JP2009282686A - 分類モデル学習装置および分類モデル学習方法 - Google Patents
分類モデル学習装置および分類モデル学習方法 Download PDFInfo
- Publication number
- JP2009282686A JP2009282686A JP2008133224A JP2008133224A JP2009282686A JP 2009282686 A JP2009282686 A JP 2009282686A JP 2008133224 A JP2008133224 A JP 2008133224A JP 2008133224 A JP2008133224 A JP 2008133224A JP 2009282686 A JP2009282686 A JP 2009282686A
- Authority
- JP
- Japan
- Prior art keywords
- expert data
- data
- reliability
- expert
- classification model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images




Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Image Analysis (AREA)
Abstract
【課題】質の悪い教師データが含まれていても精度の良い分類モデルを構築する。
【解決手段】ラベル付けの信頼度が所定の基準を満たすエキスパートデータおよびラベル付けの信頼度が不明な非エキスパートデータの各々が対応する座標を取得して非エキスパートデータからエキスパートデータまでの距離を各々算出し、所定の規則に当てはめて近傍距離を定義する。次に、選択した非エキスパートデータから近傍距離の範囲内にあるエキスパートデータを探索して同ラベル確率を算出し、付されたラベルが近傍距離の範囲内にあるエキスパートデータのラベルに一致する確率に基づく信頼度関数に当てはめて非エキスパートデータの信頼度を決定し、付加する。そして、エキスパートデータおよび信頼度が付加された非エキスパートデータに基づいて所望のデータにラベル付けを行う分類モデルを学習する。
【選択図】図1
【解決手段】ラベル付けの信頼度が所定の基準を満たすエキスパートデータおよびラベル付けの信頼度が不明な非エキスパートデータの各々が対応する座標を取得して非エキスパートデータからエキスパートデータまでの距離を各々算出し、所定の規則に当てはめて近傍距離を定義する。次に、選択した非エキスパートデータから近傍距離の範囲内にあるエキスパートデータを探索して同ラベル確率を算出し、付されたラベルが近傍距離の範囲内にあるエキスパートデータのラベルに一致する確率に基づく信頼度関数に当てはめて非エキスパートデータの信頼度を決定し、付加する。そして、エキスパートデータおよび信頼度が付加された非エキスパートデータに基づいて所望のデータにラベル付けを行う分類モデルを学習する。
【選択図】図1
Description
本発明は、機械学習において分類対象データにラベル付けを行う分類モデル学習装置および分類モデル学習方法に関する。
データマイニングにおいて重要な分野の一つに機械学習が挙げられる。機械学習は分類問題に使われることが多く、分類問題において計算機は人間のつけた評価を学習することで分類モデルを構築する。この機械学習の応用は画像認識、文字認識、テキスト分類など広い分野で多くの成果を上げている。このような学習は一般的に教師あり学習と呼ばれる。
教師あり学習には計算機に正しい判断を教える「教師データ」、つまり人間の手によって「ラベル」が付けられたデータが必要である。計算機は教師データをもとにどのような分類をすれば良いかを学習し、新しいデータに対して自動的に判断を下せるようになる。現代ではIT環境の発展により、大量で詳細なデータが機械学習に利用可能となっており、これらを教師データとして用いればより正確な分類モデルの構築に繋がると期待されている。
しかし、ここで「大量のデータ」から「大量の教師データ」を得る際のラベル付けが問題になっている。すなわち、得られたデータを教師データとして利用するためには、データに対して人間が判断したラベルを付与することが必要であるが、正確なラベル付けには、データが取られたドメインに対しての知識や経験などに基づく正確な判断が不可欠である。
理想的にはこれらの条件を満たす対象分野のエキスパートがラベル付けを行うことが望ましいが、全てのデータのラベル付けをエキスパートに依頼することは非常にコストが高くなってしまう。しかし、現実的にはコストに制限があるため、大量の教師データが必要である場合には、非エキスパートがラベル付けを行った教師データを用いることになる。エキスパートによる高コストの教師データは少量になりがちなのに対し、非エキスパートによる低コストの教師データは比較的大量に獲得できるためである。その一方、非エキスパートによる教師データには判断のミスや知識の不正確さから、比較的多くの誤ったラベルが含まれてしまうことが考えられる。
また、一般の機械学習においては、教師データの取得に関する情報は用いられず、エキスパートによるラベル付けのような「良質の教師データ」と非エキスパートによるラベル付けのような「ノイズを含む教師データ」が混在する状況においても、全てのデータを同列に扱い、等しく学習に使用する。
したがって、エキスパートによる少量の教師データと非エキスパートによる大量の教師データを従来どおり同列とみなして学習に使用した場合、非エキスパートデータに含まれるノイズが学習に大きく影響し、精度の良い分類モデルが構築できないケースが考えられる。
一方で、分類モデルを学習する際に、一部の教師データを選択的に使用して学習を行うことや、一部の教師データに重みを置いて学習を行うことが一般的に行われている。アンサンブル学習の代表的手法の1つであるAdaBoostもその一つである。AdaBoostは、学習データに対して重みを与えて学習器を生成し、その際に誤った分類をしたデータに対して重みを増して再度学習器を生成することを繰り返して複数の弱学習器を得て、それらの弱学習器の重みつき投票により分類を行う手法である(例えば特許文献1、非特許文献1参照)。
特開2002−133389号公報
Y. Freund and R.E. Shapire, "Experiments with a new boosting algorithm", Proc. of the 13th. Int. Conf. on Machine Learning, 1996, 148-156
しかしながら、従来技術は、あくまで所定のアルゴリズムに即した形で教師データに対してデータ重みをつけるものであり、教師データの精度の差異という学習過程を開始する前の知識・情報を含んだものではなく、例えばエキスパートによる少量の教師データ(以下、「エキスパートデータ」という。)と非エキスパートによる大量の教師データ(以下、「非エキスパートデータ」という。)のような、質の異なる教師データを従来どおり同列として学習に使用した場合、質の劣る教師データに含まれるノイズが学習に大きく影響し、精度の良い分類モデルが構築できないという問題があった。
このような問題に対して、本出願人は特許出願2007−278893においてエキスパートによる少量の教師データを利用することで精度の良い分類モデルの学習を行う手法を提案している。この手法は、エキスパートによる教師データを基にして非エキスパートによる教師データのラベルに信頼度を付加し、分類モデルの学習にその信頼度を反映することで分類モデルを学習するものである。この信頼度は、エキスパートデータおよび非エキスパートデータの各々を所定の規則に基づいて対応付けた座標の間の距離(例えばユークリッド距離やコサイン距離)に応じて求められている。
対象の非エキスパートデータから距離の近いN個のエキスパートデータを探索し、もしラベルが同じであればそのエキスパートデータから信頼度を得る。この信頼度は例えば距離に反比例する形で与えられ、非エキスパートデータの近くのエキスパートデータが同じラベルであれば、その非エキスパートデータは高い信頼度を得られるようになっている。これは、信頼できるデータが近くにあるほど信頼度は高いという直感的な信頼度付けを表していると言える。
しかしながら、上記の信頼度付け方法は、エキスパートデータには誤ラベルが含まれていないことを暗に仮定している。エキスパートデータに全て適切なラベルが与えられているならば、それらを参照して与えられた非エキスパートデータの信頼度も適切な値になることが期待できる。その反面、エキスパートデータに誤ラベルが含まれている場合には、このような信頼度の付加は必ずしも適切とは言えない。図10および図11は、エキスパートデータのラベル付けと非エキスパートデータのラベル付けに対する信頼度の関係を説明する図である。
図10では、ある非エキスパートデータx1の非常に近傍にエキスパートデータX1が存在している。このX1は非常に近傍にあるため、X1とx1のラベルが同じであればx1の信頼度は高く、異なれば低くなる。ここでX1、x1に本来付与されるべきラベルはL1であるとする。エキスパートデータX1に、正確なラベルL1が付与されているとすると、非エキスパートデータx1にL1が付与されている場合には信頼度は高く、異なったラベルL2が付与されている場合には信頼度は低くなる。これは、適切な信頼度であるといえる。
図11では、エキスパートデータX1に誤ラベルL2が付与されている場合を考える。このとき、非エキスパートデータx1に本来付与されるべきラベルL1が付与されていたときは信頼度が低く、反対に付与されるべきでないラベルL2が付与されていたときに信頼度が高くなってしまう。これは明らかに適切な信頼度とは反対の傾向である。
すなわち、エキスパートデータ中に誤ラベルが含まれている場合、非エキスパートデータに適切でない信頼度が付加され、その信頼度を反映して生成される分類モデルの性能が劣化してしまう。現実にはエキスパートデータ中にも少量の誤ラベルが含まれると考えられるため、エキスパートデータ中の誤ラベルに頑健な信頼度付加が必要である。
そこで、本発明は、従来技術の問題に鑑み、質の悪い教師データが含まれている状況であっても精度の良い分類モデルの構築が可能な分類モデル学習装置および分類モデル学習方法を提供することを目的とする。
本発明に係る分類モデル学習装置は、機械学習におけるラベル付けの信頼度が所定の基準を満たす教師データをエキスパートデータとして格納するエキスパートデータ格納部と、前記ラベル付けの信頼度が不明な教師データを非エキスパートデータとして格納する非エキスパートデータ格納部と、前記エキスパートデータ格納部および前記非エキスパートデータ格納部に接続され、前記エキスパートデータおよび前記非エキスパートデータの各々が対応する座標を取得して前記非エキスパートデータから前記エキスパートデータまでの距離を各々算出すると共に、この算出された距離を所定の規則に当てはめて近傍距離を定義する近傍距離定義部と、前記非エキスパートデータに付された前記ラベルが前記近傍距離の範囲内にある前記エキスパートデータに付された前記ラベルに一致する確率に基づく信頼度関数を格納する信頼度関数格納部と、前記近傍距離定義部、前記信頼度関数格納部、前記エキスパートデータ格納部、および前記非エキスパートデータ格納部に接続され、選択した前記非エキスパートデータから前記近傍距離の範囲内にある前記エキスパートデータを探索して前記確率を算出すると共に、この算出された確率を前記信頼度関数に当てはめて前記非エキスパートデータにおける前記ラベル付けの信頼度を決定する信頼度決定部と、前記エキスパートデータ格納部および前記信頼度決定部に接続され、前記エキスパートデータおよび前記信頼度が付加された非エキスパートデータに基づいて所望の分類対象データに前記ラベル付けを行う分類モデルを学習する分類モデル学習部と、を有することを特徴とする。
本発明に係る分類モデル学習方法は、機械学習におけるラベル付けの信頼度が所定の基準を満たしている教師データをエキスパートデータ、前記ラベル付けの信頼度が不明の教師データを非エキスパートデータとして格納するコンピュータが行う分類モデル学習方法であって、前記エキスパートデータおよび前記非エキスパートデータの各々が対応する座標を取得して前記非エキスパートデータから前記エキスパートデータまでの距離を各々算出すると共に、この算出された距離を所定の規則に当てはめて近傍距離を定義する近傍距離定義ステップと、前記格納された非エキスパートデータから前記信頼度の付加対象となる非エキスパートデータを選択する選択ステップと、前記選択された非エキスパートデータから前記近傍距離の範囲内にある前記エキスパートデータを探索して前記非エキスパートデータに付された前記ラベルが前記エキスパートデータに付された前記ラベルに一致する確率を算出すると共に、この算出された確率を予め定義された信頼度関数に当てはめて前記非エキスパートデータの前記ラベル付けの信頼度を決定する信頼度決定ステップと、前記決定された信頼度が付加された非エキスパートデータおよび前記エキスパートデータに基づいて所望のデータに前記ラベル付けを行う分類モデルを学習する分類モデル学習ステップと、を有することを特徴とする。
本発明によれば、質の悪い教師データが含まれている状況であっても精度の良い分類モデルの構築が可能な分類モデル学習装置および分類モデル学習方法が提供される。
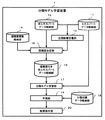
以下、本発明の実施形態について図面を用いて説明する。図1は、本発明の一実施形態に係る分類モデル学習装置1の全体構成例を示すブロック図である。同図に示されるように、本実施形態に係る分類モデル学習装置1は、エキスパートデータ格納部11、非エキスパートデータ格納部12、近傍距離定義部13、信頼度関数格納部14、信頼度決定部15、信頼度付き非エキスパートデータ格納部16、分類モデル学習部17、分類対象データ格納部18、予測部19、および結果表示部20から構成されている。
エキスパートデータ格納部11は、エキスパートデータを格納する記憶装置である。「エキスパートデータ」とは、知識、経験の豊富な専門家が機械学習においてデータを分類するためのラベル付けを行われており、ラベル付けの精度(信頼性)が高い教師データを示すものとする。
非エキスパートデータ格納部12は、非エキスパートデータを格納する記憶装置である。「非エキスパートデータ」とは、ラベル付けは行われているが、その精度(信頼性)が不明確な教師データを示すものとする。
近傍距離定義部13は、非エキスパートデータからエキスパートデータまでの座標間距離を各々算出し、この座標間距離に基づいてデータ間の類似度が基準値以上の範囲を表す近傍距離を定義するプログラムである。ここでは、算出された座標間距離の中から所定の規則に基づいて複数の距離を選択し、これらの距離の平均値から近傍距離を算出するが、算出方法はこれに限られない。
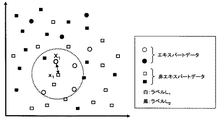
図2は、エキスパートデータおよび非エキスパートデータを2次元で具体的に説明する図である。同図において、丸印はエキスパートデータ、四角印は非エキスパートデータを表し、各印の色はラベルを表している。これらの座標は各データを所定の規則に基づいて変換することで得られる。例えば、電子メールの分類においては、多数の迷惑メールを解析することによって特徴語リストを予め作成しておき、この特徴語リストと受信メール本文内の単語を比較することで座標化を行う。具体的には、特徴語リストに含まれるN個の単語との比較結果を受信メール内に含まれる場合を1、含まれない場合を0として表すことにより、受信メールのデータをN次元の座標(例えば(1,0,1,…,1))に変換できる。ここでは、説明のためにメールデータを座標化したN次元のデータを擬似的に2次元で表しているものとする。すなわち、受信メール本文の内容が近似する場合には、座標が近似するので迷惑メールか否かのラベル付け等に用いることができる。
また、図2においては、近傍距離定義部13が非エキスパートデータを選択し、この選択された非エキスパートデータから各エキスパートデータまでの距離を順次求めることが示されている。例えば、近傍距離を“非エキスパートデータから4番目に近いエキスパートデータまでの距離の平均値”とする規則が予め定められている場合には、距離r4を非エキスパートデータ毎に求め、その平均値を算出する。
信頼度関数格納部14は、分類問題に適した信頼度関数を格納する記憶装置である。この信頼度関数は、非エキスパートデータから近傍距離内にあるエキスパートデータの同ラベル確率に基づいて信頼度を定義する関数であり、この関数は種々の分類問題に対応させて予め複数作成しておくと好適である。具体的な定義方法は後述する。
信頼度決定部15は、近傍距離定義部13により定義された近傍距離に基づいて非エキスパートデータの近傍にあるエキスパートデータを探索すると共に非エキスパートデータとの同ラベル確率を算出し、この同ラベル確率を信頼度関数格納部14から取得される信頼度関数に当てはめて非エキスパートデータの信頼度を決定するプログラムである。尚、複数の信頼度関数の内、どの関数を用いるか選択する方法としては、モデル作成時にユーザが入力装置(図示省略する)から入力した情報に基づいて選択する方法や使用する関数を予め設定しておく方法などが挙げられる。
信頼度付き非エキスパートデータ格納部16は、信頼度決定部15における処理よって信頼度が付与された非エキスパートデータ(以下、「信頼度付き非エキスパートデータ」という。)を格納する記憶装置である。
分類モデル学習部17は、エキスパートデータと信頼度付き非エキスパートデータを用いて分類モデルを学習するプログラムである。
分類対象データ格納部18は、新たに分類の対象となるデータ、すなわち、ラベルが付与されていないデータ(以下、「分類対象データ」という。)を格納する記憶装置である。
予測部19は、分類モデル学習部17で得られた分類モデルを用いて分類対象データ格納部18に格納されている分類対象データにラベル付けを行うプログラムである。尚、AdaBoostを用いた場合、予測部19での分類手法は、一般的なAdaBoostにおける手法と同様であるので説明は省略する。
結果表示部20は、予測部19における予測結果を表示するディスプレイなどの表示装置である。
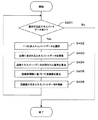
以下、分類モデル学習装置1における動作を図面に基づいて説明する。尚、本実施形態においては、エキスパートデータおよび非エキスパートデータを2次元のデータとして具体的に説明する。図3は、近傍距離定義部13における処理の具体例を示すフローチャートである。
S301においては、未だ選択されていない非エキスパートデータが存在するか否かを判断する。ここで、全ての非エキスパートデータが選択済みであればS305へ進む。これに対し、選択されていない非エキスパートデータが存在する場合にはS302へ進む。
S302においては、非エキスパートデータ格納部12から未だ選択されていない非エキスパートデータを一つ選択する。
S303においては、選択された非エキスパートデータから全てのエキスパートデータへの距離を各々算出する。
S303においては、選択された非エキスパートデータから全てのエキスパートデータへの距離を各々算出する。
S304においては、選択された非エキスパートデータからk番目に近いエキスパートデータまでの距離をバッファ領域(図示省略する)に保持する。尚、最適な整数kは問題によって異なるが、ここでは整数kをユーザが予め設定した値とする。例えば、S303で算出された距離の分布を解析し、各非エキスパートデータからの距離が所定の範囲内にあるように整数kを設定することができる。また、信頼度の付加にあたって複数の近傍エキスパートデータを考慮したい場合などには整数kを大きくすれば良い。
S305においては、保持していた全ての距離の平均をとり、その値を近傍距離として信頼度決定部15へ出力し、処理を終了する。
S305においては、保持していた全ての距離の平均をとり、その値を近傍距離として信頼度決定部15へ出力し、処理を終了する。
以上の処理により、k番目に近いエキスパートデータまでの平均距離が求められる。問題に適した整数kを設定すれば、この距離は近傍を定義する典型的な値をとると考えることができる。
図4は、信頼度決定部15における処理の具体例を示すフローチャートである。S401においては、選択する非エキスパートデータが存在するか否かを判断する。ここで、全ての非エキスパートデータに信頼度が付与されており選択する非エキスパートデータがなければ処理を終了する。これに対し、信頼度が付与されていない非エキスパートデータが存在する場合にはS402へ進む。
S402においては、非エキスパートデータ格納部12から未だ信頼度が付与されていない非エキスパートデータを1つ選択する。ここでは、下記の式(1)で表されるj番目の非エキスパートデータが選択されているとする。尚、xは座標、yはラベルを表すものとする。

S403においては、選択された非エキスパートデータの近傍に含まれるエキスパートデータをエキスパートデータ格納部11から探索して保持する。この例では、「近傍」とは近傍距離定義部13において定義された近傍距離rを用いて、上記式(1)で表される非エキスパートデータを中心とした半径rの円の中の領域を指すものとする。したがって、近傍距離rが0.5ときは、下記の式(2)のエキスパートデータXj1は近傍に含まれるが、式(3)のエキスパートデータXj2は近傍には含まれない。
S404においては、探索されたN個のエキスパートデータから同ラベル確率を算出する。この例では、対象の非エキスパートデータxjと同ラベルの近傍エキスパートデータの数をK個とし、同ラベル確率Pjを下記の式(4)で定義する。
Pj=K/N ・・・(4)
Pj=K/N ・・・(4)
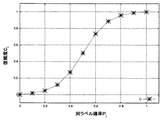
S405においては、式(4)を入力とする信頼度関数を用いて非エキスパートデータのラベルの信頼度を算出する。信頼度関数は分類問題によって適した形が考えられる。図5乃至図7は、分類問題の評価基準に応じた信頼度関数の具体例を説明する図である。この信頼度関数の性質の直感的な理解のために、対象となっている式(1)が表す非エキスパートデータの近傍にエキスパートデータが10例含まれており、さらにノイズのため本来は9例が同ラベルであるところ8例が同ラベルとなっている状況を考える。
この状況下で、例えば、非エキスパートデータのラベル付けが近傍エキスパートデータの8割以上と一致するならば、そのラベル付けに高信頼度を与えたい場合には、下記の式(5)のような信頼度関数を用いると好適である。尚、aは関数の形を決定するパラメーターである。
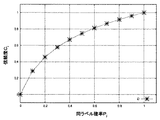
図5は、式(5)の信頼度関数を説明する図である。ここでは、横軸を同ラベル確率(Pj)、縦軸を信頼度(cj)とし、a=2.0の場合に式(5)によって求められる点を結んだ曲線で示されている。同ラベル数が9例から8例に変化するときノイズによる信頼度cjの変化はC(9/10)≒0.98からC(8/10)≒0.96となり、信頼度cjへの影響は小さい。すなわち、近傍の10例中の同ラベルが9例、8例のいずれの場合であっても、その非エキスパートデータのラベルの信頼度は高く維持されるという結果が得られる設定になっており、直感的にも妥当な信頼度関数であると言える。
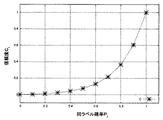
また、誤ラベルの混入に対して厳しい設定としたい場合には、下記の式(6)のような信頼度関数を用いると好適である。
図6は、式(6)の信頼度関数を示す図である。ここでは、横軸を同ラベル確率(Pj)、縦軸を信頼度(cj)とし、a=5.0の場合に式(6)によって求められる点を結んだ曲線で示されている。この関数を用いる場合には、一つでも誤ラベルがあると信頼度が大幅に下がる。例えば、医療などの高い信頼度が要求される分野において特に有用である。
更に、誤ラベルの混入に対して寛容な設定としたい場合には、下記の式(7)のような信頼度関数を用いると好適である。
図7は、式(7)の信頼度関数を示す図である。ここでは、横軸を同ラベル確率(Pj)、縦軸を信頼度(cj)とし、a=10.0の場合に式(7)によって求められる点を結んだ曲線で示されている。この関数を用いる場合には、誤ラベルが多く含まれていても信頼度が大幅に下がることはなく、誤ラベルの増加に応じて信頼度が緩やかに低下する。
S406において、S405で得られた信頼度cjを対象の非エキスパートデータに付加し、下記の式(8)のような形で信頼度付き非エキスパートデータ格納部16に格納する。
前述の2次元データの例(式(1)の非エキスパートデータ)であれば、下記の式(9)の形で信頼度付き非エキスパートデータ格納部16に格納される。
尚、エキスパートデータの信頼度は常に1としているので、エキスパートデータは擬似的に下記の式(10)の形でエキスパートデータ格納部11に格納されているとみなすことができる。
このように、近傍距離内における同ラベル確率を考慮した信頼度関数を用いることで、最近傍にあるエキスパートデータに誤ラベルが与えられていたとしても、他のラベルが正確であれば非エキスパートデータに適切な信頼度を付加することが可能になる。このような信頼度付けはデータ間の距離の長短のみに基づく信頼度付けよりもエキスパートデータの誤ラベルに対して頑健であると言える。
図8は、分類モデル学習部17における処理の具体例を示すフローチャートである。学習器については信頼度を反映する形のものであれば、どのような学習器でも機能すると考えられるが、ここではデータ重みに対する信頼度の組み込み易さを考慮してAdaBoostの手法に即した形で処理を行うものとする。尚、Baggingなどの他の手法を用いても良い。
S801においては、読み込まれた信頼度付き非エキスパートデータとエキスパートデータに、AdaBoostの手法に即して均等のデータ重みwjを付ける。本発明では、AdaBoostにおける従来のデータ重みwjに加え、信頼度決定部15で得られた信頼度cjが教師データに付加されているため、ここでは読み込まれたn個の非エキスパートデータは下記の式(11)、N個のエキスパートデータはそれぞれ下記の式(12)の形で処理されるものとする。
S802においては、非エキスパートデータに付与された信頼度cjをデータ重みに反映させる。ここでは、AdaBoostにおけるデータ重みwjに対して信頼度cjを反映させたデータ重みw’jを下記の式(13)により設定する。
w’j=cjwj ・・・(13)
w’j=cjwj ・・・(13)
このように設定することにより、データ重みwjが大きく学習に大きな影響を及ぼすと考えられる非エキスパートデータに関しても、その非エキスパートデータの信頼度cjが低ければデータ重みw’jの値は小さくなり、非エキスパートデータに含まれる信頼度cjの低い教師データの影響を自然な形で小さくすることができる。
S803においては、S802で得られたデータ重みw’jを用いて弱学習器を生成する。AdaBoostに用いられる弱学習器には決定木など様々なものが考えられる。
S804においては、AdaBoostのアルゴリズムに従い、データ重みと弱学習器の性能に依るコスト関数の更新を行う。
S804においては、AdaBoostのアルゴリズムに従い、データ重みと弱学習器の性能に依るコスト関数の更新を行う。
S805においては、終了条件を満たしているか否かを判定する。ここで、終了条件を満たすと判定された場合にはS806へ進む。これに対し、終了条件を満たさないと判定された場合はS802に戻る。尚、一般的なAdaBoostの手法における終了条件は、弱学習器の数が所定数を満たすことである。例えばユーザが弱学習器を100個作るという設定にすれば、S802〜S805を100回繰り返すことが終了条件である。
S806においては、生成された弱学習器を組合せることにより精度の高い分類モデルである強学習器を生成し、処理を終了する。
S806においては、生成された弱学習器を組合せることにより精度の高い分類モデルである強学習器を生成し、処理を終了する。
このように、教師データの精度の差異という学習過程を開始する前の知識を利用して非エキスパートデータに信頼度を付与し、分類モデルの学習に組み込むことで、エキスパートデータが少ない場合であっても精度の良い分類モデルを得ることができる。
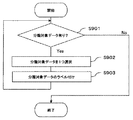
図9は、予測部19における処理の具体例を示すフローチャートである。S901においては、分類対象データ格納部18における分類対象データの有無を判定する。ここで、分類対象データが有ると判定された場合には、S902へ進む。これに対し、分類対象データが無いと判定された場合には、処理を終了する。
S902においては、分類対象データ格納部18から分類対象データを一つ選択する。
S903においては、選択した分類対象データを分類モデルに当てはめてラベル付けを行い、S901へ戻る。S901〜S903までの処理は全ての分類対象データに対してラベル付けが完了するまで繰返し行われる。
S903においては、選択した分類対象データを分類モデルに当てはめてラベル付けを行い、S901へ戻る。S901〜S903までの処理は全ての分類対象データに対してラベル付けが完了するまで繰返し行われる。
上記のように構成することで、高信頼度とされる教師データ(エキスパートデータ)の中にノイズが含まれる場合においても、同ラベル確率を入力とする信頼度関数と、各教師データの精度という事前知識を利用して非エキスパートデータに信頼度を付与し、分類モデルの学習に組み込むことで、精度の良い分類モデルを得ることができる。
尚、本発明は上記実施形態そのままに限定されるものではなく、実施段階ではその要旨を逸脱しない範囲で構成要素を変形して具体化できる。また、上記実施形態に開示されている複数の構成要素の適宜な組み合わせにより、種々の発明を形成できる。例えば、実施形態に示される全構成要素から幾つかの構成要素を削除してもよい。更に、異なる実施形態にわたる構成要素を適宜組み合わせてもよい。
また、上記実施形態においてはメールデータのようなテキストデータを例として説明したが、対象データの種類はこれに限定されない。すなわち、画像データや音声データなどのデータにおいても所定の規則に基づいて座標化することで、分類モデルを作成可能である。例えば、2次元のレントゲン画像データはM行N列に分割し、これを1行M×N列のデータに変換すればM×N次元の座標が得られる。この場合、画像データにおける色彩区分(例えば16段階のグレースケールなど)を行列の成分とすると好適である。そして、経験豊富な医師によって病変の有無が判定(ラベル付け)されたレントゲン画像データをエキスパートデータ、経験の浅い医師によって判定されたデータを非エキスパートデータとし、上記実施形態と同様に信頼度付けを行うことで精度の高い分類モデルを作成できる。
1…分類モデル学習装置、
11…エキスパートデータ格納部、
12…非エキスパートデータ格納部、
13…近傍距離定義部、
14…信頼度関数格納部、
15…信頼度決定部、
16…信頼度付き非エキスパートデータ格納部、
17…分類モデル学習部、
18…分類対象データ格納部、
19…予測部、
20…結果表示部。
11…エキスパートデータ格納部、
12…非エキスパートデータ格納部、
13…近傍距離定義部、
14…信頼度関数格納部、
15…信頼度決定部、
16…信頼度付き非エキスパートデータ格納部、
17…分類モデル学習部、
18…分類対象データ格納部、
19…予測部、
20…結果表示部。
Claims (10)
- 機械学習におけるラベル付けの信頼度が所定の基準を満たす教師データをエキスパートデータとして格納するエキスパートデータ格納部と、
前記ラベル付けの信頼度が不明な教師データを非エキスパートデータとして格納する非エキスパートデータ格納部と、
前記エキスパートデータ格納部および前記非エキスパートデータ格納部に接続され、前記エキスパートデータおよび前記非エキスパートデータの各々が対応する座標を取得して前記非エキスパートデータから前記エキスパートデータまでの距離を各々算出すると共に、この算出された距離を所定の規則に当てはめて近傍距離を定義する近傍距離定義部と、
前記非エキスパートデータに付された前記ラベルが前記近傍距離の範囲内にある前記エキスパートデータに付された前記ラベルに一致する確率に基づく信頼度関数を格納する信頼度関数格納部と、
前記近傍距離定義部、前記信頼度関数格納部、前記エキスパートデータ格納部、および前記非エキスパートデータ格納部に接続され、選択した前記非エキスパートデータから前記近傍距離の範囲内にある前記エキスパートデータを探索して前記確率を算出すると共に、この算出された確率を前記信頼度関数に当てはめて前記非エキスパートデータにおける前記ラベル付けの信頼度を決定する信頼度決定部と、
前記エキスパートデータ格納部および前記信頼度決定部に接続され、前記エキスパートデータおよび前記信頼度が付加された非エキスパートデータに基づいて所望の分類対象データに前記ラベル付けを行う分類モデルを学習する分類モデル学習部と、
を有することを特徴とする分類モデル学習装置。 - 前記信頼度関数は、前記非エキスパートデータに付された前記ラベルが前記近傍距離の範囲内にある前記エキスパートデータに付された前記ラベルに一致する確率と前記ラベル付けの信頼度との関係を定義することを特徴とする請求項1記載の分類モデル学習装置。
- 前記近傍距離定義部は、前記非エキスパートデータから前記エキスパートデータまでの前記座標間の距離を各々算出して前記非エキスパートデータ毎に順位付けを行い、所望の順位についての距離を前記非エキスパートデータの各々から集計してその平均値を算出し、この平均値を前記近傍距離として定義することを特徴とする請求項1または請求項2記載の分類モデル学習装置。
- 前記信頼度関数は、分類問題における所望の評価基準に応じて予め作成されていることを特徴とする請求項1乃至請求項3のいずれか一項記載の分類モデル学習装置。
- 前記分類モデル学習部が、アンサンブル学習におけるデータ重みに対して前記信頼度決定部で付加された信頼度を反映させることにより前記分類モデルを学習することを特徴とする請求項1乃至請求項4のいずれか一項記載の分類モデル学習装置。
- 機械学習におけるラベル付けの信頼度が所定の基準を満たしている教師データをエキスパートデータ、前記ラベル付けの信頼度が不明の教師データを非エキスパートデータとして格納するコンピュータが行う分類モデル学習方法であって、
前記エキスパートデータおよび前記非エキスパートデータの各々が対応する座標を取得して前記非エキスパートデータから前記エキスパートデータまでの距離を各々算出すると共に、この算出された距離を所定の規則に当てはめて近傍距離を定義する近傍距離定義ステップと、
前記格納された非エキスパートデータから前記信頼度の付加対象となる非エキスパートデータを選択する選択ステップと、
前記選択された非エキスパートデータから前記近傍距離の範囲内にある前記エキスパートデータを探索して前記非エキスパートデータに付された前記ラベルが前記エキスパートデータに付された前記ラベルに一致する確率を算出すると共に、この算出された確率を予め定義された信頼度関数に当てはめて前記非エキスパートデータの前記ラベル付けの信頼度を決定する信頼度決定ステップと、
前記決定された信頼度が付加された非エキスパートデータおよび前記エキスパートデータに基づいて所望のデータに前記ラベル付けを行う分類モデルを学習する分類モデル学習ステップと、
を有することを特徴とする分類モデル学習方法。 - 前記信頼度関数は、前記非エキスパートデータに付された前記ラベルが前記近傍距離の範囲内にある前記エキスパートデータに付された前記ラベルに一致する確率と前記ラベル付けの信頼度との関係を定義することを特徴とする請求項6記載の分類モデル学習方法。
- 前記近傍距離定義ステップにおいて、前記非エキスパートデータから前記エキスパートデータまでの前記座標間の距離を各々算出して前記非エキスパートデータ毎に順位付けを行い、所望の順位についての距離を前記非エキスパートデータの各々から集計してその平均値を算出し、この平均値を前記近傍距離として定義することを特徴とする請求項6または請求項7記載の分類モデル学習方法。
- 前記信頼度関数は、分類問題における所望の評価基準に応じて予め作成されていることを特徴とする請求項6乃至請求項8のいずれか一項記載の分類モデル学習方法。
- 前記分類モデル学習ステップにおいて、アンサンブル学習におけるデータ重みに対して前記信頼度決定ステップにおいて付加された信頼度を反映させることにより前記分類モデルを学習することを特徴とする請求項6乃至請求項9のいずれか一項記載の分類モデル学習方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008133224A JP2009282686A (ja) | 2008-05-21 | 2008-05-21 | 分類モデル学習装置および分類モデル学習方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008133224A JP2009282686A (ja) | 2008-05-21 | 2008-05-21 | 分類モデル学習装置および分類モデル学習方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2009282686A true JP2009282686A (ja) | 2009-12-03 |
Family
ID=41453094
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008133224A Pending JP2009282686A (ja) | 2008-05-21 | 2008-05-21 | 分類モデル学習装置および分類モデル学習方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2009282686A (ja) |
Cited By (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014063494A (ja) * | 2012-09-20 | 2014-04-10 | Fujitsu Ltd | 分類装置、分類方法及び電子設備 |
| JP2015060432A (ja) * | 2013-09-19 | 2015-03-30 | 富士通株式会社 | プログラム、コンピュータおよび訓練データ作成支援方法 |
| JP2015527635A (ja) * | 2012-06-21 | 2015-09-17 | フィリップ モリス プロダクツ エス アー | 統合デュアルアンサンブルおよび一般化シミュレーテッドアニーリング技法を用いてバイオマーカシグネチャを生成するためのシステムおよび方法 |
| JP2015166975A (ja) * | 2014-03-04 | 2015-09-24 | 富士ゼロックス株式会社 | 注釈情報付与プログラム及び情報処理装置 |
| JP2016505974A (ja) * | 2012-12-21 | 2016-02-25 | インサイドセールスドットコム インコーポレイテッドInsidesales.Com,Inc. | インスタンス重み付け学習機械学習モデル |
| JP2016143094A (ja) * | 2015-01-29 | 2016-08-08 | パナソニックIpマネジメント株式会社 | 転移学習装置、転移学習システム、転移学習方法およびプログラム |
| JP6182242B1 (ja) * | 2016-06-13 | 2017-08-16 | 三菱電機インフォメーションシステムズ株式会社 | データのラベリングモデルに係る機械学習方法、コンピュータおよびプログラム |
| JP6330092B1 (ja) * | 2017-08-02 | 2018-05-23 | 株式会社ディジタルメディアプロフェッショナル | 機械学習用教師データ生成装置及び生成方法 |
| KR101879735B1 (ko) * | 2017-03-15 | 2018-07-18 | (주)넥셀 | 자동적인 학습데이터 생성 방법 및 장치와 이를 이용하는 자가 학습 장치 및 방법 |
| JP2019046058A (ja) * | 2017-08-31 | 2019-03-22 | キヤノン株式会社 | 情報処理装置、情報処理方法、及びプログラム |
| JP2019144767A (ja) * | 2018-02-19 | 2019-08-29 | 富士通株式会社 | 学習プログラム、学習方法および学習装置 |
| KR20200039035A (ko) * | 2018-09-27 | 2020-04-16 | 주식회사 스위트케이 | 인공지능 기반의 학습데이터셋 제공 시스템 |
| WO2020166321A1 (ja) * | 2019-02-12 | 2020-08-20 | 日本電信電話株式会社 | モデル学習装置、ラベル推定装置、それらの方法、およびプログラム |
| JPWO2020240770A1 (ja) * | 2019-05-30 | 2020-12-03 | ||
| JPWO2021053776A1 (ja) * | 2019-09-18 | 2021-03-25 | ||
| CN112581093A (zh) * | 2020-12-23 | 2021-03-30 | 无锡航吴科技有限公司 | 一种融合线上线下的项目评审流程方法 |
| KR20210104299A (ko) * | 2020-02-17 | 2021-08-25 | 한국전자통신연구원 | 영상 객체 속성 분류 장치 및 방법 |
| JP2021131831A (ja) * | 2020-02-21 | 2021-09-09 | オムロン株式会社 | 情報処理装置、情報処理方法及びプログラム |
| JPWO2021186662A1 (ja) * | 2020-03-19 | 2021-09-23 | ||
| US11328812B2 (en) | 2018-11-15 | 2022-05-10 | Canon Medical Systems Corporation | Medical image processing apparatus, medical image processing method, and storage medium |
| WO2022123905A1 (ja) * | 2020-12-07 | 2022-06-16 | パナソニックIpマネジメント株式会社 | 処理システム、学習処理システム、処理方法、及びプログラム |
| US11475312B2 (en) | 2019-11-18 | 2022-10-18 | Samsung Electronics Co., Ltd. | Method and apparatus with deep neural network model fusing |
| JP2023146080A (ja) * | 2022-03-29 | 2023-10-12 | 本田技研工業株式会社 | 教師データ収集装置 |
| US11954566B2 (en) | 2019-05-28 | 2024-04-09 | Okuma Corporation | Data collection system for machine learning and a method for collecting data |
-
2008
- 2008-05-21 JP JP2008133224A patent/JP2009282686A/ja active Pending
Cited By (40)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10373708B2 (en) | 2012-06-21 | 2019-08-06 | Philip Morris Products S.A. | Systems and methods for generating biomarker signatures with integrated dual ensemble and generalized simulated annealing techniques |
| JP2015527635A (ja) * | 2012-06-21 | 2015-09-17 | フィリップ モリス プロダクツ エス アー | 統合デュアルアンサンブルおよび一般化シミュレーテッドアニーリング技法を用いてバイオマーカシグネチャを生成するためのシステムおよび方法 |
| JP2014063494A (ja) * | 2012-09-20 | 2014-04-10 | Fujitsu Ltd | 分類装置、分類方法及び電子設備 |
| JP2016505974A (ja) * | 2012-12-21 | 2016-02-25 | インサイドセールスドットコム インコーポレイテッドInsidesales.Com,Inc. | インスタンス重み付け学習機械学習モデル |
| JP2015060432A (ja) * | 2013-09-19 | 2015-03-30 | 富士通株式会社 | プログラム、コンピュータおよび訓練データ作成支援方法 |
| JP2015166975A (ja) * | 2014-03-04 | 2015-09-24 | 富士ゼロックス株式会社 | 注釈情報付与プログラム及び情報処理装置 |
| JP2016143094A (ja) * | 2015-01-29 | 2016-08-08 | パナソニックIpマネジメント株式会社 | 転移学習装置、転移学習システム、転移学習方法およびプログラム |
| JP6182242B1 (ja) * | 2016-06-13 | 2017-08-16 | 三菱電機インフォメーションシステムズ株式会社 | データのラベリングモデルに係る機械学習方法、コンピュータおよびプログラム |
| JP2017224027A (ja) * | 2016-06-13 | 2017-12-21 | 三菱電機インフォメーションシステムズ株式会社 | データのラベリングモデルに係る機械学習方法、コンピュータおよびプログラム |
| KR101879735B1 (ko) * | 2017-03-15 | 2018-07-18 | (주)넥셀 | 자동적인 학습데이터 생성 방법 및 장치와 이를 이용하는 자가 학습 장치 및 방법 |
| JP6330092B1 (ja) * | 2017-08-02 | 2018-05-23 | 株式会社ディジタルメディアプロフェッショナル | 機械学習用教師データ生成装置及び生成方法 |
| JP2019028876A (ja) * | 2017-08-02 | 2019-02-21 | 株式会社ディジタルメディアプロフェッショナル | 機械学習用教師データ生成装置及び生成方法 |
| US11636378B2 (en) | 2017-08-31 | 2023-04-25 | Canon Kabushiki Kaisha | Information processing apparatus, information processing method, and information processing system |
| JP7027070B2 (ja) | 2017-08-31 | 2022-03-01 | キヤノン株式会社 | 情報処理装置、情報処理方法、及びプログラム |
| JP2019046058A (ja) * | 2017-08-31 | 2019-03-22 | キヤノン株式会社 | 情報処理装置、情報処理方法、及びプログラム |
| JP2019144767A (ja) * | 2018-02-19 | 2019-08-29 | 富士通株式会社 | 学習プログラム、学習方法および学習装置 |
| JP7040104B2 (ja) | 2018-02-19 | 2022-03-23 | 富士通株式会社 | 学習プログラム、学習方法および学習装置 |
| KR20200039035A (ko) * | 2018-09-27 | 2020-04-16 | 주식회사 스위트케이 | 인공지능 기반의 학습데이터셋 제공 시스템 |
| KR102203320B1 (ko) | 2018-09-27 | 2021-01-15 | 주식회사 스위트케이 | 인공지능 기반의 학습데이터셋 제공 시스템 |
| US11328812B2 (en) | 2018-11-15 | 2022-05-10 | Canon Medical Systems Corporation | Medical image processing apparatus, medical image processing method, and storage medium |
| WO2020166321A1 (ja) * | 2019-02-12 | 2020-08-20 | 日本電信電話株式会社 | モデル学習装置、ラベル推定装置、それらの方法、およびプログラム |
| US11954566B2 (en) | 2019-05-28 | 2024-04-09 | Okuma Corporation | Data collection system for machine learning and a method for collecting data |
| JP7359206B2 (ja) | 2019-05-30 | 2023-10-11 | 日本電信電話株式会社 | 学習装置、学習方法、及びプログラム |
| JPWO2020240770A1 (ja) * | 2019-05-30 | 2020-12-03 | ||
| JPWO2021053776A1 (ja) * | 2019-09-18 | 2021-03-25 | ||
| JP7251643B2 (ja) | 2019-09-18 | 2023-04-04 | 日本電信電話株式会社 | 学習装置、学習方法及びプログラム |
| US11475312B2 (en) | 2019-11-18 | 2022-10-18 | Samsung Electronics Co., Ltd. | Method and apparatus with deep neural network model fusing |
| US11663816B2 (en) | 2020-02-17 | 2023-05-30 | Electronics And Telecommunications Research Institute | Apparatus and method for classifying attribute of image object |
| KR102504319B1 (ko) | 2020-02-17 | 2023-02-28 | 한국전자통신연구원 | 영상 객체 속성 분류 장치 및 방법 |
| KR20210104299A (ko) * | 2020-02-17 | 2021-08-25 | 한국전자통신연구원 | 영상 객체 속성 분류 장치 및 방법 |
| JP2021131831A (ja) * | 2020-02-21 | 2021-09-09 | オムロン株式会社 | 情報処理装置、情報処理方法及びプログラム |
| JP7440823B2 (ja) | 2020-02-21 | 2024-02-29 | オムロン株式会社 | 情報処理装置、情報処理方法及びプログラム |
| JPWO2021186662A1 (ja) * | 2020-03-19 | 2021-09-23 | ||
| JP7315091B2 (ja) | 2020-03-19 | 2023-07-26 | 日本電信電話株式会社 | モデル学習装置、その方法、およびプログラム |
| WO2022123905A1 (ja) * | 2020-12-07 | 2022-06-16 | パナソニックIpマネジメント株式会社 | 処理システム、学習処理システム、処理方法、及びプログラム |
| JP7496567B2 (ja) | 2020-12-07 | 2024-06-07 | パナソニックIpマネジメント株式会社 | 処理システム、学習処理システム、処理方法、及びプログラム |
| CN112581093B (zh) * | 2020-12-23 | 2024-04-05 | 无锡航吴科技有限公司 | 一种融合线上线下的项目评审流程方法 |
| CN112581093A (zh) * | 2020-12-23 | 2021-03-30 | 无锡航吴科技有限公司 | 一种融合线上线下的项目评审流程方法 |
| JP2023146080A (ja) * | 2022-03-29 | 2023-10-12 | 本田技研工業株式会社 | 教師データ収集装置 |
| JP7399998B2 (ja) | 2022-03-29 | 2023-12-18 | 本田技研工業株式会社 | 教師データ収集装置 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2009282686A (ja) | 分類モデル学習装置および分類モデル学習方法 | |
| US11244167B2 (en) | Generating a response to a user query utilizing visual features of a video segment and a query-response-neural network | |
| US20190354810A1 (en) | Active learning to reduce noise in labels | |
| JP2009110064A (ja) | 分類モデル学習装置および分類モデル学習方法 | |
| US11270211B2 (en) | Interactive semantic data exploration for error discovery | |
| US9886669B2 (en) | Interactive visualization of machine-learning performance | |
| US20200042825A1 (en) | Neural network orchestration | |
| US8190537B1 (en) | Feature selection for large scale models | |
| JP2018517959A (ja) | ビデオのための代表ビデオフレームの選択 | |
| CN116134454A (zh) | 用于使用知识蒸馏训练神经网络模型的方法和系统 | |
| US20210117802A1 (en) | Training a Neural Network Using Small Training Datasets | |
| US20220156585A1 (en) | Training point cloud processing neural networks using pseudo-element - based data augmentation | |
| JP2020060970A (ja) | コンテキスト情報生成方法、コンテキスト情報生成装置およびコンテキスト情報生成プログラム | |
| CN112668607A (zh) | 一种用于目标物体触觉属性识别的多标签学习方法 | |
| JP2013097723A (ja) | テキスト要約装置、方法及びプログラム | |
| JP5311899B2 (ja) | パターン検出器の学習装置、学習方法及びプログラム | |
| US20230368003A1 (en) | Adaptive sparse attention pattern | |
| US10529337B2 (en) | Symbol sequence estimation in speech | |
| US20130218817A1 (en) | Active acquisition of privileged information | |
| JP6817690B2 (ja) | 抽出装置、抽出方法とそのプログラム、及び、支援装置、表示制御装置 | |
| AU2021251463B2 (en) | Generating performance predictions with uncertainty intervals | |
| KR20220097239A (ko) | 인공지능에 기반하여 시놉시스 텍스트를 분석하고 시청률을 예측하는 서버 | |
| CN116030801A (zh) | 错误诊断和反馈 | |
| CN113780365A (zh) | 样本生成方法和装置 | |
| US20210174228A1 (en) | Methods for processing a plurality of candidate annotations of a given instance of an image, and for learning parameters of a computational model |