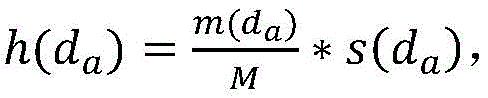发明内容
针对上述问题,本发明旨在提供一种基于区块链的远程互联网大数据智慧医疗系统。
本发明创造的目的通过以下技术方案实现:
基于区块链的远程互联网大数据智慧医疗系统,包括生命体征采集模块、医疗大数据获取模块、区块链存储模块和智慧医疗终端,所述生命体征采集模块和患者的床位号进行绑定,用于采集患者的生命体征数据,并将采集的生命体征数据和患者的床位号通过互联网传输至智慧医疗终端,所述医疗大数据获取模块用于收集生命体征大数据,并将收集的生命体征大数据传输至区块链存储模块进行存储,所述智慧医疗终端包括大数据处理单元、生命体征分析单元、智能预警单元、患者信息收录单元和人机交互单元,智慧医疗终端从区块链存储模块中调取所述生命体征大数据,并将调取的生命体征大数据输入至大数据处理单元进行处理,所述生命体征分析单元根据处理后的生命体征大数据建立根据生命体征数据对患者的身体状态进行评估的健康评估模型,将接收到的患者的生命体征数据输入到健康评估模型中,从而评估患者的身体状态是健康还是危险,当评估患者的身体状态为危险时令智能预警单元进行预警,所述患者信息收录单元用于记录患者的基础信息、患者的生命体征数据和评估所得的患者的身体状态,医护人员可以通过在人机交互单元中输入患者的基础信息查询患者的生命体征数据和患者的身体状态。
优选地,所述生命体征分析单元采用支持向量机建立根据生命体征数据进行身体状态评估的健康评估模型,采用大数据处理单元处理后的生命体征大数据作为训练和测试所述支持向量机的样本集。
优选地,所述患者的基础信息包括患者的姓名、年龄和床位号。
优选地,所述大数据处理单元用于对生命体征大数据进行聚类,并在聚类的过程中去除所述生命体征大数据中的噪声数据,确定生命体征大数据聚类所得的各个类集合对应的身体状态的标签,在支持向量机的训练过程中,将生命体征大数据的类集合作为支持向量机的输入值,将类集合所对应的身体状态的标签作为支持向量机的输出值。
优选地,所述身体状态的标签包括健康和危险。
优选地,所述大数据处理单元用于对生命体征大数据进行聚类,并在聚类的过程中去除生命体征大数据中的噪声数据,具体包括:
(1)在生命体征大数据中选取类中心;
(2)根据选取的类中心对生命体征大数据中的数据进行聚类,并在聚类的过程中去除生命体征大数据中的噪声数据。
优选地,采用下列方式在所述生命体征大数据中选取类中心:
设Y表示生命体征大数据组成的集合,y
i表示集合Y中的第i个数据,定义s(y
i)表示数据y
i在集合Y中的全局相似系数,且
其中,y
j表示集合Y中的第j个数据,M(Y)表示集合Y中的数据个数;设U(y
i)表示数据y
i的邻域数据集合,给定正整数M,采用下列步骤在集合Y中选取M个数据加入到集合U(y
i)中:
步骤1:设y
i(1)表示集合Y中距离数据y
i最近的数据,ω(y
i(1))表示数据y
i(1)的局部区域,且ω(y
i(1))为以数据
为中心、以|y
i(1)-y
i|为边长的正方体区域,将数据y
i(1)加入到集合U(y
i)中;
步骤2:在局部区域ω(y
i(1))外的数据中确定距离数据y
i最近的数据,将该数据记为y
i(2),设ω(y
i(2))表示数据y
i(2)的局部区域,且ω(y
i(2))为以数据
为中心、以|y
i(2)-y
i|为边长的正方体区域,将数据y
i(2)加入到集合U(y
i)中;
步骤3:继续在局部区域ω(y
i(1))和局部区域ω(
yi(2))外的数据中确定距离数据y
i最近的数据,将该数据记为y
i(3),设ω(y
i(3))表示数据y
i(3)的局部区域,且ω(y
i(3))为以数据
为中心、以|y
i(3)-y
i|为边长的正方体区域,将数据y
i(3)加入到集合U(y
i)中;
步骤4:继续按照上述步骤1、步骤2和步骤3中的方法确定数据加入到集合U(yi)中,直到集合U(yi)中的数据个数等于M时,则停止向集合U(yi)中加入数据;
采用下列公式在集合Y中筛选出可作为类中心的候选数据:
式中,f(y
i)表示数据y
i在集合Y中的类中心属性值,y
i(l)表示集合U(y
i)中的第l个数据,s(y
i(l))表示数据y
i(l)在集合Y中的全局相似系数,ρ(y
i(l),y
i)表示数据y
i(l)相较于数据y
i的距离权值,且
当数据y
i的类中心属性值
时,则将数据y
i视为类中心的候选数据,且判定所述类中心的候选数据为非噪声数据;当数据y
i的类中心属性值
时,则将数据y
i视为未聚类数据;
设L(Y)表示集合Y中视为类中心的候选数据组成的集合,在集合L(Y)中选取类中心,并根据选取的类中心对集合L(Y)中的候选数据进行聚类,具体包括:
Step(1):选取集合L(Y)中具有最大全局相似系数的候选数据为第一个类中心,将所述第一个类中心记为c1,类中心c1所在的类集合记为C1,将类中心c1在集合L(Y)中删除,并采用下列步骤在当前集合L(Y)中筛选出属于类集合C1的其他候选数据,具体为:
步骤(1):设lk(1)表示第1次筛选时集合L(Y)中的第k个候选数据,定义G(lk(1),C1)表示候选数据lk(1)和类集合C1之间的聚类函数,且G(lk(1),C1)的表达式为:
G(lk(1),C1)=θ(lk(1),C1)*|s(lk(1))-s(c1)|
式中,θ(lk(1),C1)表示判断函数,设N(lk(1))表示在集合Y中选取的距离候选数据lk(1)最近的M个数据组成的邻域集合,m(lk(1),C1)表示邻域集合N(lk(1))中存在的属于类集合C1的数据个数,当m(lk(1),C1)≠0时,θ(lk(1),C1)=1,当m(lk(1),C1)=0时,θ(lk(1),C1)=0,s(c1)表示类中心c1在集合Y中的全局相似系数,s(lk(1))表示候选数据lk(1)在集合Y中的全局相似系数;
当
时,则判定候选数据l
k(1)为类集合C
1中的数据,将候选数据l
k(1)加入到类集合C
1中,并将候选数据l
k(1)在集合L(Y)中删除,当G(l
k(1),C
1)=0或者
时,则将候选数据l
k(1)在集合L(Y)中保留;
步骤(2),设lK(2)表示第2次筛选时当前集合L(Y)中的第K个候选数据,定义G(lK(2),C1)表示候选数据lK(2)和类集合C1之间的聚类函数,且G(lK(2),C1)的表达式为:
其中,θ(l
K(2),C
1)表示判断函数,设N(l
k(2))表示在集合Y中选取距离候选数据l
k(2)最近的M个数据组成的邻域集合,m(l
k(2),C
1)表示邻域集合N(l
K(2))中存在的属于类集合C
1的数据个数,当m(l
K(2),C
1)≠0时,θ(l
K(2),C
1)=1,当m(l
K(2),C
1)=0时,θ(l
K(2),C
1)=0,s(l
K(2))表示候选数据l
K(2)在集合Y中的全局相似系数,y
1,z表示类集合C
1中的第z个数据,ρ(y
1,z,l
K(2))表示数据y
1,z相较于候选数据l
K(2)的距离权值,且
s(y
1,z)表示数据y
1,z在集合Y中的全局相似系数;
当
时,则判定候选数据l
K(2)为类集合C
1中的数据,将候选数据l
K(2)加入到类集合C
1中,并将候选数据l
K(2)在集合L(Y)中删除,当G(l
K(2),C
1)=0或者
时,则将候选数据L
K(2)在集合L(Y)中保留;
当第二次筛选时在集合L(Y)中筛选出属于类集合C1的数据时,则继续按照步骤(2)中的方法在集合L(Y)中进行第三次筛选,直到在当前筛选次数时没有在集合L(Y)中筛选出属于类集合C1的数据时即停止在集合L(Y)中进行下一次的筛选;
Step(2):继续选取当前集合L(Y)中具有最大全局相似系数的候选数据为第二个类中心,将所述第二个类中心记为c2,所述类中心c2所在的类集合记为C2,将类中心c2在集合L(Y)中删除,并采用上述步骤(1)和步骤(2)中的方法在当前集合L(Y)中筛选出属于类集合C2的其他候选数据;筛选完成后,将类集合C2中的候选数据在当前集合L(Y)中删除;
重复上述Step(1)和Step(2)中的方法直到当前集合L(Y)中剩余的候选数据个数为0时,即完成了在生命体征大数据中选取类中心,并完成了对所述生命体征大数据的初步聚类。
优选地,根据选取的类中心对所述生命体征大数据中的数据进行聚类,并在聚类的过程中去除生命体征大数据中的噪声数据,具体为:
根据选取的类中心和初步聚类结果对集合Y中剩余的未聚类数据进行聚类,设D(Y)表示集合Y中未聚类数据组成的集合,d
a表示集合D(Y)中的第a个未聚类数据,N(d
a)表示集合Y中距离未聚类数据d
a最近的M个数据组成的邻域集合,定义h(d
a)表示未聚类数据d
a在集合D(Y)中的聚类优先级,且
其中,m(d
a)表示邻域集合N(d
a)中已聚类数据的个数,s(d
a)表示未聚类数据d
a在集合Y中的全局相似系数;
Step1:对此时集合D(Y)中具有最大聚类优先级的未聚类数据进行优先聚类,设d
e表示集合D(Y)中的第e个未聚类数据,且
N(d
e)表示集合Y中距离未聚类数据d
e最近的M个数据组成的邻域集合,m(d
e)表示集合N(d
e)中已聚类数据的个数;
当m(de)=0时,则判定集合D(Y)中的未聚类数据均为噪声数据,并将所述噪声数据从D(Y)中都删除;
当m(de)≠0时,设Je,p表示集合N(de)中的第p个已聚类数据,将已聚类数据Je,p所在的类集合表示为Ce,p,定义J(de,Ce,p)为未聚类数据de和类集合Ce,p之间的分布检测系数,则J(de,Ce,p)的计算公式为:
式中,Me,p表示集合N(de)中存在的属于类集合Ce,p的已聚类数据的个数,N′(Je,p)表示类集合Ce,p中距离已聚类数据Je,p最近的M个已聚类数据组成的集合,Je,p,q表示集合N′(Je,p)中的第q个已聚类数据,Je,v表示集合N(de)中的第v个已聚类数据,且Je,v为类集合Ce,p中的数据,N′(Je,v)表示类集合Ce,p中距离已聚类数据Je,v最近的M个已聚类数据组成的集合,Je,v,b表示集合N′(Je,v)中的第b个已聚类数据;
设M(d
e)表示集合N(d
e)中的已聚类数据所处的不同类集合的个数,C
e,n表示数据d
e和所述M(d
e)个类集合之间拥有最小分布检测系数的类集合,即
当未聚类数据d
e和类集合C
e,n之间满足:
时,则将未聚类数据d
e加入到类集合C
e,n中,并将未聚类数据d
e在集合D(Y)中删除,判定未聚类数据d
e为非噪声数据,当未聚类数据d
e和类集合C
e,n之间满足:
时,则认定未聚类数据d
e为噪声数据,将未聚类数据d
e在集合D(Y)中删除,其中,s(d
e)表示未聚类数据d
e在集合Y中的全局相似系数,y
e,n,r表示类集合C
e,n中的第r个数据,s(y
e,n,r)表示数据y
e,n,r在集合Y中的全局相似系数,ρ(y
e,n,r,d
e)表示数据y
e,n,r相较于未聚类数据d
e的距离权值,且
Step2:按照上述Step1中的方法重新在当前集合D(Y)中选取具有最大聚类优先级的数据进行优先聚类,直到集合D(Y)中的未聚类数据个数为0时,则停止聚类。
本发明创造的有益效果:根据生命体征大数据建立根据患者的生命体征数据对患者的身体状态进行评估的健康评估模型,实现了远程对患者的身体状态进行统一监护,从而减轻了医护人员的工作量,并且能够在患者的身体状态处于危险时及时发现,从而提高了施救效率;采用大数据处理单元对生命体征大数据进行处理,并利用处理后的生命体征大数据对支持向量机进行训练,从而建立根据生命体征数据对患者的身体状态进行评估的健康评估模型,在利用生命体征大数据对支持向量机进行训练之前,先对生命体征大数据进行聚类处理,并在聚类处理的过程中去除生命体征大数据中的噪声数据,从而避免噪声数据对支持向量机的评估准确度的影响,采用聚类所得的类集合作为训练支持向量机的输入值,能够显著减少训练所需的时间并且提高了支持向量的性能;在对生命体征大数据的聚类过程中,提出一种新的类中心的选取方式,能够适应不同密度类和不同尺寸类的类中心的选取,具有较高的类中心的选取精度;提出了一种根据选取的类中心对生命体征大数据进行聚类的方法,能够在对大数据进行有效聚类的同时,避免噪声数据对聚类结果的影响,使得聚类结果具有较高的准确度。
