CN110874618B - OCR template learning method and device based on small sample, electronic equipment and medium - Google Patents
OCR template learning method and device based on small sample, electronic equipment and medium Download PDFInfo
- Publication number
- CN110874618B CN110874618B CN202010057171.3A CN202010057171A CN110874618B CN 110874618 B CN110874618 B CN 110874618B CN 202010057171 A CN202010057171 A CN 202010057171A CN 110874618 B CN110874618 B CN 110874618B
- Authority
- CN
- China
- Prior art keywords
- text
- template
- text box
- loss
- detection model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Computational Linguistics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Evolutionary Biology (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Image Analysis (AREA)
- Character Discrimination (AREA)
Abstract
The invention discloses an OCR template learning method based on small samples, which relates to the technical field of image template processing and comprises the following steps: training a neural network according to the acquired image data set to obtain a universal text detection model; the neural network comprises a feature extraction layer, a pixel classification network and a text box position network; and acquiring a new template training set to be learned, and adjusting the pixel classification network parameters and the text box position network parameters in the universal text detection model based on the new template training set to obtain the target template. The method does not need to train a new OCR model from the beginning and a large amount of new template training data, automatically migrates and learns the new template based on the universal text detection model, improves the data processing efficiency, reduces the model learning time, improves the development efficiency, saves the development cost, improves the information management efficiency, and is suitable for the customized development of various new image templates. The invention also discloses an OCR template learning device based on the small sample, electronic equipment and a computer storage medium.
Description
Technical Field
The invention relates to the technical field of image template processing, in particular to an OCR template learning method and device based on small samples, electronic equipment and a storage medium.
Background
The OCR (Optical Character Recognition) technology refers to a process of analyzing and recognizing an input image to obtain text information in the image, and is one of the most widely applied artificial intelligence technologies at present. The method can be used for automatically extracting OCR templates of fixed format pictures such as bills, cards and documents, can be applied to a plurality of scenes such as paper document classification filing, information statistical analysis and key content extraction, can effectively reduce manual input cost, and improves information management efficiency.
However, with the increasing number of OCR application scenarios, a common OCR template cannot meet the OCR structuring requirements of various application scenarios for a specific format. When OCR processing is performed on certificates, financial bills and medical documents of different formats, due to the fact that information differences of contents, typesetting, styles and the like contained in the different types of pictures are large, a general OCR template is adopted for text detection, and the obtained detection result is often not ideal enough. Therefore, different OCR templates need to be used for detecting corresponding image formats, but due to personal information privacy protection, data transmission security and the like, the amount of format image data which can be actually acquired is usually limited, and a small amount of image data cannot support the OCR depth model to train from the beginning, so that the OCR target template cannot be acquired through the model.
Disclosure of Invention
In order to overcome the defects of the prior art, an object of the present invention is to provide an OCR template learning method based on small samples, which adjusts the pixel classification network parameters and the text box position network parameters in the universal text detection model based on the new template to be learned, so as to obtain the target template.
One of the purposes of the invention is realized by adopting the following technical scheme:
acquiring an image data set, and training a neural network according to the image data set to obtain a universal text detection model; the neural network comprises a feature extraction layer, a pixel classification network and a text box position network;
and acquiring a new template training set to be learned, fixing the parameters of the feature extraction layer in the universal text detection model, and adjusting the pixel classification network parameters and the text box position network parameters in the universal text detection model based on the new template training set to obtain a target template.
Further, the image data set includes text image data and text template data, and a neural network is trained according to the image data set to obtain a universal text detection model, including:
calculating the text image data through the feature extraction layer to obtain image features;
calculating the image characteristics through the pixel classification network and the text box position network to respectively obtain a first confidence degree predicted value and a first position predicted value;
and training the neural network according to the first confidence degree predicted value, the first position predicted value and the text template data to obtain the universal text detection model.
Further, acquiring a new template training set to be learned, including:
acquiring a new template image to be learned and a text region to be extracted of the new template image;
and calculating the position coordinates of the text area according to a preset labeling rule, and obtaining a pixel classification label value and a text box position label value according to the position coordinates, wherein the new template training set comprises the new template image, the pixel classification label value and the text box position label value.
Further, adjusting the pixel classification network parameter and the text box position network parameter in the general text detection model based on the new template training set, including:
calculating the new template image through a feature extraction layer in the universal text detection model to obtain new template features;
the new template features are calculated through a pixel classification network and a text box position network in the universal text detection model to respectively obtain a second confidence degree predicted value and a second position predicted value;
and adjusting the pixel classification network parameter and the text box position network parameter according to the second confidence degree predicted value, the second position predicted value, the pixel classification tag value and the text box position tag value.
Further, adjusting the pixel classification network parameter and the text box position network parameter includes:
calculating the second confidence degree predicted value and the pixel classification label value according to a pixel classification loss function to obtain a classification loss, and adjusting the pixel classification network parameters according to the classification loss and an error back propagation algorithm;
and calculating the second position predicted value and the text box position tag value according to a text box position loss function to obtain position loss, and adjusting the text box position network parameters according to the position loss and error back-propagation algorithm.
Further, the text box position loss function includes a text box position frame loss function and a center point distance loss function, and the second position prediction value and the text box position tag value are calculated to obtain the position loss, including:
obtaining an area intersection and an area union according to the second position predicted value and the text box position tag value, and performing division calculation on the area intersection and the area union according to a text box position border loss function to obtain border loss;
obtaining two central coordinates according to the second position predicted value and the position label value of the text box, and calculating the two central coordinates according to the central point distance loss function to obtain central coordinate loss;
and adding the frame loss and the center coordinate loss to obtain the position loss.
Further, obtaining a target template, comprising:
when the parameter adjustment reaches a preset adjustment target, obtaining a text detection model after the adjustment, obtaining a target confidence coefficient and a target position according to the adjusted text detection model, and generating the target template according to the target confidence coefficient and the target position.
The second objective of the present invention is to provide an OCR template learning apparatus based on small samples, which adjusts the pixel classification network parameters and the text frame position network parameters in the universal text detection model based on the new template to be learned, so as to obtain the target template.
The second purpose of the invention is realized by adopting the following technical scheme:
a small-sample based OCR template learning device comprising:
the universal text model establishing module is used for acquiring an image data set, training a neural network according to the image data set and obtaining a universal text detection model; the neural network comprises a feature extraction layer, a pixel classification network and a text box position network;
and the target template learning module is used for acquiring a new template training set to be learned, fixing the parameters of the feature extraction layer in the universal text detection model, and adjusting the pixel classification network parameters and the text box position network parameters in the universal text detection model based on the new template training set to obtain a target template.
It is a further object of the present invention to provide an electronic device comprising a processor, a storage medium, and a computer program, the computer program being stored in the storage medium, the computer program, when executed by the processor, being a method for small sample based OCR template learning, which is one of the objects of the present invention.
It is a fourth object of the present invention to provide a computer-readable storage medium storing one of the objects of the invention, having a computer program stored thereon, which when executed by a processor, implements a small sample based OCR template learning method, which is one of the objects of the present invention.
Compared with the prior art, the invention has the beneficial effects that:
the method takes a universal text detection model as a basic model, the model structure and the parameters of a feature extraction layer are fixed and unchanged, pixel classification network parameters and text frame position network parameters are automatically adjusted according to the data of a new template training set to be learned, a new OCR model does not need to be trained from the beginning, a large amount of data of the new template training set is also not needed, and a customized target template can be obtained for detecting a new picture format; the method is based on new template data required by a user, the universal text detection model automatically migrates and learns the new template, the efficiency of processing and analyzing the new template data is effectively improved, the model learning time is reduced, the development efficiency is improved, the development cost is saved, the information management efficiency is improved, and the method is suitable for the customized development of various new image templates.
Drawings
FIG. 1 is a flowchart of a small sample-based OCR template learning method according to a first embodiment of the present invention;
FIG. 2 is a flowchart of acquiring a training set of a new template according to a second embodiment of the present invention;
FIG. 3 is a flowchart illustrating the learning of a target template according to a third embodiment of the present invention;
FIG. 4 is a schematic view of a ticket image according to a fourth embodiment of the present invention;
FIG. 5 is a flowchart of bill template learning according to a fourth embodiment of the present invention;
FIG. 6 is a diagram illustrating an order image according to a fifth embodiment of the present invention;
FIG. 7 is a flowchart of an order template learning according to a fifth embodiment of the present invention;
fig. 8 is a block diagram of a small sample-based OCR template learning apparatus according to a sixth embodiment of the present invention;
fig. 9 is a block diagram of an electronic device according to a seventh embodiment of the present invention.
Detailed Description
The present invention will now be described in more detail with reference to the accompanying drawings, in which the description of the invention is given by way of illustration and not of limitation. The various embodiments may be combined with each other to form other embodiments not shown in the following description.
Example one
The embodiment I provides an OCR template learning method based on small samples, which aims to take a general text detection model as a basic model and automatically adjust pixel classification network parameters and text frame position network parameters according to new template training set data to be learned so as to obtain a target template. The template learning method takes a universal text detection model as a basic model, the model structure and the parameters of a feature extraction layer are fixed and unchanged, a new OCR model does not need to be trained from the beginning, a large amount of new template training set data does not need to be trained, new template data are automatically migrated and learned based on the universal text detection model, and a customized target template can be obtained to detect a new picture format. The method can reduce the time of learning the new template data by the model, effectively improve the efficiency of processing and analyzing the new template data, save the development cost, improve the development efficiency and provide the customized template for various picture formats.
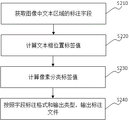
Referring to fig. 1, an OCR template learning method based on small samples includes the following steps:
s110, acquiring an image data set, training a neural network according to the image data set, and obtaining a universal text detection model; the neural network comprises a feature extraction layer, a pixel classification network and a text box position network.
The image dataset includes text image data and text template data. The text image data may be text image data acquired from an existing image database, or may be text image data acquired immediately, which is not limited herein. The text image collected immediately can be obtained by photographing, scanning and the like, for example, the image is collected by a high-definition shooting electronic device with the function of automatically adjusting the shooting angle. The image data is used as input to a neural network to train a neural network model.
The text template data is label data obtained by labeling image data. And labeling the text template data of each image data, wherein the text template data comprises position coordinates of a text box in the image and corresponding pixel label values obtained according to the labeled text box, and the position coordinates and the pixel label values are used as label values input by the neural network to train the neural network model.
In this embodiment, a full convolution neural network is used as a training target. And inputting the image data into a feature extraction layer in the full convolution neural network for calculation to obtain image features. The feature extraction layer adopts a network structure with a feature extraction function, and in the embodiment, the first five layers of convolution structures in the basic convolution neural network VGG16 are adopted as the feature extraction layer. The VGG16 convolutional neural network is provided by VGG group of Oxford university, the VGG16 convolutional neural network is divided into 16 layers, the convolutional layers are formed by adding 13 convolutional layers and 3 fully-connected layers, continuous convolution kernels of 3x3 are adopted to replace large convolution kernels, the depth of the network is improved under the condition that the same perception field is guaranteed, and the effect of the neural network is improved to a certain extent.
The full convolution neural network comprises two branch networks which share the image characteristics output by the characteristic extraction layer. And respectively carrying out pixel point classification and text box position regression on the image characteristics through a pixel classification network and a text box position network. The image characteristics of all the pixel points are classified one by the pixel classification network, whether each pixel point is a text or not is judged, a confidence value of each pixel point belonging to the text is output, and a first confidence prediction value is formed by the confidence values of all the pixel points. And performing regression calculation on the position of the text box by the text box position network, outputting four vertex coordinates of the text box, and taking the vertex coordinates as a first position predicted value.
And the image data is calculated by a full convolution neural network to obtain a first confidence coefficient predicted value and a first position predicted value. Obtaining a loss error according to the first confidence coefficient predicted value, the first position predicted value and the text template data correspondingly marked by the image data, reversely spreading the loss error to a feature extraction layer of the full convolution neural network, training the full convolution neural network based on a gradient descent method, and obtaining a universal text detection model. The universal text detection model can transfer and learn a new template, and a large amount of new template training data is not needed, so that a customized target template can be obtained. The generic text detection model can be used to learn a variety of different types of OCR new templates.
S120, acquiring a new template training set to be learned, fixing the feature extraction layer parameters in the universal text detection model, and adjusting the pixel classification network parameters and the text box position network parameters in the universal text detection model based on the new template training set to obtain the target template.
And acquiring a new template image needing to be detected according to the requirements of a user on the OCR template in the actual scene. The new template image may be obtained from an image database of the user, or may be an image collected according to the user's requirements, which is not limited herein. And acquiring a text area in the new template image by an OCR detection method.
In order to obtain the structural information required by the user from the new template image, the new template image is labeled according to preset labeling rules, such as labeling fields, field labeling formats, labeling file output types and other rules, only the key template information required by the user is extracted, and the data processing efficiency is improved.
And calculating the coordinate position of the text box to be detected in the text area according to the labeling rule, and taking the coordinates of four vertexes of the minimum circumscribed rectangle of the text box to be detected as the text box position label value of the new template image. And calculating the classification label values of all pixel points in the image according to the minimum circumscribed rectangle of the text box to serve as the pixel classification label values. Preferably, the pixel points in the image are classified into two classes, the pixel values of the pixel points are divided into non-zero values and zero values, and the pixel values of all the pixel points form a pixel classification label value.
The new template training set comprises, but is not limited to, new template information such as new template images, pixel classification label values and text box position label values, and the new template information is output according to preset labeling rules. The new template training set comprises structural information of the OCR new template required by a user, and only by acquiring new template images of which the number is more than or equal to one, the transfer learning based on the universal text detection model can be realized, the limit of the number of the new templates is avoided, the learning time is reduced, and the development efficiency of the OCR new template is improved.
And (3) based on a new template training set of the migration learning of the universal text detection model, taking the universal text detection model as a basic model, keeping the model structure of the universal text detection model unchanged, fixing the parameters of a feature extraction layer in the universal text detection model, and only adjusting the network parameters of a pixel classification network and a text frame position network in the universal text detection model. And when the pixel classification network parameters and the text box position network parameters reach preset adjustment targets, completing the adjustment of the two network parameters to obtain an adjusted text detection model. The learning of the new template data does not need to train a new OCR model from the beginning, thereby reducing the model training time and improving the development efficiency of the new template.
The adjustment target can be a preset adjustment time threshold, and when the adjustment times of the parameters reach the adjustment time threshold, a text detection model which is adjusted is obtained; the adjustment target can also be a preset variation range threshold, when the variation of the parameter tends to be stable, and the difference between the maximum value and the minimum value of the parameter in the latest N times of variation is less than or equal to the variation range threshold, the adjustment of the model parameter is completed, and the latest variation times N is determined according to the requirements of users. The adjustment target is preset according to the actual needs of the user, and is not limited herein.
And respectively obtaining a target confidence coefficient and a target position through the adjusted pixel classification network and the adjusted text box position network in the text detection model. And forming a target template by the target confidence coefficient and the target position, determining the text box positioned according to the target position, and judging whether the text box belongs to the text to be detected according to the target confidence coefficient. The adjusted text detection model can accurately detect the text to be detected in the new template image, and does not detect the text content which is not concerned by the user, so that the data management efficiency is improved.
When a plurality of types of OCR new templates need to be learned, the model structure and the feature extraction layer parameters of the general text detection model can be shared, and the transfer learning is completed through the automatic adjustment of the pixel classification network parameters and the text box position network parameters, so that the customized target template is obtained. And a new OCR model does not need to be trained for each type of new template from the beginning, so that the development period of the template is shortened, and the development cost is saved.
Example two
And the second embodiment is an improvement on the first embodiment, and the label value corresponding to the image is calculated for the acquired new template image according to a preset labeling rule to obtain a new template training set. The structured information required by the learning target template can be obtained only by extracting the key template data required by the user, the transfer learning of the universal text detection model is carried out, and the data processing efficiency is improved.
The annotation rule includes but is not limited to information such as an annotation field, a field annotation format, an output type of an annotation file, and the like. In this embodiment, the labeling rule includes a label field, a field label format, and an output type. Referring to fig. 2, the acquisition of the new template training set includes the following steps:
s210, acquiring a label field of a text area in the image. The image information concerned by the label field user is a field with fixed position in different images of the same template, such as fields of 'goods or taxation, service name', 'amount', 'tax amount', and the like in a common invoice template.
And S220, calculating a position tag value of the text box. And respectively taking the lower edge and the left edge of the image as an X axis and a Y axis to establish a plane coordinate graph. And calculating four vertex coordinates of the minimum circumscribed rectangle of the text region according to the position of the text region in the image, and taking the vertex coordinates as a text box position label value corresponding to the image.
And S230, calculating a pixel classification label value. In this embodiment, all the pixel points are classified into two categories, the pixel value corresponding to the region having the label field in the text image is non-zero, and the pixel value corresponding to the non-label region is zero. And calculating the label values of all the pixel points in the text region, and taking the label values corresponding to all the pixel points as pixel classification label values.
And S240, outputting the label file according to the field label format and the output type. The field label format is "label field: a text box position tag value; and the pixel classification tag value' corresponds to the position coordinate of the text region where the label field is located, and the pixel classification tag value corresponds to the classification tag values of all pixel points in the text region.
And a new template training set obtained by a single or a plurality of similar template images, wherein the new template training set comprises image data and an annotation file. The output types of the labeling files include but are not limited to txt, json, csv and other computer program readable files, and therefore the universal text detection model can conveniently read a new template training set to further perform transfer learning.
EXAMPLE III
The third embodiment is an improvement on the basis of the first embodiment or/and the second embodiment, and the network parameters of the pixel classification network and the text box position network in the universal text detection model are adjusted according to the new template image, so that the adjusted text detection model is obtained. Therefore, the learning of the target template is not required to be started from the structure construction or feature extraction of the model, the development period of the new template is shortened, the development efficiency is improved, and the development cost is reduced.
Referring to fig. 3, the learning of the target template includes the following steps:
and S310, calculating a second predicted value corresponding to the new template image.
And fixing the model structure of the universal text detection model and the parameters of the feature extraction layer, and calculating the new template image through the feature extraction layer in the universal text detection model to obtain the new template features. And the new template features are calculated through a pixel classification network and a text box position network in the universal text detection model to respectively obtain a second confidence degree predicted value and a second position predicted value. The two predicted values are respectively used for adjusting network parameters of the pixel classification network and the text box position network.
And S320, calculating the classification loss according to the pixel classification loss function.
And performing regularization calculation on the second confidence degree predicted value and the pixel classification label value, and inputting the regularized second confidence degree predicted value and the pixel classification label value into a pixel classification loss function to obtain the classification loss. The classification loss statistics are errors between the second confidence degree predicted values output by the pixel classification network and the classification labels of the corresponding images, and are used for adjusting the parameters of the pixel classification network. The pixel classification loss function is not limited to one of the L1 loss function, the L2 loss function, and the Huber loss function. In this embodiment, the pixel classification loss function is an L1 loss function.
And S330, calculating the position loss according to the text box position loss function.
And calculating the second position predicted value and the text box position label value according to the text box position loss function to obtain the position loss. And obtaining a corresponding predicted text region according to the second position predicted value S1, and obtaining a corresponding real text region in the image according to the position label value of the text box S0. Preferably, the text box position loss function includes a text box position bounding box loss function and a center point distance loss function.
And calculating a region intersection and a region union of the predicted text region S1 and the real text region S0, inputting the region intersection and the region union into a text box position frame loss function, and performing division calculation to obtain frame loss. The text box position bounding box loss function is not limited to one of the IoU loss function and the GIoU loss function. In this embodiment, the border loss is calculated by using an IoU loss function:
the center coordinates M1 of the predicted text region S1 and the center coordinates M0 of the real text region S0 were calculated, respectively, and the center coordinates M1 (x)pred,ypred) And center coordinate M0 (x)gt,ygt) Inputting a central point distance loss function for calculation to obtain central coordinate loss, wherein xpred、ypredTo predict the predicted value, x, of the center coordinate M1 of the text region S1gt、ygtA tag value of the center coordinate M0 of the real text region S0. The center coordinate loss function is not limited to one of the L1 loss function, the L2 loss function, and the Huber loss function. In this embodiment, the center coordinate loss is calculated by using an L2 loss function: l (M1, M0) ═ xpred-xgt)2+(ypred-ygt)2。
And adding the frame loss and the central coordinate loss to obtain the position loss. The position loss measurement is the geometric error between the predicted text region and the real text region, and is used for adjusting the text box position network parameters.
And S340, adjusting parameters of the two networks according to the classification loss error and the position loss error, and obtaining a target template according to the adjusted text detection model.
And respectively reversely propagating the classification loss and the position loss to the pixel classification network and the text box position network, performing iteration for multiple times, and updating network parameters of the two branch networks each time in an iteration manner, so that the two branch networks continuously reduce the loss errors, the geometric error of the position loss measurement is smaller and smaller, the text box position network is further ensured to accurately detect the position of the text to be detected, the error of the classification loss statistics is smaller and smaller, and the pixel classification network is ensured to be capable of returning the text to be detected.
And when the classification loss and the position loss simultaneously reach the preset adjustment target, completing parameter adjustment to obtain an adjusted text detection model. The adjustment target may be that both of the two loss values reach the loss error threshold, that both of the two loss iterations reach the iteration threshold, and that a variation range of the two loss values is smaller than the variation range threshold, but is not limited to the three adjustment targets.
And obtaining a corresponding target template required by the user according to the adjusted text detection model. According to the target template, the text content concerned by the user can be accurately detected, useless text content which is not concerned is not detected, and the information management efficiency is improved.
When a plurality of classes of OCR new templates are needed, the model structure and the feature extraction layer parameters of the general text detection model can be used, and the corresponding target templates can be obtained only by adjusting the network parameters of the pixel classification network and the text box position network. The universal text detection model automatically learns a new template without training a new OCR model from the beginning, and the template development cost is saved.
Example four
The fourth embodiment is an application of the second embodiment, in which an OCR ticket template is added to an existing user to provide a ticket image as shown in fig. 4, and the user pays attention to the contents of the fields corresponding to "goods or taxable labor, service name", "amount", "tax amount" in the ticket. Currently, there is no universal text detection model, and referring to fig. 5, the bill template learning includes the following steps:
and S410, training the full-convolution neural network by using the image data set to obtain a universal text detection model.
The image data set comprises text image data and text template data, wherein the text image data is acquired from an existing image database, and the text template data is obtained by labeling the text image data. And inputting the text image data into a feature extraction layer in a full convolution neural network for calculation to obtain image features. The image features are calculated through two branch networks to obtain a first confidence degree predicted value and a first position predicted value.
And training a full convolution neural network according to the first confidence coefficient predicted value, the first position predicted value and the text template data to obtain a universal text detection model detect. The generic text detection model can be used to learn a variety of new OCR templates.
And S420, acquiring the annotation file of the bill image according to a preset annotation rule.
The labeling rules are labeled fields and field labeling formats, wherein the labeled fields are ' goods or taxation subject to tax, service name ', ' amount ', ' tax amount ' concerned by the user, and the field labeling formats are ' field name: a text box position tag value ", which is the coordinates of the four vertices of the minimum bounding rectangle of the text region in which the field is located. The label file corresponding to the single image shown in fig. 4 is:
goods or taxation, service name: 391,893,842,893,391,983,842,983, respectively;
amount of money: 2705,903,2816,903,2705,995,2816,995, respectively;
tax amount: 3001,901,3187,901,3001,990,3187,990, respectively;
wherein, the first line represents the coordinates of the pixel points of the four vertexes of the minimum circumscribed rectangle outside the image of the corresponding text of the "goods or taxable labor, service name" in the image as [ (391,893), (842,893), (391,983), (842,983) ]. The second, third and first rows have the same meaning.
And S430, obtaining the OCR template of the bill image through transfer learning.
Fixing the model structure and the feature extraction layer parameters of the universal text detection model detect.model in the step S410, and adjusting the pixel classification network parameters and the text box position network parameters in the universal text detection model detect.model according to the image data and the label data in the step S420 as shown in fig. 4. When the number of parameter adjustments reaches the adjustment number threshold, the OCR template of the bill image is obtained as shown in fig. 4 through the adjusted text detection model.
EXAMPLE five
Fifth embodiment is an application of the third embodiment, that an OCR order template needs to be added to an existing user, where the order template includes, but is not limited to, a network appointment order, a restaurant order, and a hotel order, an order image provided by the user as shown in fig. 6 is obtained, and the user pays attention to contents of fields corresponding to "order number" and "payment time" in the order image. If a universal text detection model exists currently, such as the universal text detection model detect.model in the fourth embodiment, please refer to fig. 7, the order template learning includes the following steps:
and S510, acquiring an annotation file of the order image according to a preset annotation rule.
The labeling rule is a labeling field and a field labeling format, wherein the labeling field is an order number and a payment time concerned by a user, and the field labeling format is a field name: a text box position tag value; and the pixel classification label value' and the text box position label value are four vertex coordinates of a minimum bounding rectangle of the text region where the field is located. The label file corresponding to the single image shown in fig. 6 is:
order numbering: 100,802,436,802,100,983,842,983, respectively; a pixel classification tag value of X1;
payment time: 100,913,436,913,100,1015,913,1015, respectively; a pixel classification tag value of X2;
the first line represents that the coordinates of pixel points of four vertexes of the minimum circumscribed rectangle outside the image where the text corresponding to the order number is located in the image are [ (391,893), (842,893), (391,983) and (842,983) ], and the order real area is obtained according to the coordinates of the four vertexes. The second line and the first line have the same meaning and are used to obtain the real payment area. The pixel classification label value X1 and the pixel classification label value X2 are written as label values of all pixel points in the minimum circumscribed rectangle corresponding to the "order number" and the "payment time", respectively.
And S520, calculating the classification loss and the position loss of the order image.
Model, the order image shown in fig. 6 is input into detect, and the order features are obtained through calculation by the feature extraction layer. And calculating the order characteristics through a pixel classification network and a text box position network to obtain a second confidence degree predicted value and a second position predicted value. And obtaining a corresponding order prediction area and a corresponding payment prediction area according to the second position prediction value.
And after the second confidence degree predicted value and the pixel classification label value X1 and the pixel classification label value X2 obtained in the step S510 are normalized, inputting an L1 loss function to obtain the classification loss.
Calculating an area intersection and an area union of the order prediction area and the order real area, calculating an area intersection and an area union of the payment prediction area and the payment real area, inputting the two groups of area intersections and the area union into an IoU loss function for calculation to obtain corresponding order frame loss and payment frame loss, and adding the two frame losses to obtain the frame loss of the order image.
The center coordinate M11 of the order forecast area and the center coordinate M12 of the payment forecast area are calculated, and the order center loss of the center coordinate M11 and the center coordinate M01 of the order real area and the payment center loss of the center coordinate M12 and the center coordinate M02 of the order real area are calculated by using an L2 loss function. And adding the order center loss and the payment center loss to obtain the center coordinate loss of the order image. And adding the loss of the central coordinate and the frame loss of the order image to obtain the position loss.
And S530, transferring and learning to obtain an OCR template of the order image.
And respectively reversely transmitting the classification loss and the position loss to a pixel classification network and a text box position network of the detect. When the loss values of the two parts reach the preset error threshold, the adjusted text detection model is obtained, and the OCR template of the order image is obtained as shown in fig. 6.
The order image OCR template does not need to train a new OCR model from the beginning, and the order image can be learned by taking a general text detection model detect.
EXAMPLE six
An embodiment six discloses an OCR template learning apparatus based on small samples corresponding to the above embodiment, which is a virtual apparatus structure of the above embodiment, as shown in fig. 8, and includes:
the universal text model establishing module 610 is configured to acquire an image data set, train a neural network according to the image data set, and obtain a universal text detection model; the neural network comprises a feature extraction layer, a pixel classification network and a text box position network;
and the target template learning module 620 is configured to obtain a new template training set to be learned, fix the feature extraction layer parameters in the universal text detection model, and adjust the pixel classification network parameters and the text box position network parameters in the universal text detection model based on the new template training set to obtain a target template.
EXAMPLE seven
Fig. 9 is a schematic structural diagram of an electronic apparatus according to a seventh embodiment of the present invention, as shown in fig. 9, the electronic apparatus includes a processor 710, a memory 720, an input device 730, and an output device 740; the number of the processors 710 in the computer device may be one or more, and one processor 710 is taken as an example in fig. 9; the processor 710, the memory 720, the input device 730, and the output device 740 in the electronic apparatus may be connected by a bus or other means, and the connection by the bus is exemplified in fig. 9.
The memory 720, which is a computer-readable storage medium, can be used for storing software programs, computer-executable programs, and modules, such as program instructions/modules corresponding to the small sample-based OCR template learning method in the embodiment of the present invention (e.g., the generic text model creation module 610 and the target template learning module 620 in the small sample-based OCR template learning apparatus). The processor 710 executes various functional applications and data processing of the electronic device by running software programs, instructions and modules stored in the memory 720, that is, implements the small sample-based OCR template learning method of the first to fifth embodiments.
The memory 720 may mainly include a program storage area and a data storage area, wherein the program storage area may store an operating system, an application program required for at least one function; the storage data area may store data created according to the use of the terminal, and the like. Further, the memory 720 may include high speed random access memory, and may also include non-volatile memory, such as at least one magnetic disk storage device, flash memory device, or other non-volatile solid state storage device. In some examples, the memory 720 may further include memory located remotely from the processor 710, which may be connected to an electronic device through a network. Examples of such networks include, but are not limited to, the internet, intranets, local area networks, mobile communication networks, and combinations thereof.
The input device 730 may be used to receive an image data set, a training set of new templates, etc. The output device 740 may include a display device such as a display screen.
Example eight
An eighth embodiment of the present invention further provides a storage medium containing computer-executable instructions, which when executed by a computer processor, are configured to perform a method for OCR template learning based on small samples, the method including:
acquiring an image data set, and training a neural network according to the image data set to obtain a universal text detection model; the neural network comprises a feature extraction layer, a pixel classification network and a text box position network;
and acquiring a new template training set to be learned, fixing the parameters of the feature extraction layer in the universal text detection model, and adjusting the pixel classification network parameters and the text box position network parameters in the universal text detection model based on the new template training set to obtain a target template.
Of course, the embodiments of the present invention provide a storage medium containing computer-executable instructions, which are not limited to the method operations described above.
From the above description of the embodiments, it is obvious for those skilled in the art that the present invention can be implemented by software and necessary general hardware, and certainly, can also be implemented by hardware, but the former is a better embodiment in many cases. Based on such understanding, the technical solutions of the present invention may be embodied in the form of a software product, which may be stored in a computer-readable storage medium, such as a floppy disk, a Read-Only Memory (ROM), a Random Access Memory (RAM), a FLASH Memory (FLASH), a hard disk or an optical disk of a computer, and includes instructions for enabling an electronic device (which may be a mobile phone, a personal computer, a server, or a network device) to execute the methods according to the embodiments of the present invention.
It should be noted that, in the embodiment of the OCR template learning apparatus based on small samples, the included units and modules are only divided according to functional logic, but are not limited to the above division, as long as the corresponding functions can be realized; in addition, specific names of the functional units are only for convenience of distinguishing from each other, and are not used for limiting the protection scope of the present invention.
Various other modifications and changes may be made by those skilled in the art based on the above-described technical solutions and concepts, and all such modifications and changes should fall within the scope of the claims of the present invention.
Claims (7)
1. An OCR template learning method based on small samples is characterized in that: the method comprises the following steps:
acquiring an image data set, training a neural network according to the image data set, and acquiring a universal text detection model, wherein the universal text detection model is used for learning various different types of OCR new templates; the neural network comprises a feature extraction layer, a pixel classification network and a text box position network;
acquiring a new template training set to be learned, fixing a feature extraction layer parameter in the universal text detection model, and adjusting a pixel classification network parameter and a text box position network parameter in the universal text detection model based on the new template training set to obtain a target template, wherein the new template training set comprises a new template image, a pixel classification label value and a text box position label value;
wherein, obtain the new template training set of waiting to study, include: acquiring a new template image to be learned; the number of the new template images is more than or equal to one;
adjusting the pixel classification network parameters and the text box position network parameters in the general text detection model based on the new template training set, including: calculating the new template image through a feature extraction layer in the universal text detection model to obtain new template features; the new template features are calculated through a pixel classification network and a text box position network in the universal text detection model to respectively obtain a second confidence degree predicted value and a second position predicted value; calculating the second confidence degree predicted value and the pixel classification label value according to a pixel classification loss function to obtain classification loss, and adjusting the pixel classification network parameters according to the classification loss and an error back propagation algorithm; calculating the second position predicted value and the text box position label value according to a text box position loss function to obtain position loss, and adjusting the text box position network parameter according to the position loss and error back-propagation algorithm, wherein the text box position loss function comprises a text box position frame loss function and a center point distance loss function;
calculating the second position predicted value and the text box position tag value according to a text box position loss function to obtain position loss, wherein the method comprises the following steps: obtaining an area intersection and an area union according to the second position predicted value and the text box position tag value, and performing division calculation on the area intersection and the area union according to the text box position border loss function to obtain border loss; obtaining two central coordinates according to the second position predicted value and the text box position label value, and calculating the two central coordinates according to the central point distance loss function to obtain central coordinate loss; and adding the frame loss and the center coordinate loss to obtain the position loss.
2. An OCR template learning method based on small samples as claimed in claim 1, characterized in that: the image data set comprises text image data and text template data, a neural network is trained according to the image data set, and a universal text detection model is obtained, and the method comprises the following steps:
calculating the text image data through the feature extraction layer to obtain image features;
calculating the image characteristics through the pixel classification network and the text box position network to respectively obtain a first confidence degree predicted value and a first position predicted value;
and training the neural network according to the first confidence degree predicted value, the first position predicted value and the text template data to obtain the universal text detection model.
3. An OCR template learning method based on small samples as claimed in claim 1, characterized in that: obtaining a new template training set to be learned, further comprising:
acquiring a text region to be extracted of the new template image;
and calculating the position coordinates of the text area according to a preset labeling rule, and obtaining a pixel classification label value and a text box position label value according to the position coordinates.
4. A small sample based OCR template learning method as claimed in any one of claims 1-3 wherein: obtaining a target template, comprising:
when the parameter adjustment reaches a preset adjustment target, obtaining a text detection model after the adjustment, obtaining a target confidence coefficient and a target position according to the adjusted text detection model, and generating the target template according to the target confidence coefficient and the target position.
5. An OCR template learning device based on small samples, characterized in that it comprises:
the universal text model establishing module is used for acquiring an image data set, training a neural network according to the image data set and obtaining a universal text detection model, and the universal text detection model is used for learning various different types of OCR new templates; the neural network comprises a feature extraction layer, a pixel classification network and a text box position network;
the target template learning module is used for acquiring a new template training set to be learned, fixing the parameters of a feature extraction layer in the universal text detection model, and adjusting the pixel classification network parameters and the text box position network parameters in the universal text detection model based on the new template training set to acquire a target template, wherein the new template training set comprises a new template image, a pixel classification label value and a text box position label value; wherein, obtain the new template training set of waiting to study, include: acquiring a new template image to be learned; the number of the new template images is more than or equal to one; adjusting the pixel classification network parameters and the text box position network parameters in the general text detection model based on the new template training set, including: calculating the new template image through a feature extraction layer in the universal text detection model to obtain new template features; the new template features are calculated through a pixel classification network and a text box position network in the universal text detection model to respectively obtain a second confidence degree predicted value and a second position predicted value; calculating the second confidence degree predicted value and the pixel classification label value according to a pixel classification loss function to obtain classification loss, and adjusting the pixel classification network parameters according to the classification loss and an error back propagation algorithm; calculating the second position predicted value and the text box position label value according to a text box position loss function to obtain position loss, and adjusting the text box position network parameter according to the position loss and error back-propagation algorithm, wherein the text box position loss function comprises a text box position frame loss function and a center point distance loss function; calculating the second position predicted value and the text box position tag value according to a text box position loss function to obtain position loss, wherein the method comprises the following steps: obtaining an area intersection and an area union according to the second position predicted value and the text box position tag value, and performing division calculation on the area intersection and the area union according to the text box position border loss function to obtain border loss; obtaining two central coordinates according to the second position predicted value and the text box position label value, and calculating the two central coordinates according to the central point distance loss function to obtain central coordinate loss; and adding the frame loss and the center coordinate loss to obtain the position loss.
6. An electronic device comprising a processor, a storage medium, and a computer program stored in the storage medium, wherein the computer program, when executed by the processor, performs the small sample based OCR template learning method of any one of claims 1 to 4.
7. A computer storage medium having a computer program stored thereon, characterized in that: the computer program when executed by a processor implements the small sample based OCR template learning method of any one of claims 1 to 4.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010057171.3A CN110874618B (en) | 2020-01-19 | 2020-01-19 | OCR template learning method and device based on small sample, electronic equipment and medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010057171.3A CN110874618B (en) | 2020-01-19 | 2020-01-19 | OCR template learning method and device based on small sample, electronic equipment and medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110874618A CN110874618A (en) | 2020-03-10 |
| CN110874618B true CN110874618B (en) | 2020-11-27 |
Family
ID=69717668
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010057171.3A Active CN110874618B (en) | 2020-01-19 | 2020-01-19 | OCR template learning method and device based on small sample, electronic equipment and medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110874618B (en) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113496223B (en) * | 2020-03-19 | 2024-10-18 | 顺丰科技有限公司 | Method and device for establishing text region detection model |
| CN111582021B (en) * | 2020-03-26 | 2024-07-05 | 平安科技(深圳)有限公司 | Text detection method and device in scene image and computer equipment |
| CN111539412B (en) * | 2020-04-21 | 2021-02-26 | 上海云从企业发展有限公司 | Image analysis method, system, device and medium based on OCR |
| CN111950415A (en) * | 2020-07-31 | 2020-11-17 | 北京捷通华声科技股份有限公司 | Image detection method and device |
| CN112613402B (en) * | 2020-12-22 | 2024-09-06 | 金蝶软件(中国)有限公司 | Text region detection method, device, computer equipment and storage medium |
| CN113780260B (en) * | 2021-07-27 | 2023-09-19 | 浙江大学 | Barrier-free character intelligent detection method based on computer vision |
| CN113657236A (en) * | 2021-08-10 | 2021-11-16 | 支付宝(杭州)信息技术有限公司 | Method and device for identifying newly taken out commodities on unmanned counter |
| US20230119516A1 (en) * | 2021-10-20 | 2023-04-20 | International Business Machines Corporation | Providing text information without reading a file |
| CN114550177B (en) * | 2022-02-25 | 2023-06-20 | 北京百度网讯科技有限公司 | Image processing method, text recognition method and device |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105184265A (en) * | 2015-09-14 | 2015-12-23 | 哈尔滨工业大学 | Self-learning-based handwritten form numeric character string rapid recognition method |
| CN107239802A (en) * | 2017-06-28 | 2017-10-10 | 广东工业大学 | A kind of image classification method and device |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9530068B2 (en) * | 2014-11-10 | 2016-12-27 | International Business Machines Corporation | Template matching with data correction |
| CN107977620B (en) * | 2017-11-29 | 2020-05-19 | 华中科技大学 | Multi-direction scene text single detection method based on full convolution network |
| CN110766014B (en) * | 2018-09-06 | 2020-05-29 | 邬国锐 | Bill information positioning method, system and computer readable storage medium |
| CN109919014B (en) * | 2019-01-28 | 2023-11-03 | 平安科技(深圳)有限公司 | OCR (optical character recognition) method and electronic equipment thereof |
-
2020
- 2020-01-19 CN CN202010057171.3A patent/CN110874618B/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105184265A (en) * | 2015-09-14 | 2015-12-23 | 哈尔滨工业大学 | Self-learning-based handwritten form numeric character string rapid recognition method |
| CN107239802A (en) * | 2017-06-28 | 2017-10-10 | 广东工业大学 | A kind of image classification method and device |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110874618A (en) | 2020-03-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110874618B (en) | OCR template learning method and device based on small sample, electronic equipment and medium | |
| CN111931664B (en) | Mixed-pasting bill image processing method and device, computer equipment and storage medium | |
| CN109543690B (en) | Method and device for extracting information | |
| CN108304835B (en) | character detection method and device | |
| US11816710B2 (en) | Identifying key-value pairs in documents | |
| US20190294921A1 (en) | Field identification in an image using artificial intelligence | |
| CN111209827B (en) | Method and system for OCR (optical character recognition) bill problem based on feature detection | |
| CN115457531A (en) | Method and device for recognizing text | |
| CN112699775A (en) | Certificate identification method, device and equipment based on deep learning and storage medium | |
| CN113011144A (en) | Form information acquisition method and device and server | |
| CN113837151B (en) | Table image processing method and device, computer equipment and readable storage medium | |
| CN112686243A (en) | Method and device for intelligently identifying picture characters, computer equipment and storage medium | |
| WO2022127384A1 (en) | Character recognition method, electronic device and computer-readable storage medium | |
| CN113592807A (en) | Training method, image quality determination method and device, and electronic equipment | |
| CN112149523B (en) | Method and device for identifying and extracting pictures based on deep learning and parallel-searching algorithm | |
| CN117523586A (en) | Check seal verification method and device, electronic equipment and medium | |
| CN112395834A (en) | Brain graph generation method, device and equipment based on picture input and storage medium | |
| CN115131803A (en) | Document word size identification method and device, computer equipment and storage medium | |
| CN114494751A (en) | License information identification method, device, equipment and medium | |
| CN111414889B (en) | Financial statement identification method and device based on character identification | |
| CN112396060A (en) | Identity card identification method based on identity card segmentation model and related equipment thereof | |
| CN111881778B (en) | Method, apparatus, device and computer readable medium for text detection | |
| CN116844182A (en) | Card character recognition method for automatically recognizing format | |
| CN114511862A (en) | Form identification method and device and electronic equipment | |
| CN115880702A (en) | Data processing method, device, equipment, program product and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| TR01 | Transfer of patent right |
Effective date of registration: 20210926 Address after: 311121 room 210, building 18, No. 998, Wenyi West Road, Wuchang Street, Yuhang District, Hangzhou City, Zhejiang Province Patentee after: Hangzhou Bodun Xiyan Technology Co.,Ltd. Address before: Room 704, building 18, No. 998, Wenyi West Road, Wuchang Street, Yuhang District, Hangzhou City, Zhejiang Province Patentee before: TONGDUN HOLDINGS Co.,Ltd. |
|
| TR01 | Transfer of patent right |