CN114241279A - Image-text combined error correction method and device, storage medium and computer equipment - Google Patents
Image-text combined error correction method and device, storage medium and computer equipment Download PDFInfo
- Publication number
- CN114241279A CN114241279A CN202111651496.5A CN202111651496A CN114241279A CN 114241279 A CN114241279 A CN 114241279A CN 202111651496 A CN202111651496 A CN 202111651496A CN 114241279 A CN114241279 A CN 114241279A
- Authority
- CN
- China
- Prior art keywords
- text
- vector representation
- error correction
- information
- image
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/251—Fusion techniques of input or preprocessed data
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3347—Query execution using vector based model
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- G06F16/374—Thesaurus
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/50—Information retrieval; Database structures therefor; File system structures therefor of still image data
- G06F16/56—Information retrieval; Database structures therefor; File system structures therefor of still image data having vectorial format
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Computational Linguistics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Computation (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Processing Or Creating Images (AREA)
Abstract
The application discloses a method and a device for jointly correcting an image and text, a storage medium and computer equipment. The method comprises the following steps: acquiring text data and image data to be processed, wherein the text data comprises a target text, and the image data comprises a scene picture; extracting a text vector representation of the text data, wherein the text vector representation comprises text information of a target text; extracting a picture vector representation of the image data, the picture vector representation including image information of a scene picture; according to the text vector representation and the picture vector representation, calculating a multi-modal vector representation containing text information and image information; when the target text is used for expressing the scene picture, the error correction result aiming at the target text and the scene picture is determined according to the multi-mode vector representation, so that the image-text is corrected according to the error correction result, the image-text joint error correction is realized, and the error correction capability is improved.
Description
Technical Field
The application relates to the technical field of computers, in particular to a method and a device for jointly correcting image-text errors, a storage medium and computer equipment.
Background
Most of the current systems for correcting the error of the text are based on a language model, and then correct the error of the text through pinyin and other limiting conditions. Most commonly, words and sentences are scored, for example, by an algorithm (N-gram) based on a statistical language model, and then it is determined whether the current sentence has obvious errors in word use. Then, the pinyin and the common confusion vocabulary are combined to comprehensively judge whether the word, the word and the sentence method are wrong or not in the sentence. The problem is basically single-modal text input information, and no error correction related system related to multiple modes is found at present. N-grams are generally counted by large-scale corpora, and related work uses a Mask Language Model (MLM), but essentially all correct errors on plain text without the help of image-like related information. For the same sentence, the result of error detection and correction is generally fixed, because the score calculated for the current sentence through the language model is fixed, although sometimes the system can be adjusted by adjusting the threshold value of error detection and correction, the current multi-modal text correction system can only process the text input in a single mode and cannot correct the network data containing the pictures and texts when solving the problem of error detection and correction in text writing, and some correction systems can only correct wrongly written words, and some correction systems can only correct grammatical errors, resulting in insufficient correction capability.
Disclosure of Invention
The embodiment of the application provides a method and a device for image-text joint error correction, a storage medium and computer equipment, which can realize image-text joint error correction and improve the error correction capability.
In one aspect, a method for joint error correction of graphics and text is provided, where the method includes: acquiring text data and image data to be processed, wherein the text data comprises a target text, and the image data comprises a scene picture; extracting a text vector representation of the text data, the text vector representation including text information of the target text; extracting a picture vector representation of the image data, the picture vector representation including image information of the scene picture; calculating a multi-modal vector representation comprising text information and image information according to the text vector representation and the picture vector representation; and when the target text is used for expressing the scene picture, determining an error correction result for the target text and the scene picture according to the multi-modal vector representation.
Optionally, the extracting a text vector representation of the text data includes: and converting each word in the text data into a sequence number corresponding to each word in the word list through the word list, and searching the text vector representation of the text data according to the sequence number.
Optionally, the extracting a picture vector representation of the image data includes: and performing target detection and feature extraction on the scene picture according to a target detection model to obtain the picture vector representation, wherein the picture vector representation comprises the image information vector representation of each image target in the scene picture and the image information vector representation of the whole picture.
Optionally, the calculating a multi-modal vector representation including text information and image information according to the text vector representation and the picture vector representation includes: processing the text vector representation and the picture vector based on a self-attention model to obtain global interaction information between text information of the target text and image information of the scene picture; carrying out normalization processing on the global interaction information to obtain first normalization information; and determining a multi-modal vector representation containing text information and image information according to the global interaction information and the first normalization information.
Optionally, the processing the text vector representation and the picture vector based on a self-attention model to obtain global interaction information between the text information of the target text and the image information of the scene picture includes: inputting an embedded vector representation determined from the text vector representation and the picture vector representation from an attention model, calculating a matching matrix from a product between the embedded vector representation and a transposed matrix of the embedded vector representation; and determining global interaction information between the text information of the target text and the image information of the scene picture according to the product of the matching matrix and the embedded vector representation.
Optionally, the determining a multi-modal vector representation including text information and image information according to the global interaction information and the first normalization information includes: adding the global interaction information and the first normalization information to obtain first summation information; inputting the first summation information into a full-connection layer for processing, and then carrying out normalization processing on an output result of the full-connection layer to obtain second normalization information; and adding the first summation information and the second normalization information to obtain the multi-modal vector representation containing the text information and the image information.
Optionally, the method further includes: acquiring position vector representation and type vector representation, wherein the position vector representation is used for marking the position of each word in the text data, and the type vector representation is used for distinguishing a text type from an image type;
the computing a multimodal vector representation including text information and image information from the text vector representation and the picture vector representation comprises: and calculating a multi-modal vector representation containing text information and image information according to the text vector representation, the picture vector representation, the position vector representation and the type vector representation.
Optionally, the determining, according to the multi-modal vector representation, an error correction result for the target text and the scene picture includes: connecting the multi-modal vector representations with a full connection layer to obtain a first feature vector, wherein the first feature vector comprises vector representations corresponding to each word in the target text and each image target in the scene picture; determining error correction operation corresponding to each word in the target text and each image target in the scene picture respectively according to the first feature vector; and calculating an error correction result according to the error correction operation and the first characteristic vector so as to perform error correction processing on the target text and/or the scene picture according to the error correction result.
Optionally, the determining an error correction result according to the error correction operation and the first eigenvector further includes: if the error correction operation is error-free, determining that the error correction result is a word corresponding to the error-free error correction operation; or if the error correction operation is a deletion operation, determining that the error correction result is that words corresponding to the deletion operation in the target text are deleted; or if the error correction operation is a modification operation, determining that the error correction result is to modify a word corresponding to the modification operation in the target text into a predicted word, or modify an image target corresponding to the modification operation in the scene picture into a predicted image target.
In another aspect, a combined teletext error correction apparatus is provided, the apparatus comprising:
the device comprises an acquisition unit, a processing unit and a processing unit, wherein the acquisition unit is used for acquiring text data and image data to be processed, the text data comprises a target text, and the image data comprises a scene picture;
a first extraction unit configured to extract a text vector representation of the text data, the text vector representation including text information of the target text;
a second extraction unit configured to extract a picture vector representation of the image data, the picture vector representation including image information of the scene picture;
the computing unit is used for computing multi-modal vector representation containing text information and image information according to the text vector representation and the picture vector representation;
and the determining unit is used for determining an error correction result for the target text and the scene picture according to the multi-modal vector representation when the target text is used for expressing the scene picture.
In another aspect, a computer-readable storage medium is provided, which stores a computer program, and the computer program is suitable for being loaded by a processor to execute the steps in the combined teletext error correction method according to any one of the embodiments above.
In another aspect, a computer device is provided, which includes a processor and a memory, where the memory stores a computer program, and the processor is configured to execute the steps in the joint teletext error correction method according to any one of the above embodiments by calling the computer program stored in the memory.
In another aspect, a computer program product is provided, which includes computer instructions, and when executed by a processor, the computer instructions implement the steps in the joint teletext error correction method according to any one of the embodiments above.
The method comprises the steps of acquiring text data and image data to be processed, wherein the text data comprises a target text, and the image data comprises a scene picture; extracting a text vector representation of the text data, wherein the text vector representation comprises text information of a target text; extracting a picture vector representation of the image data, the picture vector representation including image information of a scene picture; according to the text vector representation and the picture vector representation, calculating a multi-modal vector representation containing text information and image information; and when the target text is used for expressing the scene picture, determining an error correction result for the target text and the scene picture according to the multi-modal vector representation. The method and the device for correcting the image-text combined error achieve multi-mode image-text combined error correction of image and text input through a Transformer model, the model simultaneously inputs image data and text data containing target texts, multi-mode vector representation containing text information and image information is calculated through an attention (attention) mechanism in the Transformer model, useful image information and text information are filtered out, then error information in the image is detected according to the text information in the multi-mode vector representation, an error correction result aiming at the target texts and scene images is determined, image-text combined error correction is achieved, and error correction capability is improved.
Drawings
In order to more clearly illustrate the technical solutions in the embodiments of the present application, the drawings needed to be used in the description of the embodiments are briefly introduced below, and it is obvious that the drawings in the following description are only some embodiments of the present application, and it is obvious for those skilled in the art to obtain other drawings based on these drawings without creative efforts.
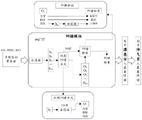
Fig. 1 is a structural framework diagram of a combined image-text error correction system according to an embodiment of the present application.
Fig. 2 is a first flowchart of a combined image-text error correction method according to an embodiment of the present application.
Fig. 3 is a schematic view of a first application scenario of the image-text joint error correction method according to the embodiment of the present application.
Fig. 4 is a second flowchart of the image-text joint error correction method according to the embodiment of the present application.
Fig. 5 is a schematic view of a second application scenario of the image-text joint error correction method according to the embodiment of the present application.
Fig. 6 is a third flowchart of the image-text joint error correction method according to the embodiment of the present application.
Fig. 7 is a schematic view of a third application scenario of the image-text joint error correction method according to the embodiment of the present application.
Fig. 8 is a schematic structural diagram of a combined image-text error correction device according to an embodiment of the present application.
Fig. 9 is a schematic structural diagram of a computer device according to an embodiment of the present application.
Detailed Description
The technical solutions in the embodiments of the present application will be clearly and completely described below with reference to the drawings in the embodiments of the present application, and it is obvious that the described embodiments are only a part of the embodiments of the present application, and not all of the embodiments. All other embodiments, which can be derived by a person skilled in the art from the embodiments given herein without making any creative effort, shall fall within the protection scope of the present application.
The embodiment of the application provides a method and a device for jointly correcting an image and text, computer equipment and a storage medium. Specifically, the image-text joint error correction method according to the embodiment of the present application may be executed by a computer device, where the computer device may be a terminal or a server. The terminal can be a smart phone, a tablet Computer, a notebook Computer, a smart television, a smart speaker, a wearable smart device, a Personal Computer (PC), and the like, and the terminal can further include a client, which can be a video client, a browser client, an instant messaging client, and the like. The server may be an independent physical server, a server cluster or a distributed system formed by a plurality of physical servers, or a cloud server providing basic cloud computing services such as a cloud service, a cloud database, cloud computing, a cloud function, cloud storage, a Network service, cloud communication, middleware service, a domain name service, a security service, a Content Delivery Network (CDN), a big data and artificial intelligence platform, and the like.
The embodiment of the application can be applied to various scenes such as artificial intelligence, voice recognition and intelligent traffic.
First, some terms or expressions appearing in the course of describing the embodiments of the present application are explained as follows:
artificial Intelligence (AI) is a theory, method, technique and application system that uses a digital computer or a machine controlled by a digital computer to simulate, extend and expand human Intelligence, perceive the environment, acquire knowledge and use the knowledge to obtain the best results. In other words, artificial intelligence is a comprehensive technique of computer science that attempts to understand the essence of intelligence and produce a new intelligent machine that can react in a manner similar to human intelligence. Artificial intelligence is the research of the design principle and the realization method of various intelligent machines, so that the machines have the functions of perception, reasoning and decision making. The artificial intelligence infrastructure generally includes technologies such as sensors, dedicated artificial intelligence chips, cloud computing, distributed storage, big data processing technologies, operation/interaction systems, mechatronics, and the like. The artificial intelligence software technology mainly comprises a computer vision technology, a voice processing technology, a natural language processing technology, machine learning/deep learning and the like.
Machine Learning (ML) is a multi-domain cross discipline, and relates to a plurality of disciplines such as probability theory, statistics, approximation theory, convex analysis, algorithm complexity theory and the like. The special research on how a computer simulates or realizes the learning behavior of human beings so as to acquire new knowledge or skills and reorganize the existing knowledge structure to continuously improve the performance of the computer. Machine learning is the core of artificial intelligence, is the fundamental approach for computers to have intelligence, and is applied to all fields of artificial intelligence. Machine learning and deep learning generally include techniques such as artificial neural networks, belief networks, reinforcement learning, transfer learning, inductive learning, and formal education learning.
Deep Learning (DL) is a branch of machine Learning, an algorithm that attempts to perform high-level abstraction of data using multiple processing layers that contain complex structures or consist of multiple nonlinear transformations. Deep learning is to learn the intrinsic rules and the expression levels of training sample data, and the information obtained in the learning process is very helpful to the interpretation of data such as characters, images and sounds. The final goal of deep learning is to make a machine capable of human-like analytical learning, and to recognize data such as characters, images, and sounds. Deep learning is a complex machine learning algorithm, and achieves the effect in speech and image recognition far exceeding the prior related art.
Neural Networks (NN) are a deep learning model that mimics the structure and function of biological Neural networks in the field of machine learning and cognitive science.
The Transformer model is an NLP (natural language processing) classical model. The Transformer model encodes inputs and computes outputs based entirely on Attention, and does not rely on a sequence-aligned cyclic or convolutional neural network, and uses the Self-Attention mechanism without adopting the sequential structure of RNNs, so that the model can be trained in parallel and can possess global information.
The related text error correction system at present mainly has the following defects when solving the problem of error detection and error correction of text composition:
1. the system can only process data entered as text. Almost all current text error correction systems can only process single-mode text input, but cannot correct network data containing pictures and texts. This results in the network data being processed incorrectly by the error correction system for the current full-scale teletext.
2. At present, error correction systems are all in a single mode, and the effect of error correction cannot be assisted and improved according to multi-mode information. The error correction is a multi-factor combined processing system, and although the current text error correction system can correct errors according to different texts and different application scenes, the current text error correction system is a pure text scene of a single mode in nature and cannot assist error correction by using extra information outside the texts.
3. The system migration is poor. Because the most basic error correction system is a language model, and the language model is obtained by large-scale text corpora through statistics or MLM training, once oriented, the language model cannot be seamlessly migrated to other fields. For example, in a language model trained by a text in the judicial field, the use effect in a daily conversation scene is poor.
4. The error correction problem is divided into fine parts, and some error correction systems can only correct different words and some error correction systems can only correct grammatical errors. Many error correction systems isolate the problem in error correction and then solve a certain problem individually, which causes an improper condition in the error detection and correction process, or the same error is detected by multiple modules, thereby causing the correction result to be non-uniform.
In the conventional error correction, the error correction is based on text error correction, and in a real-life scene, the demand for the multi-modality combined error correction is continuously increasing. For example, one sentence "there is an individual eating an apple. "the corresponding scene is that a person is playing the apple mobile phone, if the traditional text error correction system is adopted to correct the text, the error cannot be found, or the situation is identified as that the person is eating the apple mobile phone with low head. ". Alternatively, a conventional text correction system may correct for "a person is down eating an apple. "and not corrected to" someone is looking down to play the iphone. ", this requires multi-modal teletext joint error correction to accomplish this task. With the rapid development of the internet, more and more information containing pictures and texts is provided, so that combined image-text error correction becomes more and more valuable, while the traditional single-mode error correction is limited to some scenes, and error correction cannot be assisted according to specific pictures and other information. Therefore, single-modality error correction has a relatively large limit.
The embodiment of the application further introduces image information on the basis of a single text to carry out joint error correction, so that the error correction of more complex scenes can be solved, and the capabilities of finding errors and correctly correcting the errors can be improved by mutually enhancing the image information and the text information.
The multi-modal image-text combined error correction system based on the neural network and the deep learning model can overcome the problems. Firstly, the embodiment of the application can input the pictures and texts into an error correction system at the same time, and simultaneously, the error correction is carried out by using the picture and text information. At present, many internet data are mixed with pictures and texts, and only a system for correcting texts is adopted, so that the system can gradually keep up with the trend of the times. Secondly, the information of the two image-text modes can be mutually utilized, so that the integral error correction effect is improved, and the problem that errors which cannot be judged only through texts cannot be corrected is avoided. In addition, the embodiment of the application can detect the error information in the picture according to the text information, so that the quality of matching the text with the picture is improved in the error correction process, and meanwhile, the picture and text can be corrected.
Referring to fig. 1, fig. 1 is a structural framework diagram of a combined image-text error correction system according to an embodiment of the present application. The image-text combined error correction system comprises a multi-modal Transformer model and an error correction module. First, text data is entered in a text modality, which includes target text. Then there is an input of image data of the image modality, the image data comprising a picture of the scene. Then a multimodal Transformer model. A multi-modal vector representation fusing text information and image information can be calculated through a Transformer model. And then inputting the multi-modal vector representation into an error correction module to calculate information that errors can occur in the text and the image.
By simultaneously inputting signals of a target text and a scene picture, useful image information and text information are filtered out through an attention mechanism in a Transformer model, and then whether each character (or each word) and each image target in the scene picture have errors or not is calculated through an error correction module according to the filtered information.
The feature representation of the text and the image in two modes is learned when the image and the text are input simultaneously, and the model can accurately obtain useful representation information. And finally, accurately judging whether the scene picture has the problem of error expression with the current target text, if the target text has the error expression, correcting the error position, and if the scene picture has the error position, correcting the scene picture or outputting the position of the picture. For example, each detection target corresponding to the text information in the scene picture may be used as an image target, and whether the image target has an error or not, that is, where the error exists in the scene picture, may be determined by the matching degree of the image information and the text information in the image target.
The whole image-text combined error correction system directly completes multi-mode image-text error correction through one model, so the overall structure is simple, and the performance is good.
The following are detailed below. It should be noted that the description sequence of the following embodiments is not intended to limit the priority sequence of the embodiments.
The embodiments of the application provide a combined image-text error correction method, which can be executed by a terminal or a server, or can be executed by the terminal and the server together; the embodiment of the present application is described by taking an example in which the image-text joint error correction method is executed by a server.
Referring to fig. 2 to 7, fig. 2, fig. 4, and fig. 6 are schematic flow diagrams of a combined teletext error correction method according to an embodiment of the present application, and fig. 3, fig. 5, and fig. 7 are schematic application scenarios of the combined teletext error correction method according to the embodiment of the present application. The method comprises the following steps:
For example, the text data includes target text. For example, the target text to be processed is acquired as "beautiful woman wears glasses in the figure". The target text may also be a question.
For example, the image data includes a scene picture, which is a picture provided corresponding to the scene described by the target text, such as a user can answer the determination whether the target text (question) is a correct representation of the scene picture by observing the scene picture during the answering process.
Optionally, the extracting a text vector representation of the text data includes:
and converting each word in the text data into a sequence number corresponding to each word in the word list through the word list, and searching the text vector representation of the text data according to the sequence number.
First, the text data may be vectorized to map each word in the target text to a particular space to obtain a text vector representation of the text data.
For example, as described with reference to fig. 3, the system for joint teletext error correction may include a multi-modal data input processing module, a multi-modal feature extraction module, and an error correction module, where the feature extraction module may employ a Transformer model.
For example, text data in a TXT format (i.e., original text corresponding to target text in the TXT format) input into the data input processing module is converted into a sequence number (ID) in a corresponding word list of each word through the word list, and then the embedded (embedding) vector representation of each word for the word list is searched for the original text through the ID. For example, the target text: "beautiful woman wears glasses in the figure", is converted into ID [1,4,3,6,7,0,12,87,98] through a word list, because the ID of the "figure" in the word list is 1, the ID is converted into 1, and then the vector representation (w1, w2, w3, w4, w5, w6, w7, w8, w9, w10) corresponding to each word is found through the ID, so that the word vector sequence is obtained. This string of word vector sequences can then be subsequently used as input parameters for the transform model, which can be defined as a text vector representation represented as a matrix of seq _ len times hid _ size, where seq _ len represents the text length and hid _ size represents the size of the word vector.
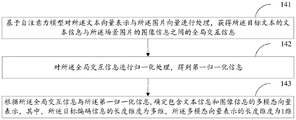
Optionally, the extracting a picture vector representation of the image data includes:
and performing target detection and feature extraction on the scene picture according to a target detection model to obtain the picture vector representation, wherein the picture vector representation comprises the image information vector representation of each image target in the scene picture and the image information vector representation of the whole picture.
For example, image data input to the data input processing module is first extracted by a target detection model (Fast RCNN) for physical numerical information, and then a Fast RCNN model capable of correctly extracting physical information is obtained by model learning. Fast RCNN (Fast Regions with CNN features) is a Fast, region-based convolutional network method for target detection.
For example, as described with reference to fig. 3, image data including a scene picture is input, object detection and feature extraction are performed on the scene picture in the image data through Fast-RCNN, and an image information vector representation of each image object in the picture and an image information vector representation of the entire picture are obtained. Wherein the image target is corresponding to an object needing attention in the text data, such as "beautiful woman in the figure" mentioned in the text data, then people in the scene picture, such as man and woman in the figure, need to be paid attention. Wherein the image information vector representation of the entire picture would be applied separately to each text word, and the image information vector representation of the individual image object would correspond to the text vector specifically representing the image information, i.e. the img text vector shown in fig. 3. The final image data as an input parameter of the transform model is also a matrix of seq _ len times hid _ size, which can be defined as a picture vector representation.
For example, an Embedding vector representation including an image and a text is input to a transform model, and a multimodal vector representation in which text information and image information are fused is calculated. A multimodal vector representation is a vector that contains both textual and image information.
Optionally, the method further includes: acquiring position vector representation and type vector representation, wherein the position vector representation is used for marking the position of each word in the text data, and the type vector representation is used for distinguishing a text type from an image type;
the computing a multimodal vector representation including text information and image information from the text vector representation and the picture vector representation comprises:
and calculating a multi-modal vector representation containing text information and image information according to the text vector representation, the picture vector representation, the position vector representation and the type vector representation.
Wherein the position vector represents a position for labeling each word in the text data, and the size of the position vector representation is a matrix of seq _ len times hid _ size. The type vector represents a matrix with the size of seq _ len multiplied by hid _ size, for example, the sub-text type is represented as 0, and the image type is represented as 1.
For example, as shown in fig. 3, the input parameters finally input into the transform model may include an embedded vector representation Embedding, denoted as E, composed of a text vector representation plus a picture vector representation plus a position vector representation and a type vector representation. For example, the Embedding vector representation of the target text and the scene picture is input into the transform model, and a multi-modal vector representation between the text and the image is calculated. The multi-modal vector representation is a vector containing both text information and image information, namely the vector representation of each word in the target text and the vector representation of each image target in the scene picture are calculated in a Transformer model, the optimal characteristic vector is extracted in a mode of co-occurrence of each group, and finally the multi-modal representation is output to an error correction module.
For example, as described with reference to fig. 3, a multi-modal vector representation including text information and image information may be calculated by processing a text vector representation and a picture vector representation according to a multi-modal feature extraction module, which may employ a transform model. The feature extraction module has the main function of calculating the multi-modal vector representation fusing the text information and the image information. As shown in fig. 3, after being processed by the transform model, a multi-modal vector representation fused with text information and image information is finally obtained, and this multi-modal vector representation can be used by the error correction module to calculate whether there is an error in the target text and the scene picture, and whether "add", "delete", or "change" is required. As shown in fig. 3, it is calculated whether the expression "woman" matches the picture and whether the woman is wearing glasses in the picture. The module is designed mainly for calculating the incidence relation between image texts and outputting a matched feature matrix.
Optionally, as shown in fig. 4, step 140 may be implemented through steps 141 to 143, specifically:
and step 141, processing the text vector representation and the picture vector based on a self-attention model, and obtaining global interaction information between the text information of the target text and the image information of the scene picture.
Optionally, the processing the text vector representation and the picture vector based on a self-attention model to obtain global interaction information between the text information of the target text and the image information of the scene picture includes: inputting an embedded vector representation determined from the text vector representation and the picture vector representation from an attention model, calculating a matching matrix from a product between the embedded vector representation and a transposed matrix of the embedded vector representation; and determining global interaction information between the text information of the target text and the image information of the scene picture according to the product of the matching matrix and the embedded vector representation.
Wherein the length dimension of the global mutual information is the same as the length dimension of the embedded vector representation.
For example, referring to fig. 5, the inputs to the feature extraction module are: vector representation of images and text, with size of seq _ len times hid _ size matrix. For example, the vector representation of the image and the text may be an Embedding vector representation composed of a text vector representation and a picture vector representation, and is denoted as E. The vector representation of the image and the text may be a text vector representation, a picture vector representation, a position vector representation, and a type vector representation, and the formed Embedding vector representation is denoted as E.
The output of the feature extraction module is: a multimodal vector representation fusing image information and all text information, with a size of seq _ len times hid _ size matrix.
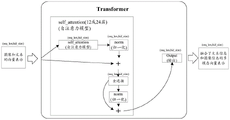
For example, referring to fig. 5, a matching matrix is calculated through a self-attention (self _ attention) model inside a feature extraction module, and an embedding vector representation E of seq _ len multiplied by hid _ size is input, and the embedding vector representation is a vector representation of an image and a text; the output is global interactive information Hs,HsIs seq _ len multiplied by hid _ size. In the specific calculation process, self _ attention represents self and self calculation attention (attention), and E is multiplied by E matrixTObtaining a matching matrix M, wherein the size of the matching matrix M is seq _ len multiplied by seq _ len, and then the M matrix is multiplied by E to obtain Hs,HsIs seq _ len multiplied by hid _ size. Wherein E isTIs the transpose of the E matrix.
And 142, performing normalization processing on the global interaction information to obtain first normalization information.
For example, referring to FIG. 5, global interaction information H for self _ interaction model outputsNormalization, i.e. norm, is performed to obtain first normalization information HnFirst normalization information HnIs seq _ len times hid _ size, normalization does not affect the matrix size. The length dimension of the global interactive information is the same as the length dimension represented by the embedded vector, and the word vector size of the global interactive information is the same as the word vector size represented by the embedded vector.
Optionally, the determining a multi-modal vector representation including text information and image information according to the global interaction information and the first normalization information includes: adding the global interaction information and the first normalization information to obtain first summation information; inputting the first summation information into a full-connection layer for processing, and then carrying out normalization processing on an output result of the full-connection layer to obtain second normalization information; and adding the first summation information and the second normalization information to obtain the multi-modal vector representation containing the text information and the image information.
For example, referring to FIG. 5, the input to the fully connected layer is Hs+HnI.e. global mutual information HsAnd the first normalization information HnAnd adding to obtain first summation information, and inputting the first summation information into a full-connection layer for processing, wherein the size of an output result of the full-connection layer is seq _ len multiplied by hid _ size. Then, normalization processing (norm) is carried out on the output result of the full connection layer to obtain second normalization information, and the obtained second normalization information is added with the first summation information again to obtain a multi-mode vector representation Hnn. Due to HnnThe self _ attribute model here can be stacked in multiple layers, as well as the size of the input E-matrix, and can be set to 1 in general2 layers or 24 layers.
For example, the multimodal vector representation HnnFinally, by directly outputting output, the size of which is a matrix of seq _ len times hid _ size, the multimodal vector representation is a multimodal vector representation in which the image information and all text information are fused. Wherein the length dimension of the multi-modal vector representation is the same as the length dimension of the embedded vector representation.
The multi-modal vector representation fused with the text and the image is obtained through calculation by the feature extraction module, the multi-modal vector representation comprises a highly abstract semantic matching relation between the text and the image, and abundant information is provided for a follow-up module to perform semantic error detection and correction according to matching information. And meanwhile, the text matching which is only performed at a simple character level in the past is converted into the matching between vector spaces. The feature extraction module raises text matching to the semantic space level.
And 150, when the target text is used for expressing the scene picture, determining an error correction result for the target text and the scene picture according to the multi-modal vector representation.
For example, the output result (multi-modal vector representation fused with text information and image information) output by the feature extraction module may be processed by an error correction module to calculate whether each word in the target text needs to be modified, how to modify, whether each image target in the scene picture has errors, whether to modify, and the like.
The error correction module mainly processes the output result of the feature extraction module to correct each word in the target text and each image target part in the scene picture, taking the target text "beautiful woman wears glasses in the picture" shown in fig. 3 as an example, the target text itself has no errors expressed in any grammar, and there is no problem place on the scene picture, but when the target text is used for expressing the scene picture, there is an error, that is, there is error information that the scene picture and the target text are not matched. The main task of the error correction module is to compute and find errors and to correct them.
Optionally, as shown in fig. 6, step 150 may be implemented through steps 151 to 153, specifically:
and 151, connecting the multi-modal vector representations to a full connection layer to obtain a first feature vector, wherein the first feature vector comprises vector representations corresponding to each word in the target text and each image target in the scene picture.
For example, referring to fig. 7, a multi-modal vector representation in which text information and image information are fused is obtained, and a first feature vector H ═ H is obtained by connecting all vectors one after another1,h2,h3,…,h15]For example, seq _ len is 15, and the total number of vectors corresponding to all words in the target text and all image targets in the scene picture contained in H is 15.
For example, referring to fig. 7, the first feature vector H is input into the recognition error correction mode module, and the recognition error correction mode module can obtain the error correction operation O ═ O [ O ] corresponding to each word and each image target on the length dimension seq _ len1,O2,O3,…,O15]The error correction operation mainly includes three types: no error, and the error-free operation specification does not need to be corrected; deleting operation, wherein the deleting operation indicates that the current word is redundant and needs to be deleted; modifying operation, wherein the modifying operation indicates that the current word is an error word and needs to be corrected; or that the current image object is an erroneous image object and needs to be corrected.
Optionally, the determining an error correction result according to the error correction operation and the first eigenvector further includes:
if the error correction operation is error-free, determining that the error correction result is a word corresponding to the error-free error correction operation; or
If the error correction operation is a deletion operation, determining that the error correction result is that words corresponding to the deletion operation in the target text are deleted; or
If the error correction operation is a modification operation, determining that the error correction result is to modify a word corresponding to the modification operation in the target text into a predicted word, or modify an image target corresponding to the modification operation in the scene picture into a predicted image target.
For example, referring to fig. 7, the error correction result is finally calculated according to the error correction operation O and the first eigenvector H. For example, "no error" directly outputs a word corresponding to error correction operation without error, or if all the error correction operations corresponding to all the words in the target text are error-free, the target text may be directly output. "delete", the word output corresponding to the delete operation is null. "modify", then h will be presenti(e.g., h in the example of FIG. 7)1) Connecting with full connection to predict a new word (or character) output if h is presentiIs an image object, and a new image object is output by full connection for the place where the image object is located in the scene picture. For example, for an input target text, that is, a beautiful woman wears glasses on a graph, error correction operations corresponding to three characters, that is, a floating character, a bright character and a woman, are modified, predicted new words are respectively commander, angry and man, and an output when error correction processing is performed on the target text according to the error correction results is that commander men wears glasses on the graph.
The image-text combined error correction system provided by the embodiment of the application can not only correct the text in the error correction process, but also identify the problematic places in the picture, and if the picture has errors, the corrected picture can be generated as a suggestion for modification.
Before the image-text combined error correction system is used, enough cross-mode data can be provided to carry out model learning on the image-text combined error correction system. After learning, the whole image-text combined error correction system can automatically correct the input including the images and the texts, and can also independently process the texts or the images.
The image-text combined error correction method provided by the embodiment of the application is characterized in that text error correction is assisted by image information, some common sense errors in the image are found through the text information, a set of error correction system combining the image and the text information is creatively designed, error correction is promoted to the level of a multi-modal exaggerated mode from a single-modal task, a multi-modal technology is innovatively applied to the error correction task, and multi-modal combined error correction is achieved. The image-text error correction mode is innovated, error correction is defined into two stages, the first stage identifies the method and means needed to be adopted for error correction, and the second stage uses the corresponding correction result to carry out error correction under a specific error correction method. A complex error correction system is designed into an end-to-end model method, so that the method is very favorable for later maintenance and deployment. The system has the advantages that the multi-modal combined image-text error correction method is advanced to a new height, the problem which cannot be solved by the conventional pure text error correction can be solved, the machine can be helped to learn knowledge and try of multiple modalities, and the method is very helpful to the error correction of a single modality. The embodiment of the application can find the improper expression in the text according to the image. Meanwhile, some pictures containing errors can be corrected by means of text information.
Compared with the traditional method only capable of correcting the text, the text and the picture can be corrected simultaneously, the text can be corrected, the corresponding theory data can be found out on the picture while the text is corrected, and the understandability of error correction is improved.
All the above technical solutions can be combined arbitrarily to form the optional embodiments of the present application, and are not described herein again.
The method comprises the steps of acquiring text data and image data to be processed, wherein the text data comprises a target text, and the image data comprises a scene picture; extracting a text vector representation of the text data, wherein the text vector representation comprises text information of a target text; extracting a picture vector representation of the image data, the picture vector representation including image information of a scene picture; according to the text vector representation and the picture vector representation, calculating a multi-modal vector representation containing text information and image information; and when the target text is used for expressing the scene picture, determining an error correction result for the target text and the scene picture according to the multi-modal vector representation. The method and the device for correcting the image-text combined error achieve multi-mode image-text combined error correction of image and text input through a Transformer model, the model simultaneously inputs image data and text data containing target texts, multi-mode vector representation containing text information and image information is calculated through an attention (attention) mechanism in the Transformer model, useful image information and text information are filtered out, then error information in the image is detected according to the text information in the multi-mode vector representation, an error correction result aiming at the target texts and scene images is determined, image-text combined error correction is achieved, and error correction capability is improved.
In order to better implement the image-text joint error correction method of the embodiment of the application, the embodiment of the application also provides an image-text joint error correction device. Referring to fig. 8, fig. 8 is a schematic structural diagram of a combined image-text error correction apparatus according to an embodiment of the present application. The teletext combined error correction device 200 may include:
an obtaining unit 201, configured to obtain text data to be processed and image data, where the text data includes a target text, and the image data includes a scene picture;
a first extracting unit 202, configured to extract a text vector representation of the text data, where the text vector representation includes text information of the target text;
a second extraction unit 203, configured to extract a picture vector representation of the image data, where the picture vector representation includes image information of the scene picture;
a calculating unit 204, configured to calculate a multi-modal vector representation including text information and image information according to the text vector representation and the picture vector representation;
a determining unit 205, configured to determine an error correction result for the target text and the scene picture according to the multi-modal vector representation when the target text is used to express the scene picture.
Optionally, the first extracting unit 202 may be configured to convert each word in the text data into a sequence number corresponding to each word in a word list through the word list, and search for text vector representation of the text data according to the sequence number.
Optionally, the second extracting unit 203 may be configured to perform target detection and feature extraction on the scene picture according to a target detection model to obtain the picture vector representation, where the picture vector representation includes an image information vector representation of each image target in the scene picture and an image information vector representation of the entire picture.
Optionally, the computing unit 204 may be specifically configured to: processing the text vector representation and the picture vector based on a self-attention model to obtain global interaction information between text information of the target text and image information of the scene picture; carrying out normalization processing on the global interaction information to obtain first normalization information; and determining a multi-modal vector representation containing text information and image information according to the global interaction information and the first normalization information.
Optionally, when the text vector representation and the picture vector are to be processed based on a self-attention model to obtain global interaction information between the text information of the target text and the image information of the scene picture, the calculating unit 204 may be configured to: inputting an embedded vector representation determined from the text vector representation and the picture vector representation from an attention model, calculating a matching matrix from a product between the embedded vector representation and a transposed matrix of the embedded vector representation; and determining global interaction information between the text information of the target text and the image information of the scene picture according to the product of the matching matrix and the embedded vector representation.
Optionally, when determining the multi-modal vector representation including text information and image information according to the global interaction information and the first normalization information, the computing unit 204 may be configured to: adding the global interaction information and the first normalization information to obtain first summation information; inputting the first summation information into a full-connection layer for processing, and then carrying out normalization processing on an output result of the full-connection layer to obtain second normalization information; and adding the first summation information and the second normalization information to obtain the multi-modal vector representation containing the text information and the image information.
Optionally, the obtaining unit 201 may be further configured to obtain a position vector representation and a type vector representation, where the position vector representation is used to mark a position of each word in the text data, and the type vector representation is used to distinguish a text type from an image type;
the calculation unit 204 may be configured to calculate a multi-modal vector representation comprising text information and image information based on the text vector representation, the picture vector representation, the location vector representation, and the type vector representation.
Optionally, the determining unit 205 may be specifically configured to: connecting the multi-modal vector representations with a full connection layer to obtain a first feature vector, wherein the first feature vector comprises vector representations corresponding to each word in the target text and each image target in the scene picture; determining error correction operation corresponding to each word in the target text and each image target in the scene picture respectively according to the first feature vector; and calculating an error correction result according to the error correction operation and the first characteristic vector so as to perform error correction processing on the target text and/or the scene picture according to the error correction result.
Optionally, when determining an error correction result according to the error correction operation and the first eigenvector, the determining unit 205 may be further configured to: if the error correction operation is error-free, determining that the error correction result is a word corresponding to the error-free error correction operation; or if the error correction operation is a deletion operation, determining that the error correction result is that words corresponding to the deletion operation in the target text are deleted; or if the error correction operation is a modification operation, determining that the error correction result is to modify a word corresponding to the modification operation in the target text into a predicted word, or modify an image target corresponding to the modification operation in the scene picture into a predicted image target.
It should be noted that, in the embodiment of the present application, the functions of each module in the combined image-text error correction apparatus 200 may refer to the specific implementation manner of any embodiment in the foregoing method embodiments, and are not described herein again.
All or part of each unit in the image-text joint error correction device can be realized by software, hardware and a combination thereof. The units may be embedded in hardware or independent from a processor in the computer device, or may be stored in a memory in the computer device in software, so that the processor can call and execute operations corresponding to the units.
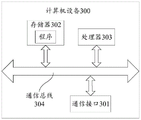
The combined teletext error correction arrangement 200 may be integrated in a terminal or server having a memory and a processor mounted with computational capability, for example, or the combined teletext error correction arrangement 200 may be the terminal or server. The terminal can be a smart phone, a tablet Computer, a notebook Computer, a smart television, a smart speaker, a wearable smart device, a Personal Computer (PC), and the like, and the terminal can further include a client, which can be a video client, a browser client, an instant messaging client, and the like. The server may be an independent physical server, a server cluster or a distributed system formed by a plurality of physical servers, or a cloud server providing basic cloud computing services such as a cloud service, a cloud database, cloud computing, a cloud function, cloud storage, a Network service, cloud communication, middleware service, a domain name service, a security service, a Content Delivery Network (CDN), a big data and artificial intelligence platform, and the like.
Fig. 9 is a schematic structural diagram of a computer device provided in an embodiment of the present application, and as shown in fig. 9, the computer device 300 may include: a communication interface 301, a memory 302, a processor 303 and a communication bus 304. The communication interface 301, the memory 302 and the processor 303 realize mutual communication through a communication bus 304. The communication interface 301 is used for the apparatus 300 to communicate data with external devices. The memory 302 may be used for storing software programs and modules, and the processor 303 may operate the software programs and modules stored in the memory 302, for example, the software programs of the corresponding operations in the foregoing method embodiments.
Alternatively, the processor 303 may call the software programs and modules stored in the memory 302 to perform the following operations: acquiring text data and image data to be processed, wherein the text data comprises a target text, and the image data comprises a scene picture; extracting a text vector representation of the text data, the text vector representation including text information of the target text; extracting a picture vector representation of the image data, the picture vector representation including image information of the scene picture; calculating a multi-modal vector representation comprising text information and image information according to the text vector representation and the picture vector representation; and when the target text is used for expressing the scene picture, determining an error correction result for the target text and the scene picture according to the multi-modal vector representation.
Optionally, the computer device 300 is the terminal or the server. The terminal can be a smart phone, a tablet computer, a notebook computer, a smart television, a smart sound box, a wearable smart device, a personal computer and the like. The server can be an independent physical server, a server cluster or a distributed system formed by a plurality of physical servers, and can also be a cloud server for providing basic cloud computing services such as cloud service, a cloud database, cloud computing, cloud functions, cloud storage, network service, cloud communication, middleware service, domain name service, security service, CDN, big data and artificial intelligence platform and the like.
Optionally, the present application further provides a computer device, which includes a memory and a processor, where the memory stores a computer program, and the processor implements the steps in the foregoing method embodiments when executing the computer program.
The present application also provides a computer-readable storage medium for storing a computer program. The computer-readable storage medium can be applied to a computer device, and the computer program enables the computer device to execute the corresponding flow in the image-text joint error correction method in the embodiment of the present application, which is not described herein again for brevity.
The present application also provides a computer program product comprising computer instructions stored in a computer readable storage medium. The processor of the computer device reads the computer instruction from the computer-readable storage medium, and executes the computer instruction, so that the computer device executes the corresponding process in the image-text joint error correction method in the embodiment of the present application, which is not described herein again for brevity.
The present application also provides a computer program comprising computer instructions stored in a computer readable storage medium. The processor of the computer device reads the computer instruction from the computer-readable storage medium, and executes the computer instruction, so that the computer device executes the corresponding process in the image-text joint error correction method in the embodiment of the present application, which is not described herein again for brevity.
It should be understood that the processor of the embodiments of the present application may be an integrated circuit chip having signal processing capabilities. In implementation, the steps of the above method embodiments may be performed by integrated logic circuits of hardware in a processor or instructions in the form of software. The Processor may be a general purpose Processor, a Digital Signal Processor (DSP), an Application Specific Integrated Circuit (ASIC), an off-the-shelf Programmable Gate Array (FPGA) or other Programmable logic device, discrete Gate or transistor logic device, or discrete hardware components. The various methods, steps, and logic blocks disclosed in the embodiments of the present application may be implemented or performed. A general purpose processor may be a microprocessor or the processor may be any conventional processor or the like. The steps of the method disclosed in connection with the embodiments of the present application may be directly implemented by a hardware decoding processor, or implemented by a combination of hardware and software modules in the decoding processor. The software module may be located in ram, flash memory, rom, prom, or eprom, registers, etc. storage media as is well known in the art. The storage medium is located in a memory, and a processor reads information in the memory and completes the steps of the method in combination with hardware of the processor.
It will be appreciated that the memory in the embodiments of the subject application can be either volatile memory or nonvolatile memory, or can include both volatile and nonvolatile memory. The non-volatile Memory may be a Read-Only Memory (ROM), a Programmable ROM (PROM), an Erasable PROM (EPROM), an Electrically Erasable PROM (EEPROM), or a flash Memory. Volatile Memory can be Random Access Memory (RAM), which acts as external cache Memory. By way of example, but not limitation, many forms of RAM are available, such as Static random access memory (Static RAM, SRAM), Dynamic Random Access Memory (DRAM), Synchronous Dynamic random access memory (Synchronous DRAM, SDRAM), Double Data Rate Synchronous Dynamic random access memory (DDR SDRAM), Enhanced Synchronous SDRAM (ESDRAM), Synchronous link SDRAM (SLDRAM), and Direct Rambus RAM (DR RAM). It should be noted that the memory of the systems and methods described herein is intended to comprise, without being limited to, these and any other suitable types of memory.
It should be understood that the above memories are exemplary but not limiting illustrations, for example, the memories in the embodiments of the present application may also be Static Random Access Memory (SRAM), dynamic random access memory (dynamic RAM, DRAM), Synchronous Dynamic Random Access Memory (SDRAM), double data rate SDRAM (DDR SDRAM), enhanced SDRAM (enhanced SDRAM, ESDRAM), Synchronous Link DRAM (SLDRAM), Direct Rambus RAM (DR RAM), and the like. That is, the memory in the embodiments of the present application is intended to comprise, without being limited to, these and any other suitable types of memory.
Those of ordinary skill in the art will appreciate that the various illustrative elements and algorithm steps described in connection with the embodiments disclosed herein may be implemented as electronic hardware or combinations of computer software and electronic hardware. Whether such functionality is implemented as hardware or software depends upon the particular application and design constraints imposed on the implementation. Skilled artisans may implement the described functionality in varying ways for each particular application, but such implementation decisions should not be interpreted as causing a departure from the scope of the present application.
It is clear to those skilled in the art that, for convenience and brevity of description, the specific working processes of the above-described systems, apparatuses and units may refer to the corresponding processes in the foregoing method embodiments, and are not described herein again.
In the several embodiments provided in the present application, it should be understood that the disclosed system, apparatus and method may be implemented in other ways. For example, the above-described apparatus embodiments are merely illustrative, and for example, the division of the units is only one logical division, and other divisions may be realized in practice, for example, a plurality of units or components may be combined or integrated into another system, or some features may be omitted, or not executed. In addition, the shown or discussed mutual coupling or direct coupling or communication connection may be an indirect coupling or communication connection through some interfaces, devices or units, and may be in an electrical, mechanical or other form.
The units described as separate parts may or may not be physically separate, and parts displayed as units may or may not be physical units, may be located in one place, or may be distributed on a plurality of network units. Some or all of the units can be selected according to actual needs to achieve the purpose of the solution of the embodiment.
In addition, functional units in the embodiments of the present application may be integrated into one processing unit, or each unit may exist alone physically, or two or more units are integrated into one unit.
The functions, if implemented in the form of software functional units and sold or used as a stand-alone product, may be stored in a computer readable storage medium. Based on such understanding, the technical solution of the present application or portions thereof that substantially contribute to the prior art may be embodied in the form of a software product stored in a storage medium and including instructions for causing a computer device (which may be a personal computer or a server) to execute all or part of the steps of the method according to the embodiments of the present application. And the aforementioned storage medium includes: various media capable of storing program codes, such as a U disk, a removable hard disk, a ROM, a RAM, a magnetic disk, or an optical disk.
The above description is only for the specific embodiments of the present application, but the scope of the present application is not limited thereto, and any person skilled in the art can easily conceive of the changes or substitutions within the technical scope of the present application, and shall be covered by the scope of the present application. Therefore, the protection scope of the present application shall be subject to the protection scope of the claims.
Claims (12)
1. A method for jointly correcting an error of an image-text is characterized by comprising the following steps:
acquiring text data and image data to be processed, wherein the text data comprises a target text, and the image data comprises a scene picture;
extracting a text vector representation of the text data, the text vector representation including text information of the target text;
extracting a picture vector representation of the image data, the picture vector representation including image information of the scene picture;
calculating a multi-modal vector representation comprising text information and image information according to the text vector representation and the picture vector representation;
and when the target text is used for expressing the scene picture, determining an error correction result for the target text and the scene picture according to the multi-modal vector representation.
2. The teletext joint error correction method of claim 1, wherein extracting the text vector representation of the text data comprises:
and converting each word in the text data into a sequence number corresponding to each word in the word list through the word list, and searching the text vector representation of the text data according to the sequence number.
3. The teletext joint error correction method of claim 1, wherein extracting the picture vector representation of the image data comprises:
and performing target detection and feature extraction on the scene picture according to a target detection model to obtain the picture vector representation, wherein the picture vector representation comprises the image information vector representation of each image target in the scene picture and the image information vector representation of the whole picture.
4. Teletext joint error correction method according to claim 1, wherein the calculating of a multi-modal vector representation comprising text information and image information from the text vector representation and the picture vector representation comprises:
processing the text vector representation and the picture vector based on a self-attention model to obtain global interaction information between text information of the target text and image information of the scene picture;
carrying out normalization processing on the global interaction information to obtain first normalization information;
and determining a multi-modal vector representation containing text information and image information according to the global interaction information and the first normalization information.
5. The method for joint teletext error correction according to claim 4, wherein the processing the text vector representation and the picture vector based on a self-attention model to obtain global interaction information between the text information of the target text and the image information of the scene picture comprises:
inputting an embedded vector representation determined from the text vector representation and the picture vector representation from an attention model, calculating a matching matrix from a product between the embedded vector representation and a transposed matrix of the embedded vector representation;
and determining global interaction information between the text information of the target text and the image information of the scene picture according to the product of the matching matrix and the embedded vector representation.
6. The teletext joint error correction method of claim 4, wherein determining a multi-modal vector representation comprising text information and image information based on the global interaction information and the first normalization information comprises:
adding the global interaction information and the first normalization information to obtain first summation information;
inputting the first summation information into a full-connection layer for processing, and then carrying out normalization processing on an output result of the full-connection layer to obtain second normalization information;
and adding the first summation information and the second normalization information to obtain the multi-modal vector representation containing the text information and the image information.
7. The teletext joint error correction method of claim 1, further comprising:
acquiring position vector representation and type vector representation, wherein the position vector representation is used for marking the position of each word in the text data, and the type vector representation is used for distinguishing a text type from an image type;
the computing a multimodal vector representation including text information and image information from the text vector representation and the picture vector representation comprises:
and calculating a multi-modal vector representation containing text information and image information according to the text vector representation, the picture vector representation, the position vector representation and the type vector representation.
8. The teletext joint error correction method according to any one of claims 1-7, wherein the determining of the error correction result for the target text and the scene picture from the multi-modal vector representation comprises:
connecting the multi-modal vector representations with a full connection layer to obtain a first feature vector, wherein the first feature vector comprises vector representations corresponding to each word in the target text and each image target in the scene picture;
determining error correction operation corresponding to each word in the target text and each image target in the scene picture respectively according to the first feature vector;
and calculating an error correction result according to the error correction operation and the first characteristic vector so as to perform error correction processing on the target text and/or the scene picture according to the error correction result.
9. The teletext joint error correction method of claim 8, wherein determining an error correction result based on the error correction operation and the first eigenvector, further comprises:
further comprising:
if the error correction operation is error-free, determining that the error correction result is a word corresponding to the error-free error correction operation; or
If the error correction operation is a deletion operation, determining that the error correction result is that words corresponding to the deletion operation in the target text are deleted; or
If the error correction operation is a modification operation, determining that the error correction result is to modify a word corresponding to the modification operation in the target text into a predicted word, or modify an image target corresponding to the modification operation in the scene picture into a predicted image target.
10. A combined teletext error correction arrangement, the arrangement comprising:
the device comprises an acquisition unit, a processing unit and a processing unit, wherein the acquisition unit is used for acquiring text data and image data to be processed, the text data comprises a target text, and the image data comprises a scene picture;
a first extraction unit configured to extract a text vector representation of the text data, the text vector representation including text information of the target text;
a second extraction unit configured to extract a picture vector representation of the image data, the picture vector representation including image information of the scene picture;
the computing unit is used for computing multi-modal vector representation containing text information and image information according to the text vector representation and the picture vector representation;
and the determining unit is used for determining an error correction result for the target text and the scene picture according to the multi-modal vector representation when the target text is used for expressing the scene picture.
11. A computer-readable storage medium, in which a computer program is stored which is adapted to be loaded by a processor for performing the steps of the method for joint teletext error correction according to any one of claims 1-9.
12. Computer arrangement, characterized in that the computer arrangement comprises a processor and a memory, in which a computer program is stored, the processor being adapted to perform the steps of the joint teletext error correction method according to any one of claims 1-9 by calling the computer program stored in the memory.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111651496.5A CN114241279A (en) | 2021-12-30 | 2021-12-30 | Image-text combined error correction method and device, storage medium and computer equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111651496.5A CN114241279A (en) | 2021-12-30 | 2021-12-30 | Image-text combined error correction method and device, storage medium and computer equipment |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114241279A true CN114241279A (en) | 2022-03-25 |
Family
ID=80744746
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111651496.5A Pending CN114241279A (en) | 2021-12-30 | 2021-12-30 | Image-text combined error correction method and device, storage medium and computer equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114241279A (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114462356A (en) * | 2022-04-11 | 2022-05-10 | 苏州浪潮智能科技有限公司 | Text error correction method, text error correction device, electronic equipment and medium |
| WO2024139307A1 (en) * | 2022-12-27 | 2024-07-04 | 苏州元脑智能科技有限公司 | Sentence correction method and apparatus for image, and electronic device and storage medium |
-
2021
- 2021-12-30 CN CN202111651496.5A patent/CN114241279A/en active Pending
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114462356A (en) * | 2022-04-11 | 2022-05-10 | 苏州浪潮智能科技有限公司 | Text error correction method, text error correction device, electronic equipment and medium |
| CN114462356B (en) * | 2022-04-11 | 2022-07-08 | 苏州浪潮智能科技有限公司 | Text error correction method and device, electronic equipment and medium |
| WO2023197512A1 (en) * | 2022-04-11 | 2023-10-19 | 苏州浪潮智能科技有限公司 | Text error correction method and apparatus, and electronic device and medium |
| WO2024139307A1 (en) * | 2022-12-27 | 2024-07-04 | 苏州元脑智能科技有限公司 | Sentence correction method and apparatus for image, and electronic device and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110795543B (en) | Unstructured data extraction method, device and storage medium based on deep learning | |
| CN109344413B (en) | Translation processing method, translation processing device, computer equipment and computer readable storage medium | |
| CN110717017B (en) | Method for processing corpus | |
| EP3926531B1 (en) | Method and system for visio-linguistic understanding using contextual language model reasoners | |
| CN112528637B (en) | Text processing model training method, device, computer equipment and storage medium | |
| CN110276023B (en) | POI transition event discovery method, device, computing equipment and medium | |
| US20190012405A1 (en) | Unsupervised generation of knowledge learning graphs | |
| WO2023201975A1 (en) | Difference description sentence generation method and apparatus, and device and medium | |
| CN114556328A (en) | Data processing method and device, electronic equipment and storage medium | |
| CN109726397B (en) | Labeling method and device for Chinese named entities, storage medium and electronic equipment | |
| CN110472548B (en) | Video continuous sign language recognition method and system based on grammar classifier | |
| CN114241279A (en) | Image-text combined error correction method and device, storage medium and computer equipment | |
| Ham et al. | Ksl-guide: A large-scale korean sign language dataset including interrogative sentences for guiding the deaf and hard-of-hearing | |
| CN113095072B (en) | Text processing method and device | |
| CN112307754A (en) | Statement acquisition method and device | |
| CN114528840A (en) | Chinese entity identification method, terminal and storage medium fusing context information | |
| CN116311312A (en) | Training method of visual question-answering model and visual question-answering method | |
| CN116913278B (en) | Voice processing method, device, equipment and storage medium | |
| CN112084788A (en) | Automatic marking method and system for implicit emotional tendency of image captions | |
| CN114238587A (en) | Reading understanding method and device, storage medium and computer equipment | |
| US20230130662A1 (en) | Method and apparatus for analyzing multimodal data | |
| CN113591493B (en) | Translation model training method and translation model device | |
| CN111681676B (en) | Method, system, device and readable storage medium for constructing audio frequency by video object identification | |
| CN117034133A (en) | Data processing method, device, equipment and medium | |
| CN114417898A (en) | Data processing method, device, equipment and readable storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB02 | Change of applicant information |
Address after: 100193 room 311-2, third floor, building 5, East District, yard 10, northwest Wangdong Road, Haidian District, Beijing Applicant after: iFLYTEK (Beijing) Co.,Ltd. Applicant after: IFLYTEK Co.,Ltd. Address before: 100193 room 311-2, third floor, building 5, East District, yard 10, northwest Wangdong Road, Haidian District, Beijing Applicant before: Zhongke Xunfei Internet (Beijing) Information Technology Co.,Ltd. Applicant before: IFLYTEK Co.,Ltd. |
|
| CB02 | Change of applicant information |