JP6866345B2 - Compounds targeting IL-23A and B cell activating factor (BAFF) and their use - Google Patents
Compounds targeting IL-23A and B cell activating factor (BAFF) and their use Download PDFInfo
- Publication number
- JP6866345B2 JP6866345B2 JP2018503151A JP2018503151A JP6866345B2 JP 6866345 B2 JP6866345 B2 JP 6866345B2 JP 2018503151 A JP2018503151 A JP 2018503151A JP 2018503151 A JP2018503151 A JP 2018503151A JP 6866345 B2 JP6866345 B2 JP 6866345B2
- Authority
- JP
- Japan
- Prior art keywords
- seq
- amino acid
- acid sequence
- polypeptide
- polypeptides
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 150000001875 compounds Chemical class 0.000 title claims description 291
- 102100036922 Tumor necrosis factor ligand superfamily member 13B Human genes 0.000 title claims description 88
- 101000852980 Homo sapiens Interleukin-23 subunit alpha Proteins 0.000 title claims description 50
- 102100036705 Interleukin-23 subunit alpha Human genes 0.000 title claims description 50
- 108010028006 B-Cell Activating Factor Proteins 0.000 title claims description 7
- 230000008685 targeting Effects 0.000 title description 7
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 834
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 812
- 229920001184 polypeptide Polymers 0.000 claims description 804
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 670
- 108090000623 proteins and genes Proteins 0.000 claims description 146
- 102000004169 proteins and genes Human genes 0.000 claims description 122
- 210000004027 cell Anatomy 0.000 claims description 107
- 239000000203 mixture Substances 0.000 claims description 65
- 238000000034 method Methods 0.000 claims description 64
- 230000027455 binding Effects 0.000 claims description 61
- 238000009739 binding Methods 0.000 claims description 59
- 201000010099 disease Diseases 0.000 claims description 48
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 48
- 108010065637 Interleukin-23 Proteins 0.000 claims description 39
- 102000013264 Interleukin-23 Human genes 0.000 claims description 39
- 239000013598 vector Substances 0.000 claims description 32
- 108060003951 Immunoglobulin Proteins 0.000 claims description 31
- 102000018358 immunoglobulin Human genes 0.000 claims description 31
- 229940124829 interleukin-23 Drugs 0.000 claims description 27
- 239000008194 pharmaceutical composition Substances 0.000 claims description 25
- 238000011282 treatment Methods 0.000 claims description 25
- 235000004279 alanine Nutrition 0.000 claims description 22
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 claims description 22
- 150000007523 nucleic acids Chemical class 0.000 claims description 22
- 201000000596 systemic lupus erythematosus Diseases 0.000 claims description 22
- 108020004707 nucleic acids Proteins 0.000 claims description 21
- 102000039446 nucleic acids Human genes 0.000 claims description 21
- 208000023275 Autoimmune disease Diseases 0.000 claims description 18
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 claims description 17
- 230000001363 autoimmune Effects 0.000 claims description 15
- 238000004519 manufacturing process Methods 0.000 claims description 15
- 208000027866 inflammatory disease Diseases 0.000 claims description 14
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 13
- 210000004899 c-terminal region Anatomy 0.000 claims description 11
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 claims description 10
- 239000004473 Threonine Substances 0.000 claims description 10
- 206010039073 rheumatoid arthritis Diseases 0.000 claims description 10
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 claims description 9
- 235000013922 glutamic acid Nutrition 0.000 claims description 9
- 239000004220 glutamic acid Substances 0.000 claims description 9
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 claims description 9
- 201000001263 Psoriatic Arthritis Diseases 0.000 claims description 8
- 208000036824 Psoriatic arthropathy Diseases 0.000 claims description 8
- 125000000291 glutamic acid group Chemical group N[C@@H](CCC(O)=O)C(=O)* 0.000 claims description 8
- 125000000341 threoninyl group Chemical group [H]OC([H])(C([H])([H])[H])C([H])(N([H])[H])C(*)=O 0.000 claims description 8
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 claims description 8
- 208000005777 Lupus Nephritis Diseases 0.000 claims description 6
- 206010025135 lupus erythematosus Diseases 0.000 claims description 5
- 230000001684 chronic effect Effects 0.000 claims description 4
- 239000007943 implant Substances 0.000 claims description 4
- 210000003734 kidney Anatomy 0.000 claims description 4
- 239000002773 nucleotide Substances 0.000 claims description 4
- 125000003729 nucleotide group Chemical group 0.000 claims description 4
- 208000002267 Anti-neutrophil cytoplasmic antibody-associated vasculitis Diseases 0.000 claims description 3
- 230000000919 anti-host Effects 0.000 claims description 3
- 208000011580 syndromic disease Diseases 0.000 claims description 3
- 208000037979 autoimmune inflammatory disease Diseases 0.000 claims description 2
- 239000002699 waste material Substances 0.000 claims 2
- 101710181056 Tumor necrosis factor ligand superfamily member 13B Proteins 0.000 description 81
- 238000012360 testing method Methods 0.000 description 55
- 241000282414 Homo sapiens Species 0.000 description 49
- 235000001014 amino acid Nutrition 0.000 description 34
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 31
- 230000014509 gene expression Effects 0.000 description 29
- 239000000523 sample Substances 0.000 description 28
- 239000000427 antigen Substances 0.000 description 27
- 108091007433 antigens Proteins 0.000 description 27
- 102000036639 antigens Human genes 0.000 description 27
- 235000018102 proteins Nutrition 0.000 description 27
- 239000012911 assay medium Substances 0.000 description 25
- 210000003719 b-lymphocyte Anatomy 0.000 description 22
- 150000001413 amino acids Chemical class 0.000 description 21
- 239000003814 drug Substances 0.000 description 21
- 239000005089 Luciferase Substances 0.000 description 20
- 239000000463 material Substances 0.000 description 20
- 101000851434 Homo sapiens Tumor necrosis factor ligand superfamily member 13B Proteins 0.000 description 19
- 238000005516 engineering process Methods 0.000 description 19
- 102000050326 human TNFSF13B Human genes 0.000 description 19
- 108060001084 Luciferase Proteins 0.000 description 18
- 239000000872 buffer Substances 0.000 description 17
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 16
- 239000013604 expression vector Substances 0.000 description 15
- 210000002966 serum Anatomy 0.000 description 15
- 241000699670 Mus sp. Species 0.000 description 14
- 239000007924 injection Substances 0.000 description 14
- 238000002347 injection Methods 0.000 description 14
- 239000000047 product Substances 0.000 description 14
- 238000006467 substitution reaction Methods 0.000 description 13
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 12
- 241000282567 Macaca fascicularis Species 0.000 description 12
- 241000700605 Viruses Species 0.000 description 12
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 12
- 230000000694 effects Effects 0.000 description 12
- 108020004414 DNA Proteins 0.000 description 11
- 241000699666 Mus <mouse, genus> Species 0.000 description 11
- 239000005557 antagonist Substances 0.000 description 11
- 210000004369 blood Anatomy 0.000 description 11
- 239000008280 blood Substances 0.000 description 11
- 230000006870 function Effects 0.000 description 11
- 230000005764 inhibitory process Effects 0.000 description 11
- 210000004962 mammalian cell Anatomy 0.000 description 11
- 239000002609 medium Substances 0.000 description 11
- 239000000178 monomer Substances 0.000 description 11
- 229940079593 drug Drugs 0.000 description 10
- 238000002474 experimental method Methods 0.000 description 10
- 238000001727 in vivo Methods 0.000 description 10
- 238000001990 intravenous administration Methods 0.000 description 10
- 239000011780 sodium chloride Substances 0.000 description 10
- 238000007920 subcutaneous administration Methods 0.000 description 10
- 230000001225 therapeutic effect Effects 0.000 description 10
- 108091026890 Coding region Proteins 0.000 description 9
- 102000004127 Cytokines Human genes 0.000 description 9
- 108090000695 Cytokines Proteins 0.000 description 9
- 230000004913 activation Effects 0.000 description 9
- 230000001965 increasing effect Effects 0.000 description 9
- 238000011534 incubation Methods 0.000 description 9
- 239000002243 precursor Substances 0.000 description 9
- 208000024891 symptom Diseases 0.000 description 9
- 210000001519 tissue Anatomy 0.000 description 9
- 239000013638 trimer Substances 0.000 description 9
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 9
- 102100029690 Tumor necrosis factor receptor superfamily member 13C Human genes 0.000 description 8
- 238000003776 cleavage reaction Methods 0.000 description 8
- 238000009472 formulation Methods 0.000 description 8
- 210000004379 membrane Anatomy 0.000 description 8
- 239000012528 membrane Substances 0.000 description 8
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 8
- 239000013612 plasmid Substances 0.000 description 8
- 230000007017 scission Effects 0.000 description 8
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 8
- 238000013518 transcription Methods 0.000 description 8
- 230000035897 transcription Effects 0.000 description 8
- 241000588724 Escherichia coli Species 0.000 description 7
- 230000002776 aggregation Effects 0.000 description 7
- 238000003556 assay Methods 0.000 description 7
- 230000009977 dual effect Effects 0.000 description 7
- 238000003908 quality control method Methods 0.000 description 7
- 102000006942 B-Cell Maturation Antigen Human genes 0.000 description 6
- 108010008014 B-Cell Maturation Antigen Proteins 0.000 description 6
- 101000998146 Homo sapiens Interleukin-17A Proteins 0.000 description 6
- 101001010626 Homo sapiens Interleukin-22 Proteins 0.000 description 6
- 102100033461 Interleukin-17A Human genes 0.000 description 6
- 208000034943 Primary Sjögren syndrome Diseases 0.000 description 6
- 210000001744 T-lymphocyte Anatomy 0.000 description 6
- 238000004220 aggregation Methods 0.000 description 6
- 239000003153 chemical reaction reagent Substances 0.000 description 6
- 201000001981 dermatomyositis Diseases 0.000 description 6
- 238000001415 gene therapy Methods 0.000 description 6
- 238000000338 in vitro Methods 0.000 description 6
- 230000002757 inflammatory effect Effects 0.000 description 6
- 239000003446 ligand Substances 0.000 description 6
- 239000000243 solution Substances 0.000 description 6
- 239000002904 solvent Substances 0.000 description 6
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 6
- 102000016605 B-Cell Activating Factor Human genes 0.000 description 5
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 5
- 101000795169 Homo sapiens Tumor necrosis factor receptor superfamily member 13C Proteins 0.000 description 5
- 206010061218 Inflammation Diseases 0.000 description 5
- 102100030703 Interleukin-22 Human genes 0.000 description 5
- 101000998145 Mus musculus Interleukin-17A Proteins 0.000 description 5
- 108091005804 Peptidases Proteins 0.000 description 5
- 102000035195 Peptidases Human genes 0.000 description 5
- 206010047115 Vasculitis Diseases 0.000 description 5
- 238000004458 analytical method Methods 0.000 description 5
- 230000015572 biosynthetic process Effects 0.000 description 5
- 239000003085 diluting agent Substances 0.000 description 5
- -1 diphenylmurislerone Chemical compound 0.000 description 5
- 239000003937 drug carrier Substances 0.000 description 5
- 108020001507 fusion proteins Proteins 0.000 description 5
- 102000037865 fusion proteins Human genes 0.000 description 5
- 230000005847 immunogenicity Effects 0.000 description 5
- 230000004054 inflammatory process Effects 0.000 description 5
- 239000004615 ingredient Substances 0.000 description 5
- 230000003993 interaction Effects 0.000 description 5
- 150000002632 lipids Chemical class 0.000 description 5
- 238000004020 luminiscence type Methods 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 230000004048 modification Effects 0.000 description 5
- 238000012986 modification Methods 0.000 description 5
- 239000002245 particle Substances 0.000 description 5
- 239000002953 phosphate buffered saline Substances 0.000 description 5
- 238000011533 pre-incubation Methods 0.000 description 5
- 238000012545 processing Methods 0.000 description 5
- 239000001509 sodium citrate Substances 0.000 description 5
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 239000006228 supernatant Substances 0.000 description 5
- 238000002560 therapeutic procedure Methods 0.000 description 5
- 238000013519 translation Methods 0.000 description 5
- 241000701161 unidentified adenovirus Species 0.000 description 5
- OZFAFGSSMRRTDW-UHFFFAOYSA-N (2,4-dichlorophenyl) benzenesulfonate Chemical compound ClC1=CC(Cl)=CC=C1OS(=O)(=O)C1=CC=CC=C1 OZFAFGSSMRRTDW-UHFFFAOYSA-N 0.000 description 4
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 4
- 239000012591 Dulbecco’s Phosphate Buffered Saline Substances 0.000 description 4
- 241000282412 Homo Species 0.000 description 4
- 102000026633 IL6 Human genes 0.000 description 4
- 102100036672 Interleukin-23 receptor Human genes 0.000 description 4
- 108090001005 Interleukin-6 Proteins 0.000 description 4
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 4
- 229930182555 Penicillin Natural products 0.000 description 4
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 4
- 239000002202 Polyethylene glycol Substances 0.000 description 4
- 229920001213 Polysorbate 20 Polymers 0.000 description 4
- 201000009594 Systemic Scleroderma Diseases 0.000 description 4
- 206010042953 Systemic sclerosis Diseases 0.000 description 4
- 208000031981 Thrombocytopenic Idiopathic Purpura Diseases 0.000 description 4
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 4
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 4
- 239000013543 active substance Substances 0.000 description 4
- 230000000890 antigenic effect Effects 0.000 description 4
- 201000003710 autoimmune thrombocytopenic purpura Diseases 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 239000012148 binding buffer Substances 0.000 description 4
- 229910002091 carbon monoxide Inorganic materials 0.000 description 4
- 239000006285 cell suspension Substances 0.000 description 4
- 238000010367 cloning Methods 0.000 description 4
- 239000013068 control sample Substances 0.000 description 4
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 4
- 238000013461 design Methods 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 230000018109 developmental process Effects 0.000 description 4
- 238000009826 distribution Methods 0.000 description 4
- 235000019253 formic acid Nutrition 0.000 description 4
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 4
- 230000028993 immune response Effects 0.000 description 4
- 230000001939 inductive effect Effects 0.000 description 4
- 230000002401 inhibitory effect Effects 0.000 description 4
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 4
- 239000003550 marker Substances 0.000 description 4
- 210000000056 organ Anatomy 0.000 description 4
- 229940049954 penicillin Drugs 0.000 description 4
- 239000000546 pharmaceutical excipient Substances 0.000 description 4
- 229920001223 polyethylene glycol Polymers 0.000 description 4
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 4
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 4
- 230000001323 posttranslational effect Effects 0.000 description 4
- 238000000746 purification Methods 0.000 description 4
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 4
- 230000009467 reduction Effects 0.000 description 4
- 230000004044 response Effects 0.000 description 4
- 210000000952 spleen Anatomy 0.000 description 4
- 230000000638 stimulation Effects 0.000 description 4
- 229960005322 streptomycin Drugs 0.000 description 4
- 230000007704 transition Effects 0.000 description 4
- 239000011534 wash buffer Substances 0.000 description 4
- 108700028369 Alleles Proteins 0.000 description 3
- 241000201370 Autographa californica nucleopolyhedrovirus Species 0.000 description 3
- 241000283707 Capra Species 0.000 description 3
- 208000011231 Crohn disease Diseases 0.000 description 3
- 241000701022 Cytomegalovirus Species 0.000 description 3
- 238000002965 ELISA Methods 0.000 description 3
- 241000588722 Escherichia Species 0.000 description 3
- 102000005720 Glutathione transferase Human genes 0.000 description 3
- 108010070675 Glutathione transferase Proteins 0.000 description 3
- 101000853012 Homo sapiens Interleukin-23 receptor Proteins 0.000 description 3
- 241000701024 Human betaherpesvirus 5 Species 0.000 description 3
- 241000124008 Mammalia Species 0.000 description 3
- 241001465754 Metazoa Species 0.000 description 3
- 206010028980 Neoplasm Diseases 0.000 description 3
- 108010076039 Polyproteins Proteins 0.000 description 3
- 239000004365 Protease Substances 0.000 description 3
- 241000219061 Rheum Species 0.000 description 3
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- 108091081024 Start codon Proteins 0.000 description 3
- 108010090804 Streptavidin Proteins 0.000 description 3
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 3
- 101710178300 Tumor necrosis factor receptor superfamily member 13C Proteins 0.000 description 3
- 125000000539 amino acid group Chemical group 0.000 description 3
- 206010003246 arthritis Diseases 0.000 description 3
- 229960003270 belimumab Drugs 0.000 description 3
- 239000011575 calcium Substances 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 239000003795 chemical substances by application Substances 0.000 description 3
- 238000004587 chromatography analysis Methods 0.000 description 3
- 239000007979 citrate buffer Substances 0.000 description 3
- 238000013270 controlled release Methods 0.000 description 3
- 238000010494 dissociation reaction Methods 0.000 description 3
- 230000005593 dissociations Effects 0.000 description 3
- 239000003623 enhancer Substances 0.000 description 3
- 150000002148 esters Chemical class 0.000 description 3
- 235000019441 ethanol Nutrition 0.000 description 3
- MMXKVMNBHPAILY-UHFFFAOYSA-N ethyl laurate Chemical compound CCCCCCCCCCCC(=O)OCC MMXKVMNBHPAILY-UHFFFAOYSA-N 0.000 description 3
- 210000003527 eukaryotic cell Anatomy 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 3
- 230000013595 glycosylation Effects 0.000 description 3
- 238000006206 glycosylation reaction Methods 0.000 description 3
- 239000001963 growth medium Substances 0.000 description 3
- 210000002865 immune cell Anatomy 0.000 description 3
- 230000001976 improved effect Effects 0.000 description 3
- 208000015181 infectious disease Diseases 0.000 description 3
- 238000007912 intraperitoneal administration Methods 0.000 description 3
- 238000002955 isolation Methods 0.000 description 3
- 229920002521 macromolecule Polymers 0.000 description 3
- 239000011777 magnesium Substances 0.000 description 3
- 238000006386 neutralization reaction Methods 0.000 description 3
- 238000011275 oncology therapy Methods 0.000 description 3
- 239000008188 pellet Substances 0.000 description 3
- 238000001556 precipitation Methods 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 230000035755 proliferation Effects 0.000 description 3
- 235000019419 proteases Nutrition 0.000 description 3
- 102000005962 receptors Human genes 0.000 description 3
- 108020003175 receptors Proteins 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 230000001105 regulatory effect Effects 0.000 description 3
- 239000012146 running buffer Substances 0.000 description 3
- 239000012679 serum free medium Substances 0.000 description 3
- 239000008223 sterile water Substances 0.000 description 3
- 101150061166 tetR gene Proteins 0.000 description 3
- 238000001757 thermogravimetry curve Methods 0.000 description 3
- 230000001256 tonic effect Effects 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 230000003612 virological effect Effects 0.000 description 3
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 2
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- KWVJHCQQUFDPLU-YEUCEMRASA-N 2,3-bis[[(z)-octadec-9-enoyl]oxy]propyl-trimethylazanium Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC(C[N+](C)(C)C)OC(=O)CCCCCCC\C=C/CCCCCCCC KWVJHCQQUFDPLU-YEUCEMRASA-N 0.000 description 2
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- 208000000659 Autoimmune lymphoproliferative syndrome Diseases 0.000 description 2
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 2
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 2
- 102000014914 Carrier Proteins Human genes 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 206010009900 Colitis ulcerative Diseases 0.000 description 2
- 102000001493 Cyclophilins Human genes 0.000 description 2
- 108010068682 Cyclophilins Proteins 0.000 description 2
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 2
- 108010074860 Factor Xa Proteins 0.000 description 2
- 102000004961 Furin Human genes 0.000 description 2
- 108090001126 Furin Proteins 0.000 description 2
- 208000007465 Giant cell arteritis Diseases 0.000 description 2
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 2
- 108010024636 Glutathione Proteins 0.000 description 2
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 2
- 239000012981 Hank's balanced salt solution Substances 0.000 description 2
- 108010068250 Herpes Simplex Virus Protein Vmw65 Proteins 0.000 description 2
- 241000238631 Hexapoda Species 0.000 description 2
- 101001002634 Homo sapiens Interleukin-1 alpha Proteins 0.000 description 2
- 108010091358 Hypoxanthine Phosphoribosyltransferase Proteins 0.000 description 2
- 206010021245 Idiopathic thrombocytopenic purpura Diseases 0.000 description 2
- 102100020881 Interleukin-1 alpha Human genes 0.000 description 2
- 108010065805 Interleukin-12 Proteins 0.000 description 2
- 102000013462 Interleukin-12 Human genes 0.000 description 2
- PIWKPBJCKXDKJR-UHFFFAOYSA-N Isoflurane Chemical compound FC(F)OC(Cl)C(F)(F)F PIWKPBJCKXDKJR-UHFFFAOYSA-N 0.000 description 2
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 2
- 108010054278 Lac Repressors Proteins 0.000 description 2
- 239000012515 MabSelect SuRe Substances 0.000 description 2
- 108091028043 Nucleic acid sequence Proteins 0.000 description 2
- 208000002193 Pain Diseases 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 2
- 101710182846 Polyhedrin Proteins 0.000 description 2
- 239000004793 Polystyrene Substances 0.000 description 2
- 201000004681 Psoriasis Diseases 0.000 description 2
- 239000012980 RPMI-1640 medium Substances 0.000 description 2
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 2
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 2
- 208000034189 Sclerosis Diseases 0.000 description 2
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 2
- 208000021386 Sjogren Syndrome Diseases 0.000 description 2
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 2
- 201000002661 Spondylitis Diseases 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- PZBFGYYEXUXCOF-UHFFFAOYSA-N TCEP Chemical compound OC(=O)CCP(CCC(O)=O)CCC(O)=O PZBFGYYEXUXCOF-UHFFFAOYSA-N 0.000 description 2
- 239000004098 Tetracycline Substances 0.000 description 2
- 210000000068 Th17 cell Anatomy 0.000 description 2
- 108090000190 Thrombin Proteins 0.000 description 2
- 108020004440 Thymidine kinase Proteins 0.000 description 2
- 241000723873 Tobacco mosaic virus Species 0.000 description 2
- 206010067584 Type 1 diabetes mellitus Diseases 0.000 description 2
- 201000006704 Ulcerative Colitis Diseases 0.000 description 2
- 230000004520 agglutination Effects 0.000 description 2
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 2
- 239000003708 ampul Substances 0.000 description 2
- 229940121363 anti-inflammatory agent Drugs 0.000 description 2
- 239000002260 anti-inflammatory agent Substances 0.000 description 2
- 206010003230 arteritis Diseases 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- 229940022836 benlysta Drugs 0.000 description 2
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 2
- 108091008324 binding proteins Proteins 0.000 description 2
- 239000000090 biomarker Substances 0.000 description 2
- 239000007853 buffer solution Substances 0.000 description 2
- 229910052791 calcium Inorganic materials 0.000 description 2
- 238000004422 calculation algorithm Methods 0.000 description 2
- 201000011510 cancer Diseases 0.000 description 2
- 230000007248 cellular mechanism Effects 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 238000013375 chromatographic separation Methods 0.000 description 2
- 239000011248 coating agent Substances 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 239000000599 controlled substance Substances 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 230000008021 deposition Effects 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- MWRBNPKJOOWZPW-CLFAGFIQSA-N dioleoyl phosphatidylethanolamine Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC(COP(O)(=O)OCCN)OC(=O)CCCCCCC\C=C/CCCCCCCC MWRBNPKJOOWZPW-CLFAGFIQSA-N 0.000 description 2
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 2
- 231100000673 dose–response relationship Toxicity 0.000 description 2
- 238000012377 drug delivery Methods 0.000 description 2
- 210000005069 ears Anatomy 0.000 description 2
- 230000005684 electric field Effects 0.000 description 2
- 238000010828 elution Methods 0.000 description 2
- 210000002950 fibroblast Anatomy 0.000 description 2
- 239000000796 flavoring agent Substances 0.000 description 2
- 238000000684 flow cytometry Methods 0.000 description 2
- 235000013355 food flavoring agent Nutrition 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- 210000000585 glomerular basement membrane Anatomy 0.000 description 2
- 229960003180 glutathione Drugs 0.000 description 2
- 229960004198 guanidine Drugs 0.000 description 2
- PJJJBBJSCAKJQF-UHFFFAOYSA-N guanidinium chloride Chemical compound [Cl-].NC(N)=[NH2+] PJJJBBJSCAKJQF-UHFFFAOYSA-N 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 210000000987 immune system Anatomy 0.000 description 2
- 238000003018 immunoassay Methods 0.000 description 2
- 238000000126 in silico method Methods 0.000 description 2
- 230000008595 infiltration Effects 0.000 description 2
- 238000001764 infiltration Methods 0.000 description 2
- 238000001802 infusion Methods 0.000 description 2
- 210000004964 innate lymphoid cell Anatomy 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 239000007928 intraperitoneal injection Substances 0.000 description 2
- 238000004255 ion exchange chromatography Methods 0.000 description 2
- 229960002725 isoflurane Drugs 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 2
- 238000011068 loading method Methods 0.000 description 2
- 235000012254 magnesium hydroxide Nutrition 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 238000004949 mass spectrometry Methods 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 238000002844 melting Methods 0.000 description 2
- 230000008018 melting Effects 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 229960000485 methotrexate Drugs 0.000 description 2
- 230000003278 mimic effect Effects 0.000 description 2
- 201000006417 multiple sclerosis Diseases 0.000 description 2
- 230000035772 mutation Effects 0.000 description 2
- 210000000440 neutrophil Anatomy 0.000 description 2
- 239000003921 oil Substances 0.000 description 2
- 235000019198 oils Nutrition 0.000 description 2
- 238000001543 one-way ANOVA Methods 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 2
- 230000035479 physiological effects, processes and functions Effects 0.000 description 2
- 208000005987 polymyositis Diseases 0.000 description 2
- 108091033319 polynucleotide Proteins 0.000 description 2
- 102000040430 polynucleotide Human genes 0.000 description 2
- 239000002157 polynucleotide Substances 0.000 description 2
- 229920002223 polystyrene Polymers 0.000 description 2
- 230000002265 prevention Effects 0.000 description 2
- 230000000770 proinflammatory effect Effects 0.000 description 2
- BDERNNFJNOPAEC-UHFFFAOYSA-N propan-1-ol Chemical group CCCO BDERNNFJNOPAEC-UHFFFAOYSA-N 0.000 description 2
- 230000000069 prophylactic effect Effects 0.000 description 2
- 235000019833 protease Nutrition 0.000 description 2
- 229950010131 puromycin Drugs 0.000 description 2
- 239000011541 reaction mixture Substances 0.000 description 2
- 238000003259 recombinant expression Methods 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 238000005316 response function Methods 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 201000000306 sarcoidosis Diseases 0.000 description 2
- 238000004062 sedimentation Methods 0.000 description 2
- 235000004400 serine Nutrition 0.000 description 2
- 239000007974 sodium acetate buffer Substances 0.000 description 2
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 238000004611 spectroscopical analysis Methods 0.000 description 2
- 210000004988 splenocyte Anatomy 0.000 description 2
- 230000000087 stabilizing effect Effects 0.000 description 2
- 239000000829 suppository Substances 0.000 description 2
- 230000009885 systemic effect Effects 0.000 description 2
- 206010043207 temporal arteritis Diseases 0.000 description 2
- 229930101283 tetracycline Natural products 0.000 description 2
- 229960002180 tetracycline Drugs 0.000 description 2
- 235000019364 tetracycline Nutrition 0.000 description 2
- 150000003522 tetracyclines Chemical class 0.000 description 2
- 229960004072 thrombin Drugs 0.000 description 2
- 229940104230 thymidine Drugs 0.000 description 2
- 230000000699 topical effect Effects 0.000 description 2
- 108091006106 transcriptional activators Proteins 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 230000032258 transport Effects 0.000 description 2
- 239000003981 vehicle Substances 0.000 description 2
- HNSDLXPSAYFUHK-UHFFFAOYSA-N 1,4-bis(2-ethylhexyl) sulfosuccinate Chemical compound CCCCC(CC)COC(=O)CC(S(O)(=O)=O)C(=O)OCC(CC)CCCC HNSDLXPSAYFUHK-UHFFFAOYSA-N 0.000 description 1
- VOXZDWNPVJITMN-ZBRFXRBCSA-N 17β-estradiol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 VOXZDWNPVJITMN-ZBRFXRBCSA-N 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- PMUNIMVZCACZBB-UHFFFAOYSA-N 2-hydroxyethylazanium;chloride Chemical compound Cl.NCCO PMUNIMVZCACZBB-UHFFFAOYSA-N 0.000 description 1
- 238000010600 3H thymidine incorporation assay Methods 0.000 description 1
- UZOVYGYOLBIAJR-UHFFFAOYSA-N 4-isocyanato-4'-methyldiphenylmethane Chemical compound C1=CC(C)=CC=C1CC1=CC=C(N=C=O)C=C1 UZOVYGYOLBIAJR-UHFFFAOYSA-N 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- 102100029457 Adenine phosphoribosyltransferase Human genes 0.000 description 1
- 108010024223 Adenine phosphoribosyltransferase Proteins 0.000 description 1
- 208000008190 Agammaglobulinemia Diseases 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- 201000004384 Alopecia Diseases 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- USFZMSVCRYTOJT-UHFFFAOYSA-N Ammonium acetate Chemical compound N.CC(O)=O USFZMSVCRYTOJT-UHFFFAOYSA-N 0.000 description 1
- 239000005695 Ammonium acetate Substances 0.000 description 1
- ATRRKUHOCOJYRX-UHFFFAOYSA-N Ammonium bicarbonate Chemical compound [NH4+].OC([O-])=O ATRRKUHOCOJYRX-UHFFFAOYSA-N 0.000 description 1
- 229910000013 Ammonium bicarbonate Inorganic materials 0.000 description 1
- 206010002556 Ankylosing Spondylitis Diseases 0.000 description 1
- 208000003343 Antiphospholipid Syndrome Diseases 0.000 description 1
- 108020005544 Antisense RNA Proteins 0.000 description 1
- 101001084702 Arabidopsis thaliana Histone H2B.10 Proteins 0.000 description 1
- 241000416162 Astragalus gummifer Species 0.000 description 1
- 206010003827 Autoimmune hepatitis Diseases 0.000 description 1
- 208000011594 Autoinflammatory disease Diseases 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 208000023328 Basedow disease Diseases 0.000 description 1
- 208000027496 Behcet disease Diseases 0.000 description 1
- 208000008439 Biliary Liver Cirrhosis Diseases 0.000 description 1
- 208000033222 Biliary cirrhosis primary Diseases 0.000 description 1
- 102100021943 C-C motif chemokine 2 Human genes 0.000 description 1
- 101710155857 C-C motif chemokine 2 Proteins 0.000 description 1
- 201000002829 CREST Syndrome Diseases 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- 208000031229 Cardiomyopathies Diseases 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- 102000019034 Chemokines Human genes 0.000 description 1
- 108010012236 Chemokines Proteins 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-M Chloride anion Chemical compound [Cl-] VEXZGXHMUGYJMC-UHFFFAOYSA-M 0.000 description 1
- 206010008874 Chronic Fatigue Syndrome Diseases 0.000 description 1
- 208000030939 Chronic inflammatory demyelinating polyneuropathy Diseases 0.000 description 1
- 208000015943 Coeliac disease Diseases 0.000 description 1
- 229940126062 Compound A Drugs 0.000 description 1
- 229920002261 Corn starch Polymers 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 101150074155 DHFR gene Proteins 0.000 description 1
- 230000026774 DNA mediated transformation Effects 0.000 description 1
- MYMOFIZGZYHOMD-UHFFFAOYSA-N Dioxygen Chemical compound O=O MYMOFIZGZYHOMD-UHFFFAOYSA-N 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 239000001856 Ethyl cellulose Substances 0.000 description 1
- ZZSNKZQZMQGXPY-UHFFFAOYSA-N Ethyl cellulose Chemical compound CCOCC1OC(OC)C(OCC)C(OCC)C1OC1C(O)C(O)C(OC)C(CO)O1 ZZSNKZQZMQGXPY-UHFFFAOYSA-N 0.000 description 1
- 108010014173 Factor X Proteins 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 208000001640 Fibromyalgia Diseases 0.000 description 1
- 206010016654 Fibrosis Diseases 0.000 description 1
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 1
- 239000012743 FreeStyle Max reagent Substances 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- 206010018364 Glomerulonephritis Diseases 0.000 description 1
- 208000024869 Goodpasture syndrome Diseases 0.000 description 1
- 208000015023 Graves' disease Diseases 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 208000001204 Hashimoto Disease Diseases 0.000 description 1
- 208000030836 Hashimoto thyroiditis Diseases 0.000 description 1
- 102000001554 Hemoglobins Human genes 0.000 description 1
- 108010054147 Hemoglobins Proteins 0.000 description 1
- 208000035186 Hemolytic Autoimmune Anemia Diseases 0.000 description 1
- 208000009889 Herpes Simplex Diseases 0.000 description 1
- NLDMNSXOCDLTTB-UHFFFAOYSA-N Heterophylliin A Natural products O1C2COC(=O)C3=CC(O)=C(O)C(O)=C3C3=C(O)C(O)=C(O)C=C3C(=O)OC2C(OC(=O)C=2C=C(O)C(O)=C(O)C=2)C(O)C1OC(=O)C1=CC(O)=C(O)C(O)=C1 NLDMNSXOCDLTTB-UHFFFAOYSA-N 0.000 description 1
- 101000990902 Homo sapiens Matrix metalloproteinase-9 Proteins 0.000 description 1
- 101000795167 Homo sapiens Tumor necrosis factor receptor superfamily member 13B Proteins 0.000 description 1
- 241000714260 Human T-lymphotropic virus 1 Species 0.000 description 1
- 101100321817 Human parvovirus B19 (strain HV) 7.5K gene Proteins 0.000 description 1
- GRRNUXAQVGOGFE-UHFFFAOYSA-N Hygromycin-B Natural products OC1C(NC)CC(N)C(O)C1OC1C2OC3(C(C(O)C(O)C(C(N)CO)O3)O)OC2C(O)C(CO)O1 GRRNUXAQVGOGFE-UHFFFAOYSA-N 0.000 description 1
- 206010020983 Hypogammaglobulinaemia Diseases 0.000 description 1
- 102100029098 Hypoxanthine-guanine phosphoribosyltransferase Human genes 0.000 description 1
- 208000010159 IgA glomerulonephritis Diseases 0.000 description 1
- 206010021263 IgA nephropathy Diseases 0.000 description 1
- 206010061598 Immunodeficiency Diseases 0.000 description 1
- 208000029462 Immunodeficiency disease Diseases 0.000 description 1
- 208000022559 Inflammatory bowel disease Diseases 0.000 description 1
- 208000027601 Inner ear disease Diseases 0.000 description 1
- 108010017515 Interleukin-12 Receptors Proteins 0.000 description 1
- 102000004560 Interleukin-12 Receptors Human genes 0.000 description 1
- 102000003810 Interleukin-18 Human genes 0.000 description 1
- 108090000171 Interleukin-18 Proteins 0.000 description 1
- 101710195550 Interleukin-23 receptor Proteins 0.000 description 1
- 102000004890 Interleukin-8 Human genes 0.000 description 1
- 208000012528 Juvenile dermatomyositis Diseases 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 241000713666 Lentivirus Species 0.000 description 1
- 206010064281 Malignant atrophic papulosis Diseases 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 102100030412 Matrix metalloproteinase-9 Human genes 0.000 description 1
- 208000027530 Meniere disease Diseases 0.000 description 1
- 229920000168 Microcrystalline cellulose Polymers 0.000 description 1
- 229920001410 Microfiber Polymers 0.000 description 1
- 208000003250 Mixed connective tissue disease Diseases 0.000 description 1
- 101001034843 Mus musculus Interferon-induced transmembrane protein 1 Proteins 0.000 description 1
- 206010028372 Muscular weakness Diseases 0.000 description 1
- 208000021908 Myocardial disease Diseases 0.000 description 1
- GXCLVBGFBYZDAG-UHFFFAOYSA-N N-[2-(1H-indol-3-yl)ethyl]-N-methylprop-2-en-1-amine Chemical compound CN(CCC1=CNC2=C1C=CC=C2)CC=C GXCLVBGFBYZDAG-UHFFFAOYSA-N 0.000 description 1
- 102100031892 Nanos homolog 2 Human genes 0.000 description 1
- 101710196785 Nanos homolog 2 Proteins 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 208000005141 Otitis Diseases 0.000 description 1
- 229930040373 Paraformaldehyde Natural products 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- 102000000447 Peptide-N4-(N-acetyl-beta-glucosaminyl) Asparagine Amidase Human genes 0.000 description 1
- 108010055817 Peptide-N4-(N-acetyl-beta-glucosaminyl) Asparagine Amidase Proteins 0.000 description 1
- 241000233805 Phoenix Species 0.000 description 1
- 241000235648 Pichia Species 0.000 description 1
- 229920002732 Polyanhydride Polymers 0.000 description 1
- 206010065159 Polychondritis Diseases 0.000 description 1
- 239000004698 Polyethylene Substances 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 239000012518 Poros HS 50 resin Substances 0.000 description 1
- 208000012654 Primary biliary cholangitis Diseases 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 108010026552 Proteome Proteins 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 208000033464 Reiter syndrome Diseases 0.000 description 1
- 108020005091 Replication Origin Proteins 0.000 description 1
- 108700008625 Reporter Genes Proteins 0.000 description 1
- 208000025747 Rheumatic disease Diseases 0.000 description 1
- 235000001537 Ribes X gardonianum Nutrition 0.000 description 1
- 235000001535 Ribes X utile Nutrition 0.000 description 1
- 235000016919 Ribes petraeum Nutrition 0.000 description 1
- 244000281247 Ribes rubrum Species 0.000 description 1
- 235000002355 Ribes spicatum Nutrition 0.000 description 1
- 239000012891 Ringer solution Substances 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- 229920005654 Sephadex Polymers 0.000 description 1
- 239000012507 Sephadex™ Substances 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 102220497176 Small vasohibin-binding protein_T47D_mutation Human genes 0.000 description 1
- 241000256248 Spodoptera Species 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- 235000021355 Stearic acid Nutrition 0.000 description 1
- 206010072148 Stiff-Person syndrome Diseases 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- 230000037453 T cell priming Effects 0.000 description 1
- 108010022394 Threonine synthase Proteins 0.000 description 1
- 102000006601 Thymidine Kinase Human genes 0.000 description 1
- 241000130764 Tinea Species 0.000 description 1
- 208000002474 Tinea Diseases 0.000 description 1
- 102000005876 Tissue Inhibitor of Metalloproteinases Human genes 0.000 description 1
- 108010005246 Tissue Inhibitor of Metalloproteinases Proteins 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- 206010052779 Transplant rejections Diseases 0.000 description 1
- 239000013504 Triton X-100 Substances 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- 108090000631 Trypsin Proteins 0.000 description 1
- 102000004142 Trypsin Human genes 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- 238000002835 absorbance Methods 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- DPXJVFZANSGRMM-UHFFFAOYSA-N acetic acid;2,3,4,5,6-pentahydroxyhexanal;sodium Chemical compound [Na].CC(O)=O.OCC(O)C(O)C(O)C(O)C=O DPXJVFZANSGRMM-UHFFFAOYSA-N 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 230000033289 adaptive immune response Effects 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 238000005054 agglomeration Methods 0.000 description 1
- 230000004931 aggregating effect Effects 0.000 description 1
- 238000007605 air drying Methods 0.000 description 1
- 231100000360 alopecia Toxicity 0.000 description 1
- VREFGVBLTWBCJP-UHFFFAOYSA-N alprazolam Chemical compound C12=CC(Cl)=CC=C2N2C(C)=NN=C2CN=C1C1=CC=CC=C1 VREFGVBLTWBCJP-UHFFFAOYSA-N 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 1
- 235000019257 ammonium acetate Nutrition 0.000 description 1
- 229940043376 ammonium acetate Drugs 0.000 description 1
- 235000012538 ammonium bicarbonate Nutrition 0.000 description 1
- 239000001099 ammonium carbonate Substances 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 208000007502 anemia Diseases 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 238000011091 antibody purification Methods 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 235000009697 arginine Nutrition 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 208000006673 asthma Diseases 0.000 description 1
- 201000000448 autoimmune hemolytic anemia Diseases 0.000 description 1
- 208000010928 autoimmune thyroid disease Diseases 0.000 description 1
- 230000005784 autoimmunity Effects 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 102000005936 beta-Galactosidase Human genes 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 238000001815 biotherapy Methods 0.000 description 1
- 239000012496 blank sample Substances 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- 239000004067 bulking agent Substances 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- CJZGTCYPCWQAJB-UHFFFAOYSA-L calcium stearate Chemical compound [Ca+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O CJZGTCYPCWQAJB-UHFFFAOYSA-L 0.000 description 1
- 235000013539 calcium stearate Nutrition 0.000 description 1
- 239000008116 calcium stearate Substances 0.000 description 1
- BPKIGYQJPYCAOW-FFJTTWKXSA-I calcium;potassium;disodium;(2s)-2-hydroxypropanoate;dichloride;dihydroxide;hydrate Chemical compound O.[OH-].[OH-].[Na+].[Na+].[Cl-].[Cl-].[K+].[Ca+2].C[C@H](O)C([O-])=O BPKIGYQJPYCAOW-FFJTTWKXSA-I 0.000 description 1
- 238000011088 calibration curve Methods 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 238000001516 cell proliferation assay Methods 0.000 description 1
- 230000003833 cell viability Effects 0.000 description 1
- 230000010001 cellular homeostasis Effects 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 235000010980 cellulose Nutrition 0.000 description 1
- 229920002301 cellulose acetate Polymers 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 201000010415 childhood type dermatomyositis Diseases 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 208000037976 chronic inflammation Diseases 0.000 description 1
- 230000006020 chronic inflammation Effects 0.000 description 1
- 201000005795 chronic inflammatory demyelinating polyneuritis Diseases 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 229940110456 cocoa butter Drugs 0.000 description 1
- 235000019868 cocoa butter Nutrition 0.000 description 1
- 206010009887 colitis Diseases 0.000 description 1
- 238000001977 collision-induced dissociation tandem mass spectrometry Methods 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 238000002648 combination therapy Methods 0.000 description 1
- 230000009137 competitive binding Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 238000003271 compound fluorescence assay Methods 0.000 description 1
- 238000002591 computed tomography Methods 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 230000001143 conditioned effect Effects 0.000 description 1
- 230000001268 conjugating effect Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 235000005687 corn oil Nutrition 0.000 description 1
- 239000002285 corn oil Substances 0.000 description 1
- 239000008120 corn starch Substances 0.000 description 1
- 235000012343 cottonseed oil Nutrition 0.000 description 1
- 239000002385 cottonseed oil Substances 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 231100000599 cytotoxic agent Toxicity 0.000 description 1
- 229940127089 cytotoxic agent Drugs 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 238000013480 data collection Methods 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 239000013578 denaturing buffer Substances 0.000 description 1
- 210000004443 dendritic cell Anatomy 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 102000004419 dihydrofolate reductase Human genes 0.000 description 1
- 239000012470 diluted sample Substances 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 239000013024 dilution buffer Substances 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 229940126534 drug product Drugs 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 238000000132 electrospray ionisation Methods 0.000 description 1
- 230000002124 endocrine Effects 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 230000003511 endothelial effect Effects 0.000 description 1
- 229940088598 enzyme Drugs 0.000 description 1
- 210000002919 epithelial cell Anatomy 0.000 description 1
- 229960005309 estradiol Drugs 0.000 description 1
- 229930182833 estradiol Natural products 0.000 description 1
- 235000019325 ethyl cellulose Nutrition 0.000 description 1
- 229920001249 ethyl cellulose Polymers 0.000 description 1
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 1
- 229940093471 ethyl oleate Drugs 0.000 description 1
- CKSJXOVLXUMMFF-UHFFFAOYSA-N exalamide Chemical compound CCCCCCOC1=CC=CC=C1C(N)=O CKSJXOVLXUMMFF-UHFFFAOYSA-N 0.000 description 1
- 229950010333 exalamide Drugs 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- 230000004761 fibrosis Effects 0.000 description 1
- 239000012997 ficoll-paque Substances 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 235000003599 food sweetener Nutrition 0.000 description 1
- 239000012634 fragment Substances 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 238000002825 functional assay Methods 0.000 description 1
- ZZUFCTLCJUWOSV-UHFFFAOYSA-N furosemide Chemical compound C1=C(Cl)C(S(=O)(=O)N)=CC(C(O)=O)=C1NCC1=CC=CO1 ZZUFCTLCJUWOSV-UHFFFAOYSA-N 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 230000001434 glomerular Effects 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 235000004554 glutamine Nutrition 0.000 description 1
- 102000005396 glutamine synthetase Human genes 0.000 description 1
- 108020002326 glutamine synthetase Proteins 0.000 description 1
- 235000011187 glycerol Nutrition 0.000 description 1
- 150000002334 glycols Chemical class 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 229910052737 gold Inorganic materials 0.000 description 1
- 239000010931 gold Substances 0.000 description 1
- 208000024908 graft versus host disease Diseases 0.000 description 1
- 102000056239 human TNFRSF13B Human genes 0.000 description 1
- 210000004408 hybridoma Anatomy 0.000 description 1
- 150000004679 hydroxides Chemical class 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- GRRNUXAQVGOGFE-NZSRVPFOSA-N hygromycin B Chemical compound O[C@@H]1[C@@H](NC)C[C@@H](N)[C@H](O)[C@H]1O[C@H]1[C@H]2O[C@@]3([C@@H]([C@@H](O)[C@@H](O)[C@@H](C(N)CO)O3)O)O[C@H]2[C@@H](O)[C@@H](CO)O1 GRRNUXAQVGOGFE-NZSRVPFOSA-N 0.000 description 1
- 229940097277 hygromycin b Drugs 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 230000007813 immunodeficiency Effects 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 239000002596 immunotoxin Substances 0.000 description 1
- 230000001771 impaired effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000000099 in vitro assay Methods 0.000 description 1
- 238000005462 in vivo assay Methods 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000036512 infertility Effects 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 239000007972 injectable composition Substances 0.000 description 1
- 230000015788 innate immune response Effects 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 108010074109 interleukin-22 Proteins 0.000 description 1
- 230000003704 interleukin-23 production Effects 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 230000009545 invasion Effects 0.000 description 1
- PGLTVOMIXTUURA-UHFFFAOYSA-N iodoacetamide Chemical compound NC(=O)CI PGLTVOMIXTUURA-UHFFFAOYSA-N 0.000 description 1
- 230000000366 juvenile effect Effects 0.000 description 1
- 210000003292 kidney cell Anatomy 0.000 description 1
- 238000011813 knockout mouse model Methods 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 238000011031 large-scale manufacturing process Methods 0.000 description 1
- 239000010410 layer Substances 0.000 description 1
- 208000002741 leukoplakia Diseases 0.000 description 1
- 238000000670 ligand binding assay Methods 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 239000003589 local anesthetic agent Substances 0.000 description 1
- 238000003670 luciferase enzyme activity assay Methods 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 239000008176 lyophilized powder Substances 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- VTHJTEIRLNZDEV-UHFFFAOYSA-L magnesium dihydroxide Chemical compound [OH-].[OH-].[Mg+2] VTHJTEIRLNZDEV-UHFFFAOYSA-L 0.000 description 1
- 239000000347 magnesium hydroxide Substances 0.000 description 1
- 229910001862 magnesium hydroxide Inorganic materials 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 230000003211 malignant effect Effects 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 229920000609 methyl cellulose Polymers 0.000 description 1
- 239000001923 methylcellulose Substances 0.000 description 1
- 235000010981 methylcellulose Nutrition 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 239000013081 microcrystal Substances 0.000 description 1
- 235000019813 microcrystalline cellulose Nutrition 0.000 description 1
- 239000008108 microcrystalline cellulose Substances 0.000 description 1
- 229940016286 microcrystalline cellulose Drugs 0.000 description 1
- 239000003658 microfiber Substances 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 210000005087 mononuclear cell Anatomy 0.000 description 1
- 238000010172 mouse model Methods 0.000 description 1
- 208000029766 myalgic encephalomeyelitis/chronic fatigue syndrome Diseases 0.000 description 1
- 230000036473 myasthenia Effects 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 230000004770 neurodegeneration Effects 0.000 description 1
- 208000015122 neurodegenerative disease Diseases 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 1
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 1
- 239000004006 olive oil Substances 0.000 description 1
- 235000008390 olive oil Nutrition 0.000 description 1
- 230000008816 organ damage Effects 0.000 description 1
- 230000011164 ossification Effects 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 229920002866 paraformaldehyde Polymers 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 238000012510 peptide mapping method Methods 0.000 description 1
- 239000000825 pharmaceutical preparation Substances 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 239000008055 phosphate buffer solution Substances 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 239000002504 physiological saline solution Substances 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 229920003023 plastic Polymers 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920000515 polycarbonate Polymers 0.000 description 1
- 239000004417 polycarbonate Substances 0.000 description 1
- 229920000728 polyester Polymers 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 229920001592 potato starch Polymers 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 229940071643 prefilled syringe Drugs 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 230000006916 protein interaction Effects 0.000 description 1
- 230000009145 protein modification Effects 0.000 description 1
- 239000012460 protein solution Substances 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 230000006337 proteolytic cleavage Effects 0.000 description 1
- LVTJOONKWUXEFR-FZRMHRINSA-N protoneodioscin Natural products O(C[C@@H](CC[C@]1(O)[C@H](C)[C@@H]2[C@]3(C)[C@H]([C@H]4[C@@H]([C@]5(C)C(=CC4)C[C@@H](O[C@@H]4[C@H](O[C@H]6[C@@H](O)[C@@H](O)[C@@H](O)[C@H](C)O6)[C@@H](O)[C@H](O[C@H]6[C@@H](O)[C@@H](O)[C@@H](O)[C@H](C)O6)[C@H](CO)O4)CC5)CC3)C[C@@H]2O1)C)[C@H]1[C@H](O)[C@H](O)[C@H](O)[C@@H](CO)O1 LVTJOONKWUXEFR-FZRMHRINSA-N 0.000 description 1
- 210000000512 proximal kidney tubule Anatomy 0.000 description 1
- 208000014237 psoriasis 1 Diseases 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 239000010453 quartz Substances 0.000 description 1
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 1
- 208000002574 reactive arthritis Diseases 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 239000004627 regenerated cellulose Substances 0.000 description 1
- 230000004043 responsiveness Effects 0.000 description 1
- 230000000979 retarding effect Effects 0.000 description 1
- 230000002207 retinal effect Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 230000000552 rheumatic effect Effects 0.000 description 1
- 201000003068 rheumatic fever Diseases 0.000 description 1
- 230000037390 scarring Effects 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 239000013606 secretion vector Substances 0.000 description 1
- 239000006152 selective media Substances 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N silicon dioxide Inorganic materials O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 1
- 239000002356 single layer Substances 0.000 description 1
- 229960002930 sirolimus Drugs 0.000 description 1
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 1
- 238000001542 size-exclusion chromatography Methods 0.000 description 1
- 235000019812 sodium carboxymethyl cellulose Nutrition 0.000 description 1
- 229920001027 sodium carboxymethylcellulose Polymers 0.000 description 1
- 239000001488 sodium phosphate Substances 0.000 description 1
- 229910000162 sodium phosphate Inorganic materials 0.000 description 1
- RPENMORRBUTCPR-UHFFFAOYSA-M sodium;1-hydroxy-2,5-dioxopyrrolidine-3-sulfonate Chemical compound [Na+].ON1C(=O)CC(S([O-])(=O)=O)C1=O RPENMORRBUTCPR-UHFFFAOYSA-M 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 235000010356 sorbitol Nutrition 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 239000003549 soybean oil Substances 0.000 description 1
- 235000012424 soybean oil Nutrition 0.000 description 1
- 229940043517 specific immunoglobulins Drugs 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 239000007921 spray Substances 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 238000011301 standard therapy Methods 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 239000008117 stearic acid Substances 0.000 description 1
- 239000000021 stimulant Substances 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 238000003883 substance clean up Methods 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 125000000020 sulfo group Chemical group O=S(=O)([*])O[H] 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 239000004094 surface-active agent Substances 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 238000013268 sustained release Methods 0.000 description 1
- 239000012730 sustained-release form Substances 0.000 description 1
- 239000003765 sweetening agent Substances 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 229950010265 tabalumab Drugs 0.000 description 1
- 239000000454 talc Substances 0.000 description 1
- 229910052623 talc Inorganic materials 0.000 description 1
- 235000012222 talc Nutrition 0.000 description 1
- 101150024821 tetO gene Proteins 0.000 description 1
- 229940124597 therapeutic agent Drugs 0.000 description 1
- 230000000451 tissue damage Effects 0.000 description 1
- 231100000827 tissue damage Toxicity 0.000 description 1
- 238000004448 titration Methods 0.000 description 1
- 239000003440 toxic substance Substances 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 108091008023 transcriptional regulators Proteins 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 1
- 239000012588 trypsin Substances 0.000 description 1
- 102000003298 tumor necrosis factor receptor Human genes 0.000 description 1
- 230000005951 type IV hypersensitivity Effects 0.000 description 1
- 238000005199 ultracentrifugation Methods 0.000 description 1
- 238000002604 ultrasonography Methods 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 230000003827 upregulation Effects 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- 238000011179 visual inspection Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- XOOUIPVCVHRTMJ-UHFFFAOYSA-L zinc stearate Chemical compound [Zn+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O XOOUIPVCVHRTMJ-UHFFFAOYSA-L 0.000 description 1
Images






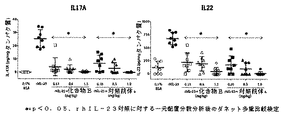
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/24—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against cytokines, lymphokines or interferons
- C07K16/244—Interleukins [IL]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/468—Immunoglobulins having two or more different antigen binding sites, e.g. multifunctional antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/24—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against cytokines, lymphokines or interferons
- C07K16/241—Tumor Necrosis Factors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/12—Drugs for disorders of the urinary system of the kidneys
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
- A61P17/06—Antipsoriatics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/02—Drugs for skeletal disorders for joint disorders, e.g. arthritis, arthrosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/06—Immunosuppressants, e.g. drugs for graft rejection
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2875—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the NGF/TNF superfamily, e.g. CD70, CD95L, CD153, CD154
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/10—Cells modified by introduction of foreign genetic material
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/39558—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against tumor tissues, cells, antigens
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/524—CH2 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/53—Hinge
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P21/00—Preparation of peptides or proteins
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Genetics & Genomics (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Biochemistry (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- Microbiology (AREA)
- General Engineering & Computer Science (AREA)
- Dermatology (AREA)
- Rheumatology (AREA)
- Epidemiology (AREA)
- Cardiology (AREA)
- Mycology (AREA)
- Orthopedic Medicine & Surgery (AREA)
- Pain & Pain Management (AREA)
- Transplantation (AREA)
- Heart & Thoracic Surgery (AREA)
- Urology & Nephrology (AREA)
- Physical Education & Sports Medicine (AREA)
- Physics & Mathematics (AREA)
- Cell Biology (AREA)
Description
関連出願の相互参照
本出願は、2015年7月23日出願の米国仮出願第62/196,170号;2015年8月4日出願の同第62/201,067号;及び2016年6月27日出願の同第62/355,302号、いずれも表題「COMPOUND TARGETING IL−23A AND B−CELL ACTIVATING FACTOR (BAFF) AND USES THEREOF」に対する米国特許法119条に基づく出願日の利益を主張するものであり、それらすべての内容全体が参照により本明細書に組み込まれる。
Mutual reference to related applications This application is a US provisional application No. 62 / 196,170 filed July 23, 2015; the same No. 62 / 201,067 filed August 4, 2015; and June 2016. No. 62 / 355,302 of the application filed on the 27th, both claiming the benefit of the filing date under Article 119 of the US Patent Law for the title "COMPOUND TARGETING IL-23A AND B-CELL ACTIVATING FACTOR (BAFF) AND USES THEREOF". And all of them are incorporated herein by reference in their entirety.
炎症は、感染との戦いに必要とされる自然免疫応答及び適応免疫応答と関連する。しかしながら、炎症が抑制されない場合、自己免疫疾患または自己炎症疾患、神経変性疾患、さらには癌をも発症する可能性がある。IL1、BAFF、TNF−α、IL6、IL12、IL17、IL18、及びIL23などの炎症誘発性サイトカインは、炎症、及び免疫細胞を活性化する特異的経路に関与することが知られているが、これらのサイトカインの1つまたは複数の阻害によって、自己免疫疾患または自己炎症疾患を治療できるのか、またどのようにすれば治療できるのかは不明である。 Inflammation is associated with the innate and adaptive immune responses required to combat infection. However, if inflammation is not suppressed, autoimmune or autoimmune diseases, neurodegenerative diseases, and even cancer can develop. Inflammatory cytokines such as IL1, BAFF, TNF-α, IL6, IL12, IL17, IL18, and IL23 are known to be involved in inflammation and specific pathways that activate immune cells. It is unclear whether or how inhibition of one or more of the cytokines in the family can treat autoimmune or auto-inflammatory diseases.
インターロイキン23(IL23)は、2つのサブユニットp40及びp19からなるヘテロ二量体サイトカインである。p19サブユニットは、IL−23Aとも呼ばれている。p19サブユニットはIL23に特有のものであるが、p40サブユニットはサイトカインIL12と共通である。IL23は、局所組織の炎症及び損傷をもたらすIL17、IL22、及び他のサイトカインの産生を促進する病原性Th17、γδT、及び自然リンパ球(ILC)の重要な調節物質として注目されている。IL23はマトリックスメタロプロテアーゼMMP9の上方調節を促進し、血管新生を増加させ、CD8+ T細胞の浸潤を減少させることから、癌性腫瘍の発生に関与するとされている。さらにIL23は、IL6及びTGFβ1と連係して、ナイーブCD4+ T細胞を刺激し、Th17細胞に分化させる。分化に伴い、Th17細胞はIL17を産生するが、これは、T細胞プライミングを増強し、IL1、IL6、TNF−α、NOS−2などの炎症誘発性サイトカインの産生を刺激すると共に、炎症及び疾患の病因を引き起こすケモカインの発現も誘導する炎症誘発性サイトカインである。IL23は、固有のサブユニットIL23Rと対となるIL12受容体のサブユニットIL12β1から構成される細胞表面受容体を介してその効果を発揮する。IL23Rの発現は、免疫細胞の特異的集団に限定され、主にT細胞のサブセット(αβ及びγδTCR+)及びNK細胞に見出される。 Interleukin 23 (IL23) is a heterodimeric cytokine consisting of two subunits, p40 and p19. The p19 subunit is also called IL-23A. Although the p19 subunit is unique to IL23, the p40 subunit is common to the cytokine IL12. IL23 has attracted attention as an important regulator of pathogenic Th17, γδT, and innate lymphoid cells (ILC), which promote the production of IL17, IL22, and other cytokines that cause inflammation and damage to local tissues. IL23 promotes upregulation of the matrix metalloproteinase MMP9, increases angiogenesis, and reduces CD8 + T cell infiltration, and is therefore implicated in the development of cancerous tumors. Furthermore, IL23 cooperates with IL6 and TGFβ1 to stimulate naive CD4 + T cells and differentiate them into Th17 cells. Upon differentiation, Th17 cells produce IL17, which enhances T cell priming and stimulates the production of pro-inflammatory cytokines such as IL1, IL6, TNF-α, NOS-2, as well as inflammation and disease. It is an pro-inflammatory cytokine that also induces the expression of chemokines that cause the etiology of. IL23 exerts its effect via a cell surface receptor composed of the subunit IL12β1 of the IL12 receptor paired with the unique subunit IL23R. Expression of IL23R is confined to a specific population of immune cells and is found primarily in subsets of T cells (αβ and γδTCR +) and NK cells.
マウスでは、IL23p19遺伝子を遺伝子破壊すると、抗原特異的免疫グロブリンの産生低下及び遅延型過敏反応の障害を含む、T依存性免疫応答の重度不全を伴うIL23機能の選択的喪失をもたらす(Ghilardi N,et al.(2004)J.Immunol.172(5):2827−33)。IL23p40もしくはIL23p19のいずれか、またはIL23受容体のいずれかのサブユニット(IL23R及びIL12β1)を欠損しているノックアウトマウスは、多発性硬化症、関節炎、及び炎症性腸疾患の動物モデルにおいて症状の重篤度の低下を示す。同様の結果はIL23p19に特異的な抗体を用いたEAEに確認されており、さらにT細胞媒介性大腸炎モデルでも、これらの疾患環境におけるIL23の役割が実証されている(Chen Y. et al.(2006)J.Clin.Invet.116(5):1317−26;Elson CO.Et al.(2007)Gastroenterology 132(7):2359−70)。このことは、慢性炎症におけるIL23の重要性を浮き彫りにしている(Langowski et al.(2006)Nature 442(7101):461−5;Kikly K,et al.(2006)Curr.Opin.Immunol.18(6):670−5)。加えて、IL23産生の上昇は、炎症性関節炎及び炎症性自己免疫疾患における主要な因子であることを意味する(Adamopoulos et al.(2011)J.Immunol.187:593−594;及びLangris et al.(2005)J.Exp.Med.201:233−240)。IL23、その下流のサイトカインIL22、及び骨形成との関連性が、IL23を過剰発現するマウスモデル系で報告されている(Sherlock et al.(2012)Nat.Med.18:1069−76)。 In mice, gene disruption of the IL23p19 gene results in a selective loss of IL23 function with severe deficiency of the T-dependent immune response, including decreased production of antigen-specific immunoglobulins and impaired delayed hypersensitivity response (Ghillardi N, et al. (2004) J. Immunol. 172 (5): 2827-33). Knockout mice deficient in either IL23p40 or IL23p19, or any subunit of the IL23 receptor (IL23R and IL12β1), have severe symptoms in animal models of multiple sclerosis, arthritis, and inflammatory bowel disease. Shows reduced severity. Similar results have been confirmed in EAE using antibodies specific for IL23p19, and a T cell-mediated colitis model has also demonstrated the role of IL23 in these disease environments (Chen Y. et al. (2006) J. Clin. Invet. 116 (5): 1317-26; Elson CO. Et al. (2007) Gastroenterology 132 (7): 2359-70). This highlights the importance of IL23 in chronic inflammation (Langowski et al. (2006) Nature 442 (7101): 461-5; Kikly K, et al. (2006) Curr. Opin. Immunol. 18). (6): 670-5). In addition, elevated IL23 production means that it is a major factor in inflammatory arthritis and inflammatory autoimmune diseases (Adamopoulos et al. (2011) J. Immunol. 187: 593-594; and Langris et al. (2005) J. Exp. Med. 201: 233-240). An association with IL23, its downstream cytokine IL22, and bone formation has been reported in a mouse model system overexpressing IL23 (Sherlock et al. (2012) Nat. Med. 18: 1069-76).
B細胞活性化因子(BAFF)は、腫瘍壊死因子(TNF)リガンドスーパーファミリーに属するサイトカインであり、受容体BAFF−R(BR3)、TACI(transmembrane activator and calcium modulator and cyclophilin ligand interactor、膜貫通活性化因子及びカルシウム調節因子及びシクロフィリンリガンド相互作用因子)、及びBCMA(B細胞成熟抗原)のリガンドとして作用する。BAFFとその受容体との間の相互作用は、B細胞の形成及び維持に必須のシグナルを誘発し、それによりB細胞は外来物質による侵入に応答して免疫グロブリンを合成する。患者のBAFFレベルが適切であれば、正常な免疫レベルの維持に役立つが、レベルが不適切であれば免疫不全につながり、レベルが過剰であれば異常に高い抗体産生をもたらす可能性がある。患者が自己免疫性を示すと、自己の身体の組織または器官に対して抗体を産生する。紅斑性狼瘡及び関節リウマチを含む自己免疫疾患は、体内のBAFFレベルの過剰に起因する。したがって、これらの疾患を有する患者を治療するには、BAFFの産生を調節することが重要である。 B-cell activating factor (BAFF) is a cytokine belonging to the tumor necrosis factor (TNF) ligand superfamily, and is a receptor BAFF-R (BR3), TACI (transmembrane activator and calcium modulator and cyclophilin ligand interlace). Factors and calcium regulators and cyclophilin ligand interacting factors), and act as ligands for BCMA (B cell maturation antigen). The interaction between BAFF and its receptors elicits signals essential for the formation and maintenance of B cells, which allow B cells to synthesize immunoglobulins in response to invasion by foreign substances. Appropriate BAFF levels in patients help maintain normal immune levels, but inadequate levels can lead to immunodeficiency, and excessive levels can lead to abnormally high antibody production. When a patient exhibits autoimmunity, it produces antibodies against tissues or organs in its own body. Autoimmune diseases, including lupus erythematosus and rheumatoid arthritis, result from excessive BAFF levels in the body. Therefore, it is important to regulate BAFF production to treat patients with these diseases.
BAFFは、膜結合(mbBAFF)、可溶性三量体BAFF(sBAFF)、及び60個のBAFF単量体(BAFF60量体)からなる多量体形態という3つの形態で存在し得る。様々な形態のBAFFが正常生理機能及び疾患生理機能に及ぼす相対的重要性は十分に解明されていない。上記のように、BAFFは3つの受容体、BAFFR(BR3)、TACI、及びBCMAに結合する。TNF受容体リガンドファミリーの関連メンバーである増殖誘導リガンド(APRIL)は、TACI及びBCMAに高親和性で結合することが示されている。高親和性のAPRIL:BCMA相互作用とは対照的に、BAFF:BCMA相互作用は低親和性(1〜2μM)であり、in vivoで重要な役割を果たすとは考えられていない(Bossen and Schneider,2006)。 BAFF can exist in three forms: membrane binding (mbBAFF), soluble trimer BAFF (sBAFF), and multimer form consisting of 60 BAFF monomers (BAFF60mer). The relative importance of various forms of BAFF on normal and disease physiology has not been fully elucidated. As mentioned above, BAFF binds to three receptors, BAFFR (BR3), TACI, and BCMA. Proliferation-inducing ligands (APRIL), a related member of the TNF receptor ligand family, have been shown to bind to TACI and BCMA with high affinity. In contrast to the high affinity APRIL: BCMA interaction, the BAFF: BCMA interaction is low affinity (1-2 μM) and is not considered to play an important role in vivo (Bossen and Schneider). , 2006).
可溶性BAFFは、全身性エリテマトーデス(SLE)を有する個体、及び炎症を起こした腎臓などの標的器官に高レベルで発現する。可溶性BAFFは、B細胞のホメオスタシス及び生存にとって重要な因子として作用する(Kalled et al.,2005;Mackay et al.,2003;Smith and Cancro,2003;Patke et al.,2004)。BAFF依存性B細胞による自己抗体形成は、糸球体基底膜(GBM)に始まり、近位尿細管上皮細胞(PTEC)内のメサンギウム及び間質組織へとICの糸球体沈着を生じさせる。このようなIC沈着は、補体結合及び好中球活性化を引き起こし、局所腎臓損傷をもたらす。損傷を受けた腎臓細胞(MC、PTEC、腎線維芽細胞、内皮細胞)によって産生される炎症性メディエーター(例えば、IL6、IL8、MCP−1)は、免疫細胞(例えば、B細胞、T細胞、樹状細胞、好中球、及びマクロファージ)の浸潤を増加させることにより炎症サイクルを促進する。 Soluble BAFF is expressed at high levels in individuals with systemic lupus erythematosus (SLE) and in target organs such as the inflamed kidney. Soluble BAFF acts as an important factor for B cell homeostasis and survival (Kalled et al., 2005; Mackay et al., 2003; Smith and Cancro, 2003; Patche et al., 2004). Autoantibody formation by BAFF-dependent B cells begins at the glomerular basement membrane (GBM) and results in glomerular deposition of ICs on mesangium and stromal tissue within the proximal tubule epithelial cells (PTEC). Such IC deposition causes complement fixation and neutrophil activation, resulting in local renal damage. Inflammatory mediators (eg, IL6, IL8, MCP-1) produced by damaged kidney cells (MC, PTEC, renal fibroblasts, endothelial cells) are immune cells (eg, B cells, T cells, etc.). It promotes the inflammatory cycle by increasing the infiltration of dendritic cells, neutrophils, and macrophages).
抗BAFFモノクローナル抗体ベリムマブ(Benlysta(登録商標))は、自己抗体形成を減少させる能力が実証されており、全身性エリテマトーデス(SLE)患者に多大な利益をもたらしている。しかしながら、SLE患者におけるベリムマブの有効性は、よくても中等度であり、改善の余地は十分にある(Furie et al,2011)。したがって、自己免疫疾患または炎症性疾患を治療及び予防するための有効性が増強された新規組成物が依然として必要性とされている。さらに、より有効な治療法を特定することで、投与量の低減が可能となり、それに加えて治療関連コストも削減されるはずである。 The anti-BAFF monoclonal antibody belimumab (Benlysta®) has been demonstrated to be capable of reducing autoantibody formation, providing significant benefits to patients with systemic lupus erythematosus (SLE). However, the efficacy of belimumab in SLE patients is at best moderate and there is ample room for improvement (Furie et al, 2011). Therefore, there is still a need for novel compositions with enhanced efficacy for treating and preventing autoimmune or inflammatory diseases. In addition, identifying more effective treatments should allow dose reductions and, in addition, reduce treatment-related costs.
本明細書では、BAFF及びIL23Aに特異的な化合物、そのような化合物を含む組成物、ならびにその使用方法及び製造方法を提供する。 The present specification provides compounds specific to BAFF and IL23A, compositions containing such compounds, and methods of use and production thereof.
本開示の態様は、第1のポリペプチド及び第2のポリペプチドを含む化合物に関し、
(A)前記第1のポリペプチドは、
(i)第1の標的タンパク質に特異的な第1の免疫グロブリンの軽鎖可変ドメイン(VL1);
(ii)第2の標的タンパク質に特異的な第2の免疫グロブリンの重鎖可変ドメイン(VH2);ならびに
(iii)ヒンジ領域、重鎖定常領域2(CH2)、及び重鎖定常領域3(CH3)を含み、
(B)前記第2のポリペプチドは、
(i)前記第2の標的タンパク質に特異的な第2の免疫グロブリンの軽鎖可変ドメイン(VL2);
(ii)前記第1の標的タンパク質に特異的な第1の免疫グロブリンの重鎖可変ドメイン(VH1)を含み、
本化合物において、
a)前記VL1及びVH1は会合して、前記第1の標的タンパク質に結合する結合部位を形成し、
b)前記VL2及びVH2は会合して、前記第2の標的タンパク質に結合する結合部位を形成し、
c)前記重鎖定常領域2(CH2)は、Kabatと同様のEUインデックスによる番号の252位にチロシン、254位にスレオニン、256位にグルタミン酸を含み、
d)前記第1の標的タンパク質がBAFFであり、前記第2の標的タンパク質がIL−23Aであるか、または前記第1の標的タンパク質がIL−23Aであり、前記第2の標的タンパク質がBAFFであり、
さらに本化合物において、
i)前記VL1は配列番号2を含み、前記VH1は配列番号1を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
ii)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号2を含み、前記VH2は配列番号1を含むか、または
iii)前記VL1は配列番号85を含み、前記VH1は配列番号84を含み、前記VL2は配列番号4を含み、前記VH2は配列番号4を含むか、または
iv)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号85を含み、前記VH2は配列番号84を含むか、または
v)前記VL1は配列番号87を含み、前記VH1は配列番号86を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
vi)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号87を含み、前記VH2は配列番号86を含むか、または
vii)前記VL1は配列番号89を含み、前記VH1は配列番号88を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
viii)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号89を含み、前記VH2は配列番号88を含むか、または
ix)前記VL1は配列番号91を含み、前記VH1は配列番号90を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
x)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号91を含み、前記VH2は配列番号90を含む。
Aspects of the present disclosure relate to compounds comprising a first polypeptide and a second polypeptide.
(A) The first polypeptide is
(I) Light chain variable domain (VL1) of the first immunoglobulin specific for the first target protein;
(Ii) Heavy chain variable domain (VH2) of the second immunoglobulin specific for the second target protein; and (iii) Hinge region, heavy chain constant region 2 (CH2), and heavy chain constant region 3 (CH3). ) Including
(B) The second polypeptide is
(I) Light chain variable domain (VL2) of the second immunoglobulin specific for the second target protein;
(Ii) Containing a heavy chain variable domain (VH1) of a first immunoglobulin specific for the first target protein.
In this compound
a) The VL1 and VH1 associate to form a binding site that binds to the first target protein.
b) The VL2 and VH2 associate to form a binding site that binds to the second target protein.
c) The heavy chain constant region 2 (CH2) contains tyrosine at position 252 and threonine at position 254 and glutamic acid at position 256 according to the EU index similar to Kabat.
d) The first target protein is BAFF and the second target protein is IL-23A, or the first target protein is IL-23A and the second target protein is BAFF. Yes,
Furthermore, in this compound,
i) The VL1 comprises SEQ ID NO: 2, the VH1 comprises SEQ ID NO: 1, the VL2 comprises SEQ ID NO: 4, the VH2 comprises SEQ ID NO: 3, or ii) the VL1 comprises SEQ ID NO: 4. , The VH1 comprises SEQ ID NO: 3, the VL2 comprises SEQ ID NO: 2, the VH2 comprises SEQ ID NO: 1, or iii) said VL1 comprises SEQ ID NO: 85, said VH1 comprises SEQ ID NO: 84. The VL2 comprises SEQ ID NO: 4, the VH2 comprises SEQ ID NO: 4, or iv) the VL1 comprises SEQ ID NO: 4, the VH1 comprises SEQ ID NO: 3, the VL2 comprises SEQ ID NO: 85, and the said. VH2 comprises SEQ ID NO: 84, or v) said VL1 comprises SEQ ID NO: 87, said VH1 comprises SEQ ID NO: 86, said VL2 comprises SEQ ID NO: 4, said VH2 comprises SEQ ID NO: 3, or vi) The VL1 comprises SEQ ID NO: 4, the VH1 comprises SEQ ID NO: 3, the VL2 comprises SEQ ID NO: 87, the VH2 comprises SEQ ID NO: 86, or vii) the VL1 comprises SEQ ID NO: 89. , The VH1 comprises SEQ ID NO: 88, the VL2 comprises SEQ ID NO: 4, the VH2 comprises SEQ ID NO: 3, or viii) The VL1 comprises SEQ ID NO: 4, the VH1 comprises SEQ ID NO: 3. The VL2 comprises SEQ ID NO: 89, the VH2 comprises SEQ ID NO: 88, or ix) the VL1 comprises SEQ ID NO: 91, said VH1 comprises SEQ ID NO: 90, said VL2 comprises SEQ ID NO: 4, said. VH2 comprises SEQ ID NO: 3 or x) said VL1 comprises SEQ ID NO: 4, said VH1 comprises SEQ ID NO: 3, said VL2 comprises SEQ ID NO: 91, said VH2 comprises SEQ ID NO: 90.
いくつかの実施形態では、前記第1のポリペプチドはさらに、前記VL1と前記VH2との間に第1のリンカーを含み、前記第2のポリペプチドはさらに、前記VL2と前記VH1との間に第2のリンカーを含む。いくつかの実施形態では、前記第1のリンカーまたは前記第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のリンカー及び前記第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のポリペプチドはさらに、前記VH2または前記VL1と前記ヒンジ領域との間に第3のリンカーを含み、前記第2のポリペプチドはさらに、前記VH1(そのC末端)または前記VL2(そのC末端)の後ろに第4のリンカーを含む。いくつかの実施形態では、前記第1のポリペプチドの前記第3のリンカーは、アミノ酸配列GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)を含み、前記第2のポリペプチドの前記第4のリンカーは、アミノ酸配列GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)を含む。他の実施形態では、前記第1のポリペプチドの前記第3のリンカーは、アミノ酸配列GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)を含み、前記第2のポリペプチドの前記第4のリンカーは、アミノ酸配列GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)を含む。いくつかの実施形態では、前記第1のポリペプチドの前記第3のリンカーは、アミノ酸配列GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)またはアミノ酸配列GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)を含む。他の実施形態では、前記第2のポリペプチドの前記第4のリンカーは、アミノ酸配列GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)またはアミノ酸配列GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)を含む。いくつかの実施形態では、前記第3のリンカーは、アミノ酸配列VEPKSC(配列番号72)またはアミノ酸配列FNRGEC(配列番号71)を含む。いくつかの実施形態では、前記第4のリンカーは、アミノ酸配列FNRGEC(配列番号71)またはアミノ酸配列VEPKSC(配列番号72)を含む。いくつかの実施形態では、前記第3のリンカーは、アミノ酸配列VEPKSC(配列番号72)を含み、前記第4のリンカーはアミノ酸配列FNRGEC(配列番号71)を含む。 In some embodiments, the first polypeptide further comprises a first linker between the VL1 and the VH2, and the second polypeptide further comprises between the VL2 and the VH1. Includes a second linker. In some embodiments, the first linker or the second linker comprises the amino acid sequence GGGSGGGG (SEQ ID NO: 69). In some embodiments, the first linker and the second linker comprise the amino acid sequence GGGSGGGG (SEQ ID NO: 69). In some embodiments, the first polypeptide further comprises a third linker between the VH2 or VL1 and the hinge region, and the second polypeptide further comprises the VH1 (its C-terminus). A fourth linker is included after the VL2 (terminal) or said VL2 (its C-terminal). In some embodiments, the third linker of the first polypeptide comprises the amino acid sequence GGCGGGGEVAACEKEVAALEKEVAALEKEVAALEK (SEQ ID NO: 82), and the fourth linker of the second polypeptide is the amino acid sequence GGCGGGKVAACKEKVALKEKALEKVA SEQ ID NO: 83) is included. In another embodiment, the third linker of the first polypeptide comprises the amino acid sequence GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE (SEQ ID NO: 83), and the fourth linker of the second polypeptide is the amino acid sequence GGCGGGGEVAACEKEVAALEKEVAALEKEVA. Includes number 82). In some embodiments, the third linker of the first polypeptide comprises the amino acid sequence GGCGGGGEVAACEKEVAALEKEVAALEKEVAALEK (SEQ ID NO: 82) or the amino acid sequence GGCGGGKVAACKEKVAALKEKVAALKEKALKE (SEQ ID NO: 83). In another embodiment, the fourth linker of the second polypeptide comprises the amino acid sequence GGCGGGGEVAACEKEVAALEKEVAALEKEVAALEK (SEQ ID NO: 82) or the amino acid sequence GGCGGGKVAACKEKVAALKEKVAALKEKALKE (SEQ ID NO: 83). In some embodiments, the third linker comprises the amino acid sequence VEPKSC (SEQ ID NO: 72) or the amino acid sequence FNRGEC (SEQ ID NO: 71). In some embodiments, the fourth linker comprises the amino acid sequence FNRGEC (SEQ ID NO: 71) or the amino acid sequence VEPKSC (SEQ ID NO: 72). In some embodiments, the third linker comprises the amino acid sequence VEPKSC (SEQ ID NO: 72) and the fourth linker comprises the amino acid sequence FNRGEC (SEQ ID NO: 71).
いくつかの実施形態では、前記第1のポリペプチドはさらに、(構成に応じて)前記VH2または前記VL1と前記ヒンジ領域との間に重鎖定常領域1ドメイン(CH1)を含み、前記第2のポリペプチドはさらに、(構成に応じて)前記VH1またはVL2のC末端に軽鎖定常領域ドメイン(CL)を含み、ここで前記CL及び前記CH1はジスルフィド結合によって共に会合され、C1ドメインを形成する。いくつかの実施形態では、前記第1のリンカー(前記VL1と前記VH2との間)または前記第2のリンカー(前記VL2と前記VH1との間)は、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のリンカー及び前記第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のポリペプチドはさらに、(構成に応じて)前記VH2または前記VL1と前記CH1との間に第3のリンカーを含み、第2のポリペプチドはさらに、(構成に応じて)前記VH1または前記VL2と前記CLとの間に第4のリンカーを含む。いくつかの実施形態では、前記第3のリンカーまたは前記第4のリンカーは、アミノ酸配列LGGGSG(配列番号70)を含む。いくつかの実施形態では、前記第3のリンカー及び前記第4のリンカーは、アミノ酸配列LGGGSG(配列番号70)を含む。いくつかの実施形態では、前記第3のリンカー及び/または前記第4のリンカーは、任意のシステイン残基を含む。いくつかの実施形態では、前記第3のリンカー及び/または前記第4のリンカーは、アミノ酸配列GGCGGG(配列番号135)またはLGGCGGGS(配列番号136)を含む。
In some embodiments, the first polypeptide further comprises (depending on the configuration) a heavy chain
いくつかの実施形態では、前記重鎖定常領域2(CH2)は、従来抗体に対するKabatと同様のEUインデックスによる番号の234位にアラニン、及び235位にアラニンを含む。 In some embodiments, the heavy chain constant region 2 (CH2) comprises alanine at position 234 and alanine at position 235 according to EU index numbers similar to Kabat for conventional antibodies.
いくつかの実施形態では、前記ヒンジ領域、前記重鎖定常領域2(CH2)、または前記重鎖定常領域3(CH3)のアミノ酸配列は、IgG1またはIgG4に由来する。いくつかの実施形態では、前記ヒンジ領域は、アミノ酸配列EPKSCDKTHTCPPCP(配列番号76)を含む。配列番号76のヒンジ領域は、例えば、配列番号5のポリペプチドに存在する。他の実施形態では、ヒンジ領域は、アミノ酸配列LEPKSSDKTHTCPPCP(配列番号130)を含む。配列番号130のヒンジ領域は、例えば、配列番号9のポリペプチドに存在する。さらに他の実施形態では、ヒンジ領域は、アミノ酸配列ESKYGPPCPPCP(配列番号134)を含む。配列番号134のヒンジ領域は、例えば、配列番号13のポリペプチドに存在する。 In some embodiments, the amino acid sequence of said hinge region, said heavy chain constant region 2 (CH2), or said heavy chain constant region 3 (CH3) is derived from IgG1 or IgG4. In some embodiments, the hinge region comprises the amino acid sequence EPKSCDKTHTCPPCP (SEQ ID NO: 76). The hinge region of SEQ ID NO: 76 is present, for example, in the polypeptide of SEQ ID NO: 5. In another embodiment, the hinge region comprises the amino acid sequence LEPKSSDKTHTCPPCP (SEQ ID NO: 130). The hinge region of SEQ ID NO: 130 is present, for example, in the polypeptide of SEQ ID NO: 9. In yet another embodiment, the hinge region comprises the amino acid sequence ESKYGPPPCPPCP (SEQ ID NO: 134). The hinge region of SEQ ID NO: 134 is present, for example, in the polypeptide of SEQ ID NO: 13.
いくつかの実施形態では、前記化合物は2つの前記第1のポリペプチドと2つの前記第2のポリペプチドとを含み、前記2つの第1のポリペプチドは少なくとも1つのジスルフィド結合によって共に会合する。いくつかの実施形態では、前記化合物は2つの前記第1のポリペプチドと2つの前記第2のポリペプチドとを含み、前記2つの第1のポリペプチドは少なくとも1つのジスルフィド結合によって共に会合し、かつ前記第1のポリペプチドのそれぞれが少なくとも1つのジスルフィド結合によって1つの前記第2のポリペプチドと会合する。 In some embodiments, the compound comprises two said first polypeptide and two said said second polypeptide, the two first polypeptides being associated together by at least one disulfide bond. In some embodiments, the compound comprises two said first polypeptide and two said said second polypeptide, the two first polypeptides being associated together by at least one disulfide bond. And each of the first polypeptides associates with one of the second polypeptides by at least one disulfide bond.
いくつかの実施形態では、
(i)前記第1のポリペプチドが配列番号5のアミノ酸配列を含み、前記第2のポリペプチドが配列番号6のアミノ酸配列を含むか、または
(ii)前記第1のポリペプチドが配列番号7のアミノ酸配列を含み、前記第2のポリペプチドが配列番号8のアミノ酸配列を含むか、または
(iii)前記第1のポリペプチドが配列番号9のアミノ酸配列を含み、前記第2のポリペプチドが配列番号10のアミノ酸配列を含むか、または
(iv)前記第1のポリペプチドが配列番号11のアミノ酸配列を含み、前記第2のポリペプチドが配列番号12のアミノ酸配列を含むか、または
(v)前記第1のポリペプチドが配列番号13のアミノ酸配列を含み、前記第2のポリペプチドが配列番号14のアミノ酸配列を含むか、または
(vi)前記第1のポリペプチドが配列番号15のアミノ酸配列を含み、前記第2のポリペプチドが配列番号16のアミノ酸配列を含むか、または
(vii)前記第1のポリペプチドが配列番号17のアミノ酸配列を含み、前記第2のポリペプチドが配列番号18のアミノ酸配列を含むか、または
(viii)前記第1のポリペプチドが配列番号19のアミノ酸配列を含み、前記第2のポリペプチドが配列番号20のアミノ酸配列を含むか、または
(ix)前記第1のポリペプチドが配列番号21のアミノ酸配列を含み、前記第2のポリペプチドが配列番号22のアミノ酸配列を含むか、または
(x)前記第1のポリペプチドが配列番号23のアミノ酸配列を含み、前記第2のポリペプチドが配列番号24のアミノ酸配列を含むか、または
(xi)前記第1のポリペプチドが配列番号25のアミノ酸配列を含み、前記第2のポリペプチドが配列番号26のアミノ酸配列を含むか、または
(xii)前記第1のポリペプチドが配列番号27のアミノ酸配列を含み、前記第2のポリペプチドが配列番号28のアミノ酸配列を含むか、または
(xiii)前記第1のポリペプチドが配列番号29のアミノ酸配列を含み、前記第2のポリペプチドが配列番号30のアミノ酸配列を含むか、または
(xiv)前記第1のポリペプチドが配列番号31のアミノ酸配列を含み、前記第2のポリペプチドが配列番号32のアミノ酸配列を含むか、または
(xv)前記第1のポリペプチドが配列番号33のアミノ酸配列を含み、前記第2のポリペプチドが配列番号34のアミノ酸配列を含むか、または
(xvi)前記第1のポリペプチドが配列番号35のアミノ酸配列を含み、前記第2のポリペプチドが配列番号36のアミノ酸配列を含むか、または
(xvii)前記第1のポリペプチドが配列番号37のアミノ酸配列を含み、前記第2のポリペプチドが配列番号38のアミノ酸配列を含むか、または
(xviii)前記第1のポリペプチドが配列番号39のアミノ酸配列を含み、前記第2のポリペプチドが配列番号40のアミノ酸配列を含むか、または
(xix)前記第1のポリペプチドが配列番号41のアミノ酸配列を含み、前記第2のポリペプチドが配列番号42のアミノ酸配列を含むか、または
(xx)前記第1のポリペプチドが配列番号43のアミノ酸配列を含み、前記第2のポリペプチドが配列番号44のアミノ酸配列を含むか、または
(xxi)前記第1のポリペプチドが配列番号45のアミノ酸配列を含み、前記第2のポリペプチドが配列番号46のアミノ酸配列を含むか、または
(xxii)前記第1のポリペプチドが配列番号47のアミノ酸配列を含み、前記第2のポリペプチドが配列番号48のアミノ酸配列を含むか、または
(xxiii)前記第1のポリペプチドが配列番号49のアミノ酸配列を含み、前記第2のポリペプチドが配列番号50のアミノ酸配列を含むか、または
(xxiv)前記第1のポリペプチドが配列番号51のアミノ酸配列を含み、前記第2のポリペプチドが配列番号52のアミノ酸配列を含むか、または
(xxv)前記第1のポリペプチドが配列番号53のアミノ酸配列を含み、前記第2のポリペプチドが配列番号54のアミノ酸配列を含むか、または
(xxvi)前記第1のポリペプチドが配列番号55のアミノ酸配列を含み、前記第2のポリペプチドが配列番号56のアミノ酸配列を含むか、または
(xxvii)前記第1のポリペプチドが配列番号57のアミノ酸配列を含み、前記第2のポリペプチドが配列番号58のアミノ酸配列を含むか、または
(xxviii)前記第1のポリペプチドが配列番号59のアミノ酸配列を含み、前記第2のポリペプチドが配列番号60のアミノ酸配列を含むか、または
(xxix)前記第1のポリペプチドが配列番号61のアミノ酸配列を含み、前記第2のポリペプチドが配列番号62のアミノ酸配列を含むか、または
(xxx)前記第1のポリペプチドが配列番号63のアミノ酸配列を含み、前記第2のポリペプチドが配列番号64のアミノ酸配列を含むか、または
(xxxi)前記第1のポリペプチドが配列番号65のアミノ酸配列を含み、前記第2のポリペプチドが配列番号66のアミノ酸配列を含むか、または
(xxxii)前記第1のポリペプチドが配列番号67のアミノ酸配列を含み、前記第2のポリペプチドが配列番号68のアミノ酸配列を含む。
In some embodiments,
(I) The first polypeptide comprises the amino acid sequence of SEQ ID NO: 5, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 6, or (ii) the first polypeptide comprises SEQ ID NO: 7. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 8 or (iii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 9 and the second polypeptide comprises. Either the amino acid sequence of SEQ ID NO: 10 is contained, or (iv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 11 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 12 or (v). ) The first polypeptide comprises the amino acid sequence of SEQ ID NO: 13, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 14, or (vi) the first polypeptide comprises the amino acid of SEQ ID NO: 15. The second polypeptide comprises a sequence and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 16 or (vii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 17 and the second polypeptide has the SEQ ID NO: Eighteen amino acid sequences are included, or (viii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 19, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 20 or (ix) said. The first polypeptide comprises the amino acid sequence of SEQ ID NO: 21, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 22, or (x) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 23. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 24, or (xi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 25 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 26. The first polypeptide comprises the amino acid sequence, or (xii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 27, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 28, or (xiii) said first. The polypeptide comprises the amino acid sequence of SEQ ID NO: 29 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 30 or (xiv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 31. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 32, or (xv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 33 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 34. Or (xvi) said first The polypeptide comprises the amino acid sequence of SEQ ID NO: 35 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 36, or (xvii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 37 and said. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 38, or (xviii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 39 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 40. The first polypeptide comprises the amino acid sequence of SEQ ID NO: 41 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 42, or (xx) said first polypeptide. Contains the amino acid sequence of SEQ ID NO: 43 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 44, or (xxi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 45 and said second. Whether the polypeptide of SEQ ID NO: 46 comprises the amino acid sequence of SEQ ID NO: 46, or (xxiii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 47 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 48. , Or (xxiii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 49 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 50, or (xxiv) the first polypeptide comprises the sequence. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 51 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 52, or (xxv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 53 and said the second poly. The peptide comprises the amino acid sequence of SEQ ID NO: 54, or (xxvi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 55 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 56, or The first polypeptide comprises the amino acid sequence of SEQ ID NO: 57 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 58, or (xxviii) the first polypeptide comprises SEQ ID NO: 59. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 60, or (xxx) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 61 and the second polypeptide comprises. The amino acid sequence of SEQ ID NO: 62 is contained, or (xxx) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 63, and the second polypeptide contains the amino acid sequence of SEQ ID NO: 64. Or (xxxi) said first polypeptide comprises the amino acid sequence of SEQ ID NO: 65 and said second polypeptide comprises the amino acid sequence of SEQ ID NO: 66, or (xxxxi) said said first poly. The peptide comprises the amino acid sequence of SEQ ID NO: 67, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 68.
いくつかの実施形態では、前記化合物が2つの前記第1のポリペプチドと2つの前記第2のポリペプチドとを含み、ここで前記2つの第1のポリペプチドは少なくとも1つのジスルフィド結合によって共に会合する。 In some embodiments, the compound comprises two said first polypeptide and two said second polypeptide, where the two first polypeptides are associated together by at least one disulfide bond. To do.
いくつかの実施形態では、前記化合物は、2つの前記第1のポリペプチドと2つの前記第2のポリペプチドとを含み、さらにここで第1のポリペプチドのうち一方のヒンジ、CH2、及びCH3が、第1のポリペプチドのうち他方のヒンジ、CH2、及びCH3と会合し、4価分子を形成する。いくつかの実施形態では、前記化合物は、2つの前記第1のポリペプチドと2つの前記第2のポリペプチドとを含み、前記第1のポリペプチドそれぞれがCH1、ヒンジ、CH2、及びCH3を含み、前記第2のポリペプチドのそれぞれがCLを含み、さらにここで第1のポリペプチドのうち一方のヒンジ、CH2、及びCH3が、第1のポリペプチドのうち他方のヒンジ、CH2、及びCH3と会合し、前記第1のポリペプチドそれぞれのCH1が、前記第2のポリペプチドの一方のCLと会合して、4価分子(例えば、実施例のセクションに記載される単量体、単量体抗体)(例えば、化合物E及びV)を形成する。いくつかの実施形態では、前記化合物は、2つの前記第1のポリペプチドと2つの前記第2のポリペプチドとを含み、前記第1のポリペプチドのそれぞれが第3のリンカー、ヒンジ、CH2、及びCH3を含み、前記第2のポリペプチドのそれぞれが第4のリンカーを含み、さらにここで第1のポリペプチドのうち一方のヒンジ、CH2、及びCH3が、第1のポリペプチドのうち他方のヒンジ、CH2、及びCH3と会合し、前記第1のポリペプチドそれぞれの第3のリンカーが、前記第2のポリペプチドの一方の第4のリンカーと会合して、4価分子(例えば、実施例のセクションに記載される単量体、単量体抗体)(例えば、化合物U及びT)を形成する。 In some embodiments, the compound comprises two said first polypeptide and two said said second polypeptide, further here one hinge of the first polypeptide, CH2, and CH3. Associates with the other hinge, CH2, and CH3 of the first polypeptide to form a tetravalent molecule. In some embodiments, the compound comprises two said first polypeptide and two said said second polypeptide, each comprising CH1, hinge, CH2, and CH3. , Each of the second polypeptides comprises CL, wherein one hinge, CH2, and CH3 of the first polypeptide is here with the other hinge, CH2, and CH3 of the first polypeptide. Associate, CH1 of each of the first polypeptides associates with one CL of the second polypeptide to associate with a tetravalent molecule (eg, a monomer, monomer described in the Examples section). Antibodies) (eg, compounds E and V). In some embodiments, the compound comprises two said first polypeptide and two said said second polypeptide, each of the first polypeptide having a third linker, hinge, CH2, and the like. And CH3, each of the second polypeptides comprising a fourth linker, wherein one hinge, CH2, and CH3 of the first polypeptide is the other of the first polypeptide. The third linker of each of the first polypeptide associates with the hinge, CH2, and CH3, and the third linker of each of the first polypeptide associates with the fourth linker of one of the second polypeptide, and is a tetravalent molecule (eg, Example). The monomers, monomeric antibodies described in the section of) (eg, compounds U and T) are formed.
本開示の他の態様は、IL−23A及びBAFFへの結合を第2の化合物と競合する第1の化合物に関し、前記第1の化合物は、第3のポリペプチド及び第4のポリペプチドを含み、本化合物において、
(A)前記第3のポリペプチドは、
(i)第1の標的タンパク質に特異的な第1の免疫グロブリンの軽鎖可変ドメイン(VL1);
(ii)第2の標的タンパク質に特異的な第2の免疫グロブリンの重鎖可変ドメイン(VH2);ならびに
(iii)ヒンジ領域、重鎖定常領域2(CH2)、及び重鎖定常領域3(CH3)を含み、
(B)前記第4のポリペプチドは、
(i)前記第2の標的タンパク質に特異的な第2の免疫グロブリンの軽鎖可変ドメイン(VL2);
(ii)前記第1の標的タンパク質に特異的な第1の免疫グロブリンの重鎖可変ドメイン(VH1)を含み、
さらに本化合物において、
(i)前記VL1及びVH1は会合して、前記第1の標的タンパク質に結合する結合部位を形成し、
(ii)前記VL2及びVH2は会合して、前記第2の標的タンパク質に結合する結合部位を形成し、
(iii)前記第1の標的タンパク質がBAFFであり、前記第2の標的タンパク質がIL−23Aであるか、または前記第1の標的タンパク質がIL−23Aであり、前記第2の標的タンパク質がBAFFであり、
さらにここで前記第2の化合物は第1のポリペプチドと第2のポリペプチドとを含み、
(i)前記第1のポリペプチドが配列番号5のアミノ酸配列を含み、前記第2のポリペプチドが配列番号6のアミノ酸配列を含むか、または
(ii)前記第1のポリペプチドが配列番号7のアミノ酸配列を含み、前記第2のポリペプチドが配列番号8のアミノ酸配列を含むか、または
(iii)前記第1のポリペプチドが配列番号9のアミノ酸配列を含み、前記第2のポリペプチドが配列番号10のアミノ酸配列を含むか、または
(iv)前記第1のポリペプチドが配列番号11のアミノ酸配列を含み、前記第2のポリペプチドが配列番号12のアミノ酸配列を含むか、または
(v)前記第1のポリペプチドが配列番号13のアミノ酸配列を含み、前記第2のポリペプチドが配列番号14のアミノ酸配列を含むか、または
(vi)前記第1のポリペプチドが配列番号15のアミノ酸配列を含み、前記第2のポリペプチドが配列番号16のアミノ酸配列を含むか、または
(vii)前記第1のポリペプチドが配列番号17のアミノ酸配列を含み、前記第2のポリペプチドが配列番号18のアミノ酸配列を含むか、または
(viii)前記第1のポリペプチドが配列番号19のアミノ酸配列を含み、前記第2のポリペプチドが配列番号20のアミノ酸配列を含むか、または
(ix)前記第1のポリペプチドが配列番号21のアミノ酸配列を含み、前記第2のポリペプチドが配列番号22のアミノ酸配列を含むか、または
(x)前記第1のポリペプチドが配列番号23のアミノ酸配列を含み、前記第2のポリペプチドが配列番号24のアミノ酸配列を含むか、または
(xi)前記第1のポリペプチドが配列番号25のアミノ酸配列を含み、前記第2のポリペプチドが配列番号26のアミノ酸配列を含むか、または
(xii)前記第1のポリペプチドが配列番号27のアミノ酸配列を含み、前記第2のポリペプチドが配列番号28のアミノ酸配列を含むか、または
(xiii)前記第1のポリペプチドが配列番号29のアミノ酸配列を含み、前記第2のポリペプチドが配列番号30のアミノ酸配列を含むか、または
(xiv)前記第1のポリペプチドが配列番号31のアミノ酸配列を含み、前記第2のポリペプチドが配列番号32のアミノ酸配列を含むか、または
(xv)前記第1のポリペプチドが配列番号33のアミノ酸配列を含み、前記第2のポリペプチドが配列番号34のアミノ酸配列を含むか、または
(xvi)前記第1のポリペプチドが配列番号35のアミノ酸配列を含み、前記第2のポリペプチドが配列番号36のアミノ酸配列を含むか、または
(xvii)前記第1のポリペプチドが配列番号37のアミノ酸配列を含み、前記第2のポリペプチドが配列番号38のアミノ酸配列を含むか、または
(xviii)前記第1のポリペプチドが配列番号39のアミノ酸配列を含み、前記第2のポリペプチドが配列番号40のアミノ酸配列を含むか、または
(xix)前記第1のポリペプチドが配列番号41のアミノ酸配列を含み、前記第2のポリペプチドが配列番号42のアミノ酸配列を含むか、または
(xx)前記第1のポリペプチドが配列番号43のアミノ酸配列を含み、前記第2のポリペプチドが配列番号44のアミノ酸配列を含むか、または
(xxi)前記第1のポリペプチドが配列番号45のアミノ酸配列を含み、前記第2のポリペプチドが配列番号46のアミノ酸配列を含むか、または
(xxii)前記第1のポリペプチドが配列番号47のアミノ酸配列を含み、前記第2のポリペプチドが配列番号48のアミノ酸配列を含むか、または
(xxiii)前記第1のポリペプチドが配列番号49のアミノ酸配列を含み、前記第2のポリペプチドが配列番号50のアミノ酸配列を含むか、または
(xxiv)前記第1のポリペプチドが配列番号51のアミノ酸配列を含み、前記第2のポリペプチドが配列番号52のアミノ酸配列を含むか、または
(xxv)前記第1のポリペプチドが配列番号53のアミノ酸配列を含み、前記第2のポリペプチドが配列番号54のアミノ酸配列を含むか、または
(xxvi)前記第1のポリペプチドが配列番号55のアミノ酸配列を含み、前記第2のポリペプチドが配列番号56のアミノ酸配列を含むか、または
(xxvii)前記第1のポリペプチドが配列番号57のアミノ酸配列を含み、前記第2のポリペプチドが配列番号58のアミノ酸配列を含むか、または
(xxviii)前記第1のポリペプチドが配列番号59のアミノ酸配列を含み、前記第2のポリペプチドが配列番号60のアミノ酸配列を含むか、または
(xxix)前記第1のポリペプチドが配列番号61のアミノ酸配列を含み、前記第2のポリペプチドが配列番号62のアミノ酸配列を含むか、または
(xxx)前記第1のポリペプチドが配列番号63のアミノ酸配列を含み、前記第2のポリペプチドが配列番号64のアミノ酸配列を含むか、または
(xxxi)前記第1のポリペプチドが配列番号65のアミノ酸配列を含み、前記第2のポリペプチドが配列番号66のアミノ酸配列を含むか、または
(xxxii)前記第1のポリペプチドが配列番号67のアミノ酸配列を含み、前記第2のポリペプチドが配列番号68のアミノ酸配列を含む。
Another aspect of the disclosure relates to a first compound that competes with a second compound for binding to IL-23A and BAFF, said first compound comprising a third polypeptide and a fourth polypeptide. , In this compound
(A) The third polypeptide is
(I) Light chain variable domain (VL1) of the first immunoglobulin specific for the first target protein;
(Ii) Heavy chain variable domain (VH2) of the second immunoglobulin specific for the second target protein; and (iii) Hinge region, heavy chain constant region 2 (CH2), and heavy chain constant region 3 (CH3). ) Including
(B) The fourth polypeptide is
(I) Light chain variable domain (VL2) of the second immunoglobulin specific for the second target protein;
(Ii) Containing a heavy chain variable domain (VH1) of a first immunoglobulin specific for the first target protein.
Furthermore, in this compound,
(I) The VL1 and VH1 associate to form a binding site that binds to the first target protein.
(Ii) The VL2 and VH2 associate to form a binding site that binds to the second target protein.
(Iii) The first target protein is BAFF and the second target protein is IL-23A, or the first target protein is IL-23A and the second target protein is BAFF. And
Further here, the second compound comprises a first polypeptide and a second polypeptide.
(I) The first polypeptide comprises the amino acid sequence of SEQ ID NO: 5, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 6, or (ii) the first polypeptide comprises SEQ ID NO: 7. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 8 or (iii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 9 and the second polypeptide comprises. Either the amino acid sequence of SEQ ID NO: 10 is contained, or (iv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 11 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 12 or (v). ) The first polypeptide comprises the amino acid sequence of SEQ ID NO: 13, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 14, or (vi) the first polypeptide comprises the amino acid of SEQ ID NO: 15. The second polypeptide comprises a sequence and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 16 or (vii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 17 and the second polypeptide has the SEQ ID NO: Eighteen amino acid sequences are included, or (viii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 19, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 20 or (ix) said. The first polypeptide comprises the amino acid sequence of SEQ ID NO: 21, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 22, or (x) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 23. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 24, or (xi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 25 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 26. The first polypeptide comprises the amino acid sequence, or (xii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 27, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 28, or (xiii) said first. The polypeptide comprises the amino acid sequence of SEQ ID NO: 29 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 30 or (xiv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 31. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 32, or (xv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 33 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 34. Or (xvi) said first The polypeptide comprises the amino acid sequence of SEQ ID NO: 35 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 36, or (xvii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 37 and said. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 38, or (xviii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 39 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 40. The first polypeptide comprises the amino acid sequence of SEQ ID NO: 41 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 42, or (xx) said first polypeptide. Contains the amino acid sequence of SEQ ID NO: 43 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 44, or (xxi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 45 and said second. Whether the polypeptide of SEQ ID NO: 46 comprises the amino acid sequence of SEQ ID NO: 46, or (xxiii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 47 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 48. , Or (xxiii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 49 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 50, or (xxiv) the first polypeptide comprises the sequence. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 51 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 52, or (xxv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 53 and said the second poly. The peptide comprises the amino acid sequence of SEQ ID NO: 54, or (xxvi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 55 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 56, or The first polypeptide comprises the amino acid sequence of SEQ ID NO: 57 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 58, or (xxviii) the first polypeptide comprises SEQ ID NO: 59. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 60, or (xxx) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 61 and the second polypeptide comprises. The amino acid sequence of SEQ ID NO: 62 is contained, or (xxx) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 63, and the second polypeptide contains the amino acid sequence of SEQ ID NO: 64. Or (xxxi) said first polypeptide comprises the amino acid sequence of SEQ ID NO: 65 and said second polypeptide comprises the amino acid sequence of SEQ ID NO: 66, or (xxxxi) said said first poly. The peptide comprises the amino acid sequence of SEQ ID NO: 67, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 68.
本開示の他の態様は、2つの第1のポリペプチドと2つの第2のポリペプチドとを含む化合物に関し、本化合物において、前記2つの第1のポリペプチドは少なくとも1つのジスルフィド結合によって共に会合し、かつ前記第1のポリペプチドのそれぞれが少なくとも1つのジスルフィド結合によって1つの前記第2のポリペプチドと会合し、
ここで前記第1のポリペプチドのそれぞれは、
(i)第1の標的タンパク質に特異的な第1の免疫グロブリンの軽鎖可変ドメイン(VL1);
(ii)第2の標的タンパク質に特異的な第2の免疫グロブリンの重鎖可変ドメイン(VH2);
(iii)重鎖定常領域1(CH1)、ヒンジ領域、重鎖定常領域2(CH2)、及び重鎖定常領域3(CH3)を含み、
前記第2のポリペプチドのそれぞれは、
(i)前記第2の標的タンパク質に特異的な第2の免疫グロブリンの軽鎖可変ドメイン(VL2);
(ii)前記第1の標的タンパク質に特異的な第1の免疫グロブリンの重鎖可変ドメイン(VH1);
(iii)軽鎖定常領域ドメイン(CL)を含み、
ここで第1のポリペプチドのうち一方のヒンジ、CH2、及びCH3が、第1のポリペプチドのうち他方のヒンジ、CH2、及びCH3と会合し、前記第1のポリペプチドそれぞれのCH1が、前記第2のポリペプチドそれぞれのCLと会合して、4価分子を形成し、
本化合物において、
a)前記VL1及びVH1は会合して、前記第1の標的タンパク質に結合する結合部位を形成し、
b)前記VL2及びVH2は会合して、前記第2の標的タンパク質に結合する結合部位を形成し、
c)前記重鎖定常領域2(CH2)は、Kabatと同様のEUインデックスによる番号の252位にチロシン、254位にスレオニン、256位にグルタミン酸を含み、
d)前記第1の標的タンパク質がBAFFであり、前記第2の標的タンパク質がIL−23Aであるか、または前記第1の標的タンパク質がIL−23Aであり、前記第2の標的タンパク質がBAFFであり、
さらに本化合物において、
(i)前記VL1は配列番号2を含み、前記VH1は配列番号1を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
(ii)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号2を含み、前記VH2は配列番号1を含むか、または
(iii)前記VL1は配列番号85を含み、前記VH1は配列番号84を含み、前記VL2は配列番号4を含み、前記VH2は配列番号4を含むか、または
(iv)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号85を含み、前記VH2は配列番号84を含むか、または
(v)前記VL1は配列番号87を含み、前記VH1は配列番号86を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
(vi)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号87を含み、前記VH2は配列番号86を含むか、または
(vii)前記VL1は配列番号89を含み、前記VH1は配列番号88を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
(viii)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号89を含み、前記VH2は配列番号88を含むか、または
(ix)前記VL1は配列番号91を含み、前記VH1は配列番号90を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
(x)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号91を含み、前記VH2は配列番号90を含む。
Another aspect of the disclosure relates to a compound comprising two first polypeptides and two second polypeptides, in which the two first polypeptides are associated together by at least one disulfide bond. And each of the first polypeptides associates with one of the second polypeptides by at least one disulfide bond.
Here, each of the first polypeptides is
(I) Light chain variable domain (VL1) of the first immunoglobulin specific for the first target protein;
(Ii) Heavy chain variable domain (VH2) of the second immunoglobulin specific for the second target protein;
(Iii) Includes heavy chain constant region 1 (CH1), hinge region, heavy chain constant region 2 (CH2), and heavy chain constant region 3 (CH3).
Each of the second polypeptides
(I) Light chain variable domain (VL2) of the second immunoglobulin specific for the second target protein;
(Ii) Heavy chain variable domain (VH1) of the first immunoglobulin specific for the first target protein;
(Iii) Containing the light chain constant region domain (CL)
Here, one hinge, CH2, and CH3 of the first polypeptide associates with the other hinge, CH2, and CH3 of the first polypeptide, and CH1 of each of the first polypeptide is said. It associates with the CL of each of the second polypeptides to form a tetravalent molecule,
In this compound
a) The VL1 and VH1 associate to form a binding site that binds to the first target protein.
b) The VL2 and VH2 associate to form a binding site that binds to the second target protein.
c) The heavy chain constant region 2 (CH2) contains tyrosine at position 252 and threonine at position 254 and glutamic acid at position 256 according to the EU index similar to Kabat.
d) The first target protein is BAFF and the second target protein is IL-23A, or the first target protein is IL-23A and the second target protein is BAFF. Yes,
Furthermore, in this compound,
(I) The VL1 comprises SEQ ID NO: 2, the VH1 comprises SEQ ID NO: 1, the VL2 comprises SEQ ID NO: 4, the VH2 comprises SEQ ID NO: 3, or (ii) the VL1 comprises SEQ ID NO: 4. The VH1 comprises SEQ ID NO: 3, the VL2 comprises SEQ ID NO: 2, the VH2 comprises SEQ ID NO: 1, or (iii) the VL1 comprises SEQ ID NO: 85 and the VH1 comprises SEQ ID NO: 84. The VL2 comprises SEQ ID NO: 4, the VH2 comprises SEQ ID NO: 4, or (iv) the VL1 comprises SEQ ID NO: 4, the VH1 comprises SEQ ID NO: 3, and the VL2 comprises SEQ ID NO: 85. The VH2 comprises SEQ ID NO: 84, or (v) the VL1 comprises SEQ ID NO: 87, the VH1 comprises SEQ ID NO: 86, the VL2 comprises SEQ ID NO: 4, and the VH2 comprises SEQ ID NO: 3. Or (vi) said VL1 comprises SEQ ID NO: 4, said VH1 comprises SEQ ID NO: 3, said VL2 comprises SEQ ID NO: 87, said VH2 comprises SEQ ID NO: 86, or (vii) said. VL1 comprises SEQ ID NO: 89, said VH1 comprises SEQ ID NO: 88, said VL2 comprises SEQ ID NO: 4, said VH2 comprises SEQ ID NO: 3, or (viii) said said VL1 contained SEQ ID NO: 4, said. VH1 comprises SEQ ID NO: 3, said VL2 comprises SEQ ID NO: 89, said VH2 comprises SEQ ID NO: 88, or (ix) said VL1 comprises SEQ ID NO: 91, said VH1 comprises SEQ ID NO: 90, said. VL2 comprises SEQ ID NO: 4, said VH2 comprises SEQ ID NO: 3, or (x) said VL1 comprises SEQ ID NO: 4, said VH1 comprises SEQ ID NO: 3, said VL2 comprises SEQ ID NO: 91, said. VH2 comprises SEQ ID NO: 90.
上記態様に関するいくつかの実施形態では、前記第1のポリペプチドのそれぞれが、前記VL1と前記VH2との間に第1のリンカーをさらに含み、前記第2のポリペプチドのそれぞれが、前記VL2と前記VH1との間に第2のリンカーをさらに含む。いくつかの実施形態では、前記第1のリンカーまたは前記第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のリンカー及び前記第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のポリペプチドのそれぞれが、前記VH2(または前記VL1)と前記CH1との間に第3のリンカーをさらに含み、前記第2のポリペプチドのそれぞれが、前記VH1(または前記VL2)と前記CLとの間に第4のリンカーをさらに含む。いくつかの実施形態では、前記第3のリンカーまたは前記第4のリンカーは、アミノ酸配列LGGGSG(配列番号70)を含む。いくつかの実施形態では、前記第3のリンカー及び前記第4のリンカーは、アミノ酸配列LGGGSG(配列番号70)を含む。いくつかの実施形態では、前記第3のリンカー及び/または前記第4のリンカーは、任意のシステイン残基を含む。いくつかの実施形態では、前記第3のリンカー及び/または前記第4のリンカーは、アミノ酸配列GGCGGG(配列番号135)またはLGGCGGGS(配列番号136)を含む。いくつかの実施形態では、前記重鎖定常領域2(CH2)は、Kabatと同様のEUインデックスによる番号の234位にアラニン、及び235位にアラニンを含む。いくつかの実施形態では、前記ヒンジ領域、前記重鎖定常領域2(CH2)、または前記重鎖定常領域3(CH3)のアミノ酸配列は、IgG1またはIgG4に由来する。いくつかの実施形態では、前記ヒンジ領域は、アミノ酸配列EPKSCDKTHTCPPCP(配列番号76)、アミノ酸配列LEPKSSDKTHTCPPCP(配列番号130)、またはアミノ酸配列ESKYGPPCPPCP(配列番号134)を含む。 In some embodiments relating to the above embodiments, each of the first polypeptides further comprises a first linker between the VL1 and the VH2, and each of the second polypeptides is with the VL2. A second linker is further included between the VH1 and the VH1. In some embodiments, the first linker or the second linker comprises the amino acid sequence GGGSGGGG (SEQ ID NO: 69). In some embodiments, the first linker and the second linker comprise the amino acid sequence GGGSGGGG (SEQ ID NO: 69). In some embodiments, each of the first polypeptides further comprises a third linker between the VH2 (or VL1) and CH1, and each of the second polypeptides is said. A fourth linker is further included between VH1 (or said VL2) and said CL. In some embodiments, the third or fourth linker comprises the amino acid sequence LGGGSG (SEQ ID NO: 70). In some embodiments, the third linker and the fourth linker include the amino acid sequence LGGGSG (SEQ ID NO: 70). In some embodiments, the third linker and / or the fourth linker comprises any cysteine residue. In some embodiments, the third linker and / or the fourth linker comprises the amino acid sequence GGCGGGG (SEQ ID NO: 135) or LGGCGGGS (SEQ ID NO: 136). In some embodiments, the heavy chain constant region 2 (CH2) comprises alanine at position 234 and alanine at position 235 according to EU index similar to Kabat. In some embodiments, the amino acid sequence of said hinge region, said heavy chain constant region 2 (CH2), or said heavy chain constant region 3 (CH3) is derived from IgG1 or IgG4. In some embodiments, the hinge region comprises the amino acid sequence EPKSCDKTHTCPPCP (SEQ ID NO: 76), the amino acid sequence LEPKSSDKTHTCPPCP (SEQ ID NO: 130), or the amino acid sequence ESKYGPPPCPPCP (SEQ ID NO: 134).
いくつかの実施形態では、
(i)前記第1のポリペプチドのそれぞれが配列番号5のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号6のアミノ酸配列を含むか、または
(ii)前記第1のポリペプチドのそれぞれが配列番号7のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号8のアミノ酸配列を含むか、または
(iii)前記第1のポリペプチドのそれぞれが配列番号13のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号14のアミノ酸配列を含むか、または
(iv)前記第1のポリペプチドのそれぞれが配列番号15のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号16のアミノ酸配列を含むか、または
(v)前記第1のポリペプチドのそれぞれが配列番号21のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号22のアミノ酸配列を含むか、または
(vi)前記第1のポリペプチドのそれぞれが配列番号25のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号26のアミノ酸配列を含むか、または
(vii)前記第1のポリペプチドのそれぞれが配列番号29のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号30のアミノ酸配列を含むか、または
(viii)前記第1のポリペプチドのそれぞれが配列番号33のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号34のアミノ酸配列を含むか、または
(ix)前記第1のポリペプチドのそれぞれが配列番号37のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号38のアミノ酸配列を含むか、または
(x)前記第1のポリペプチドのそれぞれが配列番号41のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号42のアミノ酸配列を含むか、または
(xi)前記第1のポリペプチドのそれぞれが配列番号45のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号46のアミノ酸配列を含むか、または
(xii)前記第1のポリペプチドのそれぞれが配列番号49のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号50のアミノ酸配列を含むか、または
(xiii)前記第1のポリペプチドのそれぞれが配列番号53のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号54のアミノ酸配列を含むか、または
(xiv)前記第1のポリペプチドのそれぞれが配列番号55のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号56のアミノ酸配列を含むか、または
(xv)前記第1のポリペプチドのそれぞれが配列番号57のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号58のアミノ酸配列を含むか、または
(xvi)前記第1のポリペプチドのそれぞれが配列番号59のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号60のアミノ酸配列を含むか、または
(xvii)前記第1のポリペプチドのそれぞれが配列番号61のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号62のアミノ酸配列を含むか、または
(xviii)前記第1のポリペプチドのそれぞれが配列番号63のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号64のアミノ酸配列を含むか、または
(xix)前記第1のポリペプチドのそれぞれが配列番号65のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号66のアミノ酸配列を含むか、または
(xx)前記第1のポリペプチドのそれぞれが配列番号67のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号68のアミノ酸配列を含む。
In some embodiments,
(I) Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 5, and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 6 or (ii) said first polypeptide. Each contains the amino acid sequence of SEQ ID NO: 7, each of the second polypeptide comprises the amino acid sequence of SEQ ID NO: 8, or (iii) each of the first polypeptide comprises the amino acid sequence of SEQ ID NO: 13. Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 14, or (iv) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 15, said second polypeptide. Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 16 or (v) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 21 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 22. Or (vi) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 25 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 26, or (vii) said. Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 29 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 30 or (viii) each of the first polypeptides has a sequence. Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 34, or (ix) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 37, said. Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 38, or (x) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 41 and each of the second polypeptides has a sequence. Whether it comprises the amino acid sequence of No. 42, or (xi) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 45 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 46. Alternatively, (xii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 49 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 50, or (xiii) the first poly. Each of the peptides comprises the amino acid sequence of SEQ ID NO: 53 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 54, or (xiv) said first poly. Each of the peptides comprises the amino acid sequence of SEQ ID NO: 55 and each of the second polypeptide comprises the amino acid sequence of SEQ ID NO: 56, or (xv) each of the first polypeptide comprises the amino acid of SEQ ID NO: 57. The second poly contains a sequence and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 58, or (xvi) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 59. Each of the peptides comprises the amino acid sequence of SEQ ID NO: 60, or (xvii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 61 and each of the second polypeptides contains the amino acid of SEQ ID NO: 62. Either the sequence is contained or (xviii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 63 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 64, or (xix). Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 65 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 66, or (xx) each of the first polypeptides It comprises the amino acid sequence of SEQ ID NO: 67, and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 68.
本開示の他の態様は、2つの第1のポリペプチドと2つの第2のポリペプチドとを含む化合物に関し、本化合物において、前記2つの第1のポリペプチドは少なくとも1つのジスルフィド結合によって共に会合し、かつ前記第1のポリペプチドのそれぞれが少なくとも1つのジスルフィド結合によって1つの前記第2のポリペプチドと会合し、さらに(i)前記第1のポリペプチドのそれぞれが配列番号5のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号6のアミノ酸配列を含むか、または
(ii)前記第1のポリペプチドのそれぞれが配列番号7のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号8のアミノ酸配列を含むか、または
(iii)前記第1のポリペプチドのそれぞれが配列番号13のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号14のアミノ酸配列を含むか、または
(iv)前記第1のポリペプチドのそれぞれが配列番号15のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号16のアミノ酸配列を含むか、または
(v)前記第1のポリペプチドのそれぞれが配列番号21のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号22のアミノ酸配列を含むか、または
(vi)前記第1のポリペプチドのそれぞれが配列番号25のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号26のアミノ酸配列を含むか、または
(vii)前記第1のポリペプチドのそれぞれが配列番号29のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号30のアミノ酸配列を含むか、または
(viii)前記第1のポリペプチドのそれぞれが配列番号33のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号34のアミノ酸配列を含むか、または
(ix)前記第1のポリペプチドのそれぞれが配列番号37のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号38のアミノ酸配列を含むか、または
(x)前記第1のポリペプチドのそれぞれが配列番号41のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号42のアミノ酸配列を含むか、または
(xi)前記第1のポリペプチドのそれぞれが配列番号45のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号46のアミノ酸配列を含むか、または
(xii)前記第1のポリペプチドのそれぞれが配列番号49のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号50のアミノ酸配列を含むか、または
(xiii)前記第1のポリペプチドのそれぞれが配列番号53のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号54のアミノ酸配列を含むか、または
(xiv)前記第1のポリペプチドのそれぞれが配列番号55のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号56のアミノ酸配列を含むか、または
(xv)前記第1のポリペプチドのそれぞれが配列番号57のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号58のアミノ酸配列を含むか、または
(xvi)前記第1のポリペプチドのそれぞれが配列番号59のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号60のアミノ酸配列を含むか、または
(xvii)前記第1のポリペプチドのそれぞれが配列番号61のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号62のアミノ酸配列を含むか、または
(xviii)前記第1のポリペプチドのそれぞれが配列番号63のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号64のアミノ酸配列を含むか、または
(xix)前記第1のポリペプチドのそれぞれが配列番号65のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号66のアミノ酸配列を含むか、または
(xx)前記第1のポリペプチドのそれぞれが配列番号67のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号68のアミノ酸配列を含む。
Another aspect of the disclosure relates to a compound comprising two first polypeptides and two second polypeptides, in which the two first polypeptides are associated together by at least one disulfide bond. And each of the first polypeptides associates with one of the second polypeptides by at least one disulfide bond, and (i) each of the first polypeptides has the amino acid sequence of SEQ ID NO: 5. Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 6, or (ii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 7 of the second polypeptide. Each comprises the amino acid sequence of SEQ ID NO: 8, or (iii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 13 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 14. Either (iv) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 15 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 16 or (v) said said first. Each of the 1 polypeptides comprises the amino acid sequence of SEQ ID NO: 21 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 22 or (vi) each of the first polypeptides has a SEQ ID NO: Each of the second polypeptide comprises 25 amino acid sequences and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 26, or (vii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 29 and said Each of the two polypeptides comprises the amino acid sequence of SEQ ID NO: 30, or (viii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 33 and each of the second polypeptides has a SEQ ID NO: Either contains 34 amino acid sequences, or (ix) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 37 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 38. (X) Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 41 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 42, or (xi) said first polypeptide. Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 45 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 46, or (xii) said first. Each of the polypeptides comprises the amino acid sequence of SEQ ID NO: 49 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 50, or (xiii) each of the first polypeptides of SEQ ID NO: 53. The second polypeptide comprises an amino acid sequence, each of the second polypeptide comprising the amino acid sequence of SEQ ID NO: 54, or (xiv) each of the first polypeptides comprising the amino acid sequence of SEQ ID NO: 55. Each of the polypeptides comprises the amino acid sequence of SEQ ID NO: 56, or (xv) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 57 and each of the second polypeptides of SEQ ID NO: 58. Either contain an amino acid sequence, or (xvi) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 59, and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 60, or (xvii). ) Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 61 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 62, or (xviii) each of the first polypeptides. Contains the amino acid sequence of SEQ ID NO: 63 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 64, or (xix) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 65. , Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 66, or (xx) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 67 and each of the second polypeptides. Contains the amino acid sequence of SEQ ID NO: 68.
本開示の他の態様は、2つの第1のポリペプチドと2つの第2のポリペプチドとを含む化合物に関し、本化合物において、前記2つの第1のポリペプチドは少なくとも1つのジスルフィド結合によって共に会合し、かつ前記第1のポリペプチドのそれぞれが少なくとも1つのジスルフィド結合によって1つの前記第2のポリペプチドと会合し、
ここで前記第1のポリペプチドのそれぞれは、
(iv)第1の標的タンパク質に特異的な第1の免疫グロブリンの軽鎖可変ドメイン(VL1);
(v)第2の標的タンパク質に特異的な第2の免疫グロブリンの重鎖可変ドメイン(VH2);
(vi)ヒンジ領域、重鎖定常領域2(CH2)、及び重鎖定常領域3(CH3)を含み、
前記第2のポリペプチドのそれぞれは、
(i)第2の標的タンパク質に特異的な第2の免疫グロブリンの軽鎖可変ドメイン(VL2);
(ii)前記第1の標的タンパク質に特異的な第1の免疫グロブリンの重鎖可変ドメイン(VH1)を含み、
ここで第1のポリペプチドのうち一方のヒンジ、CH2、及びCH3が、第1のポリペプチドのうち他方のヒンジ、CH2、及びCH3と会合し、
本化合物において、
e)前記VL1及びVH1は会合して、前記第1の標的タンパク質に結合する結合部位を形成し、
f)前記VL2及びVH2は会合して、前記第2の標的タンパク質に結合する結合部位を形成し、
g)前記重鎖定常領域2(CH2)は、Kabatと同様のEUインデックスによる番号の252位にチロシン、254位にスレオニン、256位にグルタミン酸を含み、
h)前記第1の標的タンパク質がBAFFであり、前記第2の標的タンパク質がIL−23Aであるか、または前記第1の標的タンパク質がIL−23Aであり、前記第2の標的タンパク質がBAFFであり、
さらに本化合物において、
(i)前記VL1は配列番号2を含み、前記VH1は配列番号1を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
(ii)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号2を含み、前記VH2は配列番号1を含むか、または
(iii)前記VL1は配列番号85を含み、前記VH1は配列番号84を含み、前記VL2は配列番号4を含み、前記VH2は配列番号4を含むか、または
(iv)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号85を含み、前記VH2は配列番号84を含むか、または
(v)前記VL1は配列番号87を含み、前記VH1は配列番号86を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
(vi)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号87を含み、前記VH2は配列番号86を含むか、または
(vii)前記VL1は配列番号89を含み、前記VH1は配列番号88を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
(viii)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号89を含み、前記VH2は配列番号88を含むか、または
(ix)前記VL1は配列番号91を含み、前記VH1は配列番号90を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
(x)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号91を含み、前記VH2は配列番号90を含む。
Another aspect of the disclosure relates to a compound comprising two first polypeptides and two second polypeptides, in which the two first polypeptides are associated together by at least one disulfide bond. And each of the first polypeptides associates with one of the second polypeptides by at least one disulfide bond.
Here, each of the first polypeptides is
(Iv) Light chain variable domain (VL1) of the first immunoglobulin specific for the first target protein;
(V) Heavy chain variable domain (VH2) of the second immunoglobulin specific for the second target protein;
(Vi) includes a hinge region, a heavy chain constant region 2 (CH2), and a heavy chain constant region 3 (CH3).
Each of the second polypeptides
(I) Light chain variable domain (VL2) of the second immunoglobulin specific for the second target protein;
(Ii) Containing a heavy chain variable domain (VH1) of a first immunoglobulin specific for the first target protein.
Here, one hinge, CH2, and CH3 of the first polypeptide associates with the other hinge, CH2, and CH3 of the first polypeptide.
In this compound
e) The VL1 and VH1 associate to form a binding site that binds to the first target protein.
f) The VL2 and VH2 associate to form a binding site that binds to the second target protein.
g) The heavy chain constant region 2 (CH2) contains tyrosine at position 252 and threonine at position 254 and glutamic acid at position 256 according to the EU index similar to Kabat.
h) The first target protein is BAFF and the second target protein is IL-23A, or the first target protein is IL-23A and the second target protein is BAFF. Yes,
Furthermore, in this compound,
(I) The VL1 comprises SEQ ID NO: 2, the VH1 comprises SEQ ID NO: 1, the VL2 comprises SEQ ID NO: 4, the VH2 comprises SEQ ID NO: 3, or (ii) the VL1 comprises SEQ ID NO: 4. The VH1 comprises SEQ ID NO: 3, the VL2 comprises SEQ ID NO: 2, the VH2 comprises SEQ ID NO: 1, or (iii) the VL1 comprises SEQ ID NO: 85 and the VH1 comprises SEQ ID NO: 84. The VL2 comprises SEQ ID NO: 4, the VH2 comprises SEQ ID NO: 4, or (iv) the VL1 comprises SEQ ID NO: 4, the VH1 comprises SEQ ID NO: 3, and the VL2 comprises SEQ ID NO: 85. The VH2 comprises SEQ ID NO: 84, or (v) the VL1 comprises SEQ ID NO: 87, the VH1 comprises SEQ ID NO: 86, the VL2 comprises SEQ ID NO: 4, and the VH2 comprises SEQ ID NO: 3. Or (vi) said VL1 comprises SEQ ID NO: 4, said VH1 comprises SEQ ID NO: 3, said VL2 comprises SEQ ID NO: 87, said VH2 comprises SEQ ID NO: 86, or (vii) said. VL1 comprises SEQ ID NO: 89, said VH1 comprises SEQ ID NO: 88, said VL2 comprises SEQ ID NO: 4, said VH2 comprises SEQ ID NO: 3, or (viii) said said VL1 contained SEQ ID NO: 4, said. VH1 comprises SEQ ID NO: 3, said VL2 comprises SEQ ID NO: 89, said VH2 comprises SEQ ID NO: 88, or (ix) said VL1 comprises SEQ ID NO: 91, said VH1 comprises SEQ ID NO: 90, said. VL2 comprises SEQ ID NO: 4, said VH2 comprises SEQ ID NO: 3, or (x) said VL1 comprises SEQ ID NO: 4, said VH1 comprises SEQ ID NO: 3, said VL2 comprises SEQ ID NO: 91, said. VH2 comprises SEQ ID NO: 90.
上記態様に関するいくつかの実施形態では、前記第1のポリペプチドのそれぞれが、前記VL1と前記VH2との間に第1のリンカーをさらに含み、前記第2のポリペプチドのそれぞれが、前記VL2と前記VH1との間に第2のリンカーをさらに含む。いくつかの実施形態では、前記第1のリンカーまたは前記第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のリンカー及び前記第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のポリペプチドのそれぞれが、前記VH2または前記VL1と前記ヒンジ領域との間に第3のリンカーをさらに含み、前記第2のポリペプチドのそれぞれが、前記VH1または前記VL2のC末端に第4のリンカーをさらに含む。いくつかの実施形態では、前記第1のポリペプチドの前記第3のリンカーは、アミノ酸配列GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)を含み、前記第2のポリペプチドの前記第4のリンカーは、アミノ酸配列GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)を含む。他の実施形態では、前記第1のポリペプチドの前記第3のリンカーは、アミノ酸配列GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)を含み、前記第2のポリペプチドの前記第4のリンカーは、アミノ酸配列GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)を含む。いくつかの実施形態では、前記第1のポリペプチドの前記第3のリンカーは、アミノ酸配列GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)またはアミノ酸配列GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)を含む。他の実施形態では、前記第2のポリペプチドの前記第4のリンカーは、アミノ酸配列GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)またはアミノ酸配列GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)を含む。いくつかの実施形態では、前記第3のリンカーは、アミノ酸配列VEPKSC(配列番号72)またはアミノ酸配列FNRGEC(配列番号71)を含む。いくつかの実施形態では、前記第4のリンカーは、アミノ酸配列FNRGEC(配列番号71)またはアミノ酸配列VEPKSC(配列番号72)を含む。いくつかの実施形態では、前記第3のリンカーは、アミノ酸配列VEPKSC(配列番号72)を含み、前記第4のリンカーはアミノ酸配列FNRGEC(配列番号71)を含む。いくつかの実施形態では、前記重鎖定常領域2(CH2)は、Kabatと同様のEUインデックスによる番号の234位にアラニン、及び235位にアラニンを含む。いくつかの実施形態では、前記ヒンジ領域、前記重鎖定常領域2(CH2)、または前記重鎖定常領域3(CH3)のアミノ酸配列は、IgG1またはIgG4に由来する。いくつかの実施形態では、前記ヒンジ領域は、アミノ酸配列EPKSCDKTHTCPPCP(配列番号76)、アミノ酸配列LEPKSSDKTHTCPPCP(配列番号130)、またはアミノ酸配列ESKYGPPCPPCP(配列番号134)を含む。いくつかの実施形態では、(i)前記第1のポリペプチドのそれぞれが配列番号9のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号10のアミノ酸配列を含むか、または
(ii)前記第1のポリペプチドのそれぞれが配列番号11のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号12のアミノ酸配列を含むか、または
(iii)前記第1のポリペプチドのそれぞれが配列番号17のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号18のアミノ酸配列を含むか、または
(iv)前記第1のポリペプチドのそれぞれが配列番号19のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号20のアミノ酸配列を含むか、または
(v)前記第1のポリペプチドのそれぞれが配列番号23のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号24のアミノ酸配列を含むか、または
(vi)前記第1のポリペプチドのそれぞれが配列番号27のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号28のアミノ酸配列を含むか、または
(vii)前記第1のポリペプチドのそれぞれが配列番号31のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号32のアミノ酸配列を含むか、または
(viii)前記第1のポリペプチドのそれぞれが配列番号35のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号36のアミノ酸配列を含むか、または
(ix)前記第1のポリペプチドのそれぞれが配列番号39のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号40のアミノ酸配列を含むか、または
(x)前記第1のポリペプチドのそれぞれが配列番号43のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号44のアミノ酸配列を含むか、または
(xi)前記第1のポリペプチドのそれぞれが配列番号47のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号48のアミノ酸配列を含むか、または
(xii)前記第1のポリペプチドのそれぞれが配列番号51のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号52のアミノ酸配列を含む。
In some embodiments relating to the above embodiments, each of the first polypeptides further comprises a first linker between the VL1 and the VH2, and each of the second polypeptides is with the VL2. A second linker is further included between the VH1 and the VH1. In some embodiments, the first linker or the second linker comprises the amino acid sequence GGGSGGGG (SEQ ID NO: 69). In some embodiments, the first linker and the second linker comprise the amino acid sequence GGGSGGGG (SEQ ID NO: 69). In some embodiments, each of the first polypeptides further comprises a third linker between the VH2 or VL1 and the hinge region, and each of the second polypeptides has the VH1. Alternatively, a fourth linker is further contained at the C-terminal of the VL2. In some embodiments, the third linker of the first polypeptide comprises the amino acid sequence GGCGGGGEVAACEKEVAALEKEVAALEKEVAALEK (SEQ ID NO: 82), and the fourth linker of the second polypeptide is the amino acid sequence GGCGGGKVAACKEKVALKEKALEKVA SEQ ID NO: 83) is included. In another embodiment, the third linker of the first polypeptide comprises the amino acid sequence GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE (SEQ ID NO: 83), and the fourth linker of the second polypeptide is the amino acid sequence GGCGGGGEVAACEKEVAALEKEVAALEKEVA. Includes number 82). In some embodiments, the third linker of the first polypeptide comprises the amino acid sequence GGCGGGGEVAACEKEVAALEKEVAALEKEVAALEK (SEQ ID NO: 82) or the amino acid sequence GGCGGGKVAACKEKVAALKEKVAALKEKALKE (SEQ ID NO: 83). In another embodiment, the fourth linker of the second polypeptide comprises the amino acid sequence GGCGGGGEVAACEKEVAALEKEVAALEKEVAALEK (SEQ ID NO: 82) or the amino acid sequence GGCGGGKVAACKEKVAALKEKVAALKEKALKE (SEQ ID NO: 83). In some embodiments, the third linker comprises the amino acid sequence VEPKSC (SEQ ID NO: 72) or the amino acid sequence FNRGEC (SEQ ID NO: 71). In some embodiments, the fourth linker comprises the amino acid sequence FNRGEC (SEQ ID NO: 71) or the amino acid sequence VEPKSC (SEQ ID NO: 72). In some embodiments, the third linker comprises the amino acid sequence VEPKSC (SEQ ID NO: 72) and the fourth linker comprises the amino acid sequence FNRGEC (SEQ ID NO: 71). In some embodiments, the heavy chain constant region 2 (CH2) comprises alanine at position 234 and alanine at position 235 according to EU index similar to Kabat. In some embodiments, the amino acid sequence of said hinge region, said heavy chain constant region 2 (CH2), or said heavy chain constant region 3 (CH3) is derived from IgG1 or IgG4. In some embodiments, the hinge region comprises the amino acid sequence EPKSCDKTHTCPPCP (SEQ ID NO: 76), the amino acid sequence LEPKSSDKTHTCPPCP (SEQ ID NO: 130), or the amino acid sequence ESKYGPPPCPPCP (SEQ ID NO: 134). In some embodiments, (i) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 9, and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 10 or (ii). ) Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 11 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 12 or (iii) each of the first polypeptides. Contains the amino acid sequence of SEQ ID NO: 17, each of the second polypeptide comprises the amino acid sequence of SEQ ID NO: 18, or (iv) each of the first polypeptide comprises the amino acid sequence of SEQ ID NO: 19. , Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 20, or (v) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 23 and each of the second polypeptides. Contains the amino acid sequence of SEQ ID NO: 24, or (vi) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 27 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 28. Or (vii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 31, and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 32, or (viii) said first. Each of the polypeptides of SEQ ID NO: 35 comprises the amino acid sequence of SEQ ID NO: 35, each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 36, or (ix) each of the first polypeptides of SEQ ID NO: 39. Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 40, or (x) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 43 and said second. Each of the polypeptides of SEQ ID NO: 44 comprises the amino acid sequence of SEQ ID NO: 44, or (xi) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 47 and each of the second polypeptides comprises SEQ ID NO: 48. Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 51 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 52.
さらに本開示の他の態様は、上記の化合物などの本明細書に記載の化合物を含む医薬組成物に関する。 Yet another aspect of the disclosure relates to a pharmaceutical composition comprising the compounds described herein, such as the compounds described above.
本開示の他の態様は、上記の化合物などの本明細書に記載の化合物、または前記化合物を含む医薬組成物を対象に投与することを含む、自己免疫疾患または炎症性疾患の治療方法に関する。 Another aspect of the present disclosure relates to a method of treating an autoimmune disease or an inflammatory disease, which comprises administering to a subject a compound described herein, such as the compound described above, or a pharmaceutical composition comprising said compound.
さらに本開示の他の態様は、医療に使用される、上記の化合物などの本明細書に記載の化合物に関する。いくつかの実施形態では、前記使用は自己免疫疾患または炎症性疾患の治療である。 Yet another aspect of the disclosure relates to compounds described herein, such as those described above, for medical use. In some embodiments, the use is the treatment of an autoimmune or inflammatory disease.
本開示の他の態様は、医療に使用される、上記の化合物などの本明細書に記載の化合物を含む医薬組成物に関する。いくつかの実施形態では、前記使用は自己免疫疾患または炎症性疾患の治療である。 Another aspect of the disclosure relates to a pharmaceutical composition comprising a compound described herein, such as the above compounds, used in medicine. In some embodiments, the use is the treatment of an autoimmune or inflammatory disease.
さらに本開示の他の態様は、上記のポリペプチドなどの本明細書に記載のポリペプチドをコードするヌクレオチド配列を含む核酸に関する。本開示の他の態様は、前記核酸を含むベクターに関する。いくつかの実施形態では、ベクターは、前記核酸に機能的に連結されたプロモーターを含む。本開示の他の態様は、前記核酸または前記ベクターを含む細胞に関する。 Yet another aspect of the disclosure relates to nucleic acids comprising nucleotide sequences encoding the polypeptides described herein, such as the polypeptides described above. Another aspect of the disclosure relates to a vector containing said nucleic acid. In some embodiments, the vector comprises a promoter operably linked to said nucleic acid. Another aspect of the disclosure relates to cells containing said nucleic acid or said vector.
本開示の他の態様は、上記の細胞などの本明細書に記載の細胞を得ることと、本明細書に記載の核酸を前記細胞に発現させることを含む、上記のポリペプチドなどの本明細書に記載の化合物またはポリペプチドの作製方法に関する。いくつかの実施形態では、本方法は前記ポリペプチドまたは化合物を単離して精製することをさらに含む。 Another aspect of the disclosure, such as the above-mentioned polypeptide, comprises obtaining a cell described herein, such as the cell described above, and expressing the nucleic acid described herein in the cell. The present invention relates to a method for producing a compound or polypeptide described in the book. In some embodiments, the method further comprises isolating and purifying the polypeptide or compound.
本開示の1つ以上の実施形態の詳細を以下の説明に記載する。本開示の他の特徴や利点は、以下の図面及び複数の実施形態の詳細な説明から、また添付の特許請求の範囲から明らかであろう。 Details of one or more embodiments of the present disclosure are provided in the description below. Other features and advantages of the present disclosure will be apparent from the drawings below and the detailed description of the embodiments and from the appended claims.
以下の図面は本明細書の一部を構成し、本開示のある特定の態様を詳細に説明するために含まれており、本明細書で提示される特定の実施形態の詳細な説明と合わせて、これらの図面の1つまたは複数を参照することにより、本開示を十分に理解することができる。 The following drawings form part of this specification and are included to illustrate certain aspects of the present disclosure in detail, in conjunction with a detailed description of the particular embodiments presented herein. The present disclosure can be fully understood by reference to one or more of these drawings.
本明細書では、BAFFとIL−23A(IL23p19またはIL23Aとも称する)の両方に結合する化合物について記載する。現在まで、BAFFとIL23Aの両方を標的とする認可済み化合物は存在しない。生物学的治療法を使用して2つ以上の重要な炎症性メディエーターを同時に中和する研究は限定的であり、またこうした研究は関節リウマチ(RA)に関する評価で臨床転帰の改善を示さなかった。加えて、そのような組み合わせは、感染リスクなどの副作用を高めることがある(例えば、Genovese,M.C.,Cohen,S.,Moreland,L.,Lium,D.,Robbins,S.,et al.(2004).Arth.Rheum.50,1412−9;Genovese,M.C.,Cohen,S.,Moreland,L.,Lium,D.,Robbins,S.,et al.(2004).Arth.Rheum.50,1412−9;及びWeinblatt,M.,Schiff,M.,Goldman,A.Kremer,J.,Luggen,M.,et al.(2007).Ann.Rheum.Dis.66,228−34を参照)。さらに、このような二重特異性化合物は、溶解性に関連する問題(例えば、凝集)及び安定性に関連する問題(例えば、不適切な薬物動態)により、設計が困難であった。 This specification describes compounds that bind to both BAFF and IL-23A (also referred to as IL23p19 or IL23A). To date, no approved compound targets both BAFF and IL23A. Limited studies have used biological therapies to simultaneously neutralize two or more important inflammatory mediators, and these studies did not show improved clinical outcome in the assessment of rheumatoid arthritis (RA). .. In addition, such combinations may increase side effects such as risk of infection (eg, Genovese, MC, Cohen, S., Moreland, L., Lium, D., Robbins, S., et. al. (2004). Arth. Rheum. 50, 1412-9; Genovese, MC, Cohen, S., Moreland, L., Lium, D., Robbins, S., et al. (2004). Arth. Rheum. 50, 1412-9; and Weinblatt, M., Schiff, M., Goldman, A. Kremer, J., Lugen, M., et al. (2007). Ann. Rheum. Dis. 66, See 228-34). Moreover, such bispecific compounds have been difficult to design due to problems related to solubility (eg, aggregation) and stability (eg, improper pharmacokinetics).
驚くべきことに、本明細書に記載のBAFFとIL−23Aに結合する化合物のいくつかは、IL−23AまたはBAFFのいずれかを標的とする個々の抗体と比較して、同様または改善された特性を有することが見出されている。また、化合物によっては、適切な薬物動態を有することが見出され、投与目的に適する範囲の可溶性を示した。さらに、いくつかの実施形態では、個々の療法の副作用の観点から、また用量低減の観点から、個々の用量の複数回投与よりも単回投与に利点がある。加えて、いくつかの実施形態では、化合物のCMC特性によると、一部の化合物が高融解温度(Tm)及び低凝集を有することを示した。一態様では、1つの例示的な化合物が、高濃度で特に低い凝集を示した。本明細書に記載の化合物は、標準的な抗体分子、例えばIgG分子または抗原結合断片(例えば、Fab)と比較して、1つ以上の有利な特性、例えば副作用の減少、投与の容易さ及び安全性の向上、半減期の延長、結合親和性の増加、または阻害活性の増加を有すると考えられる。 Surprisingly, some of the BAFF and IL-23A-binding compounds described herein were similar or improved compared to individual antibodies targeting either IL-23A or BAFF. It has been found to have properties. In addition, some compounds were found to have appropriate pharmacokinetics, and showed solubility in a range suitable for the purpose of administration. Moreover, in some embodiments, single doses are advantageous over multiple doses of individual doses, both in terms of side effects of individual therapies and in terms of dose reduction. In addition, in some embodiments, the CMC properties of the compounds showed that some compounds had a high melting temperature (Tm) and low agglomeration. In one aspect, one exemplary compound showed particularly low aggregation at high concentrations. The compounds described herein have one or more advantageous properties compared to standard antibody molecules such as IgG molecules or antigen binding fragments (eg Fab), such as reduced side effects, ease of administration and It is believed to have improved safety, longer half-life, increased binding affinity, or increased inhibitory activity.
したがって、本開示の態様はBAFFとIL−23Aの両方に特異的な化合物、ならびにそのような化合物の使用方法及び製造方法に関する。一態様では、本技術は、全身性エリテマトーデス(SLE)、腎臓に関連する全身性エリテマトーデス/ループス腎炎(LN)、ANCA関連血管炎(AAV)、原発性シェーグレン症候群(pSS)、慢性移植片対宿主病(cGVHD)、全身性強皮症(SSc)、関節リウマチ(RA)、乾癬(Ps)、強直性脊椎炎(AS)、及び乾癬性関節炎(PA)などの自己免疫疾患または炎症性疾患を治療及び予防するための有効性が増加した組成物に関する。BAFF/IL23A二重アンタゴニストは、自己抗体/免疫複合体及びIL23軸媒介性末端器官損傷の両方を阻害し、SLE及びLN治療を目的とした現在の標準治療よりも優れた臨床反応の誘導と維持を達成することができる。BAFF抗体とIL−23抗体を同時投与して、両方の経路を同時に阻害する場合と比較して、BAFF/IL23A二重アンタゴニストは、服薬遵守を改善し、痛みを緩和させることができ、患者にとっての利便性が高い。BAFF/IL23A二重アンタゴニストにより、投与量の低減が可能になり、それに加えて治療関連コストも削減されるはずである。加えて、BAFF/IL23Aアンタゴニストはまた、原発性シェーグレン症候群(pSS)、慢性移植片対宿主病(cGVHD)、全身性強皮症(SSc)、及びANCA関連血管炎(AAV)を含む、調節不全B細胞/自己抗体及びIL23媒介性組織損傷を伴う疾患群の治療に有益であり得る。 Accordingly, aspects of the present disclosure relate to compounds specific for both BAFF and IL-23A, as well as methods of use and production of such compounds. In one aspect, the technique comprises systemic lupus erythematosus (SLE), kidney-related systemic lupus erythematosus / lupus nephritis (LN), ANCA-associated vasculitis (AAV), primary Sjogren's syndrome (pSS), chronic transplant piece-to-host. Autoimmune or inflammatory diseases such as disease (cGVHD), systemic lupus erythematosus (SSc), rheumatoid arthritis (RA), psoriatic arthritis (Ps), tonic spondylitis (AS), and psoriatic arthritis (PA) For compositions with increased efficacy for treatment and prevention. The BAFF / IL23A dual antagonist inhibits both autoantibody / immune complex and IL23-axis mediated terminal organ damage, inducing and maintaining a better clinical response than current standard therapies aimed at treating SLE and LN. Can be achieved. Compared to the simultaneous administration of BAFF antibody and IL-23 antibody to block both pathways at the same time, the BAFF / IL23A dual antagonist can improve medication compliance and relieve pain, for the patient. Convenience is high. The BAFF / IL23A dual antagonist should allow for dose reductions as well as treatment-related costs. In addition, BAFF / IL23A antagonists are also dysregulated, including primary Sjogren's syndrome (pSS), chronic transplant-to-host disease (cGVHD), systemic scleroderma (SSc), and ANCA-associated vasculitis (AAV). It may be beneficial in the treatment of disease groups with B cell / autoantibodies and IL23-mediated tissue damage.
2つの薬理学的要素を集約しつつ、各成分の機能的効力を維持すると同時に、大規模製造に適した生物物理学的特性を有する二重標的治療分子を設計することは困難である。二重標的分子の開発は、in vitro及びin vivoでの安定性に関連する多数の問題、例えば、不十分な発現、凝集、貯蔵寿命の限界、不十分な血清安定性、in vivoでの不適切な薬物動態特性などに阻まれてきた(Demarest SJ,Glaser SM.(2008).Curr Opin Drug Discov Devel.11,675−87)。 It is difficult to design a dual-target therapeutic molecule with biophysical properties suitable for large-scale production while maintaining the functional efficacy of each component while aggregating the two pharmacological elements. The development of dual target molecules has a number of problems associated with in vitro and in vivo stability, such as inadequate expression, aggregation, shelf life limits, inadequate serum stability, in vivo in vivo imperfections. It has been hampered by appropriate pharmacokinetic properties and the like (Demarest SJ, Glasser SM. (2008). Curr Opin Drug Discov Devel. 11, 675-87).
本明細書では、BAFFとIL23両方の機能を阻害する二重標的分子を作製するための方法を開示する。本技術の二重標的分子は、高融解温度(Tm)、高濃度での低凝集性、及び予測ヒトPK特性などの利点及び予想外の特性を有し、隔週1回またはそれより少ない頻度での皮下投与が可能である。 This specification discloses a method for making a dual target molecule that inhibits the functions of both BAFF and IL23. The dual target molecules of the present technology have advantages and unexpected properties such as high melting temperature (Tm), low cohesiveness at high concentrations, and predicted human PK properties, once every other week or less frequently. Can be administered subcutaneously.
化合物
本開示の態様は、BAFF及びIL23Aの両方に特異的な化合物に関する。BAFFに対する例示的なタンパク質配列とIL23Aに対する例示的なタンパク質配列を以下に示す。
Compounds Aspects of the present disclosure relate to compounds specific for both BAFF and IL23A. An exemplary protein sequence for BAFF and an exemplary protein sequence for IL23A are shown below.
>sp|Q9Y275|B細胞活性化因子BAFF)−TN13B_HUMAN腫瘍壊死因子リガンドスーパーファミリーのメンバー13B OS=Homo sapiens GN=TNFSF13B PE=1 SV=1
MDDSTEREQSRLTSCLKKREEMKLKECVSILPRKESPSVRSSKDGKLLAATLLLALLSCCLTVVSFYQVAALQGDLASLRAELQGHHAEKLPAGAGAPKAGLEEAPAVTAGLKIFEPPAPGEGNSSQNSRNKRAVQGPEETVTQDCLQLIADSETPTIQKGSYTFVPWLLSFKRGSALEEKENKILVKETGYFFIYGQVLYTDKTYAMGHLIQRKKVHVFGDELSLVTLFRCIQNMPETLPNNSCYSAGIAKLEEGDELQLAIPRENAQISLDGDVTFFGALKLL(配列番号80)
>NP_057668.1−IL23A[Homo sapiens]
MLGSRAVMLLLLLPWTAQGRAVPGGSSPAWTQCQQLSQKLCTLAWSAHPLVGHMDLREEGDEETTNDVPHIQCGDGCDPQGLRDNSQFCLQRIHQGLIFYEKLLGSDIFTGEPSLLPDSPVGQLHASLLGLSQLLQPEGHHWETQQIPSLSPSQPWQRLLLRFKILRSLQAFVAVAARVFAHGAATLSP(アミノ酸1〜19は予測シグナル配列)(配列番号81)
> Sp | Q9Y275 | B cell activating factor BAFF) -TN13B_HUMAN Tumor necrosis factor ligand Superfamily member 13B OS = Homo sapiens GN = TNFSF13B PE = 1 SV = 1
MDDSTEREQSRLTSCLKKREEMKLKECVSILPRKESPSVRSSKDGKLLAATLLLALLSCCLTVVSFYQVAALQGDLASLRAELQGHHAEKLPAGAGAPKAGLEEAPAVTAGLKIFEPPAPGEGNSSQNSRNKRAVQGPEETVTQDCLQLIADSETPTIQKGSYTFVPWLLSFKRGSALEEKENKILVKETGYFFIYGQVLYTDKTYAMGHLIQRKKVHVFGDELSLVTLFRCIQNMPETLPNNSCYSAGIAKLEEGDELQLAIPRENAQISLDGDVTFFGALKLL (SEQ ID NO: 80)
> NP_057668.1-IL23A [Homo humans]
EmuerujiesuarueibuiemueruerueruerueruPidaburyutieikyujiarueibuiPijijiesuesuPieidaburyutikyushikyukyueruesukyukeierushitierueidaburyuesueieichiPierubuijieichiemudieruaruiijidiiititienudibuiPieichiaikyushijidijishidiPikyujieruarudienuesukyuefushierukyuaruaieichikyujieruaiefuwaiikeieruerujiesudiaiefutijiiPiesueruerupidiesuPibuijikyuerueichieiesueruerujieruesukyueruerukyuPiijieichieichidaburyuitikyukyuaiPiesueruesuPiesukyuPidaburyukyuarueruerueruaruefukeiILRSLQAFVAVAARVFAHGAATLSP (
いくつかの実施形態では、化合物は第1のポリペプチドと第2のポリペプチドとを含む。いくつかの実施形態では、第1のポリペプチドは、(i)第1の標的タンパク質に特異的な第1の免疫グロブリンの軽鎖可変ドメイン(VL1)、(ii)第2の標的タンパク質に特異的な第2の免疫グロブリンの重鎖可変ドメイン(VH2)、ならびに(iii)ヒンジ領域、重鎖定常領域2(CH2)、及び重鎖定常領域3(CH3)を含む。いくつかの実施形態では、第1のポリペプチドは重鎖定常領域1(CH1)をさらに含む。いくつかの実施形態では、第2のポリペプチドは、(i)第2の標的タンパク質に特異的な第2の免疫グロブリンの軽鎖可変ドメイン(VL2)、(ii)第1の標的タンパク質に特異的な第1の免疫グロブリンの重鎖可変ドメイン(VH1)を含む。いくつかの実施形態では、第2のポリペプチドは軽鎖定常領域(CL)をさらに含む。 In some embodiments, the compound comprises a first polypeptide and a second polypeptide. In some embodiments, the first polypeptide is (i) specific for the first target protein, the light chain variable domain (VL1) of the first immunoglobulin, and (ii) specific for the second target protein. Includes a heavy chain variable domain (VH2) of a second immunoglobulin, as well as a (iii) hinge region, a heavy chain constant region 2 (CH2), and a heavy chain constant region 3 (CH3). In some embodiments, the first polypeptide further comprises heavy chain constant region 1 (CH1). In some embodiments, the second polypeptide is (i) specific for the second target protein, the light chain variable domain (VL2) of the second immunoglobulin, and (ii) specific for the first target protein. Contains the heavy chain variable domain (VH1) of a primary immunoglobulin. In some embodiments, the second polypeptide further comprises a light chain constant region (CL).
第1のポリペプチドの可変ドメイン及び定常ドメイン/領域は任意の順序であってよく、第2のポリペプチドの可変ドメイン及び定常ドメイン/領域(存在する場合)は任意の順序であってよいと理解すべきである。以下に、第1及び第2のポリペプチド上のドメイン/領域に対する複数の例示的な構成をN末端からC末端の順に示す。 Understand that the variable domains and constant domains / regions of the first polypeptide may be in any order and the variable domains and constant domains / regions of the second polypeptide (if any) may be in any order. Should. Below, a plurality of exemplary configurations for domains / regions on the first and second polypeptides are shown in order from N-terminus to C-terminus.
第1のポリペプチドの構成1:N−VL1−VH2−ヒンジ−CH2−CH3−C
第1のポリペプチドの構成2:N−VH2−VL1−ヒンジ−CH2−CH3−C
第1のポリペプチドの構成3:N−VL1−VH2−CH1−ヒンジ−CH2−CH3−C
第1のポリペプチドの構成4:N−VH2−VL1−CH1−ヒンジ−CH2−CH3−C
第2のポリペプチドの構成1:N−VL2−VH1−C
第2のポリペプチドの構成2:N−VH1−VL2−C
第2のポリペプチドの構成3:N−VL2−VH1−CL−C
第2のポリペプチドの構成4:N−VH1−VL2−CL−C
Composition of First Polypeptide 1: N-VL1-VH2-Hinge-CH2-CH3-C
Composition of First Polypeptide 2: N-VH2-VL1-Hinge-CH2-CH3-C
Composition of First Polypeptide 3: N-VL1-VH2-CH1-Hinge-CH2-CH3-C
Composition of First Polypeptide 4: N-VH2-VL1-CH1-Hinge-CH2-CH3-C
Composition of the second polypeptide 1: N-VL2-VH1-C
Composition of the second polypeptide 2: N-VH1-VL2-C
Composition of the second polypeptide 3: N-VL2-VH1-CL-C
Composition of the second polypeptide 4: N-VH1-VL2-CL-C
化合物の例示的な構成を図1A及び図1Bに示す。 Illustrative configurations of the compounds are shown in FIGS. 1A and 1B.
いくつかの実施形態では、第1のポリペプチド及び第2のポリペプチドの可変領域は互いに会合して、第1の標的タンパク質に対する結合部位及び第2の標的タンパク質に対する結合部位を形成する。いくつかの実施形態では、第1のポリペプチドのVL1と第2のポリペプチドのVH1が会合して、第1の標的タンパク質に結合する結合部位を形成し、第2のポリペプチドのVL2と第1のポリペプチドのVH2が会合して、第2の標的タンパク質に結合する結合部位を形成する。いくつかの実施形態では、第1の標的タンパク質はBAFFであり、第2の標的タンパク質はIL23Aである。他の実施形態では、第1の標的タンパク質はIL23Aであり、第2の標的タンパク質はBAFFである。用語「第1」及び「第2」は、いずれかの標的タンパク質に対する重要度を意味することを意図しないと理解すべきである。 In some embodiments, the variable regions of the first and second polypeptides associate with each other to form a binding site for the first target protein and a binding site for the second target protein. In some embodiments, the VL1 of the first polypeptide and the VH1 of the second polypeptide associate to form a binding site that binds to the first target protein, and the second polypeptide, VL2, and the second. VH2 of one polypeptide associates to form a binding site that binds to a second target protein. In some embodiments, the first target protein is BAFF and the second target protein is IL23A. In other embodiments, the first target protein is IL23A and the second target protein is BAFF. It should be understood that the terms "first" and "second" are not intended to mean importance to any target protein.
VL1、VH1、VL2、及びVH2のそれぞれに対する例示的な配列の組み合わせを、以下の表1、また実施例1の表2に示す。 Illustrative sequence combinations for each of VL1, VH1, VL2, and VH2 are shown in Table 1 below and Table 2 of Example 1.

いくつかの実施形態では、化合物は、第1の軽鎖のCDR1、CDR2、及びCDR3を含むVL1配列と、第1の重鎖のCDR1、CDR2、及びCDR3を含むVH1配列と、第2の軽鎖のCDR1、CDR2、及びCDR3を含むVL2配列と、第2の重鎖のCDR1、CDR2、及びCDR3を含むVH2配列を含む。いくつかの実施形態では、CDRは、表1に記載する1つ以上のVL1、VH1、VL2、及びVH2配列のCDRである。表1に記載するVL1、VH1、VL2、及びVH2配列の例示的な軽鎖及び重鎖CDR配列を以下に示す:
配列番号1のCDR:GGTFNNNAIN(配列番号92)(CDR1)、GIIPMFGTAKYSQNFQG(配列番号93)(CDR2)、SRDLLLFPHHALSP(配列番号94)(CDR3)
配列番号2のCDR:QGDSLRSYYAS(配列番号95)(CDR1)、GKNNRPS(配列番号96)(CDR2)、SSRDSSGNHWV(配列番号97)(CDR3)
配列番号3のCDR:GYTFTDQTIH(配列番号98)(CDR1)、YIYPRDDSPKYNENFKG(配列番号99)(CDR2)、PDRSGYAWFIY(配列番号100)(CDR3)
配列番号4のCDR:KASRDVAIAVA(配列番号101)(CDR1)、WASTRHT(配列番号102)(CDR2)、HQYSSYPFT(配列番号103)(CDR3)
配列番号84のCDR:DHIFSIHWMQ(配列番号104)(CDR1)、EIFPGSGTTDYNEKFKG(配列番号105)(CDR2)、GAFDY(配列番号106)(CDR3)
配列番号85のCDR:RASQDIGNRLS(配列番号107)(CDR1)、ATSSLDS(配列番号108)(CDR2)、LQYASSPFT(配列番号109)(CDR3)
配列番号86のCDR:DHIFSIHWMQ(配列番号110)(CDR1)、EIFPGSGTTDYNEKFKG(配列番号111)(CDR2)、GAFDY(配列番号112)(CDR3)
配列番号87のCDR:RASQDIGNRLN(配列番号112)(CDR1)、ATSSLDS(配列番号113)(CDR2)、LQYASSPFT(配列番号114)(CDR3)
配列番号88のCDR:GYSFSTFFIH(配列番号115)(CDR1)、RIDPNSGATKYNEKFES(配列番号116)(CDR2)、GEDLLIRTDALDY(配列番号117)(CDR3)
配列番号89のCDR:KASQNAGIDVA(配列番号118)(CDR1)、SKSNRYT(配列番号119)(CDR2)、LQYRSYPRT(配列番号120)(CDR3)
配列番号90のCDR:GYSFSTFFIH(配列番号121)(CDR1)、GRIDPNSGATKYNEKFES(配列番号122)(CDR2)、GEDLLIRTDALDY(配列番号123)(CDR3)
配列番号91のCDR:KASQNAGIDVA(配列番号124)(CDR1)、SKSNRYT(配列番号125)(CDR2)、LQYRSYPRT(配列番号126)(CDR3)
In some embodiments, the compounds are a VL1 sequence containing CDR1, CDR2, and CDR3 of the first light chain, a VH1 sequence containing CDR1, CDR2, and CDR3 of the first heavy chain, and a second light chain. It contains a VL2 sequence containing CDR1, CDR2, and CDR3 of the chain and a VH2 sequence containing CDR1, CDR2, and CDR3 of the second heavy chain. In some embodiments, the CDRs are one or more VL1, VH1, VL2, and VH2 sequences of CDRs listed in Table 1. Illustrative light and heavy chain CDR sequences of the VL1, VH1, VL2, and VH2 sequences listed in Table 1 are shown below:
CDR of SEQ ID NO: 1: GGTFNNNAIN (SEQ ID NO: 92) (CDR1), GIIPMFGTAKYSQNFQG (SEQ ID NO: 93) (CDR2), SRDLLLFPHHALSP (SEQ ID NO: 94) (CDR3)
CDRs of SEQ ID NO: 2: QGDSLRSYYAS (SEQ ID NO: 95) (CDR1), GKNNRPS (SEQ ID NO: 96) (CDR2), SSRDSSGNHWV (SEQ ID NO: 97) (CDR3)
CDR of SEQ ID NO: 3: GYTFTDQTIH (SEQ ID NO: 98) (CDR1), YIYPRDDSPKYNENFKG (SEQ ID NO: 99) (CDR2), PDRSGYAWFIY (SEQ ID NO: 100) (CDR3)
CDR of SEQ ID NO: 4: KASRDVAIAVA (SEQ ID NO: 101) (CDR1), WASTRHT (SEQ ID NO: 102) (CDR2), HQYSSYPFT (SEQ ID NO: 103) (CDR3)
CDR of SEQ ID NO: 84: DHIFSIHWMQ (SEQ ID NO: 104) (CDR1), EIFFGSGTTDYNEKFKG (SEQ ID NO: 105) (CDR2), GAFDY (SEQ ID NO: 106) (CDR3)
CDR of SEQ ID NO: 85: RASQDIGNRLS (SEQ ID NO: 107) (CDR1), ATSSLDS (SEQ ID NO: 108) (CDR2), LQYASSPFT (SEQ ID NO: 109) (CDR3)
CDR of SEQ ID NO: 86: DHIFSIHWMQ (SEQ ID NO: 110) (CDR1), EIFFGSGTTDYNEKFKG (SEQ ID NO: 111) (CDR2), GAFDY (SEQ ID NO: 112) (CDR3)
CDRs of SEQ ID NO: 87: RASQDIGNRLN (SEQ ID NO: 112) (CDR1), ATSSLDS (SEQ ID NO: 113) (CDR2), LQYASSPFT (SEQ ID NO: 114) (CDR3)
CDRs of SEQ ID NO: 88: GYSFSTFFIH (SEQ ID NO: 115) (CDR1), RIDPNSGATKYNEKFES (SEQ ID NO: 116) (CDR2), GEDLLIRTDALDY (SEQ ID NO: 117) (CDR3)
CDRs of SEQ ID NO: 89: KASQNAGIDVA (SEQ ID NO: 118) (CDR1), SKSNRYT (SEQ ID NO: 119) (CDR2), LQYRSYPRT (SEQ ID NO: 120) (CDR3)
CDRs of SEQ ID NO: 90: GYSFSTFFIH (SEQ ID NO: 121) (CDR1), GRIDPNSGATKYNEKFES (SEQ ID NO: 122) (CDR2), GEDLLIRTDALDY (SEQ ID NO: 123) (CDR3)
CDRs of SEQ ID NO: 91: KASQNAGIDVA (SEQ ID NO: 124) (CDR1), SKSNRYT (SEQ ID NO: 125) (CDR2), LQYRSYPRT (SEQ ID NO: 126) (CDR3)
いくつかの実施形態では、化合物は、表1に記載する配列に対して、(配列全長にわたる残基単位で)少なくとも80%(例えば、85%、90%、95%、96%、97%、98%、または99%)同一である配列を含むVH1、VL1、VH2、及び/またはVL2を含む。2つのアミノ酸配列の「同一性パーセント」は、Karlin and Altschul Proc.Natl.Acad.Sci.USA 87:2264−68,1990のアルゴリズムをKarlin and Altschul Proc.Natl.Acad.Sci.USA 90:5873−77,1993に従って修正して使用し、決定する。このようなアルゴリズムは、Altschul,et al.J.Mol.Biol.215:403−10,1990のNBLAST及びXBLASTプログラム(バージョン2.0)に組み込まれている。XBLASTプログラムでスコア=50、ワード長=3としてBLASTタンパク質検索を実行することにより、目的のタンパク質分子に相同なアミノ酸配列を得ることができる。2つの配列間にギャップが存在する場合、Altschul et al.,Nucleic Acids Res.25(17):3389−3402,1997に記載のように、Gapped BLASTを利用することができる。BLAST及びGapped BLASTプログラムを利用する際、それぞれのプログラム(例えば、XBLAST及びNBLAST)の初期設定パラメーターを使用することができる。 In some embodiments, the compounds are at least 80% (eg, 85%, 90%, 95%, 96%, 97%, per residue unit over the entire sequence), relative to the sequences listed in Table 1. 98% or 99%) Includes VH1, VL1, VH2, and / or VL2 containing sequences that are identical. The "percentage of identity" of the two amino acid sequences is described in Karlin and Altschul Proc. Natl. Acad. Sci. The algorithm of USA 87: 2264-68, 1990 was described in Karlin and Altschul Proc. Natl. Acad. Sci. Modified and used and determined according to USA 90: 5873-77,1993. Such algorithms are described in Altschul, et al. J. Mol. Biol. 215: 403-10, 1990 incorporated into the NBLAST and XBLAST programs (version 2.0). By performing a BLAST protein search with a score of 50 and a word length of 3 in the XBLAST program, an amino acid sequence homologous to the protein molecule of interest can be obtained. If there is a gap between the two sequences, Altschul et al. , Nucleic Acids Res. 25 (17): As described in 3389-3402, 1997, Gapped BLAST can be used. When using BLAST and Gapped BLAST programs, the initialization parameters of the respective programs (eg, XBLAST and NBLAST) can be used.
いくつかの実施形態では、化合物は、表1に記載の配列中に1つ以上(例えば、1、2、3、4、5、6、7、8、9、10またはそれ以上)の変異を含んでいる配列を含むVH1、VL1、VH2、及び/またはVL2を含む。そのような変異は保存的アミノ酸置換であり得る。本明細書で使用される場合、「保存的アミノ酸置換」は、アミノ酸置換がなされるタンパク質の相対電荷またはサイズ特性を変化させないアミノ酸置換を指す。アミノ酸の保存的置換としては、例えば、(a)M、I、L、V;(b)F、Y、W;(c)K、R、H;(d)A、G;(e)S、T;(f)Q、N;及び(g)E、Dの各群内のアミノ酸間でなされる置換が挙げられる。 In some embodiments, the compounds have one or more mutations (eg, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 or more) in the sequences listed in Table 1. Includes VH1, VL1, VH2, and / or VL2 containing the containing sequences. Such mutations can be conservative amino acid substitutions. As used herein, "conservative amino acid substitution" refers to an amino acid substitution that does not alter the relative charge or size characteristics of the protein in which the amino acid substitution is made. Conservative substitutions of amino acids include, for example, (a) M, I, L, V; (b) F, Y, W; (c) K, R, H; (d) A, G; (e) S. , T; (f) Q, N; and (g) E, D substitutions made between amino acids within each group.
化合物のヒンジ領域、CH2、及びCH3(場合によりCH1及びCL、化合物が当該領域を含んでいる場合)のアミノ酸配列は、任意の適切な起源、例えば、IgG1、IgG2、IgG3、またはIgG4などの抗体の定常領域に由来してもよい。抗体の重鎖及び軽鎖定常領域のアミノ酸配列は、当技術分野で周知であり、例えば、IMGTデータベース(www.imgt.org)またはwww.vbase2.org/vbstat.php.に提供されているものがあり、そのいずれのサイトも参照により本明細書に組み込まれる。さらに、いくつかの発現系では、CH3ドメインのC末端リジン残基を翻訳後に除去してもよい。したがって、CH3ドメインのC末端リジン残基は任意のアミノ酸残基である。具体的に本発明によって提供されるのは、CH3ドメインのC末端リジン残基を欠失する分子である。また、具体的に本発明に包含されるのは、CH3ドメインのC末端リジン残基を含むそのような構築物である。いくつかの実施形態では、CH2及びCH3のアミノ酸配列は、IgG1(例えば、配列番号75)またはIgG4(例えば、配列番号73)に由来する。いくつかの実施形態では、CLは、カッパCLまたはラムダCLのアミノ酸配列を含む。いくつかの実施形態では、ヒンジ領域は、アミノ酸配列EPKSCDKTHTCPPCP(配列番号76)を含む。配列番号76のヒンジ領域は、例えば、配列番号5のポリペプチドに存在する。他の実施形態では、ヒンジ領域は、アミノ酸配列LEPKSSDKTHTCPPCP(配列番号130)を含む。配列番号130のヒンジ領域は、例えば、配列番号9のポリペプチドに存在する。配列番号130のヒンジ領域はまた、配列番号129のFcドメインの先頭に存在する。さらに他の実施形態では、ヒンジ領域は、アミノ酸配列ESKYGPPCPPCP(配列番号134)を含む。配列番号134のヒンジ領域は、例えば、配列番号13のポリペプチドに存在する。配列番号134のヒンジ領域はまた、配列番号127のFcドメインの先頭に存在する。
The amino acid sequences of the compound's hinge region, CH2, and CH3 (possibly CH1 and CL, where the compound comprises such region) can be of any suitable origin, eg, an antibody such as IgG1, IgG2, IgG3, or IgG4. It may be derived from the constant region of. The amino acid sequences of the heavy and light chain constant regions of an antibody are well known in the art and are described, for example, in the IMGT database (www.imgt.org) or www.
いくつかの実施形態では、化合物のCH2及び/またはCH3(場合によりCH1及びCL、化合物が当該領域を含んでいる場合)は、野生型CH2またはCH3とは異なる1つ以上のアミノ酸置換、例えば、野生型IgG1のCH2またはCH3に1つ以上のアミノ酸置換、または野生型IgG4のCH2またはCH3に1つ以上のアミノ酸置換を含んでもよい(配列番号39は例示的な野生型IgG1を示す)。そのような置換は当技術分野で既知である(例えば、US7704497、US7083784、US6821505、US8323962、US6737056、及びUS7416727を参照)。 In some embodiments, the compounds CH2 and / or CH3 (possibly CH1 and CL, where the compound comprises such region) have one or more amino acid substitutions different from wild-type CH2 or CH3, eg, CH2 or CH3 of wild-type IgG1 may contain one or more amino acid substitutions, or CH2 or CH3 of wild-type IgG4 may contain one or more amino acid substitutions (SEQ ID NO: 39 shows exemplary wild-type IgG1). Such substitutions are known in the art (see, eg, US77044497, US7083784, US6821505, US8323962, US6737056, and US7416727).
いくつかの実施形態では、CH2は、従来抗体に対するKabatと同様のEUインデックスによる番号の234位、235位、252位、254位、及び/または256位にアミノ酸置換を含む(Kabat et al.Sequences of Proteins of Immunological Interest,U.S.Department of Health and Human Services,1991、その全体が参照により本明細書に組み込まれる)。本明細書に記載のアミノ酸位置はすべて、従来抗体に対するKabatと同様のEUインデックス番号を指すと理解すべきである。いくつかの実施形態では、CH2は、252位、254位、及び/または256位にアミノ酸置換を含む。いくつかの実施形態では、252位のアミノ酸は、チロシン、フェニルアラニン、セリン、トリプトファン、またはスレオニンである。いくつかの実施形態では、254位のアミノ酸はスレオニンである。いくつかの実施形態では、254位のアミノ酸はセリン、アルギニン、グルタミン、グルタミン酸、またはアスパラギン酸である。いくつかの実施形態では、CH2は、252位にチロシン、254位にスレオニン、256位にグルタミン酸を含む(本明細書でYTE変異体と称する)。いくつかの実施形態では、CH2は、234位及び/または235位にアミノ酸置換を含む。いくつかの実施形態では、CH2は、234位にアラニン、及び235位にアラニンを含み、これはまた本明細書でKO変異体とも称する。いくつかの実施形態では、CH2は、252位にチロシン、254位にスレオニン、256位にグルタミン酸、234位にアラニン、及び235位にアラニンを含み、これはまた本明細書でKO−YTE変異体とも称する。 In some embodiments, CH2 comprises amino acid substitutions at positions 234, 235, 252, 254, and / or 256 according to the EU index similar to Kabat for conventional antibodies (Kabat et al. Sequences). of Proteins of Immunological Interest, US Department of Health and Human Services, 1991, which is incorporated herein by reference in its entirety). It should be understood that all amino acid positions described herein refer to EU index numbers similar to Kabat for conventional antibodies. In some embodiments, CH2 comprises an amino acid substitution at positions 252, 254, and / or 256. In some embodiments, the amino acid at position 252 is tyrosine, phenylalanine, serine, tryptophan, or threonine. In some embodiments, the amino acid at position 254 is threonine. In some embodiments, the amino acid at position 254 is serine, arginine, glutamine, glutamic acid, or aspartic acid. In some embodiments, CH2 contains tyrosine at position 252, threonine at position 254, and glutamic acid at position 256 (referred to herein as the YTE variant). In some embodiments, CH2 comprises an amino acid substitution at position 234 and / or position 235. In some embodiments, CH2 contains alanine at position 234 and alanine at position 235, which is also referred to herein as a KO variant. In some embodiments, CH2 contains tyrosine at position 252, threonine at position 254, glutamic acid at position 256, alanine at position 234, and alanine at position 235, which is also a KO-YTE variant herein. Also called.
いくつかの実施形態では、1つ以上のリンカーを使用して、第1及び/または第2のポリペプチドにあるドメイン/領域を一つに連結することができる。例えば、第1のポリペプチドは、VL1とVH2との間にリンカーを含んでもよい。第1のポリペプチドはさらに、(上記の構成に応じて)VL1またはVH2とヒンジとの間にリンカーを含む(例えば、−VL1−リンカー−ヒンジ、または−VH2−リンカー−ヒンジ)。第1のポリペプチドがCH1を含む場合、例えば、第1のポリペプチドは、(上記の構成に応じて)VL1またはVH2とCH1との間にリンカーを含んでもよい(例えば、−VL1−リンカー−CH1、または−VH2−リンカー−CH1)。別の例では、第2のポリペプチドは、VL2とVH1との間にリンカーを含んでもよい。第2のポリペプチドはさらに、ポリペプチド鎖のC末端のVL2またはVH1の後ろにリンカーを含んでもよい(上記の構成に応じて、例えば−VL2−リンカー、または−VH1−リンカー)。第2のポリペプチドがさらにCLを含む場合、第2のポリペプチドはさらに、(上記の構成に応じて)VL2またはVH1とCLとの間にリンカーを含んでもよい(同様に、例えば−VL2−リンカー−CL、または−VH1−リンカー−CL)。当然ながら、任意の数のリンカーを使用して、任意のドメインまたは領域を第1のポリペプチドの任意の他のドメインまたは領域に連結することも、及び/または任意の数のリンカーを使用して、任意のドメインまたは領域を第2のポリペプチドの他の任意の別のドメインまたは領域に連結することもできる。 In some embodiments, one or more linkers can be used to link the domains / regions in the first and / or second polypeptide into one. For example, the first polypeptide may contain a linker between VL1 and VH2. The first polypeptide further comprises a linker between the VL1 or VH2 (depending on the configuration described above) and the hinge (eg, -VL1-linker-hinge, or -VH2-linker-hinge). If the first polypeptide comprises CH1, for example, the first polypeptide may contain a linker (eg, -VL1-linker-) between VL1 or VH2 and CH1 (depending on the above configuration). CH1 or -VH2-linker-CH1). In another example, the second polypeptide may contain a linker between VL2 and VH1. The second polypeptide may further contain a linker after the C-terminal VL2 or VH1 of the polypeptide chain (eg, -VL2-linker, or -VH1-linker, depending on the above configuration). If the second polypeptide further comprises CL, the second polypeptide may further comprise (depending on the above configuration) a linker between VL2 or VH1 and CL (similarly, eg, -VL2-). Linker-CL, or -VH1-linker-CL). Of course, any number of linkers can be used to link any domain or region to any other domain or region of the first polypeptide, and / or any number of linkers can be used. , Any domain or region can also be linked to any other domain or region of the second polypeptide.
当技術分野で既知の好適なリンカーのいずれをも本明細書での使用が企図される。いくつかの実施形態では、リンカーはペプチドリンカーである。いくつかの実施形態では、ペプチドリンカーは、少なくとも2つのアミノ酸、例えば2、3、4、5、6、7、8、9、10、またはそれ以上のアミノ酸を含む。いくつかの実施形態では、ペプチドリンカーは、50、40、30、25、20、19、18、17、16、15、14、13、12、11、10、9、8、7、6、5、4、3、または2以下のアミノ酸長である。いくつかの実施形態では、ペプチドリンカーは、2〜50、2〜40、2〜30、2〜20、2〜10、2〜9、2〜8、2〜7、または2〜6アミノ酸長である。いくつかの実施形態では、ペプチドリンカーは、アミノ酸配列GGGSGGGG(配列番号69)、LGGGSG(配列番号70)、FNRGEC(配列番号71)、VEPKSC(配列番号72)、GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)、GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)またはそれらの組み合わせを含む。いくつかの実施形態では、ペプチドリンカーは、リンカー配列の複数のコピー、例えば、配列GGGSGGGG(配列番号69)、LGGGSG(配列番号70)、FNRGEC(配列番号71)、VEPKSC(配列番号72)またはそれらの組み合わせの複数のコピーを含んでもよい。 Any suitable linker known in the art is intended for use herein. In some embodiments, the linker is a peptide linker. In some embodiments, the peptide linker comprises at least two amino acids, such as 2, 3, 4, 5, 6, 7, 8, 9, 10, or more amino acids. In some embodiments, the peptide linkers are 50, 40, 30, 25, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5 It has an amino acid length of 4, 3, or 2 or less. In some embodiments, the peptide linker is 2-50, 2-40, 2-30, 2-20, 2-10, 2-9, 2-8, 2-7, or 2-6 amino acids long. is there. In some embodiments, the peptide linkers are the amino acid sequences GGGSGGGGG (SEQ ID NO: 69), LGGGSG (SEQ ID NO: 70), FNRGEC (SEQ ID NO: 71), VEPKSC (SEQ ID NO: 72), GGCGGGGEVAACEKEVAALEKEVAALEKEVAALEKAGEKAVALEK (SEQ ID NO: 82). SEQ ID NO: 83) or a combination thereof. In some embodiments, the peptide linker is a plurality of copies of the linker sequence, eg, the sequences GGGSGGGGG (SEQ ID NO: 69), LGGGSG (SEQ ID NO: 70), FNRGEC (SEQ ID NO: 71), VEPKSC (SEQ ID NO: 72) or them. May include multiple copies of the combination of.
いくつかの実施形態では、第1及び第2のポリペプチドは、以下の構成:
第1のポリペプチドの構成1:N−VL1−VH2−ヒンジ−CH2−CH3−C、
第1のポリペプチドの構成2:N−VH2−VL1−ヒンジ−CH2−CH3−C、
第2のポリペプチドの構成1:N−VL2−VH1−C、
第2のポリペプチドの構成2:N−VH1−VL2−Cを有し、
第1のポリペプチドのVL1とVH2との間の第1のリンカー、または第2のポリペプチドのVL2とVH1との間の第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のリンカー及び前記第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、第1のポリペプチドはさらに、VH2またはVL2と前記ヒンジ領域との間に第3のリンカーを含み、第2のポリペプチドはさらに、前記VH1またはVL2(そのC末端)の後ろに第4のリンカーを含む。いくつかの実施形態では、前記第1のポリペプチドの前記第3のリンカーは、アミノ酸配列GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)を含み、前記第2のポリペプチドの前記第4のリンカーは、アミノ酸配列GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)を含む。他の実施形態では、前記第1のポリペプチドの前記第3のリンカーは、アミノ酸配列GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)を含み、前記第2のポリペプチドの前記第4のリンカーは、アミノ酸配列GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)を含む。いくつかの実施形態では、前記第1のポリペプチドの前記第3のリンカーは、アミノ酸配列GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)またはアミノ酸配列GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)を含む。他の実施形態では、前記第2のポリペプチドの前記第4のリンカーは、アミノ酸配列GGCGGGEVAACEKEVAALEKEVAALEKEVAALEK(配列番号82)またはアミノ酸配列GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE(配列番号83)を含む。いくつかの実施形態では、前記第3のリンカーは、アミノ酸配列VEPKSC(配列番号72)またはアミノ酸配列FNRGEC(配列番号71)を含む。いくつかの実施形態では、前記第4のリンカーは、アミノ酸配列FNRGEC(配列番号71)またはアミノ酸配列VEPKSC(配列番号72)を含む。いくつかの実施形態では、前記第3のリンカーは、アミノ酸配列VEPKSC(配列番号72)を含み、前記第4のリンカーはアミノ酸配列FNRGEC(配列番号71)を含む。アミノ酸配列FNRGEC(配列番号71)は、CLドメイン(配列番号77)の最後の6アミノ酸残基であり、アミノ酸VEPKSC(配列番号72)は、CH1の最後のアミノ酸及び配列番号76のヒンジ領域の最初の5アミノ酸残基(配列番号5と同様)を含む。
In some embodiments, the first and second polypeptides have the following composition:
Composition of First Polypeptide 1: N-VL1-VH2-Hinge-CH2-CH3-C,
Composition of First Polypeptide 2: N-VH2-VL1-Hinge-CH2-CH3-C,
Composition of the second polypeptide 1: N-VL2-VH1-C,
Composition of the second polypeptide 2: It has N-VH1-VL2-C and has
The first linker between VL1 and VH2 of the first polypeptide, or the second linker between VL2 and VH1 of the second polypeptide, comprises the amino acid sequence GGGSGGGG (SEQ ID NO: 69). In some embodiments, the first linker and the second linker comprise the amino acid sequence GGGSGGGG (SEQ ID NO: 69). In some embodiments, the first polypeptide further comprises a third linker between VH2 or VL2 and the hinge region, and the second polypeptide further comprises said VH1 or VL2 (the C-terminus thereof). Includes a fourth linker after. In some embodiments, the third linker of the first polypeptide comprises the amino acid sequence GGCGGGGEVAACEKEVAALEKEVAALEKEVAALEK (SEQ ID NO: 82), and the fourth linker of the second polypeptide is the amino acid sequence GGCGGGKVAACKEKVALKEKALEKVA SEQ ID NO: 83) is included. In another embodiment, the third linker of the first polypeptide comprises the amino acid sequence GGCGGGKVAACKEKVAALKEKVAALKEKVAALKE (SEQ ID NO: 83), and the fourth linker of the second polypeptide is the amino acid sequence GGCGGGGEVAACEKEVAALEKEVAALEKEVA. Includes number 82). In some embodiments, the third linker of the first polypeptide comprises the amino acid sequence GGCGGGGEVAACEKEVAALEKEVAALEKEVAALEK (SEQ ID NO: 82) or the amino acid sequence GGCGGGKVAACKEKVAALKEKVAALKEKALKE (SEQ ID NO: 83). In another embodiment, the fourth linker of the second polypeptide comprises the amino acid sequence GGCGGGGEVAACEKEVAALEKEVAALEKEVAALEK (SEQ ID NO: 82) or the amino acid sequence GGCGGGKVAACKEKVAALKEKVAALKEKALKE (SEQ ID NO: 83). In some embodiments, the third linker comprises the amino acid sequence VEPKSC (SEQ ID NO: 72) or the amino acid sequence FNRGEC (SEQ ID NO: 71). In some embodiments, the fourth linker comprises the amino acid sequence FNRGEC (SEQ ID NO: 71) or the amino acid sequence VEPKSC (SEQ ID NO: 72). In some embodiments, the third linker comprises the amino acid sequence VEPKSC (SEQ ID NO: 72) and the fourth linker comprises the amino acid sequence FNRGEC (SEQ ID NO: 71). The amino acid sequence FNRGEC (SEQ ID NO: 71) is the last 6 amino acid residues of the CL domain (SEQ ID NO: 77), and the amino acid VEPKSC (SEQ ID NO: 72) is the last amino acid of CH1 and the first of the hinge region of SEQ ID NO: 76. Contains 5 amino acid residues (similar to SEQ ID NO: 5).
いくつかの実施形態では、第1及び第2のポリペプチドは、以下の構成:
第1のポリペプチドの構成3:N−VL1−VH2−CH1−ヒンジ−CH2−CH3−C、
第1のポリペプチドの構成4:N−VH2−VL1−CH1−ヒンジ−CH2−CH3−C、
第2のポリペプチドの構成3:N−VL2−VH1−CL−C、
第2のポリペプチドの構成4:N−VH1−VL2−CL−Cを有し、
第1のポリペプチドの前記VL1と前記VH2との間の第1のリンカー、または第2のポリペプチドの前記VL2と前記VH1との間の前記第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のリンカー及び前記第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のポリペプチドはさらに、前記VH2またはVL1と前記CH1との間に第3のリンカーを含み、第2のポリペプチドはさらに、前記VH1または前記VL2と前記CLとの間に第4のリンカーを含む。いくつかの実施形態では、前記第3のリンカーまたは前記第4のリンカーは、アミノ酸配列LGGGSG(配列番号70)を含む。いくつかの実施形態では、前記第3のリンカー及び前記第4のリンカーは、アミノ酸配列LGGGSG(配列番号70)を含む。いくつかの実施形態では、前記第3のリンカー及び/または前記第4のリンカーは、任意のシステイン残基を含む。いくつかの実施形態では、前記第3のリンカー及び/または前記第4のリンカーは、アミノ酸配列GGCGGG(配列番号135)またはLGGCGGGS(配列番号136)を含む。
In some embodiments, the first and second polypeptides have the following composition:
Composition of First Polypeptide 3: N-VL1-VH2-CH1-Hinge-CH2-CH3-C,
Composition of First Polypeptide 4: N-VH2-VL1-CH1-Hinge-CH2-CH3-C,
Composition of the second polypeptide 3: N-VL2-VH1-CL-C,
Composition of Second Polypeptide 4: Having N-VH1-VL2-CL-C
The first linker between the VL1 and the VH2 of the first polypeptide, or the second linker between the VL2 and the VH1 of the second polypeptide, is the amino acid sequence GGGSGGGG (SEQ ID NO: 69). )including. In some embodiments, the first linker and the second linker comprise the amino acid sequence GGGSGGGG (SEQ ID NO: 69). In some embodiments, the first polypeptide further comprises a third linker between the VH2 or VL1 and the CH1, and the second polypeptide further comprises the VH1 or VL2 and the CL. Includes a fourth linker between and. In some embodiments, the third or fourth linker comprises the amino acid sequence LGGGSG (SEQ ID NO: 70). In some embodiments, the third linker and the fourth linker include the amino acid sequence LGGGSG (SEQ ID NO: 70). In some embodiments, the third linker and / or the fourth linker comprises any cysteine residue. In some embodiments, the third linker and / or the fourth linker comprises the amino acid sequence GGCGGGG (SEQ ID NO: 135) or LGGCGGGS (SEQ ID NO: 136).
いくつかの実施形態では、前記重鎖定常領域2(CH2)は、従来抗体に対するKabatと同様のEUインデックスによる番号の234位にアラニン、及び235位にアラニンを含む。 In some embodiments, the heavy chain constant region 2 (CH2) comprises alanine at position 234 and alanine at position 235 according to EU index numbers similar to Kabat for conventional antibodies.
いくつかの実施形態では、化合物は2つの第1のポリペプチドと2つの第2のポリペプチドとを含む。いくつかの実施形態では、第1のポリペプチドのうち一方のヒンジ、CH2、及びCH3が、第1のポリペプチドのうち他方のヒンジ、CH2、及びCH3と会合し、4価分子(例えば、2つの第1のポリペプチドが、それぞれの対応するヒンジ、CH2、及びCH3ドメインとの会合により二量体化され、第1の標的タンパク質に特異的な2つの結合部位及び第2の標的タンパク質に特異的な2つの結合部位を含む4価分子を形成する)、すなわち実施例のセクションに記載される単量体または単量体抗体を形成する。第1のポリペプチドがCH1ドメインをさらに含み、第2のポリペプチドがCLドメインをさらに含む場合、CH1及びCLドメインはまた、4価分子(例えば、2つの第1のポリペプチドが、それぞれの対応するヒンジ、CH2、及びCH3ドメインとの会合により二量体化され、前記第1のポリペプチドそれぞれのCH1が1つの前記第2のポリペプチドのCLと会合し、第1の標的タンパク質に対する2つの結合部位及び第2の標的タンパク質に対する2つの結合部位を含む4価分子を形成する)、すなわち実施例のセクションに記載される単量体、単量体抗体の形成に関与し得る。いくつかの実施形態では、2つの第1のポリペプチドは少なくとも1つのジスルフィド結合によって共に会合する。いくつかの実施形態では、前記化合物は、2つの前記第1のポリペプチドと2つの前記第2のポリペプチドとを含み、前記第1のポリペプチドのそれぞれが第3のリンカー、ヒンジ、CH2、及びCH3を含み、前記第2のポリペプチドのそれぞれが第4のリンカーを含み、さらにここで第1のポリペプチドのうち一方のヒンジ、CH2、及びCH3が、第1のポリペプチドのうち他方のヒンジ、CH2、及びCH3と会合し、前記第1のポリペプチドそれぞれの第3のリンカーが、前記第2のポリペプチドの一方の第4のリンカーと会合して、4価分子(例えば、実施例のセクションに記載される単量体、単量体抗体)(例えば、化合物U及びT)を形成する。 In some embodiments, the compound comprises two first polypeptides and two second polypeptides. In some embodiments, one hinge, CH2, and CH3 of the first polypeptide associates with the other hinge, CH2, and CH3 of the first polypeptide and is a tetravalent molecule (eg, 2). One first polypeptide is dimerized by association with its respective corresponding hinge, CH2, and CH3 domains, and is specific to the first target protein-specific binding site and the second target protein. Form a tetravalent molecule containing two binding sites), i.e. form the monomeric or monomeric antibody described in the Examples section. If the first polypeptide further comprises the CH1 domain and the second polypeptide further comprises the CL domain, then the CH1 and CL domains are also tetravalent molecules (eg, two first polypeptides each corresponding). Dimerized by association with the hinge, CH2, and CH3 domains, each CH1 of the first polypeptide associates with the CL of one said second polypeptide, and two for the first target protein. It forms a tetravalent molecule containing a binding site and two binding sites for a second target protein), i.e., it may be involved in the formation of the monomers, monomeric antibodies described in the Examples section. In some embodiments, the two first polypeptides are associated together by at least one disulfide bond. In some embodiments, the compound comprises two said first polypeptide and two said said second polypeptide, each of the first polypeptide having a third linker, hinge, CH2, and the like. And CH3, each of the second polypeptides comprising a fourth linker, wherein one hinge, CH2, and CH3 of the first polypeptide is the other of the first polypeptide. The third linker of each of the first polypeptide associates with the hinge, CH2, and CH3, and the third linker of each of the first polypeptide associates with the fourth linker of one of the second polypeptide, and is a tetravalent molecule (eg, Example). The monomers, monomeric antibodies described in the section of) (eg, compounds U and T) are formed.
いくつかの実施形態では、本開示は、2つの第1のポリペプチドと2つの第2のポリペプチドとを含む化合物に関し、本化合物において、前記2つの第1のポリペプチドは少なくとも1つのジスルフィド結合によって共に会合し、かつ前記第1のポリペプチドのそれぞれが少なくとも1つのジスルフィド結合によって1つの前記第2のポリペプチドと会合し、
ここで前記第1のポリペプチドのそれぞれは、
(i)第1の標的タンパク質に特異的な第1の免疫グロブリンの軽鎖可変ドメイン(VL1);
(ii)第2の標的タンパク質に特異的な第2の免疫グロブリンの重鎖可変ドメイン(VH2);
(iii)重鎖定常領域1(CH1)、ヒンジ領域、重鎖定常領域2(CH2)、及び重鎖定常領域3(CH3)を含み、
前記第2のポリペプチドのそれぞれは、
(i)前記第2の標的タンパク質に特異的な第2の免疫グロブリンの軽鎖可変ドメイン(VL2);
(ii)前記第1の標的タンパク質に特異的な第1の免疫グロブリンの重鎖可変ドメイン(VH1)、
(iii)軽鎖定常領域ドメイン(CL)を含み、
ここで第1のポリペプチドのうち一方のヒンジ、CH2、及びCH3が、第1のポリペプチドのうち他方のヒンジ、CH2、及びCH3と会合し、前記第1のポリペプチドそれぞれのCH1が、前記第2のポリペプチドそれぞれのCLと会合して、4価分子を形成し、
本化合物において、
a)前記VL1及びVH1は会合して、前記第1の標的タンパク質に結合する結合部位を形成し、
b)前記VL2及びVH2は会合して、前記第2の標的タンパク質に結合する結合部位を形成し、
c)前記重鎖定常領域2(CH2)は、Kabatと同様のEUインデックスによる番号の252位にチロシン、254位にスレオニン、256位にグルタミン酸を含み、
d)前記第1の標的タンパク質がBAFFであり、前記第2の標的タンパク質がIL−23Aであるか、または前記第1の標的タンパク質がIL−23Aであり、前記第2の標的タンパク質がBAFFであり、
さらに本化合物において、
(i)前記VL1は配列番号2を含み、前記VH1は配列番号1を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
(ii)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号2を含み、前記VH2は配列番号1を含むか、または
(iii)前記VL1は配列番号85を含み、前記VH1は配列番号84を含み、前記VL2は配列番号4を含み、前記VH2は配列番号4を含むか、または
(iv)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号85を含み、前記VH2は配列番号84を含むか、または
(v)前記VL1は配列番号87を含み、前記VH1は配列番号86を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
(vi)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号87を含み、前記VH2は配列番号86を含むか、または
(vii)前記VL1は配列番号89を含み、前記VH1は配列番号88を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
(viii)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号89を含み、前記VH2は配列番号88を含むか、または
(ix)前記VL1は配列番号91を含み、前記VH1は配列番号90を含み、前記VL2は配列番号4を含み、前記VH2は配列番号3を含むか、または
(x)前記VL1は配列番号4を含み、前記VH1は配列番号3を含み、前記VL2は配列番号91を含み、前記VH2は配列番号90を含む。
In some embodiments, the present disclosure relates to a compound comprising two first polypeptides and two second polypeptides, in which the two first polypeptides have at least one disulfide bond. And each of the first polypeptides is associated with one of the second polypeptides by at least one disulfide bond.
Here, each of the first polypeptides is
(I) Light chain variable domain (VL1) of the first immunoglobulin specific for the first target protein;
(Ii) Heavy chain variable domain (VH2) of the second immunoglobulin specific for the second target protein;
(Iii) Includes heavy chain constant region 1 (CH1), hinge region, heavy chain constant region 2 (CH2), and heavy chain constant region 3 (CH3).
Each of the second polypeptides
(I) Light chain variable domain (VL2) of the second immunoglobulin specific for the second target protein;
(Ii) Heavy chain variable domain (VH1) of the first immunoglobulin specific for the first target protein,
(Iii) Containing the light chain constant region domain (CL)
Here, one hinge, CH2, and CH3 of the first polypeptide associates with the other hinge, CH2, and CH3 of the first polypeptide, and CH1 of each of the first polypeptide is said. It associates with the CL of each of the second polypeptides to form a tetravalent molecule,
In this compound
a) The VL1 and VH1 associate to form a binding site that binds to the first target protein.
b) The VL2 and VH2 associate to form a binding site that binds to the second target protein.
c) The heavy chain constant region 2 (CH2) contains tyrosine at position 252 and threonine at position 254 and glutamic acid at position 256 according to the EU index similar to Kabat.
d) The first target protein is BAFF and the second target protein is IL-23A, or the first target protein is IL-23A and the second target protein is BAFF. Yes,
Furthermore, in this compound,
(I) The VL1 comprises SEQ ID NO: 2, the VH1 comprises SEQ ID NO: 1, the VL2 comprises SEQ ID NO: 4, the VH2 comprises SEQ ID NO: 3, or (ii) the VL1 comprises SEQ ID NO: 4. The VH1 comprises SEQ ID NO: 3, the VL2 comprises SEQ ID NO: 2, the VH2 comprises SEQ ID NO: 1, or (iii) the VL1 comprises SEQ ID NO: 85 and the VH1 comprises SEQ ID NO: 84. The VL2 comprises SEQ ID NO: 4, the VH2 comprises SEQ ID NO: 4, or (iv) the VL1 comprises SEQ ID NO: 4, the VH1 comprises SEQ ID NO: 3, and the VL2 comprises SEQ ID NO: 85. The VH2 comprises SEQ ID NO: 84, or (v) the VL1 comprises SEQ ID NO: 87, the VH1 comprises SEQ ID NO: 86, the VL2 comprises SEQ ID NO: 4, and the VH2 comprises SEQ ID NO: 3. Or (vi) said VL1 comprises SEQ ID NO: 4, said VH1 comprises SEQ ID NO: 3, said VL2 comprises SEQ ID NO: 87, said VH2 comprises SEQ ID NO: 86, or (vii) said. VL1 comprises SEQ ID NO: 89, said VH1 comprises SEQ ID NO: 88, said VL2 comprises SEQ ID NO: 4, said VH2 comprises SEQ ID NO: 3, or (viii) said said VL1 contained SEQ ID NO: 4, said. VH1 comprises SEQ ID NO: 3, said VL2 comprises SEQ ID NO: 89, said VH2 comprises SEQ ID NO: 88, or (ix) said VL1 comprises SEQ ID NO: 91, said VH1 comprises SEQ ID NO: 90, said. VL2 comprises SEQ ID NO: 4, said VH2 comprises SEQ ID NO: 3, or (x) said VL1 comprises SEQ ID NO: 4, said VH1 comprises SEQ ID NO: 3, said VL2 comprises SEQ ID NO: 91, said. VH2 comprises SEQ ID NO: 90.
上記態様に関するいくつかの実施形態では、前記第1のポリペプチドのそれぞれが、前記VL1と前記VH2との間に第1のリンカーをさらに含み、前記第2のポリペプチドのそれぞれが、前記VL2と前記VH1との間に第2のリンカーをさらに含む。いくつかの実施形態では、前記第1のリンカーまたは前記第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のリンカー及び前記第2のリンカーは、アミノ酸配列GGGSGGGG(配列番号69)を含む。いくつかの実施形態では、前記第1のポリペプチドのそれぞれが、前記VH2または前記VL1と前記CH1との間に第3のリンカーをさらに含み、前記第2のポリペプチドのそれぞれが、前記VH1または前記VL2と前記CLとの間に第4のリンカーをさらに含む。いくつかの実施形態では、前記第3のリンカーまたは前記第4のリンカーは、アミノ酸配列LGGGSG(配列番号70)を含む。いくつかの実施形態では、前記第3のリンカー及び前記第4のリンカーは、アミノ酸配列LGGGSG(配列番号70)を含む。いくつかの実施形態では、前記第3のリンカー及び/または前記第4のリンカーは、任意のシステイン残基を含む。いくつかの実施形態では、前記第3のリンカー及び/または前記第4のリンカーは、アミノ酸配列GGCGGG(配列番号135)またはLGGCGGGS(配列番号136)を含む。いくつかの実施形態では、前記重鎖定常領域2(CH2)は、Kabatと同様のEUインデックスによる番号の234位にアラニン、及び235位にアラニンを含む。いくつかの実施形態では、前記ヒンジ領域、前記重鎖定常領域2(CH2)、または前記重鎖定常領域3(CH3)のアミノ酸配列は、IgG1またはIgG4に由来する。いくつかの実施形態では、前記ヒンジ領域は、アミノ酸配列EPKSCDKTHTCPPCP(配列番号76)、アミノ酸配列LEPKSSDKTHTCPPCP(配列番号130)、またはアミノ酸配列ESKYGPPCPPCP(配列番号134)を含む。いくつかの実施形態では、(i)前記第1のポリペプチドのそれぞれが配列番号5のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号6のアミノ酸配列を含むか、または
(ii)前記第1のポリペプチドのそれぞれが配列番号7のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号8のアミノ酸配列を含むか、または
(iii)前記第1のポリペプチドのそれぞれが配列番号13のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号14のアミノ酸配列を含むか、または
(iv)前記第1のポリペプチドのそれぞれが配列番号15のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号16のアミノ酸配列を含むか、または
(v)前記第1のポリペプチドのそれぞれが配列番号21のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号22のアミノ酸配列を含むか、または
(vi)前記第1のポリペプチドのそれぞれが配列番号25のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号26のアミノ酸配列を含むか、または
(vii)前記第1のポリペプチドのそれぞれが配列番号29のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号30のアミノ酸配列を含むか、または
(viii)前記第1のポリペプチドのそれぞれが配列番号33のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号34のアミノ酸配列を含むか、または
(ix)前記第1のポリペプチドのそれぞれが配列番号37のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号38のアミノ酸配列を含むか、または
(x)前記第1のポリペプチドのそれぞれが配列番号41のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号42のアミノ酸配列を含むか、または
(xi)前記第1のポリペプチドのそれぞれが配列番号45のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号46のアミノ酸配列を含むか、または
(xii)前記第1のポリペプチドのそれぞれが配列番号49のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号50のアミノ酸配列を含むか、または
(xiii)前記第1のポリペプチドのそれぞれが配列番号53のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号54のアミノ酸配列を含むか、または
(xiv)前記第1のポリペプチドのそれぞれが配列番号55のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号56のアミノ酸配列を含むか、または
(xv)前記第1のポリペプチドのそれぞれが配列番号57のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号58のアミノ酸配列を含むか、または
(xvi)前記第1のポリペプチドのそれぞれが配列番号59のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号60のアミノ酸配列を含むか、または
(xvii)前記第1のポリペプチドのそれぞれが配列番号61のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号62のアミノ酸配列を含むか、または
(xviii)前記第1のポリペプチドのそれぞれが配列番号63のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号64のアミノ酸配列を含むか、または
(xix)前記第1のポリペプチドのそれぞれが配列番号65のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号66のアミノ酸配列を含むか、または
(xx)前記第1のポリペプチドのそれぞれが配列番号67のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号68のアミノ酸配列を含む。
In some embodiments relating to the above embodiments, each of the first polypeptides further comprises a first linker between the VL1 and the VH2, and each of the second polypeptides is with the VL2. A second linker is further included between the VH1 and the VH1. In some embodiments, the first linker or the second linker comprises the amino acid sequence GGGSGGGG (SEQ ID NO: 69). In some embodiments, the first linker and the second linker comprise the amino acid sequence GGGSGGGG (SEQ ID NO: 69). In some embodiments, each of the first polypeptides further comprises a third linker between the VH2 or VL1 and CH1, and each of the second polypeptides contains the VH1 or A fourth linker is further included between the VL2 and the CL. In some embodiments, the third or fourth linker comprises the amino acid sequence LGGGSG (SEQ ID NO: 70). In some embodiments, the third linker and the fourth linker include the amino acid sequence LGGGSG (SEQ ID NO: 70). In some embodiments, the third linker and / or the fourth linker comprises any cysteine residue. In some embodiments, the third linker and / or the fourth linker comprises the amino acid sequence GGCGGGG (SEQ ID NO: 135) or LGGCGGGS (SEQ ID NO: 136). In some embodiments, the heavy chain constant region 2 (CH2) comprises alanine at position 234 and alanine at position 235 according to EU index similar to Kabat. In some embodiments, the amino acid sequence of said hinge region, said heavy chain constant region 2 (CH2), or said heavy chain constant region 3 (CH3) is derived from IgG1 or IgG4. In some embodiments, the hinge region comprises the amino acid sequence EPKSCDKTHTCPPCP (SEQ ID NO: 76), the amino acid sequence LEPKSSDKTHTCPPCP (SEQ ID NO: 130), or the amino acid sequence ESKYGPPPCPPCP (SEQ ID NO: 134). In some embodiments, (i) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 5, and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 6 or (ii). ) Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 7, each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 8, or (iii) each of the first polypeptides. Contains the amino acid sequence of SEQ ID NO: 13 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 14 or (iv) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 15. , Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 16, or (v) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 21 and each of the second polypeptides. Contains the amino acid sequence of SEQ ID NO: 22 or (vi) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 25 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 26. Or (vii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 29 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 30 or (viii) said first. Each of the polypeptides of SEQ ID NO: 33 comprises the amino acid sequence of SEQ ID NO: 33, each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 34, or (ix) each of the first polypeptides of SEQ ID NO: 37. Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 38, or (x) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 41 and said the second Each of the polypeptides of SEQ ID NO: 42 comprises the amino acid sequence of SEQ ID NO: 42, or (xi) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 45 and each of the second polypeptides comprises SEQ ID NO: 46. , Or (xii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 49, and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 50, or ( xiii) Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 53, and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 54, or (Xiv) Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 55 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 56, or (xv) said first polypeptide. Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 57 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 58, or (xvi) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 59. Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 60, or (xvii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 61, said second polypeptide. Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 62, or (xviii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 63, and each of the second polypeptides contains the amino acid sequence of SEQ ID NO: 64. Or (xx) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 65 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 66, or (xx) said. Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 67, and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 68.
本開示の他の態様は、2つの第1のポリペプチドと2つの第2のポリペプチドとを含む化合物に関し、本化合物において、前記2つの第1のポリペプチドは少なくとも1つのジスルフィド結合によって共に会合し、かつ前記第1のポリペプチドのそれぞれが少なくとも1つのジスルフィド結合によって1つの前記第2のポリペプチドと会合し、さらにここで(i)前記第1のポリペプチドのそれぞれが配列番号5のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号6のアミノ酸配列を含むか、または
(ii)前記第1のポリペプチドのそれぞれが配列番号7のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号8のアミノ酸配列を含むか、または
(iii)前記第1のポリペプチドのそれぞれが配列番号13のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号14のアミノ酸配列を含むか、または
(iv)前記第1のポリペプチドのそれぞれが配列番号15のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号16のアミノ酸配列を含むか、または
(v)前記第1のポリペプチドのそれぞれが配列番号21のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号22のアミノ酸配列を含むか、または
(vi)前記第1のポリペプチドのそれぞれが配列番号25のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号26のアミノ酸配列を含むか、または
(vii)前記第1のポリペプチドのそれぞれが配列番号29のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号30のアミノ酸配列を含むか、または
(viii)前記第1のポリペプチドのそれぞれが配列番号33のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号34のアミノ酸配列を含むか、または
(ix)前記第1のポリペプチドのそれぞれが配列番号37のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号38のアミノ酸配列を含むか、または
(x)前記第1のポリペプチドのそれぞれが配列番号41のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号42のアミノ酸配列を含むか、または
(xi)前記第1のポリペプチドのそれぞれが配列番号45のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号46のアミノ酸配列を含むか、または
(xii)前記第1のポリペプチドのそれぞれが配列番号49のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号50のアミノ酸配列を含むか、または
(xiii)前記第1のポリペプチドのそれぞれが配列番号53のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号54のアミノ酸配列を含むか、または
(xiv)前記第1のポリペプチドのそれぞれが配列番号55のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号56のアミノ酸配列を含むか、または
(xv)前記第1のポリペプチドのそれぞれが配列番号57のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号58のアミノ酸配列を含むか、または
(xvi)前記第1のポリペプチドのそれぞれが配列番号59のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号60のアミノ酸配列を含むか、または
(xvii)前記第1のポリペプチドのそれぞれが配列番号61のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号62のアミノ酸配列を含むか、または
(xviii)前記第1のポリペプチドのそれぞれが配列番号63のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号64のアミノ酸配列を含むか、または
(xix)前記第1のポリペプチドのそれぞれが配列番号65のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号66のアミノ酸配列を含むか、または
(xx)前記第1のポリペプチドのそれぞれが配列番号67のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号68のアミノ酸配列を含む。
Another aspect of the disclosure relates to a compound comprising two first polypeptides and two second polypeptides, in which the two first polypeptides are associated together by at least one disulfide bond. And each of the first polypeptides associates with one of the second polypeptides by at least one disulfide bond, where (i) each of the first polypeptides is the amino acid of SEQ ID NO: 5. The second poly contains a sequence and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 6, or (ii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 7. Each of the peptides comprises the amino acid sequence of SEQ ID NO: 8, or (iii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 13 and each of the second polypeptides contains the amino acid of SEQ ID NO: 14. Either the sequence is contained, or (iv) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 15, and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 16 or (v). Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 21 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 22 or (vi) each of the first polypeptides Each of the second polypeptide comprises the amino acid sequence of SEQ ID NO: 25 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 26, or (vii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 29. Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 30, or (viii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 33, and each of the second polypeptides Whether it comprises the amino acid sequence of SEQ ID NO: 34, or (ix) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 37 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 38. Or (x) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 41 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 42, or (xi) said first. Each of the polypeptides comprises the amino acid sequence of SEQ ID NO: 45 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 46, or (xii) said. Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 49 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 50, or (xiii) each of the first polypeptides has a sequence. Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 54, or (xiv) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 55. Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 56, or (xv) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 57 and each of the second polypeptides has a sequence. Whether it comprises the amino acid sequence of No. 58, or (xvi) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 59 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 60. Or (xvii) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 61 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 62, or (xvii) said first poly. Each of the peptides comprises the amino acid sequence of SEQ ID NO: 63 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 64, or (xix) each of the first polypeptides contains the amino acid of SEQ ID NO: 65. The second poly contains a sequence and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 66, or (xx) each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 67. Each of the peptides contains the amino acid sequence of SEQ ID NO: 68.
また、本明細書に記載の化合物と結合を競合する他の化合物、例えばBAFF及びIL23Aへの結合を本明細書に記載の化合物と競合する試験化合物も企図される。いくつかの実施形態では、試験化合物は、(配列の全長にわたるアミノ酸単位で)本明細書に記載の化合物と少なくとも80%、85%、90%、95%、96%、97%、98%、または99%の配列同一性を有し得る。競合結合は、当技術分野で既知の任意のアッセイ、例えば、平衡結合、ELISA、表面プラズモン共鳴、または分光法を用いて決定することができる。 Also contemplated are test compounds that compete with other compounds that compete for binding to the compounds described herein, such as those that compete for binding to BAFF and IL23A. In some embodiments, the test compound is at least 80%, 85%, 90%, 95%, 96%, 97%, 98%, with the compounds described herein (in amino acid units over the entire length of the sequence). Or it can have 99% sequence identity. Competitive binding can be determined using any assay known in the art, such as equilibrium binding, ELISA, surface plasmon resonance, or spectroscopy.
いくつかの実施形態では、本明細書に記載の化合物は、BAFFとIL23Aの両方に特異的に結合する。抗原またはエピトープに「特異的に結合する」化合物は、当技術分野で周知の用語であり、そのような特異的結合を決定する方法もまた当技術分野で周知である。ある分子が、特定の標的抗原に対して、別の標的に対するよりも高頻度で、迅速に、長時間持続して、及び/または高親和性で反応または会合する場合、その分子は「特異的結合」を示すと言われる。ある化合物が、他の物質と結合するよりも高親和性で、高結合活性で、より速やかに、及び/または長時間持続して結合する場合、その化合物は標的抗原またはエピトープと「特異的に結合する」。例えば、抗原(例えば、BAFFまたはIL23A)またはその抗原エピトープに特異的に(または優先的に)結合する化合物は、この標的抗原に対して、他の抗原または同じ抗原の他のエピトープに結合するよりも高親和性で、高結合活性で、より速やかに、及び/または長時間持続して結合する化合物である。また、この定義を読めば、例えば、第1の標的抗原に特異的に結合する化合物が、第2の標的抗原に特異的または優先的に結合してもしなくてもよいことが理解される。このように、「特異的結合」または「優先的結合」は、必ずしも排他的結合を必要としない(ただし、含むことは可能である)。必ずしもそうとは限らないが、一般的に結合について記述する場合、優先的結合を意味する。いくつかの例では、標的抗原またはそのエピトープに「特異的に結合する」化合物は、他の抗原または同じ抗原の他のエピトープに結合しない場合がある。 In some embodiments, the compounds described herein specifically bind to both BAFF and IL23A. Compounds that "specifically bind" to an antigen or epitope are well known in the art, and methods for determining such specific binding are also well known in the art. When a molecule reacts or associates with a particular target antigen more frequently, rapidly, for a longer period of time, and / or with higher affinity than for another target, the molecule is "specific". It is said to indicate "bonding". When a compound binds with higher affinity, higher binding activity, faster and / or longer duration than it binds to other substances, the compound "specifically" with the target antigen or epitope. Join". For example, a compound that specifically (or preferentially) binds to an antigen (eg, BAFF or IL23A) or its antigenic epitope may bind to this target antigen to another antigen or to another epitope of the same antigen. Is also a compound that has high affinity, high binding activity, and binds more rapidly and / or lasts for a long time. It is also understood by reading this definition that, for example, a compound that specifically binds to a first target antigen may or may not bind specifically or preferentially to a second target antigen. Thus, a "specific bond" or "preferential bond" does not necessarily require (but can include) an exclusive bond. This is not always the case, but in general, when describing a join, it means a preferred join. In some examples, a compound that "specifically binds" to a target antigen or an epitope thereof may not bind to another antigen or another epitope of the same antigen.
いくつかの実施形態では、本明細書に記載の化合物は、BAFF及びIL23またはそれらの抗原エピトープに対して適切な結合親和性を有する。本明細書で使用される場合、「結合親和性」とは、見かけの会合定数すなわちKAを指す。KAは、解離定数(KD)の逆数である。明細書に記載の化合物は、標的抗原または抗原エピトープの一方または両方に対して、少なくとも10−5、10−6、10−7、10−8、10−9、10−10、10−11、10−12Mまたはそれ以下の結合親和性(KD)を有し得る。結合親和性の増加はKDの低下に対応する。いくつかの実施形態では、明細書に記載の化合物は、標的抗原または抗原エピトープの一方または両方に対して、少なくとも10−11M以下の結合親和性(KD)を有する。化合物が、第3の抗原よりも第1の抗原及び第2の抗原に対して高結合親和性であることは、第3の抗原との結合のKA(または数値KD)よりも、第1の抗原及び第2の抗原との結合のKAの方が高い(または数値KDが小さい)ことにより表すことができる。この場合、化合物は、第1の抗原及び第2の抗原(例えば、第1の立体構造である第1のタンパク質またはその模倣体、及び第1の立体構造である第2のタンパク質またはその模倣体)に対して、第3の抗原(例えば、第2の立体構造である同じ第1または第2のタンパク質もしくはその模倣体;または第3のタンパク質)に対するよりも特異性を有する。結合親和性(例えば、特異性または他の比較について)の差は、少なくとも1.5、2、3、4、5、10、15、20、37.5、50、70、80、91、100、500、1000、10,000、または105倍であり得る。 In some embodiments, the compounds described herein have appropriate binding affinities for BAFF and IL23 or their antigenic epitopes. As used herein, "binding affinity" refers to the apparent association constant or K A. K A is the reciprocal of the dissociation constant (K D). Compounds described herein, to one or both of the target antigen or antigenic epitope, at least 10 -5, 10 -6, 10 -7, 10 -8, 10 -9, 10 -10, 10 -11, 10 -12 may have M or less binding affinity (K D). It increased binding affinity corresponds to a decrease in K D. In some embodiments, the compounds described herein, to one or both of the target antigen or antigenic epitope has at least 10 -11 M or less for binding affinity (K D). Compounds than the third antigen is a high binding affinity for the first antigen and the second antigen, than the binding of K A a third antigen (or number K D), the can be represented by the higher of the binding of K a with one antigen and the second antigen (or number K D of less) it. In this case, the compound is a first antigen and a second antigen (for example, a first protein having a first three-dimensional structure or a mimic thereof, and a second protein having a first three-dimensional structure or a mimic thereof). ), More specific than a third antigen (eg, the same first or second protein or imitation of the same first or second protein having a second conformation; or a third protein). Differences in binding affinity (eg, for specificity or other comparisons) are at least 1.5, 2, 3, 4, 5, 10, 15, 20, 37.5, 50, 70, 80, 91, 100. may be 500,1000,10,000 or 10, 5-fold.
結合親和性(または結合特異性)は、平衡結合、ELISA、表面プラズモン共鳴、または分光法(例えば、蛍光アッセイを用いる)を含む様々な方法によって決定することができる。結合親和性を評価する際の例示的な条件は、HBS−P緩衝液(10mM HEPES pH7.4、150mM NaCl、0.005%(v/v)Surfactant P20)中でのものである。これらの技術を使用して、結合した結合タンパク質の濃度を標的タンパク質濃度の関数として測定することができる。結合した結合タンパク質の濃度([結合])は、遊離した標的タンパク質の濃度([遊離])及び標的上の結合タンパク質の結合部位の濃度と関係性があり、(N)が標的分子あたりの結合部位の数であるとき以下の式で表される:
[結合]=[N][遊離]/(Kd+[遊離])
Binding affinity (or binding specificity) can be determined by a variety of methods including equilibrium binding, ELISA, surface plasmon resonance, or spectroscopy (eg, using a fluorescence assay). Exemplary conditions for assessing binding affinity are in HBS-P buffer (10 mM HEPES pH 7.4, 150 mM NaCl, 0.005% (v / v) Surfactant P20). These techniques can be used to measure the concentration of bound bound protein as a function of the target protein concentration. The concentration of bound binding protein ([binding]) is related to the concentration of the free target protein ([free]) and the concentration of the binding site of the binding protein on the target, where (N) is the binding per target molecule. When it is the number of parts, it is expressed by the following formula:
[Binding] = [N] [Free] / (Kd + [Free])
ただし、例えば、ELISAまたはFACS分析などの方法を用いて決定される親和性の定量的測定値を得れば十分な場合があるため、KAを正確に求めることは必ずしも必要とされない。これはKAに比例するので、親和性が高いかどうか、例えば2倍高いかどうかを決定するなどの比較に使用することで、親和性の定性的測定を得ることや、または機能的アッセイ、例えばin vitroまたはin vivoアッセイでの活性などによる親和性の推定を得ることができる。 However, for example, because there is sufficient if if you get a quantitative measure of the affinity method are determined using such as ELISA or FACS analysis, it is not necessarily required for obtaining the K A accurately. Since this is proportional to K A, whether a high affinity, for example, by using the comparison of such determining whether 2-fold higher, it and obtain a qualitative measurement of the affinity, or functional assays, Estimates of affinity can be obtained, for example, by activity in in vitro or in vivo assays.
いくつかの実施形態では、化合物は、表2Aに定義される第1のポリペプチドと第2のポリペプチドとを含む。いくつかの実施形態では、化合物は以下を含む:
(i)前記第1のポリペプチドが配列番号5のアミノ酸配列を含み、前記第2のポリペプチドが配列番号6のアミノ酸配列を含むか、または
(ii)前記第1のポリペプチドが配列番号7のアミノ酸配列を含み、前記第2のポリペプチドが配列番号8のアミノ酸配列を含むか、または
(iii)前記第1のポリペプチドが配列番号9のアミノ酸配列を含み、前記第2のポリペプチドが配列番号10のアミノ酸配列を含むか、または
(iv)前記第1のポリペプチドが配列番号11のアミノ酸配列を含み、前記第2のポリペプチドが配列番号12のアミノ酸配列を含むか、または
(v)前記第1のポリペプチドが配列番号13のアミノ酸配列を含み、前記第2のポリペプチドが配列番号14のアミノ酸配列を含むか、または
(vi)前記第1のポリペプチドが配列番号15のアミノ酸配列を含み、前記第2のポリペプチドが配列番号16のアミノ酸配列を含むか、または
(vii)前記第1のポリペプチドが配列番号17のアミノ酸配列を含み、前記第2のポリペプチドが配列番号18のアミノ酸配列を含むか、または
(viii)前記第1のポリペプチドが配列番号19のアミノ酸配列を含み、前記第2のポリペプチドが配列番号20のアミノ酸配列を含むか、または
(ix)前記第1のポリペプチドが配列番号21のアミノ酸配列を含み、前記第2のポリペプチドが配列番号22のアミノ酸配列を含むか、または
(x)前記第1のポリペプチドが配列番号23のアミノ酸配列を含み、前記第2のポリペプチドが配列番号24のアミノ酸配列を含むか、または
(xi)前記第1のポリペプチドが配列番号25のアミノ酸配列を含み、前記第2のポリペプチドが配列番号26のアミノ酸配列を含むか、または
(xii)前記第1のポリペプチドが配列番号27のアミノ酸配列を含み、前記第2のポリペプチドが配列番号28のアミノ酸配列を含むか、または
(xiii)前記第1のポリペプチドが配列番号29のアミノ酸配列を含み、前記第2のポリペプチドが配列番号30のアミノ酸配列を含むか、または
(xiv)前記第1のポリペプチドが配列番号31のアミノ酸配列を含み、前記第2のポリペプチドが配列番号32のアミノ酸配列を含むか、または
(xv)前記第1のポリペプチドが配列番号33のアミノ酸配列を含み、前記第2のポリペプチドが配列番号34のアミノ酸配列を含むか、または
(xvi)前記第1のポリペプチドが配列番号35のアミノ酸配列を含み、前記第2のポリペプチドが配列番号36のアミノ酸配列を含むか、または
(xvii)前記第1のポリペプチドが配列番号37のアミノ酸配列を含み、前記第2のポリペプチドが配列番号38のアミノ酸配列を含むか、または
(xviii)前記第1のポリペプチドが配列番号39のアミノ酸配列を含み、前記第2のポリペプチドが配列番号40のアミノ酸配列を含むか、または
(xix)前記第1のポリペプチドが配列番号41のアミノ酸配列を含み、前記第2のポリペプチドが配列番号42のアミノ酸配列を含むか、または
(xx)前記第1のポリペプチドが配列番号43のアミノ酸配列を含み、前記第2のポリペプチドが配列番号44のアミノ酸配列を含むか、または
(xxi)前記第1のポリペプチドが配列番号45のアミノ酸配列を含み、前記第2のポリペプチドが配列番号46のアミノ酸配列を含むか、または
(xxii)前記第1のポリペプチドが配列番号47のアミノ酸配列を含み、前記第2のポリペプチドが配列番号48のアミノ酸配列を含むか、または
(xxiii)前記第1のポリペプチドが配列番号49のアミノ酸配列を含み、前記第2のポリペプチドが配列番号50のアミノ酸配列を含むか、または
(xxiv)前記第1のポリペプチドが配列番号51のアミノ酸配列を含み、前記第2のポリペプチドが配列番号52のアミノ酸配列を含むか、または
(xxv)前記第1のポリペプチドが配列番号53のアミノ酸配列を含み、前記第2のポリペプチドが配列番号54のアミノ酸配列を含むか、または
(xxvi)前記第1のポリペプチドが配列番号55のアミノ酸配列を含み、前記第2のポリペプチドが配列番号56のアミノ酸配列を含むか、または
(xxvii)前記第1のポリペプチドが配列番号57のアミノ酸配列を含み、前記第2のポリペプチドが配列番号58のアミノ酸配列を含むか、または
(xxviii)前記第1のポリペプチドが配列番号59のアミノ酸配列を含み、前記第2のポリペプチドが配列番号60のアミノ酸配列を含むか、または
(xxix)前記第1のポリペプチドが配列番号61のアミノ酸配列を含み、前記第2のポリペプチドが配列番号62のアミノ酸配列を含むか、または
(xxx)前記第1のポリペプチドが配列番号63のアミノ酸配列を含み、前記第2のポリペプチドが配列番号64のアミノ酸配列を含むか、または
(xxxi)前記第1のポリペプチドが配列番号65のアミノ酸配列を含み、前記第2のポリペプチドが配列番号66のアミノ酸配列を含むか、または
(xxxii)前記第1のポリペプチドが配列番号67のアミノ酸配列を含み、前記第2のポリペプチドが配列番号68のアミノ酸配列を含む。
In some embodiments, the compound comprises a first polypeptide and a second polypeptide as defined in Table 2A. In some embodiments, the compound comprises:
(I) The first polypeptide comprises the amino acid sequence of SEQ ID NO: 5, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 6, or (ii) the first polypeptide comprises SEQ ID NO: 7. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 8 or (iii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 9 and the second polypeptide comprises. Either the amino acid sequence of SEQ ID NO: 10 is contained, or (iv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 11 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 12 or (v). ) The first polypeptide comprises the amino acid sequence of SEQ ID NO: 13, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 14, or (vi) the first polypeptide comprises the amino acid of SEQ ID NO: 15. The second polypeptide comprises a sequence and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 16 or (vii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 17 and the second polypeptide has the SEQ ID NO: Eighteen amino acid sequences are included, or (viii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 19, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 20 or (ix) said. The first polypeptide comprises the amino acid sequence of SEQ ID NO: 21, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 22, or (x) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 23. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 24, or (xi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 25 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 26. The first polypeptide comprises the amino acid sequence, or (xii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 27, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 28, or (xiii) said first. The polypeptide comprises the amino acid sequence of SEQ ID NO: 29 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 30 or (xiv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 31. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 32, or (xv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 33 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 34. Or (xvi) said first The polypeptide comprises the amino acid sequence of SEQ ID NO: 35 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 36, or (xvii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 37 and said. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 38, or (xviii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 39 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 40. The first polypeptide comprises the amino acid sequence of SEQ ID NO: 41 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 42, or (xx) said first polypeptide. Contains the amino acid sequence of SEQ ID NO: 43 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 44, or (xxi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 45 and said second. Whether the polypeptide of SEQ ID NO: 46 comprises the amino acid sequence of SEQ ID NO: 46, or (xxiii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 47 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 48. , Or (xxiii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 49 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 50, or (xxiv) the first polypeptide comprises the sequence. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 51 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 52, or (xxv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 53 and said the second poly. The peptide comprises the amino acid sequence of SEQ ID NO: 54, or (xxvi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 55 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 56, or The first polypeptide comprises the amino acid sequence of SEQ ID NO: 57 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 58, or (xxviii) the first polypeptide comprises SEQ ID NO: 59. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 60, or (xxx) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 61 and the second polypeptide comprises. The amino acid sequence of SEQ ID NO: 62 is contained, or (xxx) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 63, and the second polypeptide contains the amino acid sequence of SEQ ID NO: 64. Or (xxxi) said first polypeptide comprises the amino acid sequence of SEQ ID NO: 65 and said second polypeptide comprises the amino acid sequence of SEQ ID NO: 66, or (xxxxi) said said first poly. The peptide comprises the amino acid sequence of SEQ ID NO: 67, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 68.
化合物、核酸、ベクター、及び細胞の作製方法
本開示の態様はまた、本明細書に記載の化合物または本明細書に記載のポリペプチド(例えば、本明細書に記載の第1または第2のポリペプチド)をコードする核酸を含むが、化合物またはポリペプチドは一緒にコードされていても個別にコードされていてもよい。当技術分野で既知のいずれの方法によっても、本明細書に記載の化合物または本明細書に記載のポリペプチドをコードするポリヌクレオチドを得ることができ、またポリヌクレオチドのヌクレオチド配列を決定することができる。
Methods for Making Compounds, Nucleic Acids, Vectors, and Cells The aspects of this disclosure also include the compounds described herein or the polypeptides described herein (eg, a first or second poly described herein). A nucleic acid encoding a peptide) is included, but the compound or polypeptide may be encoded together or individually. Any method known in the art can be used to obtain a polynucleotide encoding a compound described herein or a polypeptide described herein, and the nucleotide sequence of the polynucleotide can be determined. it can.
いくつかの実施形態では、核酸は発現ベクターなどのベクター内に含まれる。いくつかの実施形態では、ベクターは、核酸に機能的に連結されたプロモーターを含む。 In some embodiments, the nucleic acid is contained within a vector, such as an expression vector. In some embodiments, the vector comprises a promoter operably linked to a nucleic acid.
本明細書に記載の化合物または本明細書に記載のポリペプチドの発現に種々のプロモーターを使用することができ、これには、限定されないが、サイトメガロウイルス(CMV)中初期(intermediate early)プロモーター、ウイルスLTR、例えばラウス肉腫ウイルスLTR、HIV−LTR、HTLV−1 LTR、シミアンウイルス40(SV40)初期プロモーター、E.coli lac UV5プロモーター、及び単純ヘルペスtkウイルスプロモーターが含まれる。 Various promoters can be used to express the compounds described herein or the polypeptides described herein, including, but not limited to, cytomegalovirus (CMV) intermediate early promoters. , Viral LTRs such as Laus sarcoma virus LTR, HIV-LTR, HTLV-1 LTR, Simian virus 40 (SV40) early promoter, E. coli. The coli lac UV5 promoter and the herpes simplex tk virus promoter are included.
また、調節可能なプロモーターを使用することもできる。そのような調節可能なプロモーターとしては、転写調節因子としてE.coli由来のlacリプレッサーを使用し、lacオペレーターを有する哺乳動物細胞プロモーターからの転写を調節するもの[Brown,M.et al.,Cell,49:603−612(1987)]、テトラサイクリンリプレッサー(tetR)を使用するもの[Gossen,M.,and Bujard,H.,Proc.Natl.Acad.Sci.USA 89:5547−5551(1992);Yao,F.et al.,Human Gene Therapy,9:1939−1950(1998);Shockelt, P.,et al.,Proc.Natl.Acad.Sci.USA,92:6522−6526(1995)]が挙げられる。他の系として、エストラジオール、RU486、ジフェノールムリスレロン(diphenol murislerone)、またはラパマイシンを使用するFK506二量体、VP16、またはp65が挙げられる。誘導系はInvitrogen、Clontech、及びAriadから入手可能である。 Also, adjustable promoters can be used. Such regulatory promoters include E. coli as transcriptional regulators. A colli-derived lac repressor that regulates transcription from a mammalian cell promoter with a lac operator [Brown, M. et al. et al. , Cell, 49: 603-612 (1987)], those using a tetracycline repressor (tetR) [Gossen, M. et al. , And Bujard, H. et al. , Proc. Natl. Acad. Sci. USA 89: 5547-5551 (1992); Yao, F. et al. et al. , Human Gene Therapy, 9: 1939-1950 (1998); Shockelt, P. et al. , Et al. , Proc. Natl. Acad. Sci. USA, 92: 6522-6526 (1995)]. Other systems include FK506 dimer using estradiol, RU486, diphenylmurislerone, or rapamycin, VP16, or p65. Induction systems are available from Invitrogen, Clontech, and Ariad.
リプレッサーを含む調節可能なプロモーターをオペロンに使用することができる。一実施形態では、Escherichia coli由来のlacリプレッサーは、lacオペレーターを有する哺乳動物細胞プロモーターからの転写を調節する転写調節因子[M.Brown et al.,Cell,49:603−612(1987)];Gossen and Bujard(1992);[M. Gossen et al.,Natl.Acad.Sci.USA,89:5547−5551(1992)]として、テトラサイクリンリプレッサー(tetR)と複合的に機能することができ、tetRは転写活性化因子(VP16)と共にtetR哺乳動物細胞転写活性化因子融合タンパク質、tTa(tetR−VP 16)を生成し、ヒトサイトメガロウイルス(hCMV)主要最初期プロモーターに由来するtetOを有する哺乳動物プロモーターと共に、哺乳動物細胞の遺伝子発現を制御するtetR−tetオペレーター系を生成する。一実施形態では、テトラサイクリン誘導性スイッチを使用する(Yao et al.,Human Gene Therapy;Gossen et al.,Natl.Acad.Sci.USA,89:5547−5551(1992);Shockett et al.,Proc.Natl.Acad.Sci.USA,92:6522−6526(1995))。 Adjustable promoters, including repressors, can be used for operons. In one embodiment, a lac repressor from Escherichia coli is a transcriptional regulator that regulates transcription from a mammalian cell promoter having a lac operator [M. Brown et al. , Cell, 49: 603-612 (1987)]; Gossen and Bujard (1992); [M. Gossen et al. , Natl. Acad. Sci. USA, 89: 5547-5551 (1992)], which can function in combination with the tetracycline repressor (tetR), which, along with the transcriptional activator (VP16), is a tetR mammalian cell transcriptional activator fusion protein, Generate tTa (tetR-VP 16) and generate a tetR-tet operator system that controls gene expression in mammalian cells, along with a mammalian promoter having tetO derived from the human cytomegalovirus (hCMV) major earliest promoter. .. In one embodiment, a tetracycline-inducible switch is used (Yao et al., Human Gene Therapy; Gossen et al., Natl. Acad. Sci. USA, 89: 5547-5551 (1992); Shockett et al., Proc. Natl. Acad. Sci. USA, 92: 6522-6526 (1995)).
加えて、ベクターには、例えば、以下の一部またはすべてを含み得る:哺乳動物細胞における安定性または一過性トランスフェクタントを選別するためのネオマイシン遺伝子などの選択マーカー遺伝子;高レベル転写のためのヒトCMVの最初期遺伝子からのエンハンサー/プロモーター配列;mRNA安定性のためのSV40からの転写終結及びRNAプロセシングシグナル;適切なエピソーム複製のためのSV40ポリオーマ複製起点及びColE1;内部リボソーム結合部位(IRES)、万能マルチクローニング部位;センス及びアンチセンスRNAのin vitro転写のためのT7及びSP6 RNAプロモーター。導入遺伝子を含んだベクターの作製に適するベクター及び方法は、当技術分野において周知であり、利用可能である。 In addition, the vector may include, for example, some or all of the following: selection marker genes such as the neomycin gene for selecting stable or transient transfectants in mammalian cells; high levels of transcription. Enhancer / promoter sequence from the earliest gene of human CMV for; transcription termination and RNA processing signal from SV40 for mRNA stability; SV40 polyoma replication origin and ColE1 for proper episome replication; internal ribosome binding site ( IRES), universal multicloning site; T7 and SP6 RNA promoters for in vitro transcription of sense and antisense RNA. Vectors and methods suitable for the preparation of vectors containing the transgene are well known and available in the art.
核酸を含む発現ベクターは、従来技術(例えば、エレクトロポレーション、リポソームトランスフェクション、及びリン酸カルシウム沈殿)によって宿主細胞に移入することができ、次いでトランスフェクトされた細胞を従来技術によって培養し、本明細書に記載の化合物を産生させる。いくつかの実施形態では、本明細書に記載の化合物の発現を、構成的プロモーター、誘導性プロモーター、または組織特異的プロモーターにより調節する。 Expression vectors containing nucleic acids can be transferred to host cells by prior art (eg, electroporation, liposome transfection, and calcium phosphate precipitation), and then the transfected cells are cultured by prior art and are described herein. To produce the compounds described in. In some embodiments, expression of the compounds described herein is regulated by a constitutive promoter, an inducible promoter, or a tissue-specific promoter.
本明細書に記載の化合物または本明細書に記載のポリペプチドの発現に使用される宿主細胞は、Escherichia coliなどの細菌細胞であってもよいが、真核細胞が好ましい。特に、チャイニーズハムスター卵巣細胞(CHO)などの哺乳動物細胞を、ヒトサイトメガロウイルス由来の主要中初期遺伝子プロモーターエレメントなどのベクターと組み合わせたものが、免疫グロブリンに有効な発現系である(Foecking et al.(1986)“Powerful And Versatile Enhancer−Promoter Unit For Mammalian Expression Vectors,” Gene 45:101−106;Cockett et al.(1990)“High Level Expression Of Tissue Inhibitor Of Metalloproteinases In Chinese Hamster Ovary Cells Using Glutamine Synthetase Gene Amplification,” Biotechnology 8:662−667)。 The host cell used to express the compounds described herein or the polypeptides described herein may be bacterial cells such as Escherichia coli, but eukaryotic cells are preferred. In particular, a combination of mammalian cells such as Chinese hamster ovary cells (CHO) with a vector such as a major mid-early gene promoter element derived from human cytomegalovirus is an effective expression system for immunoglobulin (Fooking et al). . (1986) "Powerful And Versatile Enhancer-Promoter Unit For Mammalian Expression Vectors," Gene 45:. 101-106; Cockett et al (1990) "High Level Expression Of Tissue Inhibitor Of Metalloproteinases In Chinese Hamster Ovary Cells Using Glutamine Synthetase Gene Expression, "Biotechnology 8: 662-667).
本明細書に記載の化合物または本明細書に記載のポリペプチドの発現には、種々の宿主発現ベクター系を利用することができる。そのような宿主発現系は、それによって本明細書に記載の化合物または本明細書に記載のポリペプチドのコード配列を産生し、続いてそれを精製することができる媒体を意味するが、適切なヌクレオチドコード配列で形質転換またはトランスフェクトした場合に、本明細書に記載の化合物をin situで発現することができる細胞もまた意味する。それには、本明細書に記載の化合物のコード配列を含む、組換えバクテリオファージDNA、プラスミドDNA、もしくはコスミドDNA発現ベクターで形質転換された細菌(例えば、E.coli及びB.subtilis)などの微生物;本明細書に記載の化合物をコードする配列を含む組換え酵母発現ベクターで形質転換された酵母(例えば、Saccharomyces pichia);本明細書に記載の化合物をコードする配列を含む組換えウイルス発現ベクター(例えばバキュロウイルス)で感染させた昆虫細胞系:本明細書に記載の分子化合物をコードする配列を含む、組換ウイルス発現ベクター(例えばカリフラワーモザイクウイルス(CaMV)及びタバコモザイクウイルス(TMV)で感染させたか、もしくは組換えプラスミド発現ベクター(例えば、Tiプラスミド)で形質転換した植物細胞系;または、哺乳動物細胞系(例えば、哺乳動物細胞のゲノムに由来するプロモーター(例えば、メタロチオネインプロモーター)もしくは哺乳動物ウイルス由来のプロモーター(例えば、アデノウイルス後期プロモーター;ワクシニアウイルス7.5Kプロモーター)を含む組換え発現構築物を保有する、COS、CHO、BHK、293,293T、3T3細胞、リンパ性細胞(米国特許第5,807,715号を参照)、Per C.6細胞(Crucellにより開発されたヒト網膜細胞))が挙げられるが、これらに限定されない。 Various host expression vector systems can be utilized for the expression of the compounds described herein or the polypeptides described herein. Such a host expression system means a medium by which the coding sequence of a compound described herein or a polypeptide described herein can be subsequently produced and subsequently purified, but is suitable. It also means cells capable of expressing the compounds described herein in situ when transformed or transfected with a nucleotide coding sequence. These include microorganisms such as recombinant bacteriopathic DNA, plasmid DNA, or bacteria transformed with a cosmid DNA expression vector (eg, E. coli and B. subtilis) that contain the coding sequences of the compounds described herein. A yeast transformed with a recombinant yeast expression vector containing a sequence encoding a compound described herein (eg, Saccharomyces pichia); a recombinant virus expression vector containing a sequence encoding a compound described herein. Insect cell line infected with (eg, baculovirus): Infected with recombinant virus expression vectors (eg, Califlower Mosaic Virus (CaMV) and Tobacco Mosaic Virus (TMV)) containing sequences encoding the molecular compounds described herein. Plant cell lineaged or transformed with a recombinant plasmid expression vector (eg, Ti plasmid); or mammalian cell lineage (eg, a promoter derived from the mammalian cell genome (eg, metallotionein promoter) or mammalian COS, CHO, BHK, 293,293T, 3T3 cells, lymphoid cells (US Patent No. 5) carrying recombinant expression constructs containing virus-derived promoters (eg, late adenovirus promoters; vaccinia virus 7.5K promoters). , 807, 715), Per C.6 cells (human retinal cells developed by Crucell)), but are not limited thereto.
細菌系の場合、発現させる化合物の使用目的に応じて複数の発現ベクターを選択できる点で有利である。例えば、本明細書に記載の化合物の医薬組成物を生成するために、そのようなタンパク質を大量に作製する場合、容易に精製される融合タンパク質産物を高レベルで発現させるベクターが望ましい場合がある。そのようなベクターとしては、コード配列をlac Zコード領域とインフレームになるようにベクターに個々にライゲートして、融合タンパク質を産生させることができる、E.coli発現ベクターpUR278(Ruther et al.(1983)“Easy Identification Of cDNA Clones,” EMBO J.2:1791−1794)、pINベクター(Inouye et al.(1985)“Up−Promoter Mutations In The lpp Gene Of Escherichia Coli,” Nucleic Acids Res. 13:3101−3110;Van Heeke et al.(1989)“Expression Of Human Asparagine Synthetase In Escherichia Coli,”J.Biol.Chem.24:5503−5509)などが挙げられるが、これらに限定されない。また、pGEXベクターを使用して、外来ポリペプチドをグルタチオン−S−トランスフェラーゼ(GST)との融合タンパク質として発現させることもできる。一般に、そのような融合タンパク質は可溶性であり、マトリックスであるグルタチオンアガロースビーズへの吸着及び結合と、それに続く遊離グルタチオンの存在下での溶出により、溶解細胞から容易に精製することができる。pGEXベクターは、クローニングされた標的遺伝子産物をGST部分から放出できるようにトロンビンまたは第Xa因子プロテアーゼ切断部位を含むように設計されている。 In the case of a bacterial system, it is advantageous in that a plurality of expression vectors can be selected according to the intended use of the compound to be expressed. For example, when making large quantities of such proteins to produce pharmaceutical compositions of the compounds described herein, vectors that express high levels of readily purified fusion protein products may be desirable. .. As such a vector, the coding sequence can be individually regated to the vector in frame with the lac Z coding region to produce a fusion protein. coli expression vector pUR278 (Ruther et al. (1983) "Easy Identification Of cDNA Cloning," EMBO J.2: 1791-1794), pIN vector (Inouye et al. (1985) "Up-Promoter Escherichia Coli, "Nucleic Acids Res. 13: 3101-3110; Van Heeke et al. (1989)" Expression Of Human Vector Synthesis In Eschebium5: C. , Not limited to these. The pGEX vector can also be used to express a foreign polypeptide as a fusion protein with glutathione-S-transferase (GST). In general, such fusion proteins are soluble and can be easily purified from lysed cells by adsorption and binding to the matrix glutathione agarose beads followed by elution in the presence of free glutathione. The pGEX vector is designed to contain a thrombin or factor Xa protease cleavage site so that the cloned target gene product can be released from the GST moiety.
昆虫系においては、Autographa californica核多角体病ウイルス(AcNPV)が、外来遺伝子を発現するためのベクターとして使用される。このウイルスは、Spodoptera frugiperda細胞中で増殖する。コード配列をウイルスの非必須領域(例えば、ポリヘドリン遺伝子)に個々にクローニングして、AcNPVプロモーター(例えば、ポリヘドリンプロモーター)の制御下に置くことができる。 In insects, the Autographa californica nuclear polyhedrosis virus (AcNPV) is used as a vector for expressing foreign genes. The virus grows in Prodenia frugiperda cells. The coding sequence can be individually cloned into a non-essential region of the virus (eg, the polyhedrin gene) and placed under the control of the AcNPV promoter (eg, the polyhedrin promoter).
哺乳動物宿主細胞では、いくつかのウイルスによる発現系を使用することができる。アデノウイルスを発現ベクターとして使用する場合、目的の抗体コード配列を、アデノウイルス転写/翻訳制御複合体、例えば、後期プロモーター及び三元(tripartite)リーダー配列とライゲートしてもよい。次いで、このキメラ遺伝子を、in vitroまたはin vivo組換えによりアデノウイルスゲノムに挿入することができる。ウイルスゲノムの非必須領域(例えば、領域E1またはE3)への挿入により、感染宿主内で生存可能であり、かつ、免疫グロブリン分子を発現可能な組換えウイルスが得られる(例えば、Logan et al.(1984)“Adenovirus Tripartite Leader Sequence Enhances Translation Of mRNAs Late After Infection,”Proc.Natl.Acad.Sci.USA 81:3655−3659を参照)。挿入された抗体コード配列の効率的な翻訳には、特異的開始シグナルもまた必要な場合がある。このようなシグナルとしては、ATG開始コドン及び隣接配列が挙げられる。さらに、全インサートが確実に翻訳されるように、開始コドンが、目的のコード配列のリーディングフレームと一致していなければならない。この外因性翻訳制御シグナル及び開始コドンは、天然及び合成いずれもの種々の起源のものであり得る。適切な転写エンハンサーエレメント、転写ターミネーターなどを組み込むことにより発現効率を高めることができる(Bitter et al.(1987)“Expression And Secretion Vectors For Yeast,” Methods in Enzymol.153:516−544を参照)。 For mammalian host cells, several viral expression systems can be used. When using an adenovirus as an expression vector, the antibody coding sequence of interest may be ligated with an adenovirus transcription / translation control complex, such as a late promoter and tripartite leader sequence. The chimeric gene can then be inserted into the adenovirus genome by in vitro or in vivo recombination. Insertion into a non-essential region of the viral genome (eg, region E1 or E3) results in a recombinant virus that is viable in the infected host and capable of expressing an immunoglobulin molecule (eg, Logan et al. (1984) “Adenovirus Tripartite Leader Secequence Enhances Translation Of mRNAs Late After Infection,” Proc. Natl. Acad. Sci. USA 81: 3655-3569). A specific initiation signal may also be required for efficient translation of the inserted antibody coding sequence. Such signals include the ATG start codon and adjacent sequences. In addition, the start codon must match the reading frame of the coding sequence of interest to ensure that all inserts are translated. This exogenous translation control signal and start codon can be of various origins, both natural and synthetic. Expression efficiency can be enhanced by incorporating appropriate transcription enhancer elements, transcription terminators, etc. (see "Expression And Secretion Vectors For Yeast," Methods in Enzymol. 153: 516-544).
加えて、挿入された配列の発現を調節する宿主細胞株、または望ましい特定の様式で遺伝子産物を修飾し、プロセシングする宿主細胞株を選択することができる。タンパク質産物のこのような修飾(例えば、グリコシル化)及びプロセシング(例えば、切断)が、タンパク質の機能にとって重要となる場合がある。例えば、ある種の実施形態では、本明細書に記載の化合物を単一の遺伝子産物として(例えば、単一のポリペプチド鎖として、すなわちポリタンパク質前駆体として)発現させることができるが、その場合、本明細書に記載の化合物の個々のポリペプチドを形成するには、天然または組換え細胞機構によるタンパク質分解性切断が必要となる。したがって、本開示は、本明細書に記載の化合物のポリペプチドを含むポリタンパク質前駆体分子をコードし、前記ポリタンパク質前駆体の翻訳後切断を誘導できるコード配列を含む核酸配列を遺伝子操作することを包含する。ポリタンパク質前駆体の翻訳後切断により、本明細書に記載の化合物のポリペプチドが得られる。本明細書に記載の化合物のポリペプチドを含む前駆体分子の翻訳後切断は、in vivoで(すなわち、天然または組換えの細胞系/機構、例えば適切な部位でのフューリン切断によって宿主細胞内で)発生させても、in vitro(例えば、既知の活性のプロテアーゼまたはペプチダーゼを含む組成物中、及び/または望ましいタンパク質分解性作用を促進することが知られている条件または試薬を含む組成物中での前記ポリペプチド鎖のインキュベーション)で発生させてもよい。組換えタンパク質の精製及び修飾は当技術分野で周知であり、したがってポリタンパク質前駆体の設計には、当業者によって容易に理解される複数の実施形態を含み得る。記載する前駆体分子の修飾には、当技術分野で既知である任意のプロテアーゼまたはペプチダーゼ、例えば、トロンビンまたは第Xa因子(Nagai et al.(1985)“Oxygen Binding Properties Of Human Mutant Hemoglobins Synthesized In Escherichia Coli,” Proc.Nat.Acad.Sci.USA 82:7252−7255、及びJenny et al.(2003)“A Critical Review Of The Methods For Cleavage Of Fusion Proteins With Thrombin And Factor Xa,” Protein Expr.Purif.31:1−11に概説、それぞれ全体が参照により本明細書に組み込まれる)、エンテロキナーゼ(Collins−Racie et al.(1995)“Production Of Recombinant Bovine Enterokinase Catalytic Subunit In Escherichia Coli Using The Novel Secretory Fusion Partner DsbA,” Biotechnology 13:982−987、その全体が参照により本明細書に組み込まれる)、フーリン、及びAcTEV(Parks et al.(1994)“Release Of Proteins And Peptides From Fusion Proteins Using A Recombinant Plant Virus Proteinase,” Anal.Biochem.216:413−417、その全体が参照により本明細書に組み込まれる)、及び口蹄疫ウイルスプロテアーゼC3を使用することができる。 In addition, a host cell line that regulates the expression of the inserted sequence, or a host cell line that modifies and processes the gene product in a particular desired manner, can be selected. Such modifications (eg, glycosylation) and processing (eg, cleavage) of the protein product may be important for the function of the protein. For example, in certain embodiments, the compounds described herein can be expressed as a single gene product (eg, as a single polypeptide chain, i.e. as a polyprotein precursor), in which case. , Proteolytic cleavage by natural or recombinant cell mechanisms is required to form the individual polypeptides of the compounds described herein. Accordingly, the present disclosure encodes a polypeptide precursor molecule comprising a polypeptide of a compound described herein and genetically manipulates a nucleic acid sequence containing a coding sequence capable of inducing post-translational cleavage of said polypeptide precursor. Includes. Post-translational cleavage of a polyprotein precursor gives the polypeptide of the compounds described herein. Post-translational cleavage of precursor molecules, including polypeptides of the compounds described herein, is performed in vitro (ie, in a host cell by furin cleavage at a natural or recombinant cell line / mechanism, eg, at the appropriate site. ) In vitro (eg, in a composition containing a protease or peptidase of known activity, and / or in a composition containing conditions or reagents known to promote the desired proteolytic effect). It may be generated by the incubation of the above-mentioned polypeptide chain. Purification and modification of recombinant proteins are well known in the art and therefore the design of a polyprotein precursor may include multiple embodiments that are readily understood by those of skill in the art. Modifications of the precursor molecules described include any protease or peptidase known in the art, such as thrombin or factor Xa (Nagai et al. (1985) "Oxygen Binding Properties Of Human Mutant Hemoglobin Synthesia , "Proc. Nat. Acad. Sci. USA 82: 7252-7255, and Jenny et al. (2003)" A Critical Review Of The Methods For Cleavage Of Fusion Factor X : 1-11, each of which is incorporated herein by reference in its entirety), Escherichia colis-Racie et al. (1995) "Production Of Recombinant Boveine Escherichia , "Biotechnology 13: 982-987, which is incorporated herein by reference in its entirety), Furin, and AcTEV (Parks et al. (1994)" Release Of Precursor And Peptides From Precursor "Anal. Biochem. 216: 413-417, which is incorporated herein by reference in its entirety), and the Escherichia coli virus protease C3 can be used.
異なる宿主細胞は、タンパク質及び遺伝子産物の翻訳後プロセシング及び修飾に関して特徴的かつ特異的な機構を有する。発現された外来タンパク質の正確な修飾とプロセシングが確保されるように、適切な細胞系または宿主系を選択することができる。この目的のために、一次転写物の正確なプロセシング、遺伝子産物のグリコシル化及びリン酸化のための細胞機構を有する真核生物宿主細胞を使用してもよい。そのような哺乳動物宿主細胞としては、CHO、VERY、BHK、Hela、COS、MDCK、293、293T、3T3、WI38、BT483、Hs578T、HTB2、BT20及びT47D、CRL7030、及びHs578Bst細胞が挙げられるが、これらに限定されない。 Different host cells have characteristic and specific mechanisms for post-translational processing and modification of proteins and gene products. Appropriate cell or host systems can be selected to ensure accurate modification and processing of the expressed foreign protein. For this purpose, eukaryotic host cells with accurate processing of primary transcripts, cell mechanisms for glycosylation and phosphorylation of gene products may be used. Such mammalian host cells include CHO, VERY, BHK, Hela, COS, MDCK, 293,293T, 3T3, WI38, BT483, Hs578T, HTB2, BT20 and T47D, CRL7030, and Hs578Bst cells. Not limited to these.
組換えタンパク質を長期間にわたり高収率で産生するためには、安定した発現が好ましい。例えば、本明細書に記載の化合物を安定して発現する細胞株を遺伝子操作することができる。ウイルスの複製起点を含む発現ベクターを使用する代わりに、適切な発現制御エレメント(例えば、プロモーター、エンハンサー、配列、転写ターミネーター、ポリアデニル化部位など)により制御されるDNA、及び選択マーカーを用いて宿主細胞を形質転換することができる。外来DNAの導入後、遺伝子操作した細胞を富栄養培地で1〜2日間増殖させた後、選択培地に切り換えてもよい。組換えプラスミド中の選択マーカーは、選択に対する耐性を付与し、細胞がその染色体中にプラスミドを安定的に組み込み、増殖してフォーカスを形成することを可能にする。それによってフォーカスをクローニングして細胞株に拡大することができる。この方法は、本明細書に記載の化合物を発現する細胞株の遺伝子操作に使用する際に有利であり得る。そのような遺伝子操作された細胞株は、本明細書に記載の化合物と直接的または間接的に相互作用する化合物のスクリーニング及び評価に特に有用であり得る。 Stable expression is preferred in order to produce the recombinant protein in high yield over a long period of time. For example, cell lines that stably express the compounds described herein can be genetically engineered. Instead of using an expression vector containing the origin of replication of the virus, host cells with DNA controlled by appropriate expression control elements (eg, promoters, enhancers, sequences, transcription terminators, polyadenylation sites, etc.) and selectable markers. Can be transformed. After the introduction of the foreign DNA, the genetically engineered cells may be grown in a eutrophic medium for 1 to 2 days and then switched to a selective medium. Selectable markers in recombinant plasmids confer resistance to selection and allow cells to stably integrate the plasmid into their chromosomes and proliferate to form focus. This allows the focus to be cloned and expanded into cell lines. This method may be advantageous when used for genetic engineering of cell lines expressing the compounds described herein. Such genetically engineered cell lines may be particularly useful for screening and evaluation of compounds that interact directly or indirectly with the compounds described herein.
複数の選択系を使用することができ、限定するものではないが、例えば、単純ヘルペスウイルスチミジンキナーゼ(Wigler et al.(1977)“Transfer Of Purified Herpes Virus Thymidine Kinase Gene To Cultured Mouse Cells,” Cell 11:223−232)、ヒポキサンチン−グアニンホスホリボシルトランスフェラーゼ(Szybalska et al.(1992)“Use Of The HPRT Gene And The HAT Selection Technique In DNA−Mediated Transformation Of Mammalian Cells First Steps Toward Developing Hybridoma Techniques And Gene Therapy,” Bioessays 14:495−500)、及びアデニンホスホリボシルトランスフェラーゼ(Lowy et al.(1980)“Isolation Of Transforming DNA: Cloning The Hamster aprt Gene,”Cell 22:817−823)遺伝子が挙げられるが、これらはそれぞれtk−、hgprt−、またはaprt−細胞において使用することができる。また、以下の遺伝子については、代謝拮抗物質耐性を選択の基準として利用することができる:メトトレキサート耐性を付与するdhfr(Wigler et al.(1980)“Transformation Of Mammalian Cells With An Amplifiable Dominant−Acting Gene,” Proc.Natl.Acad.Sci.USA 77:3567−3570;O’Hare et al.(1981)“Transformation Of Mouse Fibroblasts To Methotrexate Resistance By A Recombinant Plasmid Expressing A Prokaryotic Dihydrofolate Reductase,”Proc.Natl.Acad.Sci.USA 78:1527−1531);マイコフェノール酸耐性を付与するgpt(Mulligan et al.(1981)“Selection For Animal Cells That Express The Escherichia coli Gene Coding For Xanthine−Guanine Phosphoribosyltransferase,” Proc.Natl.Acad.Sci.USA 78:2072−2076);アミノグリコシドG−418耐性を付与するneo(Tolstoshev(1993)“Gene Therapy,Concepts,Current Trials And Future Directions,” Ann.Rev.Pharmacol.Toxicol.32:573−596;Mulligan(1993)“The Basic Science Of Gene Therapy,” Science 260:926−932;及びMorgan et al.(1993)“Human Gene Therapy,”Ann.Rev.Biochem.62:191−217);及びハイグロマイシン耐性を付与するhygro(Santerre et al.(1984)“Expression Of Prokaryotic Genes For Hygromycin B And G418 Resistance As Dominant−Selection Markers In Mouse L Cells,”Gene 30:147−156)。使用することができる組換えDNA技術の当技術分野で一般的に知られる方法は、Ausubel et al.(eds.),1993,Current Protocols in Molecular Biology,John Wiley & Sons,NY;Kriegler,1990,Gene Transfer and Expression,A Laboratory Manual,Stockton Press,NY;及びin Chapters 12 and 13,Dracopoli et al.(eds),1994,Current Protocols in Human Genetics,John Wiley & Sons,NY.;Colberre−Garapin et al.1981)“A New Dominant Hybrid Selective Marker For Higher Eukaryotic Cells,”J.Mol.Biol.150:1−14に記載されている。 Multiple selection systems can be used and, but are not limited to, for example, herpes simplex virus thymidine kinase (Willer et al. (1977) "Transfer Of Purified Herpes Virus Thymidine Kinase Gene To Celled Mouse Cell" : 223-232), hypoxanthine - guanine phosphoribosyl transferase (. Szybalska et al (1992) "Use Of The HPRT Gene And The HAT Selection Technique In DNA-Mediated Transformation Of Mammalian Cells First Steps Toward Developing Hybridoma Techniques And Gene Therapy, "Bioessays 14: 495-500), and adenine phosphoribosyl transferase (Lowy et al. (1980)" Isolation Of Transfer DNA: Cloning The Hamster virus Gene, "Cell 22: 817-823). They can be used in tk-, hgprt-, or aprt- cells, respectively. In addition, for the following genes, metabolic antagonist resistance can be used as a criterion for selection: dhfr (Wiler et al. (1980) "Transformation Of Mammalian Cells With An Amplifiable Dominant-Acting", which imparts methotrexate resistance. "Proc.Natl.Acad.Sci.USA 77:. 3567-3570; O'Hare et al (1981)" Transformation Of Mouse Fibroblasts To Methotrexate Resistance By A Recombinant Plasmid Expressing A Prokaryotic Dihydrofolate Reductase, "Proc.Natl.Acad. Sci. USA 78: 1527-1531); gpt (Mulligan et al. (1981) "Selection For Animal Cells That Express Strength The Escherichia color Gene Sci. USA 78: 2072-2076); neo (Tolstoshev (1993) "Gene Therapy, Concepts, Current Trials And Future Metabolisms," Ann. 596; Mulligan (1993) "The Basic Science Of Gene Therapy," Science 260: 926-932; and Morgan et al. (1993) "Human Gene Therapy," Ann. Hygro (Santare et al. (1984) "Expression Of P" that imparts resistance to hyglomycin rokaryotic Genes For Hygromycin B And G418 Response As Dominant-Selection Markers In Mouse L Cells, "Gene 30: 147-156). Commonly known methods of recombinant DNA technology in the art that can be used are described in Ausubel et al. (Eds.), 1993, Current Protocols in Molecular Biology, John Wiley & Sons, NY; Kriegler, 1990, Gene Transfer and Expression, A Laboratory National; (Eds), 1994, Currant Protocols in Human Genetics, John Wiley & Sons, NY. Colberre-Galapin et al. 1981) "A New Dominant Hybrid Selective Marker For Higher Eukaryotic Cells," J. et al. Mol. Biol. 150: 1-14.
本明細書に記載の化合物または本明細書に記載のポリペプチドの発現レベルは、ベクター増幅により上昇させることができる(概説については、Bebbington and Hentschel,The use of vectors based on gene amplification for the expression of cloned genes in mammalian cells in DNA cloning,Vol.3(Academic Press,New York,1987を参照)。本明細書に記載の化合物を発現するベクター系中のマーカーが増幅可能である場合、宿主細胞培養中に存在する阻害剤レベルを増加させればマーカー遺伝子のコピー数が増加する。増幅される領域は本明細書に記載の化合物または本明細書に記載のポリペプチドのヌクレオチド配列と関連しているため、ポリペプチドの産生もまた増加する(Crouse et al.(1983)“Expression And Amplification Of Engineered Mouse Dihydrofolate Reductase Minigenes,” Mol.Cell.Biol.3:257−266)。 The expression levels of the compounds described herein or the polypeptides described herein can be increased by vector amplification (for an overview, Bebbington and Hentscheel, The use vectors based on genome cloning for the expression of). cloned genes in mammal cells in DNA cloning, Vol. 3 (see Academic Press, New York, 1987). If the markers in the vector system expressing the compounds described herein can be amplified, they are being cultured in host cells. Increasing the level of inhibitor present in increases the number of copies of the marker gene, as the amplified region is associated with the nucleotide sequence of a compound described herein or a polypeptide described herein. , Polypeptide production is also increased (Crowse et al. (1983) "Expression And Application Of Engineered Mouse Dihydropate Vector Minines," Mol. Cell. Biol. 3: 257-2.
宿主細胞を、2つの発現ベクター、すなわち、本明細書に記載の化合物の第1のポリペプチドをコードする第1のベクターと、本明細書に記載の化合物の第2のポリペプチドをコードする第2のベクターとを用いて同時トランスフェクトしてもよい。この2つのベクターは、両方のポリペプチドの同等の発現を可能にする同一の選択マーカーを含有してもよい。あるいは、両方のポリペプチドをコードする単一ベクターを使用してもよい。本明細書に記載の化合物のポリペプチドに対するコード配列は、cDNAまたはゲノムDNAを含んでいてもよい。 The host cell is represented by two expression vectors, a first vector encoding a first polypeptide of a compound described herein and a second polypeptide of a compound described herein. Simultaneous transfection may be performed using the vector of 2. The two vectors may contain the same selectable marker that allows equivalent expression of both polypeptides. Alternatively, a single vector encoding both polypeptides may be used. The coding sequences for the polypeptides of the compounds described herein may include cDNA or genomic DNA.
本明細書に記載の化合物または本明細書に記載のポリペプチドを組換え発現した後は、ポリペプチド、ポリタンパク質、または抗体を精製するための(例えば、抗原選択性に基づいた抗体精製スキームと類似する)当技術分野で既知の任意の方法、例えば、クロマトグラフィー(例えば、イオン交換クロマトグラフィー、アフィニティークロマトグラフィー、特に特異的抗原に対する親和性によるもの(化合物がFcドメイン(またはその一部)を含む場合にはプロテインAの選択後)、及びサイズ排除カラムクロマトグラフィー)、遠心分離、示差溶解度、またはポリペプチドもしくは抗体を精製するための他の任意の標準技術によって精製することができる。 After recombinant expression of a compound described herein or a polypeptide described herein, with an antibody purification scheme for purifying a polypeptide, protein, or antibody (eg, based on antigen selectivity). Any method known in the art (similar), such as chromatography (eg, ion exchange chromatography, affinity chromatography, especially by affinity for a specific antigen (compound is Fc domain (or part thereof)). After selection of protein A, if included), and size exclusion column chromatography), centrifugation, differential solubility, or purification by any other standard technique for purifying the polypeptide or antibody.
本開示の他の態様は、本明細書に記載の核酸または本明細書に記載のベクターを含む細胞に関する。細胞は、原核細胞であっても真核細胞であってもよい。いくつかの実施形態では、細胞は哺乳動物細胞である。例示的な細胞型を本明細書に記載する。 Other aspects of the disclosure relate to cells comprising the nucleic acids described herein or the vectors described herein. The cell may be a prokaryotic cell or a eukaryotic cell. In some embodiments, the cell is a mammalian cell. Illustrative cell types are described herein.
本開示のさらに他の態様は、本明細書に記載の化合物または本明細書に記載のポリペプチド(例えば、第1のポリペプチドまたは第2のポリペプチド)の作製方法であって、本明細書に記載の細胞を得ることと、本明細書に記載の核酸を前記細胞に発現させることを含む方法に関する。いくつかの実施形態では、本方法は本明細書に記載の化合物または本明細書に記載のポリペプチドを単離して精製することをさらに含む。 Yet another aspect of the present disclosure is a method of making a compound described herein or a polypeptide described herein (eg, a first polypeptide or a second polypeptide), which is described herein. The present invention relates to a method comprising obtaining the cells described in the above and expressing the nucleic acids described in the present specification in the cells. In some embodiments, the method further comprises isolating and purifying the compounds described herein or the polypeptides described herein.
医療に使用される治療方法及び組成物
本開示の他の態様は、医療に使用される治療方法及び組成物に関する。そのような方法及び組成物に使用される化合物の非限定的な例は、以下を含むものである:
(i)前記第1のポリペプチドが配列番号5のアミノ酸配列を含み、前記第2のポリペプチドが配列番号6のアミノ酸配列を含むか、または
(ii)前記第1のポリペプチドが配列番号7のアミノ酸配列を含み、前記第2のポリペプチドが配列番号8のアミノ酸配列を含むか、または
(iii)前記第1のポリペプチドが配列番号9のアミノ酸配列を含み、前記第2のポリペプチドが配列番号10のアミノ酸配列を含むか、または
(iv)前記第1のポリペプチドが配列番号11のアミノ酸配列を含み、前記第2のポリペプチドが配列番号12のアミノ酸配列を含むか、または
(v)前記第1のポリペプチドが配列番号13のアミノ酸配列を含み、前記第2のポリペプチドが配列番号14のアミノ酸配列を含むか、または
(vi)前記第1のポリペプチドが配列番号15のアミノ酸配列を含み、前記第2のポリペプチドが配列番号16のアミノ酸配列を含むか、または
(vii)前記第1のポリペプチドが配列番号17のアミノ酸配列を含み、前記第2のポリペプチドが配列番号18のアミノ酸配列を含むか、または
(viii)前記第1のポリペプチドが配列番号19のアミノ酸配列を含み、前記第2のポリペプチドが配列番号20のアミノ酸配列を含むか、または
(ix)前記第1のポリペプチドが配列番号21のアミノ酸配列を含み、前記第2のポリペプチドが配列番号22のアミノ酸配列を含むか、または
(x)前記第1のポリペプチドが配列番号23のアミノ酸配列を含み、前記第2のポリペプチドが配列番号24のアミノ酸配列を含むか、または
(xi)前記第1のポリペプチドが配列番号25のアミノ酸配列を含み、前記第2のポリペプチドが配列番号26のアミノ酸配列を含むか、または
(xii)前記第1のポリペプチドが配列番号27のアミノ酸配列を含み、前記第2のポリペプチドが配列番号28のアミノ酸配列を含むか、または
(xiii)前記第1のポリペプチドが配列番号29のアミノ酸配列を含み、前記第2のポリペプチドが配列番号30のアミノ酸配列を含むか、または
(xiv)前記第1のポリペプチドが配列番号31のアミノ酸配列を含み、前記第2のポリペプチドが配列番号32のアミノ酸配列を含むか、または
(xv)前記第1のポリペプチドが配列番号33のアミノ酸配列を含み、前記第2のポリペプチドが配列番号34のアミノ酸配列を含むか、または
(xvi)前記第1のポリペプチドが配列番号35のアミノ酸配列を含み、前記第2のポリペプチドが配列番号36のアミノ酸配列を含むか、または
(xvii)前記第1のポリペプチドが配列番号37のアミノ酸配列を含み、前記第2のポリペプチドが配列番号38のアミノ酸配列を含むか、または
(xviii)前記第1のポリペプチドが配列番号39のアミノ酸配列を含み、前記第2のポリペプチドが配列番号40のアミノ酸配列を含むか、または
(xix)前記第1のポリペプチドが配列番号41のアミノ酸配列を含み、前記第2のポリペプチドが配列番号42のアミノ酸配列を含むか、または
(xx)前記第1のポリペプチドが配列番号43のアミノ酸配列を含み、前記第2のポリペプチドが配列番号44のアミノ酸配列を含むか、または
(xxi)前記第1のポリペプチドが配列番号45のアミノ酸配列を含み、前記第2のポリペプチドが配列番号46のアミノ酸配列を含むか、または
(xxii)前記第1のポリペプチドが配列番号47のアミノ酸配列を含み、前記第2のポリペプチドが配列番号48のアミノ酸配列を含むか、または
(xxiii)前記第1のポリペプチドが配列番号49のアミノ酸配列を含み、前記第2のポリペプチドが配列番号50のアミノ酸配列を含むか、または
(xxiv)前記第1のポリペプチドが配列番号51のアミノ酸配列を含み、前記第2のポリペプチドが配列番号52のアミノ酸配列を含むか、または
(xxv)前記第1のポリペプチドが配列番号53のアミノ酸配列を含み、前記第2のポリペプチドが配列番号54のアミノ酸配列を含むか、または
(xxvi)前記第1のポリペプチドが配列番号55のアミノ酸配列を含み、前記第2のポリペプチドが配列番号56のアミノ酸配列を含むか、または
(xxvii)前記第1のポリペプチドが配列番号57のアミノ酸配列を含み、前記第2のポリペプチドが配列番号58のアミノ酸配列を含むか、または
(xxviii)前記第1のポリペプチドが配列番号59のアミノ酸配列を含み、前記第2のポリペプチドが配列番号60のアミノ酸配列を含むか、または
(xxix)前記第1のポリペプチドが配列番号61のアミノ酸配列を含み、前記第2のポリペプチドが配列番号62のアミノ酸配列を含むか、または
(xxx)前記第1のポリペプチドが配列番号63のアミノ酸配列を含み、前記第2のポリペプチドが配列番号64のアミノ酸配列を含むか、または
(xxxi)前記第1のポリペプチドが配列番号65のアミノ酸配列を含み、前記第2のポリペプチドが配列番号66のアミノ酸配列を含むか、または
(xxxii)前記第1のポリペプチドが配列番号67のアミノ酸配列を含み、前記第2のポリペプチドが配列番号68のアミノ酸配列を含む。
Therapeutic Methods and Compositions Used in Medicine Other aspects of the disclosure relate to therapeutic methods and compositions used in medicine. Non-limiting examples of compounds used in such methods and compositions include:
(I) The first polypeptide comprises the amino acid sequence of SEQ ID NO: 5, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 6, or (ii) the first polypeptide comprises SEQ ID NO: 7. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 8 or (iii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 9 and the second polypeptide comprises. Either the amino acid sequence of SEQ ID NO: 10 is contained, or (iv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 11 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 12 or (v). ) The first polypeptide comprises the amino acid sequence of SEQ ID NO: 13, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 14, or (vi) the first polypeptide comprises the amino acid of SEQ ID NO: 15. The second polypeptide comprises a sequence and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 16 or (vii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 17 and the second polypeptide has the SEQ ID NO: Eighteen amino acid sequences are included, or (viii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 19, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 20 or (ix) said. The first polypeptide comprises the amino acid sequence of SEQ ID NO: 21, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 22, or (x) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 23. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 24, or (xi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 25 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 26. The first polypeptide comprises the amino acid sequence, or (xii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 27, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 28, or (xiii) said first. The polypeptide comprises the amino acid sequence of SEQ ID NO: 29 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 30 or (xiv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 31. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 32, or (xv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 33 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 34. Or (xvi) said first The polypeptide comprises the amino acid sequence of SEQ ID NO: 35 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 36, or (xvii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 37 and said. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 38, or (xviii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 39 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 40. The first polypeptide comprises the amino acid sequence of SEQ ID NO: 41 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 42, or (xx) said first polypeptide. Contains the amino acid sequence of SEQ ID NO: 43 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 44, or (xxi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 45 and said second. Whether the polypeptide of SEQ ID NO: 46 comprises the amino acid sequence of SEQ ID NO: 46, or (xxiii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 47 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 48. , Or (xxiii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 49 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 50, or (xxiv) the first polypeptide comprises the sequence. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 51 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 52, or (xxv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 53 and said the second poly. The peptide comprises the amino acid sequence of SEQ ID NO: 54, or (xxvi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 55 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 56, or The first polypeptide comprises the amino acid sequence of SEQ ID NO: 57 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 58, or (xxviii) the first polypeptide comprises SEQ ID NO: 59. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 60, or (xxx) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 61 and the second polypeptide comprises. The amino acid sequence of SEQ ID NO: 62 is contained, or (xxx) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 63, and the second polypeptide contains the amino acid sequence of SEQ ID NO: 64. Or (xxxi) said first polypeptide comprises the amino acid sequence of SEQ ID NO: 65 and said second polypeptide comprises the amino acid sequence of SEQ ID NO: 66, or (xxxxi) said said first poly. The peptide comprises the amino acid sequence of SEQ ID NO: 67, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 68.
いくつかの実施形態では、治療方法または使用とは、自己免疫疾患または炎症性疾患の治療方法またはそのような方法の使用である。いくつかの実施形態では、方法は、本明細書に記載の化合物または前記化合物を含む医薬組成物を、対象、例えば自己免疫疾患または炎症性疾患を有するかまたは有するリスクのある対象に投与することを含む。 In some embodiments, the therapeutic method or use is a method or use of such a method of treating an autoimmune or inflammatory disease. In some embodiments, the method administers a compound described herein or a pharmaceutical composition comprising said compound to a subject, eg, a subject having or at risk of having an autoimmune disease or an inflammatory disease. including.
本明細書に記載の方法によって治療される対象は、哺乳動物、より好ましくはヒトであり得る。哺乳動物としては、家畜、競技用動物、ペット、霊長類、ウマ、イヌ、ネコ、マウス、及びラットが挙げられるが、これらに限定されない。治療を必要とするヒト対象は、疾患を有する対象、疾患リスクのある対象、または疾患が疑われる対象であり得る。疾患を有する対象は、例えば、身体検査、臨床検査、臓器機能検査、CTスキャン、または超音波といった通常の検診により特定することができる。そのような疾患のいずれかを有することが疑われる対象は、疾患の1つ以上の症状を示す場合がある。疾患、例えば自己免疫疾患及び炎症性疾患の徴候及び症状は、当業者に周知されている。疾患リスクのある対象は、その疾患のリスク要因のうち1つ以上を有する対象であり得る。 The subject treated by the methods described herein can be a mammal, more preferably a human. Mammals include, but are not limited to, livestock, competition animals, pets, primates, horses, dogs, cats, mice, and rats. Human subjects in need of treatment can be subjects with or at risk of disease, or subjects with suspected disease. Subjects with the disease can be identified by routine examinations such as physical examinations, clinical examinations, organ function examinations, CT scans, or ultrasound. Subjects suspected of having any of such diseases may exhibit one or more symptoms of the disease. Signs and symptoms of the disease, such as autoimmune and inflammatory diseases, are well known to those of skill in the art. A subject at risk of disease can be a subject having one or more of the risk factors for the disease.
自己免疫疾患の非限定的な例としては、ループス腎炎(LN)(腎臓に関連する全身性エリテマトーデス(SLE))、全身性エリテマトーデス(SLE)、原発性シェーグレン症候群(PSS)、シェーグレン病、移植片対宿主病(GVHD)(例えば、慢性移植片対宿主病(cGVHD))、全身性強皮症(SSc)、抗好中球細胞質自己抗体(ANCA)関連血管炎(AAV)、関節リウマチ、乾癬、1型糖尿病、全身性エリテマトーデス、移植拒絶反応、自己免疫性甲状腺疾患(橋本病)、サルコイドーシス、強皮症、肉芽腫性血管炎、クローン病、潰瘍性大腸炎、シェーグレン病、強直性脊椎炎、乾癬性関節炎、多発性筋炎の皮膚筋炎、結節性多発動脈炎、免疫介在性水疱皮膚疾患、ベーチェット症候群、多発性硬化症、グッドパスチャー病、または免疫介在性糸球体腎炎が挙げられる。
Non-limiting examples of autoimmune diseases include lupus erythematosus (LN) (systemic lupus erythematosus (SLE) associated with the kidneys), systemic lupus erythematosus (SLE), primary Sjogren's syndrome (PSS), Sjogren's disease, and implants. Anti-host disease (GVHD) (eg, chronic transplanted anti-host disease (cGVHD)), systemic lupus erythematosus (SSc), anti-neutrophil cytoplasmic autoimmune (ANCA) -related vasculitis (AAV), rheumatoid arthritis,
炎症性疾患の非限定的例としては、関節リウマチ、全身性エリテマトーデス、円形脱毛症、強直性脊椎炎、抗リン脂質症候群、自己免疫アジソン病、自己免疫性溶血性貧血、自己免疫性肝炎、自己免疫性内耳疾患、自己免疫性リンパ増殖症候群(ALPS)、自己免疫性血小板減少性紫斑病(ATP)、ベーチェット病、水疱性類天疱瘡、心筋症、セリアック病皮膚炎、慢性疲労症候群免疫不全症候群(CFIDS)、慢性炎症性脱髄性多発神経障害、瘢痕性類天疱瘡、寒冷凝集素症、CREST症候群、クローン病、デゴス病、皮膚筋炎、若年性皮膚筋炎、円板状ループス、本態性混合型クリオグロブリン血症、原発性線維筋痛症、グレーブス病、ギラン・バレー、橋本甲状腺炎、特発性肺胞線維症、特発性血小板減少性紫斑病(ITP)、IgA腎症、インスリン依存性糖尿病(I型)、若年性関節炎、メニエール病、混合性結合組織病、多発性硬化症、重症筋無力症、尋常性天疱瘡、悪性貧血、結節性多発動脈炎、多発性軟骨炎、多腺性内分泌症候群、リウマチ性多発筋痛、多発性筋炎及び皮膚筋炎、原発性無ガンマグロブリン血症、原発性胆汁性肝硬変、乾癬、レイノー現象、ライター症候群、リウマチ熱、サルコイドーシス、強皮症、シェーグレン症候群、スティッフパーソン症候群、高安動脈炎、側頭動脈炎/巨細胞動脈炎、潰瘍性大腸炎、ブドウ膜炎、血管炎、白斑、多発血管炎性肉芽腫症が挙げられる。いくつかの実施形態では、自己免疫疾患または炎症性疾患は、クローン病、強直性脊椎炎、または乾癬性関節炎である。 Non-limiting examples of inflammatory diseases include rheumatoid arthritis, systemic erythematosus, circular alopecia, tonic dermatomyositis, antiphospholipid syndrome, autoimmune Azison disease, autoimmune hemolytic anemia, autoimmune hepatitis, self. Immune internal ear disease, autoimmune lymphoproliferative syndrome (ALPS), autoimmune thrombocytopenic purpura (ATP), Bechette's disease, bullous vesicles, myocardial disease, celiac disease dermatomyositis, chronic fatigue syndrome (CFIDS), Chronic inflammatory demyelinating polyneuropathy, Scarring tinea, Cold agglutinosis, CREST syndrome, Crohn's disease, Degos's disease, Dermatomyositis, Juvenile dermatomyositis, Discoid lupus, Essential mixture Chryoglobulinemia, primary fibromyositis, Graves' disease, Gillan Valley, Hashimoto dermatomyositis, idiopathic alveolar fibrosis, idiopathic thrombocytopenic purpura (ITP), IgA nephropathy, insulin-dependent diabetes (Type I), juvenile arteritis, Meniere's disease, mixed connective tissue disease, multiple sclerosis, severe myasthenia, asthma vulgaris, malignant anemia, nodular polyarteritis, polychondritis, polyglandular Endocrine syndrome, rheumatic polymyositis, polymyositis and dermatomyositis, primary agammaglobulinemia, primary biliary cirrhosis, psoriasis, Reynaud phenomenon, Reiter syndrome, rheumatic fever, sarcoidosis, sclerosis, Schegren syndrome, These include Stiffperson's syndrome, hyperan arteritis, temporal arteritis / giant cell arteritis, ulcerative colitis, vasculitis, vasculitis, leukoplakia, and polyangiitis granulomatosis. In some embodiments, the autoimmune or inflammatory disease is Crohn's disease, ankylosing spondylitis, or psoriatic arthritis.
本明細書に開示する方法を実施するために、有効量の本明細書に記載の化合物または医薬組成物を、治療を必要とする対象(例えば、ヒト)に投与することができる。様々な送達系が知られており、本技術の化合物の投与に使用することができる。投与方法には、皮内、筋肉内、腹腔内、静脈内、皮下、鼻腔内、硬膜外、及び経口といった経路が挙げられるが、これらに限定されない。本技術の化合物は、例えば、輸液、ボーラス、または注射によって投与することができ、抗炎症薬などの他の生物学的に活性な薬剤と一緒に投与することができる。投与は全身でも局所でも可能である。好ましい実施形態では、投与は皮下注射によるものである。そのような注射用製剤は、例えば、隔週回投与することができるプレフィルドシリンジ製剤であってもよい。 To carry out the methods disclosed herein, an effective amount of a compound or pharmaceutical composition described herein can be administered to a subject in need of treatment (eg, a human). Various delivery systems are known and can be used to administer compounds of the art. Administration methods include, but are not limited to, intradermal, intramuscular, intraperitoneal, intravenous, subcutaneous, intranasal, epidural, and oral routes. The compounds of the invention can be administered, for example, by infusion, bolus, or injection, and can be administered with other biologically active agents such as anti-inflammatory agents. Administration can be systemic or topical. In a preferred embodiment, administration is by subcutaneous injection. Such injectable formulations may be, for example, prefilled syringe formulations that can be administered biweekly.
本明細書で使用される場合、「有効量」とは、単独で、または1つ以上の他の化合物と組み合わせて、対象に治療効果を与えるのに必要な各化合物の量を指す。有効量は、当業者が認識しているように、治療する個別の病態、病態の重症度、年齢、体調、体格、性別及び体重を含む個々の対象のパラメーター、治療期間、併用療法の性質(受けている場合)、特定の投与経路、及び医療従事者の知識と経験の範囲内である同様の要因に応じて異なる。このような要因は、当業者に周知されており、通常の実験の範囲内で対処することができる。一般に、個々の成分またはその組み合わせの最大用量、すなわち堅実な医学的判断に基づいた最大安全用量を使用することが好ましい。ただし、医学的理由、心理的理由、または事実上他のいかなる理由から、対象が低い用量または耐用量を要求する場合があることを当業者は理解しているはずである。 As used herein, "effective amount" refers to the amount of each compound required to exert a therapeutic effect on a subject, either alone or in combination with one or more other compounds. Effective doses, as those skilled in the art are aware, are the individual subject's parameters including the individual condition to be treated, the severity of the condition, age, physical condition, physique, gender and weight, duration of treatment, nature of combination therapy ( Depending on the particular route of administration (if received) and similar factors within the knowledge and experience of the healthcare professional. Such factors are well known to those of skill in the art and can be addressed within the scope of normal experimentation. In general, it is preferred to use the maximum dose of the individual ingredients or combinations thereof, i.e. the maximum safe dose based on sound medical judgment. However, one of ordinary skill in the art should understand that a subject may require a lower dose or tolerated dose for medical, psychological, or virtually any other reason.
半減期などの実験的考察は一般に、投与量を決定する一因となる。例えば、ヒト化抗体または完全ヒト抗体からの領域を含む化合物などの、ヒト免疫系と適合性がある化合物を使用すると、化合物の半減期を延長し、宿主の免疫系による化合物への攻撃を防止することができる。治療経過に応じて投与頻度を決定及び調整してもよく、必ずしもそうとは限らないが一般にこれは、疾患の治療及び/もしくは抑制ならびに/または改善及び/もしくは遅延に基づく。あるいは、化合物を持続的に連続して放出する製剤が適切な場合もある。持続放出を実現するための様々な製剤及びデバイスが当技術分野で既知である。 Experimental considerations such as half-life generally contribute to dose determination. The use of compounds compatible with the human immune system, such as compounds containing regions from humanized or fully human antibodies, prolongs the half-life of the compound and prevents the host's immune system from attacking the compound. can do. The frequency of administration may be determined and adjusted according to the course of treatment, but generally this is based on the treatment and / or suppression and / or amelioration and / or delay of the disease. Alternatively, a formulation that releases the compound continuously and continuously may be appropriate. Various formulations and devices for achieving sustained release are known in the art.
いくつかの実施形態では、投与量は、毎日、隔日、3日ごと、4日ごと、5日ごと、または6日ごとである。いくつかの実施形態では、投与頻度は、週1回、2週に1回、4週に1回、5週に1回、6週に1回、7週に1回、8週に1回、9週に1回、もしくは10週に1回、または月1回、2か月に1回、3か月に1回であるか、またはそれ以降に1回である。この療法の進捗は、従来技術及びアッセイによって容易にモニターされる。(使用される化合物を含む)投与計画は、経時的に変更することができる。 In some embodiments, the dose is daily, every other day, every 3 days, every 4 days, every 5 days, or every 6 days. In some embodiments, the dosing frequency is once a week, once every two weeks, once every four weeks, once every five weeks, once every six weeks, once every seven weeks, once every eight weeks. , Once every 9 weeks, or once every 10 weeks, or once a month, once every two months, once every three months, or once thereafter. The progress of this therapy is easily monitored by prior art and assays. The dosing regimen (including the compounds used) can be changed over time.
いくつかの実施形態では、正常体重の成人対象の場合、約0.01〜1000mg/kgの範囲の用量を投与することができる。いくつかの実施形態では、用量は1〜200mgである。個別の投与計画、すなわち用量、タイミング、及び反復は、個別の対象及びその対象の病歴に加え、化合物の特性(例えば、化合物の半減期及び当技術分野で周知の他の考慮事項)に応じて決定される。 In some embodiments, for normal body weight adult subjects, doses ranging from about 0.01 to 1000 mg / kg can be administered. In some embodiments, the dose is 1-200 mg. Individual dosing regimens, ie doses, timings, and repetitions, depend on the individual subject and the medical history of that subject, as well as the characteristics of the compound (eg, the half-life of the compound and other considerations well known in the art). It is determined.
本開示の目的では、本明細書に記載の化合物の適切な投与量は、使用される具体的な化合物(またはその組成物)、製剤及び投与経路、疾患のタイプ及び重症度、化合物の投与が予防目的であるか治療目的であるか、過去の治療、対象の臨床歴及びアンタゴニストに対する反応性、ならびに主治医の裁量に応じて決定される。通常、臨床医は目的の結果を達成する投与量に到達するまで化合物を投与する。1つ以上の化合物の投与は、例えば、レシピエントの生理学的状態、投与の目的が治療的であるか予防的であるか、及び熟練従事者に既知である他の要因に応じて、連続的でも断続的でもよい。化合物の投与は、予め選択された期間にわたり本質的に連続していてもよく、または例えば疾患を発症する前、発症中、または発症後といった一連の間隔を空けた投与であってもよい。 For the purposes of the present disclosure, the appropriate dosage of a compound described herein is the specific compound (or composition thereof) used, the formulation and route of administration, the type and severity of the disease, the administration of the compound. Whether it is for prophylactic or therapeutic purposes is determined by past treatment, the subject's clinical history and responsiveness to the antagonist, and at the discretion of the attending physician. Clinicians usually administer the compound until a dose that achieves the desired result is reached. Administration of one or more compounds is continuous, depending on, for example, the physiological condition of the recipient, whether the purpose of administration is therapeutic or prophylactic, and other factors known to the skilled worker. But it may be intermittent. Administration of the compound may be essentially continuous over a preselected period of time, or may be a series of spaced doses, such as before, during, or after the onset of the disease.
本明細書で使用される場合、用語「治療する」とは、疾患、疾患の症状、または疾患素因の治癒(cure、heal)、緩和/軽減(alleviate、relieve)、変化、回復、改善(ameliorate、improve)、またはそれに対する作用を目的とした、疾患、疾患の症状、または疾患の素因を有する対象に、化合物または化合物を含む組成物を適用または投与することを指す。 As used herein, the term "treating" means disease, symptoms of the disease, or cure, health, alleviate, relieve, change, recovery, ameliorate. , Improve), or the application or administration of a compound or a composition comprising a compound to a subject having a disease, a symptom of a disease, or a predisposition to a disease for the purpose of acting on it.
疾患を緩和することは、疾患の発症または進行を遅延させること、または疾患の重症度を低下させることを含む。疾患を緩和することは、必ずしも治癒結果を必要としない。本明細書で使用される場合、疾患の発症を「遅延させる(delaying)」とは、疾患の進行を延期(defer)、妨害、遅延(slow、retard)、安定化、及び/または延期(postpone)することを意味する。この遅延は、治療される疾患及び/または個体の履歴に応じて様々な期間であり得る。疾患の発症を「遅延」もしくは緩和する、または疾患の発現を遅延させる方法とは、この方法を使用しない場合と比較して、所与の時間枠内で疾患の1つ以上の症状を発症する確率を低下させる方法、及び/または所与の時間枠内で症状の程度を低下させる方法である。このような比較は通常、統計的に有意な結果を得るのに十分である複数の対象を用いた臨床試験に基づく。 Relieving the disease involves delaying the onset or progression of the disease or reducing the severity of the disease. Relieving the disease does not necessarily require a cure result. As used herein, "delaying" the onset of a disease means delaying, interfering with, slowing, retarding, stabilizing, and / or postponing the progression of the disease. ) Means to do. This delay can be for varying periods of time, depending on the disease being treated and / or the history of the individual. A method of "delaying" or alleviating the onset of a disease or delaying the onset of a disease causes one or more symptoms of the disease within a given time frame as compared to not using this method. A method of reducing the probability and / or a method of reducing the severity of symptoms within a given time frame. Such comparisons are usually based on clinical trials with multiple subjects that are sufficient to obtain statistically significant results.
疾患の「発症」または「進行」とは、疾患の初期症状及び/またはその後の進行を意味する。疾患の発症は、当技術分野で周知の標準的な臨床技術を用いて検出及び評価することができる。ただし発症とはまた、検出不能であり得る進行も指す。この開示の目的で、発症または進行とは症状の生物学的経過を指す。「発症」には発生、再発、及び発現が含まれる。本明細書で使用される場合、疾患の「発現」または「発生」には、初期発現及び/または再発が含まれる。 "Onset" or "progression" of a disease means the initial symptoms and / or subsequent progression of the disease. The onset of the disease can be detected and evaluated using standard clinical techniques well known in the art. However, onset also refers to progression that may be undetectable. For the purposes of this disclosure, onset or progression refers to the biological course of symptoms. "Onset" includes development, recurrence, and expression. As used herein, "expression" or "development" of a disease includes early onset and / or recurrence.
いくつかの実施形態では、本明細書に記載の化合物は、治療を必要とする対象に、in vivoまたはin vitroでBAFFまたはIL23Aの一方または両方の活性を少なくとも20%(例えば、30%、40%、50%、60%、70%、80%、90%、またはそれ以上)阻害するのに十分な量で投与される。化合物の阻害能力を決定するための方法は、当技術分野において既知である。例示的なBAFF及びIL23A阻害アッセイを実施例に記載する。 In some embodiments, the compounds described herein have at least 20% (eg, 30%, 40) activity of one or both of BAFF or IL23A in vivo or in vitro in a subject in need of treatment. %, 50%, 60%, 70%, 80%, 90%, or more) administered in an amount sufficient to inhibit. Methods for determining the inhibitory capacity of a compound are known in the art. An exemplary BAFF and IL23A inhibition assay is described in the Examples.
治療すべき疾患のタイプまたは疾患の部位に応じて、医学分野の当業者に既知の従来の方法を使用して、化合物または医薬組成物を対象に投与することができる。この組成物はまた、例えば、経口、非経口、吸入スプレー、局所、直腸、鼻腔、頬側、膣、または埋込式リザーバーでの投与といった、他の従来の経路により投与することもできる。本明細書で使用される場合、用語「非経口」には、皮下、皮内、静脈内、筋肉内、関節内、動脈内、滑液内、胸骨内、髄腔内、病巣内、及び頭蓋内への注射または注入技術を含む。加えて、1か月、3か月、または6か月のデポー注射用または生分解性の材料及び方法を使用するような、注射によるデポー投与経路を介して対象に投与することができる。 Depending on the type of disease to be treated or the site of the disease, the compound or pharmaceutical composition can be administered to the subject using conventional methods known to those skilled in the art of medicine. The composition can also be administered by other conventional routes, such as, for example, oral, parenteral, inhalation spray, topical, rectal, nasal, buccal, vaginal, or implantable reservoir administration. As used herein, the term "parenteral" refers to subcutaneous, intradermal, intravenous, intramuscular, joint, intraarterial, synovial, intrasternal, intrathecal, intralesional, and cranial. Includes injecting or injecting techniques. In addition, it can be administered to a subject via an injectable depot route of administration, such as using 1-month, 3-month, or 6-month depot injection or biodegradable materials and methods.
医薬組成物
さらに本開示の他の態様は、本明細書に記載の化合物を含む医薬組成物に関する。本技術の化合物(例えば、BAFF及びIL23Aの両方に特異的な化合物)を含む組成物は、自己免疫疾患または炎症性疾患を有するかまたは有するリスクのある対象に投与することができる。本技術はさらに、自己免疫疾患または炎症性疾患を治療するための医薬品の製造における本技術の化合物の使用を提供する。化合物は、自己免疫疾患または炎症性疾患の予防または治療において、単独で、または他の組成物と組み合わせて投与することができる。そのような医薬組成物に使用される本技術の化合物の非限定的な例は、以下を含むものである:
(i)前記第1のポリペプチドが配列番号5のアミノ酸配列を含み、前記第2のポリペプチドが配列番号6のアミノ酸配列を含むか、または
(ii)前記第1のポリペプチドが配列番号7のアミノ酸配列を含み、前記第2のポリペプチドが配列番号8のアミノ酸配列を含むか、または
(iii)前記第1のポリペプチドが配列番号9のアミノ酸配列を含み、前記第2のポリペプチドが配列番号10のアミノ酸配列を含むか、または
(iv)前記第1のポリペプチドが配列番号11のアミノ酸配列を含み、前記第2のポリペプチドが配列番号12のアミノ酸配列を含むか、または
(v)前記第1のポリペプチドが配列番号13のアミノ酸配列を含み、前記第2のポリペプチドが配列番号14のアミノ酸配列を含むか、または
(vi)前記第1のポリペプチドが配列番号15のアミノ酸配列を含み、前記第2のポリペプチドが配列番号16のアミノ酸配列を含むか、または
(vii)前記第1のポリペプチドが配列番号17のアミノ酸配列を含み、前記第2のポリペプチドが配列番号18のアミノ酸配列を含むか、または
(viii)前記第1のポリペプチドが配列番号19のアミノ酸配列を含み、前記第2のポリペプチドが配列番号20のアミノ酸配列を含むか、または
(ix)前記第1のポリペプチドが配列番号21のアミノ酸配列を含み、前記第2のポリペプチドが配列番号22のアミノ酸配列を含むか、または
(x)前記第1のポリペプチドが配列番号23のアミノ酸配列を含み、前記第2のポリペプチドが配列番号24のアミノ酸配列を含むか、または
(xi)前記第1のポリペプチドが配列番号25のアミノ酸配列を含み、前記第2のポリペプチドが配列番号26のアミノ酸配列を含むか、または
(xii)前記第1のポリペプチドが配列番号27のアミノ酸配列を含み、前記第2のポリペプチドが配列番号28のアミノ酸配列を含むか、または
(xiii)前記第1のポリペプチドが配列番号29のアミノ酸配列を含み、前記第2のポリペプチドが配列番号30のアミノ酸配列を含むか、または
(xiv)前記第1のポリペプチドが配列番号31のアミノ酸配列を含み、前記第2のポリペプチドが配列番号32のアミノ酸配列を含むか、または
(xv)前記第1のポリペプチドが配列番号33のアミノ酸配列を含み、前記第2のポリペプチドが配列番号34のアミノ酸配列を含むか、または
(xvi)前記第1のポリペプチドが配列番号35のアミノ酸配列を含み、前記第2のポリペプチドが配列番号36のアミノ酸配列を含むか、または
(xvii)前記第1のポリペプチドが配列番号37のアミノ酸配列を含み、前記第2のポリペプチドが配列番号38のアミノ酸配列を含むか、または
(xviii)前記第1のポリペプチドが配列番号39のアミノ酸配列を含み、前記第2のポリペプチドが配列番号40のアミノ酸配列を含むか、または
(xix)前記第1のポリペプチドが配列番号41のアミノ酸配列を含み、前記第2のポリペプチドが配列番号42のアミノ酸配列を含むか、または
(xx)前記第1のポリペプチドが配列番号43のアミノ酸配列を含み、前記第2のポリペプチドが配列番号44のアミノ酸配列を含むか、または
(xxi)前記第1のポリペプチドが配列番号45のアミノ酸配列を含み、前記第2のポリペプチドが配列番号46のアミノ酸配列を含むか、または
(xxii)前記第1のポリペプチドが配列番号47のアミノ酸配列を含み、前記第2のポリペプチドが配列番号48のアミノ酸配列を含むか、または
(xxiii)前記第1のポリペプチドが配列番号49のアミノ酸配列を含み、前記第2のポリペプチドが配列番号50のアミノ酸配列を含むか、または
(xxiv)前記第1のポリペプチドが配列番号51のアミノ酸配列を含み、前記第2のポリペプチドが配列番号52のアミノ酸配列を含むか、または
(xxv)前記第1のポリペプチドが配列番号53のアミノ酸配列を含み、前記第2のポリペプチドが配列番号54のアミノ酸配列を含むか、または
(xxvi)前記第1のポリペプチドが配列番号55のアミノ酸配列を含み、前記第2のポリペプチドが配列番号56のアミノ酸配列を含むか、または
(xxvii)前記第1のポリペプチドが配列番号57のアミノ酸配列を含み、前記第2のポリペプチドが配列番号58のアミノ酸配列を含むか、または
(xxviii)前記第1のポリペプチドが配列番号59のアミノ酸配列を含み、前記第2のポリペプチドが配列番号60のアミノ酸配列を含むか、または
(xxix)前記第1のポリペプチドが配列番号61のアミノ酸配列を含み、前記第2のポリペプチドが配列番号62のアミノ酸配列を含むか、または
(xxx)前記第1のポリペプチドが配列番号63のアミノ酸配列を含み、前記第2のポリペプチドが配列番号64のアミノ酸配列を含むか、または
(xxxi)前記第1のポリペプチドが配列番号65のアミノ酸配列を含み、前記第2のポリペプチドが配列番号66のアミノ酸配列を含むか、または
(xxxii)前記第1のポリペプチドが配列番号67のアミノ酸配列を含み、前記第2のポリペプチドが配列番号68のアミノ酸配列を含む。
Pharmaceutical Compositions Yet another aspect of the disclosure relates to pharmaceutical compositions comprising the compounds described herein. Compositions comprising compounds of the art (eg, compounds specific for both BAFF and IL23A) can be administered to subjects who have or are at risk of having an autoimmune or inflammatory disease. The technology further provides the use of compounds of the technology in the manufacture of pharmaceuticals for the treatment of autoimmune or inflammatory diseases. The compounds can be administered alone or in combination with other compositions in the prevention or treatment of autoimmune or inflammatory diseases. Non-limiting examples of compounds of the art used in such pharmaceutical compositions include:
(I) The first polypeptide comprises the amino acid sequence of SEQ ID NO: 5, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 6, or (ii) the first polypeptide comprises SEQ ID NO: 7. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 8 or (iii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 9 and the second polypeptide comprises. Either the amino acid sequence of SEQ ID NO: 10 is contained, or (iv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 11 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 12 or (v). ) The first polypeptide comprises the amino acid sequence of SEQ ID NO: 13, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 14, or (vi) the first polypeptide comprises the amino acid of SEQ ID NO: 15. The second polypeptide comprises a sequence and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 16 or (vii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 17 and the second polypeptide has the SEQ ID NO: Eighteen amino acid sequences are included, or (viii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 19, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 20 or (ix) said. The first polypeptide comprises the amino acid sequence of SEQ ID NO: 21, the second polypeptide comprises the amino acid sequence of SEQ ID NO: 22, or (x) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 23. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 24, or (xi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 25 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 26. The first polypeptide comprises the amino acid sequence, or (xii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 27, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 28, or (xiii) said first. The polypeptide comprises the amino acid sequence of SEQ ID NO: 29 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 30 or (xiv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 31. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 32, or (xv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 33 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 34. Or (xvi) said first The polypeptide comprises the amino acid sequence of SEQ ID NO: 35 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 36, or (xvii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 37 and said. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 38, or (xviii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 39 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 40. The first polypeptide comprises the amino acid sequence of SEQ ID NO: 41 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 42, or (xx) said first polypeptide. Contains the amino acid sequence of SEQ ID NO: 43 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 44, or (xxi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 45 and said second. Whether the polypeptide of SEQ ID NO: 46 comprises the amino acid sequence of SEQ ID NO: 46, or (xxiii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 47 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 48. , Or (xxiii) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 49 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 50, or (xxiv) the first polypeptide comprises the sequence. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 51 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 52, or (xxv) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 53 and said the second poly. The peptide comprises the amino acid sequence of SEQ ID NO: 54, or (xxvi) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 55 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 56, or The first polypeptide comprises the amino acid sequence of SEQ ID NO: 57 and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 58, or (xxviii) the first polypeptide comprises SEQ ID NO: 59. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 60, or (xxx) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 61 and the second polypeptide comprises. The amino acid sequence of SEQ ID NO: 62 is contained, or (xxx) the first polypeptide comprises the amino acid sequence of SEQ ID NO: 63, and the second polypeptide contains the amino acid sequence of SEQ ID NO: 64. Or (xxxi) said first polypeptide comprises the amino acid sequence of SEQ ID NO: 65 and said second polypeptide comprises the amino acid sequence of SEQ ID NO: 66, or (xxxxi) said said first poly. The peptide comprises the amino acid sequence of SEQ ID NO: 67, and the second polypeptide comprises the amino acid sequence of SEQ ID NO: 68.
本明細書で使用される場合、用語「医薬組成物」は、薬学的に許容される担体と組み合わせた本明細書に記載の化合物の製剤を指す。医薬組成物はさらに、(例えば、特異的送達、半減期の延長、または他の治療化合物のための)追加薬剤を含むことができる。 As used herein, the term "pharmaceutical composition" refers to the formulation of a compound described herein in combination with a pharmaceutically acceptable carrier. The pharmaceutical composition can further include additional agents (eg, for specific delivery, half-life extension, or other therapeutic compounds).
本明細書で使用される場合、用語「薬学的に許容される担体」は、身体のある部位(例えば送達部位)から別の部位(例えば、身体の器官、組織、または部分)への化合物の運搬または輸送に関与する、液体または固体の増量剤、希釈剤、賦形剤、製造助剤(例えば、潤沢剤、タルクマグネシウム、ステアリン酸カルシウムもしくはステアリン酸亜鉛、またはステアリン酸)、または溶媒封入材料などの、薬学的に許容される材料、組成物、またはビヒクルを意味する。薬学的に許容される担体は、製剤の他の成分と適合性があり、かつ対象の組織に有害でないという意味において「許容される」ものである(例えば、生理学的適合性、滅菌性、生理学的pHなど)。薬学的に許容される担体として機能し得る材料の一部の例として、(1)ラクトース、グルコース、及びスクロースなどの糖;(2)コーンスターチ及びバレイショデンプンなどのデンプン;(3)カルボキシメチルセルロースナトリウム、メチルセルロース、エチルセルロース、微結晶セルロース、及び酢酸セルロースなどのセルロース及びその誘導体;(4)粉末トラガント;(5)麦芽;(6)ゼラチン;(7)ステアリン酸マグネシウム、ラウリル硫酸ナトリウム、及びタルクなどの滑沢剤;(8)ココアバター及び坐剤用ワックスなどの賦形剤;(9)ピーナッツ油、綿実油、ベニバナ油、ゴマ油、オリーブ油、コーン油、及び大豆油などの油;(10)プロピレングリコールなどのグリコール;(11)グリセリン、ソルビトール、マンニトール、及びポリエチレングリコール(PEG)などのポリオール;(12)オレイン酸エチル及びラウリン酸エチルなどのエステル;(13)寒天;(14)水酸化マグネシウム及び水酸化アルミニウムなどの緩衝剤;(15)アルギン酸;(16)パイロジェンフリー水;(17)等張生理食塩水;(18)リンゲル溶液;(19)エチルアルコール;(20)pH緩衝溶液;(21)ポリエステル、ポリカーボネート、及び/またはポリ無水物;(22)ポリペプチド及びアミノ酸などの充填剤;(23)血清アルブミン、HDL、及びLDLなどの血清成分;(22)エタノールなどのC2〜C12アルコール;ならびに(23)医薬製剤に用いられる他の適合可能な非毒性物質が挙げられる。製剤にはまた、湿潤剤、着色剤、剥離剤、コーティング剤、甘味剤、矯味剤、着香剤、防腐剤、及び抗酸化剤が存在してもよい。「賦形剤」、「担体」、「薬学的に許容される担体」またはそれに類する用語は、本明細書で同じ意味で用いられる。 As used herein, the term "pharmaceutically acceptable carrier" refers to a compound from one part of the body (eg, a delivery site) to another (eg, an organ, tissue, or part of the body). Liquid or solid bulking agents, diluents, excipients, manufacturing aids (eg, abundant agents, talcmagnesium, calcium stearate or zinc stearate, or stearic acid), or solvent-encapsulated materials involved in transport or transport, etc. Means a pharmaceutically acceptable material, composition, or vehicle. A pharmaceutically acceptable carrier is one that is "acceptable" in the sense that it is compatible with the other ingredients of the formulation and is not harmful to the tissue of interest (eg, physiological compatibility, sterility, physiology). PH, etc.). Some examples of materials that can function as pharmaceutically acceptable carriers are: (1) sugars such as lactose, glucose, and sucrose; (2) starches such as corn starch and potato starch; (3) sodium carboxymethyl cellulose, Cellulose such as methyl cellulose, ethyl cellulose, microcrystalline cellulose, and cellulose acetate and derivatives thereof; (4) powdered tragant; (5) malt; (6) gelatin; (7) magnesium stearate, sodium lauryl sulfate, and talc. Esters; (8) Excipients such as cocoa butter and suppository wax; (9) Oils such as peanut oil, cottonseed oil, Benibana oil, sesame oil, olive oil, corn oil, and soybean oil; (10) Propropylene glycol, etc. Glycols; (11) polyols such as glycerin, sorbitol, mannitol, and polyethylene glycol (PEG); (12) esters such as ethyl oleate and ethyl laurate; (13) agar; (14) magnesium hydroxide and hydroxides. Buffers such as aluminum; (15) excipients; (16) pyrogen-free water; (17) isotonic physiological saline; (18) Ringer solution; (19) ethyl alcohol; (20) pH buffer solution; (21) polyester , Polycarbonate, and / or polyanhydrides; (22) fillers such as polypeptides and amino acids; (23) serum components such as serum albumin, HDL, and LDL; (22) C2-C12 alcohols such as ethanol; and ( 23) Other compatible non-toxic substances used in pharmaceutical formulations. Formulations may also contain wetting agents, coloring agents, stripping agents, coating agents, sweetening agents, flavoring agents, flavoring agents, preservatives, and antioxidants. The terms "excipient", "carrier", "pharmaceutically acceptable carrier" or the like are used interchangeably herein.
いくつかの実施形態では、組成物中の本技術の化合物は、注射、カテーテル、坐剤、またはインプラントによって投与され、インプラントは、シラスティック(sialastic)膜などの膜または繊維を含む、多孔質、非多孔質、またはゼラチン状膜である。通常、組成物を投与する場合、本技術の化合物が吸収しない物質が使用される。 In some embodiments, the compounds of the art in the composition are administered by injection, catheter, suppository, or implant, the implant being porous, comprising a membrane or fiber, such as a sialastic membrane. It is a non-porous or gelatinous film. Usually, when the composition is administered, a substance that is not absorbed by the compound of the present technology is used.
他の実施形態では、本技術の化合物は制御放出系で送達される。一実施形態では、ポンプを使用してもよい(例えば、Langer,1990,Science 249:1527−1533;Sefton,1989,CRC Crit.Ref.Biomed.Eng.14:201;Buchwald et al.,1980,Surgery 88:507;Saudek et al.,1989,N.Engl.J.Med.321:574を参照)。別の実施形態では、高分子材料を使用することができる。(例えば、Medical Applications of Controlled Release(Langer and Wise eds.,CRC Press,Boca Raton,Fla.,1974);Controlled Drug Bioavailability,Drug Product Design and Performance(Smolen and Ball eds.,Wiley,New York,1984);Ranger and Peppas,1983,Macromol.Sci.Rev.Macromol.Chem.23:61を参照。また、Levy et al.,1985,Science 228:190;During et al.,1989,Ann.Neurol.25:351;Howard et al.,1989,J.Neurosurg.71:105を参照)。他の制御放出系は、例えば上記Langerに記載されている。 In other embodiments, the compounds of the art are delivered in a controlled release system. In one embodiment, a pump may be used (eg, Ranger, 1990, Science 249: 1527-1533; Sefton, 1989, CRC Crit. Ref. Biomed. Eng. 14: 201; Buchwald et al., 1980, Surgery 88: 507; Saudek et al., 1989, N. Engl. J. Med. 321: 574). In another embodiment, a polymeric material can be used. (E.g., Medical Applications of Controlled Release (Langer and Wise eds, CRC Press, Boca Raton, Fla, 1974);... Controlled Drug Bioavailability, Drug Product Design and Performance (Smolen and Ball eds, Wiley, New York, 1984) See Ranger and Peppas, 1983, Macromol. Sci. Rev. Macromol. Chem. 23:61. Also, Levy et al., 1985, Science 228: 190; During et al., 1989, Ann. Neurol. 25: 351; Howard et al., 1989, J. Neurosurg. 71: 105). Other controlled release systems are described, for example, in the above Language.
本技術の化合物は、治療有効量の結合薬及び1つ以上の薬学的適合性成分を含む医薬組成物として投与することができる。 The compounds of the present technology can be administered as a pharmaceutical composition comprising a therapeutically effective amount of a binding agent and one or more pharmaceutically compatible ingredients.
通常の実施形態では、医薬組成物は、対象、例えば、ヒトへの静脈内または皮下投与に適合した医薬組成物として、通常の手順に従って製剤化される。通常、注射により投与される組成物は、滅菌等張性緩衝液の溶液である。必要に応じて、医薬品はまた、可溶化剤及び注射部位での疼痛を緩和するためのリグノカインなどの局所麻酔剤を含んでもよい。一般に、成分は個別に、または一つに混合されて単位剤形で、例えば、活性薬剤の量を表示したアンプルまたはサシェなどの密閉容器中の凍結乾燥粉末または水を含まない濃縮物として供給される。医薬品が注入によって投与される場合、医薬品等級の滅菌水または生理食塩水を入れた輸液ボトルで調剤することができる。医薬品が注射によって投与される場合、注射用の滅菌水または生理食塩水のアンプルを提供することで、投与前に成分を混合することができる。 In conventional embodiments, the pharmaceutical composition is formulated according to conventional procedures as a pharmaceutical composition suitable for intravenous or subcutaneous administration to a subject, eg, a human. Usually, the composition administered by injection is a solution of sterile isotonic buffer. If desired, the drug may also include a solubilizer and a local anesthetic such as lignokine to relieve pain at the injection site. Generally, the ingredients are delivered individually or in a unit dosage form, eg, as a lyophilized powder or water-free concentrate in a closed container such as an ampoule or sachet indicating the amount of active agent. To. If the drug is administered by injection, it can be dispensed in an infusion bottle containing pharmaceutical grade sterile water or saline. If the drug is administered by injection, the ingredients can be mixed prior to administration by providing an ampoule of sterile water or saline for injection.
全身投与のための医薬組成物は、液体、例えば滅菌生理食塩水、乳酸加リンゲル液、またはハンクス液であり得る。加えて、医薬組成物は、固体形態であり、使用直前に再溶解または懸濁させることができる。凍結乾燥形態もまた企図される。 The pharmaceutical composition for systemic administration can be a liquid, such as sterile saline, lactated Ringer's solution, or Hanks solution. In addition, the pharmaceutical composition is in solid form and can be redissolved or suspended immediately prior to use. A lyophilized form is also contemplated.
医薬組成物は、非経口投与にも適している、リポソームまたは微結晶などの脂質粒子または小胞内に封入することができる。粒子は、組成物がその中に含まれている限り、単層または複数層などの任意の適切な構造のものであり得る。化合物は、融合誘導性脂質ジオレオイルホスファチジルエタノールアミン(DOPE)、低レベル(5〜10モル%)のカチオン性脂質を含有し、ポリエチレングリコール(PEG)コーティングにより安定化された、「安定化プラスミド脂質粒子」(SPLP)内に封入することができる(Zhang Y.P.et al.,Gene Ther.1999,6:1438−47)。N−[1−(2,3−ジオレオイロキシ)プロピル]−N,N,N−トリメチル−アンモニウムメチルサルフェート、すなわち「DOTAP」などの正荷電脂質は、このような粒子及び小胞に特に好ましい。そのような脂質粒子の調製は周知である。例えば、米国特許第4,880,635号;同第4,906,477号;同第4,911,928号;同第4,917,951号;同第4,920,016号;及び同第4,921,757号を参照。 The pharmaceutical composition can be encapsulated in lipid particles or vesicles such as liposomes or microcrystals, which are also suitable for parenteral administration. The particles can be of any suitable structure, such as single layer or multiple layers, as long as the composition is contained therein. The compound contains a fusion-inducible lipid dioleoylphosphatidylethanolamine (DOPE), a low level (5-10 mol%) of cationic lipid, stabilized by polyethylene glycol (PEG) coating, a "stabilizing plasmid". It can be encapsulated in "lipid particles" (SPLP) (Zhang Y.P. et al., Gene Ther. 1999, 6: 1438-47). N- [1- (2,3-dioleoyloxy) propyl] -N, N, N-trimethyl-ammonium methyl sulfate, ie, positively charged lipids such as "DOTAP" are particularly preferred for such particles and vesicles. The preparation of such lipid particles is well known. For example, U.S. Pat. Nos. 4,880,635; 4,906,477; 4,911,928; 4,917,951; 4,920,016; and See No. 4,921,757.
本開示の医薬組成物は、例えば、単位用量として投与または包装することができる。本開示の医薬組成物に関して使用される場合、用語「単位用量」は、対象に対する単位投与量として適した物理的な個別単位を指し、各単位は、必要な希釈剤、すなわち担体またはビヒクルと共に望ましい治療効果を生じるように計算された所定量の活性物質を含有する。 The pharmaceutical compositions of the present disclosure can be administered or packaged, for example, as a unit dose. When used with respect to the pharmaceutical compositions of the present disclosure, the term "unit dose" refers to a physical individual unit suitable as a unit dose to a subject, where each unit is preferred with the required diluent, ie carrier or vehicle. Contains a predetermined amount of active substance calculated to produce a therapeutic effect.
いくつかの実施形態では、本明細書に記載の化合物は、治療部分、例えば抗炎症剤とコンジュゲートされてもよい。そのような治療部分をポリペプチド(例えばFcドメインを含む)とコンジュゲートする技術は周知である。たとえば、Amon et al.,“Monoclonal Antibodies For Immunotargeting Of Drugs In Cancer Therapy”,in Monoclonal Antibodies And Cancer Therapy,Reisfeld et al.(eds.),1985,pp.243−56,Alan R.Liss,Inc.);Hellstrom et al.,“Antibodies For Drug Delivery”,in Controlled Drug Delivery(2nd Ed.),Robinson et al.(eds.),1987,pp.623−53,Marcel Dekker,Inc.);Thorpe,“Antibody Carriers Of Cytotoxic Agents In Cancer Therapy:A Review”,in Monoclonal Antibodies’84:Biological And Clinical Applications,Pinchera et al.(eds.),1985,pp.475−506);“Analysis,Results,And Future Prospective Of The Therapeutic Use Of Radiolabeled Antibody In Cancer Therapy”,in Monoclonal Antibodies For Cancer Detection And Therapy,Baldwin et al.(eds.),1985,pp.303−16,Academic Press;and Thorpe et al.(1982)“The Preparation And Cytotoxic Properties Of Antibody−Toxin Conjugates,”Immunol.Rev.,62:119−158を参照。 In some embodiments, the compounds described herein may be conjugated to a therapeutic moiety, such as an anti-inflammatory agent. Techniques for conjugating such therapeutic moieties with polypeptides (including, for example, the Fc domain) are well known. For example, Amon et al. , "Monoclonal Antibodies For Immunotarging Of Drugs In Cancer Therapy", in Monoclonal Antibodies And Cancer Therapy, Real. (Eds.), 1985, pp. 243-56, Alan R.M. Liss, Inc. ); Hellstrom et al. , "Antibodies For Drug Delivery", in Controlled Drug Delivery (2nd Ed.), Robinson et al. (Eds.), 1987, pp. 623-53, Marcel Dekker, Inc. ); Thorpe, "Antibody Carriers Of Cytotoxic Agents In Cancer Therapy: A Review", in Monoclonal Antibodies '84: Biological Electronic Academy. (Eds.), 1985, pp. 475-506); "Analysis, Results, And Future Protective Of The Therapeutic Use Of Radiolabeled Antibodies In Cancer Substance. (Eds.), 1985, pp. 303-16, Academic Press; and Thorpe et al. (1982) "The Preparation And Cytotoxic Properties Of Antibodies-Toxin Conjugates," Immunol. Rev. , 62: 119-158.
さらに、医薬組成物は、(a)凍結乾燥形態である本技術の化合物を含有する容器と、(b)注射用の薬学的に許容される希釈剤(例えば、滅菌水)を含有する第2の容器とを含む医薬キットとして提供することができる。薬学的に許容される希釈剤を、本技術の凍結乾燥化合物の再構成または希釈に使用することができる。場合によって、そのような容器(複数可)には、医薬品または生物学的製品の製造、使用、または販売を規制する政府当局によって定められた形態の通知が添付されることがあり、この通知はヒト投与用の製造、使用、または販売に関する当局による認可を表す。 Further, the pharmaceutical composition contains (a) a container containing the compound of the present technology in lyophilized form and (b) a second pharmaceutically acceptable diluent for injection (eg, sterile water). Can be provided as a pharmaceutical kit containing the container of. Pharmaceutically acceptable diluents can be used to reconstitute or dilute the lyophilized compounds of the art. In some cases, such containers (s) may be accompanied by a notice in the form prescribed by governmental authorities that regulate the manufacture, use, or sale of pharmaceutical or biological products, and this notice may be attached. Represents regulatory approval for manufacture, use, or sale for human administration.
別の態様では、上記の疾患の治療に有用な物質を含有する製品が含まれる。いくつかの実施形態では、製品は容器及びラベルを含む。好適な容器としては、例えば、ボトル、バイアル、シリンジ、及び試験管が挙げられる。容器は、ガラスやプラスチックなどの種々の材料で形成されていてよい。いくつかの実施形態では、容器は、本明細書に記載の疾患の治療に有効である組成物を保有し、滅菌アクセスポートを有し得る。例えば、容器は、皮下注射針によって穿孔可能な栓を有する静注液バッグまたはバイアルであり得る。組成物中の活性薬剤は本技術の化合物である。いくつかの実施形態では、容器表面のラベルまたは容器に添付されるラベルには、選ばれた疾患の治療に組成物を使用する旨が表示されている。製品は、リン酸緩衝生理食塩水、リンゲル液、またはデキストロース溶液などの薬学的に許容される緩衝液を含む第2の容器をさらに含んでもよい。さらに商業的観点及び使用者の観点から望ましい他の材料、例えば緩衝液、希釈剤、フィルター、針、シリンジ、及び使用説明書付きの添付文書を含んでもよい。 In another aspect, a product containing a substance useful in treating the above-mentioned diseases is included. In some embodiments, the product comprises a container and a label. Suitable containers include, for example, bottles, vials, syringes, and test tubes. The container may be made of various materials such as glass and plastic. In some embodiments, the container carries a composition that is effective in treating the diseases described herein and may have a sterile access port. For example, the container can be an IV bag or vial with a stopper that can be pierced by a hypodermic needle. The active agent in the composition is a compound of the present technology. In some embodiments, the label on the surface of the container or the label attached to the container indicates that the composition will be used in the treatment of the disease of choice. The product may further comprise a second container containing a pharmaceutically acceptable buffer such as phosphate buffered saline, Ringer's solution, or dextrose solution. Further may include other materials desirable from a commercial and user standpoint, such as buffers, diluents, filters, needles, syringes, and package inserts with instructions for use.
当業者は、これ以上の説明がなくとも上記の説明に基づいて、本開示を最大限に利用できると考えられる。したがって、以下の具体的な実施形態は、単なる例示として解釈されるものであり、いかなる場合においても本開示の残部を限定するものではない。本明細書に引用されるすべての刊行物は、本明細書で参照される目的または主題について参照として組み込まれる。 Those skilled in the art will be able to make the best use of this disclosure based on the above description without further explanation. Therefore, the following specific embodiments are to be construed as mere examples and do not limit the rest of the disclosure in any case. All publications cited herein are incorporated as references for the purposes or subjects referred to herein.
実施例1.IL23A及びBAFFを標的とする例示的化合物の構築
本技術の化合物は、当技術分野で既知の組換え方法(例えば、PCT公開WO2006/113665、WO2008/157379、及びWO2010/080538を参照。そのすべての内容が参照により本明細書に組み込まれる)により作製した。表2Aは、以下の各実施例で利用した、IL23A及びBAFFの両方に結合する例示的な化合物を示している。簡潔には、各化合物のための第1及び第2のポリペプチドをコードするプラスミドを、FreeStyle MAX Reagent(CHO)を使用してCHO−S細胞に一緒にトランスフェクトした。細胞を13〜14日間培養し、この細胞によって産生された化合物を、プロテインAクロマトグラフィーを使用して精製した。化合物を、サイズ排除クロマトグラフィーを使用してさらに精製した。
比較目的で対照抗体も使用した。対照は、BAFFまたはIL23のいずれかを標的とするモノクローナル抗体であった。
実施例2:化合物の熱安定性
方法
化合物のリン酸緩衝液溶液2mg/mlの、熱的アンフォールディング及び凝集を、自動化キャピラリーDSC(MicroCal,LLC、Boston)によって走査速度60℃/時にて20℃〜110℃でモニターした。対応する緩衝液で2回走査を実施して、機器の熱履歴を確認し、各サンプルについて機器ベースラインを得て、両走査の平均をその後のタンパク質サーモグラムから差し引くことにより、見かけの熱容量を得た。次いで走査を正規化してOrigin 7.0で分析した。それぞれの得られた熱容量サーモグラムから転移前のベースラインを差し引いて得られた超過熱容量(Cp,ex)を温度の関数として得た。転移温度(Tm)の報告値は、実験から得たサーモグラムの目視検査により決定されたピーク最大値の位置を表す。
Example 2: Thermal Stability of Compounds Thermal unfolding and aggregation of 2 mg / ml phosphate buffer solution of a compound is performed by an automated capillary DSC (MicroCal, LLC, Boston) at a scanning rate of 60 ° C./time at 20 ° C. Monitored at ~ 110 ° C. The apparent heat capacity was determined by performing two scans with the corresponding buffer to check the thermal history of the instrument, obtaining an instrument baseline for each sample, and subtracting the average of both scans from the subsequent protein thermogram. Obtained. Scans were then normalized and analyzed at Origin 7.0. The excess heat capacity (Cp, ex) obtained by subtracting the pre-transition baseline from each obtained heat capacity thermogram was obtained as a function of temperature. The reported value of transition temperature (Tm) represents the position of the maximum peak value determined by visual inspection of the thermogram obtained from the experiment.
結果
結果を表3に示す。データは、IL23A及びBAFFを標的とする例示的な化合物の第1ピーク(Tm1)の転移温度範囲が、51.59〜71.25℃の範囲であることを示す。例示的な化合物すべてが同じ全体構造を有し、IL−23Aを標的とする同じVH及びVL遺伝子配列を含んでいたため、この結果は意外である。転移温度が高い化合物ほど安定であり、長期の貯蔵寿命を有すると予測される。
実施例3.例示的な化合物の表面プラズモン共鳴(SPR)親和性
試験化合物をSPRによって分析し、BAFF及びIL23Aに対する親和性を決定した。
Example 3. Surface plasmon resonance (SPR) affinity of exemplary compounds Test compounds were analyzed by SPR to determine their affinity for BAFF and IL23A.
材料及び方法
SPR実験は、ProteOn XPR36装置(Bio Rad)で実施した。0.5%SDS、50mM NaOH、及び100mM HClを、垂直及び水平の両方向に流速30μl/分にて60秒間逐次注入してGLMチップを予めコンディショニングした。
Materials and Methods SPR experiments were performed on the ProteOn XPR36 device (Bio Rad). The GLM chip was preconditioned by sequentially injecting 0.5% SDS, 50 mM NaOH, and 100 mM HCl in both vertical and horizontal directions at a flow rate of 30 μl / min for 60 seconds.
次いで、1:1比のEDC(76.7mg/ml)及びスルホ−NHS(21.7mg/ml)混合物を水平6チャネルに注入して、予めコンディショニングしたGLMチップを活性化した。10mM、pH5.0の酢酸ナトリウム緩衝液中の濃度30μg/mlのヤギ抗ヒトIgG(GAHA)Fcガンマ(Invitrogen)を、水平6チャネルの活性化されたGLMチップ上に8000レゾナンスユニットとなるように固定化した。最後に、水平6チャネルに1MエタノールアミンHClを入れ、このチップを不活性化させた。調製したGAHAチップを垂直方向に回転させて、垂直5チャネルにわたり試験化合物を捕捉し、最後のチャネルはカラム標準として使用した。 A 1: 1 ratio EDC (76.7 mg / ml) and sulfo-NHS (21.7 mg / ml) mixture was then injected into the horizontal 6 channels to activate the pre-conditioned GLM chips. Goat anti-human IgG (GAHA) Fc gamma (Invitrogen) at a concentration of 30 μg / ml in 10 mM, pH 5.0 sodium acetate buffer to form 8000 resonance units on an activated GLM chip with 6 horizontal channels. Fixed. Finally, 1M ethanolamine HCl was placed in 6 horizontal channels to inactivate the chip. The prepared GAHA chip was rotated vertically to capture the test compound over 5 vertical channels, the last channel being used as a column standard.
次いで、捕捉したチップを再び水平方向に回転して結合させた。10.0nM、5.00nM、2.50nM、1.25nM、及び0.625nMの5種類の濃度の結合したヒトIL−23(Boehringer Ingelheim Pharmaceuticals,Inc.)を、以下のランニング緩衝液(Bio Rad):リン酸緩衝生理食塩水(pH7.4)、0.005%Tween20中で流速40μl/分にて10分間、試験化合物表面にわたって水平に注入した。2時間、解離させた。10分間の会合及び2時間の解離の後、0.85%リン酸(Bio Rad)を水平及び垂直の両方向に流速100μl/分で短時間パルス注入(18秒)して、GAHA表面を再生した。再生したGAHAは別の結合サイクルですぐに使用できる状態であった。カニクイザルIL23、ヒトBAFF、またはカニクイザルBAFFへの化合物の結合を同様の方法で行ったが、ヒトBAFFまたはカニクイザルBAFFへの結合での滴定濃度は、6.25nM、3.12nM、1.56nM、0.78nM、及び0.39nMである。
The captured chips were then rotated horizontally again to join. Combined human IL-23 (Boehringer Ingelheim Pharmaceuticals, Inc.) at five concentrations of 10.0 nM, 5.00 nM, 2.50 nM, 1.25 nM, and 0.625 nM was added to the following running buffer (Bio Rad). ): Phosphate buffered saline (pH 7.4), injected horizontally over the surface of the test compound at a flow rate of 40 μl / min in 0.005
結果:
表4の結果は、試験した両方の化合物がピコモル範囲の解離定数(KD)でBAFF及びIL23に結合できることを示している。
The results in Table 4 show that both compounds tested can bind to BAFF and IL23 with a dissociation constant (KD) in the picomolar range.
実施例4.BAFFR−CHOルシフェラーゼレポーター細胞におけるヒト及びカニクイザルBAFF三量体誘導性NFkB活性化の阻害
材料/方法:
簡潔には、ヒトBAFFR CHO NFkBルシフェラーゼレポーター細胞を採取、洗浄、計数し、既知組成の無血清培地(Lonza)であるX−VIVO15にペニシリン/ストレプトマイシン1%(v/v)を加えたアッセイ培地(AM)中に濃度1.6×106細胞/mlで再懸濁した。組換えヒトまたはカニクイザルBAFF三量体(Boehringer IngelheimPharmaceuticals,Inc.)をAM中にて単一濃度(52pM)で調製し、加湿インキュベーターにて、37℃、5%CO2で30分間、AM単独、または逐次滴定した試験化合物とプレインキュベートした。BAFFと試験化合物のプレインキュベーション後、50ulの混合物(複数可)を50ulの細胞に添加し、試験プレートをさらに(上記の通り)37℃で24時間インキュベートした。対照サンプルに、AM(非刺激対照)またはAMで希釈した組換えBAFF三量体(刺激対照)を加えた。24時間のインキュベーション後、細胞懸濁液を100ulのSTEADY−Glo試薬(Promega)を用いて製造業者の指示に従って処理し、ルシフェラーゼ発現についてアッセイした。結果の相対発光量(RLU)を試験化合物のLog10ナノモル濃度に対してプロットし、IC50及びIC90値を、ExcelアドインXlfit(ID Business Solutions Limited)でサポートされる4パラメーターロジスティックモデルを用いて算出した。試験化合物のIC50及びIC90値を上記のように算出し、複数の実験全体の幾何平均を算出し、表5及び表6に示した。
Example 4. Inhibition of human and cynomolgus monkey BAFF trimer-induced NFkB activation in BAFFR-CHO luciferase reporter cells Materials / Methods:
Briefly, human BAFFR CHO NFkB luciferase reporter cells were collected, washed, counted, and assayed medium (X-VIVO15, a serum-free medium (Lonza) of known composition, plus penicillin /
結果:
試験化合物は、BAFFR−CHOルシフェラーゼレポーター細胞においてヒト及びカニクイザルBAFF三量体誘導性NFkB活性化を用量依存的に阻害した。表5及び6に示す結果は、試験化合物のIC50及びIC90の幾何平均値が対照BAFFアンタゴニストに匹敵するか、またはそれよりも強力であることを示している。
The test compound dose-dependently inhibited human and cynomolgus monkey BAFF trimer-induced NFkB activation in BAFFR-CHO luciferase reporter cells. The results shown in Tables 5 and 6 show that the geometric mean values of IC 50 and IC 90 of the test compounds are comparable to or stronger than the control BAFF antagonists.
実施例5.TACI−CHOルシフェラーゼレポーター細胞におけるヒトBAFF三量体誘導性NFkB活性化の阻害
材料/方法:
簡潔には、ヒトTACI CHO NFkBルシフェラーゼレポーター細胞を採取、洗浄、計数し、既知組成の無血清培地(Lonza)であるX−VIVO15にペニシリン/ストレプトマイシン1%(v/v)を加えたアッセイ培地(AM)中に濃度1.6×106細胞/mlで再懸濁した。組換えヒトBAFF三量体(Boehringer IngelheimPharmaceuticals,Inc.)をAM中にて単一濃度(222pM)で調製し、加湿インキュベーターにて、37℃、5%CO2で30分間、AM単独、または逐次滴定した試験化合物とプレインキュベートした。BAFFと試験化合物のプレインキュベーション後、50ulの混合物(複数可)を50ulの細胞に添加し、試験プレートをさらに(上記の通り)37℃で24時間インキュベートした。対照サンプルに、AM(非刺激対照)またはAMで希釈した組換えヒトBAFF三量体(刺激対照)を加えた。24時間のインキュベーション後、細胞懸濁液を100ulのSTEADY−Glo試薬(Promega)を用いて製造業者の指示に従って処理し、ルシフェラーゼ発現についてアッセイした。結果の相対発光量(RLU)を試験化合物のLog10ナノモル濃度に対してプロットし、IC50及びIC90値を、ExcelアドインXlfit(ID Business Solutions Limited)でサポートされる4パラメーターロジスティックモデルを用いて算出した。試験化合物のIC50及びIC90値を上記のように算出し、複数の実験全体の幾何平均を算出し、表7に示した。
Example 5. Inhibition of human BAFF trimer-induced NFkB activation in TACI-CHO luciferase reporter cells Materials / Methods:
Briefly, human TACI CHO NFkB luciferase reporter cells were collected, washed, counted, and assay medium (X-VIVO15, a serum-free medium (Lonza) of known composition, plus penicillin /
結果:
試験化合物は、TACI−CHOルシフェラーゼレポーター細胞においてヒトBAFF三量体誘導性NFkB活性化を用量依存的に阻害した。表7に示す結果は、試験化合物のIC50及びIC90の幾何平均値が対照BAFFアンタゴニストに匹敵するか、またはそれよりも強力であることを示している。
The test compound dose-dependently inhibited human BAFF trimer-induced NFkB activation in TACI-CHO luciferase reporter cells. The results shown in Table 7 show that the geometric mean values of IC 50 and IC 90 of the test compounds are comparable to or stronger than the control BAFF antagonists.
実施例6.BAFFR−CHOルシフェラーゼレポーター細胞におけるBAFF60量体誘導性NFkB活性化の阻害
材料/方法:
簡潔には、ヒトBAFFR CHO NFkBルシフェラーゼレポーター細胞を採取、洗浄、計数し、既知組成の無血清培地(Lonza)であるX−VIVO15にペニシリン/ストレプトマイシン1%(v/v)を加えたアッセイ培地(AM)中に濃度1.6×106細胞/mlで再懸濁した。組換えヒトBAFF60量体(Boehringer IngelheimPharmaceuticals,Inc.)をAM中にて単一濃度(4.2pM)で調製し、加湿インキュベーターにて、37℃、5%CO2で30分間、AM単独、または逐次滴定した試験化合物とプレインキュベートした。BAFFと試験化合物のプレインキュベーション後、50ulの混合物(複数可)を50ulの細胞に添加し、試験プレートをさらに(上記の通り)37℃で24時間インキュベートした。対照サンプルに、AM(非刺激対照)またはAMで希釈した組換えヒトBAFF60量体(刺激対照)を加えた。24時間のインキュベーション後、細胞懸濁液を100ulのSTEADY−Glo試薬(Promega)を用いて製造業者の指示に従って処理し、ルシフェラーゼ発現についてアッセイした。結果の相対発光量(RLU)を試験化合物のLog10ナノモル濃度に対してプロットし、IC50及びIC90値を、ExcelアドインXlfit(ID Business Solutions Limited)でサポートされる4パラメーターロジスティックモデルを用いて算出した。試験化合物のIC50及びIC90値を上記のように算出し、複数の実験全体の幾何平均を算出し、表8に示した。
Example 6. Inhibition of BAFF60-mer-induced NFkB activation in BAFFR-CHO luciferase reporter cells Materials / Methods:
Briefly, human BAFFR CHO NFkB luciferase reporter cells were collected, washed, counted, and assayed medium (X-VIVO15, a serum-free medium (Lonza) of known composition, plus penicillin /
結果:
試験化合物は、BAFFR−CHOルシフェラーゼレポーター細胞においてヒトBAFF60量体誘導性NFkB活性化を用量依存的に阻害した。表8に示す結果は、試験化合物A、B、C、D、O、P、Q、及びRのIC50及びIC90の幾何平均値が3つすべての対照BAFFアンタゴニストよりも強力であったことを示している。
The test compound dose-dependently inhibited human BAFF60-mer-induced NFkB activation in BAFFR-CHO luciferase reporter cells. The results shown in Table 8 show that the geometric mean values of IC 50 and IC 90 of test compounds A, B, C, D, O, P, Q, and R were stronger than all three control BAFF antagonists. Is shown.
実施例7:BAFFR−CHOルシフェラーゼレポーター細胞における膜結合BAFF誘導性NFkB活性化の中和
材料/方法:
ヒトBAFFを発現するCHO−K1細胞を計数し、2×106細胞/mlの濃度で標準成長培地中に再懸濁した。膜結合BAFFの切断を停止するために、細胞を0.125%パラホルムアルデヒド(Electron Microscopy)で処理し、室温で1時間インキュベートした。次いで、固定したヒトBAFF CHO−K1細胞を洗浄し、標準成長培地中に2×106細胞/mlで再懸濁し、37℃、5%CO2で一晩インキュベートした。次いで、固定したヒトBAFF CHO−K1細胞を採取し、ペニシリン/ストレプトマイシン1%(v/v)を含有する既知組成の無血清アッセイ培地(AM)であるX−VIVO15(Lonza)に濃度3.2×106細胞/mlで再懸濁した。
Example 7: Neutralization of membrane-bound BAFF-induced NFkB activation in BAFFR-CHO luciferase reporter cells Material / Method:
CHO-K1 cells expressing human BAFF were counted and resuspended in standard growth medium at a concentration of 2 × 10 6 cells / ml. To stop cleavage of membrane-bound BAFF, cells were treated with 0.125% paraformaldehyde (Electron Microscopic) and incubated for 1 hour at room temperature. Then washed fixed human BAFF CHO-K1 cells, in a standard growth medium and resuspended at 2 × 10 6 cells / ml, 37 ° C., in 5% CO 2 and incubated overnight. Immobilized human BAFF CHO-K1 cells were then harvested and concentrated in X-VIVO15 (Lonza), a serum-free assay medium (AM) of known composition containing penicillin /
ヒトBAFFR CHO NFkBルシフェラーゼレポーター細胞を採取、洗浄し、アッセイ培地中に濃度1.6×106細胞/mlで再懸濁した。固定したヒトBAFF CHO−K1細胞を、AM中で3.2×106細胞/mlに調製し、逐次滴定した試験化合物と30分間プレインキュベートした後、50ulのヒトBAFFR CHO NFkBルシフェラーゼレポーター細胞に添加し、37℃でさらに24時間インキュベートした。対照レポーター細胞に、AM(非刺激対照)またはAMで希釈した固定したヒトBAFF CHO−K1細胞(刺激対照)を加えた。24時間のインキュベーション後、サンプルを100ulのSTEADY−Glo試薬(Promega)を用いて処理し、ルシフェラーゼ発現についてアッセイした。相対発光量(RLU)を試験化合物のLog10ナノモル濃度に対してプロットし、IC50及びIC90値を、ExcelアドインXlfit(ID Business Solutions Limited)でサポートされる4パラメーターロジスティックモデルを用いて算出した。試験化合物のIC50及びIC90値を上記のように算出し、複数の実験全体の幾何平均を算出し、表9に示した。 Harvested human BAFFR CHO NFkB luciferase reporter cells were washed and resuspended at a concentration 1.6 × 10 6 cells / ml in assay medium. Adding fixed human BAFF CHO-K1 cells, prepared in 3.2 × 10 6 cells / ml in AM, after preincubation sequentially titrated test compound and 30 minutes, the human BAFFR CHO NFkB luciferase reporter cells 50ul And incubated at 37 ° C. for an additional 24 hours. Fixed human BAFF CHO-K1 cells (stimulation control) diluted with AM (non-stimulation control) or AM were added to the control reporter cells. After 24 hours of incubation, samples were treated with 100 ul of STEADY-Glo reagent (Promega) and assayed for luciferase expression. Relative luminescence (RLU) was plotted against Log 10 nanomolar concentration of the test compound and IC 50 and IC 90 values were calculated using a 4-parameter logistic model supported by Excel add-in Xlfit (ID Business Solutions Limited). .. The IC 50 and IC 90 values of the test compounds were calculated as described above, and the geometric mean of the entire plurality of experiments was calculated and shown in Table 9.
結果
試験化合物は、BAFFR−CHOルシフェラーゼレポーター細胞において膜結合ヒトBAFF誘導性NFkB活性化を用量依存的に阻害した。表9に示す結果は、試験化合物のIC50及びIC90値が3つすべての対照BAFFアンタゴニストよりも強力であったことを示している。
実施例8:STAT3−ルシフェラーゼレポーターを用いた、リンパ芽球B細胞(DB細胞)におけるヒトIL−23活性の阻害
材料/方法:
リンパ芽球B細胞(DB細胞;ATCCカタログ番号CRL−2289)を、レンチウイルスSTAT−3/ルシフェラーゼレポーター遺伝子(Qiagen)で安定に形質導入した。形質導入された細胞は、ピューロマイシン(Life Technologies)を用いて選択した。完全培地は、10%FBS(Hyclone)及び2μg/mLピューロマイシン(Life Technologies)を補充したRPMI−1640培地(Life Technologies)であった。アッセイ培地は、10%FBS(Hyclone)を補充したRPMI−1640培地(Life Technologies)であった。
Example 8: Inhibition of human IL-23 activity in lymphoblast B cells (DB cells) using STAT3-luciferase reporter Material / Method:
Lymphoblast B cells (DB cells; ATCC Catalog No. CRL-2289) were stably transduced with the lentivirus STAT-3 / luciferase reporter gene (Qiagen). Transduced cells were selected using puromycin (Life Technologies). The complete medium was RPMI-1640 medium (Life Technologies) supplemented with 10% FBS (Hycrone) and 2 μg / mL puromycin (Life Technologies). The assay medium was RPMI-1640 medium (Life Technologies) supplemented with 10% FBS (Hycrone).
遺伝子操作したDB−STAT3細胞を、80μL/ウェルでアッセイ培地を入れた白色の平底96ウェルプレートに20,000細胞/ウェルで播種した。試験化合物(10倍)を、アッセイ培地を入れたポリプロピレンの丸底96ウェルプレート中で調製し、1μg/mL〜10pg/mLの用量範囲になるように希釈した。10μLの希釈した試験分子またはアッセイ培地(対照ウェル用)を3連の各ウェルに添加した。10μLの10倍ヒトIL−23(最終濃度1プレートあたり75ng/mLまで)を各ウェルに添加した。あるいは、10μLの培地を対照ウェルに添加した。アッセイで使用する際に選択したIL−23の用量は、以前の研究で決定された遺伝子操作DB細胞に対するヒトIL−23のEC60刺激薬用量を表す。プレートを5%CO2中、37℃で一晩インキュベートした。ONE−Glo(商標)ルシフェラーゼアッセイ試薬(Promega)を調製し、100μLを各ウェルに添加して混合した。発光をEnvisionプレートリーダーで測定した後、抗体濃度(x軸)に対してプロットした(y軸)。化合物のIC50値は、GraphPad Prism 6ソフトウェアを使用して4パラメーターシグモイド用量反応関数にデータを適用することによって決定した。IC90値は、GraphPad Prism 6ソフトウェアのFind ECanythingによりデータを算出することによって決定した。複数の実験全体の幾何平均を算出し、表10に示した。 Genetically engineered DB-STAT3 cells were seeded at 20,000 cells / well on a white flat-bottomed 96-well plate containing assay medium at 80 μL / well. Test compound (10-fold) was prepared in a polypropylene round bottom 96-well plate containing assay medium and diluted to a dose range of 1 μg / mL to 10 pg / mL. 10 μL of diluted test molecule or assay medium (for control wells) was added to each of the triple wells. 10 μL of 10-fold human IL-23 (up to 75 ng / mL final concentration per plate) was added to each well. Alternatively, 10 μL of medium was added to the control wells. The dose of IL-23 selected for use in the assay represents the EC 60 stimulant dose of human IL-23 for genetically engineered DB cells determined in previous studies. The plates were incubated overnight at 37 ° C. in 5% CO 2. ONE-Glo ™ luciferase assay reagent (Promega) was prepared and 100 μL was added to each well and mixed. Luminescence was measured with an Envision plate reader and then plotted against antibody concentration (x-axis) (y-axis). Compound IC 50 value was determined by applying the data to a four parameter sigmoidal dose-response function using GraphPad Prism 6 software. The IC 90 value was determined by calculating the data by Find E Planning of GraphPad Prism 6 software. The geometric mean of the entire plurality of experiments was calculated and shown in Table 10.
結果
結果は、試験化合物が、STAT3−ルシフェラーゼレポーターにより、DB細胞におけるヒトIL−23活性を阻害できることを示した。
実施例9:マウス脾細胞におけるヒト及びカニクイザルIL−23活性の阻害
材料及び方法
マウス脾臓(13週齢未満の雌C57BL/6;Jackson Laboratories)由来の単核細胞を単離、洗浄、計数し、標準T細胞培地(TCM)中に4×106細胞/mlで再懸濁した。100マイクロリットルのmIL−2/脾細胞懸濁液を96ウェルマイクロタイタープレートに添加した。組換えヒトIL−23(Boehringer Ingelheim Pharmaceuticals,Inc.)または組換えカニクイザルIL−23(Boehringer IngelheimPharmaceuticals,Inc.)をTCMで希釈し、TCM単独または滴定した試験サンプルと37℃で2時間プレインキュベートした。試験サンプルとIL−23のプレインキュベーション後、100ulの混合物を細胞に添加し、試験プレートを5%CO2加湿空気と共に37℃で48時間インキュベートした。対照サンプルに、TCM(非刺激対照)またはTCMで希釈した組換えIL−23(刺激対照)を加えた。インキュベーション後、製造業者の指示(R&D Systems)に従ってQuantikine(登録商標)マウスIL−17イムノアッセイを用いて上清からマウスIL−17レベルを測定した。mIL−17pg/mlの補間値を各サンプルについて測定し、対照のパーセント(POC)に変換した。POCを試験サンプル濃度に対してプロットし、IC90値を、ExcelアドインXLfit(Activity Baseソフトウェア、ID Business Solutions,Ltd.)で可能である4パラメーターロジスティックモデルを用いて算出した。試験化合物を上記のようにIC50及びIC90に関して分析し、各試験化合物に対する複数の実験全体の幾何平均を算出し、表11に示した。
Example 9: Inhibition of human and crab monkey IL-23 activity in mouse spleen Materials and methods Mononuclear cells derived from mouse spleen (female C57BL / 6 younger than 13 weeks; Jackson Laboratories) were isolated, washed and counted. It was resuspended in standard T cell medium (TCM) at 4 × 10 6 cells / ml. 100 microliters of mIL-2 / splenocyte suspension was added to 96-well microtiter plates. Recombinant human IL-23 (Boehringer Ingelheim Pharmaceuticals, Inc.) or recombinant cynomolgus monkey IL-23 (Boehringer Ingelheim Pharmaceuticals, Inc.) diluted with TCM and incubated with TCM alone or instilled at 2 ° C. .. After preincubation of the test sample and IL-23, 100 ul of the mixture was added to the cells and the test plate was incubated with 5% CO 2 humidified air at 37 ° C. for 48 hours. TCM (non-stimulated control) or recombinant IL-23 (stimulated control) diluted with TCM was added to the control sample. After incubation, mouse IL-17 levels were measured from the supernatant using the Quantikine® mouse IL-17 immunoassay according to the manufacturer's instructions (R & D Systems). Interpolated values of mIL-17 pg / ml were measured for each sample and converted to a control percentage (POC). POCs were plotted against test sample concentrations and IC 90 values were calculated using a 4-parameter logistic model enabled by Excel add-in XLfit (Activity Base software, ID Business Solutions, Ltd.). The test compounds were analyzed for IC 50 and IC 90 as described above, and the geometric mean of the entire experiment for each test compound was calculated and shown in Table 11.
結果
結果は、試験化合物が、ヒト及びカニクイザル両方のIL23誘導性マウス脾細胞のマウスIL−17の放出を阻害できることを示した。
実施例10.カニクイザルにおける化合物の薬物動態学
材料及び方法
試験化合物A、B、C、及びDについての単回静脈内(IV)用量PK試験を雄カニクイザル(分子あたりn=2)で実施した。用量を1mg/kgの低速IVボーラス注射として投与した。投与前、投与日の投与後0.25時間、2時間、及び6時間後、投与後1日、2日、3日、4日、7日、10日、14日、21日、及び28日後に全血サンプルを採取した。投与された分子の血清濃度は、MSDを用いたリガンド結合アッセイによって測定した。
Example 10. Pharmacokinetics of Compounds in Cynomolgus Monkey Materials and Methods A single intravenous (IV) dose PK test for test compounds A, B, C, and D was performed on male cynomolgus monkeys (n = 2 per molecule). The dose was administered as a slow IV bolus injection of 1 mg / kg. 0.25 hours, 2 hours, and 6 hours after administration on the day of administration, 1 day, 2 days, 3 days, 4 days, 7 days, 10 days, 14 days, 21 days, and 28 days after administration. A whole blood sample was later taken. The serum concentration of the administered molecule was measured by a ligand binding assay using MSD.
較正標準曲線及び品質管理(QC)サンプルを、100%のプールしたカニクイザル血清で調製した。各標準曲線は、開始濃度512ng/mLから3倍に系列希釈された0以外の7ポイントからなる。またブランクサンプル(アナライトを含まないマトリックス)も含めた。開始濃度256ng/mLで低範囲、中範囲、及び高範囲の5種類のQCサンプルを調製し、次いで8ng/mLまで4倍に系列希釈し、さらに2倍希釈物を使用して最低のQCを4ng/mLで調製した。標準曲線及びQCサンプルは、分析の実行ごとに2連で構成した。定量の下限及び上限は、公称濃度が30パーセント(%)を超えない再現可能な逆算濃度を有する最低及び最大のQCポイントと定義した。標準曲線ポイントの許容基準は、公称濃度の30パーセント(%)であった。 Calibration curve and quality control (QC) samples were prepared with 100% pooled cynomolgus monkey serum. Each standard curve consists of 7 non-zero points serially diluted 3-fold from the starting concentration of 512 ng / mL. A blank sample (matrix without analyze) was also included. Five low-range, medium-range, and high-range QC samples were prepared at an starting concentration of 256 ng / mL, then serially diluted 4-fold to 8 ng / mL, and a 2-fold dilution was used to obtain the lowest QC. Prepared at 4 ng / mL. The standard curve and QC sample consisted of two units for each analysis run. The lower and upper limits of quantification were defined as the lowest and highest QC points with reproducible back calculation concentrations where the nominal concentration did not exceed 30 percent. The permissible criterion for standard curve points was 30 percent (%) of the nominal concentration.
血清サンプル中の活性薬物濃度を測定するために、結合緩衝液(0.05%Tween 20を加えた1倍PBS中、5%BSA)に、0.5μg/mLのビオチン化組換えヒトBAFF及び0.5μg/mLのスルホ標識化ヤギ抗ヒトIgG検出物を混合し、マスターミックスを調製した。マスターミックスをウェルあたり50μLで96ウェル非結合性遮光プレートに添加した。25μLの標準及びQC物質(原液を結合緩衝液で1:20に希釈)を、マスターミックスを入れた非結合性プレートに2連でウェルごとに添加した。未知の血清サンプルを、結合緩衝液で1:20に、5%血清を含有する結合緩衝液で1:400に希釈した。25μLの希釈サンプルを、マスターミックスを入れた非結合性プレートにウェルごとに添加した。非結合性プレートをプレートシェーカー上で室温にてインキュベートした(500rpm、1.5時間)。並行して、MSDストレプトアビジン金プレートを150μLのブロッキング緩衝液(0.05%Tween 20を加えた1倍PBSによる5%BSA)を用いてブロッキングし、プレートシェーカー上で室温にてインキュベートした(500rpm、1.5時間)。インキュベーション後、MSDプレートをウェルあたり300μLの洗浄緩衝液(1倍PBS中、0.05%Tween20)で3回洗浄した。非結合性プレートから50μLのサンプルをMSDプレートに添加し、室温でインキュベートした(1.5時間、600rpm)。インキュベーション後、プレートを洗浄緩衝液で3回洗浄し、150μLの2倍リード緩衝液Tを各ウェルに添加し、MSD Sector Imager 2400で直ちに読み取った。MSD Discovery Workbenchソフトウェアを使用して、標準曲線を4パラメーターロジスティック式にフィッティングした。薬物動態パラメーターを、Phoenix WinNonlin 6.3(Certara、MD,USA)のノンコンパートメント解析を使用して算出した。
To measure the concentration of active drug in serum samples, 0.5 μg / mL biotinylated recombinant human BAFF and in binding buffer (5% BSA in 1x PBS plus 0.05% Tween 20) A master mix was prepared by mixing 0.5 μg / mL of sulfo-labeled goat anti-human IgG detectors. The master mix was added to a 96-well nonbonding light-shielding plate at 50 μL per well. 25 μL of standard and QC material (stock solution diluted 1:20 with binding buffer) was added well-by-well to non-bonding plates containing the master mix. Unknown serum samples were diluted 1:20 with binding buffer and 1: 400 with binding buffer containing 5% serum. A 25 μL diluted sample was added well-by-well to a non-bonding plate containing the master mix. Nonbonding plates were incubated on a plate shaker at room temperature (500 rpm, 1.5 hours). In parallel, MSD streptavidin gold plates were blocked with 150 μL of blocking buffer (5% BSA with 1x PBS plus 0.05% Tween 20) and incubated on a plate shaker at room temperature (500 rpm). , 1.5 hours). After incubation, MSD plates were washed 3 times with 300 μL wash buffer per well (0.05
結果:
試験化合物に関する平均(SD)血清濃度対時間プロファイルを図2に示す。試験化合物に関する平均(SD)薬物動態パラメーターを表12にまとめる。陽性の抗薬物抗体であることが確認され、経時的薬物濃度の急激な低下を示した血清サンプルは、薬物動態学パラメーター計算から除外した。
The mean (SD) serum concentration vs. time profile for the test compound is shown in FIG. The mean (SD) pharmacokinetic parameters for the test compounds are summarized in Table 12. Serum samples that were confirmed to be positive anti-drug antibodies and showed a sharp decrease in drug concentration over time were excluded from the pharmacokinetic parameter calculation.
実施例11.例示的な化合物のヒトPK及びヒト用量の予測
分布容積1.0、クリアランス0.85のアロメトリー指数を用いて、基本的なDedrick法によるスケーリングを使用し、化合物Bの平均サル血清濃度をヒトにスケーリングした。予測ヒト静脈内血清濃度−時間プロファイルを、線形2コンパートメントモデルにフィッティングした。2コンパートメント静脈内モデルからのパラメーターと、市販の治療用mAbで測定された平均皮下吸収速度及びバイオアベイラビリティとを組み合わせることにより、ヒト皮下血清濃度−時間プロファイルを予測した。クリアランス及び終末相半減期は、健常ヒトにおいてそれぞれ0.34L/d及び9.9dであると予測される。隔週1回の100mg皮下用量投与後の化合物Bの予測ヒト血清濃度−時間プロファイルを図3に示す。
Example 11. Prediction of human PK and human dose of an exemplary compound Using an allometry index with a volume of distribution of 1.0 and a clearance of 0.85, using basic Dedrick scaling to obtain the average monkey serum concentration of compound B in humans. Scaled. Predicted human intravenous serum concentration-time profiles were fitted into a linear two-compartment model. The human subcutaneous serum concentration-time profile was predicted by combining parameters from a two-compartment intravenous model with mean subcutaneous absorption rate and bioavailability measured with commercially available therapeutic mAbs. Clearance and terminal phase half-life are predicted to be 0.34 L / d and 9.9 d, respectively, in healthy humans. The predicted human serum concentration-time profile of Compound B after biweekly administration of 100 mg subcutaneous dose is shown in FIG.
ヒトの予測有効用量は、隔週1回の皮下送達で1mg/kgである。この用量計画は、隔週またはそれ以下の頻度の皮下投与でCmin≧30nM(6μg/mL)を維持すると予測される。予測有効用量は、SLE及びRA患者におけるベリムマブ(Benlysta(登録商標))、タバルマブ、及びブリシビモドについて観察された濃度−PDバイオマーカー応答に基づいてもよい。これらの研究では、定常状態におけるCminが30〜40nMの場合にBAFF関連バイオマーカーの阻害が最大となることを関連付けた。IL23の中和に必要な濃度は、BAFFの中和に必要とされるよりもはるかに低く、したがって二重アンタゴニスト全体で必要とされるCminには影響を及ぼさない。 The predicted effective dose for humans is 1 mg / kg for biweekly subcutaneous delivery. This dose plan is expected to maintain Cmin ≥ 30 nM (6 μg / mL) with biweekly or less frequent subcutaneous administration. The predicted effective dose may be based on the concentration-PD biomarker response observed for belimumab (Benlysta®), tabalumab, and brishibimod in patients with SLE and RA. These studies have associated maximal inhibition of BAFF-related biomarkers when steady-state Cmin is 30-40 nM. The concentration required for neutralization of IL23 is much lower than that required for neutralization of BAFF and therefore does not affect the Cmin required for the entire dual antagonist.
実施例12.化合物の精製
方法:
アフィニティー精製工程としてMab Select SuReを使用して化合物を精製した。溶出は酢酸ナトリウム緩衝液pH3.5を使用して実施した。Mab Select SuRe精製の後、サンプルを中和し、Poros 50 HS樹脂に添加して、クエン酸ナトリウム緩衝液中で塩化ナトリウム勾配を利用して溶出した。単量体ピークは20mMクエン酸ナトリウム及び120MM NaCl(pH6.0)で溶出する。イオン交換クロマトグラフィー後、サンプルは一貫して>95%単量体であった。
Example 12. Compound purification method:
Compounds were purified using Mab Select SuRe as an affinity purification step. Elution was performed using sodium acetate buffer pH 3.5. After purification of Mab Select SuRe, the sample was neutralized, added to
超遠心分析法(AUC)による沈降速度(SV)実験を用いて、サンプルの純度及び凝集状態に関する情報を得た。回転数40,000rpmのAn60Ti4穴ローターを使用して、optima XL−I(Beckman Coulter、Fullerton,CA)にて20℃でサンプルを遠心分離した。対応する希釈緩衝液を標準緩衝液として用い、280nmでの紫外線吸光度により沈降過程をモニターした。超遠心セル内の濃度分布の経時的変化を、XL−Iで動作するソフトウェアを使用して収集し、SEDFITソフトウエア(バージョン14.1)の連続c(S)分布モデルを用いて分析することにより沈降係数の分布を求めた。単量体パーセンテージを、積分ピーク面積に基づき算出した。 An area under the curve (SV) experiment by ultracentrifugal analysis (AUC) was used to obtain information on sample purity and agglutination status. Samples were centrifuged at 20 ° C. on Optima XL-I (Beckman Coulter, Fullerton, CA) using an An60Ti 4-hole rotor at 40,000 rpm. The corresponding dilution buffer was used as the standard buffer and the precipitation process was monitored by UV absorbance at 280 nm. The time course of the concentration distribution in the ultracentrifugation cell is collected using software running on XL-I and analyzed using the continuous c (S) distribution model of the SEDFIT software (version 14.1). The distribution of the sedimentation coefficient was obtained by. The monomer percentage was calculated based on the integrated peak area.
結果:
化合物の精製の結果を表13に示す。データは、化合物が高い純度及び均質性を有することを示しており、このことは良好な安定性を示す。
The results of purification of the compounds are shown in Table 13. The data show that the compound has high purity and homogeneity, which indicates good stability.
実施例13:化合物の質量分析プロファイル
方法:
未変性サンプル
この手順により、化合物またはタンパク質の未変性状態の質量を得た。サンプル0.15ulを、Agilent PoroShell 300SB−C3カラム、5um(30×1.0mm)に注入した。カラム温度は80℃であり、流速は150ul/分であった。化合物またはタンパク質を、0分の時点の10%Bから、6分で85%Bになる勾配でカラムから溶出させた。移動相Aは、水/アセトニトリル/ギ酸/酢酸アンモニウム(99/1/0.1/2mM)であり、移動相Bは、n−プロパノール/アセトニトリル/水/ギ酸(70/20/10/0.1)であった。溶出液をAgilent 6224 TOF質量分析計に送り、質量600〜質量3200をスキャンした。生データをMassHunterプログラムでデコンボリューションした。
Example 13: Mass Spectrometry Profile of Compounds Method:
Undenatured Sample This procedure gave the undenatured mass of a compound or protein. Sample 0.15 ul was injected into an Agilent PoloShell 300SB-C3 column, 5 um (30 x 1.0 mm). The column temperature was 80 ° C. and the flow rate was 150 ul / min. The compound or protein was eluted from the column with a gradient from 10% B at 0 minutes to 85% B at 6 minutes. Mobile phase A is water / acetonitrile / formic acid / ammonium acetate (99/1 / 0.1 / 2 mM), and mobile phase B is n-propanol / acetonitrile / water / formic acid (70/20/10/0. It was 1). The eluate was sent to an Agilent 6224 TOF mass spectrometer and scanned for mass 600-3200. The raw data was deconvolved with the MassHunter program.
還元サンプル
この手順により、タンパク質または軽鎖の質量、及び重鎖の質量を得た。サンプル5ulを、20:1の8MグアニジンHCL:TCEP混合物5uLに添加し、室温にて15分間インキュベートした。このサンプル0.15ulを、以下の点を除いて上記の通り注入した:化合物またはタンパク質は、0分の時点の5%Bから、6分で85%Bになる勾配でカラムから溶出させ、カラム温度は60℃であり、質量範囲は600〜2000であった。
Reduced sample By this procedure, the mass of protein or light chain and the mass of heavy chain were obtained. 5 ul of sample was added to 5 uL of a 20: 1 8M guanidine HCL: TCEP mixture and incubated for 15 minutes at room temperature. 0.15 ul of this sample was injected as described above except for the following: compound or protein was eluted from the column with a gradient from 5% B at 0 minutes to 85% B at 6 minutes. The temperature was 60 ° C. and the mass range was 600-2000.
脱グリコシル化サンプル
この手順により、タンパク質または軽鎖及び重鎖の脱グリコシル化質量を得た。サンプル7.5ulを、20:1の400mM重炭酸アンモニウム:PNGase F混合物3.2uLに添加し、37℃で3時間インキュベートした。次いで、このサンプルに20:1の8MグアニジンHCL:TCEP混合物10ulを添加し、室温にて15分間インキュベートした。このサンプルを、上記の還元サンプルの通りに注入した。
Deglycosylated sample This procedure gave the deglycosylated mass of protein or light and heavy chains. Sample 7.5 ul was added to 3.2 uL of a 20: 1 400 mM ammonium bicarbonate: PNGase F mixture and incubated at 37 ° C. for 3 hours. The sample was then added with 10 ul of a 20: 1 8M guanidine HCL: TCEP mixture and incubated for 15 minutes at room temperature. This sample was injected according to the reduction sample above.
質量分析によるペプチドマッピング
6M GdHCl、250mM Tris−HCl(pH7.5)、及び10mM DTTからなる変性緩衝液でサンプルを希釈し、次いで37℃で30分間インキュベートした。次いで、ヨードアセトアミドでサンプルをアルキル化し、暗所で室温にて30分間インキュベートした。反応混合物を精製し、Sephadex G−25 Superfineカートリッジを使用して緩衝液を100mM Tris−HCL(pH7.5)に交換した。次いで、サンプルを37℃で4時間インキュベーションする間に、トリプシンで消化した。その後、TFAを添加することにより、反応混合物の消化をクエンチした。
Peptide mapping by mass spectrometry Samples were diluted with denaturing buffer consisting of 6M GdHCl, 250 mM Tris-HCl (pH 7.5), and 10 mM DTT and then incubated at 37 ° C. for 30 minutes. The sample was then alkylated with iodoacetamide and incubated in the dark at room temperature for 30 minutes. The reaction mixture was purified and buffer was replaced with 100 mM Tris-HCL (pH 7.5) using a Sephadex G-25 Superfine cartridge. The sample was then digested with trypsin while incubating at 37 ° C. for 4 hours. The digestion of the reaction mixture was then quenched by the addition of TFA.
得られたトリプシン消化物を、Dionex Ultimate 3000 HPLCのオートサンプラー経由でPhenomenex Jupiter C18逆相カラムに注入した。溶媒A:0.1%ギ酸/99%水/1%アセトニトリル、溶媒B:0.1%ギ酸/5%水/95%アセトニトリルからなる勾配溶媒系を利用した。溶媒Bの比率を140分かけて0%から38%に増加させた。クロマトグラフィー分離は、室温にて流速100μl/分で行った。オートサンプラー内のサンプルストレージは4℃であった。クロマトグラフィー分離の後、Thermo Scientific Orbitrap Fusion質量分析計にサンプルを入れ、正エレクトロスプレーイオン化モードで作動させた。用いた方法には、分解能30,000、最小シグナル10,000、分離幅1.0、及び正規化コリジョンエネルギー35.0Vを利用した活性化型のCIDを含めた。S−レンズRFレベルは20%に設定した。データ収集型は、フルMSスキャンではプロファイル、CID MS/MSデータではセントロイドであった。データは、取得速度1スペクトル/秒で250〜2000Daの質量範囲にわたって収集する。 The resulting tryptic digest was injected into a Phenomenex Jupiter C18 reverse phase column via a Dionex Ultimate 3000 HPLC autosampler. A gradient solvent system consisting of solvent A: 0.1% formic acid / 99% water / 1% acetonitrile and solvent B: 0.1% formic acid / 5% water / 95% acetonitrile was used. The ratio of solvent B was increased from 0% to 38% over 140 minutes. Chromatographic separation was performed at room temperature at a flow rate of 100 μl / min. The sample storage in the autosampler was 4 ° C. After chromatographic separation, the sample was placed in a Thermo Scientific Orbitrap Fusion mass spectrometer and operated in positive electrospray ionization mode. The methods used included an activated CID utilizing a resolution of 30,000, a minimum signal of 10,000, a separation width of 1.0, and a normalized collision energy of 35.0 V. The S-lens RF level was set to 20%. The data collection type was profile for full MS scan and centroid for CID MS / MS data. Data are collected over a mass range of 250-2000 Da at an acquisition rate of 1 spectrum / sec.
Proteome Discover 1.4(Thermo Scientific)を利用して、酵素消化物から収集されたLC−MS及びLC−MS/MSの生断片化データを所定の配列に対して分析した。次いで、N−X−S/T(XがPではない)のコンセンサスを含む同定されたペプチドを、グリコシル化ペプチドに対するEICを手動で抽出することにより分析した。EIC全体のグリコシル化ペプチドのMS強度を用いて、グリコフォームの全存在量に占める割合を推定した。 Using Proteome Discover 1.4 (Thermo Scientific), LC-MS and LC-MS / MS raw fragmentation data collected from enzyme digests were analyzed for a given sequence. The identified peptides containing the consensus of N-X-S / T (X is not P) were then analyzed by manually extracting the EIC for the glycosylated peptide. The MS intensity of the glycosylated peptide throughout the EIC was used to estimate the proportion of glycoforms in the total abundance.
結果:
結果を表14に示す。データは、意図したアミノ酸配列及び構造が発現しており、予期せぬ不均一化を伴わずに回収されたことを示す。グリコシル化パターンは、CHO細胞で発現する従来の抗体に典型的なものであり、いかなる非定型構造も示していない。
The results are shown in Table 14. The data show that the intended amino acid sequence and structure were expressed and recovered without unexpected heterogeneity. The glycosylation pattern is typical of conventional antibodies expressed in CHO cells and does not show any atypical structure.
実施例14:高濃度での単量体含有量
このプロセスを記述する目的は、高濃度での凝集を評価することにより、化合物Bの固有の特性を評価することである。20mMクエン酸ナトリウム、120mM NaCl(pH6)の標準的な緩衝液を使用して、製剤を評価することなく分子の凝集傾向を把握する。
Example 14: Monomer Content at High Concentrations The purpose of describing this process is to assess the unique properties of compound B by assessing aggregation at high concentrations. A standard buffer of 20 mM sodium citrate, 120 mM NaCl (pH 6) is used to determine the tendency of molecules to aggregate without evaluating the formulation.
方法:
カットオフ分子量50,000ダルトンのAmicon Ultra遠心式フィルター(Millipore、Billerica)を用いて、沈殿の観察が見られない最大濃度まで徐々に化合物Bを濃縮した。次いで、濃縮したタンパク質溶液を分析的SEC解析にかけ、サンプルの純度及び凝集状態に関する情報を得た。クロマトグラフィーは、Agilent 1200シリーズHPLCシステムを使用して実行した。システムは1.0ml/分で23分間実行した。約30ugの材料をTosoh Biosciences TSKgel G3000SWXLカラム(5um 250a 7.8×30cm)に注入し、280nmの結果を読み取った。使用したランニング緩衝液は、50mMリン酸ナトリウム、0.2M L−アルギニン(pH6.8)であった。
Method:
Compound B was gradually concentrated to a maximum concentration at which no precipitation was observed using an Amicon Ultra centrifugal filter (Millipore, Billerica) having a cutoff molecular weight of 50,000 Dalton. The concentrated protein solution was then subjected to analytical SEC analysis to obtain information on sample purity and agglutination status. Chromatography was performed using an Agilent 1200 series HPLC system. The system was run at 1.0 ml / min for 23 minutes. Approximately 30 ug of material was injected into the Tosoh Biosciences TSKgel G3000SWXL column (5 um 250a 7.8 x 30 cm) and the 280 nm results were read. The running buffer used was 50 mM sodium phosphate, 0.2 ML-arginine (pH 6.8).
結果:
濃縮工程時の化合物Bに関する分析的SECデータのまとめを表15及び図4に記載する。高濃度での凝集及びサンプル純度を示すデータは、化合物Bが、高濃度で凝集する傾向を有しないことを実証していることを表す。
A summary of analytical SEC data for compound B during the concentration step is shown in Table 15 and FIG. Data showing aggregation and sample purity at high concentrations demonstrate that Compound B does not have a tendency to aggregate at high concentrations.
実施例15:化合物の原子価
方法:
Analytical Membrane−Confined Electrophoresisを使用して、10mM酢酸塩、50mM KCl(pH5.0)緩衝液に予め一晩透析した化合物の原子価を測定した。実験装置では、1mg/mLのサンプル20μLを、10MWCOの半透過性再生セルロースバイオグレード膜によって両端を封止した2×2×4mm3の石英キュベットに充填した。この膜は、巨大分子を捕捉する一方、水及び溶媒成分を通過させる。次いで、1mAの電流をキュベットに印加し、キュベットの長軸方向に電界を確立し、新鮮な緩衝液を連続して流しながら荷電した巨大分子を電界中で移動させた。リアルタイム移動濃度境界を、キュベットに沿って離間する強度読み取り値を示すリニアフォトダイオードアレイ(LPDA)を用いて検出した。濃度境界の速度を用いて、電気泳動移動度、続いて有効原子価を算出した。次いで、ストークス半径(AUCでの沈降速度のランから得た)、対イオン半径(塩化物イオンでは0.122nm)、緩衝液のコンダクタンス(6.35mS)、及びイオン強度(0.05M)などの追加情報を使用して、巨大分子の基底状態の原子価を明らかにした。
Example 15: Valence of compound Method:
Using Analytical Membrane-Confined Electrophoresis, the valence of the compound was preliminarily dialyzed against 10 mM acetate, 50 mM KCl (pH 5.0) buffer overnight. In the experimental apparatus, 20 μL of a 1 mg / mL sample was filled in a 2 × 2 × 4 mm3 quartz cuvette whose ends were sealed with a 10 MWCO semi-permeable regenerated cellulose biograde membrane. This membrane traps macromolecules while allowing water and solvent components to pass through. Next, a current of 1 mA was applied to the cuvette to establish an electric field in the long axis direction of the cuvette, and charged macromolecules were moved in the electric field while continuously flowing a fresh buffer solution. Real-time moving density boundaries were detected using a linear photodiode array (LPDA) showing intensity readings separated along the cuvette. Electrophoretic mobility was calculated using the velocity at the concentration boundary, followed by effective valence. Then Stokes radius (obtained from run of sedimentation rate at AUC), counterion radius (0.122 nm for chloride ion), buffer conductance (6.35 mS), and ionic strength (0.05 M), etc. Additional information was used to reveal the basal valences of macromolecules.
結果:
原子価データ(表16を参照)は、溶液中の化合物のコロイド安定性、すなわち溶液中のタンパク質とタンパク質との正味の相互作用を示す。原子価が15を超える化合物は、強力な正味の反発相互作用を有し、高濃度で製剤化できる可能性が高い。
Valence data (see Table 16) show the colloidal stability of a compound in solution, i.e., the net interaction between proteins in solution. Compounds with a valence of more than 15 have a strong net repulsive interaction and are likely to be formulated at high concentrations.
実施例16:化合物の全血安定性
方法
Octet RED96で全血による干渉アッセイを行い、全血(WB)の存在下での化合物に対する非特異的結合または標的外結合の影響を検出した。化合物の全血及び1倍のキネティック用ランニング緩衝液(1xkb)溶液を、温度37℃で48時間インキュベートした。インキュベートした化合物サンプルの速度論的測定は、ストレプトアビジン(SA)バイオセンサーチップ(ForteBio、Menlo Park,CA)を搭載したOctet RED96を用いて27℃で実施した。緩衝液及び全血でのオンレート/結合シグナルの比を記録した。2未満の比は干渉なしを示すとみなした。
Example 16: Whole Blood Stability Method of Compounds Whole blood interference assays were performed on Octet RED96 to detect the effects of non-specific or off-target binding to compounds in the presence of whole blood (WB). Whole blood and 1x kinetic running buffer (1xkb) solutions of the compound were incubated at a temperature of 37 ° C. for 48 hours. Kinetic measurements of the incubated compound samples were performed at 27 ° C. using an Octet RED96 equipped with a streptavidin (SA) biosensor chip (ForteBio, Menlo Park, CA). On-rate / binding signal ratios in buffer and whole blood were recorded. Ratios less than 2 were considered to indicate no interference.
結果
結果を表17に示す。試験化合物には全血の干渉は観察されなかった。
実施例17:in silico免疫原性の予測
方法
タンパク質治療薬の免疫原性を、EpiVax,Inc.(Providence,RI)が開発した計算ツールEpiMatrixを利用してin silicoで予測した。EpiMatrixには、TヘルパーエピトープならびにTregエピトープの予測が組み込まれており、前者は免疫応答を誘発するのに対して後者は阻害性である。簡潔には、最初にタンパク質配列を、クラスII HLA結合のコアであることが実証されている重複する9量体ペプチドフレームに解析した。8つの共通するクラスII HLAアレルのそれぞれに対する9量体ペプチドの結合可能性を、実験データまたは計算予測に基づいて評価する。各HLAアレルに対する9量体ペプチドの結合可能性を反映させたスコアを作成し、さらに複数のHLAアレルにまたがる9量体も比較でき、網羅的規模での免疫原性予測が可能であるように正規化を実行した。最後に、プログラムにより、全体的な「免疫原性スコア」であるtReg Adjusted Epxスコアを作成する。これは化合物がin vivoで免疫応答を誘発する尤度である。
Example 17: Prediction method of in silico immunogenicity The immunogenicity of protein therapeutic agents was described in EpiVax, Inc. Prediction was made in silico using the calculation tool EpiMatrix developed by (Providence, RI). EpiMatrix incorporates predictions of T helper epitopes as well as Treg epitopes, the former eliciting an immune response while the latter being inhibitory. Briefly, protein sequences were first analyzed into overlapping nine-mer peptide frames that have been demonstrated to be the core of Class II HLA binding. The binding potential of the nine-mer peptide to each of the eight common Class II HLA alleles is evaluated based on experimental data or computational predictions. Scores that reflect the binding potential of the nine-mer peptide to each HLA allele can be created, and nine-mer across multiple HLA alleles can be compared, enabling comprehensive immunogenicity prediction. Performed normalization. Finally, the program creates an overall "immunogenicity score", the tReg Adjusted Epx score. This is the likelihood that the compound will elicit an immune response in vivo.
結果
結果を表18に示す。試験化合物の全体的な免疫原性スコアは低く、これらの化合物がin vivoで強力な免疫応答を誘発する可能性は低いと予測される。
実施例18:初代ヒトB細胞増殖アッセイにおけるヒトBAFFの阻害
材料及び方法
本試験で使用する正常で健康な血液サンプル(n=3ドナー)は、Biological Specialty Corporation(Philadelphia,PA)から購入した。完全培地は、10%FBS(Life technologies)+Pen/Strep(Life Technologies)を補充したIMDM(Life Technologies)であった。B細胞の単離緩衝液は、2%FBS+2mM EDTA(Life technologies)を加えたMg++及びCa++フリーの滅菌DPBS(Life Technologies)で構成した。
Example 18: Inhibition of Human BAFF in Primary Human B Cell Proliferation Assay Materials and Methods Normal and healthy blood samples (n = 3 donors) used in this study were purchased from the Biological Specialty Corporation (Philadelphia, PA). The complete medium was IMDM (Life Technologies) supplemented with 10% FBS (Life technologies) + Pen / Strep (Life Technologies). B cell isolation buffer was composed of Mg ++ with 2% FBS + 2 mM EDTA (Life technologies) and sterile DPBS (Life Technologies) with Ca ++ free.
健常なヒト全血からのヒトB細胞の単離
ヘパリン化全血400mLを1000mLの滅菌ポリスチレンボトルに移し、等量のDPBSを添加した。PBSで希釈した血液35mLを、50mLのポリスチレン丸底チューブに予め充填された15mLのFicoll−Paque(商標)Plus(GE Healthcare)勾配媒体上部に配置した。チューブをブレーキなしで室温にて20分間2000rpmで遠心分離した。次に、上清の上部3分の2を吸引し、末梢血単核球(PBMC)を含む中間灰色層を50mLのコニカルチューブに移した。DPBS(CA++及びMg++フリー)+2%FBSを最大50mL容積まで添加した。チューブを1200rpmで10分間、遠心沈殿させた。得られた細胞ペレットをDPBS(CA++及びMg++フリー)+2%FBS(洗浄緩衝液)で再懸濁し、遠心分離工程(1200rpmで10分間)を繰り返した。細胞ペレットを洗浄緩衝液で再び50mLまで再懸濁した。この時点で細胞生存率及び細胞濃度を測定した。
Isolation of human B cells from healthy human whole blood 400 mL of heparinized whole blood was transferred to a 1000 mL sterile polystyrene bottle and an equal volume of DPBS was added. 35 mL of PBS-diluted blood was placed on top of a 15 mL Ficoll-Paque ™ Plus (GE Healthcare) gradient medium prefilled in a 50 mL polystyrene round bottom tube. The tubes were centrifuged at 2000 rpm for 20 minutes at room temperature without brakes. The upper two-thirds of the supernatant was then aspirated and the intermediate gray layer containing peripheral blood mononuclear cells (PBMC) was transferred to a 50 mL conical tube. DPBS (CA ++ and Mg ++ free) + 2% FBS was added up to a volume of 50 mL. The tube was centrifuged at 1200 rpm for 10 minutes. The obtained cell pellet was resuspended in DPBS (CA ++ and Mg ++ free) + 2% FBS (wash buffer), and the centrifugation step (1200 rpm for 10 minutes) was repeated. The cell pellet was resuspended in wash buffer up to 50 mL again. At this point, cell viability and cell concentration were measured.
次いでチューブを1200rpmで10分間、遠心沈殿させ、上清を廃棄した。細胞ペレットを完全培地で再懸濁し、細胞濃度を5×106細胞/mLに調整した。懸濁した細胞を75cm2の組織培養フラスコに入れ、5%C02インキュベーター内(37℃)で一晩インキュベートした。次いで、B細胞を、Dynabeads(登録商標)Untouched(商標)ヒトB細胞キット(Life Technologies)を使用し、製造業者のプロトコールに従って単離した。細胞濃度は、細胞濃度及び生存率の測定後、下流手順に適したものとなるように調整した。 The tube was then centrifuged at 1200 rpm for 10 minutes and the supernatant was discarded. The cell pellet was resuspended in complete medium, and the cell density was adjusted to 5 × 10 6 cells / mL. The suspended cells were placed in tissue culture flasks 75 cm 2, and incubated overnight at 5% C0 2 incubator (37 ° C.). B cells were then isolated using Dynabeads® Untouched ™ Human B Cell Kits (Life Technologies) according to the manufacturer's protocol. After measuring the cell concentration and viability, the cell concentration was adjusted to be suitable for the downstream procedure.
3H−チミジン取り込みアッセイを使用したB細胞増殖の評価
B細胞をFalcon組織培養用96ウェル丸底プレートに播種した(ウェルあたり1×105細胞/100μL培地)。次いで、完全培地を用いて、試験品を0.028〜20nMの範囲の4段階濃度に調製し、B細胞刺激薬(抗IgM抗体及びヒトBAFF)を4倍濃度(それぞれ、8μg/mL及び20ng/mL)で調製した。予め希釈した試験品50μLを各ウェルに添加した(最終濃度0.007〜5nM)。次いで、予め希釈したヤギ抗ヒトIgM(最終濃度2μg/mL)及びhBAFF(最終濃度5ng/mLまたは98pM)50μLを対応するウェル(図6を参照)に添加した。B細胞を37℃の5%CO2加湿インキュベーター内で72時間培養した。インキュベーションが終了する18時間前に、1μCiの3H−チミジン(Pelkin Elmer)20μLを各ウェルに添加した。セルハーベスターを使用して、3H−チミジン取り込みDNA/ウェルをマイクロファイバーガラスフィルタープレートに移した。このとき、少なくとも4時間、プレートを風乾した後、30μLのシンチレーションエンハンサーをウェルに添加した。各ウェルの計数毎分(cpm)値をMicroBeta Topcountを使用して測定し、試験品の濃度(x軸)に対するcpm値(y軸)をプロットした。
3 H- Evaluation B cells of B-cell proliferation using thymidine incorporation assay were seeded into 96-well round bottom plates for Falcon tissue culture (1 × 10 5 cells / 100 [mu] L culture medium per well). The test product was then prepared in 4-step concentrations in the range of 0.028-20 nM using complete medium and 4-fold concentrations of B cell stimulants (anti-IgM antibody and human BAFF) (8 μg / mL and 20 ng, respectively). / ML). 50 μL of pre-diluted test product was added to each well (final concentration 0.007-5 nM). Pre-diluted goat anti-human IgM (
統計分析
IC50及びIC90を、GraphPad Prism 6ソフトウェアを使用して、データを4パラメーターシグモイド用量反応関数にカーブフィッティングすることにより決定した。3実験間の幾何平均を算出し、表19に示した。
Statistical analysis IC 50 and IC 90 were determined by curve fitting the data to a 4-parameter sigmoid dose-response function using GraphPad Prism 6 software. The geometric mean between the three experiments was calculated and shown in Table 19.
結果
結果が示すように、IC50及びIC90値を比較した場合、化合物Bは対照抗体3と比べ約2倍強力であることが明らかであった。
実施例19.B10.RIIIマウスにおけるヒトBAFFの過剰発現によって誘導されるB220+B細胞数の阻害
材料及び方法
簡潔には、初日にB10.RIII雌マウス(6〜8週齢、Jackson Laboratory)を無作為に10群、10匹/群に分け、クエン酸緩衝液(20mMクエン酸ナトリウム、115mM NaCl、pH6.0)または等モル用量の試験化合物、それぞれ1.3、0.4及び0.13mg/kg対1、3及び0.1mg/kgを100μLの腹腔内注射により投与した。追加対照は未処置のナイーブマウスであった。治療初日の直後に、空のベクター(EV)対照群に対する、ヒトBAFFミニサークルDNA(System Biosciences)の単回3mg用量(1.5mg/mL)をハイドロダイナミック注入法によりマウスに投与した。クエン酸緩衝液または試験化合物のいずれかによる腹腔内処置を3、6、9、及び12日目に72時間ごとに繰り返した。
Example 19. B10. Inhibition of B220 + B Cell Number Induced by Overexpression of Human BAFF in RIII Mice Materials and Methods Briefly, B10. RIII female mice (6-8 weeks old, Jackson Laboratory) were randomly divided into 10 groups, 10 animals / group, and tested with citrate buffer (20 mM sodium citrate, 115 mM NaCl, pH 6.0) or equimolar dose. Compounds, 1.3, 0.4 and 0.13 mg / kg vs. 1, 3 and 0.1 mg / kg, respectively, were administered by intraperitoneal injection of 100 μL. Additional controls were untreated naive mice. Immediately after the first day of treatment, mice were administered a single 3 mg dose (1.5 mg / mL) of human BAFF minicircle DNA (System Biosciences) to an empty vector (EV) control group by hydrodynamic injection. Intraperitoneal treatment with either citrate buffer or test compound was repeated every 72 hours on
14日目に、マウスをイソフルラン(Butler Schein)で麻酔し、頸椎脱臼により犠牲死させた。脾臓を切除し、B220+B細胞について細胞懸濁液をフローサイトメトリーにより分析した。各処置群の平均数を決定し、一元配置分散分析後のダネット多重比較検定を用いて、対照と比較した有意差を算出した。結果を図5に示す。 On day 14, mice were anesthetized with isoflurane (Butler Chain) and killed by cervical dislocation. The spleen was resected and the cell suspension was analyzed by flow cytometry for B220 + B cells. The mean number of each treatment group was determined and the significant difference compared to the control was calculated using the Danette multiplex test after one-way ANOVA. The results are shown in FIG.
結果
結果は、化合物Bによる14日間の処置が、ヒトBAFFのミニサークルDNAによって誘導されるB220+B細胞の増殖を有意に阻害できることを示した。
Results The results showed that treatment with compound B for 14 days could significantly inhibit the proliferation of B220 + B cells induced by the minicircle DNA of human BAFF.
実施例20.C57/Bl6マウスにおけるヒトIL23誘導性マウスのIL17A及びIL22放出の阻害
材料及び方法
簡潔には、C57BL/6雌マウス(7〜10週齢、Charles River)を無作為に8群、8匹/群に分け、クエン酸緩衝液(20mMクエン酸ナトリウム、115mM NaCl、pH6.0)または等モル用量の試験化合物、それぞれ1.3、0.4及び0.13mg/kg対1、3及び0.1mg/kgを100μLの腹腔内注射により投与した。
Example 20. Inhibition of IL17A and IL22 release in human IL23-induced mice in C57 / Bl6 mice Materials and methods Briefly, C57BL / 6 female mice (7-10 weeks old, Charles River) were randomly selected in 8 groups, 8 animals / group. Divided into citrate buffer (20 mM sodium citrate, 115 mM NaCl, pH 6.0) or equimolar doses of test compound, 1.3, 0.4 and 0.13 mg / kg vs. 1, 3 and 0.1 mg, respectively. / Kg was administered by intraperitoneal injection of 100 μL.
試験化合物投与の1時間後にマウスをイソフルラン(Butler Schein)により麻酔し、生理食塩水(Invitrogen)で希釈した0.1%BSA(Sigma)対照または15μg/ml(0.3μg)のrhIL23(内製)を両耳への20μLの皮内注射により投与した。皮下への負荷を2日連続して毎日繰り返した。2回目の負荷後24時間で、マウスを頚椎脱臼により犠牲死させ、各耳を切除した。MP Biomedicals Fast−Prep 24ホモジナイザーを使用して、均質化緩衝液1ml(HBSS(Gibco);0.4%Triton X−100(Sigma);1X SigmaFastプロテアーゼ阻害剤(Sigma))中で耳組織をホモジナイズした。ホモジナイズしたサンプルを4℃で10分間遠心分離し、上清を回収した。製造業者の指示(R&D Systems)に従ってQuantikine(登録商標)マウスIL−17及びマウスIL−22イムノアッセイを用いて、マウスIL17A及びIL22の存在について上清をアッセイした。サイトカインpg/mlの補間値を各サンプルについて測定した。各処置群の平均pg/mlレベルを決定し、一元配置分散分析後のダネット多重比較検定を用いて、対照と比較した有意差を算出した。
One hour after administration of the test compound, mice were anesthetized with isoflurane (Butler Chain) and diluted with saline (Invitrogen) 0.1% BSA (Sigma) control or 15 μg / ml (0.3 μg) rhIL23 (in-house). ) Was administered by intradermal injection of 20 μL into both ears. Subcutaneous loading was repeated daily for 2 consecutive days. Twenty-four hours after the second loading, mice were sacrificed to death by cervical dislocation and each ear was resected. Homogenize ear tissue in 1 ml of homogenized buffer (HBSS (Gibco); 0.4% Triton X-100 (Sigma); 1X SigmaFast Protease Inhibitor (Sigma)) using MP Biomedicals Fast-
結果
図6の結果は、化合物Bの単回腹腔内用量での処置が、組換えヒトIL23の2日連続した内皮注射によって誘発される皮膚でのマウスIL17及びIL22の放出を有意に阻害できることを示した。
Results The results in FIG. 6 show that treatment with a single intraperitoneal dose of Compound B can significantly inhibit the release of mouse IL17 and IL22 in the skin induced by two consecutive days of endothelial injection of recombinant human IL23. Indicated.
他の実施形態
本明細書中に開示される機能はすべて、どのような組み合わせで組み合わせてもよい。本明細書中に開示される各機能は、同一の、同等な、または同様な目的を果たす代替機能で置き換えることができる。したがって、特に明示されない限り、開示される各機能は一般的な一連の等価または同様の機能の一例にすぎない。
Other Embodiments All the functions disclosed herein may be combined in any combination. Each function disclosed herein can be replaced by an alternative function that serves the same, equivalent, or similar purpose. Therefore, unless otherwise stated, each disclosed feature is merely an example of a general set of equivalent or similar features.
上記の説明から、当業者であれば本開示の本質的な特徴を容易に確認することができ、本開示の趣旨及び範囲を逸脱することなく、本開示に様々な変更及び改変を行って、本開示を様々な用途及び条件に適合させることができる。したがって、他の実施形態もまた請求項の範囲内である。 From the above description, those skilled in the art can easily confirm the essential features of the present disclosure, and make various changes and modifications to the present disclosure without departing from the spirit and scope of the present disclosure. The present disclosure can be adapted to a variety of uses and conditions. Therefore, other embodiments are also within the scope of the claims.
Claims (23)
(A)前記第1のポリペプチドは、N末端からC末端の方向に以下:
(i)第1の標的タンパク質に特異的な第1の免疫グロブリンの軽鎖可変ドメイン(VL1);
(ii)第1のリンカー;
(iii)第2の標的タンパク質に特異的な第2の免疫グロブリンの重鎖可変ドメイン(VH2);
(iv)第3のリンカー;
(v)重鎖定常領域1(CH1);
(vi)ヒンジ領域;
(vii)Kabatと同様のEUインデックスによる番号の252位にチロシン、254位にスレオニン、256位にグルタミン酸を含む、重鎖定常領域2(CH2);及び
(viii)重鎖定常領域3(CH3);
を含み、
(B)前記第2のポリペプチドは、N末端からC末端の方向に以下:
(i)前記第2の標的タンパク質に特異的な第2の免疫グロブリンの軽鎖可変ドメイン(VL2);
(ii)第2のリンカー;
(iii)前記第1の標的タンパク質に特異的な第1の免疫グロブリンの重鎖可変ドメイン(VH1);
(iv)第4のリンカー;及び
(v)軽鎖定常領域(CL);
を含み、
ここで、前記化合物において、
a)前記VL1及びVH1は会合して、前記第1の標的タンパク質に結合する結合部位を形成し;及び
b)前記VL2及びVH2は会合して、前記第2の標的タンパク質に結合する結合部位を形成し;
ここで、
(I)前記第1の標的タンパク質がインターロイキン23のp19サブユニット(IL−23A)であり、前記第2の標的タンパク質がB細胞活性化因子(BAFF)であり、ここでさらに、
(i)前記VL1は配列番号4のアミノ酸配列を含み、前記VH1は配列番号3のアミノ酸配列を含み、前記VL2は配列番号91のアミノ酸配列を含み、前記VH2は配列番号90のアミノ酸配列を含むものであるか;
(ii)前記VL1は配列番号4のアミノ酸配列を含み、前記VH1は配列番号3のアミノ酸配列を含み、前記VL2は配列番号89のアミノ酸配列を含み、前記VH2は配列番号88のアミノ酸配列を含むものであるか;若しくは
(iii)前記VL1は配列番号4のアミノ酸配列を含み、前記VH1は配列番号3のアミノ酸配列を含み、前記VL2は配列番号2のアミノ酸配列を含み、前記VH2は配列番号1のアミノ酸配列を含むものであり;
又は、
(II)前記第1の標的タンパク質がBAFFであり、前記第2の標的タンパク質がIL−23Aであり、ここでさらに、
前記VL1は配列番号2のアミノ酸配列を含み、前記VH1は配列番号1のアミノ酸配列を含み、前記VL2は配列番号4のアミノ酸配列を含み、前記VH2は配列番号3のアミノ酸配列を含むものである;
前記化合物。 A compound containing a first polypeptide and a second polypeptide.
(A) The first polypeptide is prepared from the N-terminal to the C-terminal in the following directions:
(I) Light chain variable domain (VL1) of the first immunoglobulin specific for the first target protein;
(Ii) First linker;
(Iii) Heavy chain variable domain (VH2) of a second immunoglobulin specific for a second target protein;
(Iv) Third linker;
(V) Heavy chain constant region 1 (CH1);
(Vi) Hinge area;
Heavy chain constant region 2 (CH2); and (viii) heavy chain constant region 3 (CH3) containing tyrosine at position 252 and threonine at position 254 and glutamic acid at position 256 according to EU index similar to (vii) Kabat. ;
Including
(B) The second polypeptide is prepared from the N-terminal to the C-terminal in the following directions:
(I) Light chain variable domain (VL2) of the second immunoglobulin specific for the second target protein;
(Ii) Second linker;
(Iii) Heavy chain variable domain (VH1) of a first immunoglobulin specific for the first target protein;
(Iv) Fourth linker; and (v) Light chain constant region (CL);
Including
Here, in the compound,
a) The VL1 and VH1 associate to form a binding site that binds to the first target protein; and b) the VL2 and VH2 associate to form a binding site that binds to the second target protein. Form;
here,
(I) The first target protein is the p19 subunit (IL-23A) of interleukin 23 and the second target protein is B cell activating factor (BAFF).
(I) The VL1 contains the amino acid sequence of SEQ ID NO: 4, the VH1 contains the amino acid sequence of SEQ ID NO: 3, the VL2 contains the amino acid sequence of SEQ ID NO: 91, and the VH2 contains the amino acid sequence of SEQ ID NO: 90. Is it a waste;
(Ii) The VL1 contains the amino acid sequence of SEQ ID NO: 4, the VH1 contains the amino acid sequence of SEQ ID NO: 3, the VL2 contains the amino acid sequence of SEQ ID NO: 89, and the VH2 contains the amino acid sequence of SEQ ID NO: 88. Or (iii) said VL1 comprises the amino acid sequence of SEQ ID NO: 4, said VH1 contained the amino acid sequence of SEQ ID NO: 3, said VL2 contained the amino acid sequence of SEQ ID NO: 2, and said VH2 contained the amino acid sequence of SEQ ID NO: 1. It contains an amino acid sequence;
Or
(II) The first target protein is BAFF and the second target protein is IL-23A.
The VL1 comprises the amino acid sequence of SEQ ID NO: 2, the VH1 comprises the amino acid sequence of SEQ ID NO: 1, the VL2 comprises the amino acid sequence of SEQ ID NO: 4, and the VH2 comprises the amino acid sequence of SEQ ID NO: 3;
The compound.
(i)前記CH2が、Kabatと同様のEUインデックスによる番号の234位にアラニン、及び235位にアラニンを含む;
(ii)前記CH1、前記ヒンジ領域、前記CH2、前記CH3のアミノ酸配列が、IgG1またはIgG4に由来するものである;
(iii)前記ヒンジ領域が、配列番号76のアミノ酸配列、配列番号130のアミノ酸配列、または配列番号134のアミノ酸配列を含む。 The compound according to any one of claims 1 to 3, which comprises one or more of the following characteristics:
(I) The CH2 contains alanine at position 234 and alanine at position 235 according to the EU index similar to Kabat;
(Ii) The amino acid sequences of CH1, the hinge region, CH2, and CH3 are derived from IgG1 or IgG4;
(Iii) The hinge region comprises the amino acid sequence of SEQ ID NO: 76, the amino acid sequence of SEQ ID NO: 130, or the amino acid sequence of SEQ ID NO: 134.
(i)前記CH1、前記ヒンジ領域、前記CH2、及び前記CH3のアミノ酸配列がIgG1に由来するものであり、前記ヒンジ領域が配列番号76のアミノ酸配列を含み、前記CH2が、Kabatと同様のEUインデックスによる番号の234位にアラニン、及び235位にアラニンを含むか;又は
(ii)前記CH1、前記ヒンジ領域、前記CH2、及び前記CH3のアミノ酸配列がIgG4に由来するものであり、前記ヒンジ領域が配列番号134のアミノ酸配列を含む;
前記化合物。 The compound according to any one of claims 1 to 3.
(I) The amino acid sequences of the CH1, the hinge region, the CH2, and the CH3 are derived from IgG1, the hinge region contains the amino acid sequence of SEQ ID NO: 76, and the CH2 is the same EU as Kabat. Does the index number contain alanine at position 234 and alanine at position 235; or (ii) the amino acid sequences of CH1, said hinge region, said CH2, and said CH3 are derived from IgG4 and said hinge region. Contains the amino acid sequence of SEQ ID NO: 134;
The compound.
(i)前記第1のポリペプチドが配列番号5のアミノ酸配列を含み、前記第2のポリペプチドが配列番号6のアミノ酸配列を含むか;
(ii)前記第1のポリペプチドが配列番号15のアミノ酸配列を含み、前記第2のポリペプチドが配列番号16のアミノ酸配列を含むか;
(iii)前記第1のポリペプチドが配列番号37のアミノ酸配列を含み、前記第2のポリペプチドが配列番号38のアミノ酸配列を含むか;
(iv)前記第1のポリペプチドが配列番号41のアミノ酸配列を含み、前記第2のポリペプチドが配列番号42のアミノ酸配列を含むか;
(v)前記第1のポリペプチドが配列番号45のアミノ酸配列を含み、前記第2のポリペプチドが配列番号46のアミノ酸配列を含むか;または
(vi)前記第1のポリペプチドが配列番号49のアミノ酸配列を含み、前記第2のポリペプチドが配列番号50のアミノ酸配列を含む;
前記化合物。 The compound according to claim 1.
(I) Does the first polypeptide contain the amino acid sequence of SEQ ID NO: 5 and the second polypeptide contains the amino acid sequence of SEQ ID NO: 6;
(Ii) Does the first polypeptide contain the amino acid sequence of SEQ ID NO: 15 and the second polypeptide contains the amino acid sequence of SEQ ID NO: 16;
(Iii) Does the first polypeptide contain the amino acid sequence of SEQ ID NO: 37 and the second polypeptide contains the amino acid sequence of SEQ ID NO: 38;
(Iv) Does the first polypeptide contain the amino acid sequence of SEQ ID NO: 41 and the second polypeptide contains the amino acid sequence of SEQ ID NO: 42;
(V) Is the first polypeptide comprising the amino acid sequence of SEQ ID NO: 45 and the second polypeptide comprising the amino acid sequence of SEQ ID NO: 46; or (vi) the first polypeptide comprises SEQ ID NO: 49. The second polypeptide comprises the amino acid sequence of SEQ ID NO: 50;
The compound.
前記2つの第1のポリペプチドが少なくとも1つのジスルフィド結合によって共に会合し、かつ前記第1のポリペプチドのそれぞれが少なくとも1つのジスルフィド結合によって1つの前記第2のポリペプチドと会合して、4価分子を形成し、ここで、
(A)前記第1のポリペプチドのそれぞれは、N末端からC末端の方向に以下:
(i)第1の標的タンパク質に特異的なVL1;
(ii)第1のリンカー;
(iii)第2の標的タンパク質に特異的なVH2;
(iv)第3のリンカー;
(v)CH1;
(vi)ヒンジ領域;
(vii)Kabatと同様のEUインデックスによる番号の252位にチロシン、254位にスレオニン、256位にグルタミン酸を含む、CH2;及び
(viii)CH3;
を含み、
(B)前記第2のポリペプチドのそれぞれは、N末端からC末端の方向に以下:
(i)前記第2の標的タンパク質に特異的なVL2;
(ii)第2のリンカー;
(iii)前記第1の標的タンパク質に特異的なVH1;
(iv)第4のリンカー;及び
(v)CL;
を含み、
ここで、前記化合物において、
a)前記VL1及びVH1は会合して、前記第1の標的タンパク質に結合する結合部位を形成し;及び
b)前記VL2及びVH2は会合して、前記第2の標的タンパク質に結合する結合部位を形成し;
ここで、
(I)前記第1の標的タンパク質がIL−23Aであり、前記第2の標的タンパク質がBAFFであり、ここでさらに、
(i)前記VL1は配列番号4のアミノ酸配列を含み、前記VH1は配列番号3のアミノ酸配列を含み、前記VL2は配列番号91のアミノ酸配列を含み、前記VH2は配列番号90のアミノ酸配列を含むものであるか;
(ii)前記VL1は配列番号4のアミノ酸配列を含み、前記VH1は配列番号3のアミノ酸配列を含み、前記VL2は配列番号89のアミノ酸配列を含み、前記VH2は配列番号88のアミノ酸配列を含むものであるか;若しくは
(iii)前記VL1は配列番号4のアミノ酸配列を含み、前記VH1は配列番号3のアミノ酸配列を含み、前記VL2は配列番号2のアミノ酸配列を含み、前記VH2は配列番号1のアミノ酸配列を含むものであり;
又は、
(II)前記第1の標的タンパク質がBAFFであり、前記第2の標的タンパク質がIL−23Aであり、ここでさらに、
前記VL1は配列番号2のアミノ酸配列を含み、前記VH1は配列番号1のアミノ酸配列を含み、前記VL2は配列番号4のアミノ酸配列を含み、前記VH2は配列番号3のアミノ酸配列を含むものである;
前記化合物。 A compound containing two first polypeptides and two second polypeptides.
The two first polypeptides are associated together by at least one disulfide bond, and each of the first polypeptides is associated with one of the second polypeptides by at least one disulfide bond and is tetravalent. Form molecules, where
(A) Each of the first polypeptides is described below in the direction from the N-terminal to the C-terminal:
(I) VL1 specific for the first target protein;
(Ii) First linker;
(Iii) VH2 specific for the second target protein;
(Iv) Third linker;
(V) CH1;
(Vi) Hinge area;
CH2; and (viii) CH3; containing tyrosine at position 252 and threonine at position 254 and glutamic acid at position 256 according to EU index similar to (vii) Kabat;
Including
(B) Each of the second polypeptides is described below in the direction from the N-terminal to the C-terminal:
(I) VL2 specific for the second target protein;
(Ii) Second linker;
(Iii) VH1 specific for the first target protein;
(Iv) 4th linker; and (v) CL;
Including
Here, in the compound,
a) The VL1 and VH1 associate to form a binding site that binds to the first target protein; and b) the VL2 and VH2 associate to form a binding site that binds to the second target protein. Form;
here,
(I) The first target protein is IL-23A and the second target protein is BAFF, where further.
(I) The VL1 contains the amino acid sequence of SEQ ID NO: 4, the VH1 contains the amino acid sequence of SEQ ID NO: 3, the VL2 contains the amino acid sequence of SEQ ID NO: 91, and the VH2 contains the amino acid sequence of SEQ ID NO: 90. Is it a waste;
(Ii) The VL1 contains the amino acid sequence of SEQ ID NO: 4, the VH1 contains the amino acid sequence of SEQ ID NO: 3, the VL2 contains the amino acid sequence of SEQ ID NO: 89, and the VH2 contains the amino acid sequence of SEQ ID NO: 88. Or (iii) said VL1 comprises the amino acid sequence of SEQ ID NO: 4, said VH1 contained the amino acid sequence of SEQ ID NO: 3, said VL2 contained the amino acid sequence of SEQ ID NO: 2, and said VH2 contained the amino acid sequence of SEQ ID NO: 1. It contains an amino acid sequence;
Or
(II) The first target protein is BAFF and the second target protein is IL-23A.
The VL1 comprises the amino acid sequence of SEQ ID NO: 2, the VH1 comprises the amino acid sequence of SEQ ID NO: 1, the VL2 comprises the amino acid sequence of SEQ ID NO: 4, and the VH2 comprises the amino acid sequence of SEQ ID NO: 3;
The compound.
(i)前記CH2が、Kabatと同様のEUインデックスによる番号の234位にアラニン、及び235位にアラニンを含む;
(ii)前記CH1、前記ヒンジ領域、前記CH2、前記CH3のアミノ酸配列が、IgG1またはIgG4に由来するものである;
(iii)前記ヒンジ領域が、配列番号76のアミノ酸配列、配列番号130のアミノ酸配列、または配列番号134のアミノ酸配列を含む。 The compound according to any one of claims 8 to 10, which comprises one or more of the following characteristics:
(I) The CH2 contains alanine at position 234 and alanine at position 235 according to the EU index similar to Kabat;
(Ii) The amino acid sequences of CH1, the hinge region, CH2, and CH3 are derived from IgG1 or IgG4;
(Iii) The hinge region comprises the amino acid sequence of SEQ ID NO: 76, the amino acid sequence of SEQ ID NO: 130, or the amino acid sequence of SEQ ID NO: 134.
(i)前記CH1、前記ヒンジ領域、前記CH2、及び前記CH3のアミノ酸配列がIgG1に由来するものであり、前記ヒンジ領域が配列番号76のアミノ酸配列を含み、前記CH2が、Kabatと同様のEUインデックスによる番号の234位にアラニン、及び235位にアラニンを含むか;又は
(ii)前記CH1、前記ヒンジ領域、前記CH2、及び前記CH3のアミノ酸配列がIgG4に由来するものであり、前記ヒンジ領域が配列番号134のアミノ酸配列を含む;
前記化合物。 The compound according to any one of claims 8 to 10.
(I) The amino acid sequences of the CH1, the hinge region, the CH2, and the CH3 are derived from IgG1, the hinge region contains the amino acid sequence of SEQ ID NO: 76, and the CH2 is the same EU as Kabat. Does the index number contain alanine at position 234 and alanine at position 235; or (ii) the amino acid sequences of CH1, said hinge region, said CH2, and said CH3 are derived from IgG4 and said hinge region. Contains the amino acid sequence of SEQ ID NO: 134;
The compound.
(a)前記第1のポリペプチドのそれぞれが配列番号5のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号6のアミノ酸配列を含むか;
(b)前記第1のポリペプチドのそれぞれが配列番号15のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号16のアミノ酸配列を含むか;
(c)前記第1のポリペプチドのそれぞれが配列番号37のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号38のアミノ酸配列を含むか;
(d)前記第1のポリペプチドのそれぞれが配列番号41のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号42のアミノ酸配列を含むか;
(e)前記第1のポリペプチドのそれぞれが配列番号45のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号46のアミノ酸配列を含むか;または
(f)前記第1のポリペプチドのそれぞれが配列番号49のアミノ酸配列を含み、前記第2のポリペプチドのそれぞれが配列番号50のアミノ酸配列を含む;
前記化合物。 The compound according to claim 8.
(A) Does each of the first polypeptides contain the amino acid sequence of SEQ ID NO: 5 and each of the second polypeptides contains the amino acid sequence of SEQ ID NO: 6;
(B) Does each of the first polypeptides contain the amino acid sequence of SEQ ID NO: 15 and each of the second polypeptides contains the amino acid sequence of SEQ ID NO: 16;
(C) Does each of the first polypeptides contain the amino acid sequence of SEQ ID NO: 37 and each of the second polypeptides contains the amino acid sequence of SEQ ID NO: 38;
(D) Does each of the first polypeptides contain the amino acid sequence of SEQ ID NO: 41 and each of the second polypeptides contains the amino acid sequence of SEQ ID NO: 42;
(E) Each of the first polypeptides comprises the amino acid sequence of SEQ ID NO: 45 and each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 46; or (f) the first polypeptide. Each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 49; each of the second polypeptides comprises the amino acid sequence of SEQ ID NO: 50;
The compound.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562196170P | 2015-07-23 | 2015-07-23 | |
| US62/196,170 | 2015-07-23 | ||
| US201562201067P | 2015-08-04 | 2015-08-04 | |
| US62/201,067 | 2015-08-04 | ||
| US201662355302P | 2016-06-27 | 2016-06-27 | |
| US62/355,302 | 2016-06-27 | ||
| PCT/US2016/043267 WO2017015433A2 (en) | 2015-07-23 | 2016-07-21 | Compound targeting il-23a and b-cell activating factor (baff) and uses thereof |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2018527323A JP2018527323A (en) | 2018-09-20 |
| JP2018527323A5 JP2018527323A5 (en) | 2019-08-08 |
| JP6866345B2 true JP6866345B2 (en) | 2021-04-28 |
Family
ID=57835236
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018503151A Active JP6866345B2 (en) | 2015-07-23 | 2016-07-21 | Compounds targeting IL-23A and B cell activating factor (BAFF) and their use |
Country Status (21)
| Country | Link |
|---|---|
| US (3) | US10280231B2 (en) |
| EP (1) | EP3322436A4 (en) |
| JP (1) | JP6866345B2 (en) |
| KR (1) | KR102644875B1 (en) |
| CN (1) | CN108135976B (en) |
| AU (1) | AU2016297575B2 (en) |
| BR (1) | BR112018001255A2 (en) |
| CA (1) | CA2993329A1 (en) |
| CL (1) | CL2018000182A1 (en) |
| CO (1) | CO2018001264A2 (en) |
| EA (1) | EA201890360A1 (en) |
| IL (1) | IL256665B2 (en) |
| MX (1) | MX2018000959A (en) |
| MY (1) | MY191081A (en) |
| PE (1) | PE20180774A1 (en) |
| PH (1) | PH12018500151A1 (en) |
| SA (1) | SA518390788B1 (en) |
| SG (1) | SG10201912593VA (en) |
| TW (1) | TWI733685B (en) |
| UA (1) | UA125433C2 (en) |
| WO (1) | WO2017015433A2 (en) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9963510B2 (en) | 2005-04-15 | 2018-05-08 | Macrogenics, Inc. | Covalent diabodies and uses thereof |
| KR101931591B1 (en) | 2010-11-04 | 2018-12-24 | 베링거 인겔하임 인터내셔날 게엠베하 | Anti-il-23 antibodies |
| CA2871985C (en) | 2012-05-03 | 2023-10-10 | Boehringer Ingelheim International Gmbh | Anti-il-23p19 antibodies |
| EP3708679A1 (en) | 2014-07-24 | 2020-09-16 | Boehringer Ingelheim International GmbH | Biomarkers useful in the treatment of il-23a related diseases |
| TW202323304A (en) * | 2021-09-30 | 2023-06-16 | 大陸商江蘇恆瑞醫藥股份有限公司 | Anti-il23 antibody fusion protein and uses thereof |
| WO2024140930A1 (en) * | 2022-12-28 | 2024-07-04 | Suzhou Transcenta Therapeutics Co., Ltd. | Bispecific binding protein comprising anti-baff antibody and use thereof |
Family Cites Families (38)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4880635B1 (en) | 1984-08-08 | 1996-07-02 | Liposome Company | Dehydrated liposomes |
| US5807715A (en) | 1984-08-27 | 1998-09-15 | The Board Of Trustees Of The Leland Stanford Junior University | Methods and transformed mammalian lymphocyte cells for producing functional antigen-binding protein including chimeric immunoglobulin |
| US4921757A (en) | 1985-04-26 | 1990-05-01 | Massachusetts Institute Of Technology | System for delayed and pulsed release of biologically active substances |
| US4920016A (en) | 1986-12-24 | 1990-04-24 | Linear Technology, Inc. | Liposomes with enhanced circulation time |
| JPH0825869B2 (en) | 1987-02-09 | 1996-03-13 | 株式会社ビタミン研究所 | Antitumor agent-embedded liposome preparation |
| US4911928A (en) | 1987-03-13 | 1990-03-27 | Micro-Pak, Inc. | Paucilamellar lipid vesicles |
| US4917951A (en) | 1987-07-28 | 1990-04-17 | Micro-Pak, Inc. | Lipid vesicles formed of surfactants and steroids |
| US6277375B1 (en) | 1997-03-03 | 2001-08-21 | Board Of Regents, The University Of Texas System | Immunoglobulin-like domains with increased half-lives |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| EP2275449B1 (en) * | 2000-06-16 | 2016-09-28 | Human Genome Sciences, Inc. | Antibodies that immunospecifically bind to BLyS |
| JP4336498B2 (en) | 2000-12-12 | 2009-09-30 | メディミューン,エルエルシー | Molecules with extended half-life and compositions and uses thereof |
| ES2971647T3 (en) | 2005-04-15 | 2024-06-06 | Macrogenics Inc | Covalent diabodies and their uses |
| US9284375B2 (en) * | 2005-04-15 | 2016-03-15 | Macrogenics, Inc. | Covalent diabodies and uses thereof |
| WO2008071751A1 (en) * | 2006-12-14 | 2008-06-19 | Actogenix N.V. | Delivery of binding molecules to induce immunomodulation |
| KR101599735B1 (en) | 2007-06-21 | 2016-03-07 | 마크로제닉스, 인크. | Covalent diabodies and uses thereof |
| KR101759457B1 (en) | 2007-12-21 | 2017-07-31 | 메디뮨 리미티드 | BINDING MEMBERS FOR INTERLEUKIN-4 RECEPTOR ALPHA (IL-4Rα)-173 |
| UA105768C2 (en) * | 2008-05-09 | 2014-06-25 | Ебботт Гмбх Унд Ко. Кг | Normal;heading 1;heading 2;heading 3;ANTIBODIES TO RECEPTOR OF ADVANCED GLYCATION END PRODUCTS (RAGE) AND USES THEREOF |
| EP2786762B1 (en) | 2008-12-19 | 2019-01-30 | MacroGenics, Inc. | Covalent diabodies and uses thereof |
| US20130129723A1 (en) * | 2009-12-29 | 2013-05-23 | Emergent Product Development Seattle, Llc | Heterodimer Binding Proteins and Uses Thereof |
| GB201002238D0 (en) | 2010-02-10 | 2010-03-31 | Affitech As | Antibodies |
| DK2536745T3 (en) * | 2010-02-19 | 2016-08-22 | Xencor Inc | NOVEL CTLA4-IG immunoadhesins |
| WO2011119484A1 (en) * | 2010-03-23 | 2011-09-29 | Iogenetics, Llc | Bioinformatic processes for determination of peptide binding |
| TWI426920B (en) | 2010-03-26 | 2014-02-21 | Hoffmann La Roche | Bispecific, bivalent anti-vegf/anti-ang-2 antibodies |
| EP2601216B1 (en) * | 2010-08-02 | 2018-01-03 | MacroGenics, Inc. | Covalent diabodies and uses thereof |
| KR101931591B1 (en) * | 2010-11-04 | 2018-12-24 | 베링거 인겔하임 인터내셔날 게엠베하 | Anti-il-23 antibodies |
| GB201020738D0 (en) * | 2010-12-07 | 2011-01-19 | Affitech Res As | Antibodies |
| CN103429261A (en) | 2010-12-22 | 2013-12-04 | 塞法隆澳大利亚股份有限公司 | Modified antibody with improved half-life |
| ES2668895T3 (en) * | 2011-03-16 | 2018-05-23 | Amgen Inc. | Fc variants |
| TWI671315B (en) | 2011-03-28 | 2019-09-11 | 法商賽諾菲公司 | Dual variable region antibody-like binding proteins having cross-over binding region orientation |
| BR112014018005B1 (en) | 2012-02-15 | 2021-06-29 | F. Hoffmann-La Roche Ag | USE OF A NON-COVALENT IMMOBILIZED COMPLEX |
| GB201203071D0 (en) * | 2012-02-22 | 2012-04-04 | Ucb Pharma Sa | Biological products |
| AR090626A1 (en) | 2012-04-20 | 2014-11-26 | Lilly Co Eli | ANTI-BAFF-ANTI-IL-17 BIESPECIFIC ANTIBODIES |
| US8945553B2 (en) * | 2012-05-22 | 2015-02-03 | Bristol-Myers Squibb Company | Bispecific antibodies to IL-23 and IL-17A/F |
| KR102181776B1 (en) * | 2012-06-05 | 2020-11-24 | 삼성전자주식회사 | Apparatus and method for transceiving in a general purpose deivice |
| US20140377269A1 (en) | 2012-12-19 | 2014-12-25 | Adimab, Llc | Multivalent antibody analogs, and methods of their preparation and use |
| JP2015088330A (en) * | 2013-10-30 | 2015-05-07 | トヨタ自動車株式会社 | Sulfur-including all-solid battery |
| WO2015100246A1 (en) * | 2013-12-24 | 2015-07-02 | Ossianix, Inc. | Baff selective binding compounds and related methods |
| KR20160113715A (en) * | 2014-01-31 | 2016-09-30 | 베링거 인겔하임 인터내셔날 게엠베하 | Novel anti-baff antibodies |
-
2016
- 2016-07-21 JP JP2018503151A patent/JP6866345B2/en active Active
- 2016-07-21 MX MX2018000959A patent/MX2018000959A/en unknown
- 2016-07-21 CA CA2993329A patent/CA2993329A1/en active Pending
- 2016-07-21 BR BR112018001255-6A patent/BR112018001255A2/en active Search and Examination
- 2016-07-21 US US15/215,690 patent/US10280231B2/en active Active
- 2016-07-21 CN CN201680051316.0A patent/CN108135976B/en active Active
- 2016-07-21 TW TW105123026A patent/TWI733685B/en active
- 2016-07-21 WO PCT/US2016/043267 patent/WO2017015433A2/en active Application Filing
- 2016-07-21 IL IL256665A patent/IL256665B2/en unknown
- 2016-07-21 EA EA201890360A patent/EA201890360A1/en unknown
- 2016-07-21 EP EP16828518.7A patent/EP3322436A4/en active Pending
- 2016-07-21 MY MYPI2018000034A patent/MY191081A/en unknown
- 2016-07-21 AU AU2016297575A patent/AU2016297575B2/en active Active
- 2016-07-21 UA UAA201801854A patent/UA125433C2/en unknown
- 2016-07-21 PE PE2018000111A patent/PE20180774A1/en unknown
- 2016-07-21 KR KR1020187004892A patent/KR102644875B1/en active IP Right Grant
- 2016-07-21 SG SG10201912593VA patent/SG10201912593VA/en unknown
-
2018
- 2018-01-18 PH PH12018500151A patent/PH12018500151A1/en unknown
- 2018-01-22 CL CL2018000182A patent/CL2018000182A1/en unknown
- 2018-01-23 SA SA518390788A patent/SA518390788B1/en unknown
- 2018-02-07 CO CONC2018/0001264A patent/CO2018001264A2/en unknown
-
2019
- 2019-02-18 US US16/278,216 patent/US10844138B2/en active Active
-
2020
- 2020-10-22 US US17/076,894 patent/US11884744B2/en active Active
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7072600B2 (en) | Compounds targeting IL-23A and TNF-alpha and their use | |
| JP6866345B2 (en) | Compounds targeting IL-23A and B cell activating factor (BAFF) and their use | |
| WO2022017428A1 (en) | Anti-ctla-4 antibody and use thereof | |
| CA3187576A1 (en) | Il-10 muteins and fusion proteins thereof | |
| US20230140694A1 (en) | Combination treatment for cancer involving anti-icos and anti-pd1 antibodies, optionally further involving anti-tim3 antibodies | |
| US20240141070A1 (en) | Ox40/pd-l1 bispecific antibody | |
| EA040031B1 (en) | COMPOUND TARGETING TO IL-23A AND B-LYMPHOCYTE ACTIVATION FACTOR (BAFF) AND ITS USE | |
| EA047781B1 (en) | COMPOUND TARGETING IL-23A AND TNF-ALPHA AND ITS APPLICATION | |
| BR112017004169B1 (en) | COMPOUND SPECIFIC FOR IL23A AND TNF-ALPHA COMPRISING A FIRST POLYPEPTIDE AND A SECOND POLYPEPTIDE, AND USE THEREOF |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20190628 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20190628 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20200617 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200909 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20210106 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210115 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20210308 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20210407 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6866345 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |