CN112154462A - 高性能流水线并行深度神经网络训练 - Google Patents
高性能流水线并行深度神经网络训练 Download PDFInfo
- Publication number
- CN112154462A CN112154462A CN201980033991.4A CN201980033991A CN112154462A CN 112154462 A CN112154462 A CN 112154462A CN 201980033991 A CN201980033991 A CN 201980033991A CN 112154462 A CN112154462 A CN 112154462A
- Authority
- CN
- China
- Prior art keywords
- dnn
- model
- computing device
- computer
- processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000012549 training Methods 0.000 title claims abstract description 131
- 238000013528 artificial neural network Methods 0.000 title claims abstract description 10
- 238000012545 processing Methods 0.000 claims abstract description 81
- 238000000034 method Methods 0.000 claims abstract description 46
- 238000000638 solvent extraction Methods 0.000 claims abstract description 42
- 238000004891 communication Methods 0.000 claims abstract description 32
- 238000003860 storage Methods 0.000 claims description 39
- 230000008569 process Effects 0.000 abstract description 15
- 238000010586 diagram Methods 0.000 description 17
- 238000005516 engineering process Methods 0.000 description 13
- 230000008901 benefit Effects 0.000 description 6
- 230000003287 optical effect Effects 0.000 description 5
- 230000009466 transformation Effects 0.000 description 5
- 238000012546 transfer Methods 0.000 description 4
- 238000000844 transformation Methods 0.000 description 4
- 230000004913 activation Effects 0.000 description 3
- 238000001994 activation Methods 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 230000010076 replication Effects 0.000 description 3
- 239000004065 semiconductor Substances 0.000 description 3
- 230000002776 aggregation Effects 0.000 description 2
- 238000004220 aggregation Methods 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 238000005457 optimization Methods 0.000 description 2
- 238000005192 partition Methods 0.000 description 2
- 230000001131 transforming effect Effects 0.000 description 2
- 238000013473 artificial intelligence Methods 0.000 description 1
- 238000010923 batch production Methods 0.000 description 1
- 230000002457 bidirectional effect Effects 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 239000003990 capacitor Substances 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000010365 information processing Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 210000000653 nervous system Anatomy 0.000 description 1
- 238000011176 pooling Methods 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 239000000344 soap Substances 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 229920000638 styrene acrylonitrile Polymers 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 230000007723 transport mechanism Effects 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Neurology (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
使用DNN的简档将深度神经网络(DNN)的层划分为多个阶段。阶段中的每个阶段包括DNN的层中的一个或多个层。将DNN的层划分为多个阶段以各种方式被优化,包括优化划分以最小化训练时间,最小化用于训练DNN的工作者计算设备之间的数据通信,或确保工作者计算设备执行大致相等量的处理来训练DNN。阶段被分配给工作者计算设备。工作者计算设备使用调度策略来处理训练数据的批次,该调度策略使得工作者在DNN训练数据的批次的前向处理与DNN训练数据的批次的后向处理之间交替。这些阶段可以被配置成用于模型并行处理或数据并行处理。
Description
背景技术
在诸如人脑的生物神经系统中,深度神经网络(“DNN”)在信息处理和通信模式之后被松散建模。DNN可以被用来解决复杂的分类问题,诸如但不限于对象检测、语义标记和特征提取。结果,DNN构成很多人工智能(“AI”)应用的基础,诸如计算机视觉、语音识别和机器翻译。在很多领域,DNN可以达到或甚至超过人类的准确性。
DNN的高级性能源于它们在对大数据集使用统计学习以获取输入空间的有效表示之后,从输入数据中提取高级特征的能力。但是,DNN的优越性能以高计算复杂度为代价。诸如图形处理单元(“GPU”)的高性能通用处理器通常被用来提供很多DNN应用所需要的高水平的计算性能。
然而,随着DNN变得越来越广泛被开发和使用,模型大小已经增加以提高效能。如今的模型具有数十到数百层,通常总共有一千万到两千万个参数。这种增长不仅给已经是时间和资源密集的DNN训练过程带来压力,而且还使得用于训练DNN的常用并行化方法崩溃。
关于这些和其他技术挑战,提出了本文进行的公开。
发明内容
本文公开了用于高性能流水线并行DNN模型训练的技术。所公开的DNN模型(在本文中可以被简称为“DNN”)训练系统通过将跨计算设备的训练过程的各方面流水线化,来使DNN模型的训练并行化,其中计算设备被配置成处理各范围的DNN层。除了其他技术益处之外,当训练大型DNN模型时或当有限的网络带宽引起较高的通信计算比时,所公开的流水线并行计算技术还可以消除由之前的并行化方法引起的性能影响。
对于大型DNN模型,相对于通过使能重叠的通信和计算所进行的数据并行训练,所公开的流水线并行DNN训练技术还可以将通信开销减少多达百分之九十五(95%)。附加地,所公开的技术可以通过在流水线阶段之间划分DNN层以平衡工作和最小化通信,对模型参数进行版本控制以实现后向传递正确性,以及调度双向训练流水线的前向和后向传递,来保持GPU的生产力。
使用以上简要描述并且在下文中更充分描述的机制,对于DNN训练,所公开的技术的实施方式在“达到目标精确度所需时间”方面已经显示出比数据并行训练快五倍。这种效率提高可以减少对各种类型的计算资源的利用,包括但不限于存储器、处理器周期、网络带宽和功率。还可以通过所公开的技术的实施方式来实现本文未具体标识的其他技术益处。
为了实现上面简要提及的技术益处以及潜在的其他益处,所公开的技术利用流水线机制、模型并行化和数据并行化的组合。该组合在本文中被称为“流水线并行”DNN训练。为了实现流水线并行DNN训练,生成DNN模型的简档。可以通过利用DNN训练数据的子集(例如,几千个微型批次),在少量计算设备(例如一个)上执行DNN,来生成DNN简档。
一旦已经生成了DNN简档,就基于该简档将DNN模型的层划分到阶段。阶段中的每个阶段包括DNN模型的一个或多个层。在一些实施例中,DNN的划分被优化,以最小化将DNN模型训练到所需准确性水平的时间。
DNN模型的划分也可以或备选地被优化,以最小化计算设备之间的数据通信,或将用于训练DNN模型的计算设备配置成在训练期间均执行大致相同量的处理。对DNN模型的层的划分还可以包括计算提供给用于训练的计算设备的DNN训练数据的批次的最佳数目,以最大化其处理效率。
一旦DNN模型被划分为阶段,阶段就被个体地分配给将训练DNN模型的计算设备。一些阶段或所有阶段可以被配置成用于模型并行处理,并且一些阶段或所有阶段可以被配置成用于数据并行处理。
在一些配置中,利用一次前向、一次后向(“1F1B”)调度策略来配置计算设备。1F1B调度策略将计算设备配置成在DNN训练数据的批次的前向处理和DNN训练数据的批次的后向处理之间交替。一旦以该方式配置了计算设备,它们就可以开始处理DNN训练数据以训练DNN模型。
应当理解,上述主题可以被实现为计算机控制的装置、计算机实现的方法、计算设备或诸如计算机可读介质的制品。通过阅读以下具体实施方式并且查看相关附图,这些和各种其他特征将变得明显。
提供本发明内容以便以简化的形式介绍下面在具体实施方式中进一步描述的所公开的技术的一些方面。本发明内容既不旨在标识所要求保护的主题的关键特征或必要特征,也不旨在用于限制所要求保护的主题的范围。此外,所要求保护的主题不限于能够解决在本公开的任何部分中指出的任何或所有缺点的实施方式。
附图说明
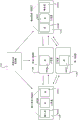
图1是示出了本文公开的用于配置计算设备以实现流水线并行DNN训练的一种机制的方面的计算架构图;
图2是示出例程的流程图,其图示了用于生成DNN的简档的说明性计算机实现的过程的方面;
图3是示出例程的流程图,其图示了用于优化DNN的层到计算设备的分配以用于DNN的管线并行训练的说明性计算机实现的过程的方面;
图4A和图4B是计算系统图,其示出了DNN的层到计算设备的几种示例分配,以用于DNN的管线并行训练;
图5是工作流图,其示出了本文公开的用于将工作分配给计算设备以进行管线并行DNN训练的一次前向一次后向调度策略的方面;
图6是示出例程的流程图,其图示了用于使用一次前向一次后向调度策略执行流水线并行DNN训练的说明性计算机实现的过程的方面;
图7是计算机架构图,其示出了用于可以实现本文提出的技术的方面的计算设备的说明性计算机硬件和软件架构;以及
图8是图示其中可以实现所公开技术的方面的分布式计算环境的网络图。
具体实施方式
以下详细描述涉及用于高性能流水线并行DNN模型训练的技术。除了其他技术益处外,当训练大型DNN模型时或当网络带宽引起较高的通信计算比时,所公开的技术还可以消除由之前的并行化技术引起的性能影响。所公开的技术还可以在流水线阶段之间划分DNN模型的层,以平衡工作和最小化网络通信,并且有效地调度双向DNN训练流水线的前向传递和后向传递。所公开技术的这些方面和其他方面可以减少对各种类型的计算资源的利用,包括但不限于存储器、处理器循环、网络带宽和功率。还可以通过所公开的技术的实施方式来实现本文未具体标识的其他技术益处。
在描述所公开的用于流水线并行DNN训练的技术之前,将提供DNN模型、DNN模型训练和DNN模型的并行训练的几种方法的简要概述。DNN模型通常由不同类型的层的序列组成(例如,卷积层、全连接层和池化层)。通常使用标记的数据集(例如,已经被标记有描述图像中内容的图像集)来训练DNN模型。跨多个代次(epoch)训练DNN模型。在每个代次,DNN模型以多个步骤通过据集中的所有训练数据来训练。在每个步骤中,当前模型首先对训练数据的子集(其在本文中可以被称为“微型批次”或“批次”)进行预测。该步骤通常被称为“前向传递”。
为了进行预测,来自微型批次的输入数据被馈送到DNN模型的第一层,该第一层通常被称为“输入层”。然后,通常使用经学习的参数或权重,DNN模型的每个层对其输入计算函数,以产生用于下一层的输入。最后一层(通常被称为“输出层”)的输出是类别预测。基于DNN模型预测的标签和训练数据的每个实例的实际标签,输出层计算损失或误差函数。在DNN模型的“后向传递”中,DNN模型的每个层将计算针对前一层的误差和梯度,或者向将DNN模型的预测移向期望输出的该层的权重来更新。
DNN训练的一个目标是在尽可能少的时间内获得具有所需准确性水平的DNN模型。可以用两个指标来量化该目标:统计学效率(即,达到所需准确性水平所需的代次的数目)和硬件效率(即,完成单个代次所需的时间)。达到所需准确性水平的总训练时间是这两个指标的乘积。训练DNN模型的结果是被称为“权重”或“核”的参数集。这些参数表示可以被应用于输入的转变函数,结果是分类或经语义标记的输出。
为了在合理的时间量内训练大型模型,可以使用以下两种方法中的一种方法来跨多个GPU并行地执行训练:模型并行性或数据并行性。在使用模型并行性或模型并行处理的情况下,整个DNN模型被复制到多个配备GPU的计算设备(在本文中,可以被称为“工作者”或“工作者设备”)上,其中每个工作者处理训练数据的不同子集。在个体工作者设备上计算的权重更新被聚合,以获得反映跨所有训练数据的更新的最终权重更新。在每次聚合期间和之后,在工作者设备之间通信的数据量与DNN模型的大小成比例。
尽管模型并行性使得能够训练非常大的模型,但是常规的模型并行性对于训练DNN模型效率低下,因为DNN训练要求:在后向传递可以确定参数更新之前,前向传递要遍历所有层。结果,常规的模型并行性可以导致计算资源的严重欠利用,因为它要么一次仅主动使用一个工作者设备(如果在各层之间进行划分),要么不能将计算和通信重叠(如果每个层被划分)。
在数据并行性或数据并行处理中,训练数据集被跨多个GPU划分。每个GPU维持DNN模型的完整副本,并且在其自己的训练数据划分上进行训练,同时周期性地与其他GPU同步权重。权重同步的频率会影响统计效率和硬件效率。权重在每个微型批次处理结束时的同步(可以被称为批量同步并行或“BSP”)减少了训练中的陈旧程度,从而确保了统计效率。但是,BSP要求每个GPU等待来自其他GPU的梯度,从而大大降低了硬件效率。
尽管数据并行DNN训练可以很好地与具有高计算通信比的一些DNN模型一起工作,但是两个趋势威胁了其有效性。首先,不断增长的DNN模型大小会增加每个聚合网络的通信。实际上,一些当前的DNN模型足够大,以至于数据通信开销超过了GPU的计算时间,这限制了扩展,并且几乎占据了整个DNN训练时间。其次,GPU计算能力的快速提高进一步将DNN训练的瓶颈转移到所有类型DNN模型的数据通信。本文公开的技术解决了这些以及潜在的其他考虑。
现在参考附图(其中贯穿几个附图,相同的附图标记表示相同的元件),将描述用于高性能流水线并行DNN训练的各种技术的方面。在下面的详细描述中,对形成其一部分的附图进行参考,并且通过说明的方式示出了特定的配置或示例。
图1是计算架构图,其示出了本文公开的用于流水线并行DNN训练的系统的方面。如将在下面更详细地讨论的,图1中图示的系统划分DNN,并且将DNN的层的子集分配给不同的工作者设备以进行训练。该系统还将对训练数据的微型批次的处理流水线化,在之前的DNN层的处理完成前,将多个微型批次注入处理第一个DNN层的工作者设备。这可以保持处理流水线满载,并且确保在工作者设备上的并发处理(即每个工作者在任何特定时间点处理不同的微型批次)。所公开的系统还将数据并行性用于所选择的层的子集,以平衡工作者设备中间的计算负载。流水线化、模型并行性和数据并行性的这种组合在本文中被称为“流水线并行”DNN训练。
如图1中所示,在描述DNN模型100的架构的一些配置中利用DNN定义102。例如但不限于,DNN定义102可以包括描述DNN模型100的架构的数据,包括但不限于:DNN模型100的层、DNN模型100的层的配置,以及将要用于训练DNN模型100的训练数据103的类型和数据量。DNN定义102被提供给处于一种配置的DNN分析器。
DNN分析器104是软件或硬件组件,其确定DNN模型100的层在用于训练DNN模型100的工作者计算设备112之间的最佳划分。DNN分析器104的输入是DNN定义102、将要由DNN模型100使用的训练数据103,以及标识将用于训练DNN模型100的工作者计算设备112的数目的数据。通过在工作者计算设备112的子集(例如,单个工作者计算设备112)上简短地训练DNN模型100并且在一些配置中观察DNN模型100的性能特性,DNN分析器104确定DNN模型100的层的最佳划分。DNN分析器104使用来自训练数据103的微型批次的子集(例如,1000个微型批次)来训练DNN模型100。DNN分析器104输出DNN简档106,其包括描述DNN模型100的性能特性的数据。
暂时参考图2,将描述示出例程200的流程图,其示出了用于生成DNN简档106的说明性计算机实现的过程的方面。应当理解,关于图2和其他附图描述的逻辑操作可以被实现为(1)在计算设备上运行的计算机实现的动作或程序模块的序列和/或(2)计算设备内的互连机器逻辑电路或电路模块。
本文公开的技术的特定实施方式是取决于计算设备的性能和其他要求的选择问题。因此,本文描述的逻辑操作被不同地称为状态、操作、结构设备、动作或模块。这些状态、操作、结构设备、动作和模块可以以硬件、软件、固件、专用数字逻辑及其任何组合来实现。应当理解,可以执行比附图中所示和本文描述更多或更少的操作。也可以以与本文描述的顺序不同的顺序执行这些操作。
例程200在操作202处开始,在此DNN分析器104针对DNN模型100中的每个层计算总计算时间。针对每个层的总计算时间被计算为该层的前向传递和后向传递所需的时间量之和。例程200然后从操作202进行到操作204,在此DNN分析器104计算DNN模型100中从每个层到下一层的输出激活的大小。这也与后向传递中的输入梯度的大小匹配。
从操作204,例程200进行到操作206,在此DNN分析器104针对DNN模型的每个层确定权重的大小。从操作206,例程200进行到操作208,在此DNN分析器104存储DNN简档106。DNN简档106包括描述针对每个层的总计算时间、从每个层到下一层的输出激活的大小以及针对每个层的权重的大小的数据。DNN简档106可以包括描述处于其他配置的DNN模型100的性能特性的其他数据。从操作208,例程200进行到操作210,其在此结束。
如图1中所示,在一些配置中,DNN分析器104将DNN简档106提供给DNN优化器108。DNN优化器108是利用DNN简档106来生成经优化的层分配110的软件或硬件组件。为了生成经优化的层分配110,DNN优化器108将DNN模型100划分为多个阶段。多个阶段中的每个阶段包括DNN模型100的一个或多个层。
在一些实施例中,DNN模型100的划分被优化,以最小化将DNN模型100训练到期望准确性水平所需的时间。DNN模型100的划分也可以,或备选地被优化,以最小化计算设备112之间的数据通信,或将用于训练DNN模型100的计算设备112配置成在训练期间执行大致相同量的处理。对DNN模型100的层的划分还可以包括计算提供给用于训练的计算设备112的DNN训练数据103的批次的最佳数目,以最大化其处理效率。
一些阶段或所有阶段可以被配置成用于模型并行处理。一些阶段或所有阶段可以被配置成用于数据并行处理。当使用数据并行处理时,可以向给定阶段分配多个工作者计算设备112,每个每个工作者计算设备在执行期间处理不同的微型批次。
一旦DNN模型被划分为多个阶段,这些阶段就被个体地分配给将训练DNN模型100的工作者计算设备112中的GPU 118。每个阶段被映射到单独的GPU 118,GPU 118针对该阶段的所有层执行前向传递和后向传递。包含输入层的阶段在本文中可以被称为输入阶段,并且包含输出层的阶段在本文中可以被称为输出阶段。
暂时参考图3,将描述示出例程300的流程图,其图示了用于优化DNN模型100的层到计算设备112的分配以用于DNN的管线并行训练的说明性计算机实现的过程的方面。例程300在操作302处开始,在此DNN优化器108计算DNN模型100的层到多个阶段的最佳划分。如上所述,DNN模型100的划分可以被优化,以最小化训练DNN模型100的时间,最小化计算设备112之间的数据通信,或将用于训练DNN模型100的计算设备112配置成在训练期间执行大致相同量的处理。在其他配置中,可以针对其他度量优化DNN模型100的划分。
从操作302,例程300进行到操作304,在此DNN优化器108计算针对每个阶段的复制因子。然后,例程300从操作304进行到操作306,在此DNN优化器108计算DNN训练数据103的微型批次的最佳数目,以提供给用于训练的计算设备112来最大化其处理效率。然后,例程300从操作306进行到操作308,在此DNN优化器108存储经优化的层分配110,包括但不限于:定义DNN模型100的层的最佳划分的数据、复制因子以及DNN训练数据103的微型批次的最佳数目,以提供给用于训练的计算设备112来最大化其处理效率。然后,例程300从操作308进行到操作310,其在此结束。
如图1中所示,在一些配置中,工作者计算设备112被配置有1F1B调度策略116。1F1B调度策略将计算设备112配置成在DNN训练数据103的批次的前向处理和DNN训练数据103的批次的后向处理之间交替。下面将参照图5和图6描述关于1F1B调度策略的附加细节。一旦使经用优化的层分配110和1F1B调度策略116配置了计算设备,它们就可以开始处理DNN训练数据来执行DNN训练114。
图4A和图4B是计算系统图,其示出了DNN模型100的层到计算设备112的几个示例分配,以用于DNN 100的流水线并行训练。在图4A中所示的示例配置中,DNN模型100包括七个层402A-402G,包括输入层402A和输出层402G。在该示例中,DNN优化器108已经生成了包括三个阶段404A-404C的优化的层分配110。输入阶段404A包括层402A-402C,阶段404B包括层402D,并且输出阶段404C包括层402E-402G。阶段404A被分配给工作者计算设备112A,阶段404B被分配给工作者计算设备112B,并且阶段404C被分配给工作者计算设备112C。
在图4A中所示的示例中,使用并行模型处理来实现阶段404A-404C中的每个阶段。然而,在图4B中所示的示例中,使用数据并行处理来实现阶段404B。在该示例中,两个工作者计算设备112B和112D通过对DNN训练数据103的不同微型批次的操作来实现阶段404B。
图5是工作流图,其示出了本文公开的用于将训练数据103的微型批次分配给计算设备112以用于流水线并行DNN训练的1F1B调度策略116的方面。如上面简要讨论的那样,1F1B调度策略116将计算设备112配置成:在DNN训练数据103的批次的前向处理和DNN训练数据103的批次的后向处理之间交替。
与常规的单向流水线不同,DNN训练是双向的(即,前向传递后跟随有后向传递,通过相同的层以相反的顺序进行)。1F1B调度策略116在每个工作者计算设备112上交织前向和后向的微型批次处理,并且在后向传递上,将训练数据103的微型批次路由通过相同的工作者112。这有助于使所有工作者计算设备112保持繁忙而不会造成流水线停顿,同时防止过多的进行中的微型批次。
在图5中所示的示例中,四个工作者计算设备112实现了DNN模型100的四个阶段并且处理训练数据103的微型批次。工作流图中被标记为‘A’的行对应于第一工作者112,被标记为‘B’的行对应于第二工作者112,行‘C’对应于第三工作者112,并且行‘D’对应于第四工作者112。每个行中的框中的数字指示当前正在由对应的工作者112处理的微型批次的编号。具有对角线的框指示正在以前向方向处理的微型批次,具有阴影线的框指示正在以后向方向处理的微型批次,没有线的框指示工作者112在对应的时间段期间空闲。
在启动状态下,输入阶段允许足够数目的训练数据103的微型批次(在该示例中为四个),以在流水线进入稳定状态时使其保持满载。这些微型批次以其方式传播到输出阶段。一旦在输出阶段完成针对第一个微型批次的前向传递,对该相同的微型批次执行后向传递,然后针对后续的微型批次,开始在执行前向传递和执行后向传递之间交替。这可以在图5中所示的工作流图的行D中看到。随着后向传递开始传播到流水线的前面的阶段,针对不同的微型批次,每个阶段开始在前向传递和后向传递之间交替。因此,在稳定状态中,每个工作者112处于忙碌,进行针对微型批次的前向传递或后向传递之一。
在完成针对微型批次的前向传递时,每个阶段将其输出激活异步地发送到下一阶段,同时开始针对另一个微型批次执行工作。同样,在完成针对微型批次的后向工作后,每个阶段将梯度异步地发送到前一阶段,同时开始针对另一个微型批次的计算。
当阶段在跨多个GPU复制的数据并行配置下运行时(如图4B中所示的示例中),确定性轮询负载平衡可以被用来跨GPU地分配来自之前阶段的工作。该确定性负载平衡确保了针对微型批次的后向工作经过微型批次在其前向工作阶段中经过的相同阶段。针对流水线中的阶段的1F1B调度策略和针对跨复制阶段的负载平衡的轮询调度策略二者都是静态策略。因此,它们可以由每个工作者112独立地执行,而无需昂贵的分布式协调。
图6是示出例程600的流程图,其图示了用于使用1F1B调度策略116来执行流水线并行DNN训练的说明性计算机实现的过程的方面。例程600在操作602处开始,在此工作者计算设备112开始处理训练数据103的微型批次。
然后,例程600从操作602进行到操作604,在此工作者计算设备112确定其是否已达到稳定状态。如果是,则例程600从操作604进行到操作606。如果否,则例程600进行回到操作602。在操作606处,工作者计算设备112针对训练数据103的微型批次执行前向处理。然后,例程600从操作606进行到操作608,在此工作者计算设备112针对微型批次执行后向处理。例程600然后进行到操作610,在此工作者计算设备112确定是否所有训练数据103都已经被处理。如果否,则例程返回操作606。一旦所有的训练数据103都已经被处理,则例程600从操作610进行到操作612,其在此结束。
本文公开的技术还可以实现DNN模型100训练流水线的其他优化。特别地,在一些配置中利用权重贮藏来维持权重的多个版本,每个活跃的微型批次有一个版本。
当执行前向工作时,每个阶段使用可用权重的最新版本来处理微型批次。在完成前向工作之后,权重的副本被存储为针对该微型批次的中间状态的一部分。当针对微型批次执行后向传递时,将使用相同版本的权重来计算权重梯度。以该方式,权重贮藏确保了:在阶段内,针对给定微型批次的前向和后向工作两者都使用相同版本的模型参数。也可以利用其他优化,包括但不限于在训练开始时预先分配所有GPU存储器以最小化动态存储器分配。
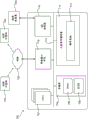
图7是计算机架构图,其示出了用于可以实现本文提出的各种技术的计算设备的说明性计算机硬件和软件架构。特别地,可以利用图7中图示的架构来实现服务器计算机、移动电话、电子阅读器、智能电话、台式计算机、交替现实或虚拟现实(“AR/VR”)设备、平板计算机、膝上型计算机、或另一种类型的计算设备。
虽然本文描述的主题是在执行DNN模型的并行化训练的服务器计算机的一般上下文中被提出,但本领域技术人员将认识到,可以结合其他类型的计算系统和模块来执行其他实施方式。本领域技术人员还将认识到,本文描述的主题可以与其他计算机系统配置一起被实践,其他计算机系统配置包括手持式设备、多处理器系统、基于微处理器或可编程的消费电子产品、嵌入在设备(诸如,可穿戴计算设备、汽车、家庭自动化等)中的计算或处理系统、微型计算机、大型计算机等。
图7所示的计算机700包括一个或多个中央处理单元702(“CPU”)、系统存储器704(包括随机存取存储器706(“RAM”)和只读存储器(“ROM”)708),以及将存储器704耦合到CPU702的系统总线710。基本输入/输出系统(“BIOS”或“固件”)可以被存储在ROM 708中,基本输入/输出系统包含用于帮助诸如在启动期间在计算机700内的元件之间传输信息的基本例程。计算机700还包括用于存储操作系统722、应用程序和其他类型的程序的大容量存储设备712。大容量存储设备712还可以被配置成存储其他类型的程序和数据,诸如DNN定义102、DNN分析器104、DNN简档106、DNN优化器108和经优化的层分配110(图7中未示出)。
大容量存储设备712通过连接到总线710的大容量存储控制器(图7中未示出)连接到CPU 702。大容量存储设备712及其关联的计算机可读介质为计算机700提供非易失性存储。尽管本文中包含的计算机可读介质的描述是指大容量存储设备,诸如硬盘、CD-ROM驱动器、DVD-ROM驱动器或USB存储密钥,但是本领域技术人员应当理解,计算机可读介质可以是计算机700可以访问的任何可用的计算机存储介质或通信介质。
通信介质包括诸如载波或其他传输机制等调制数据信号中的计算机可读指令、数据结构、程序模块或其他数据,并且包括任何传递介质。术语“调制数据信号”是指具有以能够将信息编码在信号中的方式来改变或设置其一个或多个特性的信号。作为示例而非限制,通信介质包括诸如有线网络或直接有线连接等有线介质,以及诸如声学、射频、红外和其他无线介质等无线介质。以上任何内容的组合也应当被包括在计算机可读介质的范围内。
作为示例而非限制,计算机存储介质可以包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。例如,计算机存储介质包括但不限于RAM、ROM、EPROM、EEPROM、闪存或其他固态存储技术、CD-ROM、数字多功能磁盘(“DVD”)、HD-DVD、BLU-RAY或其他光学存储器、磁带盒、磁带、磁盘存储器或其他磁性存储设备、或者可以用于存储期望信息并且可以由计算机700访问的任何其他介质。出于权利要求的目的,短语“计算机存储介质”及其变体不包括波或信号本身或通信介质。
根据各种配置,计算机700可以使用通过诸如网络720等网络到远程计算机的逻辑连接来在联网环境中操作。计算机700可以通过连接到总线710的网络接口单元716连接到网络720。应当理解,网络接口单元716也可以用于连接到其他类型的网络和远程计算机系统。计算机700还可以包括输入/输出控制器718,用于接收和处理来自多个其他设备(包括键盘、鼠标、触摸输入、电子笔(图7中未示出)或物理传感器,诸如视频相机)的输入。类似地,输入/输出控制器718可以向显示屏或其他类型的输出设备(在图7中也未示出)提供输出。
应当理解,本文中描述的软件组件在被加载到CPU 702中并且被执行时,可以将CPU 702和整个计算机700从通用计算设备转换为被定制为促进本文中介绍的功能的专用计算设备。CPU 702可以由可以个体或共同地呈现任何数目的状态的任何数目的晶体管或其他分立电路元件构成。更具体地,响应于本文中公开的软件模块中包含的可执行指令,CPU 702可以作为有限状态机操作。这些计算机可执行指令可以通过指定CPU 702如何在状态之间转换来对CPU 702进行转换,从而对构成CPU 702的晶体管或其他分立硬件元件进行转换。
对本文中提出的软件模块进行编码还可以变换本文中提出的计算机可读介质的物理结构。在本说明书的不同实现中,物理结构的特定变换取决于各种因素。这种因素的示例包括但不限于用于实现计算机可读介质的技术、计算机可读介质的特征是主要存储还是辅助存储等。例如,如果计算机可读介质被实现为基于半导体的存储器,则可以通过变换半导体存储器的物理状态来将本文中公开的软件编码在计算机可读介质上。例如,该软件可以变换构成半导体存储器的晶体管、电容器或其他分立电路元件的状态。该软件还可以转换这些组件的物理状态,以便在其上存储数据。
作为另一示例,本文中公开的计算机存储介质可以使用磁性或光学技术来实现。在这种实施方式中,当软件被编码在其中时,本文中提出的软件可以变换磁性或光学介质的物理状态。这些变换可以包括改变给定磁性介质内的特定位置的磁性特性。这些变换还可以包括改变给定光学介质内的特定位置的物理特征或特性,以改变这些位置的光学特性。在不背离本说明书的范围和精神的情况下,物理介质的其他变换是可能的,其中提供前述示例仅是为了促进该讨论。
鉴于以上所述,应当理解,在计算机700中发生了很多类型的物理变换以便存储和执行本文中提出的软件组件。还应当理解,图7中针对计算机700示出的架构或类似架构可以用于实现其他类型的计算设备,包括手持计算机、视频游戏设备、嵌入式计算机系统、移动设备(诸如智能手机、平板电脑和AR/VR设备),以及本领域技术人员已知的其他类型的计算设备。还可以想到,计算机700可以并非包括图7所示的所有组件,可以包括图7中未明确示出的其他组件,或者可以使用与图7所示的架构完全不同的架构。
图8是图示根据本文中呈现的各种配置的可以在其中实现所公开的技术的各方面的分布式网络计算环境800的网络图。如图8中所示,一个或多个服务器计算机800A可以经由通信网络720(其可以是固定有线或无线LAN、WAN、内联网、外联网、对等网络、虚拟专用网络、因特网、蓝牙通信网络、专有低压通信网络或其他通信网络)与多个客户端计算设备(诸如但不限于平板电脑800B、游戏控制台800C、智能手表800D、电话800E(诸如智能电话)、个人计算机800F和AR/VR设备800G)互连。
例如,在通信网络720是因特网的网络环境中,服务器计算机800A可以是专用服务器计算机,该专用服务器计算机可操作以经由多种已知协议中的任何一种来处理与客户端计算设备800B-800G的数据以及与客户端计算设备800B-800G传送数据,诸如超文本传输协议(“HTTP”)、文件传输协议(“FTP”)或简单对象访问协议(“SOAP”)。另外,网络计算环境800可以利用各种数据安全协议,诸如安全套接字层(“SSL”)或相当好的隐私(“PGP”)。每个客户端计算设备800B-800G可以配备有操作系统,该操作系统可操作以支持一个或多个计算应用或终端会话,诸如网络浏览器(图8中未示出)或其他图形用户界面(图8中未示出)或移动桌面环境(图8中未示出),以获取对服务器计算机800A的访问。
服务器计算机800A可以通信地耦合到其他计算环境(图8中未示出),并且接收有关参与用户的交互/资源网络的数据。在说明性操作中,用户(图8中未示出)可以与在客户端计算设备800B-800G上运行的计算应用交互以获取期望数据和/或执行其他计算应用。
数据和/或计算应用可以存储在一个或多个服务器800A上,并且通过示例性通信网络720通过客户端计算设备800B-800G传送到合作用户。参与用户(图8中未示出)可以请求访问全部或部分容纳在服务器计算机800A上的特定数据和应用。这些数据可以在客户端计算设备800B-800G与服务器计算机800A之间传送以进行处理和存储。
服务器计算机800A可以托管用于数据、应用的生成、认证、加密和通信的计算应用、过程和小程序,并且可以与其他服务器计算环境(图8中未示出)、第三方服务供应商(图8中未示出)、网络附加存储(“NAS”)和存储区域网络(“SAN”)协作以实现应用/数据交易。
应当理解,图7中所示的计算架构和图8中所示的分布式网络计算环境为了便于讨论而被简化。还应当理解,计算架构和分布式计算网络可以包括和利用本文中未具体描述的更多的计算组件、设备、软件程序、网络设备和其他组件。
本文提出的公开内容还涵盖以下实例中阐述的主题:
示例A:一种用于并行训练DNN模型的计算机实现的方法,包括:生成深度神经网络(DNN)模型的简档,所述DNN模型包括多个层;基于所述简档将所述DNN模型的所述层划分为多个阶段,其中所述多个阶段中的每个阶段包括所述DNN模型的所述层中的一个或多个层,并且其中所述划分被优化,以最小化训练所述DNN模型的时间;以及使多个计算设备训练所述DNN模型。
示例B:根据示例A所述的计算机实现的方法,其中所述划分还被优化,以最小化所述计算设备之间的数据通信。
示例C:根据示例A-B中任一项所述的计算机实现的方法,其中所述划分被进一步优化,以使所述多个计算设备中的每个计算设备在所述DNN模型的训练期间执行大致相同量的处理。
示例D:根据示例A-C中任一项所述的计算机实现的方法,其中对所述DNN模型的所述层的划分还包括:计算要被提供给所述多个计算设备的DNN训练数据的批次的最佳数目,以使所述多个计算设备的处理效率最大化。
示例E:根据示例A-D中任一项所述的计算机实现的方法,还包括将所述多个阶段中的至少一个阶段分配给多个计算设备中的每个计算设备,所述计算设备被配置成:通过在DNN训练数据的所述批次的前向处理和所述DNN训练数据的批次的后向处理之间交替,来处理DNN所述训练数据的批次以训练所述DNN模型。
示例F:根据示例A-E中任一项所述的计算机实现的方法,其中所述多个阶段中的至少一个阶段被配置成用于模型并行处理。
示例G:根据示例A-F中任一项所述的计算机实现的方法,其中所述多个阶段中的至少一个阶段被配置成用于数据并行处理。
示例H:根据示例A-G中任一项所述的计算机实现的方法,其中所述多个阶段中的至少一个阶段被配置成用于模型并行处理,并且其中所述多个阶段中的至少一个阶段被配置成用于数据并行处理。
示例I:一种计算设备,包括:一个或多个处理器;以及至少一个计算机存储介质,其上存储有计算机可执行指令,所述计算机可执行指令在由所述一个或多个处理器执行时,将使得所述计算设备:将DNN模型的所述层划分为多个阶段,其中所述多个阶段中的每个阶段包括所述DNN模型的所述层中的一个或多个层,并且其中所述划分被优化,以最小化训练所述DNN模型的时间;以及将所述多个阶段中的至少一个阶段分配给多个工作者计算设备中的每个工作者计算设备,所述计算设备被配置成:通过在DNN训练数据的所述批次的前向处理和所述DNN训练数据的批次的后向处理之间交替,来处理所述DNN训练数据的批次以训练所述DNN模型。
示例J:根据示例I所述的计算设备,其中所述划分还被优化,以最小化所述工作者计算设备之间的数据通信。
示例K:根据示例I-J中任一项所述的计算设备,其中所述划分还被优化,以使所述多个计算设备中的每个计算设备在所述DNN模型的训练期间执行大致相同量的处理。
示例L:根据示例I-K中任一项所述的计算设备,其中所述多个阶段中的至少一个阶段被配置成用于模型并行处理,并且其中所述多个阶段中的至少一个阶段被配置成用于数据并行处理。
示例M:根据示例I-L中任一项所述的计算设备,其中所述至少一个计算机存储介质在其上存储有另外的计算机可执行指令,以用于:生成所述深度神经网络(DNN)模型的简档;基于所述简档,将所述DNN模块的所述层划分为所述多个阶段。
示例N:根据示例I-M中任一项所述的计算设备,其中通过利用所述DNN训练数据的子集,在所述多个工作者计算设备的子集上训练所述DNN模型预先确定的时间段,来生成所述DNN模块的所述简档。
示例O:一种计算机存储介质,其上存储有计算机可执行指令,所述计算机可执行指令在由计算设备的一个或多个处理器执行时,将使得所述计算设备:将深度神经网络(DNN)模型的所述层划分为多个阶段,其中所述多个阶段中的每个阶段包括所述DNN模型的所述层中的一个或多个层,并且其中所述划分被优化,以最小化训练所述DNN模型的时间;以及将所述多个阶段中的至少一个阶段分配给多个工作者计算设备中的每个工作者计算设备,所述计算设备被配置成:通过在DNN训练数据的所述批次的前向处理和所述DNN训练数据的所述批次的后向处理之间交替,来处理所述DNN训练数据的批次以训练所述DNN模型。
示例P:根据示例O所述的计算机存储介质,其中所述划分还被优化,以最小化所述工作者计算设备之间的数据通信。
示例Q:根据示例O-P中任一项所述的计算机存储介质,其中所述划分还被优化,以使所述多个计算设备中的每个计算设备在训练所述DNN模型期间执行大致相同量的处理。
示例R:根据示例O-Q中任一项所述的计算机存储介质,其中对所述DNN模型的所述层的划分还包括:计算要被提供给所述多个计算设备的所述DNN训练数据的所述批次的最佳数目,以使所述多个计算设备的处理效率最大化。
示例S:根据示例O-R中任一项所述的计算机存储介质,其中所述计算机存储介质在其上存储有另外的计算机可执行指令,以用于:生成所述DNN模型的简档;以及基于所述简档,将所述DNN模块的所述层划分为所述多个阶段。
示例T:根据示例O-S中任一项所述的计算机存储介质,其中通过利用所述DNN训练数据的子集,在所述多个工作者计算设备的子集上训练所述DNN模型预先确定的时间段,来生成所述DNN模块的所述简档。
基于前述内容,应当理解,本文中已经公开了用于高性能流水线并行DNN训练的技术。尽管已经以计算机结构特征、方法和转换动作、特定的计算机器和计算机可读介质专用的语言描述了本文中提出的主题,但是应当理解,所附权利要求中阐述的主题不必限于本文中描述的特定特征、动作或介质。相反,特定特征、动作和介质被公开作为实现所要求保护的主题的示例形式。
上述主题仅以说明的方式被提供,并且不应当被解释为是限制性的。可以在不遵循示出和描述的示例配置和应用的情况下,并且在不脱离在所附权利要求中阐述的本公开的范围的情况下,对本文中描述的主题进行各种修改和改变。
Claims (15)
1.一种用于并行训练DNN模型的计算机实现的方法,包括:
生成深度神经网络(DNN)模型的简档,所述DNN模型包括多个层;
基于所述简档将所述DNN模型的所述层划分为多个阶段,其中所述多个阶段中的每个阶段包括所述DNN模型的所述层中的一个或多个层,并且其中所述划分被优化,以最小化训练所述DNN模型的时间;以及
使多个计算设备训练所述DNN模型。
2.根据权利要求1所述的计算机实现的方法,其中所述划分还被优化,以最小化所述计算设备之间的数据通信。
3.根据权利要求1所述的计算机实现的方法,其中所述划分还被优化,使得所述多个计算设备中的每个计算设备在所述DNN模型的训练期间执行大致相同量的处理。
4.根据权利要求1所述的计算机实现的方法,其中划分所述DNN模型的所述层还包括:计算要被提供给所述多个计算设备的DNN训练数据的批次的最佳数目,以使所述多个计算设备的处理效率最大化。
5.根据权利要求1所述的计算机实现的方法,还包括将所述多个阶段中的至少一个阶段分配给多个计算设备中的每个计算设备,所述计算设备被配置成:通过在DNN训练数据的所述批次的前向处理和所述DNN训练数据的批次的后向处理之间交替,来处理所述DNN训练数据的批次以训练所述DNN模型。
6.一种计算设备,包括:
一个或多个处理器;以及
至少一个计算机存储介质,其上存储有计算机可执行指令,所述计算机可执行指令在由所述一个或多个处理器执行时,将使所述计算设备:
将深度神经网络(DNN)模型的所述层划分为多个阶段,其中所述多个阶段中的每个阶段包括所述DNN模型的所述层中的一个或多个层,并且其中所述划分被优化,以最小化训练所述DNN模型的时间;以及
将所述多个阶段中的至少一个阶段分配给多个工作者计算设备中的每个工作者计算设备,所述计算设备被配置成:通过在DNN训练数据的所述批次的前向处理和所述DNN训练数据的批次的后向处理之间交替,来处理所述DNN训练数据的批次以训练所述DNN模型。
7.根据权利要求6所述的计算设备,其中所述划分还被优化,以最小化所述工作者计算设备之间的数据通信。
8.根据权利要求6所述的计算设备,其中所述划分还被优化,使得所述多个计算设备中的每个计算设备在所述DNN模型的训练期间执行大致相同量的处理。
9.根据权利要求6所述的计算设备,其中所述多个阶段中的至少一个阶段被配置用于模型并行处理,并且其中所述多个阶段中的至少一个阶段被配置用于数据并行处理。
10.根据权利要求6所述的计算设备,其中所述至少一个计算机存储介质在其上存储有另外的计算机可执行指令,以用于:
生成所述DNN模型的简档;
基于所述简档,将所述DNN模块的所述层划分为所述多个阶段。
11.一种计算机存储介质,其上存储有计算机可执行指令,所述计算机可执行指令在由计算设备的一个或多个处理器执行时,将使所述计算设备:
将深度神经网络(DNN)模型的所述层划分为多个阶段,其中所述多个阶段中的每个阶段包括所述DNN模型的所述层中的一个或多个层,并且其中所述划分被优化,以最小化训练所述DNN模型的时间;以及
将所述多个阶段中的至少一个阶段分配给多个工作者计算设备中的每个工作者计算设备,所述计算设备被配置成:通过在DNN训练数据的批次的前向处理和所述DNN训练数据的所述批次的后向处理之间交替,来处理所述DNN训练数据的所述批次以训练所述DNN模型。
12.根据权利要求11所述的计算机存储介质,其中所述划分还被优化,以最小化所述工作者计算设备之间的数据通信。
13.根据权利要求11所述的计算机存储介质,其中所述划分还被优化,使得所述多个计算设备中的每个计算设备在所述DNN模型的训练期间执行大致相同量的处理。
14.根据权利要求11所述的计算机存储介质,其中划分所述DNN模型的所述层还包括:计算要被提供给所述多个计算设备的所述DNN训练数据的所述批次的最佳数目,以使所述多个计算设备的处理效率最大化。
15.根据权利要求11所述的计算机存储介质,其中所述计算机存储介质在其上存储有另外的计算机可执行指令,以用于:
生成所述DNN模型的简档;以及
基于所述简档,将所述DNN模块的所述层划分为所述多个阶段。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862675497P | 2018-05-23 | 2018-05-23 | |
| US62/675,497 | 2018-05-23 | ||
| US16/024,369 | 2018-06-29 | ||
| US16/024,369 US12056604B2 (en) | 2018-05-23 | 2018-06-29 | Highly performant pipeline parallel deep neural network training |
| PCT/US2019/030988 WO2019226324A1 (en) | 2018-05-23 | 2019-05-07 | Highly performant pipeline parallel deep neural network training |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112154462A true CN112154462A (zh) | 2020-12-29 |
Family
ID=68614650
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201980033991.4A Pending CN112154462A (zh) | 2018-05-23 | 2019-05-07 | 高性能流水线并行深度神经网络训练 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US12056604B2 (zh) |
| EP (1) | EP3797385B1 (zh) |
| CN (1) | CN112154462A (zh) |
| WO (1) | WO2019226324A1 (zh) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112966829A (zh) * | 2021-03-03 | 2021-06-15 | 山东英信计算机技术有限公司 | 一种深度学习模型的训练方法、装置、设备及可读介质 |
| CN113177632A (zh) * | 2021-04-13 | 2021-07-27 | 支付宝(杭州)信息技术有限公司 | 一种基于流水线并行的模型训练方法、装置以及设备 |
| CN113254206A (zh) * | 2021-05-25 | 2021-08-13 | 北京一流科技有限公司 | 数据处理系统及其方法 |
| CN114035937A (zh) * | 2021-10-15 | 2022-02-11 | 北京潞晨科技有限公司 | 一种基于人工智能的分布式训练和推理方法、系统、设备和可读存储介质 |
| CN114548383A (zh) * | 2022-04-27 | 2022-05-27 | 之江实验室 | 一种面向神经网络模型计算的图执行流水并行方法和装置 |
| CN116991483A (zh) * | 2023-09-25 | 2023-11-03 | 粤港澳大湾区数字经济研究院(福田) | 一种针对语言模型计算的流水线并行方法及装置 |
| CN118114773A (zh) * | 2024-04-30 | 2024-05-31 | 山东海量信息技术研究院 | 文本生成方法、装置、设备及计算机程序产品 |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11354573B2 (en) * | 2019-03-25 | 2022-06-07 | International Business Machines Corporation | Dynamically resizing minibatch in neural network execution |
| CN112749778B (zh) * | 2019-10-29 | 2023-11-28 | 北京灵汐科技有限公司 | 一种强同步下的神经网络映射方法及装置 |
| US11954526B2 (en) * | 2020-07-10 | 2024-04-09 | Guangdong University Of Petrochemical Technology | Multi-queue multi-cluster task scheduling method and system |
| KR20220032799A (ko) * | 2020-09-08 | 2022-03-15 | 삼성전자주식회사 | 뉴럴 네트워크 프로파일링 방법 및 장치 |
| KR20220056621A (ko) * | 2020-10-28 | 2022-05-06 | 삼성전자주식회사 | 매니코어 시스템을 위한 뉴럴 네트워크 모델 처리의 병렬화 방법 및 장치 |
| EP4275351A4 (en) | 2021-03-24 | 2024-04-03 | Samsung Electronics Co., Ltd. | METHOD AND DEVICE FOR EXECUTING DEEP NEURAL NETWORK IN IoT EDGE NETWORK |
| WO2022203400A1 (en) * | 2021-03-24 | 2022-09-29 | Samsung Electronics Co., Ltd. | Method and device for execution of deep neural network in iot edge network |
| CN113312178A (zh) * | 2021-05-24 | 2021-08-27 | 河海大学 | 一种基于深度强化学习的流水线并行训练任务分配方法 |
| CN115237580B (zh) * | 2022-09-21 | 2022-12-16 | 之江实验室 | 面向智能计算的流水并行训练自适应调整系统、方法 |
| CN115437795B (zh) * | 2022-11-07 | 2023-03-24 | 东南大学 | 一种异构gpu集群负载感知的显存重计算优化方法及系统 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140142929A1 (en) * | 2012-11-20 | 2014-05-22 | Microsoft Corporation | Deep neural networks training for speech and pattern recognition |
| CN105378762A (zh) * | 2014-04-08 | 2016-03-02 | 微软技术许可有限责任公司 | 使用交替方向乘子法的深度学习 |
| US20160092765A1 (en) * | 2014-09-29 | 2016-03-31 | Microsoft Corporation | Tool for Investigating the Performance of a Distributed Processing System |
| US20160267380A1 (en) * | 2015-03-13 | 2016-09-15 | Nuance Communications, Inc. | Method and System for Training a Neural Network |
| CN107112005A (zh) * | 2015-04-17 | 2017-08-29 | 微软技术许可有限责任公司 | 深度神经支持向量机 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10452971B2 (en) * | 2015-06-29 | 2019-10-22 | Microsoft Technology Licensing, Llc | Deep neural network partitioning on servers |
| US10002402B2 (en) * | 2015-07-23 | 2018-06-19 | Sony Corporation | Learning convolution neural networks on heterogeneous CPU-GPU platform |
| US11003992B2 (en) * | 2017-10-16 | 2021-05-11 | Facebook, Inc. | Distributed training and prediction using elastic resources |
-
2018
- 2018-06-29 US US16/024,369 patent/US12056604B2/en active Active
-
2019
- 2019-05-07 EP EP19724715.8A patent/EP3797385B1/en active Active
- 2019-05-07 CN CN201980033991.4A patent/CN112154462A/zh active Pending
- 2019-05-07 WO PCT/US2019/030988 patent/WO2019226324A1/en unknown
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20140142929A1 (en) * | 2012-11-20 | 2014-05-22 | Microsoft Corporation | Deep neural networks training for speech and pattern recognition |
| CN105378762A (zh) * | 2014-04-08 | 2016-03-02 | 微软技术许可有限责任公司 | 使用交替方向乘子法的深度学习 |
| US20160092765A1 (en) * | 2014-09-29 | 2016-03-31 | Microsoft Corporation | Tool for Investigating the Performance of a Distributed Processing System |
| US20160267380A1 (en) * | 2015-03-13 | 2016-09-15 | Nuance Communications, Inc. | Method and System for Training a Neural Network |
| CN107112005A (zh) * | 2015-04-17 | 2017-08-29 | 微软技术许可有限责任公司 | 深度神经支持向量机 |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112966829A (zh) * | 2021-03-03 | 2021-06-15 | 山东英信计算机技术有限公司 | 一种深度学习模型的训练方法、装置、设备及可读介质 |
| CN113177632A (zh) * | 2021-04-13 | 2021-07-27 | 支付宝(杭州)信息技术有限公司 | 一种基于流水线并行的模型训练方法、装置以及设备 |
| CN113177632B (zh) * | 2021-04-13 | 2022-10-14 | 支付宝(杭州)信息技术有限公司 | 一种基于流水线并行的模型训练方法、装置以及设备 |
| CN113254206A (zh) * | 2021-05-25 | 2021-08-13 | 北京一流科技有限公司 | 数据处理系统及其方法 |
| CN114035937A (zh) * | 2021-10-15 | 2022-02-11 | 北京潞晨科技有限公司 | 一种基于人工智能的分布式训练和推理方法、系统、设备和可读存储介质 |
| CN114548383A (zh) * | 2022-04-27 | 2022-05-27 | 之江实验室 | 一种面向神经网络模型计算的图执行流水并行方法和装置 |
| CN116991483A (zh) * | 2023-09-25 | 2023-11-03 | 粤港澳大湾区数字经济研究院(福田) | 一种针对语言模型计算的流水线并行方法及装置 |
| CN116991483B (zh) * | 2023-09-25 | 2024-04-05 | 粤港澳大湾区数字经济研究院(福田) | 一种针对语言模型计算的流水线并行方法及装置 |
| CN118114773A (zh) * | 2024-04-30 | 2024-05-31 | 山东海量信息技术研究院 | 文本生成方法、装置、设备及计算机程序产品 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3797385A1 (en) | 2021-03-31 |
| US12056604B2 (en) | 2024-08-06 |
| EP3797385B1 (en) | 2023-08-23 |
| US20190362227A1 (en) | 2019-11-28 |
| WO2019226324A1 (en) | 2019-11-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP3797385B1 (en) | Highly performant pipeline parallel deep neural network training | |
| WO2022037337A1 (zh) | 机器学习模型的分布式训练方法、装置以及计算机设备 | |
| US11769061B2 (en) | Processing computational graphs | |
| CN110520846B (zh) | 对数据分区的动态排序 | |
| US11868880B2 (en) | Mitigating communication bottlenecks during parameter exchange in data-parallel DNN training | |
| US20200175370A1 (en) | Decentralized distributed deep learning | |
| JP2018533792A (ja) | 計算グラフの修正 | |
| Han et al. | Signal processing and networking for big data applications | |
| US11842220B2 (en) | Parallelization method and apparatus with processing of neural network model for manycore system | |
| Wang et al. | Overlapping communication with computation in parameter server for scalable DL training | |
| US11636280B2 (en) | Updating of statistical sets for decentralized distributed training of a machine learning model | |
| EP3367310A1 (en) | Method and apparatus for parallelizing layers of deep neural networks onto parallel computing systems | |
| US11551095B2 (en) | Sharing preprocessing, computations, and hardware resources between multiple neural networks | |
| Peng et al. | Mbfquant: a multiplier-bitwidth-fixed, mixed-precision quantization method for mobile cnn-based applications | |
| CN117311998B (zh) | 一种大模型部署方法及系统 | |
| Bhuiyan et al. | Parallel algorithms for switching edges in heterogeneous graphs | |
| WO2023195011A1 (en) | System and method for model training in decentralized computing environments | |
| Alam | HPC-based parallel algorithms for generating random networks and some other network analysis problems | |
| US20230140239A1 (en) | Method and apparatus with data loading | |
| US20230297487A1 (en) | Method and apparatus for estimating execution time of neural network | |
| US20240135147A1 (en) | Method and apparatus with transformer model training | |
| Fu et al. | Streaming approximation scheme for minimizing total completion time on parallel machines subject to varying processing capacity | |
| Zhang et al. | On an Approximation Algorithm Combined with D3QN for HDFS Data Block Recovery in Heterogeneous Hadoop Clusters | |
| Bhuiyan | Parallel Algorithms for Switching Edges and Generating Random Graphs from Given Degree Sequences using HPC Platforms | |
| Zhao | Data Parallel Frameworks for Training Machine Learning Models |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |