KR20140076816A - A method for detecting an audio signal and apparatus for the same - Google Patents
A method for detecting an audio signal and apparatus for the same Download PDFInfo
- Publication number
- KR20140076816A KR20140076816A KR1020120145284A KR20120145284A KR20140076816A KR 20140076816 A KR20140076816 A KR 20140076816A KR 1020120145284 A KR1020120145284 A KR 1020120145284A KR 20120145284 A KR20120145284 A KR 20120145284A KR 20140076816 A KR20140076816 A KR 20140076816A
- Authority
- KR
- South Korea
- Prior art keywords
- voice
- section
- signal
- speech
- interval
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 49
- 230000005236 sound signal Effects 0.000 title abstract description 3
- 238000001514 detection method Methods 0.000 claims abstract description 40
- 239000013598 vector Substances 0.000 claims abstract description 38
- 238000010606 normalization Methods 0.000 claims description 23
- 239000000284 extract Substances 0.000 claims description 8
- 238000000605 extraction Methods 0.000 description 15
- 230000008569 process Effects 0.000 description 7
- 238000004891 communication Methods 0.000 description 4
- 238000010586 diagram Methods 0.000 description 4
- 230000000694 effects Effects 0.000 description 2
- 230000007257 malfunction Effects 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000013500 data storage Methods 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000013179 statistical model Methods 0.000 description 1
Images






Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/04—Segmentation; Word boundary detection
- G10L15/05—Word boundary detection
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/20—Speech recognition techniques specially adapted for robustness in adverse environments, e.g. in noise, of stress induced speech
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Telephonic Communication Services (AREA)
Abstract
Description
본 발명은 음성 인식 시스템 등에 사용되는 음성 끝점 검출 및 특징 벡터 추출기의 성능 개선에 관한 것이다. BACKGROUND OF THE INVENTION 1. Field of the Invention [0001] The present invention relates to a speech endpoint detection and feature vector extractor used for a speech recognition system and the like.
현재의 일반적인 음성 인식 시스템의 경우 마이크로부터 취득된 신호는 일단 끝점 검출기를 거쳐 음성 구간이라고 판정된 신호에 한해서 특징 벡터로 변환되고 변환된 특징 벡터는 디코더에 인가되어 인식 결과를 도출하게 된다. 따라서 음성 검출기 및 특징 벡터 추출기의 오동작은 음성 인식 시스템 전반에 큰 영향을 미치게 된다. In the present general speech recognition system, a signal acquired from a microphone is converted into a feature vector only for a signal determined to be a speech segment through an end point detector, and the converted feature vector is applied to a decoder to derive a recognition result. Therefore, the malfunction of the speech detector and the feature vector extractor greatly affects the speech recognition system in general.
일반적인 음성 끝점 검출기의 경우 입력 신호의 에너지 및 통계적 모델에 따라 현재 프레임이 음성 구간인지 비음성 구간인지를 추정하고 이를 바탕으로 끝점 여부를 판정하고 된다. 이 때 정해진 환경에서는 대체로 잘 동작하나 미리 가정한 환경을 벗어나는 경우에는 오동작 확률이 높아지게 된다. 또한 실제 음성 신호의 바로 앞부분이나 바로 뒷부분에 인접한 잡음은 일반적인 끝점 검출기로는 음성 신호와의 구분이 어렵게 된다. 또한 일반적인 음성 인식기의 경우 음성 신호의 앞과 뒤에 일정 정도의 묵음 구간이 있어야 오히려 인식 결과가 바르게 나오는 경우가 많다. 음성 구간 앞뒤의 짧은 잡음은 인식기의 입장에서는 크게 문제가 되지 않으나 오히려 특징 벡터의 추출과정에서 큰 영향을 줄 수 있다. 특징 벡터의 추출과정에서는 신호의 일부분 또는 전체 구간의 통계적 특성을 이용하여 신호를 정규화하는데, 이렇게 삽입된 잡음 구간이 신호의 정규화 과정에 영향을 주기 때문이다. In the case of a general voice endpoint detector, it is determined whether the current frame is a voice interval or a non-voice interval according to the energy and statistical model of the input signal, and the end point is determined based on the estimation. In this case, it works well in a given environment, but in case of deviating from a previously assumed environment, the probability of a malfunction increases. Also, it is difficult to distinguish the noise adjacent to the immediately preceding or succeeding portion of the actual speech signal from the speech signal by a general endpoint detector. Also, in the case of a general voice recognizer, there are many silent periods before and after a voice signal in order to correctly recognize recognition results. The short noise before and after the speech interval is not a big problem in terms of the recognizer, but it can have a big influence on the extraction process of the feature vector. In the feature vector extraction process, the signal is normalized using the statistical characteristics of a part or all of the signal, because the inserted noise period affects the signal normalization process.
이러한 문제점은 차량이나 사무실과 같이 일정한 환경에서 사용하는 음성 인식 시스템의 경우에는 큰 문제가 아니나, 스마트폰 등을 이용한 모바일 환경에서 음성 인식 시스템의 경우에는 큰 영향을 줄 수 있다. Such a problem is not a serious problem in a voice recognition system used in a certain environment such as a vehicle or an office, but it may have a great influence in a voice recognition system in a mobile environment using a smart phone or the like.
본 발명은 상기 종래 기술의 문제를 해결하기 위하여 안출된 것으로서, 일반적인 끝점 검출기를 거친 이후의 신호에 대하여 보다 정교한 끝점 검출을 다시 한번 수행하여 특징 벡터의 정규화 과정에서 성능 향상에 도움을 줄 수 있는 방법을 제안하는 것을 목적으로 한다.SUMMARY OF THE INVENTION The present invention has been made in order to solve the problems of the prior art, and it is an object of the present invention to provide a method capable of improving performance in normalization of a feature vector by performing more precise end point detection on a signal after a general end- And the like.
특징 벡터 추출기의 정규화 과정에서는 묵음 구간과 음성 구간의 정보가 필요하며 중간의 잡음 구간은 정규화 과정에서 성능 저하를 가져온다. 끝점 검출기는 음성의 시작점과 끝점을 추출하나, 일반적으로 음성의 앞부분과 뒷부분에 근접하는 잡음은 구분하기 어려운 단점이 있다.Characteristics In the normalization process of the vector extractor, information of the silence interval and the voice interval is needed, and the noise interval in the middle results in the performance degradation in the normalization process. The endpoint detector extracts the starting and ending points of the speech, but generally it is difficult to distinguish the noise near the front and back of the speech.
본 발명에서는 일반적인 음성 끝점 검출기의 출력에 대하여 보다 정교한 끝점 검출기를 재적용하여 음성의 앞부분과 뒷부분에 인접한 잡음 구간을 별도로 추출해내고, 이 구간 정보를 이용하여 특징 추출부의 정규화 성능을 높이고자 한다.In the present invention, a more sophisticated end-point detector is re-applied to the output of a general speech endpoint detector to separately extract noise regions adjacent to the front and back of speech, and to improve the normalization performance of the feature extraction unit using the region information.
상기 기술적 과제를 해결하기 위한 음성 신호의 검출 방법은 입력 신호에 대하여 프레임 단위의 끝점 검출을 수행하여 음성 구간을 검출하는 단계; 검출된 상기 음성 구간 중 복수의 윈도우들에 대응되는 적어도 일부 구간의 신호의 특징값을 추출하는 단계; 및 상기 추출된 특징값을 미리 결정된 임계값과 비교하여 상기 음성 구간 중 실 음성 구간을 검출하는 단계를 포함한다.According to an aspect of the present invention, there is provided a method for detecting a speech signal, the method comprising: detecting a speech interval by performing end-point detection on a frame basis for an input signal; Extracting a feature value of a signal of at least a section corresponding to a plurality of windows among the detected speech sections; And comparing the extracted feature value with a predetermined threshold value to detect an actual voice section in the voice section.
상기 음성 신호의 검출 방법은 상기 실 음성 구간의 특징벡터를 정규화하는 단계를 더 포함하는 것이 바람직하다.Preferably, the method for detecting a voice signal further includes a step of normalizing a feature vector of the real voice section.
상기 실 음성 구간을 검출하는 단계는 상기 추출된 특징값의 극대값을 추출하고, 상기 극대값을 상기 임계값과 비교하여 상기 실 음성 구간을 검출하는 것이 바람직하다.Preferably, the step of detecting the real voice section detects the real voice section by extracting a maximum value of the extracted characteristic values and comparing the maximum value with the threshold value.
상기 실 음성 구간을 검출하는 단계는 상기 음성 구간 중 잡음 신호의 위치 및 음성 신호의 위치를 검출하여 잡음 구간을 검출하는 것이 바람직하다.Preferably, the step of detecting the real voice section detects a noise section by detecting a position of a noise signal and a position of a voice signal in the voice section.
상기 특징벡터를 정규화하는 단계는 상기 음성 구간 중 상기 잡음 구간을 제외한 구간에 대한 상기 특징벡터를 정규화하는 것이 바람직하다.The normalizing of the feature vector may desirably normalize the feature vector for a section excluding the noise section of the speech section.
상기 복수의 윈도우들은 상기 윈도우에 대응되는 구간의 적어도 일부가 다른 윈도우에 대응되는 구간과 중첩되는 것이 바람직하다.Preferably, the plurality of windows overlaps at least a part of the section corresponding to the window corresponding to another window.
상기 정규화하는 단계는 상기 잡음 신호의 위치 또는 상기 음성 신호의 위치가 검출되지 않은 경우 검출된 상기 음성 구간에 대한 상기 특징벡터를 정규화하는 것이 바람직하다.Preferably, the normalizing step normalizes the feature vector with respect to the detected speech section when the position of the noise signal or the position of the speech signal is not detected.
상기 특징값을 추출하는 단계는 상기 윈도우에 대응되는 구간의 통계적 특성을 추출하는 것이 바람직하다.The extracting of the feature value preferably extracts a statistical characteristic of a section corresponding to the window.
본 발명은 종래의 끝점 추출 방식에서 걸러낼 수 없는 음성 직전 및 직후의 잡음 신호가 특징 추출부의 정규화 과정에서 전체 특징 벡터에 영향을 주는 것을 막기 위하여 2차 끝점 검출기를 통하여 음성 직전 및 직후의 잡음 신호 구간을 찾아내고, 이를 정규화 구간에서 제외하는 방법에 관한 것이다. 본 발명에서 제시한 방법을 사용할 경우 음성 인식 시스템에서 사용하는 특징 벡터의 정규화 성능을 높일 수 있으며, 이는 잡음 환경에서의 음성 인식 성능을 높이는 역할을 한다. In order to prevent a noise signal immediately before and after a speech that can not be filtered by a conventional end point extraction method from affecting the entire feature vector in the normalization process of the feature extraction unit, a noise end signal And to exclude it from the normalization section. When the method of the present invention is used, the normalization performance of the feature vector used in the speech recognition system can be improved, which improves speech recognition performance in a noisy environment.
도 1은 본 발명의 일실시예에 따른 음성 신호의 검출 방법을 나타내는 흐름도이다.
도 2는 본 발명의 일실시예에 따라 검출된 음성 구간의 구성을 나타내는 도이다.
도 3은 도 2의 음성 구간으로부터 실 음성 구간을 검출하는 과정을 나타내는 도이다.
도 4는 본 발명의 일실시예에 따라 음성 신호의 검출 방법을 나타내는 흐름도이다.
도 5는 본 발명의 일실시예에 따른 음성 신호의 검출 방법을 나타내는 세부 흐름도이다.
도 6은 본 발명의 일실시예에 따른 음성 신호의 검출 방법이 적용된 시스템을 나타내는 도이다.
도 7은 본 발명의 일실시예에 따른 음성 신호의 검출 장치를 나타내는 블록도이다.1 is a flowchart illustrating a method of detecting a voice signal according to an embodiment of the present invention.
2 is a diagram illustrating the configuration of a detected voice interval according to an embodiment of the present invention.
FIG. 3 is a diagram illustrating a process of detecting an actual voice interval from the voice interval of FIG. 2;
4 is a flowchart illustrating a method of detecting a voice signal according to an embodiment of the present invention.
5 is a detailed flowchart illustrating a method of detecting a voice signal according to an embodiment of the present invention.
6 is a diagram illustrating a system to which a method of detecting a voice signal according to an embodiment of the present invention is applied.
7 is a block diagram showing an apparatus for detecting a voice signal according to an embodiment of the present invention.
이하의 내용은 단지 발명의 원리를 예시한다. 그러므로 당업자는 비록 본 명세서에 명확히 설명되거나 도시되지 않았지만 발명의 원리를 구현하고 발명의 개념과 범위에 포함된 다양한 장치를 발명할 수 있는 것이다. 또한, 본 명세서에 열거된 모든 조건부 용어 및 실시예들은 원칙적으로, 발명의 개념이 이해되도록 하기 위한 목적으로만 명백히 의도되고, 이와같이 특별히 열거된 실시예들 및 상태들에 제한적이지 않는 것으로 이해되어야 한다. The following merely illustrates the principles of the invention. Therefore, those skilled in the art will be able to devise various apparatuses which, although not explicitly described or shown herein, embody the principles of the invention and are included in the concept and scope of the invention. It is also to be understood that all conditional terms and examples recited in this specification are, in principle, expressly intended for the purpose of enabling the inventive concept to be understood, and are not intended to be limiting as to such specifically recited embodiments and conditions .
상술한 목적, 특징 및 장점은 첨부된 도면과 관련한 다음의 상세한 설명을 통하여 보다 분명해 질 것이며, 그에 따라 발명이 속하는 기술분야에서 통상의 지식을 가진 자가 발명의 기술적 사상을 용이하게 실시할 수 있을 것이다. 또한, 발명을 설명함에 있어서 발명과 관련된 공지 기술에 대한 구체적인 설명이 발명의 요지를 불필요하게 흐릴 수 있다고 판단되는 경우에 그 상세한 설명을 생략하기로 한다. 이하, 첨부된 도면을 참조하여 발명에 따른 바람직한 일실시예를 상세히 설명하기로 한다.BRIEF DESCRIPTION OF THE DRAWINGS The above and other objects, features and advantages of the present invention will become more apparent from the following detailed description taken in conjunction with the accompanying drawings, in which: . In the following description, a detailed description of known technologies related to the present invention will be omitted when it is determined that the gist of the present invention may be unnecessarily blurred. Hereinafter, preferred embodiments of the present invention will be described in detail with reference to the accompanying drawings.
도 1은 본 발명의 일실시예에 따른 음성 신호의 검출 방법을 나타내는 흐름도이다. 도 1을 참조하면, 본 실시예에 따른 음성 신호의 검출 방법은 프레임 단위 끝점 검출 단계(S100), 윈도우 특징값 추출 단계(S200), 실 음성 구간 검출 단계(S300)를 포함한다.1 is a flowchart illustrating a method of detecting a voice signal according to an embodiment of the present invention. Referring to FIG. 1, a method for detecting a speech signal according to an embodiment of the present invention includes a frame unit end point detection step S100, a window feature value extraction step S200, and a real voice interval detection step S300.
프레임 단위 끝점 검출 단계(S100)는 입력 신호의 음성 구간을 검출하기 위하여 프레임 단위의 끝점 검출을 수행한다.The frame unit end point detection step (S100) detects the end point of each frame in order to detect a voice interval of an input signal.
일반적인 끝점 추출기는 주로 음성 인식기의 앞단에 적용되어 입력 신호를 분석하여 음성의 시작점 및 끝점을 판정한다. 이를 위하여 여러 가지 알고리즘을 적용하고 있으나, 일반적으로 개별 프레임별 음성/비음성 판정 및 이를 바탕으로한 결정 로직 알고리즘을 이용한다.A common endpoint extractor is usually applied to the front of the speech recognizer to analyze the input signal to determine the start and end points of the speech. Although various algorithms are applied for this purpose, generally, speech / non-speech discrimination for individual frames and a decision logic algorithm based thereon are used.
즉 입력 신호가 들어오면 현재 프레임이 음성 신호에 해당하는지 그렇지 않은지를 판단한다. 이를 위해서는 음성 및 비음성 신호의 확률 모델을 이용하여 음성일 확률 또는 음성이 아닐 확률을 계산하거나, 신호의 에너지를 문턱값과 비교하여 음성 신호임을 판정하거나, 그 밖의 복잡한 판정 네트워크를 이용하여 음성일 확률을 계산하거나, 음성 구간 또는 비음성 구간이라고 확정하여 결정을 하게 된다.That is, when an input signal is received, it is determined whether or not the current frame corresponds to the audio signal. For this purpose, a probabilistic model of speech and non-speech signals is used to calculate probability of non-speech probability or probability of non-speech, or to compare the energy of a signal with a threshold value to determine a speech signal, Probability is calculated, or a voice section or a non-voice section is determined.
판정 로직에서는 시간에 따른 프레임별 결과를 분석하여 예를 들어 일정 개수 이상의 음성 프레임이 연속하여 입력되면 음성의 시작점이 검출되었다고 판정하거나, 반대로 일정 개수 이상의 비음성 프레임이 연속하여 입력되면 음성의 끝점이 검출되었다고 판정하게 된다. 최종적인 음성 끝점 검출기는 연속된 음성 신호에 대하여 현재 프레임이 음성 구간의 시작점 또는 끝점이라는 판단을 출력으로 내게 된다.For example, if a predetermined number or more of consecutive voice frames are continuously input, it is determined that the start point of the voice is detected. Otherwise, if a predetermined number or more of non-voice frames are continuously input, It is determined that it is detected. The final speech endpoint detector outputs the determination that the current frame is the starting or ending point of the speech section for the continuous speech signal.
따라서 본 실시예에서 프레임 단위 끝점 검출 단계(S100)는 1차적으로 입력 신호 중 음성 구간을 검출하기 위한 끝점을 검출하는 것으로서, 이때의 끝점 검출은 확률 모델을 이용하여 음성일 확률 또는 음성이 아닐 확률을 계산하는 등의 일반 적인 끝점 검출 방법을 이용한다.Therefore, in the present exemplary embodiment, the frame end point detection step S100 detects an end point for detecting a speech interval of an input signal, and the end point detection at this time uses a probability model, And a general endpoint detection method is used.
또한 본 실시예에서 프레임이란 입력 신호를 일반적인 10msec를 길이의 신호를 세분화하는 단위로서, 이는 인식하고자 하는 음성의 특성, 예를 들어 음성의 발화 상황이나 화자, 또는 음성의 언어에 따라 변경될 수 있다.In the present embodiment, a frame is a unit for subdividing a signal having a length of 10 msec as an input signal, which can be changed according to the characteristics of the speech to be recognized, for example, the speech state of the speech, .
다만 상술한 방식의 끝점 추출 방법은 실제 음성 구간에 인접하여 잡음이 있는 경우 이를 구분하는 것이 어렵다. 이렇게 삽입된 잡음 구간은 인식에는 큰 영향을 주지 않을 수 있으나, 특징벡터의 정규화 과정에서는 묵음 구간 및 음성 구간의 신호 특성을 왜곡시켜서 정규화 성능을 떨어뜨리게 된다.However, in the end point extraction method described above, it is difficult to distinguish an end point from the actual speech interval when noise exists. The inserted noise interval may not have a large effect on recognition, but the normalization performance of the feature vector is degraded by distorting the signal characteristics of the silent interval and the voice interval.
따라서, 본 발명에서는 일반적인 끝점 검출기를 거친 이후의 신호에 대하여 보다 정교한 끝점 검출을 다시 한번 수행하여 특징 벡터의 정규화 과정에서 성능 향상에 도움을 줄 수 있는 방법을 제안한다.Accordingly, the present invention proposes a method that can improve the performance in the process of normalizing a feature vector by performing a more precise end-point detection on a signal after a general end-point detector.
이하 보다 정교한 끝점 검출을 수행하기 위한 윈도우 특징값 추출 단계(S200)에 대하여 설명한다.Hereinafter, a window feature value extraction step (S200) for performing more precise end point detection will be described.
윈도우 특징값 추출 단계(S200)는 검출된 음성 구간 중 일부 구간의 특징 값을 추출하기 위한 복수의 윈도우들의 특징값을 추출한다. 즉 본 실시예에서 윈도우 특징값 추출 단계(S200)는 1차적인 프레임 단위 끝점 검출 단계(S100)를 통해 검출된 음성 구간에 대하여 2차적인 실 음성 구간 검출을 위한 단계이다. The window characteristic value extraction step (S200) extracts characteristic values of a plurality of windows for extracting characteristic values of a certain section of the detected speech section. That is, in the present embodiment, the window characteristic value extraction step S200 is a step for detecting a second real voice section with respect to a voice section detected through a primary frame end point detection step S100.
본 실시예에서 윈도우란 상술한 프레임과 같이 입력 신호의 특성을 판단하기 위하여 입력 신호를 특정 길이로 세분화하는 기준이 된다. 다만 본 실시예에서 윈도우의 길이는 상술한 끝점 검출 단계에서 프레임 단위의 끝점 검출 방식을 쓰는 경우에는 프레임 길이와 동일한 길이인 경우 새로운 정보를 얻을 수 없으므로, 일반적인 프레임 길이인 10msec보다 긴 구간의 길이인 것이 바람직하다.In this embodiment, a window is a reference for subdividing an input signal into a specific length in order to determine characteristics of the input signal as in the above-described frame. However, in the present embodiment, when the end point detection method of the frame unit is used in the end point detection step, new information can not be obtained if the length of the window is equal to the frame length. Therefore, the length of the window longer than 10 msec, .
또한 프레임의 길이가 인식하고자 하는 음성의 특성, 예를 들어 음성의 발화 상황이나 화자, 또는 음성의 언어에 따라 변경될 수 있는 바 본 실시예에서의 윈도우의 길이 역시 음성의 성질에 따라 변경될 수 있다.Also, the length of the frame can be changed according to the characteristics of the speech to be recognized, for example, the speech state of the speech, the speaker, or the language of the speech, and the length of the window in this embodiment can also be changed according to the nature of the speech have.
또한 본 실시예에서 음성 구간 중 일부 구간은 상술한 윈도우에 대응되는 구간으로, 음성 구간의 통계적 특성을 구하기 위한 기준이 된다. 따라서 본 실시예에서 윈도우 특징값 추출 단계(S200)는 결정된 윈도우 길이에 따른 구간에 대한 전체 구간의 통계적 특성을 이용하여 신호의 변화 정도를 측정한다. Also, in this embodiment, some sections of the speech section correspond to the windows described above, and serve as criteria for obtaining the statistical characteristics of the speech sections. Therefore, in the present embodiment, the window characteristic value extraction step S200 measures the degree of change of the signal using the statistical characteristic of the entire section with respect to the window length determined.
즉, 도 2와 같이 프레임 단위 끝점 검출 단계(S100)를 통해 음성 구간(20)이 검출되었다고 할 때, 윈도우 특징값 추출 단계(S200)는 도 3과 같이 복수의 윈도우에 대응되는 구간의 적어도 일부가 다른 윈도우에 대응되는 구간과 중첩되고 소정의 길이를 갖는 윈도우(24)를 음성 구간에 적용하여 해당 윈도우에 대응되는 음성 구간의 통계적 특성을 구한다. That is, when it is assumed that the
이 때 각 윈도우(24) 간의 중첩되는 구간이 늘어날수록 보다 정밀한 실 음성 구간의 검출이 가능하며, 줄어들수록 검출의 속도는 빨라 질 수 있는 바, 인식하고자 하는 음성의 성질 또는 그 시스템 환경에 따라 각 윈도우 들의 간격을 조절하여 중첩되는 구간의 길이를 결정하는 것이 바람직하다.In this case, as the overlapping interval between the
이하 윈도우에 대응되는 음성 구간의 통계적 특성에 대하여 설명하면, 본 실시예에 따른 통계적 특징값은 수학식 1로 계산될 수 있다.Hereinafter, the statistical characteristic of the speech interval corresponding to the window will be described. The statistical characteristic value according to the present embodiment can be calculated by Equation (1).
![]()
![]()
여기서 Fk는 k번째 윈도우의 통계적 특징값, s는 신호값, ki는 k번째 윈도우의 시작점, N은 윈도우의 길이를 의미한다.Where Fk is the statistical feature value of the kth window, s is the signal value, ki is the starting point of the kth window, and N is the length of the window.
f()는 입력 신호로부터 통계적 특성을 추출하는 함수로 신호의 평균값, 분산값, 엔트로피, Bayes Information Criterion등 다양한 방법이 사용될 수 있다.f () is a function to extract statistical characteristics from the input signal, and various methods such as mean value of signal, variance value, entropy, Bayes Information Criterion can be used.
이하 실 음성 구간 검출 단계(S300)에 대하여 설명하면, 본 실시에에서 실 음성 구간 검출 단계(S300)는 추출된 특징값을 미리 결정된 임계값과 비교하여 음성 구간 중 실 음성 구간을 검출한다. Hereinafter, the real voice interval detection step S300 will be described. In the present embodiment, the real voice interval detection step S300 detects the real voice interval in the voice interval by comparing the extracted feature value with a predetermined threshold value.
본 실시예에서 실 음성 구간이란 프레임 단위 끝점 검출 단계(S100)에서 검출된 음성 구간에 포함될 수 있는 잡음 구간을 제외한 실제의 음성 신호로 구성된 구간으로서, 도 2를 참조하면 음성 구간(20) 중 실 음성 구간의 시작 또는 끝에 인접하여 포함되는 잡음 구간(23)을 제외한 구간이 실 음성 구간(22)이다. In the present embodiment, the real voice section is a section composed of actual voice signals excluding a noise section that can be included in the voice section detected in the frame unit end point detection step S100. Referring to FIG. 2, A section excluding the
즉 실제 음성 신호의 바로 앞부분이나 바로 뒷부분에 인접한 잡음은 일반적인 끝점 검출기로는 음성 신호와의 구분이 어렵게 된다. 또한 일반적인 음성 인식기의 경우 음성 신호의 앞과 뒤에 일정 정도의 묵음 구간이 있어야 오히려 인식 결과가 바르게 나오는 경우가 많다. That is, it is difficult to distinguish the noise adjacent to the immediately preceding or following portion of the actual voice signal from the voice signal by a general endpoint detector. Also, in the case of a general voice recognizer, there are many silent periods before and after a voice signal in order to correctly recognize recognition results.
즉 실 음성 구간 앞뒤의 짧은 잡음은 인식기의 입장에서는 크게 문제가 되지 않으나 오히려 특징 벡터의 추출과정에서 큰 영향을 줄 수 있는 바, 본 실시예에서 실 음성 구간 검출 단계(S300)는 이러한 인접 잡음 구간의 영향을 제한하기 위한 동작을 수행한다.That is, the short noise before and after the real voice section is not a big problem in terms of the recognizer, but it may have a large effect on the extraction process of the feature vector. In the present embodiment, the real voice section detection step (S300) Lt; RTI ID = 0.0 > a < / RTI >
이하 도 5를 참조하여 보다 상세히 설명한다. 도 5를 참조하면, 본 실시예에 따른 실 음성 구간 검출 단계(S300)는 윈도우 특징값의 극대값 추출 단계(S310), 극대값과 임계값 비교 단계(S320)를 포함한다.This will be described in more detail with reference to FIG. Referring to FIG. 5, the real-sound interval detection step S300 according to the present embodiment includes a maximum value extraction step S310 of a window feature value, and a maximum value and a threshold value comparison step S320.
윈도우 특징값의 극대값 추출 단계(S310)는 추출된 특징값의 극대값을 추출한다.A maximum value extraction step (S310) of the window feature value extracts a maximum value of the extracted feature values.
수학식 1에 의해서 계산된 특징 값은 윈도우를 1개 또는 1개 이상의 샘플만큼 이동시켜가면서 연속된 값을 계산할 수 있다. 이 값이 극대값이 되는 점이 신호의 특성이 크게 바뀌는 시점으로 본 실시예에서 윈도우 특징값의 극대값 추출 단계(S310)는 극대값을 통해 신호의 특성이 크게 바뀌는 시점을 찾는다.The feature value calculated by Equation (1) can calculate a continuous value while moving the window by one or more samples. In this embodiment, the step of extracting the maximum value of the window feature value (S310) finds a point at which the characteristic of the signal greatly changes through the maximum value.
다음 극대값과 임계값 비교 단계(S320)는 추출된 극대값을 임계값과 비교하여 실 음성 구간을 검출한다. 이 값을 임계값과 비교하여 음성 신호 앞뒤에 인접한 잡음 신호의 위치 및 음성 신호의 위치를 찾을 수 있다. In the next step of comparing the maximum value and the threshold value (S320), the extracted maximum value is compared with the threshold value to detect the real voice section. By comparing this value with the threshold value, it is possible to find the position of the adjacent noise signal and the position of the voice signal before and after the voice signal.
따라서 본 실시예에서 실 음성 구간 검출 단계(S300)는 극대값과 임계값 비교 단계(S320)에서 잡음 신호 및 음성 신호의 위치를 통해 두 신호의 시작점을 찾고 잡음 신호의 시작점부터 음성 신호의 시작점으로 구성되는 잡음 구간을 검출한다. Therefore, in the present embodiment, the real voice interval detection step S300 finds the start point of the two signals through the positions of the noise signal and the voice signal in the step of comparing the maximum value and the threshold value (S320) Is detected.
이하 본 실시예에 따른 음성 신호의 검출 방법은 도 4와 같이 실 음성 구간 정규화 단계(S400)를 더 포함할 수 있다. The method of detecting a speech signal according to the present embodiment may further include an actual speech interval normalization step S400 as shown in FIG.
실 음성 구간 정규화 단계(S400)는 실 음성 구간의 특징벡터를 정규화한다. 특징 벡터의 정규화 방법으로는 대표적인 것은 Cepstral Mean Subtraction (CMS) 방법이다. CMS 방법은 마이크 및 화자의 발성 중 인식에 불필요한 특성 등을 정규화해주는 방법으로 켑스트럼 영역의 특징벡터를 구한 후 시간 축으로 전체 특징벡터의 평균을 구하여 이 평균값을 전체 벡터에서 빼는 방법이다. In the real voice interval normalization step (S400), the feature vectors of the real voice interval are normalized. A typical method of normalizing a feature vector is the Cepstral Mean Subtraction (CMS) method. The CMS method is a method of normalizing the characteristics of the microphone and speaker that are unnecessary to recognize during vocalization. The feature vector of the speech region is obtained, and the average of the feature vectors is obtained on the time axis, and the average value is subtracted from the whole vector.
상술한 바와 같이 실제 음성 구간에 인접하여 잡음이 있는 경우 이를 구분하는 것이 어렵고, 이렇게 삽입된 잡음 구간은 인식에는 큰 영향을 주지 않을 수 있으나, 특징벡터의 정규화 과정에서는 묵음 구간 및 음성 구간의 신호 특성을 왜곡시켜서 정규화 성능을 떨어뜨리게 된다.As described above, it is difficult to distinguish noise when there is noise adjacent to the actual voice interval, and thus the inserted noise interval may not have a great influence on recognition. However, in the normalization process of the feature vector, Lt; RTI ID = 0.0 > normalization < / RTI > performance.
따라서, 본 실시예에서 정규화 단계는 실 음성 구간 검출 단계(S300)에서 음성 신호 및 잡음 신호의 시작점이 찾아진 경우 찾아진 잡음 신호의 시작점을 tn, 음성 신호의 시작점을 ts라고 하자. Accordingly, in the normalization step, when the start point of the speech signal and the noise signal is found in the real voice interval detection step S300, the starting point of the noise signal is tn and the starting point of the speech signal is ts.
이때, 실 음성 구간 정규화 단계(S400)에서 특징 벡터의 정규화는 프레임 단위 끝점 검출 단계(S100)에서 검출된 끝점에 따른 음성구간 L 중, tn에서 ts의 구간을 제외하고 이루어진다. 예를 들어 신호 전체의 평균을 구할 경우 본 방법을 적용하지 않은 경우에는 전체 구간의 평균을 구하지만, 본 방법을 적용한 경우에는 아래 수학식2 와 같이 구해진다.In this case, the normalization of the feature vector in the real voice interval normalization step S400 is performed by excluding the interval tn to ts of the voice interval L according to the end point detected in the frame end point detection step S100. For example, if the average of the entire signal is obtained, if the present method is not applied, the average of the entire interval is obtained. However, when this method is applied, the following equation is obtained.

한편 본 실시예에서 실 음성 구간 정규화 단계(S400)는 실 음성 구간 검출 단계(S300)에서 잡음 구간의 검출 여부를 판단(S410)하고 이에 따라 정규화 범위를 결정하는 것이 바람직하다.Meanwhile, in the present embodiment, it is preferable that the real voice interval normalization step S400 determines whether the noise interval is detected in the real voice interval detection step S300 (S410) and determines the normalization range accordingly.
따라서 실 음성 구간 검출 단계(S300)에서 음성 신호 및 잡음 신호의 시작점이 찾아진 경우 특징 벡터의 정규화는 잡음 구간을 제외하고 이루어지는 것(S420)이 바람직하나, 잡음 신호의 위치 또는 음성 신호의 위치가 검출되지 않은 경우 검출된 프레임 단위 끝점 검출 단계(S100)에서 검출된 음성 구간에 대한 특징벡터를 정규화하는 것(S430)이 바람직하다.Therefore, if the start point of the speech signal and the noise signal is found in the real speech interval detection step S300, it is preferable that the normalization of the feature vector is performed except for the noise interval (S420). However, It is preferable that the feature vector for the speech interval detected in the detected frame unit end point detection step S100 is normalized (S430).
이하 도 6 및 도 7을 참고하여 본 실시예에 따른 음성 신호의 검출 방법이 적용된 음성 신호 검출 시스템에 대하여 설명한다.Hereinafter, a speech signal detection system to which the speech signal detection method according to the present embodiment is applied will be described with reference to FIGS. 6 and 7. FIG.
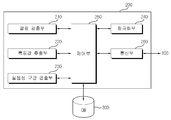
도 6을 참고하면, 본 실시예에 따른 음성 신호 검출 시스템은, 음성 신호원(10), 사용자 단말기(100), 음성 신호 검출 서버(200), 데이터 베이스(300)를 포함한다.Referring to FIG. 6, the voice signal detection system according to the present embodiment includes a
음성 신호원(10)은 음성 신호를 사용자 단말기(100)에 제공하는 사용자를 포함한다.The
음성 신호 검출 서버(200)는 사용자 단말기(100)로부터 입력 받은 신호를 통해 상술한 음성 신호의 검출 방법을 수행하고, 그 결과를 사용자 단말기(100)에 전송한다.The voice
데이터 베이스(300)는 음성 신호 검출 서버에서 음성 및 비음성 신호의 확률 모델을 이용하여 음성일 확률 또는 음성이 아닐 확률을 계산하기 위한, 또는 신호의 에너지를 문턱값과 비교하여 음성 신호임을 판정하기 위한 데이터들을 저장 및 관리한다.The
이하 도 7을 참조하여 음성 신호 검출 서버(200)에 대하여 상세히 설명하면, 본 실시예에 따른 음성 신호 검출 서버(200)는 끝점 검출부(210), 특징값 추출부(220), 실 음성 구간 검출부(230), 정규화부(240), 제어부(250), 통신부(260)를 포함한다.7, the voice
끝점 검출부(210)는 사용자 단말기를 통해 입력된 입력 신호의 음성 구간을 검출하기 위하여 프레임 단위의 끝점 검출을 수행한다.The
특징값 추출부(220)는 끝점 검출부(210)에서 검출된 음성 구간 중 일부 구간의 특징 값을 추출하기 위한 복수의 윈도우들의 특징값을 추출한다.The feature
실 음성 구간 검출부(230)는 추출된 특징값을 미리 결정된 임계값과 비교하여 음성 구간 중 실 음성 구간을 검출한다. The real
또한 정규화부(240)는 실 음성 구간의 특징벡터를 정규화하거나, 잡음 신호의 위치 또는 음성 신호의 위치가 검출되지 않은 경우 검출된 음성 구간에 대한 특징벡터를 정규화한다.Also, the
통신부(260)는 사용자 단말기를 통해 신호를 입력 받고 검출된 음성 구간의 결과를 사용자 단말기에게 다시 제공한다. 나아가 제어부(250)는 상술한 끝점 검출부(210), 특징값 추출부(220), 실 음성 구간 검출부(230), 정규화부(240), 통신부(260)들의 작동을 제어한다.The
이상의 끝점 검출부(210), 특징값 추출부(220), 실 음성 구간 검출부(230), 정규화부(240)의 세부적인 동작은 상술한 음성 신호의 검출 방법에 대응되는 것으로 이에 대한 상세한 설명은 중복되므로 생략한다.The detailed operations of the
나아가 상술한 음성 신호 검출 서버(200) 서버로 구현되는 것 외에 사용자 단말기의 성능에 따라 단말기(100) 내부에 구현되는 것도 가능하며 이때의 통신부(260) 내부의 데이터 송수신 모듈에 해당하는 것이 바람직하다.Furthermore, it may be implemented in the terminal 100 according to the performance of the user terminal in addition to being implemented in the
이상의 본 실시예에 따른 음성 신호의 검출 방법을 통하면 성 인식 시스템에서 사용하는 특징 벡터의 정규화 성능을 높일 수 있으며, 이는 잡음 환경에서의 음성 인식 성능을 높일 수 있다.According to the method of detecting a speech signal according to the present embodiment as described above, the normalization performance of the feature vector used in the gender recognition system can be enhanced, which improves speech recognition performance in a noisy environment.
한편 본 발명의 음성 신호의 검출 방법은 컴퓨터로 읽을 수 있는 기록매체에 컴퓨터가 읽을 수 있는 코드로 구현하는 것이 가능하다. 컴퓨터가 읽을 수 있는 기록 매체는 컴퓨터 시스템에 의하여 읽혀질 수 있는 데이터가 저장되는 모든 종류의 기록 장치를 포함한다.Meanwhile, the method for detecting a voice signal of the present invention can be implemented by a computer-readable code on a computer-readable recording medium. A computer-readable recording medium includes all kinds of recording apparatuses in which data that can be read by a computer system is stored.
컴퓨터가 읽을 수 있는 기록 매체의 예로는 ROM, RAM, CD-ROM, 자기 테이프, 플로피 디스크, 광데이터 저장장치 등이 있으며, 또한 컴퓨터가 읽을 수 있는 기록 매체는 네트워크로 연결된 컴퓨터 시스템에 분산되어, 분산 방식으로 컴퓨터가 읽을 수 있는 코드가 저장되고 실행될 수 있다. 그리고 본 발명을 구현하기 위한 기능적인(functional) 프로그램, 코드 및 코드 세그먼트 들은 본 발명이 속하는 기술 분야의 프로그래머들에 의하여 용이하게 추론될 수 있다.Examples of the computer-readable recording medium include ROM, RAM, CD-ROM, magnetic tape, floppy disk, optical data storage, and the like. Computer-readable code in a distributed fashion can be stored and executed. In addition, functional programs, codes, and code segments for implementing the present invention can be easily deduced by programmers skilled in the art to which the present invention belongs.
이상의 설명은 본 발명의 기술 사상을 예시적으로 설명한 것에 불과한 것으로서, 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자라면 본 발명의 본질적인 특성에서 벗어나지 않는 범위 내에서 다양한 수정, 변경 및 치환이 가능할 것이다. It will be apparent to those skilled in the art that various modifications, substitutions and substitutions are possible, without departing from the scope and spirit of the invention as disclosed in the accompanying claims. will be.
따라서, 본 발명에 개시된 실시예 및 첨부된 도면들은 본 발명의 기술 사상을 한정하기 위한 것이 아니라 설명하기 위한 것이고, 이러한 실시예 및 첨부된 도면에 의하여 본 발명의 기술 사상의 범위가 한정되는 것은 아니다. 본 발명의 보호 범위는 아래의 청구 범위에 의하여 해석되어야 하며, 그와 동등한 범위 내에 있는 모든 기술 사상은 본 발명의 권리 범위에 포함되는 것으로 해석되어야 할 것이다.Therefore, the embodiments disclosed in the present invention and the accompanying drawings are intended to illustrate and not to limit the technical spirit of the present invention, and the scope of the technical idea of the present invention is not limited by these embodiments and the accompanying drawings . The scope of protection of the present invention should be construed according to the following claims, and all technical ideas within the scope of equivalents should be construed as falling within the scope of the present invention.
Claims (16)
검출된 상기 음성 구간 중 복수의 윈도우들에 대응되는 적어도 일부 구간의 신호의 특징값을 추출하는 단계; 및
상기 추출된 특징값을 미리 결정된 임계값과 비교하여 상기 음성 구간 중 실 음성 구간을 검출하는 단계를 포함하는 음성 신호의 검출 방법. Detecting a speech interval by performing end-point detection on a frame basis with respect to an input signal;
Extracting a feature value of a signal of at least a section corresponding to a plurality of windows among the detected speech sections; And
And comparing the extracted feature value with a predetermined threshold value to detect an actual voice section in the voice section.
상기 음성 신호의 검출 방법은 상기 실 음성 구간의 특징벡터를 정규화하는 단계를 더 포함하는 것을 특징으로 하는 음성 신호의 검출 방법.The method according to claim 1,
Wherein the method for detecting a voice signal further comprises normalizing a feature vector of the real voice section.
상기 실 음성 구간을 검출하는 단계는 상기 추출된 특징값의 극대값을 추출하고, 상기 극대값을 상기 임계값과 비교하여 상기 실 음성 구간을 검출하는 것을 특징으로 하는 음성 신호의 검출 방법.3. The method of claim 2,
Wherein the step of detecting the real voice section detects the real voice section by extracting a maximum value of the extracted characteristic values and comparing the maximum value with the threshold value.
상기 실 음성 구간을 검출하는 단계는 상기 음성 구간 중 잡음 신호의 위치 및 음성 신호의 위치를 검출하여 잡음 구간을 검출하는 것을 특징으로 하는 음성 신호의 검출 방법.3. The method of claim 2,
Wherein the step of detecting the real voice section detects a position of a noise signal and a position of a voice signal in the voice section to detect a noise section.
상기 특징벡터를 정규화하는 단계는 상기 음성 구간 중 상기 잡음 구간을 제외한 구간에 대한 상기 특징벡터를 정규화하는 것을 특징으로 하는 음성 신호의 검출 방법.5. The method of claim 4,
Wherein normalizing the feature vector normalizes the feature vector for a section of the speech section excluding the noise section.
상기 복수의 윈도우들은 상기 윈도우에 대응되는 구간의 적어도 일부가 다른 윈도우에 대응되는 구간과 중첩되는 것을 특징으로 하는 음성 신호의 검출 방법.The method according to claim 1,
Wherein the plurality of windows overlap at least a part of a section corresponding to the window and a section corresponding to another window.
상기 정규화하는 단계는 상기 잡음 신호의 위치 또는 상기 음성 신호의 위치가 검출되지 않은 경우 검출된 상기 음성 구간에 대한 상기 특징벡터를 정규화하는 것을 특징으로 하는 음성 신호의 검출 방법. 5. The method of claim 4,
Wherein the normalizing step normalizes the feature vector with respect to the detected speech section when the position of the noise signal or the position of the speech signal is not detected.
상기 특징값을 추출하는 단계는 상기 윈도우에 대응되는 구간의 통계적 특성을 추출하는 것을 특징으로 하는 음성 신호의 검출 방법.The method according to claim 1,
Wherein the extracting of the feature value comprises extracting a statistical characteristic of a section corresponding to the window.
검출된 상기 음성 구간 중 복수의 윈도우들에 대응되는 적어도 일부 구간의 신호의 특징값을 추출하는 특징값 추출부; 및
상기 추출된 특징값을 미리 결정된 임계값과 비교하여 상기 음성 구간 중 실 음성 구간을 검출하는 실 음성 구간 검출부를 포함하는 음성 신호의 검출 장치. An endpoint detector for detecting a speech interval by performing end-point detection on a frame-by-frame basis with respect to an input signal;
A feature value extracting unit for extracting a feature value of a signal of at least a partial interval corresponding to a plurality of windows among the detected voice intervals; And
And an actual voice interval detector for detecting an actual voice interval in the voice interval by comparing the extracted characteristic value with a predetermined threshold value.
상기 음성 신호의 검출 장치는 상기 실 음성 구간의 특징벡터를 정규화하는 정규화부를 더 포함하는 것을 특징으로 하는 음성 신호의 검출 장치.10. The method of claim 9,
Wherein the apparatus for detecting a speech signal further includes a normalization unit for normalizing a feature vector of the real speech period.
상기 실 음성 구간 검출부는 상기 추출된 특징값의 극대값을 추출하고, 상기 극대값을 상기 임계값과 비교하여 상기 실 음성 구간을 검출하는 것을 특징으로 하는 음성 신호의 검출 장치.11. The method of claim 10,
Wherein the real voice section detecting section extracts a maximum value of the extracted characteristic values and compares the maximum value with the threshold value to detect the real voice section.
상기 실 음성 구간 검출부는 상기 음성 구간 중 잡음 신호의 위치 및 음성 신호의 위치를 검출하여 잡음 구간을 검출하는 것을 특징으로 하는 음성 신호의 검출 장치.11. The method of claim 10,
Wherein the real voice section detecting section detects a noise section by detecting a position of a noise signal and a position of a voice signal in the voice section.
상기 정규화부는 상기 음성 구간 중 상기 잡음 구간을 제외한 구간에 대한 상기 특징벡터를 정규화하는 것을 특징으로 하는 음성 신호의 검출 장치.13. The method of claim 12,
Wherein the normalizing unit normalizes the feature vector with respect to the interval excluding the noise interval of the speech interval.
상기 복수의 윈도우들은 상기 윈도우에 대응되는 구간의 적어도 일부가 다른 윈도우에 대응되는 구간과 중첩되는 것을 특징으로 하는 음성 신호의 검출 장치.10. The method of claim 9,
Wherein the plurality of windows overlap at least a part of a section corresponding to the window and a section corresponding to another window.
상기 정규화부는 상기 잡음 신호의 위치 또는 상기 음성 신호의 위치가 검출되지 않은 경우 검출된 상기 음성 구간에 대한 상기 특징벡터를 정규화하는 것을 특징으로 하는 음성 신호의 검출 장치. 13. The method of claim 12,
Wherein the normalizing unit normalizes the feature vector with respect to the detected speech interval when the position of the noise signal or the position of the speech signal is not detected.
상기 특징값을 추출부는 상기 윈도우에 대응되는 구간의 통계적 특성을 추출하는 것을 특징으로 하는 음성 신호의 검출 장치.10. The method of claim 9,
Wherein the extracting unit extracts the feature value from a statistical characteristic of a section corresponding to the window.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020120145284A KR101697651B1 (en) | 2012-12-13 | 2012-12-13 | A method for detecting an audio signal and apparatus for the same |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020120145284A KR101697651B1 (en) | 2012-12-13 | 2012-12-13 | A method for detecting an audio signal and apparatus for the same |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20140076816A true KR20140076816A (en) | 2014-06-23 |
| KR101697651B1 KR101697651B1 (en) | 2017-01-18 |
Family
ID=51128963
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020120145284A KR101697651B1 (en) | 2012-12-13 | 2012-12-13 | A method for detecting an audio signal and apparatus for the same |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR101697651B1 (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20160074784A (en) * | 2014-12-18 | 2016-06-29 | 재단법인 포항산업과학연구원 | Apparatus and method of extracting information content pattern of data |
| CN108242241A (en) * | 2016-12-23 | 2018-07-03 | 中国农业大学 | A kind of pure voice rapid screening method and its device |
| KR20180097496A (en) * | 2018-08-24 | 2018-08-31 | 에스케이텔레콤 주식회사 | Method for speech endpoint detection using normalizaion and apparatus thereof |
| CN112189232A (en) * | 2019-07-31 | 2021-01-05 | 深圳市大疆创新科技有限公司 | Audio processing method and device |
| CN112735385A (en) * | 2020-12-30 | 2021-04-30 | 科大讯飞股份有限公司 | Voice endpoint detection method and device, computer equipment and storage medium |
| JPWO2021181451A1 (en) * | 2020-03-09 | 2021-09-16 |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20210026872A (en) | 2019-09-02 | 2021-03-10 | 한국전자통신연구원 | Apparatus for Auto interpretation and the Method for composing character string of interpretation unit thereof |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060057919A (en) * | 2004-11-24 | 2006-05-29 | 한국전자통신연구원 | Voice 2 stage end-point detection apparatus for automatic voice recognition system and method therefor |
| KR20100069117A (en) * | 2008-12-16 | 2010-06-24 | 한국전자통신연구원 | Cepstrum mean subtraction method and its apparatus |
-
2012
- 2012-12-13 KR KR1020120145284A patent/KR101697651B1/en active IP Right Grant
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060057919A (en) * | 2004-11-24 | 2006-05-29 | 한국전자통신연구원 | Voice 2 stage end-point detection apparatus for automatic voice recognition system and method therefor |
| KR20100069117A (en) * | 2008-12-16 | 2010-06-24 | 한국전자통신연구원 | Cepstrum mean subtraction method and its apparatus |
Non-Patent Citations (1)
| Title |
|---|
| 신계현, 마이크로폰 어레이와 2단계 음성구간 검출을 이용한 자동차 환경에서의 음성인식 시스템, 광운대학교 대학원 컴퓨터 공학과, 석사학위논문, 2007.* * |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20160074784A (en) * | 2014-12-18 | 2016-06-29 | 재단법인 포항산업과학연구원 | Apparatus and method of extracting information content pattern of data |
| CN108242241A (en) * | 2016-12-23 | 2018-07-03 | 中国农业大学 | A kind of pure voice rapid screening method and its device |
| KR20180097496A (en) * | 2018-08-24 | 2018-08-31 | 에스케이텔레콤 주식회사 | Method for speech endpoint detection using normalizaion and apparatus thereof |
| CN112189232A (en) * | 2019-07-31 | 2021-01-05 | 深圳市大疆创新科技有限公司 | Audio processing method and device |
| JPWO2021181451A1 (en) * | 2020-03-09 | 2021-09-16 | ||
| CN112735385A (en) * | 2020-12-30 | 2021-04-30 | 科大讯飞股份有限公司 | Voice endpoint detection method and device, computer equipment and storage medium |
| CN112735385B (en) * | 2020-12-30 | 2024-05-31 | 中国科学技术大学 | Voice endpoint detection method, device, computer equipment and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| KR101697651B1 (en) | 2017-01-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101697651B1 (en) | A method for detecting an audio signal and apparatus for the same | |
| US11842748B2 (en) | System and method for cluster-based audio event detection | |
| KR101041039B1 (en) | Method and Apparatus for space-time voice activity detection using audio and video information | |
| Renevey et al. | Entropy based voice activity detection in very noisy conditions. | |
| KR101610151B1 (en) | Speech recognition device and method using individual sound model | |
| KR101417975B1 (en) | Method and system for endpoint automatic detection of audio record | |
| EP2486562B1 (en) | Method for the detection of speech segments | |
| KR101437830B1 (en) | Method and apparatus for detecting voice activity | |
| US8543402B1 (en) | Speaker segmentation in noisy conversational speech | |
| EP2994911B1 (en) | Adaptive audio frame processing for keyword detection | |
| US20160266910A1 (en) | Methods And Apparatus For Unsupervised Wakeup With Time-Correlated Acoustic Events | |
| US20040064314A1 (en) | Methods and apparatus for speech end-point detection | |
| EP2048656A1 (en) | Speaker recognition | |
| CN110232933B (en) | Audio detection method and device, storage medium and electronic equipment | |
| US9335966B2 (en) | Methods and apparatus for unsupervised wakeup | |
| CN109903752B (en) | Method and device for aligning voice | |
| EP2721609A1 (en) | Identification of a local speaker | |
| JP6087542B2 (en) | Speaker recognition device, speaker recognition method, and speaker recognition program | |
| US11335332B2 (en) | Trigger to keyword spotting system (KWS) | |
| Tong et al. | Evaluating VAD for automatic speech recognition | |
| CN109065026B (en) | Recording control method and device | |
| CN112189232A (en) | Audio processing method and device | |
| Moattar et al. | A new approach for robust realtime voice activity detection using spectral pattern | |
| EP3195314B1 (en) | Methods and apparatus for unsupervised wakeup | |
| US10950227B2 (en) | Sound processing apparatus, speech recognition apparatus, sound processing method, speech recognition method, storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant | ||
| FPAY | Annual fee payment |
Payment date: 20191223 Year of fee payment: 4 |