The PyOpenVINO is a spin-off product from my deep learning algorithm study work. This project is aiming at neither practical performance nor rich functionalities. PyOpenVINO can load an OpenVINO IR model (.xml/.bin) and run it. The implementation is quite straightforward and naive. No Optimization technique is used. Thus, the code is easy to read and modify. Supported API is quite limited, but it mimics OpenVINO IE Python API. So, you can easily read and modify the sample code too.
- Developed as a spin-off from my deep learning study work.
- Very slow and limited functionality. Not a general DL inference engine.
- Naive and straightforward code: (I hope) This is a good reference for learning deep-learning technology.
- Extensible ops: Ops are implemented as plugins. You can easily add your ops as needed.
- MNIST CNN, Googlenet-v1, and ssd-mobilenet-v1 are working.
- MNIST (Conv+FC+SoftMax)
- Googlenet-v1
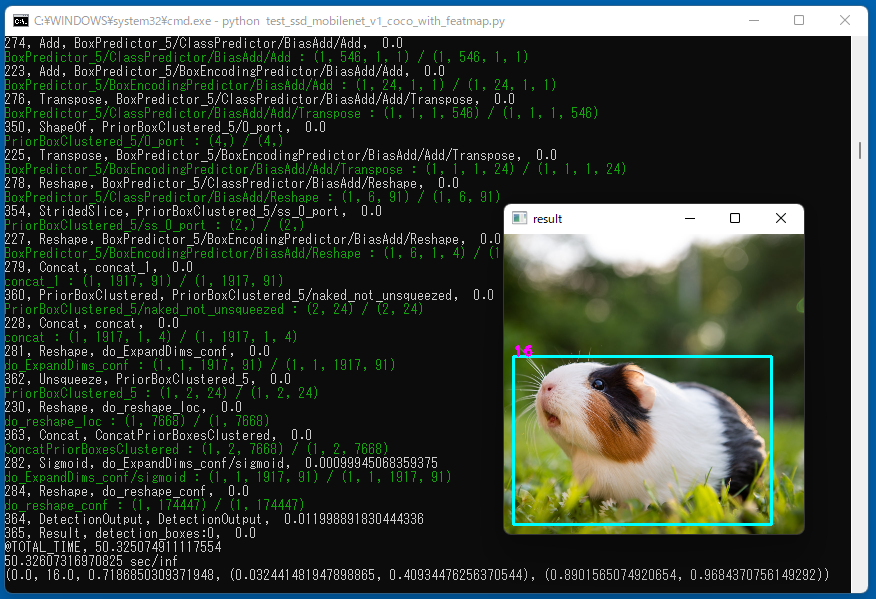
- SSD-mobilenet-v1

Steps 1 and 2 are optional since the converted MNIST IR model is provided.
- Install required Python packages (
opencv-python,numpy,networkx)
python -m pip install --upgrade pip setuptools
python -m pip install -r requirements.txt- (Optional) Train a model and generate a '
saved_model' with TensorFlow
python mnist-tf-training.pyThe trained model data will be created under ./mnist-savedmodel directory.
- (Optional) Convert TF saved_model into OpenVINO IR model
Prerequisite: You need to have OpenVINO installed (Model Optimizer is required).
convert-model.batConverted IR model (.xml/.bin) will be generated in ./models directory.
- Run pyOpenVINO sample program
python test_pyopenvino.pyYou'll see the output like this.
pyopenvino>python test_pyopenvino.py
inputs: [{'name': 'conv2d_input', 'type': 'Parameter', 'version': 'opset1', 'data': {'element_type': 'f32', 'shape': (1, 1, 28, 28)}, 'output': {0: {'precision': 'FP32', 'dims': (1, 1, 28, 28)}}}]
outputs: [{'name': 'Func/StatefulPartitionedCall/output/_11:0', 'type': 'Result', 'version': 'opset1', 'input': {0: {'precision': 'FP32', 'dims': (1, 10)}}}]
# node_name, time (sec)
conv2d_input Parameter, 0.0
conv2d_input/scale_copy Const, 0.0
StatefulPartitionedCall/sequential/conv2d/Conv2D Convolution, 0.11315417289733887
StatefulPartitionedCall/sequential/conv2d/BiasAdd/ReadVariableOp Const, 0.0
StatefulPartitionedCall/sequential/conv2d/BiasAdd/Add Add, 0.0
StatefulPartitionedCall/sequential/conv2d/Relu ReLU, 0.0010142326354980469
StatefulPartitionedCall/sequential/max_pooling2d/MaxPool MaxPool, 0.020931482315063477
:
StatefulPartitionedCall/sequential/dense_1/BiasAdd/Add Add, 0.0
StatefulPartitionedCall/sequential/dense_1/Softmax SoftMax, 0.0009992122650146484
Func/StatefulPartitionedCall/output/_11:0 Result, 0.0
@TOTAL_TIME, 0.21120882034301758
0.21120882034301758 sec/inf
Raw result: {'Func/StatefulPartitionedCall/output/_11:0': array([[7.8985136e-07, 2.0382247e-08, 9.9999917e-01, 1.0367385e-10,
1.0184062e-10, 1.6024957e-12, 2.0729640e-10, 1.6014919e-08,
6.5354638e-10, 9.5946295e-14]], dtype=float32)}
Result: [2 0 1 7 8 6 3 4 5 9]- Run MNIST
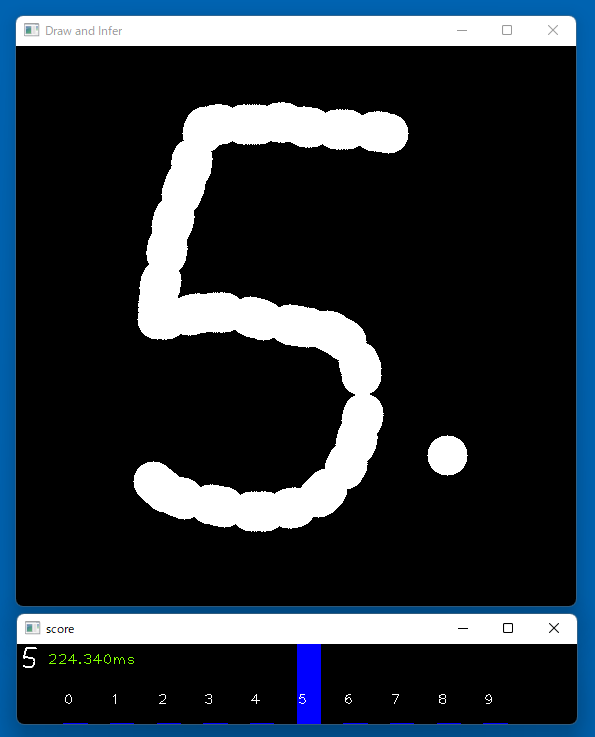
Draw-and-Interdemo
This demo program recognizes a number drawn by the user in real-time. You can draw a number on the screen by pointing device such as a mouse and the demo tells you the recognition result.
python draw-and-infer.py- Left click to draw points.
- Right click to clear the canvas.
This demo program is using 'special' kernels for performance.

This inference engine uses networkx.DiGraph as the internal representation of the IR model.
IR model will be translated into nodes and edges.
The nodes represent the ops, and it holds the attributes of the ops (e.g., strides, dilations, etc.).
The edges represent the connection between the nodes. The edges hold the port number for both ends.
The intermediate output from the nodes (feature maps) will be stored in the data attributes in the output port of the node (G.nodes[node_id_num]['output'][port_num]['data'] = feat_map)
node id= 14
name : StatefulPartitionedCall/sequential/target_conv_layer/Conv2D
type : Convolution
version : opset1
data :
auto_pad : valid
dilations : 1, 1
pads_begin : 0, 0
pads_end : 0, 0
strides : 1, 1
input :
0 :
precision : FP32
dims : (1, 64, 5, 5)
1 :
precision : FP32
dims : (64, 64, 3, 3)
output :
2 :
precision : FP32
dims : (1, 64, 3, 3)format = (from-layer, from-port, to-layer, to-port)
edge_id= (0, 2)
{'connection': (0, 0, 2, 0)}Operators are implemented as plugins. You can develop an Op in Python and place the file in the op_plugins directory. The inference_engine of pyOpenVINO will search the Python source files in the op_plugins directory at the start time and register them as the Ops plugin.
The file name of the Ops plugin will be treated as the Op name, so it must match the layer type attribute field in the IR XML file.
The inference engine will call the compute() function of the plugin to perform the calculation. The compute() function is the only API between the inference engine and the plugin. The inference engine will collect the required input data and pass it to the compute() function. The input data is in the form of Python dict. ({port_num:data[, port_num:data[, ...]]})
The op needs to calculate the result from the input data and return it as a Python dict. ({port_num:result[, port_num:result[, ...]]})
Not all, but some Ops have dual kernel implementation, a naive implementation (easy to read), and a NumPy version implementation (a bit faster).
The NumPy version might be x10+ faster than the naive version.
The kernel type can be specified with Executable_Network.kernel_type attribute. You can specify eitgher one of 'naive' (default) or 'numpy'. Please refer to the sample program test_pyopenvino.py for the details.
The fastest 'special' convolution kernel is taken from 'deep-learning-from-scratch' project.
END