具体实施方式
结合以下实施例对本发明作进一步描述。
参见图1,本实施例的基于区块链的远程互联网大数据智慧医疗系统,包括生命体征采集模块、医疗大数据获取模块、区块链存储模块和智慧医疗终端,所述生命体征采集模块和患者的床位号进行绑定,用于采集患者的生命体征数据,并将采集的生命体征数据和患者的床位号通过互联网传输至智慧医疗终端,所述医疗大数据获取模块用于收集生命体征大数据,并将收集的生命体征大数据传输至区块链存储模块进行存储,所述智慧医疗终端包括大数据处理单元、生命体征分析单元、智能预警单元、患者信息收录单元和人机交互单元,智慧医疗终端从区块链存储模块中调取所述生命体征大数据,并将调取的生命体征大数据输入至大数据处理单元进行处理,所述生命体征分析单元根据处理后的生命体征大数据建立根据生命体征数据对患者的身体状态进行评估的健康评估模型,将接收到的患者的生命体征数据输入到健康评估模型中,从而评估患者的身体状态是健康还是危险,当评估患者的身体状态为危险时令智能预警单元进行预警,所述患者信息收录单元用于记录患者的基础信息、患者的生命体征数据和评估所得的患者的身体状态,医护人员可以通过在人机交互单元中输入患者的基础信息查询患者的生命体征数据和患者的身体状态。
优选地,所述生命体征分析单元采用支持向量机建立根据生命体征数据进行身体状态评估的健康评估模型,采用大数据处理单元处理后的生命体征大数据作为训练和测试所述支持向量机的样本集。
优选地,所述患者的基础信息包括患者的姓名、年龄和床位号。
本优选实施例提供一种远程的智慧医疗系统,根据生命体征大数据建立根据患者的生命体征数据对患者的身体状态进行评估的健康评估模型,实现了远程对患者的身体状态进行统一监护,从而减轻了医护人员的工作量,并且能够在患者的身体状态处于危险时及时发现,从而提高了施救效率。
优选地,所述大数据处理单元用于对生命体征大数据进行聚类,并在聚类的过程中去除所述生命体征大数据中的噪声数据,确定生命体征大数据聚类所得的各个类集合对应的身体状态的标签,在支持向量机的训练过程中,将生命体征大数据的类集合作为支持向量机的输入值,将类集合所对应的身体状态的标签作为支持向量机的输出值。
优选地,所述身体状态的标签包括健康和危险。
本优选实施例采用大数据处理单元对生命体征大数据进行处理,并利用处理后的生命体征大数据对支持向量机进行训练,从而建立根据生命体征数据对患者的身体状态进行评估的健康评估模型,在利用生命体征大数据对支持向量机进行训练之前,先对生命体征大数据进行聚类处理,并在聚类处理的过程中去除生命体征大数据中的噪声数据,从而避免噪声数据对支持向量机的评估准确度的影响,采用聚类所得的类集合作为训练支持向量机的输入值,能够显著减少训练所需的时间并且提高了支持向量的性能。
优选地,所述大数据处理单元用于对生命体征大数据进行聚类,并在聚类的过程中去除生命体征大数据中的噪声数据,具体包括:
(1)在生命体征大数据中选取类中心;
(2)根据选取的类中心对生命体征大数据中的数据进行聚类,并在聚类的过程中去除生命体征大数据中的噪声数据。
优选地,采用下列方式在所述生命体征大数据中选取类中心:
设Y表示生命体征大数据组成的集合,y
i表示集合Y中的第i个数据,定义s(y
i)表示数据y
i在集合Y中的全局相似系数,且
其中,y
j表示集合Y中的第j个数据,m(Y)表示集合Y中的数据个数;设U(y
i)表示数据y
i的邻域数据集合,给定正整数M,M的值可以取5,采用下列步骤在集合Y中选取M个数据加入到集合U(y
i)中:
步骤1:设y
i(1)表示集合Y中距离数据y
i最近的数据,ω(y
i(1))表示数据y
i(1)的局部区域,且ω(y
i(1))为以数据
为中心、以|y
i(1)-y
i|为边长的正方体区域,将数据y
i(1)加入到集合U(y
i)中;
步骤2:在局部区域ω(y
i(1))外的数据中确定距离数据y
i最近的数据,将该数据记为y
i(2),设ω(y
i(2))表示数据y
i(2)的局部区域,且ω(y
i(2))为以数据
为中心、以|y
i(2)-y
i|为边长的正方体区域,将数据y
i(2)加入到集合U(y
i)中;
步骤3:继续在局部区域ω(y
i(1))和局部区域ω(y
i(2))外的数据中确定距离数据yi最近的数据,将该数据记为y
i(3),设ω(y
i(3))表示数据y
i(3)的局部区域,且ω(y
i(3))为以数0
为中心、以|y
i(3)-y
i|为边长的正方体区域,将数据y
i(3)加入到集合U(y
i)中;
步骤4:继续按照上述步骤1、步骤2和步骤3中的方法确定数据加入到集合U(yi)中,直到集合U(yi)中的数据个数等于M时,则停止向集合U(yi)中加入数据;
采用下列公式在集合Y中筛选出可作为类中心的候选数据:
式中,f(y
i)表示数据y
i在集合Y中的类中心属性值,y
i(l)表示集合U(y
i)中的第l个数据,s(y
i(l))表示数据y
i(l)在集合Y中的全局相似系数,ρ(y
i(l),y
i)表示数据y
i(l)相较于数据y
i的距离权值,且
当数据y
i的类中心属性值
时,则将数据y
i视为类中心的候选数据,且判定所述类中心的候选数据为非噪声数据;当数据y
i的类中心属性值
时,则将数据y
i视为未聚类数据;
设L(Y)表示集合Y中视为类中心的候选数据组成的集合,在集合L(Y)中选取类中心,并根据选取的类中心对集合L(Y)中的数据进行聚类,具体包括:
Step(1):选取集合L(Y)中具有最大全局相似系数的候选数据为第一个类中心,将所述第一个类中心记为c1,类中心c1所在的类集合记为C1,将类中心c1在集合L(Y)中删除,并采用下列步骤在当前集合L(Y)中筛选出属于类集合C1中的候选数据,具体为:
步骤(1):设lk(1)表示第1次筛选时集合L(Y)中的第k个候选数据,定义G(lk(1),C1)表示候选数据lk(1)和类集合C1之间的聚类函数,且G(lk(1),C1)的表达式为:
G(lk(1),C1)=θ(lk(1),C1)*|s(c1)-s(lk(1))|
式中,θ(lk(1),C1)表示判断函数,设N(lk(1))表示在集合Y中选取的距离候选数据lk(1)最近的M个数据组成的邻域集合,m(lk(1),C1)表示邻域集合N(lk(1))中存在的属于类集合C1的数据个数,当m(lk(1),C1)≠0时,θ(lk(1),C1)=1,当m(lk(1),C1)=0时,θ(lk(1),C1)=0,s(c1)表示类中心c1在集合Y中的全局相似系数,s(lk(1))表示候选数据lk(1)在集合Y中的全局相似系数;
当
时,则判定候选数据l
k(1)为类集合C
1中的数据,将候选数据l
k(1)加入到类集合C
1中,并将候选数据l
k(1)在集合L(Y)中删除,当G(l
k(1),C
1)=0或者
时,则将候选数据l
k(1)在集合L(Y)中保留;
步骤(2),设lK(2)表示第2次筛选时当前集合L(Y)中的第K个候选数据,定义G(lK(2),C1)表示候选数据lK(2)和类集合C1之间的聚类函数,且G(lK(2),C1)的表达式为:
其中,θ(l
K(2),C
1)表示判断函数,设N(l
K(2))表示在集合Y中选取距离候选数据l
K(2)最近的M个数据组成的邻域集合,m(l
K(2),C
1)表示邻域集合N(l
K(2))中存在的属于类集合C
1的数据个数,当m(l
K(2),C
1)≠0时,θ(l
K(2),C
1)=1,当m(l
K(2),C
1)=0时,θ(l
K(2),C
1)=0,s(l
K(2))表示候选数据l
K(2)在集合Y中的全局相似系数,y
1,z表示类集合C
1中的第z个数据,ρ(y
1,z,l
K(2))表示数据y
1,z相较于候选数据l
K(2)的距离权值,且
s(y
1,z)表示数据y
1,z在集合Y中的全局相似系数;
当
时,则判定候选数据l
K(2)为类集合C
1中的数据,将候选数据l
K(2)加入到类集合C
1中,并将候选数据l
K(2)在集合L(Y)中删除,当G(l
K(2),C
1)=0或者
时,则将候选数据l
K(2)在集合L(Y)中保留;
当第二次筛选时在集合L(Y)中筛选出属于类集合C1的数据时,则继续按照步骤(2)中的方法在集合L(Y)中进行第三次筛选,直到在当前筛选次数时没有在集合L(Y)中筛选出属于类集合C1的数据时即停止在集合L(Y)中进行下一次的筛选;
Step(2):继续选取当前集合L(Y)中具有最大全局相似系数的候选数据为第二个类中心,将所述第二个类中心记为c2,所述类中心c2所在的类集合记为C2,将类中心c2在集合L(Y)中删除,并采用上述步骤(1)和步骤(2)中的方法在当前集合L(Y)中筛选出属于类集合C2中的候选数据;筛选完成后,将类集合C2中的候选数据在当前集合L(Y)中删除;
重复上述Step(1)和Step(2)中的方法直到当前集合L(Y)中剩余的候选数据个数为0时,即完成了在生命体征大数据中选取类中心,并完成了对所述生命体征大数据的初步聚类。
本优选实施例用于在生命体征大数据中选取类中心,从而根据选取的类中心对生命体征大数据进行聚类。在对大数据进行聚类时,类中心的选取直接影响着后期聚类结果的准确度和聚类的效率,也决定着噪声数据检测的准确度;传统的类中心的选取方式多数容易受到类密度、类尺寸的影响,从而容易选取出高密度类、具有教小尺寸类的类中心而忽略低密度类或者具有较大尺寸类的类中心,从而影响最终的聚类效果,针对上述现象,本优选实施例提出的在生命体征大数据中筛选出可作为类中心的候选数据的方式能够有效的筛选出不同密度、不同尺寸类的类中心,即提出的类中心的筛选方式不受类密度和类尺寸的影响,对于低密度类或者具有较大尺寸的类具有相同的类中心的检测精度,因为本优选实施例的类中心的筛选方式是通过计算所述数据的全局相似系数和其邻域数据的全局相似系数的加权均值之间的绝对差值来衡量所述数据的中心属性,数据的全局相似系数能够有效的衡量所述数据在生命体征大数据中的分布特性,邻域数据集合中邻域数据的选取方式能够保证所述数据在选取的邻域数据中的中心性,避免选取的邻域数据都处于所述数据一边的现象,再根据所述数据的全局相似系数和其邻域数据的全局相似系数的加权均值之间的绝对差值来衡量所述数据的中心属性,当所述数据处于类中心或类中心附近时,无论其处于何种密度或尺寸的类中,其全局相似系数和选取的邻域数据的全局相似系数都具有较大的相似性,因此,通过计算所述数据和其邻域数据之间全局相似系数的相似性能够有效的判断所述数据的中心属性,并且不受类密度或者类尺寸的影响,从而提高较小密度或者较大尺寸类的类中心的检测精度;按照上述方法能够有效的筛选出生命体征大数据中处于类中心或者类中心附近的数据,继续采用本优选实施例提出的类中心的选取方式,能够有效的选取类中心的同时,将类中心附近的数据聚类到其所对应的类集合中,即完成了生命体征大数据的初步聚类,为接下来的聚类和噪声检测奠定了基础。
优选地,根据选取的类中心对所述生命体征大数据中的数据进行聚类,并在聚类的过程中去除生命体征大数据中的噪声数据,具体为:
根据选取的类中心和初步聚类结果对集合Y中剩余的未聚类数据进行聚类,设D(Y)表示集合Y中未聚类数据组成的集合,d
a表示集合D(Y)中的第a个未聚类数据,N(d
a)表示集合Y中距离未聚类数据d
a最近的M个数据组成的邻域集合,定义h(d
a)表示未聚类数据d
a在集合D(Y)中的聚类优先级,且
其中,m(d
a)表示邻域集合N(d
a)中已聚类数据的个数,s(d
a)表示未聚类数据d
a在集合Y中的全局相似系数;
Step1:对此时集合D(Y)中具有最大聚类优先级的未聚类数据进行优先聚类,设d
e表示集合D(Y)中的第e个未聚类数据,且
N(d
e)表示集合Y中距离未聚类数据d
e最近的M个数据组成的邻域集合,m(d
e)表示集合N(d
e)中已聚类数据的个数;
当m(de)=0时,则判定集合D(Y)中的未聚类数据均为噪声数据,并将所述噪声数据从D(Y)中都删除;
当m(de)≠0时,设Je,p表示集合N(de)中的第p个已聚类数据,将已聚类数据Je,p所在的类集合表示为Ce,p,定义J(de,Ce,p)为未聚类数据de和类集合Ce,p之间的分布检测系数,则J(de,Ce,p)的计算公式为:
式中,Me,p表示集合N(de)中存在的属于类集合Ce,p的已聚类数据的个数,N′(Je,p)表示类集合Ce,p中距离已聚类数据Je,p最近的M个已聚类数据组成的集合,Je,p,q表示集合N′(Je,p)中的第q个已聚类数据,Je,v表示集合N(de)中的第v个已聚类数据,且Je,v为类集合Ce,p中的数据,N′(Je,v)表示类集合Ce,p中距离已聚类数据Je,v最近的M个已聚类数据组成的集合,Je,v,b表示集合N′(Je,v)中的第b个已聚类数据;
设M(d
e)表示集合N(d
e)中的已聚类数据所处的不同类集合的个数,C
e,n表示数据d
e和所述M(d
e)个类集合之间拥有最小分布检测系数的类集合,即
当未聚类数据d
e和类集合C
e,n之间满足:
时,则将未聚类数据d
e加入到类集合C
e,n中,并将未聚类数据d
e在集合D(Y)中删除,判定未聚类数据d
e为非噪声数据,当未聚类数据d
e和类集合C
e,n之间满足:
时,则认定未聚类数据d
e为噪声数据,将未聚类数据d
e在集合D(Y)中删除,其中,s(d
e)表示未聚类数据d
e在集合Y中的全局相似系数,y
e,n,r表示类集合C
e,n中的第r个数据,s(y
e,n,r)表示数据y
e,n,r在集合Y中的全局相似系数,ρ(y
e,n,r,d
e)表示数据y
e,n,r相较于未聚类数据d
e的距离权值,且
Step2:按照上述Step1中的方法重新在当前集合D(Y)中选取具有最大聚类优先级的数据进行优先聚类,直到集合D(Y)中的未聚类数据个数为0时,则停止聚类。
本优选实施例用于根据选取的类中心和初步聚类结果对生命体征大数据中的未聚类数据进行聚类,并去除所述生命体征大数据中的噪声数据,对未聚类数据定义聚类优先级,所述聚类优先级综合考虑了未聚类数据的全局相似系数和其邻域集合中的已聚类数据个数,当所述未聚类数据拥有较大的全局相似系数并且其邻域集合中拥有较多的已聚类数据时,其具有较大概率为类集合中的数据,因此采用迭代的方式在未聚类数据集合中选取具有最大聚类优先级的未聚类数据进行聚类,能够保证优先对未聚类数据中的非噪声数据进行聚类,并且为接下来的未聚类数据的聚类奠定基础的同时,能够避免噪声数据对聚类结果的影响;在对具有最大聚类优先级的未聚类数据进行聚类时,当此时的最大聚类优先级为0时,则判定生命体征大数据中剩余的未聚类数据均为噪声数据,当此时的最大聚类优先级不为0时,则定义分布检测系数用于衡量所述未聚类数据和其邻域集合中已聚类数据所处类集合之间的分布相似性,定义的分布检测系数通过计算邻域集合中已聚类数据和其所在类集合中M个较近的已聚类数据之间的平均距离来衡量待检测类集合中数据的分布特性,通过计算所述未聚类数据和其邻域集合中已聚类数据之间的距离来衡量所述数据和待检测类集合中数据之间的分布特性,最后将这两者之间的分布特性进行比较,和未聚类数据的分布特性最为相似的类集合具有最大概率为未聚类数据所属于的类集合,因此,选取和未聚类数据之间具有最小分布检测系数值的类集合进行检测,在检测过程中,通过比较未聚类数据和待检测类集合中的数据的全局相似系数之间的相似性来判断所述未聚类数据是否为该类集合的数据,从而能够有效的对未聚类数据进行聚类,并且能够有效的检测出未聚类数据中的噪声数据。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。