JP7179947B2 - Storage system and storage control method - Google Patents
Storage system and storage control method Download PDFInfo
- Publication number
- JP7179947B2 JP7179947B2 JP2021179972A JP2021179972A JP7179947B2 JP 7179947 B2 JP7179947 B2 JP 7179947B2 JP 2021179972 A JP2021179972 A JP 2021179972A JP 2021179972 A JP2021179972 A JP 2021179972A JP 7179947 B2 JP7179947 B2 JP 7179947B2
- Authority
- JP
- Japan
- Prior art keywords
- storage
- control unit
- volume
- controller
- storage controller
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000003860 storage Methods 0.000 title claims description 1037
- 238000000034 method Methods 0.000 title claims description 64
- 238000012545 processing Methods 0.000 claims description 91
- 230000009467 reduction Effects 0.000 claims description 30
- 230000037430 deletion Effects 0.000 claims description 22
- 238000012217 deletion Methods 0.000 claims description 16
- 230000004044 response Effects 0.000 claims description 6
- 230000007423 decrease Effects 0.000 claims description 5
- 238000007726 management method Methods 0.000 description 133
- 230000010365 information processing Effects 0.000 description 37
- 230000008569 process Effects 0.000 description 37
- 238000004891 communication Methods 0.000 description 27
- 238000010586 diagram Methods 0.000 description 22
- 238000011084 recovery Methods 0.000 description 15
- 230000006870 function Effects 0.000 description 11
- 238000005516 engineering process Methods 0.000 description 9
- 230000005012 migration Effects 0.000 description 6
- 238000010276 construction Methods 0.000 description 5
- 230000002401 inhibitory effect Effects 0.000 description 5
- 230000005764 inhibitory process Effects 0.000 description 5
- 238000013508 migration Methods 0.000 description 5
- 230000008859 change Effects 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 230000008707 rearrangement Effects 0.000 description 3
- 230000004043 responsiveness Effects 0.000 description 3
- 230000015556 catabolic process Effects 0.000 description 2
- 238000012790 confirmation Methods 0.000 description 2
- 238000013523 data management Methods 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 230000014509 gene expression Effects 0.000 description 2
- 238000013507 mapping Methods 0.000 description 2
- 238000003672 processing method Methods 0.000 description 2
- 230000001629 suppression Effects 0.000 description 2
- 229910000906 Bronze Inorganic materials 0.000 description 1
- BQCADISMDOOEFD-UHFFFAOYSA-N Silver Chemical compound [Ag] BQCADISMDOOEFD-UHFFFAOYSA-N 0.000 description 1
- 239000010974 bronze Substances 0.000 description 1
- KUNSUQLRTQLHQQ-UHFFFAOYSA-N copper tin Chemical compound [Cu].[Sn] KUNSUQLRTQLHQQ-UHFFFAOYSA-N 0.000 description 1
- 239000006185 dispersion Substances 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 229910052737 gold Inorganic materials 0.000 description 1
- 239000010931 gold Substances 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 238000011946 reduction process Methods 0.000 description 1
- 229910052709 silver Inorganic materials 0.000 description 1
- 239000004332 silver Substances 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
Images















Landscapes
- Hardware Redundancy (AREA)
Description
本発明は、ストレージシステム及びその制御方法に関する。 The present invention relates to a storage system and its control method.
高い信頼性を求められる情報処理システムでは、複数のサーバを用いてシステムを冗長化することが一般的である。しかしながら、このような冗長化構成の場合、サーバ障害発生後に冗長度を回復させるために、障害が発生したサーバの代替となるスペアサーバを用意しておく必要がある。通常時にスペアのサーバは処理を行わないため、サーバの利用効率が低下する。 In an information processing system that requires high reliability, it is common to use a plurality of servers to make the system redundant. However, in the case of such a redundant configuration, it is necessary to prepare a spare server to replace the failed server in order to restore redundancy after a server failure. Since the spare server does not perform processing during normal times, the utilization efficiency of the server decreases.
一方、近年では、仮想化技術を用いて、サーバを仮想化することで、物理サーバの利用効率を向上させ、物理サーバの台数を削減する構成も増えている。仮想マシンの冗長化に関する発明が、例えば特許文献1に開示されている。特許文献1では、複数台の現用系の仮想マシンと、これら現用系の仮想マシンを冗長化するために設けられた予備系の仮想マシンとを、複数の物理サーバに配置する技術が開示されている。このような仮想マシンを配置する技術によれば、物理サーバ障害によって冗長化した仮想マシンの片方を喪失した場合に、喪失した仮想マシンを別の物理サーバ上にコピーして冗長化構成を再構築することで、スペアの物理サーバを用意することなく冗長度を回復させること可能としている。
On the other hand, in recent years, there has been an increasing number of configurations in which servers are virtualized using virtualization technology, thereby improving utilization efficiency of physical servers and reducing the number of physical servers. An invention related to redundancy of virtual machines is disclosed in
高い信頼性が求められる情報処理システムの中には、例えば、冗長化動作を行うための動作基盤といった、システム内部の基盤処理を安定動作させるために、システムが処理する情報量とは関係なく、一定量のCPUコアやメモリなどの情報処理資源を必要とするものがある。例えば、仮想化技術を用いたストレージシステムが安定動作するためには、ボリューム数などとは関係なく、一定量の情報処理資源を必要とする。 In information processing systems that require high reliability, for example, in order to stably operate the base processing inside the system, such as the operation base for performing redundant operation, regardless of the amount of information processed by the system, Some require a certain amount of information processing resources such as CPU cores and memory. For example, in order for a storage system using virtualization technology to operate stably, it requires a certain amount of information processing resources regardless of the number of volumes.
また、仮想マシン、コンテナ、マルチプロセスなどによって、1台のサーバ上で複数の独立したシステムを動作させる構成において、このような一定量の情報処理資源を最低限必要とするシステムを動作させる場合、同一サーバ上で動作する他のシステムの影響を受けないようにする必要がある。そのため、当該システムに必要な情報処理資源を予約し、当該システムに固定的に割り当てることが一般的である。 In addition, in a configuration that operates multiple independent systems on a single server using virtual machines, containers, multi-processes, etc., when operating a system that requires a certain amount of information processing resources at a minimum, It is necessary to avoid being affected by other systems running on the same server. Therefore, it is common to reserve information processing resources necessary for the system and assign them to the system in a fixed manner.
しかしながら、このようなシステムに特許文献1の配置技術を適用する場合、冗長度が低下したシステムに、当該システムが必要とする最低限の情報処理資源が再構築先の物理サーバに余っている必要がある。そのため、確実に冗長度を回復させるためには、予め物理サーバに冗長度回復用の情報処理資源を予約しておく必要がある。冗長度回復用に予約された情報処理資源は、障害等により冗長度の低下する場合以外は、利用されないため物理サーバの利用効率が低下し、システム構築コストが高くなる。
However, when applying the arrangement technology of
また、仮想化技術を用いたストレージシステムである、Software Defined Storage(SDS)は高い信頼性が求められる一方、比較的安価なサーバを用いて、低コストで情報処理システムを構築することが求められている。 Software Defined Storage (SDS), which is a storage system using virtualization technology, is required to be highly reliable, but it is also required to construct a low-cost information processing system using relatively inexpensive servers. ing.
本発明の目的は、システムの可用性を担保しつつ、低コストのストレージシステム、およびストレージ制御方法を提供することにある。 An object of the present invention is to provide a low-cost storage system and storage control method while ensuring system availability.
上記課題を解決するため、本発明の望ましい態様の一つのストレージシステムは、クラスタを構成する複数のストレージノードを有するストレージシステムにおいて、各ストレージノードは、データを記憶する記憶装置と、ストレージシステム全体の制御を行うクラスタ制御部と、記憶装置を利用してボリュームという単位で記憶領域をホスト装置に提供し、ホスト装置からのIO要求に応じて前記記憶装置にデータを保存するストレージ制御部とを有し、ストレージ制御部は、クラスタ内の他のストレージノードのストレージ制御部とストレージ制御部グループを構成し、ストレージ制御部グループの一つのストレージ制御部がアクティブモードのストレージ制御部としてホスト装置からのIO要求を処理し、ストレージ制御部グループの残りストレージ制御部がスタンバイモードのストレージ制御部として、アクティブモードのストレージ制御部が失われた場合に、アクティブモードに切り替わり、アクティブモードのストレージ制御部の処理を引き継ぐよう構成され、複数のストレージノードの内の一台のストレージノードをストレージシステムから取り除く場合、残存する他のストレージノードのクラスタ制御部は、取り除かれるストレージノードのストレージ制御部を用いて構成されるストレージ制御部グループが担当する複数のボリュームを取得し、取得した複数のボリュームの各ボリュームに対し退避先のストレージ制御部グループを決定し、取り除かれるストレージノードのストレージ制御部を用いて構成されるストレージ制御部グループを構成するストレージ制御部から退避先の複数のストレージ制御部グループのストレージ制御部へ、取り除かれるストレージノードのストレージ制御部を用いて構成されるストレージ制御部グループが担当する複数のボリュームを分散して退避させる。 In order to solve the above problems, a storage system according to one preferred aspect of the present invention is a storage system having a plurality of storage nodes forming a cluster. Each storage node includes a storage device for storing data and a It has a cluster control unit that performs control, and a storage control unit that uses a storage device to provide a host device with a storage area in units of volumes, and stores data in the storage device in response to an IO request from the host device. The storage controllers form a storage controller group with the storage controllers of other storage nodes in the cluster, and one storage controller in the storage controller group receives IO from the host device as a storage controller in active mode. The remaining storage controllers in the storage controller group are configured as standby mode storage controllers to switch to active mode if the active mode storage controller is lost, and to take over the processing of the active mode storage controllers. When one of the storage nodes configured to take over is removed from the storage system, the cluster controllers of the other remaining storage nodes are configured using the storage controller of the removed storage node. A storage that acquires multiple volumes that a storage controller group is in charge of, determines the save destination storage controller group for each of the acquired multiple volumes, and uses the storage controller of the removed storage node. A plurality of volumes that are in charge of the storage control unit group configured using the storage control unit of the storage node to be removed are transferred from the storage control unit that constitutes the control unit group to the storage control units of the multiple storage control unit groups of the backup destination. Disperse and evacuate.
本発明により、冗長度の回復可能性を保証するための予約情報処理資源が不要となり、物理サーバの利用効率が向上する。 The present invention eliminates the need for reserved information processing resources for guaranteeing the possibility of recovering redundancy, thereby improving the utilization efficiency of physical servers.
以下、図面を参照して、本発明の実施形態について詳述する。ただし、以下の記載および図面は、本発明を説明するための例示であって、説明の明確化のために、適宜省略および簡略化が行われており、本発明の技術的範囲を限定するものではない。 Hereinafter, embodiments of the present invention will be described in detail with reference to the drawings. However, the following description and drawings are examples for explaining the present invention, and are appropriately omitted and simplified for clarity of explanation, and limit the technical scope of the present invention. is not.
以後の説明では「テーブル」、「表」、「リスト」、「キュー」などの表現にて各種情報を説明するが、各種情報はこれら以外のデータ構造で表現されていてもよい。そのため、データ構造に依存しないことを示すために、単に「情報」と呼ぶことがある。各種情報の内容を説明する際に、「識別情報」、「識別子」、「名」、「名前」、「ID」、「番号」などの表現を用いるが、これらについては相互に置換が可能である。 In the following description, expressions such as "table", "table", "list", and "queue" will be used to describe various types of information, but various types of information may be expressed in data structures other than these. Therefore, it is sometimes simply called "information" to indicate that it does not depend on the data structure. Expressions such as "identification information", "identifier", "name", "name", "ID", and "number" are used when explaining the contents of various types of information, but these can be replaced with each other. be.
以後の説明では、「プログラム」を主語として説明を行う場合があるが、プログラムはプロセッサ(例えばCPU(Central Processing Unit)やGPU(Graphics Processing Unit))によって実行されることで定められた処理を、記憶資源(例えばメモリ)やインタフェースデバイス(例えば通信装置)などを適宜用いながら行うため、プロセッサを主語とした説明としてもよい。同様に、プログラムを実行して行う処理の主体が、プロセッサを有する例えばコントローラ、装置、システム、計算機、ノード、ストレージ装置、サーバ、クライアント、又はホストであってもよい。また、プログラムの一部または全ては、ハードウェア回路を用いて処理してもよい。 In the following explanation, the subject may be "program", but the program is a processor (for example, CPU (Central Processing Unit) or GPU (Graphics Processing Unit)). Since it is performed while appropriately using storage resources (for example, memory) and interface devices (for example, communication device), the processor may be the subject of the explanation. Similarly, the subject of processing performed by executing a program may be, for example, a controller, device, system, computer, node, storage device, server, client, or host having a processor. Also, part or all of the program may be processed using a hardware circuit.
各種プログラムは、プログラム配布サーバや記憶メディアによって各計算機にインストールされてもよい。また、以後の説明において、2以上のプログラムが1つのプログラムとして実現されてもよく、逆に1つのプログラムが2以上のプログラムとして実現されてもよい。 Various programs may be installed in each computer by a program distribution server or storage media. Also, in the following description, two or more programs may be implemented as one program, and conversely, one program may be implemented as two or more programs.
以下、図1~図16を参照して、実施例1について詳述する。 The first embodiment will be described in detail below with reference to FIGS. 1 to 16. FIG.
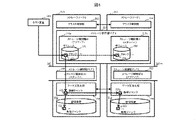
図1は、実施例1による情報処理システムの物理的な構成を示す図である。この情報処理システムは、1以上のホスト装置100と、1以上の管理端末110と、2以上のストレージノード200から構成されるマルチノード構成のストレージシステム200とを備えて構成される。各ホスト装置100及び管理端末110、各ストレージノード210間は、例えばファイバーチャネル(Fibre Channel)、イーサネット(登録商標)、無線LAN(Local Area Network)又はInfiniBandなどから構成されるネットワーク300を介して接続される。図には示していないが、ネットワーク300は、ネットワークスイッチやゲートウェイといった各種中継装置を含んでいてもよい。なお、各ストレージノード210間専用のネットワークを別途備えていてもよく、また、各ホスト装置100及び管理端末110、各ストレージノード210がそれら以外のネットワークに接続されていてもよい。
FIG. 1 is a diagram showing the physical configuration of the information processing system according to the first embodiment. This information processing system comprises one or
ホスト装置100は、インストールされたアプリケーションプログラムを実行することで各種業務処理を行うためのサーバ装置である。ホスト装置100は実行しているアプリケーションプログラムからの要求に応じて、ネットワーク300を介してストレージノード210に対してデータの読み込み要求又は書き込み要求を送信する。なお、ホスト装置100は仮想マシンやコンテナのような仮想的なサーバ装置であってもよい。
The
管理端末110は、ストレージシステムの管理者がストレージシステム200に対して各種の設定操作や状態監視を行うためのクライアント装置である。管理端末110はスマートフォンやタブレット端末のような携帯端末でもよく、一部のホスト装置100が管理端末を兼ねていてもよい。
The
ストレージシステム200は、ホスト装置100に対してデータの読み書きをするための記憶領域を提供するサーバ装置である。なお、ストレージシステム200を構成するストレージノード210は仮想マシンやコンテナのような仮想的なサーバ装置であってもよく、ホスト装置100の仮想的なサーバ装置とストレージノード210の仮想的なサーバ装置を同一の物理サーバ装置に配置する構成でもよい。
The
図2は、ストレージノード210の詳細構成を示す図である。ストレージノード210は、CPU211、メモリ212、記憶装置213、通信装置214とを備えており、これらが内部ネットワーク215を介して接続されたサーバ装置により構成される。ただし、図2はストレージノードの一例であり、本発明は図の構成に限定されるものではなく、CPU211、メモリ212、記憶装置213、通信装置214の全て或いは何れかが複数であっても良い。
FIG. 2 is a diagram showing the detailed configuration of the
CPU211は、ストレージノード210全体の動作制御を司る制御装置であり、メモリ212に格納された各種プログラムを実行することで、各種処理を実行する。メモリ212は、例えば、ストレージノード210で使用される制御情報、CPU211が実行するプログラム、ホスト装置がアクセスするデータなどを格納する。メモリ212は一般にDRAM(Dynamic RAM(Random Access Memory))で構成するが、例えば、MRAM(Magnetoresistive RAM),ReRAM(Resistive RAM)、PCM(Phase Change Memory)、NANDなど、DRAM以外の記憶メディアで構成されてもよい。
The
記憶装置213は、物理的に記憶領域を有する装置であり、例えば、HDD(Hard Disk Drive)、SSD(Solid State Drive)、SCM(Storage Class Memory)、又は光ディスクなどの不揮発性の記憶装置から構成される。記憶装置213へアクセスするためのインタフェースとして、SAS(Serial Attached SCSI)とNVMe(Non-Volatile Memory Express)を記載しているが、例えば、SATA(Serial ATA)、USB(Universal Serial Bus)など、それ以外のインタフェースであってもよい。
The
一般に、マルチノード構成のストレージシステムでは、ノード障害に備え、別のストレ
ージノード210にデータの複製を格納してデータを保護する。ノード内で複数の記憶装置213を束ねてRAID(Redundant Arrays of Independent Disks)のような高信頼化技術を使用してもよい。
Generally, in a multi-node configuration storage system, a copy of data is stored in another
通信装置214は、ネットワーク300を介してホスト装置100や他のストレージノード210、ストレージシステム200を管理するための管理端末110等と接続され、ホスト装置100や管理端末110、他のストレージノード210との通信を仲介する。図2では、通信装置214をホスト装置100向けの通信と管理端末110向けの通信、他のストレージノード210向けの通信とで共有しているが、それぞれの通信のために異なる通信装置を設けてもよい。
The
図3は、実施例1によるストレージシステムの論理的な構成を示す図である。クラスタ制御部216は、複数のストレージノードから構成されるストレージシステム全体の制御を司るソフトウェアである。クラスタ制御部216には、マスタとワーカの2種類の動作ロールがある。ワーカロールのクラスタ制御部216bはマスタロールのクラスタ制御部216aの指示に従ってストレージノード内の各種制御や状態監視を行い、マスタロールのクラスタ制御部216aはクラスタ全体での排他制御や一貫性制御が必要な処理、管理端末110を介した各種設定操作の処理や障害等発生時の通知等を行う。なお、マスタはワーカの機能を内包している。
FIG. 3 is a diagram showing the logical configuration of the storage system according to the first embodiment. The
マスタロールとして動作するクラスタ制御部はクラスタ内に常に1つ存在し、その他のクラスタ制御部はワーカロールで動作する。マスタロールのクラスタ制御部とワーカロールのクラスタ制御部は、ストレージノード間通信などによって、互いに生死監視を行っている。マスタロールのクラスタ制御部は、ストレージノード障害などによって、クラスタ制御部が失われた場合は、ストレージノード障害が発生したと判断し、障害回復処理を行う。障害回復処理の詳細に関しては、図を用いて後述する。 There is always one cluster controller operating as the master role in the cluster, and the other cluster controllers operate as worker roles. The cluster control unit of the master role and the cluster control unit of the worker role monitor each other for life and death through inter-storage node communication or the like. When the cluster control unit is lost due to a storage node failure or the like, the cluster control unit of the master role determines that a storage node failure has occurred and performs failure recovery processing. Details of the failure recovery process will be described later with reference to the drawings.
マスタロールのクラスタ制御部が失われた場合は、クラスタ内のワーカロールのクラスタ制御部の何れか1つがマスタロールに切り替わる。複数のワーカロールのクラスタ制御部からマスタロールに切り替わるクラスタ制御部の選出に関しては、一般に「リーダ選出」と呼ばれる技術及び機能を利用するため、説明は省略する。 If the cluster controller of the master role is lost, any one of the cluster controllers of the worker roles in the cluster will switch to the master role. Regarding the selection of the cluster control unit that switches from the cluster control units of a plurality of worker roles to the master role, a technique and function generally called "leader selection" is used, so the explanation is omitted.
ストレージ制御部219は、記憶領域としてホスト装置に提供するボリュームに関する各種制御を司るソフトウェアにより実現される。ストレージ制御部219は、記憶装置を利用してボリュームという単位で記憶領域をホスト装置に提供し、ホスト装置からのIO(Input/Output)要求に応じて記憶装置にデータを保存する機能を有する。また、あるストレージ制御部が担当していたボリュームを他のストレージ制御部に移動させる機能(マイグレーション機能)も有する。
The
ストレージ制御部219には、アクティブとスタンバイの2種類の動作モードがある。あるストレージノードに配置されたアクティブモードのストレージ制御部219aは、クラスタ内の異なるストレージノードに配置されたスタンバイモードのストレージ制御部219bとペア(ストレージ制御部ペア217と呼ぶ)を構成して動作する。ストレージ制御部ペアの他、一つのアクティブモードのストレージ制御部に複数のスタンバイモードのストレージ制御部を対応させる場合、ストレージ制御部グループとする。通常時は、アクティブモードのストレージ制御部219aがホスト装置からのIO要求を処理する。スタンバイモードのストレージ制御部219bは、ストレージノード障害などによるアクティブモードのストレージ制御部219aの喪失に備えて待機しておく。アクティブモードのストレージ制御部219aが失われた場合は、スタンバイモードのストレージ制御部219bがアクティブモードに切り替わり、IO要求などの処理を引き継ぐ。なお、ストレージ制御部ペアを構成する二つのストレージ制御部の両方がアクティブモードで動作していてもよく、ストレージ制御部グループを
構成する二つ以上のストレージ制御部がアクティブモードで動作していてもよい。この場合は、アクティブモードのストレージ制御部間で排他制御などの追加処理が必要になる。また、ストレージノード障害などによってアクティブモードのストレージ制御部が失われた場合に、残存しているアクティブモードのストレージ制御部が、失われたアクティブモードのストレージ制御部が担当していたIO要求などの処理を引き継いでもよい。
The
図3に示すように、1つのストレージノードに、2以上のストレージ制御部を配置してもよい。また、1つのストレージノードに配置するアクティブモードとスタンバイモードのストレージ制御部を同数に揃えることで、ストレージノード間での、例えばCPUやメモリなどの情報処理資源の利用率を均等にすることができる。 As shown in FIG. 3, one storage node may have two or more storage controllers. In addition, by arranging the same number of active mode and standby mode storage control units in one storage node, it is possible to equalize the utilization rate of information processing resources such as CPU and memory among storage nodes. .
データ冗長化部218は、複数のストレージノード210間でデータを冗長化して記憶装置に保存することで、ストレージノード障害によるデータ喪失を防止するためのソフトウェアにより実現される。データ冗長化の方法として、例えば、異なるストレージノード210にデータの複製を格納する方法や、パリティを複数のストレージノード210に分散して格納する方法などが考えられる。図には示していないが、ストレージノード内の記憶装置障害に備えて、ストレージノード間のデータ冗長化に加えて、ノード内でRAIDなどのデータ冗長化を行ってもよい。
The
このように、実施例1は、サーバを仮想化する仮想化技術の応用例として、複数台の物理サーバをストレージノードとして利用するストレージシステムに関する。このようなストレージシステムでは、ホスト装置に記憶領域としてボリュームを提供するストレージ制御部のアクティブ(現用系)とスタンバイ(予備系)を、異なるストレージノード間に配置して冗長化する。さらに、ストレージシステム全体の処理性能を向上させるために、一つのストレージノードには、アクティブとスタンバイから成るストレージ制御部ペアを複数備える。 As described above, the first embodiment relates to a storage system using a plurality of physical servers as storage nodes as an application example of virtualization technology for virtualizing servers. In such a storage system, the active (active system) and standby (backup system) storage control units that provide volumes as storage areas to the host device are arranged between different storage nodes for redundancy. Furthermore, in order to improve the processing performance of the entire storage system, one storage node has a plurality of active and standby storage controller pairs.
図4は、実施例1によるデータ管理の概要を説明する図である。図4は、ホスト装置からの書き込み要求を処理する場合を示している。 FIG. 4 is a diagram for explaining an overview of data management according to the first embodiment. FIG. 4 shows the case of processing a write request from the host device.
データ冗長化部218が、チャンクを用いて複数のストレージノード間でデータを複製する。物理チャンク222は、ストレージノード内の記憶装置を1以上の所定容量の小領域(例えば、42MB)に分割して作成した物理的な記憶領域である。論理チャンク221は1以上の物理チャンクが対応付けられた論理的なチャンクである。論理チャンク221は後述するボリューム220のブロック223に対応付けられ、ホスト装置の書き込みデータが格納される。1つの論理チャンク221に、それぞれ異なるストレージノードに作成した2以上の物理チャンク222を対応付け、論理チャンク221に書き込まれたデータを、対応付けられた全ての物理チャンク222に保存することでノード間のデータ冗長化を実現する。図4では、アクティブモードとスタンバイモードのストレージ制御部219が配置された各ストレージノード210の物理チャンク222にデータを保存している。このように、アクティブモードとスタンバイモードのストレージ制御部219が配置されるストレージノード210にデータを保存(データのローカリティを確保)しているので、ホスト装置にボリュームを提供するストレージ装置に対し、データのリード要求があった場合、他のストレージノードからデータを読み出す必要がなく、高い応答性を確保できる。
A
データのローカリティを担保しなければ、データを任意の2つのストレージノードの物理チャンクに保存してもよい。例えば、ストレージ制御部219が配置されたストレージノードの記憶装置の空き容量が不足した場合に、記憶装置の空き容量に余裕のあるストレージノードの物理チャンクに保存する、といった処理を行ってもよい。
If data locality is not guaranteed, data may be stored in physical chunks of any two storage nodes. For example, when the free space of the storage device of the storage node in which the
ボリューム220は、ストレージ制御部219がホスト装置100に提供する仮想的な記憶領域であり、ホスト装置100はボリュームに対してデータの書き込み要求を行う。ボリューム220は、ストレージシステム200の管理者が、管理端末110を介してストレージシステム200に対してボリューム作成指示を行うことによって作成される。ボリューム220の作成先となるストレージ制御部219は、ボリューム作成時に管理者が指定してもよく、ボリューム作成指示を受けたマスタロールのクラスタ制御部216aが、各ストレージノードの空き記憶容量や各ストレージ制御部のCPU利用率等を基に選択してもよい。
The
ボリューム自体は物理的な記憶領域を有しておらず、ホスト装置100からの書き込み要求に応じて論理チャンク221を割り当て、論理チャンク221にデータを論理的に書き込む。ボリューム220は、記憶領域を先頭から1以上の所定容量のブロック223に分割して管理される。このブロックは、例えば論理チャンクと一対一で対応付けられる。ボリューム作成直後は、どのブロックに対しても論理チャンクの対応付けは行われておらず、ホスト装置100がボリューム220に対してデータの書き込みを行った際に、データを書き込んだ領域に対応するブロック223に論理チャンク221が対応付けられてない場合に、論理チャンク221の作成と、ブロック223と論理チャンク221とを対応付ける処理が行われる。
A volume itself does not have a physical storage area, and
ホスト装置100からのIO要求の処理はアクティブモードのストレージ制御部219aが担当する。新しい論理チャンクを作成し、ブロックと論理チャンクとの対応付けを行った場合は、その対応関係を表す情報をスタンバイモードのストレージ制御部219bに転送する。アクティブモードのストレージ制御部219aとスタンバイモードのストレージ制御部219bとで、一つのストレージ制御ペア217を構成する。図4に示したように、ストレージノード0のスタンバイモードのストレージ制御部219は、ストレージノード1以外のストレージノードのストレージ制御部とストレージ制御ペア217を構成し、ストレージノード1のスタンバイモードのストレージ制御部219は、ストレージノード0以外のストレージノードのストレージ制御部とストレージ制御ペア217を構成する。
The processing of IO requests from the
論理チャンク221に書き込まれたデータは、データ冗長化部218が論理チャンク221と物理チャンク222の対応関係に従って、物理チャンク222に書き込む。図4の例では、物理チャンクを複製(二重化)することでデータを冗長化する場合を示しており、ホスト装置100から書き込まれたデータは、「ストレージノード0」と「ストレージノード1」の物理チャンクに書き込まれる。物理チャンクを三重化する場合や、ストレージノード間でRAIDやErasure Codingを利用して冗長化する場合なども、データ冗長化部がその冗長化方式に応じて、物理チャンクの複製やパリティの生成を行う。図4では、ブロックと論理チャンクは同容量かつ一対一で対応付けられており、以後においても、ブロックと論理チャンクは一対一に付けられているものとして説明を進める。但し、例えば、1以上のボリュームからなる、2以上ブロックが1つの論理チャンクに対応付けられるものとしてもよい。
Data written to the
図4には示していないが、「ストレージノード0」の障害時に、「ストレージノード1」のストレージ制御部とデータ冗長化部が処理を引き継ぐため、「ストレージノード1」もボリュームに関する情報、ブロックに関する情報、論理チャンクに関する情報を有しており、どちらか一方のストレージノードで情報を更新すると、それに同期して、もう一方のストレージノードに更新内容が転送されて情報が更新される。それぞれの情報の詳細に関しては管理情報が記載されている図を用いて説明する。
Although not shown in FIG. 4, when “
次に、実施例1によるストレージシステムを制御するための管理情報(管理表)について説明する。なお、各種管理情報は、管理端末110を介してストレージシステム200の管理者が参照及び設定できるようにしてもよい。
Next, management information (management table) for controlling the storage system according to the first embodiment will be described. Various types of management information may be referenced and set by the administrator of the
図5は、ストレージノード管理表256の一例である。ストレージノード管理表は、表形
式以外のデータ構造で表現されていてもよい。そのため、データ構造に依存しないことを示すために、単に「情報」と呼ぶことがある。ストレージノード管理表は、ストレージノードの動作状況と、ストレージノードが持つ各種情報処理資源を管理する情報である。ストレージノード管理表は、マスタロールのクラスタ制御部が動作するストレージノードのメモリに格納される。ストレージノード管理表256は、ストレージノードID2561、ロール2562、動作状態2563、CPUコア数2564、メモリ量2565、通信帯域利用率2566、記憶装置総容量2567、記憶装置総使用量2568を含むレコードを管理する。
FIG. 5 is an example of the storage node management table 256. As shown in FIG. The storage node management table may be expressed in a data structure other than tabular format. Therefore, it is sometimes simply called "information" to indicate that it does not depend on the data structure. The storage node management table is information for managing the operating status of the storage node and various information processing resources of the storage node. The storage node management table is stored in the memory of the storage node in which the master role cluster controller operates. The storage node management table 256 manages records including
ストレージノードID2561は、ストレージノードを一意に識別するIDであり、ストレージシステム全体でユニークなIDである。ロール2562は、当該ストレージノードで動作するクラスタ制御部の動作ロール(マスタ、ワーカ)を示す情報である。動作状態2563は、当該ストレージノードが正常に動作しているか否かを示す情報である。CPUコア数2564とメモリ量2565は、それぞれ、当該ストレージノードに搭載されたCPUのコア数とメモリの容量を示す情報である。通信帯域利用率2566は、当該ストレージノードに搭載された通信装置の帯域利用率を示す情報である。記憶装置総容量2567は、当該ストレージノードに搭載された記憶装置の容量の合計である。記憶装置総使用量2568は、当該ストレージノードに搭載された記憶装置の容量のうち、実際に利用している容量の合計である。ストレージノードIDが1のストレージノードは、マスタロールのクラスタ制御部として動作していることを示す。
A
通信帯域利用率2566、記憶装置総使用量2568は、定期的にマスタロールのクラスタ制御部が、各ストレージ制御部で動作するワーカロールのクラスタ制御部から取得した情報である。省略しているが、各ストレージノードは、マスタロールのクラスタ制御部が収集するストレージノードの情報を管理している。また、ストレージノード障害などによって、当該ストレージノードのクラスタ制御部が動作していない場合は、マスタロールのクラスタ制御部が当該ストレージノードで障害が発生していると判断し、ストレージノード管理表の動作状態を障害に変更する。図4では、ストレージノードIDが0のストレージノードで障害が発生していることを示す。またストレージノード障害により、通信帯域利用率と記憶装置総使用量を取得できなかった場合は“NA”と示している。
The communication
図6は、ストレージ制御部管理表257の一例である。ストレージ制御部管理表257は、表形式以外のデータ構造で表現されていてもよい。そのため、データ構造に依存しないことを示すために、単に「情報」と呼ぶことがある。ストレージ制御部管理表257は、ストレージ制御部のペア関係と、ストレージ制御部とストレージノードの関係、ストレージ制御部の動作状況を管理する情報である。ストレージ制御部管理表257は、マスタロールのクラスタ制御部が動作するストレージノードのメモリに格納される。ストレージ制御部管理表257は、ストレージ制御部ID2571、ストレージ制御部ペアID2572、ストレージノードID2573、動作モード2574、割り当てCPUコア数2575、割り当てメモリ量2576、CPU利用率2577、メモリ利用量2578を含むレコードを管理する。
FIG. 6 is an example of the storage controller management table 257. As shown in FIG. The storage control unit management table 257 may be expressed in a data structure other than the tabular format. Therefore, it is sometimes simply called "information" to indicate that it does not depend on the data structure. The storage controller management table 257 is information for managing the pair relationship of the storage controllers, the relationship between the storage controllers and the storage nodes, and the operating status of the storage controllers. The storage controller management table 257 is stored in the memory of the storage node in which the master role cluster controller operates. The storage control unit management table 257 is a record containing a storage
ストレージ制御部ID2571は、ストレージ制御部を一意に識別するIDであり、ストレージシステム全体でユニークなIDである。ストレージ制御部ペアID2572は、当該ストレージ制御部が属しているストレージ制御部ペアを一意に識別するためのIDである。ストレージノードID2573は、当該ストレージ制御部が配置されているストレージノードのIDを一意に識別するためのIDである。動作モード2574は、当該ストレージ制御部の動作モードがアクティブかスタンバイかの状態を示す情報である。
The
図6では、ストレージ制御部毎に一定量のCPUコアとメモリを固定的に割り当てる構成となっており、割り当てCPUコア数2575と割り当てメモリ量2576は、それぞれ、ストレージノードから当該ストレージ制御部に割り当てられているCPUコア数とメモリ量を示す情
報である。CPU利用率2577は、当該ストレージ制御部に割り当てられているCPUコアそれぞれの利用率の平均値を示す情報である。メモリ利用量2578は、当該ストレージ制御部に割り当てられているメモリのうち、実際に利用しているメモリ量を示す情報である。
In Figure 6, a fixed amount of CPU cores and memory is assigned to each storage control unit, and the number of allocated
図6では、ストレージ制御部ID2571が「0」のストレージ制御部は、ストレージノードIDが「0」のストレージノードにおいてアクティブモードで動作しており、ストレージノードIDが「1」のストレージノードにおいてスタンバイモードで動作するストレージ制御部IDが「1」のストレージ制御部とストレージ制御部ペアIDが「0」のストレージ制御部ペアを構成していることを示す。
In FIG. 6, the storage controller with the
CPU利用率2577とメモリ利用量2578は、定期的にマスタロールのクラスタ制御部216aが、各ストレージノードで動作するワーカロールのクラスタ制御部216bを介して、各ストレージ制御部から取得する情報である。図6では、ストレージノード障害などによって、当該ストレージノードのクラスタ制御部が動作していない場合は、“NA”と示している。
The
図7は、ボリューム管理表261の一例である。ボリューム管理表261は、表形式以外のデータ構造で表現されていてもよい。そのため、データ構造に依存しないことを示すために、単に「情報」と呼ぶことがある。ボリューム管理表261は、ボリュームとストレージ制御部ペアの関係と、ボリューム内のブロックと論理チャンクの関係、各ボリュームに対する単位時間当たりのIO量を管理する。ボリューム管理表261は、各ストレージノードのメモリに格納される。ボリューム管理表は、ボリュームID2611、容量2612、使用容量2613、ストレージ制御部ID2614、ブロックID2615、論理チャンクID2616、IO量2617を含むレコードを管理する。ボリューム管理表261は、ストレージ制御部により参照することができる。
FIG. 7 is an example of the volume management table 261. As shown in FIG. The volume management table 261 may be expressed in a data structure other than the tabular format. Therefore, it is sometimes simply called "information" to indicate that it does not depend on the data structure. The volume management table 261 manages the relationship between volumes and storage controller pairs, the relationship between blocks in volumes and logical chunks, and the IO amount per unit time for each volume. A volume management table 261 is stored in the memory of each storage node. The volume management table manages records including
ボリュームID2611は、ボリュームを一意に識別するためのIDである。ボリュームはホスト装置に提供される資源であり、ストレージシステム全体でユニークなIDである。容量2612は当該ボリュームの容量を示す情報である。使用容量2613は、当該ボリュームが実際に利用している物理的な記憶領域の容量を示す情報である。使用容量2613は、論理チャンクが割り当てられているブロック数にブロックサイズを積算することでも計算可能である。ストレージ制御部ペアID2614は、ホスト装置から当該ボリュームへのIO要求の処理を担当するストレージ制御部ペアを一意に識別するためのIDである。ブロックID2615は当該ボリューム先頭からのブロック位置情報である。
A
論理チャンクID2616は、当該ボリュームの当該ブロックに対応付けられた論理チャンクを一意に識別するためのIDである。ストレージ制御部ペアID2614と論理チャンクID2616を組み合わせることで、当該ボリュームの当該ブロックに対応付けられた論理チャンクを一意に識別することが可能となる。IO量2617は、各ボリュームに対する単位時間当たりのIO量を表す情報である。
The
図7では、ボリュームID2611が「0」のボリュームは、ストレージ制御部ペアID2614が「0」のストレージ制御部ペアがホスト装置からのIO要求の処理を担当し、ブロックID2615が「0」のブロックに論理チャンクID2616が「0」の論理チャンクが対応付けられている。
In FIG. 7, the volume with the
このように、ボリューム管理表261は、各ボリュームとストレージ制御部ペアとを対応付けて管理している。一つのボリュームと当該ボリュームに対するホスト装置からのIO要求を担当するストレージ制御部ペアが一対一で対応している。ストレージ制御部ペアを構成するストレージ制御部は、図6のストレージ制御部管理表にて特定され、ストレージ制御部ペアを構成するストレージ制御部の内、アクティブのストレージ制御部がボリューム
に対するホスト装置からのIOを処理するストレージ制御部として対応する構成となる。
In this way, the volume management table 261 associates and manages each volume with a storage controller pair. There is a one-to-one correspondence between one volume and a pair of storage controllers that are in charge of IO requests from the host system for that volume. The storage controllers that make up the storage controller pair are specified in the storage controller management table in FIG. It has a corresponding configuration as a storage control unit that processes IO.
図7では、ブロックと論理チャンクを一対一で対応付けた場合を示しているが、論理チャンクを分割し、1つの論理チャンクに複数のブロックを対応付ける場合は、分割した論理チャンクを識別するためのIDの列が追加される。 FIG. 7 shows a case where blocks and logical chunks are associated one-to-one. ID column added.
図8は、論理チャンク管理表271の一例である。論理チャンク管理表271は、表形式以外のデータ構造で表現されていてもよい。そのため、データ構造に依存しないことを示すために、単に「情報」と呼ぶことがある。論理チャンク管理表271は、論理チャンクと物理チャンクの関係と、論理チャンクに対応づいているストレージ制御部ペアを管理する情報である。論理チャンク管理表271は各ストレージノードのメモリに格納される。論理チャンク管理表271は、論理チャンクID2711、ストレージ制御部ペアID2712、ストレージノードID(マスタ)2713、物理チャンクID(マスタ)2714、ストレージノードID(ミラー)2715、物理チャンクID(ミラー)2716を含むレコードを管理する。論理チャンク管理表は、データ冗長化部218により参照することができる。
FIG. 8 is an example of the logical chunk management table 271. As shown in FIG. The logical chunk management table 271 may be expressed in a data structure other than tabular format. Therefore, it is sometimes simply called "information" to indicate that it does not depend on the data structure. The logical chunk management table 271 is information for managing the relationship between logical chunks and physical chunks and the storage controller pairs associated with the logical chunks. A logical chunk management table 271 is stored in the memory of each storage node. The logical chunk management table 271 includes a
論理チャンクID2711は、論理チャンクを一意に識別するためのIDである。論理チャンクはストレージ制御部ペアに対応付けられる資源であり、ストレージ制御部ペア内でユニークなIDである。ストレージ制御部ペアID2712は当該論理チャンクと対応付けられているストレージ制御部ペアを一意に識別するためのIDである。ストレージノードID(マスタ)2713は、ストレージノードを一意に識別するためのIDである。物理チャンクID(マスタ)2714は、物理チャンクを一意に識別するためのIDである。ストレージノードIDと物理チャンクIDを組み合わせることで、当該論理チャンクに対応付けられた物理チャンクを一意に識別することが可能となる。ストレージノードID(ミラー)2715と物理チャンクID(ミラー)2716には、障害に備えて冗長化(ミラー)された物理チャンクを識別するための情報である。図8では、論理チャンクID2711が「0」の論理チャンクは、ストレージ制御部ペア「0」に対応付けられており、ストレージノードID(マスタ)2713が「0」のストレージノードの物理チャンクID2714が「0」の物理チャンクと、ストレージノードID(ミラー)2715が「1」のストレージノードの物理チャンクID2716が「1」の物理チャンクに対応付けられている。
A
図8の例は、物理チャンクを複製(二重化)することでデータを冗長化する場合の論理チャンクテーブルの一例を示している。つまり、一つの論理チャンクに対し、一組のストレージ制御部ペアが対応し、マスタとミラーの複数のストレージノードにおいて、それぞれ物理チャンクが対応している。物理チャンクを3重化する場合や、ストレージノード間でRAIDやErasure Codingを適用する場合など、データ冗長化の方式に合わせて論理チャンク管理表の構造は変えてもよい。 The example of FIG. 8 shows an example of a logical chunk table in the case of making data redundant by duplicating (duplicating) physical chunks. In other words, one set of storage controller pairs corresponds to one logical chunk, and physical chunks correspond to each of a plurality of master and mirror storage nodes. The structure of the logical chunk management table may be changed according to the data redundancy method, such as tripled physical chunks or application of RAID or erasure coding between storage nodes.
図9は、物理チャンク管理表272の一例である。物理チャンク管理表272は、表形式以外のデータ構造で表現されていてもよい。そのため、データ構造に依存しないことを示すために、単に「情報」と呼ぶことがある。物理チャンク管理表272は物理チャンクに対応する記憶装置のアドレスを管理する。物理チャンク管理表は各ストレージノードのメモリに格納される。物理チャンク管理表は、物理チャンクID2721、記憶装置ID2722、記憶装置内オフセット2723を含むレコードを管理する。物理チャンク管理表272は、データ冗長化部218により参照することができる。
FIG. 9 is an example of the physical chunk management table 272. As shown in FIG. The physical chunk management table 272 may be expressed in a data structure other than tabular format. Therefore, it is sometimes simply called "information" to indicate that it does not depend on the data structure. The physical chunk management table 272 manages addresses of storage devices corresponding to physical chunks. A physical chunk management table is stored in the memory of each storage node. The physical chunk management table manages records including
物理チャンクID2721は、物理チャンクを一意に識別するためのIDである。物理チャンクはストレージノード内の資源であり、ストレージノード内でユニークなIDである。記憶装置ID2722はストレージノード内の各記憶装置を識別するためのIDである。記憶装置内オフセット2723は、物理チャンクIDで識別される物理チャンクの先頭が対応する記憶装置のア
ドレスである。図9では、物理チャンクID2721が「0」の物理チャンクは、記憶装置ID2722が「0」の記憶装置に保存されており、物理チャンクの先頭アドレスは、記憶装置内オフセット2723で示される「0x0000」である。
A
図10は、本発明の課題を説明する概念図である。図10では、図3の構成において、「ストレージノード0」で障害が発生した場合を示している。
FIG. 10 is a conceptual diagram explaining the problem of the present invention. FIG. 10 shows a case where a failure occurs in "
マスタロールのクラスタ制御部216aは、各ストレージノードで動作するワーカロールのクラスタ制御部216bとの定期的通信などにより、各ストレージノードの生死監視を行っている。
The master role
ストレージノードの障害を検出した場合は、まず、管理端末110を介してストレージシステム200の管理者に障害が発生したことを通知する。続いて、ホスト装置から当該ストレージ制御部が担当していたボリュームへのIO要求の処理を引き継ぐために、当該ストレージノードで動作していたアクティブモードのストレージ制御部219aとペアを構成していたスタンバイモードのストレージ制御部219bに対して、アクティブモードへの切り替えを指示する。図10では、「ストレージ制御部0」219aとペアを構成していた「ストレージ制御部1」219bの動作モードがスタンバイからアクティブに切り替わっている。
When a storage node failure is detected, first, the
次に、ストレージ制御部ペア217の冗長度を回復させるために、正常なストレージノードにスタンバイモードのストレージ制御部219cを再構築する。マスタロールのクラスタ制御部216aは、新しいストレージ制御部を動作させるのに必要な、CPUコアやメモリなどの情報処理資源に空きのあるストレージノードを選択し、当該ストレージノードのクラスタ制御部に対して、ストレージ制御部の再構築を指示する。図10の例では、「ストレージノード2」210に、機能を喪失した「ストレージ制御部0」の代替として「ストレージ制御部22」219cが再構築され、1つのストレージノードに3つのストレージ制御部が配置された状態となっている。また、図示していないが、「ストレージ制御部21」の代替となるストレージ制御部の再構築も行われている。
Next, in order to recover the redundancy of the
ストレージ制御部再構築先を選択する際に、情報処理資源に空きのあるストレージノードが存在しなかった場合は、ストレージ制御部を再構築することができず、冗長度を回復することができない。各ストレージノードに予めストレージ制御部再構築用の情報処理資源を予約しておけば、ストレージノード障害時に確実にストレージ制御部の冗長度を回復可能なことを保証できるが、通常時は予約した情報処理資源を利用することができず、ストレージノードの利用効率が低下し、システム構築コストが高騰することになる。 When selecting a destination to reconstruct the storage control unit, if there is no storage node with free information processing resources, the storage control unit cannot be reconstructed and the redundancy cannot be recovered. By reserving information processing resources for rebuilding the storage control unit in each storage node in advance, it is possible to guarantee that the redundancy of the storage control unit can be recovered reliably in the event of a storage node failure. Processing resources cannot be used, storage node usage efficiency decreases, and system construction costs rise.
図11~16を用いて、ストレージノードの利用効率が高く、システム構築コストを低く抑えるための技術を説明する。 11 to 16, a technique for achieving high storage node utilization efficiency and low system construction costs will be described.
図11は、ストレージノードのメモリ212に格納されている制御情報(管理表)256、257、261、271、272とプログラム250~255、258、260、270を示している。なお、実際のメモリには、これら以外のプログラムや管理情報も格納され得るが、図11は本発明の説明に必要となるものを示している。例えば、ホストからのIO要求を処理するためのプログラムやキャッシュ管理表などは省略されている。また、プログラムは各ストレージノードの記憶装置にも格納されており、ストレージシステム起動時やプログラム実行時などにメモリにロードされるものとする。電源障害などに備えて、管理表256、257、261、271、272を記憶装置に保存してもよく、メモリを記憶装置に保存した管理表のキャッシュとして用いてもよい。
FIG. 11 shows control information (management tables) 256, 257, 261, 271 and 272 and programs 250-255, 258, 260 and 270 stored in the
障害回復プログラム250、ボリューム退避プログラム251、ボリューム退避先決定プログ
ラム252、ストレージ制御部ペア作成プログラム253、ストレージ制御部ペア削除プログラム254、ストレージノード減設プログラム255は、ストレージ制御部ペア再構築プログラム258、クラスタ制御部216を構成するプログラムの一部である。障害回復プログラム250、ボリューム退避プログラム251、ボリューム退避先決定プログラム252、ストレージノード減設プログラム255、ストレージ制御部ペア再構築プログラム258は、クラスタ制御部216がマスタロールで動作する際に実行され得るプログラムである。ストレージ制御部ペア作成プログラム253、ストレージ制御部ペア削除プログラム254は、クラスタ制御部がワーカロールで動作する際に実行され得るプログラムである。
The
ストレージノード管理表256とストレージ制御部管理表257はマスタロールのクラスタ制御部216のメモリに格納される管理情報である。ストレージノード管理表256とストレージ制御部管理表257は、図5及び図6にそれぞれ内容が示されている。これらの管理表は1以上のワーカロールのクラスタ制御部に複製を保持されるものとする。これは、マスタロールのクラスタ制御部216が配置されたストレージノードに障害が発生した際に、ワーカロールのクラスタ制御部がマスタロールに昇格して処理を引き継ぐためである。後述する説明において、これらの管理表を更新する際は、クラスタ制御部間の通信などによって複製された管理表も同時に更新するものとする。
The storage node management table 256 and storage controller management table 257 are management information stored in the memory of the
ボリューム移動プログラム260は、ストレージ制御部219を構成するプログラムの一部である。ボリューム管理表261はストレージ制御部219のメモリに格納される管理情報であり、図7にその内容は示されている。ボリューム管理表261は、ストレージ制御部ペアを構成するストレージ制御部間で複製される。これは、ストレージノード障害などによってアクティブモードのストレージ制御部が動作不能に陥った際にスタンバイモードのストレージ制御部が処理を引き継ぐためである。後述する説明において、ボリューム管理表261を更新する際は、ストレージ制御部間の通信などによって複製された管理表も同時に更新するものとする。
The volume migration program 260 is part of the programs that make up the
物理チャンク再配置プログラム270は、データ冗長化部218を構成するプログラムの一部である。論理チャンク管理表271と物理チャンク管理表272はデータ冗長化部のメモリに格納される管理情報である。論理チャンク管理表271と物理チャンク管理表272は、それぞれ図8及び図9にその内容が示されている。論理チャンク管理表271は、各ストレージノードのデータ冗長化部が当該ストレージノードに配置されたストレージ制御部ペアに関連するレコードのみを保持する。図8の例では、物理チャンクはマスタとミラーに複製されるため、1つのレコードは2つのストレージノードのデータ冗長化部間で複製されていることになる。物理チャンク管理表272は、ストレージノード内の記憶装置のアドレスを管理する情報のため、複製等を行う必要はない。
The physical
図12と図13は、それぞれ障害回復プログラム250の処理の一例を示す図である。ストレージノード障害などによってストレージシステム内に冗長度が低下したストレージ制御部グループが存在する状態から、すべてのストレージ制御部グループの冗長度が保たれている状態に回復させる処理をおこなうものである。ストレージノード障害に代えて、ストレージノード減設の場合にも、障害を減設に読み替えて適用可能である。以下、説明の容易化のため、ストレージ制御部グループを、一台のアクティブモードのストレージ制御部と一台のスタンバイモードのストレージ制御部からなるストレージ制御部ペアのケースで説明する。但し、ペアに限らず、3台以上のストレージ制御部から構成されるストレージ制御部グループの場合であっても、基本的には同一の処理を行うこととなる。ストレージ制御部ペア又はグループが複数のアクティブモードのストレージ制御部を含んでいる場合、回復処理のなかで生存しているアクティブモードのストレージ制御部はスタンバイモードのストレージ制御部と基本的には同様に扱ってもよい。
12 and 13 are diagrams showing an example of processing of the
例えば、このプログラム250はストレージノード障害によるストレージ制御部ペアの冗長度低下によって低下したボリュームの冗長度を回復させるための処理を行う。また、このプログラムは、クラスタ制御部216のメモリに格納され、当該クラスタ制御部が配置されたストレージノードのCPUによって実行される。このプログラム250はマスタロールで動作するクラスタ制御部216がストレージノードの障害を検出した際に起動され、当該クラスタ制御部が実行する。なお、マスタロールのクラスタ制御部が配置されていたストレージノードで障害が発生した場合は、ワーカロールのクラスタ制御部から新たに選出されたマスタロールのクラスタ制御部が配置されたストレージノードのCPUによって、このプログラムは実行される。
For example, this
図12は、ストレージノード障害が発生した場合、ストレージ制御部ペアの片方のストレージ制御部を喪失したストレージ制御部ペアを全て削除し、解放された情報処理資源を用いて、新たにストレージ制御部ペアを作成している。図10の例によると、障害が発生したストレージノード「0」には、2つのストレージ制御部ペア0とストレージ制御部ペア10が存在するため、これら2つのストレージ制御部ペアを削除し、一つの制御部ペアを作成する。 In FIG. 12, when a storage node failure occurs, all storage controller pairs in which one of the storage controller pairs has been lost are deleted, and the released information processing resources are used to create a new storage controller pair. is creating According to the example of FIG. 10, since there are two storage controller pairs 0 and 10 in the failed storage node "0", these two storage controller pairs are deleted and one Create a control pair.
図13では、ペアの片方を喪失したストレージ制御部ペアのうち、アクティブモードのストレージ制御部を喪失したストレージ制御部ペアのみを削除し、解放された情報処理資源を用いて、スタンバイモードのストレージ制御部を喪失したストレージ制御部ペアの新しいペア相手を再構築する。図10の例によると、障害が発生したストレージノード0にあるアクティブなストレージ制御部219aが属するストレージ制御部ペア0を削除し、1つのストレージ制御部ペア10の冗長度を回復させる。つまり、ストレージ制御部ペア0(及び、ストレージ制御部1)を削除したことで、ストレージノード1にストレージ制御部1つ分の資源が解放される。これを使ってストレージノード1にストレージ制御部21を再構築して、ストレージ制御部ペア10の冗長度を回復する。
In FIG. 13, of the storage control unit pairs in which one of the pairs has been lost, only the storage control unit pair in which the active mode storage control unit has been lost is deleted, and the released information processing resources are used to perform standby mode storage control. Rebuild a new pair partner for a lost storage controller pair. According to the example of FIG. 10, the
まず、図12の処理の例について説明する。図12の障害回復プログラム(1)は、ストレージノード障害によってストレージ制御部ペアの片方を喪失したストレージ制御部ペアを特定する(S100)。この処理は、ストレージ制御部管理表257を参照し、障害となったストレージノードID2573で検索し、ストレージ制御ペアID2572を特定することで実現する。この際、特定したストレージ制御部ペアへの新規ボリューム作成を抑止する処理を追加してもよい。この処理は、図6のストレージ制御部管理表257にボリューム作成抑止フラグの列を追加し、特定したストレージ制御部に対してこのフラグをONにすることで実現できる。
First, an example of the processing in FIG. 12 will be described. The failure recovery program (1) in FIG. 12 identifies a storage controller pair in which one of the storage controller pairs has been lost due to a storage node failure (S100). This processing is realized by referring to the storage control unit management table 257, searching by the failed
続けて、障害回復プログラム(1)250は特定したストレージ制御ペアから処理対象となるストレージ制御ペアを選択する(S101)。実施例1(図10)の場合、1つのストレージノードにアクティブモードとスタンバイモードのストレージ制御部が1つずつ配置されているため、ペアの片方を喪失したストレージ制御部ペアは2つ存在し、残存しているストレージ制御部の一方はアクティブモードで動作しており、他方はスタンバイモードで動作している。 Subsequently, the failure recovery program (1) 250 selects a storage control pair to be processed from the identified storage control pairs (S101). In the case of Embodiment 1 (FIG. 10), one storage node has one active mode storage controller and one standby mode storage controller. One of the remaining storage controllers is operating in active mode and the other is operating in standby mode.
障害回復プログラム(1)250は、残存ストレージ制御部の動作モードがスタンバイか否かを判定し(S102)、スタンバイモードでなければステップS103をスキップしステップS104へ進む。スタンバイモードであれば、ステップS103で当該ストレージ制御部に対して、アクティブモードへの切り替えを指示する。動作モードの切り替えに関する処理は、以下の通り実現される。障害回復プログラム(1)250は、ストレージ制御部管理表257を参照し、ステップS101で選択したストレージ制御ペアIDで検索することにより、ステップS101で選択したストレージ制御ペアを構成するストレージ制御部IDを絞り込む。さらに、スト
レージノード管理表256を参照して、絞り込んだストレージ制御部IDで検索し、動作状態が正常であるストレージノードに対応するストレージ制御部IDを特定することで残存ストレージ制御部IDを特定できる。特定した残存ストレージ制御部ID2571に対応するストレージ制御部管理表257の動作モード2574を取得することで、動作モードを取得することができる。
The failure recovery program (1) 250 determines whether or not the operation mode of the remaining storage control unit is standby (S102), and if not standby mode, skips step S103 and proceeds to step S104. If it is in the standby mode, in step S103, the storage controller is instructed to switch to the active mode. Processing related to switching of operation modes is realized as follows. The failure recovery program (1) 250 refers to the storage control unit management table 257 and retrieves the storage control unit IDs that make up the storage control pair selected in step S101 by searching with the storage control pair ID selected in step S101. Narrow down. Further, by referring to the storage node management table 256 and searching with the narrowed down storage controller IDs, the remaining storage controller IDs can be identified by identifying the storage controller IDs corresponding to the storage nodes whose operating status is normal. . By obtaining the
障害回復プログラム(1)は、ストレージ制御部からアクティブモードの切り替え完了を受領すると、ストレージ制御部管理表257の当該ストレージ制御部の動作モードを「アクティブ」に更新する(S103)。なお、スタンバイモードのストレージ制御部がペア相手のアクティブモードの監視を行い、障害が発生したことを検知すると、自律的にアクティブモードに動作を切り替える構成でもよい。この場合、ステップS103は、スタンバイモードのストレージ制御部がアクティブに切り替わるのを待機し、切り替え完了後にストレージ制御部管理表257を更新する処理となる。いずれにせよ、このステップにより、障害が発生したストレージノードで動作していたアクティブモードのストレージ制御部が実行していたボリュームへのIO要求の処理などが、スタンバイモードであったストレージ制御部に引き継がれる。 When the failure recovery program (1) receives the active mode switching completion from the storage controller, it updates the operation mode of the storage controller in the storage controller management table 257 to "active" (S103). It should be noted that the storage control unit in the standby mode may monitor the active mode of the pair partner and autonomously switch the operation to the active mode when detecting that a failure has occurred. In this case, step S103 is a process of waiting for the standby mode storage control unit to switch to active, and updating the storage control unit management table 257 after the switching is completed. In any case, this step allows the storage controller in standby mode to take over the processing of IO requests to volumes that was being executed by the active mode storage controller that was running on the failed storage node. be
次に、障害回復プログラム(1)は、ステップS100で特定した全てのストレージ制御部ペアについて、ステップS101~S103の処理が完了したか否かを判定する(S104)。完了した場合はステップS105に進み、完了していない場合はステップS101に戻る。 Next, the failure recovery program (1) determines whether or not the processing of steps S101 to S103 has been completed for all storage controller pairs identified in step S100 (S104). If completed, proceed to step S105; if not completed, return to step S101.
なお、図には示していないが、ステップS105に進む前に残存している各ストレージノードの空き記憶容量がストレージノード障害を回復するのに十分であるか否かを確認し、空き記憶容量不足による障害回復処理の失敗を抑止してもよい。この場合、空き記憶容量が不足すると判断した場合は、管理端末110を介してストレージシステム200の管理者に空き記憶容量不足を通知し、プログラムの処理を終了する。その後、ストレージシステム200の管理者が記憶装置の増設やストレージノードの追加といった対処を行ったうえで、管理端末110を介して、マスタロールのクラスタ制御部216aに障害回復プログラム250の再実行を指示する。
Although not shown in the figure, before proceeding to step S105, it is checked whether or not the remaining free storage capacity of each storage node is sufficient to recover from the storage node failure, and if there is insufficient free storage capacity Failure of failure recovery processing due to In this case, if it is determined that the free storage capacity is insufficient, the administrator of the
物理チャンクをストレージ制御部が配置されたストレージノード以外のストレージノードにも保存する構成としている場合や、物理チャンクを三重化している場合、ストレージノード間でRAIDやErasure Codingを適用して物理チャンクを冗長化している場合は、ストレージノード障害により喪失した物理チャンクによって、喪失したストレージ制御部と関係のないストレージ制御部ペアに対応付けられた論理チャンクの冗長度が低下している可能性がある。そのため、ステップS105に進む前に、障害回復プログラム(1)が各ストレージノードのデータ冗長化部に対して、喪失したストレージ制御部と関係のないストレージ制御部ペアに対応付けられた論理チャンクの冗長度低下の確認と冗長度の回復を指示する。指示を受けたデータ冗長化部は、冗長化方式に応じて、冗長度の回復処理を実行する。 If the configuration is such that physical chunks are stored in storage nodes other than the storage node where the storage controller is located, or if the physical chunks are tripled, RAID or erasure coding is applied between the storage nodes to distribute the physical chunks. In the case of redundancy, the physical chunks lost due to the storage node failure may reduce the redundancy of the logical chunks associated with the lost storage controller pair and unrelated storage controller pairs. Therefore, before proceeding to step S105, the failure recovery program (1) performs redundancy of logical chunks associated with a pair of storage control units unrelated to the lost storage control unit for the data redundancy units of each storage node. Instruct to confirm the degree of degradation and recover the degree of redundancy. The data redundancy unit that has received the instruction executes redundancy recovery processing according to the redundancy method.
例えば、物理チャンクを複製(二重化)する冗長化方式の場合、データ冗長化部は論理チャンク管理表271から障害が発生したストレージノードに物理チャンクを保存している論理チャンクが存在するか否かを確認する。存在する場合は、当該論理チャンクに対応付けられているストレージ制御部ペアID2712が喪失したストレージ制御部を含むストレージ制御部ペアか否かを確認する。喪失したストレージ制御部を含むストレージ制御部ペアでなければ、新しい物理チャンクを確保し、当該論理チャンクを構成する喪失していないほうの物理チャンクから、新たに確保した物理チャンクにデータをコピーし、論理チャンクと物理チャンクの対応付けを更新する。全てのストレージノードで論理チャンクの冗長度低下の確認と冗長度の回復が完了すると、ステップS105に進む。 For example, in the case of a redundancy method in which physical chunks are duplicated (duplicated), the data redundancy unit checks from the logical chunk management table 271 whether or not there is a logical chunk storing a physical chunk in the failed storage node. Confirm. If it exists, it is checked whether the storage controller pair ID 2712 associated with the relevant logical chunk is a storage controller pair including the lost storage controller. If the storage control unit pair does not include the lost storage control unit, secure a new physical chunk, copy data from the unlost physical chunk that constitutes the logical chunk to the newly secured physical chunk, Update the mapping between logical chunks and physical chunks. When the confirmation of the reduction in the redundancy of the logical chunk and the restoration of the redundancy are completed in all storage nodes, the process proceeds to step S105.
次に、障害回復プログラム(1)はステップS100で特定したストレージ制御ペアから処理対象となるストレージ制御ペアを選択する(S105)。続けて、障害回復プログラム(1)は、当該ストレージ制御部ペアが担当していた全ボリュームをボリューム毎に、ストレージノード障害の影響を受けていない複数の正常なストレージ制御部ペアに、それぞれ退避させる処理を実行する(S106)。つまり、当該ストレージ制御部ペアが担当していた全ボリュームをボリューム毎に、異なるストレージ制御部ペアに分散して退避させる。このボリューム退避処理の詳細については、図14、15を用いて後述するが、この処理によって当該ストレージ制御部ペアが担当していた全ボリュームのデータが退避先のストレージ制御部ペアにコピーされ、以後、当該ボリュームへのホスト装置からのIO要求は退避先のストレージ制御部ペアが処理を担当する。 Next, the failure recovery program (1) selects a storage control pair to be processed from the storage control pairs specified in step S100 (S105). Subsequently, the failure recovery program (1) evacuates all volumes handled by the relevant storage controller pair to a plurality of normal storage controller pairs that are not affected by the storage node failure. Execute the process (S106). In other words, all the volumes that the relevant storage control unit pair was in charge of are distributed to different storage control unit pairs for each volume and saved. Details of this volume saving process will be described later with reference to FIGS. , IO requests from the host device to the volume are processed by the save destination storage control unit pair.
全ボリュームの退避完了後、障害回復プログラム(1)は、残存ストレージ制御部が動作しているストレージノードのクラスタ制御部に対して、当該ストレージ制御部ペアの削除を指示する(S107)。ストレージ制御部ペアの削除処理の詳細については、図16を用いて後述する。ストレージ制御部ペアの削除によって、当該ストレージ制御部ペアに割り当てられていたCPU、メモリといった情報処理資源や、論理チャンク、物理チャンクなどの記憶資源が解放される。削除完了後、障害回復プログラム(1)は、ストレージ制御部管理表257を更新し、当該ストレージ制御部ペア2572のレコードを削除する(S108)。 After all volumes have been saved, the failure recovery program (1) instructs the cluster controller of the storage node in which the remaining storage controller is operating to delete the storage controller pair (S107). Details of the deletion processing of the storage control unit pair will be described later with reference to FIG. 16 . By deleting the storage control unit pair, the information processing resources such as CPU and memory allocated to the storage control unit pair and the storage resources such as logical chunks and physical chunks are released. After the deletion is completed, the fault recovery program (1) updates the storage controller management table 257 and deletes the record of the storage controller pair 2572 (S108).
次に、障害回復プログラム(1)は、ステップS100で特定したストレージ制御部ペアの削除が全て完了したか否かを判定する(S109)。完了した場合はステップS110に進み、完了していない場合はステップS105に戻る。 Next, the failure recovery program (1) determines whether or not deletion of all storage control unit pairs identified in step S100 has been completed (S109). If completed, proceed to step S110; if not completed, return to step S105.
ペアを片方喪失したストレージ制御部ペアの削除が完了すると、障害回復プログラム(1)は、ペアを片方喪失したストレージ制御部ペアの残存ストレージ制御部が配置されていたストレージノードのクラスタ制御部に対して、ストレージ制御部及びストレージ制御部ペアの作成を指示する(S110)。指示を受けたクラスタ制御部(ストレージ制御部ペア作成プログラム253)は、CPUコアやメモリなどの情報処理資源を確保し、記憶装置からストレージ制御部を構成するプログラムをメモリにロードして、ストレージ制御部を起動する。新しいストレージ制御部及びストレージ制御部ペアは、削除によって解放された情報処理資源を用いて作成される。障害回復プログラム(1)は、ストレージ制御部及びストレージ制御部ペアの作成完了後、ストレージ制御部管理表257を更新し、レコードを追加する。 When the deletion of the storage controller pair that lost one of the pairs is completed, the failure recovery program (1) sends a message to the cluster controller of the storage node where the remaining storage controller of the storage controller pair that lost one of the pair was located. command to create a storage controller and a storage controller pair (S110). The cluster control unit (storage control unit pair creation program 253) that received the instruction secures information processing resources such as CPU cores and memory, loads the programs that make up the storage control unit from the storage device into the memory, and performs storage control. start the department. New storage controllers and storage controller pairs are created using the information processing resources released by the deletion. After completing the creation of the storage controller and the storage controller pair, the failure recovery program (1) updates the storage controller management table 257 and adds a record.
ストレージ制御部ペア作成プログラム253によるストレージ制御部及びストレージ制御部ペア作成処理については、ストレージシステム構築時と同様のため詳細は省略する。 The storage control unit and storage control unit pair creation processing by the storage control unit pair creation program 253 are the same as when the storage system is constructed, so the details are omitted.
次に、図13の処理の例について説明する。図13の障害回復プログラム(2)250は、図12のステップS100を実行して、ストレージ制御部ペアの片方を喪失したストレージ制御部ペアを特定する(S200)。この際、特定したストレージ制御部ペアへの新規ボリューム作成を抑止する処理を追加してもよい。この処理は、図6のストレージ制御部管理表257にボリューム作成抑止フラグの列を追加し、特定したストレージ制御部に対してこのフラグをONにすることで実現できる。 Next, an example of the processing in FIG. 13 will be described. The failure recovery program (2) 250 of FIG. 13 executes step S100 of FIG. 12 to identify the storage controller pair in which one of the storage controller pairs has been lost (S200). At this time, processing for inhibiting creation of a new volume in the identified storage control unit pair may be added. This process can be implemented by adding a volume creation inhibition flag column to the storage control unit management table 257 in FIG. 6 and turning this flag ON for the specified storage control unit.
続けて、障害回復プログラム(2)は、図12のステップS101~S104を実行して、障害が発生したストレージノードで動作していたアクティブモードのストレージ制御部が実行していたボリュームへのIO要求等の処理を、ペアを構成するスタンバイモードのストレージ制御部に引き継ぐ(S201)。 Subsequently, the failure recovery program (2) executes steps S101 to S104 in FIG. 12 to issue an IO request to the volume that was being executed by the active mode storage controller operating on the failed storage node. Such processing is handed over to the standby-mode storage control units forming the pair (S201).
なお、図には示していないが、ステップS202に進む前に残存している各ストレージノードの空き記憶容量がストレージノード障害を回復するのに十分であるか否かを確認し、空き記憶容量不足による障害回復処理の失敗を抑止してもよい。この場合、空き記憶容量が不足すると判断した場合は、管理端末110を介してストレージシステム200の管理者に空き記憶容量不足を通知し、プログラムの処理を終了する。その後、ストレージシステム200の管理者が記憶装置の増設やストレージノードの追加といった対処を行ったうえで、管理端末110を介して、マスタロールのクラスタ制御部216aに障害回復プログラム250の再実行を指示する。
Although not shown in the figure, before proceeding to step S202, it is checked whether or not the remaining free storage capacity of each storage node is sufficient to recover from the failure of the storage node. Failure of failure recovery processing due to In this case, if it is determined that the free storage capacity is insufficient, the administrator of the
なお、物理チャンクをストレージ制御部が配置されたストレージノード以外のストレージノードにも保存する構成としている場合や、物理チャンクを三重化している場合、ストレージノード間でRAIDやErasure Codingを適用して物理チャンクを冗長化している場合は、ストレージノード障害によって喪失した物理チャンクによって、喪失したストレージ制御部と関係のないストレージ制御部ペアに対応付けられた論理チャンクの冗長度が低下している可能性がある。そのため、ステップS202に進む前に、障害回復プログラム(2)が各ストレージノードのデータ冗長化部に対して、喪失したストレージ制御部と関係のないストレージ制御部ペアに対応付けられた論理チャンクの冗長度低下の確認と冗長度の回復を指示する。指示を受けたデータ冗長化部は、冗長化方式に応じて、冗長度の回復処理を実行する。例えば、物理チャンクを複製(二重化)する冗長化方式の場合、データ冗長化部は論理チャンク管理表271から障害が発生したストレージノードに物理チャンクを保存している論理チャンクが存在するか否かを確認する。存在する場合は、当該論理チャンクに対応付けられているストレージ制御部ペアID2712が喪失したストレージ制御部を含むストレージ制御部ペアか否かを確認する。喪失したストレージ制御部を含むストレージ制御部ペアでなければ、新しい物理チャンクを確保し、当該論理チャンクを構成する喪失していないほうの物理チャンクから、新たに確保した物理チャンクにデータをコピーし、論理チャンクと物理チャンクの対応付けを更新する。全てのストレージノードで論理チャンクの冗長度低下の確認と冗長度の回復が完了すると、ステップS202に進む。 If the configuration is such that physical chunks are stored in storage nodes other than the storage node where the storage control unit is located, or if the physical chunks are tripled, RAID or erasure coding is applied between the storage nodes. If chunk redundancy is used, physical chunks lost due to a storage node failure may reduce the redundancy of logical chunks associated with storage controller pairs unrelated to the lost storage controller. be. Therefore, before proceeding to step S202, the failure recovery program (2) performs redundancy of logical chunks associated with a pair of storage control units unrelated to the lost storage control unit for the data redundancy units of each storage node. Instruct to confirm the degree of degradation and recover the degree of redundancy. The data redundancy unit that has received the instruction executes redundancy recovery processing according to the redundancy method. For example, in the case of a redundancy method in which physical chunks are duplicated (duplicated), the data redundancy unit checks from the logical chunk management table 271 whether or not there is a logical chunk storing a physical chunk in the failed storage node. Confirm. If it exists, it is checked whether the storage controller pair ID 2712 associated with the relevant logical chunk is a storage controller pair including the lost storage controller. If the storage control unit pair does not include the lost storage control unit, secure a new physical chunk, copy data from the unlost physical chunk that constitutes the logical chunk to the newly secured physical chunk, Update the mapping between logical chunks and physical chunks. When the confirmation of the reduction in the redundancy of the logical chunk and the recovery of the redundancy are completed in all storage nodes, the process proceeds to step S202.
次に、障害回復プログラム(2)は、処理対象となるストレージ制御ペアを選択する(S202)。図12と同様に、図10で示した例によるとペアの片方を喪失したストレージ制御部ペアは2つ存在し、残存しているストレージ制御部の一方はアクティブモードで動作しており、他方はスタンバイモードで動作している。 Next, the failure recovery program (2) selects a storage control pair to be processed (S202). Similar to FIG. 12, according to the example shown in FIG. 10, there are two storage controller pairs in which one of the pairs has been lost, one of the remaining storage controllers is operating in active mode, and the other is Working in standby mode.
障害回復プログラム(2)は、残存ストレージ制御部の動作モードがスタンバイか否かを判定し(S203)、スタンバイモードでなければ、ステップS204をスキップしステップS205へ進む。スタンバイモードであれば、ステップS204で図12のステップS106~S108を実行し、当該ストレージ制御部ペアが担当する全ボリュームの退避、当該ストレージ制御部ペアの削除、ストレージ制御部管理表257から当該ストレージ制御部ペアに関するレコード削除を行う。 The failure recovery program (2) determines whether or not the operation mode of the remaining storage control unit is standby (S203), and if not standby mode, skips step S204 and proceeds to step S205. If in the standby mode, steps S106 to S108 of FIG. 12 are executed in step S204 to save all volumes handled by the storage control unit pair, delete the storage control unit pair, and extract the storage unit from the storage control unit management table 257. Delete records related to control unit pairs.
次に、障害回復プログラム(2)は、ステップS200で特定したストレージ制御部ペアのうち、スタンバイモードのストレージ制御部が残存しているストレージ制御部ペアの削除が完了したか否かを判定する(S205)。完了した場合はステップS206へ進み、完了していない場合はステップS202に戻る。 Next, the failure recovery program (2) determines whether or not deletion of the storage control unit pair in which the standby mode storage control unit remains among the storage control unit pairs identified in step S200 has been completed ( S205). If completed, proceed to step S206; if not completed, return to step S202.
スタンバイモードのストレージ制御部が残存しているストレージ制御部ペアの削除が完了すると、障害回復プログラム(2)は、当該残存ストレージ制御部が配置されていたストレージノードのクラスタ制御部(ストレージ制御部ペア再構築プログラム258)に対して、アクティブモードのストレージ制御部が残存しているストレージ制御部ペアの再構築を指示する(S206)。 When the deletion of the storage control unit pair in which the standby mode storage control unit remains is completed, the failure recovery program (2) deletes the cluster control unit (storage control unit pair The reconstruction program 258) is instructed to reconstruct the remaining storage controller pair by the active mode storage controller (S206).
指示を受けたクラスタ制御部は、CPUコアやメモリなどの情報処理資源を確保し、記憶装置からストレージ制御部を構成するプログラムをメモリにロードして、ストレージ制御部を起動する。起動後にアクティブモードのストレージ制御部からボリューム管理表261をコピーする。ストレージ制御部ペアの再構築は、削除によって解放された情報処理資源を用いて行われる。障害回復プログラム(2)は、ストレージ制御部及びストレージ制御部ペアの作成完了後、ストレージ制御部管理表257を更新し、当該ストレージ制御部ペアの情報を更新する。この再構築処理は、本発明を適用しない場合のストレージ制御部ペアの冗長度回復と同じ処理のため、詳細は省略する。ステップS200において、特定したストレージ制御部ペアへの新規ボリューム作成を抑止する処理を追加した場合は、このステップの後に新規ボリューム作成の抑止を解除する処理を追加する。この処理は、図6のストレージ制御部管理表257において、ストレージ制御部ペアID2572が特定したストレージ制御部ペアとなっているストレージ制御部に対して、追加したボリューム作成抑止フラグをOFFにすることで実現できる。
Upon receiving the instruction, the cluster control unit secures information processing resources such as a CPU core and memory, loads a program that configures the storage control unit from the storage device into the memory, and activates the storage control unit. After startup, the volume management table 261 is copied from the active mode storage controller. Reconstruction of the storage controller pair is performed using the information processing resources released by the deletion. After completing the creation of the storage control unit and the storage control unit pair, the failure recovery program (2) updates the storage control unit management table 257 and updates the information of the storage control unit pair. Since this reconstruction process is the same as the redundancy recovery of the storage control unit pair when the present invention is not applied, the details are omitted. In step S200, if processing for inhibiting new volume creation for the specified storage control unit pair is added, processing for canceling the inhibition of new volume creation is added after this step. This process is performed by turning off the added volume creation suppression flag for the storage control unit that is the storage control unit pair identified by the storage control
図12による処理の場合、ペアの片方を喪失した2つのストレージ制御部ペアが順番にボリューム退避を行っているが、実際には、2つのストレージ制御部ペアが同時にボリューム退避を行ってもよい。図13による処理の場合、スタンバイモードのストレージ制御部が残存しているストレージ制御部ペアからのボリューム退避とストレージ制御部ペア削除の完了まで、アクティブモードのストレージ制御部が残存しているストレージ制御部ペアのペア相手となるストレージ制御部の再構築を行うことができない。したがって、ボリュームの冗長度が低下している時間は、図12による処理方が短く、可用性が高い。一方で、図12による処理の場合、新しく作成したストレージ制御部ペアは、障害回復処理の完了直後はボリュームを1つも担当していない状態となり、ストレージ制御部に割り当てられている情報処理資源の利用効率が悪い状態になってしまう。 In the case of the processing shown in FIG. 12, the two storage control unit pairs that have lost one of the pairs perform volume evacuation in order, but in reality, the two storage control unit pairs may simultaneously perform volume evacuation. In the case of the processing according to FIG. 13, the storage control unit in which the active mode storage control unit remains until the volume evacuation from the storage control unit pair in which the standby mode storage control unit remains and the deletion of the storage control unit pair are completed. It is not possible to rebuild the storage controller that is the pair partner of the pair. Therefore, the processing according to FIG. 12 shortens the time when the redundancy of the volume is low, and the availability is high. On the other hand, in the case of the processing shown in FIG. 12, the newly created storage control unit pair will not be in charge of any volumes immediately after the completion of the failure recovery processing, and the information processing resources assigned to the storage control unit will not be used. It becomes inefficient.
このように、図12の図13の2つの処理は、可用性と情報処理資源の利用効率のトレードオフの関係にある。実際のストレージシステムにおいては、図12と図13の2つの処理方式のうち、どちらか一方のみを備えていてもよく、両方とも備えておき、クラスタ制御部が何らかの判断基準によってどちらの処理方式を実行するかを決定してもよく、ストレージシステム管理者が事前に設定した方式を実行するようにしてもよい。なお、本発明はストレージ制御部を再構築するための予約リソースを不要とすることで、情報処理資源の利用効率を改善するものだが、例えば、ストレージノード1台までの障害回復に必要な情報処理資源を予約するという構成にしてもよい。この場合、ストレージノード1台までの障害であれば、ボリューム退避を行わずに、予約しておいた情報処理資源を用いてストレージ制御部の再構築を行うことができる。 Thus, the two processes in FIG. 12 and FIG. 13 are in a trade-off relationship between availability and utilization efficiency of information processing resources. An actual storage system may have only one of the two processing methods shown in FIGS. 12 and 13, or both may be provided, and the cluster controller selects which processing method according to some criteria. It may be determined whether to execute it, or a method set in advance by the storage system administrator may be executed. The present invention improves the utilization efficiency of information processing resources by eliminating the need for reserved resources for reconstructing the storage control unit. A configuration in which resources are reserved may also be used. In this case, if up to one storage node fails, the storage control unit can be reconstructed using the reserved information processing resource without saving the volume.
図12の処理による場合、新しく作成したストレージ制御部ペアは、障害回復処理の完了直後はボリュームを1つも担当していない状態となるため、情報処理資源の利用効率を高めるために、図6に示したストレージ制御部管理表257のCPU利用率2577等を参照して、負荷の高いストレージ制御部及びストレージ制御部ペアが担当するボリュームを新しく作成したストレージ制御部ペアに移動させ、システム全体の負荷の分散を図る処理を行っても良い。
In the case of the processing in FIG. 12, the newly created storage control unit pair will not be in charge of even a single volume immediately after the completion of the failure recovery processing. By referring to the
ところで、ストレージシステム全体の空き記憶容量が不足した場合、SDSでは新しいストレージノードを追加することで、記憶容量不足を解消するという運用が一般的である。この場合、新しく追加したストレージノードの物理チャンクを論理チャンクに割り当てることで、記憶容量不足が解消される。一方、Erasure Codingの中には、他のストレージノードの物理チャンクにアクセスすることなくリード処理を行えるという特徴(リードローカリティ)を持ったものがある。リードローカリティを持つErasure Codingを適用したス
トレージシステムにおいて、記憶容量が不足を解消するために、新しいストレージノードを追加し、追加したストレージノードの物理チャンクを論理チャンクに割り当てた場合、リードローカリティという特徴を失われてしまうという問題がある。障害回復処理後に、新しく作成したストレージ制御部ペアにボリュームを移動させるのと同様に、新しく追加したノードに新しく作成したストレージ制御部ペアにボリュームを移動させることで、リードローカリティを持つErasure Codingの特徴を失うことなく、空き記憶容量不足を解消することができる。
By the way, when the free storage capacity of the entire storage system runs short, it is common practice in SDS to solve the storage capacity shortage by adding a new storage node. In this case, the storage capacity shortage is resolved by allocating the physical chunks of the newly added storage node to the logical chunks. On the other hand, some erasure coding has the feature (read locality) that read processing can be performed without accessing physical chunks of other storage nodes. In a storage system to which erasure coding with read locality is applied, when a new storage node is added and physical chunks of the added storage node are assigned to logical chunks in order to solve the shortage of storage capacity, the feature of read locality is added. There is the problem of being lost. Features of erasure coding with read locality by moving volumes to a newly created storage controller pair in a newly added node in the same way that volumes are moved to a newly created storage controller pair after failure recovery processing. You can solve the lack of free storage space without losing the
図14は、ボリューム退避プログラム251の処理の一例を示す図である。このプログラム251は、障害回復プログラム250から指示された、ストレージノード障害によってペアの片方を喪失したストレージ制御部ペアが担当する全ボリュームを、冗長度が低下していない正常なストレージ制御部ペアに退避させる処理を行う。つまり、ペアの片方を喪失したストレージ制御部ペアが担当する全ボリュームを、冗長度が低下していない正常な複数のストレージ制御部ペアに分散して退避させる処理を行う。このプログラム251は、クラスタ制御部216のメモリに格納されており、当該クラスタ制御部が配置されたストレージノードのCPUによって実行される。このプログラム251は、マスタロールのクラスタ制御部216が実行する障害回復プログラム250から起動され、当該クラスタ制御部が実行する。マスタロールのクラスタ制御部が障害により機能しない場合には、クラスタ内の他のワーカロールのクラスタ制御部がマスタロールとなり実行する。
FIG. 14 is a diagram showing an example of processing of the volume saving program 251. As shown in FIG. This program 251 saves all the volumes handled by the storage control unit pair, one of which has been lost due to a storage node failure, to a normal storage control unit pair whose redundancy has not decreased, as instructed by the
ボリューム退避プログラム251は、障害回復プログラム250から指定された退避元ストレージ制御部ペアが担当するボリューム一覧を取得する(S300)。つまり、ペアの片方を喪失したストレージ制御部ペアが担当する全ボリュームの情報を取得する。前述したように、ボリューム管理表261は、ストレージ制御部のメモリに存在する情報である。そのため、実際には当該ストレージ制御部ペアの残存ストレージ制御部が配置されているストレージノードのクラスタ制御部を介して、情報を取得することになる。ボリューム退避プログラム251は、残存ストレージ制御部が配置されているストレージノードのクラスタ制御部を介して、ストレージ制御部ペアの残存ストレージ制御部からボリューム管理表261を受け取り、ストレージ制御部ペアID2614と対応する全てのボリュームID2611を取得する。 The volume evacuation program 251 acquires a list of volumes that are in charge of the evacuation source storage control unit pair specified by the failure recovery program 250 (S300). In other words, the information of all the volumes handled by the storage control unit pair in which one of the pairs has been lost is obtained. As described above, the volume management table 261 is information existing in the memory of the storage controller. Therefore, information is actually acquired via the cluster controller of the storage node in which the remaining storage controller of the relevant storage controller pair is arranged. The volume save program 251 receives the volume management table 261 from the remaining storage control unit of the storage control unit pair via the cluster control unit of the storage node where the remaining storage control unit is arranged, and corresponds to the storage control unit pair ID 2614. Get all volume ID2611.
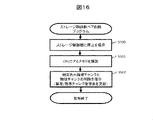
次に、ボリューム退避プログラム251は、取得したストレージ制御部ペアID2614と対応する全てのボリュームから未退避のボリュームを一つずつ選択し(S301)、ボリューム退避先のストレージ制御部ペアを決定するために、選択された各ボリュームに対してボリューム退避先決定処理を実行する(S302)。ボリューム退避先決定処理の詳細については、図15を用いて後述する。 Next, the volume evacuation program 251 selects unevacuated volumes one by one from all the volumes corresponding to the acquired storage control unit pair ID 2614 (S301), and determines the volume evacuation destination storage control unit pair. , volume save destination determination processing is executed for each selected volume (S302). Details of the volume save destination determination process will be described later with reference to FIG.
ボリュームの退避先が決定後、ボリューム退避プログラム251は、退避元のストレージ制御部と退避先にストレージ制御部に対して、当該ボリュームの移動を指示する(S303)。このボリューム移動処理自体は、一般にボリュームマイグレーションなどと呼ばれる技術及び機能と同様のため、説明は省略する。当該ボリュームの退避が完了後、ボリューム退避プログラム251は、ステップS300で特定した全てのボリュームを退避が完了したか否かを判断する(S304)。全てのボリュームの退避が完了した場合、ボリューム退避プログラム251は、処理を終了する。一方、全てのボリュームの退避が完了していない場合、ボリューム退避プログラム251は、ステップS301に戻り別のボリュームに対してステップS302~S304を実行する。 After the volume evacuation destination is determined, the volume evacuation program 251 instructs the evacuation source storage control unit and the evacuation destination storage control unit to move the volume (S303). The volume migration process itself is the same as the technique and function generally called volume migration, so the explanation is omitted. After completing the evacuation of the volume, the volume evacuation program 251 determines whether or not evacuation of all the volumes identified in step S300 has been completed (S304). When evacuation of all volumes is completed, the volume evacuation program 251 terminates processing. On the other hand, if evacuation of all volumes has not been completed, the volume evacuation program 251 returns to step S301 and executes steps S302 to S304 for another volume.
図14の例では、ボリュームの移動完了を待ちながら1つずつ退避させているが、移動完了を待たずに次のボリューム退避を開始し、複数ボリュームを同時並行的に退避してもよい。ただし、この場合は退避先ストレージ制御部ペアを決定する際に、現在同時並行して退避処理を行っているボリュームの影響を考慮する必要がある。 In the example of FIG. 14, the volumes are evacuated one by one while waiting for the completion of the movement of the volumes. However, in this case, when determining the save destination storage control unit pair, it is necessary to consider the influence of the volumes that are currently being saved in parallel.
また、ボリューム作成時などに、ボリューム毎にGold(高ランク)、Silver(中ランク)、Bronze(低ランク)のようなランク付けを行えるようにしておき、ランクに応じてボリューム移動を行う順番を変えるようにしてもよい。同様に、ボリュームのランクに応じて、ボリューム移動を行う際の処理速度を変えてもよい。例えば、ランクが高い程、先にボリューム移動を行い、処理速度も速くすることで、ランクの高いボリュームの冗長度が低下している期間を短くすることができる。これらの処理は、図7のボリューム管理表261に、ボリュームのランクを示す列を追加し、ステップS301において移動対象のボリュームを選択する際や、ステップS303においてボリューム移動の指示を行う際に、当該列を参照することで実現できる。 Also, when creating volumes, etc., it is possible to rank each volume such as Gold (high rank), Silver (middle rank), Bronze (low rank), etc., and the order of volume migration is determined according to the rank. You can change it. Similarly, the processing speed for volume migration may be changed according to the rank of the volume. For example, the higher the rank, the earlier the volume is migrated and the higher the processing speed is, so that the period during which the redundancy of the volume with the higher rank is reduced can be shortened. These processes add a column indicating the rank of the volume to the volume management table 261 of FIG. You can do this by referencing columns.
また、図14の例では、ボリューム毎に独立して退避先ストレージ制御部ペアを決定しているが、あるボリュームのスナップショットから作成したボリュームのように依存関係のある複数ボリュームに対して、まとめて1つの退避先ストレージ制御部ペアを決定してもよい。複数のボリューム間で重複しているデータを取り除く重複排除機能を有するストレージシステムにおいては、データの重複度合いが高い複数のボリュームに対して、まとめて1つの退避先ストレージ制御部ペアを決定してもよい。 In the example of FIG. 14, the save destination storage control unit pair is determined independently for each volume. Alternatively, one save destination storage controller pair may be determined by In a storage system with a deduplication function that removes duplicated data between multiple volumes, even if a single save destination storage control unit pair is determined for multiple volumes with a high degree of data duplication, good.
図15は、ボリューム退避先決定プログラム252の処理の一例である。このプログラム252はボリューム退避プログラム251から指示されたボリュームの退避先として最適なストレージ制御部ペアを決定する処理を行う。即ち、図15で示された処理は、ペアの片方を喪失したストレージ制御部ペアが担当する全ボリュームに対して、ボリューム毎に実行される。このプログラム252は、マスタロールのクラスタ制御部216のメモリに格納されており、当該クラスタ制御部が配置されたストレージノードのCPUによって実行される。このプログラム252は、マスタロールのクラスタ制御部が実行するボリューム退避プログラムから起動され、当該クラスタ制御部216が実行する。マスタロールのクラスタ制御部が障害により機能しない場合には、クラスタ内の他のワーカロールのクラスタ制御部がマスタロールとなり実行する。
FIG. 15 is an example of the processing of the volume save
ボリューム退避先決定プログラム252は、ストレージ制御部管理表257を参照し、退避先候補となるストレージ制御部ペアの一覧を取得する(S400)。つまり、ストレージ制御部管理表257のストレージ制御部ペアID2572の全ての情報を取得する。
The volume save
取得したストレージ制御部ペアの一覧から、処理対象のストレージ制御部ペアを1つずつ選択し(S401)、さらに、ストレージ制御部ペアを構成するストレージ制御部から、処理対象のストレージ制御部を1つずつ選択する(S402)。ボリューム退避先決定プログラム252は、当該ストレージ制御部が配置されたストレージノードの動作状態が正常か否かを判定する(S403)。正常でなければ、ステップS401に戻り、別のストレージ制御部ペアに対してS402~S407を実行する。
From the acquired list of storage controller pairs, select one storage controller pair to be processed (S401), and select one storage controller to be processed from the storage controllers that make up the storage controller pair. Select one by one (S402). The volume save
正常であれば、当該ストレージ制御部が配置されたストレージノードに当該ボリュームを退避させた際に、当該ストレージ制御部が配置されたストレージノードの記憶装置の空き容量が閾値以上であるか否かを確認する(S404)。閾値未満であれば、ステップS401に戻り、別のストレージ制御部ペアに対してS402~S407を実行する。 If it is normal, when the volume is saved to the storage node where the storage control unit is arranged, it is checked whether the free space of the storage device of the storage node where the storage control unit is arranged is equal to or greater than the threshold. Confirm (S404). If less than the threshold, return to step S401 and execute S402 to S407 for another storage controller pair.
閾値以上であれば、当該ストレージ制御部が配置されたストレージノードの通信帯域利用率が所定の閾値以下であるか否かを判定する(S405)。閾値よりも大きければ、ステップS401に戻り、別のストレージ制御部ペアに対してS402~S407を実行する。 If it is equal to or higher than the threshold, it is determined whether or not the communication band utilization rate of the storage node in which the storage control unit is arranged is equal to or lower than a predetermined threshold (S405). If it is larger than the threshold, the process returns to step S401 and executes S402 to S407 for another storage controller pair.
閾値以下であれば、ストレージ制御部管理表を参照し、当該ストレージ制御部のCPU利
用率が所定の閾値以下であるか否かを判定する(S406)。閾値よりも大きければ、ステップS401に戻り、別のストレージ制御部ペアに対してS402~S407を実行する。閾値以下であれば、ステップS407に進む。
If it is equal to or less than the threshold, the storage control unit management table is referenced to determine whether the CPU utilization rate of the storage control unit is equal to or less than a predetermined threshold (S406). If it is larger than the threshold, the process returns to step S401 and executes S402 to S407 for another storage controller pair. If it is equal to or less than the threshold, the process proceeds to step S407.
ボリューム退避先決定プログラム252がステップS403で判定した、ストレージ制御部が配置されたストレージノードの動作状態は、ストレージ制御部管理表257からステップS402で選択したストレージ制御部ID2571に対応するストレージノードID2573を取得し、ストレージノードID2573に対応するストレージノード管理表256の動作状態2563から取得できる。
The operating state of the storage node in which the storage control unit is arranged determined by the volume save
ステップS404で判定したボリューム退避後のストレージノードの空き容量は、ストレージノード管理表256のストレージノードID2561に対応する記憶装置総容量2567から記憶装置総使用量2568を減じ、さらに、ボリューム管理表261のボリュームID2611に対応する使用容量2613を減ずることで取得できる。
The free capacity of the storage node after volume evacuation determined in step S404 is obtained by subtracting the total
ステップS405で判定したストレージノードの通信帯域利用率は、ストレージ制御部管理表257からステップS402で選択したストレージ制御部ID2571に対応するストレージノードID2573を取得し、ストレージノードID2573に対応するストレージノード管理表256の動作状態2563と通信帯域利用率2566から取得できる。
The communication band utilization rate of the storage node determined in step S405 is obtained by acquiring the
ボリューム退避先決定プログラム252がステップS406で判定したストレージ制御部のCPU利用率は、ステップS402で選択したストレージ制御部IDに対応するストレージ制御部管理表257のCPU利用率2577から取得できる。
The CPU utilization rate of the storage control unit determined in step S406 by the volume save
ステップS404~S406での判定に用いた閾値は、ストレージシステム全体で固定の値としてもよいし、ストレージノード毎に設定できる値としてもよい。ストレージノード毎に設定可能とする場合は、ストレージノード管理表にそれぞれの閾値の列を追加しておき、ボリューム退避先決定プログラムがステップS404~S406を実行する際に取得する。 The thresholds used in the determinations in steps S404 to S406 may be fixed values for the entire storage system, or may be set for each storage node. If the settings can be made for each storage node, a column for each threshold is added to the storage node management table, and the volume save destination determination program acquires the threshold when executing steps S404 to S406.
物理チャンクをストレージ制御部が配置されたストレージノード以外のストレージノードにも保存する構成としている場合は、ステップS404を一律スキップして、ステップS405に進んでもよい。 If the physical chunk is stored in a storage node other than the storage node where the storage control unit is arranged, step S404 may be skipped across the board and the process may proceed to step S405.
ボリューム退避先決定プログラム252は、当該ストレージ制御部ペアを構成する全てのストレージ制御部に対して、ステップS403~S406が完了しているか否かを判定する(S407)。完了していれば、当該ストレージ制御部ペアを退避先として決定する(S408)。完了していないストレージ制御部が残っていれば、ステップS402に戻り、ステップS403~S407を実行する。
The volume save
図15の判定処理は一例であり、実際のストレージシステムの構造や特性などに応じて、任意の判定処理を行ってよい。例えば、ステップS403~ステップS406の判断は、退避先として求められるストレージシステムの特性に応じて、少なくとも一つのステップを実行することで判定されても良い。また、当該ボリュームを利用するホスト装置と、退避先候補のストレージ制御部が配置されたストレージノード間のネットワーク上の距離や、ネットワークを介した通信経路上に存在するネットワークスイッチの通信帯域利用率などによって判定してもよい。また、重複排除機能を有するストレージシステムにおいて、同一ストレージ制御部ペア内のボリューム間でのみ重複排除が適用可能といった制限がある場合、ボリュームの退避先によって、重複排除機能によるデータ削減量が変化する。この場合、退避先候補のストレージ制御部ペアにボリュームを退避させた際に重複排除機能によって削減されるデータ量を事前に見積もり、削減量が最も大きくなるストレージ制御部ペア
に退避させるようにしてもよい。また、ボリューム管理表261(図7)で管理するIO量を利用し、退避するボリュームに対するIO量に応じて、ステップS405の通信帯域利用率、ステップS406のCPU利用率の閾値を変更するように構成しても良い。また、図5のストレージノード管理表256に、ストレージノードに搭載しているCPUの動作周波数や、搭載している各記憶装置の種別やIO性能などの情報を追加し、障害が発生したストレージノードに搭載されているCPUや記憶装置と同等以上のものが搭載されているストレージノード上に配置されたストレージ制御部を退避先として選択することで、ボリュームを退避した後も、退避前と同等のIO性能が得られるようにしてもよい。
The determination process in FIG. 15 is an example, and any determination process may be performed according to the structure and characteristics of the actual storage system. For example, the determinations in steps S403 to S406 may be made by executing at least one step according to the characteristics of the storage system required as the save destination. In addition, the distance on the network between the host device that uses the volume and the storage node where the storage control unit of the save destination candidate is arranged, the communication bandwidth utilization rate of the network switch that exists on the communication path through the network, etc. may be determined by In addition, in a storage system with a deduplication function, if there is a restriction that deduplication can be applied only between volumes within the same storage control unit pair, the amount of data reduction by the deduplication function changes depending on the save destination of the volume. In this case, even if you estimate in advance the amount of data that will be reduced by the deduplication function when the volume is evacuated to the storage control unit pair that is the backup destination candidate, and then evacuate to the storage control unit pair that has the largest amount of reduction. good. Also, the IO amount managed by the volume management table 261 (FIG. 7) is used, and the communication band utilization rate in step S405 and the CPU utilization rate threshold in step S406 are changed according to the IO amount for the volume to be saved. may be configured. In addition, information such as the operating frequency of the CPU installed in the storage node, the type and IO performance of each installed storage device, etc. is added to the storage node management table 256 in FIG. By selecting a storage control unit placed on a storage node that is equipped with a CPU and storage device equivalent to or higher than those installed in the , as the save destination, even after saving the volume, the same level as before saving IO performance may be obtained.
図16は、ストレージ制御部ペア削除プログラム254の処理の一例である。このプログラム254は、障害回復プログラム250から指示されたストレージ制御部を削除する処理を行う。このプログラム254は、クラスタ制御部216のメモリ212に格納されており、当該クラスタ制御部が配置されたストレージノードのCPUによって実行される。このプログラム254は、マスタロールのクラスタ制御部が実行する障害回復プログラム250から起動される。そして、削除対象であり、ペアの片方を喪失しているストレージ制御部ペアの残存ストレージ制御部が動作しているストレージノードのクラスタ制御部が実行する。
FIG. 16 is an example of processing of the storage controller
ストレージ制御部ペア削除プログラム254は、当該ストレージノードで動作している削除対象のストレージ制御部ペアの残存ストレージ制御部に対して、停止を指示する(S500)。
The storage control unit
ストレージ制御部が停止すると、当該ストレージ制御部に割り当てられていたCPUコアやメモリなどの情報処理資源を解放する(S501)。なお、このプログラム254が実行された後に、解放した情報処理資源を利用して、新しいストレージ制御部を作成するため、実際には解放せずに、新しいストレージ制御部を作成する際に、解放する予定だった情報処理資源を再利用するようにしてもよい。次に、ストレージ制御部ペア削除プログラム254は、当該ストレージノードで動作するデータ冗長化部218に対して当該ストレージ制御部ペアに割り当てられていた論理チャンク及び、論理チャンクに対応付けられている物理チャンクの削除を指示する(S502)。データ冗長化部は、指示された論理チャンクと物理チャンクを削除し、論理チャンク管理表271と物理チャンク管理表272から関連するレコードを削除する。
When the storage control unit stops, the information processing resources such as CPU cores and memory allocated to the storage control unit are released (S501). After this
このように実施例1によれば、冗長度が低下したストレージ制御部の冗長度を回復させずに、ストレージ制御部が処理を担当していた複数のボリュームを正常なストレージ制御部に分散して退避させ、退避完了後に冗長度が低下したストレージ制御部自体を削除することで、冗長度の回復可能性を保証するための予約情報処理資源を不要とし、物理サーバの利用効率を向上させる。 As described above, according to the first embodiment, a plurality of volumes processed by the storage control unit are distributed to the normal storage control units without recovering the redundancy of the storage control unit whose redundancy has decreased. By evacuating and deleting the storage control unit itself whose redundancy has been lowered after the completion of the evacuation, the reserved information processing resource for guaranteeing the possibility of recovering the redundancy is unnecessary, and the utilization efficiency of the physical server is improved.
また、ストレージシステムを構成するストレージノードに障害が発生した場合、当該ストレージノードが管理している制御情報(各種管理表)と物理チャンクに格納されたデータを、予備リソースを確保することなく正常なストレージノードに引き継ぐことができる。正常なストレージノードに処理を引き継いだ後も、ストレージ制御部とボリュームの対応を管理し、ストレージ制御部が配置されるストレージノードにデータを保存(データのローカリティを確保)することで、ホスト装置からのIO要求に対し、高い応答性を維持することができる。つまり、ホスト装置にボリュームを提供するストレージ装置に対し、データのリード要求があった場合、他のストレージノードからデータを読み出す必要がない。 In addition, if a failure occurs in a storage node that configures the storage system, the control information (various management tables) managed by the storage node and data stored in physical chunks can be restored to normal without securing spare resources. It can be handed over to the storage node. Even after the processing is handed over to a normal storage node, by managing the correspondence between the storage controller and the volume and storing data in the storage node where the storage controller is located (ensuring data locality), high responsiveness to IO requests. In other words, when a data read request is issued to a storage device that provides a volume to a host device, there is no need to read data from another storage node.
また、予備リソースを確保する必要がないため、ストレージシステムの構築コストを低減し、仮想化技術を用いたSDSに求められる低コスト化に効率よく対応することができる
。尚、予備リソースを確保した従来の技術と比べ、同程度の可用性を実現するため、必要なCPUコア数やメモリ容量を2/3程度削減することができる。これにより、ストレージシステム構築コストを20パーセント低減することが可能となる。
In addition, since there is no need to secure spare resources, the construction cost of the storage system can be reduced, and the cost reduction required for SDS using virtualization technology can be efficiently met. In addition, in order to achieve the same level of availability as the conventional technology that secures reserve resources, the required number of CPU cores and memory capacity can be reduced by about 2/3. This makes it possible to reduce the storage system construction cost by 20%.
以下、図17を参照して、実施例2について詳述する。 The second embodiment will be described in detail below with reference to FIG.
実施例1では、ストレージノード障害が発生した際の回復方法を示した。実施例2では、ストレージノード減設に適用する技術について説明する。つまり、ストレージシステムから、ストレージノードを取り除く処理をおこなうものである。以下、説明の容易化のため、ストレージ制御部グループを、一台のアクティブモードのストレージ制御部と一台のスタンバイモードのストレージ制御部からなるストレージ制御部ペアのケースで説明する。但し、ペアに限らず、3台以上のストレージ制御部から構成されるストレージ制御部グループの場合であっても、基本的には同一の処理を行うこととなる。ストレージ制御部ペア又はグループが複数のアクティブモードのストレージ制御部を含んでいる場合、減設処理のなかでアクティブモードのストレージ制御部はスタンバイモードのストレージ制御部と基本的には同様に扱ってもよい。 In Example 1, a recovery method when a storage node failure occurs has been shown. In a second embodiment, a technique applied to storage node reduction will be described. In other words, the process of removing the storage node from the storage system is performed. For ease of explanation, the storage controller group will be described below as a storage controller pair consisting of one active mode storage controller and one standby mode storage controller. However, not limited to pairs, even in the case of a storage control unit group composed of three or more storage control units, basically the same processing is performed. If a storage controller pair or group contains multiple active mode storage controllers, the active mode storage controllers can be treated basically the same as the standby mode storage controllers during the removal process. good.
図17は、ストレージノード減設プログラム255の処理の一例である。このプログラム255は、ストレージシステムの管理者から指定されたストレージノードをストレージシステムから取り除くための処理を行う。このプログラム255は、管理端末110を介してストレージシステム200の管理者の指示によって起動され、マスタロールのクラスタ制御部が配置されたストレージノードのCPUによって実行される。マスタロールのクラスタ制御部218が定期的に行っている各ストレージノードの監視処理によって、当該ストレージノード障害の予兆を検出した場合に、このプログラム255を起動し、ストレージノード障害による冗長度低下を未然に防止するようにしてもよい。なお、図示していないが、減設対象のストレージノードに配置されたクラスタ制御部218がマスタロールの場合は、事前に他のストレージノードに配置されたワーカロールのクラスタ制御部の何れかをマスタロールに切り替える。
FIG. 17 is an example of processing of the storage
このプログラム255は、新たにマスタロールに切り替わったクラスタ制御部が配置されたストレージノードのCPUによって実行される。マスタロールに切り替えるクラスタ制御部の選出方法は、ストレージノード障害によってマスタロールのクラスタ制御部が失われた場合と同様でもよい。
This
また、減設対象のストレージノードに配置されたマスタロールのクラスタ制御部が、何らかの判定処理によって新しいマスタロールのクラスタ制御部を選出してもよい。なお、ストレージノード減設プログラム255は処理を開始する前に、減設対象のストレージノードを除いたストレージシステムを構成する全ストレージノードの記憶装置の総空き容量と、減設対象のストレージノードの記憶装置の総使用量とを比較して、ストレージノード減設中に記憶装置の容量が不足すると判断した場合は、処理を中止する。減設処理中に、ストレージノード減設中の容量不足を防止する処理を追加してもよい。
Also, the master role cluster control unit arranged in the storage node to be removed may select a new master role cluster control unit by some kind of determination processing. Before the storage
また、ストレージノード減設プログラム255実行中に、ストレージシステムの管理者からボリュームの作成指示を受領した場合、ストレージノード減設によって、空き容量不足が発生する可能性があるか否かを判断し、発生する可能性が高いと判断した場合は、ボリューム作成を中止し、ストレージノード減設中の容量不足を防止するといった処理を追加してもよい。
Also, when a volume creation instruction is received from the storage system administrator during execution of the storage
ストレージ減設プログラム255は、減設対象のストレージノードに配置されたストレー
ジ制御部219を含むストレージ制御部ペア217を選択する(S600)。この処理はストレージ制御部管理表257を参照し、減設対象のストレージノードID2573で検索し、ストレージ制御ペアIDを特定することで実現する。この際、特定したストレージ制御部ペアへの新規ボリューム作成を抑止する処理を追加してもよい。この処理は、図6のストレージ制御部管理表257にボリューム作成抑止フラグの列を追加し、ストレージ制御部ペアID2572が特定したストレージ制御部ペアとなっているストレージ制御部に対してこのフラグをONにすることで実現できる。図12及び図13と同様に、図10に示した例によると減設対象のストレージノードに配置されたストレージ制御部を含むストレージ制御部ペアは2つ存在し、減設対象のストレージノードに配置されたストレージ制御部の一方はアクティブモードで動作しており、他方はスタンバイモードで動作している。
The
物理チャンクをストレージ制御部217が配置されたストレージノード以外のストレージノードにも保存する構成としている場合や、物理チャンクを三重化している場合、ストレージノード間でRAIDやErasure Codingを適用して物理チャンクを冗長化している場合は、ステップS600で特定したストレージ制御部ペア以外のストレージ制御部ペアに対応付けられた論理チャンクを構成する物理チャンクが減設対象のストレージノードに保存されている可能性がある。そのため、ステップS601に進む前に、ストレージノード減設プログラム255は減設対象を除く全てのストレージノードのデータ冗長化部に対して、減設対象のストレージノードに配置されたストレージ制御部とは関係のないストレージ制御部ペアに対応付けられた論理チャンクを構成する物理チャンクが、減設対象のストレージノードに配置されているか否かの確認と、他のストレージノードへの再配置を指示する。
If the configuration is such that physical chunks are stored in storage nodes other than the storage node where the
指示を受けたデータ冗長化部は、冗長化方式に応じて、物理チャンクの配置先の確認と再配置を実行する。例えば、物理チャンクを複製(二重化)する冗長化方式の場合、データ冗長化部は論理チャンク管理表271から減設対象のストレージノードに物理チャンクを保存している論理チャンクが存在するか否かを確認する。存在する場合は、当該論理チャンクに対応付けられているストレージ制御部ペアID2712が減設対象のストレージノードに配置されたストレージ制御部を含むストレージ制御部ペアか否かを確認する。喪失したストレージ制御部を含むストレージ制御部ペアでなければ、新しい物理チャンクを確保し、当該論理チャンクを構成する物理チャンクの何れかから、新たに確保した物理チャンクにデータをコピーする。コピー完了後、論理チャンク管理表271を更新し、論理チャンクを構成する物理チャンクのうち、減設対象ノードに保存された物理チャンクを、コピー先の物理チャンクに変更する。 The data redundancy unit that has received the instruction confirms the allocation destination of the physical chunk and performs rearrangement according to the redundancy method. For example, in the case of a redundancy method in which physical chunks are duplicated (duplicated), the data redundancy unit checks from the logical chunk management table 271 whether or not there is a logical chunk that stores a physical chunk in the storage node to be removed. Confirm. If it exists, it is checked whether the storage controller pair ID 2712 associated with the relevant logical chunk is a storage controller pair including the storage controller arranged in the storage node to be removed. If the storage controller pair does not include the lost storage controller, a new physical chunk is secured, and data is copied from one of the physical chunks that make up the logical chunk to the newly secured physical chunk. After the copy is completed, the logical chunk management table 271 is updated, and among the physical chunks that make up the logical chunk, the physical chunk saved in the deletion target node is changed to the copy destination physical chunk.
減設対象を除く全てのストレージノードで物理チャンクの配置先の確認と再配置が完了すると、ステップS601に進む。 When the physical chunk placement destinations have been confirmed and rearranged in all storage nodes other than those to be removed, the process proceeds to step S601.
ストレージノード減設プログラム255は、特定したストレージ制御部ペアから処理対象となるストレージ制御部ペアを選択する(S601)。当該ストレージ制御部ペアのアクティブモードのストレージ制御部が減設対象ストレージノードに配置されているか否かを判定する(S602)。
The storage
配置されていれば、図12のステップS106~S108を実行し、当該ストレージ制御部ペアが担当している全ボリュームを退避させ、当該ストレージ制御部ペアを削除する(S603)。これにより、当該ストレージ制御部ペアのスタンバイモードが配置されていたストレージノードに、ストレージ制御部を1つ配置するのに必要な情報処理資源が解放されたことになる。アクティブモードのストレージ制御部が配置されていなければ、ステップS603をスキップし、ステップS604に進む。S602の処理は、ストレージ制御部管理表257を参照し、減設対象のストレージノードID2571とステップS601で選択したストレージ制御部ペアID2572のAND条件で検索して取得したストレージ制御部の動作モード2574を取得することで実
現する。
If so, steps S106 to S108 of FIG. 12 are executed to save all the volumes handled by the storage control unit pair and delete the storage control unit pair (S603). As a result, the information processing resources necessary for placing one storage control unit in the storage node where the standby mode of the storage control unit pair has been placed are released. If the active mode storage controller is not arranged, skip step S603 and proceed to step S604. In the process of S602, the storage control unit management table 257 is referred to, and the
ストレージノード減設プログラム255は、減設対象ストレージノードにアクティブモードのストレージ制御部が配置されている全ストレージ制御部ペアの削除が完了しているか否かを判定する(S604)。完了していれば、ステップS605に進み、完了していなければ、ステップS601に戻る。
The storage
次にストレージノード減設プログラム255は、削除したストレージ制御部ペアを構成する減設対象ではないストレージノードのクラスタ制御部216に、減設対象ストレージノードに残っているストレージ制御部ペアのスタンバイモードのストレージ制御部のコピーを指示する(S605)。当該ストレージ制御部ペアのアクティブモードのストレージ制御部から再構築せずに、スタンバイモードのストレージ制御部からコピーするのは、アクティブモードのストレージ制御部が処理を担当しているボリュームのIO処理への影響を最小化するためである。
Next, the storage
指示を受けたクラスタ制御部216は、CPUコアやメモリなどの情報処理資源を確保し、記憶装置からストレージ制御部を構成するプログラムをメモリにロードして、ストレージ制御部を起動する。確保する情報処理資源は、削除によって解放されたものを用いる。起動後に減設対象ストレージノードに残っているストレージ制御部ペアのスタンバイモードのストレージ制御部からボリューム管理表をコピーする。
Upon receipt of the instruction, the
ストレージ制御部217のコピー完了後、ストレージノード減設プログラム255は、削除したストレージ制御部ペアを構成する減設対象ではないストレージノードのデータ冗長化部に対して、ステップS605の処理対象としたストレージ制御部ペアに対応付けられた論理チャンクを構成する物理チャンクの再配置を指示する(S606)。指示を受けたデータ冗長化部は、減設対象のストレージ制御部のデータ冗長化部の論理チャンク管理表271のレコードから当該ストレージ制御部ペアID2712に対応付けられたレコードをコピーする。
After the copy of the
その後、データ冗長化部218は、新しい物理チャンクを確保し、減設対象のストレージ制御部に保存されている物理チャンクのデータをコピーする。論理チャンク管理表を更新し、論理チャンクを構成する物理チャンクのうち、減設対象のストレージノードに保存された物理チャンクを、コピーした物理チャンクに変更する。
After that, the
物理チャンクの再配置が完了すると、ストレージノード減設プログラム255は、当該ストレージ制御部ペアのスタンバイモードのストレージ制御部をコピーしたストレージ制御部に切り替える指示を行い、ストレージ制御部管理表257を更新する(S607)。ステップS600において、特定したストレージ制御部ペアへの新規ボリューム作成を抑止する処理を追加した場合は、このステップに新規ボリューム作成の抑止を解除する処理を追加する。この処理は、図6のストレージ制御部管理表257において、ストレージ制御部ペアID2572が特定したストレージ制御部ペアとなっているストレージ制御部に対して、追加したボリューム作成抑止フラグをOFFにすることで実現できる。
When the reallocation of the physical chunks is completed, the storage
次に、ストレージノード減設プログラム255は減設対象のストレージノードで動作しているクラスタ制御部とデータ冗長化部に停止を指示し(S608)、ストレージノード管理表256から当該ストレージノードに関するレコードを削除する(S609)。以上の処理が完了すると、減設対象のストレージノードは、ストレージシステムから完全に切り離され、物理的にストレージノードを取り除いても問題ない状態となる。
Next, the storage
このように実施例2によれば、減設対象のストレージノードで動作するストレージ制御部が担当していた複数のボリュームを減設対象外のストレージ制御部に分散して退避させ
、退避完了後に減設対象のストレージノードで動作するストレージ制御部を削除することで、ストレージノードを減設するための予約予備情報資源を不要とし、物理サーバの利用効率を向上させることができる。
As described above, according to the second embodiment, a plurality of volumes that were in charge of the storage control unit operating in the storage node to be deleted are distributed to the storage control units not to be deleted and saved, and after the backup is completed, the volumes are deleted. By deleting the storage control unit that operates on the storage node to be installed, it is possible to eliminate the need for a reserved spare information resource for reducing the number of storage nodes and improve the utilization efficiency of the physical server.
また、減設対象のストレージノードで動作するストレージ制御部が担当していたボリュームに対するIO要求の処理を、他のストレージ制御部が引き継いだ後も、ストレージ制御部が配置されるストレージノードにデータを保存(データのローカリティを確保)することで、ホスト装置からのIO要求に対し、高い応答性を維持することができる。つまり、ホスト装置にボリュームを提供するストレージ装置に対し、データのリード要求があった場合、他のストレージノードからデータを読み出す必要がない。 In addition, even after other storage controllers have taken over the processing of IO requests for volumes that were in charge of the storage controller running on the storage node to be removed, data will not be sent to the storage node where the storage controller is located. By saving (ensuring data locality), it is possible to maintain high responsiveness to IO requests from the host device. In other words, when a data read request is issued to a storage device that provides a volume to a host device, there is no need to read data from another storage node.
また、ストレージノードを減設するための予備リソースを確保する必要がなく、ストレージシステムをスケールインすることが可能となるため、仮想化技術を用いたSDSに求められるスケーラビリティを向上させることが可能となる。 In addition, there is no need to secure spare resources for reducing storage nodes, and the storage system can be scaled in, making it possible to improve the scalability required for SDS using virtualization technology. Become.
以上、実施例1では、障害が発生したストレージノードのストレージ制御部を用いて構成されるストレージ制御部ペアからボリュームを退避させているが、実施例2ではストレージ制御部にかかるストレージノードを減設させる場合を示した。 As described above, in the first embodiment, the volume is saved from the storage controller pair configured using the storage controller of the failed storage node, but in the second embodiment, the storage node associated with the storage controller is reduced. The case of letting
本発明は、さらに、ストレージノードは障害発生も減設もせずに稼働を続け、ボリュームの担当変更させるストレージ制御部ペアが担当ボリュームを残して稼働を続けてもよい。また、一つのストレージ制御部ペアから複数のストレージ制御部ペアにボリューム担当が分散して移動しているが、これに解らず、1つのストレージ制御部ペアから1つのストレージ制御部ペアへ、複数のストレージ制御部ペアから1つのストレージ制御部ペアへ、複数のストレージ制御部ペアから複数のストレージ制御部ペアへ、ボリューム担当を移動させてもよい。 In addition, the present invention may allow the storage node to continue operating without failure or reduction, and the storage control unit pair to be changed in charge of the volume may continue to operate while leaving the volume in charge. In addition, the person in charge of the volume is distributed and moved from one storage control unit pair to a plurality of storage control unit pairs. Volume responsibility may be moved from storage controller pairs to one storage controller pair and from multiple storage controller pairs to multiple storage controller pairs.
100:ホスト装置、200:ストレージシステム、210:ストレージノード、211:CPU、212:メモリ、213:記憶装置、214:通信装置、215:、216:クラスタ制御部、217:ストレージ制御部ペア、218:データ冗長化部、219:ストレージ制御部、220:ボリューム、221:論理チャンク、222:物理チャンク、250:障害回復プログラム、251:ボリューム退避プログラム、252:ボリューム退避先決定プログラム、256:ストレージノード管理表、257:ストレージ制御部管理表、300:ネットワーク。 100: host device, 200: storage system, 210: storage node, 211: CPU, 212: memory, 213: storage device, 214: communication device, 215:, 216: cluster controller, 217: storage controller pair, 218 : data redundancy unit, 219: storage control unit, 220: volume, 221: logical chunk, 222: physical chunk, 250: failure recovery program, 251: volume evacuation program, 252: volume evacuation destination determination program, 256: storage node Management table, 257: Storage control unit management table, 300: Network.
Claims (6)
データを記憶する記憶装置と、
ストレージシステムの制御を行うクラスタ制御部と、
各ストレージノードに設けられ、前記記憶装置を利用してボリュームという単位で記憶領域をホスト装置に提供し、ホスト装置からのIO要求に応じて記憶装置にデータを保存するストレージ制御部と、を有し、
前記ストレージ制御部は、前記クラスタ内の他のストレージノードのストレージ制御部とストレージ制御部グループを構成し、前記ストレージ制御部グループの少なくとも1のストレージ制御部がアクティブモードのストレージ制御部としてホスト装置からのIO要求を処理し、前記ストレージ制御部グループの他のストレージ制御部が前記アクティブモードのストレージ制御部の処理を引き継ぐことが可能であるよう、構成され、
前記クラスタ制御部は、
減設または障害によって、稼働するストレージノードが減少する時に、第1のストレージ制御部グループが担当するボリュームの識別情報を取得し、取得した識別情報に対応する各ボリュームに対し、複数の第2のストレージ制御部グループを決定し、第1のストレージ制御部グループを構成するストレージ制御部から第2のストレージ制御部グループのストレージ制御部へ、前記第1のストレージ制御部グループが担当するボリュームを移動させ、
前記ボリュームを移動させてボリュームがなくなったストレージ制御グループを削除することを特徴とするストレージシステム。 In a storage system having multiple storage nodes forming a cluster,
a storage device for storing data;
a cluster control unit that controls the storage system;
a storage control unit provided in each storage node for providing a host device with a storage area in units of volume using the storage device and storing data in the storage device in response to an IO request from the host device; death,
The storage controller constitutes a storage controller group with the storage controllers of other storage nodes in the cluster, and at least one storage controller in the storage controller group is configured as an active mode storage controller from a host device. processing IO requests of the storage controller group and allowing other storage controllers of the storage controller group to take over the processing of the active mode storage controller;
The cluster control unit
When the number of operating storage nodes decreases due to reduction or failure, the identification information of the volumes handled by the first storage control unit group is acquired, and for each volume corresponding to the acquired identification information, a plurality of second A storage control unit group is determined, and a volume managed by the first storage control unit group is moved from the storage control units constituting the first storage control unit group to the storage control units of the second storage control unit group. ,
A storage system that deletes a storage control group that has no volume by moving the volume .
減設するノードにアクティブモードのストレージ制御部が配置されるストレージ制御部グループのボリュームを、他のストレージ制御部グループに移動させることを特徴とする請求項1に記載のストレージシステム。 When removing a storage node, the volume is moved,
2. The storage system according to claim 1 , wherein the volume of the storage controller group in which the active mode storage controller is arranged in the node to be removed is moved to another storage controller group.
前記障害が発生したノードにアクティブモードのストレージ制御部が配置されるストレージ制御部グループは、他のノードに配置されるストレージ制御部をアクティブに切り替え、
前記障害が発生したノードにストレージ制御部が配置される少なくとも一つのストレージ制御部グループは、そのボリュームを他のストレージ制御部グループに移動させて削除されることを特徴とする請求項1に記載のストレージシステム。 When a failure occurs in a storage node, the volume is moved,
the storage controller group in which the active mode storage controller is arranged in the failed node switches the storage controller arranged in another node to active;
2. The method according to claim 1 , wherein at least one storage controller group in which the storage controller is arranged in the failed node is deleted by moving the volume to another storage controller group. storage system.
前記ストレージシステムは、
データを記憶する記憶装置と、
ストレージシステムの制御を行うクラスタ制御部と、
各ストレージノードに設けられ、前記記憶装置を利用してボリュームという単位で記憶領域をホスト装置に提供し、ホスト装置からのIO要求に応じて記憶装置にデータを保存するストレージ制御部と、を有し、
前記ストレージ制御部は、前記クラスタ内の他のストレージノードのストレージ制御部とストレージ制御部グループを構成し、前記ストレージ制御部グループの少なくとも1のストレージ制御部がアクティブモードのストレージ制御部としてホスト装置からのIO要求を処理し、前記ストレージ制御部グループの他のストレージ制御部が前記アクティブモードのストレージ制御部の処理を引き継ぐことが可能であるよう、構成され、
前記クラスタ制御部は、減設または障害によって、稼働するストレージノードが減少する時に、第1のストレージ制御部グループが担当するボリュームの識別情報を取得し、取得した識別情報に対応する各ボリュームに対し、複数の第2のストレージ制御部グループを決定し、第1のストレージ制御部グループを構成するストレージ制御部から第2のストレージ制御部グループのストレージ制御部へ、前記第1のストレージ制御部グループが担当するボリュームを移動させ、
前記ボリュームを移動させてボリュームがなくなったストレージ制御グループを削除することを特徴とするストレージシステムの制御方法。 In a control method for a storage system having a plurality of storage nodes forming a cluster,
The storage system is
a storage device for storing data;
a cluster control unit that controls the storage system;
a storage control unit provided in each storage node for providing a host device with a storage area in units of volume using the storage device and storing data in the storage device in response to an IO request from the host device; death,
The storage controller constitutes a storage controller group with the storage controllers of other storage nodes in the cluster, and at least one storage controller in the storage controller group is configured as an active mode storage controller from a host device. processing IO requests of the storage controller group and allowing other storage controllers of the storage controller group to take over the processing of the active mode storage controller;
When the number of operating storage nodes decreases due to deletion or failure, the cluster control unit acquires identification information of the volumes that the first storage control unit group is in charge of, and for each volume corresponding to the acquired identification information: , a plurality of second storage controller groups are determined, and from the storage controllers constituting the first storage controller group to the storage controllers of the second storage controller group, the first storage controller group Move the volume in charge,
A control method for a storage system, comprising the steps of: deleting a storage control group in which the volume has disappeared by moving the volume .
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021179972A JP7179947B2 (en) | 2018-09-21 | 2021-11-04 | Storage system and storage control method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018177578A JP6974281B2 (en) | 2018-09-21 | 2018-09-21 | Storage system and storage control method |
| JP2021179972A JP7179947B2 (en) | 2018-09-21 | 2021-11-04 | Storage system and storage control method |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018177578A Division JP6974281B2 (en) | 2018-09-21 | 2018-09-21 | Storage system and storage control method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2022020744A JP2022020744A (en) | 2022-02-01 |
| JP7179947B2 true JP7179947B2 (en) | 2022-11-29 |
Family
ID=87888625
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021179972A Active JP7179947B2 (en) | 2018-09-21 | 2021-11-04 | Storage system and storage control method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7179947B2 (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7519408B2 (en) | 2022-06-20 | 2024-07-19 | 株式会社日立製作所 | Computer system and redundant element configuration method |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004348701A (en) | 2003-03-27 | 2004-12-09 | Hitachi Ltd | Control method for making data dual between computer systems |
| JP2010066862A (en) | 2008-09-09 | 2010-03-25 | Fujitsu Ltd | Data management program, data management device and data management method |
| WO2015072026A1 (en) | 2013-11-18 | 2015-05-21 | 株式会社日立製作所 | Computer system |
-
2021
- 2021-11-04 JP JP2021179972A patent/JP7179947B2/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004348701A (en) | 2003-03-27 | 2004-12-09 | Hitachi Ltd | Control method for making data dual between computer systems |
| JP2010066862A (en) | 2008-09-09 | 2010-03-25 | Fujitsu Ltd | Data management program, data management device and data management method |
| WO2015072026A1 (en) | 2013-11-18 | 2015-05-21 | 株式会社日立製作所 | Computer system |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2022020744A (en) | 2022-02-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6791834B2 (en) | Storage system and control software placement method | |
| US11307789B2 (en) | Storage system and storage control method | |
| US10359967B2 (en) | Computer system | |
| US11204709B2 (en) | Storage system and storage control method | |
| JP7167078B2 (en) | Distributed storage system and storage control method | |
| US11740823B2 (en) | Storage system and storage control method | |
| JP7113832B2 (en) | Distributed storage system and distributed storage control method | |
| CN111858189A (en) | Handling of storage disk offline | |
| JP7179947B2 (en) | Storage system and storage control method | |
| JP6817340B2 (en) | calculator | |
| US12111730B2 (en) | Storage system and failure handling method | |
| JP7520773B2 (en) | STORAGE SYSTEM AND DATA PROCESSING METHOD | |
| US20240377981A1 (en) | Storage system and memory management method | |
| US20240176710A1 (en) | Storage system and storage control method | |
| US20240231707A9 (en) | Storage system and storage control method | |
| JP2020077248A (en) | Storage system, data management method, and data management program | |
| US11544005B2 (en) | Storage system and processing method | |
| JP6605762B2 (en) | Device for restoring data lost due to storage drive failure | |
| US20140019678A1 (en) | Disk subsystem and method for controlling memory access | |
| JP2023096958A (en) | Storage system and storage system control method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20211104 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20220907 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20220913 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20221024 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20221101 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20221116 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7179947 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313111 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |