CN101281520A - Interactive physical training video search method based on non-supervision learning and semantic matching characteristic - Google Patents
Interactive physical training video search method based on non-supervision learning and semantic matching characteristic Download PDFInfo
- Publication number
- CN101281520A CN101281520A CNA2007100651801A CN200710065180A CN101281520A CN 101281520 A CN101281520 A CN 101281520A CN A2007100651801 A CNA2007100651801 A CN A2007100651801A CN 200710065180 A CN200710065180 A CN 200710065180A CN 101281520 A CN101281520 A CN 101281520A
- Authority
- CN
- China
- Prior art keywords
- video
- semantic
- model
- sequence
- retrieval
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims abstract description 32
- 230000002452 interceptive effect Effects 0.000 title claims abstract description 18
- 238000012549 training Methods 0.000 title claims description 24
- 230000007246 mechanism Effects 0.000 claims abstract description 27
- 239000011159 matrix material Substances 0.000 claims description 48
- 238000005516 engineering process Methods 0.000 claims description 33
- 238000004422 calculation algorithm Methods 0.000 claims description 22
- 239000000284 extract Substances 0.000 claims description 14
- 238000000605 extraction Methods 0.000 claims description 13
- 238000010586 diagram Methods 0.000 claims description 9
- 230000006870 function Effects 0.000 claims description 9
- 230000001629 suppression Effects 0.000 claims description 9
- 230000008878 coupling Effects 0.000 claims description 6
- 238000010168 coupling process Methods 0.000 claims description 6
- 238000005859 coupling reaction Methods 0.000 claims description 6
- 230000003993 interaction Effects 0.000 claims description 6
- 239000003550 marker Substances 0.000 claims description 6
- 230000002860 competitive effect Effects 0.000 claims description 4
- 238000005457 optimization Methods 0.000 claims description 4
- 238000004364 calculation method Methods 0.000 claims description 3
- 238000005070 sampling Methods 0.000 claims description 3
- GNFTZDOKVXKIBK-UHFFFAOYSA-N 3-(2-methoxyethoxy)benzohydrazide Chemical compound COCCOC1=CC=CC(C(=O)NN)=C1 GNFTZDOKVXKIBK-UHFFFAOYSA-N 0.000 claims description 2
- FGUUSXIOTUKUDN-IBGZPJMESA-N C1(=CC=CC=C1)N1C2=C(NC([C@H](C1)NC=1OC(=NN=1)C1=CC=CC=C1)=O)C=CC=C2 Chemical compound C1(=CC=CC=C1)N1C2=C(NC([C@H](C1)NC=1OC(=NN=1)C1=CC=CC=C1)=O)C=CC=C2 FGUUSXIOTUKUDN-IBGZPJMESA-N 0.000 claims description 2
- YTAHJIFKAKIKAV-XNMGPUDCSA-N [(1R)-3-morpholin-4-yl-1-phenylpropyl] N-[(3S)-2-oxo-5-phenyl-1,3-dihydro-1,4-benzodiazepin-3-yl]carbamate Chemical compound O=C1[C@H](N=C(C2=C(N1)C=CC=C2)C1=CC=CC=C1)NC(O[C@H](CCN1CCOCC1)C1=CC=CC=C1)=O YTAHJIFKAKIKAV-XNMGPUDCSA-N 0.000 claims description 2
- 230000000694 effects Effects 0.000 abstract description 3
- 230000008569 process Effects 0.000 description 6
- 230000000007 visual effect Effects 0.000 description 6
- 238000013507 mapping Methods 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000005540 biological transmission Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 238000012163 sequencing technique Methods 0.000 description 2
- NAWXUBYGYWOOIX-SFHVURJKSA-N (2s)-2-[[4-[2-(2,4-diaminoquinazolin-6-yl)ethyl]benzoyl]amino]-4-methylidenepentanedioic acid Chemical compound C1=CC2=NC(N)=NC(N)=C2C=C1CCC1=CC=C(C(=O)N[C@@H](CC(=C)C(O)=O)C(O)=O)C=C1 NAWXUBYGYWOOIX-SFHVURJKSA-N 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 230000003203 everyday effect Effects 0.000 description 1
- 238000002386 leaching Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 238000003909 pattern recognition Methods 0.000 description 1
- 230000008447 perception Effects 0.000 description 1
- 238000003825 pressing Methods 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 238000012797 qualification Methods 0.000 description 1
- 230000001568 sexual effect Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 238000005728 strengthening Methods 0.000 description 1
- 238000005303 weighing Methods 0.000 description 1
Images




Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Image Analysis (AREA)
Abstract
The invention discloses an interactive video retrieval method based on unsupervised learning and semantic matching features, which comprises the steps of extracting image bottom layer features and model matching sequence features from the video image frame level of a video database; extracting semantic matching features from the high-level semantic level of image bottom layer features; performing unsupervised learning on the extracted model matching sequence features and semantic matching features, establishing retrieval and direct retrieval based on unsupervised learning, and forming an interactive interface by related feedback. The middle layer features, high layer features, unsupervised retrieval mechanism and interactive mechanism of an integrated video compose a set of new complete video retrieval system, which precisely measures the time-space sequence information of a video object, therefore better retrieval effect is achieved, the semantic understand of a sports video theme is developed, the online calculating complexity and retrieval time of a system are reduced, and the interactive interface greatly improves the retrieval performance of the system.
Description
Technical field
The present invention relates to the Computer Applied Technology field, particularly the multimedia retrieval technology.
Background technology
Along with the develop rapidly of multimedia technology and computer network, the whole world comprises that the multi-medium data of digital picture, audio frequency, video increases with surprising rapidity.The multi-medium data of thousands of megabyte that every day is newly-generated is because the randomness of its distribution, just as a large amount of useful informations that wherein comprised that flooded of mercilessness as the flood that spreads unchecked.In the face of so abundant and be dispersed in worldwide magnanimity multimedia resource; how the user could effectively utilize information and internet new technology to realize quick location to required multimedia resource; conveniently obtaining with effective management has become very pressing issues, also makes the multimedia retrieval technology become a very active research field gradually.
Content-based multimedia retrieval is meant that physical content and semantic content that multi-medium data is contained carry out Computer Analysis and understanding, to make things convenient for user inquiring, its essence is exactly to unordered multimedia data stream structuring, extracts semantic information, guarantees that content of multimedia can be retrieved fast.Content-based Video Retrieval and CBIR are two most important branches of multimedia retrieval.In recent years, because coding, computer media are handled and the network transmission technology develop rapidly, the user can inquire about, appreciate and produce colourful video data in real time by high speed internet, as film, animation, news and sports cast etc., and utilize the automatic processing video data stream of computing machine.Video has become people's transmission and has obtained one of main path of information.In essence, the continuous data stream that video is made up of the continuous images frame sequence is the three dimensional object that two-dimensional digital image and time dimension constitute.Principal feature is as follows: (1) video data compares to image and comprises more visual information and semantic information; (2) data volume of video is huge; (3) abstract of video, structuring degree are low, and it is effectively managed and retrieval easily exists very big difficulty.Therefore, Content-based Video Retrieval has become one of the most popular research topic of Computer Applied Technology and area of pattern recognition, has very wide application prospect.
Video data is exactly image sequence in essence, and video features used in the video frequency searching also is made up of the low-level image feature of picture frame, and used search mechanism and thought have also been established solid foundation for the development of video frequency searching in the image retrieval simultaneously.Therefore the basic fundamental of image retrieval can be described as a required link.CBIR (CBIR, Content-based ImageRetrieval) is meant that direct employing picture material carries out the retrieval technique of image information inquiry.Its main thought is that the low layer characteristics of image such as spatial relationship of the color, texture, shape and the object that comprise according to image come analysis image information, and the proper vector of setting up image is as index; Generally provide the sample image during user search, system extracts the individual features vector of this sample image, and the proper vector with all objects that are retrieved in the database compares then, and will return to the user with the image of sample feature similarity.
Content-based Video Retrieval mainly is visual signature and the space-time characteristic that depends on video.Retrieval mode commonly used is based on the retrieval of video example, and the user submits video example to, and searching system is returned the similar video that the user needs from large-scale video database.Video data is the three dimensional object that is made of two-dimensional space and time, and the similarity measurement that how to define between the video is a difficult point, needs to solve following key issue:
(1) video is not the set of simple frame sequence, but the hierarchical structure of forming by scene-group-camera lens-key frame, measuring similarity is the prerequisite of video comparison on which level between video;
(2) visual signature of key frame is the basis of whole video visual signature, but every video all has a considerable amount of key frames; For large-scale video database, the memory space of each key frame visual signature of all videos and mutual number of comparisons all are very considerable;
Whether (3) two videos are similar is a very complicated problems, and different user has different understanding, and the artificial subjective factor that mixing wants video comparison algorithm reasonable in design must take all factors into consideration various factors as far as possible.
Introduce these new ideas of camera lens centroid vector based on the video frequency search system of camera lens centroid vector, calculate the similarity of camera lens level and then produce the similarity of video-level again; Utilize the data redundancy between key frame,, greatly reduce the memory space of key frame feature, simplified the complexity of system, realized the basic skills of Content-based Video Retrieval by sacrificing certain video space time information.
" iARM " system uses based on the method for model and the space-time sequence information of video is carried out modeling accurately and the model that contents of object is mapped to prior generation is got on.This system emphasizes the accuracy to the modeling of video space time information, so its relevant feedback analysis only needs limited number of time feedback and less training sample can obtain less retrieval time and retrieval performance preferably.
Except that above-mentioned technology, all be that the present invention lays a good foundation based on the theoretical unsupervised learning algorithm of figure, Image Retrieval Relevance Feedback technology with based on the information embedded technology of user feedback etc.
Summary of the invention
The objective of the invention is to propose new middle level, high-rise video features, with the sequence space time information and the semantic topic of reflecting video; Set up new search mechanism, to reduce the online computation complexity of similarity and to reduce retrieval time based on unsupervised learning; Make up new interactive search interface,, for this reason, the invention provides a kind of interactive physical video retrieval method based on unsupervised learning and semantic matching characteristic with on-line optimization query vector, on-line correction semantic marker, raising retrieval performance and expanding data storehouse.
For achieving the above object, the invention provides interactive physical video retrieval method, comprise that step is as follows based on unsupervised learning and semantic matching characteristic:
Step 1: the video frame image level at video database extracts the image low-level image feature;
Step 2: in the video sequence level extraction model matching sequence feature of image low-level image feature;
Step 3: the senior semantic hierarchies at the image low-level image feature extract semantic matching characteristic;
Step 4: extraction model matching sequence feature and semantic matching characteristic are carried out unsupervised learning, set up search mechanism based on unsupervised learning;
Step 5: form mutual search interface by the relevant feedback technology, optimize retrieval performance.
According to embodiments of the invention, the Model Matching sequence signature comprises: Weighted T-Bin histogram and Model Matching correlogram, the space-time sequence information that is used for the reflecting video object, Weighted T-Bin histogram comprises: each dimension expression object video is quoted the frequency of a certain model, and weight reflects the significance level of different Model Matching sequences.
According to embodiments of the invention, the extraction step of Model Matching sequence signature comprises as follows:
Step 21: entire database is considered as set of frames, down-sampling is carried out in entire image frame data storehouse obtain sample frame, sample frame low-level image feature vector is configured to matrix form generates training set;
Step 22: adopt the study of competitive learning algorithm to obtain mode set;
Step 23: each frame in the object video is found N optimum matching model from mode set, with the image frame sequence column-generation N bar optimum matching model sequence of video;
Step 24: N bar optimum matching model sequence is extracted Weighted T-Bin histogram and Model Matching correlogram.
According to embodiments of the invention, the Model Matching correlogram comprises: the best semantic matches sequence of given object video is S, and any two sequence members are m
1And m
2∈ S, mode set are MS, and the contained model number of mode set is Num_MS, and the pixel span is D; Then the Model Matching correlogram of this object video is the vector of Num_MS * D dimension; For i model M odel_i ∈ MS and certain pixel span k ∈ D, (the i-1) * D+k of Model Matching correlogram dimension is as described below:

Its physical significance is: for the Model Matching sequence S of certain object video, and the sequence member of given arbitrary use Model_i, MMC
(k) Model_i(S) provided the probability that sequence member beyond k the pixel span also uses Model_i, MMC describes the model reference frequency information and the preface information of object video simultaneously.
According to embodiments of the invention, semantic matching characteristic extracts, and comprises the steps:
Step 2a: the object video of choosing representative band mark is formed training set on a small scale, and this training set is characterized under the condition of current low-level image feature descriptive power database and contains the motion theme;
Step 2b: use training set, N bar best model matching sequence further is mapped to the semantic marker layer, obtained N bar optimum mark preface coupling row;
Step 2c: N bar optimum mark matching sequence is carried out histogram extract and weighting, the high-level semantic feature that obtains object video is the semantic matches histogram.
According to embodiments of the invention, search mechanism based on unsupervised learning comprises: adopt leading clustering algorithm that video database is carried out unsupervised learning, most of calculation of similarity degree is converted into off-line operation, weigh the quality and the total leading collection number of restriction of the leading collection of each generation with the consistance function, its concrete steps comprise:
Step 31: with video database as the nonoriented edge weight graph, wherein each object video is as the node of nonoriented edge weight graph, the coupling that uses a model correlogram or semantic matches histogram, the similarity of calculating any two sections videos be as the right weights of this node, and generate full similarity matrix A;
Step 32: utilize leading clustering algorithm, the label set of getting nonzero component in the locally optimal solution generates leading collection;
Step 33: the node that will belong to existing leading collection is deleted from current figure, and repeating above-mentioned steps is empty up to node diagram.
According to embodiments of the invention, interactive search interface, be used for video sequence level and semantic hierarchies are implemented relevant feedback, comprise as follows: adopt optimum inquiry relevant feedback technology to pass through man-machine interaction mode, be used to help computing machine to understand user's request, obtain the query vector of optimization, be applicable to direct search mechanism; Adopt the relational matrix relevant feedback, be used to adjust mutual relationship between each data clusters and contain overall semantic relation between data clusters, be applicable to search mechanism based on unsupervised learning; Missed suppression relevant feedback technology is used for the data object is carried out online missed suppression, expanding data storehouse, is applicable to use the histogrammic retrieving of semantic matches.
According to embodiments of the invention, optimum inquiry relevant feedback technology comprises as follows: after the user initially exported the relevant and uncorrelated video of result queue to system, query vector was optimized for:
In the formula: f
qBe former query vector, f
R, f
I, N
R, N
IBe associated video and the uncorrelated video and the number thereof of user's mark, f
q' be the query vector of optimizing, W
q, W
R, W
IBe constant coefficient.
According to embodiments of the invention, the relational matrix relevant feedback is following three steps:
Step a: initial relational matrix, calculate similarity between any two cluster centres and obtain initial relational matrix and be:
Correlation_Matrix[i][j]=exp(-1*distance(Centroid_i,Centroid_j))
In the formula: Centroid_i, Centroid_j are two cluster centres, and distance () is certain distance function;
Step b: upgrade relational matrix, concern that the similarity of vectorial F (x) the given object of expression and each cluster centre is:
[F(x)]
i=exp(-1*dis?tan?ce(x,Centroid_i))
X is the object video proper vector in the formula, and Centroid_i is certain cluster centre, and distance () is certain distance function;
The relational matrix formula upgrades by following formula:
In the formula: q is a query vector, f
R, f
I, N
R, N
IBe associated video and the uncorrelated video and the number thereof of user's mark, k is a update times;
Step c: use the relational matrix retrieval,, in relational matrix, find N relevant cluster, therefrom return Query Result again for a certain query requests; After each feedback, the renewal of correlation matrix will be saved, and make performance boost be accumulated.
According to embodiments of the invention, the concrete steps of missed suppression relevant feedback technology are as follows:
Steps d:, obtain associated video collection RS and uncorrelated video collection IS according to field feedback;
Step e: to associated video collection RS and uncorrelated video collection IS difference computation of mean values vector RMV and mean vector IMV;
Step f: find out two the components R D and the RD2 of greatest measure in mean vector RMV, expression is to should maximally related two themes of video;
Step g: in mean vector IMV, find the component ID of greatest measure, the theme that expression is least relevant;
Step h: if (ID==RD1) RD=RD2, execution in step i;
Step I: the semantic matches histogram of optimizing inquiry:
Query_SMH[RD]=1,Query_SMH[ID]=0;
Step j: deposit new feature in database, again retrieval.
The present invention the is integrated middle level feature of video, high-level characteristic, unsupervised learning search mechanism and interaction mechanism, constituted the novel complete video frequency search system of a cover, weighed the space-time sequence information of video accurately, developed semantic understanding to the sports video theme, the online computation complexity and the retrieval time of system have been reduced, increased substantially the retrieval performance of system by interactive interface, had broad application prospects.
Description of drawings
Fig. 1 is a system architecture diagram of the present invention.
Fig. 2 is the Model Matching synoptic diagram of video in the Model Matching sequence signature.
Fig. 3 is the indicia matched synoptic diagram of video in the semantic matching characteristic.
Fig. 4 is a data clusters overall situation semantic relation synoptic diagram in the relational matrix relevant feedback technology.
Fig. 5 is the program interface synoptic diagram of " CBVR_System ".
The return results that Fig. 6 inquires about for vollyball for the unsupervised learning search modes that uses MMC.
The return results that Fig. 7 inquires about for vollyball for the direct search modes that uses SMH.
Fig. 8 is a direct result for retrieval and through result's the comparison after the feedback once.
Embodiment
Below in conjunction with accompanying drawing the present invention is described in detail, be to be noted that described embodiment only is intended to be convenient to the understanding of the present invention, and it is not played any qualification effect.
General frame of the present invention is seen Fig. 1.Program " CBVR_System " is to realize an instantiation of the inventive method, adopts a computing machine, realizes with Visual C++ programming.The interactive physical video retrieval method based on unsupervised learning and semantic matching characteristic that the present invention proposes mainly comprises following four key issues:
(1) Model Matching sequence signature;
(2) semantic matching characteristic;
(3) based on the search mechanism of unsupervised learning;
(4) interactive search interface.
General structure of the present invention can be divided into off-line operation and two parts of on-line operation.The off-line operation part is made up of feature extraction and unsupervised learning.At first at the video frame image level to database object extraction image low-level image feature; Subsequently in video sequence level extraction model matching sequence feature; Extract semantic matching characteristic at senior semantic hierarchies; The video features that is extracted is carried out unsupervised learning, set up search mechanism based on unsupervised learning; On-line operation is divided into search mechanism and interaction feedback again.Search mechanism provides five kinds of search modes: use the unsupervised learning of the direct retrieval of TBH, the direct retrieval of using MMC, the direct retrieval of using SMH, use MMC to retrieve and use the unsupervised learning retrieval of SMH; When receiving query requests, system is retrieved and return results according to user's preference pattern; Form interactive interface sophisticated systems performance by the relevant feedback technology at last.Provide the explanation of each related in this invention technical scheme detailed problem below in detail.
(1) Model Matching sequence signature
Model Matching sequence signature among the present invention is the video middle level feature that is generated by the picture frame low-level image feature, is the sequence signature of weighing space time information at video-level, is again the feature based on model of dependent learning.Its key issue is the selection of obtaining of mode set and video middle level sequence signature.It is first key that sequence signature extracts that mode set obtains, " good " model representation in the video database frame have representational generalized graph picture, and " good " mode set is exactly by such one group representative strong and model a little less than the MD is formed.After obtaining suitable mode set,, video clips can be mapped as one group of best model matching sequence by each frame of video is carried out Model Matching.Extracting what kind of middle level sequence signature from the best model matching sequence becomes second key issue, and different feature extracting methods is huge to the influence that similarity is calculated, thereby has determined the performance of retrieval to a great extent.
Among the present invention, after database extraction low-level image feature, can carry out the extraction of Model Matching sequence signature.The Model Matching sequence signature is the video middle level sequence signature that the method by Model Matching is generated by the picture frame low-level image feature, in order to the space-time sequence information of accurate reflecting video object.The low-level image feature of describing image vision information is the basis of searching system, but it is not the emphasis that the present invention pays close attention to, and adopts which kind of low-level image feature can not influence structure of the present invention and principle, so native system has simply adopted the color correlogram.Concrete leaching process mainly is made up of training set generation, model generation, Model Matching and four steps of feature extraction.
Step 1: training set generates, and entire database is considered as set of frames rather than video set; Obtain sample frame by down-sampling is carried out in entire image frame data storehouse, sample frame low-level image feature vector is configured to matrix form as training set.
Step 2: model generates, and the present invention adopts the study of competitive learning algorithm to obtain mode set.
Sample x of picked at random from training set at first, at every turn
v, by formula (1) is that it is at existing mode set { m
t, find the optimum matching model in t=1...T)

Subsequently, by formula (2) implement the competitive learning algorithm, and wherein m is an iterations, the study step-length coefficient of l (m) for successively decreasing with m.After iterations m reaches predetermined number of times, promptly obtain mode set.
Step 3: the model mapping, the concrete model mapping process is seen Fig. 2: given certain sequence of frames of video object, for its each frame finds N optimum matching model from mode set.Thereby the sequence of image frames of given video has just become N bar optimum matching model sequence.
Step 4: feature extraction, on the basis of optimum matching model sequence, the present invention has defined Weighted T-Bin histogram (WTH) and Model Matching correlogram (MMC).
The frequency that a certain model of each dimension expression of Weighted T-Bin histogram is cited, weight has reflected the significance level of different Model Matching sequences.WTH has reflected the frequency information that corresponding model is cited but has ignored the sequencing of sequence.
Defining 1. Model Matching correlogram: S is the best semantic matches sequence of given object video, m
1And m
2∈ S is any two sequence members, and MS is a mode set, and the contained model number of mode set is Num_MS, and D is the pixel span; Then the Model Matching correlogram of this object video is defined as the vector of a Num_MS * D dimension; For i model M odel_i ∈ MS and certain pixel span k ∈ D, (the i-1) * D+k of Model Matching correlogram dimension is as giving a definition:

For the Model Matching sequence S of certain object video, the sequence member of given arbitrary use Model_i, MMC
(k) Model_i(S) expression has provided the probability that sequence member beyond the k distance also uses Model_i.MMC describes out the model reference frequency information of object video simultaneously and quotes preface information.
(2) semantic matching characteristic
It is semantic matches histogram (SMH) that the present invention has defined semantic matching characteristic.Sports video can simply carry out index by their sports items title to its theme, as basketball, rugby and tennis etc.The semantic matches histogram is on the basis of image low-level image feature and video middle level feature, and the video high-level semantic feature that the method for learning by Model Matching and active generates is in order to carry out the theme mark to the sports video object.SMH provides the probability that certain object video belongs to each semantic topic, and with this video of related subject mark.Compare with the middle level feature, SMH reflects the semantic content of video to a certain extent, has reduced the proper vector dimension, has improved retrieval performance.The present invention develops Model Matching active learning algorithm in order to extract semantic feature.This algorithm learns to obtain the mode set of one group of band semantic marker by the mark training set being carried out active, then using this mode set carries out Model Matching to object video and obtains some optimum mark matching sequences, again matching sequence is carried out histogram and extract, obtain semantic matches histogram (SMH) at last.Concrete extracting method can be divided into following three steps.
Step 1: training set, training set are as the supervision message source of active study mechanism, and native system is chosen the object video of representative band mark and formed training set on a small scale.That is to say, the object video in the training set in advance the handmarking sports events theme; The training set scale is less with respect to database; Training set can be contained motion theme as much as possible under the condition of current low-level image feature descriptive power.
Step 2: model generates and mapping, and mapping process is seen Fig. 3, and model generates similar with the corresponding step of Model Matching sequence signature, and difference is only for having used different training sets.(in Fig. 2, add the semantic marker layer and form Fig. 3), N bar best model matching sequence further is mapped to the semantic marker layer, obtained N bar optimum mark preface coupling row.
Step 3: generative semantics matching histogram (SMH), N bar optimum mark matching sequence is carried out histogram extract and weighting, obtain high-level semantic feature---the SMH of object video.SMH has following characteristics: dimension is low, is equivalent to the semantic topic number of supervision message in the training set; Explicit physical meaning, its each dimension expression object video belongs to the probability of certain corresponding theme, and with this object of related subject mark; Vector is sparse, reduces storage space significantly and simplifies similarity calculating.
(3) based on the retrieval of unsupervised learning
Traditional search method is a sequencing of similarity mechanism, and this mechanism has directly, flexibly and be easy to realize characteristics such as relevant feedback; But for each query object, this method all will travel through whole data space simultaneously again in all similarities of line computation, therefore need bear very high online computation complexity; For large-scale video database, this mechanism almost can't operate as normal especially.
The present invention has set up retrieval framework based on unsupervised learning in order to replace traditional direct ordering search mechanism.This mechanism makes most of calculation of similarity degree be converted into off-line operation by video database is carried out unsupervised learning, has reduced the complexity in line computation significantly, realizes simultaneously database is more effectively managed.Like this, retrieving can be divided into coarse search and examining rope two parts, coarse search is actual to be exactly one inquiry is assigned to the assorting process of existing cluster, and examining Suo Ze only need be in a spot of similarity of line computation (similarity of inquiry and certain cluster sample, inquiry and a small amount of free sample).This part key issue is the selection of unsupervised learning algorithm.Clustering algorithm is based on the core of unsupervised learning search mechanism.Cluster time, cluster purity and cluster number are having a strong impact on the performance of searching system.
Native system adopts the search mechanism of leading clustering algorithm realization based on unsupervised learning.Leading clustering algorithm (Dominant Set Clustering) is a kind of of the theoretical clustering algorithm of figure, and this algorithm exists the consistance function to weigh the quality and the total leading collection number of restriction of the leading collection of each generation.Compare with other clustering algorithms, the cluster that leading clustering produces has higher degree, and the cluster number can determine automatically that by the setting of consistance threshold value computation complexity is less relatively simultaneously, and concrete clustering algorithm can be divided into three steps.
Step 1: full similarity matrix, video database is considered as the nonoriented edge weight graph, and wherein each object video is as the node of figure, and coupling correlogram or semantic matches histogram use a model, the similarity of calculating any two sections videos is as the right weights of this node, and forms full similarity matrix A.
Step 2: iterative equation, leading clustering algorithm is equivalent to following double optimization problem:
max?f(u)=u
T?Aus.t.u?∈Δ,(4),
Wherein
A is full similarity matrix (5),
The locally optimal solution of this problem can obtain by following iterative equation
u
i(t+1)=u
i(t) (Au (t))
i/ u (t)
TAu (t), t are iterations (6), and the label set of getting nonzero component in the locally optimal solution generates leading collection;
Step 3: the node that will belong to existing leading collection is deleted from current figure, and repeating above-mentioned steps is empty up to node diagram.
(4) interactive search interface
Relevant feedback is exactly by man-machine interaction, allows the semantic information of user's online help computer understanding object and human subjectivity needs.The sequence characteristic of video makes field feedback need the relatively long time, so the relevant feedback technical development of video frequency searching is very limited.Alleviate the user and use burden, how to obtain the development trend that best retrieval effectiveness becomes the video relevant feedback by minimum feedback.
In native system, the search modes of the matching sequence feature that uses a model so it lacks the understanding to the searching object semanteme, has been ignored the subjectivity of human perception owing to itself do not relate to any semantic content of video simultaneously.Similarly, use the search modes of semantic matching characteristic to obtain certain semantic information from supervised training is concentrated, however to such an extent as to the very limited sometimes accurate mark that can not guarantee all the time of this information to the sports video theme.For the reflection user individual sexual demand, remedy semantic wide gap and the online supervision message that is supplemented with, the present invention has set up the interactive search interface of a cover, implemented three kinds of relevant feedback technology respectively at video sequence level and semantic hierarchies: optimum inquiry relevant feedback technology, relational matrix relevant feedback technology and missed suppression relevant feedback technology, wherein:
Optimum inquiry relevant feedback technology: the real demand that usually can not describe out the user by the query vector of character representations such as TBH or MMC exactly, so the present invention uses optimum inquiry relevant feedback technology by man-machine interaction mode, helps computing machine understanding user's request to obtain the query vector of optimizing.
The user simply gives a mark for the initial retrieval result of system, marks associated video and irrelevant video.According to field feedback, optimum query vector can be obtained by formula (7).Like this, the user can help computing machine more accurately to understand search request, has improved the performance of retrieval.
In the formula: f
qBe former query vector, f
R, f
I, N
R, N
IBe associated video and the uncorrelated video and the number thereof of user's mark, f
q' be the query vector of optimizing, W
q, W
R, W
IBe constant coefficient.
Relational matrix relevant feedback technology: optimum inquiry mechanism is only optimized given query and has been ignored entire database, thus always when retrieving, lose by the performance boost that obtains alternately next time, and can not get continuing accumulation.When promptly same search request being retrieved once more, also to repeat whole reciprocal processes.
In view of this, the present invention proposes relational matrix relevant feedback technology, see Fig. 4 by adjusting the overall semantic relation that mutual relationship contains between data clusters between each data clusters, among Fig. 4, C
1-C
NN cluster centre in the expression database, weights W is represented the similarity relation between each cluster.Detailed process is divided into following three steps:
Step 1: initial relational matrix.The similarity of calculating between any two cluster centres obtains initial relational matrix:
Correlation_Matrix[i][j]=exp(-1*distance(Centroid_i,Centroid_j))(8)
In the formula: Centroid_i, Centroid_j are two cluster centres, and distance () is certain distance function.Correlation_Matrix represents the similarity relation between each cluster.
Step 2: upgrade relational matrix.The similarity that concerns vectorial F (x) the given object of expression and each cluster centre:
[F(x)]
i=exp(-1×distance(x,Centroid_i))(9)
X is the object video proper vector in the formula, and Centroid_i is certain cluster centre, and distance () is certain distance function.
Relational matrix by formula (10) upgrades:
In the formula: q is a query vector, f
R, f
I, N
R, N
IBe associated video and the uncorrelated video and the number thereof of user's mark, k is a update times.
Matrix
 In nonzero component represent that the user thinks that relevant cluster is right;
In nonzero component represent that the user thinks that relevant cluster is right;
In like manner
 In nonzero component represent that the user thinks that incoherent cluster is right; By strengthening the right similarity relation of relevant cluster, weaken the right similarity relation of uncorrelated cluster, relational matrix is upgraded.
In nonzero component represent that the user thinks that incoherent cluster is right; By strengthening the right similarity relation of relevant cluster, weaken the right similarity relation of uncorrelated cluster, relational matrix is upgraded.
Step 3: use the relational matrix retrieval.For a certain query requests, in relational matrix, find the relevant cluster of N, therefrom return Query Result again.After each feedback, the renewal of correlation matrix will be saved, and make performance boost be accumulated.
Missed suppression relevant feedback technology: be used for the data object is carried out online missed suppression, improves retrieval performance expanding data storehouse simultaneously, specific algorithm is as follows:
Step 1:, obtain associated video collection RS and uncorrelated video collection IS according to field feedback;
Step 2: to associated video collection RS and uncorrelated video collection IS difference computation of mean values vector RMV and mean vector IMV;
Step 3: find out two the components R D and the components R D2 of greatest measure in RMV, expression is to should maximally related two themes of video;
Step 4: in IMV, find the component ID of greatest measure, the theme that expression is least relevant;
Step 5: If (ID==RD1) RD=RD2;
Step 6: the semantic matches histogram of optimizing inquiry:
Query_SMH[RD]=1,Query_SMH[ID]=0;
Step 7: deposit new feature in database, again retrieval.
Fig. 5-Fig. 8 illustrates technique effect of the present invention, wherein:
Fig. 5 is the program interface synoptic diagram of " CBVR_System ".Wherein, first two field picture of video in the video data storehouse, upper right viewing area uses the button page turning, and picture slid underneath bar is used for receiving feedback information; Upper left broadcast area is used for playing chooses video; Radio box is used to select search modes; Button area is used for feature operation; Status bar real-time display program operation information.
The return results that Fig. 6 inquires about for vollyball for the unsupervised learning search modes that uses MMC.Use radio box to select " using the unsupervised learning search modes of MMC ", first two field picture of viewing area output result for retrieval is clicked image and can be play whole section video at broadcast area.Status bar shows that retrieval is consuming time.
The return results that Fig. 7 inquires about for vollyball for the direct search modes that uses SMH.Use radio box to select " using the direct search modes of SMH ", status bar shows the semantic topic of retrieving consuming time and query object.
Fig. 8 is a direct result for retrieval and through result's the comparison after the feedback once.Last figure is the original output result of " the direct search modes that uses THB ", and the user uses slider bar that feedback opinion (representing associated video to the right, to the uncorrelated video of left representation) is provided; Figure below is feedback back result, and performance obviously improves.
The above; only be the embodiment among the present invention; but protection scope of the present invention is not limited thereto; anyly be familiar with the people of this technology in the disclosed technical scope of the present invention; can understand conversion or the replacement expected; all should be encompassed in of the present invention comprising within the scope, therefore, protection scope of the present invention should be as the criterion with the protection domain of claims.
Claims (10)
1. the interactive physical video retrieval method based on unsupervised learning and semantic matching characteristic is characterized in that, comprises that step is as follows:
Step 1: the video frame image level at video database extracts the image low-level image feature;
Step 2: in the video sequence level extraction model matching sequence feature of image low-level image feature;
Step 3: the senior semantic hierarchies at the image low-level image feature extract semantic matching characteristic;
Step 4: extraction model matching sequence feature and semantic matching characteristic are carried out unsupervised learning, set up search mechanism based on unsupervised learning;
Step 5: form mutual search interface by the relevant feedback technology, optimize retrieval performance.
2. search method according to claim 1, it is characterized in that, the Model Matching sequence signature comprises: Weighted T-Bin histogram and Model Matching correlogram, be used for the space-time sequence information weighting of reflecting video object, the T-Bin histogram comprises: each dimension expression object video is quoted the frequency of a certain model, and weight reflects the significance level of different Model Matching sequences.
3. search method according to claim 1 is characterized in that, the extraction step of Model Matching sequence signature comprises as follows:
Step 21: entire database is considered as set of frames, down-sampling is carried out in entire image frame data storehouse obtain sample frame, sample frame low-level image feature vector is configured to matrix form generates training set;
Step 22: adopt the study of competitive learning algorithm to obtain mode set;
Step 23: each frame in the object video is found N optimum matching model from mode set, with the image frame sequence column-generation N bar optimum matching model sequence of video;
Step 24: N bar optimum matching model sequence is extracted Weighted T-Bin histogram and Model Matching correlogram.
4. search method according to claim 2 is characterized in that, the Model Matching correlogram comprises: the best semantic matches sequence of given object video is S, and any two sequence members are m
1And m
2∈ S, mode set are MS, and the contained model number of mode set is Num_MS, and the pixel span is D; Then the Model Matching correlogram of this object video is the vector of Num_MS * D dimension; For i model M odel_i ∈ MS and certain pixel span k ∈ D, (the i-1) * D+k of Model Matching correlogram dimension is as described below:
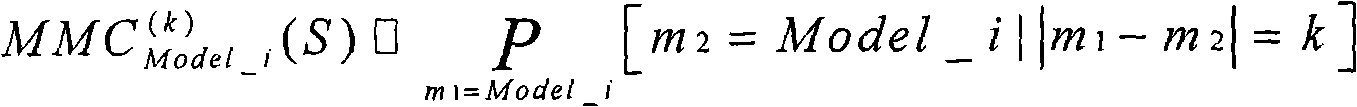
Its physical significance is: for the Model Matching sequence S of certain object video, and the sequence member of given arbitrary use Model_i, MMC
(k) Model_i(S) provided the probability that sequence member beyond k the pixel span also uses Model_i, MMC describes the model reference frequency information and the preface information of object video simultaneously.
5. search method according to claim 1 is characterized in that, semantic matching characteristic extracts, and comprises the steps:
Step 2a: the object video of choosing representative band mark is formed training set on a small scale, and this training set is characterized under the condition of current low-level image feature descriptive power database and contains the motion theme;
Step 2b: use training set, N bar best model matching sequence further is mapped to the semantic marker layer, obtained N bar optimum mark preface coupling row;
Step 2c: N bar optimum mark matching sequence is carried out histogram extract and weighting, the high-level semantic feature that obtains object video is the semantic matches histogram.
6. search method according to claim 1, it is characterized in that, search mechanism based on unsupervised learning comprises: adopt leading clustering algorithm that video database is carried out unsupervised learning, most of calculation of similarity degree is converted into off-line operation, weigh the quality and the total leading collection number of restriction of the leading collection of each generation with the consistance function, its concrete steps comprise:
Step 31: with video database as the nonoriented edge weight graph, wherein each object video is as the node of nonoriented edge weight graph, the coupling that uses a model correlogram or semantic matches histogram, the similarity of calculating any two sections videos be as the right weights of this node, and generate full similarity matrix A;
Step 32: utilize leading clustering algorithm, the label set of getting nonzero component in the locally optimal solution generates leading collection;
Step 33: the node that will belong to existing leading collection is deleted from current figure, and repeating above-mentioned steps is empty up to node diagram.
7. search method according to claim 1 is characterized in that, interactive search interface is used for video sequence level and semantic hierarchies are implemented relevant feedback, comprises as follows:
Adopt optimum inquiry relevant feedback technology by man-machine interaction mode, be used to help computing machine to understand user's request, obtain the query vector of optimization, be applicable to direct search mechanism;
Adopt the relational matrix relevant feedback, be used to adjust mutual relationship between each data clusters and contain overall semantic relation between data clusters, be applicable to search mechanism based on unsupervised learning;
Missed suppression relevant feedback technology is used for the data object is carried out online missed suppression, expanding data storehouse, is applicable to use the histogrammic retrieving of semantic matches.
8. search method according to claim 7 is characterized in that: optimum inquiry relevant feedback technology comprises as follows: after the user initially exported the relevant and uncorrelated video of result queue to system, query vector was optimized for:
In the formula: f
qBe former query vector, f
R, f
I, N
R, N
IBe associated video and the uncorrelated video and the number thereof of user's mark, f
q' be the query vector of optimizing, W
q, W
R, W
IBe constant coefficient.
9. search method according to claim 7 is characterized in that, the relational matrix relevant feedback is following three steps:
Step a: initial relational matrix, calculate similarity between any two cluster centres and obtain initial relational matrix and be:
Correlation_Matrix[i][j]=exp(-1*distance(Centroid_i,Centroid_j))
In the formula: Centroid_i, Centroid_j are two cluster centres, and distance () is certain distance function;
Step b: upgrade relational matrix, concern that the similarity of vectorial F (x) the given object of expression and each cluster centre is:
[F(x)]
i=exp(-1*dis?tan?ce(x,Centroid_i))
X is the object video proper vector in the formula, and Centroid_i is certain cluster centre, and distance () is certain distance function;
The relational matrix formula upgrades by following formula:
In the formula: q is a query vector, f
R, f
I, N
R, N
IBe associated video and the uncorrelated video and the number thereof of user's mark, k is a update times;
Step c: use the relational matrix retrieval,, in relational matrix, find N relevant cluster, therefrom return Query Result again for a certain query requests; After each feedback, the renewal of correlation matrix will be saved, and make performance boost be accumulated.
10. search method according to claim 7 is characterized in that, the concrete steps of missed suppression relevant feedback technology are as follows:
Steps d:, obtain associated video collection RS and uncorrelated video collection IS according to field feedback;
Step e: to associated video collection RS and uncorrelated video collection IS difference computation of mean values vector RMV and mean vector IMV;
Step f: find out two the components R D and the RD2 of greatest measure in mean vector RMV, expression is to should maximally related two themes of video;
Step g: in mean vector IMV, find the component ID of greatest measure, the theme that expression is least relevant;
Step h: if (ID==RD1) RD=RD2, execution in step i;
Step I: the semantic matches histogram of optimizing inquiry:
Query_SMH[RD]=1,Query_SMH[ID]=0;
Step j: deposit new feature in database, again retrieval.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2007100651801A CN101281520B (en) | 2007-04-05 | 2007-04-05 | Interactive physical training video search method based on non-supervision learning and semantic matching characteristic |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2007100651801A CN101281520B (en) | 2007-04-05 | 2007-04-05 | Interactive physical training video search method based on non-supervision learning and semantic matching characteristic |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN101281520A true CN101281520A (en) | 2008-10-08 |
| CN101281520B CN101281520B (en) | 2010-04-21 |
Family
ID=40013997
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2007100651801A Expired - Fee Related CN101281520B (en) | 2007-04-05 | 2007-04-05 | Interactive physical training video search method based on non-supervision learning and semantic matching characteristic |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN101281520B (en) |
Cited By (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101976258A (en) * | 2010-11-03 | 2011-02-16 | 上海交通大学 | Video semantic extraction method by combining object segmentation and feature weighing |
| CN102332031A (en) * | 2011-10-18 | 2012-01-25 | 中国科学院自动化研究所 | Method for clustering retrieval results based on video collection hierarchical theme structure |
| CN101739428B (en) * | 2008-11-10 | 2012-04-18 | 中国科学院计算技术研究所 | Method for creating index for multimedia |
| CN103279580A (en) * | 2013-06-24 | 2013-09-04 | 魏骁勇 | Video retrieval method based on novel semantic space |
| CN103793447A (en) * | 2012-10-26 | 2014-05-14 | 汤晓鸥 | Method and system for estimating semantic similarity among music and images |
| CN104200235A (en) * | 2014-07-28 | 2014-12-10 | 中国科学院自动化研究所 | Time-space local feature extraction method based on linear dynamic system |
| CN104239309A (en) * | 2013-06-08 | 2014-12-24 | 华为技术有限公司 | Video analysis retrieval service side, system and method |
| CN106126619A (en) * | 2016-06-20 | 2016-11-16 | 中山大学 | A kind of video retrieval method based on video content and system |
| CN106294344A (en) * | 2015-05-13 | 2017-01-04 | 北京智谷睿拓技术服务有限公司 | Video retrieval method and device |
| CN106407484A (en) * | 2016-12-09 | 2017-02-15 | 上海交通大学 | Video tag extraction method based on semantic association of barrages |
| CN107291895A (en) * | 2017-06-21 | 2017-10-24 | 浙江大学 | A kind of quick stratification document searching method |
| CN108228757A (en) * | 2017-12-21 | 2018-06-29 | 北京市商汤科技开发有限公司 | Image search method and device, electronic equipment, storage medium, program |
| CN108701118A (en) * | 2016-02-11 | 2018-10-23 | 电子湾有限公司 | Semantic classes is classified |
| CN108763295A (en) * | 2018-04-18 | 2018-11-06 | 复旦大学 | A kind of video approximate copy searching algorithm based on deep learning |
| CN109284409A (en) * | 2018-08-29 | 2019-01-29 | 清华大学深圳研究生院 | Picture group geographic positioning based on extensive streetscape data |
| CN110019910A (en) * | 2017-12-29 | 2019-07-16 | 上海全土豆文化传播有限公司 | Image search method and device |
| CN110147828A (en) * | 2019-04-29 | 2019-08-20 | 广东工业大学 | A kind of local feature matching process and system based on semantic information |
| CN110287799A (en) * | 2019-05-28 | 2019-09-27 | 东南大学 | Video UCL Semantic Indexing method and apparatus based on deep learning |
| WO2019219083A1 (en) * | 2018-05-18 | 2019-11-21 | 北京中科寒武纪科技有限公司 | Video retrieval method, and method and apparatus for generating video retrieval mapping relationship |
| CN112597341A (en) * | 2018-05-25 | 2021-04-02 | 中科寒武纪科技股份有限公司 | Video retrieval method and video retrieval mapping relation generation method and device |
| US10986400B2 (en) | 2016-08-04 | 2021-04-20 | Microsoft Technology Licensing. LLC | Compact video representation for video event retrieval and recognition |
| US11698921B2 (en) | 2018-09-17 | 2023-07-11 | Ebay Inc. | Search system for providing search results using query understanding and semantic binary signatures |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106202256B (en) * | 2016-06-29 | 2019-12-17 | 西安电子科技大学 | Web image retrieval method based on semantic propagation and mixed multi-instance learning |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1245697C (en) * | 2003-08-04 | 2006-03-15 | 北京大学计算机科学技术研究所 | Method of proceeding video frequency searching through video frequency segment |
-
2007
- 2007-04-05 CN CN2007100651801A patent/CN101281520B/en not_active Expired - Fee Related
Cited By (36)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101739428B (en) * | 2008-11-10 | 2012-04-18 | 中国科学院计算技术研究所 | Method for creating index for multimedia |
| CN101976258A (en) * | 2010-11-03 | 2011-02-16 | 上海交通大学 | Video semantic extraction method by combining object segmentation and feature weighing |
| CN102332031A (en) * | 2011-10-18 | 2012-01-25 | 中国科学院自动化研究所 | Method for clustering retrieval results based on video collection hierarchical theme structure |
| CN102332031B (en) * | 2011-10-18 | 2013-03-27 | 中国科学院自动化研究所 | Method for clustering retrieval results based on video collection hierarchical theme structure |
| CN103793447B (en) * | 2012-10-26 | 2019-05-14 | 汤晓鸥 | The estimation method and estimating system of semantic similarity between music and image |
| CN103793447A (en) * | 2012-10-26 | 2014-05-14 | 汤晓鸥 | Method and system for estimating semantic similarity among music and images |
| CN104239309A (en) * | 2013-06-08 | 2014-12-24 | 华为技术有限公司 | Video analysis retrieval service side, system and method |
| CN103279580A (en) * | 2013-06-24 | 2013-09-04 | 魏骁勇 | Video retrieval method based on novel semantic space |
| CN104200235A (en) * | 2014-07-28 | 2014-12-10 | 中国科学院自动化研究所 | Time-space local feature extraction method based on linear dynamic system |
| CN106294344A (en) * | 2015-05-13 | 2017-01-04 | 北京智谷睿拓技术服务有限公司 | Video retrieval method and device |
| US10713298B2 (en) | 2015-05-13 | 2020-07-14 | Beijing Zhigu Rui Tuo Tech Co., Ltd. | Video retrieval methods and apparatuses |
| CN106294344B (en) * | 2015-05-13 | 2019-06-18 | 北京智谷睿拓技术服务有限公司 | Video retrieval method and device |
| CN108701118B (en) * | 2016-02-11 | 2022-06-24 | 电子湾有限公司 | Semantic category classification |
| US11227004B2 (en) | 2016-02-11 | 2022-01-18 | Ebay Inc. | Semantic category classification |
| CN108701118A (en) * | 2016-02-11 | 2018-10-23 | 电子湾有限公司 | Semantic classes is classified |
| CN106126619A (en) * | 2016-06-20 | 2016-11-16 | 中山大学 | A kind of video retrieval method based on video content and system |
| US10986400B2 (en) | 2016-08-04 | 2021-04-20 | Microsoft Technology Licensing. LLC | Compact video representation for video event retrieval and recognition |
| CN106407484B (en) * | 2016-12-09 | 2023-09-01 | 上海交通大学 | Video tag extraction method based on barrage semantic association |
| CN106407484A (en) * | 2016-12-09 | 2017-02-15 | 上海交通大学 | Video tag extraction method based on semantic association of barrages |
| CN107291895A (en) * | 2017-06-21 | 2017-10-24 | 浙江大学 | A kind of quick stratification document searching method |
| CN107291895B (en) * | 2017-06-21 | 2020-05-26 | 浙江大学 | Quick hierarchical document query method |
| CN108228757A (en) * | 2017-12-21 | 2018-06-29 | 北京市商汤科技开发有限公司 | Image search method and device, electronic equipment, storage medium, program |
| CN110019910A (en) * | 2017-12-29 | 2019-07-16 | 上海全土豆文化传播有限公司 | Image search method and device |
| CN108763295A (en) * | 2018-04-18 | 2018-11-06 | 复旦大学 | A kind of video approximate copy searching algorithm based on deep learning |
| CN108763295B (en) * | 2018-04-18 | 2021-04-30 | 复旦大学 | Video approximate copy retrieval algorithm based on deep learning |
| WO2019219083A1 (en) * | 2018-05-18 | 2019-11-21 | 北京中科寒武纪科技有限公司 | Video retrieval method, and method and apparatus for generating video retrieval mapping relationship |
| US11995556B2 (en) | 2018-05-18 | 2024-05-28 | Cambricon Technologies Corporation Limited | Video retrieval method, and method and apparatus for generating video retrieval mapping relationship |
| CN112597341A (en) * | 2018-05-25 | 2021-04-02 | 中科寒武纪科技股份有限公司 | Video retrieval method and video retrieval mapping relation generation method and device |
| CN112597341B (en) * | 2018-05-25 | 2024-08-06 | 中科寒武纪科技股份有限公司 | Video retrieval method and video retrieval mapping relation generation method and device |
| CN109284409B (en) * | 2018-08-29 | 2020-08-25 | 清华大学深圳研究生院 | Picture group geographical positioning method based on large-scale street view data |
| CN109284409A (en) * | 2018-08-29 | 2019-01-29 | 清华大学深圳研究生院 | Picture group geographic positioning based on extensive streetscape data |
| US11698921B2 (en) | 2018-09-17 | 2023-07-11 | Ebay Inc. | Search system for providing search results using query understanding and semantic binary signatures |
| CN110147828B (en) * | 2019-04-29 | 2022-12-16 | 广东工业大学 | Local feature matching method and system based on semantic information |
| CN110147828A (en) * | 2019-04-29 | 2019-08-20 | 广东工业大学 | A kind of local feature matching process and system based on semantic information |
| CN110287799B (en) * | 2019-05-28 | 2021-03-19 | 东南大学 | Video UCL semantic indexing method and device based on deep learning |
| CN110287799A (en) * | 2019-05-28 | 2019-09-27 | 东南大学 | Video UCL Semantic Indexing method and apparatus based on deep learning |
Also Published As
| Publication number | Publication date |
|---|---|
| CN101281520B (en) | 2010-04-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN101281520B (en) | Interactive physical training video search method based on non-supervision learning and semantic matching characteristic | |
| CN110674407B (en) | Hybrid recommendation method based on graph convolution neural network | |
| Badrinarayanan et al. | Segnet: A deep convolutional encoder-decoder architecture for image segmentation | |
| CN101894125B (en) | Video classification method based on content | |
| CN103390063B (en) | A kind of based on ant group algorithm with the search method of related feedback images of probability hypergraph | |
| CN110008375A (en) | Video is recommended to recall method and apparatus | |
| CN101853295A (en) | Image search method | |
| CN109063568A (en) | A method of the figure skating video auto-scoring based on deep learning | |
| CN101315663A (en) | Nature scene image classification method based on area dormant semantic characteristic | |
| CN102306298B (en) | Wiki-based dynamic evolution method of image classification system | |
| CN103345645A (en) | Commodity image category forecasting method based on online shopping platform | |
| CN102542066B (en) | Video clustering method, ordering method, video searching method and corresponding devices | |
| CN1851710A (en) | Embedded multimedia key frame based video search realizing method | |
| CN106599051A (en) | Method for automatically annotating image on the basis of generation of image annotation library | |
| CN112749330B (en) | Information pushing method, device, computer equipment and storage medium | |
| CN110059587A (en) | Human bodys' response method based on space-time attention | |
| CN113032613B (en) | Three-dimensional model retrieval method based on interactive attention convolution neural network | |
| CN107729809A (en) | A kind of method, apparatus and its readable storage medium storing program for executing of adaptive generation video frequency abstract | |
| WO2021139415A1 (en) | Data processing method and apparatus, computer readable storage medium, and electronic device | |
| CN116975615A (en) | Task prediction method and device based on video multi-mode information | |
| CN102236714A (en) | Extensible markup language (XML)-based interactive application multimedia information retrieval method | |
| Papadopoulos et al. | Automatic summarization and annotation of videos with lack of metadata information | |
| Zhang et al. | Hybrid handcrafted and learned feature framework for human action recognition | |
| CN109874032A (en) | The program special topic personalized recommendation system and method for smart television | |
| CN113761359A (en) | Data packet recommendation method and device, electronic equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20100421 |
|
| CF01 | Termination of patent right due to non-payment of annual fee |