FlexGen is a high-throughput generation engine for running large language models with limited GPU memory (e.g., a 16GB T4 GPU or a 24GB RTX3090 gaming card!). FlexGen allows high-throughput generation by increasing the effective batch size through IO-efficient offloading and compression.
This is a research project developed by HazyResearch@Stanford, SkyComputing@UC Berkeley, DS3Lab@ETH Zurich, FAIR@Meta, CRFM@Stanford, and TogetherCompute.
![]()
The high computational and memory requirements of large language model (LLM) inference traditionally make it feasible only with multiple high-end accelerators. FlexGen aims to lower the resource requirements of LLM inference down to a single commodity GPU (e.g., T4, 3090) and allow flexible deployment for various hardware setups. The key technique behind FlexGen is to trade off between latency and throughput by developing techniques to increase the effective batch size.
The key features of FlexGen include:
⚡ High-Throughput, Large-Batch Offloading.
Higher-throughput generation than other offloading-based systems (e.g., Hugging Face Accelerate, DeepSpeed Zero-Inference) - sometimes by orders of magnitude. The key innovation is a new offloading technique that can effectively increase the batch size. This can be useful for batch inference scenarios, such as benchmarking (e.g., HELM) and data wrangling.
📦 Extreme Compression.
Compress both the parameters and attention cache of models, such as OPT-175B, down to 4 bits with negligible accuracy loss.
🚀 Scalability.
Come with a distributed pipeline parallelism runtime to allow scaling if more GPUs are given.
❌ Limitation.
As an offloading-based system running on weak GPUs, FlexGen also has its limitations.
The throughput of FlexGen is significantly lower than the case when you have enough powerful GPUs to hold the whole model, especially for small-batch cases.
FlexGen is mostly optimized for throughput-oriented batch processing settings (e.g., classifying or extracting information from many documents in batches), on single GPUs.
| Read Paper | Join Discord |
- Benchmark Results
- Install
- Get Started with a Single GPU
- Run Chatbot with OPT models on a Single GPU
- Scaling to Distributed GPUs
- Roadmap
| System | OPT-6.7B | OPT-30B | OPT-175B |
|---|---|---|---|
| Hugging Face Accelerate | 25.12 | 0.62 | 0.01 |
| DeepSpeed ZeRO-Inference | 9.28 | 0.60 | 0.01 |
| Petals* | - | - | 0.05 |
| FlexGen | 25.26 | 7.32 | 0.69 |
| FlexGen with Compression | 29.12 | 8.38 | 1.12 |
- Hardware: an NVIDIA T4 (16GB) instance on GCP with 208GB of DRAM and 1.5TB of SSD.
- Workload: input sequence length = 512, output sequence length = 32. The batch size is tuned to a large value that maximizes the generation throughput for each system. (e.g., 256 for OPT-175B on FlexGen).
- Metric: generation throughput (token/s) = number of the generated tokens / (time for processing prompts + time for generation).
How to reproduce.
Since FlexGen increases throughput by increasing the batch size, it also increases latency - a classic and fundamental trade-off. The figure below shows the latency and throughput trade-off of three offloading-based systems on OPT-175B (left) and OPT-30B (right). FlexGen achieves higher maximum throughput for both models. Other systems cannot further increase throughput due to out-of-memory. "FlexGen(c)" is FlexGen with compression.

FlexGen can be flexibly configured under various hardware resource constraints by aggregating memory and computation from the GPU, CPU, and disk. Through a linear programming optimizer, it searches for the best pattern to store and access the tensors, including weights, activations, and attention key/value (KV) cache. FlexGen further compresses both weights and KV cache to 4 bits with negligible accuracy loss.
