Container dynamic migration method and device and electronic equipment
Technical Field
The application relates to the technical field of computers, in particular to a container dynamic migration method and device and electronic equipment.
Background
With the expansion of cloud service scale, data centers are continuously expanded, and in order to effectively realize load balancing under a large-scale cloud service platform, computing resources need to be effectively distributed.
In a container cluster, when a large number of tasks run and are scheduled simultaneously, abnormal situations of resource preemption and excessive load may occur; when the container cluster is large in scale, due to the fact that a large number of tasks are frequently operated, when too many containers are deployed on the same node, the utilization rate of node resources is too high, cluster load is unbalanced, and therefore computing nodes break down. For such a situation, in the operation mode in the prior art, an exception is discovered through a cluster management tool, a task is no longer issued to an abnormal computing node before the exception is recovered, and the abnormal computing node is not actively recovered.
Disclosure of Invention
The application aims to provide a container dynamic migration method, a container dynamic migration device and electronic equipment, which can realize the migration of containers, so that the load balance of container clusters is realized.
In a first aspect, an embodiment of the present application provides a container dynamic migration method, including:
judging whether the load of the current computing node exceeds a resource threshold value or not according to the resource utilization rate of the current computing node;
if the load of the current computing node exceeds the resource threshold, screening a container to be migrated from the current computing node;
screening out target computing nodes from each computing node of the container cluster according to the resource utilization rate of each computing node;
and migrating the container to be migrated to the target computing node.
In an optional implementation manner, the screening out target computing nodes from each computing node of the container cluster according to the resource utilization rate of each computing stage includes:
according to the resource utilization rate of each computing node of the container cluster, sequencing each computing node from low to high according to the resource utilization rate to obtain a computing node sequencing table;
selecting a first number of computing nodes from the computing node ranking table as an initial computing node group;
and selecting a target computing node from the initial computing node group according to a set probability algorithm.
In the embodiment of the application, through a sorting mode, a corresponding target computing node is selected from a plurality of computing nodes with light current loads, rather than directly selecting the computing node with the lightest load, so that the shaking phenomenon caused by the fact that a large number of containers are migrated to the same computing node can be reduced, and the stability in the migration process can be improved. Wherein, the jitter phenomenon is that the resource utilization rate of the computing node suddenly rises to a higher value.
In an optional implementation manner, the selecting a target computing node from the initial computing node group according to a set probability algorithm includes:
determining the issuing probability of each computing node according to the resource load data of each computing node in the initial computing node group, wherein the sum of the issuing probabilities of each computing node in the initial computing node group is 1;
randomly determining a random positive number smaller than 1;
and determining a target computing node according to the random positive number and the issuing probability of each computing node.
In an optional embodiment, the determining, according to the resource load data of each computing node in the initial computing node group, an issuing probability of each computing node is implemented by the following formula:
wherein, PiRepresents the distribution probability, R, of the ith computing nodeiAnd e represents the number of the computing nodes in the initial computing node group.
In the embodiment of the application, the corresponding target computing node is determined by combining the random positive number with the issuing probability of each computing node, so that several computing nodes with light load can be selected randomly, and the phenomenon of jitter caused by that a large number of containers are migrated to the same computing node can be reduced.
In an optional embodiment, the screening the container to be migrated from the current computing node includes:
determining the resource type with the load exceeding the resource threshold according to the resource utilization rate of the current computing node;
and selecting a container to be migrated from the current computing node according to the resource type.
In the embodiment of the application, the resource type with the load exceeding the resource threshold is determined, so that the container to be migrated can be selected from the containers using the resource type, and the load of the migrated current computing node can be more balanced.
In an optional implementation manner, the selecting a container to be migrated from a current compute node according to the resource type includes:
selecting a first initial container group to be migrated from the current computing node according to the resource type;
and selecting the containers to be migrated with the time length less than the time length threshold value required for executing the task from the first initial container group to be migrated.
In the embodiment of the application, the migration is performed through the container with the shorter migration time, so that the migration cost can be reduced, and the current computing node can operate more stably.
In an optional implementation manner, the selecting a container to be migrated from a current compute node according to the resource type includes:
selecting a second initial container group to be migrated from the current computing node according to the resource type;
determining a target service corresponding to the target container and the number of containers corresponding to the target service for the target container of the second initial container group to be migrated, wherein the target container is any container in the second initial container group to be migrated;
and if the number of the containers is larger than a number threshold value, taking the target container as a container to be migrated.
In the embodiment of the application, the containers in the service with a large number of containers belonging to a certain service are selected as the containers to be migrated, so that the influence of the migration of the containers on the work in a computing node can be reduced.
In an optional implementation manner, the determining whether the load of the current computing node exceeds a resource threshold according to the resource usage rate of the current computing node includes:
acquiring the resource utilization rate of the current computing node according to a set time rule, and judging whether the resource utilization rate of the continuous second quantity of time nodes exceeds a resource threshold value;
and if the resource utilization rate of the continuous second quantity of time nodes exceeds the resource threshold, judging that the load of the current computing node exceeds the resource threshold.
In the embodiment of the application, the container migration can be determined through the judgment of a plurality of time points, so that the misjudgment caused by the normal jitter phenomenon of the resource utilization rate of the computing node is reduced, and the accuracy rate of determining the abnormal computing node can be improved.
In a second aspect, an embodiment of the present application provides a container dynamic migration apparatus, including:
the judging module is used for judging whether the load of the current computing node exceeds a resource threshold value according to the resource utilization rate of the current computing node;
the first screening module is used for screening the container to be migrated from the current computing node if the load of the current computing node exceeds a resource threshold;
the second screening module is used for screening out target computing nodes from all computing nodes of the container cluster according to the resource utilization rate of all the computing nodes;
and the migration module is used for migrating the container to be migrated to the target computing node.
In a third aspect, an embodiment of the present application provides an electronic device, including: a processor, a memory storing machine-readable instructions executable by the processor, the machine-readable instructions being executable by the processor to perform the steps of the method described above when the electronic device is run.
The beneficial effects of the embodiment of the application are that: by selecting the container of the computing node with high resource utilization rate for migration, the load of the computing node can be reduced.
Drawings
In order to more clearly illustrate the technical solutions of the embodiments of the present application, the drawings that are required to be used in the embodiments will be briefly described below, it should be understood that the following drawings only illustrate some embodiments of the present application and therefore should not be considered as limiting the scope, and for those skilled in the art, other related drawings can be obtained from the drawings without inventive effort.
Fig. 1 is a block diagram of an electronic device according to an embodiment of the present disclosure.
Fig. 2 is a flowchart of a container dynamic migration method according to an embodiment of the present application.
Fig. 3 is a detailed flowchart of step 202 of the container live migration method provided in an embodiment of the present application.
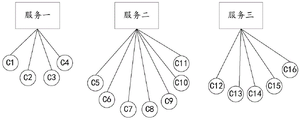
Fig. 4 is a schematic diagram of container distribution in a current compute node of the container dynamic migration method according to the embodiment of the present application.
Fig. 5 is a detailed flowchart of step 203 of the container live migration method provided in an embodiment of the present application.
Fig. 6 is a functional module schematic diagram of a container dynamic migration apparatus according to an embodiment of the present application.
Detailed Description
The technical solution in the embodiments of the present application will be described below with reference to the drawings in the embodiments of the present application.
It should be noted that: like reference numbers and letters refer to like items in the following figures, and thus, once an item is defined in one figure, it need not be further defined and explained in subsequent figures. Meanwhile, in the description of the present application, the terms "first", "second", and the like are used only for distinguishing the description, and are not to be construed as indicating or implying relative importance.
First, the concept used in the embodiments of the present application will be described.
Docker is an open source application container engine, so that developers can pack their applications and dependence packages into a portable image, and then distribute the image to any popular Linux or Windows machine, and can also realize virtualization. The containers are fully sandboxed without any interface between each other.
Swarm is a native cluster tool developed by Docker officials, and provides functions of resource scheduling, load balancing, service discovery and the like. The method is very light and easy to use, provides a high-latitude configuration mode for developers, and can quickly realize specific workflow.
Kubernets is a Google open-source container cluster management system, provides functions of application deployment, maintenance, extension mechanism and the like, and can conveniently manage cross-machine running containerized applications by utilizing the Kubernets. The main implementation language is Go language. Kubernetes is abbreviated K8 s.
The messos is an open source distributed resource management framework under the Apache flag.
Load balancing refers to balancing and distributing loads (work tasks) to a plurality of operation units for operation, such as an FTP server, a Web server, an enterprise core application server, and other main task servers, so as to cooperatively complete the work tasks.
When the cluster of the Docker is extremely large in scale, due to the large amount of frequent operation of various tasks, when too many containers are deployed on the same computing node, the resource utilization rate of the computing node is too high, and the cluster load is unbalanced. At present, in the case of abnormal recovery, Swarm, kubernets or messes do not become an effective solution. A common processing method is to stop allocating tasks to corresponding compute nodes, and not actively recover the abnormal compute nodes.
Based on the above research, embodiments of the present application provide a method and an apparatus for dynamically migrating a container, and an electronic device, so that load balancing of a cluster is achieved by migrating the container in an abnormal computing node. The present application is described below by way of several embodiments.
Example one
To facilitate understanding of the embodiment, first, an electronic device for performing the container dynamic migration method disclosed in the embodiment of the present application will be described in detail.
As shown in fig. 1, is a block schematic diagram of an electronic device. The electronic device 100 may include a memory 111, a memory controller 112, a processor 113, and a peripheral interface 114. It will be understood by those of ordinary skill in the art that the structure shown in fig. 1 is merely exemplary and is not intended to limit the structure of the electronic device 100. For example, electronic device 100 may also include more or fewer components than shown in FIG. 1, or have a different configuration than shown in FIG. 1.
The above-mentioned elements of the memory 111, the memory controller 112, the processor 113 and the peripheral interface 114 are electrically connected to each other directly or indirectly to realize data transmission or interaction. For example, the components may be electrically connected to each other via one or more communication buses or signal lines. The processor 113 is used to execute the executable modules stored in the memory.
The Memory 111 may be, but is not limited to, a Random Access Memory (RAM), a Read Only Memory (ROM), a Programmable Read-Only Memory (PROM), an Erasable Read-Only Memory (EPROM), an electrically Erasable Read-Only Memory (EEPROM), and the like. The memory 111 is configured to store a program, and the processor 113 executes the program after receiving an execution instruction, and the method executed by the electronic device 100 defined by the process disclosed in any embodiment of the present application may be applied to the processor 113, or implemented by the processor 113.
The processor 113 may be an integrated circuit chip having signal processing capability. The Processor 113 may be a general-purpose Processor, and includes a Central Processing Unit (CPU), a Network Processor (NP), and the like; the Integrated Circuit may also be a Digital Signal Processor (DSP), an Application Specific Integrated Circuit (ASIC), a Field Programmable Gate Array (FPGA) or other programmable logic device, a discrete gate or transistor logic device, or a discrete hardware component. The various methods, steps, and logic blocks disclosed in the embodiments of the present application may be implemented or performed. A general purpose processor may be a microprocessor or the processor may be any conventional processor or the like.
The peripheral interface 114 couples various input/output devices to the processor 113 and memory 111. In some embodiments, the peripheral interface 114, the processor 113, and the memory controller 112 may be implemented in a single chip. In other examples, they may be implemented separately from the individual chips.
The electronic device 100 in this embodiment may be configured to perform each step in each method provided in this embodiment. The implementation of the container live migration method is described in detail below by means of several embodiments.
Example two
Please refer to fig. 2, which is a flowchart illustrating a container live migration method according to an embodiment of the present disclosure. The specific process shown in fig. 2 will be described in detail below.
Step 201, according to the resource utilization rate of the current computing node, judging whether the load of the current computing node exceeds a resource threshold.
Optionally, the resources of the computing node may include resources such as a CPU (Central Processing Unit), a GPU (Graphics Processing Unit), and a memory.
In this embodiment, the load condition of the computing node may be determined by the resource of the computing node.
Optionally, each type of resource corresponds to a different resource threshold.
Illustratively, the resource threshold set for the CPU is a CPU utilization threshold Cmax, the resource threshold set for the GPU is a GPU utilization threshold Gmax, and the resource threshold set for the memory is a memory utilization threshold Nmax. For example, the processing power of different computing nodes may be different, and thus the resource thresholds set for different computing nodes may also be different.
Optionally, taking a CPU, a GPU, and a memory as an example, when the utilization rate of any type of resource exceeds the corresponding resource threshold, it may be determined that the load of the current computing node exceeds the resource threshold.
Further, in consideration of the fact that the resource utilization rate of the computing node may have a normal jitter phenomenon, in order to improve the accuracy of the judgment, the current computing node may be periodically monitored. And judging whether the current computing node is overloaded or not through monitoring in a plurality of periods.
Illustratively, step 201 may include: and acquiring the resource utilization rate of the current computing node according to a set time rule, and judging whether the resource utilization rate of the continuous second quantity of time nodes exceeds a resource threshold value.
And if the resource utilization rate of the continuous second quantity of time nodes exceeds the resource threshold, judging that the load of the current computing node exceeds the resource threshold.
Optionally, the value of the second number may be set as required. For example, the second number may take on values of 4, 5, 6, etc.
For example, the resource usage rate of the current computing node may be obtained every ten minutes, and the obtained resource usage rate is compared with a preset resource threshold, so as to respectively determine whether the resource usage rate of each time node of the current computing node exceeds the resource threshold.
Alternatively, the time interval corresponding to the set time law may be set as required, for example, the time interval may also be five minutes, twenty minutes, half an hour, and the like.
Taking the CPU and the value of the second number as 4 as an example, if the CPU utilization of the current computing node obtained four times continuously exceeds the CPU utilization threshold Cmax, it may be determined that the CPU utilization of the current computing node is overloaded. The container of the current compute node needs to be migrated to relieve the load of the CPU of the current compute node.
Step 202, if the load of the current computing node exceeds the resource threshold, a container to be migrated is screened from the current computing node.
Illustratively, the screened containers to be migrated may be one or more containers.
In one embodiment, as shown in FIG. 3, step 202 may include the following steps.
Step 2021, determining the resource type with the load exceeding the resource threshold according to the resource utilization rate of the current computing node.
For example, if the utilization rate of the CPU of the current compute node exceeds the resource threshold, the resource type loaded with the resource threshold is the CPU.
Step 2022, selecting a container to be migrated from the current compute node according to the resource type.
Alternatively, the number of containers to be migrated selected may be one or more.
For example, if the CPU utilization of the current compute node exceeds the resource threshold, one or more containers with higher CPU requirements may be used as containers to be migrated.
For example, if the GPU usage of the current compute node exceeds the resource threshold, one or more containers with higher GPU requirements may be used as containers to be migrated.
Optionally, the number of containers to be migrated at each time may be multiple, and when multiple resources exceed the resource threshold, multiple containers may be selected for migration based on resource usage of the multiple resources exceeding the resource threshold. When only one resource exceeds the resource threshold, then multiple containers may be selected for migration based on the resource usage of the one resource that exceeds the resource threshold.
For example, if both the GPU usage rate and the memory usage rate of the current compute node exceed the resource threshold, the container with higher GPU demand and higher memory demand may be used as the container to be migrated. For example, a first container may be selected from containers with higher GPU requirements, a second container may be selected from containers with higher memory requirements, and the first container and the second container may be used as containers to be migrated.
For example, if both the GPU usage rate and the memory usage rate of the current compute node exceed the resource threshold, the container with higher GPU demand and higher memory demand may be used as the container to be migrated. For example, a first group of containers may be selected from containers with higher GPU requirements, and a second group of containers may be selected from containers with higher memory requirements. Alternatively, the first container group and the second container group may be used as containers to be migrated. Alternatively, a plurality of containers may be selected from the first container group and the second container group as containers to be migrated.
For example, if the memory usage rate of the current computing node exceeds the resource threshold, the container with higher memory requirement may be used as the container to be migrated. For example, a plurality of containers may be selected from among containers with higher memory requirements. Alternatively, the selected plurality of containers may be used as containers to be migrated.
Optionally, the number of containers to be migrated at each time may be only one, and when multiple resources exceed the resource threshold, one container may be selected for migration based on resource usage of the multiple resources exceeding the resource threshold. When only one resource exceeds the resource threshold, then one container may be selected for migration based on one resource usage that exceeds the resource threshold.
For example, if both the GPU usage rate and the memory usage rate of the current compute node exceed the resource threshold, the container with higher GPU demand or higher memory demand may be used as the container to be migrated. For example, a third container may be selected from containers with higher GPU requirements, a fourth container may be selected from containers with higher memory requirements, and the third container or the fourth container may be used as a container to be migrated.
For example, if the CPU utilization of the current compute node exceeds the resource threshold, the container with higher CPU demand may be used as the container to be migrated. For example, one container may be selected from among containers having higher CPU requirements. Alternatively, the selected container may be used as the container to be migrated.
Considering that there may be running tasks in all containers in each computing node, migration of a container may cause the running task to be set aside, so in order to reduce the influence of migration of a container on an ongoing task, it is possible to perform screening from a container that requires a shorter execution time when executing the task.
In a first embodiment, step 2022 may be implemented as: selecting a first initial container group to be migrated from the current computing node according to the resource type; and selecting the containers to be migrated with the time length less than the time length threshold value required for executing the task from the first initial container group to be migrated.
Optionally, if the CPU utilization of the current computing node exceeds the resource threshold, one or more containers with the highest CPU utilization may be selected from the current computing node as the first initial container group to be migrated.
For example, the CPU utilization of the containers in the current compute node may be sorted from high to low, and the container sorted at the top N bits is selected as the first initial group of containers to be migrated, where N is a positive integer.
Optionally, if the CPU utilization and the memory utilization of the current compute node exceed the resource threshold, one or more containers with the highest CPU utilization and one or more containers with the highest memory utilization may be selected from the current compute node as the first initial to-be-migrated container group.
Optionally, if the CPU utilization and the memory utilization of the current compute node exceed the resource threshold, one or more containers with the highest CPU utilization may be selected from the current compute node first, or one or more containers with the highest memory utilization may be selected from the current compute node as the first initial to-be-migrated container group.
Optionally, if the CPU utilization, the memory utilization, and the GPU utilization of the current compute node all exceed the resource threshold, one or more containers with the highest CPU utilization may be selected from the current compute node, or one or more containers with the highest memory utilization may be selected from the current compute node, or one or more containers with the highest GPU utilization may be selected from the current compute node as the first initial to-be-migrated container group.
Optionally, if the CPU utilization, the memory utilization, and the GPU utilization of the current compute node all exceed the resource threshold, one or more containers with higher CPU utilization, one or more containers with higher GPU utilization, and one or more containers with higher memory utilization may also be selected as the first initial to-be-migrated container group based on the CPU utilization, the GPU utilization, and the memory utilization.
The number of the first initial migration container group may be one or more.
For example, if only one container is included in the current first initial container group to be migrated, and the time required for executing the task of the container is greater than the time threshold, the container migration is not performed on the current computing node.
For example, if the current first initial container group to be migrated includes a plurality of containers, and the time length required for executing the task of each container of the first initial container to be migrated is less than the time length threshold, all containers whose time lengths required for executing the task are less than the time length threshold are taken as containers to be migrated.
For example, if the current first initial container group to be migrated includes a plurality of containers, and the time length required for executing the task, in which each container of the first initial container to be migrated does not exist, is less than the time length threshold, container migration is not performed on the current computing node.
Alternatively, an upper limit of the length of time required to execute the task that can be selected as the container to be migrated may be set in advance. Illustratively, the duration threshold may be set as desired. For example, the time duration thresholds set by different computing nodes may be the same or different.
For example, when the set time threshold is 15min, the time required for the selected container to be migrated to perform the task is less than the 15 min.
For another example, when the set time threshold is 10min, the time required for the selected container to be migrated to perform the task is less than the 10 min.
Since moving containers under the same service at the same time may cause the service to be interrupted, in order to avoid a service being interrupted due to container migration, the number of containers under a service may be taken into consideration when selecting containers to be migrated.
In a second embodiment, step 2022 may be implemented as: selecting a second initial container group to be migrated from the current computing node according to the resource type; determining a target service corresponding to the target container and the number of containers corresponding to the target service for the target container of the second initial container group to be migrated; and if the number of the containers corresponding to the target service is greater than the number threshold, taking the target container as a container to be migrated.
Illustratively, if a container is a belonging container of a service, it means that the container is a container for performing a task of the service.
Wherein, the target container is any container in the second initial container group to be migrated.
The determining method of the second initial container group to be migrated may be the same as the determining method of the first initial container group to be migrated, and is not described herein again.
In one example, as shown in fig. 4, three services may be run in the current compute node, which are: service one, service two, and service three. The containers for executing the task corresponding to the service one are C1, C2, C3 and C4, and the number of the containers to which the service one belongs is four. The containers used for executing the tasks corresponding to the service two are C5, C6, C7, C8, C9, C10 and C11, and the number of the containers belonging to the service two is seven. The containers used for executing the tasks corresponding to the service three are C12, C13, C14, C15 and C16, and the number of the containers belonging to the service three is five.
For example, in this example, containers C1, C8, C14 are included in the second initial group of containers to be migrated.
In one example, the set number threshold may be five, and if the number of containers currently serving as targets corresponding to a container in the second initial container group to be migrated is five or less than five, the container cannot be selected as a container to be migrated.
As shown in fig. 4, the service corresponding to C1 is service one, the service corresponding to C8 is service two, and the service corresponding to C14 is service three. Since the number of belonged containers corresponding to service one and service three is less than or equal to five, C1, C14 cannot be selected as containers to be migrated in this example. Since the number of belonged containers corresponding to service two is greater than five, C8 may be selected as the container to be migrated in this example.
In one example, the set number threshold may be four, and the number of the containers currently serving as the target service corresponding to one container in the second initial container group to be migrated is five, then the container may be selected as the container to be migrated.
As shown in fig. 4, the service corresponding to C1 is service one, the service corresponding to C8 is service two, and the service corresponding to C14 is service three. Since the number of belonged containers serving a corresponding one is equal to four, C1 cannot be selected as the container to be migrated in this example. Since the number of belonged containers corresponding to service two and service three is greater than five, C8 and C14 may be selected as containers to be migrated in this example. Optionally, both C8 and C14 may be selected as containers to be migrated in this example. Alternatively, one container may be randomly selected from C8 and C14 as the container to be migrated.
Alternatively, the number of containers under a service and the length of time required for a container to perform a task may be taken into account.
In a third embodiment, step 2022 may be implemented as: selecting a third initial container group to be migrated from the current computing node according to the resource type; and selecting the containers with the task required duration less than the duration threshold from the third initial container group to be migrated, wherein the containers with the service belonged container number greater than the number threshold corresponding to the containers in the third initial container group to be migrated serve as containers to be migrated.
For other details in the third embodiment, reference may be made to the descriptions in the first embodiment and the second embodiment, which are not described herein again.
And step 203, screening out target computing nodes from each computing node of the container cluster according to the resource utilization rate of each computing node.
Selecting the target computing node may select the best performing, least loaded node in the current container cluster. However, when the container cluster is large in scale, the method may generate a severe jitter phenomenon, that is, when a large number of containers are migrated to the same target computing node at a certain time, the load of the target computing node may be increased sharply, and a severe jitter phenomenon may be generated.
In order to solve the above problem, as shown in fig. 5, step 203 may include the following steps.
Step 2031, according to the resource utilization rate of each computing node of the container cluster, sorting each computing node from low to high according to the resource utilization rate to obtain a computing node sorting table.
For example, if the current compute node is because the CPU usage exceeds the resource threshold, the CPU usage of the compute nodes in the container cluster may be sorted.
For example, if the current compute node is because GPU usage exceeds a resource threshold, then the GPU usage of the compute nodes in the container cluster may be ordered.
For example, if the current compute node is that the memory usage exceeds the resource threshold, the memory usage of the compute nodes in the container cluster may be sorted.
Step 2032, selecting the first number of the calculation nodes from the calculation node sorting table as the initial calculation node group.
Optionally, the value of the first number may be set as required. For example, the first number may take on values of 3, 5, 7, etc.
Optionally, the larger the size of the container cluster, the larger the value of the first number may be.
Step 2033, selecting target computing nodes from the initial computing node group according to a set probability algorithm.
Optionally, the issuing probability of each computing node may be determined according to the resource load data of each computing node in the initial computing node group; then, randomly determining a random positive number smaller than 1; and determining a target computing node according to the random positive number and the issuing probability of each computing node.
And the sum of the issuing probabilities of all the computing nodes in the initial computing node group is 1.
Optionally, determining an issuing probability of each computing node according to the resource load data of each computing node in the initial computing node group, and implementing by using the following formula:
wherein, PiRepresents the distribution probability, R, of the ith computing nodeiAnd e represents the number of the computing nodes in the initial computing node group.
Optionally, the distribution probability of each computing node may also be set as the distribution probability of the arithmetic progression according to the resource utilization rate of each computing node. For example, a lower resource usage of a compute node corresponds to a higher probability of delivery.
If the container cluster is large and there are many containers to be migrated currently, if multiple containers to be migrated are migrated to the same compute node, the compute node may be jittered. Therefore, the target computing node is determined from the computing nodes with lower loads by using the random positive numbers, so that the probability that the containers are migrated to the computing nodes with lower loads is the same, and the problem that the computing nodes are jittered to meet the migration requirement is reduced.
Exemplarily, the determining the target computing node according to the random positive number and the distribution probability of each computing node includes: the random positive number and the issuing probability of each computing node can be differentiated, and the computing node with the smallest difference value with the random positive number is used as a target computing node.
Exemplarily, the determining the target computing node according to the random positive number and the distribution probability of each computing node includes: and setting a probability interval for each computing node according to the issuing probability of each computing node, wherein the computing node corresponding to the probability interval in which the random positive number is positioned is used as a target computing node.
And 204, migrating the container to be migrated to the target computing node.
By the method in the embodiment of the application, the computing nodes with the excessively high resource load can be more accurately positioned, so that the computing nodes which are possibly abnormal are accurately screened out; can be accurately matched with the container to be migrated; and the appropriate migration target computing node of the container to be migrated can be relatively accurately positioned. Furthermore, due to the probability screening mode adopted by the migrated target computing node, the effect of uniform migration can be achieved, and the situation that the load of the migrated target computing node is too high is prevented. Further, according to the scheme in the embodiment of the present application, the problem of load imbalance of each computing node in the cluster is handled in a container migration manner, so that there is no case where a computing node suspends a service (suspends a delivery task), and operations such as resuming the computing node are not required, and continuous work of each computing node can also be achieved.
EXAMPLE III
Based on the same application concept, a container dynamic migration apparatus corresponding to the container dynamic migration method is further provided in the embodiments of the present application, and since the principle of the apparatus in the embodiments of the present application for solving the problem is similar to that in the embodiments of the container dynamic migration method, the apparatus in the embodiments of the present application may be implemented by referring to the description in the embodiments of the method, and repeated details are omitted.
Please refer to fig. 6, which is a schematic diagram of functional modules of a container dynamic migration apparatus according to an embodiment of the present application. Each module in the container dynamic migration apparatus in this embodiment is configured to perform each step in the above-described method embodiment. The container dynamic migration device comprises: a judging module 301, a first screening module 302, a second screening module 303 and a transferring module 304; wherein,
a judging module 301, configured to judge whether a load of a current computing node exceeds a resource threshold according to a resource utilization rate of the current computing node;
a first screening module 302, configured to screen a container to be migrated from a current computing node if a load of the current computing node exceeds a resource threshold;
a second screening module 303, configured to screen out a target computing node from each computing node of the container cluster according to a resource utilization rate of each computing node;
a migration module 304, configured to migrate the container to be migrated to the target computing node.
In a possible implementation, the second filtering module 303 includes: a obtaining unit, a selecting unit and a selecting unit, wherein,
the sorting unit is used for sorting the computing nodes from low to high according to the resource utilization rate of the computing nodes of the container cluster to obtain a computing node sorting table;
a selecting unit, configured to select a first number of compute nodes ranked in the front from the compute node ranking table as an initial compute node group;
and the selecting unit is used for selecting the target computing node from the initial computing node group according to a set probability algorithm.
In a possible embodiment, the selection unit is configured to:
determining the issuing probability of each computing node according to the resource load data of each computing node in the initial computing node group, wherein the sum of the issuing probabilities of each computing node in the initial computing node group is 1;
randomly determining a random positive number smaller than 1;
and determining a target computing node according to the random positive number and the issuing probability of each computing node.
In a possible implementation manner, the determining, according to the resource load data of each computing node in the initial computing node group, an issue probability of each computing node is implemented by the following formula:
wherein,PiRepresents the distribution probability, R, of the ith computing nodeiAnd e represents the number of the computing nodes in the initial computing node group.
In one possible implementation, the first filtering module 302 includes: a type determining unit and a container selecting unit;
the type determining unit is used for determining the resource type with the load exceeding the resource threshold according to the resource utilization rate of the current computing node;
and the container selecting unit is used for selecting a container to be migrated from the current computing node according to the resource type.
In a possible embodiment, the container selection unit is configured to:
selecting a first initial container group to be migrated from the current computing node according to the resource type;
and selecting the containers to be migrated with the time length less than the time length threshold value required for executing the task from the first initial container group to be migrated.
In a possible embodiment, the container selection unit is configured to:
selecting a second initial container group to be migrated from the current computing node according to the resource type;
determining a target service corresponding to the target container and the number of containers corresponding to the target service for the target container of the second initial container group to be migrated, wherein the target container is any container in the second initial container group to be migrated;
and if the number of the containers is larger than a number threshold value, taking the target container as a container to be migrated.
In a possible implementation, the determining module 301 is configured to:
acquiring the resource utilization rate of the current computing node according to a set time rule, and judging whether the resource utilization rate of the continuous second quantity of time nodes exceeds a resource threshold value;
and if the resource utilization rate of the continuous second quantity of time nodes exceeds the resource threshold, judging that the load of the current computing node exceeds the resource threshold.
In addition, an embodiment of the present application further provides a computer-readable storage medium, where a computer program is stored on the computer-readable storage medium, and when the computer program is executed by a processor, the computer program performs the steps of the container dynamic migration method in the foregoing method embodiment.
The computer program product of the container dynamic migration method provided in the embodiment of the present application includes a computer-readable storage medium storing a program code, where instructions included in the program code may be used to execute the steps of the container dynamic migration method in the foregoing method embodiment, which may be specifically referred to in the foregoing method embodiment, and are not described herein again.
In the embodiments provided in the present application, it should be understood that the disclosed apparatus and method can be implemented in other ways. The apparatus embodiments described above are merely illustrative, and for example, the flowchart and block diagrams in the figures illustrate the architecture, functionality, and operation of possible implementations of apparatus, methods and computer program products according to various embodiments of the present application. In this regard, each block in the flowchart or block diagrams may represent a module, segment, or portion of code, which comprises one or more executable instructions for implementing the specified logical function(s). It should also be noted that, in some alternative implementations, the functions noted in the block may occur out of the order noted in the figures. For example, two blocks shown in succession may, in fact, be executed substantially concurrently, or the blocks may sometimes be executed in the reverse order, depending upon the functionality involved. It will also be noted that each block of the block diagrams and/or flowchart illustration, and combinations of blocks in the block diagrams and/or flowchart illustration, can be implemented by special purpose hardware-based systems which perform the specified functions or acts, or combinations of special purpose hardware and computer instructions.
In addition, functional modules in the embodiments of the present application may be integrated together to form an independent part, or each module may exist separately, or two or more modules may be integrated to form an independent part.
The functions, if implemented in the form of software functional modules and sold or used as a stand-alone product, may be stored in a computer readable storage medium. Based on such understanding, the technical solution of the present application or portions thereof that substantially contribute to the prior art may be embodied in the form of a software product stored in a storage medium and including instructions for causing a computer device (which may be a personal computer, a server, or a network device) to execute all or part of the steps of the method according to the embodiments of the present application. And the aforementioned storage medium includes: a U-disk, a removable hard disk, a Read-Only Memory (ROM), a Random Access Memory (RAM), a magnetic disk or an optical disk, and other various media capable of storing program codes. It is noted that, herein, relational terms such as first and second, and the like may be used solely to distinguish one entity or action from another entity or action without necessarily requiring or implying any actual such relationship or order between such entities or actions. Also, the terms "comprises," "comprising," or any other variation thereof, are intended to cover a non-exclusive inclusion, such that a process, method, article, or apparatus that comprises a list of elements does not include only those elements but may include other elements not expressly listed or inherent to such process, method, article, or apparatus. Without further limitation, an element defined by the phrase "comprising … …" does not exclude the presence of other identical elements in a process, method, article, or apparatus that comprises the element.
The above description is only a preferred embodiment of the present application and is not intended to limit the present application, and various modifications and changes may be made by those skilled in the art. Any modification, equivalent replacement, improvement and the like made within the spirit and principle of the present application shall be included in the protection scope of the present application. It should be noted that: like reference numbers and letters refer to like items in the following figures, and thus, once an item is defined in one figure, it need not be further defined and explained in subsequent figures.
The above description is only for the specific embodiments of the present application, but the scope of the present application is not limited thereto, and any person skilled in the art can easily conceive of the changes or substitutions within the technical scope of the present application, and shall be covered by the scope of the present application. Therefore, the protection scope of the present application shall be subject to the protection scope of the claims.