CN111201565A - 用于声对声转换的系统和方法 - Google Patents
用于声对声转换的系统和方法 Download PDFInfo
- Publication number
- CN111201565A CN111201565A CN201880034452.8A CN201880034452A CN111201565A CN 111201565 A CN111201565 A CN 111201565A CN 201880034452 A CN201880034452 A CN 201880034452A CN 111201565 A CN111201565 A CN 111201565A
- Authority
- CN
- China
- Prior art keywords
- speech
- timbre
- data
- target
- segment
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims abstract description 119
- 238000006243 chemical reaction Methods 0.000 title claims abstract description 33
- 239000013598 vector Substances 0.000 claims description 170
- 238000010801 machine learning Methods 0.000 claims description 96
- 238000009826 distribution Methods 0.000 claims description 65
- 238000013528 artificial neural network Methods 0.000 claims description 49
- 238000004458 analytical method Methods 0.000 claims description 32
- 230000002123 temporal effect Effects 0.000 claims description 30
- 238000004590 computer program Methods 0.000 claims description 25
- 241000282414 Homo sapiens Species 0.000 claims description 23
- 238000013507 mapping Methods 0.000 claims description 22
- 238000001914 filtration Methods 0.000 claims description 20
- 238000012549 training Methods 0.000 claims description 10
- 230000001131 transforming effect Effects 0.000 claims description 6
- 238000010276 construction Methods 0.000 claims description 5
- 230000008569 process Effects 0.000 description 52
- 230000009466 transformation Effects 0.000 description 8
- 230000003042 antagnostic effect Effects 0.000 description 6
- 241000862969 Stella Species 0.000 description 5
- 239000000284 extract Substances 0.000 description 5
- 238000012935 Averaging Methods 0.000 description 4
- 230000009471 action Effects 0.000 description 4
- 238000010586 diagram Methods 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- 230000003278 mimic effect Effects 0.000 description 4
- 206010013952 Dysphonia Diseases 0.000 description 3
- 241000283070 Equus zebra Species 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 241001465754 Metazoa Species 0.000 description 3
- 208000027498 hoarse voice Diseases 0.000 description 3
- 230000006872 improvement Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012545 processing Methods 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 230000001960 triggered effect Effects 0.000 description 3
- 238000012795 verification Methods 0.000 description 3
- 230000008901 benefit Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 238000013527 convolutional neural network Methods 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 230000001537 neural effect Effects 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 230000033764 rhythmic process Effects 0.000 description 2
- 230000003595 spectral effect Effects 0.000 description 2
- 241000282461 Canis lupus Species 0.000 description 1
- 101001072091 Homo sapiens ProSAAS Proteins 0.000 description 1
- 241000917703 Leia Species 0.000 description 1
- 102100036366 ProSAAS Human genes 0.000 description 1
- 230000008485 antagonism Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 238000013473 artificial intelligence Methods 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000007596 consolidation process Methods 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 238000013213 extrapolation Methods 0.000 description 1
- 230000001815 facial effect Effects 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 230000008447 perception Effects 0.000 description 1
- 230000000306 recurrent effect Effects 0.000 description 1
- 238000007670 refining Methods 0.000 description 1
- 238000013515 script Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000006403 short-term memory Effects 0.000 description 1
- 230000005236 sound signal Effects 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 210000001260 vocal cord Anatomy 0.000 description 1
Images


















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/003—Changing voice quality, e.g. pitch or formants
- G10L21/007—Changing voice quality, e.g. pitch or formants characterised by the process used
- G10L21/013—Adapting to target pitch
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G10L13/033—Voice editing, e.g. manipulating the voice of the synthesiser
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/018—Audio watermarking, i.e. embedding inaudible data in the audio signal
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
- G10L2015/025—Phonemes, fenemes or fenones being the recognition units
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/003—Changing voice quality, e.g. pitch or formants
- G10L21/007—Changing voice quality, e.g. pitch or formants characterised by the process used
- G10L21/013—Adapting to target pitch
- G10L2021/0135—Voice conversion or morphing
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/27—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique
- G10L25/30—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique using neural networks
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Acoustics & Sound (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Signal Processing (AREA)
- Quality & Reliability (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Computation (AREA)
- Telephonic Communication Services (AREA)
- Machine Translation (AREA)
Abstract
一种构建话音转换系统的方法使用来自目标语音的目标信息以及源话音数据。该方法接收源话音数据和在音色空间内的目标音色数据。根据源话音数据和目标音色数据,生成器产生第一候选数据。参照多个不同语音的音色数据,鉴别器将第一候选数据与目标音色数据进行比较。鉴别器确定第一候选数据和目标音色数据之间的不一致性。鉴别器产生包含与不一致性有关的信息的不一致性消息。将不一致性消息反馈给生成器,并且生成器产生第二候选数据。使用由生成器和/或鉴别器产生的作为反馈结果的信息来改进音色空间中的目标音色数据。
Description
优先权
本专利申请要求2017年5月24日提交的名称为“利用对抗性神经网络的音色传递系统和方法(TIMBRE TRANSFER SYSTEMS AND METHODS UTILIZING ADVERSARIAL NEURALNETWORKS)”并指定William C.Huffman作为发明人的美国临时专利申请第62/510,443号的优先权,其全部公开内容通过引用并入本文。
技术领域
本发明总体上涉及语音转换,且更具体地,本发明涉及生成合成语音简档。
背景技术
由于使用个人语音激活的助理,例如Amazon Alexa、Apple Siri和GoogleAssistant,近来人们对语音技术的兴趣已经达到顶峰。此外,播客和有声读物服务最近也已经普及。
发明内容
根据本发明的一个实施例,一种构建话音转换系统的方法使用来自目标语音的目标语音信息以及表示源语音的话音段的话音数据。该方法接收表示源语音的第一话音段的源话音数据。该方法还接收与目标语音相关的目标音色数据。目标音色数据在音色空间内。生成机器学习系统根据源话音数据和目标音色数据,产生第一候选话音数据,第一候选话音数据表示第一候选语音中的第一候选话音段。鉴别机器学习系统用于参照多个不同语音的音色数据将第一候选话音数据与目标音色数据进行比较。鉴别机器学习系统参照多个不同语音的音色数据来确定第一候选话音数据和目标音色数据之间的至少一个不一致性。鉴别机器学习系统还产生具有与第一候选话音数据和目标音色数据之间的不一致性有关的信息的不一致性消息。该方法还将不一致性消息反馈给生成机器学习系统。根据不一致性消息,生成机器学习系统产生第二候选话音数据,第二候选话音数据表示第二候选语音中的第二候选话音段。使用由生成机器学习系统和/或鉴别机器学习系统产生的作为反馈结果的信息来改进音色空间中的目标音色数据。
在一些实施例中,源话音数据变换成目标音色。其中,源话音数据可以来自源语音的音频输入。以类似的方式,可以从来自目标语音的音频输入中获得目标音色数据。可以从目标话音段提取目标音色数据。此外,目标音色数据可以由时间接受域滤波。
机器学习系统可以是神经网络,并且多个语音可以在向量空间中。因此,多个语音和第一候选语音可根据每一语音提供的话音段中的频率分布映射在向量空间中。此外,根据不一致性消息可以调整向量空间中与多个语音表示相关的第一候选语音表示,以表达第二候选语音。因此,系统可通过将候选语音与多个语音进行比较来将身份分配给候选语音。
在一些实施例中,当鉴别神经网络具有小于95%的第一候选语音是目标语音的置信区间时,产生不一致性消息。因此,第二候选话音段提供比第一候选话音段更高的被鉴别器识别为目标语音的概率。因此,一些实施例使用生成机器学习系统根据空不一致性消息在最终候选语音中产生最终候选话音段。最终候选话音段模仿源话音段,但是具有目标音色。
根据一个实施例,一种用于训练话音转换系统的系统包括表示源语音的第一话音段的源话音数据。该系统还包括与目标语音相关的目标音色数据。此外,该系统包括生成机器学习系统,该生成机器学习系统配置为根据源话音数据和目标音色数据,产生第一候选话音数据,第一候选话音数据表示第一候选语音中的第一候选话音段。该系统还具有鉴别机器学习系统,其配置为参考多个不同语音的音色数据,将第一候选话音数据与目标音色数据进行比较。此外,鉴别机器学习配置以参照多个不同语音的音色数据来确定第一候选话音数据与目标音色数据之间是否存在至少一个不一致性。当存在至少一个不一致性时,鉴别机器学习产生具有与第一候选话音数据和目标音色数据之间的不一致性有关的信息的不一致性消息。此外,鉴别机器学习将不一致性消息返回生成机器学习系统。
目标音色数据由时间接受域滤波。在一些实施例中,时间接受域在约10毫秒和2,000毫秒之间。更具体地,时间接受域可以在约10毫秒和1,000毫秒之间。
在一些实施例中,语音特征提取器配置为根据不一致性消息来调整向量空间中的与多个语音的表示相关的候选语音的表示,以更新和反映第二候选语音。此外,区分性机器学习系统可配置以通过将第一或第二候选语音与多个语音进行比较来确定候选语音的说话者的身份。
可以从目标音频输入中提取目标音色数据。源话音数据可以变换为目标音色中变换的话音段。该系统还可以向变换的话音段添加水印。
根据本发明的又一实施例,一种用于构建音色向量空间的音色向量空间构建系统包括输入端。输入配置为接收a)第一语音中的包括第一音色数据的第一话音段,以及b)第二语音中的包括第二音色数据的第二话音段。该系统还包括时间接受域,用于将第一话音段变换为第一多个更小的分析音频段。第一多个更小的分析音频段中的每一个具有表示第一音色数据的不同部分的频率分布。滤波器还配置为使用时间接受域来将第二话音段变换成第二多个更小的分析音频段。第二多个更小的分析音频段中的每一个具有表示第二音色数据的不同部分的频率分布。该系统还包括配置为在音色向量空间中相对于第二语音映射第一语音的机器学习系统。根据a)来自第一话音段的第一多个分析音频段和b)来自第二话音段的第二多个分析音频段的频率分布来映射语音。
数据库还配置为接收第三语音中的第三话音段。机器学习系统配置为使用时间接受域将第三话音段滤波为多个较小的分析音频段,并且在向量空间中相对于第一语音和第二语音映射第三语音。将第三语音相对于第一语音和第二语音进行映射改变向量空间中第一语音与第二语音的相对位置。
其中,该系统配置成在至少一个语音中映射英语中的每个人类音位。接受域足够小以便不捕获语音的话音速率和/或口音。例如,时间接受域可以在约10毫秒和约2,000毫秒之间。
根据另一实施例,一种用于构造用于变换话音段的音色向量空间的方法包括接收a)第一语音中的第一话音段和b)第二语音中的第二话音段。第一话音段和第二话音段都包括音色数据。该方法使用时间接受域将每一个第一话音段和第二话音段中进行滤波为多个更小的分析音频段。每个分析音频段具有表示音色数据的频率分布。该方法还根据来自第一话音段和第二话音段的多个分析音频段的至少一个中的频率分布,在向量空间中相对于第二语音映射第一语音。
另外,该方法可以接收第三语音中的第三话音段,并且使用时间接受域将第三话音段滤波为多个更小的分析音频段。可以在向量空间中相对于第一语音和第二语音映射第三语音。根据映射第三语音,可以在向量空间中调整第一语音与第二语音的相对位置。
根据另一实施例,一种用于构建音色向量空间的音色向量空间构造系统包括输入端,该输入端配置为接收a)第一语音中的包括第一音色数据的第一话音段,以及b)第二语音中的包括第二音色数据的第二话音段。该系统还包括用于将a)第一话音段滤波为具有表示第一音色数据的不同部分的频率分布的第一多个更小的分析音频段,以及b)将第二话音段滤波为第二多个更小的分析音频段的装置,第二多个更小的分析音频段中的每一个具有表示第二音色数据的不同部分的频率分布。此外,该系统具有用于根据a)来自第一话音段的第一多个分析音频段和b)来自第二话音段的第二多个分析音频段的频率分布在音色向量空间中相对于第二语音映射第一语音的装置。
根据本发明的另一实施例,一种使用音色向量空间构建具有新音色的新语音的方法包括接收使用时间接受域滤波的音色数据。在音色向量空间中映射音色数据。音色数据与多个不同的语音相关。多个不同语音中的每一个在音色向量空间中具有各自的音色数据。该方法通过机器学习系统使用多个不同语音的音色数据来构建新音色。
在一些实施例中,该方法从新语音接收新话音段。该方法还使用神经网络将新话音段滤波为新的分析音频段。该方法还参照多个映射的语音在向量空间中映射新语音。该方法还基于新语音与多个映射的语音的关系来确定新语音的至少一个特征。其中,该特征可以是性别、种族和/或年龄。来自多个语音中的每一个的话音段可以是不同的话音段。
在一些实施例中,根据对音色数据的数学运算,生成神经网络被用于产生候选语音中的第一候选话音段。例如,音色数据可以包括与第一语音和第二语音有关的数据。此外,向量空间中的语音表示群集可以表示特定的口音。
在一些实施例中,该方法提供源话音并且将源话音转换为新音色,同时保持源韵律和源口音。该系统可以包括用于对目标音色数据滤波的装置。
根据另一实施例,一种系统使用音色向量空间产生新目标语音。该系统包括配置为存储使用时间接受域合并的音色数据的音色向量空间。使用时间接受域对音色数据滤波。音色数据与多个不同的语音相关。机器学习系统配置为使用音色数据将音色数据转换为新目标语音。
其中,通过使用音色数据的至少一个语音特征作为变量执行数学运算,可以将音色数据转换为新目标语音。
根据又一实施例,一种方法将话音段从源音色转换为目标音色。该方法存储与多个不同语音相关的音色数据。多个不同语音中的每一个在音色向量空间中具有各自的音色数据。音色数据使用时间接受域滤波,并在音色向量空间中映射。该方法接收源语音中的源话音段,用于变换为目标语音。该方法还接收对目标语音的选择。目标语音具有目标音色。参照多个不同语音在音色向量空间中映射目标语音。该方法使用机器学习系统将源话音段从源语音的音色变换为目标语音的音色。
本发明的示例性实施例具体为一种计算机程序产品,该计算机程序产品为具有计算机可读程序代码的计算机可用介质。
附图说明
本领域的技术人员应当从参照下面总结的附图讨论的“具体实施方式”中更全面地理解本发明的各种实施例的优点。
图1示意性地示出了根据本发明的示例性实施例的声对声转换系统的简化版本。
图2示意性地示出了实现本发明的示例性实施例的系统的细节。
图3示出了根据本发明的示例性实施例的用于构建表示编码语音数据的多维空间的过程。
图4示意性地示出了根据本发明的示例性实施例的对话音样本进行过滤的时间接收滤波器。
图5A-5C示出了根据本发明的示例性实施例的具有从图4的相同话音段提取的不同分析音频段的频率分布的频谱图。
图5A示出了单词“Call”中的“a”音素的频谱图。
图5B示出了“Stella”中“a”音素的频谱图。图5C示出了“Please”中“ea”音素的频谱图。
图6A-6D示意性地示出了根据本发明的示例性实施例的向量空间的片段。
图6A示意性地示出了仅映射图5B所示音素的目标语音的向量空间的片段。
图6B示意性地示出了映射目标语音和第二语音的图6A的向量空间的片段。
图6C示意性地示出了映射目标语音、第二语音和第三语音的图6A的向量空间的片段。
图6D示意性地示出了映射多个语音的图6A的向量空间的片段。
图7A示出了第二语音的音色中的单词“Call”中的“a”音素的频谱图。
图7B示出了在第三语音的音色中的单词“Call”中的“a”音素的频谱图。
图8A示意性地示出了根据本发明的示例性实施例的包括合成语音简档的向量空间的片段。
图8B示意性地示出了根据本发明的示例性实施例、在生成的对抗性神经网络改进合成语音简档之后,对应于“DOG”中的音素“D”的向量空间的片段。
图8C示意性地示出了添加了第二语音和第四语音的图8B的向量空间的片段。
图9示出了根据本发明的示例性实施例的使用生成对抗性网络来改进增强语音简档的系统的框图。
图10示出了根据本发明的示例性实施例的用于将话音转换为话音的过程。
图11示出了根据本发明的示例性实施例使用语音来验证身份的过程。
具体实施方式
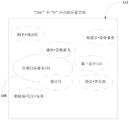
在示例性实施例中,声对声转换系统允许将源语音中所说的话音段实时或接近实时地变换为目标语音。为此,该系统具有语音特征提取器,该语音特征提取器从多个语音接收话音样本并提取与由每个语音产生的每个声音相关联的频率分量。基于所提取的频率分量在向量空间中相对于彼此映射语音,这使得能够为话音样本中未提供的声音外插合成频率分量。该系统具有机器学习,机器学习进一步经配置以将目标语音与其它语音进行比较,且改进合成频率分量以最佳地模仿该语音。因此,系统的用户可以输入话音段,选择目标音,并且系统将话音段变换为目标语音。
图1示意性地示出了根据本发明的示例性实施例的声对声转换系统100的简化版本。其中,系统100允许用户将他们的语音(或任何其他语音)转换成他们选择的目标语音104。更具体地,系统100将用户的话音段103转换为目标语音104。因此,本例中的用户语音称为源语音102,因为系统100将源语音102中所说的话音段103变换为目标语音104。变换的结果是变换的话音段106。尽管源语音102被示为人类说话者(例如,阿诺德),但是在一些实施例中,源语音102可以是合成语音。
声音的变换也称为音色转换。在整个申请中,“语音”和“音色”可互换使用。语音的音色允许收听者区分和识别以相同音调、口音、振幅和韵律另外说出相同单词的特定语音。音色是由说话者为特定声音做出的频率分量组产生的生理特性。在示例性实施例中,话音段103的音色转换为目标语音104的音色,同时保持源语音102的原来的韵律、节奏和口音/发音。
例如,阿诺德·斯瓦辛格可以使用系统100将他的话音段103(例如,“我会回来的”)转换为詹姆斯·厄尔·琼斯的语音/音色。在该示例中,阿诺德的语音是源语音102,詹姆斯的语音是目标语音104。阿诺德可以向系统100提供詹姆斯语音的话音样本105,系统100使用话音样本105来变换他的话音段(如下面进一步描述的)。系统100获取话音段103,将其变换为詹姆斯的语音104,并在目标语音104中输出变换的话音段106。因此,话音段103“我会回来的”以詹姆斯的语音104输出。然而,变换的话音段106保持原来的韵律、节奏和口音。因此,变换的话音段106听起来像詹姆斯试图模仿阿诺德的口音/发音/韵律和话音段103。换句话说,变换的话音段106是詹姆斯音色中的源话音段103。下面描述系统100如何完成该变换的细节。
图2示意性地示出了实现本发明的示例性实施例的系统100的细节。系统100具有经配置以接收音频文件(例如,目标语音104中的话音样本105)和来自源语音102的话音段103的输入端108。应当理解,虽然不同的术语用于“话音段103”和“话音样本105”,但是两者都可以包括口头单词。术语“话音样本105”和“话音段103”仅用于指示源,并且系统100利用这些音频文件中的每一个进行不同的变换。“话音样本105”指的是在目标语音104中输入到系统100中的话音。系统100使用话音样本105来提取目标语音104的频率分量。另一方面,系统100将“话音段103”从源语音102转换为目标语音104。
系统100具有经配置为提供用户界面的用户界面服务器110,用户可以通过用户界面与系统100通信。用户可以经由电子设备(诸如计算机、智能电话等)访问用户界面,并且使用该电子设备向输入端108提供话音段103。在一些实施例中,电子设备可以是联网设备,诸如连接因特网的智能电话或台式计算机。用户话音段103可以是例如由用户说出的句子(例如,“我会回来的”)。为此,用户设备可以具有用于记录用户话音段103的集成麦克风或辅助麦克风(例如,通过USB连接)。或者,用户可以上传包含用户话音段103的预先记录的数字文件(例如,音频文件)。应当理解,用户话音段103中的语音不必是用户的语音。术语“用户话音段103”用于方便地表示由用户提供的话音段,系统100将该话音段转换为目标音色。如前所述,以源语音102说出用户话音段103。
输入端108还被配置为接收目标语音104。为此,目标语音104可以由用户以类似于话音段103的方式上传到系统100。可替换地,目标语音104可以在先前提供给系统100的语音111的数据库中。如下文将进一步详细描述,如果目标语音104尚未在语音数据库111中,那么系统100使用变换引擎118处理语音104并且将其映射到表示编码的语音数据的多维离散或连续空间112中。该表示称为“映射”语音。当映射编码的语音数据时,向量空间112进行关于语音的表征,并在此基础上将它们相对于彼此放置。例如,表示的一部分可能必须与语音的音调或说话者的性别有关。
示例性实施例使用时间接收滤波器114(也称为时间接受域114)将目标语音104过滤为分析音频段,变换引擎118从分析音频段提取频率分量,当目标语音104首先由输入端108接收时,机器学习系统116映射向量空间112中的目标语音104的表示(例如,使用语音特征提取器120),并且机器学习系统116改进目标语音104的映射表示。然后,系统100可用于将话音段103变换为目标语音104。
具体地,在示例性实施例中,系统100将目标104话音样本105划分成(可能重叠的)音频段,每个音频段具有对应于语音特征提取器120的时间接受域114的大小。然后语音特征提取器120单独地对每个分析音频段进行操作,每个分析音频段可以包含由目标说话者的语音104中的目标产生的声音(例如音素、音位、音素的一部分或多个音素)。
在每个分析音频段中,语音特征提取器120提取目标说话者的语音104的特征,并基于这些特征在向量空间112中映射语音。例如,一个这样的特征可能是朝向放大用于产生一些元音声的几个频率的一些幅度的偏差,以及提取方法可将段中的声音识别为特定元音声,将所表达频率的振幅与其它语音所使用的振幅进行比较以产生类似声音,并且接着将此语音的频率与语音特征提取器120先前已暴露为作为特征的特定组的类似语音相比的差异进行编码。然后将这些特征组合在一起以改进目标语音104的映射表示。
在示例性实施例中,系统100(语音特征提取器120以及最终的组合)可以被认为是机器学习系统。一种实现方式可以包括作为语音特征提取器120的卷积神经网络,以及在末端组合所提取的特征的递归神经网络。其它例子可以包括卷积神经网络以及在末端具有注意机制的神经网络,或者在末端具有固定大小的神经网络,或者在末端简单地添加特征。
语音特征提取器120提取目标话音样本105的频率中的幅度之间的关系(例如,共振峰的相对幅度和/或共振峰的起音和衰减)。通过这样做,系统100正在学习目标的音色104。在一些实施例中,语音特征提取器120可以可选地包括频率-声音关联引擎122,其将特定分析音频段中的频率分量与特定声音关联。尽管上文将频率-声音关联引擎122描述为用于映射目标语音104,但所属领域的技术人员了解,机器学习系统116可使用额外或替代方法来映射语音。因此,该特定实现方式的讨论仅旨在作为便于讨论的示例,而不旨在限制所有示例性实施例。
每一个上述部件通过任何传统的互连机构可操作地连接。图2简单地示出了连通每个部件的总线。本领域技术人员应当理解,可以修改该一般化表示以包括其它传统的直接或间接连接。因此,对总线的讨论并不旨在限制各种实施例。
实际上,应当注意,图2仅仅示意性地示出了这些部件中的每一个。本领域技术人员应当理解,这些组件中的每一个可以以各种常规方式实现,例如通过使用硬件、软件或硬件和软件的组合,涵盖一个或多个其他功能部件。例如,语音提取器112可以使用执行固件的多个微处理器来实现。作为另一实例,机器学习系统116可使用一个或一个以上专用集成电路(即,“ASIC”)及相关软件,或者ASIC、离散电子部件(例如,晶体管)及微处理器的组合来实施。因此,图2的机器学习系统116和单个框中的其它部件的表示仅出于简化的目的。实际上,在一些实施例中,图2的机器学习系统116分布在多个不同的机器上,不必在相同的外壳或底盘内。另外,在一些实施例中,示出为分离的部件(诸如图2中的时间接受域114)可以由单个部件(诸如用于整个机器学习系统116的单个时间接受域115)替换。此外,图2中的某些部件和子部件是可选的。例如,一些实施例可以不使用关联引擎。作为另一个例子,在一些实施例中,生成器140、鉴别器142和/或语音特征提取器120可以不具有接受域114。
应当重申,图2的表示是实际声对声转换系统100的显著简化的表示。本领域技术人员应当理解,这种设备可以具有其它物理和功能部件,例如中央处理单元、其它分组处理模块和短期存储器。因此,此论述并非旨在暗示图2表示声对声转换系统100的所有元件。
图3示出了根据本发明的示例性实施例的用于构建表示编码语音数据的多维离散或连续向量空间112的过程300。应当注意,该过程实质上是根据通常用于构建向量空间112的较长过程简化而来。因此,构建向量空间112的过程可以具有本领域技术人员可能使用的许多步骤。另外,一些步骤可以以与所示顺序不同的顺序执行,或者同时执行。因此,本领域技术人员可以适当地修改该过程。
图3的过程开始于步骤302,步骤302接收目标音色104中的话音样本105。如前所述,话音样本105由输入端108接收,并且可以由系统100的用户提供给系统100。在一些实施例中,可以向系统100提供已经在向量空间112中映射的语音。已经在向量空间112中映射的语音已经经历了下面描述的过程。下面更详细地描述向量空间112。
图4示意性地示出了根据本发明的示例性实施例的对话音样本105滤波的示例性时间接收滤波器114。该过程继续到步骤304,其中话音样本105由时间接收滤波器114滤波为分析音频段124。此实例中的话音样本105是目标语音104中的1秒记录音频信号。话音样本105可以短于或长于1秒,但是出于下面讨论的原因,在一些实施例,话音样本105可以使用更长的长度。在这个例子中,时间接收滤波器114设置为100毫秒。因此,1秒话音样本105通过滤波器114分解成10个100毫秒的分析音频段124。
尽管时间接收滤波器114示出为设置成过滤100毫秒间隔,但是应当理解,可以在如下所述的参数内设置各种过滤间隔。时间接受域114(或滤波器114)的讨论涉及机器学习116的任何或所有部分(例如,生成器140、鉴别器142和/或特征提取器120)。在示例性实施例中,滤波间隔大于0毫秒且小于300毫秒。在一些其它实施例中,时间接受域114小于50毫秒、80毫秒、100毫秒、150毫秒、250毫秒、400毫秒、500毫秒、600毫秒、700毫秒、800毫秒、900毫秒、1000毫秒、1500毫秒或2000毫秒。在进一步的实施例中,时间接受域114大于5毫秒、10毫秒、15毫秒、20毫秒、30毫秒、40毫秒、50毫秒或60毫秒。尽管在图2中被示为单独的部件,但是时间接收滤波器114可以被构建到输入108中作为时间接受域114。此外,机器学习系统116可以具有单个接受域114(例如,代替所示的三个单独的接受域114)。
每个分析音频段124包含由特定目标语音104发出的一个或多个特定声音的频率数据(在步骤306中提取)。因此,分析音频段124越短,频率数据(例如,频率分布)对特定声音越具体。然而,如果分析音频段124太短,则系统100可以滤除某些低频声音。在优选实施例中,时间滤波器114设置为捕获话音样本105流中最小可区分的离散声音段。最小可区分的离散声音段被称为音素。从技术角度来看,分析音频段124应当足够短以捕获音素的共振峰特征。示例性实施例可以将分析音频段滤波到大约60毫秒和大约250毫秒之间。
人通常能够听到20Hz到20kHz范围内的声音。低频声音比高频声音具有更长的周期。例如,具有20Hz频率的声波在整个周期内花费50毫秒,而具有2kHz频率的声波在整个周期内花费0.5毫秒。因此,如果分析音频段124非常短(例如,1毫秒),则分析音频段124可能不包括足够可检测的20Hz声音。然而,一些实施例可以使用预测建模(例如,仅使用低频声波的一部分)来检测低频声音。示例性实施例可以滤除或忽略一些较低频率的声音,并且仍然包含足够的频率数据以精确地模仿目标语音104的音色。因此,发明人相信短至约10毫秒的分析音频段124足以使系统100充分预测音素的频率特征。
人类话音中的基频通常在大于100Hz的量级上。基频是音色的一部分,但不是音色本身。如果人的语音只在它们的基频上不同,则语音转换本质上是音调偏移,相当于在钢琴上弹奏低八度的同一首歌曲。但是,音色也是使钢琴和喇叭声音在演奏相同音符时不同的质量,它是频率中所有小的附加变化的集合,这些变化中没有一个具有与基频(通常)一样高的幅度,但是这些变化对声音的整体感觉有显著的贡献。
虽然基频对于音色可能是重要的,但是它不是唯一的音色指示符。考虑摩根·弗里曼和目标语音104都可以以相同的八度音程发出一些相同的音符的情况。这些音符隐含地具有相同的基频,但是目标语音104和摩根·弗里曼可以具有不同的音色,因此,单独的基频不足以识别语音。
系统100最终基于来自分析音频段124的频率数据来创建目标语音104的语音简档。因此,为了具有对应于特定音素的频率数据,时间接收滤波器114优选地将分析音频段124滤波到大约发音最小可区分音素所花费的时间。因为不同的音素可具有不同的时间长度(即,表达音素所花费的时间量),所以示例性实施例可将分析音频段124滤波到大于表达以人类语言产生的最长音素所花费的时间的长度。在示例性实施例中,由滤波器114设置的时域允许分析音频段124包含与至少整个单个音素有关的频率信息。发明人相信,将话音分解成100毫秒的分析音频段124足够短以对应于由人类语音产生的大多数音素。因此,各个分析音频段124包含对应于由话音样本105中的目标语音104产生的某些声音(例如,音素)的频率分布信息。
另一方面,示例性实施例还可以具有时间接受域114的上限。例如,示例性实施例具有足够短以避免一次捕获多于一个完整音素的接受域114。此外,如果时间接受域114较大(例如,大于1秒),则分析音频段124可以包含源102的口音和/或韵律。在一些实施例中,时间接受域114足够短(即具有上限)以避免捕获口音或韵律这些语音特征。在更长的时间间隔上获取这些语音特征。
一些现有技术的文本到话音转换系统包括口音。例如,美国口音可以将单词“zebra”发为 (“zeebrah”),而英国口音可以将单词发为
(“zeebrah”),而英国口音可以将单词发为 (“zebrah”)。美国和英国的说话人都在不同单词中使用i:和ε音素,但是文本到话音使用基于口音的特定单词“zebra”中的一个音素或另一个音素。因此,文本到话音不允许完全控制目标音色,而是受目标的特定单词发音的方式的限制。因此,通过维持足够短的接受域114,分析音频段124很大程度上避免了收集包括在更长的时间间隔(例如,在完整的单词“zebra”)上获取的这些其它特征的数据。
(“zebrah”)。美国和英国的说话人都在不同单词中使用i:和ε音素,但是文本到话音使用基于口音的特定单词“zebra”中的一个音素或另一个音素。因此,文本到话音不允许完全控制目标音色,而是受目标的特定单词发音的方式的限制。因此,通过维持足够短的接受域114,分析音频段124很大程度上避免了收集包括在更长的时间间隔(例如,在完整的单词“zebra”)上获取的这些其它特征的数据。
实际上,发明人已知的现有技术存在捕获纯音色的问题,因为接受域太长,例如,当试图映射音色(例如,口音)时,接受域使得语音映射固有地包括附加特征。映射口音的问题是说话者可以在保持说话者的音色的同时改变口音。因此,这种现有技术不能获得与这些其它特征分开的声音的真实音色。例如,诸如Arik等人描述的现有技术文本到话音转换(Sercan O.Arik,Jitong Chen,Kainan Peng,Wei Ping,以及Yanqi Zhou:具有几个样本的神经语音克隆(Neural Voice Cloning with a Few Samples),ArXiv:1708.07524,2018)基于经转换的字合成整个语音。因为转换是文本到话音,而不是话音到话音,所以系统不仅需要做出关于音色的决定,而且需要做出关于韵律、变音、口音等的决定。大多数文本到话音系统并不孤立地确定这些特征中的每一个,而是相反地,对于训练它们所针对的每个人,学习那个人的所有这些元素的组合。这意味着没有单独针对音色调整语音。
相反,示例性实施例使用话音到话音转换(也称为声对声转换)来转换话音而不是合成话音。系统100不必选择所有其它特征,如韵律、口音等,因为这些特征由输入话音提供。因此,输入话音(例如,话音段103)特定地变换成不同的音色,同时保持其它语音特征。
回到图3,过程进行到步骤306,从分析音频段124中提取频率分布。任何特定分析音频段124的频率分布对于每个语音都是不同的。这就是为什么不同说话者的音色是可区分的。为了从特定的分析音频段124中提取频率信息,变换引擎118可以执行短时傅立叶变换(STFT)。然而,应当理解,STFT仅仅是获得频率数据的一种方式。在示例性实施例中,变换引擎118可以是机器学习的一部分,并构建其自己的也产生频率数据的滤波器组。话音样本105被分解成(可能重叠的)分析音频段124,并且变换引擎对每个分析音频段124执行FFT。在一些实施例中,变换引擎118包括分析音频段124上的开窗功能,缓解边界条件的问题。即使在分析音频段124之间存在一些重叠,它们仍然被认为是不同的音频段124。在提取完成之后,获得分析音频段124的频率数据。结果是在各个时间点的一组频率强度在示例性实施例中布置为具有垂直轴上的频率和水平轴上的时间的图像(频谱图)。
图5A-5C示出了根据本发明的示例性实施例的具有从图4的相同话音样本105提取的不同分析音频段124的频率分布的频谱图126。术语“频率分布”是指存在于特定分析音频段124或其集合中的成组单独频率及其单独强度,这取决于上下文。图5A示出了由目标104产生的单词“Call”中的“a”音素的频谱图126。如本领域技术人员已知的,频谱图126绘制时间对频率的曲线,并且还通过颜色强度示出频率的幅度/强度(例如,以dB为单位)。在图5A中,频谱图126具有12个清晰可见的峰128(也称为共振峰128),并且每个峰具有与更可听频率相关的颜色强度。
系统100知道图5A的频谱图表示“a”声音。例如,关联引擎122可以分析分析音频段124的频率分布,并确定该频率分布表示单词“Call”中的“a”音素。系统100使用分析音频段124的频率分量来确定音素。例如,不管谁在讲话,“Call”中的“a”声音具有中频分量(接近2kHz),而那些频率分量对于其它元音声音可能不存在。系统100使用频率分量中的区别来猜测声音。此外,系统100知道该频率分布和强度对目标104而言是特定的。如果目标104重复相同的“a”音素,则存在非常相似(如果不相同)的频率分布。
如果特征提取器120不能确定分析音频段124与它已知的任何特定声音相关,则它可以向时间接收滤波器114发送调整消息。具体地,调整消息可以使时间接收滤波器114调整各个或所有分析音频段124的滤波时间。因此,如果分析音频段124太短而不能捕获关于特定音素的足够有意义的信息,则时间接收滤波器可以调整分析音频段124的长度和/或界限以更好地捕获音素。因此,即使在没有声音识别步骤的示例性实施例中,也可以产生不确定性的估计并将其用于调整接受域。可替换地,可以有多个机器学习系统116(例如,语音特征提取器120的子部件),这些机器学习系统116使用全部同时操作的不同接受域,并且系统的其余部分可以在来自它们中的每一个的结果之间进行选择或合并。
特征提取器120不需要查看整个接受域114中的频率分布。例如,特征提取器120可以查看部分所提供的接受域114。此外,时间接受域114的大小和步幅可以通过机器学习来调整。
图5B示出了由目标104产生的口语单词“Stella”中的“a”音素的频谱图126。该频谱图126具有七个清晰可见的峰128。当然,存在许多也具有频率数据的其它峰128,但是它们不具有与清晰可见的峰128一样大的强度。这些较不可见的峰表示由目标语音104产生的声音中的谐波130。虽然这些谐波130在频谱图126中对于人来说不是清晰可感知的,但是系统100知道基础数据并使用它来帮助创建目标语音104的语音简档。
图5C示出了由目标104产生的口头词“Please”中的“ea”音素的频谱图126。频谱图126具有五个清晰可见的峰128。以类似于图5A和5B的方式,该谱图126也具有谐波频率130。通过访问频率数据(例如,在频谱图126中),系统100确定与特定频谱图126相关联的声音。此外,对话音样本105中的各个分析音频段124重复该过程。
返回到图3,过程前进到步骤308,步骤308在向量空间112中为目标语音104映射部分语音简档。部分语音简档包括与话音样本105中的各种音素的频率分布相关的数据。例如,可以基于图5A-5C中示出的用于目标104的三个音素来创建部分语音简档。本领域技术人员应当理解,这是部分语音简档的实质上简化的示例。通常,话音样本105包含多于三个的分析音频段124,但是可以包含更少的分析音频段。系统100获取为各个分析音频段124获得的频率数据,并将它们在向量空间112中映射。
向量空间112指的是数据库中对象的集合,称为向量,在其上定义了特定的运算组。这些运算包括向量的加法,在该运算下服从诸如关联性、交换性、恒等式和可逆的数学性质;以及与单独的对象类(称为标量)相乘,考虑在该运算下的兼容性、同一性和分布性的数学特性。向量空间112中的向量通常表示为N个数字的有序列表,其中N称为向量空间的维数。当使用这种表示时,标量通常只是单个数。在实数的三维向量空间中,[1,-1,3.7]是示例向量,并且2*[1,-1,3.7]=[2,-2,7.4]是与标量相乘的示例。
向量空间112的示例性实施例使用如上所述的数字,尽管通常在更高维的使用情况下。具体地,在示例性实施例中,音色向量空间112指的是表示音色元素(例如丰富度或清晰度)的映射,使得通过添加或减去向量的相应元素,实际音色的某些部分被改变。因此,目标语音104的特征由向量空间中的数字表示,使得向量空间中的运算对应于对目标语音104的运算。例如,在示例性实施例中,向量空间112中的向量可包括两个元素:[10Hz频率的振幅,20Hz频率的振幅]。实际上,向量可以包括更多数量的元素(例如,用于每个可听频率分量的向量中的元素)和/或更细粒度的(例如,1Hz、1.5Hz、2.0Hz等)。
在示例性实施例中,在向量空间112中从高音调语音移动到低音调语音将需要修改所有频率元素。例如,这可以通过将几个高音调语音聚集在一起,将几个低音调语音聚集在一起,然后沿着通过聚类中心由线定义的方向行进来完成。采用高音调语音的几个示例和低音调语音的几个示例,并且这使你进行空间112的“音调”访问。每个语音可以由也许是多维(例如,32维)的单个向量来表示。一个维度可以是基频的音调,其近似地涉及男性语音和女性语音并区分二者。
语音数据库111保存在向量空间112中编码的对应于各种语音的向量。这些向量可以编码为数字列表,其在向量空间112的环境中具有含义。例如,数字列表的第一分量可以是-2,其在向量空间的环境中可以表示“高音调语音”,或者可以是2,其在向量空间的环境中可以表示“低音调语音”。机器学习系统116的参数确定如何处理那些数字,使得生成器140可以基于查看列表的第一分量中的a-2将输入话音转换成高音调语音,或者语音特征提取器可以将低音调语音编码为具有存储在数据库111中的数字列表的第二分量中的a 2的向量。
在示例性实施例中,向量空间112通常表现出上述类型的特性。例如,低沉的语音和高音调语音的平均值应该是大致中等范围的语音;并且在清晰语音的方向上稍稍移动的沙哑语音(例如,从清晰语音中减去沙哑语音,得到从“沙哑”指向“清晰”的向量,将其乘以小标量使得向量仅改变一点,然后将其添加到沙哑语音)应当听起来稍微更清晰。
对频谱图执行数学运算(例如,对语音求平均)产生听起来不自然的声音(例如,对两个语音声音求平均,就像两个人同时说话)。因此,使用频谱图对低沉的语音和高音调语音求平均不会产生中音调语音。相反,向量空间112允许系统100对语音执行数学运算,例如“求平均”高音调语音和低音调语音,产生中音调语音。
图6A-6D示意性地示出了根据本发明的示例性实施例的向量空间112。过程300进行到判定310,判定310确定这是否是在向量空间中映射的第一语音。如果这是映射的第一语音,则其在向量空间112中的相对位置不会随之发生。系统100可在向量空间112中的任何位置处映射语音104,因为不存在用以比较语音104的相对标度。
图6A示意性地示出了仅包含如图5B所示的单词“Stella”中的“a”声音的目标语音104的向量空间112。尽管示例性实施例讨论并示出了用于特定声音的向量空间112的图,但是本领域技术人员理解向量空间112映射独立于任何特定声音的音色。因此,听到特定的语音发出新的声音有助于向量空间112将说话者置于整个向量空间112中。示例性实施例出于简单说明机器学习系统116可映射语音的方式的目的而示出并参考用于特定声音的向量空间112。
因为目标语音104是在数据库112中映射的第一(且仅有)语音,所以整个数据库112反映仅与目标语音104相关的信息。因此,系统100认为所有语音都是目标语音104。因为这是第一语音,所以过程循环返回并映射第二语音,如前所述。
图7A示意性地示出了由第二(男性)语音132产生的单词“Call”中的“a”声音的频谱图126。这与图5A中的目标104所表达的音素相同。然而,第二男性语音132只有11个可见峰128。另外,第二男性语音132的可见峰128超过2kHz频率,而目标104的可见峰128小于2kHz频率。尽管频率分布不同(例如,如频谱图126所显示),但在示例性实施例中,关联引擎122可确定频率分布表示“call”中的“a”音素,且相应地将其映射到向量空间112中。在示例性实施例中,在系统100确定存在用于同一音素的另一说话者(例如,如单词“Call”中的“a”音素)的数据之后,系统100例如使用先前描述的过程在向量空间112中相对于彼此映射说话者。
图6B示意性地示出了音素的向量空间112:单词“Stella”中的“a”声音,映射目标语音104和第二男性语音132。系统100比较与目标语音104和第二语音132所讲的音素有关的数据。频率分布特征允许系统100绘制相对于彼此的语音。因此,如果系统100接收到“a”声音的全新输入,则它可以基于哪个声音具有与输入最相似的频率特征来区分目标声音104和第二声音132。
尽管图6B示出映射为完全分离的段的语音104和132,但应了解,界限不是如此确定。实际上,这些界限表示了特定语音代表特定频率分布的概率。因此,实际上,一个语音可以产生与另一个语音的绘制区域重叠的声音(例如,重叠的频率特征)。然而,语音界限旨在示出具有特定频率分布的声音具有来自特定说话者的最大可能性。
过程中的步骤310还确定是否有更多的语音要映射。如果有更多的语音要映射,则重复步骤302-310。图7B示意性地示出了由第三语音(女性)134产生的单词“Call”中的“a”音素的频谱图126。第三语音134具有六个可见峰128。第三语音134的峰128不像在目标语音104和第二语音132中那样被压缩。同样,尽管频率分布不同(例如,如频谱图126所显示),关联引擎122可确定频率分布以高概率表示“call”中的“a”音素。系统100在向量空间112中映射此附加语音。此外,系统100现在学习区分三个说话者之间关于单词“call”中的“a”声音,如图6C所示。在一些实施例中,语音特征提取器120和生成器140通过反向传播对抗鉴别器142而进行端到端训练。
图6D示出了在使用各种示例的过程300的几个循环之后的向量空间112。在向量空间112中映射了多个语音之后,系统100更准确地区分语音。由于向量空间112具有更多的要比较的音色数据,可归因于特定说话者的频率特征变得更具体。虽然语音示为虚线圆,但是应当理解,该虚线圆表示频谱图126中所示的一组复杂的频率及其变化(其可以被描述为音色“容限”,例如,各种稍微变化的频率分布可以听起来就好像它们来自相同的语音)。
此外,向量空间112开始与某些音色形成关联。例如,特征线136开始发展,区分男性语音和女性语音。尽管特征线136未显示为在语音之间完全区分,但预期其相当精确。通过特征(例如性别、种族、年龄等)来表征音色是可能的,因为特定语音的音色或频率分布的集合主要由生理因素引起。特定说话者发出的声音通过喉上声道滤波,喉上声道的形状决定了声音的音色。声带的尺寸(例如,厚度、宽度和长度)引起某些振动,这产生不同的频率,并因此带来不同的音色。例如,女性在遗传上倾向于具有比男性更高的共振峰频率以及峰128之间更大的间隙。因此,生理上相似的群体(例如男性与女性、白种人与非裔美国人)相对于特定音素具有更相似的频率分布。
在步骤312,该过程还推断目标语音104的合成语音简档。合成语音简档是机器学习系统116为不存在真实频率分布数据的音素预测的一组频率分布。例如,如图5A-5C所示,系统100可以具有与短语“CALL STELLA PLEASE”中的音素有关的实际数据。然而,系统100没有来自目标语音104的与Dog中的“D”音素有关的真实数据。
图8A示意性地示出了根据本发明的示例性实施例的包括合成语音简档138的向量空间112。所示的向量空间112用于“DOG”中的“D”音素。图8示出了关于已发出“D”音素的多个语音的经映射的真实数据。如图6D中所述,已针对不同音素(如“CALL”中的“A”)将目标语音104映射到这些语音。因为各种音素的频率分布的变化通常是可预测的,所以机器学习系统116对不存在真实数据的音素的频率分布进行预测。例如,机器学习相对于其它语音针对“D”音素映射目标语音104的合成语音简档138。
为了创建合成语音简档138,将目标语音104的部分简档与其它存储的语音简档进行比较,并且通过比较,外插目标语音104的合成语音简档138。因此,先前未提供给系统100的音素可从来自目标语音104的相对较小话音样本105外插。下面讨论示例性实施例的细节。
作为初始问题,应当理解,向量空间112是复杂的多维结构,因此,对于附图中的特定音素示出了向量空间112的二维片段。然而,所示的各种音素向量空间112仅仅是为了说明的目的,并且是较大的复杂三维向量空间112的一部分。将目标语音104的真实语音简档中的频率分布(例如,来自话音样本105的所有可用音素数据的频率分布)与其它映射语音简档进行比较。对于丢失的音素外插合成语音简档138。所属领域的技术人员将了解,尽管展示了针对特定音素的语音简档的片段的调整,但实际上,调整是对不容易说明的整个多维语音简档进行的。调整可以通过机器学习系统116,例如神经网络116来完成。
机器学习系统116优选地是一类专门的问题求解器,其使用自动反馈回路来优化其自身并提高其解决手头问题的能力。机器学习系统116从其试图解决的实际问题取得输入,但也具有各种参数或设置,它们完全在其自身内部。与数据科学系统相反,机器学习系统116可以配置为自动尝试针对各种输入来解决其给定问题,并且(有时,尽管不总是,借助于对其答案的自动反馈)更新其参数,使得将来的尝试产生更好的结果。该更新依照在机器学习系统116的训练开始之前选择的特定的、数学上明确限定的过程而发生。
虽然简单地参考附图进行描述,但是外插合成语音138不如比较两个音素的频率分布简单。目标语音104的部分语音简档包含与多个不同分析音频段124以及音素相关的数据。虽然不同音素的频率分布的波动具有一般趋势,但是音素之间没有通用的数学公式/转换比。例如,仅仅因为语音A直接落入针对音素“a”的语音B和语音C的中间,并不意味着语音A直接落入针对音素“d”的语音B和语音C的中间。预测语音分布的困难由于这些是复合信号(即,每个具有各自强度的频率范围)的事实而复杂化。此外,存在可以向特定音素提供类似的发声音色的大量不同频率分布。因此,机器学习系统116的任务是提供特定音素的频率分布范围。通常系统100映射的语音越多,合成语音简档138与目标语音104的音色匹配得越好。
为了帮助将目标语音104定位在向量空间112中,生成器140和鉴别器142可以执行图9描述的反馈回路。在一些实施例中,如果先前已针对许多语音训练了语音特征提取器120(即,先前使用反馈环路映射许多语音),则目标语音104可定位在向量空间中而不使用反馈环路。然而,即使已针对许多语音训练了语音特征提取器120,其它实施例仍然可以使用反馈回路。
在步骤314,该过程还改进合成语音简档138。图8B示意性地示出了根据本发明的示例性实施例、在使用生成对抗性神经网络116改进合成语音简档138之后,“DOG”中的音素“D”的向量空间112。生成对抗性神经网络116包括生成神经网络140和鉴别神经网络142。
生成神经网络140是机器学习系统116的一种类型,其“问题”是创建属于预定类别的真实示例。例如,用于面部的生成神经网络将试图生成看起来逼真的面部图像。在示例性实施例中,生成神经网络140生成目标音色104的话音的真实示例。
鉴别神经网络142是机器学习系统116的一种类型,其“问题”是识别其输入所属的类别。例如,鉴别神经网络142可以识别在图像设置中是否已经给出狗或狼的图片。在示例性实施例中,鉴别神经网络142识别输入的话音是否来自目标104。可替换地或附加地,鉴别神经网络142识别输入的话音的说话者。
图9示出了根据本发明的示例性实施例的使用生成对抗性网络116来改进增强语音简档144的系统100的框图。除了由机器学习系统116创建的合成语音简档138之外,增强语音简档144是从话音样本105获得的(真实)语音简档的组合。向量空间112将增强语音简档144提供给生成神经网络140。生成神经网络140使用增强语音简档144来生成表示候选话音段146(即,假定模仿目标104但不是来自目标104的真实语音的话音)的话音数据。所产生的候选话音段146可以说是在候选语音中。表示候选话音段146的话音数据由鉴别神经网络142评估,鉴别神经网络142确定表示候选话音段146中的候选语音的话音数据是真实的还是合成的语音。
如果系统100产生音频候选话音段146,则它固有地包含表示候选话音段146的话音数据。然而,生成器140可以提供表示实际上从不作为音频文件输出的候选话音段146的数据。因此,表示候选话音段146的话音数据可以是作为波形的音频、频谱图、声码器参数,或编码候选话音段146的韵律和音素内容的其它数据的形式。此外,话音数据可以是神经网络116的某个中间的输出。正常人类观察者可能不理解该输出(例如,韵律数据和音素数据不必分开),但是神经网络116理解该信息并以机器学习116或其部分可理解的方式对其编码。为了方便起见,下面进一步的讨论涉及“候选话音段146”,但是应当理解为包括更宽泛的“表示候选话音段146的话音数据”。
在示例性实施例中,基于源话音段103生成候选话音段146。尽管在图1中示出存在用户(即,阿诺德),但是在训练时不必将源语音102输入到系统100。源语音102可以是已存储在系统100中或由系统100合成的输入到系统100中的任何语音。因此,源话音段103可以由用户提供,可以由来自已经在系统100中的语音(例如,映射的语音)的话音段提供,或者可以由系统100生成。当用户转换他们的语音,生成的语音,和/或具有已经在系统100中的话音的语音可以被认为是源语音102。此外,当在图9所示的反馈回路期间产生不同的候选话音段146时,可以使用不同的源话音段103。
鉴别神经网络142接收候选话音段146,以及与包括目标语音104的多个语音相关的数据。在示例性实施例中,生成器140和鉴别器142接收关于包括目标语音的多个语音简档的数据。这允许神经网络116参考其它语音的多个音色数据来识别使话音或多或少类似于目标104的变化。然而,应了解,与目标语音104本身相关的数据可隐含地与多个语音相关,因为其它语音的特征在其映射或改进目标语音104时已经由鉴别器142的学习参数在某种程度上进行了解。此外,当通过训练或向向量空间112添加更多语音来改进目标语音104时,目标语音104进一步提供关于多个语音的数据。因此,示例性实施例可以但不要求生成器140和/或鉴别器142明确地从多个语音简档接收数据。相反,生成器140和/或鉴别器142可以接收来自目标语音104简档的数据,该数据已经基于多个语音简档被修改。在任一前述情形中,可认为系统100参考多个语音简档接收数据。
在示例性实施例中,(由鉴别器142)影响生成器140以产生听起来像不同于目标104的语音的候选话音段146。在示例性实施例中,生成器140、语音特征提取器120和/或鉴别器142可以访问与多个语音简档有关的数据。因此,生成器140、鉴别器142和/或语音特征提取器120可以参考多个不同语音的音色数据做出决定。因此,即使说话者非常类似于目标104,生成器140也不改变使合成话音听起来像不同于目标104的某人的目标语音104简档。因为生成器140可以访问与多个语音简档有关的数据,所以它可以区分可能听起来相似的目标和其它说话者,产生更好质量的候选话音段146。接着,鉴别器142获取更精细的细节并提供更详细的不一致性消息148。尽管图中未示出,但是不一致性消息148可以被提供给语音特征提取器120,然后语音特征提取器120修改向量空间112中的语音简档。
如上所述,鉴别神经网络142(也称为“鉴别器142”)试图识别候选话音段146是否来自目标104。本领域技术人员理解可用于确定候选话音段146是否来自目标语音104的不同方法。具体地,鉴别器142确定某些频率和/或频率分布是或不可能是目标语音104的音色的一部分。鉴别器142可通过将候选话音段146与目标音色104和在向量空间112中映射的其它语音(即,参考多个不同语音的多个音色数据)进行比较来做到这一点。于是,在向量空间112中映射的语音越多,鉴别器142越好从合成话音中辨别真实话音。因此,在一些实施例中,鉴别器142可以将身份分配给候选语音和/或候选话音段146。
在示例性实施例中,鉴别器142具有时间接受域114,该时间接受域114防止鉴别器142基于诸如韵律、口音等之类的事物来“看到”/鉴别。另外,或者可替换地,生成器140具有时间接受域114,该时间接受域114防止鉴别器142基于诸如韵律、口音等之类的事物来生成。因此,候选话音段146可以生成得足够短,以避免包括更长的时间特征,例如韵律、口音等,和/或可以使用时间接受域114滤波。因此,鉴别器142基于音色而不是通过基于这些其它特征进行鉴别来区分真实话音和虚假话音。
鉴别器142例如可以通过比较某些音素的基频开始,查看哪个可能的音色最清晰地(即,具有最高的匹配概率)匹配。如前所述,有更多的特征来定义基频之外的音色。随着时间的推移,鉴别器142学习更复杂的识别语音的方式。
本发明人已知的现有技术话音到话音转换系统产生差的质量转换(例如,音频听起来不像目标语音)。相反,示例性实施例产生显著更高质量的转换,因为生成神经网络140(也称为“生成器140”)和鉴别器142不仅仅使用目标语音104来训练。例如,可以尝试现有技术的系统将来自日本女性的话音转换为巴拉克·奥巴马的语音。该现有技术系统尽可能地接近巴拉克·奥巴马,但是不管如何与其它语音相比较,它都如此。因为这种现有技术的系统不知道我们人类是如何区分不同的人的语音,所以现有技术的生成器可以作出折衷,其实际上使得声音更接近其他人的声音,以寻求超出现有技术的鉴别器。
如果鉴别器142没有检测到差异,则过程结束。然而,如果鉴别器142检测到候选话音段146不是来自目标语音104(例如,候选语音不同于目标语音),则创建不一致性消息148。不一致性消息148提供关于鉴别器142为什么确定候选话音段146不在目标音色104中的细节。鉴别器142将候选话音段146与多个语音(包括目标104)进行比较,确定候选话音段146是否在目标语音104中。例如,通过比较由在向量空间112中映射的多个语音定义的人类话音的某些参数,不一致性消息148可以确定候选话音段146是否在人类话音的正确参数内,或者它是否落在正常人类话音之外。此外,通过与在向量空间112中映射的多个语音进行比较,不一致性消息148可提供具体关于频率数据的细节,所述频率数据具有来自不同于目标语音104的语音的较高概率。因此,向量空间112可使用此不一致性消息148作为反馈来调整目标104的增强语音简档144和/或合成语音简档138的部分。
不一致性消息148可以提供如下信息,例如涉及峰128的数量、特定峰128的强度、起音129(图5A)、衰减131(图5C)、谐波130、基频、共振峰频率和/或音素和/或分析音频段124的允许系统100将候选话音段146与目标音色104区分开的其它特征中的不一致性(例如,具有不来自目标语音104的高概率的频率数据)。不一致性消息148可以在高度复杂的组合中有效地对应于波形的任何特征。不一致性消息148可以确定,例如,第四最大幅度频率具有“可疑”幅度,并且应当从中减去一些量以使其看起来真实。这是用于说明不一致性消息148中可用的信息类型的极其简化的示例。
向量空间112接收不一致性消息,并使用它来改进合成语音简档138(并且因而,改进增进语音简档144)。因此,如图8B所示,向量空间112缩小和/或调整分配给目标语音音色104的频率分布集合。不一致性消息148参考多个音色数据来确定候选话音段146和目标音色104之间的不一致性。例如,目标语音104不再与康纳·麦格雷戈或巴拉克·奥巴马重叠。本领域的技术人员应了解,神经网络116可继续改进(例如,缩小向量空间112中的代表圆)超过语音之间的清晰区分。鉴别器142识别说话者,但还进行进一步的步骤,确定候选话音段146是否具有作为真实话音的高概率(即使话音由生成器140合成生成)。例如,即使频率特征接近特定目标(例如,说话者A的概率为90%,说话者B的概率为8%,以及分布在其余说话者之间的概率为2%),鉴别器142也可以确定频率特征不产生任何可识别的人类话音并且是合成的。向量空间112使用该数据来帮助它更好地限定增强语音简档144的界限。
参考多个语音改进增强语音简档144提供了对现有技术方法的改进。这些改进包括改进的语音转换质量,这允许用户创建使用已知现有技术方法不可用的实际语音转换。使用仅具有单个语音(例如,目标语音)的生成对抗性神经网络116不能向生成对抗性神经网络116提供足够的数据以创建导致改进的反馈(例如,不一致性消息148)的逼真问题集(候选话音段146)。改进的反馈允许系统100最终提供更加逼真的语音转换。在一些实施例中,如果鉴别器142没有检测到候选音色和目标音色之间的任何差异,则可以产生指示确定没有差异的空不一致性消息。空不一致性消息指示反馈过程可以结束。或者,系统100可以并不产生不一致性消息。
修改后的增强语音简档144再次发送到生成神经网络140,并且生成另一(例如,第二)候选话音段146以供鉴别器142考虑。第二候选话音段146(等等)可以说是在第二候选语音(等等)中。然而,在一些实施例中,第一候选语音和第二候选语音从迭代到迭代可以是非常相似的发声。在一些实施例中,鉴别器142可以如此精细地调整,使得不一致性消息148可以检测到微小的差异。因此,第一候选语音和第二候选语音可以听起来非常类似于人类观察者,但是出于讨论的目的仍然可以被认为是不同的语音。
该过程继续,直到鉴别器不能将候选话音段146与目标音色104区分开。因此,随着时间的推移,增强语音简档144与目标语音104的真实话音之间的差异不应由鉴别器142辨别(例如,候选话音段146来自目标语音104的概率可被提高到99+百分比,尽管在某些实施例中较低的百分比可能足够)。在目标语音104的增强语音简档144已经充分改进之后,用户可以将他们的话音段103转换为目标语音104。
图8C示意性地示出了添加了第二语音132和第四语音的图8B的向量空间112。应注意,将更多语音添加到向量空间112中可进一步增强鉴别器142区分语音的能力。在示例性实施例中,来自第二语音132和第四语音的数据用于改进目标语音104的合成语音简档138。另外,第二语音132和第四语音可帮助改进其它说话者(例如康纳·麦格雷戈)的频率分布。
回到图3,过程300以步骤316结束,步骤316确定是否有更多的语音要映射。如果有,则整个过程重复必要的次数。合成语音简档138通常通过将更多语音添加到向量空间112中来改进(即,可能的频率分布且因此语音的声音)。然而,如果没有其它语音要映射,则该过程完成。
示例性实施例创建先前未听到的全新语音以及语音的各种组合。如参考特征线136所描述的,机器学习系统116开始为在向量空间112中映射的语音开发某些组织模式。例如,相似性别、种族和/或年龄的语音可以具有相似的频率特征,因此被分组在一起。
如前所述,向量空间112允许对其中的数据集进行数学运算。因此,示例性实施例提供向量空间112中的数学运算,例如在阿尔·帕西诺和詹姆斯·厄尔·琼斯之间的语音。另外,语音创建引擎也可使用关于分组的概括来创建新语音。例如,可以通过从平均中国女性语音中减去平均女性语音,并加上平均男性语音来创建新语音。
图10示出了根据本发明的示例性实施例的用于将话音转换为话音的过程1000。应当注意,该过程实质上是根据通常用于将话音转换为话音的较长过程简化而来。因此,将话音转换为话音的过程具有本领域技术人员可能使用的许多步骤。另外,一些步骤可以以与所示顺序不同的顺序执行,或者同时执行。因此,本领域技术人员可以适当地修改该过程。
该过程开始于步骤1002,步骤1002向系统100提供表示话音段103的话音数据。例如,可以将固有地包含表示话音段103的话音数据的话音段103提供给输入108。可替换地,生成器140可以提供表示话音段的数据(例如,来自文本输入)。因此,表示话音段103的话音数据可以是作为波形的音频、频谱图、声码器参数,或编码话音段103的韵律和音素内容的其它数据的形式。此外,话音数据可以是神经网络116的某个中间的输出。正常人类观察者可能不理解该输出(例如,韵律数据和音素数据不必分开),但是神经网络116理解该信息并以机器学习116或其部分可理解的方式对其编码。如前所述,话音段103不必来自人类话音,而是可以被合成。为了方便起见,下面进一步的讨论涉及“话音段103”,但是应当理解为包括更宽泛的“表示话音段103的话音数据”。
在步骤1004,用户选择目标语音104。使用参考图3描述的过程,目标语音104可能先前已经在向量空间112中映射。或者,也可使用参考图3描述的过程,将新语音映射到系统中。在输入话音段103的示例性实施例中,话音段103可以但不必用于帮助映射目标语音104(例如,候选话音146可以反映话音段103的音素、口音和/或韵律)。在步骤306中,获取目标104的增强语音简档144并将其应用于话音段103。换句话说,变换话音段103的频率,反映存在于目标语音104中的频率分布。这将话音段103变换为目标语音104。
应当注意,在对抗性训练期间,生成神经网络140接收输入话音并应用目标音色(正如它在图1中运行时进行的那样),但是鉴别器142查看输出话音并通过目标语音104确定它是否是“真实”人类话音(尽管通过限定,即使鉴别器相信它是真实的,话音也将是合成的)。相反,在图1所示的语音转换期间,已经针对足够的语音训练了系统100,使得转换可以相当顺利地发生,而不需要进一步的训练,导致实时或接近实时的话音到话音转换(尽管进一步的训练是可选的)。该目标说话者的真实人类话音的训练集示例不具有任何其他说话者(例如,输入的说话者)的任何“污染”,因此生成神经网络140学习移除输入的说话者的音色并代之以使用目标说话者的音色,否则鉴别器142不会被欺骗。
在步骤308中,在目标语音104中输出变换的话音段106。然后,步骤310的处理询问是否有更多的话音段103要转换。如果有更多的话音段103,则过程1000重复。否则,该过程完成。
在一些实施例中,可以要求目标104说话者提供预先编写的话音样本105。例如,可能存在要求目标读取的脚本,其捕获许多通常发音的(如果不是全部的话)音素。因此,示例性实施例可以具有每个音素的真实频率分布数据。此外,在示例性实施例中,向量空间112具有来自至少一个,优选地,多个语音的每个音素的真实频率分布数据。因此,示例性实施例可以至少部分地基于真实数据外插合成语音简档138。
尽管示例性实施例将话音样本105称为处于目标“语音”104中,但应了解,示例性实施例不限于说出的单词和/或人类语音。示例性实施例仅仅需要话音样本105中的音素(而不是人类话语本身的一部分),例如由乐器、机器人和/或动物产生的音素。因此,在示例性实施例中,话音样本105也可以称为音频样本105。这些声音可以通过系统分析,并且被映射以创建“声音简档”。
还应当理解,示例性实施例提供了优于现有技术的许多优点。从目标语音104的相对小的话音样本105实现实时或接近实时的语音转换。声对声转换可用于娱乐,转换有声读物语音(例如,在可听应用中),定制个人语音助理(例如,Amazon Alexa),为电影重建去世的演员的语音(例如,来自星球大战的Leia公主),或人工智能机器人(例如,具有唯一语音或去世的家庭成员的语音)。其它用途可以包括“语音处理”,其中用户可以修改他们的话音的部分,或者“自动频带”,其使用任何声音输入来创建不同的歌曲/乐器部分并且将它们组合在一起成为单个频带/语音。其它用途包括使动物“说话”,即,将人类话音转换成特定动物的音色。
图11示出了根据本发明的示例性实施例使用语音来验证身份的过程。应当注意,与上面讨论的其它过程一样,该过程实质上是根据通常用于使用语音验证身份的较长过程简化而来。因此,使用语音验证身份的过程具有本领域技术人员可能使用的许多步骤。另外,一些步骤可以以与所示顺序不同的顺序执行,或者同时执行。因此,本领域技术人员可以适当地修改该过程。
过程1100开始于步骤1102,其提供具有多个映射的语音的向量空间112。向量空间可如上所述地填充有多个语音。优选地,向量空间112填充有多于1000个语音,并且每个语音已经被映射用于50个以上的音素。
在步骤1104,该方法从其身份正被验证的人接收输入话音。与机器学习系统116如何确定候选话音146是否对目标104真实的方式类似,机器学习系统116还可以通过任何输入话音确定对其身份正被验证的人的真实性。在步骤1106,为其身份正被验证的人生成真实语音简档。如前所述,可以通过使用时间接受域114滤波分析音频段124来创建语音简档。变换引擎118可以提取分析音频段124的频率分量,并且频率-声音关联引擎122可以将特定分析音频段中的频率分量与特定声音相关联。然后机器学习116可以在数据库112中映射目标语音104的真实语音简档。
在步骤1108,过程1100将真实语音简档(和/或增强语音简档144,如果已经生成的话)与向量空间112中的语音简档进行比较。类似地,在向量空间112中映射的任何语音也可以基于真实语音简档和/或增强语音简档144来验证。基于该比较,机器学习系统116可以确定向量空间112中的哪个语音(如果有的话)对应于所讨论的身份的语音。因此,在步骤1110,该过程验证和/或确认所讨论的身份的身份。
步骤1112询问身份是否被验证。在示例性实施例中,如果语音在基于频率分布的情况下达到95%匹配(例如,鉴别器提供95%置信区间)或更大,则验证语音。在一些实施例中,与系统中待验证的其它语音(称为“匹配”)相比,语音可能必须具有话音对应于身份语音的至少99%的置信度。在一些其它实施例中,语音可能必须至少99.9%匹配才能被验证。在进一步的实施例中,语音可能必须至少99.99%的匹配才能被验证。如果语音未被验证,则过程可请求接收语音的另一样本,返回到步骤1104。然而,如果语音被验证,则过程1100前进到步骤1114,其触发动作。
在步骤1114触发的动作可以是例如解锁口令。系统100可比较语音并确定特定话音的真实性/身份。因此,系统100允许使用语音口令。例如,IPHONE移动电话的更新版本可以利用语音验证来解锁电话(例如,作为面部识别和/或指纹扫描的补充或替代)。系统100分析话音(例如,将其与先前由向量空间112中的Apple映射的多个语音进行比较)并在语音匹配的情况下解锁智能电话。这使得易用性和安全性得到增加。
在示例性实施例中,触发的动作解锁和/或提供语音允许控制智能家庭应用的信号。例如,锁定和/或解锁门,打开厨房设备等的命令都可以被验证和确认为来自具有适当访问(例如,所有者)的语音。示例性实施例可以结合到智能家庭助理(例如,Amazon Alexa)中,并且允许命令的验证。这包括允许将Amazon Alexa用于敏感技术,诸如银行转账、大额转账,或通过确认用户的语音访问私人信息(例如,医疗记录)。
此外,示例性实施例可以集成到识别系统(例如,警察和/或机场)和销售点系统(例如,商店的收入记录机)中,以便于识别的验证。因此,在销售点系统处,触发的动作可以是用户使用支付命令(例如,“支付$48.12”),通过他们的语音来支付。
可选地,为了防止话音到话音转换技术的潜在误用,系统100可以添加频率分量(“水印”),其可以被容易地检测以证明话音样本是不真实的(即,制造的)。这可以通过例如添加人类听不见的低频声音来实现。因此,人类可能觉察不到水印。
尽管通过上述示例性实施例描述了本发明,但是在不脱离这里公开的发明构思的情况下,可以对所示实施例进行修改和变化。此外,所公开的方面或其部分可以以上未列出和/或未明确要求的方式组合。因此,不应将本发明视为限于所公开的实施例。
本发明的各种实施例可以至少部分地以任何常规计算机编程语言来实现。例如,一些实施例可以用程序化编程语言(例如,“C”)或面向对象的编程语言(例如,“C++”)来实现。本发明的其它实施例可被实现为预配置的、独立的硬件元件和/或预编程的硬件元件(例如,专用集成电路、FPGA和数字信号处理器)或其它相关部件。
在替换实施例中,所公开的装置和方法(例如,参见上述各种流程图)可以被实现为用于计算机系统的计算机程序产品。这种实现可以包括固定在有形的、非暂时性介质上的一系列计算机指令,例如计算机可读介质(例如,磁盘、CD-ROM、ROM或固定磁盘)。所述一系列计算机指令可体现本文先前关于所述系统描述的功能的全部或部分。
本领域技术人员应当理解,这样的计算机指令可以用多种编程语言来编写,以便与许多计算机体系结构或操作系统一起使用。此外,此类指令可存储在任何存储器装置(例如,半导体、磁性、光学或其它存储器装置)中,并且可使用任何通信技术(例如,光学、红外、微波或其它传输技术)来传输。
在其它方式中,这样的计算机程序产品可以作为具有附带的打印或电子文档(例如,压缩打包软件)的可移动介质来分发,预装载计算机系统(例如,在系统ROM或固定磁盘上),或者通过网络(例如,因特网或万维网)从服务器或电子公告板分发。实际上,一些实施例可以在软件即服务模型(“SAAS”)或云计算模型中实现。当然,本发明的一些实施例可以实现为软件(例如,计算机程序产品)和硬件的组合。本发明还有的其它实施例完全实现为硬件或完全实现为软件。
上述本发明的实施例仅仅是示例性的;许多变化和修改对于本领域技术人员是容易想到的。这些变化和修改旨在落入由所附权利要求中任一项限定的本发明的范围内。
Claims (78)
1.一种使用来自目标语音的目标语音信息和表示源语音的话音段的话音数据来构建话音转换系统的方法,所述方法包括:
接收表示源语音的第一话音段的源话音数据;
接收与所述目标语音相关的目标音色数据,所述目标音色数据在音色空间内;
根据所述源话音数据和所述目标音色数据,使用生成机器学习系统产生第一候选话音数据,所述第一候选话音数据表示第一候选语音中的第一候选话音段;
参照多个不同语音的音色数据,使用鉴别机器学习系统将所述第一候选话音数据与所述目标音色数据进行比较,
所述使用鉴别机器学习系统包括:参照多个不同语音的音色数据确定所述第一候选话音数据和所述目标音色数据之间的至少一个不一致性,所述鉴别机器学习系统产生具有与所述第一候选话音数据和所述目标音色数据之间的不一致性有关的信息的不一致性消息;
将所述不一致性消息反馈给所述生成机器学习系统;
根据所述不一致性消息,使用所述生成机器学习系统产生第二候选话音数据,所述第二候选话音数据表示第二候选语音中的第二候选话音段;以及
使用由所述生成机器学习系统和/或鉴别机器学习系统产生的作为所述反馈结果的信息来改进所述音色空间中的目标音色数据。
2.如权利要求1所述的方法,其中,所述源话音数据来自所述源语音的音频输入。
3.如权利要求1所述的方法,其中,所述第二候选话音段提供比所述第一候选话音段更高的来自所述目标语音的概率。
4.如权利要求1所述的方法,还包括将所述源话音数据变换为所述目标音色。
5.如权利要求1所述的方法,其中,从所述目标语音中的音频输入获得所述目标音色数据。
6.如权利要求1所述的方法,其中,所述机器学习系统是神经网络。
7.如权利要求1所述的方法,进一步包括:
根据每个语音提供的所述话音段中的频率分布,映射向量空间中的所述多个语音和所述第一候选语音的表示。
8.如权利要求7所述的方法,进一步包括:
根据所述不一致性消息,调整所述向量空间中的与多个语音的表示相关的所述第一候选语音的表示,来表达所述第二候选语音。
9.如权利要求1所述的方法,其中,当所述鉴别神经网络具有小于95%的所述第一候选语音是所述目标语音的置信区间时,产生所述不一致性消息。
10.如权利要求1所述的方法,进一步包括:
通过将所述候选语音与所述多个语音进行比较来将身份分配给所述候选语音。
11.如权利要求1所述的方法,其中所述多个语音在向量空间中。
12.如权利要求1所述的方法,其中,所述目标音色数据由时间接受域滤波。
13.如权利要求1所述的方法,进一步包括使用所述生成机器学习系统根据空不一致性消息在最终候选语音中产生最终候选话音段,
所述最终候选话音段模仿所述目标音色中的第一话音段。
14.如权利要求13所述的方法,其中,所述时间接受域在约10毫秒和约1000毫秒之间。
15.如权利要求1所述的方法,进一步包括用于从目标话音段提取所述目标音色数据的手段。
16.一种用于训练话音转换系统的系统,所述系统包括:
表示源语音的第一话音段的源话音数据;
涉及目标语音的目标音色数据;
生成机器学习系统,其配置为根据所述源话音数据和所述目标音色数据,产生第一候选话音数据,所述第一候选话音数据表示第一候选语音中的第一候选话音段;
鉴别机器学习系统,其配置为:
参照多个不同语音的音色数据,将所述第一候选话音数据与所述目标音色数据进行比较,以及
参照所述多个不同语音的音色数据,确定所述第一候选话音数据和所述目标音色数据之间是否存在至少一个不一致,并且当存在所述至少一个不一致时:
产生具有与所述第一候选话音数据和所述目标音色数据之间的不一致性相关的信息的不一致性消息,以及
将所述不一致性消息返回所述生成机器学习系统。
17.如权利要求16所述的系统,其中,所述生成机器学习系统配置以根据所述不一致性消息生成第二候选话音段。
18.如权利要求16所述的系统,其中,所述机器学习系统是神经网络。
19.如权利要求16所述的系统,进一步包括:
向量空间,其配置为根据每个语音提供的话音段中的频率分布,映射包括所述候选语音的多个语音的表示。
20.如权利要求19所述的系统,其中,语音特征提取器配置成根据所述不一致性消息来调整所述向量空间中的与所述多个语音的表示相关的所述候选语音的表示,以更新和表达所述第二候选语音。
21.如权利要求16所述的系统,其中,当所述鉴别神经网络具有小于95%的置信区间时,将所述候选语音与所述目标语音区分开。
22.如权利要求16所述的系统,其中,所述鉴别机器学习系统配置成通过将所述第一或第二候选语音与所述多个语音进行比较来确定所述候选语音的说话者的身份。
23.如权利要求16所述的系统,其中,还包括配置成包含多个语音的向量空间。
24.如权利要求16所述的系统,其中所述生成机器学习系统配置成根据空不一致性消息在最终候选语音中产生最终候选话音段。
所述最终候选话音段如所述目标语音一样模仿所述第一话音段。
25.如权利要求16所述的系统,其中,所述目标音色数据由时间接受域滤波。
26.如权利要求25所述的系统,其中,所述时间接受域在约10毫秒和约2,000毫秒之间。
27.如权利要求16所述的系统,其中,所述源话音数据来自源音频输入。
28.一种在计算机系统上使用的计算机程序产品,用于使用表示来自源语音的话音段的源话音数据来训练话音转换系统,以转换为具有目标语音音色的输出语音,所述计算机程序产品包括其上具有计算机可读程序代码的有形的、非瞬态的计算机可用介质,所述计算机可读程序代码包括:
用于使生成机器学习系统根据所述源话音数据和所述目标音色数据来产生第一候选话音数据的程序代码,所述第一候选话音数据表示第一候选语音中的第一候选话音段;
用于使鉴别机器学习系统参照所述多个不同语音的音色数据将所述第一候选话音数据与所述目标音色数据进行比较的程序代码;
用于使鉴别机器学习系统参照多个不同语音的音色数据来确定所述第一候选话音数据和所述目标音色数据之间的至少一个不一致性的程序代码;
用于使所述鉴别机器学习系统参照所述多个不同语音的音色数据来产生具有与所述第一候选话音数据和所述目标音色数据之间的不一致性相关的信息的不一致性消息的程序代码;
用于使所述鉴别机器学习系统将所述不一致性消息反馈给所述生成机器学习系统的程序代码;以及
用于使所述生成机器学习系统根据所述不一致性消息来产生表示第二候选语音中的第二候选话音段的第二候选话音数据的程序代码。
29.如权利要求28所述的计算机程序产品,进一步包括:
用于从目标音频输入中提取所述目标音色数据的程序代码。
30.如权利要求28所述的计算机程序产品,其中所述机器学习系统是神经网络。
31.如权利要求28所述的计算机程序产品,进一步包括:
用于根据来自每个语音的音色数据来映射在向量空间中的所述多个语音中的每个和所述候选语音的表示的程序代码。
32.如权利要求31所述的计算机程序产品,进一步包括:
用于相对于所述向量空间中的多个语音的至少一个表示来调整所述候选语音的表示,以根据所述不一致性消息来更新和反映所述第二候选语音的程序代码。
33.如权利要求28所述的计算机程序产品,进一步包括:
用于通过将所述候选语音与所述多个语音进行比较来将说话者身份分配给所述候选语音的程序代码。
34.如权利要求28所述的计算机程序产品,进一步包括:
用于使用时间接受域将输入的目标音频滤波以产生所述音色数据的程序代码。
35.如权利要求34所述的计算机程序产品,其中,所述时间接受域在约10毫秒和约2,000毫秒之间。
36.如权利要求28所述的计算机程序产品,进一步包括:
用于将表示来自所述源语音的话音段的所述源话音数据转换为所述目标音色中变换的话音段的程序代码。
37.如权利要求36所述的计算机程序产品,进一步包括:
用于向所述变换的话音段添加水印的程序代码。
38.一种用于构建音色向量空间的音色向量空间构造系统,所述空间构建系统包括:
输入端,其配置为接收a)第一语音中的包括第一音色数据的第一话音段,以及b)第二语音中的包括第二音色数据的第二话音段;
时间接受域,其用于将所述第一话音段变换为第一多个更小的分析音频段,所述第一多个更小的分析音频段中的每一个具有表示所述第一音色数据的不同部分的频率分布,
所述滤波器还配置为使用所述时间接受域来将所述第二话音段变换为第二多个更小的分析音频段,所述第二多个更小的分析音频段中的每一个具有表示所述第二音色数据的不同部分的频率分布,
机器学习系统,其配置为根据a)来自所述第一话音段的第一多个分析音频段和b)来自所述第二话音段的第二多个分析音频段的频率分布,在所述音色向量空间中相对于所述第二语音映射所述第一语音。
39.如权利要求38所述的系统,其中所述数据库配置为接收第三语音中的第三话音段,并且
所述机器学习系统配置为使用时间接受域将所述第三话音段滤波为多个较小的分析音频段,并且在所述向量空间中相对于所述第一语音和所述第二语音映射所述第三语音。
40.如权利要求39所述的系统,其中相对于所述第一语音和所述第二语音映射所述第三语音将所述第一语音的所述相对位置改变为所述向量空间中的所述第二语音。
41.如权利要求38所述的系统,其中,所述系统配置为在至少一个语音中映射英语中的每个人类音位。
42.如权利要求38所述的系统,其中,所述接受域足够小以便不捕获所述语音的话音速率和/或口音。
43.如权利要求38所述的系统,其中,所述时间接受域在约10毫秒和约2,000毫秒之间。
44.一种构造用于变换话音段的音色向量空间的方法,包括:
接收a)第一语音中的包括音色数据的第一话音段,以及b)第二语音中的包括音色数据的第二话音段;
使用时间接受域将所述第一话音段和所述第二话音段中的每一个进行滤波为多个更小的分析音频段,每个分析音频段具有表示所述音色数据的频率分布;
使用机器学习系统,根据来自所述第一话音段和所述第二话音段的多个分析音频段的至少一个中的频率分布,在向量空间中相对于所述第二语音映射所述第一语音。
45.如权利要求44所述的方法,其进一步包括用于将所述第一话音段和所述第二话音段中的每一个进行滤波的手段。
46.如权利要求44所述的方法,其进一步包括用于相对于所述第二语音映射所述第一语音的手段。
47.如权利要求44所述的方法,其中,所述滤波由机器学习系统执行。
48.如权利要求44所述的方法,进一步包括:
接收第三语音中的第三话音段;
使用时间接受域将所述第三话音段滤波为多个更小的分析音频段;以及
在所述向量空间中相对于所述第一语音和所述第二语音映射所述第三语音。
49.如权利要求48所述的方法,进一步包括:
根据映射所述第三语音,在所述向量空间中调整所述第一语音与所述第二语音的相对位置。
50.如权利要求48所述的方法,其中,所述接受域足够小以便不捕获所述语音的话音速率和/或口音。
51.如权利要求48所述的方法,进一步包括:
在至少一个语音中映射英语中的每个人类音位。
52.如权利要求48所述的方法,其中,所述时间接受域在约10毫秒和约500毫秒之间。
53.一种在计算机系统上使用的计算机程序产品,用于存储和组织语音,所述计算机程序产品包括其上具有计算机可读程序代码的有形的、非瞬态的计算机可用介质,所述计算机可读程序代码包括:
用于使输入端接收a)第一语音中的包括音色数据的第一话音段,以及b)第二语音中的包括音色数据的第二语音的程序代码;
用于使用时间接受域将所述第一话音段和所述第二话音段中的每一个进行滤波为多个更小的分析音频段的程序代码,每个分析音频段具有表示所述音色数据的频率分布;以及
用于使机器学习系统根据来自所述第一话音段和所述第二话音段的多个分析音频段的至少一个中的频率分布,在向量空间中相对于所述第二语音映射所述第一语音的程序代码。
54.如权利要求53所述的计算机程序产品,其进一步包括用于将所述第一话音段和所述第二话音段中的每一个进行滤波的装置。
55.如权利要求53所述的计算机程序产品,其进一步包括用于在所述向量空间中相对于所述第二语音映射所述第一语音的装置。
56.如权利要求53所述的计算机程序产品,进一步包括:
用于使输入端接收c)第三语音中的第三话音段的程序代码;以及
用于使用时间接受域将所述第三话音段滤波为多个更小的分析音频段的程序代码。
57.如权利要求56所述的计算机程序产品,进一步包括:
用于在所述向量空间中相对于所述第一语音和所述第二语音映射所述第三语音的程序代码,
其中,将所述第三语音相对于所述第一语音和所述第二语音进行映射改变所述第一语音在所述向量空间中与所述第二语音的相对位置。
58.如权利要求53所述的计算机程序产品,进一步包括:
配置为限定时间接受域以便不捕获所述语音的话音速率和/或口音的程序代码。
59.如权利要求58所述的计算机程序产品,其中所述时间接受域在约10毫秒和约500毫秒之间。
60.一种用于构建音色向量空间的音色向量空间构造系统,所述空间构建系统包括:
输入端,其配置为接收a)第一语音中的包括第一音色数据的第一话音段,以及b)第二语音中的包括第二音色数据的第二话音段;
用于将a)所述第一话音段滤波为具有表示所述第一音色数据的不同部分的频率分布的第一多个更小的分析音频段,以及b)将所述第二话音段滤波为第二多个更小的分析音频段的装置,所述第二多个更小的分析音频段中的每一个具有表示所述第二音色数据的不同部分的频率分布,
用于根据a)来自所述第一话音段的第一多个分析音频段和b)来自所述第二话音段的第二多个分析音频段的频率分布在所述音色向量空间中相对于所述第二语音映射所述第一语音的装置。
61.一种使用音色向量空间构建具有新音色的新语音的方法,所述方法包括:
接收使用时间接受域滤波的音色数据,将所述音色数据在所述音色向量空间中映射,所述目标音色数据与多个不同语音相关,所述多个不同语音中的每一个在所述音色向量空间中具有各自的音色数据;以及
使用机器学习系统,使用所述多个不同语音的目标音色数据来构建所述新音色。
62.如权利要求61所述的方法,进一步包括用于将所述目标音色数据滤波的手段。
63.如权利要求61所述的方法,进一步包括提供源话音;以及
在保持源韵律和源口音的同时将所述源话音转换为所述新音色。
64.如权利要求61所述的方法,进一步包括:
接收来自新语音的新话音段;
使用所述神经网络将所述新话音段滤波为新的分析音频段;
将所述向量空间中的新语音相对于多个映射的语音进行映射;以及
基于所述新语音与所述多个映射的语音的关系来确定所述新语音的所述特征中的至少一者。
65.如权利要求61所述的方法,进一步包括:
根据第一语音和第二语音之间的数学运算,使用生成神经网络产生候选语音中的第一候选话音段。
66.如权利要求61所述的方法,其中,所述向量空间中的语音表示群集表示特定口音。
67.如权利要求61所述的方法,其中,来自所述多个语音中的每一个的所述话音段是不同的话音段。
68.一种使用音色向量空间产生新目标语音的系统,所述系统包括:
音色向量空间,其配置为存储使用时间接受域合并的音色数据;
使用时间接受域滤波的音色数据,所述音色数据与多个不同语音相关;以及
机器学习系统,其配置为使用所述音色数据将所述音色数据转换为所述新目标语音。
69.如权利要求68所述的系统,其中,所述机器学习系统是神经网络。
70.如权利要求68所述的系统,其中所述机器学习系统配置为:
从新语音接收新话音段,
将所述新话音段滤波为所述新音色数据,
将所述向量空间中的新音色数据相对于多个音色数据进行映射,并且
基于所述新音色数据相对于所述多个音色数据的关系来确定所述新语音的至少一个语音特征。
71.如权利要求68所述的系统,其中,通过使用所述音色数据的至少一个语音特征作为变量执行数学运算来启动将所述音色数据转换为所述新目标语音。
72.如权利要求68所述的系统,其中,所述向量空间中的语音表示群集表示特定口音。
73.一种在计算机系统上使用的计算机程序产品,用于使用音色向量空间产生新目标语音,所述计算机程序产品包括其上具有计算机可读程序代码的有形的、非瞬态的计算机可用介质,所述计算机可读程序代码包括:
用于接收使用时间接受域滤波的音色数据的程序代码,所述音色数据存储在合并所述时间接受域的音色向量空间中,所述音色数据与多个不同语音相关;以及
用于使用机器学习系统将所述音色数据转换为使用所述音色数据的新目标语音的程序代码。
74.如权利要求73所述的程序代码,进一步包括:
用于从新语音接收新话音段的程序代码;
用于使所述机器学习系统将所述新话音段滤波为新的分析音频段的程序代码;
用于将所述向量空间中的新语音相对于多个映射的语音进行映射的程序代码;以及
用于基于新语音与所述多个映射的语音的关系来确定所述新语音的至少一个特征的程序代码。
75.如权利要求73所述的程序代码,其中,所述机器学习系统是神经网络。
76.如权利要求73所述的程序代码,其中,通过使用所述音色数据的至少一个语音特征作为变量执行数学运算来启动将所述音色数据转换为所述新目标语音。
77.如权利要求73所述的程序代码,其中,所述向量空间中的语音表示群集表示特定口音。
78.一种将话音段从源音色转换为目标音色的方法,所述方法包括:
存储与多个不同语音相关的音色数据,所述多个不同语音中的每一个在音色向量空间中具有各自的音色数据,所述音色数据已经使用时间接受域滤波并且在所述音色向量空间中映射;
接收源语音中的源话音段,转换为目标语音;
接收对目标语音的选择,所述目标语音具有目标音色,所述目标语音参考所述多个不同语音在所述音色向量空间中映射;
使用机器学习系统将所述源话音段从所述源语音的音色变换到所述目标语音的音色。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762510443P | 2017-05-24 | 2017-05-24 | |
| US62/510,443 | 2017-05-24 | ||
| PCT/US2018/034485 WO2018218081A1 (en) | 2017-05-24 | 2018-05-24 | System and method for voice-to-voice conversion |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111201565A true CN111201565A (zh) | 2020-05-26 |
| CN111201565B CN111201565B (zh) | 2024-08-16 |
Family
ID=64397077
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201880034452.8A Active CN111201565B (zh) | 2017-05-24 | 2018-05-24 | 用于声对声转换的系统和方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (6) | US10861476B2 (zh) |
| EP (1) | EP3631791A4 (zh) |
| KR (2) | KR20200027475A (zh) |
| CN (1) | CN111201565B (zh) |
| WO (1) | WO2018218081A1 (zh) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112164387A (zh) * | 2020-09-22 | 2021-01-01 | 腾讯音乐娱乐科技(深圳)有限公司 | 音频合成方法、装置及电子设备和计算机可读存储介质 |
| CN112382271A (zh) * | 2020-11-30 | 2021-02-19 | 北京百度网讯科技有限公司 | 语音处理方法、装置、电子设备和存储介质 |
| CN113555026A (zh) * | 2021-07-23 | 2021-10-26 | 平安科技(深圳)有限公司 | 语音转换方法、装置、电子设备及介质 |
Families Citing this family (51)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| BR112019006979A2 (pt) * | 2016-10-24 | 2019-06-25 | Semantic Machines Inc | sequência para sequenciar transformações para síntese de fala via redes neurais recorrentes |
| WO2018218081A1 (en) | 2017-05-24 | 2018-11-29 | Modulate, LLC | System and method for voice-to-voice conversion |
| US20190082255A1 (en) * | 2017-09-08 | 2019-03-14 | Olympus Corporation | Information acquiring apparatus, information acquiring method, and computer readable recording medium |
| US11398218B1 (en) * | 2018-04-26 | 2022-07-26 | United Services Automobile Association (Usaa) | Dynamic speech output configuration |
| EP3598344A1 (en) * | 2018-07-19 | 2020-01-22 | Nokia Technologies Oy | Processing sensor data |
| US10891949B2 (en) * | 2018-09-10 | 2021-01-12 | Ford Global Technologies, Llc | Vehicle language processing |
| WO2020089961A1 (ja) * | 2018-10-29 | 2020-05-07 | 健一 海沼 | 音声処理装置、およびプログラム |
| US11706499B2 (en) * | 2018-10-31 | 2023-07-18 | Sony Interactive Entertainment Inc. | Watermarking synchronized inputs for machine learning |
| CN109473091B (zh) * | 2018-12-25 | 2021-08-10 | 四川虹微技术有限公司 | 一种语音样本生成方法及装置 |
| WO2020141643A1 (ko) * | 2019-01-03 | 2020-07-09 | 엘지전자 주식회사 | 음성 합성 서버 및 단말기 |
| JP7309155B2 (ja) * | 2019-01-10 | 2023-07-18 | グリー株式会社 | コンピュータプログラム、サーバ装置、端末装置及び音声信号処理方法 |
| CN111554316A (zh) * | 2019-01-24 | 2020-08-18 | 富士通株式会社 | 语音处理装置、方法和介质 |
| US20200335119A1 (en) * | 2019-04-16 | 2020-10-22 | Microsoft Technology Licensing, Llc | Speech extraction using attention network |
| CN112037768B (zh) * | 2019-05-14 | 2024-10-22 | 北京三星通信技术研究有限公司 | 语音翻译方法、装置、电子设备及计算机可读存储介质 |
| US11410667B2 (en) | 2019-06-28 | 2022-08-09 | Ford Global Technologies, Llc | Hierarchical encoder for speech conversion system |
| US11538485B2 (en) * | 2019-08-14 | 2022-12-27 | Modulate, Inc. | Generation and detection of watermark for real-time voice conversion |
| US11158329B2 (en) * | 2019-09-11 | 2021-10-26 | Artificial Intelligence Foundation, Inc. | Identification of fake audio content |
| CN110600013B (zh) * | 2019-09-12 | 2021-11-02 | 思必驰科技股份有限公司 | 非平行语料声音转换数据增强模型训练方法及装置 |
| US11062692B2 (en) | 2019-09-23 | 2021-07-13 | Disney Enterprises, Inc. | Generation of audio including emotionally expressive synthesized content |
| KR102637341B1 (ko) * | 2019-10-15 | 2024-02-16 | 삼성전자주식회사 | 음성 생성 방법 및 장치 |
| EP3839947A1 (en) | 2019-12-20 | 2021-06-23 | SoundHound, Inc. | Training a voice morphing apparatus |
| CN111247584B (zh) * | 2019-12-24 | 2023-05-23 | 深圳市优必选科技股份有限公司 | 语音转换方法、系统、装置及存储介质 |
| EP4270255A3 (en) * | 2019-12-30 | 2023-12-06 | TMRW Foundation IP SARL | Cross-lingual voice conversion system and method |
| CN111213205B (zh) * | 2019-12-30 | 2023-09-08 | 深圳市优必选科技股份有限公司 | 一种流式语音转换方法、装置、计算机设备及存储介质 |
| CN111433847B (zh) * | 2019-12-31 | 2023-06-09 | 深圳市优必选科技股份有限公司 | 语音转换的方法及训练方法、智能装置和存储介质 |
| US11600284B2 (en) * | 2020-01-11 | 2023-03-07 | Soundhound, Inc. | Voice morphing apparatus having adjustable parameters |
| US11183168B2 (en) * | 2020-02-13 | 2021-11-23 | Tencent America LLC | Singing voice conversion |
| US11398216B2 (en) | 2020-03-11 | 2022-07-26 | Nuance Communication, Inc. | Ambient cooperative intelligence system and method |
| US20210304783A1 (en) * | 2020-03-31 | 2021-09-30 | International Business Machines Corporation | Voice conversion and verification |
| CN111640444B (zh) * | 2020-04-17 | 2023-04-28 | 宁波大学 | 基于cnn的自适应音频隐写方法和秘密信息提取方法 |
| WO2022024183A1 (ja) * | 2020-07-27 | 2022-02-03 | 日本電信電話株式会社 | 音声信号変換モデル学習装置、音声信号変換装置、音声信号変換モデル学習方法及びプログラム |
| WO2022024187A1 (ja) * | 2020-07-27 | 2022-02-03 | 日本電信電話株式会社 | 音声信号変換モデル学習装置、音声信号変換装置、音声信号変換モデル学習方法及びプログラム |
| CN111883149B (zh) * | 2020-07-30 | 2022-02-01 | 四川长虹电器股份有限公司 | 一种带情感和韵律的语音转换方法及装置 |
| JP2023539148A (ja) * | 2020-08-21 | 2023-09-13 | ソムニック インク. | 発話をコンピュータ生成によって視覚化するための方法およびシステム |
| CN114203147A (zh) * | 2020-08-28 | 2022-03-18 | 微软技术许可有限责任公司 | 用于文本到语音的跨说话者样式传递以及用于训练数据生成的系统和方法 |
| US11996117B2 (en) | 2020-10-08 | 2024-05-28 | Modulate, Inc. | Multi-stage adaptive system for content moderation |
| WO2022085197A1 (ja) * | 2020-10-23 | 2022-04-28 | 日本電信電話株式会社 | 音声信号変換モデル学習装置、音声信号変換装置、音声信号変換モデル学習方法及びプログラム |
| US11783804B2 (en) * | 2020-10-26 | 2023-10-10 | T-Mobile Usa, Inc. | Voice communicator with voice changer |
| KR20220067864A (ko) * | 2020-11-18 | 2022-05-25 | 주식회사 마인즈랩 | 음성의 보이스 특징 변환 방법 |
| CN112365882B (zh) * | 2020-11-30 | 2023-09-22 | 北京百度网讯科技有限公司 | 语音合成方法及模型训练方法、装置、设备及存储介质 |
| TWI763207B (zh) * | 2020-12-25 | 2022-05-01 | 宏碁股份有限公司 | 聲音訊號處理評估方法及裝置 |
| US20240303030A1 (en) * | 2021-03-09 | 2024-09-12 | Webtalk Ltd | Dynamic audio content generation |
| CN112712813B (zh) * | 2021-03-26 | 2021-07-20 | 北京达佳互联信息技术有限公司 | 语音处理方法、装置、设备及存储介质 |
| US11862179B2 (en) * | 2021-04-01 | 2024-01-02 | Capital One Services, Llc | Systems and methods for detecting manipulated vocal samples |
| US11948550B2 (en) | 2021-05-06 | 2024-04-02 | Sanas.ai Inc. | Real-time accent conversion model |
| US11996083B2 (en) | 2021-06-03 | 2024-05-28 | International Business Machines Corporation | Global prosody style transfer without text transcriptions |
| CN113823298B (zh) * | 2021-06-15 | 2024-04-16 | 腾讯科技(深圳)有限公司 | 语音数据处理方法、装置、计算机设备及存储介质 |
| US12002451B1 (en) * | 2021-07-01 | 2024-06-04 | Amazon Technologies, Inc. | Automatic speech recognition |
| CN113593588B (zh) * | 2021-07-29 | 2023-09-12 | 浙江大学 | 一种基于生成对抗网络的多唱歌人歌声合成方法和系统 |
| US12033618B1 (en) * | 2021-11-09 | 2024-07-09 | Amazon Technologies, Inc. | Relevant context determination |
| US11848005B2 (en) * | 2022-04-28 | 2023-12-19 | Meaning.Team, Inc | Voice attribute conversion using speech to speech |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20020046899A1 (en) * | 2000-09-12 | 2002-04-25 | Yamaha Corporation | Music performance information converting method with modification of timbre for emulation |
| JP2006319598A (ja) * | 2005-05-12 | 2006-11-24 | Victor Co Of Japan Ltd | 音声通信システム |
| CN101359473A (zh) * | 2007-07-30 | 2009-02-04 | 国际商业机器公司 | 自动进行语音转换的方法和装置 |
| US7987244B1 (en) * | 2004-12-30 | 2011-07-26 | At&T Intellectual Property Ii, L.P. | Network repository for voice fonts |
| CN102982809A (zh) * | 2012-12-11 | 2013-03-20 | 中国科学技术大学 | 一种说话人声音转换方法 |
| US20130151256A1 (en) * | 2010-07-20 | 2013-06-13 | National Institute Of Advanced Industrial Science And Technology | System and method for singing synthesis capable of reflecting timbre changes |
| US9305530B1 (en) * | 2014-09-30 | 2016-04-05 | Amazon Technologies, Inc. | Text synchronization with audio |
Family Cites Families (131)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3610831A (en) * | 1969-05-26 | 1971-10-05 | Listening Inc | Speech recognition apparatus |
| WO1993018505A1 (en) * | 1992-03-02 | 1993-09-16 | The Walt Disney Company | Voice transformation system |
| US5677989A (en) | 1993-04-30 | 1997-10-14 | Lucent Technologies Inc. | Speaker verification system and process |
| CA2167200A1 (en) * | 1993-07-13 | 1995-01-26 | Theodore Austin Bordeaux | Multi-language speech recognition system |
| JP3536996B2 (ja) * | 1994-09-13 | 2004-06-14 | ソニー株式会社 | パラメータ変換方法及び音声合成方法 |
| US5892900A (en) | 1996-08-30 | 1999-04-06 | Intertrust Technologies Corp. | Systems and methods for secure transaction management and electronic rights protection |
| US5749066A (en) * | 1995-04-24 | 1998-05-05 | Ericsson Messaging Systems Inc. | Method and apparatus for developing a neural network for phoneme recognition |
| JPH10260692A (ja) * | 1997-03-18 | 1998-09-29 | Toshiba Corp | 音声の認識合成符号化/復号化方法及び音声符号化/復号化システム |
| US6336092B1 (en) * | 1997-04-28 | 2002-01-01 | Ivl Technologies Ltd | Targeted vocal transformation |
| US5808222A (en) | 1997-07-16 | 1998-09-15 | Winbond Electronics Corporation | Method of building a database of timbre samples for wave-table music synthesizers to produce synthesized sounds with high timbre quality |
| JP3502247B2 (ja) * | 1997-10-28 | 2004-03-02 | ヤマハ株式会社 | 音声変換装置 |
| US8202094B2 (en) * | 1998-02-18 | 2012-06-19 | Radmila Solutions, L.L.C. | System and method for training users with audible answers to spoken questions |
| JP3365354B2 (ja) | 1999-06-30 | 2003-01-08 | ヤマハ株式会社 | 音声信号または楽音信号の処理装置 |
| US20020072900A1 (en) | 1999-11-23 | 2002-06-13 | Keough Steven J. | System and method of templating specific human voices |
| US20030158734A1 (en) | 1999-12-16 | 2003-08-21 | Brian Cruickshank | Text to speech conversion using word concatenation |
| WO2002025415A2 (en) | 2000-09-22 | 2002-03-28 | Edc Systems, Inc. | Systems and methods for preventing unauthorized use of digital content |
| KR200226168Y1 (ko) | 2000-12-28 | 2001-06-01 | 엘지전자주식회사 | 이퀄라이저 기능을 구비한 휴대 통신 장치 |
| US20030135374A1 (en) * | 2002-01-16 | 2003-07-17 | Hardwick John C. | Speech synthesizer |
| JP4263412B2 (ja) * | 2002-01-29 | 2009-05-13 | 富士通株式会社 | 音声符号変換方法 |
| US20030154080A1 (en) * | 2002-02-14 | 2003-08-14 | Godsey Sandra L. | Method and apparatus for modification of audio input to a data processing system |
| FR2843479B1 (fr) * | 2002-08-07 | 2004-10-22 | Smart Inf Sa | Procede de calibrage d'audio-intonation |
| JP4178319B2 (ja) * | 2002-09-13 | 2008-11-12 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 音声処理におけるフェーズ・アライメント |
| US7634399B2 (en) * | 2003-01-30 | 2009-12-15 | Digital Voice Systems, Inc. | Voice transcoder |
| US7412377B2 (en) | 2003-12-19 | 2008-08-12 | International Business Machines Corporation | Voice model for speech processing based on ordered average ranks of spectral features |
| DE102004012208A1 (de) * | 2004-03-12 | 2005-09-29 | Siemens Ag | Individualisierung von Sprachausgabe durch Anpassen einer Synthesestimme an eine Zielstimme |
| US7873911B2 (en) | 2004-08-31 | 2011-01-18 | Gopalakrishnan Kumar C | Methods for providing information services related to visual imagery |
| US7772477B2 (en) | 2005-03-17 | 2010-08-10 | Yamaha Corporation | Electronic music apparatus with data loading assist |
| WO2006128496A1 (en) * | 2005-06-01 | 2006-12-07 | Loquendo S.P.A. | Method of adapting a neural network of an automatic speech recognition device |
| CN101351841B (zh) * | 2005-12-02 | 2011-11-16 | 旭化成株式会社 | 音质转换系统 |
| EP1968439A4 (en) | 2005-12-23 | 2010-05-26 | Univ Queensland | SONIFIZATION OF THE AWARENESS OF A PATIENT |
| US20080082320A1 (en) * | 2006-09-29 | 2008-04-03 | Nokia Corporation | Apparatus, method and computer program product for advanced voice conversion |
| JP4878538B2 (ja) | 2006-10-24 | 2012-02-15 | 株式会社日立製作所 | 音声合成装置 |
| US8060565B1 (en) * | 2007-01-31 | 2011-11-15 | Avaya Inc. | Voice and text session converter |
| JP4966048B2 (ja) * | 2007-02-20 | 2012-07-04 | 株式会社東芝 | 声質変換装置及び音声合成装置 |
| EP1970894A1 (fr) * | 2007-03-12 | 2008-09-17 | France Télécom | Procédé et dispositif de modification d'un signal audio |
| US7848924B2 (en) * | 2007-04-17 | 2010-12-07 | Nokia Corporation | Method, apparatus and computer program product for providing voice conversion using temporal dynamic features |
| GB2452021B (en) | 2007-07-19 | 2012-03-14 | Vodafone Plc | identifying callers in telecommunication networks |
| US20110161348A1 (en) * | 2007-08-17 | 2011-06-30 | Avi Oron | System and Method for Automatically Creating a Media Compilation |
| CN101399044B (zh) * | 2007-09-29 | 2013-09-04 | 纽奥斯通讯有限公司 | 语音转换方法和系统 |
| US8131550B2 (en) | 2007-10-04 | 2012-03-06 | Nokia Corporation | Method, apparatus and computer program product for providing improved voice conversion |
| US20090177473A1 (en) * | 2008-01-07 | 2009-07-09 | Aaron Andrew S | Applying vocal characteristics from a target speaker to a source speaker for synthetic speech |
| JP5038995B2 (ja) * | 2008-08-25 | 2012-10-03 | 株式会社東芝 | 声質変換装置及び方法、音声合成装置及び方法 |
| US8571849B2 (en) | 2008-09-30 | 2013-10-29 | At&T Intellectual Property I, L.P. | System and method for enriching spoken language translation with prosodic information |
| US20100215289A1 (en) * | 2009-02-24 | 2010-08-26 | Neurofocus, Inc. | Personalized media morphing |
| US8779268B2 (en) | 2009-06-01 | 2014-07-15 | Music Mastermind, Inc. | System and method for producing a more harmonious musical accompaniment |
| JP4705203B2 (ja) * | 2009-07-06 | 2011-06-22 | パナソニック株式会社 | 声質変換装置、音高変換装置および声質変換方法 |
| US8175617B2 (en) | 2009-10-28 | 2012-05-08 | Digimarc Corporation | Sensor-based mobile search, related methods and systems |
| CN102117614B (zh) * | 2010-01-05 | 2013-01-02 | 索尼爱立信移动通讯有限公司 | 个性化文本语音合成和个性化语音特征提取 |
| GB2478314B (en) * | 2010-03-02 | 2012-09-12 | Toshiba Res Europ Ltd | A speech processor, a speech processing method and a method of training a speech processor |
| WO2011151956A1 (ja) * | 2010-06-04 | 2011-12-08 | パナソニック株式会社 | 声質変換装置及びその方法、母音情報作成装置並びに声質変換システム |
| WO2012005953A1 (en) * | 2010-06-28 | 2012-01-12 | The Regents Of The University Of California | Adaptive set discrimination procedure |
| US8759661B2 (en) | 2010-08-31 | 2014-06-24 | Sonivox, L.P. | System and method for audio synthesizer utilizing frequency aperture arrays |
| US9800721B2 (en) | 2010-09-07 | 2017-10-24 | Securus Technologies, Inc. | Multi-party conversation analyzer and logger |
| US8892436B2 (en) * | 2010-10-19 | 2014-11-18 | Samsung Electronics Co., Ltd. | Front-end processor for speech recognition, and speech recognizing apparatus and method using the same |
| US8676574B2 (en) | 2010-11-10 | 2014-03-18 | Sony Computer Entertainment Inc. | Method for tone/intonation recognition using auditory attention cues |
| EP2485213A1 (en) | 2011-02-03 | 2012-08-08 | Fraunhofer-Gesellschaft zur Förderung der Angewandten Forschung e.V. | Semantic audio track mixer |
| GB2489473B (en) * | 2011-03-29 | 2013-09-18 | Toshiba Res Europ Ltd | A voice conversion method and system |
| US8756061B2 (en) * | 2011-04-01 | 2014-06-17 | Sony Computer Entertainment Inc. | Speech syllable/vowel/phone boundary detection using auditory attention cues |
| US9196028B2 (en) | 2011-09-23 | 2015-11-24 | Digimarc Corporation | Context-based smartphone sensor logic |
| US8850535B2 (en) | 2011-08-05 | 2014-09-30 | Safefaces LLC | Methods and systems for identity verification in a social network using ratings |
| US9292335B2 (en) * | 2011-09-05 | 2016-03-22 | Ntt Docomo, Inc. | Information processing device and program |
| US8515751B2 (en) * | 2011-09-28 | 2013-08-20 | Google Inc. | Selective feedback for text recognition systems |
| US8290772B1 (en) * | 2011-10-03 | 2012-10-16 | Google Inc. | Interactive text editing |
| US9245254B2 (en) * | 2011-12-01 | 2016-01-26 | Elwha Llc | Enhanced voice conferencing with history, language translation and identification |
| US20150025892A1 (en) * | 2012-03-06 | 2015-01-22 | Agency For Science, Technology And Research | Method and system for template-based personalized singing synthesis |
| JP6290858B2 (ja) * | 2012-03-29 | 2018-03-07 | スミュール, インク.Smule, Inc. | 発話の入力オーディオエンコーディングを、対象歌曲にリズム的に調和する出力へと自動変換するための、コンピュータ処理方法、装置、及びコンピュータプログラム製品 |
| US9153235B2 (en) | 2012-04-09 | 2015-10-06 | Sony Computer Entertainment Inc. | Text dependent speaker recognition with long-term feature based on functional data analysis |
| JP5846043B2 (ja) * | 2012-05-18 | 2016-01-20 | ヤマハ株式会社 | 音声処理装置 |
| US20140046660A1 (en) | 2012-08-10 | 2014-02-13 | Yahoo! Inc | Method and system for voice based mood analysis |
| KR20150056770A (ko) * | 2012-09-13 | 2015-05-27 | 엘지전자 주식회사 | 손실 프레임 복원 방법 및 오디오 복호화 방법과 이를 이용하는 장치 |
| US8744854B1 (en) | 2012-09-24 | 2014-06-03 | Chengjun Julian Chen | System and method for voice transformation |
| US9020822B2 (en) | 2012-10-19 | 2015-04-28 | Sony Computer Entertainment Inc. | Emotion recognition using auditory attention cues extracted from users voice |
| PL401371A1 (pl) * | 2012-10-26 | 2014-04-28 | Ivona Software Spółka Z Ograniczoną Odpowiedzialnością | Opracowanie głosu dla zautomatyzowanej zamiany tekstu na mowę |
| US9085303B2 (en) * | 2012-11-15 | 2015-07-21 | Sri International | Vehicle personal assistant |
| US9798799B2 (en) * | 2012-11-15 | 2017-10-24 | Sri International | Vehicle personal assistant that interprets spoken natural language input based upon vehicle context |
| US9672811B2 (en) | 2012-11-29 | 2017-06-06 | Sony Interactive Entertainment Inc. | Combining auditory attention cues with phoneme posterior scores for phone/vowel/syllable boundary detection |
| US8886539B2 (en) | 2012-12-03 | 2014-11-11 | Chengjun Julian Chen | Prosody generation using syllable-centered polynomial representation of pitch contours |
| US8942977B2 (en) | 2012-12-03 | 2015-01-27 | Chengjun Julian Chen | System and method for speech recognition using pitch-synchronous spectral parameters |
| US9195649B2 (en) | 2012-12-21 | 2015-11-24 | The Nielsen Company (Us), Llc | Audio processing techniques for semantic audio recognition and report generation |
| US9158760B2 (en) | 2012-12-21 | 2015-10-13 | The Nielsen Company (Us), Llc | Audio decoding with supplemental semantic audio recognition and report generation |
| US20150005661A1 (en) * | 2013-02-22 | 2015-01-01 | Max Sound Corporation | Method and process for reducing tinnitus |
| CA2898095C (en) | 2013-03-04 | 2019-12-03 | Voiceage Corporation | Device and method for reducing quantization noise in a time-domain decoder |
| KR101331122B1 (ko) | 2013-03-15 | 2013-11-19 | 주식회사 에이디자인 | 모바일 기기의 수신시 통화연결 방법 |
| EP2976749A4 (en) * | 2013-03-20 | 2016-10-26 | Intel Corp | AVATAR-BASED TRANSMISSION PROTOCOLS, SYMBOL GENERATION AND PUPPET ANIMATION |
| JP2015040903A (ja) * | 2013-08-20 | 2015-03-02 | ソニー株式会社 | 音声処理装置、音声処理方法、及び、プログラム |
| US9432792B2 (en) * | 2013-09-05 | 2016-08-30 | AmOS DM, LLC | System and methods for acoustic priming of recorded sounds |
| US9183830B2 (en) | 2013-11-01 | 2015-11-10 | Google Inc. | Method and system for non-parametric voice conversion |
| US8918326B1 (en) | 2013-12-05 | 2014-12-23 | The Telos Alliance | Feedback and simulation regarding detectability of a watermark message |
| WO2015100430A1 (en) | 2013-12-24 | 2015-07-02 | Digimarc Corporation | Methods and system for cue detection from audio input, low-power data processing and related arrangements |
| US9135923B1 (en) * | 2014-03-17 | 2015-09-15 | Chengjun Julian Chen | Pitch synchronous speech coding based on timbre vectors |
| US9183831B2 (en) * | 2014-03-27 | 2015-11-10 | International Business Machines Corporation | Text-to-speech for digital literature |
| US10008216B2 (en) * | 2014-04-15 | 2018-06-26 | Speech Morphing Systems, Inc. | Method and apparatus for exemplary morphing computer system background |
| EP2933070A1 (en) * | 2014-04-17 | 2015-10-21 | Aldebaran Robotics | Methods and systems of handling a dialog with a robot |
| US20150356967A1 (en) * | 2014-06-08 | 2015-12-10 | International Business Machines Corporation | Generating Narrative Audio Works Using Differentiable Text-to-Speech Voices |
| US9613620B2 (en) * | 2014-07-03 | 2017-04-04 | Google Inc. | Methods and systems for voice conversion |
| US9881631B2 (en) * | 2014-10-21 | 2018-01-30 | Mitsubishi Electric Research Laboratories, Inc. | Method for enhancing audio signal using phase information |
| JP6561499B2 (ja) | 2015-03-05 | 2019-08-21 | ヤマハ株式会社 | 音声合成装置および音声合成方法 |
| KR101666930B1 (ko) | 2015-04-29 | 2016-10-24 | 서울대학교산학협력단 | 심화 학습 모델을 이용한 목표 화자의 적응형 목소리 변환 방법 및 이를 구현하는 음성 변환 장치 |
| US20160379641A1 (en) * | 2015-06-29 | 2016-12-29 | Microsoft Technology Licensing, Llc | Auto-Generation of Notes and Tasks From Passive Recording |
| KR102410914B1 (ko) * | 2015-07-16 | 2022-06-17 | 삼성전자주식회사 | 음성 인식을 위한 모델 구축 장치 및 음성 인식 장치 및 방법 |
| US10186251B1 (en) | 2015-08-06 | 2019-01-22 | Oben, Inc. | Voice conversion using deep neural network with intermediate voice training |
| KR101665882B1 (ko) | 2015-08-20 | 2016-10-13 | 한국과학기술원 | 음색변환과 음성dna를 이용한 음성합성 기술 및 장치 |
| CN106571145A (zh) | 2015-10-08 | 2017-04-19 | 重庆邮电大学 | 一种语音模仿方法和装置 |
| US9830903B2 (en) * | 2015-11-10 | 2017-11-28 | Paul Wendell Mason | Method and apparatus for using a vocal sample to customize text to speech applications |
| US9589574B1 (en) | 2015-11-13 | 2017-03-07 | Doppler Labs, Inc. | Annoyance noise suppression |
| US10327095B2 (en) | 2015-11-18 | 2019-06-18 | Interactive Intelligence Group, Inc. | System and method for dynamically generated reports |
| KR102390713B1 (ko) | 2015-11-25 | 2022-04-27 | 삼성전자 주식회사 | 전자 장치 및 전자 장치의 통화 서비스 제공 방법 |
| US20220224792A1 (en) * | 2016-01-12 | 2022-07-14 | Andrew Horton | Caller identification in a secure environment using voice biometrics |
| WO2017136854A1 (en) | 2016-02-05 | 2017-08-10 | New Resonance, Llc | Mapping characteristics of music into a visual display |
| US9591427B1 (en) * | 2016-02-20 | 2017-03-07 | Philip Scott Lyren | Capturing audio impulse responses of a person with a smartphone |
| US10453476B1 (en) * | 2016-07-21 | 2019-10-22 | Oben, Inc. | Split-model architecture for DNN-based small corpus voice conversion |
| US10115400B2 (en) | 2016-08-05 | 2018-10-30 | Sonos, Inc. | Multiple voice services |
| US9949020B1 (en) | 2016-08-12 | 2018-04-17 | Ocean Acoustical Services and Instrumentation System | System and method for including soundscapes in online mapping utilities |
| US20180053261A1 (en) * | 2016-08-16 | 2018-02-22 | Jeffrey Lee Hershey | Automated Compatibility Matching Based on Music Preferences of Individuals |
| US10291646B2 (en) | 2016-10-03 | 2019-05-14 | Telepathy Labs, Inc. | System and method for audio fingerprinting for attack detection |
| US10339960B2 (en) * | 2016-10-13 | 2019-07-02 | International Business Machines Corporation | Personal device for hearing degradation monitoring |
| US10706839B1 (en) * | 2016-10-24 | 2020-07-07 | United Services Automobile Association (Usaa) | Electronic signatures via voice for virtual assistants' interactions |
| US20180146370A1 (en) | 2016-11-22 | 2018-05-24 | Ashok Krishnaswamy | Method and apparatus for secured authentication using voice biometrics and watermarking |
| US10559309B2 (en) | 2016-12-22 | 2020-02-11 | Google Llc | Collaborative voice controlled devices |
| WO2018141061A1 (en) * | 2017-02-01 | 2018-08-09 | Cerebian Inc. | System and method for measuring perceptual experiences |
| US20180225083A1 (en) | 2017-02-03 | 2018-08-09 | Scratchvox Inc. | Methods, systems, and computer-readable storage media for enabling flexible sound generation/modifying utilities |
| US10706867B1 (en) * | 2017-03-03 | 2020-07-07 | Oben, Inc. | Global frequency-warping transformation estimation for voice timbre approximation |
| CA2998249A1 (en) * | 2017-03-17 | 2018-09-17 | Edatanetworks Inc. | Artificial intelligence engine incenting merchant transaction with consumer affinity |
| US11183181B2 (en) | 2017-03-27 | 2021-11-23 | Sonos, Inc. | Systems and methods of multiple voice services |
| US10861210B2 (en) * | 2017-05-16 | 2020-12-08 | Apple Inc. | Techniques for providing audio and video effects |
| WO2018218081A1 (en) | 2017-05-24 | 2018-11-29 | Modulate, LLC | System and method for voice-to-voice conversion |
| CN107293289B (zh) | 2017-06-13 | 2020-05-29 | 南京医科大学 | 一种基于深度卷积生成对抗网络的语音生成方法 |
| US10361673B1 (en) | 2018-07-24 | 2019-07-23 | Sony Interactive Entertainment Inc. | Ambient sound activated headphone |
| US11538485B2 (en) | 2019-08-14 | 2022-12-27 | Modulate, Inc. | Generation and detection of watermark for real-time voice conversion |
| US11714967B1 (en) * | 2019-11-01 | 2023-08-01 | Empowerly, Inc. | College admissions and career mentorship platform |
| US11996117B2 (en) | 2020-10-08 | 2024-05-28 | Modulate, Inc. | Multi-stage adaptive system for content moderation |
-
2018
- 2018-05-24 WO PCT/US2018/034485 patent/WO2018218081A1/en active Application Filing
- 2018-05-24 US US15/989,065 patent/US10861476B2/en active Active
- 2018-05-24 CN CN201880034452.8A patent/CN111201565B/zh active Active
- 2018-05-24 US US15/989,062 patent/US10614826B2/en active Active
- 2018-05-24 KR KR1020197038068A patent/KR20200027475A/ko not_active Application Discontinuation
- 2018-05-24 US US15/989,072 patent/US10622002B2/en active Active
- 2018-05-24 KR KR1020237002550A patent/KR20230018538A/ko not_active Application Discontinuation
- 2018-05-24 EP EP18806567.6A patent/EP3631791A4/en active Pending
-
2020
- 2020-04-13 US US16/846,460 patent/US11017788B2/en active Active
-
2021
- 2021-05-04 US US17/307,397 patent/US11854563B2/en active Active
-
2023
- 2023-12-04 US US18/528,244 patent/US20240119954A1/en active Pending
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20020046899A1 (en) * | 2000-09-12 | 2002-04-25 | Yamaha Corporation | Music performance information converting method with modification of timbre for emulation |
| US7987244B1 (en) * | 2004-12-30 | 2011-07-26 | At&T Intellectual Property Ii, L.P. | Network repository for voice fonts |
| JP2006319598A (ja) * | 2005-05-12 | 2006-11-24 | Victor Co Of Japan Ltd | 音声通信システム |
| CN101359473A (zh) * | 2007-07-30 | 2009-02-04 | 国际商业机器公司 | 自动进行语音转换的方法和装置 |
| US20130151256A1 (en) * | 2010-07-20 | 2013-06-13 | National Institute Of Advanced Industrial Science And Technology | System and method for singing synthesis capable of reflecting timbre changes |
| CN102982809A (zh) * | 2012-12-11 | 2013-03-20 | 中国科学技术大学 | 一种说话人声音转换方法 |
| US9305530B1 (en) * | 2014-09-30 | 2016-04-05 | Amazon Technologies, Inc. | Text synchronization with audio |
Non-Patent Citations (1)
| Title |
|---|
| 刘金凤,符敏,程德福: "声音转换实验系统的研究与实现" * |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112164387A (zh) * | 2020-09-22 | 2021-01-01 | 腾讯音乐娱乐科技(深圳)有限公司 | 音频合成方法、装置及电子设备和计算机可读存储介质 |
| CN112382271A (zh) * | 2020-11-30 | 2021-02-19 | 北京百度网讯科技有限公司 | 语音处理方法、装置、电子设备和存储介质 |
| CN112382271B (zh) * | 2020-11-30 | 2024-03-26 | 北京百度网讯科技有限公司 | 语音处理方法、装置、电子设备和存储介质 |
| CN113555026A (zh) * | 2021-07-23 | 2021-10-26 | 平安科技(深圳)有限公司 | 语音转换方法、装置、电子设备及介质 |
| CN113555026B (zh) * | 2021-07-23 | 2024-04-19 | 平安科技(深圳)有限公司 | 语音转换方法、装置、电子设备及介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| US10861476B2 (en) | 2020-12-08 |
| US20210256985A1 (en) | 2021-08-19 |
| KR20230018538A (ko) | 2023-02-07 |
| US11017788B2 (en) | 2021-05-25 |
| KR20200027475A (ko) | 2020-03-12 |
| EP3631791A1 (en) | 2020-04-08 |
| US20180342256A1 (en) | 2018-11-29 |
| US11854563B2 (en) | 2023-12-26 |
| US20240119954A1 (en) | 2024-04-11 |
| US20180342257A1 (en) | 2018-11-29 |
| US20200243101A1 (en) | 2020-07-30 |
| EP3631791A4 (en) | 2021-02-24 |
| CN111201565B (zh) | 2024-08-16 |
| WO2018218081A1 (en) | 2018-11-29 |
| US10622002B2 (en) | 2020-04-14 |
| US10614826B2 (en) | 2020-04-07 |
| US20180342258A1 (en) | 2018-11-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111201565B (zh) | 用于声对声转换的系统和方法 | |
| Kamble et al. | Advances in anti-spoofing: from the perspective of ASVspoof challenges | |
| JP7152791B2 (ja) | クロスリンガル音声変換システムおよび方法 | |
| WO2021030759A1 (en) | Generation and detection of watermark for real-time voice conversion | |
| EP4205109A1 (en) | Synthesized data augmentation using voice conversion and speech recognition models | |
| JP2000504849A (ja) | 音響学および電磁波を用いた音声の符号化、再構成および認識 | |
| WO2020145353A1 (ja) | コンピュータプログラム、サーバ装置、端末装置及び音声信号処理方法 | |
| Almaadeed et al. | Text-independent speaker identification using vowel formants | |
| GB2603776A (en) | Methods and systems for modifying speech generated by a text-to-speech synthesiser | |
| CN114627856A (zh) | 语音识别方法、装置、存储介质及电子设备 | |
| CN112735454A (zh) | 音频处理方法、装置、电子设备和可读存储介质 | |
| Patel et al. | Significance of source–filter interaction for classification of natural vs. spoofed speech | |
| CN114067782A (zh) | 音频识别方法及其装置、介质和芯片系统 | |
| Almutairi et al. | Detecting fake audio of Arabic speakers using self-supervised deep learning | |
| CN112863476A (zh) | 个性化语音合成模型构建、语音合成和测试方法及装置 | |
| Gao | Audio deepfake detection based on differences in human and machine generated speech | |
| Imam et al. | Speaker recognition using automated systems | |
| CN114512133A (zh) | 发声对象识别方法、装置、服务器及存储介质 | |
| CN115132204B (zh) | 一种语音处理方法、设备、存储介质及计算机程序产品 | |
| Banerjee et al. | Voice intonation transformation using segmental linear mapping of pitch contours | |
| Radhakrishnan et al. | Voice Cloning for Low‐Resource Languages: Investigating the Prospects for Tamil | |
| Cohen | Forensic Applications of Automatic Speaker Verification | |
| Wickramasinghe | Replay detection in voice biometrics: an investigation of adaptive and non-adaptive front-ends | |
| Singh | Speaker Identification Using MFCC Feature Extraction ANN Classification Technique | |
| OM et al. | I VERIFICATION |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |