CN111100886B - Biosynthesis method of N-methyl pyrroline - Google Patents
Biosynthesis method of N-methyl pyrroline Download PDFInfo
- Publication number
- CN111100886B CN111100886B CN201811265624.0A CN201811265624A CN111100886B CN 111100886 B CN111100886 B CN 111100886B CN 201811265624 A CN201811265624 A CN 201811265624A CN 111100886 B CN111100886 B CN 111100886B
- Authority
- CN
- China
- Prior art keywords
- val
- ala
- leu
- pro
- gly
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- AHVYPIQETPWLSZ-UHFFFAOYSA-N 1-methyl-2,5-dihydropyrrole Chemical compound CN1CC=CC1 AHVYPIQETPWLSZ-UHFFFAOYSA-N 0.000 title claims abstract description 82
- 238000000034 method Methods 0.000 title claims abstract description 34
- 230000015572 biosynthetic process Effects 0.000 title claims description 22
- AVFZOVWCLRSYKC-UHFFFAOYSA-N 1-methylpyrrolidine Chemical compound CN1CCCC1 AVFZOVWCLRSYKC-UHFFFAOYSA-N 0.000 claims abstract description 75
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 claims abstract description 37
- 108090000854 Oxidoreductases Proteins 0.000 claims abstract description 26
- 102000004316 Oxidoreductases Human genes 0.000 claims abstract description 24
- 238000000855 fermentation Methods 0.000 claims abstract description 22
- 230000004151 fermentation Effects 0.000 claims abstract description 22
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 claims abstract description 18
- 229960003104 ornithine Drugs 0.000 claims abstract description 18
- 102000052812 Ornithine decarboxylases Human genes 0.000 claims abstract description 14
- 108700005126 Ornithine decarboxylases Proteins 0.000 claims abstract description 14
- 108091022910 Putrescine N-methyltransferase Proteins 0.000 claims abstract description 11
- 239000000758 substrate Substances 0.000 claims abstract description 9
- 238000006555 catalytic reaction Methods 0.000 claims abstract description 7
- 240000004808 Saccharomyces cerevisiae Species 0.000 claims description 67
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 claims description 67
- 241000588724 Escherichia coli Species 0.000 claims description 20
- 244000005700 microbiome Species 0.000 claims description 20
- 150000001413 amino acids Chemical group 0.000 claims description 18
- 238000003786 synthesis reaction Methods 0.000 claims description 17
- 101150076082 ALD5 gene Proteins 0.000 claims description 10
- 101100055265 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) ALD2 gene Proteins 0.000 claims description 10
- 238000002360 preparation method Methods 0.000 claims description 10
- 101100055268 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) ALD3 gene Proteins 0.000 claims description 9
- 101100055270 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) ALD4 gene Proteins 0.000 claims description 9
- 101100394762 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) HFD1 gene Proteins 0.000 claims description 9
- 239000002609 medium Substances 0.000 claims description 9
- BUJMKGAQHPJMRF-UHFFFAOYSA-N 2-(methylamino)butanal Chemical compound CCC(NC)C=O BUJMKGAQHPJMRF-UHFFFAOYSA-N 0.000 claims description 6
- 101150021948 SAM2 gene Proteins 0.000 claims description 6
- 239000007222 ypd medium Substances 0.000 claims description 4
- 238000004519 manufacturing process Methods 0.000 claims description 2
- 102000004031 Carboxy-Lyases Human genes 0.000 claims 1
- 108090000489 Carboxy-Lyases Proteins 0.000 claims 1
- 102000004190 Enzymes Human genes 0.000 abstract description 39
- 108090000790 Enzymes Proteins 0.000 abstract description 39
- 238000006243 chemical reaction Methods 0.000 abstract description 27
- 241000894006 Bacteria Species 0.000 abstract description 10
- 238000011161 development Methods 0.000 abstract description 4
- 108020004414 DNA Proteins 0.000 description 110
- 108090000623 proteins and genes Proteins 0.000 description 53
- 239000013612 plasmid Substances 0.000 description 47
- 239000012634 fragment Substances 0.000 description 26
- 239000000047 product Substances 0.000 description 21
- KIDHWZJUCRJVML-UHFFFAOYSA-N putrescine Chemical compound NCCCCN KIDHWZJUCRJVML-UHFFFAOYSA-N 0.000 description 21
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 15
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 15
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 15
- 238000010276 construction Methods 0.000 description 14
- 239000000499 gel Substances 0.000 description 14
- 239000000203 mixture Substances 0.000 description 12
- 239000007788 liquid Substances 0.000 description 10
- 239000000243 solution Substances 0.000 description 10
- 239000006228 supernatant Substances 0.000 description 10
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 9
- 238000001514 detection method Methods 0.000 description 9
- 102000004169 proteins and genes Human genes 0.000 description 9
- 241000196324 Embryophyta Species 0.000 description 8
- GRRNUXAQVGOGFE-UHFFFAOYSA-N Hygromycin-B Natural products OC1C(NC)CC(N)C(O)C1OC1C2OC3(C(C(O)C(O)C(C(N)CO)O3)O)OC2C(O)C(CO)O1 GRRNUXAQVGOGFE-UHFFFAOYSA-N 0.000 description 8
- 238000000246 agarose gel electrophoresis Methods 0.000 description 8
- 238000002474 experimental method Methods 0.000 description 8
- GRRNUXAQVGOGFE-NZSRVPFOSA-N hygromycin B Chemical compound O[C@@H]1[C@@H](NC)C[C@@H](N)[C@H](O)[C@H]1O[C@H]1[C@H]2O[C@@]3([C@@H]([C@@H](O)[C@@H](O)[C@@H](C(N)CO)O3)O)O[C@H]2[C@@H](O)[C@@H](CO)O1 GRRNUXAQVGOGFE-NZSRVPFOSA-N 0.000 description 8
- 229940097277 hygromycin b Drugs 0.000 description 8
- 108010073969 valyllysine Proteins 0.000 description 8
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 8
- MEFKEPWMEQBLKI-AIRLBKTGSA-N S-adenosyl-L-methioninate Chemical compound O[C@@H]1[C@H](O)[C@@H](C[S+](CC[C@H](N)C([O-])=O)C)O[C@H]1N1C2=NC=NC(N)=C2N=C1 MEFKEPWMEQBLKI-AIRLBKTGSA-N 0.000 description 7
- 229960001570 ademetionine Drugs 0.000 description 7
- 150000001875 compounds Chemical class 0.000 description 7
- 238000000605 extraction Methods 0.000 description 7
- 108010026333 seryl-proline Proteins 0.000 description 7
- 238000001644 13C nuclear magnetic resonance spectroscopy Methods 0.000 description 6
- 238000005160 1H NMR spectroscopy Methods 0.000 description 6
- ZMANZCXQSJIPKH-UHFFFAOYSA-N Triethylamine Chemical compound CCN(CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-N 0.000 description 6
- 239000011543 agarose gel Substances 0.000 description 6
- 108010077245 asparaginyl-proline Proteins 0.000 description 6
- 230000006696 biosynthetic metabolic pathway Effects 0.000 description 6
- 230000003197 catalytic effect Effects 0.000 description 6
- 230000000694 effects Effects 0.000 description 6
- 239000001963 growth medium Substances 0.000 description 6
- 238000000655 nuclear magnetic resonance spectrum Methods 0.000 description 6
- 238000012163 sequencing technique Methods 0.000 description 6
- 108010061238 threonyl-glycine Proteins 0.000 description 6
- 241001052560 Thallis Species 0.000 description 5
- 230000001580 bacterial effect Effects 0.000 description 5
- 238000010367 cloning Methods 0.000 description 5
- 238000005520 cutting process Methods 0.000 description 5
- 238000001976 enzyme digestion Methods 0.000 description 5
- 108010050848 glycylleucine Proteins 0.000 description 5
- 239000012074 organic phase Substances 0.000 description 5
- NGVDGCNFYWLIFO-UHFFFAOYSA-N pyridoxal 5'-phosphate Chemical compound CC1=NC=C(COP(O)(O)=O)C(C=O)=C1O NGVDGCNFYWLIFO-UHFFFAOYSA-N 0.000 description 5
- 238000011084 recovery Methods 0.000 description 5
- 241000999530 Anisodus Species 0.000 description 4
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 4
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 4
- 241000880493 Leptailurus serval Species 0.000 description 4
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 4
- 238000012408 PCR amplification Methods 0.000 description 4
- 239000005700 Putrescine Substances 0.000 description 4
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- 229930013930 alkaloid Natural products 0.000 description 4
- 230000003321 amplification Effects 0.000 description 4
- ZPUCINDJVBIVPJ-LJISPDSOSA-N cocaine Chemical compound O([C@H]1C[C@@H]2CC[C@@H](N2C)[C@H]1C(=O)OC)C(=O)C1=CC=CC=C1 ZPUCINDJVBIVPJ-LJISPDSOSA-N 0.000 description 4
- 239000002299 complementary DNA Substances 0.000 description 4
- 239000013613 expression plasmid Substances 0.000 description 4
- 108010049041 glutamylalanine Proteins 0.000 description 4
- 229930027917 kanamycin Natural products 0.000 description 4
- 229960000318 kanamycin Drugs 0.000 description 4
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 4
- 229930182823 kanamycin A Natural products 0.000 description 4
- 108010064235 lysylglycine Proteins 0.000 description 4
- 108010054155 lysyllysine Proteins 0.000 description 4
- 108010017391 lysylvaline Proteins 0.000 description 4
- 238000003199 nucleic acid amplification method Methods 0.000 description 4
- 235000007682 pyridoxal 5'-phosphate Nutrition 0.000 description 4
- 239000011589 pyridoxal 5'-phosphate Substances 0.000 description 4
- 239000012354 sodium borodeuteride Substances 0.000 description 4
- 230000009466 transformation Effects 0.000 description 4
- LWIHDJKSTIGBAC-UHFFFAOYSA-K tripotassium phosphate Chemical compound [K+].[K+].[K+].[O-]P([O-])([O-])=O LWIHDJKSTIGBAC-UHFFFAOYSA-K 0.000 description 4
- SNICXCGAKADSCV-JTQLQIEISA-N (-)-Nicotine Chemical compound CN1CCC[C@H]1C1=CC=CN=C1 SNICXCGAKADSCV-JTQLQIEISA-N 0.000 description 3
- 101150026650 ALD4 gene Proteins 0.000 description 3
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 3
- BEMGNWZECGIJOI-WDSKDSINSA-N Ala-Gly-Glu Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O BEMGNWZECGIJOI-WDSKDSINSA-N 0.000 description 3
- 108091033409 CRISPR Proteins 0.000 description 3
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 3
- 102000012410 DNA Ligases Human genes 0.000 description 3
- 108010061982 DNA Ligases Proteins 0.000 description 3
- YMWUJEATGCHHMB-UHFFFAOYSA-N Dichloromethane Chemical compound ClCCl YMWUJEATGCHHMB-UHFFFAOYSA-N 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- OVPYIUNCVSOVNF-ZPFDUUQYSA-N Ile-Gln-Pro Natural products CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O OVPYIUNCVSOVNF-ZPFDUUQYSA-N 0.000 description 3
- 108010065920 Insulin Lispro Proteins 0.000 description 3
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 3
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 3
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 3
- FDBTVENULFNTAL-XQQFMLRXSA-N Leu-Val-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N FDBTVENULFNTAL-XQQFMLRXSA-N 0.000 description 3
- QBEPTBMRQALPEV-MNXVOIDGSA-N Lys-Ile-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN QBEPTBMRQALPEV-MNXVOIDGSA-N 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 3
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 3
- 238000005481 NMR spectroscopy Methods 0.000 description 3
- VYWNORHENYEQDW-YUMQZZPRSA-N Pro-Gly-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 VYWNORHENYEQDW-YUMQZZPRSA-N 0.000 description 3
- 101100010928 Saccharolobus solfataricus (strain ATCC 35092 / DSM 1617 / JCM 11322 / P2) tuf gene Proteins 0.000 description 3
- 101100137602 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) PRM9 gene Proteins 0.000 description 3
- 241000208292 Solanaceae Species 0.000 description 3
- 108091027544 Subgenomic mRNA Proteins 0.000 description 3
- 101150001810 TEAD1 gene Proteins 0.000 description 3
- 101150074253 TEF1 gene Proteins 0.000 description 3
- 102100029898 Transcriptional enhancer factor TEF-1 Human genes 0.000 description 3
- SCBITHMBEJNRHC-LSJOCFKGSA-N Val-Asp-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N SCBITHMBEJNRHC-LSJOCFKGSA-N 0.000 description 3
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 3
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 3
- 108010044940 alanylglutamine Proteins 0.000 description 3
- 229960000723 ampicillin Drugs 0.000 description 3
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 3
- 239000007864 aqueous solution Substances 0.000 description 3
- 108010062796 arginyllysine Proteins 0.000 description 3
- 108010038633 aspartylglutamate Proteins 0.000 description 3
- 108010047857 aspartylglycine Proteins 0.000 description 3
- 229940041514 candida albicans extract Drugs 0.000 description 3
- 229910052799 carbon Inorganic materials 0.000 description 3
- 238000005119 centrifugation Methods 0.000 description 3
- 229960005091 chloramphenicol Drugs 0.000 description 3
- WIIZWVCIJKGZOK-RKDXNWHRSA-N chloramphenicol Chemical compound ClC(Cl)C(=O)N[C@H](CO)[C@H](O)C1=CC=C([N+]([O-])=O)C=C1 WIIZWVCIJKGZOK-RKDXNWHRSA-N 0.000 description 3
- 108010060199 cysteinylproline Proteins 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- 230000029087 digestion Effects 0.000 description 3
- 238000006911 enzymatic reaction Methods 0.000 description 3
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 3
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 3
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 3
- 108010081551 glycylphenylalanine Proteins 0.000 description 3
- 108010092114 histidylphenylalanine Proteins 0.000 description 3
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 3
- 238000000338 in vitro Methods 0.000 description 3
- 239000000543 intermediate Substances 0.000 description 3
- 108010060857 isoleucyl-valyl-tyrosine Proteins 0.000 description 3
- 108010034529 leucyl-lysine Proteins 0.000 description 3
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 3
- 238000001819 mass spectrum Methods 0.000 description 3
- 238000002156 mixing Methods 0.000 description 3
- 229960002715 nicotine Drugs 0.000 description 3
- SNICXCGAKADSCV-UHFFFAOYSA-N nicotine Natural products CN1CCCC1C1=CC=CN=C1 SNICXCGAKADSCV-UHFFFAOYSA-N 0.000 description 3
- 238000005580 one pot reaction Methods 0.000 description 3
- 108010012581 phenylalanylglutamate Proteins 0.000 description 3
- 108010077112 prolyl-proline Proteins 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 3
- 239000007787 solid Substances 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 238000012360 testing method Methods 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- CYHOMWAPJJPNMW-JIGDXULJSA-N tropine Chemical class C1[C@@H](O)C[C@H]2CC[C@@H]1N2C CYHOMWAPJJPNMW-JIGDXULJSA-N 0.000 description 3
- 238000011144 upstream manufacturing Methods 0.000 description 3
- 239000012138 yeast extract Substances 0.000 description 3
- VHYFNPMBLIVWCW-UHFFFAOYSA-N 4-Dimethylaminopyridine Chemical compound CN(C)C1=CC=NC=C1 VHYFNPMBLIVWCW-UHFFFAOYSA-N 0.000 description 2
- XCVRVWZTXPCYJT-BIIVOSGPSA-N Ala-Asn-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N XCVRVWZTXPCYJT-BIIVOSGPSA-N 0.000 description 2
- WKOBSJOZRJJVRZ-FXQIFTODSA-N Ala-Glu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WKOBSJOZRJJVRZ-FXQIFTODSA-N 0.000 description 2
- NBTGEURICRTMGL-WHFBIAKZSA-N Ala-Gly-Ser Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O NBTGEURICRTMGL-WHFBIAKZSA-N 0.000 description 2
- DCVYRWFAMZFSDA-ZLUOBGJFSA-N Ala-Ser-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DCVYRWFAMZFSDA-ZLUOBGJFSA-N 0.000 description 2
- PFOYSEIHFVKHNF-FXQIFTODSA-N Asn-Ala-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PFOYSEIHFVKHNF-FXQIFTODSA-N 0.000 description 2
- GMRGSBAMMMVDGG-GUBZILKMSA-N Asn-Arg-Arg Chemical compound C(C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)CN=C(N)N GMRGSBAMMMVDGG-GUBZILKMSA-N 0.000 description 2
- XSGBIBGAMKTHMY-WHFBIAKZSA-N Asn-Asp-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O XSGBIBGAMKTHMY-WHFBIAKZSA-N 0.000 description 2
- SRUUBQBAVNQZGJ-LAEOZQHASA-N Asn-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N SRUUBQBAVNQZGJ-LAEOZQHASA-N 0.000 description 2
- BKFXFUPYETWGGA-XVSYOHENSA-N Asn-Phe-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BKFXFUPYETWGGA-XVSYOHENSA-N 0.000 description 2
- DTNUIAJCPRMNBT-WHFBIAKZSA-N Asp-Gly-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O DTNUIAJCPRMNBT-WHFBIAKZSA-N 0.000 description 2
- 101100434663 Bacillus subtilis (strain 168) fbaA gene Proteins 0.000 description 2
- 101710088194 Dehydrogenase Proteins 0.000 description 2
- 241000735552 Erythroxylum Species 0.000 description 2
- 101150095274 FBA1 gene Proteins 0.000 description 2
- CKRUHITYRFNUKW-WDSKDSINSA-N Glu-Asn-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CKRUHITYRFNUKW-WDSKDSINSA-N 0.000 description 2
- ZAPFAWQHBOHWLL-GUBZILKMSA-N Glu-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N ZAPFAWQHBOHWLL-GUBZILKMSA-N 0.000 description 2
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 2
- UPOJUWHGMDJUQZ-IUCAKERBSA-N Gly-Arg-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UPOJUWHGMDJUQZ-IUCAKERBSA-N 0.000 description 2
- OLPPXYMMIARYAL-QMMMGPOBSA-N Gly-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)CN OLPPXYMMIARYAL-QMMMGPOBSA-N 0.000 description 2
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 2
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 2
- DNVDEMWIYLVIQU-RCOVLWMOSA-N Gly-Val-Asp Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O DNVDEMWIYLVIQU-RCOVLWMOSA-N 0.000 description 2
- RVKIPWVMZANZLI-UHFFFAOYSA-N H-Lys-Trp-OH Natural products C1=CC=C2C(CC(NC(=O)C(N)CCCCN)C(O)=O)=CNC2=C1 RVKIPWVMZANZLI-UHFFFAOYSA-N 0.000 description 2
- AVQOSMRPITVTRB-CIUDSAMLSA-N His-Asn-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N AVQOSMRPITVTRB-CIUDSAMLSA-N 0.000 description 2
- 101000579123 Homo sapiens Phosphoglycerate kinase 1 Proteins 0.000 description 2
- BEWFWZRGBDVXRP-PEFMBERDSA-N Ile-Glu-Asn Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O BEWFWZRGBDVXRP-PEFMBERDSA-N 0.000 description 2
- PNDMHTTXXPUQJH-RWRJDSDZSA-N Ile-Glu-Thr Chemical compound N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H]([C@H](O)C)C(=O)O PNDMHTTXXPUQJH-RWRJDSDZSA-N 0.000 description 2
- ODPKZZLRDNXTJZ-WHOFXGATSA-N Ile-Gly-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N ODPKZZLRDNXTJZ-WHOFXGATSA-N 0.000 description 2
- CAHCWMVNBZJVAW-NAKRPEOUSA-N Ile-Pro-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)O)N CAHCWMVNBZJVAW-NAKRPEOUSA-N 0.000 description 2
- 108010093096 Immobilized Enzymes Proteins 0.000 description 2
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 2
- ZRLUISBDKUWAIZ-CIUDSAMLSA-N Leu-Ala-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O ZRLUISBDKUWAIZ-CIUDSAMLSA-N 0.000 description 2
- KVRKAGGMEWNURO-CIUDSAMLSA-N Leu-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N KVRKAGGMEWNURO-CIUDSAMLSA-N 0.000 description 2
- KWTVLKBOQATPHJ-SRVKXCTJSA-N Leu-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N KWTVLKBOQATPHJ-SRVKXCTJSA-N 0.000 description 2
- MMEDVBWCMGRKKC-GARJFASQSA-N Leu-Asp-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N MMEDVBWCMGRKKC-GARJFASQSA-N 0.000 description 2
- WIDZHJTYKYBLSR-DCAQKATOSA-N Leu-Glu-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WIDZHJTYKYBLSR-DCAQKATOSA-N 0.000 description 2
- OXRLYTYUXAQTHP-YUMQZZPRSA-N Leu-Gly-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(O)=O OXRLYTYUXAQTHP-YUMQZZPRSA-N 0.000 description 2
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 2
- YUTNOGOMBNYPFH-XUXIUFHCSA-N Leu-Pro-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YUTNOGOMBNYPFH-XUXIUFHCSA-N 0.000 description 2
- ZJZNLRVCZWUONM-JXUBOQSCSA-N Leu-Thr-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O ZJZNLRVCZWUONM-JXUBOQSCSA-N 0.000 description 2
- VDIARPPNADFEAV-WEDXCCLWSA-N Leu-Thr-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O VDIARPPNADFEAV-WEDXCCLWSA-N 0.000 description 2
- GAOJCVKPIGHTGO-UWVGGRQHSA-N Lys-Arg-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O GAOJCVKPIGHTGO-UWVGGRQHSA-N 0.000 description 2
- QQPSCXKFDSORFT-IHRRRGAJSA-N Lys-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN QQPSCXKFDSORFT-IHRRRGAJSA-N 0.000 description 2
- BEZJTLKUMFMITF-AVGNSLFASA-N Met-Lys-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CCCNC(N)=N BEZJTLKUMFMITF-AVGNSLFASA-N 0.000 description 2
- IQJMEDDVOGMTKT-SRVKXCTJSA-N Met-Val-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IQJMEDDVOGMTKT-SRVKXCTJSA-N 0.000 description 2
- -1 N-methylated putrescine (N-methylated putrescine Chemical class 0.000 description 2
- KJWZYMMLVHIVSU-IYCNHOCDSA-N PGK1 Chemical compound CCCCC[C@H](O)\C=C\[C@@H]1[C@@H](CCCCCCC(O)=O)C(=O)CC1=O KJWZYMMLVHIVSU-IYCNHOCDSA-N 0.000 description 2
- 239000001888 Peptone Substances 0.000 description 2
- 108010080698 Peptones Proteins 0.000 description 2
- WKLMCMXFMQEKCX-SLFFLAALSA-N Phe-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O WKLMCMXFMQEKCX-SLFFLAALSA-N 0.000 description 2
- RVEVENLSADZUMS-IHRRRGAJSA-N Phe-Pro-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O RVEVENLSADZUMS-IHRRRGAJSA-N 0.000 description 2
- 102100028251 Phosphoglycerate kinase 1 Human genes 0.000 description 2
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 2
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 2
- JPIDMRXXNMIVKY-VZFHVOOUSA-N Ser-Ala-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPIDMRXXNMIVKY-VZFHVOOUSA-N 0.000 description 2
- QFBNNYNWKYKVJO-DCAQKATOSA-N Ser-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N QFBNNYNWKYKVJO-DCAQKATOSA-N 0.000 description 2
- BKZYBLLIBOBOOW-GHCJXIJMSA-N Ser-Ile-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O BKZYBLLIBOBOOW-GHCJXIJMSA-N 0.000 description 2
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 2
- PMZURENOXWZQFD-UHFFFAOYSA-L Sodium Sulfate Chemical compound [Na+].[Na+].[O-]S([O-])(=O)=O PMZURENOXWZQFD-UHFFFAOYSA-L 0.000 description 2
- OKAMOYTUQMIFJO-JBACZVJFSA-N Trp-Glu-Phe Chemical compound C([C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=CC=C1 OKAMOYTUQMIFJO-JBACZVJFSA-N 0.000 description 2
- JKUZFODWJGEQAP-KBPBESRZSA-N Tyr-Gly-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)O)N)O JKUZFODWJGEQAP-KBPBESRZSA-N 0.000 description 2
- NOOMDULIORCDNF-IRXDYDNUSA-N Tyr-Gly-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O NOOMDULIORCDNF-IRXDYDNUSA-N 0.000 description 2
- 108010064997 VPY tripeptide Proteins 0.000 description 2
- UEOOXDLMQZBPFR-ZKWXMUAHSA-N Val-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N UEOOXDLMQZBPFR-ZKWXMUAHSA-N 0.000 description 2
- LABUITCFCAABSV-UHFFFAOYSA-N Val-Ala-Tyr Natural products CC(C)C(N)C(=O)NC(C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LABUITCFCAABSV-UHFFFAOYSA-N 0.000 description 2
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 2
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 2
- MIAZWUMFUURQNP-YDHLFZDLSA-N Val-Tyr-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N MIAZWUMFUURQNP-YDHLFZDLSA-N 0.000 description 2
- 108010005233 alanylglutamic acid Proteins 0.000 description 2
- 108010087924 alanylproline Proteins 0.000 description 2
- 150000003797 alkaloid derivatives Chemical class 0.000 description 2
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 2
- 150000001412 amines Chemical class 0.000 description 2
- 108010068380 arginylarginine Proteins 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- 229910021538 borax Inorganic materials 0.000 description 2
- 239000007795 chemical reaction product Substances 0.000 description 2
- 238000004140 cleaning Methods 0.000 description 2
- 235000008957 cocaer Nutrition 0.000 description 2
- 229910000366 copper(II) sulfate Inorganic materials 0.000 description 2
- 238000012258 culturing Methods 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 2
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 2
- 108010081985 glycyl-cystinyl-aspartic acid Proteins 0.000 description 2
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 2
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 2
- 108010048994 glycyl-tyrosyl-alanine Proteins 0.000 description 2
- 108010077515 glycylproline Proteins 0.000 description 2
- 108010084389 glycyltryptophan Proteins 0.000 description 2
- 108010040030 histidinoalanine Proteins 0.000 description 2
- 108010036413 histidylglycine Proteins 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 108010078274 isoleucylvaline Proteins 0.000 description 2
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 2
- 210000002429 large intestine Anatomy 0.000 description 2
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 2
- 108010057821 leucylproline Proteins 0.000 description 2
- 239000012139 lysis buffer Substances 0.000 description 2
- 108010003700 lysyl aspartic acid Proteins 0.000 description 2
- 238000004949 mass spectrometry Methods 0.000 description 2
- 230000004060 metabolic process Effects 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- 230000000813 microbial effect Effects 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 235000019319 peptone Nutrition 0.000 description 2
- 239000012071 phase Substances 0.000 description 2
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 2
- 229910000160 potassium phosphate Inorganic materials 0.000 description 2
- 235000011009 potassium phosphates Nutrition 0.000 description 2
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 2
- 108010031719 prolyl-serine Proteins 0.000 description 2
- 108010029020 prolylglycine Proteins 0.000 description 2
- 108010090894 prolylleucine Proteins 0.000 description 2
- 229960001327 pyridoxal phosphate Drugs 0.000 description 2
- 108091008146 restriction endonucleases Proteins 0.000 description 2
- 238000007363 ring formation reaction Methods 0.000 description 2
- 238000005070 sampling Methods 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 235000010339 sodium tetraborate Nutrition 0.000 description 2
- HPALAKNZSZLMCH-UHFFFAOYSA-M sodium;chloride;hydrate Chemical class O.[Na+].[Cl-] HPALAKNZSZLMCH-UHFFFAOYSA-M 0.000 description 2
- 241000894007 species Species 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- 239000008223 sterile water Substances 0.000 description 2
- 238000003756 stirring Methods 0.000 description 2
- JJBLPZMDOANPIL-UHFFFAOYSA-N tert-butyl 2-formyl-2-(methylamino)butanoate Chemical compound CCC(NC)(C=O)C(=O)OC(C)(C)C JJBLPZMDOANPIL-UHFFFAOYSA-N 0.000 description 2
- RSTVGCOTZQAAKG-UHFFFAOYSA-N tert-butyl 2-hydroxy-2-(methylamino)pentanoate Chemical compound C(=O)(OC(C)(C)C)C(CCC)(O)NC RSTVGCOTZQAAKG-UHFFFAOYSA-N 0.000 description 2
- ZFQWJXFJJZUVPI-UHFFFAOYSA-N tert-butyl n-(4-aminobutyl)carbamate Chemical compound CC(C)(C)OC(=O)NCCCCN ZFQWJXFJJZUVPI-UHFFFAOYSA-N 0.000 description 2
- 238000011426 transformation method Methods 0.000 description 2
- BSVBQGMMJUBVOD-UHFFFAOYSA-N trisodium borate Chemical compound [Na+].[Na+].[Na+].[O-]B([O-])[O-] BSVBQGMMJUBVOD-UHFFFAOYSA-N 0.000 description 2
- 108010029384 tryptophyl-histidine Proteins 0.000 description 2
- 108010084932 tryptophyl-proline Proteins 0.000 description 2
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 description 2
- 108010015385 valyl-prolyl-proline Proteins 0.000 description 2
- 238000012795 verification Methods 0.000 description 2
- CNKBMTKICGGSCQ-ACRUOGEOSA-N (2S)-2-[[(2S)-2-[[(2S)-2,6-diamino-1-oxohexyl]amino]-1-oxo-3-phenylpropyl]amino]-3-(4-hydroxyphenyl)propanoic acid Chemical compound C([C@H](NC(=O)[C@@H](N)CCCCN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 CNKBMTKICGGSCQ-ACRUOGEOSA-N 0.000 description 1
- XVZCXCTYGHPNEM-IHRRRGAJSA-N (2s)-1-[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(O)=O XVZCXCTYGHPNEM-IHRRRGAJSA-N 0.000 description 1
- RKUNBYITZUJHSG-FXUDXRNXSA-N (S)-atropine Chemical compound C1([C@@H](CO)C(=O)O[C@H]2C[C@H]3CC[C@@H](C2)N3C)=CC=CC=C1 RKUNBYITZUJHSG-FXUDXRNXSA-N 0.000 description 1
- ISMFPACIQUKJDG-UHFFFAOYSA-N 1-(methylamino)butan-1-ol Chemical compound CCCC(O)NC ISMFPACIQUKJDG-UHFFFAOYSA-N 0.000 description 1
- CQJAWZCYNRBZDL-UHFFFAOYSA-N 2-(methylazaniumyl)butanoate Chemical compound CCC(NC)C(O)=O CQJAWZCYNRBZDL-UHFFFAOYSA-N 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- 229960000549 4-dimethylaminophenol Drugs 0.000 description 1
- MKPCNMXYTMQZBE-UHFFFAOYSA-N 7h-purin-6-amine;sulfuric acid;dihydrate Chemical compound O.O.OS(O)(=O)=O.NC1=NC=NC2=C1NC=N2.NC1=NC=NC2=C1NC=N2 MKPCNMXYTMQZBE-UHFFFAOYSA-N 0.000 description 1
- AAQGRPOPTAUUBM-ZLUOBGJFSA-N Ala-Ala-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O AAQGRPOPTAUUBM-ZLUOBGJFSA-N 0.000 description 1
- BUANFPRKJKJSRR-ACZMJKKPSA-N Ala-Ala-Gln Chemical compound C[C@H]([NH3+])C(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CCC(N)=O BUANFPRKJKJSRR-ACZMJKKPSA-N 0.000 description 1
- YLTKNGYYPIWKHZ-ACZMJKKPSA-N Ala-Ala-Glu Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O YLTKNGYYPIWKHZ-ACZMJKKPSA-N 0.000 description 1
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 1
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 1
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 1
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 1
- WRDANSJTFOHBPI-FXQIFTODSA-N Ala-Arg-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N WRDANSJTFOHBPI-FXQIFTODSA-N 0.000 description 1
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 1
- IMMKUCQIKKXKNP-DCAQKATOSA-N Ala-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CCCN=C(N)N IMMKUCQIKKXKNP-DCAQKATOSA-N 0.000 description 1
- UCIYCBSJBQGDGM-LPEHRKFASA-N Ala-Arg-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N UCIYCBSJBQGDGM-LPEHRKFASA-N 0.000 description 1
- ZIBWKCRKNFYTPT-ZKWXMUAHSA-N Ala-Asn-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O ZIBWKCRKNFYTPT-ZKWXMUAHSA-N 0.000 description 1
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 1
- WQVYAWIMAWTGMW-ZLUOBGJFSA-N Ala-Asp-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N WQVYAWIMAWTGMW-ZLUOBGJFSA-N 0.000 description 1
- MKZCBYZBCINNJN-DLOVCJGASA-N Ala-Asp-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MKZCBYZBCINNJN-DLOVCJGASA-N 0.000 description 1
- YSMPVONNIWLJML-FXQIFTODSA-N Ala-Asp-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(O)=O YSMPVONNIWLJML-FXQIFTODSA-N 0.000 description 1
- LGFCAXJBAZESCF-ACZMJKKPSA-N Ala-Gln-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O LGFCAXJBAZESCF-ACZMJKKPSA-N 0.000 description 1
- SFNFGFDRYJKZKN-XQXXSGGOSA-N Ala-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C)N)O SFNFGFDRYJKZKN-XQXXSGGOSA-N 0.000 description 1
- PUBLUECXJRHTBK-ACZMJKKPSA-N Ala-Glu-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O PUBLUECXJRHTBK-ACZMJKKPSA-N 0.000 description 1
- OMMDTNGURYRDAC-NRPADANISA-N Ala-Glu-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OMMDTNGURYRDAC-NRPADANISA-N 0.000 description 1
- PCIFXPRIFWKWLK-YUMQZZPRSA-N Ala-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N PCIFXPRIFWKWLK-YUMQZZPRSA-N 0.000 description 1
- QHASENCZLDHBGX-ONGXEEELSA-N Ala-Gly-Phe Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QHASENCZLDHBGX-ONGXEEELSA-N 0.000 description 1
- NIZKGBJVCMRDKO-KWQFWETISA-N Ala-Gly-Tyr Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NIZKGBJVCMRDKO-KWQFWETISA-N 0.000 description 1
- SMCGQGDVTPFXKB-XPUUQOCRSA-N Ala-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N SMCGQGDVTPFXKB-XPUUQOCRSA-N 0.000 description 1
- ZPXCNXMJEZKRLU-LSJOCFKGSA-N Ala-His-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CN=CN1 ZPXCNXMJEZKRLU-LSJOCFKGSA-N 0.000 description 1
- IVKWMMGFLAMMKJ-XVYDVKMFSA-N Ala-His-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N IVKWMMGFLAMMKJ-XVYDVKMFSA-N 0.000 description 1
- RZZMZYZXNJRPOJ-BJDJZHNGSA-N Ala-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](C)N RZZMZYZXNJRPOJ-BJDJZHNGSA-N 0.000 description 1
- YHKANGMVQWRMAP-DCAQKATOSA-N Ala-Leu-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YHKANGMVQWRMAP-DCAQKATOSA-N 0.000 description 1
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 1
- UWIQWPWWZUHBAO-ZLIFDBKOSA-N Ala-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)CC(C)C)C(O)=O)=CNC2=C1 UWIQWPWWZUHBAO-ZLIFDBKOSA-N 0.000 description 1
- MFMDKJIPHSWSBM-GUBZILKMSA-N Ala-Lys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFMDKJIPHSWSBM-GUBZILKMSA-N 0.000 description 1
- MDNAVFBZPROEHO-DCAQKATOSA-N Ala-Lys-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O MDNAVFBZPROEHO-DCAQKATOSA-N 0.000 description 1
- NLOMBWNGESDVJU-GUBZILKMSA-N Ala-Met-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NLOMBWNGESDVJU-GUBZILKMSA-N 0.000 description 1
- GKAZXNDATBWNBI-DCAQKATOSA-N Ala-Met-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)O)N GKAZXNDATBWNBI-DCAQKATOSA-N 0.000 description 1
- DEWWPUNXRNGMQN-LPEHRKFASA-N Ala-Met-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N DEWWPUNXRNGMQN-LPEHRKFASA-N 0.000 description 1
- BFMIRJBURUXDRG-DLOVCJGASA-N Ala-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 BFMIRJBURUXDRG-DLOVCJGASA-N 0.000 description 1
- CYBJZLQSUJEMAS-LFSVMHDDSA-N Ala-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C)N)O CYBJZLQSUJEMAS-LFSVMHDDSA-N 0.000 description 1
- DXTYEWAQOXYRHZ-KKXDTOCCSA-N Ala-Phe-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N DXTYEWAQOXYRHZ-KKXDTOCCSA-N 0.000 description 1
- IHMCQESUJVZTKW-UBHSHLNASA-N Ala-Phe-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=CC=C1 IHMCQESUJVZTKW-UBHSHLNASA-N 0.000 description 1
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 1
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 1
- YHBDGLZYNIARKJ-GUBZILKMSA-N Ala-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N YHBDGLZYNIARKJ-GUBZILKMSA-N 0.000 description 1
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 1
- WNHNMKOFKCHKKD-BFHQHQDPSA-N Ala-Thr-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O WNHNMKOFKCHKKD-BFHQHQDPSA-N 0.000 description 1
- IDLBLNBDLCTPGC-HERUPUMHSA-N Ala-Trp-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CS)C(=O)O)N IDLBLNBDLCTPGC-HERUPUMHSA-N 0.000 description 1
- XKXAZPSREVUCRT-BPNCWPANSA-N Ala-Tyr-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=C(O)C=C1 XKXAZPSREVUCRT-BPNCWPANSA-N 0.000 description 1
- JNJHNBXBGNJESC-KKXDTOCCSA-N Ala-Tyr-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JNJHNBXBGNJESC-KKXDTOCCSA-N 0.000 description 1
- XCIGOVDXZULBBV-DCAQKATOSA-N Ala-Val-Lys Chemical compound CC(C)[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CCCCN)C(O)=O XCIGOVDXZULBBV-DCAQKATOSA-N 0.000 description 1
- OMSKGWFGWCQFBD-KZVJFYERSA-N Ala-Val-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OMSKGWFGWCQFBD-KZVJFYERSA-N 0.000 description 1
- SSQHYGLFYWZWDV-UVBJJODRSA-N Ala-Val-Trp Chemical compound CC(C)[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O SSQHYGLFYWZWDV-UVBJJODRSA-N 0.000 description 1
- 241000284466 Antarctothoa delta Species 0.000 description 1
- UXJCMQFPDWCHKX-DCAQKATOSA-N Arg-Arg-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O UXJCMQFPDWCHKX-DCAQKATOSA-N 0.000 description 1
- ZTKHZAXGTFXUDD-VEVYYDQMSA-N Arg-Asn-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZTKHZAXGTFXUDD-VEVYYDQMSA-N 0.000 description 1
- LMPKCSXZJSXBBL-NHCYSSNCSA-N Arg-Gln-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O LMPKCSXZJSXBBL-NHCYSSNCSA-N 0.000 description 1
- RKRSYHCNPFGMTA-CIUDSAMLSA-N Arg-Glu-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O RKRSYHCNPFGMTA-CIUDSAMLSA-N 0.000 description 1
- GOWZVQXTHUCNSQ-NHCYSSNCSA-N Arg-Glu-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O GOWZVQXTHUCNSQ-NHCYSSNCSA-N 0.000 description 1
- AQPVUEJJARLJHB-BQBZGAKWSA-N Arg-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCCN=C(N)N AQPVUEJJARLJHB-BQBZGAKWSA-N 0.000 description 1
- HQIZDMIGUJOSNI-IUCAKERBSA-N Arg-Gly-Arg Chemical compound N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQIZDMIGUJOSNI-IUCAKERBSA-N 0.000 description 1
- CYXCAHZVPFREJD-LURJTMIESA-N Arg-Gly-Gly Chemical compound NC(=N)NCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O CYXCAHZVPFREJD-LURJTMIESA-N 0.000 description 1
- PHHRSPBBQUFULD-UWVGGRQHSA-N Arg-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCCN=C(N)N)N PHHRSPBBQUFULD-UWVGGRQHSA-N 0.000 description 1
- PCQXGEUALSFGIA-WDSOQIARSA-N Arg-His-Trp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O PCQXGEUALSFGIA-WDSOQIARSA-N 0.000 description 1
- DGFXIWKPTDKBLF-AVGNSLFASA-N Arg-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCN=C(N)N)N DGFXIWKPTDKBLF-AVGNSLFASA-N 0.000 description 1
- UAOSDDXCTBIPCA-QXEWZRGKSA-N Arg-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UAOSDDXCTBIPCA-QXEWZRGKSA-N 0.000 description 1
- DNUKXVMPARLPFN-XUXIUFHCSA-N Arg-Leu-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DNUKXVMPARLPFN-XUXIUFHCSA-N 0.000 description 1
- COXMUHNBYCVVRG-DCAQKATOSA-N Arg-Leu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O COXMUHNBYCVVRG-DCAQKATOSA-N 0.000 description 1
- JEOCWTUOMKEEMF-RHYQMDGZSA-N Arg-Leu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEOCWTUOMKEEMF-RHYQMDGZSA-N 0.000 description 1
- YVTHEZNOKSAWRW-DCAQKATOSA-N Arg-Lys-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O YVTHEZNOKSAWRW-DCAQKATOSA-N 0.000 description 1
- SSZGOKWBHLOCHK-DCAQKATOSA-N Arg-Lys-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCN=C(N)N SSZGOKWBHLOCHK-DCAQKATOSA-N 0.000 description 1
- XKDYWGLNSCNRGW-WDSOQIARSA-N Arg-Lys-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCCN=C(N)N)CCCCN)C(O)=O)=CNC2=C1 XKDYWGLNSCNRGW-WDSOQIARSA-N 0.000 description 1
- PYZPXCZNQSEHDT-GUBZILKMSA-N Arg-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N PYZPXCZNQSEHDT-GUBZILKMSA-N 0.000 description 1
- FVBZXNSRIDVYJS-AVGNSLFASA-N Arg-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N FVBZXNSRIDVYJS-AVGNSLFASA-N 0.000 description 1
- YFHATWYGAAXQCF-JYJNAYRXSA-N Arg-Pro-Phe Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 YFHATWYGAAXQCF-JYJNAYRXSA-N 0.000 description 1
- ATABBWFGOHKROJ-GUBZILKMSA-N Arg-Pro-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O ATABBWFGOHKROJ-GUBZILKMSA-N 0.000 description 1
- VUGWHBXPMAHEGZ-SRVKXCTJSA-N Arg-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N VUGWHBXPMAHEGZ-SRVKXCTJSA-N 0.000 description 1
- VENMDXUVHSKEIN-GUBZILKMSA-N Arg-Ser-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VENMDXUVHSKEIN-GUBZILKMSA-N 0.000 description 1
- ISJWBVIYRBAXEB-CIUDSAMLSA-N Arg-Ser-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISJWBVIYRBAXEB-CIUDSAMLSA-N 0.000 description 1
- URAUIUGLHBRPMF-NAKRPEOUSA-N Arg-Ser-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O URAUIUGLHBRPMF-NAKRPEOUSA-N 0.000 description 1
- KMFPQTITXUKJOV-DCAQKATOSA-N Arg-Ser-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O KMFPQTITXUKJOV-DCAQKATOSA-N 0.000 description 1
- ASQKVGRCKOFKIU-KZVJFYERSA-N Arg-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ASQKVGRCKOFKIU-KZVJFYERSA-N 0.000 description 1
- AUZAXCPWMDBWEE-HJGDQZAQSA-N Arg-Thr-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O AUZAXCPWMDBWEE-HJGDQZAQSA-N 0.000 description 1
- RYQSYXFGFOTJDJ-RHYQMDGZSA-N Arg-Thr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O RYQSYXFGFOTJDJ-RHYQMDGZSA-N 0.000 description 1
- DDBMKOCQWNFDBH-RHYQMDGZSA-N Arg-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O DDBMKOCQWNFDBH-RHYQMDGZSA-N 0.000 description 1
- VYZBPPBKFCHCIS-WPRPVWTQSA-N Arg-Val-Gly Chemical compound OC(=O)CNC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N VYZBPPBKFCHCIS-WPRPVWTQSA-N 0.000 description 1
- WOZDCBHUGJVJPL-AVGNSLFASA-N Arg-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N WOZDCBHUGJVJPL-AVGNSLFASA-N 0.000 description 1
- NXVGBGZQQFDUTM-XVYDVKMFSA-N Asn-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N NXVGBGZQQFDUTM-XVYDVKMFSA-N 0.000 description 1
- QQEWINYJRFBLNN-DLOVCJGASA-N Asn-Ala-Phe Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QQEWINYJRFBLNN-DLOVCJGASA-N 0.000 description 1
- POOCJCRBHHMAOS-FXQIFTODSA-N Asn-Arg-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O POOCJCRBHHMAOS-FXQIFTODSA-N 0.000 description 1
- GOVUDFOGXOONFT-VEVYYDQMSA-N Asn-Arg-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GOVUDFOGXOONFT-VEVYYDQMSA-N 0.000 description 1
- ZZXMOQIUIJJOKZ-ZLUOBGJFSA-N Asn-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O ZZXMOQIUIJJOKZ-ZLUOBGJFSA-N 0.000 description 1
- RCENDENBBJFJHZ-ACZMJKKPSA-N Asn-Asn-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RCENDENBBJFJHZ-ACZMJKKPSA-N 0.000 description 1
- KXFCBAHYSLJCCY-ZLUOBGJFSA-N Asn-Asn-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O KXFCBAHYSLJCCY-ZLUOBGJFSA-N 0.000 description 1
- GMCOADLDNLGOFE-ZLUOBGJFSA-N Asn-Asp-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N)C(=O)N GMCOADLDNLGOFE-ZLUOBGJFSA-N 0.000 description 1
- ZDOQDYFZNGASEY-BIIVOSGPSA-N Asn-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N)C(=O)O ZDOQDYFZNGASEY-BIIVOSGPSA-N 0.000 description 1
- SPIPSJXLZVTXJL-ZLUOBGJFSA-N Asn-Cys-Ser Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O SPIPSJXLZVTXJL-ZLUOBGJFSA-N 0.000 description 1
- AYKKKGFJXIDYLX-ACZMJKKPSA-N Asn-Gln-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O AYKKKGFJXIDYLX-ACZMJKKPSA-N 0.000 description 1
- UBKOVSLDWIHYSY-ACZMJKKPSA-N Asn-Glu-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UBKOVSLDWIHYSY-ACZMJKKPSA-N 0.000 description 1
- GFFRWIJAFFMQGM-NUMRIWBASA-N Asn-Glu-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GFFRWIJAFFMQGM-NUMRIWBASA-N 0.000 description 1
- JQSWHKKUZMTOIH-QWRGUYRKSA-N Asn-Gly-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N JQSWHKKUZMTOIH-QWRGUYRKSA-N 0.000 description 1
- UDSVWSUXKYXSTR-QWRGUYRKSA-N Asn-Gly-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UDSVWSUXKYXSTR-QWRGUYRKSA-N 0.000 description 1
- YYSYDIYQTUPNQQ-SXTJYALSSA-N Asn-Ile-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YYSYDIYQTUPNQQ-SXTJYALSSA-N 0.000 description 1
- LTZIRYMWOJHRCH-GUDRVLHUSA-N Asn-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N LTZIRYMWOJHRCH-GUDRVLHUSA-N 0.000 description 1
- HFPXZWPUVFVNLL-GUBZILKMSA-N Asn-Leu-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HFPXZWPUVFVNLL-GUBZILKMSA-N 0.000 description 1
- JLNFZLNDHONLND-GARJFASQSA-N Asn-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N JLNFZLNDHONLND-GARJFASQSA-N 0.000 description 1
- ORJQQZIXTOYGGH-SRVKXCTJSA-N Asn-Lys-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O ORJQQZIXTOYGGH-SRVKXCTJSA-N 0.000 description 1
- RVHGJNGNKGDCPX-KKUMJFAQSA-N Asn-Phe-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N RVHGJNGNKGDCPX-KKUMJFAQSA-N 0.000 description 1
- FTNRWCPWDWRPAV-BZSNNMDCSA-N Asn-Phe-Phe Chemical compound C([C@H](NC(=O)[C@H](CC(N)=O)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 FTNRWCPWDWRPAV-BZSNNMDCSA-N 0.000 description 1
- RBOBTTLFPRSXKZ-BZSNNMDCSA-N Asn-Phe-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RBOBTTLFPRSXKZ-BZSNNMDCSA-N 0.000 description 1
- VHQSGALUSWIYOD-QXEWZRGKSA-N Asn-Pro-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O VHQSGALUSWIYOD-QXEWZRGKSA-N 0.000 description 1
- VWADICJNCPFKJS-ZLUOBGJFSA-N Asn-Ser-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O VWADICJNCPFKJS-ZLUOBGJFSA-N 0.000 description 1
- NPZJLGMWMDNQDD-GHCJXIJMSA-N Asn-Ser-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NPZJLGMWMDNQDD-GHCJXIJMSA-N 0.000 description 1
- HPNDKUOLNRVRAY-BIIVOSGPSA-N Asn-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N)C(=O)O HPNDKUOLNRVRAY-BIIVOSGPSA-N 0.000 description 1
- JXMREEPBRANWBY-VEVYYDQMSA-N Asn-Thr-Arg Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JXMREEPBRANWBY-VEVYYDQMSA-N 0.000 description 1
- NSTBNYOKCZKOMI-AVGNSLFASA-N Asn-Tyr-Glu Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O NSTBNYOKCZKOMI-AVGNSLFASA-N 0.000 description 1
- XEGZSHSPQNDNRH-JRQIVUDYSA-N Asn-Tyr-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XEGZSHSPQNDNRH-JRQIVUDYSA-N 0.000 description 1
- DPSUVAPLRQDWAO-YDHLFZDLSA-N Asn-Tyr-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC(=O)N)N DPSUVAPLRQDWAO-YDHLFZDLSA-N 0.000 description 1
- MJIJBEYEHBKTIM-BYULHYEWSA-N Asn-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N MJIJBEYEHBKTIM-BYULHYEWSA-N 0.000 description 1
- XZFONYMRYTVLPL-NHCYSSNCSA-N Asn-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N XZFONYMRYTVLPL-NHCYSSNCSA-N 0.000 description 1
- SYZWMVSXBZCOBZ-QXEWZRGKSA-N Asn-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)N)N SYZWMVSXBZCOBZ-QXEWZRGKSA-N 0.000 description 1
- HPNDBHLITCHRSO-WHFBIAKZSA-N Asp-Ala-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)NCC(O)=O HPNDBHLITCHRSO-WHFBIAKZSA-N 0.000 description 1
- SLHOOKXYTYAJGQ-XVYDVKMFSA-N Asp-Ala-His Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CNC=N1 SLHOOKXYTYAJGQ-XVYDVKMFSA-N 0.000 description 1
- ZVTDYGWRRPMFCL-WFBYXXMGSA-N Asp-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N ZVTDYGWRRPMFCL-WFBYXXMGSA-N 0.000 description 1
- BLQBMRNMBAYREH-UWJYBYFXSA-N Asp-Ala-Tyr Chemical compound N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O BLQBMRNMBAYREH-UWJYBYFXSA-N 0.000 description 1
- DBWYWXNMZZYIRY-LPEHRKFASA-N Asp-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N)C(=O)O DBWYWXNMZZYIRY-LPEHRKFASA-N 0.000 description 1
- FAEIQWHBRBWUBN-FXQIFTODSA-N Asp-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N)CN=C(N)N FAEIQWHBRBWUBN-FXQIFTODSA-N 0.000 description 1
- BFOYULZBKYOKAN-OLHMAJIHSA-N Asp-Asp-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BFOYULZBKYOKAN-OLHMAJIHSA-N 0.000 description 1
- PXLNPFOJZQMXAT-BYULHYEWSA-N Asp-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O PXLNPFOJZQMXAT-BYULHYEWSA-N 0.000 description 1
- ZRAOLTNMSCSCLN-ZLUOBGJFSA-N Asp-Cys-Asn Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)C(=O)O ZRAOLTNMSCSCLN-ZLUOBGJFSA-N 0.000 description 1
- ACEDJCOOPZFUBU-CIUDSAMLSA-N Asp-Cys-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N ACEDJCOOPZFUBU-CIUDSAMLSA-N 0.000 description 1
- DZQKLNLLWFQONU-LKXGYXEUSA-N Asp-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N)O DZQKLNLLWFQONU-LKXGYXEUSA-N 0.000 description 1
- PDECQIHABNQRHN-GUBZILKMSA-N Asp-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(O)=O PDECQIHABNQRHN-GUBZILKMSA-N 0.000 description 1
- OMMIEVATLAGRCK-BYPYZUCNSA-N Asp-Gly-Gly Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)NCC(O)=O OMMIEVATLAGRCK-BYPYZUCNSA-N 0.000 description 1
- POTCZYQVVNXUIG-BQBZGAKWSA-N Asp-Gly-Pro Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O POTCZYQVVNXUIG-BQBZGAKWSA-N 0.000 description 1
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 1
- SVABRQFIHCSNCI-FOHZUACHSA-N Asp-Gly-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O SVABRQFIHCSNCI-FOHZUACHSA-N 0.000 description 1
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 1
- LDGUZSIPGSPBJP-XVYDVKMFSA-N Asp-His-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC(=O)O)N LDGUZSIPGSPBJP-XVYDVKMFSA-N 0.000 description 1
- SWTQDYFZVOJVLL-KKUMJFAQSA-N Asp-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)O)N)O SWTQDYFZVOJVLL-KKUMJFAQSA-N 0.000 description 1
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 1
- SEMWSADZTMJELF-BYULHYEWSA-N Asp-Ile-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O SEMWSADZTMJELF-BYULHYEWSA-N 0.000 description 1
- HOBNTSHITVVNBN-ZPFDUUQYSA-N Asp-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N HOBNTSHITVVNBN-ZPFDUUQYSA-N 0.000 description 1
- YFSLJHLQOALGSY-ZPFDUUQYSA-N Asp-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N YFSLJHLQOALGSY-ZPFDUUQYSA-N 0.000 description 1
- HKEZZWQWXWGASX-KKUMJFAQSA-N Asp-Leu-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 HKEZZWQWXWGASX-KKUMJFAQSA-N 0.000 description 1
- CTWCFPWFIGRAEP-CIUDSAMLSA-N Asp-Lys-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O CTWCFPWFIGRAEP-CIUDSAMLSA-N 0.000 description 1
- DONWIPDSZZJHHK-HJGDQZAQSA-N Asp-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)O DONWIPDSZZJHHK-HJGDQZAQSA-N 0.000 description 1
- WWOYXVBGHAHQBG-FXQIFTODSA-N Asp-Met-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O WWOYXVBGHAHQBG-FXQIFTODSA-N 0.000 description 1
- PWAIZUBWHRHYKS-MELADBBJSA-N Asp-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)O)N)C(=O)O PWAIZUBWHRHYKS-MELADBBJSA-N 0.000 description 1
- ZKAOJVJQGVUIIU-GUBZILKMSA-N Asp-Pro-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ZKAOJVJQGVUIIU-GUBZILKMSA-N 0.000 description 1
- YFGUZQQCSDZRBN-DCAQKATOSA-N Asp-Pro-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O YFGUZQQCSDZRBN-DCAQKATOSA-N 0.000 description 1
- FAUPLTGRUBTXNU-FXQIFTODSA-N Asp-Pro-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O FAUPLTGRUBTXNU-FXQIFTODSA-N 0.000 description 1
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 1
- ZVGRHIRJLWBWGJ-ACZMJKKPSA-N Asp-Ser-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZVGRHIRJLWBWGJ-ACZMJKKPSA-N 0.000 description 1
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 1
- QOCFFCUFZGDHTP-NUMRIWBASA-N Asp-Thr-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOCFFCUFZGDHTP-NUMRIWBASA-N 0.000 description 1
- KBJVTFWQWXCYCQ-IUKAMOBKSA-N Asp-Thr-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KBJVTFWQWXCYCQ-IUKAMOBKSA-N 0.000 description 1
- YODBPLSWNJMZOJ-BPUTZDHNSA-N Asp-Trp-Arg Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N YODBPLSWNJMZOJ-BPUTZDHNSA-N 0.000 description 1
- YUELDQUPTAYEGM-XIRDDKMYSA-N Asp-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)O)N YUELDQUPTAYEGM-XIRDDKMYSA-N 0.000 description 1
- GGBQDSHTXKQSLP-NHCYSSNCSA-N Asp-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N GGBQDSHTXKQSLP-NHCYSSNCSA-N 0.000 description 1
- GXIUDSXIUSTSLO-QXEWZRGKSA-N Asp-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)O)N GXIUDSXIUSTSLO-QXEWZRGKSA-N 0.000 description 1
- 241001106067 Atropa Species 0.000 description 1
- NOCCABSVTRONIN-CIUDSAMLSA-N Cys-Ala-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CS)N NOCCABSVTRONIN-CIUDSAMLSA-N 0.000 description 1
- OIMUAKUQOUEPCZ-WHFBIAKZSA-N Cys-Asn-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIMUAKUQOUEPCZ-WHFBIAKZSA-N 0.000 description 1
- VNLYIYOYUNGURO-ZLUOBGJFSA-N Cys-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N VNLYIYOYUNGURO-ZLUOBGJFSA-N 0.000 description 1
- OLIYIKRCOZBFCW-ZLUOBGJFSA-N Cys-Asp-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N)C(=O)O OLIYIKRCOZBFCW-ZLUOBGJFSA-N 0.000 description 1
- YZFCGHIBLBDZDA-ZLUOBGJFSA-N Cys-Asp-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YZFCGHIBLBDZDA-ZLUOBGJFSA-N 0.000 description 1
- ZEXHDOQQYZKOIB-ACZMJKKPSA-N Cys-Glu-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZEXHDOQQYZKOIB-ACZMJKKPSA-N 0.000 description 1
- WTNLLMQAFPOCTJ-GARJFASQSA-N Cys-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CS)N)C(=O)O WTNLLMQAFPOCTJ-GARJFASQSA-N 0.000 description 1
- IZUNQDRIAOLWCN-YUMQZZPRSA-N Cys-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N IZUNQDRIAOLWCN-YUMQZZPRSA-N 0.000 description 1
- DIHCYBRLTVEPBW-SRVKXCTJSA-N Cys-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CS)N DIHCYBRLTVEPBW-SRVKXCTJSA-N 0.000 description 1
- HBHMVBGGHDMPBF-GARJFASQSA-N Cys-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CS)N HBHMVBGGHDMPBF-GARJFASQSA-N 0.000 description 1
- GDNWBSFSHJVXKL-GUBZILKMSA-N Cys-Lys-Gln Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O GDNWBSFSHJVXKL-GUBZILKMSA-N 0.000 description 1
- XMVZMBGFIOQONW-GARJFASQSA-N Cys-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N)C(=O)O XMVZMBGFIOQONW-GARJFASQSA-N 0.000 description 1
- ZALVANCAZFPKIR-GUBZILKMSA-N Cys-Pro-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CS)N ZALVANCAZFPKIR-GUBZILKMSA-N 0.000 description 1
- MQQLYEHXSBJTRK-FXQIFTODSA-N Cys-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N MQQLYEHXSBJTRK-FXQIFTODSA-N 0.000 description 1
- 102100035102 E3 ubiquitin-protein ligase MYCBP2 Human genes 0.000 description 1
- KWLMLNHADZIJIS-CIUDSAMLSA-N Gln-Asn-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)N)N KWLMLNHADZIJIS-CIUDSAMLSA-N 0.000 description 1
- CKNUKHBRCSMKMO-XHNCKOQMSA-N Gln-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O CKNUKHBRCSMKMO-XHNCKOQMSA-N 0.000 description 1
- BTSPOOHJBYJRKO-CIUDSAMLSA-N Gln-Asp-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O BTSPOOHJBYJRKO-CIUDSAMLSA-N 0.000 description 1
- WQWMZOIPXWSZNE-WDSKDSINSA-N Gln-Asp-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O WQWMZOIPXWSZNE-WDSKDSINSA-N 0.000 description 1
- CITDWMLWXNUQKD-FXQIFTODSA-N Gln-Gln-Asn Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CITDWMLWXNUQKD-FXQIFTODSA-N 0.000 description 1
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 1
- CGVWDTRDPLOMHZ-FXQIFTODSA-N Gln-Glu-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O CGVWDTRDPLOMHZ-FXQIFTODSA-N 0.000 description 1
- JHPFPROFOAJRFN-IHRRRGAJSA-N Gln-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O JHPFPROFOAJRFN-IHRRRGAJSA-N 0.000 description 1
- RGAOLBZBLOJUTP-GRLWGSQLSA-N Gln-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H](CCC(=O)N)N RGAOLBZBLOJUTP-GRLWGSQLSA-N 0.000 description 1
- MTCXQQINVAFZKW-MNXVOIDGSA-N Gln-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MTCXQQINVAFZKW-MNXVOIDGSA-N 0.000 description 1
- FFVXLVGUJBCKRX-UKJIMTQDSA-N Gln-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCC(=O)N)N FFVXLVGUJBCKRX-UKJIMTQDSA-N 0.000 description 1
- HPCOBEHVEHWREJ-DCAQKATOSA-N Gln-Lys-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HPCOBEHVEHWREJ-DCAQKATOSA-N 0.000 description 1
- SWDSRANUCKNBLA-AVGNSLFASA-N Gln-Phe-Asp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N SWDSRANUCKNBLA-AVGNSLFASA-N 0.000 description 1
- PIUPHASDUFSHTF-CIUDSAMLSA-N Gln-Pro-Asn Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)N)N)C(=O)N[C@@H](CC(=O)N)C(=O)O PIUPHASDUFSHTF-CIUDSAMLSA-N 0.000 description 1
- DOQUICBEISTQHE-CIUDSAMLSA-N Gln-Pro-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O DOQUICBEISTQHE-CIUDSAMLSA-N 0.000 description 1
- NPMFDZGLKBNFOO-SRVKXCTJSA-N Gln-Pro-His Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NPMFDZGLKBNFOO-SRVKXCTJSA-N 0.000 description 1
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 1
- JILRMFFFCHUUTJ-ACZMJKKPSA-N Gln-Ser-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O JILRMFFFCHUUTJ-ACZMJKKPSA-N 0.000 description 1
- SYTFJIQPBRJSOK-NKIYYHGXSA-N Gln-Thr-His Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 SYTFJIQPBRJSOK-NKIYYHGXSA-N 0.000 description 1
- VLOLPWWCNKWRNB-LOKLDPHHSA-N Gln-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O VLOLPWWCNKWRNB-LOKLDPHHSA-N 0.000 description 1
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 1
- RBSKVTZUFMIWFU-XEGUGMAKSA-N Gln-Trp-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O RBSKVTZUFMIWFU-XEGUGMAKSA-N 0.000 description 1
- CMFBOXUBWMZZMD-BPUTZDHNSA-N Gln-Trp-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N CMFBOXUBWMZZMD-BPUTZDHNSA-N 0.000 description 1
- SDSMVVSHLAAOJL-UKJIMTQDSA-N Gln-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N SDSMVVSHLAAOJL-UKJIMTQDSA-N 0.000 description 1
- GJLXZITZLUUXMJ-NHCYSSNCSA-N Gln-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCC(=O)N)N GJLXZITZLUUXMJ-NHCYSSNCSA-N 0.000 description 1
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 1
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 1
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 1
- KKCUFHUTMKQQCF-SRVKXCTJSA-N Glu-Arg-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O KKCUFHUTMKQQCF-SRVKXCTJSA-N 0.000 description 1
- VPKBCVUDBNINAH-GARJFASQSA-N Glu-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O VPKBCVUDBNINAH-GARJFASQSA-N 0.000 description 1
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 1
- NKSGKPWXSWBRRX-ACZMJKKPSA-N Glu-Asn-Cys Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N NKSGKPWXSWBRRX-ACZMJKKPSA-N 0.000 description 1
- QPRZKNOOOBWXSU-CIUDSAMLSA-N Glu-Asp-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N QPRZKNOOOBWXSU-CIUDSAMLSA-N 0.000 description 1
- DSPQRJXOIXHOHK-WDSKDSINSA-N Glu-Asp-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O DSPQRJXOIXHOHK-WDSKDSINSA-N 0.000 description 1
- RTOOAKXIJADOLL-GUBZILKMSA-N Glu-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N RTOOAKXIJADOLL-GUBZILKMSA-N 0.000 description 1
- GZWOBWMOMPFPCD-CIUDSAMLSA-N Glu-Asp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N GZWOBWMOMPFPCD-CIUDSAMLSA-N 0.000 description 1
- PBFGQTGPSKWHJA-QEJZJMRPSA-N Glu-Asp-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O PBFGQTGPSKWHJA-QEJZJMRPSA-N 0.000 description 1
- NKLRYVLERDYDBI-FXQIFTODSA-N Glu-Glu-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKLRYVLERDYDBI-FXQIFTODSA-N 0.000 description 1
- PHONAZGUEGIOEM-GLLZPBPUSA-N Glu-Glu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PHONAZGUEGIOEM-GLLZPBPUSA-N 0.000 description 1
- CUXJIASLBRJOFV-LAEOZQHASA-N Glu-Gly-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUXJIASLBRJOFV-LAEOZQHASA-N 0.000 description 1
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 1
- KRGZZKWSBGPLKL-IUCAKERBSA-N Glu-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)O)N KRGZZKWSBGPLKL-IUCAKERBSA-N 0.000 description 1
- OPAINBJQDQTGJY-JGVFFNPUSA-N Glu-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCC(=O)O)N)C(=O)O OPAINBJQDQTGJY-JGVFFNPUSA-N 0.000 description 1
- NJPQBTJSYCKCNS-HVTMNAMFSA-N Glu-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)O)N NJPQBTJSYCKCNS-HVTMNAMFSA-N 0.000 description 1
- IRXNJYPKBVERCW-DCAQKATOSA-N Glu-Leu-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IRXNJYPKBVERCW-DCAQKATOSA-N 0.000 description 1
- WNRZUESNGGDCJX-JYJNAYRXSA-N Glu-Leu-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WNRZUESNGGDCJX-JYJNAYRXSA-N 0.000 description 1
- FBEJIDRSQCGFJI-GUBZILKMSA-N Glu-Leu-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FBEJIDRSQCGFJI-GUBZILKMSA-N 0.000 description 1
- ZGEJRLJEAMPEDV-SRVKXCTJSA-N Glu-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)O)N ZGEJRLJEAMPEDV-SRVKXCTJSA-N 0.000 description 1
- XEKAJTCACGEBOK-KKUMJFAQSA-N Glu-Met-Phe Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XEKAJTCACGEBOK-KKUMJFAQSA-N 0.000 description 1
- GMAGZGCAYLQBKF-NHCYSSNCSA-N Glu-Met-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O GMAGZGCAYLQBKF-NHCYSSNCSA-N 0.000 description 1
- RXESHTOTINOODU-JYJNAYRXSA-N Glu-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CCC(=O)O)N RXESHTOTINOODU-JYJNAYRXSA-N 0.000 description 1
- FGSGPLRPQCZBSQ-AVGNSLFASA-N Glu-Phe-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O FGSGPLRPQCZBSQ-AVGNSLFASA-N 0.000 description 1
- CQAHWYDHKUWYIX-YUMQZZPRSA-N Glu-Pro-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O CQAHWYDHKUWYIX-YUMQZZPRSA-N 0.000 description 1
- DCBSZJJHOTXMHY-DCAQKATOSA-N Glu-Pro-Pro Chemical compound OC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DCBSZJJHOTXMHY-DCAQKATOSA-N 0.000 description 1
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 1
- GMVCSRBOSIUTFC-FXQIFTODSA-N Glu-Ser-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMVCSRBOSIUTFC-FXQIFTODSA-N 0.000 description 1
- QOXDAWODGSIDDI-GUBZILKMSA-N Glu-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N QOXDAWODGSIDDI-GUBZILKMSA-N 0.000 description 1
- TWYSSILQABLLME-HJGDQZAQSA-N Glu-Thr-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O TWYSSILQABLLME-HJGDQZAQSA-N 0.000 description 1
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 1
- RGJKYNUINKGPJN-RWRJDSDZSA-N Glu-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(=O)O)N RGJKYNUINKGPJN-RWRJDSDZSA-N 0.000 description 1
- MXJYXYDREQWUMS-XKBZYTNZSA-N Glu-Thr-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O MXJYXYDREQWUMS-XKBZYTNZSA-N 0.000 description 1
- SFKMXFWWDUGXRT-NWLDYVSISA-N Glu-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N)O SFKMXFWWDUGXRT-NWLDYVSISA-N 0.000 description 1
- HAGKYCXGTRUUFI-RYUDHWBXSA-N Glu-Tyr-Gly Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)O)N)O HAGKYCXGTRUUFI-RYUDHWBXSA-N 0.000 description 1
- MLILEEIVMRUYBX-NHCYSSNCSA-N Glu-Val-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O MLILEEIVMRUYBX-NHCYSSNCSA-N 0.000 description 1
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 1
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 1
- QXUPRMQJDWJDFR-NRPADANISA-N Glu-Val-Ser Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXUPRMQJDWJDFR-NRPADANISA-N 0.000 description 1
- PUUYVMYCMIWHFE-BQBZGAKWSA-N Gly-Ala-Arg Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PUUYVMYCMIWHFE-BQBZGAKWSA-N 0.000 description 1
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 1
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 1
- KRRMJKMGWWXWDW-STQMWFEESA-N Gly-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KRRMJKMGWWXWDW-STQMWFEESA-N 0.000 description 1
- WKJKBELXHCTHIJ-WPRPVWTQSA-N Gly-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N WKJKBELXHCTHIJ-WPRPVWTQSA-N 0.000 description 1
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 1
- LXXLEUBUOMCAMR-NKWVEPMBSA-N Gly-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)CN)C(=O)O LXXLEUBUOMCAMR-NKWVEPMBSA-N 0.000 description 1
- GZBZACMXFIPIDX-WHFBIAKZSA-N Gly-Cys-Asp Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)CN)C(=O)O GZBZACMXFIPIDX-WHFBIAKZSA-N 0.000 description 1
- VOCMRCVMAPSSAL-IUCAKERBSA-N Gly-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)CN VOCMRCVMAPSSAL-IUCAKERBSA-N 0.000 description 1
- HDNXXTBKOJKWNN-WDSKDSINSA-N Gly-Glu-Asn Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O HDNXXTBKOJKWNN-WDSKDSINSA-N 0.000 description 1
- FIQQRCFQXGLOSZ-WDSKDSINSA-N Gly-Glu-Asp Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FIQQRCFQXGLOSZ-WDSKDSINSA-N 0.000 description 1
- XTQFHTHIAKKCTM-YFKPBYRVSA-N Gly-Glu-Gly Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O XTQFHTHIAKKCTM-YFKPBYRVSA-N 0.000 description 1
- LHRXAHLCRMQBGJ-RYUDHWBXSA-N Gly-Glu-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)CN LHRXAHLCRMQBGJ-RYUDHWBXSA-N 0.000 description 1
- QSVCIFZPGLOZGH-WDSKDSINSA-N Gly-Glu-Ser Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QSVCIFZPGLOZGH-WDSKDSINSA-N 0.000 description 1
- GDOZQTNZPCUARW-YFKPBYRVSA-N Gly-Gly-Glu Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O GDOZQTNZPCUARW-YFKPBYRVSA-N 0.000 description 1
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 1
- KAJAOGBVWCYGHZ-JTQLQIEISA-N Gly-Gly-Phe Chemical compound [NH3+]CC(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KAJAOGBVWCYGHZ-JTQLQIEISA-N 0.000 description 1
- UTYGDAHJBBDPBA-BYULHYEWSA-N Gly-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)CN UTYGDAHJBBDPBA-BYULHYEWSA-N 0.000 description 1
- VIIBEIQMLJEUJG-LAEOZQHASA-N Gly-Ile-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O VIIBEIQMLJEUJG-LAEOZQHASA-N 0.000 description 1
- UESJMAMHDLEHGM-NHCYSSNCSA-N Gly-Ile-Leu Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O UESJMAMHDLEHGM-NHCYSSNCSA-N 0.000 description 1
- SCWYHUQOOFRVHP-MBLNEYKQSA-N Gly-Ile-Thr Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SCWYHUQOOFRVHP-MBLNEYKQSA-N 0.000 description 1
- TWTPDFFBLQEBOE-IUCAKERBSA-N Gly-Leu-Gln Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O TWTPDFFBLQEBOE-IUCAKERBSA-N 0.000 description 1
- CCBIBMKQNXHNIN-ZETCQYMHSA-N Gly-Leu-Gly Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CCBIBMKQNXHNIN-ZETCQYMHSA-N 0.000 description 1
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 1
- AFWYPMDMDYCKMD-KBPBESRZSA-N Gly-Leu-Tyr Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AFWYPMDMDYCKMD-KBPBESRZSA-N 0.000 description 1
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 1
- PTIIBFKSLCYQBO-NHCYSSNCSA-N Gly-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)CN PTIIBFKSLCYQBO-NHCYSSNCSA-N 0.000 description 1
- MHXKHKWHPNETGG-QWRGUYRKSA-N Gly-Lys-Leu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O MHXKHKWHPNETGG-QWRGUYRKSA-N 0.000 description 1
- FEUPVVCGQLNXNP-IRXDYDNUSA-N Gly-Phe-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 FEUPVVCGQLNXNP-IRXDYDNUSA-N 0.000 description 1
- SCJJPCQUJYPHRZ-BQBZGAKWSA-N Gly-Pro-Asn Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O SCJJPCQUJYPHRZ-BQBZGAKWSA-N 0.000 description 1
- HFPVRZWORNJRRC-UWVGGRQHSA-N Gly-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN HFPVRZWORNJRRC-UWVGGRQHSA-N 0.000 description 1
- GLACUWHUYFBSPJ-FJXKBIBVSA-N Gly-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN GLACUWHUYFBSPJ-FJXKBIBVSA-N 0.000 description 1
- YOBGUCWZPXJHTN-BQBZGAKWSA-N Gly-Ser-Arg Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YOBGUCWZPXJHTN-BQBZGAKWSA-N 0.000 description 1
- VNNRLUNBJSWZPF-ZKWXMUAHSA-N Gly-Ser-Ile Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNNRLUNBJSWZPF-ZKWXMUAHSA-N 0.000 description 1
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 1
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 1
- KOYUSMBPJOVSOO-XEGUGMAKSA-N Gly-Tyr-Ile Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KOYUSMBPJOVSOO-XEGUGMAKSA-N 0.000 description 1
- GWCJMBNBFYBQCV-XPUUQOCRSA-N Gly-Val-Ala Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O GWCJMBNBFYBQCV-XPUUQOCRSA-N 0.000 description 1
- YDIDLLVFCYSXNY-RCOVLWMOSA-N Gly-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN YDIDLLVFCYSXNY-RCOVLWMOSA-N 0.000 description 1
- ZVXMEWXHFBYJPI-LSJOCFKGSA-N Gly-Val-Ile Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZVXMEWXHFBYJPI-LSJOCFKGSA-N 0.000 description 1
- MVADCDSCFTXCBT-CIUDSAMLSA-N His-Asp-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MVADCDSCFTXCBT-CIUDSAMLSA-N 0.000 description 1
- FYVHHKMHFPMBBG-GUBZILKMSA-N His-Gln-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N FYVHHKMHFPMBBG-GUBZILKMSA-N 0.000 description 1
- LCNNHVQNFNJLGK-AVGNSLFASA-N His-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N LCNNHVQNFNJLGK-AVGNSLFASA-N 0.000 description 1
- QAMFAYSMNZBNCA-UWVGGRQHSA-N His-Gly-Met Chemical compound CSCC[C@H](NC(=O)CNC(=O)[C@@H](N)Cc1cnc[nH]1)C(O)=O QAMFAYSMNZBNCA-UWVGGRQHSA-N 0.000 description 1
- CSTNMMIHMYJGFR-IHRRRGAJSA-N His-His-Arg Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)C1=CN=CN1 CSTNMMIHMYJGFR-IHRRRGAJSA-N 0.000 description 1
- VFBZWZXKCVBTJR-SRVKXCTJSA-N His-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N VFBZWZXKCVBTJR-SRVKXCTJSA-N 0.000 description 1
- BXOLYFJYQQRQDJ-MXAVVETBSA-N His-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC1=CN=CN1)N BXOLYFJYQQRQDJ-MXAVVETBSA-N 0.000 description 1
- YAALVYQFVJNXIV-KKUMJFAQSA-N His-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 YAALVYQFVJNXIV-KKUMJFAQSA-N 0.000 description 1
- RNMNYMDTESKEAJ-KKUMJFAQSA-N His-Leu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 RNMNYMDTESKEAJ-KKUMJFAQSA-N 0.000 description 1
- SKOKHBGDXGTDDP-MELADBBJSA-N His-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N SKOKHBGDXGTDDP-MELADBBJSA-N 0.000 description 1
- SGLXGEDPYJPGIQ-ACRUOGEOSA-N His-Phe-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)NC(=O)[C@H](CC3=CN=CN3)N SGLXGEDPYJPGIQ-ACRUOGEOSA-N 0.000 description 1
- WHKLDLQHSYAVGU-ACRUOGEOSA-N His-Phe-Tyr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O WHKLDLQHSYAVGU-ACRUOGEOSA-N 0.000 description 1
- VDHOMPFVSABJKU-ULQDDVLXSA-N His-Phe-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CC2=CN=CN2)N VDHOMPFVSABJKU-ULQDDVLXSA-N 0.000 description 1
- PGXZHYYGOPKYKM-IHRRRGAJSA-N His-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CN=CN2)N)C(=O)N[C@@H](CCCCN)C(=O)O PGXZHYYGOPKYKM-IHRRRGAJSA-N 0.000 description 1
- PZAJPILZRFPYJJ-SRVKXCTJSA-N His-Ser-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O PZAJPILZRFPYJJ-SRVKXCTJSA-N 0.000 description 1
- FRDFAWHTPDKRHG-ULQDDVLXSA-N His-Tyr-Arg Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)C1=CN=CN1 FRDFAWHTPDKRHG-ULQDDVLXSA-N 0.000 description 1
- FFYYUUWROYYKFY-IHRRRGAJSA-N His-Val-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O FFYYUUWROYYKFY-IHRRRGAJSA-N 0.000 description 1
- RKUNBYITZUJHSG-UHFFFAOYSA-N Hyosciamin-hydrochlorid Natural products CN1C(C2)CCC1CC2OC(=O)C(CO)C1=CC=CC=C1 RKUNBYITZUJHSG-UHFFFAOYSA-N 0.000 description 1
- LQSBBHNVAVNZSX-GHCJXIJMSA-N Ile-Ala-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N LQSBBHNVAVNZSX-GHCJXIJMSA-N 0.000 description 1
- JRHFQUPIZOYKQP-KBIXCLLPSA-N Ile-Ala-Glu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O JRHFQUPIZOYKQP-KBIXCLLPSA-N 0.000 description 1
- TZCGZYWNIDZZMR-UHFFFAOYSA-N Ile-Arg-Ala Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(C)C(O)=O)CCCN=C(N)N TZCGZYWNIDZZMR-UHFFFAOYSA-N 0.000 description 1
- XENGULNPUDGALZ-ZPFDUUQYSA-N Ile-Asn-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(C)C)C(=O)O)N XENGULNPUDGALZ-ZPFDUUQYSA-N 0.000 description 1
- RPZFUIQVAPZLRH-GHCJXIJMSA-N Ile-Asp-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C)C(=O)O)N RPZFUIQVAPZLRH-GHCJXIJMSA-N 0.000 description 1
- HVWXAQVMRBKKFE-UGYAYLCHSA-N Ile-Asp-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N HVWXAQVMRBKKFE-UGYAYLCHSA-N 0.000 description 1
- BGZIJZJBXRVBGJ-SXTJYALSSA-N Ile-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N BGZIJZJBXRVBGJ-SXTJYALSSA-N 0.000 description 1
- VQUCKIAECLVLAD-SVSWQMSJSA-N Ile-Cys-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N VQUCKIAECLVLAD-SVSWQMSJSA-N 0.000 description 1
- GECLQMBTZCPAFY-PEFMBERDSA-N Ile-Gln-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N GECLQMBTZCPAFY-PEFMBERDSA-N 0.000 description 1
- ZGGWRNBSBOHIGH-HVTMNAMFSA-N Ile-Gln-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N ZGGWRNBSBOHIGH-HVTMNAMFSA-N 0.000 description 1
- LKACSKJPTFSBHR-MNXVOIDGSA-N Ile-Gln-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N LKACSKJPTFSBHR-MNXVOIDGSA-N 0.000 description 1
- OVPYIUNCVSOVNF-KQXIARHKSA-N Ile-Gln-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N OVPYIUNCVSOVNF-KQXIARHKSA-N 0.000 description 1
- WZDCVAWMBUNDDY-KBIXCLLPSA-N Ile-Glu-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](C)C(=O)O)N WZDCVAWMBUNDDY-KBIXCLLPSA-N 0.000 description 1
- MTFVYKQRLXYAQN-LAEOZQHASA-N Ile-Glu-Gly Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O MTFVYKQRLXYAQN-LAEOZQHASA-N 0.000 description 1
- FUOYNOXRWPJPAN-QEWYBTABSA-N Ile-Glu-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N FUOYNOXRWPJPAN-QEWYBTABSA-N 0.000 description 1
- CDGLBYSAZFIIJO-RCOVLWMOSA-N Ile-Gly-Gly Chemical compound CC[C@H](C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O CDGLBYSAZFIIJO-RCOVLWMOSA-N 0.000 description 1
- UAQSZXGJGLHMNV-XEGUGMAKSA-N Ile-Gly-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N UAQSZXGJGLHMNV-XEGUGMAKSA-N 0.000 description 1
- KOPIAUWNLKKELG-SIGLWIIPSA-N Ile-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N KOPIAUWNLKKELG-SIGLWIIPSA-N 0.000 description 1
- KEKTTYCXKGBAAL-VGDYDELISA-N Ile-His-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CO)C(=O)O)N KEKTTYCXKGBAAL-VGDYDELISA-N 0.000 description 1
- APDIECQNNDGFPD-PYJNHQTQSA-N Ile-His-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C(C)C)C(=O)O)N APDIECQNNDGFPD-PYJNHQTQSA-N 0.000 description 1
- KYLIZSDYWQQTFM-PEDHHIEDSA-N Ile-Ile-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N KYLIZSDYWQQTFM-PEDHHIEDSA-N 0.000 description 1
- SVBAHOMTJRFSIC-SXTJYALSSA-N Ile-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SVBAHOMTJRFSIC-SXTJYALSSA-N 0.000 description 1
- YNMQUIVKEFRCPH-QSFUFRPTSA-N Ile-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)O)N YNMQUIVKEFRCPH-QSFUFRPTSA-N 0.000 description 1
- PFPUFNLHBXKPHY-HTFCKZLJSA-N Ile-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)O)N PFPUFNLHBXKPHY-HTFCKZLJSA-N 0.000 description 1
- QZZIBQZLWBOOJH-PEDHHIEDSA-N Ile-Ile-Val Chemical compound N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(=O)O QZZIBQZLWBOOJH-PEDHHIEDSA-N 0.000 description 1
- HUORUFRRJHELPD-MNXVOIDGSA-N Ile-Leu-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N HUORUFRRJHELPD-MNXVOIDGSA-N 0.000 description 1
- GVKKVHNRTUFCCE-BJDJZHNGSA-N Ile-Leu-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)O)N GVKKVHNRTUFCCE-BJDJZHNGSA-N 0.000 description 1
- RQQCJTLBSJMVCR-DSYPUSFNSA-N Ile-Leu-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N RQQCJTLBSJMVCR-DSYPUSFNSA-N 0.000 description 1
- PWUMCBLVWPCKNO-MGHWNKPDSA-N Ile-Leu-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PWUMCBLVWPCKNO-MGHWNKPDSA-N 0.000 description 1
- ADDYYRVQQZFIMW-MNXVOIDGSA-N Ile-Lys-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ADDYYRVQQZFIMW-MNXVOIDGSA-N 0.000 description 1
- GLYJPWIRLBAIJH-UHFFFAOYSA-N Ile-Lys-Pro Natural products CCC(C)C(N)C(=O)NC(CCCCN)C(=O)N1CCCC1C(O)=O GLYJPWIRLBAIJH-UHFFFAOYSA-N 0.000 description 1
- MASWXTFJVNRZPT-NAKRPEOUSA-N Ile-Met-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(=O)O)N MASWXTFJVNRZPT-NAKRPEOUSA-N 0.000 description 1
- UFRXVQGGPNSJRY-CYDGBPFRSA-N Ile-Met-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N UFRXVQGGPNSJRY-CYDGBPFRSA-N 0.000 description 1
- VISRCHQHQCLODA-NAKRPEOUSA-N Ile-Pro-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)O)N VISRCHQHQCLODA-NAKRPEOUSA-N 0.000 description 1
- NLZVTPYXYXMCIP-XUXIUFHCSA-N Ile-Pro-Lys Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O NLZVTPYXYXMCIP-XUXIUFHCSA-N 0.000 description 1
- JODPUDMBQBIWCK-GHCJXIJMSA-N Ile-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O JODPUDMBQBIWCK-GHCJXIJMSA-N 0.000 description 1
- CNMOKANDJMLAIF-CIQUZCHMSA-N Ile-Thr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O CNMOKANDJMLAIF-CIQUZCHMSA-N 0.000 description 1
- WXLYNEHOGRYNFU-URLPEUOOSA-N Ile-Thr-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N WXLYNEHOGRYNFU-URLPEUOOSA-N 0.000 description 1
- ANTFEOSJMAUGIB-KNZXXDILSA-N Ile-Thr-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N ANTFEOSJMAUGIB-KNZXXDILSA-N 0.000 description 1
- XVUAQNRNFMVWBR-BLMTYFJBSA-N Ile-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N XVUAQNRNFMVWBR-BLMTYFJBSA-N 0.000 description 1
- PRTZQMBYUZFSFA-XEGUGMAKSA-N Ile-Tyr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)NCC(=O)O)N PRTZQMBYUZFSFA-XEGUGMAKSA-N 0.000 description 1
- BCISUQVFDGYZBO-QSFUFRPTSA-N Ile-Val-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O BCISUQVFDGYZBO-QSFUFRPTSA-N 0.000 description 1
- AUIYHFRUOOKTGX-UKJIMTQDSA-N Ile-Val-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N AUIYHFRUOOKTGX-UKJIMTQDSA-N 0.000 description 1
- YWCJXQKATPNPOE-UKJIMTQDSA-N Ile-Val-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YWCJXQKATPNPOE-UKJIMTQDSA-N 0.000 description 1
- NJGXXYLPDMMFJB-XUXIUFHCSA-N Ile-Val-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N NJGXXYLPDMMFJB-XUXIUFHCSA-N 0.000 description 1
- QSXSHZIRKTUXNG-STECZYCISA-N Ile-Val-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QSXSHZIRKTUXNG-STECZYCISA-N 0.000 description 1
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 1
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 1
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 1
- CZCSUZMIRKFFFA-CIUDSAMLSA-N Leu-Ala-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O CZCSUZMIRKFFFA-CIUDSAMLSA-N 0.000 description 1
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 1
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 1
- JUWJEAPUNARGCF-DCAQKATOSA-N Leu-Arg-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O JUWJEAPUNARGCF-DCAQKATOSA-N 0.000 description 1
- HBJZFCIVFIBNSV-DCAQKATOSA-N Leu-Arg-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(N)=O)C(O)=O HBJZFCIVFIBNSV-DCAQKATOSA-N 0.000 description 1
- HASRFYOMVPJRPU-SRVKXCTJSA-N Leu-Arg-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O HASRFYOMVPJRPU-SRVKXCTJSA-N 0.000 description 1
- DLCOFDAHNMMQPP-SRVKXCTJSA-N Leu-Asp-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DLCOFDAHNMMQPP-SRVKXCTJSA-N 0.000 description 1
- CLVUXCBGKUECIT-HJGDQZAQSA-N Leu-Asp-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CLVUXCBGKUECIT-HJGDQZAQSA-N 0.000 description 1
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 1
- VGPCJSXPPOQPBK-YUMQZZPRSA-N Leu-Gly-Ser Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O VGPCJSXPPOQPBK-YUMQZZPRSA-N 0.000 description 1
- KXODZBLFVFSLAI-AVGNSLFASA-N Leu-His-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CN=CN1 KXODZBLFVFSLAI-AVGNSLFASA-N 0.000 description 1
- MPSBSKHOWJQHBS-IHRRRGAJSA-N Leu-His-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCSC)C(=O)O)N MPSBSKHOWJQHBS-IHRRRGAJSA-N 0.000 description 1
- AVEGDIAXTDVBJS-XUXIUFHCSA-N Leu-Ile-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AVEGDIAXTDVBJS-XUXIUFHCSA-N 0.000 description 1
- SEMUSFOBZGKBGW-YTFOTSKYSA-N Leu-Ile-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SEMUSFOBZGKBGW-YTFOTSKYSA-N 0.000 description 1
- JKSIBWITFMQTOA-XUXIUFHCSA-N Leu-Ile-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O JKSIBWITFMQTOA-XUXIUFHCSA-N 0.000 description 1
- JNDYEOUZBLOVOF-AVGNSLFASA-N Leu-Leu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JNDYEOUZBLOVOF-AVGNSLFASA-N 0.000 description 1
- JLWZLIQRYCTYBD-IHRRRGAJSA-N Leu-Lys-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JLWZLIQRYCTYBD-IHRRRGAJSA-N 0.000 description 1
- WXUOJXIGOPMDJM-SRVKXCTJSA-N Leu-Lys-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O WXUOJXIGOPMDJM-SRVKXCTJSA-N 0.000 description 1
- BGZCJDGBBUUBHA-KKUMJFAQSA-N Leu-Lys-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O BGZCJDGBBUUBHA-KKUMJFAQSA-N 0.000 description 1
- RTIRBWJPYJYTLO-MELADBBJSA-N Leu-Lys-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N RTIRBWJPYJYTLO-MELADBBJSA-N 0.000 description 1
- OVZLLFONXILPDZ-VOAKCMCISA-N Leu-Lys-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OVZLLFONXILPDZ-VOAKCMCISA-N 0.000 description 1
- CPONGMJGVIAWEH-DCAQKATOSA-N Leu-Met-Ala Chemical compound CSCC[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](C)C(O)=O CPONGMJGVIAWEH-DCAQKATOSA-N 0.000 description 1
- WXZOHBVPVKABQN-DCAQKATOSA-N Leu-Met-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)O)C(=O)O)N WXZOHBVPVKABQN-DCAQKATOSA-N 0.000 description 1
- GNRPTBRHRRZCMA-RWMBFGLXSA-N Leu-Met-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N GNRPTBRHRRZCMA-RWMBFGLXSA-N 0.000 description 1
- AIRUUHAOKGVJAD-JYJNAYRXSA-N Leu-Phe-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIRUUHAOKGVJAD-JYJNAYRXSA-N 0.000 description 1
- QMKFDEUJGYNFMC-AVGNSLFASA-N Leu-Pro-Arg Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O QMKFDEUJGYNFMC-AVGNSLFASA-N 0.000 description 1
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 1
- JIHDFWWRYHSAQB-GUBZILKMSA-N Leu-Ser-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JIHDFWWRYHSAQB-GUBZILKMSA-N 0.000 description 1
- IWMJFLJQHIDZQW-KKUMJFAQSA-N Leu-Ser-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IWMJFLJQHIDZQW-KKUMJFAQSA-N 0.000 description 1
- LFSQWRSVPNKJGP-WDCWCFNPSA-N Leu-Thr-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(O)=O LFSQWRSVPNKJGP-WDCWCFNPSA-N 0.000 description 1
- GZRABTMNWJXFMH-UVOCVTCTSA-N Leu-Thr-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZRABTMNWJXFMH-UVOCVTCTSA-N 0.000 description 1
- ZGGVHTQAPHVMKM-IHPCNDPISA-N Leu-Trp-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCCCN)C(=O)O)N ZGGVHTQAPHVMKM-IHPCNDPISA-N 0.000 description 1
- HQBOMRTVKVKFMN-WDSOQIARSA-N Leu-Trp-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(O)=O HQBOMRTVKVKFMN-WDSOQIARSA-N 0.000 description 1
- RIHIGSWBLHSGLV-CQDKDKBSSA-N Leu-Tyr-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O RIHIGSWBLHSGLV-CQDKDKBSSA-N 0.000 description 1
- CGHXMODRYJISSK-NHCYSSNCSA-N Leu-Val-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O CGHXMODRYJISSK-NHCYSSNCSA-N 0.000 description 1
- QQXJROOJCMIHIV-AVGNSLFASA-N Leu-Val-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O QQXJROOJCMIHIV-AVGNSLFASA-N 0.000 description 1
- 229910009891 LiAc Inorganic materials 0.000 description 1
- 229910010082 LiAlH Inorganic materials 0.000 description 1
- 229910010084 LiAlH4 Inorganic materials 0.000 description 1
- XFIHDSBIPWEYJJ-YUMQZZPRSA-N Lys-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN XFIHDSBIPWEYJJ-YUMQZZPRSA-N 0.000 description 1
- KNKHAVVBVXKOGX-JXUBOQSCSA-N Lys-Ala-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KNKHAVVBVXKOGX-JXUBOQSCSA-N 0.000 description 1
- IRNSXVOWSXSULE-DCAQKATOSA-N Lys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN IRNSXVOWSXSULE-DCAQKATOSA-N 0.000 description 1
- DGAAQRAUOFHBFJ-CIUDSAMLSA-N Lys-Asn-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O DGAAQRAUOFHBFJ-CIUDSAMLSA-N 0.000 description 1
- MKBIVWXCFINCLE-SRVKXCTJSA-N Lys-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N MKBIVWXCFINCLE-SRVKXCTJSA-N 0.000 description 1
- PXHCFKXNSBJSTQ-KKUMJFAQSA-N Lys-Asn-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N)O PXHCFKXNSBJSTQ-KKUMJFAQSA-N 0.000 description 1
- HKCCVDWHHTVVPN-CIUDSAMLSA-N Lys-Asp-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O HKCCVDWHHTVVPN-CIUDSAMLSA-N 0.000 description 1
- WGCKDDHUFPQSMZ-ZPFDUUQYSA-N Lys-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCCCN WGCKDDHUFPQSMZ-ZPFDUUQYSA-N 0.000 description 1
- IWWMPCPLFXFBAF-SRVKXCTJSA-N Lys-Asp-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O IWWMPCPLFXFBAF-SRVKXCTJSA-N 0.000 description 1
- XTONYTDATVADQH-CIUDSAMLSA-N Lys-Cys-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(O)=O XTONYTDATVADQH-CIUDSAMLSA-N 0.000 description 1
- YVMQJGWLHRWMDF-MNXVOIDGSA-N Lys-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N YVMQJGWLHRWMDF-MNXVOIDGSA-N 0.000 description 1
- ZXEUFAVXODIPHC-GUBZILKMSA-N Lys-Glu-Asn Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZXEUFAVXODIPHC-GUBZILKMSA-N 0.000 description 1
- GCMWRRQAKQXDED-IUCAKERBSA-N Lys-Glu-Gly Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)N[C@@H](CCC([O-])=O)C(=O)NCC([O-])=O GCMWRRQAKQXDED-IUCAKERBSA-N 0.000 description 1
- PAMDBWYMLWOELY-SDDRHHMPSA-N Lys-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)C(=O)O PAMDBWYMLWOELY-SDDRHHMPSA-N 0.000 description 1
- ISHNZELVUVPCHY-ZETCQYMHSA-N Lys-Gly-Gly Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O ISHNZELVUVPCHY-ZETCQYMHSA-N 0.000 description 1
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 1
- NNKLKUUGESXCBS-KBPBESRZSA-N Lys-Gly-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NNKLKUUGESXCBS-KBPBESRZSA-N 0.000 description 1
- SQJSXOQXJYAVRV-SRVKXCTJSA-N Lys-His-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N SQJSXOQXJYAVRV-SRVKXCTJSA-N 0.000 description 1
- GTAXSKOXPIISBW-AVGNSLFASA-N Lys-His-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N GTAXSKOXPIISBW-AVGNSLFASA-N 0.000 description 1
- MXMDJEJWERYPMO-XUXIUFHCSA-N Lys-Ile-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MXMDJEJWERYPMO-XUXIUFHCSA-N 0.000 description 1
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 1
- YPLVCBKEPJPBDQ-MELADBBJSA-N Lys-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N YPLVCBKEPJPBDQ-MELADBBJSA-N 0.000 description 1
- YUAXTFMFMOIMAM-QWRGUYRKSA-N Lys-Lys-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O YUAXTFMFMOIMAM-QWRGUYRKSA-N 0.000 description 1
- JQSIGLHQNSZZRL-KKUMJFAQSA-N Lys-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N JQSIGLHQNSZZRL-KKUMJFAQSA-N 0.000 description 1
- PLDJDCJLRCYPJB-VOAKCMCISA-N Lys-Lys-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PLDJDCJLRCYPJB-VOAKCMCISA-N 0.000 description 1
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 1
- HYSVGEAWTGPMOA-IHRRRGAJSA-N Lys-Pro-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O HYSVGEAWTGPMOA-IHRRRGAJSA-N 0.000 description 1
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 1
- LOGFVTREOLYCPF-RHYQMDGZSA-N Lys-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN LOGFVTREOLYCPF-RHYQMDGZSA-N 0.000 description 1
- YSPZCHGIWAQVKQ-AVGNSLFASA-N Lys-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN YSPZCHGIWAQVKQ-AVGNSLFASA-N 0.000 description 1
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 1
- GHKXHCMRAUYLBS-CIUDSAMLSA-N Lys-Ser-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O GHKXHCMRAUYLBS-CIUDSAMLSA-N 0.000 description 1
- ZUGVARDEGWMMLK-SRVKXCTJSA-N Lys-Ser-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN ZUGVARDEGWMMLK-SRVKXCTJSA-N 0.000 description 1
- MIFFFXHMAHFACR-KATARQTJSA-N Lys-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN MIFFFXHMAHFACR-KATARQTJSA-N 0.000 description 1
- QVTDVTONTRSQMF-WDCWCFNPSA-N Lys-Thr-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CCCCN QVTDVTONTRSQMF-WDCWCFNPSA-N 0.000 description 1
- BVRNWWHJYNPJDG-XIRDDKMYSA-N Lys-Trp-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N BVRNWWHJYNPJDG-XIRDDKMYSA-N 0.000 description 1
- GVKINWYYLOLEFQ-XIRDDKMYSA-N Lys-Trp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(O)=O GVKINWYYLOLEFQ-XIRDDKMYSA-N 0.000 description 1
- SUZVLFWOCKHWET-CQDKDKBSSA-N Lys-Tyr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O SUZVLFWOCKHWET-CQDKDKBSSA-N 0.000 description 1
- RQILLQOQXLZTCK-KBPBESRZSA-N Lys-Tyr-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O RQILLQOQXLZTCK-KBPBESRZSA-N 0.000 description 1
- LMMBAXJRYSXCOQ-ACRUOGEOSA-N Lys-Tyr-Phe Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O LMMBAXJRYSXCOQ-ACRUOGEOSA-N 0.000 description 1
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 1
- RPWQJSBMXJSCPD-XUXIUFHCSA-N Lys-Val-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCCCN)C(C)C)C(O)=O RPWQJSBMXJSCPD-XUXIUFHCSA-N 0.000 description 1
- IKXQOBUBZSOWDY-AVGNSLFASA-N Lys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCCCN)N IKXQOBUBZSOWDY-AVGNSLFASA-N 0.000 description 1
- WXHHTBVYQOSYSL-FXQIFTODSA-N Met-Ala-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O WXHHTBVYQOSYSL-FXQIFTODSA-N 0.000 description 1
- HUKLXYYPZWPXCC-KZVJFYERSA-N Met-Ala-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HUKLXYYPZWPXCC-KZVJFYERSA-N 0.000 description 1
- DTICLBJHRYSJLH-GUBZILKMSA-N Met-Ala-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O DTICLBJHRYSJLH-GUBZILKMSA-N 0.000 description 1
- ZAJNRWKGHWGPDQ-SDDRHHMPSA-N Met-Arg-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N ZAJNRWKGHWGPDQ-SDDRHHMPSA-N 0.000 description 1
- XMMWDTUFTZMQFD-GMOBBJLQSA-N Met-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCSC XMMWDTUFTZMQFD-GMOBBJLQSA-N 0.000 description 1
- OSOLWRWQADPDIQ-DCAQKATOSA-N Met-Asp-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OSOLWRWQADPDIQ-DCAQKATOSA-N 0.000 description 1
- FBQMBZLJHOQAIH-GUBZILKMSA-N Met-Asp-Met Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O FBQMBZLJHOQAIH-GUBZILKMSA-N 0.000 description 1
- IZLCDZDNZFEDHB-DCAQKATOSA-N Met-Cys-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N IZLCDZDNZFEDHB-DCAQKATOSA-N 0.000 description 1
- MYKLINMAGAIRPJ-CIUDSAMLSA-N Met-Gln-Asn Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O MYKLINMAGAIRPJ-CIUDSAMLSA-N 0.000 description 1
- OOSPRDCGTLQLBP-NHCYSSNCSA-N Met-Glu-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OOSPRDCGTLQLBP-NHCYSSNCSA-N 0.000 description 1
- IUYCGMNKIZDRQI-BQBZGAKWSA-N Met-Gly-Ala Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O IUYCGMNKIZDRQI-BQBZGAKWSA-N 0.000 description 1
- UZVKFARGHHMQGX-IUCAKERBSA-N Met-Gly-Met Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCSC UZVKFARGHHMQGX-IUCAKERBSA-N 0.000 description 1
- LRALLISKBZNSKN-BQBZGAKWSA-N Met-Gly-Ser Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LRALLISKBZNSKN-BQBZGAKWSA-N 0.000 description 1
- ZEVPMOHYCQFWSE-NAKRPEOUSA-N Met-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCSC)N ZEVPMOHYCQFWSE-NAKRPEOUSA-N 0.000 description 1
- ODFBIJXEWPWSAN-CYDGBPFRSA-N Met-Ile-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O ODFBIJXEWPWSAN-CYDGBPFRSA-N 0.000 description 1
- PZUUMQPMHBJJKE-AVGNSLFASA-N Met-Leu-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCNC(N)=N PZUUMQPMHBJJKE-AVGNSLFASA-N 0.000 description 1
- QZPXMHVKPHJNTR-DCAQKATOSA-N Met-Leu-Asn Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O QZPXMHVKPHJNTR-DCAQKATOSA-N 0.000 description 1
- RBGLBUDVQVPTEG-DCAQKATOSA-N Met-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCSC)N RBGLBUDVQVPTEG-DCAQKATOSA-N 0.000 description 1
- ZIIMORLEZLVRIP-SRVKXCTJSA-N Met-Leu-Gln Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZIIMORLEZLVRIP-SRVKXCTJSA-N 0.000 description 1
- LUYURUYVNYGKGM-RCWTZXSCSA-N Met-Pro-Thr Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUYURUYVNYGKGM-RCWTZXSCSA-N 0.000 description 1
- BJPQKNHZHUCQNQ-SRVKXCTJSA-N Met-Pro-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCSC)N BJPQKNHZHUCQNQ-SRVKXCTJSA-N 0.000 description 1
- WXJLBSXNUHIGSS-OSUNSFLBSA-N Met-Thr-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WXJLBSXNUHIGSS-OSUNSFLBSA-N 0.000 description 1
- GWADARYJIJDYRC-XGEHTFHBSA-N Met-Thr-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GWADARYJIJDYRC-XGEHTFHBSA-N 0.000 description 1
- OVTOTTGZBWXLFU-QXEWZRGKSA-N Met-Val-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O OVTOTTGZBWXLFU-QXEWZRGKSA-N 0.000 description 1
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 1
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 1
- 108010079364 N-glycylalanine Proteins 0.000 description 1
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 1
- 101710167853 N-methyltransferase Proteins 0.000 description 1
- 108010087066 N2-tryptophyllysine Proteins 0.000 description 1
- 241000208125 Nicotiana Species 0.000 description 1
- 235000002637 Nicotiana tabacum Nutrition 0.000 description 1
- CYZBFPYMSJGBRL-DRZSPHRISA-N Phe-Ala-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CYZBFPYMSJGBRL-DRZSPHRISA-N 0.000 description 1
- VHWOBXIWBDWZHK-IHRRRGAJSA-N Phe-Arg-Asp Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](CC(O)=O)C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 VHWOBXIWBDWZHK-IHRRRGAJSA-N 0.000 description 1
- LJUUGSWZPQOJKD-JYJNAYRXSA-N Phe-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)Cc1ccccc1)C(O)=O LJUUGSWZPQOJKD-JYJNAYRXSA-N 0.000 description 1
- UUWCIPUVJJIEEP-SRVKXCTJSA-N Phe-Asn-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N UUWCIPUVJJIEEP-SRVKXCTJSA-N 0.000 description 1
- OJUMUUXGSXUZJZ-SRVKXCTJSA-N Phe-Asp-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O OJUMUUXGSXUZJZ-SRVKXCTJSA-N 0.000 description 1
- PDUVELWDJZOUEI-IHRRRGAJSA-N Phe-Cys-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PDUVELWDJZOUEI-IHRRRGAJSA-N 0.000 description 1
- QEPZQAPZKIPVDV-KKUMJFAQSA-N Phe-Cys-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N QEPZQAPZKIPVDV-KKUMJFAQSA-N 0.000 description 1
- MGECUMGTSHYHEJ-QEWYBTABSA-N Phe-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 MGECUMGTSHYHEJ-QEWYBTABSA-N 0.000 description 1
- BFYHIHGIHGROAT-HTUGSXCWSA-N Phe-Glu-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BFYHIHGIHGROAT-HTUGSXCWSA-N 0.000 description 1
- APJPXSFJBMMOLW-KBPBESRZSA-N Phe-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 APJPXSFJBMMOLW-KBPBESRZSA-N 0.000 description 1
- HBGFEEQFVBWYJQ-KBPBESRZSA-N Phe-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HBGFEEQFVBWYJQ-KBPBESRZSA-N 0.000 description 1
- NAOVYENZCWFBDG-BZSNNMDCSA-N Phe-His-His Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CC=CC=C1 NAOVYENZCWFBDG-BZSNNMDCSA-N 0.000 description 1
- ZKSLXIGKRJMALF-MGHWNKPDSA-N Phe-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC2=CC=CC=C2)N ZKSLXIGKRJMALF-MGHWNKPDSA-N 0.000 description 1
- VZFPYFRVHMSSNA-JURCDPSOSA-N Phe-Ile-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC1=CC=CC=C1 VZFPYFRVHMSSNA-JURCDPSOSA-N 0.000 description 1
- RGZYXNFHYRFNNS-MXAVVETBSA-N Phe-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N RGZYXNFHYRFNNS-MXAVVETBSA-N 0.000 description 1
- KRYSMKKRRRWOCZ-QEWYBTABSA-N Phe-Ile-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O KRYSMKKRRRWOCZ-QEWYBTABSA-N 0.000 description 1
- AUJWXNGCAQWLEI-KBPBESRZSA-N Phe-Lys-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O AUJWXNGCAQWLEI-KBPBESRZSA-N 0.000 description 1
- PTLMYJOMJLTMCB-KKUMJFAQSA-N Phe-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N PTLMYJOMJLTMCB-KKUMJFAQSA-N 0.000 description 1
- ACJULKNZOCRWEI-ULQDDVLXSA-N Phe-Met-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O ACJULKNZOCRWEI-ULQDDVLXSA-N 0.000 description 1
- RYQWALWYQWBUKN-FHWLQOOXSA-N Phe-Phe-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O RYQWALWYQWBUKN-FHWLQOOXSA-N 0.000 description 1
- GRVMHFCZUIYNKQ-UFYCRDLUSA-N Phe-Phe-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O GRVMHFCZUIYNKQ-UFYCRDLUSA-N 0.000 description 1
- MMJJFXWMCMJMQA-STQMWFEESA-N Phe-Pro-Gly Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)NCC(O)=O)C1=CC=CC=C1 MMJJFXWMCMJMQA-STQMWFEESA-N 0.000 description 1
- FZBGMXYQPACKNC-HJWJTTGWSA-N Phe-Pro-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FZBGMXYQPACKNC-HJWJTTGWSA-N 0.000 description 1
- ZVRJWDUPIDMHDN-ULQDDVLXSA-N Phe-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 ZVRJWDUPIDMHDN-ULQDDVLXSA-N 0.000 description 1
- ZJPGOXWRFNKIQL-JYJNAYRXSA-N Phe-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 ZJPGOXWRFNKIQL-JYJNAYRXSA-N 0.000 description 1
- HBXAOEBRGLCLIW-AVGNSLFASA-N Phe-Ser-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N HBXAOEBRGLCLIW-AVGNSLFASA-N 0.000 description 1
- BONHGTUEEPIMPM-AVGNSLFASA-N Phe-Ser-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O BONHGTUEEPIMPM-AVGNSLFASA-N 0.000 description 1
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 1
- IPFXYNKCXYGSSV-KKUMJFAQSA-N Phe-Ser-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N IPFXYNKCXYGSSV-KKUMJFAQSA-N 0.000 description 1
- IAOZOFPONWDXNT-IXOXFDKPSA-N Phe-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IAOZOFPONWDXNT-IXOXFDKPSA-N 0.000 description 1
- JHSRGEODDALISP-XVSYOHENSA-N Phe-Thr-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O JHSRGEODDALISP-XVSYOHENSA-N 0.000 description 1
- BSKMOCNNLNDIMU-CDMKHQONSA-N Phe-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O BSKMOCNNLNDIMU-CDMKHQONSA-N 0.000 description 1
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 1
- SHUFSZDAIPLZLF-BEAPCOKYSA-N Phe-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N)O SHUFSZDAIPLZLF-BEAPCOKYSA-N 0.000 description 1
- GNRMAQSIROFNMI-IXOXFDKPSA-N Phe-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GNRMAQSIROFNMI-IXOXFDKPSA-N 0.000 description 1
- QTDBZORPVYTRJU-KKXDTOCCSA-N Phe-Tyr-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O QTDBZORPVYTRJU-KKXDTOCCSA-N 0.000 description 1
- IPVPGAADZXRZSH-RNXOBYDBSA-N Phe-Tyr-Trp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O IPVPGAADZXRZSH-RNXOBYDBSA-N 0.000 description 1
- CDHURCQGUDNBMA-UBHSHLNASA-N Phe-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 CDHURCQGUDNBMA-UBHSHLNASA-N 0.000 description 1
- RGMLUHANLDVMPB-ULQDDVLXSA-N Phe-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N RGMLUHANLDVMPB-ULQDDVLXSA-N 0.000 description 1
- 229920002562 Polyethylene Glycol 3350 Polymers 0.000 description 1
- FYQSMXKJYTZYRP-DCAQKATOSA-N Pro-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 FYQSMXKJYTZYRP-DCAQKATOSA-N 0.000 description 1
- LNLNHXIQPGKRJQ-SRVKXCTJSA-N Pro-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 LNLNHXIQPGKRJQ-SRVKXCTJSA-N 0.000 description 1
- OCSACVPBMIYNJE-GUBZILKMSA-N Pro-Arg-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O OCSACVPBMIYNJE-GUBZILKMSA-N 0.000 description 1
- HPXVFFIIGOAQRV-DCAQKATOSA-N Pro-Arg-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O HPXVFFIIGOAQRV-DCAQKATOSA-N 0.000 description 1
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 1
- VCYJKOLZYPYGJV-AVGNSLFASA-N Pro-Arg-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VCYJKOLZYPYGJV-AVGNSLFASA-N 0.000 description 1
- XZGWNSIRZIUHHP-SRVKXCTJSA-N Pro-Arg-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 XZGWNSIRZIUHHP-SRVKXCTJSA-N 0.000 description 1
- ORPZXBQTEHINPB-SRVKXCTJSA-N Pro-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H]1CCCN1)C(O)=O ORPZXBQTEHINPB-SRVKXCTJSA-N 0.000 description 1
- INXAPZFIOVGHSV-CIUDSAMLSA-N Pro-Asn-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1 INXAPZFIOVGHSV-CIUDSAMLSA-N 0.000 description 1
- OBVCYFIHIIYIQF-CIUDSAMLSA-N Pro-Asn-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O OBVCYFIHIIYIQF-CIUDSAMLSA-N 0.000 description 1
- MTHRMUXESFIAMS-DCAQKATOSA-N Pro-Asn-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O MTHRMUXESFIAMS-DCAQKATOSA-N 0.000 description 1
- JARJPEMLQAWNBR-GUBZILKMSA-N Pro-Asp-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JARJPEMLQAWNBR-GUBZILKMSA-N 0.000 description 1
- KPDRZQUWJKTMBP-DCAQKATOSA-N Pro-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 KPDRZQUWJKTMBP-DCAQKATOSA-N 0.000 description 1
- YFNOUBWUIIJQHF-LPEHRKFASA-N Pro-Asp-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O YFNOUBWUIIJQHF-LPEHRKFASA-N 0.000 description 1
- SFECXGVELZFBFJ-VEVYYDQMSA-N Pro-Asp-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SFECXGVELZFBFJ-VEVYYDQMSA-N 0.000 description 1
- XUSDDSLCRPUKLP-QXEWZRGKSA-N Pro-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 XUSDDSLCRPUKLP-QXEWZRGKSA-N 0.000 description 1
- LHALYDBUDCWMDY-CIUDSAMLSA-N Pro-Glu-Ala Chemical compound C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1)C(O)=O LHALYDBUDCWMDY-CIUDSAMLSA-N 0.000 description 1
- FRKBNXCFJBPJOL-GUBZILKMSA-N Pro-Glu-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FRKBNXCFJBPJOL-GUBZILKMSA-N 0.000 description 1
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 1
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 1
- FKLSMYYLJHYPHH-UWVGGRQHSA-N Pro-Gly-Leu Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O FKLSMYYLJHYPHH-UWVGGRQHSA-N 0.000 description 1
- QEWBZBLXDKIQPS-STQMWFEESA-N Pro-Gly-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QEWBZBLXDKIQPS-STQMWFEESA-N 0.000 description 1
- VWXGFAIZUQBBBG-UWVGGRQHSA-N Pro-His-Gly Chemical compound C([C@@H](C(=O)NCC(=O)[O-])NC(=O)[C@H]1[NH2+]CCC1)C1=CN=CN1 VWXGFAIZUQBBBG-UWVGGRQHSA-N 0.000 description 1
- XFFIGWGYMUFCCQ-ULQDDVLXSA-N Pro-His-Tyr Chemical compound C1=CC(O)=CC=C1C[C@@H](C([O-])=O)NC(=O)[C@@H](NC(=O)[C@H]1[NH2+]CCC1)CC1=CN=CN1 XFFIGWGYMUFCCQ-ULQDDVLXSA-N 0.000 description 1
- TYMBHHITTMGGPI-NAKRPEOUSA-N Pro-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@@H]1CCCN1 TYMBHHITTMGGPI-NAKRPEOUSA-N 0.000 description 1
- XYHMFGGWNOFUOU-QXEWZRGKSA-N Pro-Ile-Gly Chemical compound OC(=O)CNC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 XYHMFGGWNOFUOU-QXEWZRGKSA-N 0.000 description 1
- KLSOMAFWRISSNI-OSUNSFLBSA-N Pro-Ile-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 KLSOMAFWRISSNI-OSUNSFLBSA-N 0.000 description 1
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 1
- YXHYJEPDKSYPSQ-AVGNSLFASA-N Pro-Leu-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 YXHYJEPDKSYPSQ-AVGNSLFASA-N 0.000 description 1
- FXGIMYRVJJEIIM-UWVGGRQHSA-N Pro-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FXGIMYRVJJEIIM-UWVGGRQHSA-N 0.000 description 1
- BRJGUPWVFXKBQI-XUXIUFHCSA-N Pro-Leu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRJGUPWVFXKBQI-XUXIUFHCSA-N 0.000 description 1
- XYSXOCIWCPFOCG-IHRRRGAJSA-N Pro-Leu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XYSXOCIWCPFOCG-IHRRRGAJSA-N 0.000 description 1
- WCNVGGZRTNHOOS-ULQDDVLXSA-N Pro-Lys-Tyr Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O WCNVGGZRTNHOOS-ULQDDVLXSA-N 0.000 description 1
- XZBYTHCRAVAXQQ-DCAQKATOSA-N Pro-Met-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O XZBYTHCRAVAXQQ-DCAQKATOSA-N 0.000 description 1
- AUYKOPJPKUCYHE-SRVKXCTJSA-N Pro-Met-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@@H]1CCCN1 AUYKOPJPKUCYHE-SRVKXCTJSA-N 0.000 description 1
- MLKVIVZCFYRTIR-KKUMJFAQSA-N Pro-Phe-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O MLKVIVZCFYRTIR-KKUMJFAQSA-N 0.000 description 1
- GFHOSBYCLACKEK-GUBZILKMSA-N Pro-Pro-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O GFHOSBYCLACKEK-GUBZILKMSA-N 0.000 description 1
- FYKUEXMZYFIZKA-DCAQKATOSA-N Pro-Pro-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FYKUEXMZYFIZKA-DCAQKATOSA-N 0.000 description 1
- QAAYIXYLEMRULP-SRVKXCTJSA-N Pro-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 QAAYIXYLEMRULP-SRVKXCTJSA-N 0.000 description 1
- LNICFEXCAHIJOR-DCAQKATOSA-N Pro-Ser-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LNICFEXCAHIJOR-DCAQKATOSA-N 0.000 description 1
- SXJOPONICMGFCR-DCAQKATOSA-N Pro-Ser-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O SXJOPONICMGFCR-DCAQKATOSA-N 0.000 description 1
- QKDIHFHGHBYTKB-IHRRRGAJSA-N Pro-Ser-Phe Chemical compound N([C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C(=O)[C@@H]1CCCN1 QKDIHFHGHBYTKB-IHRRRGAJSA-N 0.000 description 1
- FDMCIBSQRKFSTJ-RHYQMDGZSA-N Pro-Thr-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O FDMCIBSQRKFSTJ-RHYQMDGZSA-N 0.000 description 1
- JRBWMRUPXWPEID-JYJNAYRXSA-N Pro-Trp-Cys Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CS)C(=O)O)C(=O)[C@@H]1CCCN1 JRBWMRUPXWPEID-JYJNAYRXSA-N 0.000 description 1
- QHSSUIHLAIWXEE-IHRRRGAJSA-N Pro-Tyr-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O QHSSUIHLAIWXEE-IHRRRGAJSA-N 0.000 description 1
- LZHHZYDPMZEMRX-STQMWFEESA-N Pro-Tyr-Gly Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O LZHHZYDPMZEMRX-STQMWFEESA-N 0.000 description 1
- OABLKWMLPUGEQK-JYJNAYRXSA-N Pro-Tyr-Met Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(O)=O OABLKWMLPUGEQK-JYJNAYRXSA-N 0.000 description 1
- QKWYXRPICJEQAJ-KJEVXHAQSA-N Pro-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@@H]2CCCN2)O QKWYXRPICJEQAJ-KJEVXHAQSA-N 0.000 description 1
- FIDNSJUXESUDOV-JYJNAYRXSA-N Pro-Tyr-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O FIDNSJUXESUDOV-JYJNAYRXSA-N 0.000 description 1
- OQSGBXGNAFQGGS-CYDGBPFRSA-N Pro-Val-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OQSGBXGNAFQGGS-CYDGBPFRSA-N 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 239000002262 Schiff base Substances 0.000 description 1
- 150000004753 Schiff bases Chemical class 0.000 description 1
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 1
- FCRMLGJMPXCAHD-FXQIFTODSA-N Ser-Arg-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O FCRMLGJMPXCAHD-FXQIFTODSA-N 0.000 description 1
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 1
- RDFQNDHEHVSONI-ZLUOBGJFSA-N Ser-Asn-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDFQNDHEHVSONI-ZLUOBGJFSA-N 0.000 description 1
- CNIIKZQXBBQHCX-FXQIFTODSA-N Ser-Asp-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O CNIIKZQXBBQHCX-FXQIFTODSA-N 0.000 description 1
- CTRHXXXHUJTTRZ-ZLUOBGJFSA-N Ser-Asp-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N)C(=O)O CTRHXXXHUJTTRZ-ZLUOBGJFSA-N 0.000 description 1
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 1
- HEQPKICPPDOSIN-SRVKXCTJSA-N Ser-Asp-Tyr Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HEQPKICPPDOSIN-SRVKXCTJSA-N 0.000 description 1
- SWSRFJZZMNLMLY-ZKWXMUAHSA-N Ser-Asp-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O SWSRFJZZMNLMLY-ZKWXMUAHSA-N 0.000 description 1
- COLJZWUVZIXSSS-CIUDSAMLSA-N Ser-Cys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N COLJZWUVZIXSSS-CIUDSAMLSA-N 0.000 description 1
- XWCYBVBLJRWOFR-WDSKDSINSA-N Ser-Gln-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O XWCYBVBLJRWOFR-WDSKDSINSA-N 0.000 description 1
- BQWCDDAISCPDQV-XHNCKOQMSA-N Ser-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N)C(=O)O BQWCDDAISCPDQV-XHNCKOQMSA-N 0.000 description 1
- SQBLRDDJTUJDMV-ACZMJKKPSA-N Ser-Glu-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O SQBLRDDJTUJDMV-ACZMJKKPSA-N 0.000 description 1
- UFKPDBLKLOBMRH-XHNCKOQMSA-N Ser-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N)C(=O)O UFKPDBLKLOBMRH-XHNCKOQMSA-N 0.000 description 1
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 1
- HMRAQFJFTOLDKW-GUBZILKMSA-N Ser-His-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O HMRAQFJFTOLDKW-GUBZILKMSA-N 0.000 description 1
- JEHPKECJCALLRW-CUJWVEQBSA-N Ser-His-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEHPKECJCALLRW-CUJWVEQBSA-N 0.000 description 1
- ZUDXUJSYCCNZQJ-DCAQKATOSA-N Ser-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CO)N ZUDXUJSYCCNZQJ-DCAQKATOSA-N 0.000 description 1
- DJACUBDEDBZKLQ-KBIXCLLPSA-N Ser-Ile-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O DJACUBDEDBZKLQ-KBIXCLLPSA-N 0.000 description 1
- HBTCFCHYALPXME-HTFCKZLJSA-N Ser-Ile-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HBTCFCHYALPXME-HTFCKZLJSA-N 0.000 description 1
- RIAKPZVSNBBNRE-BJDJZHNGSA-N Ser-Ile-Leu Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O RIAKPZVSNBBNRE-BJDJZHNGSA-N 0.000 description 1
- FKZSXTKZLPPHQU-GQGQLFGLSA-N Ser-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CO)N FKZSXTKZLPPHQU-GQGQLFGLSA-N 0.000 description 1
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 1
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 1
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 1
- PMCMLDNPAZUYGI-DCAQKATOSA-N Ser-Lys-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O PMCMLDNPAZUYGI-DCAQKATOSA-N 0.000 description 1
- AMRRYKHCILPAKD-FXQIFTODSA-N Ser-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CO)N AMRRYKHCILPAKD-FXQIFTODSA-N 0.000 description 1
- JAWGSPUJAXYXJA-IHRRRGAJSA-N Ser-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)N)CC1=CC=CC=C1 JAWGSPUJAXYXJA-IHRRRGAJSA-N 0.000 description 1
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 1
- FKYWFUYPVKLJLP-DCAQKATOSA-N Ser-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FKYWFUYPVKLJLP-DCAQKATOSA-N 0.000 description 1
- XGQKSRGHEZNWIS-IHRRRGAJSA-N Ser-Pro-Tyr Chemical compound N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O XGQKSRGHEZNWIS-IHRRRGAJSA-N 0.000 description 1
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 1
- OZPDGESCTGGNAD-CIUDSAMLSA-N Ser-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CO OZPDGESCTGGNAD-CIUDSAMLSA-N 0.000 description 1
- ILZAUMFXKSIUEF-SRVKXCTJSA-N Ser-Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ILZAUMFXKSIUEF-SRVKXCTJSA-N 0.000 description 1
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 1
- KKKVOZNCLALMPV-XKBZYTNZSA-N Ser-Thr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KKKVOZNCLALMPV-XKBZYTNZSA-N 0.000 description 1
- PCJLFYBAQZQOFE-KATARQTJSA-N Ser-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N)O PCJLFYBAQZQOFE-KATARQTJSA-N 0.000 description 1
- PLQWGQUNUPMNOD-KKUMJFAQSA-N Ser-Tyr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O PLQWGQUNUPMNOD-KKUMJFAQSA-N 0.000 description 1
- PMTWIUBUQRGCSB-FXQIFTODSA-N Ser-Val-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O PMTWIUBUQRGCSB-FXQIFTODSA-N 0.000 description 1
- PCMZJFMUYWIERL-ZKWXMUAHSA-N Ser-Val-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O PCMZJFMUYWIERL-ZKWXMUAHSA-N 0.000 description 1
- LSHUNRICNSEEAN-BPUTZDHNSA-N Ser-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CO)N LSHUNRICNSEEAN-BPUTZDHNSA-N 0.000 description 1
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 1
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 1
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 1
- LVHHEVGYAZGXDE-KDXUFGMBSA-N Thr-Ala-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(=O)O)N)O LVHHEVGYAZGXDE-KDXUFGMBSA-N 0.000 description 1
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 1
- XYEXCEPTALHNEV-RCWTZXSCSA-N Thr-Arg-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XYEXCEPTALHNEV-RCWTZXSCSA-N 0.000 description 1
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 1
- VASYSJHSMSBTDU-LKXGYXEUSA-N Thr-Asn-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N)O VASYSJHSMSBTDU-LKXGYXEUSA-N 0.000 description 1
- OJRNZRROAIAHDL-LKXGYXEUSA-N Thr-Asn-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OJRNZRROAIAHDL-LKXGYXEUSA-N 0.000 description 1
- JEDIEMIJYSRUBB-FOHZUACHSA-N Thr-Asp-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O JEDIEMIJYSRUBB-FOHZUACHSA-N 0.000 description 1
- DCLBXIWHLVEPMQ-JRQIVUDYSA-N Thr-Asp-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 DCLBXIWHLVEPMQ-JRQIVUDYSA-N 0.000 description 1
- OYTNZCBFDXGQGE-XQXXSGGOSA-N Thr-Gln-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C)C(=O)O)N)O OYTNZCBFDXGQGE-XQXXSGGOSA-N 0.000 description 1
- VUVCRYXYUUPGSB-GLLZPBPUSA-N Thr-Gln-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O VUVCRYXYUUPGSB-GLLZPBPUSA-N 0.000 description 1
- LAFLAXHTDVNVEL-WDCWCFNPSA-N Thr-Gln-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O LAFLAXHTDVNVEL-WDCWCFNPSA-N 0.000 description 1
- CQNFRKAKGDSJFR-NUMRIWBASA-N Thr-Glu-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O CQNFRKAKGDSJFR-NUMRIWBASA-N 0.000 description 1
- LHEZGZQRLDBSRR-WDCWCFNPSA-N Thr-Glu-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LHEZGZQRLDBSRR-WDCWCFNPSA-N 0.000 description 1
- ONNSECRQFSTMCC-XKBZYTNZSA-N Thr-Glu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ONNSECRQFSTMCC-XKBZYTNZSA-N 0.000 description 1
- VYEHBMMAJFVTOI-JHEQGTHGSA-N Thr-Gly-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O VYEHBMMAJFVTOI-JHEQGTHGSA-N 0.000 description 1
- IMULJHHGAUZZFE-MBLNEYKQSA-N Thr-Gly-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IMULJHHGAUZZFE-MBLNEYKQSA-N 0.000 description 1
- QQWNRERCGGZOKG-WEDXCCLWSA-N Thr-Gly-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O QQWNRERCGGZOKG-WEDXCCLWSA-N 0.000 description 1
- JQAWYCUUFIMTHE-WLTAIBSBSA-N Thr-Gly-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JQAWYCUUFIMTHE-WLTAIBSBSA-N 0.000 description 1
- JKGGPMOUIAAJAA-YEPSODPASA-N Thr-Gly-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O JKGGPMOUIAAJAA-YEPSODPASA-N 0.000 description 1
- UDNVOQMPQBEITB-MEYUZBJRSA-N Thr-His-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O UDNVOQMPQBEITB-MEYUZBJRSA-N 0.000 description 1
- GMXIJHCBTZDAPD-QPHKQPEJSA-N Thr-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N GMXIJHCBTZDAPD-QPHKQPEJSA-N 0.000 description 1
- MEJHFIOYJHTWMK-VOAKCMCISA-N Thr-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)O MEJHFIOYJHTWMK-VOAKCMCISA-N 0.000 description 1
- PRNGXSILMXSWQQ-OEAJRASXSA-N Thr-Leu-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PRNGXSILMXSWQQ-OEAJRASXSA-N 0.000 description 1
- UUSQVWOVUYMLJA-PPCPHDFISA-N Thr-Lys-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UUSQVWOVUYMLJA-PPCPHDFISA-N 0.000 description 1
- WFAUDCSNCWJJAA-KXNHARMFSA-N Thr-Lys-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(O)=O WFAUDCSNCWJJAA-KXNHARMFSA-N 0.000 description 1
- KDGBLMDAPJTQIW-RHYQMDGZSA-N Thr-Met-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)O)N)O KDGBLMDAPJTQIW-RHYQMDGZSA-N 0.000 description 1
- WNQJTLATMXYSEL-OEAJRASXSA-N Thr-Phe-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O WNQJTLATMXYSEL-OEAJRASXSA-N 0.000 description 1
- YGZWVPBHYABGLT-KJEVXHAQSA-N Thr-Pro-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 YGZWVPBHYABGLT-KJEVXHAQSA-N 0.000 description 1
- BCYUHPXBHCUYBA-CUJWVEQBSA-N Thr-Ser-His Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O BCYUHPXBHCUYBA-CUJWVEQBSA-N 0.000 description 1
- UQCNIMDPYICBTR-KYNKHSRBSA-N Thr-Thr-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UQCNIMDPYICBTR-KYNKHSRBSA-N 0.000 description 1
- NHQVWACSJZJCGJ-FLBSBUHZSA-N Thr-Thr-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NHQVWACSJZJCGJ-FLBSBUHZSA-N 0.000 description 1
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 1
- JNKAYADBODLPMQ-HSHDSVGOSA-N Thr-Trp-Val Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)[C@@H](C)O)=CNC2=C1 JNKAYADBODLPMQ-HSHDSVGOSA-N 0.000 description 1
- VMSSYINFMOFLJM-KJEVXHAQSA-N Thr-Tyr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCSC)C(=O)O)N)O VMSSYINFMOFLJM-KJEVXHAQSA-N 0.000 description 1
- DIHPMRTXPYMDJZ-KAOXEZKKSA-N Thr-Tyr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N)O DIHPMRTXPYMDJZ-KAOXEZKKSA-N 0.000 description 1
- CYCGARJWIQWPQM-YJRXYDGGSA-N Thr-Tyr-Ser Chemical compound C[C@@H](O)[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CO)C([O-])=O)CC1=CC=C(O)C=C1 CYCGARJWIQWPQM-YJRXYDGGSA-N 0.000 description 1
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 1
- BKIOKSLLAAZYTC-KKHAAJSZSA-N Thr-Val-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O BKIOKSLLAAZYTC-KKHAAJSZSA-N 0.000 description 1
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 1
- BKVICMPZWRNWOC-RHYQMDGZSA-N Thr-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O BKVICMPZWRNWOC-RHYQMDGZSA-N 0.000 description 1
- SPIFGZFZMVLPHN-UNQGMJICSA-N Thr-Val-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SPIFGZFZMVLPHN-UNQGMJICSA-N 0.000 description 1
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 1
- BDWDMRSGCXEDMR-WFBYXXMGSA-N Trp-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N BDWDMRSGCXEDMR-WFBYXXMGSA-N 0.000 description 1
- KZIQDVNORJKTMO-WDSOQIARSA-N Trp-Arg-His Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)N KZIQDVNORJKTMO-WDSOQIARSA-N 0.000 description 1
- MVHHTXAUJCIOMZ-WDSOQIARSA-N Trp-Arg-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N MVHHTXAUJCIOMZ-WDSOQIARSA-N 0.000 description 1
- UTQBQJNSNXJNIH-IHPCNDPISA-N Trp-Asn-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N UTQBQJNSNXJNIH-IHPCNDPISA-N 0.000 description 1
- IQLVYVFBJUWZNT-BPUTZDHNSA-N Trp-Cys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N IQLVYVFBJUWZNT-BPUTZDHNSA-N 0.000 description 1
- PTAWAMWPRFTACW-SZMVWBNQSA-N Trp-Gln-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N PTAWAMWPRFTACW-SZMVWBNQSA-N 0.000 description 1
- GIAMKIPJSRZVJB-IHPCNDPISA-N Trp-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N GIAMKIPJSRZVJB-IHPCNDPISA-N 0.000 description 1
- JEYRCNVVYHTZMY-SZMVWBNQSA-N Trp-Pro-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O JEYRCNVVYHTZMY-SZMVWBNQSA-N 0.000 description 1
- SSSDKJMQMZTMJP-BVSLBCMMSA-N Trp-Tyr-Val Chemical compound C([C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CC=C(O)C=C1 SSSDKJMQMZTMJP-BVSLBCMMSA-N 0.000 description 1
- UOXPLPBMEPLZBW-WDSOQIARSA-N Trp-Val-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 UOXPLPBMEPLZBW-WDSOQIARSA-N 0.000 description 1
- RWTFCAMQLFNPTK-UMPQAUOISA-N Trp-Val-Thr Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)=CNC2=C1 RWTFCAMQLFNPTK-UMPQAUOISA-N 0.000 description 1
- JONPRIHUYSPIMA-UWJYBYFXSA-N Tyr-Ala-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JONPRIHUYSPIMA-UWJYBYFXSA-N 0.000 description 1
- IELISNUVHBKYBX-XDTLVQLUSA-N Tyr-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 IELISNUVHBKYBX-XDTLVQLUSA-N 0.000 description 1
- DLZKEQQWXODGGZ-KWQFWETISA-N Tyr-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DLZKEQQWXODGGZ-KWQFWETISA-N 0.000 description 1
- OOEUVMFKKZYSRX-LEWSCRJBSA-N Tyr-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N OOEUVMFKKZYSRX-LEWSCRJBSA-N 0.000 description 1
- FBVGQXJIXFZKSQ-GMVOTWDCSA-N Tyr-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N FBVGQXJIXFZKSQ-GMVOTWDCSA-N 0.000 description 1
- DXYWRYQRKPIGGU-BPNCWPANSA-N Tyr-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DXYWRYQRKPIGGU-BPNCWPANSA-N 0.000 description 1
- AYPAIRCDLARHLM-KKUMJFAQSA-N Tyr-Asn-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O AYPAIRCDLARHLM-KKUMJFAQSA-N 0.000 description 1
- GAYLGYUVTDMLKC-UWJYBYFXSA-N Tyr-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GAYLGYUVTDMLKC-UWJYBYFXSA-N 0.000 description 1
- NRFTYDWKWGJLAR-MELADBBJSA-N Tyr-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O NRFTYDWKWGJLAR-MELADBBJSA-N 0.000 description 1
- TZXFLDNBYYGLKA-BZSNNMDCSA-N Tyr-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 TZXFLDNBYYGLKA-BZSNNMDCSA-N 0.000 description 1
- NGALWFGCOMHUSN-AVGNSLFASA-N Tyr-Gln-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NGALWFGCOMHUSN-AVGNSLFASA-N 0.000 description 1
- QAYSODICXVZUIA-WLTAIBSBSA-N Tyr-Gly-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O QAYSODICXVZUIA-WLTAIBSBSA-N 0.000 description 1
- JHORGUYURUBVOM-KKUMJFAQSA-N Tyr-His-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O JHORGUYURUBVOM-KKUMJFAQSA-N 0.000 description 1
- KIJLSRYAUGGZIN-CFMVVWHZSA-N Tyr-Ile-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O KIJLSRYAUGGZIN-CFMVVWHZSA-N 0.000 description 1
- WSFXJLFSJSXGMQ-MGHWNKPDSA-N Tyr-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N WSFXJLFSJSXGMQ-MGHWNKPDSA-N 0.000 description 1
- GULIUBBXCYPDJU-CQDKDKBSSA-N Tyr-Leu-Ala Chemical compound [O-]C(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CC1=CC=C(O)C=C1 GULIUBBXCYPDJU-CQDKDKBSSA-N 0.000 description 1
- OLYXUGBVBGSZDN-ACRUOGEOSA-N Tyr-Leu-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 OLYXUGBVBGSZDN-ACRUOGEOSA-N 0.000 description 1
- VTCKHZJKWQENKX-KBPBESRZSA-N Tyr-Lys-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O VTCKHZJKWQENKX-KBPBESRZSA-N 0.000 description 1
- FMXFHNSFABRVFZ-BZSNNMDCSA-N Tyr-Lys-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O FMXFHNSFABRVFZ-BZSNNMDCSA-N 0.000 description 1
- LMKKMCGTDANZTR-BZSNNMDCSA-N Tyr-Phe-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 LMKKMCGTDANZTR-BZSNNMDCSA-N 0.000 description 1
- PSALWJCUIAQKFW-ACRUOGEOSA-N Tyr-Phe-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N PSALWJCUIAQKFW-ACRUOGEOSA-N 0.000 description 1
- SOEGLGLDSUHWTI-STECZYCISA-N Tyr-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=C(O)C=C1 SOEGLGLDSUHWTI-STECZYCISA-N 0.000 description 1
- BIWVVOHTKDLRMP-ULQDDVLXSA-N Tyr-Pro-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O BIWVVOHTKDLRMP-ULQDDVLXSA-N 0.000 description 1
- XGZBEGGGAUQBMB-KJEVXHAQSA-N Tyr-Pro-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC2=CC=C(C=C2)O)N)O XGZBEGGGAUQBMB-KJEVXHAQSA-N 0.000 description 1
- ZPFLBLFITJCBTP-QWRGUYRKSA-N Tyr-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O ZPFLBLFITJCBTP-QWRGUYRKSA-N 0.000 description 1
- XUIOBCQESNDTDE-FQPOAREZSA-N Tyr-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O XUIOBCQESNDTDE-FQPOAREZSA-N 0.000 description 1
- PWKMJDQXKCENMF-MEYUZBJRSA-N Tyr-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O PWKMJDQXKCENMF-MEYUZBJRSA-N 0.000 description 1
- WQOHKVRQDLNDIL-YJRXYDGGSA-N Tyr-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O WQOHKVRQDLNDIL-YJRXYDGGSA-N 0.000 description 1
- ULUXAIYMVXLDQP-PMVMPFDFSA-N Tyr-Trp-His Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)NC(=O)[C@H](CC4=CC=C(C=C4)O)N ULUXAIYMVXLDQP-PMVMPFDFSA-N 0.000 description 1
- KUXCBJFJURINGF-PXDAIIFMSA-N Tyr-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CC=C(C=C3)O)N KUXCBJFJURINGF-PXDAIIFMSA-N 0.000 description 1
- NVJCMGGZHOJNBU-UFYCRDLUSA-N Tyr-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N NVJCMGGZHOJNBU-UFYCRDLUSA-N 0.000 description 1
- DDRBQONWVBDQOY-GUBZILKMSA-N Val-Ala-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O DDRBQONWVBDQOY-GUBZILKMSA-N 0.000 description 1
- REJBPZVUHYNMEN-LSJOCFKGSA-N Val-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N REJBPZVUHYNMEN-LSJOCFKGSA-N 0.000 description 1
- RUCNAYOMFXRIKJ-DCAQKATOSA-N Val-Ala-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN RUCNAYOMFXRIKJ-DCAQKATOSA-N 0.000 description 1
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 1
- ZLFHAAGHGQBQQN-AEJSXWLSSA-N Val-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZLFHAAGHGQBQQN-AEJSXWLSSA-N 0.000 description 1
- LABUITCFCAABSV-BPNCWPANSA-N Val-Ala-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 LABUITCFCAABSV-BPNCWPANSA-N 0.000 description 1
- CVUDMNSZAIZFAE-UHFFFAOYSA-N Val-Arg-Pro Natural products NC(N)=NCCCC(NC(=O)C(N)C(C)C)C(=O)N1CCCC1C(O)=O CVUDMNSZAIZFAE-UHFFFAOYSA-N 0.000 description 1
- LNYOXPDEIZJDEI-NHCYSSNCSA-N Val-Asn-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N LNYOXPDEIZJDEI-NHCYSSNCSA-N 0.000 description 1
- NWDOPHYLSORNEX-QXEWZRGKSA-N Val-Asn-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCSC)C(=O)O)N NWDOPHYLSORNEX-QXEWZRGKSA-N 0.000 description 1
- DBOXBUDEAJVKRE-LSJOCFKGSA-N Val-Asn-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N DBOXBUDEAJVKRE-LSJOCFKGSA-N 0.000 description 1
- HZYOWMGWKKRMBZ-BYULHYEWSA-N Val-Asp-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N HZYOWMGWKKRMBZ-BYULHYEWSA-N 0.000 description 1
- KXUKIBHIVRYOIP-ZKWXMUAHSA-N Val-Asp-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N KXUKIBHIVRYOIP-ZKWXMUAHSA-N 0.000 description 1
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 1
- DDNIHOWRDOXXPF-NGZCFLSTSA-N Val-Asp-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N DDNIHOWRDOXXPF-NGZCFLSTSA-N 0.000 description 1
- LMSBRIVOCYOKMU-NRPADANISA-N Val-Gln-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N LMSBRIVOCYOKMU-NRPADANISA-N 0.000 description 1
- AHHJARQXFFGOKF-NRPADANISA-N Val-Glu-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N AHHJARQXFFGOKF-NRPADANISA-N 0.000 description 1
- VVZDBPBZHLQPPB-XVKPBYJWSA-N Val-Glu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O VVZDBPBZHLQPPB-XVKPBYJWSA-N 0.000 description 1
- YDPFWRVQHFWBKI-GVXVVHGQSA-N Val-Glu-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N YDPFWRVQHFWBKI-GVXVVHGQSA-N 0.000 description 1
- VCAWFLIWYNMHQP-UKJIMTQDSA-N Val-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N VCAWFLIWYNMHQP-UKJIMTQDSA-N 0.000 description 1
- XWYUBUYQMOUFRQ-IFFSRLJSSA-N Val-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N)O XWYUBUYQMOUFRQ-IFFSRLJSSA-N 0.000 description 1
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 1
- NXRAUQGGHPCJIB-RCOVLWMOSA-N Val-Gly-Asn Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O NXRAUQGGHPCJIB-RCOVLWMOSA-N 0.000 description 1
- BEGDZYNDCNEGJZ-XVKPBYJWSA-N Val-Gly-Gln Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O BEGDZYNDCNEGJZ-XVKPBYJWSA-N 0.000 description 1
- BVWPHWLFGRCECJ-JSGCOSHPSA-N Val-Gly-Tyr Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N BVWPHWLFGRCECJ-JSGCOSHPSA-N 0.000 description 1
- FEFZWCSXEMVSPO-LSJOCFKGSA-N Val-His-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](C)C(O)=O FEFZWCSXEMVSPO-LSJOCFKGSA-N 0.000 description 1
- SDSCOOZQQGUQFC-GVXVVHGQSA-N Val-His-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N SDSCOOZQQGUQFC-GVXVVHGQSA-N 0.000 description 1
- BZMIYHIJVVJPCK-QSFUFRPTSA-N Val-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N BZMIYHIJVVJPCK-QSFUFRPTSA-N 0.000 description 1
- LKUDRJSNRWVGMS-QSFUFRPTSA-N Val-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LKUDRJSNRWVGMS-QSFUFRPTSA-N 0.000 description 1
- SDUBQHUJJWQTEU-XUXIUFHCSA-N Val-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](C(C)C)N SDUBQHUJJWQTEU-XUXIUFHCSA-N 0.000 description 1
- JZWZACGUZVCQPS-RNJOBUHISA-N Val-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N JZWZACGUZVCQPS-RNJOBUHISA-N 0.000 description 1
- OVBMCNDKCWAXMZ-NAKRPEOUSA-N Val-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N OVBMCNDKCWAXMZ-NAKRPEOUSA-N 0.000 description 1
- BZWUSZGQOILYEU-STECZYCISA-N Val-Ile-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BZWUSZGQOILYEU-STECZYCISA-N 0.000 description 1
- AGXGCFSECFQMKB-NHCYSSNCSA-N Val-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N AGXGCFSECFQMKB-NHCYSSNCSA-N 0.000 description 1
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 1
- XTDDIVQWDXMRJL-IHRRRGAJSA-N Val-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N XTDDIVQWDXMRJL-IHRRRGAJSA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- MCRPZFQGVZLTAI-UHFFFAOYSA-N Val-Leu-Trp-Tyr Natural products C=1NC2=CC=CC=C2C=1CC(NC(=O)C(NC(=O)C(N)C(C)C)CC(C)C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 MCRPZFQGVZLTAI-UHFFFAOYSA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- ZRSZTKTVPNSUNA-IHRRRGAJSA-N Val-Lys-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(O)=O ZRSZTKTVPNSUNA-IHRRRGAJSA-N 0.000 description 1
- YMTOEGGOCHVGEH-IHRRRGAJSA-N Val-Lys-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O YMTOEGGOCHVGEH-IHRRRGAJSA-N 0.000 description 1
- WSUWDIVCPOJFCX-TUAOUCFPSA-N Val-Met-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N WSUWDIVCPOJFCX-TUAOUCFPSA-N 0.000 description 1
- QPPZEDOTPZOSEC-RCWTZXSCSA-N Val-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N)O QPPZEDOTPZOSEC-RCWTZXSCSA-N 0.000 description 1
- YQMILNREHKTFBS-IHRRRGAJSA-N Val-Phe-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)O)N YQMILNREHKTFBS-IHRRRGAJSA-N 0.000 description 1
- YLRAFVVWZRSZQC-DZKIICNBSA-N Val-Phe-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YLRAFVVWZRSZQC-DZKIICNBSA-N 0.000 description 1
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 1
- YTNGABPUXFEOGU-SRVKXCTJSA-N Val-Pro-Arg Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O YTNGABPUXFEOGU-SRVKXCTJSA-N 0.000 description 1
- SJRUJQFQVLMZFW-WPRPVWTQSA-N Val-Pro-Gly Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SJRUJQFQVLMZFW-WPRPVWTQSA-N 0.000 description 1
- DOFAQXCYFQKSHT-SRVKXCTJSA-N Val-Pro-Pro Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DOFAQXCYFQKSHT-SRVKXCTJSA-N 0.000 description 1
- QWCZXKIFPWPQHR-JYJNAYRXSA-N Val-Pro-Tyr Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QWCZXKIFPWPQHR-JYJNAYRXSA-N 0.000 description 1
- DEGUERSKQBRZMZ-FXQIFTODSA-N Val-Ser-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DEGUERSKQBRZMZ-FXQIFTODSA-N 0.000 description 1
- LTTQCQRTSHJPPL-ZKWXMUAHSA-N Val-Ser-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N LTTQCQRTSHJPPL-ZKWXMUAHSA-N 0.000 description 1
- QZKVWWIUSQGWMY-IHRRRGAJSA-N Val-Ser-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QZKVWWIUSQGWMY-IHRRRGAJSA-N 0.000 description 1
- VBTFUDNTMCHPII-UHFFFAOYSA-N Val-Trp-Tyr Natural products C=1NC2=CC=CC=C2C=1CC(NC(=O)C(N)C(C)C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 VBTFUDNTMCHPII-UHFFFAOYSA-N 0.000 description 1
- DOBHJKVVACOQTN-DZKIICNBSA-N Val-Tyr-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=C(O)C=C1 DOBHJKVVACOQTN-DZKIICNBSA-N 0.000 description 1
- RTJPAGFXOWEBAI-SRVKXCTJSA-N Val-Val-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RTJPAGFXOWEBAI-SRVKXCTJSA-N 0.000 description 1
- DFQZDQPLWBSFEJ-LSJOCFKGSA-N Val-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N DFQZDQPLWBSFEJ-LSJOCFKGSA-N 0.000 description 1
- ZHWZDZFWBXWPDW-GUBZILKMSA-N Val-Val-Cys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O ZHWZDZFWBXWPDW-GUBZILKMSA-N 0.000 description 1
- AOILQMZPNLUXCM-AVGNSLFASA-N Val-Val-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN AOILQMZPNLUXCM-AVGNSLFASA-N 0.000 description 1
- JSOXWWFKRJKTMT-WOPDTQHZSA-N Val-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N JSOXWWFKRJKTMT-WOPDTQHZSA-N 0.000 description 1
- WHNSHJJNWNSTSU-BZSNNMDCSA-N Val-Val-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 WHNSHJJNWNSTSU-BZSNNMDCSA-N 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 108010011559 alanylphenylalanine Proteins 0.000 description 1
- 150000001299 aldehydes Chemical class 0.000 description 1
- 239000008346 aqueous phase Substances 0.000 description 1
- 108010043240 arginyl-leucyl-glycine Proteins 0.000 description 1
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 1
- 108010093581 aspartyl-proline Proteins 0.000 description 1
- 108010092854 aspartyllysine Proteins 0.000 description 1
- 239000011942 biocatalyst Substances 0.000 description 1
- 230000001851 biosynthetic effect Effects 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 239000007853 buffer solution Substances 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 229960003920 cocaine Drugs 0.000 description 1
- 238000001816 cooling Methods 0.000 description 1
- 108010069495 cysteinyltyrosine Proteins 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 108010009297 diglycyl-histidine Proteins 0.000 description 1
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 1
- 108010054812 diprotin A Proteins 0.000 description 1
- 108010054813 diprotin B Proteins 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 238000001035 drying Methods 0.000 description 1
- 238000000119 electrospray ionisation mass spectrum Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 238000003912 environmental pollution Methods 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 239000000706 filtrate Substances 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 108010079547 glutamylmethionine Proteins 0.000 description 1
- HPAIKDPJURGQLN-UHFFFAOYSA-N glycyl-L-histidyl-L-phenylalanine Natural products C=1C=CC=CC=1CC(C(O)=O)NC(=O)C(NC(=O)CN)CC1=CN=CN1 HPAIKDPJURGQLN-UHFFFAOYSA-N 0.000 description 1
- 108010090037 glycyl-alanyl-isoleucine Proteins 0.000 description 1
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 1
- 108010075431 glycyl-alanyl-phenylalanine Proteins 0.000 description 1
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 1
- 108010077435 glycyl-phenylalanyl-glycine Proteins 0.000 description 1
- 108010089804 glycyl-threonine Proteins 0.000 description 1
- 108010059898 glycyl-tyrosyl-lysine Proteins 0.000 description 1
- 108010015792 glycyllysine Proteins 0.000 description 1
- 108010087823 glycyltyrosine Proteins 0.000 description 1
- 108010037850 glycylvaline Proteins 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 108010028295 histidylhistidine Proteins 0.000 description 1
- 108010085325 histidylproline Proteins 0.000 description 1
- 108010018006 histidylserine Proteins 0.000 description 1
- 229930005342 hyoscyamine Natural products 0.000 description 1
- 229960003210 hyoscyamine Drugs 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 238000009776 industrial production Methods 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 108010027338 isoleucylcysteine Proteins 0.000 description 1
- 108010030617 leucyl-phenylalanyl-valine Proteins 0.000 description 1
- 108010000761 leucylarginine Proteins 0.000 description 1
- 108010012058 leucyltyrosine Proteins 0.000 description 1
- 238000009630 liquid culture Methods 0.000 description 1
- 239000012280 lithium aluminium hydride Substances 0.000 description 1
- 108010025153 lysyl-alanyl-alanine Proteins 0.000 description 1
- 108010009298 lysylglutamic acid Proteins 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000011177 media preparation Methods 0.000 description 1
- 238000012269 metabolic engineering Methods 0.000 description 1
- 108010016686 methionyl-alanyl-serine Proteins 0.000 description 1
- 108010063431 methionyl-aspartyl-glycine Proteins 0.000 description 1
- 108700023046 methionyl-leucyl-phenylalanine Proteins 0.000 description 1
- 108010090114 methionyl-tyrosyl-lysine Proteins 0.000 description 1
- 108010056582 methionylglutamic acid Proteins 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 239000012452 mother liquor Substances 0.000 description 1
- 229930014626 natural product Natural products 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 238000003068 pathway analysis Methods 0.000 description 1
- 108010084572 phenylalanyl-valine Proteins 0.000 description 1
- 108010018625 phenylalanylarginine Proteins 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 108010014614 prolyl-glycyl-proline Proteins 0.000 description 1
- 108010025826 prolyl-leucyl-arginine Proteins 0.000 description 1
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 1
- 108010093296 prolyl-prolyl-alanine Proteins 0.000 description 1
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 1
- 108010020432 prolyl-prolylisoleucine Proteins 0.000 description 1
- 108010079317 prolyl-tyrosine Proteins 0.000 description 1
- 108010004914 prolylarginine Proteins 0.000 description 1
- 108010070643 prolylglutamic acid Proteins 0.000 description 1
- 108010053725 prolylvaline Proteins 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 238000010992 reflux Methods 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 108010048818 seryl-histidine Proteins 0.000 description 1
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 1
- 239000000741 silica gel Substances 0.000 description 1
- 229910002027 silica gel Inorganic materials 0.000 description 1
- 229910052938 sodium sulfate Inorganic materials 0.000 description 1
- 235000011152 sodium sulphate Nutrition 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 1
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 239000012137 tryptone Substances 0.000 description 1
- 108010080629 tryptophan-leucine Proteins 0.000 description 1
- 108010044292 tryptophyltyrosine Proteins 0.000 description 1
- 108010005834 tyrosyl-alanyl-glycine Proteins 0.000 description 1
- 108010051110 tyrosyl-lysine Proteins 0.000 description 1
- 108010020532 tyrosyl-proline Proteins 0.000 description 1
- 108010003137 tyrosyltyrosine Proteins 0.000 description 1
- 108010003885 valyl-prolyl-glycyl-glycine Proteins 0.000 description 1
- 108700026220 vif Genes Proteins 0.000 description 1
- 108010027345 wheylin-1 peptide Proteins 0.000 description 1
Images




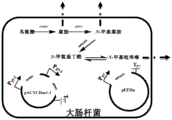









Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P17/00—Preparation of heterocyclic carbon compounds with only O, N, S, Se or Te as ring hetero atoms
- C12P17/10—Nitrogen as only ring hetero atom
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/0004—Oxidoreductases (1.)
- C12N9/0012—Oxidoreductases (1.) acting on nitrogen containing compounds as donors (1.4, 1.5, 1.6, 1.7)
- C12N9/0014—Oxidoreductases (1.) acting on nitrogen containing compounds as donors (1.4, 1.5, 1.6, 1.7) acting on the CH-NH2 group of donors (1.4)
- C12N9/0022—Oxidoreductases (1.) acting on nitrogen containing compounds as donors (1.4, 1.5, 1.6, 1.7) acting on the CH-NH2 group of donors (1.4) with oxygen as acceptor (1.4.3)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1003—Transferases (2.) transferring one-carbon groups (2.1)
- C12N9/1007—Methyltransferases (general) (2.1.1.)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/88—Lyases (4.)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y104/00—Oxidoreductases acting on the CH-NH2 group of donors (1.4)
- C12Y104/03—Oxidoreductases acting on the CH-NH2 group of donors (1.4) with oxygen as acceptor (1.4.3)
- C12Y104/03006—Amine oxidase (copper-containing)(1.4.3.6)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y201/00—Transferases transferring one-carbon groups (2.1)
- C12Y201/01—Methyltransferases (2.1.1)
- C12Y201/01053—Putrescine N-methyltransferase (2.1.1.53)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y401/00—Carbon-carbon lyases (4.1)
- C12Y401/01—Carboxy-lyases (4.1.1)
- C12Y401/01017—Ornithine decarboxylase (4.1.1.17)
Landscapes
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Genetics & Genomics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Medicinal Chemistry (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
The invention provides a method for preparing N-methylpyrrolidine by three-enzyme combined catalysis, which comprises the following steps: the L-ornithine is taken as a substrate, and is obtained by combined catalysis of ornithine decarboxylase EcODC, putrescine-N-methyltransferase AtPMT and amine oxidase AaDAO 3. The above method can also be realized by fermentation of genetically engineered bacteria expressing these three enzymes. The method of the invention is environment-friendly, has mild reaction conditions and has industrial development prospect.
Description
Technical Field
The invention belongs to the technical field of biocatalysis and metabolic engineering, and particularly relates to a biosynthesis method of N-methylpyrrolidine.
Background
The compound N-methylpyrrolidinium (shown as formula I) mainly exists in the form of salt, and the molecular formula is C5H10N+In equilibrium with N-methylaminobutyraldehyde under certain solution environments) are common key intermediates in the biosynthetic pathway of plant-derived nicotine and plant natural product drug, tropine alkaloids. The N-methylpyrrolidine biosynthetic route starting from L-ornithine is reported ((Chase et al 2003; 2004;
2004; et al.2005; ruetsch et al.2001.), see fig. 1, comprising three steps: l-ornithine is catalyzed by ornithine decarboxylase to generate putrescine, the putrescine is catalyzed by N-methyltransferase to generate N-methylated putrescine, the N-methylated putrescine is further catalyzed by amine oxidase to generate N-methylamino butyraldehyde, and the N-methylamino butyraldehyde spontaneously forms ring through the spontaneous reaction of Schiff base to form N-methylpyrrolidine.
et al.2005; ruetsch et al.2001.), see fig. 1, comprising three steps: l-ornithine is catalyzed by ornithine decarboxylase to generate putrescine, the putrescine is catalyzed by N-methyltransferase to generate N-methylated putrescine, the N-methylated putrescine is further catalyzed by amine oxidase to generate N-methylamino butyraldehyde, and the N-methylamino butyraldehyde spontaneously forms ring through the spontaneous reaction of Schiff base to form N-methylpyrrolidine.

At present, nicotine and tropine alkaloids taking N-methylpyrrolidine as a biosynthesis intermediate are mainly extracted from plants. In the synthetic biology technology developed in recent years, microbial strains are used as chassis cells, genes related to biosynthesis pathways of target compounds are introduced, heterologous high-efficiency synthesis (Kotopka et al.2018; Li et al.2018.) of some important medicinal compounds from plant sources is realized, and the establishment of the biosynthesis method of N-methylpyrrolidine can not only make up for the defects of the chemical synthesis method, but also provides a basis for pathway analysis and heterologous synthesis of nicotine and tropine alkaloid taking N-methylpyrrolidine as an intermediate.
In the biosynthetic pathway of N-methylpyrrolidine, only the metabolism of putrescine is engineered in the microbial host (Nguyen et al 2015; Qian et al 2010). Related enzymes in the biosynthetic pathway of N-methylpyrrolidine are also identified in many species at present (Docimo et al 2012; Heim et al 2007; Liu et al 2005), and since the solubility of tobacco-derived amine oxidases in the large intestine is low, amine oxidases in other species were found and identified as key steps in achieving the biosynthesis of N-methylpyrrolidine. The thirteen-thirds plant of solanaceae is a unique resource plant for producing toline alkaloid in China, also called wild , the content of total alkaloids in a dry product is up to 1.2 percent, the total content of the toline alkaloid is higher than that of common solanaceae plants such as belladonna, hyoscyamine, stramonium and the like (Kai et al.2012), and the transcriptome data of the solanaceae plants is published (Cui et al.2015.), so that the function of amine oxidase (AaDAOs) of the thirteen-thirds plant is researched.
As is well known, the chemical synthesis of N-methyl pyrroline has the problem of great environmental pollution, so that the development of an environment-friendly green preparation process is necessary. Therefore, biological preparation methods such as bio-enzyme catalysis methods, which have the advantages of mild reaction conditions, high catalytic efficiency, few byproducts, and the like, are attractive and promising methods.
Disclosure of Invention
In order to realize the biosynthesis of N-methylpyrrolidine, cocaine-derived ornithine decarboxylase (EcODC) with known function and high activity, putrescine-N-methyltransferase (AtPMT) from Shan downy and amine oxidase (AaDAOs) from Satsubishi are selected to carry out in-vitro co-catalysis reaction of a substrate L-ornithine, and the feasibility of the selected enzyme combination is verified. Because the genetic background of the large intestine and yeast is clear and the genetic manipulation is easy, we select the recombinant DNA as a chassis cell to explore the in vivo de novo synthesis of N-methylpyrrolidine, and hopefully provide a foundation for the industrial production of N-methylpyrrolidine and the heterologous synthesis of important alkaloids from N-methylpyrrolidine sources.
Specifically, the invention provides a method for preparing N-methylpyrrolidine, which comprises the following steps: the L-ornithine is taken as a substrate, and is obtained by carrying out combined catalysis on ornithine decarboxylase EcODC with an amino acid sequence of SEQ ID NO. 2, putrescine-N-methyltransferase AtPMT with an amino acid sequence of SEQ ID NO. 6 and amine oxidase from acutangular anisodus sources.
Preferably, pyridoxal phosphate aldehyde PLP, S-adenosylmethionine SAM and CuSO are also added into the reaction system4。
The amine oxidase derived from anisodus acutangula is preferably AaDAO1 having an amino acid sequence of SEQ ID NO. 10, AaDAO2 having an amino acid sequence of SEQ ID NO. 14, or AaDAO3 having an amino acid sequence of SEQ ID NO. 18. More preferably, the amine oxidase is AaDAO3 having the amino acid sequence of SEQ ID NO 18.
According to a second aspect of the present invention, there is provided a microorganism expressing the ornithine decarboxylase EcODC, putrescine-N-methyltransferase attpmt and amine oxidase described above.
Preferably, the microorganism is selected from the group consisting of Escherichia coli and Saccharomyces cerevisiae.
When the microorganism is Escherichia coli, it is preferable that the EcODC gene and the AtPMT gene are constructed on one plasmid and the amine oxidase gene is constructed on the other plasmid, and the two plasmids are transformed into Escherichia coli to form a genetically engineered bacterium for producing N-methylpyrrolidine.
The above-mentioned Escherichia coli is preferably BL21(DE 3).
Preferably, the plasmid for cloning the EcODC gene and AtPMT gene is pET24a or pACYCDuet-1, and the plasmid for cloning the amine oxidase AaDAO1, AaDAO2 or AaDAO3 gene is pET30 a. Preferably the amine oxidase is AaDAO 3.
When the microorganism is saccharomyces cerevisiae, the EcODC gene and the AtPMT gene are preferably constructed on one plasmid and transformed into saccharomyces cerevisiae to obtain saccharomyces cerevisiae containing the EcODC gene and the AtPMT gene; the amine oxidase gene AaDAO1, AaDAO2 or AaDAO3 gene is integrated into the genome of Saccharomyces cerevisiae containing EcODC and AtPMT genes to form a genetically engineered bacterium for producing N-methylpyrrolidine.
The Saccharomyces cerevisiae is preferably BY 4742.
Preferably, the plasmid used to clone the EcODC gene and the AtPMT gene is the plasmid p2M (constructed in the Zhou Shiwa laboratory, the Shanghai Life sciences research institute of Chinese academy of sciences) having the sequence of SEQ ID NO: 35.
In a preferred embodiment, the microorganism is Saccharomyces cerevisiae and the genes ALD4, ALD5 and HFD1 metabolizing N-methylaminobutyraldehyde in the genome are knocked out.
Preferably, the saccharomyces cerevisiae overexpresses the cofactor synthesis gene SAM 2.
The preferred sequence of the cofactor synthesizing gene SAM2 is SEQ ID NO: 84.
According to a second aspect of the present invention, there is provided the use of the above-mentioned microorganism for the preparation of N-methylpyrrolidine.
Preferably, N-methylpyrrolidine is produced by fermentation of the above-mentioned microorganisms.
When the microorganism is Escherichia coli, preferably the culture medium is LB medium, or any medium suitable for Escherichia coli fermentation; when the microorganism is Saccharomyces cerevisiae, preferably the medium is YPD medium, or any medium suitable for fermentation by Saccharomyces cerevisiae.
The ornithine decarboxylase EcODC, putrescine-N-methyltransferase AtPMT, and amine oxidases AaDAO1, AaDAO2, and AaDAO3 may be in the form of an enzyme or in the form of a cell containing an enzyme.
Accordingly, the combination of the above three enzymes may be in the form of enzyme + enzyme, enzyme + cell, or cell + cell in the catalytic system.
The three-enzyme combined catalytic system can catalyze L-ornithine reaction to obtain N-methylpyrrolidine by a one-pot method, and escherichia coli expressing ornithine decarboxylase EcODC, putrescine-N-methyltransferase AtPMT and amine oxidase can produce 4.33mg/L of N-methylpyrrolidine through fermentation; the saccharomyces cerevisiae expressing the three enzymes can produce 3.22mg/L of N-methyl pyrroline through fermentation; the saccharomyces cerevisiae which expresses the three enzymes and has genes ALD4, ALD5 and HFD1 knocked out from the genome can generate 9.88mg/L of N-methylpyrrolidine through fermentation; the saccharomyces cerevisiae expressing the three enzymes, knocking out genes ALD4, ALD5 and HFD1 in a genome and over-expressing SAM2 gene can generate 21.92mg/L of N-methylpyrrolidine through fermentation, and has industrial development and application prospects.
Drawings
FIG. 1 shows the biosynthetic pathway from the reaction starting with L-ornithine up to the product N-methylpyrrolidine. The detection reaction of N-methylpyrrolidine to N-methylpyrrolidine is shown in the box.
FIG. 2A shows the mass spectra of the results of AaDAO2 and AaDAO3 reactions catalyzing the conversion of N-methylated putrescine to N-methylpyrrolidine. Wherein (i) is a deuterated N-methylpyrrolidine standard; (ii) AaDAO2 boil control; (iii) is AaDAO2 reaction; (iv) AaDAO3 boil control; (v) is the reaction product of AaDAO 3.
FIG. 2B shows the mass spectrum of the results of the reaction in which EcODC, AtPMT and AaDAO3 mix enzymes jointly catalyze the conversion of L-ornithine to N-methylpyrrolidine. Wherein (i) is a deuterated N-methylpyrrolidine standard; (ii) AtPMT and AaDAO3 blanks; (iii) AaDAO3 blank; (iv) mixing the enzyme reaction products.
FIG. 3 shows SDS-PAGE gel photographs of purified proteins of various enzymes involved in the N-methylpyrrolidine synthesis pathway.
FIG. 4 shows a schematic diagram of construction of an engineered Escherichia coli bacterium producing N-methylpyrrolidine.
FIG. 5 shows the fermentation process and N-methylpyrrolidine yield of Escherichia coli BL 21-OP-A3.
FIG. 6 shows a schematic diagram of construction of engineered N-methylpyrrolidine-producing Saccharomyces cerevisiae.
FIG. 7A shows the fermentation process and N-methylpyrrolidine yield of Saccharomyces cerevisiae engineering bacteria BY 4742-OP-A3.
FIG. 7B shows a graph of fermentation history and N-methylpyrrolidine yield of Saccharomyces cerevisiae engineering bacteria Δ BY 4742-OP-A3.
FIG. 7C shows a graph of fermentation history and N-methylpyrrolidine yield of Saccharomyces cerevisiae engineering bacteria Δ BY4742-OP-A3-SAM 2.
FIG. 8A is the NMR spectrum of N-methylated putrescine (N-methylated putrescine1H NMR)。
FIG. 8B is the NMR spectrum of N-methylated putrescine (C:)13C NMR)。
FIG. 9A is a NMR spectrum of N-methylpyrrolidine (N-methylpyrrolidine1H NMR)。
FIG. 9B is the NMR spectrum of N-methylpyrrolidine (NMR)13C NMR)。
Detailed Description
The present invention will be described in further detail with reference to specific examples. It should be understood that the following examples are illustrative only and are not intended to limit the scope of the present invention.
The addition amount, content and concentration of various substances are referred to herein, wherein the percentage refers to the mass percentage unless otherwise specified.
The N-methylpyrrolidine is synthesized by catalyzing L-ornithine for a plurality of reactions by a combined catalytic system consisting of three enzymes in a one-pot method. Wherein the term "combined catalytic system" refers to a combination of ornithine decarboxylase EcODC, putrescine-N-methyltransferase AtPMT and amine oxidase (AaDAO1, AaDAO2 or AaDAO3), including but not limited to a combination of enzyme expression strains.
When used as a biocatalyst for the production of compound I, the enzymes EcODC, attpmt, AaDAO1, AaDAO2 and AaDAO3 of the present invention may take the form of an enzyme or the form of a bacterial cell. The enzyme forms comprise free enzyme and immobilized enzyme, including purified enzyme, crude enzyme, fermentation liquor, carrier-immobilized enzyme and the like. Moreover, techniques for the isolation and purification of these enzymes, including the preparation of immobilized enzymes, are well known to those skilled in the art. The thallus form comprises a viable thallus and a dead thallus, and comprises a freeze-thaw thallus and an immobilized thallus.
When the microorganism fermentation is adopted to produce the N-methylpyrrolidine, the L-ornithine is not required to be added as a substrate, because the L-ornithine is generated in cells in the growth process of escherichia coli and saccharomyces cerevisiae, and the L-ornithine can be used as a carbon source and a nitrogen source in a culture solution to be converted into the N-methylpyrrolidine through metabolism only by fermentation.
In this context, sometimes for the sake of simplicity of description, the names of enzymes such as ornithine decarboxylase EcODC protein will be mixed with the names of the genes (DNA) encoding them, and the skilled person will understand that they represent different substances in different description situations. For example, for EcODC (Gene), when used to describe an ornithine decarboxylase function or class, a protein is referred to; when described as a gene, refers to the gene encoding the ornithine decarboxylase, and so on, as will be readily understood by those skilled in the art.
The enzymes EcODC, attpmt, AaDAO1, AaDAO2, and AaDAO3 used in the present invention are well defined in sequence, and thus those skilled in the art can easily obtain the genes encoding them, expression cassettes and plasmids containing the genes, and transformants containing the plasmids. These genes, expression cassettes, plasmids, and transformants can be obtained by genetic engineering construction means well known to those skilled in the art.
The invention also provides a method for detecting the content of the N-methylpyrrolidine by using the NaBD4And (3) reducing N-methylpyrrolidine by using isotope (preferably 1M dissolved in 0.1M sodium borate buffer solution, and having the pH value of 10.0) to generate deuterated N-methylpyrrolidine, and determining the content of the N-methylpyrrolidine in the liquid by combining liquid phase-mass spectrometry detection. By the detection method, the activity of amine oxidase (namely AaDAO1, AaDAO2 and AaDAO3) for catalyzing the conversion of N-methylated putrescine into N-methylpyrrolidine can be determined; and the activity of the EcODC, AtPMT and amine oxidase (i.e., AaDAO1, AaDAO2 or AaDAO3) in combination catalyzing the conversion of L-ornithine to N-methylpyrrolidine can be determined. The boxes in FIG. 1 show N-methylpyrrolidine and NaBD4Fig. 2A and 2B show the results of mass spectrometric detection of deuterated N-methylpyrrolidine.
Examples
Materials and methods
The whole gene synthesis, primer synthesis and sequencing in the examples were performed by Jinzhi Biotechnology, Inc., Suzhou.
The molecular biological experiments in the examples include plasmid construction, digestion, ligation, competent cell preparation, transformation, culture medium preparation, and the like, and are mainly performed with reference to "molecular cloning experimental manual" (third edition), sambrook, d.w. rasel (american), translation of huang peitang et al, scientific press, beijing, 2002). The specific experimental conditions can be determined by simple experiments if necessary.
PCR amplification experiments were performed according to the reaction conditions or kit instructions provided by the supplier of the plasmid or DNA template. If necessary, it can be adjusted by simple experiments.
LB culture medium: 10g/L tryptone, 5g/L yeast extract, 10g/L sodium chloride, pH 7.0.
YPD medium: 1 wt% yeast extract, 2 wt% peptone, 2 wt% glucose.
YPAD medium: 10.0g/L yeast extract, 20.0g/L peptone, 20.0g/L D-glucose, 0.4g/L adenine sulfate.
HPLC determination conditions: the liquid phase-mass spectrometer is an Agilent 1290UHPLC-Agilent 6545Q-TOF ESI mass spectrum; the column was Agilent C18 (4.6X 150mm,3.5 μm), mobile phase A was 0.1% formic acid in water and mobile phase B was 0.1% acetonitrile at a flow rate of 0.35 mL/min. The separation procedure was: 0-1min, 2% B; 1-2min, 2-3% of B; 2-10min, 3-5% B; 10-12min, 5-95% B; 12-15min, 95% B; 15-16min, 95-2% B. Mass spectrometry Using Positive mode, N-Methylpyrroline by NaBD4After reduction, N-methyl pyrrolidine is generated, and the molecular weight of the target compound is 87.1027.
Example 1 preparation of enzymes related to the biosynthetic pathway of N-Methylpyrroline
1. Preparation of Ornithine decarboxylase EcODC
1.1 Using the EcODC coding gene (SEQ ID NO:1) synthesized by Jinzhi Biotechnology Ltd, Suzhou as a template, PCR amplification was performed with KOD DNA polymerase (94 ℃ C. for 2 min; 98 ℃ C. for 10s, 55 ℃ C. for 30s, 68 ℃ C. for 1 min; 30 cycles; 68 ℃ C. for 7min) using a primer pair (SEQ ID NO:3, 4), and a target DNA fragment was recovered using Axygen gel recovery kit (AxyPrep DNASELL extraction kit).
1.2 digestion of the fragment with NdeI and NotI double-enzyme Gel-cutting from Thermofish for 2h at 37 ℃ and clean recovery of the digested product with AxyPrep PCR clean Kit from AXYGEN, and recovery of the desired fragment with Axygen Gel recovery Kit (AxyPrep DNA Gel Extraction Kit). Connecting with T4DNA ligase from NEB at 20 deg.C for 2h, adding Top10 competent cells into the connection system, ice-cooling for 10min, heat-shocking at 42 deg.C for 1min30s, placing on ice for 5min, adding 1mL LB, shake culturing at 37 deg.C, 200rpm, and incubating for 45 min. Centrifugation was carried out at 12000rpm for 1min, 800. mu.l of the supernatant was discarded, and 200. mu.l of the supernatant was spread on a solid LB plate containing 50. mu.g/mL of kanamycin antibiotic and incubated overnight in an incubator at 37 ℃.
1.3 Single-clone transformants were picked, sequenced, and the correctly sequenced plasmid pET24a-EcODC was transformed into E.coli BL21(DE3) and spread on LB plates containing kanamycin. A single colony was cultured overnight at 37 ℃ and 200rpm in 10mL of LB containing kanamycin antibiotic (50. mu.g/mL). Transferring 10mL of the bacterial liquid into a 1L shake flask, culturing at 37 ℃ and 200rpm until the bacterial liquid is OD600About 0.6. mu.L of 1M IPTG (final concentration of 0.5mM) was added and the induction was carried out at 16 ℃ for 20 hours.
1.4 the cells were collected from the shake flask, and 5 times the weight volume of lysis buffer (50mM potassium phosphate, pH 8.0, 150mM NaCl) was added thereto, and crushed by squeezing at 800bar for 3 times. Centrifuge at 18000rpm for 45min at 4 ℃. Mixing the supernatant with a Ni column, incubating for 40min, collecting the effluent supernatant Flow-through (FT), eluting 20 column volumes of the hybrid protein by using a lysis buffer containing 25mM imidazole, eluting the target protein by 250mM, and detecting by SDS-PAGE to obtain the target protein EcODC with high purity, wherein the amino acid sequence of the EcODC is SEQ ID NO: 2.
2. Preparation of putrescine N-methyltransferase AtPMT, amine oxidases AaDAO1, AaDAO2 and AaDAO3
Plasmids pET24a-AtPMT, pET30a-AaDAO1, pET30a-AaDAO2 and pET30a-AaDAO3 were obtained, respectively, according to the same method as the above-mentioned step, and the objective protein was purified.
SDS-PAGE gel electrophoresis of the purified proteins of these enzymes is shown in FIG. 3, and soluble and high-purity proteins EcODC, AaDAO2 and AaDAO3 are obtained, which can be used for the next enzyme activity experiment. Wherein
The gene sequence of AtPMT is SEQ ID NO. 5, obtained by amplification of primer pair (SEQ ID NO:7, 8), and the amino acid sequence of coded enzyme AtPMT is SEQ ID NO. 6.
AaDAO1 gene (SEQ ID NO:9) is obtained by using plant acutangular anisodus cDNA as a template and amplifying the cDNA by using a primer pair (SEQ ID NO:11, 12), and the amino acid sequence of the coded enzyme AaDAO1 is SEQ ID NO: 10.
The AaDAO2 gene (SEQ ID NO:13) is obtained by amplifying the three-thirds cDNA as a template by using a primer pair (SEQ ID NO:15, 16), and the amino acid sequence of the coded enzyme AaDAO2 is SEQ ID NO: 14.
AaDAO3 gene (SEQ ID NO:17) is obtained by using the acutangular anisodus cDNA as a template and amplifying the primer pair (SEQ ID NO:19, 20), and the amino acid sequence of the coded enzyme AaDAO3 is SEQ ID NO: 18.
Example 2AaDAO2, AaDAO3 Activity test and Synthesis of N-Methylpyrroline by in vitro Mixed enzyme reaction
2.1 amine oxidases AaDAO2 and AaDAO3 Activity experiments (100 microliters):
2mM substrate N-methylated putrescine, 20. mu.M CuSO450mM potassium phosphate (pH 8.0) and 10. mu.M of an enzyme protein were added to the mixture, and the mixture was made into a 100. mu.l system and reacted at 30 ℃ for 30 min. Add 10. mu.l NaBD4(mother liquor 1M in 0.1M sodium borate buffer, pH 10.0). The liquid phase-mass spectrum detects that the N-methyl pyrroline can be reduced to generate N-methyl pyrrolidine, and the molecular weight of the target compound is 87.1027. As shown in FIG. 2A, the experimental results show that AaDAO2 and AaDAO3 can both catalyze N-methylated putrescine to generate N-methylpyrrolidine.
2.2EcODC, AtPMT and AaDAO3 mix enzyme reactions (100. mu.l):
5mM substrate L-ornithine, 5mM PLP (pyridoxal phosphate aldehyde), 5mM SAM (S-adenosylmethionine), 20. mu.M CuSO 410 μ M EcODC,10 μ M AtPMT, 10 μ M AaDAO 3. The reaction solution was incubated at 30 ℃ for 2h, and the product detection procedure was the same as in the above step 1 experiment. As shown in FIG. 2B, the results of the experiments show that the combination of EcODC, AtPMT and AaDAO3 can catalyze the conversion of L-ornithine to N-methylpyrrolidine in vitro.
Example 3 construction and fermentation of E.coli engineering bacteria producing N-methylpyrrolidine
3.1 PCR amplification (94 ℃ for 2 min; 98 ℃ for 10s, 55 ℃ for 30s, 68 ℃ for 1 min; 30 cycles; 68 ℃ for 7min) with KOD DNA polymerase using the EcODC coding gene (SEQ ID NO:1) as a template and a primer pair (SEQ ID NO:21, 22). And (5) performing agarose gel electrophoresis and recovering the target fragment.
3.2 using BamHI and HindIII to double enzyme digestion to recover fragment and pACYCDuet-1 plasmid, carrying out enzyme digestion for 2h at 37 ℃, cleanly recovering the enzyme digestion product, carrying out gel recovery on the pACYCDuet-1 plasmid after enzyme digestion, and connecting for 2h at 20 ℃ by using T4DNA ligase. E.coli TOP10 competent was added to the ligation system, ice-washed for 10min, heat-shocked at 42 ℃ for 1min30s, placed on ice for 5min, added with 1mL LB, incubated at 37 ℃ for 45min with 200rpm shaking. Centrifugation was carried out at 12000rpm for 1min, 800. mu.l of the supernatant was discarded, and 200. mu.l of the supernatant was spread on a solid LB plate containing 34. mu.g/mL of chloramphenicol, followed by overnight incubation in an incubator at 37 ℃. And (4) selecting a monoclonal transformant for sequencing to obtain a correct plasmid pACYCDuet-EcODC.
3.3 PCR amplification (94 ℃ for 2 min; 98 ℃ for 10s, 55 ℃ for 30s, 68 ℃ for 1 min; 30 cycles; 68 ℃ for 7min) with KOD DNA polymerase using the coding gene (SEQ ID NO:5) of AtPMT as a template and a primer pair (SEQ ID NO:23, 24), agarose gel electrophoresis, and recovering the target fragment.
3.4 the fragments and pACYCDuet-EcODC plasmid were digested at 37 ℃ for 2h with NdeI and KpnI double-enzyme digestion, the desired fragment was recovered from the gel and ligated with T4DNA ligase at 20 ℃ for 2 h. E.coli TOP10 competent was added to the ligation system, ice-washed for 10min, heat-shocked at 42 ℃ for 1min30s, placed on ice for 5min, added with 1mL LB, incubated at 37 ℃ for 45min with 200rpm shaking. Centrifugation was carried out at 12000rpm for 1min, 800. mu.l of the supernatant was discarded, and 200. mu.l of the supernatant was spread on a solid LB plate containing 34. mu.g/mL of chloramphenicol, followed by overnight incubation in an incubator at 37 ℃. And (4) selecting a monoclonal transformant for sequencing to obtain a correct plasmid pACYCDuet-EcODC-AtPMT. The plasmid contains two genes, EcODC and AtPMT.
3.5 mu.l of pACYCDuet-EcODC-AtPMT plasmid was transformed into E.coli BL21(DE3) to obtain strain BL 21-OP. BL21-OP strain was made competent, and plasmid pET30a-AaDAO3 prepared in example 1 was transformed into competent cells to obtain strain BL21-OP-A3, and a schematic diagram of the strain construction is shown in FIG. 4.
3.6 Single colonies of the strain were picked from the plate and shake-cultured overnight in a test tube containing LB liquid medium (containing 34. mu.g/mL chloramphenicol and 50. mu.g/mL kanamycin). Transfer into 50ml LB-containing Erlenmeyer flask to OD600To 0.6-0.8, 0.15mM IPTG, and 50. mu.M CuSO were added4Placing the bacterial liquid in a shaking table at 25 ℃, fermenting at 120rpm, sampling at different time points and detecting OD600And N-methylpyrrolidine yield. As shown in FIG. 5, the experimental result shows that the strain can synthesize N-methylpyrrolidine, and the yield reaches 4.33mg/L in 48 h.
Example 4 construction of engineered Saccharomyces cerevisiae producing N-methylpyrrolidine
4.1 construction of BY4742-OP Yeast strains:
4.1.1 the primers and templates shown in Table 1 are used for amplifying EcODC, AtPMT gene, yeast endogenous promoter PGK1(SEQ ID NO:33) and terminator FBA1(SEQ ID NO:34) by a PCR method, and 15-21 bp homologous sequences are introduced between adjacent fragments through the primers. The DNA polymerase is high-fidelity DNA polymerase I-5 from TSINGKETM2X HighFidelity Master Mix, the PCR program was set up with reference to the description: 2min at 98 ℃; 35 cycles of 98 ℃ for 15s, 58 ℃ for 10s and 72 ℃ for 1 min; 5min at 72 ℃; keeping the temperature at 10 ℃.
4.1.2 detecting the PCR product by agarose gel electrophoresis, and cutting off a band with the same size with the target DNA under ultraviolet light. Then, the DNA fragment was recovered from the agarose gel using AxyPrep DNASELExtractionkit from AXYGEN. The yeast high copy plasmid p2M (supplied by Zhoujihua laboratory of Shanghai Life sciences research institute of China academy of sciences, full length sequence is SEQ ID NO:35) was digested with both the restriction enzymes BamHI and EcoRI from Takara for 30min, and the digested product was collected by cleaning with AxyPrep PCR clean Kit from AXYGEN. By using the Hieff Clone of YeasenTMThe recombinant enzyme of Plus Multi One Step Cloning Kit recombines the recovered gel product and the plasmid of p2M double digestion (the reaction conditions refer to the Kit instructions).
4.1.3 ligation products E.coli TOP10 competent cells were transformed and plated on LB plates supplemented with 100. mu.g/mL ampicillin. Positive transformants were verified by colony PCR and further verified by sequencing, which indicated that the yeast expression plasmid p2M-EcODC-AtPMT was successfully constructed. The plasmid contains two genes, EcODC and AtPMT.
4.1.4 transfer the yeast expression plasmid p2M-EcODC-AtPMT into Saccharomyces cerevisiae BY4742 competence (reference for competence preparation and conversion method (Gietz and Schiestl 2007.), pick out BY4742 single clone to 5mLYPAD liquid culture medium with sterile inoculating loop, culture at 200rpm and 30 ℃, transfer to 50mL YPAD culture medium after 12h-16h, culture at 200rpm and 30 ℃ to OD600When the concentration is 2, centrifuging for 5min at 3000g, collecting thalli, and suspending in 25mL sterile water; 3000g, centrifuging for 5min to collect thalli, suspending the thalli in 1mL sterile water, sucking 100 microliters of bacteria liquid into a 1.5mL centrifuge tube, 13000g, centrifuging for 30s, and discarding the supernatant. Preparing a transformation system: mu.L of PEG 3350 (50% w/v), 36. mu.L of 1.0M LiAc, 50. mu.L of Single-stranded carrier DNA (Invitrogen) (2.0mg/mL), 34. mu.L of plasmid p2M-EcODC-AtPMT, in a total volume of 360. mu.L. The transformation system is added into BY4742 competence, the thalli is resuspended, the thalli is thermally shocked at 42 ℃ for 40min, 13000g is centrifuged for 30s, the supernatant is discarded, 1mL of YPD culture medium is added, the temperature is 30 ℃, the rpm is 200, and the mixture is incubated for 2 h. 200. mu.l of the suspension was spread on YPAD plates supplemented with 300. mu.g/mL of hygromycin B (hygromycin B), and cultured at 30 ℃ for 48 hours. And (4) obtaining a positive transformant through yeast colony PCR verification, namely obtaining the BY4742-OP strain.
TABLE 1
| Segment names | Form panel | Forward primer | Reverse primer |
| EcODC gene | pACYCDuet-EcODC-AtPMT plasmid | SEQ ID NO:25 | SEQ ID NO:26 |
| FBA1 terminator | Saccharomyces cerevisiae BY4742 genome | SEQ ID NO:27 | SEQ ID NO:28 |
| PGK1 promoter | Saccharomyces cerevisiae BY4742 genome | SEQ ID NO:29 | SEQ ID NO:30 |
| AtPMT gene | pACYCDuet-EcODC-AtPMT plasmid | SEQ ID NO:31 | SEQ ID NO:32 |
4.2 construction of BY4742-OP-A3 Yeast Strain:
4.2.1 amplification of the transformed fragment by PCR using the primers and templates of Table 2: an upstream homologous sequence (SEQ ID NO:48) of an X-4 site, a TEF1 promoter (SEQ ID NO:49), an AaDAO3 gene, a PRM9 terminator (SEQ ID NO:50), a KanMX expression cassette (SEQ ID NO:51) and a downstream homologous sequence (SEQ ID NO:52) of the X-4 site, wherein 60-80 bp homologous sequences are introduced between adjacent fragments through primers. The DNA polymerase is high-fidelity DNA polymerase I-5 from TSINGKETM2X High Fidelity Master Mix, the PCR program was set up with reference to the description: 2min at 98 ℃; 35 cycles of 98 ℃ for 15s, 58 ℃ for 10s and 72 ℃ for 1 min; 5min at 72 ℃; keeping the temperature at 10 ℃.
4.2.2 agarose gel electrophoresis detection is carried out on the PCR product, and a band with the same size with the target DNA is cut off under ultraviolet light. Then, the DNA fragment was recovered from the agarose Gel using AxyPrep DNA Gel Extraction Kit from AXYGEN.
4.2.3 the 6 fragments are transformed into BY4742-OP competence (reference for competence making and transformation method (Gietz and Schiestl 2007)), and spread on YPAD plates added with 300. mu.g/mL hygromycin B (hygromycin B) and 200mg/L G418, and cultured at 30 ℃ for 48h, and positive transformants are obtained through yeast colony PCR verification, namely the BY4742-OP-A3 strain, and genes of three enzymes of EcODC, AtPMT and AaDAO3 are introduced into the saccharomyces cerevisiae.
TABLE 2
| Segment names | Form panel | Forward primer | Reverse primer |
| Homologous sequence at the upstream of X-4 site | Saccharomyces cerevisiae BY4742 genome | SEQ ID NO:36 | SEQ ID NO:37 |
| TEF1 promoter | Saccharomyces cerevisiae BY4742 genome | SEQ ID NO:38 | SEQ ID NO:39 |
| AaDAO3 gene | pET30a-AaDAO3 plasmid | SEQ ID NO:40 | SEQ ID NO:41 |
| PRM9 terminator | Saccharomyces cerevisiae BY4742 genome | SEQ ID NO:42 | SEQ ID NO:43 |
| KanMX expression cassette | pMEL13 plasmid | SEQ ID NO:44 | SEQ ID NO:45 |
| Downstream homologous sequence of X-4 site | Saccharomyces cerevisiae BY4742 genome | SEQ ID NO:46 | SEQ ID NO:47 |
pMEL13 plasmid is a commercial plasmid that can be used to transcribe sgrnas, purchased from euroscaf.
4.3 construction of dehydrogenase knockout strain Δ BY 4742:
4.3.1 design sgRNA sequences (PAM sequences in bold) knocking out Saccharomyces cerevisiae endogenous genes ALD4(SEQ ID NO:53), ALD5(SEQ ID NO:54), HFD1(SEQ ID NO:55) on the Yeast website (https:// yeastraction. tnw. tudelft. nl /): ALD 4: 5'-CTTGTCCTGTTCAATTAATTCGG-3', respectively; ALD 5: 5'-TGGCAAATGATTCTCAATATGGG-3', respectively; HFD 1: 5'-AGGGTAAAATCATTCCAATATGG-3' are provided.
Using the primers and templates shown in Table 3, a fragment of CAS9 gene (SEQ ID NO:56) was amplified by PCR, and 21bp homologous sequences were introduced at both ends via the primers. The DNA polymerase is high-fidelity DNA polymerase I-5 from TSINGKETM2X High Fidelity Master Mix, the PCR program was set up with reference to the description: 2min at 98 ℃; 15s at 98 ℃,10 s at 58 ℃ and 1.5mi at 72 DEG Cn, 35 cycles; 5min at 72 ℃; keeping the temperature at 10 ℃.
4.3.2 agarose gel electrophoresis detection is carried out on the PCR product, and a band with the same size with the target DNA is cut off under ultraviolet light. Then, the DNA fragment was recovered from the agarose Gel using AxyPrep DNA Gel Extraction Kit from AXYGEN. The yeast high copy plasmid p2M (provided by Zhou Shiwa laboratory of Shanghai Life sciences institute of Chinese academy of sciences, full length sequence shown in SEQ ID NO:43) was double digested with the restriction enzymes BamHI and XhoI from Takara for 30min, and the digested product was recovered by cleaning with AxyPrep PCR clean Kit from AXYGEN. By using the Hieff Clone of YeasenTMThe recombinant enzyme of Plus Mlti One Step Cloning Kit recombines and ligates the recovered gel product with the p2M double-digested plasmid.
4.3.3 recombinant products were transformed into E.coli TOP10 competent cells and plated on LB plates supplemented with 100. mu.g/mL ampicillin. Positive transformants were verified by colony PCR and further verified by sequencing, indicating that the construction of the CAS9 expression plasmid p2M-CAS9 was successful.
TABLE 3
| Segment names | Form panel | Forward primer | Reverse primer |
| CAS9 fragment | IMX673 Strain genome | SEQ ID NO:63 | SEQ ID NO:64 |
| Linearized pMEL13-ALD4 | pMEL13 plasmid | SEQ ID NO:65 | SEQ ID NO:66 |
| ALD4-repair-UP | Saccharomyces cerevisiae BY4742 genome | SEQ ID NO:67 | SEQ ID NO:68 |
| ALD4-repair-DOWN | Saccharomyces cerevisiae BY4742 genome | SEQ ID NO:69 | SEQ ID NO:70 |
| Linearized pMEL13-ALD5 | pMEL13 plasmid | SEQ ID NO:71 | SEQ ID NO:72 |
| ALD5-repair-UP | Saccharomyces cerevisiae BY4742 genome | SEQ ID NO:73 | SEQ ID NO:74 |
| ALD5-repair-DOWN | Saccharomyces cerevisiae BY4742 genome | SEQ ID NO:75 | SEQ ID NO:76 |
| Linearized pMEL13-HFD1 | pMEL13 plasmid | SEQ ID NO:77 | SEQ ID NO:78 |
| HFD1-repair-UP | Saccharomyces cerevisiae BY4742 genome | SEQ ID NO:79 | SEQ ID NO:80 |
| HFD1-repair-DOWN | Saccharomyces cerevisiae BY4742 genome | SEQ ID NO:81 | SEQ ID NO:82 |
IMX673 strain was a commercial saccharomyces cerevisiae strain purchased from euroscaf.
4.3.4 knock-out ALD4 gene:
the primers and templates in Table 3 are used for amplification by a PCR method to obtain a linearized pMEL13-ALD4 plasmid, and a sgRNA homologous sequence of 20bp is introduced at two ends through the primers. The DNA polymerase is high-fidelity DNA polymerase I-5 from TSINGKETM2X High Fidelity Master Mix, the PCR program was set up with reference to the description: 2min at 98 ℃; 15s at 98 ℃,10 s at 58 ℃ and 1.5min at 72 ℃ for 35 cycles; 5min at 72 ℃; keeping the temperature at 10 ℃.
And (3) carrying out agarose gel electrophoresis detection on the PCR product, and cutting off a band with the size consistent with that of the target DNA under ultraviolet light. Then, the DNA fragment was recovered from the agarose Gel using AxyPrep DNA Gel Extraction Kit from AXYGEN. By using the Hieff Clone of YeasenTMThe recombinant enzyme of Plus Multi One Step Cloning Kit recombines the recovered gel products for cyclization (reaction conditions refer to Kit instructions).
Coli TOP10 competent cells were transformed with the cyclization product and plated on LB plates supplemented with 100. mu.g/mL ampicillin. Positive transformants were verified by colony PCR and further verified by sequencing, which indicated successful construction of sgRNA expression plasmid pMEL13-ALD 4.
Using the primers and templates in Table 3, ALD4-repair-UP (SEQ ID NO:57) and ALD4-repair-DOWN (SEQ ID NO:58) were amplified by PCR, and 53bp homologous sequences were introduced into the junction by the primers. The DNA polymerase is high-fidelity DNA polymerase I-5 from TSINGKETM2X High Fidelity Master Mix, the PCR program was set up with reference to the description: 2min at 98 ℃; 15s at 98 ℃,10 s at 58 ℃ and 0.5min at 72 ℃ for 35 cycles; 5min at 72 ℃; keeping the temperature at 10 ℃.
And (3) carrying out agarose gel electrophoresis detection on the PCR product, and cutting off a band with the size consistent with that of the target DNA under ultraviolet light. Then, the DNA fragment was recovered from the agarose Gel using AxyPrep DNA Gel Extraction Kit from AXYGEN.
The two fragments obtained were transformed into Saccharomyces cerevisiae BY4742 competence together with the two plasmids constructed (p2M-CAS9 and pMEL13-ALD4), spread on YPAD plates supplemented with 300. mu.g/mL hygromycin B (hygromycin B) and 200mg/LG418, and cultured at 30 ℃ for 48 h. ALD4 knockout transformants were verified by yeast colony PCR. The Δ BY4742-1 strain was obtained BY subculturing missing the p2M-CAS9 and pMEL13-ALD4 plasmids.
4.3.5 knock-out of ALD5 and HFD1 genes:
with reference to the method for knocking out the ALD4 gene in the step 4.3.4, a pMEL13-ALD5 plasmid is constructed, ALD5-repair-UP (SEQ ID NO:59) and ALD5-repair-DOWN (SEQ ID NO:60) fragments are amplified, ALD5 is knocked out on the basis of delta BY4742-1, and a delta BY4742-2 strain is obtained through plasmid loss.
With reference to the method for knocking out the ALD4 gene in the step 4.3.4, a pMEL13-HFD1 plasmid is constructed, HFD1-repair-UP (SEQ ID NO:61) and HFD1-repair-DOWN (SEQ ID NO:62) fragments are amplified, gene HFD1 is continuously knocked out on the basis of delta BY4742-2, and an ALD4-ALD5-HFD1 knock-out strain, namely the delta BY4742 strain, is finally obtained through plasmid loss.
4.3.6 construction of the Δ BY4742-OP-A3 Strain:
referring to the method for constructing the BY4742-OP-A3 strain in the step 4.2, genes EcODC, AtPMT and AaDAO3 are transferred into the delta BY4742 strain to obtain the delta BY4742-OP-A3 strain. The saccharomyces cerevisiae is introduced with genes of EcODC, AtPMT and AaDAO3, and is knocked out with genes of ALD4, ALD5 and HFD 1.
4.4 construction of a.DELTA.BY 4742-OP-A3-SAM2 yeast strain overexpressing Gene SAM 2:
4.4.1 amplification of the transformed fragment by PCR using the primers and templates of Table 4: upstream homologous sequence of X-4 site, TEF1 promoter, AaDAO3 gene, PRM9 terminator, PGI terminator (SEQ ID NO:83), SAM2 gene (SEQ ID NO:84), TCCTDH promoter (enhanced TDH3 promoter, sequence SEQ ID NO:85), KanMX expression cassette, downstream homologous sequence of X-4 site, and 60-80 bp homologous sequence is introduced between adjacent fragments through primers. The DNA polymerase is high-fidelity DNA polymerase I-5 from TSINGKETM2X High Fidelity Master Mix, the PCR program was set up with reference to the description: 2min at 98 ℃; 35 cycles of 98 ℃ for 15s, 58 ℃ for 10s and 72 ℃ for 1 min; 5min at 72 ℃; keeping the temperature at 10 ℃.
4.4.2 detecting the PCR product by agarose gel electrophoresis, and cutting off a band with the same size with the target DNA under ultraviolet light. Then, the DNA fragment was recovered from the agarose Gel using AxyPrep DNA Gel extraction kit from AXYGEN.
4.4.3 transformation of 9 fragments above with p2M-EcODC-AtPMT plasmid into Δ BY4742 competence (competence creation and transformation method reference (Gietz and Schiestl 2007), spread on YPAD plates supplemented with 300. mu.g/mL hygromycin B (hygromycin B) and 200mg/L G418, and culture at 30 ℃ for 48 h. Positive results were confirmed BY yeast colony PCR, i.e., Δ BY4742-OP-A3-SAM2 strain, in which genes for EcODC, AtPMT and AaDAO3 were introduced, and ALD4, ALD5 and HFD1 genes were knocked out, and cofactor synthesis gene SAM2 was introduced. the yeast strain was constructed as shown in FIG. 6.
TABLE 4


TCCTDH sequence was ligated into pUC57 plasmid.
EXAMPLE 5 fermentation of engineered Saccharomyces cerevisiae producing N-methylpyrrolidine
Wild-type Saccharomyces cerevisiae BY4742, engineered Saccharomyces cerevisiae BY4742-OP, BY4742-OP-A3, Δ BY4742-OP-A3, Δ BY4742-OP-A3-SAM2 constructed in examples 3 and 4 above were picked from the plate and shake-cultured overnight in a test tube containing 5mL of YPD medium. The flask was transferred to a 50ml YPD flask and 50. mu.M CuSO was added4Placing the bacterial liquid in a 30 ℃ shaking table, performing fermentation culture at 200rpm, sampling at different time points and detecting OD600And N-methylpyrrolidine yield. As shown in FIG. 7A, N-methylpyrrolidine was accumulated in yeast strain BY4742-OP-A3 containing EcODC, AtPMT and AaDAO3 genes, and the yield of N-methylpyrrolidine was 3.22mg/L when the fermentation time reached 120 hours. To further increase the target product yield, we knocked out the dehydrogenase genes ALD4, ALD5 and HFD1 for converting N-methylaminobutyraldehyde to N-methylaminobutyric acid, and the fermentation results indicated that the N-methylpyrrolidine yield of yeast strain Δ BY4742-OP-A3 increased to 9.88mg/L (fig. 7B). In order to further improve the yield of the N-methylpyrrolidine, SAM2 is overexpressed to improve the supply amount of a cofactor SAM required BY AtPMT catalysis, and the optimized strain delta BY4742-OP-A3-SAM2 finally generates 21.92mg/L of the N-methylpyrrolidine (figure 7C), and compared with the yeast strain BY4742-OP-A3, the yield is improved BY about 7 times.
Example 7 chemical Synthesis of N-methylated putrescine and N-methylpyrroline
Since N-methylated putrescine and N-methylpyrroline are difficult to obtain by commercial purchase, the N-methylated putrescine and N-methylpyrroline are synthesized by a chemical method to serve as reaction substrates and product standards. The specific method comprises the following steps:
7.1 Synthesis of N-methylated putrescine

Adding Et3N (1mmol) and (Boc)2O (262mg, 1.2mmol) was added to 10mL of methanol containing 1.0mol putrescine, and the mixture was stirred at room temperatureFor 2h, 10mL of 0.1N aqueous NaOH solution was added and extracted with 15mL of ethyl acetate. The organic phase was then back extracted with 20mL of 0.1N HCl, the resulting aqueous phase adjusted to pH10, extracted three times with 20mL of ethyl acetate, the organic phases combined, washed once with saturated brine, dried over anhydrous sodium sulfate, filtered, and spin dried to give Boc-putrescine. Mixing LiAlH4(6.33mmol) was added to 10mL of anhydrous THF, ice-cooled, the flask was purged with nitrogen to maintain an oxygen-free environment, Boc-putrescine (1mmol) was dissolved in 5mL of anhydrous THF, LiAlH was added dropwise4In THF solution, the temperature of the reaction solution is gradually increased to 85 ℃, reflux is carried out for 18h, the reaction solution is placed in an ice bath after being cooled to room temperature, sodium sulfate is slowly added to stop the reaction, the filtration is carried out, 20mL of 0.1N NaOH aqueous solution is added into the filtrate, 25mL of ethyl acetate is added to extract, then 25mL of 0.1N HCl is added to back extract the organic phase, and the obtained aqueous solution is dried in a rotating mode to obtain the pure N-methylated putrescine.
FIG. 8A and FIG. 8B show the NMR spectra of N-methylated putrescine (R) ((R))1H NMR), and nuclear magnetic resonance carbon spectrum (C13C NMR)。
1H NMR(400MHz,D2O)δ3.09(dd,J=15.2,7.4Hz,4H),2.74(s,3H),1.94-1.64(m,4H)。
13C NMR(101MHz,D2O)δ48.26,38.79,32.68,23.83,22.56。
7.2 Synthesis of N-methylpyrrolidine

1mL Et3N and 0.1mmol DMAP were added dropwise to a solution of 1mmol N-methylaminobutanol in 5mL THF, 1.1mmol (Boc) were added slowly2O, the solution was stirred at room temperature for 1h, then 10mL of 0.1N aqueous NaOH solution was added and extracted with 15mL of ethyl acetate. 15mL of 0.1N HCl was added to the organic phase, the resulting aqueous solution was adjusted to pH10, and then extracted 3 times with 15mL of ethyl acetate, the organic phases were combined, dried with saturated brine, filtered, and spin-dried to give Boc-N-methylaminobutanol. 0.5mmol Boc-N-methylaminobutanol, 1mL DMSO and 0.5mL Et3N was dissolved in 4mL of anhydrous dichloromethane,adding 1.5mmol of SO3And maintaining the temperature of the/Pyr compound at 0 ℃, stirring for 30min, purifying by a silica gel column to obtain Boc-N-methylamino butyraldehyde, dissolving 0.4mmol of Boc-N-methylamino butyraldehyde in 10mL of water, adding 2N HCl, stirring for 1h at room temperature, and carrying out rotary drying to obtain the pure N-methylpyrrolidine.
FIG. 9A and FIG. 9B show the NMR spectra of N-methylpyrrolidine ((H))1H NMR), and nuclear magnetic resonance carbon spectrum (C13C NMR)。
1H NMR(500MHz,D2O)δ8.63(s,1H),4.16(t,J=7.4Hz,2H),3.63(s,3H),3.16(d,J=29.4Hz,2H),2.44–2.27(m,2H)。
13C NMR(101MHz,D2O)δ181.56,60.59,40.39,35.74,19.48。
In a word, the EcODC, AtPMT and AaDAO2-3 three-enzyme combined catalytic system can catalyze L-ornithine reaction to obtain N-methylpyrrolidine by a one-pot method, and the constructed escherichia coli engineering bacteria and saccharomyces cerevisiae engineering bacteria can directly produce the N-methylpyrrolidine through fermentation. It is obvious to those skilled in the art that the biosynthesis method of the present invention has natural advantages of environmental protection compared with the chemical synthesis method, and thus has industrial development and application prospects.
It should also be noted that the listing or discussion of a prior-published document in this specification should not be taken as an admission that the document is prior art or common general knowledge.
Reference to the literature
Chase MW,Knapp S,Cox AV,Clarkson JJ,Butsko Y,Joseph J,Savolainen V,Parokonny AS.2003.Molecular systematics,GISH and the origin of hybrid taxa in Nicotiana(Solanaceae).Annals of Botany 92(1):107-127.
Cui L,Huang F,Zhang D,Lin Y,Liao P,Zong J,Kai G.2015.Transcriptome exploration for further understanding of the tropane alkaloids biosynthesis inAnisodus acutangulus.Molecular Genetics&Genomics 290(4):1367-1377.
Docimo T,Reichelt M,Schneider B,Kai M,Kunert G,GershenzonJ,D'Auria JC.2012.The first step inthe biosynthesis of cocaine in Erythroxylum coca:the characterization of arginine and ornithine decarboxylases.Plant Molecular Biology 78(6):599-615.

Gietz RD,Schiestl RH.2007.High-efficiency yeast transformation using the LiAc/SScarrier DNA/PEG method.Nat Protoc 2(1):31-4.


Heim WG,Sykes KA,Hildreth SB,Sun J,Lu RH,Jelesko JG.2007.Cloning and characterization of a Nicotiana tabacum methylputrescine oxidase transcript.Phytochemistry 68(4):454-463.
Kai G,Zhang A,Guo Y,Li L,Cui L,Luo X,Liu C,Xiao J.2012.Enhancing the production of tropane alkaloids in transgenic Anisodus acutangulus hairy root cultures by over-expressing tropinone reductase I and hyoscyamine-6β-hydroxylase.Molecular BioSystems 8(11):2883-2890.
Kotopka BJ,Li Y,Smolke CD.2018.Synthetic biology strategies toward heterologous phytochemical production.Natural product reports.
Li S,Li Y,Smolke CD.2018.Strategies for microbial synthesis of high-value phytochemicals.Nature chemistry 10(4):395-404.
Liu T,Zhu P,Cheng KD,Meng C,Zhu HX.2005.Molecular cloning and expression of putrescine N-methyltransferase from the hairy roots of Anisodus tanguticus.Planta Medica 71(10):987-989.
Nguyen AQ,Schneider J,Reddy GK,Wendisch VF.2015.Fermentative Production of the Diamine Putrescine:System Metabolic Engineering of Corynebacterium Glutamicum.5(2):211-231.
Qian ZG,Xia XX,Sangyup L.2010.Metabolic engineering of Escherichia coli for the production of putrescine:a four carbon diamine.Biotechnology&Bioengineering 104(4):651-662.
Ruetsch YA, T,Borgeat A.2001.From cocaine to ropivacaine:the history of localanesthetic drugs.Current Topics in Medicinal Chemistry 1(3).
T,Borgeat A.2001.From cocaine to ropivacaine:the history of localanesthetic drugs.Current Topics in Medicinal Chemistry 1(3).
Sequence listing
<110> Shanghai Life science research institute of Chinese academy of sciences
Biosynthesis method of <120> N-methyl pyrroline
<130> SHPI1811334
<160> 93
<170> SIPOSequenceListing 1.0
<210> 1
<211> 1242
<212> DNA
<213> coca ()
<400> 1
atgggttcta atgctagaaa cttgcaagca gtcttgggtg ctccaggtgt taggggtagg 60
agggttgctg ctttgccaaa ggacggtttg acagatttta tgcaatctat tataatgaaa 120
agaaatgaat caaaggaacc attctacgtt ttggacttgg gagctgtctc tggtttgatg 180
gataaatggt ctagaacttt gccaatggtc aggccattct acgcagtcaa gtgcaaccca 240
gagcctgctt tgttgggttc tttggctgca atgggtgcaa actttgattg cgcttcaagg 300
gctgaaattg aagctgtctt gtcattgagg gtctcaccag acaggattgt ttacgctaat 360
ccatgcaaac aagaatcaca tataaaatat gctgcttctg ttggtgttaa tttgactaca 420
ttcgattcta aagacgaatt ggagaagatg agaaagtggc acccaaagtg cgcattgttg 480
ttgagagtca aggctccaga agatggtggt gctagatgcc cattgggtcc aaagtacggt 540
gctttgccag aggaagtcat tccattgttg caggctgcac aagctgctag gttgtctgtc 600
gtcggagctt ctttccacat tggttcaggt gctactcatt tttcttctta tagaggtgca 660
attgcagaag ctaagaaggt ttttgaaact gctgttaaaa tgggtatgcc aaggatgact 720
atgttaaata taggaggtgg tttcactgca ggttctcagt tcgacgaagc tgctacagct 780
attaaatcag cattacagac ttattttcca aatgaaccag gtttaacaat tatttctgaa 840
ccaggtagat tttttgctga atctgctttc actttagcta caaatgtcat tggtagaaga 900
gttagaggtg aattgagaga atactggatt aatgatggta tttacggttc tatgaattgt 960
atattatatg atcatgcaac tgttacttgt aagccattgg catgtacttc ttctagggct 1020
aacccaatgt gtaagggtgc tagggtttat aactctacag tcttcggtcc aacatgcgac 1080
gcattagaca ctgtcatgac tggtcacttg ttgccagact tgcaagtctc tgactggttg 1140
gtcttcccaa acatgggtgc ttacactgct gctgctggtt catcttttaa tggttttaaa 1200
actgctgcta ttttaactta tttagcatat tcaaaccctt aa 1242
<210> 2
<211> 413
<212> PRT
<213> coca ()
<400> 2
Met Gly Ser Asn Ala Arg Asn Leu Gln Ala Val Leu Gly Ala Pro Gly
1 5 10 15
Val Arg Gly Arg Arg Val Ala Ala Leu Pro Lys Asp Gly Leu Thr Asp
20 25 30
Phe Met Gln Ser Ile Ile Met Lys Arg Asn Glu Ser Lys Glu Pro Phe
35 40 45
Tyr Val Leu Asp Leu Gly Ala Val Ser Gly Leu Met Asp Lys Trp Ser
50 55 60
Arg Thr Leu Pro Met Val Arg Pro Phe Tyr Ala Val Lys Cys Asn Pro
65 70 75 80
Glu Pro Ala Leu Leu Gly Ser Leu Ala Ala Met Gly Ala Asn Phe Asp
85 90 95
Cys Ala Ser Arg Ala Glu Ile Glu Ala Val Leu Ser Leu Arg Val Ser
100 105 110
Pro Asp Arg Ile Val Tyr Ala Asn Pro Cys Lys Gln Glu Ser His Ile
115 120 125
Lys Tyr Ala Ala Ser Val Gly Val Asn Leu Thr Thr Phe Asp Ser Lys
130 135 140
Asp Glu Leu Glu Lys Met Arg Lys Trp His Pro Lys Cys Ala Leu Leu
145 150 155 160
Leu Arg Val Lys Ala Pro Glu Asp Gly Gly Ala Arg Cys Pro Leu Gly
165 170 175
Pro Lys Tyr Gly Ala Leu Pro Glu Glu Val Ile Pro Leu Leu Gln Ala
180 185 190
Ala Gln Ala Ala Arg Leu Ser Val Val Gly Ala Ser Phe His Ile Gly
195 200 205
Ser Gly Ala Thr His Phe Ser Ser Tyr Arg Gly Ala Ile Ala Glu Ala
210 215 220
Lys Lys Val Phe Glu Thr Ala Val Lys Met Gly Met Pro Arg Met Thr
225 230 235 240
Met Leu Asn Ile Gly Gly Gly Phe Thr Ala Gly Ser Gln Phe Asp Glu
245 250 255
Ala Ala Thr Ala Ile Lys Ser Ala Leu Gln Thr Tyr Phe Pro Asn Glu
260 265 270
Pro Gly Leu Thr Ile Ile Ser Glu Pro Gly Arg Phe Phe Ala Glu Ser
275 280 285
Ala Phe Thr Leu Ala Thr Asn Val Ile Gly Arg Arg Val Arg Gly Glu
290 295 300
Leu Arg Glu Tyr Trp Ile Asn Asp Gly Ile Tyr Gly Ser Met Asn Cys
305 310 315 320
Ile Leu Tyr Asp His Ala Thr Val Thr Cys Lys Pro Leu Ala Cys Thr
325 330 335
Ser Ser Arg Ala Asn Pro Met Cys Lys Gly Ala Arg Val Tyr Asn Ser
340 345 350
Thr Val Phe Gly Pro Thr Cys Asp Ala Leu Asp Thr Val Met Thr Gly
355 360 365
His Leu Leu Pro Asp Leu Gln Val Ser Asp Trp Leu Val Phe Pro Asn
370 375 380
Met Gly Ala Tyr Thr Ala Ala Ala Gly Ser Ser Phe Asn Gly Phe Lys
385 390 395 400
Thr Ala Ala Ile Leu Thr Tyr Leu Ala Tyr Ser Asn Pro
405 410
<210> 3
<211> 31
<212> DNA
<213> Artificial sequence ()
<400> 3
ggaattccat atgatgggtt ctaatgctag a 31
<210> 4
<211> 34
<212> DNA
<213> Artificial sequence ()
<400> 4
ataagaatgc ggccgcaggg tttgaatatg ctaa 34
<210> 5
<211> 1017
<212> DNA
<213> mountain Dang ()
<400> 5
atggaagtta tttctaatca taacaatggt tctactacta aaattatttt gaaaaatggt 60
tctatttgta atggtaatgt taatggtaat tcacattctc atgaaaaaat tgaaaacaaa 120
ttagttgaat gtacaaattc tattaaacca ggttggtttt cagaattttc agcattgtgg 180
ccaggtgaag cattttcttt gaaaattgaa aaattattgt ttcaaggtaa atcagattat 240
caagatgtta tgttgtttga atctgcaaca tacggtaaag ttttaacttt agatggtgca 300
attcaacata cagaaaatgg tggttttcca tatacagaaa tgattgttca cctccctttg 360
ggttctattc catctcctaa aaaagttttg attattggtg gtggtattgg ttttactttg 420
tttgaagttt ctcgctaccc tactattgaa actattgata ttgttgaaat tgatgatgtt 480
gttgttgatg tttctaggaa attcttccca tacctggctg cgggttttga tgatcctaga 540
gttactttga ttattgggga tggtgcagca tttgttaaag ctgcacaacc aggttattat 600
gatgctatta ttgttgattc atcagatcca attggtcctg ctaaagattt gtttgaaaga 660
ccattcttcg aggcgttagc taaagcgtta aggccaggtg gtgttgtttg tactcaagca 720
gaatcaattt ggttacacat gcatttgatt aaacaaatta ttgctaattg taggcaagtt 780
tttaaaggtt cagttaatta tgcttggaca acagttccaa cttatcctac aggtgttatt 840
ggttatatgt tgtgttcaac agaaggtcca gaagttaatt ttaaaaatcc agttaattca 900
attgataaag atacatctca tgttaaatct aaaggtcctt taaaatttta taattctgat 960
attcataaag cagccttcat tttgccatct tttgctaggg atctcgttga attttaa 1017
<210> 6
<211> 337
<212> PRT
<213> mountain Dang ()
<400> 6
Met Glu Val Ile Ser Asn His Asn Asn Gly Ser Thr Thr Lys Ile Ile
1 5 10 15
Leu Lys Asn Gly Ser Ile Cys Asn Gly Asn Val Asn Gly Asn Ser His
20 25 30
Ser His Glu Lys Ile Glu Asn Lys Leu Val Glu Cys Thr Asn Ser Ile
35 40 45
Lys Pro Gly Trp Phe Ser Glu Phe Ser Ala Leu Trp Pro Gly Glu Ala
50 55 60
Phe Ser Leu Lys Ile Glu Lys Leu Leu Phe Gly Lys Ser Asp Tyr Gln
65 70 75 80
Asp Val Met Leu Phe Glu Ser Ala Thr Tyr Gly Lys Val Leu Thr Leu
85 90 95
Asp Gly Ala Ile Gln His Thr Glu Asn Gly Gly Phe Pro Tyr Thr Glu
100 105 110
Met Ile Val His Leu Pro Leu Gly Ser Ile Pro Ser Pro Lys Lys Val
115 120 125
Leu Ile Ile Gly Gly Gly Ile Gly Phe Thr Leu Phe Glu Val Ser Arg
130 135 140
Tyr Pro Thr Ile Glu Thr Ile Asp Ile Val Glu Ile Asp Asp Val Val
145 150 155 160
Val Asp Val Ser Arg Lys Phe Phe Pro Tyr Leu Ala Ala Gly Phe Asp
165 170 175
Asp Pro Arg Val Thr Leu Ile Ile Gly Asp Gly Ala Ala Phe Val Lys
180 185 190
Ala Ala Gln Pro Gly Tyr Tyr Asp Ala Ile Ile Val Asp Ser Ser Asp
195 200 205
Pro Ile Gly Pro Ala Lys Asp Leu Phe Glu Arg Pro Phe Phe Glu Ala
210 215 220
Leu Ala Lys Ala Leu Arg Pro Gly Gly Val Val Cys Thr Gln Ala Glu
225 230 235 240
Ser Ile Trp Leu His Met His Leu Ile Lys Gln Ile Ile Ala Asn Cys
245 250 255
Arg Gln Val Phe Lys Gly Ser Val Asn Tyr Ala Trp Thr Thr Val Pro
260 265 270
Thr Tyr Pro Thr Gly Val Ile Gly Tyr Met Leu Cys Ser Thr Glu Gly
275 280 285
Pro Glu Val Asn Phe Lys Asn Pro Val Asn Ser Ile Asp Lys Asp Thr
290 295 300
Ser His Val Lys Ser Lys Gly Pro Leu Lys Phe Tyr Asn Ser Asp Ile
305 310 315 320
His Lys Ala Ala Phe Ile Leu Pro Ser Phe Ala Arg Asp Leu Val Glu
325 330 335
Phe
<210> 7
<211> 33
<212> DNA
<213> Artificial sequence ()
<400> 7
ggaattccat atgatggaag ttatttctaa tca 33
<210> 8
<211> 36
<212> DNA
<213> Artificial sequence ()
<400> 8
ataagaatgc ggccgcaaat tcaacgagat ccctag 36
<210> 9
<211> 2127
<212> DNA
<213> three thirds ()
<400> 9
atgagatata tcttctttct cattagcata attttgcttt taattttcac ttttttaaac 60
ttaccatctc ctctttctca cacaactgag ttattagact gcaccactta ctctccatgg 120
tgcactaagc ccttttccca acacaaaaat cactatgcca atttcccaaa atacccttta 180
gatccattaa caataaaaga aattcaaaaa gtgaaaaaaa tcattaattc aattgatgag 240
tttagtaaaa aaggttatgt tctccactct gtggtacttg aagagccggc aaaggaggtg 300
gtggtgaact ggcggaaagg tcgccgcctt ccgccacgga aggcggcggt ggttgtacgt 360
gcggttggtg ttgtgcacgt gcttactgtg gatattgaaa cgggtcgggt gacccgacgt 420
gaaacgggtg attattcggg ttacccgatc atgacgatcg aggatatgat tacggcgact 480
actgcaccac ttgcgaacgc tgattttaac cgttcgattc tcgagcgtgg cgttgatttg 540
gctgaccttg catgtttgcc tattgccact ggttggtacg ggaaagctga ggagaataga 600
agagtcatca aagtacagtg ctacacaatg aaggacacaa ttaatttcta catgagaccc 660
attgaaggac taacagtact tcttgattta gacacccaac aagtcataga tattctagat 720
gaaggaaaga acataccaat accaaaggcc gccaacacag actatcgctt ctctactaaa 780
aaacacacac aaaaaataaa cttactcaaa ccaatatcta tcgaacaacc aaatggtcca 840
agtttcacta tagagaacaa ccatatagtg aaatgggcaa attgggaatt tcacctcaag 900
cccgacccga gagccggggt gattatatcc caggtcatga tccaagatcc ggatacgggg 960
aagattagaa atgtcatgta taaagggttt acgtcggagt tgtttgtgcc ttacatggat 1020
ccatcagatg catggtattt taagacgtat atggatgcgg gtgaatacgg gttcgggtta 1080
caagcaatgc cgcttgaccc gttaaatgat tgtccacgta atgcgtatta tatggatggt 1140
gtgtttgtgg cagctgatgg aacaccatat gttcgtgaaa atatgatttg tgtgtttgag 1200
agatatgctg gtgatattgg atggcgacat gctgaatctc ccattactgg tttgccgatt 1260
agagaagtga ggccgaaggt gacgttagta gttagaatgg cagcgtcagt ggctaactat 1320
gattacattg tggattggga gttccagact gatggactta tccgagctaa ggttggacta 1380
agtggaatat tgatggtgaa aggctctcca tatgtgaaca tgaaccaagt gaaccaaaat 1440
gagtatctct acggcaccct cttatctgaa aacataatag gagtcatcca tgatcactac 1500
ataactttcc atctcgacat ggacatcgat ggtccatcga acaattcttt cgtgaaggtg 1560
aatctccaga aggagatgac ttctcctgga gaatccccgc gaaggagcta cttaaaagct 1620
gttcgacatg tggctaaaac tgaaaaggat gcacagatta agctcaagtt atatgatcct 1680
tcagaattcc atgtgattaa tcctaacaag aagtcaagag ttgggaaccc tgttggttac 1740
aaagtggttc ctggtggcac tgcagctagt ttactggacc atgatgatcc tccacagaag 1800
agaggtgctt ttactaataa ccaaatttgg gtcacacctt ataatgaatc tgagcaatgg 1860
gctgctggct tgtttgttta ccaaagtcaa ggtgatgata ctcttgctgt ttggtctgac 1920
agagacaggc caattgagaa taaagacata gtggtgtggt atacattagg gttccatcat 1980
attccatgcc aagaggattt cccaatcatg ccaacagtat catcaagctt tgagataaag 2040
ccagtgaatt tctttgagag caatccaatt atgaggattc aacctaattc tccaaaggac 2100
ctgccaattt gcaaagcttc tgcttga 2127
<210> 10
<211> 707
<212> PRT
<213> three thirds ()
<400> 10
Met Arg Tyr Ile Phe Phe Leu Ile Ser Ile Ile Leu Leu Leu Ile Phe
1 5 10 15
Thr Phe Leu Asn Leu Pro Ser Pro Leu Ser His Thr Thr Glu Leu Leu
20 25 30
Asp Cys Thr Thr Tyr Ser Pro Trp Cys Thr Lys Pro Phe Ser Gln His
35 40 45
Lys Asn His Tyr Ala Asn Phe Pro Lys Tyr Pro Leu Asp Pro Leu Thr
50 55 60
Ile Lys Glu Ile Gln Lys Val Lys Lys Ile Ile Asn Ser Ile Asp Glu
65 70 75 80
Phe Ser Lys Lys Gly Tyr Val Leu His Ser Val Val Leu Glu Glu Pro
85 90 95
Ala Lys Glu Val Val Val Asn Trp Arg Lys Gly Arg Arg Leu Pro Pro
100 105 110
Arg Lys Ala Ala Val Val Val Arg Ala Val Gly Val Val His Val Leu
115 120 125
Thr Val Asp Ile Glu Thr Gly Arg Val Thr Arg Arg Glu Thr Gly Asp
130 135 140
Tyr Ser Gly Tyr Pro Ile Met Thr Ile Glu Asp Met Ile Thr Ala Thr
145 150 155 160
Thr Ala Pro Leu Ala Asn Ala Asp Phe Asn Arg Ser Ile Leu Glu Arg
165 170 175
Gly Val Asp Leu Ala Asp Leu Ala Cys Leu Pro Ile Ala Thr Gly Trp
180 185 190
Tyr Gly Lys Ala Glu Glu Asn Arg Arg Val Ile Lys Val Gln Cys Tyr
195 200 205
Thr Met Lys Asp Thr Ile Asn Phe Tyr Met Arg Pro Ile Glu Gly Leu
210 215 220
Thr Val Leu Leu Asp Leu Asp Thr Gln Gln Val Ile Asp Ile Leu Asp
225 230 235 240
Glu Gly Lys Asn Ile Pro Ile Pro Lys Ala Ala Asn Thr Asp Tyr Arg
245 250 255
Phe Ser Thr Lys Lys His Thr Gln Lys Ile Asn Leu Leu Lys Pro Ile
260 265 270
Ser Ile Glu Gln Pro Asn Gly Pro Ser Phe Thr Ile Glu Asn Asn His
275 280 285
Ile Val Lys Trp Ala Asn Trp Glu Phe His Leu Lys Pro Asp Pro Arg
290 295 300
Ala Gly Val Ile Ile Ser Gln Val Met Ile Gln Asp Pro Asp Thr Gly
305 310 315 320
Lys Ile Arg Asn Val Met Tyr Lys Gly Phe Thr Ser Glu Leu Phe Val
325 330 335
Pro Tyr Met Asp Pro Ser Asp Ala Trp Tyr Phe Lys Thr Tyr Met Asp
340 345 350
Ala Gly Glu Tyr Gly Phe Gly Leu Gln Ala Met Pro Leu Asp Pro Leu
355 360 365
Asn Asp Cys Pro Arg Asn Ala Tyr Met Asp Gly Val Phe Val Ala Ala
370 375 380
Asp Gly Thr Pro Tyr Val Arg Glu Asn Met Ile Cys Val Phe Glu Arg
385 390 395 400
Tyr Ala Gly Asp Ile Gly Trp Arg His Ala Glu Ser Pro Ile Thr Gly
405 410 415
Leu Pro Ile Arg Glu Val Arg Pro Lys Val Thr Leu Val Val Arg Met
420 425 430
Ala Ala Ser Val Ala Asn Tyr Asp Tyr Ile Val Asp Trp Glu Phe Gln
435 440 445
Thr Asp Gly Leu Ile Arg Ala Lys Val Gly Leu Ser Gly Ile Leu Met
450 455 460
Val Lys Gly Ser Pro Tyr Val Asn Met Asn Gln Val Asn Gln Asn Glu
465 470 475 480
Tyr Leu Tyr Gly Thr Leu Leu Ser Glu Asn Ile Ile Gly Val Ile His
485 490 495
Asp His Tyr Ile Thr Phe His Leu Asp Met Asp Ile Asp Gly Pro Ser
500 505 510
Asn Asn Ser Phe Val Lys Val Asn Leu Gln Lys Glu Met Thr Ser Pro
515 520 525
Gly Glu Ser Pro Arg Arg Ser Tyr Leu Lys Ala Val Arg His Val Ala
530 535 540
Lys Thr Glu Lys Asp Ala Gln Ile Lys Leu Lys Leu Tyr Asp Pro Ser
545 550 555 560
Glu Phe His Val Ile Asn Pro Asn Lys Lys Ser Arg Val Gly Asn Pro
565 570 575
Val Gly Tyr Lys Val Val Pro Gly Gly Thr Ala Ala Ser Leu Leu Asp
580 585 590
His Asp Asp Pro Pro Gln Lys Arg Gly Ala Phe Thr Asn Asn Gln Ile
595 600 605
Trp Val Thr Pro Tyr Asn Glu Ser Glu Gln Trp Ala Ala Gly Leu Phe
610 615 620
Val Tyr Gln Ser Gln Gly Asp Asp Thr Leu Ala Val Trp Ser Asp Arg
625 630 635 640
Asp Arg Pro Ile Glu Asn Lys Asp Ile Val Val Trp Tyr Thr Leu Gly
645 650 655
Phe His His Ile Pro Cys Gln Glu Asp Phe Pro Ile Met Pro Thr Val
660 665 670
Ser Ser Ser Phe Glu Ile Lys Pro Val Asn Phe Phe Glu Ser Asn Pro
675 680 685
Ile Met Arg Ile Gln Pro Asn Ser Pro Lys Asp Leu Pro Ile Cys Lys
690 695 700
Ala Ser Ala
705
<210> 11
<211> 43
<212> DNA
<213> Artificial sequence ()
<400> 11
gatatcatga gatatatctt ctttctcatt agcataattt tgc 43
<210> 12
<211> 46
<212> DNA
<213> Artificial sequence ()
<400> 12
ataagaatgc ggccgcctag tatatattca cgaatcataa ttacac 46
<210> 13
<211> 2322
<212> DNA
<213> three thirds ()
<400> 13
atggcctcaa ctcaggaaaa ggcgacgtca cgaaatgttt ccgccgcttc tgcaacggaa 60
tggactgccg gaagcgtagg tcaagtttcc gatctttcct catcggcgaa cgtcaaaagt 120
actgctgctg ctgctccgtc tcctttgacg gctgtgatcg actctattga tcgtccttct 180
ccaccaaatc cgcctgccgt taaaggactg cctaccctgt tgagggctca aactcaccat 240
cccttggacc ccttaactgc tgctgaaatt tccgtggccg tggcgactgt cagggcagct 300
ggaagcactc ctgaggtgag agatagcatg cgctttgtcg aggctgtttt ggtggaacca 360
gataagagtg tggttgcttt agctgatgca tacttcttcc ctcctttcca accatcttta 420
ttgccgagaa caaaaggtgg gcctgtaatt cctagtaaac ttcctccaag gaaggctaaa 480
ctgattgttt ataacaagaa atcaaatgag accagcatat ggattgttga gctctcagag 540
gttcatgctg ttactcgagg aggccaccac cgtggcaaag ttatttcatc taaggttgta 600
cccgatatac agcctccaat ggacgctgct gaatatgctg aatgtgaatc tgtggtgaag 660
gatttccctc cttttcgtga tgcaatgaag aagagaggaa tcgatgatat ggatcttgtg 720
atggtcgatg cctggtgtgc aggttatttc agtgaggctg atgcacctaa ccgccgtcta 780
ggaaaacctc ttatcttttg cagaactgag agcgactgtc caatggaaaa tggctatgct 840
cggccagttg aagggattca tatactggtt gatatgcaga atatggttgt gatagagttt 900
gaagatcgta aactggttcc attaccacca gctgatccat tgagaaatta cacttccggt 960
gaaacgagag gaggggttga ccgaagtgat gttaaacctc ttcttattag tcagcctgaa 1020
ggtcctagct tccgtgtcag tgggcacttt gttcaatggc agaagtggaa ctttcgtatt 1080
ggctttaccc ccaaagaggg tctggttatc tattctgttg catatattga cggtagcaga 1140
ggccgtagac cagttgcgca tagactgagc ttcattgaaa tggtagtccc ctatggggat 1200
ccaaatgagc cacattacag gaaaaatgct tttgatgcag gggaagatgg gcttggcaaa 1260
aatgcgcatt ccttaaagaa gggttgtgat tgcttaggct atattaaata tttcgatgca 1320
cattttacaa acttcacagg cggtgttgag acaatagaaa attgtgtctg cttacatgag 1380
gaggatcatg gaatcttatg gaagcatcaa gattggagaa caggtttagc tgaagtacga 1440
cgttcccgac ggctaacagt gtctttcatc tgtactgtgg caaactatga atatggattt 1500
tactggcatt tttatcagga tgggaaaatc gaggctgagg ttaagctgac cggaattctc 1560
agcttaggtg ctcttctacc aggggaagtt cgaaaatatg ggacaactat tgcacctggc 1620
ttgtatgcac ctgtacatca gcacttcttt gtggctcgca tggatatggc tgttgattgc 1680
aaagcagggg agtcacataa tcaggtggtt gaagtaaatg ctagaattga accaccagga 1740
gaaaataatg ttcataataa tgcattttat gctgaagaga gattgcttaa aactgaactg 1800
gaagcaatgc gtgattgtaa tcctctaact gctcggcatt ggattatccg gaacacaaga 1860
acagtcaatc gcactgggca gttaactggt tacaagctag taccaggtac aaactgtctg 1920
ccactagctg gctcagaggc aaaattcttg aggagagctg ctttcttaaa gcataatctt 1980
tgggtcaccc cttactctct tgatgagatg tttcctggag gagaatttcc aaatcaaaat 2040
cctcgtgttg gtgagggatt ggctacttgg gttcagcaga atcgatccct ggaagaaacg 2100
caaatagtac tttggtatgt ttttggactt atacatgttc cacggctaga agactggccg 2160
gtcatgccag tagagcacat tggttttatg ctacagcctc atgggttctt caattgctcc 2220
ccagctgttg atgttcctcc cagcacggct gacttggata ttaaggaaaa tggggtagtg 2280
gcaaagtctt gccacaatga tggtataatg gctaagcttt ga 2322
<210> 14
<211> 773
<212> PRT
<213> three thirds ()
<400> 14
Met Ala Ser Thr Gln Glu Lys Ala Thr Ser Arg Asn Val Ser Ala Ala
1 5 10 15
Ser Ala Thr Glu Trp Thr Ala Gly Ser Val Gly Gln Val Ser Asp Leu
20 25 30
Ser Ser Ser Ala Asn Val Lys Ser Thr Ala Ala Ala Ala Pro Ser Pro
35 40 45
Leu Thr Ala Val Ile Asp Ser Ile Asp Arg Pro Ser Pro Pro Asn Pro
50 55 60
Pro Ala Val Lys Gly Leu Pro Thr Leu Leu Arg Ala Gln Thr His His
65 70 75 80
Pro Leu Asp Pro Leu Thr Ala Ala Glu Ile Ser Val Ala Val Ala Thr
85 90 95
Val Arg Ala Ala Gly Ser Thr Pro Glu Val Arg Asp Ser Met Arg Phe
100 105 110
Val Glu Ala Val Leu Val Glu Pro Asp Lys Ser Val Val Ala Leu Ala
115 120 125
Asp Ala Tyr Phe Phe Pro Pro Phe Gln Pro Ser Leu Leu Pro Arg Thr
130 135 140
Lys Gly Gly Pro Val Ile Pro Ser Lys Leu Pro Pro Arg Lys Ala Lys
145 150 155 160
Leu Ile Val Tyr Asn Lys Lys Ser Asn Glu Thr Ser Ile Trp Ile Val
165 170 175
Glu Leu Ser Glu Val His Ala Val Thr Arg Gly Gly His His Arg Gly
180 185 190
Lys Val Ile Ser Ser Lys Val Val Pro Asp Ile Gln Pro Pro Met Asp
195 200 205
Ala Ala Glu Tyr Ala Glu Cys Glu Ser Val Val Lys Asp Phe Pro Pro
210 215 220
Phe Arg Asp Ala Met Lys Lys Arg Gly Ile Asp Asp Met Asp Leu Val
225 230 235 240
Met Val Asp Ala Trp Cys Ala Gly Tyr Phe Ser Glu Ala Asp Ala Pro
245 250 255
Asn Arg Arg Leu Gly Lys Pro Leu Ile Phe Cys Arg Thr Glu Ser Asp
260 265 270
Cys Pro Met Glu Asn Gly Tyr Ala Arg Pro Val Glu Gly Ile His Ile
275 280 285
Leu Val Asp Met Gln Asn Met Val Val Ile Glu Phe Glu Asp Arg Lys
290 295 300
Leu Val Pro Leu Pro Pro Ala Asp Pro Leu Arg Asn Tyr Thr Ser Gly
305 310 315 320
Glu Thr Arg Gly Gly Val Asp Arg Ser Asp Val Lys Pro Leu Leu Ile
325 330 335
Ser Gln Pro Glu Gly Pro Ser Phe Arg Val Ser Gly His Phe Val Gln
340 345 350
Trp Gln Lys Trp Asn Phe Arg Ile Gly Phe Thr Pro Lys Glu Gly Leu
355 360 365
Val Ile Tyr Ser Val Ala Tyr Ile Asp Gly Ser Arg Gly Arg Arg Pro
370 375 380
Val Ala His Arg Leu Ser Phe Ile Glu Met Val Val Pro Tyr Gly Asp
385 390 395 400
Pro Asn Glu Pro His Tyr Arg Lys Asn Ala Phe Asp Ala Gly Glu Asp
405 410 415
Gly Leu Gly Lys Asn Ala His Ser Leu Lys Lys Gly Cys Asp Cys Leu
420 425 430
Gly Tyr Ile Lys Tyr Phe Asp Ala His Phe Thr Asn Phe Thr Gly Gly
435 440 445
Val Glu Thr Ile Glu Asn Cys Val Cys Leu His Glu Glu Asp His Gly
450 455 460
Ile Leu Trp Lys His Gln Asp Trp Arg Thr Gly Leu Ala Glu Val Arg
465 470 475 480
Arg Ser Arg Arg Leu Thr Val Ser Phe Ile Cys Thr Val Ala Asn Tyr
485 490 495
Glu Tyr Gly Phe Tyr Trp His Phe Tyr Gln Asp Gly Lys Ile Glu Ala
500 505 510
Glu Val Lys Leu Thr Gly Ile Leu Ser Leu Gly Ala Leu Leu Pro Gly
515 520 525
Glu Val Arg Lys Tyr Gly Thr Thr Ile Ala Pro Gly Leu Tyr Ala Pro
530 535 540
Val His Gln His Phe Phe Val Ala Arg Met Asp Met Ala Val Asp Cys
545 550 555 560
Lys Ala Gly Glu Ser His Asn Gln Val Val Glu Val Asn Ala Arg Ile
565 570 575
Glu Pro Pro Gly Glu Asn Asn Val His Asn Asn Ala Phe Tyr Ala Glu
580 585 590
Glu Arg Leu Leu Lys Thr Glu Leu Glu Ala Met Arg Asp Cys Asn Pro
595 600 605
Leu Thr Ala Arg His Trp Ile Ile Arg Asn Thr Arg Thr Val Asn Arg
610 615 620
Thr Gly Gln Leu Thr Gly Tyr Lys Leu Val Pro Gly Thr Asn Cys Leu
625 630 635 640
Pro Leu Ala Gly Ser Glu Ala Lys Phe Leu Arg Arg Ala Ala Phe Leu
645 650 655
Lys His Asn Leu Trp Val Thr Pro Tyr Ser Leu Asp Glu Met Phe Pro
660 665 670
Gly Gly Glu Phe Pro Asn Gln Asn Pro Arg Val Gly Glu Gly Leu Ala
675 680 685
Thr Trp Val Gln Gln Asn Arg Ser Leu Glu Glu Thr Gln Ile Val Leu
690 695 700
Trp Tyr Val Phe Gly Leu Ile His Val Pro Arg Leu Glu Asp Trp Pro
705 710 715 720
Val Met Pro Val Glu His Ile Gly Phe Met Leu Gln Pro His Gly Phe
725 730 735
Phe Asn Cys Ser Pro Ala Val Asp Val Pro Pro Ser Thr Ala Asp Leu
740 745 750
Asp Ile Lys Glu Asn Gly Val Val Ala Lys Ser Cys His Asn Asp Gly
755 760 765
Ile Met Ala Lys Leu
770
<210> 15
<211> 31
<212> DNA
<213> Artificial sequence ()
<400> 15
gatatcatgg cctcaactca ggaaaaggcg a 31
<210> 16
<211> 46
<212> DNA
<213> Artificial sequence ()
<400> 16
ataagaatgc ggccgctcaa agcttagcca ttataccatc attgtg 46
<210> 17
<211> 2310
<212> DNA
<213> three thirds ()
<400> 17
atggccacaa cctcgcataa gccttctttc tgtcatccac cttctgcttc tgtcgtccgt 60
cgtgaaacgg cctccgcctc cgccgtggct ccgtccgtgg acgatcagca gaaacaaacg 120
ccgccgctag cgtcaatatt ggttgactct caaatacctt cctccaactc gtctaccaaa 180
gggatccaaa tcatgctaag agctcaaact tgtcatcctt tggacccttt atctgctgct 240
gagatctctg tggctgtggc aaccgttaga gctgctggtg acacacctga ggtcagagat 300
ggcatgcggt ttgttgaggt ggttcttttg gaaccagata aaactttcat tgcactcgca 360
gacgcctatt tcttcccacc ttttcaatca tcattgatgc ccagaaccaa aggagggctt 420
cttgttcctt ctaaacttcc cccaaggcaa gctagactta ttgtttacaa taagaaaaca 480
aatgagacaa gcgtatggat tgttcagcta actgaagtac atgctgctgc tcgaggtgga 540
caacacaggg gaaaagtgat ttcatccaaa gttgttccag atgttcagcc acctatagat 600
gcacaagagt atgctgactg tgaatccgtg gttaaaaatt atccttcttt tatagaagca 660
atgaagagaa ggggtattga tgacatggat cttgtgatgg ttgacccctg gtgtgttggt 720
tatcacagtg aagctgatgc tcctagccgc aggcttgcca aaccactggt attctgcaga 780
acagagagcg actgtccaat ggaaaatgga tatgcaagac cagttgaagg aatacatgtg 840
cttgttgatg tgcaaaacat gcaggtgata gagttcgaag accgcaaagt tgtaccttta 900
ccccctgctg atccactgag gaattacact gctggtgaga caagaggagg ggttgatcga 960
agtgatgtga aacccctaca aattattcag ccagatggtc caagctttcg cgtcgatggg 1020
aactatgtac aatggcaaaa gtggaacttc cgagtaggtt tcacccctag ggagggtttg 1080
gttatacact ctgtggcata tcttgacggt agcaggggtc gaagatccat agcccatagg 1140
ttgagttttg tggagatggt tgtcccctat ggagatccaa atgacccaca ttacagaaag 1200
aacgcatttg atgcaggaga agatggcctt ggaaagaatg ctcattcact taagagggga 1260
tgcgattgtc taggatacat aaaatacttc gatgccaatt ttacaaattt cacgggagga 1320
gtagaaacca ttgaaaattg tgtatgtttg catgaagaag atcacgggat gctttggaag 1380
catcaagatt ggagaactgg ccttgctgaa gttagacggt ctagacgact gacagtttct 1440
tttatttgca ctgtggccaa ttatgaatat ggattctact ggcactttta ccaggatggg 1500
aaaattgaag cagaagtcaa actcacagga attctcagtt tgggagcatt gcaacctgga 1560
gagtctcgta aatatggcac cacaataaca ccaggattgt atgcacctgt tcatcagcac 1620
ttctttgttg ctcgtatgaa tatggcagtt gattgtaagc caggagaagc acacaatcag 1680
attgttgaag taaatgtcaa agttgaagaa cctgggaagg aaaatgttca caataatgca 1740
ttctatgctg aagaaacact gcttaggtct gaattgcaag caatgcgtga ctgtgatcct 1800
ttatctgctc ggcattgggt tgttaggaac acaagaacgg ccaacagaac aggaaagcta 1860
acaggttaca agctggtacc tggtccgaac tgtttgccat tggctggtcc tgaggctaag 1920
ttcttgagaa gagcggcatt tttgaagcac aatttatggg ttacacaata tgcacctgga 1980
gaagattttc ccgggggaga gttccctaat caaaatccac gtgttggtga aggattagct 2040
tcttgggtta agcaagatcg ttctctggaa gaaagtgata ttgttctctg gtatgttttt 2100
ggaatcaccc atgtccctcg gttggaggac tggcctgtta tgcctgttga acatatcggc 2160
tttatgcttc agccacacgg attctttaac tgctctcctg ctgtagatgt acctccatct 2220
cggggatgtg actcggaaag caaagacagt gatgtttcag aaaatggtgt agcaaagccc 2280
actaccactg gtttgatggc caagctttga 2310
<210> 18
<211> 769
<212> PRT
<213> three thirds ()
<400> 18
Met Ala Thr Thr Ser His Lys Pro Ser Phe Cys His Pro Pro Ser Ala
1 5 10 15
Ser Val Val Arg Arg Glu Thr Ala Ser Ala Ser Ala Val Ala Pro Ser
20 25 30
Val Asp Asp Gln Gln Lys Gln Thr Pro Pro Leu Ala Ser Ile Leu Val
35 40 45
Asp Ser Gln Ile Pro Ser Ser Asn Ser Ser Thr Lys Gly Ile Gln Ile
50 55 60
Met Leu Arg Ala Gln Thr Cys His Pro Leu Asp Pro Leu Ser Ala Ala
65 70 75 80
Glu Ile Ser Val Ala Val Ala Thr Val Arg Ala Ala Gly Asp Thr Pro
85 90 95
Glu Val Arg Asp Gly Met Arg Phe Val Glu Val Val Leu Leu Glu Pro
100 105 110
Asp Lys Thr Phe Ile Ala Leu Ala Asp Ala Tyr Phe Phe Pro Pro Phe
115 120 125
Gln Ser Ser Leu Met Pro Arg Thr Lys Gly Gly Leu Leu Val Pro Ser
130 135 140
Lys Leu Pro Pro Arg Gln Ala Arg Leu Ile Val Tyr Asn Lys Lys Thr
145 150 155 160
Asn Glu Thr Ser Val Trp Ile Val Gln Leu Thr Glu Val His Ala Ala
165 170 175
Ala Arg Gly Gly Gln His Arg Gly Lys Val Ile Ser Ser Lys Val Val
180 185 190
Pro Asp Val Gln Pro Pro Ile Asp Ala Gln Glu Tyr Ala Asp Cys Glu
195 200 205
Ser Val Val Lys Asn Tyr Pro Ser Phe Ile Glu Ala Met Lys Arg Arg
210 215 220
Gly Ile Asp Asp Met Asp Leu Val Met Val Asp Pro Trp Cys Val Gly
225 230 235 240
Tyr His Ser Glu Ala Asp Ala Pro Ser Arg Arg Leu Ala Lys Pro Leu
245 250 255
Val Phe Cys Arg Thr Glu Ser Asp Cys Pro Met Glu Asn Gly Tyr Ala
260 265 270
Arg Pro Val Glu Gly Ile His Val Leu Val Asp Val Gln Asn Met Gln
275 280 285
Val Ile Glu Phe Glu Asp Arg Lys Val Val Pro Leu Pro Pro Ala Asp
290 295 300
Pro Leu Arg Asn Tyr Thr Ala Gly Glu Thr Arg Gly Gly Val Asp Arg
305 310 315 320
Ser Asp Val Lys Pro Leu Gln Ile Ile Gln Pro Asp Gly Pro Ser Phe
325 330 335
Arg Val Asp Gly Asn Tyr Val Gln Trp Gln Lys Trp Asn Phe Arg Val
340 345 350
Gly Phe Thr Pro Arg Glu Gly Leu Val Ile His Ser Val Ala Tyr Leu
355 360 365
Asp Gly Ser Arg Gly Arg Arg Ser Ile Ala His Arg Leu Ser Phe Val
370 375 380
Glu Met Val Val Pro Tyr Gly Asp Pro Asn Asp Pro His Tyr Arg Lys
385 390 395 400
Asn Ala Phe Asp Ala Gly Glu Asp Gly Leu Gly Lys Asn Ala His Ser
405 410 415
Leu Lys Arg Gly Cys Asp Cys Leu Gly Tyr Ile Lys Tyr Phe Asp Ala
420 425 430
Asn Phe Thr Asn Phe Thr Gly Gly Val Glu Thr Ile Glu Asn Cys Val
435 440 445
Cys Leu His Glu Glu Asp His Gly Met Leu Trp Lys His Gln Asp Trp
450 455 460
Arg Thr Gly Leu Ala Glu Val Arg Arg Ser Arg Arg Leu Thr Val Ser
465 470 475 480
Phe Ile Cys Thr Val Ala Asn Tyr Glu Tyr Gly Phe Tyr Trp His Phe
485 490 495
Tyr Gln Asp Gly Lys Ile Glu Ala Glu Val Lys Leu Thr Gly Ile Leu
500 505 510
Ser Leu Gly Ala Leu Gln Pro Gly Glu Ser Arg Lys Tyr Gly Thr Thr
515 520 525
Ile Thr Pro Gly Leu Tyr Ala Pro Val His Gln His Phe Phe Val Ala
530 535 540
Arg Met Asn Met Ala Val Asp Cys Lys Pro Gly Glu Ala His Asn Gln
545 550 555 560
Ile Val Glu Val Asn Val Lys Val Glu Glu Pro Gly Lys Glu Asn Val
565 570 575
His Asn Asn Ala Phe Tyr Ala Glu Glu Thr Leu Leu Arg Ser Glu Leu
580 585 590
Gln Ala Met Arg Asp Cys Asp Pro Leu Ser Ala Arg His Trp Val Val
595 600 605
Arg Asn Thr Arg Thr Ala Asn Arg Thr Gly Lys Leu Thr Gly Tyr Lys
610 615 620
Leu Val Pro Gly Pro Asn Cys Leu Pro Leu Ala Gly Pro Glu Ala Lys
625 630 635 640
Phe Leu Arg Arg Ala Ala Phe Leu Lys His Asn Leu Trp Val Thr Gln
645 650 655
Tyr Ala Pro Gly Glu Asp Phe Pro Gly Gly Glu Phe Pro Asn Gln Asn
660 665 670
Pro Arg Val Gly Glu Gly Leu Ala Ser Trp Val Lys Gln Asp Arg Ser
675 680 685
Leu Glu Glu Ser Asp Ile Val Leu Trp Tyr Val Phe Gly Ile Thr His
690 695 700
Val Pro Arg Leu Glu Asp Trp Pro Val Met Pro Val Glu His Ile Gly
705 710 715 720
Phe Met Leu Gln Pro His Gly Phe Phe Asn Cys Ser Pro Ala Val Asp
725 730 735
Val Pro Pro Ser Arg Gly Cys Asp Ser Glu Ser Lys Asp Ser Asp Val
740 745 750
Ser Glu Asn Gly Val Ala Lys Pro Thr Thr Thr Gly Leu Met Ala Lys
755 760 765
Leu
<210> 19
<211> 32
<212> DNA
<213> Artificial sequence ()
<400> 19
gatatcatgg ccacaacctc gcataagcct tc 32
<210> 20
<211> 44
<212> DNA
<213> Artificial sequence ()
<400> 20
ataagaatgc ggccgctcaa agcttggcca tcaaaccagt ggca 44
<210> 21
<211> 28
<212> DNA
<213> Artificial sequence ()
<400> 21
ggatcccatg ggttctaatg ctagaaac 28
<210> 22
<211> 29
<212> DNA
<213> Artificial sequence ()
<400> 22
cccaagcttt taagggtttg aatatgcta 29
<210> 23
<211> 31
<212> DNA
<213> Artificial sequence ()
<400> 23
ggaattccat atgatggaag ttatttctaa t 31
<210> 24
<211> 32
<212> DNA
<213> Artificial sequence ()
<400> 24
cggggtacct taaaattcaa cgagatccct ag 32
<210> 25
<211> 46
<212> DNA
<213> Artificial sequence ()
<400> 25
ctaagtttta attacaaagg atccatgggt tcgaacgcca ggaacc 46
<210> 26
<211> 30
<212> DNA
<213> Artificial sequence ()
<400> 26
tgaattaacc tacggattgg aataggcaag 30
<210> 27
<211> 33
<212> DNA
<213> Artificial sequence ()
<400> 27
aatccgtagg ttaattcaaa ttaattgata tag 33
<210> 28
<211> 29
<212> DNA
<213> Artificial sequence ()
<400> 28
tctgtgcgtt aaaagatgat gttgaactt 29
<210> 29
<211> 29
<212> DNA
<213> Artificial sequence ()
<400> 29
catcttttaa cgcacagata ttataacat 29
<210> 30
<211> 26
<212> DNA
<213> Artificial sequence ()
<400> 30
cattgtttta tatttgttgt aaaaag 26
<210> 31
<211> 42
<212> DNA
<213> Artificial sequence ()
<400> 31
aacaaatata aaacaatgat ggaagttatt tctaatcata ac 42
<210> 32
<211> 47
<212> DNA
<213> Artificial sequence ()
<400> 32
gtgtgatgga tatctgcaga attcttaaaa ttcaacgaga tccctag 47
<210> 33
<211> 750
<212> DNA
<213> Artificial sequence ()
<400> 33
acgcacagat attataacat ctgcataata ggcatttgca agaattactc gtgagtaagg 60
aaagagtgag gaactatcgc atacctgcat ttaaagatgc cgatttgggc gcgaatcctt 120
tattttggct tcaccctcat actattatca gggccagaaa aaggaagtgt ttccctcctt 180
cttgaattga tgttaccctc ataaagcacg tggcctctta tcgagaaaga aattaccgtc 240
gctcgtgatt tgtttgcaaa aagaacaaaa ctgaaaaaac ccagacacgc tcgacttcct 300
gtcttcctat tgattgcagc ttccaatttc gtcacacaac aaggtcctag cgacggctca 360
caggttttgt aacaagcaat cgaaggttct ggaatggcgg gaaagggttt agtaccacat 420
gctatgatgc ccactgtgat ctccagagca aagttcgttc gatcgtactg ttactctctc 480
tctttcaaac agaattgtcc gaatcgtgtg acaacaacag cctgttctca cacactcttt 540
tcttctaacc aagggggtgg tttagtttag tagaacctcg tgaaacttac atttacatat 600
atataaactt gcataaattg gtcaatgcaa gaaatacata tttggtcttt tctaattcgt 660
agtttttcaa gttcttagat gctttctttt tctctttttt acagatcatc aaggaagtaa 720
ttatctactt tttacaacaa atataaaaca 750
<210> 34
<211> 480
<212> DNA
<213> Artificial sequence ()
<400> 34
gttaattcaa attaattgat atagtttttt aatgagtatt gaatctgttt agaaataatg 60
gaatattatt tttatttatt tatttatatt attggtcggc tcttttcttc tgaaggtcaa 120
tgacaaaatg atatgaagga aataatgatt tctaaaattt tacaacgtaa gatattttta 180
caaaagccta gctcatcttt tgtcatgcac tattttactc acgcttgaaa ttaacggcca 240
gtccactgcg gagtcatttc aaagtcatcc taatcgatct atcgtttttg atagctcatt 300
ttggagttcg cgattgtctt ctgttattca caactgtttt aatttttatt tcattctgga 360
actcttcgag ttctttgtaa agtctttcat agtagcttac tttatcctcc aacatattta 420
acttcatgtc aatttcggct cttaaatttt ccacatcatc aagttcaaca tcatctttta 480
<210> 35
<211> 6312
<212> DNA
<213> Artificial sequence ()
<400> 35
atagcttcaa aatgtttcta ctcctttttt actcttccag attttctcgg actccgcgca 60
tcgccgtacc acttcaaaac acccaagcac agcatactaa atttcccctc tttcttcctc 120
tagggtgtcg ttaattaccc gtactaaagg tttggaaaag aaaaaagaga ccgcctcgtt 180
tctttttctt cgtcgaaaaa ggcaataaaa atttttatca cgtttctttt tcttgaaaat 240
tttttttttg atttttttct ctttcgatga cctcccattg atatttaagt taataaacgg 300
tcttcaattt ctcaagtttc agtttcattt ttcttgttct attacaactt tttttacttc 360
ttgctcatta gaaagaaagc atagcaatct aatctaagtt ttaattacaa aggatccact 420
agtaacggcc gccagtgtgc tggaattctg cagatatcca tcacactggc ggccgctcga 480
gcatgcatct agagggccgc atcatgtaat tagttatgtc acgcttacat tcacgccctc 540
cccccacatc cgctctaacc gaaaaggaag gagttagaca acctgaagtc taggtcccta 600
tttatttttt tatagttatg ttagtattaa gaacgttatt tatatttcaa atttttcttt 660
tttttctgta cagacgcgtg tacgcatgta acattatact gaaaaccttg cttgagaagg 720
ttttgggacg ctcgaaggct ttaatttgca agctgcggcc ctgcattaat gaatcggcca 780
acgcgcgggg agaggcggtt tgcgtattgg gcgctcttcc gcttcctcgc tcactgactc 840
gctgcgctcg gtcgttcggc tgcggcgagc ggtatcagct cactcaaagg cggtaatacg 900
gttatccaca gaatcagggg ataacgcagg aaagaacatg tgagcaaaag gccagcaaaa 960
gcccaggaac cgtaaaaagg ccgcgttgct ggcgtttttc cataggctcc gcccccctga 1020
cgagcatcac aaaaatcgac gctcaagtca gaggtggcga aacccgacag gactataaag 1080
ataccaggcg tttccccctg gaagctccct cgtgcgctct cctgttccga ccctgccgct 1140
taccggatac ctgtccgcct ttctcccttc gggaagcgtg gcgctttctc atagctcacg 1200
ctgtaggtat ctcagttcgg tgtaggtcgt tcgctccaag ctgggctgtg tgcacgaacc 1260
ccccgttcag cccgaccgct gcgccttatc cggtaactat cgtcttgagt ccaacccggt 1320
aagacacgac ttatcgccac tggcagcagc cactggtaac aggattagca gagcgaggta 1380
tgtaggcggt gctacagagt tcttgaagtg gtggcctaac tacggctaca ctagaaggac 1440
agtatttggt atctgcgctc tgctgaagcc agttaccttc ggaaaaagag ttggtagctc 1500
ttgatccggc aaacaaacca ccgctggtag cggtggtttt tttgtttgca agcagcagat 1560
tacgcgcaga aaaaaaggat ctcaagaaga tcctttgatc ttttctacgg ggtctgacgc 1620
tcagtggaac gaaaactcac gttaagggat tttggtcatg agattatcaa aaaggatctt 1680
cacctagatc cttttaaatt aaaaatgaag ttttaaatca atctaaagta tatatgagta 1740
aacttggtct gacagttacc aatgcttaat cagtgaggca cctatctcag cgatctgtct 1800
atttcgttca tccatagttg cctgactccc cgtcgtgtag ataactacga tacgggagcg 1860
cttaccatct ggccccagtg ctgcaatgat accgcgagac ccacgctcac cggctccaga 1920
tttatcagca ataaaccagc cagccggaag ggccgagcgc agaagtggtc ctgcaacttt 1980
atccgcctcc attcagtcta ttaattgttg ccgggaagct agagtaagta gttcgccagt 2040
taatagtttg cgcaacgttg ttggcattgc tacaggcatc gtggtgtcac tctcgtcgtt 2100
tggtatggct tcattcagct ccggttccca acgatcaagg cgagttacat gatcccccat 2160
gttgtgcaaa aaagcggtta gctccttcgg tcctccgatc gttgtcagaa gtaagttggc 2220
cgcagtgtta tcactcatgg ttatggcagc actgcataat tctcttactg tcatgccatc 2280
cgtaagatgc ttttctgtga ctggtgagta ctcaaccaag tcattctgag aatagtgtat 2340
gcggcgaccg agttgctctt gcccggcgtc aatacgggat aatagtgtat cacatagcag 2400
aactttaaaa gtgctcatca ttggaaaacg ttcttcgggg cgaaaactct caaggatctt 2460
accgctgttg agatccagtt cgatgtaacc cactcgtgca cccaactgat cttcagcatc 2520
ttttactttc accagcgttt ctgggtgagc aaaaacagga aggcaaaatg ccgcaaaaaa 2580
gggaataagg gcgacacgga aatgttgaat actcatactc ttcctttttc aatgagctcg 2640
ttttcgacac tggatggcgg cgttagtatc gaatcgacag cagtatagcg accagcattc 2700
acatacgatt gacgcatgat attactttct gcgcacttaa cttcgcatct gggcagatga 2760
tgtcgaggcg aaaaaaaata taaatcacgc taacatttga ttaaaataga acaactacaa 2820
tataaaaaaa ctatacaaat gacaagttct tgaaaacaag aatcttttta ttgtcagtac 2880
tgattattcc tttgccctcg gacgagtgct ggggcgtcgg tttccactat cggcgagtac 2940
ttctacacag ccatcggtcc agacggccgc gcttctgcgg gcgatttgtg tacgcccgac 3000
agtcccggct ccggatcgga cgattgcgtc gcatcgaccc tgcgcccaag ctgcatcatc 3060
gaaattgccg tcaaccaagc tctgatagag ttggtcaaga ccaatgcgga gcatatacgc 3120
ccggagccgc ggcgatcctg caagctccgg atgcctccgc tcgaagtagc gcgtctgctg 3180
ctccatacaa gccaaccacg gcctccagaa gaagatgttg gcgacctcgt attgggaatc 3240
cccgaacatc gcctcgctcc agtcaatgac cgctgttatg cggccattgt ccgtcaggac 3300
attgttggag ccgaaatccg cgtgcacgag gtgccggact tcggggcagt cctcggccca 3360
aagcatcagc tcatcgagag cctgcgcgac ggacgcactg acggtgtcgt ccatcacagt 3420
ttgccagtga tacacatggg gatcagcaat cgcgcatatg aaatcacgcc atgtagtgta 3480
ttgaccgatt ccttgcggtc cgaatgggcc gaacccgctc gtctggctaa gatcggccgc 3540
agcgatcgca tccatggcct ccgcgaccgg ctgcagaaca gcgggcagtt cggtttcagg 3600
caggtcttgc aacgtgacac cctgtgcacg gcgggagatg caataggtca ggctctcgct 3660
gaattcccca atgtcaagca cttccggaat cgggagcgcg gccgatgcaa agtgccgata 3720
aacataacga tctttgtaga aaccatcggc gcagctattt acccgcagga catatccacg 3780
ccctcctaca tcgaagctga aagcacgaga ttcttcgccc tccgagagct gcatcaggtc 3840
ggagacgctg tcgaactttt cgatcagaaa cttctcgaca gacgtcgcgg tgagttcagg 3900
ctttttaccc atggttgttt atgttcggat gtgatgtgag aactgtatcc tagcaagatt 3960
ttaaaaggaa gtatatgaaa gaagaacctc agtggcaaat cctaaccttt tatatttctc 4020
tacaggggcg cggcgtgggg acaattcaac gcgtctgtga ggggagcgtt tccctgctcg 4080
caggtccgca gcgaggagcc gtaatttttg cttcgcgccg tgcggccatc aaaatgtatg 4140
gatgcaaatg attatacatg gggatgtatg ggctaaatgt acgggcgaca gtcacatcat 4200
gcccctgagc tgcgcacgtc aagactgtca aggagggtat tctgggcctc catgtcgctg 4260
gccgggtgac ccggcgggga cgaggcaagc taaacagagc ttatcgatga taagctgtca 4320
aagatgagaa ttaattccac ggactataga ctatactaga tactccgtct actgtacgat 4380
acacttccgc tcaggtcctt gtcctttaac gaggccttac cactcttttg ttactctatt 4440
gatccagctc agcaaaggca gtgtgatcta agattctatc ttcgcgatgt agtaaaacta 4500
gctagaccga gaaagagact agaaatgcaa aaggcacttc tacaatggct gccatcatta 4560
ttatccgatg tgacgctgca gcttctcaat gatattcgaa tacgctttga ggagatacag 4620
cctaatatcc gacaaactgt tttacagatt tacgatcgta cttgttaccc atcattgaat 4680
tttgaacatc cgaacctggg agttttccct gaaacagata gtatatttga acctgtataa 4740
taatatatag tctagcgctt tacggaagac aatgtatgta tttcggttcc tggagaaact 4800
attgcatcta ttgcataggt aatcttgcac gtcgcatccc cggttcattt tctgcgtttc 4860
catcttgcac ttcaatagca tatctttgtt aacgaagcat ctgtgcttca ttttgtagaa 4920
caaaaatgca acgcgagagc gctaattttt caaacaaaga atctgagctg catttttaca 4980
gaacagaaat gcaacgcgaa agcgctattt taccaacgaa gaatctgtgc ttcatttttg 5040
taaaacaaaa atgcaacgcg acgagagcgc taatttttca aacaaagaat ctgagctgca 5100
tttttacaga acagaaatgc aacgcgagag cgctatttta ccaacaaaga atctatactt 5160
cttttttgtt ctacaaaaat gcatcccgag agcgctattt ttctaacaaa gcatcttaga 5220
ttactttttt tctcctttgt gcgctctata atgcagtctc ttgataactt tttgcactgt 5280
aggtccgtta aggttagaag aaggctactt tggtgtctat tttctcttcc ataaaaaaag 5340
cctgactcca cttcccgcgt ttactgatta ctagcgaagc tgcgggtgca ttttttcaag 5400
ataaaggcat ccccgattat attctatacc gatgtggatt gcgcatactt tgtgaacaga 5460
aagtgatagc gttgatgatt cttcattggt cagaaaatta tgaacggttt cttctatttt 5520
gtctctatat actacgtata ggaaatgttt acattttcgt attgttttcg attcactcta 5580
tgaatagttc ttactacaat ttttttgtct aaagagtaat actagagata aacataaaaa 5640
atgtagaggt cgagtttaga tgcaagttca aggagcgaaa ggtggatggg taggttatat 5700
agggatatag cacagagata tatagcaaag agatactttt gagcaatgtt tgtggaagcg 5760
gtattcgcaa tgggaagctc caccccggtt gataatcaga aaagccccaa aaacaggaag 5820
attgtataag caaatattta aattgtaaac gttaatattt tgttaaaatt cgcgttaaat 5880
ttttgttaaa tcagctcatt ttttaacgaa tagcccgaaa tcggcaaaat cccttataaa 5940
tcaaaagaat agaccgagat agggttgagt gttgttccag tttccaacaa gagtccacta 6000
ttaaagaacg tggactccaa cgtcaaaggg cgaaaaaggg tctatcaggg cgatggccca 6060
ctacgtgaac catcacccta atcaagtttt ttggggtcga ggtgccgtaa agcagtaaat 6120
cggaagggta aacggatgcc cccatttaga gcttgacggg gaaagccggc gaacgtggcg 6180
agaaaggaag ggaagaaagc gaaaggagcg ggcgctaggg cgctggcaag tgtagcggtc 6240
acgctgcgcg taaccaccac acccgccgcg cttaatgcgc cgctacaggg cgcgtgggga 6300
tgatccacta gt 6312
<210> 36
<211> 20
<212> DNA
<213> Artificial sequence ()
<400> 36
cccaaagcta agagtcccat 20
<210> 37
<211> 59
<212> DNA
<213> Artificial sequence ()
<400> 37
tggaagagta aaaaaggagt agaaacattt tgaagctatc tgctcttgaa tggcgacag 59
<210> 38
<211> 59
<212> DNA
<213> Artificial sequence ()
<400> 38
ggaacactgg ggcaataggc tgtcgccatt caagagcaga tagcttcaaa atgtttcta 59
<210> 39
<211> 59
<212> DNA
<213> Artificial sequence ()
<400> 39
accagaccag aagaatgatg atgatgatgg tgcattttgt aattaaaact tagattaga 59
<210> 40
<211> 59
<212> DNA
<213> Artificial sequence ()
<400> 40
aaagcatagc aatctaatct aagttttaat tacaaaatgc accatcatca tcatcattc 59
<210> 41
<211> 59
<212> DNA
<213> Artificial sequence ()
<400> 41
cctggtaaag ttgtgtgcta gtgtctcccg tcttctgttc aaagcttggc catcaaacc 59
<210> 42
<211> 59
<212> DNA
<213> Artificial sequence ()
<400> 42
agcaaagccc actaccactg gtttgatggc caagctttga acagaagacg ggagacact 59
<210> 43
<211> 59
<212> DNA
<213> Artificial sequence ()
<400> 43
ctgtcgattc gatactaacg ccgccatcca gtgtcgaatt ttcaacatcg tattttccg 59
<210> 44
<211> 59
<212> DNA
<213> Artificial sequence ()
<400> 44
cattatgcaa cgcttcggaa aatacgatgt tgaaaattcg acactggatg gcggcgtta 59
<210> 45
<211> 59
<212> DNA
<213> Artificial sequence ()
<400> 45
aattcaaaaa aaaaaagcga atcttcccat gcctgttcag cgacatggag gcccagaat 59
<210> 46
<211> 59
<212> DNA
<213> Artificial sequence ()
<400> 46
agactgtcaa ggagggtatt ctgggcctcc atgtcgctga acaggcatgg gaagattcg 59
<210> 47
<211> 22
<212> DNA
<213> Artificial sequence ()
<400> 47
tctggtgagg atttacggta tg 22
<210> 48
<211> 522
<212> DNA
<213> Artificial sequence ()
<400> 48
cccaaagcta agagtcccat tttattcttc tatatgtata ttttcgatac tctaaaccac 60
cctacaatgt agccctatac taaatctgct caattttcag cttctacaag tgactcgaga 120
ccacgtggaa agatccaact actccagcac aacgattcaa tataatcgat tgctccactc 180
ataagaggca agaacaagct tcaacttttg gtaagccgcc gtttataaac agggaagatg 240
tcctttgtca agggaggcac agagcatggc caatttggca aattgcaggt ttttctgagt 300
gaaaaatgaa aaagcattgt agtagagtcg gctcactgaa aaaccgggga ggacgaaaag 360
gtttccagcc acagttgtag tcacgtgcgc gccatgctga ctaatggcag ccgtcgttgg 420
gcagaagaga attagtatgg tacaggatac gctaattgcg ctccaactac caaggttgtt 480
gagggaacac tggggcaata ggctgtcgcc attcaagagc ag 522
<210> 49
<211> 430
<212> DNA
<213> Artificial sequence ()
<400> 49
agtgatcccc cacacaccat agcttcaaaa tgtttctact ccttttttac tcttccagat 60
tttctcggac tccgcgcatc gccgtaccac ttcaaaacac ccaagcacag catactaaat 120
ttcccctctt tcttcctcta gggtgtcgtt aattacccgt actaaaggtt tggaaaagaa 180
aaaagagacc gcctcgtttc tttttcttcg tcgaaaaagg caataaaaat ttttatcacg 240
tttctttttc ttgaaaattt ttttttttga tttttttctc tttcgatgac ctcccattga 300
tatttaagtt aataaacggt cttcaatttc tcaagtttca gtttcatttt tcttgttcta 360
ttacaacttt ttttacttct tgctcattag aaagaaagca tagcaatcta atctaagttt 420
taattacaaa 430
<210> 50
<211> 250
<212> DNA
<213> Artificial sequence ()
<400> 50
acagaagacg ggagacacta gcacacaact ttaccaggca aggtatttga cgctagcatg 60
tgtccaattc agtgtcattt atgatttttt gtagtaggat ataaatatat acagcgctcc 120
aaatagtgcg gttgccccaa aaacaccacg gaacctcatc tgttctcgta ctttgttgtg 180
acaaagtagc tcactgcctt attatcacat tttcattatg caacgcttcg gaaaatacga 240
tgttgaaaat 250
<210> 51
<211> 1398
<212> DNA
<213> Artificial sequence ()
<400> 51
cagcgacatg gaggcccaga ataccctcct tgacagtctt gacgtgcgca gctcaggggc 60
atgatgtgac tgtcgcccgt acatttagcc catacatccc catgtataat catttgcatc 120
catacatttt gatggccgca cggcgcgaag caaaaattac ggctcctcgc tgcagacctg 180
cgagcaggga aacgctcccc tcacagacgc gttgaattgt ccccacgccg cgcccctgta 240
gagaaatata aaaggttagg atttgccact gaggttcttc tttcatatac ttccttttaa 300
aatcttgcta ggatacagtt ctcacatcac atccgaacat aaacaaccat gggtaaggaa 360
aagactcacg tttcgaggcc gcgattaaat tccaacatgg atgctgattt atatgggtat 420
aaatgggctc gcgataatgt cgggcaatca ggtgcgacaa tctatcgatt gtatgggaag 480
cccgatgcgc cagagttgtt tctgaaacat ggcaaaggta gcgttgccaa tgatgttaca 540
gatgagatgg tcagactaaa ctggctgacg gaatttatgc ctcttccgac catcaagcat 600
tttatccgta ctcctgatga tgcatggtta ctcaccactg cgatccccgg caaaacagca 660
ttccaggtat tagaagaata tcctgattca ggtgaaaata ttgttgatgc gctggcagtg 720
ttcctgcgcc ggttgcattc gattcctgtt tgtaattgtc cttttaacag cgatcgcgta 780
tttcgtctcg ctcaggcgca atcacgaatg aataacggtt tggttgatgc gagtgatttt 840
gatgacgagc gtaatggctg gcctgttgaa caagtctgga aagaaatgca taagcttttg 900
ccattctcac cggattcagt cgtcactcat ggtgatttct cacttgataa ccttattttt 960
gacgagggga aattaatagg ttgtattgat gttggacgag tcggaatcgc agaccgatac 1020
caggatcttg ccatcctatg gaactgcctc ggtgagtttt ctccttcatt acagaaacgg 1080
ctttttcaaa aatatggtat tgataatcct gatatgaata aattgcagtt tcatttgatg 1140
ctcgatgagt ttttctaatc agtactgaca ataaaaagat tcttgttttc aagaacttgt 1200
catttgtata gtttttttat attgtagttg ttctatttta atcaaatgtt agcgtgattt 1260
atattttttt tcgcctcgac atcatctgcc cagatgcgaa gttaagtgcg cagaaagtaa 1320
tatcatgcgt caatcgtatg tgaatgctgg tcgctatact gctgtcgatt cgatactaac 1380
gccgccatcc agtgtcga 1398
<210> 52
<211> 452
<212> DNA
<213> Artificial sequence ()
<400> 52
aacaggcatg ggaagattcg cttttttttt ttgaattaca atagtatgtc tgatgtctgc 60
aagaagtaac aggcgtgtgc acaagaatac gtgtgtgtgc gtaagcgtat gcactggtgg 120
cataacttat ctaagaagta tatatcactg acatagaaat gtagatatac aggtattttt 180
ctcgataatc gataaaaatc tcgtcgcgct gaaccaaact tggtggttac ggagagtttt 240
tctctcatca ttactgtctt tcgcattgat ttcccctttg accgataaaa tcccttggat 300
tcataagatt aaacaaagag gtgatcaaag agaaccctgt gaaagtttat gtttataacc 360
gggcataaag tgaactagac actttcaaga agccaaccaa agcatgagta acgaagctta 420
ccagcatgat cataccgtaa atcctcacca ga 452
<210> 53
<211> 1560
<212> DNA
<213> Saccharomyces cerevisiae BY4742()
<400> 53
atgttcagta gatctacgct ctgcttaaag acgtctgcat cctccattgg gagacttcaa 60
ttgagatatt tctcacacct tcctatgaca gtgcctatca agctgcccaa tgggttggaa 120
tatgagcaac caacggggtt gttcatcaac aacaagtttg ttccttctaa acagaacaag 180
accttcgaag tcattaaccc ttccacggaa gaagaaatat gtcatattta tgaaggtaga 240
gaggacgatg tggaagaggc cgtgcaggcc gccgaccgtg ccttctctaa tgggtcttgg 300
aacggtatcg accctattga caggggtaag gctttgtaca ggttagccga attaattgaa 360
caggacaagg atgtcattgc ttccatcgag actttggata acggtaaagc tatctcttcc 420
tcgagaggag atgttgattt agtcatcaac tatttgaaat cttctgctgg ctttgctgat 480
aaaattgatg gtagaatgat tgatactggt agaacccatt tttcttacac taagagacag 540
cctttgggtg tttgtgggca gattattcct tggaatttcc cactgttgat gtgggcctgg 600
aagattgccc ctgctttggt caccggtaac accgtcgtgt tgaagactgc cgaatccacc 660
ccattgtccg ctttgtatgt gtctaaatac atcccacagg cgggtattcc acctggtgtg 720
atcaacattg tatccgggtt tggtaagatt gtgggtgagg ccattacaaa ccatccaaaa 780
atcaaaaagg ttgccttcac agggtccacg gctacgggta gacacattta ccagtccgca 840
gccgcaggct tgaaaaaagt gactttggag ctgggtggta aatcaccaaa cattgtcttc 900
gcggacgccg agttgaaaaa agccgtgcaa aacattatcc ttggtatcta ctacaattct 960
ggtgaggtct gttgtgcggg ttcaagggtg tatgttgaag aatctattta cgacaaattc 1020
attgaagagt tcaaagccgc ttctgaatcc atcaaggtgg gcgacccatt cgatgaatct 1080
actttccaag gtgcacaaac ctctcaaatg caactaaaca aaatcttgaa atacgttgac 1140
attggtaaga atgaaggtgc tactttgatt accggtggtg aaagattagg tagcaagggt 1200
tacttcatta agccaactgt ctttggtgac gttaaggaag acatgagaat tgtcaaagag 1260
gaaatctttg gccctgttgt cactgtaacc aaattcaaat ctgccgacga agtcattaac 1320
atggcgaacg attctgaata cgggttggct gctggtattc acacctctaa tattaatacc 1380
gccttaaaag tggctgatag agttaatgcg ggtacggtct ggataaacac ttataacgat 1440
ttccaccacg cagttccttt cggtgggttc aatgcatctg gtttgggcag ggaaatgtct 1500
gttgatgctt tacaaaacta cttgcaagtt aaagcggtcc gtgccaaatt ggacgagtaa 1560
<210> 54
<211> 1563
<212> DNA
<213> Saccharomyces cerevisiae BY4742()
<400> 54
atgctttctc gcacaagagc tgcagctccg aattccagaa tattcactag aagcttgtta 60
cgtctttatt ctcaagcacc attacgcgtt ccaattactc ttccaaatgg tttcacctac 120
gaacagccaa cagggttatt catcaatggt gaatttgttg cctcgaagca aaagaaaacg 180
tttgacgtga tcaatccatc taacgaagaa aagataacaa ctgtatacaa ggctatggaa 240
gatgatgttg atgaagccgt tgcagcggct aaaaaagctt ttgaaacgaa gtggtctatt 300
gtagagccgg aggttcgcgc taaagcttta ttcaatctcg ctgacttggt tgagaaacac 360
caagaaacac tggctgccat tgagtcaatg gataatggta agtcattgtt ttgtgcgcgc 420
ggtgacgtcg ctttagtatc taaatacttg cgttcttgcg gtggttgggc agataaaatc 480
tacggtaacg ttattgacac aggtaaaaac cattttacct actcaattaa ggaaccatta 540
ggcgtttgcg gccaaataat cccttggaac ttccctttat tgatgtggtc atggaaaatt 600
gggcctgctc tggctacagg taacaccgtc gtattgaaac ccgctgaaac aacaccttta 660
tctgcccttt tcgcttccca gttgtgtcag gaagcaggca tacccgctgg tgtagtcaat 720
atccttccgg gttccggtag agttgttgga gaaagattga gtgcacaccc agacgtgaag 780
aagattgctt ttacaggctc tactgccacc ggccgccata ttatgaaggt cgctgccgat 840
actgtcaaga aagtcacttt ggagctggga ggtaaatcac caaatattgt gtttgctgac 900
gctgatctag ataaagccgt caagaacatt gccttcggta ttttttacaa ctctggtgaa 960
gtttgctgcg ctggttccag aatatacatt caagatacag tatacgagga ggtgttgcaa 1020
aaactaaagg attacaccga gtcactaaag gtcggtgacc catttgatga ggaagttttc 1080
caaggtgctc aaacatctga caaacagctg cataaaattt tagactatgt cgatgtagca 1140
aaatcagagg gggctcgtct tgtgactgga ggggccagac atggcagtaa aggttatttt 1200
gtcaagccaa cagtgtttgc tgatgtcaaa gaagatatga gaattgttaa ggaggaagtg 1260
tttggtccca ttgtaactgt atccaagttt tctactgttg atgaagtgat tgctatggca 1320
aatgattctc aatatgggtt agccgcaggt attcacacta acgatattaa caaggctgtt 1380
gatgtgtcca aaagagtgaa agctggtact gtttggataa atacctataa caacttccac 1440
caaaatgttc ctttcggtgg cttcggccag tcaggtattg gccgtgaaat gggtgaggct 1500
gctttaagta actacactca aacaaaatct gtcagaattg ccattgacaa gccaattcgt 1560
tga 1563
<210> 55
<211> 1599
<212> DNA
<213> Saccharomyces cerevisiae BY4742()
<400> 55
atgtcaaacg acggctcaaa aatattgaat tataccccag tgtctaaaat agatgaaata 60
gttgaaatct caagaaattt cttctttgag aaacaattga aattgtccca cgaaaataac 120
ccaaggaaaa aagatctaga attcaggcag ttgcagttga aaaaactcta ttatgccgtc 180
aaagatcatg aggaagaact gatcgatgct atgtacaagg actttcatcg gaacaaaatt 240
gaatcggttc tgaatgaaac gaccaaactt atgaacgata tacttcacct aattgagatt 300
ttaccaaaat tgatcaaacc tcggagagta tctgattctt ctcctccatt tatgtttggt 360
aaaacaatcg tggagaaaat atcaaggggc agtgtcttga ttattgctcc tttcaatttt 420
cccctacttt tagcatttgc cccattggca gcagctcttg ctgcaggtaa caccattgtt 480
ctgaagccaa gtgaactaac accacacact gctgtagtta tggaaaattt gttaaccaca 540
gctggtttcc ctgatggatt gattcaagta gttcagggag ctatagatga aactacaaga 600
ctactagatt gtggaaaatt tgacctaata ttctacacag gttctccccg tgtcggatca 660
atagttgctg agaaagcagc aaaaagtcta acaccttgtg tacttgaact tggtggtaaa 720
tcacctacct ttattacaga aaatttcaaa gcaagtaaca taaaaattgc tttgaaaagg 780
attttttttg gtgctttcgg aaattctggc cagatttgtg tttcaccaga ttatttgtta 840
gtacataaat ctatctatcc aaaagtcatt aaagagtgtg aatcagtact aaatgaattt 900
tatccaagct ttgatgaaca aacagatttc actcgtatga ttcatgagcc tgcttacaaa 960
aaggccgttg caagtataaa ctcaactaac ggctccaaga ttgtgccttc aaaaatttct 1020
atcaattcag atactgagga tctatgcctt gtaccaccaa ccatagttta taacattggt 1080
tgggatgatc ctttgatgaa acaggaaaac tttgctcctg tattgcccat cattgagtac 1140
gaggatcttg atgagaccat taacaagata atagaagaac atgacactcc attggtgcaa 1200
tacatattct ctgatagcca aactgaaata aatcgtatct tgacgcgctt aagatctggt 1260
gactgtgttg tcggtgatac agtgattcat gtaggaatta ccgacgctcc atttggaggg 1320
atcggtactt caggttatgg taactatggt ggatattatg gattcaatac ctttagtcat 1380
gaaagaacaa tttttaaaca accatattgg aatgatttta ccctttttat gagataccct 1440
ccaaatagcg cacaaaagga aaagctcgtc cgttttgcga tggaaagaaa accttggttt 1500
gacagaaatg gcaataacaa gtgggggtta cgccaatatt tttcattatc tgccgccgtt 1560
attttaatta gtaccattta cgctcattgt tcttcctga 1599
<210> 56
<211> 4140
<212> DNA
<213> Artificial sequence ()
<400> 56
atggacaaga agtactccat tgggctcgat atcggcacaa acagcgtcgg ctgggccgtc 60
attacggacg agtacaaggt gccgagcaaa aaattcaaag ttctgggcaa taccgatcgc 120
cacagcataa agaagaacct cattggcgcc ctcctgttcg actccgggga gacggccgaa 180
gccacgcggc tcaaaagaac agcacggcgc agatataccc gcagaaagaa tcggatctgc 240
tacctgcagg agatctttag taatgagatg gctaaggtgg atgactcttt cttccatagg 300
ctggaggagt cctttttggt ggaggaggat aaaaagcacg agcgccaccc aatctttggc 360
aatatcgtgg acgaggtggc gtaccatgaa aagtacccaa ccatatatca tctgaggaag 420
aagcttgtag acagtactga taaggctgac ttgcggttga tctatctcgc gctggcgcat 480
atgatcaaat ttcggggaca cttcctcatc gagggggacc tgaacccaga caacagcgat 540
gtcgacaaac tctttatcca actggttcag acttacaatc agcttttcga agagaacccg 600
atcaacgcat ccggagttga cgccaaagca atcctgagcg ctaggctgtc caaatcccgg 660
cggctcgaaa acctcatcgc acagctccct ggggagaaga agaacggcct gtttggtaat 720
cttatcgccc tgtcactcgg gctgaccccc aactttaaat ctaacttcga cctggccgaa 780
gatgccaagc ttcaactgag caaagacacc tacgatgatg atctcgacaa tctgctggcc 840
cagatcggcg accagtacgc agaccttttt ttggcggcaa agaacctgtc agacgccatt 900
ctgctgagtg atattctgcg agtgaacacg gagatcacca aagctccgct gagcgctagt 960
atgatcaagc gctatgatga gcaccaccaa gacttgactt tgctgaaggc ccttgtcaga 1020
cagcaactgc ctgagaagta caaggaaatt ttcttcgatc agtctaaaaa tggctacgcc 1080
ggatacattg acggcggagc aagccaggag gaattttaca aatttattaa gcccatcttg 1140
gaaaaaatgg acggcaccga ggagctgctg gtaaagctta acagagaaga tctgttgcgc 1200
aaacagcgca ctttcgacaa tggaagcatc ccccaccaga ttcacctggg cgaactgcac 1260
gctatcctca ggcggcaaga ggatttctac ccctttttga aagataacag ggaaaagatt 1320
gagaaaatcc tcacatttcg gataccctac tatgtaggcc ccctcgcccg gggaaattcc 1380
agattcgcgt ggatgactcg caaatcagaa gagaccatca ctccctggaa cttcgaggaa 1440
gtcgtggata agggggcctc tgcccagtcc ttcatcgaaa ggatgactaa ctttgataaa 1500
aatctgccta acgaaaaggt gcttcctaaa cactctctgc tgtacgagta cttcacagtt 1560
tataacgagc tcaccaaggt caaatacgtc acagaaggga tgagaaagcc agcattcctg 1620
tctggagagc agaagaaagc tatcgtggac ctcctcttca agacgaaccg gaaagttacc 1680
gtgaaacagc tcaaagaaga ctatttcaaa aagattgaat gtttcgactc tgttgaaatc 1740
agcggagtgg aggatcgctt caacgcatcc ctgggaacgt atcacgatct cctgaaaatc 1800
attaaagaca aggacttcct ggacaatgag gagaacgagg acattcttga ggacattgtc 1860
ctcaccctta cgttgtttga agatagggag atgattgaag aacgcttgaa aacttacgct 1920
catctcttcg acgacaaagt catgaaacag ctcaagaggc gccgatatac aggatggggg 1980
cggctgtcaa gaaaactgat caatgggatc cgagacaagc agagtggaaa gacaatcctg 2040
gattttctta agtccgatgg atttgccaac cggaacttca tgcagttgat ccatgatgac 2100
tctctcacct ttaaggagga catccagaaa gcacaagttt ctggccaggg ggacagtctt 2160
cacgagcaca tcgctaatct tgcaggtagc ccagctatca aaaagggaat actgcagacc 2220
gttaaggtcg tggatgaact cgtcaaagta atgggaaggc ataagcccga gaatatcgtt 2280
atcgagatgg cccgagagaa ccaaactacc cagaagggac agaagaacag tagggaaagg 2340
atgaagagga ttgaagaggg tataaaagaa ctggggtccc aaatccttaa ggaacaccca 2400
gttgaaaaca cccagcttca gaatgagaag ctctacctgt actacctgca gaacggcagg 2460
gacatgtacg tggatcagga actggacatc aatcggctct ccgactacga cgtggatcat 2520
atcgtgcccc agtcttttct caaagatgat tctattgata ataaagtgtt gacaagatcc 2580
gataaaaata gagggaagag tgataacgtc ccctcagaag aagttgtcaa gaaaatgaaa 2640
aattattggc ggcagctgct gaacgccaaa ctgatcacac aacggaagtt cgataatctg 2700
actaaggctg aacgaggtgg cctgtctgag ttggataaag ccggcttcat caaaaggcag 2760
cttgttgaga cacgccagat caccaagcac gtggcccaaa ttctcgattc acgcatgaac 2820
accaagtacg atgaaaatga caaactgatt cgagaggtga aagttattac tctgaagtct 2880
aagctggtct cagatttcag aaaggacttt cagttttata aggtgagaga gatcaacaat 2940
taccaccatg cgcatgatgc ctacctgaat gcagtggtag gcactgcact tatcaaaaaa 3000
tatcccaagc ttgaatctga atttgtttac ggagactata aagtgtacga tgttaggaaa 3060
atgatcgcaa agtctgagca ggaaataggc aaggccaccg ctaagtactt cttttacagc 3120
aatattatga attttttcaa gaccgagatt acactggcca atggagagat tcggaagcga 3180
ccacttatcg aaacaaacgg agaaacagga gaaatcgtgt gggacaaggg tagggatttc 3240
gcgacagtcc ggaaggtcct gtccatgccg caggtgaaca tcgttaaaaa gaccgaagta 3300
cagaccggag gcttctccaa ggaaagtatc ctcccgaaaa ggaacagcga caagctgatc 3360
gcacgcaaaa aagattggga ccccaagaaa tacggcggat tcgattctcc tacagtcgct 3420
tacagtgtac tggttgtggc caaagtggag aaagggaagt ctaaaaaact caaaagcgtc 3480
aaggaactgc tgggcatcac aatcatggag cgatcaagct tcgaaaaaaa ccccatcgac 3540
tttctcgagg cgaaaggata taaagaggtc aaaaaagacc tcatcattaa gcttcccaag 3600
tactctctct ttgagcttga aaacggccgg aaacgaatgc tcgctagtgc gggcgagctg 3660
cagaaaggta acgagctggc actgccctct aaatacgtta atttcttgta tctggccagc 3720
cactatgaaa agctcaaagg gtctcccgaa gataatgagc agaagcagct gttcgtggaa 3780
caacacaaac actaccttga tgagatcatc gagcaaataa gcgaattctc caaaagagtg 3840
atcctcgccg acgctaacct cgataaggtg ctttctgctt acaataagca cagggataag 3900
cccatcaggg agcaggcaga aaacattatc cacttgttta ctctgaccaa cttgggcgcg 3960
cctgcagcct tcaagtactt cgacaccacc atagacagaa agcggtacac ctctacaaag 4020
gaggtcctgg acgccacact gattcatcag tcaattacgg ggctctatga aacaagaatc 4080
gacctctctc agctcggtgg agacagcagg gctgacccca agaagaagag gaaggtgtga 4140
<210> 57
<211> 591
<212> DNA
<213> Artificial sequence ()
<400> 57
cacgagcttg cattaccggc agttgctcca gcttgctggc ctctgccagc agcaatgtcc 60
cgccctggcg accctctggt tagatgacac tcctgcccca actgccacga atctgtaacc 120
ccataactat acccgtacgc agtactaaaa atgtatgtaa ttagtaaatg tatgtaacaa 180
tttcaccgtt ttgtgtaaca attcattcat tcattctttt gatcctttag taccgtccgc 240
acatgatgtc atttccccct catttttgtt tgctggtatg attccccgcc cgggcgacgg 300
tacggctgtt atccagcgat gcgggacttc cgtccacagg tatctttttc tccaactcca 360
acagagatgg aaaatgaggg gcgggtgtag gtaagcagaa tgaggagaaa tttgtaatga 420
aaatggaagt tcggcggtta tataaatggg gggggtttgt cggtgacaat tgacttcact 480
ctcctttcct caaaaattct tgggtgttag gattagaagt atctggaaaa ccaaccaaga 540
aaactacaat aacaaaaata aataaagcgg tcatcaataa gcctggtgtc c 591
<210> 58
<211> 588
<212> DNA
<213> Artificial sequence ()
<400> 58
gaaaactaca ataacaaaaa taaataaagc ggtcatcaat aagcctggtg tccaatcgat 60
gcttacatac ataaaattaa atattctgtc tctgttatat ttccacatgt catcatttca 120
aatatatgta ctttaaagaa aataaaataa aaaataaaat ttttttctcc cgataatcaa 180
ttttcttaat taattaattg cgttacgatt ccgttttttt acttctttta tctcattatc 240
tatctaagtt atttaaaaaa aagaaagaac tttttatgaa ctttcctctt ttctttcttt 300
tagactattt aaaatacatc accttggtca aacatagcat cagagacctt gatgaaactt 360
gcgatattag cacctttgac caaagatggc aagaccttac cgtccttagt gtacttcttg 420
gcatagtcga tacattcatt gaaacagttg atcataattc tcttcaactc ttggtcaact 480
ctttcgctag tccatgtgat tctttgagag ttttgtgcca tttctaaacc agaaacagca 540
acaccaccca agttagcagc ctttggtgga ccgtaccaaa cagcttcg 588
<210> 59
<211> 576
<212> DNA
<213> Artificial sequence ()
<400> 59
gccgtttaca catcaatgat aaataagtat acaaaaaggg ttccattttt ttttttggcc 60
gctaccggac tagcaagggc ctaatggtac gctgagcgta gtacaaccaa gcgcttgtta 120
gccgtagagt taagctcttg actactatta cggtaaaagc cgggaacgtg cgtaacaatt 180
tttttttgca ttaggttaaa gaggctcgct cgcggagcct ttagaatacc gcttaaggcg 240
ccaaaagatg gaagctattc tctttctttt ttttttcaca aactgagagg ggttgtgtat 300
cgttaaaaat gttggaagac ttctgactca tcactacgca gattgttaga gtttttcgat 360
gagaatggct tcaaagaaca gaacaaaaca cgattatata agccccatgt aaaaagaacg 420
tcttaattta ttttgaattt aggacttctt gacattttta gcatatataa caatacgata 480
agtgtctcat caaacgtggt taagacagaa aacttcttca caacattaac aaaaagccaa 540
agaagaagaa agtaactcag gcccgagttg actgct 576
<210> 60
<211> 556
<212> DNA
<213> Artificial sequence ()
<400> 60
cattaacaaa aagccaaaga agaagaaagt aactcaggcc cgagttgact gctcattgaa 60
ggtatgtatg ataaacatta tagaataatg aaaaatgcct cgtgacatac agataaaatc 120
taacaaggat atattcaaaa aaaaaaaaac aaaacaaaaa aataataacg tgataaacat 180
taatgaacaa tgtatttaca ttcttaagca taggtgagaa attaccttct ttactttttt 240
tttttttttt ggtgatattg tatattgaaa tatatagtaa tcaaattcgt ttcattgatc 300
aaattgctca ctagttctgt ttttcaaaat ttcatcttta taggtagata caagtgccag 360
agagatatat aaacagaaaa ctctatcgat gtgataatgt atgccaatat cgggactgta 420
cacccacaca tttacaagcc cacacatcct acaactttct tttcatttct tgcgcttctt 480
ccactgtcat aaaatatgat tgtccgatgc cgcagcctac gcctcggcga gtattcatca 540
cctaagcgtc ctgtag 556
<210> 61
<211> 473
<212> DNA
<213> Artificial sequence ()
<400> 61
tggtctctcg ggaaacttct ggatggctct aaggaaggtt gggtgccaac agcttacatg 60
aaaccacatt ccggaaataa taatatccct actcctcctc aaaacaggga tgttcctaaa 120
cccgttctga attctgtaca acatgataac acctctgcaa acgttattcc agctgcagcc 180
caagcaagtt tgggtgatgg tttggcgaat gcgcttgctg ctagggccaa taaaatgaga 240
ttagagagtg atgacgagga ggctaacgaa gatgaagagg aagatgattg gtaatcaaaa 300
tgtatttagc gagtatatac tctatacgag caaatagagt aaattgtaat taataaatat 360
tgatatatta tcgcccatat gaaattttta aacgaaaggt tacttataca tcaaataatt 420
aattaacctt aaacattacg tgttggtgat aaattactat ggctatggtt tta 473
<210> 62
<211> 468
<212> DNA
<213> Artificial sequence ()
<400> 62
aataattaat taaccttaaa cattacgtgt tggtgataaa ttactatggc tatggtttta 60
gaatattcct tttagataat caatatgcct gaagttttgt tttttatata tggagtatcc 120
gtttatccct aaaatccgaa gaatctcctc ctaaaacgac aaaaaaaagg gtaagcaatc 180
caccatctaa ttaaatcact aatattagat tgaattttcg aacctatcta aaagtgggat 240
cttgatgtaa aattgactga tagataaaag gcttggagtc gatagttgat atatcagtac 300
accggtaatt gtctattata taccctgttg gcatgaaatc catataggac ggtatatatt 360
tatatataaa atgcatgtaa aaatctttca tcatgaacta ctcggaattt ttggctggaa 420
attcgttgtt ccatttcctc taagtgtctt gatcatgttc tggtgtgc 468
<210> 63
<211> 40
<212> DNA
<213> Artificial sequence ()
<400> 63
agttttaatt acaaaggatc catggacaag aagtactcca 40
<210> 64
<211> 40
<212> DNA
<213> Artificial sequence ()
<400> 64
ccctctagat gcatgctcga gtcacacctt cctcttcttc 40
<210> 65
<211> 44
<212> DNA
<213> Artificial sequence ()
<400> 65
cttgtcctgt tcaattaatt gttttagagc tagaaatagc aagt 44
<210> 66
<211> 47
<212> DNA
<213> Artificial sequence ()
<400> 66
aattaattga acaggacaag gatcatttat ctttcactgc ggagaag 47
<210> 67
<211> 18
<212> DNA
<213> Artificial sequence ()
<400> 67
<210> 68
<211> 48
<212> DNA
<213> Artificial sequence ()
<400> 68
ggacaccagg cttattgatg accgctttat ttatttttgt tattgtag 48
<210> 69
<211> 48
<212> DNA
<213> Artificial sequence ()
<400> 69
gaaaactaca ataacaaaaa taaataaagc ggtcatcaat aagcctgg 48
<210> 70
<211> 18
<212> DNA
<213> Artificial sequence ()
<400> 70
<210> 71
<211> 44
<212> DNA
<213> Artificial sequence ()
<400> 71
tggcaaatga ttctcaatat gttttagagc tagaaatagc aagt 44
<210> 72
<211> 47
<212> DNA
<213> Artificial sequence ()
<400> 72
atattgagaa tcatttgcca gatcatttat ctttcactgc ggagaag 47
<210> 73
<211> 18
<212> DNA
<213> Artificial sequence ()
<400> 73
<210> 74
<211> 46
<212> DNA
<213> Artificial sequence ()
<400> 74
agcagtcaac tcgggcctga gttactttct tcttctttgg cttttt 46
<210> 75
<211> 47
<212> DNA
<213> Artificial sequence ()
<400> 75
cattaacaaa aagccaaaga agaagaaagt aactcaggcc cgagttg 47
<210> 76
<211> 18
<212> DNA
<213> Artificial sequence ()
<400> 76
<210> 77
<211> 44
<212> DNA
<213> Artificial sequence ()
<400> 77
agggtaaaat cattccaata gttttagagc tagaaatagc aagt 44
<210> 78
<211> 47
<212> DNA
<213> Artificial sequence ()
<400> 78
cttctccgca gtgaaagata aatgatcagg gtaaaatcat tccaata 47
<210> 79
<211> 18
<212> DNA
<213> Artificial sequence ()
<400> 79
<210> 80
<211> 50
<212> DNA
<213> Artificial sequence ()
<400> 80
taaaaccata gccatagtaa tttatcacca acacgtaatg tttaaggtta 50
<210> 81
<211> 50
<212> DNA
<213> Artificial sequence ()
<400> 81
aataattaat taaccttaaa cattacgtgt tggtgataaa ttactatggc 50
<210> 82
<211> 18
<212> DNA
<213> Artificial sequence ()
<400> 82
<210> 83
<211> 400
<212> DNA
<213> Artificial sequence ()
<400> 83
acaaatcgct cttaaatata tacctaaaga acattaaagc tatattataa gcaaagatac 60
gtaaattttg cttatattat tatacacata tcatatttct atatttttaa gatttggtta 120
tataatgtac gtaatgcaaa ggaaataaat tttatacatt attgaacagc gtccaagtaa 180
ctacattatg tgcactaata gtttagcgtc gtgaagactt tattgtgtcg cgaaaagtaa 240
aaattttaaa aattagagca ccttgaactt gcgaaaaagg ttctcatcaa ctgtttaaaa 300
ggaggatatc aggtcctatt tctgacaaac aatatacaaa tttagtttca aagatgaatc 360
agtgcgcgaa ggacataact catgaagcct ccagtatacc 400
<210> 84
<211> 1152
<212> DNA
<213> Saccharomyces cerevisiae BY4742()
<400> 84
atgtccaaga gcaaaacttt cttatttacc tctgaatccg tcggtgaagg tcacccagac 60
aagatttgtg accaagtttc tgatgctatt ttggacgctt gtttagaaca agatccattc 120
tccaaggttg cctgtgaaac agctgccaaa actggtatga ttatggtttt cggtgaaatt 180
accaccaaag ctagacttga ctaccaacaa atagtaagag ataccatcaa gaagattggt 240
tatgacgatt ctgccaaggg tttcgactac aagacatgta atgttttagt agctatcgaa 300
caacaatctc cagatatcgc tcaaggtctg cactatgaaa agagcttaga agacttaggt 360
gctggtgacc aaggtataat gtttggttac gctacagacg aaactccaga agggttacca 420
ttgaccattc ttttggctca caaattgaac atggctatgg cagatgctag aagagatggt 480
tctctcccat ggttgagacc agacacaaag actcaagtca ctgtcgaata cgaagacgac 540
aatggtagat gggttccaaa gaggatagat accgttgtta tttctgctca acatgctgat 600
gaaatttcca ccgctgactt gagaactcaa cttcaaaaag atattgttga aaaggtcata 660
ccaaaggata tgttagacga aaataccaaa tatttcatcc aaccatccgg tagattcgtc 720
atcggtggtc ctcaaggtga cgctggtttg accggtagaa agattattgt cgacgcttac 780
ggtggtgcct catccgtcgg tggtggtgcc ttctccggta aggactattc caaggtcgat 840
cgttccgctg cttacgctgc tagatgggtt gccaagtctc tagttgccgc tggtttgtgt 900
aagagagtcc aagtccaatt ttcatatgct attggtattg ctgaaccatt gtctttacat 960
gtggacacct atggtacagc tacaaaatca gatgacgaaa tcattgaaat tattaagaag 1020
aacttcgact tgagaccagg tgtgttagta aaggaattag atttggctag accaatttac 1080
ttaccaaccg cttcttatgg tcacttcact aatcaagagt actcatggga aaaaccaaag 1140
aaattggaat tt 1152
<210> 85
<211> 1556
<212> DNA
<213> Artificial sequence ()
<400> 85
cgcgccatag cttcaaaatg tttctactcc ttttttactc ttccagattt tctcggactc 60
cgcgcatcgc cgtaccactt caaaacaccc aagcacagca tactaaattt cccctctttc 120
ttcctctagg gtgtcgttaa ttacccgtac taaaggtttg gaaaagaaaa aagagaccgc 180
ctcgtttctt tttcttcgtc gaaaaaggct taattaatag agattactac atattccaac 240
aagaccttcg caggaaagta tacctaaact aattaaagaa atctccgaag ttcgcatttc 300
attgaacggc tcaattaatc tttgtaaata tgagcgtttt tacgttcaca ttgccttttt 360
ttttatgtat ttaccttgca tttttgtgct aaaaggcgtc acgttttttt ccgccgcagc 420
cgcccggaaa tgaaaagtat gacccccgct agaccaaaaa tacttttgtg ttattggagg 480
atcgcaatcc ctaagcttag tggaattatt agaatgacca ctactccttc taatcaaaca 540
cgcggaaata gccgccaaaa gacagatttt attccaaatg cgggtaacta tttgtataat 600
atgtttacat attgagcccg tttaggaaag tgcaagttca aggcactaat caaaaaagga 660
gatttgtaaa tatagcgacc gaatcaggaa aaggtcaaca acgaagttcg cgatatggat 720
gaacttcggt gcctgtccgt ttaaacatcg gatcccatac tagcgttgaa tgttagcgtc 780
aacaacaaga agtttaatga cgcggaggcc aaggcaaaaa gattccttga ttacgtaagg 840
gagttagaat cattttgaat aaaaaacacg ctttttcagt tcgagtttat cattatcaat 900
actgccattt caaagaatac gtaaataatt aatagtagtg attttcctaa ctttatttag 960
tcaaaaaatt agccttttaa ttctgctgta acccgtacat gcccaaaata gggggcgggt 1020
tacacagaat atataacatc gtaggtgtct gggtgaacag tttattcctg gcatccacta 1080
aatataatgg agcccgcttt ttaagctggc atccagaaaa aaaaagaatc ccagcaccaa 1140
aatattgttt tcttcaccaa ccatcagttc ataggtccat tctcttagcg caactacaga 1200
gaacaggggc acaaacaggc aaaaaacggg cacaacctca atggagtgat gcaacctgcc 1260
tggagtaaat gatgacacaa ggcaattgac ccacgcatgt atctatctca ttttcttaca 1320
ccttctatta ccttctgctc tctctgattt ggaaaaagct gaaaaaaaag gttgaaacca 1380
gttccctgaa attattcccc tacttgacta ataagtatat aaagacggta ggtattgatt 1440
gtaattctgt aaatctattt cttaaacttc ttaaattcta cttttatagt tagtcttttt 1500
tttagtttta aaacaccaag aacttagttt cgaataaaca cacataaaca aacaaa 1556
<210> 86
<211> 58
<212> DNA
<213> Artificial sequence ()
<400> 86
gcgcgaagga cataactcat gaagcctcca gtataccatt ttcaacatcg tattttcc 58
<210> 87
<211> 53
<212> DNA
<213> Artificial sequence ()
<400> 87
atgcaacgct tcggaaaata cgatgttgaa aatggtatac tggaggcttc atg 53
<210> 88
<211> 57
<212> DNA
<213> Artificial sequence ()
<400> 88
agtactcatg ggaaaaacca aagaaattgg aatttacaaa tcgctcttaa atatata 57
<210> 89
<211> 56
<212> DNA
<213> Artificial sequence ()
<400> 89
aatgttcttt aggtatatat ttaagagcga tttgtaaatt ccaatttctt tggttt 56
<210> 90
<211> 56
<212> DNA
<213> Artificial sequence ()
<400> 90
aacttagttt cgaataaaca cacataaaca aacaaaatgt ccaagagcaa aacttt 56
<210> 91
<211> 55
<212> DNA
<213> Artificial sequence ()
<400> 91
tcagaggtaa ataagaaagt tttgctcttg gacattttgt ttgtttatgt gtgtt 55
<210> 92
<211> 53
<212> DNA
<213> Artificial sequence ()
<400> 92
gtcgattcga tactaacgcc gccatccagt gtcgacgcgc catagcttca aaa 53
<210> 93
<211> 53
<212> DNA
<213> Artificial sequence ()
<400> 93
aaaaaggagt agaaacattt tgaagctatg gcgcgtcgac actggatggc ggc 53
Claims (9)
1. A method for preparing N-methylpyrrolidine, comprising the steps of: is prepared by using L-ornithine as a substrate and performing combined catalysis on ornithine decarboxylase EcODC with an amino acid sequence of SEQ ID NO. 2, putrescine-N-methyltransferase AtPMT with an amino acid sequence of SEQ ID NO. 6 and amine oxidase from acutangular anisotrophin, wherein the L-ornithine is used as a substrate, and the amino acid is obtained by using the L-ornithine decarboxylase EcODC, the putrescine-N-methyltransferase AtPMT with an amino acid sequence of SEQ ID NO. 6 and the amine oxidase from acutangular anisotrophin
The amine oxidase is AaDAO2 with the amino acid sequence of SEQ ID NO. 14 or AaDAO3 with the amino acid sequence of SEQ ID NO. 18.
2. The method of claim 1, wherein the amine oxidase is AaDAO3 having the amino acid sequence of SEQ ID NO. 18.
3. A microorganism expressing the ornithine decarboxylase EcODC, putrescine-N-methyltransferase AtPMT of claim 1 or 2, and an amine oxidase.
4. The microorganism of claim 3, wherein the microorganism is selected from the group consisting of E.coli and Saccharomyces cerevisiae.
5. The microorganism according to claim 3, wherein the microorganism is Saccharomyces cerevisiae and the genes ALD4, ALD5 and HFD1 metabolizing N-methylaminobutyraldehyde in the genome are knocked out.
6. The microorganism of claim 5, wherein the Saccharomyces cerevisiae overexpresses the cofactor synthesis gene SAM2 having the sequence of SEQ ID NO 84.
7. Use of a microorganism as claimed in any one of claims 3 to 6 for the preparation of N-methylpyrrolidine.
8. Use according to claim 7, for the production of N-methylpyrrolidine by fermentation of a microorganism according to any of claims 3 to 6.
9. The use according to claim 8, wherein when the microorganism is Escherichia coli, the medium is LB medium; when the microorganism is Saccharomyces cerevisiae, the medium is YPD medium.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811265624.0A CN111100886B (en) | 2018-10-29 | 2018-10-29 | Biosynthesis method of N-methyl pyrroline |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811265624.0A CN111100886B (en) | 2018-10-29 | 2018-10-29 | Biosynthesis method of N-methyl pyrroline |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111100886A CN111100886A (en) | 2020-05-05 |
| CN111100886B true CN111100886B (en) | 2021-07-20 |
Family
ID=70419506
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201811265624.0A Expired - Fee Related CN111100886B (en) | 2018-10-29 | 2018-10-29 | Biosynthesis method of N-methyl pyrroline |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111100886B (en) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104894158A (en) * | 2006-06-19 | 2015-09-09 | 加拿大国家研究委员会 | Nucleic acid encoding N-methylputrescine oxidase and uses thereof |
| CN106367434A (en) * | 2005-02-28 | 2017-02-01 | 二十二世纪有限公司 | Method for reducing alkaloids in plants, genetically engineered plant cells, and products with reduced alkaloids |
-
2018
- 2018-10-29 CN CN201811265624.0A patent/CN111100886B/en not_active Expired - Fee Related
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106367434A (en) * | 2005-02-28 | 2017-02-01 | 二十二世纪有限公司 | Method for reducing alkaloids in plants, genetically engineered plant cells, and products with reduced alkaloids |
| CN104894158A (en) * | 2006-06-19 | 2015-09-09 | 加拿大国家研究委员会 | Nucleic acid encoding N-methylputrescine oxidase and uses thereof |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111100886A (en) | 2020-05-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU2023241335A1 (en) | Biosynthesis Of Benzylisoquinoline Alkaloids And Benzylisoquinoline Alkaloid Precursors | |
| CN109735479A (en) | A kind of recombined bacillus subtilis synthesizing 2'-Fucosyl lactose and its construction method and application | |
| CN108998464B (en) | pSP107 plasmid and application and construction method thereof | |
| CN112746083B (en) | Method for editing target gene promoter inactivated gene through single base | |
| CN113166772B (en) | Recombinant coryneform bacterium having 1,3-PDO productivity and reduced 3-HP productivity and method for producing 1,3-PDO using the same | |
| CN109022285B (en) | Method for improving tolerance capacity of Synechocystis PCC6803 ammonium salt and application thereof | |
| CN111100886B (en) | Biosynthesis method of N-methyl pyrroline | |
| CN114395568A (en) | Porcine epidemic diarrhea virus infectious cDNA clone and construction method and application thereof | |
| CN108531502A (en) | The structure and inoculation method of citrus decline virus infectious clone | |
| CN112553238A (en) | CRISPR/Cas9 vector applicable to coniothyrium minitans FS482 as well as construction method and application thereof | |
| CN113621640B (en) | Method for constructing glutamic acid-cysteine dipeptide producing strain | |
| CN110724689B (en) | Cas 9-mediated dendrocalamus latiflorus gene editing vector and application | |
| KR102176555B1 (en) | Strain with increased squalene production through cell wall redesign and method for producing squalene using the same | |
| CN113403335A (en) | Mulberry leaf type dwarf associated virus MMDaV infectious clone vector and construction method and application thereof | |
| KR102170566B1 (en) | Vector for premature termination of target gene expression and strain containing the same | |
| KR102176556B1 (en) | Strain with increased squalene production and method for producing squalene using the same | |
| CN112359045A (en) | Carotenoid metabolic pathway related gene and application thereof | |
| CN111378677A (en) | DNA assembling method and application thereof | |
| CN115819537B (en) | AP2/ERF transcription factor, and coding gene and application thereof | |
| CN117165597B (en) | Application of larch TdERF gene in improving capacity of mountain new Yang Kanglao | |
| CN107828825A (en) | A kind of recombinant vector and its application for being used to isolate and purify esophageal squamous cell carcinoma tumor stem cell | |
| KR101562866B1 (en) | Strain for manufacturing of 2,3-butanediol and method for producing 2,3-butanediol using the same | |
| CN113373173B (en) | Preparation method of SmDXS5 transgenic salvia miltiorrhiza | |
| CN115992168A (en) | Tea tree net spot virus infectious clone and construction method and application of VIGS vector thereof | |
| CN112980710B (en) | Engineering strain, construction method and application thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| TA01 | Transfer of patent application right |
Effective date of registration: 20200612 Address after: 200032 Shanghai city Xuhui District Fenglin Road No. 300 Applicant after: Center for excellence and innovation in molecular plant science, Chinese Academy of Sciences Address before: 200031 No. 320, Yueyang Road, Shanghai, Xuhui District Applicant before: SHANGHAI INSTITUTES FOR BIOLOGICAL SCIENCES, CHINESE ACADEMY OF SCIENCES |
|
| TA01 | Transfer of patent application right | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20210720 |