CN114841342A - Tensor-based efficient Transformer construction method - Google Patents
Tensor-based efficient Transformer construction method Download PDFInfo
- Publication number
- CN114841342A CN114841342A CN202210556441.4A CN202210556441A CN114841342A CN 114841342 A CN114841342 A CN 114841342A CN 202210556441 A CN202210556441 A CN 202210556441A CN 114841342 A CN114841342 A CN 114841342A
- Authority
- CN
- China
- Prior art keywords
- tensor
- weight
- matrix
- att
- layer
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000010276 construction Methods 0.000 title description 4
- 238000000034 method Methods 0.000 claims abstract description 53
- 239000011159 matrix material Substances 0.000 claims description 51
- 230000008569 process Effects 0.000 claims description 32
- 238000004364 calculation method Methods 0.000 claims description 29
- 238000013507 mapping Methods 0.000 claims description 27
- 238000000354 decomposition reaction Methods 0.000 claims description 17
- 238000012549 training Methods 0.000 claims description 17
- 230000007246 mechanism Effects 0.000 claims description 15
- 238000013528 artificial neural network Methods 0.000 claims description 3
- 238000006243 chemical reaction Methods 0.000 claims description 3
- 238000004806 packaging method and process Methods 0.000 claims description 3
- 238000013473 artificial intelligence Methods 0.000 abstract description 3
- 238000003062 neural network model Methods 0.000 description 6
- 230000006835 compression Effects 0.000 description 5
- 238000007906 compression Methods 0.000 description 5
- 238000004891 communication Methods 0.000 description 4
- 238000007667 floating Methods 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 3
- 238000013138 pruning Methods 0.000 description 3
- 238000013461 design Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 238000004821 distillation Methods 0.000 description 2
- 238000005265 energy consumption Methods 0.000 description 2
- 238000013139 quantization Methods 0.000 description 2
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 238000013506 data mapping Methods 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 230000006866 deterioration Effects 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 238000007499 fusion processing Methods 0.000 description 1
- 238000013140 knowledge distillation Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 230000005055 memory storage Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000003058 natural language processing Methods 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/082—Learning methods modifying the architecture, e.g. adding, deleting or silencing nodes or connections
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Computing Systems (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Complex Calculations (AREA)
Abstract
The invention is suitable for the field of artificial intelligence and provides a tensor-based high-efficiency Transformer architecture method.
Description
Technical Field
The invention belongs to the field of artificial intelligence, and particularly relates to a tensor-based high-efficiency Transformer construction method.
Background
Along with the rapid development of artificial intelligence technology, communication technology and electronic chip technology, the industrial internet of things tightly connects billions of terminal devices such as intelligent mobile devices, wearable devices and sensors in green infrastructures, smart cities, smart medical treatment, smart power grids and intelligent traffic systems, so that more intelligent services are provided, and the production and life of people become more convenient. However, the industrial internet of things can generate a huge amount of multi-source heterogeneous data, and secondly, due to the excellent performance of the deep neural network model, the deep neural network model is widely applied to feature extraction and intelligent decision making. However, due to the complexity of the task and the huge amount of data, a large deep neural network model is usually required to train the data so as to obtain excellent task performance.
The Transformer is a popular deep neural network model at present, and has been widely applied to the industrial internet of things. The Transformer completely abandons the design concept of a convolution module and a circulation module, and the network model is only composed of an attention layer and a full connection layer. Transformers and other derived models, such as BERT, VIT, GPT, and Universal transformers, achieve superior task performance in terms of natural language processing, computer vision, recommendation systems, intelligent transportation, and the like. However, these network models are very large in size, typically containing hundreds of millions of training parameters, and thus require high performance chips that take weeks or even months to train these network models. Therefore, a large amount of computing resources and energy resources are consumed in the training process of the network model. Furthermore, with the advent of the federal learning paradigm and the increasing demand for real-time applications, smart mobile devices and other embedded devices need to participate in the training and decision-making of intelligent tasks. However, smart mobile devices and other embedded devices often have poor chip performance and high performance chips are bulky and cannot be mounted on edge devices. Therefore, the existing large-scale deep neural network model cannot be trained and deployed on the smart mobile device and other embedded devices. In addition, in the federal learning paradigm, each client needs to upload network model data to the cloud, and then the model fusion process is completed at the cloud. However, since the network model is huge in scale and data security of the network model is protected during uploading, the model data needs to be encrypted by using an encryption method. Encrypting the network model can effectively prevent privacy disclosure, but further increases the amount of communication data. In order to reduce the communication data volume in the federal learning process, reduce the bandwidth occupation and improve the communication efficiency, it becomes important how to reduce the number of training parameters in the network model. In addition, in some real-time applications such as traffic identification and fault detection, data is easily attacked by a network in the process of uploading the data to a cloud end, so that privacy disclosure and safety accidents are caused. Moreover, certain time is consumed for uploading data to the cloud, processing the data by the cloud and issuing a result to the terminal by the cloud, so that time delay is increased, and the requirement of a real-time task is not met. In summary, offloading the computing task to the cloud is not the best option. In addition, the large-scale network model consumes a large amount of energy resources in the training process, so that the carbon emission is increased, and the deterioration of the global environment is aggravated. Therefore, how to reduce the number of training parameters and floating point operation in the deep neural network model on a large scale on the premise of ensuring that the performance of the network model is not changed or the precision loss is within a tolerable range, quicken the training process of the network model, reduce the energy consumption in the training process, and facilitate the deployment on edge equipment with limited resources is a problem which needs to be solved urgently. Fortunately, a large number of redundant learning parameters and floating point operations usually exist in a large-scale network model, so that redundant parts in the network model can be eliminated, the number of learning parameters and the calculation complexity of the model are reduced, the training process of the model is accelerated, the consumption of power resources is reduced, and the development of green economy is promoted.
Since the Transformer shows excellent performance in various fields, the complexity of the network model limits the training and deployment of the Transformer on intelligent mobile devices and other embedded devices. Therefore, more and more researchers are beginning to investigate how to reduce the complexity of the model. And optimizing according to the structural characteristics of the transform model directly to reduce the number of blocks in the transform, so that the size and complexity of the model can be reduced, but the performance of the model is greatly reduced. Therefore, how to reduce the number of parameters and the computational complexity of the network model on the premise of ensuring that the model performance is not changed is a research hotspot. The current methods for model compression mainly include model pruning, low-order approximation, model quantification and knowledge distillation. Liu et al quantizes the trained vision transform model, reducing the memory storage and calculation costs of the model. Chung et al propose a mixed precision quantization strategy, which represents the weight of a transform by a small number of bits, so as to reduce the memory occupation of the model and improve the reasoning speed of the model. Zhu et al reduced the number of model parameters by pruning the Vision transform. Mao et al prune the Transformer components by analyzing their attributes, thereby reducing the number of parameters of the model and reducing the inference time of the model. Jiao et al propose a new Transformer distillation method that is used to transfer the knowledge of a complex teacher model to a small student model. Tensor decomposition method as an emerging high-efficiency network model compression method has achieved excellent performance in other network model compression. Hrinchunk et al compress the parameters of the embedded layer using a tensor chain decomposition method, thereby reducing the complexity of the model. Ma and the like propose a self-attention model based on BT decomposition based on the thought of tensor decomposition and parameter sharing, and reduce the number of parameters of a transform model. Although the above method can efficiently reduce the number of learning parameters and the computational complexity of the model, the method still has defects. Although the memory occupation of the model can be greatly reduced by the model quantization method, the performance of the model is usually greatly lost. Model pruning and knowledge-based distillation methods, while reducing the complexity of the model, are often overly cumbersome and require redesigning the compression scheme for the new model. Therefore, the two methods are less reusable. Hrinchunk only compresses the embedded layer, but has no compression effect for other models that do not contain embedded layers. Ma et al, although reducing the number of transform learning parameters, undermines the characteristics of attention mechanism.
Disclosure of Invention
The invention aims to provide a tensor-based high-efficiency Transformer architecture method, and aims to solve the problem that a current Transformer model cannot be deployed to intelligent mobile equipment and other embedded equipment for training and reasoning in the background art.
The invention provides a tensor-based high-efficiency Transformer construction method, which comprises the following steps of:
step 10, weighting matrix of multi-head attention layer Mapping to tensor space, and then expressing the tensor space as a tensor decomposition form chain of a k mode;
Mapping to tensor space, and then expressing the tensor space as a tensor decomposition form chain of a k mode;
step 20, inputting data (Q) att ,K att ,V att ) Mapping to tensor space and then corresponding The weight tensor chain of (a) is operated on, and the result is operated on by 'Attention' and then is compared with
The weight tensor chain of (a) is operated on, and the result is operated on by 'Attention' and then is compared with The weight tensor chain is operated to obtain a final output result, and a lightweight tensor multi-head attention mechanism is constructed;
The weight tensor chain is operated to obtain a final output result, and a lightweight tensor multi-head attention mechanism is constructed;
step 30, integrating similar linear operations in the multi-head attention layer of the encoder layer and the multi-head attention layer of the first sublayer of the decoder layer, namely splicing the corresponding weight tensors to form the weight tensors Integrating similar linear operations in the second sublayer of the decoder layer to form a weight tensor
Integrating similar linear operations in the second sublayer of the decoder layer to form a weight tensor Constructing a lightweight tensor multi-head attention mechanism +;
Constructing a lightweight tensor multi-head attention mechanism +;
step 40Weight matrix in Position-wise feedforward neural network And
And mapping to a tensor space, representing the tensor space as a tensor decomposition form of an m mode, and operating with input data to construct a lightweight tensor Position-wise feedforward network;
mapping to a tensor space, representing the tensor space as a tensor decomposition form of an m mode, and operating with input data to construct a lightweight tensor Position-wise feedforward network;
and step 50, forming a lightweight tensor multi-head attention mechanism and a lightweight tensor Position-Wise feedforward network into an LTtensorized _ transformer, forming the lightweight tensor Position-Wise feedforward network and the lightweight tensor multi-head attention mechanism + + into an LTensorized _ transformer + +, and constructing a lightweight Transrormer framework.
Further, the step 10 includes the following specific steps:
packaging the series, keys and values into a matrix Q att ,K att And V att And to matrix Q att ,K att And V att H times of linear projection is carried out, wherein the involved weight matrixes can be uniformly expressed as And
And will d model Expressed as the product of a plurality of positive factors, d model ={d 1 ×...×d k }×{d k+1 ×...×d 2k }×...×{d (m-1)k+1 ×...×d mk };
will d model Expressed as the product of a plurality of positive factors, d model ={d 1 ×...×d k }×{d k+1 ×...×d 2k }×...×{d (m-1)k+1 ×...×d mk };
Weighting matrix And W O Mapping to tensor space yields the weight tensor
And W O Mapping to tensor space yields the weight tensor
 And
And


tensor of weight according to equation (1) And
And expressed as a tensor decomposed form of the k-mode, equation (1) is defined as follows:
expressed as a tensor decomposed form of the k-mode, equation (1) is defined as follows:

further, the step 20 includes the following specific steps:
step 21, by mapping the input data to the tensor space And performing operation with the corresponding small weight tensor kernel, wherein the operation process is shown as formula (2), and the definition of the formula (2) is as follows:
And performing operation with the corresponding small weight tensor kernel, wherein the operation process is shown as formula (2), and the definition of the formula (2) is as follows:

step 22, reshape operation is performed on the operation result, the operation result is split into h equal parts, the split result is stored by a list L, and the whole calculation process is as follows:
D′=Reshape(D,[-1,d model ]) (3)
T=Split(D′)=(D′ 1 ,...,D′ h ) (4)
step 23, the stored data in the list L is taken out, and
and each of which is composed of h matrices, and the input matrix (5) is used to obtain the corresponding subscript
each of which is composed of h matrices, and the input matrix (5) is used to obtain the corresponding subscript And
And ) And performing attention calculation so as to obtain a corresponding attention output, wherein the formula (5) is defined as follows:
) And performing attention calculation so as to obtain a corresponding attention output, wherein the formula (5) is defined as follows:
R i =Get(R,i) (5)
step 24, calculating the output result (head) of each attention by using the formula (6) i ) And concatenating the results of each attention with a small weight tensor kernel: ( The k-mode tensor decomposition form) and using the formula (2) to perform multi-step feature calculation to obtain the final output result of the multi-head attention layer, wherein the formula (6) is defined as follows:
The k-mode tensor decomposition form) and using the formula (2) to perform multi-step feature calculation to obtain the final output result of the multi-head attention layer, wherein the formula (6) is defined as follows:

further, the step 30 includes the following specific steps:
step 31, the multi-head attention layer of the encoder layer and the first sub-layer of the decoder layer have the same structural property, and the query matrix Q att Key matrix K att Sum matrix V att Similar linear mapping operation is carried out, and weight matrixes are used And
And concatenated into a large weight matrix
concatenated into a large weight matrix
 As shown in equation (7), the weight matrix W is then transformed using equation (1) QKV Mapping to tensor space and weighting tensor
As shown in equation (7), the weight matrix W is then transformed using equation (1) QKV Mapping to tensor space and weighting tensor
Expressed as a tensor decomposed form of the k-mode, said formula (7) is defined as follows:

step 32, reshape operation is performed on the input data M, and then a formula (2) is used for calculating a tensor chain of M and the small weight The results are reported as
The results are reported as To pair
To pair Carrying out reshape operation, then slicing to obtain corresponding
Carrying out reshape operation, then slicing to obtain corresponding And
And the specific process is as follows:
the specific process is as follows:






to pair And
And splitting, storing the splitting result in a list, and performing the operations of the step 23 and the step 24 on the splitting result to obtain final output;
splitting, storing the splitting result in a list, and performing the operations of the step 23 and the step 24 on the splitting result to obtain final output;
step 33. the linear projection process of the key matrix and the value matrix in the multi-headed attention layer of the second sub-layer of the decoder layer is similar, so the weight matrix is used And
And are connected to form a weight matrix
are connected to form a weight matrix The weight matrix W is also expressed by equation (14) KV Mapping to tensor space and weighting tensor
The weight matrix W is also expressed by equation (14) KV Mapping to tensor space and weighting tensor
Expressed as a tensor decomposed form of the k-mode, said equation (14) is defined as follows:

step 34, reshape operation is performed on the input data N, and then a formula (2) is used for calculating a N and small weight tensor chain The results are reported as
The results are reported as To pair
To pair Carrying out reshape operation, then slicing to obtain corresponding
Carrying out reshape operation, then slicing to obtain corresponding And
And the specific process is as follows:
the specific process is as follows:





wherein, and the calculation flow of (2) and step 21
and the calculation flow of (2) and step 21 Are consistent in the calculation process, and are also in the same way
Are consistent in the calculation process, and are also in the same way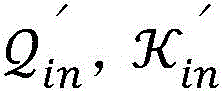 And
And and (5) performing splitting operation, storing the splitting result by using a list, and performing the operations of the step 23 and the step 24 on the splitting result to obtain a final output.
and (5) performing splitting operation, storing the splitting result by using a list, and performing the operations of the step 23 and the step 24 on the splitting result to obtain a final output.
Further, the step 40 includes the following specific steps:
step 41, d model And d ff Conversion into a positive integer factor product of smaller value, d model ={O 1 ×...×O m }×{O m+1 ×...×O 2m }×...×{O (n-1)m+1 ×...×O nm And d ff ={P 1 ×...×P m }×{P m+1 ×...×P 2m }×...×{P (n-1)m+1 ×...×P nm }, weight matrix And
And become weight tensors
become weight tensors And
And wherein
wherein And
And
 offset vector
offset vector And
And becomes the offset tensor
becomes the offset tensor And
And
step 42, tensor weight using formula (1) And
And the tensor decomposition form expressed as the m mode is used for reducing the number of training parameters and the calculation complexity in the network model;
the tensor decomposition form expressed as the m mode is used for reducing the number of training parameters and the calculation complexity in the network model;
step 43, mapping the input data of the Position-wise feedforward network to a tensor space, and performing multi-step calculation with a small weight tensor chain, wherein the calculation process is shown as formulas (20) and (21):

further, the sequence of the step 3 and the step 4 is not sequential.
The invention has the beneficial effects that:
(1) a plug-and-play lightweight tensor multi-head attention mechanism and a lightweight tensor position-wise feedforward network are designed, the number of learning parameters and floating point operation of a Transformer are reduced, the training process of the model is accelerated, and the energy consumption in the training process is reduced.
(2) According to the characteristics of the encoding process and the decoding process of the transform model, the weight matrixes of the multi-head attention layer are spliced in different modes, the spliced weight matrixes are expressed in a low-rank multi-modal tensor decomposition form, and a lightweight tensor quantized multi-head attention mechanism + +, so that the number of LTensorized _ transform learning parameters and floating point operation are further reduced, and the network model can be deployed on edge equipment with limited resources.
(3) The efficient lightweight tensor coupling Transformer can check input data through a plurality of small weight tensors to extract features step by step, the performance of a Transformer model is kept, the design concept of the Transformer is considered, three lightweight modules can be flexibly embedded into various network models, and the number of training parameters of corresponding networks and the calculation complexity are reduced.
Drawings
Fig. 1 is a flowchart of an implementation of a tensor-based efficient Transformer architecture method according to an embodiment of the present invention.
Detailed Description
In order to make the objects, technical solutions and advantages of the present invention more apparent, the present invention is described in further detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are merely illustrative of the invention and are not intended to limit the invention.
The following detailed description of specific implementations of the present invention is provided in conjunction with specific embodiments:
example (b):
fig. 1 shows an implementation flow of the tensor-based efficient Transformer architecture method provided by the embodiment of the present invention, and for convenience of description, only the relevant parts to the embodiment of the present invention are shown. The details are as follows:
step 10, weighting matrix of multi-head attention layer Mapping to tensor space, and then expressing the tensor space as a tensor decomposition form chain of a k mode;
Mapping to tensor space, and then expressing the tensor space as a tensor decomposition form chain of a k mode;
step 20, inputting data Mapping to tensor space and then corresponding
Mapping to tensor space and then corresponding The weight tensor chain of (a) is operated on, and the result is operated on by 'Attention' and then is compared with
The weight tensor chain of (a) is operated on, and the result is operated on by 'Attention' and then is compared with The weight tensor chain is operated to obtain a final output result, and a lightweight tensor multi-head attention mechanism is constructed;
The weight tensor chain is operated to obtain a final output result, and a lightweight tensor multi-head attention mechanism is constructed;
step 30, integrating similar linear operations in the multi-head attention layer of the encoder layer and the multi-head attention layer of the first sublayer of the decoder layer, namely splicing the corresponding weight tensors to form the weight tensors Integrating similar linear operations in the second sublayer of the decoder layer to form a weight tensor
Integrating similar linear operations in the second sublayer of the decoder layer to form a weight tensor Constructing a lightweight tensor multi-head attention mechanism +;
Constructing a lightweight tensor multi-head attention mechanism +;
step 40, weighting matrix in Position-wise feedforward neural network And
And mapping to a tensor space, representing the tensor space as a tensor decomposition form of an m mode, and operating with input data to construct a lightweight tensor Position-wise feedforward network;
mapping to a tensor space, representing the tensor space as a tensor decomposition form of an m mode, and operating with input data to construct a lightweight tensor Position-wise feedforward network;
and step 50, forming a lightweight tensor multi-head attention mechanism and a lightweight tensor Position-Wise feedforward network into an LTtensorized _ Transformer, and forming the lightweight tensor Position-Wise feedforward network and the lightweight tensor multi-head attention mechanism + + into an LTensorized _ Transformer + +, so as to construct a lightweight Transformer framework.
Further, the step 10 includes the following specific steps:
packaging the series, keys and values into a matrix Q att ,K att And V att And to matrix Q att ,K att And V att H times of linear projection is carried out, wherein the involved weight matrixes can be uniformly expressed as And
And will d model Expressed as the product of a plurality of positive factors, d model ={d 1 ×...×d k }×{d k+1 ×...×d 2k }×...×{d (m-1)k+1 ×...×d mk };
will d model Expressed as the product of a plurality of positive factors, d model ={d 1 ×...×d k }×{d k+1 ×...×d 2k }×...×{d (m-1)k+1 ×...×d mk };
Weighting matrix And W O Mapping to tensor space yields the weight tensor
And W O Mapping to tensor space yields the weight tensor
 And
And

tensor of weight according to equation (1) And
And expressed as a tensor decomposed form of the k-mode, equation (1) is defined as follows:
expressed as a tensor decomposed form of the k-mode, equation (1) is defined as follows:

further, step 20 includes the following specific steps:
step 21, by mapping the input data to the tensor space And the calculation is carried out with the corresponding small weight tensor kernel, the calculation process is shown as formula (2), and the definition of formula (2) is as follows:
And the calculation is carried out with the corresponding small weight tensor kernel, the calculation process is shown as formula (2), and the definition of formula (2) is as follows:

step 22, reshape operation is performed on the operation result, the operation result is split into h equal parts, the split result is stored by a list L, and the whole calculation process is as follows:
D′=Reshape(D,[-1,d model ]) (3)
T=Split(D′)=(D′ 1 ,...,D′ h ) (4)
step 23, the stored data in the list L is taken out, to know
to know Each of which is composed of h matrices, and the input matrix (5) is used to obtain the corresponding subscript
Each of which is composed of h matrices, and the input matrix (5) is used to obtain the corresponding subscript And
And ) And attention calculations are performed to obtain corresponding attention outputs, and equation (5) is defined as follows:
) And attention calculations are performed to obtain corresponding attention outputs, and equation (5) is defined as follows:
R i =Get(R,i) (5)
step 24, calculating the output result (head) of each attention by using the formula (6) i ) And concatenating the results of each attention with a small weight tensor kernel: ( The k-mode tensor decomposition form) and performs multi-step feature calculation by using the formula (2) to obtain the final output result of the multi-head attention layer, wherein the formula (6) is defined as follows:
The k-mode tensor decomposition form) and performs multi-step feature calculation by using the formula (2) to obtain the final output result of the multi-head attention layer, wherein the formula (6) is defined as follows:

further, step 30 includes the following specific steps:
step 31, the multi-head attention layer of the encoder layer and the first sub-layer of the decoder layer have the same structural property, and the query matrix Q att Key matrix K att Sum matrix V att Similar linear mapping operation is carried out, and weight matrixes are used And
And concatenated into a large weight matrix
concatenated into a large weight matrix
 As shown in equation (7), the weight matrix W is then transformed using equation (1) QKV Mapping to tensor space and weighting tensor
As shown in equation (7), the weight matrix W is then transformed using equation (1) QKV Mapping to tensor space and weighting tensor
Expressed as a tensor decomposed form of the k-mode, equation (7) is defined as follows:

step 32, reshape operation is performed on the input data M, and then a formula (2) is used for calculating a tensor chain of M and the small weight The results are reported as
The results are reported as To pair
To pair Carrying out reshape operation, then slicing to obtain corresponding
Carrying out reshape operation, then slicing to obtain corresponding And
And the specific process is as follows:
the specific process is as follows:






to pair And
And splitting, storing the splitting result in a list, and performing the operations of the step 23 and the step 24 on the splitting result to obtain final output;
splitting, storing the splitting result in a list, and performing the operations of the step 23 and the step 24 on the splitting result to obtain final output;
step 33. the linear projection process of the key matrix and the value matrix in the multi-headed attention layer of the second sub-layer of the decoder layer is similar, so the weight matrix is used And
And are connected to form a weight matrix
are connected to form a weight matrix The weight matrix W is also expressed by equation (14) KV Mapping to tensor space and weighting tensor
The weight matrix W is also expressed by equation (14) KV Mapping to tensor space and weighting tensor
Expressed as a tensor decomposed form of the k-mode, equation (14) is defined as follows:

step 34, reshape operation is performed on the input data N, and then a formula (2) is used for calculating a N and small weight tensor chain The results are reported as
The results are reported as For is to
For is to Carrying out reshape operation, then slicing to obtain corresponding
Carrying out reshape operation, then slicing to obtain corresponding And
And the specific process is as follows:
the specific process is as follows:





wherein, and the calculation flow of (2) and step 21
and the calculation flow of (2) and step 21 Are consistent in the calculation process, and are also in the same way
Are consistent in the calculation process, and are also in the same way And
And and (5) performing splitting operation, storing the splitting result by using a list, and performing the operations of the step 23 and the step 24 on the splitting result to obtain a final output.
and (5) performing splitting operation, storing the splitting result by using a list, and performing the operations of the step 23 and the step 24 on the splitting result to obtain a final output.
Further, step 40 includes the following specific steps:
step 41, d model And d ff Conversion into a positive integer factor product of smaller value, d model ={O 1 ×...×O m }×{O m+1 ×...×O 2m }×...×{O (n-1)m+1 ×...×O nm And d ff ={P 1 ×...×P m }×{P m+1 ×...×P 2m }×...×{P (n-1)m+1 ×...×P nm }, weight matrix And
And become weight tensors
become weight tensors And
And wherein
wherein And
And offset vector
offset vector And
And becomes the offset tensor
becomes the offset tensor And
And
step 42, tensor weight using formula (1) And
And the tensor decomposition form expressed as the m mode is used for reducing the number of training parameters and the calculation complexity in the network model;
the tensor decomposition form expressed as the m mode is used for reducing the number of training parameters and the calculation complexity in the network model;
step 43, mapping the input data of the Position-wise feedforward network to a tensor space, and performing multi-step calculation with a small weight tensor chain, wherein the calculation process is shown as formulas (20) and (21):

further, the sequence of step 3 and step 4 is not sequential.
The present invention is not limited to the above preferred embodiments, and any modifications, equivalents and improvements made within the spirit and principle of the present invention should be included in the protection scope of the present invention.
Claims (6)
1. A tensor-based efficient Transformer architecture method, comprising:
step 10, weighting matrix of multi-head attention layer Mapping to tensor space, and then expressing the tensor space as a tensor decomposition form chain of a k mode;
Mapping to tensor space, and then expressing the tensor space as a tensor decomposition form chain of a k mode;
step 20, inputting data (Q) att ,K att ,V att ) Mapping to tensor space and then corresponding The weight tensor chain of (a) is operated on, and the result is operated on by 'Attention' and then is compared with
The weight tensor chain of (a) is operated on, and the result is operated on by 'Attention' and then is compared with The weight tensor chain is operated to obtain a final output result, and a lightweight tensor multi-head attention mechanism is constructed;
The weight tensor chain is operated to obtain a final output result, and a lightweight tensor multi-head attention mechanism is constructed;
step 30, integrating similar linear operations in the multi-head attention layer of the encoder layer and the multi-head attention layer of the first sublayer of the decoder layer, namely splicing the corresponding weight tensors to form the weight tensors Integrating similar linear operations in the second sublayer of the decoder layer to form a weight tensor
Integrating similar linear operations in the second sublayer of the decoder layer to form a weight tensor Constructing a lightweight tensor multi-head attention mechanism +;
Constructing a lightweight tensor multi-head attention mechanism +;
step 40, weighting matrix in Position-wise feedforward neural network And
And mapping to tensor space and mapping itThe tensor decomposition form expressed as the m mode is operated with input data to construct a lightweight tensor Position-wise feedforward network;
mapping to tensor space and mapping itThe tensor decomposition form expressed as the m mode is operated with input data to construct a lightweight tensor Position-wise feedforward network;
and step 50, forming a lightweight tensor multi-head attention mechanism and a lightweight tensor Position-Wise feedforward network into an LTtensorized _ Transformer, and forming the lightweight tensor Position-Wise feedforward network and the lightweight tensor multi-head attention mechanism + + into an LTensorized _ Transformer + +, so as to construct a lightweight Transformer framework.
2. The tensor-based efficient Transformer architecture method as recited in claim 1, wherein the step 10 comprises the following specific steps:
packaging the series, keys and values into a matrix Q att ,K att And V att And to matrix Q att ,K att And V att H times of linear projection is carried out, wherein the involved weight matrixes can be uniformly expressed as And
And will d model Expressed as the product of a plurality of positive factors, d model ={d 1 ×...×d k }×{d k+1 ×...×d 2k }×...×{d (m-1)k+1 ×...×d mk };
will d model Expressed as the product of a plurality of positive factors, d model ={d 1 ×...×d k }×{d k+1 ×...×d 2k }×...×{d (m-1)k+1 ×...×d mk };
Weighting matrix And W O Mapping to tensor space yields the weight tensor
And W O Mapping to tensor space yields the weight tensor
 And
And

tensor of weight according to equation (1) And
And expressed as a tensor decomposed form of the k-mode, equation (1) is defined as follows:
expressed as a tensor decomposed form of the k-mode, equation (1) is defined as follows:

3. the tensor-based efficient Transformer architecture method as recited in claim 2, wherein the step 20 comprises the following specific steps:
step 21, by mapping the input data to the tensor space And performing operation with the corresponding small weight tensor kernel, wherein the operation process is shown as formula (2), and the definition of the formula (2) is as follows:
And performing operation with the corresponding small weight tensor kernel, wherein the operation process is shown as formula (2), and the definition of the formula (2) is as follows:

step 22, reshape operation is performed on the operation result, the operation result is split into h equal parts, the split result is stored by a list L, and the whole calculation process is as follows:
D′=Reshape(D,[-1,d model ]) (3)
T=Spht(D′)=(D′ 1 ,...,D′ h ) (4)
step 23, the stored data in the list L is taken out, and
and each of which is composed of h matrices, and the input matrix (5) is used to obtain the corresponding subscript
each of which is composed of h matrices, and the input matrix (5) is used to obtain the corresponding subscript And
And ) And performing attention calculation so as to obtain a corresponding attention output, wherein the formula (5) is defined as follows:
) And performing attention calculation so as to obtain a corresponding attention output, wherein the formula (5) is defined as follows:
R i =Get(R,i) (5)
step 24, calculating the output result (head) of each attention by using the formula (6) i ) And concatenating the results of each attention with a small weight tensor kernel: ( The k-mode tensor decomposition form) and using the formula (2) to perform multi-step feature calculation to obtain the final output result of the multi-head attention layer, wherein the formula (6) is defined as follows:
The k-mode tensor decomposition form) and using the formula (2) to perform multi-step feature calculation to obtain the final output result of the multi-head attention layer, wherein the formula (6) is defined as follows:

4. the tensor-based efficient Transformer architecture method as recited in claim 3, wherein the step 30 comprises the following specific steps:
step 31, the multi-head attention layer of the encoder layer and the first sub-layer of the decoder layer have the same structural property, and the query matrix Q att Key matrix K att Sum matrix V att Similar linear mapping operation is carried out, and weight matrixes are used And
And concatenated into a large weight matrix
concatenated into a large weight matrix
 As shown in equation (7), the weight matrix W is then transformed using equation (1) QKV Mapping to tensor space and weighting tensor
As shown in equation (7), the weight matrix W is then transformed using equation (1) QKV Mapping to tensor space and weighting tensor Expressed as a tensor decomposed form of the k-mode, said formula (7) is defined as follows:
Expressed as a tensor decomposed form of the k-mode, said formula (7) is defined as follows:

step 32, reshape operation is performed on the input data M, and then a formula (2) is used for calculating a tensor chain of M and the small weight The results are given as
The results are given as To pair
To pair Carrying out reshape operation, then slicing to obtain corresponding
Carrying out reshape operation, then slicing to obtain corresponding And
And the specific process is as follows:
the specific process is as follows:






to pair And
And splitting, storing the splitting result in a list, and performing the operations of the step 23 and the step 24 on the splitting result to obtain final output;
splitting, storing the splitting result in a list, and performing the operations of the step 23 and the step 24 on the splitting result to obtain final output;
step 33. the linear projection process of the key matrix and the value matrix in the multi-headed attention layer of the second sub-layer of the decoder layer is similar, so the weight matrix is used And
And are connected to form a weight matrix
are connected to form a weight matrix The weight matrix W is also expressed by equation (14) KV Mapping to tensor space and tensor of weights obtained
The weight matrix W is also expressed by equation (14) KV Mapping to tensor space and tensor of weights obtained Expressed as a tensor decomposed form of the k-mode, said equation (14) is defined as follows:
Expressed as a tensor decomposed form of the k-mode, said equation (14) is defined as follows:

step 34, reshape operation is performed on the input data N, and then a formula (2) is used for calculating a N and small weight tensor chain The results are reported as
The results are reported as To pair
To pair Carrying out reshape operation, then slicing to obtain corresponding
Carrying out reshape operation, then slicing to obtain corresponding And
And the specific process is as follows:
the specific process is as follows:





wherein, and the calculation flow of (2) and step 21
and the calculation flow of (2) and step 21 Are consistent in the calculation process, and are also in the same way
Are consistent in the calculation process, and are also in the same way And
And and (5) performing splitting operation, storing the splitting result by using a list, and performing the operations of the step 23 and the step 24 on the splitting result to obtain a final output.
and (5) performing splitting operation, storing the splitting result by using a list, and performing the operations of the step 23 and the step 24 on the splitting result to obtain a final output.
5. The tensor-based efficient Transformer architecture method as recited in claim 4, wherein the step 40 comprises the following specific steps:
step 41, willd model And d ff Conversion into a positive integer factor product of smaller value, d model ={O 1 ×...×O m }×{O m+1 ×...×O 2m }×...×{O (n-1)m+1 ×...×O nm And d ff ={P 1 ×...×P m }×{P m+1 ×...×P 2m }×...×{P (n-1)m+1 ×...×P nm }, weight matrix And
And become weight tensors
become weight tensors And
And wherein
wherein And
And offset vector
offset vector And
And becomes the offset tensor
becomes the offset tensor And
And
step 42, tensor weight using formula (1) And
And the tensor decomposition form expressed as the m mode is used for reducing the number of training parameters and the calculation complexity in the network model;
the tensor decomposition form expressed as the m mode is used for reducing the number of training parameters and the calculation complexity in the network model;
step 43, mapping the input data of the Position-wise feedforward network to a tensor space, and performing multi-step calculation with a small weight tensor chain, wherein the calculation process is shown as formulas (20) and (21):


6. the tensor-based efficient Transformer architecture method as recited in claim 1, wherein the steps 3 and 4 are not ordered sequentially.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210556441.4A CN114841342A (en) | 2022-05-19 | 2022-05-19 | Tensor-based efficient Transformer construction method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210556441.4A CN114841342A (en) | 2022-05-19 | 2022-05-19 | Tensor-based efficient Transformer construction method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114841342A true CN114841342A (en) | 2022-08-02 |
Family
ID=82571464
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210556441.4A Pending CN114841342A (en) | 2022-05-19 | 2022-05-19 | Tensor-based efficient Transformer construction method |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114841342A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115861762A (en) * | 2023-02-27 | 2023-03-28 | 中国海洋大学 | Plug-and-play infinite deformation fusion feature extraction method and application thereof |
-
2022
- 2022-05-19 CN CN202210556441.4A patent/CN114841342A/en active Pending
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115861762A (en) * | 2023-02-27 | 2023-03-28 | 中国海洋大学 | Plug-and-play infinite deformation fusion feature extraction method and application thereof |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ZainEldin et al. | Image compression algorithms in wireless multimedia sensor networks: A survey | |
| Wang et al. | Qtt-dlstm: A cloud-edge-aided distributed lstm for cyber–physical–social big data | |
| CN110751265A (en) | Lightweight neural network construction method and system and electronic equipment | |
| CN110503135B (en) | Deep learning model compression method and system for power equipment edge side recognition | |
| CN113516133B (en) | Multi-modal image classification method and system | |
| Ding et al. | Slimyolov4: lightweight object detector based on yolov4 | |
| CN114841342A (en) | Tensor-based efficient Transformer construction method | |
| Xiong et al. | STC: Significance-aware transform-based codec framework for external memory access reduction | |
| CN111193618B (en) | 6G mobile communication system based on tensor calculation and data processing method thereof | |
| US20230308681A1 (en) | End-to-end stereo image compression method and device based on bi-directional coding | |
| CN114817773A (en) | Time sequence prediction system and method based on multi-stage decomposition and fusion | |
| Liu et al. | Scalable tensor-train-based tensor computations for cyber–physical–social big data | |
| CN118260689A (en) | Log anomaly detection method based on high-efficiency fine adjustment of self-adaptive low-rank parameters | |
| Hsieh et al. | C3-SL: Circular convolution-based batch-wise compression for communication-efficient split learning | |
| He et al. | Towards real-time practical image compression with lightweight attention | |
| CN111479286B (en) | Data processing method for reducing communication flow of edge computing system | |
| EP4354872A1 (en) | Point cloud attribute information encoding and decoding method and apparatus, and related device | |
| Rao et al. | Image compression using artificial neural networks | |
| CN115170613A (en) | Human motion prediction method based on time sequence grading and recombination mechanism | |
| Liu et al. | MoTransFrame: Model Transfer Framework for CNNs on Low-Resource Edge Computing Node. | |
| CN117388716B (en) | Battery pack fault diagnosis method, system and storage medium based on time sequence data | |
| CN117915107B (en) | Image compression system, image compression method, storage medium and chip | |
| CN116128737B (en) | Image super-resolution network robustness improving device based on data compression | |
| Hassan et al. | SpikeBottleNet: Energy Efficient Spike Neural Network Partitioning for Feature Compression in Device-Edge Co-Inference Systems | |
| Liu | Analysis on lightweight network methods and technologies |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |