CN107683289B - IL13Rα2结合剂和其在癌症治疗中的用途 - Google Patents
IL13Rα2结合剂和其在癌症治疗中的用途 Download PDFInfo
- Publication number
- CN107683289B CN107683289B CN201680018571.5A CN201680018571A CN107683289B CN 107683289 B CN107683289 B CN 107683289B CN 201680018571 A CN201680018571 A CN 201680018571A CN 107683289 B CN107683289 B CN 107683289B
- Authority
- CN
- China
- Prior art keywords
- il13r
- seq
- cell
- cells
- binding
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 102100020793 Interleukin-13 receptor subunit alpha-2 Human genes 0.000 title claims abstract description 326
- 101710112634 Interleukin-13 receptor subunit alpha-2 Proteins 0.000 title claims abstract description 315
- 206010028980 Neoplasm Diseases 0.000 title claims abstract description 253
- 201000011510 cancer Diseases 0.000 title claims abstract description 127
- 239000011230 binding agent Substances 0.000 title claims description 132
- 238000011282 treatment Methods 0.000 title description 19
- 210000004027 cell Anatomy 0.000 claims abstract description 280
- 230000027455 binding Effects 0.000 claims abstract description 166
- 238000009739 binding Methods 0.000 claims abstract description 165
- 210000001744 T-lymphocyte Anatomy 0.000 claims abstract description 107
- 238000000034 method Methods 0.000 claims abstract description 101
- 239000012634 fragment Substances 0.000 claims abstract description 64
- 239000013598 vector Substances 0.000 claims abstract description 50
- 239000008194 pharmaceutical composition Substances 0.000 claims abstract description 45
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 31
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 31
- 239000002157 polynucleotide Substances 0.000 claims abstract description 31
- 208000005017 glioblastoma Diseases 0.000 claims abstract description 27
- 201000010915 Glioblastoma multiforme Diseases 0.000 claims abstract description 11
- 230000005754 cellular signaling Effects 0.000 claims abstract description 11
- 101100232357 Homo sapiens IL13RA1 gene Proteins 0.000 claims description 90
- 101100232360 Homo sapiens IL13RA2 gene Proteins 0.000 claims description 90
- 150000007523 nucleic acids Chemical class 0.000 claims description 76
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 74
- 239000000427 antigen Substances 0.000 claims description 74
- 108091007433 antigens Proteins 0.000 claims description 73
- 102000036639 antigens Human genes 0.000 claims description 73
- 102000039446 nucleic acids Human genes 0.000 claims description 69
- 108020004707 nucleic acids Proteins 0.000 claims description 69
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 claims description 67
- 206010018338 Glioma Diseases 0.000 claims description 41
- 208000032612 Glial tumor Diseases 0.000 claims description 38
- 239000012636 effector Substances 0.000 claims description 34
- 239000003814 drug Substances 0.000 claims description 20
- 108020001507 fusion proteins Proteins 0.000 claims description 20
- 102000037865 fusion proteins Human genes 0.000 claims description 20
- 102000004190 Enzymes Human genes 0.000 claims description 18
- 108090000790 Enzymes Proteins 0.000 claims description 18
- 241000700605 Viruses Species 0.000 claims description 15
- 239000003937 drug carrier Substances 0.000 claims description 15
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 claims description 12
- 230000006907 apoptotic process Effects 0.000 claims description 12
- 238000010494 dissociation reaction Methods 0.000 claims description 10
- 230000005593 dissociations Effects 0.000 claims description 10
- 238000004519 manufacturing process Methods 0.000 claims description 10
- 238000006243 chemical reaction Methods 0.000 claims description 9
- 239000000758 substrate Substances 0.000 claims description 9
- 231100000599 cytotoxic agent Toxicity 0.000 claims description 8
- 238000002360 preparation method Methods 0.000 claims description 8
- 206010009944 Colon cancer Diseases 0.000 claims description 7
- 239000012472 biological sample Substances 0.000 claims description 7
- 102000006426 human interleukin-13 receptor Human genes 0.000 claims description 7
- 108010044118 human interleukin-13 receptor Proteins 0.000 claims description 7
- 239000007787 solid Substances 0.000 claims description 7
- 108090001008 Avidin Proteins 0.000 claims description 6
- 108700012411 TNFSF10 Proteins 0.000 claims description 6
- 239000011616 biotin Substances 0.000 claims description 6
- 229960002685 biotin Drugs 0.000 claims description 6
- 235000020958 biotin Nutrition 0.000 claims description 6
- 239000007850 fluorescent dye Substances 0.000 claims description 6
- 210000000056 organ Anatomy 0.000 claims description 6
- 241000701161 unidentified adenovirus Species 0.000 claims description 6
- 208000029742 colonic neoplasm Diseases 0.000 claims description 5
- 102000046283 TNF-Related Apoptosis-Inducing Ligand Human genes 0.000 claims description 4
- 239000002619 cytotoxin Substances 0.000 claims description 4
- 239000011159 matrix material Substances 0.000 claims description 4
- 238000005829 trimerization reaction Methods 0.000 claims description 4
- 101710112752 Cytotoxin Proteins 0.000 claims description 3
- 229950003499 fibrin Drugs 0.000 claims description 3
- 108090000765 processed proteins & peptides Proteins 0.000 abstract description 56
- 102000004196 processed proteins & peptides Human genes 0.000 abstract description 38
- -1 host cells Substances 0.000 abstract description 36
- 230000011664 signaling Effects 0.000 abstract description 34
- 229920001184 polypeptide Polymers 0.000 abstract description 30
- 230000006870 function Effects 0.000 abstract description 14
- 208000024891 symptom Diseases 0.000 abstract description 14
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 abstract description 9
- 230000009870 specific binding Effects 0.000 abstract description 8
- 230000006044 T cell activation Effects 0.000 abstract description 7
- 238000002372 labelling Methods 0.000 abstract description 6
- 230000002255 enzymatic effect Effects 0.000 abstract description 4
- 108091006024 signal transducing proteins Proteins 0.000 abstract description 4
- 102000034285 signal transducing proteins Human genes 0.000 abstract description 4
- 230000009131 signaling function Effects 0.000 abstract description 3
- 102100020791 Interleukin-13 receptor subunit alpha-1 Human genes 0.000 description 87
- 241000282414 Homo sapiens Species 0.000 description 85
- 108090000623 proteins and genes Proteins 0.000 description 70
- 239000000203 mixture Substances 0.000 description 67
- 235000001014 amino acid Nutrition 0.000 description 49
- 235000018102 proteins Nutrition 0.000 description 49
- 102000004169 proteins and genes Human genes 0.000 description 49
- 229940024606 amino acid Drugs 0.000 description 42
- 150000001413 amino acids Chemical class 0.000 description 42
- 229920001223 polyethylene glycol Polymers 0.000 description 39
- 201000009030 Carcinoma Diseases 0.000 description 38
- 125000003729 nucleotide group Chemical group 0.000 description 38
- 239000005090 green fluorescent protein Substances 0.000 description 37
- 230000014509 gene expression Effects 0.000 description 36
- 239000002773 nucleotide Substances 0.000 description 36
- 206010025323 Lymphomas Diseases 0.000 description 35
- 206010039491 Sarcoma Diseases 0.000 description 34
- 239000002202 Polyethylene glycol Substances 0.000 description 32
- 239000003795 chemical substances by application Substances 0.000 description 32
- 241001465754 Metazoa Species 0.000 description 30
- 210000004408 hybridoma Anatomy 0.000 description 29
- 229920000642 polymer Polymers 0.000 description 27
- 150000001875 compounds Chemical class 0.000 description 25
- 239000013604 expression vector Substances 0.000 description 25
- 230000004927 fusion Effects 0.000 description 25
- 102000005962 receptors Human genes 0.000 description 25
- 108020003175 receptors Proteins 0.000 description 25
- 210000001519 tissue Anatomy 0.000 description 25
- 238000002965 ELISA Methods 0.000 description 23
- 102000003816 Interleukin-13 Human genes 0.000 description 23
- 108090000176 Interleukin-13 Proteins 0.000 description 23
- 230000001225 therapeutic effect Effects 0.000 description 23
- 238000009472 formulation Methods 0.000 description 22
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 21
- 238000003259 recombinant expression Methods 0.000 description 21
- 230000008685 targeting Effects 0.000 description 21
- 238000000684 flow cytometry Methods 0.000 description 20
- 230000003993 interaction Effects 0.000 description 20
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 19
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 19
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 19
- 241000699670 Mus sp. Species 0.000 description 19
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 19
- 241000699666 Mus <mouse, genus> Species 0.000 description 18
- 238000001727 in vivo Methods 0.000 description 18
- 125000005647 linker group Chemical group 0.000 description 18
- 101710117290 Aldo-keto reductase family 1 member C4 Proteins 0.000 description 17
- 239000007924 injection Substances 0.000 description 17
- 238000002347 injection Methods 0.000 description 17
- 230000000694 effects Effects 0.000 description 16
- 229940088598 enzyme Drugs 0.000 description 16
- 208000032839 leukemia Diseases 0.000 description 16
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 16
- 239000002671 adjuvant Substances 0.000 description 15
- 239000000872 buffer Substances 0.000 description 15
- 229940127089 cytotoxic agent Drugs 0.000 description 15
- 238000011160 research Methods 0.000 description 15
- 150000003839 salts Chemical class 0.000 description 15
- 101001003132 Homo sapiens Interleukin-13 receptor subunit alpha-2 Proteins 0.000 description 14
- 102000015696 Interleukins Human genes 0.000 description 14
- 108010063738 Interleukins Proteins 0.000 description 14
- 241000124008 Mammalia Species 0.000 description 14
- 241001529936 Murinae Species 0.000 description 14
- 230000004083 survival effect Effects 0.000 description 14
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 13
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 13
- VSJKWCGYPAHWDS-FQEVSTJZSA-N camptothecin Chemical group C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-FQEVSTJZSA-N 0.000 description 13
- 238000005516 engineering process Methods 0.000 description 13
- 238000002474 experimental method Methods 0.000 description 13
- 230000001965 increasing effect Effects 0.000 description 13
- 238000006467 substitution reaction Methods 0.000 description 13
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 12
- 239000002246 antineoplastic agent Substances 0.000 description 12
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 12
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 11
- 238000003556 assay Methods 0.000 description 11
- 239000003085 diluting agent Substances 0.000 description 11
- 206010041823 squamous cell carcinoma Diseases 0.000 description 11
- 238000010186 staining Methods 0.000 description 11
- 229940124597 therapeutic agent Drugs 0.000 description 11
- 108060003951 Immunoglobulin Proteins 0.000 description 10
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 10
- DLRVVLDZNNYCBX-UHFFFAOYSA-N Polydextrose Polymers OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(O)O1 DLRVVLDZNNYCBX-UHFFFAOYSA-N 0.000 description 10
- 150000001720 carbohydrates Chemical class 0.000 description 10
- 238000012512 characterization method Methods 0.000 description 10
- 102000018358 immunoglobulin Human genes 0.000 description 10
- 239000000463 material Substances 0.000 description 10
- 239000000243 solution Substances 0.000 description 10
- 210000004881 tumor cell Anatomy 0.000 description 10
- 108091023037 Aptamer Proteins 0.000 description 9
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 9
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 9
- 101710112663 Interleukin-13 receptor subunit alpha-1 Proteins 0.000 description 9
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 9
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 description 9
- 235000014633 carbohydrates Nutrition 0.000 description 9
- 239000002299 complementary DNA Substances 0.000 description 9
- 239000000835 fiber Substances 0.000 description 9
- 238000009169 immunotherapy Methods 0.000 description 9
- 239000003446 ligand Substances 0.000 description 9
- 108020004999 messenger RNA Proteins 0.000 description 9
- 230000004048 modification Effects 0.000 description 9
- 238000012986 modification Methods 0.000 description 9
- 239000000546 pharmaceutical excipient Substances 0.000 description 9
- 238000012216 screening Methods 0.000 description 9
- 239000000126 substance Substances 0.000 description 9
- 238000001262 western blot Methods 0.000 description 9
- 206010004146 Basal cell carcinoma Diseases 0.000 description 8
- 241000283707 Capra Species 0.000 description 8
- 108091026890 Coding region Proteins 0.000 description 8
- 108020004705 Codon Proteins 0.000 description 8
- 241000282412 Homo Species 0.000 description 8
- 102000003812 Interleukin-15 Human genes 0.000 description 8
- 108090000172 Interleukin-15 Proteins 0.000 description 8
- 230000004988 N-glycosylation Effects 0.000 description 8
- 230000001588 bifunctional effect Effects 0.000 description 8
- 210000004369 blood Anatomy 0.000 description 8
- 239000008280 blood Substances 0.000 description 8
- 229920001577 copolymer Polymers 0.000 description 8
- 238000003384 imaging method Methods 0.000 description 8
- 230000002401 inhibitory effect Effects 0.000 description 8
- 208000025113 myeloid leukemia Diseases 0.000 description 8
- 229910052697 platinum Inorganic materials 0.000 description 8
- 230000002265 prevention Effects 0.000 description 8
- 108010010803 Gelatin Proteins 0.000 description 7
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 7
- 241000283973 Oryctolagus cuniculus Species 0.000 description 7
- 206010035226 Plasma cell myeloma Diseases 0.000 description 7
- 239000012980 RPMI-1640 medium Substances 0.000 description 7
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 7
- 208000009956 adenocarcinoma Diseases 0.000 description 7
- 229930013930 alkaloid Natural products 0.000 description 7
- 125000000539 amino acid group Chemical group 0.000 description 7
- 239000003242 anti bacterial agent Substances 0.000 description 7
- 238000013459 approach Methods 0.000 description 7
- 210000003719 b-lymphocyte Anatomy 0.000 description 7
- 235000014113 dietary fatty acids Nutrition 0.000 description 7
- 229930195729 fatty acid Natural products 0.000 description 7
- 239000000194 fatty acid Substances 0.000 description 7
- 239000008273 gelatin Substances 0.000 description 7
- 229920000159 gelatin Polymers 0.000 description 7
- 235000019322 gelatine Nutrition 0.000 description 7
- 235000011852 gelatine desserts Nutrition 0.000 description 7
- 230000002209 hydrophobic effect Effects 0.000 description 7
- 230000001900 immune effect Effects 0.000 description 7
- 238000000338 in vitro Methods 0.000 description 7
- 239000003550 marker Substances 0.000 description 7
- 230000035772 mutation Effects 0.000 description 7
- 239000000843 powder Substances 0.000 description 7
- 239000000047 product Substances 0.000 description 7
- 230000002829 reductive effect Effects 0.000 description 7
- 239000000523 sample Substances 0.000 description 7
- 239000006228 supernatant Substances 0.000 description 7
- 238000012360 testing method Methods 0.000 description 7
- 108020004414 DNA Proteins 0.000 description 6
- 241000283073 Equus caballus Species 0.000 description 6
- 101000679851 Homo sapiens Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 description 6
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 6
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 6
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 6
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 6
- 241000699660 Mus musculus Species 0.000 description 6
- 208000034176 Neoplasms, Germ Cell and Embryonal Diseases 0.000 description 6
- 108091028043 Nucleic acid sequence Proteins 0.000 description 6
- 206010041067 Small cell lung cancer Diseases 0.000 description 6
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 6
- 230000004913 activation Effects 0.000 description 6
- 230000002927 anti-mitotic effect Effects 0.000 description 6
- 231100000433 cytotoxic Toxicity 0.000 description 6
- 230000001472 cytotoxic effect Effects 0.000 description 6
- 239000000032 diagnostic agent Substances 0.000 description 6
- 229940039227 diagnostic agent Drugs 0.000 description 6
- 230000036541 health Effects 0.000 description 6
- 239000012216 imaging agent Substances 0.000 description 6
- 208000015181 infectious disease Diseases 0.000 description 6
- 238000007917 intracranial administration Methods 0.000 description 6
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 6
- 208000003747 lymphoid leukemia Diseases 0.000 description 6
- 230000002101 lytic effect Effects 0.000 description 6
- 230000036210 malignancy Effects 0.000 description 6
- 239000003921 oil Substances 0.000 description 6
- 235000019198 oils Nutrition 0.000 description 6
- 238000002823 phage display Methods 0.000 description 6
- 230000003248 secreting effect Effects 0.000 description 6
- 239000002904 solvent Substances 0.000 description 6
- 241000894007 species Species 0.000 description 6
- 239000003381 stabilizer Substances 0.000 description 6
- 239000004094 surface-active agent Substances 0.000 description 6
- 239000000725 suspension Substances 0.000 description 6
- 238000010361 transduction Methods 0.000 description 6
- 230000026683 transduction Effects 0.000 description 6
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 5
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 5
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 5
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 5
- 241000283690 Bos taurus Species 0.000 description 5
- 208000003174 Brain Neoplasms Diseases 0.000 description 5
- KLWPJMFMVPTNCC-UHFFFAOYSA-N Camptothecin Natural products CCC1(O)C(=O)OCC2=C1C=C3C4Nc5ccccc5C=C4CN3C2=O KLWPJMFMVPTNCC-UHFFFAOYSA-N 0.000 description 5
- 108010085418 Interleukin-13 Receptor alpha2 Subunit Proteins 0.000 description 5
- 102000007482 Interleukin-13 Receptor alpha2 Subunit Human genes 0.000 description 5
- 108010002350 Interleukin-2 Proteins 0.000 description 5
- 102000000588 Interleukin-2 Human genes 0.000 description 5
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 5
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 5
- 229920001100 Polydextrose Polymers 0.000 description 5
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 description 5
- 108020004511 Recombinant DNA Proteins 0.000 description 5
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 5
- 229930006000 Sucrose Natural products 0.000 description 5
- UELITFHSCLAHKR-UHFFFAOYSA-N acibenzolar-S-methyl Chemical compound CSC(=O)C1=CC=CC2=C1SN=N2 UELITFHSCLAHKR-UHFFFAOYSA-N 0.000 description 5
- 238000004458 analytical method Methods 0.000 description 5
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 5
- 229940127093 camptothecin Drugs 0.000 description 5
- 229920002678 cellulose Polymers 0.000 description 5
- 239000003153 chemical reaction reagent Substances 0.000 description 5
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 5
- 238000012875 competitive assay Methods 0.000 description 5
- 238000013270 controlled release Methods 0.000 description 5
- 230000001419 dependent effect Effects 0.000 description 5
- 201000010099 disease Diseases 0.000 description 5
- VSJKWCGYPAHWDS-UHFFFAOYSA-N dl-camptothecin Natural products C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-UHFFFAOYSA-N 0.000 description 5
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 5
- 239000000499 gel Substances 0.000 description 5
- 230000012010 growth Effects 0.000 description 5
- 230000003053 immunization Effects 0.000 description 5
- 239000007928 intraperitoneal injection Substances 0.000 description 5
- 238000001990 intravenous administration Methods 0.000 description 5
- 239000007788 liquid Substances 0.000 description 5
- 201000001441 melanoma Diseases 0.000 description 5
- 201000005962 mycosis fungoides Diseases 0.000 description 5
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 5
- 238000005457 optimization Methods 0.000 description 5
- 201000008968 osteosarcoma Diseases 0.000 description 5
- 238000007911 parenteral administration Methods 0.000 description 5
- 239000013612 plasmid Substances 0.000 description 5
- 239000001259 polydextrose Substances 0.000 description 5
- 235000013856 polydextrose Nutrition 0.000 description 5
- 229940035035 polydextrose Drugs 0.000 description 5
- 239000003755 preservative agent Substances 0.000 description 5
- 230000010076 replication Effects 0.000 description 5
- 208000000587 small cell lung carcinoma Diseases 0.000 description 5
- 239000011780 sodium chloride Substances 0.000 description 5
- 239000005720 sucrose Substances 0.000 description 5
- 239000011593 sulfur Substances 0.000 description 5
- 229910052717 sulfur Inorganic materials 0.000 description 5
- 238000002560 therapeutic procedure Methods 0.000 description 5
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 5
- 229920003169 water-soluble polymer Polymers 0.000 description 5
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 4
- 108010006654 Bleomycin Proteins 0.000 description 4
- 102100027207 CD27 antigen Human genes 0.000 description 4
- 101150013553 CD40 gene Proteins 0.000 description 4
- 206010007953 Central nervous system lymphoma Diseases 0.000 description 4
- 108091007741 Chimeric antigen receptor T cells Proteins 0.000 description 4
- 208000006332 Choriocarcinoma Diseases 0.000 description 4
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 4
- 241000699800 Cricetinae Species 0.000 description 4
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 4
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 4
- 101001076430 Homo sapiens Interleukin-13 Proteins 0.000 description 4
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 4
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 4
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 4
- 206010052178 Lymphocytic lymphoma Diseases 0.000 description 4
- XUMBMVFBXHLACL-UHFFFAOYSA-N Melanin Chemical compound O=C1C(=O)C(C2=CNC3=C(C(C(=O)C4=C32)=O)C)=C2C4=CNC2=C1C XUMBMVFBXHLACL-UHFFFAOYSA-N 0.000 description 4
- 208000034578 Multiple myelomas Diseases 0.000 description 4
- 206010061535 Ovarian neoplasm Diseases 0.000 description 4
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 4
- 239000004372 Polyvinyl alcohol Substances 0.000 description 4
- 208000006265 Renal cell carcinoma Diseases 0.000 description 4
- 229920002125 Sokalan® Polymers 0.000 description 4
- 208000031673 T-Cell Cutaneous Lymphoma Diseases 0.000 description 4
- 206010042971 T-cell lymphoma Diseases 0.000 description 4
- 208000027585 T-cell non-Hodgkin lymphoma Diseases 0.000 description 4
- 208000024770 Thyroid neoplasm Diseases 0.000 description 4
- 239000007983 Tris buffer Substances 0.000 description 4
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 4
- 238000004115 adherent culture Methods 0.000 description 4
- 235000010443 alginic acid Nutrition 0.000 description 4
- 229920000615 alginic acid Polymers 0.000 description 4
- 230000001093 anti-cancer Effects 0.000 description 4
- 210000001130 astrocyte Anatomy 0.000 description 4
- 239000002585 base Substances 0.000 description 4
- 229960001561 bleomycin Drugs 0.000 description 4
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 4
- 230000000903 blocking effect Effects 0.000 description 4
- 230000037396 body weight Effects 0.000 description 4
- 210000004556 brain Anatomy 0.000 description 4
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 4
- 239000001768 carboxy methyl cellulose Substances 0.000 description 4
- 235000010980 cellulose Nutrition 0.000 description 4
- 239000001913 cellulose Substances 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 208000006990 cholangiocarcinoma Diseases 0.000 description 4
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 4
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 4
- 229960004316 cisplatin Drugs 0.000 description 4
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 4
- 239000002254 cytotoxic agent Substances 0.000 description 4
- 238000012217 deletion Methods 0.000 description 4
- 230000037430 deletion Effects 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 230000018109 developmental process Effects 0.000 description 4
- 239000000839 emulsion Substances 0.000 description 4
- 238000011049 filling Methods 0.000 description 4
- 201000003444 follicular lymphoma Diseases 0.000 description 4
- 238000001415 gene therapy Methods 0.000 description 4
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 4
- 102000006602 glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 4
- 235000011187 glycerol Nutrition 0.000 description 4
- 239000003102 growth factor Substances 0.000 description 4
- 102000019207 human interleukin-13 Human genes 0.000 description 4
- 229910052739 hydrogen Inorganic materials 0.000 description 4
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 4
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 4
- FDGQSTZJBFJUBT-UHFFFAOYSA-N hypoxanthine Chemical compound O=C1NC=NC2=C1NC=N2 FDGQSTZJBFJUBT-UHFFFAOYSA-N 0.000 description 4
- 230000028993 immune response Effects 0.000 description 4
- 238000002649 immunization Methods 0.000 description 4
- 229940072221 immunoglobulins Drugs 0.000 description 4
- 238000011534 incubation Methods 0.000 description 4
- 238000003780 insertion Methods 0.000 description 4
- 230000037431 insertion Effects 0.000 description 4
- 239000008101 lactose Substances 0.000 description 4
- 150000002632 lipids Chemical class 0.000 description 4
- 238000011580 nude mouse model Methods 0.000 description 4
- 230000002611 ovarian Effects 0.000 description 4
- 239000008188 pellet Substances 0.000 description 4
- 229920002451 polyvinyl alcohol Polymers 0.000 description 4
- 208000016800 primary central nervous system lymphoma Diseases 0.000 description 4
- 230000000069 prophylactic effect Effects 0.000 description 4
- 230000004044 response Effects 0.000 description 4
- 201000006845 reticulosarcoma Diseases 0.000 description 4
- 208000029922 reticulum cell sarcoma Diseases 0.000 description 4
- 230000001177 retroviral effect Effects 0.000 description 4
- 238000007920 subcutaneous administration Methods 0.000 description 4
- 235000000346 sugar Nutrition 0.000 description 4
- 239000000375 suspending agent Substances 0.000 description 4
- 238000013268 sustained release Methods 0.000 description 4
- 239000012730 sustained-release form Substances 0.000 description 4
- 239000003826 tablet Substances 0.000 description 4
- 201000002510 thyroid cancer Diseases 0.000 description 4
- 206010044412 transitional cell carcinoma Diseases 0.000 description 4
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 4
- 230000004565 tumor cell growth Effects 0.000 description 4
- LNAZSHAWQACDHT-XIYTZBAFSA-N (2r,3r,4s,5r,6s)-4,5-dimethoxy-2-(methoxymethyl)-3-[(2s,3r,4s,5r,6r)-3,4,5-trimethoxy-6-(methoxymethyl)oxan-2-yl]oxy-6-[(2r,3r,4s,5r,6r)-4,5,6-trimethoxy-2-(methoxymethyl)oxan-3-yl]oxyoxane Chemical compound CO[C@@H]1[C@@H](OC)[C@H](OC)[C@@H](COC)O[C@H]1O[C@H]1[C@H](OC)[C@@H](OC)[C@H](O[C@H]2[C@@H]([C@@H](OC)[C@H](OC)O[C@@H]2COC)OC)O[C@@H]1COC LNAZSHAWQACDHT-XIYTZBAFSA-N 0.000 description 3
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 3
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 3
- WVDDGKGOMKODPV-UHFFFAOYSA-N Benzyl alcohol Chemical compound OCC1=CC=CC=C1 WVDDGKGOMKODPV-UHFFFAOYSA-N 0.000 description 3
- 206010004593 Bile duct cancer Diseases 0.000 description 3
- 206010005003 Bladder cancer Diseases 0.000 description 3
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 3
- 208000009458 Carcinoma in Situ Diseases 0.000 description 3
- VYZAMTAEIAYCRO-UHFFFAOYSA-N Chromium Chemical compound [Cr] VYZAMTAEIAYCRO-UHFFFAOYSA-N 0.000 description 3
- 108020004635 Complementary DNA Proteins 0.000 description 3
- 208000006402 Ductal Carcinoma Diseases 0.000 description 3
- 241000196324 Embryophyta Species 0.000 description 3
- 206010014759 Endometrial neoplasm Diseases 0.000 description 3
- ZZSNKZQZMQGXPY-UHFFFAOYSA-N Ethyl cellulose Chemical compound CCOCC1OC(OC)C(OCC)C(OCC)C1OC1C(O)C(O)C(OC)C(CO)O1 ZZSNKZQZMQGXPY-UHFFFAOYSA-N 0.000 description 3
- 239000001856 Ethyl cellulose Substances 0.000 description 3
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 3
- 241000287828 Gallus gallus Species 0.000 description 3
- 208000021309 Germ cell tumor Diseases 0.000 description 3
- AEMRFAOFKBGASW-UHFFFAOYSA-N Glycolic acid Polymers OCC(O)=O AEMRFAOFKBGASW-UHFFFAOYSA-N 0.000 description 3
- 229920002153 Hydroxypropyl cellulose Polymers 0.000 description 3
- 206010061252 Intraocular melanoma Diseases 0.000 description 3
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 3
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 3
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 3
- 235000010643 Leucaena leucocephala Nutrition 0.000 description 3
- 240000007472 Leucaena leucocephala Species 0.000 description 3
- 208000028018 Lymphocytic leukaemia Diseases 0.000 description 3
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 3
- 206010027476 Metastases Diseases 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 108091034117 Oligonucleotide Proteins 0.000 description 3
- 206010033128 Ovarian cancer Diseases 0.000 description 3
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 3
- 229920001213 Polysorbate 20 Polymers 0.000 description 3
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 3
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 3
- 241000283984 Rodentia Species 0.000 description 3
- 108091008874 T cell receptors Proteins 0.000 description 3
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 3
- 208000033781 Thyroid carcinoma Diseases 0.000 description 3
- 101710183280 Topoisomerase Proteins 0.000 description 3
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 description 3
- 201000005969 Uveal melanoma Diseases 0.000 description 3
- 239000004480 active ingredient Substances 0.000 description 3
- 230000001464 adherent effect Effects 0.000 description 3
- 208000020990 adrenal cortex carcinoma Diseases 0.000 description 3
- 208000007128 adrenocortical carcinoma Diseases 0.000 description 3
- 230000002411 adverse Effects 0.000 description 3
- 239000000443 aerosol Substances 0.000 description 3
- 235000004279 alanine Nutrition 0.000 description 3
- 150000003797 alkaloid derivatives Chemical class 0.000 description 3
- 230000003302 anti-idiotype Effects 0.000 description 3
- 229940088710 antibiotic agent Drugs 0.000 description 3
- 239000003963 antioxidant agent Substances 0.000 description 3
- 235000006708 antioxidants Nutrition 0.000 description 3
- UMWYYMCOBYVEPY-UHFFFAOYSA-N azanide;platinum(2+) Chemical class [NH2-].[NH2-].[Pt+2] UMWYYMCOBYVEPY-UHFFFAOYSA-N 0.000 description 3
- 239000002775 capsule Substances 0.000 description 3
- 229910052799 carbon Inorganic materials 0.000 description 3
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 3
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 3
- 230000010261 cell growth Effects 0.000 description 3
- 210000003169 central nervous system Anatomy 0.000 description 3
- 229910052804 chromium Inorganic materials 0.000 description 3
- 239000011651 chromium Substances 0.000 description 3
- 239000011248 coating agent Substances 0.000 description 3
- 238000000576 coating method Methods 0.000 description 3
- 230000000295 complement effect Effects 0.000 description 3
- 238000012790 confirmation Methods 0.000 description 3
- 238000007796 conventional method Methods 0.000 description 3
- 201000007241 cutaneous T cell lymphoma Diseases 0.000 description 3
- 208000017763 cutaneous neuroendocrine carcinoma Diseases 0.000 description 3
- 235000018417 cysteine Nutrition 0.000 description 3
- 230000034994 death Effects 0.000 description 3
- 238000001514 detection method Methods 0.000 description 3
- 238000010790 dilution Methods 0.000 description 3
- 239000012895 dilution Substances 0.000 description 3
- 239000006185 dispersion Substances 0.000 description 3
- 238000009510 drug design Methods 0.000 description 3
- 239000000975 dye Substances 0.000 description 3
- 150000002148 esters Chemical class 0.000 description 3
- 235000019325 ethyl cellulose Nutrition 0.000 description 3
- 229920001249 ethyl cellulose Polymers 0.000 description 3
- 210000003527 eukaryotic cell Anatomy 0.000 description 3
- 230000001747 exhibiting effect Effects 0.000 description 3
- 150000004665 fatty acids Chemical class 0.000 description 3
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 3
- 229960005277 gemcitabine Drugs 0.000 description 3
- 239000008103 glucose Substances 0.000 description 3
- 229960002989 glutamic acid Drugs 0.000 description 3
- 208000014829 head and neck neoplasm Diseases 0.000 description 3
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 3
- 235000010977 hydroxypropyl cellulose Nutrition 0.000 description 3
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 3
- UFVKGYZPFZQRLF-UHFFFAOYSA-N hydroxypropyl methyl cellulose Chemical compound OC1C(O)C(OC)OC(CO)C1OC1C(O)C(O)C(OC2C(C(O)C(OC3C(C(O)C(O)C(CO)O3)O)C(CO)O2)O)C(CO)O1 UFVKGYZPFZQRLF-UHFFFAOYSA-N 0.000 description 3
- 210000000987 immune system Anatomy 0.000 description 3
- 201000004933 in situ carcinoma Diseases 0.000 description 3
- 230000001939 inductive effect Effects 0.000 description 3
- 239000003112 inhibitor Substances 0.000 description 3
- 239000007972 injectable composition Substances 0.000 description 3
- 238000007918 intramuscular administration Methods 0.000 description 3
- 229960004768 irinotecan Drugs 0.000 description 3
- 229910052742 iron Inorganic materials 0.000 description 3
- 230000000670 limiting effect Effects 0.000 description 3
- 210000005073 lymphatic endothelial cell Anatomy 0.000 description 3
- 208000025036 lymphosarcoma Diseases 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 210000004379 membrane Anatomy 0.000 description 3
- 239000012528 membrane Substances 0.000 description 3
- 229920000609 methyl cellulose Polymers 0.000 description 3
- 235000010981 methylcellulose Nutrition 0.000 description 3
- 239000001923 methylcellulose Substances 0.000 description 3
- 201000000050 myeloid neoplasm Diseases 0.000 description 3
- 210000000822 natural killer cell Anatomy 0.000 description 3
- 239000013642 negative control Substances 0.000 description 3
- 239000002777 nucleoside Substances 0.000 description 3
- 150000003833 nucleoside derivatives Chemical class 0.000 description 3
- 201000002575 ocular melanoma Diseases 0.000 description 3
- 239000002674 ointment Substances 0.000 description 3
- 238000001543 one-way ANOVA Methods 0.000 description 3
- 238000007427 paired t-test Methods 0.000 description 3
- 229960001972 panitumumab Drugs 0.000 description 3
- 229920003229 poly(methyl methacrylate) Polymers 0.000 description 3
- 239000004926 polymethyl methacrylate Substances 0.000 description 3
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 3
- 229920002635 polyurethane Polymers 0.000 description 3
- 239000004814 polyurethane Substances 0.000 description 3
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 3
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 3
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 3
- 208000025638 primary cutaneous T-cell non-Hodgkin lymphoma Diseases 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 239000003380 propellant Substances 0.000 description 3
- 230000002285 radioactive effect Effects 0.000 description 3
- 230000009257 reactivity Effects 0.000 description 3
- 238000012552 review Methods 0.000 description 3
- 210000002966 serum Anatomy 0.000 description 3
- 210000000952 spleen Anatomy 0.000 description 3
- 239000007921 spray Substances 0.000 description 3
- 239000002562 thickening agent Substances 0.000 description 3
- 208000013077 thyroid gland carcinoma Diseases 0.000 description 3
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 description 3
- 229940035893 uracil Drugs 0.000 description 3
- 210000000626 ureter Anatomy 0.000 description 3
- 239000003981 vehicle Substances 0.000 description 3
- GBABOYUKABKIAF-GHYRFKGUSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-GHYRFKGUSA-N 0.000 description 3
- 229960002066 vinorelbine Drugs 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- DBTMGCOVALSLOR-DEVYUCJPSA-N (2s,3r,4s,5r,6r)-4-[(2s,3r,4s,5r,6r)-3,5-dihydroxy-6-(hydroxymethyl)-4-[(2s,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoxan-2-yl]oxy-6-(hydroxymethyl)oxane-2,3,5-triol Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](O)[C@H](O[C@H]2[C@@H]([C@@H](CO)O[C@H](O)[C@@H]2O)O)O[C@H](CO)[C@H]1O DBTMGCOVALSLOR-DEVYUCJPSA-N 0.000 description 2
- RFLVMTUMFYRZCB-UHFFFAOYSA-N 1-methylguanine Chemical compound O=C1N(C)C(N)=NC2=C1N=CN2 RFLVMTUMFYRZCB-UHFFFAOYSA-N 0.000 description 2
- XDOFQFKRPWOURC-UHFFFAOYSA-N 16-methylheptadecanoic acid Chemical compound CC(C)CCCCCCCCCCCCCCC(O)=O XDOFQFKRPWOURC-UHFFFAOYSA-N 0.000 description 2
- FZWGECJQACGGTI-UHFFFAOYSA-N 2-amino-7-methyl-1,7-dihydro-6H-purin-6-one Chemical compound NC1=NC(O)=C2N(C)C=NC2=N1 FZWGECJQACGGTI-UHFFFAOYSA-N 0.000 description 2
- HSTOKWSFWGCZMH-UHFFFAOYSA-N 3,3'-diaminobenzidine Chemical compound C1=C(N)C(N)=CC=C1C1=CC=C(N)C(N)=C1 HSTOKWSFWGCZMH-UHFFFAOYSA-N 0.000 description 2
- NDMPLJNOPCLANR-UHFFFAOYSA-N 3,4-dihydroxy-15-(4-hydroxy-18-methoxycarbonyl-5,18-seco-ibogamin-18-yl)-16-methoxy-1-methyl-6,7-didehydro-aspidospermidine-3-carboxylic acid methyl ester Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 NDMPLJNOPCLANR-UHFFFAOYSA-N 0.000 description 2
- OIVLITBTBDPEFK-UHFFFAOYSA-N 5,6-dihydrouracil Chemical compound O=C1CCNC(=O)N1 OIVLITBTBDPEFK-UHFFFAOYSA-N 0.000 description 2
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 2
- FUXVKZWTXQUGMW-FQEVSTJZSA-N 9-Aminocamptothecin Chemical compound C1=CC(N)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 FUXVKZWTXQUGMW-FQEVSTJZSA-N 0.000 description 2
- LRFVTYWOQMYALW-UHFFFAOYSA-N 9H-xanthine Chemical compound O=C1NC(=O)NC2=C1NC=N2 LRFVTYWOQMYALW-UHFFFAOYSA-N 0.000 description 2
- 208000002008 AIDS-Related Lymphoma Diseases 0.000 description 2
- 241000321096 Adenoides Species 0.000 description 2
- 208000003200 Adenoma Diseases 0.000 description 2
- 206010001233 Adenoma benign Diseases 0.000 description 2
- 108010088751 Albumins Proteins 0.000 description 2
- 102000009027 Albumins Human genes 0.000 description 2
- PQSUYGKTWSAVDQ-ZVIOFETBSA-N Aldosterone Chemical compound C([C@@]1([C@@H](C(=O)CO)CC[C@H]1[C@@H]1CC2)C=O)[C@H](O)[C@@H]1[C@]1(C)C2=CC(=O)CC1 PQSUYGKTWSAVDQ-ZVIOFETBSA-N 0.000 description 2
- PQSUYGKTWSAVDQ-UHFFFAOYSA-N Aldosterone Natural products C1CC2C3CCC(C(=O)CO)C3(C=O)CC(O)C2C2(C)C1=CC(=O)CC2 PQSUYGKTWSAVDQ-UHFFFAOYSA-N 0.000 description 2
- 208000001446 Anaplastic Thyroid Carcinoma Diseases 0.000 description 2
- PAYRUJLWNCNPSJ-UHFFFAOYSA-N Aniline Chemical compound NC1=CC=CC=C1 PAYRUJLWNCNPSJ-UHFFFAOYSA-N 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 2
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 2
- 241000894006 Bacteria Species 0.000 description 2
- 206010006187 Breast cancer Diseases 0.000 description 2
- 208000026310 Breast neoplasm Diseases 0.000 description 2
- 208000003170 Bronchiolo-Alveolar Adenocarcinoma Diseases 0.000 description 2
- 208000011691 Burkitt lymphomas Diseases 0.000 description 2
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 2
- 241000759905 Camptotheca acuminata Species 0.000 description 2
- 241001466804 Carnivora Species 0.000 description 2
- 240000001829 Catharanthus roseus Species 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 206010008342 Cervix carcinoma Diseases 0.000 description 2
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 description 2
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 2
- 229920002261 Corn starch Polymers 0.000 description 2
- 241000186216 Corynebacterium Species 0.000 description 2
- 241000701022 Cytomegalovirus Species 0.000 description 2
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 2
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 2
- 102000003915 DNA Topoisomerases Human genes 0.000 description 2
- 108090000323 DNA Topoisomerases Proteins 0.000 description 2
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- 238000008157 ELISA kit Methods 0.000 description 2
- 206010014733 Endometrial cancer Diseases 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 2
- 208000004463 Follicular Adenocarcinoma Diseases 0.000 description 2
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 239000007995 HEPES buffer Substances 0.000 description 2
- WZUVPPKBWHMQCE-UHFFFAOYSA-N Haematoxylin Chemical compound C12=CC(O)=C(O)C=C2CC2(O)C1C1=CC=C(O)C(O)=C1OC2 WZUVPPKBWHMQCE-UHFFFAOYSA-N 0.000 description 2
- 102100026122 High affinity immunoglobulin gamma Fc receptor I Human genes 0.000 description 2
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 2
- 101001003135 Homo sapiens Interleukin-13 receptor subunit alpha-1 Proteins 0.000 description 2
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 2
- UGQMRVRMYYASKQ-UHFFFAOYSA-N Hypoxanthine nucleoside Natural products OC1C(O)C(CO)OC1N1C(NC=NC2=O)=C2N=C1 UGQMRVRMYYASKQ-UHFFFAOYSA-N 0.000 description 2
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 2
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 2
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 2
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 2
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 2
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 2
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 2
- 102000008070 Interferon-gamma Human genes 0.000 description 2
- 108010074328 Interferon-gamma Proteins 0.000 description 2
- 208000007766 Kaposi sarcoma Diseases 0.000 description 2
- 208000008839 Kidney Neoplasms Diseases 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N Lactic Acid Natural products CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 2
- 229920001543 Laminarin Polymers 0.000 description 2
- 239000005717 Laminarin Substances 0.000 description 2
- 206010062038 Lip neoplasm Diseases 0.000 description 2
- 206010073099 Lobular breast carcinoma in situ Diseases 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- 101150053046 MYD88 gene Proteins 0.000 description 2
- 208000006644 Malignant Fibrous Histiocytoma Diseases 0.000 description 2
- 229930195725 Mannitol Natural products 0.000 description 2
- 229930192392 Mitomycin Natural products 0.000 description 2
- 208000003445 Mouth Neoplasms Diseases 0.000 description 2
- 101001003131 Mus musculus Interleukin-13 receptor subunit alpha-2 Proteins 0.000 description 2
- 241001467552 Mycobacterium bovis BCG Species 0.000 description 2
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 description 2
- 208000014767 Myeloproliferative disease Diseases 0.000 description 2
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 2
- HYVABZIGRDEKCD-UHFFFAOYSA-N N(6)-dimethylallyladenine Chemical compound CC(C)=CCNC1=NC=NC2=C1N=CN2 HYVABZIGRDEKCD-UHFFFAOYSA-N 0.000 description 2
- 206010061306 Nasopharyngeal cancer Diseases 0.000 description 2
- 206010061309 Neoplasm progression Diseases 0.000 description 2
- 239000000020 Nitrocellulose Substances 0.000 description 2
- 241000060380 Nothapodytes Species 0.000 description 2
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 2
- 208000007571 Ovarian Epithelial Carcinoma Diseases 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- 108090000526 Papain Proteins 0.000 description 2
- 206010033701 Papillary thyroid cancer Diseases 0.000 description 2
- 102000057297 Pepsin A Human genes 0.000 description 2
- 108090000284 Pepsin A Proteins 0.000 description 2
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 2
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 2
- 229920001305 Poly(isodecyl(meth)acrylate) Polymers 0.000 description 2
- 229920002319 Poly(methyl acrylate) Polymers 0.000 description 2
- 229920002732 Polyanhydride Polymers 0.000 description 2
- 239000004793 Polystyrene Substances 0.000 description 2
- 241000288906 Primates Species 0.000 description 2
- 208000033766 Prolymphocytic Leukemia Diseases 0.000 description 2
- ATUOYWHBWRKTHZ-UHFFFAOYSA-N Propane Chemical compound CCC ATUOYWHBWRKTHZ-UHFFFAOYSA-N 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 108010076504 Protein Sorting Signals Proteins 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- 208000015634 Rectal Neoplasms Diseases 0.000 description 2
- 206010039710 Scleroderma Diseases 0.000 description 2
- 241000700584 Simplexvirus Species 0.000 description 2
- 208000000453 Skin Neoplasms Diseases 0.000 description 2
- 108091027967 Small hairpin RNA Proteins 0.000 description 2
- 229920002472 Starch Polymers 0.000 description 2
- 235000021355 Stearic acid Nutrition 0.000 description 2
- 229930182558 Sterol Natural products 0.000 description 2
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 2
- 241000282898 Sus scrofa Species 0.000 description 2
- 208000000389 T-cell leukemia Diseases 0.000 description 2
- 208000028530 T-cell lymphoblastic leukemia/lymphoma Diseases 0.000 description 2
- 201000009365 Thymic carcinoma Diseases 0.000 description 2
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 2
- 102000006601 Thymidine Kinase Human genes 0.000 description 2
- 108020004440 Thymidine kinase Proteins 0.000 description 2
- 102100024598 Tumor necrosis factor ligand superfamily member 10 Human genes 0.000 description 2
- 208000025865 Ulcer Diseases 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 2
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 2
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 2
- 229920002494 Zein Polymers 0.000 description 2
- FJWGYAHXMCUOOM-QHOUIDNNSA-N [(2s,3r,4s,5r,6r)-2-[(2r,3r,4s,5r,6s)-4,5-dinitrooxy-2-(nitrooxymethyl)-6-[(2r,3r,4s,5r,6s)-4,5,6-trinitrooxy-2-(nitrooxymethyl)oxan-3-yl]oxyoxan-3-yl]oxy-3,5-dinitrooxy-6-(nitrooxymethyl)oxan-4-yl] nitrate Chemical compound O([C@@H]1O[C@@H]([C@H]([C@H](O[N+]([O-])=O)[C@H]1O[N+]([O-])=O)O[C@H]1[C@@H]([C@@H](O[N+]([O-])=O)[C@H](O[N+]([O-])=O)[C@@H](CO[N+]([O-])=O)O1)O[N+]([O-])=O)CO[N+](=O)[O-])[C@@H]1[C@@H](CO[N+]([O-])=O)O[C@@H](O[N+]([O-])=O)[C@H](O[N+]([O-])=O)[C@H]1O[N+]([O-])=O FJWGYAHXMCUOOM-QHOUIDNNSA-N 0.000 description 2
- KMLCRELJHYKIIL-UHFFFAOYSA-N [1-(azanidylmethyl)cyclohexyl]methylazanide;platinum(2+);sulfuric acid Chemical compound [Pt+2].OS(O)(=O)=O.[NH-]CC1(C[NH-])CCCCC1 KMLCRELJHYKIIL-UHFFFAOYSA-N 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- 238000010521 absorption reaction Methods 0.000 description 2
- DPXJVFZANSGRMM-UHFFFAOYSA-N acetic acid;2,3,4,5,6-pentahydroxyhexanal;sodium Chemical compound [Na].CC(O)=O.OCC(O)C(O)C(O)C(O)C=O DPXJVFZANSGRMM-UHFFFAOYSA-N 0.000 description 2
- 230000002378 acidificating effect Effects 0.000 description 2
- 208000006336 acinar cell carcinoma Diseases 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 239000000654 additive Substances 0.000 description 2
- 210000002534 adenoid Anatomy 0.000 description 2
- 208000002517 adenoid cystic carcinoma Diseases 0.000 description 2
- 239000011543 agarose gel Substances 0.000 description 2
- 150000001298 alcohols Chemical class 0.000 description 2
- 150000001299 aldehydes Chemical class 0.000 description 2
- 229960002478 aldosterone Drugs 0.000 description 2
- 229920013820 alkyl cellulose Polymers 0.000 description 2
- 125000000217 alkyl group Chemical group 0.000 description 2
- 108010004469 allophycocyanin Proteins 0.000 description 2
- 229960000723 ampicillin Drugs 0.000 description 2
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 2
- 239000012491 analyte Substances 0.000 description 2
- 230000000844 anti-bacterial effect Effects 0.000 description 2
- 230000001348 anti-glioma Effects 0.000 description 2
- 229940124691 antibody therapeutics Drugs 0.000 description 2
- 239000003429 antifungal agent Substances 0.000 description 2
- 229940121375 antifungal agent Drugs 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 235000009582 asparagine Nutrition 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- 229910052789 astatine Inorganic materials 0.000 description 2
- RYXHOMYVWAEKHL-UHFFFAOYSA-N astatine atom Chemical compound [At] RYXHOMYVWAEKHL-UHFFFAOYSA-N 0.000 description 2
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 2
- 229960000190 bacillus calmette–guérin vaccine Drugs 0.000 description 2
- 210000000270 basal cell Anatomy 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- 229920002988 biodegradable polymer Polymers 0.000 description 2
- 239000004621 biodegradable polymer Substances 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 230000029918 bioluminescence Effects 0.000 description 2
- 238000005415 bioluminescence Methods 0.000 description 2
- VWCPNTATQBOMGQ-UHFFFAOYSA-M bis(2-azanidylethyl)azanide;platinum(4+);chloride Chemical compound [Cl-].[Pt+4].[NH-]CC[N-]CC[NH-] VWCPNTATQBOMGQ-UHFFFAOYSA-M 0.000 description 2
- 201000001531 bladder carcinoma Diseases 0.000 description 2
- 210000000988 bone and bone Anatomy 0.000 description 2
- 210000001185 bone marrow Anatomy 0.000 description 2
- 208000003362 bronchogenic carcinoma Diseases 0.000 description 2
- 239000006172 buffering agent Substances 0.000 description 2
- 239000011575 calcium Substances 0.000 description 2
- 229910052791 calcium Inorganic materials 0.000 description 2
- 235000001465 calcium Nutrition 0.000 description 2
- 238000002619 cancer immunotherapy Methods 0.000 description 2
- 229960004562 carboplatin Drugs 0.000 description 2
- 208000002458 carcinoid tumor Diseases 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 239000006285 cell suspension Substances 0.000 description 2
- 229920002301 cellulose acetate Polymers 0.000 description 2
- 229920003086 cellulose ether Polymers 0.000 description 2
- 201000010881 cervical cancer Diseases 0.000 description 2
- 239000002738 chelating agent Substances 0.000 description 2
- 238000002512 chemotherapy Methods 0.000 description 2
- OSASVXMJTNOKOY-UHFFFAOYSA-N chlorobutanol Chemical compound CC(C)(O)C(Cl)(Cl)Cl OSASVXMJTNOKOY-UHFFFAOYSA-N 0.000 description 2
- 235000012000 cholesterol Nutrition 0.000 description 2
- 239000004927 clay Substances 0.000 description 2
- 239000003086 colorant Substances 0.000 description 2
- 230000009137 competitive binding Effects 0.000 description 2
- 229910052802 copper Inorganic materials 0.000 description 2
- 239000010949 copper Substances 0.000 description 2
- 239000008120 corn starch Substances 0.000 description 2
- 230000009260 cross reactivity Effects 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 230000001461 cytolytic effect Effects 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 2
- 229960000975 daunorubicin Drugs 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 239000003599 detergent Substances 0.000 description 2
- UQLDLKMNUJERMK-UHFFFAOYSA-L di(octadecanoyloxy)lead Chemical compound [Pb+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O UQLDLKMNUJERMK-UHFFFAOYSA-L 0.000 description 2
- 230000029087 digestion Effects 0.000 description 2
- 150000002016 disaccharides Chemical class 0.000 description 2
- 239000002612 dispersion medium Substances 0.000 description 2
- 239000008298 dragée Substances 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 150000002066 eicosanoids Chemical class 0.000 description 2
- 201000002246 embryonal cancer Diseases 0.000 description 2
- 239000003995 emulsifying agent Substances 0.000 description 2
- 201000003914 endometrial carcinoma Diseases 0.000 description 2
- 230000002357 endometrial effect Effects 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 210000002919 epithelial cell Anatomy 0.000 description 2
- 230000008029 eradication Effects 0.000 description 2
- 201000004101 esophageal cancer Diseases 0.000 description 2
- 150000002170 ethers Chemical class 0.000 description 2
- 201000008819 extrahepatic bile duct carcinoma Diseases 0.000 description 2
- 239000000945 filler Substances 0.000 description 2
- 239000010408 film Substances 0.000 description 2
- 239000000796 flavoring agent Substances 0.000 description 2
- 239000012530 fluid Substances 0.000 description 2
- 230000002538 fungal effect Effects 0.000 description 2
- 230000002496 gastric effect Effects 0.000 description 2
- 238000003197 gene knockdown Methods 0.000 description 2
- 201000007116 gestational trophoblastic neoplasm Diseases 0.000 description 2
- 230000000762 glandular Effects 0.000 description 2
- 230000002518 glial effect Effects 0.000 description 2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 2
- SYUXAJSOZXEFPP-UHFFFAOYSA-N glutin Natural products COc1c(O)cc2OC(=CC(=O)c2c1O)c3ccccc3OC4OC(CO)C(O)C(O)C4O SYUXAJSOZXEFPP-UHFFFAOYSA-N 0.000 description 2
- 150000002334 glycols Chemical class 0.000 description 2
- 201000009277 hairy cell leukemia Diseases 0.000 description 2
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 2
- BXWNKGSJHAJOGX-UHFFFAOYSA-N hexadecan-1-ol Chemical compound CCCCCCCCCCCCCCCCO BXWNKGSJHAJOGX-UHFFFAOYSA-N 0.000 description 2
- JYGXADMDTFJGBT-VWUMJDOOSA-N hydrocortisone Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 JYGXADMDTFJGBT-VWUMJDOOSA-N 0.000 description 2
- 239000000017 hydrogel Substances 0.000 description 2
- 239000001257 hydrogen Substances 0.000 description 2
- 229920001477 hydrophilic polymer Polymers 0.000 description 2
- 229920013821 hydroxy alkyl cellulose Polymers 0.000 description 2
- 239000001863 hydroxypropyl cellulose Substances 0.000 description 2
- 201000006866 hypopharynx cancer Diseases 0.000 description 2
- 230000002163 immunogen Effects 0.000 description 2
- 230000005847 immunogenicity Effects 0.000 description 2
- 238000002991 immunohistochemical analysis Methods 0.000 description 2
- 238000003364 immunohistochemistry Methods 0.000 description 2
- 238000001802 infusion Methods 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 229960003130 interferon gamma Drugs 0.000 description 2
- 238000001361 intraarterial administration Methods 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 238000007913 intrathecal administration Methods 0.000 description 2
- 239000011630 iodine Substances 0.000 description 2
- 229910052740 iodine Inorganic materials 0.000 description 2
- 150000002500 ions Chemical class 0.000 description 2
- 210000004153 islets of langerhan Anatomy 0.000 description 2
- 239000007951 isotonicity adjuster Substances 0.000 description 2
- 210000003734 kidney Anatomy 0.000 description 2
- 231100000518 lethal Toxicity 0.000 description 2
- 230000001665 lethal effect Effects 0.000 description 2
- 210000000265 leukocyte Anatomy 0.000 description 2
- 208000012987 lip and oral cavity carcinoma Diseases 0.000 description 2
- 239000002502 liposome Substances 0.000 description 2
- 208000014018 liver neoplasm Diseases 0.000 description 2
- 238000001325 log-rank test Methods 0.000 description 2
- 239000007937 lozenge Substances 0.000 description 2
- 239000000314 lubricant Substances 0.000 description 2
- 210000004072 lung Anatomy 0.000 description 2
- 230000001926 lymphatic effect Effects 0.000 description 2
- 210000004698 lymphocyte Anatomy 0.000 description 2
- 201000007919 lymphoplasmacytic lymphoma Diseases 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 2
- 239000000594 mannitol Substances 0.000 description 2
- 235000010355 mannitol Nutrition 0.000 description 2
- 208000023356 medullary thyroid gland carcinoma Diseases 0.000 description 2
- 210000002901 mesenchymal stem cell Anatomy 0.000 description 2
- 230000009401 metastasis Effects 0.000 description 2
- 206010061289 metastatic neoplasm Diseases 0.000 description 2
- 244000005700 microbiome Species 0.000 description 2
- 239000002480 mineral oil Substances 0.000 description 2
- 235000010446 mineral oil Nutrition 0.000 description 2
- 229960004857 mitomycin Drugs 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 150000002772 monosaccharides Chemical class 0.000 description 2
- 210000003550 mucous cell Anatomy 0.000 description 2
- 210000004400 mucous membrane Anatomy 0.000 description 2
- 239000002086 nanomaterial Substances 0.000 description 2
- 230000009826 neoplastic cell growth Effects 0.000 description 2
- 230000007935 neutral effect Effects 0.000 description 2
- 229920001220 nitrocellulos Polymers 0.000 description 2
- 239000002736 nonionic surfactant Substances 0.000 description 2
- 230000001453 nonthrombogenic effect Effects 0.000 description 2
- 231100000252 nontoxic Toxicity 0.000 description 2
- 230000003000 nontoxic effect Effects 0.000 description 2
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 2
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 2
- 208000021284 ovarian germ cell tumor Diseases 0.000 description 2
- 201000002528 pancreatic cancer Diseases 0.000 description 2
- 208000008443 pancreatic carcinoma Diseases 0.000 description 2
- 201000002530 pancreatic endocrine carcinoma Diseases 0.000 description 2
- 229940055729 papain Drugs 0.000 description 2
- 235000019834 papain Nutrition 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 230000035515 penetration Effects 0.000 description 2
- 229940111202 pepsin Drugs 0.000 description 2
- 210000005105 peripheral blood lymphocyte Anatomy 0.000 description 2
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 2
- 102000013415 peroxidase activity proteins Human genes 0.000 description 2
- 108040007629 peroxidase activity proteins Proteins 0.000 description 2
- 239000008180 pharmaceutical surfactant Substances 0.000 description 2
- 235000021317 phosphate Nutrition 0.000 description 2
- 150000003013 phosphoric acid derivatives Chemical class 0.000 description 2
- 229910052698 phosphorus Inorganic materials 0.000 description 2
- 239000011574 phosphorus Substances 0.000 description 2
- 208000010626 plasma cell neoplasm Diseases 0.000 description 2
- 229920003023 plastic Polymers 0.000 description 2
- 239000004033 plastic Substances 0.000 description 2
- 229920001983 poloxamer Polymers 0.000 description 2
- 229920001490 poly(butyl methacrylate) polymer Polymers 0.000 description 2
- 229920001483 poly(ethyl methacrylate) polymer Polymers 0.000 description 2
- 229920000212 poly(isobutyl acrylate) Polymers 0.000 description 2
- 229920000205 poly(isobutyl methacrylate) Polymers 0.000 description 2
- 229920000196 poly(lauryl methacrylate) Polymers 0.000 description 2
- 229920000184 poly(octadecyl acrylate) Polymers 0.000 description 2
- 239000004584 polyacrylic acid Substances 0.000 description 2
- 229920001281 polyalkylene Polymers 0.000 description 2
- 229920000129 polyhexylmethacrylate Polymers 0.000 description 2
- 229920000197 polyisopropyl acrylate Polymers 0.000 description 2
- 229920005862 polyol Polymers 0.000 description 2
- 150000003077 polyols Chemical class 0.000 description 2
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 2
- 229920000182 polyphenyl methacrylate Polymers 0.000 description 2
- 229920001282 polysaccharide Polymers 0.000 description 2
- 239000005017 polysaccharide Substances 0.000 description 2
- 150000004804 polysaccharides Chemical class 0.000 description 2
- 229920002223 polystyrene Polymers 0.000 description 2
- 239000011148 porous material Substances 0.000 description 2
- 238000002600 positron emission tomography Methods 0.000 description 2
- 150000003135 prenol lipids Chemical class 0.000 description 2
- 210000001236 prokaryotic cell Anatomy 0.000 description 2
- 238000000159 protein binding assay Methods 0.000 description 2
- 230000005180 public health Effects 0.000 description 2
- 230000002685 pulmonary effect Effects 0.000 description 2
- 208000005069 pulmonary fibrosis Diseases 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 206010038038 rectal cancer Diseases 0.000 description 2
- 201000001275 rectum cancer Diseases 0.000 description 2
- 238000004064 recycling Methods 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 208000015347 renal cell adenocarcinoma Diseases 0.000 description 2
- 231100000241 scar Toxicity 0.000 description 2
- 238000002741 site-directed mutagenesis Methods 0.000 description 2
- 235000020183 skimmed milk Nutrition 0.000 description 2
- 210000003491 skin Anatomy 0.000 description 2
- 239000004055 small Interfering RNA Substances 0.000 description 2
- 208000000649 small cell carcinoma Diseases 0.000 description 2
- 239000011734 sodium Substances 0.000 description 2
- 229910052708 sodium Inorganic materials 0.000 description 2
- DAEPDZWVDSPTHF-UHFFFAOYSA-M sodium pyruvate Chemical compound [Na+].CC(=O)C([O-])=O DAEPDZWVDSPTHF-UHFFFAOYSA-M 0.000 description 2
- 238000001179 sorption measurement Methods 0.000 description 2
- 210000004988 splenocyte Anatomy 0.000 description 2
- 235000019698 starch Nutrition 0.000 description 2
- 239000008107 starch Substances 0.000 description 2
- 239000008117 stearic acid Substances 0.000 description 2
- 235000003702 sterols Nutrition 0.000 description 2
- 238000003860 storage Methods 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 2
- 229960001052 streptozocin Drugs 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- 201000008205 supratentorial primitive neuroectodermal tumor Diseases 0.000 description 2
- 238000012353 t test Methods 0.000 description 2
- 239000000454 talc Substances 0.000 description 2
- 229910052623 talc Inorganic materials 0.000 description 2
- 235000012222 talc Nutrition 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 208000008732 thymoma Diseases 0.000 description 2
- 201000008440 thyroid gland anaplastic carcinoma Diseases 0.000 description 2
- 208000030901 thyroid gland follicular carcinoma Diseases 0.000 description 2
- 208000030045 thyroid gland papillary carcinoma Diseases 0.000 description 2
- 208000019179 thyroid gland undifferentiated (anaplastic) carcinoma Diseases 0.000 description 2
- 229960000303 topotecan Drugs 0.000 description 2
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 2
- 230000001988 toxicity Effects 0.000 description 2
- 231100000419 toxicity Toxicity 0.000 description 2
- 239000003053 toxin Substances 0.000 description 2
- 231100000765 toxin Toxicity 0.000 description 2
- 108700012359 toxins Proteins 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- 238000002054 transplantation Methods 0.000 description 2
- 229960000575 trastuzumab Drugs 0.000 description 2
- 230000010415 tropism Effects 0.000 description 2
- 230000005751 tumor progression Effects 0.000 description 2
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 2
- 208000010570 urinary bladder carcinoma Diseases 0.000 description 2
- NQPDZGIKBAWPEJ-UHFFFAOYSA-N valeric acid Chemical compound CCCCC(O)=O NQPDZGIKBAWPEJ-UHFFFAOYSA-N 0.000 description 2
- 210000003556 vascular endothelial cell Anatomy 0.000 description 2
- 229960003048 vinblastine Drugs 0.000 description 2
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 2
- UGGWPQSBPIFKDZ-KOTLKJBCSA-N vindesine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(N)=O)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1N=C1[C]2C=CC=C1 UGGWPQSBPIFKDZ-KOTLKJBCSA-N 0.000 description 2
- 229960004355 vindesine Drugs 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- 238000002424 x-ray crystallography Methods 0.000 description 2
- 239000005019 zein Substances 0.000 description 2
- 229940093612 zein Drugs 0.000 description 2
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 2
- WWUZIQQURGPMPG-UHFFFAOYSA-N (-)-D-erythro-Sphingosine Natural products CCCCCCCCCCCCCC=CC(O)C(N)CO WWUZIQQURGPMPG-UHFFFAOYSA-N 0.000 description 1
- HZSBSRAVNBUZRA-RQDPQJJXSA-J (1r,2r)-cyclohexane-1,2-diamine;tetrachloroplatinum(2+) Chemical compound Cl[Pt+2](Cl)(Cl)Cl.N[C@@H]1CCCC[C@H]1N HZSBSRAVNBUZRA-RQDPQJJXSA-J 0.000 description 1
- JWDFQMWEFLOOED-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(pyridin-2-yldisulfanyl)propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCSSC1=CC=CC=N1 JWDFQMWEFLOOED-UHFFFAOYSA-N 0.000 description 1
- KIUKXJAPPMFGSW-DNGZLQJQSA-N (2S,3S,4S,5R,6R)-6-[(2S,3R,4R,5S,6R)-3-Acetamido-2-[(2S,3S,4R,5R,6R)-6-[(2R,3R,4R,5S,6R)-3-acetamido-2,5-dihydroxy-6-(hydroxymethyl)oxan-4-yl]oxy-2-carboxy-4,5-dihydroxyoxan-3-yl]oxy-5-hydroxy-6-(hydroxymethyl)oxan-4-yl]oxy-3,4,5-trihydroxyoxane-2-carboxylic acid Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O[C@H]1[C@H](O)[C@@H](O)[C@H](O[C@H]2[C@@H]([C@@H](O[C@H]3[C@@H]([C@@H](O)[C@H](O)[C@H](O3)C(O)=O)O)[C@H](O)[C@@H](CO)O2)NC(C)=O)[C@@H](C(O)=O)O1 KIUKXJAPPMFGSW-DNGZLQJQSA-N 0.000 description 1
- OMDQUFIYNPYJFM-XKDAHURESA-N (2r,3r,4s,5r,6s)-2-(hydroxymethyl)-6-[[(2r,3s,4r,5s,6r)-4,5,6-trihydroxy-3-[(2s,3s,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoxan-2-yl]methoxy]oxane-3,4,5-triol Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1OC[C@@H]1[C@@H](O[C@H]2[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O)[C@H](O)[C@H](O)[C@H](O)O1 OMDQUFIYNPYJFM-XKDAHURESA-N 0.000 description 1
- ASWBNKHCZGQVJV-UHFFFAOYSA-N (3-hexadecanoyloxy-2-hydroxypropyl) 2-(trimethylazaniumyl)ethyl phosphate Chemical compound CCCCCCCCCCCCCCCC(=O)OCC(O)COP([O-])(=O)OCC[N+](C)(C)C ASWBNKHCZGQVJV-UHFFFAOYSA-N 0.000 description 1
- SSOORFWOBGFTHL-OTEJMHTDSA-N (4S)-5-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[2-[(2S)-2-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S,3S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-5-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-5-amino-1-[[(2S)-5-carbamimidamido-1-[[(2S)-5-carbamimidamido-1-[[(1S)-4-carbamimidamido-1-carboxybutyl]amino]-1-oxopentan-2-yl]amino]-1-oxopentan-2-yl]amino]-1,5-dioxopentan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-1-oxohexan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1,5-dioxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-1-oxopropan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-3-methyl-1-oxopentan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxopropan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]carbamoyl]pyrrolidin-1-yl]-2-oxoethyl]amino]-3-(1H-indol-3-yl)-1-oxopropan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-3-(1H-imidazol-4-yl)-1-oxopropan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-4-[[(2S)-2-[[(2S)-2-[[(2S)-2,6-diaminohexanoyl]amino]-3-methylbutanoyl]amino]propanoyl]amino]-5-oxopentanoic acid Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@H](Cc1c[nH]cn1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)CCCCN)C(C)C)C(C)C)C(C)C)C(C)C)C(C)C)C(C)C)C(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SSOORFWOBGFTHL-OTEJMHTDSA-N 0.000 description 1
- WRIDQFICGBMAFQ-UHFFFAOYSA-N (E)-8-Octadecenoic acid Natural products CCCCCCCCCC=CCCCCCCC(O)=O WRIDQFICGBMAFQ-UHFFFAOYSA-N 0.000 description 1
- WHBMMWSBFZVSSR-GSVOUGTGSA-N (R)-3-hydroxybutyric acid Chemical compound C[C@@H](O)CC(O)=O WHBMMWSBFZVSSR-GSVOUGTGSA-N 0.000 description 1
- ZORQXIQZAOLNGE-UHFFFAOYSA-N 1,1-difluorocyclohexane Chemical compound FC1(F)CCCCC1 ZORQXIQZAOLNGE-UHFFFAOYSA-N 0.000 description 1
- TZCPCKNHXULUIY-RGULYWFUSA-N 1,2-distearoyl-sn-glycero-3-phosphoserine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@H](N)C(O)=O)OC(=O)CCCCCCCCCCCCCCCCC TZCPCKNHXULUIY-RGULYWFUSA-N 0.000 description 1
- GEYOCULIXLDCMW-UHFFFAOYSA-N 1,2-phenylenediamine Chemical compound NC1=CC=CC=C1N GEYOCULIXLDCMW-UHFFFAOYSA-N 0.000 description 1
- LDVVTQMJQSCDMK-UHFFFAOYSA-N 1,3-dihydroxypropan-2-yl formate Chemical compound OCC(CO)OC=O LDVVTQMJQSCDMK-UHFFFAOYSA-N 0.000 description 1
- ZAGUSKAXELYWCE-UHFFFAOYSA-N 1,3-dioxolan-2-ylmethanol Chemical compound OCC1OCCO1 ZAGUSKAXELYWCE-UHFFFAOYSA-N 0.000 description 1
- QDVBKXJMLILLLB-UHFFFAOYSA-N 1,4'-bipiperidine Chemical group C1CCCCN1C1CCNCC1 QDVBKXJMLILLLB-UHFFFAOYSA-N 0.000 description 1
- WJNGQIYEQLPJMN-IOSLPCCCSA-N 1-methylinosine Chemical compound C1=NC=2C(=O)N(C)C=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O WJNGQIYEQLPJMN-IOSLPCCCSA-N 0.000 description 1
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 1
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 1
- IHPYMWDTONKSCO-UHFFFAOYSA-N 2,2'-piperazine-1,4-diylbisethanesulfonic acid Chemical compound OS(=O)(=O)CCN1CCN(CCS(O)(=O)=O)CC1 IHPYMWDTONKSCO-UHFFFAOYSA-N 0.000 description 1
- RPZANUYHRMRTTE-UHFFFAOYSA-N 2,3,4-trimethoxy-6-(methoxymethyl)-5-[3,4,5-trimethoxy-6-(methoxymethyl)oxan-2-yl]oxyoxane;1-[[3,4,5-tris(2-hydroxybutoxy)-6-[4,5,6-tris(2-hydroxybutoxy)-2-(2-hydroxybutoxymethyl)oxan-3-yl]oxyoxan-2-yl]methoxy]butan-2-ol Chemical compound COC1C(OC)C(OC)C(COC)OC1OC1C(OC)C(OC)C(OC)OC1COC.CCC(O)COC1C(OCC(O)CC)C(OCC(O)CC)C(COCC(O)CC)OC1OC1C(OCC(O)CC)C(OCC(O)CC)C(OCC(O)CC)OC1COCC(O)CC RPZANUYHRMRTTE-UHFFFAOYSA-N 0.000 description 1
- UFBJCMHMOXMLKC-UHFFFAOYSA-N 2,4-dinitrophenol Chemical compound OC1=CC=C([N+]([O-])=O)C=C1[N+]([O-])=O UFBJCMHMOXMLKC-UHFFFAOYSA-N 0.000 description 1
- HLYBTPMYFWWNJN-UHFFFAOYSA-N 2-(2,4-dioxo-1h-pyrimidin-5-yl)-2-hydroxyacetic acid Chemical compound OC(=O)C(O)C1=CNC(=O)NC1=O HLYBTPMYFWWNJN-UHFFFAOYSA-N 0.000 description 1
- SGAKLDIYNFXTCK-UHFFFAOYSA-N 2-[(2,4-dioxo-1h-pyrimidin-5-yl)methylamino]acetic acid Chemical compound OC(=O)CNCC1=CNC(=O)NC1=O SGAKLDIYNFXTCK-UHFFFAOYSA-N 0.000 description 1
- YSAJFXWTVFGPAX-UHFFFAOYSA-N 2-[(2,4-dioxo-1h-pyrimidin-5-yl)oxy]acetic acid Chemical compound OC(=O)COC1=CNC(=O)NC1=O YSAJFXWTVFGPAX-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- MWBWWFOAEOYUST-UHFFFAOYSA-N 2-aminopurine Chemical compound NC1=NC=C2N=CNC2=N1 MWBWWFOAEOYUST-UHFFFAOYSA-N 0.000 description 1
- XMSMHKMPBNTBOD-UHFFFAOYSA-N 2-dimethylamino-6-hydroxypurine Chemical compound N1C(N(C)C)=NC(=O)C2=C1N=CN2 XMSMHKMPBNTBOD-UHFFFAOYSA-N 0.000 description 1
- CERHNUFCZQUAIQ-UHFFFAOYSA-L 2-ethylpropanedioate;platinum(2+) Chemical compound [Pt+2].CCC(C([O-])=O)C([O-])=O CERHNUFCZQUAIQ-UHFFFAOYSA-L 0.000 description 1
- SMADWRYCYBUIKH-UHFFFAOYSA-N 2-methyl-7h-purin-6-amine Chemical compound CC1=NC(N)=C2NC=NC2=N1 SMADWRYCYBUIKH-UHFFFAOYSA-N 0.000 description 1
- LQJBNNIYVWPHFW-UHFFFAOYSA-N 20:1omega9c fatty acid Natural products CCCCCCCCCCC=CCCCCCCCC(O)=O LQJBNNIYVWPHFW-UHFFFAOYSA-N 0.000 description 1
- HRGUSFBJBOKSML-UHFFFAOYSA-N 3',5'-di-O-methyltricetin Chemical compound COC1=C(O)C(OC)=CC(C=2OC3=CC(O)=CC(O)=C3C(=O)C=2)=C1 HRGUSFBJBOKSML-UHFFFAOYSA-N 0.000 description 1
- DVLFYONBTKHTER-UHFFFAOYSA-N 3-(N-morpholino)propanesulfonic acid Chemical compound OS(=O)(=O)CCCN1CCOCC1 DVLFYONBTKHTER-UHFFFAOYSA-N 0.000 description 1
- HVCOBJNICQPDBP-UHFFFAOYSA-N 3-[3-[3,5-dihydroxy-6-methyl-4-(3,4,5-trihydroxy-6-methyloxan-2-yl)oxyoxan-2-yl]oxydecanoyloxy]decanoic acid;hydrate Chemical compound O.OC1C(OC(CC(=O)OC(CCCCCCC)CC(O)=O)CCCCCCC)OC(C)C(O)C1OC1C(O)C(O)C(O)C(C)O1 HVCOBJNICQPDBP-UHFFFAOYSA-N 0.000 description 1
- KOLPWZCZXAMXKS-UHFFFAOYSA-N 3-methylcytosine Chemical compound CN1C(N)=CC=NC1=O KOLPWZCZXAMXKS-UHFFFAOYSA-N 0.000 description 1
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 1
- UPXRTVAIJMUAQR-UHFFFAOYSA-N 4-(9h-fluoren-9-ylmethoxycarbonylamino)-1-[(2-methylpropan-2-yl)oxycarbonyl]pyrrolidine-2-carboxylic acid Chemical compound C1C(C(O)=O)N(C(=O)OC(C)(C)C)CC1NC(=O)OCC1C2=CC=CC=C2C2=CC=CC=C21 UPXRTVAIJMUAQR-UHFFFAOYSA-N 0.000 description 1
- GJAKJCICANKRFD-UHFFFAOYSA-N 4-acetyl-4-amino-1,3-dihydropyrimidin-2-one Chemical compound CC(=O)C1(N)NC(=O)NC=C1 GJAKJCICANKRFD-UHFFFAOYSA-N 0.000 description 1
- TVZGACDUOSZQKY-LBPRGKRZSA-N 4-aminofolic acid Chemical compound C1=NC2=NC(N)=NC(N)=C2N=C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 TVZGACDUOSZQKY-LBPRGKRZSA-N 0.000 description 1
- WQEBMDXDYKHCSG-UHFFFAOYSA-L 4-carboxybenzene-1,3-dicarboxylate;cyclohexane-1,2-diamine;platinum(2+) Chemical compound [H+].[Pt+2].NC1CCCCC1N.[O-]C(=O)C1=CC=C(C([O-])=O)C(C([O-])=O)=C1 WQEBMDXDYKHCSG-UHFFFAOYSA-L 0.000 description 1
- HIQIXEFWDLTDED-UHFFFAOYSA-N 4-hydroxy-1-piperidin-4-ylpyrrolidin-2-one Chemical compound O=C1CC(O)CN1C1CCNCC1 HIQIXEFWDLTDED-UHFFFAOYSA-N 0.000 description 1
- MQJSSLBGAQJNER-UHFFFAOYSA-N 5-(methylaminomethyl)-1h-pyrimidine-2,4-dione Chemical compound CNCC1=CNC(=O)NC1=O MQJSSLBGAQJNER-UHFFFAOYSA-N 0.000 description 1
- WPYRHVXCOQLYLY-UHFFFAOYSA-N 5-[(methoxyamino)methyl]-2-sulfanylidene-1h-pyrimidin-4-one Chemical compound CONCC1=CNC(=S)NC1=O WPYRHVXCOQLYLY-UHFFFAOYSA-N 0.000 description 1
- LQLQRFGHAALLLE-UHFFFAOYSA-N 5-bromouracil Chemical compound BrC1=CNC(=O)NC1=O LQLQRFGHAALLLE-UHFFFAOYSA-N 0.000 description 1
- VKLFQTYNHLDMDP-PNHWDRBUSA-N 5-carboxymethylaminomethyl-2-thiouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=S)NC(=O)C(CNCC(O)=O)=C1 VKLFQTYNHLDMDP-PNHWDRBUSA-N 0.000 description 1
- ZFTBZKVVGZNMJR-UHFFFAOYSA-N 5-chlorouracil Chemical compound ClC1=CNC(=O)NC1=O ZFTBZKVVGZNMJR-UHFFFAOYSA-N 0.000 description 1
- KSNXJLQDQOIRIP-UHFFFAOYSA-N 5-iodouracil Chemical compound IC1=CNC(=O)NC1=O KSNXJLQDQOIRIP-UHFFFAOYSA-N 0.000 description 1
- KELXHQACBIUYSE-UHFFFAOYSA-N 5-methoxy-1h-pyrimidine-2,4-dione Chemical compound COC1=CNC(=O)NC1=O KELXHQACBIUYSE-UHFFFAOYSA-N 0.000 description 1
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 description 1
- FJHBVJOVLFPMQE-QFIPXVFZSA-N 7-Ethyl-10-Hydroxy-Camptothecin Chemical compound C1=C(O)C=C2C(CC)=C(CN3C(C4=C([C@@](C(=O)OC4)(O)CC)C=C33)=O)C3=NC2=C1 FJHBVJOVLFPMQE-QFIPXVFZSA-N 0.000 description 1
- QSBYPNXLFMSGKH-UHFFFAOYSA-N 9-Heptadecensaeure Natural products CCCCCCCC=CCCCCCCCC(O)=O QSBYPNXLFMSGKH-UHFFFAOYSA-N 0.000 description 1
- 208000030507 AIDS Diseases 0.000 description 1
- 208000002874 Acne Vulgaris Diseases 0.000 description 1
- NIXOWILDQLNWCW-UHFFFAOYSA-N Acrylic acid Chemical group OC(=O)C=C NIXOWILDQLNWCW-UHFFFAOYSA-N 0.000 description 1
- 208000016557 Acute basophilic leukemia Diseases 0.000 description 1
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 1
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 description 1
- 208000031261 Acute myeloid leukaemia Diseases 0.000 description 1
- 208000006468 Adrenal Cortex Neoplasms Diseases 0.000 description 1
- PLXMOAALOJOTIY-FPTXNFDTSA-N Aesculin Natural products OC[C@@H]1[C@@H](O)[C@H](O)[C@@H](O)[C@H](O)[C@H]1Oc2cc3C=CC(=O)Oc3cc2O PLXMOAALOJOTIY-FPTXNFDTSA-N 0.000 description 1
- 239000012114 Alexa Fluor 647 Substances 0.000 description 1
- 239000012099 Alexa Fluor family Substances 0.000 description 1
- 208000037540 Alveolar soft tissue sarcoma Diseases 0.000 description 1
- 239000004382 Amylase Substances 0.000 description 1
- 102000013142 Amylases Human genes 0.000 description 1
- 108010065511 Amylases Proteins 0.000 description 1
- 108010083359 Antigen Receptors Proteins 0.000 description 1
- 102000006306 Antigen Receptors Human genes 0.000 description 1
- 208000007860 Anus Neoplasms Diseases 0.000 description 1
- 208000032467 Aplastic anaemia Diseases 0.000 description 1
- 244000080767 Areca catechu Species 0.000 description 1
- 206010003445 Ascites Diseases 0.000 description 1
- 241000416162 Astragalus gummifer Species 0.000 description 1
- 206010003571 Astrocytoma Diseases 0.000 description 1
- 108091008875 B cell receptors Proteins 0.000 description 1
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 description 1
- 208000003950 B-cell lymphoma Diseases 0.000 description 1
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 1
- 238000011725 BALB/c mouse Methods 0.000 description 1
- 241000534000 Berula erecta Species 0.000 description 1
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 1
- 102000004506 Blood Proteins Human genes 0.000 description 1
- 108010017384 Blood Proteins Proteins 0.000 description 1
- 206010005949 Bone cancer Diseases 0.000 description 1
- 208000020084 Bone disease Diseases 0.000 description 1
- 208000018084 Bone neoplasm Diseases 0.000 description 1
- 241000701822 Bovine papillomavirus Species 0.000 description 1
- 206010006143 Brain stem glioma Diseases 0.000 description 1
- 206010058354 Bronchioloalveolar carcinoma Diseases 0.000 description 1
- YDNKGFDKKRUKPY-JHOUSYSJSA-N C16 ceramide Natural products CCCCCCCCCCCCCCCC(=O)N[C@@H](CO)[C@H](O)C=CCCCCCCCCCCCCC YDNKGFDKKRUKPY-JHOUSYSJSA-N 0.000 description 1
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 description 1
- 229920000018 Callose Polymers 0.000 description 1
- 241000282465 Canis Species 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- KXDHJXZQYSOELW-UHFFFAOYSA-M Carbamate Chemical compound NC([O-])=O KXDHJXZQYSOELW-UHFFFAOYSA-M 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-L Carbonate Chemical compound [O-]C([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-L 0.000 description 1
- 206010007279 Carcinoid tumour of the gastrointestinal tract Diseases 0.000 description 1
- 208000005024 Castleman disease Diseases 0.000 description 1
- 229920000623 Cellulose acetate phthalate Polymers 0.000 description 1
- DQEFEBPAPFSJLV-UHFFFAOYSA-N Cellulose propionate Chemical compound CCC(=O)OCC1OC(OC(=O)CC)C(OC(=O)CC)C(OC(=O)CC)C1OC1C(OC(=O)CC)C(OC(=O)CC)C(OC(=O)CC)C(COC(=O)CC)O1 DQEFEBPAPFSJLV-UHFFFAOYSA-N 0.000 description 1
- 229920002284 Cellulose triacetate Polymers 0.000 description 1
- 229920002101 Chitin Polymers 0.000 description 1
- 208000005243 Chondrosarcoma Diseases 0.000 description 1
- 102000008186 Collagen Human genes 0.000 description 1
- 108010035532 Collagen Proteins 0.000 description 1
- 206010010099 Combined immunodeficiency Diseases 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 239000000055 Corticotropin-Releasing Hormone Substances 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- 229920002785 Croscarmellose sodium Polymers 0.000 description 1
- JPVYNHNXODAKFH-UHFFFAOYSA-N Cu2+ Chemical compound [Cu+2] JPVYNHNXODAKFH-UHFFFAOYSA-N 0.000 description 1
- 102000001189 Cyclic Peptides Human genes 0.000 description 1
- 108010069514 Cyclic Peptides Proteins 0.000 description 1
- 229920000858 Cyclodextrin Polymers 0.000 description 1
- 102000000311 Cytosine Deaminase Human genes 0.000 description 1
- 108010080611 Cytosine Deaminase Proteins 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 108091008102 DNA aptamers Proteins 0.000 description 1
- 239000004375 Dextrin Substances 0.000 description 1
- 229920001353 Dextrin Polymers 0.000 description 1
- 239000004338 Dichlorodifluoromethane Substances 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 229910052692 Dysprosium Inorganic materials 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 108060006698 EGF receptor Proteins 0.000 description 1
- 102000001301 EGF receptor Human genes 0.000 description 1
- 239000001692 EU approved anti-caking agent Substances 0.000 description 1
- 239000004097 EU approved flavor enhancer Substances 0.000 description 1
- 206010063045 Effusion Diseases 0.000 description 1
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 1
- 208000005431 Endometrioid Carcinoma Diseases 0.000 description 1
- 206010014967 Ependymoma Diseases 0.000 description 1
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 1
- 201000005231 Epithelioid sarcoma Diseases 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 229910052691 Erbium Inorganic materials 0.000 description 1
- IAYPIBMASNFSPL-UHFFFAOYSA-N Ethylene oxide Chemical compound C1CO1 IAYPIBMASNFSPL-UHFFFAOYSA-N 0.000 description 1
- PIICEJLVQHRZGT-UHFFFAOYSA-N Ethylenediamine Chemical compound NCCN PIICEJLVQHRZGT-UHFFFAOYSA-N 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 229910052693 Europium Inorganic materials 0.000 description 1
- 208000006168 Ewing Sarcoma Diseases 0.000 description 1
- 208000012468 Ewing sarcoma/peripheral primitive neuroectodermal tumor Diseases 0.000 description 1
- 208000009331 Experimental Sarcoma Diseases 0.000 description 1
- 108010021468 Fc gamma receptor IIA Proteins 0.000 description 1
- 108010021472 Fc gamma receptor IIB Proteins 0.000 description 1
- 108010087819 Fc receptors Proteins 0.000 description 1
- 102000009109 Fc receptors Human genes 0.000 description 1
- CWYNVVGOOAEACU-UHFFFAOYSA-N Fe2+ Chemical compound [Fe+2] CWYNVVGOOAEACU-UHFFFAOYSA-N 0.000 description 1
- 241000282324 Felis Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 101710189104 Fibritin Proteins 0.000 description 1
- 201000008808 Fibrosarcoma Diseases 0.000 description 1
- 206010016654 Fibrosis Diseases 0.000 description 1
- 108090000331 Firefly luciferases Proteins 0.000 description 1
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- 229930091371 Fructose Natural products 0.000 description 1
- 239000005715 Fructose Substances 0.000 description 1
- RFSUNEUAIZKAJO-ARQDHWQXSA-N Fructose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-ARQDHWQXSA-N 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 229910052688 Gadolinium Inorganic materials 0.000 description 1
- 229920000926 Galactomannan Polymers 0.000 description 1
- 201000003741 Gastrointestinal carcinoma Diseases 0.000 description 1
- 206010017993 Gastrointestinal neoplasms Diseases 0.000 description 1
- 206010051066 Gastrointestinal stromal tumour Diseases 0.000 description 1
- 229920002148 Gellan gum Polymers 0.000 description 1
- JZNWSCPGTDBMEW-UHFFFAOYSA-N Glycerophosphorylethanolamin Natural products NCCOP(O)(=O)OCC(O)CO JZNWSCPGTDBMEW-UHFFFAOYSA-N 0.000 description 1
- ZWZWYGMENQVNFU-UHFFFAOYSA-N Glycerophosphorylserin Natural products OC(=O)C(N)COP(O)(=O)OCC(O)CO ZWZWYGMENQVNFU-UHFFFAOYSA-N 0.000 description 1
- 229930186217 Glycolipid Natural products 0.000 description 1
- 108010008488 Glycylglycine Proteins 0.000 description 1
- 229920002907 Guar gum Polymers 0.000 description 1
- 208000002250 Hematologic Neoplasms Diseases 0.000 description 1
- 208000032843 Hemorrhage Diseases 0.000 description 1
- 101710182312 High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 description 1
- 208000017662 Hodgkin disease lymphocyte depletion type stage unspecified Diseases 0.000 description 1
- 208000021519 Hodgkin lymphoma Diseases 0.000 description 1
- 208000010747 Hodgkins lymphoma Diseases 0.000 description 1
- 241001272567 Hominoidea Species 0.000 description 1
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 1
- 101001033312 Homo sapiens Interleukin-4 receptor subunit alpha Proteins 0.000 description 1
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 1
- 101100369992 Homo sapiens TNFSF10 gene Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 241001135569 Human adenovirus 5 Species 0.000 description 1
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 1
- 229920000663 Hydroxyethyl cellulose Polymers 0.000 description 1
- 239000004354 Hydroxyethyl cellulose Substances 0.000 description 1
- 206010021042 Hypopharyngeal cancer Diseases 0.000 description 1
- 206010056305 Hypopharyngeal neoplasm Diseases 0.000 description 1
- 108010042653 IgA receptor Proteins 0.000 description 1
- 108010073816 IgE Receptors Proteins 0.000 description 1
- 102000009438 IgE Receptors Human genes 0.000 description 1
- 108010073807 IgG Receptors Proteins 0.000 description 1
- 206010053574 Immunoblastic lymphoma Diseases 0.000 description 1
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 1
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 1
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 1
- 238000012404 In vitro experiment Methods 0.000 description 1
- 208000005726 Inflammatory Breast Neoplasms Diseases 0.000 description 1
- 206010021980 Inflammatory carcinoma of the breast Diseases 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- 102000004559 Interleukin-13 Receptors Human genes 0.000 description 1
- 108010017511 Interleukin-13 Receptors Proteins 0.000 description 1
- 102100039078 Interleukin-4 receptor subunit alpha Human genes 0.000 description 1
- 108090001005 Interleukin-6 Proteins 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 238000010824 Kaplan-Meier survival analysis Methods 0.000 description 1
- ZQISRDCJNBUVMM-UHFFFAOYSA-N L-Histidinol Natural products OCC(N)CC1=CN=CN1 ZQISRDCJNBUVMM-UHFFFAOYSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- 229930182816 L-glutamine Natural products 0.000 description 1
- ZQISRDCJNBUVMM-YFKPBYRVSA-N L-histidinol Chemical compound OC[C@@H](N)CC1=CNC=N1 ZQISRDCJNBUVMM-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- 241000283953 Lagomorpha Species 0.000 description 1
- 208000031671 Large B-Cell Diffuse Lymphoma Diseases 0.000 description 1
- 206010023825 Laryngeal cancer Diseases 0.000 description 1
- 241000288903 Lemuridae Species 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 206010024305 Leukaemia monocytic Diseases 0.000 description 1
- 206010061523 Lip and/or oral cavity cancer Diseases 0.000 description 1
- 239000012097 Lipofectamine 2000 Substances 0.000 description 1
- 102100029204 Low affinity immunoglobulin gamma Fc region receptor II-a Human genes 0.000 description 1
- 102100029205 Low affinity immunoglobulin gamma Fc region receptor II-b Human genes 0.000 description 1
- 102100029193 Low affinity immunoglobulin gamma Fc region receptor III-A Human genes 0.000 description 1
- 101710099301 Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 1
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 1
- 208000007433 Lymphatic Metastasis Diseases 0.000 description 1
- 206010025312 Lymphoma AIDS related Diseases 0.000 description 1
- 239000007993 MOPS buffer Substances 0.000 description 1
- 206010026673 Malignant Pleural Effusion Diseases 0.000 description 1
- 208000030070 Malignant epithelial tumor of ovary Diseases 0.000 description 1
- 206010025557 Malignant fibrous histiocytoma of bone Diseases 0.000 description 1
- 208000032271 Malignant tumor of penis Diseases 0.000 description 1
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 1
- WAEMQWOKJMHJLA-UHFFFAOYSA-N Manganese(2+) Chemical compound [Mn+2] WAEMQWOKJMHJLA-UHFFFAOYSA-N 0.000 description 1
- 229920000057 Mannan Polymers 0.000 description 1
- 208000009018 Medullary thyroid cancer Diseases 0.000 description 1
- 208000037196 Medullary thyroid carcinoma Diseases 0.000 description 1
- 208000015021 Meningeal Neoplasms Diseases 0.000 description 1
- 206010027406 Mesothelioma Diseases 0.000 description 1
- 206010027452 Metastases to bone Diseases 0.000 description 1
- CERQOIWHTDAKMF-UHFFFAOYSA-M Methacrylate Chemical compound CC(=C)C([O-])=O CERQOIWHTDAKMF-UHFFFAOYSA-M 0.000 description 1
- 229920003091 Methocel™ Polymers 0.000 description 1
- 229920000168 Microcrystalline cellulose Polymers 0.000 description 1
- 101710159910 Movement protein Proteins 0.000 description 1
- 206010057269 Mucoepidermoid carcinoma Diseases 0.000 description 1
- 201000003793 Myelodysplastic syndrome Diseases 0.000 description 1
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 1
- 201000007224 Myeloproliferative neoplasm Diseases 0.000 description 1
- SGSSKEDGVONRGC-UHFFFAOYSA-N N(2)-methylguanine Chemical compound O=C1NC(NC)=NC2=C1N=CN2 SGSSKEDGVONRGC-UHFFFAOYSA-N 0.000 description 1
- GXCLVBGFBYZDAG-UHFFFAOYSA-N N-[2-(1H-indol-3-yl)ethyl]-N-methylprop-2-en-1-amine Chemical compound CN(CCC1=CNC2=C1C=CC=C2)CC=C GXCLVBGFBYZDAG-UHFFFAOYSA-N 0.000 description 1
- CRJGESKKUOMBCT-VQTJNVASSA-N N-acetylsphinganine Chemical compound CCCCCCCCCCCCCCC[C@@H](O)[C@H](CO)NC(C)=O CRJGESKKUOMBCT-VQTJNVASSA-N 0.000 description 1
- JOCBASBOOFNAJA-UHFFFAOYSA-N N-tris(hydroxymethyl)methyl-2-aminoethanesulfonic acid Chemical compound OCC(CO)(CO)NCCS(O)(=O)=O JOCBASBOOFNAJA-UHFFFAOYSA-N 0.000 description 1
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 1
- 206010028767 Nasal sinus cancer Diseases 0.000 description 1
- 208000002454 Nasopharyngeal Carcinoma Diseases 0.000 description 1
- 208000001894 Nasopharyngeal Neoplasms Diseases 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 208000034179 Neoplasms, Glandular and Epithelial Diseases 0.000 description 1
- 102000008730 Nestin Human genes 0.000 description 1
- 108010088225 Nestin Proteins 0.000 description 1
- 206010029260 Neuroblastoma Diseases 0.000 description 1
- 208000009277 Neuroectodermal Tumors Diseases 0.000 description 1
- 206010029266 Neuroendocrine carcinoma of the skin Diseases 0.000 description 1
- VEQPNABPJHWNSG-UHFFFAOYSA-N Nickel(2+) Chemical compound [Ni+2] VEQPNABPJHWNSG-UHFFFAOYSA-N 0.000 description 1
- 102000004459 Nitroreductase Human genes 0.000 description 1
- 206010061534 Oesophageal squamous cell carcinoma Diseases 0.000 description 1
- 239000005642 Oleic acid Substances 0.000 description 1
- ZQPPMHVWECSIRJ-UHFFFAOYSA-N Oleic acid Natural products CCCCCCCCC=CCCCCCCCC(O)=O ZQPPMHVWECSIRJ-UHFFFAOYSA-N 0.000 description 1
- 201000010133 Oligodendroglioma Diseases 0.000 description 1
- 206010031096 Oropharyngeal cancer Diseases 0.000 description 1
- 206010057444 Oropharyngeal neoplasm Diseases 0.000 description 1
- 206010061328 Ovarian epithelial cancer Diseases 0.000 description 1
- 239000007990 PIPES buffer Substances 0.000 description 1
- 239000002033 PVDF binder Substances 0.000 description 1
- 239000005662 Paraffin oil Substances 0.000 description 1
- 208000003937 Paranasal Sinus Neoplasms Diseases 0.000 description 1
- 208000000821 Parathyroid Neoplasms Diseases 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 229930182555 Penicillin Natural products 0.000 description 1
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 1
- 208000002471 Penile Neoplasms Diseases 0.000 description 1
- 206010034299 Penile cancer Diseases 0.000 description 1
- 240000008154 Piper betle Species 0.000 description 1
- 235000008180 Piper betle Nutrition 0.000 description 1
- IDDMFNIRSJVBHE-UHFFFAOYSA-N Piscigenin Natural products COC1=C(O)C(OC)=CC(C=2C(C3=C(O)C=C(O)C=C3OC=2)=O)=C1 IDDMFNIRSJVBHE-UHFFFAOYSA-N 0.000 description 1
- 208000007913 Pituitary Neoplasms Diseases 0.000 description 1
- 206010035148 Plague Diseases 0.000 description 1
- 241000288935 Platyrrhini Species 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 229920002845 Poly(methacrylic acid) Polymers 0.000 description 1
- 229920001283 Polyalkylene terephthalate Polymers 0.000 description 1
- 239000004952 Polyamide Substances 0.000 description 1
- 239000004698 Polyethylene Substances 0.000 description 1
- 229920002535 Polyethylene Glycol 1500 Polymers 0.000 description 1
- 229920000954 Polyglycolide Polymers 0.000 description 1
- 239000004721 Polyphenylene oxide Substances 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 208000037062 Polyps Diseases 0.000 description 1
- 206010065857 Primary Effusion Lymphoma Diseases 0.000 description 1
- 101710101148 Probable 6-oxopurine nucleoside phosphorylase Proteins 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- GOOHAUXETOMSMM-UHFFFAOYSA-N Propylene oxide Chemical compound CC1CO1 GOOHAUXETOMSMM-UHFFFAOYSA-N 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 108700033844 Pseudomonas aeruginosa toxA Proteins 0.000 description 1
- 102000030764 Purine-nucleoside phosphorylase Human genes 0.000 description 1
- 108091008103 RNA aptamers Proteins 0.000 description 1
- 238000011529 RT qPCR Methods 0.000 description 1
- MUPFEKGTMRGPLJ-RMMQSMQOSA-N Raffinose Natural products O(C[C@H]1[C@@H](O)[C@H](O)[C@@H](O)[C@@H](O[C@@]2(CO)[C@H](O)[C@@H](O)[C@@H](CO)O2)O1)[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 MUPFEKGTMRGPLJ-RMMQSMQOSA-N 0.000 description 1
- 101100425901 Rattus norvegicus Tpm1 gene Proteins 0.000 description 1
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 1
- 206010038389 Renal cancer Diseases 0.000 description 1
- 201000000582 Retinoblastoma Diseases 0.000 description 1
- 241001092459 Rubus Species 0.000 description 1
- 208000004337 Salivary Gland Neoplasms Diseases 0.000 description 1
- 206010061934 Salivary gland cancer Diseases 0.000 description 1
- 206010039605 Schistosomiasis bladder Diseases 0.000 description 1
- 201000001542 Schneiderian carcinoma Diseases 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 1
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 1
- 208000009574 Skin Appendage Carcinoma Diseases 0.000 description 1
- PMZURENOXWZQFD-UHFFFAOYSA-L Sodium Sulfate Chemical compound [Na+].[Na+].[O-]S([O-])(=O)=O PMZURENOXWZQFD-UHFFFAOYSA-L 0.000 description 1
- 208000000277 Splenic Neoplasms Diseases 0.000 description 1
- 208000000102 Squamous Cell Carcinoma of Head and Neck Diseases 0.000 description 1
- 208000036765 Squamous cell carcinoma of the esophagus Diseases 0.000 description 1
- UQZIYBXSHAGNOE-USOSMYMVSA-N Stachyose Natural products O(C[C@H]1[C@@H](O)[C@H](O)[C@H](O)[C@@H](O[C@@]2(CO)[C@H](O)[C@@H](O)[C@@H](CO)O2)O1)[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@H](CO[C@@H]2[C@@H](O)[C@@H](O)[C@@H](O)[C@H](CO)O2)O1 UQZIYBXSHAGNOE-USOSMYMVSA-N 0.000 description 1
- 208000005718 Stomach Neoplasms Diseases 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 241001493546 Suina Species 0.000 description 1
- 229920001963 Synthetic biodegradable polymer Polymers 0.000 description 1
- 108010092262 T-Cell Antigen Receptors Proteins 0.000 description 1
- 239000007994 TES buffer Substances 0.000 description 1
- 229910052771 Terbium Inorganic materials 0.000 description 1
- 108020005038 Terminator Codon Proteins 0.000 description 1
- 208000024313 Testicular Neoplasms Diseases 0.000 description 1
- 206010057644 Testis cancer Diseases 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- 210000000447 Th1 cell Anatomy 0.000 description 1
- 210000004241 Th2 cell Anatomy 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical group OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 229920001615 Tragacanth Polymers 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- GSEJCLTVZPLZKY-UHFFFAOYSA-N Triethanolamine Chemical compound OCCN(CCO)CCO GSEJCLTVZPLZKY-UHFFFAOYSA-N 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 208000034953 Twin anemia-polycythemia sequence Diseases 0.000 description 1
- MUPFEKGTMRGPLJ-UHFFFAOYSA-N UNPD196149 Natural products OC1C(O)C(CO)OC1(CO)OC1C(O)C(O)C(O)C(COC2C(C(O)C(O)C(CO)O2)O)O1 MUPFEKGTMRGPLJ-UHFFFAOYSA-N 0.000 description 1
- 208000015778 Undifferentiated pleomorphic sarcoma Diseases 0.000 description 1
- 208000023915 Ureteral Neoplasms Diseases 0.000 description 1
- 206010046392 Ureteric cancer Diseases 0.000 description 1
- 208000002495 Uterine Neoplasms Diseases 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- XTXRWKRVRITETP-UHFFFAOYSA-N Vinyl acetate Chemical compound CC(=O)OC=C XTXRWKRVRITETP-UHFFFAOYSA-N 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- 206010047741 Vulval cancer Diseases 0.000 description 1
- 208000004354 Vulvar Neoplasms Diseases 0.000 description 1
- 208000033559 Waldenström macroglobulinemia Diseases 0.000 description 1
- 208000008383 Wilms tumor Diseases 0.000 description 1
- 241000607479 Yersinia pestis Species 0.000 description 1
- 229910052769 Ytterbium Inorganic materials 0.000 description 1
- VWQVUPCCIRVNHF-OUBTZVSYSA-N Yttrium-90 Chemical compound [90Y] VWQVUPCCIRVNHF-OUBTZVSYSA-N 0.000 description 1
- QCWXUUIWCKQGHC-UHFFFAOYSA-N Zirconium Chemical compound [Zr] QCWXUUIWCKQGHC-UHFFFAOYSA-N 0.000 description 1
- NNLVGZFZQQXQNW-ADJNRHBOSA-N [(2r,3r,4s,5r,6s)-4,5-diacetyloxy-3-[(2s,3r,4s,5r,6r)-3,4,5-triacetyloxy-6-(acetyloxymethyl)oxan-2-yl]oxy-6-[(2r,3r,4s,5r,6s)-4,5,6-triacetyloxy-2-(acetyloxymethyl)oxan-3-yl]oxyoxan-2-yl]methyl acetate Chemical compound O([C@@H]1O[C@@H]([C@H]([C@H](OC(C)=O)[C@H]1OC(C)=O)O[C@H]1[C@@H]([C@@H](OC(C)=O)[C@H](OC(C)=O)[C@@H](COC(C)=O)O1)OC(C)=O)COC(=O)C)[C@@H]1[C@@H](COC(C)=O)O[C@@H](OC(C)=O)[C@H](OC(C)=O)[C@H]1OC(C)=O NNLVGZFZQQXQNW-ADJNRHBOSA-N 0.000 description 1
- IZGWICDVZSUMBA-UHFFFAOYSA-N [Pt].C(C(=O)C)(=O)O Chemical compound [Pt].C(C(=O)C)(=O)O IZGWICDVZSUMBA-UHFFFAOYSA-N 0.000 description 1
- 238000002835 absorbance Methods 0.000 description 1
- 239000006096 absorbing agent Substances 0.000 description 1
- 239000003070 absorption delaying agent Substances 0.000 description 1
- 206010059394 acanthoma Diseases 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 206010000496 acne Diseases 0.000 description 1
- 125000000641 acridinyl group Chemical group C1(=CC=CC2=NC3=CC=CC=C3C=C12)* 0.000 description 1
- 150000001252 acrylic acid derivatives Chemical class 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 230000001154 acute effect Effects 0.000 description 1
- 208000036676 acute undifferentiated leukemia Diseases 0.000 description 1
- 238000005917 acylation reaction Methods 0.000 description 1
- 230000000996 additive effect Effects 0.000 description 1
- 201000000452 adenoid squamous cell carcinoma Diseases 0.000 description 1
- 201000008395 adenosquamous carcinoma Diseases 0.000 description 1
- 208000024447 adrenal gland neoplasm Diseases 0.000 description 1
- 239000003463 adsorbent Substances 0.000 description 1
- 210000002945 adventitial reticular cell Anatomy 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 238000012867 alanine scanning Methods 0.000 description 1
- 239000000783 alginic acid Substances 0.000 description 1
- 229960001126 alginic acid Drugs 0.000 description 1
- 150000004781 alginic acids Chemical class 0.000 description 1
- 230000003113 alkalizing effect Effects 0.000 description 1
- 125000002947 alkylene group Chemical group 0.000 description 1
- 230000000172 allergic effect Effects 0.000 description 1
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 208000008524 alveolar soft part sarcoma Diseases 0.000 description 1
- 230000001668 ameliorated effect Effects 0.000 description 1
- 230000002707 ameloblastic effect Effects 0.000 description 1
- 229960003896 aminopterin Drugs 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 239000003708 ampul Substances 0.000 description 1
- 235000019418 amylase Nutrition 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 230000003616 anti-epidemic effect Effects 0.000 description 1
- 230000000845 anti-microbial effect Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 230000000840 anti-viral effect Effects 0.000 description 1
- 239000003146 anticoagulant agent Substances 0.000 description 1
- 229940127219 anticoagulant drug Drugs 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 201000007436 apocrine adenocarcinoma Diseases 0.000 description 1
- 210000003567 ascitic fluid Anatomy 0.000 description 1
- 229960005070 ascorbic acid Drugs 0.000 description 1
- 235000010323 ascorbic acid Nutrition 0.000 description 1
- 239000011668 ascorbic acid Substances 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 230000003140 astrocytic effect Effects 0.000 description 1
- 208000010668 atopic eczema Diseases 0.000 description 1
- 229940120638 avastin Drugs 0.000 description 1
- 208000005266 avian sarcoma Diseases 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 208000003373 basosquamous carcinoma Diseases 0.000 description 1
- DZBUGLKDJFMEHC-UHFFFAOYSA-N benzoquinolinylidene Chemical group C1=CC=CC2=CC3=CC=CC=C3N=C21 DZBUGLKDJFMEHC-UHFFFAOYSA-N 0.000 description 1
- 235000019445 benzyl alcohol Nutrition 0.000 description 1
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QUYVBRFLSA-N beta-maltose Chemical compound OC[C@H]1O[C@H](O[C@H]2[C@H](O)[C@@H](O)[C@H](O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@@H]1O GUBGYTABKSRVRQ-QUYVBRFLSA-N 0.000 description 1
- 229960000397 bevacizumab Drugs 0.000 description 1
- 239000000227 bioadhesive Substances 0.000 description 1
- 238000004166 bioassay Methods 0.000 description 1
- 239000003139 biocide Substances 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 229960000074 biopharmaceutical Drugs 0.000 description 1
- 229920001222 biopolymer Polymers 0.000 description 1
- 238000001574 biopsy Methods 0.000 description 1
- 229910052797 bismuth Inorganic materials 0.000 description 1
- JCXGWMGPZLAOME-UHFFFAOYSA-N bismuth atom Chemical compound [Bi] JCXGWMGPZLAOME-UHFFFAOYSA-N 0.000 description 1
- 229930189065 blasticidin Natural products 0.000 description 1
- 201000000053 blastoma Diseases 0.000 description 1
- 230000000740 bleeding effect Effects 0.000 description 1
- 229920001400 block copolymer Polymers 0.000 description 1
- 201000006491 bone marrow cancer Diseases 0.000 description 1
- 201000008873 bone osteosarcoma Diseases 0.000 description 1
- 201000009480 botryoid rhabdomyosarcoma Diseases 0.000 description 1
- 210000004958 brain cell Anatomy 0.000 description 1
- 210000000133 brain stem Anatomy 0.000 description 1
- 210000005013 brain tissue Anatomy 0.000 description 1
- 201000005389 breast carcinoma in situ Diseases 0.000 description 1
- 208000030270 breast disease Diseases 0.000 description 1
- 201000002143 bronchus adenoma Diseases 0.000 description 1
- 230000003139 buffering effect Effects 0.000 description 1
- DQXBYHZEEUGOBF-UHFFFAOYSA-N but-3-enoic acid;ethene Chemical compound C=C.OC(=O)CC=C DQXBYHZEEUGOBF-UHFFFAOYSA-N 0.000 description 1
- 230000000981 bystander Effects 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- CJZGTCYPCWQAJB-UHFFFAOYSA-L calcium stearate Chemical compound [Ca+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O CJZGTCYPCWQAJB-UHFFFAOYSA-L 0.000 description 1
- 235000013539 calcium stearate Nutrition 0.000 description 1
- 239000008116 calcium stearate Substances 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 230000005880 cancer cell killing Effects 0.000 description 1
- 229920003064 carboxyethyl cellulose Polymers 0.000 description 1
- 229940096529 carboxypolymethylene Drugs 0.000 description 1
- 208000022033 carcinoma of urethra Diseases 0.000 description 1
- 239000005018 casein Substances 0.000 description 1
- BECPQYXYKAMYBN-UHFFFAOYSA-N casein, tech. Chemical compound NCCCCC(C(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(CC(C)C)N=C(O)C(CCC(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(C(C)O)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(COP(O)(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(N)CC1=CC=CC=C1 BECPQYXYKAMYBN-UHFFFAOYSA-N 0.000 description 1
- 235000021240 caseins Nutrition 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 230000020411 cell activation Effects 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 230000007910 cell fusion Effects 0.000 description 1
- 230000004709 cell invasion Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 229920006217 cellulose acetate butyrate Polymers 0.000 description 1
- 229940081734 cellulose acetate phthalate Drugs 0.000 description 1
- 229920006218 cellulose propionate Polymers 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 229940106189 ceramide Drugs 0.000 description 1
- ZVEQCJWYRWKARO-UHFFFAOYSA-N ceramide Natural products CCCCCCCCCCCCCCC(O)C(=O)NC(CO)C(O)C=CCCC=C(C)CCCCCCCCC ZVEQCJWYRWKARO-UHFFFAOYSA-N 0.000 description 1
- 210000001638 cerebellum Anatomy 0.000 description 1
- 229960005395 cetuximab Drugs 0.000 description 1
- 229960000541 cetyl alcohol Drugs 0.000 description 1
- 125000003636 chemical group Chemical group 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- 239000003638 chemical reducing agent Substances 0.000 description 1
- 208000012191 childhood neoplasm Diseases 0.000 description 1
- 239000000460 chlorine Substances 0.000 description 1
- 229910052801 chlorine Inorganic materials 0.000 description 1
- 229960004926 chlorobutanol Drugs 0.000 description 1
- BFGKITSFLPAWGI-UHFFFAOYSA-N chromium(3+) Chemical compound [Cr+3] BFGKITSFLPAWGI-UHFFFAOYSA-N 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 208000009060 clear cell adenocarcinoma Diseases 0.000 description 1
- 208000030748 clear cell sarcoma of kidney Diseases 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 238000003501 co-culture Methods 0.000 description 1
- 229910017052 cobalt Inorganic materials 0.000 description 1
- 239000010941 cobalt Substances 0.000 description 1
- XLJKHNWPARRRJB-UHFFFAOYSA-N cobalt(2+) Chemical compound [Co+2] XLJKHNWPARRRJB-UHFFFAOYSA-N 0.000 description 1
- 229920001436 collagen Polymers 0.000 description 1
- 229940075614 colloidal silicon dioxide Drugs 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 230000006957 competitive inhibition Effects 0.000 description 1
- 230000024203 complement activation Effects 0.000 description 1
- 230000009918 complex formation Effects 0.000 description 1
- 238000005094 computer simulation Methods 0.000 description 1
- 238000009833 condensation Methods 0.000 description 1
- 230000005494 condensation Effects 0.000 description 1
- 210000002808 connective tissue Anatomy 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 239000002872 contrast media Substances 0.000 description 1
- 235000005687 corn oil Nutrition 0.000 description 1
- 239000002285 corn oil Substances 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 230000000875 corresponding effect Effects 0.000 description 1
- 230000001054 cortical effect Effects 0.000 description 1
- IDLFZVILOHSSID-OVLDLUHVSA-N corticotropin Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)NC(=O)[C@@H](N)CO)C1=CC=C(O)C=C1 IDLFZVILOHSSID-OVLDLUHVSA-N 0.000 description 1
- 229960000258 corticotropin Drugs 0.000 description 1
- 230000000139 costimulatory effect Effects 0.000 description 1
- 235000012343 cottonseed oil Nutrition 0.000 description 1
- 239000002385 cottonseed oil Substances 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 239000006071 cream Substances 0.000 description 1
- 229960001681 croscarmellose sodium Drugs 0.000 description 1
- 238000004132 cross linking Methods 0.000 description 1
- 235000010947 crosslinked sodium carboxy methyl cellulose Nutrition 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 208000030381 cutaneous melanoma Diseases 0.000 description 1
- CCQPAEQGAVNNIA-UHFFFAOYSA-N cyclobutane-1,1-dicarboxylic acid Chemical compound OC(=O)C1(C(O)=O)CCC1 CCQPAEQGAVNNIA-UHFFFAOYSA-N 0.000 description 1
- SSJXIUAHEKJCMH-UHFFFAOYSA-N cyclohexane-1,2-diamine Chemical compound NC1CCCCC1N SSJXIUAHEKJCMH-UHFFFAOYSA-N 0.000 description 1
- OGAPHRMCCQCJOE-UHFFFAOYSA-N cyclohexane-1,2-diamine;oxalic acid;platinum Chemical compound [Pt].OC(=O)C(O)=O.NC1CCCCC1N OGAPHRMCCQCJOE-UHFFFAOYSA-N 0.000 description 1
- POQBJIOLWPDPJE-UHFFFAOYSA-N cyclohexane-1,2-diamine;platinum Chemical compound [Pt].NC1CCCCC1N POQBJIOLWPDPJE-UHFFFAOYSA-N 0.000 description 1
- HMXSKRJTCBMSQD-UHFFFAOYSA-L cyclohexane-1,2-diamine;platinum(2+);sulfate;hydrate Chemical compound O.[Pt+2].[O-]S([O-])(=O)=O.NC1CCCCC1N HMXSKRJTCBMSQD-UHFFFAOYSA-L 0.000 description 1
- 150000001945 cysteines Chemical class 0.000 description 1
- 201000011129 cystic basal cell carcinoma Diseases 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 238000002784 cytotoxicity assay Methods 0.000 description 1
- 231100000263 cytotoxicity test Toxicity 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 230000003412 degenerative effect Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 238000004925 denaturation Methods 0.000 description 1
- 230000036425 denaturation Effects 0.000 description 1
- 239000002274 desiccant Substances 0.000 description 1
- 239000000645 desinfectant Substances 0.000 description 1
- 230000001066 destructive effect Effects 0.000 description 1
- 235000019425 dextrin Nutrition 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 238000002059 diagnostic imaging Methods 0.000 description 1
- PXBRQCKWGAHEHS-UHFFFAOYSA-N dichlorodifluoromethane Chemical compound FC(F)(Cl)Cl PXBRQCKWGAHEHS-UHFFFAOYSA-N 0.000 description 1
- 235000019404 dichlorodifluoromethane Nutrition 0.000 description 1
- 235000005911 diet Nutrition 0.000 description 1
- 230000037213 diet Effects 0.000 description 1
- 238000002050 diffraction method Methods 0.000 description 1
- KCFYHBSOLOXZIF-UHFFFAOYSA-N dihydrochrysin Natural products COC1=C(O)C(OC)=CC(C2OC3=CC(O)=CC(O)=C3C(=O)C2)=C1 KCFYHBSOLOXZIF-UHFFFAOYSA-N 0.000 description 1
- 239000007884 disintegrant Substances 0.000 description 1
- KAKKHKRHCKCAGH-UHFFFAOYSA-L disodium;(4-nitrophenyl) phosphate;hexahydrate Chemical compound O.O.O.O.O.O.[Na+].[Na+].[O-][N+](=O)C1=CC=C(OP([O-])([O-])=O)C=C1 KAKKHKRHCKCAGH-UHFFFAOYSA-L 0.000 description 1
- 239000002270 dispersing agent Substances 0.000 description 1
- 238000004090 dissolution Methods 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 230000007783 downstream signaling Effects 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 208000028715 ductal breast carcinoma in situ Diseases 0.000 description 1
- KBQHZAAAGSGFKK-UHFFFAOYSA-N dysprosium atom Chemical compound [Dy] KBQHZAAAGSGFKK-UHFFFAOYSA-N 0.000 description 1
- 201000008184 embryoma Diseases 0.000 description 1
- 239000003974 emollient agent Substances 0.000 description 1
- 230000002124 endocrine Effects 0.000 description 1
- 208000028730 endometrioid adenocarcinoma Diseases 0.000 description 1
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 230000003511 endothelial effect Effects 0.000 description 1
- 230000007071 enzymatic hydrolysis Effects 0.000 description 1
- 238000006047 enzymatic hydrolysis reaction Methods 0.000 description 1
- YQGOJNYOYNNSMM-UHFFFAOYSA-N eosin Chemical compound [Na+].OC(=O)C1=CC=CC=C1C1=C2C=C(Br)C(=O)C(Br)=C2OC2=C(Br)C(O)=C(Br)C=C21 YQGOJNYOYNNSMM-UHFFFAOYSA-N 0.000 description 1
- 210000002615 epidermis Anatomy 0.000 description 1
- 208000010932 epithelial neoplasm Diseases 0.000 description 1
- 210000000981 epithelium Anatomy 0.000 description 1
- UYAHIZSMUZPPFV-UHFFFAOYSA-N erbium Chemical compound [Er] UYAHIZSMUZPPFV-UHFFFAOYSA-N 0.000 description 1
- 230000003628 erosive effect Effects 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 208000007276 esophageal squamous cell carcinoma Diseases 0.000 description 1
- 125000004185 ester group Chemical group 0.000 description 1
- JXDQXTJOVCSFJY-UHFFFAOYSA-L ethane-1,2-diamine;platinum(2+);propanedioate Chemical compound [Pt+2].NCCN.[O-]C(=O)CC([O-])=O JXDQXTJOVCSFJY-UHFFFAOYSA-L 0.000 description 1
- BEFDCLMNVWHSGT-UHFFFAOYSA-N ethenylcyclopentane Chemical compound C=CC1CCCC1 BEFDCLMNVWHSGT-UHFFFAOYSA-N 0.000 description 1
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 1
- 229940093471 ethyl oleate Drugs 0.000 description 1
- 239000005038 ethylene vinyl acetate Substances 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 238000013265 extended release Methods 0.000 description 1
- 208000024519 eye neoplasm Diseases 0.000 description 1
- 235000019197 fats Nutrition 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 230000004761 fibrosis Effects 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 235000019634 flavors Nutrition 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- 230000003325 follicular Effects 0.000 description 1
- 235000013355 food flavoring agent Nutrition 0.000 description 1
- 235000019264 food flavour enhancer Nutrition 0.000 description 1
- 235000003599 food sweetener Nutrition 0.000 description 1
- 238000004108 freeze drying Methods 0.000 description 1
- 239000012737 fresh medium Substances 0.000 description 1
- UIWYJDYFSGRHKR-UHFFFAOYSA-N gadolinium atom Chemical compound [Gd] UIWYJDYFSGRHKR-UHFFFAOYSA-N 0.000 description 1
- 229930182830 galactose Natural products 0.000 description 1
- 229910052733 gallium Inorganic materials 0.000 description 1
- 206010017758 gastric cancer Diseases 0.000 description 1
- 201000011243 gastrointestinal stromal tumor Diseases 0.000 description 1
- 239000003349 gelling agent Substances 0.000 description 1
- OKKDEIYWILRZIA-OSZBKLCCSA-N gemcitabine hydrochloride Chemical group [H+].[Cl-].O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 OKKDEIYWILRZIA-OSZBKLCCSA-N 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 230000005017 genetic modification Effects 0.000 description 1
- 235000013617 genetically modified food Nutrition 0.000 description 1
- 210000004392 genitalia Anatomy 0.000 description 1
- 210000004907 gland Anatomy 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- 125000005456 glyceride group Chemical group 0.000 description 1
- 150000002313 glycerolipids Chemical class 0.000 description 1
- 150000002327 glycerophospholipids Chemical class 0.000 description 1
- YMAWOPBAYDPSLA-UHFFFAOYSA-N glycylglycine Chemical compound [NH3+]CC(=O)NCC([O-])=O YMAWOPBAYDPSLA-UHFFFAOYSA-N 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 229910052737 gold Inorganic materials 0.000 description 1
- 239000010931 gold Substances 0.000 description 1
- CBMIPXHVOVTTTL-UHFFFAOYSA-N gold(3+) Chemical compound [Au+3] CBMIPXHVOVTTTL-UHFFFAOYSA-N 0.000 description 1
- 239000008187 granular material Substances 0.000 description 1
- 239000003979 granulating agent Substances 0.000 description 1
- 210000003714 granulocyte Anatomy 0.000 description 1
- 238000000227 grinding Methods 0.000 description 1
- 235000010417 guar gum Nutrition 0.000 description 1
- 239000000665 guar gum Substances 0.000 description 1
- 229960002154 guar gum Drugs 0.000 description 1
- 229940093915 gynecological organic acid Drugs 0.000 description 1
- 230000003394 haemopoietic effect Effects 0.000 description 1
- 210000003128 head Anatomy 0.000 description 1
- 201000010536 head and neck cancer Diseases 0.000 description 1
- 201000000459 head and neck squamous cell carcinoma Diseases 0.000 description 1
- 229910001385 heavy metal Inorganic materials 0.000 description 1
- 210000002443 helper t lymphocyte Anatomy 0.000 description 1
- 201000002222 hemangioblastoma Diseases 0.000 description 1
- 201000005787 hematologic cancer Diseases 0.000 description 1
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 description 1
- 230000002008 hemorrhagic effect Effects 0.000 description 1
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 1
- 210000003494 hepatocyte Anatomy 0.000 description 1
- 229940022353 herceptin Drugs 0.000 description 1
- 208000029824 high grade glioma Diseases 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 230000001744 histochemical effect Effects 0.000 description 1
- SCKNFLZJSOHWIV-UHFFFAOYSA-N holmium(3+) Chemical compound [Ho+3] SCKNFLZJSOHWIV-UHFFFAOYSA-N 0.000 description 1
- 229920001519 homopolymer Polymers 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- 239000003906 humectant Substances 0.000 description 1
- 229920002674 hyaluronan Polymers 0.000 description 1
- 229960003160 hyaluronic acid Drugs 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- 150000004677 hydrates Chemical class 0.000 description 1
- 230000036571 hydration Effects 0.000 description 1
- 238000006703 hydration reaction Methods 0.000 description 1
- 229960000890 hydrocortisone Drugs 0.000 description 1
- 230000005660 hydrophilic surface Effects 0.000 description 1
- 229920001600 hydrophobic polymer Polymers 0.000 description 1
- 235000019447 hydroxyethyl cellulose Nutrition 0.000 description 1
- 230000033444 hydroxylation Effects 0.000 description 1
- 238000005805 hydroxylation reaction Methods 0.000 description 1
- UACSZOWTRIJIFU-UHFFFAOYSA-N hydroxymethyl 2-methylprop-2-enoate Chemical compound CC(=C)C(=O)OCO UACSZOWTRIJIFU-UHFFFAOYSA-N 0.000 description 1
- 230000002267 hypothalamic effect Effects 0.000 description 1
- 239000012729 immediate-release (IR) formulation Substances 0.000 description 1
- 230000002519 immonomodulatory effect Effects 0.000 description 1
- 210000002865 immune cell Anatomy 0.000 description 1
- 230000036737 immune function Effects 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 230000001024 immunotherapeutic effect Effects 0.000 description 1
- 239000007943 implant Substances 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- APFVFJFRJDLVQX-UHFFFAOYSA-N indium atom Chemical compound [In] APFVFJFRJDLVQX-UHFFFAOYSA-N 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 208000023986 infiltrating bladder urothelial carcinoma Diseases 0.000 description 1
- 230000008595 infiltration Effects 0.000 description 1
- 238000001764 infiltration Methods 0.000 description 1
- 201000004653 inflammatory breast carcinoma Diseases 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 229910052500 inorganic mineral Inorganic materials 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 108010052754 interleukin-14 receptor Proteins 0.000 description 1
- 230000004073 interleukin-2 production Effects 0.000 description 1
- 201000002313 intestinal cancer Diseases 0.000 description 1
- 239000007926 intracavernous injection Substances 0.000 description 1
- 238000000185 intracerebroventricular administration Methods 0.000 description 1
- 208000014899 intrahepatic bile duct cancer Diseases 0.000 description 1
- 201000008893 intraocular retinoblastoma Diseases 0.000 description 1
- 230000009545 invasion Effects 0.000 description 1
- 201000003325 invasive bladder transitional cell carcinoma Diseases 0.000 description 1
- 238000011835 investigation Methods 0.000 description 1
- 229950010897 iproplatin Drugs 0.000 description 1
- 230000007794 irritation Effects 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- QXJSBBXBKPUZAA-UHFFFAOYSA-N isooleic acid Natural products CCCCCCCC=CCCCCCCCCC(O)=O QXJSBBXBKPUZAA-UHFFFAOYSA-N 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 230000000366 juvenile effect Effects 0.000 description 1
- 210000002510 keratinocyte Anatomy 0.000 description 1
- 229960004184 ketamine hydrochloride Drugs 0.000 description 1
- 108010045069 keyhole-limpet hemocyanin Proteins 0.000 description 1
- 201000010982 kidney cancer Diseases 0.000 description 1
- 201000007211 kidney clear cell sarcoma Diseases 0.000 description 1
- 210000000244 kidney pelvis Anatomy 0.000 description 1
- 230000002147 killing effect Effects 0.000 description 1
- 238000012933 kinetic analysis Methods 0.000 description 1
- CZMAIROVPAYCMU-UHFFFAOYSA-N lanthanum(3+) Chemical compound [La+3] CZMAIROVPAYCMU-UHFFFAOYSA-N 0.000 description 1
- 206010023841 laryngeal neoplasm Diseases 0.000 description 1
- 235000010445 lecithin Nutrition 0.000 description 1
- 239000000787 lecithin Substances 0.000 description 1
- 229940067606 lecithin Drugs 0.000 description 1
- 230000000610 leukopenic effect Effects 0.000 description 1
- 150000002617 leukotrienes Chemical class 0.000 description 1
- 201000006721 lip cancer Diseases 0.000 description 1
- 206010024627 liposarcoma Diseases 0.000 description 1
- 239000012669 liquid formulation Substances 0.000 description 1
- 239000006193 liquid solution Substances 0.000 description 1
- 201000011059 lobular neoplasia Diseases 0.000 description 1
- 201000005202 lung cancer Diseases 0.000 description 1
- 208000026807 lung carcinoid tumor Diseases 0.000 description 1
- 208000020816 lung neoplasm Diseases 0.000 description 1
- 201000000966 lung oat cell carcinoma Diseases 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 201000010453 lymph node cancer Diseases 0.000 description 1
- 208000012804 lymphangiosarcoma Diseases 0.000 description 1
- 210000004324 lymphatic system Anatomy 0.000 description 1
- 201000011649 lymphoblastic lymphoma Diseases 0.000 description 1
- 230000000527 lymphocytic effect Effects 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 230000005291 magnetic effect Effects 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- FPYJFEHAWHCUMM-UHFFFAOYSA-N maleic anhydride Chemical compound O=C1OC(=O)C=C1 FPYJFEHAWHCUMM-UHFFFAOYSA-N 0.000 description 1
- 230000003211 malignant effect Effects 0.000 description 1
- 201000011614 malignant glioma Diseases 0.000 description 1
- 208000020984 malignant renal pelvis neoplasm Diseases 0.000 description 1
- 208000028676 malignant spindle cell neoplasm Diseases 0.000 description 1
- 208000022006 malignant tumor of meninges Diseases 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 208000000516 mast-cell leukemia Diseases 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 210000003071 memory t lymphocyte Anatomy 0.000 description 1
- 150000002734 metacrylic acid derivatives Chemical class 0.000 description 1
- 208000037819 metastatic cancer Diseases 0.000 description 1
- 208000011575 metastatic malignant neoplasm Diseases 0.000 description 1
- 208000037970 metastatic squamous neck cancer Diseases 0.000 description 1
- 229920003145 methacrylic acid copolymer Polymers 0.000 description 1
- 229940117841 methacrylic acid copolymer Drugs 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- XMYQHJDBLRZMLW-UHFFFAOYSA-N methanolamine Chemical compound NCO XMYQHJDBLRZMLW-UHFFFAOYSA-N 0.000 description 1
- 229940087646 methanolamine Drugs 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 239000004530 micro-emulsion Substances 0.000 description 1
- 239000003094 microcapsule Substances 0.000 description 1
- 239000008108 microcrystalline cellulose Substances 0.000 description 1
- 235000019813 microcrystalline cellulose Nutrition 0.000 description 1
- 229940016286 microcrystalline cellulose Drugs 0.000 description 1
- 239000011859 microparticle Substances 0.000 description 1
- 238000007431 microscopic evaluation Methods 0.000 description 1
- 239000011707 mineral Substances 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 201000006894 monocytic leukemia Diseases 0.000 description 1
- 229940126619 mouse monoclonal antibody Drugs 0.000 description 1
- 201000010879 mucinous adenocarcinoma Diseases 0.000 description 1
- 230000003232 mucoadhesive effect Effects 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 210000000663 muscle cell Anatomy 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- XJVXMWNLQRTRGH-UHFFFAOYSA-N n-(3-methylbut-3-enyl)-2-methylsulfanyl-7h-purin-6-amine Chemical compound CSC1=NC(NCCC(C)=C)=C2NC=NC2=N1 XJVXMWNLQRTRGH-UHFFFAOYSA-N 0.000 description 1
- 239000002105 nanoparticle Substances 0.000 description 1
- 208000018795 nasal cavity and paranasal sinus carcinoma Diseases 0.000 description 1
- 201000011216 nasopharynx carcinoma Diseases 0.000 description 1
- 210000000581 natural killer T-cell Anatomy 0.000 description 1
- 239000006199 nebulizer Substances 0.000 description 1
- QEFYFXOXNSNQGX-UHFFFAOYSA-N neodymium atom Chemical compound [Nd] QEFYFXOXNSNQGX-UHFFFAOYSA-N 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 210000005170 neoplastic cell Anatomy 0.000 description 1
- 210000005055 nestin Anatomy 0.000 description 1
- 210000000276 neural tube Anatomy 0.000 description 1
- 210000004498 neuroglial cell Anatomy 0.000 description 1
- 230000003472 neutralizing effect Effects 0.000 description 1
- 210000000440 neutrophil Anatomy 0.000 description 1
- VVGIYYKRAMHVLU-UHFFFAOYSA-N newbouldiamide Natural products CCCCCCCCCCCCCCCCCCCC(O)C(O)C(O)C(CO)NC(=O)CCCCCCCCCCCCCCCCC VVGIYYKRAMHVLU-UHFFFAOYSA-N 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 108020001162 nitroreductase Proteins 0.000 description 1
- 201000000743 nodular basal cell carcinoma Diseases 0.000 description 1
- 208000029809 non-keratinizing sinonasal squamous cell carcinoma Diseases 0.000 description 1
- 238000010899 nucleation Methods 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- OIPZNTLJVJGRCI-UHFFFAOYSA-M octadecanoyloxyaluminum;dihydrate Chemical compound O.O.CCCCCCCCCCCCCCCCCC(=O)O[Al] OIPZNTLJVJGRCI-UHFFFAOYSA-M 0.000 description 1
- 239000003883 ointment base Substances 0.000 description 1
- ZQPPMHVWECSIRJ-KTKRTIGZSA-N oleic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O ZQPPMHVWECSIRJ-KTKRTIGZSA-N 0.000 description 1
- 229920001542 oligosaccharide Polymers 0.000 description 1
- 150000002482 oligosaccharides Chemical class 0.000 description 1
- 239000004006 olive oil Substances 0.000 description 1
- 235000008390 olive oil Nutrition 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 230000000174 oncolytic effect Effects 0.000 description 1
- 235000015205 orange juice Nutrition 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 150000007530 organic bases Chemical class 0.000 description 1
- 239000003960 organic solvent Substances 0.000 description 1
- 229950008017 ormaplatin Drugs 0.000 description 1
- 201000006958 oropharynx cancer Diseases 0.000 description 1
- 230000001582 osteoblastic effect Effects 0.000 description 1
- 208000008798 osteoma Diseases 0.000 description 1
- 210000002394 ovarian follicle Anatomy 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 201000010198 papillary carcinoma Diseases 0.000 description 1
- 239000012188 paraffin wax Substances 0.000 description 1
- 230000005298 paramagnetic effect Effects 0.000 description 1
- 201000003913 parathyroid carcinoma Diseases 0.000 description 1
- 208000017954 parathyroid gland carcinoma Diseases 0.000 description 1
- 235000010603 pastilles Nutrition 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- 235000010987 pectin Nutrition 0.000 description 1
- 239000001814 pectin Substances 0.000 description 1
- 229920001277 pectin Polymers 0.000 description 1
- 229940049954 penicillin Drugs 0.000 description 1
- 239000000816 peptidomimetic Substances 0.000 description 1
- 210000005259 peripheral blood Anatomy 0.000 description 1
- 239000011886 peripheral blood Substances 0.000 description 1
- 230000002085 persistent effect Effects 0.000 description 1
- 239000003208 petroleum Substances 0.000 description 1
- 229960003742 phenol Drugs 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 208000028591 pheochromocytoma Diseases 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- WTJKGGKOPKCXLL-RRHRGVEJSA-N phosphatidylcholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCC=CCCCCCCCC WTJKGGKOPKCXLL-RRHRGVEJSA-N 0.000 description 1
- 150000008104 phosphatidylethanolamines Chemical class 0.000 description 1
- 150000003905 phosphatidylinositols Chemical class 0.000 description 1
- 150000004713 phosphodiesters Chemical class 0.000 description 1
- 150000003904 phospholipids Chemical class 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-L phosphoramidate Chemical compound NP([O-])([O-])=O PTMHPRAIXMAOOB-UHFFFAOYSA-L 0.000 description 1
- 239000000049 pigment Substances 0.000 description 1
- 201000000734 pigmented basal cell carcinoma Diseases 0.000 description 1
- 201000003113 pineoblastoma Diseases 0.000 description 1
- 208000031223 plasma cell leukemia Diseases 0.000 description 1
- 239000004014 plasticizer Substances 0.000 description 1
- 206010035653 pneumoconiosis Diseases 0.000 description 1
- 238000005498 polishing Methods 0.000 description 1
- 229920000191 poly(N-vinyl pyrrolidone) Polymers 0.000 description 1
- 229920000111 poly(butyric acid) Polymers 0.000 description 1
- 229920001200 poly(ethylene-vinyl acetate) Polymers 0.000 description 1
- 229920000747 poly(lactic acid) Polymers 0.000 description 1
- 229920001306 poly(lactide-co-caprolactone) Polymers 0.000 description 1
- 229920001583 poly(oxyethylated polyols) Polymers 0.000 description 1
- 229920001495 poly(sodium acrylate) polymer Polymers 0.000 description 1
- 229920000058 polyacrylate Polymers 0.000 description 1
- 229920001515 polyalkylene glycol Polymers 0.000 description 1
- 229920002647 polyamide Polymers 0.000 description 1
- 229920000447 polyanionic polymer Polymers 0.000 description 1
- 239000004417 polycarbonate Substances 0.000 description 1
- 229920000515 polycarbonate Polymers 0.000 description 1
- 229920000728 polyester Polymers 0.000 description 1
- 229920000570 polyether Polymers 0.000 description 1
- 229920000573 polyethylene Polymers 0.000 description 1
- 229920000139 polyethylene terephthalate Polymers 0.000 description 1
- 239000005020 polyethylene terephthalate Substances 0.000 description 1
- 229920002338 polyhydroxyethylmethacrylate Polymers 0.000 description 1
- 229930001119 polyketide Natural products 0.000 description 1
- 150000003881 polyketide derivatives Chemical class 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 229920002503 polyoxyethylene-polyoxypropylene Polymers 0.000 description 1
- 208000014081 polyp of colon Diseases 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 229920001451 polypropylene glycol Polymers 0.000 description 1
- 229920001296 polysiloxane Polymers 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 229920002689 polyvinyl acetate Polymers 0.000 description 1
- 239000011118 polyvinyl acetate Substances 0.000 description 1
- 229920001290 polyvinyl ester Polymers 0.000 description 1
- 229920001289 polyvinyl ether Polymers 0.000 description 1
- 229920001291 polyvinyl halide Polymers 0.000 description 1
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 238000010149 post-hoc-test Methods 0.000 description 1
- 229920001592 potato starch Polymers 0.000 description 1
- 239000002244 precipitate Substances 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- 210000004986 primary T-cell Anatomy 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 208000029340 primitive neuroectodermal tumor Diseases 0.000 description 1
- 230000009465 prokaryotic expression Effects 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 239000001294 propane Substances 0.000 description 1
- 150000003180 prostaglandins Chemical class 0.000 description 1
- 239000012474 protein marker Substances 0.000 description 1
- 230000006337 proteolytic cleavage Effects 0.000 description 1
- 208000013368 pseudoglandular squamous cell carcinoma Diseases 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 239000002510 pyrogen Substances 0.000 description 1
- 238000004445 quantitative analysis Methods 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 238000001959 radiotherapy Methods 0.000 description 1
- MUPFEKGTMRGPLJ-ZQSKZDJDSA-N raffinose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO[C@@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O2)O)O1 MUPFEKGTMRGPLJ-ZQSKZDJDSA-N 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 201000007444 renal pelvis carcinoma Diseases 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 210000003660 reticulum Anatomy 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 201000009410 rhabdomyosarcoma Diseases 0.000 description 1
- 229910052702 rhenium Inorganic materials 0.000 description 1
- 238000010079 rubber tapping Methods 0.000 description 1
- 201000007416 salivary gland adenoid cystic carcinoma Diseases 0.000 description 1
- DOSGOCSVHPUUIA-UHFFFAOYSA-N samarium(3+) Chemical compound [Sm+3] DOSGOCSVHPUUIA-UHFFFAOYSA-N 0.000 description 1
- HFHDHCJBZVLPGP-UHFFFAOYSA-N schardinger α-dextrin Chemical compound O1C(C(C2O)O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC(C(O)C2O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC2C(O)C(O)C1OC2CO HFHDHCJBZVLPGP-UHFFFAOYSA-N 0.000 description 1
- 238000007423 screening assay Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 239000006152 selective media Substances 0.000 description 1
- 229910052711 selenium Inorganic materials 0.000 description 1
- 239000011669 selenium Substances 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 239000003352 sequestering agent Substances 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- 231100000004 severe toxicity Toxicity 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 238000002603 single-photon emission computed tomography Methods 0.000 description 1
- 230000005783 single-strand break Effects 0.000 description 1
- 208000030147 skin cystic basal cell carcinoma Diseases 0.000 description 1
- 201000003708 skin melanoma Diseases 0.000 description 1
- 208000030099 skin pigmented basal cell carcinoma Diseases 0.000 description 1
- 230000000391 smoking effect Effects 0.000 description 1
- 239000000344 soap Substances 0.000 description 1
- 235000019812 sodium carboxymethyl cellulose Nutrition 0.000 description 1
- 229920001027 sodium carboxymethylcellulose Polymers 0.000 description 1
- NNMHYFLPFNGQFZ-UHFFFAOYSA-M sodium polyacrylate Chemical compound [Na+].[O-]C(=O)C=C NNMHYFLPFNGQFZ-UHFFFAOYSA-M 0.000 description 1
- 229940054269 sodium pyruvate Drugs 0.000 description 1
- 229910052938 sodium sulfate Inorganic materials 0.000 description 1
- 235000011152 sodium sulphate Nutrition 0.000 description 1
- 239000012453 solvate Substances 0.000 description 1
- 235000010199 sorbic acid Nutrition 0.000 description 1
- 239000004334 sorbic acid Substances 0.000 description 1
- 229940075582 sorbic acid Drugs 0.000 description 1
- 235000011069 sorbitan monooleate Nutrition 0.000 description 1
- 239000001593 sorbitan monooleate Substances 0.000 description 1
- 229940035049 sorbitan monooleate Drugs 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 239000003549 soybean oil Substances 0.000 description 1
- 235000012424 soybean oil Nutrition 0.000 description 1
- 125000006850 spacer group Chemical group 0.000 description 1
- 150000003408 sphingolipids Chemical class 0.000 description 1
- WWUZIQQURGPMPG-KRWOKUGFSA-N sphingosine Chemical compound CCCCCCCCCCCCC\C=C\[C@@H](O)[C@@H](N)CO WWUZIQQURGPMPG-KRWOKUGFSA-N 0.000 description 1
- 201000002471 spleen cancer Diseases 0.000 description 1
- 210000004989 spleen cell Anatomy 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- UQZIYBXSHAGNOE-XNSRJBNMSA-N stachyose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO[C@@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO[C@@H]3[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O3)O)O2)O)O1 UQZIYBXSHAGNOE-XNSRJBNMSA-N 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 238000011146 sterile filtration Methods 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 150000003432 sterols Chemical class 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 238000003756 stirring Methods 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 201000011549 stomach cancer Diseases 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- 201000010033 subleukemic leukemia Diseases 0.000 description 1
- 125000001424 substituent group Chemical group 0.000 description 1
- 150000005846 sugar alcohols Chemical class 0.000 description 1
- 201000011138 superficial basal cell carcinoma Diseases 0.000 description 1
- 239000002511 suppository base Substances 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 239000003765 sweetening agent Substances 0.000 description 1
- 208000011580 syndromic disease Diseases 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
- 206010042863 synovial sarcoma Diseases 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 238000011521 systemic chemotherapy Methods 0.000 description 1
- 238000002626 targeted therapy Methods 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- 229910052713 technetium Inorganic materials 0.000 description 1
- GKLVYJBZJHMRIY-UHFFFAOYSA-N technetium atom Chemical compound [Tc] GKLVYJBZJHMRIY-UHFFFAOYSA-N 0.000 description 1
- GZCRRIHWUXGPOV-UHFFFAOYSA-N terbium atom Chemical compound [Tb] GZCRRIHWUXGPOV-UHFFFAOYSA-N 0.000 description 1
- 201000003120 testicular cancer Diseases 0.000 description 1
- 210000001550 testis Anatomy 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- VUYXVWGKCKTUMF-UHFFFAOYSA-N tetratriacontaethylene glycol monomethyl ether Chemical compound COCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCO VUYXVWGKCKTUMF-UHFFFAOYSA-N 0.000 description 1
- RTKIYNMVFMVABJ-UHFFFAOYSA-L thimerosal Chemical compound [Na+].CC[Hg]SC1=CC=CC=C1C([O-])=O RTKIYNMVFMVABJ-UHFFFAOYSA-L 0.000 description 1
- 229940033663 thimerosal Drugs 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- 210000000115 thoracic cavity Anatomy 0.000 description 1
- RZWIIPASKMUIAC-VQTJNVASSA-N thromboxane Chemical compound CCCCCCCC[C@H]1OCCC[C@@H]1CCCCCCC RZWIIPASKMUIAC-VQTJNVASSA-N 0.000 description 1
- 229940104230 thymidine Drugs 0.000 description 1
- 201000002341 thymus lymphoma Diseases 0.000 description 1
- 210000001685 thyroid gland Anatomy 0.000 description 1
- 208000013818 thyroid gland medullary carcinoma Diseases 0.000 description 1
- 230000036962 time dependent Effects 0.000 description 1
- 230000009258 tissue cross reactivity Effects 0.000 description 1
- 150000004992 toluidines Chemical class 0.000 description 1
- 239000012049 topical pharmaceutical composition Substances 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 231100000167 toxic agent Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 239000003440 toxic substance Substances 0.000 description 1
- 231100000048 toxicity data Toxicity 0.000 description 1
- 235000010487 tragacanth Nutrition 0.000 description 1
- 239000000196 tragacanth Substances 0.000 description 1
- 229940116362 tragacanth Drugs 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000005026 transcription initiation Effects 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 238000011830 transgenic mouse model Methods 0.000 description 1
- 230000010474 transient expression Effects 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- BMCJATLPEJCACU-UHFFFAOYSA-N tricin Natural products COc1cc(OC)c(O)c(c1)C2=CC(=O)c3c(O)cc(O)cc3O2 BMCJATLPEJCACU-UHFFFAOYSA-N 0.000 description 1
- UFTFJSFQGQCHQW-UHFFFAOYSA-N triformin Chemical compound O=COCC(OC=O)COC=O UFTFJSFQGQCHQW-UHFFFAOYSA-N 0.000 description 1
- 208000029387 trophoblastic neoplasm Diseases 0.000 description 1
- 201000007423 tubular adenocarcinoma Diseases 0.000 description 1
- 230000004614 tumor growth Effects 0.000 description 1
- 210000003171 tumor-infiltrating lymphocyte Anatomy 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 238000002604 ultrasonography Methods 0.000 description 1
- 208000022810 undifferentiated (embryonal) sarcoma Diseases 0.000 description 1
- 208000018417 undifferentiated high grade pleomorphic sarcoma of bone Diseases 0.000 description 1
- 201000011294 ureter cancer Diseases 0.000 description 1
- 201000005112 urinary bladder cancer Diseases 0.000 description 1
- 210000001635 urinary tract Anatomy 0.000 description 1
- 206010046766 uterine cancer Diseases 0.000 description 1
- 208000037965 uterine sarcoma Diseases 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- 206010046885 vaginal cancer Diseases 0.000 description 1
- 208000013139 vaginal neoplasm Diseases 0.000 description 1
- 229940005605 valeric acid Drugs 0.000 description 1
- 238000010200 validation analysis Methods 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 229910052720 vanadium Inorganic materials 0.000 description 1
- LEONUFNNVUYDNQ-UHFFFAOYSA-N vanadium atom Chemical compound [V] LEONUFNNVUYDNQ-UHFFFAOYSA-N 0.000 description 1
- 230000002792 vascular Effects 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 239000008158 vegetable oil Substances 0.000 description 1
- 235000013311 vegetables Nutrition 0.000 description 1
- 210000003501 vero cell Anatomy 0.000 description 1
- 208000008662 verrucous carcinoma Diseases 0.000 description 1
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 1
- 229960004528 vincristine Drugs 0.000 description 1
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 1
- 229920002554 vinyl polymer Polymers 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 210000000605 viral structure Anatomy 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 210000000239 visual pathway Anatomy 0.000 description 1
- 230000004400 visual pathway Effects 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 150000003722 vitamin derivatives Chemical class 0.000 description 1
- 201000005102 vulva cancer Diseases 0.000 description 1
- 238000010792 warming Methods 0.000 description 1
- 239000008215 water for injection Substances 0.000 description 1
- 239000001993 wax Substances 0.000 description 1
- 230000003442 weekly effect Effects 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- WCNMEQDMUYVWMJ-JPZHCBQBSA-N wybutoxosine Chemical compound C1=NC=2C(=O)N3C(CC([C@H](NC(=O)OC)C(=O)OC)OO)=C(C)N=C3N(C)C=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O WCNMEQDMUYVWMJ-JPZHCBQBSA-N 0.000 description 1
- 229940075420 xanthine Drugs 0.000 description 1
- 238000012447 xenograft mouse model Methods 0.000 description 1
- 229920001221 xylan Polymers 0.000 description 1
- 150000004823 xylans Chemical class 0.000 description 1
- NAWDYIZEMPQZHO-UHFFFAOYSA-N ytterbium Chemical compound [Yb] NAWDYIZEMPQZHO-UHFFFAOYSA-N 0.000 description 1
- XOOUIPVCVHRTMJ-UHFFFAOYSA-L zinc stearate Chemical compound [Zn+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O XOOUIPVCVHRTMJ-UHFFFAOYSA-L 0.000 description 1
- 229910052726 zirconium Inorganic materials 0.000 description 1
Images












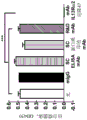


























Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2866—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for cytokines, lymphokines, interferons
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/461—Cellular immunotherapy characterised by the cell type used
- A61K39/4611—T-cells, e.g. tumor infiltrating lymphocytes [TIL], lymphokine-activated killer cells [LAK] or regulatory T cells [Treg]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/463—Cellular immunotherapy characterised by recombinant expression
- A61K39/4631—Chimeric Antigen Receptors [CAR]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464402—Receptors, cell surface antigens or cell surface determinants
- A61K39/464416—Receptors for cytokines
- A61K39/464419—Receptors for interleukins [IL]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/70521—CD28, CD152
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/715—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons
- C07K14/7155—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons for interleukins [IL]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3053—Skin, nerves, brain
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N7/00—Viruses; Bacteriophages; Compositions thereof; Preparation or purification thereof
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/52—Use of compounds or compositions for colorimetric, spectrophotometric or fluorometric investigation, e.g. use of reagent paper and including single- and multilayer analytical elements
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/531—Production of immunochemical test materials
- G01N33/532—Production of labelled immunochemicals
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57407—Specifically defined cancers
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/10—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterized by the structure of the chimeric antigen receptor [CAR]
- A61K2239/11—Antigen recognition domain
- A61K2239/13—Antibody-based
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/46—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterised by the cancer treated
- A61K2239/47—Brain; Nervous system
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/03—Fusion polypeptide containing a localisation/targetting motif containing a transmembrane segment
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/20—Fusion polypeptide containing a tag with affinity for a non-protein ligand
- C07K2319/21—Fusion polypeptide containing a tag with affinity for a non-protein ligand containing a His-tag
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/40—Fusion polypeptide containing a tag for immunodetection, or an epitope for immunisation
- C07K2319/41—Fusion polypeptide containing a tag for immunodetection, or an epitope for immunisation containing a Myc-tag
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2710/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA dsDNA viruses
- C12N2710/00011—Details
- C12N2710/10011—Adenoviridae
- C12N2710/10311—Mastadenovirus, e.g. human or simian adenoviruses
- C12N2710/10341—Use of virus, viral particle or viral elements as a vector
- C12N2710/10343—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/705—Assays involving receptors, cell surface antigens or cell surface determinants
- G01N2333/71—Assays involving receptors, cell surface antigens or cell surface determinants for growth factors; for growth regulators
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/5005—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells
- G01N33/5091—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells for testing the pathological state of an organism
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Biochemistry (AREA)
- Cell Biology (AREA)
- Biomedical Technology (AREA)
- Microbiology (AREA)
- Zoology (AREA)
- Biophysics (AREA)
- Hematology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Urology & Nephrology (AREA)
- Biotechnology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Physics & Mathematics (AREA)
- Toxicology (AREA)
- Gastroenterology & Hepatology (AREA)
- Food Science & Technology (AREA)
- Analytical Chemistry (AREA)
- General Physics & Mathematics (AREA)
- Pathology (AREA)
- General Engineering & Computer Science (AREA)
- Mycology (AREA)
- Epidemiology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Oncology (AREA)
- General Chemical & Material Sciences (AREA)
Abstract
提供结合到IL13Rα2的抗原决定基的特异性结合分子或其片段,所述抗原决定基是优先发现于癌细胞而非健康细胞的表面上的受体多肽。示范性的特异性结合分子是包含IL13Rα2结合分子的片段和提供第二功能的肽的双特异性结合分子,所述第二功能提供T细胞信号传导蛋白的信号传导域的信号传导功能、T细胞活化的肽调节物或标记系统的酶组分。还提供编码这类特异性结合分子(例如双特异性结合分子)的聚核苷酸、载体、宿主细胞、医药组合物,和预防、治疗或改善与癌症疾病如实体肿瘤疾病(例如多形性成胶质细胞瘤)相关的症状的方法。
Description
相关申请的交叉引用
本申请依据35 U.S.C.§119(e)要求2015年1月26日提交的美国临时专利申请第62/107,984号的优先权权益,所述申请的公开内容均以全文引用的方式并入本文中。
以引用的方式并入以电子版提交的材料
本申请含有呈计算机可读形式的序列表作为本公开的单独部分,所述序列表以全文 引用的方式并入并且标识如下:文件名:49102A_Seqlisting.txt;182,500个字节,2016年1月20日生成。
技术领域
本公开大体上涉及癌症生物学领域并且涉及分子抗体-受体技术。
背景技术
癌症对人类和非人类动物的健康具有重大威胁,其降低生活品质并且在太多情况下 导致死亡。就所需的来源和人力来说,置于国家、区域和地方保健组织上的治疗和预防各种形式癌症的负担相当重。脊椎动物(包括人类)必须对抗疾病的一种主要武器是功 能免疫系统。简单考虑治疗或预防癌症的免疫疗法可以让人得出如下结论:由于免疫系 统提防外来或非自身物质并且癌细胞起因于内部,即其是自身物质,因此努力后成功的 希望极小。然而,在我们的理解中,癌症和免疫学的持续进展正在可见地改善。
例如在小鼠中突变体抗原是肿瘤破坏的有力标靶,并且在患者中靶向这些突变的肿 瘤-浸润淋巴细胞引起持久的肿瘤消退。然而,对于疫苗方法,非突变体抗原已经被许多科学家推测为是癌症特异性或“相对癌症特异性”并且安全的抗原。然而,过继转移的T 细胞可以在数量级上比接种更有效并且更具破坏性。因此,在现在停止的临床试验中用 T细胞靶向MAGE-A3、HER-2或CEA已引起死亡或产生严重毒性(8-11)。如在2002 年显示,具有极高或极低表达水平的靶抗原的癌细胞仅在免疫应答诱导中不同,而在效 应阶段不如此(15)。
高亲和力白介素-13受体α2(IL13Rα2)由多形性成胶质细胞瘤(GBM)以及若干 其它肿瘤类型以高频率选择性地表达。靶向这种肿瘤特异性受体的一种方法利用缀合到 细胞毒性分子的同源配位体IL-13。然而,这种方法缺乏特异性,因为针对IL-13、IL13Rα1 的较低亲和力受体由正常组织广泛地表达。
大多数的人类癌症缺乏可预测地存在并且充当有效标靶以由T细胞根除的特异性抗 原。每一癌细胞类型具有产生不同肿瘤特异性抗原的独特的突变集合。尽管技术取得了巨大进展,但仍难以鉴别有效独特的抗原并且分离适当TCR用于自体T细胞的转导而 用于过继免疫疗法。使用抗体或T细胞的过继免疫疗法在临床上以及实验上是最有效的 免疫疗法,至少当考虑临床相关癌症时如此(22)。然而,使用嵌合抗体受体(CAR) 和双特异性T细胞啮合蛋白(BiTE)的过继免疫疗法的显著成功在很大程度上受限于特 异于患者中的CD19/CD20根除B细胞恶性病和正常B细胞的那些者,即,造血癌症。 因此,需要对大范围实体肿瘤鉴别共享但具肿瘤特异性的抗原,并且同时需要开发可以 诊断、预防、治疗或改善这些癌症的症状的预防剂和治疗剂,以及用于诊断、预防和治 疗各种癌症的方法。
发明内容
本公开提供(i)特异性靶向人类肿瘤相关抗原IL13Rα2的单克隆抗体的重链(SEQID NO:7)和轻链(SEQ ID NO:8)可变区的序列,和(ii)展现由重链和轻链cDNA编 码的呈scFv抗体型式的蛋白质或与其它功能部分的融合体的功能性的数据。重链和轻 链可以按不同型式布置,如单链抗体、双功能抗体、双特异性抗体和三特异性抗体、具 有治疗蛋白和其它部分的融合体、人类或人源化全抗体以及人类或人源化Fab片段和其 它功能衍生物。单链抗体或由重链和轻链编码的蛋白质的其它布置,例如双特异性结合 分子,可以经过表达并且缀合到治疗载体(例如病毒、细胞、纳米材料)用于将治疗剂 特异性递送到IL13Rα2过表达肿瘤中或用于使肿瘤负荷成像。
由肿瘤细胞而非正常细胞表达的蛋白质是用于选择性递送细胞毒性分子的有吸引 力的分子。因此,针对白介素-13(IL-13)的高亲和力受体白介素-13受体α2(IL13Rα2)是一种有前景的候选物。IL13Rα2以高频率在称为多形性成胶质细胞瘤(GBM)的侵蚀 性并不可治愈形式的原发性脑肿瘤(1-3)中表达,以及被其它实体肿瘤(4)表达。相 反,除睪丸之外,正常组织表达极少到不表达IL13Rα2(6)。值得注意地,许多组织广 泛表达对IL-13具有低亲和力的一不同受体IL13Rα1(7-9),使其成为肿瘤特异性免疫 治疗应用的选择性靶向的较差候选物。
若干研究已在临床前动物模型和临床试验中所测试的患者中研究出与衍生自假单 胞菌外毒素A的重组细胞毒素缀合的IL-13融合蛋白(IL-13PE)的治疗特性,所述假 单胞菌外毒素A在体外诱导IL13Rα2表达神经胶质瘤细胞中的细胞凋亡(17-22)。然而, 这类药剂缺乏与IL13Rα2的相互作用的高特异性,因为其替代性地结合于广泛表达的 IL13Rα1。因此,预期开发针对IL13Rα2表达细胞的特异性可以与效应子(例如T细胞、 毒素)组合的高度选择性抗体片段会产生治疗有益的结果。
本公开通过提供特异于IL13Rα2的蛋白质结合伴侣而非模拟IL13自身来获得IL13Rα2的肿瘤特异性,其将产生展现结合于IL13Rα1和IL13Rα2两者的能力的分子。 此外,本公开提供一种编码这些癌症特异性IL13Rα2结合伴侣中的一种的聚核苷酸,包 括针对特异于这些IL13Rα2结合伴侣中的一种的抗原决定基的结合伴侣包含密码子优化 编码区的聚核苷酸。明确涵盖融合蛋白或嵌合体,其包含呈连接到肽的可操作连接形式 的如上文所定义的IL13Rα2结合伴侣,所述肽提供第二功能,如T细胞信号传导蛋白的 信号传导域的信号传导功能,T细胞活化的肽调节物或标记系统的酶组分。示范性的T 细胞信号传导蛋白包括4-1BB(CD137)、CD3ζ和融合蛋白,例如CD28-CD3ζ和 4-1BBCD3ζ。4-1BB(CD137)和CD28是T细胞的共刺激分子;CD3ζ是T细胞抗原受 体的信号转导组分。提供第二功能的肽或蛋白质可以提供T细胞活化的调节物,如IL-15、 IL-15Rα、IL-15/IL-15Rα融合体的调节物,或其可以编码适用于体内或体外监测结合的 程度和/或位置的标记系统的标记物或酶组分。在本公开的一些实施例中,编码置于T 细胞如自体T细胞情形下的这些预防和治疗活性生物分子的药剂提供有力的平台用于招 募过继转移的T细胞,以预防或治疗各种癌症。对特异于癌细胞上发现的抗原决定基的 结合伴侣的编码区的密码子优化提供一种递送本文所公开的诊断、预防和/或治疗蛋白的 有效方法。
在一个方面中,本公开提供一种白介素13受体α2(IL13Rα2)结合伴侣,其包含 SEQID NO:1的抗体重链可变片段(VH)互补决定区1(CDR1)、SEQ ID NO:2的VH CDR2、SEQ ID NO:3的VH CDR3、SEQ ID NO:4的轻链(VL)互补决定区1(CDR1)、 SEQ ID NO:5的VLCDR2和SEQ IDNO:6的VLCDR3,其中IL13Rα2结合伴侣特异性 结合到IL13Rα2的抗原决定基。在一些实施例中,VH序列阐述为SEQ ID NO:7并且在 一些相同和一些不同实施例,VL序列阐述为SEQ IDNO:8。
本公开的一相关方面提供一种双特异性结合分子,其包含结合于IL13Rα2抗原决定 基的本文所描述的IL13Rα2结合伴侣的片段,所述片段共价连接到提供第二功能的肽以形成双特异性结合分子。在一些实施例中,肽的第二功能选自由以下组成的组:T细胞 信号传导蛋白的信号传导域的信号传导功能、T细胞活化的肽调节物和标记系统的酶组 分。在一些实施例中,片段是单链可变片段(scFv),其可以含于双特异性T细胞啮合 体(BiTE)或嵌合抗原受体(CAR)内。提供一些实施例,其中如本文所描述的双特异 性结合分子缀合到治疗载体。
本公开的另一方面涉及一种医药组合物,其包含如本文所描述的IL13Rα2结合伴侣 和药学上可接受的载剂、佐剂或稀释剂。
一相关方面提供一种试剂盒,其包含本文所描述的医药组合物和用于给予组合物的 方案。也相关的是如下一方面:提供编码如本文所描述的IL13Rα2结合伴侣的聚核苷酸和包含如本文所描述的聚核苷酸的载体。在示范性实施例中,载体是病毒,如腺病毒。 在特定实施例中,腺病毒是血清5型腺病毒。本公开的另一方面是包含本文所公开的载 体和本文所公开的核酸的重组聚核苷酸。在一些实施例中,重组聚核苷酸是 Ad5FFscFv47。又一方面是针对一种宿主细胞,其包含本文所描述的聚核苷酸或本文所 描述的载体。
本公开的又一方面提供一种预防、治疗或改善癌症疾病的症状的方法,所述方法包 含给予治疗有效量的如本文所描述的医药组合物。在一些实施例中,癌症是实体肿瘤,如多形性成胶质细胞瘤(GBM)。在一些实施例中,癌症通过抑制实体肿瘤的生长速率 治疗。在一些实施例中,所改善的症状是疼痛。
更确切地说,本公开的一个方面涉及一种IL13Rα2结合剂,其包含以下的氨基酸序列中的每一个:NYLMN(SEQ ID NO:1);RIDPYDGDIDYNQNFKD(SEQ ID NO:2); GYGTAYGVDY(SEQ ID NO:3);RASESVDNYGISFMN(SEQ ID NO:4);AASRQGSG (SEQ ID NO:5)和QQSKEVPWT(SEQ ID NO:6)。在一些实施例中,本文所公开的 IL13Rα2结合剂包含SEQ ID NO:7和/或SEQ ID NO:8的氨基酸序列中的一个或两个。 在一些实施例中,SEQ ID NO:7的氨基酸序列经由连接子融合到SEQ ID NO:8的氨基 酸序列。在一些实施例中,连接子包含EEGEFSEAR(SEQ ID NO 10)的氨基酸序列。 在一些实施例中,本文所公开的IL13Rα2结合剂包含SEQID NO:13的氨基酸序列。在 一些实施例中,本文所公开的IL13Rα2结合剂进一步包含SEQID NO:28的氨基酸序列, 或与SEQ ID NO:28至少90%一致的氨基酸序列。在一些实施例中,本文所公开的 IL13Rα2结合剂进一步包含SEQ ID NO:30的氨基酸序列,或与SEQ IDNO:30至少90% 一致的氨基酸序列。在一些实施例中,本文所公开的IL13Rα2结合剂是抗体或其抗原结 合片段,其中其抗原结合片段至少包含SEQ ID NO:1-6的氨基酸序列。在一些实施例中, 结合剂是为单链可变片段(scFv)的抗原结合片段。在一些实施例中,本文所公开的 IL13Rα2结合剂进一步包含METDTLLLWVLLLWVPGSTGD(SEQ ID NO:9)的Igκ前 导序列。在一些实施例中,本文所公开的IL13Rα2结合剂进一步包含EEGEFSEAR(SEQ ID NO 10)的连接子序列。在一些实施例中,本文所公开的IL13Rα2结合剂进一步包含 GGPEQKLISEEDLN(SEQ ID NO:11)的Myc标签序列。在一些实施例中,本文所公 开的IL13Rα2结合剂进一步包含HHHHHH(SEQ ID NO:12)的His标签序列。在一些 实施例中,本文所公开的IL13Rα2结合剂包含SEQ ID NO:14的氨基酸序列。在一些实 施例中,本文所公开的IL13Rα2结合剂结合到人类IL13Rα2但不结合到人类IL13Rα1。 在一些实施例中,本文所公开的IL13Rα2结合剂具有不大于约1.39×10-9M的针对人类 IL13Rα2的平衡解离常数(KD)。
在一相关方面中,本公开提供一种缀合物,其包含共价连接到效应域的本文所公开 的IL13Rα2结合剂。在一些实施例中,缀合物是融合蛋白或嵌合蛋白。在一些实施例中,效应域是细胞毒素、细胞凋亡标签、T细胞信号传导域或标记物。在一些实施例中,效 应域是T细胞信号传导域并且缀合物是IL13Rα2特异性嵌合抗原受体(CAR)。在一些 实施例中,细胞凋亡标签是TRAIL蛋白质或其一部分,任选地,其中细胞凋亡标签包 含SEQ ID NO:27的氨基酸序列。在一些实施例中,缀合物包含SEQ ID NO:25的氨基 酸序列。在一些实施例中,标记物是放射性标记物、荧光标记物、催化量热或荧光反应 的酶、酶底物、固体基质、生物素或抗生物素蛋白。在一些实施例中,效应域是放射性 标记物、荧光标记物、生物素或抗生物素蛋白。
在另一方面中,本公开提供一种核酸,其编码本文所公开的IL13Rα2结合剂或如本文所公开的任何这类结合剂的缀合物。在一些实施例中,本文所公开的核酸包含SEQ IDNO:15或SEQ ID NO:16或SEQ ID NO:15和16这两者的序列。
在另一方面中,本公开存在一种包含本文所公开的核酸的载体。
又一方面涉及一种包含本文所公开的载体的宿主细胞。另一方面是针对一种医药组 合物,其包含本文所公开的结合剂、本文所公开的缀合物、本文所公开的核酸、本文所公开的载体或本文所公开的宿主细胞,和药学上可接受的载剂。
另一方面是一种治疗个体的癌症的方法,其包含以有效治疗个体的癌症的量向个体 给予本文所公开的结合剂或本文所公开的缀合物。在一些实施例中,癌症是结肠癌。
又一方面是一种鉴别IL13Rα2阳性癌细胞的方法,其包含使生物样品与可检测量的 如本文所公开的结合剂或如本文所公开的缀合物接触;和测量结合到生物样品的至少一 种细胞的结合剂或缀合物的量,由此鉴别IL13Rα2阳性癌细胞。在一些实施例中,生物样品是个体的身体内的细胞块、组织或器官,并且在其它实施例中生物样品是离体细胞块、组织和/或器官。在一些实施例中,IL13Rα2阳性癌细胞是神经胶质瘤细胞。在一些 实施例中,结合剂包含scFv47。在一些实施例中,结合剂是如本文所公开的缀合物,其 中效应域是放射性标记物、荧光标记物、催化量热或荧光反应的酶、酶底物、固体基质、 生物素或抗生物素蛋白。在一些实施例中,效应域是放射性标记物、荧光标记物、生物 素或抗生物素蛋白。
本公开的其他特征和优势将从包括图式的以下详细描述变得显而易见。然而,应理 解,虽然详细描述和具体实例指示优选实施例,但仅提供其用于说明,因为对于所属领域的技术人员,本发明的精神和范围内的各种改变和修改将从详细描述变得显而易见。
附图说明
图1.杂交瘤克隆的抗原识别和筛选的表征。A:B-D13 mAb与涂布有0.1和1μg/ml的rhIL13Rα2hFc的ELISA板的结合。B:板结合的ELISA中,IL13Rα2 mAb与原生和 变性(在β-巯基乙醇存在下在95℃下)rhIL13Rα2hFc的结合。配对t检验用以评估对照 组(n=4)之间的差异。*:p<0.1;***:p<0.001。误差棒表示S.D。这些数据是两 个独立实验的代表。C:板结合的ELISA中,针对rhIL13Rα2hFc的所选择杂交瘤群体 的筛选。D:使用蛋白质印迹针对rhIL13Rα2hFC的所选择杂交瘤群体的筛选。
图2.IL13Rα2(克隆47)mAb特异性结合到CHO细胞的细胞表面上表达的 rhIL13Rα2和IL13Rα2。A:板结合的ELISA中,IL13Rα2(克隆47、83807和B-D13) mAb与rhIL13Rα2的结合。B:IL13Rα2(克隆47)mAb与CHO细胞表面上表达的人 类IL13Rα2的结合。C:IL13Rα2(克隆47)mAb与hrIL13Rα1的交叉反应性。D:IL13Rα2 (克隆47、83807和B-D13)mAb与小鼠rIL13Rα2的交叉反应性。误差条表示S.D。
图3.IL13Rα2 mAb与神经胶质瘤细胞的结合A:结合于神经胶质瘤细胞、正常人类原代星形胶质细胞和转染有IL13Rα2的HEK细胞的表面的IL13Rα2(克隆47、83807 和B-D13)mAb的流程图。B:通过流式细胞测量术分析的IL13Rα2(克隆47、83807 和B-D13)mAb之间与各种细胞系的结合的中位荧光强度的数据。对于每一细胞系,高 于条棒的数目表示当与克隆B-D13相比较时克隆47的结合的差值。A和B的颜色键相 同。C:神经胶质瘤细胞以及正常人类原代星形胶质细胞中的IL13Rα2的mRNA表达。 D:图a-c,展现IL13Rα2(克隆47)mAb与来自颅内异种移植物(xeno)的带GFP标 记的U251神经胶质瘤细胞的特异性结合的流式细胞测量术。具有子图B中的曲线下的 有效面积的曲线描绘mAb IL13Rα2(克隆47)与GFP阴性细胞的结合;具有子图C中 的曲线下的有效面积的曲线描绘mAb IL13Rα2(克隆47)与GFP阳性细胞的结合。具 有曲线下的灰色面积的子图b和c中的曲线显示当将对照IgG暴露到GFP阴性细胞(子 图B)或GFP阳性(子图C)细胞时的结果。neg:阴性。A:面积;SSC-A:侧向散射 面积;APC-A:别藻蓝蛋白面积。
图4.IL13Rα2(克隆47)mAb与rhIL13Rα2之间的亲和力。显示了IL13Rα2(克隆 47)mAb(A)和可商购mAb克隆83807(B)和B-D13(C)与rhIL13Rα2的相互作用 的动力学,如通过SPR在Biacore 3000中目测。在20μl/min的恒定流速下在固定化抗 体上和对照聚葡萄糖表面上以1到100nM范围内的浓度(下部到上部曲线,所显示的1 nM、2.5nM、5nM、7.5nM、10nM、15nM、20nM、25nM浓度)注射rhIL13Rα2(从 信号中减去这些值)。监测缔合和解离阶段300秒,随后监测以RU给出的SPR信号的 变化(彩色曲线)。黑色曲线表示数据与一个位点结合模型的拟合。对于衍生的动力学 参数,参见表1。下面三个图显示一个位点结合模型的残数,指示极佳的拟合。
图5.IL13Rα2(克隆47)mAb与rhIL-13竞争IL13Rα2的结合位点。A:使用竞争 结合板分析,IL13Rα2(克隆47)mAb而非对照mIgG或抗体克隆83807、B-D13和YY-23Z 显著消除rhIL-13与吸收到塑料的rhIL13Rα2Fc嵌合体的结合。进行单因素方差分析, 随后进行邓尼特事后检验(Dunnett′s post hoc test)。显示单一代表性实验的数据。B:重 组人类IL-13与IL13Rα2(克隆47)mAb竞争HEK细胞表面上表达的WT IL13Rα2而 非4胺基酸(4aa)突变体IL13Rα2的结合位点。C:IL13Rα2(克隆47)mAb与rhIL-13 竞争WT和4胺基酸突变体形式的IL13Rα2的结合位点。进行配对t检验。数据表示B 和C中所示的三个独立实验的汇总。*:p<0.05;**:p<0.01;***:p<0.001。误差 棒表示S.D。
图6.IL13Rα2的Tyr207、Asp271、Tyr315和Asp318残基对结合IL13Rα2(克隆47)mAb的贡献。A:产生编码IL13Rα2的突变成Ala的个别突变或组合性4胺基酸突变体 (4aamut)的cDNA的变异体。HEK细胞转染有对照载体或编码IL13Rα2变异体的载体。 48小时后,通过流式细胞测量术分析IL13Rα2(克隆47)mAb与经转染细胞的表面的 结合。在这一分析中抗IL13Rα2抗体克隆83807和B-D13用作参考抗体。将抗体的结合 确定为阳性细胞的百分比。确定每一IL13Rα2突变体的结合克隆的比率并且与野生型受 体相比较。进行单因素方差分析,随后进行邓尼特事后检验。数据表示四个独立实验的 汇总。误差棒表示S.D。B:流式细胞测量术数据的代表图,其展现克隆47或rhIL-13 与HEK细胞表面上表达的IL13Rα2受体的WT和4胺基酸突变变异体的结合。填充曲 线:阴性对照,用同型对照IgG+二级抗体染色;开口曲线:用抗IL13Rα2(克隆47) 单克隆抗体+二级抗体染色。A:面积;APC-A:别藻蓝蛋白面积;FITC-A:异硫氰酸 荧光素面积。
图7.N-连接糖基化对IL13Rα2与重组IL13Rα2的结合的影响。A:IL13Rα2与对照 和Pngase F处理的rhIL13Rα2的结合。用1μg/ml的hrIL13Rα2涂布板并且在37℃下用 天然缓冲液或用天然缓冲液中的1毫单位(milliunit)/孔Pngase F处理3小时。进行相 较于抗体克隆B-D13、83807和YY-23Z以及rhIL-13,针对IL13Rα2(克隆47)mAb 的结合的ELISA,并且显示来自三个独立实验的一个代表性实验的数据。配对t检验用 以评估对照组与Pngase F处理组(n=4)之间的差异。*:p<0.5;**:p<0.01;***: p<0.001。B:蛋白质印迹显示由于从分子中去除N-连接糖基化加合物,因此Pngase F 处理的rhIL13Rα2的分子量较低。C:流式细胞测量术显示在37℃下IL13Rα2 mAb与用 1毫单位Pngase F处理1小时的IL13Rα2表达U251和HEK293细胞的结合。数据是三 个独立实验的代表。配对t检验用以评估对照组与Pngase F处理组之间的差异。*:p<0.5。 MFI:平均荧光强度。误差棒表示S.D。
图8.IL13Rα2(克隆47)mAb识别GBM组织和人类神经胶质瘤异种移植物中的 IL13Rα2。用3μg/ml浓度的IL13Rα2(克隆47)mAb或mIgG对来自三个人类GBM样 品和U251异种移植物的冷冻组织切片上进行免疫组织化学分析。GBM组织的染色展现 样品1中大多数细胞的阳性染色、样品2中仅一部分细胞的阳性反应性和样品3中的阴 性染色。在同一实验中对所有三个样品进行染色。也在U251异种移植物组织中检测到 阳性染色。箭头指向个别阳性细胞。比例尺=100μm。
图9.在原位人类神经胶质瘤异种移植物模型中,IL13Rα2(克隆47)mAb提高小 鼠的存活率。A:用U251神经胶质瘤细胞(2.5×104个)单独注射或与对照IgG或IL13Rα2 (克隆47)mAb组合注射的动物的存活率。B:来自用U251细胞单独注射(图a和b) 或与mIgG(图c和d)或mAb IL13Rα2(克隆47)(图e和f)组合注射的小鼠的染色 有H&E的10μm厚组织切片的代表性显微照片。箭头指向肿瘤和侵入细胞。比例尺(图 a、c和e)=100μm。比例尺(图b、d和f)=100μm。
图10.IL13Rα2(克隆47)mAb与N10神经胶质瘤细胞表面的竞争结合分析。A.在 冰上将IL13Rα2(克隆47)mAb与10×过量rhIL13Rα2一起预培育30分钟。随后将N10 细胞与同型对照mIgG或IL13Rα2(克隆47)mAb单独或在rhIL13Rα2存在下一起培育 并且通过流式细胞测量术分析结合抗体。B.在冰上将N10神经胶质瘤细胞与10×过量 rhIL13(左图)或10×过量IL13Rα2(克隆47)mAb(右图)一起预培育30分钟。随后 将N10细胞与同型对照mIgG、IL13Rα2(克隆47)mAb或rhIL13一起培育。用二级抗 体检测结合抗体或rhIL13并且通过流式细胞测量术分析。数据呈现为阳性细胞的百分 比。
图11.在已确立的人类U251神经胶质瘤下,IL13Rα2(克隆47)mAb对小鼠的存 活率的影响。用2.5×104个U251神经胶质瘤细胞颅内注射小鼠并且处理三天,稍后单 次注射PBS(n=7)或10μg IL13Rα2(克隆47或B-D13)mAb(n=7)。使用对数秩检 验分析动物的存活率。相对于分别用B-D13和47IL13Rα2 mAb处理的组的23和35天 的中位存活期,PBS组中的中位存活期确定为27天(p>0.05)。
图12.(a)针对VH和VL,使用经过设定的VH和VL特异性引物的对亲本杂交瘤 IL13Rα2细胞mRNA的筛选(表2)。(b)板ELISA中IL13Rα2克隆47噬菌体与 IL13Rα2hFc的结合。这些数据证实在3轮生物淘选后,针对IL13Rα2Fc嵌合蛋白,阳 性选择存在scFv IL13Rα2(克隆47)的噬菌体。左图:所指示轮次的生物淘选后,scFv IL13Rα2(克隆47)与IL13Rα2Fc的结合;右图:scFv IL13Rα2(克隆47)与对照hFC 的结合,对照hFC即为不融合到IL13Rα2的对照IgG抗体的恒定区。对着这两个图, 从左到右移动的每一次轮的条棒顺序反映1∶32、1∶16、1∶8、1∶4、1∶2和非稀释(即,1∶1) 的稀释度。
图13.结合scFv IL13Rα2克隆47与IL13Rα2hFc竞争性分析的特异性。这些数据 显示存在于噬菌体表面上的scFvIL13Rα2(克隆47)与重组IL13Rα2的结合通过亲本单 克隆抗体(克隆47)而非针对IL13Rα2的其它抗体被完全消除。其指示scFvIL13Rα2 (克隆47)和亲本单克隆抗体(克隆47)共享IL13Rα2分子上的抗原决定基(即,识别 位点)。
图14.可溶scFv IL13Rα2(克隆47)与IL13Rα2hFc嵌合体的结合。这些数据显示 在原核表达系统(大肠杆菌(E.coli))中产生的可溶scFvIL13Rα2(克隆47)特异性结 合于IL13Rα2Fc重组蛋白。亲本抗体、mAb IL13Rα2(克隆47)和对照小鼠IgG分别充 当阳性和阴性对照
图15.分泌scFvIL13Rα2 sTRAIL融合蛋白的间叶干细胞对U87-IL13Rα2神经胶质瘤细胞系的影响。这些数据显示在IL13Rα2表达U87神经胶质瘤细胞系中,经修饰分泌scFvIL13Rα2(克隆47)与TRAIL蛋白的基因融合体的间叶干细胞展现治疗作用。所述 结果确立将scFV结合到TRAIL细胞因子的功效。癌细胞杀死的量等效于在无scFV下 单独使用TRAIL,但在靶向IL13Rα2的scFv赋予特异性的情况下,预期scFV-TRAIL 对非癌组织的危害将更小。
图16.编码IL13Rα2特异性scFv CAR的反转录病毒载体的示意性图。CAR由以下 组成:免疫球蛋白重链前导肽、IL13Rα2特异性scFv克隆47(M47)、短铰链(SH)或 长铰链(LH)、衍生自CD28的跨膜域(TM)和CD28.ζ胞内域。LTR:长末端重复序 列(反转录病毒主链)。域被鉴别为嵌段结构。图不按比例绘制。
图17.IL13Rα2-scFv CAR T细胞剂:T细胞中相对于CAR剂的αGAPDH,αCD3.ζ 的表达。SH:短铰链。LH:长铰链。
图18.IL13Rα2-scFv CAR在T细胞表面上表达。IL13Rα2-CAR T细胞由反转录病 毒转导产生并且CAR表达通过FACS分析确定。短铰链CAR用特异于鼠类scFV的抗 体检测。长铰链CAR用特异于长铰链的抗体检测。同型:开口曲线;特异性抗体:填 充曲线。
图19.IL13Rα2-CAR T细胞-细胞毒性的功能表征。用Raji(IL13Rα1-/IL13Rα2-)、293T(IL13Rα1+/IL13Rα2-)、经过遗传修饰以表达IL13Rα2的293T细胞(293T-IL13Rα2;IL13Rα1+/IL13Rα2+)或U373(IL13Rα1+/IL13Rα2+)细胞作为标靶进行标准51铬细胞 毒性分析。使用IL13Rα2-CAR.SH.CD28.ζT细胞、IL13Rα2-CAR.SH.CD28.ζT细胞、 IL13Rα2-CAR.SH.ΔT细胞或IL13Rα2-CAR.LH.ΔT细胞作为效应子非转导(NT)T细胞。 仅IL13Rα2-CAR.SH.CD28.ζT细胞和IL13Rα2-CAR.LH.CD28.ζT细胞杀死IL13Rα2+靶 细胞(U373和293T-IL13Rα2;n=4)。表达非功能性CAR(IL13Rα2-CAR.SH.Δ和 IL13Rα2-CAR.LH.Δ)的T细胞不具有溶细胞活性,证实杀死活性取决于功能性 IL13Rα2-CAR的表达。NT T细胞不杀死标靶,进一步确认特异性。
图20.IL13Rα2-CAR T细胞-IFNγ和IL2细胞因子分泌的功能表征。A.NT T细胞、IL13Rα2-CAR.SH.CD28.ζT细胞、IL13Rα2-CAR.LH.CD28.ζT细胞、IL13Rα2-CAR.SH.Δ T细胞或IL13Rα2-CAR.LH.ΔT细胞与U373细胞共培养24到48小时(n=4)。仅 IL13Rα2-CAR.SH.CD28.ζT细胞和IL13Rα2-CAR.LH.CD28.ζT细胞分泌IFNγ,证实与 IL13Rα2-CAR.SH.ΔT细胞、IL13Rα2-CAR.LH.ΔT细胞或NT T细胞相比,靶细胞的识 别。B.NT T细胞、IL13Rα2-CAR.SH.CD28.ζT细胞、IL13Rα2-CAR.LH.CD28.ζT细胞、 IL13Rα2-CAR.SH.ΔT细胞或IL13Rα2-CAR.LH.ΔT细胞与U373细胞共培养24到48小 时(n=4)。仅IL13Rα2-CAR.SH.CD28.ζT细胞分泌IL2,证实相较于 IL13Rα2-CAR.LH.CD28.ζ,IL13Rα2-CAR.SH.CD28.ζ诱导优异的T细胞活化。 IL13Rα2-CAR.SH.ΔT细胞、IL13Rα2-CAR.LH.ΔT细胞或NT T细胞也不诱导IL2产生。
图21.IL13Rα2-SH CAR在体内具有抗神经胶质瘤活性。用1×105个表达萤火虫荧光 素酶的U373细胞颅内注射严重联合免疫缺陷(SCID)小鼠。在第7天,用1×106个 IL13Rα2-CAR.SH.CD28.ζT细胞、IL13Rα2-CAR.LH.CD28.ζT细胞、IL13Rα2-CAR.SH.Δ T细胞或IL13Rα2-CAR.LH.ΔT细胞处理小鼠(每组5只小鼠)。通过生物发光成像监测 肿瘤生长。仅IL13Rα2-CAR.SH.CD28.ζT细胞具有显著的抗神经胶质瘤作用,其中4/5 只小鼠具有完全应答。
图22.m47 CAR T细胞剂的特性。m47-CAR T细胞识别IL13Rα2+而非IL13Rα1+标 靶。数据显示就效应功能来说,短铰链CD28z-CAR(SH2)T细胞比CD28z-CAR(SH3)、 CD28z-CAR(LH2)、CD28z-CAR(LH3)、CD28z-CAR(SH2Δ)或CD28z-CAR(SH3Δ) 表现得更好。
图23.m47 CAR T细胞剂的功能比较。开口曲线:二级抗体;填充曲线:IL13Rα2Fc +二级抗体。
图24.m47 CAR T细胞剂在转导后高度表达。开口曲线:二级抗体;填充曲线:IL13Rα2Fc+二级抗体。
图25.m47 CAR T细胞产生干扰素γ和白介素2,但仅在IL13Rα2刺激后产生。
图26.IL13Rα2-和IL13Rα1-阳性细胞系是通过HEK 293T细胞的遗传修饰制备。填充曲线:同型抗体对照;开口曲线:特异性抗体。
图27.m47 CAR T细胞仅杀死IL13Rα2+细胞系。体外实验提供确立如下的数据:m47 CAR T细胞在细胞表面上存在重组CAR蛋白,其除特异性识别IL13Rα2外不识别 IL4R、IL13Rα1或任何受体。识别的特异性延伸到仅针对那些表达IL13Rα2的细胞系的 特异性。
图28.比较裸小鼠中m47 CAR T细胞剂、未处理和NT处理的多形性成胶质细胞瘤异种移植物的作用的体内数据。使用U373多形性成胶质细胞瘤异种移植物小鼠模型。 在第0天,每只小鼠给予1×105个GFP-ffluc U373细胞。在第7天,给予2×106个m47 CAR T细胞或NT细胞。在第7天未处理样品不接受处理。不给予外源性白介素2并且 通过连续生物发光成像记录存活分析的结果。n=3。
图29.m47 CAR T细胞剂延长具有多形性成胶质细胞瘤的裸小鼠的存活。
图30.IL13Rα2-CAR T细胞的表征。(A、B)使用重组蛋白的共培养分析证实以IL14Rα2依赖性方式产生干扰素γ和白介素2;(C)标准铬释放分析中的溶细胞活性。
图31.scFv47与IL13Rα2的结合特征。(a)在板ELISA中确定经过纯化的可溶scFv47与rhIL13Rα2和rhIL13Rα1蛋白的结合。(b)可溶scFv47的蛋白质印迹分析。与所预测 分子量一致,scFv47蛋白在还原条件下按30kDa蛋白形式操作。(c)在Biacore 3000 中通过SPR目测scFv47与rhIL13Rα2之间的相互作用的动力学。在20μL/min的恒定流 速下在固定化rhIL13Rα2上以1到50nM(下部到上部曲线)范围内的浓度注射scFv47。 监测缔合阶段30秒,监测解离阶段900秒,随后监测以RU形式给出的SPR信号的变 化(彩色曲线)。黑色曲线表示数据与一个位点结合模型的拟合。对于衍生的动力学参 数,参见表1。下部图显示一个位点结合模型的残数,指示极佳的拟合。
图32.IL13Rα2向性病毒结构和稳定性的设计、产生和确认。(a) Ad5FFscFv47-CMV-GFP的抗IL13Rα2 scFv特异性嵌合体纤维的示意图。Ad5的纤维结 (knob)和干(shaft)域经纤维-纤维蛋白(fiber fibritin)三聚域替代,并且抗IL13Rα2 scFv47 并入嵌合纤维的C端中。(b)纤维修饰的PCR确认。(c)嵌合纤维结构的验证。当嵌 合纤维未煮沸(U:在室温下培育10分钟)时,蛋白质印迹分析检测到稳定的纤维三聚, 并且当纤维经过煮沸(B:在95℃下培育10分钟)时检测到变性的单体结构。
图33.Ad5FFscFv47-CMV-GFP的向性修饰的确认。(a)Ad5FFscFv47-CMV-GFP病 毒的CAR不依赖性感染力。用Ad5CMV-GFP或Ad5FFscFv47-CMV-GFP病毒感染CAR 阴性CHO和CAR阳性CHO-hCAR细胞系。感染后72小时通过流式细胞测量术分析细 胞的GFP表达。(b)使用mAb IL13Rα2(克隆47)检测的IL13Rα2在CHO-IL13Rα2 细胞系表面上的表达。(c)通过CHO-IL13Rα2细胞的有效转导和IL13Rα2阴性CHO细 胞的转导缺乏而展现的Ad5FFscFv47-CMV-GFP的IL13Rα2依赖性感染力。(d)在 U87MG、U251MG、GBM39和GBM43神经胶质瘤细胞系的表面上的IL13Rα2表达。 数据呈现为阳性细胞的百分比。(e)Ad5FFscFv47-CMV-GFP而非Ad5CMV-GFP病毒的 转导效率强烈地与U87MG、U251MG、GBM39和GBM43神经胶质瘤细胞中的IL13Rα2 表达水平相关。感染后72小时通过流式细胞测量术分析所转导的神经胶质瘤细胞的GFP 表达。(f)随着MOI增加,Ad5FFscFv47-CMV-GFP的感染力的稳定增加。在100、200 和300个病毒粒子/细胞(vp/cell)的MOI下用Ad5FFscFv47-CMV-GFP或Ad5CMV-GFP 感染U251MG细胞。感染后72小时,针对细胞中的GFP表达,进行流式细胞分析。在 所有图中每一个数据点是3个独立重复的平均值。数据呈现为平均值±SEM。***p< 0.001。
图34.Ad5FFscFv47-CMV-GFP的IL13Rα2特异性感染力。(a)U251MG细胞中的 IL13Rα2表达的流式细胞测量术分析,其紧接着用对照shRNA(IL13Rα2+U251MG) 或IL13Rα2特异性shRNA(IL13Rα2 KDU251MG)的基因敲低(knockdown),其呈现 为阳性细胞的百分比(流程图)和中位荧光强度(MFI)。(b)通过IL13Rα2+U251MG 和IL13Rα2.KDU251MG细胞系中的GFP的差异表达而展现的Ad5FFscFv47-CMV-GFP 的IL13Rα2依赖性感染力。(c)竞争结合分析。用如本文所描述的抗IL13Rα2 mAb预 处理U251MG细胞。随后用Ad5scFv47-CMV-GFP病毒感染对照和处理细胞。72小时 后通过流式细胞测量术分析细胞的GFP转基因表达。每一个数据点是3个独立重复的平 均值。绘制平均值±SEM。***p<0.001。
图35.神经球通过Ad5FFscFv47-CMV-GFP的感染。(a)对以粘附培养物形式或以 神经球形式生长的U87MG细胞中的IL13Rα2表达的比较。(b)通过RT-PCR分析以粘 附培养物形式或以神经球形式生长的U87MG神经胶质瘤细胞中的相对IL13Rα2 mRNA 表达。(c)针对GFP阳性细胞,通过流式细胞测量术分析确定相对于神经球以粘附培养 物形式生长的U87MG神经胶质瘤细胞的Ad5FFscFv47-CMV-GFP感染力。(d)感染有 Ad5FFscFv47-CMV-GFP的U87MG神经球的显微图像(相差图像-左图)。GFP表达(右 图)以绿色荧光形式显示。比例条是100μm。每一个数据点是3个独立重复的平均值。 绘制平均值±SEM。***p<0.001,**p<0.01。
图36.神经胶质瘤的异种移植物模型中的IL13Rα2特异性感染。将小鼠脑切片并且针对DAPI(蓝色)、GFP(病毒感染)、抗GFP(紫色)和抗人类巢蛋白(红色,肿瘤) 进行染色。(a)IL13Rα2.KDU251MG细胞植入的小鼠的免疫组织化学分析。在肿瘤区域 中,不可观测到GFP阳性细胞。(b)IL13Rα2+U251MG细胞植入的小鼠的免疫组织化 学分析。虽然在肿瘤区域中观测到GFP阳性细胞,但在肿瘤相邻区域中不可观测到经过 病毒感染的细胞,指示Ad5FFscFv47-CMV-GFP的感染力对IL13Rα2表达水平具有高度 特异性。比例条是10μm。
图37.Ad5FFscFv47-CMV-GFP病毒产生的效率。如本文所描述对Ad5-CMV-GFP 和Ad5FFscFv47-CMV-GFP两者进行扩展、纯化和滴定。每一个数据点是3个独立重复 的平均值。绘制平均值±SEM。
图38.原代GBM细胞通过Ad5FFscFv47-CMV-GFP病毒的感染。A.通过qRT-PCR 分析以粘附或神经球培养物形式生长的源自患者的原代GBM39和GBM43细胞中的相 对IL13Rα2mRNA表达。将IL13Rα2 mRNA表达水平归一化成GAPDH mRNA表达。 B.对在以粘附培养物形式或以神经球形式生长的原代GBM细胞的表面上的IL13Rα2表 达的比较。C.针对GFP阳性细胞,通过流式细胞测量术分析确定以粘附或神经球培养物 形式生长的原代GBM细胞的Ad5FFscFv47-CMV-GFP感染力。每一个数据点是3个独 立重复的平均值。绘制平均值±SEM。***P<0.001。
图39.可溶性双特异性scFvIL13Rα2-scFvCD3在大肠杆菌表达系统中的表达。LL-长连接子(Gly4S)3;SL-短连接子Gly4S。
具体实施方式
本公开提供特异性地识别白介素13受体α2(IL13Rα2)的结合剂或伴侣,以用于 诊断、预防、治疗或改善通过存在IL13Rα2的细胞表征的大范围癌症中的任一种的症状。 更确切地说,本公开提供(i)特异性靶向人类肿瘤相关抗原、即白介素13受体α2 (IL13Rα2)的单克隆抗体(m47)的六个互补决定区的序列,和(ii)展现由重链和轻 链cDNA编码的呈scFv抗体型式的蛋白质或与其它功能部分的缀合物(例如融合体) 的功能性的数据。与免疫技术中的理解一致,m47单克隆抗体的六个互补决定区赋予针 对IL13Rα2的结合特异性。在一些实施例中,scFv包含抗体m47的完整重链和轻链可 变区或抗体m47的完整重链和轻链。在一些实施例中,重链和轻链片段包含例如m47 CDR或m47可变区,并且这些域可以按不同型式布置,如抗体的单链可变片段(即, scFv)、双功能抗体、双特异性抗体片段、三特异性抗体片段、具有广泛多种治疗蛋白 中的任一种和/或其它部分的融合蛋白、人源化抗体片段、Fab片段、Fab′片段、F(ab)2′ 片段和提供靶向功能和效应功能的双功能肽的任何其它功能型式。此外,单链抗体或由 重链和轻链编码的蛋白质的其它布置可以经过表达并且缀合到治疗载体(例如病毒、细 胞、纳米材料)用于将治疗剂特异性递送到IL13Rα2表达肿瘤中。根据本公开的材料也 适用于使肿瘤负荷成像。
所述技术解决阻碍免疫疗法进展的最严重障碍,即假想不存在所定义的肿瘤特异性 抗原,所述抗原可以预测地发现于人类癌症的至少一更大子组上并且可以充当有效标靶 以用于癌症根除。寻找这类抗原将会使所述领域超出用于治疗CD19/CD20表达B细胞 恶性病的方法。
当在本公开的情形下视为整体时,除非本文清楚地指出不同含义,否则,在所属领域中给出贯穿本公开所使用的术语的普通和习惯含义。
本公开描述对IL13Rα2具有特异性的单克隆抗体(mAb)片段的开发和表征,以用于靶向IL13Rα2表达肿瘤的治疗目的。高亲和力IL13Rα2由多形性成胶质细胞瘤(GBM) 以及若干其它肿瘤类型以高频率选择性地表达。靶向这种肿瘤特异性受体的一种方法利 用缀合到细胞毒性分子的同源配位体IL-113。然而,这种方法缺乏特异性,因为针对IL-13、IL13Rα1的较低亲和力受体由正常组织广泛地表达。预期对IL13Rα2具有特异性的单克 隆抗体(mAb)解决困扰识别两种IL13受体即IL13Rα1以及IL13Rα2的方法的特异性 缺乏。这类mAb将治疗性地适用于靶向并且治疗IL13Rα2表达癌症,包括肿瘤。
如本文所公开,产生杂交瘤细胞系并且比较其与重组人类IL13Rα2(rhIL13Rα2)的结合亲和力。克隆47展现与IL13Rα2的原生构形的结合并且因此被选择用于进一步研 究。克隆47特异性结合到rhIL13Rα2而非rhIL13Rα1或鼠类IL13Rα2并且与rhIL13Rα2 具有高亲和力(KD=1.39×10-9M)。此外,克隆47特异性识别在CHO和HEK细胞以 及若干神经胶质瘤细胞系的表面上表达的野生型IL13Rα2。竞争结合分析揭露克隆47 也显著抑制人类可溶IL-13与IL13Rα2受体之间的相互作用。此外,IL13Rα2的N-连接 糖基化部分地促进抗体与IL13Rα2的相互作用。在体内,IL13Rα2 mAb提高颅内植入有 人类U251神经胶质瘤异种移植物的裸小鼠的存活率。
本公开至少部分地基于如下发现:IL13Rα2优先发现于如肿瘤细胞的癌细胞上。这种受体充当已被使用以诱发高亲和力单克隆抗体m47以及所述抗体的抗原结合片段的 癌症或肿瘤特异性抗原。m47抗体的VL和VH可变区已被工程改造成单链(sc)可变 片段(scFv)以产生缀合物,如嵌合抗原受体(即,CAR),以引入到T细胞中用于过 继转移。因此,预期CAR转导的T细胞靶向肿瘤特异性IL13Rα2抗原决定基,根除存 在所述受体的癌细胞。相信识别IL13Rα2的CAR转导的T细胞将破坏大实体肿瘤。然 而,CAR转导的T细胞仅直接靶向癌细胞并且抗原阴性癌细胞可能会逃脱。所预期的是 CAR转导的T细胞也将在经由旁观者效应消除抗原阴性癌细胞中有效。
根据本公开的蛋白质缀合物特异于与癌症例如肿瘤相关的IL13Rα2。此外,本公开提供一种编码这些癌症特异性结合伴侣中的一种的聚核苷酸,包括针对特异于IL13Rα2 的抗原决定基的结合伴侣包含密码子优化编码区的聚核苷酸。本公开的聚核苷酸编码缀 合物或双功能多肽,所述缀合物或双功能多肽适用于诊断、预防、治疗或改善癌症的症 状,所述癌症如各种人类癌症、包括形成实体肿瘤的那些癌症中的任一种。也涵盖包含 如本文所公开的聚核苷酸的载体、包含这类聚核苷酸和/或如上文所描述的载体的宿主细 胞,以及治疗、预防或改善癌症疾病例如实体肿瘤、原发性癌症部位或转移癌症的症状 的方法。
本公开涵盖所属领域中已知的各种形式的缀合物。这些缀合物提供对癌症以及蛋白 质极具特异性的抗体受体,所述受体可以并入提供效应功能的各种骨架中,如下文所提到的双特异性T细胞啮合体(BITE)或嵌合抗原受体(CAR)。本公开的示范性的缀合 物包括CAR;融合蛋白,包括包含单链可变(抗体)片段(scFv)多聚体的融合体,或 与编码适用于治疗癌症的产物例如IL-15、IL15Rα或IL-15/IL15Rα剂的编码区融合的 scFv融合体;双功能抗体;三功能抗体;四功能抗体和双特异性二价scFv,包括双特异 性串联二价scFv,也称为双特异性T细胞啮合体或BITE。此外,这些缀合物形式中的 任一种可以展现各种相对结构中的任一种,如在所属领域中已知,不同域顺序(例如 H2N-VH-连接子-VL-CO2H和H2N-VL-连接子-VH-CO2H)与特异性结合相容。也涵盖本 文所描述的缀合物的更高级形式,如包含本文所公开的缀合物的至少一种形式的肽体。 本公开的缀合物特异性结合到癌症特异性抗原决定基(例如IL13Rα2)并且可以对编码 其的聚核苷酸进行密码子优化,以例如用于最大化翻译,用于在所靶向细胞(例如人类 或小鼠细胞)中表达。在表达本公开的缀合物如CAR的情形下,为确保蛋白质的产生 有效并且足够稳固以适用作治疗剂源,密码子优化至关重要。
本公开也涵盖其中靶向部分(抗IL13Rα2抗体或其片段)连接到提供第二功能的肽的缀合物,所述第二功能例如效应功能,如涉及T细胞活化的T细胞信号传导域;影响 或调节针对癌细胞的免疫应答的肽;或在缀合物的编码区经过密码子优化用于在靶细胞 中表达的情况下,产生由根据本公开的聚核苷酸编码的CAR的标记系统的酶组分。示 范性的缀合物包括抗IL13Rα2 scFv,其连接到铰链、跨膜域和效应化合物或域,例如 CD28、CD3ζ、CD134(OX40)、CD137(41BB)、ICOS、CD40、CD27或Myd88,由 此产生CAR。
本公开的聚核苷酸方面包含如下实施例:其中提供较慢生长的更高级真核生物如脊 椎动物(例如人类)中关于密码子优化的未预期变化,其聚焦于翻译优化(最大化高保真性翻译率)而非用于这类生物体中的典型的密码子优化,其经设计以适应突变偏移并 且由此将突变降到最小。也公开诊断、预防、治疗或改善癌症的症状的方法。示意性地 描述,聚核苷酸包含用于抗原受体的密码子优化编码区,所述抗原受体特异性识别连接 到以下中的任一个的IL13Rα2抗原决定基:涉及T细胞活化的T细胞信号传导域的编码 区;影响或调节针对癌细胞的免疫应答的基因产物,如IL15/IL15Rα融合体;或标记组 分,如标记系统的酶组分。连接的编码区产生根据本公开的编码缀合物如BITE或嵌合 抗原受体(CAR)的聚核苷酸。
在诊断、预防、治疗或改善癌症的症状的方法中,本公开的组合物典型地以缀合物转导的细胞形式给予,所述缀合物转导的细胞如T细胞、NK细胞或不为T细胞的淋巴 细胞,但也涵盖对包含本公开的聚核苷酸的载体的给予或对本公开的聚核苷酸的给予, 这取决于缀合物的功能性。如贯穿本公开所使用,术语“鉴别(identifying)”和所述术语 的其它形式(例如鉴别(identify))可与术语“诊断(diagnosing)”和所述术语的其它形 式(例如诊断(diagnose))互换使用。将本公开的聚核苷酸、载体或宿主细胞与生理学 上合适的缓冲液、佐剂或稀释剂组合得到根据本公开的医药组合物,并且这些医药组合 物适用于给药以诊断、预防、治疗或改善癌症的症状。
在本文所描述的实验工作的过程中,产生杂交瘤细胞系并且比较其与重组人类IL13Rα2(rhIL13Rα2)的结合亲和力。克隆47展现与IL13Rα2的原生构形的结合并且 因此进一步被表征。克隆47特异性结合到rhIL13Rα2而非rhIL13Rα1或鼠类IL13Rα2 并且与rhIL13Rα2具有高亲和力(KD 1.39×10-9M)。此外,克隆47特异性识别在CHO 和HEK细胞以及若干神经胶质瘤细胞系的表面上表达的野生型IL13Rα2。竞争结合分 析揭露克隆47也显著抑制人类可溶IL-13与IL13Rα2受体之间的相互作用。此外,发 现IL13Rα2的N-连接糖基化部分地促进抗体与IL13Rα2的相互作用。在体内,IL13Rα2 单克隆抗体提高颅内植入有人类U251神经胶质瘤异种移植物的裸小鼠的存活率。总起 来说,这些数据确立本文所公开的癌症的免疫调节治疗的功效。
IL13Rα2在多形性成胶质细胞瘤(GBM)中而非在正常脑组织中的过表达独特地将这种受体定位为用于靶向肿瘤细胞的候选物。GBM是高度浸润性肿瘤,经常使完全的 手术去除变得不可能。此外,GBM高度耐辐射和化学疗法(16),使进一步开发用于治 疗患者的新颖并靶向的疗法有必要。
已使用噬菌体展示文库方法来选择对人类IL13Rα2具有特异性的小抗体片段,随后 在体外和体内对其进行评估(23)。尽管与IL13Rα2的相互作用具高特异性,但当与 IL-13PE38的作用相比较时,与毒素的结合不能增加IL13Rα2表达神经胶质瘤和肾细胞 癌细胞系中的细胞毒性。所产生的抗体片段的低亲和力是对缺乏成功最合理的解释。已 知衍生自噬菌体呈现文库的抗体片段在亲和力和亲合力方面比由常规杂交瘤技术产生 的抗体更低(24)。经常需要修饰那些小抗体片段以增强其与所靶向蛋白质的亲和力和 亲合力。近年来,单克隆抗体作为靶向抗癌和诊断药剂日益取得成功(25、26),并且 需要进一步探索对肿瘤相关抗原具有受限制特异性的高亲和力试剂。设计本文所公开的 实验以发现、开发并且表征特异性地识别在癌细胞表面上表达的IL13Rα2的高亲和力抗 体。与所述设计一致,本文公开如下实验:确立拥有体内对IL13Rα2表达肿瘤的免疫治 疗靶向关键的特性并且潜在地适用于各种其它应用的抗体的产生。
单克隆抗体看起来是有价值的研究和诊断工具以及治疗剂。由于具有特异性靶向癌 细胞同时避免与未转化组织相互作用的能力,因此特异于肿瘤相关抗原的单克隆抗体具 有优于系统性化学疗法的显著优势。因此,对新颖“灵丹妙药(magic bullet)”的探索持续增长,经全球市场确认,截至2010年,治疗抗体值480亿美元。治疗抗体是传统杂 交瘤技术或抗体片段的文库筛选和其成为人源化片段或实际大小分子的后续工程改造 的产物。在本研究之前,在科学界不可获得分泌对肿瘤特异性抗原IL13Rα2具高亲和力 的抗体的杂交瘤细胞系。此处,我们描述对肿瘤特异性抗原IL13Rα2具高亲和力的抗体 的产生和表征,并且论述其在不同应用中的可能用途。
新发现的抗体与人类IL13Rα2的相互作用的特异性通过ELISA使用rhIL13Rα2hFc融合蛋白、在CHO和HEK细胞的表面上表达的重组人类IL13Rα2和表达各种含量的 IL13Rα2的若干神经胶质瘤细胞系通过流式细胞测量术来分析。本文中所鉴别的抗体和 使用其结合域的药剂展现与人类IL13Rα2的相互作用的特异性并且不与人类IL13Rα1或 小鼠IL13Rα2交叉反应。此外,对于在HEK细胞表面上表达的IL13Rα2的检测,在竞 争结合分析中使用rhIL13Rα2hFc融合蛋白通过ELISA或通过流式细胞测量术确认与 IL13Rα2的结合的特异性。在这些分析中,IL13Rα2(克隆47)mAb与重组人类IL-13 竞争其抗原决定基并且能够阻断IL-13与IL13Rα2之间约80%的结合。相反,人类重组 IL-13能够阻断约50%的与IL13Rα2的抗体结合。类似地,当rhIL13R2hFc嵌合体和 rhIL-13用作竞争者时,观测到IL13Rα2(克隆47)mAb与N10神经胶质瘤细胞的结合 显著降低。rhIL-13与N10细胞的结合也通过IL13Rα2(克隆47)mAb消除。这些数据 指示两个分子在其针对IL13Rα2的识别位点中具有显著的重叠。
IL-13是小10kDa分子(31),然而抗体的分子质量比其大约15倍。rhIL-13与抗体竞争结合位点的能力表明抗体的抑制特性有可能是由于与促进IL-13与同源受体的结合的氨基酸残基的特异性相互作用而非位阻所致,所述位阻也可以防止IL-13与其受体的 相互作用。先前,Tyr207、Asp271、Tyr315和Asp318被鉴别成为与IL-13的相互作用 所需的IL13Rα2的关键残基(28)。在本文所公开的分析中,当与野生型受体相比较时, IL-13与携带突变成丙氨酸的所有4个氨基酸突变的组合的突变体IL13Rα2的结合被显 著消除。然而,IL13Rα2mAb与IL13Rα2的个别形式或4胺基酸突变体形式的结合不受 显著影响。这些发现指示Tyr207、Asp271、Tyr315和Asp318残基对于经IL13Rα2 mAb 识别IL13Rα2来说不关键。人类IL13Rα2和鼠类IL13Rα2在结构上保守并且共享59% 的氨基酸一致性(32)。此外,Tyr207、Asp271、Tyr315和Asp318残基在人类和鼠类 IL13Rα2中是保守的。IL13Rα2 mAb与鼠类IL13Rα2hFc融合体的结合的缺乏进一步支 持如下预期:这些氨基酸残基有助于IL-13与IL13Rα2的结合并且对于这种抗体与受体 的相互作用不关键。
为进一步表征IL13Rα2与本文所公开的抗体和抗体药剂的相互作用,测量IL13Rα2mAb的亲和力并且使用表面等离子体共振法(surface plasmon resonance method)将其与两种可商购抗体的结合特性相比较。经过测定IL13Rα2 mAb的亲和力等于1.39×10-9M, 大大超过可比较的可商购抗体的亲和力,超出达75倍。与亲和力研究一致,在与各种 神经胶质瘤细胞表面上表达的IL13Rα2的结合和ELISA方面,IL13Rα2 mAb(克隆47) 展现超越两种商业抗体的优越性。尽管应在具体使用之前考虑抗体的许多特性,包括亲 和力和亲合力、体内稳定性、清除速率和内化速率、肿瘤渗透和保持力,但已经报导对 于免疫治疗肿瘤靶向应用,更高亲和力的抗体更佳(33)。针对表皮生长因子受体变异 体III的单链抗体片段(scFv)MR1-1展现比亲本scFvMR1高约15倍的亲和力,并且 还显示比scFvMR1的肿瘤吸收高平均244%的肿瘤吸收(34)。有可能本文所公开的 IL13Rα2 mAb和其药剂的高亲和力特性将有利于利用靶向表达IL13Rα2的肿瘤细胞的抗 体或相关衍生物的应用。
IL13Rα2的N-连接糖基化已被鉴别为是与IL-13的有效结合的必需要求(30)。考虑到本文所公开的IL13Rα2 mAb抑制约80%的IL-13与同源受体IL13Rα2的结合,合理 地期望在IL13Rα2的去糖基化形式下这种抗体或含有其结合域的药剂的结合也会受影 响。IL13Rα2分子具有四个可能的N-连接糖基化位点。当与非处理对照相比较时,抗体 与rhIL13Rα2或与在用Pngase F处理的HEK或U251细胞的表面上表达的IL13Rα2的 结合分别降低35和30%。当与克隆83807和B-D13相比较时,克隆47的结合活性的部 分变化表明使用Pngase F从IL13Rα2中去除碳水化合物加合物使得受体的构形发生变 化,间接影响IL-13(30)和IL13Rα2 mAb与IL13Rα2的结合。这也支持如下预期:抗 体直接结合到IL13Rα2胺基酸主链而非与翻译后添加的碳水化合物部分相互作用。支持 这种预期,若干研究先前已证实蛋白质的构形概况和结构刚度取决于N-连接糖基化(22、 35-38)。
为调查IL13Rα2 mAb和其药剂的治疗特性,进行体内研究,其中将神经胶质瘤细胞和IL13Rα2(克隆47)mAb颅内共注射于脑中,或将抗体注射于经确立带有肿瘤的小鼠 中。有趣地,IL13Rα2 mAb能够延迟肿瘤发展,并且提高具有颅内U251神经胶质瘤异 种移植物的动物的存活率,在共注射模型中最显著,进而展现提高具有已确立的神经胶 质瘤的动物的中位存活期的趋势。尽管对于这种抗肿瘤作用的基础机制仍然不清楚,但 所述结果确立这种抗体或其药剂(含有IL13Rα2结合域,所述结合域呈六个CDR区形 式,或呈克隆47抗IL13Rα2的两个可变域形式)单独或与药物载剂组合的治疗适用性, 由此提供用于治疗IL13Rα2表达神经胶质和其它谱系肿瘤的疗法。已显示若干抗体通过 Fc介导的补体活化介导肿瘤中的细胞毒性作用(39)。抗体依赖性细胞介导的细胞毒性 诱导的效应细胞活化也可以对针对所靶向细胞的抗体的细胞毒性作用做出贡献(40、 41)。衍生自用表达人类IL13Rα2的D5黑素瘤细胞攻击的动物的血清的抗IL13Rα2活 性证实体外抑制细胞生长的能力(4)。
适合于所描述治疗的癌症包括已发现表达IL13Rα2的癌症,包括成胶质细胞瘤;神经管胚细胞瘤;卡波西(Kaposi)肉瘤;和头颈癌、卵巢癌、胰脏癌、肾癌和结肠直肠 癌(2、43-47)。尽管IL13Rα2在一些癌症中的作用尚不界定,但最新报导已证实IL13Rα2 对卵巢癌、胰脏癌和结肠直肠癌的侵袭性表型有贡献(5、13)。此外,Minn等人(42) 已表明IL13Rα2表达与到肺的乳癌转移之间的关系。此外,Fichtner-Feigl等人(11)证 实IL-13与IL13Rα2的相互作用上调TGF-β1,介导博莱霉素(bleomycin)诱导的肺纤 维化模型中的纤维化。根据这种发现,预期抗IL13Rα2抗体(克隆47)和其结合剂将能 够减弱TGF-β1诱导的肺纤维化。
如本文所公开,所描述实验产生抗IL13Rα2抗体和其结合剂,其均对人类IL13Rα2具有特异性。抗体和其药剂拥有针对IL13Rα2的高亲和力并且与IL-13竞争IL13Rα2上 的结合位点。抗体识别在神经胶质瘤细胞以及其它IL13Rα2表达细胞的细胞表面上表达 的抗原,确立体内用于靶向IL13Rα2表达肿瘤细胞的适合性。也预期抗IL13Rα2抗体和 其结合剂在诊断成像、抗体放射性核素缀合物的递送、检测IL13Rα2的生物分析中有效 并且经济,并且作为治疗剂在不同类型的IL13Rα2过表达肿瘤中的载体。
在诊断、预防、治疗或改善癌症的症状的方法中,本公开的组合物典型地以缀合物转导的T细胞形式给予,但也涵盖对包含本公开的聚核苷酸的载体的给予或对本公开的 聚核苷酸的给予,这取决于缀合物的功能。将本公开的聚核苷酸、载体或宿主细胞与生 理学上合适的缓冲液、佐剂或稀释剂组合得到根据本公开的医药组合物,并且这些医药 组合物适用于给药以诊断、预防、治疗或改善癌症的症状。
也涵盖根据本公开的缀合物,如由融合到IL15/IL15Rα的针对IL13Rα2抗原决定基的scFv受体构成的融合蛋白。预期融合蛋白将消除临床大小肿瘤或仅初期和微散播的 癌细胞。本公开进一步涵盖对人类癌症上的两种独立的IL13Rα2抗原决定基的同时靶向, 其可能为防止逃脱治疗(如CAR治疗)所必需。
通过CAR的对不同IL13Rα2抗原决定基的同时靶向应降低癌症亚群逃脱的可能性,其提供了鉴别额外IL13Rα2抗体产物和/或抗原决定基的强有力的理由。
本公开提供可调适并且可以充当具有可观增长可能性的平台技术的基础的材料和 方法。预期IL13Rα2的癌症特异性性质向癌症诊断剂、预防剂和治疗剂提供主要优势优于先前和当前使用的标靶的标靶。
与前述的精神一致,以下提供对本文所提供的材料和方法的描述。
本文公开IL13Rα2结合剂,其包含以下的氨基酸序列中的每一个:NYLMN(SEQ IDNO:1);RIDPYDGDIDYNQNFKD(SEQ ID NO:2);GYGTAYGVDY(SEQ ID NO:3); RASESVDNYGISFMN(SEQ ID NO:4);AASRQGSG(SEQ ID NO:5);和QQSKEVPWT (SEQ ID NO:6)。在示范性方面中,除提供构架以支撑结合到IL13Rα2的三维构形的其 它序列以外,结合剂包含前述六个氨基酸序列中的每一个。在示范性方面中,IL13Rα2 结合剂包含SEQ ID NO:7和/或SEQ ID NO:8的氨基酸序列中的一个或两个。在示范性 方面中,IL13Rα2结合剂包含SEQ ID NO:7的氨基酸序列。在示范性方面中,IL13Rα2 结合剂包含SEQ ID NO:8的氨基酸序列。在示范性方面中,IL13Rα2结合剂包含SEQ ID NO:7和SEQ ID NO:8的氨基酸序列两者。在SEQ ID NO:7和SEQ ID NO:8的氨基酸 序列存在于结合剂中的示范性方面中,SEQ ID NO:7的氨基酸序列经由连接子融合到 SEQ ID NO:8的氨基酸序列。合适的连接子在所属领域中已知。在示范性方面中,连接 子包含约5到约25个氨基酸、例如约10到约20个氨基酸的短氨基酸序列。在示范性 方面中,连接子包含EEGEFSEAR(SEQ ID NO 10)的氨基酸序列。在示范性方面中,连接子包含AKTTPPKLEEGEFSEARV(SEQ ID NO:80)的氨基酸序列。在示范性方面 中,IL13Rα2结合剂包含SEQ ID NO:13的氨基酸序列。
在示范性实施例中,本文所提供的结合剂进一步包含额外氨基酸序列。在示范性方 面中,结合剂进一步包含重链的恒定区和/或轻链的恒定区。重链和轻链恒定区的序列是 公众可获得的。举例来说,美国国家生物技术信息中心(NCBI)核苷酸数据库提供IgG1 κ轻链的恒定区的序列。参见以引用的方式并入本文中的基因银行(GenBank)登录号DQ381549.1。在示范性方面中,结合剂包含SEQ ID NO:28的氨基酸序列。在示范性方 面中,结合剂包含SEQ ID NO:28的经过修饰的氨基酸序列。。在示范性方面中,结合 剂包含与SEQID NO:28至少90%、至少93%、至少95%或至少98%一致的氨基酸序列。 同样,举例来说,NCBI核苷酸数据库提供小家鼠(Mus musculus)IgG1的恒定区的序 列。参见基因银行登录号DQ381544.1。在示范性方面中,结合剂包含SEQ ID NO:29 的氨基酸序列。在示范性方面中,结合剂包含SEQ ID NO:29的经过修饰的氨基酸序列。。 在示范性方面中,结合剂包含与SEQ ID NO:29至少90%、至少93%、至少95%或至少 98%一致的氨基酸序列。
在示范性方面中,IL13Rα2结合剂是抗体或其抗原结合片段。在示范性方面中,抗体包含SEQ ID NO:1-6的氨基酸序列中的每一个。在示范性方面中,抗体包含SEQ ID NO:7和/或SEQ ID NO:8的氨基酸序列。在示范性方面中,抗体包含SEQ ID NO:7和 SEQ ID NO:8的氨基酸序列。在示范性方面中,抗体包含SEQ ID NO:7和SEQ ID NO: 8的氨基酸序列,并且SEQ ID NO:7的氨基酸序列经由连接子融合到SEQ ID NO:8的 氨基酸序列。在示范性方面中,连接子包含约5到约25个氨基酸、例如约10到约20 个氨基酸的短氨基酸序列。在示范性方面中,连接子包含EEGEFSEAR(SEQ ID NO 10) 的氨基酸序列。在示范性方面中,连接子包含AKTTPPKLEEGEFSEARV(SEQ ID NO:80) 的氨基酸序列。在示范性方面中,抗体包含SEQID NO:13的氨基酸序列。
在示范性方面中,抗体可以是所属领域中已知的任何类型的免疫球蛋白。举例来说, 抗体可以具有任何同型,例如IgA、IgD、IgE、IgG或IgM。抗体可以是单克隆或多克 隆的。抗体可以是天然存在的抗体,即,从哺乳动物例如小鼠、兔、山羊、马、鸡、仓 鼠、人类等等中分离和/或纯化的抗体。在这点上,抗体可被认为是哺乳动物抗体,例如 小鼠抗体、兔抗体、山羊抗体、马抗体、鸡抗体、仓鼠抗体、人类抗体等等。如本文所 用,术语“分离”意指已从其天然环境去除。如本文所用,术语“纯化”涉及分子或化合物 以大体上不含污染物(其通常与分子或化合物在原生或天然环境中缔合)的形式分离, 并且意指已因与初始组合物的其它组分分离而导致纯度增加。应认识到,“纯度”是相对 术语,并且不必解释为绝对纯度或绝对富集或绝对选择。在一些方面中,纯度是至少或 约50%、至少或约60%、至少或约70%、至少或约80%、或至少或约90%(例如,至少 或约91%、至少或约92%、至少或约93%、至少或约94%、至少或约95%、至少或约 96%、至少或约97%、至少或约98%、至少或约99%或约100%)。
在示范性方面中,抗体包含IgG的恒定区。在示范性方面中,抗体包含IgG1的恒定区。在示范性方面中,抗体包含IgGκ轻链的恒定区。举例来说,抗体可以包含SEQ ID NO:28的氨基酸序列。在示范性方面中,抗体包含高度类似于SEQ ID NO:28的氨基酸 序列。举例来说,抗体可以包含与SEQ ID NO:28具有至少85%序列一致性的氨基酸序 列,或与SEQ IDNO:28具有至少90%序列一致性的氨基酸序列,或与SEQ ID NO:28 具有至少93%序列一致性的氨基酸序列,或与SEQ ID NO:28具有至少95%序列一致性 的氨基酸序列,或与SEQ IDNO:28具有至少98%序列一致性的氨基酸序列。
在示范性方面中,抗体包含小家鼠IgG1的恒定区。举例来说,抗体可以包含SEQ IDNO:30的氨基酸序列。在示范性方面中,抗体包含高度类似于SEQ ID NO:30的氨基酸 序列。举例来说,抗体可以包含与SEQ ID NO:30具有至少85%序列一致性的氨基酸序 列,或与SEQ ID NO:30具有至少90%序列一致性的氨基酸序列,或与SEQ ID NO:30 具有至少93%序列一致性的氨基酸序列,或与SEQ ID NO:30具有至少95%序列一致性 的氨基酸序列,或与SEQ ID NO:30具有至少98%序列一致性的氨基酸序列。
本公开的抗IL13Rα2抗体和其片段可以具有针对IL13Rα2的任何水平的亲和力或亲 合力。解离常数(KD)可以是本文关于结合单元所描述的那些示范性解离常数中的任一项。结合常数,包括解离常数,通过所属领域中已知的方法确定,所述方法包括例如利 用表面等离子体共振原理的方法,例如利用BiacoreTM系统的方法。根据前述,在一些 实施例中,抗体呈单体形式,而在其它实施例中,抗体呈聚合物形式。在抗体包含两个 或多于两个不同抗原结合区或片段的某些实施例中,抗体视为双特异性、三特异性或多 特异性的或二价、三价或多价的,这取决于经结合剂识别并结合的不同抗原决定基的数 目。
因为本公开的结合剂可以针对与IL13Rα2的结合而与lL13竞争,所以示范性方面中的抗体被视为阻断抗体或中和抗体。在一些方面中,针对IL13Rα2,结合剂的KD大 约与原生配位体IL13的KD相同。在一些方面中,针对IL13Rα2,结合剂的KD比IL13 的KD更低(例如低至少0.5倍、低至少1倍、低至少2倍、低至少5倍、低至少10倍、 低至少25倍、低至少50倍、低至少75倍、低至少100倍)。在示范性方面中,KD在约 0.0001nM与约100nM之间。在一些实施例中,KD是至少或约0.0001nM、至少或约 0.001nM、至少或约0.01nM、至少或约0.1nM、至少或约1nM、或至少或约10nM。 在一些实施例中,KD不大于或约100nM、不大于或约75nM、不大于或约50nM、或 不大于或约25nM。在示范性方面中,针对人类IL13Rα2,抗体具有不大于约1.39×10-9 M的KD。
在示范性方面中,结合剂,例如抗体或其抗原结合片段,不结合到人类IL13Rα1。
在示范性实施例中,抗体是基因工程改造过的抗体,例如单链抗体、人源化抗体、嵌合抗体、CDR接枝抗体、包括特异于IL13Rα2的CDR序列的部分的抗体(例如包括 SEQ IDNO:1-6的CDR序列的抗体)、人改造或人源化抗体、双特异性抗体、三特异性 抗体等等,如本文中更详细地定义。基因工程技术还提供制备非人类中的全人类抗体的 能力。
在一些方面中,抗体是嵌合抗体。术语“嵌合抗体”在本文中用以指如下抗体:含有来自一种物种的恒定域和来自第二物种的可变域,或更通常含有来自至少两种物种的氨基酸序列片段。
在一些方面中,抗体是人源化抗体。当相关于抗体使用时,术语“人源化”用以指抗体具有来自非人类源的至少CDR区,经过工程改造而具有相对于初始源抗体更类似于 真实人类抗体的结构和免疫功能。举例来说,人源化可以涉及将来自非人类抗体如小鼠 抗体的CDR接枝于人类抗体中。如将在所属领域中已知,人源化也可以涉及选择氨基 酸取代以制备更类似于人类序列的非人类序列。
本文中对术语“嵌合或人源化”的使用不意指为相互排斥的;相反,意指涵盖嵌合抗 体、人源化抗体和已进一步经过人源化的嵌合抗体。除非上下文另外指示,否则关于嵌合抗体(嵌合抗体的特性、用途、测试等)的陈述适用于人源化抗体,并且关于人源化 抗体的陈述也涉及嵌合抗体。同样,除非上下文规定,否则这类陈述也应理解为适用于 抗体和这类抗体的抗原结合片段。
在本公开的一些方面中,结合剂是特异性结合到根据本发明的IL13Rα2的抗体的抗 原结合片段。抗原结合片段(在本文中也被称作“抗原结合部分”)可以是任一种本文所描述抗体的抗原结合片段。抗原结合片段可以是具有至少一个抗原结合位点的抗体的任何一部分,包括但不限于Fab、F(ab′)2、dsFv、sFv、双功能抗体、三功能抗体、双scFv、 通过Fab表达文库表达的片段、域抗体、VhH域、V-NAR域、VH域、VL域等等。然 而,本发明的抗体片段不限于这些示范性类型的抗体片段。
在示范性方面中,IL13Rα2结合剂是抗原结合片段。在示范性方面中,抗原结合片段包含SEQ ID NO:1-6的氨基酸序列中的每一个。在示范性方面中,抗原结合片段包含 SEQID NO:7和/或SEQ ID NO:8的氨基酸序列。在示范性方面中,抗原结合片段包含 SEQ IDNO:7和SEQ ID NO:8的氨基酸序列。在示范性方面中,抗原结合片段包含SEQ ID NO:7和SEQID NO:8的氨基酸序列,并且SEQ ID NO:7的氨基酸序列经由连接子 融合到SEQ ID NO:8的氨基酸序列。在示范性方面中,连接子包含约5到约25个氨基 酸、例如约10到约20个氨基酸的短氨基酸序列。在示范性方面中,连接子包含 EEGEFSEAR(SEQ ID NO 10)的氨基酸序列。在示范性方面中,连接子包含 AKTTPPKLEEGEFSEARV(SEQ ID NO:80)的氨基酸序列。在示范性方面中,本文所 提供的抗原结合片段包含SEQ ID NO:13的氨基酸序列。
在示范性方面中,抗原结合片段包含前导序列。任选地,在一些方面中,前导序列位于重链可变区的N端。在示范性方面中,抗原结合片段包含Igκ前导序列。合适的前 导序列在所属领域中已知,并且包括例如METDTLLLWVLLLWVPGSTGD(SEQ ID NO: 9)的Igκ前导序列。
在示范性方面中,抗原结合片段包含一个更多个标签序列。标签序列可以有助于产 生并且表征所制造的抗原结合片段。在示范性方面中,抗原结合片段包含一个或多个在轻链可变区的C端的标签序列。合适的标签序列在所属领域中已知并且包括但不限于 Myc标签、His标签等等。在示范性方面中,抗原结合片段包含GGPEQKLISEEDLN(SEQ ID NO:11)的Myc标签。在示范性方面中,抗原结合片段包含HHHHHH(SEQ ID NO: 12)的His标签序列。
在示范性方面中,本公开的抗原结合片段从N端到C端包含前导序列、重链可变区、连接子序列、轻链可变区、Myc标签(例如SEQ ID NO:11)和His标签(例如SEQ ID NO:12)。在示范性方面中,本公开的抗原结合片段包含SEQ ID NO:14的氨基酸序列。
在示范性方面中,抗原结合片段是域抗体。域抗体包含抗体的功能结合单元,并且可以对应于抗体的重(VH)或轻(VL)链的可变区。域抗体可以具有约13kDa,或全 抗体的约十分之一重量的分子量。域抗体可以衍生自全抗体,如本文所描述的那些抗体。 在一些实施例中,抗原结合片段是单体或聚合的、双特异性或三特异性的并且是二价或 三价的。
含有抗体分子的抗原结合或独特位(idiotope)的抗体片段共享常见独特型并且由本 公开涵盖。这类抗体片段可以由所属领域中已知的技术产生,并且包括但不限于可以通 过抗体分子的胃蛋白酶消化产生的F(ab′)2片段;可以通过减少F(ab′)2片段的二硫桥键产 生的Fab′片段;和可以通过用木瓜蛋白酶和还原剂处理抗体分子产生的两个Fab′片段。
在示范性方面中,本文所提供的结合剂是单链可变区片段(scFv)抗体片段。scFv可以由包含抗体重链的可变(V)域的截短Fab片段组成,所述可变(V)域经由合成 肽连接到抗体轻链的V域,并且scFv可以使用常规重组DNA技术技术产生(参见例如 Janeway等人,《免疫生物学(Immunobiology)》,第2版,加兰出版社(Garland出版), 纽约(New York),(1996))。类似地,二硫键稳定化可变区片段(dsFv)可以通过重组 DNA技术制备(参见例如Reiter等人,《蛋白质工程(Protein Engineering)》,7, 697-704(1994))。
在示范性方面中,本文所提供的IL13Rα2结合剂是scFv。在示范性方面中,scFv 包含SEQ ID NO:1-6的氨基酸序列中的每一个。在示范性方面中,scFv包含SEQ ID NO: 7或SEQ ID NO:8的氨基酸序列。在示范性方面中,scFv包含SEQ ID NO:7和SEQ ID NO:8的氨基酸序列。在示范性方面中,scFv包含SEQ ID NO:7和SEQ ID NO:8的氨 基酸序列,并且SEQID NO:7的氨基酸序列经由连接子融合到SEQ ID NO:8的氨基酸 序列。在示范性方面中,连接子包含约5到约25个氨基酸、例如约10到约20个氨基 酸的短氨基酸序列。在示范性方面中,连接子包含EEGEFSEAR(SEQ ID NO 10)的氨 基酸序列。在示范性方面中,连接子包含AKTTPPKLEEGEFSEARV(SEQ ID NO:80) 的氨基酸序列。在示范性方面中,本文所提供的scFv包含SEQ ID NO:13的氨基酸序列。
重组抗体片段,例如本公开的scFv,也可以经过工程改造以组装于对不同靶抗原具 有高结合亲合力和特异性的稳定多聚体寡聚物中。这类双功能抗体(二聚体)、三功能抗体(三聚体)或四功能抗体(四聚体)在所属领域中是众所周知的。参见例如Kortt 等人,《生物分子工程(Biomol Eng)》.2001 18:95-108,(2001)和Todorovska等人,《免 疫学方法杂志(J Immunol Methods)》.248:47-66,(2001)。
在示范性方面中,结合剂是双特异性抗体(bscAb)。双特异性抗体是包含两个单链Fv片段的分子,所述两个单链Fv片段使用重组方法经由甘氨酸-丝氨酸连接子接合。在 示范性实施例中,所关注的两个抗体的V轻链(VL)和V重链(VH)域使用标准PCR 方法分离。随后在两步融合PCR中,获自每一杂交瘤的VL和VH cDNA接合以形成单链 片段。双特异性融合蛋白以类似方式制备。双特异性单链抗体和双特异性融合蛋白是包 括在本发明范围内的抗体物质。示范性的双特异性抗体教示于美国专利申请公开第 2005-0282233A1号和国际专利申请公开第WO 2005/087812号中,以上公开的应用均以 全文引用的方式并入本文中。
在示范性方面中,结合剂是含有两个产生为单一多肽链的scFv的双特异性T细胞啮合抗体(BiTE)。在示范性方面中,结合剂是包含两个scFV的BiTE,其中至少一个 scFv包含SEQ ID NO:1-6的氨基酸序列中的每一个或包含SEQ ID NO:7和/或SEQ ID NO:8。制备并且使用BiTE抗体的方法描述于所属领域中。参见例如Cioffi等人,《临 床癌症研究(ClinCancer Res)》18:465,Brischwein等人,《分子免疫学(Mol Immunol)》 43:1129-43(2006);Amann M等人,《癌症研究(Cancer Res)》68:143-51(2008);Schlereth 等人,《癌症研究》65:2882-2889(2005);和Schlereth等人,《癌症免疫与免疫疗法 (Cancer ImmunolImmunother)》55:785-796(2006)。
在示范性方面中,结合剂是双重亲和力再靶向抗体(dual affinity re-targeting antibody,DART)。DART产生为通过使链间二硫键稳定而接合的单独多肽。在示范性 方面中,结合剂是包含scFv的DART,所述scFv包含SEQ ID NO:1-6的氨基酸序列中 的每一个或包含SEQ ID NO:7和/或SEQ ID NO:8。制备并且使用DART抗体的方法描 述于所属领域中。参见例如Rossi等人,《mAb》6:381-91(2014);Fournier和 Schirrmacher,生物制药《BioDrugs》27:35-53(2013);Johnson等人,《分子生物学杂 志(J Mol Biol)》399:436-449(2010);Brien等人,《病毒学杂志(J Virol)》87:7747-7753 (2013);和Moore等人,《血液(Blood)》117:4542(2011)。
在示范性方面中,结合剂是四价串联双功能抗体(TandAb),其中抗体片段产生为呈头到尾布置形式的非共价均二聚体折叠子(folder)。在示范性方面中,结合剂是包含scFv的TandAb,所述scFv包含SEQ ID NO:1-6的氨基酸序列中的每一个或包含SEQ ID NO:7和/或SEQ ID NO:8。TandAb在所属领域中已知。参见例如McAleese等人,《未 来肿瘤学(Future Oncol)》8:687-695(2012);Portner等人,《癌症免疫与免疫疗法(Cancer ImmunolImmunother)》61:1869-1875(2012);和Reusch等人,《mAb》6:728(2014)。
在示范性方面中,BiTE、DART或TandAb包含SEQ ID NO:1-6的CDR。在示范性 方面中,BiTE、DART或TandAb包含SEQ ID NO:7和8的氨基酸序列。在示范性方面 中,BiTE、DART或TandAb包含SEQ ID NO:13。
合适的制备抗体的方法在所属领域中已知。举例来说,标准杂交瘤方法描述于例如 Harlow和Lane(编),《抗体:实验室手册(Antibodies:A Laboratory Manual)》,CSH出版社(CSH Press)(1988),和CA.Janeway等人(编),免疫生物学,第5版,加兰出版 社,纽约,纽约州(NY)(2001))。
用于本发明中的单克隆抗体可以使用任何技术制备,所述任何技术通过培养物中的 传代细胞系提供抗体分子的产生。这些技术包括但不限于最初由Koehler和Milstein(《自 然(Nature)》256:495-497,1975)描述的杂交瘤技术;人类B细胞杂交瘤技术(Kosbor等人,《今日免疫学(Immunol Today)》4:72,1983;Cote等人,《美国国家科学院院 刊(ProcNatl Acad Sci)》80:2026-2030,1983);和EBV杂交瘤技术(Cole等人,《单 克隆抗体和癌症疗法(Monoclonal Antibodies and Cancer Therapy)》,Alan R Liss Inc,纽 约州纽约,第77-96页,(1985)。
简单来说,多克隆抗体是通过用包含本发明多肽的免疫原免疫动物并且从经过免疫 的动物中收集抗血清来制备。大范围动物物种可以用于产生抗血清。在一些方面中,用于产生抗抗血清的动物是非人类动物,包括兔、小鼠、大鼠、仓鼠、山羊、绵羊、猪或 马。因为兔的血量相对大,所以在一些示范性方面中兔是用于产生多克隆抗体的优选选 择。在用于产生对所选择IL13Rα2抗原决定基具免疫反应性的多克隆抗血清的一示范性 方法中,在弗氏完全佐剂(Freund′s Complete Adjuvant)中乳化50μg IL13Rα2抗原用于 兔的免疫接种。在例如21天的间隔下,在弗氏不完全佐剂中乳化50μg抗原决定基用于 增强。多克隆抗血清可以在抗体产生的允许时间后仅通过使动物出血并且由全血制备血 清样品来获得。
简单来说,在示范性实施例中,为产生单克隆抗体,用重组IL13Rα2(针对其抗体待升高)(例如10-20μg乳化于弗氏完全佐剂中的IL13Rα2)周期性地注射小鼠。小鼠 获得含有允许特异性识别PBS中的淋巴内皮细胞的抗原决定基的IL13Rα2多肤的最终 预融合加强,并且四天后处死小鼠并且移出其脾。将脾置于10ml无血清RPMI 1640中, 并且通过在两个玻璃显微镜载片的毛端之间研磨脾而形成单细胞悬浮液,所述载片浸没 于补充有2mM L谷氨酰胺、1mM丙酮酸钠、100单位/毫升青霉素和100μg/ml链霉素 的无血清RPMI 1640中(RPMI)(吉毕科(Gibco),加拿大(Canada))。经由无菌70 目Nitex细胞过滤器(贝克顿-迪金森(Becton Dickinson),新泽西州派西派尼市 (Parsippany,N.J.)过滤细胞悬浮液,并且通过在200g下离心5分钟而洗涤两次,并且 将离心块再悬浮于20ml无血清RPMI中。以类似方式制备获自三只未处理Balb/c小鼠 的脾细胞并且将其用作对照。将NS-1骨髓瘤细胞,其在融合之前在具有11%胎牛血清 (FBS)(海克隆实验室公司(Hyclone Laboratories,Inc.),犹他州洛根(Logan,Utah))的 RPMI中维持对数期三天,在200g下离心5分钟,并且洗涤离心块两次。
将脾细胞(1×108)与2.0×107NS-1细胞组合并且离心,并且抽吸上清液。通过 轻敲试管移出细胞离心块,并且历经1分钟时程在搅拌下添加1ml的37℃PEG 1500 (50%于75mM Hepes中,pH 8.0)(宝灵曼(Boehringer Mannheim)),随后历经7分钟 添加7ml无血清RPMI。添加额外8ml RPMI并且在200g下离心细胞10分钟。舍弃上 清液后,将离心块再悬浮于200ml含有15%FBS、100μM次黄嘌呤钠、0.4μM氨基喋 呤、16μM胸苷(HAT)(吉毕科)、25单位/毫升IL-6(宝灵曼)和1.5×106个脾细胞/ 毫升的RPMI中,并且接种于10个康宁(Corning)底部平坦的96孔组织培养板(康宁, 纽约州康宁)中。
在第2、4和6天,在融合后,从融合板的孔中去除100μl培养基并且用新鲜培养 基替换。在第8天,通过ELISA筛选融合体,如下测试结合到IL13Rα2的小鼠IgG的 存在。在37℃下用100纳克/孔的稀释于25mM pH 7.5 Tris中的IL13Rα2涂布Immulon 4 个板(Dynatech(戴雷泰克),马萨诸塞州剑桥市(Cambridge,Mass.),持续2小时。抽 吸涂布溶液并且添加200微升/孔的阻断溶液(稀释于CMF-PBS中的0.5%鱼皮明胶(西 格玛(Sigma)),并且在37℃下培育30分钟。用含有0.05%Tween 20(PBST)的PBS 洗涤板三次,并且添加50μ培养物上清液。在37℃下培育30分钟并且如上洗涤后,添 加50μl按1∶3500稀释于PBST中的辣根过氧化酶缀合的山羊抗小鼠IgG(Fc)(杰克逊 免疫研究(Jackson ImmunoResearch),宾夕法尼亚州西格罗夫(West Grove,Pa.))。如 上培育板,用PBST洗涤四次并且添加100μl底物,所述底物由于100mM pH 4.5柠檬 酸盐中的1mg/ml邻亚苯基二胺(西格玛)和0.1μl/ml 30%H2O2组成。5分钟后停止显 色反应,添加50μl15%H2SO4。使用板读取器(戴雷泰克)测定A490吸光度。
通过稀释于96孔板中将所选择融合孔克隆两次,并且5天后对每孔的菌落数进行视觉评分。使用Isostrip系统(宝灵曼,印第安纳州的印第安纳波利斯(Indianapolis,Ind.)) 对杂交瘤产生的单克隆抗体进行同型化。
当采用杂交瘤技术时,可以使用骨髓瘤细胞系。适合用于产生杂交瘤的融合程序中 的这类细胞系优选是非抗体产生的,具有高融合效率和酶不足,所述酶不足使其不能在仅支持所期望融合细胞(杂交瘤)生长的某种选择性培养基中生长。举例来说,在经过 免疫的动物是小鼠时,可以使用P3-X63/Ag8、P3-X63-Ag8.653、NS1/1.Ag 4 1、 Sp210-Ag14、FO、NSO/U、MPC-11、MPC11-X45-GTG 1.7和S194/15XX0 Bul;对于大 鼠,可以使用R210.RCY3、Y3-Ag 1.2.3、IR983F和4B210;并且U-266、GM1500-GRG2、 LICR-LON-HMy2和UC729-6均适用于与细胞融合体连接。应注意,通过用于产生单克 隆抗体的这类技术产生的杂交瘤和细胞系预期是本公开的组合物。
取决于宿主物种,可以使用各种佐剂来增加免疫应答。这类佐剂包括但不限于弗氏; 矿物凝胶,如氢氧化铝;和表面活性物质,如溶血卵磷脂、普朗尼克多元醇(pluronicpolyol)、聚阴离子、肽、油乳液、匙孔螺血氰蛋白和二硝基苯酚。卡介苗((bacilliCalmette-Guerin,BCG)和短小棒状杆菌(Corynebacterium parvum)是潜在适用的人类 佐剂。
或者,可以使用其它方法,如所属领域中已知的EBV杂交瘤方法(Haskard和Archer, 《免疫学方法杂志(J.Immunol.Methods)》,74(2),361-67(1984)和Roder等人5《酶学 方法(Methods Enzymol.)》,121,140-67(1986));和噬菌体载体表达系统(参见例如Huse 等人,《科学(Science)》,246,1275-81(1989))。此外,在非人类动物中产生抗体的方法描述于例如美国专利5,545,806、5,569,825和5,714,352以及美国专利申请公开第2002/0197266 A1)号中。
抗体还可以通过诱导淋巴细胞群体的体内产生或通过筛选高度特异性结合试剂的 重组免疫球蛋白文库或图来产生,如Orlandi等人(《美国国家科学院院刊》86: 3833-3837;1989)以及Winter和Milstein(《自然》349:293-299,1991)中所公开。
此外,噬菌体呈现可用以产生本公开的抗体。在这点上,编码抗体的抗原结合可变(V)域的噬菌体文库可以使用标准分子生物学和重组DNA技术产生(参见例如Sambrook 等人(编),《分子克隆实验指南(Molecular Cloning,A Laboratory Manual)》,第3版,冷 泉港实验室出版社(Cold Spring Harbor Laboratory Press),纽约(2001))。编码具有所期望特异性的可变区的噬菌体选用于特异性结合到所期望抗原,并且完全或部分抗体经过复原包含所选择的可变域。编码复原抗体的核酸序列被引入到适合的细胞系如用于杂交瘤产生的骨髓瘤细胞中,使得细胞分泌具有单克隆抗体特征的抗体(参见例如Janeway 等人,前述;Huse等人,前述和美国专利6,265,150)。相关方法也描述于美国专利第 5,403,484号;第5,571,698号;第5,837,500号;和第5,702,892号中。美国专利第5,780,279 号、第5,821,047号、第5,824,520号、第5,855,885号、第5,858,657号、第5,871,907 号、第5,969,108号、第6,057,098号和第6,225,447号中所描述的技术也预期为适用于 制备根据本公开的抗体。
抗体可以由特异性重链和轻链免疫球蛋白基因为转基因的转基因小鼠产生。这类方 法在所属领域中已知并且描述于例如美国专利第5,545,806号和第5,569,825号以及Janeway等人,前述中。
用于产生人源化抗体的方法在所属领域中众所周知并且详细地描述于例如Janeway 等人,前述;美国专利第5,225,539号、第5,585,089号和第5,693,761号;欧洲专利第 0239400 B1号;和联合王国专利第2188638号中。人源化抗体也可以使用美国专利第 5,639,641号和Pedersen等人,《分子生物学杂志(J.Mol.Biol.)》,235:959-973(1994) 中所描述的抗体表面重修技术来产生。
可以使用经过开发用于“嵌合抗体”产生的技术,即将小鼠抗体基因与人类抗体基因 拼接以获得具有适当抗原特异性和生物活性的分子(Morrison等人,《美国国家科学院院刊》81:6851-6855,1984;Neuberger等人,《自然》312:604-608,1984;和Takeda 等人,《自然》314:452-454;1985)。或者,经过描述用于产生单链抗体的技术(美国 专利第4,946,778号)可以适于产生IL13Rα2特异性单链抗体。
优选的嵌合或人源化抗体具有人类恒定区,而抗体的可变区或至少一CDR衍生自非人类物种。用于使非人类抗体人源化的方法在所属领域中众所周知。(参见美国专利 第5,585,089号和第5,693,762号)。一般来说,人源化抗体具有一个或多个引入到来自 非人类来源的CDR区和/或其构架区中的氨基酸残基。人源化可以例如使用Jones等人 (《自然》321:522-525,1986)、Riechmann等人(《自然》332:323-327,1988)和Verhoeyen 等人(《科学》239:1534-1536,1988)中所描述的方法,通过用啮齿动物互补决定区(CDR) 的至少一部分取代人类抗体的对应区来进行。用于制备工程改造抗体的诸多技术描述于 例如Owens和Young,《免疫学方法杂志(J.Immunol.Meth.)》,168:149-165(1994)中。 随后可以将其它变化引入到抗体构架中以调节亲和力或免疫原性。
与前述描述一致,包含CDR的组合物可以至少部分地使用所属领域中已知的技术来产生以分离CDR。互补决定区的特征在于六个多肽环,三个环针对重链或轻链可变区 中的每一个。CDR中的氨基酸位置由Kabat等人,《免疫学感兴趣的蛋白质的序列 (Sequencesof Proteins of Immunological Interest)》,美国卫生和公众服务部(U.S. Departmentof Health and Human Serviees),(1983)界定,所述文献以引用的方式并入本 文中。举例来说,人类抗体的高变区经过粗略地界定发现在重链和轻链可变区的残基28 到35、49-59和残基92-103处[Janeway等人,前述]。发现鼠类CDR也恰在这些氨基酸 残基处。应理解,在所属领域中,CDR区可以发现于具有上文所阐述的适当氨基酸位置 的若干氨基酸内。免疫球蛋白可变区也由围绕CDR的四个“构架”区(FR1-4)组成。不 同轻链或重链的构架区的序列在物种内高度保守,并且也在人类与鼠类序列之间保守。
产生包含单克隆抗体的重链可变区或轻链可变区的一个、两个和/或三个CDR的组合物。举例来说,使用包含具有SEQ ID NO:1-6序列的CDR的杂交瘤克隆47的抗体, 产生包含这些CDR的多肽组合物。也涵盖包含抗体的一个、二个、三个、四个、五个 和/或六个互补决定区的多肽组合物。使用围绕CDR的保守构架序列,产生与这些共同 构架序列互补的PCR引物,以扩增定位于引物区之间的CDR序列。用于克隆并且表达 核苷酸和多肽序列的技术在所属领域中是公认的[参见例如Sambrook等人,《分子克隆 实验指南》,第2版,冷泉港,纽约(1989)]。所扩增的CDR序列接合于适当质粒中。包 含一个、二个、三个、四个、五个和/或六个克隆CDR的质粒任选地含有编码连接到CDR 的区域的额外多肽。
预期产生经过修饰的多肽组合物,其包含具有SEQ ID NO:1-6的重链或轻链的一个、二个、三个、四个、五个或六个CDR,其中CDR经过改变以提供针对标靶IL13Rα2 的增加的特异性或亲和力或亲合力。在CDR中的位置处的位点典型地经过连续修饰, 例如通过首先用保守选择取代(例如疏水性氨基酸取代不相同的疏水性氨基酸)并且随 后用更不相似的选择取代(例如疏水性氨基酸取代带电荷氨基酸),并且随后可以在标 靶位点处进行缺失或插入。
鼠类抗体的构架区(FR)通过取代相容的人类构架区人源化,所述相容的人类构架区选自人类抗体可变序列的大数据库,包括超过一千二百个人类VH序列和超过一千个 VL序列。用于比较的抗体序列的数据库从Andrew C.R.Martin′s KabatMan web page (http://www.rubic.rdg.ac.uk/abs/)下载。用于鉴别CDR的卡巴特(Kabat)法提供用于描 绘任何人类抗体的近似CDR和构架区并且针对相似性比较鼠类抗体的序列以确定CDR 和FR的手段。最匹配的人类VH和VL序列基于高的整体构架匹配、类似CDR长度以 及典型和VH/VL接触残基的最小错配而选择。最类似于鼠类序列的人类构架区被插入在 鼠类CDR之间。或者,鼠类构架区可以通过对更接近地类似人类抗体构架区的原生构 架区的全部或部分进行氨基酸取代来修饰。
“保守”氨基酸取代基于所涉及残基的极性、电荷、溶解性、疏水性、亲水性和/或两亲性性质的相似性来进行。举例来说,非极性(疏水性)氨基酸包括丙氨酸(Ala,A)、 亮氨酸(Leu,L)、异亮氨酸(Ile,I)、缬氨酸(Val,V)、脯氨酸(Pro,P)、苯丙氨 酸(Phe,F)、色氨酸(Trp,W)和甲硫氨酸(Met,M);极性中性氨基酸包括甘氨酸 (Gly,G)、丝氨酸(Ser,S)、苏氨酸(Thr,T)、半胱氨酸(Cys,C)、酪氨酸(Tyr, Y)、天冬酰胺(Asn,N)和谷氨酰胺(Gln,Q);带正电(基础)氨基酸包括精氨酸(Arg, R)、赖氨酸(Lys,K)和组氨酸(His,H);并且带负电(酸性)氨基酸包括天冬氨酸 (Asp,D)和谷氨酸(Glu,E)。“插入”或“缺失”优选在约1到20个氨基酸、更优选1 到10个氨基酸范围内。可以通过使用重组DNA技术在多肽分子中系统地进行氨基酸取 代并且分析所得重组变异体的活性来引入变化。可以在不同物种在核酸方面不同的位点 (可变位置)处或在高度保守区(恒定区)中进行核酸改变。下文更详细地描述用于表 达适用于本发明的多肽组合物的方法。
此外,用于产生用于本公开方法的抗体的另一适用技术可以是使用合理设计型方法 的技术。合理设计的目标是制造相互作用的生物活性多肽或化合物的结构类似物(促效剂、拮抗剂、抑制剂、肽模拟物、结合伴侣等等)。在这种情况下,活性多肽包含本文 所公开的SEQ ID NO:1-6的序列。通过生成这类类似物,有可能形成比原生或天然分子 更具免疫反应性的额外抗体。在一种方法中,将产生抗体或其抗原决定基结合片段的三 维结构。这可以通过x射线结晶学、计算机建模或通过两种方法的组合实现。一种替代 方法-“丙氨酸扫描”-涉及残基贯穿具有丙氨酸的分子的随机替代,并且确定对功能的所 得影响。
解析特异性抗体的晶体结构也是可能的。原则上,这种方法得到后续药物设计可以 以其为基础的制药核心(pharmacore)。有可能通过将抗独特型抗体产生为功能性药理学 活性抗体而完全绕过蛋白质结晶学。作为镜像的镜像,预期抗独特型抗体的结合位点是初始抗原的类似物。随后抗独特型抗体用以从以化学或生物学方式产生的肽的库中鉴别并且分离额外抗体。
化学合成的双特异性抗体可以通过借助化学物质如异双官能试剂丁二酰亚胺基-3-(2-吡啶基二硫醇)-丙酸酯(SPDP,Pierce Chemicals,伊利诺斯州罗克福德(Rockford,Ill))使异源Fab或F(ab′)2片段化学交联来制备。Fab和F(ab′)2片段可以通过分别用木 瓜蛋白酶或胃蛋白酶消化完整抗体而获自完整抗体(Karpovsky等人,《实验医学杂志(J.Exp.Med.)》160:1686-701,1984;Titus等人,《免疫学杂志(J.Immunol.)》, 138:4018-22,1987)。
无论抗体怎样产生,测试抗体结合到IL13Rα2的抗原决定基的能力的方法在所属领 域中已知并且包括任何抗体-抗原结合分析,例如放射免疫分析(RIA)、ELISA、蛋白质印迹、免疫沉淀和竞争抑制分析(参见例如Janeway等人,下文,和美国专利申请公开 第2002/0197266 A1号)。
出于本文的目的,从抗体群体中选择抗体也包括使用血管内皮细胞“减去”与在这类 细胞上的不为IL13Rα2抗原决定基的抗原决定基交叉反应的那些抗体。剩余的抗体群体在优先用于IL13Rα2抗原决定基的抗体中富集。
适体
组合科学领域中的最新进展已鉴别出对给定标靶具有高的亲和力和特异性的短聚 合物序列(例如寡核苷酸或肽分子)。举例来说,已使用SELEX技术来鉴别竞争哺乳动 物抗体的具有结合特性的DNA和RNA适体,免疫学领域已产生并且分离结合到大量化 合物的抗体或抗体片段,并且已经利用噬菌体呈现来发现具有极有利结合特性的新肽序 列。基于这些分子演变技术的成功,确定可以生成结合到任何靶分子的分子。环结构经 常涉及如在适体的情况下提供所期望的结合属性,所述适体经常利用产自无互补碱基配 对的短区域的发夹环,利用环形高可变区的组合布置的天然衍生的抗体,和利用环肽的 新噬菌体呈现文库,所述新噬菌体呈现文库当与线性肽噬菌体呈现结果相比较时已显示 提高的结果。因此,已产生足够的证据以指示到高亲和力配位体可以通过组合分子演变 技术来生成和鉴别。对于本发明,分子演变技术可以用以分离特异于本文所公开的 IL13Rα2的结合剂。关于适体的更多内容,一般参见Gold,L.,Singer,B.,He,Y.Y.,Brody. E.,“作为治疗剂和诊断剂的适体(Aptamers As Therapeutic And Diagnostic Agents),”《生 物技术杂志(J.Biotechnol.)》74:5-13(2000)。用于产生适体的相关技术见于美国专利 第6,699,843号,所述专利以全文引用的方式并入本文中。
在一些实施例中,适体通过制备核酸文库、使核酸文库与生长因子接触来产生,其中选择并且扩增对生长因子具有更大结合亲和力(相对于其它文库核酸)的核酸以得到 富含针对结合到生长因子具有相对较高的亲和力和特异性的核酸的核酸混合物。可以重 复所述过程,并且使所选择的核酸突变并且重新筛选,其中生长因子适体被鉴别。可以 筛选核酸以选择结合到多于标靶的分子。结合多于一种标靶可以指同时或竞争性地结合 多于一种标靶。在一些实施例中,结合剂包含至少一种适体,其中第一结合单元结合 IL13Rα2的第一抗原决定基并且第二结合单元结合IL13Rα2的第二抗原决定基。
关于本公开组合物的结合剂,在将结合剂结合到IL13Rα2时IL13Rα2的配位体诱导的活化降低。如本文所使用,术语“降低”以及类似术语例如“抑制”未必暗示100%或完全的降低或抑制。相反,存在降低或抑制的变化程度,其中所属领域的一般技术人员认为 具有潜在益处或治疗作用。相应地,在一些实施例中,IL13Rα2的配位体诱导的活化被 完全消除。在一些实施例中,当不存在结合剂或其不结合到IL13Rα2时,相较于IL13Rα2 的配位体诱导的活化,配位体诱导的活化基本上降低,例如降低约10%(例如约20%、 约30%、约40%、约50%、约60%、约70%、约80%、约90%)或更多。测量IL13Rα2 的配位体诱导的活化的方法在所属领域中已知,并且包括例如下文实例中所描述的分 析。
缀合物
本文公开包含靶向域和效应域的缀合物。在示范性实施例中,缀合物包含本文所公 开的结合剂中的任一种作为靶向域以将缀合物定位到表达IL13Rα2的细胞,例如表达IL13Rα2的肿瘤细胞;和效应域。在示范性方面中,缀合物是融合蛋白。在示范性方面 中,缀合物是嵌合蛋白。如本文所使用,术语“嵌合”是指由不同来源的部分构成的分子。 总体上嵌合分子是非天然存在的,例如合成或重组的,但包含嵌合分子的部分可以是天 然存在的。
示范性效应域
如本文所使用,术语“效应域”是指影响所期望的生物功能的缀合物的一部分。在示 范性方面中,效应域鉴别或定位IL13Rα2表达细胞。举例来说,效应域可以是诊断剂, 例如放射性标记、荧光标记、酶(例如催化量热或荧光反应)、底物、固体基质或载体 (例如生物素或抗生物素蛋白)。在一些方面中诊断剂是成像剂。许多适当的成像剂在所 属领域中已知,将标记剂附接到本发明肽的方法也一样(参见例如美国专利第4,965,392 号;第4,472,509号;第5,021,236号;和第5,037,630号;每一专利以引用的方式并入 本文中)。向个体给予在药学上可接受的载剂中的成像剂,并且使其积累于具有淋巴内 皮细胞的标靶位点处。随后这种成像剂充当用于标靶位点的X射线、磁共振、正电子发 射断层扫描(positron emission tomography)、单光子发射计算机断层扫描(single photonemission computed tomography,SPECT),或超声或闪烁成像的对比试剂。当然,应理解,成像可以在体外进行,其中来自个体的组织经由活检获得,并且淋巴内皮细胞的存在借 助于本文所描述的成像剂以及用于制备和固定组织的组织化学技术来确定。适用于本发 明的成像剂的顺磁离子包括例如铬(III)、锰(II)、铁(III)、铁(II)、钴(II)、镍(II)、 铜(II)、钕(III)、钐(III)、镱(III)、钆(III)、钒(II)、铽(III)、镝(III)、钬(III) 和铒(III)。适用于X射线成像的离子包括但不限于镧(III)、金(III)、铅(II)并且 尤其铋(III)。用于诊断应用的放射性同位素包括例如211砹、14碳、51铬、36氯、57钴、 67铜、152铕、67镓、3氢、123碘、125碘、111铟、59铁、32磷、186铼、75硒、35硫、99m锝、 90钇和99锆。
效应域可以是改变缀合物的物理-化学特征的一者,例如赋予增加的溶解性和/或稳 定性和/或半衰期、抗蛋白水解分裂性、清除率的调节的效应子。在示范性方面中,效应域是聚合物、碳水化合物或脂质。
聚合物可以是分枝或未分枝的。聚合物可以具有任何分子量。在一些实施例中,聚合物具有在约2kDa到约100kDa之间的平均分子量(术语“约”指示在制备水溶性聚合 物中,一些分子将比所规定的分子量更重,一些分子比所规定的分子量更轻)。在一些 方面中,聚合物的平均分子量在约5kDa与约50kDa之间,在约12kDa到约40kDa之 间或在约20kDa到约35kDa之间。在一些实施例中,聚合物经过修饰具有单个反应性 基团,如针对酰化的活性酯或针对烷基化的醛,使得聚合度可以受到控制。在一些实施 例中,聚合物是水溶性的,使得其附接的蛋白质不在水性环境如生理环境中沉淀。在一 些实施例中,当例如组合物用于治疗用途时,聚合物是药学上可接受的。此外,在一些 方面中,聚合物是聚合物的混合物,例如共聚物、嵌段共聚物。在一些实施例中,聚合 物选自由以下组成的组:聚酰胺;聚碳酸酯;聚亚烷基和其衍生物,包括聚亚烷二醇、 聚烷醚、聚对苯二甲酸亚烷酯;丙烯酸酯和甲基丙烯酸酯的聚合物,包括聚(甲基丙烯酸 甲酯)、聚(甲基丙烯酸乙酯)、聚(甲基丙烯酸丁酯)、聚(甲基丙烯酸异丁酯)、聚(甲基丙 烯酸己酯)、聚(甲基丙烯酸异癸酯)、聚(甲基丙烯酸月桂酯)、聚(甲基丙烯酸苯酯)、聚(丙 烯酸甲酯)、聚(丙烯酸异丙酯)、聚(丙烯酸异丁酯)和聚(丙烯酸十八烷酯);聚乙烯基聚合 物,包括聚乙烯醇、聚乙烯醚、聚乙烯酯、聚乙烯基卤化物、聚(乙酸乙烯酯)和聚乙烯 吡咯烷酮;聚乙交酯;聚硅氧烷;聚氨基甲酸酯和其共聚物;纤维素,包括烷基纤维素、 羟基烷基纤维素、纤维素醚、纤维素酯、硝基纤维素、甲基纤维素、乙基纤维素、羟丙 基纤维素、羟基-丙基甲基纤维素、羟基丁基甲基纤维素、乙酸纤维素、丙酸纤维素、乙 酸丁酸纤维素、邻苯二甲酸乙酸纤维素、羧乙基纤维素、三乙酸纤维素和硫酸纤维素钠 盐;聚丙烯;聚乙烯,包括聚(乙二醇)、聚(氧化乙烯)及聚(对苯二甲酸乙二酯);和聚苯 乙烯。在一些方面中,聚合物是生物可降解聚合物,包括合成生物可降解聚合物(例如 乳酸与乙醇酸的聚合物、聚酸酐、聚(原)酸酯、聚氨基甲酸酯、聚(丁酸)、聚(戊酸)和聚 (丙交酯-共-己内酯)),和天然生物可降解聚合物(例如,海藻酸盐和其它多糖(包括聚 葡萄糖和纤维素)、胶原蛋白、其化学衍生物(取代、添加例如烷基、亚烷基的化学基团、羟基化、氧化和所属领域的技术人员通常进行的其它修饰)、白蛋白和其它亲水性 蛋白质(例如,玉米蛋白(zein)和其它醇溶谷蛋白(prolamine)和疏水性蛋白质)), 以及其任何共聚物或混合物。一般来说,这些材料在体内通过酶水解或暴露于水、通过 表面或整体侵蚀而降解。在一些方面中,聚合物是生物粘附聚合物,如生物可侵蚀性水 凝胶(由H.S.Sawhney,C.P.Pathak和J.A.Hubbell于《大分子(Macromolecules)》,1993, 26,581-587中描述,该文献的教示内容并入本文中)、聚玻尿酸、酪蛋白、明胶、明胶 蛋白(glutin)、聚酸酐、聚丙烯酸、海藻酸盐、聚葡萄胺糖、聚(甲基丙烯酸甲酯)、聚(甲 基丙烯酸乙酯)、聚(甲基丙烯酸丁酯)、聚(甲基丙烯酸异丁酯)、聚(甲基丙烯酸己酯)、聚 (甲基丙烯酸异癸酯)、聚(甲基丙烯酸月桂酯)、聚(甲基丙烯酸苯酯)、聚(丙烯酸甲酯)、 聚(丙烯酸异丙酯)、聚(丙烯酸异丁酯)及聚(丙烯酸十八烷酯)。在一些实施例中,聚合物 是水溶性聚合物或亲水性聚合物。合适的水溶性聚合物在所属领域中已知并且包括例如 聚乙烯吡咯烷酮、羟丙基纤维素(HPC;Klucel)、羟丙基甲基纤维素(HPMC;Methocel)、 硝基纤维素、羟丙基乙基纤维素、羟丙基丁基纤维素、羟丙基戊基纤维素、甲基纤维素、 乙基纤维素(Ethocel)、羟乙基纤维素、各种烷基纤维素和羟烷基纤维素、各种纤维素 醚、乙酸纤维素、羧甲基纤维素、羧甲基纤维素钠、羧甲基纤维素钙、乙酸乙烯酯/丁烯 酸共聚物、聚甲基丙烯酸羟基烷酯、甲基丙烯酸羟基甲酯、甲基丙烯酸共聚物、聚甲基 丙烯酸、聚甲基丙烯酸甲酯、马来酸酐/甲基乙烯醚共聚物、聚乙烯醇、聚丙烯酸钠和聚 丙烯酸钙、聚丙烯酸、酸性羧基聚合物、羧基聚亚甲基、羧基乙烯基聚合物、聚氧乙烯 聚氧丙烯共聚物、聚甲基乙烯醚-共-马来酸酐、羧甲基酰胺、甲基丙烯酸钾二乙烯基苯 共聚物、聚氧基乙二醇、聚氧化乙烯,以及其衍生物、其盐和其组合。在一些方面中, 水溶性聚合物或其混合物包括但不限于N连接或O连接的碳水化合物、糖、磷酸盐、 碳水化合物;糖;磷酸盐;聚乙二醇(PEG)(包括已经用以衍生蛋白质的PEG形式, 包括单(C1-C10)烷氧基-或芳氧基-聚乙二醇);单甲氧基-聚乙二醇;聚葡萄糖(如,例如 约6kD的低分子量聚葡萄糖);纤维素;其它碳水化合物基聚合物;聚-(N-乙烯基吡咯 烷酮);聚乙二醇、丙二醇均聚物、聚氧化丙烯/氧化乙烯共聚物;聚氧乙基化多元醇(例 如甘油)和聚乙烯醇。本公开也涵盖可以用以制备共价连接的多聚体的双官能交联分子。 本文中使用的特别优选的水溶性聚合物是聚乙二醇(PEG)。如本文所使用,聚乙二醇意指涵盖可以用于衍生其它蛋白质的PEG形式中的任一种,如单(C1-C10)烷氧基-或芳氧 基-聚乙二醇。PEG是线性或分枝的中性聚醚,以广泛范围的分子量获得,并且可溶于 水和大多数有机溶剂中。当存在于水中时,PEG主要经由其高动态链运动性和疏水性在 排除其它聚合物或肽方面有效,由此当附接到其它蛋白质或聚合物表面时生成水壳或水 合球面。PEG是无毒性、非免疫原性的,并且由食品和药物管理局(Food and Drug Administration)认可用于内部消耗。蛋白质或酶当缀合到PEG时具有经过证实的生物 活性、非抗原特性和当在动物中给予时降低的清除率。F.M.Veronese等人,用于治疗应 用的单甲氧基聚(乙二醇)修饰的酶的制备和特性(Preparation and Properties of Monomethoxypoly(ethyleneglycol)-modified Enzymes for Therapeutic Applications),于J. M.Harris编,《聚(乙二醇)化学--生物技术和生物医学应用(Poly(Ethylene Glycol) Chemistry--Biotechnical and Biomedical Applications)》,127-36,1992中,所述文献以引 用的方式并入本文中。不希望受理论所束缚,这些现象可能归因于PEG在预防通过免疫 系统的识别中的排除特性。此外,PEG已广泛地用于表面修饰程序以降低蛋白质吸附并 且提高血液相容性。S.W.Kim等人,《纽约科学院年鉴(Ann.N.Y.Acad.Sci.)》516: 116-30 1987;Jacobs等人,《人工器官(Artif.Organs)》12:500-501,1988;Park等人, 《聚合物科学杂志,A辑(J.Poly.Sci,Part A)》29:1725-31,1991,每一文献以全文引用 的方式并入本文中。疏水性聚合物表面,如聚氨基甲酸酯和聚苯乙烯,可以通过PEG(MW 3,400)的接枝来修饰并且用作非血栓形成性表面(nonthrombogenic surface)。归因于PEG 的水合作用,表面特性(接触角)可以与亲水性表面更加一致。更重要地,由PEG的高 链运动性、水合球面和蛋白质排除特性所造成,蛋白质(白蛋白和其它血浆蛋白)吸附 会大大地降低。在表面固定研究中,PEG(MW 3,400)被确定为理想大小,Park等人,《生 物医学材料研究杂志(J.Biomed.Mat.Res.)》26:739-45,1992,而PEG(Mw 5,000) 在降低蛋白质抗原性方面是最有益的。F.M.Veronese等人,于J.M.Harris,等人,《聚(乙 二醇)化学--生物技术和生物医学应用》,127-36中。用于制备PEG化结合剂多肽的方法 可以包含以下步骤(a)使多肽与聚乙二醇(如PEG的反应性酯或醛衍生物)在结合剂 多肽附接到一个或多个PEG基团的条件下反应,和(b)获得反应产物。一般来说,酰 化反应的理想反应条件将基于已知参数和所期望的结果来确定。举例来说,PEG:蛋白质 的比率越大,聚-PEG化产物的百分比越大。在一些实施例中,结合剂将在N端具有单 个PEG部分。参见美国专利第8,234,784号,所述专利以引用的方式并入本文中。
在一些实施例中,效应域是碳水化合物。在一些实施例中,碳水化合物是单糖(例如葡萄糖、半乳糖、果糖)、双糖(例如蔗糖、乳糖、麦芽糖)、寡糖(例如棉籽糖、水 苏糖)、多糖(例如淀粉、淀粉酶、胶淀粉、纤维素、几丁质、愈创聚葡糖(callose)、 昆布糖(laminarin)、木聚糖、甘露聚糖、褐藻糖胶或半乳甘露聚糖)。
在一些实施例中,效应域是脂质。在一些实施例中,脂质是脂肪酸、类廿烷酸(eicosanoid)、前列腺素、白三烯、血栓素、N-酰基乙醇胺、甘油脂质(例如,单取代甘 油、双取代甘油、三取代甘油)、甘油磷脂(例如,磷脂酰胆碱、磷脂酰肌醇、磷脂酰 乙醇胺、磷脂酰丝氨酸)、鞘脂(例如,神经鞘胺醇、神经酰胺)、固醇脂质(例如,类 固醇、胆固醇)、异戊烯醇脂质(prenol lipid)、糖脂质、或聚酮化合物(polyketide)、 油、蜡、胆固醇、固醇、脂溶性维生素、单酸甘油酯、二酸甘油酯、三酸甘油酯或磷脂。
致死域
在示范性方面中,效应域是赋予致死性的致死域,使得当缀合物定位到表达IL13Rα2 的细胞例如表达IL13Rα2的肿瘤细胞时。效应域向缀合物赋予一旦结合剂已发现并且结合到其IL13Rα2标靶就杀死IL13Rα2表达细胞的能力。
在示范性方面中,效应域是细胞毒素(在本文中也被称作“细胞毒性剂”)。细胞毒性剂是对细胞具有毒性的任何(化学或生物化学)分子。在一些实施例中,细胞毒性剂 是化学治疗剂。化学治疗剂在所属领域中已知并且包括但不限于铂配位化合物、拓扑异 构酶抑制剂、抗生素、抗有丝分裂生物碱和二氟核苷,如美国专利第6,630,124号中所 描述。在一些实施例中,化学治疗剂是铂配位化合物。术语“铂配位化合物”是指提供呈 离子形式的铂的任何肿瘤细胞生长抑制铂配位化合物。在一些实施例中,铂配位化合物 是顺-二氨二水合铂(II)-离子(cis-diamminediaquoplatinum(II)-ion);氯(二亚乙基三胺)- 氯化铂(II)(chloro(diethylenetriamine)-platinum(II)chloride);(乙二胺)-二氯合铂(II)(dichloro(ethylenediamine)-platinum(II))、(1,1-环丁烷二甲酸)二氨合铂(II)(卡铂(carboplatin));螺铂;异丙铂;(2-乙基丙二酸)-二氨合铂(II) (diammine(2-ethylmalonato)-platinum(II));乙二胺丙二酸铂(II);(1,2-二氨基环己烷)- 水合硫酸铂(II);(1,2-二氨基环己烷)丙二酸铂(II);(1,2-二氨基环己烷)(4-羧基邻苯二 甲酸)铂(II)((4-caroxyphthalato)(1,2-diaminocyclohexane)platinum(II));(1,2-二氨基环己烷)-(异柠檬酸)铂(II);(1,2-二氨基环己烷)顺(丙酮酸)铂(II);(1,2-二氨基环己烷)草 酸铂(II);奥马铂(ormaplatin);或四铂。在一些实施例中,顺铂是本发明的组合物和方法中所采用的铂配位化合物。顺铂可按名称PLATINOLTM商购自Bristol Myers-SquibbCorporation,并且可以用于与水、无菌盐水或其它合适的媒剂配制的粉末形式获得。适 合用于本发明中的其它铂配位化合物是已知的并且可商购和/或可以通过常规技术制备。 在各种人类实体恶性肿瘤的治疗中,顺铂或顺-二氯二氨铂II已作为化学治疗剂成功地 使用了很多年。近年来,在各种人类实体恶性肿瘤的治疗中,其它二氨基-铂络合物也已 显示作为化学治疗剂的功效。这类二氨基-铂络合物包括但不限于螺铂和卡铂。尽管顺铂 和其它二氨基-铂络合物已广泛地用作人类的化学治疗剂,但其不得不以会引起毒性问题 如肾损害的高剂量水平递送。
在一些实施例中,化学治疗剂是拓扑异构酶抑制剂。拓扑异构酶是能够改变真核细 胞中的DNA拓扑结构的酶。其对细胞功能和细胞增殖很关键。一般来说,在真核细胞 中存在两种类别的拓扑异构酶,I型和II型。拓扑异构酶I是具有约100,000分子量的单 体酶。所述酶结合到DNA并且引入短暂的单链断裂,使双螺旋解旋(或允许其展开), 并且随后将裂口再封合,之后从DNA链解离。各种拓扑异构酶抑制剂最近已在罹患卵 巢癌、食道癌或非小细胞肺癌的人类的治疗中显示临床功效。在一些方面中,拓扑异构 酶抑制剂是喜树碱(camptothecin)或喜树碱类似物。喜树碱是水不溶性的细胞毒性生 物碱,由中国本土的喜树(Camptotheca accuminata tree)和印度本土的青脆枝树 (Nothapodytesfoetidatree)产生。喜树碱展现针对许多肿瘤细胞的肿瘤细胞生长抑制活 性。喜树碱类似物类别的化合物是DNA拓扑异构酶I的典型的特异性抑制剂。术语“拓 扑异构酶的抑制剂”意指结构上与喜树碱相关的任何肿瘤细胞生长抑制化合物。喜树碱 类似物类别的化合物包括但不限于拓朴替康(topotecan)、伊立替康(irinotecan)和9- 氨基-喜树碱。在额外实施例中,细胞毒性剂是以下中所要求或描述的任何肿瘤细胞生长 抑制喜树碱类似物:美国专利第5,004,758号;欧洲专利申请号88311366.4(公开号EP 0 321 122);美国专利第4,604,463号;欧洲专利申请公开号EP 0 137 145;美国专利第 4,473,692号;欧洲专利申请公开号EP 0 074 256;美国专利第4,545,880号;欧洲专利 申请公开号EP 0 074 256;欧洲专利申请公开号EP 0 088 642;Wani等人,《药物化学 杂志(J.Med.Chem.)》,29,2358-2363(1986);和Nitta等人,《会刊(Proc.)》第14 届国际化疗会议(14th InternationalCongr.Chemotherapy),京都(Kyoto),1985,东京 出版社(Tokyo Press),抗癌章节1,第28-30页。确切地说,本公开涵盖称作CPT-11 的化合物。CPT-11是具有4-(哌啶基)-哌啶侧链的喜树碱类似物,所述侧链经由氨甲酸 酯连接在10-羟基-7-乙基喜树碱的C-10处接合。CPT-11目前正经历人类临床试验并且 还被称作伊立替康;Wani等人,《药物化学杂志》,23,554(1980);Wani等人,《药物 化学杂志》,30,1774(1987);美国专利第4,342,776号;欧洲专利申请公开号EP 418 099; 美国专利第4,513,138号;欧洲专利申请公开号EP 0 074 770;美国专利第4,399,276号; 欧洲专利申请公开号0 056 692;以上文献中的每一个的全部揭示内容由此以引用的方式 并入。喜树碱类似物类别的所有上文所列举化合物可商购和/或可以通过常规技术(包括 上文所列举文献中所描述的那些技术)来制备。拓扑异构酶抑制剂可以选自由以下组成 的组:拓朴替康、伊立替康和9-氨基喜树碱。
喜树碱类似物类别的诸多化合物(包括其药学上可接受的盐、水合物和溶剂合物)的制备,以及包含喜树碱类似物类别的这类化合物和惰性的药学上可接受的载剂或稀释剂的口服和肠胃外医药组合物的制备广泛地描述于美国专利第5,004,758号和欧洲专利申请号88311366.4(公开号EP 0 321 122)中,所述专利中的每一个的教示内容以全文 引用的方式并入本文中。
在本发明的再一实施例中,化学治疗剂是抗生素化合物。合适的抗生素包括但不限 于小红莓(doxorubicin)、丝裂霉素(mitomycin)、博莱霉素(bleomycin)、道诺霉素(daunorubicin)和链脲霉素(streptozocin)。在一些实施例中,化学治疗剂是抗有丝分裂生物碱。一般来说,抗有丝分裂生物碱可以从从长春花(Cantharanthus roseus)中提取,并且作为抗癌化学治疗剂已显示为有效的。已在化学上和药理学上研究了大量的半合成衍生物(参见O.Van Tellingen等人,《抗癌研究(Anticancer Research)》,12,1699-1716(1992))。本发明的抗有丝分裂生物碱包括但不限于长春碱(vinblastine)、长春新碱(vincristine)、长春地辛(vindesine)、紫杉醇(Taxol)和长春瑞宾(vinorelbine)。后两种抗有丝分裂生物碱可分别商购自礼来公司(Eli Lilly and Company)和皮耶法柏实验室(Pierre Fabre Laboratories)(参见美国专利第5,620,985号)。在本发明的一个方面中,抗 有丝分裂生物碱是长春瑞宾。
在本发明的另一实施例中,化学治疗剂是二氟核苷。2′-脱氧-2′,2′-二氟核苷在所属领 域中已知为具有抗病毒活性。这类化合物公开并且教示于美国专利第4,526,988号和第 4,808614号中。欧洲专利申请公开184,365公开到这些相同的二氟核苷具有溶瘤活性。 在某些特定方面中,本公开的组合物和方法中所使用的2′-脱氧-2′,2′-二氟核苷是2′-脱氧 -2′,2′-二氟胞苷盐酸盐,也称为吉西他滨(gemcitabine)盐酸盐。吉西他滨可商购或可以 按如美国专利第4,526,988号、第4,808,614号和第5,223,608号中所公开的多步方法合 成,所述专利中的每一个的教示内容以全文引用的方式并入本文中。
在示范性方面中,效应域是造成IL13Rα2表达细胞编程性细胞死亡(apoptose)的细胞凋亡标签。在示范性方面中,细胞凋亡标签是TRAIL蛋白或其一部分。在示范性 方面中,细胞凋亡标签包含SEQ ID NO:27的氨基酸序列。在示范性方面中,缀合物包 含SEQ IDNO:25的氨基酸序列。
在示范性实施例中,效应域是IgG或其它免疫球蛋白的Fc域。对于取代基,如人 类IgG的Fc区,融合体可以直接融合到结合剂或经由插入序列融合。举例来说,人类 IgG铰链、CH2和CH3区可以在结合剂的N端或C端处融合以附接Fc区。所得Fc-融 合体药剂使得能够经由蛋白A亲和柱(Pierce,伊利诺斯州罗克福德)纯化。融合到Fc 区的肽和蛋白质可以展现体内比未融合对应体基本上更大的半衰期。融合到Fc区的融 合体允许融合多肽进行二聚化/多聚化。Fc区可以是天然存在的Fc区,或可以针对优异 特征例如治疗质量、循环时间、减少的聚集而经过修饰。如上所指出,在一些实施例中, 结合剂缀合(例如融合)到免疫球蛋白或其部分(例如可变区、CDR或Fc区)。已知类 型的免疫球蛋白(Ig)包括IgG、IgA、IgE、IgD或IgM。Fc区是Ig重链的C端区,其 负责与进行如再循环(其导致半衰期延长)的活动的Fc受体的结合、抗体依赖性细胞 介导细胞毒性(ADCC)和补体依赖性细胞毒性(CDC)。
举例来说,根据一些定义,人类IgG重链Fc区从重链的Cys226延展到C端。“铰 链区”一般从人类IgG1的Glu216延伸到Pro230(通过比对半胱氨酸键结中所涉及的半 胱氨酸,可以将其它IgG同型物的铰链区与IgG1序列进行比对)。IgG的Fc区包括两 个恒定域CH2和CH3。人类IgG Fc区的CH2域通常从氨基酸231延伸到氨基酸341。 人类IgG Fc区的CH3域通常从氨基酸342延伸到447。对免疫球蛋白或免疫球蛋白片 段或区域的氨基酸编号的参考均基于Kabat等人1991,《免疫学感兴趣的蛋白质的序列》, 美国公共卫生部(U.S.Department of Public Health),马里兰州贝塞斯达(Bethesda,Md.), 其以引用的方式并入本文中。在相关实施例中,Fc区可以包含一个或多个不为CH1的 来自免疫球蛋白重链的原生或经过修饰的恒定区,例如IgG和IgA的CH2区和CH3区, 或IgE的CH3区和CH4区。
合适的缀合物部分包括包含FcRn结合位点的免疫球蛋白序列的部分。救助受体FcRn负责再循环免疫球蛋白并且使其返回到血液中的循环。已基于X射线结晶学描述 了结合到FcRn受体的IgG Fc部分的区域(Burmeister等人1994,《自然》372:379)。 Fc与FcRn的主要接触区域接近CH2域与CH3域的接面。Fc-FcRn接触点均在单一Ig 重链内。主要接触位点包括CH2域的氨基酸残基248、250-257、272、285、288、290-291、 308-311和314,和CH3域的氨基酸残基385-387、428和433-436。
一些缀合物部分可能包括或可能不包括FcγR结合位点。FcγR负责抗体依赖性细胞 介导细胞毒性(ADCC)和补体依赖性细胞毒性(CDC)。与FcγR直接接触的Fc区内位 置的实例是氨基酸234-239(下端铰链区)、氨基酸265-269(B/C环)、氨基酸297-299 (C′/E环)和氨基酸327-332(F/G)环(Sondermann等人,《自然》406:267-273,2000)。 IgE的下端铰链区也已与FcRI结合有关(Henry等人,《生物化学(Biochemistry)》36, 15568-15578,1997)。涉及IgA受体结合的残基描述于Lewis等人,(《免疫学杂志》 175:6694-701,2005)中。涉及IgE受体结合的氨基酸残基描述于Sayers等人(《生物化学 杂志(J Biol Chem.)》279(34):35320-5,2004)中。
可以对免疫球蛋白的Fc区进行氨基酸修饰。这类变异Fc区在Fc区的CH3域(残 基342-447)中包含至少一个氨基酸修饰和/或在Fc区的CH2域(残基231-341)中包含 至少一个氨基酸修饰。相信赋予FcRn以增加的亲和力的突变包括T256A、T307A、E380A 和N434A(Shields等人2001,《生物化学杂志》276:6591)。其它突变可以降低Fc区 与FcγRI、FcγRIIA、FcγRIIB和/或FcγRIIIA的结合而不显著降低对FcRn的亲和力。举 例来说,用Ala或另一氨基酸取代Fc区的位置297处的Asn去除高度保守的N-糖基化 位点并且可以降低Fc区的免疫原性,同时延长Fc区的半衰期,以及降低与FcγR的结 合(劳特利奇等人1995,《移植(Transplantation)》60:847;Friend等人1999,《移 植》68:1632;Shields等人1995,《生物化学杂志》276:6591)。已对IgG1的位置233-236 处进行氨基酸修饰以降低与FcγR的结合(Ward和Ghetie 1995,《治疗免疫学(Therapeutic Immunology)》2:77;和Armour等人1999,《欧洲免疫学杂志(Eur.J.Immunol.)》 29:2613)。一些示范性的氨基酸取代描述于美国专利第7,355,008号和第7,381,408号中, 所述专利中的每一个以全文引用的方式并入本文中。
在一些实施例中,结合剂融合到碱性磷酸酶(AP)。用于制备Fc或AP融合剂的方 法提供于WO 02/060950中。
嵌合抗原受体(CAR)
在示范性方面中,效应域是T细胞信号传导域。在示范性方面中,缀合物是嵌合抗原受体(CAR)。嵌合抗原受体(CAR)是经过工程改造的跨膜蛋白,其将抗原-特异性 抗体的特异性与T细胞受体功能组合起来。一般来说,CAR包含胞外域、跨膜域和胞内 域。在示范性方面中,CAR的胞外域包含抗原识别区域,其可以是抗原-特异性抗体的 scFV。在一些实施例中,胞外域也包含将新生蛋白质引入内质网中的信号肽。在示范性 方面中,胞外域包含将抗原识别区连接到跨膜域的间隔区。跨膜(TM)域是穿越细胞 膜的CAR的部分。在示范性方面中,TM域包含疏水性α螺旋。在示范性方面中,TM 域包含CD28的TM域的全部或一部分。在示范性方面中,TM域包含CD8α的TM域 的全部或一部分。CAR的胞内域包含一个或多个信号传导域。在示范性方面中,胞内域 包含CD3的ζ链,其包含免疫受体酪胺酸基活化基元(ITAM)的三个拷贝。ITAM一 般包含由来自Leu或Ile的两个氨基酸分隔开的Tyr残基。在免疫细胞受体例如T细胞 受体和B细胞受体的情况下,ITAM多次出现(至少两个)并且每一个ITAM通过6-8 个氨基酸与另一ITAM分隔开。CAR的胞内域还可以包含对下游信号转导至关重要的额 外信号传导域,例如蛋白质部分。在示范性方面中,胞内域包含来自CD28、41BB或4-1BB(CD137)、ICOS、CD27、CD40、OX40(CD134)或Myd88中的一个或多个的 信号传导域。编码这类蛋白质的信号传导域的序列在本文中以SEQ ID NO:39-42、68-79、 81和83形式提供。制备CAR、在例如T细胞的细胞中表达CAR和在疗法中利用CAR 表达T细胞的方法在所属领域中已知。参见例如国际专利申请公开第WO2014/208760 号、第WO2014/190273号、第WO2014/186469号、第WO2014/184143号、第 WO2014180306号、第WO2014/179759号、第WO2014/153270号;美国申请公开第 US20140369977号、第US20140322212号、第US20140322275号、第US20140322183 号、第US20140301993号、第US20140286973号、第US20140271582号、第 US20140271635号、第US20140274909号;欧洲申请公开第2814846号,其中的每一个 以全文引用的方式并入。
在示范性方面中,本公开的缀合物是IL13Rα2特异性嵌合抗原受体(CAR),其包 含本文所描述的结合剂、铰链区和胞内域,所述胞内域包含CD3ζ链的信号传导域和 CD28、CD134和/或CD137的信号传导域的。在示范性方面中,CAR包含(A)以下的 氨基酸序列中的每一个:NYLMN(SEQ ID NO:1);RIDPYDGDIDYNQNFKD(SEQ ID NO:2);GYGTAYGVDY(SEQ IDNO:3);RASESVDNYGISFMN(SEQ ID NO:4); AASRQGSG(SEQ ID NO:5);和QQSKEVPWT(SEQ IDNO:6);(B)铰链区;和(C) 胞内域,所述胞内域包含CD3ζ链的信号传导域和CD28、CD134和/或CD137的信号 传导域。在示范性方面中,CD3ζ链信号传导域包含SEQ ID NO:41的氨基酸序列。在 示范性方面中,CAR基于CD28的跨膜(TM)域进一步包含TM域。在示范性方面中,CAR包含SEQ ID NO:47的氨基酸序列。在示范性方面中,CAR基于CD8α的跨膜(TM) 域进一步包含TM域。在示范性方面中,CAR包含SEQ ID NO:85的氨基酸序列。在示 范性方面中,铰链区包含SEQ ID NO:35或SEQ ID NO:37的氨基酸序列。在示范性方 面中,CAR包含SEQ IDNO:49或SEQ ID NO:51的氨基酸序列。在示范性方面中,本 公开的CAR的胞内域包含SEQ IDNO:53或SEQ ID NO:55的氨基酸序列。在示范性方 面中,本公开的CAR的胞内域包含SEQ IDNO:87或SEQ ID NO:89的氨基酸序列。在 示范性方面中,本公开的CAR的胞内域包含SEQ IDNO:91、SEQ ID NO:93或SEQ ID NO:95的氨基酸序列。在示范性方面中,本公开的CAR的胞内域包含SEQ ID NO:97、 SEQ ID NO:99或SEQ ID NO:101的氨基酸序列。
在示范性方面中,胞内域进一步包含以下中的一种或多种的信号传导域:CD137、CD134、CD27、CD40、ICOS和Myd88。在示范性方面中,胞内域包含SEQ ID NO:68、 70、72、74、76和78的氨基酸序列中的一个或多个,上述氨基酸序列分别提供包含CD27 信号传导域的序列、包含CD40信号传导域的序列、包含CD134信号传导域的序列、包 含CD137信号传导域的序列、包含ICOS信号传导域的序列和包含Myd88信号传导域 的序列。
在示范性方面中,CAR包含(A)以下的氨基酸序列中的每一个:NYLMN(SEQ ID NO:1);RIDPYDGDIDYNQNFKD(SEQ ID NO:2);GYGTAYGVDY(SEQ ID NO:3); RASESVDNYGISFMN(SEQ ID NO:4);AASRQGSG(SEQ ID NO:5);和QQSKEVPWT (SEQ ID NO:6);(B)铰链区;(C)胞内域,所述胞内域包含CD3ζ链的信号传导域和 CD28的信号传导域和至少一个其它信号传导域。在示范性方面中,CAR包含包含41BB 的信号传导域(CD137)的胞内域。在示范性方面中,CAR包含包含SEQ ID NO:81的 氨基酸序列的胞内域。在示范性方面中,CD137信号传导是CD3ζ链信号传导链的N 端。在示范性方面中,胞内域包含SEQ ID NO:87的氨基酸序列。在示范性方面中,CAR 包含SEQ ID NO:91的氨基酸序列。在示范性方面中,CAR包含SEQ IDNO:97的氨基 酸序列。
在示范性方面中,CAR包含包含OX40的信号传导域(CD134)的胞内域。在示范 性方面中,CAR包含包含SEQ ID NO:83的氨基酸序列的胞内域。在示范性方面中, CD137信号传导是CD3ζ链信号传导链的N端。在示范性方面中,胞内域包含SEQ ID NO:89的氨基酸序列。在示范性方面中,CAR包含SEQ ID NO:95的氨基酸序列。在 示范性方面中,CAR包含SEQ IDNO:99的氨基酸序列。
在示范性方面中,CAR包含(A)以下的氨基酸序列中的每一个:NYLMN(SEQ ID NO:1);RIDPYDGDIDYNQNFKD(SEQ ID NO:2);GYGTAYGVDY(SEQ ID NO:3); RASESVDNYGISFMN(SEQ ID NO:4);AASRQGSG(SEQ ID NO:5);和QQSKEVPWT (SEQ ID NO:6);(B)铰链区;(C)CD8α链的跨膜域;和(D)胞内域,所述胞内域 包含CD3ζ链的信号传导域和任选地至少一个其它信号传导域。在示范性方面中,跨膜 域包含SEQ ID NO:85的氨基酸序列。在示范性方面中,CAR进一步包含CD137信号 传导域和CD3ζ链信号传导域。在示范性方面中,CAR包含SEQ ID NO:93的氨基酸序 列。在示范性方面中,CAR包含SEQ ID NO:101的氨基酸序列。
作为一实例,提供三种额外IL13Rα2特异性CAR的序列。一种CAR含有CD8αTM 域和41BB.ζ信号传导域(由SEQ ID NO:94编码的SEQ ID NO:93)。其它两种CAR含 有CD28 TM域和CD28.CD134.ζ(由SEQ ID NO:100编码的SEQ ID NO:99)或 CD28.CD137.ζ(由SEQ ID NO:102编码的SEQ ID NO:101)信号传导域。
核酸、载体、宿主细胞
本公开进一步提供一种核酸,其包含编码本文所描述的结合剂和缀合物(例如嵌合 蛋白、融合蛋白、CAR)中的任一种的核苷酸序列。核酸可以包含编码本文所描述的结 合剂和缀合物中的任一种的任何核苷酸序列。在示范性方面中,核酸包含编码SEQ ID NO:1-6的CDR中的每一个的核苷酸序列。在示范性方面中,本公开的核酸包含编码 SEQ ID NO:7和/或SEQ ID NO:8的核酸序列。在示范性方面中,本公开的核酸包含编 码SEQ ID NO:13或SEQ ID NO:14的核酸序列。在示范性方面中,本文所提供的核酸 包含SEQ ID NO:15和/或SEQ ID NO:16的序列。在示范性方面中,核酸包含SEQ ID NO: 66或67的核苷酸序列。在示范性方面中,核酸包含编码SEQ ID NO:25的序列的核苷 酸序列。在示范性方面中,核酸包含SEQ ID NO:26的核苷酸序列。在示范性方面中, 核酸包含编码SEQ ID NO:1-6中的每一个并且编码SEQ ID NO:28或30的核苷酸序列。 在示范性方面中,核酸包含编码SEQ ID NO:1-6中的每一个并且编码与SEQ ID NO:28 或30至少90%一致的氨基酸序列的核苷酸序列。在示范性方面中,核酸包含编码SEQ ID NO:1-6中的每一个并且包含SEQ ID NO:29或31的核苷酸序列。在示范性方面中,核 酸包含编码SEQ ID NO:33的核苷酸序列。在示范性方面中,核酸包含SEQ ID NO:34 的核苷酸序列。在示范性方面中,核酸包含编码SEQ ID NO:1-6中的每一个并且编码 SEQ ID NO:35或37的核苷酸序列。在示范性方面中,核酸包含编码SEQ ID NO:1-6 中的每一个并且包含SEQ ID NO:36或38的核苷酸序列。在示范性方面中,核酸包含 编码SEQ ID NO:1-6中的每一个并且编码SEQ ID NO:39或41的核苷酸序列。在示范 性方面中,核酸包含编码SEQ ID NO:1-6中的每一个并且包含SEQ ID NO:40或42的 核苷酸序列。在示范性方面中,核酸包含编码SEQ ID NO:1-6中的每一个并且编码SEQ ID NO:47的核苷酸序列。在示范性方面中,核酸包含编码SEQ ID NO:1-6中的每一个 并且包含SEQID NO:48的核苷酸序列。在示范性方面中,核酸包含编码SEQ ID NO:1-6 中的每一个并且编码SEQ ID NO:49或51的核苷酸序列。在示范性方面中,核酸包含 编码SEQ ID NO:1-6中的每一个并且包含SEQ ID NO:50或52的核苷酸序列。在示范 性方面中,核酸包含编码SEQID NO:53或55的核苷酸序列。在示范性方面中,核酸 包含编码SEQ ID NO:1-6中的每一个并且包含SEQ ID NO:54或56的核苷酸序列。在 示范性方面中,核酸包含编码SEQ ID NO:1-6中的每一个并且编码SEQ ID NO:68、70、 72、74、76和78中的一个或多个的核苷酸序列。在示范性方面中,核酸包含编码SEQ ID NO:1-6中的每一个并且包含SEQ ID NO:69、71、73、75、77和79中的一个或多个的 核苷酸序列。在示范性方面中,核酸包含编码SEQ ID NO:1-6中的每一个并且包含SEQ ID NO:82、84、86、88、90、92、94、96中的一个或多个的核苷酸序列。在示范性方 面中,核酸包含包含SEQ ID NO:98、100和102中的一个的核苷酸序列。
如本文所用,“核酸”包括“聚核苷酸”、“寡核苷酸”和“核酸分子”,并且一般意指DNA 或RNA的聚合物,其可以是单链或双链的,合成的或从天然来源中获得(例如分离和/或纯化),其可以含有天然、非天然或改变的核苷酸,并且其可以含有天然、非天然或 改变的核苷酸间连接,如氨基磷酸酯连接或硫代磷酸酯连接,而不是发现于未经修饰的 寡核苷酸的核苷酸之间的磷酸二酯。一般优选的是核酸不包含任何插入、缺失、倒置和 /或取代。然而,如本文所论述,在一些情况下核酸包含一个或多个插入、缺失、倒置和 /或取代可能合适。
在示范性方面中,本公开的核酸是重组的。如本文所使用,术语“重组(的)”是指(i)通过将天然或合成的核酸片段接合到可以在活细胞中复制的核酸分子而构筑在活细胞外部的分子,或(ii)由上文(i)中所描述的那些分子的复制产生的分子。出于本文 的目的,复制可以是体外复制或体内复制。
在示范性方面中,核酸基于化学合成和/或酶连接反应使用所属领域中已知的程序构 筑。参见例如Sambrook等人,前述,和Ausubel等人,前述。举例来说,核酸可以使用 天然存在的核苷酸或各种各样经过修饰的核苷酸以化学方式合成,所述经过修饰的核苷 酸经过设计以增加分子的生物稳定性或增加杂交时形成的双螺旋体的物理稳定性(例如 硫代磷酸酯衍生物和吖啶取代的核苷酸)。可以用于产生核酸的经过修饰的核苷酸的实 例包括但不限于5-氟尿嘧啶、5-溴尿嘧啶、5-氯尿嘧啶、5-碘尿嘧啶、次黄嘌呤、黄嘌 呤、4-乙酰基胞嘧啶、5-(羧基羟甲基)尿嘧啶、5-羧甲基氨甲基-2-硫代尿苷、5-羧甲基氨 甲基尿嘧啶、二氢尿嘧啶、β-D-半乳糖基Q核苷、肌苷、N6-异戊烯基腺嘌呤、1-甲基 鸟嘌呤、1-甲基肌苷、2,2-二甲基鸟嘌呤、2-甲基腺嘌呤、2-甲基鸟嘌呤、3-甲基胞嘧啶、 5-甲基胞嘧啶、N-取代的腺嘌呤、7-甲基鸟嘌呤、5-甲基氨甲基尿嘧啶、5-甲氧基氨甲 基-2-硫尿嘧啶、β-D-甘露糖基Q核苷、5′-甲氧基羧甲基尿嘧啶、5-甲氧基尿嘧啶、2-甲 硫基-N6-异戊烯基腺嘌呤、尿嘧啶-5-氧基乙酸(v)、丁氧核苷(wybutoxosine)、假尿嘧 啶、Q核苷、2-硫胞嘧啶、5-甲基-2-硫尿嘧啶、2-硫尿嘧啶、4-硫尿嘧啶、5-甲基尿嘧啶、 尿嘧啶-5-氧基乙酸甲酯、3-(3-氨基-3-N-2-羧丙基)尿嘧啶和2,6-二氨基嘌呤。或者,本 公开的核酸中的一个或多个可以购自如Macromolecular Resources(科罗拉多州柯林斯堡 (Fort Collins,CO))和Synthegen(德克萨斯州休斯顿(Houston,TX))的公司。
在示范性方面中,本公开的核酸并入重组表达载体中。在这点上,本公开提供包含本公开的核酸中的任一个的重组表达载体。出于本文的目的,术语“重组表达载体”意指 基因修饰的寡核苷酸或聚核苷酸构筑体,当构筑体包含编码mRNA、蛋白质、多肽或肽 的核苷酸序列,并且载体在足以使mRNA、蛋白质、多肽、或肽在细胞内表达的条件下 与细胞接触时,所述构筑体准许由宿主细胞表达mRNA、蛋白质、多肽或肽。本公开的 载体总体上不是天然存在的。然而,载体的部分可以是天然存在的。本发明的重组表达 载体可以包含任何类型的核苷酸,包括但不限于如下DNA和RNA:其可以是单链或双 链的,合成的或部分地从天然来源中获得,并且其可以含有天然、非天然或改变的核苷 酸。重组表达载体可以包含天然存在或非天然存在的核苷酸间连接,或这两种类型的连 接。在示范性方面中,改变的核苷酸或非天然存在的核苷酸间连接不阻碍载体的转录或 复制。
本公开的重组表达载体可以是任何合适的重组表达载体,并且可以用于转化或转染 任何合适的宿主。合适的载体包括经过设计用于扩展和扩增或用于表达或以上两项的那 些载体,如质粒和病毒。载体可以选自由以下组成的组:pUC系列(Fermentas LifeSciences)、pBluescript系列(Stratagene,加利福尼亚州拉荷亚(LaJolla,CA))、pET系 列(Novagen,威斯康星州麦迪逊(Madison,WI))、pGEX系列(Pharmacia Biotech,瑞 典乌普萨拉(Uppsala,Sweden))和pEX系列(Clontech,加利福尼亚州帕洛阿尔托(Palo Alto))。也可以使用噬菌体载体,如λGTIO、λGTl1、λZapII(Stratagene)、λEMBL4和 λNMl 149。植物表达载体的实例包括pBIOl、pBI101.2、pBI101.3、pBI121和pBIN19 (Clontech)。动物表达载体的实例包括pEUK-Cl、pMAM和pMAMneo(Clontech)。优 选地,重组表达载体是病毒载体,例如反转录病毒载体。
本公开的重组表达载体可以使用描述于例如Sambrook等人,前述和Ausubel等人,前述中的标准重组DNA技术制备。可以制备环形或线性的表达载体构筑体以在原核或 真核宿主细胞中含有复制系统功能。复制系统可以衍生自例如CoIEl、2μ质粒、λ、SV40、 牛乳头瘤病毒等等。
在示范性方面中,重组表达载体包含调节序列,如转录与翻译起始和终止密码子,其按需要并且考虑载体是否是基于DNA或RNA的而对待引入载体的宿主类型(例如细 菌、真菌、植物或动物)具有特异性。
重组表达载体可以包括一个或多个允许选择转化或转染的宿主的标记基因。标记基 因包括杀生物剂抗性,例如对抗生素、重金属等的抗性,在营养缺陷型宿主中提供原营养的互补性等等。用于本发明表达载体的合适的标记基因包括例如新霉素/G418抗性基因、潮霉素抗性基因、组氨醇(histidinol)抗性基因、四环素抗性基因和安比西林(ampicillin)抗性基因。
重组表达载体可以包含原生或正常启动子,所述启动子可操作地连接到编码结合剂 或缀合物的核苷酸序列,或与编码结合剂或缀合物的核苷酸序列互补或与其杂交的核苷 酸序列。启动子的选择,例如强、弱、诱导型、组织特异性和发育特异性,在从业者的 普通技能内。
类似地,核苷酸序列与启动子的组合也在从业者的技能内。启动子可以是非病毒启 动子或病毒启动子,例如巨细胞病毒(CMV)启动子、SV40启动子、RSV启动子和鼠 类干细胞病毒的长末端重复序列中所发现的启动子。
本发明的重组表达载体可以经过设计用于短暂表达、用于稳定表达或用于两者。同 样,重组表达载体可以经过制备用于组成型表达或用于诱导型表达。此外,重组表达载体可以经过制备以包括自杀基因。
如本文所使用,术语“自杀基因”是指造成表达自杀基因的细胞死亡的基因。自杀基 因可以是如下基因:给表达所述基因的细胞时赋予对药剂例如药物的敏感性,并且当细胞与药剂接触或暴露于药剂时造成细胞死亡。自杀基因在所属领域中已知(参见例如《自杀基因疗法:方法和评论.(Suicide Gene Therapy:Methods and Reviews.)》Springer,Caroline J.(Maycer研究所的Maycer治疗剂的Maycer研究英国中心(Maycer Research UKCentre for Maycer Therapeutics at the Institute of Maycer Research),英国萨里萨顿 (Sutton,Surrey)),胡马纳出版社(Humana Press),2004),并且包括例如单纯疱疹病毒(HSV)胸苷激酶(TK)基因、胞嘧啶脱氨酶、嘌呤核苷磷酸化酶和硝基还原酶。
本公开进一步提供包含本文所描述的核酸或载体中的任一种的宿主细胞。如本文所 使用,术语“宿主细胞”是指可以含有本文所描述的核酸或载体的任何类型的细胞。在示范性方面中,宿主细胞是真核细胞,例如植物、动物、真菌或海藻;或可以是原核细胞, 例如细菌或原生动物。在示范性方面中,如本文所描述,宿主细胞是起源于或获自个体 的细胞。在示范性方面中,宿主细胞来源于或获自哺乳动物。如本文所使用,术语“哺 乳动物”是指任何哺乳动物,包括但不限于啮齿目(order Rodentia)哺乳动物,如小鼠 和仓鼠;和兔形目(order Lagomorpha)哺乳动物,如兔。优选地,哺乳动物来自食肉 目(orderCarnivora),包括猫科动物(猫)和犬科动物(犬)。更优选地,哺乳动物来 自偶蹄目(orderArtiodactyla),包括牛科动物(牛)和猪科动物(猪),或属于奇蹄目(orderPerssodactyla),包括马科动物(马)。最优选地,哺乳动物属于灵长目(order Primate)、新世界猴类(Ceboids)或狐猴类(Simoids)(猴)或属于类人猿亚目(order Anthropoids)(人类和猿)。特别优选的哺乳动物是人类。
在示范性方面中,宿主细胞是培养细胞或原代细胞,即,直接从生物体例如人类中分离。在示范性方面中,宿主细胞是粘附细胞或悬浮细胞,即,在悬浮液中生长的细胞。 合适的宿主细胞在所属领域中已知并且包括例如DH5α大肠杆菌细胞、中国仓鼠卵巢 (CHO)细胞、猴VERO细胞、T293细胞、COS细胞、HEK293细胞等等。出于扩增或 复制重组表达载体的目的,宿主细胞优选是原核细胞,例如DH5a细胞。出于产生结合 剂或缀合物的目的,在一些方面中,宿主细胞是哺乳动物细胞。在示范性方面中,宿主 细胞是人类细胞。虽然宿主细胞可以具有任何细胞类型,但宿主细胞可以来源于任何类 型的组织,并且可以具有任何发育阶段。在示范性方面中,宿主细胞是造血干细胞或祖 细胞。参见例如Nakamura De Oliveira等人,《人类基因疗法(Human Gene Therapy)》 24:824-839(2013)。在示范性方面中,宿主细胞是外周血液淋巴细胞(PBL)。在示范性 方面中,宿主细胞是自然杀伤细胞。在示范性方面中,宿主细胞是T细胞。
出于本文的目的,T细胞可以是任何T细胞,如培养T细胞,例如原代T细胞,或 来自培养T细胞系的T细胞,例如Jurkat、SupTl等,或获自哺乳动物的T细胞。如果 获自哺乳动物,那么T细胞可以获自诸多来源,包括但不限于血液、骨髓、淋巴结、胸 腺或其它组织或流体。T细胞还可以被富集或被化。T细胞可以通过在体外或体内将造 血干细胞成熟化成T细胞而获得。在示范性方面中,T细胞是人类T细胞。在示范性方 面中,T细胞是从人类中分离的T细胞。T细胞可以是任何类型的T细胞,包括NKT 细胞,并且可以具有任何发育阶段,包括但不限于CD4+/CD8+双阳性T细胞;CDA+辅 助T细胞;例如Th1和Th2细胞,CD8+T细胞(例如细胞毒性T细胞);外周血液单 核细胞(PBMC);外周血液白细胞(PBL);肿瘤浸润细胞(TIL);记忆T细胞;未处 理T细胞等等。优选地,T细胞是CD8+T细胞或CD4+T细胞。
本公开还提供包含至少一种本文所描述的宿主细胞的细胞群体。细胞群体可以是异 质群体,除至少一种其它细胞以外,所述异质群体包含包含任一种所描述重组表达载体的宿主细胞,所述至少一种其它细胞例如不包含任一种重组表达载体的宿主细胞(例如 T细胞),或不为T细胞的细胞,例如B细胞、巨噬细胞、中性粒细胞、红细胞、肝细 胞、内皮细胞、上皮细胞、肌肉细胞、脑细胞等。或者,细胞群体可以是基本上均质的 群体,其中群体主要包含包含重组表达载体(例如基本上由重组表达载体组成)的宿主 细胞。群体也可以是细胞克隆群体,其中群体的所有细胞是包含重组表达载体的单一宿 主细胞的克隆,使得群体的所有细胞包含重组表达载体。在本公开的示范性实施例中, 细胞群体是包含表达本文所描述的核酸或载体的宿主细胞的克隆群体。
医药组合物和给药途径
在本公开的一些实施例中,结合剂、缀合物、核酸、载体、宿主细胞或细胞群体与药学上可接受的载剂掺合。相应地,涵盖医药组合物,其包含本文所描述的结合剂、缀 合物、核酸、载体、宿主细胞或细胞群体中的任一种,并且包含药学上可接受的载剂、 稀释剂或赋形剂。
药学上可接受的载剂是常规使用的那些载剂中的任一种,并且仅受到物理-化学考虑 因素(如溶解性和与活性结合剂的反应性的缺乏)限制,并且受给药途径限制。本文所描述的药学上可接受的载剂,例如媒剂、佐剂、赋形剂和稀释剂为所属领域的技术人员 所熟知并且公众可容易获得。在一个方面中,药学上可接受的载剂是对医药组合物的活 性成分例如第一结合剂和第二结合剂具有化学惰性的载剂,并且是在使用条件下不具有 不利的副作用或毒性的载剂。在一些实施例中,当向动物或人类给予时,载体不产生不 良、过敏或其它不适当的反应。在一些方面中,医药组合物不含热原质以及会对人类或 动物有害的其它杂质。药学上可接受的载剂包括任何和所有溶剂、分散介质、涂料、抗 细菌剂和抗真菌剂、等张剂和吸收延迟剂等等;其用途在所属领域中是众所周知。
可接受的载剂、赋形剂或稳定剂对接受者无毒性并且优选在所采用的剂量和浓度下 是惰性的,并且包括缓冲夜,如磷酸盐、柠檬酸盐或其它有机酸;抗氧化剂,如抗坏血酸;低分子量多肽;蛋白质,如血清白蛋白、明胶或免疫球蛋白;亲水性聚合物,如聚 乙烯吡咯烷酮;氨基酸,如甘氨酸、谷氨酰胺、天冬酰胺、精氨酸或赖氨酸;单糖、双 糖和其它碳水化合物,包括葡萄糖、甘露糖或糊精;螯合剂,如EDTA;糖醇,如甘露 糖醇或山梨糖醇;盐形成抗衡离子,如钠;和/或非离子表面活性剂,如Tween、Pluronics 或聚乙二醇(PEG)。
适用于实施本文所公开的方法的组合物的治疗配制物,如多肽、聚核苷酸或抗体,可以通过以冻干饼或水溶液的形式将具有所期望纯度的所选择组合物与任选的生理学 上药学上可接受的载剂、赋形剂或稳定剂混合(《雷明顿的药物科学(Remington′sPharmaceutical Sciences)》,第18版,A.R.Gennaro编,马克出版公司(Mack PublishingCompany)(1990))来制备用于储存。医药组合物可以通过与一种或多种合适的载剂或 佐剂掺合来制造,所述载剂或佐剂如水、矿物油、聚乙二醇、淀粉、滑石、乳糖、增稠 剂、稳定剂、悬浮剂等等。这类组合物可以呈溶液、悬浮液、片剂、胶囊、乳膏、油膏、 软膏的形式或呈其它常规形式。
体内给药所用的组合物应为无菌的。这通过在冻干和复原之前或之后经由无菌过滤 膜过滤容易地实现。治疗性组合物一般置于具有无菌接入端口的容器中,例如具有可被皮下注射针刺穿的塞子的静脉内溶液袋或小瓶。适用于可注射用途的医药形式包括无菌水溶液或分散液和用于临时制备无菌可注射溶液或分散液的无菌粉末。在一些情况下, 所述形式应为无菌的,并且应是流体,以达到能够易于注射的程度。其应在制造和储存 的条件下稳定并且应被保存以免遭微生物如细菌和真菌的污染作用。用于肠胃外给药的 组合物通常将以冻干形式或以溶液形式储存。
载剂可以是含有例如水、乙醇、多元醇(例如,甘油、丙二醇和液体聚乙二醇等等)、其合适的混合物和植物油的溶剂或分散介质。适当的流动性可以例如通过使用涂层如卵磷脂、在分散液情况下通过维持所需粒径和通过使用表面活性剂来维持。微生物作用的 预防可以通过各种抗细菌剂和/或抗真菌剂例如对羟苯甲酸酯、氯丁醇、苯酚、山梨酸、 硫柳汞等等来实现。在许多情况下,优选的将是包括等张剂,例如糖或氯化钠。可注射 组合物的长期吸收可以通过在组合物中包括延迟吸收剂例如单硬脂酸铝和明胶来实现。
载剂的选择将部分地通过医药组合物的结合剂的特定类型以及通过用以给予医药 组合物的特定途径来确定。相应地,存在各种合适的医药组合物的配制物。
本发明的医药组合物可以包含任何药学上可接受的成份,包括例如酸化剂、添加剂、 吸附剂、气雾剂推进剂(aerosol propellant)、空气置换剂、碱化剂、防结块剂、抗凝剂、 抗微生物防腐剂、抗氧化剂、抗菌剂(antiseptic)、基质、粘合剂、缓冲剂、螯合剂、涂布剂、着色剂、干燥剂、清洁剂、稀释剂、消毒剂(disinfectant)、崩解剂、分散剂、溶 解增强剂、染料、润肤剂、乳化剂、乳液稳定剂、填充剂、成膜剂、香味增强剂、调味 剂、流动增强剂、胶凝剂、粒化剂、保温剂、润滑剂、粘膜粘着剂、软膏基质、软膏、 油性媒剂、有机碱、锭剂基质、颜料、增塑剂、抛光剂、防腐剂、多价螯合剂、皮肤渗 透剂、增溶剂、溶剂、稳定剂、栓剂基质、表面活性剂(surface active agent)、表面活 性剂(surfactant)、悬浮剂、甜味剂、治疗剂、增稠剂、张力剂、毒性剂、增粘剂、吸 水剂、水可混溶性共溶剂、水软化剂或湿润剂。
医药组合物可以经过配制以获得生理学上相容的pH。在一些实施例中,取决于配制物和给药途径,医药组合物的pH可以是至少5、至少5.5、至少6、至少6.5、至少7、 至少7.5、至少8、至少8.5、至少9、至少9.5、至少10或至少10.5到并且包括pH 11。 在某些实施例中,医药组合物可以包含缓冲剂以获得生理学上相容的pH。缓冲剂可以 包括能够在所期望的pH下缓冲的任何化合物,例如磷酸盐缓冲液(例如PBS)、三乙醇 胺、Tris、二甘氨酸、TAPS、麦黄酮、HEPES、TES、MOPS、PIPES、甲次砷酸盐、 MES和所属领域中已知的其它化合物。
在一些实施例中,包含本文所描述的结合剂的医药组合物经过配制用于肠胃外给药、皮下给药、静脉内给药、肌内给药、动脉内给药、鞘内给药或腹膜内给药。在其它 实施例中,医药组合物通过经鼻、喷雾、口服、气雾剂、直肠或阴道给药来给予。组合 物可以通过输注、快速注射或通过植入装置来给予。
仅提供关于给药途径的以下论述来说明示范性实施例并且不应解释为以任何方式 限制所公开主题的范围。
适用于口服给药的配制物可以由以下组成:(a)液体溶液,如有效量的本发明组合物溶解于稀释剂如水、盐水或橙汁中;(b)胶囊、药囊、片剂、糖锭和糖衣锭,每一种 含有预定量的活性成分,呈固体或颗粒形式;(c)粉末;(d)适当液体中的悬浮液;和 (e)合适的乳剂。液体配制物可以包括稀释剂,如水和醇,例如乙醇、苯甲醇和聚乙烯 醇,其中添加有或未添加药学上可接受的表面活性剂。胶囊形式可以具有含有例如表面 活性剂、润滑剂和惰性填充剂如乳糖、蔗糖、磷酸钙和玉米淀粉的普通硬壳或软壳明胶 类型。片剂形式可以包括以下中的一种或多种:乳糖、蔗糖、甘露糖醇、玉米淀粉、马 铃薯淀粉、海藻酸、微晶纤维素、阿拉伯胶、明胶、瓜尔胶、胶态二氧化硅、交联羧甲 纤维素钠、滑石、硬脂酸镁、硬脂酸钙、硬脂酸锌、硬脂酸和其它赋形剂、着色剂、稀 释剂、缓冲剂、崩解剂、湿润剂、防腐剂、调味剂和其它药理学上相容的赋形剂。糖锭 形式可以包含于通常蔗糖和阿拉伯胶或黄蓍的调味剂中的本公开组合物,以及锭剂包含 于如明胶和丙三醇或蔗糖和阿拉伯胶的惰性基质中的本公开组合物,乳液、凝胶等等任 选地也含有如所属领域中已知的这类赋形剂。
单独或与其它适合组分组合的本发明组合物可以经由肺部给药递送,并且可以制成 待经由吸入给予的气雾剂配制物。这些气雾剂配制物可以置于可接受的加压推进剂如二 氯二氟甲烷、丙烷、氮气等等中。其也可以被配制为如在喷雾器或雾化器中的非加压制剂的医药。这类喷雾配制物也可以用于喷雾粘膜。在一些实施例中,组合物被配制成粉 末掺合物或微米粒子或纳米粒子。合适的肺部配制物在所属领域中已知。参见例如Qian 等人,《国际医药学杂志(Int J Pharm)》366:218-220(2009);Adjei和Garren,《医药 研究(Pharmaceutical Research)》,7(6):565-569(1990);Kawashima等人,《控制释放杂 志(JControlled Release)》62(1-2):279-287(1999);Liu等人,《医药研究》10(2):228-232(1993);国际专利申请公开第WO 2007/133747号和第WO 2007/141411号。
局部配制物为所属领域的技术人员所熟知。这类配制物在本发明的背景下尤其适于 施用到皮肤。
在一些实施例中,本文所描述的医药组合物经过配制用于肠胃外给药。出于本文的 目的,肠胃外给药包括但不限于静脉内、动脉内、肌内、脑内、脑室内、心内、皮下、 骨内、皮内、鞘内、腹膜内、眼球后、肺内、膀胱内和阴茎海绵体内注射或输注。也涵 盖通过在特定部位处手术植入的给药。
适用于肠胃外给药的配制物包括水性和非水性等张无菌注射溶液,其可以含有抗氧 化剂、缓冲液、抑菌剂和使配制物与预期接受者的血液等张的溶解物;以及水性和非水性无菌悬浮液,其可以包括悬浮剂、增溶剂、增稠剂、稳定剂和防腐剂。术语“肠胃外” 意指不经由消化道而是通过如皮下、肌内、脊柱内或静脉内的某一其它途径。本发明的 组合物可以在医药载剂中与生理学上可接受的稀释剂一起给予,所述医药载剂如无菌液 体或液体的混合物,包括水、盐水、右旋糖水溶液和相关糖溶液、醇(如乙醇或十六醇)、 二醇(如丙二醇或聚乙二醇)、二甲亚砜、甘油、缩酮(如2,2-二甲基-1,5,3-二氧杂环戊 烷-4-甲醇)、醚、聚(乙二醇)400、油、脂肪酸、脂肪酸酯或甘油酯、或乙酰化脂肪酸甘 油酯,其中添加有或未添加药学上可接受的表面活性剂(如皂或清洁剂)、悬浮剂(如 果胶)、卡波姆(carbomer)、甲基纤维素、羟丙基甲基纤维素或羧甲基纤维素、或乳化 剂和其它医药佐剂。
可以用于肠胃外配制物中的油包括石油、动物油、植物油或合成油。油的具体实例包括花生油、大豆油、芝麻油、棉籽油、玉米油、橄榄油、石蜡油和矿物油。用于肠胃 外配制物中的合适的脂肪酸包括油酸、硬脂酸和异硬脂酸。油酸乙酯和十四烷酸异丙酯 是合适脂肪酸酯的实例。
在一些实施例中,肠胃外配制物含有防腐剂或缓冲液。为了将注射部位处的刺激降 到最小或消除,这类组合物任选地含有一种或多种具有约12到约17的亲水-亲油平衡(HLB)的非离子表面活性剂。这类配制物中的表面活性剂的量典型地在约5重量%到约 15重量%范围内。合适的表面活性剂包括聚乙二醇脱水山梨糖醇脂肪酸酯,如脱水山梨 糖醇单油酸酯;和氧化乙烯与通过氧化丙烯与丙二醇缩合形成的疏水性基质的高分子量 加合物。肠胃外配制物可以存在于单位剂量或多剂量密封容器如安瓿和小瓶中,并且可 以储存于冷冻干燥(冻干)条件下,仅需要在即将使用之前添加无菌液体赋形剂,例如 注射用水。临时注射溶液和悬浮液可以由先前描述并且在所属领域中已知的种类的无菌 粉末、颗粒和片剂制备。
可注射配制物是根据本发明。所属领域的普通技术人员熟知用于可注射组合物的有 效医药载剂的要求(参见例如《制药学和药学实践(Pharmaceutics and PharmacyPractice)》,J.B.利平科特公司(J.B.Lippincott Company),宾夕法尼亚州费城(Philadelphia),Banker和Chalmers编,第238-250页(1982);和《可注射药物的ASHP 手册(ASHP Handbook on Injectable Drugs)》,Toissel,第4版,第622-630页(1986))。
所属领域的技术人员应了解,除上述医药组合物以外,本公开的组合物可以被配制 成包合物,如环糊精包合物,或脂质体。
剂量
出于本文的目的,在合理的时间范围内,所给予的医药组合物的量或剂量在个体或 动物中足以发挥作用,例如治疗或预防应答。举例来说,医药组合物的剂量足以自给药时间起在约12小时、约18小时、约1到4天或更长,例如5天、6天、1周、10天、2 周、16到20天或更长时间的周期内治疗或预防疾病或医学病状。在某些实施例中,时 间段甚至更长。剂量通过特定医药组合物的功效和动物(例如人类)的条件以及待治疗 的动物(例如人类)的体重来确定。
用于确定给予剂量的许多分析在所属领域中已知。在一些实施例中,一种分析用以 确定待给予到哺乳动物的起始剂量,所述分析包含在一组每一只被给予不同剂量的结合 剂的哺乳动物中,向一哺乳动物给予给定剂量时,比较结合剂阻断IL13Rα2介导的细胞生长的程度。在给予某一剂量时结合剂阻断IL13Rα2介导的细胞生长的程度可以通过所 属领域中已知的方法分析。
也将通过给予特定医药组合物可能伴随产生的任何不良副作用的存在、性质和程度 来确定医药组合物的剂量。典型地,主治医生将考虑到各种因素如年龄、体重、一般健康状况、饮食、性别、待给予的医药组合物的结合剂、给药途径和被治疗的病状的严重 程度,来决定用于治疗每一个别患者的医药组合物的剂量。
通过实例并且不意图限制本发明,本发明结合剂的剂量可以是约0.0001到约1克/被治疗个体的千克体重/天、约0.0001到约0.001克/千克体重/天或约0.01毫克到约1克 /千克体重/天。在一些方面中,医药组合物包含浓度是至少A的本发明结合剂,其中A 是约0.001mg/ml、约0.01mg/ml、0约1mg/ml、约0.5mg/ml、约1mg/ml、约2mg/ml、 约3mg/ml、约4mg/ml、约5mg/ml、约6mg/ml、约7mg/ml、约8mg/ml、约9mg/ml、 约10mg/ml、约11mg/ml、约12mg/ml、约13mg/ml、约14mg/ml、约15mg/ml、约 16mg/ml、约17mg/ml、约18mg/ml、约19mg/ml、约20mg/ml、约21mg/ml、约22mg/ml、 约23mg/ml、约24mg/ml、约25mg/ml或更高。在一些实施例中,医药组合物包含浓 度是至多B的结合剂,其中B是约30mg/ml、约25mg/ml、约24mg/ml、约23mg/ml、 约22mg/ml、约21mg/ml、约20mg/ml、约19mg/ml、约18mg/ml、约17mg/ml、约 16mg/ml、约15mg/ml、约14mg/ml、约13mg/ml、约12mg/ml、约11mg/ml、约10mg/ml、 约9mg/ml、约8mg/ml、约7mg/ml、约6mg/ml、约5mg/ml、约4mg/ml、约3mg/ml、 约2mg/ml、约1mg/ml或约0.1mg/ml。在一些实施例中,组合物可以含有浓度范围是 A到B mg/ml.例如约0.001到约30.0mg/ml的类似物。
额外给药指导可以根据其它抗体治疗剂估量,所述其它抗体治疗剂如贝伐单抗(bevacizumab)(AvastinTMGenentech)、西妥昔单抗(西妥昔单抗)(ExbituxTMImclone)、 帕尼单抗(Panitumumab)(VectibixTMAmgen)和曲妥珠单抗(Trastuzumab)(HerceptinTMGenentech)。
给药时序
可以根据任何方案给予所公开的医药配制物,所述方案包括例如每天(每天1次、每天2次、每天3次、每天4次、每天5次、每天6次)、每两天、每三天、每四天、 每五天、每六天、每周、每两周、每三周、每月或每两月。类似于给药,时序可以基于 剂量反应研究、功效和毒性数据细调,并且最初基于用于其它抗体治疗剂的时序来估量。
控制释放配制物
在某些方面中,医药组合物被修改成长效制剂形式(depot form),使得医药组合物 的活性成分(例如结合剂)释放于给予其的身体中的方式在时间和身体内的位置方面受到控制(参见例如美国专利第4,450,150号)。在各种方面中,长效制剂形式包括例如包 含多孔或无孔材料如聚合物的可植入组合物,其中结合剂通过材料和/或无孔材料的降解 来囊封或贯穿材料而扩散。随后长效制剂植入身体内的所期望位置中并且结合剂以预定 速率从植入物中释放。
相应地,在某些方面中,医药组合物经过修改以具有任何类型的体内释放曲线。在一些方面中,医药组合物是立即释放、控制释放、持续释放、延长释放、延迟释放或两 相释放配制物。配制用于控制释放的肽(例如肽结合剂)的方法在所属领域中已知。参 见例如Qian等人,《医药学杂志(J Pharm)》374:46-52(2009)和国际专利申请公开第 WO 2008/130158号、第WO2004/033036号、第WO2000/032218号和第WO 1999/040942 号。持续释放制剂的合适实例包括呈成型制品例如膜或微胶囊形式的半渗透聚合物基 质。持续释放基质包括聚酯、水凝胶、聚丙交酯(美国专利第3,773,919号、EP 58,481)、 L-谷氨酸与γ乙基-L-谷氨酸的共聚物(Sidman等人,《生物聚合物(Biopolymers)》,22: 547-556(1983))、聚(2-羟乙基-甲基丙烯酸酯)(Langer等人,《生物医学材料研究杂志(J.Biomed.Mater.Res.)》,15:167-277(1981)和Langer,《化学技术(Chem.Tech.)》, 12:98-105(1982))、乙烯乙酸乙烯酯(Langer等人,前述)或聚-D(-)-3-羟基丁酸(EP 133,988)。持续释放组合物也可以包括脂质体,其可以通过所属领域中已知的若干方法 中的任一种制备(例如DE 3,218,121;Epstein等人,《美国国家科学院院刊》,82:3688-3692(1985);Hwang等人,《美国国家科学院院刊》,77:4030-4034(1980);EP 52,322;EP 36,676;EP 88,046;EP 143,949)。
组合
本公开的组合物可以单独采用或与其它药剂组合采用。在一些实施例中,给予多于 一种类型的结合剂。举例来说,所给予的组合物例如医药组合物可以包含抗体以及scFv。 在一些实施例中,本公开的组合物连同另一治疗剂或诊断剂(包括本文所描述的那些药 剂中的任一种)一起给予。与单独使用任何一种疗法相比,某些疾病例如癌症或患者可 能适于组合药剂的治疗以获得相加效应或甚至协同效应。
用途
部分地基于本文所提供的数据,结合剂、缀合物、宿主细胞、细胞群体和医药组合物适用于治疗赘瘤、肿瘤或癌症。
出于本发明的目的,如本文所使用,术语“治疗”和“预防”以及由其词干提取的词未 必暗示100%或完全的治疗(例如治愈)或预防。相反,存在治疗或预防的变化程度, 其中所属领域的一般技术人员认为具有潜在益处或治疗作用。在这方面中,本发明的方 法可以在患者例如人类中提供癌症的任何量或任何水平的治疗或预防。此外,本文所公 开的方法提供的治疗或预防可以包括对疾病例如被治疗或预防的癌症的一种或多种病 状或症状的治疗或预防。同样,出于本文的目的,“预防”可以涵盖延迟疾病或其症状或 病状的发作。
本文所描述的材料和方法特别适用于抑制赘生性细胞生长或扩散;确切地说抑制结 合剂所靶向的IL13Rα2起作用的赘生性细胞生长。
可通过本公开的结合剂、缀合物、宿主细胞、细胞群体和医药组合物治疗的赘瘤包括实体肿瘤,例如癌瘤和肉瘤。癌瘤包括衍生自上皮细胞的浸润(例如侵袭)周围组织 并且引起转移的恶性赘瘤。腺癌是衍生自腺组织或衍生自形成可识别腺结构的组织的癌 瘤。另一广泛类别的癌症包括肉瘤和纤维肉瘤,其是细胞嵌入于纤维状或均质物质如胚 胎结缔组织中的肿瘤。本发明也提供治疗骨髓或淋巴系统的癌症的方法,所述癌症包括 白血病、淋巴瘤和典型地不作为肿瘤块存在但分布在血管或淋巴网状系统中的其它癌 症。进一步涵盖用于治疗以下的方法:成人和小儿肿瘤、实体肿瘤/恶性病的生长、粘液 样和圆形细胞癌瘤、局部晚期肿瘤、癌转移,包括淋巴性转移。本文所列举的癌症并不 打算为限制性的。年龄(儿童和成人)、性别(男性和女性)、原发性和继发性、转移前 和转移后、急性和慢性、良性和恶性、解剖位置癌症实施例和变化形式均是所涵盖的目 标。癌症根据胚胎来源(例如癌瘤、淋巴瘤和肉瘤)、根据器官或生理系统并且通过杂 项分组来分组。特定癌症可以在其分类中重叠,并且其在一组中的列举不将其从另一组 中排除。
可以被靶向的癌瘤包括肾上腺皮质癌、腺泡状癌、腺泡细胞癌、腺泡癌、腺囊癌、腺样囊性癌、腺样鳞状细胞癌、癌症腺瘤(cancer adenomatosum)癌、腺鳞癌、附属器 癌、肾上腺皮质的癌症、肾上腺皮质癌、醛固酮产生癌、醛固酮分泌癌、肺泡癌、肺泡 细胞癌、成釉细胞癌、壶腹癌、甲状腺退行性癌症、大汗腺癌、基底细胞癌、基底细胞 癌、肺泡癌、粉刺状基底细胞癌、囊性基底细胞癌、硬斑病样基底细胞癌、多中心基底 细胞癌、结节溃疡性基底细胞(nodulo-ulcerative basal cell)癌、有色基底细胞癌、硬化 性基底细胞癌、表层基底细胞癌、基底细胞样癌、鳞状基底细胞癌、胆管癌、肝外胆管 癌、肝内胆管癌、支气管肺泡癌、细支气管癌、细支气管细胞癌、支气管肺癌癌、髓样 癌、胆管细胞癌、绒毛膜癌、脉络丛癌、透明细胞癌、泄殖腔源性癌、胶质癌、粉刺状 癌、体癌、子宫体癌、皮质醇产生癌、筛形癌、圆柱形癌、圆柱形细胞癌、导管癌、腺 管癌、前列腺导管癌、导管原位癌(ductal cancerin situ,DCIS)、分泌腺癌、胚胎癌、 铠甲状癌(cancer en cuirasse)、子宫内膜癌、子宫内膜的癌症、子宫内膜样癌、表皮样 瘤、混肿瘤状癌(cancer ex mixed tumor)、多形性腺瘤外癌(cancer ex pleomorphic adenoma)、外生性癌、纤维板型癌、纤维软疣癌(cancerfibrosum)、滤泡性甲状腺癌、 胃癌、凝胶样癌、胶状癌、巨大细胞癌、巨大细胞甲状腺癌、巨细胞癌、腺癌、颗粒细 胞癌、肝细胞癌、许特尔(Hurthle)细胞癌、肾上腺样癌、婴儿型胚胎癌、胰岛细胞 癌、乳房发炎性癌、原位癌、导管内癌、表皮内癌、上皮内癌、幼年型胚胎癌、库利奇 茨基(Kulchitsky)细胞癌、大细胞癌、软脑膜癌、小叶癌、浸润性小叶癌、侵袭性小 叶癌、小叶原位癌(lobular cancer in situ,LCIS)、淋巴上皮癌、髓样癌、髓质癌、甲状 腺髓质癌、髓质甲状腺癌、黑色素癌、脑膜癌、默克(Merkel)细胞癌、变型细胞癌、 微乳头状癌、软性癌(cancer molle)、粘液性癌、粘液癌(cancer muciparum)、粘液细 胞癌、粘液表皮样癌、粘液癌(cancer mucosum)、黏液癌(mucous carcinoma)、鼻咽癌、 神经内分泌皮肤癌(neuroendocrine cancer of the skin)、非浸润性癌、非小细胞癌、非小 细胞肺癌(NSCLC)、燕麦细胞癌、骨化性癌(cancer ossificans)、骨化性癌(osteoid carcinoma)、佩吉特氏(Paget′s)骨病或乳房病、乳头状癌、乳头状甲状腺癌、壶腹周 围癌、蔓延前癌(preinvasive carcinoma)、棘细胞癌、原发性中央型癌(primary intrasseouscarcinoma)、肾细胞癌、疤痕癌、血吸虫性膀胱癌(schistosomal bladder carcinoma)、施奈德癌(Schneiderian carcinoma)、硬癌、皮脂癌、印指环状细胞癌、单工癌(cancersimplex)、小细胞癌、小细胞肺癌(SCLC)、梭形细胞癌、海绵体癌、鳞状癌、鳞状细 胞癌、多形性低度恶性癌(terminal duct carcinoma)、退行性甲状腺癌、滤泡甲状腺癌、 髓质甲状腺癌、乳头状甲状腺癌、小梁皮肤癌、移行细胞癌、管状癌、甲状腺未分化癌、 子宫体癌、疣状癌、绒毛状癌(villous carcinoma)、绒毛状癌(cancer villosum)、卵黄 囊癌、鳞状细胞癌(确切地说头颈部鳞状细胞癌)、食道鳞状细胞癌和口癌。
可以被靶向的肉瘤包括脂肪肉瘤、肺泡软部分肉瘤、成釉细胞肉瘤、禽肉瘤、葡萄样肉瘤、葡萄状肉瘤、鸡肉瘤、绿色肉瘤、软骨型肉瘤、肾脏透明细胞肉瘤、胚胎肉瘤、 子宫内膜间质肉瘤、上皮状肉瘤、尤文氏(Ewing′s)肉瘤、筋膜肉瘤(fascial sarcomas)、 成纤维细胞肉瘤、飞禽肉瘤、巨大细胞肉瘤、粒细胞肉瘤、血管内皮细胞肉瘤、霍奇金 氏(Hodgkin′s)肉瘤、特发性多色出血性肉瘤、成免疫细胞B细胞肉瘤(immunoblasticsarcoma of B cell)、成免疫细胞T细胞肉瘤、詹森氏(Jensen′s)肉瘤、卡波西氏(Kaposi′s) 肉瘤、库普弗(Kupffer)细胞肉瘤、白细胞肉瘤、淋巴肉瘤、黑色素肉瘤、混合细胞肉 瘤、多肉瘤、淋巴管肉瘤、特发性出血性肉瘤、多潜能原发性骨肉瘤、成骨细胞肉瘤、 成骨性肉瘤、骨膜外肉瘤、多晶型肉瘤、伪卡波西(Kaposi)肉瘤、网状细胞肉瘤、网 状细胞脑肉瘤、横纹肌肉瘤、劳斯(Rous)肉瘤、软组织肉瘤、梭形细胞肉瘤、滑膜肉 瘤、毛细血管扩张性肉瘤、骨的肉瘤(骨肉瘤(osteosarcoma))/恶性纤维组织细胞瘤和 软组织肉瘤。
可以被靶向的淋巴瘤包括AIDS相关淋巴瘤、非霍奇金氏淋巴瘤、霍奇金氏淋巴瘤、T细胞淋巴瘤、T细胞白血病/淋巴瘤、非洲淋巴瘤、B细胞淋巴瘤、B细胞单核球淋巴 瘤、牛恶性淋巴瘤、伯基特氏(Burkitt′s)淋巴瘤、中央细胞淋巴瘤、皮肤淋巴瘤(lymphoma cutis)、弥漫性淋巴瘤、弥漫性淋巴瘤、大细胞淋巴瘤、弥漫性淋巴瘤、混合小细胞和 大细胞淋巴瘤、弥漫性淋巴瘤、小裂解细胞淋巴瘤、滤泡性淋巴瘤、滤泡性中央细胞淋 巴瘤、滤泡性淋巴瘤、混合小裂解细胞和大细胞淋巴瘤、滤泡性淋巴瘤、主要大细胞淋 巴瘤、滤泡性淋巴瘤、主要小裂解细胞淋巴瘤、巨大滤泡性淋巴瘤、巨大滤泡性淋巴瘤、 肉芽肿性淋巴瘤、组织细胞淋巴瘤、大细胞淋巴瘤、成免疫细胞淋巴瘤、大裂解细胞淋 巴瘤、大非裂解细胞淋巴瘤、伦纳特氏(Lennert′s)淋巴瘤、成淋巴细胞淋巴瘤、淋巴 细胞性淋巴瘤、中间性淋巴瘤、淋巴细胞性淋巴瘤、中度分化性淋巴瘤、浆细胞性淋巴 瘤、分化不良的淋巴细胞性淋巴瘤、小淋巴细胞性淋巴瘤、分化良好的淋巴细胞性淋巴 瘤、牛淋巴瘤、MALT、外膜细胞淋巴瘤、外膜区淋巴瘤、边际区淋巴瘤、地中海 (Mediterranean)淋巴瘤混合的淋巴细胞-组织细胞淋巴瘤、节状淋巴瘤、浆细胞性淋巴 瘤、多形性淋巴瘤、原发性中枢神经系统淋巴瘤、原发性渗出性淋巴瘤、小B细胞淋巴 瘤、小裂解细胞淋巴瘤、小非裂解细胞淋巴瘤、T细胞淋巴瘤、卷积T细胞淋巴瘤、皮 肤t细胞淋巴瘤、小淋巴细胞性T细胞淋巴瘤、不确定的淋巴瘤、u细胞淋巴瘤、未分 化型淋巴瘤、aids相关淋巴瘤、中枢神经系统淋巴瘤、皮肤T细胞淋巴瘤、渗出性(基 于体腔的)淋巴瘤、胸腺淋巴瘤和皮肤T细胞淋巴瘤。
可以被靶向的白血病和其它血细胞恶性病包括急性成淋巴细胞白血病、急性骨髓白 血病、淋巴细胞性白血病、慢性骨髓性白血病、毛状细胞白血病、成淋巴细胞白血病、 骨髓白血病、淋巴细胞性白血病、骨髓性白血病、白血病、毛状细胞白血病、T细胞白 血病、单核细胞性白血病、成髓细胞性白血病、粒细胞白血病、格罗斯(gross)白血病、 手镜细胞白血病(hand mirror-cell leukemia)、嗜碱性白血病、成血细胞白血病(hemoblasticleukemia)、组织细胞白血病、白细胞减少性白血病、淋巴白血病、希林氏(Schilling′s) 白血病、干细胞白血病、骨髓单核细胞性白血病、前淋巴细胞性白血病、小成髓细胞白 血病、成巨核细胞白血病、巨核细胞白血病、瑞登(Rieder)细胞白血病、牛白血病、 白细胞不增多性白血病、肥大细胞白血病、骨髓细胞性白血病、浆细胞白血病、亚白血 性白血病、多发性骨髓瘤、非淋巴细胞白血病和慢性骨髓细胞白血病。
可以被靶向的脑和中枢神经系统(CNS)癌症和肿瘤包括星形细胞瘤(包括小脑和大脑)、神经胶质瘤(包括恶性神经胶质瘤、成胶质细胞瘤、脑干神经胶质瘤、视觉路 径和下丘脑神经胶质瘤)、脑肿瘤、室管膜瘤、神经管胚细胞瘤、幕上原始神经外胚层 肿瘤、原发性中枢神经系统淋巴瘤、颅外生殖细胞肿瘤、骨髓发育不良综合症、少突神 经胶质瘤、骨髓发育不良/骨髓增生疾病、骨髓性白血病、骨髓白血病、多发性骨髓瘤、 骨髓增生病症、神经母细胞瘤、浆细胞赘瘤/多发性骨髓瘤、中枢神经系统淋巴瘤、固有 脑肿瘤、星形胶质细胞脑肿瘤和中枢神经系统中的转移性肿瘤细胞侵犯。
可以被靶向的胃肠道癌症包括肝外胆管癌、结肠癌、结肠和直肠癌、结直肠癌、胆囊癌、胃(胃部)癌、胃肠道类癌肿瘤、胃肠道类癌肿瘤、胃肠道间质瘤、膀胱癌、胰 岛细胞癌(内分泌胰腺)、胰脏癌、胰岛细胞胰脏癌、前列腺癌、直肠癌、唾液腺癌、 小肠癌、结肠癌和与结直肠瘤形成相关的息肉。对结直肠癌的论述描述在Barderas等人, 《癌症研究》72:2780-2790(2012)中。
可以被靶向的骨癌症包括骨肉瘤和恶性纤维组织细胞瘤、骨髓癌、骨转移、骨的骨肉瘤/恶性纤维组织细胞瘤,和骨瘤和骨肉瘤。可以被靶向的乳癌包括小细胞癌和腺管癌。
可以被靶向的肺和呼吸性癌症包括支气管腺瘤/类癌瘤、食道癌食道癌、食道癌、下 咽癌、喉癌、下咽癌、肺类癌肿瘤、非小细胞肺癌、小细胞肺癌(small cell lungcancer)、 小细胞肺癌(small cell carcinoma of the lung)、间皮瘤、鼻腔和副鼻窦癌、鼻咽癌、鼻 咽癌、口癌、口腔和唇癌、口咽癌、副鼻窦和鼻腔癌,和胸膜肺母细胞瘤。
可以被靶向的泌尿道和生殖性癌症包括宫颈癌、子宫内膜癌、卵巢上皮癌、性腺外生殖细胞肿瘤、颅外生殖细胞肿瘤、性腺外生殖细胞肿瘤、卵巢生殖细胞肿瘤、妊娠期 滋养细胞肿瘤、脾癌、肾癌、卵巢癌、卵巢上皮癌、卵巢生殖细胞肿瘤、卵巢低恶性潜 在肿瘤、阴茎癌、肾细胞癌(包括癌瘤)、肾细胞癌、肾盂和输尿管(移行细胞癌)、肾 盂和输尿管的移行细胞癌、妊娠期滋养细胞肿瘤、睾丸癌、输尿管和肾盂癌、移行细胞 癌、尿道癌、子宫内膜子宫癌、子宫肉瘤、阴道癌、外阴癌、卵巢癌、原发性腹膜上皮 赘瘤、宫颈癌、子宫癌和卵巢滤泡中的实体肿瘤、浅表性膀胱肿瘤、侵袭性膀胱移行细 胞癌和肌肉侵袭性膀胱癌。
可以被靶向的皮肤癌和黑素瘤(以及非黑素瘤)包括皮肤T细胞淋巴瘤、眼内黑素瘤、人类皮肤角化细胞的肿瘤进展、基底细胞癌和鳞状细胞癌。可以被靶向的肝癌包括 肝外胆管癌和肝细胞癌。可以被靶向的眼癌包括眼内黑素瘤、成视网膜细胞瘤,并且可 以被靶向的眼内黑素瘤激素癌包括:甲状旁腺癌、松果体和幕上原始神经外胚层肿瘤、 垂体肿瘤、胸腺瘤和胸腺癌、胸腺瘤、胸腺癌、甲状腺癌、肾上腺皮质癌和ACTH产生 肿瘤。
可以被靶向的各种其它癌症包括晚期癌症、AIDS相关癌、肛门癌、肾上腺癌、皮 质癌、再生障碍性贫血、苯胺癌、槟榔癌、萎叶性颊癌(buyo cheek cancer)、髓样癌、 烟囱扫除癌(chimney-sweep cancer)、粘土管癌(clay pipe cancer)、胶质癌、接触癌、 囊性癌、树突状癌、配偶癌(cancer a deux)、乳腺管癌、染料工人(dye workers)癌症、 脑样癌、铠甲状癌、子宫内膜癌、内皮癌、上皮癌、腺癌、原位癌、康(kang)癌、康 格里(kangri)癌、潜在癌症、髓质癌、黑色素癌、骡-旋转式癌(mule-spinners′ cancer)、 非小细胞肺癌、隐性癌症、石蜡癌、沥青工癌(pitch workers′ cancer)、疤痕癌、血吸虫 性膀胱癌、硬癌、淋巴结癌、小细胞肺癌、软癌、烟尘癌、梭形细胞癌、沼泽癌(swamp cancer)、焦油癌和管状癌。
可以被靶向的各种其它癌症也包括类癌(胃肠道和支气管)、卡斯特莱曼氏(Castleman′s)病、慢性骨髓增生病症、腱鞘透明细胞肉瘤、尤文氏肿瘤家族、头颈癌、 唇和口腔癌、瓦尔登斯特伦氏(Waldenstrom′s)巨球蛋白血症、隐性原发性转移性鳞状 颈癌(metastatic squamous neck cancer with occult primary)、多发性内分泌腺瘤综合症、多发性骨髓瘤/浆细胞赘瘤、维尔姆斯(Wilms′)瘤、蕈样真菌病、嗜铬细胞瘤、塞扎里(sezary)综合征、幕上原始神经外胚层肿瘤、未知原发部位、腹膜渗出、恶性肋膜积液、 滋养细胞赘瘤和血管外皮瘤。
在示范性方面中,癌症是前述的中的任一种,其中IL13Rα2在癌细胞上表达。在示范性方面中,癌症是结肠癌。在示范性方面中,癌症是多形性成胶质细胞瘤。在示范性 方面中,治疗有需要个体的癌症的方法包含以有效治疗癌症的量向所述个体给予本文所 描述的结合剂、缀合物、核酸、载体、宿主细胞、细胞群体或医药组合物中的任一种。 在示范性方面中,所述方法包含给予本文所描述的缀合物。在示范性方面中,所述方法 包含给予本公开的宿主细胞,并且相关于被治疗的个体,宿主细胞是自体细胞。在示范 性方面中,所述方法包含给予本公开的宿主细胞,并且宿主细胞是获自被治疗的个体的 细胞。在示范性方面中,细胞是T淋巴细胞。在替代方面中,细胞是自然杀伤细胞。
将参照以下实例更完全地理解本公开,所述实例详述本公开的示范性实施例。然而, 实例不应解释为限制本公开的范围。
实例1
材料
脂染胺(Lipofectamine)2000和pEF6/Myc-His载体获自英杰公司(Invitrogen)。IL13Rα2的单克隆抗体(克隆YY-23Z和B-D13)和IsoStrip小鼠单克隆抗体同型试剂 盒购自圣克鲁斯生物技术(Santa Cruz Biotechnology)(加利福尼亚州圣克鲁斯(Santa Cruz))。IL13Rα2的mAb(克隆83807)和重组型人类和小鼠IL13Rα2hFc和IL13Rα1hFc 嵌合体购自R&DSystems(明尼苏达州明尼阿波利斯(Minneapolis,MN))。生物素化马 抗小鼠抗体和Elite试剂盒获自载体实验室(Vector Laboratories)(加利福尼亚州伯林盖 姆(Burlingame))。3,3′-二氨基联苯胺底物购自达科公司(Dako)(加利福尼亚州卡平特 里亚(Carpinteria)。与过氧化酶缀合的山羊抗小鼠抗体购自Chemicon International(加 利福尼亚州坦密库拉(Temicula),并且Pngase F购自新英格兰生物实验室(New England Biolabs)(马萨诸塞州伊普威治(Ipswich,MA)。QuikChange Lightning定点突变诱发试 剂盒购自安捷伦科技有限公司(Agilent Technologies,Inc.)(加利福尼亚州圣克拉拉 (Santa Clara)),并且RNeasy Plus试剂盒接受自凯杰(Qiagen)(加利福尼亚州巴伦西亚 (Valencia))。cDNAiScript试剂盒、7.5%Tris-HCl凝胶和ImmunStar WesternC开发试剂 和蛋白质标记物购自伯乐(Bio-Rad)。人类IL-13 ELISA试剂盒购自电子生物科学 (eBioscience)(加利福尼亚州圣地亚哥(San Diego))。GBM12和GBM43由David C.James 博士(加州大学旧金山分校(University of California-San Francisco))友情提供,并且编 码人类野生型IL13Rα2的cDNA获自Waldemar Debinski博士(维克弗斯特大学(Wake Forest University))。获得编码人类野生型IL13Rα2或大多数其它蛋白质的cDNA涉及使 用熟知技术和可容易获得的试剂。
免疫接种
为获得对原生IL13Rα2具有特异性的单克隆抗体,针对动物的免疫接种并且在所有 筛选分析中使用人类重组IL13Rα2hFc融合体。持续2个月在2周间隔下,用完全弗氏 佐剂(Freund′s adjuvant)中的10μg rhIL13Rα2hFc蛋白质的腹膜内注射使两只6周龄雌 性BALB/c小鼠免疫,随后用在不完全弗氏佐剂中的10μg rhIL13Rα2hFc蛋白质的腹膜 内注射免疫。在最后一次腹膜内注射后的两周和融合前的3天,通过组合无弗氏佐剂的 10μg抗原的静脉内和腹膜内注射进行加强。通过使用 和Milstein(27)描述的 程序进行小鼠脾细胞与小鼠骨髓瘤细胞系X63.Ag8.653亚克隆P3O1的融合。针对 IL13Rα2抗体的存在,使用酶联免疫吸附分析(ELISA)分析杂交瘤上清液。对所选择 群体进行克隆,并且分析上清液以鉴别具有最强结合的克隆。
和Milstein(27)描述的 程序进行小鼠脾细胞与小鼠骨髓瘤细胞系X63.Ag8.653亚克隆P3O1的融合。针对 IL13Rα2抗体的存在,使用酶联免疫吸附分析(ELISA)分析杂交瘤上清液。对所选择 群体进行克隆,并且分析上清液以鉴别具有最强结合的克隆。
表达人类IL13Rα2的CHO细胞系的产生
用以下引物对扩增编码人类野生型IL13Rα2的cDNA:正向 5′-GCTTGGTACCGAATGGCTTTCGTTTGCTTGGC-3′(SEQ ID NO:17),和反向 5′-GTTTTTGTTCGAATGTATCACAGAAAAATTCTGG-3′(SEQ ID NO:18)。将纯化的 PCR产物用KpnI和BstBI酶限制,琼脂糖凝胶纯化,并且随后在具有Myc和His6标签 的阅读框中克隆于pEF6/Myc-His载体中。在80%汇合下接种CHO细胞并且使用脂染胺 2000用编码IL13Rα2的质粒转染。第二天,添加4μg/ml杀稻瘟菌素(blasticidin)以选 择已稳定并入并且表达IL13Rα2转录物的细胞。将稳定的细胞群体进一步以一个细胞/ 孔的密度亚克隆于96孔板中。十天后,针对IL13Rα2的细胞表面表达,通过流式细胞 测量术使用IL13Rα2的抗体(克隆B-D13)来筛选单克隆。选择并且扩增具有最高水平 的IL13Rα2表达的克隆以用于分泌IL13Rα2抗体的杂交瘤的后续筛选。
ELISA
在4℃下用50μl人类或小鼠重组IL13Rα2hFc或IL13Rα1hFc或浓度是1μg/ml的人类对照IgG涂布96孔板,过夜。用TBS-Tween 20缓冲液洗涤并且用1%脱脂奶粉阻断 后,将50μl纯化的抗体、血清或杂交瘤上清液(在各种稀释度下)施用到板并且在室 温下培育1小时。用缀合到碱性磷酸酶的山羊抗小鼠抗体检测结合抗体,之后用碱性磷 酸酶底物显色。在A405下使用UniRead 800板读取器(伯腾(BioTek))读取板。
流式细胞测量术
用1μg/ml的IL13Rα2(克隆47)单克隆抗体染色表达IL13Rαα2的CHO或HEK细 胞;神经胶质瘤细胞系A172、N10、U251、U87和U118;源自患者的GBM12和GBM43 以及原代人类星形胶质细胞,随后用山羊抗小鼠Alexa Fluor 647(1∶500)染色。所有染 色程序在冰上进行。使用BD FACSCanto流式细胞仪和FACSDiVaTM软件分析样品。
PCR
为测定IL13Rα2在各种神经胶质瘤细胞和星形胶质细胞中的表达,使用RNeasyPlus 试剂盒由细胞离心块产生总RNA。随后使用cDNA iScript试剂盒将200ng的总RNA转化成cDNA。针对IL13Rα2和GAPDH,使用IL13Rα2和GAPDH引物通过PCR进一步 扩增cDNA 30个循环,并且在1%琼脂糖凝胶上显现。
表面等离子体共振
用Biacore 3000生物传感器通过表面等离子体共振(SPR)测量IL13Rα2(克隆47)单克隆抗体、可商购的IL13Rα2单克隆抗体(克隆83807和B-D13)与标靶(rhIL13Rα2) 之间的相互作用的亲和力和速率。使用氨基偶合试剂盒将单克隆抗体固定(以共价方式) 到传感器芯片(CM5)的聚萄萄糖基质。用含有0.2MN-乙基-N’-(3-二乙氨基-丙基)-碳 化二亚胺和0.05MN-羟基丁二酰亚胺的溶液的注射来活化传感器表面上的羧基。通过注 射1甲醇胺盐酸盐以阻断剩余酯基完成固定程序。以10μl/min的流速进行固定方法的 所有步骤。除了注射操作缓冲液而非单克隆抗体,以类似方式制备对照表面。在25℃下 在HBSP缓冲液(20mM HEPES,pH 7.4,150mM NaCl,和0.005%(v/v)表面活性剂 P20)中使用20μl/min的流速进行结合反应。在结合阶段期间在流动中添加各种浓度的 标靶(rhIL13Rα2)。通过折射率(由应答单位(RU)表示)的变化监测结合到传感器芯 片的蛋白质的量。对仪器进行编程以在同一表面上在标靶的增加的浓度下进行一系列结 合测量。对标靶的每一浓度重复注射三次。使用BIAevaluation v4.1分析传感图(表面 上RU随时间变化的图)。使用1∶1结合模型通过曲线拟合估算亲和常数。
数据准备和动力学分析
通过在固定化mAb上重复注射一系列标靶浓度来估算动力学参数。通过“双参考”方法准备数据。这种方法利用对照聚葡萄糖表面上每一标靶样品的平行注射,以及固定 化mAb和对照聚葡萄糖表面两者上的操作缓冲液注射。这些传感图的扣除产生对照; 这由实验传感图扣除。使用各种动力学模型分析每一数据组(由增加的标靶浓度在相同 水平的固定化mAb上的传感图组成)。随后BIAevaluation v 4.1软件用于数据分析。使 用1∶1结合模型通过曲线拟合估算亲和常数。局部或总体地拟合传感图缔合和解离曲线。 通过以下类型的方程式描述样品注射期间复合物形成的速率:dR/dt=kaC(Rmax-R)-kdR (针对1∶1相互作用),其中R是以RU为单位的SPR信号,C是分析物的浓度,Rmax是 以RU为单位的最大的分析物结合能力,并且dR/dt是SPR信号的改变速率。早期结合 阶段(300s)用以确定mAb与标靶之间的缔合常数(ka)。在标靶注射结束时使用引入 游离缓冲液时RU的降低速率测量解离阶段(dissociation phase,kd)。通过软件程序(全 局拟合算法)同时拟合数据,并且复合物的解离常数(KD)以比率ka/kd形式测定。对 于定量分析,每一个样品有三个独立的重复。数据表述为平均值±S.E。
竞争结合分析
针对竞争结合板分析,用pH 9.6的碳酸盐缓冲液中的50μl 1μg/ml的亲和纯化的hrIL13Rα2hFc涂布96孔板,并且在4℃下储存过夜。在用含有0.05%Tween 20的PBS 洗涤后,在室温下添加IL13Rα2的mAb(10μg/ml)或对照mIgG,持续30分钟。洗涤 后,在室温下添加PBS中的50μl纯化rhIL-13和0.1%10ng/ml的BSA用于1小时培 育,并且使用来自人类IL-13ELISA试剂盒的检测试剂分析结合的rhIL-13。单独地,在 冰上用2μg/ml的rhIL-13或mAbIL13Rα2(克隆47)预处理表达野生型IL13Rα2或在 IL13Rα2序列中的4氨基酸突变体(参见实例10)的HEK细胞30分钟,随后分别与 100ng/ml的IL13Rα2(克隆47)mAb或rhIL-13一起培育1小时。单独或在竞争对手存 在下,用人类IL-13 mAb-FITC检测rhIL-13与IL13Rα2的结合。单独或在竞争对手存在 下,用缀合到Alexa Fluor 649的抗小鼠抗体检测IL13Rα2(克隆47)mAb与rhIL13Rα2 的结合,并且通过流式细胞测量术分析。
IL13Rα的突变诱发
先前,人类IL13Rα2的Tyr207、Asp271、Tyr315和Asp318被鉴别为对与人类IL-13的 相互作用关键的残基(28)。为判定那些残基是否对IL13Rα2(克隆47)mAb与IL13Rα2 的结合至关重要,根据制造商的建议,使用QuikChange Lightning定点突变诱发试剂盒, 将Tyr207、Asp271、Tyr315和Asp318残基单独地或同时突变成Ala(4氨基酸突变体)。使 用常规技术测序所选择的克隆,其确认所选择的突变的存在。使用Lipofectamine Plus 转染试剂,在pEF6Myc-His载体中用IL13Rα2 cDNA的野生型或突变变异体转染HEK 细胞。在转染后48小时,收集细胞并且经由流式细胞测量术分析与IL13Rα2(克隆47) mAb的结合。
蛋白质印迹
将rhIL13Rα2以200纳克/泳道施用到7.5%Tris-HCl凝胶(伯乐)并且在还原条件下解析。在将蛋白质转移到PVDF膜(伯乐)并且用2%脱脂奶粉阻断后,所述膜用2μg/ml 的抗IL13Rα2 mAb(克隆YY-23Z和B-D13)或用从杂交瘤克隆收集的上清液(稀释10 倍)染色,随后用与过氧化酶缀合的山羊抗小鼠抗体染色。使用ImmunStar WesternC使 反应显色。使用伯乐ChemiDoc成像系统捕获图像。
免疫组织化学
根据芝加哥大学(University of Chicago)机构审查委员会(InstitutionalReview Board) 认可的方案收集GBM组织。将快速冷冻的脑肿瘤组织切成10μm厚。用-20℃甲醇固定 组织切片,并且针对人类IL13Rα2,使用浓度是3μg/ml的小鼠IL13Rα2(克隆47)mAb 或同型对照mIgG1染色。用生物素化马抗小鼠抗体检测结合抗体(1∶100)。用3,3′-二氨基联苯胺底物利用Elite试剂盒检测抗原-抗体结合。使用CRI全景扫描全幻灯片扫描器(CRI Panoramic Scan Whole Slide Scanner)和全景查看器(Panoramic Viewer)软件分析 载片。
动物研究
根据机构动物照护与使用委员会(Institutional Animal Care and UseCommittee)方 案并且根据美国国家卫生研究院(National Institutes of Health)指南维护并照护所有动 物。实验中所使用的动物是6到7周龄雄性无胸腺nu/nu小鼠。用氯胺酮盐酸盐/甲苯噻 嗪(25mg/ml/2.5mg/ml)混合物的腹膜内注射来麻醉小鼠。为确立颅内肿瘤,制备中线 颅骨切口,并且在矢状缝侧2mm和λ上约2mm放置右侧钻孔。将动物安置在立体定 位框中,并且将汉密尔顿(Hamilton)针插入通过钻孔并前移3mm。紧接着颅内渗透的 是(i)注射2.5×104个U251神经胶质瘤细胞,所述细胞在与200ng mIgG或IL13Rα2 (克隆47)mAb组合的2.5μl无菌PBS中,或(ii)用如先前所描述的PBS或10μg IL13Rα2 (克隆47或B-D13)mAb对神经胶质瘤细胞进行3天后的颅内注射(29,以引用的方式 并入本文中)。监测所有小鼠的存活。在第17天处死每组的三只动物,并且收集脑并冷 冻用于切片、苏木精和伊红(H&E)染色和显微镜分析。
统计
通过史都登氏(Student′s)t检验或使用事后比较杜凯氏(Tukey′s)检验或邓尼特检 验的单因素方差分析评估各组之间的差异。对于体内存活率数据,使用卡普兰-迈耶存活 率分析,并且使用对数秩检验进行统计分析。P<0.05视为在统计学上显著。
实例2
抗原的表征和分泌抗IL13Rα2抗体的杂交瘤克隆的筛选
本研究的主要目标是产生适用于靶向在肿瘤细胞表面上表达的IL13Rα2的高亲和力 单克隆抗体。因此我们将小鼠免疫并且对于针对抗原rhIL13Rα2(呈其原生构形)的反应性筛选所得杂交瘤克隆。针对rhIL13Rα2的检测,确立利用针对rhIL13Rα2的杂交瘤 克隆YY-23Z的板结合的ELISA。发现1μg/ml的吸收到塑料的rhIL13Rα2的浓度适用 于检测抗体结合(图1A)。然后,通过利用一对仅识别原生(发现于细胞表面上)和变 性(在还原条件下使用蛋白质印迹法)形式的IL13Rα2的可商购抗体来表征 rhIL13Rα2hFc的“原生性”,并且分别使用抗体克隆B-D13和YY-23Z在ELISA中表征 其与rhIL13Rα2的结合特性。在板结合的ELISA中,克隆B-D13和YY-23Z均能够识别 rhIL13Rα2hFc(图1B)。在β-巯基乙醇存在下在95℃下持续5分钟的抗原变性完全消除 抗体克隆B-D13通过ELISA识别抗原的能力,然而YY-23Z克隆保持结合变性抗原的 能力。因此,吸收到塑料的rhIL13Rα2hFc,含有蛋白质的原生和变性形式的ELISA板。 分析来自用rhIL13Ra2和hFc的融合体免疫的动物的血清揭露了针对rhIL13Rα2和人类 Fc片段的抗体的存在。为选择特异于融合体的IL13Rα2部分的抗体,将人类IgG作为 额外阴性对照包括,以用于筛选杂交瘤群体。在39个筛选的原代群体中,仅15个群体 对IL13Rα2具有特异性,并且四个与人类IgG具反应性。最后,进一步扩增并且再克隆 与原生IL13Rα2强烈反应的五个克隆。仅识别变性抗原的两个克隆选自具有 rhIL13Rα2hFc嵌合体的单独免疫接种组。在板结合的ELISA(图1C)中并且通过蛋白 质印迹法(图1D)比较所选择克隆的上清液结合hrIL13Rα2的能力。图1C显示在板结 合的ELISA中而非通过蛋白质印迹法,克隆47强烈地结合到抗原,指示克隆47识别抗 原的原生构形的能力。因此,选择克隆47用于进一步表征并且用于其它实验。发现克 隆47具有IgG1同型,拥有κ链。
实例3
IL13Rα2(克隆47)mAb与在细胞表面上表达的重组人类IL13Rα2和IL13Rα2的结 合特异性
我们研究在板结合的ELISA中,相对于可商购的克隆83807和B-D13,IL13Rα2(克隆47)mAb与rhIL13Rα2的结合特性。图2A显示当与克隆83807和B-D13相比较时, 克隆47与rhIL13Rα2的结合较强并且具特异性。克隆47在0.05μg/ml的低浓度下达到 结合平台。在这些实验中,无抗体显示与用作额外阴性对照的人类IgG的结合。为进一 步验证克隆47与人类IL13Rα2的相互作用的特异性,产生表达实际大小野生型人类 IL13Rα2的CHO细胞的克隆系(克隆6)。将抗体与转染有空白载体的对照CHO细胞的 结合与抗体与表达IL13Rα2的CHO细胞的组合相比较。再次,IL13Rα2(克隆47)mAb 展现与在细胞表面上表达的IL13Rα2而非与对照CHO细胞的结合较强并且具特异性, 指示这种抗体特异性地识别IL13Rα2的原生构形(图2B)。克隆47在0.25μg/ml的最 低测试浓度下展现针对IL13Rα2的最强亲和力。值得注意地,其它所选择的杂交瘤克隆 展现类似的与在CHO细胞的细胞表面上表达的IL13Rα2而非与对照CHO细胞的相互作 用的特异性。在板结合的ELISA中获得的数据也揭露到克隆47不与IL-13的低亲和力 受体IL13Rα1(图2C)或小鼠重组IL13Rα2相互作用,进一步验证克隆47与IL13Rα2 之间的相互作用的特异性(图2D)。克隆83807和B-D13并不显示与小鼠rIL13Rα2的 结合,这与目前对这些抗体与小鼠IL13Rα2的交叉反应性的理解一致。
然后,我们表征克隆47与各种神经胶质瘤细胞系、源自患者的神经胶质瘤系GBM12和GBM43以及正常人类星形胶质细胞的结合能力。在44-47%人类GBM切除的样本(3) 中和在多达82%(14/17)的衍生自GBM和正常脑外植体的原代细胞培养物中(2)报 导相对于正常脑组织IL13Rα2基因的增加的表达。图3的A和B显示神经胶质瘤细胞、 人类星形胶质细胞和在细胞表面上表达重组人类IL13Rα2的HEK细胞与IL13Rα2(克 隆47、83807和B-D13)mAb的比较染色的流程图。图3的A和B揭露(i)细胞表面 上IL13Rα2表达的各种水平,和(ii)相对于克隆B-D13(细胞系之间1.2-4.6倍的差异) 和83807,克隆47与所分析细胞系的表面的优异结合。有趣地,我们观测到与表达 IL13Rα2的HEK细胞相比,克隆83807与神经胶质瘤细胞系的结合几乎完全不存在。 未检测到克隆47与正常人类星形胶质细胞的结合,确认克隆47与表达IL13Rα2的人类 神经胶质瘤细胞的相互作用的特异性。IL13Rα2 mRNA在这些细胞中的表达一般与细胞 表面上的IL13Rα2表达水平相关。此外,表达低IL13Rα2 mRNA到不表达IL13Rα2 mRNA 的细胞,包括U118和原代人类星形胶质细胞,展现IL13Rα2在细胞表面上低表达到不 表达(图3B)。在额外实验中,将N10神经胶质瘤细胞与1μg/ml的IL13Rα2(克隆47) mAb或用10倍过量的rhIL13Rα2预培育的IL13Rα2(克隆47)mAb一起培育(图10), 并且通过流式细胞测量术分析。当与单独的克隆47相比较时,发现在10倍过量的 rhIL13Rα2存在下的IL13Rα2(克隆47)mAb之间的相互作用显著去除。类似地,N10 细胞与10倍过量的rhIL-13或IL13Rα2(克隆47)mAb的预培育几乎完全阻断抗体或 rhIL-13与N10细胞之间的相互作用(补充图1B),指示在神经胶质瘤细胞表面上表达 的IL13Rα2与克隆47之间的识别的特异性(图10)。
为验证IL13Rα2(克隆47)mAb拥有原位结合神经胶质瘤细胞表面上的IL13Rα2 的能力,在裸小鼠中确立表达绿色荧光蛋白(GFP)的U251细胞的颅内神经胶质瘤异 种移植物。三周后,处死动物,并且获得细胞并将其放置于体外培养条件下。48小时后, 收集细胞并且用对照mIgG或IL13Rα2(克隆47)mAb染色。所培养的表达GFP的U251 细胞充当阳性对照。GFP阳性U251细胞代表全部细胞的约56%(图3C,图a),并且 96%的细胞与IL13Rα2(克隆47)mAb具反应性(图3C,图c),然而GFP阴性细胞不 与抗体相互作用(图3C,图b)。这些数据进一步确认IL13Rα2(克隆47)mAb特异性 地识别表达小鼠异种移植物中的IL13Rα2的神经胶质瘤细胞,并且不与来自小鼠脑的其 它细胞具反应性。
实例4
亲和力研究
使用表面等离子体共振来确定IL13Rα2(克隆47)mAb与rhIL13Rα2之间的相互作用的亲和力和速率。相较于针对IL13Rα2的两种商业抗体克隆83807和B-D13,进行所 有测量。图4显示每一抗体的传感图。测量结果概述在表1中。
表1
结合到人类重组IL13Rα2的单克隆抗体的动力学

如实例1中所描述估算动力学参数。将复合物的解离常数(KD)确定为比率ka/kd。对于定量分析,每一个样品有三个独立的重复。数据表述为平均值±S.E。这些数据证 实IL13Rα2(克隆47)mAb与重组IL13Rα2的亲和力分别超过可商购的mAb克隆83807 和B-D13的亲和力75倍和33倍。
图4A显示到,克隆47展现与rhIL13Rα2在30分钟时间范围内测量的长期并稳定 的缔合,然而克隆83807(图4B)和B-D13(图4C)相对快速地解离。IL13Rα2(克隆 47)mAb与rhIL13Rα2的结合亲和力计算为1.39×10-9M。这个值分别超过可商购的抗 体克隆83807和B-D13与rhIL13Rα2的亲和力75倍和33倍。当分别与克隆83807和 B-D13的250和8-16RU相比较时,克隆47在390RU下展现与rhIL13Rα2的最高结合 亲和力(Rmax)。这些数据指示IL13Rα2(克隆47)mAb拥有比克隆83807和B-D13优 异的特性以及展现针对rhIL13Rα2的更高的亲和力。
实例5
单克隆抗体与rhIL-13竞争与IL13Rα2的结合
为判定IL13Rα2(克隆47)mAb是否拥有抑制特性,进行利用rhIL13Rα2hFc嵌合 体和短暂表达人类IL13Rα2的HEK细胞的竞争结合分析。以板结合的ELISA型式设定 竞争结合分析。吸收到板的rhIL13Rα2hFc充当靶抗原。为判定IL13Rα2 mAb是否特异 性抑制IL-13与rhIL13Rα2的结合,将板与100倍过量的mIgG、IL13Rα2(克隆47) mAb或包括83807、YY-23Z和B-D13的其它IL13Rα2 mAb克隆预培育,随后与rhIL13 一起培育。图5A显示IL13Rα2(克隆47)mAb显著消除rhIL-13与rhIL13Rα2的结合, 然而针对人类IL-13的结合,IL13Rα2 mAb克隆B-D13和83807展现显著较小的竞争。
为进一步验证IL13Rα2(克隆47)mAb的抑制特性,将HEK 293T细胞用编码IL13Rα2cDNA的野生型或4氨基酸突变体形式的药剂转染,在所述突变体形式中Tyr207、 Asp271、Tyr315和Asp318残基被Ala取代。先前,人类IL13Rα2的这些残基被鉴别为 与同源配位体IL-13的相互作用所需要的氨基酸。所有四种突变在一个分子中的存在已 显示使IL-13几乎完全丧失与IL13Rα2的突变体形式的结合(28)。48小时后,将细胞 用20倍过量的rhIL-13或IL13Rα2(克隆47)mAb预处理,随后分别与IL13Rα2(克隆 47)mAb或rhIL-13一起培育。图5B显示通过20倍过量的rhIL-13,IL13Rα2(克隆47) mAb与野生型(WT)IL13Rα2而非IL13Rα2的4氨基酸突变体形式有约50%的结合抑 制。当在细胞表面上表达80%时,20倍过量的抗体消除rhIL-13与IL13Rα2的结合,这 类似于板ELISA中所观测到的结果。IL-13与IL13Rα2的4氨基酸突变体形式的残余结 合进一步通过过量的IL13Rα2(克隆47)mAb降低(图5C)。总起来说,这些数据指示 IL13Rα2(克隆47)mAb与rhIL-13特异性竞争IL13Rα2上的结合位点。同样,这些数 据指示IL13Rα2(克隆47)mAb与IL-13在其IL13Rα2分子的识别位点中具有显著重叠。
实例6
Tyr207、Asp271、Tyr315和Asp318残基对IL13Rα2(克隆47)mAb结合的作用
考虑到IL-13和IL13Rα2(克隆47)单克隆抗体可以彼此显著竞争IL13Rα2的结合,我们判定促进IL-13与IL13Rα2的相互作用(28)的残基Tyr207、Asp271、Tyr315和 Asp318是否也对IL13Rα2(克隆47)mAb与IL13Rα2的结合至关重要。产生如下质粒: 其编码针对携带Tyr207、Asp271、Tyr315或Asp318残基到Ala的个别突变或所有四个 突变在一个分子中的组合的IL13Rα2的cDNA,并且其在HEK细胞中短暂表达。通过 流式细胞测量术分析IL13Rα2(克隆47)mAb与IL13Rα2的野生型和突变体形式的结 合。IL13Rα2 mAb 83807和B-D13用作参考抗体,以排除HEK细胞表面上IL13Rα2的 野生型或突变变异体的表达水平变化的可能影响(图6A)。当与抗体克隆83807和B-D13 相比较时,将数据计算为IL13Rα2(克隆47)与IL13Rα2的结合的比率。图6A展现当 与野生型受体相比较时,IL13Rα2(克隆47)mAb的结合不受IL13Rα2的个别突变或4 氨基酸突变体形式的显著影响。相反,IL-13与IL13Rα2的4氨基酸突变体形式的结合 几乎被消除(图6B)。这些数据指示Tyr207、Asp271、Tyr315和Asp318残基对IL13Rα2 (克隆47)mAb与IL13Rα2的相互作用不关键,但为与IL-13的结合所必需。
实例7
N-连接糖基化影响IL13Rα2 mAb对IL13Rα2的亲和力
先前已证实N-连接糖基化对IL-13与同源受体IL13Rα2的有效结合至关重要(30)。考虑到IL13Rα2(克隆47)mAb与IL-13之间的抗原决定基识别的显著重叠,我们预期 IL13Rα2的N-连接糖基化有助于IL13Rα2(克隆47)mAb的结合。为确认这种预期, 用Pngase F处理rhIL13Rα2hFc以从蛋白质中去除N-连接糖基化。研究IL13Rα2(克隆 47)mAb与对照和去糖基化靶蛋白的结合。在原生条件下(在不存在SDS下)用Pngase F处理rhIL13Rα2,以避免影响抗体结合的rhIL13Rα2的变性。在分析中包括IL13Rα2 的额外mAb(克隆83807、B-D13和YY23Z)和rhIL-13以证实结合的特异性。在板结 合的ELISA中,当与未处理蛋白质相比较时,IL13Rα2(克隆47)mAb与Pngase F处 理的IL13Rα2的结合降低35%(n=4;P<0.001)。当与未处理蛋白质相比较时,IL13Rα2 (克隆83807)的结合降低80%,并且IL13Rα2mAb B-D13和YY-23Z分别完全不存在 结合(n=4;P<0.001)(图7A)。rhIL-13与Pngase F处理的rhIL13Rα2的结合也显著 减弱。为验证Pngase F处理导致蛋白质去糖基化,通过蛋白质印迹解析对照和Pngase F 处理的rhIL13Rα2hFc蛋白质。图7B显示Pngase F处理的蛋白质具有更低分子量,确认 N-连接聚糖从IL13Rα2分子中去除。当与对照未处理细胞相比较时,IL13Rα2(克隆47) mAb与Pngase F处理的U251神经胶质瘤和表达野生型IL13Rα2的HEK 293细胞的结 合也降低约30%(n=3;P<0.05)(图7C)。
实例8
免疫组织化学
在新鲜的冷冻组织中评估IL13Rα2(克隆47)mAb检测IL13Rα2的能力。用同型 对照mIgG1或IL13Rα2(克隆47)mAb染色快速冷冻的人类GBM样品或U251神经胶 质瘤侧腹异种移植物。图8显示两个人类GBM样品中的阳性(褐色)染色,只是在样 品以及基于U251神经胶质瘤细胞的神经胶质瘤异种移植物中的阳性细胞有不同频率。 在所分析的三个GBM样品中的两个中检测到阳性染色,这与少于50%的原发性GBM 表达IL13Rα2的预期一致(3)。这些数据也与这种抗体识别在细胞表面上和在ELISA 应用中表达的IL13Rα2的原生形式的能力一致,以及与这种mAb通过蛋白质印迹法检 测变性抗原的折衷能力一致。
实例9
IL13Rα2单克隆抗体延长具有颅内神经胶质瘤异种移植物的动物的存活
也在人类神经胶质瘤的原位小鼠模型中确定IL13Rα2(克隆47)mAb的潜在治疗特性。在对照mIgG存在下或在IL13Rα2(克隆47)mAb下,将U251神经胶质瘤细胞单 独地颅内注射于裸小鼠的脑中。图9A显示对照PBS(n=15)和mIgG(n=16)组中的 动物分别展现27和25天的类似中位存活期。相反,用IL13Rα2(克隆47)mAb共注射 的动物的存活期(n=13)显著增加到34天的中位数(p=0.0001;mIgG相对于IL13Rα2 mAb 组)。对来自在第17天收集的脑的神经胶质瘤异种移植物的H&E染色的分析揭露了神 经胶质瘤细胞分布在对照组的脑中的类似模式。相反,用IL13Rα2 mAb共注射的动物组 中的肿瘤块的大小显著降低(图9B)。独立地,在小鼠的脑中接种U251细胞并且3天 后经由同一钻孔用如先前所描述的PBS或IL13Rα2(克隆47或B-D13)mAb注射(29)。 有趣地,类似于在共注射实验中所发现的(图9A),当与PBS和克隆B-D13组相比较 时,用克隆47注射的小鼠展现中位存活期的提高(35天分别相对于27和23天;n=7; P>0.05)(图11)。然而,所有动物最终因疾病而死亡。这些数据指示在小鼠脑中,IL13Rα2 (克隆47)mAb在促进IL13Rα2表达U251神经胶质瘤细胞的肿瘤排斥中展示前景。这 种发现预期并入IL13Rα2(克隆47)mAb的IL13Rα2结合域的抗体药剂将在治疗通过 IL13Rα2的呈递表征的各种人类和非人类癌症(如IL13Rα2表达神经胶质瘤细胞和其它恶性细胞类型)中有效。
参考文献-除非以其它方式特定确认,否则针对实例1-9和贯穿申请的引用
1.Debinski,W.,Obiri,N.I.,Powers,S.K.,Pastan,I.和Puri,R.K.(1995)《临床癌症 研究》1,1253-1258.
2.Joshi,B.H.,Plautz,G.E.和Puri,R.K.(2000)《癌症研究(Cancer Res.)》60,1168-1172.
3.Jarboe,J.S.,Johnson,K.R.,Choi,Y.,Lonser,R.R.和Park,J.K.(2007)《癌症研 究》67,7983-7986.
4.Kawakami,K.,Terabe,M.,Kawakami,M.,Berzofsky,J.A.和Puri,R.K.(2006)《癌 症研究》66,4434-4442.
5.Fujisawa,T.,Joshi,B.,Nakajima,A.和Puri,R.K.(2009)《癌症研究》69,8678-8685.
6.Debinski,W.,Slagle,B.,Gibo,D.M.,Powers,S.K.和Gillespie,G.Y.(2000)《神 经肿瘤学杂志(J.Neurooncol.)》48,103-111.
7.Aman,M.J.,Tayebi,N.,Obiri,N.I.,Puri,R.K.,Modi,W.S.和Leonard,W.J.(1996)《生物化学杂志》271,29265-29270.
8.Gauchat,J.F.,Schlagenhauf,E.,Feng,N.P.,Moser,R.,Yamage,M.,Jeannin,P., Alouani,S.,Elson,G.,Notarangelo,L.D.,Wells,T.,Eugster,H.P.和Bonnefoy,J.Y.(1997) 《欧洲免疫学杂志》27,971-978.
9.Akaiwa,M.,Yu,B.,Umeshita-Suyama,R.,Terada,N.,Suto,H.,Koga,T.,Arima,K., Matsushita,S.,Saito,H.,Ogawa,H.,Furue,M.,Hamasaki,N.,Ohshima,K.和Izuhara,K. (2001)《细胞因子(Cytokine)》13,75-84.
10.Rahaman,S.O.,Sharma,P.,Harbor,P.C.,Aman,M.J.,Vogelbaum,M.A.和Haque, S.J.(2002)《癌症研究》62,1103-1109.
11.Fichther-Feigl,S.,Strober,W.,Kawakami,K.,Puri,R.K.和Kitani,A.(2006)《自 然医学(Nat.Med.)》12,99-106.
12.Shimamura,T.,Fujisawa,T.,Husain,S.R.,Joshi,B.和Puri,R.K.(2010)《临床癌 症研究》16,577-586.
13.Fujisawa,T.,Joshi,B.H.和Puri,R.K.(2012)《国际癌症杂志(Int.J.Cancer)》 131,344-356.
14.Murphy,E.V.,Zhang,Y.,Zhu,W.和Biggs,J.(1995)《基因(Gene)》159,131-135.
15.Rich,T.,Chen,P.,Furman,F.,Huynh,N.和Israel,M.A.(1996)《基因》180,125-130.
16.Stupp,R.,Mason,W.P.,van den Bent,M.J.,Weller,M.,Fisher,B.,Taphoorn,M.J., Belanger,K.,Brandes,A.A.,Marosi,C.,Bogdahn,U.,Curschmann,J.,Janzer,R.C., Ludwin,S.K.,Gorlia,T.,Allgeier,A.,Lacombe,D.,Cairncross,J.G.,Eisenhauer,E.和 Mirimanoff,R.O.(2005)《新英格兰医学杂志(N.Engl.J.Med.)》352,987-996.
17.Kunwar,S.,Prados,M.D.,Chang,S.M.,Berger,M.S.,Lang,F.F.,Piepmeier,J.M., Sampson,J.H.,Ram,Z.,Gutin,P.H.,Gibbons,R.D.,Aldape,K.D.,Croteau,D.J.,Sherman,J.W.和Puri,R.K.(2007)《临床肿瘤学杂志(J.Clin.Oncol.)》25,837-844.
18.Wykosky,J.,Gibo,D.M.,Stanton,C.和Debinski,W.(2008)《临床癌症研究》14, 199-208.
19.Debinski,w.,Gibo,D.M.,Obiri,N.I.,Kealiher,A.和Puri,R.K.(1998)《自然生 物技术(Nat.Biotechnol.)》16,449-453.
20.Kawakami,M.,Kawakami,K.和Puri,R.K.(2002)《分子癌症治疗(Mol.CancerTher.)》1,999-1007.
21.Husain,S.R.和Puri,R.K.(2000)《血液》95,3506-3513.
22.Bartolazzi,A.,Nocks,A.,Aruffo,A.,Spring,F.和Stamenkovic,I.(1996)《细胞生 物学杂志(J.Cell Biol.)》132,1199-1208.
23.Kioi,M.,Seetharam,S.和Puri,R.K.(2008)《分子癌症治疗》7,1579-1587.
24.Pini,A.和Bracci,L.(2000)《当今蛋白质与肽科学(Curr.ProteinPept.Sci.)》1, 155-169.
25.Ross,J.S.,Gray,K.,Gray,G.S.,Worland,P.J.和Rolfe,M.(2003)《美国临床病理 学杂志(Am.J.Clin.Pathol.)》119,472-485.
26.Souriau,C.和Hudson,P.J.(2003)《生物疗法专家评论(ExpertOpin.Biol.Ther.)》 3,305-318.
27. G.和Milstein,C.(1975)《自然》256,495-497.
G.和Milstein,C.(1975)《自然》256,495-497.
28.Arima,K.,Sato,K.,Tanaka,G.,Kanaji,S.,Terada,T.,Honjo,E.,Kuroki,R.,Matsuo,Y.和Izuhara,K.(2005)《生物化学杂志》280,24915-24922.
29.Sampson,J.H.,Crotty,L.E.,Lee,S.,Archer,G.E.,Ashley,D.M.,Wikstrand,C.J., Hale,L.P.,Small,C.,Dranoff,G.,Friedman,A.H.,Friedman,H.S.和Bigner,D.D.(2000) 《美国国家科学院院刊(Proc.Natl.Acad.Sci.U.S.A.)》97,7503-7508.
30.Kioi,M.,Seetharam,S.和Puri,R.K.(2006)《美国实验生物学联合会会刊(FASEB J.)》20,2378-2380.
31.McKenzie,A.N.,Culpepper,J.A.,de Waal Malefyt,R.,Brière,F.,Punnonen,J., Aversa,G.,Sato,A.,Dang,W.,Cocks,B.G.和Menon,S.(1993)《美国国家科学院院刊》 90,3735-3739.
32.Donaldson,D.D.,Whitters,M.J.,Fitz,L.J.,Neben,T.Y.,Finnerty,H.,Henderson, S.L.,O’Hara,R.M.,Jr,Beier,D.R.,Turner,K.J.,Wood,C.R.和Collins,M.(1998)《免 疫学杂志》161,2317-2324.
33.Hansen,H.J.,Goldenberg,D.M.,Newman,E.S.,Grebenau,R.和Sharkey,R.M.(1993)《癌症(Cancer)》71,3478-3485.
34.Kuan,C.T.,Wikstrand,C.J.,Archer,G.,Beers,R.,Pastan,I.,Zalutsky,M.R.和 Bigner,D.D.(2000)《国际癌症杂志》88,962-969.
35.Imperiali,B.和Rickert,K.W.(1995)《美国国家科学院院刊》92,97-101.
36.Sondermann,P.,Huber,R.,Oosthuizen,V.和Jacob,U.(2000)《自然》406,267-273.
37.Krapp,S.,Mimura,Y.,Jefferis,R.,Huber,R.和Sondermann,P.(2003)《分子生物 学杂志》325,979-989.
38.Fernandes,H.,Cohen,S.和Bishayee,S.(2001)《生物化学杂志》276,5375-5383.
39.Hsu,Y.F.,Ajona,D.,Corrales,L.,Lopez-Picazo,J.M.,Gurpide,A.,Montuenga,L. M.和Pio,R.(2010)《分子癌症(Mol.Cancer)》9,139.
40.Cartron,G.,Watier,H.,Golay,J.和Solal-Celigny,P.(2004)《血液》104,2635-2642.
41.de Haij,S.,Jansen,J.H.,Boross,P.,Beurskens,F.J.,Bakema,J.E.,Bos,D.L., Martens,A.,Verbeek,J.S.,Parren,P.W.,van de Winkel,J.G.和Leusen,J.H.(2010)《癌症 研究》70,3209-3217.
42.Minn,A.J.,Kang,Y.,Serganova,I.,Gupta,G.P.,Giri,D.D.,Doubrovin,M.,Ponomarev,V.,Gerald,W.L.,Blasberg,R.和Massagué,J.(2005)《临床研究杂志(J.Clin.Investig.)》115,44-55.
43.Kawakami,M.,Kawakami,K.,Kasperbauer,J.L.,Hinkley,L.L.,Tsukuda,M.,Strome,S.E.和Puri,R.K.(2003)《临床癌症研究》9,6381-6388.
44.Husain,S.R.,Obiri,N.I.,Gill,P.,Zheng,T.,Pastan,I.,Debinski,W.和Puri,R.K. (1997)《临床癌症研究》3,151-156.
45.Puri,R.K.,Leland,P.,Obiri,N.I.,Husain,S.R.,Kreitman,R.J.,Haas,G.P., Pastan,I.和Debinski,W.(1996)《血液》87,4333-4339.
46.Joshi,B.H.,Leland,P.和Puri,R.K.(2003)《克罗地亚医学杂志(Croat.Med.J.)》 44,455-462.
47.Barderas R,Bartolomé RA,Fernandez- MJ,Torres S,Casal JI.《癌症研究》 2012Jun 1;72(11):2780-90.
MJ,Torres S,Casal JI.《癌症研究》 2012Jun 1;72(11):2780-90.
实例10
用于选择性靶向IL13Rα2表达脑肿瘤的单链抗体
IL13Rα2在大多数高级星形细胞瘤和其它恶性病中过度表达,并且在各种临床前模 型中其已被验证为用于治疗应用的标靶。然而,由于与由正常或健康细胞广泛表达的IL13Rα1受体的相互作用,目前基于IL13的治疗剂缺乏特异性。严格地结合到IL13Rα2 的靶向剂的产生将显著扩大用于治疗IL13Rα2表达癌症的治疗潜在性。最近,已开发出 单克隆抗体47(mAb47)并且其被广泛地表征。mAb47排他性地结合到人类IL13Rα2 的原生形式。使用mAb47,单链抗体(scFv)片段从由亲本杂交瘤细胞系表达的mAb47 中工程改造。测试单链抗体(scFv)片段作为可溶药剂的靶向特性,并且将具有并有 scFv47作为靶向基元的经修饰纤维的腺病毒(Ad)药剂化。
利用噬菌体呈现方法来选择来自产生mAb47的所确立杂交瘤细胞的可变重(VH)和轻(VL)链的功能组合。测试呈现scFv47的纯化噬菌体与IL13Rα2hFc重组蛋白-即 IL13Rα2和抗体的Fc区的融合体-的相互作用。利用竞争性ELISA来验证亲本mAb47 和结合到相同抗原决定基的scFv47片段。通过SDS-PAGE分析在大肠杆菌和CHO细胞 中表达的scFv47的可溶形式,并且测试其稳定性和靶向特性。为产生IL13Rα2特异性 Ad,用由在其C端处连接到scFV47的T4纤维蛋白三聚域构成的嵌合纤维基因替代编 码绿色荧光蛋白的复制缺陷型Ad5的纤维(AdFFscFv47-CMV-GFP)。为产生病毒粒子, 在HEK293F28细胞中拯救编码腺病毒基因组的药剂,扩展并且纯化。IL13Rα2+和 IL13Rα2 U251细胞系分别经由用对照或IL13Rα2特异性shRNA(U251-IL13Rα2.KO) 稳定转染来确立。在这些U251细胞系中并且在IL13Rα2表达U87细胞中测试 AdFFscFv47-CMV-GFP病毒的靶向特性。
在板ELISA中,噬菌体的生物淘选选择库以及若干个别克隆展现与IL13Rα2hFc蛋白质而非hIgG的特异性结合。scFv47呈现的噬菌体与IL13Rα2的结合由mAb47而非对 照IgG或其它所测试的IL13R1α2 mAb完全消除,由此确认如由亲本mAb47所识别,同 一IL13Rα2抗原决定基由scFv47识别。类似于噬菌体呈现的scFv47,可溶scFv47显示 与IL123Rα2而非IL13Rα1的特异性结合。相对于U251-IL13Rα2.KO细胞,针对 U251-IL13Rα2+细胞中的GFP表达,如通过流式细胞测量术所判断, Ad5FFscFv47-CMV-GFP的相互作用也对IL13Rα2表达U251细胞具有特异性。此外, 感染有Ad5FFscFv47-CMV-GFP的细胞中的GFP表达强烈地与IL13Rα2的表面表达水 平相关。进一步在U251神经胶质瘤模型中验证病毒感染的特异性。
所述数据将scFv47验证为高度选择性的IL13Rα2靶向剂,其提供适用于诊断并且治疗IL13Rα2表达癌症如神经胶质瘤、结肠癌(参见实例12)等的可溶性单链生物制剂。
实例11
IL13Rα2-CAR的产生
为产生IL13Rα2特异性T细胞,最初使IL13Rα2特异性嵌合抗原受体(CAR)药 剂化。合成密码子优化微基因,其含有免疫球蛋白重链前导肽和由连接子分隔开的 IL13Rα2特异性单链可变片段(scFv)的重链和轻链(scFv衍生自杂交瘤47,Balyasnikova 等人《生物化学杂志》2012;287(36):30215-30277)。将微基因亚克隆于SFG反转录病 毒载体中,所述SFG反转录病毒载体含有人类IgG1-CH2CH3域、CD28跨膜域和衍生 自CD28和CD3ζ-链的共刺激域。用RD114假型化的反转录病毒粒子转导CD3/CD28活 化的人类T细胞并且随后使用IL2扩增。功能分析揭露到如通过细胞因子产生(IFNγ 和IL2;图19和20)所判断,表达IL13Rα2特异性CAR的T细胞(IL13Rα2-CAR T细 胞)识别重组IL13Rα2蛋白,并且在细胞毒性分析中杀死IL13Rα2阳性细胞(图18)。 非转导(NT)T细胞不产生细胞因子并且不具有溶细胞活性。
实例12
将T细胞再引导到IL13Rα2阳性小儿神经胶质瘤
IL13Rα2在多形性成胶质细胞瘤中异常表达,并且因此是一种用于CAR T细胞免疫疗法的有前景的标靶。CAR的抗原识别域通常由单链可变片段(scFv)组成,但目前的 IL13Rα2特异性CAR使用IL13突变蛋白作为抗原识别域。然而,已显示基于IL13突变 蛋白的CAR也识别IL13Rα1,产生重大的安全问题。为解决这种障碍,已将高亲和力 IL13Rα2特异性scFv药剂化。这种scFv用于开发基于scFv的IL13Rα2特异性CAR (IL13Rα2-CAR),其在T细胞中表达时将提供具有细胞毒性效应功能的IL13Rα2-CAR T 细胞。
将抗原特异性T细胞并入用于扩散型内因性脑桥神经胶质瘤(diffuse intrinsicpontine glioma,DIPG)和成胶质细胞瘤(GBM)的有效免疫疗法中,所述瘤在儿童中 是最具侵蚀性的均一致死性的原发性人类脑肿瘤。IL13Rα2在DIPG和GBM两者中而 非在正常脑中以高频率表达,使得其成为用于T细胞免疫疗法和融合有提供效应功能的 其它构架的scFv融合体的有前景的标靶,所述T细胞免疫疗法包括基于scFv的疗法、 基于scFv-CAR T细胞的疗法,所述scFv融合体如BITE和scFv-CAR-NK。已使用IL13 的突变体形式作为CAR结合域产生IL13结合CAR,但这些CAR也识别IL13Rα1,产 生重大的毒性问题。
为克服这种限制,产生不识别IL13Rα1的高亲和力IL13Rα2特异性scFv。将一组IL13Rα2-CAR药剂化,其含有作为胞外域的IL13Rα2特异性scFv、短铰链(SH)或长 铰链(LH)、CD28跨膜域和胞内域,所述胞内域含有衍生自CD3ζ的信号传导域和共刺 激分子(例如CD28.ζ、CD137.ζ、CD28.CD137.ζ、CD28.CD134.ζ)。IL13Rα2-CAR T细 胞通过反转录病毒转导来产生,并且效应功能在体外使用共培养和细胞毒性分析确定, 并且在体内使用U373脑异种移植物模型确定(图21)。
如通过蛋白质印迹分析所判断,所有CAR在T细胞中的表达是类似的。然而,取 决于药剂的铰链和胞内域,CAR细胞表面表达是不同的。在细胞毒性分析中,各种 IL13Rα2-CAR T细胞仅杀死表达IL13Rα2并且不表达IL13Rα1的靶细胞,确认了特异性 (图18)。虽然所有IL13Rα2-CAR T细胞在与IL13Rα2+神经胶质瘤细胞系U373的共培 养分析中分泌显著含量的IFNγ(图19),但仅短铰链CAR T细胞分泌显著量的IL2(图 20)。表达具有缺失胞内域的IL13Rα2-CAR(IL13Rα2Δ-CAR)的T细胞不分泌细胞因 子,确认细胞因子产生取决于功能IL13Rα2-CAR的存在。如通过生物发光成像所判断, 体内IL13Rα2.SH.CD28.ζ-CAR T细胞于带有U373的小鼠中的注射使神经胶质瘤异种移 植物消退(图21)。IL13Rα2.LH.CD28.ζ-或IL13Rα2.Δ-CAR T细胞不具有抗肿瘤作用。 数据确立到CAR仅识别IL13Rα2并且无IL13Rα1产生,并且CAR优先靶向表达IL13Rα2 的肿瘤细胞。对若干IL13Rα2-CAR的比较揭露:如通过IL2产生和体内抗神经胶质瘤 活性所判断,具有SH和CD28.ζ胞内域的CAR产生显著的T细胞活化。结果显示儿童 中原发性人类脑肿瘤例如高级神经胶质瘤的过继性免疫疗法是可行并有前景的。
实例13
体外和体内靶向细胞标记物
在本实例中所公开的研究中,scFv47-靶向IL13Rα2的scFv-经显示拥有结合到IL13Rα2的排它性特异性。同样,scFv47经显示以高亲和力识别与亲本单克隆抗体相同 的抗原决定基。此外,作为显示其治疗适用性的原理论证,通过将scFv47并入纤维-纤 维蛋白修饰的腺病毒的纤维结域中构筑IL13Rα2靶向腺病毒载体21-23。体外和体内,纤 维修饰成功地将病毒向性特异性地重新定向到IL13Rα2表达神经胶质瘤细胞。数据验证 scFv47代表用于开发对患者的肿瘤表型进行特定调适的个人化治疗剂的有价值试剂。
材料和方法
细胞系和试剂.
纯化的抗c-myc抗体(克隆9E10)获自芝加哥大学的Frank W.Fitch单克隆抗体机构(Monoclonal Antibody Facility)。抗M13-HRP抗体获自安发玛西亚生物技术(Amersham Pharmacia Biotech)(瑞典乌普萨拉(Uppsala,Sweden))。山羊抗小鼠碱性磷酸酶缀合物购自密苏里州圣路易斯的西格玛-奥德里奇(Sigma-Aldrich St.Louis,MO)。使用人类胚胎肾(HEK)293、稳定表达Ad5野生型纤维的HEK 293-F28、中国仓鼠卵 巢(Chinese hamster ovary,CHO)细胞、稳定表达人类CAR的CHO-hCAR细胞、 CHO-IL13Rα219、U87MG和U251MG神经胶质瘤细胞系。为产生IL13Rα2+U251MG 和IL13Rα2.KDU251MG,用编码对照或IL13Rα2 shRNA的慢病毒粒子转导U251细胞 (西格玛-奥德里奇,密苏里州圣路易斯)。所转导的细胞用2μg/ml的嘌呤霉素选择并且 使用抗IL13Rα2单克隆抗体(克隆47)通过流式细胞测量术分析其IL13Rα2表达19。 在补充有10%热不活化FBS(海克隆(Hyclone);犹他州洛根)和青霉素-链霉素(美的 泰克公司(Mediatech,Inc.),弗吉尼亚州赫恩登(Herndon,VA))的DMEM培养基(美 的泰克公司,弗吉尼亚州赫恩登)中培养细胞系。对于神经球的形成,如先前所描述43, 使神经胶质瘤细胞生长于补充有EGF和bFGF(浓度是20ng/ml)以及N10和B27补充 剂(西格玛-奥德里奇,密苏里州圣路易斯)的神经基质培养基(生命技术(Life Technologies),俄勒冈州尤金(Eugene,OR))中,持续7天。源自患者的GBM43和GBM39神经胶质瘤细胞获自西北大学费恩柏格医学院(Northwestern UniversityFeinberg School of Medicine)的Charles D.James博士。在裸小鼠的侧腹中经由连续传代繁殖细 胞。
克隆mAb IL13Rα2(克隆47)的scFv片段
使用先前公开24,25的免疫球蛋白重链和轻链序列的一组基因特异性引物(表2)克隆针对人类IL13Rα219的单克隆抗体(克隆47)的重链和轻链。如先前所描述44,再扩 增重链和轻链cDNA以分别引入NcoI和HindIII以及MluI和NotI限制位点,用于后续 亚克隆于噬菌粒载体pSEX 81中。通过电穿孔用由噬菌粒载体编码的scFv文库转化XL1 blue细胞,并且如先前所描述25产生噬菌体。使用涂布于96孔板上的重组型人类 IL13Rα2hFc融合蛋白(rhIL13Rα2hFc)(R&D Systems)在三轮中选择免疫反应性噬菌 体。人类IgG充当阴性对照。针对由全大小scFv和scFv插件的上游和下游的质粒序列 组成的适当大小PCR产物的存在,通过PCR筛选用阳性选择的噬菌体感染的细菌克隆 的DNA。纯化约1000bp的八种PCR产物用于后续序列分析。将针对人类IL13Rα2的 所获得的scFv指定为scFv47。为了产生可溶蛋白,如先前所描述24,44,在细菌表达盒中 再克隆编码scFv47的cDNA。根据已确立的方案24利用XL-1 blue细胞产生可溶蛋白。
表2

ELISA
针对其与rhIL13Rα2蛋白的结合特异性,使用板ELISA分析来自所有轮次生物淘选的含有噬菌体的上清液。涂布有人类IgG的孔用作阴性对照。具体地说,用2%脱脂奶 粉阻断孔30分钟,并且将含有噬菌体的上清液以不同稀释度施用到孔。在震荡下培育 30分钟并且在无震荡的情况下再培育1.5小时后,用PBS/0.05%Tween 20洗涤未结合噬 菌体,并且添加缀合有过氧化酶的抗M13抗体(安发玛西亚生物技术,瑞典乌普萨拉) (在2%脱脂奶粉中以1/2000稀释)。在用PBS/0.05%Tween 20充分洗涤后,针对ELISA 使用1步慢3,3′5,5′-四甲基-联苯胺(TMB)底物使板显色,并且在用3N盐酸停止反应 后在OD450下读取。
对于可溶scFv47与rhIL13Rα2的结合的分析,用编码scFv47基因的用c-myc标记的表达载体转化XL-1 blue大肠杆菌的克隆,并且在补充有100mM葡萄糖和100μg/ml 安比西林(LBGA)的LB培养基中将6-His序列生长过夜,如先前所描述24。将过夜培 养物以1/100稀释并且在震荡(在37℃下250rpm)下于50ml LBGA培养基中生长, 直至密度OD600=0.8。培育后,在1500g下离心细菌培养物10分钟。将离心块再悬浮 于50ml含有0.4M蔗糖和0.1mMIPTG的LBGA培养基中,并且在室温(RT)下生 长20小时。根据制造商的建议(赛默科技(Thermo Scientific),伊利诺斯州罗克福德 (Rockford,IL))使用Co树脂从培养物上清液中获得纯化的可溶scFv47。在板ELISA 中测试纯化的scFv47,并且亲和力如本文所描述研究。用2%脱脂奶粉阻断涂布有1μg/ml rhIL13Rα1或rhIL13Rα2蛋白的96孔板,并且在室温(RT)下施用各种浓度的scFv47, 持续2小时。洗涤后,添加1μg/ml的抗c-myc单克隆抗体(克隆9E10)用于1小时培 育,洗涤未结合抗体,并且随后用缀合到碱性磷酸酶的抗小鼠抗体(西格玛奥德里奇, 密苏里州圣路易斯)显色。随后在分光光度计中在OD405下读取反应物。
竞争性分析
用浓度是1μg/ml的100μl IL13Rα2hFc涂布易于洗液的96孔板(赛默科技,伊利 诺斯州罗克福德),并且在4℃下储存过夜。在用PBS/0.05%Tween 20洗涤后,用2%脱 脂奶粉阻断孔并且将其与浓度是2μg/ml的作为阴性对照的PBS或小鼠IgG1或一组抗 IL13Rα2 mAb一起培育1小时,所述抗IL13Rα2 mAb与亲本抗IL13Rα2 mAb(克隆47) 识别不重叠的抗原决定基19。在洗掉未结合抗体后,在第三轮的生物淘选后在室温下将 含有噬菌体的上清液施用到所有孔,持续2小时。如本文所描述检测结合噬菌体。
表面等离子体共振和动力学分析
如所描述19,用Biacore 3000生物传感器经由表面等离子体共振(SPR)测量scFv47与标靶(rhIL13Rα2)之间的相互作用的亲和力和速率。通过在固定化rhIL13Rα2上重 复注射一系列标靶浓度来估算动力学参数。使用各种动力学模型分析每一个数据组,所 述数据组由增加的scFv47浓度在相同水平的固定化rhIL13Rα2上的传感图组成。 BIAevaluationv 4.1软件用于数据分析。使用1∶1结合模型通过曲线拟合估算亲和常数。 局部或总体地拟合传感图缔合和解离曲线。通过以下类型的方程式描述样品注射期间复 合物形成的速率:dR/dt=kaC(Rmax-R)-kdR(针对1∶1相互作用)(R=呈RU形式的 SPR信号;C=分析物的浓度;Rmax=呈RU形式的最大的分析物结合能力;dR/dt=SPR 信号的改变速率)。早期结合阶段(300秒)用以确定mAb与标靶之间的缔合常数(ka)。 在标靶注射结束时使用引入游离缓冲液时RU的降低速率测量解离阶段(kd)。通过软件 程序(全局拟合算法)同时拟合数据,并且将复合物的解离常数(KD)确定为比率ka/kd。 对于定量分析,对每一个样品进行3次独立的重复。数据表述为平均值±SEM。
腺病毒基因修饰和病毒产生
为了产生纤维穿梭载体,使用含有纤维-纤维蛋白的基因的pKan 566腺病毒基因组 (圣路易斯华盛顿大学(Washington University in Saint Louis)的Curiel博士友情赠送)。 通过使用标准分子技术将scFv47的cDNA插入在纤维-纤维蛋白的C末端处,产生pKan-scFv47FF21,27,45。使用这种纤维穿梭载体,产生重组HAd5骨架,其含有增强型绿 色荧光蛋白(eGFP),处于E1缺失区中的CMV启动子的控制下(不可复制型 Ad5scFv47FF-CMV-GFP)。在HEK293-F28细胞中拯救重组病毒并且随后在HEK293细 胞中扩展。通过两轮的CsCl梯度超速离心来纯化病毒27。
流式细胞测量术
为了分析IL13Rα2在细胞表面上的表达,用2μg/mL的抗IL13Rα2(克隆47)mAb 染色U87MG和U251MG神经胶质瘤细胞系,随后用山羊抗小鼠Alexa Fluor 647(1∶500) 染色。在冰上进行所有染色程序。基于GFP表达来分析使用对照或Ad5FFscFv47病毒 的神经胶质瘤细胞的转导。使用BD FACS Canto流式细胞仪和FACS DiVaTM软件分析样 品。
PCR分析
含于Ad5-CMV-GFP和Ad5FFscFv47-CMV-GFP病毒粒子(109个)中的病毒DNA 用作模板,使用以下引物组来进行PCR扩增:HAdV5特异性引物组:正向: 5′-CAGCTCCATCTCCTAACTGT-3′(SEQ ID NO:140)和反向: 5′-TTCTTGGGCAATGTATGAAA-3′(SEQID NO:141),以及scFv47特异性引物组:正 向:5′-CAGGTCCAACTGCAGCA-3′(SEQ ID NO:142)和反向: 5′-TTTGATTTCCAGCTTGGT-3′(SEQ ID NO:143)。
蛋白质印迹
在勒姆利(Laemmli)缓冲液中稀释含有scFv47或纯化的腺病毒粒子的XL1-blue大肠杆菌细胞的上清液,在室温(未煮沸样品)下或在95℃(煮沸样品)下培育10min, 并且负载于7.5%SDS-聚丙烯酰胺凝胶(伯乐(Bio-Rad),加利福尼亚州埃库莱斯 (Hercules))上。电泳分离后,将样品转移于PVDF膜上,并且针对可溶scFv47或抗纤 维尾mAb4D2的检测,用1μg/ml的抗myc mAb(9E10)(1∶3,000)(赛默科技,伊利诺 斯州罗克福德)检测,随后用HRP标记的抗小鼠IgG二级抗体(1∶5,000)(圣克鲁斯, 美国加利福尼亚州)检测。
定量实时实时PCR(qRT-PCR)分析
通过qRT-PCR来表征以粘附培养物形式或以神经球形式生长的U87MG细胞中的IL13Rα2表达。使用RNeasy plus试剂盒(凯杰,马萨诸塞州波士顿(Boston))从神经 胶质瘤细胞中分离RNA,并且使用iScript cDNA转化试剂盒(伯乐(Biorad),美国加 利福尼亚州)反向转录。使用SYBR绿色qPCR试剂盒(伯乐,美国加利福尼亚州), 用以下引物进行qRT-PCR:GAPDH正向引物:5′-GGTCGGAGTCAACGGATTTGG-3′ (SEQ ID NO:144);GAPDH反向引物:5′-CATGGGTGGAATCATATTGGAAC-3′(SEQ ID NO:145);IL13Rα2正向引物:5′-TTGGGACCTATTCCAGCAAGGTGT-3′(SEQ ID NO: 146);IL13Rα2反向引物:5′-CACTCCACTCACTCCAAATCCCGT-3′(SEQ ID NO:147)。 对于IL13Rα2表达的相对定量,将所有IL13Rα2值归一化成甘油醛3磷酸脱氢酶 (GAPDH)表达值。使用2-ΔΔCT方法46进行数据分析。
病毒感染力分析
将细胞(3×105个)接种在24孔板中并且培育过夜。对于单克隆抗IL13Rα2抗体介导的抑制分析,将2μg抗IL13Rα2 mAb(克隆47)添加到细胞中并且在4℃下使其培 育1小时。在500μl含有于DMEM中的2%FBS的感染培养基中,将每一个病毒样品稀 释到300个病毒粒子(vp)/细胞的感染复数。在37℃下用Ad5FFscFv47-CMV-GFP感 染细胞2小时。随后用含有2%FBS的新鲜培养基替代含有病毒的培养基,并且在37℃ 下在含有5%CO2的大气加湿下将细胞保持3天,随后如本文所描述进行流式细胞测量 术分析。
动物实验
雄性无胸腺/裸小鼠获自查尔斯河实验室(Charles River Laboratory)(马萨诸塞州威 明顿(Wilmington)),并且根据芝加哥大学机构动物照护与使用委员会(University of Chicago Institutional Animal Care and Use Committee)认可的研究特定动物方案照护。对 于肿瘤细胞植入,用氯胺酮/甲苯噻嗪混合物(115/17mg/kg)麻醉小鼠。制备钻孔以允 许进行使用10μl汉密尔顿注射器(汉密尔顿,内华达州里诺(Reno,NV)进行的立体 定位注射。将针安装到小鼠特异性立体定位仪器(哈佛仪器(HarvardApparatus),马萨 诸塞州霍利斯顿(Holliston)),并且随后通过钻孔插入到3mm深的解剖位置。具体地 说,小鼠植入有IL13Rα2+U251MG的颅内神经胶质瘤异种移植物或 IL13Rα2.KDU251MG细胞(5.0×105个细胞)。肿瘤植入后十天,在与肿瘤细胞相同的座 标中用5μlPBS中的109个Ad5FFscFv47-CMV-GFP的病毒粒子(vp)注射小鼠,并且 3天后处死。
共焦显微镜
将快速冷冻的脑肿瘤组织切成10μm厚。固定组织切片并且染色人类巢蛋白以使用小鼠mAb(R&D systems,明尼苏达州明尼阿波利斯)观察U251神经胶质瘤细胞。为 分析使用Ad5FFscFv47-CMV-GFP的神经胶质瘤细胞的转导,使用生物素化抗GFP抗体 (生命技术,俄勒冈州尤金)和抗生蛋白链菌素-Alexa Fluor647(杰克逊免疫研究,宾夕 法尼亚州西格罗夫))揭露转基因GFP表达。使用DAPI核染色观察细胞核。用3i Marianas Yokogawa型旋转盘共焦显微镜捕获共焦显微图像,所述共焦显微镜具有Evolve EM-CCD相机(Photometrics,亚利桑那州土桑(Tucson,AZ)),运行SlideBook v5.5软 件(Intelligent ImagingInnovations,科罗拉多州丹佛(Denver,CO))。
统计分析
使用格拉夫帕德Prism 4(格拉夫帕德软件公司(GraphPad Software Inc.),加利福 尼亚州圣地亚哥(San Diego))进行所有统计分析。每组的样品大小≥3,并且数字数据按平均值±SEM报导。史都登氏t检验用于两组之间的比较,并且使用杜凯氏事后检验 的ANOVA用于多于两个组之间的比较。所有被报导的p值是双侧的并且在*p<0.05、 **p<0.01、***p<0.001下视为统计学上显著的。
mAb47的克隆和表征scFv片段.
单克隆抗IL13Rα2(克隆47)抗体拥有独特特性,如与IL13Rα2的原生抗原决定基强结合,与IL13Rα2的相互作用的高亲和力,和与IL13竞争其在IL13Rα2上的识别位 点的能力19。在这个实例中报导scFv47从分泌亲本抗体(克隆47)的杂交瘤细胞系中 的工程改造。对来自这个杂交瘤细胞系的mRNA的分析揭露对应于抗IL13Rα2单克隆 抗体的重链和轻链,存在多个转录物(图12a)24,25。为了获得组装在scFv47中的重链 和轻链可变区的功能组合,使用噬菌体呈现方法24,25。出于所述原因,产生呈scFv型式 的重链和轻链变异体的噬菌体文库,并且如下文所描述针对重组人类IL13Rα2 (rhIL13Rα2)进行筛选。
在产生scFv47后,验证其对rhIL13Rα2的结合特异性。为此目的,产生所有轮次的生物淘选期间的含有噬菌体的上清液,并且通过ELISA分析与rhIL13Rα2的结合特异性。 图12b和13显示随着每一后续轮次的生物淘选,噬菌体与rhIL13Rα2蛋白的相互作用 的特异性大大增加,然而与阴性对照人类IgG的非特异性结合降低到不可检测的水平。 在最后一轮的生物淘选后,产生个别噬菌体克隆。对感染有个别噬菌体克隆的XL1 blue 大肠杆菌的序列分析揭露到所有所选择噬菌体含有相同的scFv47序列。因此,这些数 据指示经由三轮的噬菌体生物淘选,成功地产生scFv47。
然后,进行竞争性分析以确定新克隆的scFv47和亲本mAb IL13Rα2(克隆47)是 否结合到IL13Rα2分子上的同一抗原决定基。图13显示mAb IL13Rα2(克隆47)完全 防止scFv47表达噬菌体与固定化rhIL13Rα2蛋白的相互作用。对照mIgG和针对IL13Rα2 的三种其它mAb,其识别人类IL13Rα2上的mAb IL13Rα2(克隆47)的不重叠抗原决 定基19,干扰scFv47与IL13Rα2的结合。这种结果证实scFv47共享与亲本单克隆抗体 相同的IL13Rα2上的识别位点。
进一步验证可溶scFv47与IL13Rα2的结合的特异性。对此,在XL1 blue大肠杆菌中产生可溶scFv47并且如本文所描述纯化。对板ELISA中可溶scFv47的结合的分析证 实缺乏与rhIL13Rα1的相互作用和与rhIL13Rα2的特异性结合(图31a)。图31b显示可 溶scFv47蛋白的分子量是约30kDa,这对应于其预测值。此外,等离子共振分析揭露 类似于亲本抗体19,可溶scFv47以高亲和力(0.9×10-9M)结合到rhIL13Rα2(图31c)。 确切地说,发现scFv具有ka(1/Ms)=3.08e3±16、kd(1/s)=2.63e-6±1.8e-8、KD(M)=0.9× 10-9和Rmax(RU)=496。如本文所描述对结合到人类重组IL13Rα2的scFv47的动力学参 数进行估算。复合物的解离常数(KD)确定为比率ka/kd。对于定量分析,每一个样品有 3个独立的重复。数据表述为平均值±SEM。这些数据证实scFv47与rhIL13Rα2的亲和 力类似于亲本抗IL13Rα2 mAb(克隆47)(1.39×10-9)19。因此,如通过scFv47表达 噬菌体和可溶scFv47与rhIL13Rα2的特异性相互作用所确定,认为所获得的scFv47具 有完整的功能。
IL13Rα2靶向腺病毒载体的产生.
为将病毒向性重新定向到IL13Rα2,对腺病毒的病毒纤维干和结域进行遗传修饰22,26。 首先,用纤维-纤维蛋白(FF)三聚域替代干域以确保结合基元结构的稳定性,并且随 后将scFv47併入FF干域的C末端中(图32a)。纯化的Ad5scFv47FF-CMV-GFP病毒效 价与Ad5-CMV-GFP的效价相当,指示scFv47并入不影响病毒的产生(图37)。为确认 纤维的遗传修饰,使用纤维特异性或scFv47特异性引物组,用纯化的病毒DNA进行PCR 分析。图32b证实scFv47成功并入腺病毒(Ad5FFscFv47)的FF域中。此外,野生型 和重组病毒的蛋白质印迹分析进一步确认(图32c)新嵌合纤维具有类似于野生型纤维 的组成,指示并入scFv47不阻碍纤维三聚或不导致纤维结构不稳定。
CAR不依赖性感染的论证.
人类血清5型腺病毒(Ad5)的主要受体是柯沙奇(coxsackie)和腺病毒受体 (CAR)27-29。因此,预期Ad5FFscFv47病毒将以CAR不依赖性方式感染细胞。为确认 我们的修饰使CAR结合能力丧失,在人类CAR(hCAR)阴性和hCAR阳性(CHO-hCAR) 中国仓鼠卵巢细胞系中分析Ad5FFscFv47和野生型病毒Ad5-CMV-GFP的病毒感染力, 所述Ad5FFscFv47在CMV启动子的控制下编码绿色荧光蛋白 (Ad5FFscFv47-CMV-GFP)。图33a证实野生型Ad5-CMV-GFP有效地感染CHO-hCAR 而非hCAR阴性CHO细胞,而Ad5FFscFv47-CMV-GFP在任一细胞系中显示极小的感 染力,指示CAR结合能力丧失。
体外神经胶质瘤细胞的IL13Rα2特异性感染.
为证实Ad5FFscFv47-CMV-GFP病毒所致的IL13Rα2特异性感染力,将病毒暴露于CHO和CHO-IL13Rα2细胞系19。如图33b、c中所示,Ad5FFscFv47-CMV-GFP有效地 感染CHO-IL13Rα2细胞(80%的IL13Rα2细胞是GFP阳性的)而非IL13Rα2阴性的对 照CHO细胞。为进一步验证Ad5FFscFv47-CMV-GFP的IL-13Rα2依赖性感染力,在 U87MG和U251MG细胞系中分析病毒转导。也在源自患者的原代GBM43和GBM39 神经胶质瘤细胞中评估Ad5FFscFv47-CMV-GFP感染力,所述神经胶质瘤细胞内源性地 表达不同含量的IL13Rα2(图33d)。流式细胞测量术分析揭露Ad5FFscFv47-CMV-GFP 的感染力强烈地与所分析细胞系中的IL13Rα2表达水平相关。分别在约20%U87MG和 90%U251MG神经胶质瘤细胞系以及1%和20%的GBM39和GBM43神经胶质瘤细胞中 观测GFP表达(图33e)。相反,根据通过神经胶质瘤细胞的充分表征的低水平CAR表 达30,31,观测到两种神经胶质瘤细胞系的野生型Ad5-CMV-GFP感染处于极低水平下。 重要地,Ad5FFscFv47-CMV-GFP在U251MG细胞中的感染力随着分析中所使用的病毒 感染复数(MOI)按比例增加(图33f),而不引起任何可观测的细胞毒性。
为进一步验证Ad5FFscFv47-CMV-GFP的IL13Rα2依赖性感染力,经由用分别编码对照或IL13Rα2特异性shRNA的慢病毒转导,产生两种细胞系IL13Rα2+U251MG和 IL13Rα2.KDU251MG。慢病毒转导后,IL13Rα2+U251MG细胞在其细胞表面上保持极 高(高于92%的阳性细胞)的IL13Rα2表达,而IL13Rα2.KDU251MG神经胶质瘤细胞 大多数是IL13Rα2阴性的(约12%的IL13Rα2阳性细胞)(图34a)。 Ad5FFscFv47-CMV-GFP感染超过90%的IL13Rα2+U251MG细胞和小于5%的 IL13Rα2.KDU251MG细胞(图34b)。此外,在竞争性分析中,抗IL13Rα2 mAb有效地 抑制通过Ad5FFscFv47-CMV-GFP的U251MG细胞的感染(图34c)。总起来说,这些 数据证实类似于scFv47蛋白,Ad5FFscFv47是IL13Rα2特异性病毒药剂。
类干细胞癌症神经胶质瘤细胞通过Ad5FFscFv47病毒的感染.
由于癌症干细胞已作为潜在标靶用于成胶质细胞瘤治疗,因此如本文所描述,体外 通过培养呈神经球形式的U87MG细胞模拟癌症类干细胞特性。IL13Rα2表达的分析揭 露到与以粘附(例如分化)形式生长的细胞相比,U87MG神经球具有比其高13倍的 mRNA表达和高1.7倍的表面蛋白质表达(图35a、b)。相应地,Ad5FFscFv47-CMV-GFP 感染力在神经球中比在粘附生长的U87MG细胞中高约1.6倍(图35c、d)。为进一步验 证Ad5FFscFv47-CMV-GFP转导衍生自IL13Rα2表达神经胶质瘤细胞的神经球的能力, 分析源自患者的原代神经胶质瘤细胞和GBM39和GBM43。虽然在呈神经球形式培养的 GBM39和GBM43细胞系两者中观测到IL13Rα2 mRNA的表达略微地增加,但在任一 细胞系中,不可检测到IL13Rα2的表面表达或使用Ad5FFscFv47-CMV-GFP的感染力的 变化(图38)。在所有所研究的神经胶质瘤细胞系中,Ad5FFscFv47-CMV-GFP感染力 与细胞表面上的IL13Rα2表达水平良好相关。
因此,我们的数据指示使用scFv47靶向治疗剂,如scFv47工程改造的腺病毒,对IL13Rα2过表达癌症干细胞的靶向是高度可实行的。
体内IL13Rα2特异性感染的论证.
总起来说,本文所公开和上文所描述的体外分析证实Ad5FFscFv47-CMV-GFP特异性感染IL13Rα2表达神经胶质瘤细胞。然后,在神经胶质瘤的异种移植物鼠类模型中, 使用颅内植入的IL13Rα2+U251MG和IL13Rα2.KDU251MG细胞,体内验证 Ad5FFscFv47-CMV-GFP感染力的特异性。如通过GFP转基因表达的缺乏所判断,在大 部分IL13Rα2阴性IL13Rα2.KDU251MG异种移植物组织中或在肿瘤周围的脑组织中, 未检测到感染(图36a)。然而,观测到表达IL13Rα2的IL13Rα2+U251MG异种移植物 的高感染水平,并且再一次,在邻近于肿瘤的脑组织中不可检测到GFP信号(图36b)。 因此,所述数据确认Ad5FFscFv47-CMV-GFP不仅在体外而且在体内能够特异性转导 IL13Rα2表达肿瘤细胞。
公开一种scFv,即,scFv47,其经由噬菌体呈现方法由亲本抗IL13Rα2单克隆抗体产生。scFv47经显示以排他性的高亲和力特异性地识别原生IL13Rα2,并且识别与亲本 抗IL13Rα2 mAb(克隆47)相同的抗原决定基。此外,scFv47经证实成功地并入腺病 毒载体中并且Ad5FFscFv47-CMV-GFP病毒也在体外和体内排他性地感染IL13Rα2表达 神经胶质瘤细胞。
一系列靶向IL13Rα2的免疫治疗剂已展现临床前的前景10,11,32,33,但那些药剂也识别分布广泛的IL13Rα1,指示仍需要特异性靶向剂10,11,34。为了提高IL13Rα2靶向特异 性,产生排他性地识别IL13Rα2蛋白上的原生抗原决定基的单克隆抗体。然而,工程改 造的抗体片段具有优于全抗体的优势,因为其可以易于被遗传操控并且并入治疗剂中。 考虑到这些,scFv47单链可变片段被工程改造为各种治疗剂的IL13Rα2特异性靶向部 分。
本文所公开的数据证实scFv47通过重新定向常用抗癌剂腺病毒的向性(经由修饰其纤维)而具有治疗适用性。尽管已知因scFv自身和纤维三聚的稳定性所致,scFv于 腺病毒纤维中的并入较困难21,23,但scFv47修饰的纤维展现与野生型腺病毒纤维的稳定 性相当的稳定性,并且Ad5FFscFv47-CMV-GFP不再能够识别原生腺病毒受体CAR。取 而代之,病毒在体外和体内均排他性地感染IL13Rα2表达细胞。本文所公开的结果验证 scFv47为高度选择性的IL13Rα2靶向剂,并且确认其可以用于将腺病毒向性重新定向到 癌症和癌症类干细胞神经胶质瘤细胞。
最近,研究聚焦于鉴别可以成功地根除癌症干细胞的治疗剂,所述癌症干细胞对传 统的抗癌疗法具有抵抗性并且认为负责治疗性治疗后的癌症复发35。基于这些特性,神经胶质瘤干细胞是用于治疗性靶向的高度有吸引力的肿瘤细胞子组。与先前报导36,37一致,IL13Rα2的表达在呈神经球生长的源自患者的原代神经胶质瘤细胞中得到维持,这 准许通过Ad5FFscFv47-CMV-GFP病毒有效转导这些细胞。最近IL13Rα2表达与增加的 恶性病级别和较差患者预后相关17。因此,提供一种特异性靶向IL13Rα2表达类干细胞 和分化的神经胶质瘤细胞的治疗选择将对患有最具侵蚀性并且最难以治疗的癌症中的 一些的患者有益处。
先前,已显示几乎50%的GBM患者具有表达IL13Rα2的肿瘤38,百分比比其它常 用的神经胶质瘤特异性标记物EGFRvIII39更高,这指示这种分子标靶对大多数GBM患 者的重要性38。此外,神经胶质瘤细胞死亡后,‘抗原决定基扩散(epitope spreading)’ 的现象可能增强针对肿瘤的免疫应答,并且进一步去除肿瘤,包括去除甚至那些不表达 最初靶向抗原的细胞40。随着更多的神经胶质瘤特异性药剂被开发,可以给予个人化治 疗混合物以获得针对既定患者神经胶质瘤表型的加强特异性和功效。
总之,scFv47可以充当IL13Rα2定向治疗剂的特异性靶向剂,所述治疗剂如T和 NK免疫细胞、融合蛋白、纳米载体、病毒和其它药剂。恶性神经胶质瘤的大量分子异 质性可能对有效靶向疗法的缺乏有贡献。目前,存在针对患有神经胶质瘤的患者的个人 疗法所设计的若干活跃和待定的临床试验。最终,随着靶向疗法武器(arsenal)的开发, 如特异性靶向并且破坏IL13Rα2表达肿瘤细胞和其它肿瘤相关抗原如EGFRvIII的药剂, 个人化治疗方案可以结合传统疾病疗法如手术和辐射来实施,以改善患有GBM的患者 的结果。
仅针对实例13的参考文献
1.Stupp,R.等人用于成胶质细胞瘤的放射疗法加伴随和佐剂替莫唑胺(Radiotherapy plus concomitant and adjuvant temozolomide for glioblastoma).《新英格兰 医学杂志(N Engl J Med)》352,987-996(2005).
2.Zheng,S.等人纤维结修饰增强恶性神经胶质瘤中的腺病毒向性和基因转移(Fiber-knob modifications enhance adenoviral tropism and gene transfer inmalignant glioma).《基因医学杂志(Thejournal of gene medicine)》9,151-160(2007).
3.Van Houdt,W.J.等人人类存活素启动子:用于治疗神经胶质瘤的新颖转录靶向策略(The human survivin promoter:a novel transcriptional targeting strategyfor treatment of glioma).《神经外科杂志(J Neurosurg)》104,583-592(2006).
4.Ulasov,I.V.等人对用于神经胶质瘤基因疗法的转录靶向的存活素、中期因子和 CXCR4启动子的比较评估(Comparative evaluation of survivin,midkine and CXCR4promoters for transcriptional targeting of glioma gene therapy).《癌症生物学与疗法 (Cancer biology&therapy)》6,679-685(2007).
5.Ulasov,I.V.等人存活素驱动并且纤维修饰的溶瘤腺病毒在所确立的颅内神经胶 质瘤中展现有力的抗肿瘤活性(Survivin-driven and fiber-modified oncolyticadenovirus exhibits potent antitumor activity in established intracranialglioma).《人类基因疗法 (Human gene therapy)》18,589-602(2007).
6.Ulasov,I.V.等人腺病毒病毒疗法和替莫唑胺化学疗法的组合在体内经由自噬性 和凋亡细胞死亡根除恶性神经胶质瘤(Combination of adenoviral virotherapy andtemozolomide chemotherapy eradicates malignant glioma through autophagic andapoptotic cell death in vivo).《英国癌症杂志(British journal of cancer)》100,1154-1164(2009).
7.Chakravarti,A.等人定量确定的存活素表达水平在人类神经胶质瘤中具有预后 价值(Quantitatively determined survivin expression levels are ofprognostic value in human gliomas).《临床肿瘤学杂志:美国临床肿瘤学学会的官方杂志(Journal of clinical oncology:official journal of the American Society ofClinical Oncology)》20,1063-1068 (2002).
8.Uematsu,M.等人神经胶质瘤中存活素的免疫组织化学指数的预后显著性:具有MIB-1指数的比较研究(Prognostic significance of the immunohistochemical indexof survivin in glioma:a comparative study with the MIB-1 index).《神经肿瘤学杂志(Journal of neuro-oncology)》72,231-238(2005).
9.Choi,B.D.等人靶向EGFRvIII的双特异性抗体的系统性给药成功地治疗脑内神经胶质瘤(Systemic administration of a bispecific antibody targeting EGFRvIIIsuccessfully treats intracerebral glioma).《美利坚合众国国家科学院院刊(Proceedings of the National Academy of Sciences of the United States ofAmerica)》110,270-275(2013).
10.Kong,S.等人使用第二代IL13R特异性嵌合抗原受体修饰的T细胞抑止人类神经胶质瘤异种移植物(Suppression of human glioma xenografts with second-generation IL13R-specific chimeric antigen receptor-modified T cells).《临床癌症研究:美国癌症研 究协会的官方杂志(Clinical cancer research:an officialjournal of the American Association for Cancer Research)》18,5949-5960(2012).
11.Krebs,S.等人具有白介素-13突变蛋白-嵌合抗原受体的重新定向到白介素 -13Rα2的T细胞具有抗神经胶质瘤活性并且也识别白介素-13Ralphal(T cells redirectedto interleukin-13Ralpha2 with interleukin-13 mutein-chimeric antigenreceptors have anti-glioma activity but also recognize interleukin-13Ralphal).《细胞疗法(Cytotherapy)》 16,1121-1131(2014).
12.Riccione,K.等人在成胶质细胞瘤标准护理的情形下用于过继性疗法的CAR T细胞的产生(Generation of CAR T Cells for Adoptive Therapy in the Context ofGlioblastoma Standard of Care).《可视化实验期刊:JoVE(Journal of visualizedexperiments:JoVE)》,doi:10.3791/52397(2015).
13.Zitron,I.M.等人用装备有双特异性抗体的活化T细胞靶向并且杀死成胶质细胞 瘤(Targeting and killing of glioblastoma with activated T cells armed withbispecific antibodies).《生物医学中心癌症(BMC cancer)》13,83(2013).
14.Debinski,W.,Obiri,N.I.,Powers,S.K.,Pastan,I.&Puri,R.K.人类神经胶质瘤 细胞过度表达白介素13和由白介素13和假单胞菌外毒素构成的新颖嵌合蛋白的受体并且对新颖嵌合蛋白极敏感(Human glioma cells overexpress receptors forinterleukin 13 and are extremely sensitive to a novel chimeric proteincomposed of interleukin 13 and pseudomonas exotoxin).《临床癌症研究:美国癌症研究协会的官方杂志(Clinical cancer research:an official journal of the AmericanAssociation for Cancer Research)》1, 1253-1258(1995).
15.Joshi,B.H.,Plautz,G.E.&Puri,R.K.白介素-13受体α链:人类恶性神经胶质瘤的原始外植体中的新颖肿瘤相关跨膜蛋白(nterleukin-13 receptor alpha chain:anovel tumor-associated transmembrane protein in primary explants of humanmalignant gliomas). 《癌症研究》60,1168-1172(2000).
16.Jarboe,J.S.,Johnson,K.R.,Choi,Y.,Lonser,R.R.&Park,J.K.白介素-13受体 α2在多形性成胶质细胞瘤中的表达:靶向疗法的推论(Expression of interleukin-13receptor alpha2 in glioblastoma multiforme:implications for targetedtherapies).《癌症研 究》67,7983-7986(2007).
17.Brown,C.E.等人神经胶质瘤IL13Rα2与间叶细胞标签基因表达和不良患者预后相关(Glioma IL13Rα2 Is Associated with Mesenchymal Signature GeneExpression and Poor Patient Prognosis).《公共科学图书馆期刊(PLoS One)》8,e77769(2013).
18.Ulasov,I.V.,Tyler,M.A.,Han,Y.,Glasgow,J.N.&Lesniak,M.S.靶向白介素-13 受体α2链的新颖重组腺病毒载体准许到恶性神经胶质瘤的有效基因转移(Novelrecombinant adenoviral vector that targets the interleukin-13 receptor alpha2chain permits effective gene transfer to malignant glioma).《人类基因疗法》18,118-129(2007).
19.Balyashikova,I.V.等人靶向白介素(IL)-13受体α2的新颖抗体的表征和免疫治疗推论(Characterization and immunotherapeutic implications for a novelantibody targeting interleukin(IL)-13 receptor alpha2).《生物化学杂志(TheJournal of biological chemistry)》287,30215-30227(2012).
20.Bartolomé,R.A.等人IL13受体α2信号传导需要骨架蛋白FAM120A以在结肠癌转移中活化FAK和PI3K路径(IL13 Receptor α2 Signaling Requires a ScaffoldProtein, FAM120A,to Activate the FAK and PI3K Pathways in Colon CancerMetastasis).《癌症研 究》75,2434-2444(2015).
21.Hedley,S.J.等人具有并入稳定化单链抗体的嵌合纤维的腺病毒载体实现靶向 的基因递送(An adenovirus vector with a chimeric fiber incorporatingstabilized single chain antibody achieves targeted gene delivery).《基因疗法(Gene Ther)》13,88-94(2006).
22.Krasnykh,V.,Belousova,N.,Korokhov,N.,Mikheeva,G.&Curiel,D.T.经由用噬 菌体T4纤维蛋白替代纤维蛋白质的腺病毒载体的基因靶向(Genetic targeting of anadenovirus vector via replacement of the fiber protein with the phage T4fibritin).《病毒学 杂志(Journal of virology)》75,4176-4183(2001).
23.Kaliberov,S.A.等人使用遗传并入的骆驼科单可变域的腺病毒靶向(Adenoviral targeting using genetically incorporated camelid single variabledomains).《实验室调查; 技术方法和病变杂志(Laboratory investigation;a journalof technical methods and pathology)》94,893-905(2014).
24.Kipriyanov,S.M.,Kupriyanova,O.A.,Little,M.&Moldenhauer,G.通过流式细 胞测量术的针对细胞表面抗原的重组抗体片段的快速检测(Rapid detection ofrecombinant antibody fragments directed against cell-surface antigens by flowcytometry). 《免疫方法杂志(Journal of immunological methods)》196,51-62(1996).
25.Toleikis,L.,Broders,O.&Dubel,S.从杂交瘤细胞中克隆单链抗体片段(scFv) (Cloning single-chain antibody fragments(scFv)from hybridoma cells).《分子药学方法 (Methods in molecular medicine)》94,447-458(2004).
26.Curiel,D.T.使用于靶向递送的腺病毒载体适应的策略(Strategies toadapt adenoviral vectors for targeted delivery).《纽约科学院年鉴(Annals of theNew York Academy of Sciences)》886,158-171(1999).
27.Kim,J.W.等人具有并入纤维-纤维蛋白嵌合体中的噬菌体呈现衍生的肽的遗传 修饰的腺病毒载体延长实验神经胶质瘤的存活(A Genetically Modified AdenoviralVector with a Phage Display Derived Peptide Incorporated into Fiber FibritinChimera Prolongs Survival in Experimental Glioma).《人类基因疗法》(2015).
28.Bergelson,J.M.等人柯沙奇B病毒以及腺病毒2和5的常见受体的分离(Isolation of a common receptor for Coxsackie B viruses and adenoviruses 2and 5).《科学》 (纽约州纽约)275,1320-1323(1997).
29.Tomko,R.P.,Xu,R.&Philipson,L.HCAR和MCAR:用于子组C腺病毒和组B 柯沙奇病毒的人类和小鼠细胞受体(HCAR and MCAR:the human and mouse cellularreceptors for subgroup C adenoviruses and group B coxsackieviruses).《美利坚合众国国 家科学院院刊》94,3352-3356(1997).
30.Fuxe,J.等人柯沙奇和腺病毒受体在人类星形胶质细胞肿瘤和异种移植物中的 表达(Expression of the coxsackie and adenovirus receptor in humanastrocytic tumors and xenografts.International journal of cancer).《国际癌症杂志(Journal international du cancer)》103,723-729(2003).
31.Asaoka,K.,Tada,M.,Sawamura,Y.,Ikeda,J.&Abe,H.在恶性神经胶质瘤细胞中 的有效腺病毒基因递送对柯萨奇病毒和腺病毒受体的表达水平的依赖性(Dependenceof efficient adenoviral gene delivery in malignant glioma cells on theexpression levels of the Coxsackievirus and adenovirus receptor).《神经外科杂志》92,1002-1008(2000).
32.Allen,C.等人呈现白介素-13的再靶向溶瘤麻疹病毒株在改善的特异性下具有 针对神经胶质瘤的显著活性(Interleukin-13 displaying retargeted oncolyticmeasles virus strains have significant activity against gliomas with improvedspecificity).《分子治疗学 (Mol Ther)》16,1556-1564(2008).
33.Kioi,M.,Seetharam,S.&Puri,R.K.用由单链抗体和突变假单胞菌外毒素构成的新颖重组免疫毒素靶向IL-13Rα2阳性癌症(Targeting IL-13Ralpha2-positive cancerwith a novel recombinant immunotoxin composed of a single-chain antibody andmutated Pseudomonas exotoxin).《分子癌症治疗(Mol Cancer Ther)》7,1579-1587(2008).
34.Kunwar,S.等人针对复发性成胶质细胞瘤,相较于Gliadel晶片,IL13-PE38QQR的CED的III期随机试验(Phase III randomized trial of CED of IL13-PE38QQR vsGliadel wafers for recurrent glioblastoma).《神经肿瘤学(Neuro-oncology)》12,871-881(2010).
35.Auffnger,B.,Spencer,D.,Pytel,P.,Ahmed,A.U.&Lesniak,M.S.神经胶质瘤干 细胞在抗化学疗法和多形性成胶质细胞瘤复发中的作用(The role of glioma stemcells in chemotherapy resistance and glioblastoma multiforme recurrence).《神经治疗学专家评论 (Expert review of neurotherapeutics)》,1-12(2015).
36.Brown,C.E.等人从IL13Rα2表达神经胶质瘤中分离的类干细胞肿瘤引发细胞被IL13-ζ因子重新定向的T细胞靶向和杀死(Stem-like tumor-initiating cellsisolated from IL 13 Ralpha2 expressing gliomas are targeted and killed by IL13-zetakine-redirected T Cells).《临床癌症研究:美国癌症研究协会的官方杂志》18,2199-2209(2012).
37.Ogden,A.T.等人成年人类神经胶质瘤中的A2B5+CD133肿瘤引发细胞的鉴别(Identification of A2B5+CD133-tumor-initiating cells in adult human gliomas).《神经外 科(Neurosurgery)》62,505-514(2008).
38.Jarboe,J.S.,Johnson,K.R.,Choi,Y.,Lonser,R.R.&Park,J.K.白介素-13受体α 2在多形性成胶质细胞瘤中的表达:靶向疗法的推论(Expression of Interleukin-13Receptorα2 in Glioblastoma Multiforme:Implications for Targeted Therapies).《癌症研 究》67,7983-7986(2007).
39.Gan,H.K.,Kaye,A.H.&Luwor,R.B.多形性成胶质细胞瘤中的EGFRvIII变异 体(The EGFRvIII variant in glioblastoma multiforme).《临床神经科学杂志:澳大拉西亚神经外科学会的官方杂志(Journal of clinical neuroscience:official journal ofthe Neurosurgical Society of Australasia)》16,748-754(2009).
40.Beatty,G.L.等人间皮素特异性嵌合抗原受体mRNA工程改造的T细胞诱导固体恶性病中的抗肿瘤活性(Mesothelin-specific chimcric antigen receptor mRNA-engineered T cells induce anti-tumor activity in solid malignancies).《癌症免疫学 研究(Cancer immunology research)》2,112-120(2014).
41.Kane,J.R.等人自成一体:用于治疗成胶质细胞瘤的基因疗法和递送系统(Suigeneris:gene therapy and delivery systems for the treatment of glioblastoma).《神经肿瘤 学(Neuro-oncology)》17增刊2,ii24-ii36(2015).
42.Patel,M.A.,Kim,J.E.,Ruzevick,J.,Li,G.&Lim,M.成胶质细胞瘤疗法的未来: 标准护理和免疫疗法的协同效应(The future of glioblastoma therapy:synergismof standard of care and immunotherapy).《癌症(Cancers)》6,1953-1985(2014).
43.Yan,K.等人神经胶质瘤癌干细胞分泌Gremlin1以促进其在肿瘤层次内的维持(Glioma cancer stem cells secrete Gremlin1 to promote their maintenancewithin the tumor hierarchy).《基因与开发(Genes&development)》28,1085-1100(2014).
44.Balyasnikova,I.V.等人适用于肺内皮靶向的ACE的单克隆抗体单链片段的克隆 和表征(Cloning and characterization of a single-chain fragment ofmonoclonal antibody to ACE suitable for lung endothelial targeting).《微血管研究(Microvascular research)》80, 355-364(2010).
45.Wilkinson-Ryan,I.等人猪腺病毒4纤维蛋白质的并入增强腺病毒载体对树突状 细胞的感染力:免疫介导的癌症疗法的推论(Incorporation of porcine adenovirus4 fiber protein enhances infectivity of adenovirus vector on dendritic cells:implications for immune-mediated cancer therapy).《公共科学图书馆期刊》10,e0125851(2015).
46.Livak,K.J.&Schmittgen,T.D.使用实时定量PCR和2(-ΔΔC(T))方法分析相对 基因表达数据(Analysis of relative gene expression data using real-timequantitative PCR and the 2(-Delta Delta C(T))Method).《方法(Methods)》25,402-408(2001).
如将从引用的情形中显而易见,本文所引用的每一个参考文献以全文或相关部分引 用的方式并入本文中。
从本文的公开内容应了解,尽管本文中已出于说明的目的描述了本公开的特定实施 例,但可以在不背离本公开的精神和范围的情况下进行各种修改。
序列表
<110> Balyasnikova等人
<120> IL13Rα2结合剂和其在癌症治疗中的用途
<130> 27373/49102A
<150> US 62/107,984
<151> 2015-01-26
<160> 147
<170> PatentIn version 3.5
<210> 1
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 1
Asn Tyr Leu Met Asn
1 5
<210> 2
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 2
Arg Ile Asp Pro Tyr Asp Gly Asp Ile Asp Tyr Asn Gln Asn Phe Lys
1 5 10 15
Asp
<210> 3
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 3
Gly Tyr Gly Thr Ala Tyr Gly Val Asp Tyr
1 5 10
<210> 4
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 4
Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile Ser Phe Met Asn
1 5 10 15
<210> 5
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 5
Ala Ala Ser Arg Gln Gly Ser Gly
1 5
<210> 6
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 6
Gln Gln Ser Lys Glu Val Pro Trp Thr
1 5
<210> 7
<211> 119
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 7
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Ser Asn Tyr
20 25 30
Leu Met Asn Trp Val Lys Gln Arg Pro Glu Gln Asp Leu Asp Trp Ile
35 40 45
Gly Arg Ile Asp Pro Tyr Asp Gly Asp Ile Asp Tyr Asn Gln Asn Phe
50 55 60
Lys Asp Lys Ala Ile Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Tyr Gly Thr Ala Tyr Gly Val Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 8
<211> 111
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 8
Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Asn Tyr
20 25 30
Gly Ile Ser Phe Met Asn Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Ala Ala Ser Arg Gln Gly Ser Gly Val Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Ser Leu Asn Ile His
65 70 75 80
Pro Met Glu Glu Asp Asp Thr Ala Met Tyr Phe Cys Gln Gln Ser Lys
85 90 95
Glu Val Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 9
<211> 21
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 9
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp
20
<210> 10
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 10
Glu Glu Gly Glu Phe Ser Glu Ala Arg
1 5
<210> 11
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 11
Gly Gly Pro Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu Asn
1 5 10
<210> 12
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 12
His His His His His His
1 5
<210> 13
<211> 248
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 13
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Ser Asn Tyr
20 25 30
Leu Met Asn Trp Val Lys Gln Arg Pro Glu Gln Asp Leu Asp Trp Ile
35 40 45
Gly Arg Ile Asp Pro Tyr Asp Gly Asp Ile Asp Tyr Asn Gln Asn Phe
50 55 60
Lys Asp Lys Ala Ile Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Tyr Gly Thr Ala Tyr Gly Val Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser Ala Lys Thr Thr Pro Pro Lys Leu Glu
115 120 125
Glu Gly Glu Phe Ser Glu Ala Arg Val Asp Ile Val Leu Thr Gln Ser
130 135 140
Pro Ala Ser Leu Ala Val Ser Leu Gly Gln Arg Ala Thr Ile Ser Cys
145 150 155 160
Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile Ser Phe Met Asn Trp
165 170 175
Phe Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile Tyr Ala Ala
180 185 190
Ser Arg Gln Gly Ser Gly Val Pro Ala Arg Phe Ser Gly Ser Gly Ser
195 200 205
Gly Thr Asp Phe Ser Leu Asn Ile His Pro Met Glu Glu Asp Asp Thr
210 215 220
Ala Met Tyr Phe Cys Gln Gln Ser Lys Glu Val Pro Trp Thr Phe Gly
225 230 235 240
Gly Gly Thr Lys Leu Glu Ile Lys
245
<210> 14
<211> 297
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 14
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu
20 25 30
Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr
35 40 45
Thr Phe Ser Asn Tyr Leu Met Asn Trp Val Lys Gln Arg Pro Glu Gln
50 55 60
Asp Leu Asp Trp Ile Gly Arg Ile Asp Pro Tyr Asp Gly Asp Ile Asp
65 70 75 80
Tyr Asn Gln Asn Phe Lys Asp Lys Ala Ile Leu Thr Val Asp Lys Ser
85 90 95
Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser
100 105 110
Ala Val Tyr Tyr Cys Ala Arg Gly Tyr Gly Thr Ala Tyr Gly Val Asp
115 120 125
Tyr Trp Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Lys Thr Thr
130 135 140
Pro Pro Lys Leu Glu Glu Gly Glu Phe Ser Glu Ala Arg Val Asp Ile
145 150 155 160
Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly Gln Arg
165 170 175
Ala Thr Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile
180 185 190
Ser Phe Met Asn Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu
195 200 205
Leu Ile Tyr Ala Ala Ser Arg Gln Gly Ser Gly Val Pro Ala Arg Phe
210 215 220
Ser Gly Ser Gly Ser Gly Thr Asp Phe Ser Leu Asn Ile His Pro Met
225 230 235 240
Glu Glu Asp Asp Thr Ala Met Tyr Phe Cys Gln Gln Ser Lys Glu Val
245 250 255
Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Ala Ala Ala
260 265 270
Arg Gly Gly Pro Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu Asn Ser
275 280 285
Ala Val Asp His His His His His His
290 295
<210> 15
<211> 357
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 15
caggtccaac tgcagcagcc tggggctgag ctggtgaggc ctggggcttc agtgaagctg 60
tcctgcaagg cttctggcta cacgttctcc aactacttga tgaactgggt taagcagagg 120
cctgagcaag accttgactg gattggaagg attgatcctt acgatggtga cattgactac 180
aatcaaaact tcaaggacaa ggccatattg actgtagaca aatcctccag cacagcctac 240
atgcaactca gcagcctgac atctgaggac tctgcggtct attactgtgc aagaggttat 300
ggcacggcct atggtgtgga ctactggggt caaggaacct cagtcaccgt ctcctca 357
<210> 16
<211> 333
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 16
gatattgtgc taactcagtc tccagcttct ttggctgtgt ctctaggaca gagggccacc 60
atctcctgca gagccagcga aagtgttgat aattatggca ttagttttat gaactggttc 120
caacagaaac caggacagcc acccaaactc ctcatctatg ctgcatccag gcaaggatcc 180
ggggtccctg ccaggtttag tggcagtggg tctgggacag acttcagcct caacatccat 240
cctatggagg aggatgatac tgcaatgtat ttctgtcagc aaagtaagga ggttccgtgg 300
acgttcggtg gaggcaccaa gctggaaatc aaa 333
<210> 17
<211> 32
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 17
gcttggtacc gaatggcttt cgtttgcttg gc 32
<210> 18
<211> 34
<212> PRT
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 18
Gly Thr Thr Thr Thr Thr Gly Thr Thr Cys Gly Ala Ala Thr Gly Thr
1 5 10 15
Ala Thr Cys Ala Cys Ala Gly Ala Ala Ala Ala Ala Thr Thr Cys Thr
20 25 30
Gly Gly
<210> 19
<211> 146
<212> PRT
<213> 智人
<220>
<221> SIGNAL
<222> (1)..(34)
<220>
<221> mat_peptide
<222> (35)..(132)
<400> 19
Met His Pro Leu Leu Asn Pro Leu Leu Leu Ala Leu Gly Leu Met Ala
-30 -25 -20
Leu Leu Leu Thr Thr Val Ile Ala Leu Thr Cys Leu Gly Gly Phe Ala
-15 -10 -5
Ser Pro Gly Pro Val Pro Pro Ser Thr Ala Leu Arg Glu Leu Ile Glu
-1 1 5 10
Glu Leu Val Asn Ile Thr Gln Asn Gln Lys Ala Pro Leu Cys Asn Gly
15 20 25 30
Ser Met Val Trp Ser Ile Asn Leu Thr Ala Gly Met Tyr Cys Ala Ala
35 40 45
Leu Glu Ser Leu Ile Asn Val Ser Gly Cys Ser Ala Ile Glu Lys Thr
50 55 60
Gln Arg Met Leu Ser Gly Phe Cys Pro His Lys Val Ser Ala Gly Gln
65 70 75
Phe Ser Ser Leu His Val Arg Asp Thr Lys Ile Glu Val Ala Gln Phe
80 85 90
Val Lys Asp Leu Leu Leu His Leu Lys Lys Leu Phe Arg Glu Gly Gln
95 100 105 110
Phe Asn
<210> 20
<211> 1282
<212> DNA
<213> 智人
<400> 20
aagccaccca gcctatgcat ccgctcctca atcctctcct gttggcactg ggcctcatgg 60
cgcttttgtt gaccacggtc attgctctca cttgccttgg cggctttgcc tccccaggcc 120
ctgtgcctcc ctctacagcc ctcagggagc tcattgagga gctggtcaac atcacccaga 180
accagaaggc tccgctctgc aatggcagca tggtatggag catcaacctg acagctggca 240
tgtactgtgc agccctggaa tccctgatca acgtgtcagg ctgcagtgcc atcgagaaga 300
cccagaggat gctgagcgga ttctgcccgc acaaggtctc agctgggcag ttttccagct 360
tgcatgtccg agacaccaaa atcgaggtgg cccagtttgt aaaggacctg ctcttacatt 420
taaagaaact ttttcgcgag ggacagttca actgaaactt cgaaagcatc attatttgca 480
gagacaggac ctgactattg aagttgcaga ttcatttttc tttctgatgt caaaaatgtc 540
ttgggtaggc gggaaggagg gttagggagg ggtaaaattc cttagcttag acctcagcct 600
gtgctgcccg tcttcagcct agccgacctc agccttcccc ttgcccaggg ctcagcctgg 660
tgggcctcct ctgtccaggg ccctgagctc ggtggaccca gggatgacat gtccctacac 720
ccctcccctg ccctagagca cactgtagca ttacagtggg tgcccccctt gccagacatg 780
tggtgggaca gggacccact tcacacacag gcaactgagg cagacagcag ctcaggcaca 840
cttcttcttg gtcttattta ttattgtgtg ttatttaaat gagtgtgttt gtcaccgttg 900
gggattgggg aagactgtgg ctgctagcac ttggagccaa gggttcagag actcagggcc 960
ccagcactaa agcagtggac accaggagtc cctggtaata agtactgtgt acagaattct 1020
gctacctcac tggggtcctg gggcctcgga gcctcatccg aggcagggtc aggagagggg 1080
cagaacagcc gctcctgtct gccagccagc agccagctct cagccaacga gtaatttatt 1140
gtttttcctt gtatttaaat attaaatatg ttagcaaaga gttaatatat agaagggtac 1200
cttgaacact gggggagggg acattgaaca agttgtttca ttgactatca aactgaagcc 1260
agaaataaag ttggtgacag at 1282
<210> 21
<211> 427
<212> PRT
<213> 智人
<220>
<221> SIGNAL
<222> (1)..(21)
<220>
<221> mat_peptide
<222> (22)..(427)
<400> 21
Met Glu Trp Pro Ala Arg Leu Cys Gly Leu Trp Ala Leu Leu Leu Cys
-20 -15 -10
Ala Gly Gly Gly Gly Gly Gly Gly Gly Ala Ala Pro Thr Glu Thr Gln
-5 -1 1 5 10
Pro Pro Val Thr Asn Leu Ser Val Ser Val Glu Asn Leu Cys Thr Val
15 20 25
Ile Trp Thr Trp Asn Pro Pro Glu Gly Ala Ser Ser Asn Cys Ser Leu
30 35 40
Trp Tyr Phe Ser His Phe Gly Asp Lys Gln Asp Lys Lys Ile Ala Pro
45 50 55
Glu Thr Arg Arg Ser Ile Glu Val Pro Leu Asn Glu Arg Ile Cys Leu
60 65 70 75
Gln Val Gly Ser Gln Cys Ser Thr Asn Glu Ser Glu Lys Pro Ser Ile
80 85 90
Leu Val Glu Lys Cys Ile Ser Pro Pro Glu Gly Asp Pro Glu Ser Ala
95 100 105
Val Thr Glu Leu Gln Cys Ile Trp His Asn Leu Ser Tyr Met Lys Cys
110 115 120
Ser Trp Leu Pro Gly Arg Asn Thr Ser Pro Asp Thr Asn Tyr Thr Leu
125 130 135
Tyr Tyr Trp His Arg Ser Leu Glu Lys Ile His Gln Cys Glu Asn Ile
140 145 150 155
Phe Arg Glu Gly Gln Tyr Phe Gly Cys Ser Phe Asp Leu Thr Lys Val
160 165 170
Lys Asp Ser Ser Phe Glu Gln His Ser Val Gln Ile Met Val Lys Asp
175 180 185
Asn Ala Gly Lys Ile Lys Pro Ser Phe Asn Ile Val Pro Leu Thr Ser
190 195 200
Arg Val Lys Pro Asp Pro Pro His Ile Lys Asn Leu Ser Phe His Asn
205 210 215
Asp Asp Leu Tyr Val Gln Trp Glu Asn Pro Gln Asn Phe Ile Ser Arg
220 225 230 235
Cys Leu Phe Tyr Glu Val Glu Val Asn Asn Ser Gln Thr Glu Thr His
240 245 250
Asn Val Phe Tyr Val Gln Glu Ala Lys Cys Glu Asn Pro Glu Phe Glu
255 260 265
Arg Asn Val Glu Asn Thr Ser Cys Phe Met Val Pro Gly Val Leu Pro
270 275 280
Asp Thr Leu Asn Thr Val Arg Ile Arg Val Lys Thr Asn Lys Leu Cys
285 290 295
Tyr Glu Asp Asp Lys Leu Trp Ser Asn Trp Ser Gln Glu Met Ser Ile
300 305 310 315
Gly Lys Lys Arg Asn Ser Thr Leu Tyr Ile Thr Met Leu Leu Ile Val
320 325 330
Pro Val Ile Val Ala Gly Ala Ile Ile Val Leu Leu Leu Tyr Leu Lys
335 340 345
Arg Leu Lys Ile Ile Ile Phe Pro Pro Ile Pro Asp Pro Gly Lys Ile
350 355 360
Phe Lys Glu Met Phe Gly Asp Gln Asn Asp Asp Thr Leu His Trp Lys
365 370 375
Lys Tyr Asp Ile Tyr Glu Lys Gln Thr Lys Glu Glu Thr Asp Ser Val
380 385 390 395
Val Leu Ile Glu Asn Leu Lys Lys Ala Ser Gln
400 405
<210> 22
<211> 4006
<212> DNA
<213> 智人
<400> 22
tgccaaggct ccagcccggc cgggctccga ggcgagaggc tgcatggagt ggccggcgcg 60
gctctgcggg ctgtgggcgc tgctgctctg cgccggcggc gggggcgggg gcgggggcgc 120
cgcgcctacg gaaactcagc cacctgtgac aaatttgagt gtctctgttg aaaacctctg 180
cacagtaata tggacatgga atccacccga gggagccagc tcaaattgta gtctatggta 240
ttttagtcat tttggcgaca aacaagataa gaaaatagct ccggaaactc gtcgttcaat 300
agaagtaccc ctgaatgaga ggatttgtct gcaagtgggg tcccagtgta gcaccaatga 360
gagtgagaag cctagcattt tggttgaaaa atgcatctca cccccagaag gtgatcctga 420
gtctgctgtg actgagcttc aatgcatttg gcacaacctg agctacatga agtgttcttg 480
gctccctgga aggaatacca gtcccgacac taactatact ctctactatt ggcacagaag 540
cctggaaaaa attcatcaat gtgaaaacat ctttagagaa ggccaatact ttggttgttc 600
ctttgatctg accaaagtga aggattccag ttttgaacaa cacagtgtcc aaataatggt 660
caaggataat gcaggaaaaa ttaaaccatc cttcaatata gtgcctttaa cttcccgtgt 720
gaaacctgat cctccacata ttaaaaacct ctccttccac aatgatgacc tatatgtgca 780
atgggagaat ccacagaatt ttattagcag atgcctattt tatgaagtag aagtcaataa 840
cagccaaact gagacacata atgttttcta cgtccaagag gctaaatgtg agaatccaga 900
atttgagaga aatgtggaga atacatcttg tttcatggtc cctggtgttc ttcctgatac 960
tttgaacaca gtcagaataa gagtcaaaac aaataagtta tgctatgagg atgacaaact 1020
ctggagtaat tggagccaag aaatgagtat aggtaagaag cgcaattcca cactctacat 1080
aaccatgtta ctcattgttc cagtcatcgt cgcaggtgca atcatagtac tcctgcttta 1140
cctaaaaagg ctcaagatta ttatattccc tccaattcct gatcctggca agatttttaa 1200
agaaatgttt ggagaccaga atgatgatac tctgcactgg aagaagtacg acatctatga 1260
gaagcaaacc aaggaggaaa ccgactctgt agtgctgata gaaaacctga agaaagcctc 1320
tcagtgatgg agataattta tttttacctt cactgtgacc ttgagaagat tcttcccatt 1380
ctccatttgt tatctgggaa cttattaaat ggaaactgaa actactgcac catttaaaaa 1440
caggcagctc ataagagcca caggtcttta tgttgagtcg cgcaccgaaa aactaaaaat 1500
aatgggcgct ttggagaaga gtgtggagtc attctcattg aattataaaa gccagcaggc 1560
ttcaaactag gggacaaagc aaaaagtgat gatagtggtg gagttaatct tatcaagagt 1620
tgtgacaact tcctgaggga tctatacttg ctttgtgttc tttgtgtcaa catgaacaaa 1680
ttttatttgt aggggaactc atttggggtg caaatgctaa tgtcaaactt gagtcacaaa 1740
gaacatgtag aaaacaaaat ggataaaatc tgatatgtat tgtttgggat cctattgaac 1800
catgtttgtg gctattaaaa ctcttttaac agtctgggct gggtccggtg gctcacgcct 1860
gtaatcccag caatttggga gtccgaggcg ggcggatcac tcgaggtcag gagttccaga 1920
ccagcctgac caaaatggtg aaacctcctc tctactaaaa ctacaaaaat taactgggtg 1980
tggtggcgcg tgcctgtaat cccagctact cgggaagctg aggcaggtga attgtttgaa 2040
cctgggaggt ggaggttgca gtgagcagag atcacaccac tgcactctag cctgggtgac 2100
agagcaagac tctgtctaaa aaacaaaaca aaacaaaaca aaacaaaaaa acctcttaat 2160
attctggagt catcattccc ttcgacagca ttttcctctg ctttgaaagc cccagaaatc 2220
agtgttggcc atgatgacaa ctacagaaaa accagaggca gcttctttgc caagaccttt 2280
caaagccatt ttaggctgtt aggggcagtg gaggtagaat gactccttgg gtattagagt 2340
ttcaaccatg aagtctctaa caatgtattt tcttcacctc tgctactcaa gtagcattta 2400
ctgtgtcttt ggtttgtgct aggcccccgg gtgtgaagca cagacccctt ccaggggttt 2460
acagtctatt tgagactcct cagttcttgc cacttttttt tttaatctcc accagtcatt 2520
tttcagacct tttaactcct caattccaac actgatttcc ccttttgcat tctccctcct 2580
tcccttcctt gtagcctttt gactttcatt ggaaattagg atgtaaatct gctcaggaga 2640
cctggaggag cagaggataa ttagcatctc aggttaagtg tgagtaatct gagaaacaat 2700
gactaattct tgcatatttt gtaacttcca tgtgagggtt ttcagcattg atatttgtgc 2760
attttctaaa cagagatgag gtggtatctt cacgtagaac attggtattc gcttgagaaa 2820
aaaagaatag ttgaacctat ttctctttct ttacaagatg ggtccaggat tcctcttttc 2880
tctgccataa atgattaatt aaatagcttt tgtgtcttac attggtagcc agccagccaa 2940
ggctctgttt atgcttttgg ggggcatata ttgggttcca ttctcaccta tccacacaac 3000
atatccgtat atatcccctc tactcttact tcccccaaat ttaaagaagt atgggaaatg 3060
agaggcattt cccccacccc atttctctcc tcacacacag actcatatta ctggtaggaa 3120
cttgagaact ttatttccaa gttgttcaaa catttaccaa tcatattaat acaatgatgc 3180
tatttgcaat tcctgctcct aggggagggg agataagaaa ccctcactct ctacaggttt 3240
gggtacaagt ggcaacctgc ttccatggcc gtgtagaagc atggtgccct ggcttctctg 3300
aggaagctgg ggttcatgac aatggcagat gtaaagttat tcttgaagtc agattgaggc 3360
tgggagacag ccgtagtaga tgttctactt tgttctgctg ttctctagaa agaatatttg 3420
gttttcctgt ataggaatga gattaattcc tttccaggta ttttataatt ctgggaagca 3480
aaacccatgc ctccccctag ccatttttac tgttatccta tttagatggc catgaagagg 3540
atgctgtgaa attcccaaca aacattgatg ctgacagtca tgcagtctgg gagtggggaa 3600
gtgatctttt gttcccatcc tcttctttta gcagtaaaat agctgaggga aaagggaggg 3660
aaaaggaagt tatgggaata cctgtggtgg ttgtgatccc taggtcttgg gagctcttgg 3720
aggtgtctgt atcagtggat ttcccatccc ctgtgggaaa ttagtaggct catttactgt 3780
tttaggtcta gcctatgtgg attttttcct aacataccta agcaaaccca gtgtcaggat 3840
ggtaattctt attctttcgt tcagttaagt ttttcccttc atctgggcac tgaagggata 3900
tgtgaaacaa tgttaacatt tttggtagtc ttcaaccagg gattgtttct gtttaacttc 3960
ttataggaaa gcttgagtaa aataaatatt gtctttttgt atgtca 4006
<210> 23
<211> 380
<212> PRT
<213> 智人
<220>
<221> SIGNAL
<222> (1)..(26)
<220>
<221> mat_peptide
<222> (27)..(380)
<400> 23
Met Ala Phe Val Cys Leu Ala Ile Gly Cys Leu Tyr Thr Phe Leu Ile
-25 -20 -15
Ser Thr Thr Phe Gly Cys Thr Ser Ser Ser Asp Thr Glu Ile Lys Val
-10 -5 -1 1 5
Asn Pro Pro Gln Asp Phe Glu Ile Val Asp Pro Gly Tyr Leu Gly Tyr
10 15 20
Leu Tyr Leu Gln Trp Gln Pro Pro Leu Ser Leu Asp His Phe Lys Glu
25 30 35
Cys Thr Val Glu Tyr Glu Leu Lys Tyr Arg Asn Ile Gly Ser Glu Thr
40 45 50
Trp Lys Thr Ile Ile Thr Lys Asn Leu His Tyr Lys Asp Gly Phe Asp
55 60 65 70
Leu Asn Lys Gly Ile Glu Ala Lys Ile His Thr Leu Leu Pro Trp Gln
75 80 85
Cys Thr Asn Gly Ser Glu Val Gln Ser Ser Trp Ala Glu Thr Thr Tyr
90 95 100
Trp Ile Ser Pro Gln Gly Ile Pro Glu Thr Lys Val Gln Asp Met Asp
105 110 115
Cys Val Tyr Tyr Asn Trp Gln Tyr Leu Leu Cys Ser Trp Lys Pro Gly
120 125 130
Ile Gly Val Leu Leu Asp Thr Asn Tyr Asn Leu Phe Tyr Trp Tyr Glu
135 140 145 150
Gly Leu Asp His Ala Leu Gln Cys Val Asp Tyr Ile Lys Ala Asp Gly
155 160 165
Gln Asn Ile Gly Cys Arg Phe Pro Tyr Leu Glu Ala Ser Asp Tyr Lys
170 175 180
Asp Phe Tyr Ile Cys Val Asn Gly Ser Ser Glu Asn Lys Pro Ile Arg
185 190 195
Ser Ser Tyr Phe Thr Phe Gln Leu Gln Asn Ile Val Lys Pro Leu Pro
200 205 210
Pro Val Tyr Leu Thr Phe Thr Arg Glu Ser Ser Cys Glu Ile Lys Leu
215 220 225 230
Lys Trp Ser Ile Pro Leu Gly Pro Ile Pro Ala Arg Cys Phe Asp Tyr
235 240 245
Glu Ile Glu Ile Arg Glu Asp Asp Thr Thr Leu Val Thr Ala Thr Val
250 255 260
Glu Asn Glu Thr Tyr Thr Leu Lys Thr Thr Asn Glu Thr Arg Gln Leu
265 270 275
Cys Phe Val Val Arg Ser Lys Val Asn Ile Tyr Cys Ser Asp Asp Gly
280 285 290
Ile Trp Ser Glu Trp Ser Asp Lys Gln Cys Trp Glu Gly Glu Asp Leu
295 300 305 310
Ser Lys Lys Thr Leu Leu Arg Phe Trp Leu Pro Phe Gly Phe Ile Leu
315 320 325
Ile Leu Val Ile Phe Val Thr Gly Leu Leu Leu Arg Lys Pro Asn Thr
330 335 340
Tyr Pro Lys Met Ile Pro Glu Phe Phe Cys Asp Thr
345 350
<210> 24
<211> 1376
<212> DNA
<213> 智人
<400> 24
gtaagaacac tctcgtgagt ctaacggtct tccggatgaa ggctatttga agtcgccata 60
acctggtcag aagtgtgcct gtcggcgggg agagaggcaa tatcaaggtt ttaaatctcg 120
gagaaatggc tttcgtttgc ttggctatcg gatgcttata tacctttctg ataagcacaa 180
catttggctg tacttcatct tcagacaccg agataaaagt taaccctcct caggattttg 240
agatagtgga tcccggatac ttaggttatc tctatttgca atggcaaccc ccactgtctc 300
tggatcattt taaggaatgc acagtggaat atgaactaaa ataccgaaac attggtagtg 360
aaacatggaa gaccatcatt actaagaatc tacattacaa agatgggttt gatcttaaca 420
agggcattga agcgaagata cacacgcttt taccatggca atgcacaaat ggatcagaag 480
ttcaaagttc ctgggcagaa actacttatt ggatatcacc acaaggaatt ccagaaacta 540
aagttcagga tatggattgc gtatattaca attggcaata tttactctgt tcttggaaac 600
ctggcatagg tgtacttctt gataccaatt acaacttgtt ttactggtat gagggcttgg 660
atcatgcatt acagtgtgtt gattacatca aggctgatgg acaaaatata ggatgcagat 720
ttccctattt ggaggcatca gactataaag atttctatat ttgtgttaat ggatcatcag 780
agaacaagcc tatcagatcc agttatttca cttttcagct tcaaaatata gttaaacctt 840
tgccgccagt ctatcttact tttactcggg agagttcatg tgaaattaag ctgaaatgga 900
gcataccttt gggacctatt ccagcaaggt gttttgatta tgaaattgag atcagagaag 960
atgatactac cttggtgact gctacagttg aaaatgaaac atacaccttg aaaacaacaa 1020
atgaaacccg acaattatgc tttgtagtaa gaagcaaagt gaatatttat tgctcagatg 1080
acggaatttg gagtgagtgg agtgataaac aatgctggga aggtgaagac ctatcgaaga 1140
aaactttgct acgtttctgg ctaccatttg gtttcatctt aatattagtt atatttgtaa 1200
ccggtctgct tttgcgtaag ccaaacacct acccaaaaat gattccagaa tttttctgtg 1260
atacatgaag actttccata tcaagagaca tggtattgac tcaacagttt ccagtcatgg 1320
ccaaatgttc aatatgagtc tcaataaact gaatttttct tgcgaatgtt gaaaaa 1376
<210> 25
<211> 479
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 25
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp Ala Ala Gln Pro Ala Gln Val Gln Leu Gln Gln
20 25 30
Pro Gly Ala Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys
35 40 45
Lys Ala Ser Gly Tyr Thr Phe Ser Asn Tyr Leu Met Asn Trp Val Lys
50 55 60
Gln Arg Pro Glu Gln Asp Leu Asp Trp Ile Gly Arg Ile Asp Pro Tyr
65 70 75 80
Asp Gly Asp Ile Asp Tyr Asn Gln Asn Phe Lys Asp Lys Ala Ile Leu
85 90 95
Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Leu
100 105 110
Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala Arg Gly Tyr Gly Thr
115 120 125
Ala Tyr Gly Val Asp Tyr Trp Gly Gln Gly Thr Ser Val Thr Val Ser
130 135 140
Ser Ala Lys Thr Thr Pro Pro Lys Leu Glu Glu Gly Glu Phe Ser Glu
145 150 155 160
Ala Arg Val Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val
165 170 175
Ser Leu Gly Gln Arg Ala Thr Ile Ser Cys Arg Ala Ser Glu Ser Val
180 185 190
Asp Asn Tyr Gly Ile Ser Phe Met Asn Trp Phe Gln Gln Lys Pro Gly
195 200 205
Gln Pro Pro Lys Leu Leu Ile Tyr Ala Ala Ser Arg Gln Gly Ser Gly
210 215 220
Val Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Ser Leu
225 230 235 240
Asn Ile His Pro Met Glu Glu Asp Asp Thr Ala Met Tyr Phe Cys Gln
245 250 255
Gln Ser Lys Glu Val Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu
260 265 270
Ile Lys Ala Ala Ala Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Thr Ser Glu Glu Thr Ile Ser Thr Val Gln Glu Lys
290 295 300
Gln Gln Asn Ile Ser Pro Leu Val Arg Glu Arg Gly Pro Gln Arg Val
305 310 315 320
Ala Ala His Ile Thr Gly Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser
325 330 335
Pro Asn Ser Lys Asn Glu Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp
340 345 350
Glu Ser Ser Arg Ser Gly His Ser Phe Leu Ser Asn Leu His Leu Arg
355 360 365
Asn Gly Glu Leu Val Ile His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser
370 375 380
Gln Thr Tyr Phe Arg Phe Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn
385 390 395 400
Asp Lys Gln Met Val Gln Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp
405 410 415
Pro Ile Leu Leu Met Lys Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp
420 425 430
Ala Glu Tyr Gly Leu Tyr Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu
435 440 445
Lys Glu Asn Asp Arg Ile Phe Val Ser Val Thr Asn Glu His Leu Ile
450 455 460
Asp Met Asp His Glu Ala Ser Phe Phe Gly Ala Phe Leu Val Gly
465 470 475
<210> 26
<211> 1440
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 26
atggagacag acacactcct gctatgggta ctgctgctct gggttccagg ttccactggt 60
gacgcggccc agccggccca ggtccaactg cagcagcctg gggctgagct ggtgaggcct 120
ggggcttcag tgaagctgtc ctgcaaggct tctggctaca cgttctccaa ctacttgatg 180
aactgggtta agcagaggcc tgagcaagac cttgactgga ttggaaggat tgatccttac 240
gatggtgaca ttgactacaa tcaaaacttc aaggacaagg ccatattgac tgtagacaaa 300
tcctccagca cagcctacat gcaactcagc agcctgacat ctgaggactc tgcggtctat 360
tactgtgcaa gaggttatgg cacggcctat ggtgtggact actggggtca aggaacctca 420
gtcaccgtct cctcagccaa aacgacaccc ccaaagcttg aagaaggtga attttcagaa 480
gcacgcgtag atattgtgct aactcagtct ccagcttctt tggctgtgtc tctaggacag 540
agggccacca tctcctgcag agccagcgaa agtgttgata attatggcat tagttttatg 600
aactggttcc aacagaaacc aggacagcca cccaaactcc tcatctatgc tgcatccagg 660
caaggatccg gggtccctgc caggtttagt ggcagtgggt ctgggacaga cttcagcctc 720
aacatccatc ctatggagga ggatgatact gcaatgtatt tctgtcagca aagtaaggag 780
gttccgtgga cgttcggtgg aggcaccaag ctggaaatca aagcggccgc tggcggaggc 840
ggttcgggcg gaggtggctc tggcggtggc ggatcaacct ctgaggaaac catttctaca 900
gttcaagaaa agcaacaaaa tatttctccc ctagtgagag aaagaggtcc tcagagagta 960
gcagctcaca taactgggac cagaggaaga agcaacacat tgtcttctcc aaactccaag 1020
aatgaaaagg ctctgggccg caaaataaac tcctgggaat catcaaggag tgggcattca 1080
ttcctgagca acttgcactt gaggaatggt gaactggtca tccatgaaaa agggttttac 1140
tacatctatt cccaaacata ctttcgattt caggaggaaa taaaagaaaa cacaaagaac 1200
gacaaacaaa tggtccaata tatttacaaa tacacaagtt atcctgaccc tatattgttg 1260
atgaaaagtg ctagaaatag ttgttggtct aaagatgcag aatatggact ctattccatc 1320
tatcaagggg gaatatttga gcttaaggaa aatgacagaa tttttgtttc tgtaacaaat 1380
gagcacttga tagacatgga ccatgaagcc agttttttcg gggccttttt agttggctaa 1440
<210> 27
<211> 187
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 27
Thr Ser Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile
1 5 10 15
Ser Pro Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile
20 25 30
Thr Gly Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys
35 40 45
Asn Glu Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg
50 55 60
Ser Gly His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu
65 70 75 80
Val Ile His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe
85 90 95
Arg Phe Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met
100 105 110
Val Gln Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu
115 120 125
Met Lys Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly
130 135 140
Leu Tyr Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp
145 150 155 160
Arg Ile Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp His
165 170 175
Glu Ala Ser Phe Phe Gly Ala Phe Leu Val Gly
180 185
<210> 28
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 28
Arg Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu
1 5 10 15
Gln Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe
20 25 30
Tyr Pro Lys Asp Ile Asn Val Lys Trp Lys Ile Asp Gly Ser Glu Arg
35 40 45
Gln Asn Gly Val Leu Asn Ser Trp Thr Asp Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Met Ser Ser Thr Leu Thr Leu Thr Lys Asp Glu Tyr Glu
65 70 75 80
Arg His Asn Ser Tyr Thr Cys Glu Ala Thr His Lys Thr Ser Thr Ser
85 90 95
Pro Ile Val Lys Ser Phe Asn Arg Asn Glu Cys
100 105
<210> 29
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 29
cgggctgatg ctgcaccaac tgtatccatc ttcccaccat ccagtgagca gttaacatct 60
ggaggtgcct cagtcgtgtg cttcttgaac aacttctacc ccaaagacat caatgtcaag 120
tggaagattg atggcagtga acgacaaaat ggcgtcctga acagttggac tgatcaggac 180
agcaaagaca gcacctacag catgagcagc accctcacgt tgaccaagga cgagtatgaa 240
cgacataaca gctatacctg tgaggccact cacaagacat caacttcacc cattgtcaag 300
agcttcaaca ggaatgagtg ttag 324
<210> 30
<211> 324
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 30
Ala Lys Thr Thr Pro Pro Ser Val Tyr Pro Leu Ala Pro Gly Ser Ala
1 5 10 15
Ala Gln Thr Asn Ser Met Val Thr Leu Gly Cys Leu Val Lys Gly Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Thr Trp Asn Ser Gly Ser Leu Ser Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Asp Leu Tyr Thr Leu
50 55 60
Ser Ser Ser Val Thr Val Pro Ser Ser Thr Trp Pro Ser Glu Thr Val
65 70 75 80
Thr Cys Asn Val Ala His Pro Ala Ser Ser Thr Lys Val Asp Lys Lys
85 90 95
Ile Val Pro Arg Asp Cys Gly Cys Lys Pro Cys Ile Cys Thr Val Pro
100 105 110
Glu Val Ser Ser Val Phe Ile Phe Pro Pro Lys Pro Lys Asp Val Leu
115 120 125
Thr Ile Thr Leu Thr Pro Lys Val Thr Cys Val Val Val Asp Ile Ser
130 135 140
Lys Asp Asp Pro Glu Val Gln Phe Ser Trp Phe Val Asp Asp Val Glu
145 150 155 160
Val His Thr Ala Gln Thr Gln Pro Arg Glu Glu Gln Phe Asn Ser Thr
165 170 175
Phe Arg Ser Val Ser Glu Leu Pro Ile Met His Gln Asp Trp Leu Asn
180 185 190
Gly Lys Glu Phe Lys Cys Arg Val Asn Ser Ala Ala Phe Pro Ala Pro
195 200 205
Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Arg Pro Lys Ala Pro Gln
210 215 220
Val Tyr Thr Ile Pro Pro Pro Lys Glu Gln Met Ala Lys Asp Lys Val
225 230 235 240
Ser Leu Thr Cys Met Ile Thr Asp Phe Phe Pro Glu Asp Ile Thr Val
245 250 255
Glu Trp Gln Trp Asn Gly Gln Pro Ala Glu Asn Tyr Lys Asn Thr Gln
260 265 270
Pro Ile Met Asp Thr Asp Gly Ser Tyr Phe Val Tyr Ser Lys Leu Asn
275 280 285
Val Gln Lys Ser Asn Trp Glu Ala Gly Asn Thr Phe Thr Cys Ser Val
290 295 300
Leu His Glu Gly Leu His Asn His His Thr Glu Lys Ser Leu Ser His
305 310 315 320
Ser Pro Gly Lys
<210> 31
<211> 975
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 31
gccaaaacga cacccccatc tgtctatcca ctggcccctg gatctgctgc ccaaactaac 60
tccatggtga ccctgggatg cctggtcaag ggctatttcc ctgagccagt gacagtgacc 120
tggaactctg gatccctgtc cagcggtgtg cacaccttcc cagctgtcct gcagtctgac 180
ctctacactc tgagcagctc agtgactgtc ccctccagca cctggcccag cgagaccgtc 240
acctgcaacg ttgcccaccc ggccagcagc accaaggtgg acaagaaaat tgtgcccagg 300
gattgtggtt gtaagccttg catatgtaca gtcccagaag tatcatctgt cttcatcttc 360
cccccaaagc ccaaggatgt gctcaccatt actctgactc ctaaggtcac gtgtgttgtg 420
gtagacatca gcaaggatga tcccgaggtc cagttcagct ggtttgtaga tgatgtggag 480
gtgcacacag ctcagacgca accccgggag gagcagttca acagcacttt ccgctcagtc 540
agtgaacttc ccatcatgca ccaggactgg ctcaatggca aggagttcaa atgcagggtc 600
aacagtgcag ctttccctgc ccccatcgag aaaaccatct ccaaaaccaa aggcagaccg 660
aaggctccac aggtgtacac cattccacct cccaaggagc agatggccaa ggataaagtc 720
agtctgacct gcatgataac agacttcttc cctgaagaca ttactgtgga gtggcagtgg 780
aatgggcagc cagcggagaa ctacaagaac actcagccca tcatggacac agatggctct 840
tacttcgtct acagcaagct caatgtgcag aagagcaact gggaggcagg aaatactttc 900
acctgctctg tgttacatga gggcctgcac aaccaccata ctgagaagag cctctcccac 960
tctcctggta aatga 975
<210> 32
<211> 19
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 32
Met Asp Trp Ile Trp Arg Ile Leu Phe Leu Val Gly Ala Ala Thr Gly
1 5 10 15
Ala His Ser
<210> 33
<211> 267
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 33
Met Asp Trp Ile Trp Arg Ile Leu Phe Leu Val Gly Ala Ala Thr Gly
1 5 10 15
Ala His Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg
20 25 30
Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Ser Asn Tyr Leu Met Asn Trp Val Lys Gln Arg Pro Glu Gln Asp Leu
50 55 60
Asp Trp Ile Gly Arg Ile Asp Pro Tyr Asp Gly Asp Ile Asp Tyr Asn
65 70 75 80
Gln Asn Phe Lys Asp Lys Ala Ile Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Gly Tyr Gly Thr Ala Tyr Gly Val Asp Tyr Trp
115 120 125
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Lys Thr Thr Pro Pro
130 135 140
Lys Leu Glu Glu Gly Glu Phe Ser Glu Ala Arg Val Asp Ile Val Leu
145 150 155 160
Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly Gln Arg Ala Thr
165 170 175
Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile Ser Phe
180 185 190
Met Asn Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Ala Ala Ser Arg Gln Gly Ser Gly Val Pro Ala Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Ser Leu Asn Ile His Pro Met Glu Glu
225 230 235 240
Asp Asp Thr Ala Met Tyr Phe Cys Gln Gln Ser Lys Glu Val Pro Trp
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
260 265
<210> 34
<211> 801
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 34
atggactgga tctggcgcat cctgtttctc gtgggagccg ccacaggcgc ccattctcag 60
gtgcagctgc agcagcctgg cgctgaactc gtgcggccag gcgcttctgt gaagctgagc 120
tgtaaagcca gcggctacac cttcagcaac tacctgatga actgggtcaa gcagcggccc 180
gagcaggacc tggattggat cggcagaatc gacccctacg acggcgacat cgactacaac 240
cagaacttca aggacaaggc catcctgacc gtggacaaga gcagcagcac cgcctacatg 300
cagctgtcca gcctgaccag cgaggacagc gccgtgtact actgcgccag aggctacggc 360
acagcctacg gcgtggacta ttggggccag ggcacaagcg tgaccgtgtc cagcgccaag 420
accacccccc ctaagctgga agagggcgag ttctccgagg cccgggtgga cattgtgctg 480
acacagtctc cagccagcct ggccgtgtcc ctgggacaga gagccaccat cagctgtagg 540
gccagcgaga gcgtggacaa ctacggcatc agcttcatga attggttcca gcagaagccc 600
ggccagcccc ccaagctgct gatctatgcc gccagcagac agggcagcgg agtgcctgcc 660
agattttctg gcagcggctc cggcaccgac ttcagcctga acatccaccc tatggaagag 720
gacgacaccg ccatgtactt ttgccagcag agcaaagagg tgccctggac ctttggcgga 780
ggcaccaagc tggaaatcaa g 801
<210> 35
<211> 236
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 35
Asp Pro Ala Glu Pro Lys Ser Pro Asp Lys Thr His Thr Cys Pro Pro
1 5 10 15
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
20 25 30
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
35 40 45
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
50 55 60
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
65 70 75 80
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
85 90 95
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
100 105 110
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
115 120 125
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
130 135 140
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
145 150 155 160
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
165 170 175
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
180 185 190
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
195 200 205
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
210 215 220
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys Lys
225 230 235
<210> 36
<211> 708
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 36
gatcccgccg agcccaaatc tcctgacaaa actcacacat gcccaccgtg cccagcacct 60
gaactcctgg ggggaccgtc agtcttcctc ttccccccaa aacccaagga caccctcatg 120
atctcccgga cccctgaggt cacatgcgtg gtggtggacg tgagccacga agaccctgag 180
gtcaagttca actggtacgt ggacggcgtg gaggtgcata atgccaagac aaagccgcgg 240
gaggagcagt acaacagcac gtaccgtgtg gtcagcgtcc tcaccgtcct gcaccaggac 300
tggctgaatg gcaaggagta caagtgcaag gtctccaaca aagccctccc agcccccatc 360
gagaaaacca tctccaaagc caaagggcag ccccgagaac cacaggtgta caccctgccc 420
ccatcccggg atgagctgac caagaaccag gtcagcctga cctgcctggt caaaggcttc 480
tatcccagcg acatcgccgt ggagtgggag agcaatgggc aaccggagaa caactacaag 540
accacgcctc ccgtgctgga ctccgacggc tccttcttcc tctacagcaa gctcaccgtg 600
gacaagagca ggtggcagca ggggaacgtc ttctcatgct ccgtgatgca tgaggctctg 660
cacaaccact acacgcagaa gagcctctcc ctgtctccgg gtaaaaaa 708
<210> 37
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 37
Asp Leu Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
1 5 10 15
Pro
<210> 38
<211> 51
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 38
gatctcgagc ccaaatcttg tgacaaaact cacacatgcc caccgtgccc g 51
<210> 39
<211> 68
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 39
Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu
1 5 10 15
Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser
20 25 30
Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly
35 40 45
Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala
50 55 60
Ala Tyr Arg Ser
65
<210> 40
<211> 204
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 40
ttttgggtgc tggtggtggt tggtggagtc ctggcttgct atagcttgct agtaacagtg 60
gcctttatta ttttctgggt gaggagtaag aggagcaggc tcctgcacag tgactacatg 120
aacatgactc cccgccgccc cgggcccacc cgcaagcatt accagcccta tgccccacca 180
cgcgacttcg cagcctatcg ctcc 204
<210> 41
<211> 112
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 41
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly
1 5 10 15
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
20 25 30
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
35 40 45
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys
50 55 60
Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
65 70 75 80
Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala
85 90 95
Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
100 105 110
<210> 42
<211> 336
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 42
agagtgaagt tcagcaggag cgcagacgcc cccgcgtacc agcagggcca gaaccagctc 60
tataacgagc tcaatctagg acgaagagag gagtacgatg ttttggacaa gagacgtggc 120
cgggaccctg agatgggggg aaagccgaga aggaagaacc ctcaggaagg cctgtacaat 180
gaactgcaga aagataagat ggcggaggcc tacagtgaga ttgggatgaa aggcgagcgc 240
cggaggggca aggggcacga tggcctttac cagggtctca gtacagccac caaggacacc 300
tacgacgccc ttcacatgca ggccctgccc cctcgc 336
<210> 43
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 43
Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu
1 5 10 15
Leu
<210> 44
<211> 105
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 44
ttttgggtgc tggtggtggt tggtggagtc ctggcttgct atagcttgct agtaacagtg 60
gcctttatta ttttctgggt gaggagtaag aggagcaggc tcctg 105
<210> 45
<211> 24
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 45
Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu
1 5 10 15
Leu Val Thr Val Ala Phe Ile Ile
20
<210> 46
<211> 105
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 46
ttttgggtgc tggtggtggt tggtggagtc ctggcttgct atagcttgct agtaacagtg 60
gcctttatta ttttctgggt gaggagtaag aggagcaggc tcctg 105
<210> 47
<211> 180
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 47
Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu
1 5 10 15
Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser
20 25 30
Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly
35 40 45
Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala
50 55 60
Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
65 70 75 80
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
85 90 95
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
100 105 110
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
115 120 125
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
130 135 140
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
145 150 155 160
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
165 170 175
Leu Pro Pro Arg
180
<210> 48
<211> 540
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 48
ttttgggtgc tggtggtggt tggtggagtc ctggcttgct atagcttgct agtaacagtg 60
gcctttatta ttttctgggt gaggagtaag aggagcaggc tcctgcacag tgactacatg 120
aacatgactc cccgccgccc cgggcccacc cgcaagcatt accagcccta tgccccacca 180
cgcgacttcg cagcctatcg ctccagagtg aagttcagca ggagcgcaga cgcccccgcg 240
taccagcagg gccagaacca gctctataac gagctcaatc taggacgaag agaggagtac 300
gatgttttgg acaagagacg tggccgggac cctgagatgg ggggaaagcc gagaaggaag 360
aaccctcagg aaggcctgta caatgaactg cagaaagata agatggcgga ggcctacagt 420
gagattggga tgaaaggcga gcgccggagg ggcaaggggc acgatggcct ttaccagggt 480
ctcagtacag ccaccaagga cacctacgac gcccttcaca tgcaggccct gccccctcgc 540
<210> 49
<211> 419
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 49
Asp Pro Ala Glu Pro Lys Ser Pro Asp Lys Thr His Thr Cys Pro Pro
1 5 10 15
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
20 25 30
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
35 40 45
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
50 55 60
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
65 70 75 80
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
85 90 95
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
100 105 110
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
115 120 125
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
130 135 140
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
145 150 155 160
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
165 170 175
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
180 185 190
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
195 200 205
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
210 215 220
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys Lys Asp Pro Lys Phe
225 230 235 240
Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu
245 250 255
Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg
260 265 270
Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro
275 280 285
Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala
290 295 300
Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr
305 310 315 320
Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg
325 330 335
Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met
340 345 350
Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu
355 360 365
Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys
370 375 380
Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu
385 390 395 400
Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu
405 410 415
Pro Pro Arg
<210> 50
<211> 1257
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 50
gatcccgccg agcccaaatc tcctgacaaa actcacacat gcccaccgtg cccagcacct 60
gaactcctgg ggggaccgtc agtcttcctc ttccccccaa aacccaagga caccctcatg 120
atctcccgga cccctgaggt cacatgcgtg gtggtggacg tgagccacga agaccctgag 180
gtcaagttca actggtacgt ggacggcgtg gaggtgcata atgccaagac aaagccgcgg 240
gaggagcagt acaacagcac gtaccgtgtg gtcagcgtcc tcaccgtcct gcaccaggac 300
tggctgaatg gcaaggagta caagtgcaag gtctccaaca aagccctccc agcccccatc 360
gagaaaacca tctccaaagc caaagggcag ccccgagaac cacaggtgta caccctgccc 420
ccatcccggg atgagctgac caagaaccag gtcagcctga cctgcctggt caaaggcttc 480
tatcccagcg acatcgccgt ggagtgggag agcaatgggc aaccggagaa caactacaag 540
accacgcctc ccgtgctgga ctccgacggc tccttcttcc tctacagcaa gctcaccgtg 600
gacaagagca ggtggcagca ggggaacgtc ttctcatgct ccgtgatgca tgaggctctg 660
cacaaccact acacgcagaa gagcctctcc ctgtctccgg gtaaaaaaga tcccaaattt 720
tgggtgctgg tggtggttgg tggagtcctg gcttgctata gcttgctagt aacagtggcc 780
tttattattt tctgggtgag gagtaagagg agcaggctcc tgcacagtga ctacatgaac 840
atgactcccc gccgccccgg gcccacccgc aagcattacc agccctatgc cccaccacgc 900
gacttcgcag cctatcgctc cagagtgaag ttcagcagga gcgcagacgc ccccgcgtac 960
cagcagggcc agaaccagct ctataacgag ctcaatctag gacgaagaga ggagtacgat 1020
gttttggaca agagacgtgg ccgggaccct gagatggggg gaaagccgag aaggaagaac 1080
cctcaggaag gcctgtacaa tgaactgcag aaagataaga tggcggaggc ctacagtgag 1140
attgggatga aaggcgagcg ccggaggggc aaggggcacg atggccttta ccagggtctc 1200
agtacagcca ccaaggacac ctacgacgcc cttcacatgc aggccctgcc ccctcgc 1257
<210> 51
<211> 200
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 51
Asp Leu Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
1 5 10 15
Pro Asp Pro Lys Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala
20 25 30
Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg
35 40 45
Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro
50 55 60
Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro
65 70 75 80
Arg Asp Phe Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala
85 90 95
Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu
100 105 110
Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly
115 120 125
Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu
130 135 140
Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser
145 150 155 160
Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly
165 170 175
Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu
180 185 190
His Met Gln Ala Leu Pro Pro Arg
195 200
<210> 52
<211> 600
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 52
Gly Ala Thr Cys Thr Cys Gly Ala Gly Cys Cys Cys Ala Ala Ala Thr
1 5 10 15
Cys Thr Thr Gly Thr Gly Ala Cys Ala Ala Ala Ala Cys Thr Cys Ala
20 25 30
Cys Ala Cys Ala Thr Gly Cys Cys Cys Ala Cys Cys Gly Thr Gly Cys
35 40 45
Cys Cys Gly Gly Ala Thr Cys Cys Cys Ala Ala Ala Thr Thr Thr Thr
50 55 60
Gly Gly Gly Thr Gly Cys Thr Gly Gly Thr Gly Gly Thr Gly Gly Thr
65 70 75 80
Thr Gly Gly Thr Gly Gly Ala Gly Thr Cys Cys Thr Gly Gly Cys Thr
85 90 95
Thr Gly Cys Thr Ala Thr Ala Gly Cys Thr Thr Gly Cys Thr Ala Gly
100 105 110
Thr Ala Ala Cys Ala Gly Thr Gly Gly Cys Cys Thr Thr Thr Ala Thr
115 120 125
Thr Ala Thr Thr Thr Thr Cys Thr Gly Gly Gly Thr Gly Ala Gly Gly
130 135 140
Ala Gly Thr Ala Ala Gly Ala Gly Gly Ala Gly Cys Ala Gly Gly Cys
145 150 155 160
Thr Cys Cys Thr Gly Cys Ala Cys Ala Gly Thr Gly Ala Cys Thr Ala
165 170 175
Cys Ala Thr Gly Ala Ala Cys Ala Thr Gly Ala Cys Thr Cys Cys Cys
180 185 190
Cys Gly Cys Cys Gly Cys Cys Cys Cys Gly Gly Gly Cys Cys Cys Ala
195 200 205
Cys Cys Cys Gly Cys Ala Ala Gly Cys Ala Thr Thr Ala Cys Cys Ala
210 215 220
Gly Cys Cys Cys Thr Ala Thr Gly Cys Cys Cys Cys Ala Cys Cys Ala
225 230 235 240
Cys Gly Cys Gly Ala Cys Thr Thr Cys Gly Cys Ala Gly Cys Cys Thr
245 250 255
Ala Thr Cys Gly Cys Thr Cys Cys Ala Gly Ala Gly Thr Gly Ala Ala
260 265 270
Gly Thr Thr Cys Ala Gly Cys Ala Gly Gly Ala Gly Cys Gly Cys Ala
275 280 285
Gly Ala Cys Gly Cys Cys Cys Cys Cys Gly Cys Gly Thr Ala Cys Cys
290 295 300
Ala Gly Cys Ala Gly Gly Gly Cys Cys Ala Gly Ala Ala Cys Cys Ala
305 310 315 320
Gly Cys Thr Cys Thr Ala Thr Ala Ala Cys Gly Ala Gly Cys Thr Cys
325 330 335
Ala Ala Thr Cys Thr Ala Gly Gly Ala Cys Gly Ala Ala Gly Ala Gly
340 345 350
Ala Gly Gly Ala Gly Thr Ala Cys Gly Ala Thr Gly Thr Thr Thr Thr
355 360 365
Gly Gly Ala Cys Ala Ala Gly Ala Gly Ala Cys Gly Thr Gly Gly Cys
370 375 380
Cys Gly Gly Gly Ala Cys Cys Cys Thr Gly Ala Gly Ala Thr Gly Gly
385 390 395 400
Gly Gly Gly Gly Ala Ala Ala Gly Cys Cys Gly Ala Gly Ala Ala Gly
405 410 415
Gly Ala Ala Gly Ala Ala Cys Cys Cys Thr Cys Ala Gly Gly Ala Ala
420 425 430
Gly Gly Cys Cys Thr Gly Thr Ala Cys Ala Ala Thr Gly Ala Ala Cys
435 440 445
Thr Gly Cys Ala Gly Ala Ala Ala Gly Ala Thr Ala Ala Gly Ala Thr
450 455 460
Gly Gly Cys Gly Gly Ala Gly Gly Cys Cys Thr Ala Cys Ala Gly Thr
465 470 475 480
Gly Ala Gly Ala Thr Thr Gly Gly Gly Ala Thr Gly Ala Ala Ala Gly
485 490 495
Gly Cys Gly Ala Gly Cys Gly Cys Cys Gly Gly Ala Gly Gly Gly Gly
500 505 510
Cys Ala Ala Gly Gly Gly Gly Cys Ala Cys Gly Ala Thr Gly Gly Cys
515 520 525
Cys Thr Thr Thr Ala Cys Cys Ala Gly Gly Gly Thr Cys Thr Cys Ala
530 535 540
Gly Thr Ala Cys Ala Gly Cys Cys Ala Cys Cys Ala Ala Gly Gly Ala
545 550 555 560
Cys Ala Cys Cys Thr Ala Cys Gly Ala Cys Gly Cys Cys Cys Thr Thr
565 570 575
Cys Ala Cys Ala Thr Gly Cys Ala Gly Gly Cys Cys Cys Thr Gly Cys
580 585 590
Cys Cys Cys Cys Thr Cys Gly Cys
595 600
<210> 53
<211> 688
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 53
Met Asp Trp Ile Trp Arg Ile Leu Phe Leu Val Gly Ala Ala Thr Gly
1 5 10 15
Ala His Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg
20 25 30
Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Ser Asn Tyr Leu Met Asn Trp Val Lys Gln Arg Pro Glu Gln Asp Leu
50 55 60
Asp Trp Ile Gly Arg Ile Asp Pro Tyr Asp Gly Asp Ile Asp Tyr Asn
65 70 75 80
Gln Asn Phe Lys Asp Lys Ala Ile Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Gly Tyr Gly Thr Ala Tyr Gly Val Asp Tyr Trp
115 120 125
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Lys Thr Thr Pro Pro
130 135 140
Lys Leu Glu Glu Gly Glu Phe Ser Glu Ala Arg Val Asp Ile Val Leu
145 150 155 160
Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly Gln Arg Ala Thr
165 170 175
Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile Ser Phe
180 185 190
Met Asn Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Ala Ala Ser Arg Gln Gly Ser Gly Val Pro Ala Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Ser Leu Asn Ile His Pro Met Glu Glu
225 230 235 240
Asp Asp Thr Ala Met Tyr Phe Cys Gln Gln Ser Lys Glu Val Pro Trp
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Ala Glu Asp Pro Ala
260 265 270
Glu Pro Lys Ser Pro Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
275 280 285
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
290 295 300
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
305 310 315 320
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
325 330 335
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
340 345 350
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
355 360 365
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
370 375 380
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
385 390 395 400
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr
405 410 415
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
420 425 430
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
435 440 445
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
450 455 460
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
465 470 475 480
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
485 490 495
Ser Leu Ser Leu Ser Pro Gly Lys Lys Asp Pro Lys Phe Trp Val Leu
500 505 510
Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val
515 520 525
Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His
530 535 540
Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys
545 550 555 560
His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser
565 570 575
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly
580 585 590
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
595 600 605
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
610 615 620
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys
625 630 635 640
Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
645 650 655
Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala
660 665 670
Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
675 680 685
<210> 54
<211> 2064
<212> PRT
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 54
Ala Thr Gly Gly Ala Cys Thr Gly Gly Ala Thr Cys Thr Gly Gly Cys
1 5 10 15
Gly Cys Ala Thr Cys Cys Thr Gly Thr Thr Thr Cys Thr Cys Gly Thr
20 25 30
Gly Gly Gly Ala Gly Cys Cys Gly Cys Cys Ala Cys Ala Gly Gly Cys
35 40 45
Gly Cys Cys Cys Ala Thr Thr Cys Thr Cys Ala Gly Gly Thr Gly Cys
50 55 60
Ala Gly Cys Thr Gly Cys Ala Gly Cys Ala Gly Cys Cys Thr Gly Gly
65 70 75 80
Cys Gly Cys Thr Gly Ala Ala Cys Thr Cys Gly Thr Gly Cys Gly Gly
85 90 95
Cys Cys Ala Gly Gly Cys Gly Cys Thr Thr Cys Thr Gly Thr Gly Ala
100 105 110
Ala Gly Cys Thr Gly Ala Gly Cys Thr Gly Thr Ala Ala Ala Gly Cys
115 120 125
Cys Ala Gly Cys Gly Gly Cys Thr Ala Cys Ala Cys Cys Thr Thr Cys
130 135 140
Ala Gly Cys Ala Ala Cys Thr Ala Cys Cys Thr Gly Ala Thr Gly Ala
145 150 155 160
Ala Cys Thr Gly Gly Gly Thr Cys Ala Ala Gly Cys Ala Gly Cys Gly
165 170 175
Gly Cys Cys Cys Gly Ala Gly Cys Ala Gly Gly Ala Cys Cys Thr Gly
180 185 190
Gly Ala Thr Thr Gly Gly Ala Thr Cys Gly Gly Cys Ala Gly Ala Ala
195 200 205
Thr Cys Gly Ala Cys Cys Cys Cys Thr Ala Cys Gly Ala Cys Gly Gly
210 215 220
Cys Gly Ala Cys Ala Thr Cys Gly Ala Cys Thr Ala Cys Ala Ala Cys
225 230 235 240
Cys Ala Gly Ala Ala Cys Thr Thr Cys Ala Ala Gly Gly Ala Cys Ala
245 250 255
Ala Gly Gly Cys Cys Ala Thr Cys Cys Thr Gly Ala Cys Cys Gly Thr
260 265 270
Gly Gly Ala Cys Ala Ala Gly Ala Gly Cys Ala Gly Cys Ala Gly Cys
275 280 285
Ala Cys Cys Gly Cys Cys Thr Ala Cys Ala Thr Gly Cys Ala Gly Cys
290 295 300
Thr Gly Thr Cys Cys Ala Gly Cys Cys Thr Gly Ala Cys Cys Ala Gly
305 310 315 320
Cys Gly Ala Gly Gly Ala Cys Ala Gly Cys Gly Cys Cys Gly Thr Gly
325 330 335
Thr Ala Cys Thr Ala Cys Thr Gly Cys Gly Cys Cys Ala Gly Ala Gly
340 345 350
Gly Cys Thr Ala Cys Gly Gly Cys Ala Cys Ala Gly Cys Cys Thr Ala
355 360 365
Cys Gly Gly Cys Gly Thr Gly Gly Ala Cys Thr Ala Thr Thr Gly Gly
370 375 380
Gly Gly Cys Cys Ala Gly Gly Gly Cys Ala Cys Ala Ala Gly Cys Gly
385 390 395 400
Thr Gly Ala Cys Cys Gly Thr Gly Thr Cys Cys Ala Gly Cys Gly Cys
405 410 415
Cys Ala Ala Gly Ala Cys Cys Ala Cys Cys Cys Cys Cys Cys Cys Thr
420 425 430
Ala Ala Gly Cys Thr Gly Gly Ala Ala Gly Ala Gly Gly Gly Cys Gly
435 440 445
Ala Gly Thr Thr Cys Thr Cys Cys Gly Ala Gly Gly Cys Cys Cys Gly
450 455 460
Gly Gly Thr Gly Gly Ala Cys Ala Thr Thr Gly Thr Gly Cys Thr Gly
465 470 475 480
Ala Cys Ala Cys Ala Gly Thr Cys Thr Cys Cys Ala Gly Cys Cys Ala
485 490 495
Gly Cys Cys Thr Gly Gly Cys Cys Gly Thr Gly Thr Cys Cys Cys Thr
500 505 510
Gly Gly Gly Ala Cys Ala Gly Ala Gly Ala Gly Cys Cys Ala Cys Cys
515 520 525
Ala Thr Cys Ala Gly Cys Thr Gly Thr Ala Gly Gly Gly Cys Cys Ala
530 535 540
Gly Cys Gly Ala Gly Ala Gly Cys Gly Thr Gly Gly Ala Cys Ala Ala
545 550 555 560
Cys Thr Ala Cys Gly Gly Cys Ala Thr Cys Ala Gly Cys Thr Thr Cys
565 570 575
Ala Thr Gly Ala Ala Thr Thr Gly Gly Thr Thr Cys Cys Ala Gly Cys
580 585 590
Ala Gly Ala Ala Gly Cys Cys Cys Gly Gly Cys Cys Ala Gly Cys Cys
595 600 605
Cys Cys Cys Cys Ala Ala Gly Cys Thr Gly Cys Thr Gly Ala Thr Cys
610 615 620
Thr Ala Thr Gly Cys Cys Gly Cys Cys Ala Gly Cys Ala Gly Ala Cys
625 630 635 640
Ala Gly Gly Gly Cys Ala Gly Cys Gly Gly Ala Gly Thr Gly Cys Cys
645 650 655
Thr Gly Cys Cys Ala Gly Ala Thr Thr Thr Thr Cys Thr Gly Gly Cys
660 665 670
Ala Gly Cys Gly Gly Cys Thr Cys Cys Gly Gly Cys Ala Cys Cys Gly
675 680 685
Ala Cys Thr Thr Cys Ala Gly Cys Cys Thr Gly Ala Ala Cys Ala Thr
690 695 700
Cys Cys Ala Cys Cys Cys Thr Ala Thr Gly Gly Ala Ala Gly Ala Gly
705 710 715 720
Gly Ala Cys Gly Ala Cys Ala Cys Cys Gly Cys Cys Ala Thr Gly Thr
725 730 735
Ala Cys Thr Thr Thr Thr Gly Cys Cys Ala Gly Cys Ala Gly Ala Gly
740 745 750
Cys Ala Ala Ala Gly Ala Gly Gly Thr Gly Cys Cys Cys Thr Gly Gly
755 760 765
Ala Cys Cys Thr Thr Thr Gly Gly Cys Gly Gly Ala Gly Gly Cys Ala
770 775 780
Cys Cys Ala Ala Gly Cys Thr Gly Gly Ala Ala Ala Thr Cys Ala Ala
785 790 795 800
Gly Gly Cys Cys Gly Ala Gly Gly Ala Thr Cys Cys Cys Gly Cys Cys
805 810 815
Gly Ala Gly Cys Cys Cys Ala Ala Ala Thr Cys Thr Cys Cys Thr Gly
820 825 830
Ala Cys Ala Ala Ala Ala Cys Thr Cys Ala Cys Ala Cys Ala Thr Gly
835 840 845
Cys Cys Cys Ala Cys Cys Gly Thr Gly Cys Cys Cys Ala Gly Cys Ala
850 855 860
Cys Cys Thr Gly Ala Ala Cys Thr Cys Cys Thr Gly Gly Gly Gly Gly
865 870 875 880
Gly Ala Cys Cys Gly Thr Cys Ala Gly Thr Cys Thr Thr Cys Cys Thr
885 890 895
Cys Thr Thr Cys Cys Cys Cys Cys Cys Ala Ala Ala Ala Cys Cys Cys
900 905 910
Ala Ala Gly Gly Ala Cys Ala Cys Cys Cys Thr Cys Ala Thr Gly Ala
915 920 925
Thr Cys Thr Cys Cys Cys Gly Gly Ala Cys Cys Cys Cys Thr Gly Ala
930 935 940
Gly Gly Thr Cys Ala Cys Ala Thr Gly Cys Gly Thr Gly Gly Thr Gly
945 950 955 960
Gly Thr Gly Gly Ala Cys Gly Thr Gly Ala Gly Cys Cys Ala Cys Gly
965 970 975
Ala Ala Gly Ala Cys Cys Cys Thr Gly Ala Gly Gly Thr Cys Ala Ala
980 985 990
Gly Thr Thr Cys Ala Ala Cys Thr Gly Gly Thr Ala Cys Gly Thr Gly
995 1000 1005
Gly Ala Cys Gly Gly Cys Gly Thr Gly Gly Ala Gly Gly Thr Gly
1010 1015 1020
Cys Ala Thr Ala Ala Thr Gly Cys Cys Ala Ala Gly Ala Cys Ala
1025 1030 1035
Ala Ala Gly Cys Cys Gly Cys Gly Gly Gly Ala Gly Gly Ala Gly
1040 1045 1050
Cys Ala Gly Thr Ala Cys Ala Ala Cys Ala Gly Cys Ala Cys Gly
1055 1060 1065
Thr Ala Cys Cys Gly Thr Gly Thr Gly Gly Thr Cys Ala Gly Cys
1070 1075 1080
Gly Thr Cys Cys Thr Cys Ala Cys Cys Gly Thr Cys Cys Thr Gly
1085 1090 1095
Cys Ala Cys Cys Ala Gly Gly Ala Cys Thr Gly Gly Cys Thr Gly
1100 1105 1110
Ala Ala Thr Gly Gly Cys Ala Ala Gly Gly Ala Gly Thr Ala Cys
1115 1120 1125
Ala Ala Gly Thr Gly Cys Ala Ala Gly Gly Thr Cys Thr Cys Cys
1130 1135 1140
Ala Ala Cys Ala Ala Ala Gly Cys Cys Cys Thr Cys Cys Cys Ala
1145 1150 1155
Gly Cys Cys Cys Cys Cys Ala Thr Cys Gly Ala Gly Ala Ala Ala
1160 1165 1170
Ala Cys Cys Ala Thr Cys Thr Cys Cys Ala Ala Ala Gly Cys Cys
1175 1180 1185
Ala Ala Ala Gly Gly Gly Cys Ala Gly Cys Cys Cys Cys Gly Ala
1190 1195 1200
Gly Ala Ala Cys Cys Ala Cys Ala Gly Gly Thr Gly Thr Ala Cys
1205 1210 1215
Ala Cys Cys Cys Thr Gly Cys Cys Cys Cys Cys Ala Thr Cys Cys
1220 1225 1230
Cys Gly Gly Gly Ala Thr Gly Ala Gly Cys Thr Gly Ala Cys Cys
1235 1240 1245
Ala Ala Gly Ala Ala Cys Cys Ala Gly Gly Thr Cys Ala Gly Cys
1250 1255 1260
Cys Thr Gly Ala Cys Cys Thr Gly Cys Cys Thr Gly Gly Thr Cys
1265 1270 1275
Ala Ala Ala Gly Gly Cys Thr Thr Cys Thr Ala Thr Cys Cys Cys
1280 1285 1290
Ala Gly Cys Gly Ala Cys Ala Thr Cys Gly Cys Cys Gly Thr Gly
1295 1300 1305
Gly Ala Gly Thr Gly Gly Gly Ala Gly Ala Gly Cys Ala Ala Thr
1310 1315 1320
Gly Gly Gly Cys Ala Ala Cys Cys Gly Gly Ala Gly Ala Ala Cys
1325 1330 1335
Ala Ala Cys Thr Ala Cys Ala Ala Gly Ala Cys Cys Ala Cys Gly
1340 1345 1350
Cys Cys Thr Cys Cys Cys Gly Thr Gly Cys Thr Gly Gly Ala Cys
1355 1360 1365
Thr Cys Cys Gly Ala Cys Gly Gly Cys Thr Cys Cys Thr Thr Cys
1370 1375 1380
Thr Thr Cys Cys Thr Cys Thr Ala Cys Ala Gly Cys Ala Ala Gly
1385 1390 1395
Cys Thr Cys Ala Cys Cys Gly Thr Gly Gly Ala Cys Ala Ala Gly
1400 1405 1410
Ala Gly Cys Ala Gly Gly Thr Gly Gly Cys Ala Gly Cys Ala Gly
1415 1420 1425
Gly Gly Gly Ala Ala Cys Gly Thr Cys Thr Thr Cys Thr Cys Ala
1430 1435 1440
Thr Gly Cys Thr Cys Cys Gly Thr Gly Ala Thr Gly Cys Ala Thr
1445 1450 1455
Gly Ala Gly Gly Cys Thr Cys Thr Gly Cys Ala Cys Ala Ala Cys
1460 1465 1470
Cys Ala Cys Thr Ala Cys Ala Cys Gly Cys Ala Gly Ala Ala Gly
1475 1480 1485
Ala Gly Cys Cys Thr Cys Thr Cys Cys Cys Thr Gly Thr Cys Thr
1490 1495 1500
Cys Cys Gly Gly Gly Thr Ala Ala Ala Ala Ala Ala Gly Ala Thr
1505 1510 1515
Cys Cys Cys Ala Ala Ala Thr Thr Thr Thr Gly Gly Gly Thr Gly
1520 1525 1530
Cys Thr Gly Gly Thr Gly Gly Thr Gly Gly Thr Thr Gly Gly Thr
1535 1540 1545
Gly Gly Ala Gly Thr Cys Cys Thr Gly Gly Cys Thr Thr Gly Cys
1550 1555 1560
Thr Ala Thr Ala Gly Cys Thr Thr Gly Cys Thr Ala Gly Thr Ala
1565 1570 1575
Ala Cys Ala Gly Thr Gly Gly Cys Cys Thr Thr Thr Ala Thr Thr
1580 1585 1590
Ala Thr Thr Thr Thr Cys Thr Gly Gly Gly Thr Gly Ala Gly Gly
1595 1600 1605
Ala Gly Thr Ala Ala Gly Ala Gly Gly Ala Gly Cys Ala Gly Gly
1610 1615 1620
Cys Thr Cys Cys Thr Gly Cys Ala Cys Ala Gly Thr Gly Ala Cys
1625 1630 1635
Thr Ala Cys Ala Thr Gly Ala Ala Cys Ala Thr Gly Ala Cys Thr
1640 1645 1650
Cys Cys Cys Cys Gly Cys Cys Gly Cys Cys Cys Cys Gly Gly Gly
1655 1660 1665
Cys Cys Cys Ala Cys Cys Cys Gly Cys Ala Ala Gly Cys Ala Thr
1670 1675 1680
Thr Ala Cys Cys Ala Gly Cys Cys Cys Thr Ala Thr Gly Cys Cys
1685 1690 1695
Cys Cys Ala Cys Cys Ala Cys Gly Cys Gly Ala Cys Thr Thr Cys
1700 1705 1710
Gly Cys Ala Gly Cys Cys Thr Ala Thr Cys Gly Cys Thr Cys Cys
1715 1720 1725
Ala Gly Ala Gly Thr Gly Ala Ala Gly Thr Thr Cys Ala Gly Cys
1730 1735 1740
Ala Gly Gly Ala Gly Cys Gly Cys Ala Gly Ala Cys Gly Cys Cys
1745 1750 1755
Cys Cys Cys Gly Cys Gly Thr Ala Cys Cys Ala Gly Cys Ala Gly
1760 1765 1770
Gly Gly Cys Cys Ala Gly Ala Ala Cys Cys Ala Gly Cys Thr Cys
1775 1780 1785
Thr Ala Thr Ala Ala Cys Gly Ala Gly Cys Thr Cys Ala Ala Thr
1790 1795 1800
Cys Thr Ala Gly Gly Ala Cys Gly Ala Ala Gly Ala Gly Ala Gly
1805 1810 1815
Gly Ala Gly Thr Ala Cys Gly Ala Thr Gly Thr Thr Thr Thr Gly
1820 1825 1830
Gly Ala Cys Ala Ala Gly Ala Gly Ala Cys Gly Thr Gly Gly Cys
1835 1840 1845
Cys Gly Gly Gly Ala Cys Cys Cys Thr Gly Ala Gly Ala Thr Gly
1850 1855 1860
Gly Gly Gly Gly Gly Ala Ala Ala Gly Cys Cys Gly Ala Gly Ala
1865 1870 1875
Ala Gly Gly Ala Ala Gly Ala Ala Cys Cys Cys Thr Cys Ala Gly
1880 1885 1890
Gly Ala Ala Gly Gly Cys Cys Thr Gly Thr Ala Cys Ala Ala Thr
1895 1900 1905
Gly Ala Ala Cys Thr Gly Cys Ala Gly Ala Ala Ala Gly Ala Thr
1910 1915 1920
Ala Ala Gly Ala Thr Gly Gly Cys Gly Gly Ala Gly Gly Cys Cys
1925 1930 1935
Thr Ala Cys Ala Gly Thr Gly Ala Gly Ala Thr Thr Gly Gly Gly
1940 1945 1950
Ala Thr Gly Ala Ala Ala Gly Gly Cys Gly Ala Gly Cys Gly Cys
1955 1960 1965
Cys Gly Gly Ala Gly Gly Gly Gly Cys Ala Ala Gly Gly Gly Gly
1970 1975 1980
Cys Ala Cys Gly Ala Thr Gly Gly Cys Cys Thr Thr Thr Ala Cys
1985 1990 1995
Cys Ala Gly Gly Gly Thr Cys Thr Cys Ala Gly Thr Ala Cys Ala
2000 2005 2010
Gly Cys Cys Ala Cys Cys Ala Ala Gly Gly Ala Cys Ala Cys Cys
2015 2020 2025
Thr Ala Cys Gly Ala Cys Gly Cys Cys Cys Thr Thr Cys Ala Cys
2030 2035 2040
Ala Thr Gly Cys Ala Gly Gly Cys Cys Cys Thr Gly Cys Cys Cys
2045 2050 2055
Cys Cys Thr Cys Gly Cys
2060
<210> 55
<211> 467
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 55
Met Asp Trp Ile Trp Arg Ile Leu Phe Leu Val Gly Ala Ala Thr Gly
1 5 10 15
Ala His Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg
20 25 30
Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Ser Asn Tyr Leu Met Asn Trp Val Lys Gln Arg Pro Glu Gln Asp Leu
50 55 60
Asp Trp Ile Gly Arg Ile Asp Pro Tyr Asp Gly Asp Ile Asp Tyr Asn
65 70 75 80
Gln Asn Phe Lys Asp Lys Ala Ile Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Gly Tyr Gly Thr Ala Tyr Gly Val Asp Tyr Trp
115 120 125
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Lys Thr Thr Pro Pro
130 135 140
Lys Leu Glu Glu Gly Glu Phe Ser Glu Ala Arg Val Asp Ile Val Leu
145 150 155 160
Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly Gln Arg Ala Thr
165 170 175
Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile Ser Phe
180 185 190
Met Asn Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Ala Ala Ser Arg Gln Gly Ser Gly Val Pro Ala Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Ser Leu Asn Ile His Pro Met Glu Glu
225 230 235 240
Asp Asp Thr Ala Met Tyr Phe Cys Gln Gln Ser Lys Glu Val Pro Trp
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Asp Leu Glu Pro Lys
260 265 270
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Asp Pro Lys Phe
275 280 285
Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu
290 295 300
Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg
305 310 315 320
Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro
325 330 335
Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala
340 345 350
Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr
355 360 365
Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg
370 375 380
Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met
385 390 395 400
Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu
405 410 415
Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys
420 425 430
Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu
435 440 445
Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu
450 455 460
Pro Pro Arg
465
<210> 56
<211> 1401
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 56
atggactgga tctggcgcat cctgtttctc gtgggagccg ccacaggcgc ccattctcag 60
gtgcagctgc agcagcctgg cgctgaactc gtgcggccag gcgcttctgt gaagctgagc 120
tgtaaagcca gcggctacac cttcagcaac tacctgatga actgggtcaa gcagcggccc 180
gagcaggacc tggattggat cggcagaatc gacccctacg acggcgacat cgactacaac 240
cagaacttca aggacaaggc catcctgacc gtggacaaga gcagcagcac cgcctacatg 300
cagctgtcca gcctgaccag cgaggacagc gccgtgtact actgcgccag aggctacggc 360
acagcctacg gcgtggacta ttggggccag ggcacaagcg tgaccgtgtc cagcgccaag 420
accacccccc ctaagctgga agagggcgag ttctccgagg cccgggtgga cattgtgctg 480
acacagtctc cagccagcct ggccgtgtcc ctgggacaga gagccaccat cagctgtagg 540
gccagcgaga gcgtggacaa ctacggcatc agcttcatga attggttcca gcagaagccc 600
ggccagcccc ccaagctgct gatctatgcc gccagcagac agggcagcgg agtgcctgcc 660
agattttctg gcagcggctc cggcaccgac ttcagcctga acatccaccc tatggaagag 720
gacgacaccg ccatgtactt ttgccagcag agcaaagagg tgccctggac ctttggcgga 780
ggcaccaagc tggaaatcaa ggatctcgag cccaaatctt gtgacaaaac tcacacatgc 840
ccaccgtgcc cggatcccaa attttgggtg ctggtggtgg ttggtggagt cctggcttgc 900
tatagcttgc tagtaacagt ggcctttatt attttctggg tgaggagtaa gaggagcagg 960
ctcctgcaca gtgactacat gaacatgact ccccgccgcc ccgggcccac ccgcaagcat 1020
taccagccct atgccccacc acgcgacttc gcagcctatc gctccagagt gaagttcagc 1080
aggagcgcag acgcccccgc gtaccagcag ggccagaacc agctctataa cgagctcaat 1140
ctaggacgaa gagaggagta cgatgttttg gacaagagac gtggccggga ccctgagatg 1200
gggggaaagc cgagaaggaa gaaccctcag gaaggcctgt acaatgaact gcagaaagat 1260
aagatggcgg aggcctacag tgagattggg atgaaaggcg agcgccggag gggcaagggg 1320
cacgatggcc tttaccaggg tctcagtaca gccaccaagg acacctacga cgcccttcac 1380
atgcaggccc tgccccctcg c 1401
<210> 57
<211> 257
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 57
Asp Pro Ala Glu Pro Lys Ser Pro Asp Lys Thr His Thr Cys Pro Pro
1 5 10 15
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
20 25 30
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
35 40 45
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
50 55 60
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
65 70 75 80
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
85 90 95
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
100 105 110
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
115 120 125
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
130 135 140
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
145 150 155 160
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
165 170 175
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
180 185 190
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
195 200 205
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
210 215 220
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys Lys Asp Pro Lys Phe
225 230 235 240
Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu
245 250 255
His
<210> 58
<211> 822
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 58
gatcccgccg agcccaaatc tcctgacaaa actcacacat gcccaccgtg cccagcacct 60
gaactcctgg ggggaccgtc agtcttcctc ttccccccaa aacccaagga caccctcatg 120
atctcccgga cccctgaggt cacatgcgtg gtggtggacg tgagccacga agaccctgag 180
gtcaagttca actggtacgt ggacggcgtg gaggtgcata atgccaagac aaagccgcgg 240
gaggagcagt acaacagcac gtaccgtgtg gtcagcgtcc tcaccgtcct gcaccaggac 300
tggctgaatg gcaaggagta caagtgcaag gtctccaaca aagccctccc agcccccatc 360
gagaaaacca tctccaaagc caaagggcag ccccgagaac cacaggtgta caccctgccc 420
ccatcccggg atgagctgac caagaaccag gtcagcctga cctgcctggt caaaggcttc 480
tatcccagcg acatcgccgt ggagtgggag agcaatgggc aaccggagaa caactacaag 540
accacgcctc ccgtgctgga ctccgacggc tccttcttcc tctacagcaa gctcaccgtg 600
gacaagagca ggtggcagca ggggaacgtc ttctcatgct ccgtgatgca tgaggctctg 660
cacaaccact acacgcagaa gagcctctcc ctgtctccgg gtaaaaaaga tcccaaattt 720
tgggtgctgg tggtggttgg tggagtcctg gcttgctata gcttgctagt aacagtggcc 780
tttattattt tctgggtgag gagtaagagg agcaggctcc tg 822
<210> 59
<211> 44
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 59
Asp Leu Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
1 5 10 15
Pro Asp Pro Lys Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala
20 25 30
Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile
35 40
<210> 60
<211> 165
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 60
gatctcgagc ccaaatcttg tgacaaaact cacacatgcc caccgtgccc ggatcccaaa 60
ttttgggtgc tggtggtggt tggtggagtc ctggcttgct atagcttgct agtaacagtg 120
gcctttatta ttttctgggt gaggagtaag aggagcaggc tcctg 165
<210> 61
<211> 526
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 61
Met Asp Trp Ile Trp Arg Ile Leu Phe Leu Val Gly Ala Ala Thr Gly
1 5 10 15
Ala His Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg
20 25 30
Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Ser Asn Tyr Leu Met Asn Trp Val Lys Gln Arg Pro Glu Gln Asp Leu
50 55 60
Asp Trp Ile Gly Arg Ile Asp Pro Tyr Asp Gly Asp Ile Asp Tyr Asn
65 70 75 80
Gln Asn Phe Lys Asp Lys Ala Ile Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Gly Tyr Gly Thr Ala Tyr Gly Val Asp Tyr Trp
115 120 125
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Lys Thr Thr Pro Pro
130 135 140
Lys Leu Glu Glu Gly Glu Phe Ser Glu Ala Arg Val Asp Ile Val Leu
145 150 155 160
Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly Gln Arg Ala Thr
165 170 175
Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile Ser Phe
180 185 190
Met Asn Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Ala Ala Ser Arg Gln Gly Ser Gly Val Pro Ala Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Ser Leu Asn Ile His Pro Met Glu Glu
225 230 235 240
Asp Asp Thr Ala Met Tyr Phe Cys Gln Gln Ser Lys Glu Val Pro Trp
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Ala Glu Asp Pro Ala
260 265 270
Glu Pro Lys Ser Pro Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
275 280 285
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
290 295 300
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
305 310 315 320
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
325 330 335
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
340 345 350
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
355 360 365
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
370 375 380
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
385 390 395 400
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr
405 410 415
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
420 425 430
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
435 440 445
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
450 455 460
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
465 470 475 480
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
485 490 495
Ser Leu Ser Leu Ser Pro Gly Lys Lys Asp Pro Lys Phe Trp Val Leu
500 505 510
Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu His
515 520 525
<210> 62
<211> 1632
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 62
atggactgga tctggcgcat cctgtttctc gtgggagccg ccacaggcgc ccattctcag 60
gtgcagctgc agcagcctgg cgctgaactc gtgcggccag gcgcttctgt gaagctgagc 120
tgtaaagcca gcggctacac cttcagcaac tacctgatga actgggtcaa gcagcggccc 180
gagcaggacc tggattggat cggcagaatc gacccctacg acggcgacat cgactacaac 240
cagaacttca aggacaaggc catcctgacc gtggacaaga gcagcagcac cgcctacatg 300
cagctgtcca gcctgaccag cgaggacagc gccgtgtact actgcgccag aggctacggc 360
acagcctacg gcgtggacta ttggggccag ggcacaagcg tgaccgtgtc cagcgccaag 420
accacccccc ctaagctgga agagggcgag ttctccgagg cccgggtgga cattgtgctg 480
acacagtctc cagccagcct ggccgtgtcc ctgggacaga gagccaccat cagctgtagg 540
gccagcgaga gcgtggacaa ctacggcatc agcttcatga attggttcca gcagaagccc 600
ggccagcccc ccaagctgct gatctatgcc gccagcagac agggcagcgg agtgcctgcc 660
agattttctg gcagcggctc cggcaccgac ttcagcctga acatccaccc tatggaagag 720
gacgacaccg ccatgtactt ttgccagcag agcaaagagg tgccctggac ctttggcgga 780
ggcaccaagc tggaaatcaa ggccgaggat cccgccgagc ccaaatctcc tgacaaaact 840
cacacatgcc caccgtgccc agcacctgaa ctcctggggg gaccgtcagt cttcctcttc 900
cccccaaaac ccaaggacac cctcatgatc tcccggaccc ctgaggtcac atgcgtggtg 960
gtggacgtga gccacgaaga ccctgaggtc aagttcaact ggtacgtgga cggcgtggag 1020
gtgcataatg ccaagacaaa gccgcgggag gagcagtaca acagcacgta ccgtgtggtc 1080
agcgtcctca ccgtcctgca ccaggactgg ctgaatggca aggagtacaa gtgcaaggtc 1140
tccaacaaag ccctcccagc ccccatcgag aaaaccatct ccaaagccaa agggcagccc 1200
cgagaaccac aggtgtacac cctgccccca tcccgggatg agctgaccaa gaaccaggtc 1260
agcctgacct gcctggtcaa aggcttctat cccagcgaca tcgccgtgga gtgggagagc 1320
aatgggcaac cggagaacaa ctacaagacc acgcctcccg tgctggactc cgacggctcc 1380
ttcttcctct acagcaagct caccgtggac aagagcaggt ggcagcaggg gaacgtcttc 1440
tcatgctccg tgatgcatga ggctctgcac aaccactaca cgcagaagag cctctccctg 1500
tctccgggta aaaaagatcc caaattttgg gtgctggtgg tggttggtgg agtcctggct 1560
tgctatagct tgctagtaac agtggccttt attattttct gggtgaggag taagaggagc 1620
aggctcctga ct 1632
<210> 63
<211> 312
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 63
Met Asp Trp Ile Trp Arg Ile Leu Phe Leu Val Gly Ala Ala Thr Gly
1 5 10 15
Ala His Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg
20 25 30
Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Ser Asn Tyr Leu Met Asn Trp Val Lys Gln Arg Pro Glu Gln Asp Leu
50 55 60
Asp Trp Ile Gly Arg Ile Asp Pro Tyr Asp Gly Asp Ile Asp Tyr Asn
65 70 75 80
Gln Asn Phe Lys Asp Lys Ala Ile Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Gly Tyr Gly Thr Ala Tyr Gly Val Asp Tyr Trp
115 120 125
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Lys Thr Thr Pro Pro
130 135 140
Lys Leu Glu Glu Gly Glu Phe Ser Glu Ala Arg Val Asp Ile Val Leu
145 150 155 160
Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly Gln Arg Ala Thr
165 170 175
Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile Ser Phe
180 185 190
Met Asn Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Ala Ala Ser Arg Gln Gly Ser Gly Val Pro Ala Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Ser Leu Asn Ile His Pro Met Glu Glu
225 230 235 240
Asp Asp Thr Ala Met Tyr Phe Cys Gln Gln Ser Lys Glu Val Pro Trp
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Asp Leu Glu Pro Lys
260 265 270
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Asp Pro Lys Phe
275 280 285
Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu
290 295 300
Val Thr Val Ala Phe Ile Ile His
305 310
<210> 64
<211> 969
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 64
atggactgga tctggcgcat cctgtttctc gtgggagccg ccacaggcgc ccattctcag 60
gtgcagctgc agcagcctgg cgctgaactc gtgcggccag gcgcttctgt gaagctgagc 120
tgtaaagcca gcggctacac cttcagcaac tacctgatga actgggtcaa gcagcggccc 180
gagcaggacc tggattggat cggcagaatc gacccctacg acggcgacat cgactacaac 240
cagaacttca aggacaaggc catcctgacc gtggacaaga gcagcagcac cgcctacatg 300
cagctgtcca gcctgaccag cgaggacagc gccgtgtact actgcgccag aggctacggc 360
acagcctacg gcgtggacta ttggggccag ggcacaagcg tgaccgtgtc cagcgccaag 420
accacccccc ctaagctgga agagggcgag ttctccgagg cccgggtgga cattgtgctg 480
acacagtctc cagccagcct ggccgtgtcc ctgggacaga gagccaccat cagctgtagg 540
gccagcgaga gcgtggacaa ctacggcatc agcttcatga attggttcca gcagaagccc 600
ggccagcccc ccaagctgct gatctatgcc gccagcagac agggcagcgg agtgcctgcc 660
agattttctg gcagcggctc cggcaccgac ttcagcctga acatccaccc tatggaagag 720
gacgacaccg ccatgtactt ttgccagcag agcaaagagg tgccctggac ctttggcgga 780
ggcaccaagc tggaaatcaa ggatctcgag cccaaatctt gtgacaaaac tcacacatgc 840
ccaccgtgcc cggatcccaa attttgggtg ctggtggtgg ttggtggagt cctggcttgc 900
tatagcttgc tagtaacagt ggcctttatt attttctggg tgaggagtaa gaggagcagg 960
ctcctgact 969
<210> 65
<211> 747
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 65
tctcaggtgc agctgcagca gcctggcgct gaactcgtgc ggccaggcgc ttctgtgaag 60
ctgagctgta aagccagcgg ctacaccttc agcaactacc tgatgaactg ggtcaagcag 120
cggcccgagc aggacctgga ttggatcggc agaatcgacc cctacgacgg cgacatcgac 180
tacaaccaga acttcaagga caaggccatc ctgaccgtgg acaagagcag cagcaccgcc 240
tacatgcagc tgtccagcct gaccagcgag gacagcgccg tgtactactg cgccagaggc 300
tacggcacag cctacggcgt ggactattgg ggccagggca caagcgtgac cgtgtccagc 360
gccaagacca ccccccctaa gctggaagag ggcgagttct ccgaggcccg ggtggacatt 420
gtgctgacac agtctccagc cagcctggcc gtgtccctgg gacagagagc caccatcagc 480
tgtagggcca gcgagagcgt ggacaactac ggcatcagct tcatgaattg gttccagcag 540
aagcccggcc agccccccaa gctgctgatc tatgccgcca gcagacaggg cagcggagtg 600
cctgccagat tttctggcag cggctccggc accgacttca gcctgaacat ccaccctatg 660
gaagaggacg acaccgccat gtacttttgc cagcagagca aagaggtgcc ctggaccttt 720
ggcggaggca ccaagctgga aatcaag 747
<210> 66
<211> 690
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 66
caggtccaac tgcagcagcc tggggctgag ctggtgaggc ctggggcttc agtgaagctg 60
tcctgcaagg cttctggcta cacgttctcc aactacttga tgaactgggt taagcagagg 120
cctgagcaag accttgactg gattggaagg attgatcctt acgatggtga cattgactac 180
aatcaaaact tcaaggacaa ggccatattg actgtagaca aatcctccag cacagcctac 240
atgcaactca gcagcctgac atctgaggac tctgcggtct attactgtgc aagaggttat 300
ggcacggcct atggtgtgga ctactggggt caaggaacct cagtcaccgt ctcctcagat 360
attgtgctaa ctcagtctcc agcttctttg gctgtgtctc taggacagag ggccaccatc 420
tcctgcagag ccagcgaaag tgttgataat tatggcatta gttttatgaa ctggttccaa 480
cagaaaccag gacagccacc caaactcctc atctatgctg catccaggca aggatccggg 540
gtccctgcca ggtttagtgg cagtgggtct gggacagact tcagcctcaa catccatcct 600
atggaggagg atgatactgc aatgtatttc tgtcagcaaa gtaaggaggt tccgtggacg 660
ttcggtggag gcaccaagct ggaaatcaaa 690
<210> 67
<211> 1488
<212> PRT
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 67
Cys Ala Gly Gly Thr Gly Cys Ala Gly Cys Thr Gly Cys Ala Gly Cys
1 5 10 15
Ala Gly Cys Cys Thr Gly Gly Cys Gly Cys Thr Gly Ala Ala Cys Thr
20 25 30
Cys Gly Thr Gly Cys Gly Gly Cys Cys Ala Gly Gly Cys Gly Cys Thr
35 40 45
Thr Cys Thr Gly Thr Gly Ala Ala Gly Cys Thr Gly Ala Gly Cys Thr
50 55 60
Gly Thr Ala Ala Ala Gly Cys Cys Ala Gly Cys Gly Gly Cys Thr Ala
65 70 75 80
Cys Ala Cys Cys Thr Thr Cys Ala Gly Cys Ala Ala Cys Thr Ala Cys
85 90 95
Cys Thr Gly Ala Thr Gly Ala Ala Cys Thr Gly Gly Gly Thr Cys Ala
100 105 110
Ala Gly Cys Ala Gly Cys Gly Gly Cys Cys Cys Gly Ala Gly Cys Ala
115 120 125
Gly Gly Ala Cys Cys Thr Gly Gly Ala Thr Thr Gly Gly Ala Thr Cys
130 135 140
Gly Gly Cys Ala Gly Ala Ala Thr Cys Gly Ala Cys Cys Cys Cys Thr
145 150 155 160
Ala Cys Gly Ala Cys Gly Gly Cys Gly Ala Cys Ala Thr Cys Gly Ala
165 170 175
Cys Thr Ala Cys Ala Ala Cys Cys Ala Gly Ala Ala Cys Thr Thr Cys
180 185 190
Ala Ala Gly Gly Ala Cys Ala Ala Gly Gly Cys Cys Ala Thr Cys Cys
195 200 205
Thr Gly Ala Cys Cys Gly Thr Gly Gly Ala Cys Ala Ala Gly Ala Gly
210 215 220
Cys Ala Gly Cys Ala Gly Cys Ala Cys Cys Gly Cys Cys Thr Ala Cys
225 230 235 240
Ala Thr Gly Cys Ala Gly Cys Thr Gly Thr Cys Cys Ala Gly Cys Cys
245 250 255
Thr Gly Ala Cys Cys Ala Gly Cys Gly Ala Gly Gly Ala Cys Ala Gly
260 265 270
Cys Gly Cys Cys Gly Thr Gly Thr Ala Cys Thr Ala Cys Thr Gly Cys
275 280 285
Gly Cys Cys Ala Gly Ala Gly Gly Cys Thr Ala Cys Gly Gly Cys Ala
290 295 300
Cys Ala Gly Cys Cys Thr Ala Cys Gly Gly Cys Gly Thr Gly Gly Ala
305 310 315 320
Cys Thr Ala Thr Thr Gly Gly Gly Gly Cys Cys Ala Gly Gly Gly Cys
325 330 335
Ala Cys Ala Ala Gly Cys Gly Thr Gly Ala Cys Cys Gly Thr Gly Thr
340 345 350
Cys Cys Ala Gly Cys Gly Cys Cys Ala Ala Gly Ala Cys Cys Ala Cys
355 360 365
Cys Cys Cys Cys Cys Cys Thr Ala Ala Gly Cys Thr Gly Gly Ala Ala
370 375 380
Gly Ala Gly Gly Gly Cys Gly Ala Gly Thr Thr Cys Thr Cys Cys Gly
385 390 395 400
Ala Gly Gly Cys Cys Cys Gly Gly Gly Thr Gly Gly Ala Cys Ala Thr
405 410 415
Thr Gly Thr Gly Cys Thr Gly Ala Cys Ala Cys Ala Gly Thr Cys Thr
420 425 430
Cys Cys Ala Gly Cys Cys Ala Gly Cys Cys Thr Gly Gly Cys Cys Gly
435 440 445
Thr Gly Thr Cys Cys Cys Thr Gly Gly Gly Ala Cys Ala Gly Ala Gly
450 455 460
Ala Gly Cys Cys Ala Cys Cys Ala Thr Cys Ala Gly Cys Thr Gly Thr
465 470 475 480
Ala Gly Gly Gly Cys Cys Ala Gly Cys Gly Ala Gly Ala Gly Cys Gly
485 490 495
Thr Gly Gly Ala Cys Ala Ala Cys Thr Ala Cys Gly Gly Cys Ala Thr
500 505 510
Cys Ala Gly Cys Thr Thr Cys Ala Thr Gly Ala Ala Thr Thr Gly Gly
515 520 525
Thr Thr Cys Cys Ala Gly Cys Ala Gly Ala Ala Gly Cys Cys Cys Gly
530 535 540
Gly Cys Cys Ala Gly Cys Cys Cys Cys Cys Cys Ala Ala Gly Cys Thr
545 550 555 560
Gly Cys Thr Gly Ala Thr Cys Thr Ala Thr Gly Cys Cys Gly Cys Cys
565 570 575
Ala Gly Cys Ala Gly Ala Cys Ala Gly Gly Gly Cys Ala Gly Cys Gly
580 585 590
Gly Ala Gly Thr Gly Cys Cys Thr Gly Cys Cys Ala Gly Ala Thr Thr
595 600 605
Thr Thr Cys Thr Gly Gly Cys Ala Gly Cys Gly Gly Cys Thr Cys Cys
610 615 620
Gly Gly Cys Ala Cys Cys Gly Ala Cys Thr Thr Cys Ala Gly Cys Cys
625 630 635 640
Thr Gly Ala Ala Cys Ala Thr Cys Cys Ala Cys Cys Cys Thr Ala Thr
645 650 655
Gly Gly Ala Ala Gly Ala Gly Gly Ala Cys Gly Ala Cys Ala Cys Cys
660 665 670
Gly Cys Cys Ala Thr Gly Thr Ala Cys Thr Thr Thr Thr Gly Cys Cys
675 680 685
Ala Gly Cys Ala Gly Ala Gly Cys Ala Ala Ala Gly Ala Gly Gly Thr
690 695 700
Gly Cys Cys Cys Thr Gly Gly Ala Cys Cys Thr Thr Thr Gly Gly Cys
705 710 715 720
Gly Gly Ala Gly Gly Cys Ala Cys Cys Ala Ala Gly Cys Thr Gly Gly
725 730 735
Ala Ala Ala Thr Cys Ala Ala Gly Cys Ala Gly Gly Thr Gly Cys Ala
740 745 750
Gly Cys Thr Gly Cys Ala Gly Cys Ala Gly Cys Cys Thr Gly Gly Cys
755 760 765
Gly Cys Thr Gly Ala Ala Cys Thr Cys Gly Thr Gly Cys Gly Gly Cys
770 775 780
Cys Ala Gly Gly Cys Gly Cys Thr Thr Cys Thr Gly Thr Gly Ala Ala
785 790 795 800
Gly Cys Thr Gly Ala Gly Cys Thr Gly Thr Ala Ala Ala Gly Cys Cys
805 810 815
Ala Gly Cys Gly Gly Cys Thr Ala Cys Ala Cys Cys Thr Thr Cys Ala
820 825 830
Gly Cys Ala Ala Cys Thr Ala Cys Cys Thr Gly Ala Thr Gly Ala Ala
835 840 845
Cys Thr Gly Gly Gly Thr Cys Ala Ala Gly Cys Ala Gly Cys Gly Gly
850 855 860
Cys Cys Cys Gly Ala Gly Cys Ala Gly Gly Ala Cys Cys Thr Gly Gly
865 870 875 880
Ala Thr Thr Gly Gly Ala Thr Cys Gly Gly Cys Ala Gly Ala Ala Thr
885 890 895
Cys Gly Ala Cys Cys Cys Cys Thr Ala Cys Gly Ala Cys Gly Gly Cys
900 905 910
Gly Ala Cys Ala Thr Cys Gly Ala Cys Thr Ala Cys Ala Ala Cys Cys
915 920 925
Ala Gly Ala Ala Cys Thr Thr Cys Ala Ala Gly Gly Ala Cys Ala Ala
930 935 940
Gly Gly Cys Cys Ala Thr Cys Cys Thr Gly Ala Cys Cys Gly Thr Gly
945 950 955 960
Gly Ala Cys Ala Ala Gly Ala Gly Cys Ala Gly Cys Ala Gly Cys Ala
965 970 975
Cys Cys Gly Cys Cys Thr Ala Cys Ala Thr Gly Cys Ala Gly Cys Thr
980 985 990
Gly Thr Cys Cys Ala Gly Cys Cys Thr Gly Ala Cys Cys Ala Gly Cys
995 1000 1005
Gly Ala Gly Gly Ala Cys Ala Gly Cys Gly Cys Cys Gly Thr Gly
1010 1015 1020
Thr Ala Cys Thr Ala Cys Thr Gly Cys Gly Cys Cys Ala Gly Ala
1025 1030 1035
Gly Gly Cys Thr Ala Cys Gly Gly Cys Ala Cys Ala Gly Cys Cys
1040 1045 1050
Thr Ala Cys Gly Gly Cys Gly Thr Gly Gly Ala Cys Thr Ala Thr
1055 1060 1065
Thr Gly Gly Gly Gly Cys Cys Ala Gly Gly Gly Cys Ala Cys Ala
1070 1075 1080
Ala Gly Cys Gly Thr Gly Ala Cys Cys Gly Thr Gly Thr Cys Cys
1085 1090 1095
Ala Gly Cys Gly Cys Cys Ala Ala Gly Ala Cys Cys Ala Cys Cys
1100 1105 1110
Cys Cys Cys Cys Cys Thr Ala Ala Gly Cys Thr Gly Gly Ala Ala
1115 1120 1125
Gly Ala Gly Gly Gly Cys Gly Ala Gly Thr Thr Cys Thr Cys Cys
1130 1135 1140
Gly Ala Gly Gly Cys Cys Cys Gly Gly Gly Thr Gly Gly Ala Cys
1145 1150 1155
Ala Thr Thr Gly Thr Gly Cys Thr Gly Ala Cys Ala Cys Ala Gly
1160 1165 1170
Thr Cys Thr Cys Cys Ala Gly Cys Cys Ala Gly Cys Cys Thr Gly
1175 1180 1185
Gly Cys Cys Gly Thr Gly Thr Cys Cys Cys Thr Gly Gly Gly Ala
1190 1195 1200
Cys Ala Gly Ala Gly Ala Gly Cys Cys Ala Cys Cys Ala Thr Cys
1205 1210 1215
Ala Gly Cys Thr Gly Thr Ala Gly Gly Gly Cys Cys Ala Gly Cys
1220 1225 1230
Gly Ala Gly Ala Gly Cys Gly Thr Gly Gly Ala Cys Ala Ala Cys
1235 1240 1245
Thr Ala Cys Gly Gly Cys Ala Thr Cys Ala Gly Cys Thr Thr Cys
1250 1255 1260
Ala Thr Gly Ala Ala Thr Thr Gly Gly Thr Thr Cys Cys Ala Gly
1265 1270 1275
Cys Ala Gly Ala Ala Gly Cys Cys Cys Gly Gly Cys Cys Ala Gly
1280 1285 1290
Cys Cys Cys Cys Cys Cys Ala Ala Gly Cys Thr Gly Cys Thr Gly
1295 1300 1305
Ala Thr Cys Thr Ala Thr Gly Cys Cys Gly Cys Cys Ala Gly Cys
1310 1315 1320
Ala Gly Ala Cys Ala Gly Gly Gly Cys Ala Gly Cys Gly Gly Ala
1325 1330 1335
Gly Thr Gly Cys Cys Thr Gly Cys Cys Ala Gly Ala Thr Thr Thr
1340 1345 1350
Thr Cys Thr Gly Gly Cys Ala Gly Cys Gly Gly Cys Thr Cys Cys
1355 1360 1365
Gly Gly Cys Ala Cys Cys Gly Ala Cys Thr Thr Cys Ala Gly Cys
1370 1375 1380
Cys Thr Gly Ala Ala Cys Ala Thr Cys Cys Ala Cys Cys Cys Thr
1385 1390 1395
Ala Thr Gly Gly Ala Ala Gly Ala Gly Gly Ala Cys Gly Ala Cys
1400 1405 1410
Ala Cys Cys Gly Cys Cys Ala Thr Gly Thr Ala Cys Thr Thr Thr
1415 1420 1425
Thr Gly Cys Cys Ala Gly Cys Ala Gly Ala Gly Cys Ala Ala Ala
1430 1435 1440
Gly Ala Gly Gly Thr Gly Cys Cys Cys Thr Gly Gly Ala Cys Cys
1445 1450 1455
Thr Thr Thr Gly Gly Cys Gly Gly Ala Gly Gly Cys Ala Cys Cys
1460 1465 1470
Ala Ala Gly Cys Thr Gly Gly Ala Ala Ala Thr Cys Ala Ala Gly
1475 1480 1485
<210> 68
<211> 48
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 68
Gln Arg Arg Lys Tyr Arg Ser Asn Lys Gly Glu Ser Pro Val Glu Pro
1 5 10 15
Ala Glu Pro Cys His Tyr Ser Cys Pro Arg Glu Glu Glu Gly Ser Thr
20 25 30
Ile Pro Ile Gln Glu Asp Tyr Arg Lys Pro Glu Pro Ala Cys Ser Pro
35 40 45
<210> 69
<211> 144
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 69
caacgaagga aatatagatc aaacaaagga gaaagtcctg tggagcctgc agagccttgt 60
cgttacagct gccccaggga ggaggagggc agcaccatcc ccatccagga ggattaccga 120
aaaccggagc ctgcctgctc cccc 144
<210> 70
<211> 62
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 70
Lys Lys Val Ala Lys Lys Pro Thr Asn Lys Ala Pro His Pro Lys Gln
1 5 10 15
Glu Pro Gln Glu Ile Asn Phe Pro Asp Asp Leu Pro Gly Ser Asn Thr
20 25 30
Ala Ala Pro Val Gln Glu Thr Leu His Gly Cys Gln Pro Val Thr Gln
35 40 45
Glu Asp Gly Lys Glu Ser Arg Ile Ser Val Gln Glu Arg Gln
50 55 60
<210> 71
<211> 186
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 71
aagaaggtgg ccaagaagcc caccaacaag gccccccacc ctaagcagga accccaggaa 60
atcaacttcc ccgacgacct gcccggcagc aatactgctg ctcccgtgca ggaaaccctg 120
cacggctgtc agcctgtgac ccaggaagat ggcaaagaaa gccggatcag cgtgcaggaa 180
cggcag 186
<210> 72
<211> 36
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 72
Arg Asp Gln Arg Leu Pro Pro Asp Ala His Lys Pro Pro Gly Gly Gly
1 5 10 15
Ser Phe Arg Thr Pro Ile Gln Glu Glu Gln Ala Asp Ala His Ser Thr
20 25 30
Leu Ala Lys Ile
35
<210> 73
<211> 108
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 73
agggaccaga ggctgccccc cgatgcccac aagccccctg ggggaggcag tttccggacc 60
cccatccaag aggagcaggc cgacgcccac tccaccctgg ccaagatc 108
<210> 74
<211> 42
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 74
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
1 5 10 15
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
20 25 30
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu
35 40
<210> 75
<211> 126
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 75
aaacggggca gaaagaaact cctgtatata ttcaaacaac catttatgag accagtacaa 60
actactcaag aggaagatgg ctgtagctgc cgatttccag aagaagaaga aggaggatgt 120
gaactg 126
<210> 76
<211> 38
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 76
Cys Trp Leu Thr Lys Lys Lys Tyr Ser Ser Ser Val His Asp Pro Asn
1 5 10 15
Gly Glu Tyr Met Phe Met Arg Ala Val Asn Thr Ala Lys Lys Ser Arg
20 25 30
Leu Thr Asp Val Thr Leu
35
<210> 77
<211> 114
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 77
tgctggctga ccaaaaaaaa atatagcagc agcgtgcatg atccgaacgg cgaatatatg 60
tttatgcgcg cggtgaacac cgcgaaaaaa agccgcctga ccgatgtgac cctg 114
<210> 78
<211> 172
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 78
Met Ala Ala Gly Gly Pro Gly Ala Gly Ser Ala Ala Pro Val Ser Ser
1 5 10 15
Thr Ser Ser Leu Pro Leu Ala Ala Leu Asn Met Arg Val Arg Arg Arg
20 25 30
Leu Ser Leu Phe Leu Asn Val Arg Thr Gln Val Ala Ala Asp Trp Thr
35 40 45
Ala Leu Ala Glu Glu Met Asp Phe Glu Tyr Leu Glu Ile Arg Gln Leu
50 55 60
Glu Thr Gln Ala Asp Pro Thr Gly Arg Leu Leu Asp Ala Trp Gln Gly
65 70 75 80
Arg Pro Gly Ala Ser Val Gly Arg Leu Leu Glu Leu Leu Thr Lys Leu
85 90 95
Gly Arg Asp Asp Val Leu Leu Glu Leu Gly Pro Ser Ile Glu Glu Asp
100 105 110
Cys Gln Lys Tyr Ile Leu Lys Gln Gln Gln Glu Glu Ala Glu Lys Pro
115 120 125
Leu Gln Val Ala Ala Val Asp Ser Ser Val Pro Arg Thr Ala Glu Leu
130 135 140
Ala Gly Ile Thr Thr Leu Asp Asp Pro Leu Gly His Met Pro Glu Arg
145 150 155 160
Phe Asp Ala Phe Ile Cys Tyr Cys Pro Ser Asp Ile
165 170
<210> 79
<211> 516
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 79
atggctgctg gcggacctgg cgccggatct gctgctcctg tgtctagcac aagcagcctg 60
cctctggccg ccctgaacat gagagtgcgg agaaggctga gcctgttcct gaacgtgcgg 120
acacaggtgg ccgccgattg gacagccctg gccgaggaaa tggacttcga gtacctggaa 180
atccggcagc tggaaaccca ggccgaccct acaggcagac tgctggatgc ttggcagggc 240
agaccaggcg cttctgtggg aaggctgctg gaactgctga ccaagctggg cagggacgac 300
gtgctgctgg aactgggccc tagcatcgaa gaggactgcc agaagtacat cctgaagcag 360
cagcaggaag aggccgagaa gcctctgcag gtggcagccg tggatagcag cgtgccaaga 420
acagccgagc tggccggcat caccaccctg gatgatcctc tgggccacat gcccgagaga 480
ttcgacgcct tcatctgcta ctgccccagc gacatc 516
<210> 80
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 80
Ala Lys Thr Thr Pro Pro Lys Leu Glu Glu Gly Glu Phe Ser Glu Ala
1 5 10 15
Arg Val
<210> 81
<211> 42
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 81
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
1 5 10 15
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
20 25 30
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu
35 40
<210> 82
<211> 126
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 82
aaacggggca gaaagaaact cctgtatata ttcaaacaac catttatgag accagtacaa 60
actactcaag aggaagatgg ctgtagctgc cgatttccag aagaagaaga aggaggatgt 120
gaactg 126
<210> 83
<211> 36
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 83
Arg Asp Gln Arg Leu Pro Pro Asp Ala His Lys Pro Pro Gly Gly Gly
1 5 10 15
Ser Phe Arg Thr Pro Ile Gln Glu Glu Gln Ala Asp Ala His Ser Thr
20 25 30
Leu Ala Lys Ile
35
<210> 84
<211> 108
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 84
agggaccaga ggctgccccc cgatgcccac aagccccctg ggggaggcag tttccggacc 60
cccatccaag aggagcaggc cgacgcccac tccaccctgg ccaagatc 108
<210> 85
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 85
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
1 5 10 15
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Asn His Arg Asn
20 25 30
<210> 86
<211> 90
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 86
tgtgatatct acatctgggc gcccttggcc gggacttgtg gggtccttct cctgtcactg 60
gttatcaccc tttactgcaa ccacaggaac 90
<210> 87
<211> 154
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 87
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
1 5 10 15
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
20 25 30
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg
35 40 45
Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn
50 55 60
Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg
65 70 75 80
Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro
85 90 95
Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala
100 105 110
Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His
115 120 125
Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp
130 135 140
Ala Leu His Met Gln Ala Leu Pro Pro Arg
145 150
<210> 88
<211> 462
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 88
aaacggggca gaaagaaact cctgtatata ttcaaacaac catttatgag accagtacaa 60
actactcaag aggaagatgg ctgtagctgc cgatttccag aagaagaaga aggaggatgt 120
gaactgagag tgaagttcag caggagcgca gacgcccccg cgtaccagca gggccagaac 180
cagctctata acgagctcaa tctaggacga agagaggagt acgatgtttt ggacaagaga 240
cgtggccggg accctgagat ggggggaaag ccgagaagga agaaccctca ggaaggcctg 300
tacaatgaac tgcagaaaga taagatggcg gaggcctaca gtgagattgg gatgaaaggc 360
gagcgccgga ggggcaaggg gcacgatggc ctttaccagg gtctcagtac agccaccaag 420
gacacctacg acgcccttca catgcaggcc ctgccccctc gc 462
<210> 89
<211> 148
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 89
Arg Asp Gln Arg Leu Pro Pro Asp Ala His Lys Pro Pro Gly Gly Gly
1 5 10 15
Ser Phe Arg Thr Pro Ile Gln Glu Glu Gln Ala Asp Ala His Ser Thr
20 25 30
Leu Ala Lys Ile Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
35 40 45
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
50 55 60
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
65 70 75 80
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
85 90 95
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
100 105 110
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
115 120 125
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
130 135 140
Leu Pro Pro Arg
145
<210> 90
<211> 444
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 90
agggaccaga ggctgccccc cgatgcccac aagccccctg ggggaggcag tttccggacc 60
cccatccaag aggagcaggc cgacgcccac tccaccctgg ccaagatcag agtgaagttc 120
agcaggagcg cagacgcccc cgcgtaccag cagggccaga accagctcta taacgagctc 180
aatctaggac gaagagagga gtacgatgtt ttggacaaga gacgtggccg ggaccctgag 240
atggggggaa agccgagaag gaagaaccct caggaaggcc tgtacaatga actgcagaaa 300
gataagatgg cggaggccta cagtgagatt gggatgaaag gcgagcgccg gaggggcaag 360
gggcacgatg gcctttacca gggtctcagt acagccacca aggacaccta cgacgccctt 420
cacatgcagg ccctgccccc tcgc 444
<210> 91
<211> 222
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 91
Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu
1 5 10 15
Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser
20 25 30
Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly
35 40 45
Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala
50 55 60
Ala Tyr Arg Ser Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys
65 70 75 80
Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys
85 90 95
Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val
100 105 110
Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn
115 120 125
Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val
130 135 140
Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg
145 150 155 160
Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys
165 170 175
Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg
180 185 190
Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys
195 200 205
Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
210 215 220
<210> 92
<211> 666
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 92
ttttgggtgc tggtggtggt tggtggagtc ctggcttgct atagcttgct agtaacagtg 60
gcctttatta ttttctgggt gaggagtaag aggagcaggc tcctgcacag tgactacatg 120
aacatgactc cccgccgccc cgggcccacc cgcaagcatt accagcccta tgccccacca 180
cgcgacttcg cagcctatcg ctccaaacgg ggcagaaaga aactcctgta tatattcaaa 240
caaccattta tgagaccagt acaaactact caagaggaag atggctgtag ctgccgattt 300
ccagaagaag aagaaggagg atgtgaactg agagtgaagt tcagcaggag cgcagacgcc 360
cccgcgtacc agcagggcca gaaccagctc tataacgagc tcaatctagg acgaagagag 420
gagtacgatg ttttggacaa gagacgtggc cgggaccctg agatgggggg aaagccgaga 480
aggaagaacc ctcaggaagg cctgtacaat gaactgcaga aagataagat ggcggaggcc 540
tacagtgaga ttgggatgaa aggcgagcgc cggaggggca aggggcacga tggcctttac 600
cagggtctca gtacagccac caaggacacc tacgacgccc ttcacatgca ggccctgccc 660
cctcgc 666
<210> 93
<211> 184
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 93
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
1 5 10 15
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Asn His Arg Asn Lys Arg
20 25 30
Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro
35 40 45
Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu
50 55 60
Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala
65 70 75 80
Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu
85 90 95
Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly
100 105 110
Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu
115 120 125
Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser
130 135 140
Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly
145 150 155 160
Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu
165 170 175
His Met Gln Ala Leu Pro Pro Arg
180
<210> 94
<211> 552
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 94
tgtgatatct acatctgggc gcccttggcc gggacttgtg gggtccttct cctgtcactg 60
gttatcaccc tttactgcaa ccacaggaac aaacggggca gaaagaaact cctgtatata 120
ttcaaacaac catttatgag accagtacaa actactcaag aggaagatgg ctgtagctgc 180
cgatttccag aagaagaaga aggaggatgt gaactgagag tgaagttcag caggagcgca 240
gacgcccccg cgtaccagca gggccagaac cagctctata acgagctcaa tctaggacga 300
agagaggagt acgatgtttt ggacaagaga cgtggccggg accctgagat ggggggaaag 360
ccgagaagga agaaccctca ggaaggcctg tacaatgaac tgcagaaaga taagatggcg 420
gaggcctaca gtgagattgg gatgaaaggc gagcgccgga ggggcaaggg gcacgatggc 480
ctttaccagg gtctcagtac agccaccaag gacacctacg acgcccttca catgcaggcc 540
ctgccccctc gc 552
<210> 95
<211> 216
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 95
Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu
1 5 10 15
Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser
20 25 30
Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly
35 40 45
Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala
50 55 60
Ala Tyr Arg Ser Arg Asp Gln Arg Leu Pro Pro Asp Ala His Lys Pro
65 70 75 80
Pro Gly Gly Gly Ser Phe Arg Thr Pro Ile Gln Glu Glu Gln Ala Asp
85 90 95
Ala His Ser Thr Leu Ala Lys Ile Arg Val Lys Phe Ser Arg Ser Ala
100 105 110
Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu
115 120 125
Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly
130 135 140
Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu
145 150 155 160
Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser
165 170 175
Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly
180 185 190
Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu
195 200 205
His Met Gln Ala Leu Pro Pro Arg
210 215
<210> 96
<211> 648
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 96
ttttgggtgc tggtggtggt tggtggagtc ctggcttgct atagcttgct agtaacagtg 60
gcctttatta ttttctgggt gaggagtaag aggagcaggc tcctgcacag tgactacatg 120
aacatgactc cccgccgccc cgggcccacc cgcaagcatt accagcccta tgccccacca 180
cgcgacttcg cagcctatcg ctccagggac cagaggctgc cccccgatgc ccacaagccc 240
cctgggggag gcagtttccg gacccccatc caagaggagc aggccgacgc ccactccacc 300
ctggccaaga tcagagtgaa gttcagcagg agcgcagacg cccccgcgta ccagcagggc 360
cagaaccagc tctataacga gctcaatcta ggacgaagag aggagtacga tgttttggac 420
aagagacgtg gccgggaccc tgagatgggg ggaaagccga gaaggaagaa ccctcaggaa 480
ggcctgtaca atgaactgca gaaagataag atggcggagg cctacagtga gattgggatg 540
aaaggcgagc gccggagggg caaggggcac gatggccttt accagggtct cagtacagcc 600
accaaggaca cctacgacgc ccttcacatg caggccctgc cccctcgc 648
<210> 97
<211> 509
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 97
Met Asp Trp Ile Trp Arg Ile Leu Phe Leu Val Gly Ala Ala Thr Gly
1 5 10 15
Ala His Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg
20 25 30
Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Ser Asn Tyr Leu Met Asn Trp Val Lys Gln Arg Pro Glu Gln Asp Leu
50 55 60
Asp Trp Ile Gly Arg Ile Asp Pro Tyr Asp Gly Asp Ile Asp Tyr Asn
65 70 75 80
Gln Asn Phe Lys Asp Lys Ala Ile Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Gly Tyr Gly Thr Ala Tyr Gly Val Asp Tyr Trp
115 120 125
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Lys Thr Thr Pro Pro
130 135 140
Lys Leu Glu Glu Gly Glu Phe Ser Glu Ala Arg Val Asp Ile Val Leu
145 150 155 160
Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly Gln Arg Ala Thr
165 170 175
Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile Ser Phe
180 185 190
Met Asn Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Ala Ala Ser Arg Gln Gly Ser Gly Val Pro Ala Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Ser Leu Asn Ile His Pro Met Glu Glu
225 230 235 240
Asp Asp Thr Ala Met Tyr Phe Cys Gln Gln Ser Lys Glu Val Pro Trp
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Asp Leu Glu Pro Lys
260 265 270
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Asp Pro Lys Phe
275 280 285
Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu
290 295 300
Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg
305 310 315 320
Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro
325 330 335
Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala
340 345 350
Tyr Arg Ser Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln
355 360 365
Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser
370 375 380
Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys
385 390 395 400
Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln
405 410 415
Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu
420 425 430
Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg
435 440 445
Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met
450 455 460
Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly
465 470 475 480
Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp
485 490 495
Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
500 505
<210> 98
<211> 1527
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 98
atggactgga tctggcgcat cctgtttctc gtgggagccg ccacaggcgc ccattctcag 60
gtgcagctgc agcagcctgg cgctgaactc gtgcggccag gcgcttctgt gaagctgagc 120
tgtaaagcca gcggctacac cttcagcaac tacctgatga actgggtcaa gcagcggccc 180
gagcaggacc tggattggat cggcagaatc gacccctacg acggcgacat cgactacaac 240
cagaacttca aggacaaggc catcctgacc gtggacaaga gcagcagcac cgcctacatg 300
cagctgtcca gcctgaccag cgaggacagc gccgtgtact actgcgccag aggctacggc 360
acagcctacg gcgtggacta ttggggccag ggcacaagcg tgaccgtgtc cagcgccaag 420
accacccccc ctaagctgga agagggcgag ttctccgagg cccgggtgga cattgtgctg 480
acacagtctc cagccagcct ggccgtgtcc ctgggacaga gagccaccat cagctgtagg 540
gccagcgaga gcgtggacaa ctacggcatc agcttcatga attggttcca gcagaagccc 600
ggccagcccc ccaagctgct gatctatgcc gccagcagac agggcagcgg agtgcctgcc 660
agattttctg gcagcggctc cggcaccgac ttcagcctga acatccaccc tatggaagag 720
gacgacaccg ccatgtactt ttgccagcag agcaaagagg tgccctggac ctttggcgga 780
ggcaccaagc tggaaatcaa ggatctcgag cccaaatctt gtgacaaaac tcacacatgc 840
ccaccgtgcc cggatcccaa attttgggtg ctggtggtgg ttggtggagt cctggcttgc 900
tatagcttgc tagtaacagt ggcctttatt attttctggg tgaggagtaa gaggagcagg 960
ctcctgcaca gtgactacat gaacatgact ccccgccgcc ccgggcccac ccgcaagcat 1020
taccagccct atgccccacc acgcgacttc gcagcctatc gctccaaacg gggcagaaag 1080
aaactcctgt atatattcaa acaaccattt atgagaccag tacaaactac tcaagaggaa 1140
gatggctgta gctgccgatt tccagaagaa gaagaaggag gatgtgaact gagagtgaag 1200
ttcagcagga gcgcagacgc ccccgcgtac cagcagggcc agaaccagct ctataacgag 1260
ctcaatctag gacgaagaga ggagtacgat gttttggaca agagacgtgg ccgggaccct 1320
gagatggggg gaaagccgag aaggaagaac cctcaggaag gcctgtacaa tgaactgcag 1380
aaagataaga tggcggaggc ctacagtgag attgggatga aaggcgagcg ccggaggggc 1440
aaggggcacg atggccttta ccagggtctc agtacagcca ccaaggacac ctacgacgcc 1500
cttcacatgc aggccctgcc ccctcgc 1527
<210> 99
<211> 503
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 99
Met Asp Trp Ile Trp Arg Ile Leu Phe Leu Val Gly Ala Ala Thr Gly
1 5 10 15
Ala His Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg
20 25 30
Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Ser Asn Tyr Leu Met Asn Trp Val Lys Gln Arg Pro Glu Gln Asp Leu
50 55 60
Asp Trp Ile Gly Arg Ile Asp Pro Tyr Asp Gly Asp Ile Asp Tyr Asn
65 70 75 80
Gln Asn Phe Lys Asp Lys Ala Ile Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Gly Tyr Gly Thr Ala Tyr Gly Val Asp Tyr Trp
115 120 125
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Lys Thr Thr Pro Pro
130 135 140
Lys Leu Glu Glu Gly Glu Phe Ser Glu Ala Arg Val Asp Ile Val Leu
145 150 155 160
Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly Gln Arg Ala Thr
165 170 175
Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile Ser Phe
180 185 190
Met Asn Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Ala Ala Ser Arg Gln Gly Ser Gly Val Pro Ala Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Ser Leu Asn Ile His Pro Met Glu Glu
225 230 235 240
Asp Asp Thr Ala Met Tyr Phe Cys Gln Gln Ser Lys Glu Val Pro Trp
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Asp Leu Glu Pro Lys
260 265 270
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Asp Pro Lys Phe
275 280 285
Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu Leu
290 295 300
Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser Arg
305 310 315 320
Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro
325 330 335
Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala
340 345 350
Tyr Arg Ser Arg Asp Gln Arg Leu Pro Pro Asp Ala His Lys Pro Pro
355 360 365
Gly Gly Gly Ser Phe Arg Thr Pro Ile Gln Glu Glu Gln Ala Asp Ala
370 375 380
His Ser Thr Leu Ala Lys Ile Arg Val Lys Phe Ser Arg Ser Ala Asp
385 390 395 400
Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
405 410 415
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
420 425 430
Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly
435 440 445
Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu
450 455 460
Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu
465 470 475 480
Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His
485 490 495
Met Gln Ala Leu Pro Pro Arg
500
<210> 100
<211> 1509
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 100
atggactgga tctggcgcat cctgtttctc gtgggagccg ccacaggcgc ccattctcag 60
gtgcagctgc agcagcctgg cgctgaactc gtgcggccag gcgcttctgt gaagctgagc 120
tgtaaagcca gcggctacac cttcagcaac tacctgatga actgggtcaa gcagcggccc 180
gagcaggacc tggattggat cggcagaatc gacccctacg acggcgacat cgactacaac 240
cagaacttca aggacaaggc catcctgacc gtggacaaga gcagcagcac cgcctacatg 300
cagctgtcca gcctgaccag cgaggacagc gccgtgtact actgcgccag aggctacggc 360
acagcctacg gcgtggacta ttggggccag ggcacaagcg tgaccgtgtc cagcgccaag 420
accacccccc ctaagctgga agagggcgag ttctccgagg cccgggtgga cattgtgctg 480
acacagtctc cagccagcct ggccgtgtcc ctgggacaga gagccaccat cagctgtagg 540
gccagcgaga gcgtggacaa ctacggcatc agcttcatga attggttcca gcagaagccc 600
ggccagcccc ccaagctgct gatctatgcc gccagcagac agggcagcgg agtgcctgcc 660
agattttctg gcagcggctc cggcaccgac ttcagcctga acatccaccc tatggaagag 720
gacgacaccg ccatgtactt ttgccagcag agcaaagagg tgccctggac ctttggcgga 780
ggcaccaagc tggaaatcaa ggatctcgag cccaaatctt gtgacaaaac tcacacatgc 840
ccaccgtgcc cggatcccaa attttgggtg ctggtggtgg ttggtggagt cctggcttgc 900
tatagcttgc tagtaacagt ggcctttatt attttctggg tgaggagtaa gaggagcagg 960
ctcctgcaca gtgactacat gaacatgact ccccgccgcc ccgggcccac ccgcaagcat 1020
taccagccct atgccccacc acgcgacttc gcagcctatc gctccaggga ccagaggctg 1080
ccccccgatg cccacaagcc ccctggggga ggcagtttcc ggacccccat ccaagaggag 1140
caggccgacg cccactccac cctggccaag atcagagtga agttcagcag gagcgcagac 1200
gcccccgcgt accagcaggg ccagaaccag ctctataacg agctcaatct aggacgaaga 1260
gaggagtacg atgttttgga caagagacgt ggccgggacc ctgagatggg gggaaagccg 1320
agaaggaaga accctcagga aggcctgtac aatgaactgc agaaagataa gatggcggag 1380
gcctacagtg agattgggat gaaaggcgag cgccggaggg gcaaggggca cgatggcctt 1440
taccagggtc tcagtacagc caccaaggac acctacgacg cccttcacat gcaggccctg 1500
ccccctcgc 1509
<210> 101
<211> 471
<212> PRT
<213> 人工序列
<220>
<223> 合成多肽
<400> 101
Met Asp Trp Ile Trp Arg Ile Leu Phe Leu Val Gly Ala Ala Thr Gly
1 5 10 15
Ala His Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg
20 25 30
Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Ser Asn Tyr Leu Met Asn Trp Val Lys Gln Arg Pro Glu Gln Asp Leu
50 55 60
Asp Trp Ile Gly Arg Ile Asp Pro Tyr Asp Gly Asp Ile Asp Tyr Asn
65 70 75 80
Gln Asn Phe Lys Asp Lys Ala Ile Leu Thr Val Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Gly Tyr Gly Thr Ala Tyr Gly Val Asp Tyr Trp
115 120 125
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Ala Lys Thr Thr Pro Pro
130 135 140
Lys Leu Glu Glu Gly Glu Phe Ser Glu Ala Arg Val Asp Ile Val Leu
145 150 155 160
Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly Gln Arg Ala Thr
165 170 175
Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile Ser Phe
180 185 190
Met Asn Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
195 200 205
Tyr Ala Ala Ser Arg Gln Gly Ser Gly Val Pro Ala Arg Phe Ser Gly
210 215 220
Ser Gly Ser Gly Thr Asp Phe Ser Leu Asn Ile His Pro Met Glu Glu
225 230 235 240
Asp Asp Thr Ala Met Tyr Phe Cys Gln Gln Ser Lys Glu Val Pro Trp
245 250 255
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Asp Leu Glu Pro Lys
260 265 270
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Asp Pro Lys Cys
275 280 285
Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu
290 295 300
Leu Ser Leu Val Ile Thr Leu Tyr Cys Asn His Arg Asn Lys Arg Gly
305 310 315 320
Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val
325 330 335
Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu
340 345 350
Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp
355 360 365
Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
370 375 380
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
385 390 395 400
Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly
405 410 415
Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu
420 425 430
Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu
435 440 445
Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His
450 455 460
Met Gln Ala Leu Pro Pro Arg
465 470
<210> 102
<211> 1413
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<400> 102
atggactgga tctggcgcat cctgtttctc gtgggagccg ccacaggcgc ccattctcag 60
gtgcagctgc agcagcctgg cgctgaactc gtgcggccag gcgcttctgt gaagctgagc 120
tgtaaagcca gcggctacac cttcagcaac tacctgatga actgggtcaa gcagcggccc 180
gagcaggacc tggattggat cggcagaatc gacccctacg acggcgacat cgactacaac 240
cagaacttca aggacaaggc catcctgacc gtggacaaga gcagcagcac cgcctacatg 300
cagctgtcca gcctgaccag cgaggacagc gccgtgtact actgcgccag aggctacggc 360
acagcctacg gcgtggacta ttggggccag ggcacaagcg tgaccgtgtc cagcgccaag 420
accacccccc ctaagctgga agagggcgag ttctccgagg cccgggtgga cattgtgctg 480
acacagtctc cagccagcct ggccgtgtcc ctgggacaga gagccaccat cagctgtagg 540
gccagcgaga gcgtggacaa ctacggcatc agcttcatga attggttcca gcagaagccc 600
ggccagcccc ccaagctgct gatctatgcc gccagcagac agggcagcgg agtgcctgcc 660
agattttctg gcagcggctc cggcaccgac ttcagcctga acatccaccc tatggaagag 720
gacgacaccg ccatgtactt ttgccagcag agcaaagagg tgccctggac ctttggcgga 780
ggcaccaagc tggaaatcaa ggatctcgag cccaaatctt gtgacaaaac tcacacatgc 840
ccaccgtgcc cggatcccaa atgtgatatc tacatctggg cgcccttggc cgggacttgt 900
ggggtccttc tcctgtcact ggttatcacc ctttactgca accacaggaa caaacggggc 960
agaaagaaac tcctgtatat attcaaacaa ccatttatga gaccagtaca aactactcaa 1020
gaggaagatg gctgtagctg ccgatttcca gaagaagaag aaggaggatg tgaactgaga 1080
gtgaagttca gcaggagcgc agacgccccc gcgtaccagc agggccagaa ccagctctat 1140
aacgagctca atctaggacg aagagaggag tacgatgttt tggacaagag acgtggccgg 1200
gaccctgaga tggggggaaa gccgagaagg aagaaccctc aggaaggcct gtacaatgaa 1260
ctgcagaaag ataagatggc ggaggcctac agtgagattg ggatgaaagg cgagcgccgg 1320
aggggcaagg ggcacgatgg cctttaccag ggtctcagta cagccaccaa ggacacctac 1380
gacgcccttc acatgcaggc cctgccccct cgc 1413
<210> 103
<211> 18
<212> PRT
<213> 智人
<220>
<221> MISC_FEATURE
<223> hIgG1的铰链区
<400> 103
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
1 5 10 15
Glu Leu
<210> 104
<211> 291
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 克隆47重链恒定区1
<400> 104
gccaaaacga cacccccatc tgtctatcca ctggcccctg gatctgctgc ccaaactaac 60
tccatggtga ccctgggatg cctggtcaag ggctatttcc ctgagccagt gacagtgacc 120
tggaactctg gatccctgtc cagcggtgtg cacaccttcc cagctgtcct gcagtctgac 180
ctctacactc tgagcagctc agtgactgtc ccctccagca cctggcccag cgagaccgtc 240
acctgcaacg ttgcccaccc ggccagcagc accaaggtgg acaagaaaat t 291
<210> 105
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 克隆47重链恒定区2
<400> 105
gtcccagaag tatcatctgt cttcatcttc cccccaaagc ccaaggatgt gctcaccatt 60
actctgactc ctaaggtcac gtgtgttgtg gtagacatca gcaaggatga tcccgaggtc 120
cagttcagct ggtttgtaga tgatgtggag gtgcacacag ctcagacgca accccgggag 180
gagcagttca acagcacttt ccgctcagtc agtgaacttc ccatcatgca ccaggactgg 240
ctcaatggca aggagttcaa atgcagggtc aacagtgcag ctttccctgc ccccatcgag 300
aaaaccatct ccaaaaccaa a 321
<210> 106
<211> 287
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 克隆47重链恒定区3
<400> 106
ggcagaccga aggctccaca ggtgtacacc attccacctc ccaaggagca gatggccaag 60
gataaagtca gtctgacctg catgataaca gacttcttcc ctgaagacat tactgtggag 120
tggcagtgga atgggcagcc agcggagaac tacaagaaca ctcagcccat catggacaca 180
gatggctctt acttcgtcta cagcaagctc aatgtgcaga agagcaactg ggaggcagga 240
aatactttca cctgctctgt gttacatgag ggcctgcaca accacca 287
<210> 107
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 克隆47轻链恒定区
<400> 107
cgggctgatg ctgcaccaac tgtatccatc ttcccaccat ccagtgagca gttaacatct 60
ggaggtgcct cagtcgtgtg cttcttgaac aacttctacc ccaaagacat caatgtcaag 120
tggaagattg atggcagtga acgacaaaat ggcgtcctga acagttggac tgatcaggac 180
agcaaagaca gcacctacag catgagcagc accctcacgt tgaccaagga cgagtatgaa 240
cgacataaca gctatacctg tgaggccact cacaagacat caacttcacc cattgtcaag 300
agcttcaaca ggaatgagtg ttag 324
<210> 108
<211> 39
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 克隆47铰链区
<400> 108
gtgcccaggg attgtggttg taagccttgc atatgtaca 39
<210> 109
<211> 66
<212> DNA
<213> 猪捷申病毒(Porcine teschovirus)
<400> 109
ggaagcggag ctactaactt cagcctgctg aagcaggctg gagacgtgga ggagaaccct 60
ggacct 66
<210> 110
<211> 22
<212> PRT
<213> 猪捷申病毒(Porcine teschovirus)
<400> 110
Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val
1 5 10 15
Glu Glu Asn Pro Gly Pro
20
<210> 111
<211> 63
<212> DNA
<213> 明脉扁刺蛾β四体病毒(Thoseaasigna virus)
<400> 111
ggaagcggag agggcagagg aagtctgcta acatgcggtg acgtcgagga gaatcctgga 60
cct 63
<210> 112
<211> 21
<212> PRT
<213> 明脉扁刺蛾β四体病毒(Thoseaasigna virus)
<400> 112
Gly Ser Gly Glu Gly Arg Gly Ser Leu Leu Thr Cys Gly Asp Val Glu
1 5 10 15
Glu Asn Pro Gly Pro
20
<210> 113
<211> 69
<212> DNA
<213> 马鼻炎A病毒(Equine rhinitis A virus)
<400> 113
ggaagcggac agtgtactaa ttatgctctc ttgaaattgg ctggagatgt tgagagcaac 60
cctggacct 69
<210> 114
<211> 23
<212> PRT
<213> 马鼻炎A病毒(Equine rhinitis A virus)
<400> 114
Gly Ser Gly Gln Cys Thr Asn Tyr Ala Leu Leu Lys Leu Ala Gly Asp
1 5 10 15
Val Glu Ser Asn Pro Gly Pro
20
<210> 115
<211> 84
<212> DNA
<213> 口蹄疫病毒(Foot and Mouth Disease virus,FMDV)
<400> 115
ggaagcggag tgaaacagac tttgaatttt gaccttctca agggaagcgg agtgaaacag 60
actttgaatt ttgaccttct caag 84
<210> 116
<211> 25
<212> PRT
<213> 口蹄疫病毒(Foot and Mouth Disease virus,FMDV)
<400> 116
Gly Ser Gly Val Lys Gln Thr Leu Asn Phe Asp Leu Leu Lys Leu Ala
1 5 10 15
Gly Asp Val Glu Ser Asn Pro Gly Pro
20 25
<210> 117
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 重链正向引物1
<400> 117
gatgtgaagc ttcaggagtc 20
<210> 118
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 轻κ链正向引物1
<400> 118
gatgttttga tgacccaaac t 21
<210> 119
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 重链正向引物2
<400> 119
caggtgcagc tgaaggagtc 20
<210> 120
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 轻κ链正向引物2
<400> 120
gatattgtga tgacgcaggc t 21
<210> 121
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 重链正向引物3
<400> 121
caggtgcagc tgaagcagtc 20
<210> 122
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 轻κ链正向引物3
<400> 122
gatattgtga taacccag 18
<210> 123
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 重链正向引物4
<400> 123
caggttactc tgaaagagtc 20
<210> 124
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 轻κ链正向引物4
<400> 124
gacattgtgc tgacccaatc t 21
<210> 125
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸3
<220>
<221> misc_feature
<223> 重链正向引物5
<400> 125
gaggtccagc tgcaacaatc t 21
<210> 126
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 轻κ链正向引物5
<400> 126
gacattgtga tgacccagtc t 21
<210> 127
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 重链正向引物6
<400> 127
gaggtccagc tgcagcagtc 20
<210> 128
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 轻κ链正向引物6
<400> 128
gatattgtgc taactcagtc t 21
<210> 129
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 重链正向引物7
<400> 129
caggtccaac tgcagcagcc t 21
<210> 130
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 轻κ链正向引物7
<400> 130
gatatccaga tgacacagac t 21
<210> 131
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 重链正向引物8
<400> 131
gaggtgaagc tggtggagtc 20
<210> 132
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 轻κ链正向引物8
<400> 132
gacatccagc tgactcagtc t 21
<210> 133
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 重链正向引物9
<400> 133
gaggtgaagc tggtggaatc 20
<210> 134
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 轻κ链正向引物9
<400> 134
caaattgttc tcacccagtc t 21
<210> 135
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 重链正向引物10
<400> 135
gatgtgaact tggaagtgtc 20
<210> 136
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 轻κ链正向引物10
<400> 136
gacattctga tgacccagtc t 21
<210> 137
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 重链正向引物11
<400> 137
gaggtgcagc tggaggagtc 20
<210> 138
<211> 36
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 重链反向引物
<400> 138
ggccagtgga tagtcagatg ggggtgtcgt tttggc 36
<210> 139
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> 轻κ链反向引物
<400> 139
ggatacagtt ggtgcagcat c 21
<210> 140
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> HAdV5正向引物
<400> 140
cagctccatc tcctaactgt 20
<210> 141
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> HAdV5反向引物
<400> 141
ttcttgggca atgtatgaaa 20
<210> 142
<211> 17
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> scFv47正向引物
<400> 142
caggtccaac tgcagca 17
<210> 143
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> scFv47反向引物
<400> 143
tttgatttcc agcttggt 18
<210> 144
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> GAPDH正向引物
<400> 144
ggtcggagtc aacggatttg g 21
<210> 145
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> GAPDH反向引物
<400> 145
catgggtgga atcatattgg aac 23
<210> 146
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> IL13Rα2正向引物
<400> 146
ttgggaccta ttccagcaag gtgt 24
<210> 147
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> 合成聚核苷酸
<220>
<221> misc_feature
<223> IL13Rα2反向引物
<400> 147
cactccactc actccaaatc ccgt 24
Claims (39)
1.一种IL13Rα2结合剂,包含以下的氨基酸序列中的每一个:
NYLMN(SEQ ID NO:1);
RIDPYDGDIDYNQNFKD(SEQ ID NO:2);
GYGTAYGVDY(SEQ ID NO:3);
RASESVDNYGISFMN(SEQ ID NO:4);
AASRQGSG(SEQ ID NO:5);和
QQSKEVPWT(SEQ ID NO:6)。
2.根据权利要求1所述的IL13Rα2结合剂,包含SEQ ID NO:7和/或SEQ ID NO:8的氨基酸序列中的一个或两个。
3.根据权利要求2所述的IL13Rα2结合剂,其中SEQ ID NO:7的所述氨基酸序列经由连接子融合到SEQ ID NO:8的所述氨基酸序列。
4.根据权利要求3所述的IL13Rα2结合剂,其中所述连接子包含EEGEFSEAR(SEQ ID NO10)的氨基酸序列。
5.根据权利要求4所述的IL13Rα2结合剂,包含SEQ ID NO:13的氨基酸序列。
6.根据权利要求1到5中任一项所述的IL13Rα2结合剂,进一步包含SEQ ID NO:28的氨基酸序列,或与SEQ ID NO:28至少90%一致的氨基酸序列。
7.根据权利要求1到5中任一项所述的IL13Rα2结合剂,进一步包含SEQ ID NO:30的氨基酸序列,或与SEQ ID NO:30至少90%一致的氨基酸序列。
8.根据权利要求1到5中任一项所述的IL13Rα2结合剂,所述IL13Rα2结合剂是抗体或其抗原结合片段,其中所述其抗原结合片段至少包含SEQ ID NO:1-6的氨基酸序列。
9.根据权利要求8所述的IL13Rα2结合剂,其中所述结合剂是为单链可变片段(scFv)的抗原结合片段。
10.根据权利要求9所述的IL13Rα2结合剂,进一步包含METDTLLLWVLLLWVPGSTGD(SEQID NO:9)的Igκ前导序列。
11.根据权利要求9或10所述的IL13Rα2结合剂,进一步包含EEGEFSEAR(SEQ ID NO 10)的连接子序列。
12.根据权利要求9或10所述的IL13Rα2结合剂,进一步包含GGPEQKLISEEDLN(SEQ IDNO:11)的Myc标签序列。
13.根据权利要求9或10所述的IL13Rα2结合剂,进一步包含HHHHHH(SEQ ID NO:12)的His标签序列。
14.根据权利要求9或10所述的IL13Rα2结合剂,包含SEQ ID NO:14的氨基酸序列。
15.根据权利要求1到5和9到10中任一项所述的IL13Rα2结合剂,其结合到人类IL13Rα2但不结合到人类IL13Rα1。
16.根据权利要求1到5和9到10中任一项所述的IL13Rα2结合剂,具有不大于1.39×10- 9M的针对人类IL13Rα2的平衡解离常数(KD)。
17.一种缀合物,包含共价连接到效应域的根据权利要求1到16中任一项所述的IL13Rα2结合剂。
18.根据权利要求17所述的缀合物,其中所述缀合物是融合蛋白或嵌合蛋白。
19.根据权利要求17或18所述的缀合物,其中所述效应域是细胞毒素、细胞凋亡标签、T细胞信号传导域或标记物。
20.根据权利要求19所述的缀合物,其中所述效应域是T细胞信号传导域并且所述缀合物是IL13Rα2特异性嵌合抗原受体(CAR)。
21.根据权利要求20所述的缀合物,其中所述细胞凋亡标签是TRAIL蛋白或其一部分,任选地,其中所述细胞凋亡标签包含SEQ ID NO:27的氨基酸序列。
22.根据权利要求21所述的缀合物,包含SEQ ID NO:25的氨基酸序列。
23.一种核酸,编码根据权利要求1到16中任一项所述的IL13Rα2结合剂,或根据权利要求17到22中任一项所述的缀合物。
24.根据权利要求23所述的核酸,包含SEQ ID NO:15或SEQ ID NO:16或SEQ ID NO:15和16这两者的序列。
25.一种载体,包含根据权利要求23或24所述的核酸。
26.根据权利要求25所述的载体,其中所述载体是病毒。
27.根据权利要求26所述的载体,其中所述病毒是腺病毒。
28.根据权利要求27所述的载体,其中所述腺病毒是血清5型腺病毒。
29.一种重组聚核苷酸,包含根据权利要求26到28中任一项所述的载体,或根据权利要求23或24中任一项所述的核酸。
30.根据权利要求29所述的重组聚核苷酸,其中所述聚核苷酸是Ad5-纤维-纤维蛋白三聚域-scFv47,其中所述Ad5-纤维-纤维蛋白三聚域-scFv47编码包含SEQ ID NO:13的氨基酸序列的scFv47。
31.一种宿主细胞,包含根据权利要求25所述的载体。
32.一种医药组合物,包含根据权利要求1到16中任一项所述的结合剂、根据权利要求17到22中任一项所述的缀合物、根据权利要求23或24所述的核酸、根据权利要求25到28中任一项所述的载体、根据权利要求29或30中任一项所述的重组聚核苷酸或根据权利要求31所述的宿主细胞,和药学上可接受的载剂。
33.根据权利要求1到16中任一项所述的结合剂或根据权利要求17到22中任一项所述的缀合物在制备用于一种治疗个体的癌症的方法的药物中的用途,其中所述方法包括以可有效治疗所述个体的所述癌症的量向所述个体给予根据权利要求1到16中任一项所述的结合剂,或根据权利要求17到22中任一项所述的缀合物。
34.根据权利要求33所述的用途,其中所述癌症是多形性成胶质细胞瘤或结肠癌。
35.根据权利要求1到16中任一项所述的结合剂或根据权利要求17到22中任一项所述的缀合物在制备用于一种鉴别IL13Rα2阳性癌细胞的方法的试剂盒中的用途,其中所述方法包括
a.使生物样品与可检测量的根据权利要求1到16中任一项所述的结合剂或根据权利要求17到22中任一项所述的缀合物接触;和
b.测量结合到所述生物样品的至少一种细胞的所述结合剂或缀合物的量,由此鉴别IL13Rα2阳性癌细胞。
36.根据权利要求35所述的用途,其中所述生物样品是个体的身体内的细胞块、组织或器官。
37.根据权利要求35所述的用途,其中所述IL13Rα2阳性癌细胞是神经胶质瘤细胞。
38.根据权利要求35所述的用途,其中所述结合剂包含scFv47,其中所述scFv47包含SEQ ID NO:13的氨基酸序列。
39.根据权利要求35所述的用途,其中所述结合剂是根据权利要求17所述的缀合物,并且其中所述效应域是放射性标记物、荧光标记物、催化量热或荧光反应的酶、酶底物、固体基质、生物素或抗生物素蛋白。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562107984P | 2015-01-26 | 2015-01-26 | |
| US62/107984 | 2015-01-26 | ||
| PCT/US2016/014984 WO2016123142A1 (en) | 2015-01-26 | 2016-01-26 | IL13RAα2 BINDING AGENTS AND USE THEREOF IN CANCER TREATMENT |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN107683289A CN107683289A (zh) | 2018-02-09 |
| CN107683289B true CN107683289B (zh) | 2021-08-06 |
Family
ID=56544250
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201680018571.5A Active CN107683289B (zh) | 2015-01-26 | 2016-01-26 | IL13Rα2结合剂和其在癌症治疗中的用途 |
Country Status (6)
| Country | Link |
|---|---|
| US (3) | US10308719B2 (zh) |
| EP (1) | EP3250609A4 (zh) |
| JP (1) | JP7264592B2 (zh) |
| CN (1) | CN107683289B (zh) |
| HK (1) | HK1245287A1 (zh) |
| WO (1) | WO2016123142A1 (zh) |
Families Citing this family (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016123142A1 (en) | 2015-01-26 | 2016-08-04 | The University Of Chicago | IL13RAα2 BINDING AGENTS AND USE THEREOF IN CANCER TREATMENT |
| WO2016123143A1 (en) * | 2015-01-26 | 2016-08-04 | The University Of Chicago | CAR T-CELLS RECOGNIZING CANCER-SPECIFIC IL 13Rα2 |
| US11446398B2 (en) | 2016-04-11 | 2022-09-20 | Obsidian Therapeutics, Inc. | Regulated biocircuit systems |
| EP3645566A1 (en) * | 2017-06-30 | 2020-05-06 | ASLAN Pharmaceuticals Pte Ltd | Method of treatment using il-13r antibody |
| US20200165347A1 (en) * | 2017-06-30 | 2020-05-28 | Aslan Pharmaceuticals Pte Ltd | Method of treatment using il-13r antibody |
| EA202091982A1 (ru) * | 2018-03-14 | 2021-06-10 | Сиэтл Чилдрен'С Хоспитал (Дба Сиэтл Чилдрен'С Ресёрч Инститьют) | Химерный антигенный рецептор к рецептору il-13 альфа 2 (il13r2) для опухолеспецифической т-клеточной иммунотерапии |
| GB201809700D0 (en) * | 2018-06-13 | 2018-08-01 | Singapore Health Serv Pte Ltd | IL-11 antibodies |
| WO2020023888A2 (en) * | 2018-07-26 | 2020-01-30 | TCR2 Therapeutics Inc. | Compositions and methods for tcr reprogramming using target specific fusion proteins |
| EP3946469A4 (en) * | 2019-03-26 | 2022-12-28 | The Penn State Research Foundation | METHODS AND MATERIALS FOR THE TREATMENT OF CANCER |
| EP3955955A1 (en) * | 2019-04-19 | 2022-02-23 | Synerkine Pharma B.V. | A fusion protein comprising il13 |
| US20230312731A1 (en) * | 2020-04-11 | 2023-10-05 | Northwestern University | Humanized antibody targeting the tumor associated antigen il13ra2 |
| CA3173893A1 (en) * | 2020-05-15 | 2021-11-18 | Di YU | Anti-il13r.alpha.2 antibodies, antigen-binding fragments and uses thereof |
| GB202011993D0 (en) * | 2020-07-31 | 2020-09-16 | Adc Therapeutics Sa | ANTI-IL 13Ra2 antibodies |
| WO2022174808A1 (zh) * | 2021-02-19 | 2022-08-25 | 上海齐鲁制药研究中心有限公司 | 针对IL-13Rα2的抗体及其应用 |
| EP4314051A1 (en) * | 2021-03-31 | 2024-02-07 | Consejo Superior De Investigaciones Científicas | Antibody and use thereof for the treatment of cancer |
| JP2024514101A (ja) * | 2021-04-01 | 2024-03-28 | ザ ユナイテッド ステイツ オブ アメリカ, アズ リプレゼンテッド バイ ザ セクレタリー, デパートメント オブ ヘルス アンド ヒューマン サービシーズ | Il-13ra2キメラ抗原受容体および使用方法 |
| EP4176895A1 (en) * | 2021-11-08 | 2023-05-10 | AvenCell Europe GmbH | Targeting modules against il13ra2 or her2 for use in combination with a chimeric antigen receptor |
| US20230285580A1 (en) * | 2021-11-19 | 2023-09-14 | Adc Therapeutics Sa | Anti-il-13ralpha2 conjugates |
| WO2023225531A2 (en) * | 2022-05-16 | 2023-11-23 | Northwestern University | Il15-modified car t cells for dual targeting |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102241774A (zh) * | 2010-05-27 | 2011-11-16 | 四川大学 | 重组IgE-Fc-抗EGFR单链抗体融合蛋白及其制备方法和用途 |
| WO2014152361A1 (en) * | 2013-03-15 | 2014-09-25 | Wake Forest University Health Sciences | Antibodies against human and canine il-13ra2 |
Family Cites Families (90)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3773919A (en) | 1969-10-23 | 1973-11-20 | Du Pont | Polylactide-drug mixtures |
| US4450150A (en) | 1973-05-17 | 1984-05-22 | Arthur D. Little, Inc. | Biodegradable, implantable drug delivery depots, and method for preparing and using the same |
| US4263428A (en) | 1978-03-24 | 1981-04-21 | The Regents Of The University Of California | Bis-anthracycline nucleic acid function inhibitors and improved method for administering the same |
| US4342776A (en) | 1979-11-05 | 1982-08-03 | Merck & Co., Inc. | 4-Substituted-3-hydroxy-3-pyrroline-2,5-dione inhibitors of glycolic acid oxidase |
| EP0052322B1 (de) | 1980-11-10 | 1985-03-27 | Gersonde, Klaus, Prof. Dr. | Verfahren zur Herstellung von Lipid-Vesikeln durch Ultraschallbehandlung, Anwendung des Verfahrens und Vorrichtung zur Durchführung des Verfahrens |
| US4399276A (en) | 1981-01-09 | 1983-08-16 | Kabushiki Kaisha Yakult Honsha | 7-Substituted camptothecin derivatives |
| IE52535B1 (en) | 1981-02-16 | 1987-12-09 | Ici Plc | Continuous release pharmaceutical compositions |
| US4957939A (en) | 1981-07-24 | 1990-09-18 | Schering Aktiengesellschaft | Sterile pharmaceutical compositions of gadolinium chelates useful enhancing NMR imaging |
| US4473692A (en) | 1981-09-04 | 1984-09-25 | Kabushiki Kaisha Yakult Honsha | Camptothecin derivatives and process for preparing same |
| JPS5839685A (ja) | 1981-09-04 | 1983-03-08 | Yakult Honsha Co Ltd | 新規なカンプトテシン誘導体及びその製造法 |
| DE3374837D1 (en) | 1982-02-17 | 1988-01-21 | Ciba Geigy Ag | Lipids in the aqueous phase |
| JPS58154582A (ja) | 1982-03-10 | 1983-09-14 | Yakult Honsha Co Ltd | 新規なカンプトテシン誘導体およびその製造法 |
| DE3218121A1 (de) | 1982-05-14 | 1983-11-17 | Leskovar, Peter, Dr.-Ing., 8000 München | Arzneimittel zur tumorbehandlung |
| US4472509A (en) | 1982-06-07 | 1984-09-18 | Gansow Otto A | Metal chelate conjugated monoclonal antibodies |
| US4526988A (en) | 1983-03-10 | 1985-07-02 | Eli Lilly And Company | Difluoro antivirals and intermediate therefor |
| JPS6019790A (ja) | 1983-07-14 | 1985-01-31 | Yakult Honsha Co Ltd | 新規なカンプトテシン誘導体 |
| HUT35524A (en) | 1983-08-02 | 1985-07-29 | Hoechst Ag | Process for preparing pharmaceutical compositions containing regulatory /regulative/ peptides providing for the retarded release of the active substance |
| US4615885A (en) | 1983-11-01 | 1986-10-07 | Terumo Kabushiki Kaisha | Pharmaceutical composition containing urokinase |
| EP0184365B1 (en) | 1984-12-04 | 1993-08-04 | Eli Lilly And Company | Improvements in the treatment of tumors in mammals |
| US5037630A (en) | 1985-01-14 | 1991-08-06 | Neorx Corporation | Metal radionuclide labeled proteins for diagnosis and therapy |
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| GB8607679D0 (en) | 1986-03-27 | 1986-04-30 | Winter G P | Recombinant dna product |
| US4946778A (en) | 1987-09-21 | 1990-08-07 | Genex Corporation | Single polypeptide chain binding molecules |
| US4965392A (en) | 1987-03-26 | 1990-10-23 | Neorx Corporation | Chelating compounds for metal-radionuclide labeled proteins |
| US5223608A (en) | 1987-08-28 | 1993-06-29 | Eli Lilly And Company | Process for and intermediates of 2',2'-difluoronucleosides |
| US5004758A (en) | 1987-12-01 | 1991-04-02 | Smithkline Beecham Corporation | Water soluble camptothecin analogs useful for inhibiting the growth of animal tumor cells |
| US5223409A (en) | 1988-09-02 | 1993-06-29 | Protein Engineering Corp. | Directed evolution of novel binding proteins |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| EP0418099B1 (en) | 1989-09-15 | 2001-12-19 | Research Triangle Institute | Process of preparation of 10, 11-Methylenedioxy-20 (RS) camptothecin and 10, 11-methylenedioxy-20 (S) - camptothecin analog |
| GB9015198D0 (en) | 1990-07-10 | 1990-08-29 | Brien Caroline J O | Binding substance |
| US5545806A (en) | 1990-08-29 | 1996-08-13 | Genpharm International, Inc. | Ransgenic non-human animals for producing heterologous antibodies |
| AU8507191A (en) | 1990-08-29 | 1992-03-30 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5780279A (en) | 1990-12-03 | 1998-07-14 | Genentech, Inc. | Method of selection of proteolytic cleavage sites by directed evolution and phagemid display |
| CA2095633C (en) | 1990-12-03 | 2003-02-04 | Lisa J. Garrard | Enrichment method for variant proteins with altered binding properties |
| US6225447B1 (en) | 1991-05-15 | 2001-05-01 | Cambridge Antibody Technology Ltd. | Methods for producing members of specific binding pairs |
| DE69230142T2 (de) | 1991-05-15 | 2000-03-09 | Cambridge Antibody Technology Ltd. | Verfahren zur herstellung von spezifischen bindungspaargliedern |
| US5858657A (en) | 1992-05-15 | 1999-01-12 | Medical Research Council | Methods for producing members of specific binding pairs |
| US5639641A (en) | 1992-09-09 | 1997-06-17 | Immunogen Inc. | Resurfacing of rodent antibodies |
| US5855885A (en) | 1993-01-22 | 1999-01-05 | Smith; Rodger | Isolation and production of catalytic antibodies using phage technology |
| FR2707988B1 (fr) | 1993-07-21 | 1995-10-13 | Pf Medicament | Nouveaux dérivés antimitotiques des alcaloïdes binaires du catharantus rosesus, leur procédé de préparation et les compositions pharmaceutiques les comprenant. |
| US5702892A (en) | 1995-05-09 | 1997-12-30 | The United States Of America As Represented By The Department Of Health And Human Services | Phage-display of immunoglobulin heavy chain libraries |
| US6265150B1 (en) | 1995-06-07 | 2001-07-24 | Becton Dickinson & Company | Phage antibodies |
| US6699843B2 (en) | 1995-06-07 | 2004-03-02 | Gilead Sciences, Inc. | Method for treatment of tumors using nucleic acid ligands to PDGF |
| US5714352A (en) | 1996-03-20 | 1998-02-03 | Xenotech Incorporated | Directed switch-mediated DNA recombination |
| US6057098A (en) | 1997-04-04 | 2000-05-02 | Biosite Diagnostics, Inc. | Polyvalent display libraries |
| KR20010040819A (ko) | 1998-02-10 | 2001-05-15 | 가마꾸라 아끼오 | 제어방출형 제제 |
| ATE342350T1 (de) * | 1998-02-17 | 2006-11-15 | Uab Research Foundation | Modifizierte adenoviren welche ein faserersatzprotein enthalten |
| AU756796B2 (en) | 1998-10-16 | 2003-01-23 | Government Of The United States Of America, As Represented By The Secretary Of The Department Of Health And Human Services, The | Combination therapy with VIP antagonist |
| GB2344287A (en) | 1998-12-03 | 2000-06-07 | Ferring Bv | Controlled release pharmaceutical formulation |
| US6943152B1 (en) | 1999-06-10 | 2005-09-13 | Merial | DNA vaccine-PCV |
| EP1196435A1 (en) * | 1999-07-06 | 2002-04-17 | Got-A-Gene AB | Recombinant adenovirus |
| WO2001058479A1 (en) | 2000-02-08 | 2001-08-16 | The Penn State Research Foundation | Immunotherapy using interleukin 13 receptor subunit alpha 2 |
| US7754208B2 (en) | 2001-01-17 | 2010-07-13 | Trubion Pharmaceuticals, Inc. | Binding domain-immunoglobulin fusion proteins |
| CN1494552A (zh) | 2001-01-19 | 2004-05-05 | ·��ά��֢�о�Ժ | Flt4(VEGFR-3)作为靶用于肿瘤成像和抗肿瘤治疗 |
| US7446190B2 (en) | 2002-05-28 | 2008-11-04 | Sloan-Kettering Institute For Cancer Research | Nucleic acids encoding chimeric T cell receptors |
| AU2003279842A1 (en) | 2002-10-04 | 2004-05-04 | Microchips, Inc. | Medical device for controlled drug delivery and cardiac monitoring and/or stimulation |
| AU2004204494B2 (en) | 2003-01-09 | 2011-09-29 | Macrogenics, Inc. | Identification and engineering of antibodies with variant Fc regions and methods of using same |
| WO2004087758A2 (en) | 2003-03-26 | 2004-10-14 | Neopharm, Inc. | Il 13 receptor alpha 2 antibody and methods of use |
| TWI353991B (en) | 2003-05-06 | 2011-12-11 | Syntonix Pharmaceuticals Inc | Immunoglobulin chimeric monomer-dimer hybrids |
| US20050282233A1 (en) | 2004-03-05 | 2005-12-22 | Ludwig Institute For Cancer Research | Multivalent antibody materials and methods for VEGF/PDGF family of growth factors |
| US7375245B2 (en) * | 2004-07-07 | 2008-05-20 | Everlight Usa, Inc. | N-(4-oxo-butanoic acid) -L-amino acid-ester derivatives and methods of preparation thereof |
| US20090317329A2 (en) | 2005-07-05 | 2009-12-24 | Baker Idi Heart & Diabetes Institute Holdings Limited | Anticoagulation agent and uses thereof |
| CA2651283A1 (en) | 2006-05-15 | 2007-11-22 | Wisconsin Alumni Research Foundation | Pulmonary delivery of 1.alpha.,25-dihydroxyvitamin d3 and co-administration of parathyroid hormone or calcitonin |
| FR2902092B1 (fr) | 2006-06-07 | 2008-09-05 | Sapelem Soc Par Actions Simpli | Appareil de manutention de charge |
| KR101034888B1 (ko) | 2007-04-19 | 2011-05-17 | 동아제약주식회사 | 지속제어 방출 양상을 갖는 당조절 펩타이드 함유 생분해성고분자 미립구 및 그 제조방법 |
| US8234784B2 (en) | 2008-02-13 | 2012-08-07 | Younger Steven W | Valve piston repositioning apparatus and method |
| PL3006459T3 (pl) | 2008-08-26 | 2022-01-17 | City Of Hope | Sposób i kompozycje dla wzmocnionego działania efektorowego komórek t przeciw guzowi nowotworowemu |
| HUE030854T2 (en) * | 2010-02-24 | 2017-06-28 | Immunogen Inc | Immunoconjugates against folate receptor 1 and their use |
| JO3756B1 (ar) | 2010-11-23 | 2021-01-31 | Regeneron Pharma | اجسام مضادة بشرية لمستقبلات الجلوكاجون |
| CN103890193A (zh) * | 2011-08-29 | 2014-06-25 | 心脏Dx公司 | 用于确定吸烟状态的方法和组合物 |
| BR112014008849A2 (pt) | 2011-10-20 | 2017-09-12 | Us Health | receptores quiméricos de antígeno anti-cd22 |
| WO2013063419A2 (en) | 2011-10-28 | 2013-05-02 | The Trustees Of The University Of Pennsylvania | A fully human, anti-mesothelin specific chimeric immune receptor for redirected mesothelin-expressing cell targeting |
| EP2814846B1 (en) | 2012-02-13 | 2020-01-08 | Seattle Children's Hospital d/b/a Seattle Children's Research Institute | Bispecific chimeric antigen receptors and therapeutic uses thereof |
| US20130280220A1 (en) | 2012-04-20 | 2013-10-24 | Nabil Ahmed | Chimeric antigen receptor for bispecific activation and targeting of t lymphocytes |
| US10117896B2 (en) | 2012-10-05 | 2018-11-06 | The Trustees Of The University Of Pennsylvania | Use of a trans-signaling approach in chimeric antigen receptors |
| AU2014218976B2 (en) | 2013-02-20 | 2018-11-15 | Novartis Ag | Treatment of cancer using humanized anti-EGFRvIII chimeric antigen receptor |
| US9573988B2 (en) | 2013-02-20 | 2017-02-21 | Novartis Ag | Effective targeting of primary human leukemia using anti-CD123 chimeric antigen receptor engineered T cells |
| CA2905352A1 (en) | 2013-03-14 | 2014-09-25 | Bellicum Pharmaceuticals, Inc. | Methods for controlling t cell proliferation |
| US9657105B2 (en) | 2013-03-15 | 2017-05-23 | City Of Hope | CD123-specific chimeric antigen receptor redirected T cells and methods of their use |
| US9745368B2 (en) | 2013-03-15 | 2017-08-29 | The Trustees Of The University Of Pennsylvania | Targeting cytotoxic cells with chimeric receptors for adoptive immunotherapy |
| US9446105B2 (en) | 2013-03-15 | 2016-09-20 | The Trustees Of The University Of Pennsylvania | Chimeric antigen receptor specific for folate receptor β |
| UY35468A (es) | 2013-03-16 | 2014-10-31 | Novartis Ag | Tratamiento de cáncer utilizando un receptor quimérico de antígeno anti-cd19 |
| US10358494B2 (en) | 2013-05-03 | 2019-07-23 | Ohio State Innovation Foundation | CS1-specific chimeric antigen receptor engineered immune effector cells |
| CN104140974B (zh) | 2013-05-08 | 2017-09-29 | 科济生物医药(上海)有限公司 | 编码gpc‑3嵌合抗原受体蛋白的核酸及表达gpc‑3嵌合抗原受体蛋白的t淋巴细胞 |
| WO2014186469A2 (en) | 2013-05-14 | 2014-11-20 | Board Of Regents, The University Of Texas System | Human application of engineered chimeric antigen receptor (car) t-cells |
| CA2913052A1 (en) | 2013-05-24 | 2014-11-27 | Board Of Regents, The University Of Texas System | Chimeric antigen receptor-targeting monoclonal antibodies |
| EP3008092A4 (en) | 2013-06-14 | 2017-01-11 | The University Of Houston System | Targeting tumor neovasculature with modified chimeric antigen receptors |
| WO2014208760A1 (ja) | 2013-06-27 | 2014-12-31 | 国立大学法人九州大学 | 抗がんモノクローナル抗体及びその製造方法 |
| EA201990575A3 (ru) | 2013-10-08 | 2019-11-29 | Cd19-специфический химерный антигенный рецептор и его применения | |
| WO2016123142A1 (en) | 2015-01-26 | 2016-08-04 | The University Of Chicago | IL13RAα2 BINDING AGENTS AND USE THEREOF IN CANCER TREATMENT |
-
2016
- 2016-01-26 WO PCT/US2016/014984 patent/WO2016123142A1/en active Application Filing
- 2016-01-26 CN CN201680018571.5A patent/CN107683289B/zh active Active
- 2016-01-26 JP JP2017558362A patent/JP7264592B2/ja active Active
- 2016-01-26 US US15/545,945 patent/US10308719B2/en active Active
- 2016-01-26 EP EP16743989.2A patent/EP3250609A4/en active Pending
-
2018
- 2018-04-04 HK HK18104508.7A patent/HK1245287A1/zh unknown
-
2019
- 2019-04-16 US US16/385,853 patent/US10851169B2/en active Active
-
2020
- 2020-11-19 US US16/949,900 patent/US11827712B2/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102241774A (zh) * | 2010-05-27 | 2011-11-16 | 四川大学 | 重组IgE-Fc-抗EGFR单链抗体融合蛋白及其制备方法和用途 |
| WO2014152361A1 (en) * | 2013-03-15 | 2014-09-25 | Wake Forest University Health Sciences | Antibodies against human and canine il-13ra2 |
Non-Patent Citations (3)
| Title |
|---|
| Characterization and Immunotherapeutic Implications for a Novel Antibody Targeting Interleukin (IL)-13 Receptor α2;Irina V. Balyasnikova,et al.;《THE JOURNAL OF BIOLOGICAL CHEMISTRY》;20120831;第287卷(第36期);摘要以及第30215-30227页全部 * |
| Influence of Structural Variations on Biological Activity of Anti-PSMA scFv and Immunotoxins;PATRICK BÜHLER,et al.;《ANTICANCER RESEARCH》;20100930;第30卷(第9期);第3374页左栏倒数第2段以及图1 * |
| Irina V. Balyasnikova,et al..Characterization and Immunotherapeutic Implications for a Novel Antibody Targeting Interleukin (IL)-13 Receptor α2.《THE JOURNAL OF BIOLOGICAL CHEMISTRY》.2012,第287卷(第36期),第30215-30227页. * |
Also Published As
| Publication number | Publication date |
|---|---|
| US10308719B2 (en) | 2019-06-04 |
| EP3250609A1 (en) | 2017-12-06 |
| JP7264592B2 (ja) | 2023-04-25 |
| WO2016123142A1 (en) | 2016-08-04 |
| US20190300616A1 (en) | 2019-10-03 |
| EP3250609A4 (en) | 2018-07-11 |
| US20180134796A1 (en) | 2018-05-17 |
| HK1245287A1 (zh) | 2018-08-24 |
| JP2018506301A (ja) | 2018-03-08 |
| US11827712B2 (en) | 2023-11-28 |
| CN107683289A (zh) | 2018-02-09 |
| US10851169B2 (en) | 2020-12-01 |
| US20210221895A1 (en) | 2021-07-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107683289B (zh) | IL13Rα2结合剂和其在癌症治疗中的用途 | |
| CN107835820B (zh) | 识别癌症特异性IL13Rα2的CAR T细胞 | |
| JP7333104B2 (ja) | B7-h3に対するモノクローナル抗体および細胞治療におけるその使用 | |
| CN107530419B (zh) | 治疗疾病的组合疗法 | |
| TW202039575A (zh) | 新穎之抗ccr8抗體 | |
| US10865247B2 (en) | Anti-human CD69 antibody, and use thereof for medical purposes | |
| CN113195542B (zh) | Cd30-结合部分、嵌合抗原受体及其用途 | |
| KR20210142638A (ko) | Cd3 항원 결합 단편 및 이의 응용 | |
| WO2022152186A1 (zh) | 靶向cd5的全人源单域串联嵌合抗原受体(car)及其应用 | |
| TW202031687A (zh) | 一種融合蛋白及其用途 | |
| JP2021514625A (ja) | 抗muc1抗体およびil−15を含む融合タンパク質構築物 | |
| CN114641310A (zh) | 治疗癌症和其他疾病的靶向α3β1整合素 | |
| WO2020108636A1 (zh) | 全人抗gitr抗体及其制备方法 | |
| JP2020508636A (ja) | IFN−γ誘導性制御性T細胞転換性抗癌(IRTCA)抗体およびその使用 | |
| CN116323671A (zh) | 具有增加的选择性的多靶向性双特异性抗原结合分子 | |
| WO2024093147A1 (zh) | 一种特异性结合CD44的v5外显子的抗体及其用途 | |
| US11883433B1 (en) | Chimeric antigen receptor comprising anti-mesothelin scFv, and use thereof | |
| CN114933654B (zh) | 靶向cd123的抗体、嵌合抗原受体及其用途 | |
| CN113166264B (zh) | 一种分离的抗原结合蛋白及其用途 | |
| WO2023173393A1 (zh) | 结合b7-h3的抗体及其用途 | |
| CN113164601B (zh) | 一种分离的抗原结合蛋白及其用途 | |
| TW202235436A (zh) | Siglec-15結合蛋白的製備及其用途 | |
| CN117377687A (zh) | 抗癌组合疗法中的ltbr激动剂 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |