간의 유사도와 관련된 값이고, 상기 하나 이상의 제2 코스트 값들은 상기 현재 블록과 상기 하나 이상의 제2 보정된 움직임 정보들 각각에 대응되는 참조 블록간의 유사도와 관련된 값인 것을 특징으로 한다.The one or more first cost values are values related to the similarity between the current block and the reference block corresponding to each of the one or more first corrected motion information, and the one or more second cost values are related to the similarity between the current block and the one or more first corrected motion information. It is characterized in that it is a value related to the similarity between reference blocks corresponding to each of the second corrected motion information.
상기 제2 움직임 정보 리스트는 상기 하나 이상의 제1 보정된 움직임 정보들에 각각 대응되는 코스트 값이 오름차순으로 정렬되는 것을 특징으로 한다.The second motion information list is characterized in that cost values corresponding to each of the one or more pieces of first corrected motion information are sorted in ascending order.
상기 제1 움직임 정보는 상기 제1 코스트 값들 중 가장 작은 코스트 값에 대응하는 보정된 움직임 정보인 것을 특징으로 한다.The first motion information is characterized as corrected motion information corresponding to the smallest cost value among the first cost values.
상기 제2 움직임 정보는 상기 제2 코스트 값들 중 가장 작은 코스트 값에 대응하는 보정된 움직임 정보인 것을 특징으로 한다.The second motion information is characterized as corrected motion information corresponding to the smallest cost value among the second cost values.
상기 하나 이상의 제1 움직임 정보들은 각각 서로 다른 픽쳐에 포함되고, 상기 하나 이상의 제2 움직임 정보들은 각각 서로 다른 픽쳐에 포함되는 것을 특징으로 한다.The one or more pieces of first motion information are respectively included in different pictures, and the one or more pieces of second motion information are respectively included in different pictures.
상기 하나 이상의 제1 보정된 움직임 정보들 및 상기 하나 이상의 제2 보정된 움직임 정보들은, MVD(Motion Vector Difference), TM(Template Matching), BM(Bilateral Matching), MMVD(Merge mode with MVD), MMVD(Merge mode with MVD) 기반의 TM, 광 흐름(Optical flow)에 기초한 기반 TM, 멀티 패스 DMVR (Multi pass Decoder-side Motion Vector Refinement) 중 적어도 어느 하나 이상에 기초하여 보정되는 것을 특징으로 한다.The one or more first corrected motion information and the one or more second corrected motion information may include Motion Vector Difference (MVD), Template Matching (TM), Bilateral Matching (BM), Merge mode with MVD (MMVD), and MMVD. It is characterized by correction based on at least one of (Merge mode with MVD)-based TM, optical flow-based TM, and multi-pass DMVR (Multi pass Decoder-side Motion Vector Refinement).
상기 현재 블록의 부호화 모드가 머지(merge) 모드인 경우, 상기 하나 이상의 제1 움직임 정보들 및 상기 하나 이상의 제2 움직임 정보들은 MMVD(Merge mode with MVD)에 의해 유도되는 움직임 정보인 것을 특징으로 한다.When the encoding mode of the current block is a merge mode, the one or more first motion information and the one or more second motion information are characterized in that they are motion information derived by MMVD (Merge mode with MVD). .
상기 하나 이상의 제1 움직임 정보들 각각에 대응되는 블록들은 제1 탐색 영역 내에 위치하는 블록이고, 상기 하나 이상의 제2 움직임 정보들 각각에 대응되는 블록들은 제2 탐색 영역 내에 위치하는 블록이고, 상기 제1 탐색 영역과 상기 제2 탐색 영역은 서로 상이한 것을 특징으로 한다.Blocks corresponding to each of the one or more pieces of first motion information are blocks located in a first search area, blocks corresponding to each of the one or more pieces of second motion information are blocks located in a second search area, and the blocks corresponding to each of the one or more pieces of second motion information are blocks located in a second search area. The first search area and the second search area are characterized in that they are different from each other.
상기 제1 코스트 값들은 상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대해 순차적으로 계산되고, 상기 제2 코스트 값들은 상기 하나 이상의 제2 보정된 움직임 정보들 각각에 대해 순차적으로 계산되는 것을 특징으로 한다.The first cost values are sequentially calculated for each of the one or more first corrected motion information, and the second cost values are sequentially calculated for each of the one or more second corrected motion information. do.
상기 제1 코스트 값들이 순차적으로 계산되는 중 기 설정된 제1 값보다 작은 코스트 값이 계산되는 경우, 나머지 보정된 움직임 정보들에 대한 코스트 값들은 계산되지 않고, 상기 제2 코스트 값들이 순차적으로 계산되는 중 기 설정된 제2 값보다 작은 코스트 값이 계산되는 경우, 나머지 보정된 움직임 정보들에 대한 코스트 값들은 계산되지 않는 것을 특징으로 한다.When the first cost values are calculated sequentially and a cost value smaller than the preset first value is calculated, cost values for the remaining corrected motion information are not calculated, and the second cost values are calculated sequentially. When a cost value smaller than the preset second value is calculated, cost values for the remaining corrected motion information are not calculated.
본 명세서는 효율적으로 비디오 신호를 처리하기 위한 방법을 제공한다.This specification provides a method for efficiently processing video signals.
본 명세서에서 얻을 수 있는 효과는 이상에서 언급한 효과들로 제한되지 않으며, 언급하지 않은 또 다른 효과들은 아래의 기재로부터 본 발명이 속하는 기술분야에서 통상의 지식을 가진 자에게 명확하게 이해될 수 있을 것이다.The effects that can be obtained in this specification are not limited to the effects mentioned above, and other effects not mentioned can be clearly understood by those skilled in the art from the description below. will be.
도 1은 본 발명의 일 실시예에 따른 비디오 신호 인코딩 장치의 개략적인 블록도이다.
도 2는 본 발명의 일 실시예에 따른 비디오 신호 디코딩 장치의 개략적인 블록도이다.
도 3은 픽쳐 내에서 코딩 트리 유닛이 코딩 유닛들로 분할되는 실시예를 도시한다.
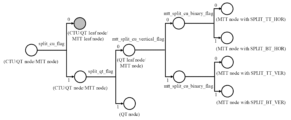
도 4는 쿼드 트리 및 멀티-타입 트리의 분할을 시그널링하는 방법의 일 실시예를 도시한다.
도 5 및 도 6은 본 발명의 실시예에 따른 인트라 예측 방법을 더욱 구체적으로 도시한다.
도 7은 인터 예측에서 움직임 후보 리스트를 구성하기 위해 사용되는 주변 블록들의 위치를 나타낸 도면이다.
도 8은 본 발명의 일 실시예에 따른 움직임 정보를 보정하는 방법을 나타내는 도면이다.
도 9는 본 발명의 일 실시예에 따른 움직임 보정 방법을 재귀적으로 수행하여 현재 블록에 대한 움직임 정보를 보정하는 방법을 나타내는 도면이다.
도 10은 본 발명의 일 실시예에 따른 TM 방법이 수행되는 순서를 나타내는 도면이다.
도 11은 본 발명의 일 실시예에 따른 초기 움직임 정보에 기초하여 TM 방법을 위한 탐색 영역을 설정하는 방법을 나타내는 도면이다.
도 12는 본 발명의 일 실시예에 따른 탐색 영역 내에서 탐색되는 움직임 후보의 위치를 나타내는 도면이다.
도 13은 본 발명의 일 실시예에 따른 움직임 후보의 위치를 탐색하는 과정을 나타내는 도면이다.
도 14는 본 발명의 일 실시예 따른 탐색 후보를 평가하는 과정을 나타내는 도면이다.
도 15는 본 발명의 일 실시예에 따른 현재 픽쳐 내 객체의 경계 부분에 대한 움직임 특성을 나타내는 도면이다.
도 16은 본 발명의 일 실시예에 따른 템플릿 매칭을 이용하여 참조 픽쳐를 결정하는 방법을 나타내는 도면이다.
도 17, 도 18은 본 발명의 일 실시예에 따른 템플릿 매칭을 수행하는 과정을 나타내는 도면이다.
도 19는 본 발명의 일 실시예에 따른 현재 블록의 주변 블록으로부터 유도되는 초기 움직임 정보들이 서로 붙어 있는 경우를 나타내는 도면이다.
도 20, 21은 본 발명의 일 실시예에 따른 초기 움직임 정보를 변경하는 방법을 나타내는 도면이다.
도 22는 본 발명의 일 실시예에 따른 초기 움직임 정보를 통해 유도되는 움직임 후보가 탐색되는 위치를 나타내는 도면이다.
도 23은 본 발명의 일 실시예에 따른 움직임 후보가 탐색되는 탐색 위치를 변경하는 방법을 나타내는 도면이다.
도 24는 본 발명의 일 실시예에 따른 움직임 벡터의 코스트 값에 기초한 TM을 나타내는 도면이다.
도 25, 도 26은 본 발명의 일 실시예에 따른 DMVR을 사용하여 움직임 정보를 보정하는 방법을 나타내는 도면이다.
도 27은 본 발명의 일 실시예에 따른 다중 DMVR이 수행되는 과정을 나타내는 도면이다.
도 28은 본 발명의 일 실시예에 따른 코딩 블록의 보정된 움직임 정보와 관련된 코스트 값을 획득하기 위한 탐색 방법을 나타내는 도면이다.
도 29는 본 발명의 일 실시예에 따른 3x3 Square 탐색 방법을 나타내는 도면이다.
도 30은 본 발명의 일 실시예에 따른 정수 단위 전역 탐색 과정에서 탐색 영역을 구역별로 나누어 진 것을 나타낸 도면이다.
도 31, 도 32는 본 발명의 일 실시예에 따른 정수 단위의 전역 탐색 과정을 나타내는 도면이다.
도 33, 34는 본 발명의 일 실시예에 따른 BDOF에 기반한 움직임 정보의 보정을 수행하는 방법을 나타내는 도면이다.
도 35, 도 36은 본 발명의 일 실시예에 따른 BDOF에 기반한 현재 블록에 대한 예측 블록을 생성하는 방법을 나타내는 도면이다.
도 37은 본 발명의 일 실시예에 따른 DMVR이 적용되는 서브블록을 나타내는 도면이다.
도 38은 본 발명의 일 실시예에 따른 다중 DMVR을 수행하면서 현재 블록에 대한 예측 블록을 생성하는 방법을 나타내는 도면이다.1 is a schematic block diagram of a video signal encoding device according to an embodiment of the present invention.
Figure 2 is a schematic block diagram of a video signal decoding device according to an embodiment of the present invention.
Figure 3 shows an embodiment in which a coding tree unit is divided into coding units within a picture.
Figure 4 shows one embodiment of a method for signaling splitting of quad trees and multi-type trees.
Figures 5 and 6 show the intra prediction method according to an embodiment of the present invention in more detail.
Figure 7 is a diagram showing the positions of neighboring blocks used to construct a motion candidate list in inter prediction.
Figure 8 is a diagram showing a method for correcting motion information according to an embodiment of the present invention.
Figure 9 is a diagram illustrating a method of correcting motion information for a current block by recursively performing a motion correction method according to an embodiment of the present invention.
Figure 10 is a diagram showing the order in which the TM method is performed according to an embodiment of the present invention.
FIG. 11 is a diagram illustrating a method for setting a search area for a TM method based on initial motion information according to an embodiment of the present invention.
Figure 12 is a diagram showing the location of a motion candidate searched within a search area according to an embodiment of the present invention.
Figure 13 is a diagram showing the process of searching for the location of a motion candidate according to an embodiment of the present invention.
Figure 14 is a diagram showing a process for evaluating search candidates according to an embodiment of the present invention.
Figure 15 is a diagram showing movement characteristics of the boundary portion of an object in the current picture according to an embodiment of the present invention.
Figure 16 is a diagram showing a method of determining a reference picture using template matching according to an embodiment of the present invention.
Figures 17 and 18 are diagrams showing the process of performing template matching according to an embodiment of the present invention.
FIG. 19 is a diagram illustrating a case where initial motion information derived from neighboring blocks of the current block are attached to each other according to an embodiment of the present invention.
20 and 21 are diagrams showing a method of changing initial motion information according to an embodiment of the present invention.
Figure 22 is a diagram showing the location where a motion candidate derived through initial motion information is searched according to an embodiment of the present invention.
Figure 23 is a diagram illustrating a method of changing the search location where motion candidates are searched according to an embodiment of the present invention.
Figure 24 is a diagram showing TM based on the cost value of a motion vector according to an embodiment of the present invention.
Figures 25 and 26 are diagrams showing a method of correcting motion information using DMVR according to an embodiment of the present invention.
Figure 27 is a diagram showing a process in which multiple DMVR is performed according to an embodiment of the present invention.
FIG. 28 is a diagram illustrating a search method for obtaining a cost value related to corrected motion information of a coding block according to an embodiment of the present invention.
Figure 29 is a diagram showing a 3x3 Square search method according to an embodiment of the present invention.
Figure 30 is a diagram showing that the search area is divided into zones in the integer global search process according to an embodiment of the present invention.
Figures 31 and 32 are diagrams showing a global search process in integer units according to an embodiment of the present invention.
Figures 33 and 34 are diagrams showing a method of performing correction of motion information based on BDOF according to an embodiment of the present invention.
Figures 35 and 36 are diagrams showing a method of generating a prediction block for a current block based on BDOF according to an embodiment of the present invention.
Figure 37 is a diagram showing a subblock to which DMVR is applied according to an embodiment of the present invention.
Figure 38 is a diagram showing a method of generating a prediction block for a current block while performing multiple DMVR according to an embodiment of the present invention.
본 명세서에서 사용되는 용어는 본 발명에서의 기능을 고려하면서 가능한 현재 널리 사용되는 일반적인 용어를 선택하였으나, 이는 당 분야에 종사하는 기술자의 의도, 관례 또는 새로운 기술의 출현 등에 따라 달라질 수 있다. 또한 특정 경우는 출원인이 임의로 선정한 용어도 있으며, 이 경우 해당되는 발명의 설명 부분에서 그 의미를 기재할 것이다. 따라서 본 명세서에서 사용되는 용어는, 단순한 용어의 명칭이 아닌 그 용어가 가진 실질적인 의미와 본 명세서의 전반에 걸친 내용을 토대로 해석되어야 함을 밝혀두고자 한다.The terms used in this specification are general terms that are currently widely used as much as possible while considering the function in the present invention, but this may vary depending on the intention of a person skilled in the art, custom, or the emergence of new technology. In addition, in certain cases, there are terms arbitrarily selected by the applicant, and in this case, the meaning will be described in the description of the relevant invention. Therefore, we would like to clarify that the terms used in this specification should be interpreted based on the actual meaning of the term and the overall content of this specification, not just the name of the term.
본 명세서에서 'A 및/또는 B'는 'A 또는 B 중 적어도 하나를 포함하는'과 같은 의미로 해석될 수 있다.In this specification, ‘A and/or B’ may be interpreted as meaning ‘including at least one of A or B.’
본 명세서에서 일부 용어들은 다음과 같이 해석될 수 있다. 코딩은 경우에 따라 인코딩 또는 디코딩으로 해석될 수 있다. 본 명세서에서 비디오 신호의 인코딩(부호화)을 수행하여 비디오 신호 비트스트림을 생성하는 장치는 인코딩 장치 또는 인코더로 지칭되며, 비디오 신호 비트스트림의 디코딩(복호화)을 수행하여 비디오 신호를 복원하는 장치는 디코딩 장치 또는 디코더로 지칭된다. 또한, 본 명세서에서 비디오 신호 처리 장치는 인코더 및 디코더를 모두 포함하는 개념의 용어로 사용된다. 정보(information)는 값(values), 파라미터(parameter), 계수(coefficients), 성분(elements) 등을 모두 포함하는 용어로서, 경우에 따라 의미는 달리 해석될 수 있으므로 본 발명은 이에 한정되지 아니한다. '유닛'은 영상 처리의 기본 단위 또는 픽쳐의 특정 위치를 지칭하는 의미로 사용되며, 휘도(luma) 성분 및 색차(chroma) 성분 중 적어도 하나를 포함하는 이미지 영역을 가리킨다. 또한, '블록'은 휘도 성분 및 색차 성분들(즉, Cb 및 Cr) 중 특정 성분을 포함하는 이미지 영역을 가리킨다. 다만, 실시예에 따라서 '유닛', '블록', '파티션', '신호' 및 '영역' 등의 용어는 서로 혼용하여 사용될 수 있다. 또한, 본 명세서에서 '현재 블록'은 현재 부호화를 진행할 예정인 블록을 의미하며, '참조 블록'은 이미 부호화 또는 복호화가 완료된 블록으로 현재 블록에서 참조로 사용되는 블록을 의미한다. 또한, 본 명세서에서 '루마', 'luma', '휘도', 'Y' 등의 용어는 서로 혼용하여 사용될 수 있다. 또한, 본 명세서에서 '크로마', 'chroma' '색차', 'Cb 또는 Cr' 등의 용어는 서로 혼용하여 사용될 수 있으며, 색차 성분은 Cb와 Cr 2가지로 나누어지므로 각 색차 성분은 구분되어 사용될 수 있다. 또한, 본 명세서에서 유닛은 코딩 유닛, 예측 유닛, 변환 유닛을 모두 포함하는 개념으로 사용될 수 있다. 픽쳐는 필드 또는 프레임을 가리키며, 실시예에 따라 상기 용어들은 서로 혼용하여 사용될 수 있다. 구체적으로 촬영된 영상이 비월주사식(interlace) 영상일 경우, 하나의 프레임은 홀수(또는 기수, top) 필드와 짝수(또는 우수, bottom) 필드로 분리되어, 각 필드는 하나의 픽쳐 단위로 구성되어 부호화 또는 복호화 될 수 있다. 만일 촬영된 영상이 순차주사(progressive) 영상일 경우, 하나의 프레임이 픽쳐로서 구성되어 부호화 또는 복호화 될 수 있다. 또한, 본 명세서에서 '오차 신호', '레지듀얼 신호', '잔차 신호', '잔여 신호' 및 '차분 신호' 등의 용어는 서로 혼용하여 사용될 수 있다. 또한, 본 명세서에서 '인트라 예측 모드', '인트라 예측 방향성 모드', '화면 내 예측 모드' 및 '화면 내 예측 방향성 모드' 등의 용어는 서로 혼용하여 사용될 수 있다. 또한, 본 명세서에서 '모션', '움직임' 등의 용어는 서로 혼용하여 사용될 수 있다. 또한, 본 명세서에서 '좌측', '좌상측', '상측', '우상측', '우측', '우하측', '하측', '좌하측'은 '좌단', '좌상단', '상단', '우상단', '우단', '우하단', '하단', '좌하단'와 서로 혼용하여 사용될 수 있다. 또한, 원소(element), 멤버(member)는 서로 혼용하여 사용될 수 있다. POC(Picture Order Count)는 픽쳐(또는 프레임)의 시간적 위치 정보를 나타내며, 화면에 출력되는 재생 순서가 될 수 있으며, 픽쳐마다 고유의 POC를 가질 수 있다.Some terms in this specification may be interpreted as follows. Coding can be interpreted as encoding or decoding depending on the case. In this specification, a device that performs encoding (encoding) of a video signal to generate a video signal bitstream is referred to as an encoding device or encoder, and a device that performs decoding (decoding) of a video signal bitstream to restore a video signal is referred to as a decoder. Referred to as a device or decoder. Additionally, in this specification, a video signal processing device is used as a term that includes both an encoder and a decoder. Information is a term that includes values, parameters, coefficients, elements, etc., and the meaning may be interpreted differently depending on the case, so the present invention is not limited thereto. 'Unit' is used to refer to a basic unit of image processing or a specific location of a picture, and refers to an image area containing at least one of a luminance (luma) component and a chrominance (chroma) component. Additionally, 'block' refers to an image area containing specific components among the luminance component and chrominance component (i.e., Cb and Cr). However, depending on the embodiment, terms such as 'unit', 'block', 'partition', 'signal', and 'area' may be used interchangeably. Additionally, in this specification, 'current block' refers to a block currently scheduled to be encoded, and 'reference block' refers to a block for which encoding or decoding has already been completed and is used as a reference in the current block. Additionally, in this specification, terms such as 'luma', 'luma', 'luminance', and 'Y' may be used interchangeably. In addition, in this specification, terms such as 'chroma', 'chroma', 'color difference', and 'Cb or Cr' may be used interchangeably, and since the color difference component is divided into two types, Cb and Cr, each color difference component will be used separately. You can. Additionally, in this specification, a unit may be used as a concept that includes all coding units, prediction units, and transformation units. A picture refers to a field or frame, and depending on the embodiment, the above terms may be used interchangeably. Specifically, when the captured image is an interlaced image, one frame is divided into an odd (or odd, top) field and an even (or even, bottom) field, and each field consists of one picture unit. and can be encoded or decoded. If the captured image is a progressive image, one frame can be configured as a picture and encoded or decoded. Additionally, in this specification, terms such as 'error signal', 'residual signal', 'residual signal', 'residual signal', and 'difference signal' may be used interchangeably. Additionally, in this specification, terms such as 'intra prediction mode', 'intra prediction directional mode', 'intra-screen prediction mode', and 'intra-screen prediction directional mode' may be used interchangeably. Additionally, in this specification, terms such as 'motion' and 'movement' may be used interchangeably. In addition, in this specification, 'left', 'upper left', 'upper', 'upper right', 'right', 'lower right', 'bottom', and 'lower left' mean 'left', 'upper left', ' It can be used interchangeably with 'top', 'top right', 'bottom right', 'bottom right', 'bottom', and 'bottom left'. Additionally, element and member can be used interchangeably. POC (Picture Order Count) represents temporal location information of a picture (or frame), can be the playback order displayed on the screen, and each picture can have a unique POC.
도 1은 본 발명의 일 실시예에 따른 비디오 신호 인코딩 장치(100)의 개략적인 블록도이다. 도 1을 참조하면, 본 발명의 인코딩 장치(100)는 변환부(110), 양자화부(115), 역양자화부(120), 역변환부(125), 필터링부(130), 예측부(150) 및 엔트로피 코딩부(160)를 포함한다.Figure 1 is a schematic block diagram of a video
변환부(110)는 입력 받은 비디오 신호와 예측부(150)에서 생성된 예측 신호의 차이인 레지듀얼 신호를 변환하여 변환 계수 값을 획득한다. 예를 들어, 이산 코사인 변환(Discrete Cosine Transform, DCT), 이산 사인 변환(Discrete Sine Transform, DST) 또는 웨이블릿 변환(Wavelet Transform) 등이 사용될 수 있다. 이산 코사인 변환 및 이산 사인 변환은 입력된 픽쳐 신호를 블록 형태로 나누어 변환을 수행하게 된다. 변환에 있어서 변환 영역 내의 값들의 분포와 특성에 따라서 코딩 효율이 달라질 수 있다. 레지듀얼 블록에 대한 변환에 사용되는 변환 커널은 수직 변환 및 수평 변환의 분리 가능한 특성을 가지는 변환 커널일 수 있다. 이 경우, 레지듀얼 블록에 대한 변환은 수직 변환 및 수평 변환으로 분리되어 수행될 수 있다. 예를 들어, 인코더는 레지듀얼 블록의 수직 방향으로 변환 커널을 적용하여 수직 변환을 수행할 수 있다. 또한, 인코더는 레지듀얼 블록의 수평 방향으로 변환 커널을 적용하여 수평 변환을 수행할 수 있다. 본 개시에서, 변환 커널은 변환 매트릭스, 변환 어레이, 변환 함수, 변환과 같이 레지듀얼 신호의 변환에 사용되는 파라미터 세트를 지칭하는 용어로 사용될 수 있다. 예를 들어, 변환 커널은 복수의 사용 가능한 커널들 중 어느 하나일 수 있다. 또한, 수직 변환 및 수평 변환 각각에 대해 서로 다른 변환 타입에 기반한 변환 커널이 사용될 수도 있다.The
변환계수는 블록의 좌상단으로 갈수록 높은 계수가 분포하고, 블록의 우하단으로 갈수록 '0'에 가까운 계수가 분포한다. 현재 블록의 크기가 커질수록 우하단 영역에서 계수 '0'이 많이 존재할 가능성이 있다. 크기가 큰 블록의 변환 복잡도를 감소시키기 위해서, 임의의 좌상단 영역만을 남기고 나머지 영역은 '0'으로 재설정될 수 있다.Higher conversion coefficients are distributed toward the top left of the block, and coefficients closer to '0' are distributed toward the bottom right of the block. As the size of the current block increases, there is a possibility that there will be more coefficients of '0' in the lower right area. In order to reduce the conversion complexity of large blocks, only the upper left area can be left and the remaining areas can be reset to '0'.
또한, 코딩 블록에서 일부 영역에만 오차 신호가 존재할 수 있다. 이 경우, 임의의 일부 영역에 대해서만 변환 과정이 수행될 수 있다. 실시 일 예로, 2Nx2N 크기의 블록에서 첫번째 2NxN 블록에만 오차 신호가 존재할 수 있으며, 첫번째 2NxN블록에만 변환과정이 수행되지만 두번째 2NxN 블록은 변환과정이 수행되지 않고 인코딩 또는 디코딩되지 않을 수 있다. 여기서 N은 임의의 양의 정수가 될 수 있다.Additionally, error signals may exist only in some areas of the coding block. In this case, the conversion process may be performed only for some arbitrary areas. As an example, in a block of size 2Nx2N, an error signal may exist only in the first 2NxN block, and a conversion process is performed only on the first 2NxN block, but the conversion process is not performed on the second 2NxN block and may not be encoded or decoded. Here N can be any positive integer.
인코더는 변환 계수가 양자화되기 전에 추가적인 변환을 수행할 수 있다. 전술한 변환 방법은 1차 변환(primary transform)으로 지칭되고, 추가적인 변환은 2차 변환(secondary transform)으로 지칭될 수 있다. 2차 변환은 레지듀얼 블록 별로 선택적일 수 있다. 일 실시예에 따라, 인코더는 1차 변환만으로 저주파 영역에 에너지를 집중시키기 어려운 영역에 대해 2차 변환을 수행하여 코딩 효율을 향상시킬 수 있다. 예를 들어, 레지듀얼 값들이 레지듀얼 블록의 수평 또는 수직 방향 이외의 방향에서 크게 나타나는 블록에 대해 2차 변환이 추가로 수행될 수 있다. 2차 변환은 1차 변환과 달리 수직 변환 및 수평 변환으로 분리되어 수행되지 않을 수 있다. 이러한 2차 변환은 저대역 비-분리 변환(Low Frequency Non-Separable Transform, LFNST)으로 지칭될 수 있다.The encoder may perform additional transformations before the transform coefficients are quantized. The above-described transformation method may be referred to as a primary transform, and additional transformation may be referred to as a secondary transform. Secondary transformation may be optional for each residual block. According to one embodiment, the encoder may improve coding efficiency by performing secondary transformation on a region where it is difficult to concentrate energy in the low-frequency region only through primary transformation. For example, secondary transformation may be additionally performed on a block whose residual values appear large in directions other than the horizontal or vertical direction of the residual block. Unlike primary transformation, secondary transformation may not be performed separately into vertical transformation and horizontal transformation. This secondary transform may be referred to as Low Frequency Non-Separable Transform (LFNST).
양자화부(115)는 변환부(110)에서 출력된 변환 계수 값을 양자화한다.The quantization unit 115 quantizes the transform coefficient value output from the
코딩 효율을 높이기 위하여 픽쳐 신호를 그대로 코딩하는 것이 아니라, 예측부(150)를 통해 이미 코딩된 영역을 이용하여 픽쳐를 예측하고, 예측된 픽쳐에 원본 픽쳐와 예측 픽쳐 간의 레지듀얼 값을 더하여 복원 픽쳐를 획득하는 방법이 사용된다. 인코더와 디코더에서 미스매치가 발생되지 않도록 하기 위해, 인코더에서 예측을 수행할 때에는 디코더에서도 사용 가능한 정보를 사용해야 한다. 이를 위해, 인코더에서는 부호화한 현재 블록을 다시 복원하는 과정을 수행한다. 역양자화부(120)에서는 변환 계수 값을 역양자화하고, 역변환부(125)에서는 역양자화된 변환 계수값을 이용하여 레지듀얼 값을 복원한다. 한편, 필터링부(130)는 복원된 픽쳐의 품질 개선 및 부호화 효율 향상을 위한 필터링 연산을 수행한다. 예를 들어, 디블록킹 필터, 샘플 적응적 오프셋(Sample Adaptive Offset, SAO) 및 적응적 루프 필터 등이 포함될 수 있다. 필터링을 거친 픽쳐는 출력되거나 참조 픽쳐로 이용하기 위하여 복호 픽쳐 버퍼(Decoded Picture Buffer, DPB, 156)에 저장된다.In order to increase coding efficiency, rather than coding the picture signal as is, the picture is predicted using the already coded area through the prediction unit 150, and the residual value between the original picture and the predicted picture is added to the predicted picture to create a reconstructed picture. A method of obtaining is used. To prevent mismatches between the encoder and decoder, information available in the decoder must be used when performing prediction in the encoder. For this purpose, the encoder performs a process of restoring the current encoded block. The
디블록킹 필터(deblocking filter)는 복원된 픽쳐에서 블록 간의 경계에 생성된 블록 내의 왜곡을 제거하기 위한 필터이다. 인코더는 블록 내의 임의 경계(edge)를 기준으로 몇 개의 열 또는 행에 포함된 픽셀들의 분포를 통해, 해당 경계에 디블록킹 필터를 적용할지 여부를 판단할 수 있다. 블록에 디블록킹 필터를 적용되는 경우, 인코더는 디블록킹 필터링 강도에 따라 긴 필터(Long Filter), 강한 필터(Strong Filter) 또는 약한 필터(Weak Filter)를 적용할 수 있다. 또한, 수평 방향 필터링 및 수직 방향 필터링이 병렬적으로 처리될 수 있다. 샘플 적응적 오프셋(SAO)은 디블록킹 필터가 적용된 레지듀얼 블록에 대하여, 픽셀 단위로 원본 영상과의 오프셋을 보정하는데 사용될 수 있다. 인코더는 특정 픽쳐에 대한 오프셋을 보정하기 위하여 영상에 포함된 픽셀을 일정한 수의 영역으로 구분한 후, 오프셋 보정을 수행할 영역을 결정하고, 해당 영역에 오프셋을 적용하는 방법(Band Offset)을 사용할 수 있다. 또는 인코더는 각 픽셀의 에지 정보를 고려하여 오프셋을 적용하는 방법(Edge Offset)을 사용할 수 있다. 적응적 루프 필터(Adaptive Loop Filter, ALF)는 영상에 포함된 픽셀을 소정의 그룹으로 나눈 후, 해당 그룹에 적용될 하나의 필터를 결정하여 그룹마다 차별적으로 필터링을 수행하는 방법이다. ALF를 적용할지 여부에 관련된 정보는 코딩 유닛 단위로 시그널링될 수 있고, 각각의 블록에 따라 적용될 ALF 필터의 모양 및 필터 계수가 달라질 수 있다. 또한, 적용할 대상 블록의 특성에 관계없이 동일한 형태(고정된 형태)의 ALF 필터가 적용될 수도 있다.A deblocking filter is a filter for removing distortion within blocks created at the boundaries between blocks in a restored picture. The encoder can determine whether to apply a deblocking filter to the edge based on the distribution of pixels included in several columns or rows based on an arbitrary edge within the block. When a deblocking filter is applied to a block, the encoder can apply a long filter, strong filter, or weak filter depending on the deblocking filtering strength. Additionally, horizontal filtering and vertical filtering can be processed in parallel. Sample adaptive offset (SAO) can be used to correct the offset from the original image on a pixel basis for a residual block to which a deblocking filter has been applied. In order to correct the offset for a specific picture, the encoder divides the pixels included in the image into a certain number of areas, determines the area to perform offset correction, and uses a method (Band Offset) to apply the offset to the area. You can. Alternatively, the encoder can use a method of applying an offset (Edge Offset) by considering the edge information of each pixel. Adaptive Loop Filter (ALF) is a method of dividing pixels included in an image into predetermined groups, then determining a filter to be applied to the group, and performing differential filtering for each group. Information related to whether to apply ALF may be signaled in units of coding units, and the shape and filter coefficients of the ALF filter to be applied may vary for each block. Additionally, an ALF filter of the same type (fixed type) may be applied regardless of the characteristics of the target block to be applied.
예측부(150)는 인트라 예측부(152)와 인터 예측부(154)를 포함한다. 인트라 예측부(152)에서는 현재 픽쳐 내에서 인트라(intra) 예측을 수행하며, 인터 예측부(154)에서는 복호 픽쳐 버퍼(156)에 저장된 참조 픽쳐를 이용하여 현재 픽쳐를 예측하는 인터(inter) 예측을 수행한다. 인트라 예측부(152)는 현재 픽쳐 내의 복원된 영역들로부터 인트라 예측을 수행하여, 인트라 부호화 정보를 엔트로피 코딩부(160)에 전달한다. 인트라 부호화 정보는 인트라 예측 모드, MPM(Most Probable Mode) 플래그, MPM 인덱스, 참조 샘플에 관한 정보 중 적어도 하나를 포함할 수 있다. 인터 예측부(154)는 다시 모션 추정부(154a) 및 모션 보상부(154b)를 포함하여 구성될 수 있다. 모션 추정부(154a)에서는 복원된 참조 픽쳐의 특정 영역을 참조하여 현재 영역과 가장 유사한 부분을 찾고 영역 간의 거리인 모션 벡터 값을 획득한다. 모션 추정부(154a)에서 획득한 참조 영역에 대한 모션 정보(참조 방향 지시 정보(L0 예측, L1 예측, 양방향 예측), 참조 픽쳐 인덱스, 모션 벡터 정보 등) 등을 엔트로피 코딩부(160)로 전달하여 비트스트림에 포함될 수 있도록 한다. 모션 추정부(154a)에서 전달된 모션 정보를 이용하여 모션 보상부(154b)에서는 인터 모션 보상을 수행하여 현재 블록을 위한 예측 블록을 생성한다. 인터 예측부(154)는 참조 영역에 대한 모션 정보를 포함하는 인터 부호화 정보를 엔트로피 코딩부(160)에 전달한다.The prediction unit 150 includes an
추가적인 실시예에 따라, 예측부(150)는 인트라 블록 카피(Intra block copy, IBC) 예측부(미도시)를 포함할 수 있다. IBC 예측부는 현재 픽쳐 내의 복원된 샘플들로부터 IBC 예측을 수행하여, IBC 부호화 정보를 엔트로피 코딩부(160)에 전달한다. IBC 예측부는 현재 픽쳐 내의 특정 영역을 참조하여 현재 영역의 예측에 이용되는 참조 영역을 지시하는 블록 벡터값을 획득한다. IBC 예측부는 획득된 블록 벡터값을 이용하여 IBC 예측을 수행할 수 있다. IBC 예측부는 IBC 부호화 정보를 엔트로피 코딩부(160)로 전달한다. IBC 부호화 정보는 참조 영역의 크기 정보, 블록 벡터 정보(움직임 후보 리스트 내에서 현재 블록의 블록 벡터 예측을 위한 인덱스 정보, 블록 벡터 차분 정보) 중에서 적어도 하나를 포함할 수 있다.According to an additional embodiment, the prediction unit 150 may include an intra block copy (IBC) prediction unit (not shown). The IBC prediction unit performs IBC prediction from the reconstructed samples in the current picture and transmits IBC encoding information to the entropy coding unit 160. The IBC prediction unit refers to a specific region in the current picture and obtains a block vector value indicating a reference region used for prediction of the current region. The IBC prediction unit may perform IBC prediction using the obtained block vector value. The IBC prediction unit transmits IBC encoding information to the entropy coding unit 160. IBC encoding information may include at least one of reference area size information and block vector information (index information for block vector prediction of the current block within the motion candidate list, block vector difference information).
위와 같은 픽쳐 예측이 수행될 경우, 변환부(110)는 원본 픽쳐와 예측 픽쳐 간의 레지듀얼 값을 변환하여 변환 계수 값을 획득한다. 이때, 변환은 픽쳐 내에서 특정 블록 단위로 수행될 수 있으며, 특정 블록의 크기는 기 설정된 범위 내에서 가변할 수 있다. 양자화부(115)는 변환부(110)에서 생성된 변환 계수 값을 양자화하여 양자화된 변환 계수를 엔트로피 코딩부(160)로 전달한다.When the above picture prediction is performed, the
상기 2차원 배열 형태의 양자화된 변환 계수는 엔트로피 코딩을 위해 1차원의 배열 형태로 재정렬될 수 있다. 양자화된 변환 계수를 스캐닝하는 방법은 변환 블록의 크기 및 화면 내 예측 모드에 따라 어떠한 스캔 방법이 사용될지 여부가 결정될 수 있다. 실시 일 예로, 대각(Diagonal), 수직(vertical), 수평(horizontal) 스캔이 적용될 수 있다. 이러한 스캔 정보는 블록 단위로 시그널링될 수 있으며, 이미 정해진 규칙에 따라 유도될 수 있다.The quantized transform coefficients in the form of a two-dimensional array can be rearranged into a one-dimensional array for entropy coding. The scanning method for the quantized transform coefficient may be determined depending on the size of the transform block and the intra-screen prediction mode. As an example, diagonal, vertical, and horizontal scans may be applied. This scan information can be signaled in block units and can be derived according to already established rules.
엔트로피 코딩부(160)는 양자화된 변환 계수를 나타내는 정보, 인트라 부호화 정보, 및 인터 부호화 정보 등을 엔트로피 코딩하여 비디오 신호 비트스트림을 생성한다. 엔트로피 코딩부(160)에서는 가변 길이 코딩(Variable Length Coding, VLC) 방식과 산술 코딩(arithmetic coding) 방식 등이 사용될 수 있다. 가변 길이 코딩(VLC) 방식은 입력되는 심볼들을 연속적인 코드워드로 변환하는데, 코드워드의 길이는 가변적일 수 있다. 예를 들어, 자주 발생하는 심볼들을 짧은 코드워드로, 자주 발생하지 않은 심볼들은 긴 코드워드로 표현하는 것이다. 가변 길이 코딩 방식으로서 컨텍스트 기반 적응형 가변 길이 코딩(Context-based Adaptive Variable Length Coding, CAVLC) 방식이 사용될 수 있다. 산술 코딩은 각 데이터 심볼들의 확률 분포를 이용하여 연속적인 데이터 심볼들을 하나의 소수로 변환하는데, 산술 코딩은 각 심볼을 표현하기 위하여 필요한 최적의 소수 비트를 얻을 수 있다. 산술 코딩으로서 컨텍스트 기반 적응형 산술 부호화(Context-based Adaptive Binary Arithmetic Code, CABAC)가 이용될 수 있다. The entropy coding unit 160 generates a video signal bitstream by entropy coding information representing quantized transform coefficients, intra encoding information, and inter encoding information. The entropy coding unit 160 may use a variable length coding (VLC) method or an arithmetic coding method. The variable length coding (VLC) method converts input symbols into continuous codewords, and the length of the codewords may be variable. For example, frequently occurring symbols are expressed as short codewords, and infrequently occurring symbols are expressed as long codewords. As a variable length coding method, Context-based Adaptive Variable Length Coding (CAVLC) can be used. Arithmetic coding converts consecutive data symbols into a single decimal number using the probability distribution of each data symbol. Arithmetic coding can obtain the optimal decimal bits needed to express each symbol. As arithmetic coding, context-based adaptive binary arithmetic code (CABAC) can be used.
CABAC은 실험을 통해 얻은 확률을 기반으로 생성된 여러 개의 문맥 모델(context model)을 통해 이진 산술 부호화하는 방법이다. 먼저, 심볼이 이진 형태가 아닐 경우, 인코더는 exp-Golomb 등을 사용하여 각 심볼을 이진화한다. 이진화된 0 또는 1은 빈(bin)으로 기술될 수 있다. CABAC 초기화 과정은 문맥 초기화와 산술 코딩 초기화로 구분된다. 문맥 초기화는 각 심볼의 발생 확률을 초기화하는 과정으로, 심볼의 종류, 양자화 파라미터(QP), 슬라이스 타입(I, P, B 인지)에 따라 결정된다. 이러한 초기화 정보를 가지는 문맥 모델은 실험을 통해 얻은 확률 기반 값을 사용할 수 있다. 문맥 모델은 현재 코딩하려는 심볼에 대한 LPS(Least Probable Symbol) 또는 MPS(Most Probable Symbol)의 발생 확률과 0과 1중에서 어떤 빈 값이 MPS에 해당되는지에 대한 정보(valMPS)를 제공한다. 문맥 인덱스(Context index, ctxIdx)를 통해 여러 개의 문맥 모델 중에서 하나가 선택되며, 문맥 인덱스는 현재 부호화할 블록의 정보 또는 주변 블록의 정보를 통해 유도될 수 있다. 문맥 모델에서 선택된 확률 모델을 기반으로 이진 산술 코딩을 위한 초기화가 수행된다. 이진 산술 부호화는 0과 1의 발생 확률을 통해 확률 구간으로 분할한 후, 처리할 빈에 해당하는 확률 구간이 다음에 처리될 빈에 대한 전체 확률 구간이 되는 과정을 통해 부호화가 진행된다. 마지막 빈이 처리된 확률 구간 안의 위치 정보가 출력된다. 단, 확률 구간이 무한정 분할될 수 없으므로, 일정 크기 이내로 줄어들 경우에는 재규격화(renormalization)과정이 수행되어 확률 구간이 넓어지고 해당 위치 정보가 출력된다. 또한, 각 빈이 처리된 후, 처리된 빈의 정보를 통해 다음 처리될 빈에 대한 확률이 새롭게 설정되는 확률 업데이트 과정이 수행될 수 있다.CABAC is a method of binary arithmetic encoding using multiple context models created based on probabilities obtained through experiments. First, if the symbols are not in binary form, the encoder binarizes each symbol using exp-Golomb, etc.
상기 생성된 비트스트림은 NAL(Network Abstraction Layer) 유닛을 기본 단위로 캡슐화 된다. NAL 유닛은 영상 데이터를 포함하는 VCL(Video Coding Layer) NAL 유닛과 영상 데이터를 디코딩하기 위한 파라미터 정보를 포함하는 non-VCL NAL 유닛으로 구분되며, 다양한 종류의 VCL 또는 non-VCL NAL 유닛이 존재한다. NAL 유닛은 NAL 헤더 정보와 데이터인 RBSP(Raw Byte Sequence Payload)로 구성되며, NAL 헤더 정보에는 RBSP에 대한 요약 정보가 포함된다. VCL NAL 유닛의 RBSP에는 부호화된 정수 개의 코딩 트리 유닛(coding tree unit)을 포함한다. 비디오 디코더에서 비트스트림을 복호화하기 위해서는 먼저 비트스트림을 NAL 유닛 단위로 분리한 후, 분리된 각각의 NAL 유닛을 복호화해야 한다. 한편, 비디오 신호 비트스트림의 복호화를 위해 필요한 정보들은 픽쳐 파라미터 세트(Picture Parameter Set, PPS), 시퀀스 파라미터 세트(Sequence Parameter Set, SPS), 비디오 파라미터 세트(Video Parameter Set, VPS) 등에 포함되어 전송될 수 있다.The generated bitstream is encapsulated in a NAL (Network Abstraction Layer) unit as a basic unit. NAL units are divided into VCL (Video Coding Layer) NAL units containing video data and non-VCL NAL units containing parameter information for decoding video data. There are various types of VCL or non-VCL NAL units. . The NAL unit consists of NAL header information and data, RBSP (Raw Byte Sequence Payload), and the NAL header information includes summary information about the RBSP. The RBSP of the VCL NAL unit includes an encoded integer number of coding tree units. In order to decode a bitstream in a video decoder, the bitstream must first be separated into NAL units, and then each separated NAL unit must be decoded. Meanwhile, the information required for decoding the video signal bitstream will be transmitted in a picture parameter set (PPS), sequence parameter set (SPS), video parameter set (VPS), etc. You can.
한편, 도 1의 블록도는 본 발명의 일 실시예에 따른 인코딩 장치(100)를 나타낸 것으로서, 분리하여 표시된 블록들은 인코딩 장치(100)의 엘리먼트들을 논리적으로 구별하여 도시한 것이다. 따라서 전술한 인코딩 장치(100)의 엘리먼트들은 디바이스의 설계에 따라 하나의 칩으로 또는 복수의 칩으로 장착될 수 있다. 일 실시예에 따르면, 전술한 인코딩 장치(100)의 각 엘리먼트의 동작은 프로세서(미도시)에 의해 수행될 수 있다.Meanwhile, the block diagram of FIG. 1 shows the
도 2는 본 발명의 일 실시예에 따른 비디오 신호 디코딩 장치(200)의 개략적인 블록도이다. 도 2를 참조하면 본 발명의 디코딩 장치(200)는 엔트로피 디코딩부(210), 역양자화부(220), 역변환부(225), 필터링부(230) 및 예측부(250)를 포함한다.Figure 2 is a schematic block diagram of a video
엔트로피 디코딩부(210)는 비디오 신호 비트스트림을 엔트로피 디코딩하여, 각 영역에 대한 변환 계수 정보, 인트라 부호화 정보, 인터 부호화 정보 등을 추출한다. 예를 들어, 엔트로피 디코딩부(210)는 비디오 신호 비트스트림으로부터 특정 영역의 변환 계수 정보에 대한 이진화 코드를 획득할 수 있다. 또한, 엔트로피 디코딩부(210)는 이진화 코드를 역 이진화하여 양자화된 변환 계수를 획득한다. 역양자화부(220)는 양자화된 변환 계수를 역양자화하고, 역변환부(225)는 역양자화된 변환 계수를 이용하여 레지듀얼 값을 복원한다. 비디오 신호 처리 장치(200)는 역변환부(225)에서 획득된 레지듀얼 값을 예측부(250)에서 획득된 예측 값과 합산하여 원래의 화소값을 복원한다.The entropy decoding unit 210 entropy decodes the video signal bitstream and extracts transform coefficient information, intra encoding information, and inter encoding information for each region. For example, the entropy decoder 210 may obtain a binarization code for transform coefficient information of a specific area from a video signal bitstream. Additionally, the entropy decoding unit 210 inversely binarizes the binarization code to obtain a quantized transform coefficient. The
한편, 필터링부(230)는 픽쳐에 대한 필터링을 수행하여 화질을 향상시킨다. 여기에는 블록 왜곡 현상을 감소시키기 위한 디블록킹 필터 및/또는 픽쳐 전체의 왜곡 제거를 위한 적응적 루프 필터 등이 포함될 수 있다. 필터링을 거친 픽쳐는 출력되거나 다음 픽쳐에 대한 참조 픽쳐로 이용하기 위하여 복호 픽쳐 버퍼(DPB, 256)에 저장된다.Meanwhile, the filtering unit 230 improves image quality by performing filtering on the picture. This may include a deblocking filter to reduce block distortion and/or an adaptive loop filter to remove distortion of the entire picture. The filtered picture is output or stored in the decoded picture buffer (DPB, 256) to be used as a reference picture for the next picture.
예측부(250)는 인트라 예측부(252) 및 인터 예측부(254)를 포함한다. 예측부(250)는 전술한 엔트로피 디코딩부(210)를 통해 복호화된 부호화 타입, 각 영역에 대한 변환 계수, 인트라/인터 부호화 정보 등을 활용하여 예측 픽쳐를 생성한다. 복호화가 수행되는 현재 블록을 복원하기 위해서, 현재 블록이 포함된 현재 픽쳐 또는 다른 픽쳐들의 복호화된 영역이 이용될 수 있다. 복원에 현재 픽쳐만을 이용하는, 즉 인트라 예측 또는 인트라 BC 예측을 수행하는 픽쳐(또는, 타일/슬라이스)를 인트라 픽쳐 또는 I 픽쳐(또는, 타일/슬라이스), 인트라 예측, 인터 예측 및 인트라 BC 예측을 모두 수행할 수 있는 픽쳐(또는, 타일/슬라이스)를 인터 픽쳐(또는, 타일/슬라이스)라고 한다. 인터 픽쳐(또는, 타일/슬라이스) 중 각 블록의 샘플값들을 예측하기 위하여 최대 하나의 모션 벡터 및 참조 픽쳐 인덱스를 이용하는 픽쳐(또는, 타일/슬라이스)를 예측 픽쳐(predictive picture) 또는 P 픽쳐(또는, 타일/슬라이스)라고 하며, 최대 두 개의 모션 벡터 및 참조 픽쳐 인덱스를 이용하는 픽쳐(또는, 타일/슬라이스)를 쌍예측 픽쳐(Bi-predictive picture) 또는 B 픽쳐(또는, 타일/슬라이스) 라고 한다. 다시 말해서, P 픽쳐(또는, 타일/슬라이스)는 각 블록을 예측하기 위해 최대 하나의 모션 정보 세트를 이용하고, B 픽쳐(또는, 타일/슬라이스)는 각 블록을 예측하기 위해 최대 두 개의 모션 정보 세트를 이용한다. 여기서, 모션 정보 세트는 하나 이상의 모션 벡터와 하나의 참조 픽쳐 인덱스를 포함한다.The prediction unit 250 includes an
인트라 예측부(252)는 인트라 부호화 정보 및 현재 픽쳐 내의 복원된 샘플들을 이용하여 예측 블록을 생성한다. 전술한 바와 같이, 인트라 부호화 정보는 인트라 예측 모드, MPM(Most Probable Mode) 플래그, MPM 인덱스 중 적어도 하나를 포함할 수 있다. 인트라 예측부(252)는 현재 블록의 좌측 및/또는 상측에 위치한 복원된 샘플들을 참조 샘플들로 이용하여 현재 블록의 샘플 값들을 예측한다. 본 개시에서, 복원된 샘플들, 참조 샘플들 및 현재 블록의 샘플들은 픽셀들을 나타낼 수 있다. 또한, 샘플 값(sample value)들은 픽셀 값들을 나타낼 수 있다.The
일 실시예에 따르면, 참조 샘플들은 현재 블록의 주변 블록에 포함된 샘플들일 수 있다. 예를 들어, 참조 샘플들은 현재 블록의 좌측 경계에 인접한 샘플들 및/또는 상측 경계에 인접한 샘플들일 수 있다. 또한, 참조 샘플들은 현재 블록의 주변 블록의 샘플들 중 현재 블록의 좌측 경계로부터 기 설정된 거리 이내의 라인 상에 위치하는 샘플들 및/또는 현재 블록의 상측 경계로부터 기 설정된 거리 이내의 라인 상에 위치하는 샘플들일 수 있다. 이때, 현재 블록의 주변 블록은 현재 블록에 인접한 좌측(L) 블록, 상측(A) 블록, 하좌측(Below Left, BL) 블록, 상우측(Above Right, AR) 블록 또는 상좌측(Above Left, AL) 블록 중 적어도 하나를 포함할 수 있다.According to one embodiment, the reference samples may be samples included in neighboring blocks of the current block. For example, the reference samples may be samples adjacent to the left border and/or samples adjacent to the upper boundary of the current block. In addition, the reference samples are samples of neighboring blocks of the current block, which are located on a line within a preset distance from the left border of the current block and/or are located on a line within a preset distance from the upper border of the current block. These may be samples that do. At this time, the surrounding blocks of the current block are the left (L) block, upper (A) block, Below Left (BL) block, Above Right (AR) block, or Above Left block adjacent to the current block. AL) may include at least one block.
인터 예측부(254)는 복호 픽쳐 버퍼(256)에 저장된 참조 픽쳐 및 인터 부호화 정보를 이용하여 예측 블록을 생성한다. 인터 부호화 정보는 참조 블록에 대한 현재 블록의 모션 정보 세트(참조 픽쳐 인덱스, 모션 벡터 정보 등)를 포함할 수 있다. 인터 예측에는 L0 예측, L1 예측 및 쌍예측(Bi-prediction)이 있을 수 있다. L0 예측은 L0 픽쳐 리스트에 포함된 1개의 참조 픽쳐를 이용한 예측이고, L1 예측은 L1 픽쳐 리스트에 포함된 1개의 참조 픽쳐를 이용한 예측을 의미한다. 이를 위해서는 1세트의 모션 정보(예를 들어, 모션 벡터 및 참조 픽쳐 인덱스)가 필요할 수 있다. 쌍예측 방식에서는 최대 2개의 참조 영역을 이용할 수 있는데, 이 2개의 참조 영역은 동일한 참조 픽쳐에 존재할 수도 있고, 서로 다른 픽쳐에 각각 존재할 수도 있다. 즉, 쌍예측 방식에서는 최대 2세트의 모션 정보(예를 들어, 모션 벡터 및 참조 픽쳐 인덱스)가 이용될 수 있는데, 2개의 모션 벡터가 동일한 참조 픽쳐 인덱스에 대응될 수도 있고 서로 다른 참조 픽쳐 인덱스에 대응될 수도 있다. 이때, 참조 픽쳐들은 현재 픽쳐를 기준으로 시간적으로 이전 또는 이후에 위치하는 픽쳐로서, 이미 복원된 완료된 픽쳐가 될 수 있다. 일 실시예에 따라, 쌍예측 방식에서는 사용되는 2개의 참조 영역은 L0 픽쳐 리스트 및 L1 픽쳐 리스트 각각에서 선택된 영역일 수 있다.The
인터 예측부(254)는 모션 벡터 및 참조 픽쳐 인덱스를 이용하여 현재 블록의 참조 블록을 획득할 수 있다. 상기 참조 블록은 참조 픽쳐 인덱스에 대응하는 참조 픽쳐 내에 존재한다. 또한, 모션 벡터에 의해서 특정된 블록의 샘플 값 또는 이의 보간(interpolation)된 값이 현재 블록의 예측자(predictor)로 이용될 수 있다. 서브펠(sub-pel) 단위의 픽셀 정확도를 갖는 모션 예측을 위하여 이를 테면, 휘도 신호에 대하여 8-탭 보간 필터가, 색차 신호에 대하여 4-탭 보간 필터가 사용될 수 있다. 다만, 서브펠 단위의 모션 예측을 위한 보간 필터는 이에 한정되지 않는다. 이와 같이 인터 예측부(254)는 이전에 복원된 픽쳐로부터 현재 유닛의 텍스쳐를 예측하는 모션 보상(motion compensation)을 수행한다. 이때, 인터 예측부는 모션 정보 세트를 이용할 수 있다.The
추가적인 실시예에 따라, 예측부(250)는 IBC 예측부(미도시)를 포함할 수 있다. IBC 예측부는 현재 픽쳐 내의 복원된 샘플들을 포함하는 특정 영역을 참조하여 현재 영역을 복원할 수 있다. IBC 예측부는 엔트로피 디코딩부(210)로부터 획득된 IBC 부호화 정보를 이용하여 IBC 예측을 수행할 수 있다. IBC 부호화 정보는 블록 벡터 정보를 포함할 수 있다.According to an additional embodiment, the prediction unit 250 may include an IBC prediction unit (not shown). The IBC prediction unit can reconstruct the current region by referring to a specific region containing reconstructed samples in the current picture. The IBC prediction unit may perform IBC prediction using the IBC encoding information obtained from the entropy decoding unit 210. IBC encoding information may include block vector information.
상기 인트라 예측부(252) 또는 인터 예측부(254)로부터 출력된 예측값, 및 역변환부(225)로부터 출력된 레지듀얼 값이 더해져서 복원된 비디오 픽쳐가 생성된다. 즉, 비디오 신호 디코딩 장치(200)는 예측부(250)에서 생성된 예측 블록과 역변환부(225)로부터 획득된 레지듀얼을 이용하여 현재 블록을 복원한다.The predicted value output from the
한편, 도 2의 블록도는 본 발명의 일 실시예에 따른 디코딩 장치(200)를 나타낸 것으로서, 분리하여 표시된 블록들은 디코딩 장치(200)의 엘리먼트들을 논리적으로 구별하여 도시한 것이다. 따라서 전술한 디코딩 장치(200)의 엘리먼트들은 디바이스의 설계에 따라 하나의 칩으로 또는 복수의 칩으로 장착될 수 있다. 일 실시예에 따르면, 전술한 디코딩 장치(200)의 각 엘리먼트의 동작은 프로세서(미도시)에 의해 수행될 수 있다.Meanwhile, the block diagram of FIG. 2 shows a
한편, 본 명세서에서 제안된 기술은 인코더와 디코더의 방법 및 장치에 모두 적용 가능한 기술이며, 시그널링과 파싱으로 기술된 부분은 설명의 편의를 위해 기술한 것일 수 있다. 일반적으로 시그널링은 인코더 관점에서 각 신택스(syntax)를 부호화하기 위한 것이고, 파싱은 디코더 관점에서 각 신택스의 해석을 위한 것으로 설명될 수 있다. 즉, 각 신택스는 인코더로부터 비트스트림에 포함되어 시그널링될 수 있으며, 디코더에서는 신택스를 파싱하여 복원과정에서 사용할 수 있다. 이때, 규정된 계층적 구성대로 나열한 각 신택스에 대한 비트의 시퀀스를 비트스트림이라고 할 수 있다.Meanwhile, the technology proposed in this specification is applicable to both encoder and decoder methods and devices, and parts described as signaling and parsing may be described for convenience of explanation. In general, signaling can be described as encoding each syntax from an encoder's perspective, and parsing can be described as interpreting each syntax from a decoder's perspective. That is, each syntax can be signaled by being included in the bitstream from the encoder, and the decoder can parse the syntax and use it in the restoration process. At this time, the sequence of bits for each syntax arranged according to the prescribed hierarchical structure can be referred to as a bitstream.
하나의 픽쳐는 서브 픽쳐(sub-picture), 슬라이스(slice), 타일(tile) 등으로 분할되어 부호화될 수 있다. 서브 픽쳐는 하나 이상의 슬라이스 또는 타일을 포함할 수 있다. 하나의 픽쳐가 여러 개의 슬라이스 또는 타일로 분할되어 부호화되었을 경우, 픽쳐 내의 모든 슬라이스 또는 타일이 디코딩이 완료되어야만 화면에 출력이 가능하다. 반면에, 하나의 픽쳐가 여러 개의 서브 픽쳐로 부호화되었을 경우, 임의의 서브 픽쳐만 디코딩되어 화면에 출력될 수 있다. 슬라이스는 여러 개의 타일 또는 서브 픽쳐를 포함할 수 있다. 또는 타일은 여러 개의 서브 픽쳐 또는 슬라이스를 포함할 수 있다. 서브 픽쳐, 슬라이스, 타일은 서로 독립적으로 인코딩 또는 디코딩이 가능하므로 병렬처리 및 처리 속도 향상에 효과적이다. 하지만, 인접한 다른 서브 픽쳐, 다른 슬라이스, 다른 타일의 부호화된 정보를 이용할 수 없으므로 비트량이 증가되는 단점이 있다. 서브 픽쳐, 슬라이스, 타일은 여러 개의 코딩 트리 유닛(Coding Tree Unit, CTU)으로 분할되어 부호화될 수 있다.One picture may be divided into sub-pictures, slices, tiles, etc. and encoded. A subpicture may include one or more slices or tiles. When one picture is divided into multiple slices or tiles and encoded, it can be displayed on the screen only when all slices or tiles in the picture have been decoded. On the other hand, when one picture is encoded with several subpictures, only arbitrary subpictures can be decoded and displayed on the screen. A slice may contain multiple tiles or subpictures. Alternatively, a tile may include multiple subpictures or slices. Subpictures, slices, and tiles can be encoded or decoded independently of each other, which is effective in improving parallel processing and processing speed. However, there is a disadvantage in that the bit amount increases because encoded information of other adjacent subpictures, other slices, and other tiles cannot be used. Subpictures, slices, and tiles can be divided into multiple Coding Tree Units (CTUs) and encoded.
도 3은 픽쳐 내에서 코딩 트리 유닛(Coding Tree Unit, CTU)이 코딩 유닛들(Coding Units, CUs)로 분할되는 실시예를 도시한다. 비디오 신호의 코딩 과정에서, 픽쳐는 코딩 트리 유닛(CTU)들의 시퀀스로 분할될 수 있다. 코딩 트리 유닛은 휘도(luma) 코딩 트리 블록(Coding Tree Block, CTB)와 2개의 색차(chroma) 코딩 트리 블록들, 그리고 그것의 부호화된 신택스(syntax) 정보로 구성될 수 있다. 하나의 코딩 트리 유닛은 하나의 코딩 유닛으로 구성될 수 있으며, 또는 하나의 코딩 트리 유닛은 여러 개의 코딩 유닛으로 분할될 수 있다. 하나의 코딩 유닛은 휘도 코딩 블록(Coding Block, CB)과 2개의 색차 코딩 블록들, 그리고 그것의 부호화된 신택스 정보로 구성될 수 있다. 하나의 코딩 블록은 여러 개의 서브 코딩 블록으로 분할될 수 있다. 하나의 코딩 유닛은 하나의 변환 유닛(Transform Unit, TU)으로 구성될 수 있으며, 또는 하나의 코딩 유닛은 여러 개의 변환 유닛으로 분할될 수 있다. 하나의 변환 유닛은 휘도 변환 블록(Transform Block, TB)과 2개의 색차 변환 블록들, 그리고 그것의 부호화된 신택스 정보로 구성될 수 있다. 코딩 트리 유닛은 복수의 코딩 유닛들로 분할될 수 있다. 코딩 트리 유닛은 분할되지 않고 리프 노드가 될 수도 있다. 이 경우, 코딩 트리 유닛 자체가 코딩 유닛이 될 수 있다. Figure 3 shows an embodiment in which a Coding Tree Unit (CTU) is divided into Coding Units (CUs) within a picture. In the process of coding a video signal, a picture can be divided into a sequence of coding tree units (CTUs). A coding tree unit may be composed of a luma coding tree block (CTB), two chroma coding tree blocks, and its encoded syntax information. One coding tree unit may consist of one coding unit, or one coding tree unit may be divided into multiple coding units. One coding unit may be composed of a luminance coding block (CB), two chrominance coding blocks, and its encoded syntax information. One coding block can be divided into several sub-coding blocks. One coding unit may consist of one transform unit (TU), or one coding unit may be divided into several transform units. One transformation unit may be composed of a luminance transformation block (Transform Block, TB), two chrominance transformation blocks, and its encoded syntax information. A coding tree unit may be divided into a plurality of coding units. A coding tree unit may be a leaf node without being split. In this case, the coding tree unit itself may be a coding unit.
코딩 유닛은 상기에서 설명한 비디오 신호의 처리 과정, 즉 인트라/인터 예측, 변환, 양자화 및/또는 엔트로피 코딩 등의 과정에서 픽쳐를 처리하기 위한 기본 단위를 가리킨다. 하나의 픽쳐 내에서 코딩 유닛의 크기 및 모양은 일정하지 않을 수 있다. 코딩 유닛은 정사각형 또는 직사각형의 모양을 가질 수 있다. 직사각형 코딩 유닛(또는, 직사각형 블록)은 수직 코딩 유닛(또는, 수직 블록)과 수평 코딩 유닛(또는, 수평 블록)을 포함한다. 본 명세서에서, 수직 블록은 높이가 너비보다 큰 블록이며, 수평 블록은 너비가 높이보다 큰 블록이다. 또한, 본 명세서에서 정사각형이 아닌(non-square) 블록은 직사각형 블록을 가리킬 수 있지만, 본 발명은 이에 한정되지 않는다.A coding unit refers to a basic unit for processing a picture in the video signal processing process described above, that is, intra/inter prediction, transformation, quantization, and/or entropy coding. The size and shape of a coding unit within one picture may not be constant. The coding unit may have a square or rectangular shape. A rectangular coding unit (or rectangular block) includes a vertical coding unit (or vertical block) and a horizontal coding unit (or horizontal block). In this specification, a vertical block is a block whose height is greater than its width, and a horizontal block is a block whose width is greater than its height. Additionally, in this specification, a non-square block may refer to a rectangular block, but the present invention is not limited thereto.
도 3을 참조하면, 코딩 트리 유닛은 먼저 쿼드 트리(Quad Tree, QT) 구조로 분할된다. 즉, 쿼드 트리 구조에서 2NX2N 크기를 가지는 하나의 노드는 NXN 크기를 가지는 네 개의 노드들로 분할될 수 있다. 본 명세서에서 쿼드 트리는 4진(quaternary) 트리로도 지칭될 수 있다. 쿼드 트리 분할은 재귀적으로 수행될 수 있으며, 모든 노드들이 동일한 깊이로 분할될 필요는 없다.Referring to Figure 3, the coding tree unit is first divided into a quad tree (Quad Tree, QT) structure. That is, in a quad tree structure, one node with a size of 2NX2N can be divided into four nodes with a size of NXN. In this specification, a quad tree may also be referred to as a quaternary tree. Quad-tree partitioning can be performed recursively, and not all nodes need to be partitioned to the same depth.
한편, 전술한 쿼드 트리의 리프 노드(leaf node)는 멀티-타입 트리(Multi-Type Tree, MTT) 구조로 더욱 분할될 수 있다. 본 발명의 실시예에 따르면, 멀티 타입 트리 구조에서는 하나의 노드가 수평 또는 수직 분할의 2진(binary, 바이너리) 또는 3진(ternary, 터너리) 트리 구조로 분할될 수 있다. 즉, 멀티-타입 트리 구조에는 수직 바이너리 분할, 수평 바이너리 분할, 수직 터너리 분할 및 수평 터너리 분할의 4가지 분할 구조가 존재한다. 본 발명의 실시예에 따르면, 상기 각 트리 구조에서 노드의 너비 및 높이는 모두 2의 거듭제곱 값을 가질 수 있다. 예를 들어, 바이너리 트리(Binary Tree, BT) 구조에서, 2NX2N 크기의 노드는 수직 바이너리 분할에 의해 2개의 NX2N 노드들로 분할되고, 수평 바이너리 분할에 의해 2개의 2NXN 노드들로 분할될 수 있다. 또한, 터너리 트리(Ternary Tree, TT) 구조에서, 2NX2N 크기의 노드는 수직 터너리 분할에 의해 (N/2)X2N, NX2N 및 (N/2)X2N의 노드들로 분할되고, 수평 터너리 분할에 의해 2NX(N/2), 2NXN 및 2NX(N/2)의 노드들로 분할될 수 있다. 이러한 멀티-타입 트리 분할은 재귀적으로 수행될 수 있다.Meanwhile, the leaf nodes of the aforementioned quad tree can be further divided into a multi-type tree (MTT) structure. According to an embodiment of the present invention, in a multi-type tree structure, one node may be divided into a binary or ternary tree structure with horizontal or vertical division. That is, there are four division structures in the multi-type tree structure: vertical binary division, horizontal binary division, vertical ternary division, and horizontal ternary division. According to an embodiment of the present invention, the width and height of the nodes in each tree structure may both have values that are powers of 2. For example, in a Binary Tree (BT) structure, a node of size 2NX2N may be divided into two NX2N nodes by vertical binary division and into two 2NXN nodes by horizontal binary division. Additionally, in the Ternary Tree (TT) structure, a node of size 2NX2N is divided into nodes of (N/2)X2N, NX2N and (N/2)X2N by vertical ternary division, and horizontal ternary division By division, it can be divided into nodes of 2NX(N/2), 2NXN, and 2NX(N/2). This multi-type tree partitioning can be performed recursively.
멀티-타입 트리의 리프 노드는 코딩 유닛이 될 수 있다. 코딩 유닛이 최대 변환 길이에 비해 크지 않은 경우, 해당 코딩 유닛은 더 이상의 분할 없이 예측 및/또는 변환의 단위로 사용될 수 있다. 일 실시예로서, 현재 코딩 유닛의 너비 또는 높이가 최대 변환 길이보다 큰 경우, 현재 코딩 유닛은 분할에 관한 명시적 시그널링 없이 복수의 변환 유닛으로 분할될 수 있다. 한편, 전술한 쿼드 트리 및 멀티-타입 트리에서 다음의 파라메터들 중 적어도 하나가 사전에 정의되거나 PPS, SPS, VPS 등과 같은 상위 레벨 세트의 RBSP를 통해 전송될 수 있다. 1) CTU 크기: 쿼드 트리의 루트 노드(root node) 크기, 2) 최소 QT 크기(MinQtSize): 허용된 최소 QT 리프 노드 크기, 3) 최대 BT 크기(MaxBtSize): 허용된 최대 BT 루트 노드 크기, 4) 최대 TT 크기(MaxTtSize): 허용된 최대 TT 루트 노드 크기, 5) 최대 MTT 깊이(MaxMttDepth): QT의 리프 노드로부터의 MTT 분할의 최대 허용 깊이, 6) 최소 BT 크기(MinBtSize): 허용된 최소 BT 리프 노드 크기, 7) 최소 TT 크기(MinTtSize): 허용된 최소 TT 리프 노드 크기.Leaf nodes of a multi-type tree can be coding units. If the coding unit is not larger than the maximum transformation length, the coding unit can be used as a unit of prediction and/or transformation without further division. As an example, if the width or height of the current coding unit is greater than the maximum transform length, the current coding unit may be split into a plurality of transform units without explicit signaling regarding splitting. Meanwhile, in the above-described quad tree and multi-type tree, at least one of the following parameters may be defined in advance or transmitted through an RBSP of a higher level set such as PPS, SPS, VPS, etc. 1) CTU size: the root node size of the quad tree, 2) minimum QT size (MinQtSize): minimum allowed QT leaf node size, 3) maximum BT size (MaxBtSize): maximum allowed BT root node size, 4) Maximum TT Size (MaxTtSize): Maximum TT root node size allowed, 5) Maximum MTT Depth (MaxMttDepth): Maximum allowed depth of MTT split from leaf nodes of QT, 6) Minimum BT Size (MinBtSize): Allowed Minimum BT leaf node size, 7) Minimum TT size (MinTtSize): Minimum TT leaf node size allowed.
도 4는 쿼드 트리 및 멀티-타입 트리의 분할을 시그널링하는 방법의 일 실시예를 도시한다. 전술한 쿼드 트리 및 멀티-타입 트리의 분할을 시그널링하기 위해 기 설정된 플래그들이 사용될 수 있다. 도 4를 참조하면, 노드의 분할 여부를 지시하는 플래그 'split_cu_flag', 쿼드 트리 노드의 분할 여부를 지시하는 플래그 'split_qt_flag', 멀티-타입 트리 노드의 분할 방향을 지시하는 플래그 'mtt_split_cu_vertical_flag' 또는 멀티-타입 트리 노드의 분할 모양을 지시하는 플래그 'mtt_split_cu_binary_flag' 중 적어도 하나가 사용될 수 있다.Figure 4 shows one embodiment of a method for signaling splitting of quad trees and multi-type trees. Preset flags can be used to signal division of the above-described quad tree and multi-type tree. Referring to Figure 4, a flag 'split_cu_flag' indicating whether to split a node, a flag 'split_qt_flag' indicating whether to split a quad tree node, a flag 'mtt_split_cu_vertical_flag' indicating the splitting direction of a multi-type tree node, or a multi-type tree node. At least one of the flags 'mtt_split_cu_binary_flag' that indicates the split shape of the type tree node can be used.
본 발명의 실시예에 따르면, 현재 노드의 분할 여부를 지시하는 플래그인 'split_cu_flag'가 먼저 시그널링될 수 있다. 'split_cu_flag'의 값이 0인 경우, 현재 노드가 분할되지 않는 것을 나타내며, 현재 노드는 코딩 유닛이 된다. 현재 노드가 코팅 트리 유닛인 경우, 코딩 트리 유닛은 분할되지 않은 하나의 코딩 유닛을 포함한다. 현재 노드가 쿼드 트리 노드 'QT node'인 경우, 현재 노드는 쿼드 트리의 리프 노드 'QT leaf node'이며 코딩 유닛이 된다. 현재 노드가 멀티-타입 트리 노드 'MTT node'인 경우, 현재 노드는 멀티-타입 트리의 리프 노드 'MTT leaf node'이며 코딩 유닛이 된다.According to an embodiment of the present invention, 'split_cu_flag', a flag indicating whether to split the current node, may be signaled first. If the value of 'split_cu_flag' is 0, it indicates that the current node is not split, and the current node becomes a coding unit. If the current node is a coating tree unit, the coding tree unit includes one undivided coding unit. If the current node is a quad tree node 'QT node', the current node is a leaf node 'QT leaf node' of the quad tree and becomes a coding unit. If the current node is a multi-type tree node 'MTT node', the current node is a leaf node 'MTT leaf node' of the multi-type tree and becomes a coding unit.
'split_cu_flag'의 값이 1인 경우, 현재 노드는 'split_qt_flag'의 값에 따라 쿼드 트리 또는 멀티-타입 트리의 노드들로 분할될 수 있다. 코딩 트리 유닛은 쿼드 트리의 루트 노드이며, 쿼드 트리 구조로 우선 분할될 수 있다. 쿼드 트리 구조에서는 각각의 노드 'QT node' 별로 'split_qt_flag'가 시그널링된다. 'split_qt_flag'의 값이 1인 경우 해당 노드는 4개의 정사각형 노드들로 분할되며, 'split_qt_flag'의 값이 0인 경우 해당 노드는 쿼드 트리의 리프 노드 'QT leaf node'가 되며, 해당 노드는 멀티-타입 노드들로 분할된다. 본 발명의 실시예에 따르면, 현재 노드의 종류에 따라서 쿼드 트리 분할은 제한될 수 있다. 현재 노드가 코딩 트리 유닛(쿼트 트리의 루트 노드) 또는 쿼트 트리 노드인 경우에 쿼드 트리 분할이 허용될 수 있으며, 현재 노드가 멀티-타입 트리 노드인 경우 쿼트 트리 분할은 허용되지 않을 수 있다. 각각의 쿼드 트리 리프 노드 'QT leaf node'는 멀티-타입 트리 구조로 더 분할될 수 있다. 상술한 바와 같이, 'split_qt_flag'가 0인 경우 현재 노드는 멀티-타입 노드들로 분할될 수 있다. 분할 방향 및 분할 모양을 지시하기 위하여, 'mtt_split_cu_vertical_flag' 및 'mtt_split_cu_binary_flag'가 시그널링될 수 있다. 'mtt_split_cu_vertical_flag'의 값이 1인 경우 노드 'MTT node'의 수직 분할이 지시되며, 'mtt_split_cu_vertical_flag'의 값이 0인 경우 노드 'MTT node'의 수평 분할이 지시된다. 또한, 'mtt_split_cu_binary_flag'의 값이 1인 경우 노드 'MTT node'는 2개의 직사각형 노드들로 분할되며, 'mtt_split_cu_binary_flag'의 값이 0인 경우 노드 'MTT node'는 3개의 직사각형 노드들로 분할된다.If the value of 'split_cu_flag' is 1, the current node can be divided into nodes of a quad tree or multi-type tree according to the value of 'split_qt_flag'. The coding tree unit is the root node of the quad tree and can be first divided into a quad tree structure. In the quad tree structure, 'split_qt_flag' is signaled for each node 'QT node'. If the value of 'split_qt_flag' is 1, the node is split into 4 square nodes. If the value of 'split_qt_flag' is 0, the node becomes a leaf node 'QT leaf node' of the quad tree, and the node becomes a multi-square node. -Divided into type nodes. According to an embodiment of the present invention, quad tree division may be limited depending on the type of the current node. Quad tree splitting may be allowed if the current node is a coding tree unit (root node of the quot tree) or a quot tree node, and quot tree splitting may not be allowed if the current node is a multi-type tree node. Each quad tree leaf node 'QT leaf node' can be further divided into a multi-type tree structure. As described above, if 'split_qt_flag' is 0, the current node can be split into multi-type nodes. To indicate the split direction and split shape, 'mtt_split_cu_vertical_flag' and 'mtt_split_cu_binary_flag' may be signaled. If the value of 'mtt_split_cu_vertical_flag' is 1, vertical splitting of the node 'MTT node' is indicated, and if the value of 'mtt_split_cu_vertical_flag' is 0, horizontal splitting of the node 'MTT node' is indicated. Additionally, if the value of 'mtt_split_cu_binary_flag' is 1, the node 'MTT node' is divided into two rectangular nodes, and if the value of 'mtt_split_cu_binary_flag' is 0, the node 'MTT node' is divided into three rectangular nodes.
트리 분할 구조는 휘도 블록과 색차 블록이 동일한 형태로 분할될 수 있다. 즉, 색차 블록은 휘도 블록의 분할 형태를 참조하여 색차 블록을 분할할 수 있다. 현재 색차 블록이 임의의 정해진 크기보다 적다면, 휘도 블록이 분할되었더라도 색차 블록은 분할되지 않을 수 있다.In the tree division structure, the luminance block and the chrominance block can be divided into the same form. That is, the chrominance block can be divided by referring to the division type of the luminance block. If the current chrominance block is smaller than a certain size, the chrominance block may not be divided even if the luminance block is divided.
트리 분할 구조는 휘도 블록과 색차 블록이 서로 다른 형태를 가질 수 있다. 이때, 휘도 블록에 대한 분할 정보와 색차 블록에 대한 분할 정보가 각각 시그널링될 수 있다. 또한, 분할 정보 뿐만 아니라 휘도 블록과 색차 블록의 부호화 정보도 다를 수 있다. 실시 일 예로, 휘도 블록과 색차 블록의 인트라 부호화 모드, 움직임 정보에 대한 부호화 정보 등이 적어도 하나 이상 다를 수 있다.In the tree division structure, the luminance block and the chrominance block may have different forms. At this time, division information for the luminance block and division information for the chrominance block may be signaled, respectively. Additionally, not only the division information but also the encoding information of the luminance block and the chrominance block may be different. As an example of an embodiment, at least one intra coding mode of a luminance block and a chrominance block, encoding information for motion information, etc. may be different.
가장 작은 단위로 분할될 노드는 하나의 코딩 블록으로 처리될 수 있다. 현재 블록이 코딩 블록일 경우, 코딩 블록은 여러 개의 서브 블록(서브 코딩 블록)으로 분할될 수 있으며, 각 서브 블록의 예측 정보는 서로 같거나 또는 다를 수 있다. 실시 일 예로, 코딩 유닛이 인트라 모드일 경우, 각 서브 블록의 인트라 예측 모드는 서로 같거나 또는 다를 수 있다. 또한, 코딩 유닛이 인터 모드일 경우, 각 서브 블록의 움직임 정보는 서로 같거나 또는 다를 수 있다. 또한, 각 서브 블록은 서로 독립적으로 인코딩 또는 디코딩이 가능할 수 있다. 각각의 서브 블록은 서브 블록 인덱스(sub-block index, sbIdx)를 통해 구분될 수 있다. 또한 코딩 유닛이 서브 블록으로 분할될 때, 수평 또는 수직 방향으로 분할되거나 사선으로 분할될 수 있다. 인트라 모드에서 현재 코딩 유닛을 수평 또는 수직 방향으로 2개 또는 4개의 서브 블록으로 분할하는 모드를 ISP(Intra Sub Partitions)이라 한다. 인터 모드에서 현재 코딩 블록을 사선으로 분할하는 모드를 GPM(Geometric partitioning mode)이라 한다. GPM모드에서 사선의 위치와 방향은 미리 정해진 각도 테이블을 사용하여 유도하고, 각도 테이블의 인덱스 정보가 시그널링된다.A node to be divided into the smallest unit can be processed as one coding block. When the current block is a coding block, the coding block may be divided into several sub-blocks (sub-coding blocks), and the prediction information of each sub-block may be the same or different. As an example embodiment, when the coding unit is an intra mode, the intra prediction mode of each subblock may be the same or different from each other. Additionally, when the coding unit is in inter mode, the motion information of each sub-block may be the same or different. Additionally, each sub-block may be encoded or decoded independently from each other. Each sub-block can be distinguished through a sub-block index (sbIdx). Additionally, when a coding unit is divided into sub-blocks, it may be divided horizontally or vertically or diagonally. In intra mode, the mode in which the current coding unit is divided into 2 or 4 sub-blocks horizontally or vertically is called ISP (Intra Sub Partitions). In inter mode, the mode in which the current coding block is divided diagonally is called GPM (Geometric partitioning mode). In GPM mode, the position and direction of the diagonal line are derived using a predetermined angle table, and the index information of the angle table is signaled.
코딩을 위한 픽쳐 예측(모션 보상)은 더 이상 나누어지지 않는 코딩 유닛(즉 코딩 트리 유닛의 리프 노드)을 대상으로 이루어진다. 이러한 예측을 수행하는 기본 단위를 이하에서는 예측 유닛(prediction unit) 또는 예측 블록(prediction block)이라고 한다.Picture prediction (motion compensation) for coding is performed on coding units that are no longer divided (i.e., leaf nodes of coding tree units). The basic unit that performs such prediction is hereinafter referred to as a prediction unit or prediction block.
이하, 본 명세서에서 사용되는 유닛이라는 용어는 예측을 수행하는 기본 단위인 상기 예측 유닛을 대체하는 용어로 사용될 수 있다. 다만, 본 발명이 이에 한정되는 것은 아니며, 더욱 광의적으로는 상기 코딩 유닛을 포함하는 개념으로 이해될 수 있다.Hereinafter, the term unit used in this specification may be used as a replacement for the prediction unit, which is a basic unit for performing prediction. However, the present invention is not limited to this, and can be understood more broadly as a concept including the coding unit.
도 5 및 도 6은 본 발명의 실시예에 따른 인트라 예측 방법을 더욱 구체적으로 도시한다. 전술한 바와 같이, 인트라 예측부는 현재 블록의 좌측 및/또는 상측에 위치한 복원된 샘플들을 참조 샘플들로 이용하여 현재 블록의 샘플 값들을 예측한다.Figures 5 and 6 show the intra prediction method according to an embodiment of the present invention in more detail. As described above, the intra prediction unit predicts sample values of the current block using reconstructed samples located to the left and/or above the current block as reference samples.
먼저, 도 5는 인트라 예측 모드에서 현재 블록의 예측을 위해 사용되는 참조 샘플들의 일 실시예를 도시한다. 일 실시예에 따르면, 참조 샘플들은 현재 블록의 좌측 경계에 인접한 샘플들 및/또는 상측 경계에 인접한 샘플들일 수 있다. 도 5에 도시된 바와 같이, 현재 블록의 크기가 WXH이고 현재 블록에 인접한 단일 참조 라인(line)의 샘플들이 인트라 예측에 사용될 경우, 현재 블록의 좌측 및/또는 상측에 위치한 최대 2W+2H+1개의 주변 샘플들을 사용하여 참조 샘플들이 설정될 수 있다.First, Figure 5 shows an example of reference samples used for prediction of the current block in intra prediction mode. According to one embodiment, the reference samples may be samples adjacent to the left boundary and/or samples adjacent to the upper boundary of the current block. As shown in Figure 5, when the size of the current block is WXH and samples of a single reference line adjacent to the current block are used for intra prediction, a maximum of 2W+2H+1 located to the left and/or above the current block Reference samples can be set using the surrounding samples.
한편, 현재 블록의 인트라 예측을 위해 다중 참조 라인의 픽셀들이 사용될 수 있다. 다중 참조 라인은 현재 블록으로부터 기 설정된 범위 이내에 위치한 n개의 라인들로 구성될 수 있다. 일 실시예에 따르면, 인트라 예측을 위해 다중 참조 라인의 픽셀들이 사용될 경우, 참조 픽셀들로 설정될 라인들을 지시하는 별도의 인덱스 정보가 시그널링될 수 있으며, 이를 참조 라인 인덱스라고 명명할 수 있다.Meanwhile, pixels of multiple reference lines may be used for intra prediction of the current block. Multiple reference lines may be composed of n lines located within a preset range from the current block. According to one embodiment, when pixels of multiple reference lines are used for intra prediction, separate index information indicating lines to be set as reference pixels may be signaled, and may be called a reference line index.
또한, 참조 샘플로 사용될 적어도 일부의 샘플이 아직 복원되지 않은 경우, 인트라 예측부는 참조 샘플 패딩 과정을 수행하여 참조 샘플을 획득할 수 있다. 또한, 인트라 예측부는 인트라 예측의 오차를 줄이기 위해 참조 샘플 필터링 과정을 수행할 수 있다. 즉, 주변 샘플들 및/또는 참조 샘플 패딩 과정에 의해 획득된 참조 샘플들에 필터링을 수행하여 필터링된 참조 샘플들을 획득할 수 있다. 인트라 예측부는 이와 같이 획득된 참조 샘플들을 이용하여 현재 블록의 샘플들을 예측한다. 인트라 예측부는 필터링되지 않은 참조 샘플들 또는 필터링된 참조 샘플들을 이용하여 현재 블록의 샘플들을 예측한다. 본 개시에서, 주변 샘플들은 적어도 하나의 참조 라인 상의 샘플들을 포함할 수 있다. 예를 들어, 주변 샘플들은 현재 블록의 경계에 인접한 라인 상의 인접 샘플들을 포함할 수 있다.Additionally, when at least some samples to be used as reference samples have not yet been reconstructed, the intra prediction unit may obtain reference samples by performing a reference sample padding process. Additionally, the intra prediction unit may perform a reference sample filtering process to reduce the error of intra prediction. That is, filtered reference samples can be obtained by performing filtering on surrounding samples and/or reference samples obtained through a reference sample padding process. The intra prediction unit predicts samples of the current block using the reference samples obtained in this way. The intra prediction unit predicts samples of the current block using unfiltered or filtered reference samples. In this disclosure, peripheral samples may include samples on at least one reference line. For example, neighboring samples may include adjacent samples on a line adjacent to the boundary of the current block.
다음으로, 도 6은 인트라 예측에 사용되는 예측 모드들의 일 실시예를 도시한다. 인트라 예측을 위해, 인트라 예측 방향을 지시하는 인트라 예측 모드 정보가 시그널링될 수 있다. 인트라 예측 모드 정보는 인트라 예측 모드 세트를 구성하는 복수의 인트라 예측 모드들 중 어느 하나를 지시한다. 현재 블록이 인트라 예측 블록일 경우, 디코더는 비트스트림으로부터 현재 블록의 인트라 예측 모드 정보를 수신한다. 디코더의 인트라 예측부는 추출된 인트라 예측 모드 정보에 기초하여 현재 블록에 대한 인트라 예측을 수행한다.Next, Figure 6 shows an example of prediction modes used for intra prediction. For intra prediction, intra prediction mode information indicating the intra prediction direction may be signaled. Intra prediction mode information indicates one of a plurality of intra prediction modes constituting an intra prediction mode set. If the current block is an intra prediction block, the decoder receives intra prediction mode information of the current block from the bitstream. The intra prediction unit of the decoder performs intra prediction on the current block based on the extracted intra prediction mode information.
본 발명의 실시예에 따르면, 인트라 예측 모드 세트는 인트라 예측에 사용되는 모든 인트라 예측 모드들(예, 총 67개의 인트라 예측 모드들)을 포함할 수 있다. 더욱 구체적으로, 인트라 예측 모드 세트는 평면 모드, DC 모드 및 복수의(예, 65개의) 각도 모드들(즉, 방향 모드들)을 포함할 수 있다. 각각의 인트라 예측 모드는 기 설정된 인덱스(즉, 인트라 예측 모드 인덱스)를 통해 지시될 수 있다. 예를 들어, 도 6에 도시된 바와 같이 인트라 예측 모드 인덱스 0은 평면(planar) 모드를 지시하고, 인트라 예측 모드 인덱스 1은 DC 모드를 지시한다. 또한, 인트라 예측 모드 인덱스 2 내지 66은 서로 다른 각도 모드들을 각각 지시할 수 있다. 각도 모드들은 기 설정된 각도 범위 이내의 서로 다른 각도들을 각각 지시한다. 예를 들어, 각도 모드는 시계 방향으로 45도에서 -135도 사이의 각도 범위(즉, 제1 각도 범위) 이내의 각도를 지시할 수 있다. 상기 각도 모드는 12시 방향을 기준으로 정의될 수 있다. 이때, 인트라 예측 모드 인덱스 2는 수평 대각(Horizontal Diagonal, HDIA) 모드를 지시하고, 인트라 예측 모드 인덱스 18은 수평(Horizontal, HOR) 모드를 지시하고, 인트라 예측 모드 인덱스 34는 대각(Diagonal, DIA) 모드를 지시하고, 인트라 예측 모드 인덱스 50은 수직(Vertical, VER) 모드를 지시하며, 인트라 예측 모드 인덱스 66은 수직 대각(Vertical Diagonal, VDIA) 모드를 지시한다.According to an embodiment of the present invention, the intra prediction mode set may include all intra prediction modes used for intra prediction (eg, a total of 67 intra prediction modes). More specifically, the intra prediction mode set may include a planar mode, a DC mode, and multiple (e.g., 65) angular modes (i.e., directional modes). Each intra prediction mode may be indicated through a preset index (i.e., intra prediction mode index). For example, as shown in FIG. 6, intra
한편, 기 설정된 각도 범위는 현재 블록의 모양에 따라 서로 다르게 설정될 수 있다. 예를 들어, 현재 블록이 직사각형 블록일 경우 시계 방향으로 45도를 초과하거나 -135도 미만 각도를 지시하는 광각 모드가 추가적으로 사용될 수 있다. 현재 블록이 수평 블록일 경우, 각도 모드는 시계 방향으로 (45+offset1)도에서 (-135+offset1)도 사이의 각도 범위(즉, 제2 각도 범위) 이내의 각도를 지시할 수 있다. 이때, 제1 각도 범위를 벗어나는 각도 모드 67 내지 76이 추가적으로 사용될 수 있다. 또한, 현재 블록이 수직 블록일 경우, 각도 모드는 시계 방향으로 (45-offset2)도에서 (-135-offset2)도 사이의 각도 범위(즉, 제3 각도 범위) 이내의 각도를 지시할 수 있다. 이때, 제1 각도 범위를 벗어나는 각도 모드 -10 내지 -1이 추가적으로 사용될 수 있다. 본 발명의 실시예에 따르면, offset1 및 offset2의 값은 직사각형 블록의 너비와 높이 간의 비율에 따라 서로 다르게 결정될 수 있다. 또한, offset1 및 offset2는 양수일 수 있다.Meanwhile, the preset angle range may be set differently depending on the shape of the current block. For example, if the current block is a rectangular block, a wide-angle mode indicating an angle exceeding 45 degrees or less than -135 degrees clockwise may be additionally used. If the current block is a horizontal block, the angle mode may indicate an angle within an angle range (i.e., a second angle range) between (45+offset1) degrees and (-135+offset1) degrees in a clockwise direction. At this time, angle modes 67 to 76 outside the first angle range may be additionally used. Additionally, if the current block is a vertical block, the angle mode may indicate an angle within an angle range between (45-offset2) degrees and (-135-offset2) degrees clockwise (i.e., a third angle range). . At this time, angle modes -10 to -1 outside the first angle range may be additionally used. According to an embodiment of the present invention, the values of offset1 and offset2 may be determined differently depending on the ratio between the width and height of the rectangular block. Additionally, offset1 and offset2 can be positive numbers.
본 발명의 추가적인 실시예에 따르면, 인트라 예측 모드 세트를 구성하는 복수의 각도 모드들은 기본 각도 모드와 확장 각도 모드를 포함할 수 있다. 이때, 확장 각도 모드는 기본 각도 모드에 기초하여 결정될 수 있다.According to a further embodiment of the present invention, the plurality of angle modes constituting the intra prediction mode set may include a basic angle mode and an extended angle mode. At this time, the extended angle mode may be determined based on the basic angle mode.
일 실시예에 따르면, 기본 각도 모드는 기존 HEVC(High Efficiency Video Coding) 표준의 인트라 예측에서 사용되는 각도에 대응하는 모드이고, 확장 각도 모드는 차세대 비디오 코덱 표준의 인트라 예측에서 새롭게 추가되는 각도에 대응하는 모드일 수 있다. 더욱 구체적으로, 기본 각도 모드는 인트라 예측 모드 {2, 4, 6, …, 66} 중 어느 하나에 대응하는 각도 모드이고, 확장 각도 모드는 인트라 예측 모드 {3, 5, 7, …, 65} 중 어느 하나에 대응하는 각도 모드일 수 있다. 즉, 확장 각도 모드는 제1 각도 범위 내에서 기본 각도 모드들 사이의 각도 모드일 수 있다. 따라서, 확장 각도 모드가 지시하는 각도는 기본 각도 모드가 지시하는 각도에 기초하여 결정될 수 있다.According to one embodiment, the basic angle mode corresponds to the angle used in intra prediction of the existing HEVC (High Efficiency Video Coding) standard, and the extended angle mode corresponds to the angle newly added in intra prediction of the next-generation video codec standard. It may be a mode that does this. More specifically, the default angle mode is the intra prediction mode {2, 4, 6,... , 66}, and the extended angle mode is the intra prediction mode {3, 5, 7,... , 65} may be an angle mode corresponding to one of the following. That is, the extended angle mode may be an angle mode between basic angle modes within the first angle range. Accordingly, the angle indicated by the extended angle mode can be determined based on the angle indicated by the basic angle mode.
다른 실시예에 따르면, 기본 각도 모드는 기 설정된 제1 각도 범위 이내의 각도에 대응하는 모드이고, 확장 각도 모드는 상기 제1 각도 범위를 벗어나는 광각 모드일 수 있다. 즉, 기본 각도 모드는 인트라 예측 모드 {2, 3, 4, …, 66} 중 어느 하나에 대응하는 각도 모드이고, 확장 각도 모드는 인트라 예측 모드 {-14, -13, -12, …, -1} 및 {67, 68, …, 80} 중 어느 하나에 대응하는 각도 모드일 수 있다. 확장 각도 모드가 지시하는 각도는 대응하는 기본 각도 모드가 지시하는 각도의 반대편 각도로 결정될 수 있다. 따라서, 확장 각도 모드가 지시하는 각도는 기본 각도 모드가 지시하는 각도에 기초하여 결정될 수 있다. 한편, 확장 각도 모드들의 개수는 이에 한정되지 않으며, 현재 블록의 크기 및/또는 모양에 따라 추가적인 확장 각도들이 정의될 수 있다. 한편, 인트라 예측 모드 세트에 포함되는 인트라 예측 모드들의 총 개수는 전술한 기본 각도 모드와 확장 각도 모드의 구성에 따라 가변할 수 있다.According to another embodiment, the basic angle mode may be a mode corresponding to an angle within a preset first angle range, and the extended angle mode may be a wide angle mode outside the first angle range. That is, the default angle mode is the intra prediction mode {2, 3, 4, … , 66}, and the extended angle mode is the intra prediction mode {-14, -13, -12,... , -1} and {67, 68, … , 80} may be an angle mode corresponding to one of the following. The angle indicated by the extended angle mode may be determined as the angle opposite to the angle indicated by the corresponding basic angle mode. Accordingly, the angle indicated by the extended angle mode can be determined based on the angle indicated by the basic angle mode. Meanwhile, the number of expansion angle modes is not limited to this, and additional expansion angles may be defined depending on the size and/or shape of the current block. Meanwhile, the total number of intra prediction modes included in the intra prediction mode set may vary depending on the configuration of the basic angle mode and extended angle mode described above.
상기 실시예에서, 확장 각도 모드들 간의 간격은 대응하는 기본 각도 모드들 간의 간격에 기초하여 설정될 수 있다. 예를 들어, 확장 각도 모드들 {3, 5, 7, …, 65} 간의 간격은 대응하는 기본 각도 모드들 {2, 4, 6, …, 66} 간의 간격에 기초하여 결정될 수 있다. 또한, 확장 각도 모드들 {-14, -13, …, -1} 간의 간격은 대응하는 반대편의 기본 각도 모드들 {53, 53, …, 66} 간의 간격에 기초하여 결정되고, 확장 각도 모드들 {67, 68, …, 80} 간의 간격은 대응하는 반대편의 기본 각도 모드들 {2, 3, 4, …, 15} 간의 간격에 기초하여 결정될 수 있다. 확장 각도 모드들 간의 각도 간격은 대응하는 기본 각도 모드들 간의 각도 간격과 동일하도록 설정될 수 있다. 또한, 인트라 예측 모드 세트에서 확장 각도 모드들의 개수는 기본 각도 모드들의 개수 이하로 설정될 수 있다.In the above embodiment, the spacing between extended angle modes may be set based on the spacing between corresponding basic angle modes. For example, the extended angle modes {3, 5, 7, … , 65} are the corresponding fundamental angular modes {2, 4, 6, … , 66} can be determined based on the interval between them. Additionally, the extended angle modes {-14, -13, … , -1} are the corresponding opposite fundamental angular modes {53, 53,... , 66} is determined based on the spacing between the extended angle modes {67, 68,... , 80} are the corresponding opposite fundamental angular modes {2, 3, 4, … , 15} can be determined based on the interval between them. The angular spacing between the extended angle modes may be set to be equal to the angular spacing between the corresponding basic angle modes. Additionally, the number of extended angle modes in the intra prediction mode set may be set to less than the number of basic angle modes.
본 발명의 실시예에 따르면, 확장 각도 모드는 기본 각도 모드를 기초로 시그널링될 수 있다. 예를 들어, 광각 모드(즉, 확장 각도 모드)는 제1 각도 범위 이내의 적어도 하나의 각도 모드(즉, 기본 각도 모드)를 대체할 수 있다. 대체되는 기본 각도 모드는 광각 모드의 반대편에 대응하는 각도 모드일 수 있다. 즉, 대체되는 기본 각도 모드는 광각 모드가 지시하는 각도의 반대 방향의 각도에 대응하거나 또는 상기 반대 방향의 각도로부터 기 설정된 오프셋 인덱스만큼 차이 나는 각도에 대응하는 각도 모드이다. 본 발명의 실시예에 따르면, 기 설정된 오프셋 인덱스는 1이다. 대체되는 기본 각도 모드에 대응하는 인트라 예측 모드 인덱스는 광각 모드에 다시 매핑되어 해당 광각 모드를 시그널링할 수 있다. 예를 들어, 광각 모드 {-14, -13, …, -1}은 인트라 예측 모드 인덱스 {52, 53, …, 66}에 의해 각각 시그널링될 수 있고, 광각 모드 {67, 68, …, 80}은 인트라 예측 모드 인덱스 {2, 3, …, 15}에 의해 각각 시그널링될 수 있다. 이와 같이 기본 각도 모드를 위한 인트라 예측 모드 인덱스가 확장 각도 모드를 시그널링하도록 함으로, 각 블록의 인트라 예측에 사용되는 각도 모드들의 구성이 서로 다르더라도 동일한 세트의 인트라 예측 모드 인덱스들이 인트라 예측 모드의 시그널링에 사용될 수 있다. 따라서, 인트라 예측 모드 구성의 변화에 따른 시그널링 오버헤드가 최소화될 수 있다.According to an embodiment of the present invention, the extended angle mode may be signaled based on the basic angle mode. For example, a wide angle mode (i.e., extended angle mode) may replace at least one angle mode (i.e., basic angle mode) within the first angle range. The basic angle mode that is replaced may be an angle mode corresponding to the opposite side of the wide angle mode. That is, the basic angle mode that is replaced is an angle mode that corresponds to an angle in the opposite direction of the angle indicated by the wide-angle mode or to an angle that differs from the angle in the opposite direction by a preset offset index. According to an embodiment of the present invention, the preset offset index is 1. The intra-prediction mode index corresponding to the replaced basic angle mode may be remapped to the wide-angle mode to signal the corresponding wide-angle mode. For example, wide angle mode {-14, -13, … , -1} is the intra prediction mode index {52, 53, … , 66}, respectively, and the wide-angle mode {67, 68, … , 80} is the intra prediction mode index {2, 3, … , 15} can be signaled respectively. In this way, the intra prediction mode index for the basic angle mode signals the extended angle mode, so that even if the configurations of the angle modes used for intra prediction of each block are different, the same set of intra prediction mode indexes are used for signaling of the intra prediction mode. can be used Accordingly, signaling overhead due to changes in intra prediction mode configuration can be minimized.
한편, 확장 각도 모드의 사용 여부는 현재 블록의 모양 및 크기 중 적어도 하나에 기초하여 결정될 수 있다. 일 실시예에 따르면, 현재 블록의 크기가 기 설정된 크기보다 클 경우 확장 각도 모드가 현재 블록의 인트라 예측을 위해 사용되고, 그렇지 않을 경우 기본 각도 모드만 현재 블록의 인트라 예측을 위해 사용될 수 있다. 다른 실시예에 따르면, 현재 블록이 정사각형이 아닌 블록인 경우 확장 각도 모드가 현재 블록의 인트라 예측을 위해 사용되고, 현재 블록이 정사각형 블록인 경우 기본 각도 모드만 현재 블록의 인트라 예측을 위해 사용될 수 있다.Meanwhile, whether to use the extended angle mode may be determined based on at least one of the shape and size of the current block. According to one embodiment, if the size of the current block is larger than the preset size, the extended angle mode may be used for intra prediction of the current block, otherwise, only the basic angle mode may be used for intra prediction of the current block. According to another embodiment, if the current block is a non-square block, the extended angle mode may be used for intra prediction of the current block, and if the current block is a square block, only the basic angle mode may be used for intra prediction of the current block.
인트라 예측부는 현재 블록의 인트라 예측 모드 정보에 기초하여, 현재 블록의 인트라 예측에 사용될 참조 샘플들 및/또는 보간된 참조 샘플들을 결정한다. 인트라 예측 모드 인덱스가 특정 각도 모드를 지시할 경우, 현재 블록의 현재 샘플로부터 상기 특정 각도에 대응하는 참조 샘플 또는 보간된 참조 샘플이 현재 픽셀의 예측에 사용된다. 따라서, 인트라 예측 모드에 따라 서로 다른 세트의 참조 샘플들 및/또는 보간된 참조 샘플들이 인트라 예측에 사용될 수 있다. 참조 샘플들 및 인트라 예측 모드 정보를 이용하여 현재 블록의 인트라 예측이 수행되고 나면, 디코더는 역변환부로부터 획득된 현재 블록의 잔차 신호를 현재 블록의 인트라 예측 값과 더하여 현재 블록의 샘플 값들을 복원한다.The intra prediction unit determines reference samples and/or interpolated reference samples to be used for intra prediction of the current block, based on intra prediction mode information of the current block. When the intra prediction mode index indicates a specific angle mode, a reference sample or an interpolated reference sample corresponding to the specific angle from the current sample of the current block is used for prediction of the current pixel. Accordingly, different sets of reference samples and/or interpolated reference samples may be used for intra prediction depending on the intra prediction mode. After intra prediction of the current block is performed using reference samples and intra prediction mode information, the decoder restores the sample values of the current block by adding the residual signal of the current block obtained from the inverse transformer to the intra prediction value of the current block. .
인터 예측에 사용되는 움직임(모션) 정보에는 참조 방향 지시 정보(inter_pred_idc), 참조 픽쳐 인덱스(ref_idx_l0, ref_idx_l1), 움직임(모션) 벡터(mvL0, mvL1)이 포함될 수 있다. 참조 방향 지시 정보에 따라 참조 픽쳐 리스트 활용 정보(predFlagL0, predFlagL1)가 설정될 수 있다. 실시 일 예로, L0 참조 픽쳐를 사용하는 단방향 예측인 경우, predFlagL0=1, predFlagL1=0로 설정될 수 있다. L1 참조 픽쳐를 사용하는 단방향 예측인 경우, predFlagL0=0, predFlagL1=1로 설정될 수 있다. L0와 L1 참조 픽쳐를 모두 사용하는 양방향 예측인 경우, predFlagL0=1, predFlagL1=1로 설정될 수 있다.Movement (motion) information used for inter prediction may include reference direction indication information (inter_pred_idc), reference picture indices (ref_idx_l0, ref_idx_l1), and motion (motion) vectors (mvL0, mvL1). Reference picture list utilization information (predFlagL0, predFlagL1) may be set according to the reference direction indication information. As an example of an embodiment, in the case of unidirectional prediction using an L0 reference picture, predFlagL0=1 and predFlagL1=0 may be set. In the case of unidirectional prediction using an L1 reference picture, predFlagL0=0 and predFlagL1=1 can be set. In the case of bidirectional prediction using both L0 and L1 reference pictures, predFlagL0=1 and predFlagL1=1 can be set.
현재 블록이 코딩 유닛일 경우, 코딩 유닛은 여러 개의 서브 블록으로 분할될 수 있으며, 각 서브 블록의 예측 정보는 서로 같거나 또는 다를 수 있다. 실시 일 예로, 코딩 유닛이 인트라 모드일 경우, 각 서브 블록의 인트라 예측 모드는 서로 같거나 또는 다를 수 있다. 또한, 코딩 유닛이 인터 모드일 경우, 각 서브 블록의 움직임 정보는 서로 같거나 또는 다를 수 있다. 또한, 각 서브 블록은 서로 독립적으로 인코딩 또는 디코딩이 가능할 수 있다. 각각의 서브 블록은 서브 블록 인덱스(sub-block index, sbIdx)를 통해 구분될 수 있다.When the current block is a coding unit, the coding unit may be divided into several sub-blocks, and the prediction information of each sub-block may be the same or different. As an example embodiment, when the coding unit is an intra mode, the intra prediction mode of each subblock may be the same or different from each other. Additionally, when the coding unit is in inter mode, the motion information of each sub-block may be the same or different. Additionally, each sub-block may be encoded or decoded independently from each other. Each sub-block can be distinguished through a sub-block index (sbIdx).
현재 블록의 움직임 벡터는 주변 블록의 움직임 벡터와 유사할 가능성이 높다. 따라서, 주변 블록의 움직임 벡터는 움직임 예측 값(motion vector predictor, mvp)으로 사용될 수 있고, 현재 블록의 움직임 벡터는 주변 블록의 움직임 벡터를 이용하여 유도될 수 있다. 또한, 움직임 벡터의 정확성을 높이기 위해서, 인코더에서 원본 영상으로 찾은 현재 블록의 최적의 움직임 벡터와 움직임 예측 값 간의 움직임 벡터의 차이(motion vector difference, mvd)가 시그널링될 수 있다.The motion vector of the current block is likely to be similar to the motion vector of neighboring blocks. Therefore, the motion vector of the neighboring block can be used as a motion vector predictor (mvp), and the motion vector of the current block can be derived using the motion vector of the neighboring block. Additionally, in order to increase the accuracy of the motion vector, the motion vector difference (mvd) between the optimal motion vector of the current block found in the original image by the encoder and the motion prediction value may be signaled.
움직임 벡터는 다양한 해상도를 가질 수 있으며, 블록 단위로 움직임 벡터의 해상도가 달라질 수 있다. 움직임 벡터 해상도는 정수 단위, 반화소 단위, 1/4 화소 단위, 1/16 화소 단위, 4의 정수 화소 단위 등으로 표현될 수 있다. 스크린 콘텐츠와 같은 영상은 문자와 같은 단순한 그래픽 형태이므로 보간(interpolation) 필터를 적용하지 않아도 되므로, 정수 단위와 4의 정수 화소 단위가 블록 단위 선택적으로 적용될 수 있다. 회전 및 스케일을 표현할 수 있는 어파인(Affine) 모드로 부호화된 블록은 형태의 변화가 심하므로, 정수 단위, 1/4 화소 단위, 1/16 화소 단위가 블록 기반 선택적으로 적용될 수 있다. 블록 단위로 움직임 벡터 해상도를 선택적으로 적용할 지에 대한 여부 정보는 amvr_flag으로 시그널링된다. 만일 적용되는 경우, 어떠한 움직임 벡터 해상도를 현재 블록에 적용할지는 amvr_precision_idx으로 시그널링된다.The motion vector may have various resolutions, and the resolution of the motion vector may vary on a block basis. Motion vector resolution can be expressed in integer units, half-pixel units, 1/4 pixel units, 1/16 pixel units, integer pixel units of 4, etc. Since images such as screen content are in the form of simple graphics such as text, there is no need to apply an interpolation filter, so integer units and integer pixel units of 4 can be selectively applied on a block basis. Blocks encoded in affine mode, which can express rotation and scale, have significant changes in shape, so integer units, 1/4 pixel units, and 1/16 pixel units can be selectively applied on a block basis. Information on whether to selectively apply motion vector resolution on a block basis is signaled with amvr_flag. If applied, which motion vector resolution to apply to the current block is signaled with amvr_precision_idx.
양방향 예측이 적용되는 블록의 경우, 가중치 평균을 적용할 때 2개의 예측 블록 간의 가중치를 같거나 또는 다르게 적용할 수 있으며, 가중치에 대한 정보는 bcw_idx를 통해 시그널링된다. For blocks to which bidirectional prediction is applied, when applying weight average, the weights between the two prediction blocks can be applied the same or different, and information about the weights is signaled through bcw_idx.
움직임 예측 값의 정확도를 높이기 위해서, 머지(Merge) 또는 AMVP(dvanced motion vector prediction) 방법이 블록 단위 선택적으로 사용될 수 있다. Merge 방법은 현재 블록의 움직임 정보를 현재 블록에 인접한 주변 블록의 움직임 정보와 동일하게 구성하는 방법으로, 동질성을 갖는 움직임 영역에서 움직임 정보가 변화없이 공간적으로 전파됨으로써 움직임 정보의 부호화 효율을 증가시키는 장점이 있다. 반면에 AMVP 방법은 정확한 움직임 정보를 표현하기 위해 L0 및 L1 예측 방향으로 각각 움직임 정보를 예측하고 가장 최적의 움직임 정보를 시그널링하는 방법이다. 디코더는 AMVP 또는 Merge 방법을 통해 현재 블록에 대한 움직임 정보를 유도한 후, 참조 픽쳐(reference picture)에서 유도한 움직임 정보에 위치한 참조 블록을 현재 블록을 위한 예측 블록으로 사용한다. To increase the accuracy of motion prediction values, merge or advanced motion vector prediction (AMVP) methods can be selectively used on a block basis. The Merge method is a method that configures the motion information of the current block to be the same as the motion information of neighboring blocks adjacent to the current block. The Merge method has the advantage of increasing the coding efficiency of motion information by spatially propagating motion information without change in a motion region with homogeneity. There is. On the other hand, the AMVP method is a method that predicts motion information in the L0 and L1 prediction directions respectively and signals the most optimal motion information in order to express accurate motion information. The decoder derives motion information for the current block through the AMVP or Merge method and then uses the reference block located in the motion information derived from the reference picture as a prediction block for the current block.
Merge 또는 AMVP에서 움직임 정보를 유도하는 방법은 현재 블록의 주변 블록으로부터 유도된 움직임 예측 값을 사용하여 움직임 후보 리스트를 구성한 후, 최적의 움직임 후보에 대한 인덱스 정보가 시그널링되는 방법일 수 있다. AMVP의 경우, L0와 L1 각각 움직임 후보 리스트가 유도되므로, L0와 L1 각각에 대한 최적의 움직임 후보 인덱스(mvp_l0_flag, mvp_l1_flag)가 시그널링된다. Merge의 경우, 하나의 움직임 후보 리스트가 유도되므로, 하나의 머지 인덱스(merge_idx)가 시그널링된다. 하나의 코딩 유닛에서 유도되는 움직임 후보 리스트는 다양할 수 있으며, 각 움직임 후보 리스트마다 움직임 후보 인덱스 또는 머지 인덱스가 시그널링될 수 있다. 이때, Merge 모드로 부호화된 블록에서 잔여 블록에 대한 정보가 없는 모드를 머지 스킵(MergeSkip) 모드라고 할 수 있다. A method of deriving motion information in Merge or AMVP may be a method in which a motion candidate list is constructed using motion prediction values derived from neighboring blocks of the current block, and then index information for the optimal motion candidate is signaled. In the case of AMVP, since motion candidate lists are derived for each of L0 and L1, the optimal motion candidate indices (mvp_l0_flag, mvp_l1_flag) for each of L0 and L1 are signaled. In the case of Merge, since one motion candidate list is derived, one merge index (merge_idx) is signaled. The motion candidate list derived from one coding unit may vary, and a motion candidate index or merge index may be signaled for each motion candidate list. At this time, a mode in which there is no information about the remaining blocks in blocks encoded in Merge mode can be called Merge Skip mode.
SMVD(Symmetric MVD)는 양방향 예측(bi-directional prediction)의 경우에, L0 방향과 L1 방향의 MVD(Motion Vector Difference) 값이 대칭을 이루도록 하여 전송되는 움직임 정보의 비트량을 줄이는 방법이다. L0 방향과 대칭을 이루는 L1 방향의 MVD 정보는 전송하지 않으며, 더불어 L0 및 L1 방향의 참조 픽쳐 정보도 전송하지 않고 복호화 과정에서 유도한다.SMVD (Symmetric MVD) is a method of reducing the amount of bits of transmitted motion information by ensuring that the MVD (Motion Vector Difference) values in the L0 and L1 directions are symmetrical in the case of bi-directional prediction. MVD information in the L1 direction, which is symmetrical to the L0 direction, is not transmitted, and in addition, reference picture information in the L0 and L1 directions is not transmitted and is derived during the decoding process.
OBMC(Overlapped Block Motion Compensation)는 블록 간의 움직임 정보가 서로 다른 경우, 주변 블록들의 움직임 정보를 사용하여 현재 블록에 대한 예측 블록들을 생성한 후, 예측 블록들을 가중치 평균하여 현재 블록에 대한 최종 예측 블록을 생성하는 방법이다. 이는 움직임 보상된 영상의 블록 경계에서 발생되는 블록킹 현상을 줄여주는 효과가 있다.OBMC (Overlapped Block Motion Compensation) generates prediction blocks for the current block using the motion information of neighboring blocks when the motion information between blocks is different, and then weight averages the prediction blocks to create the final prediction block for the current block. How to create it. This has the effect of reducing the blocking phenomenon that occurs at the block boundaries of motion compensated images.
일반적으로 머지 움직임 후보는 움직임의 정확도가 낮다. 이러한 머지 움직임 후보의 정확도를 높이기 위해서, MMVD(Merge mode with MVD) 방법이 사용될 수 있다. MMVD 방법은 몇 개의 움직임 차분 값 후보들 중에서 선택된 하나의 후보를 이용하여 움직임 정보를 보정하는 방법이다. MMVD 방법을 통해 획득되는 움직임 정보의 보정 값에 대한 정보(예를 들어, 움직임 차분 값 후보들 중에서 선택된 하나의 후보를 지시하는 인덱스 등)은 비트스트림에 포함되어 디코더로 전송될 수 있다. 기존의 움직임 정보 차분 값을 비트스트림에 포함하는 것에 비해 움직임 정보의 보정 값에 대한 정보를 비트스트림에 포함함으로써 비트량을 절약할 수 있다.In general, merge movement candidates have low movement accuracy. To increase the accuracy of these merge motion candidates, the MMVD (Merge mode with MVD) method can be used. The MMVD method is a method of correcting motion information using one candidate selected from among several motion difference value candidates. Information on the correction value of the motion information obtained through the MMVD method (eg, an index indicating one candidate selected from motion difference value candidates, etc.) may be included in the bitstream and transmitted to the decoder. Compared to including existing motion information differential values in the bitstream, the amount of bits can be saved by including information about the correction value of motion information in the bitstream.
TM(Template Matching) 방법은 현재 블록의 주변 화소를 통해 템플릿을 구성하여 템플릿과 가장 유사도가 높은 매칭 영역을 찾아서 움직임 정보를 보정하는 방법이다. TM(Template matching)은 부호화되는 비트스트림의 크기를 줄이기 위해서, 움직임 정보를 비트스트림에 포함하지 않고 디코더에서 움직임 예측을 수행하는 방법이다. 이때, 디코더는 원본 영상이 없으므로 이미 복원된 주변 블록을 사용하여 현재 블록에 대한 움직임 정보를 개략적으로 유도할 수 있다.The TM (Template Matching) method is a method of compensating motion information by constructing a template using surrounding pixels of the current block and finding a matching area with the highest similarity to the template. Template matching (TM) is a method of performing motion prediction in a decoder without including motion information in the bitstream in order to reduce the size of the encoded bitstream. At this time, since the decoder does not have the original image, it can roughly derive motion information about the current block using already restored neighboring blocks.
DMVR(Decoder-side Motion Vector Refinement) 방법은 조금 더 정확한 움직임 정보를 찾기 위해 이미 복원된 참조 영상들의 상관성을 통해 움직임 정보를 보정하는 방법으로써, 현재 블록의 양방향 움직임 정보를 사용하여 2개의 참조 픽쳐의 임의의 정해진 영역 내에서 참조 픽쳐 내의 참조 블록 간의 가장 매칭이 잘되는 지점을 새로운 양방향 움직임으로 사용하는 방법이다. 이러한 DMVR이 수행될 때, 인코더는 하나의 블록 단위에서 DMVR을 수행하여 움직임 정보를 보정한 후, 다시 블록을 서브 블록으로 분할하여 각 서브 블록 단위에서 DMVR을 수행하여 서브 블록의 움직임 정보를 다시 보정할 수 있으며, 이를 MP-DMVR(Multi-pass DMVR)이라 할 수 있다. The DMVR (Decoder-side Motion Vector Refinement) method is a method of correcting motion information through the correlation of already restored reference images in order to find more accurate motion information. It uses the bidirectional motion information of the current block to compare the two reference pictures. This is a method of using the point with the best matching between reference blocks in a reference picture within a certain area as a new bidirectional movement. When such DMVR is performed, the encoder corrects the motion information by performing DMVR in one block unit, then divides the block into sub-blocks and performs DMVR in each sub-block unit to correct the motion information of the sub-block again. This can be done, and this can be called MP-DMVR (Multi-pass DMVR).
LIC(Local Illumination Compensation) 방법은 블록 간의 휘도 변화를 보상하는 방법으로, 현재 블록에 인접한 주변 화소들을 사용하여 선형 모델을 유도한 후, 선형 모델을 통해 현재 블록의 휘도 정보를 보상하는 방법이다.The LIC (Local Illumination Compensation) method is a method of compensating for luminance changes between blocks. It derives a linear model using surrounding pixels adjacent to the current block, and then compensates for the luminance information of the current block through the linear model.
기존 비디오 부호화 방법들은 상하좌우의 평행 이동만을 고려한 움직임 보상을 수행하기 때문에, 현실에서 일반적으로 접하는 확대, 축소, 회전 등과 같은 움직임 포함하고 있는 비디오들의 부호화 시 부호화 효율이 저하된다. 이러한 확대, 축소, 회전에 대한 움직임을 표현하기 위하여, 4개(회전) 또는 6개(확대, 축소, 회전) 파라미터 모델을 이용하는 Affine 모델 기반 움직임 예측 기술이 적용될 수 있다.Existing video coding methods perform motion compensation considering only horizontal, vertical, and horizontal movements, so coding efficiency deteriorates when coding videos that include movements such as enlargement, reduction, and rotation that are commonly encountered in reality. To express such movements for enlargement, reduction, and rotation, an Affine model-based motion prediction technology that uses a 4 (rotation) or 6 (enlargement, reduction, rotation) parameter model can be applied.
BDOF(Bi-Directional Optical Flow)는 양방향 움직임으로 구성된 블록의 참조 블록으로부터 광-흐름(optical-flow) 기반으로 화소의 변화량을 추정하여 예측 블록을 보정하는데 사용된다. 이러한 VVC의 BDOF에서 유도된 움직임 정보를 이용하여 현재 블록의 움직임을 보정할 수 있다.BDOF (Bi-Directional Optical Flow) is used to correct the prediction block by estimating the amount of pixel change based on optical-flow from the reference block of the block composed of bi-directional movement. The motion of the current block can be corrected using motion information derived from the BDOF of this VVC.
PROF(Prediction refinement with optical flow)는 서브 블록 단위 Affine 움직임 예측의 정확도를 픽셀 단위 움직임 예측의 정확도와 유사하도록 개선하기 위한 기술이다. PROF는 BDOF와 유사하게 광-흐름(optical-flow)에 기반하여 서브 블록 단위로 Affine 움직임 보상된 픽셀 값들에 대해 픽셀 단위로 보정 값을 계산하여 최종 예측 신호를 획득하는 기술이다.PROF (Prediction refinement with optical flow) is a technology to improve the accuracy of sub-block-level affine motion prediction to be similar to the accuracy of pixel-level motion prediction. PROF, similar to BDOF, is a technology that obtains the final prediction signal by calculating correction values in pixel units for affine motion compensated pixel values in sub-block units based on optical flow.
CIIP(Combined Inter-/Intra-picture Prediction)방법은 현재 블록에 대한 예측 블록을 생성할 때, 화면 내 예측 방법으로 생성한 예측 블록과 화면 간 예측 방법으로 생성한 예측 블록들을 가중치 평균하여 최종 예측 블록을 생성하는 방법이다.When generating a prediction block for the current block, the CIIP (Combined Inter-/Intra-picture Prediction) method performs a weighted average of the prediction blocks generated by the intra-picture prediction method and the prediction blocks generated by the inter-picture prediction method to create the final prediction block. This is a method to create .
IBC(Intra Block Copy) 방법은 현재 블록과 가장 유사한 부분을 현재 픽쳐 내의 이미 복원된 영역에서 찾아서, 해당 참조 블록을 현재 블록에 대한 예측 블록으로 사용하는 방법이다. 이때, 현재 블록과 참조 블록 간의 거리인 블록 벡터(Block Vector)와 관련된 정보는 비트스트림에 포함될 수 있다. 디코더는 비스트스림에 포함된 블록 벡터와 관련된 정보를 파싱하여 현재 블록을 위한 블록 벡터를 계산하거나 설정할 수 있다.The IBC (Intra Block Copy) method is a method that finds the part most similar to the current block in an already reconstructed area in the current picture and uses the corresponding reference block as a prediction block for the current block. At this time, information related to the block vector, which is the distance between the current block and the reference block, may be included in the bitstream. The decoder can calculate or set the block vector for the current block by parsing information related to the block vector contained in Beaststream.
BCW(Bi-prediction with CU-level Weights) 방법은 서로 다른 참조 픽쳐로 부터 움직임 보상된 두 개의 예측 블록에 대하여, 평균으로 예측 블록을 생성하지 않고, 블록 단위로 적응적으로 가중치를 적용하여 움직임 보상된 두 개의 예측 블록에 가중치 평균을 수행하는 방법이다.The BCW (Bi-prediction with CU-level Weights) method does not generate a prediction block by averaging two prediction blocks that have been motion-compensated from different reference pictures, but applies weights adaptively on a block-by-block basis to compensate for motion. This is a method of performing a weighted average on two prediction blocks.
MHP(Multi-hypothesis prediction) 방법은 화면 간 예측 시 단방향 및 양방향 움직임 정보에 추가적인 움직임 정보를 전송함으로써, 다양한 예측 신호를 통한 가중치 예측을 수행하는 방법이다.The MHP (Multi-hypothesis prediction) method is a method of performing weight prediction using various prediction signals by transmitting additional motion information to unidirectional and bidirectional motion information when predicting between screens.
CCLM(Cross-component linear model)은 휘도 신호와 해당 휘도 신호와 동일한 위치에 있는 색차 신호 간의 높은 상관성을 이용하여 선형 모델을 구성한 후, 해당 선형 모델을 통해 색차 신호를 예측하는 방법이다. 현재 블록에 인접한 주변 블록 중에서 복원이 완료된 블록을 사용하여 템플릿을 구성한 후, 템플릿을 통해 선형 모델에 대한 파라미터가 유도된다. 다음으로, 영상 포맷에 따라 선택적으로 색차 블록의 크기에 맞게 복원된 현재 휘도 블록이 다운 샘플링된다. 마지막으로, 다운 샘플링된 휘도 블록과 해당 선형 모델을 이용하여 현재 블록의 색차 블록을 예측한다. 이때, 2개 이상의 선형 모델을 사용하는 방법을 MMLM(Multi-model Linear mode)이라고 한다.CCLM (Cross-component linear model) is a method of constructing a linear model using the high correlation between a luminance signal and a chrominance signal located at the same location as the luminance signal, and then predicting the chrominance signal through the linear model. After constructing a template using restored blocks among neighboring blocks adjacent to the current block, parameters for the linear model are derived through the template. Next, depending on the video format, the restored current luminance block is selectively down-sampled to fit the size of the chrominance block. Finally, the chrominance block of the current block is predicted using the down-sampled luminance block and the corresponding linear model. At this time, the method of using two or more linear models is called MMLM (Multi-model Linear mode).
독립 스칼라 양자화(independent scalar quantization)에서, 입력된 계수 tk에 대한 복원된 계수 t'k는 관련된 양자화 인덱스(quantization index) qk에만 의존적이다. 즉, 임의의 복원된 계수에 대한 양자화 인덱스(quantization index)는 다른 복원된 계수들에 대한 양자화 인덱스들과는 다른 값을 가진다. 이때 t'k는 tk에서 양자화 오차가 포함된 값일 수 있으며, 양자화 파라미터에 따라 서로 다르거나 또는 같을 수 있다. 여기서, t'k는 복원된 변환 계수 또는 역양자화된 변환계수라고 명명할 수 있으며, 양자화 인덱스를 양자화된 변환 계수라고 명명할 수도 있다.In independent scalar quantization, the restored coefficients t' k for input coefficients t k depend only on the associated quantization index q k . That is, the quantization index for any restored coefficient has a different value from the quantization indexes for other restored coefficients. At this time, t' k may be a value including the quantization error at t k and may be different or the same depending on the quantization parameter. Here, t'k may be named a restored transform coefficient or a dequantized transform coefficient, and the quantization index may be named a quantized transform coefficient.
균일 복원 양자화(URQ; Uniform Reconstruction Quantizers)에서, 복원된 계수들은 동일한 간격으로 배치되는 특성을 지닌다. 이때 인접하는 두 복원 값들 사이의 거리를 양자화 단계 크기(quantization step size)라고 할 수 있다. 복원된 값 중에는 0을 포함할 수 있으며, 사용 가능한 복원 값들의 전체 집합(set)은 양자화 단계 크기에 따라 고유하게 정의될 수 있다. 양자화 단계 크기는 양자화 파라미터에 따라 달라질 수 있다.In Uniform Reconstruction Quantizers (URQ), the reconstructed coefficients have the characteristic of being arranged at equal intervals. At this time, the distance between two adjacent restored values can be referred to as the quantization step size. The restored values may include 0, and the entire set of available restored values may be uniquely defined depending on the quantization step size. The quantization step size may vary depending on the quantization parameter.
기존 방법에서는 양자화로 인해 허용 가능한 복원된 변환 계수들의 집합(세트)이 감소하며, 이러한 집합의 원소(element)는 유한 개일 수 있다. 이로 인해, 원본 영상과 복원된 영상 간의 평균적인 오차를 최소화하는데 한계가 존재한다. 이러한 평균적인 오차를 최소화하기 위한 방법으로 벡터 양자화(Vector Quantization)를 사용할 수 있다.In the existing method, the set of allowable restored transform coefficients decreases due to quantization, and the number of elements of this set may be finite. Because of this, there is a limit to minimizing the average error between the original image and the restored image. Vector quantization can be used as a method to minimize this average error.
비디오 부호화에서 사용되는 간단한 형태의 벡터 양자화 방법에는 부호 데이터 은닉(sign data hiding)이 있다. 이는 인코더에서 0이 아닌 하나의 계수에 대한 부호를 부호화하지 않고, 디코더에서는 해당 계수에 대한 부호를 모든 계수들에 대한 절대값의 합이 짝수인지 또는 홀수인지에 따라 결정하는 방법이다. 이를 위해 인코더에서는 적어도 하나의 계수가 '1'이 증가되거나 또는 감소될 수 있으며, 이는 율-왜곡(rate-distortion)에 대한 비용(Cost) 관점에서 최적이 되도록 적어도 하나의 계수가 선택되어 값이 조정될 수 있다. 실시 일 예로, 양자화 간격의 경계에 가까운 값을 가지는 계수가 선택될 수 있다.A simple form of vector quantization method used in video encoding is sign data hiding. This is a method in which the encoder does not encode the sign of one non-zero coefficient, and the decoder determines the sign for the corresponding coefficient depending on whether the sum of the absolute values of all coefficients is even or odd. To this end, at least one coefficient may be increased or decreased by '1' in the encoder, and at least one coefficient is selected to be optimal in terms of cost for rate-distortion, so that the value is It can be adjusted. As an example embodiment, a coefficient having a value close to the boundary of the quantization interval may be selected.
또 다른 벡터 양자화 방법에는 트렐리스 부호화된 양자화(Trellis-Coded Quantization)가 있으며, 비디오 부호화에서는 종속 양자화(dependent quantization)에서 최적화된 양자화 값을 얻기 위한 최적의 경로 탐색 기법으로 활용된다. 블록 단위로, 블록 내 모든 계수들에 대한 양자화 후보들을 트렐리스 그래프에 배치하고, 최적화된 양자화 후보들 간의 최적의 트렐리스 경로를 율-왜곡(rate-distortion)에 대한 비용(Cost)을 고려하여 탐색한다. 구체적으로, 비디오 부호화에 적용된 종속 양자화는 변환 계수에 대한 허용 가능한 복원된 변환 계수들의 집합이 복원 순서에서 현재 변환 계수에 선행하는 변환 계수의 값에 의존하도록 설계될 수 있다. 이때, 여러 개의 양자화기를 변환 계수에 따라 선택적으로 사용하게 함으로써, 원본 영상과 복원된 영상 간의 평균적인 오차를 최소화하여 부호화 효율을 높이는 효과가 있다. Another vector quantization method is Trellis-Coded Quantization, and in video coding, it is used as an optimal path search technique to obtain an optimized quantization value in dependent quantization. On a block basis, quantization candidates for all coefficients within the block are placed in a trellis graph, and the optimal trellis path between optimized quantization candidates is taken into consideration the cost of rate-distortion. and explore. Specifically, dependent quantization applied to video encoding may be designed such that the set of allowable restored transform coefficients for a transform coefficient depends on the value of the transform coefficient that precedes the current transform coefficient in reconstruction order. At this time, by selectively using multiple quantizers according to the transformation coefficient, the average error between the original image and the restored image is minimized, thereby increasing coding efficiency.
인트라 예측 부호화 기술 중에서 MIP(Matrix Intra Prediction) 방법은 행렬 기반 인트라 예측 방법으로 현재 블록에 인접한 주변 블록의 픽셀로부터 방향성을 가지는 예측 방법과 달리, 주변 블록의 좌측 및 상단의 픽셀들을 미리 정의된 행렬 매트릭스와 오프셋 값을 이용하여 예측 신호를 구하는 방법이다.Among intra prediction coding technologies, the MIP (Matrix Intra Prediction) method is a matrix-based intra prediction method. Unlike prediction methods that have directionality from pixels of neighboring blocks adjacent to the current block, pixels on the left and top of neighboring blocks are used as a predefined matrix. This is a method of obtaining a prediction signal using the and offset values.
현재 블록의 인트라 예측 모드를 유도하기 위해서, 현재 블록에 인접하면서 복원된 임의의 영역인 템플릿(template)을 기반으로, 해당 템플릿의 주변 픽셀을 통해 유도된 템플릿에 대한 인트라 예측 모드가 현재 블록의 복원을 위해 이용할 수 있다. 우선, 디코더는 템플릿에 인접한 주변 픽셀(reference)을 이용하여 템플릿에 대한 예측 템플릿을 생성하고, 이미 복원된 템플릿과 가장 유사한 예측 템플릿을 생성한 인트라 예측 모드를 현재 블록의 복원을 위해 사용할 수 있다. 이러한 방법을 TIMD(Template intra mode derivation)이라고 할 수 있다.In order to derive the intra prediction mode of the current block, based on a template, which is a random area restored while adjacent to the current block, the intra prediction mode for the template derived through the surrounding pixels of the template is used to restore the current block. It can be used for. First, the decoder can generate a prediction template for the template using surrounding pixels (references) adjacent to the template, and use the intra prediction mode, which generates a prediction template most similar to the already restored template, to restore the current block. This method can be called TIMD (Template intra mode derivation).
일반적으로 인코더는 예측 블록을 생성하기 위한 예측 모드를 결정하여 결정된 예측 모드에 대한 정보가 포함된 비트스트림을 생성할 수 있다. 디코더는 수신한 비트스트림을 파싱하여 인트라 예측 모드를 설정할 수 있다. 이때, 예측 모드에 대한 정보의 비트량은 전체 비트스트림 크기의 10% 정도일 수 있다. 예측 모드에 대한 정보의 비트량을 감소시키기 위해 인코더는 비트스트림에 인트라 예측 모드에 대한 정보를 포함하지 않을 수 있다. 이에, 디코더는 주변 블록의 특성을 이용하여 현재 블록의 복원을 위한 인트라 예측 모드를 유도(결정)할 수 있고, 유도된 인트라 예측 모드를 이용하여 현재 블록을 복원할 수 있다. 이때, 디코더는 인트라 예측 모드를 유도하기 위해 현재 블록에 인접한 주변 화소(픽셀)들마다 소벨(Sobel) 필터를 가로 및 세로 방향으로 적용하여 방향성 정보를 유추한 후, 해당 방향성 정보를 인트라 예측 모드로 매핑하는 방법을 이용할 수 있다. 디코더가 주변 블록을 이용하여 인트라 예측 모드를 유도하는 방법은 DIMD(Decoder side intra mode derivation)로 기술될 수 있다.In general, an encoder can determine a prediction mode for generating a prediction block and generate a bitstream containing information about the determined prediction mode. The decoder can set the intra prediction mode by parsing the received bitstream. At this time, the bit amount of information about the prediction mode may be about 10% of the total bitstream size. In order to reduce the bit amount of information about the prediction mode, the encoder may not include information about the intra prediction mode in the bitstream. Accordingly, the decoder can derive (determine) an intra prediction mode for restoration of the current block using the characteristics of the surrounding blocks, and can restore the current block using the derived intra prediction mode. At this time, in order to derive the intra prediction mode, the decoder applies a Sobel filter horizontally and vertically to each neighboring pixel (pixel) adjacent to the current block to infer directionality information, and then converts the directionality information into the intra prediction mode. A mapping method can be used. The method by which the decoder derives an intra prediction mode using neighboring blocks can be described as DIMD (Decoder side intra mode derivation).
도 7은 인터 예측에서 움직임 후보 리스트를 구성하기 위해 사용되는 주변 블록들의 위치를 나타낸 도면이다. Figure 7 is a diagram showing the positions of neighboring blocks used to construct a motion candidate list in inter prediction.
주변 블록들은 공간적인 위치의 블록이거나 시간적인 위치의 블록일 수 있다. 현재 블록에 공간적으로 인접한 주변 블록은 좌측(Left, A1) 블록, 좌하측(Left Below, A0) 블록, 상측(Above, B1) 블록, 상우측(Above Right, B0) 블록 또는 상좌측(Above Left, B2) 블록 중 적어도 하나가 될 수 있다. 현재 블록에 시간적으로 인접한 주변 블록은 대응되는 픽쳐(Collocated picture)에서 현재 블록의 하우측(bottom Right, BR) 블록의 좌상단 픽셀 위치를 포함하는 블록이 될 수 있다. 상기 현재 블록에 시간적으로 인접한 주변 블록이 인트라 모드로 부호화되거나 상기 현재 블록에 시간적으로 인접한 주변 블록이 사용할 수 없는 위치에 존재하면, 현재 픽쳐에 대응되는 픽쳐(Collocated picture)에서 현재 블록의 가로 및 세로의 중앙(Center, Ctr) 픽셀 위치를 포함하는 블록이 시간적 주변 블록으로 사용될 수 있다. 대응되는 픽쳐에서 유도된 움직임 후보 정보는 TMVP(Temporal Motion Vector Predictor)라 지칭될 수 있다. TMVP는 하나의 블록에서 하나만 유도될 수 있고, 하나의 블록을 여러 개의 서브 블록으로 분할한 후, 각 서브 블록마다 각각의 TMVP 후보가 유도될 수 있다. 서브 블록 단위의 TMVP 유도 방법은 sbTMVP(sub-block Temporal Motion Vector Predictor)로 지칭될 수 있다.Surrounding blocks may be blocks in a spatial location or blocks in a temporal location. Surrounding blocks that are spatially adjacent to the current block are Left (A1) block, Left Below (A0) block, Above (B1) block, Above Right (B0) block, or Above Left. , B2) It can be at least one of the blocks. The neighboring block temporally adjacent to the current block may be a block containing the upper left pixel position of the bottom right (BR) block of the current block in the corresponding picture (Collocated picture). If a neighboring block temporally adjacent to the current block is encoded in intra mode or a neighboring block temporally adjacent to the current block exists in an unusable position, the horizontal and vertical dimensions of the current block in the picture corresponding to the current picture (Collocated picture) A block containing the center (Ctr) pixel position of can be used as a temporal neighboring block. Motion candidate information derived from the corresponding picture may be referred to as TMVP (Temporal Motion Vector Predictor). Only one TMVP can be derived from one block, and after dividing one block into several sub-blocks, each TMVP candidate can be derived for each sub-block. The TMVP derivation method on a sub-block basis may be referred to as sbTMVP (sub-block Temporal Motion Vector Predictor).
본 명세서에서 설명하는 방법들이 적용될 것인지 여부는 슬라이스 타입 정보 (예, I 슬라이스, P 슬라이스, B 슬라이스 인지 여부), 타일인지 여부, 서브 픽쳐인지 여부, 현재 블록의 크기, 코딩 유닛의 깊이, 현재 블록이 휘도 블록인지 색차 블록인지 여부, 참조 프레임인지 비참조 프레임인지 여부, 참조 순서 및 계층에 따른 시간적인 계층 등에 대한 정보들 중 적어도 어느 하나에 기초하여 결정될 수 있다. 본 명세서에서 설명하는 방법들이 적용될 것인지 여부를 결정하기 위해 사용되는 정보들은 디코더 및 인코더 간 미리 약속된 정보일 수 있다. 또한, 이러한 정보들은 프로파일 및 레벨에 따라 결정되어 있을 수 있다. 이러한 정보들은 변수 값으로 표현될 수 있고, 비트스트림에는 변수 값에 대한 정보가 포함될 수 있다. 즉, 디코더는 비트스트림에 포함된 변수 값에 대한 정보를 파싱하여 상술한 방법들이 적용되는지 여부를 결정할 수 있다. 예를 들어, 코딩 유닛의 가로의 길이 또는 세로의 길이에 기초하여 상술한 방법들이 적용될 것인지 여부가 결정될 수 있다. 가로의 길이 또는 세로의 길이가 32 이상(예, 32, 64, 128 등)이면 상술한 방법들은 적용될 수 있다. 또한 가로의 길이 또는 세로의 길이가 32 보다 작은 경우(예, 2, 4, 8, 16)에 상술한 방법들은 적용될 수 있다. 또한 가로의 길이 또는 세로의 길이가 4 또는 8인 경우 상술한 방법들은 적용될 수 있다.Whether the methods described herein will be applied depends on slice type information (e.g., whether it is an I slice, a P slice, or a B slice), whether it is a tile, whether it is a subpicture, the size of the current block, the depth of the coding unit, and the current block. It may be determined based on at least one of information about whether it is a luminance block or a chrominance block, whether it is a reference frame or a non-reference frame, reference order, and temporal hierarchy according to the hierarchy. Information used to determine whether the methods described in this specification will be applied may be information previously agreed upon between the decoder and encoder. Additionally, this information may be determined according to profile and level. This information can be expressed as variable values, and the bitstream can include information about the variable values. That is, the decoder can determine whether the above-described methods are applied by parsing information about variable values included in the bitstream. For example, it may be determined whether the above-described methods will be applied based on the horizontal or vertical length of the coding unit. If the horizontal or vertical length is 32 or more (e.g., 32, 64, 128, etc.), the above-described methods can be applied. Additionally, the above-described methods can be applied when the horizontal or vertical length is less than 32 (e.g., 2, 4, 8, 16). Additionally, the above-described methods can be applied when the horizontal or vertical length is 4 or 8.
도 8은 본 발명의 일 실시예에 따른 움직임 정보를 보정하는 방법을 나타내는 도면이다.Figure 8 is a diagram showing a method for correcting motion information according to an embodiment of the present invention.
도 8(a)는 현재 블록의 주변 블록으로부터 유도된 움직임 정보를 보정(revision)하여 새로운 움직임 정보를 출력하는 과정을 나타낸다. 도 8(a)를 참조하면 디코더는 현재 블록의 주변 블록에 대한 움직임 정보를 다양한 움직임 보정 방법으로 보정하여 보정된 움직임 정보를 획득할 수 있다. 도 8(b)를 참조하면 디코더는 현재 블록의 주변 블록으로부터 움직임 후보 리스트를 유도한 후, 유도된 움직임 후보 리스트 내의 하나 이상의 움직임 후보들을 다양한 움직임 보정 방법으로 보정하여 보정된 움직임 후보 리스트를 획득할 수 있다. 움직임 후보 리스트는 현재 블록의 주변 블록으로부터 유도된 움직임 정보를 이용하여 구성될 수 있다. 디코더는 움직임 후보 리스트 내의 하나 이상의 움직임 후보들을 각각 또는 전부에 대해 움직임 보정 과정을 수행하여 보정된 하나 이상의 움직임 후보들을 포함하는 보정된 움직임 후보 리스트를 획득할 수 있다. 도 8(c)를 참조하면 디코더는 현재 블록에 대한 초기 움직임 정보를 다양한 움직임 보정 방법으로 보정하여 보정된 움직임 정보를 획득할 수 있다.Figure 8(a) shows the process of revising motion information derived from neighboring blocks of the current block and outputting new motion information. Referring to FIG. 8(a), the decoder can obtain corrected motion information by correcting motion information about neighboring blocks of the current block using various motion correction methods. Referring to FIG. 8(b), the decoder derives a motion candidate list from neighboring blocks of the current block, then corrects one or more motion candidates in the derived motion candidate list using various motion correction methods to obtain a corrected motion candidate list. You can. The motion candidate list can be constructed using motion information derived from neighboring blocks of the current block. The decoder may obtain a corrected motion candidate list including one or more corrected motion candidates by performing a motion correction process on each or all of the one or more motion candidates in the motion candidate list. Referring to FIG. 8(c), the decoder can obtain corrected motion information by correcting the initial motion information for the current block using various motion correction methods.
도 9는 본 발명의 일 실시예에 따른 움직임 보정 방법을 재귀적으로 수행하여 현재 블록에 대한 움직임 정보를 보정하는 방법을 나타내는 도면이다.Figure 9 is a diagram illustrating a method of correcting motion information for a current block by recursively performing a motion correction method according to an embodiment of the present invention.
디코더는 움직임 보정 방법을 재귀적으로 수행하여 현재 블록에 대한 초기 움직임 정보를 보정할 수 있다. 디코더는 현재 블록의 주변 블록들을 이용하여 현재 블록에 대한 움직임 후보 리스트를 구성하고, 하나 이상의 움직임 보정 방법을 재귀적으로 수행하여 움직임 정보를 보정할 수 있다. 이때, 하나 이상의 움직임 보정 방법은 MVD(Motion Vector Difference), TM(Template Matching), BM(Bilateral Matching), MMVD(Merge mode with MVD), MMVD(Merge mode with MVD) 기반의 TM, Optical flow 기반 TM, Multi pass DMVR 등일 수 있다. MVD는 인코더가 움직임 정보에 대한 보정 값을 비트스트림에 포함하여 생성하고, 디코더는 비트스트림을 통해 움직임 정보에 대한 보정 값을 획득하여 움직임 정보를 보정하는 방법일 수 있다(도 9의 MV 차분 값 보정). TM은 디코더가 현재 블록의 주변 화소에 기초하여 템플릿을 구성하고, 구성된 템플릿과 가장 유사도가 높은 매칭 영역을 찾아 움직임 정보를 보정하는 방법일 수 있다. BM은 디코더가 현재 블록의 움직임 정보를 기반으로 유도된 L0 픽쳐 리스트에 포함된 픽쳐 내의 참조 블록과 L1 픽쳐 리스트에 포함된 픽쳐 내의 참조 블록 간의 유사도에 기초하여 움직임 정보를 보정하는 방법일 수 있다. MMVD 방법은 하나 이상의 움직임 차분 값 후보들 중에서 하나를 이용하여 움직임 정보를 보정하는 방법이다. 인코더는 하나 이상의 움직임 차분 값 후보들 중에서 어느 하나를 나타내는 인덱스에 대한 정보를 포함하는 비트스트림을 생성할 수 있다. 디코더는 비트스트림에 포함된 인덱스에 대한 정보를 파싱하여 인덱스가 지시하는 차분 값 후보를 획득하고, 획득한 차분 값 후보에 기초하여 움직임 정보를 보정할 수 있다. MMVD 기반의 TM 방법은 움직임 후보 리스트와 하나 이상의 움직임 차분 값 후보들을 이용하여 구성되는 확장된 움직임 후보 리스트가 TM 코스트 값에 기초하여 재정렬되고, 재정렬된 리스트 내의 움직임 후보를 이용하여 현재 블록의 움직임 정보를 보정하는 방법이다. 인코더는 재정렬된 리스트 내의 후보들 중 어느 하나를 나타내는 인덱스에 대한 정보를 포함하는 비트스트림을 생성할 수 있다. 디코더는 비트스트림에 포함된 인덱스에 대한 정보를 파싱하여 해당 인덱스가 지시하는 움직임 보정 후보를 현재 블록의 움직임 정보의 보정 값으로 사용할 수 있다. Optical flow 기반 TM 방법은 디코더가 현재 블록에 인접한 영역의 템플릿을 Optical flow 맵으로 구성하여 참조 픽쳐의 Optical flow 맵과 유사한 영역을 찾아서 움직임 정보를 보정하는 방법일 수 있다.The decoder can correct the initial motion information for the current block by recursively performing a motion correction method. The decoder may construct a motion candidate list for the current block using neighboring blocks of the current block, and may correct motion information by recursively performing one or more motion correction methods. At this time, one or more motion correction methods include MVD (Motion Vector Difference), TM (Template Matching), BM (Bilateral Matching), MMVD (Merge mode with MVD), MMVD (Merge mode with MVD)-based TM, and Optical flow-based TM. , Multi pass DMVR, etc. MVD may be a method in which the encoder generates a correction value for the motion information by including it in a bitstream, and the decoder obtains the correction value for the motion information through the bitstream to correct the motion information (MV difference value in FIG. 9 correction). TM may be a method in which a decoder constructs a template based on surrounding pixels of the current block, finds a matching area with the highest similarity to the constructed template, and corrects motion information. BM may be a method in which a decoder corrects motion information based on the similarity between a reference block in a picture included in an L0 picture list derived based on motion information of the current block and a reference block in a picture included in an L1 picture list. The MMVD method is a method of correcting motion information using one of one or more motion difference value candidates. The encoder may generate a bitstream including information about an index representing one of one or more motion difference value candidates. The decoder may parse information about the index included in the bitstream, obtain a difference value candidate indicated by the index, and correct motion information based on the obtained difference value candidate. In the MMVD-based TM method, an extended motion candidate list consisting of a motion candidate list and one or more motion difference value candidates is reordered based on the TM cost value, and motion information of the current block is obtained using the motion candidates in the reordered list. This is a way to correct. The encoder may generate a bitstream containing information about an index indicating one of the candidates in the reordered list. The decoder can parse information about the index included in the bitstream and use the motion correction candidate indicated by the index as the correction value of the motion information of the current block. The optical flow-based TM method may be a method in which the decoder configures a template of an area adjacent to the current block into an optical flow map, finds an area similar to the optical flow map of the reference picture, and corrects motion information.
하나 이상의 움직임 보정 방법은 머지 또는 AMVP 모드에 적용될 수 있다. 도 9를 참조하면 디코더는 현재 블록에 대한 움직임 후보 리스트(예, 머지 후보 리스트)를 유도(구성)할 수 있다. 그리고 디코더는 하나 이상의 움직임 보정 방법을 이용하여 움직임 후보 리스트 내 움직임 정보(예, 머지 후보)를 각각 또는 전부 보정할 수 있다. 디코더는 보정된 움직임 정보에 대한 코스트(Cost) 값에 기초하여 움직임 후보 리스트를 재정렬할 수 있다. 상술한 바와 같이 디코더는 재정렬된 움직임 후보 리스트 내의 움직임 후보들 각각 또는 전부에 대해 상술한 보정 방법을 수행하고, 움직임 후보 리스트를 재정렬할 수 있다. 즉, 디코더는 상술한 움직임 후보들에 대한 보정 및 움직임 후보 리스트의 재정렬을 재귀적으로 수행할 수 있다. 이러한 방법이 적용되면 움직임 후보 리스트 내 움직임 후보에 대한 움직임 정보의 정확도가 높아지고, 이로 인해, 잔여 신호가 줄어들 수 있어, 잔여 신호에 대한 비트량이 감소되는 효과가 있을 수 있다. 디코더는 재정렬된 움직임 후보 리스트 내의 움직임 후보들 중 어느 하나를 지시하는 인덱스를 별도로 시그널링 받고 인덱스가 지시하는 움직임 후보에 기초하여 현재 블록을 예측(복원) 할 수 있다. 또는 디코더는 코스트 값이 가장 낮은 움직임 후보를 선택하여 코스트 값이 가장 낮은 움직임 후보에 기초하여 현재 블록을 예측(복원)할 수 있다.One or more motion compensation methods may be applied in merge or AMVP mode. Referring to FIG. 9, the decoder can derive (construct) a motion candidate list (eg, merge candidate list) for the current block. Additionally, the decoder may correct each or all of the motion information (e.g., merge candidates) in the motion candidate list using one or more motion correction methods. The decoder may rearrange the motion candidate list based on the cost value for the corrected motion information. As described above, the decoder may perform the above-described correction method on each or all of the motion candidates in the rearranged motion candidate list and rearrange the motion candidate list. That is, the decoder can recursively perform correction for the above-described motion candidates and rearrangement of the motion candidate list. When this method is applied, the accuracy of motion information for motion candidates in the motion candidate list increases, and as a result, the residual signal can be reduced, which may have the effect of reducing the amount of bits for the residual signal. The decoder can separately receive an index indicating one of the motion candidates in the reordered motion candidate list and predict (restore) the current block based on the motion candidate indicated by the index. Alternatively, the decoder may select the motion candidate with the lowest cost value and predict (restore) the current block based on the motion candidate with the lowest cost value.
머지 후보의 정확도를 높이기 위해서, 인코더는 MMVD(Merge mode with MVD) 방법을 사용하여 획득되는 움직임 정보의 보정 값들 중 어느 하나를 나타내는 인덱스에 대한 정보를 포함하여 비트스트림을 생성할 수 있고, 디코더는 비트스트림에 포함된 인덱스에 대한 정보를 파싱하여 획득되는 인덱스를 통해 움직임 정보의 보정 값을 획득하고, 움직임 종보의 보정 값을 현재 블록을 예측(복원)하는데 사용할 수 있다. MMVD 방법은 복수 개의 움직임 차분 값 후보들 중에서 어느 하나를 선택하는 방법으로 기존의 움직임 정보 차분 값을 정확하게 보내는 것 대비 정확도는 다소 부족하나 많은 비트량을 절약할 수 있다는 효과가 있다. 정확도를 조금 더 높이기 위해 디코더는 MMVD 방법을 사용하여 획득되는 움직임 정보의 보정 값에 기초하여 보정되는 제1 보정 움직임 정보에 TM, BM, MMVD(Merge mode with MVD), MMVD(Merge mode with MVD) 기반의 TM, Optical flow기반 TM, Multi pass DMVR 방법 중 적어도 어느 하나의 방법을 추가적으로 적용하여 제2 보정 움직임 정보를 획득할 수 있다. 또는, 인코더는 TM, BM, MMVD(Merge mode with MVD), MMVD(Merge mode with MVD) 기반의 TM, Optical flow 기반 TM, Multi pass DMVR 방법 중 적어도 어느 하나의 방법을 적용하여 움직임 정보를 보정한 후, 상기 적어도 어느 하나의 방법을 적용하여 획득되는 움직임 정보에 대한 보정 값에 대한 정보를 추가적으로 포함하여 비트스트림을 생성할 수 있다.In order to increase the accuracy of the merge candidate, the encoder may generate a bitstream including information about an index indicating one of the correction values of motion information obtained using the MMVD (Merge mode with MVD) method, and the decoder may generate a bitstream The correction value of the motion information can be obtained through the index obtained by parsing the information about the index included in the bitstream, and the correction value of the motion information can be used to predict (restore) the current block. The MMVD method is a method of selecting one of a plurality of motion difference value candidates. Although it is less accurate than accurately transmitting the existing motion information difference value, it has the effect of saving a large amount of bits. In order to slightly increase accuracy, the decoder adds TM, BM, MMVD (Merge mode with MVD), and MMVD (Merge mode with MVD) to the first corrected motion information, which is corrected based on the correction value of the motion information obtained using the MMVD method. The second corrected motion information can be obtained by additionally applying at least one of the TM-based TM, Optical flow-based TM, and Multi pass DMVR methods. Alternatively, the encoder corrects the motion information by applying at least one method among TM, BM, MMVD (Merge mode with MVD), MMVD (Merge mode with MVD)-based TM, Optical flow-based TM, and Multi pass DMVR method. Afterwards, a bitstream can be generated by additionally including information on correction values for motion information obtained by applying at least one of the above methods.
AMVP를 위해서는 움직임 정보의 차분 값이 비스트스트림에 포함될 수 있다. 디코더는 비트스트림에 포함된 움직임 정보의 차분 값을 사용하여 현재 블록에 대한 예측 블록을 생성할 수 있다. 움직임 정보의 차분 값이 비트스트림에 포함되기 때문에, 비트량이 증가되는 문제가 있다. 이를 위해 상술한 방법은 AMVP 후보 리스트에도 적용될 수 있다. 즉, AMVP를 이용하여 획득된 후보 리스트 내 하나 이상의 후보들 각각 또는 전부는 TM, BM, MMVD(Merge mode with MVD), MMVD(Merge mode with MVD) 기반의 TM, Optical flow기반 TM, Multi pass DMVR 중 적어도 어느 하나의 방법에 기초하여 보정될 수 있다. 보정된 움직임 정보가 사용되기 때문에 실제 비트스트림에 포함되는 움직임 정보의 차분 값에 대한 비트량이 줄어드는 효과가 있다.For AMVP, the difference value of motion information may be included in the beast stream. The decoder can generate a prediction block for the current block using the difference value of the motion information included in the bitstream. Since the difference value of motion information is included in the bitstream, there is a problem that the bit amount increases. For this purpose, the above-described method can also be applied to the AMVP candidate list. In other words, each or all of the one or more candidates in the candidate list obtained using AMVP are TM, BM, MMVD (Merge mode with MVD), MMVD (Merge mode with MVD)-based TM, Optical flow-based TM, and Multi pass DMVR. It can be corrected based on at least one method. Since the corrected motion information is used, the bit amount for the difference value of the motion information included in the actual bit stream is reduced.
MVD 방법이 먼저 수행되고, TM, BM, MMVD(Merge mode with MVD), MMVD(Merge mode with MVD) 기반의 TM, Optical flow기반 TM, Multi pass DMVR 중 적어도 어느 하나를 이용한 보정 방법이 수행될 수 있다. 또는 인코더는 MVD를 사용하여 초기 움직임 정보에 대한 보정 값을 포함한 비트스트림을 생성할 수 있다. 디코더는 비트스트림에 포함된 초기 움직임 정보에 대한 보정 값에 기초하여 상술한 움직임 보정 방법을 수행할 수 있다.The MVD method is performed first, and then a correction method using at least one of TM, BM, MMVD (Merge mode with MVD), MMVD (Merge mode with MVD)-based TM, Optical flow-based TM, and Multi pass DMVR can be performed. there is. Alternatively, the encoder can use MVD to generate a bitstream containing correction values for the initial motion information. The decoder may perform the above-described motion correction method based on the correction value for the initial motion information included in the bitstream.
이하에서 MVD(Motion Vector Difference), TM(Template Matching), BM(Bilateral Matching), MMVD(Merge mode with MVD), MMVD(Merge mode with MVD) 기반의 TM, Optical flow 기반 TM, Multi pass DMVR 등을 적용하는 방법에 대해 설명한다.Below, MVD (Motion Vector Difference), TM (Template Matching), BM (Bilateral Matching), MMVD (Merge mode with MVD), MMVD (Merge mode with MVD)-based TM, Optical flow-based TM, Multi pass DMVR, etc. Explains how to apply it.
현재 블록의 부호화 모드(예측 모드)에 기초하여 사용되는 움직임 보정 방법이 결정될 수 있다. 예를 들어, 현재 블록이 GPM 모드로 부호화된 경우, 먼저 MMVD를 이용하여 보정된 MV 차분 값에 대해 TM, BM, Optical flow 기반 TM 방법 중에서 적어도 어느 하나가 수행될 수 있다. 예를 들어, 현재 블록이 AMVP 모드로 부호화된 경우, 머지 모드의 MMVD를 이용하여 보정된 MV 차분 값에 대해 TM, BM, Optical flow 기반 TM 방법 중에서 적어도 어느 하나가 수행될 수 있다. 이때, AMVP 모드의 MVD는 적용되지 않을 수 있다.The motion correction method to be used may be determined based on the encoding mode (prediction mode) of the current block. For example, if the current block is encoded in GPM mode, at least one of TM, BM, and optical flow-based TM methods may be performed on the MV difference value corrected using MMVD. For example, if the current block is encoded in AMVP mode, at least one of TM, BM, and optical flow-based TM methods may be performed on the MV difference value corrected using merge mode MMVD. At this time, MVD in AMVP mode may not be applied.
예를 들어, 현재 블록에 인접한 주변 블록들의 움직임 정보가 서로 같거나 비슷한 경우, MV 차분 값에 대한 보정은 수행되지 않고, TM, BM, Optical flow 기반 TM 방법 중에서 적어도 어느 하나가 수행될 수 있다. 현재 블록의 움직임도 주변 블록의 움직임과 비슷할 가능성이 크기 때문이다. 한편 현재 블록에 인접한 주변 블록들의 움직임 정보들의 분포가 서로 비슷하지 않는 경우, MVD 또는 MMVD를 이용하여 보정된 MV 차분 값에 대해 TM, BM, Optical flow 기반 TM 방법 중에서 적어도 어느 하나가 수행될 수 있다. 현재 블록의 움직임이 주변 블록과 상이할 수 있기 때문이다.For example, if the motion information of neighboring blocks adjacent to the current block is the same or similar to each other, correction for the MV difference value is not performed, and at least one of TM, BM, and optical flow-based TM methods may be performed. This is because the movement of the current block is likely to be similar to the movement of surrounding blocks. Meanwhile, if the distribution of motion information of neighboring blocks adjacent to the current block is not similar to each other, at least one of TM, BM, and optical flow-based TM methods may be performed on the MV difference value corrected using MVD or MMVD. . This is because the movement of the current block may be different from the surrounding blocks.
예를 들어, 현재 블록의 크기, 현재 블록이 휘도 성분 블록인지 색차 성분 블록인지 여부, 현재 블록에 대한 양자화 파라미터 정보, 현재 블록의 움직임 해상도 정보들, 현재 블록에 차분 신호가 존재하는지 여부, 현재 블록에 대한 차분 신호에서 0이 아닌 양자화 인덱스들의 절대값의 합 혹은 개수 중 적어도 어느 하나에 기초하여 움직임 보정 방법(예, MVD(Motion Vector Difference), TM(Template Matching), BM(Bilateral Matching), Optical flow 기반 TM, Multi pass DMVR 등)이 선택될 수 있다. 현재 블록의 크기가 임의의 크기 이상이거나 현재 블록의 움직임 해상도가 1/16 화소 단위인 경우, TM 방법은 선택되지 않을 수 있다. TM 방법은 복잡도가 높기 때문이다. 현재 블록이 색차 성분 블록인 경우, TM 방법이 수행되지 않고, 현재 블록의 휘도 성분 블록에서 TM 방법을 통해 보정된 움직임 정보가 사용될 수 있다. 예를 들어, 현재 블록의 휘도 성분 블록에서 TM 방법을 통해 보정된 움직임 정보는 스케일(scale)되어 현재 블록의 색차 블록에 사용될 수 있다.For example, the size of the current block, whether the current block is a luminance component block or a chrominance component block, quantization parameter information for the current block, motion resolution information of the current block, whether a differential signal exists in the current block, current block A motion compensation method (e.g., Motion Vector Difference (MVD), Template Matching (TM), Bilateral Matching (BM), Optical flow-based TM, Multi pass DMVR, etc.) can be selected. If the size of the current block is larger than a certain size or the motion resolution of the current block is 1/16 pixel unit, the TM method may not be selected. This is because the TM method has high complexity. If the current block is a chrominance component block, the TM method is not performed, and motion information corrected through the TM method can be used in the luminance component block of the current block. For example, motion information corrected through the TM method in the luminance component block of the current block may be scaled and used in the chrominance block of the current block.
예를 들어, 현재 블록의 특성에 따라 움직임 보정 방법(예, MVD(Motion Vector Difference), TM(Template Matching), BM(Bilateral Matching), MMVD(Merge mode with MVD), MMVD(Merge mode with MVD) 기반의 TM, Optical flow 기반 TM, Multi pass DMVR 등)은 선택될 수 있다. 각 움직임 보정 방법마다 복잡도 및 정확도 간의 상충관계(trade-off)가 존재하기 때문이다. 예를 들어, TM은 복잡도가 높고 병렬처리가 불가한 반면에 가장 높은 성능을 보이며, BM은 TM보다 성능은 낮지만 병렬처리가 가능하며, Optical flow는 복잡도는 낮고 병렬처리도 가능하지만, 성능이 낮다는 단점이 있다. 이때, 선택되는 움직임 보정 방법은 별도로 시그널링될 수 있다. 예를 들어, 디코더는 비트스트림에 포함된 신택스 요소에 의해 움직임 보정 방법을 결정할 수 있다. 이때, 신택스 요소는 SPS 레벨, PPS 레벨, 픽쳐 레벨, 또는 슬라이스 레벨, CU(Coding Unit) 레벨에서 시그널링될 수 있다.For example, depending on the characteristics of the current block, a motion correction method (e.g., Motion Vector Difference (MVD), Template Matching (TM), Bilateral Matching (BM), Merge mode with MVD (MMVD), Merge mode with MVD (MMVD) TM-based TM, Optical flow-based TM, Multi pass DMVR, etc.) can be selected. This is because there is a trade-off between complexity and accuracy for each motion compensation method. For example, TM has high complexity and is not capable of parallel processing but shows the highest performance, BM has lower performance than TM but allows parallel processing, and Optical flow has low complexity and is capable of parallel processing but has poor performance. It has the disadvantage of being low. At this time, the selected motion correction method may be signaled separately. For example, the decoder can determine the motion correction method based on syntax elements included in the bitstream. At this time, the syntax element may be signaled at the SPS level, PPS level, picture level, slice level, or CU (Coding Unit) level.
도 10은 본 발명의 일 실시예에 따른 TM 방법이 수행되는 순서를 나타내는 도면이다.Figure 10 is a diagram showing the order in which the TM method is performed according to an embodiment of the present invention.
도 10을 참조하면 디코더는 주변 블록으로부터 유도된 초기 움직임 정보(initial MV, reference index)를 획득할 수 있다. 디코더는 초기 움직임 정보에 기초하여 참조 영상 내에서 탐색 영역을 설정할 수 있다. 디코더는 미리 정의된 탐색 패턴에 따라, 탐색 영역 내에서 몇 개의 후보 위치를 선정할 수 있다. 디코더는 현재 블록의 주변 블록을 사용하여 현재 블록에 대한 템플릿을 구성하고, 후보 위치를 기준으로 현재 블록에 대한 템플릿과 동일한 크기의 참조 영상 템플릿을 구성할 수 있다. 디코더는 현재 블록에 대한 템플릿과 참조 영상 템플릿 간의 코스트(cost) 값을 획득할 수 있다. 코스트 값은 SAD(Sum of Absolute Differences) 또는 MRSAD(Mean-Removed SAD)를 통해 획득될 수 있다. 디코더는 탐색 영역 내의 모든 후보 위치들에 대하여, 코스트 값을 획득하고, 최소의 코스트 값에 대응되는 위치의 움직임 후보의 정보를 최종 움직임 정보(도 10의 개선된 움직임 정보)로 사용할 수 있다. 본 명세서에서 코스트 값을 획득한다는 의미는 디코더가 코스트 값을 계산한다는 의미와 동일할 수 있다.Referring to FIG. 10, the decoder can obtain initial motion information (initial MV, reference index) derived from neighboring blocks. The decoder can set a search area within the reference image based on the initial motion information. The decoder can select several candidate locations within the search area according to a predefined search pattern. The decoder may construct a template for the current block using neighboring blocks of the current block, and may construct a reference image template of the same size as the template for the current block based on the candidate location. The decoder can obtain the cost value between the template for the current block and the reference video template. The cost value can be obtained through Sum of Absolute Differences (SAD) or Mean-Removed SAD (MRSAD). The decoder can obtain cost values for all candidate positions in the search area and use information on the motion candidate at the position corresponding to the minimum cost value as final motion information (improved motion information in FIG. 10). In this specification, the meaning of obtaining a cost value may be the same as the meaning of the decoder calculating the cost value.
도 11은 본 발명의 일 실시예에 따른 초기 움직임 정보에 기초하여 TM 방법을 위한 탐색 영역을 설정하는 방법을 나타내는 도면이다. Figure 11 is a diagram illustrating a method for setting a search area for a TM method based on initial motion information according to an embodiment of the present invention.
도 11을 참조하면 디코더는 참조 픽쳐에서 현재 블록에 대응되는 참조 블록을 찾기 위해, 현재 블록의 좌상단 위치를 기준으로 초기 움직임 정보(initial MV)만큼 이동한 위치를 참조 블록의 위치로 설정할 수 있다. 디코더는 참조 블록의 좌상단 위치를 기준으로 임의의 (m x n) 크기만큼 탐색 영역(Search range)을 설정할 수 있다. 이때, m x n 은 16 x 16일 수 있다. 예를 들어, 탐색 영역은 초기 움직임 정보의 위치를 기준으로 수평 방향으로 -8에서 8만큼의 범위를 가질 수 있고, 수직 방향으로 -8에서 8까지의 범위를 가질 수 있다. 구체적으로 초기 움직임 정보가 나타내는 위치를 수평 방향, 수직 방향의 좌표 형태로 표현하면 (x, y)일 수 있다. 이때, 탐색 영역의 수평 방향의 좌표는 x-8에서 x+8 까지의 범위일 수 있고, 수직 방향의 좌표는 y-8에서 y+8 까지의 범위일 수 있다. 이후 디코더는 현재 블록에 인접한 블록을 이용하여 현재 블록의 좌측 템플릿과 현재 블록의 상측 템플릿을 구성할 수 있다. 또한, 디코더는 참조 픽쳐에서도 설정한 참조 블록의 위치를 기준으로 참조 블록의 좌측 템플릿과 참조 블록의 상측 템플릿을 구성한다. 이때, 현재 블록의 좌측 템플릿과 참조 블록의 좌측 템플릿의 크기는 동일할 수 있고, 현재 블록의 상측 템플릿과 참조 블록의 상측 템플릿의 크기는 동일할 수 있다.Referring to FIG. 11, in order to find a reference block corresponding to the current block in the reference picture, the decoder may set the position moved by the initial motion information (initial MV) based on the upper left position of the current block as the position of the reference block. The decoder can set a search range of an arbitrary (m x n) size based on the upper left position of the reference block. At this time, m x n may be 16 x 16. For example, the search area may range from -8 to 8 in the horizontal direction and from -8 to 8 in the vertical direction, based on the position of the initial motion information. Specifically, if the position indicated by the initial motion information is expressed in the form of horizontal and vertical coordinates, it may be (x, y). At this time, the horizontal coordinates of the search area may range from x-8 to x+8, and the vertical coordinates may range from y-8 to y+8. Afterwards, the decoder can construct a left template of the current block and an upper template of the current block using blocks adjacent to the current block. Additionally, the decoder configures the left template of the reference block and the upper template of the reference block based on the position of the reference block set in the reference picture. At this time, the size of the left template of the current block and the left template of the reference block may be the same, and the sizes of the upper template of the current block and the upper template of the reference block may be the same.
도 12는 본 발명의 일 실시예에 따른 탐색 영역 내에서 탐색되는 움직임 후보의 위치를 나타내는 도면이다. Figure 12 is a diagram showing the location of a motion candidate searched within a search area according to an embodiment of the present invention.
도 12를 참조하면 TM 방법을 위한 탐색 영역 내에서 탐색되는 움직임 후보의 위치는 초기 움직임 정보에 대한 위치(도 12의 가운데 점)를 기준으로 설정될 수 있다. 움직임 후보가 탐색되는 위치는 탐색 패턴에 따라 달라질 수 있다. 탐색 패턴은 다이아몬드(DIAMOND) 패턴, 크로스(CROSS) 패턴 등이 있을 수 있다. 도 12에서 ◇는 다이아몬드 패턴에 따라 움직임 후보가 탐색되는 위치를 나타내고, +는 크로스 패턴에 따라 움직임 후보가 탐색되는 위치를 나타낼 수 있다. 패턴의 간격은 초기 움직임 정보에서 멀어질수록 간격이 더 넓어지도록 설정되거나 좁아지도록 설정될 수 있다.Referring to FIG. 12, the position of the motion candidate searched within the search area for the TM method may be set based on the position of the initial motion information (center point in FIG. 12). The location where the motion candidate is searched may vary depending on the search pattern. Search patterns may include DIAMOND patterns, CROSS patterns, etc. In FIG. 12, ◇ may indicate a position where a motion candidate is searched according to a diamond pattern, and + may indicate a position where a motion candidate is searched according to a cross pattern. The spacing of the patterns may be set to become wider or narrower as the distance from the initial motion information increases.
도 13은 본 발명의 일 실시예에 따른 움직임 후보의 위치를 탐색하는 과정을 나타내는 도면이다.Figure 13 is a diagram showing the process of searching for the location of a motion candidate according to an embodiment of the present invention.
구체적으로, 도 13은 TM 방법을 위한 움직임 후보가 탐색되는 위치에 대한 탐색 수행 과정을 나타낸 순서도이다. 도 13을 참조하면 디코더는 초기 움직임 정보에 대한 화소(픽셀) 기반 코스트 값을 획득(계산)할 수 있다. 디코더는 탐색 수행의 반복횟수가 '0'이라면, TM 방법을 수행하지 않고 종료할 수 있다. 그렇지 않다면(즉, 탐색 수행의 반복횟수가 '0'이 아니라면), 디코더는 TM 방법을 수행할 수 있다. 이때, 반복횟수는 1 이상의 임의의 정수 값일 수 있다. 또한, 반복횟수, 초기 탐색 패턴, 초기 탐색 간격은 도 13을 통해 설명하는 탐색 수행 과정이 수행되기 전에 설정될 수 있다. 예를 들어, 반복횟수는 '375', 초기 탐색 패턴은 '다이아몬드(DIAMOND)', 초기 탐색 간격은 '6'으로 설정될 수 있다.Specifically, Figure 13 is a flowchart showing the search process for the location where motion candidates for the TM method are searched. Referring to FIG. 13, the decoder can obtain (calculate) a pixel-based cost value for initial motion information. If the number of repetitions of search performance is '0', the decoder can terminate without performing the TM method. Otherwise (i.e., if the number of iterations of search performance is not '0'), the decoder may perform the TM method. At this time, the number of repetitions may be any integer value of 1 or more. Additionally, the number of repetitions, initial search pattern, and initial search interval can be set before the search performance process described with reference to FIG. 13 is performed. For example, the number of repetitions can be set to '375', the initial search pattern can be set to 'DIAMOND', and the initial search interval can be set to '6'.
다음으로, 탐색 패턴과 탐색 간격이 재설정될 수 있다. 탐색 패턴과 탐색 간격은 현재 블록의 크기, 현재 블록이 휘도 성분 블록인지 색차 성분 블록인지 여부, 현재 움직임 해상도, 반복횟수, 이전 반복 단계에서 계산된 움직임 후보 위치에 대한 코스트 값의 분포 중에서 적어도 하나 이상에 기초하여 결정될 수 있다. 이하에서 탐색 패턴과 탐색 간격을 설정하는 방법에 대해 설명한다. Next, the search pattern and search interval can be reset. The search pattern and search interval are at least one of the following: the size of the current block, whether the current block is a luminance component block or a chrominance component block, the current motion resolution, the number of repetitions, and the distribution of cost values for the motion candidate positions calculated in the previous iteration step. It can be decided based on. Below, we will explain how to set the search pattern and search interval.
탐색 간격은 현재 블록의 움직임 정보 해상도에 따라 결정될 수 있다. 움직임 정보 해상도는 1의 정수 화소, 4의 정수 화소, 1/2 정수 화소, 1/4 정수 화소, 1/16 정수 화소 단위가 될 수 있다. 움직임 정보 해상도가 1/4 정수 화소인 경우 초기 탐색 간격은 6으로 설정될 수 있고 그 외의 경우에 초기 탐색 간격은 4로 설정될 수 있다.The search interval may be determined according to the motion information resolution of the current block. The motion information resolution may be in units of 1 integer pixel, 4 integer pixel, 1/2 integer pixel, 1/4 integer pixel, and 1/16 integer pixel. If the motion information resolution is 1/4 integer pixels, the initial search interval may be set to 6, and in other cases, the initial search interval may be set to 4.
탐색 패턴은 다이아몬드 패턴 또는 크로스 패턴으로 결정될 수 있다. 탐색 간격은 초기 탐색 간격에서 임의의 간격만큼 감소되거나 증가되면서 조정될 수 있다. 예를 들어, 탐색 패턴과 탐색 간격은 반복 단계에 다라 달라질 수 있다. 반복 단계는 반복횟수가 0이 아닌 경우 탐색 패턴과 탐색 간격의 재설정이 몇 번째로 반복되는지를 나타낼 수 있다. 즉, 몇 번째 반복 단계인지에 따라 탐색 패턴과 탐색 간격이 달라질 수 있다. 예를 들어 첫 번째 반복 단계에서 탐색 패턴과 탐색 간격은 다이아몬드 탐색 패턴과 초기 탐색 간격으로 설정될 수 있다. 두 번째 단계에서 탐색 패턴과 탐색 간격은 크로스 패턴과 초기 탐색 간격에서 1만큼 감소시킨 탐색 간격으로 설정될 수 있다. 두 번째 단계 이후 단계에서 탐색 패턴과 탐색 간격은 크로스 패턴과 이전 단계보다 1만큼 감소된 탐색 간격으로 설정될 수 있다.The search pattern may be determined as a diamond pattern or a cross pattern. The search interval may be adjusted by decreasing or increasing an arbitrary interval from the initial search interval. For example, search patterns and search intervals may vary depending on the iteration step. The repetition step may indicate how many times the reset of the search pattern and search interval is repeated if the repetition number is not 0. In other words, the search pattern and search interval may vary depending on the number of repetition steps. For example, in the first iteration step, the search pattern and search interval can be set to a diamond search pattern and an initial search interval. In the second step, the search pattern and search interval can be set to a cross pattern and a search interval reduced by 1 from the initial search interval. In stages after the second stage, the search pattern and search interval can be set to a cross pattern and a search interval reduced by 1 compared to the previous stage.
탐색 패턴과 탐색 간격은 현재 블록의 컬러 성분에 따라 설정될 수 있다. 색차 성분에 대한 탐색 패턴과 탐색 간격은 휘도 성분에 대한 탐색 패턴과 탐색 간격보다 넓게 설정될 수 있다. 휘도 성분(신호) 대비 색차 성분(신호)는 공간적인 상관도가 높기 때문이다. 또는, 성능을 높이기 위해서 색차 성분에 대한 탐색 패턴과 탐색 간격은 휘도 성분에 대한 탐색 패턴과 탐색 간격보다 더 짧게 설정될 수 있다.The search pattern and search interval can be set according to the color component of the current block. The search pattern and search interval for the chrominance component may be set wider than the search pattern and search interval for the luminance component. This is because the spatial correlation between the chrominance component (signal) and the luminance component (signal) is high. Alternatively, to improve performance, the search pattern and search interval for the chrominance component may be set shorter than the search pattern and search interval for the luminance component.
탐색 패턴과 탐색 간격은 현재 블록의 크기에 기초하여 설정될 수 있다. 현재 블록의 크기가 임의의 정해진 값보다 큰 경우, 탐색 패턴은 크로스 패턴이 사용되고 탐색 간격은 초기 탐색 간격보다 넓게 설정될 수 있다. 예를 들어 탐색 간격은 '7'일 수 있다. 또는, 성능을 높이기 위해 현재 블록의 크기가 임의의 정해진 수보다 큰 경우, 탐색 패턴은 다이아몬드 패턴이 사용되고 탐색 간격은 초기 탐색 간격보다 짧게 설정될 수 있다. 예를 들어 탐색 간격은 '5'일 수 있다. 현재 블록의 크기는 16x16, 32x32가 될 수 있으며, 탐색 패턴과 탐색 간격은 현재 블록의 가로의 크기 및 세로의 크기의 합에 기초하여 설정될 수 있다.The search pattern and search interval can be set based on the size of the current block. If the size of the current block is larger than a certain value, a cross pattern is used as the search pattern and the search interval can be set wider than the initial search interval. For example, the search interval may be '7'. Alternatively, to improve performance, if the size of the current block is larger than a certain number, a diamond pattern may be used as the search pattern and the search interval may be set shorter than the initial search interval. For example, the search interval may be '5'. The size of the current block can be 16x16 or 32x32, and the search pattern and search interval can be set based on the sum of the horizontal and vertical sizes of the current block.
다음으로, 디코더는 탐색 패턴과 탐색 간격을 이용하여 탐색되는 움직임 후보의 위치에 대한 보정 값(offset)을 설정하고, 탐색되는 움직임 후보들에 대한 평가를 수행할 수 있다. 본 명세서에서의 평가는 코스트 값을 획득하는 것을 의미할 수 있다. 움직임 후보가 탐색되는 위치는 탐색 패턴에 따라 달라질 수 있다. 예를 들어, 탐색 패턴이 크로스 패턴인 경우, 보정 값은 (0, 1), (1, 0), (0, -1), (-1, 0)이며, 탐색 패턴이 다이아몬드 패턴인 경우, 보정 값은 (0, 2), (1, 1), (2, 0), (1, -1), (0, -2), (-1, -1), (-2, 0), (-1, 1)이다. 이때 보정 값 (x, y)는 (수평, 수직)으로 x는 수평 방향에 대한 보정 값이고 y는 수직 방향에 대한 보정 값일 수 있다.Next, the decoder can set a correction value (offset) for the position of the searched motion candidate using the search pattern and search interval and perform evaluation on the searched motion candidates. Evaluation in this specification may mean obtaining a cost value. The location where the motion candidate is searched may vary depending on the search pattern. For example, if the search pattern is a cross pattern, the correction values are (0, 1), (1, 0), (0, -1), (-1, 0), and if the search pattern is a diamond pattern, Correction values are (0, 2), (1, 1), (2, 0), (1, -1), (0, -2), (-1, -1), (-2, 0), It is (-1, 1). At this time, the correction value (x, y) may be (horizontal, vertical), where x may be a correction value for the horizontal direction and y may be a correction value for the vertical direction.
도 13을 통해 설명한 방법은 임의의 정해진 반복횟수만큼 재귀적으로 수행될 수 있다. 예를 들어 반복횟수가 1이면 1회 이상 수행될 수 있다. 디코더는 움직임 후보들을 탐색하여 탐색되는 움직임 후보들 전부에 대한 평가를 수행하였다면 가장 작은 코스트 값에 대응되는 움직임 후보의 움직임 정보를 최종 움직임 정보로 사용할 수 있다.The method described with reference to FIG. 13 can be performed recursively as many as an arbitrary number of repetitions. For example, if the number of iterations is 1, it can be performed more than once. If the decoder searches for motion candidates and evaluates all of the searched motion candidates, it can use the motion information of the motion candidate corresponding to the smallest cost value as the final motion information.
도 13의 초기 움직임 후보는 이전 반복 단계에서 가장 작은 코스트 값에 기초하여 재설정될 수 있다. 첫 번째 단계에서 가장 작은 코스트 값에 대응되는 움직임 후보를 기준으로 다음 단계의 초기 움직임 후보가 재설정될 수 있다. 예를 들어, 첫 번째 단계에서 가장 작은 코스트 값에 대응되는 움직임 후보가 좌상단에 위치한 움직임 후보인 경우, 다음 반복 단계에서는 좌상단에 위치한 움직임 후보에 인접한 움직임 후보에 대해서 디코더는 평가를 수행할 수 있다. The initial motion candidate in FIG. 13 may be reset based on the smallest cost value in the previous iteration step. The initial motion candidate for the next step may be reset based on the motion candidate corresponding to the smallest cost value in the first step. For example, if the motion candidate corresponding to the smallest cost value in the first step is the motion candidate located in the upper left corner, the decoder may perform evaluation on the motion candidate adjacent to the motion candidate located in the upper left corner in the next iteration step.
현재 블록이 코딩 유닛(블록)인지 서브 블록(서브 코딩 블록)인지에 따라 도 13을 참조하여 설명한 탐색 수행 과정은 다르게 진행될 수 있다. The search performance process described with reference to FIG. 13 may proceed differently depending on whether the current block is a coding unit (block) or a sub-block (sub-coding block).
현재 블록이 코딩 블록이고 현재 블록에 AMVP 모드가 적용되는 경우, 현재 블록의 L0 예측을 위한 L0 움직임 후보 리스트와 L1 예측을 위한 L1 움직임 후보 리스트가 유도될 수 있다. 유도된 후보 리스트의 일부 또는 모든 움직임 후보에 대해 탐색 수행 과정이 진행되어 보정된 움직임 정보가 유도될 수 있다. 한편, 현재 블록이 코딩 블록이고 현재 블록에 Merge 모드가 적용되는 경우, 현재 블록의 L0 및 L1 예측을 위한 하나의 움직임 후보 리스트가 유도될 수 있다. 유도된 하나의 움직임 후보 리스트 내의 일부 또는 모든 움직임 후보들에 대해 탐색 수행 과정이 진행될 수 있다. 본 명세서에서 기술하는 L0는 L0 예측, L1은 L1 예측을 의미할 수 있다.If the current block is a coding block and the AMVP mode is applied to the current block, an L0 motion candidate list for L0 prediction and an L1 motion candidate list for L1 prediction of the current block may be derived. A search process may be performed on some or all motion candidates of the derived candidate list to derive corrected motion information. Meanwhile, when the current block is a coding block and Merge mode is applied to the current block, one motion candidate list for L0 and L1 prediction of the current block can be derived. A search process may be performed on some or all motion candidates in one derived motion candidate list. L0 described in this specification may mean L0 prediction, and L1 may mean L1 prediction.
현재 블록에는 L0 단방향 예측, L1 단방향 예측 또는 양방향 예측이 적용될 수 있다. 현재 블록에는 L0 단방향 예측, L1 단방향 예측 또는 양방향 예측 중 어느 것이 적용되는지 여부는 참조 방향 지시 정보에 의해 지시될 수 있다. 참조 방향 지시 정보는 코스트 값에 기초하여 재설정될 수 있다. 예를 들어, L0의 초기 움직임 정보를 이용하여 생성되는 예측 블록의 코스트 값, L1의 초기 움직임 정보를 이용하여 생성되는 예측 블록의 코스트 값, L0와 L1의 초기 움직임 정보를 통해 양방향 예측을 수행하여 2개의 예측 블록을 가중치 평균하여 생성되는 예측 블록의 코스트 값, L0의 보정된 움직임 정보를 이용하여 생성되는 예측 블록의 코스트 값, L1의 보정된 움직임 정보를 이용하여 생성되는 예측 블록의 코스트 값, L0와 L1의 보정된 움직임을 통해 양방향 예측을 수행하여 2개의 예측 블록을 가중치 평균하여 생성되는 예측 블록의 코스트 값 중에서 가장 작은 코스트 값에 대응되는 움직임 정보 및 참조 방향 지시 정보가 현재 블록에 재설정될 수 있다.L0 unidirectional prediction, L1 unidirectional prediction, or bidirectional prediction may be applied to the current block. Whether L0 unidirectional prediction, L1 unidirectional prediction, or bidirectional prediction is applied to the current block may be indicated by reference direction indication information. Reference direction information may be reset based on the cost value. For example, bidirectional prediction is performed using the cost value of the prediction block generated using the initial motion information of L0, the cost value of the prediction block generated using the initial motion information of L1, and the initial motion information of L0 and L1. Cost value of the prediction block generated by weighted average of two prediction blocks, cost value of the prediction block generated using the corrected motion information of L0, cost value of the prediction block generated using the corrected motion information of L1, By performing bidirectional prediction through the corrected movements of L0 and L1, the motion information and reference direction information corresponding to the smallest cost value among the cost values of the prediction blocks generated by weighting the two prediction blocks are reset to the current block. You can.
현재 코딩 블록은 여러 개의 서브 블록들로 분할될 수 있다. 각 서브 블록의 초기 움직임 정보는 탐색 수행 과정에 따라 보정된 움직임 정보로 재설정될 수 있다. 각 서브 블록마다 템플릿은 상이할 수 있고, 인접한 서브 블록의 화소(픽셀)가 템플릿으로 사용될 수 있다. 다만, 디코더는 인접한 서브 블록이 복원된 경우에만 다음 서브 블록에 대한 탐색을 수행할 수 있으므로, 탐색 수행 과정이 각 서브 블록 별로 병렬적으로 처리되지 않는 문제가 있다. 이를 위해 현재 블록의 경계에 위치하는 서브 블록에 대해서만 탐색 수행 과정이 진행될 수 있다. 또는, 현재 블록의 경계에 위치한 서브 블록에 대해 디코더는 TM 방법으로 보정된 움직임 정보를 유도하고, 현재 블록의 경계에 위치하지 않는 서브 블록에 대해 디코더는 BM, Optical flow 기반 TM, Multi pass DMVR 방법 중에서 어느 하나 이상을 이용하여 보정된 움직임 정보를 유도할 수 있다.The current coding block may be divided into several sub-blocks. The initial motion information of each sub-block may be reset to corrected motion information according to the search performance process. The template may be different for each sub-block, and a pixel of an adjacent sub-block may be used as a template. However, since the decoder can perform a search for the next sub-block only when an adjacent sub-block is restored, there is a problem in that the search process is not processed in parallel for each sub-block. To this end, the search process can be performed only for sub-blocks located at the boundary of the current block. Alternatively, for sub-blocks located on the boundary of the current block, the decoder derives corrected motion information using the TM method, and for sub-blocks not located on the boundary of the current block, the decoder uses BM, optical flow-based TM, and multi-pass DMVR methods. Corrected motion information can be derived using any one or more of these.
현재 블록이 코딩 블록으로 처리되는 경우, 디코더는 L0와 L1에 대한 초기 움직임 정보를 사용하여 현재 블록 전체에 대한 코스트 값을 계산하고, 계산된 코스트 값에 기초하여 보정된 움직임 정보를 유도할 수 있다. 이때, 코딩 블록으로 처리되는 블록 내의 우하단 일부 영역의 움직임은 코딩 블록의 전체 움직임과 조금 상이할 수 있다. 템플릿이 어떻게 구성되는지에 따라 탐색 수행 과정은 달라질 수 있고, 보정된 움직임 정보도 달라질 수 있다. 따라서, 현재 블록이 코딩 블록으로 처리되더라도 보정된 움직임 정보는 서브 블록 기반으로 구성된 템플릿에 대한 코스트 값에 기초하여 서브 블록 단위로 보정된 움직임 정보가 유도될 수 있다.If the current block is processed as a coding block, the decoder can calculate the cost value for the entire current block using the initial motion information for L0 and L1 and derive the corrected motion information based on the calculated cost value. . At this time, the movement of the lower right part of the block processed as a coding block may be slightly different from the overall movement of the coding block. Depending on how the template is constructed, the search performance process may vary, and the corrected motion information may also vary. Therefore, even if the current block is processed as a coding block, the corrected motion information can be derived in sub-block units based on the cost value for the template configured based on the sub-block.
도 14는 본 발명의 일 실시예 따른 탐색 후보를 평가하는 과정을 나타내는 도면이다.Figure 14 is a diagram showing a process for evaluating search candidates according to an embodiment of the present invention.
구체적으로 도 14는 도 13을 참조하여 설명한 탐색 패턴과 탐색 간격에 따라 선정된 후보 위치에 대한 보정 값들을 사용하여 탐색 후보를 평가하는 과정을 나타내는 순서도이다. 디코더는 초기 움직임 정보를 최종 움직임 정보로 저장할 수 있다. 그리고 디코더는 탐색 후보 전부에 대한 보정 값들에 대해 후술하는 과정을 수행할 수 있다.Specifically, FIG. 14 is a flowchart showing a process of evaluating search candidates using correction values for candidate locations selected according to the search pattern and search interval described with reference to FIG. 13. The decoder may store initial motion information as final motion information. And the decoder can perform the process described later on correction values for all search candidates.
디코더는 탐색할 후보 위치에 대한 보정 값들 중에서 하나를 선택할 수 있다. 보정 값은 현재 블록에서 사용될 움직임 해상도(resolution)에 적합하도록 재설정될 수 있다. 디코더는 재설정된 보정 값을 초기 움직임 정보에 더하여 평가할 움직임 정보를 재구성할 수 있다. 재구성된 움직임 정보에 기초하여 코스트 값을 획득할 수 있다. 이때, 움직임 정보에 기초하여 획득되는 코스트 값은 초기 움직임 정보와 재구성된 움직임 정보 간의 수평 방향 성분들의 절대값의 차이 값과 수직 방향 성분들의 절대값의 차이 값을 더한 후, 임의의 가중치 값을 곱하여 계산될 수 있다. 임의의 가중치 값은 '4'일 수 있다. 디코더는 움직임 정보에 기초하여 획득한 코스트 값 화소(픽셀)에 기초하여 획득한 초기 움직임 정보의 코스트 값보다 작은 경우에만 재구성된 움직임 정보에 대한 화소(픽셀)기반 코스트 값을 계산할 수 있다.The decoder can select one of the correction values for the candidate location to search. The correction value can be reset to suit the motion resolution to be used in the current block. The decoder may reconstruct the motion information to be evaluated by adding the reset correction value to the initial motion information. A cost value can be obtained based on the reconstructed motion information. At this time, the cost value obtained based on the motion information is calculated by adding the difference between the absolute values of the horizontal components and the absolute values of the vertical components between the initial motion information and the reconstructed motion information, and then multiplying by an arbitrary weight value. can be calculated. An arbitrary weight value may be '4'. The decoder can calculate the pixel (pixel)-based cost value for the reconstructed motion information only when the cost value obtained based on the motion information is smaller than the cost value of the initial motion information obtained based on the pixel (pixel).
디코더는 모든 탐색 후보에 대한 보정 값들에 대하여 평가한 후, 가장 작은 코스트 값에 대응되는 움직임 정보를 최종 움직임 정보로 설정할 수 있다.After evaluating correction values for all search candidates, the decoder may set the motion information corresponding to the smallest cost value as the final motion information.
움직임 정보에 기초하여 획득되는 코스트 값들 각각은 초기 움직임 정보에 따라 선정되는 위치에 대응되는 복수의 움직임 후보들 각각에 보정 값을 더하여 획득되는 움직임 정보들 간의 차분 값을 통해 획득될 수 있다. 움직임 정보에 기초하여 획득되는 코스트 값은 보정 값의 크기에 따라 달라질 수 있다. 즉, 보정 값이 작을수록 코스트 값은 작아질 수 있다. 가장 작은 코스트 값에 대응되는 움직임 정보가 최종 움직임 정보로 설정되기 때문에, 보정 값이 작은 초기 움직임 정보가 나타내는 위치의 주변 움직임 후보에 대해서만 평가가 수행될 수 있다. 그러나, 보정 값이 큰 움직임 후보가 최적의 움직임 후보일 수 있다. 따라서, 다양한 움직임 후보에 대한 평가를 수행하여 최적의 움직임 후보를 선정하기 위해, 코스트 값은 후술하는 방법을 이용하여 획득될 수 있다. 코스트 값은 주변 블록 각각의 움직임 정보 값 간의 차이, 양자화 파라미터, 현재 블록의 크기 등을 이용하여 획득될 수 있다.Each of the cost values obtained based on the motion information may be obtained through a difference value between the motion information obtained by adding a correction value to each of a plurality of motion candidates corresponding to a position selected according to the initial motion information. The cost value obtained based on motion information may vary depending on the size of the correction value. That is, the smaller the correction value, the smaller the cost value can be. Since the motion information corresponding to the smallest cost value is set as the final motion information, evaluation can be performed only on motion candidates surrounding the position indicated by the initial motion information with a small correction value. However, a motion candidate with a large correction value may be the optimal motion candidate. Therefore, in order to select the optimal motion candidate by evaluating various motion candidates, the cost value can be obtained using a method described later. The cost value can be obtained using the difference between the motion information values of each neighboring block, the quantization parameter, the size of the current block, etc.
코스트 값은 주변 블록의 움직임 정보의 분포를 이용하여 획득될 수 있다. 다양한 움직임 후보에 대한 평가를 위해, 디코더는 보정된 움직임 정보와 주변 블록의 움직임 정보 간의 차이 값을 이용하여 코스트 값을 획득할 수 있다. 예를 들어, 보정된 움직임 정보와 주변 블록의 움직임 정보 간의 차이 값과 임의의 정해진 값을 비교하여 비교 결과에 따라 코스트 값을 획득할 수 있다. 구체적으로 보정된 움직임 정보와 주변 블록의 움직임 정보 간의 차이 값이 임의의 정해진 값보다 큰 경우(또는 작은 경우, 같은 경우) 디코더는 코스트 값을 획득할 수 있다. 이때 주변 블록은 현재 블록에 인접한 주변 블록이거나 또는 대응 픽쳐(Collocated picture)에서 현재 블록과 동일한 위치에 있는 시간적인 주변 블록일 수 있다.The cost value can be obtained using the distribution of motion information of neighboring blocks. To evaluate various motion candidates, the decoder can obtain a cost value using the difference value between the corrected motion information and the motion information of neighboring blocks. For example, a cost value can be obtained according to the comparison result by comparing the difference value between the corrected motion information and the motion information of the surrounding block with an arbitrarily determined value. Specifically, if the difference value between the corrected motion information and the motion information of the surrounding block is greater than (or less than, or equal to) a certain value, the decoder can obtain a cost value. At this time, the neighboring block may be a neighboring block adjacent to the current block or a temporal neighboring block located at the same position as the current block in the corresponding picture (Collocated picture).
코스트 값은 현재 블록의 크기에 기초하여 획득될 수 있다. 예를 들어, 상술한 코스트 값을 획득하기 위한 가중치는 현재 블록의 크기에 따라 설정될 수 있다. 가중치는 현재 블록의 크기와 반비례하게 설정될 수 있다. 즉, 현재 블록의 크기가 클수록 가중치는 낮게 설정될 수 있다. 이는, 적합한 움직임 후보를 선정하기 위해 보다 더 넓은 범위의 움직임 후보를 평가하기 위함이다. 한편 가중치는 현재 블록의 크기와 비례하게 설정될 수 있다. 즉, 현재 블록의 크기가 클수록 가중치는 높게 설정될 수 있다. 이는 복잡도를 낮추기 위함이다. 예를 들어, 현재 블록의 크기는 16x16, 32x32가 될 수 있고, 현재 블록의 가로 및 세로 크기의 합으로 설정될 수 있다. 가중치는 1, 2, 3, 4, 5, 6 등의 정수 값이 될 수 있다. 또한 가중치가 커질수록 코스트 값이 높아지므로 가중치가 특정 값 이상인 경우 디코더는 코스트 값을 획득하기 위한 평가를 수행하지 않을 수 있다.The cost value can be obtained based on the size of the current block. For example, the weight for obtaining the above-described cost value may be set according to the size of the current block. The weight can be set in inverse proportion to the size of the current block. That is, the larger the size of the current block, the lower the weight can be set. This is to evaluate a wider range of motion candidates in order to select an appropriate motion candidate. Meanwhile, the weight can be set proportional to the size of the current block. That is, the larger the size of the current block, the higher the weight can be set. This is to reduce complexity. For example, the size of the current block can be 16x16, 32x32, and can be set to the sum of the horizontal and vertical sizes of the current block. Weights can be integer values such as 1, 2, 3, 4, 5, 6, etc. Additionally, as the weight increases, the cost value increases, so if the weight is greater than a certain value, the decoder may not perform evaluation to obtain the cost value.
도 15는 본 발명의 일 실시예에 따른 현재 픽쳐 내 객체의 경계 부분에 대한 움직임 특성을 나타내는 도면이다. Figure 15 is a diagram showing movement characteristics of the boundary portion of an object in the current picture according to an embodiment of the present invention.
일반적으로 현재 블록의 움직임 정보는 주변 블록의 움직임 정보와 상관성이 높다. 하지만, 현재 블록이 객체의 경계 부분에 위치한 경우, 현재 블록은 배경 영역일 수 있다. 이 경우, 주변 블록의 움직임은 현재 블록의 움직임과 다를 수 있다. 또한 카메라의 위치(시점) 변경 없이 촬영된 영상의 경우, 배경은 움직이지 않으므로, 배경에 대한 움직임 정보는 영 벡터(0, 0)일 수 있다. 디코더는 TM을 위해 주변 블록의 움직임 정보를 이용하여 움직임 후보를 탐색할 수 있다. 이때 현재 블록이 배경에 해당하는 경우, 주변 블록의 움직임 정보를 이용하여 움직임 후보를 탐색하기 보다 영 벡터에 대한 탐색이 보다 효과적일 수 있다. 따라서, TM이 수행되는 경우, 탐색되는 움직임 후보에 영 벡터가 포함될 수 있다. In general, the motion information of the current block has a high correlation with the motion information of surrounding blocks. However, if the current block is located at the border of an object, the current block may be a background area. In this case, the movement of surrounding blocks may be different from the movement of the current block. Additionally, in the case of an image captured without changing the position (viewpoint) of the camera, the background does not move, so the motion information about the background may be a zero vector (0, 0). The decoder can search for motion candidates for TM using motion information of neighboring blocks. At this time, if the current block corresponds to the background, searching for the zero vector may be more effective than searching for motion candidates using motion information of surrounding blocks. Therefore, when TM is performed, a zero vector may be included in the searched motion candidate.
카메라가 일정한 속도로 이동하며 촬영한 영상의 경우, 배경 부분에 대한 움직임 정보는 일정한 값(전역 움직임)을 가질 수 있다. 이 경우에는 TM을 위해 탐색되는 움직임 후보에 전역(global) 움직임 후보가 포함될 수 있다.In the case of an image captured while the camera moves at a constant speed, the motion information about the background may have a constant value (global motion). In this case, global motion candidates may be included in the motion candidates searched for TM.
현재 픽쳐에 대한 참조 픽쳐는 콘텐츠를 사용하는 환경에 따라 다르게 구성될 수 있다. 예를 들어, 실시간 방송 환경에서는 지연 속도가 낮은 low delay B와 같은 참조 픽쳐가 사용될 수 있다. 즉, 픽쳐의 재생 시간 순서상 과거에 위치하는 디코딩된 픽쳐만이 참조 픽쳐로 사용될 수 있다. 또한 VoD(Video on Demand)와 같은 스트리밍 서비스에서는 임의 접근이 중요하므로 GOP(Group of Picture) 단위로 I, P 픽쳐가 부호화되는 랜덤 액세스(random access)와 같은 참조 픽쳐 구성이 사용될 수 있다. 즉, 픽쳐의 재생 시간 순서상 과거 그리고 미래에 위치하는 디코딩된 픽쳐가 참조 픽쳐로 사용될 수 있다. 현재 픽쳐에 대한 참조 픽쳐를 구성하는 방법은 슬라이스(Slice) 헤더를 통해 시그널링되므로, 디코더는 현재 픽쳐를 부호화할 때 이미 참조 픽쳐로 사용할 픽쳐들을 확인할 수 있다. 이때 블록 단위로 사용되는 참조 픽쳐가 달라질 수 있으며, 어떠한 참조 픽쳐를 사용되는지에 대한 정보는 블록 단위로 시그널링될 수 있다.The reference picture for the current picture may be configured differently depending on the environment in which the content is used. For example, in a real-time broadcasting environment, a reference picture such as low delay B with a low delay rate can be used. That is, only decoded pictures located in the past in the picture reproduction time order can be used as reference pictures. Additionally, since random access is important in streaming services such as Video on Demand (VoD), a reference picture configuration such as random access in which I and P pictures are encoded in GOP (Group of Picture) units can be used. That is, decoded pictures located in the past and future in the picture reproduction time order can be used as reference pictures. Since the method of configuring a reference picture for the current picture is signaled through a slice header, the decoder can already check pictures to be used as reference pictures when encoding the current picture. At this time, the reference picture used on a block basis may vary, and information on which reference picture is used may be signaled on a block basis.
도 16은 본 발명의 일 실시예에 따른 템플릿 매칭을 이용하여 참조 픽쳐를 결정하는 방법을 나타내는 도면이다. Figure 16 is a diagram showing a method of determining a reference picture using template matching according to an embodiment of the present invention.
참조 픽쳐는 현재 블록과 가장 유사한 블록을 포함하는 픽쳐로 디코더는 템플릿 매칭을 통해 참조 픽쳐를 찾을 수 있다. 참조 픽쳐와 관련된 정보는 비트스트림에 포함되지 않고, 탬플릿 매칭을 통해 유도될 수 있다.A reference picture is a picture that contains the block most similar to the current block, and the decoder can find the reference picture through template matching. Information related to the reference picture is not included in the bitstream and can be derived through template matching.
먼저, 디코더는 평가할 참조 픽쳐 후보들과 평가할 움직임 후보들을 선정할 수 있다. 다음으로, 디코더는 각각의 참조 픽쳐에 대한 움직임 후보들을 평가할 수 있다. 이때, 각 움직임 후보들은 참조 픽쳐와 현재 픽쳐와의 거리 및 현재 픽쳐와 움직임 후보들의 참조 픽쳐 간의 거리(즉, Picture Order Count(POC) 차이)에 기초하여 스케일링될 수 있다. 디코더는 스케일링된 움직임 후보에 대한 평가를 수행할 수 있다. 모든 참조 픽쳐 후보와 모든 움직임 후보들에 대한 조합에 대하여 평가가 완료되었다면, 가장 작은 코스트 값에 대응되는 참조 픽쳐의 움직임 후보의 움직임 정보가 최종 움직임 정보일 수 있다. 예를 들어, 현재 픽쳐가 B 픽쳐인 경우(양 방향 예측이 사용되는 경우), 디코더는 가장 작은 코스트 값에 대응되는 참조 픽쳐의 움직임 후보의 움직임 정보와 두 번째로 작은 코스트 값에 대응되는 참조 픽쳐의 움직임 후보의 움직임 정보를 이용하여 양방향 움직임 정보를 구성할 수 있다. 또는 각 참조 픽쳐 리스트 내의 참조 픽쳐들 중 가장 작은 코스트 값을 가지는 각 참조 픽쳐의 움직임 후보를 이용하여 최종 움직임 정보가 획득될 수 있다. 참조 픽쳐 리스트내 참조 픽쳐 수는 복잡도 측면에서 한정될 수 있다. 이때, 한정되는 참조 픽쳐 수는 별도의 시그널링을 통해 설정될 수 있다.First, the decoder can select reference picture candidates to be evaluated and motion candidates to be evaluated. Next, the decoder can evaluate motion candidates for each reference picture. At this time, each motion candidate may be scaled based on the distance between the reference picture and the current picture and the distance between the current picture and the reference picture of the motion candidates (i.e., Picture Order Count (POC) difference). The decoder may perform evaluation on the scaled motion candidates. If the evaluation of the combination of all reference picture candidates and all motion candidates has been completed, the motion information of the motion candidate of the reference picture corresponding to the smallest cost value may be the final motion information. For example, if the current picture is a B picture (when two-way prediction is used), the decoder uses the motion information of the motion candidate of the reference picture corresponding to the smallest cost value and the reference picture corresponding to the second smallest cost value. Bidirectional motion information can be constructed using the motion information of the motion candidate. Alternatively, final motion information can be obtained using the motion candidate of each reference picture with the smallest cost value among the reference pictures in each reference picture list. The number of reference pictures in the reference picture list may be limited in terms of complexity. At this time, the limited number of reference pictures can be set through separate signaling.
또 다른 방법으로 모든 참조 픽쳐 후보와 모든 움직임 후보들에 대한 조합에 대하여 평가가 완료되었다면, 인코더는 조합 정보에 대한 리스트를 구성한 후 코스트 값을 기반으로 오름차순으로 재정렬을 수행한 후, 최적의 조합 정보에 대한 인덱스 정보를 포함한 비트스트림을 생성할 수 있다. 디코더는 비트스트림에 포함된 인덱스 정보에 기초하여 현재 블록에 대한 참조 픽쳐 혹은 움직임 후보를 결정할 수 있다.In another method, if the evaluation of the combination of all reference picture candidates and all motion candidates has been completed, the encoder constructs a list of combination information, performs reordering in ascending order based on the cost value, and then selects the optimal combination information. A bitstream including index information can be created. The decoder can determine a reference picture or motion candidate for the current block based on index information included in the bitstream.
도 16(a)는 랜덤 액세스 환경에서의 참조 픽쳐 구성을 나타낸다. 도 16(a)를 참조하면 L0 참조 픽쳐들 중에서 첫 번째 참조 픽쳐(reference index 0)의 참조 블록이 가장 작은 코스트 값을 가질 수 있고, L1 참조 픽쳐들 중에서 두 번째 참조 픽쳐(reference index 1)의 참조 블록이 가장 작은 코스트 값을 가질 수 있다. 디코더는 L0 참조 픽쳐들 중에서 첫 번째 참조 픽쳐(reference index 0)의 참조 블록에 대한 움직임 정보와 L1 참조 픽쳐들 중에서 두 번째 참조 픽쳐(reference index 1)의 참조 블록에 대한 움직임 정보를 이용하여 현재 블록에 대한 움직임 정보를 획득할 수 있다. 이때, L0 및 L1에 대한 참조 픽쳐 인덱스 정보는 비트스트림을 통해 시그널링되지 않고 템플릿 매칭을 통해 유도될 수 있다. Figure 16(a) shows a reference picture configuration in a random access environment. Referring to FIG. 16(a), the reference block of the first reference picture (reference index 0) among the L0 reference pictures may have the smallest cost value, and the reference block of the second reference picture (reference index 1) among the L1 reference pictures may have the lowest cost value. The reference block may have the lowest cost value. The decoder uses motion information about the reference block of the first reference picture (reference index 0) among L0 reference pictures and motion information about the reference block of the second reference picture (reference index 1) among L1 reference pictures to determine the current block. Movement information can be obtained. At this time, reference picture index information for L0 and L1 may not be signaled through a bitstream but may be derived through template matching.
도 16(b)는 저지연 환경에서의 참조 픽쳐 구성을 나타낸다. 도 16(b)를 참조하면 L0 참조 픽쳐와 L1 참조 픽쳐는 동일하게 구성될 수 있다. L0 참조 픽쳐들 중에서 두 번째 참조 픽쳐(reference index 1)의 참조 블록이 가장 작은 코스트 값을 가질 수 있고, L1 참조 픽쳐들 중에서 L0 참조 블록을 제외하고 세 번째 참조 픽쳐(reference index 2)의 참조 블록이 가장 작은 코스트 값을 가질 수 있다. 디코더는 L0 참조 픽쳐들 중에서 두 번째 참조 픽쳐(reference index 1)의 참조 블록에 대한 움직임 정보와 L1 참조 픽쳐들 중에서 세 번째 참조 픽쳐(reference index 2)의 참조 블록에 대한 움직임 정보를 이용하여 현재 블록에 대한 움직임 정보를 획득할 수 있다. 이때, L0 및 L1에 대한 참조 픽쳐 인덱스 정보는 비트스트림을 통해 시그널링되지 않고 템플릿 매칭을 통해 유도될 수 있다.Figure 16(b) shows the reference picture configuration in a low-delay environment. Referring to FIG. 16(b), the L0 reference picture and the L1 reference picture may be configured identically. Among the L0 reference pictures, the reference block of the second reference picture (reference index 1) may have the smallest cost value, and among the L1 reference pictures, excluding the L0 reference block, the reference block of the third reference picture (reference index 2) This can have the smallest cost value. The decoder uses motion information about the reference block of the second reference picture (reference index 1) among L0 reference pictures and motion information about the reference block of the third reference picture (reference index 2) among L1 reference pictures to determine the current block. Movement information can be obtained. At this time, reference picture index information for L0 and L1 may not be signaled through a bitstream but may be derived through template matching.
상기 방법을 적용하는 참조 픽쳐 리스트 내 참조 픽쳐 수를 한정할 수 있다. 한정된 참조 픽쳐 수 내에서만 적용함으로써 복잡도를 줄일 수 있다. 한정된 개수는 미리 정해진 값으로 설정되거나 혹은 SPS 레벨, PPS 레벨, 픽쳐 레벨, 또는 슬라이스 레벨, CU(Coding Unit) 레벨에서 시그널링되어 비트스트림에 포함될 수 있으며, 디코더는 비트스트림으로부터 한정된 개수를 획득하여 적응적으로 참조 픽쳐 리스트 내 참조 픽쳐 수를 변경할 수 있다.The number of reference pictures in the reference picture list to which the above method is applied can be limited. Complexity can be reduced by applying only within a limited number of reference pictures. The limited number can be set to a predetermined value or signaled at the SPS level, PPS level, picture level, slice level, or CU (Coding Unit) level and included in the bitstream, and the decoder acquires a limited number from the bitstream and adapts. In effect, the number of reference pictures in the reference picture list can be changed.
도 17, 도 18은 본 발명의 일 실시예에 따른 템플릿 매칭을 수행하는 과정을 나타내는 도면이다. Figures 17 and 18 are diagrams showing the process of performing template matching according to an embodiment of the present invention.
도 17을 참조하면 먼저 현재 블록의 주변 블록들로부터 움직임 후보가 유도될 수 있다. Referring to FIG. 17, motion candidates can first be derived from neighboring blocks of the current block.
현재 블록의 상단 블록을 통해 첫 번째 초기 움직임 후보가 유도될 수 있다. 첫 번째 초기 움직임 후보에 기초하여 참조 픽쳐 내에서 움직임 후보를 탐색하기 위한 위치가 선정될 수 있다. 움직임 후보가 탐색되는 위치는 ◇(다이아몬드 패턴), +(크로스 패턴)로 표시된 위치가 될 수 있다. 디코더는 초기 움직임 후보에서 가장 멀리 떨어진 위치의 움직임 후보부터 가장 가까운 위치의 움직임 후보 순으로 평가를 수행할 수 있다. 또한, 이전 반복 단계에서 보정된 움직임 후보의 위치는 다음 반복 단계의 초기 움직임 후보 위치로 설정될 수 있다. 움직임 후보들 중에서 가장 작은 코스트 값에 대응되는 움직임 후보의 움직임 정보가 첫 번째 보정된 움직임 후보(1710)가 될 수 있다. The first initial movement candidate can be derived through the upper block of the current block. A position for searching for a motion candidate within a reference picture may be selected based on the first initial motion candidate. The location where the motion candidate is searched may be a location marked with ◇ (diamond pattern) or + (cross pattern). The decoder may perform evaluation in order from the motion candidate at the furthest position from the initial motion candidate to the motion candidate at the closest position. Additionally, the position of the motion candidate corrected in the previous iteration step may be set as the initial motion candidate position of the next iteration step. Among the motion candidates, the motion information of the motion candidate corresponding to the smallest cost value may become the first corrected
다음으로, 현재 블록의 좌측 블록을 통해 두 번째 초기 움직임 후보가 유도될 수 있다. 디코더는 템플릿 매칭을 이용하여 가장 작은 코스트 값에 대응되는 두 번째 보정된 움직임 후보(1720)를 유도할 수 있다.Next, a second initial motion candidate can be derived through the block to the left of the current block. The decoder may use template matching to derive the second corrected
첫 번째 보정된 움직임 후보(1710)의 코스트 값과 두 번째 보정된 움직임 후보(1720)의 코스트 값 중 작은 코스트 값에 대응되는 보정된 움직임 후보가 현재 블록에 대한 최종 움직임 후보가 된다.The corrected motion candidate corresponding to the smaller cost value between the cost value of the first corrected
움직임 후보들을 탐색하는 범위가 넓을 수록, 탐색되는 위치가 많을수록 보다 정확한 최종 움직임 후보를 획득할 수 있다. 본 명세서에서 기술하는 TM에서도 탐색 범위, 탐색 위치에 따라 서로 다른 결과가 유도될 수 있다. 도 18을 참조하면 현재 블록의 주변 블록으로부터 유도되는 초기 움직임 정보(1801, 1802, 1803)의 분포가 서로 떨어져 있는 경우, 탐색되는 위치가 서로 중복되지 않으므로 다양하고 넓은 범위의 움직임 후보가 평가될 수 있고 가장 최적의 움직임 정보가 유도될 수 있다. The wider the range for searching motion candidates and the more positions searched, the more accurate the final motion candidate can be obtained. Even in the TM described herein, different results may be derived depending on the search range and search location. Referring to FIG. 18, when the distributions of the initial motion information (1801, 1802, 1803) derived from the neighboring blocks of the current block are distant from each other, the searched positions do not overlap with each other, so a diverse and wide range of motion candidates can be evaluated. and the most optimal movement information can be derived.
디코더는 새로운 위치의 움직임 후보를 추가로 평가할 수 있다. 이하에서는 추가로 평가되는 움직임 후보의 새로운 위치에 대해 설명한다.The decoder can further evaluate motion candidates at the new location. Below, the new location of the motion candidate that is additionally evaluated will be described.
현재 블록의 주변 블록으로부터 유도되는 움직임 정보들을 사용하여 유도된 가운데 위치의 움직임 후보가 추가적으로 평가될 수 있다. 즉, 디코더는 2개 이상의 움직임 후보들의 중앙 위치에 대응하는 움직임 후보를 추가적으로 평가할 수 있다.A motion candidate for the center position derived using motion information derived from neighboring blocks of the current block may be additionally evaluated. That is, the decoder can additionally evaluate a motion candidate corresponding to the central position of two or more motion candidates.
디코더는 현재 블록의 주변 블록으로부터 유도되는 움직임 정보들과 서로 다른 위치의 움직임 후보를 추가적으로 평가할 수 있다. 디코더는 초기 움직임 후보들 각각에 대한 탐색 범위를 모두 포함하는 더 큰 영역의 전역 탐색 범위(global search range)를 설정한 후, 전역 탐색 범위 내 비어있는 공간을 지시하는 움직임 후보에 대해 추가적으로 평가할 수 있다. 먼저, 디코더는 현재 블록의 주변 블록으로부터 유도되는 움직임 후보들이 지시하는 참조 블록들을 모두 포함하는 영역들을 전역 탐색 범위로 설정할 수 있다. 또는 디코더는 현재 블록의 좌상단 픽셀 위치와 현재 블록의 크기를 기준으로 미리 약속된 범위를 전역 탐색 범위로 설정될 수 있다. 전역 탐색 범위는 동일한 크기로 4등분되고, 각 사분면의 움직임 후보의 개수가 임의의 정해진 수보다 작을 경우, 임의의 정해진 수보다 작은 움직임 후보의 개수에 대응되는 사분면의 중앙 위치는 새로운 움직임 후보 위치로 설정되고, 디코더는 새로운 움직임 후보 위치의 움직임 후보에 대한 평가를 수행할 수 있다. The decoder can additionally evaluate motion information derived from neighboring blocks of the current block and motion candidates at different positions. The decoder may set a global search range of a larger area that includes all search ranges for each of the initial motion candidates, and then additionally evaluate motion candidates indicating empty spaces within the global search range. First, the decoder can set areas including all reference blocks indicated by motion candidates derived from neighboring blocks of the current block as the global search range. Alternatively, the decoder may set a pre-arranged range as the global search range based on the upper left pixel position of the current block and the size of the current block. The global search range is divided into four equal sizes, and if the number of motion candidates in each quadrant is less than a certain number, the center position of the quadrant corresponding to the number of motion candidates less than a certain number is used as the new motion candidate position. Once set, the decoder can perform evaluation of the motion candidate at the new motion candidate location.
현재 블록이 Merge 모드로 부호화된 경우, 디코더는 MMVD 방법으로 표현될 수 있는 모든 움직임 후보들에 대해 추가적인 평가를 수행할 수 있다 MMVD는 미리 정해진 움직임 차분 값들에 대한 거리 테이블과 수직 또는 수평 방향에 대한 부호 테이블을 정의하고, 차분 값의 거리에 대한 인덱스 정보와 방향에 대한 인덱스 정보를 시그널링하는 방법이다. MMVD를 통해 유도할 수 있는 모든 움직임 후보들이 TM에 사용될 수 있다. 이때, 별도의 시그널링 없이 움직임 후보들 중 가장 작은 코스트 값에 대응되는 움직임 후보가 현재 블록의 예측에 사용될 수 있다. 또는, 인코더는 MMVD를 통해 유도할 수 있는 모든 움직임 후보들을 사용하여 움직임 후보 리스트를 구성한 후, 움직임 후보 리스트 내의 움직임 후보들을 코스트 값에 기초하여 오름차순으로 재정렬한 후, 최적의 움직임 후보에 대한 인덱스에 대한 정보를 포함하는 비트스트림을 획득할 수 있다. 디코더는 비트스트림으로부터 인덱스에 대한 정보를 파싱하여 인덱스가 지시하는 움직임 후보를 통해 현재 블록을 예측(복원)할 수 있다.If the current block is encoded in Merge mode, the decoder can perform additional evaluation on all motion candidates that can be expressed by the MMVD method. MMVD is a distance table for predetermined motion difference values and a sign for the vertical or horizontal direction. This is a method of defining a table and signaling index information about the distance and direction of the difference value. All motion candidates that can be derived through MMVD can be used in TM. At this time, the motion candidate corresponding to the smallest cost value among the motion candidates can be used for prediction of the current block without separate signaling. Alternatively, the encoder constructs a motion candidate list using all motion candidates that can be derived through MMVD, then rearranges the motion candidates in the motion candidate list in ascending order based on the cost value, and then adds them to the index for the optimal motion candidate. A bitstream containing information can be obtained. The decoder can parse information about the index from the bitstream and predict (restore) the current block through the motion candidate indicated by the index.
도 19는 본 발명의 일 실시예에 따른 현재 블록의 주변 블록으로부터 유도되는 초기 움직임 정보들이 서로 붙어 있는 경우를 나타내는 도면이다. FIG. 19 is a diagram illustrating a case where initial motion information derived from neighboring blocks of the current block are attached to each other according to an embodiment of the present invention.
초기 움직임 정보들(1901, 1902, 1903) 간에 근접한 경우 초기 움직임 정보들에 의해 설정되는 탐색 위치의 일부가 중복될 수 있다. 그러나 움직임 후보들이 탐색되는 위치가 보다 세분화되어 정밀한 움직임 후보들에 대한 평가가 수행될 수 있어, 정밀한 움직임 정보의 획득이 가능하다는 효과가 있다. 이는, 보다 정밀한 움직임 정보가 요구되는 환경(과정)에서 적용될 수 있다.If the
초기 움직임 정보에 대한 분포는 현재 블록의 주변 블록의 움직임 정보에 따라 결정된다. 따라서, 디코더는 초기 움직임 정보들이 서로 붙어 있거나 너무 떨어져 있는 경우, 해당 초기 움직임 정보의 위치를 수정함으로써 탐색 범위를 조정할 수 있다. 이때, 움직임 정보들의 분포는 특정 값을 기준으로 판단될 수 있다. 예를 들어, 움직임 정보들 간 거리가 특정 값보다 큰 경우 움직임 정보들은 떨어져 있는 것으로 판단될 수 있고, 움직임 정보들 간 거리가 특정 값보다 작은 경우 움직임 정보들은 서로 붙어 있는 것으로 판단될 수 있다. 이때, 특정 값은 움직임 해상도에 따라 달라지는 값으로 정수 또는 소수의 값일 수 있다.The distribution of initial motion information is determined according to the motion information of blocks surrounding the current block. Therefore, when the initial motion information is close to each other or too far apart, the decoder can adjust the search range by modifying the position of the initial motion information. At this time, the distribution of motion information can be determined based on a specific value. For example, if the distance between the motion information pieces is greater than a specific value, the motion pieces of information may be determined to be separated, and if the distance between the motion pieces of information is smaller than a certain value, the motion pieces of information may be determined to be close to each other. At this time, the specific value is a value that varies depending on the motion resolution and may be an integer or decimal value.
도 20, 21은 본 발명의 일 실시예에 따른 초기 움직임 정보를 변경하는 방법을 나타내는 도면이다.20 and 21 are diagrams showing a method of changing initial motion information according to an embodiment of the present invention.
도 20은 초기 움직임 정보들이 떨어져 있는 경우, 가까워지도록 초기 움직임 정보를 변경하는 일 예를 나타내고, 도 21은 초기 움직임 정보들이 가까이 있는 경우, 떨어지도록 초기 움직임 정보를 변경하는 일 예를 나타낸다. 도 20, 21을 참조하면 점선 화살표는 초기 움직임 후보(정보)(Initial MV Candidate 1, Initial MV Candidate 2)를 나타내고, 실선 화살표는 변경된 움직임 후보(정보)(Modified MV Candidate 1, Modified MV Candidate 2)를 나타낸다. 점선 원은 초기 움직임 후보에 따른 탐색 영역을 나타내고, 실선 원은 변경된 움직임 정보에 따른 탐색 영역을 나타낸다. 초기 움직임 정보의 수평 또는 수직 값을 조정하여 움직임 정보들을 가까워지도록 또는 떨어지도록 변경할 수 있다. FIG. 20 shows an example of changing the initial motion information to make it closer when the initial motion information is distant, and FIG. 21 shows an example of changing the initial motion information to move it closer when the initial motion information is close. Referring to Figures 20 and 21, the dotted arrows represent the initial motion candidates (information) (
도 22는 본 발명의 일 실시예에 따른 초기 움직임 정보를 통해 유도되는 움직임 후보가 탐색되는 위치를 나타내는 도면이다.Figure 22 is a diagram showing the location where a motion candidate derived through initial motion information is searched according to an embodiment of the present invention.
디코더는 초기 움직임 정보를 기준으로 임의의 정해진 간격만큼 떨어진 위치의 움직임 후보를 탐색할 수 있다. 이때, 임의의 정해진 간격은 다양하게 설정될 수 있다. 수평 방향으로 임의의 정해진 간격만큼 변경된 위치의 움직임 후보가 탐색될 수 있고, 수직 방향으로 임의의 정해진 간격만큼 변경된 위치의 움직임 후보가 탐색될 수 있고 수평 및 수직 방향으로 임의의 정해진 간격만큼 변경된 위치의 움직임 후보가 탐색될 수 있다. 예를 들어, 도 22(a)는 초기 움직임 정보를 통해 유도되는 움직임 후보가 탐색되는 기본적인 위치를 나타낸다. 도 22(b)는 수직 방향으로 임의의 정해진 간격만큼 변경된 탐색되는 움직임 후보의 위치를 나타낸다. 도 22(b)를 참조하면 움직임 후보가 탐색되는 위치는 수직 방향으로 1/2 만큼 줄어들 수 있다. 도 22(c)는 수평 방향으로 임의의 정해진 간격만큼 변경된 탐색되는 움직임 후보의 위치를 나타낸다. 도 22(c)를 참조하면 움직임 후보가 탐색되는 위치는 수평 방향으로 1/2 만큼 줄어들 수 있다.The decoder can search for motion candidates at positions separated by an arbitrary predetermined interval based on the initial motion information. At this time, any given interval can be set in various ways. Motion candidates of positions that have changed by a certain set interval in the horizontal direction can be searched, motion candidates of positions that have changed by a certain set interval in the vertical direction can be searched, and motion candidates of positions that have changed by a certain set interval in the horizontal and vertical directions can be searched. Movement candidates may be searched. For example, Figure 22(a) shows the basic position where a motion candidate derived through initial motion information is searched. Figure 22(b) shows the position of a motion candidate to be searched that has changed by a certain interval in the vertical direction. Referring to FIG. 22(b), the position where the motion candidate is searched may be reduced by 1/2 in the vertical direction. Figure 22(c) shows the position of the searched motion candidate changed by a certain interval in the horizontal direction. Referring to FIG. 22(c), the position where the motion candidate is searched may be reduced by 1/2 in the horizontal direction.
도 23은 본 발명의 일 실시예에 따른 움직임 후보가 탐색되는 탐색 위치를 변경하는 방법을 나타내는 도면이다. Figure 23 is a diagram illustrating a method of changing the search location where motion candidates are searched according to an embodiment of the present invention.
도 23을 참조하면 현재 블록의 주변 블록으로부터 유도된 움직임 정보(Initial MV Candidate 1, Initial MV Candidate 2)를 사용하여 움직임 후보가 탐색되는 위치는 적응적으로 설정될 수 있다. 움직임 후보의 탐색을 위한 탐색 간격, 탐색 위치는 유도된 움직임 정보들이 서로 직선으로 연결되는 지점들의 위치로 변경될 수 있다. 디코더는 첫 번째 초기 움직임 정보에 대한 제1 탐색 범위를 수직 방향 및 수평 방향 중 적어도 어느 하나의 방향으로 줄여서 움직임 후보가 탐색되는 위치를 변경할 수 있다. 그리고 디코더는 두 번째 움직임 정보에 대한 제2 탐색 범위를 회전하여 제2 탐색 범위 내 움직임 후보가 탐색되는 위치를 첫 번째 초기 움직임 정보에 대한 변경된 움직임 후보 탐색 위치와 일직선 상에 위치하도록 변경할 수 있다. 이후, 디코더는 변경된 움직임 후보 탐색 위치들의 움직임 후보를 평가할 수 있다. 마찬가지로, 디코더는 두 번째 초기 움직임 정보에 대한 제2 탐색 범위를 수직 방향 및 수평 방향 중 적어도 어느 하나의 방향으로 줄여서 움직임 후보가 탐색되는 위치를 변경할 수 있다. 그리고 디코더는 첫 번째 움직임 정보에 대한 제1 탐색 범위를 회전하여 제1 탐색 범위 내 움직임 후보가 탐색되는 위치를 두 번째 초기 움직임 정보에 대한 변경된 움직임 후보 탐색 위치와 일직선 상에 위치하도록 변경할 수 있다. 이후, 디코더는 변경된 움직임 후보 탐색 위치들의 움직임 후보를 평가할 수 있다. 움직임 후보가 탐색되는 위치가 탐색 범위 내에 있더라도, 픽쳐 밖에 위치하는 경우 픽쳐 밖에 위치하는 움직임 후보는 평가되지 않는다. 탐색 범위가 변경(줄이거나 늘리는 경우)되는 경우 움직임 후보가 탐색되는 위치는 움직임 해상도와 일치하지 않을 수 있다. 이 경우, 가까운 움직임 해상도와 일치되도록 움직임 후보가 탐색되는 위치가 조정될 수 있다.Referring to FIG. 23, the location where the motion candidate is searched can be adaptively set using motion information (Initial
TM은 현재 블록에 인접한 주변 화소(픽셀)들을 사용하여 획득되는 코스트 값을 이용하므로 현재 블록의 주변 블록들이 복원되어 있어야 한다. 따라서, 현재 블록과 주변 블록들이 서로 의존적이므로 병렬적으로 TM이 처리될 수 없어 처리 속도에 불리하다는 문제점이 있다. 이러한 문제점을 해결하기 위해 현재 블록과 주변 블록 간의 의존성을 제거할 필요가 있다. 구체적으로 의존성을 제거하기 위해 디코더는 현재 블록의 주변 화소(픽셀)들을 이용하여 코스트 값을 획득하지 않고, 주변 블록들의 움직임 정보를 화소 단위로 유도하여 움직임 정보를 이용하여 코스트 값을 획득할 수 있다. 이 경우, 주변 블록들의 움직임 정보는 디코더가 비트스트림을 파싱함에 따라 병렬적으로 복원될 수 있어, 블록 간 병렬적으로 복원이 가능하다는 효과가 있다. 즉 디코더는 병렬적으로 TM을 이용한 블록 복원을 수행할 수 있다.Since TM uses a cost value obtained using neighboring pixels (pixels) adjacent to the current block, neighboring blocks of the current block must be restored. Therefore, since the current block and surrounding blocks are dependent on each other, TM cannot be processed in parallel, which is a problem in processing speed. To solve this problem, it is necessary to remove the dependency between the current block and neighboring blocks. Specifically, in order to remove dependency, the decoder does not use the surrounding pixels of the current block to obtain the cost value, but can derive the motion information of the surrounding blocks on a pixel basis and obtain the cost value using the motion information. . In this case, the motion information of neighboring blocks can be restored in parallel as the decoder parses the bitstream, which has the effect of enabling parallel restoration between blocks. That is, the decoder can perform block restoration using TM in parallel.
도 24는 본 발명의 일 실시예에 따른 움직임 벡터의 코스트 값에 기초한 TM을 나타내는 도면이다.Figure 24 is a diagram showing TM based on the cost value of a motion vector according to an embodiment of the present invention.
도 24를 참조하면 현재 블록의 주변 블록으로부터 유도된 초기 움직임 정보(Initial MV Candidate)를 사용하여 움직임 후보의 탐색을 위한 탐색 영역과 위치가 설정될 수 있다. 움직임 벡터의 코스트 값을 획득하기 위해 초기 움직임 정보가 지시하는 참조 블록 주변의 움직임 정보들을 이용하여 화소(픽셀) 단위 optical flow MV 맵이 생성될 수 있다. 현재 블록에 인접한 주변 템플릿에 대해서도 주변 움직임 정보들을 통해 화소(픽셀) 단위 optical flow MV 템플릿이 생성될 수 있다. 디코더는 움직임 후보의 탐색을 위한 위치들 중에서 현재 블록 MV 템플릿과 가장 유사한 optical flow MV 참조 템플릿을 구해서 보정된 움직임 정보로 사용할 수 있다. MV 템플릿 간의 코스트 값은 다양한 방법으로 획득될 수 있다. 예를 들어, MV 템플릿 간의 코스트 값은 수평 또는 수직 방향의 MV 차이의 절대합을 통해 계산될 수 있다. 복잡도를 감소시키기 위해서 MV 템플릿을 화소 단위가 아닌 2x2 또는 4x4 단위의 MV 템플릿이 유도될 수 있다.Referring to FIG. 24, a search area and location for searching a motion candidate can be set using initial motion information (Initial MV Candidate) derived from neighboring blocks of the current block. In order to obtain the cost value of the motion vector, a pixel-level optical flow MV map can be created using motion information around the reference block indicated by the initial motion information. Even for surrounding templates adjacent to the current block, a pixel-level optical flow MV template can be created through surrounding motion information. The decoder can obtain the optical flow MV reference template that is most similar to the current block MV template among the positions for motion candidate search and use it as the corrected motion information. Cost values between MV templates can be obtained in various ways. For example, the cost value between MV templates can be calculated through the absolute sum of the MV differences in the horizontal or vertical direction. In order to reduce complexity, the MV template may be derived in units of 2x2 or 4x4 rather than units of pixels.
이하에서 DMVR을 사용하여 움직임 정보를 보정하는 방법에 대해 설명한다.Below, a method for correcting motion information using DMVR will be described.
도 25, 도 26은 본 발명의 일 실시예에 따른 DMVR을 사용하여 움직임 정보를 보정하는 방법을 나타내는 도면이다. Figures 25 and 26 are diagrams showing a method of correcting motion information using DMVR according to an embodiment of the present invention.
DMVR은 BM(Bilateral Matching) 방법을 사용하여 현재 블록에 대한 보정된 움직임 정보를 획득하는 방법이다. BM(Bilateral Matching) 방법은 양방향 움직임을 가지는 블록에서 L0 참조 블록의 주변 탐색 영역(Search area)과 L1 참조 블록의 주변 탐색 영역에서 서로 간의 가장 유사한 부분을 찾아서 초기 움직임 정보를 보정하고, 보정된 움직임 정보를 현재 블록의 예측에 사용하는 방법이다. 탐색 영역의 크기는 참조 블록의 특정 지점을 기준으로 임의의 (m x n)크기로 설정될 수 있다. 예를 들어, 특정 지점은 참조 블록의 좌상단 위치 또는 참조 블록의 중앙 위치일 수 있고, 임의의 크기는 16 x 16일 수 있다. 가장 유사한 부분은 각 블록 간 화소 단위의 코스트 값을 계산하여 가장 작은 코스트 값에 대응되는 지점일 수 있다. 코스트 값은 SAD(Sum of Absolute Differences) 혹은 MRSAD(Mean-Removed SAD)를 이용하여 계산될 수 있다. 탐색 영역에 따라 코스트 값은 달라질 수 있고, 보정된 움직임 정보 또한 달라질 수 있다. 디코더는 현재 블록을 복수 개의 서브 블록으로 분할하여 각 서브 블록에 대하여 DMVR을 사용한 움직임 정보를 보정할 수 있다. 크기가 큰 블록들 대비 크기가 작은 블록들에 대한 움직임 정보가 더 정확하기 때문이다. 이때, 크기가 큰 블록에서는 DMVR이 수행되지 않고, 분할된 작은 블록(예, 서브 블록)에서만 DMVR이 수행될 수 있다. 도 26을 참조하면 하나의 블록은 4개의 서브 블록으로 분할될 수 있다. 디코더는 분할된 각 서브 블록마다 DMVR을 사용하여 보정된 움직임 정보를 획득할 수 있다. 또는 디코더는 큰 블록에서 DMVR을 통해 찾은 보정된 움직임 정보를 사용하여 분할된 작은 블록에서 DMVR을 통해 보다 정확한 움직임 정보를 유도하는 다중 DMVR 방법을 사용할 수 있다.DMVR is a method of obtaining corrected motion information for the current block using the BM (Bilateral Matching) method. The BM (Bilateral Matching) method corrects the initial motion information by finding the most similar parts in the surrounding search area of the L0 reference block and the surrounding search area of the L1 reference block in blocks with bidirectional movement, and corrects the corrected movement. This is a method of using information to predict the current block. The size of the search area can be set to an arbitrary (m x n) size based on a specific point of the reference block. For example, the specific point may be the upper left location of the reference block or the center location of the reference block, and an arbitrary size may be 16 x 16. The most similar part may be the point corresponding to the smallest cost value by calculating the pixel-unit cost value between each block. The cost value can be calculated using SAD (Sum of Absolute Differences) or MRSAD (Mean-Removed SAD). The cost value may vary depending on the search area, and the corrected motion information may also vary. The decoder can divide the current block into a plurality of sub-blocks and correct motion information using DMVR for each sub-block. This is because the motion information for small-sized blocks is more accurate than for large-sized blocks. At this time, DMVR is not performed on large blocks, and DMVR can be performed only on small divided blocks (eg, sub-blocks). Referring to FIG. 26, one block can be divided into four sub-blocks. The decoder can obtain corrected motion information using DMVR for each divided sub-block. Alternatively, the decoder can use a multiple DMVR method that uses the corrected motion information found through DMVR in the large block to derive more accurate motion information through DMVR in the divided small blocks.
이하에서 다중 DMVR 방법에 대해 설명한다.The multiple DMVR method is described below.
디코더는 현재 코딩 블록에 대한 파싱(parsing) 단계 후, 현재 코딩 블록에 대한 디코딩을 시작하기 전에, 현재 코딩 블록에 대한 움직임 정보를 유도하는 단계에서 후술하는 조건들을 판단하여 다중 DMVR 보정 수행 여부를 결정할 수 있다. 다중 DMVR 수행 조건은 i) merge 모드의 움직임이 양방향인 경우, ii) 참조 픽쳐들과 현재 픽쳐 간의 거리가 동일한 경우, iii) merge 모드의 움직임 차분 값이 존재하는 경우, iv) 참조 블록들 간의 가중치 예측이 적용되지 않은 블록인 경우일 수 있다. 디코더는 i) 내지 iv) 조건 중 어느 하나라도 만족하는 경우, 다중 DMVR을 수행할 수 있다. After the parsing step for the current coding block and before starting decoding for the current coding block, the decoder determines whether to perform multiple DMVR correction by judging the conditions described later in the step of deriving motion information for the current coding block. You can. The conditions for performing multiple DMVR are i) when the motion in merge mode is bidirectional, ii) when the distance between reference pictures and the current picture is the same, iii) when a motion difference value in merge mode exists, iv) weight between reference blocks. This may be a block to which prediction has not been applied. The decoder can perform multiple DMVR when any one of conditions i) to iv) is satisfied.
만일, 현재 코딩 블록의 머지 후보 리스트 내의 제1 머지 움직임 후보와 다른 머지 후보 간의 움직임 차이가 임의의 한계치보다 작은 경우 다중 DMVR은 수행되지 않을 수 있다. 또한, 머지 후보 리스트 내의 제1 머지 움직임 후보와 다른 머지 움직임 후보가 복수 개인 경우, 움직임 차이가 임의의 한계치보다 작은 경우가 하나라도 있으면, 다중 DMVR은 수행되지 않을 수 있다. 이때, 머지 후보 리스트의 머지 후보들 중 현재 코딩 블록의 머지 움직임 후보를 지시하는 인덱스보다 낮은 인덱스로 지시되는 머지 후보만 움직임 차이를 비교할 수 있다. 복잡도를 감소하기 위함이다. 즉, 머지 후보 리스트 내의 머지 움직임 후보들 각각과 현재 코딩 블록의 머지 후보와의 움직임 차이를 계산하고 계산된 움직임 차이들 전부가 임의의 지정된 한계치보다 큰 경우 디코더는 다중 DMVR을 수행할 수 있다. 현재 코딩 블록의 머지 움직임 후보와 머지 후보 리스트 내 머지 움직임 후보들 간의 유사성을 비교하는 것은 주변 블록들이 다양한 움직임을 가지는지 판단하기 위함이다. 일반적으로 주변 블록의 움직임이 유사할 경우, 현재 블록의 움직임도 주변 블록의 움직임과 유사할 가능성이 높다. 이때에는 주변 블록과 현재 블록은 동일한 움직임을 가지는 객체 내의 블록으로 유추될 수 있다. 반대로, 주변 블록의 움직임이 유사하지 않고 서로 다른 움직임 특성을 나타내는 경우, 현재 코딩 블록을 포함한 주변 블록들은 동일 객체가 아닐 수 있으므로, 보다 정확한 움직임을 찾는 과정이 필요할 수 있다.If the motion difference between the first merge motion candidate and other merge candidates in the merge candidate list of the current coding block is smaller than an arbitrary threshold, multiple DMVR may not be performed. Additionally, when there are a plurality of merge motion candidates different from the first merge motion candidate in the merge candidate list, if there is even one case where the motion difference is smaller than an arbitrary threshold, multiple DMVR may not be performed. At this time, among the merge candidates in the merge candidate list, only the merge candidate indicated by an index lower than the index indicating the merge motion candidate of the current coding block can be compared for motion differences. This is to reduce complexity. That is, the motion difference between each of the merge motion candidates in the merge candidate list and the merge candidate of the current coding block is calculated, and if all of the calculated motion differences are greater than a certain specified threshold, the decoder can perform multiple DMVR. Comparing the similarity between the merge motion candidate of the current coding block and the merge motion candidates in the merge candidate list is to determine whether neighboring blocks have various motions. In general, if the movements of surrounding blocks are similar, there is a high possibility that the movement of the current block will be similar to the movements of the surrounding blocks. In this case, the surrounding blocks and the current block can be inferred as blocks within the object with the same movement. Conversely, if the movements of neighboring blocks are not similar and show different movement characteristics, the neighboring blocks, including the current coding block, may not be the same object, so a process of finding more accurate motion may be necessary.
도 27은 본 발명의 일 실시예에 따른 다중 DMVR이 수행되는 과정을 나타내는 도면이다.Figure 27 is a diagram showing a process in which multiple DMVR is performed according to an embodiment of the present invention.
도 27(a)는 다중 DMVR이 수행되는 일반적인 과정을 나타내고, 도 27(b)는 다중 DMVR의 일반적인 과정을 보다 구체적으로 나타낸다.Figure 27(a) shows the general process of performing multiple DMVR, and Figure 27(b) shows the general process of multiple DMVR in more detail.
도 27(a)를 참조하면, 다중 DMVR은 초기 움직임 정보에 기초하여 코딩 유닛(블록) 단위의 DMVR을 수행하여 하나 이상의 보정된 움직임 정보를 획득할 수 있다(S2710). 현재 코딩 블록에 TM이 적용되는 경우, 디코더는 S2710 단계에서 획득한 하나 이상의 보정된 움직임 정보를 이용하여 TM을 수행할 수 있다(S2720). TM을 수행하여 결정되는 현재 코딩 블록의 보정된 움직임 정보가 양방향에서 단방향으로 변경되었다면, DMVR 과정을 수행할 수 없으므로 S2720 이후의 단계들(S2730, S2740)은 수행되지 않고, 현재 블록의 움직임은 단방향으로 최종 결정된다. TM을 수행한 결과, 현재 코딩 블록의 보정된 움직임 정보가 양방향이라면, 디코더는 서브 블록 단위의 DMVR을 수행하여 각 서브 블록마다 서브 블록 단위의 보정된 움직임 정보를 획득할 수 있다(S2730). 그리고 디코더는 S2740 단계에서 획득한 서브 블록 단위의 보정된 움직임 정보를 BDOF에 기반하여 다시 보정하고, BDOF에 기반하여 보정된 움직임 정보를 최종적으로 획득할 수 있다.Referring to FIG. 27(a), multiple DMVR can obtain one or more corrected motion information by performing DMVR in units of coding units (blocks) based on the initial motion information (S2710). When TM is applied to the current coding block, the decoder may perform TM using one or more corrected motion information obtained in step S2710 (S2720). If the corrected motion information of the current coding block determined by performing TM has changed from bidirectional to unidirectional, the DMVR process cannot be performed, so the steps (S2730, S2740) after S2720 are not performed, and the movement of the current block is unidirectional. is finally decided. As a result of performing TM, if the corrected motion information of the current coding block is bidirectional, the decoder can perform DMVR on a sub-block basis to obtain the corrected motion information on a sub-block basis for each sub-block (S2730). Then, the decoder can re-correct the sub-block-unit corrected motion information obtained in step S2740 based on the BDOF, and finally obtain the corrected motion information based on the BDOF.
한편, S2710 단계에서 획득된 하나 이상의 보정된 움직임 정보들에 대한 코스트 값들 중 가장 작은 코스트 값이 임의의 값보다 크다면 S2730 단계가 수행될 수 있다. 한편, 가장 작은 코스트 값이 임의의 값보다 같거나 작다면 디코더는 S2710 단계에서 획득한 하나 이상의 보정된 움직임 정보들을 서브 블록 단위로 저장하고, 현재 코딩 블록의 움직임 정보를 초기 움직임 정보로 재설정하여 S2710 내지 S2740 단계를 수행할 수 있다. 이때, 서브 블록 단위로 저장된 하나 이상의 보정된 움직임 정보들은 S2740 단계에서의 움직임 보정을 위해 사용될 수 있다. 최종적으로 초기 움직임 정보를 사용한 코딩 블록의 코스트 값과 S2740 단계를 수행하여 획득되는 서브 블록 단위로 보정된 움직임을 사용한 코딩 블록의 코스트 값을 비교하여 작은 코스트 값을 가지는 블록 단위와 그에 대한 움직임 정보가 최종적으로 현재 코딩 블록에 사용될 수 있다. 임의의 값은 현재 코딩 블록 내 화소(픽셀)의 개수 또는 현재 코딩 블록의 크기(가로 또는 세로 중 어느 하나의 크기 또는 가로 및 세로의 합)일 수 있다.Meanwhile, if the smallest cost value among the cost values for one or more pieces of corrected motion information obtained in step S2710 is greater than a random value, step S2730 may be performed. Meanwhile, if the smallest cost value is equal to or smaller than a random value, the decoder stores one or more corrected motion information obtained in step S2710 in sub-block units, resets the motion information of the current coding block to the initial motion information, and performs S2710. Steps through S2740 can be performed. At this time, one or more pieces of corrected motion information stored in sub-block units can be used for motion correction in step S2740. Finally, by comparing the cost value of the coding block using the initial motion information with the cost value of the coding block using motion corrected in sub-block units obtained by performing step S2740, the block unit with a small cost value and the corresponding motion information are calculated. Finally, it can be used in the current coding block. The arbitrary value may be the number of pixels in the current coding block or the size of the current coding block (either horizontal or vertical, or the sum of horizontal and vertical).
도 27(b)를 참조하면, 도 27(a)의 S2710 단계는 정수 단위의 탐색을 이용하여 코딩 유닛(블록) 단위의 DMVR을 수행하는 단계(S2701)과 반화소 단위의 탐색을 이용하여 코딩 유닛(블록) 단위의 DMVR을 수행하는 단계(S2702)로 세분화 될 수 다. 이때, 움직임 해상도는 S2701 단계에서는 정수 단위로, S2702 단계에서는 반화소 단위로 설정될 수 있다. S2701 단계에서 디코더는 초기 움직임 정보와 정수 단위 보정 값을 사용하여 보정된 움직임 정보를 획득할 수 있다. S2702 단계에서 디코더는 초기 움직임 정보와 반화소 단위 보정 값을 사용하여 보정된 움직임 정보를 획득할 수 있다. 디코더는 S2701 단계에서 획득된 보정된 움직임 정보를 S2702 단계를 위한 기준 움직임 정보로 사용할 수 있다. 즉, 디코더는 S2701 단계에서 획득된 보정된 움직임 정보에 기초하여 새로운 움직임 후보를 생성하고, 새로운 움직임 후보에 대한 평가를 수행할 수 있다. 이때, 새로운 움직임 후보에 대한 코스트 값이 S2701 단계에서 획득된 보정된 움직임 정보의 코스트 값보다 크다면 S2701 단계에서 획득된 보정된 움직임 정보가 코딩 유닛(블록) 단위 DMVR의 출력이 될 수 있다. 반대로, 새로운 움직임 후보에 대한 코스트 값이 S2701 단계에서 획득된 보정된 움직임 정보의 코스트 값보다 작다면 S2702 단계에서 획득된 보정된 움직임 정보가 코딩 유닛(블록) 단위 DMVR의 출력이 될 수 있다. 즉 S2701 단계에서 획득한 코스트 값과 S2702 단계에서 획득한 코스트 값 중 작은 코스트 값에 대응되는 보정된 움직임 정보를 TM(S2703, S2720)을 위해 사용할 수 있다. 이때, 새로운 움직임 후보 전부에 대한 코스트 값을 계산하는 경우, 복잡도가 증가하는 문제가 있다. 이를 위해, 디코더는 MV(움직임 정보) 기반 코스트 값을 계산하고, 움직임 정보에 기초하여 획득되는 코스트 값이 임의의 값보다 작은 경우에만 새로운 움직임 후보에 대한 화소(픽셀) 기반 코스트 값을 계산할 수 있다. 움직임 정보에 기초하여 획득되는 코스트 값은 새로운 움직임 후보와 초기 움직임 정보 간의 수평 및 수직 성분 값의 차이에 대한 절대값의 합에 가중치를 곱해서 획득될 수 있다. 또한 움직임 정보에 기초하여 획득되는 코스트 값은 새로운 움직임 후보와 S2701 단계에서 획득된 보정된 움직임 정보 간의 차이를 이용하여 획득될 수 있다.Referring to FIG. 27(b), step S2710 of FIG. 27(a) includes a step of performing DMVR in units of coding units (blocks) using integer-unit search (S2701) and coding using search in half-pixel units. It can be subdivided into a step (S2702) of performing DMVR on a unit (block) basis. At this time, the motion resolution may be set in integer units in step S2701 and in half-pixel units in step S2702. In step S2701, the decoder may obtain corrected motion information using the initial motion information and an integer correction value. In step S2702, the decoder may obtain corrected motion information using the initial motion information and the half-pixel unit correction value. The decoder can use the corrected motion information obtained in step S2701 as reference motion information for step S2702. That is, the decoder may generate a new motion candidate based on the corrected motion information obtained in step S2701 and perform evaluation on the new motion candidate. At this time, if the cost value for the new motion candidate is greater than the cost value of the corrected motion information obtained in step S2701, the corrected motion information obtained in step S2701 may be the output of the DMVR in coding unit (block) units. Conversely, if the cost value for the new motion candidate is smaller than the cost value of the corrected motion information obtained in step S2701, the corrected motion information obtained in step S2702 may be the output of the DMVR in coding unit (block) units. That is, the corrected motion information corresponding to the smaller cost value between the cost value obtained in step S2701 and the cost value obtained in step S2702 can be used for TM (S2703, S2720). At this time, when calculating cost values for all new motion candidates, there is a problem of increased complexity. To this end, the decoder calculates an MV (motion information)-based cost value, and can calculate a pixel-based cost value for a new motion candidate only if the cost value obtained based on the motion information is less than a random value. . The cost value obtained based on the motion information may be obtained by multiplying the sum of the absolute values of the differences in horizontal and vertical component values between the new motion candidate and the initial motion information by the weight. Additionally, the cost value obtained based on the motion information may be obtained using the difference between the new motion candidate and the corrected motion information obtained in step S2701.
움직임 정보에 기초하여 획득되는 코스트 값들 각각은 초기 움직임 정보에 따라 선정되는 위치에 대응되는 복수의 움직임 후보들 각각에 보정 값을 더하여 획득되는 움직임 정보들 간의 차분 값을 통해 획득될 수 있다. 움직임 정보에 기초하여 획득되는 코스트 값은 보정 값의 크기에 따라 달라질 수 있다. 즉, 보정 값이 작을수록 코스트 값은 작아질 수 있다. 가장 작은 코스트 값에 대응되는 움직임 정보가 최종 움직임 정보로 설정되기 때문에, 보정 값이 작은 초기 움직임 정보가 나타내는 위치의 주변 움직임 후보에 대해서만 평가가 수행될 수 있다. 그러나, 보정 값이 큰 움직임 후보가 최적의 움직임 후보일 수 있다. 따라서, 다양한 움직임 후보에 대한 평가를 수행하여 최적의 움직임 후보를 선정하기 위해, 코스트 값은 후술하는 방법을 이용하여 획득될 수 있다. 코스트 값은 주변 블록 각각의 움직임 정보 값 간의 차이, 양자화 파라미터, 현재 블록의 크기 등을 이용하여 획득될 수 있다.Each of the cost values obtained based on the motion information may be obtained through a difference value between the motion information obtained by adding a correction value to each of a plurality of motion candidates corresponding to a position selected according to the initial motion information. The cost value obtained based on motion information may vary depending on the size of the correction value. That is, the smaller the correction value, the smaller the cost value can be. Since the motion information corresponding to the smallest cost value is set as the final motion information, evaluation can be performed only on motion candidates surrounding the position indicated by the initial motion information with a small correction value. However, a motion candidate with a large correction value may be the optimal motion candidate. Therefore, in order to select the optimal motion candidate by evaluating various motion candidates, the cost value can be obtained using a method described later. The cost value can be obtained using the difference between the motion information values of each neighboring block, the quantization parameter, the size of the current block, etc.
코스트 값은 주변 블록의 움직임 정보의 분포를 이용하여 획득될 수 있다. 다양한 움직임 후보에 대한 평가를 위해, 디코더는 보정된 움직임 정보와 주변 블록의 움직임 정보 간의 차이 값을 이용하여 코스트 값을 획득할 수 있다. 예를 들어, 보정된 움직임 정보와 주변 블록의 움직임 정보 간의 차이 값과 임의의 정해진 값을 비교하여 비교 결과에 따라 코스트 값을 획득할 수 있다. 구체적으로 보정된 움직임 정보와 주변 블록의 움직임 정보 간의 차이 값이 임의의 정해진 값보다 큰 경우(또는 작은 경우, 같은 경우) 디코더는 코스트 값을 획득할 수 있다. 이때 주변 블록은 현재 블록에 인접한 주변 블록이거나 또는 대응 픽쳐(Collocated picture)에서 현재 블록과 동일한 위치에 있는 시간적인 주변 블록일 수 있다.The cost value can be obtained using the distribution of motion information of neighboring blocks. To evaluate various motion candidates, the decoder can obtain a cost value using the difference value between the corrected motion information and the motion information of neighboring blocks. For example, a cost value can be obtained according to the comparison result by comparing the difference value between the corrected motion information and the motion information of the surrounding block with an arbitrarily determined value. Specifically, if the difference value between the corrected motion information and the motion information of the surrounding block is greater than (or less than, or equal to) a certain value, the decoder can obtain a cost value. At this time, the neighboring block may be a neighboring block adjacent to the current block or a temporal neighboring block located at the same position as the current block in the corresponding picture (Collocated picture).
코스트 값은 현재 블록의 크기에 기초하여 획득될 수 있다. 예를 들어, 상술한 코스트 값을 획득하기 위한 가중치는 현재 블록의 크기에 따라 설정될 수 있다. 가중치는 현재 블록의 크기와 반비례하게 설정될 수 있다. 즉, 현재 블록의 크기가 클수록 가중치는 낮게 설정될 수 있다. 이는, 적합한 움직임 후보를 선정하기 위해 보다 더 넓은 범위의 움직임 후보를 평가하기 위함이다. 한편 가중치는 현재 블록의 크기와 비례하게 설정될 수 있다. 즉, 현재 블록의 크기가 클수록 가중치는 높게 설정될 수 있다. 이는 복잡도를 낮추기 위함이다. 예를 들어, 현재 블록의 크기는 16x16, 32x32가 될 수 있고, 현재 블록의 가로 및 세로 크기의 합으로 설정될 수 있다. 가중치는 1, 2, 3, 4, 5, 6, 등의 정수 값이 될 수 있다. 또한 가중치가 커질수록 코스트 값이 높아지므로 가중치가 특정 값 이상인 경우 디코더는 코스트 값을 획득하기 위한 평가를 수행하지 않을 수 있다.The cost value can be obtained based on the size of the current block. For example, the weight for obtaining the above-described cost value may be set according to the size of the current block. The weight can be set in inverse proportion to the size of the current block. That is, the larger the size of the current block, the lower the weight can be set. This is to evaluate a wider range of motion candidates in order to select an appropriate motion candidate. Meanwhile, the weight can be set proportional to the size of the current block. That is, the larger the size of the current block, the higher the weight can be set. This is to reduce complexity. For example, the size of the current block can be 16x16, 32x32, and can be set to the sum of the horizontal and vertical sizes of the current block. Weights can be integer values such as 1, 2, 3, 4, 5, 6, etc. Additionally, as the weight increases, the cost value increases, so if the weight is greater than a certain value, the decoder may not perform evaluation to obtain the cost value.
이하에서 도 27(a)의 S2730 단계에 대해 자세히 설명한다.Hereinafter, step S2730 of FIG. 27(a) will be described in detail.
S2730 단계에서 디코더는 현재 코딩 블록을 여러 개의 서브 블록으로 분할한 후, 각 서브 블록마다 도 27(b)의 S2704, S2705 단계가 수행될 수 있다. 서브 블록의 너비는 코딩 블록의 너비와 기 설정된 최대 너비와 비교하여 작은 값이 서브 블록의 너비가 될 수 있다. 서브 블록의 높이는 코딩 블록의 높이와 기 설정된 최대 높이와 비교하여 최소값이 서브 블록의 높이가 될 수 있다. 이때 서브 블록 크기는 최대 16x16으로 설정될 수 있다. In step S2730, the decoder divides the current coding block into several sub-blocks, and then steps S2704 and S2705 of FIG. 27(b) may be performed for each sub-block. The width of the subblock may be a smaller value compared to the width of the coding block and the preset maximum width. The height of the subblock may be compared to the height of the coding block and the preset maximum height, and the minimum value may be the height of the subblock. At this time, the subblock size can be set to a maximum of 16x16.
디코더는 S2730 단계에서 획득한 보정된 움직임 정보를 S2704, S2705 단계를 위한 초기 움직임 정보로 설정할 수 있다. 디코더는 초기 움직임 정보를 이용하여 정수 단위의 전역 탐색을 수행하고, 현재 서브 블록에 대한 최적의 움직임 정보와 최적의 움직임 정보에 대한 코스트 값을 획득할 수 있다(S2704). 최적의 움직임 정보를 획득하기 위해 서브 블록에 대한 움직임 정보들 각각에 대한 코스트 값이 획득될 수 있다. 임의의 서브 블록에 대한 코스트 값이 임의의 값보다 작다면, 정수 단위의 전역 탐색에서 획득된 현재 서브 블록에 대한 움직임 정보가 저장되고 이후 과정은 수행되지 않을 수 있다. 만일 임의의 서브 블록에 대한 코스트 값이 임의의 값보다 같거나 크다면 임의의 서브 블록에 대한 코스트 값은 기 설정된 다른 값으로 설정될 수 있다. 임의의 값은 현재 서브 블록의 픽셀 수 또는 현재 서브 블록의 크기가 될 수 있다. 예를 들어, 서브 블록의 크기는 16 x 16일 수 있다. 또한 기 설정된 다른 값은, 인코더 및 디코더가 표현할 수 있는 수의 범위에서의 최대 값일 수 있다. S2704단계 이후, 디코더는 반화소(1/2) 단위의 3x3 Square 탐색을 수행할 수 있다. S2704 단계를 통해 획득되는 움직임 정보는 S2705 단계의 기준 움직임 정보로 사용될 수 있다. 즉, S2704 단계를 통해 획득된 정보에 기초하여 새로운 움직임 후보가 획득되고, 디코더는 새로운 움직임 후보를 평가할 수 있다(S2705). 디코더는 새로운 움직임 후보에 대한 평가를 수행하고, 최종 움직임 정보를 현재 서브 블록에 대해 저장할 수 있다. S2704, S2705 단계는 모든 서브 블록에 대해 반복되어 수행될 수 있다. 서브 블록 단위의 DMVR 과정은 서브 블록 간의 의존성이 없으므로, 모든 서브 블록이 병렬적으로 DMVR을 수행할 수 있다는 장점이 있다.The decoder may set the corrected motion information obtained in step S2730 as initial motion information for steps S2704 and S2705. The decoder can perform a global search in integer units using the initial motion information and obtain optimal motion information for the current sub-block and a cost value for the optimal motion information (S2704). In order to obtain optimal motion information, a cost value for each piece of motion information for a sub-block can be obtained. If the cost value for a random subblock is smaller than a random value, motion information for the current subblock obtained through global search in integer units is stored and subsequent processes may not be performed. If the cost value for any subblock is equal to or greater than the random value, the cost value for the random subblock may be set to another preset value. The arbitrary value can be the number of pixels of the current sub-block or the size of the current sub-block. For example, the size of a subblock may be 16 x 16. Additionally, other preset values may be the maximum value within the range of numbers that the encoder and decoder can express. After step S2704, the decoder can perform a 3x3 Square search in half-pixel (1/2) units. The motion information obtained through step S2704 can be used as the reference motion information in step S2705. That is, a new motion candidate is obtained based on the information obtained through step S2704, and the decoder can evaluate the new motion candidate (S2705). The decoder may perform evaluation on a new motion candidate and store the final motion information for the current sub-block. Steps S2704 and S2705 may be performed repeatedly for all subblocks. The DMVR process on a sub-block basis has the advantage that all sub-blocks can perform DMVR in parallel because there is no dependency between sub-blocks.
도 28은 본 발명의 일 실시예에 따른 코딩 블록의 보정된 움직임 정보와 관련된 코스트 값을 획득하기 위한 탐색 방법을 나타내는 도면이다.FIG. 28 is a diagram illustrating a search method for obtaining a cost value related to corrected motion information of a coding block according to an embodiment of the present invention.
도 28을 참조하면 디코더는 초기 움직임 정보를 획득하고, 획득된 초기 움직임 정보에 기초하여 탐색할 움직임 후보들을 설정할 수 있다. 그리고 디코더는 설정된 움직임 후보들에 대한 평가를 수행하여 획득되는 코스트 값에 기초하여 보정된 움직임 정보을 획득할 수 있다. 그리고 디코더는 현재 블록의 움직임 정보 해상도에 따라 모델 기반 fractional MVD 최적화를 이용하여 최종적인 보정된 움직임 정보를 획득할 수 있다. 도 27(b)의 S2701, S2702, S2705 단계에서 획득되는 보정된 움직임 정보는 도 28과 도 29를 통해 설명한 방법을 통해 획득될 수 있다.Referring to FIG. 28, the decoder may obtain initial motion information and set motion candidates to search based on the obtained initial motion information. And the decoder can obtain corrected motion information based on the cost value obtained by evaluating the set motion candidates. And the decoder can obtain the final corrected motion information using model-based fractional MVD optimization according to the motion information resolution of the current block. The corrected motion information obtained in steps S2701, S2702, and S2705 of FIG. 27(b) can be obtained through the method described with reference to FIGS. 28 and 29.
도 29는 본 발명의 일 실시예에 따른 3x3 Square 탐색 방법을 나타내는 도면이다.Figure 29 is a diagram showing a 3x3 Square search method according to an embodiment of the present invention.
이하에서 도 29를 참조하여 도 28을 통해 설명한 최종적인 보정된 움직임 정보를 획득하는 방법을 보다 구체적으로 설명한다.Below, with reference to FIG. 29, the method of obtaining the final corrected motion information described with reference to FIG. 28 will be described in more detail.
디코더는 이전 단계에서 보정된 움직임 정보에 대한 코스트 값을 획득(계산)할 수 있다(S2901). 이때, 기존에 획득한 보정된 움직임 정보에 대한 코스트 값이 존재한다면 S2901 단계는 생략될 수 있다. S2901 단계에서 획득되는 코스트 값은 움직임 해상도에 따라 다른 방법으로 획득될 수 있다. 예를 들어, 움직임 해상도가 정수 단위라면, 보정된 움직임 정보에 대한 화소(픽셀) 기반 코스트 값으로 획득될 수 있으며 기준 코스트 값으로 사용된다. 움직임 해상도가 반화소(1/2) 단위라면, 디코더는 초기 움직임 정보와 보정된 움직임 정보를 사용하여 획득되는 움직임 정보에 기반한 코스트 값을 획득하고 보정된 움직임 정보에 대한 화소 기반 코스트 값을 획득한다. 다음으로 움직임 정보에 기반한 코스트 값이 화소(픽셀) 기반으로 계산된 코스트 값보다 크다면, 보정된 움직임 정보가 저장되고 다음 과정은 수행되지 않고 생략된다. 만일 움직임 정보에 기반한 코스트 값이 화소(픽셀) 기반으로 계산된 코스트 값보다 같거나 작다면, 화소(픽셀) 기반 코스트 값에 움직임 정보에 기반한 코스트 값을 더한 코스트 값이 기준 코스트 값으로 사용된다. 디코더는 탐색할 움직임 후보들에 대한 보정 값을 설정할 수 있다(S2902). 구체적으로, 정해진 3x3 Square 탐색 패턴에 따라 움직임 보정 후보 값은 유도될 수 있다. 이때 움직임 보정 후보 값은 움직임 해상도에 기초하여 설정될 수 있다. 움직임 해상도에 따라 움직임 보정 후보 값은 스케일되어 범위가 확장될 수 있다. 예를 들어, 정해진 3x3 Square 탐색 패턴의 수평 및 수직 방향은 Mv(-1, 1), Mv(0, 1), Mv(1, 1), Mv(1, 0), Mv(1, -1), Mv(0, -1), Mv(-1, -1), Mv(-1, 0)일 수 있다. 움직임 해상도가 반화소(1/2) 단위일 경우, 계산 복잡도를 감소시키기 위해 3x3 Square 탐색 패턴에서 홀수 번째만 평가가 수행되고, 짝수 번째는 평가가 수행되지 않을 수 있다. 디코더는 보정된 움직임 후보와 움직임 보정 후보 값을 이용하여 새로운 움직임 후보를 설정할 수 있다. 디코더는 L0 픽쳐리스트 내 픽쳐의 참조 블록에 대한 움직임 정보와 L1 픽쳐리스트 내 픽쳐의 참조 블록에 대한 움직임 정보를 재구성할 수 있다(S2904). 선형적인 특성을 가지는 L0 및 L1 움직임을 평가하기 위해서, 디코더는 보정된 L0 움직임 후보에는 움직임 보정 후보 값을 합산하고, 보정된 L1 움직임 후보에는 움직임 보정 후보 값을 차분하여 새로운 움직임 후보를 생성할 수 있다. 또한, 비선형적인 특성을 지니는 L0 및 L1 움직임을 평가하기 위해서, 디코더는 보정된 L0 움직임 후보는 수정하지 않고, 보정된 L1 움직임 후보에는 움직임 보정 후보 값을 합산하여 새로운 움직임 후보를 생성할 수 있다. 또는, 디코더는 보정된 L1 움직임 후보는 수정하지 않고, 보정된 L0 움직임 후보에는 움직임 보정 후보 값을 합산하여 새로운 움직임 후보를 생성할 수 있다. 디코더는 새로운 움직임 후보에 대한 움직임 정보에 기초한 코스트 값을 계산할 수 있다(S2905). 디코더는 새로운 움직임 후보에 대한 움직임 정보에 기초한 코스트 값을 기준 코스트 값과 비교할 수 있다(S2906). 움직임 정보에 기초한 코스트 값이 기준 코스트 값보다 큰 경우, 디코더는 움직임 정보에 기초한 코스트 값의 2배에 해당하는 값을 메모리에 저장할 수 있다. 그리고 디코더는 S2906 단계 이후의 과정은 수행하지 않고 S2902 단계부터 반복하여 다시 수행할 수 있다. 움직임 정보에 기초한 코스트 값이 기준 코스트 값보다 작은 경우, 디코더는 새로운 움직임 후보에 대한 화소(픽셀) 기반 코스트 값을 획득할 수 있다(S2907). 그리고, 기준 코스트 값을 움직임 정보에 기초한 코스트 값과 새로운 움직임 후보에 대한 화소 기반 코스트 값을 합산한 값으로 갱신할 수 있다. 만약 움직임 해상도가 반화소(1/2) 단위일 경우, 디코더는 다른 새로운 움직임 후보를 평가하기 위해서 S2901 단계부터 다시 반복하여 수행할 수 있다. 즉, 움직임 해상도가 반화소(1/2) 단위일 경우에는 디코더는 새로운 움직임 후보에 대한 평가 결과만 저장하고 최적의 움직임 후보로는 사용하지 않을 수 있다. 저장된 새로운 움직임 후보에 대한 평가 결과(코스트 값)는 이후에 수행될 수 있는 모델 기반 fractional MVD 최적화 단계에서 사용될 수 있다. 만일 움직임 해상도가 정수 단위일 경우, 새로운 움직임 후보에 대한 움직임 정보에 기초한 코스트 값과 화소(픽셀) 기반 코스트 값을 합산한 값이 초기 보정된 움직임 정보에 대한 화소(픽셀) 기반 코스트 값보다 작다면, 디코더는 새로운 움직임 후보를 최적의 움직임 정보로 저장할 수 있다. 만약 움직임 해상도가 정수 단위일 경우, 디코더는 S2907 단계에서 획득한 새로운 움직임 후보에 대한 화소(픽셀) 기반 코스트 값을 최적의 움직임 정보에 대한 코스트 값으로 저장할 수 있다. 이후, 디코더는 아직 탐색하지 못한 움직임 후보가 있는지 확인할 수 있다(S2908). 디코더는 아직 탐색하지 못한 움직임 후보가 있다면 새로운 움직임 후보를 평가하기 위해서 S2901 단계를 반복하여 수행할 수 있고, 모든 움직임 후보에 대해 평가를 하였다면 탐색한 움직임 후보에 대한 코스트 값들 중 가장 작은 코스트 값에 대응하는 움직임 후보를 최종 보정 움직임으로 저장할 수 있다(S2909). 디코더는 움직임 해상도가 반화소(1/2) 단위일 경우, 이전 단계에서 저장된 움직임 후보들에 대한 코스트 값들을 사용하여 모델 기반 fractional MVD 최적화 과정이 수행되어 최적의 반화소 단위의 보정 움직임 정보를 다시 계산할 수 있다(S2910). S2910 단계는 VVC(Versatile Video Coding)의 DMVR에서 정수 단위의 화소(픽셀) 기반 코스트 값을 사용하여 소수 화소 단위의 움직임을 유도하는 과정과 유사할 수 있다. 디코더는 최적 움직임 정보의 위치에 인접한 주변(좌, 우, 위, 아래) 움직임 정보에 대한 코스트 값을 사용하여 최적 움직임 정보를 획득할 수 있다.The decoder can obtain (calculate) a cost value for the motion information corrected in the previous step (S2901). At this time, if there is a cost value for the previously obtained corrected motion information, step S2901 can be omitted. The cost value obtained in step S2901 may be obtained in different ways depending on the motion resolution. For example, if the motion resolution is an integer unit, it can be obtained as a pixel-based cost value for the corrected motion information and is used as a reference cost value. If the motion resolution is a half-pixel (1/2) unit, the decoder obtains a cost value based on the motion information obtained using the initial motion information and the corrected motion information and obtains a pixel-based cost value for the corrected motion information. . Next, if the cost value based on the motion information is greater than the cost value calculated based on the pixel (pixel), the corrected motion information is stored and the next process is not performed and is skipped. If the cost value based on motion information is equal to or smaller than the cost value calculated based on pixel (pixel), the cost value obtained by adding the cost value based on motion information to the pixel (pixel) based cost value is used as the reference cost value. The decoder may set correction values for motion candidates to be searched (S2902). Specifically, motion correction candidate values can be derived according to a determined 3x3 Square search pattern. At this time, the motion correction candidate value may be set based on the motion resolution. Depending on the motion resolution, the motion correction candidate value may be scaled to expand the range. For example, the horizontal and vertical directions of a given 3x3 Square search pattern are Mv(-1, 1), Mv(0, 1), Mv(1, 1), Mv(1, 0), Mv(1, -1) ), Mv(0, -1), Mv(-1, -1), Mv(-1, 0). If the motion resolution is half pixel (1/2), evaluation may be performed only on odd numbers in the 3x3 Square search pattern, and evaluation may not be performed on even numbers in the 3x3 Square search pattern, in order to reduce computational complexity. The decoder can set a new motion candidate using the corrected motion candidate and the motion correction candidate value. The decoder can reconstruct motion information about the reference block of the picture in the L0 picture list and motion information about the reference block of the picture in the L1 picture list (S2904). In order to evaluate L0 and L1 motions with linear characteristics, the decoder can generate a new motion candidate by adding motion correction candidate values to the corrected L0 motion candidate and subtracting the motion correction candidate values from the corrected L1 motion candidate. there is. Additionally, in order to evaluate L0 and L1 motions with non-linear characteristics, the decoder may generate a new motion candidate by adding the motion correction candidate value to the corrected L1 motion candidate without modifying the corrected L0 motion candidate. Alternatively, the decoder may generate a new motion candidate by adding the motion correction candidate value to the corrected L0 motion candidate without modifying the corrected L1 motion candidate. The decoder may calculate a cost value based on motion information for a new motion candidate (S2905). The decoder may compare the cost value based on motion information for the new motion candidate with the reference cost value (S2906). If the cost value based on motion information is greater than the reference cost value, the decoder may store a value in memory that is twice the cost value based on motion information. And the decoder can repeat the process again from step S2902 without performing the process after step S2906. If the cost value based on motion information is smaller than the reference cost value, the decoder can obtain a pixel-based cost value for a new motion candidate (S2907). Additionally, the reference cost value can be updated to a value that is the sum of the cost value based on motion information and the pixel-based cost value for the new motion candidate. If the motion resolution is a half-pixel (1/2) unit, the decoder can repeatedly perform from step S2901 to evaluate other new motion candidates. That is, if the motion resolution is in half-pixel (1/2) units, the decoder may only store the evaluation results for new motion candidates and may not use them as optimal motion candidates. The evaluation results (cost values) for the stored new motion candidates can be used in the model-based fractional MVD optimization step that can be performed later. If the motion resolution is an integer unit, the sum of the cost value based on motion information for the new motion candidate and the pixel-based cost value is smaller than the pixel-based cost value for the initially corrected motion information. , the decoder can store the new motion candidate as optimal motion information. If the motion resolution is an integer unit, the decoder can store the pixel-based cost value for the new motion candidate obtained in step S2907 as the cost value for optimal motion information. Afterwards, the decoder can check whether there are motion candidates that have not yet been explored (S2908). If there are motion candidates that have not yet been searched, the decoder can repeat step S2901 to evaluate new motion candidates. If all motion candidates have been evaluated, it corresponds to the smallest cost value among the cost values for the searched motion candidates. The motion candidate can be saved as the final corrected motion (S2909). If the motion resolution is in half-pixel (1/2) units, the decoder performs a model-based fractional MVD optimization process using the cost values for the motion candidates stored in the previous step to recalculate the optimal half-pixel-level compensation motion information. (S2910). Step S2910 may be similar to the process of deriving movement in units of fractional pixels using a pixel (pixel)-based cost value in integer units in DMVR of Versatile Video Coding (VVC). The decoder can obtain optimal motion information using cost values for surrounding (left, right, up, down) motion information adjacent to the location of optimal motion information.
도 29를 참조하여 설명한 탐색 방법은 임의의 정해진 횟수만큼 반복 수행될 수 있고, 반복 수행될 때, 디코더는 이전 탐색에서 획득한 최적 움직임 정보의 주변 위치만을 탐색할 수 있다.The search method described with reference to FIG. 29 can be repeatedly performed any set number of times, and when repeated, the decoder can only search for locations surrounding the optimal motion information obtained in the previous search.
도 30은 본 발명의 일 실시예에 따른 정수 단위 전역 탐색 과정에서 탐색 영역을 구역별로 나누어 진 것을 나타낸 도면이다.Figure 30 is a diagram showing the search area divided into zones in the integer global search process according to an embodiment of the present invention.
도 30을 참조하면, 정수 단위 전역 탐색은 탐색 영역을 가운데 위치를 중심으로 여러 개의 구역으로 나누고, 구역별로 서로 다른 가중치를 설정해서 수행되는 탐색일 수 있다. 탐색 영역의 가운데 위치는 초기 움직임 정보가 지시하는 참조 블록의 좌상단 화소(픽셀) 위치일 수 있다. 각 구역별 가중치는 현재 블록의 주변 블록 및 현재 블록의 움직임 특성에 따라 다르게 설정될 수 있다. 예를 들어, 현재 블록의 주변 블록 및 현재 블록의 움직임 간 유사성이 높을 경우, 가중치는 가운데 구역부터 가장자리 구역 순으로 높아지도록 설정될 수 있다. 반대로, 현재 블록의 주변 블록 및 현재 블록의 움직임 간 유사성이 낮을 경우, 가중치는 가운데 구역부터 가장자리 구역 순으로 낮아지도록 설정될 수 있다. 도 27(a)의 S2710 단계에서 획득되는 보정된 움직임 정보에 대한 화소(픽셀) 기반 코스트 값이 임의의 값보다 작다면, 정수 단위 전역 탐색은 수행되지 않을 수 있다. 또한, 탐색 영역 내에서 임의의 움직임 보정 값에 대한 화소(픽셀) 기반 코스트 값이 임의의 값보다 작다면, 임의의 움직임 보정 값이 최종 보정된 움직임 정보가 되고, 정수 단위 전역 탐색은 종료될 수 있다. 임의의 값은 현재 블록의 화소(픽셀) 수 또는 현재 블록의 크기가 될 수 있다. 예를 들어, 현재 블록의 크기는 16x16 일 수 있다.Referring to FIG. 30, global search in integer units may be a search performed by dividing the search area into several zones centered on the center position and setting different weights for each zone. The center position of the search area may be the top left pixel (pixel) position of the reference block indicated by the initial motion information. The weight for each zone may be set differently depending on the movement characteristics of the current block and neighboring blocks of the current block. For example, if the similarity between the movement of the current block and neighboring blocks of the current block is high, the weight may be set to increase from the center area to the edge area. Conversely, if the similarity between the movement of the current block and neighboring blocks of the current block is low, the weights may be set to decrease in order from the center area to the edge area. If the pixel-based cost value for the corrected motion information obtained in step S2710 of FIG. 27(a) is smaller than an arbitrary value, the global search in integer units may not be performed. Additionally, if the pixel-based cost value for a random motion compensation value within the search area is smaller than a random value, the random motion compensation value becomes the final corrected motion information, and the global search in integer units can be terminated. there is. The arbitrary value can be the number of pixels (pixels) of the current block or the size of the current block. For example, the size of the current block may be 16x16.
도 31, 도 32는 본 발명의 일 실시예에 따른 정수 단위의 전역 탐색 과정을 나타내는 도면이다. Figures 31 and 32 are diagrams showing a global search process in integer units according to an embodiment of the present invention.
도 31을 참조하면 디코더는 입력된 초기 움직임 정보에 기초하여 탐색할 움직임 후보들을 설정할 수 있다. 그리도 디코더는 움직임 후보들에 대한 평가를 수행하여 최종 보정 움직임 정보를 획득할 수 있다. 정수 단위의 전역 탐색은 도 30에 도시된 바와 같이 가운데 구역부터 가장자리 구역 순으로, 각 구역별 모든 위치에 대하여 수행될 수 있다. Referring to FIG. 31, the decoder can set motion candidates to be searched based on the input initial motion information. Even so, the decoder can obtain final corrected motion information by performing evaluation on motion candidates. Global search in integer units can be performed for all locations in each zone in the order from the center zone to the edge zone, as shown in FIG. 30.
이하에서 도 32를 참조하여 정수 단위의 전역 탐색에 대해 보다 자세히 설명한다. 도 32를 참조하면 디코더는 블록의 크기에 따라 탐색 영역 내의 각 구역별 탐색 위치를 재설정할 수 있다(S3201). 이때, 블록의 크기가 임의의 값보다 작다면, 디코더는 계산 복잡도 감소를 위해 도 30의 가운데 위치를 기준으로 임의의 값만큼 축소된 탐색 영역만을 평가한다. 임의의 값은 현재 블록의 크기의 절반이거나 양의 정수가 될 수 있으며, 예를 들어, '8'일 수 있다. 초기 움직임 정보를 사용하여 화소(픽셀) 기반 코스트 값을 계산한 후, 그것을 최소 코스트 값으로 설정한다. 디코더는 움직임 후보의 탐색 위치에 대한 움직임 보정 값을 설정하고, 움직임 보정 값을 현재 블록에서 사용될 움직임 해상도(resolution)에 맞게 재설정할 수 있다(S3202, S3203). 디코더는 S3203 단계에서 재설정된 움직임 보정 값을 이용하여 새로운 움직임 후보를 설정할 수 있다. 디코더는 L0 픽쳐리스트 내 픽쳐의 참조 블록에 대한 움직임 정보와 L1 픽쳐리스트 내 픽쳐의 참조 블록에 대한 움직임 정보를 재구성할 수 있다(S3204). 선형적인 특성을 지니는 L0 및 L1 움직임을 평가하기 위해서, 디코더는 보정된 L0 움직임 후보에는 움직임 보정 후보 값을 합산하고, 보정된 L1 움직임 후보에는 움직임 보정 후보 값을 차분하여 새로운 움직임 후보를 생성할 수 있다. 또한 비선형적인 특성을 지니는 L0 및 L1 움직임을 평가하기 위해서, 디코더는 보정된 L0 움직임 후보는 수정하지 않고, 보정된 L1 움직임 후보에는 움직임 보정 후보 값을 합산하여 새로운 움직임 후보를 생성할 수 있다. 또한 디코더는 보정된 L1 움직임 후보는 수정하지 않고, 보정된 L0 움직임 후보에는 움직임 보정 후보 값을 합산하여 새로운 움직임 후보를 생성할 수 있다. 디코더는 새로운 움직임 후보에 대한 화소(픽셀) 기반 코스트 값을 획득할 수 있다(S3205). 각 구역별로 코스트 값을 차별화하기 위해 디코더는 미리 정의된 각 구역별 가중치 값을 사용하여 코스트 값을 재획득할 수 있다(S3206). 가중치 값은 실험을 통해 구해진 값으로 양의 정수 값이 될 수 있다. 예를 들어, 가중치 값은 '1', '2', … , '63'일 수 있다. 디코더는 재획득된 코스트 값이 최소 코스트 값보다 작다면, 최소 코스트 값을 재획득된 코스트 값으로 갱신할 수 있다. 디코더는 모든 움직임 후보에 대한 평가가 완료되었는지 여부를 평가할 수 있다(S3207). 아직 평가가 완료되지 않은 움직임 후보가 있다면 최소 코스트 값을 이용하여 S3202 단계부터 다시 수행할 수 있다. 모든 움직임 후보에 대한 평가가 완료되었다면 디코더는 움직임 후보들 각각의 코스트 값 중 가장 작은 코스트 값에 대응되는 움직임 후보의 정보를 최종 보정된 움직임 정보로 설정할 수 있다. 정수 단위의 전역 탐색은 복잡도를 낮추기 위해서 조기 종료 방법이 적용될 수 있다. S3206 단계에서 재획득된 코스트 값이 최소 코스트 값보다 작고, 재획득된 코스트 값에서 최소 코스트 값을 뺀 차이 값이 임의의 값보다 작을 경우, S3207 단계를 검사하지 않고 S3208 단계가 수행되고 정수 단위의 전역 탐색이 종료될 수 있다. 임의의 값은 현재 블록의 크기 혹은 픽셀 수가 될 수 있으며, 예를 들어, 16x16 일 수 있다.Below, global search in integer units will be described in more detail with reference to FIG. 32. Referring to FIG. 32, the decoder can reset the search position for each zone within the search area according to the size of the block (S3201). At this time, if the size of the block is smaller than a random value, the decoder evaluates only the search area reduced by a random value based on the center position of FIG. 30 to reduce computational complexity. The random value can be half the size of the current block or a positive integer, for example '8'. After calculating the pixel-based cost value using the initial motion information, set it as the minimum cost value. The decoder may set a motion correction value for the search position of the motion candidate and reset the motion correction value to match the motion resolution to be used in the current block (S3202, S3203). The decoder can set a new motion candidate using the motion correction value reset in step S3203. The decoder can reconstruct motion information about the reference block of the picture in the L0 picture list and motion information about the reference block of the picture in the L1 picture list (S3204). In order to evaluate L0 and L1 motions with linear characteristics, the decoder can generate a new motion candidate by adding motion compensation candidate values to the corrected L0 motion candidate and subtracting the motion compensation candidate value from the corrected L1 motion candidate. there is. Additionally, in order to evaluate L0 and L1 motions with non-linear characteristics, the decoder may generate a new motion candidate by adding the motion correction candidate value to the corrected L1 motion candidate without modifying the corrected L0 motion candidate. Additionally, the decoder may generate a new motion candidate by adding the motion correction candidate values to the corrected L0 motion candidate without modifying the corrected L1 motion candidate. The decoder can obtain a pixel-based cost value for a new motion candidate (S3205). In order to differentiate the cost value for each zone, the decoder can reacquire the cost value using a predefined weight value for each zone (S3206). The weight value is a value obtained through experiment and can be a positive integer value. For example, weight values can be '1', '2',... , could be '63'. If the reacquired cost value is less than the minimum cost value, the decoder may update the minimum cost value with the reacquired cost value. The decoder may evaluate whether evaluation of all motion candidates has been completed (S3207). If there are motion candidates for which evaluation has not yet been completed, the process can be performed again from step S3202 using the minimum cost value. If the evaluation of all motion candidates is completed, the decoder can set the motion candidate information corresponding to the smallest cost value among the cost values of each motion candidate as the final corrected motion information. An early termination method can be applied to global search in integer units to reduce complexity. If the reacquired cost value in step S3206 is less than the minimum cost value, and the difference value obtained by subtracting the minimum cost value from the reacquired cost value is less than an arbitrary value, step S3208 is performed without checking step S3207, and the integer unit Global search may be terminated. The arbitrary value can be the size of the current block or the number of pixels, for example 16x16.
도 33, 34는 본 발명의 일 실시예에 따른 BDOF에 기반한 움직임 정보의 보정을 수행하는 방법을 나타내는 도면이다.33 and 34 are diagrams showing a method of performing correction of motion information based on BDOF according to an embodiment of the present invention.
도 33, 34의 BDOF에 기반한 움직임 정보의 보정은 도 27의 S2740, S2706 단계의 BDOF 기반 움직임 정보의 보정을 구체적으로 나타낸다. Correction of motion information based on BDOF in FIGS. 33 and 34 specifically shows correction of motion information based on BDOF in steps S2740 and S2706 of FIG. 27.
도 33을 참조하면, 디코더는 현재 블록을 서브 블록으로 분할한 후, 입력된 초기 움직임 정보에 기초하여 BDOF 기반 움직임 정보의 보정 값을 계산하여 최종 보정 움직임 정보를 획득할 수 있다. BDOF는 양방향 움직임으로 구성된 블록의 참조 블록으로부터 화소의 변화량을 추정하여 예측 블록을 보정하는데 사용될 수 있다. BDOF에서 유도된 움직임 정보를 이용하여 현재 블록의 움직임을 보정할 수 있다. 현재 블록이 affine, LIC, OBMC, sub-block MC, CIIP, SMVD, BCW with different weight, MMVD 중에서 적어도 하나의 모드로 부호화 되었다면, BDOF 기반 움직임 보정은 수행되지 않을 수 있다. 한편, BDOF 기반 움직임 보정은 다음의 조건 중 어느 하나라도 만족할 때 수행될 수 있다. BDOF 기반 움직임 보정이 수행되기 위한 조건은 현재 블록이 i) merge 모드의 움직임이 양방향인 경우, ii) 참조 픽쳐들과 현재 픽쳐 간의 거리가 동일한 경우, iii) 참조 블록들 간의 가중치 예측이 적용되지 않은 블록인 경우, iv) 현재 블록의 크기가 임의의 정해진 크기 이상일 경우일 수 있다. 임의의 정해진 크기는 블록의 가로, 세로일 수 있다. 예를 들어, 블록의 가로의 크기는 '8', 세로의 크기는 '8'일 수 있다. 또한, BDOF 기반 움직임 보정은 서브 블록 단위로 수행될 수 있고, 서브 블록의 크기는 최대 16x16일 수 있다.Referring to FIG. 33, the decoder may divide the current block into sub-blocks and then calculate the correction value of the BDOF-based motion information based on the input initial motion information to obtain final corrected motion information. BDOF can be used to correct a prediction block by estimating the amount of change in a pixel from the reference block of a block composed of bidirectional motion. The motion of the current block can be corrected using motion information derived from BDOF. If the current block is encoded in at least one mode among affine, LIC, OBMC, sub-block MC, CIIP, SMVD, BCW with different weight, and MMVD, BDOF-based motion compensation may not be performed. Meanwhile, BDOF-based motion compensation can be performed when any one of the following conditions is satisfied. The conditions for performing BDOF-based motion compensation are: i) when motion in merge mode is bidirectional, ii) when the distance between reference pictures and the current picture is the same, and iii) when weight prediction between reference blocks is not applied. In the case of a block, iv) the size of the current block may be larger than a certain size. Any given size can be the width and height of the block. For example, the horizontal size of the block may be '8' and the vertical size may be '8'. Additionally, BDOF-based motion compensation can be performed on a sub-block basis, and the size of a sub-block can be up to 16x16.
이하에서는 각 서브 블록에 대해 BDOF 기반 움직임 보정을 수행하는 과정에 대해 설명한다. 도 34를 참조하면 인접한 서브 블록들 간에는 움직임 정보가 동일할 수 있으며, 동일한 움직임 정보를 가지는 서브 블록들을 병합하여 BDOF는 한 번만 수행할 수 있다(S3401, S3402). 현재 블록의 너비와 높이의 크기 차이에 따라 서브 블록들을 가로 혹은 세로 방향으로 병합할지 결정할 수 있다. 예를 들어, 현재 블록의 너비보다 높이가 크다면, 서브 블록들은 세로 방향으로 병합될 수 있고, 현재 블록의 높이보다 너비가 크다면, 서브 블록들은 가로 방향으로 병합될 수 있다. 디코더는 각각의 서브 블록 또는 병합된 서브 블록들에 대하여 S3403 내지 S3414 단계를 반복적으로 수행하여 보정된 움직임 정보 혹은 예측 블록을 획득할 수 있다.Below, the process of performing BDOF-based motion compensation for each sub-block is described. Referring to FIG. 34, motion information may be the same between adjacent sub-blocks, and BDOF can be performed only once by merging sub-blocks with the same motion information (S3401, S3402). Depending on the size difference between the width and height of the current block, you can decide whether to merge subblocks horizontally or vertically. For example, if the height is greater than the width of the current block, the sub-blocks can be merged vertically, and if the width is greater than the height of the current block, the sub-blocks can be merged horizontally. The decoder may obtain corrected motion information or a prediction block by repeatedly performing steps S3403 to S3414 for each sub-block or merged sub-blocks.
디코더는 L0 참조 블록과 L1 참조 블록을 이용하여 BDOF 파라미터를 획득할 수 있다(S3403). BDOF 파라미터는 화소 값 간의 변화량 등이 있을 수 있다. 디코더는 현재 블록을 최대 8x8 크기의 서브 블록으로 분할한 후(S3404), 각각의 서브 블록마다 S3405 내지 S3412의 단계를 반복 수행할 수 있다.The decoder can obtain BDOF parameters using the L0 reference block and L1 reference block (S3403). BDOF parameters may include the amount of change between pixel values. The decoder may divide the current block into sub-blocks of up to 8x8 in size (S3404) and then repeat steps S3405 to S3412 for each sub-block.
디코더는 L0 및 L1 참조 블록 간의 화소(픽셀) 기반 코스트 값을 획득할 수 있다(S3405). 디코더는 코스트 값을 기 설정된 한계 값과 비교할 수 있다(S3406). 비교 결과 코스트 값이 기 설정된 한계 값보다 작다면 디코더는 움직임 보정을 수행하지 않고 움직임 보정 값에 (0,0)을 대입하여 L0 및 L1 참조 블록을 사용하여 서브 블록에 대한 예측 블록을 생성할 수 있다(S3407, S3409). 반대로, 비교 결과 코스트 값이 기 설정된 한계 값보다 같거나 크다면 디코더는 BDOF에 기반한 움직임 보정 값을 획득할 수 있다(S3408). 디코더는 움직임 보정 값이 (0,0)인지 여부를 확인할 수 있다(S3410). 움직임 보정 값이 (0,0)이라면, 디코더는 BDOF에 기반한 예측 블록을 생성할 수 있고, 움직임 보정 값이 (0,0)이 아니라면, S3408 단계에서 획득한 보정 값을 저장할 수 있다(S3411, S3412). S3412 단계에서 저장되는 보정된 움직임 정보는 도 33의 최종 보정된 움직임 정보일 수 있다.The decoder can obtain a pixel-based cost value between L0 and L1 reference blocks (S3405). The decoder may compare the cost value with a preset limit value (S3406). If the cost value as a result of the comparison is less than the preset limit value, the decoder can generate a prediction block for the sub-block using the L0 and L1 reference blocks by substituting (0,0) for the motion compensation value without performing motion compensation. There is (S3407, S3409). Conversely, if the cost value as a result of the comparison is equal to or greater than the preset limit value, the decoder can obtain a motion compensation value based on BDOF (S3408). The decoder can check whether the motion compensation value is (0,0) (S3410). If the motion correction value is (0,0), the decoder can generate a prediction block based on BDOF, and if the motion correction value is not (0,0), the correction value obtained in step S3408 can be stored (S3411, S3412). The corrected motion information stored in step S3412 may be the final corrected motion information of FIG. 33.
디코더는 S3403 내지 S3412 단계가 모든 8x8 서브 블록마다 수행되었는지 확인할 수 있다(S3413). S3405 내지 S3412 단계가 수행되지 않은 8x8 서브 블록이 있다면 디코더는 S3405 내지 S3412 단계를 반복하여 수행할 수 있다. S3405 내지 S3412 단계가 모든 8x8 서브 블록에 수행되었다면 디코더는 모든 16x16 서브 블록에 대하여 S3403 내지 S3412 단계가 수행되었는지 확인할 수 있다(S3414). S3403 내지 S3412 단계가 수행되지 않은 16x16 서브 블록이 있다면 디코더는 S3403 내지 S3412 단계를 반복하여 수행할 수 있다. S3403 내지 S3412 단계가 모든 16x16 서브 블록에 수행되었다면 BDOF에 기반한 움직임 보정을 종료할 수 있다. 이때, 8x8 서브 블록은 16x16 서브 블록을 구성하는 서브 블록일 수 있다.The decoder can check whether steps S3403 to S3412 have been performed for every 8x8 subblock (S3413). If there is an 8x8 subblock for which steps S3405 to S3412 have not been performed, the decoder may repeatedly perform steps S3405 to S3412. If steps S3405 to S3412 have been performed for all 8x8 sub-blocks, the decoder can check whether steps S3403 to S3412 have been performed for all 16x16 sub-blocks (S3414). If there is a 16x16 subblock for which steps S3403 to S3412 have not been performed, the decoder may repeatedly perform steps S3403 to S3412. If steps S3403 to S3412 have been performed on all 16x16 sub-blocks, motion compensation based on BDOF can be terminated. At this time, the 8x8 subblock may be a subblock constituting a 16x16 subblock.
도 35, 도 36은 본 발명의 일 실시예에 따른 BDOF에 기반한 현재 블록에 대한 예측 블록을 생성하는 방법을 나타내는 도면이다.Figures 35 and 36 are diagrams showing a method of generating a prediction block for a current block based on BDOF according to an embodiment of the present invention.
도 35를 참조하면 디코더는 도 33, 도 34에서 설명한 과정을 수행하여 획득된 최종 보정된 움직임 정보를 이용하여 현재 블록에 대한 예측 블록을 생성할 수 있다. 디코더는 현재 블록을 서브 블록으로 분할하여 각 서브 블록 단위로 최종 보정된 움직임 정보를 이용하여 BDOF에 기반한 현재 블록에 대한 예측 블록을 생성할 수 있다. Referring to FIG. 35, the decoder can generate a prediction block for the current block using the final corrected motion information obtained by performing the process described in FIGS. 33 and 34. The decoder can divide the current block into sub-blocks and use the final corrected motion information for each sub-block to generate a prediction block for the current block based on BDOF.
이하에서 BDOF에 기반한 예측 블록을 생성하는 구체적인 과정에 대해 설명한다.Below, the specific process of generating a prediction block based on BDOF is described.
도 36을 참조하면 디코더는 현재 블록을 8x8 서브 블록으로 분할할 수 있다(S3601). 디코더는 도 27의 S2730 또는 S2704, S2705 단계를 수행하여 획득되는 보정된 움직임 정보와 S2740 또는 S2706 단계를 수행하여 획득되는 움직임 보정 값을 합산하여 최종 보정된 움직임 정보를 획득할 수 있다(S3602). 이때, 디코더는 도 27의 S2740 또는 S2706 단계에서 획득된 움직임 보정 값이 (0,0)인지 여부를 확인할 수 있다(S3603). 확인 결과 움직임 보정 값이 (0,0)인 경우, 디코더는 휘도 성분에 대한 예측 블록으로 도 34의 S3409, S3411 단계에서 획득된 예측 블록을 사용할 수 있다(S3604). 또한, 확인 결과 움직임 보정 값이 (0,0)인 경우, 디코더는 색차 성분에 대한 예측 블록을 생성할 수 있다(S3606). 한편, 확인 결과 움직임 보정 값이 (0,0)이 아닌 경우, 디코더는 BDOF에 기반한 휘도 성분 및 색차 성분에 대한 예측 블록을 생성할 수 있다(S3605). 디코더는 상술한 S3602 내지 S3606 단계가 모든 8x8 서브 블록에 대해 수행되었는지 여부를 확인하고, 수행되지 않은 서브 블록이 있다면 S3602 내지 S3606 단계를 반복하여 수행할 수 있다(S3607).Referring to FIG. 36, the decoder can divide the current block into 8x8 subblocks (S3601). The decoder may obtain final corrected motion information by adding the corrected motion information obtained by performing steps S2730, S2704, and S2705 of FIG. 27 and the motion correction value obtained by performing steps S2740 or S2706 (S3602). At this time, the decoder can check whether the motion correction value obtained in step S2740 or S2706 of FIG. 27 is (0,0) (S3603). As a result of confirmation, if the motion compensation value is (0,0), the decoder can use the prediction block obtained in steps S3409 and S3411 of FIG. 34 as a prediction block for the luminance component (S3604). Additionally, if the motion correction value is (0,0) as a result of confirmation, the decoder can generate a prediction block for the chrominance component (S3606). Meanwhile, if the motion correction value is not (0,0) as a result of confirmation, the decoder can generate a prediction block for the luminance component and chrominance component based on BDOF (S3605). The decoder checks whether the above-described steps S3602 to S3606 have been performed for all 8x8 subblocks, and if there are subblocks that have not been performed, steps S3602 to S3606 may be repeatedly performed (S3607).
도 37은 본 발명의 일 실시예에 따른 DMVR이 적용되는 서브블록을 나타내는 도면이다.Figure 37 is a diagram showing a subblock to which DMVR is applied according to an embodiment of the present invention.
이하에서 도 27을 참조하여 상술한 다중 DMVR을 수행하는 다양한 방법에 대해 설명한다. Hereinafter, various methods of performing the above-described multiple DMVR will be described with reference to FIG. 27.
도 27을 통해 설명한 DMVR의 각 단계가 수행되는지 여부는 현재 블록의 크기, 현재 블록의 컬러 성분(현재 블록이 휘도 성분 블록인지 색차 성분 블록인지), 현재 블록에 대한 양자화 파라미터 정보, 현재 블록의 움직임 해상도 정보, 현재 블록의 주변 블록의 잔차 신호의 존재 여부와 관련된 정보들 적어도 어느 하나에 기초하여 결정될 수 있다. 예를 들어, 현재 블록이 색차 성분 블록이거나 현재 블록의 주변 블록의 잔차 신호가 임의의 값 이내인 경우, 도 27의 단계들 중 일부는 생략되거나 특정 단계 이후의 단계는 생략될 수 있다. 계산 복잡도를 감소시키기 위함이다. Whether each step of the DMVR described with reference to FIG. 27 is performed depends on the size of the current block, the color component of the current block (whether the current block is a luminance component block or a chrominance component block), quantization parameter information for the current block, and the movement of the current block. It may be determined based on at least one of resolution information and information related to the presence or absence of a residual signal of a neighboring block of the current block. For example, if the current block is a chrominance component block or the residual signal of a neighboring block of the current block is within a certain value, some of the steps in FIG. 27 may be omitted or steps after a specific step may be omitted. This is to reduce computational complexity.
도 27을 통해 설명한 DMVR의 각 단계의 수행 여부는 현재 블록의 크기에 따라 결정될 수 있다. 크기가 큰 블록일수록 분할되는 서브 블록의 수가 증가하기 때문에 현재 블록의 크기가 임의의 값보다 같거나 크다면, DMVR의 각 단계 중 일부 또는 전부는 수행되지 않을 수 있다. 이때, 임의의 값은 현재 블록의 가로와 세로의 크기의 합일 수 있고, 구체적으로 128일 수 있다. Whether or not to perform each step of DMVR described with reference to FIG. 27 may be determined depending on the size of the current block. As the size of the block increases, the number of divided sub-blocks increases, so if the size of the current block is equal to or greater than a random value, some or all of the steps of DMVR may not be performed. At this time, the arbitrary value may be the sum of the width and height sizes of the current block, and specifically may be 128.
한편, 현재 블록(예, 코딩 블록)의 크기가 임의의 값보다 크다면 서브 블록의 크기도 비례적으로 크게 분할되도록 설정하여 도 27을 통해 설명한 DMVR의 각 단계가 수행될 수 있다. 이때의 임의의 값은 16일 수 있다. 현재 블록이 임의의 값보다 크다면 서브 블록의 너비 및 높이를 기 설정된 크기보다 n(예, 자연수)배만큼 확장하여 확장된 크기로 서브 블록은 분할될 수 있다. 또는 현재 블록에 적용될 수 있는 서브 블록의 최대 개수가 설정될 수 있고, 최대 개수에 기초하여 서브 블록의 너비 및 높이가 결정될 수 있다.Meanwhile, if the size of the current block (e.g., coding block) is larger than an arbitrary value, the size of the sub-block can be set to be divided proportionally large, and each step of DMVR described with reference to FIG. 27 can be performed. The arbitrary value at this time may be 16. If the current block is larger than a random value, the subblock may be divided into the expanded size by expanding the width and height of the subblock by n (e.g., a natural number) times the preset size. Alternatively, the maximum number of sub-blocks that can be applied to the current block may be set, and the width and height of the sub-block may be determined based on the maximum number.
비디오 신호 처리 장치의 허용 가능한 병렬 프로세스의 개수에 따라 도 27을 통해 설명한 DMVR의 각 단계의 수행 여부가 결정될 수 있다. 비디오 신호 처리 장치마다 병렬적으로 처리 가능한 자원(예, 프로세스 및 쓰레드)의 개수가 제한적이기 때문이다. 따라서, 제한된 처리 가능한 자원 하에서 DMVR의 단계별 수행 여부가 달라질 수 있고, 블록마다 DMVR이 선택적으로 적용될 수 있다. 예를 들어 처리 가능한 자원의 개수가 임의의 값보다 같거나 작은 경우 도 27을 통해 설명한 DMVR의 각 단계의 일부가 생략되거나 특정 단계 이후의 단계가 생략될 수 있다. 또한 서브 블록들 중에서 특정 위치의 서브 블록에만 DMVR이 적용될 수 있다. 특정 위치는 분할된 서브 블록 중에서 홀수 또는 짝수 번째 블록이 될 수 있다. 또는 도 37에 나타난 바와 같이 DMVR이 적용되는 서브 블록은 좌상단, 우상단, 좌하단, 우하단에 위치한 서브 블록일 수 있다. DMVR이 적용되지 않은 서브 블록에 대한 움직임 정보는 DMVR이 적용된 블록의 주변 블록들의 보정된 움직임 정보를 이용하여 획득될 수 있다. Whether or not to perform each step of DMVR described with reference to FIG. 27 may be determined depending on the number of allowable parallel processes of the video signal processing device. This is because the number of resources (eg, processes and threads) that can be processed in parallel for each video signal processing device is limited. Accordingly, whether or not DMVR is performed step by step may vary under limited processing resources, and DMVR may be selectively applied to each block. For example, if the number of resources that can be processed is equal to or smaller than an arbitrary value, some of each step of the DMVR described with reference to FIG. 27 may be omitted or steps after a specific step may be omitted. Additionally, DMVR can be applied only to subblocks at specific locations among subblocks. The specific location may be an odd or even block among the divided sub-blocks. Alternatively, as shown in FIG. 37, the subblocks to which DMVR is applied may be subblocks located at the top left, top right, bottom left, and bottom right. Motion information for a sub-block to which DMVR is not applied can be obtained using corrected motion information of neighboring blocks of a block to which DMVR is applied.
병렬적으로 처리 가능한 자원의 개수에 따라 분할되는 서브 블록의 크기가 결정될 수 있다. 분할되는 서브 블록의 개수가 많을수록, 비디오 신호 처리 장치의 처리 속도는 느려질 수 있다. 병렬적으로 처리 가능한 자원의 개수와 서브 블록의 크기는 반비례할 수 있다. 예를 들어 병렬적으로 처리 가능한 자원의 개수가 많을수록 분할되는 서브 블록의 크기는 작아질 수 있다. 즉, 병렬적으로 처리 가능한 자원의 개수가 많을수록 분할되는 서브 블록의 개수는 많아질 수 있다. 반대로, 병렬적으로 처리 가능한 자원의 개수가 작을수록 분할되는 서브 블록의 크기는 커질 수 있다. 또한, 병렬적으로 처리 가능한 자원의 개수가 많고 적고는 임의의 값보다 큰지 작은지 여부로 결정될 수 있고, 임의의 값에 따라 결정되는 자원의 개수에 따라 서브 블록의 크기도 결정될 수 있다. 또한 서브 블록의 크기는 병렬적으로 처리 가능한 자원의 개수뿐 아니라 현재 블록의 양자화 파라미터 정보, 현재 블록의 크기 또는 현재 블록의 컬러 성분(휘도 또는 색차 성분), 현재 블록의 움직임 해상도 정보, 현재 블록의 주변 블록의 잔차 신호의 존재 여부와 관련된 정보들 중 적어도 어느 하나에 기초하여 결정될 수 있다. 이때, 서브 블록의 크기, 분할되는 서브 블록의 개수는 별도로 시그널링될 수 있다. 예를 들어, 디코더는 비트스트림에 포함된 신택스 요소를 파싱하여 서브 블록의 크기, 분할되는 서브 블록의 개수를 결정할 수 있다. 이때, 신택스 요소는 SPS 레벨, PPS 레벨, 픽쳐 레벨, 또는 슬라이스 레벨, CU(Coding Unit) 레벨에서 시그널링될 수 있다.The size of the divided subblock may be determined depending on the number of resources that can be processed in parallel. The greater the number of divided sub-blocks, the slower the processing speed of the video signal processing device may be. The number of resources that can be processed in parallel and the size of the subblock may be inversely proportional. For example, the larger the number of resources that can be processed in parallel, the smaller the size of the divided subblock can be. In other words, the greater the number of resources that can be processed in parallel, the greater the number of divided sub-blocks. Conversely, the smaller the number of resources that can be processed in parallel, the larger the size of the divided subblock can be. In addition, the number of resources that can be processed in parallel can be determined by whether it is larger or smaller than an arbitrary value, and the size of the subblock can also be determined according to the number of resources determined by an arbitrary value. In addition, the size of the subblock is not only the number of resources that can be processed in parallel, but also the quantization parameter information of the current block, the size of the current block or the color component (luminance or chrominance component) of the current block, the motion resolution information of the current block, and the quantization parameter information of the current block. It may be determined based on at least one of information related to the presence or absence of a residual signal of a neighboring block. At this time, the size of the subblock and the number of divided subblocks may be signaled separately. For example, the decoder may parse syntax elements included in the bitstream to determine the size of the subblock and the number of divided subblocks. At this time, the syntax element may be signaled at the SPS level, PPS level, picture level, slice level, or CU (Coding Unit) level.
상기 다중 DMVR 과정에서 움직임 보정 과정은 현재 블록의 휘도 성분에 대해서만 수행되고, 색차 성분에는 수행되지 않을 수 있다. 이때, 다중 DMVR을 통해 획득되는 현재 블록의 휘도 성분에 대한 보정된 움직임 정보는 현재 블록의 색차 성분에 사용될 수 있다.In the multi-DMVR process, the motion compensation process may be performed only on the luminance component of the current block and not on the chrominance component. At this time, the corrected motion information for the luminance component of the current block obtained through multiple DMVR can be used for the chrominance component of the current block.
도 38은 본 발명의 일 실시예에 따른 다중 DMVR을 수행하면서 현재 블록에 대한 예측 블록을 생성하는 방법을 나타내는 도면이다.Figure 38 is a diagram showing a method of generating a prediction block for a current block while performing multiple DMVR according to an embodiment of the present invention.
DMVR 방법은 보다 더 정확한 움직임 정보를 찾기 위한 방법으로써, 디코더는 최종적으로 보정된 움직임 정보를 사용하여 하나의 예측 블록을 생성할 수 있다. DMVR은 이미 복원된 참조 영상들의 상관성을 통해 움직임 정보를 보정하는 방법이므로, 실제 원본 영상에서 찾은 움직임 정보에 비해 정확도가 낮을 수 있다. 이러한 낮은 정확도를 보완해주기 위해서, 도 38을 참조하면 디코더는 DMVR을 수행하는 과정에서 획득되는 각 단계별 움직임 정보들을 선택적으로 활용하여 여러 개의 예측 블록들을 생성할 수 있다. 디코더는 예측 블록들 간의 가중치 평균을 통해 최종적으로 현재 블록에 대한 예측 블록을 생성할 수 있다. 컨트롤러에서는 각 단계별로 생성된 예측 블록들의 사용 여부를 결정할 수 있으며, 가중치 평균 단계에서 각 예측 블록들의 가중치를 설정할 수 있다. 각 단계별 예측 블록들의 사용 여부는 예측 블록을 생성할 때 이미 구해진 화소(픽셀) 기반 코스트 값에 기초하여 결정될 수 있다. 또한 코스트 값을 임의의 값과 비교한 결과에 따라 사용되는 예측 블록의 수가 결정될 수 있다. 예를 들어, 코스트 값이 임의의 값보다 작다면 기 설정된 X개의 예측 블록이 사용될 수 있고, 임의의 값보다 크다면 기 설정된 Y개의 예측 블록이 사용될 수 있다. 이때, X, Y는 같거나 다른 정수 값일 수 있다. 컨트롤러는 DMVR의 각 단계별 수행 여부도 결정할 수 있다. DMVR의 각 단계별 수행 여부는 현재 블록의 양자화 파라미터, 현재 블록의 크기 현재 블록의 컬러 성분(휘도 성분인지 색차 성분인지) 현재 블록의 움직임 해상도 정보, 현재 블록의 주변 블록의 잔차 신호의 존재 여부와 관련된 정보들 중 적어도 어느 하나에 기초하여 결정될 수 있다.The DMVR method is a method for finding more accurate motion information, and the decoder can ultimately generate one prediction block using the corrected motion information. Since DMVR is a method of correcting motion information through correlation between already restored reference images, accuracy may be lower than that of motion information found in the actual original image. In order to compensate for this low accuracy, referring to FIG. 38, the decoder can generate multiple prediction blocks by selectively using motion information at each stage obtained in the process of performing DMVR. The decoder can finally generate a prediction block for the current block through weighted average between prediction blocks. The controller can decide whether to use prediction blocks generated at each stage, and can set the weight of each prediction block at the weight average stage. Whether or not to use prediction blocks at each stage can be determined based on the pixel-based cost value already obtained when generating the prediction block. Additionally, the number of prediction blocks used may be determined according to the result of comparing the cost value with a random value. For example, if the cost value is less than a random value, X preset prediction blocks can be used, and if the cost value is greater than a random value, Y preset prediction blocks can be used. At this time, X and Y may be the same or different integer values. The controller can also decide whether to perform each step of DMVR. Whether or not each step of DMVR is performed is related to the quantization parameters of the current block, the size of the current block, the color component of the current block (whether it is a luminance component or a chrominance component), the motion of the current block, resolution information, and the presence or absence of residual signals in blocks surrounding the current block. It may be determined based on at least one of the information.
도 39는 본 발명의 일 실시예에 따른 현재 블록을 예측하는 방법을 나타내는 순서도이다.Figure 39 is a flowchart showing a method for predicting a current block according to an embodiment of the present invention.
도 39는 도1 내지 도 38을 통해 설명한 코스트 값에 기초하여 현재 블록을 예측하는 방법을 나타낸다.FIG. 39 shows a method of predicting the current block based on the cost values described with reference to FIGS. 1 to 38.
도 39를 참조하면 디코더는 현재 블록과 관련된 하나 이상의 제1 움직임 정보들을 포함하는 제1 움직임 정보 리스트를 획득할 수 있다(S3910). 디코더는 상기 하나 이상의 제1 움직임 정보들을 보정하여 하나 이상의 제1 보정된 움직임 정보들을 획득할 수 있다(S3920). 디코더는 상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대한 하나 이상의 제1 코스트 값들을 획득할 수 있다(S3930). 디코더는 상기 하나 이상의 제1 보정된 움직임 정보들을 상기 제1 코스트 값들에 기초하여 재정렬하여 제2 움직임 정보 리스트를 획득할 수 있다(S3940). 디코더는 상기 제2 움직임 정보 리스트에 포함되는 제1 움직임 정보에 기초하여 하나 이상의 제2 움직임 정보들을 획득할 수 있다(S3950). 디코더는 상기 하나 이상의 제2 움직임 정보들을 보정하여 하나 이상의 제2 보정된 움직임 정보들을 획득할 수 있다(S3960). 디코더는 상기 제2 보정된 움직임 정보들 각각에 대한 하나 이상의 제2 코스트 값들을 획득할 수 있다(S3970). 디코더는 상기 제2 코스트 값들에 기초하여 결정되는 제2 움직임 정보에 기초하여 상기 현재 블록을 예측할 수 있다(S3980).Referring to FIG. 39, the decoder may obtain a first motion information list including one or more pieces of first motion information related to the current block (S3910). The decoder may obtain one or more pieces of first corrected motion information by correcting the one or more pieces of first motion information (S3920). The decoder may obtain one or more first cost values for each of the one or more first corrected motion information (S3930). The decoder may obtain a second motion information list by rearranging the one or more pieces of first corrected motion information based on the first cost values (S3940). The decoder may obtain one or more pieces of second motion information based on the first motion information included in the second motion information list (S3950). The decoder may obtain one or more second corrected motion information by correcting the one or more second motion information (S3960). The decoder may obtain one or more second cost values for each of the second corrected motion information (S3970). The decoder may predict the current block based on second motion information determined based on the second cost values (S3980).
이때, 상기 하나 이상의 제1 코스트 값들은 상기 현재 블록과 상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대응되는 참조 블록간의 유사도와 관련된 값일 수 있다. 상기 하나 이상의 제2 코스트 값들은 상기 현재 블록과 상기 하나 이상의 제2 보정된 움직임 정보들 각각에 대응되는 참조 블록간의 유사도와 관련된 값일 수 있다.At this time, the one or more first cost values may be values related to the similarity between the current block and the reference block corresponding to each of the one or more pieces of first corrected motion information. The one or more second cost values may be values related to the similarity between the current block and the reference block corresponding to each of the one or more pieces of second corrected motion information.
상기 제2 움직임 정보 리스트의 제1 보정된 움직임 정보들은 상기 하나 이상의 제1 보정된 움직임 정보들에 각각 대응되는 코스트 값이 오름차순이 되도록 정렬될 수 있다.The first corrected motion information in the second motion information list may be arranged in ascending order of cost values corresponding to each of the one or more pieces of first corrected motion information.
상기 제1 움직임 정보는 상기 제1 코스트 값들 중 가장 작은 코스트 값에 대응하는 보정된 움직임 정보이고, 상기 제2 움직임 정보는 상기 제2 코스트 값들 중 가장 작은 코스트 값에 대응하는 보정된 움직임 정보일 수 있다.The first motion information may be corrected motion information corresponding to the smallest cost value among the first cost values, and the second motion information may be corrected motion information corresponding to the smallest cost value among the second cost values. there is.
상기 하나 이상의 제1 움직임 정보들은 각각 서로 다른 픽쳐에 포함되고, 상기 하나 이상의 제2 움직임 정보들은 각각 서로 다른 픽쳐에 포함될 수 있다.The one or more pieces of first motion information may each be included in different pictures, and the one or more pieces of second motion information may each be included in different pictures.
상기 하나 이상의 제1 보정된 움직임 정보들 및 상기 하나 이상의 제2 보정된 움직임 정보들은, MVD(Motion Vector Difference), TM(Template Matching), BM(Bilateral Matching), MMVD(Merge mode with MVD), MMVD(Merge mode with MVD) 기반의 TM, 광 흐름(Optical flow)에 기초한 기반 TM, 멀티 패스 DMVR (Multi pass Decoder-side Motion Vector Refinement) 중 적어도 어느 하나 이상에 기초하여 보정될 수 있다.The one or more first corrected motion information and the one or more second corrected motion information may include Motion Vector Difference (MVD), Template Matching (TM), Bilateral Matching (BM), Merge mode with MVD (MMVD), and MMVD. It may be corrected based on at least one of (Merge mode with MVD)-based TM, optical flow-based TM, and multi-pass DMVR (Multi pass Decoder-side Motion Vector Refinement).
상기 현재 블록의 부호화 모드가 머지(merge) 모드인 경우, 상기 하나 이상의 제1 움직임 정보들 및 상기 하나 이상의 제2 움직임 정보들은 MMVD(Merge mode with MVD)에 의해 유도되는 움직임 정보일 수 있다.When the encoding mode of the current block is a merge mode, the one or more pieces of first motion information and the one or more pieces of second motion information may be motion information derived by Merge mode with MVD (MMVD).
상기 하나 이상의 제1 움직임 정보들 각각에 대응되는 블록들은 제1 탐색 영역 내에 위치하는 블록이고, 상기 하나 이상의 제2 움직임 정보들 각각에 대응되는 블록들은 제2 탐색 영역 내에 위치하는 블록이고, 상기 제1 탐색 영역과 상기 제2 탐색 영역은 서로 상이할 수 있다.Blocks corresponding to each of the one or more pieces of first motion information are blocks located in a first search area, blocks corresponding to each of the one or more pieces of second motion information are blocks located in a second search area, and the blocks corresponding to each of the one or more pieces of second motion information are blocks located in a second search area. The first search area and the second search area may be different from each other.
상기 제1 코스트 값들은 상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대해 순차적으로 계산되고, 상기 제2 코스트 값들은 상기 하나 이상의 제2 보정된 움직임 정보들 각각에 대해 순차적으로 계산될 수 있다. 이때, 상기 제1 코스트 값들이 순차적으로 계산되는 중 기 설정된 제1 값보다 작은 코스트 값이 계산되는 경우, 나머지 보정된 움직임 정보들에 대한 코스트 값들은 계산되지 않을 수 있다. 상기 제2 코스트 값들이 순차적으로 계산되는 중 기 설정된 제2 값보다 작은 코스트 값이 계산되는 경우, 나머지 보정된 움직임 정보들에 대한 코스트 값들은 계산되지 않을 수 있다.The first cost values may be sequentially calculated for each of the one or more pieces of first corrected motion information, and the second cost values may be sequentially calculated for each of the one or more pieces of second corrected motion information. At this time, if a cost value smaller than the preset first value is calculated while the first cost values are sequentially calculated, cost values for the remaining corrected motion information may not be calculated. If a cost value smaller than the preset second value is calculated while the second cost values are sequentially calculated, cost values for the remaining corrected motion information may not be calculated.
본 명세서에서 상술한 방법들은 디코더 또는 인코더의 프로세서를 통해 수행될 수 있다. 또한, 인코더는 상술한 방법들에 의해 디코딩되는 비트스트림을 생성할 수 있다. 또한, 인코더가 생성한 비트스트림은 컴퓨터 판독 가능한 비 일시적 저장 매체(기록 매체)에 저장될 수 있다.The methods described above in this specification may be performed through a processor of a decoder or encoder. Additionally, the encoder can generate a bitstream that is decoded by the methods described above. Additionally, the bitstream generated by the encoder may be stored in a computer-readable non-transitory storage medium (recording medium).
본 명세서는 주로 디코더 관점에서 기술되었으나 인코더에서도 동일하게 동작될 수 있다. 본 명세서의 파싱이라는 용어는 비트스트림으로부터 정보를 획득하는 과정을 중점으로하여 설명되었으나 인코더 측면에서는 비트스트림에 해당 정보를 구성하는 것으로 해석될 수 있다. 따라서 파싱이라는 용어는 디코더 동작으로만 한정되지 않고 인코더에서는 비트스트림을 구성하는 행위로까지 해석될 수 있다. 또한, 이러한 비트스트림은 컴퓨터 판독 가능한 기록 매체에 저장되어 구성될 수 있다.Although this specification is mainly described from the perspective of a decoder, it can be operated equally in an encoder. The term parsing in this specification has been described with a focus on the process of obtaining information from the bitstream, but from the encoder perspective, it can be interpreted as configuring the information in the bitstream. Therefore, the term parsing is not limited to the decoder operation, but can also be interpreted as the act of constructing a bitstream in the encoder. Additionally, this bitstream may be stored and configured in a computer-readable recording medium.
상술한 본 발명의 실시예들은 다양한 수단을 통해 구현될 수 있다. 예를 들어, 본 발명의 실시예들은 하드웨어, 펌웨어(firmware), 소프트웨어 또는 그것들의 결합 등에 의해 구현될 수 있다.Embodiments of the present invention described above can be implemented through various means. For example, embodiments of the present invention may be implemented by hardware, firmware, software, or a combination thereof.
하드웨어에 의한 구현의 경우, 본 발명의 실시예들에 따른 방법은 하나 또는 그 이상의 ASICs(Application Specific Integrated Circuits), DSPs(Digital Signal Processors), DSPDs(Digital Signal Processing Devices), PLDs(Programmable Logic Devices), FPGAs(Field Programmable Gate Arrays), 프로세서, 컨트롤러, 마이크로 컨트롤러, 마이크로 프로세서 등에 의해 구현될 수 있다.In the case of hardware implementation, the method according to embodiments of the present invention uses one or more Application Specific Integrated Circuits (ASICs), Digital Signal Processors (DSPs), Digital Signal Processing Devices (DSPDs), and Programmable Logic Devices (PLDs). , can be implemented by FPGAs (Field Programmable Gate Arrays), processors, controllers, microcontrollers, microprocessors, etc.
펌웨어나 소프트웨어에 의한 구현의 경우, 본 발명의 실시예들에 따른 방법은 이상에서 설명된 기능 또는 동작들을 수행하는 모듈, 절차 또는 함수 등의 형태로 구현될 수 있다. 소프트웨어 코드는 메모리에 저장되어 프로세서에 의해 구동될 수 있다. 상기 메모리는 프로세서의 내부 또는 외부에 위치할 수 있으며, 이미 공지된 다양한 수단에 의해 프로세서와 데이터를 주고받을 수 있다.In the case of implementation by firmware or software, the method according to embodiments of the present invention may be implemented in the form of a module, procedure, or function that performs the functions or operations described above. Software code can be stored in memory and run by a processor. The memory may be located inside or outside the processor, and may exchange data with the processor through various known means.
일부 실시예는 컴퓨터에 의해 실행되는 프로그램 모듈과 같은 컴퓨터에 의해 실행가능한 명령어를 포함하는 기록 매체의 형태로도 구현될 수 있다. 컴퓨터 판독 가능 매체는 컴퓨터에 의해 액세스될 수 있는 임의의 가용 매체일 수 있고, 휘발성 및 비휘발성 매체, 분리형 및 비분리형 매체를 모두 포함한다. 또한, 컴퓨터 판독 가능 매체는 컴퓨터 저장 매체 및 통신 매체를 모두 포함할 수 있다. 컴퓨터 저장 매체는 컴퓨터 판독가능 명령어, 데이터 구조, 프로그램 모듈 또는 기타 데이터와 같은 정보의 저장을 위한 임의의 방법 또는 기술로 구현된 휘발성 및 비휘발성, 분리형 및 비분리형 매체를 모두 포함한다. 통신 매체는 전형적으로 컴퓨터 판독가능 명령어, 데이터 구조 또는 프로그램 모듈과 같은 변조된 데이터 신호의 기타 데이터, 또는 기타 전송 메커니즘을 포함하며, 임의의 정보 전달 매체를 포함한다.Some embodiments may also be implemented in the form of a recording medium containing instructions executable by a computer, such as program modules executed by a computer. Computer-readable media can be any available media that can be accessed by a computer and includes both volatile and non-volatile media, removable and non-removable media. Additionally, computer-readable media may include both computer storage media and communication media. Computer storage media includes both volatile and non-volatile, removable and non-removable media implemented in any method or technology for storage of information such as computer-readable instructions, data structures, program modules or other data. Communication media typically includes computer readable instructions, data structures or other data of modulated data signals such as program modules, or other transmission mechanisms, and includes any information delivery medium.
전술한 본 발명의 설명은 예시를 위한 것이며, 본 발명이 속하는 기술분야의 통상의 지식을 가진 자는 본 발명의 기술적 사상이나 필수적인 특징을 변경하지 않고서 다른 구체적인 형태로 쉽게 변형이 가능하다는 것을 이해할 수 있을 것이다. 그러므로 이상에서 기술한 실시예들은 모든 면에서 예시적인 것이며 한정적인 것이 아는 것으로 해석해야 한다. 예를 들어, 단일형으로 설명되어 있는 각 구성 요소는 분산되어 실시될 수도 있으며, 마찬가지로 분산된 것으로 설명되어 있는 구성 요소들도 결합된 형태로 실시될 수 있다.The description of the present invention described above is for illustrative purposes, and those skilled in the art will understand that the present invention can be easily modified into other specific forms without changing the technical idea or essential features of the present invention. will be. Therefore, the embodiments described above are illustrative in all respects and should be interpreted as limited. For example, each component described as single may be implemented in a distributed manner, and similarly, components described as distributed may also be implemented in a combined form.
본 발명의 범위는 상기 상세한 설명보다는 후술하는 특허청구범위에 의하여 나타내어지며, 특허청구범위의 의미 및 범위 그리고 그 균등 개념으로부터 도출되는 모든 변경 또는 변형된 형태가 본 발명의 범위에 포함되는 것으로 해석되어야 한다.The scope of the present invention is indicated by the claims described below rather than the detailed description above, and all changes or modified forms derived from the meaning and scope of the claims and their equivalent concepts should be construed as being included in the scope of the present invention. do.
Claims (20)
프로세서를 포함하며,
상기 프로세서는,
현재 블록과 관련된 하나 이상의 제1 움직임 정보들을 포함하는 제1 움직임 정보 리스트를 획득하고,
상기 하나 이상의 제1 움직임 정보들을 보정하여 하나 이상의 제1 보정된 움직임 정보들을 획득하고,
상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대한 하나 이상의 제1 코스트 값들을 획득하고,
상기 하나 이상의 제1 보정된 움직임 정보들을 상기 제1 코스트 값들에 기초하여 재정렬하여 제2 움직임 정보 리스트를 획득하고,
상기 제2 움직임 정보 리스트에 포함되는 제1 움직임 정보에 기초하여 하나 이상의 제2 움직임 정보들을 획득하고,
상기 하나 이상의 제2 움직임 정보들을 보정하여 하나 이상의 제2 보정된 움직임 정보들을 획득하고,
상기 제2 보정된 움직임 정보들 각각에 대한 하나 이상의 제2 코스트 값들을 획득하고,
상기 제2 코스트 값들에 기초하여 결정되는 제2 움직임 정보에 기초하여 상기 현재 블록을 예측하는 것을 특징으로 하는 비디오 신호 디코딩 장치.In the video signal decoding device,
Contains a processor,
The processor,
Obtain a first motion information list including one or more pieces of first motion information related to the current block,
Correcting the one or more first motion information to obtain one or more first corrected motion information,
Obtaining one or more first cost values for each of the one or more first corrected motion information,
Obtain a second motion information list by rearranging the one or more pieces of first corrected motion information based on the first cost values,
Obtaining one or more pieces of second motion information based on first motion information included in the second motion information list,
Correcting the one or more second motion information to obtain one or more second corrected motion information,
Obtain one or more second cost values for each of the second corrected motion information,
A video signal decoding device, characterized in that predicting the current block based on second motion information determined based on the second cost values.
상기 하나 이상의 제1 코스트 값들은 상기 현재 블록과 상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대응되는 참조 블록간의 유사도와 관련된 값이고,
상기 하나 이상의 제2 코스트 값들은 상기 현재 블록과 상기 하나 이상의 제2 보정된 움직임 정보들 각각에 대응되는 참조 블록간의 유사도와 관련된 값인 것을 특징으로 하는 비디오 신호 디코딩 장치.According to clause 1,
The one or more first cost values are values related to the similarity between the current block and the reference block corresponding to each of the one or more first corrected motion information,
The one or more second cost values are values related to the similarity between the current block and the reference block corresponding to each of the one or more second corrected motion information.
상기 제2 움직임 정보 리스트는 상기 하나 이상의 제1 보정된 움직임 정보들에 각각 대응되는 코스트 값이 오름차순으로 정렬되는 것을 특징으로 하는 비디오 신호 디코딩 장치.According to clause 1,
The second motion information list is arranged in ascending order of cost values corresponding to each of the one or more pieces of first corrected motion information.
상기 제1 움직임 정보는 상기 제1 코스트 값들 중 가장 작은 코스트 값에 대응하는 보정된 움직임 정보인 것을 특징으로 하는 비디오 신호 디코딩 장치.According to clause 1,
A video signal decoding device, characterized in that the first motion information is corrected motion information corresponding to the smallest cost value among the first cost values.
상기 제2 움직임 정보는 상기 제2 코스트 값들 중 가장 작은 코스트 값에 대응하는 보정된 움직임 정보인 것을 특징으로 하는 비디오 신호 디코딩 장치.According to clause 1,
A video signal decoding device, characterized in that the second motion information is corrected motion information corresponding to the smallest cost value among the second cost values.
상기 하나 이상의 제1 움직임 정보들은 각각 서로 다른 픽쳐에 포함되고,
상기 하나 이상의 제2 움직임 정보들은 각각 서로 다른 픽쳐에 포함되는 것을 특징으로 하는 비디오 신호 디코딩 장치.According to clause 1,
The one or more pieces of first motion information are each included in different pictures,
A video signal decoding device, wherein the one or more pieces of second motion information are included in different pictures.
상기 하나 이상의 제1 보정된 움직임 정보들 및 상기 하나 이상의 제2 보정된 움직임 정보들은,
MVD(Motion Vector Difference), TM(Template Matching), BM(Bilateral Matching), MMVD(Merge mode with MVD), MMVD(Merge mode with MVD) 기반의 TM, 광 흐름(Optical flow)에 기초한 기반 TM, 멀티 패스 DMVR (Multi pass Decoder-side Motion Vector Refinement) 중 적어도 어느 하나 이상에 기초하여 보정되는 것을 특징으로 하는 비디오 신호 디코딩 장치. According to clause 1,
The one or more first corrected motion information and the one or more second corrected motion information include:
MVD (Motion Vector Difference), TM (Template Matching), BM (Bilateral Matching), MMVD (Merge mode with MVD), MMVD (Merge mode with MVD)-based TM, optical flow-based TM, multi A video signal decoding device characterized in that correction is made based on at least one of multi-pass decoder-side motion vector refinement (DMVR).
상기 현재 블록의 부호화 모드가 머지(merge) 모드인 경우,
상기 하나 이상의 제1 움직임 정보들 및 상기 하나 이상의 제2 움직임 정보들은 MMVD(Merge mode with MVD)에 의해 유도되는 움직임 정보인 것을 특징으로 하는 비디오 신호 디코딩 장치.According to clause 1,
If the encoding mode of the current block is merge mode,
A video signal decoding device, characterized in that the one or more first motion information and the one or more second motion information are motion information derived by MMVD (Merge mode with MVD).
상기 하나 이상의 제1 움직임 정보들 각각에 대응되는 블록들은 제1 탐색 영역 내에 위치하는 블록이고,
상기 하나 이상의 제2 움직임 정보들 각각에 대응되는 블록들은 제2 탐색 영역 내에 위치하는 블록이고,
상기 제1 탐색 영역과 상기 제2 탐색 영역은 서로 상이한 것을 특징으로 하는 비디오 신호 디코딩 장치.According to clause 1,
Blocks corresponding to each of the one or more pieces of first motion information are blocks located within a first search area,
Blocks corresponding to each of the one or more pieces of second motion information are blocks located in a second search area,
A video signal decoding device, wherein the first search area and the second search area are different from each other.
상기 제1 코스트 값들은 상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대해 순차적으로 계산되고,
상기 제2 코스트 값들은 상기 하나 이상의 제2 보정된 움직임 정보들 각각에 대해 순차적으로 계산되는 것을 특징으로 하는 비디오 신호 디코딩 장치.According to clause 1,
The first cost values are sequentially calculated for each of the one or more first corrected motion information,
The second cost values are sequentially calculated for each of the one or more pieces of second corrected motion information.
상기 제1 코스트 값들이 순차적으로 계산되는 중 기 설정된 제1 값보다 작은 코스트 값이 계산되는 경우, 나머지 보정된 움직임 정보들에 대한 코스트 값들은 계산되지 않고,
상기 제2 코스트 값들이 순차적으로 계산되는 중 기 설정된 제2 값보다 작은 코스트 값이 계산되는 경우, 나머지 보정된 움직임 정보들에 대한 코스트 값들은 계산되지 않는 것을 특징으로 하는 비디오 신호 디코딩 장치.According to clause 10,
When the first cost values are sequentially calculated and a cost value smaller than the preset first value is calculated, cost values for the remaining corrected motion information are not calculated,
A video signal decoding device, wherein when a cost value smaller than a preset second value is calculated while the second cost values are sequentially calculated, cost values for the remaining corrected motion information are not calculated.
프로세서를 포함하며,
상기 프로세서는,
디코딩 방법에 의해 디코딩되는 비트스트림을 획득하고,
상기 디코딩 방법은,
현재 블록과 관련된 하나 이상의 제1 움직임 정보들을 포함하는 제1 움직임 정보 리스트를 획득하는 단계;
상기 하나 이상의 제1 움직임 정보들을 보정하여 하나 이상의 제1 보정된 움직임 정보들을 획득하는 단계;
상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대한 하나 이상의 제1 코스트 값들을 획득하는 단계;
상기 하나 이상의 제1 보정된 움직임 정보들을 상기 제1 코스트 값들에 기초하여 재정렬하여 제2 움직임 정보 리스트를 획득하는 단계;
상기 제2 움직임 정보 리스트에 포함되는 제1 움직임 정보에 기초하여 하나 이상의 제2 움직임 정보들을 획득하는 단계;
상기 하나 이상의 제2 움직임 정보들을 보정하여 하나 이상의 제2 보정된 움직임 정보들을 획득하는 단계;
상기 제2 보정된 움직임 정보들 각각에 대한 하나 이상의 제2 코스트 값들을 획득하는 단계; 및
상기 제2 코스트 값들에 기초하여 결정되는 제2 움직임 정보에 기초하여 상기 현재 블록을 예측하는 단계를 포함하는 것을 특징으로 하는 비디오 신호 인코딩 장치.In the video signal encoding device,
Contains a processor,
The processor,
Obtaining a bitstream decoded by a decoding method,
The decoding method is,
Obtaining a first motion information list including one or more pieces of first motion information related to the current block;
Correcting the one or more pieces of first motion information to obtain one or more pieces of first corrected motion information;
Obtaining one or more first cost values for each of the one or more pieces of first corrected motion information;
Obtaining a second motion information list by rearranging the one or more pieces of first corrected motion information based on the first cost values;
Obtaining one or more pieces of second motion information based on first motion information included in the second motion information list;
Correcting the one or more pieces of second motion information to obtain one or more pieces of second corrected motion information;
Obtaining one or more second cost values for each of the second corrected motion information; and
A video signal encoding device comprising predicting the current block based on second motion information determined based on the second cost values.
상기 제2 움직임 정보 리스트는 상기 하나 이상의 제1 보정된 움직임 정보들에 각각 대응되는 코스트 값이 오름차순으로 정렬되는 것을 특징으로 하는 비디오 신호 인코딩 장치.According to clause 12,
The second motion information list is arranged in ascending order of cost values corresponding to each of the one or more pieces of first corrected motion information.
상기 제1 움직임 정보는 상기 제1 코스트 값들 중 가장 작은 코스트 값에 대응하는 보정된 움직임 정보인 것을 특징으로 하는 비디오 신호 인코딩 장치. According to clause 12,
A video signal encoding device, wherein the first motion information is corrected motion information corresponding to the smallest cost value among the first cost values.
상기 제2 움직임 정보는 상기 제2 코스트 값들 중 가장 작은 코스트 값에 대응하는 보정된 움직임 정보인 것을 특징으로 하는 비디오 신호 인코딩 장치.According to clause 12,
The second motion information is corrected motion information corresponding to the smallest cost value among the second cost values.
상기 하나 이상의 제1 움직임 정보들은 각각 서로 다른 픽쳐에 포함되고,
상기 하나 이상의 제2 움직임 정보들은 각각 서로 다른 픽쳐에 포함되는 것을 특징으로 하는 비디오 신호 인코딩 장치.According to clause 12,
The one or more pieces of first motion information are each included in different pictures,
A video signal encoding device, wherein the one or more pieces of second motion information are each included in different pictures.
상기 현재 블록의 부호화 모드가 머지(merge) 모드인 경우,
상기 하나 이상의 제1 움직임 정보들 및 상기 하나 이상의 제2 움직임 정보는 MMVD(Merge mode with MVD)에 의해 유도되는 움직임 정보인 것을 특징으로 하는 비디오 신호 인코딩 장치.According to clause 12,
If the encoding mode of the current block is merge mode,
A video signal encoding device, characterized in that the one or more first motion information and the one or more second motion information are motion information derived by MMVD (Merge mode with MVD).
상기 제1 코스트 값들은 상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대해 순차적으로 계산되고,
상기 제2 코스트 값들은 상기 하나 이상의 제2 보정된 움직임 정보들 각각에 대해 순차적으로 계산되는 것을 특징으로 하는 비디오 신호 인코딩 장치.According to clause 12,
The first cost values are sequentially calculated for each of the one or more first corrected motion information,
The second cost values are sequentially calculated for each of the one or more pieces of second corrected motion information.
상기 제1 코스트 값들이 순차적으로 계산되는 중 기 설정된 제1 값보다 작은 코스트 값이 계산되는 경우, 나머지 보정된 움직임 정보들에 대한 코스트 값들은 계산되지 않고,
상기 제2 코스트 값들이 순차적으로 계산되는 중 기 설정된 제2 값보다 작은 코스트 값이 계산되는 경우, 나머지 보정된 움직임 정보들에 대한 코스트 값들은 계산되지 않는 것을 특징으로 하는 비디오 신호 인코딩 장치.According to clause 12,
When the first cost values are sequentially calculated and a cost value smaller than the preset first value is calculated, cost values for the remaining corrected motion information are not calculated,
A video signal encoding device, wherein when a cost value smaller than a preset second value is calculated while the second cost values are sequentially calculated, cost values for the remaining corrected motion information are not calculated.
상기 디코딩 방법은,
현재 블록과 관련된 하나 이상의 제1 움직임 정보들을 포함하는 제1 움직임 정보 리스트를 획득하는 단계;
상기 하나 이상의 제1 움직임 정보들을 보정하여 하나 이상의 제1 보정된 움직임 정보들을 획득하는 단계;
상기 하나 이상의 제1 보정된 움직임 정보들 각각에 대한 하나 이상의 제1 코스트 값들을 획득하는 단계;
상기 하나 이상의 제1 보정된 움직임 정보들을 상기 제1 코스트 값들에 기초하여 재정렬하여 제2 움직임 정보 리스트를 획득하는 단계;
상기 제2 움직임 정보 리스트에 포함되는 제1 움직임 정보에 기초하여 하나 이상의 제2 움직임 정보들을 획득하는 단계;
상기 하나 이상의 제2 움직임 정보들을 보정하여 하나 이상의 제2 보정된 움직임 정보들을 획득하는 단계;
상기 제2 보정된 움직임 정보들 각각에 대한 하나 이상의 제2 코스트 값들을 획득하는 단계; 및
상기 제2 코스트 값들에 기초하여 결정되는 제2 움직임 정보에 기초하여 상기 현재 블록을 예측하는 단계를 포함하는 것을 특징으로 하는 비 일시적 저장 매체.A computer-readable non-transitory storage medium storing a bitstream, wherein the bitstream is decoded by a decoding method,
The decoding method is,
Obtaining a first motion information list including one or more pieces of first motion information related to the current block;
Correcting the one or more pieces of first motion information to obtain one or more pieces of first corrected motion information;
Obtaining one or more first cost values for each of the one or more pieces of first corrected motion information;
Obtaining a second motion information list by rearranging the one or more pieces of first corrected motion information based on the first cost values;
Obtaining one or more pieces of second motion information based on first motion information included in the second motion information list;
Correcting the one or more pieces of second motion information to obtain one or more pieces of second corrected motion information;
Obtaining one or more second cost values for each of the second corrected motion information; and
A non-transitory storage medium comprising predicting the current block based on second motion information determined based on the second cost values.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR20210114039 | 2021-08-27 | ||
| KR1020210114039 | 2021-08-27 | ||
| KR20210124790 | 2021-09-17 | ||
| KR1020210124790 | 2021-09-17 | ||
| PCT/KR2022/012897 WO2023027564A1 (en) | 2021-08-27 | 2022-08-29 | Method for correcting motion information and device therefor |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20240050408A true KR20240050408A (en) | 2024-04-18 |
Family
ID=85323342
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020247010188A KR20240050408A (en) | 2021-08-27 | 2022-08-29 | Method for correcting motion information and device therefor |
Country Status (2)
| Country | Link |
|---|---|
| KR (1) | KR20240050408A (en) |
| WO (1) | WO2023027564A1 (en) |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10511835B2 (en) * | 2015-09-02 | 2019-12-17 | Mediatek Inc. | Method and apparatus of decoder side motion derivation for video coding |
| CN117528110A (en) * | 2016-11-28 | 2024-02-06 | 英迪股份有限公司 | Image encoding method, image decoding method, and method for transmitting bit stream |
| WO2019190211A1 (en) * | 2018-03-27 | 2019-10-03 | 주식회사 윌러스표준기술연구소 | Video signal processing method and device using motion compensation |
| US11146810B2 (en) * | 2018-11-27 | 2021-10-12 | Qualcomm Incorporated | Decoder-side motion vector refinement |
-
2022
- 2022-08-29 KR KR1020247010188A patent/KR20240050408A/en unknown
- 2022-08-29 WO PCT/KR2022/012897 patent/WO2023027564A1/en active Application Filing
Also Published As
| Publication number | Publication date |
|---|---|
| WO2023027564A1 (en) | 2023-03-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102643116B1 (en) | Method and apparatus for encoding/decoding image, recording medium for stroing bitstream | |
| US20240015317A1 (en) | Method for encoding/decoding image signal, and device therefor | |
| KR102678729B1 (en) | Method and apparatus for encoding/decoding image, recording medium for stroing bitstream | |
| KR102595689B1 (en) | Method and apparatus for encoding/decoding image and recording medium for storing bitstream | |
| US11825085B2 (en) | Method for encoding/decoding image signal and device therefor | |
| US20200051288A1 (en) | Image processing method, and image decoding and encoding method using same | |
| US20240179312A1 (en) | Method for encoding/decoding image signal, and device for same | |
| US12069263B2 (en) | Image signal encoding/decoding method and device for same | |
| KR20210091208A (en) | Video signal processing method and apparatus using current picture reference | |
| KR20240050409A (en) | Video signal processing method and device therefor | |
| KR20240052025A (en) | Video signal processing method using LIC (LOCAL ILLUMINATION COMPENSATION) mode and device therefor | |
| KR20240050408A (en) | Method for correcting motion information and device therefor | |
| US20240373036A1 (en) | Video signal processing method using intra prediction and device therefor | |
| KR20240087758A (en) | Video signal processing method and device for the same based on MHP (MULTI-HYPOTHESIS PREDICTION) mode | |
| KR20240118089A (en) | Video signal processing method and device therefor | |
| KR20240090216A (en) | Video signal processing method and device for determining intra prediction mode based on reference picture | |
| KR20240164524A (en) | Video signal processing method based on template matching and device therefor | |
| KR20240065097A (en) | Video signal processing method using OBMC and device therefor | |
| KR20240082214A (en) | Method and Apparatus for Video Coding Using Inter Prediction Based on Template Matching | |
| KR20240136982A (en) | Video signal processing method using out-of-boundary block and device therefor | |
| US20220038695A1 (en) | Method for encoding/decoding image signal, and device for same | |
| KR20240132290A (en) | Video signal processing method using dependent quantization and device therefor | |
| KR20240021107A (en) | Method and Apparatus for Video Coding Using Rearranging Prediction Signals in Intra Block Copy Mode | |
| KR20240080128A (en) | Method and Apparatus for Video Coding Using Motion Compensation Filter Adaptively in Affine Model Based Prediction | |
| KR20240163514A (en) | Method for Adaptive Determining Search Area for Template Matching Prediction |