CN108628454B - Visual interaction method and system based on virtual human - Google Patents
Visual interaction method and system based on virtual human Download PDFInfo
- Publication number
- CN108628454B CN108628454B CN201810442311.1A CN201810442311A CN108628454B CN 108628454 B CN108628454 B CN 108628454B CN 201810442311 A CN201810442311 A CN 201810442311A CN 108628454 B CN108628454 B CN 108628454B
- Authority
- CN
- China
- Prior art keywords
- interaction
- data
- arm
- virtual human
- action
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000003993 interaction Effects 0.000 title claims abstract description 236
- 230000000007 visual effect Effects 0.000 title claims abstract description 80
- 238000000034 method Methods 0.000 title claims abstract description 55
- 230000009471 action Effects 0.000 claims abstract description 128
- 230000002452 interceptive effect Effects 0.000 claims abstract description 34
- 230000008451 emotion Effects 0.000 claims abstract description 27
- 230000008447 perception Effects 0.000 claims abstract description 14
- 230000004438 eyesight Effects 0.000 claims abstract description 9
- 210000004556 brain Anatomy 0.000 claims description 36
- 230000014509 gene expression Effects 0.000 claims description 22
- 230000006870 function Effects 0.000 claims description 20
- 210000003811 finger Anatomy 0.000 claims description 16
- 230000001149 cognitive effect Effects 0.000 claims description 11
- 230000008449 language Effects 0.000 claims description 7
- 238000004458 analytical method Methods 0.000 claims description 6
- 210000003813 thumb Anatomy 0.000 claims description 6
- 238000003860 storage Methods 0.000 claims description 4
- 230000008569 process Effects 0.000 description 16
- 238000012545 processing Methods 0.000 description 16
- 238000004891 communication Methods 0.000 description 14
- 238000010586 diagram Methods 0.000 description 12
- 230000008909 emotion recognition Effects 0.000 description 8
- 238000005516 engineering process Methods 0.000 description 7
- 238000004364 calculation method Methods 0.000 description 6
- 238000001514 detection method Methods 0.000 description 6
- 230000002996 emotional effect Effects 0.000 description 5
- 238000000605 extraction Methods 0.000 description 5
- 230000004044 response Effects 0.000 description 5
- 230000008921 facial expression Effects 0.000 description 4
- 210000004247 hand Anatomy 0.000 description 4
- 230000008901 benefit Effects 0.000 description 3
- 238000004422 calculation algorithm Methods 0.000 description 3
- 210000003414 extremity Anatomy 0.000 description 3
- 210000002478 hand joint Anatomy 0.000 description 3
- 230000003578 releasing effect Effects 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 230000008859 change Effects 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 238000005034 decoration Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 238000007781 pre-processing Methods 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 230000001953 sensory effect Effects 0.000 description 2
- 230000016776 visual perception Effects 0.000 description 2
- 241000282412 Homo Species 0.000 description 1
- 238000013473 artificial intelligence Methods 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 230000008602 contraction Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 210000004709 eyebrow Anatomy 0.000 description 1
- 210000000887 face Anatomy 0.000 description 1
- 210000003128 head Anatomy 0.000 description 1
- 238000003711 image thresholding Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 210000000214 mouth Anatomy 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 238000003058 natural language processing Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000004088 simulation Methods 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000007480 spreading Effects 0.000 description 1
- 238000003892 spreading Methods 0.000 description 1
- 238000012549 training Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
Images









Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/017—Gesture based interaction, e.g. based on a set of recognized hand gestures
Landscapes
- Engineering & Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- User Interface Of Digital Computer (AREA)
Abstract
The invention provides a visual interaction method based on a virtual human, wherein the virtual human is displayed through intelligent equipment, and voice, emotion, vision and perception capability are started when the virtual human is in an interaction state, and the method comprises the following steps: outputting multi-modal data through the virtual human; receiving multimodal interaction data provided by a user for multimodal data; parsing multimodal interaction data, wherein: detecting and extracting hand stretching actions or arm retracting actions in the multi-modal interaction data as interaction intents through visual ability; and performing multi-mode interactive output according to the interactive intention through the virtual human. The visual interaction method and system based on the virtual human provided by the invention provide the virtual human, and the virtual human has a preset image and preset attributes and can perform multi-mode interaction with a user. In addition, the visual interaction method and the visual interaction system for the virtual human provided by the invention can also judge the intention of the user through the hand stretching action or the arm stretching action, and can be interacted with the user, so that the user can enjoy anthropomorphic interaction experience.
Description
Technical Field
The invention relates to the field of artificial intelligence, in particular to a visual interaction method and system based on a virtual human.
Background
The development of robotic multi-modal interaction systems has been directed to mimicking human dialog in an attempt to mimic interactions between humans between contexts. However, at present, the development of a multi-modal robot interaction system related to a virtual human is not perfect, a virtual human performing multi-modal interaction does not appear, and more importantly, a visual interaction product based on a virtual human, which is specific to limbs, particularly to gesture interaction, and is responsive to the limbs, particularly to gesture interaction, does not exist yet.
Therefore, the invention provides a visual interaction method and system based on a virtual human.
Disclosure of Invention
In order to solve the above problems, the present invention provides a visual interaction method based on a virtual human, wherein the virtual human is displayed by an intelligent device, and voice, emotion, vision and perception capabilities are activated when the virtual human is in an interaction state, and the method comprises the following steps:
outputting multi-modal data through the avatar;
receiving multimodal interaction data provided by a user for the multimodal data;
parsing the multi-modal interaction data, wherein: detecting and extracting hand stretching actions or arm retracting actions in the multi-modal interaction data as interaction intents through visual ability;
and performing multi-mode interactive output through the virtual human according to the interactive intention.
According to one embodiment of the invention, in the judgment period, if the similarity between the extracted hand motion of the user and the hand stretching information stored in advance is larger than a first threshold value, the hand motion is identified as the hand stretching motion;
and in the judgment period, if the similarity between the extracted arm action of the user and the pre-stored arm retraction information is greater than a first threshold value, identifying the arm action as the arm retraction action.
According to an embodiment of the invention, the interaction intention is identified as a first intention or a second intention depending on the hand retracting motion or the arm retracting motion, wherein,
if the hand stretching motion is used as a first gesture, recognizing the interaction intention as the first intention, wherein the first intention indicates that the user will zoom in or zoom out on a target operation object by taking a preset point as a center;
and if the hand stretching movement is used as a second gesture or the arm movement is used as an arm folding and unfolding movement, identifying the interaction intention as the second intention, wherein the second intention indicates that the intention of the user is to enlarge or reduce the target operation object by taking the fixed point determined by the second gesture or the arm folding and unfolding movement as the center.
According to an embodiment of the present invention, in the step of detecting and extracting a hand stretching motion or an arm retracting motion in the multi-modal interaction data as the interaction intention through visual ability, the method further includes: capturing an operation object in a display picture of the intelligent device corresponding to the hand of the user, wherein the operation object comprises: virtual human, system function picture, multimedia picture.
According to one embodiment of the invention, the virtual human receives multi-modal interaction data provided by a plurality of users aiming at the multi-modal data, identifies a main user in the plurality of users, and detects the hand stretching and retracting actions and the arm stretching and retracting actions of the main user;
or the like, or, alternatively,
the method comprises the steps of collecting the hand stretching action and the arm stretching and retracting action of all or part of the current users, and determining the interaction intentions of the collected users according to a preset user collection proportion.
According to an embodiment of the present invention, when the multi-modal interaction data includes voice data or expression data, the above steps further include, according to the hand stretching action or the arm retracting action as an interaction intention:
detecting and extracting voice data or expression data in the multi-modal interaction data;
analyzing the voice data or the expression data, and judging whether the voice data or the expression data accords with the intention of the hand stretching action or the arm stretching action;
if the hand stretching action or the arm stretching action is matched with the hand stretching action or the arm stretching action, the hand stretching action or the arm stretching action is combined as an interaction intention according to the analysis result;
and if not, the hand stretching action or the arm retracting action is taken as an interaction intention.
According to one embodiment of the invention, the multi-modal interactive output is carried out by the virtual human according to the interactive intention, and comprises the following steps: outputting and displaying multi-mode interactive output according to the interaction intention corresponding to the hand stretching action or the arm stretching action through the virtual human, wherein the multi-mode interactive output comprises the following steps: result data corresponding to the first intent or the second intent.
According to another aspect of the invention, there is also provided a program product containing a series of instructions for carrying out the steps of the method according to any one of the above.
According to another aspect of the invention, a virtual human is provided, which has specific virtual images and preset attributes, and adopts the method as any one of the above to perform multi-modal interaction.
According to another aspect of the present invention, there is also provided a virtual human-based visual interaction system, comprising:
the intelligent equipment is loaded with the virtual human, is used for acquiring multi-mode interactive data and has the capability of outputting language, emotion, expression and action;
and the cloud brain is used for performing semantic understanding, visual recognition, cognitive computation and emotion computation on the multi-modal interaction data so as to decide that the virtual human outputs the multi-modal interaction data.
The visual interaction method and system based on the virtual human provided by the invention provide the virtual human, and the virtual human has a preset image and preset attributes and can perform multi-mode interaction with a user. In addition, the visual interaction method and the visual interaction system for the virtual human provided by the invention can also judge the intention of the user through the hand stretching action or the arm stretching action, and can be used for carrying out interaction with the user, so that the user can smoothly communicate with the virtual human, and the user can enjoy anthropomorphic interaction experience.
Additional features and advantages of the invention will be set forth in the description which follows, and in part will be obvious from the description, or may be learned by practice of the invention. The objectives and other advantages of the invention will be realized and attained by the structure particularly pointed out in the written description and claims hereof as well as the appended drawings.
Drawings
The accompanying drawings, which are included to provide a further understanding of the invention and are incorporated in and constitute a part of this specification, illustrate embodiments of the invention and together with the description serve to explain the principles of the invention and not to limit the invention. In the drawings:
FIG. 1 shows a block diagram of a virtual human-based visual interaction system according to an embodiment of the invention;
FIG. 2 shows a block diagram of a virtual human-based visual interaction system, according to an embodiment of the invention;
FIG. 3 shows a block diagram of a virtual human-based visual interaction system according to another embodiment of the present invention;
FIG. 4 shows a block diagram of a virtual human-based visual interaction system according to another embodiment of the present invention;
FIG. 5 shows a schematic diagram of a virtual human-based visual interaction system for visual interaction, according to an embodiment of the invention;
FIG. 6 shows a flow diagram of a method of visual interaction based on a avatar, according to an embodiment of the invention;
FIG. 7 shows a flowchart for determining interaction intent of a method of visual interaction based on a avatar, according to an embodiment of the present invention;
FIG. 8 shows a flowchart of determining an interaction intention of a virtual human-based visual interaction method according to another embodiment of the present invention;
FIG. 9 shows another flow diagram of a method of visual interaction based on a avatar, according to an embodiment of the present invention; and
fig. 10 shows a flow chart of communication between three parties, namely a user, a smart device and a cloud brain, according to an embodiment of the invention.
Detailed Description
In order to make the objects, technical solutions and advantages of the present invention more apparent, embodiments of the present invention are described in further detail below with reference to the accompanying drawings.
For clarity, the following description is required before the examples:
the virtual human provided by the invention is carried on intelligent equipment supporting input and output modules of perception, control and the like; the high-simulation 3d virtual character image is taken as a main user interface, and the appearance with remarkable character characteristics is achieved; the system supports multi-mode human-computer interaction and has AI capabilities of natural language understanding, visual perception, touch perception, language voice output, emotion expression and action output and the like; the social attributes, personality attributes, character skills and the like can be configured, so that the user can enjoy the virtual character with intelligent and personalized smooth experience.
The intelligent device carried by the virtual human is as follows: the intelligent equipment comprises a screen (a holographic screen, a television screen, a multimedia display screen, an LED screen and the like) which is not touched or input by a mouse and a keyboard, and intelligent equipment with a camera, and meanwhile, the intelligent equipment can be holographic equipment, VR equipment and a PC. But other intelligent devices are not excluded, such as: handheld tablets, naked eye 3D devices, even smart phones, etc.
The virtual human interacts with the user at a system level, and an operating system is operated in system hardware, such as a holographic device built-in system, and a PC is a windows or a MAC OS.
A virtual human being is a system application, or an executable file.
The virtual robot acquires multi-mode interactive data of a user based on the hardware of the intelligent device, and performs semantic understanding, visual recognition, cognitive computation and emotion computation on the multi-mode interactive data under the support of the capability of a cloud brain so as to complete a decision output process.
The cloud brain realizes interaction with the user for the terminal providing the processing capability of the virtual human for performing semantic understanding (language semantic understanding, action semantic understanding, visual recognition, emotion calculation and cognitive calculation) on the interaction requirement of the user, so as to decide the output multi-mode interaction data of the virtual human.
Various embodiments of the present invention will be described in detail below with reference to the accompanying drawings.
Fig. 1 shows a block diagram of a virtual human-based visual interaction system according to an embodiment of the present invention. As shown in fig. 1, conducting multi-modal interactions requires a user 101, a smart device 102, a avatar 103, and a cloud brain 104. The user 101 interacting with the avatar may be a real avatar, another avatar, and an entity avatar, and the interaction process of the other avatar and the entity avatar with the avatar is similar to that of a single avatar. Thus, only the multi-modal interaction process of the user (human) with the avatar is illustrated in fig. 1.
In addition, the smart device 102 includes a display area 1021 and hardware support devices 1022 (essentially core processors). The display area 1021 is used for displaying the image of the virtual human 103, and the hardware support device 1022 is used in cooperation with the cloud brain 104 for data processing in the interaction process. The avatar 103 requires a screen carrier to present. Thus, the display area 1021 includes: holographic screen, TV screen, multimedia display screen, LED screen, etc.
The process of interaction between the avatar and the user 101 in fig. 1 is as follows:
the avatar is mounted and run on the smart device 102, and the avatar has certain character characteristics. The virtual human has AI capabilities of natural language understanding, visual perception, touch perception, language output, emotion expression action output and the like. In order to match with the touch sensing function of the virtual human, a component with the touch sensing function also needs to be installed on the intelligent device. According to one embodiment of the invention, in order to improve the interactive experience, the virtual human is displayed in the preset area after being started.
It should be noted here that the avatar and the dress of avatar 103 are not limited to one mode. Avatar 103 may be provided with different images and with a dress. The avatar of avatar 103 is typically a 3D high-modulus animated avatar. The avatar 103 may have different appearances and decorations. Each kind of virtual human 103 image can also correspond to different kinds of dressing, and the dressing classification can be classified according to seasons and occasions. These images and masquerades may be present in cloud brain 104 or in smart device 102 and may be invoked at any time when they need to be invoked.
The social attributes, personality attributes, and character skills of the avatar 103 are also not limited to one or one category. The avatar 103 may have a variety of social attributes, a variety of personality attributes, and a variety of personality skills. The social attributes, personality attributes and character skills can be matched respectively, and are not fixed in a matching mode, so that a user can select and match the social attributes, the personality attributes and the character skills according to needs.
Specifically, the social attributes may include: attributes such as appearance, name, apparel, decoration, gender, native place, age, family relationship, occupation, position, religious belief, emotional state, academic calendar, etc.; personality attributes may include: character, temperament, etc.; the character skills may include: singing, dancing, storytelling, training, and the like, and character skill display is not limited to body, expression, head, and/or mouth skill display.
In the application, the social attribute, the personality attribute, the character skill and the like of the virtual human can make the analysis and decision result of the multi-modal interaction more inclined or more suitable for the virtual human.
The following is a multimodal interaction process, first, multimodal data is output through a virtual human. When the avatar 103 communicates with the user 101, the avatar 103 first outputs multimodal data to wait for the user 101 to respond to the multimodal data. In actual practice, the avatar 103 may output a speech, music or video.
Next, multimodal interaction data provided by a user for the multimodal data is received. The multimodal interaction data may contain information in a variety of modalities, such as text, speech, visual, and perceptual information. The receiving devices for obtaining the multimodal interactive data are installed or configured on the smart device 102, and include a text receiving device for receiving text, a voice receiving device for receiving voice, a camera for receiving vision, an infrared device for receiving perception information, and the like.
Then, multimodal interaction data is parsed, wherein: and detecting and extracting hand stretching actions or arm retracting actions in the multi-modal interaction data as interaction intentions through visual ability. And in the judgment period, if the similarity between the extracted hand motion of the user and the hand stretching information stored in advance is larger than a first threshold value, recognizing the hand motion as the hand stretching motion. And in the judgment period, if the similarity between the extracted arm action of the user and the pre-stored arm retraction information is greater than a first threshold value, identifying the arm action as the arm retraction action.
The hand stretch information includes: and in the judgment period of the hand, the positions of the key points of the hand joints correspond to the relationship of the key points of the hand joints and the dynamic change process of the key points of the hand joints, and the intention indicates the enlargement and reduction of the operation object.
The arm receiving and releasing information comprises: and in the judgment short period of the arm, the relation between the palm key point position and the arm key point, the relation between the elbow key point position and the shoulder key point, and the relation between the two arm key points represent the corresponding intention of the dynamic change process of the arm, and the intention indicates the enlargement and reduction of the operation object.
And finally, performing multi-mode interactive output through the virtual human according to the interactive intention.
In addition, the avatar 103 may also receive multi-modal interaction data provided for the multi-modal data from a plurality of users, recognize a main user among the plurality of users, and detect a hand stretching motion and an arm retracting motion of the main user. Or the virtual human 103 collects the hand stretching action and the arm stretching and retracting action of all or part of the current users, and determines the interaction intention of the collected users according to the preset user collection proportion.
According to another embodiment of the invention, the virtual human has a specific virtual image and preset attributes, and multi-modal interaction is carried out by adopting a visual interaction method based on the virtual human.
Fig. 2 shows a block diagram of a virtual human-based visual interaction system according to an embodiment of the present invention. As shown in fig. 2, the completion of multi-modal interactions by the system requires: user 101, smart device 102, and cloud brain 104. The smart device 102 includes a receiving device 102A, a processing device 102B, an output device 102C, and a connecting device 102D. Cloud brain 104 includes communication device 104A.
The virtual human-based visual interaction system provided by the invention needs to establish a smooth communication channel among the user 101, the intelligent device 102 and the cloud brain 104 so as to complete the interaction between the user 101 and the virtual human. To accomplish the task of interaction, the smart device 102 and the cloud brain 104 are provided with devices and components that support the completion of interaction. The object interacting with the virtual human can be one party or multiple parties.
The smart device 102 includes a receiving device 102A, a processing device 102B, an output device 102C, and a connecting device 102D. Wherein the receiving device 102A is configured to receive multimodal interaction data. Examples of receiving devices 102A include a microphone for voice operation, a scanner, a camera (detecting motion not involving touch using visible or invisible wavelengths), and so forth. The smart device 102 may obtain multimodal interaction data through the aforementioned input devices. The output device 102C is configured to output multi-modal output data of the avatar interacting with the user 101, and is substantially equivalent to the configuration of the receiving device 102A, which is not described herein again.
The processing device 102B is configured to process interaction data transmitted by the cloud brain 104 during an interaction process. The connection device 102D is used for communication with the cloud brain 104, and the processing device 102B processes the multi-modal interaction data pre-processed by the receiving device 102A or the data transmitted by the cloud brain 104. The connection device 102D sends a call instruction to call the robot capability on the cloud brain 104.
The cloud brain 104 includes a communication device 104A for completing communication with the smart device 102. The communication device 104A communicates with the connection device 102D on the smart device 102, receives the request from the smart device 102, and sends the processing result from the cloud brain 104, which is a medium for communication between the smart device 102 and the cloud brain 104.
Fig. 3 shows a block diagram of a virtual human-based visual interaction system according to another embodiment of the present invention. As shown in fig. 3, the system includes an interaction module 301, a receiving module 302, a parsing module 303, and a decision module 304. The receiving module 302 includes a text capture unit 3021, an audio capture unit 3022, a visual capture unit 3023, and a perception capture unit 3024.
The interaction module 301 is used for outputting multi-modal data through the avatar. The avatar 103 is exposed through the smart device 102, enabling voice, emotion, vision, and perception capabilities while in an interactive state. In one round of interaction, the avatar 103 first outputs multimodal data to await responses from the user 101 to the multimodal data. According to one embodiment of the invention, the interaction module 301 comprises an output unit 3011. The output unit 3011 can output multi-modal data.
The receiving module 302 is configured to receive multimodal interaction data. The text collection unit 3021 is used to collect text information. The audio capture unit 3022 is used to capture audio information. The vision acquisition unit 3023 is used to acquire visual information. The perception acquisition unit 3024 is used to acquire perception information. Examples of receiving modules 302 include microphones, scanners, cameras, sensory devices for voice operation, such as using visible or invisible wavelengths of radiation, signals, environmental data, and so forth. Multimodal interaction data may be acquired through the above-mentioned input devices. The multi-modal interaction may comprise one or more of text, audio, visual, and perceptual data, and the invention is not limited thereto.
The parsing module 303 is configured to parse the multimodal interaction data, wherein: and detecting and extracting hand stretching actions or arm retracting actions in the multi-modal interaction data as interaction intentions through visual ability. The analysis module 303 includes a detection unit 3031 and an extraction unit 3032. The detecting unit 3031 is configured to detect a hand stretching motion or an arm retracting motion in the multi-modal interaction data through visual ability.
If the detection unit 3031 detects that the hand stretching action or the arm stretching action exists in the multi-modal interaction data, the extraction unit 3032 extracts the hand stretching action or the arm stretching action and takes the hand stretching action or the arm stretching action as the interaction intention. According to one embodiment of the present invention, the interaction intents are divided into two categories, a first intent and a second intent. The process of determining the category of the interaction intention may be: if the hand telescoping action is the first gesture, the interaction intention is recognized as the first intention indicating that the user intends to zoom in or out on the target operation object centered on the preset point. According to an embodiment of the present invention, the first gesture is an action of all fingers of either or both hands of the user from curling to outstretching or from unfolding to insiding, and the target operation object includes: virtual human, system function picture, multimedia picture.
In addition, if the hand expansion and contraction movement is the second gesture or the arm movement is the arm retracting movement, the interaction intention is recognized as the second intention indicating that the user intends to enlarge or reduce the target operation object around the fixed point determined by the second gesture or the arm retracting movement. According to an embodiment of the present invention, the second gesture is an action of closing the thumb and the index finger of either hand of the user from the finger pulp to the outward opening or from the opening to the finger pulp closing, and the target operation object includes: virtual human, system function picture, multimedia picture.
The output module 304 is used for performing multi-modal interactive output according to the interactive intention through the virtual human. After the interaction intention is determined by the parsing module 303, the output module 304 outputs a multi-modal interaction output according with the interaction intention. The output module 304 includes an output data unit 3041, which can determine a multi-modal interaction output required to be output according to the interaction intention, and display the multi-modal interaction output to the user 101 through the virtual human.
Fig. 4 shows a block diagram of a virtual human-based visual interaction system according to another embodiment of the present invention. As shown in fig. 4, completing the interaction requires a user 101, a smart device 102, and a cloud brain 104. The smart device 102 includes a human-machine interface 401, a data processing unit 402, an input/output device 403, and an interface unit 404. Cloud brain 104 includes semantic understanding interface 1041, visual recognition interface 1042, cognitive computation interface 1043, and emotion computation interface 1044.
The virtual human-based visual interaction system provided by the invention comprises an intelligent device 102 and a cloud brain 104. The avatar 103 runs in the smart device 102, and the avatar 103 has a preset image and preset attributes, and can activate voice, emotion, vision, and perception capabilities when in an interactive state.
In one embodiment, the smart device 102 may include: a human-machine interface 401, a data processing unit 402, an input-output device 403, and an interface unit 404. The human-machine interface 401 displays the virtual human 103 in the running state in a preset area of the intelligent device 102.
The data processing unit 402 is used for processing data generated in the process of multi-modal interaction between the user 101 and the avatar 103. The Processor may be a data Processing Unit (CPU), other general purpose Processor, a Digital Signal Processor (DSP), an Application Specific Integrated Circuit (ASIC), an off-the-shelf Programmable Gate Array (FPGA) or other Programmable logic device, discrete Gate or transistor logic device, discrete hardware component, etc. The general purpose processor may be a microprocessor or the processor may be any conventional processor or the like, the processor being the control center of the terminal, and various interfaces and lines connecting the various parts of the overall terminal.
The smart device 102 includes a memory, which mainly includes a storage program area and a storage data area, wherein the storage program area may store an operating system, an application program (such as a sound playing function, an image playing function, etc.) required by at least one function, and the like; the stored data area may store data created from use of the smart device 102 (e.g., audio data, browsing recordings, etc.), and the like. In addition, the memory may include high speed random access memory, and may also include non-volatile memory, such as a hard disk, a memory, a plug-in hard disk, a Smart Media Card (SMC), a Secure Digital (SD) Card, a Flash memory Card (Flash Card), at least one magnetic disk storage device, a Flash memory device, or other volatile solid state storage device.
The input/output device 403 is used for acquiring multi-modal interaction data and outputting output data in the interaction process. The interface unit 404 is configured to communicate with the cloud brain 104, and invoke the virtual human capability in the cloud brain 104 by interfacing with the interface in the cloud brain 104.
As shown in fig. 4, each capability interface calls corresponding logic processing in the multi-modal data parsing process. The following is a description of the various interfaces:
a semantic understanding interface 1041 that receives specific voice commands forwarded from the interface unit 404, performs voice recognition thereon, and natural language processing based on a large corpus.
The visual recognition interface 1042 can perform video content detection, recognition, tracking, and the like according to a computer vision algorithm, a deep learning algorithm, and the like for human bodies, human faces, and scenes. Namely, the image is identified according to a preset algorithm, and a quantitative detection result is given. The system has an image preprocessing function, a feature extraction function, a decision function and a specific application function;
the image preprocessing function can be basic processing of the acquired visual acquisition data, including color space conversion, edge extraction, image transformation and image thresholding;
the characteristic extraction function can extract characteristic information of complexion, color, texture, motion, coordinates and the like of a target in the image;
the decision function can be that the feature information is distributed to specific multi-mode output equipment or multi-mode output application needing the feature information according to a certain decision strategy, such as the functions of face detection, person limb identification, motion detection and the like are realized.
The cognitive computing interface 1043 receives the multimodal data forwarded from the interface unit 404, and the cognitive computing interface 1043 is used for processing the multimodal data to perform data acquisition, recognition and learning so as to obtain a user portrait, a knowledge graph and the like, so as to make a reasonable decision on the multimodal output data.
And emotion calculation interface 1044 for receiving the multimodal data forwarded from interface unit 404 and calculating the current emotional state of the user by using emotion calculation logic (which may be emotion recognition technology). The emotion recognition technology is an important component of emotion calculation, the content of emotion recognition research comprises the aspects of facial expression, voice, behavior, text, physiological signal recognition and the like, and the emotional state of a user can be judged through the content. The emotion recognition technology may monitor the emotional state of the user only through the visual emotion recognition technology, or may monitor the emotional state of the user in a manner of combining the visual emotion recognition technology and the voice emotion recognition technology, and is not limited thereto. In this embodiment, it is preferable to monitor the emotion by a combination of both.
The emotion calculation interface 1044 is used for collecting human facial expression images by using image acquisition equipment during visual emotion recognition, converting the human facial expression images into analyzable data, and then performing expression emotion analysis by using technologies such as image processing and the like. Understanding facial expressions typically requires detecting subtle changes in the expression, such as changes in cheek muscles, mouth, and eyebrow plucking.
Fig. 5 shows a schematic diagram of a virtual human-based visual interaction system for visual interaction according to an embodiment of the invention. As shown in fig. 5, multimodal interaction data is parsed, wherein: and detecting and extracting hand stretching actions or arm retracting actions in the multi-modal interaction data as interaction intentions through visual ability. The smart device 102 is configured with a hardware device capable of detecting visual ability, and is used for monitoring the hand stretching action and the arm retracting action of the user.
In one embodiment of the invention, in the judgment period, if the similarity between the extracted hand motion of the user and the hand stretching information stored in advance is larger than a first threshold value, the hand motion is identified as the hand stretching motion. And in the judgment period, if the similarity between the extracted arm action of the user and the pre-stored arm retraction information is greater than a first threshold value, identifying the arm action as the arm retraction action.
Further, it can be determined that the hand movement of the hand stretching movement includes a first gesture and a second gesture. The first gesture is the action of all fingers of either or both hands of the user from curling to outstretching or from unfolding to curling inwards, and the second gesture is the action of closing the thumb and the index finger of either hand of the user from the finger pulp to open outwards or from opening to finger pulp closing.
And when the hand stretching motion is recognized as the first gesture, recognizing the interaction intention as the first intention. The first intention indicates that the user's intention is to zoom in or out on the target operation object centering on the preset point. And when the hand stretching movement is recognized as a second gesture or the arm movement is recognized as the arm folding and unfolding movement, recognizing the interaction intention as a second intention, wherein the second intention indicates that the intention of the user is to enlarge or reduce the target operation object by taking the fixed point determined by the second gesture or the arm folding and unfolding movement as the center.
In addition, the step of detecting and extracting a hand stretching motion or an arm retracting motion in the multi-modal interaction data as the interaction intention through visual ability further comprises: capturing an operation object in a display picture of the intelligent equipment corresponding to the hand of the user, wherein the operation object comprises: virtual human, system function picture, multimedia picture.
After the interaction intention of the user is determined, multi-mode interaction output can be performed through the virtual human according to the interaction intention, and the multi-mode interaction output comprises the following steps: outputting and displaying multi-mode interactive output according to the interaction intention corresponding to the hand stretching action or the arm stretching action through the virtual human, wherein the multi-mode interactive output comprises the following steps: result data corresponding to the first intent or the second intent.
As shown in fig. 5, a first gesture 501 may be an action of all fingers of either or both hands of the user from curling to outstretching or from spreading to inwardly curling, and a second gesture 502 may be an action of either thumb and index finger of the user from pulp closure to outstretching or from opening to pulp closure. The arm retraction 503 may be a closing and unfolding motion of both arms.
When the hand retracting motion is recognized as the first gesture, the target operation object is enlarged or reduced centering on the predetermined point according to the user's intention. The preset point may be set to the center of the display screen of the smart device, or may be other positions set by the user in advance, which is not limited by the present invention.
When the hand retracting motion is recognized as the second gesture, the target operation object is enlarged or reduced around the fixed point specified by the second gesture according to the intention of the user. According to an embodiment of the invention, the second gesture may be determined by a gesture corresponding to a finger on the display of the smart device when the thumb and the index finger are closed.
And when the arm action is recognized as the arm folding and unfolding action, the target operation object is enlarged or reduced by taking the fixed point determined by the arm folding and unfolding action as the center according to the will of the user. According to an embodiment of the invention, the fixed point determined by the arm retracting and releasing action can be a fixed point corresponding to the display screen of the intelligent device when the left hand and the right hand are closed.
It should be noted that the first gesture and the second gesture are generally applied to a smart device with a small screen size, such as a handheld terminal desktop. The arm retracting and releasing actions are generally applied to intelligent equipment with a large screen size, such as a multimedia display screen or an LED screen.
The first gesture may be a left hand, a right hand, or both hands. The second gesture can be a thumb and an index finger, or any two fingers capable of realizing the zooming function. The opening and closing direction of the arm motion can be any direction, and the invention does not limit the above.
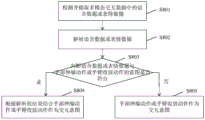
Fig. 6 shows a flow chart of a method of visual interaction based on a avatar according to an embodiment of the invention.
As shown in fig. 6, in step S601, multimodal data is output through the avatar. In this step, the avatar 103 in the smart device 102 outputs multimodal data to the user 101 in the hope of developing a dialog or other interaction with the user 101 in a round of interaction. The multimodal data output by the avatar 103 may be a piece of speech, a piece of music, or a piece of video.
In step S602, multimodal interaction data provided by a user for multimodal data is received. In this step, the smart device 102 may obtain the multi-modal interaction data, and the smart device 102 may be configured with a corresponding apparatus for obtaining the multi-modal interaction data. The multimodal interaction data may be input in the form of text input, audio input, and sensory input.
In step S603, multimodal interaction data is parsed, wherein: and detecting and extracting hand stretching actions or arm retracting actions in the multi-modal interaction data as interaction intentions through visual ability. The multi-modal interaction data may or may not include a hand stretching operation or an arm stretching operation, and it is necessary to detect whether the multi-modal interaction data includes a hand stretching operation or an arm stretching operation in order to determine the interaction intention. And in the judgment period, if the similarity between the extracted hand motion of the user and the hand stretching information stored in advance is larger than a first threshold value, recognizing the hand motion as the hand stretching motion. And in the judgment period, if the similarity between the extracted arm action of the user and the pre-stored arm retraction information is greater than a first threshold value, identifying the arm action as the arm retraction action.
In this step, it is first detected whether the multi-modal interaction data includes a hand stretching action or an arm stretching action, and if the multi-modal interaction data includes a hand stretching action or an arm stretching action, the hand stretching action or the arm stretching action is taken as an interaction intention of the current round of interaction. And if the multi-modal interaction data does not contain the hand stretching action or the arm retracting action, other data in the multi-modal interaction data is used as the interaction intention.
In one embodiment of the invention, the interaction intent is divided into a first intent and a second intent. The first intention represents a user's intention to zoom in or out on a target operation object centering on a preset point. The second intention indicates that the user intends to enlarge or reduce the target operation object around the fixed point determined by the second gesture or the arm retracting motion.
Finally, in step S604, a multi-modal interactive output is performed by the virtual human according to the interactive intention. After the interaction intention is determined, the avatar 103 can output a corresponding multi-modal interaction output according to the determined interaction intention.
In addition, the virtual human-based visual interaction system provided by the invention can also be matched with a program product which comprises a series of instructions for executing the steps of the visual interaction method for completing the virtual human. The program product is capable of executing computer instructions comprising computer program code, which may be in the form of source code, object code, an executable file or some intermediate form, etc.
The program product may include: any entity or device capable of carrying computer program code, recording medium, U.S. disk, removable hard disk, magnetic disk, optical disk, computer Memory, Read-Only Memory (ROM), Random Access Memory (RAM), electrical carrier wave signals, telecommunications signals, software distribution media, and the like.
It should be noted that the program product may include content that is appropriately increased or decreased as required by legislation and patent practice in jurisdictions, for example, in some jurisdictions, the program product does not include electrical carrier signals and telecommunications signals in accordance with legislation and patent practice.
Fig. 7 shows a flowchart of determining an interaction intention of a virtual human-based visual interaction method according to an embodiment of the present invention.
In step S701, multimodal interaction data is parsed, wherein: and detecting and extracting hand stretching actions or arm retracting actions in the multi-modal interaction data as interaction intentions through visual ability. In this step, the multi-modal interaction data needs to be parsed, and the multi-modal interaction data includes data in various forms. In order to know the interaction intention, whether the multi-modal interaction data includes a hand stretching action or an arm retracting action needs to be detected. When the multi-modal interaction data is detected to contain the hand stretching action or the arm stretching action, the detected hand stretching action or the detected arm stretching action needs to be extracted, and the hand stretching action or the arm stretching action serves as the interaction intention.
According to one embodiment of the invention, the interaction intents are divided into two categories, a first intent and a second intent. In step S702, when the other hand pinch is the first gesture, the interaction intention is recognized as the first intention indicating that the user intends to zoom in or out the target operation object centering on the preset point.
Meanwhile, in step S703, when it is recognized that the hand stretching movement is the second gesture or the arm movement is the arm retracting movement, the interaction intention is recognized as the second intention, where the second intention indicates that the user intends to enlarge or reduce the target operation object centering on the fixed point determined by the second gesture or the arm retracting movement. Finally, in step S704, a multi-modal interactive output is performed by the virtual human according to the interactive intention.
Fig. 8 shows a flowchart of determining an interaction intention of a virtual human-based visual interaction method according to another embodiment of the present invention.
In step S801, voice data or emotion data in the multimodal interaction data is detected and extracted. The multi-modal interaction data contains data in various forms, and the data may contain the current willingness of the user 101 to interact with. In this step, it is detected whether the multimodal interaction data contains speech data or expression data to make reference for determining the interaction intention.
Next, in step S802, the voice data or the emotion data is parsed. If the multi-modal interactive data comprises voice data or expression data, in the step, the voice data or the expression data is analyzed, the interactive intention of the user in the voice data or the expression data is obtained, and an analysis result is obtained.
Then, in step S803, it is determined whether or not the voice data or the expression data matches the intention of the hand retracting motion or the arm retracting motion. If the voice data or the expression data is in accordance with the intention of the hand stretching action or the arm stretching action, the step S804 is entered, and the hand stretching action or the arm stretching action is combined as the interaction intention according to the analyzed result. If the voice data or the expression data does not match the intention of the hand stretching action or the arm stretching action, the process proceeds to step S805, and the hand stretching action or the arm stretching action is used as the interaction intention.
Fig. 9 shows another flowchart of a method for visual interaction based on a avatar according to an embodiment of the present invention.
As shown in fig. 9, in step S901, the smart device 102 issues a request to the cloud brain 104. Thereafter, in step S902, the smart device 102 is in a state of waiting for the cloud brain 104 to reply. During the waiting period, the smart device 102 will time the time it takes to return data.
In step S903, if the returned response data is not obtained for a long time, for example, the time length exceeds a predetermined time length of 5S, the smart device 102 may select to perform local reply, and generate local general response data. Then, in step S904, an animation associated with the local general response is output, and the voice playback device is called to perform voice playback.
Fig. 10 shows a flow chart of communication between three parties, namely a user, a smart device and a cloud brain, according to an embodiment of the invention.
To enable multi-modal interaction between the smart device 102 and the user 101, a communication connection needs to be established between the user 101, the smart device 102, and the cloud brain 104. The communication connection should be real-time and unobstructed to ensure that the interaction is not affected.
In order to complete the interaction, some conditions or preconditions need to be met. These conditions or preconditions include that the avatar is loaded and run in the smart device 102, and that the smart device 102 has hardware facilities for sensing and controlling functions. The avatar activates speech, emotion, vision, and perception capabilities when in an interactive state.
After the preparation in the previous stage is completed, the smart device 102 starts to interact with the user 101, and first, the smart device 102 outputs multimodal data through the avatar 103. The multimodal data may be a piece of speech, a piece of music, or a piece of video output by the avatar in a round of interaction. At this time, the smart device 102 and the user 101 are two parties of the developed communication, and the direction of data transfer is from the smart device 102 to the user 101.
Then, the smart device 102 receives the multimodal interaction data. The multimodal interaction data is a response provided by the user to the multimodal data. The multimodal interaction data may include various forms of data, for example, text data, voice data, perception data, and motion data. The smart device 102 is configured with a corresponding device for receiving multi-modal interaction data, and is used for receiving the multi-modal interaction data sent by the user 101. At this time, the user 101 and the smart device 102 are both parties of data transfer, and the direction of data transfer is from the user 101 to the smart device 102.
In turn, smart device 102 sends a request to cloud brain 104. Requesting the cloud brain 104 to perform semantic understanding, visual recognition, cognitive computation and emotion computation on the multimodal interaction data to help the user make a decision. At this time, the hand stretching motion or the arm retracting motion in the multi-modal interaction data is detected and extracted as the interaction intention by the visual ability. Cloud brain 104 then transmits the reply data to smart device 102. At this time, two parties that perform communication are the smart device 102 and the cloud brain 104.
Finally, after the smart device 102 receives the data transmitted by the cloud brain 104, the smart device 102 performs multi-modal interactive output according to the interactive intention through the virtual human. At this time, the smart device 102 and the user 101 are two parties of the developed communication.
The visual interaction method and system based on the virtual human provided by the invention provide the virtual human, and the virtual human has a preset image and preset attributes and can perform multi-mode interaction with a user. In addition, the visual interaction method and the visual interaction system for the virtual human provided by the invention can also judge the intention of the user through the hand stretching action or the arm stretching action, and can be used for carrying out interaction with the user, so that the user can smoothly communicate with the virtual human, and the user can enjoy anthropomorphic interaction experience.
It is to be understood that the disclosed embodiments of the invention are not limited to the particular structures, process steps, or materials disclosed herein but are extended to equivalents thereof as would be understood by those ordinarily skilled in the relevant arts. It is also to be understood that the terminology used herein is for the purpose of describing particular embodiments only, and is not intended to be limiting.
Reference in the specification to "one embodiment" or "an embodiment" means that a particular feature, structure, or characteristic described in connection with the embodiment is included in at least one embodiment of the invention. Thus, the appearances of the phrase "one embodiment" or "an embodiment" in various places throughout this specification are not necessarily all referring to the same embodiment.
Although the embodiments of the present invention have been described above, the above description is only for the convenience of understanding the present invention, and is not intended to limit the present invention. It will be understood by those skilled in the art that various changes in form and details may be made therein without departing from the spirit and scope of the invention as defined by the appended claims.
Claims (8)
1. A visual interaction method based on a virtual human, which is characterized in that the virtual human is displayed through an intelligent device, and voice, emotion, vision and perception abilities are started when the virtual human is in an interaction state, and the method comprises the following steps:
outputting multi-modal data through the avatar;
receiving multimodal interaction data provided by a user for the multimodal data;
parsing the multi-modal interaction data, wherein: detecting and extracting hand stretching actions or arm retracting actions in the multi-modal interaction data as interaction intents through visual ability;
performing multi-mode interactive output through the virtual human according to the interactive intention;
when the multi-modal interaction data comprises voice data or expression data, taking the hand stretching action or the arm stretching and retracting action as an interaction intention, and the steps further comprise:
detecting and extracting voice data or expression data in the multi-modal interaction data;
analyzing the voice data or the expression data, and judging whether the voice data or the expression data accords with the intention of the hand stretching action or the arm stretching action;
if the hand stretching action or the arm stretching action is matched with the hand stretching action or the arm stretching action, the hand stretching action or the arm stretching action is combined as an interaction intention according to the analysis result;
if not, the hand stretching action or the arm retracting action is taken as an interaction intention;
in a judgment period, if the similarity between the extracted arm action of the user and the prestored arm folding and unfolding information is greater than a first threshold value, identifying the arm action as an arm folding and unfolding action, and using the arm folding and unfolding action as closing and unfolding actions of two arms;
if the hand stretching movement is used as a second gesture or the arm movement is used as an arm folding and unfolding movement, identifying the interaction intention as a second intention, wherein the second intention indicates that the will of the user is to enlarge or reduce the target operation object by taking the fixed point determined by the second gesture or the arm folding and unfolding movement as a center, the fixed point determined by the second gesture is a fixed point corresponding to the display screen of the intelligent equipment when the finger pulp of the thumb and the index finger is closed, and the fixed point determined by the arm folding and unfolding movement is a fixed point corresponding to the display screen of the intelligent equipment when the left hand and the right hand are closed;
in the step of detecting and extracting the hand stretching action or the arm retracting action in the multi-modal interaction data as the interaction intention through visual ability, the method further comprises the following steps: capturing an operation object in a display picture of the intelligent device corresponding to the hand of the user, wherein the operation object comprises: virtual human, system function picture, multimedia picture.
2. Virtual human-based visual interaction method according to claim 1,
and in the judgment period, if the similarity between the extracted hand motion of the user and the hand stretching information stored in advance is larger than a first threshold value, identifying the hand motion as the hand stretching motion.
3. A virtual human-based visual interaction method as claimed in claim 2, wherein the interaction intent is identified as a first intent or a second intent in dependence on the hand retraction motion or the arm retraction motion, wherein,
and if the hand stretching motion is used as a first gesture, recognizing the interaction intention as the first intention, wherein the first intention indicates that the user intends to zoom in or zoom out a target operation object by taking a preset point as a center.
4. A virtual human-based visual interaction method as claimed in any one of claims 1-3, wherein the virtual human receives multi-modal interaction data provided for the multi-modal data from a plurality of users, identifies a main user of the plurality of users, and detects a hand stretching action and an arm retracting action of the main user;
or the like, or, alternatively,
the method comprises the steps of collecting the hand stretching action and the arm stretching and retracting action of all or part of the current users, and determining the interaction intentions of the collected users according to a preset user collection proportion.
5. A visual interaction method based on a virtual human being as claimed in claim 4, characterized in that, by the virtual human being, multi-modal interaction output is performed according to the interaction intention, comprising: outputting and displaying multi-mode interactive output according to the interaction intention corresponding to the hand stretching action or the arm stretching action through the virtual human, wherein the multi-mode interactive output comprises the following steps: result data corresponding to the first intent or the second intent.
6. A storage medium containing a series of instructions for performing the method steps of any of claims 1-5.
7. Avatar, characterized in that it has specific avatars and preset attributes, performing multimodal interactions using the method according to any of claims 1 to 5.
8. A virtual human-based visual interaction system, the system comprising:
the intelligent device is loaded with the virtual human of claim 7 and used for acquiring multi-modal interaction data and has the capability of outputting language, emotion, expression and action;
and the cloud brain is used for performing semantic understanding, visual recognition, cognitive computation and emotion computation on the multi-modal interaction data so as to decide that the virtual human outputs the multi-modal interaction data.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810442311.1A CN108628454B (en) | 2018-05-10 | 2018-05-10 | Visual interaction method and system based on virtual human |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810442311.1A CN108628454B (en) | 2018-05-10 | 2018-05-10 | Visual interaction method and system based on virtual human |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108628454A CN108628454A (en) | 2018-10-09 |
| CN108628454B true CN108628454B (en) | 2022-03-22 |
Family
ID=63692366
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810442311.1A Active CN108628454B (en) | 2018-05-10 | 2018-05-10 | Visual interaction method and system based on virtual human |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108628454B (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111273990A (en) * | 2020-01-21 | 2020-06-12 | 腾讯科技(深圳)有限公司 | Information interaction method and device, computer equipment and storage medium |
| CN113239172B (en) * | 2021-06-09 | 2024-08-27 | 腾讯科技(深圳)有限公司 | Conversation interaction method, device, equipment and storage medium in robot group |
| CN114967937B (en) * | 2022-08-03 | 2022-09-30 | 环球数科集团有限公司 | Virtual human motion generation method and system |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107632706A (en) * | 2017-09-08 | 2018-01-26 | 北京光年无限科技有限公司 | The application data processing method and system of multi-modal visual human |
| CN107765856A (en) * | 2017-10-26 | 2018-03-06 | 北京光年无限科技有限公司 | Visual human's visual processing method and system based on multi-modal interaction |
| CN107992191A (en) * | 2017-10-30 | 2018-05-04 | 捷开通讯(深圳)有限公司 | A kind of electronic equipment and its control method, camera of electronic equipment module |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10491705B2 (en) * | 2015-09-08 | 2019-11-26 | At&T Intellectual Property I, L.P. | Visualization for network virtualization platform |
| CN105843381B (en) * | 2016-03-18 | 2020-07-28 | 北京光年无限科技有限公司 | Data processing method for realizing multi-modal interaction and multi-modal interaction system |
-
2018
- 2018-05-10 CN CN201810442311.1A patent/CN108628454B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107632706A (en) * | 2017-09-08 | 2018-01-26 | 北京光年无限科技有限公司 | The application data processing method and system of multi-modal visual human |
| CN107765856A (en) * | 2017-10-26 | 2018-03-06 | 北京光年无限科技有限公司 | Visual human's visual processing method and system based on multi-modal interaction |
| CN107992191A (en) * | 2017-10-30 | 2018-05-04 | 捷开通讯(深圳)有限公司 | A kind of electronic equipment and its control method, camera of electronic equipment module |
Non-Patent Citations (1)
| Title |
|---|
| 面向自然交互的多通道人机对话系统;杨明浩等;《计算机科学》;20141031;第41卷(第10期);第14页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108628454A (en) | 2018-10-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10664060B2 (en) | Multimodal input-based interaction method and device | |
| WO2022048403A1 (en) | Virtual role-based multimodal interaction method, apparatus and system, storage medium, and terminal | |
| CN107894833B (en) | Multi-modal interaction processing method and system based on virtual human | |
| CN109871450B (en) | Multi-mode interaction method and system based on textbook reading | |
| CN108665492B (en) | Dance teaching data processing method and system based on virtual human | |
| CN109176535B (en) | Interaction method and system based on intelligent robot | |
| Zheng et al. | Recent advances of deep learning for sign language recognition | |
| CN108942919B (en) | Interaction method and system based on virtual human | |
| CN109522835A (en) | Children's book based on intelligent robot is read and exchange method and system | |
| CN109086860B (en) | Interaction method and system based on virtual human | |
| TW201937344A (en) | Smart robot and man-machine interaction method | |
| CN110825164A (en) | Interaction method and system based on wearable intelligent equipment special for children | |
| CN106502382B (en) | Active interaction method and system for intelligent robot | |
| CN108628454B (en) | Visual interaction method and system based on virtual human | |
| CN113723327A (en) | Real-time Chinese sign language recognition interactive system based on deep learning | |
| CN110737335B (en) | Interaction method and device of robot, electronic equipment and storage medium | |
| CN108595012A (en) | Visual interactive method and system based on visual human | |
| CN113703585A (en) | Interaction method, interaction device, electronic equipment and storage medium | |
| CN109343695A (en) | Exchange method and system based on visual human's behavioral standard | |
| CN109086351B (en) | Method for acquiring user tag and user tag system | |
| CN110767005A (en) | Data processing method and system based on intelligent equipment special for children | |
| CN108681398A (en) | Visual interactive method and system based on visual human | |
| CN108415561A (en) | Gesture interaction method based on visual human and system | |
| CN108388399B (en) | Virtual idol state management method and system | |
| CN112149599B (en) | Expression tracking method and device, storage medium and electronic equipment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| TR01 | Transfer of patent right | ||
| TR01 | Transfer of patent right |
Effective date of registration: 20230927 Address after: 100000 6198, Floor 6, Building 4, Yard 49, Badachu Road, Shijingshan District, Beijing Patentee after: Beijing Virtual Dynamic Technology Co.,Ltd. Address before: 100000 Fourth Floor Ivy League Youth Venture Studio No. 193, Yuquan Building, No. 3 Shijingshan Road, Shijingshan District, Beijing Patentee before: Beijing Guangnian Infinite Technology Co.,Ltd. |