CN109918680B - Entity identification method and device and computer equipment - Google Patents
Entity identification method and device and computer equipment Download PDFInfo
- Publication number
- CN109918680B CN109918680B CN201910243952.9A CN201910243952A CN109918680B CN 109918680 B CN109918680 B CN 109918680B CN 201910243952 A CN201910243952 A CN 201910243952A CN 109918680 B CN109918680 B CN 109918680B
- Authority
- CN
- China
- Prior art keywords
- slot
- sequence
- identified
- corpus
- slot position
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims abstract description 79
- 239000013598 vector Substances 0.000 claims abstract description 63
- 238000002372 labelling Methods 0.000 claims abstract description 54
- 238000013135 deep learning Methods 0.000 claims abstract description 36
- 238000004891 communication Methods 0.000 claims description 12
- 238000001914 filtration Methods 0.000 claims description 10
- 238000003062 neural network model Methods 0.000 claims description 8
- 238000004590 computer program Methods 0.000 claims description 3
- 238000011068 loading method Methods 0.000 claims description 2
- 230000008569 process Effects 0.000 abstract description 29
- 238000004422 calculation algorithm Methods 0.000 abstract description 14
- 238000012545 processing Methods 0.000 description 16
- 238000013528 artificial neural network Methods 0.000 description 13
- 238000010586 diagram Methods 0.000 description 9
- 238000004364 calculation method Methods 0.000 description 8
- 238000000605 extraction Methods 0.000 description 8
- 230000003993 interaction Effects 0.000 description 8
- 238000012549 training Methods 0.000 description 8
- 238000004458 analytical method Methods 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 230000002457 bidirectional effect Effects 0.000 description 3
- 238000011049 filling Methods 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 230000004927 fusion Effects 0.000 description 3
- 238000013473 artificial intelligence Methods 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 238000007781 pre-processing Methods 0.000 description 2
- 238000003672 processing method Methods 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 238000013136 deep learning model Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000014509 gene expression Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000000750 progressive effect Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 238000010408 sweeping Methods 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 239000002023 wood Substances 0.000 description 1
Images






Landscapes
- Machine Translation (AREA)
Abstract
The application provides an entity identification method, a device and computer equipment, in the process of recalling linguistic data to be identified, a dictionary matching mode is adopted to recall possible candidate slot combinations of the linguistic data to be identified, the linguistic data to be identified is labeled according to the possible candidate slot combinations to obtain corresponding slot labeling sequences, a coding vector of the linguistic data to be identified and a coding vector of each slot labeling sequence are respectively obtained by utilizing a deep learning network, the coding vector of the slot labeling sequence which is most similar to the coding vector of the linguistic data to be identified is selected, the corresponding slot labeling sequence is used as the optimal slot labeling sequence, and accordingly, a named entity of the linguistic data to be identified is obtained. Therefore, the method and the device have the advantages that the advantages of the rule template and the deep learning algorithm are utilized, the named entities of various types of corpora are quickly, simply and accurately recognized, the cold start problem is solved, the obtained recognition result is usually a computer language, and the electronic device can directly respond to the recognition result.
Description
Technical Field
The application relates to the technical field of artificial intelligence, in particular to an entity identification method, an entity identification device and computer equipment.
Background
In recent years, with the development of artificial intelligence, man-machine interactive systems are widely applied to application platforms in various fields. The man-machine interaction system is a computer system capable of interacting with people, and after a question raised by a user is obtained, named entities in the question need to be identified so as to provide answers or corresponding operations required by the user, and the man-machine interaction process is simplified.
Currently, in an application of Named Entity Recognition (NER), deep learning is proposed to recognize Named entities in a corpus, that is, the Named entities are used as sequence labels, a label model is learned by using a large-scale corpus to label each position of a sentence, and thus the Named entities in a target corpus are obtained. However, the entity identification method needs a large amount of high-quality labeled corpora for model training, and has poor feasibility; only some simple entities can be identified, the identification accuracy is low for proper nouns and ambiguous nouns, and even the entities with high update frequency cannot be identified.
Therefore, although the method can accurately identify all complex entities, under the condition that the product functional domain is complex, a large amount of templates need to be constructed, the workload is extremely high, the later maintenance and the handover performance are poor, and the method is difficult to multiplex in different scenes.
Therefore, how to accurately and simply realize the identification of various named entities in various scenes becomes one of the important research directions in the field.
Disclosure of Invention
In view of this, embodiments of the present application provide an entity identification method, an entity identification device, and a computer device, which utilize the advantages of a rule template and a deep learning algorithm to achieve fast, simple, and accurate identification of various corpus named entities, and are not only suitable for simple entity identification, but also suitable for complex entity identification, and solve the problem of cold start, and the obtained identification result is usually a computer language, and an electronic device can directly respond to the identification result.
In order to achieve the above purpose, the embodiments of the present application provide the following technical solutions:
a method of entity identification, the method comprising:
obtaining corpora to be identified;
acquiring a candidate slot position combination of the linguistic data to be identified by using a slot value matching mode;
marking the corpus to be identified by using the candidate slot position combination to obtain a corresponding slot position marking sequence;
respectively coding the word sequence of the corpus to be identified and the slot position tagging sequence based on a deep learning network to obtain a first coding vector of the corpus to be identified and a second coding vector of the slot position tagging sequence;
determining a target annotation sequence in the slot annotation sequence based on the similarity between the first encoding vector and the second encoding vector;
and obtaining the named entity of the corpus to be identified by utilizing the target labeling sequence.
An entity identification apparatus, the apparatus comprising:
the first acquisition module is used for acquiring the linguistic data to be identified;
the second acquisition module is used for acquiring the candidate slot position combination of the linguistic data to be identified by using a slot value matching mode;
the labeling module is used for labeling the corpus to be identified by utilizing the candidate slot position combination to obtain a corresponding slot position labeling sequence;
a third obtaining module, configured to code the word sequence of the corpus to be identified and the slot position tagging sequence respectively based on a deep learning network, so as to obtain a first coding vector of the corpus to be identified and a second coding vector of the slot position tagging sequence;
and the identification module is used for determining a target labeling sequence in the slot labeling sequence based on the similarity between the first coding vector and the second coding vector, and obtaining the named entity of the corpus to be identified by using the target labeling sequence.
A computer device, comprising:
a communication interface;
a memory for storing a program for implementing the entity identification method as described above;
and the processor is used for loading and executing the program stored in the memory to realize the steps of the entity identification method.
A storage medium having stored thereon a program which is loaded and executed by a processor to implement the steps of the above-described entity identification method.
Therefore, the method converts the slot extraction problem of the linguistic data to be recognized into the recall-ordering problem, recalls the possible candidate slot combination of the linguistic data to be recognized by adopting a dictionary matching mode in the recall processing process of the linguistic data to be recognized, labels the linguistic data to be recognized according to the possible candidate slot combination to obtain a corresponding slot position labeling sequence, inputs the word sequence and the slot position labeling sequence of the linguistic data to be recognized into a deep learning network to respectively obtain a coding vector of the linguistic data to be recognized and a coding vector of each slot position labeling sequence, selects the coding vector of the slot position labeling sequence which is most similar to the coding vector of the linguistic data to be recognized, uses the corresponding slot position labeling sequence as an optimal slot position labeling sequence, and obtains the named entity of the linguistic data to be recognized according to the optimal slot position labeling sequence. Therefore, the method and the device have the advantages that the advantages of the rule template and the deep learning algorithm are utilized, the various corpus named entities are quickly, simply and accurately identified, the method and the device are not only suitable for simple entity identification, but also suitable for complex, long-tailed and newly-appeared entity identification, the cold start problem is solved, the obtained identification result is usually a computer language, and the electronic device can directly respond to the identification result.
Drawings
In order to more clearly illustrate the embodiments of the present application or the technical solutions in the prior art, the drawings used in the embodiments or the prior art descriptions will be briefly described below, it is obvious that the drawings in the following description are only the embodiments of the present application, and for those skilled in the art, other drawings can be obtained according to the provided drawings without creative efforts.
Fig. 1 is a schematic structural diagram of an entity identification system according to an embodiment of the present disclosure;
fig. 2 is a schematic flowchart of an entity identification method according to an embodiment of the present application;
fig. 3 is a schematic flowchart of another entity identification method according to an embodiment of the present disclosure;
fig. 4 is a schematic flow chart illustrating another entity identification method according to an embodiment of the present application;
fig. 5 is a schematic structural diagram of an entity identification apparatus according to an embodiment of the present disclosure;
fig. 6 is a schematic structural diagram of another entity identification apparatus according to an embodiment of the present disclosure;
fig. 7 is a schematic structural diagram of another entity identification apparatus according to an embodiment of the present application;
fig. 8 is a schematic hardware structure diagram of a computer device according to an embodiment of the present application.
Detailed Description
By combining the analysis of the background technology part, the method for recognizing the named entity is realized by using a Bi-directional Long Short-Term Memory-Conditional Random Fields algorithm or other deep learning algorithms in the prior art, has universality, simple code realization, good maintainability and transferability, and can well extract a plurality of simple entities in complex grammatical structures and different human speaking habits. The method for realizing named entity recognition by using the rule template is suitable for fields with complex entities and simple sentence patterns, such as related fields of stocks, sports and media.
Through the analysis, aiming at the fields with complex entities and complex sentence patterns, such as the music field of voice assistance, the application needs a scheme which can identify all complex entities and reduce the complexity of a heap template algorithm, and simultaneously has maintainability and methodological reusability, namely a new scheme which combines the advantages of the two entity identification methods.
Based on the above concept, considering the advantages of the template recognition text vocabulary and the advantages of deep learning processing complex sentence patterns, the inventor of the present application introduces the Match Ranking (recall-sorting) concept of the recommendation system, and converts the named entity problem in the recognized corpus, i.e., the slot extraction problem, into the Match Ranking problem, i.e., the mode of finding back first and then sorting. Specifically, possible slot combinations of the corpus to be identified can be recalled through dictionary matching and simple rules, namely, a plurality of slot combinations are recalled; and labeling the original corpus by using each slot combination to obtain a plurality of sequence labels, establishing a deep learning model, sequencing each candidate slot combination (candidate sequence label) to obtain the optimal slot combination, and further obtaining the named entity contained in the corpus to be identified.
The technical solutions in the embodiments of the present application will be clearly and completely described below with reference to the drawings in the embodiments of the present application, and it is obvious that the described embodiments are only a part of the embodiments of the present application, and not all of the embodiments. All other embodiments, which can be derived by a person skilled in the art from the embodiments given herein without making any creative effort, shall fall within the protection scope of the present application.
Referring to fig. 1, a schematic structural diagram of a system for implementing the entity identification method provided in the present application, where the system may include a server 11 and an electronic device 12, it should be understood that the server 11 and the electronic device 12 shown in fig. 1 are only exemplary and are not limited to the implementation forms of the two.
In practical applications, the server 11 and the electronic device 12 may be connected by a wired or wireless network, and specifically, the server 11 and the electronic device 12 may be connected in communication by a mobile network such as GSM, GPRS, LTE, or the like, or connected in communication by a bluetooth, WIFI, infrared, or the like.
The server 11 may be a service device providing services for a user, specifically, an independent application service device, or a service cluster formed by a plurality of servers, and in actual application, the server may be a cloud server, a cloud host, a virtual center, and the like.
In the application scenario of the man-machine conversation, the server 11 may be mainly responsible for functions of speech recognition, speech understanding, speech generation, speech synthesis, and the like in the process of the man-machine conversation, and cooperate with the electronic device 12 to implement the man-machine conversation. It can be seen that the entity identification method provided in the present application may be executed by the server 11, and specific implementation processes may refer to the following description of method embodiments.
The electronic device 12 may be a terminal facing the user and capable of performing voice interaction with the user, such as a mobile phone, a notebook computer, an iPad, an intelligent sound device, and the like, and may also be various voice-interactive self-service terminals, such as self-service machines in places such as hospitals, banks, stations, and the like, and in addition, the electronic device 12 may also be an intelligent machine supporting voice interaction, such as a chat robot, a floor-sweeping robot, a meal-ordering service robot, and the like. The product type and the physical form of the electronic equipment are not limited, and the electronic equipment has a voice interaction function and can be realized by installing voice interaction application programs such as a voice assistant.
Referring to fig. 2 in combination with the system structure diagram shown in fig. 1, a flowchart of an entity identification method is provided for the embodiment of the present application, and may be applied to a man-machine conversation process in various application scenarios, and specifically may be executed by a server, as shown in fig. 2, the method may include, but is not limited to, the following steps:
step S101, obtaining linguistic data to be identified;
in this embodiment, the corpus to be recognized may be data input by a user when the user starts an application program of the electronic device, and the application program has a voice interaction function, where the data may be voice data or text data. It should be noted that if the corpus to be recognized is text data, speech recognition is not required in the subsequent processing process, or speech synthesis is not required.
The method includes that after the electronic equipment collects linguistic data to be recognized input by a user, the linguistic data can be sent to a server to be processed, in the period, an application program of the electronic equipment started by the user can wait for a feedback result of the server, the feedback result can be voice or text data or a control instruction and can be determined according to specific content of the linguistic data to be recognized, and the content and the type of the linguistic data to be recognized are not limited.
Step S102, preprocessing the corpus to be recognized;
the preprocessing operation content is not limited in the present application, if the corpus to be recognized is a long sentence, the corpus to be recognized may be cut into a plurality of short sentences in the present embodiment, and if the corpus to be recognized includes the wakeup word of the electronic device, in order to avoid a functional conflict with the wakeup word, the present embodiment may remove the wakeup word in the corpus to be recognized, and the like, and the present embodiment does not detail the specific implementation method of step S102.
Step S103, acquiring a plurality of slot combinations matched with the preprocessed corpus to be recognized by using a slot value matching mode;
in the art, a semantic slot may be a specific concept extracted from a corpus by a NLU (Natural Language Understanding) wood block, such as a named entity; filling a slot may be a process of completing information for the purpose of translating a user's intent into a user-specific instruction; slot filling can be viewed as a sequence labeling problem, i.e., labeling each word in a given corpus with a corresponding label. In practical application, a slot may be formed by slot positions, a slot value may be a value that is possible for the slot, such as a slot at a departure location, which may be obtained by context, directly, or the like, and specifically, the content of the departure location may be the slot value, and one slot position may be a slot filling manner
For example, the following steps are carried out: taking a ticket booking scene as an example, the semantic slots may include "departure place", "departure time", "destination place", and the like, the slot values corresponding to the "departure place" may include place names of "beijing", "shanghai", "shenzhen", and the like, and the slot values corresponding to the "departure time" may include times of "seven am", "ten am", "three pm", and the like; the slot value corresponding to the destination point may include names of places such as "Hangzhou", "Beijing", "Hainan", etc.
Based on the above analysis, the slot value dictionaries corresponding to various slots can be obtained in this embodiment, and thus a slot dictionary is formed and stored, it can be seen that the slot dictionary can include various slot values corresponding to different slots, and the content of the slot value dictionaries and the obtaining manner are not limited in the present application.
And then, matching the linguistic data to be recognized with each slot value in the slot dictionary one by one, and storing possible slots matched with the slot values, wherein under the normal condition, the slots matched with the slot values are often multiple in each matching of the linguistic data to be recognized, namely, a slot combination can be obtained as a matching result once, and a plurality of slot combinations can be obtained through multiple matching with the slot dictionary.
Optionally, since there may be multiple expressions for the slot value in the same meaning in practical application, for example, playing the slot value may be represented by a plurality of words such as put, get, play, and click, the present application may map such words to "play". Based on this, the present application may obtain corpora input by the user in the human-computer interaction system and corresponding instruction contents (i.e., slot values) that can be recognized by the computer device, to obtain various corpora corresponding to the same instruction contents, and at this time, may consider these corpora as synonyms and map them to the instruction contents. In this way, the present application may derive a synonymy map of various slot values and generate a synonym dictionary therefrom. It can be seen that the synonym dictionary can represent the mapping relationship between the slot values and the synonyms, that is, the synonyms corresponding to the slot values are included.
Therefore, in the process of slot value matching of the linguistic data to be recognized, the slot value dictionary and the synonym dictionary can be used together, namely, the linguistic data to be recognized is matched with the slot value dictionary and the synonym dictionary one by one to obtain the slot position combination corresponding to the linguistic data to be recognized, and the specific matching process is not limited.
In summary, the embodiment can utilize the dictionary mechanism of the rule template to accurately and completely identify the correct entity in the corpus to be identified, so as to obtain various possible entity candidate sets, that is, to obtain the entity combination which may express the meaning of the corpus to be identified.
Step S104, filtering the obtained slot position combinations according to a preset logic limiting condition to obtain candidate slot position combinations;
in practical application, because the slot value dictionaries of some slots contain too many words and part of entities belong to common words, after slot matching is carried out according to the above mode, the obtained slot combinations are often more, which will affect the recognition efficiency and accuracy of the corpus named entity, so that the filtering conditions can be set according to the logics such as the number of slot values, the occurrence times, the relation between slots and the like, and are recorded as the preset logic limiting conditions.
And then, filtering a plurality of slot combinations matched with the corpus to be identified according to the filtering conditions, filtering a part of slot combinations with lower matching degree under the condition of not reducing the recall rate, reserving the most possible slot combinations, and marking as candidate slot combinations. It should be noted that, the content of the preset logic limiting condition is not limited in the present application, and may be determined by experience or experimental results in the industry, and the content of the preset logic limiting condition may be different for different types of linguistic data to be recognized.
Step S105, labeling the linguistic data to be identified by utilizing the candidate slot position combination to obtain a slot position labeling sequence;
in this embodiment, each slot combination obtained in the above description may include information such as a slot value, a position of the slot value in the corpus to be identified, and a slot type. After the filtering processing is performed to obtain a plurality of candidate slot combinations, the slot type in each candidate slot combination can be used to label the slot type of the corresponding slot value in the corpus to be identified, so as to obtain a slot labeling sequence formed by a plurality of slot types.
Then, a deep learning algorithm can be used to obtain the most similar one of the corpora to be identified from the obtained slot position labeling sequence set, and the best labeling corpus is determined, so as to obtain the named entity of the corpus to be identified.
Step S106, respectively inputting the word sequence and the slot position tagging sequence of the corpus to be identified into a deep learning network for coding, and obtaining a first coding vector of the corpus to be identified and a second coding vector of the slot position tagging sequence;
in the Ranking part, a deep learning network is utilized to convert an initial corpus, namely a word sequence of the corpus to be identified and a slot position tagging sequence set into corresponding coding vectors, and a fusion layer is used for calculating the similarity of the two coding vectors so as to obtain an optimal slot position tagging sequence corresponding to the corpus to be identified and further obtain a named entity of the corpus to be identified.
The word sequence of the corpus to be recognized may be composed of each chinese character and an english letter in the corpus to be recognized, that is, in this embodiment, each chinese character of the corpus to be recognized may be used as a sequence element, and if there is an english word, each english letter may be used as a sequence element, and according to this rule, the word sequence of the corpus to be recognized is obtained.
Optionally, the deep learning network may be a neural network, specifically, the neural network for encoding the word sequence of the corpus to be recognized may be Attention Based on BiLSTM, and the neural network for encoding the slot tagging sequence may be BiLSTM, but is not limited to the neural network provided herein.
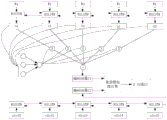
In the practical application of this embodiment, referring to the schematic flow chart of the processing method of the neural network on the input sequence shown in fig. 3, since the word sequence and the slot tagging sequence of the corpus to be recognized belong to different descriptions of the same connotation, it is said that the deep learning network architecture cannot be shared, that is, the word sequence and the slot tagging sequence cannot be simultaneously input into one neural network, and two neural networks are adopted to respectively process the two sequences.
As shown in fig. 3, W1 to W5 may represent each element of the word sequence of the corpus to be recognized (i.e., the initial corpus), that is, a chinese character or an english letter, and slot1 to slot5 represent each element in the slot tagging sequence, that is, each slot type tagged with the corpus to be recognized may use one slot type as one character. It should be understood that the number of corpora to be identified that include W is not limited to 5, and the number of W may be determined according to actually obtained corpus content to be identified, in this embodiment, only 5 are taken as an example for description, and similarly, the number of elements included in the slot tagging sequence obtained by tagging the corpus to be identified, that is, the number of slots, is also not limited to 5 shown in fig. 3, and is generally the same as the number of W included in the corpus to be identified.
Optionally, in practical application, the number of elements of the neural network input sequence, that is, the length of the preset input sequence, may be set by counting the number of elements constituting the word sequence of a large number of corpora, and when the word sequence and the slot position tag sequence of the corpus to be recognized are actually input, if the number of sequence elements is smaller than the length of the preset sequence, zero padding may be performed later. The present application does not limit the value of the length of the preset input sequence.
In this embodiment, W1 to W5 may be index inputs of the corpus word to be identified, and after processing of a BiLSTM network (that is, a slot extraction model obtained by pre-training), a hidden layer of each time unit may be obtained, and meanwhile, an attention mechanism is introduced to adjust weights of the hidden layers at different times, and then, dot products of the adjusted weights and output results ht (t =1, 2, 3,4, 5) of the corresponding hidden layers are calculated, and the dot product results are linearly added to obtain a coding vector C1 of the corpus to be identified, which may be denoted as a first coding vector C1 in this embodiment.
In addition, in this embodiment, according to the processing manner described above that the BilsTM model is used to process the corpus to be recognized, a BilsTM network (i.e., a slot extraction model obtained by pre-training) is used to perform corresponding processing on the slot annotation sequence, as shown in fig. 3, that is, the slot annotation sequences slot1 to slot5 are input into the BilsTM network, so that a coding vector C2 of the slot annotation sequence can be obtained, which is denoted as a second coding vector in this embodiment, and a specific implementation process can be determined by combining the working principle of the slot extraction model, which is not described in detail in this embodiment.
Wherein, biLSTM denotes a bidirectional LSTM, which considers both past features (extracted by a forward process) and future features (extracted by a backward process), the backward process is equivalent to reversely inputting an original sequence (e.g. W1 to W5, or slot1 to slot5 in fig. 3) into the LSTM, and thus, the bidirectional LSTM is equivalent to two LSTMs, one forward input sequence, one reverse input sequence, and then combining the outputs of the two as a final result. The application does not detail the specific processing process of the BilSTM network on the input sequence, and can be realized by combining the principle of the BilSTM network.
It should be noted that, for the above neural network that respectively processes the corpus and the slot position tagging sequences to be recognized, a neural network algorithm may be utilized to train a large amount of sample data, for example, a large amount of tagging corpus is obtained from the present application platform or other application platforms, according to the processing method of the Match portion, 10 (not limited to 10) slot position tagging sequences are recalled for each tagging corpus as sample data, and then the recalled slot position tagging sequences and corresponding tagging corpora are trained by using the BiLSTM algorithm to obtain a slot position extraction model, that is, the above neural network, and the present application does not detail the specific implementation process of the model training.
In addition, the network used for coding the word sequence and the slot tagging sequence of the corpus to be recognized in the present application is not limited to the neural network given above, and other deep learning networks may also be used, which are not described in detail herein.
Based on the above description of the deep learning network on the processing process of the input sequence, in the embedded layer of the deep learning network, the word sequence (also referred to as word vector) of the corpus to be recognized is selected as the input sequence, and no external word sequence is introduced, so that the introduction of noise is avoided, and the accuracy of the output result is improved. And the deep learning layer adopts a more appropriate neural network to process the word sequence of the linguistic data to be recognized and the slot position labeling sequence respectively, and does not share the same network architecture, so that the accuracy of an output result is further improved. In the last fusion layer, cosine similarity is selected for calculation, other parameters are avoided being introduced, the problem that the generalization capability of a network model is reduced due to the fact that the result is greatly influenced by the parameters of a transposed dot product parameter matrix when the transposed dot product parameter matrix is used for processing is solved, namely, the overfitting problem is avoided due to the similarity calculation mode adopted by the method, and the accuracy of obtaining the best matching slot position combination solution of the linguistic data to be recognized is improved.
Optionally, because the word sequence of the corpus to be recognized and the slot tagging sequence input by the Ranking part have the same length, and the slot tagging sequence is obtained by tagging the corpus to be recognized, the deep learning network architecture different from that provided by the embodiment can be adopted in the present application, and if the word sequence of the corpus to be recognized and the slot tagging sequence are directly convolved or fused, detailed implementation processes are not described in the present application.
Step S107, calculating the similarity of the acquired first coded vector and each second coded vector;
and S108, selecting the slot position labeling sequence corresponding to the second coding vector with the maximum similarity as a target labeling sequence, and extracting the named entity of the corpus to be identified by using the target labeling sequence.
Optionally, in this embodiment, a similarity calculation method may be used to implement similarity calculation between two coding vectors, specifically, a cosine similarity algorithm may be used to implement the similarity calculation, and a detailed calculation process is not described in detail.
In combination with the above description of the obtaining process of the slot position tagging sequence, the corpus to be identified is tagged by using the candidate slot position combination, and then, the candidate slot position combination corresponding to the target tagging sequence may be determined as the target slot position combination, so that the slot position value included in the target slot position combination is used to obtain the named entity of the corpus to be identified, that is, the slot position value and/or the synonym included in the corpus to be identified are/is used as the named entity, and the specific implementation process is not limited in this embodiment.
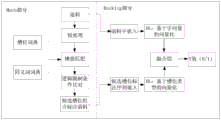
To sum up, referring to fig. 4, in the embodiment, the slot extraction problem of the corpus to be recognized is converted into a recall-sorting (Mach-Ranking) problem, and in the process of recalling the corpus to be recognized, a dictionary matching method is adopted to recall a possible candidate slot combination of the corpus to be recognized, and the corpus to be recognized is labeled according to the possible candidate slot combination to obtain a corresponding slot labeling sequence, and then, the word sequence and the slot labeling sequence of the corpus to be recognized are input into a deep learning network to respectively obtain a coding vector of the corpus to be recognized and a coding vector of each slot labeling sequence, and a coding vector of the slot labeling sequence most similar to the coding vector of the corpus to be recognized is selected and the corresponding slot labeling sequence is used as an optimal slot labeling sequence, so as to obtain a named entity of the corpus to be recognized.
Therefore, the method and the device have the advantages that the advantages of the rule template and the deep learning algorithm are utilized, the various corpus named entities are quickly, simply and accurately identified, the method and the device are not only suitable for simple entity identification, but also suitable for complex, long-tailed and newly-appeared entity identification, the cold start problem is solved, the obtained identification result is usually a computer language, and the electronic device can directly respond to the identification result.
Based on the above analysis, the entity identification method of the present application will be described more clearly by combining with specific application scenarios, specifically taking the to-be-identified corpus as "happy song bar" as an example for description. In order to accurately extract the named entity in the corpus to be recognized, the following operations may be performed:
in this embodiment, the "happy song for us" may be preprocessed, and if the awakening word is included, the awakening word may be removed, and then the corpus to be recognized may be matched with the slot dictionary and the synonym dictionary one by one, and the matched possible slot combination candidates may be stored.
For the same slot position value, different slot positions may be corresponded, and the slot position value content of the same slot position is various, for example, "give us" may be a song name, may also be an album name, and on the basis of this, after the corpus to be recognized is matched with the slot position dictionary and synonym, many slot position combinations are often obtained, including some slot position combinations with very low matching degree with the real slot position combination of the corpus to be recognized, so this embodiment may further filter the recalled multiple slot position combinations, to obtain a plurality of candidate slot position combinations.
In the synonym dictionary of this embodiment, words such as putting one word, putting a song, coming one word, etc. can be mapped to "play", so after the above processing, the corpus to be recognized "happy song for us" can obtain four sets of slot candidate combinations as follows:
{ (3,4, ' play ' operation '), (0,2, ' give us ' song name '), (8,8, ' music ' object ') };
{ (3,4, ' play ' operation '), (5,8, ' happy song ');
{ (3,4, ' play ' operation '), (8,8, ' music ' object '), (5,6, ' cheerful ' style ') };
{ (5,6, ' cheerful ' style '), (8,8, ' music ' object '), (1,5, ' we ' album name ') };
in the candidate slot combination, the content in each small bracket sequentially represents the position in the corpus to be identified, the slot value after synonym translation and the slot type. Therefore, the candidate slot combination obtained by the present application may be composed of several parts, such as a slot type, a slot value, and a position of the slot value in the corpus to be identified, but is not limited thereto.
Then, according to the four groups of candidate slot combinations obtained above, labeling the corpus to be identified respectively to obtain corresponding slot labeling sequences, where the labeling manner is as shown in table one below:
watch 1

In the above table, the first row is the corpus to be recognized, and each subsequent row represents a sequence of labeling the corpus to be recognized by one candidate slot combination, which may be used as an input of a subsequent Ranking part to determine a most probable correct slot combination among the four sets of candidate slot combinations.
Based on the processing of the Mach part described by way of example above, in the practice of real network data (voice assistant), taking a music domain as an example, the music domain generally includes 12 core slots, such as singer name, album name, genre, voice genre, music genre, scene, theme type, and the like, which is not listed in this embodiment, through the matching and screening processing of the to-be-recognized corpus described in the above steps S102 to S105, the recall rate of the slot combination of the to-be-recognized corpus can reach about 89.6%, and an average one sentence of the to-be-recognized corpus can recall 11 sets of slot candidate combinations. It should be noted that the recall ratio and the number of candidate slot combinations recalled in each sentence are not limited to the examples listed herein, and may be calculated according to actual situations.
The research shows that the reasons for low recall rate of slot combination mainly include the reasons of labeled corpus quality, error of upstream speech recognition ASR result, ambiguity of corpus itself, strict preset logic limiting conditions, and the like, so that optimization can be performed from these aspects in order to improve the recall rate of slot combination, and the specific implementation process is not described in detail in this embodiment.
Based on the above description of the processing process of the corpus to be recognized and the slot annotation sequence (i.e., the annotated sentence) by using the deep learning network, regarding the corpus to be recognized, which is "the song which brings us a lot of popularity", each Chinese character in the corpus is taken as a character and is sequentially recorded as W1, W2, … and W10, and similarly, the elements in the slot annotation sequence are sequentially recorded as slot1, slot2, … and slot10, and according to the actual requirement, if the number of the elements in the input sequence of the deep learning network is preset to be 14, the obtained word sequence and slot annotation sequence are expanded, i.e., 0 is supplemented in the last four bits, thereby forming a sequence which meets the network input requirement.
Then, according to the encoding method shown in fig. 3, the encoding vector of the corpus to be identified and the encoding vector corresponding to each slot position labeling sequence are obtained, and then the encoding vector of the corpus to be identified and the similarity of the encoding vector corresponding to each slot position labeling sequence are respectively calculated, so as to determine the slot position combination most matched with the corpus to be identified.
In this embodiment, as shown in fig. 4, after the similarity calculation of the fusion layer, the output result Y may be a numerical value, for example, 0 or 1,0 may represent a candidate slot combination corresponding to the slot combination sequence, which is different from the actual slot combination of the corpus to be recognized, that is, the matching degree between the candidate slot combination and the corpus to be recognized is low; 1 may represent a candidate slot combination corresponding to the slot combination sequence, which is the same as the real slot combination of the corpus to be identified, that is, the matching degree of the candidate slot combination and the corpus to be identified is higher, as in the four candidate slot combinations obtained in the above example, the third candidate slot combination obtains Y =1 correspondingly; other slot candidate combinations correspond to the resulting Y =0, but are not limited thereto.
Based on this, in this embodiment, based on the value of Y output by the deep learning network, the slot combination solution that is the most matched corpus to be identified, that is, the slot combination candidate corresponding to Y =1, may be directly determined, and the named entity of the corpus to be identified may be obtained accordingly.
In the present application, the architecture of the deep learning network may be obtained by pre-training, the training corpus used for training may be 100w + labeled corpuses in an application inside an enterprise, 10 slot position labeled sentences (i.e., slot position labeled sequences) may be found back from each training corpus on average according to the processing manner described in the mac part, and then the deep learning network model meeting a certain convergence requirement is obtained by testing the deep learning network model on a test set, so that the deep learning network model is directly called for use in practical application. Through tests, the slot combination equivalence rate of the network model collected in the Ranking part can reach 98.4%, the accuracy rate and the recall rate of output results can reach more than 98%, and specific numerical values are not limited.
Compared with the almost unavailable test result of pure deep learning, the entity identification method realized by using the rule template and the deep learning can effectively borrow the identification degree of the template to the complex entity, reduce the number of recalls, effectively improve the recalling capability and borrow the generalization capability of the deep learning to the general grammar rule. The complexity is reduced, and meanwhile, the performance index of the algorithm is effectively guaranteed, so that the slot extraction in the complex field has a good effect.
Fig. 5 is a schematic structural diagram of an entity identification apparatus provided in the present application, where the apparatus includes:
a first obtaining module 21, configured to obtain a corpus to be identified;
a second obtaining module 22, configured to obtain a candidate slot combination of the corpus to be identified in a slot value matching manner;
optionally, as shown in fig. 6, the second obtaining module 22 may include:
a first obtaining unit 221, configured to obtain, by using a slot value matching manner, a plurality of slot combinations of the corpus to be identified;
the filtering unit 222 is configured to filter the slot combinations according to a preset logic constraint condition, so as to obtain candidate slot combinations.
Wherein, the first obtaining unit may include:
the dictionary acquisition unit is used for acquiring a slot value dictionary and a synonym dictionary;
and the matching unit is used for matching the linguistic data to be recognized with the slot value dictionary and the synonym dictionary one by one to obtain a plurality of slot combinations.
The labeling module 23 is configured to label the corpus to be identified by using the candidate slot position combination to obtain a corresponding slot position labeling sequence;
a third obtaining module 24, configured to code the word sequence of the corpus to be identified and the slot position tagging sequence based on a deep learning network, respectively, to obtain a first coding vector of the corpus to be identified and a second coding vector of the slot position tagging sequence;
optionally, as shown in fig. 7, the third obtaining module 24 may include:
a sequence obtaining unit 241, configured to obtain a word sequence of the corpus to be identified;
a first encoding unit 242, configured to input the word sequence into a first neural network model for encoding, so as to obtain a first encoding vector;
the second encoding unit 243 is configured to input the slot position labeling sequence into a second neural network model for encoding, so as to obtain a second encoding vector.
Wherein the first neural network model and the second neural network model are different types of bidirectional long-short term memory networks (BilSTM), but are not limited thereto.
And the identifying module 25 is configured to determine a target labeling sequence in the slot labeling sequence based on the similarity between the first encoding vector and the second encoding vector, and obtain the named entity of the corpus to be identified by using the target labeling sequence.
Optionally, the identification module 25 may include:
a similarity calculation unit configured to calculate a similarity between the first encoded vector and the second encoded vector;
and the selecting unit is used for selecting the slot position marking sequence corresponding to the second coding vector with the maximum similarity as the target marking sequence.
The embodiment of the present application further provides a storage medium, where a computer program is stored, where the computer program is executed by a processor to implement the steps of the entity identification method, and a specific implementation process may refer to the description of the embodiment of the method, which is not described herein again.
As shown in fig. 8, an embodiment of the present application further provides a hardware structure diagram of a computer device, where the computer device may be the server, and may include a communication interface 31, a memory 32, and a processor 33;
in the embodiment of the present application, the communication interface 31, the memory 32, and the processor 33 may implement communication with each other through a communication bus, and the number of the communication interface 31, the memory 32, the processor 33, and the communication bus may be at least one.
Alternatively, the communication interface 31 may be an interface of a communication module, such as an interface of a GSM module;
the processor 33 may be a central processing unit CPU, or an Application Specific Integrated Circuit ASIC (Application Specific Integrated Circuit), or one or more Integrated circuits configured to implement embodiments of the present Application.
The memory 32 may comprise high-speed RAM memory, and may also include non-volatile memory, such as at least one disk memory.
The memory 32 stores a program, and the processor 33 calls the program stored in the memory 32 to implement the steps of the entity identification method.
In practical application, after obtaining the named entity of the corpus to be identified, the server can send the named entity to the corresponding client, so that the client performs subsequent operations according to the named entity, or the server can perform data search according to the obtained named entity, and then feeds back the searched related data to the client for output.
It should be noted that, in the present specification, the embodiments are described in a progressive manner, each embodiment focuses on differences from other embodiments, and the same and similar parts among the embodiments may be referred to each other. The device and the server disclosed by the embodiment correspond to the method disclosed by the embodiment, so that the description is simple, and the relevant points can be referred to the description of the method part.
Those of skill would further appreciate that the various illustrative elements and algorithm steps described in connection with the embodiments disclosed herein may be implemented as electronic hardware, computer software, or combinations of both, and that the various illustrative components and steps have been described above generally in terms of their functionality in order to clearly illustrate this interchangeability of hardware and software. Whether such functionality is implemented as hardware or software depends upon the particular application and design constraints imposed on the implementation. Skilled artisans may implement the described functionality in varying ways for each particular application, but such implementation decisions should not be interpreted as causing a departure from the scope of the present application.
The steps of a method or algorithm described in connection with the embodiments disclosed herein may be embodied directly in hardware, in a software module executed by a processor, or in a combination of the two. A software module may reside in Random Access Memory (RAM), memory, read-only memory (ROM), electrically programmable ROM, electrically erasable programmable ROM, registers, hard disk, a removable disk, a CD-ROM, or any other form of storage medium known in the art.
The previous description of the disclosed embodiments is provided to enable any person skilled in the art to make or use the present application. Various modifications to these embodiments will be readily apparent to those skilled in the art, and the generic principles defined herein may be applied to other embodiments without departing from the spirit or scope of the disclosure. Thus, the present application is not intended to be limited to the embodiments shown herein but is to be accorded the widest scope consistent with the principles and novel features disclosed herein.
Claims (7)
1. An entity identification method, comprising:
obtaining corpora to be identified;
acquiring a slot value dictionary and a synonym dictionary;
matching the linguistic data to be recognized with the slot value dictionary and the synonym dictionary one by one to obtain a plurality of slot position combinations;
filtering the slot combinations according to preset logic limiting conditions to obtain candidate slot combinations;
marking the corpus to be identified by using the candidate slot position combination to obtain a corresponding slot position marking sequence;
respectively coding the word sequence of the corpus to be identified and the slot position tagging sequence based on a deep learning network to obtain a first coding vector of the corpus to be identified and a second coding vector of the slot position tagging sequence;
determining a target annotation sequence in the slot annotation sequence based on the similarity between the first encoding vector and the second encoding vector;
and obtaining the named entity of the corpus to be identified by utilizing the target labeling sequence.
2. The method of claim 1, wherein the determining a target annotation sequence in the slot annotation sequences based on the similarity between the first coded vector and the second coded vector comprises:
calculating the similarity of the first encoding vector and the second encoding vector;
and selecting the slot position marking sequence corresponding to the second coding vector with the maximum similarity as a target marking sequence.
3. The method according to any one of claims 1 to 2, wherein the encoding the word sequence of the corpus to be identified and the slot annotation sequence based on the deep learning network to obtain a first encoding vector of the corpus to be identified and a second encoding vector of the slot annotation sequence respectively comprises:
acquiring a word sequence of the linguistic data to be recognized;
inputting the word sequence into a first neural network model for coding to obtain a first coding vector;
and inputting the slot position labeling sequence into a second neural network model for coding to obtain a second coding vector.
4. The method of claim 3, wherein the first neural network model and the second neural network model are different types of two-way long-short term memory networks.
5. An entity identification apparatus, the apparatus comprising:
the first acquisition module is used for acquiring the linguistic data to be identified;
the second acquisition module is used for acquiring the candidate slot position combination of the linguistic data to be identified by using a slot value matching mode;
the marking module is used for marking the corpus to be identified by utilizing the candidate slot position combination to obtain a corresponding slot position marking sequence;
a third obtaining module, configured to code the word sequence of the corpus to be identified and the slot position tagging sequence respectively based on a deep learning network, so as to obtain a first coding vector of the corpus to be identified and a second coding vector of the slot position tagging sequence;
the identification module is used for determining a target labeling sequence in the slot position labeling sequence based on the similarity between the first coding vector and the second coding vector and obtaining a named entity of the corpus to be identified by using the target labeling sequence;
the second acquisition module comprises:
the first acquisition unit is used for acquiring a plurality of slot position combinations of the linguistic data to be identified by using a slot value matching mode;
the filtering unit is used for filtering the slot combinations according to preset logic limiting conditions to obtain candidate slot combinations;
the first acquisition unit includes:
the dictionary acquisition unit is used for acquiring a slot value dictionary and a synonym dictionary;
and the matching unit is used for matching the linguistic data to be recognized with the slot value dictionary and the synonym dictionary one by one to obtain a plurality of slot combinations.
6. A computer device, comprising:
a communication interface;
a memory for storing a program for implementing the entity identification method according to any one of claims 1 to 4;
a processor for loading and executing said memory-stored program to implement the steps of the entity identification method of any one of claims 1 to 4.
7. A computer-readable storage medium, having stored thereon a computer program which, when executed by a processor, carries out the steps of the entity identification method of any one of claims 1 to 4.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910243952.9A CN109918680B (en) | 2019-03-28 | 2019-03-28 | Entity identification method and device and computer equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910243952.9A CN109918680B (en) | 2019-03-28 | 2019-03-28 | Entity identification method and device and computer equipment |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109918680A CN109918680A (en) | 2019-06-21 |
| CN109918680B true CN109918680B (en) | 2023-04-07 |
Family
ID=66967499
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910243952.9A Active CN109918680B (en) | 2019-03-28 | 2019-03-28 | Entity identification method and device and computer equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN109918680B (en) |
Families Citing this family (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110442332A (en) * | 2019-07-04 | 2019-11-12 | 深圳壹账通智能科技有限公司 | Natural language is converted into the method, apparatus and computer equipment of program language |
| CN112215010B (en) * | 2019-07-10 | 2024-10-22 | 北京猎户星空科技有限公司 | Semantic recognition method and device |
| CN110413756B (en) | 2019-07-29 | 2022-02-15 | 北京小米智能科技有限公司 | Method, device and equipment for processing natural language |
| CN112395414B (en) * | 2019-08-16 | 2024-06-04 | 北京地平线机器人技术研发有限公司 | Text classification method, training method of classification model, training device of classification model, medium and training equipment |
| CN110533324B (en) * | 2019-08-29 | 2022-04-22 | 深圳市慧择时代科技有限公司 | Method and device for automatically distributing insurance customer service |
| CN112528666A (en) * | 2019-08-30 | 2021-03-19 | 北京猎户星空科技有限公司 | Semantic recognition method and device and electronic equipment |
| CN110750991B (en) * | 2019-09-18 | 2022-04-15 | 平安科技(深圳)有限公司 | Entity identification method, device, equipment and computer readable storage medium |
| CN112580298B (en) * | 2019-09-29 | 2024-05-07 | 大众问问(北京)信息科技有限公司 | Method, device and equipment for acquiring annotation data |
| CN110705267B (en) * | 2019-09-29 | 2023-03-21 | 阿波罗智联(北京)科技有限公司 | Semantic parsing method, semantic parsing device and storage medium |
| CN110727782A (en) * | 2019-10-22 | 2020-01-24 | 苏州思必驰信息科技有限公司 | Question and answer corpus generation method and system |
| CN110825875B (en) * | 2019-11-01 | 2022-12-06 | 科大讯飞股份有限公司 | Text entity type identification method and device, electronic equipment and storage medium |
| CN111079418B (en) * | 2019-11-06 | 2023-12-05 | 科大讯飞股份有限公司 | Named entity recognition method, device, electronic equipment and storage medium |
| CN113051919B (en) * | 2019-12-26 | 2023-04-04 | 中国电信股份有限公司 | Method and device for identifying named entity |
| CN111782278A (en) * | 2019-12-26 | 2020-10-16 | 北京沃东天骏信息技术有限公司 | Functional program awakening method and device |
| CN113128225B (en) * | 2019-12-31 | 2024-06-21 | 阿里巴巴集团控股有限公司 | Named entity identification method and device, electronic equipment and computer storage medium |
| CN111339770B (en) * | 2020-02-18 | 2023-07-21 | 百度在线网络技术(北京)有限公司 | Method and device for outputting information |
| CN111339780B (en) * | 2020-05-14 | 2020-11-06 | 北京金山数字娱乐科技有限公司 | Word processing method and device based on multitask model |
| CN111738016B (en) * | 2020-06-28 | 2023-09-05 | 中国平安财产保险股份有限公司 | Multi-intention recognition method and related equipment |
| CN112003960B (en) * | 2020-08-06 | 2022-11-15 | 杭州安恒信息技术股份有限公司 | Network interface management method and device of industrial control equipment and electronic device |
| CN112364649B (en) * | 2020-09-08 | 2022-07-19 | 深圳平安医疗健康科技服务有限公司 | Named entity identification method and device, computer equipment and storage medium |
| CN112183075B (en) * | 2020-10-10 | 2023-06-30 | 网易(杭州)网络有限公司 | Method and device for extracting slots in conversation, electronic equipment and storage medium |
| CN112215005A (en) * | 2020-10-12 | 2021-01-12 | 小红书科技有限公司 | Entity identification method and device |
| CN113408292A (en) * | 2020-11-03 | 2021-09-17 | 腾讯科技(深圳)有限公司 | Semantic recognition method and device, electronic equipment and computer-readable storage medium |
| CN112528001B (en) * | 2020-12-23 | 2023-07-25 | 北京百度网讯科技有限公司 | Information query method and device and electronic equipment |
| CN112800769B (en) * | 2021-02-20 | 2024-06-14 | 深圳追一科技有限公司 | Named entity recognition method, named entity recognition device, named entity recognition computer equipment and named entity recognition storage medium |
| CN112926326B (en) * | 2021-02-20 | 2024-01-19 | 深圳追一科技有限公司 | Named entity recognition method, named entity recognition device, named entity recognition computer equipment and named entity recognition storage medium |
| CN112599214A (en) * | 2021-03-04 | 2021-04-02 | 中译语通科技股份有限公司 | Method and system for extracting ICD (interface control document) codes from electronic medical records |
| CN113221644A (en) * | 2021-04-06 | 2021-08-06 | 珠海远光移动互联科技有限公司 | Slot position word recognition method and device, storage medium and electronic equipment |
| CN114023319B (en) * | 2021-11-02 | 2024-09-17 | 北京声智科技有限公司 | Slot position identification method and device, electronic equipment and readable storage medium |
| CN114625850A (en) * | 2022-03-09 | 2022-06-14 | 上海弘玑信息技术有限公司 | Method and device for generating field extraction engine, electronic equipment and storage medium |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003044502A (en) * | 2001-07-30 | 2003-02-14 | Nippon Telegr & Teleph Corp <Ntt> | Information generation system for supporting ontology, method, program, recording medium |
| CN101154379B (en) * | 2006-09-27 | 2011-11-23 | 夏普株式会社 | Method and device for locating keywords in voice and voice recognition system |
| KR100977000B1 (en) * | 2008-06-26 | 2010-08-19 | 주식회사 예스피치 | Grammar-creating method and the system |
| CN104834849B (en) * | 2015-04-14 | 2018-09-18 | 北京远鉴科技有限公司 | Dual-factor identity authentication method and system based on Application on Voiceprint Recognition and recognition of face |
| CN106782560B (en) * | 2017-03-06 | 2020-06-16 | 海信集团有限公司 | Method and device for determining target recognition text |
| TWI753034B (en) * | 2017-03-31 | 2022-01-21 | 香港商阿里巴巴集團服務有限公司 | Method, device and electronic device for generating and searching feature vector |
| CN108304439B (en) * | 2017-10-30 | 2021-07-27 | 腾讯科技(深圳)有限公司 | Semantic model optimization method and device, intelligent device and storage medium |
| CN107797992A (en) * | 2017-11-10 | 2018-03-13 | 北京百分点信息科技有限公司 | Name entity recognition method and device |
| CN109492215A (en) * | 2018-09-18 | 2019-03-19 | 平安科技(深圳)有限公司 | News property recognition methods, device, computer equipment and storage medium |
| CN109284361A (en) * | 2018-09-29 | 2019-01-29 | 深圳追科技有限公司 | A kind of entity abstracting method and system based on deep learning |
-
2019
- 2019-03-28 CN CN201910243952.9A patent/CN109918680B/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| CN109918680A (en) | 2019-06-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109918680B (en) | Entity identification method and device and computer equipment | |
| CN109241524B (en) | Semantic analysis method and device, computer-readable storage medium and electronic equipment | |
| CN107291783B (en) | Semantic matching method and intelligent equipment | |
| CN108287858B (en) | Semantic extraction method and device for natural language | |
| CN106776544B (en) | Character relation recognition method and device and word segmentation method | |
| CN110163181B (en) | Sign language identification method and device | |
| CN112100349A (en) | Multi-turn dialogue method and device, electronic equipment and storage medium | |
| CN111310440B (en) | Text error correction method, device and system | |
| CN110619051B (en) | Question sentence classification method, device, electronic equipment and storage medium | |
| CN112084789B (en) | Text processing method, device, equipment and storage medium | |
| CN107291690A (en) | Punctuate adding method and device, the device added for punctuate | |
| CN112699686B (en) | Semantic understanding method, device, equipment and medium based on task type dialogue system | |
| CN111274797A (en) | Intention recognition method, device and equipment for terminal and storage medium | |
| CN114757176A (en) | Method for obtaining target intention recognition model and intention recognition method | |
| CN111046674B (en) | Semantic understanding method and device, electronic equipment and storage medium | |
| CN112463942A (en) | Text processing method and device, electronic equipment and computer readable storage medium | |
| CN111444695B (en) | Text generation method, device and equipment based on artificial intelligence and storage medium | |
| CN114818665B (en) | Multi-purpose recognition method and system based on bert+bilstm+crf and xgboost model | |
| CN112307179A (en) | Text matching method, device, equipment and storage medium | |
| CN107424612A (en) | Processing method, device and machine readable media | |
| CN114611529B (en) | Intention recognition method and device, electronic equipment and storage medium | |
| CN116978367A (en) | Speech recognition method, device, electronic equipment and storage medium | |
| CN115691503A (en) | Voice recognition method and device, electronic equipment and storage medium | |
| CN109727591B (en) | Voice search method and device | |
| CN111489742B (en) | Acoustic model training method, voice recognition device and electronic equipment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| TG01 | Patent term adjustment | ||
| TG01 | Patent term adjustment |