CN116403231A - 基于双视图对比学习与图剪枝的多跳阅读理解方法及系统 - Google Patents
基于双视图对比学习与图剪枝的多跳阅读理解方法及系统 Download PDFInfo
- Publication number
- CN116403231A CN116403231A CN202310398450.XA CN202310398450A CN116403231A CN 116403231 A CN116403231 A CN 116403231A CN 202310398450 A CN202310398450 A CN 202310398450A CN 116403231 A CN116403231 A CN 116403231A
- Authority
- CN
- China
- Prior art keywords
- node
- paragraph
- graph
- nodes
- paragraphs
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000034 method Methods 0.000 title claims abstract description 56
- 238000013138 pruning Methods 0.000 title claims abstract description 29
- 238000012549 training Methods 0.000 claims abstract description 61
- 238000013135 deep learning Methods 0.000 claims abstract description 22
- 239000011159 matrix material Substances 0.000 claims description 85
- 230000000873 masking effect Effects 0.000 claims description 30
- 230000006870 function Effects 0.000 claims description 22
- 239000013598 vector Substances 0.000 claims description 18
- 238000004364 calculation method Methods 0.000 claims description 15
- 235000009508 confectionery Nutrition 0.000 claims description 15
- 238000010586 diagram Methods 0.000 claims description 11
- 238000009826 distribution Methods 0.000 claims description 9
- 230000007246 mechanism Effects 0.000 claims description 8
- 230000008569 process Effects 0.000 claims description 7
- 238000012545 processing Methods 0.000 claims description 7
- 238000004422 calculation algorithm Methods 0.000 claims description 4
- ORILYTVJVMAKLC-UHFFFAOYSA-N Adamantane Natural products C1C(C2)CC3CC1CC2C3 ORILYTVJVMAKLC-UHFFFAOYSA-N 0.000 claims description 3
- 238000006243 chemical reaction Methods 0.000 claims description 3
- 230000009977 dual effect Effects 0.000 claims description 3
- 238000001914 filtration Methods 0.000 claims description 3
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 claims description 3
- 239000010931 gold Substances 0.000 claims description 3
- 229910052737 gold Inorganic materials 0.000 claims description 3
- 238000011478 gradient descent method Methods 0.000 claims description 3
- 238000005457 optimization Methods 0.000 claims description 3
- 238000011176 pooling Methods 0.000 claims description 3
- 238000005070 sampling Methods 0.000 claims description 3
- 230000017105 transposition Effects 0.000 claims description 3
- 238000012512 characterization method Methods 0.000 claims description 2
- 230000009286 beneficial effect Effects 0.000 abstract description 3
- 238000004590 computer program Methods 0.000 description 7
- 238000013528 artificial neural network Methods 0.000 description 4
- 235000019580 granularity Nutrition 0.000 description 4
- 238000003860 storage Methods 0.000 description 3
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012216 screening Methods 0.000 description 2
- 241000283074 Equus asinus Species 0.000 description 1
- 235000008694 Humulus lupulus Nutrition 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000003058 natural language processing Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/40—Document-oriented image-based pattern recognition
- G06V30/41—Analysis of document content
- G06V30/412—Layout analysis of documents structured with printed lines or input boxes, e.g. business forms or tables
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/16—Matrix or vector computation, e.g. matrix-matrix or matrix-vector multiplication, matrix factorization
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/082—Learning methods modifying the architecture, e.g. adding, deleting or silencing nodes or connections
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/19—Recognition using electronic means
- G06V30/191—Design or setup of recognition systems or techniques; Extraction of features in feature space; Clustering techniques; Blind source separation
- G06V30/19147—Obtaining sets of training patterns; Bootstrap methods, e.g. bagging or boosting
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Pure & Applied Mathematics (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- Mathematical Analysis (AREA)
- General Health & Medical Sciences (AREA)
- Computational Mathematics (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Mathematical Optimization (AREA)
- Computational Linguistics (AREA)
- Evolutionary Computation (AREA)
- Databases & Information Systems (AREA)
- Algebra (AREA)
- Machine Translation (AREA)
Abstract
本发明涉及一种基于双视图对比学习与图剪枝的多跳阅读理解方法及系统,该方法包括以下步骤:步骤A:采集问题、文章上下文、答案和支持事实数据,构建多跳阅读理解训练集;步骤B:使用训练集训练用于多跳阅读理解的基于双视图对比学习与图剪枝的深度学习网络模型D;步骤C:将问题、文章数据依次输入深度学习网络模型D中,输出当前的问题的相应答案。该方法及系统有利于提高多跳阅读理解答案预测的准确性。
Description
技术领域
本发明属于自然语言处理领域,具体涉及一种基于双视图对比学习与图剪枝的多跳阅读理解方法及系统。
背景技术
机器阅读理解是人机问答系统的重要组成部分,其目标为使计算机拥有与人类相媲美的文章理解能力。与信息检索任务不同,机器阅读理解不是简单地让机器根据问题匹配文本数据库中相似度最高的字符串,而是让机器能够理解用户所描述的自然语言问题,这些问题的答案可能存在于文本段落中,可能是“是或否”,也有可能是无法回答的,甚至需要机器根据自己的理解生成或计算出正确的答案。多跳阅读理解是指给出的问题无法在单个段落或单个文档中回答,需要经过至少两次文档跳转的推理链才能得到答案。相较于传统的阅读理解问题更需要提高模型的推理能力,要求模型具有更好的解释性和拓展性。对文本语义理解的准确性会影响人机问答系统下游的各种学习任务的性能,而仅通过文本和问题词的简单匹配忽略了未能获取到具体的文章语义信息。因此获得真实的文本语义信息至关重要。
近年来,随着GPT、BERT等预训练模型的出现,以及在阅读理解任务上的强大性能提升,诞生了一批优秀的预训练语言模型。单跳阅读理解的简单阅读理解任务如SQuAD、TriviaQA、SearchQA等已取得重大突破,研究者们逐渐将目光转移到更能检验模型的理解程度的“多跳”、“推理”情形上。多跳数据集HotpotQA提供了各种推理策略,其中包含多种问题类型,每个问题对应多段文档,模型应根据不同问题类型在多段文档中构造一条多跳推理链,整合推理链上的信息得出最终答案。由于单跳任务的成功,许多方法可跨任务借鉴,如多任务方法辅助主任务答案预测。然而,大多数研究依旧使用检索方式查找可能包含正确答案的段落,接着使用单文档答案预测方法。由于多跳推理需要同时应用不同粒度的信息,单一的检索方式不能有效地将收集到的推理证据进行整合。由于图神经网络能够有效整理节点之间的依赖关系,许多模型提出实体词构图、使用关系构图或使用段落和实体词混合构图,使用图神经网络方法更好的整合细粒度信息,可以在图网络层后的实体词中选择答案。但是,此类方法所构造的图难以考虑支持事实信息,仅是单一地通过整合段落和实体词信息进行答案预测。鉴于此,有研究工作使用段落、句子、实体词构造多粒度异构图,通过图注意力机制整合不同粒度信息之间的上下文依赖,利用更新后的节点标识用于不同的子任务,针对多种类型问题,引入跨度预测模块来进行最终答案预测。但是多层次细粒度图将所有线索合并成一个图,难以解释模型的决策,多粒度信息的繁多使得关键信息的获取受到挑战。图神经网络方法过于依赖邻接矩阵,缺乏扩展性。
综上,图注意力网络在融合文本和问题之间语义表示中取得了一定的成就,但在语义理解方面依旧存在不足,在证据句子中易被相似性噪声影响。由分析人类阅读理解过程可知,在阅读回答时人们通常需要再结合问题以明确答案应该具有的关键信息,列出候选答案,再通过候选答案得出正确答案。在阅读时人类通常会通过辨别文章和问题中的关键信息以及干扰信息来得到正确答案。
发明内容
本发明的目的在于提供一种基于双视图对比学习与图剪枝的多跳阅读理解方法及系统,该方法及系统有利于提高多跳阅读理解答案预测的准确性。
为实现上述目的,本发明采用的技术方案是:一种基于双视图对比学习与图剪枝的多跳阅读理解方法,包括以下步骤:
步骤A:采集问题、文章上下文、答案和支持事实数据,构建多跳阅读理解训练集;
步骤B:使用训练集训练用于多跳阅读理解的基于双视图对比学习与图剪枝的深度学习网络模型D;
步骤C:将问题、文章数据输入深度学习网络模型D中,输出当前问题的相应答案。
进一步地,所述步骤B具体包括以下步骤:
步骤B1:使用预训练模型Roberta对训练集中各个样本的各个段落包含黄金支持事实的概率进行计算,同时将各个样本的标题和段落的关系对与问题进行文本匹配,得到N个候选段落pcandi={p1,p2,...,pN};
步骤B2:将步骤B1得到的候选段落pcandi和问题、段落中句子、段落中实体词、超链接一同作为节点构造层次图G,并通过G中各节点边关系构造层次图的邻接矩阵Aadj;
步骤B3:将步骤B2得到的层次图G使用预训练模型Roberta获得所有图节点的初始表示,得到段落、句子、实体三种类型的节点表示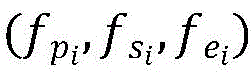 以及问题节点表示fq,以此获得层次图的总体节点表示
以及问题节点表示fq,以此获得层次图的总体节点表示
步骤B4:将步骤B2、B3得到的层次图的邻接矩阵Aadj及节点表示F用随机删除边关系和随机掩蔽节点特征的方法对层次图分别进行两次损坏,两个损坏后的层次图即为双视图,从而得到两个视图的邻接矩阵A1,A2和节点表示F1,F2;然后将两个视图分别输入到图注意力网络中,得到更新后的节点表示
步骤B5:使用门控注意力机制计算初始上下文嵌入E和更新后图节点表示 得到相关性系数
得到相关性系数 和上下文表征EG;同时,被损坏的两个视图的邻接矩阵A1,A2和特征矩阵F1,F2相互作为正负样本,以余弦相似度计算每一对样本相似性,得到两个图的对比学习损失
和上下文表征EG;同时,被损坏的两个视图的邻接矩阵A1,A2和特征矩阵F1,F2相互作为正负样本,以余弦相似度计算每一对样本相似性,得到两个图的对比学习损失 最大化双视图正例对总体目标损失Lgra;
最大化双视图正例对总体目标损失Lgra;
步骤B6:在步骤5中得到的上下文表征EG中包含候选答案节点 将其与步骤B3得到的问题节点表示fq采用关系过滤方法生成注意力权重稀疏矩阵
将其与步骤B3得到的问题节点表示fq采用关系过滤方法生成注意力权重稀疏矩阵 将其用来筛选当前候选答案节点;
将其用来筛选当前候选答案节点;
步骤B7:将步骤B4和B6得到的所有的不同类型节点分别输入多层感知机进行子任务预测,得到段落、支持事实、实体词、答案类型预测结果,使用交叉熵函数计算各类预测损失;随后根据答案类型预测结果返回相应类型的答案;然后根据目标损失函数,通过反向传播方法计算深度学习网络模型中各参数的梯度,并利用随机梯度下降方法更新各参数;
步骤B8:当深度学习网络模型产生的损失值小于设定的阈值或达到最大的迭代次数时,终止深度学习网络模型D的训练。
进一步地,所述步骤B1具体包括以下步骤:
步骤B11:对训练集进行遍历,对于训练集中的每个样本,使用Roberta模型作为编码器计算样本中每个段落包含黄金支持事实的概率Pranking,使用Pranking对段落进行排序,Pranking表示为:
Pranking=Robertaranking(P)
其中,P=(ti,pi)为样本中的段落集,ti为段落的标题,pi为段落文本;
将问题中的短语跨度(qstart,qend)与段落标题中的短语跨度 相匹配;如果段落标题与问题匹配时有多个段落匹配成功,则选择Pranking前二的段落;如果标题匹配没有匹配到段落,则将问题中的实体词
相匹配;如果段落标题与问题匹配时有多个段落匹配成功,则选择Pranking前二的段落;如果标题匹配没有匹配到段落,则将问题中的实体词 匹配段落中的实体词
匹配段落中的实体词 如果实体词匹配也失败,则取Pranking最高的段落,选取出的段落Psel表示为:
如果实体词匹配也失败,则取Pranking最高的段落,选取出的段落Psel表示为:

其中,psel表示段落标题与问题匹配成功的段落数量, 表示此种情况所选择的Pranking前二的段落;esel表示问题中的实体词与段落匹配是否成功,esel>0表示匹配成功;Pesel表示此种情况问题与段落实体词匹配到的段落;Peesl表示问题与段落实体词匹配结果;
表示此种情况所选择的Pranking前二的段落;esel表示问题中的实体词与段落匹配是否成功,esel>0表示匹配成功;Pesel表示此种情况问题与段落实体词匹配到的段落;Peesl表示问题与段落实体词匹配结果;
步骤B12:将步骤B1 1的结果Psel相对应的数据集中的超链接来搜索第二跳段落;第一跳选出的段落与问题构建双向边(q,pi),若第二跳段落存在则构建两段落节点之间的双向边(pi,pj),pi为第一跳中选中的段落,pj为第二跳中选中的段落;得到n个候选段落pcandi={p1,p2,...,pn},使用Pranking选择排名前N的段落,得到N个候选段落pcandi={p1,p2,...,pN}。
进一步地,所述步骤B2具体包括以下步骤:
步骤B21:对于训练集中的每个样本,将步骤B1中匹配到的段落、各段落中的句子、各句子中的实体词与问题一起构建层次图G;定义层次图中存在四种节点和七种边关系:
G={V,E}
其中,V为问题节点q、匹配得到的段落节点pcandi={p1,p2,..,pN}、各段落中的句子节点 各句子中的实体词节点
各句子中的实体词节点 构成的集合,N,ns,ne分别表示层次图中限定的段落、句子、实体词节点的个数;E为七种边关系组成的集合;
构成的集合,N,ns,ne分别表示层次图中限定的段落、句子、实体词节点的个数;E为七种边关系组成的集合;
步骤B22:利用层次图G中各节点的边关系构造邻接矩阵Aadj:

其中,Aij非零表示两节点之间的关系属于集合E中的一种,为零则表示两节点之间不存在集合E中的关系。
进一步地,所述步骤B3具体包括以下步骤:
步骤B31:将每个训练样本中的问题对应的选定段落合并,并与问题连接,然后输入Roberta获得初始表征;经互注意力层获得问题表示 和段落上下文表示
和段落上下文表示 其中,m和n分别为问题数量和段落数量,d表示表征向量维度;
其中,m和n分别为问题数量和段落数量,d表示表征向量维度;
步骤B32:将问题和上下文表示分开处理,上下文表示中,对于不同类型的结点,均以跨度形式计算,经Bi-LSTM网络提取段落、句子、实体三种类型的节点表示



其中, 表示段落节点的起始位置和结束位置,句子结点和实体节点的表示类似;[;]代表两向量拼接,左右两边分别代表Bi-LSTM的前向和后向计算;
表示段落节点的起始位置和结束位置,句子结点和实体节点的表示类似;[;]代表两向量拼接,左右两边分别代表Bi-LSTM的前向和后向计算;
步骤B33:将问题节点经过最大池化层获得节点表示fq:
fq=maxpooling(Q)。
进一步地,所述步骤B4具体包括以下步骤:
步骤B41:对于层次图G=(V,E),其中,V为图中的节点集合,E为图中的边关系集合;图的邻接矩阵为 将邻接矩阵Aadj转换为稀疏矩阵Acoo,根据节点个数随机构造一个掩蔽矩阵
将邻接矩阵Aadj转换为稀疏矩阵Acoo,根据节点个数随机构造一个掩蔽矩阵 作为掩蔽矩阵,当Aadj中存在边关系的时候为掩蔽矩阵分配值,其值根据伯努利分布计算得到:
作为掩蔽矩阵,当Aadj中存在边关系的时候为掩蔽矩阵分配值,其值根据伯努利分布计算得到:
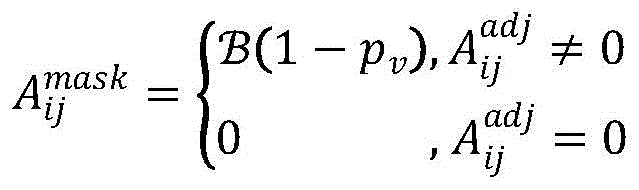
其中, 为伯努利分布,pv为自定义的掩蔽概率;
为伯努利分布,pv为自定义的掩蔽概率;
步骤B42:将掩蔽矩阵与原邻接矩阵做哈达玛乘积得到被损坏的邻接矩阵


其中, 为哈达玛积,以此生成两个邻接矩阵:
为哈达玛积,以此生成两个邻接矩阵:
步骤B43:采样随机向量fmask作为d维掩蔽向量,向量中的值采用伯努利分布提取:

其中,pf为自定义的掩蔽概率;
步骤B44:将节点特征 展开为
展开为 并与掩蔽向量做哈达玛乘积生成被损坏的节点特征
并与掩蔽向量做哈达玛乘积生成被损坏的节点特征

其中,[·]T为转置运算,对原节点特征进行两次掩蔽损坏生成两个特征矩阵:

步骤B45:设图中相邻结点集合为 计算步骤B42和步骤B44生成的两个图的节点i与邻居节点之间的相关性系数eij,再经过归一化后得到注意力系数αij:
计算步骤B42和步骤B44生成的两个图的节点i与邻居节点之间的相关性系数eij,再经过归一化后得到注意力系数αij:


其中,hi为当前计算的节点i的表示,hj为节点i的邻居节点j表示, 为共享参数矩阵;
为共享参数矩阵;
步骤B46:将每个损坏后的节点特征矩阵的注意力系数αij与邻居节点 进行加权计算得到更新后的节点表示
进行加权计算得到更新后的节点表示 为更新后的节点特征,计算过程如下:
为更新后的节点特征,计算过程如下:

其中, 为共享参数矩阵,h′i为节点i更新后的节点表示。
为共享参数矩阵,h′i为节点i更新后的节点表示。
进一步地,所述步骤B5具体包括以下步骤:
步骤B51:设E={Q,P}为上下文编码层经Roberta编码后的初始嵌入表示,以注意力机制的计算方式计算出上下文嵌入和更新图节点的相关性系数 再结合门控机制获得门控上下文表征
再结合门控机制获得门控上下文表征


其中, 是可学习参数矩阵;
是可学习参数矩阵;
步骤B52:对于图A1上的任一节点 图A2中对应的节点
图A2中对应的节点 为正样本,图A2中的其余节点以及图A1中的其余节点为负样本,A2对于A1也是同样计算;以余弦相似度计算两个图样本损失
为正样本,图A2中的其余节点以及图A1中的其余节点为负样本,A2对于A1也是同样计算;以余弦相似度计算两个图样本损失 正例对的训练目标为epv,负例对的训练目标为
正例对的训练目标为epv,负例对的训练目标为 另一图中负例对的训练目标为
另一图中负例对的训练目标为




其中, 分别为A1中除
分别为A1中除 之外的其他节点的集合以及A2中除
之外的其他节点的集合以及A2中除 之外的其他节点的集合,τ是温度系数,cos()为余弦相似度计算;
之外的其他节点的集合,τ是温度系数,cos()为余弦相似度计算;
步骤B53:以最大化双图正例对总体目标损失Lgra为此模块任务损失:

进一步地,所述步骤B6具体包括以下步骤:
步骤B61:将上下文编码后的问题表示fq与更新后的候选答案节点 采用注意力机制生成注意力矩阵
采用注意力机制生成注意力矩阵

步骤B62:将步骤B61生成的注意力矩阵按维度降序排序生成矩阵 再将该矩阵中联系最为紧密的Nrelation个关系保留,生成较为精准的注意力权重稀疏矩阵
再将该矩阵中联系最为紧密的Nrelation个关系保留,生成较为精准的注意力权重稀疏矩阵


其中,sort()为降序排序函数,fPruning()为剪枝函数;
步骤B63:将步骤B62生成的注意力权重稀疏矩阵与候选答案节点 相乘,得到筛选后的候选答案节点
相乘,得到筛选后的候选答案节点

进一步地,所述步骤B7具体包括以下步骤:
步骤B71:对于图中的段落结点、句子节点使用二分类多层感知机进行段落预测、句子预测;对于实体词结点使用多分类的多层感知机进行实体词预测:



其中, 表示段落中包含支持事实的概率,
表示段落中包含支持事实的概率, 表示句子被选择为支持事实的概率,
表示句子被选择为支持事实的概率, 表示实体节点中存在正确答案的概率;
表示实体节点中存在正确答案的概率;
步骤B72:使用MLP基于门控注意力层的隐藏状态来进行答案类型预测:
ptype=MLP7(EG[0])
其中,ptype为答案类型概率;
步骤B73:对于是非类型,直接返回答案;对于实体类型答案,返回实体词预测结果;对于跨度类型答案,使用上述门控注意力层的隐藏状态计算跨度预测:
pstart=MLP8(EG)
pend=MLP9(EG)
其中,pstart、pend为跨度开始与结束预测概率;
步骤B74:用交叉熵作为损失函数计算损失值,通过梯度优化算法Adam对学习率进行更新,利用反向传播迭代更新模型参数,以最小化损失函数来训练模型;模型总损失为上述各项预测的损失加权相加:
Lall=Lstart+Lend+μ1Lpara+μ2(Lsent+μgraLgra)+μ3Lent+μ4Ltype
其中,μ1,μ2,μ3,μ4,μgra为超参数,Lstart,Lend为跨度预测的损失,Lpara,Lsent,Lent,Ltype分别为段落预测、句子预测、实体词预测、答案类型预测的损失。
本发明还提供了采用上述方法的多跳阅读理解系统,包括:
构建训练集模块,用于采集对话上下文和回答数据,构建对话训练集;
模型训练模块,用于训练基于双视图对比学习与图剪枝的深度学习网络模型D;以及
多跳阅读理解模块,将用于多跳阅读理解的过程中将问题和文章输入训练好的深度网络模型中输出当前的预测答案。
与现有技术相比,本发明具有以下有益效果:本发明首先通过基于图的节点级正负样本对比学习任务来获取更加丰富的上下文互信息,经对比学习后的模型拥有更丰富的上下文语义信息,能够有效辨别多粒度上下文信息以及干扰信息,使得模型更能关注到与问题有关的正确答案的范围。另外,本发明通过问题指导筛选答案节点来缩小候选答案范围,使用问题表示对答案实体节点构造注意力权重矩阵,再利用关系筛选算法对该矩阵进行筛选,仅保留关联性最强的部分关系,减弱相似性表述对模型预测候选答案造成的噪声。
附图说明
图1是本发明实施例的方法实现流程图;
图2是本发明实施例中深度学习网络模型的架构图;
图3是本发明实施例的系统结构示意图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
应该指出,以下详细说明都是示例性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
如图1所示,本实施例提供了一种基于双视图对比学习与图剪枝的多跳阅读理解方法,包括以下步骤:
步骤A:采集问题、文章上下文、答案和支持事实数据,构建多跳阅读理解训练集。
步骤B:使用训练集训练用于多跳阅读理解的基于双视图对比学习与图剪枝的深度学习网络模型D。本实施例中深度学习网络模型的结构如图2所示。
步骤C:将问题、文章数据输入深度学习网络模型D中,输出当前问题的相应答案。
在本实施例中,所述步骤B具体包括以下步骤:
步骤B1:使用预训练模型Roberta对训练集中各个样本的各个段落包含黄金支持事实的概率进行计算,同时将各个样本的标题和段落的关系对与问题进行文本匹配,得到N个候选段落pcandi={p1,p2,...,pN}。所述步骤B1具体包括以下步骤:
步骤B11:对训练集进行遍历,对于训练集中的每个样本,使用Roberta模型作为编码器计算样本中每个段落包含黄金支持事实的概率Pranking,使用Pranking对段落进行排序,Pranking表示为:
Pranking=Robertaranking(P)
其中,P=(ti,pi)为样本中的段落集,ti为段落的标题,pi为段落文本。
将问题中的短语跨度(qstart,qend)与段落标题中的短语跨度 相匹配;问题跨度(qstart,qend)指的是问题中短语的起止位置,标题跨度
相匹配;问题跨度(qstart,qend)指的是问题中短语的起止位置,标题跨度 指的是段落标题中短语的起止位置,即每个段落都有一个标题,检索标题短语存在于问题中的段落;如果段落标题与问题匹配时有多个段落匹配成功,则选择Pranking前二的段落;如果标题匹配没有匹配到段落,则将问题中的实体词
指的是段落标题中短语的起止位置,即每个段落都有一个标题,检索标题短语存在于问题中的段落;如果段落标题与问题匹配时有多个段落匹配成功,则选择Pranking前二的段落;如果标题匹配没有匹配到段落,则将问题中的实体词 匹配段落中的实体词
匹配段落中的实体词 如果实体词匹配也失败,则取Pranking最高的段落,选取出的段落Psel表示为:
如果实体词匹配也失败,则取Pranking最高的段落,选取出的段落Psel表示为:

其中,psel表示段落标题与问题匹配成功的段落数量, 表示此种情况所选择的Pranking前二的段落;esel表示问题中的实体词与段落匹配是否成功,esel>0表示匹配成功;
表示此种情况所选择的Pranking前二的段落;esel表示问题中的实体词与段落匹配是否成功,esel>0表示匹配成功; 表示此种情况问题与段落实体词匹配到的段落;
表示此种情况问题与段落实体词匹配到的段落; 表示问题与段落实体词匹配结果。
表示问题与段落实体词匹配结果。
步骤B12:将步骤B11的结果Psel相对应的数据集中的超链接来搜索第二跳段落;第一跳选出的段落与问题构建双向边(q,pi),若第二跳段落存在则构建两段落节点之间的双向边(pi,pj),pi为第一跳中选中的段落,pj为第二跳中选中的段落;得到n个候选段落pcandi={p1,p2,...,pn},使用pranking选择排名前N的段落,得到N个候选段落pcandi={p1,p2,...,pN}。
多跳阅读理解,即指的是问题的解答要结合段落中多个线索得出,且线索不是一次就能检索出,当找到一个线索时,要接着在文中寻找下一个线索,这就是多跳意义所在。第一跳即为步骤B11中问题与段落的匹配结果Psel,再次利用上一步结果继续检索,即为第二跳。
步骤B2:将步骤B1得到的候选段落pcandi和问题、段落中句子、段落中实体词、超链接一同作为节点构造层次图G,并通过G中各节点边关系构造层次图的邻接矩阵Aadj。所述步骤B2具体包括以下步骤:
步骤B21:对于训练集中的每个样本,将步骤B1中匹配到的段落、各段落中的句子、各句子中的实体词与问题一起构建层次图G;定义层次图中存在四种节点和七种边关系:
G={V,E}
其中,V为问题节点q、匹配得到的段落节点pcandi={p1,p2,..,pN}、各段落中的句子节点 各句子中的实体词节点
各句子中的实体词节点 构成的集合,N,ns,ne分别表示层次图中限定的段落、句子、实体词节点的个数;E为七种边关系组成的集合。
构成的集合,N,ns,ne分别表示层次图中限定的段落、句子、实体词节点的个数;E为七种边关系组成的集合。
步骤B22:利用层次图G中各节点的边关系构造邻接矩阵Aadj:

其中,Aii非零表示两节点之间的关系属于集合E中的一种,为零则表示两节点之间不存在集合E中的关系。
步骤B3:将步骤B2得到的层次图G使用预训练模型Roberta获得所有图节点的初始表示,得到段落、句子、实体三种类型的节点表示 以及问题节点表示fq,以此获得层次图的总体节点表示
以及问题节点表示fq,以此获得层次图的总体节点表示 所述步骤B3具体包括以下步骤:
所述步骤B3具体包括以下步骤:
步骤B31:将每个训练样本中的问题对应的选定段落合并,并与问题连接,然后输入Roberta获得初始表征;经互注意力层获得问题表示 和段落上下文表示
和段落上下文表示 其中,m和n分别为问题数量和段落数量,d表示表征向量维度。
其中,m和n分别为问题数量和段落数量,d表示表征向量维度。
步骤B32:将问题和上下文表示分开处理,上下文表示中,对于不同类型的结点,均以跨度形式计算,经Bi-LSTM网络提取段落、句子、实体三种类型的节点表示
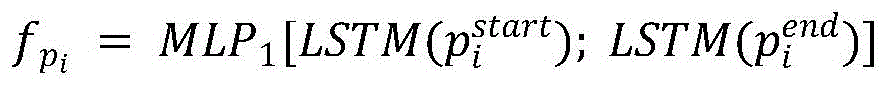


其中, 表示段落节点的起始位置和结束位置,句子结点和实体节点的表示类似;[;]代表两向量拼接,左右两边分别代表Bi-LSTM的前向和后向计算。
表示段落节点的起始位置和结束位置,句子结点和实体节点的表示类似;[;]代表两向量拼接,左右两边分别代表Bi-LSTM的前向和后向计算。
步骤B33:将问题节点经过最大池化层获得节点表示fq:
fq=maxpooling(Q)。
步骤B4:将步骤B2、B3得到的层次图的邻接矩阵Aadj及节点表示F用随机删除边关系和随机掩蔽节点特征的方法对层次图分别进行两次损坏,两个损坏后的层次图即为双视图,从而得到两个视图的邻接矩阵A1,A2和节点表示F1,F2;然后将两个视图分别输入到图注意力网络中,得到更新后的节点表示 所述步骤B4具体包括以下步骤:
所述步骤B4具体包括以下步骤:
步骤B41:对于层次图G=(V,E),其中,V为图中的节点集合,E为图中的边关系集合;图的邻接矩阵为 将邻接矩阵Aadj转换为稀疏矩阵Acoo,根据节点个数随机构造一个掩蔽矩阵
将邻接矩阵Aadj转换为稀疏矩阵Acoo,根据节点个数随机构造一个掩蔽矩阵 作为掩蔽矩阵,当Aadj中存在边关系的时候为掩蔽矩阵分配值,其值根据伯努利分布计算得到:
作为掩蔽矩阵,当Aadj中存在边关系的时候为掩蔽矩阵分配值,其值根据伯努利分布计算得到:

其中, 为伯努利分布,pv为自定义的掩蔽概率。
为伯努利分布,pv为自定义的掩蔽概率。
步骤B42:将掩蔽矩阵与原邻接矩阵做哈达玛乘积得到被损坏的邻接矩阵


其中, 为哈达玛积,以此生成两个邻接矩阵:
为哈达玛积,以此生成两个邻接矩阵:
由于双视图就是损坏后的两个层次图,而层次图在模型层的计算中主要是以节点边关系构建的邻接矩阵和节点特征所构成,故本方法生成双视图的方式就是损坏邻接矩阵和节点特征。
步骤B43:采样随机向量fmask作为d维掩蔽向量,向量中的值采用伯努利分布提取:

其中,pf为自定义的掩蔽概率。
步骤B44:将节点特征 展开为
展开为 并与掩蔽向量做哈达玛乘积生成被损坏的节点特征
并与掩蔽向量做哈达玛乘积生成被损坏的节点特征

其中,[·]T为转置运算,对原节点特征进行两次掩蔽损坏生成两个特征矩阵:

步骤B45:设图中相邻结点集合为 计算步骤B42和步骤B44生成的两个图的节点i与邻居节点之间的相关性系数eij,再经过归一化后得到注意力系数αij:
计算步骤B42和步骤B44生成的两个图的节点i与邻居节点之间的相关性系数eij,再经过归一化后得到注意力系数αij:


其中,hi为当前计算的节点i的表示,hj为节点i的邻居节点j表示, 为共享参数矩阵。
为共享参数矩阵。
步骤B46:将每个损坏后的节点特征矩阵的注意力系数αij与邻居节点 进行加权计算得到更新后的节点表示
进行加权计算得到更新后的节点表示 为更新后的节点特征,计算过程如下:
为更新后的节点特征,计算过程如下:

其中, 为共享参数矩阵,h′i为节点i更新后的节点表示。
为共享参数矩阵,h′i为节点i更新后的节点表示。
这里的 指的是任一被损坏后的节点特征矩阵,且后续两个特征矩阵操作都相同,故用此代称。h′i与
指的是任一被损坏后的节点特征矩阵,且后续两个特征矩阵操作都相同,故用此代称。h′i与 是包含关系,h′i指的是节点i的表示,而
是包含关系,h′i指的是节点i的表示,而 指的是图中所有结点的表示。
指的是图中所有结点的表示。
步骤B5:使用门控注意力机制计算初始上下文嵌入E和更新后图节点表示 得到相关性系数
得到相关性系数 和上下文表征EG;同时,被损坏的两个视图的邻接矩阵A1,A2和特征矩阵F1,F2相互作为正负样本,以余弦相似度计算每一对样本相似性,得到两个图的对比学习损失
和上下文表征EG;同时,被损坏的两个视图的邻接矩阵A1,A2和特征矩阵F1,F2相互作为正负样本,以余弦相似度计算每一对样本相似性,得到两个图的对比学习损失 最大化双视图正例对总体目标损失Lgra。所述步骤B5具体包括以下步骤:
最大化双视图正例对总体目标损失Lgra。所述步骤B5具体包括以下步骤:
步骤B51:设E={Q,P}为上下文编码层经Roberta编码后的初始嵌入表示,以注意力机制的计算方式计算出上下文嵌入和更新图节点的相关性系数 再结合门控机制获得门控上下文表征
再结合门控机制获得门控上下文表征


其中, 是可学习参数矩阵。
是可学习参数矩阵。
步骤B52:对于图A1上的任一节点 图A2中对应的节点
图A2中对应的节点 为正样本,图A2中的其余节点以及图A1中的其余节点为负样本,A2对于A1也是同样计算;以余弦相似度计算两个图样本损失
为正样本,图A2中的其余节点以及图A1中的其余节点为负样本,A2对于A1也是同样计算;以余弦相似度计算两个图样本损失 正例对的训练目标为epv,负例对的训练目标为
正例对的训练目标为epv,负例对的训练目标为 另一图中负例对的训练目标为
另一图中负例对的训练目标为




其中, 分别为A1中除
分别为A1中除 之外的其他节点的集合以及A2中除
之外的其他节点的集合以及A2中除 之外的其他节点的集合,τ是温度系数,cos()为余弦相似度计算。
之外的其他节点的集合,τ是温度系数,cos()为余弦相似度计算。
由于正例对和负例对都是建立在两个视图之上的,正例对指的是图A1中的节点i和图A2中节点i相对应的那个节点,故这里的正例对指的是两个视图中所有的正例对,训练目标相同;负例对的类型有图内和图外两种,故有1、2之分。
步骤B53:以最大化双图正例对总体目标损失Lgra为此模块任务损失:

步骤B6:在步骤5中得到的上下文表征EG中包含候选答案节点 将其与步骤B3得到的问题节点表示fq采用关系过滤方法生成注意力权重稀疏矩阵
将其与步骤B3得到的问题节点表示fq采用关系过滤方法生成注意力权重稀疏矩阵 将其用来筛选当前候选答案节点。所述步骤B6具体包括以下步骤:
将其用来筛选当前候选答案节点。所述步骤B6具体包括以下步骤:
步骤B61:将上下文编码后的问题表示fq与更新后的候选答案节点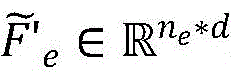 采用注意力机制生成注意力矩阵
采用注意力机制生成注意力矩阵

步骤B62:将步骤B61生成的注意力矩阵按维度降序排序生成矩阵 再将该矩阵中联系最为紧密的Nrelation个关系保留,生成较为精准的注意力权重稀疏矩阵
再将该矩阵中联系最为紧密的Nrelation个关系保留,生成较为精准的注意力权重稀疏矩阵


其中,sort()为降序排序函数,fPruning()为剪枝函数。
步骤B63:将步骤B62生成的注意力权重稀疏矩阵与候选答案节点 相乘,得到筛选后的候选答案节点
相乘,得到筛选后的候选答案节点

步骤B7:将步骤B4和B6得到的所有的不同类型节点分别输入多层感知机进行子任务预测,得到段落、支持事实、实体词、答案类型预测结果,使用交叉熵函数计算各类预测损失;随后根据答案类型预测结果返回相应类型的答案;然后根据目标损失函数,通过反向传播方法计算深度学习网络模型中各参数的梯度,并利用随机梯度下降方法更新各参数。所述步骤B7具体包括以下步骤:
步骤B71:对于图中的段落结点、句子节点使用二分类多层感知机进行段落预测、句子预测;对于实体词结点使用多分类的多层感知机进行实体词预测:



其中, 表示段落中包含支持事实的概率,
表示段落中包含支持事实的概率, 表示句子被选择为支持事实的概率,
表示句子被选择为支持事实的概率, 表示实体节点中存在正确答案的概率。
表示实体节点中存在正确答案的概率。
步骤B72:使用MLP基于门控注意力层的隐藏状态来进行答案类型预测:
ptype=MLP7(EG[0])
其中,ptype为答案类型概率。
步骤B73:对于是非类型,直接返回答案;对于实体类型答案,返回实体词预测结果;对于跨度类型答案,使用上述门控注意力层的隐藏状态计算跨度预测:
pstart=MLP8(EG)
pend=MLP9(EG)
其中,pstart、pend为跨度开始与结束预测概率。
步骤B74:用交叉熵作为损失函数计算损失值,通过梯度优化算法Adam对学习率进行更新,利用反向传播迭代更新模型参数,以最小化损失函数来训练模型;模型总损失为上述各项预测的损失加权相加:
Lall=Lstart+Lend+μ1Lpara+μ2(Lsent+μgraLgra)+μ3Lent+μ4Ltype
其中,μ1,μ2,μ3,μ4,μgra为超参数,Lstart,Lend为跨度预测的损失,Lpara,Lsent,Lent,Ltype分别为段落预测、句子预测、实体词预测、答案类型预测的损失。
步骤B8:当深度学习网络模型产生的损失值小于设定的阈值或达到最大的迭代次数时,终止深度学习网络模型D的训练。
如图3所示,本实施例还提供了用于实现上述方法的多跳阅读理解系统,包括构建训练集模块、模型训练模块和多跳阅读理解模块。
所述构建训练集模块用于采集对话上下文和回答数据,构建对话训练集。
所述模型训练模块用于训练基于双视图对比学习与图剪枝的深度学习网络模型D。
所述多跳阅读理解模块将用于多跳阅读理解的过程中将问题和文章输入训练好的深度网络模型中输出当前的预测答案。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例。但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
Claims (10)
1.一种基于双视图对比学习与图剪枝的多跳阅读理解方法,其特征在于,包括以下步骤:
步骤A:采集问题、文章上下文、答案和支持事实数据,构建多跳阅读理解训练集;
步骤B:使用训练集训练用于多跳阅读理解的基于双视图对比学习与图剪枝的深度学习网络模型D;
步骤C:将问题、文章数据输入深度学习网络模型D中,输出当前问题的相应答案。
2.根据权利要求1所述的基于双视图对比学习与图剪枝的多跳阅读理解方法,其特征在于,所述步骤B具体包括以下步骤:
步骤B1:使用预训练模型Roberta对训练集中各个样本的各个段落包含黄金支持事实的概率进行计算,同时将各个样本的标题和段落的关系对与问题进行文本匹配,得到N个候选段落pcandi={p1,p2,...,pN};
步骤B2:将步骤B1得到的候选段落pcandi和问题、段落中句子、段落中实体词、超链接一同作为节点构造层次图G,并通过G中各节点边关系构造层次图的邻接矩阵Aadj;
步骤B3:将步骤B2得到的层次图G使用预训练模型Roberta获得所有图节点的初始表示,得到段落、句子、实体三种类型的节点表示 以及问题节点表示fq,以此获得层次图的总体节点表示
以及问题节点表示fq,以此获得层次图的总体节点表示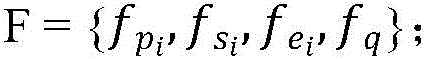
步骤B4:将步骤B2、B3得到的层次图的邻接矩阵Aadj及节点表示F用随机删除边关系和随机掩蔽节点特征的方法对层次图分别进行两次损坏,两个损坏后的层次图即为双视图,从而得到两个视图的邻接矩阵A1,A2和节点表示F1,F2;然后将两个视图分别输入到图注意力网络中,得到更新后的节点表示
步骤B5:使用门控注意力机制计算初始上下文嵌入E和更新后图节点表示 得到相关性系数
得到相关性系数 和上下文表征EG;同时,被损坏的两个视图的邻接矩阵A1,A2和特征矩阵F1,F2相互作为正负样本,以余弦相似度计算每一对样本相似性,得到两个图的对比学习损失
和上下文表征EG;同时,被损坏的两个视图的邻接矩阵A1,A2和特征矩阵F1,F2相互作为正负样本,以余弦相似度计算每一对样本相似性,得到两个图的对比学习损失 最大化双视图正例对总体目标损失Lgra;
最大化双视图正例对总体目标损失Lgra;
步骤B6:在步骤5中得到的上下文表征EG中包含候选答案节点 将其与步骤B3得到的问题节点表示fq采用关系过滤方法生成注意力权重稀疏矩阵
将其与步骤B3得到的问题节点表示fq采用关系过滤方法生成注意力权重稀疏矩阵 将其用来筛选当前候选答案节点;
将其用来筛选当前候选答案节点;
步骤B7:将步骤B4和B6得到的所有的不同类型节点分别输入多层感知机进行子任务预测,得到段落、支持事实、实体词、答案类型预测结果,使用交叉熵函数计算各类预测损失;随后根据答案类型预测结果返回相应类型的答案;然后根据目标损失函数,通过反向传播方法计算深度学习网络模型中各参数的梯度,并利用随机梯度下降方法更新各参数;
步骤B8:当深度学习网络模型产生的损失值小于设定的阈值或达到最大的迭代次数时,终止深度学习网络模型D的训练。
3.根据权利要求2所述的基于双视图对比学习与图剪枝的多跳阅读理解方法,其特征在于,所述步骤B1具体包括以下步骤:
步骤B11:对训练集进行遍历,对于训练集中的每个样本,使用Roberta模型作为编码器计算样本中每个段落包含黄金支持事实的概率Pranking,使用Pranking对段落进行排序,Pranking表示为:
Pranking=Robertaranking(P)
其中,P=(ti,pi)为样本中的段落集,ti为段落的标题,pi为段落文本;
将问题中的短语跨度(qstart,qend)与段落标题中的短语跨度 相匹配;如果段落标题与问题匹配时有多个段落匹配成功,则选择Pranking前二的段落;如果标题匹配没有匹配到段落,则将问题中的实体词
相匹配;如果段落标题与问题匹配时有多个段落匹配成功,则选择Pranking前二的段落;如果标题匹配没有匹配到段落,则将问题中的实体词 匹配段落中的实体词
匹配段落中的实体词 如果实体词匹配也失败,则取Pranking最高的段落,选取出的段落Psel表示为:
如果实体词匹配也失败,则取Pranking最高的段落,选取出的段落Psel表示为:

其中,psel表示段落标题与问题匹配成功的段落数量, 表示此种情况所选择的Pranking前二的段落;esel表示问题中的实体词与段落匹配是否成功,esel>0表示匹配成功;
表示此种情况所选择的Pranking前二的段落;esel表示问题中的实体词与段落匹配是否成功,esel>0表示匹配成功; 表示此种情况问题与段落实体词匹配到的段落;
表示此种情况问题与段落实体词匹配到的段落; 表示问题与段落实体词匹配结果;
表示问题与段落实体词匹配结果;
步骤B12:将步骤B11的结果Psel相对应的数据集中的超链接来搜索第二跳段落;第一跳选出的段落与问题构建双向边(q,pi),若第二跳段落存在则构建两段落节点之间的双向边(pi,pj),pi为第一跳中选中的段落,pj为第二跳中选中的段落;得到n个候选段落pcandi={p1,p2,...,pn},使用Pranking选择排名前N的段落,得到N个候选段落pcandi={p1,p2,…,pN}。
4.根据权利要求3所述的基于双视图对比学习与图剪枝的多跳阅读理解方法,其特征在于,所述步骤B2具体包括以下步骤:
步骤B21:对于训练集中的每个样本,将步骤B1中匹配到的段落、各段落中的句子、各句子中的实体词与问题一起构建层次图G;定义层次图中存在四种节点和七种边关系:
G={V,E}
其中,V为问题节点q、匹配得到的段落节点pcandi={p1,p2,..,pN}、各段落中的句子节点 各句子中的实体词节点
各句子中的实体词节点 构成的集合,N,ns,ne分别表示层次图中限定的段落、句子、实体词节点的个数;E为七种边关系组成的集合;
构成的集合,N,ns,ne分别表示层次图中限定的段落、句子、实体词节点的个数;E为七种边关系组成的集合;
步骤B22:利用层次图G中各节点的边关系构造邻接矩阵Aadj:
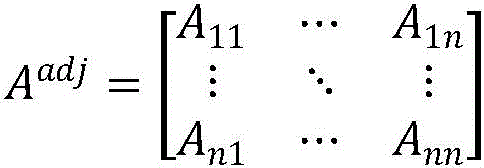
其中,Aij非零表示两节点之间的关系属于集合E中的一种,为零则表示两节点之间不存在集合E中的关系。
5.根据权利要求4所述的基于双视图对比学习与图剪枝的多跳阅读理解方法,其特征在于,所述步骤B3具体包括以下步骤:
步骤B31:将每个训练样本中的问题对应的选定段落合并,并与问题连接,然后输入Roberta获得初始表征;经互注意力层获得问题表示 和段落上下文表示
和段落上下文表示 其中,m和n分别为问题数量和段落数量,d表示表征向量维度;
其中,m和n分别为问题数量和段落数量,d表示表征向量维度;
步骤B32:将问题和上下文表示分开处理,上下文表示中,对于不同类型的结点,均以跨度形式计算,经Bi-LSTM网络提取段落、句子、实体三种类型的节点表示



其中, 表示段落节点的起始位置和结束位置,句子结点和实体节点的表示类似;[;]代表两向量拼接,左右两边分别代表Bi-LSTM的前向和后向计算;
表示段落节点的起始位置和结束位置,句子结点和实体节点的表示类似;[;]代表两向量拼接,左右两边分别代表Bi-LSTM的前向和后向计算;
步骤B33:将问题节点经过最大池化层获得节点表示fq:
fq=maxpooling(Q)。
6.根据权利要求5所述的基于双视图对比学习与图剪枝的多跳阅读理解方法,其特征在于,所述步骤B4具体包括以下步骤:
步骤B41:对于层次图G=(V,E),其中,V为图中的节点集合,E为图中的边关系集合;图的邻接矩阵为 将邻接矩阵Aadj转换为稀疏矩阵Acoo,根据节点个数随机构造一个掩蔽矩阵
将邻接矩阵Aadj转换为稀疏矩阵Acoo,根据节点个数随机构造一个掩蔽矩阵 作为掩蔽矩阵,当Aadj中存在边关系的时候为掩蔽矩阵分配值,其值根据伯努利分布计算得到:
作为掩蔽矩阵,当Aadj中存在边关系的时候为掩蔽矩阵分配值,其值根据伯努利分布计算得到:

其中, 为伯努利分布,pv为自定义的掩蔽概率;
为伯努利分布,pv为自定义的掩蔽概率;
步骤B42:将掩蔽矩阵与原邻接矩阵做哈达玛乘积得到被损坏的邻接矩阵


其中, 为哈达玛积,以此生成两个邻接矩阵:
为哈达玛积,以此生成两个邻接矩阵:
步骤B43:采样随机向量fmask作为d维掩蔽向量,向量中的值采用伯努利分布提取:

其中,pf为自定义的掩蔽概率;
步骤B44:将节点特征 展开为
展开为 并与掩蔽向量做哈达玛乘积生成被损坏的节点特征
并与掩蔽向量做哈达玛乘积生成被损坏的节点特征

其中,[·]T为转置运算,对原节点特征进行两次掩蔽损坏生成两个特征矩阵:

步骤B45:设图中相邻结点集合为 计算步骤B42和步骤B44生成的两个图的节点i与邻居节点之间的相关性系数eij,再经过归一化后得到注意力系数αij:
计算步骤B42和步骤B44生成的两个图的节点i与邻居节点之间的相关性系数eij,再经过归一化后得到注意力系数αij:


其中,hi为当前计算的节点i的表示,hj为节点i的邻居节点j表示, 为共享参数矩阵;
为共享参数矩阵;
步骤B46:将每个损坏后的节点特征矩阵的注意力系数αij与邻居节点 进行加权计算得到更新后的节点表示
进行加权计算得到更新后的节点表示 为更新后的节点特征,计算过程如下:
为更新后的节点特征,计算过程如下:

其中, 为共享参数矩阵,h′i为节点i更新后的节点表示。
为共享参数矩阵,h′i为节点i更新后的节点表示。
7.根据权利要求6所述的基于双视图对比学习与图剪枝的多跳阅读理解方法,其特征在于,所述步骤B5具体包括以下步骤:
步骤B51:设E={Q,P}为上下文编码层经Roberta编码后的初始嵌入表示,以注意力机制的计算方式计算出上下文嵌入和更新图节点的相关性系数 再结合门控机制获得门控上下文表征
再结合门控机制获得门控上下文表征


其中, 是可学习参数矩阵;
是可学习参数矩阵;
步骤B52:对于图A1上的任一节点 图A2中对应的节点
图A2中对应的节点 为正样本,图A2中的其余节点以及图A1中的其余节点为负样本,A2对于A1也是同样计算;以余弦相似度计算两个图样本损失
为正样本,图A2中的其余节点以及图A1中的其余节点为负样本,A2对于A1也是同样计算;以余弦相似度计算两个图样本损失 正例对的训练目标为epv,负例对的训练目标为
正例对的训练目标为epv,负例对的训练目标为 另一图中负例对的训练目标为
另一图中负例对的训练目标为




其中, 分别为A1中除
分别为A1中除 之外的其他节点的集合以及A2中除
之外的其他节点的集合以及A2中除 之外的其他节点的集合,τ是温度系数,cos()为余弦相似度计算;
之外的其他节点的集合,τ是温度系数,cos()为余弦相似度计算;
步骤B53:以最大化双图正例对总体目标损失Lgra为此模块任务损失:

8.根据权利要求7所述的基于双视图对比学习与图剪枝的多跳阅读理解方法,其特征在于,所述步骤B6具体包括以下步骤:
步骤B61:将上下文编码后的问题表示fq与更新后的候选答案节点 采用注意力机制生成注意力矩阵
采用注意力机制生成注意力矩阵

步骤B62:将步骤B61生成的注意力矩阵按维度降序排序生成矩阵 再将该矩阵中联系最为紧密的Nrelation个关系保留,生成较为精准的注意力权重稀疏矩阵
再将该矩阵中联系最为紧密的Nrelation个关系保留,生成较为精准的注意力权重稀疏矩阵

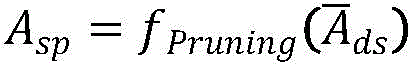
其中,sort()为降序排序函数,fPruning()为剪枝函数;
步骤B63:将步骤B62生成的注意力权重稀疏矩阵与候选答案节点 相乘,得到筛选后的候选答案节点
相乘,得到筛选后的候选答案节点

9.根据权利要求8所述的基于双视图对比学习与图剪枝的多跳阅读理解方法,其特征在于,所述步骤B7具体包括以下步骤:
步骤B71:对于图中的段落结点、句子节点使用二分类多层感知机进行段落预测、句子预测;对于实体词结点使用多分类的多层感知机进行实体词预测:



其中, 表示段落中包含支持事实的概率,
表示段落中包含支持事实的概率, 表示句子被选择为支持事实的概率,
表示句子被选择为支持事实的概率, 表示实体节点中存在正确答案的概率;
表示实体节点中存在正确答案的概率;
步骤B72:使用MLP基于门控注意力层的隐藏状态来进行答案类型预测:
ptype=MLP7(EG[0])
其中,ptype为答案类型概率;
步骤B73:对于是非类型,直接返回答案;对于实体类型答案,返回实体词预测结果;对于跨度类型答案,使用上述门控注意力层的隐藏状态计算跨度预测:
pstart=MLP8(EG)
pend=MLP9(EG)
其中,pstart、pend为跨度开始与结束预测概率;
步骤B74:用交叉熵作为损失函数计算损失值,通过梯度优化算法Adam对学习率进行更新,利用反向传播迭代更新模型参数,以最小化损失函数来训练模型;模型总损失为上述各项预测的损失加权相加:
Lall=Lstart+Lend+μ1Lpara+μ2(Lsent+μgraLgra)+μ3Lent+μ4Ltype
其中,μ1,μ2,μ3,μ4,μgra为超参数,Lstart,Lend为跨度预测的损失,Lpara,Lsent,Lent,Ltype分别为段落预测、句子预测、实体词预测、答案类型预测的损失。
10.一种采用如权利要求1-9任一项所述方法的多跳阅读理解系统,其特征在于,包括:
构建训练集模块,用于采集对话上下文和回答数据,构建对话训练集;
模型训练模块,用于训练基于双视图对比学习与图剪枝的深度学习网络模型D;以及
多跳阅读理解模块,将用于多跳阅读理解的过程中将问题和文章输入训练好的深度网络模型中输出当前的预测答案。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310398450.XA CN116403231A (zh) | 2023-04-14 | 2023-04-14 | 基于双视图对比学习与图剪枝的多跳阅读理解方法及系统 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310398450.XA CN116403231A (zh) | 2023-04-14 | 2023-04-14 | 基于双视图对比学习与图剪枝的多跳阅读理解方法及系统 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116403231A true CN116403231A (zh) | 2023-07-07 |
Family
ID=87015748
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310398450.XA Pending CN116403231A (zh) | 2023-04-14 | 2023-04-14 | 基于双视图对比学习与图剪枝的多跳阅读理解方法及系统 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116403231A (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116720008A (zh) * | 2023-08-11 | 2023-09-08 | 之江实验室 | 一种机器阅读方法、装置、存储介质及电子设备 |
| CN117910573A (zh) * | 2023-12-19 | 2024-04-19 | 国家移民管理局常备力量第二总队 | 一种基于多任务的混合表格文本问答方法及系统 |
-
2023
- 2023-04-14 CN CN202310398450.XA patent/CN116403231A/zh active Pending
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116720008A (zh) * | 2023-08-11 | 2023-09-08 | 之江实验室 | 一种机器阅读方法、装置、存储介质及电子设备 |
| CN116720008B (zh) * | 2023-08-11 | 2024-01-09 | 之江实验室 | 一种机器阅读方法、装置、存储介质及电子设备 |
| CN117910573A (zh) * | 2023-12-19 | 2024-04-19 | 国家移民管理局常备力量第二总队 | 一种基于多任务的混合表格文本问答方法及系统 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110083705B (zh) | 一种用于目标情感分类的多跳注意力深度模型、方法、存储介质和终端 | |
| CN111310438B (zh) | 基于多粒度融合模型的中文句子语义智能匹配方法及装置 | |
| CN111259127B (zh) | 一种基于迁移学习句向量的长文本答案选择方法 | |
| CN104834747B (zh) | 基于卷积神经网络的短文本分类方法 | |
| CN112667818B (zh) | 融合gcn与多粒度注意力的用户评论情感分析方法及系统 | |
| CN111027595B (zh) | 双阶段语义词向量生成方法 | |
| CN110321563B (zh) | 基于混合监督模型的文本情感分析方法 | |
| CN108229582A (zh) | 一种面向医学领域的多任务命名实体识别对抗训练方法 | |
| CN112232087B (zh) | 一种基于Transformer的多粒度注意力模型的特定方面情感分析方法 | |
| CN113326374B (zh) | 基于特征增强的短文本情感分类方法及系统 | |
| CN111782961B (zh) | 一种面向机器阅读理解的答案推荐方法 | |
| CN111414481A (zh) | 基于拼音和bert嵌入的中文语义匹配方法 | |
| CN116403231A (zh) | 基于双视图对比学习与图剪枝的多跳阅读理解方法及系统 | |
| CN113297364A (zh) | 一种面向对话系统中的自然语言理解方法及装置 | |
| CN117094291B (zh) | 基于智能写作的自动新闻生成系统 | |
| CN116304748A (zh) | 一种文本相似度计算方法、系统、设备及介质 | |
| CN116956228A (zh) | 一种技术交易平台的文本挖掘方法 | |
| CN110889505A (zh) | 一种图文序列匹配的跨媒体综合推理方法和系统 | |
| CN113806543A (zh) | 一种基于残差跳跃连接的门控循环单元的文本分类方法 | |
| Hung | Vietnamese keyword extraction using hybrid deep learning methods | |
| CN117932066A (zh) | 一种基于预训练的“提取-生成”式答案生成模型及方法 | |
| CN118227790A (zh) | 基于多标签关联的文本分类方法、系统、设备及介质 | |
| CN117076608A (zh) | 一种基于文本动态跨度的整合外部事件知识的脚本事件预测方法及装置 | |
| CN114386425B (zh) | 用于对自然语言文本内容进行处理的大数据体系建立方法 | |
| CN116167353A (zh) | 一种基于孪生长短期记忆网络的文本语义相似度度量方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |