此文档是《OCR文字识别实战教程-零基础,SpringBoot结合PaddleOCR》实现 车牌识别、文本识别、身份证识别 地址:https://www.bilibili.com/video/BV1RK411b7DU/?vd_source=b4307343204f5c0271966f7fe276f0eb,教程对应的部分文档,全部文档共89页,剩余文档和完整源代码 请关注B站视频
上面的图片为Android APP 的界面,从左边开始,分别为主界面、拍照界面、识别及结果界面。
OCR实战项目整体架构图如下:

- APP/WEB/小程序为OCR识别接口调用端,调用OCR接口,实现OCR功能。本项目我们只实现Android APP开发。
- Nginx反向代理和负载均衡功能,通过Nginx实现对外网暴露接口,对内负载均衡SpringBoot实现的OCR服务。
- OCR服务通过Springboot实现,主要功能是提供具体的OCR接口实现,其流程是调用内部PaddleOCR服务,解析和处理返回结果,最终返回结果给接口调用者。为了稳定性和安全性,添加了熔断限流、Token认证功能。为了方便部署,会以Docker形式部署该服务。
- PaddleOCR是OCR识别的具体实现,会提供一个OCR识别接口,供内部调用。由于不同的部署方式(普通部署和paddleocr serving方式部署),PaddleOCR在普通部署方式下,无法利用CPU多核(Servering方式不存在该问题),因此会在同一个服务器部署多个实例,解决CPU利用率差以提升性能。为了方便PaddleOCR部署,会以Docker形式部署。后边会讲解普通方式部署和Servering方式部署,如何构建docker镜像及部署流程。
- 开发语言:java、python(不需要python基础)
- springboot 实现业务接口
- python flask 实现识别接口
- Sentinel限流熔断
- JWT Token 认证
- PaddlePaddle
- PaddleOCR
- Nginx 反向代理和负载均衡
- Docker 镜像制作及部署服务
- Android 原生开发
本课程我们将借助PaddleOCR 和 PP-OPCRv4/3 实现文本识别、车牌识别、身份证识别。本课程不涉及算法、模型训练等知识,使用PaddleOCR提供的训练好的模型,没有晦涩难懂的技术,小白也能轻松入手。
文档中的代码会和实际源代码有细微差别,以源代码为准(对实际学习不会有任何影响)
PaddleOCR是一款由百度开发的OCR(光学字符识别)工具库。它旨在为开发者提供一套丰富、领先、且实用的OCR工具,以帮助他们训练出更好的模型并应用于实际场景。 PaddleOCR具有以下特点:
- 超轻量模型:PaddleOCR采用了轻量级模型,以便在移动设备和嵌入式设备上运行。
- 通用识别大模型:除了轻量级模型外,PaddleOCR还提供了通用识别大模型,以适应更多的应用场景。
- 算法丰富且开源:PaddleOCR集成了多种与OCR相关的前沿算法,并进行了开源,以便更多的开发者可以共享和使用。
- 支持自定义训练:开发者可以根据自己的需求,使用PaddleOCR提供的工具和框架自定义训练模型。
- 支持C++预测、端侧部署、服务部署:PaddleOCR不仅支持C++预测,还支持在端侧和服务上进行部署,具有很好的灵活性和可扩展性。
- 行业特色模型:PaddleOCR开发了具有行业特色的模型PP-OCR和PP-Structure,并打通了数据生产、模型训练、压缩、预测部署的全流程。
总的来说,PaddleOCR是一款功能强大、实用便捷的OCR工具库,它提供了一系列前沿的算法和自定义训练的支持,旨在帮助开发者更好地应用OCR技术于各种实际场景中。 github:https://github.com/PaddlePaddle/PaddleOCR
表单识别、票据识别、电表识别、车牌识别、身份证&银行卡、手写体识别、化验单识别 等等
PP-OCRv4提供一套通用的OCR识别模型,可以识别多语言的文字,在速度和精度上都达到了比较好的效果。不指定模型版本,会默认下载最新的模型(PP-OCRv4)。



下载安装包:https://www.python.org/ftp/python/3.8.10/python-3.8.10-amd64.exe
1.双击安装包进行安装




打开:https://www.paddlepaddle.org.cn/ ,选择 pip方式,安装比较简单方便。 选择如下(CPU版本),复制安装命令,安装:

python -m pip install paddlepaddle==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple验证安装
安装完成后,打开命令行,您可以使用输入 python 或 python3 进入 python 解释器,输入import paddle ,再输入paddle.utils.run_check()
如果出现PaddlePaddle is installed successfully!,说明您已成功安装。

参考https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/quickstart.md 执行如下命令:
pip install "paddleocr>=2.6.0" -i https://mirror.baidu.com/pypi/simple如果安装时提示如下:

验证 1.输入 pip list ,看是否有paddleocr模块 2.使用paddocr命令,进行ocr识别。./imgs/11.jpg 替换成某个图片路径,windows下替换成windos风格的路径,例如”C:\文档资料\ocr\1.png“
#--use_angle_cls true设置使用方向分类器识别180度旋转文字,--use_gpu false设置不使用GPU
paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu false例如输出如下:

centos下安装相对windows来说,会复杂一些,会遇到一些问题,不过大家不用担心,本文档后面会提供基于docker的环境构建和部署,会简单很多。这里只是让大家从0开始体验一centos下搭建paddleocr环境。
1.安装依赖包
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make mysql-devel gcc-devel python-devel -y2.再执行安装libffi-devel,不安装会导致pip安装失败
yum install libffi-devel wget -y缺少这一步,会出现 ModuleNotFound:No module named ‘_ctypes’ ** 3.下载python3.8包,并解压**
wget https://www.python.org/ftp/python/3.8.1/Python-3.8.1.tgz4.安装python3.8
tar -zxvf Python-3.8.1.tgz
cd Python-3.8.1/
./configure ; make && make install5.配置环境变量 输入"python3.8 -V", 打印3.8.1 说明3.8.1安装成功 输入"python3 -V",看python3对应的版本; 例如阿里云服务器会默认按照 python2.7 (对应python -V) 和 python3.6.x (对应python3 -V)
mv /usr/bin/python /usr/bin/python.bak
ln -s /usr/local/bin/python3.8 /usr/bin/python
mv /usr/bin/pip /usr/bin/pip.bak
ln -s /usr/local/bin/pip3.8 /usr/bin/pip6.验证 输入 "python -V" , 输出 3.8.1 环境变量配置成功 输入 "pip -V", 输出19.2.3 ,配置成功 7.配置yum 上面操作完成后,输入yum会报错如下,是因为yum依赖python2.7,现在版本改成3.8.1了,因此会出错
yum update File “/usr/bin/yum”, line 30 except KeyboardInterrupt, e: ^ SyntaxError: invalid syntax编辑文件/usr/libexec/urlgrabber-ext-down
vim /usr/libexec/urlgrabber-ext-down改成和下图一样:

sudo yum install libxml2-devel libxslt-devel -y
sudo pip install lxml
sudo pip install requests参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/install/pip/linux-pip.html 1.确认pip版本,要求 pip 版本为 20.2.2 或更高版本,如果版本低那么更新
pip -V如果pip版本低于20.2.2
pip install --upgrade pip2.需要确认 Python 和 pip 是 64bit,并且处理器架构是 x86_64(或称作 x64、Intel 64、AMD64)架构。 下面的第一行输出的是”64bit”,第二行输出的是”x86_64”、”x64”或”AMD64”即可:
python -c "import platform;print(platform.architecture()[0]);print(platform.machine())"3.安装paddlepaddle
python -m pip install paddlepaddle==2.5.1 -i https://mirror.baidu.com/pypi/simple4.验证paddlepaddle安装
安装完成后您可以使用命令 python 进入 python 解释器,输入import paddle ,再输入 paddle.utils.run_check()
如果出现PaddlePaddle is installed successfully!,说明您已成功安装。
问题处理
验证是否成功安装时可能会出现如下错误:

1. 查看系统版本
strings /usr/lib64/libstdc++.so.6 | grep ,输出如下:
GLIBCXX
GLIBCXX_3.4
GLIBCXX_3.4.1
GLIBCXX_3.4.2
GLIBCXX_3.4.3
GLIBCXX_3.4.4
GLIBCXX_3.4.5
GLIBCXX_3.4.6
GLIBCXX_3.4.7
GLIBCXX_3.4.8
GLIBCXX_3.4.9
GLIBCXX_3.4.10
GLIBCXX_3.4.11
GLIBCXX_3.4.12
GLIBCXX_3.4.13
GLIBCXX_3.4.14
GLIBCXX_3.4.15
GLIBCXX_3.4.16
GLIBCXX_3.4.17
GLIBCXX_3.4.18
GLIBCXX_3.4.19
GLIBCXX_DEBUG_MESSAGE_LENGTH
发现少了GLIBCXX_3.4.20,解决方法是升级libstdc++.
2. sudo yum provides libstdc++.so.6 ,输出如下:
Loaded plugins: fastestmirror, langpacks
Determining fastest mirrors
libstdc++-4.8.5-39.el7.i686 : GNU Standard C++ Library
Repo : base
Matched from:
Provides : libstdc++.so.6
3. cd /usr/local/lib64
# 下载最新版本的libstdc.so_.6.0.26
sudo wget https://www.vuln.cn/wp-content/uploads/2019/08/libstdc.so_.6.0.26.zip
unzip libstdc.so_.6.0.26.zip
# 将下载的最新版本拷贝到 /usr/lib64
cp libstdc++.so.6.0.26 /usr/lib64
cd /usr/lib64
# 查看 /usr/lib64下libstdc++.so.6链接的版本
ls -l | grep libstdc++ ,输出如下:
libstdc++.so.6 ->libstdc++.so.6.0.19
# 删除/usr/lib64原来的软连接libstdc++.so.6,删除之前先备份一份
sudo rm libstdc++.so.6
# 链接新的版本
sudo ln -s libstdc++.so.6.0.26 libstdc++.so.6
# 查看新版本,成功
strings /usr/lib64/libstdc++.so.6 | grep GLIBCXX ,输出如下:
...
GLIBCXX_3.4.18
GLIBCXX_3.4.19
GLIBCXX_3.4.20
GLIBCXX_3.4.21
GLIBCXX_3.4.22
GLIBCXX_3.4.23
GLIBCXX_3.4.24
GLIBCXX_3.4.25
GLIBCXX_3.4.26
GLIBCXX_DEBUG_MESSAGE_LENGTH
...同windows下步骤一样,这里不再赘述 错误处理,执行paddleocr命令时可能会有以下错误: 错误1:缺少libGL ,“ImportError: libGL.so.1: cannot open shared object file: No such file or directory”,执行如下指令解决:
yum install mesa-libGL.x86_64错误2:urllib3版本高,依赖的openssl版本低, ImportError: urllib3 v2.0 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with 'OpenSSL 1.0.2k-fips 26 Jan 2017'. See: urllib3/urllib3#2168 解决:降低urllibs3的版本,执行如下指令:
pip install urllib3==1.26.16 -i https://pypi.tuna.tsinghua.edu.cn/simple前面在验证PaddleOCR安装是否成功时已经简单使用过命令了,下面我们详细的讲解一下paddleocr指令。查看具体使用方法:
paddleocr --help1.检测+方向分类器+识别全流程(一般都是用这个):
paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu false --ocr_version PP-OCRv3--image_dir 识别图片的路径 --use_angle_cls true 设置使用方向分类器识别180度旋转文字 --use_gpu false 设置不使用GPU --ocr_version PP-OCRv3 制定模型 , PaddleOCR默认会下载使用最新的模型,当前是PP-OCRv3, 这里只是告诉大家这个参数怎么用 输出结果是结果是一个list,每个item包含了文本框(坐标),文字和识别置信度:
[[[28.0, 37.0], [302.0, 39.0], [302.0, 72.0], [27.0, 70.0]], ('纯臻营养护发素', 0.9658738374710083)]
......文本框分别表示 左上、右上、右下、左下 顺时针方向矩形框的四个角像素坐标
2.单独使用检测:设置 --rec为false
paddleocr --image_dir ./imgs/11.jpg --rec false结果是一个list,每个item只包含文本框:
[[27.0, 459.0], [136.0, 459.0], [136.0, 479.0], [27.0, 479.0]]
[[28.0, 429.0], [372.0, 429.0], [372.0, 445.0], [28.0, 445.0]]
......3.单独使用识别:设置**--det为false**
paddleocr --image_dir ./imgs_words/ch/word_1.jpg --det false结果是一个list,每个item只包含识别结果和识别置信度
['韩国小馆', 0.994467]4.指定语言 --lang(默认也能识别英文,制定语言效果会更好)
paddleocr --image_dir ./imgs_en/254.jpg --lang=en5.paddleocr也支持输入pdf文件,并且可以通过指定参数page_num来控制推理前面几页,默认为0,表示推理所有页
paddleocr --image_dir ./xxx.pdf --use_angle_cls true --use_gpu false --page_num 2- 检测+方向分类器+识别全流程,只需要下面三行代码
#导入依赖
from paddleocr import PaddleOCR
#创建PaddleOCR对象,只需要在初始化时执行一次该语句
ocr = PaddleOCR(use_angle_cls=True, det=False, use_gpu=False)
#识别图片返回结果,cls=True 表示识别旋转180度的文字,如果没有文字旋转180度,那么
#可以cls=False,这样会提升性能,旋转90度和270度也能够识别
result = ocr.ocr(imgPath, cls=True)
开发工具为PyCharm 社区版
新建一个项目,将下面的代码,拷贝到main.py(PyCharm默认会新建一个)

import json
import logging
from paddleocr import PaddleOCR
from flask import Flask, request, jsonify
# 设置日志输出等级
logging.basicConfig(level=logging.DEBUG)
# 只需要初始化加载一次
ocr = PaddleOCR(use_angle_cls=True)
# 所有的Flask都必须创建程序实例,程序实例是Flask的对象,一般情况下用如下方法实例化
app = Flask(__name__)
# https://cloud.tencent.com/developer/article/1539199 flask request常用方法
# @app.route('/ocr', methods=["GET"])
# def paddleOcr():
# params = request.args
# # 获取参数
# imgPath = params.get("imgPath", 0)
# logging.info("paddle ocr img %s", imgPath)
# result = ocr.ocr(imgPath, cls=True)
# return jsonify(data=result), 200
@app.route('/ocr', methods=["POST"])
def paddleOcr():
# 获取传入参数
data = json.loads(request.data)
# 获取传入的图片路径
imgPath = data["imgPath"]
logging.info("paddle ocr2 imgPath %s", imgPath)
#进行ocr识别
# 如果不需要检测坐标,那么可以设置 det=False,result = ocr.ocr(imgPath, cls=True, det=False)
result = ocr.ocr(imgPath, cls=True)
#识别结果通过json格式返回
return jsonify(data=result), 200
# 程序实例用run方法启动flask集成的web服务器
if __name__ == '__main__':
# 可以返回中文字符,否则汉字会以Unicode编码形式返回
app.config['JSON_AS_ASCII'] = False
# 接收所有IP的请求,debug=True 代码修改,web容器会重启
app.run(host='0.0.0.0', debug=True, port=8888)-
import 表示导入整个module(模块),一个.py文件就是一个module
-
from A import B 表示导入A模块中的B(可以为方法、类)
-
flask是python实现的web框架,类似Tomcat
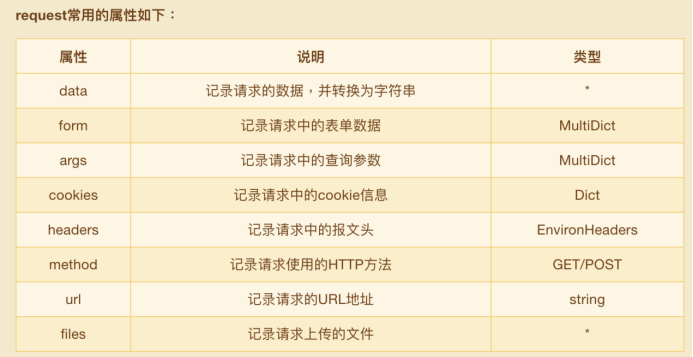 1.如果是json格式的请求数据,则是采用request.data来获取请求体的字符串。 2.如果是form表单的请求体,那么则可以使用request.form来获取参数。 3.如果是url参数,例如:url?param1=xx¶m2=xx,那么则可以使用request.args来获取参数。 4.如果需要区分GET\POST请求方法,则可以使用request.method来进行判断区分 5.参考:[https://cloud.tencent.com/developer/article/1539199](https://cloud.tencent.com/developer/article/1539199),解释的很清楚 [email protected] 声明一个接口,指定请求方法和U请求路径 -
作为 Python 的内置变量,name它是每个 Python 模块必备的属性,但它的值取决于你是如何执行这段代码。通过name 变量,可以判断出这时代码是被直接运行,还是被导入到其他程序中去了。当直接执行一段脚本的时候,这段脚本的 name变量等于 'main',当这段脚本被导入其他程序的时候,name 变量等于脚本本身的名字。
运行main.py,在项目下创建test文件夹,并拷贝一张图片到该文件下


{
"data": [
[
[
[
[
20.0,
35.0
],
[
190.0,
35.0
],
[
190.0,
61.0
],
[
20.0,
61.0
]
],
[
"Docker部署",
0.9223976731300354
]
]
]
]
}此文档是《OCR文字识别实战教程-零基础,SpringBoot结合PaddleOCR》 地址:https://www.bilibili.com/video/BV1RK411b7DU/?vd_source=b4307343204f5c0271966f7fe276f0eb,教程对应的部分文档,全部文档共89页,剩余文档和完整源代码 请关注B站视频