CN112463964A - Text classification and model training method, device, equipment and storage medium - Google Patents
Text classification and model training method, device, equipment and storage medium Download PDFInfo
- Publication number
- CN112463964A CN112463964A CN202011386332.XA CN202011386332A CN112463964A CN 112463964 A CN112463964 A CN 112463964A CN 202011386332 A CN202011386332 A CN 202011386332A CN 112463964 A CN112463964 A CN 112463964A
- Authority
- CN
- China
- Prior art keywords
- training
- text
- classification
- training text
- difficulty
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
The application discloses a text classification and model training method, a device, equipment and a storage medium, wherein a training text set is divided into a plurality of training text subsets, each subset is used for training a corresponding initial text classification model, each subset is further used as a verification set, each training text in the verification set is subjected to classification prediction by using the initial text classification models corresponding to other subsets except the verification set so as to obtain the classification difficulty of each training text, and each training text in the training text set is divided into a plurality of training text subsets with different classification difficulties again according to the classification difficulty. The text classification method provides powerful training data support for better training target text classification models, and the target text classification models can be trained progressively from low to high according to classification difficulty on the basis of training text subsets with different classification difficulties subsequently, so that the problem of poor model training effect caused by the phenomenon of unbalanced training text difficulty is solved.
Description
Technical Field
The present application relates to the field of training data processing technologies, and in particular, to a method, an apparatus, a device, and a storage medium for text classification and model training.
Background
There is a fundamental and important task in the field of natural language understanding, namely to classify text. To implement text classification, the prior art generally trains neural network models to perform text classification processing through the models.
Under a real-world scene, a large number of training texts often show a long tail phenomenon (also called a sample imbalance problem), and different training texts contain different amounts of information, which causes different training texts to be learned by models in different degrees of difficulty, that is, a sample imbalance phenomenon caused by imbalance in training difficulty of a single training text. In the prior art, training texts are not distinguished, but a model is directly trained based on samples with unbalanced training difficulty, so that the knowledge learned by the model is limited, and the final classification capability is poor.
Disclosure of Invention
In view of the above problems, the present application provides a text classification and model training method, device, equipment and storage medium, so as to solve the problem that the training difficulty of the existing training text is unbalanced, and the model training effect is affected when the model is trained. The specific scheme is as follows:
a method of text classification, comprising:
dividing a training text set into a plurality of training text subsets, and training a corresponding initial text classification model by using each training text subset;
respectively taking each training text subset as a verification set, and performing classification prediction on each training text in the verification set by using an initial text classification model corresponding to each training text subset except the verification set to obtain the classification difficulty of each training text in the verification set;
and according to the classification difficulty, each training text in the training text set is divided into a plurality of training text subsets with different classification difficulties again.
Preferably, the dividing the training text set into a plurality of training text subsets includes:
and randomly dividing the training text set into a plurality of training text subsets which are not crossed with each other by adopting a random division mode.
Preferably, the process of performing classification prediction on each training text in the verification set by using each initial text classification model to obtain the classification difficulty of each training text includes:
aiming at each training text in the verification set, carrying out classification prediction on the training text by utilizing each initial text classification model respectively to obtain the confidence coefficient of the training text predicted by each initial text classification model, wherein the training text belongs to the labeled class;
and determining the classification difficulty of the training texts based on the confidence coefficient of the training texts, which are predicted by each initial text classification model and belong to the labeling category.
Preferably, the determining the classification difficulty of the training text based on the confidence level that the training text predicted by each initial text classification model belongs to the labeling category includes:
determining the training texts predicted by the initial text classification models to belong to a set of confidence degrees of labeling categories as classification difficulty representations of the training texts;
or the like, or, alternatively,
and performing mathematical operation on the confidence coefficients of the training texts predicted by the initial text classification models and belonging to the labeling categories to obtain a comprehensive confidence coefficient, and determining the comprehensive confidence coefficient as the classification difficulty expression of the training texts.
Preferably, the repartitioning, according to the classification difficulty, each training text in the training text set into a plurality of training text subsets with different classification difficulties includes:
determining a classification difficulty interval where the classification difficulty of each training text in the training text set is located by referring to each set classification difficulty interval;
and dividing each training text in the training text set into a new training text subset corresponding to the classification difficulty interval to obtain a new training text subset corresponding to each classification difficulty interval.
Preferably, the repartitioning, according to the classification difficulty, each training text in the training text set into a plurality of training text subsets with different classification difficulties includes:
clustering each training text in the training text set by taking the classification difficulty as a clustering condition to obtain a plurality of clustered clusters;
and taking the training text in each cluster as a new training text subset, and determining the classification difficulty of the new training text subset corresponding to the cluster based on the classification difficulty of each training text in the cluster.
A text classification model training method comprises the following steps:
acquiring training text subsets of different classification difficulties divided by the text classification method;
and training the target text classification model by using the training text subsets in sequence according to the sequence of the classification difficulty from low to high.
Preferably, the training of the target text classification model by using the training text subsets in sequence according to the sequence of the classification difficulty from low to high includes:
and training the target text classification model by sequentially utilizing each training text subset in an incremental training mode according to the sequence of the classification difficulty from low to high.
Preferably, after the training of the target text classification model by using the training text subsets in sequence, the method further includes:
and forming a full training text set by the training text subsets with different difficulties, and training the target text classification model by using the full training text set.
Preferably, the training of the target text classification model by sequentially using the training text subsets in an incremental training manner according to the sequence of the classification difficulty from low to high includes:
determining a training stage corresponding to each training text subset according to the sequence of the classification difficulty of each training text subset from low to high;
in each training stage, training texts are sampled from training text subsets respectively corresponding to the training stage and each preceding training stage, and a training text set corresponding to the training stage is formed by sampling results;
and training a target text classification model by using the training text set corresponding to the training stage.
Preferably, the training a target text classification model by using the training text set corresponding to the training phase includes:
and training a target text classification model by using a training text set corresponding to the training stage and the distribution information of each class of texts in the training text set.