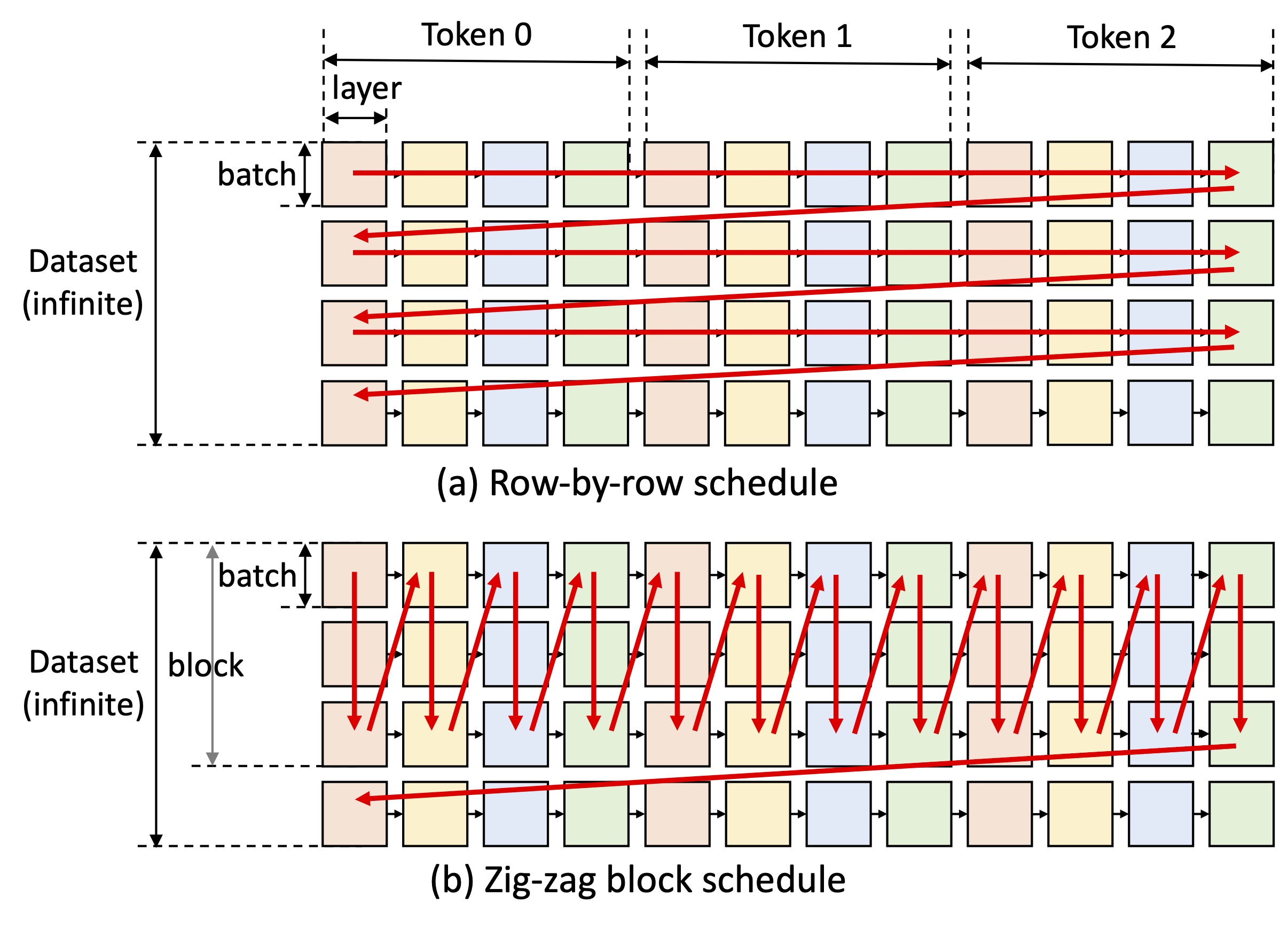
One key idea of FlexGen is to play the latency-throughput trade-off. Achieving low latency is inherently challenging for offloading methods, but the I/O efficiency of offloading can be greatly boosted for throughput-oriented scenarios (see the figure above). FlexGen utilizes a block schedule to reuse weight and overlap I/O with computation, as shown in figure (b) below, while other baseline systems use an inefficient row-by-row schedule, as shown in figure (a) below.
More details can be found in our paper.
Requirements:
- PyTorch >= 1.12 (Help)
Instructions:
git clone https://github.com/FMInference/FlexGen.git
cd FlexGen
pip3 install -e .
# (Optional) Install openmpi for multi-gpu execution
# sudo apt install openmpi-bin
To get started, you can try a small model like OPT-1.3B first. It fits into a single GPU so no offloading is required. FlexGen will automatically download weights from Hugging Face.
python3 -m flexgen.flex_opt --model facebook/opt-1.3b
You should see some text generated by OPT-1.3B and the benchmark results.
To run large models like OPT-30B, you will need to use CPU offloading. You can try commands below.
The --percent argument specifies the offloading strategy for parameters, attention cache and hidden states separately.
The exact meaning of this argument can be found here.
python3 -m flexgen.flex_opt --model facebook/opt-30b --percent 0 100 100 0 100 0
To run OPT-175B, you need to download the weights from metaseq and convert the weights into Alpa format. You can then try to offloading all weights to disk by
python3 -m flexgen.flex_opt --model facebook/opt-175b --percent 0 0 100 0 100 0 --offload-dir YOUR_SSD_FOLDER
We will release an automatic policy optimizer later, but now you have to manually try a few strategies.
The idea of high-throughput generation is to offload parameters and attention cache as much as possible to the CPU and disk if necessary.
You can see the reference strategies in our benchmark here.
To avoid out-of-memory, you can tune the --percent of offload more tensors to the CPU and disk.
If you have more GPUs, FlexGen can combine offloading with pipeline parallelism to allow scaling. For example, if you have 2 GPUs but the aggregated GPU memory is less than the model size, you still need offloading. FlexGen allow you to do pipeline parallelism with these 2 GPUs to accelerate the generation. See examples he