EP2980790A1 - Apparatus and method for comfort noise generation mode selection - Google Patents
Apparatus and method for comfort noise generation mode selection Download PDFInfo
- Publication number
- EP2980790A1 EP2980790A1 EP14178782.0A EP14178782A EP2980790A1 EP 2980790 A1 EP2980790 A1 EP 2980790A1 EP 14178782 A EP14178782 A EP 14178782A EP 2980790 A1 EP2980790 A1 EP 2980790A1
- Authority
- EP
- European Patent Office
- Prior art keywords
- comfort noise
- frequency
- noise generation
- generation mode
- audio information
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 238000000034 method Methods 0.000 title claims description 35
- 230000007774 longterm Effects 0.000 claims description 24
- 238000004590 computer program Methods 0.000 claims description 11
- 238000006243 chemical reaction Methods 0.000 claims description 3
- 230000005284 excitation Effects 0.000 description 19
- 230000005540 biological transmission Effects 0.000 description 6
- 238000007493 shaping process Methods 0.000 description 4
- 230000002194 synthesizing effect Effects 0.000 description 4
- 238000013459 approach Methods 0.000 description 3
- 230000005236 sound signal Effects 0.000 description 3
- 238000004891 communication Methods 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003595 spectral effect Effects 0.000 description 1
Images





Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/012—Comfort noise or silence coding
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/0204—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders using subband decomposition
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/16—Vocoder architecture
- G10L19/18—Vocoders using multiple modes
- G10L19/22—Mode decision, i.e. based on audio signal content versus external parameters
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
- G10L21/0232—Processing in the frequency domain
Definitions
- the present invention relates to audio signal encoding, processing and decoding, and, in particular, to an apparatus and method for comfort noise generation mode selection.
- Communication speech and audio codecs generally include a discontinuous transmission (DTX) scheme and a comfort noise generation (CNG) algorithm.
- DTX discontinuous transmission
- CNG comfort noise generation
- the DTX/CNG operation is used to reduce the transmission rate by simulating background noise during inactive signal periods.
- CNG may, for example, be implemented in several ways.
- the most commonly used method, employed in codecs like AMR-WB (ITU-T G.722.2 Annex A) and G.718 (ITU-T G.718 Sec. 6.12 and 7.12), is based on an excitation + linear-prediction (LP) model.
- LP linear-prediction
- a random excitation signal is first generated, then scaled by a gain, and finally synthesized using a LP inverse filter, producing the time-domain CNG signal.
- the two main parameters transmitted are the excitation energy and the LP coefficients (generally using a LSF or ISF representation). This method is referred here as LP-CNG.
- the object of the present invention is to provide improved concepts for comfort noise generation.
- the object of the present invention is solved by an apparatus according to claim 1, by an apparatus according to claim 10, by a system according to claim 13, by a method according to claim 14, by a method according to claim 15, and by a computer program according to claim 16.
- the apparatus for encoding audio information comprises a selector for selecting a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal, and an encoding unit for encoding the audio information, wherein the audio information comprises mode information indicating the selected comfort noise generation mode.
- embodiments are based on the finding that FD-CNG gives better quality on high-tilt background noise signals like e.g. car noise, while LP-CNG gives better quality on more spectrally flat background noise signals like e.g. office noise.
- both CNG approaches are used and one of them is selected depending on the background noise characteristics.
- Embodiments provide a selector that decides which CNG mode should be used, for example, either LP-CNG or FD-CNG.
- the selector may, e.g., be configured to determine a tilt of a background noise of the audio input signal as the background noise characteristic.
- the selector may, e.g., be configured to select said comfort noise generation mode from two or more comfort noise generation modes depending on the determined tilt.
- the apparatus may, e.g., further comprise a noise estimator for estimating a per-band estimate of the background noise for each of a plurality of frequency bands.
- the selector may, e.g., be configured to determine the tilt depending on the estimated background noise of the plurality of frequency bands.
- the noise estimator may, e.g., be configured to estimate a per-band estimate of the background noise by estimating an energy of the background noise of each of the plurality of frequency bands.
- the noise estimator may, e.g., be configured to determine a low-frequency background noise value indicating a first background noise energy for a first group of the plurality of frequency bands depending on the per-band estimate of the background noise of each frequency band of the first group of the plurality of frequency bands.
- the noise estimator may, e.g., be configured to determine a high-frequency background noise value indicating a second background noise energy for a second group of the plurality of frequency bands depending on the per-band estimate of the background noise of each frequency band of the second group of the plurality of frequency bands.
- At least one frequency band of the first group may, e.g., have a lower centre-frequency than a centre-frequency of at least one frequency band of the second group.
- each frequency band of the first group may, e.g., have a lower centre-frequency than a centre-frequency of each frequency band of the second group.
- the selector may, e.g., be configured to determine the tilt depending on the low-frequency background noise value and depending on the high-frequency background noise value.
- the selector may, e.g., be configured to determine the tilt as a current short-term tilt value. Moreover, the selector may, e.g., be configured to determine a current long-term tilt value depending on the current short-term tilt value and depending on a previous long-term tilt value. Furthermore, the selector may, e.g., be configured to select one of two or more comfort noise generation modes depending on the current long-term tilt value.
- a first one of the two or more comfort noise generation modes may, e.g., be a frequency-domain comfort noise generation mode.
- a second one of the two or more comfort noise generation modes may, e.g., be a linear-prediction-domain comfort noise generation mode.
- the selector may, e.g., be configured to select the frequency-domain comfort noise generation mode, if a previously selected generation mode, being previously selected by the selector, is the linear-prediction-domain comfort noise generation mode and if the current long-term tilt value is greater than a first threshold value.
- the selector may, e.g., be configured to select the linear-prediction-domain comfort noise generation mode, if the previously selected generation mode, being previously selected by the selector, is the frequency-domain comfort noise generation mode and if the current long-term tilt value is smaller than a second threshold value.
- an apparatus for generating an audio output signal based on received encoded audio information comprises a decoding unit for decoding encoded audio information to obtain mode information being encoded within the encoded audio information, wherein the mode information indicates an indicated comfort noise generation mode of two or more comfort noise generation modes.
- the apparatus comprises a signal processor for generating the audio output signal by generating, depending on the indicated comfort noise generation mode, comfort noise.
- a first one of the two or more comfort noise generation modes may, e.g., be a frequency-domain comfort noise generation mode.
- the signal processor may, e.g., be configured, if the indicated comfort noise generation mode is the frequency-domain comfort noise generation mode, to generate the comfort noise in a frequency domain and by conducting a frequency-to-time conversion of the comfort noise being generated in the frequency domain.
- the signal processor may, e.g., be configured, if the indicated comfort noise generation mode is the frequency-domain comfort noise generation mode, to generate the comfort noise by generating random noise in a frequency domain, by shaping the random noise in the frequency domain to obtain shaped noise, and by converting the shaped noise from the frequency-domain to the time domain.
- a second one of the two or more comfort noise generation modes may, e.g., be a linear-prediction-domain comfort noise generation mode.
- the signal processor may, e.g., be configured, if the indicated comfort noise generation mode is the linear-prediction-domain comfort noise generation mode, to generate the comfort noise by employing a linear prediction filter.
- the signal processor may, e.g., be configured, if the indicated comfort noise generation mode is the linear-prediction-domain comfort noise generation mode, to generate the comfort noise by generating a random excitation signal, by scaling the random excitation signal to obtain a scaled excitation signal, and by synthesizing the scaled excitation signal using a LP inverse filter.
- the system comprises an apparatus for encoding audio information according to one of the above-described embodiments and an apparatus for generating an audio output signal based on received encoded audio information according to one of the above-described embodiments.
- the selector of the apparatus for encoding audio information is configured to select a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal.
- the encoding unit of the apparatus for encoding audio information is configured to encode the audio information, comprising mode information indicating the selected comfort noise generation mode as an indicated comfort noise generation mode, to obtain encoded audio information.
- the decoding unit of the apparatus for generating an audio output signal is configured to receive the encoded audio information, and is furthermore configured to decode the encoded audio information to obtain the mode information being encoded within the encoded audio information.
- the signal processor of the apparatus for generating an audio output signal is configured to generate the audio output signal by generating, depending on the indicated comfort noise generation mode, comfort noise.
- the method comprises:
- the method comprises:
- the proposed selector may, e.g., be mainly based on the tilt of the background noise. For example, if the tilt of the background noise is high then FD-CNG is selected, otherwise LP-CNG is selected.
- a smoothed version of the background noise tilt and a hysteresis may, e.g., be used to avoid switching often from one mode to another.
- the tilt of the background noise may, for example, be estimated using the ratio of the background noise energy in the low frequencies and the background noise energy in the high frequencies.
- the background noise energy may, for example, be estimated in the frequency domain using a noise estimator.
- Fig. 1 illustrates an apparatus for encoding audio information according to an embodiment.
- the apparatus for encoding audio information comprises a selector 110 for selecting a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal.
- the apparatus comprises an encoding unit 120 for encoding the audio information, wherein the audio information comprises mode information indicating the selected comfort noise generation mode.
- a first one of the two or more comfort noise generation modes may, e.g., be a frequency-domain comfort noise generation mode.
- a second one of the two or more generation modes may, e.g., be a linear-prediction-domain comfort noise generation mode.
- a signal processor on the decoder side may, for example, generate the comfort noise by generating random noise in a frequency domain, by shaping the random noise in the frequency domain to obtain shaped noise, and by converting the shaped noise from the frequency-domain to the time domain.
- the signal processor on the decoder side may, for example, generate the comfort noise by generating a random excitation signal, by scaling the random excitation signal to obtain a scaled excitation signal, and by synthesizing the scaled excitation signal using a LP inverse filter.
- the encoded audio information not only the information on the comfort noise generation mode, but also additional information may be encoded.
- frequency-band specific gain factors may also be encoded, for example, one gain factor for each frequency band.
- one or more LP filter coefficients, or LSF coefficients or ISF coefficients may, e.g., be encoded within the encoded audio information.
- the information on the selected comfort noise generation mode may be encoded explicitly or implicitly.
- one or more bits may, for example, be employed to indicate which one of the two or more comfort noise generation modes the selected comfort noise generation mode is. In such an embodiment, said one or more bits are then the encoded mode information.
- the selected comfort noise generation mode is implicitly encoded within the audio information.
- the frequency-band specific gain factors and the one or more LP (or LSF or ISF) coefficients may, e.g., have a different data format or may, e.g., have a different bit length. If, for example, frequency-band specific gain factors are encoded within the audio information, this may, e.g., indicate that the frequency-domain comfort noise generation mode is the selected comfort noise generation mode.
- the one or more LP (or LSF or ISF) coefficients are encoded within the audio information, this may, e.g., indicate that the linear-prediction-domain comfort noise generation mode is the selected comfort noise generation mode.
- the frequency-band specific gain factors or the one or more LP (or LSF or ISF) coefficients then represent the mode information being encoded within the encoded audio signal, wherein this mode information indicates the selected comfort noise generation mode.
- the selector 110 may, e.g., be configured to determine a tilt of a background noise of the audio input signal as the background noise characteristic.
- the selector 110 may, e.g., be configured to select said comfort noise generation mode from two or more comfort noise generation modes depending on the determined tilt.
- a low-frequency background noise value and a high-frequency background noise value may be employed, and the tilt of the background noise may, e.g., be calculated depending on the low-frequency background noise value and depending on the high-frequency background-noise value.
- Fig. 2 illustrates an apparatus for encoding audio information according to a further embodiment.
- the apparatus of Fig. 2 further comprises a noise estimator 105 for estimating a per-band estimate of the background noise for each of a plurality of frequency bands.
- the selector 110 may, e.g., be configured to determine the tilt depending on the estimated background noise of the plurality of frequency bands.
- the noise estimator 105 may, e.g., be configured to estimate a per-band estimate of the background noise by estimating an energy of the background noise of each of the plurality of frequency bands.
- the noise estimator 105 may, e.g., be configured to determine a low-frequency background noise value indicating a first background noise energy for a first group of the plurality of frequency bands depending on the per-band estimate of the background noise of each frequency band of the first group of the plurality of frequency bands.
- the noise estimator 105 may, e.g., be configured to determine a high-frequency background noise value indicating a second background noise energy for a second group of the plurality of frequency bands depending on the per-band estimate of the background noise of each frequency band of the second group of the plurality of frequency bands.
- At least one frequency band of the first group may, e.g., have a lower centre-frequency than a centre-frequency of at least one frequency band of the second group.
- each frequency band of the first group may, e.g., have a lower centre-frequency than a centre-frequency of each frequency band of the second group.
- the selector 110 may, e.g., be configured to determine the tilt depending on the low-frequency background noise value and depending on the high-frequency background noise value.
- the selector 110 may, e.g., be configured to determine the tilt as a current short-term tilt value. Moreover, the selector 110 may, e.g., be configured to determine a current long-term tilt value depending on the current short-term tilt value and depending on a previous long-term tilt value. Furthermore, the selector 110 may, e.g., be configured to select one of two or more comfort noise generation modes depending on the current long-term tilt value.
- a first one of the two or more comfort noise generation modes may, e.g., be a frequency-domain comfort noise generation mode FD_CNG.
- a second one of the two or more comfort noise generation modes may, e.g., be a linear-prediction-domain comfort noise generation mode LP_CNG.
- the selector 110 may, e.g., be configured to select the frequency-domain comfort noise generation mode FD_CNG , if a previously selected generation mode cng_mode_prev , being previously selected by the selector 110, is the linear-prediction-domain comfort noise generation mode LP_CNG and if the current long-term tilt value is greater than a first threshold value thr 1 .
- the selector 110 may, e.g., be configured to select the linear-prediction-domain comfort noise generation mode LP_CNG , if the previously selected generation mode cng_mode_prev , being previously selected by the selector 110, is the frequency-domain comfort noise generation mode FD_CNG and if the current long-term tilt value is smaller than a second threshold value thr 2 .
- the first threshold value is equal to the second threshold value. In some other embodiments, however, the first threshold value is different from the second threshold value.
- Fig. 4 illustrates an apparatus for generating an audio output signal based on received encoded audio information according to an embodiment.
- the apparatus comprises a decoding unit 210 for decoding encoded audio information to obtain mode information being encoded within the encoded audio information.
- the mode information indicates an indicated comfort noise generation mode of two or more comfort noise generation modes.
- the apparatus comprises a signal processor 220 for generating the audio output signal by generating, depending on the indicated comfort noise generation mode, comfort noise.
- a first one of the two or more comfort noise generation modes may, e.g., be a frequency-domain comfort noise generation mode.
- the signal processor 220 may, e.g., be configured, if the indicated comfort noise generation mode is the frequency-domain comfort noise generation mode, to generate the comfort noise in a frequency domain and by conducting a frequency-to-time conversion of the comfort noise being generated in the frequency domain.
- the signal processor may, e.g., be configured, if the indicated comfort noise generation mode is the frequency-domain comfort noise generation mode, to generate the comfort noise by generating random noise in a frequency domain, by shaping the random noise in the frequency domain to obtain shaped noise, and by converting the shaped noise from the frequency-domain to the time domain.
- Shaping of the random noise may, e.g., be conducted by individually computing the amplitude of the random sequences in each band such that the spectrum of the generated comfort noise resembles the spectrum of the actual background noise present, for example, in a bitstream, comprising, e.g., an audio input signal.
- the computed amplitude may, e.g., be applied on the random sequence, e.g., by multiplying the random sequence with the computed amplitude in each frequency band.
- converting the shaped noise from the frequency domain to the time domain may be employed.
- a second one of the two or more comfort noise generation modes may, e.g., be a linear-prediction-domain comfort noise generation mode.
- the signal processor 220 may, e.g., be configured, if the indicated comfort noise generation mode is the linear-prediction-domain comfort noise generation mode, to generate the comfort noise by employing a linear prediction filter.
- the signal processor may, e.g., be configured, if the indicated comfort noise generation mode is the linear-prediction-domain comfort noise generation mode, to generate the comfort noise by generating a random excitation signal, by scaling the random excitation signal to obtain a scaled excitation signal, and by synthesizing the scaled excitation signal using a LP inverse filter.
- comfort noise generation as described in G.722.2 (see ITU-T G.722.2 Annex A) and/or as described in G.718 (see ITU-T G.718 Sec. 6.12 and 7.12) may be employed.
- Such comfort noise generation in a random excitation domain by scaling a random excitation signal to obtain a scaled excitation signal, and by synthesizing the scaled excitation signal using a LP inverse filter is well known to a person skilled in the art.
- Fig. 5 illustrates a system according to an embodiment.
- the system comprises an apparatus 100 for encoding audio information according to one of the above-described embodiments and an apparatus 200 for generating an audio output signal based on received encoded audio information according to one of the above-described embodiments.
- the selector 110 of the apparatus 100 for encoding audio information is configured to select a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal.
- the encoding unit 120 of the apparatus 100 for encoding audio information is configured to encode the audio information, comprising mode information indicating the selected comfort noise generation mode as an indicated comfort noise generation mode, to obtain encoded audio information.
- the decoding unit 210 of the apparatus 200 for generating an audio output signal is configured to receive the encoded audio information, and is furthermore configured to decode the encoded audio information to obtain the mode information being encoded within the encoded audio information.
- the signal processor 220 of the apparatus 200 for generating an audio output signal is configured to generate the audio output signal by generating, depending on the indicated comfort noise generation mode, comfort noise.
- Fig. 3 illustrates a step-by-step approach for selecting a comfort noise generation mode according to an embodiment.
- Any noise estimator producing a per-band estimate of the background noise energy can be used.
- One example is the noise estimator used in G.718 (ITU-T G.718 Sec. 6.7).
- L may be considered as a low-frequency background noise value as described above.
- H may be considered as a high-frequency background noise value as described above.
- Steps 320 and 330 may, e.g., be conducted subsequently or independently from each other.
- T LT on the left side of the equals sign is the current long-term tilt value T cLT mentioned above
- T LT on the right side of the equals sign is said previous long-term tilt value T pLT mentioned above.
- cng_mode is the comfort noise generation mode that is (currently) selected by the selector 110.
- cng_mode_prev is a previously selected (comfort noise) generation mode that has previously been selected by the selector 110.
- thr 1 is different from thr 2 , in some other embodiments, however, thr 1 is equal to thr 2 .
- aspects have been described in the context of an apparatus, it is clear that these aspects also represent a description of the corresponding method, where a block or device corresponds to a method step or a feature of a method step. Analogously, aspects described in the context of a method step also represent a description of a corresponding block or item or feature of a corresponding apparatus.
- the inventive decomposed signal can be stored on a digital storage medium or can be transmitted on a transmission medium such as a wireless transmission medium or a wired transmission medium such as the Internet.
- embodiments of the invention can be implemented in hardware or in software.
- the implementation can be performed using a digital storage medium, for example a floppy disk, a DVD, a CD, a ROM, a PROM, an EPROM, an EEPROM or a FLASH memory, having electronically readable control signals stored thereon, which cooperate (or are capable of cooperating) with a programmable computer system such that the respective method is performed.
- a digital storage medium for example a floppy disk, a DVD, a CD, a ROM, a PROM, an EPROM, an EEPROM or a FLASH memory, having electronically readable control signals stored thereon, which cooperate (or are capable of cooperating) with a programmable computer system such that the respective method is performed.
- Some embodiments according to the invention comprise a non-transitory data carrier having electronically readable control signals, which are capable of cooperating with a programmable computer system, such that one of the methods described herein is performed.
- embodiments of the present invention can be implemented as a computer program product with a program code, the program code being operative for performing one of the methods when the computer program product runs on a computer.
- the program code may for example be stored on a machine readable carrier.
- inventions comprise the computer program for performing one of the methods described herein, stored on a machine readable carrier.
- an embodiment of the inventive method is, therefore, a computer program having a program code for performing one of the methods described herein, when the computer program runs on a computer.
- a further embodiment of the inventive methods is, therefore, a data carrier (or a digital storage medium, or a computer-readable medium) comprising, recorded thereon, the computer program for performing one of the methods described herein.
- a further embodiment of the inventive method is, therefore, a data stream or a sequence of signals representing the computer program for performing one of the methods described herein.
- the data stream or the sequence of signals may for example be configured to be transferred via a data communication connection, for example via the Internet.
- a further embodiment comprises a processing means, for example a computer, or a programmable logic device, configured to or adapted to perform one of the methods described herein.
- a processing means for example a computer, or a programmable logic device, configured to or adapted to perform one of the methods described herein.
- a further embodiment comprises a computer having installed thereon the computer program for performing one of the methods described herein.
- a programmable logic device for example a field programmable gate array
- a field programmable gate array may cooperate with a microprocessor in order to perform one of the methods described herein.
- the methods are preferably performed by any hardware apparatus.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Signal Processing (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Computational Linguistics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Quality & Reliability (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Transmission Systems Not Characterized By The Medium Used For Transmission (AREA)
Abstract
An apparatus for encoding audio information is provided. The apparatus for encoding audio information comprises a selector (110) for selecting a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal, and an encoding unit (120) for encoding the audio information, wherein the audio information comprises mode information indicating the selected comfort noise generation mode.
Description
- The present invention relates to audio signal encoding, processing and decoding, and, in particular, to an apparatus and method for comfort noise generation mode selection.
- Communication speech and audio codecs (e.g. AMR-WB, G.718) generally include a discontinuous transmission (DTX) scheme and a comfort noise generation (CNG) algorithm. The DTX/CNG operation is used to reduce the transmission rate by simulating background noise during inactive signal periods.
- CNG may, for example, be implemented in several ways.
- The most commonly used method, employed in codecs like AMR-WB (ITU-T G.722.2 Annex A) and G.718 (ITU-T G.718 Sec. 6.12 and 7.12), is based on an excitation + linear-prediction (LP) model. A random excitation signal is first generated, then scaled by a gain, and finally synthesized using a LP inverse filter, producing the time-domain CNG signal. The two main parameters transmitted are the excitation energy and the LP coefficients (generally using a LSF or ISF representation). This method is referred here as LP-CNG.
- Another method, proposed recently and described in e.g. the patent application
WO2014/096279 , "Generation of a comfort noise with high spectro-temporal resolution in discontinuous transmission of audio signals", is based on a frequency-domain (FD) representation of the background noise. Random noise is generated in a frequency-domain (e.g. FFT, MDCT, QMF), then shaped using a FD representation of the background noise, and finally converted from the frequency to the time domain, producing the time-domain CNG signal. The two main parameters transmitted are a global gain and a set of band noise levels. This method is referred here as FD-CNG. - The object of the present invention is to provide improved concepts for comfort noise generation. The object of the present invention is solved by an apparatus according to claim 1, by an apparatus according to claim 10, by a system according to claim 13, by a method according to claim 14, by a method according to claim 15, and by a computer program according to claim 16.
- An apparatus for encoding audio information is provided. The apparatus for encoding audio information comprises a selector for selecting a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal, and an encoding unit for encoding the audio information, wherein the audio information comprises mode information indicating the selected comfort noise generation mode.
- Inter alia, embodiments are based on the finding that FD-CNG gives better quality on high-tilt background noise signals like e.g. car noise, while LP-CNG gives better quality on more spectrally flat background noise signals like e.g. office noise.
- To get the best possible quality out of a DTX/CNG system, according to embodiments, both CNG approaches are used and one of them is selected depending on the background noise characteristics.
- Embodiments provide a selector that decides which CNG mode should be used, for example, either LP-CNG or FD-CNG.
- According to an embodiment, the selector may, e.g., be configured to determine a tilt of a background noise of the audio input signal as the background noise characteristic. The selector may, e.g., be configured to select said comfort noise generation mode from two or more comfort noise generation modes depending on the determined tilt.
- In an embodiment, the apparatus may, e.g., further comprise a noise estimator for estimating a per-band estimate of the background noise for each of a plurality of frequency bands. The selector may, e.g., be configured to determine the tilt depending on the estimated background noise of the plurality of frequency bands.
- According to an embodiment, the noise estimator may, e.g., be configured to estimate a per-band estimate of the background noise by estimating an energy of the background noise of each of the plurality of frequency bands.
- In an embodiment, the noise estimator may, e.g., be configured to determine a low-frequency background noise value indicating a first background noise energy for a first group of the plurality of frequency bands depending on the per-band estimate of the background noise of each frequency band of the first group of the plurality of frequency bands.
- Moreover, in such an embodiment, the noise estimator may, e.g., be configured to determine a high-frequency background noise value indicating a second background noise energy for a second group of the plurality of frequency bands depending on the per-band estimate of the background noise of each frequency band of the second group of the plurality of frequency bands. At least one frequency band of the first group may, e.g., have a lower centre-frequency than a centre-frequency of at least one frequency band of the second group. In a particular embodiment, each frequency band of the first group may, e.g., have a lower centre-frequency than a centre-frequency of each frequency band of the second group.
- Furthermore, the selector may, e.g., be configured to determine the tilt depending on the low-frequency background noise value and depending on the high-frequency background noise value.
- According to an embodiment, the noise estimator may, e.g., be configured to determine the low-frequency background noise value L according to

- In an embodiment, the noise estimator may, e.g., be configured to determine the high-frequency background noise value H according to

- According to an embodiment, the selector may, e.g., be configured to determine the tilt T depending on the low frequency background noise value L and depending on the high frequency background noise value H according to the formula

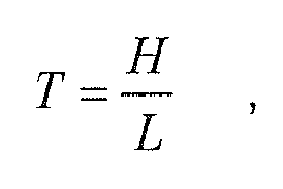


- In an embodiment, the selector may, e.g., be configured to determine the tilt as a current short-term tilt value. Moreover, the selector may, e.g., be configured to determine a current long-term tilt value depending on the current short-term tilt value and depending on a previous long-term tilt value. Furthermore, the selector may, e.g., be configured to select one of two or more comfort noise generation modes depending on the current long-term tilt value.
- According to an embodiment, the selector may, e.g., be configured to determine the current long-term tilt value TcLT according to the formula:

- In an embodiment, a first one of the two or more comfort noise generation modes may, e.g., be a frequency-domain comfort noise generation mode. Moreover, a second one of the two or more comfort noise generation modes may, e.g., be a linear-prediction-domain comfort noise generation mode. Furthermore, the selector may, e.g., be configured to select the frequency-domain comfort noise generation mode, if a previously selected generation mode, being previously selected by the selector, is the linear-prediction-domain comfort noise generation mode and if the current long-term tilt value is greater than a first threshold value. Moreover, the selector may, e.g., be configured to select the linear-prediction-domain comfort noise generation mode, if the previously selected generation mode, being previously selected by the selector, is the frequency-domain comfort noise generation mode and if the current long-term tilt value is smaller than a second threshold value.
- Moreover, an apparatus for generating an audio output signal based on received encoded audio information is provided. The apparatus comprises a decoding unit for decoding encoded audio information to obtain mode information being encoded within the encoded audio information, wherein the mode information indicates an indicated comfort noise generation mode of two or more comfort noise generation modes. Moreover, the apparatus comprises a signal processor for generating the audio output signal by generating, depending on the indicated comfort noise generation mode, comfort noise.
- According to an embodiment, a first one of the two or more comfort noise generation modes may, e.g., be a frequency-domain comfort noise generation mode. The signal processor may, e.g., be configured, if the indicated comfort noise generation mode is the frequency-domain comfort noise generation mode, to generate the comfort noise in a frequency domain and by conducting a frequency-to-time conversion of the comfort noise being generated in the frequency domain. For example, in a particular embodiment, the signal processor may, e.g., be configured, if the indicated comfort noise generation mode is the frequency-domain comfort noise generation mode, to generate the comfort noise by generating random noise in a frequency domain, by shaping the random noise in the frequency domain to obtain shaped noise, and by converting the shaped noise from the frequency-domain to the time domain.
- In an embodiment, a second one of the two or more comfort noise generation modes may, e.g., be a linear-prediction-domain comfort noise generation mode. The signal processor may, e.g., be configured, if the indicated comfort noise generation mode is the linear-prediction-domain comfort noise generation mode, to generate the comfort noise by employing a linear prediction filter. For example, in a particular embodiment, the signal processor may, e.g., be configured, if the indicated comfort noise generation mode is the linear-prediction-domain comfort noise generation mode, to generate the comfort noise by generating a random excitation signal, by scaling the random excitation signal to obtain a scaled excitation signal, and by synthesizing the scaled excitation signal using a LP inverse filter.
- Furthermore, a system is provided. The system comprises an apparatus for encoding audio information according to one of the above-described embodiments and an apparatus for generating an audio output signal based on received encoded audio information according to one of the above-described embodiments. The selector of the apparatus for encoding audio information is configured to select a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal. The encoding unit of the apparatus for encoding audio information is configured to encode the audio information, comprising mode information indicating the selected comfort noise generation mode as an indicated comfort noise generation mode, to obtain encoded audio information. Moreover, the decoding unit of the apparatus for generating an audio output signal is configured to receive the encoded audio information, and is furthermore configured to decode the encoded audio information to obtain the mode information being encoded within the encoded audio information. The signal processor of the apparatus for generating an audio output signal is configured to generate the audio output signal by generating, depending on the indicated comfort noise generation mode, comfort noise.
- Moreover, a method for encoding audio information is provided. The method comprises:
- Selecting a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal. And:
- Encoding the audio information, wherein the audio information comprises mode information indicating the selected comfort noise generation mode.
- Furthermore, a method for generating an audio output signal based on received encoded audio information is provided. The method comprises:
- Decoding encoded audio information to obtain mode information being encoded within the encoded audio information, wherein the mode information indicates an indicated comfort noise generation mode of two or more comfort noise generation modes. And:
- Generating the audio output signal by generating, depending on the indicated comfort noise generation mode, comfort noise.
- Moreover, a computer program for implementing the above-described method when being executed on a computer or signal processor is provided.
- So, in some embodiments, the proposed selector may, e.g., be mainly based on the tilt of the background noise. For example, if the tilt of the background noise is high then FD-CNG is selected, otherwise LP-CNG is selected.
- A smoothed version of the background noise tilt and a hysteresis may, e.g., be used to avoid switching often from one mode to another.
- The tilt of the background noise may, for example, be estimated using the ratio of the background noise energy in the low frequencies and the background noise energy in the high frequencies.
- The background noise energy may, for example, be estimated in the frequency domain using a noise estimator.
- In the following, embodiments of the present invention are described in more detail with reference to the figures, in which:
- Fig. 1
- illustrates an apparatus for encoding audio information according to an embodiment,
- Fig. 2
- illustrates an apparatus for encoding audio information according to another embodiment,
- Fig. 3
- illustrates a step-by-step approach for selecting a comfort noise generation mode according to an embodiment,
- Fig. 4
- illustrates an apparatus for generating an audio output signal based on received encoded audio information according to an embodiment, and
- Fig. 5
- illustrates a system according to an embodiment.
-
Fig. 1 illustrates an apparatus for encoding audio information according to an embodiment. - The apparatus for encoding audio information comprises a
selector 110 for selecting a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal. - Moreover, the apparatus comprises an
encoding unit 120 for encoding the audio information, wherein the audio information comprises mode information indicating the selected comfort noise generation mode. - For example, a first one of the two or more comfort noise generation modes may, e.g., be a frequency-domain comfort noise generation mode. And/or, for example, a second one of the two or more generation modes may, e.g., be a linear-prediction-domain comfort noise generation mode.
- For example, if, on a decoder side, the encoded audio information is received, wherein the mode information, being encoded within the encoded audio information, indicates that the selected comfort noise generation mode is the frequency-domain comfort noise generation mode, then, a signal processor on the decoder side may, for example, generate the comfort noise by generating random noise in a frequency domain, by shaping the random noise in the frequency domain to obtain shaped noise, and by converting the shaped noise from the frequency-domain to the time domain.
- However, if for example, the mode information, being encoded within the encoded audio information, indicates that the selected comfort noise generation mode is the linear-prediction-domain comfort noise generation mode, then, the signal processor on the decoder side may, for example, generate the comfort noise by generating a random excitation signal, by scaling the random excitation signal to obtain a scaled excitation signal, and by synthesizing the scaled excitation signal using a LP inverse filter.
- Within the encoded audio information, not only the information on the comfort noise generation mode, but also additional information may be encoded. For example, frequency-band specific gain factors may also be encoded, for example, one gain factor for each frequency band. Or, for example, one or more LP filter coefficients, or LSF coefficients or ISF coefficients may, e.g., be encoded within the encoded audio information. The information on the selected comfort noise generation mode and the additional information, being encoded within the encoded audio information may then, e.g., be transmitted to a decoder side, for example, within an SID frame (SID = Silence Insertion Descriptor).
- The information on the selected comfort noise generation mode may be encoded explicitly or implicitly.
- When explicitly encoding the selected comfort noise generation mode, then, one or more bits may, for example, be employed to indicate which one of the two or more comfort noise generation modes the selected comfort noise generation mode is. In such an embodiment, said one or more bits are then the encoded mode information.
- In other embodiments, however, the selected comfort noise generation mode is implicitly encoded within the audio information. For example, in the above-mentioned example, the frequency-band specific gain factors and the one or more LP (or LSF or ISF) coefficients may, e.g., have a different data format or may, e.g., have a different bit length. If, for example, frequency-band specific gain factors are encoded within the audio information, this may, e.g., indicate that the frequency-domain comfort noise generation mode is the selected comfort noise generation mode. If, however, the one or more LP (or LSF or ISF) coefficients are encoded within the audio information, this may, e.g., indicate that the linear-prediction-domain comfort noise generation mode is the selected comfort noise generation mode. When such an implicit encoding is used, the frequency-band specific gain factors or the one or more LP (or LSF or ISF) coefficients then represent the mode information being encoded within the encoded audio signal, wherein this mode information indicates the selected comfort noise generation mode.
- According to an embodiment, the
selector 110 may, e.g., be configured to determine a tilt of a background noise of the audio input signal as the background noise characteristic. Theselector 110 may, e.g., be configured to select said comfort noise generation mode from two or more comfort noise generation modes depending on the determined tilt. - For example, a low-frequency background noise value and a high-frequency background noise value may be employed, and the tilt of the background noise may, e.g., be calculated depending on the low-frequency background noise value and depending on the high-frequency background-noise value.
-
Fig. 2 illustrates an apparatus for encoding audio information according to a further embodiment. The apparatus ofFig. 2 further comprises anoise estimator 105 for estimating a per-band estimate of the background noise for each of a plurality of frequency bands. Theselector 110 may, e.g., be configured to determine the tilt depending on the estimated background noise of the plurality of frequency bands. - According to an embodiment, the
noise estimator 105 may, e.g., be configured to estimate a per-band estimate of the background noise by estimating an energy of the background noise of each of the plurality of frequency bands. - In an embodiment, the
noise estimator 105 may, e.g., be configured to determine a low-frequency background noise value indicating a first background noise energy for a first group of the plurality of frequency bands depending on the per-band estimate of the background noise of each frequency band of the first group of the plurality of frequency bands. - Moreover, the
noise estimator 105 may, e.g., be configured to determine a high-frequency background noise value indicating a second background noise energy for a second group of the plurality of frequency bands depending on the per-band estimate of the background noise of each frequency band of the second group of the plurality of frequency bands. At least one frequency band of the first group may, e.g., have a lower centre-frequency than a centre-frequency of at least one frequency band of the second group. In a particular embodiment, each frequency band of the first group may, e.g., have a lower centre-frequency than a centre-frequency of each frequency band of the second group. - Furthermore, the
selector 110 may, e.g., be configured to determine the tilt depending on the low-frequency background noise value and depending on the high-frequency background noise value. - According to an embodiment, the
noise estimator 105 may, e.g., be configured to determine the low-frequency background noise value L according to
- Similarly, in an embodiment, the
noise estimator 105 may, e.g., be configured to determine the high-frequency background noise value H according to
- According to an embodiment, the
selector 110 may, e.g., be configured to determine the tilt T depending on the low frequency background noise value L and depending on the high frequency background noise value H according to the formula:



- For example, when L and H are represented in a logarithmic domain, one of the subtraction formulae (T = L - H or T = H - L) may be employed.
- In an embodiment, the
selector 110 may, e.g., be configured to determine the tilt as a current short-term tilt value. Moreover, theselector 110 may, e.g., be configured to determine a current long-term tilt value depending on the current short-term tilt value and depending on a previous long-term tilt value. Furthermore, theselector 110 may, e.g., be configured to select one of two or more comfort noise generation modes depending on the current long-term tilt value. - According to an embodiment, the
selector 110 may, e.g., be configured to determine the current long-term tilt value TcLT according to the formula:
- In an embodiment, a first one of the two or more comfort noise generation modes may, e.g., be a frequency-domain comfort noise generation mode FD_CNG. Moreover, a second one of the two or more comfort noise generation modes may, e.g., be a linear-prediction-domain comfort noise generation mode LP_CNG. The
selector 110 may, e.g., be configured to select the frequency-domain comfort noise generation mode FD_CNG, if a previously selected generation mode cng_mode_prev, being previously selected by theselector 110, is the linear-prediction-domain comfort noise generation mode LP_CNG and if the current long-term tilt value is greater than a first threshold value thr 1 . Moreover, theselector 110 may, e.g., be configured to select the linear-prediction-domain comfort noise generation mode LP_CNG, if the previously selected generation mode cng_mode_prev, being previously selected by theselector 110, is the frequency-domain comfort noise generation mode FD_CNG and if the current long-term tilt value is smaller than a second threshold value thr 2 . - In some embodiments, the first threshold value is equal to the second threshold value. In some other embodiments, however, the first threshold value is different from the second threshold value.
-
Fig. 4 illustrates an apparatus for generating an audio output signal based on received encoded audio information according to an embodiment. - The apparatus comprises a
decoding unit 210 for decoding encoded audio information to obtain mode information being encoded within the encoded audio information. The mode information indicates an indicated comfort noise generation mode of two or more comfort noise generation modes. - Moreover, the apparatus comprises a
signal processor 220 for generating the audio output signal by generating, depending on the indicated comfort noise generation mode, comfort noise. - According to an embodiment, a first one of the two or more comfort noise generation modes may, e.g., be a frequency-domain comfort noise generation mode. The
signal processor 220 may, e.g., be configured, if the indicated comfort noise generation mode is the frequency-domain comfort noise generation mode, to generate the comfort noise in a frequency domain and by conducting a frequency-to-time conversion of the comfort noise being generated in the frequency domain. For example, in a particular embodiment, the signal processor may, e.g., be configured, if the indicated comfort noise generation mode is the frequency-domain comfort noise generation mode, to generate the comfort noise by generating random noise in a frequency domain, by shaping the random noise in the frequency domain to obtain shaped noise, and by converting the shaped noise from the frequency-domain to the time domain. - For example, the concepts described in
WO 2014/096279 A1 may be employed. - For example, a random generator may be applied to excite each individual spectral band in the FFT domain and/or in the QMF domain by generating one or more random sequences (FFT = Fast Fourier Transform; QMF = Quadrature Mirror Filter). Shaping of the random noise may, e.g., be conducted by individually computing the amplitude of the random sequences in each band such that the spectrum of the generated comfort noise resembles the spectrum of the actual background noise present, for example, in a bitstream, comprising, e.g., an audio input signal. Then, for example, the computed amplitude may, e.g., be applied on the random sequence, e.g., by multiplying the random sequence with the computed amplitude in each frequency band. Then, converting the shaped noise from the frequency domain to the time domain may be employed.
- In an embodiment, a second one of the two or more comfort noise generation modes may, e.g., be a linear-prediction-domain comfort noise generation mode. The
signal processor 220 may, e.g., be configured, if the indicated comfort noise generation mode is the linear-prediction-domain comfort noise generation mode, to generate the comfort noise by employing a linear prediction filter. For example, in a particular embodiment, the signal processor may, e.g., be configured, if the indicated comfort noise generation mode is the linear-prediction-domain comfort noise generation mode, to generate the comfort noise by generating a random excitation signal, by scaling the random excitation signal to obtain a scaled excitation signal, and by synthesizing the scaled excitation signal using a LP inverse filter. - For example, comfort noise generation as described in G.722.2 (see ITU-T G.722.2 Annex A) and/or as described in G.718 (see ITU-T G.718 Sec. 6.12 and 7.12) may be employed. Such comfort noise generation in a random excitation domain by scaling a random excitation signal to obtain a scaled excitation signal, and by synthesizing the scaled excitation signal using a LP inverse filter is well known to a person skilled in the art.
-
Fig. 5 illustrates a system according to an embodiment. The system comprises anapparatus 100 for encoding audio information according to one of the above-described embodiments and anapparatus 200 for generating an audio output signal based on received encoded audio information according to one of the above-described embodiments. - The
selector 110 of theapparatus 100 for encoding audio information is configured to select a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal. Theencoding unit 120 of theapparatus 100 for encoding audio information is configured to encode the audio information, comprising mode information indicating the selected comfort noise generation mode as an indicated comfort noise generation mode, to obtain encoded audio information. - Moreover, the
decoding unit 210 of theapparatus 200 for generating an audio output signal is configured to receive the encoded audio information, and is furthermore configured to decode the encoded audio information to obtain the mode information being encoded within the encoded audio information. Thesignal processor 220 of theapparatus 200 for generating an audio output signal is configured to generate the audio output signal by generating, depending on the indicated comfort noise generation mode, comfort noise. -
Fig. 3 illustrates a step-by-step approach for selecting a comfort noise generation mode according to an embodiment. - In
step 310, a noise estimator is used to estimate the background noise energy in the frequency domain. This is generally performed on a per-band basis, producing one energy estimate per band
- Any noise estimator producing a per-band estimate of the background noise energy can be used. One example is the noise estimator used in G.718 (ITU-T G.718 Sec. 6.7).
- In
step 320, the background noise energy in the low frequencies is computed using
- L may be considered as a low-frequency background noise value as described above.
- In
step 330, the background noise energy in the high frequencies is computed using
- H may be considered as a high-frequency background noise value as described above.
-
Steps - In
step 340, the background noise tilt is computed using
- Some embodiments may, e.g., proceed according to
step 350. Instep 350, the background noise tilt is smoothed, producing a long-term version of the background noise tilt
- In
step 360, the CNG mode is finally selected using the following classifier with hysteresis

- cng_mode is the comfort noise generation mode that is (currently) selected by the
selector 110. - cng_mode_prev is a previously selected (comfort noise) generation mode that has previously been selected by the
selector 110. - What happens when none of the above-conditions of
step 360 are fulfilled, depends on the implementation. In an embodiment, for example, if none of both conditions ofstep 360 are fulfilled, the CNG mode may remain the same as it was, so that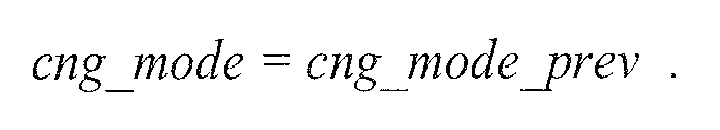
- Other embodiments may implement other selection strategies.
- While in the embodiment of
Fig. 3 , thr 1 is different from thr 2 , in some other embodiments, however, thr1 is equal to thr 2 . - Although some aspects have been described in the context of an apparatus, it is clear that these aspects also represent a description of the corresponding method, where a block or device corresponds to a method step or a feature of a method step. Analogously, aspects described in the context of a method step also represent a description of a corresponding block or item or feature of a corresponding apparatus.
- The inventive decomposed signal can be stored on a digital storage medium or can be transmitted on a transmission medium such as a wireless transmission medium or a wired transmission medium such as the Internet.
- Depending on certain implementation requirements, embodiments of the invention can be implemented in hardware or in software. The implementation can be performed using a digital storage medium, for example a floppy disk, a DVD, a CD, a ROM, a PROM, an EPROM, an EEPROM or a FLASH memory, having electronically readable control signals stored thereon, which cooperate (or are capable of cooperating) with a programmable computer system such that the respective method is performed.
- Some embodiments according to the invention comprise a non-transitory data carrier having electronically readable control signals, which are capable of cooperating with a programmable computer system, such that one of the methods described herein is performed.
- Generally, embodiments of the present invention can be implemented as a computer program product with a program code, the program code being operative for performing one of the methods when the computer program product runs on a computer. The program code may for example be stored on a machine readable carrier.
- Other embodiments comprise the computer program for performing one of the methods described herein, stored on a machine readable carrier.
- In other words, an embodiment of the inventive method is, therefore, a computer program having a program code for performing one of the methods described herein, when the computer program runs on a computer.
- A further embodiment of the inventive methods is, therefore, a data carrier (or a digital storage medium, or a computer-readable medium) comprising, recorded thereon, the computer program for performing one of the methods described herein.
- A further embodiment of the inventive method is, therefore, a data stream or a sequence of signals representing the computer program for performing one of the methods described herein. The data stream or the sequence of signals may for example be configured to be transferred via a data communication connection, for example via the Internet.
- A further embodiment comprises a processing means, for example a computer, or a programmable logic device, configured to or adapted to perform one of the methods described herein.
- A further embodiment comprises a computer having installed thereon the computer program for performing one of the methods described herein.
- In some embodiments, a programmable logic device (for example a field programmable gate array) may be used to perform some or all of the functionalities of the methods described herein. In some embodiments, a field programmable gate array may cooperate with a microprocessor in order to perform one of the methods described herein. Generally, the methods are preferably performed by any hardware apparatus.
- The above described embodiments are merely illustrative for the principles of the present invention. It is understood that modifications and variations of the arrangements and the details described herein will be apparent to others skilled in the art. It is the intent, therefore, to be limited only by the scope of the impending patent claims and not by the specific details presented by way of description and explanation of the embodiments herein.
Claims (16)
- An apparatus for encoding audio information, comprising:a selector (110) for selecting a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal, andan encoding unit (120) for encoding the audio information, wherein the audio information comprises mode information indicating the selected comfort noise generation mode.
- An apparatus according to claim 1,
wherein the selector (110) is configured to determine a tilt of a background noise of the audio input signal as the background noise characteristic, and
wherein the selector (110) is configured to select said comfort noise generation mode from two or more comfort noise generation modes depending on the determined tilt. - An apparatus according to claim 2,
wherein the apparatus further comprises a noise estimator (105) for estimating a per-band estimate of the background noise for each of a plurality of frequency bands, and
wherein the selector (110) is configured to determine the tilt depending on the estimated background noise of the plurality of frequency bands. - An apparatus according to claim 3,
wherein, the noise estimator (105) is configured to determine a low-frequency background noise value indicating a first background noise energy for a first group of the plurality of frequency bands depending on the per-band estimate of the background noise of each frequency band of the first group of the plurality of frequency bands,
wherein the noise estimator (105) is configured to determine a high-frequency background noise value indicating a second background noise energy for a second group of the plurality of frequency bands depending on the per-band estimate of the background noise of each frequency band of the second group of the plurality of frequency bands, wherein at least one frequency band of the first group has a lower centre-frequency than a centre-frequency of at least one frequency band of the second group, and
wherein the selector (110) is configured to determine the tilt depending on the low-frequency background noise value and depending on the high-frequency background noise value. - An apparatus according to claim 4,
wherein the noise estimator (105) is configured to determine the low-frequency background noise value L according to
wherein i indicates an i-th frequency band of the first group of frequency bands, wherein I 1 indicates a first one of the plurality of frequency bands, wherein I 2 indicates a second one of the plurality of frequency bands, and wherein N[i] indicates the energy estimate of the background noise energy of the i-th frequency band,
wherein the noise estimator (105) is configured to determine the high-frequency background noise value H according to
wherein i indicates an i-th frequency band of the second group of frequency bands, wherein I 3 indicates a third one of the plurality of frequency bands, wherein I 4 indicates a fourth one of the plurality of frequency bands, and wherein N[i] indicates the energy estimate of the background noise energy of the i-th frequency band. - An apparatus according to claim 4 or 5,
wherein the selector (110) is configured to determine the tilt T depending on the low frequency background noise value L and depending on the high frequency background noise value H according to the formula
or according to the formula
or according to the formula

- An apparatus according to one of claims 2 to 6,
wherein the selector (110) is configured to determine the tilt as a current short-term tilt value (T),
wherein the selector (110) is configured to determine a current long-term tilt value depending on the current short-term tilt value and depending on a previous long-term tilt value,
wherein the selector (110) is configured to select one of two or more comfort noise generation modes depending on the current long-term tilt value. - An apparatus according to claim 7,
wherein the selector (110) is configured to determine the current long-term tilt value TcLT according to the formula: wherein T is the current short-term tilt value,wherein TpLT is said previous long-term tilt value, andwherein α is a real number with 0 < a < 1.
wherein T is the current short-term tilt value,wherein TpLT is said previous long-term tilt value, andwherein α is a real number with 0 < a < 1. - An apparatus according to claim 7 or 8,
wherein a first one of the two or more comfort noise generation modes is a frequency-domain comfort noise generation mode,
wherein a second one of the two or more comfort noise generation modes is a linear-prediction-domain comfort noise generation mode,
wherein the selector (110) is configured to select the frequency-domain comfort noise generation mode, if a previously selected generation mode, being previously selected by the selector (110), is the linear-prediction-domain comfort noise generation mode and if the current long-term tilt value is greater than a first threshold value, and
wherein the selector (110) is configured to select the linear-prediction-domain comfort noise generation mode, if the previously selected generation mode, being previously selected by the selector (110), is the frequency-domain comfort noise generation mode and if the current long-term tilt value is smaller than a second threshold value. - An apparatus for generating an audio output signal based on received encoded audio information, comprising:a decoding unit (210) for decoding encoded audio information to obtain mode information being encoded within the encoded audio information, wherein the mode information indicates an indicated comfort noise generation mode of two or more comfort noise generation modes, anda signal processor (220) for generating the audio output signal by generating, depending on the indicated comfort noise generation mode, comfort noise.
- An apparatus according to claim 10,
wherein a first one of the two or more comfort noise generation modes is a frequency-domain comfort noise generation mode, and
wherein the signal processor is configured, if the indicated comfort noise generation mode is the frequency-domain comfort noise generation mode, to generate the comfort noise in a frequency domain and by conducting a frequency-to-time conversion of the comfort noise being generated in the frequency domain. - An apparatus according to claim 10 or 11,
wherein a second one of the two or more comfort noise generation modes is a linear-prediction-domain comfort noise generation mode, and
wherein the signal processor (220) is configured, if the indicated comfort noise generation mode is the linear-prediction-domain comfort noise generation mode, to generate the comfort noise by employing a linear prediction filter. - A system comprising:an apparatus (100) according to one of claims 1 to 9 for encoding audio information, andan apparatus (200) according to one of claims 10 to 12 for generating an audio output signal based on received encoded audio information,wherein the selector (110) of the apparatus (100) according to one of claims 1 to 9 is configured to select a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal,wherein the encoding unit (120) of the apparatus (100) according to one of claims 1 to 9 is configured to encode the audio information, comprising mode information indicating the selected comfort noise generation mode as an indicated comfort noise generation mode, to obtain encoded audio information,wherein the decoding unit (210) of the apparatus (200) according to one of claims 10 to 12 is configured to receive the encoded audio information, and is furthermore configured to decode the encoded audio information to obtain the mode information being encoded within the encoded audio information, andwherein the signal processor (220) of the apparatus (200) according to one of claims 10 to 12 is configured to generate the audio output signal by generating, depending on the indicated comfort noise generation mode, comfort noise.
- A method for encoding audio information, comprising:selecting a comfort noise generation mode from two or more comfort noise generation modes depending on a background noise characteristic of an audio input signal, andencoding the audio information, wherein the audio information comprises mode information indicating the selected comfort noise generation mode.
- A method for generating an audio output signal based on received encoded audio information, comprising:decoding encoded audio information to obtain mode information being encoded within the encoded audio information, wherein the mode information indicates an indicated comfort noise generation mode of two or more comfort noise generation modes, andgenerating the audio output signal by generating, depending on the indicated comfort noise generation mode, comfort noise.
- A computer program for implementing the method of claim 14 or 15 when being executed on a computer or signal processor.
Priority Applications (26)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP14178782.0A EP2980790A1 (en) | 2014-07-28 | 2014-07-28 | Apparatus and method for comfort noise generation mode selection |
| EP15738365.4A EP3175447B1 (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| JP2017504787A JP6494740B2 (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for selecting a comfortable noise generation mode |
| ES15738365T ES2802373T3 (en) | 2014-07-28 | 2015-07-16 | Comfort noise generation mode selection apparatus and method |
| PT157383654T PT3175447T (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| AU2015295679A AU2015295679B2 (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| BR112017001394-0A BR112017001394B1 (en) | 2014-07-28 | 2015-07-16 | APPLIANCE AND METHOD FOR SELECTING THE COMFORT NOISE GENERATION MODE |
| EP20172529.8A EP3706120A1 (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| CA2955757A CA2955757C (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| KR1020177005524A KR102008488B1 (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| CN202110274103.7A CN113140224B (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| MYPI2017000134A MY181456A (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| SG11201700688RA SG11201700688RA (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| CN201580040583.3A CN106663436B (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| PCT/EP2015/066323 WO2016016013A1 (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| MX2017001237A MX360556B (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection. |
| PL15738365T PL3175447T3 (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| RU2017105449A RU2696466C2 (en) | 2014-07-28 | 2015-07-16 | Device and method for comfort noise generation mode selection |
| TW104123733A TWI587287B (en) | 2014-07-28 | 2015-07-22 | Apparatus and method for comfort noise generation mode selection |
| ARP150102396A AR101342A1 (en) | 2014-07-28 | 2015-07-28 | APPARATUS AND COMFORTABLE NOISE GENERATION MODE SELECTION METHOD |
| US15/417,228 US10089993B2 (en) | 2014-07-28 | 2017-01-27 | Apparatus and method for comfort noise generation mode selection |
| ZA2017/01285A ZA201701285B (en) | 2014-07-28 | 2017-02-21 | Apparatus and method for comfort noise generation mode selection |
| US16/141,115 US11250864B2 (en) | 2014-07-28 | 2018-09-25 | Apparatus and method for comfort noise generation mode selection |
| JP2019039146A JP6859379B2 (en) | 2014-07-28 | 2019-03-05 | Equipment and methods for comfortable noise generation mode selection |
| JP2021051567A JP7258936B2 (en) | 2014-07-28 | 2021-03-25 | Apparatus and method for comfort noise generation mode selection |
| US17/568,498 US12009000B2 (en) | 2014-07-28 | 2022-01-04 | Apparatus and method for comfort noise generation mode selection |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP14178782.0A EP2980790A1 (en) | 2014-07-28 | 2014-07-28 | Apparatus and method for comfort noise generation mode selection |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| EP2980790A1 true EP2980790A1 (en) | 2016-02-03 |
Family
ID=51224868
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP14178782.0A Withdrawn EP2980790A1 (en) | 2014-07-28 | 2014-07-28 | Apparatus and method for comfort noise generation mode selection |
| EP15738365.4A Active EP3175447B1 (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| EP20172529.8A Pending EP3706120A1 (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
Family Applications After (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP15738365.4A Active EP3175447B1 (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
| EP20172529.8A Pending EP3706120A1 (en) | 2014-07-28 | 2015-07-16 | Apparatus and method for comfort noise generation mode selection |
Country Status (18)
| Country | Link |
|---|---|
| US (3) | US10089993B2 (en) |
| EP (3) | EP2980790A1 (en) |
| JP (3) | JP6494740B2 (en) |
| KR (1) | KR102008488B1 (en) |
| CN (2) | CN106663436B (en) |
| AR (1) | AR101342A1 (en) |
| AU (1) | AU2015295679B2 (en) |
| CA (1) | CA2955757C (en) |
| ES (1) | ES2802373T3 (en) |
| MX (1) | MX360556B (en) |
| MY (1) | MY181456A (en) |
| PL (1) | PL3175447T3 (en) |
| PT (1) | PT3175447T (en) |
| RU (1) | RU2696466C2 (en) |
| SG (1) | SG11201700688RA (en) |
| TW (1) | TWI587287B (en) |
| WO (1) | WO2016016013A1 (en) |
| ZA (1) | ZA201701285B (en) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6424942B1 (en) * | 1998-10-26 | 2002-07-23 | Telefonaktiebolaget Lm Ericsson (Publ) | Methods and arrangements in a telecommunications system |
| WO2014096279A1 (en) | 2012-12-21 | 2014-06-26 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Generation of a comfort noise with high spectro-temporal resolution in discontinuous transmission of audio signals |
Family Cites Families (45)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3989897A (en) * | 1974-10-25 | 1976-11-02 | Carver R W | Method and apparatus for reducing noise content in audio signals |
| FI110826B (en) * | 1995-06-08 | 2003-03-31 | Nokia Corp | Eliminating an acoustic echo in a digital mobile communication system |
| JPH11513813A (en) | 1995-10-20 | 1999-11-24 | アメリカ オンライン インコーポレイテッド | Repetitive sound compression system |
| US5794199A (en) * | 1996-01-29 | 1998-08-11 | Texas Instruments Incorporated | Method and system for improved discontinuous speech transmission |
| US5903819A (en) * | 1996-03-13 | 1999-05-11 | Ericsson Inc. | Noise suppressor circuit and associated method for suppressing periodic interference component portions of a communication signal |
| US5960389A (en) * | 1996-11-15 | 1999-09-28 | Nokia Mobile Phones Limited | Methods for generating comfort noise during discontinuous transmission |
| US6163608A (en) * | 1998-01-09 | 2000-12-19 | Ericsson Inc. | Methods and apparatus for providing comfort noise in communications systems |
| DE10084675T1 (en) * | 1999-06-07 | 2002-06-06 | Ericsson Inc | Method and device for generating artificial noise using parametric noise model measures |
| US6782361B1 (en) * | 1999-06-18 | 2004-08-24 | Mcgill University | Method and apparatus for providing background acoustic noise during a discontinued/reduced rate transmission mode of a voice transmission system |
| US6510409B1 (en) * | 2000-01-18 | 2003-01-21 | Conexant Systems, Inc. | Intelligent discontinuous transmission and comfort noise generation scheme for pulse code modulation speech coders |
| US6615169B1 (en) * | 2000-10-18 | 2003-09-02 | Nokia Corporation | High frequency enhancement layer coding in wideband speech codec |
| US6662155B2 (en) * | 2000-11-27 | 2003-12-09 | Nokia Corporation | Method and system for comfort noise generation in speech communication |
| US20030120484A1 (en) * | 2001-06-12 | 2003-06-26 | David Wong | Method and system for generating colored comfort noise in the absence of silence insertion description packets |
| US20030093270A1 (en) * | 2001-11-13 | 2003-05-15 | Domer Steven M. | Comfort noise including recorded noise |
| US6832195B2 (en) * | 2002-07-03 | 2004-12-14 | Sony Ericsson Mobile Communications Ab | System and method for robustly detecting voice and DTX modes |
| CN1703736A (en) * | 2002-10-11 | 2005-11-30 | 诺基亚有限公司 | Methods and devices for source controlled variable bit-rate wideband speech coding |
| JP2004078235A (en) * | 2003-09-11 | 2004-03-11 | Nec Corp | Voice encoder/decoder including unvoiced sound encoding, operated at a plurality of rates |
| US8767974B1 (en) * | 2005-06-15 | 2014-07-01 | Hewlett-Packard Development Company, L.P. | System and method for generating comfort noise |
| JP2008546341A (en) * | 2005-06-18 | 2008-12-18 | ノキア コーポレイション | System and method for adaptive transmission of pseudo background noise parameters in non-continuous speech transmission |
| US7610197B2 (en) * | 2005-08-31 | 2009-10-27 | Motorola, Inc. | Method and apparatus for comfort noise generation in speech communication systems |
| US8032370B2 (en) * | 2006-05-09 | 2011-10-04 | Nokia Corporation | Method, apparatus, system and software product for adaptation of voice activity detection parameters based on the quality of the coding modes |
| CN101087319B (en) * | 2006-06-05 | 2012-01-04 | 华为技术有限公司 | A method and device for sending and receiving background noise and silence compression system |
| CN101246688B (en) * | 2007-02-14 | 2011-01-12 | 华为技术有限公司 | Method, system and device for coding and decoding ambient noise signal |
| US8032359B2 (en) * | 2007-02-14 | 2011-10-04 | Mindspeed Technologies, Inc. | Embedded silence and background noise compression |
| US20080208575A1 (en) * | 2007-02-27 | 2008-08-28 | Nokia Corporation | Split-band encoding and decoding of an audio signal |
| CN101320563B (en) * | 2007-06-05 | 2012-06-27 | 华为技术有限公司 | Background noise encoding/decoding device, method and communication equipment |
| PT2165328T (en) * | 2007-06-11 | 2018-04-24 | Fraunhofer Ges Forschung | Encoding and decoding of an audio signal having an impulse-like portion and a stationary portion |
| CN101394225B (en) * | 2007-09-17 | 2013-06-05 | 华为技术有限公司 | Method and device for speech transmission |
| CN101335003B (en) * | 2007-09-28 | 2010-07-07 | 华为技术有限公司 | Noise generating apparatus and method |
| US8139777B2 (en) * | 2007-10-31 | 2012-03-20 | Qnx Software Systems Co. | System for comfort noise injection |
| CN101430880A (en) * | 2007-11-07 | 2009-05-13 | 华为技术有限公司 | Encoding/decoding method and apparatus for ambient noise |
| DE102008009720A1 (en) * | 2008-02-19 | 2009-08-20 | Siemens Enterprise Communications Gmbh & Co. Kg | Method and means for decoding background noise information |
| DE102008009719A1 (en) * | 2008-02-19 | 2009-08-20 | Siemens Enterprise Communications Gmbh & Co. Kg | Method and means for encoding background noise information |
| CN101483495B (en) * | 2008-03-20 | 2012-02-15 | 华为技术有限公司 | Background noise generation method and noise processing apparatus |
| CN102136271B (en) * | 2011-02-09 | 2012-07-04 | 华为技术有限公司 | Comfortable noise generator, method for generating comfortable noise, and device for counteracting echo |
| WO2012110481A1 (en) * | 2011-02-14 | 2012-08-23 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio codec using noise synthesis during inactive phases |
| MY167776A (en) * | 2011-02-14 | 2018-09-24 | Fraunhofer Ges Forschung | Noise generation in audio codecs |
| MY159444A (en) | 2011-02-14 | 2017-01-13 | Fraunhofer-Gesellschaft Zur Forderung Der Angewandten Forschung E V | Encoding and decoding of pulse positions of tracks of an audio signal |
| PL2661745T3 (en) | 2011-02-14 | 2015-09-30 | Fraunhofer Ges Forschung | Apparatus and method for error concealment in low-delay unified speech and audio coding (usac) |
| US20120237048A1 (en) * | 2011-03-14 | 2012-09-20 | Continental Automotive Systems, Inc. | Apparatus and method for echo suppression |
| CN102903364B (en) * | 2011-07-29 | 2017-04-12 | 中兴通讯股份有限公司 | Method and device for adaptive discontinuous voice transmission |
| CN103093756B (en) * | 2011-11-01 | 2015-08-12 | 联芯科技有限公司 | Method of comfort noise generation and Comfort Noise Generator |
| CN103137133B (en) * | 2011-11-29 | 2017-06-06 | 南京中兴软件有限责任公司 | Inactive sound modulated parameter estimating method and comfort noise production method and system |
| SG11201504899XA (en) * | 2012-12-21 | 2015-07-30 | Fraunhofer Ges Forschung | Comfort noise addition for modeling background noise at low bit-rates |
| CN103680509B (en) * | 2013-12-16 | 2016-04-06 | 重庆邮电大学 | A kind of voice signal discontinuous transmission and ground unrest generation method |
-
2014
- 2014-07-28 EP EP14178782.0A patent/EP2980790A1/en not_active Withdrawn
-
2015
- 2015-07-16 AU AU2015295679A patent/AU2015295679B2/en active Active
- 2015-07-16 PL PL15738365T patent/PL3175447T3/en unknown
- 2015-07-16 SG SG11201700688RA patent/SG11201700688RA/en unknown
- 2015-07-16 WO PCT/EP2015/066323 patent/WO2016016013A1/en active Application Filing
- 2015-07-16 PT PT157383654T patent/PT3175447T/en unknown
- 2015-07-16 JP JP2017504787A patent/JP6494740B2/en active Active
- 2015-07-16 CN CN201580040583.3A patent/CN106663436B/en active Active
- 2015-07-16 MX MX2017001237A patent/MX360556B/en active IP Right Grant
- 2015-07-16 MY MYPI2017000134A patent/MY181456A/en unknown
- 2015-07-16 EP EP15738365.4A patent/EP3175447B1/en active Active
- 2015-07-16 CA CA2955757A patent/CA2955757C/en active Active
- 2015-07-16 EP EP20172529.8A patent/EP3706120A1/en active Pending
- 2015-07-16 RU RU2017105449A patent/RU2696466C2/en active
- 2015-07-16 KR KR1020177005524A patent/KR102008488B1/en active IP Right Grant
- 2015-07-16 CN CN202110274103.7A patent/CN113140224B/en active Active
- 2015-07-16 ES ES15738365T patent/ES2802373T3/en active Active
- 2015-07-22 TW TW104123733A patent/TWI587287B/en active
- 2015-07-28 AR ARP150102396A patent/AR101342A1/en active IP Right Grant
-
2017
- 2017-01-27 US US15/417,228 patent/US10089993B2/en active Active
- 2017-02-21 ZA ZA2017/01285A patent/ZA201701285B/en unknown
-
2018
- 2018-09-25 US US16/141,115 patent/US11250864B2/en active Active
-
2019
- 2019-03-05 JP JP2019039146A patent/JP6859379B2/en active Active
-
2021
- 2021-03-25 JP JP2021051567A patent/JP7258936B2/en active Active
-
2022
- 2022-01-04 US US17/568,498 patent/US12009000B2/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6424942B1 (en) * | 1998-10-26 | 2002-07-23 | Telefonaktiebolaget Lm Ericsson (Publ) | Methods and arrangements in a telecommunications system |
| WO2014096279A1 (en) | 2012-12-21 | 2014-06-26 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Generation of a comfort noise with high spectro-temporal resolution in discontinuous transmission of audio signals |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP2352145B1 (en) | Transient speech signal encoding method and device, decoding method and device, processing system and computer-readable storage medium | |
| EP3125239B1 (en) | Method and appartus for controlling audio frame loss concealment | |
| CN104321815A (en) | Method and apparatus for high-frequency encoding/decoding for bandwidth extension | |
| EP3131094A1 (en) | Noise signal processing and generation method, encoder/decoder and encoding/decoding system | |
| EP3096314B1 (en) | Audio frame loss concealment | |
| CN101521010B (en) | Coding and decoding method for voice frequency signals and coding and decoding device | |
| EP3136386B1 (en) | Apparatus and method for generating a frequency enhanced signal using shaping of the enhancement signal | |
| EP2407963B1 (en) | Linear prediction analysis method, apparatus and system | |
| US12009000B2 (en) | Apparatus and method for comfort noise generation mode selection | |
| KR20220050924A (en) | Multi-lag format for audio coding |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| AX | Request for extension of the european patent |
Extension state: BA ME |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION IS DEEMED TO BE WITHDRAWN |
|
| 18D | Application deemed to be withdrawn |
Effective date: 20160804 |