Preferably, the training of the target text classification model by using the training text set corresponding to the training phase and the distribution information of each category of text in the training text set includes:
inputting the coding characteristics of each training text in the training text set corresponding to the training stage into a target text classification model;
processing the coding features by a hidden layer of the target text classification model, and predicting scores of the training text on each classification label based on the processed coding features;
adding the score of the training text on each classification label to the number of training texts under the corresponding classification label in the training text set by the target text classification model to obtain the comprehensive score of the training text on each classification label, and performing normalization processing on the comprehensive score on each classification label;
and training a target text classification model by taking the classification loss of the training text as a loss function in combination with the comprehensive score of the training text after normalization on each classification label.
A text classification apparatus comprising:
the initial text classification model training unit is used for dividing the training text set into a plurality of training text subsets and training corresponding initial text classification models by utilizing each training text subset;
the classification difficulty prediction unit is used for performing classification prediction on each training text in the verification set by using each training text subset as a verification set and using the initial text classification model corresponding to each training text subset except the verification set to obtain the classification difficulty of each training text in the verification set;
and the training text subdividing unit is used for subdividing each training text in the training text set into a plurality of training text subsets with different classification difficulties according to the classification difficulties.
A text classification model training apparatus comprising:
a training text subset obtaining unit, configured to obtain training text subsets with different difficulties divided by the text classification method;
and the target text classification model training unit is used for training the target text classification model by sequentially utilizing the training text subsets according to the sequence of the classification difficulty from low to high.
A text classification apparatus comprising: a memory and a processor;
the memory is used for storing programs;
the processor is configured to execute the program to implement the steps of the text classification method.
A storage medium having stored thereon a computer program which, when executed by a processor, carries out the steps of the text classification method as described above.
By the technical scheme, the text classification method firstly divides the training text set into a plurality of training text subsets, trains the corresponding initial text classification model by utilizing each subset, and then using each subset as a verification set, using the initial text classification model corresponding to each subset except the verification set to perform classification prediction on each training text in the verification set to obtain the classification difficulty of each training text, the classification difficulty measures the difficulty degree of the training texts to be learned by the model, and then each training text in the training text set can be divided into a plurality of training text subsets with different classification difficulties again according to the classification difficulty, and then the target text classification model can be progressively trained from low to high according to the training text subsets with different classification difficulties, therefore, the problem of poor model training effect caused by the phenomenon of unbalanced difficulty of the training text is solved. The text classification method provided by the embodiment of the application can provide the training text subsets which are divided according to the classification difficulty for the training of the target text classification model, and also provides powerful training data support for better training of the target text classification model. Meanwhile, according to the training texts provided by the text classification method, the problem of poor model training effect caused by the phenomenon of unbalanced difficulty of the training texts can be solved, and the classification capability of the trained target text classification model is more excellent.
Drawings
Various other advantages and benefits will become apparent to those of ordinary skill in the art upon reading the following detailed description of the preferred embodiments. The drawings are only for purposes of illustrating the preferred embodiments and are not to be construed as limiting the application. Also, like reference numerals are used to refer to like parts throughout the drawings. In the drawings:
fig. 1 is a schematic flow chart of a text classification method according to an embodiment of the present application;
FIG. 2 illustrates a schematic diagram of a training process for a target text classification model;
fig. 3 is a schematic structural diagram of a text classification apparatus according to an embodiment of the present application;
fig. 4 is a schematic structural diagram of a text classification model training apparatus according to an embodiment of the present application;
fig. 5 is a schematic structural diagram of a text classification device according to an embodiment of the present application.
Detailed Description
The technical solutions in the embodiments of the present application will be clearly and completely described below with reference to the drawings in the embodiments of the present application, and it is obvious that the described embodiments are only a part of the embodiments of the present application, and not all of the embodiments. All other embodiments, which can be derived by a person skilled in the art from the embodiments given herein without making any creative effort, shall fall within the protection scope of the present application.
The application provides a text classification scheme, which can be used for dividing a training text set with unbalanced classification difficulty to obtain training text subsets with different classification difficulties. On the basis, a model training scheme is further provided, the training text subsets with different classification difficulties are applied, and the target text classification models are trained in sequence from low classification difficulty to high classification difficulty, so that the classification effect of the trained target text classification models is better.
The scheme can be realized based on a terminal with data processing capacity, and the terminal can be a mobile phone, a computer, a server, a cloud terminal and the like.
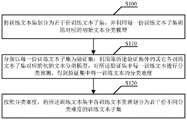
Next, as described in conjunction with fig. 1, the text classification method of the present application may include the following steps:
and S100, dividing the training text set into a plurality of training text subsets, and training corresponding initial text classification models by using each training text subset.
Specifically, the number k of the training text subsets after the division may be predefined, and the training text set may be randomly divided into k training text subsets by random division or other methods. k may be a set value of 2 or more.
In addition, other division modes can be adopted to divide the training text set into a plurality of training text subsets. The training text subsets are not crossed with each other, that is, the training texts contained in the training text subsets are different from each other. Each subset of training text follows the same spatial distribution of samples as the set of training text.
And aiming at each divided training text subset, training a corresponding initial text classification model by using the training text subset.
It will be understood that if there are k training text subsets, they are respectively denoted as xi(i is 1 to k), there are k corresponding initial text classification models, which are in one-to-one correspondence with k training text subsets, and are respectively represented as yi(i=1~k)。
For the initial text classification model, a plurality of neural network models with different architectures can be adopted, the text classification model is used for realizing text classification, and the specific classification tasks can be various, such as reading understanding, sequence labeling and the like.
Step S110, taking each training text subset as a verification set, and performing classification prediction on each training text in the verification set by using the initial text classification model corresponding to each training text subset except the verification set to obtain the classification difficulty of each training text in the verification set.
In particular, assume the value of xjTo validate a set, then y can be utilizedi(i ≠ j) separately for xjPerforming classification prediction on each training text to obtain a verification set xjThe classification difficulty of each training text in (1).
Through j traversal 1-k, namely, respectively taking each training text subset as a verification set, the classification difficulty of each training text in the training text set can be finally obtained.
In the step, for each training text, classification prediction is carried out by using k-1 initial text classification models, so that the deviation caused by single model prediction can be reduced, the confidence coefficient of a model result is improved, and the error rate of individual decision making is reduced. In addition, although each initial text classification model is trained through different training text subsets, the training text subsets are from an original training text set, are different expressions or expressions under the same class label, and have high similarity between classes, so that the training texts are classified and predicted by integrating k-1 initial text classification models, and the classification difficulty of the training texts can be measured by combining the classification prediction result.
The classification difficulty measures the difficulty of the training text to be learned by the model, namely reflects the information content of the training text. For example, if the confidence degrees of the prediction classification results of the initial classification models for a training text are all high, it indicates that the training text contains a small amount of information and has a low learning difficulty, and the current initial classification model can easily learn the information contained in the training text. On the contrary, if the confidence degrees of the prediction classification results of the initial classification models to a training text are all low, it indicates that the training text contains a large amount of information and has a high learning difficulty, and the current initial classification model cannot learn all the information contained in the training text.
And step S120, according to the classification difficulty, each training text in the training text set is divided into a plurality of training text subsets with different classification difficulties again.
Specifically, after the classification difficulty of each training text is determined, each training text in the training text set may be subdivided into a plurality of training text subsets with different classification difficulties according to the classification difficulty of each training text, and the classification difficulties corresponding to the divided training text subsets are different.
The text classification method provided by the embodiment of the application can determine the classification difficulty of each training text in the training text set, and further can divide each training text in the training text set into a plurality of training text subsets with different classification difficulties again according to the classification difficulty, and subsequently can progressively train the target text classification model from low to high according to the classification difficulty based on the training text subsets with different classification difficulties. The text classification method provided by the embodiment of the application can provide the training text subsets which are divided according to the classification difficulty for the training of the target text classification model, and also provides powerful training data support for better training of the target text classification model.
In some embodiments of the present application, a process of performing classification prediction on each training text in the verification set by using each initial text classification model in the step S110 to obtain a classification difficulty of each training text is introduced.
Specifically, for each training text in the verification set, the training text is classified and predicted by using each initial text classification model, and the confidence degree of the training text predicted by each initial text classification model, which belongs to the labeling category, is obtained.
Taking the example of the above embodiment that there are k initial text classification models in total, for a training text in a validation set, classification prediction may be performed on the training text by using k-1 initial text classification models, so that k-1 confidence degrees may be obtained in total.
The confidence coefficient is the confidence coefficient that the training text predicted by the model belongs to the labeling category, that is, the confidence coefficient score of the predicted training text on the category corresponding to the label to which the training text belongs.
Further, based on the confidence degree of the training texts, predicted by each initial text classification model, belonging to the labeling category, the classification difficulty of the training texts is determined.
Specifically, each confidence coefficient can measure the classification difficulty of the training text to a certain extent, and in order to reduce the deviation caused by the individual decision, k-1 confidence coefficients can be comprehensively considered in the step to determine the final classification difficulty of the training text.
In an alternative embodiment, the confidence level that the training text predicted by each initial text classification model belongs to the labeling category may be determined as the classification difficulty representation of the training text.
That is, a set of k-1 confidence levels may be determined as the classification difficulty representation of the training text.
In another optional implementation manner, mathematical operation may be performed on the confidence levels of the training texts predicted by the initial text classification models and belonging to the labeling categories to obtain a comprehensive confidence level, and the comprehensive confidence level is determined as the classification difficulty representation of the training texts.
The mathematical operation on each confidence coefficient may include various different modes, such as calculating an average value, a median value, a maximum value, a minimum value, and the like of a plurality of confidence coefficients, taking a mathematical operation result as a comprehensive confidence coefficient, and determining the comprehensive confidence coefficient as a classification difficulty representation of the training text.
Of course, the above only illustrates two optional ways of determining the classification difficulty of the training text, and in addition, other optional ways may also be adopted to achieve the purpose of determining the classification difficulty of the training text based on the confidence that the training text predicted by each initial text classification model belongs to the labeling category.
In some embodiments of the present application, a process of re-dividing each training text in the training text set into a plurality of training text subsets with different classification difficulties according to the classification difficulty in the step S120 is further described.
In the embodiment of the present application, two optional implementation manners of the step S120 are introduced, which are respectively as follows:
a first kind,
And S1, referring to the set classification difficulty intervals, and determining the classification difficulty interval where the classification difficulty of each training text in the training text set is located.
Specifically, in the embodiment of the present application, a plurality of different classification difficulty intervals may be preset, and the interval ranges of the classification difficulty intervals may be the same or different.
After the classification difficulty intervals are divided, the classification difficulty intervals of the training texts in the training text set can be determined according to the classification difficulty of the training texts.
And S2, dividing each training text in the training text set into a new training text subset corresponding to the classification difficulty interval to obtain a new training text subset corresponding to each classification difficulty interval.
Specifically, each training text in the training text set can be divided into new training text subsets corresponding to the classification difficulty intervals according to the classification difficulty intervals in which the classification difficulty of each training text is located. That is, a new training text subset is set corresponding to each classification difficulty interval.
Examples are as follows:
n pre-defined classification difficulty intervals are provided, and a new training text subset is arranged corresponding to each classification difficulty interval. Then, for each training text in the training text set, according to the classification difficulty interval where the classification difficulty is located, the training text can be divided into corresponding new training text subsets, and finally, the training text subsets can be obtainedN new training text subsets Ci(i ═ 1, 2.., N). Wherein, the number of training texts contained in each new training text subset is represented as Num (C)i)。
In an optional case, the N classification difficulty intervals may be: [0,0.2),[0.2,0.4),[0.4,0.5),[0.5,0.6),[0.6,0.7),[0.7,0.8),[0.8,0.9),[0.9,0.95),[0.95,1.0).
When the classification difficulty interval to which the classification difficulty of the training text belongs is determined, the corresponding scheme can be designed according to different representation forms of the classification difficulty of the training text.
The description is given by taking two different classification difficulty expressions of the training texts as examples in the foregoing embodiment:
when the classification difficulty of the training text is expressed as a set of multiple confidence degrees, a voting principle can be adopted to determine a classification difficulty interval to which the classification difficulty of the training text belongs.
Specifically, each confidence in the confidence set is used as a voting object, and a classification difficulty interval to which each voting object belongs is determined. And for each classification difficulty interval, adding 1 to the number of votes in the current classification difficulty interval when one voting object falls into the current classification difficulty interval. And after the voting of all the voting objects is finished, counting the final votes of all the classification difficulty intervals, and selecting the classification difficulty interval with the highest final vote number as the classification difficulty interval to which the classification difficulty of the training text belongs.
It should be noted that, when the final votes of a plurality of classification difficulty intervals are the same, for consistency, one classification difficulty interval with a smaller classification difficulty may be uniformly selected as the classification difficulty interval to which the classification difficulty of the training text belongs. Or, a classification difficulty interval with a high classification difficulty can be uniformly selected as the classification difficulty interval to which the classification difficulty of the training text belongs.
A second kind,
And S1, clustering the training texts in the training text set by taking the classification difficulty as a clustering condition to obtain a plurality of clustered clusters.
Specifically, each training text is clustered by using the attribute of the classification difficulty as a clustering condition, each clustered cluster comprises training texts with the same or similar classification difficulties, and the classification difficulties of the training texts in different clusters are different greatly.
And S2, taking the training text in each cluster as a new training text subset, and determining the classification difficulty of the new training text subset corresponding to the cluster based on the classification difficulty of each training text in the cluster.
Specifically, for each new training text subset, a classification difficulty interval composed of the maximum classification difficulty and the minimum classification difficulty of each training text included in the new training text subset may be used as the classification difficulty corresponding to the new training text subset. Or, the classification difficulty corresponding to the clustering center may be determined as the classification difficulty of the new training text subset. Or, the classification difficulty of each training text included in the new training text subset may be used to calculate an average value, a median value, a maximum value, a minimum value, and the like, and the result is used as the classification difficulty corresponding to the new training text subset.
For example, N new training text subsets C can be finally obtained by clusteringi(i ═ 1, 2.., N). Wherein, the number of training texts contained in each new training text subset is represented as Num (C)i)。
In another embodiment of the present application, a method for training a text classification model is further provided. In the training method of the text classification model in this embodiment, the used training data is the training text subsets with different classification difficulties divided by the text classification method described in the foregoing embodiment.
Because the classification difficulty of different training text subsets is different, the target text classification model can be trained by using the training text subsets in sequence according to the sequence from low classification difficulty to high classification difficulty.
According to the training method of the text classification model, the target text classification model is trained progressively from low to high according to the classification difficulty by training text subsets based on different classification difficulties, and the progressive learning essentially simulates the process of learning new knowledge by human brain, namely, from easy to difficult, and progressively, so that the problem of poor model training effect caused by the unbalanced difficulty of training texts is solved.
Optionally, the process of training the target text classification model by sequentially using the training text subsets according to the sequence from low classification difficulty to high classification difficulty may include:
the training process of the target text classification model is divided into a plurality of stages, each stage uses a training text subset for training, and the training text subsets used in each training stage are in the sequence from low to high according to the classification difficulty.
In another optional implementation manner, the process of training the target text classification model by sequentially using the training text subsets in the order from low classification difficulty to high classification difficulty may include:
and training the target text classification model by sequentially utilizing each training text subset in an incremental training mode according to the sequence of the classification difficulty from low to high.
Specifically, the training stage corresponding to each training text subset may be determined according to the sequence of the classification difficulty of each training text subset from low to high. Defining N training text subsets, denoted Ci(i ═ 1, 2.., N). There are N training phases, which are respectively expressed as: si(i=1,2,...,N)。
In each training stage, training texts are sampled from training text subsets respectively corresponding to the training stage and the previous training stages, and the sampling results form a training text set corresponding to the training stage.
Assume that the current training phase is SiThen from C1,C2,...CiRespectively sampling training texts, and forming a current training stage S by sampling resultsiA corresponding set of training texts.
Wherein optionally, from C1,C2,...CiThe number of training texts sampled in each subset of training texts may be the same or different, for example, from C1,C2,...CiRespectively sampling in each training text subset A training text consisting of the sampling results in the current training stage SiA corresponding set of training texts.
A training text consisting of the sampling results in the current training stage SiA corresponding set of training texts.
After the training text set corresponding to each training stage is determined, the target text classification model may be trained sequentially by using the training text set corresponding to each training stage.
According to the model training method provided by the embodiment, the model is trained in an incremental training mode, so that the phenomenon that the model is forgotten catastrophically to cause the fact that the model forgets knowledge learned in a training stage is avoided.
Further optionally, after training the target text classification model by using each training text subset in sequence, the scheme of the application may further increase a full data training process, that is:
and forming a full-scale training text set by the training text subsets with different difficulties, and training the target text classification model by using the full-scale training text set.
By further increasing the training of the target text classification model by using the full-scale training text set, the model convergence is better, namely the performance of the target text classification model is better.
In some embodiments of the present application, a process of training a target text classification model using a training text set is described for each of the training stages described above.
One straightforward way is to train the target text classification model directly with the training text set.
In addition, in a real scene, the problem of unbalanced sample classification may also exist in a large number of training texts, that is, only a small amount of training text data is contained under most of the classification labels. Due to the fact that different types of labeled data are lost, the target text classification model trained based on the labeled data is easily affected by bad bias of the head label data, and the accuracy of the classification result of the target text classification model is affected.
Therefore, the embodiment provides a solution, that is, in each training stage, a target text classification model is trained by using a training text set corresponding to the training stage and distribution information of texts of various classes in the training text set.
Compared with the former method, the latter training method integrates the prior distribution information of each category of texts in the training text set in the training process of the target text classification model, that is, integrates the prior distribution information of each category of texts in the training text set in the modeling process, so that the problem caused by unbalanced distribution of different label categories can be further solved, and the overfitting phenomenon of the target text classification model to the head labels can be reduced.
The method includes the steps of merging the prior distribution information of each category of texts in the training text set into a modeling process, and particularly merging the prior distribution information of each category of texts into the modeling process in a mutual information mode.
The mutual information represents the degree of correlation between two random variables, and the mathematical formula can be expressed as:

for the target text classification model, the common classification loss functions are cross-entropy loss functions, which can be expressed as:

wherein p (y | x) represents the conditional probability of a given input sample x and the prediction type is y, m represents the number of classification labels, and f (y | x) represents the predicted value of the given input sample x and the model on the type y.
By analogy with mutual information, the present application can derive the following formula:

wherein f isy(x, Θ) represents the predicted value of the model on each class y for a given input sample x, and log (p (y)) represents the prior distribution information for class y.
Therefore, before the target text classification model performs softmax normalization on the score predicted by each input training text, the prior distribution information of each category can be further added, so that the influence on the model caused by uneven category distribution is relieved, the prior distribution information of the category distribution is added into the model, and the model can be focused on essential parts which cannot be solved by the prior distribution information.
The score of the target text classification model is a probability value, which is a process of normalizing the output of the model, the essence of model learning is a process of modeling p (yx), most neural networks model conditional probabilities, but compared with the fitting conditional probabilities, if the model can be directly fitted with mutual information, the model learns more essential knowledge, but compared with the fitting conditional probabilities (which are directly trained by cross entropy), the fitting mutual information is not easy to train. Therefore, the embodiment of the application provides a better scheme, and even if the target text classification model uses cross entropy as a loss function, the essence is to fit mutual information. Specifically, the derivation process of the above formulas 1 to 3 is a relationship between modeling mutual information and conditional probability, and the prior distribution information of each category of texts in the training text set can be merged into the model in this way, so that the model can pay attention to other knowledge during training, and the problem of sample category imbalance is alleviated.
For the above formula 3, normalization processing is performed on the formula 3 in a form of a right end, so that:

thus, p can be usedθ(yx) is used as the final loss function loss of the target text classification model, namely, the loss is expressed as:

the training process of the target text classification model may be described with reference to fig. 2, and the process of training the target text classification model by using the training text set corresponding to the training phase and the distribution information of each category of text in the training text set may include the following steps:
and S1, inputting the coding features of each training text in the training text set corresponding to the training stage into the target text classification model.
And S2, processing the coding features by the hidden layer of the target text classification model, and predicting the scores of the training texts on the classification labels based on the processed coding features.
The hidden layer of the target text classification model may include a BERT encoder and a plurality of fully connected layers.
And the hidden layer performs feature processing on the coding features of the training text to obtain processed coding features, and predicts the scores of the training text on each classification label based on the processed coding features. Illustrated in fig. 2 is a total of m classification tags.
The last fully connected layer in the hidden layer outputs the respective scores of the training text on 1-m classification labels, which are the probability scores logtis without normalization.
And S3, adding the score of the training text on each classification label with the number of training texts under the corresponding classification label in the training text set by the target text classification model to obtain the comprehensive score of the training text on each classification label, and normalizing the comprehensive score on each classification label.
Specifically, the prior distribution information of each category in the training text set, that is, the number of training texts under each classification label in the training text set, corresponds to the prior distribution information log (p (y)) of the category in fig. 2.
In this step, the non-normalized scores of the training texts on the 0-m classification labels are respectively added to the number of the training texts under the corresponding classification labels, and the result is used as the comprehensive score of the training texts on the corresponding classification labels, namely the final finalscore.
And S4, combining the comprehensive scores of the training texts normalized on the classification labels, and training a target text classification model by taking the classification loss of the training texts as a loss function.
Specifically, the loss function of the target text classification model may be a loss function shown in the above formula 5, which is fused with mutual information of distribution information of each category of text in the training text set.
The following describes the text classification device provided in the embodiment of the present application, and the text classification device described below and the text classification method described above may be referred to in correspondence with each other.
Referring to fig. 3, fig. 3 is a schematic structural diagram of a text classification device disclosed in the embodiment of the present application.
As shown in fig. 3, the apparatus may include:
the initial text classification model training unit 11 is configured to divide a training text set into a plurality of training text subsets, and train a corresponding initial text classification model by using each training text subset;
the classification difficulty prediction unit 12 is configured to use each training text subset as a validation set, and perform classification prediction on each training text in the validation set by using an initial text classification model corresponding to each training text subset except the validation set, so as to obtain a classification difficulty of each training text in the validation set;
and the training text subdividing unit 13 is configured to subdivide each training text in the training text set into a plurality of training text subsets with different classification difficulties according to the classification difficulty.
Optionally, the process of dividing the training text set into a plurality of training text subsets by the initial text classification model training unit may include:
and randomly dividing the training text set into a plurality of training text subsets which are not crossed with each other by adopting a random division mode.
Optionally, the classifying difficulty predicting unit performs classifying prediction on each training text in the verification set by using each initial text classification model to obtain the classifying difficulty of each training text, and the process may include:
aiming at each training text in the verification set, carrying out classification prediction on the training text by utilizing each initial text classification model respectively to obtain the confidence coefficient of the training text predicted by each initial text classification model, wherein the training text belongs to the labeled class;
and determining the classification difficulty of the training texts based on the confidence coefficient of the training texts, which are predicted by each initial text classification model and belong to the labeling category.
Optionally, the process of determining the classification difficulty of the training text by the classification difficulty prediction unit based on the confidence level that the training text predicted by each initial text classification model belongs to the annotation class may include:
determining the training texts predicted by the initial text classification models to belong to a set of confidence degrees of labeling categories as classification difficulty representations of the training texts;
or the like, or, alternatively,
and performing mathematical operation on the confidence coefficients of the training texts predicted by the initial text classification models and belonging to the labeling categories to obtain a comprehensive confidence coefficient, and determining the comprehensive confidence coefficient as the classification difficulty expression of the training texts.
Optionally, an embodiment of the present application discloses two different implementation manners in which the training text subdivision unit subdivides each training text in the training text set into a plurality of training text subsets with different classification difficulties according to the classification difficulty, where the two different implementation manners are as follows:
the first embodiment may include:
determining a classification difficulty interval where the classification difficulty of each training text in the training text set is located by referring to each set classification difficulty interval;
and dividing each training text in the training text set into a new training text subset corresponding to the classification difficulty interval to obtain a new training text subset corresponding to each classification difficulty interval.
The second embodiment may include:
clustering each training text in the training text set by taking the classification difficulty as a clustering condition to obtain a plurality of clustered clusters;
and taking the training text in each cluster as a new training text subset, and determining the classification difficulty of the new training text subset corresponding to the cluster based on the classification difficulty of each training text in the cluster.
The following describes the text classification model training apparatus provided in the embodiment of the present application, and the text classification model training apparatus described below and the text classification model training method described above may be referred to in a corresponding manner.
Referring to fig. 4, fig. 4 is a schematic structural diagram of a text classification model training apparatus disclosed in the embodiment of the present application.
As shown in fig. 4, the apparatus may include:
a training text subset obtaining unit 21, configured to obtain training text subsets with different difficulties that are divided by the text classification method according to the foregoing embodiment;
and the target text classification model training unit 22 is used for training the target text classification model by using the training text subsets in sequence from low classification difficulty to high classification difficulty.
Optionally, the process of training the target text classification model by the target text classification model training unit sequentially using the training text subsets according to the sequence from low classification difficulty to high classification difficulty may include:
and training the target text classification model by sequentially utilizing each training text subset in an incremental training mode according to the sequence of the classification difficulty from low to high.
Optionally, the text classification model training device of the present application may further include:
and the full training unit is used for forming a full training text set by the training text subsets with different difficulties after the target text classification model is trained by sequentially utilizing the training text subsets, and training the target text classification model by utilizing the full training text set.
Optionally, the step of training the target text classification model by the target text classification model training unit sequentially using the training text subsets in an incremental training manner according to the sequence from low classification difficulty to high classification difficulty may include:
determining a training stage corresponding to each training text subset according to the sequence of the classification difficulty of each training text subset from low to high;
in each training stage, training texts are sampled from training text subsets respectively corresponding to the training stage and each preceding training stage, and a training text set corresponding to the training stage is formed by sampling results;
and training a target text classification model by using the training text set corresponding to the training stage.
Optionally, the process of training the target text classification model by the target text classification model training unit using the training text set corresponding to the training stage may include:
and training a target text classification model by using a training text set corresponding to the training stage and the distribution information of each class of texts in the training text set.
Optionally, the process of training the target text classification model by using the training text set corresponding to the training phase and the distribution information of each category of text in the training text set by the target text classification model may include:
inputting the coding characteristics of each training text in the training text set corresponding to the training stage into a target text classification model;
processing the coding features by a hidden layer of the target text classification model, and predicting scores of the training text on each classification label based on the processed coding features;
adding the score of the training text on each classification label to the number of training texts under the corresponding classification label in the training text set by the target text classification model to obtain the comprehensive score of the training text on each classification label, and performing normalization processing on the comprehensive score on each classification label;
and training a target text classification model by taking the classification loss of the training text as a loss function in combination with the comprehensive score of the training text after normalization on each classification label.
The text classification device provided by the embodiment of the application can be applied to text classification equipment, such as a terminal: mobile phones, computers, etc. Alternatively, fig. 5 shows a block diagram of a hardware structure of the text classification device, and referring to fig. 5, the hardware structure of the text classification device may include: at least one processor 1, at least one communication interface 2, at least one memory 3 and at least one communication bus 4;
in the embodiment of the application, the number of the processor 1, the communication interface 2, the memory 3 and the communication bus 4 is at least one, and the processor 1, the communication interface 2 and the memory 3 complete mutual communication through the communication bus 4;
the processor 1 may be a central processing unit CPU, or an application Specific Integrated circuit asic, or one or more Integrated circuits configured to implement embodiments of the present invention, etc.;
the memory 3 may include a high-speed RAM memory, and may further include a non-volatile memory (non-volatile memory) or the like, such as at least one disk memory;
wherein the memory stores a program and the processor can call the program stored in the memory, the program for:
dividing a training text set into a plurality of training text subsets, and training a corresponding initial text classification model by using each training text subset;
respectively taking each training text subset as a verification set, and performing classification prediction on each training text in the verification set by using an initial text classification model corresponding to each training text subset except the verification set to obtain the classification difficulty of each training text in the verification set;
and according to the classification difficulty, each training text in the training text set is divided into a plurality of training text subsets with different classification difficulties again.
Alternatively, the detailed function and the extended function of the program may be as described above.
Embodiments of the present application further provide a storage medium, where a program suitable for execution by a processor may be stored, where the program is configured to:
dividing a training text set into a plurality of training text subsets, and training a corresponding initial text classification model by using each training text subset;
respectively taking each training text subset as a verification set, and performing classification prediction on each training text in the verification set by using an initial text classification model corresponding to each training text subset except the verification set to obtain the classification difficulty of each training text in the verification set;
and according to the classification difficulty, each training text in the training text set is divided into a plurality of training text subsets with different classification difficulties again.
Alternatively, the detailed function and the extended function of the program may be as described above.
Finally, it should also be noted that, herein, relational terms such as first and second, and the like may be used solely to distinguish one entity or action from another entity or action without necessarily requiring or implying any actual such relationship or order between such entities or actions. Also, the terms "comprises," "comprising," or any other variation thereof, are intended to cover a non-exclusive inclusion, such that a process, method, article, or apparatus that comprises a list of elements does not include only those elements but may include other elements not expressly listed or inherent to such process, method, article, or apparatus. Without further limitation, an element defined by the phrase "comprising an … …" does not exclude the presence of other identical elements in a process, method, article, or apparatus that comprises the element.
The embodiments in the present description are described in a progressive manner, each embodiment focuses on differences from other embodiments, the embodiments may be combined as needed, and the same and similar parts may be referred to each other.
The previous description of the disclosed embodiments is provided to enable any person skilled in the art to make or use the present application. Various modifications to these embodiments will be readily apparent to those skilled in the art, and the generic principles defined herein may be applied to other embodiments without departing from the spirit or scope of the application. Thus, the present application is not intended to be limited to the embodiments shown herein but is to be accorded the widest scope consistent with the principles and novel features disclosed herein.
Claims (14)
1. A method of text classification, comprising:
dividing a training text set into a plurality of training text subsets, and training a corresponding initial text classification model by using each training text subset;
respectively taking each training text subset as a verification set, and performing classification prediction on each training text in the verification set by using an initial text classification model corresponding to each training text subset except the verification set to obtain the classification difficulty of each training text in the verification set;
and according to the classification difficulty, each training text in the training text set is divided into a plurality of training text subsets with different classification difficulties again.
2. The method according to claim 1, wherein the step of performing classification prediction on each training text in the verification set by using each initial text classification model to obtain the classification difficulty of each training text comprises:
aiming at each training text in the verification set, carrying out classification prediction on the training text by utilizing each initial text classification model respectively to obtain the confidence coefficient of the training text predicted by each initial text classification model, wherein the training text belongs to the labeled class;
and determining the classification difficulty of the training texts based on the confidence coefficient of the training texts, which are predicted by each initial text classification model and belong to the labeling category.
3. The method of claim 2, wherein determining the classification difficulty of the training text based on the confidence level that the training text predicted by each initial text classification model belongs to the label class comprises:
determining the training texts predicted by the initial text classification models to belong to a set of confidence degrees of labeling categories as classification difficulty representations of the training texts;
or the like, or, alternatively,
and performing mathematical operation on the confidence coefficients of the training texts predicted by the initial text classification models and belonging to the labeling categories to obtain a comprehensive confidence coefficient, and determining the comprehensive confidence coefficient as the classification difficulty expression of the training texts.
4. The method of claim 1, wherein said repartitioning each training text in the set of training texts into a plurality of training text subsets of different classification difficulties according to the classification difficulty comprises:
determining a classification difficulty interval where the classification difficulty of each training text in the training text set is located by referring to each set classification difficulty interval;
and dividing each training text in the training text set into a new training text subset corresponding to the classification difficulty interval to obtain a new training text subset corresponding to each classification difficulty interval.
5. The method of claim 1, wherein said repartitioning each training text in the set of training texts into a plurality of training text subsets of different classification difficulties according to the classification difficulty comprises:
clustering each training text in the training text set by taking the classification difficulty as a clustering condition to obtain a plurality of clustered clusters;
and taking the training text in each cluster as a new training text subset, and determining the classification difficulty of the new training text subset corresponding to the cluster based on the classification difficulty of each training text in the cluster.
6. A text classification model training method is characterized by comprising the following steps:
acquiring training text subsets of different classification difficulties divided by the text classification method according to any one of claims 1 to 5;
and training the target text classification model by using the training text subsets in sequence according to the sequence of the classification difficulty from low to high.
7. The method of claim 6, wherein after the training the target text classification model with the training text subsets in sequence, the method further comprises:
and forming a full training text set by the training text subsets with different difficulties, and training the target text classification model by using the full training text set.
8. The method of claim 6, wherein training the target text classification model with the training text subsets in sequence from low to high in classification difficulty comprises:
determining a training stage corresponding to each training text subset according to the sequence of the classification difficulty of each training text subset from low to high;
in each training stage, training texts are sampled from training text subsets respectively corresponding to the training stage and each preceding training stage, and a training text set corresponding to the training stage is formed by sampling results;
and training a target text classification model by using the training text set corresponding to the training stage.
9. The method of claim 8, wherein the training a target text classification model using the training text set corresponding to the training phase comprises:
and training a target text classification model by using a training text set corresponding to the training stage and the distribution information of each class of texts in the training text set.
10. The method according to claim 9, wherein the training a target text classification model using the training text set corresponding to the training phase and the distribution information of each category of text in the training text set comprises:
inputting the coding characteristics of each training text in the training text set corresponding to the training stage into a target text classification model;
processing the coding features by a hidden layer of the target text classification model, and predicting scores of the training text on each classification label based on the processed coding features;
adding the score of the training text on each classification label to the number of training texts under the corresponding classification label in the training text set by the target text classification model to obtain the comprehensive score of the training text on each classification label, and performing normalization processing on the comprehensive score on each classification label;
and training a target text classification model by taking the classification loss of the training text as a loss function in combination with the comprehensive score of the training text after normalization on each classification label.
11. A text classification apparatus, comprising:
the initial text classification model training unit is used for dividing the training text set into a plurality of training text subsets and training corresponding initial text classification models by utilizing each training text subset;
the classification difficulty prediction unit is used for performing classification prediction on each training text in the verification set by using each training text subset as a verification set and using the initial text classification model corresponding to each training text subset except the verification set to obtain the classification difficulty of each training text in the verification set;
and the training text subdividing unit is used for subdividing each training text in the training text set into a plurality of training text subsets with different classification difficulties according to the classification difficulties.
12. A text classification model training device, comprising:
a training text subset obtaining unit, configured to obtain training text subsets with different difficulty levels, which are divided by the text classification method according to any one of claims 1 to 5;
and the target text classification model training unit is used for training the target text classification model by sequentially utilizing the training text subsets according to the sequence of the classification difficulty from low to high.
13. A text classification apparatus, comprising: a memory and a processor;
the memory is used for storing programs;
the processor is used for executing the program and realizing the steps of the text classification method according to any one of claims 1-5.
14. A storage medium having stored thereon a computer program, wherein the computer program, when executed by a processor, performs the steps of the text classification method according to any one of claims 1 to 5.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011386332.XA CN112463964B (en) | 2020-12-01 | 2020-12-01 | Text classification and model training method, device, equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011386332.XA CN112463964B (en) | 2020-12-01 | 2020-12-01 | Text classification and model training method, device, equipment and storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112463964A true CN112463964A (en) | 2021-03-09 |
| CN112463964B CN112463964B (en) | 2023-01-17 |
Family
ID=74806303
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011386332.XA Active CN112463964B (en) | 2020-12-01 | 2020-12-01 | Text classification and model training method, device, equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112463964B (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113191343A (en) * | 2021-03-31 | 2021-07-30 | 成都飞机工业(集团)有限责任公司 | Aviation wire identification code automatic identification method based on convolutional neural network |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180018576A1 (en) * | 2016-07-12 | 2018-01-18 | International Business Machines Corporation | Text Classifier Training |
| CN110309302A (en) * | 2019-05-17 | 2019-10-08 | 江苏大学 | A kind of uneven file classification method and system of combination SVM and semi-supervised clustering |
| CN111309912A (en) * | 2020-02-24 | 2020-06-19 | 深圳市华云中盛科技股份有限公司 | Text classification method and device, computer equipment and storage medium |
| CN111723209A (en) * | 2020-06-28 | 2020-09-29 | 上海携旅信息技术有限公司 | Semi-supervised text classification model training method, text classification method, system, device and medium |
| CN111767400A (en) * | 2020-06-30 | 2020-10-13 | 平安国际智慧城市科技股份有限公司 | Training method and device of text classification model, computer equipment and storage medium |
| CN111832613A (en) * | 2020-06-03 | 2020-10-27 | 北京百度网讯科技有限公司 | Model training method and device, electronic equipment and storage medium |
-
2020
- 2020-12-01 CN CN202011386332.XA patent/CN112463964B/en active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180018576A1 (en) * | 2016-07-12 | 2018-01-18 | International Business Machines Corporation | Text Classifier Training |
| CN110309302A (en) * | 2019-05-17 | 2019-10-08 | 江苏大学 | A kind of uneven file classification method and system of combination SVM and semi-supervised clustering |
| CN111309912A (en) * | 2020-02-24 | 2020-06-19 | 深圳市华云中盛科技股份有限公司 | Text classification method and device, computer equipment and storage medium |
| CN111832613A (en) * | 2020-06-03 | 2020-10-27 | 北京百度网讯科技有限公司 | Model training method and device, electronic equipment and storage medium |
| CN111723209A (en) * | 2020-06-28 | 2020-09-29 | 上海携旅信息技术有限公司 | Semi-supervised text classification model training method, text classification method, system, device and medium |
| CN111767400A (en) * | 2020-06-30 | 2020-10-13 | 平安国际智慧城市科技股份有限公司 | Training method and device of text classification model, computer equipment and storage medium |
Non-Patent Citations (3)
| Title |
|---|
| XUE ZHANG 等: "《Clustering based two-stage text classification requiring minimal training data》", 《 2012 INTERNATIONAL CONFERENCE ON SYSTEMS AND INFORMATICS》 * |
| 张晓辉等: "基于对抗训练的文本表示和分类算法", 《计算机科学》 * |
| 徐禹洪 等: "《基于优化样本分布抽样集成学习的半监督文本分类方法研究》", 《中文信息学报》 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113191343A (en) * | 2021-03-31 | 2021-07-30 | 成都飞机工业(集团)有限责任公司 | Aviation wire identification code automatic identification method based on convolutional neural network |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112463964B (en) | 2023-01-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110503531B (en) | Dynamic social scene recommendation method based on time sequence perception | |
| CN110069709B (en) | Intention recognition method, device, computer readable medium and electronic equipment | |
| CN110909205B (en) | Video cover determination method and device, electronic equipment and readable storage medium | |
| CN111667022A (en) | User data processing method and device, computer equipment and storage medium | |
| TW201909112A (en) | Image feature acquisition | |
| CN113128671B (en) | Service demand dynamic prediction method and system based on multi-mode machine learning | |
| CN112819023A (en) | Sample set acquisition method and device, computer equipment and storage medium | |
| CN110442721B (en) | Neural network language model, training method, device and storage medium | |
| CN113656699B (en) | User feature vector determining method, related equipment and medium | |
| CN110264311B (en) | Business promotion information accurate recommendation method and system based on deep learning | |
| CN112529638B (en) | Service demand dynamic prediction method and system based on user classification and deep learning | |
| CN111159481B (en) | Edge prediction method and device for graph data and terminal equipment | |
| CN112463964B (en) | Text classification and model training method, device, equipment and storage medium | |
| Parker et al. | Nonlinear time series classification using bispectrum‐based deep convolutional neural networks | |
| CN117392714A (en) | Face beauty prediction method, equipment and medium based on semi-supervised learning | |
| Yang et al. | An academic social network friend recommendation algorithm based on decision tree | |
| CN118035800A (en) | Model training method, device, equipment and storage medium | |
| CN113010687B (en) | Exercise label prediction method and device, storage medium and computer equipment | |
| CN112507185B (en) | User portrait determination method and device | |
| CN115063858A (en) | Video facial expression recognition model training method, device, equipment and storage medium | |
| CN109308565B (en) | Crowd performance grade identification method and device, storage medium and computer equipment | |
| CN114861004A (en) | Social event detection method, device and system | |
| CN116091133A (en) | Target object attribute identification method, device and storage medium | |
| CN118196567B (en) | Data evaluation method, device, equipment and storage medium based on large language model | |
| CN115102852B (en) | Internet of things service opening method and device, electronic equipment and computer medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| TR01 | Transfer of patent right |
Effective date of registration: 20230506 Address after: 230026 Jinzhai Road, Baohe District, Hefei, Anhui Province, No. 96 Patentee after: University of Science and Technology of China Patentee after: IFLYTEK Co.,Ltd. Address before: NO.666, Wangjiang West Road, hi tech Zone, Hefei City, Anhui Province Patentee before: IFLYTEK Co.,Ltd. |
|
| TR01 | Transfer of patent right |