KR20220117341A - 차선 검출 모델의 트레이닝 방법, 장치, 전자 기기 및 저장 매체 - Google Patents
차선 검출 모델의 트레이닝 방법, 장치, 전자 기기 및 저장 매체 Download PDFInfo
- Publication number
- KR20220117341A KR20220117341A KR1020227027156A KR20227027156A KR20220117341A KR 20220117341 A KR20220117341 A KR 20220117341A KR 1020227027156 A KR1020227027156 A KR 1020227027156A KR 20227027156 A KR20227027156 A KR 20227027156A KR 20220117341 A KR20220117341 A KR 20220117341A
- Authority
- KR
- South Korea
- Prior art keywords
- lane
- target
- elements
- training
- sample road
- Prior art date
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/50—Context or environment of the image
- G06V20/56—Context or environment of the image exterior to a vehicle by using sensors mounted on the vehicle
- G06V20/588—Recognition of the road, e.g. of lane markings; Recognition of the vehicle driving pattern in relation to the road
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G06N3/0454—
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/26—Segmentation of patterns in the image field; Cutting or merging of image elements to establish the pattern region, e.g. clustering-based techniques; Detection of occlusion
- G06V10/267—Segmentation of patterns in the image field; Cutting or merging of image elements to establish the pattern region, e.g. clustering-based techniques; Detection of occlusion by performing operations on regions, e.g. growing, shrinking or watersheds
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/70—Labelling scene content, e.g. deriving syntactic or semantic representations
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Databases & Information Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Data Mining & Analysis (AREA)
- Molecular Biology (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Image Analysis (AREA)
Abstract
본 발명은 차선 검출 모델의 트레이닝 방법, 장치, 전자 기기 및 저장 매체를 제공하며, 인공지능 기술분야, 구체적으로 컴퓨터 비전, 딥러닝 등 기술분야에 관한 것이고, 스마트 교통 시나리오에 적용될 수 있다. 구체적인 구현 수단은 복수의 샘플 도로 상황 이미지 및 상기 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득하는 단계; 상기 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 상기 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정하는 단계; 및 상기 복수의 샘플 도로 상황 이미지, 상기 복수의 요소, 상기 복수의 요소 어의 및 상기 복수의 표기된 차선 정보에 따라 초기 인공지능 모델을 트레이닝하여, 차선 검출 모델을 획득하는 단계;를 포함한다. 이에 따라, 도로 상황 이미지에서 차선 검출 인식의 연산 복잡도를 효과적으로 낮추고, 차선 검출 인식 효율을 향상시키고, 차선 검출 인식 효과를 향상시킬 수 있다.
Description
본 발명은 2021년 4월 28일 제출한 중국 특허 출원 번호가 "202110470476.1"인 우선권을 주장하고, 당해 중국 특허 출원의 전문을 참조로 인용한다.
본 발명은 인공지능 기술 분야에 관한 것으로, 구체적으로 컴퓨터 비전, 딥러닝 등 기술분야에 관한 것이고, 스마트 교통 시나리오에 적용될 수 있으며, 특히 차선 검출 모델의 트레이닝 방법, 장치, 전자 기기 및 저장 매체에 관한 것이다.
인공지능은 인간의 특정 사유 과정 및 지능 행위(예컨대, 러닝, 추리, 사고, 계획 등)를 컴퓨터로 시뮬레이션하기 위해 연구하는 학과이며, 하드웨어 층면의 기술 뿐만 아니라 소프트웨어 층면의 기술도 포함한다. 인공지능 하드웨어 기술은 일반적으로 센서, 전용 인공지능 칩, 클라우드 컴퓨팅, 분산 스토리지, 빅데이터 처리 등과 같은 기술을 포함하고; 인공지능 소프트웨어 기술은 주로 컴퓨터 비전 기술, 음성 인식 기술, 자연 언어 처리 기술 및 기계 러닝/딥러닝, 빅데이터 처리 기술, 지식 그래프 기술 등 몇 가지 주요 방향을 포함한다.
관련 기술에서, 도로 상황 이미지의 요소에 대한 의미론적 분할 방법 로직은 차선에 대한 검출 분할에 직접 적용할 수 없으며 차선 검출 분할의 연산 복잡도가 높고, 실시간 요구를 충족할 수 없다.
차선 검출 모델의 트레이닝 방법, 장치, 전자 기기, 저장 매체 및 컴퓨터 프로그램 제품을 제공한다.
제1 측면에 따르면, 차선 검출 모델의 트레이닝 방법을 제공하며, 복수의 샘플 도로 상황 이미지 및 상기 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득하는 단계; 상기 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 상기 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정하는 단계; 및 상기 복수의 샘플 도로 상황 이미지, 상기 복수의 요소, 상기 복수의 요소 어의 및 상기 복수의 표기된 차선 정보에 따라 초기 인공지능 모델을 트레이닝하여, 차선 검출 모델을 획득하는 단계;를 포함한다.
제2 측면에 따르면, 차선 검출 모델의 트레이닝 장치를 제공하며, 복수의 샘플 도로 상황 이미지 및 상기 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득하는 획득 모듈; 상기 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 상기 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정하는 결정 모듈; 및 상기 복수의 샘플 도로 상황 이미지, 상기 복수의 요소, 상기 복수의 요소 어의 및 상기 복수의 표기된 차선 정보에 따라 초기 인공지능 모델을 트레이닝하여, 차선 검출 모델을 획득하는 트레이닝 모듈;을 포함한다.
제3 측면에 따르면, 전자 기기를 제공하며, 적어도 하나의 프로세서; 및 상기 적어도 하나의 프로세서와 통신 가능하게 연결되는 메모리;를 포함하고, 상기 메모리에 상기 적어도 하나의 프로세서에 의해 수행 가능한 명령이 저장되어 있고, 상기 명령이 상기 적어도 하나의 프로세서에 의해 수행될 경우, 상기 적어도 하나의 프로세서가 본 발명의 실시예의 차선 검출 모델의 트레이닝 방법을 수행한다.
제4 측면에 따르면, 컴퓨터 명령이 저장되어 있는 비일시적 컴퓨터 판독 가능 저장 매체를 제공하며, 상기 컴퓨터 명령은 컴퓨터가 본 발명의 실시예의 차선 검출 모델의 트레이닝 방법을 수행하는데 사용된다.
제5 측면에 따르면, 컴퓨터 프로그램을 포함하는 컴퓨터 프로그램 제품을 제공하며, 상기 컴퓨터 프로그램이 프로세서에 의해 수행될 경우, 본 발명의 실시예의 차선 검출 모델의 트레이닝 방법을 구현한다.
이해 가능한 바로는, 본 부분에서 설명된 내용은 본 발명의 실시예의 핵심 또는 중요한 특징을 식별하기 위한 것이 아니며, 본 발명의 범위를 한정하지도 않는다. 본 발명의 다른 특징들은 하기의 명세서에 의해 쉽게 이해될 것이다.
첨부된 도면은 본 기술 수단을 더 잘 이해하기 위한 것으로, 본 발명에 대한 한정이 구성되지 않는다.
도1은 본 발명의 제1 실시예에 따른 개략도이다.
도2는 본 발명의 제2 실시예에 따른 개략도이다.
도3은 본 발명의 제3 실시예에 따른 개략도이다.
도4는 본 발명의 제4 실시예에 따른 개략도이다.
도5는 본 발명의 실시예의 차선 검출 모델의 트레이닝 방법을 구현하기 위한 전자 기기의 블록도이다.
도1은 본 발명의 제1 실시예에 따른 개략도이다.
도2는 본 발명의 제2 실시예에 따른 개략도이다.
도3은 본 발명의 제3 실시예에 따른 개략도이다.
도4는 본 발명의 제4 실시예에 따른 개략도이다.
도5는 본 발명의 실시예의 차선 검출 모델의 트레이닝 방법을 구현하기 위한 전자 기기의 블록도이다.
이하, 첨부된 도면을 결부하여 본 발명의 예시적인 실시예에 대해 설명하며, 여기에는 이해를 돕기 위해 본 발명의 실시예의 다양한 세부 사항을 포함하므로, 이는 단지 예시적인 것으로 이해해야 한다. 따라서, 당업자는 본 발명의 범위 및 사상을 벗어나지 않는 한 여기에 설명된 실시예에 대해 다양한 변경 및 수정이 이루어질 수 있음을 인식해야 한다. 마찬가지로, 명확성과 간결성을 위해, 하기의 설명에서는 공지된 기능 및 구조에 대한 설명을 생략한다.
도1은 본 발명의 제1 실시예에 따른 개략도이다.
설명해야 하는 바로는, 본 발명의 실시예의 차선 검출 모델의 트레이닝 방법의 수행 주체는 차선 검출 모델의 트레이닝 장치이며, 당해 장치는 소프트웨어 및 하드웨어 중의 적어도 하나의 방식으로 구현될 수 있고, 당해 장치는 전자 기기에 구성될 수 있으며, 전자 기기는 단말, 서버 등을 포함하지만, 이에 제한되지 않는다.
본 발명의 실시예는 인공지능 기술분야에 관한 것으로, 구체적으로 컴퓨터 비전, 딥러닝 등 기술분야에 관한 것이고, 스마트 교통 시나리오에 적용될 수 있으며, 도로 상황 이미지에서 차선 검출 인식의 연산 복잡도를 효과적으로 낮추고, 차선 검출 인식 효율을 향상시키고, 차선 검출 인식 효과를 향상시킬 수 있다.
인공지능(Artificial Intelligence)의 영문 약자는 AI이다. 인공지능은 인간의 지능을 시뮬레이션, 연장 및 확장하기 위한 이론, 방법, 기술 및 응용 시스템을 연구하고 개발하는 하나의 새로운 기술 과학이다.
딥러닝은 샘플 데이터의 내재적 법칙 및 표현 계층을 학습하는 것이며, 이러한 학습 과정에서 획득한 정보는 문자, 이미지 및 소리 등과 같은 데이터의 해석에 대해 큰 도움이 된다. 딥러닝의 최종 목적은 기계로 하여금 인간과 같은 분석 학습 능력을 구비할 수 있고, 문자, 이미지 및 소리 등과 같은 데이터를 인식할 수 있도록 한다.
컴퓨터 비전은 사람의 눈 대신 카메라와 컴퓨터를 사용하여 타겟에 대해 인식, 추적 및 측정 등 기계 비전을 수행하고, 나아가 이미지 처리를 수행하여 컴퓨터 처리를 통해 사람의 눈으로 관찰하기 더 적합하거나 또는 기기에 전송하여 검출을 위한 이미지를 제공하는 것을 의미한다.
도1에 도시된 바와 같이, 당해 차선 검출 모델의 트레이닝 방법은 단계 S101 내지 S103을 포함한다.
S101, 복수의 샘플 도로 상황 이미지 및 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득한다.
차선 검출 모델을 트레이닝하는데 사용되는 도로 상황 이미지는 샘플 도로 상황 이미지로 불리울 수 있으며, 도로 상황 이미지는 스마트 교통 시나리오에서 환경 중의 촬영 장치가 포획한 이미지일 수 있으나, 이에 대해 한정하지 않는다.
본 발명의 실시예에서, 복수의 샘플 도로 상황 이미지는 샘플 도로 상황 이미지 풀로부터 획득될 수 있으며, 당해 복수의 샘플 도로 상황 이미지는 초기 인공지능 모델을 트레이닝하여 인체 속성 검출 모델을 획득하는데 사용될 수 있다.
전술한 복수의 샘플 도로 상황 이미지 및 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득하는 단계에서, 당해 표기된 차선 정보는 초기 인공지능 모델을 트레이닝할 때 참조 표기로 사용할 수 있다.
전술한 차선 정보는 샘플 도로 상황 이미지 중의 차선 관련 정보를 묘사하는데 사용될 수 있으며, 예를 들어 차선 유형, 차선의 이미지 영역에 대응되는 이미지 특징, 또는 차선의 유무(차선의 유무는 차선 상태로 불리울 수 있음), 또는 기타 임의의 가능한 차선 정보일 수 있으나, 이에 대해 한정하지 않는다.
즉, 본 발명의 실시예에서, 복수의 샘플 도로 상황 이미지 및 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득한 후, 복수의 샘플 도로 상황 이미지 및 복수의 표기된 차선 정보를 결합하여 초기 인공지능 모델을 트레이닝할 수 있다.
S102, 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정한다.
상기에서 복수의 샘플 도로 상황 이미지를 획득한 후, 복수의 샘플 도로 상황 이미지에 대해 이미지 인식을 각각 수행하여, 각 샘플 도로 상황 이미지에 각각 대응되는 요소 및 각 요소에 대응되는 요소 어의를 획득할 수 있다. 요소는 예를 들어 샘플 도로 상황 이미지 중의 하늘, 나무, 도로 등일 수 있으며, 요소 어의는 하늘, 나무, 도로의 요소 유형 및 요소 특징을 의미할 수 있다. 일반적으로, 요소는 이미지의 일부 픽셀을 포함하며, 포함된 픽셀의 문맥 정보를 통해 요소를 분류하여 요소 어의를 획득할 수 있으나, 이에 대해 한정하지 않는다.
상기에서 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정한 후, 샘플 도로 상황 이미지 중 대응되는 요소와 요소 어의, 및 복수의 표기된 차선 정보를 기반으로 초기 인공지능 모델을 트레이닝하여, 차선 검출 모델을 획득할 수 있다.
즉, 본 발명의 실시예에서, 차선 검출 모델을 트레이닝할 때 복수의 샘플 도로 상황 이미지에 대해 이미지 해석을 각각 수행하기 때문에, 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정한 다음, 샘플 도로 상황 이미지 중 대응되는 요소와 요소 어의, 및 복수의 표기된 차선 정보를 기반으로 초기 인공지능 모델을 트레이닝한다. 따라서, 요소의 의미론적 분할 방법 로직 및 차선의 검출 인식의 융합 응용을 구현하여, 요소 인식의 처리 로직을 기반으로 차선 인스턴스를 검출하고 인식할 수 있으므로, 도로 상황 이미지 중 차선의 앵커 박스 anchor 정보에 의존하는 것을 방지하고, 모델 연산의 복잡도를 낮추고, 검출 인식 효율을 향상시킨다.
S103, 복수의 샘플 도로 상황 이미지, 복수의 요소, 복수의 요소 어의 및 복수의 표기된 차선 정보에 따라 초기 인공지능 모델을 트레이닝하여, 차선 검출 모델을 획득한다.
초기 인공지능 모델은 예를 들어 신경망 모델, 기계 러닝 모델, 또는 그래프 신경망 모델일 수 있고, 물론, 이미지 인식 해석 태스크를 수행할 수 있는 기타 임의의 가능한 모델일 수도 있으나, 이에 대해 한정하지 않는다.
상기에서 복수의 샘플 도로 상황 이미지, 복수의 요소, 복수의 요소 어의 및 복수의 표기된 차선 정보를 획득한 후, 복수의 샘플 도로 상황 이미지, 복수의 요소, 복수의 요소 어의를 상기 신경망 모델, 또는 기계 러닝 모델, 또는 그래프 신경망 모델에 각각 대응되게 입력하여, 전술한 임의의 모델에서 출력하는 예측된 차선 정보를 획득할 수 있다. 당해 예측된 차선 정보는 전술한 임의의 모델이 모델 알고리즘 처리 로직을 기반으로 샘플 도로 상황 이미지 중의 요소 및 요소 어의를 결합하여 예측한 차선 정보일 수 있다.
일부 실시예에서, 초기 인공지능 모델을 트레이닝할 때, 복수의 샘플 도로 상황 이미지, 복수의 요소 및 복수의 요소 어의를 초기 인공지능 모델에 입력하여, 인공지능 모델에서 출력하는 복수의 예측된 차선 정보를 획득한 다음, 복수의 예측된 차선 정보 및 복수의 표기된 차선 정보에 따라 인공지능 모델의 수렴 시기를 결정할 수 있다. 즉, 복수의 예측된 차선 정보와 복수의 표기된 차선 정보 사이의 타겟 손실값이 설정 조건을 만족함에 응답하여, 트레이닝하여 획득된 인공지능 모델을 차선 검출 모델로 결정한다. 따라서, 모델의 수렴 시기를 적시에 결정할 수 있고, 트레이닝하여 획득된 차선 검출 모델이 스마트 교통 시나리오에서의 차선의 이미지 특징을 효과적으로 모델링할 수 있고, 차선 검출 모델의 차선 검출 인식 효율을 효과적으로 향상시킬 수 있으므로, 트레이닝된 차선 검출 모델로 하여금 실시간 요구가 상대적으로 높은 응용 시나리오에 효과적으로 적용될 수 있다.
상기 타겟 손실값의 수량은 하나 또는 복수일 수 있다. 예측된 차선 정보와 표기된 차선 정보 사이의 손실값은 타겟 손실값으로 불리울 수 있다.
다른 일부 실시예에서, 초기 인공지능 모델의 수렴 시기를 결정하도록 기타 임의의 가능한 방식을 사용할 수 있고, 인공지능 모델이 일정한 수렴 조건을 만족할 때까지 트레이닝된 인공지능 모델을 차선 검출 모델로 결정한다.
본 발명의 실시예에서, 복수의 샘플 도로 상황 이미지 및 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득하고, 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정하고, 복수의 샘플 도로 상황 이미지, 복수의 요소, 복수의 요소 어의 및 복수의 표기된 차선 정보에 따라 초기 인공지능 모델을 트레이닝하여, 차선 검출 모델을 획득한다. 따라서, 도로 상황 이미지에서 차선 검출 인식의 연산 복잡도를 효과적으로 낮추고, 차선 검출 인식 효율을 향상시키고, 차선 검출 인식 효과를 향상시킬 수 있다.
도2는 본 발명의 제2 실시예에 따른 개략도이다.
도2에 도시된 바와 같이, 당해 차선 검출 모델의 트레이닝 방법은 단계 S201 내지 S209를 포함한다.
S201, 복수의 샘플 도로 상황 이미지 및 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득한다.
S202, 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정한다.
S201-S202의 설명은 구체적으로 상기 실시예를 참조할 수 있으나, 여기서 반복하지 않는다.
S203, 복수의 샘플 도로 상황 이미지, 복수의 요소 및 복수의 요소 어의를 요소 검출 서브모델에 입력하여, 요소 검출 서브모델에서 출력하는 타겟 요소를 획득한다.
본 발명의 실시예에서, 초기 인공지능 모델은 순차적으로 연결된 요소 검출 서브모델 및 차선 검출 서브모델을 포함할 수 있으며, 초기 인공지능 모델을 트레이닝할 때, 복수의 샘플 도로 상황 이미지, 복수의 요소 및 복수의 요소 어의를 요소 검출 서브모델에 입력하여, 요소 검출 서브모델에서 출력하는 타겟 요소를 획득할 수 있다. 당해 타겟 요소는 차선 인스턴스의 검출 인식을 보조할 수 있다.
상기 요소 검출 서브모델은 이미지 특징 추출을 수행하는데 사용될 수 있고, 차선 인스턴스 분할의 예비 트레이닝 모델로 간주할 수 있다. 상기에서 획득한 복수의 샘플 도로 상황 이미지가 시티 경관 Cityscapes 데이터 세트를 구성한 상황에서, 요소 검출 서브모델의 백본 네트워크 backbone을 트레이닝하여, Cityscapes 데이터 세트 중 각 샘플 도로 상황 이미지 특징 추출에 사용되어, 각 샘플 도로 상황 이미지에서 요소 및 대응되는 요소 어의를 인식할 수 있다.
상기 요소 검출 서브모델은 구체적으로 비전 인식의 심층 고해상도 표현 학습-객체 문맥 표현 모델(Deep High-Resolution Representation Learning for Visual Recognition Object Contextual Representation, HRNet-OCR)에 사용될 수 있으나, 이에 대해 한정하지 않는다. 즉, HRNet-OCR 모델의 백본 네트워크를 사용하여 이미지 특징 추출을 수행할 수 있고, 다음, 본 발명의 실시예에서 HRNet-OCR 모델의 구조를 개선하고, 개선된 HRNet-OCR 모델을 트레이닝하여 요소의 의미론적 분할 방법 로직 및 차선의 검출 인식의 융합 응용을 구현할 수 있도록 한다.
이해 가능한 바로는, 일반적으로 차선이 도로 표면에 표기되어있기 때문에, 본 발명의 실시예에서, 요소 검출 서브모델을 기반으로 복수의 샘플 도로 상황 이미지, 복수의 요소 및 복수의 요소 어의를 처리하여 타겟 요소를 출력하는 것을 지지할 수 있다. 당해 타겟 요소는 구체적으로 요소 유형이 도로 유형인 요소일 수 있으며, 타겟 요소를 먼저 인식한 후, 타겟 요소, 타겟 요소에 대응되는 타겟 요소 어의, 및 복수의 샘플 도로 상황 이미지를 차선 검출 서브모델에 입력하여, 차선 검출 서브모델에서 출력하는 복수의 예측된 차선 정보를 획득하기 때문에, 모델 처리 인식의 목표성을 향상시킬 수 있고, 기타 요소가 차선 검출을 방해하는 것을 방지할 수 있고, 차선 검출 모델의 검출 인식 효율의 향상을 보조하는 동시에, 검출 인식의 정확성을 향상시킬 수 있다.
S204, 타겟 요소, 타겟 요소에 대응되는 타겟 요소 어의, 및 복수의 샘플 도로 상황 이미지를 차선 검출 서브모델에 입력하여, 차선 검출 서브모델에서 출력하는 복수의 예측된 차선 정보를 획득한다.
상기에서 요소 검출 서브모델을 기반으로 복수의 샘플 도로 상황 이미지, 복수의 요소 및 복수의 요소 어의를 처리하여, 타겟 요소를 출력한 후, 타겟 요소, 타겟 요소에 대응되는 타겟 요소 어의, 및 복수의 샘플 도로 상황 이미지를 차선 검출 서브모델에 입력하여, 차선 검출 서브모델에서 출력하는 복수의 예측된 차선 정보를 획득할 수 있다.
타겟 요소에 대응되는 요소 어의는 타겟 요소 어의로 불리울 수 있다. 타겟 요소가 요소 유형이 도로 유형인 요소일 경우, 타겟 요소 어의는 도로 유형 및 도로에 대응되는 이미지 특징 등일 수 있다.
상기 예측된 차선 정보는 구체적으로 예측된 차선 상태, 및/또는 차선이 커버한 이미지 영역 중 복수의 픽셀의 예측 문맥 정보를 의미할 수 있다.
상응하게, 표기된 차선 정보는 구체적으로 표기된 차선 상태, 및/또는 차선이 커버한 이미지 영역 중 복수의 픽셀의 표기 문맥 정보를 의미할 수 있다.
즉, 각 샘플 도로 상황 이미지에 대해, 표기된 차선 상태 및/또는 표기 문맥 정보는 대응되게 존재한다. 각 샘플 도로 상황 이미지에 대해, 인공지능 모델에서 출력하는 예측된 차선 상태 및/또는 예측 문맥 정보는 대응되게 존재한다.
상기 차선 상태는 차선 있음, 차선 없음을 의미할 수 있고, 문맥 정보는 차선이 커버한 이미지 영역 중 각 픽셀에 대응되는 픽셀 특징, 및 각 픽셀과 기타 픽셀 사이의 이미지 특징 차원을 기반으로 하는 대응 관계(예를 들어, 상대 위치 관계, 상대 심층 관계 등)를 특징화할 수 있으나, 이에 대해 한정하지 않는다.
따라서, 본 발명의 실시예에서, 상기 예측된 차선 상태 및/또는 차선이 커버한 이미지 영역 중 복수의 픽셀의 예측 문맥 정보, 및 대응되는 표기된 차선 상태 및/또는 표기 문맥 정보를 결합하여 인공지능 모델의 수렴 시기를 결정할 수 있으므로, 인공지능 모델의 수렴 시기를 정확하게 결정할 수 있고, 모델 트레이닝의 연산 자원 소비를 효과적으로 낮출 수 있고, 트레이닝된 차선 검출 모델의 검출 인식 효과를 보장할 수 있다.
S205, 복수의 예측된 차선 상태, 및 대응되는 복수의 표기된 차선 상태 사이의 복수의 제1 손실값을 결정한다.
상기에서 복수의 예측된 차선 상태, 및 대응되는 복수의 표기된 차선 상태를 결정한 후, 각 예측된 차선 상태와 대응되는 표기된 차선 상태 사이의 손실값을 결정하여, 제1 손실값으로 결정할 수 있다. 당해 제1 손실값은 차선 검출 모델이 차선 상태에 대해 예측한 손실 차이 상황을 특징화할 수 있다.
S206, 복수의 제1 손실값에서 타겟 제1 손실값을 선택하여, 타겟 제1 손실값에 대응되는 타겟 예측 차선 정보 및 타겟 표기 차선 정보를 결정한다.
일부 실시예에서, 복수의 제1 손실값 중 설정된 손실 임계값보다 큰 제1 손실값을 타겟 제1 손실값으로 결정할 수 있다. 즉, 제1 손실값이 설정된 손실 임계값보다 클 경우, 예측된 차선 상태가 표기된 차선 상태에 더 근접하는 것을 의미하며, 이때의 모델은 이미 상대적으로 정확한 상태 인식 결과를 구비함을 반영하여, 손실값의 결정으로서 실제 모델의 검출 로직에 더 적합하고, 방법의 실용성과 합리성을 보장할 수 있다.
설정된 손실 임계값은 예를 들어 0.5이고, 제1 손실값이 0.5보다 클 경우, 당해 단계에서의 차선 검출 모델이 차선 상태에 대한 검출 정확률은 일정한 요구에 부합하는 것을 의미할 수 있으므로, 나아가 당해 차선 검출 모델이 차선 유형 또는 기타 차선 정보에 대한 예측 검출 결과를 결정한다.
상기에서 복수의 제1 손실값에서 일정 조건을 만족하는 제1 손실값을 선택하여, 제1 타겟 손실값으로 불리울 수 있다. 제1 타겟 손실값에 대응되는 예측된 차선 상태가 속하는 예측된 차선 정보는 타겟 예측 차선 정보로 불리울 수 있고, 제1 타겟 손실값에 대응되는 표기된 차선 상태가 속하는 표기된 차선 정보는 타겟 표기 차선 정보로 불리울 수 있다.
S207, 타겟 예측 차선 정보에 포함된 예측 문맥 정보를 결정하고, 타겟 표기 차선 정보에 포함된 표기 문맥 정보를 결정한다.
상기에서 타겟 제1 손실값에 대응되는 타겟 예측 차선 정보 및 타겟 표기 차선 정보를 결정한 후, 타겟 예측 차선 정보에 포함된 예측 문맥 정보를 결정하고, 타겟 표기 차선 정보에 포함된 표기 문맥 정보를 결정한 후, 후속 단계를 트리거링할 수 있다.
S208, 예측 문맥 정보와 타겟 표기 차선 정보 사이의 제2 손실값을 결정하여, 제2 손실값을 타겟 손실값으로 결정한다.
예컨대, 상기 개선된 HRNet-OCR 모델의 구조에 대해 손실 함수를 설정하고, 당해 손실 함수를 사용하여 예측 문맥 정보와 타겟 표기 차선 정보 사이의 차이를 피팅하여, 획득된 제2 손실값을 상기 타겟 손실값으로 결정할 수 있으나, 이에 대해 한정하지 않는다.
즉, 본 발명의 실시예에서, 복수의 차원의 손실값을 사용하여 인공지능 모델의 수렴 시기를 결정하는 것을 지지한다. 차선 상태를 기반으로 결정된 제1 손실값이 일정한 조건을 만족하는 경우에만 예측 문맥 정보 및 타겟 표기 차선 정보를 기반으로 대응되는 제2 손실값을 타겟 손실값으로 결정하는 것을 트리거링하여, 수렴 시기를 결정한다. 따라서, 손실값 피팅의 정확성을 효과적으로 향상시킬 수 있고, 당해 타겟 손실값을 기반으로 모델의 수렴 시기를 결정한 상황에서, 차선 검출 모델은 더 정확한 검출 인식 효과를 획득할 수 있다.
예를 들어 설명하면, HRNet-OCR 모델의 네트워크 구조에 하나의 분기 구조를 추가하여, 차선 인스턴스의 검출 분할을 수행할 수 있다. 미리 설정된 차선의 수량은 4이고, 요소 분류의 기반에서 4를 더하여 HRNet-OCR 모델에서 출력하는 총 분류로 한다. 요소 분할의 손실이  인 상황에서, 차선 검출 인식의 손실을 상응하게 추가할 수 있고, 당해 차선 분할의 손실은 2개의 부분을 포함하는 바, 일부는 픽셀 손실
인 상황에서, 차선 검출 인식의 손실을 상응하게 추가할 수 있고, 당해 차선 분할의 손실은 2개의 부분을 포함하는 바, 일부는 픽셀 손실  이고, 일부는 4개의 차선의 유무에 따라 형성된 이진 분류 손실
이고, 일부는 4개의 차선의 유무에 따라 형성된 이진 분류 손실  이며, i번때 차선이 존재하는 상황에서
이며, i번때 차선이 존재하는 상황에서  , i번때 차선이 존재하자 않을 경우
, i번때 차선이 존재하자 않을 경우 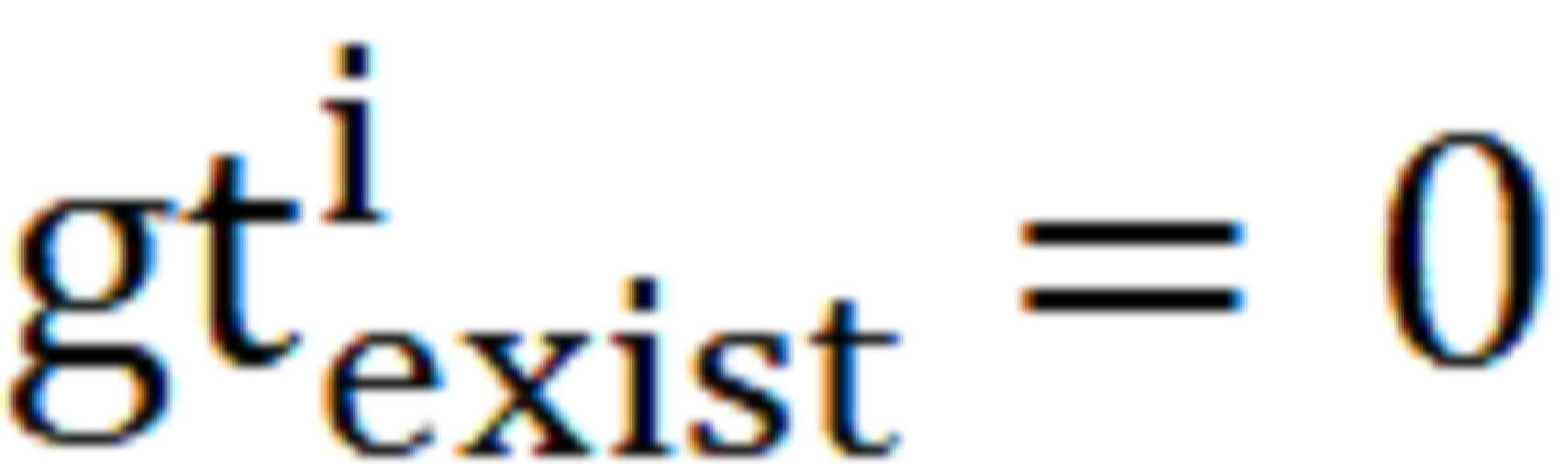 , 상응하게 HRNet-OCR 모델 총 출력의 손실값은,
, 상응하게 HRNet-OCR 모델 총 출력의 손실값은,
차선 검출 인식 단계에서,  일 경우, i번때 차선 상태는 차선이 존재함이며, 따라서, 그의 픽셀 예측 결과(예측 문맥 정보, 예측 차선 분류 등을 포함함)를 출력하고, 아닐 경우 당해 차선이 존재하지 않은 것으로 간주한다.
일 경우, i번때 차선 상태는 차선이 존재함이며, 따라서, 그의 픽셀 예측 결과(예측 문맥 정보, 예측 차선 분류 등을 포함함)를 출력하고, 아닐 경우 당해 차선이 존재하지 않은 것으로 간주한다.
따라서, 본 발명의 실시예에서, 도로 상황 이미지에 대해 요소 어의와 차선 인스턴스 인식을 효과적으로 융합하는 분할 네트워크 구조를 구현함으로써, 요소 어의와 차선 인스턴스 분할의 정확성을 향상시키고, 스마트 교통, 스마트 시티 시스템을 위해 믿음직한 차선 분할 결과를 제공한다.
S209, 복수의 예측된 차선 정보와 복수의 표기된 차선 정보 사이의 타겟 손실값이 설정 조건을 만족함에 응답하여, 트레이닝된 인공지능 모델을 차선 검출 모델로 결정한다.
S209의 설명은 구체적으로 상기 실시예를 참조할 수 있으나, 여기서 반복하지 않는다.
본 발명의 실시예에서, 복수의 샘플 도로 상황 이미지 및 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득하고, 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정하고, 복수의 샘플 도로 상황 이미지, 복수의 요소, 복수의 요소 어의 및 복수의 표기된 차선 정보에 따라 초기 인공지능 모델을 트레이닝하여, 차선 검출 모델을 획득한다. 따라서, 도로 상황 이미지에서 차선 검출 인식의 연산 복잡도를 효과적으로 낮추고, 차선 검출 인식 효율을 향상시키고, 차선 검출 인식 효과를 향상시킬 수 있다. 타겟 요소를 먼저 인식한 후, 타겟 요소, 타겟 요소에 대응되는 타겟 요소 어의, 및 복수의 샘플 도로 상황 이미지를 차선 검출 서브모델에 입력하여, 차선 검출 서브모델에서 출력하는 복수의 예측된 차선 정보를 획득하기 때문에, 모델 처리 인식의 목표성을 향상시킬 수 있고, 기타 요소가 차선 검출을 방해하는 것을 방지할 수 있고, 차선 검출 모델의 검출 인식 효율의 향상을 보조하는 동시에, 검출 인식의 정확성을 향상시킬 수 있다. 본 발명의 실시예에서, 상기 예측된 차선 상태 및/또는 차선이 커버한 이미지 영역 중 복수의 픽셀의 예측 문맥 정보, 및 대응되는 표기된 차선 상태 및/또는 표기 문맥 정보를 결합하여 인공지능 모델의 수렴 시기를 결정할 수 있으므로, 인공지능 모델의 수렴 시기를 정확하게 결정할 수 있고, 모델 트레이닝의 연산 자원 소비를 효과적으로 낮출 수 있고, 트레이닝된 차선 검출 모델의 검출 인식 효과를 보장할 수 있다.
도3은 본 발명의 제3 실시예에 따른 개략도이다.
도3에 도시된 바와 같이, 당해 차선 검출 모델의 트레이닝 장치(30)는,
복수의 샘플 도로 상황 이미지 및 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득하는 획득 모듈(301);
복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정하는 결정 모듈(302); 및
복수의 샘플 도로 상황 이미지, 복수의 요소, 복수의 요소 어의 및 복수의 표기된 차선 정보에 따라 초기 인공지능 모델을 트레이닝하여, 차선 검출 모델을 획득하는 트레이닝 모듈(303);을 포함한다.
본 발명의 일부 실시예에서, 도4에 도시된 바와 같이, 도4는 본 발명의 제4 실시예에 따른 개략도이다. 당해 차선 검출 모델의 트레이닝 장치(40)는 획득 모듈(401), 결정 모듈(402), 및 트레이닝 모듈(403)을 포함하는 바, 트레이닝 모듈(403)은,
복수의 샘플 도로 상황 이미지, 복수의 요소 및 복수의 요소 어의를 초기 인공지능 모델에 입력하여, 인공지능 모델에서 출력하는 복수의 예측된 차선 정보를 획득하는 획득 서브모듈(4031); 및
상기 복수의 예측된 차선 정보와 상기 복수의 표기된 차선 정보 사이의 타겟 손실값이 설정 조건을 만족함에 응답하여, 트레이닝된 인공지능 모델을 상기 차선 검출 모델로 결정하는 트레이닝 서브모듈(4032);을 포함한다.
본 발명의 일부 실시예에서, 차선 정보는 차선 상태 및 차선이 커버한 이미지 영역 중 복수의 픽셀의 문맥 정보 중의 적어도 하나를 포함하고, 이미지 영역은 차선이 속하는 샘플 도로 상황 이미지 중의 국부 이미지 영역이다.
본 발명의 일부 실시예에서, 트레이닝 서브모듈(4032)은 구체적으로,
복수의 예측된 차선 상태와, 대응되는 복수의 표기된 차선 상태 사이의 복수의 제1 손실값을 결정하고;
복수의 제1 손실값에서 타겟 제1 손실값을 선택하여, 타겟 제1 손실값에 대응되는 타겟 예측 차선 정보 및 타겟 표기 차선 정보를 결정하고;
타겟 예측 차선 정보에 포함된 예측 문맥 정보를 결정하고, 타겟 표기 차선 정보에 포함된 표기 문맥 정보를 결정하고;
예측 문맥 정보와 타겟 표기 차선 정보 사이의 제2 손실값을 결정하여, 제2 손실값을 타겟 손실값으로 결정하는;데 사용된다.
본 발명의 일부 실시예에서, 트레이닝 서브모듈(4032)은 구체적으로,
복수의 제1 손실값 중 설정된 손실 임계값보다 큰 제1 손실값을 타겟 제1 손실값으로 결정하는데 사용된다.
본 발명의 일부 실시예에서, 초기 인공지능 모델은 순차적으로 연결된 요소 검출 서브모델 및 차선 검출 서브모델을 포함하며, 획득 서브모듈(4031)은 구체적으로,
복수의 샘플 도로 상황 이미지, 복수의 요소 및 복수의 요소 어의를 요소 검출 서브모델에 입력하여, 요소 검출 서브모델에서 출력하는 타겟 요소를 획득하고;
타겟 요소, 타겟 요소에 대응되는 타겟 요소 어의, 및 복수의 샘플 도로 상황 이미지를 차선 검출 서브모델에 입력하여, 차선 검출 서브모델에서 출력하는 복수의 예측된 차선 정보를 획득하는;데 사용된다.
이해 가능한 바로는, 본 발명의 실시예의 도4에서 도시된 차선 검출 모델의 트레이닝 장치(40)와 전술한 실시예의 차선 검출 모델의 트레이닝 장치(30)에 있어서, 획득 모듈(401)과 전술한 실시예의 획득 모듈(301), 결정 모듈(402)과 전술한 실시예의 결정 모듈(302), 트레이닝 모듈(403)과 전술한 실시예의 트레이닝 모듈(303)은 같은 기능과 구조를 구비할 수 있다.
설명해야 하는 바로는, 전술한 차선 검출 모델의 트레이닝 방법에 관한 해석과 설명은 본 발명의 실시예의 차선 검출 모델의 트레이닝 장치에도 적용되며, 여기서 반복하지 않는다.
본 발명의 실시예에서, 복수의 샘플 도로 상황 이미지 및 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득하고, 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정하고, 복수의 샘플 도로 상황 이미지, 복수의 요소, 복수의 요소 어의 및 복수의 표기된 차선 정보에 따라 초기 인공지능 모델을 트레이닝하여, 차선 검출 모델을 획득한다. 따라서, 도로 상황 이미지에서 차선 검출 인식의 연산 복잡도를 효과적으로 낮추고, 차선 검출 인식 효율을 향상시키고, 차선 검출 인식 효과를 향상시킬 수 있다.
본 발명의 실시예에 따르면, 본 발명은 전자 기기, 판독 가능 저장 매체 및 컴퓨터 프로그램 제품을 더 제공한다.
도5는 본 발명의 실시예의 차선 검출 모델의 트레이닝 방법을 구현하기 위한 전자 기기의 블록도이다. 전자 기기는 랩톱 컴퓨터, 데스크톱 컴퓨터, 워크 스테이션, 개인용 디지털 비서, 서버, 블레이드 서버, 메인 프레임워크 컴퓨터 및 기타 적합한 컴퓨터와 같은 다양한 형태의 디지털 컴퓨터를 나타내기 위한 것이다. 전자 기기는 또한 개인용 디지털 처리, 셀룰러 폰, 스마트 폰, 웨어러블 기기 및 기타 유사한 컴퓨팅 장치와 같은 다양한 형태의 모바일 장치를 나타낼 수도 있다. 본 명세서에서 제시된 구성 요소, 이들의 연결 및 관계, 또한 이들의 기능은 단지 예일 뿐이며 본문에서 설명되거나 및/또는 요구되는 본 발명의 구현을 제한하려는 의도가 아니다.
도5에 도시된 바와 같이, 기기(500)는 컴퓨팅 유닛(501)을 포함하며, 읽기 전용 메모리(ROM)(502)에 저장된 컴퓨터 프로그램에 의해 또는 저장 유닛(508)으로부터 랜덤 액세스 메모리(RAM)(503)에 로딩된 컴퓨터 프로그램에 의해 수행되어 각종 적절한 동작 및 처리를 수행할 수 있다. RAM(503)에, 또한 기기(500)가 조작을 수행하기 위해 필요한 각종 프로그램 및 데이터가 저장되어 있다. 컴퓨팅 유닛(501), ROM(502) 및 RAM(503)은 버스(504)를 통해 서로 연결되어 있다. 입력/출력(I/O) 인터페이스(505)도 버스(504)에 연결되어 있다.
키보드, 마우스 등과 같은 입력 유닛(506); 각종 유형의 모니터, 스피커 등과 같은 출력 유닛(507); 자기 디스크, 광 디스크 등과 같은 저장 유닛(508); 및 네트워크 카드, 모뎀, 무선 통신 트랜시버 등과 같은 통신 유닛(509)을 포함하는 기기(500) 중의 복수의 부품은 I/O 인터페이스(505)에 연결된다. 통신 유닛(509)은 기기(500)가 인터넷과 같은 컴퓨터 네트워크 및/또는 다양한 통신 네트워크를 통해 다른 기기와 정보/데이터를 교환하는 것을 허락한다.
컴퓨팅 유닛(501)은 프로세싱 및 컴퓨팅 능력을 구비한 다양한 범용 및/또는 전용 프로세싱 컴포넌트일 수 있다. 컴퓨팅 유닛(501)의 일부 예시는 중앙 처리 유닛(CPU), 그래픽 처리 유닛(GPU), 다양한 전용 인공 지능(AI) 컴퓨팅 칩, 기계 러닝 모델 알고리즘을 수행하는 다양한 컴퓨팅 유닛, 디지털 신호 처리기(DSP), 및 임의의 적절한 프로세서, 컨트롤러, 마이크로 컨트롤러 등을 포함하지만, 이에 제한되지 않는다. 컴퓨팅 유닛(501)은 예를 들어 차선 검출 모델의 트레이닝 방법과 같은 윗글에서 설명된 각 방법 및 처리를 수행한다.
예를 들어, 일부 실시예에서, 차선 검출 모델의 트레이닝 방법은 저장 유닛(508)과 같은 기계 판독 가능 매체에 유형적으로 포함되어 있는 컴퓨터 소프트웨어 프로그램으로 구현될 수 있다. 일부 실시예에서, 컴퓨터 프로그램의 일부 또는 전부는 ROM(502) 및/또는 통신 유닛(509)을 통해 기기(500)에 로드 및/또는 설치될 수 있다. 컴퓨터 프로그램이 RAM(503)에 로딩되고 컴퓨팅 유닛(501)에 의해 수행될 경우, 전술한 차선 검출 모델의 트레이닝 방법의 하나 또는 하나 이상의 단계를 수행할 수 있다. 대안적으로, 다른 실시예에서, 컴퓨팅 유닛(501)은 임의의 다른 적절한 방식을 통해(예를 들어, 펌웨어에 의해) 구성되어 차선 검출 모델의 트레이닝 방법을 수행하도록 한다.
상기에서 설명한 시스템 및 기술의 다양한 실시 방식은 디지털 전자 회로 시스템, 집적 회로 시스템, 필드 프로그래머블 게이트 어레이(FPGA), 주문형 집적 회로(ASIC), 특정 용도 표준 제품(ASSP), 시스템온칩(SOC), 복합 프로그래머블 논리 소자(CPLD), 컴퓨터 하드웨어, 펌웨어, 소프트웨어 및 이들의 조합 중의 적어도 하나로 구현될 수 있다. 이러한 다양한 실시 방식은 하나 또는 하나 이상의 컴퓨터 프로그램에서의 구현을 포함할 수 있으며, 당해 하나 또는 하나 이상의 컴퓨터 프로그램은 적어도 하나의 프로그램 가능 프로세서를 포함하는 프로그램 가능 시스템에서 수행 및/또는 해석될 수 있고, 당해 프로그램 가능 프로세서는 전용 또는 일반용일 수 있고, 저장 시스템, 적어도 하나의 입력 장치 및 적어도 하나의 출력 장치로부터 데이터 및 명령을 수신하고 또한 데이터 및 명령을 당해 저장 시스템, 당해 적어도 하나의 입력 장치 및 당해 적어도 하나의 출력 장치에 전송할 수 있다.
본 발명의 차선 검출 모델의 트레이닝 방법을 구현하기 위해 사용되는 프로그램 코드는 하나 또는 하나 이상의 프로그래밍 언어의 임의의 조합으로 작성될 수 있다. 이러한 프로그램 코드는 범용 컴퓨터, 전용 컴퓨터 또는 기타 프로그래머블 데이터 처리 장치의 프로세서 또는 컨트롤러에 제공될 수 있으므로, 프로그램 코드가 프로세서 또는 컨트롤러에 의해 수행될 경우, 흐름도 및/또는 블록도에서 규정한 기능/조작을 구현하도록 한다. 프로그램 코드는 전체적으로 기계에서 수행되거나, 부분적으로 기계에서 수행되거나, 독립 소프트웨어 패키지로서 부분적으로 기계에서 수행되고 부분적으로 원격 기계에서 수행되거나 또는 전체적으로 원격 기계 또는 서버에서 수행될 수 있다.
본 발명의 문맥에서, 기계 판독 가능 매체는 자연어 수행 시스템, 장치 또는 기기에 의해 사용되거나 자연어 수행 시스템, 장치 또는 기기와 결합하여 사용되는 프로그램을 포함하거나 저장할 수 있는 유형의 매체일 수 있다. 기계 판독 가능 매체는 기계 판독 가능 신호 매체 또는 기계 판독 가능 저장 매체일 수 있다. 기계 판독 가능 매체는 전자, 자기, 광학, 전자기, 적외선 또는 반도체 시스템, 장치 또는 기기, 또는 상기 내용의 임의의 적절한 조합을 포함할 수 있지만 이에 제한되지 않는다. 기계 판독 가능 저장 매체의 더 구체적인 예시는 하나 또는 하나 이상의 전선을 기반하는 전기 연결, 휴대용 컴퓨터 디스크, 하드 디스크, 랜덤 액세스 메모리(RAM), 읽기 전용 메모리(ROM), 지울 수 있는 프로그래머블 읽기 전용 메모리(EPROM 또는 플래시 메모리), 광섬유, 휴대용 컴팩트 디스크 읽기 전용 메모리(CD-ROM), 광학 저장 기기, 자기 저장 기기 또는 상기 내용의 임의의 적절한 조합을 포함할 수 있지만 이에 제한되지 않는다.
사용자와의 인터랙션을 제공하기 위해 여기에 설명된 시스템 및 기술은 컴퓨터에서 실시될 수 있다. 당해 컴퓨터는 사용자에게 정보를 디스플레이하기 위한 디스플레이 장치(예를 들어, CRT(음극선관) 또는 LCD(액정 디스플레이) 모니터); 및 키보드 및 포인팅 장치(예를 들어, 마우스 또는 트랙볼)를 구비하며, 사용자는 당해 키보드 및 당해 포인팅 장치를 통해 컴퓨터에 입력을 제공할 수 있다. 다른 유형의 장치를 사용하여 사용자와의 인터랙션을 제공할 수도 있으며, 예를 들어, 사용자에게 제공되는 피드백은 임의의 형태의 감지 피드백(예를 들어, 시각적 피드백, 청각적 피드백 또는 촉각적 피드백)일 수 있고; 임의의 형태(소리 입력, 음성 입력 또는 촉각 입력을 포함)로 사용자로부터의 입력을 수신할 수 있다.
여기서 설명되는 시스템 및 기술은 백엔드 부품을 포함하는 컴퓨팅 시스템(예를 들어, 데이터 서버로서), 또는 미들웨어 부품을 포함하는 컴퓨팅 시스템(예를 들어, 응용 서버), 또는 프런트 엔드 부품을 포함하는 컴퓨팅 시스템(예를 들어, 그래픽 사용자 인터페이스 또는 네트워크 브라우저를 구비하는 사용자 컴퓨터인 바, 사용자는 당해 그래픽 사용자 인터페이스 또는 네트워크 브라우저를 통해 여기서 설명되는 시스템 및 기술의 실시 방식과 인터랙션할 수 있음), 또는 이러한 백엔드 부품, 미들웨어 부품 또는 프런트 엔드 부품의 임의의 조합을 포함하는 컴퓨팅 시스템에서 실시될 수 있다. 시스템의 부품은 임의의 형태 또는 매체의 디지털 데이터 통신(예를 들어, 통신 네트워크)을 통해 서로 연결될 수 있다. 통신 네트워크의 예시는 근거리 통신망(LAN), 광역 통신망(WAN), 인터넷 및 블록체인 네트워크를 포함한다.
컴퓨터 시스템은 클라이언트 및 서버를 포함할 수 있다. 클라이언트 및 서버는 일반적으로 서로 멀리 떨어져 있고, 통신 네트워크를 통해 인터랙션한다. 서로 클라이언트-서버 관계를 가지는 컴퓨터 프로그램을 대응되는 컴퓨터에서 수행하여 클라이언트와 서버 간의 관계를 생성한다. 서버는 클라우드 컴퓨팅 서버 또는 클라우드 호스트라고도 하는 클라우드 서버일 수 있고, 클라우드 컴퓨팅 서비스 시스템 중의 하나의 호스트 제품이고, 기존의 물리적 호스트 및 VPS 서버("Virtual Private Server", 또는 약자 "VPS")에 존재하고 있는 관리가 어렵고 업무 확장이 약한 결점을 해결하기 위한 것이다. 서버는 또한 분산 시스템의 서버, 또는 블록체인을 결합한 서버일 수 있다.
이해 가능한 바로는, 전술한 다양한 형식의 프로세스에 있어서 단계 재정렬, 추가 또는 삭제를 할 수 있다. 예를 들어, 본 발명에 개시된 기술 수단이 이루고자 하는 결과를 구현할 수 있는 한, 본 출원에 기재된 각 단계들은 병렬로, 순차적으로 또는 다른 순서로 수행될 수 있으나, 본 명세서에서 이에 대해 한정하지 않는다.
전술한 구체적인 실시 방식들은 본 발명의 보호 범위에 대한 한정을 구성하지 않는다. 당업자라면 본 발명의 설계 요건 및 기타 요인에 따라 다양한 수정, 조합, 서비스 조합 및 대체가 이루어질 수 있음을 이해해야 한다. 본 발명의 정신과 원칙 내에서 이루어진 모든 수정, 동등한 대체 및 개선은 본 발명의 보호 범위에 포함된다.
Claims (15)
- 차선 검출 모델의 트레이닝 방법에 있어서,
복수의 샘플 도로 상황 이미지 및 상기 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득하는 단계;
상기 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 상기 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정하는 단계; 및
상기 복수의 샘플 도로 상황 이미지, 상기 복수의 요소, 상기 복수의 요소 어의 및 상기 복수의 표기된 차선 정보에 따라 초기 인공지능 모델을 트레이닝하여, 차선 검출 모델을 획득하는 단계;를 포함하는,
차선 검출 모델의 트레이닝 방법. - 제1항에 있어서,
상기 복수의 샘플 도로 상황 이미지, 상기 복수의 요소, 상기 복수의 요소 어의 및 상기 복수의 표기된 차선 정보에 따라 초기 인공지능 모델을 트레이닝하여, 차선 검출 모델을 획득하는 단계는,
상기 복수의 샘플 도로 상황 이미지, 상기 복수의 요소 및 상기 복수의 요소 어의를 상기 초기 인공지능 모델에 입력하여, 상기 인공지능 모델에서 출력하는 복수의 예측된 차선 정보를 획득하는 단계; 및
상기 복수의 예측된 차선 정보와 상기 복수의 표기된 차선 정보 사이의 타겟 손실값이 설정 조건을 만족함에 응답하여, 트레이닝된 인공지능 모델을 상기 차선 검출 모델로 결정하는 단계;를 포함하는,
차선 검출 모델의 트레이닝 방법. - 제2항에 있어서,
상기 차선 정보는 차선 상태 및 상기 차선이 커버한 이미지 영역 중 복수의 픽셀의 문맥 정보 중의 적어도 하나를 포함하고, 상기 이미지 영역은 상기 차선이 속하는 샘플 도로 상황 이미지 중의 국부 이미지 영역인,
차선 검출 모델의 트레이닝 방법. - 제3항에 있어서,
상기 복수의 예측된 차선 정보와 상기 복수의 표기된 차선 정보 사이의 타겟 손실값을 결정하는 단계는,
상기 복수의 예측된 차선 상태와, 대응되는 상기 복수의 표기된 차선 상태 사이의 복수의 제1 손실값을 결정하는 단계;
상기 복수의 제1 손실값에서 타겟 제1 손실값을 선택하고, 상기 타겟 제1 손실값에 대응되는 타겟 예측 차선 정보 및 타겟 표기 차선 정보를 결정하는 단계;
상기 타겟 예측 차선 정보에 포함된 예측 문맥 정보를 결정하고, 상기 타겟 표기 차선 정보에 포함된 표기 문맥 정보를 결정하는 단계; 및
상기 예측 문맥 정보와 상기 타겟 표기 차선 정보 사이의 제2 손실값을 결정하여, 상기 제2 손실값을 타겟 손실값으로 결정하는 단계;를 포함하는,
차선 검출 모델의 트레이닝 방법. - 제4항에 있어서,
상기 복수의 제1 손실값에서 타겟 제1 손실값을 선택하는 단계는,
상기 복수의 제1 손실값 중 설정된 손실 임계값보다 큰 제1 손실값을 상기 타겟 제1 손실값으로 결정하는 단계를 포함하는,
차선 검출 모델의 트레이닝 방법. - 제2항 내지 제5항 중 어느 한 항에 있어서,
상기 초기 인공지능 모델은 순차적으로 연결된 요소 검출 서브모델 및 차선 검출 서브모델을 포함하며,
상기 복수의 샘플 도로 상황 이미지, 상기 복수의 요소 및 상기 복수의 요소 어의를 상기 초기 인공지능 모델에 입력하여, 상기 인공지능 모델에서 출력하는 복수의 예측된 차선 정보를 획득하는 단계는,
상기 복수의 샘플 도로 상황 이미지, 상기 복수의 요소 및 상기 복수의 요소 어의를 상기 요소 검출 서브모델에 입력하여, 상기 요소 검출 서브모델에서 출력하는 타겟 요소를 획득하는 단계; 및
상기 타겟 요소, 상기 타겟 요소에 대응되는 타겟 요소 어의, 및 상기 복수의 샘플 도로 상황 이미지를 상기 차선 검출 서브모델에 입력하여, 상기 차선 검출 서브모델에서 출력하는 복수의 예측된 차선 정보를 획득하는 단계;를 포함하는,
차선 검출 모델의 트레이닝 방법. - 차선 검출 모델의 트레이닝 장치에 있어서,
복수의 샘플 도로 상황 이미지 및 상기 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 표기된 차선 정보를 획득하는 획득 모듈;
상기 복수의 샘플 도로 상황 이미지에 각각 대응되는 복수의 요소 및 상기 복수의 요소에 각각 대응되는 복수의 요소 어의를 결정하는 결정 모듈; 및
상기 복수의 샘플 도로 상황 이미지, 상기 복수의 요소, 상기 복수의 요소 어의 및 상기 복수의 표기된 차선 정보에 따라 초기 인공지능 모델을 트레이닝하여, 차선 검출 모델을 획득하는 트레이닝 모듈;을 포함하는,
차선 검출 모델의 트레이닝 장치. - 제7항에 있어서,
상기 트레이닝 모듈은,
상기 복수의 샘플 도로 상황 이미지, 상기 복수의 요소 및 상기 복수의 요소 어의를 상기 초기 인공지능 모델에 입력하여, 상기 인공지능 모델에서 출력하는 복수의 예측된 차선 정보를 획득하는 획득 서브모듈; 및
상기 복수의 예측된 차선 정보와 상기 복수의 표기된 차선 정보 사이의 타겟 손실값이 설정 조건을 만족함에 응답하여, 트레이닝된 인공지능 모델을 상기 차선 검출 모델로 결정하는 트레이닝 서브모듈;을 포함하는,
차선 검출 모델의 트레이닝 장치. - 제8항에 있어서,
상기 차선 정보는 차선 상태 및 상기 차선이 커버한 이미지 영역 중 복수의 픽셀의 문맥 정보 중의 적어도 하나를 포함하고, 상기 이미지 영역은 상기 차선이 속하는 샘플 도로 상황 이미지 중의 국부 이미지 영역인,
차선 검출 모델의 트레이닝 장치. - 제9항에 있어서,
상기 트레이닝 서브모듈은,
상기 복수의 예측된 차선 상태와, 대응되는 상기 복수의 표기된 차선 상태 사이의 복수의 제1 손실값을 결정하고;
상기 복수의 제1 손실값에서 타겟 제1 손실값을 선택하여, 상기 타겟 제1 손실값에 대응되는 타겟 예측 차선 정보 및 타겟 표기 차선 정보를 결정하고;
상기 타겟 예측 차선 정보에 포함된 예측 문맥 정보를 결정하고, 상기 타겟 표기 차선 정보에 포함된 표기 문맥 정보를 결정하고; 및
상기 예측 문맥 정보와 상기 타겟 표기 차선 정보 사이의 제2 손실값을 결정하여, 상기 제2 손실값을 타겟 손실값으로 결정하는;데 사용되는,
차선 검출 모델의 트레이닝 장치. - 제10항에 있어서,
상기 트레이닝 서브모듈은,
상기 복수의 제1 손실값 중 설정된 손실 임계값보다 큰 제1 손실값을 상기 타겟 제1 손실값으로 결정하는데 사용되는,
차선 검출 모델의 트레이닝 장치. - 제8항 내지 제11항 중 어느 한 항에 있어서,
상기 초기 인공지능 모델은 순차적으로 연결된 요소 검출 서브모델 및 차선 검출 서브모델을 포함하며,
상기 획득 서브모듈은,
상기 복수의 샘플 도로 상황 이미지, 상기 복수의 요소 및 상기 복수의 요소 어의를 상기 요소 검출 서브모델에 입력하여, 상기 요소 검출 서브모델에서 출력하는 타겟 요소를 획득하고; 및
상기 타겟 요소, 상기 타겟 요소에 대응되는 타겟 요소 어의, 및 상기 복수의 샘플 도로 상황 이미지를 상기 차선 검출 서브모델에 입력하여, 상기 차선 검출 서브모델에서 출력하는 복수의 예측된 차선 정보를 획득하는;데 사용되는,
차선 검출 모델의 트레이닝 장치. - 전자 기기에 있어서,
적어도 하나의 프로세서; 및
상기 적어도 하나의 프로세서와 통신 가능하게 연결되는 메모리;를 포함하고,
상기 메모리에 상기 적어도 하나의 프로세서에 의해 수행 가능한 명령이 저장되어 있고, 상기 명령이 상기 적어도 하나의 프로세서에 의해 수행될 경우, 상기 적어도 하나의 프로세서가 제1항 내지 제6항 중 어느 한 항에 따른 방법을 수행하는,
전자 기기. - 컴퓨터 명령이 저장되어 있는 비일시적 컴퓨터 판독 가능 저장 매체에 있어서,
상기 컴퓨터 명령은 컴퓨터가 제1항 내지 제6항 중 어느 한 항에 따른 방법을 수행하는데 사용되는,
비일시적 컴퓨터 판독 가능 저장 매체. - 컴퓨터 프로그램을 포함하는 컴퓨터 프로그램 제품에 있어서,
상기 컴퓨터 프로그램이 프로세서에 의해 수행될 경우, 제1항 내지 제6항 중 어느 한 항에 따른 방법을 구현하는,
컴퓨터 프로그램 제품.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110470476.1 | 2021-04-28 | ||
| CN202110470476.1A CN113191256B (zh) | 2021-04-28 | 2021-04-28 | 车道线检测模型的训练方法、装置、电子设备及存储介质 |
| PCT/CN2022/075105 WO2022227769A1 (zh) | 2021-04-28 | 2022-01-29 | 车道线检测模型的训练方法、装置、电子设备及存储介质 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220117341A true KR20220117341A (ko) | 2022-08-23 |
Family
ID=83103526
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227027156A KR20220117341A (ko) | 2021-04-28 | 2022-01-29 | 차선 검출 모델의 트레이닝 방법, 장치, 전자 기기 및 저장 매체 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20230245429A1 (ko) |
| JP (1) | JP2023531759A (ko) |
| KR (1) | KR20220117341A (ko) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20220013203A (ko) * | 2020-07-24 | 2022-02-04 | 현대모비스 주식회사 | 차량의 차선 유지 보조 시스템 및 이를 이용한 차선 유지 방법 |
| CN117437792B (zh) * | 2023-12-20 | 2024-04-09 | 中交第一公路勘察设计研究院有限公司 | 基于边缘计算的实时道路交通状态监测方法、设备及系统 |
-
2022
- 2022-01-29 KR KR1020227027156A patent/KR20220117341A/ko unknown
- 2022-01-29 US US18/003,463 patent/US20230245429A1/en active Pending
- 2022-01-29 JP JP2022580383A patent/JP2023531759A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| US20230245429A1 (en) | 2023-08-03 |
| JP2023531759A (ja) | 2023-07-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2022227769A1 (zh) | 车道线检测模型的训练方法、装置、电子设备及存储介质 | |
| CN112857268B (zh) | 对象面积测量方法、装置、电子设备和存储介质 | |
| KR20220122566A (ko) | 텍스트 인식 모델의 트레이닝 방법, 텍스트 인식 방법 및 장치 | |
| CN113361578B (zh) | 图像处理模型的训练方法、装置、电子设备及存储介质 | |
| EP3852008A2 (en) | Image detection method and apparatus, device, storage medium and computer program product | |
| US20210357710A1 (en) | Text recognition method and device, and electronic device | |
| KR102721493B1 (ko) | 차선 검출 방법, 장치, 전자기기, 저장 매체 및 차량 | |
| CN115063875B (zh) | 模型训练方法、图像处理方法、装置和电子设备 | |
| CN113378712B (zh) | 物体检测模型的训练方法、图像检测方法及其装置 | |
| US20220351398A1 (en) | Depth detection method, method for training depth estimation branch network, electronic device, and storage medium | |
| CN113947188A (zh) | 目标检测网络的训练方法和车辆检测方法 | |
| KR20230139296A (ko) | 포인트 클라우드 처리 모델의 훈련과 포인트 클라우드 인스턴스 분할 방법 및 장치 | |
| EP4123594A2 (en) | Object detection method and apparatus, computer-readable storage medium, and computer program product | |
| KR20220117341A (ko) | 차선 검출 모델의 트레이닝 방법, 장치, 전자 기기 및 저장 매체 | |
| CN113361572A (zh) | 图像处理模型的训练方法、装置、电子设备以及存储介质 | |
| CN112580666A (zh) | 图像特征的提取方法、训练方法、装置、电子设备及介质 | |
| CN116152833B (zh) | 基于图像的表格还原模型的训练方法及表格还原方法 | |
| EP4191544A1 (en) | Method and apparatus for recognizing token, electronic device and storage medium | |
| CN114972910B (zh) | 图文识别模型的训练方法、装置、电子设备及存储介质 | |
| CN114220163B (zh) | 人体姿态估计方法、装置、电子设备及存储介质 | |
| CN114111813B (zh) | 高精地图元素更新方法、装置、电子设备及存储介质 | |
| CN114581732A (zh) | 一种图像处理及模型训练方法、装置、设备和存储介质 | |
| CN113706705A (zh) | 用于高精地图的图像处理方法、装置、设备以及存储介质 | |
| CN113051926B (zh) | 文本抽取方法、设备和存储介质 | |
| CN112818972B (zh) | 兴趣点图像的检测方法、装置、电子设备及存储介质 |