CN108074218B - Image super-resolution method and device based on light field acquisition device - Google Patents
Image super-resolution method and device based on light field acquisition device Download PDFInfo
- Publication number
- CN108074218B CN108074218B CN201711474559.8A CN201711474559A CN108074218B CN 108074218 B CN108074218 B CN 108074218B CN 201711474559 A CN201711474559 A CN 201711474559A CN 108074218 B CN108074218 B CN 108074218B
- Authority
- CN
- China
- Prior art keywords
- resolution
- image
- super
- light field
- acquisition device
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims abstract description 40
- 238000013135 deep learning Methods 0.000 claims abstract description 16
- 230000000007 visual effect Effects 0.000 claims abstract description 12
- 238000013528 artificial neural network Methods 0.000 claims description 20
- 238000013527 convolutional neural network Methods 0.000 claims description 19
- 238000001914 filtration Methods 0.000 claims description 14
- 238000005070 sampling Methods 0.000 claims description 12
- 230000002146 bilateral effect Effects 0.000 claims description 7
- 238000000638 solvent extraction Methods 0.000 claims description 5
- 238000000605 extraction Methods 0.000 claims description 3
- 238000004519 manufacturing process Methods 0.000 abstract description 7
- 238000012544 monitoring process Methods 0.000 description 5
- 238000003491 array Methods 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- HEFNNWSXXWATRW-UHFFFAOYSA-N Ibuprofen Chemical compound CC(C)CC1=CC=C(C(C)C(O)=O)C=C1 HEFNNWSXXWATRW-UHFFFAOYSA-N 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- 239000004411 aluminium Substances 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 238000005286 illumination Methods 0.000 description 1
- 238000003709 image segmentation Methods 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000011514 reflex Effects 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T3/00—Geometric image transformations in the plane of the image
- G06T3/40—Scaling of whole images or parts thereof, e.g. expanding or contracting
- G06T3/4053—Scaling of whole images or parts thereof, e.g. expanding or contracting based on super-resolution, i.e. the output image resolution being higher than the sensor resolution
- G06T3/4076—Scaling of whole images or parts thereof, e.g. expanding or contracting based on super-resolution, i.e. the output image resolution being higher than the sensor resolution using the original low-resolution images to iteratively correct the high-resolution images
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/50—Depth or shape recovery
- G06T7/55—Depth or shape recovery from multiple images
- G06T7/557—Depth or shape recovery from multiple images from light fields, e.g. from plenoptic cameras
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10052—Images from lightfield camera
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20021—Dividing image into blocks, subimages or windows
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20024—Filtering details
- G06T2207/20032—Median filtering
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20228—Disparity calculation for image-based rendering
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Image Processing (AREA)
- Studio Devices (AREA)
Abstract
The invention discloses an image super-resolution method and device based on a light field acquisition device, wherein the light field acquisition device comprises a plurality of USB cameras and cameras to form the light field acquisition device with a 3 x 3 visual angle, and the USB cameras at the side visual angle are regularly arranged in a square space form and surround the cameras, wherein the method comprises the following steps: acquiring a plurality of side-view low-resolution images and middle-view high-resolution images by collecting light field images; performing super-resolution on the collected low-resolution images of the plurality of side viewing angles by utilizing dictionary learning and deep learning; and obtaining the depth information of the scene according to the parallax between the light field images of different visual angles. The method can predict and restore the high-frequency part of the input image through single-view and multi-view information, and calculate the depth of the scene by using the information of the multi-view high-resolution image, thereby reducing the manufacturing cost and ensuring the accuracy of the spatial and angular resolution.
Description
Technical Field
The invention relates to the technical field of computer vision, in particular to an image super-resolution method and device based on a light field acquisition device.
Background
The light field acquisition and reconstruction technology is a very important problem in the field of computer vision, and the three-dimensional reconstruction by using the light field has great advantages compared with the traditional three-dimensional reconstruction method: the dependence on hardware resources is small, and real-time reconstruction is convenient to carry out on a PC; the applicability is strong, and the complexity of the scene has no influence on the complexity of calculation. However, although the three-dimensional reconstruction with high precision can be performed by using the three-dimensional scanner, the practical application is limited by the expensive equipment price and the limitation of the application. The light field technology is widely applied to occasions such as lighting engineering, light field rendering, relighting, refocusing camera shooting, synthetic aperture imaging, 3D display, security monitoring and the like.
In the related art, the optical field acquisition device mainly includes: using camera arrays, most commonly spherical camera arrays and planar/linear camera arrays, typically requires simultaneous acquisition of the same scene using tens or hundreds of cameras arranged in appropriate positions in the scene; the lens array is used, photos of different depths of field of a scene are shot at one time, focusing of any range of the scene can be achieved, such light field cameras are already on the market and enter the commercial application field, and the acquisition device usually has high requirements on the spatial resolution of the camera, so that the development of the light field cameras is limited by high hardware cost.
One of the core problems of the light-field three-dimensional reconstruction technique is to improve the resolution of the light-field image. Since the resolution of the acquired image will directly affect the calculation of the scene depth, performing super-resolution on the acquired image will improve the accuracy of depth estimation and the accuracy of three-dimensional reconstruction. The scene can be subjected to three-dimensional modeling by utilizing the high-resolution image information, and on the basis, virtual imaging of any viewpoint and any illumination of the scene, image segmentation, three-dimensional display and other very meaningful applications can be realized. The traditional light field image super-resolution algorithm is mainly based on a multi-view dictionary learning method, mutual corresponding relation is established by extracting dictionary information in images with different viewpoints and different resolutions, and super-resolution is carried out on low-resolution images by means of weighted addition of high-resolution image blocks. Because the light field acquisition device is used for acquiring larger angular resolution, images at different viewing angles are often larger in parallax, and the dictionary learning method cannot effectively perform super resolution under the condition, so that ghost, blur and other results are caused, the accuracy of information carried by the light field image is greatly restricted, and the accuracy of subsequent scene reconstruction is further influenced and needs to be solved.
Disclosure of Invention
The present invention is directed to solving, at least to some extent, one of the technical problems in the related art.
Therefore, one purpose of the invention is to provide an image super-resolution method based on a light field acquisition device, which can greatly reduce the manufacturing cost, ensure the accuracy of spatial and angular resolution and realize the refocusing of a light field camera.
The invention also aims to provide an image super-resolution device based on the light field acquisition device.
In order to achieve the above object, an embodiment of an aspect of the present invention provides an image super-resolution method based on a light field acquisition device, where the light field acquisition device includes a plurality of USB cameras and a camera to form a light field acquisition device with a 3 × 3 viewing angle, and the USB cameras at the side viewing angle are regularly arranged in a square spatial form and surround the camera, where the method includes the following steps: acquiring a light field image through the light field acquisition device to acquire a plurality of side-view low-resolution images and a plurality of middle-view high-resolution images; performing super-resolution on the acquired side-view low-resolution images by utilizing dictionary learning and deep learning; and obtaining the depth information of the scene according to the parallax between the light field images of different visual angles.
According to the image super-resolution method based on the light field acquisition device, the high-frequency part of the input image is predicted and recovered through single-view-angle and multi-view-angle information, the depth of the scene is further calculated by utilizing the information of the multi-view-angle high-resolution image, the method can be used for scene reconstruction and large scene monitoring, the manufacturing cost is greatly reduced, the accuracy of the spatial and angular resolutions is guaranteed, and the refocusing of the light field camera can be realized.
In addition, the image super-resolution method based on the light field acquisition device according to the above embodiment of the present invention may further have the following additional technical features:
further, in an embodiment of the present invention, the super-resolution of the acquired plurality of side-view low-resolution images by using dictionary learning and deep learning further includes: the intermediate view angle high-resolution image is subjected to down sampling, the super-resolution of the view angle is carried out through a trained convolutional neural network by utilizing the deep learning method, and a residual image is obtained by subtracting the image before the down sampling so as to reflect the residual of the super-resolution of the neural network; extracting dictionary information from the multiple side-view low-resolution images and the middle high-resolution image by using image partitioning, and making information correspondence between low-resolution image blocks and high-resolution image blocks; and performing initial super-resolution on each low-resolution image of the side view through the convolutional neural network, converting the residual image into the side view by utilizing the information corresponding relation, and adding the result to a super-resolution result obtained preliminarily through the neural network to obtain a final super-resolution result.
Further, in an embodiment of the present invention, the residual image block corresponding to each position is obtained by the following formula:

wherein, for the high-resolution image blocks reconstructed at the side view angle, k is the index of the selected 9 most approximate intermediate high-resolution image blocks, ωkIs the weight of the k-th one,
for the high-resolution image blocks reconstructed at the side view angle, k is the index of the selected 9 most approximate intermediate high-resolution image blocks, ωkIs the weight of the k-th one, and (3) forming a kth intermediate high resolution image block required by the jth side view angle high resolution image block, wherein R is a value on the intermediate high resolution image, and j is an index of the side view angle image block.
and (3) forming a kth intermediate high resolution image block required by the jth side view angle high resolution image block, wherein R is a value on the intermediate high resolution image, and j is an index of the side view angle image block.
Further, in an embodiment of the present invention, the final super-resolution result is:

wherein, for the reconstructed super-resolution image block, HR is the super-resolution, fCNN(SLR) For super-resolution of image blocks via neural networks, SERRFor subtraction of the pre-downsampled image to obtain a residual image, LR represents the low resolution.
for the reconstructed super-resolution image block, HR is the super-resolution, fCNN(SLR) For super-resolution of image blocks via neural networks, SERRFor subtraction of the pre-downsampled image to obtain a residual image, LR represents the low resolution.
Further, in an embodiment of the present invention, the obtaining depth information of the scene according to a parallax between the plurality of light field images of different viewing angles further includes: acquiring the edge confidence of each light field image to obtain an edge confidence mask; obtaining the parallax value of the pixel point marked as the confidence edge according to the edge confidence mask; filtering the initial parallax image by combining bilateral median filtering to obtain the parallax values of the pixel points in the non-edge area and the pixel points with the parallax confidence coefficient smaller than a preset threshold value; and generating a disparity map according to the disparity value of each pixel point.
In order to achieve the above object, another embodiment of the present invention provides an image super-resolution device based on a light field acquisition device, where the light field acquisition device includes a plurality of USB cameras and a camera to form a light field acquisition device with a 3 × 3 viewing angle, and the USB cameras at the side viewing angle are regularly arranged in a square spatial form and surround the camera, where the device includes: the acquisition module is used for acquiring the light field image through the light field acquisition device so as to acquire a plurality of side view angle low-resolution images and a plurality of middle view angle high-resolution images; the super-resolution module is used for performing super-resolution on the acquired side-view low-resolution images by utilizing dictionary learning and deep learning; and the acquisition module is used for obtaining the depth information of the scene according to the parallax between the light field images of the plurality of different visual angles.
The image super-resolution device based on the light field acquisition device of the embodiment of the invention predicts and restores the high-frequency part of the input image through single-view-angle and multi-view-angle information, further calculates the depth of the scene by utilizing the information of the multi-view-angle high-resolution image, can be used for scene reconstruction and large scene monitoring, greatly reduces the manufacturing cost, ensures the accuracy of space and angular resolution and can realize the refocusing of the light field camera.
In addition, the image super-resolution device based on the light field acquisition device according to the above embodiment of the present invention may further have the following additional technical features:
further, in an embodiment of the present invention, the super-resolution module further includes: the computing unit is used for performing down-sampling on the intermediate view angle high-resolution image, performing super-resolution on the view angle through a trained convolutional neural network by using the deep learning method, and subtracting the image before down-sampling to obtain a residual image so as to reflect the residual of the super-resolution of the neural network; the extraction unit is used for extracting dictionary information from the plurality of side-view low-resolution images and the middle high-resolution image by using image partitioning, and performing information correspondence between low-resolution image blocks and high-resolution image blocks; and the first acquisition unit is used for performing initial super-resolution on the low-resolution image of each side view angle through the convolutional neural network, converting the residual image into the side view angle by using the information corresponding relation, and adding the residual image and the preliminarily obtained super-resolution result of the neural network to acquire a final super-resolution result.
Further, in an embodiment of the present invention, the residual image block corresponding to each position is obtained by the following formula:

wherein, for the high-resolution image blocks reconstructed at the side view angle, k is the index of the selected 9 most approximate intermediate high-resolution image blocks, ωkIs the weight of the k-th one,
for the high-resolution image blocks reconstructed at the side view angle, k is the index of the selected 9 most approximate intermediate high-resolution image blocks, ωkIs the weight of the k-th one, and (3) forming a kth intermediate high resolution image block required by the jth side view angle high resolution image block, wherein R is a value on the intermediate high resolution image, and j is an index of the side view angle image block.
and (3) forming a kth intermediate high resolution image block required by the jth side view angle high resolution image block, wherein R is a value on the intermediate high resolution image, and j is an index of the side view angle image block.
Further, in an embodiment of the present invention, the final super-resolution result is:

wherein, for the reconstructed super-resolution image block, HR is the super-resolution, fCNN(SLR) For super-resolution of image blocks via neural networks, SERRFor subtraction of the pre-downsampled image to obtain a residual image, LR represents the low resolution.
for the reconstructed super-resolution image block, HR is the super-resolution, fCNN(SLR) For super-resolution of image blocks via neural networks, SERRFor subtraction of the pre-downsampled image to obtain a residual image, LR represents the low resolution.
Further, in an embodiment of the present invention, the obtaining module further includes: the second acquisition unit is used for acquiring the edge confidence of each light field image to obtain an edge confidence mask; the third acquisition unit is used for acquiring the parallax value of the pixel point marked as the confidence edge according to the edge confidence mask; the fourth obtaining unit is used for filtering the initial disparity map by combining bilateral median filtering to obtain disparity values of pixel points in a non-edge area and pixel points with disparity confidences smaller than a preset threshold; and the generating unit is used for generating a disparity map according to the disparity value of each pixel point.
Additional aspects and advantages of the invention will be set forth in part in the description which follows and, in part, will be obvious from the description, or may be learned by practice of the invention.
Drawings
The foregoing and/or additional aspects and advantages of the present invention will become apparent and readily appreciated from the following description of the embodiments, taken in conjunction with the accompanying drawings of which:
fig. 1 is a schematic structural diagram of a light field acquisition device according to an embodiment of the present invention;
FIG. 2 is a flow chart of an image super-resolution method based on a light field acquisition device according to an embodiment of the present invention;
fig. 3 is a flowchart of a three-dimensional reconstruction method of a super-resolution light field acquisition device according to an embodiment of the present invention;
fig. 4 is a schematic structural diagram of an image super-resolution device based on a light field acquisition device according to an embodiment of the invention.
Detailed Description
Reference will now be made in detail to embodiments of the present invention, examples of which are illustrated in the accompanying drawings, wherein like or similar reference numerals refer to the same or similar elements or elements having the same or similar function throughout. The embodiments described below with reference to the drawings are illustrative and intended to be illustrative of the invention and are not to be construed as limiting the invention.
Before the image super-resolution method and device based on the light field acquisition device of the embodiment of the present invention are introduced, the light field acquisition device of the embodiment of the present invention is first introduced.
The light field collecting device shown in fig. 1 includes a plurality of USB cameras and a camera to form a light field collecting device with a 3 × 3 viewing angle, and the plurality of USB cameras at the side viewing angle are regularly arranged in a square spatial form and surround the camera.
Specifically, the light field acquisition device may include: 8 non-professional low-quality USB cameras, 1 high resolution camera, 1 customization aluminium frame. The 8 low-quality cameras at the side view angles are regularly arranged around the camera in a square shape, the distance between two adjacent cameras on the same edge is 60mm, 9 cameras form a sparse light field acquisition device with a 3X 3 view angle, and for a high-resolution camera, a Canon 600D single lens reflex camera can be adopted in the embodiment of the invention.
Before the light field acquisition device provided by the embodiment of the invention is used for acquiring images, the focal points of all cameras are set, and the inherent parameters of the whole device system are calibrated; each side view image is projected onto a plane whose reference plane is parallel to the intermediate view image, and the image is corrected into a light field image according to the calibration result. All the side view angle images thus obtained are distributed on a 3 × 3 grid with an average pitch.
In the subsequent image processing flow, it is necessary to crop the overlapping regions of the images acquired by all the cameras, and after the cropping processing, the resolution of the intermediate view angle image acquired by the high-resolution camera is 2944 × 1808, the resolution of the side view angle image is 368 × 266, and the resolution of the intermediate view angle image is 1/8.
In summary, the light field acquisition device according to the embodiment of the present invention is composed of 8 non-professional quality USB cameras and 1 high resolution camera, and realizes multi-view acquisition of a scene. The light field acquisition device can acquire the three-dimensional sparse light field with higher angular resolution by correction, and has high acquisition speed and high efficiency.
The image super-resolution method and device based on the light field acquisition device according to the embodiments of the present invention will be described below with reference to the accompanying drawings, and first, the image super-resolution method based on the light field acquisition device according to the embodiments of the present invention will be described with reference to the accompanying drawings.
Fig. 2 is a flowchart of an image super-resolution method based on a light field acquisition device according to an embodiment of the present invention.
As shown in fig. 2, the image super-resolution method based on the light field acquisition device comprises the following steps:
in step S201, a light field image is acquired by a light field acquisition device to acquire a plurality of side-view low resolution images and a plurality of middle-view high resolution images.
It can be understood that, as shown in fig. 3, the embodiment of the present invention takes as an example that 1 side view angle low resolution image S and the middle view angle high resolution image R are input, and are respectively applied to all 8 side view angles to acquire the light field image through the light field acquisition device, so as to acquire a plurality of side view angle low resolution images and middle view angle high resolution images.
In step S202, the acquired plurality of side-view low-resolution images are super-resolved using dictionary learning and deep learning.
Further, in an embodiment of the present invention, performing super-resolution on the plurality of acquired side-view low-resolution images by using dictionary learning and deep learning, further includes: down-sampling the intermediate view angle high-resolution image, performing super-resolution of the view angle through a trained convolutional neural network by using a deep learning method, and subtracting the image before down-sampling to obtain a residual image so as to reflect the residual of the super-resolution of the neural network; extracting dictionary information from a plurality of side-view low-resolution images and a plurality of middle high-resolution images by using image blocks, and making information correspondence between low-resolution image blocks and high-resolution image blocks; and performing initial super-resolution on each low-resolution image at the side view angle through a convolutional neural network, converting the residual image into the side view angle by utilizing the information corresponding relation, and adding the residual image to a super-resolution result obtained initially through the neural network to obtain a final super-resolution result.
It can be understood that, in the embodiment of the present invention, dictionary information can be extracted from low-resolution images and intermediate high-resolution images of 8 surrounding perspectives by using image blocking, and information correspondence between low-resolution image blocks and high-resolution image blocks is performed.
Specifically, the dictionary information of the intermediate-view-angle high-resolution image R is DR={fR,1,…,fR,NIn which fR,i(i ═ 1,2, …, N) are the first and second gradient results for the image block extracted from R. Similarly, the residual image R of the corresponding positionERRThe dictionary information can also be obtained by the same method, and is marked as { eR,1,…,eR,N}. For each image block position j in the low resolution image of the side view, a first gradient and a second gradient are calculated and applied at DRIn the middle of using L2Calculating the norm distance to obtain 9 neighbors and recording the 9 neighbors as Thus obtaining corresponding 9 characteristics in the residual dictionary and recording as
Thus obtaining corresponding 9 characteristics in the residual dictionary and recording as

Further, in an embodiment of the present invention, the residual image block corresponding to each position is obtained by the following formula:

wherein, for the high-resolution image blocks reconstructed at the side view angle, k is the index of the selected 9 most approximate intermediate high-resolution image blocks, ωkIs the weight of the k-th one,
for the high-resolution image blocks reconstructed at the side view angle, k is the index of the selected 9 most approximate intermediate high-resolution image blocks, ωkIs the weight of the k-th one, and (3) forming a kth intermediate high resolution image block required by the jth side view angle high resolution image block, wherein R is a value on the intermediate high resolution image, and j is an index of the side view angle image block.
and (3) forming a kth intermediate high resolution image block required by the jth side view angle high resolution image block, wherein R is a value on the intermediate high resolution image, and j is an index of the side view angle image block.
Further, in one embodiment of the present invention, the final super-resolution result is:

wherein, for the reconstructed super-resolution image block, HR is the super-resolution, fCNN(SLR) For super-resolution of image blocks via neural networks, SERRFor subtraction of the pre-downsampled image to obtain a residual image, LR represents the low resolution.
for the reconstructed super-resolution image block, HR is the super-resolution, fCNN(SLR) For super-resolution of image blocks via neural networks, SERRFor subtraction of the pre-downsampled image to obtain a residual image, LR represents the low resolution.
It can be understood that the embodiment of the invention can perform initial super-resolution on the low-resolution image of each side visual angle through the convolutional neural network, convert the residual image into the side visual angle by using the information corresponding relation, and add the result to the super-resolution result obtained through the neural network to obtain the final super-resolution result.
In particular, from residual candidate dictionaries Obtaining each position j in S by using weighted averageCorresponding residual image block
Obtaining each position j in S by using weighted averageCorresponding residual image block Wherein,
Wherein, thus, a residual image corresponding to S is estimated by using a dictionary learning method and is recorded as SERR. Then, the original side-view angle low-resolution image is added with the residual image through a convolution neural network to finally obtain a super-resolution light field image, namely
thus, a residual image corresponding to S is estimated by using a dictionary learning method and is recorded as SERR. Then, the original side-view angle low-resolution image is added with the residual image through a convolution neural network to finally obtain a super-resolution light field image, namely
In step S203, depth information of a scene is obtained according to parallax between a plurality of light field images of different viewing angles.
Further, in an embodiment of the present invention, obtaining depth information of a scene according to a parallax between a plurality of light field images of different viewing angles further includes: acquiring the edge confidence of each light field image to obtain an edge confidence mask; obtaining a parallax value of a pixel point marked as a confidence edge according to the edge confidence mask; filtering the initial parallax image by combining bilateral median filtering to obtain the parallax values of the pixel points in the non-edge area and the pixel points with the parallax confidence coefficient smaller than a preset threshold value; and generating a disparity map according to the disparity value of each pixel point.
It can be understood that the light field depth information calculation of the embodiment of the present invention specifically includes the following steps:
step 1: calculating the edge confidence of each image to obtain an edge confidence mask;
step 2: calculating the parallax value of the pixel point marked as the confidence edge according to the edge confidence mask;
and step 3: filtering the initial disparity map by joint bilateral median filtering;
and 5: and generating a disparity map according to the disparity value of each pixel point.
According to the image super-resolution method based on the light field acquisition device, provided by the embodiment of the invention, the high-frequency part of the input image is predicted and recovered through single-view-angle and multi-view-angle information, and the depth of the scene is further calculated by utilizing the information of the multi-view-angle high-resolution image, so that the method can be used for scene reconstruction and large scene monitoring, greatly reduces the manufacturing cost, ensures the accuracy of spatial and angular resolutions, and can realize the refocusing of the light field camera.
Next, an image super-resolution device based on a light field acquisition device according to an embodiment of the present invention will be described with reference to the drawings.
Fig. 4 is a schematic structural diagram of an image super-resolution device based on a light field acquisition device according to an embodiment of the present invention.
As shown in fig. 4, the image super-resolution device 10 based on the light field acquisition device comprises: an acquisition module 100, a super-resolution module 200 and an acquisition module 300.
The acquisition module 100 is configured to acquire a light field image through a light field acquisition device to acquire a plurality of side-view low-resolution images and a plurality of middle-view high-resolution images. The super-resolution module 200 is configured to perform super-resolution on the acquired plurality of side-view low-resolution images by using dictionary learning and deep learning. The obtaining module 300 is configured to obtain depth information of a scene according to a parallax between a plurality of light field images at different viewing angles. The device 10 of the embodiment of the invention can predict and restore the high-frequency part of the input image through single-view and multi-view information, further calculate the depth of the scene by utilizing the information of the multi-view high-resolution image, reduce the manufacturing cost, ensure the accuracy of the spatial and angular resolutions and realize the refocusing of the light field camera.
Further, in an embodiment of the present invention, the super-resolution module further includes: the computing unit is used for performing down-sampling on the intermediate-view-angle high-resolution image, performing super-resolution on the view angle through a trained convolutional neural network by using a deep learning method, and subtracting the image before down-sampling to obtain a residual image so as to reflect the residual of the super-resolution of the neural network; the extraction unit is used for extracting dictionary information from the multiple side-view low-resolution images and the middle high-resolution image by using image partitioning, and performing information correspondence between the low-resolution image blocks and the high-resolution image blocks; and the first acquisition unit is used for performing initial super-resolution on the low-resolution image of each side view angle through a convolutional neural network, converting the residual image into the side view angle by using the information corresponding relation, and adding the residual image and the preliminarily obtained super-resolution result of the neural network to acquire a final super-resolution result.
Further, in an embodiment of the present invention, the residual image block corresponding to each position is obtained by the following formula:

wherein,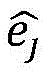 for the high-resolution image blocks reconstructed at the side view angle, k is the index of the selected 9 most approximate intermediate high-resolution image blocks, ωkIs the weight of the k-th one,
for the high-resolution image blocks reconstructed at the side view angle, k is the index of the selected 9 most approximate intermediate high-resolution image blocks, ωkIs the weight of the k-th one, and (3) forming a kth intermediate high resolution image block required by the jth side view angle high resolution image block, wherein R is a value on the intermediate high resolution image, and j is an index of the side view angle image block.
and (3) forming a kth intermediate high resolution image block required by the jth side view angle high resolution image block, wherein R is a value on the intermediate high resolution image, and j is an index of the side view angle image block.
Further, in one embodiment of the present invention, the final super-resolution result is:

wherein, for the reconstructed super-resolution image block, HR is the super-resolution, fCNN(SLR) For super-resolution of image blocks via neural networks, SERRFor subtraction of the pre-downsampled image to obtain a residual image, LR represents the low resolution.
for the reconstructed super-resolution image block, HR is the super-resolution, fCNN(SLR) For super-resolution of image blocks via neural networks, SERRFor subtraction of the pre-downsampled image to obtain a residual image, LR represents the low resolution.
Further, in an embodiment of the present invention, the obtaining module further includes: the second acquisition unit is used for acquiring the edge confidence of each light field image to obtain an edge confidence mask; the third acquisition unit is used for acquiring the parallax value of the pixel point marked as the confidence edge according to the edge confidence mask; the fourth obtaining unit is used for filtering the initial disparity map by combining bilateral median filtering to obtain disparity values of pixel points in a non-edge area and pixel points with disparity confidences smaller than a preset threshold; and the generating unit is used for generating a disparity map according to the disparity value of each pixel point.
It should be noted that the foregoing explanation on the embodiment of the image super-resolution method based on the light field acquisition device also applies to the image super-resolution device based on the light field acquisition device of this embodiment, and details are not repeated here.
According to the image super-resolution based on the light field acquisition device provided by the embodiment of the invention, the high-frequency part of the input image is predicted and recovered through single-view and multi-view information, and the depth of the scene is further calculated by utilizing the information of the multi-view high-resolution image, so that the method can be used for scene reconstruction and large scene monitoring, the manufacturing cost is reduced, the accuracy of the spatial and angular resolutions is ensured, and the refocusing of the light field camera can be realized.
In the description of the present invention, it is to be understood that the terms "central," "longitudinal," "lateral," "length," "width," "thickness," "upper," "lower," "front," "rear," "left," "right," "vertical," "horizontal," "top," "bottom," "inner," "outer," "clockwise," "counterclockwise," "axial," "radial," "circumferential," and the like are used in the orientations and positional relationships indicated in the drawings for convenience in describing the invention and to simplify the description, and are not intended to indicate or imply that the referenced devices or elements must have a particular orientation, be constructed and operated in a particular orientation, and are therefore not to be considered limiting of the invention.
Furthermore, the terms "first", "second" and "first" are used for descriptive purposes only and are not to be construed as indicating or implying relative importance or implicitly indicating the number of technical features indicated. Thus, a feature defined as "first" or "second" may explicitly or implicitly include at least one such feature. In the description of the present invention, "a plurality" means at least two, e.g., two, three, etc., unless specifically limited otherwise.
In the present invention, unless otherwise expressly stated or limited, the terms "mounted," "connected," "secured," and the like are to be construed broadly and can, for example, be fixedly connected, detachably connected, or integrally formed; can be mechanically or electrically connected; they may be directly connected or indirectly connected through intervening media, or they may be connected internally or in any other suitable relationship, unless expressly stated otherwise. The specific meanings of the above terms in the present invention can be understood by those skilled in the art according to specific situations.
In the present invention, unless otherwise expressly stated or limited, the first feature "on" or "under" the second feature may be directly contacting the first and second features or indirectly contacting the first and second features through an intermediate. Also, a first feature "on," "over," and "above" a second feature may be directly or diagonally above the second feature, or may simply indicate that the first feature is at a higher level than the second feature. A first feature being "under," "below," and "beneath" a second feature may be directly under or obliquely under the first feature, or may simply mean that the first feature is at a lesser elevation than the second feature.
In the description herein, references to the description of the term "one embodiment," "some embodiments," "an example," "a specific example," or "some examples," etc., mean that a particular feature, structure, material, or characteristic described in connection with the embodiment or example is included in at least one embodiment or example of the invention. In this specification, the schematic representations of the terms used above are not necessarily intended to refer to the same embodiment or example. Furthermore, the particular features, structures, materials, or characteristics described may be combined in any suitable manner in any one or more embodiments or examples. Furthermore, various embodiments or examples and features of different embodiments or examples described in this specification can be combined and combined by one skilled in the art without contradiction.
Although embodiments of the present invention have been shown and described above, it is understood that the above embodiments are exemplary and should not be construed as limiting the present invention, and that variations, modifications, substitutions and alterations can be made to the above embodiments by those of ordinary skill in the art within the scope of the present invention.
Claims (8)
1. An image super-resolution method based on a light field acquisition device, wherein the light field acquisition device comprises a plurality of USB cameras and cameras to form a light field acquisition device with a 3 x 3 visual angle, and the USB cameras at the side visual angle are regularly arranged in a square space form and surround the cameras, wherein the method comprises the following steps:
acquiring a light field image through the light field acquisition device to acquire a plurality of side-view low-resolution images and a plurality of middle-view high-resolution images;
performing super-resolution on the acquired side-view low-resolution images by utilizing dictionary learning and deep learning; and
obtaining depth information of a scene according to parallax between a plurality of light field images with different viewing angles;
wherein the super-resolution of the collected low-resolution images of the plurality of side viewing angles by using dictionary learning and deep learning further comprises: the intermediate view angle high-resolution image is subjected to down sampling, the super-resolution of the view angle is carried out through a trained convolutional neural network by utilizing the deep learning method, and a residual image is obtained by subtracting the image before the down sampling so as to reflect the residual of the super-resolution of the neural network; extracting dictionary information from the multiple side-view low-resolution images and the middle high-resolution image by using image partitioning, and making information correspondence between low-resolution image blocks and high-resolution image blocks; and performing initial super-resolution on each low-resolution image of the side view through the convolutional neural network, converting the residual image into the side view by utilizing the information corresponding relation, and adding the result to a super-resolution result obtained preliminarily through the neural network to obtain a final super-resolution result.
2. The image super-resolution method based on the light field acquisition device according to claim 1, wherein the residual image block corresponding to each position is obtained by the following formula:

wherein, for the high-resolution image blocks reconstructed at the side view angle, k is the index of the selected 9 most approximate intermediate high-resolution image blocks, ωkIs the weight of the k-th one,
for the high-resolution image blocks reconstructed at the side view angle, k is the index of the selected 9 most approximate intermediate high-resolution image blocks, ωkIs the weight of the k-th one, and (3) forming a kth intermediate high resolution image block required by the jth side view angle high resolution image block, wherein R is a value on the intermediate high resolution image, and j is an index of the side view angle image block.
and (3) forming a kth intermediate high resolution image block required by the jth side view angle high resolution image block, wherein R is a value on the intermediate high resolution image, and j is an index of the side view angle image block.
3. The image super-resolution method based on the light field acquisition device according to claim 2, wherein the final super-resolution result is:

wherein, for the reconstructed super-resolution image block, HR is the super-resolution, fCNN(SLR) For super-resolution of image blocks via neural networks, SERRFor subtraction of the pre-downsampled image to obtain a residual image, LR represents the low resolution.
for the reconstructed super-resolution image block, HR is the super-resolution, fCNN(SLR) For super-resolution of image blocks via neural networks, SERRFor subtraction of the pre-downsampled image to obtain a residual image, LR represents the low resolution.
4. The image super-resolution method based on the light field acquisition device according to any one of claims 1 to 3, wherein the obtaining of the depth information of the scene according to the parallax between the plurality of light field images at different viewing angles further comprises:
acquiring the edge confidence of each light field image to obtain an edge confidence mask;
obtaining the parallax value of the pixel point marked as the confidence edge according to the edge confidence mask;
filtering the initial parallax image by combining bilateral median filtering to obtain the parallax values of the pixel points in the non-edge area and the pixel points with the parallax confidence coefficient smaller than a preset threshold value; and
and generating a disparity map according to the disparity value of each pixel point.
5. An image super-resolution device based on a light field acquisition device, wherein the light field acquisition device comprises a plurality of USB cameras and a camera to form a light field acquisition device with a 3 x 3 visual angle, and the plurality of USB cameras at the side visual angle are regularly arranged in a square space form and surround the camera, wherein the device comprises:
the acquisition module is used for acquiring the light field image through the light field acquisition device so as to acquire a plurality of side view angle low-resolution images and a plurality of middle view angle high-resolution images;
the super-resolution module is used for performing super-resolution on the acquired side-view low-resolution images by utilizing dictionary learning and deep learning; and
the acquisition module is used for acquiring the depth information of a scene according to the parallax among the light field images of different visual angles;
wherein, the super-resolution module further comprises: the computing unit is used for performing down-sampling on the intermediate view angle high-resolution image, performing super-resolution on the view angle through a trained convolutional neural network by using the deep learning method, and subtracting the image before down-sampling to obtain a residual image so as to reflect the residual of the super-resolution of the neural network; the extraction unit is used for extracting dictionary information from the plurality of side-view low-resolution images and the middle high-resolution image by using image partitioning, and performing information correspondence between low-resolution image blocks and high-resolution image blocks; and the first acquisition unit is used for performing initial super-resolution on the low-resolution image of each side view angle through the convolutional neural network, converting the residual image into the side view angle by using the information corresponding relation, and adding the residual image and the preliminarily obtained super-resolution result of the neural network to acquire a final super-resolution result.
6. The light field acquisition device-based image super-resolution device according to claim 5, wherein the residual image block corresponding to each position is obtained by the following formula:

wherein, for the high-resolution image blocks reconstructed at the side view angle, k is the index of the selected 9 most approximate intermediate high-resolution image blocks, ωkIs the weight of the k-th one,
for the high-resolution image blocks reconstructed at the side view angle, k is the index of the selected 9 most approximate intermediate high-resolution image blocks, ωkIs the weight of the k-th one, and (3) forming a kth intermediate high resolution image block required by the jth side view angle high resolution image block, wherein R is a value on the intermediate high resolution image, and j is an index of the side view angle image block.
and (3) forming a kth intermediate high resolution image block required by the jth side view angle high resolution image block, wherein R is a value on the intermediate high resolution image, and j is an index of the side view angle image block.
7. The light field acquisition device-based image super-resolution device of claim 6, wherein the final super-resolution result is:

wherein, for the reconstructed super-resolution image block, HR is the super-resolution, fCNN(SLR) For super-resolution of image blocks via neural networks, SERRFor subtraction of the pre-downsampled image to obtain a residual image, LR represents the low resolution.
for the reconstructed super-resolution image block, HR is the super-resolution, fCNN(SLR) For super-resolution of image blocks via neural networks, SERRFor subtraction of the pre-downsampled image to obtain a residual image, LR represents the low resolution.
8. The light field acquisition device-based image super-resolution device according to any one of claims 5 to 7, wherein the acquisition module further comprises:
the second acquisition unit is used for acquiring the edge confidence of each light field image to obtain an edge confidence mask;
the third acquisition unit is used for acquiring the parallax value of the pixel point marked as the confidence edge according to the edge confidence mask;
the fourth obtaining unit is used for filtering the initial disparity map by combining bilateral median filtering to obtain disparity values of pixel points in a non-edge area and pixel points with disparity confidences smaller than a preset threshold; and
and the generating unit is used for generating a disparity map according to the disparity value of each pixel point.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201711474559.8A CN108074218B (en) | 2017-12-29 | 2017-12-29 | Image super-resolution method and device based on light field acquisition device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201711474559.8A CN108074218B (en) | 2017-12-29 | 2017-12-29 | Image super-resolution method and device based on light field acquisition device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108074218A CN108074218A (en) | 2018-05-25 |
| CN108074218B true CN108074218B (en) | 2021-02-23 |
Family
ID=62156067
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201711474559.8A Active CN108074218B (en) | 2017-12-29 | 2017-12-29 | Image super-resolution method and device based on light field acquisition device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108074218B (en) |
Families Citing this family (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110555800A (en) | 2018-05-30 | 2019-12-10 | 北京三星通信技术研究有限公司 | image processing apparatus and method |
| CN108876907A (en) * | 2018-05-31 | 2018-11-23 | 大连理工大学 | A kind of active three-dimensional rebuilding method of object-oriented object |
| CN111630840B (en) * | 2018-08-23 | 2021-12-03 | 深圳配天智能技术研究院有限公司 | Super-resolution image acquisition method and device and image sensor |
| CN109447919B (en) * | 2018-11-08 | 2022-05-06 | 电子科技大学 | Light field super-resolution reconstruction method combining multi-view angle and semantic texture features |
| CN109302600B (en) * | 2018-12-06 | 2023-03-21 | 成都工业学院 | Three-dimensional scene shooting device |
| US10868945B2 (en) * | 2019-04-08 | 2020-12-15 | Omnivision Technologies, Inc. | Light-field camera and method using wafer-level integration process |
| CN111818274A (en) * | 2019-04-09 | 2020-10-23 | 深圳市视觉动力科技有限公司 | Optical unmanned aerial vehicle monitoring method and system based on three-dimensional light field technology |
| CN111080774B (en) * | 2019-12-16 | 2020-09-15 | 首都师范大学 | Method and system for reconstructing light field by applying depth sampling |
| CN111818298B (en) * | 2020-06-08 | 2021-10-22 | 北京航空航天大学 | High-definition video monitoring system and method based on light field |
| CN111815513B (en) * | 2020-06-09 | 2023-06-23 | 四川虹美智能科技有限公司 | Infrared image acquisition method and device |
| CN111815515B (en) * | 2020-07-01 | 2024-02-09 | 成都智学易数字科技有限公司 | Object three-dimensional drawing method based on medical education |
| CN112102165B (en) * | 2020-08-18 | 2022-12-06 | 北京航空航天大学 | Light field image angular domain super-resolution system and method based on zero sample learning |
| CN112037136B (en) * | 2020-09-18 | 2023-12-26 | 中国科学院国家天文台南京天文光学技术研究所 | Super-resolution imaging method based on aperture modulation |
| CN113220251B (en) * | 2021-05-18 | 2024-04-09 | 北京达佳互联信息技术有限公司 | Object display method, device, electronic equipment and storage medium |
| CN113538307B (en) * | 2021-06-21 | 2023-06-20 | 陕西师范大学 | Synthetic aperture imaging method based on multi-view super-resolution depth network |
| CN113592716B (en) * | 2021-08-09 | 2023-08-01 | 上海大学 | Light field image space domain super-resolution method, system, terminal and storage medium |
| CN115187454A (en) * | 2022-05-30 | 2022-10-14 | 元潼(北京)技术有限公司 | Multi-view image super-resolution reconstruction method and device based on meta-imaging |
| CN118297864B (en) * | 2024-06-04 | 2024-08-16 | 深圳市斯贝达电子有限公司 | Light field display method and device for sub-aperture image color enhancement |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103838568A (en) * | 2012-11-26 | 2014-06-04 | 诺基亚公司 | Method, apparatus and computer program product for generating super-resolved images |
| CN104050662A (en) * | 2014-05-30 | 2014-09-17 | 清华大学深圳研究生院 | Method for directly obtaining depth image through light field camera one-time imaging |
| CN105023275A (en) * | 2015-07-14 | 2015-11-04 | 清华大学 | Super-resolution light field acquisition device and three-dimensional reconstruction method thereof |
| CN105551050A (en) * | 2015-12-29 | 2016-05-04 | 深圳市未来媒体技术研究院 | Optical field based image depth estimation method |
-
2017
- 2017-12-29 CN CN201711474559.8A patent/CN108074218B/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103838568A (en) * | 2012-11-26 | 2014-06-04 | 诺基亚公司 | Method, apparatus and computer program product for generating super-resolved images |
| CN104050662A (en) * | 2014-05-30 | 2014-09-17 | 清华大学深圳研究生院 | Method for directly obtaining depth image through light field camera one-time imaging |
| CN105023275A (en) * | 2015-07-14 | 2015-11-04 | 清华大学 | Super-resolution light field acquisition device and three-dimensional reconstruction method thereof |
| CN105551050A (en) * | 2015-12-29 | 2016-05-04 | 深圳市未来媒体技术研究院 | Optical field based image depth estimation method |
Non-Patent Citations (4)
| Title |
|---|
| Relighting with 4D Incident Light Fields;Vincent Masselus;《ACM Digital Library》;20031231;第613-620页 * |
| 光场成像技术及其在计算机视觉中的应用;张驰等;《中国图像图形学报》;20160531;第21卷(第3期);第3.2节 * |
| 全光场多视角图像超分辨率重建;李梦娜;《中国优秀硕士学位论文全文数据库信息科技辑》;20160515(第05期);第2.3节,图2.7 * |
| 基于相机阵列的光场成像与深度估计方法研究;肖照林;《中国博士学位论文全文数据库信息科技辑》;20150715(第07期);第4.2节 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108074218A (en) | 2018-05-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108074218B (en) | Image super-resolution method and device based on light field acquisition device | |
| CN112367514B (en) | Three-dimensional scene construction method, device and system and storage medium | |
| CN105023275B (en) | Super-resolution optical field acquisition device and its three-dimensional rebuilding method | |
| CN106846463B (en) | Microscopic image three-dimensional reconstruction method and system based on deep learning neural network | |
| CN108921781B (en) | Depth-based optical field splicing method | |
| CN103198524B (en) | A kind of three-dimensional reconstruction method for large-scale outdoor scene | |
| CN111343367B (en) | Billion-pixel virtual reality video acquisition device, system and method | |
| CN111028281B (en) | Depth information calculation method and device based on light field binocular system | |
| CN109118544B (en) | Synthetic aperture imaging method based on perspective transformation | |
| EP3035285B1 (en) | Method and apparatus for generating an adapted slice image from a focal stack | |
| CN113436130B (en) | Intelligent sensing system and device for unstructured light field | |
| CN106257537B (en) | A kind of spatial depth extracting method based on field information | |
| CN117456114B (en) | Multi-view-based three-dimensional image reconstruction method and system | |
| CN115035235A (en) | Three-dimensional reconstruction method and device | |
| CN109218706B (en) | Method for generating stereoscopic vision image from single image | |
| CN105466399A (en) | Quick semi-global dense matching method and device | |
| Chowdhury et al. | Fixed-Lens camera setup and calibrated image registration for multifocus multiview 3D reconstruction | |
| CN112767246A (en) | Multi-magnification spatial super-resolution method and device for light field image | |
| CN108615221B (en) | Light field angle super-resolution method and device based on shearing two-dimensional polar line plan | |
| CN118037952A (en) | Three-dimensional human body reconstruction method and system | |
| CN116563807A (en) | Model training method and device, electronic equipment and storage medium | |
| CN112634139B (en) | Optical field super-resolution imaging method, device and equipment | |
| Sun et al. | Blind calibration for focused plenoptic cameras | |
| CN113506213B (en) | Light field image visual angle super-resolution method and device adapting to large parallax range | |
| Shoujiang et al. | Microlens Light Field Imaging Method Based on Bionic Vision and 3-3 Dimensional Information Transforming |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |